KR20070007817A - Self-processing plants and plant parts - Google Patents
Self-processing plants and plant parts Download PDFInfo
- Publication number
- KR20070007817A KR20070007817A KR1020067020881A KR20067020881A KR20070007817A KR 20070007817 A KR20070007817 A KR 20070007817A KR 1020067020881 A KR1020067020881 A KR 1020067020881A KR 20067020881 A KR20067020881 A KR 20067020881A KR 20070007817 A KR20070007817 A KR 20070007817A
- Authority
- KR
- South Korea
- Prior art keywords
- starch
- plant
- enzyme
- seq
- amylase
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 238000012545 processing Methods 0.000 title claims abstract description 215
- 241000196324 Embryophyta Species 0.000 claims abstract description 423
- 102000004190 Enzymes Human genes 0.000 claims abstract description 372
- 108090000790 Enzymes Proteins 0.000 claims abstract description 372
- 229920002472 Starch Polymers 0.000 claims abstract description 275
- 235000019698 starch Nutrition 0.000 claims abstract description 274
- 239000008107 starch Substances 0.000 claims abstract description 270
- 238000000034 method Methods 0.000 claims abstract description 206
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 184
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 184
- 239000002157 polynucleotide Substances 0.000 claims abstract description 182
- 235000002017 Zea mays subsp mays Nutrition 0.000 claims abstract description 151
- 230000014509 gene expression Effects 0.000 claims abstract description 147
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 claims abstract description 121
- 235000005822 corn Nutrition 0.000 claims abstract description 121
- 235000000346 sugar Nutrition 0.000 claims abstract description 101
- 239000013598 vector Substances 0.000 claims abstract description 80
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 claims abstract description 56
- 239000000203 mixture Substances 0.000 claims abstract description 29
- 235000013305 food Nutrition 0.000 claims abstract description 24
- 238000004519 manufacturing process Methods 0.000 claims abstract description 10
- 229940088598 enzyme Drugs 0.000 claims description 368
- 108090000637 alpha-Amylases Proteins 0.000 claims description 170
- 240000008042 Zea mays Species 0.000 claims description 147
- 210000004027 cell Anatomy 0.000 claims description 116
- 102000004139 alpha-Amylases Human genes 0.000 claims description 107
- 229940024171 alpha-amylase Drugs 0.000 claims description 102
- 235000013339 cereals Nutrition 0.000 claims description 76
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 72
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 66
- 229920001184 polypeptide Polymers 0.000 claims description 65
- 102100024295 Maltase-glucoamylase Human genes 0.000 claims description 62
- 108700040099 Xylose isomerases Proteins 0.000 claims description 62
- 108010028144 alpha-Glucosidases Proteins 0.000 claims description 62
- 210000001519 tissue Anatomy 0.000 claims description 62
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 60
- 230000000694 effects Effects 0.000 claims description 60
- 102100022624 Glucoamylase Human genes 0.000 claims description 59
- 108010073178 Glucan 1,4-alpha-Glucosidase Proteins 0.000 claims description 57
- 239000008187 granular material Substances 0.000 claims description 50
- 150000004676 glycans Chemical class 0.000 claims description 43
- 229920001282 polysaccharide Polymers 0.000 claims description 43
- 239000005017 polysaccharide Substances 0.000 claims description 43
- 239000004365 Protease Substances 0.000 claims description 37
- 239000012634 fragment Substances 0.000 claims description 37
- -1 pullulase Proteins 0.000 claims description 36
- 108010059892 Cellulase Proteins 0.000 claims description 35
- 230000000295 complement effect Effects 0.000 claims description 35
- 108091005804 Peptidases Proteins 0.000 claims description 33
- 150000008163 sugars Chemical class 0.000 claims description 31
- 101710121765 Endo-1,4-beta-xylanase Proteins 0.000 claims description 30
- 108090000371 Esterases Proteins 0.000 claims description 28
- 240000007594 Oryza sativa Species 0.000 claims description 28
- 235000007164 Oryza sativa Nutrition 0.000 claims description 28
- 239000007864 aqueous solution Substances 0.000 claims description 28
- 108010047754 beta-Glucosidase Proteins 0.000 claims description 28
- 102000006995 beta-Glucosidase Human genes 0.000 claims description 28
- 229940106157 cellulase Drugs 0.000 claims description 28
- 108090001060 Lipase Proteins 0.000 claims description 27
- 150000001413 amino acids Chemical class 0.000 claims description 27
- 235000009566 rice Nutrition 0.000 claims description 27
- 108010011619 6-Phytase Proteins 0.000 claims description 26
- 102000004882 Lipase Human genes 0.000 claims description 26
- 235000013399 edible fruits Nutrition 0.000 claims description 26
- 238000009396 hybridization Methods 0.000 claims description 26
- 239000004367 Lipase Substances 0.000 claims description 25
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 claims description 25
- 235000019421 lipase Nutrition 0.000 claims description 25
- 229940085127 phytase Drugs 0.000 claims description 25
- 241000589158 Agrobacterium Species 0.000 claims description 24
- 230000008569 process Effects 0.000 claims description 24
- 102000013142 Amylases Human genes 0.000 claims description 22
- 108010065511 Amylases Proteins 0.000 claims description 22
- 235000019418 amylase Nutrition 0.000 claims description 22
- 230000009261 transgenic effect Effects 0.000 claims description 22
- 239000004382 Amylase Substances 0.000 claims description 21
- 235000016383 Zea mays subsp huehuetenangensis Nutrition 0.000 claims description 21
- 235000009973 maize Nutrition 0.000 claims description 21
- 229920001353 Dextrin Polymers 0.000 claims description 20
- 239000004375 Dextrin Substances 0.000 claims description 20
- 235000019425 dextrin Nutrition 0.000 claims description 20
- 230000001086 cytosolic effect Effects 0.000 claims description 19
- 241000209140 Triticum Species 0.000 claims description 18
- 235000021307 Triticum Nutrition 0.000 claims description 18
- 238000006243 chemical reaction Methods 0.000 claims description 18
- 235000010469 Glycine max Nutrition 0.000 claims description 17
- 210000002421 cell wall Anatomy 0.000 claims description 17
- 229940040461 lipase Drugs 0.000 claims description 17
- 244000068988 Glycine max Species 0.000 claims description 16
- 210000003660 reticulum Anatomy 0.000 claims description 16
- 240000005979 Hordeum vulgare Species 0.000 claims description 15
- 235000007340 Hordeum vulgare Nutrition 0.000 claims description 15
- 230000003213 activating effect Effects 0.000 claims description 15
- 210000003763 chloroplast Anatomy 0.000 claims description 14
- 229920002494 Zein Polymers 0.000 claims description 13
- 239000002773 nucleotide Substances 0.000 claims description 13
- 125000003729 nucleotide group Chemical group 0.000 claims description 13
- 235000013311 vegetables Nutrition 0.000 claims description 13
- 239000005019 zein Substances 0.000 claims description 13
- 229940093612 zein Drugs 0.000 claims description 13
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 claims description 12
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 12
- 244000061456 Solanum tuberosum Species 0.000 claims description 11
- 230000000593 degrading effect Effects 0.000 claims description 11
- 230000004927 fusion Effects 0.000 claims description 11
- 239000008103 glucose Substances 0.000 claims description 11
- 230000001939 inductive effect Effects 0.000 claims description 11
- 229920001542 oligosaccharide Polymers 0.000 claims description 11
- 150000002482 oligosaccharides Chemical class 0.000 claims description 11
- 235000007238 Secale cereale Nutrition 0.000 claims description 10
- 235000002595 Solanum tuberosum Nutrition 0.000 claims description 10
- RAHZWNYVWXNFOC-UHFFFAOYSA-N Sulphur dioxide Chemical compound O=S=O RAHZWNYVWXNFOC-UHFFFAOYSA-N 0.000 claims description 10
- 210000003934 vacuole Anatomy 0.000 claims description 10
- 238000001238 wet grinding Methods 0.000 claims description 10
- 235000007319 Avena orientalis Nutrition 0.000 claims description 9
- 244000075850 Avena orientalis Species 0.000 claims description 9
- 241001057636 Dracaena deremensis Species 0.000 claims description 9
- 240000000111 Saccharum officinarum Species 0.000 claims description 9
- 235000007201 Saccharum officinarum Nutrition 0.000 claims description 9
- 108010028688 Isoamylase Proteins 0.000 claims description 8
- 229920002774 Maltodextrin Polymers 0.000 claims description 8
- 102000035195 Peptidases Human genes 0.000 claims description 8
- 108010019077 beta-Amylase Proteins 0.000 claims description 8
- 230000002124 endocrine Effects 0.000 claims description 8
- 238000003306 harvesting Methods 0.000 claims description 8
- 238000002156 mixing Methods 0.000 claims description 8
- 235000010627 Phaseolus vulgaris Nutrition 0.000 claims description 7
- 244000046052 Phaseolus vulgaris Species 0.000 claims description 7
- 238000010438 heat treatment Methods 0.000 claims description 7
- 235000007688 Lycopersicon esculentum Nutrition 0.000 claims description 6
- 239000005913 Maltodextrin Substances 0.000 claims description 6
- 235000010582 Pisum sativum Nutrition 0.000 claims description 6
- 240000004713 Pisum sativum Species 0.000 claims description 6
- 244000082988 Secale cereale Species 0.000 claims description 6
- 240000003768 Solanum lycopersicum Species 0.000 claims description 6
- 235000007244 Zea mays Nutrition 0.000 claims description 6
- 239000003795 chemical substances by application Substances 0.000 claims description 6
- 235000014113 dietary fatty acids Nutrition 0.000 claims description 6
- 238000009837 dry grinding Methods 0.000 claims description 6
- 229930195729 fatty acid Natural products 0.000 claims description 6
- 239000000194 fatty acid Substances 0.000 claims description 6
- 150000004665 fatty acids Chemical class 0.000 claims description 6
- 229940035034 maltodextrin Drugs 0.000 claims description 6
- 235000012015 potatoes Nutrition 0.000 claims description 6
- 102100032487 Beta-mannosidase Human genes 0.000 claims description 5
- 235000009854 Cucurbita moschata Nutrition 0.000 claims description 5
- 108010055059 beta-Mannosidase Proteins 0.000 claims description 5
- 244000099147 Ananas comosus Species 0.000 claims description 4
- 235000007119 Ananas comosus Nutrition 0.000 claims description 4
- 206010020843 Hyperthermia Diseases 0.000 claims description 4
- 244000062793 Sorghum vulgare Species 0.000 claims description 4
- 230000003190 augmentative effect Effects 0.000 claims description 4
- 235000003599 food sweetener Nutrition 0.000 claims description 4
- 230000036031 hyperthermia Effects 0.000 claims description 4
- 235000019713 millet Nutrition 0.000 claims description 4
- 238000011084 recovery Methods 0.000 claims description 4
- 239000007787 solid Substances 0.000 claims description 4
- 239000003765 sweetening agent Substances 0.000 claims description 4
- 239000002023 wood Substances 0.000 claims description 4
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 3
- 101710152845 Arabinogalactan endo-beta-1,4-galactanase Proteins 0.000 claims description 3
- 235000000832 Ayote Nutrition 0.000 claims description 3
- 241000219310 Beta vulgaris subsp. vulgaris Species 0.000 claims description 3
- 241000219122 Cucurbita Species 0.000 claims description 3
- 235000009804 Cucurbita pepo subsp pepo Nutrition 0.000 claims description 3
- 101710147028 Endo-beta-1,4-galactanase Proteins 0.000 claims description 3
- 241000209510 Liliopsida Species 0.000 claims description 3
- 241000209504 Poaceae Species 0.000 claims description 3
- 235000021536 Sugar beet Nutrition 0.000 claims description 3
- 241000219094 Vitaceae Species 0.000 claims description 3
- 108010048056 beta-1,3-exoglucanase Proteins 0.000 claims description 3
- 210000004899 c-terminal region Anatomy 0.000 claims description 3
- 235000021021 grapes Nutrition 0.000 claims description 3
- 235000015136 pumpkin Nutrition 0.000 claims description 3
- 240000009088 Fragaria x ananassa Species 0.000 claims description 2
- 108010093031 Galactosidases Proteins 0.000 claims description 2
- 102000002464 Galactosidases Human genes 0.000 claims description 2
- 102000004366 Glucosidases Human genes 0.000 claims description 2
- 108010056771 Glucosidases Proteins 0.000 claims description 2
- 108010054377 Mannosidases Proteins 0.000 claims description 2
- 102000001696 Mannosidases Human genes 0.000 claims description 2
- 241001330028 Panicoideae Species 0.000 claims description 2
- 235000021015 bananas Nutrition 0.000 claims description 2
- 238000009835 boiling Methods 0.000 claims description 2
- 235000021152 breakfast Nutrition 0.000 claims description 2
- 239000003086 colorant Substances 0.000 claims description 2
- 238000012258 culturing Methods 0.000 claims description 2
- 238000000354 decomposition reaction Methods 0.000 claims description 2
- 239000000796 flavoring agent Substances 0.000 claims description 2
- 235000019634 flavors Nutrition 0.000 claims description 2
- 229910052500 inorganic mineral Inorganic materials 0.000 claims description 2
- 235000010755 mineral Nutrition 0.000 claims description 2
- 239000011707 mineral Substances 0.000 claims description 2
- 238000010025 steaming Methods 0.000 claims description 2
- 239000010907 stover Substances 0.000 claims description 2
- 235000021012 strawberries Nutrition 0.000 claims description 2
- 235000020357 syrup Nutrition 0.000 claims description 2
- 239000006188 syrup Substances 0.000 claims description 2
- 239000011782 vitamin Substances 0.000 claims description 2
- 235000013343 vitamin Nutrition 0.000 claims description 2
- 229940088594 vitamin Drugs 0.000 claims description 2
- 229930003231 vitamin Natural products 0.000 claims description 2
- 125000003275 alpha amino acid group Chemical group 0.000 claims 22
- 241000609240 Ambelania acida Species 0.000 claims 1
- 241000234435 Lilium Species 0.000 claims 1
- 240000005561 Musa balbisiana Species 0.000 claims 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 claims 1
- 239000010905 bagasse Substances 0.000 claims 1
- 210000004186 follicle cell Anatomy 0.000 claims 1
- 210000000609 ganglia Anatomy 0.000 claims 1
- 108010032581 isopullulanase Proteins 0.000 claims 1
- 125000000740 n-pentyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 claims 1
- 235000021487 ready-to-eat food Nutrition 0.000 claims 1
- 150000003722 vitamin derivatives Chemical class 0.000 claims 1
- 239000000758 substrate Substances 0.000 abstract description 20
- 230000004913 activation Effects 0.000 abstract description 9
- 230000001976 improved effect Effects 0.000 abstract description 5
- 230000002977 hyperthermial effect Effects 0.000 abstract description 4
- 241000209149 Zea Species 0.000 abstract 1
- 235000019985 fermented beverage Nutrition 0.000 abstract 1
- 108090000623 proteins and genes Proteins 0.000 description 124
- 230000009466 transformation Effects 0.000 description 58
- 239000000047 product Substances 0.000 description 53
- 102000004169 proteins and genes Human genes 0.000 description 31
- 235000018102 proteins Nutrition 0.000 description 29
- 108020004414 DNA Proteins 0.000 description 25
- 239000002245 particle Substances 0.000 description 19
- 239000000843 powder Substances 0.000 description 19
- 239000002609 medium Substances 0.000 description 18
- 235000019419 proteases Nutrition 0.000 description 16
- 230000001105 regulatory effect Effects 0.000 description 16
- 239000003550 marker Substances 0.000 description 15
- 150000007523 nucleic acids Chemical group 0.000 description 15
- 230000008685 targeting Effects 0.000 description 15
- 108091028043 Nucleic acid sequence Proteins 0.000 description 13
- 210000002257 embryonic structure Anatomy 0.000 description 13
- 239000013612 plasmid Substances 0.000 description 13
- 239000011541 reaction mixture Substances 0.000 description 13
- 241000894007 species Species 0.000 description 13
- 238000000855 fermentation Methods 0.000 description 12
- 230000004151 fermentation Effects 0.000 description 12
- 102000039446 nucleic acids Human genes 0.000 description 12
- 108020004707 nucleic acids Proteins 0.000 description 12
- 241000588724 Escherichia coli Species 0.000 description 11
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 11
- 210000001938 protoplast Anatomy 0.000 description 11
- 108020004705 Codon Proteins 0.000 description 10
- 230000007062 hydrolysis Effects 0.000 description 10
- 238000006460 hydrolysis reaction Methods 0.000 description 10
- 108091026890 Coding region Proteins 0.000 description 9
- 241000482268 Zea mays subsp. mays Species 0.000 description 9
- 238000004520 electroporation Methods 0.000 description 9
- 238000005516 engineering process Methods 0.000 description 9
- 230000006870 function Effects 0.000 description 9
- 239000004009 herbicide Substances 0.000 description 9
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 8
- 206010020649 Hyperkeratosis Diseases 0.000 description 8
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 8
- 239000000306 component Substances 0.000 description 8
- 230000001404 mediated effect Effects 0.000 description 8
- 238000003801 milling Methods 0.000 description 8
- 210000000056 organ Anatomy 0.000 description 8
- 238000012546 transfer Methods 0.000 description 8
- 229930091371 Fructose Natural products 0.000 description 7
- 239000005715 Fructose Substances 0.000 description 7
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 7
- 101150103518 bar gene Proteins 0.000 description 7
- 238000010367 cloning Methods 0.000 description 7
- 238000011534 incubation Methods 0.000 description 7
- 238000002360 preparation method Methods 0.000 description 7
- 238000000926 separation method Methods 0.000 description 7
- 230000001131 transforming effect Effects 0.000 description 7
- 102000005575 Cellulases Human genes 0.000 description 6
- 108010084185 Cellulases Proteins 0.000 description 6
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 6
- 239000002202 Polyethylene glycol Substances 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 238000007654 immersion Methods 0.000 description 6
- 229930027917 kanamycin Natural products 0.000 description 6
- 229960000318 kanamycin Drugs 0.000 description 6
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 6
- 229930182823 kanamycin A Natural products 0.000 description 6
- 229920001223 polyethylene glycol Polymers 0.000 description 6
- 238000003752 polymerase chain reaction Methods 0.000 description 6
- 229920002261 Corn starch Polymers 0.000 description 5
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 5
- 108010068370 Glutens Proteins 0.000 description 5
- 241000219823 Medicago Species 0.000 description 5
- IAJOBQBIJHVGMQ-UHFFFAOYSA-N Phosphinothricin Natural products CP(O)(=O)CCC(N)C(O)=O IAJOBQBIJHVGMQ-UHFFFAOYSA-N 0.000 description 5
- 229930006000 Sucrose Natural products 0.000 description 5
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 5
- 239000002253 acid Substances 0.000 description 5
- 150000007513 acids Chemical class 0.000 description 5
- 238000007792 addition Methods 0.000 description 5
- 239000006227 byproduct Substances 0.000 description 5
- 239000007795 chemical reaction product Substances 0.000 description 5
- 239000008120 corn starch Substances 0.000 description 5
- 239000013604 expression vector Substances 0.000 description 5
- IAJOBQBIJHVGMQ-BYPYZUCNSA-N glufosinate-P Chemical compound CP(O)(=O)CC[C@H](N)C(O)=O IAJOBQBIJHVGMQ-BYPYZUCNSA-N 0.000 description 5
- 235000021312 gluten Nutrition 0.000 description 5
- 230000002363 herbicidal effect Effects 0.000 description 5
- 239000003112 inhibitor Substances 0.000 description 5
- 210000001161 mammalian embryo Anatomy 0.000 description 5
- 238000012216 screening Methods 0.000 description 5
- 239000005720 sucrose Substances 0.000 description 5
- 108700028369 Alleles Proteins 0.000 description 4
- 244000105624 Arachis hypogaea Species 0.000 description 4
- 240000002791 Brassica napus Species 0.000 description 4
- 229920000742 Cotton Polymers 0.000 description 4
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 4
- 244000299507 Gossypium hirsutum Species 0.000 description 4
- 244000020551 Helianthus annuus Species 0.000 description 4
- 235000003222 Helianthus annuus Nutrition 0.000 description 4
- 108091022912 Mannose-6-Phosphate Isomerase Proteins 0.000 description 4
- 235000017587 Medicago sativa ssp. sativa Nutrition 0.000 description 4
- 101150090155 R gene Proteins 0.000 description 4
- 241000209056 Secale Species 0.000 description 4
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 4
- 240000006394 Sorghum bicolor Species 0.000 description 4
- 230000035508 accumulation Effects 0.000 description 4
- 238000009825 accumulation Methods 0.000 description 4
- 235000001014 amino acid Nutrition 0.000 description 4
- 230000001580 bacterial effect Effects 0.000 description 4
- 238000009395 breeding Methods 0.000 description 4
- 230000001488 breeding effect Effects 0.000 description 4
- 239000000872 buffer Substances 0.000 description 4
- YCIMNLLNPGFGHC-UHFFFAOYSA-N catechol Chemical compound OC1=CC=CC=C1O YCIMNLLNPGFGHC-UHFFFAOYSA-N 0.000 description 4
- 238000010276 construction Methods 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 230000004069 differentiation Effects 0.000 description 4
- 239000000835 fiber Substances 0.000 description 4
- 230000006872 improvement Effects 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 230000035772 mutation Effects 0.000 description 4
- 108010082527 phosphinothricin N-acetyltransferase Proteins 0.000 description 4
- 230000000644 propagated effect Effects 0.000 description 4
- 230000010076 replication Effects 0.000 description 4
- 239000011780 sodium chloride Substances 0.000 description 4
- 108700026215 vpr Genes Proteins 0.000 description 4
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- 241000219198 Brassica Species 0.000 description 3
- 108010004032 Bromelains Proteins 0.000 description 3
- 244000025254 Cannabis sativa Species 0.000 description 3
- 235000003255 Carthamus tinctorius Nutrition 0.000 description 3
- 244000020518 Carthamus tinctorius Species 0.000 description 3
- 108010008885 Cellulose 1,4-beta-Cellobiosidase Proteins 0.000 description 3
- 108010077544 Chromatin Proteins 0.000 description 3
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 3
- 241000219112 Cucumis Species 0.000 description 3
- 235000015510 Cucumis melo subsp melo Nutrition 0.000 description 3
- 101710129170 Extensin Proteins 0.000 description 3
- 101100288095 Klebsiella pneumoniae neo gene Proteins 0.000 description 3
- 241000219739 Lens Species 0.000 description 3
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 3
- 241000234295 Musa Species 0.000 description 3
- 241000208125 Nicotiana Species 0.000 description 3
- 244000061176 Nicotiana tabacum Species 0.000 description 3
- 235000010617 Phaseolus lunatus Nutrition 0.000 description 3
- 108700001094 Plant Genes Proteins 0.000 description 3
- 241000220324 Pyrus Species 0.000 description 3
- 235000011684 Sorghum saccharatum Nutrition 0.000 description 3
- 238000002105 Southern blotting Methods 0.000 description 3
- 241000219793 Trifolium Species 0.000 description 3
- 235000010208 anthocyanin Nutrition 0.000 description 3
- 239000004410 anthocyanin Substances 0.000 description 3
- 229930002877 anthocyanin Natural products 0.000 description 3
- 150000004636 anthocyanins Chemical class 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 108010005774 beta-Galactosidase Proteins 0.000 description 3
- 235000019835 bromelain Nutrition 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 210000003483 chromatin Anatomy 0.000 description 3
- 239000003593 chromogenic compound Substances 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 3
- 229910052802 copper Inorganic materials 0.000 description 3
- 239000010949 copper Substances 0.000 description 3
- 230000000875 corresponding effect Effects 0.000 description 3
- 101150036876 cre gene Proteins 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 239000003623 enhancer Substances 0.000 description 3
- 108010041969 feruloyl esterase Proteins 0.000 description 3
- 238000000227 grinding Methods 0.000 description 3
- 230000012010 growth Effects 0.000 description 3
- 238000004128 high performance liquid chromatography Methods 0.000 description 3
- 230000001965 increasing effect Effects 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 235000021374 legumes Nutrition 0.000 description 3
- 238000002703 mutagenesis Methods 0.000 description 3
- 231100000350 mutagenesis Toxicity 0.000 description 3
- 230000003204 osmotic effect Effects 0.000 description 3
- 210000002706 plastid Anatomy 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 230000008929 regeneration Effects 0.000 description 3
- 238000011069 regeneration method Methods 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 229960000268 spectinomycin Drugs 0.000 description 3
- UNFWWIHTNXNPBV-WXKVUWSESA-N spectinomycin Chemical compound O([C@@H]1[C@@H](NC)[C@@H](O)[C@H]([C@@H]([C@H]1O1)O)NC)[C@]2(O)[C@H]1O[C@H](C)CC2=O UNFWWIHTNXNPBV-WXKVUWSESA-N 0.000 description 3
- 238000010561 standard procedure Methods 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- 238000006467 substitution reaction Methods 0.000 description 3
- 238000013518 transcription Methods 0.000 description 3
- 230000035897 transcription Effects 0.000 description 3
- 238000011426 transformation method Methods 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- 108010020183 3-phosphoshikimate 1-carboxyvinyltransferase Proteins 0.000 description 2
- 244000283070 Abies balsamea Species 0.000 description 2
- 235000007173 Abies balsamea Nutrition 0.000 description 2
- 241000234282 Allium Species 0.000 description 2
- 235000002732 Allium cepa var. cepa Nutrition 0.000 description 2
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 2
- 244000144725 Amygdalus communis Species 0.000 description 2
- 235000011437 Amygdalus communis Nutrition 0.000 description 2
- 244000226021 Anacardium occidentale Species 0.000 description 2
- 241000219194 Arabidopsis Species 0.000 description 2
- 235000010777 Arachis hypogaea Nutrition 0.000 description 2
- 241000228212 Aspergillus Species 0.000 description 2
- 235000011331 Brassica Nutrition 0.000 description 2
- 235000011299 Brassica oleracea var botrytis Nutrition 0.000 description 2
- 240000003259 Brassica oleracea var. botrytis Species 0.000 description 2
- 235000004977 Brassica sinapistrum Nutrition 0.000 description 2
- 101000583086 Bunodosoma granuliferum Delta-actitoxin-Bgr2b Proteins 0.000 description 2
- 241001674345 Callitropsis nootkatensis Species 0.000 description 2
- 244000045232 Canavalia ensiformis Species 0.000 description 2
- 241000218645 Cedrus Species 0.000 description 2
- 235000010523 Cicer arietinum Nutrition 0.000 description 2
- 244000045195 Cicer arietinum Species 0.000 description 2
- 241000207199 Citrus Species 0.000 description 2
- 235000013162 Cocos nucifera Nutrition 0.000 description 2
- 244000060011 Cocos nucifera Species 0.000 description 2
- 241000218631 Coniferophyta Species 0.000 description 2
- 240000008067 Cucumis sativus Species 0.000 description 2
- 240000001980 Cucurbita pepo Species 0.000 description 2
- 235000009852 Cucurbita pepo Nutrition 0.000 description 2
- 101150074155 DHFR gene Proteins 0.000 description 2
- NDUPDOJHUQKPAG-UHFFFAOYSA-N Dalapon Chemical compound CC(Cl)(Cl)C(O)=O NDUPDOJHUQKPAG-UHFFFAOYSA-N 0.000 description 2
- 235000009355 Dianthus caryophyllus Nutrition 0.000 description 2
- 240000006497 Dianthus caryophyllus Species 0.000 description 2
- 244000078127 Eleusine coracana Species 0.000 description 2
- 240000002395 Euphorbia pulcherrima Species 0.000 description 2
- 108050008938 Glucoamylases Proteins 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 244000267823 Hydrangea macrophylla Species 0.000 description 2
- 235000014486 Hydrangea macrophylla Nutrition 0.000 description 2
- 102000004157 Hydrolases Human genes 0.000 description 2
- 108090000604 Hydrolases Proteins 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- 102000004195 Isomerases Human genes 0.000 description 2
- 108090000769 Isomerases Proteins 0.000 description 2
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 2
- 235000003228 Lactuca sativa Nutrition 0.000 description 2
- 240000008415 Lactuca sativa Species 0.000 description 2
- 235000014647 Lens culinaris subsp culinaris Nutrition 0.000 description 2
- WHXSMMKQMYFTQS-UHFFFAOYSA-N Lithium Chemical compound [Li] WHXSMMKQMYFTQS-UHFFFAOYSA-N 0.000 description 2
- 241000219745 Lupinus Species 0.000 description 2
- 235000014826 Mangifera indica Nutrition 0.000 description 2
- 240000007228 Mangifera indica Species 0.000 description 2
- 240000003183 Manihot esculenta Species 0.000 description 2
- 102000048193 Mannose-6-phosphate isomerases Human genes 0.000 description 2
- XUMBMVFBXHLACL-UHFFFAOYSA-N Melanin Chemical compound O=C1C(=O)C(C2=CNC3=C(C(C(=O)C4=C32)=O)C)=C2C4=CNC2=C1C XUMBMVFBXHLACL-UHFFFAOYSA-N 0.000 description 2
- 235000007199 Panicum miliaceum Nutrition 0.000 description 2
- 101710091688 Patatin Proteins 0.000 description 2
- 235000007195 Pennisetum typhoides Nutrition 0.000 description 2
- 240000007377 Petunia x hybrida Species 0.000 description 2
- 235000005205 Pinus Nutrition 0.000 description 2
- 241000218602 Pinus <genus> Species 0.000 description 2
- 108010059820 Polygalacturonase Proteins 0.000 description 2
- 101710150114 Protein rep Proteins 0.000 description 2
- 108020001991 Protoporphyrinogen Oxidase Proteins 0.000 description 2
- 102000005135 Protoporphyrinogen oxidase Human genes 0.000 description 2
- 240000001416 Pseudotsuga menziesii Species 0.000 description 2
- 101710152114 Replication protein Proteins 0.000 description 2
- 240000005498 Setaria italica Species 0.000 description 2
- 241000187747 Streptomyces Species 0.000 description 2
- 239000004098 Tetracycline Substances 0.000 description 2
- 244000299461 Theobroma cacao Species 0.000 description 2
- 235000009470 Theobroma cacao Nutrition 0.000 description 2
- 241000204666 Thermotoga maritima Species 0.000 description 2
- 241000204664 Thermotoga neapolitana Species 0.000 description 2
- 108010022394 Threonine synthase Proteins 0.000 description 2
- 108020004566 Transfer RNA Proteins 0.000 description 2
- 108090000704 Tubulin Proteins 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 208000027418 Wounds and injury Diseases 0.000 description 2
- FJJCIZWZNKZHII-UHFFFAOYSA-N [4,6-bis(cyanoamino)-1,3,5-triazin-2-yl]cyanamide Chemical compound N#CNC1=NC(NC#N)=NC(NC#N)=N1 FJJCIZWZNKZHII-UHFFFAOYSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- WQZGKKKJIJFFOK-DVKNGEFBSA-N alpha-D-glucose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-DVKNGEFBSA-N 0.000 description 2
- 229960000723 ampicillin Drugs 0.000 description 2
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 2
- 229940025131 amylases Drugs 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 230000000692 anti-sense effect Effects 0.000 description 2
- 229940088710 antibiotic agent Drugs 0.000 description 2
- 239000000427 antigen Substances 0.000 description 2
- 108091007433 antigens Proteins 0.000 description 2
- 102000036639 antigens Human genes 0.000 description 2
- 102000005936 beta-Galactosidase Human genes 0.000 description 2
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 238000003390 bioluminescence detection Methods 0.000 description 2
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 2
- 244000022203 blackseeded proso millet Species 0.000 description 2
- 230000002759 chromosomal effect Effects 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 235000020971 citrus fruits Nutrition 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 238000007598 dipping method Methods 0.000 description 2
- 244000013123 dwarf bean Species 0.000 description 2
- 230000000408 embryogenic effect Effects 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 238000006911 enzymatic reaction Methods 0.000 description 2
- 235000021331 green beans Nutrition 0.000 description 2
- 101150054900 gus gene Proteins 0.000 description 2
- 238000010348 incorporation Methods 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 238000006317 isomerization reaction Methods 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- 150000002632 lipids Chemical class 0.000 description 2
- 229910052744 lithium Inorganic materials 0.000 description 2
- 230000014759 maintenance of location Effects 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 229960000485 methotrexate Drugs 0.000 description 2
- 230000000813 microbial effect Effects 0.000 description 2
- 238000000520 microinjection Methods 0.000 description 2
- 108010058731 nopaline synthase Proteins 0.000 description 2
- 230000031787 nutrient reservoir activity Effects 0.000 description 2
- 101150113864 pat gene Proteins 0.000 description 2
- 235000020232 peanut Nutrition 0.000 description 2
- 235000021017 pears Nutrition 0.000 description 2
- 239000000049 pigment Substances 0.000 description 2
- 230000010152 pollination Effects 0.000 description 2
- 238000006116 polymerization reaction Methods 0.000 description 2
- 238000003672 processing method Methods 0.000 description 2
- 239000001054 red pigment Substances 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 239000000523 sample Substances 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 239000002002 slurry Substances 0.000 description 2
- 238000002791 soaking Methods 0.000 description 2
- 230000000392 somatic effect Effects 0.000 description 2
- 235000020354 squash Nutrition 0.000 description 2
- 230000000638 stimulation Effects 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 229960002180 tetracycline Drugs 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 235000019364 tetracycline Nutrition 0.000 description 2
- 150000003522 tetracyclines Chemical class 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 230000017260 vegetative to reproductive phase transition of meristem Effects 0.000 description 2
- GEWDNTWNSAZUDX-WQMVXFAESA-N (-)-methyl jasmonate Chemical compound CC\C=C/C[C@@H]1[C@@H](CC(=O)OC)CCC1=O GEWDNTWNSAZUDX-WQMVXFAESA-N 0.000 description 1
- FCHBECOAGZMTFE-ZEQKJWHPSA-N (6r,7r)-3-[[2-[[4-(dimethylamino)phenyl]diazenyl]pyridin-1-ium-1-yl]methyl]-8-oxo-7-[(2-thiophen-2-ylacetyl)amino]-5-thia-1-azabicyclo[4.2.0]oct-2-ene-2-carboxylate Chemical compound C1=CC(N(C)C)=CC=C1N=NC1=CC=CC=[N+]1CC1=C(C([O-])=O)N2C(=O)[C@@H](NC(=O)CC=3SC=CC=3)[C@H]2SC1 FCHBECOAGZMTFE-ZEQKJWHPSA-N 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- VGONTNSXDCQUGY-RRKCRQDMSA-N 2'-deoxyinosine Chemical group C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC2=O)=C2N=C1 VGONTNSXDCQUGY-RRKCRQDMSA-N 0.000 description 1
- 239000005631 2,4-Dichlorophenoxyacetic acid Substances 0.000 description 1
- UPMXNNIRAGDFEH-UHFFFAOYSA-N 3,5-dibromo-4-hydroxybenzonitrile Chemical compound OC1=C(Br)C=C(C#N)C=C1Br UPMXNNIRAGDFEH-UHFFFAOYSA-N 0.000 description 1
- CAAMSDWKXXPUJR-UHFFFAOYSA-N 3,5-dihydro-4H-imidazol-4-one Chemical compound O=C1CNC=N1 CAAMSDWKXXPUJR-UHFFFAOYSA-N 0.000 description 1
- ALYNCZNDIQEVRV-UHFFFAOYSA-N 4-aminobenzoic acid Chemical compound NC1=CC=C(C(O)=O)C=C1 ALYNCZNDIQEVRV-UHFFFAOYSA-N 0.000 description 1
- QUTYKIXIUDQOLK-PRJMDXOYSA-N 5-O-(1-carboxyvinyl)-3-phosphoshikimic acid Chemical class O[C@H]1[C@H](OC(=C)C(O)=O)CC(C(O)=O)=C[C@H]1OP(O)(O)=O QUTYKIXIUDQOLK-PRJMDXOYSA-N 0.000 description 1
- HUNCSWANZMJLPM-UHFFFAOYSA-N 5-methyltryptophan Chemical compound CC1=CC=C2NC=C(CC(N)C(O)=O)C2=C1 HUNCSWANZMJLPM-UHFFFAOYSA-N 0.000 description 1
- 235000004507 Abies alba Nutrition 0.000 description 1
- 235000014081 Abies amabilis Nutrition 0.000 description 1
- 244000101408 Abies amabilis Species 0.000 description 1
- 244000178606 Abies grandis Species 0.000 description 1
- 235000017894 Abies grandis Nutrition 0.000 description 1
- 108010000700 Acetolactate synthase Proteins 0.000 description 1
- 101710197633 Actin-1 Proteins 0.000 description 1
- 101710146995 Acyl carrier protein Proteins 0.000 description 1
- 101150021974 Adh1 gene Proteins 0.000 description 1
- 241000567139 Aeropyrum pernix Species 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- 241000589156 Agrobacterium rhizogenes Species 0.000 description 1
- 241000589159 Agrobacterium sp. Species 0.000 description 1
- 241000589155 Agrobacterium tumefaciens Species 0.000 description 1
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 1
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 1
- 235000005254 Allium ampeloprasum Nutrition 0.000 description 1
- 240000006108 Allium ampeloprasum Species 0.000 description 1
- 240000002234 Allium sativum Species 0.000 description 1
- 240000002470 Amphicarpaea bracteata Species 0.000 description 1
- 229920001685 Amylomaize Polymers 0.000 description 1
- 229920000856 Amylose Polymers 0.000 description 1
- 235000001274 Anacardium occidentale Nutrition 0.000 description 1
- 241000272525 Anas platyrhynchos Species 0.000 description 1
- 108010037870 Anthranilate Synthase Proteins 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- 240000007087 Apium graveolens Species 0.000 description 1
- 235000015849 Apium graveolens Dulce Group Nutrition 0.000 description 1
- 235000010591 Appio Nutrition 0.000 description 1
- 241000219195 Arabidopsis thaliana Species 0.000 description 1
- 101000834552 Arabidopsis thaliana Alpha-glucosidase 2 Proteins 0.000 description 1
- 235000003911 Arachis Nutrition 0.000 description 1
- 235000017060 Arachis glabrata Nutrition 0.000 description 1
- 235000018262 Arachis monticola Nutrition 0.000 description 1
- 235000005340 Asparagus officinalis Nutrition 0.000 description 1
- 241000228245 Aspergillus niger Species 0.000 description 1
- 241000228136 Aspergillus shirousami Species 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 101100068894 Bacillus subtilis (strain 168) glvA gene Proteins 0.000 description 1
- KHBQMWCZKVMBLN-UHFFFAOYSA-N Benzenesulfonamide Chemical compound NS(=O)(=O)C1=CC=CC=C1 KHBQMWCZKVMBLN-UHFFFAOYSA-N 0.000 description 1
- 235000021533 Beta vulgaris Nutrition 0.000 description 1
- 241000335053 Beta vulgaris Species 0.000 description 1
- 101710099630 Beta-glucosidase 2 Proteins 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 235000011293 Brassica napus Nutrition 0.000 description 1
- 235000017647 Brassica oleracea var italica Nutrition 0.000 description 1
- 240000008100 Brassica rapa Species 0.000 description 1
- 235000000540 Brassica rapa subsp rapa Nutrition 0.000 description 1
- 239000005489 Bromoxynil Substances 0.000 description 1
- 235000004936 Bromus mango Nutrition 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- BHPQYMZQTOCNFJ-UHFFFAOYSA-N Calcium cation Chemical compound [Ca+2] BHPQYMZQTOCNFJ-UHFFFAOYSA-N 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 241000253373 Caldanaerobacter subterraneus subsp. tengcongensis Species 0.000 description 1
- 235000012766 Cannabis sativa ssp. sativa var. sativa Nutrition 0.000 description 1
- 235000012765 Cannabis sativa ssp. sativa var. spontanea Nutrition 0.000 description 1
- 235000002566 Capsicum Nutrition 0.000 description 1
- 235000009467 Carica papaya Nutrition 0.000 description 1
- 240000006432 Carica papaya Species 0.000 description 1
- 241000701489 Cauliflower mosaic virus Species 0.000 description 1
- 229930186147 Cephalosporin Natural products 0.000 description 1
- 235000007516 Chrysanthemum Nutrition 0.000 description 1
- 244000189548 Chrysanthemum x morifolium Species 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 101710190853 Cruciferin Proteins 0.000 description 1
- 235000004035 Cryptotaenia japonica Nutrition 0.000 description 1
- 244000241257 Cucumis melo Species 0.000 description 1
- 235000010799 Cucumis sativus var sativus Nutrition 0.000 description 1
- 241000219130 Cucurbita pepo subsp. pepo Species 0.000 description 1
- 235000003954 Cucurbita pepo var melopepo Nutrition 0.000 description 1
- 244000007835 Cyamopsis tetragonoloba Species 0.000 description 1
- 241000192700 Cyanobacteria Species 0.000 description 1
- 108010025880 Cyclomaltodextrin glucanotransferase Proteins 0.000 description 1
- 235000017788 Cydonia oblonga Nutrition 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 241000209210 Dactylis Species 0.000 description 1
- 235000002767 Daucus carota Nutrition 0.000 description 1
- 244000000626 Daucus carota Species 0.000 description 1
- 241000205236 Desulfurococcus Species 0.000 description 1
- 108090000204 Dipeptidase 1 Proteins 0.000 description 1
- 102000016607 Diphtheria Toxin Human genes 0.000 description 1
- 108010053187 Diphtheria Toxin Proteins 0.000 description 1
- AHMIDUVKSGCHAU-UHFFFAOYSA-N Dopaquinone Natural products OC(=O)C(N)CC1=CC(=O)C(=O)C=C1 AHMIDUVKSGCHAU-UHFFFAOYSA-N 0.000 description 1
- 235000014466 Douglas bleu Nutrition 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- UPEZCKBFRMILAV-JNEQICEOSA-N Ecdysone Natural products O=C1[C@H]2[C@@](C)([C@@H]3C([C@@]4(O)[C@@](C)([C@H]([C@H]([C@@H](O)CCC(O)(C)C)C)CC4)CC3)=C1)C[C@H](O)[C@H](O)C2 UPEZCKBFRMILAV-JNEQICEOSA-N 0.000 description 1
- 235000007349 Eleusine coracana Nutrition 0.000 description 1
- 235000013499 Eleusine coracana subsp coracana Nutrition 0.000 description 1
- 108010001817 Endo-1,4-beta Xylanases Proteins 0.000 description 1
- 101100344377 Escherichia coli (strain K12) malQ gene Proteins 0.000 description 1
- 101100236462 Escherichia coli (strain K12) malT gene Proteins 0.000 description 1
- 101001091269 Escherichia coli Hygromycin-B 4-O-kinase Proteins 0.000 description 1
- 108010087894 Fatty acid desaturases Proteins 0.000 description 1
- 102000009114 Fatty acid desaturases Human genes 0.000 description 1
- 241000218218 Ficus <angiosperm> Species 0.000 description 1
- 108090000331 Firefly luciferases Proteins 0.000 description 1
- 206010064571 Gene mutation Diseases 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 101710186901 Globulin 1 Proteins 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010033128 Glucan Endo-1,3-beta-D-Glucosidase Proteins 0.000 description 1
- 108700023224 Glucose-1-phosphate adenylyltransferases Proteins 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- 108010070675 Glutathione transferase Proteins 0.000 description 1
- 102000005720 Glutathione transferase Human genes 0.000 description 1
- 108700037728 Glycine max beta-conglycinin Proteins 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 108700023372 Glycosyltransferases Proteins 0.000 description 1
- 239000005562 Glyphosate Substances 0.000 description 1
- 240000000047 Gossypium barbadense Species 0.000 description 1
- 235000009429 Gossypium barbadense Nutrition 0.000 description 1
- 235000009432 Gossypium hirsutum Nutrition 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102000002812 Heat-Shock Proteins Human genes 0.000 description 1
- 108010004889 Heat-Shock Proteins Proteins 0.000 description 1
- 235000005206 Hibiscus Nutrition 0.000 description 1
- 235000007185 Hibiscus lunariifolius Nutrition 0.000 description 1
- 244000284380 Hibiscus rosa sinensis Species 0.000 description 1
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 1
- 208000006877 Insect Bites and Stings Diseases 0.000 description 1
- 235000021506 Ipomoea Nutrition 0.000 description 1
- 241000207783 Ipomoea Species 0.000 description 1
- 244000017020 Ipomoea batatas Species 0.000 description 1
- 235000002678 Ipomoea batatas Nutrition 0.000 description 1
- 241000588744 Klebsiella pneumoniae subsp. ozaenae Species 0.000 description 1
- WTDRDQBEARUVNC-UHFFFAOYSA-N L-Dopa Natural products OC(=O)C(N)CC1=CC=C(O)C(O)=C1 WTDRDQBEARUVNC-UHFFFAOYSA-N 0.000 description 1
- AHMIDUVKSGCHAU-LURJTMIESA-N L-dopaquinone Chemical compound [O-]C(=O)[C@@H]([NH3+])CC1=CC(=O)C(=O)C=C1 AHMIDUVKSGCHAU-LURJTMIESA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 241000219729 Lathyrus Species 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- 241000234280 Liliaceae Species 0.000 description 1
- 240000004296 Lolium perenne Species 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 241000034009 Lycopus Species 0.000 description 1
- 239000007993 MOPS buffer Substances 0.000 description 1
- 241000208467 Macadamia Species 0.000 description 1
- 235000018330 Macadamia integrifolia Nutrition 0.000 description 1
- 240000007575 Macadamia integrifolia Species 0.000 description 1
- 241000710118 Maize chlorotic mottle virus Species 0.000 description 1
- 244000070406 Malus silvestris Species 0.000 description 1
- 235000004456 Manihot esculenta Nutrition 0.000 description 1
- 235000016735 Manihot esculenta subsp esculenta Nutrition 0.000 description 1
- 102100025022 Mannose-6-phosphate isomerase Human genes 0.000 description 1
- 240000004658 Medicago sativa Species 0.000 description 1
- 235000010624 Medicago sativa Nutrition 0.000 description 1
- 241000213996 Melilotus Species 0.000 description 1
- 101710140999 Metallocarboxypeptidase inhibitor Proteins 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 241000203407 Methanocaldococcus jannaschii Species 0.000 description 1
- 241000204641 Methanopyrus kandleri Species 0.000 description 1
- 241001302042 Methanothermobacter thermautotrophicus Species 0.000 description 1
- 229920000881 Modified starch Polymers 0.000 description 1
- 101150109579 Mrps7 gene Proteins 0.000 description 1
- 235000018290 Musa x paradisiaca Nutrition 0.000 description 1
- 241000234479 Narcissus Species 0.000 description 1
- 235000006508 Nelumbo nucifera Nutrition 0.000 description 1
- 240000002853 Nelumbo nucifera Species 0.000 description 1
- 235000006510 Nelumbo pentapetala Nutrition 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 101100363725 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) crp-15 gene Proteins 0.000 description 1
- 102100027814 Non-lysosomal glucosylceramidase Human genes 0.000 description 1
- 101710083785 Non-lysosomal glucosylceramidase Proteins 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- 241000795633 Olea <sea slug> Species 0.000 description 1
- 240000007817 Olea europaea Species 0.000 description 1
- 101710089395 Oleosin Proteins 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 244000038248 Pennisetum spicatum Species 0.000 description 1
- 244000115721 Pennisetum typhoides Species 0.000 description 1
- 241000218196 Persea Species 0.000 description 1
- 235000008673 Persea americana Nutrition 0.000 description 1
- 244000025272 Persea americana Species 0.000 description 1
- 244000100170 Phaseolus lunatus Species 0.000 description 1
- 108091000041 Phosphoenolpyruvate Carboxylase Proteins 0.000 description 1
- 240000000020 Picea glauca Species 0.000 description 1
- 235000008127 Picea glauca Nutrition 0.000 description 1
- 241000218595 Picea sitchensis Species 0.000 description 1
- 235000008331 Pinus X rigitaeda Nutrition 0.000 description 1
- 235000011613 Pinus brutia Nutrition 0.000 description 1
- 241000018646 Pinus brutia Species 0.000 description 1
- 235000008593 Pinus contorta Nutrition 0.000 description 1
- 241000218606 Pinus contorta Species 0.000 description 1
- 235000013267 Pinus ponderosa Nutrition 0.000 description 1
- 241000555277 Pinus ponderosa Species 0.000 description 1
- 235000008577 Pinus radiata Nutrition 0.000 description 1
- 241000218621 Pinus radiata Species 0.000 description 1
- 235000008566 Pinus taeda Nutrition 0.000 description 1
- 241000218679 Pinus taeda Species 0.000 description 1
- 241000758706 Piperaceae Species 0.000 description 1
- 241000206607 Porphyra umbilicalis Species 0.000 description 1
- 235000009827 Prunus armeniaca Nutrition 0.000 description 1
- 244000018633 Prunus armeniaca Species 0.000 description 1
- 241001290151 Prunus avium subsp. avium Species 0.000 description 1
- 240000005809 Prunus persica Species 0.000 description 1
- 235000006029 Prunus persica var nucipersica Nutrition 0.000 description 1
- 235000006040 Prunus persica var persica Nutrition 0.000 description 1
- 244000017714 Prunus persica var. nucipersica Species 0.000 description 1
- 235000008572 Pseudotsuga menziesii Nutrition 0.000 description 1
- 235000005386 Pseudotsuga menziesii var menziesii Nutrition 0.000 description 1
- 241000508269 Psidium Species 0.000 description 1
- 240000001679 Psidium guajava Species 0.000 description 1
- 235000013929 Psidium pyriferum Nutrition 0.000 description 1
- 241000205160 Pyrococcus Species 0.000 description 1
- 241000205156 Pyrococcus furiosus Species 0.000 description 1
- 235000014443 Pyrus communis Nutrition 0.000 description 1
- 244000184734 Pyrus japonica Species 0.000 description 1
- 101150020647 RPS7 gene Proteins 0.000 description 1
- 244000088415 Raphanus sativus Species 0.000 description 1
- 235000006140 Raphanus sativus var sativus Nutrition 0.000 description 1
- 108700005075 Regulator Genes Proteins 0.000 description 1
- 101710151532 Replicating protein Proteins 0.000 description 1
- 240000005384 Rhizopus oryzae Species 0.000 description 1
- 235000013752 Rhizopus oryzae Nutrition 0.000 description 1
- 241000208422 Rhododendron Species 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 235000011449 Rosa Nutrition 0.000 description 1
- 241000220317 Rosa Species 0.000 description 1
- 240000007651 Rubus glaucus Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 1
- 241000209051 Saccharum Species 0.000 description 1
- 241001466077 Salina Species 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 108010016634 Seed Storage Proteins Proteins 0.000 description 1
- 241001138418 Sequoia sempervirens Species 0.000 description 1
- 235000008515 Setaria glauca Nutrition 0.000 description 1
- 235000007226 Setaria italica Nutrition 0.000 description 1
- BQCADISMDOOEFD-UHFFFAOYSA-N Silver Chemical compound [Ag] BQCADISMDOOEFD-UHFFFAOYSA-N 0.000 description 1
- 235000007230 Sorghum bicolor Nutrition 0.000 description 1
- 235000009337 Spinacia oleracea Nutrition 0.000 description 1
- 244000300264 Spinacia oleracea Species 0.000 description 1
- 235000009184 Spondias indica Nutrition 0.000 description 1
- 108010039811 Starch synthase Proteins 0.000 description 1
- 101710154134 Stearoyl-[acyl-carrier-protein] 9-desaturase, chloroplastic Proteins 0.000 description 1
- 241000187391 Streptomyces hygroscopicus Species 0.000 description 1
- 101001091268 Streptomyces hygroscopicus Hygromycin-B 7''-O-kinase Proteins 0.000 description 1
- 241000187191 Streptomyces viridochromogenes Species 0.000 description 1
- 108010043934 Sucrose synthase Proteins 0.000 description 1
- 241000205101 Sulfolobus Species 0.000 description 1
- 241000205091 Sulfolobus solfataricus Species 0.000 description 1
- 229940100389 Sulfonylurea Drugs 0.000 description 1
- 108700025695 Suppressor Genes Proteins 0.000 description 1
- 244000269722 Thea sinensis Species 0.000 description 1
- 235000006468 Thea sinensis Nutrition 0.000 description 1
- 241000205188 Thermococcus Species 0.000 description 1
- 241000204074 Thermococcus hydrothermalis Species 0.000 description 1
- 241000204667 Thermoplasma Species 0.000 description 1
- 241000489996 Thermoplasma volcanium Species 0.000 description 1
- 241001313699 Thermosynechococcus elongatus Species 0.000 description 1
- 101100055062 Thermotoga neapolitana aglB gene Proteins 0.000 description 1
- 102000002933 Thioredoxin Human genes 0.000 description 1
- 102000013090 Thioredoxin-Disulfide Reductase Human genes 0.000 description 1
- 108010079911 Thioredoxin-disulfide reductase Proteins 0.000 description 1
- 241000218638 Thuja plicata Species 0.000 description 1
- 102000004357 Transferases Human genes 0.000 description 1
- 108090000992 Transferases Proteins 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 102000007641 Trefoil Factors Human genes 0.000 description 1
- 235000015724 Trifolium pratense Nutrition 0.000 description 1
- 235000001484 Trigonella foenum graecum Nutrition 0.000 description 1
- 244000250129 Trigonella foenum graecum Species 0.000 description 1
- 244000098338 Triticum aestivum Species 0.000 description 1
- 102000004243 Tubulin Human genes 0.000 description 1
- 241000722923 Tulipa Species 0.000 description 1
- 241000722921 Tulipa gesneriana Species 0.000 description 1
- 108060008724 Tyrosinase Proteins 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 244000078534 Vaccinium myrtillus Species 0.000 description 1
- 240000004922 Vigna radiata Species 0.000 description 1
- 235000010721 Vigna radiata var radiata Nutrition 0.000 description 1
- 235000011469 Vigna radiata var sublobata Nutrition 0.000 description 1
- 235000011453 Vigna umbellata Nutrition 0.000 description 1
- 240000001417 Vigna umbellata Species 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- 101710201961 Virion infectivity factor Proteins 0.000 description 1
- 206010052428 Wound Diseases 0.000 description 1
- 108700031584 Zea mays R Proteins 0.000 description 1
- KRWTWSSMURUMDE-UHFFFAOYSA-N [1-(2-methoxynaphthalen-1-yl)naphthalen-2-yl]-diphenylphosphane Chemical compound COC1=CC=C2C=CC=CC2=C1C(C1=CC=CC=C1C=C1)=C1P(C=1C=CC=CC=1)C1=CC=CC=C1 KRWTWSSMURUMDE-UHFFFAOYSA-N 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- 244000193174 agave Species 0.000 description 1
- 230000032683 aging Effects 0.000 description 1
- 230000001270 agonistic effect Effects 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 235000020224 almond Nutrition 0.000 description 1
- UPEZCKBFRMILAV-UHFFFAOYSA-N alpha-Ecdysone Natural products C1C(O)C(O)CC2(C)C(CCC3(C(C(C(O)CCC(C)(C)O)C)CCC33O)C)C3=CC(=O)C21 UPEZCKBFRMILAV-UHFFFAOYSA-N 0.000 description 1
- 102000005840 alpha-Galactosidase Human genes 0.000 description 1
- 108010030291 alpha-Galactosidase Proteins 0.000 description 1
- 108010012864 alpha-Mannosidase Proteins 0.000 description 1
- 102000019199 alpha-Mannosidase Human genes 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229910021529 ammonia Inorganic materials 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000009833 antibody interaction Effects 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 235000021016 apples Nutrition 0.000 description 1
- 108091010938 auxin binding proteins Proteins 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 235000021028 berry Nutrition 0.000 description 1
- 102000006635 beta-lactamase Human genes 0.000 description 1
- 239000003139 biocide Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 238000005415 bioluminescence Methods 0.000 description 1
- 230000029918 bioluminescence Effects 0.000 description 1
- 235000021029 blackberry Nutrition 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 229910001424 calcium ion Inorganic materials 0.000 description 1
- 235000009120 camo Nutrition 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000020226 cashew nut Nutrition 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 108091092356 cellular DNA Proteins 0.000 description 1
- 229940124587 cephalosporin Drugs 0.000 description 1
- 150000001780 cephalosporins Chemical class 0.000 description 1
- 235000005607 chanvre indien Nutrition 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 235000019693 cherries Nutrition 0.000 description 1
- 229960005091 chloramphenicol Drugs 0.000 description 1
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 1
- 210000001726 chromosome structure Anatomy 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 238000003501 co-culture Methods 0.000 description 1
- 230000008045 co-localization Effects 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 235000005687 corn oil Nutrition 0.000 description 1
- 239000002285 corn oil Substances 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000018044 dehydration Effects 0.000 description 1
- 238000006297 dehydration reaction Methods 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- LTNZEXKYNRNOGT-UHFFFAOYSA-N dequalinium chloride Chemical compound [Cl-].[Cl-].C1=CC=C2[N+](CCCCCCCCCC[N+]3=C4C=CC=CC4=C(N)C=C3C)=C(C)C=C(N)C2=C1 LTNZEXKYNRNOGT-UHFFFAOYSA-N 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 229940079919 digestives enzyme preparation Drugs 0.000 description 1
- 102000004419 dihydrofolate reductase Human genes 0.000 description 1
- 108010056535 dihydrofolate reductase type II Proteins 0.000 description 1
- MHUWZNTUIIFHAS-CLFAGFIQSA-N dioleoyl phosphatidic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC(COP(O)(O)=O)OC(=O)CCCCCCC\C=C/CCCCCCCC MHUWZNTUIIFHAS-CLFAGFIQSA-N 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000022602 disease susceptibility Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 1
- 210000005069 ears Anatomy 0.000 description 1
- UPEZCKBFRMILAV-JMZLNJERSA-N ecdysone Chemical compound C1[C@@H](O)[C@@H](O)C[C@]2(C)[C@@H](CC[C@@]3([C@@H]([C@@H]([C@H](O)CCC(C)(C)O)C)CC[C@]33O)C)C3=CC(=O)[C@@H]21 UPEZCKBFRMILAV-JMZLNJERSA-N 0.000 description 1
- 230000013020 embryo development Effects 0.000 description 1
- 210000002242 embryoid body Anatomy 0.000 description 1
- YERABYSOHUZTPQ-UHFFFAOYSA-P endo-1,4-beta-Xylanase Chemical compound C=1C=CC=CC=1C[N+](CC)(CC)CCCNC(C(C=1)=O)=CC(=O)C=1NCCC[N+](CC)(CC)CC1=CC=CC=C1 YERABYSOHUZTPQ-UHFFFAOYSA-P 0.000 description 1
- 210000001900 endoderm Anatomy 0.000 description 1
- 108010091371 endoglucanase 1 Proteins 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 230000006353 environmental stress Effects 0.000 description 1
- 230000007515 enzymatic degradation Effects 0.000 description 1
- 230000007071 enzymatic hydrolysis Effects 0.000 description 1
- 238000006047 enzymatic hydrolysis reaction Methods 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 238000000105 evaporative light scattering detection Methods 0.000 description 1
- 230000003090 exacerbative effect Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 108010038658 exo-1,4-beta-D-xylosidase Proteins 0.000 description 1
- 108010093305 exopolygalacturonase Proteins 0.000 description 1
- 238000004880 explosion Methods 0.000 description 1
- 235000013410 fast food Nutrition 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 229930003935 flavonoid Natural products 0.000 description 1
- 235000017173 flavonoids Nutrition 0.000 description 1
- 238000005755 formation reaction Methods 0.000 description 1
- 239000013505 freshwater Substances 0.000 description 1
- 230000005078 fruit development Effects 0.000 description 1
- 230000004345 fruit ripening Effects 0.000 description 1
- 235000011389 fruit/vegetable juice Nutrition 0.000 description 1
- 235000012055 fruits and vegetables Nutrition 0.000 description 1
- 239000000446 fuel Substances 0.000 description 1
- 235000004611 garlic Nutrition 0.000 description 1
- 238000010363 gene targeting Methods 0.000 description 1
- 238000012252 genetic analysis Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 230000035784 germination Effects 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 102000005396 glutamine synthetase Human genes 0.000 description 1
- 108020002326 glutamine synthetase Proteins 0.000 description 1
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- 102000045442 glycosyltransferase activity proteins Human genes 0.000 description 1
- 108700014210 glycosyltransferase activity proteins Proteins 0.000 description 1
- XDDAORKBJWWYJS-UHFFFAOYSA-N glyphosate Chemical compound OC(=O)CNCP(O)(O)=O XDDAORKBJWWYJS-UHFFFAOYSA-N 0.000 description 1
- 229940097068 glyphosate Drugs 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 239000001307 helium Substances 0.000 description 1
- 229910052734 helium Inorganic materials 0.000 description 1
- SWQJXJOGLNCZEY-UHFFFAOYSA-N helium atom Chemical compound [He] SWQJXJOGLNCZEY-UHFFFAOYSA-N 0.000 description 1
- 108010002430 hemicellulase Proteins 0.000 description 1
- 229940059442 hemicellulase Drugs 0.000 description 1
- 239000011487 hemp Substances 0.000 description 1
- 150000002402 hexoses Chemical class 0.000 description 1
- 101150029559 hph gene Proteins 0.000 description 1
- 230000036571 hydration Effects 0.000 description 1
- 238000006703 hydration reaction Methods 0.000 description 1
- 229960002591 hydroxyproline Drugs 0.000 description 1
- 239000007943 implant Substances 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 210000004020 intracellular membrane Anatomy 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 239000004310 lactic acid Substances 0.000 description 1
- 235000014655 lactic acid Nutrition 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 229960004502 levodopa Drugs 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000001050 lubricating effect Effects 0.000 description 1
- 238000004020 luminiscence type Methods 0.000 description 1
- 101150095832 malA gene Proteins 0.000 description 1
- 230000008774 maternal effect Effects 0.000 description 1
- 239000002923 metal particle Substances 0.000 description 1
- 150000002739 metals Chemical class 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- GEWDNTWNSAZUDX-UHFFFAOYSA-N methyl 7-epi-jasmonate Natural products CCC=CCC1C(CC(=O)OC)CCC1=O GEWDNTWNSAZUDX-UHFFFAOYSA-N 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 210000001700 mitochondrial membrane Anatomy 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 235000019426 modified starch Nutrition 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 239000006870 ms-medium Substances 0.000 description 1
- 150000002825 nitriles Chemical class 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000005305 organ development Effects 0.000 description 1
- 230000000888 organogenic effect Effects 0.000 description 1
- 235000002252 panizo Nutrition 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 238000002161 passivation Methods 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 238000003359 percent control normalization Methods 0.000 description 1
- 235000011007 phosphoric acid Nutrition 0.000 description 1
- 150000003016 phosphoric acids Chemical class 0.000 description 1
- 230000008121 plant development Effects 0.000 description 1
- 238000004161 plant tissue culture Methods 0.000 description 1
- 235000021018 plums Nutrition 0.000 description 1
- 231100000614 poison Toxicity 0.000 description 1
- 230000007096 poisonous effect Effects 0.000 description 1
- 238000005498 polishing Methods 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 230000007065 protein hydrolysis Effects 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 235000021013 raspberries Nutrition 0.000 description 1
- 239000000376 reactant Substances 0.000 description 1
- 239000011535 reaction buffer Substances 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 230000023276 regulation of development, heterochronic Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 238000012021 retail method of payment Methods 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 101150036132 rpsG gene Proteins 0.000 description 1
- YGSDEFSMJLZEOE-UHFFFAOYSA-M salicylate Chemical compound OC1=CC=CC=C1C([O-])=O YGSDEFSMJLZEOE-UHFFFAOYSA-M 0.000 description 1
- 229960001860 salicylate Drugs 0.000 description 1
- 238000003345 scintillation counting Methods 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 230000008117 seed development Effects 0.000 description 1
- 230000035040 seed growth Effects 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 239000010865 sewage Substances 0.000 description 1
- 239000011257 shell material Substances 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 229910052709 silver Inorganic materials 0.000 description 1
- 239000004332 silver Substances 0.000 description 1
- 235000021309 simple sugar Nutrition 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- 238000009331 sowing Methods 0.000 description 1
- 238000002798 spectrophotometry method Methods 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000035882 stress Effects 0.000 description 1
- YROXIXLRRCOBKF-UHFFFAOYSA-N sulfonylurea Chemical class OC(=N)N=S(=O)=O YROXIXLRRCOBKF-UHFFFAOYSA-N 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 108060008226 thioredoxin Proteins 0.000 description 1
- 229940094937 thioredoxin Drugs 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- FGMPLJWBKKVCDB-UHFFFAOYSA-N trans-L-hydroxy-proline Natural products ON1CCCC1C(O)=O FGMPLJWBKKVCDB-UHFFFAOYSA-N 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- 101150003560 trfA gene Proteins 0.000 description 1
- 235000001019 trigonella foenum-graecum Nutrition 0.000 description 1
- HRXKRNGNAMMEHJ-UHFFFAOYSA-K trisodium citrate Chemical compound [Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O HRXKRNGNAMMEHJ-UHFFFAOYSA-K 0.000 description 1
- 229940038773 trisodium citrate Drugs 0.000 description 1
- WFKWXMTUELFFGS-UHFFFAOYSA-N tungsten Chemical compound [W] WFKWXMTUELFFGS-UHFFFAOYSA-N 0.000 description 1
- 229910052721 tungsten Inorganic materials 0.000 description 1
- 239000010937 tungsten Substances 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 101150101900 uidA gene Proteins 0.000 description 1
- 241001148471 unidentified anaerobic bacterium Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 101150085703 vir gene Proteins 0.000 description 1
- 230000029812 viral genome replication Effects 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
- 230000002087 whitening effect Effects 0.000 description 1
Images




























Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/52—Genes encoding for enzymes or proenzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
Landscapes
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Chemical & Material Sciences (AREA)
- Molecular Biology (AREA)
- Organic Chemistry (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Enzymes And Modification Thereof (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
본 발명은 식물에서의 발현에 최적화시킨 가공 효소를 암호화하는 폴리뉴클레오타이드, 바람직하게는 합성 폴리뉴클레오타이드를 제공한다. 당해 폴리뉴클레오타이드는 목적하는 기질에 따라 작용하도록 적합한 활성화 조건하에 활성화시킨 중온성, 호열성 또는 초호열성 가공 효소를 암호화한다. 또한 이들 효소 중 하나 이상을 발현하며 식물 및 곡립 처리를 촉진하는 대체 조성물을 갖는 "자가-가공" 형질전환된 식물 및 식물 부분, 예를 들면, 곡립을 제공한다. 예를 들면, 개선된 맛을 갖는 식품을 제조하고 에탄올 및 발효 음료의 제조를 위한 발효성 기질을 제조하기 위한, 이들 식물의 제조 및 사용 방법을 또한 제공한다. The present invention provides polynucleotides, preferably synthetic polynucleotides, which encode processing enzymes optimized for expression in plants. The polynucleotides encode mesophilic, thermophilic or hyperthermic processing enzymes activated under suitable activation conditions to act upon the substrate of interest. Also provided are "self-processing" transformed plants and plant parts, such as grains, having an alternative composition that expresses one or more of these enzymes and facilitates plant and grain processing. Also provided are methods of making and using these plants, for example, for preparing foods with improved taste and for producing fermentable substrates for the production of ethanol and fermented beverages.
자가 가공 효소, 형질전환된 식물, 벡터, 전분, 발효성 당, 옥수수 γ-제인 프로모터, 옥수수 ADP-gpp 프로모터 Autologous Enzyme, Transformed Plant, Vector, Starch, Fermentable Sugar, Corn γ-Zane Promoter, Corn ADP-gpp Promoter
Description
관련 출원Related Applications
본 출원은 각각 전문이 본원에 참조로 인용되어 있는, 2001년 8월 27일자로 출원된 미국 특허 출원 제60/315,281호에 대한 우선권을 주장하는, 2002년 8월 27일자로 출원된 미국 특허 출원 제10/228,063호의 부분연속출원이다.This application is a US patent application filed on Aug. 27, 2002 that claims priority to US patent application Ser. No. 60 / 315,281, filed Aug. 27, 2001, which is hereby incorporated by reference in its entirety. Partial serial application of
본 발명은 식물 분자 생물학 분야, 및 보다 특히, 식물 또는 이의 생성물에 목적하는 특성을 제공하는 가공(processing) 효소를 발현하는 식물의 생산에 관한 것이다. The present invention relates to the field of plant molecular biology, and more particularly to the production of plants expressing processing enzymes that provide the desired properties to the plant or its products.
효소는 목질, 과실 및 채소, 전분, 즙 등과 같은 각종 농산물을 가공하는 데 사용된다. 통상적으로, 가공 효소는 미생물 발효{바실러스(Bacillus) α-아밀라제} 또는 식물에서 분리(식물 부분로부터의 커피 β-갈락토시다제 또는 파파인)와 같이 각종 공급원으로부터 산업용 규모로 제조 및 회수된다. 효소 제제를 습도, 온도, 시간 및 기계적 혼합의 적합한 조건하에 효소와 기질을 혼합함으로써 상이한 가공 적용에 사용하여 효소적 반응을 상업적으로 실용적인 방법으로 성취한다. 당해 방법은 효소 제조, 효소 제제의 제조, 효소와 기질 혼합, 및 혼합물을 효소 반응을 촉진시키기에 적합한 조건에 적용시키는 분리된 단계를 포함한다. 시간, 에너지, 혼합, 자본 지출, 및/또는 효소 제조 단가를 절감 또는 제거하는 방법, 또는 개선된 또는 신규한 생성물을 산출하는 방법이 유용하며 이득이 될 것이다. 이러한 개선이 필요한 한 예는 옥수수 제분의 영역이다. Enzymes are used to process various agricultural products such as wood, fruit and vegetables, starch, juice and the like. Typically, processing enzymes are produced and recovered on an industrial scale from various sources, such as microbial fermentation ( Bacillus α-amylase) or separation from plants (coffee β-galactosidase or papain from plant parts). Enzyme preparations are used in different processing applications by mixing enzymes and substrates under suitable conditions of humidity, temperature, time and mechanical mixing to achieve enzymatic reactions in a commercially viable manner. The method includes preparing an enzyme, preparing an enzyme preparation, mixing an enzyme with a substrate, and subjecting the mixture to conditions suitable to catalyze the enzymatic reaction. Methods of reducing or eliminating time, energy, mixing, capital expenditure, and / or enzyme manufacturing costs, or yielding improved or novel products, may be useful and beneficial. One example where such improvements are needed is in the area of corn milling.
오늘날 옥수수 전분 및 기타 옥수수-제분 부산물(예를 들면, 옥수수 글루텐 사료, 옥수수 글루텐 분말 및 옥수수유)을 수득하기 위해 옥수수를 제분한다. 당해 방법으로부터 수득된 전분은 종종 파생 전분 및 당과 같은 다른 생성물로 추가로 가공되거나 알콜 또는 젖산을 포함하는 각종 생성물을 제조하기 위해 발효된다. 옥수수전분의 가공은 흔히 효소, 특히, 전분을 발효 당 또는 프럭토즈(α- 및 글루코-아밀라제, α- 글루코시다제, 글루코즈 이소머라제 등)으로 가수분해 및 전환하는 효소의 사용을 포함한다. 현재 상업적으로 사용되는 방법은 대량 제분기의 제작이 적절한 비용 효과를 필요로 하는 규모로 옥수수를 가공하는 것을 요구하기 때문에 자본 집약적이다. 게다가, 당해 방법은 전분-가수분해 또는 변형 효소의 분리 제조 및 이에 이은 가수분해된 전분 생성물을 제조하기 위한 효소 및 기질 혼합 기계를 필요로 한다. Corn is milled today to obtain corn starch and other corn-milling by-products (eg corn gluten feed, corn gluten powder and corn oil). Starches obtained from this process are often further processed into derivatives starch and other products such as sugars or fermented to produce a variety of products including alcohols or lactic acid. Processing of corn starch often involves the use of enzymes, in particular enzymes that hydrolyze and convert starch into fermented sugars or fructose (α- and gluco-amylases, α-glucosidase, glucose isomerase, etc.). Current commercially available methods are capital intensive because the manufacture of bulk mills requires processing of corn on a scale that requires adequate cost effectiveness. In addition, the process requires an enzyme and substrate mixing machine for the separate preparation of starch-hydrolyzed or modified enzymes followed by hydrolyzed starch products.
옥수수 곡립으로부터의 전분 회수 방법이 널리 공지되어 있으며 습식 제분 방법이 포함된다. 옥수수 습식 제분은 옥수수 낟알(kernel)을 침지시키는 단계, 옥수수 낟알을 연마하는 단계 및 옥수수 성분을 분리하는 단계를 포함한다. 낟알 을 침지 탱크에서 약 120°F에서 역류수로 침지하며 침지 탱크 내에서 24 내지 48시간 동안 잔류시킨다. 당해 침지수는 통상 약 0.2중량% 농도의 이산화황을 함유한다. 이산화황은 당해 방법에서 사용되어 미생물 성장 감소를 돕고 또한 내배유 단백질 내의 이황화 결합을 감소시켜 보다 효율적인 전분-단백질 분리를 촉진한다. 일반적으로, 옥수수 부쉘당 침지수 약 0.59 갤론을 사용한다. 침지수는 폐기물로서 간주되며 종종 바람직하지 않은 수준의 잔류 이산화황을 함유한다. Methods of recovering starch from corn grains are well known and include wet milling methods. Corn wet milling includes soaking corn kernels, grinding the corn kernels, and separating the corn components. The grains are immersed in countercurrent at about 120 ° F in the immersion tank and remain in the immersion tank for 24 to 48 hours. The immersion water usually contains sulfur dioxide at a concentration of about 0.2% by weight. Sulfur dioxide is used in the process to help reduce microbial growth and also to reduce disulfide bonds in endosperm proteins to promote more efficient starch-protein separation. Generally, about 0.59 gallons of immersion is used per corn bushel. Dipping water is considered waste and often contains undesirable levels of residual sulfur dioxide.
이어서 침지된 낟알을 탈수시키고 마찰형 제분기 세트에 적용시킨다. 마찰형 제분기 제1 세트는 낟알을 파열시켜 낟알의 나머지로부터 배를 방출시킨다. 습식 제분 작업에 적합한 시판되는 마찰형 제분기는 상표명 Bauer하에 시판된다. 원심분리를 사용하여 낟알의 나머지로부터 배를 분리한다. 통상 시판되는 원심분리기는 Merco 원심분리기이다. 마찰 제분기 및 원심분리기는 작동하는 데 에너지가 소요되는 매우 비싼 품목이다.The soaked grains are then dewatered and applied to a set of friction mills. The first set of friction mills ruptures the grains to release the vessel from the rest of the grains. Commercially available friction mills suitable for wet milling operations are sold under the trade name Bauer. Centrifuge is used to separate vessels from the rest of the grain. Commercially available centrifuges are Merco centrifuges. Friction mills and centrifuges are very expensive items that require energy to operate.
당해 방법의 다음 단계에서, 전분, 외피, 섬유소 및 글루텐을 포함하는 나머지 낟알 성분을 다른 세트의 마찰 제분기에 적용시키고 세척 선별 세트에 통과시켜 전분 및 글루텐(내배유 단백질)으로부터 섬유소 성분을 분리한다. 전분 및 글루텐은 선별기를 통해 통과되지만, 섬유소는 통과하지 않는다. 원심분리 또는 제3 연마 후의 원심분리를 사용하여 내배유 단백질로부터 전분을 분리한다. 원심분리는 탈수된 전분 슬러리를 생산하며, 이어서 담수로 세척하고 약 12% 습도로 건조시킨다. 실질적으로 순수한 전분은 통상 효소를 사용하여 추가로 가공한다. In the next step of the process, the remaining grain components, including starch, shell, fiber and gluten, are applied to another set of friction mills and passed through a wash screening set to separate the fiber components from starch and gluten (endosperm protein). Starch and gluten pass through the selector, but not fiber. Starch is separated from the endosperm protein using centrifugation or centrifugation after third grinding. Centrifugation produces a dehydrated starch slurry, which is then washed with fresh water and dried to about 12% humidity. Substantially pure starch is usually further processed using enzymes.
곡립의 기타 성분으로부터의 전분의 분리를 수행하는데, 이는 종자 외피, 배 아 및 내배유 단백질의 제거가 전분과 가공 효소를 효율적으로 접촉하게 하여, 수득된 가수분해 생성물을 기타 낟알 성분으로부터의 오염원을 실질적으로 유리시키기 때문이다. 분리는 또한 곡립의 기타 성분을 효율적으로 회수하고 이어서 부산물로 시판하여 제분으로부터의 수익을 증가할 수 있게 한다.Separation of starch from other components of the grain is carried out, which allows the removal of seed hulls, embryos and endosperm proteins to efficiently contact the starch and the processing enzymes, thereby substantially removing contaminants from other grain components. This is because it is liberated. Separation also allows for efficient recovery of other components of the grain and subsequently marketed as by-products to increase profit from milling.
전분을 습식 제분 과정으로부터 회수한 후, 통상적으로 말토덱스트린 제조를 위해 젤라틴화, 액화 및 덱스트린화의 가공 단계를 수행하고, 글루코즈, 말토즈 및 프럭토즈의 제조를 위한 당화, 이성화 및 정제의 연속한 단계를 수행한다. After the starch is recovered from the wet milling process, the processing steps of gelatinization, liquefaction and dextrinization are usually carried out for the preparation of maltodextrins, and the succession of saccharification, isomerization and purification for the preparation of glucose, maltose and fructose Perform the steps.
젤라틴화는 현재 사용가능한 효소가 결정질 전분을 신속히 가수분해할 수 없기 때문에 전분의 가수분해에 사용한다. 가수분해성 효소에 사용가능한 전분을 제조하기 위해, 전분을 통상 수분을 함유한 슬러리(20-40% 건조 고형)로 제조하고 적합한 겔화 온도에서 가열한다. 옥수수 전분의 경우, 이러한 온도는 약 105 - 110℃이다. 젤라틴화된 전분은 통상 매우 점성이 높으며 따라서 액화로 지칭되는 다음 단계에서 농도가 묽어진다. 액화는 전분의 글루코즈 분자 사이의 일부 결합을 파괴하고 효소 또는 산을 이용하여 달성된다. 내열성 엔도 α-아밀라제 효소를 상기 단계 및 후속적 덱스트린화 단계에 사용한다. 가수분해 정도는 덱스트린화 단계에서 조절하여 목적하는 퍼센트의 덱스트로스의 가수분해 생성물을 산출한다. Gelatinization is used for starch hydrolysis because currently available enzymes cannot rapidly hydrolyze crystalline starch. To prepare starch usable for hydrolysable enzymes, the starch is usually made into a slurry containing water (20-40% dry solids) and heated at a suitable gelling temperature. For corn starch, this temperature is about 105-110 ° C. Gelatinized starch is usually very viscous and therefore dilutes in the next step, referred to as liquefaction. Liquefaction breaks down some of the bonds between the glucose molecules of the starch and is achieved using enzymes or acids. The heat resistant endo α-amylase enzyme is used in this and subsequent dextrinization steps. The degree of hydrolysis is adjusted in the dextrinization step to yield the desired percent of the hydrolysis product of dextrose.
액화 단계로부터의 덱스트린 생성물의 추가의 가수분해는 목적하는 생성물에 따라, 다수의 상이한 엑소-아밀라제 및 탈분지 효소로 수행한다. 최종적으로, 프럭토즈가 목적되는 경우, 통상적으로 고정된 글루코즈 이소머라제 효소를 사용하여 글루코즈를 프럭토즈로 전환시킨다.Further hydrolysis of the dextrin product from the liquefaction step is performed with a number of different exo-amylases and debranching enzymes, depending on the desired product. Finally, if fructose is desired, glucose is usually converted to fructose using an immobilized glucose isomerase enzyme.
옥수수전분으로부터 발효성 당(및 예를 들면, 이어서 에탄올)을 제조하는 건식 제분 방법은 외인성 효소와 전분의 효과적인 접촉을 촉진한다. 이들 방법은 습식 제분보다 덜 자본집약적이지만, 흔히 이들 방법으로부터 파생된 부산물은 습식 제분으로부터 파생된 부산물만큼의 가치가 없기 때문에, 현저한 비용우위가 여전히 요망된다. 예를 들면, 옥수수를 건식 제분하는 경우, 낟알을 분말로 연마하여 효소 분해에 의한 전분의 효율적인 접촉을 촉진한다. 옥수수 분말의 효소 가수분해 후, 잔여 고형물은 이들이 단백질 및 일부 기타 성분을 함유하기 때문에, 사료로서 약간의 가치를 갖는다. 에크호프(Eckhoff)는 최근에 "단기-배 가공을 사용한 옥수수로부터의 연료 에탄올의 발효 및 비용"이라는 제목의 논문에서 건식 제분에 관한 개선 가능성 및 관련 문제를 기술하였다(문헌[참조: Appl. Biochem. Biotechnol., 94:41(2001)]). "단기 배" 방법은 감소된 침지 시간을 사용하여 전분으로부터 농후유 배를 분리할 수 있게 한다.The dry milling method of preparing fermentable sugars (and, for example, ethanol) from corn starch, promotes effective contact of the exogenous enzyme with the starch. These methods are less capital intensive than wet milling, but significant cost advantages are still desired because often the by-products derived from these methods are not worth as much as the by-products derived from wet milling. For example, in the case of dry milling of corn, the grains are ground into powder to promote efficient contact of the starch by enzymatic degradation. After enzymatic hydrolysis of corn powder, the residual solids have some value as feed because they contain proteins and some other ingredients. Eckhoff recently described the possibility and improvement of dry milling in a paper entitled "Fermentation and Cost of Fuel Ethanol from Corn Using Short-Pear Processing" (Appl. Biochem). Biotechnol., 94:41 (2001)]. The "short pear" method makes it possible to separate rich pears from starch using reduced soaking times.
식물 내의 내인성 가공 효소의 조절 및/또는 농도가 바람직한 생성물을 초래할 수 있는 한 예는 단옥수수이다. 통상적으로 단옥수수 품종은, 이러한 단옥수수가 평균 수준의 전분 생합성이 불가능하다는 사실로 인해 야생 옥수수 품종과 구분된다. 통상적으로 옥수수 생합성에 관여하는 효소를 암호화하는 유전자 내의 유전자 돌연변이를 단옥수수 품종에 사용하여 옥수수 생합성을 제한한다. 이러한 돌연변이는 전분 신타제 및 ADP-글루코즈 파이로포스포릴라제를 암호화하는 유전자 내에 일으킨다(예를 들면, 당질 및 초고당도 돌연변이). 신선한 식용 옥수수의 소비자가 요구하는 선호되는 당도를 제조하기 위해 필요한 단순당인 프럭토즈, 글루코 즈 및 슈크로즈는 이러한 돌연변이체의 발생중인 내배유에 축적된다. 그러나, 옥수수가 너무 오랫동안 성숙하도록 방치되거나(늦은 수확) 옥수수를 소비하기 전 과도한 기간 동안 저장했기 때문에, 전분 축적 농도가 너무 높은 경우, 생성물은 당도를 잃고 거북한 미감 및 입안에서의 느낌이 나게 된다. 따라서 단옥수수에 대한 수확 적기는 매우 좁으며, 저장 기간도 제한적이다. One example where control and / or concentration of endogenous processing enzymes in plants can lead to desirable products. Typically, sweet corn varieties are distinguished from wild corn varieties due to the fact that the average level of starch biosynthesis is not possible. Gene mutations in genes encoding enzymes involved in corn biosynthesis are commonly used in sweet corn varieties to limit corn biosynthesis. Such mutations result in genes encoding starch synthase and ADP-glucose pyrophosphorylase (eg, saccharide and ultra-high sugar mutations). Fructose, glucose and sucrose, the simple sugars needed to produce the desired sugar content required by consumers of fresh edible corn, accumulate in the developing endocrine of these mutants. However, if the corn is left to mature for too long (late harvest) or stored for an excessive period before the corn is consumed, if the starch accumulation concentration is too high, the product loses sugar content and feels in a pale taste and mouth. Therefore, the harvest time for sweet corn is very narrow and the storage period is limited.
단옥수수 품종을 경작하는 농장주에 있어서 다른 중요한 단점은 이들 품종의 유용성이 전적으로 식용 식품으로만 제한된다는 것이다. 농장주가, 종자 발달 동안 식용 식품으로 사용하기 위해 그의 단옥수수를 선행하여 수확하고자 하는 경우, 당해 작물은 필연적으로 손실될 것이다. 단옥수수의 곡립 수율 및 품질은 2가지의 근본적인 이유로 불량하다. 첫째 이유는 전분 생합성 경로의 돌연변이가 전분 생합성 기작을 손상시키며 곡립이 완전히 여물지 못해, 수율 및 품질을 위태롭게 한다는 것이다. 둘째, 곡립 내에 존재하는 높은 당 농도 및 이들 당의 전분으로의 격리 불가능 때문에, 종자의 총 수용부위(sink) 강도가 감소하여, 곡립 내의 영양분 저장의 감소를 악화시킨다. 단옥수수 품종 종자의 내배유가 수축 및 붕괴되어, 적합한 탈수를 수행하지 못하고 질병에 대한 감수성이 커진다. 단옥수수 곡립의 불량한 질은 추가로 부적합한 전분 축전으로 인해 유발된 요인들의 조합으로 인한 불량한 종자 생육력, 불량한 발아, 묘목 질병 감수성 및 불량한 조기 묘목 생장력과 같은 농경법적 영향을 준다. 따라서, 단옥수수의 불량한 질 문제는 소비자, 농장주/재배자, 유통업자 및 종자 생산자에게 영향을 미친다. Another important disadvantage for farmers cultivating sweet corn varieties is that their usefulness is entirely limited to edible food. If a farmer wants to harvest his sweet corn ahead of time for use as an edible food during seed development, the crop will inevitably be lost. Grain yield and quality of sweet corn are poor for two fundamental reasons. The first reason is that mutations in the starch biosynthesis pathway impair starch biosynthesis mechanisms and the grains do not fully collapse, which compromises yield and quality. Second, because of the high concentrations of sugar present in the grains and their inability to sequester into the starch, the total sink strength of the seeds decreases, exacerbating the reduction in nutrient storage in the grains. The endosperm of the sweet corn varieties is contracted and collapsed, resulting in improper dehydration and increased susceptibility to disease. Poor quality of sweet corn grains further has agricultural effects such as poor seed growth, poor germination, seedling disease susceptibility and poor early seedling growth due to a combination of factors caused by inadequate starch storage. Thus, the poor quality problem of sweet corn affects consumers, farmers / cultivators, distributors and seed producers.
따라서, 건식 제분에 대하여, 당해 방법의 효율을 개선 및/또는 부산물의 가 치를 증가시킬 방법이 필요하다. 습식 제분에 대하여는, 연장된 침지, 연마, 제분 및/또는 낟알의 성분의 분리에 필요한 장비를 필요로 하지 않는 전분 가공 방법이 필요하다. 예를 들면, 습식 제분에서 침지 단계를 변형 또는 제거할 필요가 있는데, 이는 폐기를 필요로 하는 오수량을 감소시켜, 에너지 및 시간을 절약하고, 제분 능력을 증가시킬 것이다(낟알은 침지 탱크에서 더 적은 시간을 소비하게 될 것이다). 또한 배아로부터 전분-함유 내배유를 분리하는 과정을 제거 또는 개선할 필요가 있다. Therefore, for dry milling, there is a need for a method that will improve the efficiency of the process and / or increase the value of by-products. For wet milling, there is a need for a starch processing method that does not require the equipment necessary for extended dipping, grinding, milling and / or separation of the components of the grain. For example, in wet milling, it is necessary to modify or remove the immersion step, which will reduce the amount of sewage that requires disposal, saving energy and time, and increasing the milling capacity (grain will be less in the immersion tank). Will spend time). There is also a need to eliminate or improve the process of separating starch-containing endoderm from embryos.
발명의 요약Summary of the Invention
본 발명은 자가-가공 식물 및 식물 부분 및 이의 사용 방법에 관한 것이다. 본 발명의 자가 가공 식물 및 식물 부분은 효소(들)(중온성, 호열성 및/또는 초호열성)를 발현시키고 활성화시킬 수 있다. 효소(들)(중온성, 호열성 또는 초호열성)의 활성화시, 식물 또는 식물 부분은 이러한 효소들이 작용하는 기질을 자가 가공하여 목적하는 결과를 수득하게 할 수 있다.The present invention relates to self-processing plants and plant parts and methods of use thereof. Self-processing plants and plant parts of the invention can express and activate enzyme (s) (medium, thermophilic and / or hyperthermia). Upon activation of the enzyme (s) (medium, thermophilic or superthermophilic), the plant or plant part can self-process the substrate on which these enzymes act to obtain the desired result.
본 발명은 a) 서열번호 2, 4, 6, 9, 19, 21, 25, 37, 39, 41, 43, 46, 48, 50, 52 또는 59 또는 이의 상보체를 갖거나, 낮은 엄중성 하이브리드화 조건하에 서열번호 2, 4, 6, 9, 19, 21, 25, 37, 39, 41, 43, 46, 48, 50, 52 또는 59 중 어느 하나의 상보체와 하이브리드화하고 α-아밀라제, 풀룰라나제, α-글루코시다제, 글루코즈 이소머라제 또는 글루코아밀라제 활성을 갖는 폴리펩타이드를 암호화하거나 b) 서열번호 10, 13, 14, 15, 16, 18, 20, 24, 26, 27, 28, 29, 30, 33, 34, 35, 36, 38, 40, 42, 44, 45, 47, 49 또는 51을 포함하는 폴리펩타이드 또는 이의 효소적 활성 단편을 암호화하는 폴리뉴클레오타이드를 포함하는 분리된 폴리뉴클레오타이드에 관한 것이다. 바람직하게는, 분리된 폴리뉴클레오타이드는 제1 폴리펩타이드 및 제2 펩타이드를 포함하는 융합 폴리펩타이드를 암호화하며, 여기서 제1 폴리펩타이드는 α-아밀라제, 풀룰라나제, α-글루코시다제, 글루코즈 이소머라제 또는 글루코아밀라제 활성을 갖는다. 가장 바람직하게는, 제2 펩타이드는 제1 폴리펩타이드를 식물의 액포, 세포질세망, 엽록체, 전분 과립, 종자 또는 세포벽으로 표적화할 수 있는 시그날 서열 펩타이드를 포함한다. 예를 들면, 시그날 서열은 wawy로부터의 N-말단 시그날 서열, γ-제인으로부터의 N-말단 시그날 서열, 전분 결합 도메인 또는 C-말단 전분 결합 도메인일 수 있다. 낮은 엄중성 하이브리드화 조건하에 서열번호 2, 9 또는 52 중 어느 하나의 상보체와 하이브리드화하고 α-아밀라제 활성을 갖는 폴리뉴클레오타이드를 암호화하는 폴리뉴클레오타이드; 낮은 엄중성 하이브리드화 조건하에 서열번호 4 또는 25의 상보체와 하이브리드화하고 풀룰라나제 활성을 갖는 폴리펩타이드를 암호화하는 폴리뉴클레오타이드; 서열번호 6의 상보체와 하이브리드화하고 α-글루코시다제 활성을 갖는 폴리펩타이드를 암호화하는 폴리뉴클레오타이드; 낮은 엄중성 하이브리드화 조건하에 서열번호 19, 21, 37, 39, 41 또는 43 중 어느 하나의 상보체와 하이브리드화하고 글루코즈 이소머라제 활성을 갖는 폴리펩타이드를 암호화하는 폴리뉴클레오타이드; 낮은 엄중성 하이브리드화 조건하에 서열번호 46, 48, 50 또는 59 중의 어느 하나의 상보체와 하이브리드화하고 글루코아밀라제 활성을 갖는 폴리펩타이드를 암호화하는 폴리뉴클레오타이드가 추가로 포함된다. The present invention is directed to a) having a SEQ ID NO: 2, 4, 6, 9, 19, 21, 25, 37, 39, 41, 43, 46, 48, 50, 52 or 59 or its complement, or low stringency hybridization Under conditions hybridize with the complement of any one of SEQ ID NOs: 2, 4, 6, 9, 19, 21, 25, 37, 39, 41, 43, 46, 48, 50, 52 or 59, and α-amylase, pool Encoding a polypeptide having lulanase, α-glucosidase, glucose isomerase or glucoamylase activity, or b) SEQ ID NOs: 10, 13, 14, 15, 16, 18, 20, 24, 26, 27, 28, Isolated polynucleotides comprising polynucleotides encoding polypeptides comprising 29, 30, 33, 34, 35, 36, 38, 40, 42, 44, 45, 47, 49 or 51 or enzymatically active fragments thereof It is about. Preferably, the isolated polynucleotide encodes a fusion polypeptide comprising a first polypeptide and a second peptide, wherein the first polypeptide is α-amylase, pullulanase, α-glucosidase, glucose isomera Or glucoamylase activity. Most preferably, the second peptide comprises a signal sequence peptide capable of targeting the first polypeptide to vacuoles, cytoplasmic reticulum, chloroplasts, starch granules, seeds or cell walls of the plant. For example, the signal sequence can be an N-terminal signal sequence from wawy, an N-terminal signal sequence from γ-jane, a starch binding domain or a C-terminal starch binding domain. Polynucleotides that hybridize with the complement of any one of SEQ ID NOs: 2, 9 or 52 under low stringency hybridization conditions and encode a polynucleotide having α-amylase activity; Polynucleotides that hybridize with the complement of SEQ ID NO: 4 or 25 under low stringency hybridization conditions and encode a polypeptide having pullulanase activity; Polynucleotides that hybridize with the complement of SEQ ID NO: 6 and encode a polypeptide having α-glucosidase activity; Polynucleotides that hybridize with the complement of any one of SEQ ID NOs: 19, 21, 37, 39, 41 or 43 under low stringency hybridization conditions and encode a polypeptide having glucose isomerase activity; Further included are polynucleotides that hybridize with the complement of any one of SEQ ID NOs: 46, 48, 50 or 59 under low stringency hybridization conditions and encode a polypeptide having glucoamylase activity.
본 발명은 a) 서열번호 61, 63, 65, 79, 81, 83, 85, 87, 89, 91, 93, 94, 95, 96, 97, 99, 108 및 110 또는 이의 상보체를 포함하거나, 낮은 엄중성 하이브리드화 조건하에 서열번호 61, 63, 65, 79, 81, 83, 85, 87, 89, 91, 93, 94, 95, 96, 97, 99, 108 및 110 중 어느 하나의 상보체와 하이브리드화하고, 자일라나제, 셀룰라제, 글루카나제, 베타 글루코시다제, 에스테라제 또는 피타제 활성을 갖는 폴리펩타이드를 암호화하거나 b) 서열번호 62, 64, 66, 70, 80, 82, 84, 86, 88, 90, 92, 109 또는 111을 포함하는 폴리뉴클레오타이드 또는 이의 효소적 활성 단편을 암호화하는 분리된 폴리뉴클레오타이드에 관한 것이다. 분리된 폴리뉴클레오타이드는 제1 폴리펩타이드 및 제2 폴리펩타이드를 포함하는 융합 폴리펩타이드를 암호화할 수 있으며, 여기서 제1 폴리펩타이드는 자일라나제, 셀룰라제, 글루카나제, 베타 글루코시다제, 프로테아제 또는 피타제 활성을 갖는다. 제2 펩타이드는 제1 폴리펩타이드를 식물의 액포, 세포질세망, 엽록체, 전분 과립, 종자 또는 세포벽으로 표적화할 수 있는 시그날 서열 펩타이드를 포함할 수 있다. 예를 들면, 시그날 서열은 waxy로부터의 N-말단 시그날 서열, γ-제인으로부터의 N-말단 시그날 서열, 전분 결합 도메인 또는 C-말단 전분 결합 도메인일 수 있다. The present invention includes a) SEQ ID NOs: 61, 63, 65, 79, 81, 83, 85, 87, 89, 91, 93, 94, 95, 96, 97, 99, 108 and 110 or complements thereof; The complement of any one of SEQ ID NOs: 61, 63, 65, 79, 81, 83, 85, 87, 89, 91, 93, 94, 95, 96, 97, 99, 108 and 110 under low stringency hybridization conditions Hybridize and encode a polypeptide having xylanase, cellulase, glucanase, beta glucosidase, esterase or phytase activity or b) SEQ ID NOs: 62, 64, 66, 70, 80, 82, A polynucleotide comprising 84, 86, 88, 90, 92, 109 or 111, or an isolated polynucleotide encoding an enzymatically active fragment thereof. The isolated polynucleotide may encode a fusion polypeptide comprising a first polypeptide and a second polypeptide, wherein the first polypeptide is xylanase, cellulase, glucanase, beta glucosidase, protease or Has phytase activity. The second peptide may comprise a signal sequence peptide capable of targeting the first polypeptide to vacuoles, cytoplasmic reticulum, chloroplasts, starch granules, seeds or cell walls of the plant. For example, the signal sequence can be an N-terminal signal sequence from waxy, an N-terminal signal sequence from γ-Zane, a starch binding domain or a C-terminal starch binding domain.
본 발명에 제공되고 유용한 예시적 자일라나제는 서열번호 61, 63 또는 65에 의해 암호화된 것이다. 서열번호 69에 의해 암호화된 예시적 프로테아제, 즉, 브로멜라인이 또한 제공된다. 예시적 셀룰라제에는 본원에 제공되고 서열번호 79, 81, 93 및 94에 의해 암호화된 셀로바이오하이드롤라제 I 및 II가 포함된다. 예시적 글루카나제는 서열번호 85에 의해 암호화된, 본원에 기술된 6GP1으로 제공된다. 예시적 베타 글루코시다제에는 본원에 기술되고 서열번호 96 및 97에 의해 암호화된 바와 같은 베타 글루코시다제 2 및 D가 포함된다. 예시적 에스테라제, 즉, 서열번호 99에 의해 암호화된 페룰산 에스테라제가 또한 제공된다. 그리고, 서열번호 109-112에 의해 암호화된 예시적 피타제, Nov9X가 또한 제공된다. Exemplary xylanases provided and useful herein are those encoded by SEQ ID NOs: 61, 63 or 65. Exemplary proteases encoded by SEQ ID NO: 69, ie bromelain, are also provided. Exemplary cellulases include cellobiohydrolases I and II provided herein and encoded by SEQ ID NOs: 79, 81, 93, and 94. Exemplary glucanases are provided as 6GP1 described herein, encoded by SEQ ID NO: 85. Exemplary beta glucosidases include
또한 서열번호 2, 4, 6, 9, 19, 21, 25, 37, 39, 41, 43, 46, 48, 50, 52 또는 59 또는 이의 상보체를 갖거나, 낮은 엄중성 하이브리드화 조건하에 2, 4, 6, 9, 19, 21, 25, 37, 39, 41, 43, 46, 48, 50, 52 또는 59 중 어느 하나의 상보체와 하이브리드화하고 α-아밀라제, 풀룰라나제, α-글루코시다제, 글루코즈 이소머라제 또는 글루코아밀라제 활성을 갖는 폴리펩타이드를 암호화하거나 b) 서열번호 10, 13, 14, 15, 16, 18, 20, 24, 26, 27, 28, 29, 30, 33, 34, 35, 36, 38, 40, 42, 44, 45, 47, 49 또는 51을 포함하는 폴리펩타이드 또는 효소적으로 활성성인 이의 단편을 암호화하는 폴리뉴클레오타이드를 포함하는 발현 카세트가 포함된다. 발현 카세트는 추가로 유도성 프로모터, 조직-특이적 프로모터 또는 바람직하게는 내배유-특이적 프로모터와 같은 폴리뉴클레오타이드에 작동적으로 연결된 프로모터를 포함한다. 바람직하게는, 내배유-특이적 프로모터는 옥수수 γ-제인 프로모터 또는 옥수수 ADP-gpp 프로모터 또는 옥수수 Q 프로모터 또는 벼 글루텔린-1 프로모터이다. 바람직한 양태에서, 프로모터는 서열번호 11 또는 서열번호 12 또는 서열번호 67 또는 서열번호 98을 포함한다. 추가로, 다른 바람직한 양태에서, 폴리뉴클레오타이드는 프로모터에 대하여 센스(sense) 방향으로 배향된다. 본 발명의 발현 카세트는 추가로 당해 폴리뉴클레오타이드에 의해 암호화된 폴리펩타이드에 작 동적으로 연결된 시그날 서열을 암호화할 수 있다. 시그날 서열은 바람직하게는 작동적으로 연결된 폴리펩타이드를 식물의 액포, 세포질세망, 엽록체, 전분 과립, 종자 또는 세포벽으로 표적화한다. 시그날 서열에는 waxy로부터의 N-말단 시그날 서열, γ-제인으로부터의 N-말단 시그날 서열 또는 전분 결합 도메인이 포함된다. And have SEQ ID NO: 2, 4, 6, 9, 19, 21, 25, 37, 39, 41, 43, 46, 48, 50, 52 or 59 or complements thereof, or under low
추가로, a) 서열번호 61, 63, 65, 79, 81, 83, 85, 87, 89, 91, 93, 94, 95, 96, 97, 99, 108 및 110 또는 이의 상보체를 갖거나, 낮은 엄중성 하이브리드화 조건하에 서열번호 61, 63, 65, 79, 81, 83, 85, 87, 89, 91, 93, 94, 95, 96, 97, 99, 108 및 110 중 어느 하나의 상보체와 하이브리드화하고 자일라나제, 셀룰라제, 글루카나제, 베타-글루코시다제, 에스테라제 또는 피타제 활성을 갖는 폴리펩타이드를 암호화하거나, b) 서열번호 62, 64, 66, 70. 80, 82, 84, 86, 88, 90, 92, 109 또는 111을 포함하는 폴리펩타이드 또는 이의 효소적 활성 단편을 암호화하는 폴리펩타이드를 포함하는 발현 카세트가 포함된다. 당해 발현 카세트는 추가로 유도성 프로모터, 조직-특이성 프로모터 또는 바람직하게는 내배유-특이적 프로모터와 같은 폴리뉴클레오타이드에 작동적으로 연결된 프로모터를 포함한다. 내배유-특이적 프로모터는 옥수수 γ-제인 프로모터 또는 옥수수 ADP-gpp 프로모터 또는 옥수수 Q 프로모터 또는 벼 글루텔린-1 프로모터일 수 있다. 한 양태에서, 프로모터는 서열번호 11 또는 서열번호 12 또는 서열번호 67 또는 서열번호 98을 포함한다. 추가로, 다른 양태에서, 폴리뉴클레오타이드는 프로모터에 대해 센스 방향으로 향해 있다. 본 발명의 발현 카세트는 추가로 폴리뉴클레오타이드에 의해 암호화된 폴리펩타이드에 작동적으로 연결된 시그날 서열을 포함할 수 있다. 시그날 서열은 작동적으로 연결된 폴리펩타이드를 바람직하게는 식물의 액포, 세포질세망, 엽록체, 전분 과립, 종자 또는 세포벽으로 표적화한다. 시그날 서열에는 waxy로부터의 N-말단 시그날 서열, γ-제인으로부터의 N-말단 시그날 서열 또는 전분 결합 도메인이 포함된다. In addition, a) has SEQ ID NOs: 61, 63, 65, 79, 81, 83, 85, 87, 89, 91, 93, 94, 95, 96, 97, 99, 108 and 110 or complements thereof; The complement of any one of SEQ ID NOs: 61, 63, 65, 79, 81, 83, 85, 87, 89, 91, 93, 94, 95, 96, 97, 99, 108 and 110 under low stringency hybridization conditions Encode a polypeptide that hybridizes and has xylanase, cellulase, glucanase, beta-glucosidase, esterase or phytase activity, or b) SEQ ID NOs: 62, 64, 66, 70. 80, 82 , Expression cassettes comprising polypeptides encoding 84, 86, 88, 90, 92, 109 or 111 or polypeptides encoding enzymatically active fragments thereof. The expression cassette further comprises a promoter operably linked to a polynucleotide, such as an inducible promoter, a tissue-specific promoter or preferably an endosperm-specific promoter. The endosperm-specific promoter may be a corn γ-zein promoter or a corn ADP-gpp promoter or a corn Q promoter or a rice glutelin-1 promoter. In one embodiment, the promoter comprises SEQ ID NO: 11 or SEQ ID NO: 12 or SEQ ID NO: 67 or SEQ ID NO: 98. Further, in other embodiments, the polynucleotides are directed in the sense direction relative to the promoter. The expression cassette of the present invention may further comprise a signal sequence operably linked to a polypeptide encoded by a polynucleotide. The signal sequence targets the operably linked polypeptide, preferably to plant vacuoles, cytoplasmic reticulum, chloroplasts, starch granules, seeds or cell walls. Signal sequences include N-terminal signal sequences from waxy, N-terminal signal sequences from γ-Zane or starch binding domains.
본 발명은 추가로 본 발명의 발현 카세트를 포함하는 벡터 또는 세포에 관한 것이다. 세포는 애그로박테리움(Agrobacterium), 단자엽 세포, 쌍자엽 세포, 백합아강(Liliposida) 세포, 기장아과(Panicoideae) 세포, 옥수수 세포 및 벼 세포와 같은 곡물 세포로 이루어진 그룹 중에서 선택할 수 있다. The invention further relates to a vector or cell comprising the expression cassette of the invention. The cells may be selected from the group consisting of grain cells such as Agrobacterium , monocotyledonous cells, dicotyledonous cells, Liliposida cells, Panicoideae cells, corn cells and rice cells.
추가로, 본 발명은 본 발명의 벡터로 안정하게 형질전환된 식물을 포함한다. 서열번호 1, 10, 13, 14, 15, 16, 33, 35 또는 88 중 어느 하나의 아미노산 서열을 갖거나 서열번호 2, 9 또는 87 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 α-아밀라제를 포함하는 벡터로 안정하게 형질전환된 식물을 제공한다. In addition, the present invention encompasses plants stably transformed with the vectors of the present invention. Α-amylase having an amino acid sequence of any one of SEQ ID NOs: 1, 10, 13, 14, 15, 16, 33, 35 or 88 or encoded by a polynucleotide comprising any of SEQ ID NOs: 2, 9 or 87 It provides a plant stably transformed with a vector comprising a.
다른 양태에서는, 서열번호 24 또는 34 중 어느 하나의 아미노산 서열을 갖거나 서열번호 4 또는 25 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 풀룰라나제를 포함하는 벡터로 안정하게 형질전환된 식물을 제공한다. 서열번호 26 또는 27 중 어느 하나의 아미노산 서열을 갖거나 서열번호 6을 포함하는 폴리뉴클레오타이드에 의해 암호화된 α-글루코시다제를 포함하는 벡터로 안정하게 형질전환된 식물을 추가로 제공한다. 서열번호 18, 20, 28, 29, 30, 38, 40, 42 또는 44 중 어느 하나의 아미노산 서열을 갖거나 서열번호 19, 21, 37, 39, 41 또 는 43 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 글루코즈 이소머라제를 포함하는 벡터로 안정하게 형질전환된 식물이 본원에 추가로 기술되어 있다. 다른 양태에서, 서열번호 45, 47 또는 49 중 어느 하나의 아미노산 서열을 갖거나 서열번호 46, 48, 50 또는 59 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 글루코즈 아밀라제를 포함하는 벡터로 안정하게 형질전환된 식물이 기술되어 있다. In another embodiment, a plant having an amino acid sequence of any one of SEQ ID NOs: 24 or 34, or stably transformed with a vector comprising a pullulanase encoded by a polynucleotide comprising any of SEQ ID NOs: 4 or 25 to provide. Further provided is a plant stably transformed with a vector having an amino acid sequence of any one of SEQ ID NOs: 26 or 27 or comprising an α-glucosidase encoded by a polynucleotide comprising SEQ ID NO: 6. A polynucleotide having an amino acid sequence of any one of SEQ ID NOs: 18, 20, 28, 29, 30, 38, 40, 42 or 44 or comprising any of SEQ ID NOs: 19, 21, 37, 39, 41 or 43 Further described herein are plants stably transformed with a vector comprising a glucose isomerase encoded by. In another embodiment, it is stable with a vector comprising a glucose amylase having an amino acid sequence of any of SEQ ID NOs: 45, 47 or 49 or encoded by a polynucleotide comprising any of SEQ ID NOs: 46, 48, 50 or 59 Transformed plants are described.
추가의 양태는 서열번호 62, 64 또는 66 중 어느 하나의 아미노산 서열을 갖거나, 서열번호 61, 63 또는 65 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 자일라나제를 포함하는 벡터로 안정하게 형질전환된 식물을 제공한다. 프로테아제를 포함하는 벡터로 안정하게 형질전환된 식물을 또한 제공한다. 프로테아제는 서열번호 70에 제시된 아미노산 서열을 갖거나 서열번호 69를 갖는 폴리뉴클레오타이드에 의해 암호화된 브로멜라인일 수 있다. 다른 양태에서는, 셀룰라제를 포함하는 벡터로 안정하게 형질전환된 식물을 제공한다. 셀룰라제는 서열번호 79, 80, 81, 82, 93 또는 94 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 셀로바이오하이드롤라제일 수 있다. A further embodiment is stably with a vector comprising a xylanase having an amino acid sequence of any of SEQ ID NOs: 62, 64 or 66 or encoded by a polynucleotide comprising any of SEQ ID NOs: 61, 63 or 65 Provide a transformed plant. Also provided are plants stably transformed with the vector comprising the protease. The protease may be a bromelain having the amino acid sequence set forth in SEQ ID NO: 70 or encoded by a polynucleotide having SEQ ID NO: 69. In another embodiment, a plant is stably transformed with a vector comprising cellulase. The cellulase may be a cellobiohydrolase encoded by a polynucleotide comprising any of SEQ ID NOs: 79, 80, 81, 82, 93 or 94.
다른 양태는 엔도글루카나제와 같은 글루카나제를 포함하는 벡터로 안정하게 형질전환된 식물을 제공한다. 엔도글루카나제는 서열번호 84의 아미노산 서열을 갖거나 서열번호 83을 포함하는 폴리뉴클레오타이드에 의해 암호화된 엔도글루카나제 I일 수 있다. 베타 글루코시다제를 포함하는 벡터로 안정하게 형질전환된 식물을 또한 제공한다. 베타 글루코시다제는 서열번호 90 또는 92에 제시된 아미노산 서열을 갖거나 서열번호 89 또는 91을 갖는 폴리뉴클레오타이드에 의해 암호화된 글루코시다제 2 또는 베타 글루코시다제 D일 수 있다. 다른 양태에서는, 에스테라제를 포함하는 벡터로 안정하게 형질전환된 식물을 제공한다. 에스테라제는 서열번호 99를 포함하는 폴리뉴클레오타이드에 의해 암호화된 페룰산 에스테라제일 수 있다. Another aspect provides a plant stably transformed with a vector comprising a glucanase, such as endoglucanase. Endoglucanase may be endoglucanase I having the amino acid sequence of SEQ ID NO: 84 or encoded by a polynucleotide comprising SEQ ID NO: 83. Also provided are plants stably transformed with the vector comprising beta glucosidase. Beta glucosidase may be glucosidase 2 or beta glucosidase D having the amino acid sequence set forth in SEQ ID NO: 90 or 92 or encoded by a polynucleotide having SEQ ID NO: 89 or 91. In another embodiment, a plant is stably transformed with a vector comprising an esterase. The esterase may be a ferulic acid esterase encoded by a polynucleotide comprising SEQ ID NO: 99.
본 발명의 안정하게 형질전환된 식물로부터의 종자, 과실 또는 곡립과 같은 식물 생성물을 추가로 제공한다. Further provided are plant products such as seeds, fruits or grains from the stably transformed plants of the present invention.
다른 양태에서, 본 발명은 게놈이 프로모터 서열에 작동적으로 연결된 하나 이상의 가공 효소를 암호화하는 재조합 폴리뉴클레오타이드로 증강된 형질전환된 식물에 관한 것이며, 여기서 폴리뉴클레오타이드의 서열은 식물에서의 발현에 최적화되어 있다. 식물은 옥수수 또는 벼와 같은 단자엽이거나 쌍자엽일 수 있다. 식물은 곡류 식물 또는 상업적으로 재배한 식물일 수 있다. 가공 효소는 α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, 글루카나제, β-아밀라제, α-글루코시다제, 이소아밀라제, 풀룰라나제, 네오-풀룰라나제, 이소-풀룰라나제, 아밀로풀룰라나제, 셀룰라제, 엑소-1,4-β-셀로바이오하이드롤라제, 엑소-1,3-β-D-글루카나제, β-글루코시다제, 엔도글루카나제, L-아라비나제, α-아라비노시다제, 갈락타나제, 갈락토시다제, 만나나제, 만노시다제, 자일라나제, 자일로시다제, 프로테아제, 글루카나제, 자일라나제, 에스테라제, 피타제 및 리파제로 이루어진 그룹 중에서 선택된다. 가공 효소는 α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, β-아밀라제, α-글루코시다제, 아이소아밀라제, 풀룰라나제, 네오-풀룰랄나제, 이 소-풀룰라나제 및 아밀로풀룰라나제로 이루어진 그룹 중에서 선택된 전분-가공 효소이다. 효소는 α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, α-글루코시다제 및 풀룰라나제 중에서 선택할 수 있다. 가공 효소는 초호열성일 수 있다. 본 발명의 이러한 측면에 따라, 효소는 프로테아제, 글루카나제, 자일라나제, 에스테라제, 피타제, 셀룰라제, 베타 글루코시다제 및 리파제로 이루어진 그룹 중에서 선택된 비전분 분해 효소일 수 있다. 이러한 효소는 초호열성일 수 있다. 한 양태에서, 효소는 식물의 액포, 세포질세망, 엽록체, 전분 과립, 종자 또는 세포벽에 축적된다. 추가로, 다른 양태에서, 식물의 게놈은 추가로 비-초호열성 효소를 포함하는 제2의 재조합 폴리뉴클레오타이드 증강될 수 있다.In another aspect, the invention relates to a transformed plant in which the genome is enhanced with recombinant polynucleotides encoding one or more processing enzymes operably linked to a promoter sequence, wherein the sequence of the polynucleotides is optimized for expression in the plant have. The plant can be monocotyledonous or dicotyledonous, such as corn or rice. The plant may be a cereal plant or a commercially grown plant. Processing enzymes include α-amylase, glucoamylase, glucose isomerase, glucanase, β-amylase, α-glucosidase, isoamylase, pullulanase, neo-pululanase, iso-pululanase, amylo Pullulanase, cellulase, exo-1,4-β-cellobiohydrolase, exo-1,3-β-D-glucanase, β-glucosidase, endoglucanase, L-arabina Agent, α-arabinosidase, galactanase, galactosidase, mannase, mannosidase, xylanase, xylosidase, protease, glucanase, xylanase, esterase, phytase And lipases. Processing enzymes include α-amylase, glucoamylase, glucose isomerase, β-amylase, α-glucosidase, isoamylase, pullulanase, neo-pululanase, iso-pululanase and amylopululana Starch-processing enzyme selected from the group consisting of zero. The enzyme may be selected from α-amylase, glucoamylase, glucose isomerase, α-glucosidase and pullulanase. The processing enzyme may be superthermophilic. According to this aspect of the invention, the enzyme may be a non-starch degrading enzyme selected from the group consisting of proteases, glucanases, xylanases, esterases, phytases, cellulases, beta glucosidases and lipases. Such enzymes may be superthermophilic. In one embodiment, the enzyme accumulates in the vacuoles, cytoplasmic reticulum, chloroplasts, starch granules, seeds or cell walls of the plant. In addition, in other embodiments, the genome of the plant may be further enhanced with a second recombinant polynucleotide comprising a non-thermophilic enzyme.
본 발명의 다른 측면에서는, 게놈이 프로모터 서열에 작동적으로 연결된 α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, α-글루코시다제, 풀룰라나제, 자일라나제, 셀룰라제, 프로테아제, 글루카나제, 베타 글루코시다제, 에스테라제, 피타제 또는 리파제로 이루어진 그룹 중에서 선택된 하나 이상의 가공 효소를 암호화하는 재조합 폴리뉴클레오타이드로 증강된 형질전환된 식물을 제공하며, 여기서 폴리뉴클레오타이드의 서열은 식물에서의 발현에 최적화되어 있다. In another aspect of the invention, α-amylase, glucoamylase, glucose isomerase, α-glucosidase, pullulase, xylanase, cellulase, protease, glucanase, whose genome is operably linked to a promoter sequence Provided are transformed plants enhanced with recombinant polynucleotides encoding at least one processing enzyme selected from the group consisting of beta glucosidase, esterase, phytase or lipase, wherein the sequence of polynucleotides is expressed in a plant Optimized for
다른 양태는 게놈이 프로모터 서열에 작동적으로 연결된 α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, α-글루코시다제, 풀룰라나제, 자일라나제, 셀룰라제, 프로테아제, 글루카나제, 피타제, 베타 글루코시다제, 에스테라제 또는 리파제로 이루어진 그룹 중에서 선택된 하나 이상의 가공 효소를 암호화하는 재조합 폴리뉴클레오타이드로 증강된 형질전환 옥수수 식물에 관한 것이며, 폴리뉴클레오 타이드의 서열은 옥수수 식물에서의 발현에 최적화되어 있다. In another embodiment, α-amylase, glucoamylase, glucose isomerase, α-glucosidase, pullulanase, xylanase, cellulase, protease, glucanase, phytase, To a transformed corn plant enhanced with recombinant polynucleotides encoding at least one processing enzyme selected from the group consisting of beta glucosidase, esterase or lipase, the sequence of the polynucleotides optimized for expression in corn plants It is.
게놈이 프로모터 및 시그날 서열에 작동적으로 연결된 서열번호 83을 갖는 재조합 폴리뉴클레오타이드로 증강된 형질전환된 식물을 제공한다. 추가로, 게놈이 프로모터 및 시그날 서열에 작동적으로 연결된 서열번호 93 또는 94를 갖는 재조합 폴리뉴틀레오타이드로 증강된 형질전환된 식물을 기술한다. 다른 양태에서, 게놈이 프로모터 및 시그날 서열에 작동적으로 연결된 서열번호 95를 갖는 재조합 폴리뉴클레오타이드로 증강된 형질전환된 식물을 기술한다. 추가로, 게놈이 서열번호 96을 갖는 재조합 폴리뉴클레오타이드로 증강된 형질전환된 식물을 기술한다. 또한 게놈이 서열번호 97을 갖는 재조합 폴리뉴클레오타이드로 증강된 형질전환된 식물을 기술한다. 또한 게놈이 서열번호 99를 갖는 재조합 폴리펩타이드로 증강된 형질전환된 식물을 기술한다.Provided are transformed plants in which the genome has been enhanced with recombinant polynucleotides having SEQ ID NO: 83 operably linked to a promoter and signal sequence. In addition, a transgenic plant is described wherein the genome is enhanced with recombinant polynucleotides having SEQ ID NOs: 93 or 94 operably linked to a promoter and signal sequence. In another aspect, a transformed plant is described wherein the genome is enhanced with recombinant polynucleotides having SEQ ID NO: 95 operably linked to a promoter and signal sequence. In addition, it describes transformed plants whose genome has been enhanced with recombinant polynucleotides having SEQ ID NO. Also described are transformed plants whose genome has been augmented with recombinant polynucleotides having SEQ ID NO. It also describes a transformed plant whose genome has been enhanced with a recombinant polypeptide having
형질전환된 식물의 생성물을 추가로 본원에서 고려한다. 예를 들면, 생성물에는 종자, 과실 또는 곡립이 포함된다. 생성물은 대안적으로 가공 효소, 전분 또는 당일 수 있다. The product of the transformed plant is further contemplated herein. For example, the product includes seeds, fruits or grains. The product may alternatively be a processing enzyme, starch or sugar.
본 발명의 안정하게 형질전환된 식물로부터 수득된 식물을 추가로 기술한다. 이러한 측면에서, 식물은 하이브리드 식물 또는 근교계 식물일 수 있다. Further described are plants obtained from the stably transformed plants of the present invention. In this aspect, the plant may be a hybrid plant or a suburban plant.
전분 조성물은 프로테아제, 글루카나제 또는 에스테라제인 하나 이상의 가공 효소를 포함하는 본 발명의 추가의 양태이다. Starch compositions are a further aspect of the invention comprising one or more processing enzymes that are proteases, glucanases or esterases.
곡립은 α-아밀라제, 풀룰라나제, α-글루코시다제, 글루코아밀라제, 글루코즈 이소머라제, 자일라나제, 셀룰라제, 글루카나제, 베타 글루코시다제, 에스테라 제, 프로테아제, 리파제 또는 피타제인, 하나 이상의 가공 효소를 포함하는 본 발명의 기타 양태이다. The grains are α-amylase, pullulanase, α-glucosidase, glucoamylase, glucose isomerase, xylanase, cellulase, glucanase, beta glucosidase, esterase, protease, lipase or phytase And one or more processing enzymes.
다른 양태에서, 게놈이 하나 이상의 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 하나 이상의 비-전분 가공 효소를 포함하는 곡립을 하나 이상의 효소를 활성화하는 조건하에 처리하는 단계, 전분 과립 및 비-전분 분해 생성물을 포함하는 혼합물을 산출하는 단계, 및 당해 혼합물에서 전분 과립을 분리하는 단계를 포함하는 방법을 제공한다. 여기서, 효소는 프로테아제, 글루카나제, 자일라나제, 피타제, 리파제, 베타 글루코시다제, 셀룰라제 또는 에스테라제일 수 있다. 추가로, 효소는 바람직하게는 초호열성이다. 곡립은 동할립일 수 있고/거나 낮거나 높은 습도 조건하에 가공할 수 있다. 대안적으로, 곡립을 이산화황으로 가공할 수 있다. 본 발명은 추가로 혼합물에서 비-전분 생성물을 분리하는 단계를 포함할 수 있다. 이러한 방법으로 수득한 전분 생성물 및 비-전분 생성물을 추가로 기술한다. In another embodiment, treating a grain comprising one or more non-starch processing enzymes, obtained from a transformed plant whose genome is enhanced with an expression cassette encoding one or more enzymes, under conditions that activate one or more enzymes, starch A method comprising the steps of yielding a mixture comprising granules and non-starch decomposition products, and separating starch granules from the mixture. Here, the enzyme may be a protease, glucanase, xylanase, phytase, lipase, beta glucosidase, cellulase or esterase. In addition, the enzyme is preferably superthermophilic. The grains may be copper granules and / or may be processed under low or high humidity conditions. Alternatively, the grain can be processed into sulfur dioxide. The invention may further comprise the step of separating the non-starch product from the mixture. The starch products and non-starch products obtained in this way are further described.
다른 양태에서, 하나 이상의 효소를 활성화하는 조건하에, 형질전환 옥수수 또는 이의 일부분, 하나 이상의 전분-분해 또는 전분-이성체화 효소를 암호화하는 발현 카세트로 증강시키고 이를 내배유 내에서 발현하는 게놈을 처리하여 옥수수 내의 다당류를 당으로 전환시키는 단계, 및 초고당도 옥수수를 수득하는 단계를 포함하여 초고당도 옥수수를 제조하는 방법을 제공한다. 발현 카세트는 추가로 효소를 암호화하는 폴리뉴클레오타이드에 작동적으로 연결된 프로모터를 포함할 수 있다. 당해 프로모터는 예를 들면, 구성성 프로모터, 종자-특이적 프로모터 또는 내 배유-특이적 프로모터일 수 있다. 효소는 초호열성일 수 있으며 α-아밀라제일 수 있다. 본원에 사용한 발현 카세트는 추가로 하나 이상의 효소에 작동적으로 연결된 시그날 서열을 암호화하는 폴리뉴클레오타이드를 포함할 수 있다. 시그날 서열은 당해 효소를 예를 들면, 아포플라스트 또는 세포질세망으로 지시할 수 있다. 당해 효소는 서열번호 13, 14, 15, 16, 33 또는 35 중의 어느 하나를 포함한다. 당해 효소는 또한 서열번호 87을 포함할 수 있다. In another embodiment, under conditions of activating one or more enzymes, the corn is processed by enhancing the transformed corn or a portion thereof, an expression cassette encoding one or more starch-degrading or starch-isomerizing enzymes, and processing the genome expressing it in endocrine. There is provided a method of producing ultra-high sugar corn, including the step of converting the polysaccharide in the sugar to sugar, and obtaining ultra-high sugar corn. The expression cassette may further comprise a promoter operably linked to the polynucleotide encoding the enzyme. The promoter may be, for example, a constitutive promoter, seed-specific promoter or endocrine-specific promoter. The enzyme may be superthermophilic and may be α-amylase. As used herein, an expression cassette may further comprise a polynucleotide encoding a signal sequence operably linked to one or more enzymes. The signal sequence can direct the enzyme to, for example, apoplast or cytoplasmic net. The enzyme comprises any of SEQ ID NOs: 13, 14, 15, 16, 33 or 35. The enzyme may also include SEQ ID NO: 87.
가장 바람직한 양태에서, 하나 이상의 효소를 활성화하는 조건하에, 게놈이 α-아밀라제를 암호화하는 발현 카세트로 증강되어 있고 당해 발현 카세트를 내배유 내에서 발현하는 형질전환된 옥수수 또는 이의 일부를 처리하여 옥수수 내의 다당류를 당으로 전환시키는 단계, 및 초고당도 옥수수를 수득하는 단계를 포함하여 초고당도 옥수수를 제조하는 방법을 기술한다. 당해 효소는 초호열성일 수 있으며 초호열성 α-아밀라제는 서열번호 10, 13, 14, 15, 16, 33 또는 35 중 어느 하나 또는 α-아밀라제 활성을 갖는 이의 효소적 활성 단편의 아미노산 서열을 포함할 수 있다. 당해 효소는 서열번호 87을 포함한다. In the most preferred embodiment, under conditions of activating one or more enzymes, the polysaccharide in maize is processed by processing a transformed maize or part thereof whose genome is enhanced with an expression cassette encoding α-amylase and expressing the expression cassette in endocrine. It describes a method of producing ultra-high sugar corn, including the step of converting the sugar to sugar, and obtaining the ultra high sugar corn. The enzyme may be superthermophilic and the superthermophilic α-amylase will comprise the amino acid sequence of any of SEQ ID NOs: 10, 13, 14, 15, 16, 33 or 35 or an enzymatically active fragment thereof having α-amylase activity. Can be. The enzyme comprises SEQ ID NO: 87.
게놈이 하나 이상의 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 전분 과립 및 하나 이상의 가공 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화시키는 조건하에 처리하고 이에 따라 전분 과립을 가공하여 가수분해된 전분 생성물을 포함하는 수용액을 형성하는 단계; 및 가수분해된 전분 생성물을 포함하는 수용액을 수거하는 단계를 포함하여 가수분해된 전분 생성물의 용액을 제조하는 방법이 본원에 기술되어 있다. 가수분해된 전분 생성물 은 덱스트린, 말토올리고당, 글루코즈 및/또는 이의 혼합물을 포함할 수 있다. 효소는 α-아밀라제, α-글루코시다제, 글루코아밀라제, 풀룰라나제, 아밀로풀룰라나제, 글루코즈 이소머라제 또는 이의 임의의 배합물일 수 있다. 추가로, 당해 효소는 초호열성일 수 있다. 다른 측면에서, 식물 부분의 게놈은 비-초호열성 전분 가공 효소를 암호화하는 발현 카세트로 추가로 증강시킬 수 있다. 비-초호열성 전분 가공 효소는 아밀라제, 글루코아밀라제, α-글루코시다제, 풀룰라나제, 글루코즈 이소머라제 또는 이의 배합물로 이루어진 그룹 중에서 선택될 수 있다. 다른 측면에서, 가공 효소는 바람직하게는 내배유에서 발현된다. 식물 부분은 곡립일 수 있으며, 옥수수, 밀, 보리, 호밀, 귀리, 사탕수수 또는 벼로부터 기원한 것일 수 있다. 하나 이상의 가공 효소는 프로모터 및 당해 효소를 전분 과립 또는 세포질 세망 또는 세포벽으로 표적화하는 시그날 서열에 작동적으로 연결된다. 당해 방법은 추가로 가수분해된 전분 생성물을 분리하는 단계 및/또는 가수분해된 전분 생성물을 발효시키는 단계를 포함할 수 있다. Starch granules and plant parts comprising one or more processing enzymes obtained from a transformed plant whose genome has been enriched with an expression cassette encoding one or more processing enzymes are treated under conditions that activate one or more enzymes and thus starch granules Processing to form an aqueous solution comprising the hydrolyzed starch product; And collecting an aqueous solution comprising the hydrolyzed starch product is described herein. Hydrolyzed starch products may include dextrins, maltooligosaccharides, glucose and / or mixtures thereof. The enzyme may be α-amylase, α-glucosidase, glucoamylase, pullulanase, amylopululase, glucose isomerase or any combination thereof. In addition, the enzyme may be superthermophilic. In another aspect, the genome of the plant part can be further enhanced with an expression cassette encoding a non-superthermotropic starch processing enzyme. The non-superthermotropic starch processing enzyme may be selected from the group consisting of amylase, glucoamylase, α-glucosidase, pullulanase, glucose isomerase or combinations thereof. In another aspect, the processing enzyme is preferably expressed in endocrine. The plant part may be grain and may be from corn, wheat, barley, rye, oats, sugar cane or rice. One or more processing enzymes are operably linked to a promoter and signal sequence that targets the enzyme to starch granules or cytoplasmic reticulum or cell walls. The method may further comprise separating the hydrolyzed starch product and / or fermenting the hydrolyzed starch product.
본 발명의 다른 측면에서, 게놈이 하나 이상의 α-아밀라제를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 전분 과립 및 하나 이상의 전분 가공 효소를 포함하는 식물 부분을 하나 이상의 당해 효소를 활성화하는 조건하에 처리하고 이에 따라 전분 과립을 가공하여 가수분해된 전분 생성물을 포함하는 수용액을 형성하는 단계; 및 가수분해된 전분 생성물을 포함하는 수용액을 수거하는 단계를 포함하는, 가수분해된 전분 생성물의 제조방법을 기술한다. α-아밀라제는 초호열성이며 초호열성 α-아밀라제는 서열번호 1, 10, 13, 14, 15, 16, 33 또는 35, 또는 α-아밀라제 활성을 갖는 이의 활성 단편의 아미노산 서열을 포함한다. 발현 카세트는 서열번호 2, 9, 46 또는 52 중 어느 하나, 이의 상보체 중에서 선택된 폴리뉴클레오타이드 또는 낮은 엄중성 하이브리드화 조건하에 서열번호 2, 9, 46 또는 52 중 어느 하나와 하이브리드화하고 α-아밀라제 활성을 갖는 폴리펩타이드를 암호화하는 폴리뉴클레오타이드를 포함할 수 있다. 게다가, 본 발명은 비-호열성 전분-가공 효소를 암호화하는 폴리뉴클레오타이드를 추가로 포함하는 형질전환된 식물의 게놈에 대한 것을 추가로 제공한다. 대안적으로, 식물 부분은 비-초호열성 전분-가공 효소로 처리할 수 있다. In another aspect of the invention, a plant portion comprising starch granules and one or more starch processing enzymes, obtained from a transformed plant whose genome is enhanced with an expression cassette encoding one or more α-amylases, activates one or more such enzymes. Processing under such conditions and thereby processing the starch granules to form an aqueous solution comprising the hydrolyzed starch product; And collecting an aqueous solution comprising the hydrolyzed starch product. α-amylases are superthermophilic and superthermophilic α-amylases comprise the amino acid sequence of SEQ ID NO: 1, 10, 13, 14, 15, 16, 33 or 35, or active fragments thereof having α-amylase activity. The expression cassette hybridizes with any one of SEQ ID NOs: 2, 9, 46, or 52, polynucleotide selected from its complement, or any of SEQ ID NOs: 2, 9, 46, or 52 under low stringency hybridization conditions and has α-amylase activity. Polynucleotides encoding a polypeptide having: In addition, the present invention further provides for the genome of a transformed plant further comprising a polynucleotide encoding a non-thermophilic starch-processing enzyme. Alternatively, plant parts may be treated with non-superthermotropic starch-processing enzymes.
본 발명은 추가로, 게놈이 하나 이상의 전분 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 식물 세포에 존재하는 하나 이상의 전분-가공 효소를 포함하는 형질전환된 식물 부분에 관한 것이다. 바람직하게는, 효소는 α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, β-아밀라제, α-글루코시다제, 아이소아밀라제, 풀룰라나제, 네오-풀룰라나제, 이소-풀룰라나제 및 아밀로풀룰라나제로 이루어진 그룹 중에서 선택된 전분-가공 효소이다. 추가로, 당해 효소는 초호열성일 수 있다. 당해 식물은 예를 들면, 옥수수 또는 벼와 같은 임의의 식물일 수 있다. The invention further relates to a transformed plant portion comprising one or more starch-processing enzymes present in plant cells obtained from a transformed plant whose genome has been enhanced with an expression cassette encoding one or more starch processing enzymes. will be. Preferably, the enzyme is α-amylase, glucoamylase, glucose isomerase, β-amylase, α-glucosidase, isoamylase, pullulanase, neo-pululanase, iso-pululanase and amyloful Starch-processing enzyme selected from the group consisting of lulanase. In addition, the enzyme may be superthermophilic. The plant may be any plant, for example corn or rice.
본 발명의 다른 양태는 게놈이 하나 이상의 비-전분 가공 효소 또는 하나 이상의 비-전분 다당류 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 식물의 세포 벽 또는 세포에 존재하는 하나 이상의 비-전분 가공 효소를 포함하는 형질전환된 식물 부분이다. 당해 효소는 초호열성일 수 있다. 추가로, 비-전분 가공 효소는 프로테아제, 글루카나제, 자일라나제, 에스테라제, 피타제, 베타 글루코시다제, 셀룰라제 또는 리파제일 수 있다. 식물 부분은 임의의 식물 부분일 수 있지만, 바람직하게는 이삭, 종자, 과실, 곡립, 스토버(stover), 겨 또는 바가스(baggasse)이다. Another aspect of the invention is one wherein the genome is from a transformed plant obtained from a transformed plant with an expression cassette encoding at least one non-starch processing enzyme or at least one non-starch polysaccharide processing enzyme. A transformed plant part comprising the above non-starch processing enzyme. The enzyme may be superthermophilic. In addition, the non-starch processing enzyme may be a protease, glucanase, xylanase, esterase, phytase, beta glucosidase, cellulase or lipase. The plant part may be any plant part, but is preferably ear, seed, fruit, grain, stover, bran or baggasse.
본 발명은 또한 형질전환된 식물 부분에 관한 것이다. 예를 들면, 서열번호 1, 10, 13, 14, 15, 16, 33 또는 35 중 어느 하나의 아미노산 서열을 갖거나, 서열번호 2, 9, 46 또는 52 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 α-아밀라제를 포함하는 형질전환된 식물 부분, 서열번호 5, 26 또는 27 중 어느 하나의 아미노산 서열을 갖거나 서열번호 6을 포함하는 폴리뉴클레오타이드에 의해 암호화된 α-글루코시다제를 포함하는 형질전환된 식물 부분, 서열번호 28, 29, 30, 38, 40, 42 또는 44 중 어느 하나의 아미노산 서열을 갖거나 서열번호 19, 21, 37, 39, 41 또는 43 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 글루코즈 이소머라제를 포함하는 형질전환된 식물 부분, 서열번호 45 또는 서열번호 47 또는 서열번호 49의 아미노산 서열을 갖거나, 서열번호 46, 48, 50 또는 59 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 글루코아밀라제를 포함하는 형질전환된 식물 부분, 및 서열번호 4 또는 25 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 풀룰라나제를 포함하는 형질전환된 식물 부분이 기술되어 있다.The invention also relates to a transformed plant part. For example, by a polynucleotide having an amino acid sequence of any one of SEQ ID NOs: 1, 10, 13, 14, 15, 16, 33 or 35, or comprising any of SEQ ID NOs: 2, 9, 46 or 52 A transformed plant part comprising an encoded α-amylase, comprising an α-glucosidase having an amino acid sequence of any of SEQ ID NO: 5, 26 or 27 or encoded by a polynucleotide comprising SEQ ID NO: 6 A poly having an amino acid sequence of any of the transformed plant parts, SEQ ID NOs: 28, 29, 30, 38, 40, 42 or 44 or comprising any of SEQ ID NOs: 19, 21, 37, 39, 41 or 43 Transformed plant part comprising a glucose isomerase encoded by nucleotides, having the amino acid sequence of SEQ ID NO: 45 or SEQ ID NO: 47 or SEQ ID NO: 49, or comprising any of SEQ ID NOs: 46, 48, 50, or 59 Ha A transformed plant portion comprising a glucoamylase encoded by a polynucleotide and a transformed plant portion comprising a pullulanase encoded by a polynucleotide comprising any of SEQ ID NOs: 4 or 25 are described. .
본 발명은 추가로 형질전환된 식물 부분에 관한 것이다. 예를 들면, 서열번호 62, 64 또는 66 중 어느 하나의 아미노산 서열을 갖거나, 서열번호 61, 63 또는 65 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 자일라나제를 포함하는 형질전환된 식물 부분이다. 프로테아제를 포함하는 형질전환된 식물 부분을 또한 제공한다. 프로테아제는 서열번호 70에 제시된 아미노산 서열을 갖거나 서열번호 69를 갖는 폴리뉴클레오타이드에 의해 암호화된 브로멜라인일 수 있다. 다른 양태에서, 셀룰라제를 포함하는 형질전환된 식물 부분을 제공한다. 셀룰라제는 서열번호 79, 80, 81, 82, 93 또는 94 중 어느 하나를 포함하는 폴리뉴클레오타이드에 의해 암호화된 셀로바이오하이드롤라제일 수 있다. The present invention further relates to a transformed plant part. For example, a transformed plant having an amino acid sequence of any one of SEQ ID NOs: 62, 64, or 66 or comprising a xylanase encoded by a polynucleotide comprising any of SEQ ID NOs: 61, 63, or 65 Part. Also provided is a transformed plant portion comprising a protease. The protease may be a bromelain having the amino acid sequence set forth in SEQ ID NO: 70 or encoded by a polynucleotide having SEQ ID NO: 69. In another aspect, a transformed plant portion comprising cellulase is provided. The cellulase may be a cellobiohydrolase encoded by a polynucleotide comprising any of SEQ ID NOs: 79, 80, 81, 82, 93 or 94.
추가의 양태는 엔도글루카나제와 같은 글루카나제를 포함하는 형질전환된 식물 부분을 제공한다. 엔도글루카나제는 서열번호 84에 제시된 아미노산 서열을 갖거나 서열번호 83을 포함하는 폴리뉴클레오타이드에 의해 암호화된 엔도글루카나제 I일 수 있다. 베타 글루코시다제를 포함하는 형질전환된 식물 부분을 또한 제공한다. 베타 글루코시다제는 서열번호 90 또는 92로 진술되거나, 서열번호 89 또는 91을 갖는 폴리뉴클레오타이드에 의해 암호화된 베타 글루코시다제 2 또는 베타 글루코시다제 D일 수 있다. 다른 양태에서, 에스테라제를 포함하는 형질전환된 식물 부분을 제공한다. 에스테라제는 서열번호 99를 포함하는 폴리뉴클레오타이드에 의해 암호화된 페룰산 에스테라제일 수 있다. Further embodiments provide a transformed plant portion comprising a glucanase, such as endoglucanase. Endoglucanases may be endoglucanas I having the amino acid sequence set forth in SEQ ID NO: 84 or encoded by a polynucleotide comprising SEQ ID NO: 83. Also provided are transformed plant parts comprising beta glucosidase. Beta glucosidase may be stated as SEQ ID NO: 90 or 92, or
다른 양태는 형질전환된 식물 부분에 함유된 전분 가공 효소를 활성화시키는 단계를 포함하여, 형질전환된 식물 부분에서 전분을 전환시키는 방법이다. 당해 방법에 따라 제조된 전분, 덱스트린, 말토올리고당 또는 당이 추가로 기술된다.Another aspect is a method of converting starch in a transformed plant part, comprising activating starch processing enzymes contained in the transformed plant part. Starch, dextrins, maltooligosaccharides or sugars prepared according to the process are further described.
본 발명은 추가로 게놈이 하나 이상의 비-전분 다당류 가공 효소를 암호화하 는 발현 카세트로 증강된 형질전환된 식물로부터 수득된 하나 이상의 비-전분 다당류 가공 효소를 포함하는 형질전환된 식물 부분을 하나 이상의 효소를 활성화하는 조건하에 처리하여, 이에 따라 비전분 다당류를 분해하여 올리고당 및/또는 당을 포함하는 수용액을 형성하는 단계; 및 올리고당 및/또는 당을 포함하는 수용액을 수거하는 단계를 포함하여 세포 벽 또는 식물 부분의 세포 내의 하나 이상의 비-전분 가공 효소를 포함하는, 형질전환된 식물 부분을 사용하는 방법을 기술한다. 비-전분 다당류 가공 효소는 초호열성일 수 있다. The invention further comprises one or more transformed plant parts comprising one or more non-starch polysaccharide processing enzymes obtained from a transformed plant whose genome is enhanced with an expression cassette encoding one or more non-starch polysaccharide processing enzymes. Treating under enzyme activating conditions, thereby degrading the non-starch polysaccharide to form an aqueous solution comprising oligosaccharides and / or sugars; And collecting an aqueous solution comprising oligosaccharides and / or sugars, wherein the method comprises using a transformed plant portion comprising one or more non-starch processing enzymes in the cells of the cell wall or plant portion. Non-starch polysaccharide processing enzymes may be superthermophilic.
게놈이 하나 이상의 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 하나 이상의 프로테아제 또는 리파제를 포함하는 형질전환 종자를 하나 이상의 효소를 활성화시키는 조건하에 처리하여, 아미노산 및 지방산을 포함하는 수성 혼합물을 수득하는 단계; 및 수성 혼합물을 수거하는 단계를 포함하여, 하나 이상의 가공 효소를 포함하는 형질전환 종자를 사용하는 방법을 기술한다. 바람직하게는 아미노산, 지방산 또는 이들 둘다를 분리한다. 하나 이상의 프로테아제 또는 리파제는 초호열성일 수 있다. A transgenic seed comprising one or more proteases or lipases, obtained from a transformed plant whose genome is enriched with an expression cassette encoding one or more enzymes, is subjected to conditions comprising activating one or more enzymes to contain amino acids and fatty acids. Obtaining an aqueous mixture; And harvesting the aqueous mixture, describing a method of using a transgenic seed comprising one or more processing enzymes. Preferably, amino acids, fatty acids or both are separated. One or more proteases or lipases may be hyperthermia.
게놈이 하나 이상의 다당류 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 하나 이상의 다당류 가공 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화시키는 조건하에 처리하여 다당류를 분해하여 올리고당 또는 발효성 당을 형성하는 단계; 및 발효성 당 또는 올리고당의 에탄올로의 전환을 촉진하는 조건하에 발효성 당을 항온처리하는 단계를 포함하여 에탄올을 제조하는 방법을 기술한다. 식물 부분은 곡립, 과실, 종자, 줄기, 목질, 채소 또는 뿌리일 수 있다. 식물 부분은 귀리, 보리, 밀, 딸기류, 포도, 호밀, 옥수수, 벼, 감자, 사탕무, 사탕수수, 파인애플, 목초 및 나무로 이루어진 그룹 중에서 선택된 식물로부터 수득할 수 있다. 다른 바람직한 양태에서, 다당류 가공 효소는 α-아밀라제, 글루코아밀라제, α-글루코시다제, 글루코즈 이소머라제, 풀룰라나제 또는 이의 배합물이다. A plant portion comprising one or more polysaccharide processing enzymes, obtained from a transformed plant whose genome is enriched with an expression cassette encoding one or more polysaccharide processing enzymes, is subjected to treatment under conditions that activate one or more enzymes to degrade the polysaccharides to oligosaccharides or Forming a fermentable sugar; And incubating the fermentable sugars under conditions that facilitate the conversion of the fermentable sugars or oligosaccharides to ethanol. Plant parts may be grains, fruits, seeds, stems, wood, vegetables or roots. Plant parts can be obtained from plants selected from the group consisting of oats, barley, wheat, berries, grapes, rye, corn, rice, potatoes, sugar beets, sugar cane, pineapples, grasses and trees. In another preferred embodiment, the polysaccharide processing enzyme is α-amylase, glucoamylase, α-glucosidase, glucose isomerase, pullulanase or combinations thereof.
게놈이 하나 이상의 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, α-아밀라제, 글루코아밀라제, α-글루코시다제, 글루코즈 이소머라제 또는 풀룰랄나제 또는 이의 배합물로 이루어진 그룹 중에서 선택된 하나 이상의 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화시키는 조건하에 충분한 시간 동안 가열함으로써 처리하여 다당류를 분해하여 발효성 당을 형성하는 단계; 및 발효성 당의 에탄올로의 전환을 촉진하는 조건하에 발효성 당을 항온처리하는 단계를 포함하여 에탄올을 제조하는 방법을 제공한다. 하나 이상의 효소는 초호열성 또는 중온성일 수 있다. Α-amylase, glucoamylase, α-glucosidase, glucose isomerase or pullulanase or combinations thereof, obtained from a transformed plant whose genome is enhanced with an expression cassette encoding one or more enzymes Treating the plant portion comprising one or more enzymes by heating for a sufficient time under conditions activating the one or more enzymes to degrade the polysaccharides to form fermentable sugars; And incubating the fermentable sugar under conditions that promote the conversion of the fermentable sugar to ethanol. One or more enzymes may be superthermophilic or mesophilic.
다른 양태에서는, 게놈이 하나 이상의 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 하나 이상의 비-전분 가공 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화시키는 조건하에 처리하여 비-전분 다당류를 올리고당 및 발효성 당으로 분해하는 단계; 및 발효성 당의 에탄올로의 전환을 촉진하는 조건하에 발효성 당을 항온처리하는 단계를 포함하여 에탄올을 제조하는 방법을 제공한다. 비-전분 가공 효소는 자일라나제, 셀룰라제, 글루카나제, 베타 글루코시다제, 프로테아제, 에스테라제, 리파제 또는 피타제일 수 있다. In another embodiment, a plant portion comprising one or more non-starch processing enzymes, obtained from a transformed plant whose genome is enriched with an expression cassette encoding one or more enzymes, is subjected to a non- Degrading starch polysaccharides into oligosaccharides and fermentable sugars; And incubating the fermentable sugar under conditions that promote the conversion of the fermentable sugar to ethanol. The non-starch processing enzyme may be xylanase, cellulase, glucanase, beta glucosidase, protease, esterase, lipase or phytase.
게놈이 하나 이상의 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, α-아밀라제, 글루코아밀라제, α-글루코시다제, 글루코즈 이소머라제 또는 풀룰라나제 또는 이의 배합물로 이루어진 그룹 중에서 선택된 하나 이상의 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화하는 조건하에 처리하여 다당류를 분해하여 발효성 당을 형성하는 단계; 및 발효성 당의 에탄올로의 전환을 촉진하는 조건하에 발효성 당을 항온처리하는 단계를 포함하여 에탄올을 제조하는 방법을 추가로 제공한다. 당해 효소는 초호열성일 수 있다. Α-amylase, glucoamylase, α-glucosidase, glucose isomerase or pullulanase or combinations thereof, obtained from a transformed plant whose genome is enhanced with an expression cassette encoding one or more enzymes Treating the plant portion comprising one or more enzymes under conditions activating the one or more enzymes to degrade the polysaccharides to form fermentable sugars; And incubating the fermentable sugar under conditions that promote the conversion of the fermentable sugar to ethanol. The enzyme may be superthermophilic.
추가로, 게놈이 하나 이상의 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 하나 이상의 전분 가공 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화하는 조건하에 처리하여 식물 부분 내의 전분 과립을 당으로 가공하여 고당도 생성물을 형성하는 단계; 및 고당도 생성물을 전분질 식품으로 가공하는 단계를 포함하여, 추가의 감미료 첨가 없이 고당도 전분질 식품을 제조하는 방법을 기술한다. 고당도 식품은 고당도 생성물 및 물로부터 형성될 수 있다. 추가로, 고당도 식품은 맥아, 향미제, 비타민, 미네랄, 착색제 또는 이의 임의의 배합물을 함유할 수 있다. 하나 이상의 효소는 초호열성일 수 있다. 효소는 α-아밀라제, α-글루코시다제, 글루코아밀라제, 풀룰라나제, 글루코즈 이소머라제 또는 이의 임의의 배합물 중에서 선택될 수 있다. 식물은 추가로 대두, 호밀, 귀리, 보리, 밀, 옥수수, 벼 및 사탕수수로 이루어진 그룹 중에서 선택할 수 있다. 전분질 식품은 곡물, 조식용 식품, 편의식품 또는 구운 식품일 수 있다. 가공은 굽기, 끓이기, 가열, 찜, 전기 방전 또는 이의 임의의 조합을 포함할 수 있다. In addition, plant parts comprising one or more starch processing enzymes, obtained from transformed plants whose genome has been enriched with expression cassettes encoding one or more enzymes, are subjected to starch granules in the plant parts by subjecting them to conditions that activate one or more enzymes. Processing it to sugar to form a high sugar content product; And processing the high sugar product into a starch food, thereby describing a method for producing a high sugar starch food without the addition of additional sweeteners. High sugar content foods can be formed from high sugar content and water. In addition, high sugar content foods may contain malts, flavors, vitamins, minerals, colorants or any combination thereof. One or more enzymes may be superthermophilic. The enzyme may be selected from α-amylase, α-glucosidase, glucoamylase, pullulanase, glucose isomerase or any combination thereof. The plant may further be selected from the group consisting of soybean, rye, oats, barley, wheat, corn, rice and sugar cane. The starch food may be cereals, breakfast foods, convenience foods or baked foods. Processing may include baking, boiling, heating, steaming, electric discharge, or any combination thereof.
본 발명은 추가로, 게놈이 하나 이상의 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 하나 이상의 전분 가공 효소를 포함하는 전분을 하나 이상의 효소를 활성화하는 조건하에 처리하고, 이에 따라 전분을 분해하여 당을 형성하여 고당도 전분을 형성하는 단계; 및 고당도 전분을 생성물에 첨가하여 식품을 함유하는 고당도 전분을 제조하는 단계를 포함하여, 감미료 첨가 없이 전분-함유 생성물에 단맛을 내는 방법에 관한 것이다. 형질전환된 식물은 옥수수, 대두, 호밀, 귀리, 보리, 밀, 벼 및 사탕수수로 이루어진 그룹 중에서 선택될 수 있다. 하나 이상의 효소는 초호열성일 수 있다. 하나 이상의 효소는 α-아밀라제, α-글루코시다제, 글루코아밀라제, 풀룰라나제, 글루코즈 이소머라제 또는 이의 임의의 배합물일 수 있다. The invention further provides that starches comprising one or more starch processing enzymes, obtained from transformed plants whose genome is enhanced with an expression cassette encoding one or more enzymes, are subjected to conditions under which one or more enzymes are activated. Decomposing starch to form sugar to form high sugar starch; And adding high sugar starch to the product to produce a high sugar starch containing food, thereby sweetening the starch-containing product without the addition of sweeteners. Transformed plants can be selected from the group consisting of corn, soybean, rye, oats, barley, wheat, rice and sugar cane. One or more enzymes may be superthermophilic. One or more enzymes may be α-amylase, α-glucosidase, glucoamylase, pullulanase, glucose isomerase or any combination thereof.
전분질 식품 및 고당도 전분-함유 생성물이 본원에 제공되어 있다. Starch foods and high sugar starch-containing products are provided herein.
본 발명은 또한, 게놈이 하나 이상의 다당류 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 하나 이상의 다당류 가공 효소를 포함하는 과실 또는 채소를 하나 이상의 효소를 활성화하는 조건하에 처리하여, 과실 또는 채소 내의 다당류를 가공하여 당을 형성하는 단계, 고당도 과실 또는 채소를 수득하는 단계를 포함하여 다당류-함유 과실 또는 채소에 단맛을 내는 방법에 관한 것이다. 당해 과실 또는 채소는 감자, 토마토, 바나나, 호박, 완두 및 콩으로 이루어진 그룹 중에서 선택된다. 하나 이상의 효소는 초호열성일 수 있다. The invention also provides for the treatment of fruits or vegetables comprising one or more polysaccharide processing enzymes obtained from a transformed plant whose genome has been enhanced with an expression cassette encoding one or more polysaccharide processing enzymes under conditions that activate one or more enzymes. The present invention relates to a method of sweetening a polysaccharide-containing fruit or vegetable, including processing the polysaccharide in the fruit or vegetable to form a sugar, and obtaining a high sugar fruit or vegetable. The fruit or vegetable is selected from the group consisting of potatoes, tomatoes, bananas, pumpkins, peas and beans. One or more enzymes may be superthermophilic.
본 발명은 추가로 하나 이상의 효소를 활성화하는 조건하에 식물 부분로부터 수득한 전분 과립을 처리하여 당을 포함하는 수용액을 산출함을 포함하여 당을 포 함하는 수용액을 제조하는 방법에 관한 것이다. The present invention further relates to a process for producing an aqueous solution comprising sugars, including treating the starch granules obtained from the plant part under conditions activating one or more enzymes to yield an aqueous solution comprising sugars.
다른 양태는 게놈이 하나 이상의 전분 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 전분 과립 및 하나 이상의 전분 가공 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화하는 조건하에 처리하고, 이에 따라 전분 과립을 가공하여 덱스트린 또는 당을 포함하는 수용액을 형성하는 단계; 및 전분 유래 생성물을 포함하는 수용액을 수거하는 단계를 포함하여, 전분 유래 생성물의 회수 전에 곡립을 습식 또는 건식 제분하지 않으면서 곡립로부터 전분 유래 생성물을 제조하는 방법에 관한 것이다. 하나 이상의 전분 가공 효소는 초호열성일 수 있다. In another embodiment, a plant portion comprising starch granules and one or more starch processing enzymes, obtained from a transformed plant whose genome is enhanced with an expression cassette encoding one or more starch processing enzymes, is subjected to conditions under which one or more enzymes are activated. Thereby processing starch granules to form an aqueous solution comprising dextrin or sugar; And collecting an aqueous solution comprising the starch derived product, wherein the starch derived product is produced from the grain without wet or dry milling the grain prior to recovery of the starch derived product. One or more starch processing enzymes may be superthermophilic.
α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, α-글루코시다제 또는 풀룰라나제를 함유하는 형질전환된 식물을 배양하는 단계 및 이로부터 α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, α-글루코시다제 또는 풀룰라나제를 분리하는 단계를 포함하여 α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, α-글루코시다제 및 풀룰라나제를 분리하는 방법을 추가로 제공한다. 또한 자일라나제, 셀룰라제, 글루카나제, 베타 글루코시다제, 프로테아제, 에스테라제, 피타제 또는 리파제를 함유하는 형질전환된 식물을 배양하고 자일라나제, 셀룰라제, 글루카나제, 베타 글루코시다제, 프로테아제, 에스테라제, 피타제 또는 리파제를 분리함을 포함하여 자일라나제, 셀룰라제, 글루카나제, 베타 글루코시다제, 프로테아제, 에스테라제, 피타제 또는 리파제를 분리하는 방법을 제공한다. culturing the transformed plant containing α-amylase, glucoamylase, glucose isomerase, α-glucosidase or pullulanase and from therefrom α-amylase, glucoamylase, glucose isomerase, α-glucose There is further provided a method of separating α-amylase, glucoamylase, glucose isomerase, α-glucosidase and pullulanase, comprising the step of isolating cedarase or pullulanase. In addition, cultured transformed plants containing xylanase, cellulase, glucanase, beta glucosidase, protease, esterase, phytase or lipase and cultured xylanase, cellulase, glucanase, beta glucose A method for separating xylanase, cellulase, glucanase, beta glucosidase, protease, esterase, phytase or lipase, including isolating sidase, protease, esterase, phytase or lipase to provide.
형질전환 곡립을 물과 혼합하고, 당해 혼합물을 가열하고, 제조된 덱스트린 시럽으로부터 고형물을 분리하고, 말토덱스트린을 수거함을 포함하여, 말토덱스트린을 제조하는 방법을 제공한다. 형질전환 곡립은 하나 이상의 전분 가공 효소를 포함한다. 전분 가공 효소는 α-아밀라제, 글루코아밀라제, α-글루코시다제 및 글루코즈 이소머라제일 수 있다. 추가로, 당해 방법에 의해 제조된 말토덱스트린 및 당해 방법에 의해 제조된 조성물을 제공한다. Provided are methods for preparing maltodextrin, including mixing the transformed grains with water, heating the mixture, separating solids from the prepared dextrin syrup, and collecting maltodextrin. The transformed grains comprise one or more starch processing enzymes. The starch processing enzyme may be α-amylase, glucoamylase, α-glucosidase and glucose isomerase. Further provided are maltodextrins prepared by the process and compositions prepared by the process.
게놈이 하나 이상의 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 전분 과립 및 하나 이상의 전분 가공 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화하는 조건하에 처리하고, 이에 따라 전분 과립을 가공하여 덱스트린 또는 당을 포함하는 수용액을 형성하는 단계; 및 당 및/또는 덱스트린을 포함하는 수용액을 수거하는 단계를 포함하여 전분-유래 생성물의 회수 전에 곡립의 기계적 파쇄를 필요로 하지 않고 곡립으로부터 덱스트린 또는 당을 제조하는 방법을 제공한다. A plant part comprising starch granules and one or more starch processing enzymes, obtained from a transformed plant whose genome is enriched with an expression cassette encoding one or more processing enzymes, is treated under conditions that activate one or more enzymes, and thus starch Processing the granules to form an aqueous solution comprising dextrin or sugar; And collecting an aqueous solution comprising sugars and / or dextrins, thereby providing a method for preparing dextrins or sugars from the grains without requiring mechanical shredding of the grains prior to recovery of the starch-derived product.
본 발명은 추가로, 게놈이 하나 이상의 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 전분 과립 및 하나 이상의 전분 가공 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화하는 조건하에 처리하고, 이에 따라 전분 과립을 가공하여 덱스트린 또는 당을 포함하는 수용액을 형성하는 단계; 및 발효성 당을 포함하는 수용액을 수거하는 단계를 포함하여 발효성 당을 제조하는 방법에 관한 것이다. The invention further provides that a plant portion comprising starch granules and one or more starch processing enzymes, obtained from a transformed plant whose genome is enhanced with an expression cassette encoding one or more processing enzymes, under conditions that activate one or more enzymes. Processing, thereby processing the starch granules to form an aqueous solution comprising dextrin or sugar; And collecting an aqueous solution containing fermentable sugars.
추가로, 초호열성 α-아밀라제를 포함하는 벡터로 안정하게 형질전환된 옥수수 식물이 본원에 제공되어 있다. 예를 들면, 바람직하게는, 서열번호 1 또는 서 열번호 51과 60% 초과 동일한 α-아밀라제를 암호화하는 폴리뉴클레오타이드 서열을 포함하는 벡터로 안정하게 형질전환된 옥수수 식물이 포함된다. In addition, provided herein are corn plants stably transformed with a vector comprising a superthermophilic α-amylase. For example, corn plants preferably transformed with a vector comprising a polynucleotide sequence encoding α-amylase that is greater than 60% identical to SEQ ID NO: 1 or SEQ ID NO: 51 is included.
도 1A 및 1B는 pNOV6201 식물 및 및 6개의 pNOV6200 주로부터 T1 낟알을 분리함으로써 옥수수 낟알 및 내배유에서 발현되는 α-아밀라제의 활성을 도시한다.1A and 1B show the activity of α-amylase expressed in corn kernels and endosperm by separating T1 kernels from pNOV6201 plants and six pNOV6200 strains.
도 2는 pNOV6201 주로부터 T1 낟알을 분리시 α-아밀라제의 활성을 도시한다. 2 shows the activity of α-amylase in separating T1 kernels from the pNOV6201 strain.
도 3은 85℃ 및 95℃에서 60분 이하의 액화 시간에 적용시킨 내열성 797GL3 알파 아밀라제를 함유하는, 형질전환 옥수수의 매쉬(mash)의 발효에 따라 제조된 에탄올의 양을 도시한 것이다. 당해 도면은 발효 72시간째의 에탄올 수율이 15분 내지 60분의 액화 동안 거의 변하지 않았음을 나타낸다. 추가로, 이는 95℃에서의 액화에 의해 제조된 매쉬가 85℃에서의 액화에 의해 제조된 매쉬 보다 각각의 시점에서 더 많은 에탄올을 제조함을 보여준다.FIG. 3 shows the amount of ethanol produced upon fermentation of a mash of transgenic maize containing heat resistant 797GL3 alpha amylase applied at liquefaction times of up to 60 minutes at 85 ° C. and 95 ° C. FIG. The figure shows that the ethanol yield at 72 hours of fermentation hardly changed during the liquefaction of 15 to 60 minutes. In addition, this shows that the mash prepared by liquefaction at 95 ° C. produces more ethanol at each time point than the mash prepared by liquefaction at 85 ° C.
도 4는 85℃ 및 95℃에서 60분 이하의 액화 시간에 적용시킨 내열성 알파 아밀라제를 함유하는 형질전환 옥수수의 매쉬의 발효 후에 남은 잔류 전분의 양(%)을 도시한 것이다. 당해 도면은 발효 72시간째의 에탄올 수율이 15분 내지 60분의 액화 동안 거의 변하지 않았음을 나타낸다. 추가로, 이는 95℃에서의 액화에 의해 제조된 매쉬가 85℃에서의 액화에 의해 제조된 매쉬 보다 각각의 시점에서 더 많은 에탄올을 제조함을 보여준다.FIG. 4 shows the percentage of residual starch remaining after fermentation of a mash of transgenic maize containing heat resistant alpha amylase applied to liquefaction times of up to 60 minutes at 85 ° C. and 95 ° C. FIG. The figure shows that the ethanol yield at 72 hours of fermentation hardly changed during the liquefaction of 15 to 60 minutes. In addition, this shows that the mash prepared by liquefaction at 95 ° C. produces more ethanol at each time point than the mash prepared by liquefaction at 85 ° C.
도 5는 85℃ 및 95℃에서 제조된 형질전환 옥수수, 대조군 옥수수 및 이의 각종 혼합물의 매쉬에 대한 에탄올 수율을 도시한 것이다. 당해 도면은 α-아밀라제를 포함하는 형질전환 옥수수가 발효 후에 남은 전분의 환원 때문에, 발효 가능한 전분의 제조시에 현저한 개선을 초래함을 설명한다. FIG. 5 shows ethanol yields for mash of transgenic maize, control maize and various mixtures thereof prepared at 85 ° C. and 95 ° C. FIG. This figure illustrates that transgenic corn containing α-amylase results in a significant improvement in the production of fermentable starch due to the reduction of the starch remaining after fermentation.
도 6은 85℃ 및 95℃에서 제조한 형질전환 곡립, 대조군 옥수수 및 이의 각종 혼합물의 매쉬에 대한 발효 후에 건조시킨 찌꺼기(stillage)에서 측정한 잔류 전분의 양을 도시한 것이다. FIG. 6 shows the amount of residual starch measured in dried dregs after fermentation on mash of transgenic grains, control corn and various mixtures thereof prepared at 85 ° C. and 95 ° C. FIG.
도 7은 5.2 내지 6.4의 다양한 pH 범위에서 20 내지 80 시간의 기간에 걸친 3% 형질전환 옥수수를 포함하는 샘플의 발효 시간의 함수로서의 에탄올 수율을 도시한 것이다. 당해 도면은 낮은 pH에서 수행한 발효가 6.0 이상의 pH에서보다 더 빠르게 진행됨을 설명한다. FIG. 7 shows ethanol yield as a function of fermentation time of a sample comprising 3% transgenic corn over a period of 20 to 80 hours at various pH ranges from 5.2 to 6.4. This figure illustrates that fermentation performed at low pH proceeds faster than at pH 6.0 or higher.
도 8은 5.2 내지 6.4의 다양한 범위의 pH에서 0 내지 12중량%의 다양한 중량%의 형질전환 옥수수를 포함하는 매쉬의 발효 중의 에탄올 수율을 도시한 것이다. 당해 도면은 에탄올 수율이 샘플에 포함된 형질전환 곡립의 양과 무관하였음을 설명한다. FIG. 8 shows the ethanol yield during fermentation of a mash comprising 0-12 wt% of varying wt% transgenic corn at various pH ranges from 5.2 to 6.4. This figure illustrates that ethanol yield was independent of the amount of transgenic grain included in the sample.
도 9는 pNOV 7005로 형질전환시킨 상이한 이벤트(event)로부터의 T2 종자의 분석을 나타낸다. 비-형질전환 대조군과 비교하여, 풀룰라나제 활성의 고 발현은 다양한 이벤트에서 관측될 수 있다. 9 shows analysis of T2 seeds from different events transformed with pNOV 7005. Compared to the non-transformation control, high expression of pullulanase activity can be observed in various events.
도 10A 및 10B는 형질전환 옥수수 분말 중 전분으로부터 풀룰라나제를 발현시킴으로써 생산한 가수분해 생성물의 HPLC 분석의 결과를 나타낸다. 75℃의 반응 완충액에서 30분 동안의 풀룰라나제 발현 옥수수의 분말의 항온처리는 옥수수전분으로부터 중쇄 올리고당{중합도(DP) ~10 내지 30} 및 아밀로스 단쇄(DP ~100-200)의 생산을 야기한다. 도 10A 및 10B는 또한 풀룰라나제의 활성에 대한 첨가된 칼슘 이온의 효과를 나타낸다. 10A and 10B show the results of HPLC analysis of hydrolysis products produced by expressing pullulanase from starch in transgenic corn powder. Incubation of the powder of pullulanase expressing corn for 30 minutes in a reaction buffer at 75 ° C. results in production of heavy chain oligosaccharides (degree of polymerization (DP) ˜10 to 30} and amylose short chain (DP to 100-200) from corn starch. do. 10A and 10B also show the effect of added calcium ions on the activity of pullulanase.
도 11A 및 11B는 2가지의 반응 혼합물로부터의 전분 가수분해 생성물의 HPLC 분석으로부터 도출된 데이타를 도시한 것이다. '아밀라제'로 나타낸 제1 반응은 α-아밀라제 발현 형질전환 옥수수 및 비-형질전환 옥수수 A188의 옥수수 분말 샘플의 혼합물[1:1 (w/w)]을 함유하며; 제2 반응 혼합물 '아밀라제 + 풀룰라나제'는 α-아밀라제 발현 형질전환 옥수수 및 풀룰라나제 발현 형질전환 옥수수의 옥수수 분말 샘플의 혼합물[1:1 (w/w)]를 함유한다.11A and 11B show data derived from HPLC analysis of starch hydrolysis products from two reaction mixtures. The first reaction, denoted 'amylase', contained a mixture [1: 1 (w / w)] of corn powder samples of α-amylase expressing transformed corn and non-transformed corn A188; The second reaction mixture 'amylase + pullulanase' contains a mixture [1: 1 (w / w)] of corn powder samples of α-amylase expressing transformed corn and pullulanase expressing transformed corn.
도 12는 2가지의 반응 혼합물에 대한 반응 혼합물 25㎕ 중 ㎍ 단위의 당 생성물의 양을 도시한 것이다. '아밀라제'로 나타낸 제1 반응은 α-아밀라제 발현 형질전환 옥수수 및 비-형질전환 옥수수 A188의 옥수수 분말 샘플의 혼합물[1:1 (w/w)]을 함유하며; 제2 반응 혼합물 '아밀라제 + 풀룰라나제'는 α-아밀라제 발현 형질전환 옥수수 및 풀룰라나제 발현 형질전환 옥수수의 옥수수 분말 샘플의 혼합물[1:1 (w/w)]를 함유한다.FIG. 12 shows the amount of sugar product in μg in 25 μl of the reaction mixture for the two reaction mixtures. The first reaction, denoted 'amylase', contained a mixture [1: 1 (w / w)] of corn powder samples of α-amylase expressing transformed corn and non-transformed corn A188; The second reaction mixture 'amylase + pullulanase' contains a mixture [1: 1 (w / w)] of corn powder samples of α-amylase expressing transformed corn and pullulanase expressing transformed corn.
도 13A 및 13B는 85℃ 및 95℃에서 30분 동안의 항온처리 말기에 반응 혼합물의 2가지 세트로부터의 전분 가수분해 생성물을 나타낸다. 각각의 세트에 대해 2가지 반응 혼합물이 있다; '아밀라제 X 플룰라나제'로 나타낸 제1 반응은 α-아밀라제 및 풀룰라나제 둘 다를 발현하는 형질전환 옥수수로부터의 분말을 함유하며; '아밀라제'로 나타낸 제2 반응 혼합물은 동일한 양의 α-아밀라제 활성이 수득되는 비율의 α-아밀라제 발현 형질전환 옥수수 및 비-형질전환 옥수수 A188의 옥수수 분말 샘플의 혼합물이 교배 중에 관찰된다(아밀라제 X 풀룰라나제). 13A and 13B show starch hydrolysis products from two sets of reaction mixtures at the end of incubation at 85 ° C. and 95 ° C. for 30 minutes. There are two reaction mixtures for each set; The first reaction, denoted 'amylase X flulanase', contained a powder from transgenic maize expressing both α-amylase and pullulanase; The second reaction mixture, denoted 'amylase', is observed in a mixture of a mixture of corn powder samples of α-amylase expressing transformed corn and non-transformed corn A188 at a rate where the same amount of α-amylase activity is obtained (amylase X Pullulanase).
도 14는 비-형질전환 옥수수 종자(대조군), 797GL3 α-아밀라제를 포함하는 형질전환 옥수수 및 Mal A α-글루코시다제와 797GL3 형질전환 옥수수 종자의 배합물을 사용한 전분의 글루코즈로의 분해를 도시한 것이다. FIG. 14 shows degradation of starch into glucose using non-transformed corn seed (control), transgenic maize containing 797GL3 α-amylase, and a combination of Mal A α-glucosidase and 797GL3 transgenic maize seed. will be.
도 15는 실온 또는 30℃에서 날전분의 전환을 도시한 것이다. 당해 도면에서, 반응 혼합물 1 및 2는 각각 실온 및 30℃에서의 물과 전분의 배합물이다. 반응 혼합물 3 및 4는 각각 실온 및 30℃에서의 보리 α-아밀라제 및 전분의 배합물이다. 반응 혼합물 5 및 6은 각각 실온 및 30℃에서의 호열혐기성 세균 글루코아밀라제 및 전분의 배합물이다. 반응 혼합물 7 및 8은 각각 실온 및 30℃에서의 보리 α-아밀라제(sigma) 및 호열혐기성 세균 글루코아밀라제 및 전분의 배합물이다. 반응 혼합물 9 및 10은 각각 실온 및 30℃에서의 보리 알파-아밀라제(sigma) 대조군 및 전분의 배합물이다. 호열혐기성 세균 글루코아밀라제의 생성물의 중합도(DP)가 제시되어 있다. 15 shows the conversion of raw starch at room temperature or 30 ° C. In this figure,
도 16은 실시예 19에 기술한 바와 같이 알파 아밀라제, 알파 글루코시다제 및 글루코즈 이소머라제를 사용한 아밀라제 형질전환 옥수수 분말로부터의 프럭토즈의 제조를 도시한 것이다. 아밀라제 옥수수 분말을 물 또는 완충액을 가한 효소 용액과 혼합하였다. 모든 반응물은 아밀라제 분말 60mg과 액체 총 600㎕를 함유하였으며 90℃에서 2시간 동안 항온처리하였다. FIG. 16 depicts the preparation of fructose from amylase transgenic corn powder using alpha amylase, alpha glucosidase and glucose isomerase as described in Example 19. FIG. Amylase corn powder was mixed with enzyme solution added water or buffer. All reactions contained 60 mg of amylase powder and 600 μl of total liquid and were incubated at 90 ° C. for 2 hours.
도 17은 90℃에서 0-1200분의 항온처리 시간의 함수로서의 자가-가공 낟알으로부터의 100% 아밀라제 분말을 갖는 반응 생성물의 피크면적을 도시한 것이다.FIG. 17 shows the peak area of the reaction product with 100% amylase powder from self-processing grains as a function of incubation time 0-1200 minutes at 90 ° C.
도 18은 90℃에서 0-1200분의 항온처리 시간의 함수로서 자가-가공 낟알 및 90% 대조군 옥수수 분말로부터의 10% 형질전환 아밀라제 분말을 갖는 반응 생성물의 피크면적을 도시한 것이다. FIG. 18 shows the peak area of the reaction product with self-processed grains and 10% transformed amylase powder from 90% control corn powder as a function of incubation time 0-1200 minutes at 90 ° C.
도 19는 전분 가수분해에 대한 온도의 효과를 평가하기 위해 90분 이하 동안 70℃, 80℃, 90℃ 또는 100℃에서 항온처리한 형질전환 아밀라제 분말의 HPLC 분석의 결과를 제공한다. FIG. 19 provides the results of HPLC analysis of transformed amylase powder incubated at 70 ° C., 80 ° C., 90 ° C. or 100 ° C. for up to 90 minutes to assess the effect of temperature on starch hydrolysis.
도 20은 각종 반응 조건하에 물 또는 완충액을 가한 효소 용액과 혼합한 형질전환 아밀라제 분말 60mg을 함유한 샘플에 대한 ELSD 피크면적을 도시한 것이다. 반응물의 한 세트를 pH 7.0의 50mM MOPS와 10mM MgSO4 및 1mM CoCl2로 완충시켰고; 반응물의 제2 세트에서 금속-함유 완충용액을 물로 대체하였다. 모든 반응은 90℃에서 2시간 동안 항온처리하였다. FIG. 20 shows the ELSD peak areas for samples containing 60 mg of transformed amylase powder mixed with enzyme solution to which water or buffer was added under various reaction conditions. One set of reactions was buffered with 50 mM MOPS, 10 mM MgSO 4 and 1 mM CoCl 2 at pH 7.0; In the second set of reactants the metal-containing buffer was replaced with water. All reactions were incubated at 90 ° C. for 2 hours.
본 발명에 따르면, "자가-가공" 식물 또는 식물 부분은 가공, 예를 들면, 식물 내의 전분, 다당류, 지질, 단백질 등을 변형시킬 수 있는 가공 효소를 암호화하는 분리된 폴리뉴클레오타이드를 그 내부에 포함하고 있으며, 여기서, 가공 효소는 중온성, 호열성 또는 초호열성일 수 있으며 연마, 물 첨가, 가열 또는 효소의 작용을 위해 제공된 기타 유리한 조건에 의해 활성화될 수 있다. 가공 효소를 암호화하는 분리된 폴리뉴클레오타이드는 식물 또는 식물 부분에서의 발현을 위해 식물 또는 식물 부분에 통합된다. 가공 효소의 발현 및 활성화에 따라, 본 발명의 식물 또는 식물 부분은 가공 효소의 작용에 따라 기질을 가공한다. 따라서, 본 발명의 식물 또는 식물 부분은 일반적으로 이들 기질을 가공하는 데 필요한 환원된 외부 공급원의 유무하에 그 안에 함유된 가공 효소의 활성화에 따라 효소의 기질을 자가-가공할 수 있다. 이와 같이, 형질전환된 식물, 형질전환된 식물 세포 및 형질전환된 식물 부분은 본 발명에 따라 그 안에 포함된 효소를 통해 목적하는 기질을 가공하는 "붙박이" 가공 능력을 가진다. 바람직하게는, 가공 효소-암호화 폴리뉴클레오타이드는 "유전적으로 안정하다", 즉, 당해 폴리뉴클레오타이드는 본 발명의 형질전환된 식물 또는 식물 부분 내에서 안정하게 유지되며 연속한 세대를 통해 자손에 안정적으로 유전된다. According to the present invention, a "self-processing" plant or plant part comprises therein an isolated polynucleotide encoding a processing enzyme that can process, for example, modify starch, polysaccharides, lipids, proteins, etc. in the plant. Wherein the processing enzyme may be mesophilic, thermophilic or superthermophilic and may be activated by polishing, water addition, heating or other advantageous conditions provided for the action of the enzyme. Isolated polynucleotides encoding processing enzymes are incorporated into a plant or plant part for expression in the plant or plant part. Depending on the expression and activation of the processing enzyme, the plant or plant part of the present invention processes the substrate under the action of the processing enzyme. Thus, the plant or plant part of the present invention is generally capable of self-processing the substrate of an enzyme upon activation of the processing enzyme contained therein, with or without the reduced external source required to process these substrates. As such, transformed plants, transformed plant cells, and transformed plant parts have the "built-in" processing capacity to process the desired substrate via the enzymes contained therein according to the present invention. Preferably, the processing enzyme-encoding polynucleotide is “genetically stable”, ie the polynucleotide remains stable within the transformed plant or plant part of the invention and is stably inherited to the progeny through successive generations. do.
본 발명에 따르면, 이러한 식물 및 식물 부분을 사용하는 방법은 전분-유래 생성물을 수거하기 전 온전한 식물 부분을 제분 또는 달리 물리적으로 파쇄할 필요성을 제거할 수 있다. 예를 들면, 본 발명은 전분-유래 생성물을 수거하기 위해 옥수수 또는 다른 곡립을 가공하는 개선된 방법을 제공한다. 본 발명은 또한 외생적으로 제조된 전분 가수분해 효소를 첨가할 필요 없이 전분 내의 특이적 결합의 가수분해에 적합한, 과립 내 또는 과립 상의 전분 분해 효소의 농도를 함유하는 전분 과립의 수거를 가능케 하는 방법을 제공한다. 본 발명은 또한 본 발명의 방법에 의해 수득된 자가-가공 식물 또는 식물 부분로부터의 개선된 생성물을 제공한다. According to the present invention, methods using these plants and plant parts may obviate the need for milling or otherwise physically crushing the intact plant parts before harvesting the starch-derived product. For example, the present invention provides an improved method of processing corn or other grains to harvest starch-derived products. The present invention also provides a method for enabling the collection of starch granules containing concentrations of starch degrading enzymes in or on granules suitable for hydrolysis of specific bonds in starch without the need of adding exogenously produced starch hydrolase. To provide. The present invention also provides improved products from self-processing plants or plant parts obtained by the process of the invention.
추가로, "자가-가공" 형질전환된 식물 부분, 예를 들면, 곡립 및 형질전환된 식물은 현존하는 기술이 갖는 주요 문제(즉, 가공 효소가 통상적으로 배양 상층액으로부터 효소를 분리할 필요가 있고, 비용이 많이 소요되는 미생물의 발효에 의해 제조되며, 분리된 효소는 특정 적용을 위해 제형화되어야 할 필요가 있으며, 당해 효소의 첨가, 혼합 및 이의 기질과의 반응을 위한 과정 및 기작이 개발되어야 한다)를 피한다. 본 발명의 형질전환된 식물 또는 이의 일부는 또한 가공 효소 그 자체 및 당, 아미노산, 지방산 및 전분 및 비-전분 다당류와 같은 효소의 기질 및 생성물의 공급원이다. 본 발명의 식물은 또한 하이브리드 및 근교계와 같은 자손 식물을 제조하기 위해 사용할 수 있다. In addition, "self-processing" transformed plant parts, such as grains and transformed plants, are a major problem with existing techniques (ie, processing enzymes typically do not require separation of enzymes from the culture supernatant). Prepared by fermentation of expensive, costly microorganisms, the isolated enzyme needs to be formulated for a particular application, and processes and mechanisms for the addition, mixing and reaction of the enzyme with its substrate have been developed. Should be avoided). Transformed plants of the present invention or parts thereof are also a source of processing enzymes themselves and substrates and products of enzymes such as sugars, amino acids, fatty acids and starch and non-starch polysaccharides. The plants of the present invention can also be used to produce progeny plants such as hybrids and suburbs.
가공 효소 및 이들을 암호화하는 폴리뉴클레오타이드Processing enzymes and polynucleotides encoding them
가공 효소(중온성, 호열성 또는 초호열성)를 암호화하는 폴리뉴클레오타이드를 식물 또는 식물 부분에 도입한다. 가공 효소는 식물 또는 형질전환된 식물 및/또는 목적하는 최종 생성물에서 발견된 바와 같이 이것이 작용하는 목적하는 기질을 기초로 하여 선택한다. 예를 들면, 가공 효소는 전분-분해 또는 전분-이성체화 효소와 같은 전분-가공 효소 또는 비-전분 가공 효소일 수 있다. 적합한 가공 효소에는 예를 들면, α-아밀라제, 엔도 또는 엑소-1,4, 또는 1,6-α-D, 글루코아밀라제, 글루코즈 이소머라제, β-아밀라제, α-글루코시다제 및 기타 엑소-아밀라제를 포함하는 전분 분해 또는 이성체화 효소; 및 아이소아밀라제, 풀룰라나제, 네오-풀룰라나제, 이소-풀룰라나제, 아밀로풀룰라나제 등과 같은 전분 탈분지화 효소, 사이클로덱스트린 글라이코실트렌스퍼라제 등과 같은 글라이코실 트랜스퍼라제, 엑소-1,4-β-셀로바이오하이드롤라제, 엑소-1,3-β-D-글루카나제, 헤미셀룰라제, β-글루코시다제 등과 같은 셀룰라제; 엔도-1,3-β-글루카나제 및 엔도-1,4-β-글루카나제 등과 같은 엔도글루카나제; 엔도-1,5-α-L-아라비나제, α-아라비노시다제 등과 같은 L-아라비나제; 엔도-1,4-β-D-갈락타나제, 엔도-1,3-β-D-갈락타나제, β-갈락토시다제, α-갈락토시다제 등과 같은 갈락타나제; 엔도-1,4-β-D-만나나제, β-만노시다제, α-만노시다제 등과 같은 만나나제; 엔도-1,4-β-자일라나제, β-D-자일로시다제, 1,3-β-D-자일라나제 등과 같은 자일라나제; 및 펙티나제; 및 프로테아제, 글루카나제, 자일라나제, 티오레독신/티오레독신 환원효소, 에스테라제, 피타제 및 리파제를 포함하는 비전분 가공 효소가 포함되지만, 이에 제한되지는 않는다. A polynucleotide encoding a processing enzyme (meteophilic, thermophilic or superthermophilic) is introduced into a plant or plant part. The processing enzyme is selected based on the substrate of interest on which it acts, as found in the plant or transformed plant and / or the desired end product. For example, the processing enzyme may be a starch-processing enzyme such as starch-degrading or starch-isomerase or a non-starch processing enzyme. Suitable processing enzymes include, for example, α-amylase, endo or exo-1,4, or 1,6-α-D, glucoamylase, glucose isomerase, β-amylase, α-glucosidase and other exo- Starch degradation or isomerization enzymes including amylases; And glycosyl transferases, exo, such as starch debranching enzymes such as isoamylase, pullulanase, neo-pululanase, iso-pululanase, amylopululase, cyclodextrin glycosyltransferase, and the like. Cellulase such as -1,4-β-cellobiohydrolase, exo-1,3-β-D-glucanase, hemicellulase, β-glucosidase and the like; Endoglucanases such as endo-1,3-β-glucanase and endo-1,4-β-glucanase; L-arabinases such as endo-1,5-α-L-arabinase, α-arabinosidase and the like; Galactanases such as endo-1,4-β-D-galactanase, endo-1,3-β-D-galactanase, β-galactosidase, α-galactosidase and the like; Mannaases such as endo-1,4-β-D-mannase, β-mannosidase, α-mannosidase, and the like; Xylanases such as endo-1,4-β-xylanase, β-D-xylosidase, 1,3-β-D-xylanase and the like; And pectinase; And non-starch processing enzymes including, but not limited to, proteases, glucanases, xylanases, thioredoxin / thioredoxin reductases, esterases, phytase and lipases.
한 양태에서, 가공 효소는 α-아밀라제, 풀룰라나제, α-글루코시다제, 글루코아밀라제, 아밀로풀룰라나제, 글루코즈 이소머라제 또는 이의 배합물로 이루어진 그룹 중에서 선택된 전분-분해 효소이다. 당해 양태에 따르면, 전분-분해 효소는 식물 또는 식물 부분에 함유된 효소의 활성화에 따라 자가-가공 식물 또는 식물 부분을 분해하게 할 수 있으며, 추가로 본원에 기술할 것이다. 전분-분해 효소(들)은 목적하는 최종 생성물에 따라 선택한다. 예를 들면, 글루코즈-이소머라제는 글루코즈(헥소즈)을 프럭토즈로 전환하기 위해 선택할 수 있다. 대안적으로, 당해 효소는 예를 들면, 가공 정도의 함수를 기초로 하여 다양한 쇄 길이를 갖거나 목적하는 다양한 가지화 유형을 갖는 목적하는 전분-유래 최종 생성물을 기초로 하여 선택할 수 있다. 예를 들면, α-아밀라제, 글루코아밀라제 또는 아밀로풀룰라나제를 덱스트린 생성물을 제조하기 위해 짧은 항온처리 시간 하에 사용하고 단쇄 생성물 또는 당을 제조하기 위해 보다 긴 항온처리 시간 하에 사용할 수 있다. 전분 내의 분지 지점을 특이적으로 가수분해하여 고-아밀로스 전분을 산출하기 위해 풀룰라나제를 사용할 수 있거나, 산재된 α 1,6 결합을 갖는 α 1,4 결합의 신장부를 갖는 전분을 제조하기 위해 네오풀룰라나제를 사용할 수 있다. 제한된 덱스트린을 제조하기 위해 글루코시다제를 사용할 수 있고, 또는 다른 전분 유도체를 제조하기 위해 상이한 효소의 배합물을 사용할 수 있다. In one embodiment, the processing enzyme is a starch-degrading enzyme selected from the group consisting of α-amylase, pullulanase, α-glucosidase, glucoamylase, amylopululase, glucose isomerase or combinations thereof. In accordance with this embodiment, the starch-degrading enzyme may cause degradation of the self-processing plant or plant part upon activation of the enzyme contained in the plant or plant part and will be further described herein. Starch-degrading enzyme (s) are selected according to the desired end product. For example, glucose-isomerase can be selected to convert glucose (hexose) to fructose. Alternatively, the enzyme may be selected based on the desired starch-derived end product, for example, having a variety of chain lengths or a variety of branching types desired based on a function of the degree of processing. For example, α-amylase, glucoamylase or amylopululase can be used under short incubation times to produce dextrin products and longer incubation times to produce short chain products or sugars. Pullulanase can be used to specifically hydrolyze the branching points in the starch to yield high-amylose starches, or to prepare starches with stretches of
다른 양태에서, 가공 효소는 프로테아제, 글루카나제, 자일라나제, 피타제, 리파제, 셀룰라제, 베타 글루코시다제 및 에스테라제 중에서 선택된 비-전분 가공 효소이다. 이들 비-전분 분해 효소는 본 발명의 자가-가공 식물 또는 식물 부분의 식물의 표적 영역 내로의 혼입을 가능하게 하며, 활성화에 따라, 식물은 파쇄하는 한편 전분 과립은 그 안에 손상되지 않은 채로 유지되게 한다. 예를 들면, 바람직한 양태에서, 비전분 분해 효소는 식물 세포의 내배유 기질을 표적으로 하며, 활성화에 따라, 내배유 기질을 파쇄하는 한편 전분 과립은 손상되지 않은 채로 그 안에 유지되게 하며 수득된 물질로부터 보다 용이하게 회수가능하게 한다. In other embodiments, the processing enzyme is a non-starch processing enzyme selected from protease, glucanase, xylanase, phytase, lipase, cellulase, beta glucosidase and esterase. These non-starch degrading enzymes allow the incorporation of the self-processing plant or plant part of the invention into the target area of the plant and, upon activation, causes the plant to shred while the starch granules remain intact therein. do. For example, in a preferred embodiment, the non-starch degrading enzyme targets the endosperm substrate of the plant cell and, upon activation, disrupts the endosperm substrate while leaving the starch granules intact and more intact from the material obtained. Makes it easy to recover.
가공 효소의 배합이 본 발명에 의해 추가로 고려된다. 예를 들면, 전분-가공 및 비-전분 가공 효소를 배합하여 사용할 수 있다. 가공 효소의 배합은 각각의 효소를 암호화하는 다중 유전자 작제물의 용도를 활용하여 수득할 수 있다. 대안적으로, 효소로 안정하게 형질전환시킨 개별 형질전환된 식물을 공지된 방법으로 교배시켜 효소 둘 다를 함유하는 식물을 수득할 수 있다. 다른 방법은 형질전환된 식물과 외인성 효소(들)의 사용을 포함한다. Combination of processing enzymes is further contemplated by the present invention. For example, starch-processed and non-starch processed enzymes can be combined and used. Combination of processing enzymes can be obtained utilizing the use of multiple gene constructs encoding each enzyme. Alternatively, individual transformed plants stably transformed with enzymes can be crossed by known methods to obtain plants containing both enzymes. Another method involves the use of transformed plants and exogenous enzyme (s).
가공 효소는 임의의 공급원으로부터 분리 또는 유래한 것일 수 있으며 이에 상응하는 폴리뉴클레오타이드는 당해 분야의 숙련가에 의해 확인될 수 있다. 예를 들면, α-아밀라제와 같은 가공 효소는 파이로코쿠스{예를 들면, 파이로코쿠스 퓨리오서스(Pyrococcus furiosus)}, 터무스, 터모코쿠스{예를 들면, 터모코쿠스 하이드로터말리스(Thermococcus hydrothermalis)}, 설폴로부스{예를 들면, 설폴로부스 솔파타리쿠스(Sulfolobus solfataricus)}, 터모토가{예를 들면, 터모토가 마리티마(Thermotoga maritima) 및 터모토가 네아폴리타나(Thermotoga neapolitana)}, 호열혐기성 세균(예를 들면, 터모안애어로박터 텐콘젠시스(Thermoanaerobacter tengcongensis)}, 아스퍼길러스{예를 들면, 아스퍼길러스 쉬로우사미(Aspergillus shirousami) 및 아스퍼길러스 니거(Aspergillus niger)}, 리조푸스{예를 들면, 리조푸스 오리재(Rhizopus oryzae)}, 터모프로틸레스, 데설푸로코쿠스{예를 들면, 데설푸로코쿠스 아밀로리티쿠스(Desulfurococcus amylolyticus)}, 메타노박테리움 터모아우토트로피쿰(Methanobacterium thermoautotrophicum), 메타노코쿠스 자나스키(Methanococcus jannaschii ), 메타노파이러스 칸들레리(Methanopyrus kandleri), 터모시네초코쿠스 엘롱가투스(Thermosynechococcus elongatus), 터모플라스마 애시도필룸(Thermoplasma acidophilum), 터모플라스마 볼카니움(Thermoplasma volcanium), 에어로파이룸 퍼닉스(Aeropyrum pernix) 및 옥수수, 보리 및 벼와 같은 식물로부터 유래한다. The processing enzyme may be isolated or derived from any source and the corresponding polynucleotides may be identified by one skilled in the art. For example, processing enzymes such as α-amylase may be pyrococcus (e.g. Pyrococcus furiosus ), thermomus, thermococcus {e.g. Thermococcus hydrothermalis )}, sulfolobus {e.g. Sulfolobus solfataricus }, turmotoga {e.g. Thermotoga maritima and Turmotoga neapolitana ( Thermotoga neapolitana)}, thermophilic anaerobic bacteria (e. g., teomo anae fishing bakteo X konjen sheath (Thermoanaerobacter tengcongensis)}, AAS peogil Russ {e.g., Aspergillus peogil Russ swiro Usami (Aspergillus shirousami) and Aspergillus peogil Russ nigeo (Aspergillus niger )}, lycopus {for example Rhizopus oryzae }, thermophiles, desulfurococcus {for example, desulfurococc amylolyticus } , Metanobacterium Methanobacterium thermoautotrophicum ), Methanococcus jannaschii ) , Methanopyrus kandleri , Thermosynechococcus elongatus ), Thermoplasma ashdofilum acidophilum ), Thermoplasma volcanium , Aeropyrum pernix ) and plants such as corn, barley and rice.
본 발명의 가공 효소는 식물의 게놈 내에서 도입 및 발현된 후, 활성화될 수 있다. 효소의 활성화를 위한 조건은 각각의 개별 효소에 따라 결정되며 온도, pH, 수화작용, 금속의 존재, 활성화 화합물, 불활성화 화합물 등과 같은 다양한 조건을 포함할 수 있다. 예를 들면, 온도-의존성 효소는 중온성, 호열성 및 초호열성 효소를 포함할 수 있다. 중온성 효소는 통상 20℃ 내지 65℃의 온도에서 최대 활성을 가지며, 70℃ 이상의 온도에서는 불활성화된다. 중온성 효소는 30℃ 내지 37℃에서 현저한 활성을 가지며, 30℃에서의 활성은 바람직하게는 최대 활성의 10% 이상, 보다 바람직하게는 최대 활성의 20% 이상이다. The processing enzyme of the present invention can be activated after being introduced and expressed in the genome of a plant. Conditions for the activation of enzymes are determined for each individual enzyme and may include various conditions such as temperature, pH, hydration, the presence of metals, activating compounds, inactivating compounds and the like. For example, temperature-dependent enzymes may include mesophilic, thermophilic and hyperthermic enzymes. Mesophilic enzymes usually have maximum activity at temperatures between 20 ° C. and 65 ° C. and are inactivated at temperatures above 70 ° C. The mesophilic enzyme has significant activity at 30 ° C. to 37 ° C., and the activity at 30 ° C. is preferably at least 10% of the maximum activity, more preferably at least 20% of the maximum activity.
호열성 효소는 50℃ 내지 80℃의 온도에서 최대 활성을 갖는다. 중온성 효소는 바람직하게는 30℃에서 최대 활성의 20% 미만을, 보다 바람직하게는 최대 활성의 10% 미만을 가질 것이다. Thermophilic enzymes have maximum activity at temperatures between 50 ° C and 80 ° C. The mesophilic enzyme will preferably have less than 20% of the maximum activity at 30 ° C., more preferably less than 10% of the maximum activity.
"초호열성" 효소는 보다 높은 온도에서 활성을 갖는다. 초호열성 효소는 80℃ 이상의 온도에서 최대 활성을 가지며 80℃ 이상의 온도에서 활성을 유지하며, 보다 바람직하게는 90℃ 이상의 온도에서 활성을 유지하며, 가장 바람직하게는 95℃ 이상의 온도에서 활성을 유지한다. 초호열성 효소는 또한 저온에서 감소된 활성을 갖는다. 초호열성 효소는 30℃에서 활성을 가질 수 있으며, 이는 최대 활성의 10% 미만 및 바람직하게는 최대 활성의 5% 미만이다. "Superthermic" enzymes are active at higher temperatures. Superthermolytic enzymes have a maximum activity at temperatures above 80 ° C. and maintain activity at temperatures above 80 ° C., more preferably maintain activity at temperatures above 90 ° C., and most preferably maintain activity at temperatures above 95 ° C. . Superthermic enzymes also have reduced activity at low temperatures. The hyperthermic enzyme may have activity at 30 ° C., which is less than 10% of the maximum activity and preferably less than 5% of the maximum activity.
가공 효소를 암호화하는 폴리뉴클레오타이드는 식물과 같은 선택된 개체 내애서의 발현에 최적화시킨 코돈을 포함하도록 바람직하게 변형시킨다(예를 들면, 문헌[Wada et al., Nucl. Acids Res., 18:2367 (1990), Murray et al., Nucl. Acids Res., 17:477 (1989), 미국 특허 제5,096,825호, 제5,625,136호, 제5,670,356호 및 제5,874,304호]를 참조한다). 코돈 최적화 서열은 합성 서열이며, 즉, 이들은 자연에서는 발생하지 않으며, 바람직하게는 가공 효소를 암호화하는 비-코돈 최적화된 모 폴리뉴클레오타이드에 의해 암호화된 동일한 폴리펩타이드(또는 실질적으로 전장 폴리펩타이드와 동일한 활성을 갖는 전장 폴리펩타이드의 효소적 활성 단편)를 암호화한다. 당해 폴리펩타이드는 예를 들면, 모원 폴리펩타이드로부터의 특정한 가공 효소를 암호화하는 DNA의 회귀 돌연변이유발을 통해 생화학적으로 구별되거나 개선되어, 이의 가공 방법에서의 성능을 개선하는 것이 바람직하다. 바람직한 폴리뉴클레오타이드는 표적 숙주 식물 내에서의 발현에 최적화되어 있으며 가공 효소를 암호화한다. 이들 효소를 제조하는 방법에는 돌연변이, 예를 들면, 회귀 돌연변이유발법 및 선별법이 포함된다. 돌연변이유발 및 뉴클레오타이드 서열 변경 방법은 당해 분야에 널리 공지되어 있다. 예를 들면, 문헌[Kunkel, Proc. Natl. Acad. Sci. USA, 82: 488, (1985); Kunkel et al., Methods in Enzymol., 154:367 (1987); 미국 특허 제4,873,192호; Walker and Gaastra, eds.(1983) Techniques in Molecular Biology (MacMillan 출판사, 뉴욕 소재)] 및 본원에 인용되어 있는 참조문헌 및 문헌[참조: Arnold et al., Chem.Eng. Sci., 51:5091 (1996)]을 참조한다. 표적 식물 또는 유기체 내에서의 핵산 단편의 발현을 최적화시키는 방법은 당해 분야에 널리 공지되어 있다. 간략히, 표적 개체에 의해 사용되는 최적 코돈을 나타내는 코돈 사용 표를 입수하고 최적 코돈을 선택하여 이들을 표적 폴리뉴클레오타이드로 대체하고, 이어서 최적화된 서열을 화학적으로 합성한다. 옥수수에 대한 바람직한 코돈은 미국 특허 제5,625,136호에 기술되어 있다. Polynucleotides encoding processing enzymes are preferably modified to include codons optimized for expression in selected individuals, such as plants (see, eg, Wada et al., Nucl. Acids Res., 18: 2367 ( 1990), Murray et al., Nucl.Acids Res., 17: 477 (1989), US Pat. Nos. 5,096,825, 5,625,136, 5,670,356 and 5,874,304. Codon optimization sequences are synthetic sequences, that is, they do not occur in nature, preferably the same polypeptide (or substantially the same activity as the full length polypeptide) encoded by a non-codon optimized parent polynucleotide encoding a processing enzyme. Enzymatically active fragments of full length polypeptides). The polypeptide is preferably biochemically distinguished or improved, for example, via regression mutagenesis of DNA encoding a particular processing enzyme from the parent polypeptide, thereby improving performance in its processing method. Preferred polynucleotides are optimized for expression in the target host plant and encode processing enzymes. Methods for preparing these enzymes include mutations such as regression mutagenesis and screening. Mutagenesis and nucleotide sequence alteration methods are well known in the art. See, eg, Kunkel, Proc. Natl. Acad. Sci. USA, 82: 488, (1985); Kunkel et al., Methods in Enzymol., 154: 367 (1987); US Patent No. 4,873,192; Walker and Gaastra, eds. (1983) Techniques in Molecular Biology (MacMillan Publishing, New York) and references and references cited herein by Arnold et al., Chem. Eng. Sci., 51: 5091 (1996). Methods for optimizing the expression of nucleic acid fragments in a target plant or organism are well known in the art. Briefly, codon usage tables representing the optimal codons used by the target individual are obtained and the optimal codons are selected to replace them with target polynucleotides, followed by chemical synthesis of the optimized sequence. Preferred codons for corn are described in US Pat. No. 5,625,136.
본 발명의 폴리뉴클레오타이드의 상보적 핵산을 추가로 고려한다. 서던(Southern) 또는 노던(Northern) 블롯에서 필터 상에 100개 이상의 상보적 잔기를 갖는 상보적 핵산의 하이브리드화를 위한 낮은 엄중성 조건의 예는 50% 포름아마이드, 예를 들면, 37℃에서 50% 포름아마이드, 1M NaCl, 1% SDS에서의 하이브리드화, 및 60℃ 내지 65℃에서 0.1X SSC에서의 세척이다. 낮은 엄중성 조건의 예에는 37℃에서 30 내지 35% 포름아마이드, 1M NaCl, 1% SDS(도데실 황산나트륨)의 완충액을 사용한 하이브리드화, 및 50 내지 55℃에서 1X 내지 2X SSC(20X SSC=3.0M NaCl/0.3M 시트르산삼나트륨) 중의 세척이 포함된다. 예시적 중간 엄중성 하이브리드화 조건에는 27℃에서 40 내지 45% 포름아마이드, 1.0M NaCl, 1% SDS에서의 하이브리드화, 및 55℃ 내지 60℃에서 0.5X 내지 1X SSC에서의 세척이 포함된다.Further contemplated are the complementary nucleic acids of the polynucleotides of the present invention. An example of low stringency conditions for hybridization of complementary nucleic acids with 100 or more complementary residues on a filter in Southern or Northern blots is 50% formamide, for example 50% at 37 ° C. Formamide, 1M NaCl, hybridization in 1% SDS, and washing in 0.1 × SSC at 60 ° C. to 65 ° C. Examples of low stringency conditions include hybridization with a buffer of 30-35% formamide, 1M NaCl, 1% SDS (sodium dodecyl sulfate) at 37 ° C, and 1X-2X SSC (20X SSC = 3.0M at 50-55 ° C). Washing in NaCl / 0.3M trisodium citrate). Exemplary medium stringency hybridization conditions include 40 to 45% formamide at 27 ° C., 1.0 M NaCl, hybridization at 1% SDS, and washing at 0.5 × 1 × SSC at 55 ° C. to 60 ° C.
게다가, 가공 효소의 "효소적 활성" 단편을 암호화하는 폴리뉴클레오타이드를 추가로 고려한다. 본원에 사용한 바와 같은 "효소적으로 활성"은 가공 효소가 적합한 조건하에 정상적으로 작용함에 따라 기질을 변형시키는 데 있어 가공 효소와 실질적으로 동일한 생물학적 활성을 갖는 가공 효소의 폴리펩타이드 단편을 의미한다. In addition, polynucleotides encoding "enzymatically active" fragments of processing enzymes are further contemplated. As used herein, “enzymatically active” means a polypeptide fragment of a processing enzyme that has substantially the same biological activity as the processing enzyme in modifying the substrate as the processing enzyme normally functions under suitable conditions.
바람직한 양태에서, 본 발명의 폴리뉴클레오타이드는 서열번호 2, 9, 46 및 52로 제공된 바와 같은, α-아밀라제를 암호화하는 옥수수-최적화된 폴리뉴클레오타이드이다. 다른 바람직한 양태에서, 폴리뉴클레오타이드는 서열번호 4 및 25로 제공된 바와 같은, 풀룰라나제를 암호화하는 옥수수-최적화된 폴리뉴클레오타이드이다. 다른 바람직한 양태에서, 폴리뉴클레오타이드는 서열번호 6으로 제공된 바와 같은 α-글루코시다제를 암호화하는 옥수수-최적화된 폴리뉴클레오타이드이다. 다른 바람직한 폴리뉴클레오타이드는 서열번호 19, 21, 37, 39, 41 또는 43을 갖는 글루코스 이소머라제를 암호화하는 옥수수-최적화된 폴리뉴클레오타이드이다. 다른 양태에서는, 서열번호 46, 48 또는 50에 제시된 바와 같은 글루코아밀라제를 암호화하는 옥수수-최적화된 폴리뉴클레오타이드가 바람직하다. 추가로, 글루카나제/만나나제 융합 폴리펩타이드에 대한 옥수수-최적화된 폴리뉴클레오타이드는 서열번호 57로 제공되어 있다. 본 발명은 추가로 중간 또는 바람직하게는 낮은 엄중성 하이브리드화 조건하에 하이브리드화하고, 경우에 따라 아마도 α-아밀라제, 풀룰라나제, α-글루코시다제, 글루코즈 이소머라제, 글루코아밀라제, 글루카나제 또는 만나나제 활성을 암호화하는 이러한 폴리뉴클레오타이드의 상보체를 제공한다. In a preferred embodiment, the polynucleotides of the invention are corn-optimized polynucleotides encoding α-amylase, as provided in SEQ ID NOs: 2, 9, 46 and 52. In another preferred embodiment, the polynucleotides are corn-optimized polynucleotides encoding pullulanases, as provided in SEQ ID NOs: 4 and 25. In another preferred embodiment, the polynucleotide is a corn-optimized polynucleotide encoding an α-glucosidase as provided in SEQ ID NO: 6. Another preferred polynucleotide is a corn-optimized polynucleotide encoding glucose isomerase having SEQ ID NOs: 19, 21, 37, 39, 41 or 43. In another embodiment, corn-optimized polynucleotides encoding glucoamylases as set forth in SEQ ID NOs: 46, 48 or 50 are preferred. In addition, a corn-optimized polynucleotide for the glucanase / mannase fusion polypeptide is provided as SEQ ID NO: 57. The present invention further hybridizes under moderate or preferably low stringency hybridization conditions, optionally with α-amylase, pullulanase, α-glucosidase, glucose isomerase, glucoamylase, glucanase or The complement of such polynucleotides that encodes mannase activity is provided.
폴리뉴클레오타이드는 "핵산" 또는 "폴리핵산"과 상호교환적으로 사용할 수 있으며, 당, 인산 및 염기(퓨린 또는 피리미딘)를 함유하는 단량체(뉴클레오타이드)로 구성된 단일 나선 또는 이중나선형의 데옥시리보뉴클레오타이드 또는 리보뉴클레오타이드 및 이의 중합체를 지칭한다. 특별하게 제한되지 않는 한, 당해 용어는 참조 핵산과 유사한 결합 특성을 가지며 자연적으로 발생한 뉴클레오타이드와 유사한 방식으로 대사되는, 자연 뉴클레오타이드의 공지된 유사체를 함유하는 핵산을 포함한다. 달리 제시되지 않는 한, 특정 핵산 서열은 또한 보존적으로 변형된 이의 변이체(예를 들면, 축퇴 코돈 치환) 및 상보적 서열 및 함축적으로 제시된 서열을 함축적으로 포함한다. 특히, 축퇴 코돈 치환은 하나 이상의 선택된(또는 모든) 코돈의 3번째 위치를 혼합된-염기 및/또는 데옥시이노신 잔기로 치환한 서열을 제조함으로써 달성할 수 있다. Polynucleotides can be used interchangeably with "nucleic acid" or "polynucleic acid" and are single- or double-helix deoxyribonucleotides consisting of monomers (nucleotides) containing sugars, phosphoric acids and bases (purines or pyrimidines) Or ribonucleotides and polymers thereof. Unless specifically limited, the term includes nucleic acids containing known analogues of natural nucleotides that have similar binding properties as the reference nucleic acid and are metabolized in a manner similar to naturally occurring nucleotides. Unless otherwise indicated, certain nucleic acid sequences also implicitly include conservatively modified variants thereof (eg, degenerate codon substitutions) and complementary and implicitly shown sequences. In particular, degenerate codon substitutions can be achieved by preparing a sequence in which the third position of one or more selected (or all) codons is substituted with mixed-base and / or deoxyinosine residues.
"변이체" 또는 실질적으로 유사한 서열이 추가로 본원에 포함된다. 뉴클레오타이드 서열에 대하여, 변이체는 유전자 코드의 축퇴 때문에, 천연 단백질의 동일한 아미노산 서열을 암호화하는 이들 서열을 포함한다. 이들과 같은 자연적으로 발생한 대립 변이체는 널리 공지된 분자 생물학 기법(예를 들면, 폴리머라제 연쇄반응(PCR), 하이브리드화 기법 및 연결 조립 기법)으로 동정할 수 있다. 변이체 뉴클레오타이드 서열은 또한 예를 들면, 부위-지시적 돌연변이유발법을 사용하여 제조한, 천연 단백질을 암호화하는 합성적으로 유래한 뉴클레오타이드 서열, 및 아미노산 치환을 갖는 폴리펩타이드를 암호화하는 합성적으로 유래한 뉴클레오타이드를 포함한다. 일반적으로, 본 발명의 뉴클레오타이드 서열 변이체는 이들 부류 계열의 천연 뉴클레오타이드 서열에 대한 40%, 50%, 60% 이상, 바람직하게는 70%, 보다 바람직하게는 80%, 보다 더 바람직하게는 90%, 가장 바람직하게는 99% 및 단일 단위 동일성%를 가질 것이다. 예를 들면, 71%, 72%, 73% 등 내지 90% 이상의 부류. 변이체는 또한 동정된 유전자 단편에 상응하는 전장 유전자를 포함할 수 있다. “Variants” or substantially similar sequences are further included herein. For nucleotide sequences, variants include those sequences that encode the same amino acid sequence of a native protein because of the degeneracy of the genetic code. Naturally occurring allelic variants such as these can be identified by well known molecular biology techniques (eg, polymerase chain reaction (PCR), hybridization techniques, and linkage assembly techniques). Variant nucleotide sequences may also be used, for example, synthetically derived nucleotide sequences encoding natural proteins, prepared using site-directed mutagenesis, and synthetically derived nucleotides encoding polypeptides having amino acid substitutions. It includes. In general, the nucleotide sequence variants of the present invention are at least 40%, 50%, 60%, preferably 70%, more preferably 80%, even more preferably 90%, of these classes of native nucleotide sequences, Most preferably will have 99% and single unit identity. For example, 71%, 72%, 73%, etc. to 90% or more. Variants may also include full-length genes corresponding to the identified gene fragments.
조절 서열: 프로모터/시그날 서열/선별 마커Regulatory Sequences: Promoter / Signal Sequences / Selection Markers
본 발명의 가공 효소를 암호화하는 폴리뉴클레오타이스 서열을 예를 들면, 초호열성 효소를 식물 내의 특정한 부위로 표적화하는 국소화 시그날 또는 시그날 서열(폴리펩타이드의 N- 또는 C-말단의)을 암호화하는 폴리뉴클레오타이드에 작동적으로 연결할 수 있다. 이러한 표적의 예로는 액포, 세포질세망, 엽록체, 전분체, 전분 과립 또는 세포벽 또는 특정 조직, 예를 들면, 종자가 포함되지만, 이에 제한되지는 않는다. 식물체 내에서의 조직-특이적 또는 유도성 프로모터의 사용과 함께, 시그날 서열을 갖는 가공 효소를 암호화하는 폴리뉴클레오타이드의 발현은 식물 내의 국소화된 가공 효소의 높은 수준을 산출할 수 있다. 다수의 시그날 서열이 폴리뉴클레오타이드의 발현 또는 특정 부위 또는 특정 부위 외로의 표적화에 영향을 주는 것으로 공지되어 있다. 적합한 시그날 서열 및 표적화 프로모터가 당해 분야에 공지되어 있으며 본원에 제공된 것들이 포함되지만, 이에 제한되지는 않는다. Polynucleotide sequences encoding the processing enzymes of the invention, for example, polycoding the localizing signal or signal sequence (N- or C-terminus of the polypeptide) that targets the superthermophilic enzyme to a specific site within the plant. It can be operatively linked to nucleotides. Examples of such targets include, but are not limited to, vacuoles, cytoplasmic reticulum, chloroplasts, starch, starch granules or cell walls or specific tissues such as seeds. With the use of tissue-specific or inducible promoters in plants, the expression of polynucleotides encoding a processing enzyme with a signal sequence can yield high levels of localized processing enzymes in the plant. Many signal sequences are known to affect the expression of polynucleotides or targeting to or from specific sites. Suitable signal sequences and targeting promoters are known in the art and include, but are not limited to, those provided herein.
예를 들면, 특이적 조직 또는 기관 내에서의 발현이 목적되는 경우, 조직 특이적 프로모터를 사용할 수 있다. 대조적으로, 자극에 반응한 유전자 발현이 목적되는 경우, 유도성 프로모터가 조절 요소의 선택이다. 식물 세포 전체에 걸친 지속적 발현이 목적되는 경우, 구성성 프로모터를 사용한다. 핵심 프로모터 서열의 상류 및/또는 하류의 부가적 조절 서열을 형질전환 벡터의 발현 작제물에 포함시켜 형질전환된 식물에서의 이종성 뉴클레오타이드 서열의 다양한 수준의 발현을 유도할 수 있다. For example, where expression in specific tissues or organs is desired, tissue specific promoters can be used. In contrast, where gene expression in response to stimulation is desired, an inducible promoter is the choice of regulatory element. If sustained expression across plant cells is desired, a constitutive promoter is used. Additional regulatory sequences upstream and / or downstream of the core promoter sequence can be included in the expression construct of the transformation vector to induce the expression of various levels of heterologous nucleotide sequences in the transformed plant.
다수의 식물 프로모터가 각종 발현 특성으로 기술되어 왔다. 기술된 일부 구성성 프로모터의 예에는 벼 액틴 1(문헌[참조: Wang et al., Mol. Cell. Biol., 12:3399 (1992) ; 미국 특허 제5,641,876호]), CaMV 35S(문헌[참조: Odell et al., Nature, 313:810 (1985)]), CaMV 19S(문헌[참조: Lawton et al., 1987]), nos(문헌[참조: Ebert et al., 1987]), Adh(문헌[참조: Walker et al., 1987]), 슈크로즈 신타제(문헌[참조: Yang & Russell, 1990]) 및 유비퀴틴 프로모터가 포함된다.Many plant promoters have been described with various expression properties. Examples of some of the constitutive promoters described include rice actin 1 (Wang et al., Mol. Cell. Biol., 12: 3399 (1992); US Pat. No. 5,641,876), CaMV 35S (see, eg, Odell et al., Nature, 313: 810 (1985)), CaMV 19S (Lawton et al., 1987), nos (Ebert et al., 1987), Adh ( Walker et al., 1987), sucrose synthase (Yang & Russell, 1990) and ubiquitin promoters.
형질전환된 식물 내의 유전자의 조직-특이적 표적화에 사용하기 위한 벡터는 통상적으로 조직 특이적 프로모터를 포함할 것이며 또한 인핸서(enhancer) 서열과 같은 기타 조직 특이적 조절 요소를 포함할 수 있다. 특정 식물 조직 내에서의 특이적 또는 증강된 발현을 지시하는 프로모터가 본 개시내용의 견지에서 당해 분야의 숙련가에게 공지될 것이다. 이들에는 예를 들면, 녹색 조직에 특이적인 rbcS 프로모터, 뿌리 또는 상처입은 잎 조직에서 높은 활성을 갖는 ocs, nos 및 mas 프로모터, 뿌리에서의 증강된 발현을 지시하는 절두된 (-90 내지 +8) 35S 프로모터, 뿌리에서의 발현을 지시하는 α-튜불린 유전자 및 내배유에서의 발현을 지시하는 제인 저장 단백질 유전자로부터 유래한 프로모터가 포함딘다. Vectors for use in tissue-specific targeting of genes in transformed plants will typically include tissue specific promoters and may also include other tissue specific regulatory elements such as enhancer sequences. Promoters that direct specific or enhanced expression in specific plant tissues will be known to those of skill in the art in light of the present disclosure. These include, for example, the rbcS promoter specific for green tissue, the ocs, nos and mas promoters with high activity in root or injured leaf tissue, truncated (-90 to +8) to direct enhanced expression in the roots. Promoters derived from the 35S promoter, the α-tubulin gene that directs expression in roots and the zein storage protein gene that directs expression in endosperm.
조직 특이적 발현은 본질적으로 발현되는 유전자(모든 조직)를 유전자 생성물을 목적하지 않는 경우, 오직 이들 조직 내에서만 발현되는 안티센스 유전자와 함께 도입함으로써 기능적으로 수행할 수 있다. 예를 들면, 리파제를 암호화하는 유전자를 도입하여 컬리플라워 모자이크 바이러스로부터의 35S 프로모터를 사용하여 모든 조직 내에서 발현시킬 수 있다. 예를 들면, 제인 프로모터를 사용한, 옥수수 낟알 내의 리파제 유전자의 안티센스 전사체의 발현은 종자 내의 리파제 단백질의 축적을 막을 것이다. 따라서, 도입된 유전자에 의해 암호화된 단백질이 낟알을 제외한 모든 조직 내에 존재하게 될 것이다. Tissue specific expression can be functionally performed by introducing the genes that are essentially expressed (all tissues) together with antisense genes expressed only within these tissues, if the gene product is not desired. For example, genes encoding lipases can be introduced and expressed in all tissues using a 35S promoter from the cauliflower mosaic virus. For example, expression of the antisense transcript of the lipase gene in corn kernels using the zein promoter will prevent the accumulation of lipase protein in the seed. Thus, the protein encoded by the introduced gene will be present in all tissues except grain.
추가로, 식물 내의 수개의 조직-특이적 조절 유전자 및/또는 프로모터가 보고되어왔다. 일부 보고된 조직-특이적 유전자에는 종자 저장 단백질(예를 들면, 냅핀, 크루시페린, 베타-콘글라이시닌 및 파제올린) 제인 또는 오일 소체 단백질(예를 들면, 올레오신)을 암호화하는 유전자 또는 지방산 생합성을 수행하는 유전자(아실 담체 단백질, 스테아로일-ACP 탈포화효소 및 지방산 탈포화효소(fad 2-1)를 포함하는) 및 배아 발달 중 발현되는 기타 유전자(예를 들면, Bce4, 예를 들면, 문헌[유럽특허 제EP 255378호 및 Kridl et al., Seed Science Research, 1:209(1991)]을 참조한다)가 포함된다. 기술된 조직-특이적 프로모터의 예로는 렉틴(문헌[참조; Vodkin, Prog. Clin. Biol. Res., 138;87 (1983); Lindstrom et al., Der. Genet., 11:160(1990)]), 옥수수 알콜 탈수소화효소 I(문헌[참조: Vogel et al., 1989; Dennis et al., Nucleic Acids Res., 12:3983(1984)]), 옥수수 광 수확 복합체(문헌[참조: Simpson, 1986; Bansal et al., Proc. Natl. Acad. Sci. USA, 89:3654(1992)]), 옥수수 열충격 단백질(문헌[참조: Odell et al., 1985; Rochester et al., 1986]), 완두 소 아단위 RuBP 카복실라제(문헌[참조: Poulsen et al., 1986; Cashmore et al., 1983]), Ti 플라스미드 모노파인 신타제(문헌[참조: Langridge et al., 1989]), Ti 플라스미드 노팔린 신타제(Langridge et al., 1989]), 페튜니아 챌콘 이소머라제(문헌[참조: vanTuene et al., EMBO J/. 7:1257(1988)]), 콩 글라이신 농후 단백질 1(문헌[참조: Keller et al., Genes Dev., 3:1639(1989)]), 절두된 CaMV 35s(문헌[참조: Odell et al., Nature, 313:810(1985)]), 감자 파타틴(문헌[참조: Wenzler et al., Plant Mol. Biol.,13:347 (1989)]), 뿌리 세포(문헌[참조; Yamamoto et al., Nucleic Acids Res., 18:7449 (1990)]), 옥수수 제인(문헌[참조: Reina et al., Nucleic Acids Res., 18:6425 (1990); Kriz et al., Mol. Gen. Genet., 207:90(1987); Wandelt et al., Nucleic Acids Res., 17:2354(1989); Langridge et al., Cell,34:1015(1983); Reina et al., Nucleic Acids Res., 18:7449(1990)]), 글로불린-1(문헌[참조: Belanger et al., Genetics, 129:863(1991)]), α-튜불린, 캡(문헌[참조: Sullivan et al., Mol. Gen. Genet., 215:431(1989)]), PEPCase(문헌[참조: Hudspeth & Grula, 1989]), R 유전자 복합체-관련 프로모터(문헌[참조: Chandler et al., Plant Cell, 1:1175(1989)), 및 캘콘 신타제 프로모터(문헌[참조: Franken et al., EMBO J., 10:2605(1991)])가 포함된다. 종자-특이적 발현에 특히 유용한 프로모터는 완두 비실린 프로모터이다(문헌[참조: Czako et al., Mol. Gen. Genet., 235:33 (1992)]).(또한 본원에 참조로 인용되어 있는 미국 특허 제5,625,136호를 참조한다). 성숙한 잎에서의 발현에 유용한 다른 프로모터는 애기장대(Arabidopsis)로부터의 SAG와 같은 노화의 개시에서 발현되는(switch on) 프로모터이다(문헌[참조: Gan et al., Science, 270:1986(1995)].In addition, several tissue-specific regulatory genes and / or promoters in plants have been reported. Some reported tissue-specific genes include genes or fatty acids encoding seed storage proteins (eg, nappine, cruciferin, beta-conglycinin and pazeolin) zein or oil body proteins (eg, oleosin). Genes that perform biosynthesis (including acyl carrier proteins, stearoyl-ACP desaturase and fatty acid desaturase (fad 2-1)) and other genes expressed during embryonic development (eg, Bce4, e.g. See, eg, European Patent No. EP 255378 and Kridl et al., Seed Science Research, 1: 209 (1991). Examples of tissue-specific promoters described include lectins (Vodkin, Prog. Clin. Biol. Res., 138; 87 (1983); Lindstrom et al., Der. Genet., 11: 160 (1990) ], Corn alcohol dehydrogenase I (Vogel et al., 1989; Dennis et al., Nucleic Acids Res., 12: 3983 (1984)), corn light harvesting complex (Simpson , 1986; Bansal et al., Proc. Natl. Acad. Sci. USA, 89: 3654 (1992)), corn heat shock protein (Odell et al., 1985; Rochester et al., 1986) Pea subunit RuBP carboxylase (Poulsen et al., 1986; Cashmore et al., 1983), Ti plasmid monopine synthase (Langridge et al., 1989), Ti Plasmid nopalin synthase (Langridge et al., 1989), petunia challenge corn isomerase (vanTuene et al., EMBO J /. 7: 1257 (1988)), soybean glycine enriched protein 1 (documents) (Keller et al., Genes Dev., 3: 1639 (1989)), truncated CaMV 35s (Odell et al., Nature, 313: 810 (1985)), potato patatin (Wenzler et al., Plant Mol. Biol., 13: 347 (1989)), root cells (Yamamoto et al., Nucleic Acids Res., 18: 7449 (1990)), corn zein (Reina et al., Nucleic Acids Res., 18: 6425 (1990); Kriz et al., Mol. Gen. Genet., 207 : 90 (1987); Wandelt et al., Nucleic Acids Res., 17: 2354 (1989); Langridge et al., Cell, 34: 1015 (1983); Reina et al., Nucleic Acids Res., 18: 7449 (1990)), globulin-1 (Belanger et al., Genetics, 129: 863 (1991)), α-tubulin, cap ( Sullivan et al., Mol. Gen. Genet., 215: 431 (1989)), PEPCase (Hudspeth & Grula, 1989), R gene complex-related promoters (see: Chandler et al., Plant Cell, 1: 1175 (1989)), and the Calcon synthase promoter (Franken et al., EMBO J., 10: 2605 (1991)). Particularly useful promoters for seed-specific expression are the pea vicillin promoter (Czako et al., Mol. Gen. Genet., 235: 33 (1992)). (Also cited herein by reference) See US Pat. No. 5,625,136). Another promoter useful for expression in mature leaves is a promoter that is switched on at the onset of aging, such as SAG from Arabidopsis (Gan et al., Science, 270: 1986 (1995). ].
과실의 발달 전반에 걸쳐 최소한 성숙되기 시작할 때까지 개화 시기에 또는 개화 중에 발현되는 과실-특이적 프로모터의 부류가 본원에 참조로 인용되어 있는 문헌인 미국 특허 제4,943,674호에 논의되어 있다. 면 섬유에서 선택적으로 발현되는 cDNA 클론이 분리되었다(문헌[참조: John et al., Proc. Natl. Acad. Sci. USA, 89:5769(1992)]. 과실 성장 중 차등 발현을 나타내는 토마토로부터의 cDNA 클론이 분리 및 특성화되었다(문헌[참조: Mansson et al., Gen. Genet., 200: 356 (1985), Slater et al., Plant Mol. Biol., 5:137 (1985)]). 폴리갈락투로나제 유전자에 대한 프로모터가 과실 성숙 중에 활성화된다. 폴리갈락투로나제 유전자는 본원에 참조로 인용되어 있는 문헌인, 미국 특허 제4,535,060호, 미국 특허 제4,769,061호, 미국 특허 제4,801,590호, 및 미국 특허 제5,107,065호에 기술되어 있다. A class of fruit-specific promoters that are expressed at flowering time or during flowering, at least until they begin to mature throughout fruit development, is discussed in US Pat. No. 4,943,674, which is incorporated herein by reference. CDNA clones selectively expressed in cotton fibers were isolated (John et al., Proc. Natl. Acad. Sci. USA, 89: 5769 (1992)) from tomatoes exhibiting differential expression during fruit growth. cDNA clones were isolated and characterized (Mansson et al., Gen. Genet., 200: 356 (1985), Slater et al., Plant Mol. Biol., 5: 137 (1985)). The promoter for galacturonase gene is activated during fruit maturation The polygalacturonase gene is disclosed in US Pat. No. 4,535,060, US Pat. No. 4,769,061, US Pat. No. 4,801,590, which is incorporated herein by reference. And US Pat. No. 5,107,065.
조직-특이적 프로모터의 다른 예에는 잎(예를 들면, 곤충이 물어 뜯어서)에 상처를 입은 후 잎 세포에서, 덩이줄기(예를 들면, 파타틴 유전자 프로모터) 및 섬유 세포(발달적으로-조절된 섬유 세포 단백질의 예는 E6이다)에서의 발현을 지시하는 프로모터가 포함된다(문헌[참조: John et al., Proc. Natl. Acad. Sci. USA, 89: 5769 (1992)]. E6 유전자는 낮은 농도의 전사체가 잎, 배주 및 꽃에서 발견되기는 하지만, 섬유에서 가장 활성적이다.Other examples of tissue-specific promoters include leaf stems (eg, patatin gene promoters) and fibrous cells (developmentally-regulated) in leaf cells after injury to leaves (eg, by insect bites). Examples of fibroblast proteins that have been synthesized are E6, which includes a promoter directing expression (John et al., Proc. Natl. Acad. Sci. USA, 89: 5769 (1992)). Is the most active in fiber, although low concentrations of transcripts are found in leaves, embryos and flowers.
일부 "조직-특이적" 프로모터의 조직-특이성은 절대적이지 않을 수 있으며 디프테리아 독소 서열을 사용하여 당해 분야의 숙련가가 시험할 수 있다. 또한 상이한 조직-특이적 프로모터의 조합에 의해 "누출성(leaky)" 발현을 갖는 조직-특이적 발현을 성취할 수 있다(문헌[참조: Beals et al., Plant Cell, 9:1527(1997)]). 당해 분야의 숙련가는 기타 조직-특이적 프로모터를 분리할 수 있다(미국 특허 제5,589,379호를 참조한다).The tissue-specificity of some "tissue-specific" promoters may not be absolute and may be tested by one skilled in the art using diphtheria toxin sequences. It is also possible to achieve tissue-specific expression with “leaky” expression by a combination of different tissue-specific promoters (Beals et al., Plant Cell, 9: 1527 (1997). ]). One skilled in the art can isolate other tissue-specific promoters (see US Pat. No. 5,589,379).
한 양태에서, α-아밀라제와 같은 다당류 가수분해 유전자로부터의 생성물의 방향을 세포질 보다 아포플라스트와 같은 특정 기관으로 표적화할 수 있다. 이는 단백질의 아포플라스트-특이적 표적화를 부여하는 옥수수 γ-제인 N-말단 시그날 서열(서열번호 17)의 사용으로 예시된다. 단백질 또는 효소를 특이적 구획으로 지시하는 것은 효소를 기질과 접촉하지 않도록 국소화시킬 수 있게 할 것이다. 이러한 방식에서, 효소의 효소 작용은 효소가 이의 기질과 접촉할 때까지 발생하지 않을 것이다. 효소는 효소를 함유하는 식물 세포 또는 기관의 물리적 통일성을 파괴하기 위한 제분(세포 완결성의 물리적 파괴) 또는 세포 또는 식물 조직의 가열의 과정에 의해 이의 기질과 접촉할 수 있다. 예를 들면, 중온성 전분-가수분해 효소는 아포플라스트 또는 세포질 세망으로 표적화될 수 있으며 따라서 전분체 내의 전분 과립과 접촉하지 않게 된다. 곡립의 제분은 곡립의 완결성을 파괴할 것이며 이어서 전분 가수분해 효소가 전분 과립과 접촉하게 될 것이다. 이러한 방식으로, 효소 및 이의 기질의 동시-국소화의 잠정적인 부정적 효과를 회피할 수 있다. In one embodiment, the direction of the product from a polysaccharide hydrolysis gene such as α-amylase can be targeted to specific organs such as apoplasts rather than the cytoplasm. This is exemplified by the use of the N-terminal signal sequence (SEQ ID NO: 17), a corn γ-agent that confers apoplast-specific targeting of the protein. Directing proteins or enzymes to specific compartments will allow localization of the enzymes from contact with the substrate. In this way, the enzyme's enzymatic action will not occur until the enzyme comes into contact with its substrate. An enzyme may be contacted with its substrate by a process of milling (physical disruption of cell integrity) or heating of the cell or plant tissue to destroy the physical unity of the plant cell or organ containing the enzyme. For example, mesophilic starch-hydrolase may be targeted to apoplasts or cytoplasmic reticulum and thus not in contact with starch granules in starch. Milling of the grains will destroy the integrity of the grains and the starch hydrolase will then come into contact with the starch granules. In this way, the potential negative effects of co-localization of enzymes and their substrates can be avoided.
다른 양태에서, 조직-특이적 프로모터는 옥수수 γ-제인 프로모터(서열번호 12로 예시되어 있는) 또는 옥수수 ADP-gpp 프로모터(5' 비해독 및 인트론 서열을 포함하는, 서열번호 11로 예시되어 있는) 또는 Q 단백질 프로모터(서열번호 98로 예시되어 있는) 또는 벼 플루텔린 1 프로모터(서열번호 67로 예시되어 있는)와 같은 내배유-특이적 프로모터를 포함한다. 따라서, 본 발명은 서열번호 11, 12, 67 또는 98을 포함하는 프로모터를 포함하는 분리된 폴리뉴클레오타이드, 낮은 엄중성 하이브리드화 조건하에 이의 상보체와 하이브리드화하는 폴리뉴클레오타이드 또는 예를 들면, 10% 이상, 바람직하게는 50% 이상의 서열번호 11, 12, 67 또는 98을 갖는 프로모터의 활성을 갖는 이의 단편을 포함한다. In another embodiment, the tissue-specific promoter is a corn γ-zein promoter (illustrated as SEQ ID NO: 12) or a maize ADP-gpp promoter (illustrated in SEQ ID NO: 11, including 5 'non-toxin and intron sequences). Or endosperm-specific promoters such as the Q protein promoter (illustrated by SEQ ID NO: 98) or the
본 발명의 다른 양태에서, 폴리뉴클레오타이드는 엽록체(전분체) 통과 펩타이드(CTP) 및 예를 들면, waxy 융전자로부터의 전분 결합 도메인에 작동적으로 연결된 초호열성 가공 효소를 암호화한다. 당해 양태의 예시적 폴리뉴클레오타이드는 서열번호 10(waxy로부터의 전분 결합 도메인에 연결된 α-아밀라제)을 암호화한다. 다른 예시적 폴리뉴클레오타이드는 효소를 세포질 세망으로 표적화하고 아포플라스트로 분비하는 시그날 서열에 연결된 초호열성 가공 효소(각각 α-아밀라제, α-글루코시다제, 글루코즈 이소머라제에 작동적으로 연결된 옥수수 γ-제인으로부터의 N-말단 서열을 포함하는, 서열번호 13, 27 또는 30을 암호화하는 폴리뉴클레오타이드로 예시된), 세포질세망에 효소를 유지시키는 시그날 서열에 연결된 초호열성 가공 효소{SEKDEL에 작동적으로 연결된 초호열성 효소(여기서, 효소는 α-아밀라제, malA α-글루코시다제, 티. 마리티마(T. maritima) 글루코즈 이소머라제, 티. 니아폴리타나(T. neapolitana) 글루코즈 이소머라제이다)에 작동적으로 연결된 옥수수 γ-제인으로부터의 N-말단 서열을 포함하는, 서열번호 14, 26, 28, 29, 33, 34, 35 또는 36을 암호화하는 폴리뉴클레오타이드로 예시된), 효소를 전분체로 표적화하는 N-말단 서열에 연결된 초호열성 가공 효소(α-아밀라제에 작동적으로 연결된 waxy로부터의 N-말단 전분체 표적화 서열을 포함하는, 서열번호 15를 암호화하는 폴리뉴클레오타이드로 예시된), 효소를 전분 과립으로 표적화하는 초호열성 융합 폴리펩타이드(waxy 전분 결합 도메인을 포함하는 α-아밀라제/waxy 융합 폴리펩타이드에 작동적으로 연결된 waxy로부터의 N-말단 전분체 표적화 서열을 포함하는, 서열번호 16을 암호화하는 폴리뉴클레오타이드로 예시된), ER 체류 시그날에 연결된 초호열성 가공 효소(서열번호 38 및 39를 암호화하는 폴리뉴클레오타이드로 예시된)를 암호화한다. 추가로, 초호열성 가공 효소는 아미노산 서열(서열번호 53)을 갖는 생전분 결합 부위에 연결될 수 있으며, 여기서, 가공 효소를 암호화하는 폴리뉴클레오타이드는 당해 결합 부위를 암호화하는 옥수수-최적화된 핵산 서열(서열번호 54)에 연결된다. In another embodiment of the invention, the polynucleotides encode a superthermophilic processing enzyme operably linked to the chloroplast (starch) transit peptide (CTP) and, for example, a starch binding domain from a waxy fusion. Exemplary polynucleotides of this embodiment encode SEQ ID NO: 10 (α-amylase linked to the starch binding domain from waxy). Another exemplary polynucleotide is a hyperthermic processing enzyme (alpha-amylase, α-glucosidase, corn isomerase, respectively) operatively linked to a signal sequence that targets the enzyme to cytoplasmic reticulum and secretes into apoplasts. A super thermophilic enzyme (operated to SEKDEL) linked to a signal sequence that retains the enzyme in the cytoplasmic network, exemplified by a polynucleotide encoding SEQ ID NO: 13, 27 or 30, including the N-terminal sequence from Jane Super thermophilic enzymes, wherein the enzymes are α-amylase, malA α-glucosidase, T. maritima glucose isomerase, T. neapolitana glucose isomerase Polynucleic encoding SEQ ID NO: 14, 26, 28, 29, 33, 34, 35 or 36, comprising an N-terminal sequence from an operably linked corn γ-Zane Coding for SEQ ID NO: 15, which includes an N-terminal starch targeting sequence from waxy operably linked to an α-amylase, linked to an N-terminal sequence that targets the enzyme to a starch N-terminal starch targeting from waxy operably linked to an α-amylase / waxy fusion polypeptide comprising a starch binding domain that targets the enzyme to starch granules, Encoding a polynucleotide encoding SEQ ID NO: 16, comprising a sequence), a super thermophilic processing enzyme (exemplified as a polynucleotide encoding SEQ ID NOs: 38 and 39) linked to an ER retention signal. In addition, the superthermophilic processing enzyme may be linked to a live starch binding site having an amino acid sequence (SEQ ID NO: 53), wherein the polynucleotide encoding the processing enzyme is a corn-optimized nucleic acid sequence (sequence that encodes the binding site). Number 54).
수개의 유도성 프로모터가 보고되어 있다. 많은 프로모터들이 문헌[참조: Gatz, in Current Opinion in Biotechnology,7:168 (1996) 및 Gatz, C. , Annu. Rev. Plant Physiol. Plant Mol. Biol., 48: 89 (1997)]의 개관에 기술되어 있다. 예로는 테트라사이클린 억제자 시스템, Lac 억제자 시스템, 구리-유도성 시스템, 살리실레이트-유도성 시스템(예를 들면, PR1a 시스템), 글루코코르티코이드-유도성(문헌[참조; Aoyama T. et al., N-H Plant Journal, 11:605 (1997)]) 및 엑디손-유도성 시스템이 포함된다. 다른 유도성 프로모터에는 ABA- 및 팽압-유도성 프로모터, 옥신-결합 단백질 유전자의 프로모터(문헌[참조: Schwob et al., Plant J., 4: 423 (1993)]), UDP 글루코즈 플라보노이드 글라이코실-프랜스퍼라제 유전자 프로모터(문헌[참조: Ralston et al., Genetics, 119:185 (1988)]), MPI 프로테이나제 억제자 프로모터(문헌[참조: Cordero et al., Plant J., 6:141 (1994)] 및 글라이세르알데하이드-3-포스페이트 탈수소화효소 유전자 프로모터(문헌[참조: Kohler et al., Plant Mol. Biol., 29;1293 (1995) ; Quigley et al., J. Mol. Evol. , 29: 412 (1989) ; Martinez et al., J. Mol. Biol., 208: 551 (1989)])이 포함된다. 또한 벤젠 설폰아미드-유도성(미국 특허 5,364,780호) 및 알콜-유도성(국제공개공보 제WO 97/06269호 및 제WO 97/06268호) 시스템 및 글루타티온 S-트랜스퍼라제 프로모터가 포함된다. Several inducible promoters have been reported. Many promoters are described in Gatz, in Current Opinion in Biotechnology, 7: 168 (1996) and Gatz, C., Annu. Rev. Plant Physiol. Plant Mol. Biol., 48: 89 (1997). Examples include tetracycline inhibitor systems, Lac inhibitor systems, copper-induced systems, salicylate-induced systems (eg, PR1a systems), glucocorticoid-induced (see Aoyama T. et al. , NH Plant Journal, 11: 605 (1997)) and ecdysone-induced systems. Other inducible promoters include ABA- and swell-induced promoters, promoters of auxin-binding protein genes (Schwob et al., Plant J., 4: 423 (1993)), UDP glucose flavonoid glycosyls -Transferase gene promoter (Ralston et al., Genetics, 119: 185 (1988)), MPI proteinase inhibitor promoter (see Cordero et al., Plant J., 6) : 141 (1994)] and glyceraldehyde-3-phosphate dehydrogenase gene promoter (Kohler et al., Plant Mol. Biol., 29; 1293 (1995); Quigley et al., J. Mol. Evol., 29: 412 (1989); Martinez et al., J. Mol. Biol., 208: 551 (1989)), and also benzene sulfonamide-derived (US Pat. No. 5,364,780) and Alcohol-derived (WO 97/06269 and WO 97/06268) systems and glutathione S-transferase promoters.
다른 연구는 증가된 염도, 가뭄, 병원체 및 상처와 같은 환경 스트레스 또는 자극에 반응하여 유도적으로 조절되는 유전자에 초점을 맞춰 왔다(문헌[참조: Graham et al., J. Biol. Chem. , 260: 6555 (1985) ; Graham et al., J. Biol. Chem., 260: 6561 (1985), Smith et al., Planta, 168: 94 (1986)]). 메탈로카복시펩티다아제-억제자 단백질의 축적이 상처 입은 감자 식물의 잎에서 보고되었다(문헌[참조: Graham et al., Biochem. Biophys. Res. Comm.,101:1164 (1981)]). 다른 식물 유전자가 메틸 쟈스모네이트, 유발자, 열-충격, 혐기성 스트레스 또는 제초제 독성완화제에 의해 유도된다고 보고되어 왔다. Other studies have focused on genes that are inductively regulated in response to environmental stress or stimulation such as increased salinity, drought, pathogens and wounds (Graham et al., J. Biol. Chem., 260). : 6555 (1985); Graham et al., J. Biol. Chem., 260: 6561 (1985), Smith et al., Planta, 168: 94 (1986)]. Accumulation of metallocarboxypeptidase-inhibitor proteins has been reported in the leaves of wounded potato plants (Graham et al., Biochem. Biophys. Res. Comm., 101: 1164 (1981)). Other plant genes have been reported to be induced by methyl jasmonate, inducers, heat-shock, anaerobic stress or herbicides.
키메라성 트랜스(trans) 작용성 바이러스 복제 단백질의 조절된 발현을 예를 들면, Cre-매개유전자 활성화와 같은 다른 유전자 기작으로 추가로 조절할 수 있다(문헌[참조: Odell et al., Mol. Gen. Genet., 113:369(1990)]). 따라서, 프로모터와 프로모터로부터의 키메라 복제의 발현을 차단하는 복제 단백질 암호화 서열 사이의 lox 위치에 의해 결합된 3' 조절 서열을 포함하는 DNA 단편을 Cre-매개된 절단으로 제거할 수 있으며 트랜스-작용성 복제 유전자의 발현을 초래한다. 이러한 경우, 키메라성 Cre 유전자, 키메라성 트랜스-작용성 복제 유전자 또는 이 둘 다를 조직- 및 발달-특이적 또는 유도성 프로모터의 제어 하에 둘 수 있다. 대안적 유전자 기작은 tRNA 억제자 유전자의 사용이다. 예를 들면, tRAN 억제자 유전자의 조적된 발현은 적합한 종결 코돈을 포함하는 트랜스-작용성 복제 단백질 암호화 서열의 발현을 조건적으로 제어할 수 있다(문헌[참조: Ulmasov et al., Plant Mol. Biol., 35:417(1997)]). 다시, 키메라성 tRNA 억제자 유전자 또는 키메라성 트랜스-작용성 복제 유전자, 또는 이 둘 다 조직- 및 발달-특이적 또는 유도성 프로모터의 제어 하에 둘 수 있다. The regulated expression of chimeric trans agonistic viral replication proteins can be further regulated by other gene mechanisms such as, for example, Cre-mediated gene activation (Odell et al., Mol. Gen. Genet., 113: 369 (1990)). Thus, a Cre-mediated cleavage of a DNA fragment comprising a 3 'regulatory sequence bound by a lox position between a promoter and a replicating protein coding sequence that blocks expression of chimeric replication from the promoter can be eliminated by trans-functionality. Results in expression of the replicating gene. In such cases, the chimeric Cre gene, chimeric trans-acting replication gene or both can be placed under the control of tissue- and development-specific or inducible promoters. An alternative gene mechanism is the use of tRNA suppressor genes. For example, coordinated expression of a tRAN inhibitor gene can conditionally control the expression of a trans-acting replication protein coding sequence comprising a suitable stop codon (see Ulmasov et al., Plant Mol. Biol., 35: 417 (1997)]. Again, a chimeric tRNA inhibitor gene or chimeric trans-acting replication gene, or both, can be placed under control of a tissue- and development-specific or inducible promoter.
바람직하게는, 다중세포 개체의 경우, 프로모터는 특정 조직, 기관 또는 발달 단계에 특이적일 수 있다. 이러한 프로모터의 예에는 제아 메이스(Zea mays), ADP-gpp 및 제아 메이스 γ-제인 프로모터 및 제아 메이스 글로불린 프로모터가 포함되지만, 이에 제한되지는 않는다. Preferably, for multicellular individuals, the promoter may be specific for a particular tissue, organ or stage of development. Examples of such promoters include, but are not limited to, Zea mays , ADP-gpp and Zea mays γ-zein promoters and Zea mays globulin promoters.
형질전환된 식물 내에서의 유전자 발현은 식물의 발달 중 오직 특정한 시기에만 바람직할 수 있다. 발달상의 적정 시기는 흔히 조직 특이적 유전자 발현과 관련되어 있다. 예를 들면, 제인 저장 단백질의 발현은 수분 후 약 15일에 내배유에서 개시된다. Gene expression in transformed plants may be desirable only at certain times during plant development. Developmental timing is often associated with tissue specific gene expression. For example, expression of the Jane storage protein is initiated in endosperm about 15 days after pollination.
부가적으로, 벡터를 작제하여 형질전환된 식물의 세포 내로의 특이적 유전자 생성물의 세포내 표적화 및 단백질의 세포외 환경으로의 지시에 사용할 수 있다. 이는 일반적으로 전이 또는 시그날 펩타이드 서열을 암호화하는 DNA 서열을 특정 유전자의 암호화 서열에 결합함으로써 달성될 것이다. 수득된 전이 또는 시그날 펩타이드는 단백질을 각각 특정한 세포내 또는 세포외 목적지로 통과시킬 것이고, 이어서 해독후 제거될 것이다. 전이 또는 시그날 펩타이드는 세포내 막, 예를 들면, 액포, 소포, 플라스티드 및 미토콘드리아 막을 통한 단백질 수송을 촉진시킴으로써 작용하는 반면, 시그날 펩타이드는 단백질을 세포외 막을 통해 지시한다. Additionally, vectors can be constructed and used for intracellular targeting of specific gene products into cells of transformed plants and for directing the protein to the extracellular environment. This will generally be accomplished by binding the DNA sequence encoding the transfer or signal peptide sequence to the coding sequence of a particular gene. The resulting transition or signal peptides will pass the protein to specific intracellular or extracellular destinations, respectively, and then be removed after translation. Metastasis or signal peptides act by promoting protein transport through intracellular membranes such as vacuoles, vesicles, plastids and mitochondrial membranes, while signal peptides direct proteins through extracellular membranes.
세포질 세망으로의 표적화 및 아포플라스트로의 분비를 위한 옥수수 γ-제인 N-말단 시그날 서열과 같은 시그날 서열을 본 발명에 따라 초호열성 가공 효소를 암호화하는 폴리뉴클레오타이드에 작동적으로 연결할 수 있다(문헌[참조: Torrent et al., 1997]). 예를 들면, 서열번호 13, 27 및 30은 옥수수 γ-제인 단백질로부터의 N-말단 서열에 작동적으로 연결된 초호열성 효소를 암호화하는 폴리뉴클레오타이드에 제공한다. 다른 시그날 서열은 세포질 세망 내의 폴리펩타이드의 체류를 위한 아미노산 서열 SEKDEL이다(문헌[참조: Munro and Pelham, 1987]). 예를 들면, 서열번호 14, 25, 28, 29, 33, 34, 35 또는 36을 암호화하는 폴리뉴클레오타이드는 SEKDEL에 작동적으로 연결된 가공 효소에 작동적으로 연결된 옥수수 γ-제인으로부터의 N-말단 서열을 포함한다. 폴리펩타이드는 waxy 전분체 표적화 펩타이드(문헌[참조: Klosgen et al., 1986]) 또는 전분 과립에 융합함으로써 전분체에 표적화될 수 있다. 예를 들면, 초호열성 가공 효소를 암호화하는 폴리뉴클레오타이드는 엽록체(전분체) 전이 효소(CTP) 및 전분 결합 도메인(예를 들면, waxy 유전자로부터의)에 작동적으로 연결될 수 있다. 서열번호 10은 waxy로부터의 전분 결합 도메인에 연결된 α-아밀라제를 예시한다. 서열번호 15는 α-아밀라제에 작동적으로 연결된 waxy로부터의 N-말단 서열 전분체 표적화 서열을 예시한다. 추가로, 가공 효소를 암호화하는 폴리뉴클레오타이드를 waxy 전분 결합 도메인을 사용하여 전분 과립을 표적화하기 위해 융합시킬 수 있다. 예를 들면, 서열번호 16은 waxy 전분 결합 도메인을 포함하는 α-아밀라제/waxy 융합 폴리펩타이드에 작동적으로 연결된 waxy로부터 N-말단 전분체 표적화 서열을 포함하는 융합 폴리펩타이드를 예시한다. Signal sequences, such as the corn γ-zein N-terminal signal sequence for targeting to cytoplasmic reticulum and secretion of apoplasts, can be operably linked to polynucleotides encoding superthermophilic processing enzymes according to the present invention. See Torrent et al., 1997]. For example, SEQ ID NOs: 13, 27 and 30 provide for a polynucleotide encoding a super thermophilic enzyme operably linked to an N-terminal sequence from a corn γ-zein protein. Another signal sequence is the amino acid sequence SEKDEL for retention of polypeptides in the cytoplasmic reticulum (Munro and Pelham, 1987). For example, a polynucleotide encoding SEQ ID NO: 14, 25, 28, 29, 33, 34, 35 or 36 may be an N-terminal sequence from corn γ-Zane operably linked to a processing enzyme operably linked to SEKDEL. It includes. Polypeptides can be targeted to starches by fusing to waxy starch targeting peptides (Klosgen et al., 1986) or starch granules. For example, polynucleotides encoding superthermophilic processing enzymes can be operatively linked to chloroplast (starch) transferase (CTP) and starch binding domains (eg, from the waxy gene). SEQ ID NO: 10 illustrates an α-amylase linked to a starch binding domain from waxy. SEQ ID NO: 15 illustrates an N-terminal sequence starch targeting sequence from waxy operably linked to α-amylase. In addition, polynucleotides encoding processing enzymes can be fused to target starch granules using waxy starch binding domains. For example, SEQ ID NO: 16 illustrates a fusion polypeptide comprising an N-terminal starch targeting sequence from waxy operably linked to an α-amylase / waxy fusion polypeptide comprising a waxy starch binding domain.
가공 시그날 외에 본 발명의 폴리펩타이드는 당해 분야에 공지된 기타 조절 서열을 추가로 포함할 수 있다. "조절 서열" 및 "적합한 조절 서열"은 각각 암호화 서열의 상류(5' 비-암호화 서열), 암호화 서열의 내부 또는 하류(3' 비-암호화 서열)에 위치하고, 전사, RNA 가공 또는 안정화, 또는 관련 암호화 서열의 해독에 영향을 주는 뉴클레오타이드 서열을 지칭한다. 조절 서열은 인핸서, 프로모터, 해독 리더 서열, 인트론 및 폴리아데닐화 시그날 서열을 포함한다. 이들은 천연 및 합성 서열 및 합성 및 천연 서열의 조합일 수 있는 서열을 포함한다.In addition to the processing signals, the polypeptides of the present invention may further comprise other regulatory sequences known in the art. "Regulatory sequence" and "suitable regulatory sequence" are each located upstream of the coding sequence (5 'non-coding sequence), inside or downstream of the coding sequence (3' non-coding sequence), and transcription, RNA processing or stabilization, or It refers to a nucleotide sequence that affects the translation of the relevant coding sequence. Regulatory sequences include enhancers, promoters, translation leader sequences, introns, and polyadenylation signal sequences. These include sequences that can be natural and synthetic sequences and combinations of synthetic and natural sequences.
당해 분야에 널리 공지된 선별 마커를 또한 본 발명에 사용하여 형질전환된 식물 및 식물 조직을 선별할 수 있다. 선별 또는 감별 마커 유전자 또는 이 외에, 관심 있는 발현가능한 유전자를 사용하는 것이 바람직할 수 있다. "마커 유전자"는 마커 유전자를 발현하는 세포에 뚜렷한 표현형을 부여하여, 이러한 형질전환 세포가 마커를 갖지 않은 세포와 구별되게 하는 유전자이다. 이러한 유전자는 마커가 화학적 방법, 즉, 선택성 제제(예를 들면, 제초제, 항생제 등)의 사용을 통해 선별될 수 있는 형질을 부여하는지의 여부, 또는 단순히 관찰 또는 시험, 즉, 감별(예를 들면, R-좌 형질)에 의해 동정될 수 있는 형질인지의 여부에 따라, 선별 또는 감별 마커를 암호화할 수 있다. 물론, 적합한 마커 유전자의 많은 예가 당해 분야에 공지되어 있으며 본 발명의 실행에 사용될 수 있다. Selection markers well known in the art can also be used in the present invention to select transformed plants and plant tissues. It may be desirable to use selectable or differential marker genes or in addition to expressable genes of interest. A "marker gene" is a gene that gives a distinct phenotype to cells expressing a marker gene, so that these transformed cells are distinguished from cells without markers. Such genes may be used to determine whether the marker confers traits that can be selected through chemical methods, i.e. the use of selective agents (e.g., herbicides, antibiotics, etc.), or simply observed or tested, i.e. Depending on whether or not the trait can be identified by the R-left trait), a selection or differential marker can be encoded. Of course, many examples of suitable marker genes are known in the art and can be used in the practice of the present invention.
용어 선별 또는 감별 마커 유전자 내에 포함되는 것은 또한 이들의 분비가 형질전환 세포에 대한 동정 또는 선별 방법으로 검출될 수 있는 "선별 마커"를 암호화하는 유전자이다. 예에는 항체 상호작용에 의해 동정될 수 있는 분비가능한 항원 또는 심지어, 이들의 촉매 활성에 의해 검출될 수 있는 분비가능한 효소를 암호화는 마커가 포함된다. 분비가능한 단백질은 예를 들면, ELISA에 의해 검출가능한 소형 확산성 단백질; 세포외 용액에서 검출가능한 소형 활성 효소(예를 들면, α-아밀라제, β-락타마제, 포스피노트리신 아세틸트랜스퍼라제); 및 세포 벽에 삽입되거나 포획되는 단백질(예를 들면, 익스텐신 또는 담배 PR-S의 발현 단위에서 발견되는 바와 같은 리더 서열을 포함하는 단백질)을 포함하는, 다수의 부류에 속한다.Included within the term selection or differentiation marker gene are also genes encoding "selection markers" whose secretion can be detected by identification or selection methods for transforming cells. Examples include markers encoding secretable antigens that can be identified by antibody interaction or even secretable enzymes that can be detected by their catalytic activity. Secretable proteins include, for example, small diffuse proteins detectable by ELISA; Small active enzymes detectable in extracellular solution (eg, α-amylase, β-lactamase, phosphinothricin acetyltransferase); And proteins that are inserted or captured in the cell wall (eg, proteins comprising leader sequences as found in expression units of extensin or tobacco PR-S).
선별 분비가능한 마커를 고려하여, 세포 벽에 격리되며, 고유의 에피토프를 포함하는 단백질을 암호화하는 유전자의 사용이 특히 유리하다고 사료된다. 이러한 분비된 항원 마커는 이론적으로 식물 조직 내의 낮은 배경을 제공할 에피토프 서열, 효율적인 발현 및 원형질막을 통한 표적화을 부여하고, 세포벽에 결합하며 게다가 항체에 접근가능한 단백질을 제조할 프로모터-리더 서열을 사용할 것이다. 고유한 에피토프를 포함하도록 변형시킨 정상적으로 분비되는 벽 단백질은 이러한 모든 필요조건을 만족시킬 것이다. In view of selectable secretory markers, it is considered particularly advantageous to use genes that are sequestered to the cell wall and that encode proteins comprising native epitopes. Such secreted antigen markers will theoretically use epitope sequences that will provide a low background in plant tissue, efficient expression and targeting through the plasma membrane, and will use promoter-leader sequences to make proteins that bind to the cell wall and moreover are accessible to antibodies. Normally secreted wall proteins modified to contain unique epitopes will meet all of these requirements.
이러한 방법으로의 변형에 적합한 단백질의 한 예는 익스텐신 또는 하이드록시프롤린 풍부 당단백질(HPRG)이다. 예를 들면, 옥수수 HPRG(문헌[참조: Steifel et al., The Plant Cell, 2:785(1990)]) 분자는 분자 생물학, 발현 및 단백질 구조적 관점에서 잘 특징화되어 있다. 그러나, 각종 익스텐신 및/또는 글라이신-농후 벽 단백질 중 어느 하나(문헌[참조: Keller et al., EMBO Journal, 8:1309(1989)])를 항원 부위의 첨가에 의해 변형시켜 감벽 마커를 제조할 수 있었다. One example of a protein suitable for modification in this way is extensin or hydroxyproline rich glycoprotein (HPRG). For example, maize HPRG (Steifel et al., The Plant Cell, 2: 785 (1990)) molecules are well characterized in terms of molecular biology, expression and protein structure. However, any one of a variety of extensin and / or glycine-rich wall proteins (Keller et al., EMBO Journal, 8: 1309 (1989)) was modified by addition of antigenic sites to produce wall markers. Could be manufactured.
a. 선별 마커a. Screening marker
본 발명과 관련지어 사용 가능한 선별 마커에는 카나마이신 내성을 암호화하며 카나마이신, G418 등을 사용하기 위해 선별할 수 있는 neo 또는 ntpII 유전자(문헌[참조: Potrykus et al., Mol. Gen. Genet., 199:183(1985)]); 제초제 포스피노트리신에 내성을 부여하는 bar 유전자; 변형된 EPSP 신타제 단백질을 암호화하여 글라이포세이트 내성을 부여하는 유전자(문헌[참조: Hinchee et al., Biotech., 6:915(1988)]); 브로목시닐에 내성을 부여하는 클레브실라 오재내(Klebsiella ozaenae)로부터의 bxn과 같은 니트릴라제 유전자(문헌[참조: Stalker et al., Science, 242:419 (1988)]); 이미다졸리논, 설포닐유레아 또는 기타 ALS-억제 화학물질에 내성을 부여하는 돌연변이체 아세토락테이트 신타제 유전자(ALS)(문헌[참조: 유럽 특허 출원 제154,204호, 1985); 메토트레세이트-내성 DHFR 유전자(문헌[참조: Thillet et al., J. Biol. Chem., 263:12500 (1988)]); 제초제 달라폰에 내성을 부여하는 달라폰 탈할로겐효소 유전자; 포스포만노즈 이소머라제(PMI) 유전자; 5-메틸 트립토판에 대한 내성을 부여하는 돌연변이된 안트라닐레이트 신타제 유전자; 항생제 하이그로마이신에 대한 내성을 부여하는 hph 유전자; 또는 만노즈를 대사할 수 있는 능력을 제공하는 만노즈-6-포스페이트 이소머라제 유전자(또한 본원에서 포스포만노즈 이소머라제 유전자로도 지칭됨)(미국 특허 제5,767,378호 및 제5,994,629호)가 포함되지만, 이에 제한되지는 않는다. 당해 분야의 숙련가는 본 발명의 사용에 적합한 선별 마커 유전자를 선택할 수 있다. 돌연변이체 EPSP 신타제 유전자를 사용하는 경우, 적합한 엽록체 전이 펩타이드, CTP의 혼입을 통해 부가적 이익이 실현될 수 있다(유럽 특허 출원 제0,218,571호, 1987).Selectable markers that can be used in connection with the present invention include neo or ntpII genes that encode kanamycin resistance and can be screened for use with kanamycin, G418 and the like (Potrykus et al., Mol. Gen. Genet., 199: 183 (1985)); Bar gene that confers resistance to herbicide phosphinothricin; Genes encoding modified EPSP synthase proteins to confer glyphosate resistance (Hinchee et al., Biotech., 6: 915 (1988)); Nitrile genes such as bxn from Klebsiella ozaenae that confer resistance to bromoxynil (Stalker et al., Science, 242: 419 (1988)); Mutant acetolactate synthase gene (ALS) that confers resistance to imidazolinone, sulfonylurea or other ALS-inhibiting chemicals (European Patent Application No. 154,204, 1985); Methotrexate-resistant DHFR gene (Thillet et al., J. Biol. Chem., 263: 12500 (1988)); The dalapon dehalogenase gene that confers resistance to the herbicide dalapon; Phosphomannose isomerase (PMI) gene; Mutated anthranilate synthase genes that confer resistance to 5-methyl tryptophan; Hph gene conferring resistance to antibiotic hygromycin; Or the mannose-6-phosphate isomerase gene (also referred to herein as the phosphomannose isomerase gene) which provides the ability to metabolize mannose (US Pat. Nos. 5,767,378 and 5,994,629) Included, but not limited to. One skilled in the art can select a selection marker gene suitable for use in the present invention. When using the mutant EPSP synthase gene, additional benefits can be realized through the incorporation of a suitable chloroplast transfer peptide, CTP (European Patent Application No. 0,218,571, 1987).
형질전환체를 선별하기 위해 시스템 내에 사용할 수 있는 선별 마커 유전자의 예시적 양태는 효소 포스피노트리신 아세틸트랜스퍼라제를 암호화하는 유전자{예를 들면, 스트렙토마이세스 하이드로스코피쿠스(Streptomyces hygroscopicus)로부터의 bar 유전자 또는 스트렙토마이세스 비리도크로모젠스(Streptomyces viridochromogenes)로부터의 pat 유전자}이다. 효소 포스피노트리신 아세틸 트랜스퍼라제(PAT)는 제초제 바이알라포스, 포스피노트리신(PPT) 내의 활성 성분을 불활성화시킨다. PPT는 글루타민 합성효소를 억제하여 암모니아의 급속한 축적 및 세포 사멸을 초래한다(문헌[참조: Murakami et al., Mol. Gen. Genet., 205:42 (1986); Twell et al., Plant Physiol., 91:1270(1989)]). 곡물의 형질전환에 보고되어 온 주요 난점 때문에 단자엽 식물과 함께 당해 선별 시스템을 사용하는 데 있어서의 성공은 특히 놀라웠다(문헌[참조: Potrykus, Trends Biotech., 7:269 (1989)]).Exemplary embodiments of selectable marker genes that can be used within the system to select transformants include genes encoding the enzyme phosphinothricin acetyltransferase (eg, from Streptomyces hygroscopicus ). bar gene or pat gene from Streptomyces viridochromogenes }. The enzyme phosphinothricin acetyl transferase (PAT) inactivates the active ingredient in the herbicide vialaphos, phosphinothricin (PPT). PPT inhibits glutamine synthetase resulting in rapid accumulation of ammonia and cell death (Murakami et al., Mol. Gen. Genet., 205: 42 (1986); Twell et al., Plant Physiol. , 91: 1270 (1989). The success of using this selection system with monocotyledonous plants was particularly surprising because of the major difficulties reported in the transformation of grains (Potrykus, Trends Biotech., 7: 269 (1989)).
본 발명의 실시에 바이알라포스 내성 유전자를 사용하는 것이 바람직한 경우, 당해 목적에 특히 유용한 유전자는 스트렙토마이세스 종(예를 들면, ATCC 제21,705호)으로부터 수득가능한 bar 또는 pat 유전자이다. bar 유전자의 클로닝은 단자엽 식물 이외의 식물의 관점에서 bar 유전자의 용도를 갖는 것으로(문헌[참조: De Block et al., EMBO Journal, 6:2513(1987); De Block et al., PlantPhvsiol., 91:694(1989)] 기술되었다(문헌[참조: (Murakami et al., Mol. Gen. Genet. , 205: 42 (1986); Thompson et al., EMBO Journal, 6:2519 (1987)]). Where it is desired to use a vialaphos resistance gene in the practice of the present invention, a gene particularly useful for this purpose is the bar or pat gene obtainable from Streptomyces spp. (Eg ATCC 21,705). Cloning of the bar gene has the use of the bar gene in terms of plants other than monocotyledonous plants (De Block et al., EMBO Journal, 6: 2513 (1987); De Block et al., Plant Phhsiol., 91: 694 (1989)] (Murakami et al., Mol. Gen. Genet., 205: 42 (1986); Thompson et al., EMBO Journal, 6: 2519 (1987)) .
b. 감별 마커b. Differential marker
사용할 수 있는 감별 마커에는 각종 발색성 기질이 공지된 효소를 암호화하는 β-글루쿠로니다제 또는 uidA 유전자(GUS); 식물 조직 내에서의 안토시아닌 색소(붉은색)의 생성을 조절하는 생성물을 암호화하는 R-좌 유전자(문헌[참조: Dellaporta et al., in Chromosome Structure and Function, pp. 263-282 (1988)]); 각종 발색성 기질(예를 들면, PADAC, 발색성 세팔로스포린)이 공지된 효소를 암호화하는 β-락타메이즈 유전자(문헌[참조: Sutcliffe, PNAS USA, 75:3737 (1978)]); 발색성 카테콜을 전환할 수 있는 카테콜 디옥시게나제를 암호화하는 xylE 유전자(문헌[참조: Zukowsky et al., PNAS USA, 80:1101 (1983)]); α-아밀라제 유전자(문헌[참조: Ikuta et al., Biotech., 8: 241 (1990)]); 타이로신을 DOPA 및 도파퀴논으로 산화시키고, 이어서 응축되어 용이하게 검출가능한 화합물 멜라닌을 형성할 수 있는 효소를 암호화하는 타이로시나제 유전자(Katz et al., J. Gen. Microbiol., 129:2703 (1983)]); 발색성 기질인 효소를 암호화하는 β-갈락토시다제 유전자; 생물발광 검출을 가능하게 하는 루시퍼라제(lux) 유전자(문헌[참조: Ow et al., Science, 234:856 (1986)]); 또는 칼슘-민감성 생물발광 검출에 사용할 수 있는 애쿼린 유전자(문헌[참조: Prasher et al., Biochem. Biophys. Res. Comm., 126: 1259 (1985)] 또는 녹색 형광 단백질 유전자(문헌[참조: Niedz et al., Plant Cell Reports, 14: 403 (1995)])가 포함되지만, 이에 제한되지는 않는다.Differentiation markers that can be used include β-glucuronidase or uidA gene (GUS), which encodes enzymes for which various chromogenic substrates are known; R-left genes encoding products that regulate the production of anthocyanin pigment (red) in plant tissues (Delaporta et al., In Chromosome Structure and Function, pp. 263-282 (1988)) ; [Beta] -lactamase gene, in which various chromogenic substrates (eg PADAC, chromogenic cephalosporin) encode known enzymes (Sutcliffe, PNAS USA, 75: 3737 (1978)); XylE gene encoding catechol deoxygenase capable of converting chromogenic catechol (Zukowsky et al., PNAS USA, 80: 1101 (1983)); α-amylase gene (Ikuta et al., Biotech., 8: 241 (1990)); Tyrosinase gene (Katz et al., J. Gen. Microbiol., 129: 2703), which encodes an enzyme that oxidizes tyrosine to DOPA and dopaquinone and then condenses to form the easily detectable compound melanin 1983)]); Β-galactosidase gene encoding an enzyme that is a chromogenic substrate; Luciferase (lux) gene that enables bioluminescence detection (Ow et al., Science, 234: 856 (1986)); Or aquarin genes that can be used for calcium-sensitive bioluminescence detection (Praser et al., Biochem. Biophys. Res. Comm., 126: 1259 (1985)) or green fluorescent protein genes (see: Niedz et al., Plant Cell Reports, 14: 403 (1995)].
옥수수 R 유전자 복합체로부터의 유전자가 감별 마커로 특히 유용하다고 사료된다. 옥수수 내의 R 유전자 복합체는 대부분의 종자 및 식물 조직 내의 안토시아닌 색소의 생성을 조절하는 작용을 하는 단백질을 암호화한다. R 유전자 복합체로부터의 유전자는 옥수수 형질전환에 유용한데, 이는 형질전환 세포 내에서의 당해 유전자의 발현이 세포에 해를 주지 않기 때문이다. 따라서, 이러한 세포 내에 도입된 R 유전자는 붉은 색소의 발현을 유발할 것이며, 안정하게 혼입된 경우, 붉은 구역으로 가시적으로 기록될 수 있다. 옥수수 주가 안토시아닌 생합성 경로에서 효소적 중간체를 암호화하는 유전자에 대한 우성 대립형질을 보유하지만(Ce, A1, A2, Bz1 및 Bz2), R 좌에는 열성 대립형질을 보유하는 경우, R을 갖는 주로부터의 임의의 세포의 형질전환은 붉은 색소 형성을 야기할 것이다. 예시적 주에는 rg-Stadler 대립형질 및 TR112를 함유하는 위스콘신 22, r-g, b, P1인 K55 유도체가 포함된다. 대안적으로, C1 및 R 대립형질을 함께 도입하는 경우, 옥수수의 임의의 유전형을 사용할 수 있다. 본 발명에의 사용에 대해 고려된 추가의 감별 마커는 lux 유전자에 의해 암호화된 개똥벌레 루시퍼라제이다. 형질전환 세포 내의 lux 유전자의 존재는 예를 들면, X-선 필름, 섬광계수법, 형광 분광광도측정법, 저광 비디오 카메라, 광자 계수 마케라 또는 다중웰 발광측정법을 사용하여 검출할 수 있다. 또한 당해 시스템은 조직 배양 플레이트와 같은 생물발광 또는 심지어 전체 식물의 감별을 위한 집단 감별용으로 개발될 수 있다고 사료된다. Genes from the maize R gene complex are thought to be particularly useful as differential markers. The R gene complex in maize encodes a protein that functions to regulate the production of anthocyanin pigments in most seed and plant tissues. Genes from the R gene complex are useful for maize transformation because the expression of these genes in transformed cells does not harm the cells. Thus, the R gene introduced into these cells will cause the expression of the red pigment and, if stablely incorporated, can be visually recorded as a red zone. If the maize strain retains the dominant allele for the gene encoding the enzymatic intermediate in the anthocyanin biosynthetic pathway (Ce, A1, A2, Bz1 and Bz2), but has a recessive allele at the R locus, Transformation of any cell will result in red pigment formation. Exemplary notes include K55 derivatives of
식물을 형질전환시키는 데 사용되는 폴리뉴클레오타이드에는 식물 유전자 및비-식물 유전자(예를 들면, 세균, 효모, 동물 또는 바이러스로부터의 유전자)로부터의 DNA가 포함되지만, 이에 제한되지는 않는다. 도입된 DNA에는 변형 유전자, 유전자의 일부 또는 동일하거나 상이한 옥수수 유전자형으로부터의 유전자를 포함하는 키메라 유전자가 포함될 수 있다. 용어 "키메라 유전자" 또는 "키메라 DNA"는 자연적인 조건하에서는 DNA를 결합하지 않거나, DNA 서열 또는 단편이 비형질전환된 식물의 천연 게놈 내에서 통상적으로는 발생하지 않는 방법으로 위치하거나 결합된 종으로부터의 2개 이상의 DNA 서열 또는 단편을 포함하는 유전자 또는 DNA 서열 또는 단편으로 정의된다. Polynucleotides used to transform plants include, but are not limited to, DNA from plant genes and non-plant genes (eg, genes from bacteria, yeast, animals, or viruses). The introduced DNA may include chimeric genes, including modified genes, portions of genes or genes from the same or different maize genotypes. The term “chimeric gene” or “chimeric DNA” refers to a species from a species that is located or bound in a manner that does not bind DNA under natural conditions or that does not normally occur in the natural genome of a plant whose DNA sequence or fragment is untransformed. It is defined as a gene or DNA sequence or fragment comprising two or more DNA sequences or fragments of.
초호열성 가공 효소를 암호화하는 폴리뉴클레오타이드, 및 바람직하게는 코돈-최적화된 폴리뉴클레오타이드를 포함하는 발현 카세트를 추가로 제공한다. 발현 카세트 내의 폴리뉴클레오타이드(제1 폴리뉴클레오타이드)를 프로모터, 인핸서, 인트론, 종결 서열 또는 이의 임의의 조합과 같은 조절 서열, 및 임의로, 제1 폴리뉴클레오타이드에 의해 암호화된 효소를 특정 세포 또는 아세포 위치로 지시하는 시그날 서열(N- 또는 C-말단)을 암호화하는 제2 폴리뉴클레오타이드에 작동적으로 연결하는 것이 바람직하다. 따라서, 프로모터 및 하나 이상의 시그날 서열을 식물, 식물 조직 또는 식물 세포 내의 특정한 위치에의 높은 수준의 효소 발현을 위해 제공할 수 있다. 프로모터는 구성성 프로모터, 유도성(조건적) 프로모터 또는 조직-특이적 프로모터, 예를 들면, 옥수수 γ-제인 프로모터(서열번호 12로 예시된) 또는 옥수수 ADP-gpp 프로모터(5' 비해독 및 인트론 서열을 포함하는, 서열번호 11로 예시된)와 같은 내배유-특이적 프로모터일 수 있다. 본 발명은 또한 서열번호 11 또는 12를 포함하는 프로모터를 포함하는 분리된 폴리뉴클레오타이드, 낮은 엄중성 하이브리드화 조건하에 이의 상보체에 하이브리드화되는 폴리뉴클레오타이드, 또는 서열번호 11 또는 12를 갖는 프로모터의 예를 들면 10% 이상, 및 바람직하게는 50% 이상의 활성을 갖는 이의 단편을 제공한다. 또한 본 발명의 발현 카세트 또는 폴리뉴클레오타이드를 포함하는 벡터 및 본 발명의 폴리뉴클레오타이드, 발현 카세트 또는 벡터를 포함하는 형질전환 세포를 제공한다. 본 발명의 벡터는 본 발명의 초호열성 가공 효소 중 하나 이상을 암호화하는 폴리뉴클레오타이드 서열(당해 서열은 센스 또는 안티센스 방향일 수 있다)을 포함할 수 있으며, 형질전환 세포는 본 발명의 하나 이상의 벡터를 포함할 수 있다. 바람직한 벡터는 핵산을 식물 세포 내로 도입하는 데 유용한 것들이다. There is further provided an expression cassette comprising a polynucleotide encoding an ultra thermophilic processing enzyme, and preferably a codon-optimized polynucleotide. A regulatory sequence such as a polynucleotide (first polynucleotide) in an expression cassette, a promoter, enhancer, intron, termination sequence, or any combination thereof, and optionally, an enzyme encoded by the first polynucleotide to a particular cell or subcellular location It is preferred to operably link to a second polynucleotide encoding a signal sequence (N- or C-terminus). Thus, a promoter and one or more signal sequences can be provided for high levels of enzyme expression at specific locations within a plant, plant tissue or plant cell. The promoter may be a constitutive promoter, an inducible (conditional) promoter or a tissue-specific promoter, for example a corn γ-zein promoter (illustrated in SEQ ID NO: 12) or a corn ADP-gpp promoter (5 ′ overdose and introns). Endocrine-specific promoters, such as those exemplified by SEQ ID NO: 11, comprising the sequence. The invention also relates to isolated polynucleotides comprising promoters comprising SEQ ID NOs: 11 or 12, polynucleotides hybridized to their complements under low stringency hybridization conditions, or examples of promoters having SEQ ID NOs: 11 or 12 Fragments thereof having at least 10% and preferably at least 50% activity. Also provided are vectors comprising the expression cassette or polynucleotide of the present invention and transformed cells comprising the polynucleotide, expression cassette or vector of the present invention. The vector of the invention may comprise a polynucleotide sequence encoding one or more of the superthermophilic processing enzymes of the invention (the sequence may be in the sense or antisense direction), and the transformed cell may comprise one or more vectors of the invention. It may include. Preferred vectors are those useful for introducing nucleic acids into plant cells.
형질전환Transformation
발현 카세트 또는 발현 카세트를 포함하는 발현 작제물을 세포 내로 삽입할 수 있다. 발현 카세트 또는 벡터 작제물을 에피좀 상태로 운반하거나 세포의 게놈 내로 삽입할 수 있다. 이어서 형질전환 세포를 형질전환된 식물로 배양할 수 있다. 따라서, 본 발명은 형질전환된 식물의 생성물을 제공한다. 이러한 생성물에는 종자, 과실, 자손 및 형질전환된 식물의 자손의 생성물이 포함되지만, 이에 제한되지는 않는다. An expression cassette or expression construct comprising an expression cassette can be inserted into a cell. Expression cassettes or vector constructs can be transported in the episomal state or inserted into the genome of a cell. The transformed cells can then be cultured with the transformed plants. Thus, the present invention provides a product of a transformed plant. Such products include, but are not limited to, products of seeds, fruits, progeny, and progeny of transformed plants.
작제물의 세포 숙주 내로의 도입을 위한 각종 기법이 사용가능하며 당해 분야의 숙련가에게 공지되어 있다. 세균 및 많은 진핵 세포의 형질전환은 폴리에틸렌 글라이콜, 염화칼슘, 바이러스 감염, 파지 감염, 전기천공 및 당해 분야에 공지된 기타 방법을 사용하여 수행할 수 있다. 식물 세포 또는 조직을 형질전환시키기 위한 기법에는 형질전환제로서 에이. 튬패시엔스(A. tumefaciens) 또는 에이. 리조젠스(A. rhizogenes), 전기천공, DNA 주입, 미세발사 폭격, 입자 가속 등을 사용한 DNA로의 형질전환이 포함된다(예를 들면, 유럽 특허 제EP 295959호 및 제EP 138341호를 참조한다). Various techniques for the introduction of the constructs into the cell host are available and are known to those skilled in the art. Transformation of bacteria and many eukaryotic cells can be performed using polyethylene glycol, calcium chloride, viral infections, phage infections, electroporation and other methods known in the art. Techniques for transforming plant cells or tissues include a. A. tumefaciens or A. Transformation to DNA using A. rhizogenes , electroporation, DNA injection, microblast bombardment, particle acceleration, and the like (see, for example, EP 295959 and EP 138341). .
한 양태에서, 애그로박테리움 에스피피.의 Ti 및 Ri 플라스미드의 이원형 벡터를 제공한다. Ti-유래 벡터는 단자엽 식물 및 쌍자엽 식물(예를 들면, 대두, 면, 유채, 담배 및 벼)을 포함하는 매우 다양한 고등 식물을 형질전환시키기 위해 사용된다(문헌[참조: Pacciotti et al. Bio/Technology.3:241 (1985): Byrne et al. Plant Cell Tissue and Organ Culture, 8:3(1987); Sukhapinda et al. Plant Mol. Biol., 8: 209(1987); Lorz et al. Mol. Gen. Genet., 199:178 (1985); Potrykus Mol. Gen. Genet., 199:183(1985); Park et al., J. Plant Biol., 38: 365 (1985): Hiei et al., Plant J., 6:271(1994)]). 식물 세포를 형질전환시키기 위한 T-DNA,의 사용은 광범위한 연구의 대상이 되어 왔으며 충분히 기술되어 있다(문헌[참조: 유럽 특허 제EP 120516호; Hoekema, In: The Binary Plant Vector System. Offset-drukkerij Kanters B.V.; Alblasserdam (1985), Chapter V; Knauf, et al., Genetic Analysis of Host Range Expression by Agrobacterium In: Molecular Genetics of the Bacteria-Plant Interaction, Puhler, A. ed. , Springer-Verlag, New York, 1983, p.245; 및 An. et al., EMBO J., 4:277 (1985)]).In one aspect, a binary vector of Ti and Ri plasmids of Agrobacterium sp. Ti-derived vectors are used to transform a wide variety of higher plants, including monocotyledonous plants and dicotyledonous plants (e.g., soybean, cotton, rapeseed, tobacco and rice) (Pacciotti et al. Bio / Technology. 3: 241 (1985): Byrne et al. Plant Cell Tissue and Organ Culture, 8: 3 (1987); Sukhapinda et al. Plant Mol. Biol., 8: 209 (1987); Lorz et al. Mol. Gen. Genet., 199: 178 (1985); Potrykus Mol. Gen. Genet., 199: 183 (1985); Park et al., J. Plant Biol., 38: 365 (1985): Hiei et al., Plant J., 6: 271 (1994)]. The use of T-DNA, to transform plant cells, has been the subject of extensive research and has been fully described (European Patent EP 120516; Hoekema, In: The Binary Plant Vector System.Offset-drukkerij Kanters BV; Alblasserdam (1985), Chapter V; Knauf, et al., Genetic Analysis of Host Range Expression by Agrobacterium In: Molecular Genetics of the Bacteria-Plant Interaction, Puhler, A. ed., Springer-Verlag, New York, 1983, p. 245; and An. Et al., EMBO J., 4: 277 (1985)).
당해 분야의 숙련가는 외래 DNA 작제물의 직접적 수용(유럽 특허 제EP 295959호를 참조), 전기천공 기법(문헌[참조: Fromm et al., Nature(London), 319:791(1986)]) 또는 핵산 작제물로 피복한 금속 입자를 사용한 고속 탄도 충격(문헌[참조: Kline et al., Nature(London) 327:70(1987) 및 미국 특허 제4,945,050호])와 같은 기타 형질전환 방법을 사용할 수 있다. 일단 형질전환된 세포는 당해 분야의 숙련가에 의해 재생될 수 있다. 특정한 관련된 것은 왜래 유전자를 유채종자(문헌[참조: De Block et al., Plant Physiol. 91:694-701(1989)]), 해바라기 (문헌[참조: Everett et al.,Bio/Technology. 5:1201(1987)]), 대두(문헌[참조: McCabe et al., Bio/Technology, 6:923(1988); Hinchee et al., Bio/Technology, 6:915(1988); Chee et al., Plant Physiol., 91:1212(1989); Christou et al., Proc. Natl. Acad. Sci USA, 86:7500(1989), 유럽 특허 제EP 301749호]), 벼(문헌[참조: Hiei et al., Plant J., 6:271(1994)), 및 옥수수(문헌[참조: Gordon Kamm et al., Plant Cell, 2:603 (1990); Fromm et al., Biotechnology, 8:833, (1990)])와 같은 상업적으로 중요한 작물로 형질전환시키는 최근에 기술된 방법이다. Those skilled in the art will appreciate the direct acceptance of foreign DNA constructs (see European Patent No. EP 295959), electroporation techniques (Fromm et al., Nature (London), 319: 791 (1986)) or Other transformation methods, such as high speed ballistic impact using metal particles coated with nucleic acid constructs (Kline et al., Nature (London) 327: 70 (1987) and US Pat. No. 4,945,050), can be used. have. Once transformed cells can be regenerated by those skilled in the art. Of particular relevance are the hereditary genes for rape seed (De Block et al., Plant Physiol. 91: 694-701 (1989)), sunflower (Everett et al., Bio / Technology. 5: 1201 (1987)), soybeans (Mccabe et al., Bio / Technology, 6: 923 (1988); Hinchee et al., Bio / Technology, 6: 915 (1988); Chee et al., Plant Physiol., 91: 1212 (1989); Christou et al., Proc. Natl. Acad. Sci USA, 86: 7500 (1989), European Patent No. EP 301749]), rice (Hei et al. , Plant J., 6: 271 (1994), and corn (Gordon Kamm et al., Plant Cell, 2: 603 (1990); Fromm et al., Biotechnology, 8: 833, (1990) It is a recently described method of transforming a commercially important crop such as)]).
게놈 또는 합성 단편을 포함하는 발현 벡터를 원형질체 또는 온전한 조직 또는 분리된 세포 내로 도입할 수 있다. 바람직하게는 발현 벡터를 온전한 조직 내로 도입한다. 일반적인 식물 조직 배양 방법이 예를 들면, 문헌[참조: Maki et al. "Procedures for Introducing Foreign DNA into Plants" in Methods in Plant Molecular Biology & Biotechnology, Glich et al. (Eds.), pp. 67-88 CRC Press (1993) ; 및 Phillips et al. "Cell-Tissue Culture and In-Vitro Manipulation" in Corn & Corn Improvement, 3rd Edition 10, Sprague et al. (Eds.) pp. 345-387, American Society of Agronomy Inc. (1988)]에 제공되어 있다. Expression vectors comprising genomic or synthetic fragments can be introduced into protoplasts or intact tissues or isolated cells. Preferably the expression vector is introduced into intact tissue. General plant tissue culture methods are described, for example, in Maki et al. "Procedures for Introducing Foreign DNA into Plants" in Methods in Plant Molecular Biology & Biotechnology, Glich et al. (Eds.), Pp. 67-88 CRC Press (1993); And Phillips et al. "Cell-Tissue Culture and In-Vitro Manipulation" in Corn & Corn Improvement,
한 양태에서, 발현 벡터를 미세발사(microprojectile)-매개 전달, DNA 주입, 전기천공 등과 같은 직접적인 유전자 전달 방법을 사용하여 옥수수 또는 기타 식물 조직 내로 도입할 수 있다. 발현 벡터를 생탄도(biolistics) 장비를 이용하는 미세발사 매체 전달을 사용하여 식물 조직 내로 도입한다. 예를 들면, 문헌[Tomes et al. "Direct DNA transfer into intact plant cells via microprojectile bombardment" in Gamborg and Phillips (Eds.) Plant Cell, Tissue and Organ Culture: Fundamental Methods, Springer Verlag, Berlin (1995)]을 참조한다. 그럼에도 불구하고, 본 발명은 공지된 형질전환 방법에 따라 초호열성 가공 효소를 사용한 식물의 형질전환을 고려한다. 또한, 문헌[Weissinger et al., Annual Rev. Genet., 22: 421 (1988); Sanford et al., Particulate Science and Technology, 5:27(1987)(양파); Christou et al., Plant Physiol., 87: 671 (1988)(대두); McCabe et al., Bio/Technology, 6:923(1988)(대두); Datta et al., Bio/Technology, 8:736(1990) (벼); Klein et al., Proc. Natl. Acad. Sci. USA, 85:4305(1988)(옥수수); Klein et al., Bio/Technology, 6:559(1988)(옥수수); Klein et al., Plant Physiol., 91: 440(1988)(옥수수); Fromm et al., Bio/Technology, 8:833(1990)(옥수수); 및 Gordon-Kamm et al., Plant Cell, 2, 603(1990)(옥수수); Svab et al., Proc. Natl. Acad. Sci. USA, 87:8526(1990)(감자 엽록체); Koziel et al., Biotechnology, 11:194(1993)(옥수수); Shimamoto et al., Nature, 338:274 (1989)(벼); Christou et al., Biotechnology, 9:957(1991)(벼); 유럽 특허 출원 제EP 0 332 581호(오리새 및 기타 포아풀아과); Vasil et al., Biotechnology, 11:1553(1993)(밀); Weeks et al., Plant Physiol., 102:1077(1993)(밀); Methods in Molecular Biology, 82. Arabidopsis Protocols Ed. Martinez-Zapater and Salinas 1998 Humana Press (애기장대)]를 참조한다. In one embodiment, expression vectors can be introduced into maize or other plant tissue using direct gene transfer methods such as microprojectile-mediated delivery, DNA injection, electroporation, and the like. The expression vector is introduced into plant tissue using microprojectile media delivery using biolistics equipment. See, eg, Tomes et al. "Direct DNA transfer into intact plant cells via microprojectile bombardment" in Gamborg and Phillips (Eds.) Plant Cell, Tissue and Organ Culture: Fundamental Methods, Springer Verlag, Berlin (1995). Nevertheless, the present invention contemplates the transformation of plants using super thermophilic processing enzymes according to known transformation methods. In addition, Weissinger et al., Annual Rev. Genet., 22: 421 (1988); Sanford et al., Particulate Science and Technology, 5:27 (1987) (onion); Christou et al., Plant Physiol., 87: 671 (1988) (soy); McCabe et al., Bio / Technology, 6: 923 (1988) (soybean); Datta et al., Bio / Technology, 8: 736 (1990) (rice); Klein et al., Proc. Natl. Acad. Sci. USA, 85: 4305 (1988) (corn); Klein et al., Bio / Technology, 6: 559 (1988) (corn); Klein et al., Plant Physiol., 91: 440 (1988) (corn); Fromm et al., Bio / Technology, 8: 833 (1990) (corn); And Gordon-Kamm et al., Plant Cell, 2, 603 (1990) (corn); Svab et al., Proc. Natl. Acad. Sci. USA, 87: 8526 (1990) (potato chloroplast); Koziel et al., Biotechnology, 11: 194 (1993) (corn); Shimamoto et al., Nature, 338: 274 (1989) (rice); Christou et al., Biotechnology, 9: 957 (1991) (rice); European Patent Application EP 0 332 581 (Duck and other Poapuaceae); Vasil et al., Biotechnology, 11: 1553 (1993) (wheat); Weeks et al., Plant Physiol., 102: 1077 (1993) (wheat); Methods in Molecular Biology, 82. Arabidopsis Protocols Ed. Martinez-Zapater and Salinas 1998 Humana Press (Baby Pole).
식물의 형질전환은 단일 DNA 분자 또는 다중 DNA 분자(즉, 공-형질전환)를 사용하여 수행할 수 있으며, 이들 기법 둘 다 발현 카세트 및 본 발명의 작제물과 함께 사용하기에 적합하다. 다수의 형질전환 벡터를 식물 형질전환에 사용할 수 있으며, 본 발명의 발현 카세트를 임의의 이러한 벡터와 함께 사용할 수 있다. 벡터의 선별은 바람직한 형질전환 기법 및 형질전환을 위한 표적 종에 의존할 것이다.Plant transformation can be performed using a single DNA molecule or multiple DNA molecules (ie, co-transformation), both of which are suitable for use with expression cassettes and constructs of the invention. Many transformation vectors can be used for plant transformation and the expression cassettes of the invention can be used with any such vector. The selection of the vector will depend on the desired transformation technique and the target species for transformation.
궁극적으로, 단자엽 게놈 내로의 도입을 위한 가장 바람직한 DNA 단편은 목적하는 형질(예를 들면, 단백질, 지질 또는 다당류의 가수분해)을 암호화하고, 신규한 프로모터 또는 인핸서 등, 또는 아마도 심지어는 상동성 또는 조직 특이적(예를 들면, 뿌리-, 경령/엽초-, 나층-, 줄기-, 귓대-, 낟알- 또는 잎-특이적) 프로모터 또는 제어 요소의 제어 하에 도입되는 상동성 유전자 또는 유전자 계열일 수 있다. 사실, 본 발명의 특정한 용도는 구성적 방법 또는 유도적 방법의 유전자 표적화일 수 있다고 사료된다. Ultimately, the most preferred DNA fragments for introduction into the monocot genome encode the desired trait (e.g., hydrolysis of proteins, lipids or polysaccharides), novel promoters or enhancers, etc., or perhaps even homology or Can be a homologous gene or gene family introduced under the control of a tissue-specific (eg, root-, age / leaf vine-, stratum-, stem-, chock-, grain- or leaf-specific) promoter or control element have. In fact, it is contemplated that certain uses of the present invention may be gene targeting of constitutive or inductive methods.
적합한 형질전환 벡터의 예Examples of suitable transformation vectors
식물 형질전환에 사용할 수 있는 다수의 형질전환 벡터가 식물 형질전환 분야의 통상의 숙련가에게 공지되어 있으며, 본 발명과 관계된 유전자를 당해 분야에 공지된 임의의 이러한 벡터와 함께 사용할 수 있다. 벡터의 선별은 바람직한 형질전환 기법 및 형질전환을 위한 표적 종에 의존할 것이다. Many transformation vectors that can be used for plant transformation are known to those of ordinary skill in the art of plant transformation, and the genes involved in the present invention can be used with any such vectors known in the art. The selection of the vector will depend on the desired transformation technique and the target species for transformation.
a. 애그로박테리움 형질전환에 적합한 벡터a. Vectors Suitable for Agrobacterium Transformation
많은 벡터가 애그로박테리움 튬패시엔스를 사용한 형질전환에 사용가능하다. 이들은 통상적으로 하나 이상의 T-DNA 서열을 보유하며 pBIN19와 같은 벡터를 포함한다(문헌[참조: Bevan, Nucl. Acids Res.(1984)]). 아래에, 애그로박테리움 형질전환에 적합한 2가지의 통상적인 벡터의 작제가 기술되어 있다. Many vectors are available for transformation with Agrobacterium lithium passance. These typically have one or more T-DNA sequences and include vectors such as pBIN19 (Bevan, Nucl. Acids Res. (1984)). Below, the construction of two conventional vectors suitable for Agrobacterium transformation are described.
pCIB200 및 pCIB2001pCIB200 and pCIB2001
이원 벡터 pCIB200 및 pCIB2001을 애그로박테리움과 함께 사용하기 위한 재조합 벡터의 벡터의 작제를 위해 사용하며 다음의 방법으로 작제한다. pTJS75을 NarI로 분해하여(문헌[참조: Schmidhauser & Helinski, J. Bacteriol., 164:446 (1985)]) 테트라사이클린-내성 유전자를 절단한 후, NPTII를 보유한 pUC4K로부터의 AccI 단편을 삽입하여(문헌[참조: Messing & Vierra, Gene, 19: 259 (1982): Bevan et al., Nature, 304:184(1983): McBride et al., Plant MolecularBiology, 14:266 (1990)]) pTJS75kan을 제조한다. XhoI 연결자를 왼편 및 오른편 T-DNA 경계부, 식물 선별 nos/nptII 키메라 유전자 및 pUC 다중연결자(문헌[참조: Rothstein et al., Gene, 53:153 (1987)])를 포함하는 pCIB7의 EcoRV 단편에 연결하고, XhoI-분해 단편을 SalI-분해 pTJS75kan 내로 클로닝시켜 pCIB200을 제조한다(또한 유럽 특허 제EP 0 332 104호, 실시예 19를 참조한다). pCIB200은 다음의 고유한 다중연결자 제한 부위를 포함한다: EcoRI, SstI, Kpnl,BgIII, Xbal, 및 Sall. pCIB2001의 다중연결자 내의 고유한 제한 부위는 EcoRI, SstI, KpnI, BgIII, XbaI, Sall, Mlul,Bell, AvrII, Apal, HpaI 및 StuI이다. pCIB2001은 이들 고유한 제한 부위를 포함하는 것 외에, 또한 식물 및 세균 카나마이신 선별, 애그로박테리움-매개 형질전환용 왼편 및 오른편 T-DNA 경계, 이. 콜라이 및 기타 숙주 사이의 기동을 위한 RK2-유래 trfA 기능, 및 또한 RK2로부터의 OriT 및 OriV 기능을 갖는다. pCIB2001 다중연결자는 이들 자신의 조절 시그날을 포함하는 식물 발현 카세트의 클로닝에 적합하다. Binary vectors pCIB200 and pCIB2001 are used for the construction of vectors of recombinant vectors for use with Agrobacterium and are constructed in the following manner. pTJS75 was digested with NarI (Schmidhauser & Helinski, J. Bacteriol., 164: 446 (1985)) to cleave the tetracycline-resistant gene, followed by insertion of an AccI fragment from pUC4K carrying NPTII ( See Messing & Vierra, Gene, 19: 259 (1982): Bevan et al., Nature, 304: 184 (1983): McBride et al., Plant Molecular Biology, 14: 266 (1990)) to prepare pTJS75kan. do. The XhoI connector was attached to the EcoRV fragment of pCIB7, including the left and right T-DNA borders, the plant selected nos / nptII chimeric gene and the pUC multi-linker (Rothstein et al., Gene, 53: 153 (1987)). Ligation and cloning XhoI-digestion fragments into SalI-digestion pTJS75kan to prepare pCIB200 (see also
pCIB10 및 이의 하이그로마이신 선별 유도체:pCIB10 and its hygromycin selection derivatives:
이원 벡터 pCIB10은 식물 내에서의 선별을 위한 카나마이신 내성을 암호화하는 유전자 및 T-DNA 왼편 및 오른편 경계 서열을 포함하며, 이. 콜라이 및 애그로박테리움 둘 다에서의 복제를 가능하게 하는 넓은 숙주-범위의 플라스미드 pRK252로부터의 서열을 포함한다. 이의 작제물은 저자 Rothstein 등에 의해 기술되어 있다(문헌[참조: Gene, 53: 153(1987)]). 저자 Gritz 등의 문헌([참조: Gene, 25: 179(1983)])에 기술된 하이그로마이신 B 포스포트랜스퍼라제에 대한 유전자를 포함하는 pCIB10의 각종 유도체를 작제한다. 이들 유도체는 오직 하이그로마이신(pCIB743), 또는 하이그로마이신 및 카나마이신(pCIB715, pCIB717) 상의 형질전환된 식물 세포의 선별을 가능하게 한다. The binary vector pCIB10 comprises genes encoding kanamycin resistance for selection in plants and T-DNA left and right border sequences, comprising two. It includes sequences from a broad host-range plasmid pRK252 that allows replication in both E. coli and Agrobacterium. Its construct is described by the author Rothstein et al. (Gen, 53: 153 (1987)). Various derivatives of pCIB10 are constructed that include genes for the hygromycin B phosphotransferase described in the author, Gritz et al. (Gen, 25: 179 (1983)). These derivatives only allow for the selection of transformed plant cells on hygromycin (pCIB743) or hygromycin and kanamycin (pCIB715, pCIB717).
b. 비-애그로박테리움 형질전환에 적합한 벡터b. Vectors Suitable for Non-Agrobacterium Transformation
애그로박테리움 튬패시엔스를 사용하지 않는 형질전환은 선택된 형질전환 벡터의 T-DNA 서열을 필요로 하지 않으며, 그 결과 T-DNA 서열을 포함하는 상기한 것과 같은 벡터 이외에 이들 서열이 결핍된 벡터를 사용할 수 있다. 애그로박테리움에 의존하지 않는 형질전환 기법에는 입자 충격(particle bombardment), 원형질체 흡수(예를 들면, PEG 및 전기천공) 및 미세주입을 통한 형질전환이 포함된다. 벡터의 선택은 대부분 형질전환시킬 종의 바람직한 선별에 의존한다. 비-애그로박테리움 형질전환에 적합한 통상적인 벡터의 작제의 비-제한적 예가 추가로 기술되어 있다. Transformation without using Agrobacterium lithium passivation does not require the T-DNA sequence of the selected transformation vector, resulting in a vector lacking these sequences in addition to the vector as described above containing the T-DNA sequence. Can be used. Transformation techniques that do not depend on Agrobacterium include particle bombardment, protoplast uptake (eg PEG and electroporation) and transformation via microinjection. The choice of vector depends largely on the desired selection of the species to be transformed. Non-limiting examples of construction of conventional vectors suitable for non-Agrobacterium transformation are further described.
pCIB3064 pCIB3064
pCIB3064는 제초제 바스타(또는 포스피노트리신)에 의한 선별과 함께 직접적인 유전자 전달 기법에 적합한 pUC-유래 벡터이다. 플라스미드 pBIC246은 이. 콜라이 GUS 유전자에 대한 작동적 융합의 CaMV 35S 프로모터 및 CaMV 35S 전사 종결자를 포함하며 PCT 공개 출원 제WO 93/07278호에 기술되어 있다. 이들 벡터의 35S 프로모터는 출발 부위의 2개의 ATG 서열 5'을 포함한다. 이들 부위는 ATG를 제거하고 제한 부위 SspI 및 PvuII를 산출하는 방식으로 표준 PCR 기법을 사용하여 돌연변이시킨다. 새로운 제한 부위는 고유한 SalI 부위로부터 96 및 37bp, 및 실제 출발 부위로부터 101 및 42bp 떨어져 있다. 수득된 pCIB246의 유도체를 pCIB3025로 명명한다. 이어서 GUS 유전자를 SalI 및 SacI으로 분해하여 pCIB3025로부터 절단하고, 말단을 평활한 상태가 되게 하고 재연결하여 플라스미드 pCIB3060을 제조한다. 플라스미드 pJIT82는 노리치 소재의 기관[John Innes Centre]로부터 입수할 수 있으며, 스트렙토마이세스 비리도크로모젠스로부터의 bar 유전자를 포함하는 400bp 길이의 SmaI 단편을 절단하고 pCIB3060의 HpaI 부위 내로 삽입한다(문헌[참조: Thompson et al., EMBO J, 6: 2519 (1987)]). 이는 제초제 선별용의, CaMV 35S 프로모터 및 종결자의 제어 하의 bar 유전자, 앰피실린 내성 유전자(이. 콜라이 내에서의 선별을 위한) 및 고유한 부위 SphI, PstI, HindIII 및 BamHI 내의 다중연결자를 포함하는 pCIB3064를 생성시켰다. 당해 벡터는 이들 자신의 조절 시그날을 포함하는 식물 발현 카세트의 클로닝에 적합하다. pCIB3064 is a pUC-derived vector suitable for direct gene transfer techniques with selection by the herbicide Vaster (or phosphinothricin). Plasmid pBIC246 is E. coli. CaMV 35S promoter and CaMV 35S transcription terminators of operative fusion to the E. coli GUS gene and are described in PCT Publication No. WO 93/07278. The 35S promoter of these vectors comprises two ATG sequences 5 'of the starting site. These sites are mutated using standard PCR techniques in order to remove ATG and yield restriction sites SspI and PvuII. The new restriction site is 96 and 37 bp from the unique SalI site and 101 and 42 bp from the actual starting site. The derivative of pCIB246 obtained is named pCIB3025. The GUS gene is then digested with SalI and SacI to cleave from pCIB3025, leave the ends smooth and reconnect to prepare plasmid pCIB3060. Plasmid pJIT82, available from the John Innes Center, Norwich,
pSOG19 및 pSOG35:pSOG19 and pSOG35:
플라스미드 pSOG35는 메토트렉세이트에 대한 내성을 부여하는 선별 마커로서 이. 콜라이 유전자 다이하이드로폴레이트 환원효소(DHFR)를 사용하는 형질전환 벡터이다. PCR를 사용하여 35S 프로모터(-800bp), 옥수수 Adh1 유전자로부터의 인트론 6(-550bp) 및 pSOG10으로부터의 GUS 비해독 리더 서열의 18bp를 증폭하였다. 이. 콜라이 다이하이드로폴레이트 환원효소 제II형 유전자를 암호화하는 250-bp 단편을 또한 PCR로 증폭하고 이들 2개의 PCR 단편을 pUC19 벡터 골격 및 노팔린 신타제 종결자를 포함하는 pB1221(Clontech)로부터의 SacI-PstI 단편과 조립한다. 이들 단편의 조립은 인트론 6 서열, GUS 리더, DHFR 유전자 및 노팔린 신타제 종결자를 갖는 융합물에 35S 프로모터를 포함하는 pSOG19를 생성시킨다. pSOG19의 GUS 리더 서열의 옥수수 백화 반점 바이러스(MCMV)로부터의 리더 서열로의 대체는 벡터 pSOG35를 생성시킨다. pSOG19 및 pSOG35는 앰피실린 내성을 위한 pUC 유전자를 보유하며, 외래 물질의 클로닝을 가능하게 하는 HindIII, SphI, PstI 및 EcoRI 부위를 갖는다.Plasmid pSOG35 is a screening marker that confers resistance to methotrexate. Transformation vector using E. coli gene dihydrofolate reductase (DHFR). PCR was used to amplify the 35S promoter (-800bp), intron 6 (-550bp) from the maize Adh1 gene and 18bp of the GUS non-poisonous leader sequence from pSOG10. this. 250-bp fragments encoding E. coli dihydrofolate reductase type II genes were also amplified by PCR and these two PCR fragments were SacI- from pB1221 (Clontech) containing the pUC19 vector backbone and nopaline synthase terminator. Assemble with PstI fragment. Assembly of these fragments results in pSOG19 comprising a 35S promoter in a fusion with the
c. 엽록체 형질전환에 적합한 벡터c. Vectors Suitable for Chloroplast Transformation
식물 색소체에서의 본 발명의 뉴클레오타이드 서열의 발현을 위해, 색소체 형질전환 벡터 pPH143(국제공개공보 제WO 97/32011호, 실시예 36)을 사용한다. 당해 뉴클레오타이드 서열을 pPH143으로 삽입하여 PROTOX 암호화 서열을 치환한다. 이어서 당해 벡터를 색소체 형질전환 및 스펙티노마이신 내성을 위한 형질전환체 선별에 사용한다. 대안적으로, 당해 뉴클레오타이드 서열을 pPH143에 삽입하여, aadH 유전자를 대체한다. 이러한 경우, 형질전환체는 PROTOX 억제자에 대한 내성에 대해 선별한다. For expression of the nucleotide sequences of the present invention in plant plastids, the plastiform transformation vector pPH143 (WO 97/32011, Example 36) is used. The nucleotide sequence is inserted into pPH143 to replace the PROTOX coding sequence. The vector is then used for chromatin transformation and screening for transformants for spectinomycin resistance. Alternatively, the nucleotide sequence is inserted into pPH143 to replace the aadH gene. In this case, the transformants are selected for resistance to PROTOX inhibitors.
형질전환 방법에 적용하는 식물 숙주Plant host applied to the transformation method
기관형성성인지 배아발생성인지에 관계없이, 이후의 클론 증식이 가능한 임의의 식물 조직을 본 발명의 작제물로 형질전환시킬 수 있다. 용어 기관형성은 순 또는 뿌리가 분열조직 중심으로부터 순차적으로 발달하는 과정을 의미하는 반면, 용어 배아발생은 순 및 뿌리가 체세포 유래인지 생식세포 유래인지에 관계없이, 계획된 방식(비순차적으로)으로 함께 발달하는 과정을 의미한다. 선택되는 특정한 조직은 형질전환시킬 특정 종에 사용가능하고, 가장 적합한 클론 증식 시스템에 따라 다양할 것이다. 예시적 조직 표적에는 잎 화반, 뿌리, 줄기, 순, 잎, 화분, 종자, 배아, 자엽, 배축, 자성배우체, 유합 조직, 기존의 분열조직(예를 들면, 정단 분열조직, 측생 눈, 및 뿌리 분열조직) 및 유도된 분열조직(예를 들면, 자엽 분열조직 및 배축 분열조직), 종양 조직 및 단일 세포, 원형질체, 배아 및 유합 조직과 같은 세포 및 배양물의 다양한 형태를 포함하지만, 이에 제한되지는 않는 분화 및 비분화 조직 또는 식물이 포함된다. 식물 조직은 식물 또는 기관, 조직 또는 세포 배양물일 수 있다. Regardless of whether they are organogenic or embryogenic, any plant tissue capable of subsequent clonal proliferation can be transformed with the constructs of the invention. The term organogenesis refers to the process by which shoots or roots develop sequentially from the meristem center, whereas the term embryogenicity refers together in a planned manner (out of order), regardless of whether the shoots and roots are somatic or germline derived. It means the process of development. The particular tissue selected will be available for the particular species to be transformed and will vary depending on the most suitable clone propagation system. Exemplary tissue targets include leaf beds, roots, stems, shoots, leaves, pollen, seeds, embryos, cotyledon, hypocotyls, female embryoid bodies, union tissues, existing meristems (eg, apical meristem, side eyes, and roots) Meristem) and induced meristems (eg, cotyledonic and embryonic meristems), tumor tissues and various forms of cells and cultures such as single cells, protoplasts, embryos and callus tissues, including but not limited to Non-differentiated and undifferentiated tissues or plants are included. Plant tissue may be a plant or organ, tissue or cell culture.
본 발명의 식물은 각종 형태를 취할 수 있다. 식물은 형질전환 세포 및 비-형질전환 세포의 키메라일 수 있으며; 식물은 클론성 형질전환체(예를 들면, 발현 카세트를 포함하도록 형질전환된 모든 세포)일 수 있으며; 식물은 형질전환 및 비형질전환 조직의 이식물(예를 들면, 감귤류 종에 비형질전환 접순에 이식한 형질전환 뿌리 근경)을 포함할 수 있다. 형질전환된 식물은 클론 증식 또는 전형적인 육종 기법과 같은 다양한 방법에 의해 번식시킬 수 있다. 예를 들면, 제1세대(또는 T1) 형질전환된 식물을 자가증식시켜 동형 제2세대(또는 T2) 형질전환된 식물을 제공할 수 있으며, T2 식물을 고전적인 육종 기법을 통해 추가로 번식시킬 수 있다. 육종을 지원하기 위해 우세한 선별 마커(예를 들면, nptII)를 발현 벡터와 연관시킬 수 있다. The plant of the present invention may take various forms. The plant can be a chimera of transformed and non-transformed cells; The plant may be a clonal transformant (eg, all cells transformed to contain an expression cassette); Plants may include implants of transformed and non-transformed tissues (eg, transgenic roots roots implanted in ciliated species in untransformed scion). Transformed plants can be propagated by various methods such as clonal propagation or typical breeding techniques. For example, a first generation (or T1) transformed plant can be self-proliferated to provide a homogenous second generation (or T2) transformed plant, and the T2 plants can be further propagated through classical breeding techniques. Can be. Preferred selection markers (eg nptII) can be associated with expression vectors to support sarcoma.
본 발명은 옥수수(제아 메이스), 브라시카 종(Brassica ssp.){예를 들면, 비. 나푸스(B. napus), 비. 라파(B. rapa), 비. 준시아(B. junciea)}, 특히 종자유의 공급원으로서 유용한 이들 브라시카 종, 자주개자리(Medicago sativa), 벼(Oryza sativa), 호밀(Secale cereale), 수수(Sorghum bicolor, Sorghum vulgare), 기장{예를 들면, 진주기장(Pennisetum glaucum), 프로소(proso) 기장(Panicum miliaceum), 여우꼬리 기장(Setaria italica), 손가락 기장(Eleusine coracana)}, 해바라기(Helianthus annuus), 잇꽃(Carthamus tinctorius), 밀(Triticum aestivum), 대두(Glycine max), 담배(Nicotiana tabacum), 감자(Solanum tuberosum), 땅콩(Arachis hypogaea), 목화(Gossypium barbadense, Gossypium hirsutum), 고구마(Ipomoea batatus), 카사바(Manihot esculenta), 커피(Cofea spp.), 코코넛(Cocos nucifera), 파인애플(Ananas comosus), 감귤 나무(Citrus spp.), 코코아(Theobroma cacao), 차(Camellia sinensis), 바나나(Musa spp.), 아보카도(Persea americana), 무화과(Ficus casica), 구아바(Psidium guajava), 망고(Mangifera indica), 올리브(Olea europaea), 파파야(Carica papaya), 캐슈(Anacardium occidentale), 마카다미아(Macadamia integrifolia), 아몬드(Prunus amygdalus), 사탕무(Beta vulgaris), 사탕수수(Saccharum spp.), 귀리, 보리, 채소, 장식용, 목재 식물(예를 들면, 침엽수 및 낙엽수), 스쿼시, 호박, 대마, 서양호박, 사과, 배, 마르멜로, 멜론, 자두, 체리, 복숭아, 승도복숭아, 살구, 딸기, 포도, 라즈베리, 블랙베리, 대두, 수수, 사탕수수, 평지시, 클로버, 당근 및 아라비돕시스 틸리아나(Arabidopsis thaliana)를 포함하지만, 이에 제한되지는 않는 단자엽 또는 쌍자엽을 포함하는 임의의 식물 종의 형질전환에 사용할 수 있다. The present invention relates to corn (zea mays), Brassica ssp. B. napus, b. B. rapa, b. B. junciea}, especially those brassica species useful as a source of seed oil, Medicago sativa, Oryza sativa, Rye (Secale cereale), Sorghum bicolor (Sorghum vulgare), millet { For example, the pearl millet (Pennisetum glaucum), the proso millet (Panicum miliaceum), the foxtail millet (Setaria italica), the finger millet (Eleusine coracana)}, the sunflower (Helianthus annuus), the safflower (Carthamus tinctorius), Wheat (Triticum aestivum), Soybean (Glycine max), Tobacco (Nicotiana tabacum), Potatoes (Solanum tuberosum), Peanuts (Arachis hypogaea), Cotton (Gossypium barbadense, Gossypium hirsutum), Sweet potato (Ipomoea batatus), Cassava (Manihot esculenta , Coffee (Cofea spp.), Coconut (Cocos nucifera), Pineapple (Ananas comosus), Citrus tree (Citrus spp.), Cocoa (Theobroma cacao), Tea (Camellia sinensis), Banana (Musa spp.), Avocado (Persea) americana), fig (Ficus casica), guava (Psidium guajava), mango (Mangifera indica), olive (Olea europa ea, Carica papaya, Cashew (Anacardium occidentale), Macadamia (Macadamia integrifolia), Almond (Prunus amygdalus), Sugar beet (Beta vulgaris), Saccharum spp., Oats, Barley, Vegetables, Ornamental, Wood Plants (e.g. conifers and deciduous trees), squash, pumpkins, hemp, zucchini, apples, pears, quince, melons, plums, cherries, peaches, nectarines, apricots, strawberries, grapes, raspberries, blackberries, soybeans Can be used for transformation of any plant species, including, but not limited to, sorghum, sugar cane, rape, clover, carrots and Arabidopsis thaliana .
채소에는 토마토(Lycopersicon esculentum), 상추(예를 들면, Lactuca sativa), 생두(Phaseolus vulgaris), 라이마콩(Phaseolus limensis), 완두(Lathyrus spp.), 콜리플라워, 브로콜리, 순무, 무, 시금치, 아스파라거스, 양파, 마늘, 고추, 샐러리, 및 오이(C. sativus), 칸탈루프 멜론(C. cantalupensis), 및 머스크 멜론(C. melo)과 같은 멜론 속의 구성원이 포함된다. 장식용 식물에는 진달래(Rhododendron spp.), 수국(Macrophylla hydrangea), 히비스커스(Hibiscys rosasanensis), 장미(Rosa spp.), 튤립(Tulipa spp.), 나팔수선화(Narcissus spp.), 페튜니아(Petunia hybrida), 카네이션(Dianthus caryophyllus), 포인세티아(Euphorbia pulcherrima) 및 국화가 포함된다. 본 발명의 실행에 사용할 수 있는 침엽수에는 예를 들면, 테다소나무(Pinus taeda), 슬래쉬 소나무(Pinus elliotii), 폰데로사 소나무(Pinus ponderosa), 로지폴 소나무(Pinus contorta) 및 몬테레이 소나무(Pinus radiata)와 같은 소나무, 더글라스 전나무(Pseudotsuga menziesii); 미국솔송나무(Tsuga canadensis); 싯카 가문비나무(Picea glauca); 미국삼나무(Sequoia sempervirens); 은색 전나무(Abies amabilis) 및 발삼 전나무(Abies balsamea)와 같은 참전나무; 및 미국붉은삼나무(Thuja plicata) 및 알래래스카 황색삼나무(Chamaecyparis nootkatensis)와 같은 삼나무가 포함된다. 콩과 식물에는 콩 및 완두가 포함된다. 콩에는 구아르, 구주콩, 호로파, 대두, 은원콩, 광저기, 녹두, 리마콩, 파바콩, 렌즈콩, 병아리콩 등이 포함된다. 콩과 식물에는 아라키스(예를 들면, 땅콩), 비시아(예를 들면, 황금싸리, 헤어리 베치, 팥, 녹두 및 병아리콩), 루피너스(예를 들면, 루핀, 트리폴리움), 파설루스(예를 들면, 채두 및 리마콩), 피섬(예를 들면, 잠두), 멜릴로투스(예를 들면, 클로버), 메디카고(예를 들면, 자주개자리), 로투스(예를 들면, 트레포일), 렌즈(예를 들면, 렌즈콩 및 낭아초)가 포함되지만, 이에 제한되지는 않는다. 본 발명의 방법에 사용하기에 바람직한 목초 및 잔디풀에는 자주개자리, 새발풀, 큰김의털, 페레니알 라이그래스(perennial ryegrass), 눈겨이삭 잔디 및 붉은겨이삭이 포함된다. Vegetables include tomatoes (Lycopersicon esculentum), lettuce (e.g., Lactuca sativa), green beans (Phaseolus vulgaris), lyca beans (Phaseolus limensis), peas (Lathyrus spp.), Cauliflower, broccoli, turnips, radishes, spinach, Asparagus, onions, garlic, peppers, celery, and members of the genus Melon, such as cucumber (C. sativus), C. cantalupensis, and C. melo. Ornamental plants include Rhododendron spp., Hydrangea (Macrophylla hydrangea), Hibiscus (Hibiscys rosasanensis), Rose (Rosa spp.), Tulip (Tulipa spp.), Narcissus spp., Petunia hybrida, Carnations (Dianthus caryophyllus), Poinsettia (Euphorbia pulcherrima) and chrysanthemum. Conifers that may be used in the practice of the present invention include, for example, Pinus taeda, Pinus elliotii, Pinus ponderosa, Pinus contorta, and Monterey pine (Pinus). pines such as radiata, Douglas fir (Pseudotsuga menziesii); Tsuga canadensis; Sitka spruce (Picea glauca); American cedar (Sequoia sempervirens); Veterans such as silver fir (Abies amabilis) and Abies balsamea; And cedars such as the American Red Cedar (Thuja plicata) and Alaska Yellow Cedar (Chamaecyparis nootkatensis). Legumes include beans and peas. Soybeans include guar, soybeans, fenugreek, soybeans, silver beans, madgi, green beans, lima beans, paba beans, lentils, and chickpeas. Legumes include arachis (e.g. peanuts), bisia (e.g. golden leeks, hairy bitches, red beans, mung beans and chickpeas), lupine (e.g. lupines, trifolium) Ruth (e.g., soybeans and lima beans), P. sume (e.g., alfalfa), Melilotus (e.g. clover), Medicago (e.g. alfalfa), Lotus (e.g. trefoil) ), But are not limited to lenses (eg lentils and cyanobacteria). Preferred grasses and turfgrass for use in the method of the present invention include alfalfa, stalk grass, laver hair, perennial ryegrass, snow ear grass and red ear wheat.
바람직하게는, 본 발명의 식물은 작물, 예를 들면, 옥수수, 자주개자리, 해바라기, 브라시카, 대두, 목화, 잇꽃, 땅콩, 수수, 밀, 기장, 담배, 보리, 벼, 토마토, 감자, 스쿼시, 멜론, 콩과 작물 등이 포함된다. 다른 바람직한 식물에는 백합아강 및 기장아과가 포함된다. Preferably, the plant of the present invention is a crop, for example, corn, alfalfa, sunflower, brassica, soybean, cotton, safflower, peanut, sorghum, wheat, millet, tobacco, barley, rice, tomato, potato, squash , Melon, legumes and more. Other preferred plants include the Liliaceae and Elderaceae.
일단 목적하는 DNA 서열을 특정한 식물 종 내로 형질전환한 후, 통상적인 육종 기법을 사용하여 그 종 내에서 증식시키거나 다른 다양한 동일한 종(특히 상업적 품종을 포함하는)으로 이동시킨다. Once the desired DNA sequence is transformed into a particular plant species, it can be propagated within that species using conventional breeding techniques or transferred to various other identical species (including commercial varieties in particular).
다음은 쌍자엽 및 단자엽 식물 둘 다를 형질전환시키는 대표적 기법 및 대표적인 색소체 형질전환 기법의 기술이다.The following is a description of representative techniques and representative chromatin transformation techniques for transforming both dicotyledonous and monocotyledonous plants.
a. 쌍자엽 식물의 형질전환a. Transformation of Dicotyledonous Plants
쌍자엽 식물에 대한 형질전환 기법은 당해 분야에 널리 공지되어 있으며 애그로박테리움-계 기법 및 애그로박테리움을 필요로 하지 않는 기법이 포함된다. 비-애그로박테리움 기법은 원형질체 또는 세포에 의한 직접적인 외인성 유전자 물질의 수용을 포함한다. 이는 PEG 또는 전기천공 매개 수용, 입자 충격-매개 전달 또는 미세주입에 의해 성취할 수 있다. 이들 기법의 예는 문헌[참조: Paszkowski et al., EMBO J, 3: 2717 (1984), Potrykus et al., Mol. Gen. Genet., 199:169 (1985), Reich et al., Biotechnology, 4: 1001(1986), 및 Klein et al., Nature, 327:70 (1987)]에 기술되어 있다. 각각의 경우에, 형질전환 세포는 당해 분야에 공지된 표준 기법을 사용하여 전체 식물로 재생된다. Transformation techniques for dicotyledonous plants are well known in the art and include Agrobacterium-based techniques and techniques that do not require Agrobacterium. Non-Agrobacterium techniques include the uptake of exogenous genetic material directly by protoplasts or cells. This can be accomplished by PEG or electroporation mediated reception, particle impact-mediated delivery or microinjection. Examples of these techniques are described in Paszkowski et al., EMBO J, 3: 2717 (1984), Potrykus et al., Mol. Gen. Genet., 199: 169 (1985), Reich et al., Biotechnology, 4: 1001 (1986), and Klein et al., Nature, 327: 70 (1987). In each case, the transformed cells are regenerated into whole plants using standard techniques known in the art.
애그로박테리움-매개 형질전환은 이의 높은 형질전환 효율 및 이의 많은 상이한 종과의 폭넓은 효용성 때문에, 쌍자엽 식물의 형질전환을 위한 바람직한 기법이다. 애그로박테리움 형질전환은 통상 동시-정주 Ti 플라스미드 또는 염색체성의 숙주 애그로박테리움 균주(예를 들면, pCIB200 및 pCIB2001용 균주 CIB542)에 의해 보유된 vir 유전자의 상보체에 따를 수 있는 적합한 애그로벡티리움 균주로의 관심의 외래 DNA를 보유하는 이원 벡터(예를 들면, pCIB200 또는 pCIB2001)의 전달을 포함한다(문헌[참조: Uknes et al., Plant Cell, 5:159(1993)]). 재조합 이원 벡터의 애그로박테리움으로의 전달은 재조합 이원 벡터를 보유하는 이. 콜라이, pRK2013과 같은 플라스미드를 보유하며, 재조합 이원 벡터를 표적 애그로박테리움으로 이동시킬 수 있는 조력 이. 콜라이 균주를 사용하는 삼친 교배 과정으로 달성한다. 대안적으로, 재조합 이원 벡터를 DNA 형질전환에 의해 애그로박테리움으로 전달할 수 있다(문헌[참조: Hofgen & Willmitzer, Nucl., Acids Res., 16:9877(1988)]).Agrobacterium-mediated transformation is a preferred technique for the transformation of dicotyledonous plants because of its high transformation efficiency and its wide utility with many different species. Agrobacterium transformation is usually a suitable Agro that can be followed by the complement of the vir gene carried by a co-stable Ti plasmid or a chromosomal host Agrobacterium strain (eg strain CIB542 for pCIB200 and pCIB2001). Delivery of a binary vector (eg, pCIB200 or pCIB2001) that carries foreign DNA of interest to the Vectrium strain (Uknes et al., Plant Cell, 5: 159 (1993)). Delivery of the recombinant binary vector to Agrobacterium results in E. coli carrying the recombinant binary vector. E. coli, which has a plasmid such as pRK2013 and which is capable of transferring a recombinant binary vector to a target Agrobacterium. Achieved by the maternal breeding process using E. coli strains. Alternatively, recombinant binary vectors can be delivered to Agrobacterium by DNA transformation (Hofgen & Willmitzer, Nucl., Acids Res., 16: 9877 (1988)).
재조합체 애그로박테리움에 의한 표적 식물 종의 형질전환은 일반적으로 식물로부터의 외식체와 애그로박테리움의 공동-배양을 포함하며, 다음의 프로토콜이 당해 분야에 널리 공지되어 있다. 형질전환 조직을 이원 플라스미드 T-DNA 경계 사이에 존재하는 항생제 또는 제초제 내성 마커를 보유하는 선별 배지에서 재생한다.Transformation of target plant species by recombinant Agrobacterium generally involves co-culture of explants and Agrobacterium from plants, and the following protocols are well known in the art. Transformed tissue is regenerated in selection medium containing antibiotic or herbicide resistance markers present between the binary plasmid T-DNA boundaries.
당해 벡터를 공지된 방법으로 식물 세포 내로 도입할 수 있다. 형질전환에 바람직한 세포에는 애그로박테리움, 단자엽 세포 및 쌍자엽 세포(백합아강 세포 및 기장아과 세포를 포함하는)가 포함된다. 바람직한 단자엽 세포는 곡류 세포, 예를 들면, 옥수수(옥수수), 보리 및 밀, 및 전분 축적 쌍자엽 세포, 예를 들면, 감자이다. The vector can be introduced into plant cells by known methods. Preferred cells for transformation include Agrobacterium, monocotyledonous cells and dicotyledonous cells (including celiac cells and millet pediatric cells). Preferred monocotyledonous cells are cereal cells such as corn (corn), barley and wheat, and starch accumulating dicotyledonous cells such as potatoes.
유전자로 식물 세포를 형질전환시키는 다른 방법은 식물 조직 및 세포에서 불활성 또는 생물학적 활성 입자를 추진하는 단계를 포함한다. 당해 기법은 미국 특허 제4,945,050호, 5,036,006호 및 제5,100,792호에 개시되어 있다. 일반적으로, 당해 방법은 세포 외부 표면에 침투하고 이의 내부로 혼입시키는 데 효과적인 조건하에 불활성 또는 생물학적 활성 입자를 세포로 추진하는 단계를 포함한다. 불활성 입자를 사용하는 경우, 목적하는 유전자를 포함하는 벡터로 입자를 피복하여 세포 내로 벡터를 도입할 수 있다. 대안적으로, 표적 세포를 벡터로 둘러쌓이게 하여 벡터가 입자의 궤적을 따라서 세포 내로 운반되게 할 수 있다. 생물학적 활성 입자(예를 들면, 각각 도입시키고자 하는 DNA를 포함하는 무수 효소 세포, 무수 세균 또는 박테리오파지)를 또한 식물 세포 조직 내로 추진할 수 있다.Another method of transforming plant cells with genes includes propagating inert or biologically active particles in plant tissues and cells. This technique is disclosed in US Pat. Nos. 4,945,050, 5,036,006 and 5,100,792. In general, the method includes propelling the inert or biologically active particles into the cell under conditions effective to penetrate and incorporate into the outer surface of the cell. When inert particles are used, the vector can be introduced into cells by coating the particles with a vector containing the gene of interest. Alternatively, the target cells can be surrounded by a vector to allow the vector to be carried into the cell along the trajectory of the particle. Biologically active particles (eg, anhydrous enzyme cells, anhydrous bacteria or bacteriophages, each comprising DNA to be introduced) may also be propagated into plant cell tissue.
b. 단자엽 식물의 형질전환b. Transformation of monocotyledonous plants
대부분의 단자엽 종의 형질전환도 또한 현재는 통상적인 것이 되었다. 바람직한 기법에는 폴리에틸렌 글라이콜(PEG) 또는 전기천공 기법을 사용한 원형질체 내로의 유전자의 직접적 전달 및 유합 조직 내로의 입자 충격이 포함된다. 형질전환은 단일 DNA 종 또는 다중 DNA 종(즉, 공-형질전환)을 사용하여 수행할 수 있으며, 이들 기법 둘 다 본 발명과 함께 사용하기에 적합하다. 공-형질전환은 완전한 벡터 작제 및 관심 유전자 및 선별 마커에 대한 연계되지 않은 좌를 갖는 형질전환된 식물의 초래를 피하고, 후세대에서 선별 마커를 제거할 수 있다는(이것이 바람직하다고 간주되는 경우) 이점을 가질 수 있다. 그러나, 공-형질전환의 사용의 불이익은 분리된 DNA 종이 게놈 내로 통합되는 빈도가 100% 미만이라는 것이다(문헌[참조: Schocher et al., Biotechnology, 4: 1093, 1986]).Transformation of most monocot species is also now common. Preferred techniques include direct delivery of genes into protoplasts using polyethylene glycol (PEG) or electroporation techniques and particle bombardment into callus tissue. Transformation can be performed using a single DNA species or multiple DNA species (ie co-transformation), both of which are suitable for use with the present invention. Co-transformation has the advantage of being able to avoid complete vector construction and transformed plants with unassociated loci for genes of interest and selection markers, and to remove the selection markers in later generations (if this is deemed desirable). Can have. However, a disadvantage of the use of co-transformation is that the frequency of integration of isolated DNA species into the genome is less than 100% (Schocher et al., Biotechnology, 4: 1093, 1986).
유럽 특허원 제EP 0 292 435호, 제EP 0 392 225호 및 제WO 93/07278호는 옥수수의 우수 근교계로부터의 유합 조직 및 원형질체의 제조, PEG 또는 전기천공을 사용한 원형질체의 형질전환, 및 형질전환 원형질체로부터의 옥수수 식물의 재생에 대한 기법을 기술한다. 저자 Gordon-Kamm 등(문헌[참조: Plant Cell, 2: 603(1990)]) 및 저자 Fromm 등(문헌[참조: Biotechnology, 8: 833 (1990)])는 입자 충격을 사용한 A188-유래 옥수수 RPduf의 형질전환 기법을 출판하였다. 추가로, 국제공개공보 제WO 93/07278호 및 저자 Koziel 등의 문헌[참조: Biotechnology, 11: 194 (1993)])은 입자 충격에 의한 옥수수의 우수 순계의 형질전환 기법을 기술한다. 당해 기법은 수분 후 14 내지 15일째에 옥수수 이삭으로부터 절제한 1.5 내지 2.5mm 길이의 미성숙 옥수수 배아 및 충격용 PDS-1000He 생탄도 장비를 사용한다.
벼의 형질전환은 또한 원형질체 또는 입자 충격을 사용하는 직접적 유전자 전달 기법으로 수행할 수 있다. 원형질체-매개 형질전환은 쟈포니카(Japonica)형 및 인디카(Indica)형에 대하여 기술되어 있다(문헌[참조: Zhang et al., Plant Cell Rep, 7:379(1988); Shimamoto et al., Nature, 338: 274 (1989) ; Datta et al., Biotechnology, 8: 736 (1990)]). 또한, 이들 두 형태 모두 입자 충격을 사용하여 통상적으로 형질전환가능하다(문헌[참조: Christou et al.,Biotechnology, 9: 957 (1991)]). 추가로, 국제공개공보 제WO 93/21335호는 전기천공법을 통한 벼의 형질전환 기법을 기술한다. 특허 출원 제EP 0 332 581호는 포아풀아과 원형질체의 발생, 형질전환 및 재생 기법을 기술한다. 이들 기법은 닥틸리스(Dactylis) 및 밀의 형질전환을 가능하게 한다. 추가로, 밀 형질전환이 C형 장기 재생가능 유합 조직의 세포 내로의 입자 충격을 사용한 문헌[참조: Vasil et al., Biotechnology, 10: 667(1992)], 및 또한 미성숙 배아 및 미성숙 배아-유래 유합세포의 입자 충격을 사용한 문헌[참조: Vasil et al. (Biotechnology, 11: 1553 (1993)) 및 Weeks et al.(Plant Physiol., 102: 1077 (1993)]에 기술되어 있다. 그러나 바람직한 밀 전환 기법은 미성숙 배아의 입자 충격에 의한 밀의 형질전환을 포함하며, 유전자 전달 전의 고 슈크로즈 또는 고 말토즈 단계를 포함한다. 충격 전, 임의의 수의 배아(0.75 내지 1mm 길이)를 3% 슈크로즈(문헌[참조: Murashiga & Skoog, Physiologia Plantarum, 15: 473 (1962)]) 및 암실에서 진행할 수 있는, 체세포 배아의 유도를 위한 2,4-D 3mg/l를 갖는 MS 배지 상에 평판 배양한다. 선택된 충격 당일, 항온처리 배지로부터 배아를 제거하고 삼투배지(즉, 목적하는 농도, 통상적으로는 15%로 첨가한 슈크로즈 또는 말토즈를 갖는 유도 배지) 상에 둔다. 배아를 2 내지 3시간 동안 원형질분리시킨 후 충격을 가한다. 표적 플레이트 당 20개의 배아가 통상적이지만, 결정적인 것은 아니다. 적합한 유전자-보유 플라스미드(예를 들면, pCIB3064 또는 pSG35)를 표준 방법을 사용하여 마이크로미터 크기의 금 입자 상에 침착시킨다. 각각의 배아의 플레이트에 표준 80 메시 스크린을 사용하는 약 1000psi의 폭발압을 사용하는 DuPont BiolosticsR 헬륨 장비를 사용하여 쏜다. 충격을 가한 후, 배아를 다시 암실에 두어 약 24시간 동안(여전히 삼투배지 상에서) 회복시킨다. 24시간 후, 배아를 삼투배지에서 제거하고 다시 유도 배지 상에 두고, 재생 전 한달 동안 머무르게 한다. 대략 한달 후, 발생중인 배아발생성 유합조직을 갖는 배아 외식체를 추가로 적합한 선별 제제(pCIB3064의 경우 10mg/1 바스타 및 pSOG35의 경우, 메토트레세이트 2mg/l)를 함유하는 재생 배지(MS + 1mg/리터 NAA, 5mg/리터 GA)로 옮긴다. 대략 한달 후, 발달한 순을 중간 강도의 MS, 2% 슈크로즈 및 동일한 농도의 선별 제제를 함유하는 "GA7s"로 공지된 대형 멸균 용기로 옮긴다. Rice transformation can also be accomplished by direct gene transfer techniques using protoplasts or particle bombardment. Protoplast-mediated transformation has Jockey pony car is (Japonica) is described with respect to the types and Indica (Indica) type (as described in Reference: Zhang et al, Plant Cell Rep , 7: 379 (1988); Shimamoto et al,.. Nature, 338: 274 (1989); Datta et al., Biotechnology, 8: 736 (1990)). In addition, both forms are commonly transformable using particle bombardment (Christou et al., Biotechnology, 9: 957 (1991)). In addition, WO 93/21335 describes a technique for transforming rice through electroporation.
애그로박테리움을 사용한 단자엽 식물의 형질전환 또한 기술되어 있다. 본원에 참조로 인용되어 있는, 국제공개공보 제WO 94/00977호 및 미국 특허 제5,591,616호를 참조한다. Transformation of monocotyledonous plants with Agrobacterium is also described. See WO 94/00977 and US Pat. No. 5,591,616, which are incorporated herein by reference.
c. 색소체의 형질전환c. Transformation of the Chromosome
니코티아나 타바쿰 씨.브이.(Nicotiana tabacum c.v.) "Xanthi nc"의 종자를 T 아가 배지 상의 1" 환형 정렬로 플레이트당 7개씩 발아시키고, 기술된 바와 같이 필수적으로 플라스미드 pPH143 및 pPH145로부터의 DNA로 피복한 1㎛ 텅스텐 입자(M10, Biorad, 캘리포니아주 헤르쿨레스 소재)로 파종한 후 12 내지 14일째에 충격을 가한다(문헌[참조: Svab and Maliga, PNAS, 90: 913 (1993)]). 충격을 가한 묘목을 잎을 제거하고 스펙티노마이신 다이하이드로클로라이드(제조사[Sigma], 미주리주 세인트 루이스 소재) 500㎍/ml을 함유하는 RMOP 배지(Svab, Hajdukiewicz and Maliga, PNAS, 87:8526(1990))의 플레이트 상에 밝은 광(350-500μmol 광자/m2/s)하에 배축이 위를 향하게 놓은 후 2일 동안 T 배지에서 항온처리한다. 충격을 가한지 3주 내지 8주 후, 탈색된 잎 아래에 나타난 내성을 갖는 순을 동일한 선별 배지에서 계대 클로닝하여 유합조직을 형성하고, 제2 순을 분리 및 계대 클로닝한다. 독립적 계대 클론의 형질전환된 색소체 게놈의 복사체(상동색소체)의 완전한 분리는 서던 블롯팅의 표준 기법으로 사정한다(문헌[참조: Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, Cold Spring Harbor (1989)]). BamHI/EcoRI-분해된 총 세포성 DNA(문헌[참조: Mettler, I. J. Plant Mol Biol Reporter, 5:346(1987)])을 1% 트리스-붕산염(TBE) 아가로스 겔 상에서 분리하고, 나일론 막(Amersham)으로 옮겨 rps7/12 색소체 표적화 서열의 부위를 포함하는 pC8으로부터의 0.7kb BamHI/HindIII DNA 단편에 상응하는 32P-표지된 무작위적 프라이밍된 DNA 서열로 프로빙(probing)한다. 상동색소체성 순을 스펙티노마이신-함유 MS/IBA 배지 상에 살균적으로 활착시키고(문헌[참조: McBride et al., PNAS, 91:7301(1994)]), 온실로 옮긴다. Nicotiana tabacum cv. Seeds of "Xanthi nc" are germinated 7 per plate in 1 "cyclic alignment on T agar medium and essentially with DNA from plasmids pPH143 and pPH145 as described. Shock is applied 12 to 14 days after sowing with coated 1 μm tungsten particles (M10, Biorad, Hercules, Calif.) (Svab and Maliga, PNAS, 90: 913 (1993)). Seedlings were removed from leaves and RMOP medium (Svab, Hajdukiewicz and Maliga, PNAS, 87: 8526 (1990) containing 500 μg / ml of spectinomycin dihydrochloride (Sigma, St. Louis, MO) Incubate in T medium for 2 days with the embryonic axis facing upwards under bright light (350-500 μmol photons / m 2 / s) on a plate of 3). The order of resistance shown below was obtained from the same selection medium. Passage cloning to form a callus, separation and passage cloning of the second order Complete isolation of the copy (homologous chromosome) of the transformed plastid genome of an independent passage clone is assessed by standard techniques of Southern blotting. See Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, Cold Spring Harbor (1989)). BamHI / EcoRI-lysed total cellular DNA (Mettler, IJ Plant Mol Biol Reporter). , 5: 346 (1987)]) were separated on a 1% tris-borate (TBE) agarose gel and transferred to a nylon membrane (Amersham) 0.7 kb BamHI / from pC8 containing the site of the rps7 / 12 chromatin targeting sequence. Probing with 32 P-labeled randomly primed DNA sequences corresponding to HindIII DNA fragments. Homologous chromosomal order is sterilely adhered on spectinomycin-containing MS / IBA medium (McBride et al., PNAS, 91: 7301 (1994)) and transferred to a greenhouse.
안정하게 형질전환된 식물의 제조 및 특성화Preparation and Characterization of Stably Transformed Plants
이어서 형질전환된 식물 세포를 형질전환 세포의 선별에 적합한 선별 배지에 놓은 후, 유합 조직으로 성장시킨다. 순이 유합 조직으로부터 성장되며 활착 배지에서 배양함에 따라 순으로부터 모종이 발생된다. 일반적으로 각종 작제물을 식물 세포에서의 선별용 마커에 결합할 것이다. 통상적으로, 마커는 살생물제(특히, 카나마이신, G418, 블레오마이신, 하이그로마이신, 클로람페니콜, 제초제 등과 같은 항생제)에 대하여 내성을 가질 수 있다. 사용된 특정 마커는 도입된 DNA가 결실된 세포와 비교하여 형질전환 세포의 선별을 가능하게 할 것이다. 본 발명의 전사/발현 카세트를 포함하는 DNA 작제물의 성분을 숙주에 대한 천연(내인성) 또는 외래(외인성) 서열로부터 제조할 수 있다. "외래"는 당해 서열이 작제물이 도입된 야생형 숙주 내에서 발견되지 않음을 의미한다. 이종성 작제물은 전사-개시-영역이 유래한 유전자가 원산지가 아닌 하나 이상의 영역을 포함할 것이다.The transformed plant cells are then placed in a selection medium suitable for the selection of the transformed cells, which are then grown into callus tissue. The shoots are grown from the callus and seedlings are generated from the shoots as they are cultured in lubricating medium. In general, various constructs will bind to markers for selection in plant cells. Typically, the marker may be resistant to biocides (particularly antibiotics such as kanamycin, G418, bleomycin, hygromycin, chloramphenicol, herbicides and the like). The specific marker used will allow the selection of transformed cells as compared to cells in which the introduced DNA has been deleted. Components of the DNA constructs comprising the transcription / expression cassettes of the invention can be prepared from native (endogenous) or foreign (exogenous) sequences to the host. "Exotic" means that the sequence is not found in the wild type host into which the construct was introduced. Heterologous constructs will include one or more regions from which the gene from which the transcription-initiation-region originated is not native.
형질전환 세포 및 식물 내의 전이유전자의 존재를 확인하기 위해, 당해 분야의 숙련가에게 공지되어 있는 방법을 사용하여 서던 블롯 분석을 수행할 수 있다. 폴리핵산 단편의 게놈 내로의 삽입을 서던 블롯으로 검출 및 정량화할 수 있는데, 이는 이들이 적합한 제한 효소의 사용으로 단편을 포함하는 작제물과 용이하게 구별될 수 있기 때문이다. 전이유전자의 발현 생성물을 생성물의 성질에 따르며, 웨스턴 블롯 및 효소 검정을 포함하는, 임의의 각종 방법으로 검출할 수 있다. 상이한 식물 조직 내에서의 단백질 발현을 정량화하고 복제를 검측하는 한가지 특히 유용한 방법은 GUS와 같은 보고 유전자를 사용하는 것이다. 일단 형질전환된 식물을 수득하면, 이들을 목적하는 표현형을 갖는 식물 조직 및 일부를 제조하기 위해 배양할 수 있다. 식물 조직 또는 식물 부분을 수확하고/거나 종자를 수거할 수 있다. 종자를 목적하는 특성을 갖는 조직 또는 일부를 갖는 부가의 식물을 배양하기 위한 공급원으로서 제공할 수 있다. Southern blot analysis can be performed using methods known to those of skill in the art to confirm the presence of transgenes in transformed cells and plants. Insertion of polynucleic acid fragments into the genome can be detected and quantified by Southern blot, as they can be readily distinguished from the construct containing the fragments by the use of suitable restriction enzymes. The expression product of the transgene is dependent on the nature of the product and can be detected by any of a variety of methods, including Western blots and enzyme assays. One particularly useful method of quantifying protein expression and detecting replication in different plant tissues is to use report genes such as GUS. Once the transformed plants are obtained, they can be cultured to produce plant tissues and parts having the desired phenotype. Plant tissue or plant parts may be harvested and / or seed collected. Seeds can be provided as a source for culturing additional plants having a portion or tissue having the desired properties.
따라서 본 발명은 하나 이상의 본 발명의 폴리펩타이드, 발현 카세트 또는 벡터를 포함하는 형질전환된 식물 또는 식물 부분(예를 들면, 이삭, 종자, 과실, 곡립, 스토버, 겨 또는 바가스), 당해 식물의 제조방법 및 당해 식물 또는 이의 일부의 사용 방법을 제공한다. 형질전환된 식물 또는 식물 부분은 임의로 특정한 조직의 특정 세포 또는 아세포 구획 또는 발생중인 곡립에 국소화된 가공 효소를 발현한다. 예를 들면, 본 발명은 게놈이 하나 이상의 전분 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 식물 세포 내에 존재하는 하나 이상의 전분 가공 효소를 포함하는 형질전환된 식물 부분을 제공한다. 가공 효소는 가열, 연마 또는 효소가 활성인 조건하에 효소를 기질에 접촉하게 하는 기타 방법과 같은 방법에 의해 활성화되지 않는 한 표적 기질에 작용하지 않는다. Thus, the present invention is directed to transformed plants or plant parts (eg, ear, seed, fruit, grain, stover, bran or vargas) comprising one or more polypeptides, expression cassettes or vectors of the invention, such plants It provides a method of producing and a method of using the plant or part thereof. Transformed plants or plant parts optionally express processing enzymes localized in specific cell or blast compartments or developing grains of specific tissues. For example, the present invention provides a transformed plant portion comprising one or more starch processing enzymes present in plant cells, obtained from transformed plants whose genome is enhanced with an expression cassette encoding one or more starch processing enzymes. do. The processing enzyme does not act on the target substrate unless activated by heating, polishing or other methods of bringing the enzyme into contact with the substrate under conditions in which the enzyme is active.
본 발명의 예시적 방법Exemplary Methods of the Invention
본 발명의 자가-가공 식물 및 식물 부분은 당해 자가-가공 식물 및 식물 부분에서 발현 및 활성화되는 가공 효소(중온성, 호열성 또는 초호열성)을 사용하는 각종 방법에 사용할 수 있다. 본 발명에 따르면, 게놈이 하나 이상의 가공 효소로 증강된 형질전환된 식물로부터 수득한 형질전환된 식물 부분은 가공 효소가 발현 및 활성화되는 조건하에 둔다. 활성화에 따라, 가공 효소는 활성화되고 목적하는 결과를 얻기 위해 이 효소가 통상적으로 작용하는 기질 기질에 작용하도록 기능한다. 예를 들면, 전분-가공 효소는 전분에 작용하여 분해, 가수분해, 이성체화 또는 그밖에 변형시켜 목적하는 결과를 수득할 수 있게 한다. 비-전분 가공 효소는 전분, 지질, 아미노산 또는 기타 식물로부터의 생성물의 추출을 촉진하기 위해 식물 세포막을 파괴하는 데 사용될 수 있다. 추가로, 비-초호열성 및 초호열성 효소는 본 발명의 자가-가공 식물 또는 식물 부분와 함께 사용할 수 있다. 예를 들면, 중온성 비-전분 분해 효소를 활성화하여 전분 추출을 위해 식물 세포막을 파괴할 수 있으며, 연속하여, 초호열성 전분-분해 효소를 이어서 자가-가공 식물 내에서 활성화하여 전분을 분해할 수 있다. The self-processing plants and plant parts of the present invention can be used in various methods using processing enzymes (medium, thermophilic or superthermophilic) that are expressed and activated in such self-processing plants and plant parts. According to the invention, the transformed plant part obtained from the transformed plant whose genome has been enhanced with one or more processing enzymes is placed under conditions under which the processing enzyme is expressed and activated. Upon activation, the processing enzyme is activated and functions to act on the substrate substrate to which it normally functions to achieve the desired result. For example, starch-processing enzymes can act on starch to degrade, hydrolyze, isomerize or otherwise modify to yield the desired results. Non-starch processing enzymes can be used to disrupt plant cell membranes to facilitate extraction of starch, lipids, amino acids or other products from plants. Additionally, non-superthermophilic and superthermotropic enzymes can be used with the self-processing plants or plant parts of the present invention. For example, mesophilic non-starch degrading enzymes can be activated to destroy plant cell membranes for starch extraction, and subsequently, superthermotropic starch-degrading enzymes can then be activated in self-processing plants to degrade starch. have.
곡립 내에서 발현하는 효소는 이들의 활성을 증진하는 조건하에 이들을 함유하는 식물 또는 식물 부분을 위치시켜 활성화시킬 수 있다. 예를 들면, 다음의 기법 중 하나 이상을 사용할 수 있다. 식물 부분을 가수분해 효소에 대한 기질을 제공하는 물과 접촉시킬 수 있으며 , 이에 따라 효소가 활성화될 것이다. 식물 부분을 효소가 식물 부분의 발달 중 침전되었던 구획으로부터 이동시킬 물과 접촉시켜 이의 기질과 연결할 수 있다. 성숙, 곡립의 건조 및 재-수화 중에는 구획화가 이행되지 않기 때문에 효소의 이동은 가능하다. 효소를 식물 부분의 발달 중 침전되었던 구획으로부터 이동시킬 물과 원형의 또는 동할립을 접촉시켜 이의 기질과 연결할 수 있다. 효소는 또한 활성화 화합물의 첨가에 의해 활성화할 수 있다. 예를 들면, 칼슘-의존 효소는 칼슘의 첨가에 의해 활성화될 수 있다. 기타 활성화 화합물은 당해 분야의 숙련가가 결정할 수 있다. 효소는 불활성화제의 제거에 의해 활성화될 수 있다. 예를 들면, 아밀라제 효소의 펩타이드 억제제가 공지되어 있으며, 아밀라제는 아밀라제 억제제와 동시-발현한 후 프로테아제의 첨가에 의해 활성화될 수 있다. 효소는 pH를 당해 효소가 가장 활성적인 pH로 변화시킴으로써 활성화될 수 있다. 효소는 또한 온도를 높임으로써 활성화될 수 있다. 효소는 일반적으로 당해 효소에 대한 최적 온도까지 활성이 증가한다. 중온성 효소는 활성 주위 온도의 수준으로부터 통상적으로 70℃ 이하인 활성을 잃는 온도까지 활성이 증가할 것이다. 유사하게 호열성 및 초호열성 효소는 또한 온도가 증가함에 따라 활성화될 수 있다. 호열성 효소는 활성 또는 안정성의 최대 온도 이하의 온도로 가열함으로써 활성화할 수 있다. 호열성 효소에 대한 안정성 및 활성의 최대 온도는 일반적으로 70℃ 내지 85℃일 것이다. 초호열성 효소는 25℃에서 85℃ 내지 95℃ 또는 심지어 100℃까지의 큰 잠재 변화 때문에, 중온성 또는 호열성 효소보다 상대적으로 더 큰 활성을 가질 것이다. 온도 증가는 임의의 방법(예를 들면, 굽기, 끓이기, 가열, 찜, 전기 방전 또는 이의 임의의 조합과 같은 가열)에 의해 달성할 수 있다. 추가로, 중온성 또는 호열성 효소(들)를 발현하는 식물 내에서, 효소를 연마하여 활성화시킬 수 있으며, 이에 따라 효소를 기질과 접촉시킬 수 있다. Enzymes that express in grains can be activated by placing plants or plant parts containing them under conditions that enhance their activity. For example, one or more of the following techniques may be used. The plant part may be contacted with water, which provides a substrate for the hydrolase, which will activate the enzyme. The plant part can be contacted with its substrate by contacting water to be moved from the compartment where the enzyme has precipitated during the development of the plant part. Enzyme migration is possible because no compartmentalization occurs during maturation, grain drying and rehydration. Enzymes can be contacted with their substrates by contacting circular or copper alleles with water to be removed from the compartments that have settled during the development of the plant part. Enzymes can also be activated by the addition of activating compounds. For example, calcium-dependent enzymes can be activated by the addition of calcium. Other activating compounds can be determined by one skilled in the art. The enzyme can be activated by removal of the inactivating agent. For example, peptide inhibitors of amylase enzymes are known and amylases can be activated by addition of protease after co-expression with amylase inhibitors. An enzyme can be activated by changing the pH to the pH at which the enzyme is most active. Enzymes can also be activated by raising the temperature. Enzymes generally increase in activity to an optimum temperature for that enzyme. The mesophilic enzyme will increase in activity from the level of the ambient temperature of activity to the temperature at which it loses activity, which is typically below 70 ° C. Similarly, thermophilic and superthermophilic enzymes can also be activated as the temperature increases. Thermophilic enzymes can be activated by heating to a temperature below the maximum temperature of the activity or stability. The maximum temperature of stability and activity for thermophilic enzymes will generally be between 70 ° C and 85 ° C. Superthermophilic enzymes will have relatively greater activity than mesophilic or thermophilic enzymes due to large potential changes from 25 ° C to 85 ° C to 95 ° C or even 100 ° C. The temperature increase can be achieved by any method (eg, heating, such as baking, boiling, heating, steaming, electric discharge or any combination thereof). In addition, in plants expressing mesophilic or thermophilic enzyme (s), the enzyme can be polished and activated, thereby allowing the enzyme to contact the substrate.
최적 조건(예를 들면, 온도, 수화, pH 등)은 당해 분야의 숙련가에 의해 결정될 수 있으며 사용할 개별 효소 및 목적하는 효소의 적용에 따를 수 있다. Optimum conditions (eg, temperature, hydration, pH, etc.) may be determined by one skilled in the art and may depend on the individual enzyme to be used and the application of the desired enzyme.
본 발명은 추가로 특정 방법에서 보조할 수 있는 외인성 효소의 용도를 제공한다. 예를 들면, 본 발명의 자가-가공 식물 또는 식물 부분의 용도는 외인성으로 제공된 효소와 함께 사용하여 반응을 촉진할 수 있다. 예를 들면, 형질전환 α-아밀라제 옥수수를 풀룰라나제, α-글루코시다제, 글루코즈 이소머라제, 만나나제 헤미셀룰라제 등과 같은 기타 전분-가공 효소와 함께 사용하여 전분을 가수분해하거나 에탄올을 제조할 수 있다. 사실, 형질전환 α-아밀라제 옥수수와 당해 효소의 조합이 기대치 않게 형질전환 α-아밀라제 옥수수만의 사용에 비하여 우수한 정도의 전분 전환을 제공함이 밝혀졌다. The invention further provides for the use of exogenous enzymes that can assist in certain methods. For example, the use of self-processing plants or plant parts of the present invention can be used in conjunction with an exogenously provided enzyme to facilitate the reaction. For example, transgenic α-amylase maize is used in combination with other starch-processing enzymes such as pullulanase, α-glucosidase, glucose isomerase, mannase hemicellulase and the like to hydrolyze starch or produce ethanol. can do. In fact, it has been found that the combination of transgenic α-amylase corn and the enzyme unexpectedly provides an excellent degree of starch conversion compared to the use of transgenic α-amylase corn alone.
본원에서 고찰한 적합한 방법의 예가 제공되어 있다. Examples of suitable methods discussed herein are provided.
a. 식물로부터의 전분 추출물a. Starch extract from plants
본 발명은 식물로부터의 전분의 추출을 촉진하는 방법을 제공한다. 특히, 내배유의 물리적 억제 기질(세포벽, 비-전분 다당류 및 단백질 기질)을 붕괴하는 가공 효소를 암호화하는 하나 이상의 폴리뉴클레오타이드를 식물로 도입하여, 바람직하게는 효소가 식물 내의 전분 과립에 근접하게 한다. 본 발명의 이러한 양태에서, 형질전환된 식물은 하나 이상의 프로테아제, 글루카나제, 자일라나제, 티오레독신/티오레독신 환원효소, 셀룰라제, 피타제, 리파제, 베타 글루코시다제, 에스테라제 등을 발현하지만, 임의의 전분 분해 활성을 갖는 효소는 발현하지 않아, 전분 과립의 온전함을 유지한다. 따라서 곡립과 같은 식물 부분 내에서의 이들 효소의 발현은 곡립의 가공 특성을 개선한다. 가공 효소는 중온성, 호열성 또는 초호열성일 수 있다. 한 예로, 본 발명의 형질전환된 식물로부터의 곡립을 비-초호열성 가공 효소를 불활성화하고 종자 온전성을 개선하기에 알맞게 가열 건조한다. 곡립(또는 동할립)을 저온 또는 고온(시간이 가장 중요함)에서 이산화황의 유무하에 고 또는 저 함수량 또는 조건으로 침지한다(본원에 참조로 인용되어 있는 문헌[Primary Cereal Processing, Gordon and Willm, eds., pp. 319-337(1994)]을 참조한다). 임의로는 특정한 습도 조건에서, 증가된 온도에 도달함에 따라, 내배유 기질의 온전성을 내배유 내에 존재하는 전분 과립은 손상되지 않은 채로 유지하고 수득된 물질로부터 보다 용이하게 회수가능하게 하면서, 그 안의 단백질 및 비-전분 다당류는 분해하는 효소(예를 들면, 프로테아제, 자일라나제, 피타제 또는 글루카나제)를 활성화시켜 파쇄한다. 추가로, 유출물 내의 단백질 및 비-전분 다당류를 최소한 부분적으로 분해 및 고도로 농축시켜, 동물 사료, 식품을 개선하기 위해 또는 미생물 발효용 배지 성분으로 사용할 수 있다. 유출물은 개선된 조성물을 갖는 옥수수-침지액으로 간주된다. The present invention provides a method for promoting the extraction of starch from plants. In particular, one or more polynucleotides encoding the processing enzymes that disrupt the endosperm's physical inhibitory substrates (cell walls, non-starch polysaccharides and protein substrates) are introduced into the plant, preferably bringing the enzyme close to the starch granules in the plant. In this aspect of the invention, the transformed plant is at least one protease, glucanase, xylanase, thioredoxin / thioredoxin reductase, cellulase, phytase, lipase, beta glucosidase, esterase And the like, but do not express any starch-degrading activity, thereby maintaining the integrity of the starch granules. The expression of these enzymes in plant parts such as grains thus improves the processing properties of the grains. The processing enzyme may be mesophilic, thermophilic or hyperthermia. In one example, the grains from the transformed plants of the present invention are heat dried to suitably inactivate non-thermophilic processing enzymes and improve seed integrity. The grains (or copper grains) are immersed at high or low water content or conditions at low or high temperatures (time is most important) with or without sulfur dioxide (Primary Cereal Processing, Gordon and Willm, eds, which is incorporated herein by reference). , pp. 319-337 (1994). Optionally, under certain humidity conditions, as the increased temperature is reached, the starch granules present in the endosperm remain intact and are more easily recoverable from the material obtained, Non-starch polysaccharides are disrupted by activating enzymes that degrade (eg, proteases, xylanase, phytase or glucanase). In addition, the proteins and non-starch polysaccharides in the effluent may be at least partially degraded and highly concentrated to improve animal feed, food or as a medium component for microbial fermentation. Effluents are considered to be corn-simmers with improved compositions.
따라서, 본 발명은 전분 과립을 제조하는 방법을 제공한다. 당해 방법은 하나 이상의 효소를 활성화하는 조건하에, 하나 이상의 비-전분 가공 효소를 포함하는 곡립(예를 들면, 동할립)을 처리하는 단계, 전분 과립 및 비-전분 분해 과립(예를 들면, 분해된 내배유 기질 생성물)을 포함하는 혼합물을 산출하는 단계를 포함한다. 비-전분 가공 효소는 중온성, 호열성 또는 초호열성일 수 있다. 효소의 활성화 후, 전분 과립을 혼합물로부터 분리한다. 당해 곡립은 게놈이 하나 이상의 가공 효소를 암호화하는 발현 카세트를 포함하는(발현 카세트로 증강된) 형질전환된 식물로부터 수득한다. 예를 들면, 가공 효소는 프로테아제, 글루카나제, 자일라나제, 피타제, 티오레독신/티오레독신 환원효소, 에스테라제, 셀룰라제, 리파제 또는 베타 글루코시다제일 수 있다. 가공 효소는 초호열성일 수 있다. 당해 곡립을 이산화황의 존재 혹은 부재하에, 저 또는 고 습도 조건하에 처리할 수 있다. 형질전환된 식물로부터의 곡립 내의 가공 효소의 발현 수준에 따라, 형질전환 곡립을 가공 전 또는 가공 중 상품 곡립과 혼합할 수 있다. 또한 전분, 비-전분 생성물 및 하나 이상의 부가 성분을 포함하는 개선된 침지수와 같은 당해 방법으로부터 수득한 생성물을 제공한다. Accordingly, the present invention provides a method for preparing starch granules. The method comprises the steps of treating a grain comprising one or more non-starch processing enzymes (e.g., cohalib) under conditions that activate one or more enzymes, starch granules and non-starch degraded granules (e.g., degradation). Calculating a mixture comprising the endosperm reflux substrate product). Non-starch processing enzymes may be mesophilic, thermophilic or hyperthermic. After activation of the enzyme, starch granules are separated from the mixture. The grains are obtained from transformed plants in which the genome comprises an expression cassette encoding one or more processing enzymes (enhanced with an expression cassette). For example, the processing enzyme may be a protease, glucanase, xylanase, phytase, thioredoxin / thioredoxin reductase, esterase, cellulase, lipase or beta glucosidase. The processing enzyme may be superthermophilic. The grains can be treated in the presence or absence of sulfur dioxide, under low or high humidity conditions. Depending on the expression level of the processing enzyme in the grains from the transformed plant, the transgenic grains may be mixed with the product grains before or during processing. Also provided are products obtained from this process, such as improved immersion water comprising starch, non-starch products and one or more additional ingredients.
b. 전분-가공 방법b. Starch-processing method
본 발명의 형질전환된 식물 또는 식물 부분은 전분 과립을 덱스트린, 기타 변형 전분 또는 헥소즈로 분해하거나(예를 들면, α-아밀라제, 풀룰라나제, α-글루코시다제, 글루코아밀라제, 아밀로풀룰라나제) 글루코즈를 프럭토즈로 전환하는(예를 들면, 글루코즈 이소머라제), 본원에 개시된 바와 같은 전분-분해 효소를 포함할 수 있다. 바람직하게는, 전분-분해 효소를 곡립을 형질전환하는 데 사용하는 α-아밀라제, α-글루코시다제, 글루코아밀라제, 풀룰라나제, 네오풀룰라나제, 아밀로풀룰라나제, 글루코즈 이소머라제 및 이의 배합물 중에서 선택한다. 추가로, 바람직하게는, 당해 효소를 프로모터 및 효소를 전분 과립, 전분체, 아포플라스트 또는 세포질세망으로 표절 설정하는 시그날 서열에 작동적으로 연결한다. 가장 바람직하게는, 당해 효소를 내배유, 및 특히, 옥수수 내배유에서 발현시키며, 하나 이상의 세포 구획 또는 그 자체의 전분 과립 내에 국소화시킨다. 바람직한 식물 부분은 곡립이다. 바람직한 식물 부분은 옥수수, 밀, 보리, 호밀, 귀리, 사탕수수 또는 벼로부터의 것이다. Transformed plants or plant parts of the invention can be used to degrade starch granules into dextrins, other modified starches or hexose (e.g., α-amylase, pullulanase, α-glucosidase, glucoamylase, amyloful). Lulanase) may comprise starch-degrading enzymes as disclosed herein, which convert glucose to fructose (eg, glucose isomerase). Preferably, α-amylase, α-glucosidase, glucoamylase, pullulanase, neofululanase, amylopululase, glucose isomerase, and the like, wherein the starch-degrading enzyme is used to transform the grains; Choose from combinations thereof. Further, preferably, the enzyme is operably linked to a signal sequence that plagigates the promoter and enzyme to starch granules, starch, apoplasts or cytoplasmic reticulum. Most preferably, the enzyme is expressed in endoderm, and in particular maize endocrine, and localized in one or more cell compartments or starch granules of its own. Preferred plant parts are grains. Preferred plant parts are from corn, wheat, barley, rye, oats, sugar cane or rice.
본 발명의 전분-분해 방법에 따라, 형질전환 곡립은 전분 과립 내의 전분-분해 효소를 축적하며, 50℃ 내지 60℃의 통상적인 온도에서 침지하며, 당해 분야에 공지된 바와 같이 습식-제분한다. 바람직하게는, 전분-분해 효소는 초호열성이다. 당해 효소의 전분 과립으로의 아세포 표적화, 또는 당해 효소와 전분 과립과의 연관 때문에, 통상적인 온도에서의 습식-제분 과정 중 효소와 전분 과립을 접촉시켜, 가공 효소를 전분 과립과 함께 동시-정제하여 전분 과립/효소 혼합물을 수득한다. 전분 과립/효소 혼합물의 회수에 이어, 효소의 활성화에 유리한 조건하에 당해 효소를 활성화한다. 예를 들면, 전분의 헥소즈으로의 부분적(유도 전분 또는 덱스트린을 제조하기 위해) 또는 완전한 가수분해를 촉진하기 위한 다양한 습도 및/또는 온도 조건에서 가공을 수행할 수 있다. 고 덱스트로스 또는 프럭토즈 당량을 함유하는 시럽을 이러한 방법으로 수득한다. 당해 방법은 시간, 에너지 및 효소 비용을 효과적으로 절약하며, 전분을 상응하는 헥소즈으로 전환하는 효율, 및 고당 침지수 및 고덱스트로스 당량 시럽과 같은 생성물의 제조 효율을 증가시킨다. According to the starch-degradation method of the present invention, the transformed grain accumulates starch-degrading enzymes in the starch granules, soaked at conventional temperatures of 50 ° C. to 60 ° C. and wet-milled as is known in the art. Preferably, the starch-degrading enzyme is superthermophilic. Because of the subcellular targeting of the enzyme to starch granules, or the association of the enzyme with starch granules, the enzyme and starch granules are contacted during wet-milling at normal temperature, thereby co-purifying the processing enzyme with the starch granules. Starch granules / enzyme mixtures are obtained. Recovery of the starch granule / enzyme mixture is followed by activation of the enzyme under conditions favorable for the activation of the enzyme. For example, processing may be carried out at various humidity and / or temperature conditions to promote partial hydrolysis of starch to hexose (to produce induced starch or dextrin) or complete hydrolysis. Syrups containing high dextrose or fructose equivalents are obtained in this way. The method effectively saves time, energy and enzyme costs, increases the efficiency of converting starch to the corresponding hexose, and the production efficiency of products such as high sugar immersion water and high dextrose equivalent syrups.
다른 양태에서, 식물, 또는 과실 또는 곡립과 같은 식물의 생성물, 또는 당해 효소를 발현하는 곡립으로부터 제조된 분말을 처리하여 효소를 활성화하고 식물 내에서 발현 및 함유된 다당류를 당으로 전환한다. 바람직하게는, 본원에 개시된 바와 같이, 당해 효소를 전분 과립, 전분체, 아포플라스트 또는 세포질로 표적화하는 시그날 서열에 당해 효소를 융합한다. 이어서 제조된 당을 식물 또는 식물의 생성물로부터 분리 또는 회수할 수 있다. 다른 양태에서, 다당류를 당으로 전환할 수 있는 가공 효소를 당해 분야에 공지되고 본원에 개시된 방법에 따라 유도성 프로모터의 제어하에 둔다. 가공 효소는 중온성, 호열성 또는 초호열성일 수 있다. 식물을 목적하는 단계까지 배양하고, 효소의 발현 및 식물 또는 식물 생성물 내의 다당류의 당으로의 전환을 유발하는 프로모터를 유도한다. 바람직하게는, 효소를 전분 과립, 전분체, 아포플라스트 또는 세포질세망으로 표적화하는 시그날 서열에 당해 효소를 작동적으로 연결한다. 다른 양태에서는, 전분을 당으로 전환할 수 있는 가공 효소를 발현하는 형질전환된 식물을 제조한다. 당해 효소를 식물 내의 전분 과립으로 표적화하는 시그날 서열에 당해 효소를 융합시킨다. 이어서 형질전환된 식물에 의해 발현되는 효소를 함유하는 형질전환된 식물로부터 전분을 분리한다. 이어서 분리된 전분에 함유된 효소를 활성화하여 전분을 당으로 전환할 수 있다. 당해 효소는 중온성, 호열성 또는 초호열성일 수 있다. 전분을 당으로 전환할 수 있는 초호열성 효소의 예가 본원에 제공되어 있다. 당해 방법은 다당류를 제조하고 다당류를 당 또는 덱스트린, 말토올리고당, 글루코즈 및/또는 이의 혼합물과 같은 가수분해된 전분 생성물로 전환할 수 있는 효소를 발현할 수 있는 임의의 식물과 함께 사용할 수 있다. In another embodiment, plants or products of plants, such as fruits or grains, or powders prepared from grains expressing the enzymes are treated to activate the enzymes and convert the polysaccharides expressed and contained in the plants to sugars. Preferably, as disclosed herein, the enzyme is fused to a signal sequence that targets the enzyme to starch granules, starch, apoplasts or cytoplasm. The sugars produced can then be separated or recovered from the plant or product of the plant. In another embodiment, processing enzymes capable of converting polysaccharides to sugars are placed under the control of an inducible promoter according to methods known in the art and disclosed herein. The processing enzyme may be mesophilic, thermophilic or hyperthermia. The plant is incubated to the desired stage and induces a promoter that causes the expression of enzymes and the conversion of the polysaccharides into sugars in the plant or plant product. Preferably, the enzyme is operably linked to a signal sequence that targets the enzyme to starch granules, starch, apoplasts, or cytoplasmic nets. In another embodiment, a transformed plant is produced that expresses a processing enzyme capable of converting starch into sugar. The enzyme is fused to a signal sequence that targets the enzyme to starch granules in the plant. The starch is then isolated from the transformed plant containing the enzyme expressed by the transformed plant. The starch can then be converted to sugars by activating the enzyme contained in the isolated starch. The enzyme may be mesophilic, thermophilic or hyperthermic. Provided herein are examples of superthermophilic enzymes capable of converting starch to sugar. The method can be used with any plant capable of producing polysaccharides and expressing enzymes capable of converting the polysaccharides into hydrolyzed starch products such as sugars or dextrins, maltooligosaccharides, glucose and / or mixtures thereof.
본 발명은 다당류의 특정한 공유 결합을 가수분해하여 다당류 유도체를 형성하는 가공 효소로 형질전환시킨 식물, 또는 식물로부터의 생성물로부터 덱스트린 및 변형된 전분을 제조하는 방법을 제공한다. 한 양태에서, 식물 또는 과실 또는 곡립과 같은 식물의 생성물, 또는 당해 효소를 발현하는 곡립으로부터 제조된 분말을 당해 효소를 활성화하고 식물 내에 함유된 다당류를 감소된 분자량의 다당류로 전환하는 데 충분한 조건하에 둔다. 바람직하게는, 당해 효소를 본원에 개시된 바와 같이 전분 과립, 전분체, 아포플라스트 또는 세포질세망으로 표적화하는 시그날 서열에 당해 효소를 융합시킨다. 이어서 제조된 덱스트린 또는 유도 전분을 식물 또는 식물의 생성물로부터 분리 또는 회수할 수 있다. 다른 양태에서는, 다당류를 덱스트린 또는 변형 전분으로 전환할 수 있는 가공 효소를 당해 분야에 공지되고 본원에 개시된 방법에 따라 유도성 프로모터의 제어하에 둔다. 당해 식물을 목적하는 단계로 배양하고, 식물 또는 식물의 생성물 내의 효소의 발현 및 다당류의 덱스트린 또는 변형 전분으로의 전환을 유발하는 프로모터를 유도한다. 바람직하게는 효소는 α-아밀라제, 풀룰라나제, 아이소 또는 네오 풀룰라나제이며 효소를 전분 과립, 전분체, 아포플라스트 또는 세포질세망으로 표적화하는 시그날 서열에 작동적으로 연결된다. 한 양태에서, 당해 효소를 아포플라스트 또는 세포질세망으로 표적화한다. 다른 양태에서, 효소가 전분을 덱스트린 또는 변형 전분으로 전환할 수 있는 형질전환된 식물을 제조한다. 당해 효소를 식물 내의 전분 과립으로 표적화하는 시그날 서열에 당해 효소를 융합한다. 이어서 형질전환된 식물에 의해 발현된 효소를 함유하는 전분을 형질전환된 식물로부터 분리한다. 이어서 분리된 전분 내에 함유된 표소를 전분의 덱스트린 또는 변형 전분으로의 전환에 충분한 조건하에 활성화할 수 있다. 예를 들면, 전분을 전분 가수분해된 전분 생성물로 전환할 수 있는 초호열성 효소의 예가 본원에 제공되어 있다. 당해 방법은 다당류를 제조하고 다당류를 당으로 전환할 수 있는 효소를 발현할 수 있는 임의의 식물과 함께 사용할 수 있다. The present invention provides a method for producing dextrins and modified starches from plants, or products from plants transformed with processing enzymes that hydrolyze specific covalent bonds of polysaccharides to form polysaccharide derivatives. In one embodiment, a plant or a product of a plant, such as fruit or a grain, or a powder prepared from a grain expressing the enzyme, is subjected to conditions sufficient to activate the enzyme and convert the polysaccharides contained in the plant to a reduced molecular weight polysaccharide. Put it. Preferably, the enzyme is fused to a signal sequence that targets the enzyme to starch granules, starch, apoplasts or cytoplasmic reticulum as disclosed herein. The prepared dextrin or derived starch can then be separated or recovered from the plant or product of the plant. In another embodiment, processing enzymes capable of converting polysaccharides to dextrins or modified starches are placed under the control of an inducible promoter according to methods known in the art and disclosed herein. The plant is cultivated to the desired stage and induces a promoter that causes expression of the enzyme in the plant or plant product and conversion of the polysaccharide to dextrin or modified starch. Preferably the enzyme is α-amylase, pullulanase, iso or neo pullulanase and is operably linked to a signal sequence that targets the enzyme to starch granules, starches, apoplasts or cytoplasmic reticulum. In one embodiment, the enzyme is targeted to apoplast or cytoplasmic reticulum. In another embodiment, the enzyme produces a transformed plant capable of converting starch to dextrin or modified starch. The enzyme is fused to a signal sequence that targets the enzyme to starch granules in the plant. The starch containing the enzyme expressed by the transformed plant is then separated from the transformed plant. The elements contained in the isolated starch can then be activated under conditions sufficient to convert the starch to dextrin or modified starch. For example, provided herein are examples of superthermolytic enzymes capable of converting starch into starch hydrolyzed starch products. The method can be used with any plant capable of producing an polysaccharide and expressing an enzyme capable of converting the polysaccharide to a sugar.
다른 양태에서, 전분 과립의 결합을 덱스트란, 변형 전분 또는 헥소즈(예를 들면, α-아밀라제, 풀룰라나제, α-글루코시다제, 글루코아밀라제, 아밀로풀룰라나제)로 분해하는 전분-분해 효소를 축적하는, 본 발명의 형질전환된 식물로부터의 곡립을 다양한 시간 동안 전분 분해 효소의 활성화에 유리한 조건하에 침지시킨다. 수득된 혼합물은 높은 농도의 전분-유래 생성물을 함유할 수 있다. 당해 곡립의 사용은 1) 곡립 제분의 필요를 제거하거나, 달리 당해 곡립을 우선 전분 과립을 수득하기 위해 가공하며, 2) 효소를 곡립의 내배유 조직 내에 직접 위치시킴으로써 전분의 효소에 대한 접근 가능성을 더 좋게 하며, 3) 미생물에 의한 전분-가수분해 효소의 생산에 대한 필요를 제거한다. 따라서, 헥소즈 회수 전의 습식 제분의 전체 과정이 단지 곡립, 바람직하게는 옥수수 곡립을 효소가 전분에 작용가능하게 하기 위해 물의 존재 하에 가열함으로써 제거된다. In another embodiment, starch-decomposes the binding of starch granules to dextran, modified starch or hexose (e.g., α-amylase, pullulanase, α-glucosidase, glucoamylase, amylopululase) Grains from the transformed plants of the present invention, which accumulate degrading enzymes, are immersed under conditions favorable for activation of starch degrading enzymes for various times. The resulting mixture may contain high concentrations of starch-derived product. The use of the grains further enhances the accessibility of the starch to enzymes by either 1) eliminating the need for grain milling or otherwise processing the grains first to obtain starch granules, and 2) placing the enzyme directly within the endocrine tissue of the grains. 3) eliminates the need for the production of starch-hydrolase by microorganisms. Thus, the entire process of wet milling before hex recovery is removed by heating only the grains, preferably corn grains, in the presence of water to enable the enzyme to act on the starch.
당해 방법은 에탄올, 고프럭토즈 시럽, 발효 배지를 함유하는 헥소즈(글루코즈)의 제조 또는 곡립 성분의 정제를 필요로 하지 않는 전분의 임의의 다른 용도에 사용될 수 있다. The method can be used for ethanol, high fructose syrup, for the production of hexose (glucose) containing fermentation medium or for any other use of starch that does not require purification of the grain components.
본 발명은 추가로 전분 과립 및 하나 이상의 전분 가공 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화하는 조건하에 처리하고, 이에 따라 전분 과립을 분해하여 당을 포함하는 수용액을 형성하는 단계를 포함하여 덱스트린, 말토올리고당 및/또는 당을 제조하는 방법을 제공한다. 식물 부분은 게놈이 하나 이상의 가공 효소를 암호화하는 발현 카세트로 증강된 게놈으로부터 수득한다. 덱스트린, 말토올리고당, 및/또는 당을 포함하는 수용액을 수거한다. 한 양태에서, 가공 효소는 α-아밀라제, α-글루코시다제, 풀룰라나제, 글루코아밀라제, 아밀로풀룰라나제, 글루코즈 이소머라제 또는 이의 임의의 배합물이다. 바람직하게는, 효소는 초호열성이다. 다른 양태에서, 본 발명은 추가로 덱스트린, 말토올리고당 및/또는 당의 분리 단계를 포함한다. The present invention further comprises the steps of treating a plant part comprising starch granules and one or more starch processing enzymes under conditions activating one or more enzymes, thereby degrading the starch granules to form an aqueous solution comprising sugars. It provides a method for producing maltooligosaccharide and / or sugar. Plant parts are obtained from genomes whose genomes have been enhanced with expression cassettes encoding one or more processing enzymes. An aqueous solution comprising dextrin, maltooligosaccharide, and / or sugar is collected. In one embodiment, the processing enzyme is α-amylase, α-glucosidase, pullulase, glucoamylase, amylopululase, glucose isomerase, or any combination thereof. Preferably, the enzyme is superthermophilic. In another embodiment, the invention further comprises the step of separating the dextrin, maltooligosaccharide and / or sugar.
c. 개선된 옥수수 품종c. Improved Corn Varieties
본 발명은 또한 정상 수준의 전분 축적을 가지며, 내배유 또는 전분 축적 기관 내에 충분한 수준의 전분분해 효소(들)을 축적하여, 초호열성 효소인 경우에는 이의 식물 또는 식물 부분을 끓이거나 가열함과 같은 함유된 효소의 활성화에 따라 효소가 전분을 단순 당으로의 급속한 전환을 활성화시키고 촉진하는 개선된 옥수수 품종(및 기타 작물의 품종)의 제조 방법을 제공한다. 이들 단순 당(주로 글루코즈)은 처리된 옥수수에 감미를 제공할 것이다. 수득된 옥수수 식물은 곡립 제조 하이브리드 및 단옥수수로서의 이중 사용을 위한 개선된 품종이다. 따라서, 본 발명은 게놈이 하나 이상의 전분분해 효소를 암호화하는 제1 폴리뉴클레오타이드에 작동적으로 연결된 프로모터를 포함하는 발현 카세트로 증강되어 있고, 당해 발현 카세트를 내배유내에서 발현하는 형질전환된 식물 또는 이의 식물 부분을 하나 이상의 효소를 활성화하는 조건하에 처리하여 옥수수 내의 다당류를 당으로 전환하는 단계, 단옥수수를 산출하는 단계를 포함하여, 초-단옥수수를 제조하는 방법을 제공한다. 당해 프로모터는 구성성 프로모터. 종자-특이적 프로모터 또는 α-아밀라제(예를 들면, 서열번호 13, 14 또는 16을 포함하는 것)와 같은 가공 효소를 암호화하는 폴리뉴클레오타이드에 연결된 내배유-특이적 프로모터일 수 있다. 바람직하게는, 효소는 초호열성이다. 한 양태에서, 발현 카세트는 추가로 제1 폴리뉴클레오타이드에 의해 암호화된 효소에 작동적으로 연결된 시그날 서열을 암호화하는 제2 폴리뉴클레오타이드를 포함한다. 본 발명의 당해 양태의 예시적 시그날 서열은 효소를 아포플라스트, 세포질세망, 전분 과립 또는 전분체로 안내한다. 옥수수 식물을 성장시켜 낟알을 갖는 이삭을 형성하고, 이어서 당해 프로모터를 유도하여 효소가 발현되고 식물 내에 함유된 다당류가 당으로 전환되게 한다. The present invention also has a normal level of starch accumulation, accumulates sufficient levels of starch dehydrogenase (s) in the endocrine or starch accumulation organs, such as boiling or heating its plants or plant parts in the case of superthermolytic enzymes. Upon activation of the enzyme, the enzyme provides a method for producing improved corn varieties (and other crop varieties) which activate and promote the rapid conversion of starch into simple sugars. These simple sugars, mainly glucose, will provide sweetness to the treated corn. The corn plants obtained are improved varieties for dual use as grain preparation hybrids and sweet corn. Accordingly, the present invention is a transformed plant or its derivatives, wherein the genome is enriched with an expression cassette comprising a promoter operably linked to a first polynucleotide encoding one or more starch enzymes, the expression cassette being expressed in endocrine. A plant portion is processed under conditions that activate one or more enzymes to convert polysaccharides in corn to sugars, yielding sweet corn, thereby providing a method for producing ultra-sweet corn. The promoter is a constitutive promoter. It may be an endocrine-specific promoter linked to a polynucleotide encoding a processing enzyme such as a seed-specific promoter or α-amylase (eg, comprising SEQ ID NO: 13, 14 or 16). Preferably, the enzyme is superthermophilic. In one embodiment, the expression cassette further comprises a second polynucleotide encoding a signal sequence operably linked to an enzyme encoded by the first polynucleotide. Exemplary signal sequences of this embodiment of the invention direct enzymes to apoplasts, cytoplasmic reticulum, starch granules or starch bodies. Corn plants are grown to form grains with a grain, and the promoter is then induced to allow the enzyme to be expressed and the polysaccharides contained in the plant to be converted to sugars.
d. 자가-발효 식물d. Self-fermenting plant
본 발명의 다른 양태에서, 옥수수, 벼, 밀 또는 사탕수수와 같은 식물을 세포벽에 다량의 가공 효소{예를 들면, 자일라나제, 셀룰라제, 헤미셀룰라제, 글루카나제, 펙티나제, 리파제, 에스테라제, 베타 글루코시다제, 피타제, 프로테아제 등(비-전분 다당류 분해 효소)}를 축적하도록 조작한다. 곡립 성분(또는 사탕 수수의 경우 당), 스토버, 겨 또는 바가스의 수확 후, 세포벽에서의 발현 및 축적을 위해 표적화된 효소의 공급원, 및 바이오매스(biomass)의 공급원으로서 사용한다. 스토버(또는 기타 잔여 조직)를 당해 방법에서 공급재료로 사용하여 발효성 당을 회수한다. 발효성 당의 수득 방법은 비-전분 다당류 분해 효소의 활성화로 이루어진다. 예를 들면, 활성화는 비-전분 다당류의 수득되는 당으로의 가수분해에 적합한 시간 동안 물의 존재 하에 식물 조직을 가열하는 단계를 포함할 수 있다. 따라서, 자가-가공 스토버는 다당류의 단당류로의 전환에 필요한 효소를 제조하며, 이들이 공급재료의 성분이기 때문에 본질적으로 단가는 증가하지 않는다. 추가로, 온도-의존성 효소는 식물 성장 및 발달, 및 세포벽 표적화, 심지어는 단백질에 융합된 셀룰로스/자일로스 결합 도메인에 의한 다당류 미세원섬유로의 표적화에 대한 어떠한 불리한 효과도 갖지 않으며, 기질의 효소로의 접근가능성을 개선한다. In another embodiment of the present invention, plants such as corn, rice, wheat or sugar cane can be treated with large amounts of processing enzymes (eg xylanase, cellulase, hemicellulase, glucanase, pectinase, lipase) on the cell wall. , Esterase, beta glucosidase, phytase, protease and the like (non-starch polysaccharide degrading enzyme)}. After harvesting of the grain component (or sugar in sugar cane), stover, bran or vargas, it is used as a source of targeted enzymes for expression and accumulation in the cell wall, and as a source of biomass. A stove (or other residual tissue) is used as feedstock in the process to recover fermentable sugars. The method of obtaining fermentable sugars consists in the activation of non-starch polysaccharide degrading enzymes. For example, activation may comprise heating the plant tissue in the presence of water for a time suitable for hydrolysis of the non-starch polysaccharides to the sugars obtained. Thus, self-processing stoves produce the enzymes necessary for the conversion of polysaccharides to monosaccharides, and since they are components of the feedstock, essentially no unit cost increases. In addition, temperature-dependent enzymes have no adverse effects on plant growth and development and cell wall targeting, even targeting to polysaccharide microfibrils by cellulose / xylose binding domains fused to proteins, enzymes of substrates. Improve accessibility
따라서, 본 발명은 또한 세포벽 또는 식물 부분의 세포의 하나 이상의 비-전분 다당류 가공 효소를 포함하는 형질전환된 식물 부분의 사용 방법을 제공한다. 당해 방법은 게놈이 하나 이상의 비-전분 다당류 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득된, 하나 이상의 비-전분 다당류 가공 효소를 포함하는 형질전환된 식물 부분을 하나 이상의 효소를 활성하는 조건하에 처리하고, 이에 따라 전분 과립을 분해하여 당을 포함하는 수용액을 형성하는 단계; 및 당을 포함하는 수용액을 수거하는 단계를 포함한다. 본 발명은 또한 식물 또는 식물 부분의 세포 또는 세포의 세포벽에 존재하는 하나 이상의 비-전분 다당류 가공 효소를 포함하는 형질전환된 식물 또는 식물 부분을 포함한다. 당해 식물 부분은 게놈이 하나 이상의 비-전분 가공 효소(예를 들면, 자일라나제, 셀룰라제, 글루카나제, 펙티나제, 리파제, 에스테라제, 베타 글루코시다제, 피타제, 프로테아제 또는 이의 임의의 배합물)를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득한다. Accordingly, the present invention also provides a method of using a transformed plant portion comprising one or more non-starch polysaccharide processing enzymes of cells of the cell wall or plant portion. The method comprises the steps of transforming a plant part comprising one or more non-starch polysaccharide processing enzymes obtained from a transformed plant whose genome is enhanced with an expression cassette encoding one or more non-starch polysaccharide processing enzymes. Treating under active conditions, thereby degrading starch granules to form an aqueous solution comprising sugar; And collecting an aqueous solution containing sugar. The invention also includes a transformed plant or plant part comprising one or more non-starch polysaccharide processing enzymes present in the cells or cell walls of the plant or plant part. The plant part may have one or more non-starch processing enzymes (eg, xylanase, cellulase, glucanase, pectinase, lipase, esterase, beta glucosidase, phytase, protease or its genome). From a transformed plant enhanced with an expression cassette encoding any combination).
e. 단백질 및 당 함량이 높은 수성 상e. Aqueous phase with high protein and sugar content
다른 양태에서, 프로테아제 및 리파제가 종자, 예를 들면, 대두 종자에 축적되도록 조작한다. 프로테아제 또는 리파제의 활성화(예를 들면, 가열에 의한) 후, 종자 내의 이들 효소는 가공 중 대두 내에 존재하는 지질 및 저장 단백질을 가수분해한다. 따라서 사료, 식품 또는 발효 배지로 사용할 수 있는, 아미노산을 포함하는 가용성 생성물을 수득할 수 있다. 다당류는 통상적으로 가공된 곡립의 불용성 분획 내에서 발견된다. 그러나, 종자 내에서의 다당류 분해 효소 발현 및 축적을 조합하여, 단백질 및 다당류를 가수분해할 수 있고 수성 상에서 발견된다. 예를 들면, 옥수수 및 저장 단백질로부터의 제인 및 대두로부터의 전분 다당류를 이러한 방법으로 가용화시킬 수 있다. 수성 및 소수성 상의 성분은 유기 용매 또는 임계초과의 이산화탄소로 추출함으로써 용이하게 분리할 수 있다. 따라서, 고농도의 단백질, 아미노산, 당 또는 단당류를 함유하는 곡립의 수성 추출물의 제조 방법이 제공된다. In other embodiments, the protease and lipase are engineered to accumulate in seeds, such as soybean seeds. After activation of the protease or lipase (eg by heating), these enzymes in the seed hydrolyze lipids and storage proteins present in the soy during processing. Thus soluble products comprising amino acids can be obtained which can be used as feed, food or fermentation medium. Polysaccharides are commonly found in insoluble fractions of processed grains. However, by combining polysaccharide degrading enzyme expression and accumulation in seeds, proteins and polysaccharides can be hydrolyzed and found in the aqueous phase. For example, starch polysaccharides from zein and soybeans from corn and stock proteins can be solubilized in this way. The components of the aqueous and hydrophobic phases can be easily separated by extraction with organic solvents or supercritical carbon dioxide. Thus, there is provided a process for the preparation of an aqueous extract of grains containing high concentrations of proteins, amino acids, sugars or monosaccharides.
f. 자가-가공 발효f. Self-Processing Fermentation
본 발명은 에탄올, 발효 음료 또는 기타 발효-유래 생성물(들)을 제조하는 방법을 제공한다. 당해 방법은 식물, 또는 식물의 생성물 또는 식물 부분, 또는 곡립 분말과 같은 식물 유도체를 수득하는 단계를 포함하며, 여기서, 다당류를 당으로 전환하는 가공 효소가 발현된다. 식물, 또는 이의 생성물을 처리하여 상기한 바와 같이 당을 다당류의 전환에 의해 제조한다. 이어서 당해 분야에 공지된 방법에 따라 당 및 기타 식물의 성분을 발효하여 에탄올 또는 발효 음료, 또는 발효-유래 생성물을 형성한다. 예를 들면, 미국 특허 제4,929,452호를 참조한다. 간략히, 다당류의 전환에 의해 제조된 당을 당의 에탄올로의 전환을 촉진하는 조건하에 효모와 함께 항온처리한다. 적합한 효모에는 효모의 고 알콜-내성 및 고-당 내성 균주{예를 들면, 효모, 에스. 세레비지애(S. cerevisiae) ATCC 제20867호}가 포함된다. 당해 균주는 미들랜드주 록빌 소재의 수탁기관[American Type Culture Collection]에 1987년 9월 17일자로 기탁되었으며, ATCC 제20867호를 부여받았다. 이어서 발효 생성물 또는 발효 음료를 증류하여 에탄올 또는 증류 음료를 분리하거나, 아니면 발효 생성물을 회수한다. 당해 방법에 사용된 식물은 다당류를 포함하고 본 발명의 효소를 발현할 수 있는 임의의 식물일 수 있다. 많은 이러한 식물이 본원에 개시되어 있다. 바람직하게는, 식물은 상업적으로 재배된 것이다. 보다 바람직하게는, 식물은 통상적으로 에탄올 또는 발효 음료, 또는 발효 생성물, 예를 들면, 밀, 보리, 옥수수, 귀리, 감자, 포도 또는 벼를 제조하는 데 사용되는 것이다.The present invention provides a process for preparing ethanol, fermented beverages or other fermentation-derived product (s). The method comprises obtaining a plant, or a plant derivative, such as a product or plant part of a plant, or grain powder, wherein a processing enzyme is expressed that converts the polysaccharide into a sugar. The plants, or products thereof, are treated to produce sugars by conversion of polysaccharides as described above. The components of sugar and other plants are then fermented according to methods known in the art to form ethanol or fermented beverages or fermentation-derived products. See, for example, US Pat. No. 4,929,452. Briefly, sugars prepared by the conversion of polysaccharides are incubated with yeast under conditions that promote the conversion of sugars to ethanol. Suitable yeasts include high alcohol-resistant and high-sugar resistant strains of yeast (eg yeast, S. aureus). S. cerevisiae ATCC 20867}. The strain was deposited on September 17, 1987 by the American Type Culture Collection, Rockville, Midland, and was assigned ATCC 20867. The fermentation product or fermentation beverage is then distilled off to separate the ethanol or distillation beverage or the fermentation product is recovered. The plant used in the method may be any plant that contains polysaccharides and can express the enzymes of the present invention. Many such plants are disclosed herein. Preferably, the plant is commercially grown. More preferably, the plants are typically used to make ethanol or fermented beverages or fermentation products, such as wheat, barley, corn, oats, potatoes, grapes or rice.
당해 방법은 하나 이상의 다당류 가공 효소를 포함하는 식물 부분을 하나 이상의 효소를 활성화하는 조건하에 처리하고, 이에 다라 식물 부분의 다당류를 분해하여 발효성 당을 형성하는 단계를 포함한다. 다당류 가공 효소는 중온성, 호열성 또는 초호열성일 수 있다. 식물 부분은 게놈이 하나 이상의 다당류 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득한다. 본 발명의 당해 양태를 위한 식물 부분에는 곡립, 과실, 종자, 줄기, 목질, 채소 또는 뿌리가 포함되지만, 이에 제한되지는 않는다. 식물에는 귀리, 보리, 밀, 딸기류, 포도, 호밀, 옥수수, 벼, 감자, 사탕무, 사탕수수, 파인애플, 목초 및 나무가 포함되지만, 이에 제한되지는 않는다. 당해 식물 부분을 상품 곡립 또는 기타 상업적으로 입수가능한 기질과 배합할 수 있으며, 가공을 위한 기질의 공급원은 자가-가공 식물 이외의 공급원일 수 있다. 이어서 발효성 당을 예를 들면, 효모 및/또는 기타 미생물을 사용한 발효성 당의 에탄올로의 전환을 촉진하는 조건하에서 항온처리한다. 한 양태에서, 식물 부분은 α-아밀라제로 형질전환시킨 옥수수로부터 유래한 것이며, 이는 발효 시간 및 비용을 감소시키는 것으로 밝혀졌다.The method includes treating a plant portion comprising one or more polysaccharide processing enzymes under conditions that activate one or more enzymes, thereby degrading the polysaccharides of the plant portion to form fermentable sugars. Polysaccharide processing enzymes may be mesophilic, thermophilic or superthermophilic. Plant parts are obtained from transformed plants whose genome is enhanced with an expression cassette encoding at least one polysaccharide processing enzyme. Plant parts for this aspect of the invention include, but are not limited to, grains, fruits, seeds, stems, wood, vegetables or roots. Plants include, but are not limited to oats, barley, wheat, berries, grapes, rye, corn, rice, potatoes, sugar beets, sugar cane, pineapples, grasses and trees. The plant part can be combined with commodity grains or other commercially available substrates, and the source of the substrate for processing can be a source other than a self-processing plant. The fermentable sugars are then incubated under conditions that promote the conversion of fermentable sugars to ethanol, for example using yeast and / or other microorganisms. In one embodiment, the plant part is from corn transformed with α-amylase, which has been found to reduce fermentation time and cost.
예를 들면, 호열성 α-아밀라제를 발현하는, 본 발명에 따라 제조된 형질전환 옥수수를 발효에 사용한 경우, 잔류 전분의 양이 감소함이 밝혀졌다. 이는 더 많은 전분이 발효 중 가용화됨을 나타낸다. 잔류 전분의 감소한 양은 고단백질 중량함량과 보다 높은 가치를 갖는 증류 곡립을 야기한다. 추가로, 본 발명의 형질전환 옥수수의 발효는 저 pH에서 수행하는 액화 과정을 가능하게 하여, 고온(예를 들면, 85℃ 이상, 바람직하게는 90℃ 이상, 보다 바람직하게는 95℃ 이상)에서의, pH를 조정하는 데 필요한 화학적 비용을 절약하게 하고, 보다 짧은 액화 시간 및 보다 완전한 전분 가용화 및 액화 시간의 감소를 초래하여, 모두 고수율의 에탄올을 갖는 효율적인 발효 반응을 야기한다. For example, when the transgenic maize prepared according to the present invention expressing thermophilic α-amylase was used for fermentation, the amount of residual starch was found to decrease. This indicates that more starch is solubilized during fermentation. The reduced amount of residual starch results in distillation grains having higher protein weight content and higher value. In addition, the fermentation of the transformed corn of the present invention allows the liquefaction process to be carried out at low pH, so that at high temperatures (eg, at least 85 ℃, preferably at least 90 ℃, more preferably at least 95 ℃) This results in saving the chemical cost needed to adjust the pH and results in shorter liquefaction time and more complete starch solubilization and reduction of liquefaction time, all leading to an efficient fermentation reaction with high yield of ethanol.
추가로, 심지어 본 발명에 따라 제조된 형질전환된 식물의 작은 부위와 통상적인 식물 부분을 접촉시키는 것이 발효 시간 및 이와 관련된 비용을 감소시킬 수 있음이 밝혀졌다. 이와 같이, 본 발명은 다당류 가공 효소를 포함하지 않는 식물 부분의 사용에 비하여, 다당류를 당으로 전환하는 다당류 가공 효소를 포함하는 식물로부터의 형질전환된 식물 부분을 적용함을 포함하는, 식물의 발효 시간 감소에 관한 것이다. In addition, it has been found that even contacting small parts of the transformed plants produced according to the invention with conventional plant parts can reduce fermentation time and the costs associated therewith. As such, the present invention involves applying a transformed plant portion from a plant comprising a polysaccharide processing enzyme that converts the polysaccharide to a sugar, as compared to the use of a plant portion that does not include the polysaccharide processing enzyme. It is about time reduction.
g. 생전분 가공 효소 및 이를 암호화하는 폴리뉴클레오타이드g. Raw starch processing enzymes and polynucleotides encoding them
중온성 가공 효소(들)을 암호화하는 폴리뉴클레오타이드를 식물 또는 식물 부분 내로 도입한다. 한 양태에서, 본 발명의 폴리뉴클레오타이드는 서열번호 47 또는 49로 제공된 바와 같은 글루코아밀라제를 암호화하는, 서열번호 48, 50 및 59로 제공된 바와 같은 옥수수-최적화된 폴리뉴클레오타이드이다. 다른 양태에서, 본 발명의 폴리뉴클레오타이드는 서열번호 51로 제공된 바와 같은 알파-아밀라제를 암호화하는, 서열번호 52로 제공된 바와 같은 옥수수-최적화된 폴리뉴클레오타이드이다. 이에 덧붙여, 가공 효소의 융합 생성물을 추가로 고찰한다. 한 양태에서, 본 발명의 폴리뉴클레오타이드는 알파-아밀라제 및 서열번호 45로 제공된 바와 같은 글루코아밀라제 융합물을 암호화하는, 서열번호 46으로 제공된 바와 같은 옥수수-최적화 폴리뉴클레오타이드이다. 추가로 본 발명에서 가공 효소의 배합을 고찰한다. 예를 들면, 전분-가공 효소 및 비-전분 가공 효소의 배합을 본원에서 고찰한다. 이러한 가공 효소의 배합은 각각의 당해 유전자를 암호화하는 다중 유전자 작제물의 용도를 사용하여 수득할 수 있다. 대안적으로, 당해 효소로 안정하게 형질전환시킨 개별 형질전환된 식물을 공지된 방법으로 교배시켜 효소 둘 다를 포함하는 식물을 수득할 수 있다. 다른 방법은 형질전환된 식물과 함께하는 외인성 효소(들)의 사용을 포함한다.Polynucleotides encoding mesophilic processing enzyme (s) are introduced into a plant or plant part. In one embodiment, the polynucleotides of the present invention are corn-optimized polynucleotides as provided in SEQ ID NOs: 48, 50 and 59, encoding glucoamylases as provided in SEQ ID NOs: 47 or 49. In another embodiment, the polynucleotides of the present invention are corn-optimized polynucleotides as provided in SEQ ID NO: 52, encoding the alpha-amylase as provided in SEQ ID NO: 51. In addition, the fusion products of the processing enzymes are further considered. In one embodiment, the polynucleotide of the present invention is a corn-optimized polynucleotide as provided in SEQ ID NO: 46, encoding an alpha-amylase and a glucoamylase fusion as provided in SEQ ID NO: 45. Further in the present invention, the combination of the processing enzyme is considered. For example, combinations of starch-processing enzymes and non-starch processing enzymes are discussed herein. Combinations of such processing enzymes can be obtained using the use of multiple gene constructs encoding each of the genes of interest. Alternatively, individual transformed plants stably transformed with the enzyme can be crossed by known methods to obtain plants comprising both enzymes. Another method involves the use of exogenous enzyme (s) with the transformed plant.
전분-가공 및 비-전분 가공 효소의 공급원은 임의의 공급원으로부터 분리 또는 유래할 수 있으며 이에 상응하는 폴리뉴클레오타이드는 당해 분야의 숙련가가 확인할 수 있다. α-아밀라제는 아스퍼길러스{예를 들면, 아스퍼길러스 쉬로우사미 및 아스퍼길러스 니거), 리조푸스(예를 들면, 리조푸스 오리재) 및 옥수수, 보리 및 벼와 같은 식물로부터 유래할 수 있다. 글루코아밀라제는 아스퍼길러스(예를 들면, 아스퍼길러스 쉬로우사미 및 아스퍼길러스 니거), 리조푸스(예를 들면, 리조푸스 오리재) 및 호열염기성 세균(예를 들면, 터모안에어로박터 터모사카롤리티쿰)으로부터 유래할 수 있다. Sources of starch-processed and non-starch processed enzymes can be isolated or derived from any source and the corresponding polynucleotides can be identified by one skilled in the art. α-amylases may be derived from plants such as aspergillus (eg, Aspergillus Schlossami and Aspergillus niger), lycopus (eg lycopus duck) and corn, barley and rice . Glucoamylases include aspergillus (e.g. Aspergillus Schlossami and Aspergillus niger), lycopus (e.g. lycopus duck), and thermophilic bacteria (e.g., Thermomobacter termosa) Carolithic).
본 발명의 다른 양태에서, 당해 폴리뉴클레오타이드는 서열번호 53으로 제공된 바와 같은 생전분 결합 도메인을 암호화하는, 서열번호 54로 제공된 바와 같은 옥수수-최적화된 폴리뉴클레오타이드에 작동적으로 연결된 중온성 전분-가공 효소를 암호화한다. In another embodiment of the invention, the polynucleotide is a mesophilic starch-processing enzyme operably linked to a corn-optimized polynucleotide as provided in SEQ ID NO: 54, encoding a biostarch binding domain as provided in SEQ ID NO: 53. Encrypt it.
다른 양태에서, 조직-특이적 프로모터는 옥수수 γ-제인 프로모터(서열번호 12로 예시된) 또는 옥수수 ADP-gpp 프로모터(5' 비해독 및 인트론 서열을 포함하는, 서열번호 11로 예시된) 또는 Q 단백질 프로모터(서열번호 98로 예시된) 또는 벼 글루텔린 프로모터(서열번호 67로 예시된)와 같은 내배유-특이적 프로모터를 포함한다. 따라서, 본 발명은 서열번호 11, 12, 67 또는 98을 포함하는 프로모터를 포함하는 분리된 폴리뉴클레오타이드, 낮은 엄중성 하이브리드화 조건하에 이의 상보체와 하이브리드화하는 폴리뉴클레오타이드, 또는 서열번호 11, 13, 67 또는 98의 서열을 갖는 프로모터의 활성(예를 들면, 10% 이상 및 바람직하게는 50% 이상)을 갖는 이의 단편을 포함한다. In another embodiment, the tissue-specific promoter is a corn γ-zein promoter (illustrated as SEQ ID NO: 12) or a maize ADP-gpp promoter (illustrated in SEQ ID NO: 11, including 5 'non-toxin and intron sequences) or Q Endosperm-specific promoters such as protein promoters (illustrated by SEQ ID NO: 98) or rice glutelin promoter (illustrated by SEQ ID NO: 67). Thus, the present invention provides isolated polynucleotides comprising a promoter comprising SEQ ID NO: 11, 12, 67 or 98, a polynucleotide that hybridizes with its complement under low stringency hybridization conditions, or SEQ ID NOs: 11, 13, 67 Or a fragment thereof having the activity of a promoter having a sequence of 98 (eg, at least 10% and preferably at least 50%).
한 양태에서, α-아밀라제, 글루코아밀라제 또는 α-아밀라제/글루코아밀라제 융합물과 같은 전분-가수분해 유전자로부터의 생성물을 세포질보다는, 세포질세망 또는 아포플라스트와 같은 특정 기관 또는 위치로 표적화할 수 있다. 이는 단백질의 아포플라스트-특이적 표적화을 부여하는 옥수수 γ-제인 n-말단 시그날 서열(서열번호 17)의 사용, 및 세포질세망 내에서의 체류를 위한 서열 SEKDEK에 작동적으로 연결된 가공 효소에 작동적으로 연결된 γ-제인 N-말단 시그날 서열(서열번호 17)의 사용에 의해 예시된다. 단백질 또는 효소의 특이적 구획으로의 안내는 효소가 기질과 접촉하지 않을 방법으로 국소화되게 할 것이다. 당해 방법에서, 당해 효소의 효소 작용은 효소가 이의 기질과 접촉할 때까지 발생하지 않을 것이다. 당해 효소를 제분(세포 온전성의 물리적 파쇄) 및 수화작용의 방법으로 이의 기질과 접촉시킬 수 있다. 예를 들면, 중온성 전분-가수분해 효소를 아포플라스트 또는 세포질세망으로 표적화할 수 있고, 이에 따라 아포플라스트 내의 전분 과립과 접촉하게 될 것이다. 곡립의 제분은 곡립의 온전성을 파쇄할 것이며, 이어서 전분 가수분해 효소가 전분 과립과 접촉하게 될 것이다. 당해 방법에서, 효소 및 이의 기질의 동시-국소화의 잠정적인 부정적 효과를 우회할 수 있다.In one embodiment, products from starch-hydrolysing genes such as α-amylase, glucoamylase or α-amylase / glucoamylase fusions can be targeted to specific organs or locations, such as cytoplasmic reticulum or apoplasts, rather than cytoplasm. . This is operative for the use of the n-terminal signal sequence (SEQ ID NO: 17), a corn γ-agent conferring apoplast-specific targeting of the protein, and a processing enzyme operably linked to the sequence SEKDEK for retention in the cytoplasmic network. Is illustrated by the use of a γ-zein N-terminal signal sequence (SEQ ID NO: 17) linked to Guidance to specific compartments of a protein or enzyme will allow the enzyme to be localized in a manner that will not contact the substrate. In this method, the enzymatic action of the enzyme will not occur until the enzyme is in contact with its substrate. The enzyme can be contacted with its substrate by methods of milling (physical disruption of cell integrity) and hydration. For example, mesophilic starch-hydrolase may be targeted to apoplasts or cytoplasmic reticulum, and thus will be in contact with starch granules in apoplasts. Milling of the grains will break the integrity of the grains, and then the starch hydrolase will come into contact with the starch granules. In this method, it is possible to bypass the potential negative effects of co-localization of enzymes and their substrates.
h. 감미료를 첨가하지 않은 식품h. Sweetener-free food
또한 부가적인 감미료 첨가 없이 고당도 전분질 식품을 제조하는 방법을 제공한다. 전분질 생성물의 예로는 조식용 식품, 편의 식품, 구운 식품, 파스타 및 곡류 식품(예를 들면, 조식용 곡물)이 포함되지만, 이에 제한되지는 않는다. 당해 방법은 하나 이상의 가공 효소를 포함하는 식물 부분을 전분 가공 효소를 활성화하는 조건하에 처리하고, 이에 따라 식물 부분 내의 전분 과립을 당으로 가공하여, 예를 들면, 초호열성 효소를 포함하지 않는 식물 부분로부터의 전분 과립을 가공하여 제조한 생성물과 비교하여 고당도인 생성물을 형성하는 단계를 포함한다. 바람직하게는, 당해 전분 가공 효소는 초호열성이며, 가열(예를 들면, 굽기, 끓이기, 가열, 찜, 전기 방전 또는 이의 임의의 조합)에 의해 활성화된다. 당해 식물 부분은 게놈이 하나 이상의 초호열성 전분 가공 효소(예를 들면, α-아밀라제, α-글루코시다제, 글루코아밀라제, 풀룰라나제, 글루코즈 이소머라제 또는 이의 임의의 배합물)를 암호화하는 발현 카세트로 증강된 형질전환된 식물(예를 들면, 형질전환 대두, 호밀, 귀리, 보리, 밀, 옥수수, 벼 또는 사탕수수)로부터 수득한다. 이어서 고당도 생성물을 전분질 식품으로 가공한다. 본 발명은 또한 당해 방법에 의해 제조된 전분질 식품(예를 들면, 곡물 식품, 조식용 식품, 편의 식품 또는 구운 식품)을 제공한다. 당해 전분질 식품은 고당도 생성물 및 물로부터 형성될 수 있으며, 맥아, 향미제, 비타민, 미네랄, 착색제 또는 이의 임의의 배합물을 함유할 수 있다. It also provides a method for preparing high sugar starch foods without the addition of additional sweeteners. Examples of starch products include, but are not limited to, breakfast foods, convenience foods, baked goods, pasta, and cereal foods (eg, breakfast grains). The method treats plant parts comprising one or more processing enzymes under conditions that activate starch processing enzymes, thereby processing the starch granules in the plant parts into sugars, for example plant parts that do not contain superthermolytic enzymes. Processing the starch granules from to form a product that is highly sugary as compared to the product produced. Preferably, the starch processing enzyme is superthermophilic and activated by heating (eg, baking, boiling, heating, steaming, electric discharge or any combination thereof). The plant part is an expression cassette in which the genome encodes one or more superthermotropic starch processing enzymes (e.g., α-amylase, α-glucosidase, glucoamylase, pullulanase, glucose isomerase or any combination thereof). It is obtained from transformed plants (e.g., transgenic soybean, rye, oats, barley, wheat, corn, rice or sugar cane) which have been fortified with. The high sugar content product is then processed into starch foods. The present invention also provides starch foods (eg, grain foods, breakfast foods, convenience foods or baked foods) prepared by the process. The starch food may be formed from high sugar content products and water and may contain malts, flavors, vitamins, minerals, colorants or any combination thereof.
당해 효소를 활성화하여 식물 물질의 곡물 생성물로의 봉입 전 또는 곡물 식품의 가공 중, 식물 물질 내에 함유된 다당류를 당으로 전환할 수 있다. 따라서, 식물 물질 내에 함유된 다당류를 전분질 생성물 내로의 봉입 전에 당해 물질을 활성화함으로써(예를 들면, 초호열성 효소의 경우, 가열하여) 당으로 전환할 수 있다. 이어서 다당류의 전환에 의해 제조된 당 함유 식물 물질을 당해 생성물에 첨가하여 고당도 생성물을 제조한다. 대안적으로, 전분질 생성물의 가공 중 효소에 의해 다당류를 당으로 전환할 수 있다. 곡물 생성물을 제조하는 데 사용된 가공 방법의 예는 당해 분야에 널리 공지되어 있으며, 미국 특허 제6,183,788호; 제6,159,530호; 제6,149,965호; 제4,988,521호 및 제5,368,870호에 기술된 바와 같은 가열, 굽기, 끓이기 등이 포함된다. The enzyme can be activated to convert the polysaccharides contained in the plant material into sugars prior to inclusion of the plant material into the grain product or during processing of the grain food. Thus, the polysaccharides contained in the plant material can be converted to sugars by activating the material (eg, in the case of a superthermophilic enzyme by heating) prior to inclusion in the starch product. The sugar-containing plant material prepared by the conversion of polysaccharides is then added to the product to produce a high sugar content product. Alternatively, polysaccharides can be converted to sugars by enzymes during processing of the starch product. Examples of processing methods used to make grain products are well known in the art and are described in US Pat. No. 6,183,788; 6,159,530; 6,159,530; 6,149,965; 6,149,965; Heating, baking, boiling and the like as described in US Pat. Nos. 4,988,521 and 5,368,870.
간략히, 각종 무수 성분과 물을 함께 혼합하고 조리하여 가루 반죽을 제조하여, 전분질 성분을 젤라틴화하고 조리 풍미를 더할 수 있다. 이어서 조리된 물질을 기계적으로 반죽하여 조리 반죽(예를 들면, 곡물 반죽)을 형성한다. 무수 성분은 당, 전분, 염, 비타민, 미네랄, 착색제, 향료 등과 같은 각종 첨가제를 포함할 수 있다. 물 외에, 옥수수 또는 맥아 시럽과 같은 각종 액상 성분을 첨가할 수 있다. 전분질 물질은 곡물 곡립, 밀, 벼, 옥수수, 귀리, 보리, 호밀 또는 기타 곡물 곡립으로부터의 거칠게 빻은 곡물 또는 분말 및 본 발명의 형질전환된 식물로로부터의 이의 혼합물을 포함할 수 있다. 이어서 가루 반죽을 압출성형 또는 압인과 같은 방법을 통해 목적하는 모양으로 가공하고, 추가로 James 조리기, 오븐 또는 전기 방전 기구와 같은 수단을 사용하여 추가로 조리할 수 있다. Briefly, various anhydrous ingredients and water may be mixed together and cooked to prepare a dough, to gelatinize the starch ingredients and add cooking flavor. The cooked material is then mechanically kneaded to form cooking dough (eg, grain dough). The anhydrous component may include various additives such as sugars, starches, salts, vitamins, minerals, colorants, flavors and the like. In addition to water, various liquid components such as corn or malt syrup can be added. Starch materials may include coarse grains or powders from grain grains, wheat, rice, corn, oats, barley, rye or other grain grains and mixtures thereof from the transformed plants of the invention. The dough can then be processed into the desired shape by methods such as extrusion or stamping, and further cooked using means such as a James cooker, oven or electric discharge device.
추가로, 감미료 첨가 없이 전분 함유 생성물에 단맛을 내는 방법을 제공한다. 당해 방법은 하나 이상의 전분 가공 효소를 포함하는 전분을 하나 이상의 효소를 활성화하는 조건하에 처리하고, 이에 따라 전분을 분해하여 당을 형성하고, 이에 따라 예를 들면, 초호열성 효소를 포함하지 않는 전분을 처리하여 제조한 생성물에 비하여 처리된(고당도) 전분을 형성하는 단계를 포함한다. 본 발명의 전분은 게놈이 하나 이상의 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득한다. 효소는 α-아밀라제, α-글루코시다제, 글루코아밀라제, 풀룰라나제, 글루코즈 이소머라제 또는 이의 임의의 배합물을 vhg마한다. 당해 효소는 초호열성일 수 있으며 열에 의해 활성화될 수 있다. 바람직한 형질전환된 식물에는 옥수수, 대두, 호밀, 귀리, 보리, 밀, 벼 및 사탕수수가 포함된다. 이어서 처리된 전분을 생성물에 첨가하여, 생성물(예를 들면, 전분질 식품)을 함유하는 고당도 전분을 제조한다. 또한 당해 방법에 의해 제조된 생성물을 함유하는 고당도 전분을 제공한다. In addition, a method is provided for sweetening starch-containing products without the addition of sweeteners. The method treats starch comprising one or more starch processing enzymes under conditions activating one or more enzymes, thereby degrading the starch to form sugars, and thus, for example, starch that does not contain superthermolytic enzymes. Forming treated (high sugar) starch as compared to the product produced by treatment. Starches of the invention are obtained from transformed plants in which the genome is enhanced with an expression cassette encoding one or more processing enzymes. The enzyme vhg ma α-amylase, α-glucosidase, glucoamylase, pullulanase, glucose isomerase or any combination thereof. The enzyme may be superthermophilic and may be activated by heat. Preferred transformed plants include corn, soybean, rye, oats, barley, wheat, rice and sugar cane. The treated starch is then added to the product to produce a high sugar starch containing the product (eg, starch food). Also provided are high sugar starch containing products produced by the process.
본 발명은 추가로 하나 이상의 다당류 가공 효소를 포함하는 과실 또는 야체를 하나 이상의 효소를 활성화하는 조건하에 처리하고, 이에 따라 과실 또는 채소 내의 다당류를 가공하여 당을 형성하는 단계, 예를 들면, 다당류 가공 효소를 포함하지 않는 식물로부터의 과실 또는 채소에 비하여 고당도 과실 또는 채소를 산출하는 단계를 포함하여, 다당류 함유 과실 또는 채소에 단맛을 내는 방법을 제공한다. 본 발명의 과실 또는 채소는 게놈이 하나 이상의 다당류 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득한다. 과실 및 채소에는 감자, 토마토, 바나나, 스쿼시, 완두 및 콩이 포함된다. 효소에는 α-아밀라제, α-글루코시다제, 글루코아밀라제, 풀룰라나제, 글루코즈 이소머라제 또는 이의 임의의 배합물이 포함된다. 당해 효소는 초호열성일 수 있다. The present invention further comprises processing a fruit or vegetable comprising one or more polysaccharide processing enzymes under conditions activating the one or more enzymes, thereby processing the polysaccharides in the fruit or vegetable to form a sugar, eg, polysaccharide processing. It provides a method of sweetening a polysaccharide-containing fruit or vegetable, comprising the step of producing a high sugar fruit or vegetable compared to the fruit or vegetable from a plant that does not contain enzymes. Fruits or vegetables of the present invention are obtained from transformed plants whose genome has been enhanced with an expression cassette encoding at least one polysaccharide processing enzyme. Fruits and vegetables include potatoes, tomatoes, bananas, squash, peas and beans. Enzymes include α-amylase, α-glucosidase, glucoamylase, pullulanase, glucose isomerase, or any combination thereof. The enzyme may be superthermophilic.
i. 다당류 함유 식물 또는 식물 생성물의 감미부여i. Sweetening of Polysaccharide-Containing Plants or Plant Products
당해 방법은 기술한 바와 같이 다당류를 당으로 전환하는 다당류 가공 효소를 발현하는 식물을 수득함을 포함한다. 따라서, 당해 효소는 식물 및 과실 또는 채소와 같은 식물이 생성물 내에서 발현한다. 한 양태에서, 효소를 유도성 프로모터의 제어 하에 두어, 당해 효소의 발현이 외부 자극에 의해 유도될 수 있게 한다. 이러한 유도성 프로모터 및 작제물은 당해 분야에 널리 공지되어 있으며 본원에 기술되어 있다. 식물 또는 이의 생성물 내의 효소의 발현은 식물 또는 이의 생성물 내에 함유된 다당류의 당으로의 전환을 유발하며 식물 또는 이의 생성물에 감미를부여한다. 다른 양태에서, 다당류 가공 효소는 본질적으로 발현된다. 따라서, 식물 또는 이의 생성물을 효소의 활성화에 충분한 조건하에서 활성화하여 효소의 작용을 통해 다당류를 당으로 전환하여 식물 또는 이의 생성물에 감미를 부여할 수 있다. 결과적으로, 당을 형성하기 위한 과실 또는 채소 내의 다당류의 자가-가공은 고당도(예를 들면, 다당류 가공 효소를 포함하지 않는 식물로부터의 과실 또는 채소에 비하여) 과실 또는 채소를 산출한다. 본 발명의 과실 또는 채소는, 게놈이 하나 이상의 다당류 가공 효소를 암호화하는 발현 카세트로 증강된 형질전환된 식물로부터 수득한다. 과실 및 채소는 감자, 토마토, 바나나, 호박, 완두 및 콩을 포함한다. 효소는 α-아밀라제, α-글루코시다제, 글루코아밀라제, 풀룰라나제, 글루코즈 이소머라제 또는 이의 임의의 배합물을 포함한다. 다당류 가공 효소는 초호열성일 수 있다. The method involves obtaining a plant expressing a polysaccharide processing enzyme that converts the polysaccharide to a sugar as described. Thus, the enzyme is expressed in plants and plants such as fruits or vegetables in the product. In one embodiment, the enzyme is placed under the control of an inducible promoter to allow expression of the enzyme to be induced by external stimulation. Such inducible promoters and constructs are well known in the art and described herein. Expression of enzymes in plants or their products causes conversion of the polysaccharides contained in the plants or their products to sugars and sweetens the plants or their products. In other embodiments, the polysaccharide processing enzyme is expressed essentially. Thus, plants or their products may be activated under conditions sufficient for the activation of the enzymes to convert the polysaccharides to sugars through the action of the enzymes to sweeten the plants or their products. As a result, self-processing of polysaccharides in fruits or vegetables to form sugars yields fruits or vegetables that are highly sugary (for example, as compared to fruits or vegetables from plants that do not contain polysaccharide processing enzymes). Fruits or vegetables of the present invention are obtained from transformed plants whose genome has been enhanced with an expression cassette encoding at least one polysaccharide processing enzyme. Fruits and veggies include potatoes, tomatoes, bananas, pumpkins, peas and beans. Enzymes include α-amylase, α-glucosidase, glucoamylase, pullulanase, glucose isomerase, or any combination thereof. Polysaccharide processing enzymes can be superthermophilic.
j. 내배유기질을 파괴하는 효소를 함유하는 형질전환된 곡립으로부터의 전분의 분리j. Isolation of Starch from Transformed Grains Containing Enzymes That Disrupt Endocrine Substrate
본 발명은 내배유 기질을 파괴하는 효소가 발현되는 형질전환된 곡립으로부터 준분을 분리하는 방법을 제공한다. 당해 방법은 예를 들면, 세포벽, 비-전분 다당류 및/또는 단백질의 변이체 의해 내배유 기질을 파괴하는 효소를 발현하는 식물을 수득하는 단계를 포함한다. 이러한 효소의 예로는 프로테아제, 글루카나제, 티오레독신, 티오레독신 환원효소, 피타제, 리파제, 셀룰라제, 베타 글루코시다제, 자일라나제 및 에스테라제가 포함되지만, 이에 제한되지는 않는다. 당해 효소에는 전분-분해 활성을 나타내는 어떠한 효소도 포함하지 않기 때문에, 전분 과립의 온전성을 유지한다. 당해 효소를 전분 과립으로 표적화하는 시그날 서열에 당해 효소를 융합할 수 있다. 한 양태에서, 곡립을 가열 건조시켜 효소를 활성화하고 곡립 내에 함유된 내인성 효소는 불활성화한다. 열 처리는 효소의 활성화를 유발하여, 내배유 기질을 파괴한 후, 이어서 전분 과립으로부터 용이하게 분리되게 한다. 다른 양태에서, 곡립을 이산화황의 유무하에, 고 또는 저 습도로, 저 또는 고온에서 침지한다. 이어서 당해 곡립을 열 처리하여 내배유 기질을 파괴하고 전분 과립의 용이한 분리를 가능하게 한다. 다른 양태에서, 적합한 온도 및 습도 조건을 조성하여 프로테아제가 전분 과립에 진입하여, 과립 내에 함유된 단백질을 분해하게 한다. 이러한 처리는 고수율 및 적은 오염 단백질을 갖는 전분 과립을 제조할 것이다. The present invention provides a method for separating subages from transformed grains in which an enzyme that destroys an endosperm substrate is expressed. The method includes obtaining a plant that expresses an enzyme that destroys an endosperm substrate, for example by variant of cell walls, non-starch polysaccharides and / or proteins. Examples of such enzymes include, but are not limited to, proteases, glucanase, thioredoxin, thioredoxin reductase, phytase, lipase, cellulase, beta glucosidase, xylanase and esterase. Since the enzyme does not contain any enzyme that exhibits starch-degrading activity, the integrity of the starch granules is maintained. The enzyme can be fused to a signal sequence that targets the enzyme to starch granules. In one embodiment, the grains are heat dried to activate the enzymes and the endogenous enzymes contained within the grains are inactivated. The heat treatment triggers the activation of the enzyme, destroying the endosperm substrate and then easily separating from the starch granules. In another embodiment, the grains are immersed at low or high temperatures, with or without sulfur dioxide, at high or low humidity. The grains are then heat treated to destroy the endosperm matrix and to facilitate separation of the starch granules. In another embodiment, suitable temperature and humidity conditions are established to allow the protease to enter starch granules to degrade the proteins contained in the granules. This treatment will produce starch granules with high yield and low contaminating protein.
k. 높은 당 당량을 갖는 시럽 및 에탄올 또는 발효 음료의 제조를 위한 시럽의 용도k. Use of syrups for the production of syrups with high equivalent weight and ethanol or fermented beverage
당해 방법은 상기한 바와 같이 다당류를 당으로 전환하는 다당류 가공 효소를 발현하는 식물을 수득하는 단계를 포함한다. 식물 또는 이의 생성물을 발현된 효소가 식물 또는 이의 생성물 내에 함유된 다당류를 덱스트린, 말토올리고당 및/또는 당으로 전환하는 조건하에 수성 수류에 침지한다. 이어서 다당류의 전환을 통해 제조된 덱스트린, 말토올리고당 및/또는 당을 함유하는 수성 수류를 분리하여 높은 당 당량을 갖는 시럽을 제조한다. 당해 방법은 전분 과립을 수득하기 위한, 식물 또는 이의 생성물을 습식-제분하는 추가의 단계를 포함하거나 포함하지 않을 수 있다. 당해 방법에 사용할 수 있는 효소의 예로는 α-아밀라제, 글루코아밀라제, 풀룰라나제 및 α-글루코시다제가 포함되지만, 이에 제한되지는 않는다. 당해 효소는 초호열성일 수 있다. 당해 방법에 따라 제조된 당에는 헥소즈, 글루코즈 및 프럭토즈가 포함되지만, 이에 제한되지는 않는다. 당해 방법에 사용할 수 있는 식물의 예로는 옥수수, 밀 또는 보리가 포함되지만, 이에 제한되지는 않는다. 사용할 수 있는 식물의 생성물의 예로는 과실, 곡립 및 채소가 포함되지만, 이에 제한되지는 않는다. 한 양태에서, 다당류 가공 효소를 유도성 프로모터의 제어 하에 둔다. 따라서, 침지 과정 전 또는 침지 과정 중. 당해 프로모터를 유도하여 효소의 발현을 유발하고, 이어서 다당류를 당으로 전환한다. 유도성 프로모터 및 이를 함유하는 작제물의 예는 당해 분야에 널리 공지되어 있으며, 본원에 제공되어 있다. 따라서, 다당류 가공이 초호열성인 경우, 침지는 고온에서 수행하여 초호열성 효소를 활성화하고 식물 또는 이의 생성물 내에서 발견되는 내인성 효소는 불활성화한다. 다른 양태에서, 다당류를 당으로 전환할 수 있는 초호열성 효소는 본질적으로 발현된다. 당해 효소는 시그날 서열을 사용하여, 식물 내의 구획으로 표적화되거나 되지 않을 수 있다. 식물 또는 이의 생성물을 식물 내에 함유된 다당류의 당으로의 전환을 유발하는 고온 조건하에 침지한다. The method comprises obtaining a plant expressing a polysaccharide processing enzyme that converts the polysaccharide to a sugar as described above. The plant or product thereof is immersed in an aqueous stream under conditions in which the expressed enzyme converts the polysaccharides contained in the plant or product thereof into dextrins, maltooligosaccharides and / or sugars. The aqueous stream containing dextrin, maltooligosaccharides and / or sugars prepared through the conversion of polysaccharides is then separated to produce syrups with high sugar equivalents. The method may or may not include the additional step of wet-milling the plant or product thereof to obtain starch granules. Examples of enzymes that can be used in the method include, but are not limited to, α-amylase, glucoamylase, pullulanase, and α-glucosidase. The enzyme may be superthermophilic. Sugars prepared according to the method include, but are not limited to, hexose, glucose and fructose. Examples of plants that can be used in the method include, but are not limited to, corn, wheat or barley. Examples of plant products that can be used include, but are not limited to, fruits, grains, and vegetables. In one embodiment, the polysaccharide processing enzyme is placed under the control of an inducible promoter. Thus, before or during the dipping process. The promoter is induced to induce the expression of an enzyme, which then converts the polysaccharide to a sugar. Examples of inducible promoters and constructs containing them are well known in the art and provided herein. Thus, if the polysaccharide processing is superthermophilic, soaking is performed at high temperatures to activate the hyperthermic enzymes and to inactivate the endogenous enzymes found in plants or their products. In other embodiments, superthermophilic enzymes capable of converting polysaccharides to sugars are expressed essentially. The enzyme may or may not be targeted to a compartment in the plant using the signal sequence. The plant or product thereof is immersed under high temperature conditions causing conversion of the polysaccharides contained in the plant to sugars.
또한 높은 당 당량을 갖는 시럽으로부터의 에탄올 또는 발효 음료를 제조하는 방법을 제공한다. 당해 방법은 시럽 내에 함유된 당의 에탄올 또는 발효 음료로의 전환을 가능하게 하는 조건하에서 당해 시럽과 효모를 함께 항온처리하는 단계를 포함한다. 이러한 발효 음료의 예로는 맥주 및 포도주가 포함되지만, 이에 제한되지는 않는다. 발효 조건은 당해 분야에 널리 공지되어 있으며 미국 특허 제4,929,452호 및 본원에 기술되어 있다. 바람직하게는 효모는 에스. 세리비지애 ATCC 제20867호와 같은 효모의 고알콜-내성 및 고당 내성 균주이다. 발효 음료의 발효 생성물은 증류하여 에탄올 또는 증류 음료를 분리할 수 있다. Also provided are methods of making ethanol or fermented beverages from syrups having a high equivalent weight. The method includes incubating the syrup and yeast together under conditions that allow the conversion of sugars contained in the syrup to ethanol or fermented beverages. Examples of such fermented beverages include, but are not limited to, beer and wine. Fermentation conditions are well known in the art and are described in US Pat. No. 4,929,452 and herein. Preferably the yeast is S. It is a high alcohol-resistant and high sugar resistant strain of yeast such as Seribizia ATCC 20867. Fermentation products of fermentation beverages can be distilled to separate ethanol or distilled beverages.
l. 식물의 세포벽 내의 초호열성 효소의 축적l. Accumulation of Superthermolytic Enzymes in Plant Cell Walls
본 발명은 식물의 세포벽 내에 초호열성 효소를 축적하는 방법을 제공한다. 당해 방법은 식물 내에서 세포벽 표적화 시그날와 융합된 초호열성 효소를 발현시켜 표적화된 효소를 세포벽에 축적하는 단계를 포함한다. 바람직하게는, 당해 효소는 다당류를 단당류로 전환할 수 있다. 표적화 서열의 예로는 셀룰로스 또는 자일로스 결합 도메인이 포함되지만, 이에 제한되지는 않는다. 초호열성 효소의 예에는 서열번호 1, 3, 5, 10, 13, 14, 15 또는 16으로 기입된 것이 포함된다. 식물 물질을 함유하는 세포벽을 공급재료로부터 당을 회수하기 위한 과정의 목적하는 효소의 공급원 또는 다른 공급원으로부터 유래한 다당류의 단당류로의 전환용 효소 공급원으로서 첨가할 수 있다. 추가로, 세포벽을 효소를 정제할 수 있는 공급원으로 제공할 수 있다. 효소를 정제하는 방법은 당해 분야에 널리 공지되어 있으며, 겔 여과, 이온-교환 크로마토그래피, 크로마토포커싱, 등전집속, 친화 크로마토그래피, FPLC, HPLC, 염 침전, 투석 등이 포함되지만, 이에 제한되지는 않는다. 따라서, 본 발명은 또한 식물의 세포벽으로부터 분리한 정제된 효소를 제공한다. The present invention provides a method for accumulating superthermophilic enzymes in the cell wall of a plant. The method includes expressing a superthermophilic enzyme fused with a cell wall targeting signal in a plant to accumulate the targeted enzyme in the cell wall. Preferably, the enzyme can convert polysaccharides to monosaccharides. Examples of targeting sequences include, but are not limited to, cellulose or xylose binding domains. Examples of superthermophilic enzymes include those listed as SEQ ID NOs: 1, 3, 5, 10, 13, 14, 15 or 16. The cell wall containing the plant material may be added as a source of enzyme for conversion of a polysaccharide from a source of the desired enzyme or other source of polysaccharide derived from another source in the process for recovering sugars from the feedstock. In addition, the cell wall can be provided as a source from which the enzyme can be purified. Methods for purifying enzymes are well known in the art and include, but are not limited to, gel filtration, ion-exchange chromatography, chromatographic focusing, isoelectric focusing, affinity chromatography, FPLC, HPLC, salt precipitation, dialysis, and the like. Does not. Accordingly, the present invention also provides purified enzymes isolated from the cell walls of plants.
m. 가공 효소의 제조 및 분리 방법m. Preparation and Separation Methods of Processed Enzymes
본 발명에 따르면, 본 발명의 재조합으로 제조된 가공 효소는 형질전환된 식물 조직 또는 세포를 위해 선택한, 식물에서 활성화될 수 있는 본 발명의 가공 효소를 포함하는 식물 조직 또는 식물 세포를 형질전환하고, 형질전환된 식물 조직 또는 세포를 형질전환된 식물로 배양하고, 당해 형질전환된 식물 또는 이의 이부로부터 가공 효소를 분리하여 제조할 수 있다. 재조합으로 제조된 효소는 α-아밀라제, 글루코아밀라제, 글루코즈 이소머라제, α-글루코시다제, 풀룰라나제, 자일라나제, 프로테아제, 글루카나제, 베타 글루코시다제, 에스테라제, 리파제 또는 피타제일 수 있다. 당해 효소는 서열번호 2, 4, 6, 9, 19, 21, 25, 37, 39, 41, 43, 46, 48, 50, 52, 59, 61, 63, 65, 79, 81, 83, 85, 87, 89, 91, 93, 94, 95, 96, 97 또는 99 중 어느 하나에서 선택된 폴리뉴클레오타이드에 의해 암호화될 수 있다. According to the present invention, a recombinantly prepared processing enzyme of the present invention transforms a plant tissue or plant cell comprising the processing enzyme of the present invention that can be activated in a plant selected for the transformed plant tissue or cell, Transformed plant tissues or cells may be cultured into transformed plants and prepared by separating the processing enzymes from the transformed plant or parts thereof. Recombinantly prepared enzymes include α-amylase, glucoamylase, glucose isomerase, α-glucosidase, pullulanase, xylanase, protease, glucanase, beta glucosidase, esterase, lipase or pitase You can be the best. The enzyme has SEQ ID NOs: 2, 4, 6, 9, 19, 21, 25, 37, 39, 41, 43, 46, 48, 50, 52, 59, 61, 63, 65, 79, 81, 83, 85 , 87, 89, 91, 93, 94, 95, 96, 97 or 99 can be encoded by a polynucleotide selected from.
본 발명은 추가로 다음의 실시예에 의해 기술될 것이며, 본 발명의 영역을 어떠한 방법으로도 제한하고자 하는 것은 아니다. The invention will be further described by the following examples, which are not intended to limit the scope of the invention in any way.
실시예 1Example 1
초호열성 전분-가공/이성체화 효소에 대한 옥수수-최적화된 유전자의 작제Construction of Corn-Optimized Genes for Superthermic Starch-Processing / Isomerase
전분 분해 또는 글루코즈 이성체화에 관여하는 효소 α-아밀라제, 풀룰라나제, α-글루코시다제 및 글루코즈 이소머라제를 이들의 목적하는 활성 특성 중에서 선택하였다. 이들은 예를 들면, 주위 온도에서의 최소 활성, 고온 활성/안정성 및 저 pH에서의 활성을 포함한다. 이어서 상응하는 유전자를 미국 특허 제5,625,136호에 기술된 바와 같은 옥수수 선호 코돈을 사용하여 설계하였고, 제조사[Integrated DNA Technologies, Inc.(아이오와주 코랄빌 소재)]에서 합성하였다. Enzymes α-amylase, pullulanase, α-glucosidase and glucose isomerase, which are involved in starch degradation or glucose isomerization, were chosen from their desired active properties. These include, for example, minimal activity at ambient temperature, high temperature activity / stability and activity at low pH. Corresponding genes were then designed using corn preferred codons as described in US Pat. No. 5,625,136 and synthesized by the manufacturer (Integrated DNA Technologies, Inc., Coralville, Iowa).
서열번호 1의 아미노산 서열을 갖는 797GL3 α-아밀라제를 이의 초호열성 활성에 대하여 선택하였다. 당해 효소의 핵산 서열을 추론하고 옥수수-최적화시키고, 서열번호 2로 나타내었다. 유사하게, 서열번호 3에 제시된 아미노산 서열을 갖는 6gp3 풀룰라나제를 선택하였다. 6gp3 풀룰라나제에 대한 핵산 서열을 추론하고, 옥수수 최적화시키고, 서열번호 4로 나타내었다. 797GL3 α-amylase having the amino acid sequence of SEQ ID NO: 1 was selected for its supertherogenic activity. The nucleic acid sequence of the enzyme was deduced and corn-optimized and represented by SEQ ID NO: 2. Similarly, 6gp3 pullulanase was selected having the amino acid sequence set forth in SEQ ID NO: 3. Nucleic acid sequences for 6gp3 pullulanase were inferred, corn optimized and represented by SEQ ID NO: 4.
설폴로부스 솔파타리쿠스로부터의 malA α-글루코시다제에 대한 아미노산 서열을 문헌[참조: J. Bact. 177: 482-485 (1995); J. Bact. 180:1287-1295 (1998)]으로부터 입수하였다. 당해 단백질의 공개된 아미노산 서열(서열번호 5)을 기초로 하여, malA α-글루코시다제를 암호화하는 옥수수-최적화된 합성 유전자(서열번호 6)를 설계하였다. The amino acid sequence for malA α-glucosidase from sulfolobus solfataricus is described in J. Bact. 177: 482-485 (1995); J. Bact. 180: 1287-1295 (1998). Based on the published amino acid sequence of the protein (SEQ ID NO: 5), a corn-optimized synthetic gene (SEQ ID NO: 6) encoding malA α-glucosidase was designed.
수개의 글루코즈 이소머라제 효소를 선택하였다. 터모토가 마리티마로부터 유래한 글루코즈 이소머라제에 대한 아미노산 서열(서열번호 18)을 수탁번호 제 NC_000853호를 갖는 공개된 DNA 서열을 기초로 하여 예측하고, 옥수수-최적화 합성 유전자를 설계하였다(서열번호 19). 유사하게, 터모토가 니아폴리타나로부터 유래한 글루코즈 이소머라제에 대한 아미노산 서열(서열번호 20)을 문헌[참조: Appl. Envir. Microbiol. 61(5):1867-1875(1995)], 수탁 번호 제L38994호로부터의 공개된 DNA 서열을 기초로 하여 예측하였다. 터모토가 니아폴리타나 글루코즈 이소머라제를 암호화하는 옥수수-최적화된 합성 유전자를 설계하였다(서열번호 21).Several glucose isomerase enzymes were selected. Turmoto predicted the amino acid sequence for glucose isomerase derived from Marittima (SEQ ID NO: 18) based on the published DNA sequence with accession number NC_000853 and designed a corn-optimized synthetic gene (SEQ ID NO: 1). Number 19). Similarly, the amino acid sequence (SEQ ID NO: 20) for glucose isomerases derived from Niapolitana is described in Appl. Envir. Microbiol. 61 (5): 1867-1875 (1995)], on the basis of published DNA sequences from Accession No. L38994. Turmoto designed a corn-optimized synthetic gene encoding niapolitana or glucose isomerase (SEQ ID NO: 21).
실시예 2Example 2
이. 콜라이 내의 797GL3 α-아밀라제 융합물의 발현 및 전분 캡슐화 영역 융합물의 발현 this. Expression of 797GL3 α-amylase fusions in E. coli and expression of starch encapsulation region fusions
옥수수 과립-결합 전분 신타제(waxy)로부터의 전분 캡슐화 영역(SER)에 융합된 초호열성 797GL3 α-아밀라제를 암호화하는 작제물을 이. 콜라이 내에 도입하고 발현시켰다. 당해 아미노산 서열(서열번호 8)을 암호화하는 옥수수 과립-결합 전분 신타제 cDNA(서열번호 7)(문헌[참조: Klosgen RB, et al., 1986])를 전분 결합 도메인 또는 전분 캡슐화 영역(SER)의 공급원으로서 클로닝하였다. 전장 cDNA를 GenBank 수탁번호 제X03935호로 의장된 프라이머 SV57(5' AGCGAATTCATGGCGGCTCTGGCCACGT 3')(서열번호 22) 및 SV58(5' AGCTAAGCTTCAGGGCGCGGCCACGTTCT 3')(서열번호 23)을 사용하여, 옥수수 종자로부터 제조한 RNA로부터 RT-PCR하여 증폭하였다. 완전한 cDNA를 EcoRI/HindIII 단편으로서 pBluescrip로 클로닝하였고, 당해 플라스미드를 pNOV4022로 명명하였다. Constructs encoding super-thermophilic 797GL3 α-amylase fused to starch encapsulation regions (SER) from corn granule-bound starch synthase (waxy). It was introduced into E. coli and expressed. Corn granules-binding starch synthase cDNA (SEQ ID NO: 7) encoding the amino acid sequence (SEQ ID NO: 8) (Klosgen RB, et al., 1986) was added to the starch binding domain or starch encapsulation region (SER). Cloned as a source of. Full length cDNA from RNA prepared from corn seeds using primers SV57 (5 'AGCGAATTCATGGCGGCTCTGGCCACGT 3') (SEQ ID NO: 22) and SV58 (5 'AGCTAAGCTTCAGGGCGCGGCCACGTTCT 3') (SEQ ID NO: 23) designed as GenBank Accession No. X03935 Amplification by RT-PCR. The complete cDNA was cloned into pBluescrip as an EcoRI / HindIII fragment and the plasmid was named pNOV4022.
전분-결합 도메인을 포함하는 waxy cDNA의 C-말단 부위(bp 919-1818에 의해 암호화된)를 pNOV4022로부터 증폭하고, 전장 옥수수-최적화 797GL3 유전자(서열번호 2)의 3' 말단에 뼈대를 완성하여 융합시켰다. 핵산 서열번호 9를 갖고 서열번호 10의 아미노산 서열을 암호화하는 융합된 유전자 생성물, 797GL3/Waxy를 NcoI/XbaI 단편으로서, NcoI/NheI으로 절단한 pET28b(제조사[NOVAGEN], 위스콘신주 매디슨 소재) 내로 클로닝하였다. 또한 797GL3 유전자만을 NcoI/XbaI 단편으로 pET28b 벡터 내로 클로닝하였다. The C-terminal portion of the waxy cDNA containing the starch-binding domain (encoded by bp 919-1818) was amplified from pNOV4022 and the skeleton was completed at the 3 'end of the full-length maize-optimized 797GL3 gene (SEQ ID NO: 2). Fused. A fused gene product, 797GL3 / Waxy, having nucleic acid SEQ ID NO: 9 and encoding the amino acid sequence of SEQ ID NO: 10 as a NcoI / XbaI fragment, cloned into pET28b digested with NcoI / NheI (NOVAGEN, Madison, WI) It was. In addition, only the 797GL3 gene was cloned into the pET28b vector as an NcoI / XbaI fragment.
pET28/797GL3 및 pET28/797GL3/Waxy 벡터를 BL21/DE3 이. 콜라이 세포(NOVAGEN)로 형질전환하였고, 제조사 지침에 따라 배양 및 유도하였다. PAGE/쿠마시 염색에 의한 분석은 추출물 둘 다에서 각각 융합 및 비융합 아밀라제의 예측된 크기에 상응하는 유도된 단백질을 나타내었다. pET28 / 797GL3 and pET28 / 797GL3 / Waxy vectors are BL21 / DE3. E. coli cells (NOVAGEN) were transformed, cultured and induced according to manufacturer's instructions. Analysis by PAGE / Kumasi staining revealed induced proteins corresponding to the predicted size of fused and unfused amylase in both extracts, respectively.
총 세포 추출물을 다음과 같이 초호열성 아밀라제 활성에 대해 분석하였다: 전분 5mg을 물 20㎕에 현탁한 후 에탄올 25㎕로 희석하였다. 표준 아밀라제 양성 대조군 및 아밀라제 활성에 대해 시험할 샘플을 당해 혼합물에 첨가하고, 500㎕의 최종 반응 용적까지 물을 가하였다. 당해 반응은 80℃에서 15분 내지 45분 동안 수행하였다. 이어서 당해 반응물을 실온으로 냉각하고, o-다이아니시딘 및 글루코즈 산화효소/과산화효소혼합물(Sigma) 500㎕를 첨가하였다. 당해 혼합물을 37℃에서 30분 동안 항온처리하였다. 12N 황산 500㎕을 첨가하여 반응을 중지시켰다. 540nm에서의 흡광도를 측정하여 아밀라제/샘플에 의해 방출된 글루코즈의 양을 정량하였다. 융합 및 비융합 아밀라제 추출물 둘 다의 검정은 유사한 수준의 초호열성 아밀라제 활성을 나타낸 반면, 대조군 추출물은 음성이었다. 이는 797GL3 아밀 라제가 waxy 단백질의 C-말단 부위에 융합된 경우, 여전히 활성적이었음을(고온에서) 나타내었다. Total cell extracts were analyzed for hyperthermic amylase activity as follows: 5 mg of starch was suspended in 20 μl of water and diluted with 25 μl of ethanol. Samples to be tested for standard amylase positive control and amylase activity were added to the mixture and water was added up to 500 μl final reaction volume. The reaction was carried out at 80 ° C. for 15 to 45 minutes. The reaction was then cooled to room temperature and 500 [mu] l of o- dianisidine and glucose oxidase / peroxidase mixture (Sigma) was added. The mixture was incubated at 37 ° C. for 30 minutes. The reaction was stopped by adding 500 μl of 12N sulfuric acid. Absorbance at 540 nm was measured to quantify the amount of glucose released by amylase / sample. Assays for both fused and unfused amylase extracts showed similar levels of superthermophilic amylase activity, whereas the control extract was negative. This indicated that when 797GL3 amylase was fused to the C-terminal region of the waxy protein, it was still active (at high temperature).
실시예 3Example 3
옥수수에서의 내배유-특이적 발현용 프로모터 단편의 분리 Isolation of Promoter Fragments for Endocrine-Specific Expression in Maize
옥수수 종 제이 메이스 ADP-gpp(ADP-글루코즈 파이로포스포릴라제)의 대 아단위로부터의 프로모터 및 5' 비암호화 영역 I(최초 인트론을 포함하는)을 Genbank 수탁번호 제M81603호로 의장된 프라이머를 사용하여 옥수수 게놈 DNA로부터 1515 염기쌍 단편(서열번호 11)으로 증폭하였다. ADP-gpp 프로모터는 내배유-특이적(문헌[참조: Shaw and Hannah, 1992])에 나타내어져 있다. The promoter from the subunit of maize species J. mays ADP-gpp (ADP-glucose pyrophosphorylase) and the 5 'non-coding region I (including the first intron) were subjected to primers designed under Genbank Accession No. M81603. Using 1515 base pair fragment (SEQ ID NO: 11) from maize genomic DNA. The ADP-gpp promoter is shown in endosperm-specific (Shaw and Hannah, 1992).
제아 메이스 γ-제인으로부터의 프로모터를 플라스미드 pGZ27.3(브라이언 라킨 박사로부터 입수한)으로부터 673bp 단편(서열번호 12)으로 증폭하였다. 당해 γ-제인 프로모터는 내배유-특이적인 것으로 보여진다(문헌[참조: Torrent et al. 1997]).The promoter from Zea mays γ-Zane was amplified into a 673 bp fragment (SEQ ID NO: 12) from plasmid pGZ27.3 (obtained from Dr Brian Lakin). This γ-zein promoter has been shown to be endocrine-specific (Torrent et al. 1997).
실시예 4Example 4
797GL3 초호열성 α-아밀라제용 형질전환 벡터의 작제Construction of 797GL3 Superthermophilic α-amylase Transformation Vector
옥수수 내배유 내에서 797GL3 초호열성 아밀라제를 발현시키기 위해 다음과 같이 다양한 표적화 시그날을 갖는 발현 카세트를 작제하였다.Expression cassettes with various targeting signals were constructed to express 797GL3 superthermic amylase in corn endosperm.
pNOV6200(서열번호 13)은 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위한, 실시예 1에서 상기한 바와 같은 합성 797GL3 아밀라제에 융합된 옥수수 γ-제인 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함한다(문헌[참조: Torrent et al. 1997]). 당해 융합물을 내배유에서의 특이적 발현을 위해 옥수수 ADP-gpp 프로모터 뒤에 클로닝하였다. pNOV6200 (SEQ ID NO: 13) contains a corn γ-zein signal sequence (MRVLLVALALLALAASATS) (SEQ ID NO: 17) fused to a synthetic 797GL3 amylase as described above in Example 1 for targeting to cytoplasmic reticulum and secretion of apoplasts. (See Torrent et al. 1997). This fusion was cloned after the corn ADP-gpp promoter for specific expression in endocrine.
pNOV6201(서열번호 14)는 세포질세망(ER)으로의 표적화 및 세포질세망에서의 체류를 위한 서열 SEKDEL의 C-말단 첨가와 함께, 합성 797GL3에 융합된 γ-제인 N-말단 시그날 서열을 포함한다(문헌[참조: Munro and Pelham, 1987]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 ADP-gpp 프로모터 뒤에 클로닝하였다. pNOV6201 (SEQ ID NO: 14) comprises an N-terminal signal sequence γ-agent fused to Synthetic 797GL3, with C-terminal addition of the sequence SEKDEL for targeting to cytoplasmic network (ER) and retention in cytoplasmic network (ER) Munro and Pelham, 1987). This fusion was cloned after the corn ADP-gpp promoter for specific expression in endocrine.
pNOV7013은 세포질세망(ER)으로의 표적화 및 그 안에서의 체류를 위한 서열 SEKDEL의 C-말단 첨가와 함께, 합성 797GL3에 융합된 γ-제인 N-말단 시그날 서열을 포함한다. PNOV7013은 내배유 내에서 융합물을 발현시키기 위해 옥수수 AD-spp 프로모터 대신 옥수수 γ-제인 프로모터(서열번호 12)를 사용한다는 것 외에는 pNOV6201과 동일하다. pNOV7013 comprises an N-terminal signal sequence, a γ-agent fused to synthetic 797GL3, with C-terminal addition of the sequence SEKDEL for targeting to and retention in cytoplasmic reticulum (ER). PNOV7013 is identical to pNOV6201 except that the corn γ-zein promoter (SEQ ID NO: 12) is used in place of the corn AD-spp promoter to express the fusion in endocrine.
pNOV4029(서열번호 15)는 전분체로의 표적화을 위해 합성 797GL3 아밀라제에 융합시킨 waxy 전분체 표적화 펩타이드(문헌[참조: Klosgen et al., 1986])를 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 ADP-gpp 프로모터 뒤에 클로닝하였다.pNOV4029 (SEQ ID NO: 15) includes a waxy starch targeting peptide (Klosgen et al., 1986) fused to synthetic 797GL3 amylase for targeting to starch. This fusion was cloned after the corn ADP-gpp promoter for specific expression in endocrine.
pNOV4031(서열번호 16)은 전분 과립으로의 표적화을 위해 합성 797GL3/waxy 융합 단백질과 융합시킨 waxy 전분체 표적화 펩타이드를 포함한다. 당해 융합물은 내배유 내에서의 특이적 발현을 위해 옥수수 ADP-gpp 프로모터 뒤에 클로닝하였다. pNOV4031 (SEQ ID NO: 16) contains a waxy starch targeting peptide fused with a synthetic 797GL3 / waxy fusion protein for targeting to starch granules. This fusion was cloned after the corn ADP-gpp promoter for specific expression in endocrine.
보다 높은 수준의 효소 발현을 얻기 위해 부가적 작제물을 옥수수 γ-제인 프로모터 뒤로 클로닝한 이들 융합물을 사용하여 제조하여 제조하였다. 모든 발현 카세트를 애그로박테리움 감염을 통해 옥수수로의 형질전환용 이원 벡터 내로 이동시켰다. 이원 벡터는 만노즈를 갖는 형질전환 세포의 선별을 가능하게 하는 포스포만노즈 이소머라제(PMI)를 함유한다. 형질전환 옥수수 식물을 자가 수분 또는 이계 교배하였고, 분석용 종자를 수거하였다. Additional constructs were prepared by using these fusions cloned behind the corn γ-zein promoter to obtain higher levels of enzyme expression. All expression cassettes were transferred into a binary vector for transformation into maize via Agrobacterium infection. Binary vectors contain phosphomannose isomerase (PMI) which allows for the selection of transformed cells with mannose. Transformed corn plants were self-pollinated or crossbred, and analytical seeds were harvested.
부가적 작제물은 α-아밀라제에 대해 상기 기술한 바와 동일한 방법으로 정확하게 6gp3 풀룰라나제 또는 340g12 α-글루코시다제에 융합시킨 상기한 표적화 시그날을 사용하여 제조하였다. 이를 융합물을 옥수수 ADP-gpp 프로모터 및/또는 γ-제인 프로모터 뒤로 클로닝하였고 상기한 바와 같이 옥수수로 형질전환하였다. 형질전환 옥수수 식물을 자가 수분 또는 이계 교배하였고, 분석용 종자를 수거하였다. Additional constructs were prepared using the targeting signal described above fused to 6gp3 pullulanase or 340g12 α-glucosidase exactly in the same manner as described above for α-amylase. This fusion was cloned behind the maize ADP-gpp promoter and / or the γ-zein promoter and transformed into maize as described above. Transformed corn plants were self-pollinated or crossbred, and analytical seeds were harvested.
효소의 배합물은 개별 유전자를 발현하는 식물을 이종 교배하거나 수개의 발현 카세트를 공형질전환이 가능한 동일한 이원 벡터로 클로닝하여 제조할 수 있다. Combinations of enzymes can be prepared by heterogeneously crossing plants expressing individual genes or by cloning several expression cassettes into the same binary vector capable of cotransformation.
실시예 5Example 5
6GP3 호열성 풀룰라나제용 식물 형질전환 벡터의 작제Construction of a Plant Transformation Vector for 6GP3 Thermophilic Fulanase
다음과 같이 6GP3 호열성 풀룰라나제의 옥수수 내배유의 세포질세망 내에서의 발현을 위한 발현 카세트를 작제하였다:An expression cassette for expression in cytoplasmic reticulum of maize endosperm of 6GP3 thermophilic pullulanase was constructed as follows:
pNOV7005(서열번호 24 및 25)은 ER로의 표적화 및 ER에서의 체류를 위한 서열 SEKDEL의 C-말단 첨가와 함께, 합성 6GP3 풀룰라나제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 아미노산 펩타이드 SEKDEL은 합성 유전자를 증폭하고 동시에 단백질의 C-말단에 6개의 아미노산을 첨가하기 위해 설계한 프라이머를 이용하는 PCR을 사용하여 당해 효소의 C-말단에 융합시켰다. 당해 융합물은 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. pNOV7005 (SEQ ID NOS: 24 and 25) comprises an N-terminal signal sequence, a corn γ-agent fused to synthetic 6GP3 pullulanase, with C-terminal addition of the sequence SEKDEL for targeting to ER and retention in ER. The amino acid peptide SEKDEL was fused to the C-terminus of the enzyme using PCR using a primer designed to amplify the synthetic gene and simultaneously add six amino acids to the C-terminus of the protein. This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
실시예 6Example 6
malA용 식물 형질전환 벡터의 작제Construction of plant transformation vector for malA
초호열성 α-글루코시다제Superthermophilic α-glucosidase
옥수수 내배유 내에서 설폴로부스 솔파타리쿠스 malA 초호열성 α-글루코시다제를 발현시키기 위해 다음과 같이 다양한 표적화 시그날을 갖는 발현 카세트를 작제하였다. Expression cassettes with various targeting signals were constructed to express sulfolobus solfataricus malA hyperthermia a-glucosidase in corn endosperm as follows.
pNOV4831(서열번호 26)은 세포질세망(ER)으로의 표적화 및 ER에서의 체류를 위해 서열 SEKDEL의 C-말단 첨가와 함께, 합성 malA α-글루코시다제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함한다(문헌[참조: Munro and Pelham, 1987]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. pNOV4831 (SEQ ID NO: 26) is a corn γ-agent N-terminal signal fused to synthetic malA α-glucosidase, with C-terminal addition of the sequence SEKDEL for targeting to cytoplasmic network (ER) and retention in ER Sequence (MRVLLVALALLALAASATS) (SEQ ID NO: 17) (Munro and Pelham, 1987). This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4839(서열번호 27)은 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위해 합성 MalA α-글루코시다제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함한다(문헌[참조: Torrent et al., 1997]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. pNOV4839 (SEQ ID NO: 27) comprises an N-terminal signal sequence (MRVLLVALALLALAASATS) (SEQ ID NO: 17) which is a corn γ-agent fused to synthetic MalA α-glucosidase for targeting to cytoplasmic networks and secretion of apoplasts (Torrent et al., 1997). This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4837은 ER로의 표적화 및 ER에서의 체류를 위해 서열 SEKDEL의 C-말단 첨가와 함께, 합성 malA α-글루코시다제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 ADP-gpp 프로모터 뒤로 클로닝하였다. 당해 클론에 대한 아미노산 서열은 pNOV4831(서열번호 26)의 서열과 동일하다. pNOV4837 contains a N-terminal signal sequence (MRVLLVALALLALAASATS), a corn γ-agent fused to synthetic malA α-glucosidase, with C-terminal addition of the sequence SEKDEL for targeting to ER and retention in ER. Include. This fusion was cloned behind the corn ADP-gpp promoter for specific expression in endocrine. The amino acid sequence for this clone is identical to the sequence of pNOV4831 (SEQ ID NO: 26).
실시예 7Example 7
초호열성 터모토가 마리티마 및 터모토가 니아폴리타나 글루코즈 이소머라제용 식물 형질전환 벡터의 작제Construction of Plant Transformation Vectors for Superthermophilic Turmotoga Marittima and Turmotoga niapolitana Glucose Isomerase
옥수수 내배유 내에서 터모토가 마리티마 및 터모토가 니아폴리타나 초호열성 글루코즈 이소머라제를 발현시키기 위해 다음과 같이 다양한 표적화 시그날을 갖는 발현 카세트를 작제하였다. Expression cassettes with various targeting signals were constructed to express Turmotoga maritima and Turmotoga niapolitana or hyperthermic glucose isomerase in corn endosperm as follows.
pNOV4832(서열번호 28)은 ER로의 표적화 및 ER에서의 체류를 위해 서열 SEKDEL의 C-말단 첨가와 함께, 합성 터모토가 마리티마 글루코즈 이소머라제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. pNOV4832 (SEQ ID NO: 28) is a N-terminal signal sequence, a corn γ-agent fused to maritima glucose isomerase by Synthetic Turmoto with C-terminal addition of the sequence SEKDEL for targeting to ER and retention in the ER. MRVLLVALALLALAASATS) (SEQ ID NO: 17). This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4833(서열번호 29)은 ER로의 표적화 및 ER에서의 체류를 위해 서열 SEKDEL의 C-말단 첨가와 함께, 합성 터모토가 니아폴리타나 글루코즈 이소머라제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. pNOV4833 (SEQ ID NO: 29) is a N-terminal signal sequence that is a corn γ-agent fused to niapolitana or glucose isomerase by synthetic turmoto with C-terminal addition of the sequence SEKDEL for targeting to ER and retention in the ER. (MRVLLVALALLALAASATS) (SEQ ID NO: 17). This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4840(서열번호 30)은 ER로의 표적화 및 아포플라스트로의 분비를 위해 합성 터모토가 니아폴리타나 글루코즈 이소머라제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함한다(문헌[참조: Torrent et al. 1997]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 ADP-gpp 프로모터 뒤로 클로닝하였다. pNOV4840 (SEQ ID NO: 30) shows the N-terminal signal sequence (MRVLLVALALLALAASATS) (SEQ ID NO: 17), a corn γ-agent fused with synthetic turmoto niapolitana or glucose isomerase for targeting to ER and secretion of apoplasts. (See Torrent et al. 1997). This fusion was cloned behind the corn ADP-gpp promoter for specific expression in endocrine.
pNOV4838은 ER로의 표적화 및 ER에서의 체류를 위해 서열 SEKDEL의 C-말단 첨가와 함께, 합성 터모토가 니아폴리타나 글루코즈 이소머라제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 ADP-gpp 프로모터 뒤로 클로닝하였다. 당해 클론에 대한 아미노산 서열은 pNOV4833(서열번호 29)의 서열과 동일하다. pNOV4838 is an N-terminal signal sequence (MRVLLVALALLALAASATS), a corn γ-agent fused to niapolitana or glucose isomerase, with C-terminal addition of the sequence SEKDEL for targeting to ER and retention in the ER Number 17). This fusion was cloned behind the corn ADP-gpp promoter for specific expression in endocrine. The amino acid sequence for this clone is identical to the sequence of pNOV4833 (SEQ ID NO: 29).
실시예 8Example 8
초호열성 글루카나제 EglA의 발현용 식물 형질전환 벡터의 작제Construction of Plant Transformation Vectors for the Expression of Superthermoglucanase EglA
pNOV4800(서열번호 58)은 아포플라스트로의 국소화를 위한 EglA 성숙 단백질 서열과 융합시킨 보리 알파 아밀라제 AMY32b 시그날 서열(MGKNGNLCCFSLLLLLLAGLASGHQ)(서열번호 31)을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위한 γ-제인 프로모터 뒤로 클로닝시켰다. pNOV4800 (SEQ ID NO: 58) comprises a barley alpha amylase AMY32b signal sequence (MGKNGNLCCFSLLLLLLAGLASGHQ) (SEQ ID NO: 31) fused with an EglA mature protein sequence for localization of apoplasts. This fusion was cloned behind a γ-zein promoter for specific expression in endocrine.
실시예 9Example 9
다중 초호열성 효소의 발현용 식물 형질전환 벡터의 작제Construction of Plant Transformation Vectors for Expression of Multiple Superthermophilic Enzymes
pNOV4841은 797GL3 α-아밀라제 융합물 및 6GP3 풀룰라나제 융합물의 이중 유전자 작제물을 포함한다. 797GL3 융합물(서열번호 33) 및 6GP3 융합물(서열번호 34) 둘 다 ER로의 표적화 및 ER에서의 체류를 위한 옥수수 γ-제인 N-말단 시그날 서열 및 SEKDEL 서열을 포함한다. 각각의 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. pNOV4841 includes a dual gene construct of the 797GL3 α-amylase fusion and the 6GP3 pullulase fusion. Both the 797GL3 fusions (SEQ ID NO: 33) and the 6GP3 fusions (SEQ ID NO: 34) include the N-terminal signal sequence and the SEKDEL sequence, which are corn γ-agents for targeting to and retention in the ER. Each fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4842는 797GL3 α-아밀라제 융합물 및 malA α-글루코시다제 융합물의 이중 유전자 작제물을 포함한다. 797GL3 융합물 폴리펩타이드(서열번호 35) 및 malA α-글루코시다제 융합물 폴리펩타이드(서열번호 36) 둘 다 ER로의 표적화 및 ER에서의 체류를 위한 옥수수 γ-제인 N-말단 시그날 서열 및 SEKDEL 서열을 포함한다. 각각의 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. pNOV4842 includes a dual gene construct of the 797GL3 α-amylase fusion and malA α-glucosidase fusion. Both the 797GL3 fusion polypeptide (SEQ ID NO: 35) and the malA α-glucosidase fusion polypeptide (SEQ ID NO: 36) are N-terminal signal sequences and SEKDEL sequences, which are corn γ-agents for targeting to and retention in the ER It includes. Each fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4843은 797GL3 α-아밀라제 융합물 및 malA α-글루코시다제 융합물의 이중 유전자 작제물을 포함한다. 797GL3 융합물 및 α-글루코시다제 융합물 폴리펩타이드(서열번호 36) 둘 다 ER로의 표적화 및 ER에서의 체류를 위한 옥수수 γ-제인 N-말단 시그날 서열 및 SEKDEL 서열을 포함한다. 797GL3 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. 797GL3 융합물 및 malA 융합물의 아미노산 서열은 pNOV4842의 아미노산 서열(각각 서열번호 35 및 36)과 동일하다. pNOV4843 includes a dual gene construct of the 797GL3 α-amylase fusion and malA α-glucosidase fusion. Both the 797GL3 fusion and the α-glucosidase fusion polypeptide (SEQ ID NO: 36) include a N-terminal signal sequence and a SEKDEL sequence, a corn γ-agent for targeting to and retention in the ER. The 797GL3 fusion was cloned behind the maize γ-zein promoter for specific expression in endocrine. The amino acid sequence of the 797GL3 fusion and malA fusion is identical to the amino acid sequence of pNOV4842 (SEQ ID NOs: 35 and 36, respectively).
pNOV4844는 797GL3 α-아밀라제 융합물, 6GP3 풀룰라나제 융합물 및 malA α-글루코시다제 융합물의 삼중 유전자 작제물을 포함한다. 797GL3, malA 및 6GP3 모두 ER로의 표적화 및 ER에서의 체류를 위한 옥수수 γ-제인 N-말단 시그날 서열 및 SEKDEL 서열을 포함한다. 내배유 내에서의 특이적 발현을 위해 797GL3 및 malA 융합물은 2개의 분리된 옥수수 γ-제인 프로모터 뒤로 클로닝하였고, 6GP3 융합물은 옥수수 ADP-gpp 프로모터 뒤로 클로닝하였다. 797GL3 및 malA 융합물에 대한 아미노산 서열은 pNOV4842(각각 서열번호 35 및 36)의 아미노산 서열과 동일하다. 6GP3 융합물에 대한 아미노산 서열은 pNOV4841 중 6GP3 융합물의 아미노산 서열(서열번호 34)과 동일하다. pNOV4844 includes triple gene constructs of the 797GL3 α-amylase fusion, 6GP3 pullulase fusion and malA α-glucosidase fusion. 797GL3, malA and 6GP3 all comprise a corn γ-agent N-terminal signal sequence and SEKDEL sequence for targeting to ER and retention in ER. The 797GL3 and malA fusions were cloned behind two separate corn γ-zein promoters and the 6GP3 fusions were cloned behind the corn ADP-gpp promoters for specific expression in endocrine. The amino acid sequence for the 797GL3 and malA fusions is identical to the amino acid sequence of pNOV4842 (
당해 실시예 및 이후의 실시예에 진술된 모든 발현 카세트를 애그로박테리움 감염을 통한 옥수수로의 형질전환을 위해 이원 벡터 pNOV2117로 옮겼다. pNOV2117은 만노즈를 갖는 형질전환 세포의 선별을 가능하게 하는 포스포만노즈 이소머라제(PMI) 유전자를 포함한다. pNOV2117은 pVS1 및 ColE1 복제 기원 둘 다를 갖는 이원 벡터이다. 당해 벡터는 pAD1289로부터의 기본구성 VirG 유전자(본원에 참조로 인용된 문헌[참조: Hansen, G., et al., PNAS USA 91:7603-7607(1994)]) 및 Tn7으로부터의 스펙티노마이신 내성 유전자를 포함한다. 우측 및 좌측 경계 사이의 다중연결자 내로 옥수수 유비퀴틴 프로모터, PMI 암호화 영역 및 pNOV117의 노팔린 신타제 종결자를 클로닝한다(본원에 참조로 인용된 문헌[Negrotto, D., et al., Plant Cell Reports 19:798-803(2000)]). 형질전환 옥수수 식물을 자가 수분 또는 이계 교배하였고, 분석용 종자를 수거하였다. 상이한 효소의 배합물은 개별 효소를 발현하는 식물을 이종 교배하거나 식물을 다중-유전자 카세트 중 하나로 형질전환하여 제조할 수 있다. All expression cassettes set forth in this and subsequent examples were transferred to binary vector pNOV2117 for transformation into maize via Agrobacterium infection. pNOV2117 contains a phosphomannose isomerase (PMI) gene that enables the selection of transformed cells with mannose. pNOV2117 is a binary vector with both pVS1 and ColE1 replication origins. This vector is a native VirG gene from pAD1289 (Hansen, G., et al., PNAS USA 91: 7603-7607 (1994)) and spectinomycin resistance from Tn7. Contains the genes. Clones the corn ubiquitin promoter, the PMI coding region and the nopaline synthase terminator of pNOV117 into the multi-linker between the right and left boundaries (Negrotto, D., et al., Plant Cell Reports 19: 798-803 (2000)]. Transformed corn plants were self-pollinated or crossbred, and analytical seeds were harvested. Combinations of different enzymes can be prepared by heterogeneous crossing of plants expressing individual enzymes or by transforming the plants with one of a multi-gene cassette.
실시예 10Example 10
세균성 및 피키아(Pichia) 발현 벡터의 작제Construction of Bacterial and Pichia Expression Vectors
피키아 또는 세균 내에서 초호열성 α-글루코시다제 및 글루코즈 이소머라제를 발현시키기 위해 다음과 같이 발현 카세트를 작제하였다:Expression cassettes were constructed as follows to express hyperthermia a-glucosidase and glucose isomerase in Pichia or bacteria:
pNOV4829(서열번호 37 및 38)은 세균성 발현 벡터 pET29a 내에 ER 체류 시그날을 갖는 합성 터모토가 마리티마 글루코즈 이소머라제 융합 유전자를 포함한다. 당해 글루코즈 이소머라제 유전자를 pET29a의 NcoI 및 SacI 위치로 클로닝하였고, 이는 단백질 정제를 위한 N-말단 S-꼬리표의 첨가를 야기한다. pNOV4829 (SEQ ID NOs: 37 and 38) contains a synthetic Turmotoga maritima glucose isomerase fusion gene with an ER retention signal in the bacterial expression vector pET29a. The glucose isomerase gene was cloned into the NcoI and SacI positions of pET29a, which resulted in the addition of an N-terminal S-tag for protein purification.
pNOV4830(서열번호 39 및 40)은 세균성 발현 벡터 pET29a 내에 ER 체류 시그날을 갖는 합성 터모토가 니아폴리타나 글루코즈 이소머라제 융합물을 포함한다. 당해 글루코즈 이소머라제 유전자를 pET29a의 NcoI 및 SacI 위치로 클로닝하였고, 이는 단백질 정제를 위한 N-말단 S-꼬리표의 첨가를 야기한다.pNOV4830 (SEQ ID NOs: 39 and 40) comprises a synthetic turmotoga niapolitana or glucose isomerase fusion with an ER retention signal in the bacterial expression vector pET29a. The glucose isomerase gene was cloned into the NcoI and SacI positions of pET29a, which resulted in the addition of an N-terminal S-tag for protein purification.
pNOV4835(서열번호 41 및 42)은 세균성 발현 벡터 pET28C의 BamHI 및 EcoRI 위치 내로 클로닝한 합성 토모토가 마리티마 글루코즈 이소머라제 유전자를 포함한다. 이는 당해 글루코즈 이소머라제의 N-말단과 His-꼬리표(단백질 정제용)의 융합을 초래한다. pNOV4835 (SEQ ID NOs: 41 and 42) contains a synthetic Tomoto marimarima glucose isomerase gene cloned into the BamHI and EcoRI positions of the bacterial expression vector pET28C. This results in the fusion of the N-terminus of the glucose isomerase and His-tag (for protein purification).
pNOV4836(서열번호 43 및 44)은 세균성 발현 벡터 pET28C의 BamHI 및 EcoRI 위치 내로 클로닝한 합성 토모토가 니아폴리타나 글루코즈 이소머라제 유전자를 포함한다. 이는 당해 글루코즈 이소머라제의 N-말단과 His-꼬리표(단백질 정제용)의 융합을 초래한다. pNOV4836 (SEQ ID NOs: 43 and 44) contains a synthetic Tomotoga niapolitana or glucose isomerase gene cloned into the BamHI and EcoRI positions of the bacterial expression vector pET28C. This results in the fusion of the N-terminus of the glucose isomerase and His-tag (for protein purification).
실시예 11Example 11
비성숙 옥수수 배아의 형질전환은 기본적으로 문헌[참조: Negrotto et al., Plant Cell Reports 19: 798-803])에 기술된 바와 같이 수행하였다. 당해 실시예에 대하여, 모든 배지 구성성분은 상기한 문헌[참조: Negrotto et al.])에 기술된 바와 같았다. 그러나, 당해 문헌에 기술된 각종 배지 구성성분은 대체될 수 있다. Transformation of immature corn embryos was performed basically as described in Negrotto et al., Plant Cell Reports 19: 798-803. For this example, all media components were as described in Negrotto et al., Supra. However, the various media components described in this document can be replaced.
A. 형질전환 플라스미드 및 선별 마커A. Transformation Plasmids and Selectable Markers
형질전환에 사용할 유전자를 옥수수 형질전환에 적합한 벡터 내로 클로닝하였다. 당해 실시예에 사용된 벡터는 형질전환주의 성별을 위한 포스포만노즈 이소머라제(PMI)를 포함하였다(문헌[참조: Negrotto et al., Plant Cell Reports 19: 798-803]).The gene to be used for transformation was cloned into a vector suitable for maize transformation. The vector used in this example included phosphomannose isomerase (PMI) for the sex of the transformants (Negrotto et al., Plant Cell Reports 19: 798-803).
B. 애그로박테리움 튬패시엔스의 제조B. Preparation of Agrobacterium Lithium Passenger
식물 형질전환 플라스미드를 포함하는 애그로박테리움 균주 LBA4404(pSB1)을 YEP(효모 추출물(5g/L), 펩톤(10g/L), NaCl(5g/L), 15g/L 아가, pH 6.8) 고체 배지에서 2일 내지 4일 동안 28℃에서 배양하였다. 대략 0.8X 109개의 애그로박테리움을 100μM As를 첨가한 LS-inf 배지에 현탁시켰다(문헌[참조: Negrotto et al., Plant Cell Reports 19: 798-803]). 세균을 당해 배지에서 30분 내지 60분 동안 예비-유도하였다. Agrobacterium strain LBA4404 (pSB1) comprising a plant transgenic plasmid was isolated from YEP (yeast extract (5 g / L), peptone (10 g / L), NaCl (5 g / L), 15 g / L agar, pH 6.8) solid. The medium was incubated at 28 ° C. for 2-4 days. Approximately 0.8 × 10 9 Agrobacterium were suspended in LS-inf medium with 100 μM As added (Negrotto et al., Plant Cell Reports 19: 798-803). Bacteria were pre-induced in the medium for 30 to 60 minutes.
C. 접종C. Inoculation
A188 또는 기타 적합한 유전형의 미성숙 배아를 8일 내지 12일 된 이삭에서 잘라내어 액체 LS-inf + 100μM As에 넣었다. 배아를 신선한 감염 배지로 1회 세 정하였다. 이어서 애그로박테리움 용액을 첨가하고 배아를 30초 동안 격렬히 교반하고 5분 동안 세균과 함께 가라앉게 하였다. 이어서 배아는 배반쪽을 LSA 배지로 옮기고 암실에서 2일 내지 3일 동안 배양하였다. 이어서, 페트리 플레이트 당 20 내지 25개의 배아를 세포탁심(250mg/l) 및 질산은(1.6mg/l)을 첨가한 LSDc 배지로 옮기고 28℃의 암실에서 10일 동안 배양하였다. Immature embryos of A188 or other suitable genotype were cut from 8-12 day old ears and placed in liquid LS-inf + 100 μM As. Embryos were washed once with fresh infection medium. Agrobacterium solution was then added and the embryo was stirred vigorously for 30 seconds and allowed to settle with bacteria for 5 minutes. Embryos were then transferred to the LSA medium and incubated for 2 to 3 days in the dark. Subsequently, 20-25 embryos per petri plate were transferred to LSDc medium with Cytoxim (250 mg / l) and silver nitrate (1.6 mg / l) and incubated for 10 days in the dark at 28 ° C.
D. 형질전환 세포의 선별 및 형질전환된 식물의 재생D. Selection of Transformed Cells and Regeneration of Transformed Plants
배발생성 유합조직을 생산하는 미성숙 배아를 LSD1M0.5S 배지로 옮겼다. 당해 배양물을 3주의 계대배양 단계로 6주 동안 당해 배지에서 선별하였다. 생존한 유합조직을 만노즈를 첨가한 Reg1 배지로 옮겼다. 광원하에 배양(16시간 명/8시간 암 조직)한 후, 이어서 녹색 조직을 성장 조절자가 없는 Reg2 배지로 옮기고 1-2주 동안 항온처리하였다. 모종을 Reg3 배지를 함유하는 Magenta GA-7 박스(제조사[Magenta Corp], 일리노이주 시카고 소재)로 옮기고 광원하에 배양하였다. 2주 내지 3주 후, 식물을 PMI 유전자 및 다른 관심 유전자의 존재에 대하여 PCR로 검사하였다. PCR 검정에서 양성인 식물을 온실로 옮겼다. Immature embryos producing embryogenic callus were transferred to LSD1M0.5S medium. The cultures were selected from the medium for 6 weeks in three weeks of subculture. Surviving callus was transferred to Reg1 medium with mannose. After incubation (16 hours light / 8 hours cancer tissue) under light source, green tissue was then transferred to Reg2 medium without growth regulator and incubated for 1-2 weeks. Seedlings were transferred to a Magenta GA-7 box containing Reg3 medium (Magenta Corp, Chicago, Ill.) And cultured under light source. After two to three weeks, plants were examined by PCR for the presence of PMI genes and other genes of interest. Plants positive in the PCR assay were transferred to the greenhouse.
실시예 12Example 12
아포플라스트 또는 ER로 표적화된 α-아밀라제를 발현하는 옥수수 식물로부터의 T1 종자의 분석Analysis of T1 Seeds from Corn Plants Expressing α-amylase Targeted with Apoplast or ER
실시예 4에 기술된 바와 같은 pNOV6200 또는 pNOV6201로 형질전환된 자가 수분된 옥수수 식물로부터의 T1 종자를 수득하였다. 이들 낟알 내의 전분 축적은 시각적 검사 및 고온에의 임의의 노출 전 요오드 용액을 사용한 전분의 통상적인 염 색을 기초로 하여 정상인 것으로 나타났다. 미성숙 낟알을 절개하고, 정제된 내배유를 미세원심관에 개별적으로 넣고 50mM NaPO4 완충액 200㎕에 침윤시켰다. 당해 튜브를 85℃ 수욕에 20분 동안 둔 후, 얼음 위에서 냉각시켰다. 1% 요오드 용액 20마이크로리터를 각각의 튜브에 첨가하고 혼합하였다. 분리된 낟알 중 대략 25%가 정상적으로 전분에 대하여 염색되었다. 나머지 75%는 염색에 실패하였고, 이는 전분이 요오드로 염색되지 않는 저분자량 당으로 분해되었음을 나타낸다. pNOV6200 및pNOV6201의 T1 낟알이 옥수수 전분을 자가-가수분해하였음이 밝혀졌다. 37℃에서 항온처리한 후 전분의 관측가능한 감소는 없었다. T1 seeds from self-pollinated corn plants transformed with pNOV6200 or pNOV6201 as described in Example 4 were obtained. Starch accumulation in these grains has been shown to be normal based on visual inspection and conventional dyeing of starch using iodine solution prior to any exposure to high temperatures. Immature grains were excised and the purified endosperm was individually placed in the microcentrifuge tube and infiltrated into 200 μl of 50 mM NaPO 4 buffer. The tube was placed in an 85 ° C. water bath for 20 minutes and then cooled on ice. 20 microliters of 1% iodine solution was added to each tube and mixed. Approximately 25% of the isolated grains were normally stained for starch. The remaining 75% failed to stain, indicating that the starch degraded to low molecular weight sugars that were not stained with iodine. It was found that T1 grains of pNOV6200 and pNOV6201 self-hydrolyzed corn starch. There was no observable decrease in starch after incubation at 37 ° C.
추가로 아밀라제의 발현을 내배유로부터의 초호열성 단백질 분획을 분리한 후 PAGE/쿠마시 염색하여 분석하였다. 적합한 분자량(50kD)의 분리된 단백질 밴드가 관찰되었다. 이들 샘플을 시판되는 염색된 아밀로스{아일랜드 소재의 제조사[Megazyme]의 AMYLAZYME(아밀라자임)}를 사용하는 α-아밀라제 검정에 적용하였다. 높은 수준의 초호열성 아밀라제 활성은 50kD 단백질의 존재와 상관관계가 있었다.In addition, expression of amylase was analyzed by PAGE / Kumasi staining after separating the superthermophilic protein fraction from endocrine. An isolated protein band of suitable molecular weight (50 kD) was observed. These samples were subjected to the α-amylase assay using commercially available dyed amylose (AMYLAZYME from Amyzyme, Ireland). High levels of superthermophilic amylase activity correlated with the presence of 50kD protein.
추가로 효소가 전분 과립과 직접적으로 접촉 가능한 경우, 초호열성 α-아밀라제를 발현하고, 전분체로 표적화되고, 주위 온도에서 충분히 활성화되는 다수의 형질전환 옥수수의 낟알 내의 전분은 대부분 가수분해됨이 밝혀졌다. 전분체로 표적화된 초호열성 α-아밀라제를 갖는 80개 주 중, 낟알 내에 전분을 축적하는 4개 주가 동정되었다. 이들 주 중 3개를 비색 아밀라자임 분석(Megazyme)을 사용하여 내열성 α-아밀라제 활성에 대하여 분석하였다. 당해 아밀라제 효소 검정은 이들 3개 주를 적합한 습도 및 가열 조건하에 처리한 경우, 전분이 가수분해되었으며, 이는 이들 주로부터 제조된 전분의 자동-가수분해를 촉진하기 위한 적합한 수준의 α-아밀라제의 존재를 나타내는 것이었다.In addition, it has been found that when the enzyme is in direct contact with starch granules, the starch in the grains of many transgenic maizes expressing superthermophilic α-amylase, targeted to starch and sufficiently activated at ambient temperature is found to be hydrolyzed. Of the 80 strains with superthermophilic α-amylase targeted to starch, four strains of starch accumulation in the grains were identified. Three of these strains were analyzed for heat-resistant α-amylase activity using colorimetric amylazyme assay (Megazyme). The amylase enzyme assay showed that when these three strains were treated under suitable humidity and heating conditions, the starch was hydrolyzed, which indicates the presence of suitable levels of α-amylase to promote auto-hydrolysis of the starches made from these strains. It was to represent.
pNOV6200 및 pNOV6201 형질전환체 둘 다의 다중 독립 주로부터의 T1 종자를 수득하였다. 각각의 주로부터의 개별 낟알을 절개하고 정제된 내배유를 50mM NaPO4 완충액 300㎕에서 개별적으로 균질화시켰다. 내배유 현탁액의 분취액을 85℃에서 α-아밀라제 활성에 대하여 분석하였다. 당해 주의 약 80%를 초호열성 활성에 대하여 분리하였다(도 1A, 1B 및 도2 참조).T1 seeds from multiple independent strains of both pNOV6200 and pNOV6201 transformants were obtained. Individual grains from each strain were excised and purified endosperm was homogenized individually in 300 μl of 50 mM NaPO 4 buffer. An aliquot of the endosperm suspension was analyzed for α-amylase activity at 85 ° C. About 80% of the strains were isolated for superthermic activity (see Figures 1A, 1B and 2).
야생형 식물 또는 pNOV6201로 형질전환한 식물로부터의 낟알을 100℃에서 1, 2, 3, 또는 6시간 동안 가열한 후, 요오드 용액으로 전분에 대하여 염색하였다. 각각 3시간 또는 6시간 후, 성숙한 낟알에서 전분이 거의 또는 전혀 검출되지 않았다. 따라서, 고온에서 항온처리한 경우, 세포질세망으로 표적화된 초호열성 아밀라제를 발현하는 형질전환 옥수수로부터의 성숙한 낟알 내의 전분을 가수분해하였다. The grains from wild type plants or plants transformed with pNOV6201 were heated at 100 ° C. for 1, 2, 3, or 6 hours and then stained for starch with iodine solution. After 3 or 6 hours, respectively, little or no starch was detected in mature grains. Thus, when incubated at high temperature, starch in mature grains from transgenic maize expressing hyperthermic amylase targeted with cytoplasmic nets was hydrolyzed.
다른 양태에서, 50℃에서 16시간 동안 침지한 pNOV6201 식물로부터의 성숙한 T 낟알으로부터의 부분적으로 정제된 전분을 85℃에서 5분 동안 가수분해하였다. 이는 낟알을 연마한 후, 세포질세망으로 표적화된 α-아밀라제가 전분에 결합하며, 가열함에 따라 전분을 가수분해할 수 있음을 설명한다. 요오드 염색은 50℃에서 16시간 동안 침지한 후 성숙한 종자 내에 전분이 손상되지 않은 채로 남아있음을 나타내었다. In another embodiment, partially purified starch from mature T kernels from pNOV6201 plants soaked at 50 ° C. for 16 hours was hydrolyzed at 85 ° C. for 5 minutes. This demonstrates that after grinding the grains, the α-amylase targeted by cytoplasmic nets binds to the starch and can hydrolyze the starch upon heating. Iodine staining showed that starch remained intact in mature seeds after soaking at 50 ° C. for 16 hours.
다른 실험에서, pNOV6201로 형질전환한 식물로부터 분리한 성숙한 낟알을 16시간 동안 95℃에서 가열한 후 건조시켰다. 초호열성 α-아밀라제를 발현하는 종자에서, 전분의 당으로의 가수분해는 건조 후 주름진 외형을 야기한다. In another experiment, mature grains isolated from plants transformed with pNOV6201 were heated at 95 ° C. for 16 hours and then dried. In seeds expressing superthermophilic α-amylase, hydrolysis of starch to sugar results in a wrinkled appearance after drying.
실시예 13Example 13
전분체로 표적화된 α-아밀라제를 발현하는 옥수수 식물로부터의 T1 종자의 분석Analysis of T1 Seeds from Corn Plants Expressing Targeted α-amylase
실시예 4에 기술된 바와 같은 pNOV4029 또는 pNOV4031로 형질전환한 자가-수분된 옥수수 식물로부터의 T1 종자를 수득하였다. 이들 주의 낟알 내의 전분 축적은 분명히 정상적이지 않았다. 중증도에 다소 차이를 갖는 모든 주를 매우 낮은 전분 표현형 또는 무전분 표현형에 대하여 분리하였다. 고온에 노출하기 전, 요오드로 단지 약하게 염색한 미성숙 낟알으로부터 내배유를 정제하였다. 85℃에서 20분 후, 염색이 되지 않았다. 이삭을 건조시킨 경우, 낟알은 주름졌다. 당해 특정 아밀라제는 과립과 직접적으로 접촉시키는 경우, 분명히 온실 온도에서 전분을 가수분해하는 데 충분한 활성을 가졌다. T1 seeds from self-pollinated corn plants transformed with pNOV4029 or pNOV4031 as described in Example 4 were obtained. Starch accumulation in the grains of these strains was clearly not normal. All strains with some differences in severity were separated for very low starch phenotype or no starch phenotype. Prior to exposure to high temperatures, endosperm was purified from immature grains that were only slightly stained with iodine. After 20 minutes at 85 ° C., no staining occurred. When the ear was dried, the grain was wrinkled. This particular amylase, when in direct contact with the granules, apparently had sufficient activity to hydrolyze starch at greenhouse temperatures.
실시예 14Example 14
α-아밀라제를 발현하는 옥수수 식물로부터의 곡립의 발효Fermentation of Grains from Corn Plants Expressing α-amylase
다양한 액화 시간에서, 100% 형질전환 곡립 85℃ 대 95℃ At various liquefaction times, 100% transgenic grains 85 ° C. to 95 ° C.
외인성 α-아밀라제의 첨가 없이 잘 발효되는 내열성 α-아밀라제를 포함하는 형질전환 옥수수(pNOV6201)는 액화 시간을 훨씬 덜 필요로 하며, 전분의 보다 완전한 가용화를 야기한다. 다음의 단계(아래에 상세히 기술된)를 갖는 프로토콜 에 따라 실험실 규모의 발효를 수행하였다: 1) 연마, 2) 수분 분석, 3) 연마된 옥수수, 물, 백세트(backset) 및 α-아밀라제를 함유하는 슬러리의 제조, 4)액화 및 5)동시 당화 및 발효(SSF). 당해 실시예에서, 액화 단계의 온도 및 시간은 하기한 바와 같이 다양하였다. 형질전환 옥수수를 외인성 α-아밀라제의 유무하에 액화시켰고, 에탄올 제조 성능을 시판되는 α-아밀라제를 사용하여 처리한 대조군 옥수수와 비교하였다. Transgenic maize (pNOV6201) containing heat-resistant α-amylase that ferments well without addition of exogenous α-amylase requires much less liquefaction time and results in more complete solubilization of starch. Laboratory scale fermentations were performed according to a protocol having the following steps (described in detail below): 1) grinding, 2) moisture analysis, 3) grinding corn, water, backset and α-amylase. Preparation of Slurry Containing, 4) Liquefaction and 5) Simultaneous Saccharification and Fermentation (SSF). In this example, the temperature and time of the liquefaction step varied as described below. Transgenic maize was liquefied with or without exogenous α-amylase and ethanol production performance was compared to control corn treated with commercially available α-amylase.
당해 실시예에 사용된 형질전환 옥수수는 α-아밀라제 유전자 및 PMI 마커를포함하는 벡터, 즉, pNOV6201을 사용하여 실시예 4에 진술된 과정에 따라 제조하였다. 당해 형질전환 옥수수는 고농도의 내열성 α-아밀라제를 발현하는 형질전환주로부터의 화분으로 시판되는 하이브리드(N3030BT)를 수분하여 제조하였다. 당해 옥수수를 11% 수분으로 건조시켰고 실온에서 저장하였다. 형질전환 옥수수 분말의 α-아밀라제 함량은 95단위/g이었고, 여기서, 효소 1 단위는 pH 6.0 MES 완충액 중 85℃에서의 옥수수 분말로부터 분 당 1 마이크로몰 감소하는 결과를 낸다. 사용한 대조군 옥수수는 에탄올 제조를 잘 수행하는 것으로 공지된 황색 이(yellow dent) 옥수수였다. The transgenic maize used in this example was prepared according to the procedure set forth in Example 4 using a vector comprising the α-amylase gene and a PMI marker, ie pNOV6201. The transgenic corn was prepared by pollinating a commercially available hybrid (N3030BT) as a pollen from a transformant expressing a high concentration of heat-resistant α-amylase. The corn was dried to 11% moisture and stored at room temperature. The α-amylase content of the transformed corn powder was 95 units / g, where 1 unit of enzyme resulted in a 1 micromole decrease per minute from the corn powder at 85 ° C. in pH 6.0 MES buffer. The control corn used was yellow dent corn, which is known to perform well with ethanol production.
1) 연마: 형질전환 옥수수(1180g)를 2.0mm 스크린을 장착한 Perten 3100 해머 제분기(hammer mill)로 연마하였다. 대조군 옥수수를 형질전환 옥수수에 의한 오염을 막기 위해 철저히 세척한 후, 동일한 제분기에서 연마하였다. 1) Polishing: Transformed corn (1180 g) was ground with a Perten 3100 hammer mill equipped with a 2.0 mm screen. Control corn was washed thoroughly to prevent contamination by transgenic corn and then ground in the same mill.
2) 수분 분석: 형질전환 옥수수 및 대조군 옥수수 샘플(20g)을 알루미늄 중량 보트로 칭량하였고 100℃에서 4시간 동안 가열하였다. 당해 샘플을 다시 칭량 하였고, 중량 손실로부터 함수량을 계산하였다. 형질전환 분말의 함수량은 9.26%였으며; 대조군 분말의 함수량은 12.54%였다. 2) Moisture Analysis: Transgenic and control corn samples (20 g) were weighed by aluminum weight boat and heated at 100 ° C. for 4 hours. The sample was weighed again and the water content was calculated from the weight loss. The water content of the transformed powder was 9.26%; The water content of the control powder was 12.54%.
3) 슬러리 제조: 슬러리의 조성물은 SSF의 시작에서 36% 고형을 갖는 매쉬(mash)를 산출하도록 설계하였다. 대조군 샘플은 100ml 들이 플라스틱 병에 제조하였고, 대조군 옥수수 분말 21.50g, 탈이온수 23ml, 백세트(8중량% 고형) 6.0ml, 및 물로 1/50으로 희석한 시판되는 α-아밀라제 0.30ml을 함유하였다. α-아밀라제 용량은 산업적 용도의 예와 같이 선택하였다. 형질전환 α-아밀라제의 검정을 위한 상기한 조건하에 검정한 경우, 대조군 α-아밀라제 용량은 2U/g 옥수수 분말이었다. pH는 수산화암모늄을 첨가하여 6.0으로 적정하였다. 형질전환 샘플은 동일한 방식으로 제조하였지만, 저 함수량의 형질전환 분말 때문에 옥수수 분말 20g을 함유하였다. 형질전환 분말의 슬러리는 대조군 샘플과 동일한 용량의 α-아밀라제를 사용하거나 외인성 α-아밀라제 없이 제조하였다. 3) Slurry Preparation: The composition of the slurry was designed to yield a mash with 36% solids at the start of SSF. The control sample was prepared in a 100 ml plastic bottle and contained 21.50 g of control corn powder, 23 ml of deionized water, 6.0 ml of a backset (8 wt% solids), and 0.30 ml of commercial α-amylase diluted 1/50 with water. . The α-amylase dose was chosen as an example of industrial use. When assayed under the above conditions for the assay of transformed α-amylase, the control α-amylase dose was 2 U / g corn powder. pH was titrated to 6.0 by addition of ammonium hydroxide. Transformed samples were prepared in the same manner but contained 20 g of corn powder due to the low water content of the transformed powder. Slurry of the transformed powder was prepared using the same dose of α-amylase or without exogenous α-amylase as control sample.
4) 액화: 형질전환 옥수수 분말의 슬러리를 함유하는 병을 5, 15, 30, 45 또는 60분 동안 85℃ 또는 95℃의 수욕에 침윤시켰다. 대조군 슬러리를 60분 동안 85℃에서 항온처리하였다. 고온 항온처리 중, 슬러리를 5분마다 수동으로 격렬하게 혼합하였다. 고온 단계 후, 슬러리를 얼음 위에서 냉각시켰다. 4) Liquefaction: A bottle containing a slurry of transgenic corn powder was infiltrated in a water bath at 85 ° C. or 95 ° C. for 5, 15, 30, 45 or 60 minutes. The control slurry was incubated at 85 ° C. for 60 minutes. During the high temperature incubation, the slurry was manually vigorously mixed every 5 minutes. After the hot step, the slurry was cooled on ice.
5) 동시 당화 및 발효: 액화에 의해 제조된 매쉬를 글루코아밀라제(시판되는 L-400 글루코아밀라제 1/50 희석액 0.65ml), 프로테아제(시판되는 프로테아제 1,000배 희석액 0.60ml), 0.2mg 락토사이드 & 요소(50% 요소액의 10배 희석액 0.85ml)와 혼합하였다. 매쉬를 함유하는 100ml 들이 병의 마개로 구멍을 내어 CO2 가 발산되게 하였다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하였고 90F로 설정한 수욕에서 항온처리하였다. 발효 24시간 후, 온도를 86F로 낮추었고, 48시간째에 82F로 설정하였다. 5) Simultaneous Glycation and Fermentation: Mash prepared by liquefaction was prepared using glucoamylase (0.65 ml of a commercially available L-400 glucoamylase 0.65 ml), protease (0.60 ml of commercial protease 1,000-fold dilution), 0.2 mg lactoside & urea. (0.85 ml of a 10-fold dilution of 50% urea solution). 100 ml containing mesh were punctured with a bottle cap to allow CO 2 to dissipate. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set to 90F. After 24 hours of fermentation, the temperature was lowered to 86F and set to 82F at 48 hours.
접종용 효모는 효모(0.12g), 말토덱스트린 70g, 물 230ml, 백세트 100ml, 글루코아밀라제(시판되는 글루코아밀라제 10배 희석액 0.88ml), 프로테아제(시판되는 효소의 100배 희석액 1.76ml), 요소(1.07g), 페니실린(0.67mg) 및 황산아연(0.13g)을 함유하는 혼합물을 제조하여 증식시켰다. 증식 배양은 그것이 필요한 전날에 시작하였고 90°F에서 혼합하며 항온처리하였다. Yeast for inoculation is yeast (0.12 g), maltodextrin 70 g, water 230 ml, 100 ml of bag set, glucoamylase (0.88 ml of 10-fold dilution of commercial glucoamylase), protease (1.76 ml of 100-fold dilution of commercially available enzymes), urea ( 1.07 g), a mixture containing penicillin (0.67 mg) and zinc sulfate (0.13 g) was prepared and grown. Proliferation culture was started the day before it was needed and incubated with mixing at 90 ° F.
24, 48 & 72시간째에, 샘플을 각각의 발효 용기로부터 취하고, 0.2μm 필터를 통해 여과하고 에탄올 & 당용 HPLC로 분석하였다. 72시간째, 샘플을 총 용해된 고형물 및 잔류 전분에 대하여 분석하였다.At 24, 48 & 72 hours, samples were taken from each fermentation vessel, filtered through a 0.2 μm filter and analyzed by ethanol & sugar HPLC. At 72 hours, samples were analyzed for total dissolved solids and residual starch.
HPLC 분석은 굴절지수 검측기, 칼럼 가열기 & Bio-Rad Aminex HPX-87G 칼럼을 장착한 이원 구배 시스템 상에서 수행하였다. 당해 시스템은 수중 0.005 H2SO4를 사용하여 1ml/분으로 평형화시켰다. 칼럼 온도는 50℃였다. 샘플 주입 용적은 5㎕였고; 동일한 용매에서 용출시켰다. RI 반응은 공지된 표준을 주입하여 측정하였다. 에탄올 및 글루코즈 둘 다 각각의 주입에서 측정하였다. HPLC analysis was performed on a binary gradient system equipped with a refractive index detector, column heater & Bio-Rad Aminex HPX-87G column. The system was equilibrated to 1 ml / min with 0.005 H 2 SO 4 in water. Column temperature was 50 ° C. Sample injection volume was 5 μl; Eluted in the same solvent. RI reactions were measured by injecting known standards. Both ethanol and glucose were measured at each infusion.
잔류 전분은 다음과 같이 측정하였다. 샘플 및 표준을 오븐에서 50℃에서 건조시킨 후, 샘플 제분기에서 분말로 연마하였다. 당해 분말(0.2g)을 15ml 눈금 원심분리 튜브로 칭량하였다. 당해 분말을 10ml 수성 에탄올(80%)로 교반하며 3회 세척한 후, 원심분리하고 상층액을 제거하였다. DMSO(2.0ml)을 펠렛에 첨가한 후, MOPS 완충액 중 내열성 알파-아밀라제(300 단위) 3.0ml을 첨가하였다. 격렬한 혼합 후, 당해 튜브를 85℃에서 60분 동안 물에서 항온처리하였다. 항온처리 중, 뉴브를 4회 혼합하였다. 샘플을 냉각하고 아세트산나트륨 완충액(200mM, pH 4.5) 4.0ml을 첨가한 후, 글루코아밀라제(20U) 0.1ml을 첨가하였다. 샘플을 50℃에서 2시간 동안 항온처리하고, 교반한 후 3,500rpm에서 5분 동안 원심분리하였다. 당해 상층액을 0.2μm 필터에 여과하고 상기한 HPLC 방법으로 글루코즈에 대하여 분석하였다. 낮은 잔류 전분(고형물 중 <20%)을 갖는 샘플에 대하여 50㎕의 주입 크기를 사용하였다. Residual starch was measured as follows. Samples and standards were dried at 50 ° C. in an oven and then ground to powder in a sample mill. The powder (0.2 g) was weighed into a 15 ml graduated centrifuge tube. The powder was washed three times with 10 ml aqueous ethanol (80%), then centrifuged and the supernatant removed. DMSO (2.0 ml) was added to the pellet, followed by 3.0 ml of heat resistant alpha-amylase (300 units) in MOPS buffer. After vigorous mixing, the tubes were incubated in water at 85 ° C. for 60 minutes. During incubation, the nubs were mixed four times. The sample was cooled and 4.0 ml of sodium acetate buffer (200 mM, pH 4.5) was added followed by 0.1 ml of glucoamylase (20 U). Samples were incubated at 50 ° C. for 2 hours, stirred and centrifuged at 3,500 rpm for 5 minutes. The supernatant was filtered through a 0.2 μm filter and analyzed for glucose by the HPLC method described above. An injection size of 50 μl was used for samples with low residual starch (<20% in solids).
결과: 형질전환 옥수수는 α-아밀라제의 첨가 없이 잘 발효되었다. 72시간째의 에탄올의 수율은 표 I에 나타낸 바와 같이 외인성 α-아밀라제의 유무하에 본질적으로 동일하였다. 이들 데이타는 또한 액화 온도가 높을 경우 에탄올의 고수율이 달성되며, 형질전환 옥수수에서 발현되는 본 발명의 효소가 바실러스 리퀘패시엔스(Bacillus liquefaciens) α-아밀라제와 같은 상업적으로 사용되는 다른 효소보다 높은 온도에서 활성을 가짐을 나타낸다. Results: Transgenic maize fermented well without the addition of α-amylase. The yield of ethanol at 72 hours was essentially the same with or without exogenous α-amylase as shown in Table I. These data also when higher the liquid temperature is achieved a high yield of the ethanol, the enzyme of the invention as expressed in the transgenic corn Bacillus Li kwepae when Enschede (Bacillus liquefaciens ) has activity at higher temperatures than other commercially available enzymes such as α-amylase.
액화 시간이 다양한 경우, 효율적인 에탄올 제조를 위해 필요한 액화 시간은 통상적인 과정에 의해 요구되는 시간보다 훨씬 적었다. 도 3은 발효 72시간째의 에탄올 수율이 액화 15분에서 60분까지 거의 변하지 않았음을 나타낸다. 이 외에, 95℃에서의 액화는 85℃에서의 액화보다 각각의 시점에서 보다 많은 에탄올을 제공하였다. 이러한 관측은 초호열성 효소의 사용에 의해 성취된 방법 개선을 입증한다. In the case of various liquefaction times, the liquefaction time required for efficient ethanol production was much less than the time required by conventional procedures. Figure 3 shows that the ethanol yield at 72 hours of fermentation changed little from 15 minutes to 60 minutes of liquefaction. In addition, liquefaction at 95 ° C. provided more ethanol at each time point than liquefaction at 85 ° C. These observations demonstrate the method improvements achieved by the use of superthermophilic enzymes.
대조군 옥수수는 형질전환 옥수수보다 높은 최종 에탄올 수율을 제공하였지만, 대조군은 발효가 매우 잘되기 때문에 선택하였다. 대조적으로, 형질전환 옥수수는 형질전환을 촉진하기 위해 선택한 유전적 배경을 갖는다. 널리 공지된 육종 기법에 의한 우수한 옥수수 배원질 내로의 α-아밀라제-형질의 도입이 이러한 차이를 제거할 것이다. The control corn provided a higher final ethanol yield than the transformed corn, but the control was chosen because the fermentation was very good. In contrast, transgenic maize has a genetic background chosen to promote transformation. The introduction of the α-amylase-type into good maize embryos by well known breeding techniques will eliminate this difference.
72시간째에 제조된 맥주의 잔류 전분 수준의 조사(도 4)는 형질전환 α-아밀라제가 발효용으로 사용가능한 전분의 제조에 유의적인 개선을 초래하며, 발효 후 훨씬 적은 전분이 남았음을 나타낸다. Investigation of residual starch levels of beer prepared at 72 hours (FIG. 4) results in a significant improvement in the production of starch transgenic α-amylase usable for fermentation, indicating that much less starch remains after fermentation.
에탄올 수준 및 잔류 전분 수준 둘 다를 사용하여, 최적 액화 시간은 95℃에서 15분 및 85℃에서 30분이었다. 본 실험에서, 이들 시간은 발효 용기를 수욕에 두는 총 시간이었으며, 따라서 샘플의 온도가 실온에서 85℃ 또는 95℃로 증가하는 중의 시간을 포함한다. 제트 요리기와 같은 장비를 사용하여 매쉬를 급속하게 가열하는 대규모의 공업 과정에는 보다 짧은 액화 시간이 최적일 수 있다. 통상적인 공업적 액화 과정은 매쉬를 1시간 이상 고온에서 항온처리할 수 있게 하는 저장 탱크를 필요로 한다. 본 발명은 이러한 저장 탱크 필요를 제거하며 액화 장치의 생산성을 증가시킬 것이다. Using both ethanol levels and residual starch levels, the optimum liquefaction time was 15 minutes at 95 ° C and 30 minutes at 85 ° C. In this experiment, these times were the total time the fermentation vessel was left in the water bath, thus including the time during which the temperature of the sample increased from room temperature to 85 ° C or 95 ° C. Shorter liquefaction times may be optimal for large scale industrial processes where equipment such as jet cookers heat up the mesh rapidly. Conventional industrial liquefaction processes require storage tanks that allow the mesh to be incubated at high temperatures for at least one hour. The present invention will eliminate this storage tank need and increase the productivity of the liquefaction apparatus.
발효 과정 중 α-아밀라제의 한가지 중요한 기능은 매쉬의 점도를 감소시키는 것이다. 모든 시점에, 형질전환 옥수수 분말을 함유하는 샘플은 대조군 샘플보다 두드러지게 점도가 덜했다. 이 외에, 형질전환 샘플은 모든 대조군 샘플을 사용하여 관측된 젤라틴성 상을 거치는 것으로 나타나지 않았으며; 젤라틴화는 통상적으로 옥수수 슬러리를 요리할 때 발생한다. 따라서, 내배유의 단편에 분배된 α-아밀라제가 확산은 늦추고 매쉬의 혼합 및 펌핑(pumping) 에너지 비용은 증가시키는 대형 겔의 형성을 막음으로써 요리 중 매쉬에 유리한 물리적 특성을 제공한다. One important function of α-amylase during fermentation is to reduce the viscosity of the mash. At all time points, the sample containing the transformed corn powder was noticeably less viscous than the control sample. In addition, the transformed samples did not appear to go through the gelatinous phase observed using all control samples; Gelatinization typically occurs when cooking corn slurries. Thus, the α-amylase distributed in fragments of the endosperm provides beneficial physical properties to the mash during cooking by preventing the formation of large gels that slow down diffusion and increase mesh mixing and pumping energy costs.
형질전환 옥수수 중 α-아밀라제의 고용량은 또한 형질전환 매쉬의 유리한 특성에 기여할 수 있다. 85℃에서, 형질전환 옥수수의 α-아밀라제 활성은 대조군에 사용된 외인성 α-아밀라제의 용량보다 몇 배 더 큰 활성이었다. 상업적 용도 비율의 예로 후자를 선택하였다.High doses of α-amylase in transgenic maize may also contribute to the beneficial properties of the transgenic mesh. At 85 ° C., the α-amylase activity of the transgenic maize was several times greater than the dose of exogenous α-amylase used in the control. The latter was chosen as an example of a commercial use ratio.
실시예 15Example 15
대조군 옥수수와 혼합한 경우, 형질전환 옥수수의 효과적인 기능Effective function of transgenic maize when mixed with control maize
형질전환 옥수수 분말을 5% 내지 100% 형질전환 옥수수 분말의 다양한 농도로 대조군 옥수수 분말과 혼합하였다. 이들을 실시예 14에 기술한 바와 같이 처리하였다. 형질전환적으로 발현된 α-아밀라제를 함유하는 매쉬를 85℃에서 30분 동안 액화시키거나 95℃에서 15분 동안 액화시켰고; 대조군 매쉬는 실시예 14에 기술한 바와 같이 제조하였고 85℃에서 30분 또는 60분(각각 1회) 또는 95℃에서 15분 또는 60분(각각 1회) 액화시켰다. The transformed corn powder was mixed with the control corn powder at various concentrations of 5% to 100% transformed corn powder. These were treated as described in Example 14. Mash containing transformed expressed α-amylase was liquefied at 85 ° C. for 30 minutes or at 95 ° C. for 15 minutes; Control meshes were prepared as described in Example 14 and liquefied at 85 ° C. for 30 or 60 minutes (once each) or at 95 ° C. for 15 minutes or 60 minutes (once each).
48시간 및 72시간째의 에탄올 및 잔류 전분에 대한 데이타가 표 2에 제공되어 있다. 48시간째의 에탄올 농도가 도 5에 그래프로 나타내어져 있고; 잔류 전분 측정은 도 6에 나타내어져 있다. 이들 데이타는 형질전환적으로 발현된 내열성 α-아밀라제가 형질전환 곡립이 매쉬의 총 곡립 중 단지 작은 몫(5% 정도로 낮은)인 경우, 심지어 에탄올 제조에도 매우 우수한 성능을 제공함을 나타낸다. 당해 데이타는 또한 형질전환 곡립이 총 곡립 중 40% 이상을 포함하는 경우, 잔류 전분이 대조군 매쉬에서보다 현저히 적음을 나타낸다. Data for ethanol and residual starch at 48 and 72 hours are provided in Table 2. Ethanol concentration at 48 hours is graphically represented in FIG. 5; Residual starch measurements are shown in FIG. 6. These data indicate that the transgenic expressed heat resistant α-amylase provides very good performance even in ethanol production when the transformed grain is only a small share (as low as 5%) of the total grain of the mesh. The data also show that when the transgenic grains contain at least 40% of the total grains, the residual starch is significantly less than in the control mesh.

* 대조군 샘플. 값은 2회 측정치의 평균이다.Control sample. The value is the average of two measurements.
실시예 16 Example 16
형질전환 옥수수를 총 옥수수의 1.5% 내지 12% 비율로 사용하는 경우 액화 pH의 함수로서의 에탄올 생산Ethanol production as a function of liquefied pH when transgenic maize is used at a rate of 1.5% to 12% of total maize
형질전환 옥수수는 총 옥수수의 5 내지 10%의 수준에서 발효가 잘 되기 때문에, 형질전환 옥수수가 총 옥수수의 1.5 내지 12%로 포함되는 부가적인 일련의 발효를 수행하였다. pH는 6.4 내지 5.2로 다양하였으며 형질전환 옥수수 내에서 발현된 α-아밀라제는 공업적으로 통상적으로 사용되는 것보다 낮은 pH에서의 활성에 최적화되었다. Since the transformed corn is well fermented at a level of 5 to 10% of the total corn, an additional series of fermentations were performed in which the transformed corn contained 1.5 to 12% of the total corn. The pH varied from 6.4 to 5.2 and the α-amylase expressed in transgenic maize was optimized for activity at lower pH than is commonly used in industry.
당해 실험은 다음을 제외하고 실시예 15에 기술된 바와 같이 수행하였다.This experiment was performed as described in Example 15 except for the following.
1) 형질전환 분말을 1.5% 내지 12.0% 범위의 수준의 총 무수중량의 퍼센트로 대조군 분말과 혼합하였다. 1) The transformed powder was mixed with the control powder at a percentage of total anhydrous weight ranging from 1.5% to 12.0%.
2) 대조군 옥수수는 실시예 14 및 15에 사용한 대조군보다 형질전환 옥수수와 더 유사한 N3030BT였다. 2) Control corn was N3030BT more similar to transgenic corn than the control used in Examples 14 and 15.
3) 형질전환 분말을 함유하는 샘플에 어떠한 외인성 α-아밀라제도 첨가하지 않았다. 3) No exogenous α-amylase was added to the sample containing the transformed powder.
4) 샘플을 액화 전 pH 5.2, 5.6, 6.0 또는 6.4로 적정하였다. 0% 형질전환 옥수수 분말 내지 12% 형질전환 옥수수 분말 범위로 고정한 5개 이상의 샘플을 각각의 pH에 대하여 제조하였다. 4) Samples were titrated to pH 5.2, 5.6, 6.0 or 6.4 before liquefaction. Five or more samples fixed in the range of 0% transgenic maize powder to 12% transgenic maize powder were prepared for each pH.
5) 모든 샘플에 대한 액화는 85℃에서 60분 동안 수행하였다.5) Liquefaction for all samples was carried out at 85 ° C. for 60 minutes.
발효 시간의 함수로서 에탄올 함량의 변화가 도 7에 나타내어져 있다. 당해 도면은 3% 형질전환 옥수수를 함유하는 샘플로부터 수득한 데이타를 나타낸다. 보다 낮은 pH에서, 발효는 pH 6.0 이상에서 보다 신속하게 진행되며; 유사한 작용이 다른 용량의 형질전환 곡립을 갖는 샘플에서 관찰되었다. 높은 수준의 발현과 결합된 형질전환 효소의 활성의 pH 프로필은 저 pH 액화가 보다 신속한 발효 및, 이에 따라 통상적인 pH 6.0 과정에서 가능한 것보다 더 높은 결과를 초래할 것이다. The change in ethanol content as a function of fermentation time is shown in FIG. 7. This figure shows data obtained from a sample containing 3% transgenic maize. At lower pH, fermentation proceeds more rapidly at pH 6.0 and above; Similar action was observed in samples with different doses of transgenic grains. The pH profile of the activity of the transforming enzyme combined with high levels of expression will result in lower pH liquefaction being faster than fermentation and thus higher than is possible in conventional pH 6.0 procedures.
72시간째의 에탄올 수율은 도 8에 나타내어져 있다. 보다시피, 에탄올의 수율을 기초로 하여, 당해 결과는 샘플에 포함된 형질전환 곡립의 양에 대한 어느 정도의 의존성을 보여주었다. 따라서, 당해 곡립은 에탄올의 발효 제조를 촉진하기 위해 풍부한 아밀라제를 함유한다. 이는 또한 저 pH의 액화가 고 에탄올 수율을 초래함을 증명한다. Ethanol yield at 72 hours is shown in FIG. As you can see, based on the yield of ethanol, the results showed some dependence on the amount of transgenic grains included in the sample. Thus, the grains contain abundant amylase to promote fermentation production of ethanol. It also proves that low pH liquefaction results in high ethanol yield.
액화 후의 샘플의 점도를 관찰하였고, pH 6.0에서, 6% 형질전환 곡립이 적합한 점도 감소에 충분한 것으로 관측되었다. pH 5.2 및 5.6에서, 점도는 12% 형질전환 곡립에서의 대조군의 점도와 동등하였지만, 형질전환 곡립의 더 낮은 퍼센트에서는 동등하지 않았다. The viscosity of the sample after liquefaction was observed, and at pH 6.0, 6% transgenic grains were observed to be sufficient for a suitable viscosity reduction. At pH 5.2 and 5.6, the viscosity was equivalent to that of the control in 12% transgenic grains, but not at the lower percentage of transgenic grains.
실시예 17Example 17
호열성 효소를 사용한 옥수수 분말로부터의 프럭토즈 제조Preparation of fructose from corn powder using thermophilic enzyme
초호열성 α-아밀라제를 발현하는 옥수수, 797GL3은 α-글루코시다제(MalA) 및 자일로스 이소머라제(XylA)와 함께 혼합하는 경우 프럭토즈의 제조를 촉진하는 것으로 나타났다. Corn, which expresses superthermotropic α-amylase, 797GL3, has been shown to promote the production of fructose when mixed with α-glucosidase (MalA) and xylose isomerase (XylA).
797GL3을 발현하는 pNOV6201 형질전환된 식물로부터의 종자를 Kleco 세포 중 분말로 연마하여 아밀라제 분말을 제조하였다. 비-형질전환 옥수수 낟알을 동일한 방법으로 연마하여 대조군 분말을 제조하였다. Amylase powder was prepared by grinding seeds from pNOV6201 transformed plants expressing 797GL3 with powder in Kleco cells. Non-transformed corn kernels were ground in the same manner to prepare a control powder.
α-글루코시다제, MalA(에스. 솔파타리쿠스로부터의)를 이. 콜라이에서 발현시켰다. 수거한 세균을 1mM 4-(2-아미노에틸)벤젠설포닐 플루오라이드를 함유하는 pH 7.0의 인산칼륨 완충액 50mM 중에 현탁시킨 후, 고압력 세포파쇄기(French pressure cell)에서 용해시켰다. 용해물을 23,000xg에서 15분 동안 4℃에서 원심분리하였다. 상층액 용액을 제거하고, 70℃에서 10분 동안 가열하고, 얼음 위에서 10분 동안 냉각한 후, 34,000xg에서 30분 동안 4℃에서 원심분리하였다. 상층액 용액을 제거하고 MalA를 센트리콘(centricon) 10 기구에서 2배 농축시켰다. 센트리콘 10 단계의 여액을 MalA에 대한 음성 대조군으로 사용하기 위해 보존하였다. α-glucosidase, MalA (from S. solfataricus) Expressed in E. coli. The harvested bacteria were suspended in 50 mM potassium phosphate buffer at pH 7.0 containing 1 mM 4- (2-aminoethyl) benzenesulfonyl fluoride and then lysed in a high pressure cell crusher. The lysates were centrifuged at 23,000 × g for 15 minutes at 4 ° C. The supernatant solution was removed, heated at 70 ° C. for 10 minutes, cooled on ice for 10 minutes and then centrifuged at 34,000 × g for 30 minutes at 4 ° C. The supernatant solution was removed and MalA was concentrated twice in a
자일로스(글루코즈) 이소머라제를 이. 콜라이에서 티. 니아폴리타나의 xylA 유전자를 발현시켜 제조하였다. 세균을 pH 7.0의 인산나트륨 100mM에 현탁하였고 고압력 세포파쇄기에 통과시켜 용해하였다. 세포 잔해의 침전 후, 추출물을 80℃에서 10분 동안 가열한 후 원심분리하였다. 상층액 용액은 XylA 효소 활성을 포함하였다. 공-벡터 대조군 추출물을 XylA 추출물과 동시에 제조하였다. Xylose (glucose) isomerase. Tea from E. coli. It was prepared by expressing the niapolitana xylA gene. The bacteria were suspended in 100 mM sodium phosphate pH 7.0 and lysed through a high pressure cell disrupter. After precipitation of cell debris, the extract was heated at 80 ° C. for 10 minutes and then centrifuged. The supernatant solution contained XylA enzyme activity. Co-vector control extracts were prepared simultaneously with the XylA extract.
옥수수 분말(샘플 당 60mg)을 완충액 및 이. 콜라이로부터의 추출물과 혼합하였다. 표 3에 나타낸 바와 같이, 샘플은 아밀로스 옥수수 분말(아밀라제) 또는 대조군 옥수수 분말(대조군), MalA 추출물(+) 또는 여액(-) 50㎕, 및 XylA 추출물(+) 또는 공 벡터 대조군(-) 20㎕을 함유하였다. 모든 샘플은 또한 50mM MOPS, 10mM MgSO4 및 1mM CoCl2 230㎕을 함유하였고; 완충액의 pH는 실온에서 7.0이었다. Corn powder (60 mg per sample) was added to buffer and E. coli. Mixed with extract from E. coli. As shown in Table 3, the samples contained amylose corn powder (amylase) or control corn powder (control), MalA extract (+) or filtrate (-) 50 μl, and XylA extract (+) or empty vector control (-) 20 Μl was contained. All samples also contained 230
샘플을 85℃에서 18시간 동안 항온처리하였다. 항온처리 시간의 말기에, 샘플을 85℃의 물 0.9ml로 희석하고 원심분리하여 불용성 물질을 제거하였다. 이어서 상층액 분획을 신트리콘3 한외여과 기구로 여과하고 ELSD 검측기를 사용하는 HPLC로 분석하였다. Samples were incubated at 85 ° C. for 18 hours. At the end of the incubation time, the sample was diluted with 0.9 ml of water at 85 ° C. and centrifuged to remove insoluble matter. The supernatant fractions were then filtered through a
구배 HPLC 시스템은 아스텍(Astec) 중합체 아미노 칼럼, 5㎛ 입자 크기, 250 X 4.6mm 및 Alltech ELSD 2000 검측기가 장착되어 있다. 당해 시스템은 물:아세토니트릴 15:85 혼합물로 예비-평형화시켰다. 유속은 1ml/분이었다. 주입 후 초기 조건을 5분 동안 유지한 후, 50:50 물:아세토니트릴의 구배로 20분 유지한 후, 동일한 용매로 10분 유지하였다. 당해 시스템을 80:20 물:아세토니트릴로 20분 동안 세척한 후 출발 용매로 재-평형화시켰다. 프럭토즈는 5.8분에 용출되었고 글루코즈는 8.7분에 용출되었다. The gradient HPLC system is equipped with an Astec polymer amino column, 5 μm particle size, 250 × 4.6 mm and an

HPLC 결과는 또한 α-아밀라제를 함유하는 모든 샘플 내의 대량의 말토올리고당의 존재를 나타내었다. 이들 결과는 3가지 호열성 효소가 고온에서 옥수수 분말로부터의 프럭토즈의 제조를 위해 함께 작용할 수 있음을 입증한다. HPLC results also showed the presence of large amounts of maltooligosaccharides in all samples containing α-amylase. These results demonstrate that three thermophilic enzymes can work together for the production of fructose from corn powder at high temperatures.
실시예 18Example 18
이소머라제를 갖는 아밀라제 분말Amylase Powder with Isomerase
다른 예에서, 아밀라제 분말을 정제된 MalA 및 2가지 세균성 자일로스 이소머라제 각각과 혼합하였다: 티. 마리티마의 XylA 및 달팽이로부터 수득한 BD8037로 명명된 효소. 아밀라제 분말을 실시예 18에 기술한 바와 같이 제조하였다. In another example, amylase powder was mixed with purified MalA and two bacterial xylose isomerases, respectively: T. Enzyme named BD8037 obtained from XylA of Marittima and Snail. Amylase powder was prepared as described in Example 18.
6His 정제 태그를 갖는 에스. 솔파타리쿠스 MalA를 이. 콜라이 내에서 발현시켰다. 세포 용해물을 실시예 18에 기술한 바와 같이 제조한 후, 니켈 친화 수지(Probond, Invitrogen)을 사용하고 천연 단백질 정제에 대한 제조자 지침에 따라 명백히 균질해질 때까지 정제하였다. S with 6His tablet tag. Solfataricus MalA. It was expressed in E. coli. Cell lysates were prepared as described in Example 18, and then purified using nickel affinity resin (Probond, Invitrogen) and clearly until homogeneous according to manufacturer's instructions for natural protein purification.
S 태그 및 ER 체류 시그날을 첨가한 티. 마리티마 XylA를 이. 콜라이 내에서 발현시키고 실시예 18에 기술한 바와 같이 티. 니아폴리타나 XylA와 동일한 방법으로 제조하였다. Tee with S tag and ER retention signal added. This is Marittima XylA. T. expression in E. coli and as described in Example 18. It was prepared by the same method as niapolitana or XylA.
자일로스 이소머라제 BD8037을 동결건조 분말로서 수득하였고 원래 부피의 0.4x의 물에 재현탁시켰다. Xylose isomerase BD8037 was obtained as lyophilized powder and resuspended in 0.4 × of original volume of water.
아밀라제 옥수수 분말을 물 또는 완충액을 가한 효소 용액과 혼합하였다. 모든 반응물은 아밀라제 분말 60mg 및 액체 총 600㎕을 함유하였다. 반응물의 한 세트를 10mM MgSO4 및 1mM CoCl2를 가한 pH 7.0의 50mM MOPS로 실온에서 완충하였고; 두번째 세트의 반응물에서는, 금속-함유 완충액을 물로 대체하였다. 이소머라제 효소량은 표 4에 나타낸 바와 같이 다양하였다. 모든 반응물을 90℃에서 2시간 동안 항온처리하였다. 반응 상층액 분획을 원심분리하여 제조하였다. 펠렛을 추가의 H2O 600㎕로 세척하고 재원심분리하였다. 각각의 반응물로부터의 상층액 분획을 합하고, 실시예 17에 기술한 바와 같이 센트리콘 10을 통해 여과하고, ELSD 검출기를 사용하는 HPLC로 분석하였다. 관측된 글루코즈 및 프럭토즈의 양은 도 15에 그래프로 나타내어져 있다. Amylase corn powder was mixed with enzyme solution added water or buffer. All reactions contained 60 mg amylase powder and 600 μl total liquid. One set of reactions was buffered at room temperature with 50 mM MOPS at pH 7.0 added 10 mM MgSO 4 and 1 mM CoCl 2 ; In the second set of reactants, the metal-containing buffer was replaced with water. The amount of isomerase enzyme varied as shown in Table 4. All reactions were incubated at 90 ° C. for 2 hours. The reaction supernatant fractions were prepared by centrifugation. The pellet was washed with additional 600 μl of H 2 O and recentrifuged. Supernatant fractions from each reaction were combined, filtered through
α-아밀라제 및 α-글루코시다제가 당해 반응물에 존재하는 경우, 각각의 이소머라제와 함께, 용량-의존적 방법으로 옥수수 분말로부터 프럭토즈를 제조하였다. 이들 결과는 곡립-발현된 아밀라제 797GL3이 첨가된 금속 이온의 유무하에 MalA 및 각종 상이한 호열성 이소머라제와 함께 작용하여 고온에서 옥수수 분말로부터 프럭토즈를 제조할 수 있음을 입증한다. 첨가된 이가 금속 이온의 존재하에, 이소머라제는 90℃에서 대략 55% 프럭토즈의 예측된 프럭토즈:글루코즈 평형을 달성할 수 있다. 이는 프럭토즈 농도를 증가시키기 위해 크로마토그래피 분리를 필요로 하는, 중온성 이소머라제를 사용하는 현재의 방법 이상의 개선일 것이다. If α-amylase and α-glucosidase are present in the reaction, fructose was prepared from corn powder in a dose-dependent manner, with each isomerase. These results demonstrate that grain-expressed amylase 797GL3 can work with MalA and various different thermophilic isomerases with or without metal ions added to produce fructose from corn powder at high temperatures. In the presence of added divalent metal ions, isomerase can achieve an expected fructose: glucose equilibrium of approximately 55% fructose at 90 ° C. This would be an improvement over current methods using mesogenic isomerase, which requires chromatographic separation to increase the fructose concentration.
실시예 19Example 19
옥수수에서의 풀룰라나제의 발현Expression of pullulanase in maize
pNOV7013 또는 pNOV7005에 대하여 동형인 형질전환된 식물을 이종교배하여 797GL3 α-아밀라제 및 6GP3 풀룰라나제 둘 다를 발현하는 형질전환 옥수수 종자를 제조하였다. Transgenic plants homologous to pNOV7013 or pNOV7005 were cross-crossed to produce transgenic corn seeds expressing both 797GL3 α-amylase and 6GP3 pullulase.
pNOV 7005 또는 pNOV 4093으로 형질전환시킨 자가-수분된 옥수수 식물로부터의 T1 또는 T2 종자를 수득하였다. pNOV4093은 융합 단백질의 전분체로의 국소화를 위한 전분체 표적화 서열(서열번호 7, 8)을 갖는 6GP3(서열번호 3, 4)에 대한 옥수수 최적화된 합성 유전자의 융합물이다. 당해 융합 단백질을 내배유에서의 특이적 발현을 위한 ADPgpp 프로모터(서열번호 11)의 제어 하에 두었다. pNOV7005 작제물은 내배유의 세포질 세망에서의 풀룰라나제의 발현을 표적화하였다. ER 내의 당해 효소의 국소화는 낟알 내의 전분의 정상적인 축적을 가능하게 한다. 고온에의 임의의 노출 전, 요오드 용액을 사용한 전분에 대한 정상적인 염색이 또한 관찰되었다. T1 or T2 seeds from self-pollinated corn plants transformed with pNOV 7005 or pNOV 4093 were obtained. pNOV4093 is a fusion of maize optimized synthetic gene for 6GP3 (SEQ ID NOs: 3, 4) with starch targeting sequence (SEQ ID NOs: 7, 8) for localization of the fusion protein into starch. The fusion protein was placed under the control of the ADPgpp promoter (SEQ ID NO: 11) for specific expression in endocrine. The pNOV7005 construct targeted the expression of pullulanase in endocytic cytoplasmic reticulum. Localization of this enzyme in the ER allows for the normal accumulation of starch in the kernel. Prior to any exposure to high temperatures, normal staining for starch with iodine solution was also observed.
α-아밀라제의 경우에 기술한 바와 같이, 전분체로 표적화된 풀룰라나제의 발현(pNOV4093)은 낟알에의 비정상적인 전분 축적을 야기하였다. 옥수수-이삭을 건조시킨 경우, 낟알에 주름이 졌다. 명백히, 당해 호열성 풀룰라나제는 저온에서 충분히 활성적이며 종자 내배유 내의 전분 과립과 직접적으로 접촉하게 하는 경우 전분을 가수분해한다. As described in the case of α-amylase, expression of starul-targeted pullulanase (pNOV4093) resulted in abnormal starch accumulation in the kernel. When the corn-ears were dried, the grains were wrinkled. Clearly, the thermophilic pullulanase is sufficiently active at low temperatures and hydrolyzes starch when brought into direct contact with starch granules in the seed endosperm.
효소 제조 또는 옥수수 분말로부터의 효소의 추출: 풀룰라나제 효소는 형질전환 종자를 Kleco 연마기로 연마한 후 분말을 pH 5.55의 50mM NaOAc 완충액에 실온에서 1시간 동안 계속 교반하며 항온처리하여 이로부터 추출하였다. 이이서 항온처리한 혼합물을 14000rpm에서 15분 동안 회전시켰다. 상층액을 효소 공급원으로서 사용하였다. Enzyme Preparation or Extraction of Enzymes from Corn Powder: The pullulanase enzyme was extracted from the seed by grinding the transformed seed with a Kleco polisher, followed by incubation of the powder in 50 mM NaOAc buffer at pH 5.55 for 1 hour at room temperature with constant stirring. . The incubated mixture was then spun at 14000 rpm for 15 minutes. Supernatant was used as the enzyme source.
풀룰라나제 검정: 검정 반응을 96웰 플레이트에서 수행하였다. 옥수수 분말(100㎕)로부터 추출된 효소는 40mM CaCl2를 함유하는 pH 5.5의 50mM NaOAc 완충액 900㎕로 10배 희석하였다. 당해 혼합물을 격렬히 교반하고, Limit-Dextrizyme(제조사[Megazyme]의 아주린-가교결합된-풀룰란) 1정을 각각의 반응 혼합물에 첨가하고 75℃에서 30분 동안(또는 언급한 바와 같이) 항온처리하였다. 항온처리 말기에, 반응 혼합물을 3500rpm에서 15분 동안 회전시켰다. 상층액을 5배 희석하고 590nm에서의 흡광도 측정을 위해 96-웰 평저 플레이트로 옮겼다. 풀룰라나제에 의한 아주린-가교결합된-풀룰란 기질의 가수분해는 수용성의 염색 단편을 제조하며 이들의 방출률(590nm에서의 흡광도의 증가로 측정한)은 효소 활성과 직접적인 관련이 있다. Pullulanase Assay: The assay reaction was performed in 96 well plates. The enzyme extracted from the corn powder (100 μl) was diluted 10-fold with 900 μl of 50 mM NaOAc buffer at pH 5.5 containing 40 mM CaCl 2 . Stir the mixture vigorously, add 1 tablet of Limit-Dextrizyme (Megazyme's Azurin-crosslinked-Pullulan) to each reaction mixture and incubate at 75 ° C. for 30 minutes (or as mentioned). Treated. At the end of incubation, the reaction mixture was spun at 3500 rpm for 15 minutes. The supernatant was diluted 5 fold and transferred to a 96-well flat plate for absorbance measurement at 590 nm. Hydrolysis of the azurin-crosslinked- pullulan substrate by pullulanase produces water soluble stained fragments and their release rate (measured by increase in absorbance at 590 nm) is directly related to enzyme activity.
도 9는 pNOV7005로 형질전환한 상이한 사건으로부터의 T2 종자의 분석을 나타낸다. 비-형질전환 대조군에 비교한 풀룰라나제 활성의 고 발현이 다수의 사건에서 검측될 수 있다. 9 shows analysis of T2 seeds from different events transformed with pNOV7005. High expression of pullulanase activity compared to non-transforming controls can be detected in a number of events.
형질전환(풀룰라나제 또는 아밀라제 또는 그 둘 다를 발현하는) 및/또는 대조군(비-형질전환)으로부터 무수 옥수수 분말의 양(~100㎍)을 측정하기 위해, 40mM CaCl2를 함유하는 pH 5.5의 50mM NaOAc 1000㎕를 첨가하였다. 반응 혼합물을 격렬하게 교반한 후 교반기 위에서 1시간 동안 항온처리하였다. 항온처리 혼합물을 고온(75℃, 풀룰라나제에 대한 최적 반응 온도 또는 도면에서 언급한 바와 같은)으로 도면에 나타낸 바와 같은 시간 동안 옮김으로써 효소 반응을 개시하였다. 당해 반응은 이들을 얼음 위에 두어 냉각시킴으로써 종결시켰다. 이어서 반응 혼합물을 14000rpm에서 10분 동안 원심분리하였다. 상층액의 분취액(100㎕)을 3배 희석하고, HPLC 분석을 위해 0.2 미크론 필터로 여과하였다. PH 5.5 containing 40 mM CaCl 2 to determine the amount of dry corn powder (˜100 μg) from transformation (expressing pullulanase or amylase or both) and / or control (non-transformation). 1000 μl 50 mM NaOAc was added. The reaction mixture was vigorously stirred and then incubated for 1 hour on a stirrer. The enzymatic reaction was initiated by transferring the incubation mixture to a high temperature (75 ° C., optimal reaction temperature for pullulanase or as mentioned in the figure) for the time indicated in the figure. The reaction was terminated by placing them on ice and cooling. The reaction mixture was then centrifuged at 14000 rpm for 10 minutes. Aliquots of the supernatant (100 μl) were diluted 3-fold and filtered through a 0.2 micron filter for HPLC analysis.
당해 샘플을 다음의 조건을 사용하는 HPLC로 분석하였다:The sample was analyzed by HPLC using the following conditions:
칼럼: Alletch Prevail Carbohydrate ES 5 미크론 250 X 4.6mmColumn: Alletch Prevail
검측기: Alltech ELSD 2000Detector:
펌프: Gilson 322Pump: Gilson 322
주입기: Gilson 215 주입기/희석기Injector: Gilson 215 Injector / Dilutor
용매: HPLC 구배 아세토니트릴(Fisher Scientific) 및 물(Waters Millipore 시스템으로 정제한)Solvent: HPLC gradient acetonitrile (Fisher Scientific) and water (purified by Waters Millipore system)
낮은 중합도(DP 1 내지 15)의 올리고당용으로 사용된 구배Gradient used for oligosaccharides of low polymerization degree (
시간 %물 %아세토니트릴Time% Water% Acetonitrile
0 15 85 0 15 85
5 15 85 5 15 85
25 50 5025 50 50
35 50 5035 50 50
36 80 2036 80 20
55 80 2055 80 20
56 15 8556 15 85
76 15 8576 15 85
높은 중합도(DP 20 내지 100 및 그 이상)의 단당류용으로 사용된 구배Gradient used for monosaccharides of high polymerization degree (
시간 %물 %아세토니트릴Time% Water% Acetonitrile
0 35 650 35 65
60 85 1560 85 15
70 85 1570 85 15
85 35 6585 35 65
100 35 65100 35 65
데이타 분석을 위해 사용된 시스템: Gilson Unipoint 소프트웨어 시스템 3.2판Systems Used for Data Analysis: Gilson Unipoint Software System Edition 3.2
도 10A 및 10B는 형질전환 옥수수 분말에서 전분으로부터 발현된 풀룰라나제에 의해 제조된 가수분해 생성물의 HPLC 분석을 나타낸다. 풀룰라나제 발현 옥수수의 분말을 75℃의 반응 완충액에서 30분 동안 항온처리하여 옥수수 전분으로부터 중쇄 올리고당(DP ~10-30) 및 더 짧은 아밀로스 쇄(DP ~100-200)를 제조한다. 당해 도면은 또한 칼슘 이온의 존재 하의 풀룰라나제 활성의 의존도를 나타낸다. 10A and 10B show HPLC analysis of hydrolysis products prepared by pullulanase expressed from starch in transgenic corn powder. The powder of pullulanase expressing corn is incubated for 30 minutes in 75 ° C. reaction buffer to produce heavy chain oligosaccharides (DP ˜10-30) and shorter amylose chains (DP ˜100-200) from corn starch. The figure also shows the dependence of pullulanase activity in the presence of calcium ions.
풀룰라나제 발현 형질전환 옥수수를 탈분지화된(α1-6 결합 절단된) 변형-전분/덱스트린을 제조하기 위해 사용할 수 있으며, 따라서 고농도의 아밀로스/직쇄 덱스트린을 갖게 될 것이다. 또한 사용되는 전분의 종류(예를 들면, waxy, 고아밀로스 등)에 따라 풀룰라나제에 의해 제조된 아밀로스/덱스트린의 쇄 길이 분포는 다양할 것이며, 변형 전분/덱스트린의 특성도 다양할 것이다. Pullulanase expressing transformed corn can be used to prepare debranched (α1-6 binding truncated) modified starch / dextrins, and thus will have high concentrations of amylose / chain dextrins. In addition, the chain length distribution of amylose / dextrin produced by pullulanase will vary depending on the type of starch used (eg, waxy, high amylose, etc.), and the properties of the modified starch / dextrin will also vary.
α1-6 결합의 가수분해는 또한 기질로서 풀룰란을 사용하여 증명하였다. 옥수수 분말로부터 분리한 풀룰라나제는 풀룰란을 효과적으로 가수분해하였다. 항온처리 말기에 제조된 생성물의 HPLC 분석(기술한 바와 같은)은 예상대로 말토트리오스의 제조를 나타내었으며, 이는 옥수수로부터의 효소에 의한 풀룰란 분자 내의 α1-6 결합의 가수분해 때문이다. Hydrolysis of α1-6 bonds was also demonstrated using pullulan as substrate. Pullulanase isolated from the corn powder effectively hydrolyzed pullulan. HPLC analysis of the product prepared at the end of the incubation (as described) indicated the preparation of maltotriose as expected due to the hydrolysis of α1-6 bonds in the pullulan molecule by enzymes from corn.
실시예 20Example 20
옥수수에서 풀룰라나제의 발현Expression of pullulanase in maize
6gp3 풀룰라나제의 발현은 옥수수 분말로부터 추출한 후 PAGE 및 쿠마시 염색하여 추가로 분석하였다. 종자를 Kleco 연마기에서 30초 동안 연마하여 옥수수 분말을 제조하였다. pH 5.5의 50mM NaOAc 완충액 1ml을 사용하여 분말 약 150mg으로부터 당해 효소를 추출하였다. 당해 혼합물을 격렬하게 교반하고 RT에서 1시간 동안 교반기 상에서 항온처리한 후, 70℃에서 추가로 15분 동안 항온처리하였다. 이어서 당해 혼합물을 회전강하시키고(RT에서 15분 동안 14000rpm) 상층액을 SDS-PAGE 분석에 사용하였다. 적합한 분자량(95kDal)의 단백질 밴드가 관찰되었다. 이들 샘플을 시판되는 염료-접합 한계 덱스트린(LIMIT-DEXTRIZYME, 아일랜드 소재의 제조사[Megazyme])을 사용하여 풀룰라나제 검정에 적용한다. 높은 수준의 초호열성 풀룰라나제 활성은 95kD 단백질의 존재와 상관관계가 있다. Expression of 6gp3 pullulanase was further extracted from corn powder and further analyzed by PAGE and Coomassie staining. Seeds were ground in a Kleco grinder for 30 seconds to produce corn powder. The enzyme was extracted from about 150 mg of powder using 1 ml of 50 mM NaOAc buffer at pH 5.5. The mixture was stirred vigorously and incubated on a stirrer at RT for 1 hour and then incubated at 70 ° C. for an additional 15 minutes. The mixture was then spin down (14000 rpm for 15 minutes at RT) and the supernatant was used for SDS-PAGE analysis. A protein band of suitable molecular weight (95 kDal) was observed. These samples are subjected to pullulanase assay using commercial dye-conjugation limit dextrin (LIMIT-DEXTRIZYME, Megazyme, Ireland). High levels of hyperthermic pullulanase activity correlate with the presence of 95 kD protein.
형질전환 옥수수 종자의 웨스턴 블롯 및 ELISA 분석은 또한 풀룰라나제(이. 콜라이에서 발현된)에 대항하여 제조된 항체와 반응하는 ~95kD 단백질의 발현을 입증한다.Western blot and ELISA analysis of transgenic maize seed also demonstrates the expression of ˜95 kD protein that reacts with antibodies prepared against pullulanase (expressed in E. coli).
실시예 21Example 21
풀룰라나제 발현 옥수수의 첨가에 의한 단쇄(발효성) 올리고당의 전분 가수분해율의 증가 및 개선된 수율Increased starch hydrolysis rate and improved yield of short-chain (fermentable) oligosaccharides by the addition of pullulanase expressing corn
도 11A 및 11B에 나타낸 데이타는 상기한 바와 같은 2가지의 반응 혼합물로부터의 전분 가수분해 생성물의 HPLC 분석으로부터 산출하였다. '아밀라제'로 나타낸 제1 반응물은 예를 들면, 실시예 4에 기술된 방법에 따라 제조된 α-아밀라제 발현 형질전환 옥수수의 옥수수 분말 샘플 및 비-형질전환 옥수수 A188의 혼합물[1:1 (w/w)]을 함유하며; 제2 반응 혼합물 '아밀라제 + 풀룰라나제'는 실시예 19에 기술된 방법에 따라 제조된 α-아밀라제 발현 형질전환 옥수수 및 풀룰라나제 발현 형질전환 옥수수의 옥수수 분말 샘플의 혼합물[1:1(w/w)]을 함유한다. 수득된 결과는 전분 가수분해 과정 중 풀룰라나제와 α-아밀라제를 함께 사용하는 경우의 이득을 지지한다. 당해 이득은 증가된 전분 가수분해율(도 11A) 및 저 DP를 갖는 발효성 올리고당의 수율 증가(도 11B)로부터 인한 것이다.Data shown in FIGS. 11A and 11B were calculated from HPLC analysis of starch hydrolysis products from two reaction mixtures as described above. The first reactant, denoted 'amylase' is a mixture of a corn powder sample of α-amylase expressing transformed corn and a non-transformed corn A188 [1: 1 (w), for example, prepared according to the method described in Example 4. / w)]; The second reaction mixture 'amylase + pullulanase' is a mixture of corn powder samples of α-amylase expressing transformed corn and pullulanase expressing transformed corn prepared according to the method described in Example 19 [1: 1 (w / w)]. The results obtained support the benefit of using pullulanase and α-amylase together during starch hydrolysis. This gain is due to increased starch hydrolysis rate (FIG. 11A) and increased yield of fermentable oligosaccharides with low DP (FIG. 11B).
옥수수에서 발현되는 단독의 α-아밀라제 또는 α-아밀라제 및 풀룰라나제(또는 전분 가수분해 효소의 임의의 다른 조합)를 사용하여 덱스트린(직쇄 또는 측쇄 올리고당)을 제조할 수 있다(도 11A, 11B, 12 및 13A). 반응 조건, 가수분해 효소의 종류 및 이들의 조합, 및 사용된 전분의 종류에 따라, 제조된 말토덱스트린의 조성물 및 따라서 이들의 특성이 다양할 것이다. Dextrins (straight or branched chain oligosaccharides) can be prepared using either α-amylase or α-amylase and pullulanase (or any other combination of starch hydrolase) expressed in maize (FIGS. 11A, 11B, 12 and 13A). Depending on the reaction conditions, the type of hydrolase and combinations thereof, and the type of starch used, the composition of the maltodextrin produced and therefore its properties will vary.
도 12는 도 11에 기술한 바와 동일한 방식으로 수행한 실험의 결과를 도시한다. 반응물의 항온처리 동안 수행한 상이한 온도 및 시간 도식이 당해 도면에 나타내어져 있다. 풀룰라나제에 대한 최적 반응 온도는 75℃이며 α-아밀라제에 대하여는 >95℃이다. 따라서, 제시된 도식은 이들의 각각의 최적 반응 온도에서의 풀룰라나제 및/또는 α-아밀라제에 의한 촉매작용을 수행하는 영역을 제공하기 위해 따르게 된다. 나타낸 결과로부터 α-아밀라제 및 풀룰라나제의 조합이 60분의 항온처리 기간의 말기에 옥수수 전분의 가수분해를 더 잘 수행하였음을 추론할 수 있다. FIG. 12 shows the results of experiments performed in the same manner as described in FIG. 11. The different temperature and time schemes performed during incubation of the reactants are shown in this figure. The optimum reaction temperature for pullulanase is 75 ° C. and> 95 ° C. for α-amylase. Thus, the schemes presented follow to provide a region for carrying out catalysis by pullulanase and / or α-amylase at their respective optimum reaction temperatures. From the results shown it can be inferred that the combination of α-amylase and pullulanase performed better hydrolysis of corn starch at the end of the 60 minute incubation period.
30분 항온처리의 말기에 두 세트의 반응 혼합물로부터의 전분 가수분해 생성물의 상기한 바와 같은(이들 반응에는 ~150mg의 옥수수 분말을 사용하는 것을 제외하고) HPLC 분석이 도 13A 및 13B에 나타내어져 있다. 제1 세트의 반응물을 85℃에서 항온처리하였고, 제2 세트는 95℃에서 항온처리하였다. 각각의 세트에 대하여, 2가지 반응 혼합물이 있으며; '아밀라제 X 풀룰라나제'로 제시된 제1 반응물은 α-아밀라제 및 풀룰라나제 둘 다를 발현하는 형질전환 옥수수(교차 수분으로 발생된)로부터의 분말을 함유하며, '아밀라제'로 제시된 제2 반응물은 교배(아밀라제 X 풀룰라나제)에서 관측된 것과 동일한 정도의 α-아밀라제 활성을 얻기 위한 비율의, α-아밀라제 발현 형질전환 옥수수 및 비-형질전환 옥수수 A188의 옥수수 분말 샘플의 혼합물이다. 옥수수 분말 샘플을 85℃에서 항온처리한 경우, 저 DP 올리고당의 총 수율은 α-아밀라제만을 발현하는 옥수수와 비교하여 α-아밀라제 및 풀룰라나제 교배의 경우 더 높았다. 95℃의 항온처리 온도는 풀룰라나제 효소를 불활성화시켰고(최소한 부분적으로), 따라서 '아밀라제 X 풀룰라나제'와 '아밀라제' 사이에 다소간의 차이가 관찰될 수 있다. 그러나, 항온처리 온도 둘 다에 대한 데이타는 α-아밀라제 및 풀룰라나제 교배의 옥수수 분말을 α-아밀라제만을 발현하는 옥수수와 비교한 경우, 항온처리 시기의 말기에, 제조된 글루코즈의 양(도 13B)에 유의적인 개선을 나타낸다. 따라서, α-아밀라제 및 풀룰라나제 둘 다를 발현하는 옥수수의 사용은 전분의 글루코즈로의 완전한 가수분해가 중요한 과정에 특히 유리할 수 있다. HPLC analysis of the starch hydrolysis products from two sets of reaction mixtures at the end of the 30 minute incubation (except using ~ 150 mg corn powder for these reactions) is shown in FIGS. 13A and 13B. . The first set of reactants was incubated at 85 ° C. and the second set was incubated at 95 ° C. For each set, there are two reaction mixtures; The first reactant, represented as 'amylase X pullulanase', contains a powder from transgenic corn (generated with cross pollination) that expresses both α-amylase and pullulase, and the second reactant, represented as 'amylase' A mixture of corn powder samples of α-amylase expressing transformed maize and non-transformed maize A188 in a ratio to obtain the same degree of α-amylase activity as observed in the crossover (amylase X pullulanase). When corn powder samples were incubated at 85 ° C., the total yield of low DP oligosaccharides was higher for α-amylase and pullulanase crosses compared to corn expressing only α-amylase. The incubation temperature of 95 ° C. inactivated the pullulanase enzyme (at least in part), and thus some differences could be observed between 'amylase X pullulanase' and 'amylase'. However, data on both incubation temperatures showed that the amount of glucose produced (late 13B) at the end of the incubation period when the corn powder of the α-amylase and pullulanase cross was compared with the corn expressing only the α-amylase. ) Represents a significant improvement. Thus, the use of maize expressing both α-amylase and pullulanase may be particularly advantageous for processes in which complete hydrolysis of starch to glucose is important.
상기한 예는 α-아밀라제와 함께 사용하는 경우, 옥수수 종자에서 발현하는 풀룰라나제가 전분 가수분해 과정을 개선한다는 충분한 증거를 제공한다. α1-6 결합 특이적인 풀룰라나제 효소 활성은 α-아밀라제(α-1-4 결합 특이적 효소)보다 더 효과적으로 전분을 탈분지화시켜, 분지된 올리고당(예를 들면, 제한-덱스트린, 파노스; 이들은 일반적으로 비-발효성이다)의 양을 감소시키고 단직쇄 올리고당(에탄올 등으로 용이하게 발효가능한)의 양을 증가시킨다. 둘째, 탈분지화가 촉진된 풀룰라나제에 의한 전분 분자의 발효는 α-아밀라제에 대한 기질 접근가능성을 증가시켜, α-아밀라제 촉진 반응의 효율성을 증가시킨다. The above examples provide sufficient evidence that when used in combination with α-amylase, the pullulanase expressed in corn seeds improves the starch hydrolysis process. α1-6 binding specific pullulanase enzyme activity debranches starch more effectively than α-amylase (α-1-4 binding specific enzymes), resulting in branched oligosaccharides (eg, restriction-dextrins, panos) They are generally non-fermentable) and increase the amount of short chain oligosaccharides (easily fermentable with ethanol or the like). Second, fermentation of starch molecules by debranching-promoted pullulanase increases substrate accessibility to α-amylase, increasing the efficiency of α-amylase promoting reactions.
실시예 22Example 22
797GL3 알파 아밀라제 및 malA 알파-글루코시다제가 유사한 pH 및 온도 조건하에 작용하여 단독의 효소만으로 제조한 것 이상의 증가된 양의 글루코즈를 산출할 수 있는지의 여부를 측정하기 위해, 대략 0.35㎍의 malA 알파 글루코시다제 효소(세균에서 생산된)를 1% 전분 및 비-형질전환 옥수수 종자(대조군) 또는 797GL3 형질전환 옥수수 종자(797GL3 옥수수 종자에서 알파 아밀라제를 전분과 함께 동시-정제한다)로부터 정제한 전분을 함유하는 용액에 첨가하였다. 추가로, 비-형질전환 및 797GL3 형질전환 옥수수 종자로부터의 정제된 전분을 임의의 malA 효소가 없는 1% 옥수수 전분에 첨가하였다. 당해 혼합물을 90℃, pH 6.0에서 1시간 동안 항온처리하였고, 회전 강화시켜 임의의 불용성 물질을 제거하였고, 수용성 분획은 글루코즈 농도에 대하여 HPLC로 분석하였다. 도 14에 나타낸 바와 같이, 797GL3 알파-아밀라제 및 malA 알파-글루코시다제는 유사한 pH 및 온도에서 작용하여 전분을 글루코즈로 분해한다. 제조된 글루코즈의 양은 단독의 효소만으로 제조된 것보다 유의적으로 높았다. Approximately 0.35 μg malA alpha glucose to determine whether 797GL3 alpha amylase and malA alpha-glucosidase can operate under similar pH and temperature conditions to yield increased amounts of glucose beyond that produced by enzyme alone. Starch purified from cedar enzyme (produced in bacteria) from 1% starch and non-transformed corn seeds (control) or 797GL3 transgenic corn seeds (co-purified with alpha amylase with starch in 797GL3 corn seeds) It was added to the containing solution. In addition, purified starch from non-transformed and 797GL3 transgenic corn seeds was added to 1% corn starch without any malA enzyme. The mixture was incubated for 1 hour at 90 ° C., pH 6.0, rotationally strengthened to remove any insoluble material, and the aqueous fraction was analyzed by HPLC for glucose concentration. As shown in FIG. 14, 797GL3 alpha-amylase and malA alpha-glucosidase act at similar pH and temperature to break down starch into glucose. The amount of glucose produced was significantly higher than that produced with enzyme alone.
실시예 23Example 23
생전분 가수분해를 위한 호열혐기세균 글루코아밀라제의 효용성을 측정하였다. 도 15에 진술된 바와 같이, 생전분의 가수분해 전환을 물, 보리 α-아밀라제(제조사[Sigma]의 시판용 제제), 호열혐기세균 글루코아밀라제 및 이의 배합물을 실온 및 30℃에서 규명하여 시험하였다. 나타낸 바와 같이, 호열혐기세균 글루코아밀라제와 보리 α-아밀라제의 배합물은 생전분을 글루코즈로 가수분해할 수 있었다. 게다가, 보리 아밀라제 및 호열혐기세균 GA에 의해 생산된 글루코즈의 양은 단독의 효소만으로 생산된 것보다 유의적으로 높았다. The efficacy of thermophilic anaerobic bacteria glucoamylase for raw starch hydrolysis was measured. As stated in FIG. 15, the hydrolysis conversion of raw starch was tested by identifying water, barley α-amylase (commercially available from Sigma), thermophilic anaerobic glucoamylase and combinations thereof at room temperature and 30 ° C. As shown, the combination of thermophilic anaerobic bacterium glucoamylase and barley α-amylase was able to hydrolyze raw starch to glucose. In addition, the amount of glucose produced by barley amylase and thermophilic anaerobes GA was significantly higher than that produced by enzyme alone.
실시예 24Example 24
생전분 가수분해용 옥수수-최적화된 유전자 및 서열 및 식물 형질전환용 벡터Corn-optimized genes and sequences for raw starch hydrolysis and vector for plant transformation
당해 효소는 대략 20℃ 내지 50℃ 범위의 온도에서의 생전분의 가수분해능력을 기초로 하여 선택하였다. 이어서 상응하는 유전자 또는 유전자 단편을 실시예 1에 진술한 바와 같은 합성 유전자의 작제에 바람직한 옥수수 코돈을 사용하여 설계하였다. The enzyme was selected based on the hydrolyzability of the raw starch at temperatures ranging from approximately 20 ° C. to 50 ° C. Corresponding genes or gene fragments were then designed using the corn codons preferred for the construction of synthetic genes as set forth in Example 1.
아스퍼길러스 쉬로우사미 α-아밀라제/글루코아밀라제 융합 폴리펩타이드(시그날 서열이 없는)를 선택하였고, 문헌[참조: Biosci. Biotech. Biochem., 56:884-889(1992); Agric.Biol.Chem. 545:1905-14(1990); Biosci. Biotechnol. Biochem. 56:174-79(1992)]에서 확인된 바와 같은 서열번호 45에 제시된 아미노산 서열을 갖는다. Aspergillus shrousami α-amylase / glucoamylase fusion polypeptide (without signal sequence) was selected and described in Biosci. Biotech. Biochem., 56: 884-889 (1992); Agric. Biol. Chem. 545: 1905-14 (1990); Biosci. Biotechnol. Biochem. 56: 174-79 (1992), and has the amino acid sequence set forth in SEQ ID NO: 45.
유사하게, 문헌[참조: Biosci. Biotech. Biochem., 62:302-308 (1998)]에 공개된 바와 같은 서열번호 47의 아미노산 서열을 갖는 터모안애어로박테리움 터모사카롤리티쿰 글루코아밀라제를 선택하였다. 옥수수-최적화된 핵산을 설계하였다(서열번호 48).Similarly, Biosci. Biotech. Biochem., 62: 302-308 (1998), was selected as a thermoan bacterium termosacaroticum glucoamylase having the amino acid sequence of SEQ ID NO: 47. Corn-optimized nucleic acids were designed (SEQ ID NO 48).
문헌[참조: Agric. Biol. Chem. (1986) 50, pg 957-964]에 기술된 바와 같은 아미노산 서열(시그날 서열이 없는)(서열번호 50)을 갖는 리조푸스 오리재 글루코아밀라제를 선택하였다. 옥수수-최적화된 핵산을 설계하였고 서열번호 51로 나타내었다. See Agric. Biol. Chem. (1986) 50, pg 957-964, was selected for Rizopus auria glucoamylase having an amino acid sequence (without signal sequence) (SEQ ID NO: 50). Corn-optimized nucleic acid was designed and represented by SEQ ID NO: 51.
추가로, 옥수수 α-아밀라제를 선택하였고, 아미노산 서열(서열번호 51) 및 핵산 서열(서열번호 52)을 문헌으로부터 입수하였다. 예를 들면, 문헌[Plant Physiol. 105:759-760(1994)]을 참조한다. In addition, corn α-amylase was selected and amino acid sequence (SEQ ID NO: 51) and nucleic acid sequence (SEQ ID NO: 52) were obtained from the literature. See, eg, Plant Physiol. 105: 759-760 (1994).
서열번호 46으로 나타낸 바와 같이 설계한, 옥수수-최적화된 핵산으로부터의 아스퍼길러스 쉬로우사미 α-아밀라제/글루코아밀라제 융합 폴리펩타이드, 서열번호 48로 나타낸 바와 같이 설계한, 옥수수-최적화된 핵산으로부터의 터모안애어로박테리움 터모사카롤리티쿰 글루코아밀라제, 설계하고 서열번호 50으로 나타낸 옥수수-최적화된 핵산으로부터의 아미노산 서열(시그날 서열이 없는)(서열번호 49)을 갖는 선택된 리조푸스 오리재 글루코아밀라제 및 옥수수 α-아밀라제를 발현시키기 위한 발현 카세트를 작제한다. Aspergillus Schlossami α-amylase / glucoamylase fusion polypeptide from a corn-optimized nucleic acid, designed as shown in SEQ ID NO: 46, a turmeric from a corn-optimized nucleic acid, designed as shown in SEQ ID NO: 48 Selected Rizopus auricum glucoamylase and maize having an amino acid sequence (without signal sequence) (SEQ ID NO: 49) from a corn-optimized nucleic acid designed and represented by SEQ ID NO: 50, as shown An expression cassette for expressing α-amylase is constructed.
옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함하는 플라스미드를 당해 효소를 암호화하는 합성 유전자에 융합시킨다. 임의로, 서열 SEKDEL을 ER로의 표적화 및 ER에서의 체류를 위해 합성 유전자의 C-말단에 융합시킨다. 당해 융합물을 식물 형질전환 플라스미드에서 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝한다. 당해 융합물을 애그로박테리움 형질감염을 통해 옥수수 조직 내로 전달한다. A plasmid comprising maize γ-zein N-terminal signal sequence (MRVLLVALALLALAASATS) (SEQ ID NO: 17) is fused to a synthetic gene encoding the enzyme. Optionally, the sequence SEKDEL is fused to the C-terminus of the synthetic gene for targeting to and retention at the ER. This fusion is cloned behind the corn γ-zein promoter for specific expression in endocrine in plant transgenic plasmids. The fusion is delivered into maize tissue via Agrobacterium transfection.
실시예 25Example 25
선택된 효소를 포함하는 발현 카세트를 작제하여 당해 효소를 발현시킨다. 생전분 결합 부위에 대한 서열을 포함하는 플라스미드를 당해 효소를 암호화하는 합성 유전자에 융합시킨다. 생전분 결합 부위는 당해 효소 융합물이 비-젤라틴화 전분에 결합하도록 한다. 생전분 결합 부위 아미노산 서열(서열번호 53)을 문헌을 토대로 하여 결정하였고, 핵산 서열은 서열번호 54의 서열을 제공하기 위해 옥수수-최적화시켰다. 옥수수-최적화된 핵산 서열을 식물에서의 발현용 플라스미드 내의 효소를 암호화하는 합성 유전자에 융합시킨다. An expression cassette containing the selected enzyme is constructed to express the enzyme. The plasmid containing the sequence for the raw starch binding site is fused to a synthetic gene encoding the enzyme. The raw starch binding site allows the enzyme fusion to bind to non-gelatinized starch. The raw starch binding site amino acid sequence (SEQ ID NO: 53) was determined based on the literature, and the nucleic acid sequence was corn-optimized to provide the sequence of SEQ ID NO: 54. Corn-optimized nucleic acid sequences are fused to synthetic genes encoding enzymes in plasmids for expression in plants.
실시예 26Example 26
식물 형질전환용 옥수수-최적화된 유전자 및 벡터의 작제Construction of Corn-optimized Genes and Vectors for Plant Transformation
실시예 1에 진술된 바와 같은 합성 유전자의 작제를 위한 옥수수 선호 코돈을 사용하여 유전자 및 유전자 단편을 설계하였다. Genes and gene fragments were designed using maize preference codons for the construction of synthetic genes as stated in Example 1.
파이로코쿠스 퓨리오서스 EGLA, 초호열성 엔도글루카나제 아미노산 서열(시그날 서열이 없는)을 선택하였고 이는 문헌[참조: Journal of Bacteriology(1999) 181, pg 284-290]에서 확인된 바와 같이, 서열번호 55에 제시된 바와 같은 아미노산 서열을 갖는다. 옥수수-최적화된 핵산을 설계하였고 서열번호 56으로 나타내어져 있다.Pyrococcus puriosus EGLA, the superthermophilic endoglucanase amino acid sequence (without signal sequence) was selected and this sequence was identified as in Journal of Bacteriology (1999) 181, pg 284-290. Have an amino acid sequence as set forth in No. 55. Maize-optimized nucleic acid was designed and represented by SEQ ID NO: 56.
터무스 플라버스 자일로스 이소머라제를 선택하였고 문헌[참조: Applied Biochemistry and Biotechnology 62:15-27(1997)]에 기술된 바와 같이, 서열번호 57에 제시된 바와 같은 아미노산 서열을 갖는다. Termus Plabus xylose isomerase was selected and has an amino acid sequence as set forth in SEQ ID NO: 57 as described in Applied Biochemistry and Biotechnology 62: 15-27 (1997).
발현 카세트를 작제하여 옥수수-최적화된 핵산(서열번호 56)으로부터의 파이로코쿠스 퓨리오서스 EGLA(엔도글루카나제) 및 서열번호 57의 아미노산 서열을 암호화하는 옥수수-최적화된 핵산으로부터의 터무스 플라버스 자일로스 이소머라제를 발현시켰다. 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함하는 플라스미드를 당해 효소를 암호화하는 합성 유전자에 융합시킨다. 임의로, 서열 SEKDEL을 ER로의 표적화 및 ER에서의 체류를 위해 합성 유전자의 C-말단에 융합시킨다. 당해 융합물을 식물 형질전환 플라스미드에서 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝한다. 당해 융합물을 애그로박테리움 형질감염을 통해 옥수수 조직 내로 전달한다.An expression cassette was constructed to form a pyrococcus puriosus EGLA (endoglucanase) from a corn-optimized nucleic acid (SEQ ID NO: 56) and a mutus plaus from a corn-optimized nucleic acid encoding the amino acid sequence of SEQ ID NO: 57. Bus xylose isomerase was expressed. A plasmid comprising maize γ-zein N-terminal signal sequence (MRVLLVALALLALAASATS) (SEQ ID NO: 17) is fused to a synthetic gene encoding the enzyme. Optionally, the sequence SEKDEL is fused to the C-terminus of the synthetic gene for targeting to and retention at the ER. This fusion is cloned behind the corn γ-zein promoter for specific expression in endocrine in plant transgenic plasmids. The fusion is delivered into maize tissue via Agrobacterium transfection.
실시예 27Example 27
옥수수에서 발현되는 호열성 효소를 사용하는 옥수수 분말로부터의 글루코즈의 제조Preparation of Glucose from Corn Powder Using Thermophilic Enzyme Expressed in Corn
초호열성 α-아밀라제, 797GL3 및 α-글루코시다제(MalA)의 발현은 수용액과 함께 혼합하고 90℃에서 항온처리한 경우, 글루코즈의 생산을 야기하는 것으로 나타났다. Expression of superthermophilic α-amylase, 797GL3 and α-glucosidase (MalA) has been shown to result in production of glucose when mixed with aqueous solutions and incubated at 90 ° C.
MalA 효소를 발현하는 형질전환 옥수수 주(주 168A10B, pNOV4831)을 p-니트로페닐-α-글루코시드의 가수분해에 의해 제시된 바와 같이 α-글루코시다제 활성을 측정함으로써 동정하였다. Transgenic maize strains expressing MalA enzyme (Note 168A10B, pNOV4831) were identified by measuring α-glucosidase activity as shown by hydrolysis of p-nitrophenyl-α-glucoside.
797GL3를 발현하는 형질전환된 식물로부터의 옥수수 낟알을 Kleco 연마기에서 가루로 연마하여 아밀라제 분말을 제조하였다. MalA를 발현하는 형질전환된 식물로부터의 옥수수 낟알을 Kleco 연마기에서 분말로 연마하여 MalA 분말을 제조하였다. 비-형질전환 옥수수 낟알은 동일한 방식으로 연마하여 대조군 분말을 제조하였다. Amylase powder was prepared by grinding corn kernels from transformed plants expressing 797GL3 into powder in a Kleco grinder. Corn grains from transformed plants expressing MalA were ground to powder in a Kleco grinder to prepare MalA powders. Non-transformed corn kernels were ground in the same manner to prepare a control powder.
완충액은 pH 6.0의 50mM MES 완충액이었다.The buffer was 50 mM MES buffer at pH 6.0.
옥수수 분말 가수분해 반응: 샘플을 아래의 표 5에 나타낸 바와 같이 제조하였다. 옥수수 분말(샘플 당 약 60mg)을 pH 6.0의 50mM MES 완충액 40ml과 혼합하였다. 샘플을 90℃로 설정한 수욕에서 2.5시간 및 14시간 동안 항온처리하였다. 제시한 항온처리 시간에, 샘플을 옮기고 글루코즈 함량에 대하여 분석하였다. Corn Powder Hydrolysis Reaction: Samples were prepared as shown in Table 5 below. Corn powder (about 60 mg per sample) was mixed with 40 ml of 50 mM MES buffer at pH 6.0. Samples were incubated for 2.5 hours and 14 hours in a water bath set at 90 ° C. At the indicated incubation time, samples were transferred and analyzed for glucose content.
당해 샘플을 글루코즈 산화효소/홍당무 과산화효소계 검정으로 글루코즈에 대하여 검정하였다. GOPOD 시약은 o-다이아니시딘 0.2mg/ml, 100mM 트리스 pH 7.5, 글루코즈 산화효소 100U/ml & 홍당무 과산화효소 10U/ml을 함유하였다. 샘플 또는 희석된 샘플 20㎕를 글루코즈 표준(0 내지 0.22ml/ml로 다양한)을 사용하여 96웰 플레이트에서 검정하였다. GOPGD 시약 100㎕를 혼합하며 각각의 웰에 첨가하였고, 당해 플레이트를 37℃에서 30분 동안 항온처리하였다. 황산(9M) 100㎕를 첨가하였고 540nm에서의 흡광도를 판독하였다. 샘플의 글루코즈 농도는 표준 곡선을 참고하여 결정하였다. 각각의 샘플에서 관측된 글루코즈의 양이 표 5에 나타내어져 있다. The samples were assayed for glucose with a glucose oxidase / blush peroxidase based assay. The GOPOD reagent contained 0.2 mg / ml o- dianisidine, 100 mM Tris pH 7.5, 100 U / ml glucose oxidase and 10 U / ml blush peroxidase. 20 μl of samples or diluted samples were assayed in 96 well plates using glucose standards (variable from 0 to 0.22 ml / ml). 100 μl of GOPGD reagent was mixed and added to each well and the plates incubated at 37 ° C. for 30 minutes. 100 μl of sulfuric acid (9M) was added and the absorbance at 540 nm was read. The glucose concentration of the sample was determined by reference to the standard curve. The amount of glucose observed in each sample is shown in Table 5.

이들 데이타는 옥수수에서의 초호열성 α-아밀라제 및 α-글루코시다제의 발현이 적합한 조건하에 수화 및 가열하는 경우 글루코즈를 산출해낼 옥수수 생성물을 야기함을 입증한다. These data demonstrate that the expression of superthermophilic α-amylase and α-glucosidase in maize results in corn products that will yield glucose when hydrated and heated under suitable conditions.
실시예 28Example 28
말토덱스트린의 제조Preparation of Maltodextrin
호열성 α-아밀라제를 발현하는 곡립을 사용하여 말토덱스트린을 제조하였다. 예시된 과정은 전분의 선행 분리를 필요로 하지 않으며 외인성 효소의 첨가도 필요로 하지 않는다. Maltodextrins were prepared using grains expressing thermophilic α-amylase. The illustrated process does not require prior separation of starch and does not require the addition of exogenous enzymes.
797GL3을 발현하는 형질전환된 식물로부터의 옥수수 낟알을 Kleco 연마기에서 분말로 연마하여 "아밀라제 분말"을 제조하였다. 10% 형질전환/90% 비-형질전환 낟알의 혼합물을 동일한 방식으로 연마하여 "10% 아밀라제 분말"을 제조하였다. Corn kernels from transformed plants expressing 797GL3 were ground into powder in a Kleco grinder to produce "amylase powder". A mixture of 10% transformed / 90% non-transformed grains was ground in the same manner to prepare a “10% amylase powder”.
아밀라제 분말 및 10% 아밀라제 분말(대략 60mg/샘플)을 물과 분말 mg당 물 5㎕의 비율로 혼합하였다. 수득된 슬러리를 표 6에 나타낸 바와 같이 최대 20분 동안 90℃에서 항온처리하였다. 85℃에서 50mM EDTA 0.9ml을 첨가하여 반응을 종결하였고 피펫팅(pipetting)하여 혼합하였다. 슬러리 0.2ml의 샘플을 옮기고, 원심분리하여 불용성 물질을 제거하고 물에 3x 희석하였다. 당해 샘플을 당 및 말토덱스트린에 대하여 ELSD 검측기를 사용하는 HPLC로 분석하였다. 구배 HPLC 시스템은 5 미크론 입자 크기, 250 X 4.6mm의 아스텍 중합체 아미노 칼럼 및 Alltech ELSD 2000 검측기를 장착하였다. 당해 시스템을 물:아세토니트릴의 15:85 혼합물로 재-평형화시켰다. 유속은 1ml/분이었다. 초기 조건은 주입 후 5분 동안 유지하였고 50:50 물:아세토니트릴의 구배로 20분 동안 유지한 후, 동일한 용매로 10분 동안 유지하였다. 당해 시스템을 80:20 물:아세토니트릴로 20분간 세척한 후 출발 용매로 재-평형화시켰다. Amylase powder and 10% amylase powder (approximately 60 mg / sample) were mixed at a rate of 5 μl of water per mg of powder. The resulting slurry was incubated at 90 ° C. for up to 20 minutes as shown in Table 6. The reaction was terminated by addition of 0.9 ml of 50 mM EDTA at 85 ° C. and mixed by pipetting. A 0.2 ml sample of slurry was transferred and centrifuged to remove insoluble material and diluted 3 × in water. The samples were analyzed for sugar and maltodextrin by HPLC using an ELSD detector. The gradient HPLC system was equipped with a 5 micron particle size, 250 x 4.6 mm Astec polymer amino column and an
수득된 피크면적을 분말의 용적 및 중량에 대하여 표준화하였다. 탄수화물의 ㎍ 당 ELSD의 반응 인자를 DP를 증가시키면서 감소시켰고, 따라서 고 DP 말토덱스트린이 피크면적에 의해 나타내어진 것보다 더 높은 총 퍼센트를 나타낸다. The peak area obtained is normalized to the volume and weight of the powder. The response factor of ELSD per μg of carbohydrates was reduced with increasing DP, thus high DP maltodextrin showed a higher total percentage than indicated by the peak area.
100% 아밀라제 분말을 사용한 반응 생성물의 상대 피크면적이 도 17에 나타내어져 있다. 10% 아밀라제 분말을 사용한 반응 생성물의 상대 피크면적은 도 18에 나타내어져 있다. The relative peak area of the reaction product using 100% amylase powder is shown in FIG. 17. The relative peak area of the reaction product using 10% amylase powder is shown in FIG. 18.
이들 데이타는 가열 시간을 변화시킴으로써 각종 말토덱스트린 혼합물을 제조할 수 있음을 입증한다. α-아밀라제 활성의 수준을 야생형 옥수수와 α-아밀라제-발현 옥수수를 혼합함으로써 변화시켜 말토덱스트린 특성을 변형시킬 수 있다. These data demonstrate that various maltodextrin mixtures can be prepared by varying the heating time. The level of α-amylase activity can be altered by mixing wild type corn and α-amylase-expressing corn to modify maltodextrin properties.
당해 실시예에 기술된 가수분해 반응 생성물을 식품 및 원심분리, 여과, 이온-교환, 겔 투과, 한외여과, 나노여과, 역 삼투, 탄소 입자를 사용한 탈색, 분무 건조 및 당해 분야에 공지된 기타 표준 기법을 포함하는 잘 정의된 각종 방법의 사용에 의한 기타 적용을 위해 농축 및 정제할 수 있다. The hydrolysis reaction products described in this example were subjected to food and centrifugation, filtration, ion-exchange, gel permeation, ultrafiltration, nanofiltration, reverse osmosis, bleaching with carbon particles, spray drying and other standards known in the art. It can be concentrated and purified for other applications by the use of a variety of well-defined methods, including techniques.
실시예 29Example 29
말토덱스트린 제조에 대한 시간 및 온도의 효과Effect of time and temperature on maltodextrin production
호열성 α-아밀라제를 함유하는 곡립의 자가가수분해의 말토덱스트린 생성물의 조성물을 반응 시간 및 온도를 변화시킴으로써 변형할 수 있다. The composition of the autohydrolysis maltodextrin product of grains containing thermophilic α-amylase can be modified by varying the reaction time and temperature.
다른 실험에서, 아밀라제 분말을 상기한 실시예 28에 기술한 바와 같이 제조하였고 물과 분말 60mg 당 물 300㎕의 비율로 혼합하였다. 샘플을 최대 90분 동안 70℃, 80℃, 90℃ 또는 100℃에서 항온처리하였다. 90℃에서 50mM EDTA 900ml을 첨가하여 반응을 종결시키고, 원심분리하여 불용성 물질을 제거하고 0.45㎛ 나일론 필터를 통해 여과하였다. 필터를 실시에 28에 기술된 바와 같이 HPLC에 의해 분석하였다. In another experiment, amylase powder was prepared as described in Example 28 above and mixed with water at a rate of 300 μl of water per 60 mg of powder. Samples were incubated at 70 ° C., 80 ° C., 90 ° C. or 100 ° C. for up to 90 minutes. The reaction was terminated by addition of 900 ml of 50 mM EDTA at 90 ° C., centrifuged to remove insoluble material and filtered through a 0.45 μm nylon filter. The filter was analyzed by HPLC as described in Example 28.
당해 분석 결과는 도 19에 나타내어져 있다. DP 수 명칭은 중합도를 지칭한다. DP2는 말토오스이고; DP3는 말토트리오스인 등이다. 단일 피크에서 용출된 대 DP 말토덱스트린은 용출 말기의 근처에 있으며 ">DP12"로 라벨링되어 있다. 당해 집합체는 0.45㎛ 여과기 및 방호 칼럼을 통과한 덱스트린은 포함하지만, 여과기 또는 방호 칼럼에 의해 갇힌 임의의 매우 큰 전분 단편은 포함하지 않는다. The analysis result is shown in FIG. The DP number designation refers to the degree of polymerization. DP2 is maltose; DP3 is maltotriose and the like. Large DP maltodextrin eluted at a single peak is near the end of the elution and is labeled "> DP12". The aggregate includes dextrin that passed through a 0.45 μm filter and protective column, but does not include any very large starch fragments trapped by the filter or protective column.
당해 실험은 생성물의 말토덱스트린 조성물을 온도 및 항온처리 시간을 변화시킴으로써 변형하여 목적하는 말토올리고당 또는 말토덱스트린 생성물을 수득할 수 있음을 입증한다. This experiment demonstrates that the maltodextrin composition of the product can be modified by varying the temperature and incubation time to obtain the desired maltooligosaccharide or maltodextrin product.
실시예 30Example 30
말토덱스트린 생산Maltodextrin production
호열성 α-아밀라제를 함유하는 형질전환 옥수수로부터의 말토덱스트린 생성물의 조성물은 α-글루코시다제 및 자일로스 이소머라제와 같은 기타 효소를 첨가하여, 그리고 가열 처리하기 전 수성 분말 혼합물에 염을 첨가하여 변형시킬 수 있다. Compositions of maltodextrin products from transgenic corn containing thermophilic α-amylase are added with other enzymes such as α-glucosidase and xylose isomerase, and salts are added to the aqueous powder mixture prior to heat treatment. Can be modified.
이와 달리, 상기한 바와 같이 제조한 아밀로스 분말을 정제한 MalA 및/또는 BD8037로 명명된 세균 자일로스 이소머라제와 혼합하였다. 6His 정제 태그를 갖는 에스. 설포타리쿠스 MalA를 이. 콜라이 내에서 발현시켰다. 세포 용해물을 실시예 28에 기술된 바와 같이 제조한 후, 니켈 친화 수지(Probond, Invitrogen)를 사용하고 천연 단백질 정제를 위한 제조자 지침서에 따라 명백한 균등성으로 정제하였다. 자일로스 이소머라제 BD8037은 Diversa로부터 동결건조된 분말로 입수하였고 원래 부피의 0.4x의 물에 재현탁하였다. Alternatively, the amylose powder prepared as described above was mixed with purified MalA and / or bacterial xylose isomerase designated BD8037. S with 6His tablet tag. Sulpotaricus MalA. It was expressed in E. coli. Cell lysates were prepared as described in Example 28 and then purified using apparent affinity with nickel affinity resin (Probond, Invitrogen) and according to manufacturer's instructions for natural protein purification. Xylose isomerase BD8037 was obtained as a lyophilized powder from Diversa and resuspended in 0.4 × of original volume of water.
아밀라제 옥수수 분말을 물 또는 완충액을 가한 효소 용액과 혼합하였다. 모든 반응물은 아밀라제 분말 60mg 및 총 600㎕의 용액을 함유하였다. 제1 세트의 반응물을 실온에서 pH 7.0의 50mM MOPS와 10mM MgSO4 및 1mM CoCl2로 완충하였고; 제2 세트의 반응물에서는 금속 함유 완충 용액을 물로 대체하였다. 모든 반응물을 90℃에서 2시간 동안 항온처리하였다. 반응 상층액 분획을 원심분리하여 제조하였다. 당해 펠렛을 추가로 H2O 600㎕로 세척하였고 재-원심분리하였다. 각각의 반응물로부터의 상층액 분획을 합하고, 센트리콘 10을 통해 여과하고 상기한 바와 같이 ELSD 검출기를 사용하는 HPLC로 분석하였다. Amylase corn powder was mixed with enzyme solution added water or buffer. All reactions contained 60 mg amylase powder and a total of 600 μl of solution. The first set of reactions were buffered with 50 mM MOPS, 10 mM MgSO 4 and 1 mM CoCl 2 at pH 7.0 at room temperature; In the second set of reactants, the metal containing buffer solution was replaced with water. All reactions were incubated at 90 ° C. for 2 hours. The reaction supernatant fractions were prepared by centrifugation. The pellet was further washed with 600 μl H 2 O and re-centrifuged. Supernatant fractions from each reaction were combined, filtered through
당해 결과는 도 20에 그래프로 나타내어져 있다. 이들은 곡립-발현 아밀라제 797GL3가 첨가된 금속 이온의 유무하에 기타 호열성 효소와 함께 작용하여 고온에서 옥수수 분말로부터 각종 말토덱스트린 혼합물을 제조할 수 있음을 입증한다. 특히, 글루코아밀라제 또는 α-글루코시다제의 포함은 더 많은 글루코즈 및 기타 저 DP 생성물을 갖는 생성물을 야기할 수 있다. 글루코즈 이소머라제 활성을 갖는 효소의 포함은 프럭토즈를 갖는 생성물을 야기하며 따라서 아밀라제만 또는 α-글루코시다제와 함께 아밀라제를 사용하여 제조한 것보다 고당도일 것이다. 추가로, 당해 데이타는 DP5, DP6 및 DP7 말토올리고당의 비율이 CoCl2 및 MgSO4와 같은 이가 양이온 염을 포함시킴으로 인해 증가할 수 있음을 제시한다. The results are shown graphically in FIG. 20. They demonstrate that grain-expressing amylase 797GL3 can be combined with other thermophilic enzymes in the presence or absence of added metal ions to produce various maltodextrin mixtures from corn powder at high temperatures. In particular, the inclusion of glucoamylase or α-glucosidase can lead to products with more glucose and other low DP products. Inclusion of enzymes with glucose isomerase activity results in products with fructose and will therefore be higher sugar than those prepared using amylases with amylase alone or with α-glucosidase. In addition, the data suggest that the proportion of DP5, DP6 and DP7 maltooligosaccharides may increase due to the inclusion of divalent cation salts such as CoCl 2 and MgSO 4 .
본원에 기술된 바와 같은 반응에 의해 제조된 말토덱스트린 조성물을 변형시키는 기타 방법에는 반응 pH 변화, 형질전환 또는 비-형질전환 곡립의 전분 유형 변화, 고체 비율 변화 또는 유기 용매의 첨가가 포함된다. Other methods of modifying maltodextrin compositions prepared by reactions as described herein include changes in reaction pH, changes in starch type of transformed or non-transformed grains, changes in solid ratios or addition of organic solvents.
실시예 31Example 31
전분-유래 생성물의 회수 전 곡립을 기계적으로 파쇄하지 않는 곡립으로부터 덱스트린 또는 당의 제조Preparation of Dextrins or Sugars from Grains that Do Not Mechanically Crush Grains Before Recovery of Starch-Derived Products
α-아밀라제를 발현하는 형질전환 곡립, 797GL3을 물과 접촉시키고 90℃로 밤새(>14시간) 가열함으로써 당 및 말토덱스트린을 제조하였다. 이어서 액체를 여과함으로써 곡립과 분리하였다. 당해 액체 생성물을 실시예 15에 기술한 방법에 의해 HPLC로 분석하였다. 표 6은 검출된 생성물의 특성을 나타낸다. Sugars and maltodextrins were prepared by contacting the transgenic grain, 797GL3, expressing α-amylase with water and heating to 90 ° C. overnight (> 14 hours). The liquid was then separated from the grain by filtration. The liquid product was analyzed by HPLC by the method described in Example 15. Table 6 shows the properties of the detected products.

* DP3의 정량화는 말토트리오스를 포함하며 α(1→4) 결합 대신 α(1→6) 결합을 갖는 말토트리오스의 이성체를 포함할 수 있다. 유사하게 DP4 내지 DP7 정량화는 주어진 쇄 길이의 선형 말토올리고당 및 하나 이상의 α(1→4) 결합 대신 하나 이상의 (1→6) 결합을 갖는 이성체를 포함한다. * Quantification of DP3 includes maltotriose and may include isomers of maltotriose with α (1 → 6) bonds instead of α (1 → 4) bonds. Similarly, DP4 to DP7 quantification includes linear maltooligosaccharides of a given chain length and isomers having one or more (1 → 6) bonds instead of one or more α (1 → 4) bonds.
이들 데이타는 당 및 말토덱스트린을 α-아밀라제-발현 곡립을 물과 접촉시키고 가열함으로써 제조할 수 있음을 입증한다. 이어서 당해 생성물을 여과 또는 원심분리하거나 중력 침전시켜 무손상 곡립으로부터 분리할 수 있다. These data demonstrate that sugars and maltodextrins can be prepared by contacting and heating α-amylase-expressing grains with water. The product can then be separated from intact grains by filtration or centrifugation or gravity precipitation.
실시예 32Example 32
리조푸스 오리재 글루코아밀라제를 발현하는 옥수수 내의 생전분의 발효Fermentation of Raw Starch in Maize Expressing Rizopus Duck Glucoamylase
형질전환 옥수수 낟알을 실시예 29에 기술한 바와 같이 제조한 형질전환된 식물로부터 수거한다. 당해 낟알을 분말로 연마한다. 당해 옥수수 낟알은 세포질세망으로 표적화된 리조푸스 오리재의 글루코아밀라제(서열번호 49)의 활성 단편을 포함하는 단백질을 발현한다. Transformed corn kernels are harvested from the transformed plants prepared as described in Example 29. The grain is ground into a powder. The corn kernel expresses a protein comprising an active fragment of glucoamylase (SEQ ID NO: 49) of lyspus ducks targeted with cytoplasmic reticulum.
당해 옥수수 낟알을 실시예 15에 기술된 바와 같이 분말로 연마한다. 이어서, 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)을 함유하는 매쉬를 제조한다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 매쉬에 첨가한다: 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은 100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90℃의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86℃로 낮추고, 48시간에 82℃로 설정한다. The corn kernels are ground to a powder as described in Example 15. A mash containing 20 g of corn powder, 23 ml of deionized water and 6.0 ml of bag set (8 wt% solids) is prepared. The pH is titrated to 6.0 by the addition of ammonium hydroxide. Add the following ingredients to the mesh: 0.2 mg of protease (0.60 ml of 1,000-fold dilution of commercial protease), lactoside & urea (0.85 ml of 10-fold dilution of 50% urea solution). 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to escape. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set at 90 ° C. After 24 hours of fermentation, the temperature is lowered to 86 ° C. and set to 82 ° C. at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 33Example 33
형질전환 옥수수 낟알을 실시예 28에 기술된 바와 같이 제조한 형질전환된 식물로부터 수거한다. 낟알을 분말로 연마한다. 당해 옥수수 낟알은 세포질세망으로 표적화된 리조푸스 오리재의 글루코아밀라제(서열번호 49)의 활성 단편을 포함하는 단백질을 발현한다. Transformed corn kernels are harvested from the transformed plants prepared as described in Example 28. Grind the grain into powder. The corn kernel expresses a protein comprising an active fragment of glucoamylase (SEQ ID NO: 49) of lyspus ducks targeted with cytoplasmic reticulum.
당해 옥수수 낟알을 실시예 15에 기술된 바와 같이 분말로 연마한다. 이어서, 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)을 함유하는 매쉬를 제조한다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 매쉬에 첨가한다: 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은 100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90℃의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86℃로 낮추고, 48시간에 82℃로 설정한다. The corn kernels are ground to a powder as described in Example 15. A mash containing 20 g of corn powder, 23 ml of deionized water and 6.0 ml of bag set (8 wt% solids) is prepared. The pH is titrated to 6.0 by the addition of ammonium hydroxide. Add the following ingredients to the mesh: 0.2 mg of protease (0.60 ml of 1,000-fold dilution of commercial protease), lactoside & urea (0.85 ml of 10-fold dilution of 50% urea solution). 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to escape. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set at 90 ° C. After 24 hours of fermentation, the temperature is lowered to 86 ° C. and set to 82 ° C. at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 34Example 34
외인성 α-아밀라제의 첨가 하에 리조푸스 오리재 글루코아밀라제를 발현하는 옥수수의 전체 낟알 중 생전분의 발효의 예Example of Fermentation of Raw Starch in Whole Grains of Corn Expressing Ripuspus Duck Residue Glucoamylase Under Addition of Exogenous α-amylase
형질전환 옥수수 낟알을 실시예 28에 기술된 바와 같이 제조한 형질전환된 식물로부터 수거한다. 당해 옥수수 낟알은 세포질세망으로 표적화된 리조푸스 오리재의 글루코아밀라제(서열번호 49)의 활성 단편을 포함하는 단백질을 발현한다. Transformed corn kernels are harvested from the transformed plants prepared as described in Example 28. The corn kernel expresses a protein comprising an active fragment of glucoamylase (SEQ ID NO: 49) of lyspus ducks targeted with cytoplasmic reticulum.
당해 옥수수 낟알을 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)과 접촉시킨다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 매쉬에 첨가한다: 제조사[Sigma]로부터 구입한 보리 α-아밀라제(2mg), 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은 100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90℃의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86℃로 낮추고, 48시간에 82℃로 설정한다. The corn kernels are contacted with 20 g of corn powder, 23 ml of deionized water, and 6.0 ml of bag set (8 wt% solids). The pH is titrated to 6.0 by the addition of ammonium hydroxide. Add the following ingredients to the mash: Barley α-amylase (2 mg), protease (0.60 ml of 1,000-fold dilution of commercial protease), lactoside & urea (10-fold dilution of 50% urea solution) from Sigma 0.85 ml) 0.2 mg. 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to escape. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set at 90 ° C. After 24 hours of fermentation, the temperature is lowered to 86 ° C. and set to 82 ° C. at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 35Example 35
리조푸스 오리재 글루코아밀라제 및 제아 메이스 아밀라제를 발현하는 옥수수 중 생전분의 발효Fermentation of Raw Starch in Maize Expressing Rizopus Duck Glucoamylase and Zea Mays Amylase
형질전환 옥수수 낟알을 실시예 28에 기술된 바와 같이 제조한 형질전환된 식물로부터 수거한다. 당해 옥수수 낟알은 세포질세망으로 표적화된 리조푸스 오리재의 글루코아밀라제(서열번호 49)의 활성 단편을 포함하는 단백질을 발현한다. 당해 낟알은 또한 실시예 28에 기술된 바와 같은 생전분 결합 도메인을 갖는 옥수수 아밀라제를 발현한다. Transformed corn kernels are harvested from the transformed plants prepared as described in Example 28. The corn kernel expresses a protein comprising an active fragment of glucoamylase (SEQ ID NO: 49) of lyspus ducks targeted with cytoplasmic reticulum. The kernel also expresses corn amylase having a live starch binding domain as described in Example 28.
당해 옥수수 낟알을 실시예 14에 기술된 바와 같이 분말로 연마한다. 이어서, 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)을 함유하는 매쉬를 제조한다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 매쉬에 첨가한다: 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은 100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90F의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86F로 낮추고, 48시간에 82F로 설정한다. The corn kernels are ground to a powder as described in Example 14. A mash containing 20 g of corn powder, 23 ml of deionized water and 6.0 ml of bag set (8 wt% solids) is prepared. The pH is titrated to 6.0 by the addition of ammonium hydroxide. Add the following ingredients to the mesh: 0.2 mg of protease (0.60 ml of 1,000-fold dilution of commercial protease), lactoside & urea (0.85 ml of 10-fold dilution of 50% urea solution). 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to escape. The mash was then incubated with yeast (1.44 ml) and incubated in a 90 F water bath set. After 24 hours of fermentation, the temperature is lowered to 86F and set to 82F at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 36Example 36
터모안애어로박터 터모사카롤리티쿰 글루코아밀라제를 발현하는 옥수수 중 생전분의 발효의 예Example of Fermentation of Raw Starch in Maize Expressing Thermobacterium Termosacaroticum Glucoamylase
형질전환 옥수수 낟알을 실시예 28에 기술된 바와 같이 제조한 형질전환된 식물로부터 수거한다. 당해 옥수수 낟알은 세포질세망으로 표적화된 리조푸스 오리재의 글루코아밀라제(서열번호 47)의 활성 단편을 포함하는 단백질을 발현한다. Transformed corn kernels are harvested from the transformed plants prepared as described in Example 28. The corn kernel expresses a protein comprising an active fragment of glucoamylase (SEQ ID NO: 47) of Rizopus duck, targeted with cytoplasmic reticulum.
당해 옥수수 낟알을 실시예 15에 기술된 바와 같이 분말로 연마한다. 이어서, 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)을 함유하는 매쉬를 제조한다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 매쉬에 첨가한다: 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은 100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90℃의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86℃로 낮추고, 48시간에 82℃로 설정한다. The corn kernels are ground to a powder as described in Example 15. A mash containing 20 g of corn powder, 23 ml of deionized water and 6.0 ml of bag set (8 wt% solids) is prepared. The pH is titrated to 6.0 by the addition of ammonium hydroxide. Add the following ingredients to the mesh: 0.2 mg of protease (0.60 ml of 1,000-fold dilution of commercial protease), lactoside & urea (0.85 ml of 10-fold dilution of 50% urea solution). 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to escape. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set at 90 ° C. After 24 hours of fermentation, the temperature is lowered to 86 ° C. and set to 82 ° C. at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 37Example 37
아스퍼길러스 니거 글루코아밀라제를 발현하는 옥수수 중 생전분의 발효의 예Example of Fermentation of Raw Starch in Corn Expressing Aspergillus niger glucoamylase
형질전환 옥수수 낟알을 실시예 28에 기술된 바와 같이 제조한 형질전환된 식물로부터 수거한다. 당해 옥수수 낟알은 아스퍼길러스 니거(문헌[참조: Fiil,N.P. "Glucoamylases Gland G2 from Aspergillus niger are synthesized from two different but closely related mRNAs" EMBO J. 3 (5), 1097-1102 (1984)], 수탁 번호 제P04064호)의 글루코아밀라제의 활성 단편을 포함하는 단백질을 발현한다. 당해 글루코아밀라제를 암호화하는 옥수수-최적화된 핵산은 서열번호 59를 가지며 세포질세망으로 표적화 되어 있다. Transformed corn kernels are harvested from the transformed plants prepared as described in Example 28. The corn kernels are entrusted with Aspergillus niger (Fiil, NP "Glucoamylases Gland G2 from Aspergillus niger are synthesized from two different but closely related mRNAs" EMBO J. 3 (5), 1097-1102 (1984)). Protein containing an active fragment of Glucoamylase (No. P04064). The corn-optimized nucleic acid encoding the glucoamylase has SEQ ID NO: 59 and is targeted to cytoplasmic reticulum.
당해 옥수수 낟알을 실시예 14에 기술된 바와 같이 분말로 연마한다. 이어서, 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)을 함유하는 매쉬를 제조한다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 매쉬에 첨가한다: 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은 100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90℃의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86℃로 낮추고, 48시간에 82℃로 설정한다. The corn kernels are ground to a powder as described in Example 14. A mash containing 20 g of corn powder, 23 ml of deionized water and 6.0 ml of bag set (8 wt% solids) is prepared. The pH is titrated to 6.0 by the addition of ammonium hydroxide. Add the following ingredients to the mesh: 0.2 mg of protease (0.60 ml of 1,000-fold dilution of commercial protease), lactoside & urea (0.85 ml of 10-fold dilution of 50% urea solution). 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to escape. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set at 90 ° C. After 24 hours of fermentation, the temperature is lowered to 86 ° C. and set to 82 ° C. at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 38Example 38
아스퍼길러스 니거 글루코아밀라제 및 제아 메이스 아밀라제를 발현하는 옥수수 중 생전분의 발효의 예Example of Fermentation of Raw Starch in Corn Expressing Aspergillus niger glucoamylase and Zea mays amylase
형질전환 옥수수 낟알을 실시예 28에 기술된 바와 같이 제조한 형질전환된 식물로부터 수거한다. 당해 옥수수 낟알은 아스퍼길러스 니거(문헌[참조: Fiil,N.P. "Glucoamylases Gland G2 from Aspergillus niger are synthesized from two different but closely related mRNAs" EMBO J. 3 (5), 1097-1102 (1984)], 수탁 번호 제P04064호)(서열번호 59, 옥수수-최적화된 핵산)의 글루코아밀라제의 활성 단편을 포함하는 단백질을 발현하며, 세포질세망으로 표적화 되어 있다. 당해 낟알은 또한 실시예 28에 기술된 바와 같은 생전분 결합 도메인을 갖는 옥수수 아밀라제를 발현한다. Transformed corn kernels are harvested from the transformed plants prepared as described in Example 28. The corn kernels are entrusted with Aspergillus niger (Fiil, NP "Glucoamylases Gland G2 from Aspergillus niger are synthesized from two different but closely related mRNAs" EMBO J. 3 (5), 1097-1102 (1984)). No. P04064) (SEQ ID NO: 59, corn-optimized nucleic acid) expresses a protein comprising an active fragment of glucoamylase and is targeted to cytoplasmic reticulum. The kernel also expresses corn amylase having a live starch binding domain as described in Example 28.
당해 옥수수 낟알을 실시예 14에 기술된 바와 같이 분말로 연마한다. 이어서, 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)을 함유하는 매쉬를 제조한다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 매쉬에 첨가한다: 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은 100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90℃의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86℃로 낮추고, 48시간에 82℃로 설정한다. The corn kernels are ground to a powder as described in Example 14. A mash containing 20 g of corn powder, 23 ml of deionized water and 6.0 ml of bag set (8 wt% solids) is prepared. The pH is titrated to 6.0 by the addition of ammonium hydroxide. Add the following ingredients to the mesh: 0.2 mg of protease (0.60 ml of 1,000-fold dilution of commercial protease), lactoside & urea (0.85 ml of 10-fold dilution of 50% urea solution). 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to escape. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set at 90 ° C. After 24 hours of fermentation, the temperature is lowered to 86 ° C. and set to 82 ° C. at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 39Example 39
터모안애어로박터 터모사카롤리티쿰 글루코아밀라제 및 보리 아밀라제를 발현하는 옥수수 중 생전분의 발효의 예Example of Fermentation of Raw Starch in Maize Expressing Thermobacterium Termosacaroticum Glucoamylase and Barley Amylase
형질전환 옥수수 낟알을 실시예 28에 기술된 바와 같이 제조한 형질전환된 식물로부터 수거한다. 당해 옥수수 낟알은 세포질세망으로 표적화된 터모안애어로박터 터모사카롤리티쿰(서열번호 47)의 글루코아밀라제의 활성 단편을 포함하는 단백질을 발현한다. 당해 낟알은 또한 당해 단백질의 발현을 세포질세망으로 표적화하도록 변형시킨 저 pI 보리 아밀라제 amy1 유전자(문헌[참조: Rogers, J.C. and Milliman,C. "Isolation and sequence analysis of a barley alpha-amylase cDNA clone" J. Biol. Chem. 258 (13), 8169-8174 (1983)])를 발현한다. Transformed corn kernels are harvested from the transformed plants prepared as described in Example 28. The corn kernel expresses a protein comprising an active fragment of glucoamylase of thermobacterium termosacarolitum (SEQ ID NO: 47) targeted to cytoplasmic reticulum. The kernel also contains a low pI barley amylase amy1 gene (Rogers, JC and Milliman, C. "Isolation and sequence analysis of a barley alpha-amylase cDNA clone" J that has been modified to target the expression of the protein to cytoplasmic reticulum. Biol. Chem. 258 (13), 8169-8174 (1983)].
당해 옥수수 낟알을 실시예 14에 기술된 바와 같이 분말로 연마한다. 이어서, 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)을 함유하는 매쉬를 제조한다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 매쉬에 첨가한다: 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은 100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90℃의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86℃로 낮추고, 48시간에 82℃로 설정한다. The corn kernels are ground to a powder as described in Example 14. A mash containing 20 g of corn powder, 23 ml of deionized water and 6.0 ml of bag set (8 wt% solids) is prepared. The pH is titrated to 6.0 by the addition of ammonium hydroxide. Add the following ingredients to the mesh: 0.2 mg of protease (0.60 ml of 1,000-fold dilution of commercial protease), lactoside & urea (0.85 ml of 10-fold dilution of 50% urea solution). 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to escape. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set at 90 ° C. After 24 hours of fermentation, the temperature is lowered to 86 ° C. and set to 82 ° C. at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 40Example 40
터모안애어로박터 터모사카롤리티쿰 글루코아밀라제 및 보리 아밀라제를 발현하는 옥수수의 전체 낟알 중 생전분의 발효의 예Example of Fermentation of Raw Starch in Whole Kernels of Corn Expressing Thermobacterus Termosacaroticum Glucoamylase and Barley Amylase
형질전환 옥수수 낟알을 실시예 28에 기술된 바와 같이 제조한 형질전환된 식물로부터 수거한다. 당해 옥수수 낟알은 세포질세망으로 표적화된 터모안애어로박터 터모사카롤리티쿰(서열번호 47)의 글루코아밀라제의 활성 단편을 포함하는 단백질을 발현한다. 당해 낟알은 또한 당해 단백질의 발현을 세포질세망으로 표적화하도록 변형시킨 저 pI 보리 아밀라제 amy1 유전자(문헌[참조: Rogers, J.C. and Milliman,C. "Isolation and sequence analysis of a barley alpha-amylase cDNA clone" J. Biol. Chem. 258 (13), 8169-8174 (1983)])를 발현한다. Transformed corn kernels are harvested from the transformed plants prepared as described in Example 28. The corn kernel expresses a protein comprising an active fragment of glucoamylase of thermobacterium termosacarolitum (SEQ ID NO: 47) targeted to cytoplasmic reticulum. The kernel also contains a low pI barley amylase amy1 gene (Rogers, JC and Milliman, C. "Isolation and sequence analysis of a barley alpha-amylase cDNA clone" J that has been modified to target the expression of the protein to cytoplasmic reticulum. Biol. Chem. 258 (13), 8169-8174 (1983)].
당해 옥수수 낟알을 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)과 접촉시킨다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 당해 혼합물에 첨가한다: 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은 100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90℃의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86℃로 낮추고, 48시간에 82℃로 설정한다. The corn kernels are contacted with 20 g of corn powder, 23 ml of deionized water, and 6.0 ml of bag set (8 wt% solids). The pH is titrated to 6.0 by the addition of ammonium hydroxide. The following ingredients are added to this mixture: Protease (0.60 ml of 1,000-fold dilution of commercial protease), 0.2 mg of lactoside & urea (0.85 ml of 10-fold dilution of 50% urea solution). 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to escape. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set at 90 ° C. After 24 hours of fermentation, the temperature is lowered to 86 ° C. and set to 82 ° C. at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 41Example 41
알파-아밀라제 및 글루코아밀라제 융합물을 발현하는 옥수수 중 생전분의 발효의 예Example of Fermentation of Raw Starch in Corn Expressing Alpha-amylase and Glucoamylase Fusions
형질전환 옥수수 낟알을 실시예 28에 기술된 바와 같이 제조한 형질전환된 식물로부터 수거한다. 당해 옥수수 낟알은 세포질세망으로 표적화된, 서열번호 45로 제공된 바와 같은 알파-아밀라제 및 글루코아밀라제 융합물을 암호화하는, 서열번호 46으로 제공된 바와 같은 옥수수-최적화된 폴리뉴클레오타이드를 발현한다.Transformed corn kernels are harvested from the transformed plants prepared as described in Example 28. The corn kernel expresses a corn-optimized polynucleotide as provided in SEQ ID NO: 46, encoding an alpha-amylase and glucoamylase fusion as provided in SEQ ID NO: 45, targeted to cytoplasmic reticulum.
당해 옥수수 낟알을 실시예 14에 기술된 바와 같이 분말로 연마한다. 이어서 옥수수 분말 20g, 탈이온수 23ml, 백세트 6.0ml(고체 8중량%)을 함유하는 매쉬를 제조한다. 수산화암모늄을 첨가하여 pH를 6.0으로 적정한다. 다음의 성분을 당해 혼합물에 첨가한다: 프로테아제(시판되는 프로테아제의 1,000배 희석액 0.60ml), 락토시드 & 요소(50% 요소액의 10배 희석액 0.85ml) 0.2mg. 당해 매쉬를 담은100ml 들이 병의 마개에 구멍을 내어 CO2가 발산되게 한다. 이어서 당해 매쉬를 효모(1.44ml)와 함께 항온처리하고 90℃의 수욕 세트에서 항온처리하였다. 발효 24시간 후, 온도를 86℃로 낮추고, 48시간에 82℃로 설정한다. The corn kernels are ground to a powder as described in Example 14. A mash containing 20 g of corn powder, 23 ml of deionized water and 6.0 ml (8 weight percent solids) of a bag set was prepared. The pH is titrated to 6.0 by the addition of ammonium hydroxide. The following ingredients are added to this mixture: Protease (0.60 ml of 1,000-fold dilution of commercial protease), 0.2 mg of lactoside & urea (0.85 ml of 10-fold dilution of 50% urea solution). 100 ml containing the mesh are punctured in the bottle cap to allow CO 2 to be released. The mash was then incubated with yeast (1.44 ml) and incubated in a water bath set at 90 ° C. After 24 hours of fermentation, the temperature is lowered to 86 ° C. and set to 82 ° C. at 48 hours.
접종용 효모를 실시예 14에 기술된 바와 같이 증식시킨다.Yeast for inoculation is grown as described in Example 14.
샘플을 실시예 14에 기술된 바와 같이 옮긴 후 실시예 14에 기술된 방법으로 분석한다. The sample is transferred as described in Example 14 and then analyzed by the method described in Example 14.
실시예 42Example 42
형질전환 벡터의 작제Construction of Transformation Vectors
옥수수에서 초호열성 베타-글루카나제 EglA를 발현시키기 위해 다음과 같이 발현 카세트를 작제하였다.An expression cassette was constructed as follows to express super thermophilic beta-glucanase EglA in maize.
pNOV4800은 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위해 EglA 베타-글루카나제에 대한 합성 유전자에 융합시킨 보리 Amy32b 시그날 펩타이드(MGKNGNLCCFSLLLLLLAGLASGHQ)를 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위한 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. pNOV4800 includes barley Amy32b signal peptide (MGKNGNLCCFSLLLLLLAGLASGHQ) fused to a synthetic gene for EglA beta-glucanase for targeting to cytoplasmic reticulum and secretion of apoplasts. This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4803은 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위해 EglA 베타-글루카나제에 대한 합성 유전자에 융합시킨 보리 Amy32b 시그날 펩타이드를 포함한다. 당해 융합물을 식물 전체에 걸친 발현을 위한 옥수수 유비퀴틴 프로모터 뒤로 클로닝하였다.pNOV4803 contains a barley Amy32b signal peptide fused to a synthetic gene for EglA beta-glucanase for targeting to cytoplasmic reticulum and secretion of apoplasts. This fusion was cloned behind the corn ubiquitin promoter for plant-wide expression.
옥수수에서 초호열성 베타-글루카나제/만나나제 6GP1(서열번호 85)를 발현시키기 위해 다음과 같이 발현 카세트를 작제하였다:Expression cassettes were constructed to express superthermophilic beta-glucanase / mannase 6GP1 (SEQ ID NO: 85) in maize as follows:
pNOV4819는 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위해 6GP1 베타-글루카나제/만나나제에 대한 합성 유전자에 융합시킨 담배 PR1a 시그날 펩타이드(MGFVLFSQLPSFLLVSTLLLFLVISHSCRA)를 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위한 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. pNOV4819 includes a tobacco PR1a signal peptide (MGFVLFSQLPSFLLVSTLLLFLVISHSCRA) fused to a synthetic gene for 6GP1 beta-glucanase / mannase for targeting to cytoplasmic reticulum and secretion of apoplasts. This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4820은 세포질 국소화 및 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프롤모터 뒤로 클로닝한 6GP1에 대한 합성 유전자를 포함한다. pNOV4820 contains a synthetic gene for 6GP1 cloned behind maize γ-zein prolomotor for cytoplasmic localization and specific expression in endocrine.
pNOV4823은 세포질세망으로의 표적화 및 그 내에서의 체류를 위한 서열 KDEL의 C-말단 첨가와 함께, 6GP1 베타-글루카나제/만나나제에 대한 합성 유전자에 융합시킨 담배 PR1a 시그날 펩타이드를 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위한 옥수수 γ-제인 프로모터 뒤로 클로닝하였다.pNOV4823 comprises a tobacco PR1a signal peptide fused to a synthetic gene for 6GP1 beta-glucanase / mannase, with C-terminal addition of the sequence KDEL for targeting to and retention within cytoplasmic reticulum. This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4825은 세포질세망으로의 표적화 및 그 내에서의 체류를 위한 서열 KDEL의 C-말단 첨가와 함께, 6GP1 베타-글루카나제/만나나제에 대한 합성 유전자에 융합시킨 담배 PR1a 시그날 펩타이드를 포함한다. 당해 융합물을 식물 전체에 걸친 발현을 위한 옥수수 유비퀴틴 프로모터 뒤로 클로닝하였다.pNOV4825 comprises a tobacco PR1a signal peptide fused to a synthetic gene for 6GP1 beta-glucanase / mannase, with C-terminal addition of the sequence KDEL for targeting to and retention within cytoplasmic reticulum. This fusion was cloned behind the corn ubiquitin promoter for plant-wide expression.
옥수수에서 보리 AmyI 알파-아밀라제(서열번호 87)를 발현시키기 위해 다음과 같은 발현 카세트를 작제하였다:The following expression cassettes were constructed to express barley AmyI alpha-amylase (SEQ ID NO: 87) in maize:
pNOV4867은 세포질세망으로의 표적화 및 그 내에서의 체류를 위한 서열 SEKDEL의 C-말단 첨가와 함께, 보리 AmyI 알파-아밀라제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 식물 전체에 걸친 발현을 위한 옥수수 γ-제인 프로모터 뒤로 클로닝하였다.pNOV4867 comprises the N-terminal signal sequence, a corn γ-agent fused to barley AmyI alpha-amylase, with C-terminal addition of the sequence SEKDEL for targeting to and retention within cytoplasmic reticulum. This fusion was cloned behind the corn γ-zein promoter for expression throughout the plant.
pNOV4879는 세포질세망으로의 표적화 및 그 내에서의 체류를 위한 서열 SEKDEL의 C-말단 첨가를 갖는 보리 AmyI 알파-아밀라제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 배아에서의 발현을 위한 옥수수 글로불린 프로모터 뒤로 클로닝하였다.pNOV4879 comprises an N-terminal signal sequence, a corn γ-agent fused to barley AmyI alpha-amylase with a C-terminal addition of the sequence SEKDEL for targeting to and retention within cytoplasmic reticulum. This fusion was cloned behind the corn globulin promoter for expression in embryos.
pNOV4897은 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위해 보리 AmyI 알파-아밀라제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 배아에서의 발현을 위한 옥수수 글로불린 프로모터 뒤로 클로닝하였다.pNOV4897 comprises an N-terminal signal sequence, a corn γ-agent fused to barley AmyI alpha-amylase for targeting to cytoplasmic reticulum and secretion of apoplasts. This fusion was cloned behind the corn globulin promoter for expression in embryos.
pNOV4895는 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위해 보리 AmyI 알파-아밀라제에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위한 옥수수 γ-제인 프로모터 뒤로 클로닝하였다.pNOV4895 contains an N-terminal signal sequence, a corn γ-agent fused to barley AmyI alpha-amylase for targeting to cytoplasmic reticulum and secretion of apoplasts. This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4901은 세포질 국소화 및 배아 내에서의 특이적 발현을 위해 옥수수 글로불린 프로모터 뒤로 클로닝한 보리 AmyI 알파-아밀라제에 대한 유전자를 포함한다.pNOV4901 contains genes for barley AmyI alpha-amylase cloned behind the corn globulin promoter for cytoplasmic localization and specific expression in embryos.
옥수수에서 보리 리조푸스 글루코아밀라제(서열번호 50)를 발현시키기 위해 다음과 같이 발현 카세트를 작제하였다:An expression cassette was constructed to express barley rispus glucoamylase (SEQ ID NO: 50) in maize as follows:
pNOV4872는 세포질세망으로의 표적화 및 그 내에서의 체류를 위한 서열 SEKDEL의 C-말단 첨가와 함께, 리조푸스 글루코아밀라제에 대한 합성 유전자에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위한 옥수수 γ-제인 프로모터 뒤로 클로닝하였다.pNOV4872 comprises an N-terminal signal sequence, a corn γ-agent fused to a synthetic gene for rispus glucoamylase, with C-terminal addition of the sequence SEKDEL for targeting to and retention within cytoplasmic reticulum. This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4880은 세포질세망으로의 표적화 및 그 내에서의 체류를 위한 서열 SEKDEL의 C-말단 첨가와 함께, 리조푸스 글루코아밀라제에 대한 합성 유전자에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 배아에서의 발현을 위한 옥수수 글로불린 프로모터 뒤로 클로닝하였다.pNOV4880 comprises a N-terminal signal sequence, a corn γ-agent fused to a synthetic gene for rispus glucoamylase, with C-terminal addition of the sequence SEKDEL for targeting to and retention in cytoplasmic reticulum. This fusion was cloned behind the corn globulin promoter for expression in embryos.
pNOV4889는 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위해 리조푸스 글루코아밀라제에 대한 합성 유전자에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 배아에서의 발현을 위한 옥수수 글로불린 프로모터 뒤로 클로닝하였다.pNOV4889 contains an N-terminal signal sequence, a corn γ-agent, fused to a synthetic gene for lysopus glucoamylase for targeting to cytoplasmic reticulum and secretion of apoplasts. This fusion was cloned behind the corn globulin promoter for expression in embryos.
pNOV4890은 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위해 리조푸스 글루코아밀라제에 대한 합성 유전자에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위한 옥수수 γ-제인 프로모터 뒤로 클로닝하였다.pNOV4890 contains an N-terminal signal sequence, a corn γ-agent, fused to a synthetic gene for lysopus glucoamylase for targeting to cytoplasmic reticulum and secretion of apoplasts. This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
pNOV4891은 세포질 국소화 및 배아 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝한 리조푸스 글루코아밀라제에 대한 합성 유전자를 포함한다.pNOV4891 contains a synthetic gene for lysopus glucoamylase cloned behind the corn γ-zein promoter for cytoplasmic localization and specific expression in the embryo.
실시예 43Example 43
옥수수 내에서의 중온성 리조푸스 글루코아밀라제의 발현Expression of Mesophilic Lycopus Glucoamylase in Corn
옥수수 내에서의 리조푸스 글루코아밀라제의 발현을 위한 각종 작제물을 작제하였다. 각각 옥수수 γ-제인 및 글로불린 프로모터를 사용하여 내배유 또는 배아 내에서 특이적으로 글루코아밀라제를 발현시켰다. 추가로, 옥수수 γ-제인 시그날 서열 및 합성 ER 체류 시그날을 사용하여 글루코아밀라제 단백질의 아세포성 국소화를 조절하였다. 5개의 작제물 모두(pNOV4872, pNOV4880, pNOV4889, pNOV4890 및 pNOV4891) 종자에서 검출된 글루코아밀라제 활성을 갖는 형질전환된 식물을 산출하였다. 표 7 및 8은 각각 개별 형질전환 종자(작제물 pNOV4872) 및 집합 종자(작제물 pNOV4889)의 결과를 나타낸다. 당해 리조푸스 글루코아밀라제를 발현하는 임의의 형질전환된 식물에 대한 어떠한 불리한 표현형도 관찰되지 않았다. Various constructs for the expression of Rifupus glucoamylase in corn were constructed. Corn γ-Zane and globulin promoters were used to express glucoamylase specifically in endocrine or embryos, respectively. In addition, corn γ-zein signal sequences and synthetic ER retention signals were used to regulate the subcellular localization of the glucoamylase protein. Transformed plants with glucoamylase activity detected in all five constructs (pNOV4872, pNOV4880, pNOV4889, pNOV4890 and pNOV4891) seeds were produced. Tables 7 and 8 show the results of the individual transformed seeds (build pNOV4872) and the aggregated seeds (build pNOV4889), respectively. No adverse phenotype was observed for any transformed plant expressing Rizopus glucoamylase.
글루코아밀라제 검정: 종자를 분말로 연마하고 당해 분말을 물에 현탁시켰다. 샘플을 30℃에서 50분 동안 항온처리하여 글루코아밀라제가 전분과 반응하도록 하였다. 불용성 물질은 펠렛화시켰고, 상층액에 대한 글루코즈 농도를 측정하였다. 각각의 샘플에서 유리된 양을 존재하는 글루코아밀라제의 수준의 지표로 삼았다. 당해 샘플을 GOHOD 시약{300mM 트리스/Cl pH 7.5, 글루코즈 산화효소(20U/ml), 홍당무 과산화효소(20U/ml), o-다이아니시딘 (0.1mg/ml)}과 함께 37℃에서 30분 동안 항온처리하고, 12N H2SO4 0.5용적을 첨가하고, OD540을 측정하여 글루코즈 농도를 측정하였다. Glucoamylase Assay: Seeds were ground to a powder and the powder suspended in water. Samples were incubated at 30 ° C. for 50 minutes to allow glucoamylase to react with starch. Insoluble material was pelleted and the glucose concentration for the supernatant was measured. The amount liberated in each sample was used as an indicator of the level of glucoamylase present. The sample was mixed with GOHOD reagent (300 mM Tris / Cl pH 7.5, glucose oxidase (20 U / ml), Blush Peroxidase (20 U / ml), o-Dianisidine (0.1 mg / ml)} for 30 minutes at 37 ° C. Were incubated, 0.5 volume of
표 7은 개별 형질전환 옥수수 종자(작제물 pNOV4872) 내에서의 리조푸스 글루코아밀라제의 활성을 나타낸다.Table 7 shows the activity of Rifupus glucoamylase in individual transgenic maize seeds (build pNOV4872).

표 8은 집합된 형질전환 옥수수 종자(작제물 pNOV4889) 내에서의 리조푸스 글루코아밀라제의 활성을 나타낸다. Table 8 shows the activity of lyfupus glucoamylase in aggregated transgenic corn seeds (build pNOV4889).
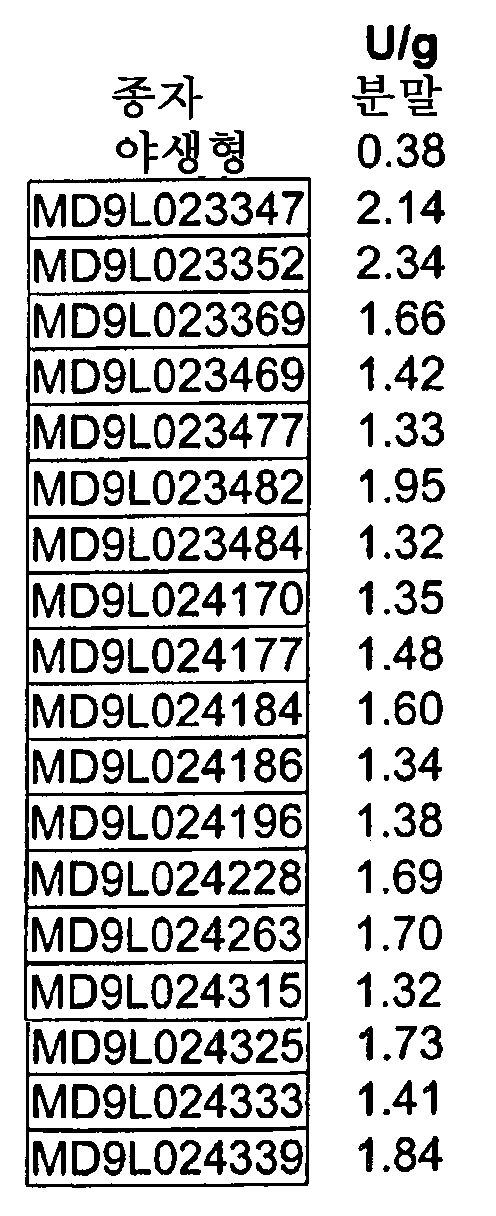
애그로박테리움 감염을 통한 옥수수 내로의 형질전환을 위해 모든 발현 카세트를 이원 벡터 pNOV2117로 삽입하였다. 이원 벡터는 만노즈를 갖는 형질전환 세포의 선별을 가능하게 하는 포스포만노즈 이소머라제(PMI) 유전자를 포함하였다. 형질전환 옥수수 식물을 자가-수분 또는 이계교배하였고, 분석을 위해 종자를 수거하였다. All expression cassettes were inserted into the binary vector pNOV2117 for transformation into maize via Agrobacterium infection. The binary vector contained a phosphomannose isomerase (PMI) gene that allows the selection of transformed cells with mannose. Transformed corn plants were self-pollinated or crossbred and seeds were harvested for analysis.
실시예 44Example 44
옥수수 내에서의 초호열성 베타-글루카나제 EglA의 발현Expression of Superthermophilic Beta-glucanase EglA in Corn
옥수수 내에서의 초호열성 베타-글루카나제 EglA의 발현을 위해 본 발명자는 식물 전체에 결친 발현용 유비퀴틴 프로모터 및 옥수수 종자의 내배유 내에서의 특이적 발현용 γ-제인 프로모터를 사용하였다. 보리 Amy32b 시그날 펩타이드를 아포플라스트 내에서의 국소화를 위해 EglA에 융합시켰다. 형질전환 옥수수 종자 및 잎 내에서의 초호열성 베타-글루카나제 EglA의 발현을 효소 검정 및 웨스턴 블롯팅을 사용하여 분석하였다. For expression of superthermophilic beta-glucanase EglA in corn, the present inventors used the ubiquitin promoter for expression throughout the plant and the γ-zein promoter for specific expression in the endocrine of corn seeds. Barley Amy32b signal peptide was fused to EglA for localization in apoplasts. Expression of superthermophilic beta-glucanase EglA in transformed corn seeds and leaves was analyzed using enzyme assay and western blotting.
작제물 pNOV4800 또는 pNOV4803에 대한 형질전환 종자 분리는 베타-글루카나제에 대한 웨스턴 블롯팅 및 효소 검정 둘 다를 사용하여 분석하였다. 개별 종자를 물에 48시간 동안 침지시킨 후 그로부터 내배유를 분리하였다. 내배유를 50mM NaPO4 완충액(pH 6.0) 중에서 연마하여 단백질을 추출하였다. 당해 추출물을 100℃에서 15분 동안 가열하여 내열성 단백질을 분리한 후, 불용성 물질을 펠렛화하였다. 내열성 단백질을 함유하는 상층액을 아조-보리 글루칸 방법(megazyme)을 사용하여 베타 글루카나제 활성에 대하여 분석하였다. 샘플을 100℃에서 10분 동안 예비 항온처리하고 아조-보리 글루칸 기질을 사용하여 100℃에서 10분 동안 검정하였다. 항온처리 후, 침전 용액 3 용적을 각각의 샘플에 첨가하고, 샘플을 1분 동안 원심분리하고, 각각의 상층액의 OD590을 측정하였다. 추가로, 단백질 5㎍을 SDS-PAGE로 분리하고 EglA 단백질에 대한 항체를 사용하는 웨스턴 블롯용 니트로셀룰로스에 블롯팅하였다. 웨스턴 블롯 검정은 EglA 양성 내배유 추출물 내에서 특이적인 내열성 단백질(들)을 검출하였고, 음성 추출물에서는 검출하지 못했다. EglA 활성의 수준과 관련된 웨스턴 블롯 시그날을 효소로 검출하였다.Transformed seed isolation for construct pNOV4800 or pNOV4803 was analyzed using both Western blotting and enzyme assay for beta-glucanase. Individual seeds were soaked in water for 48 hours and then endosperm was separated therefrom. Proteins were extracted by grinding the endosperm in 50
EglA 활성을 각각 형질전환 작제물 pNOV4803 및 pNOV4800을 포함하는 식물의 잎 및 종자에서 분석하였다. 검정(상기한 바와 같이 수행한)은 내열성 베타-글루카나제 EglA가 형질전환된 식물의 잎(표 9) 및 종자(표 10)에서 다양한 수준으로 발현된 반면, 비형질전환 대조군 식물에서는 어떠한 활성도 검출되지 않았음을 나타내었다. 작제물 pNOV4800 및 pNOV4803을 사용하는 옥수수 내에서의 EglA의 발현은 어떠한 검출가능한 음성 표현형도 야기하지 않았다. EglA activity was analyzed in the leaves and seeds of plants comprising the transforming constructs pNOV4803 and pNOV4800, respectively. Assays (performed as described above) were expressed at varying levels in the leaves (Table 9) and seeds (Table 10) of heat-resistant beta-glucanase EglA transformed plants, whereas no activity was observed in nontransgenic control plants. It was not detected. Expression of EglA in maize using the constructs pNOV4800 and pNOV4803 did not result in any detectable negative phenotype.
표 9는 형질전환 옥수수 식물의 잎 내의 초호열성 베타-글루카나제 EglA의 활성을 나타낸다. 초호열성 베타-글루카나제 활성을 검출하기 위하여 pNOV4803 형질전환된 식물의 잎으로부터의 추출물에 대한 효소 검정을 수행하였다. 검정은 아조-보리 글루칸 방법(megazyme)을 사용하여 100℃에서 수행하였다. 당해 결과는 형질전환 잎이 다양한 수준의 초호열성 베타-글루카나제 활성을 가짐을 나타낸다.Table 9 shows the activity of superthermophilic beta-glucanase EglA in the leaves of transgenic corn plants. Enzyme assays were performed on extracts from the leaves of pNOV4803 transformed plants to detect superthermophilic beta-glucanase activity. The assay was performed at 100 ° C. using the azo-barley glucan method (megazyme). The results indicate that the transgenic leaves have varying levels of superthermophilic beta-glucanase activity.

표 10은 형질전환 옥수수 식물의 종자 내에서의 초호열성 베타-글루카나제 EglA의 활성을 나타낸다. 초호열성 베타-글루카나제 활성을 검출하기 위해 pNOV4800 형질전환된 식물의 개별적인, 분리된 종자로부터의 추출물에 대한 효소 검정을 수행하였다. 검정은 아조-보리 글루칸 방법(megazyme)을 사용하여 100℃에서 수행하였다. 당해 결과는 형질전환 종자가 다양한 수준의 초호열성 베타-글루카나제 활성을 가짐을 나타낸다. Table 10 shows the activity of super thermophilic beta-glucanase EglA in the seeds of transgenic maize plants. Enzyme assays were performed on extracts from individual, isolated seeds of pNOV4800 transformed plants to detect superthermophilic beta-glucanase activity. The assay was performed at 100 ° C. using the azo-barley glucan method (megazyme). The results indicate that the transgenic seeds have varying levels of super thermophilic beta-glucanase activity.

세포벽 조성에 대한 엔도글루카나제 EglA의 형질전환 발현 효과 & 시험관 내 분해가능성 분석Effects of Endoglucanase EglA on the Expression of Cell Transformation and In Vitro Degradability Analysis
각각 Egla(pNOV4803)을 발현하지 않거나 발현하는 2개의 주, #263 & #266 각각으로부터의 5개의 개별 종자를 온실에서 재배하였다. 미성숙 식물로부터의 작은 잎 샘플로부터 제조된 단백질 추출물을 사용하여 형질전환 엔도글루카나제 활성이 #266 식물에는 존재하지만 #263 식물에는 존재하지 않음을 입증하였다. 총 식물 성숙기에, 수분 후 약 30일에, 상기한 연마한 식물 전체를 수확하고, 조악하게 자르고 72시간 동안 오븐 건조시켰다. 각각의 샘플을 2개의 이중 샘플(각각 A & B로 라벨링한)로 나누고, 물질을 시험관 내 분해가능성 분석 전에 40℃ 또는 90℃에서 예비 항온처리로 처리한 것을 제외하고, 통상적인 과정(문헌[참조: H. K. Goering and P. J. Van Soest, Goering, H. Keith 1941 (Washington, D.C.): Agricultural Research Service, U. S. Dept. of Agriculture, 1970. iv, 20 p.: ill.-- Agriculture handbook; no. 379)]의 사료 섬유 분석 기구, 시약, 과정 및 일부 적용)을 사용하여 신장시킨 반추위액을 사용하는 시험관내 분해가능성 분석에 적용하였다. 시험관 내 분해가능성 분석은 다음과 같이 수행하였다. Five individual seeds from each of the two states, # 263 &# 266, each of which expressed or did not express Egla (pNOV4803), were grown in a greenhouse. Protein extracts prepared from small leaf samples from immature plants were used to demonstrate that the transforming endoglucanase activity is present in # 266 plants but not in # 263 plants. At the total plant maturation, about 30 days after the moisture, the entirety of the abraded plants were harvested, coarsely cut and oven dried for 72 hours. Each procedure was divided into two duplicate samples (labeled A & B, respectively) and the material was subjected to conventional procedures (except for pretreatment at 40 ° C. or 90 ° C. prior to in vitro degradability analysis). HK Goering and PJ Van Soest, Goering, H. Keith 1941 (Washington, DC): Agricultural Research Service, US Dept. of Agriculture, 1970.iv, 20 p .: ill .-- Agriculture handbook; no. 379) Feed fiber analysis instrument, reagents, procedures, and some applications). In vitro degradability analysis was performed as follows.
샘플을 wiley 제분기를 사용하여 약 1mm 너비로 자른 후, 분석을 위해 16개의 칭량한 분취액으로 하위-분류하였다. 물질을 완충액에 현탁하고 40℃ 또는 90℃에서 2시간 동안 항온처리한 후, 밤새 냉각시켰다. 미세영양분, 트립티카제 & 카세인 & 아황산나트륨을 첨가한 후, 신장시킨 반추위액을 첨가하고, 37℃에서 30분 동안 항온처리하였다. 중성 세제 섬유(NDF), 산성 세제 섬유(ADF) 및 산성 세제 리그닌(AD-L)의 분석을 표준 중력측정방법(문헌[참조: Van Soest & Wine, Use of Detergents in the Analysis of fibrous Feeds. IV. Determination of plant cell-wall constituents. P. J. Van Soest & R. H. Wine. (1967). Journal of The AOAC, 50: 50-55; 또한 Methods for dietry fiber, neutral detergent fiber and nonstarch polysaccharides in relation to animal nutrition(1991). P. J. Van Soest, J. B. Robertson & B. A. Lewis. J. Dairy Science, 74: 3583-3597])을 사용하여 수행하였다. Samples were cut to about 1 mm wide using a wiley mill and then sub-classified into 16 weighed aliquots for analysis. The material was suspended in buffer and incubated at 40 ° C. or 90 ° C. for 2 hours and then cooled overnight. Micronutrients, tryticase & casein & sodium sulfite were added, followed by elongated rumen solution and incubated at 37 ° C. for 30 minutes. The analysis of neutral detergent fibers (NDF), acid detergent fibers (ADF), and acid detergent lignin (AD-L) was performed by standard gravimetric methods (Van Soest & Wine, Use of Detergents in the Analysis of fibrous Feeds.IV). Determination of plant cell-wall constituents.PJ Van Soest & RH Wine. (1967) .Journal of The AOAC, 50: 50-55; see also Methods for dietry fiber, neutral detergent fiber and nonstarch polysaccharides in relation to animal nutrition (1991). PJ Van Soest, JB Robertson & BA Lewis. J. Dairy Science, 74: 3583-3597].
데이타는 EglA 발현 형질전환된 식물(#266)이 대조군 식물(#233) 보다 더 많은 NDF를 함유하며, 반면 ADF & 리그닌은 상대적으로 변하지 않음을 나타낸다. 형질전환된 식물의 NDF 분획은 비-형질전환된 식물보다 용이하게 분해되며, 이는 엔도뉴클라제 효소를 형질전환적으로 발현함에 의한 세포 벽 셀룰로스의 "자가-분해"와 일치하는, 셀룰로스(NDF-ADF-AD-L)의 분해가능성의 증가 때문이다. The data show that EglA expressing transformed plants (# 266) contain more NDF than control plants (# 233), while ADF & lignin are relatively unchanged. NDF fractions of transformed plants are more readily degraded than non-transformed plants, which is consistent with the “self-degradation” of cell wall cellulose by transformatively expressing endonuclease enzymes, cellulose (NDF). -ADF-AD-L) is due to the increased degradability.
실시예 45Example 45
옥수수 내에서의 호열성 베타-글루카나제/만나나제(6GP1)의 발현Expression of Thermophilic Beta-Glucanase / Mannana (6GP1) in Corn
pNOV4820 및 pNOV4823에 대한 형질전환 종자를 아조-보리 글루칸 방법(megazyme)을 사용하여 6GP1 베타 글루카나제 활성에 대하여 분석하였다. 50℃에서 수행한 효소 검정은 형질전환 종자는 초호열성 6GP1 베타-글루카나제 활성을 가진 반면, 비-형질전환 종자에서는 어떠한 활성도 검출되지 않았음을 나타낸다(양성 시그날은 당해 검정과 관련된 배경 소음을 나타낸다).Transformed seeds for pNOV4820 and pNOV4823 were analyzed for 6GP1 beta glucanase activity using the azo-barley glucan method (megazyme). Enzyme assays performed at 50 ° C. indicated that the transgenic seeds had super thermophilic 6GP1 beta-glucanase activity, whereas no activity was detected in the non-transgenic seeds (positive signals indicated background noise associated with the assay). Indicates).
표 11은 형질전환 옥수수 종자 내에서의 호열성 베타-글루카나제/만나나제 6GP1의 활성을 나타낸다. pNOV4820(결과 1-6) 및 pNOV4823(결과 7-9)에 대한 형질전환 종자를 아조-보리 글루칸 방법(megazyme)을 사용하여 6GP1 베타-글루카나제 활성에 대하여 분석하였다. 효소 검정을 50℃에서 수행하였으며, 당해 결과는 형질전환 종자는 초호열성 6GP1 베타-글루카나제 활성을 갖는 반면, 비-형질전환 종자에서는 어떠한 활성도 검출되지 않음을 나타낸다. Table 11 shows the activity of thermophilic beta-glucanase / mannase 6GP1 in transgenic corn seeds. Transformed seeds for pNOV4820 (Results 1-6) and pNOV4823 (Results 7-9) were analyzed for 6GP1 beta-glucanase activity using the azo-barley glucan method (megazyme). Enzyme assays were performed at 50 ° C. and the results indicate that the transgenic seeds had super thermophilic 6GP1 beta-glucanase activity, while no activity was detected in non-transgenic seeds.

실시예 46Example 46
옥수수 내에서의 중온성 보리 AmyI 아밀라제의 발현Expression of Mesophilic Barley AmyI Amylase in Corn
옥수수 내에서의 보리 AmyI 알파-아밀라제의 발현을 위한 각종 작제물을 생산하였다. 옥수수 γ-제인 및 글로불린 프로모터를 사용하여 아밀라제를 내배유 또는 배아 각각에서 특이적으로 발현시켰다. 추가로, 옥수수 γ-제인 시그날 서열 및 합성 ER 체류 시그날을 사용하여 아밀라제 단백질의 아세포성 국소화를 조절하였다. 5개의 작제물 모두(pNOV4867, pNOV4879, pNOV4897, pNOV4895 및 pNOV4901) 종자에서 검출된 알파-아밀라제 활성을 갖는 형질전환된 식물을 산출하였다. 표 12는 5개의 독립적인, 분리된 결과(작제물 pNOV4879 및 pNOV4897)에 대한 개별 종자에서의 활성을 나타낸다. 작제물 모두 보기 AmyI 아밀라제의 합성이 전분 형성, 축적 또는 분해에 영향을 줄 수 있음을 나타내는 주름진 종자 표현형을 갖는 임의의 형질전환 결과를 내었다. Various constructs were produced for the expression of barley AmyI alpha-amylase in corn. The corn γ-Zane and globulin promoters were used to specifically express amylase in each endocrine or embryo. In addition, corn γ-zein signal sequences and synthetic ER retention signals were used to regulate the subcellular localization of amylase protein. Transformed plants with alpha-amylase activity detected in all 5 constructs (pNOV4867, pNOV4879, pNOV4897, pNOV4895 and pNOV4901) seeds were produced. Table 12 shows the activity in individual seeds for five independent, isolated results (builds pNOV4879 and pNOV4897). View All Constructs Any transformation resulted with a wrinkled seed phenotype indicating that the synthesis of AmyI amylase could affect starch formation, accumulation or degradation.
표 12는 개별 옥수수 종자(작제물 pNOV4879 및 pNOV4897) 내에서의 보리 AmyI 알파-아밀라제의 활성을 나타낸다. 작제물 pNOV4879(종자 샘플 1 및 2) 및 pNOV4897(종자 샘플 3-5)에 대한 개별적인, 분리된 종자를 상기한 바와 같이 알파-아밀라제 활성에 대하여 분석하였다. Table 12 shows the activity of barley AmyI alpha-amylase in individual corn seeds (build pNOV4879 and pNOV4897). Separate, isolated seeds for constructs pNOV4879 (

실시예 47Example 47
자일라나제 작제물의 제조Preparation of Xylanase Constructs
표 13은 각각이 고유한 자일라나제 발현 카세트를 포함하는 9개의 이원 벡터를 나열한다. 자일라나제 발현 카세트는 프로모터, 합성 자일라나제 유전자(암호화 서열), 인트론(PEPC, 역전된) 및 종결자(35S)를 포함한다. Table 13 lists nine binary vectors, each containing a unique xylanase expression cassette. The xylanase expression cassette includes a promoter, synthetic xylanase gene (coding sequence), intron (PEPC, inverted) and terminator (35S).
2개의 합성 옥수수-최적화된 엔도-자일라나제 유전자를 이원 벡터 pNOV2117에 클로닝하였다. 이들 2개의 자일라나제 유전자를 BD7436(서열번호 61) 및 BD6002A(서열번호 63)로 명명하였다. 제3의 옥수수-최적화된 서열, BD6002B(서열번호 65)를 포함하는 추가의 이원 벡터를 제조할 수 있다. Two synthetic corn-optimized endo-xylanase genes were cloned into binary vector pNOV2117. These two xylanase genes were named BD7436 (SEQ ID NO: 61) and BD6002A (SEQ ID NO: 63). Additional binary vectors can be prepared comprising a third corn-optimized sequence, BD6002B (SEQ ID NO: 65).
2개의 프로모터를 사용하였다: 옥수수 글루텔린-2 프로모터(27-kD 감마-제인 프로모터(서열번호 12)) 및 벼 글루텔린-1(Osgt1) 프로모터(서열번호 67). 표 1에 나열한 처음의 6개의 벡터를 사용하여 형질전환된 식물을 제조하였다. 나중의 3개의 벡터를 또한 제조하고 사용하여 형질전환된 식물을 제조할 수 있다. Two promoters were used: the corn glutelin-2 promoter (27-kD gamma-jane promoter (SEQ ID NO: 12)) and the rice glutelin-1 (Osgt1) promoter (SEQ ID NO: 67). Transformed plants were prepared using the first six vectors listed in Table 1. The latter three vectors can also be prepared and used to produce transformed plants.
벡터 11560 및 11562는 서열번호 62(BD7436)로 나타낸 폴리펩타이드를 암호화한다. 작제물 11559 및 11561은 서열번호 62의 N-말단에 융합시킨 서열번호 17로 이루어진 폴리펩타이드를 암호화한다. 서열번호 17은 27kD 감마-제인 단백질로부터의 19개의 아미노산 시그날 서열이다. Vectors 11560 and 11562 encode the polypeptide represented by SEQ ID NO: 62 (BD7436). Constructs 11559 and 11561 encode polypeptides consisting of SEQ ID NO: 17 fused to the N-terminus of SEQ ID NO: 62. SEQ ID NO: 17 is the 19 amino acid signal sequence from a 27kD gamma-zein protein.
벡터 12175는 서열번호 64(BD6002A)로 나타낸 폴리펩타이드를 암호화한다. 작제물 12174는 서열번호 64의 N-말단에 융합시킨 감마-제인 시그날 서열(서열번호 17)로 이루어진 융합 단백질을 암호화한다. Vector 12175 encodes the polypeptide represented by SEQ ID NO: 64 (BD6002A). Construct 12174 encodes a fusion protein consisting of a gamma-zein signal sequence (SEQ ID NO: 17) fused to the N-terminus of SEQ ID NO: 64.
벡터 pWIN062 및 pWIN064는 서열번호 66(BD6002B)로 나타낸 폴리펩타이드를 암호화한다. 벡터 pWIN058은 서열번호 66의 N-말단에 융합시킨 옥수수 waxy 단백질의 엽록체 전이 펩타이드(서열번호 68)로 이루어진 융합 단백질을 암호화한다.Vectors pWIN062 and pWIN064 encode the polypeptide represented by SEQ ID NO: 66 (BD6002B). Vector pWIN058 encodes a fusion protein consisting of the chloroplast transfer peptide (SEQ ID NO: 68) of corn waxy protein fused to the N-terminus of SEQ ID NO: 66.
모든 작제물은 PMI에 대한 발현 카세트를 포함하여, 만노즈-함유 매지 상에서의 재생된 형질전환 조직의 양성 선별을 가능하게 한다.All constructs include an expression cassette for PMI, allowing positive selection of regenerated transformed tissue on mannose-containing medium.
실시예 48Example 48
자일라나제 활성 검정 결과Xylanase Activity Assay Results
표 14 및 15에 나타낸 데이타는 자일라나제 활성이 자일라나제 유전자 BD7436(실시예 47의 서열번호 61) 및 BD6002A(실시예 47의 서열번호 63)를 포함하는 이원 벡터로 안정하게 형질전환된 재생된(T0) 옥수수 식물로부터 수확한 T1 생산 종자에 축적됨을 입증한다. 아조-WAXY 검정(Megazyme)을 사용하자, 집합된(분리된) 형질전환 종자 및 단일 형질전환 종자 둘 다로부터의 추출물에서 활성이 검출되었다.The data shown in Tables 14 and 15 shows that regeneration of stably transformed xylanase activity with a binary vector comprising the xylanase gene BD7436 (SEQ ID NO: 61 of Example 47) and BD6002A (SEQ ID NO: 63 of Example 47) Demonstrates accumulation in T1 producing seeds harvested from corn (T0) corn plants. Using the Azo-WAXY assay (Megazyme), activity was detected in extracts from both aggregated (isolated) transformed seeds and single transformed seeds.
T1 종자를 분쇄하고 시트르산염-인산염 완충액(pH 5.4)을 사용하여 분말 샘플로부터 수용성 단백질을 추출하였다. 분말 현탁액을 실온에서 60분 동안 교반하였고, 불용성 물질은 원심분리하여 제거하였다. 상층액 분획의 자일라나제 활성을 아조-WAXY 검정(문헌[참조: McCleary, B.V. "Problems in the measurement of beta-xylanase, beta-glucanase and alpha-amylase in feed enzymes and animal feeds". In proceedings of Second European Symposium on Feed Enzymes" (W.van Hartingsveldt, M. Hessing, J. P. van der Jugt, and W. A.C Somers Eds.), Noordwiijkerhout, Netherlands, 25-27 October, 1995])을 사용하여 측정하였다. 추출물 및 기질을 37℃에서 예비-항온처리하였다. 1X 추출물 상층액의 1 용적에, 기질(1% 아조-밀 아라비녹실란 S-AWAXP) 1용적을 첨가한 후 37℃에서 5분 동안 항온처리하였다. 옥수수 분말 추출물 중에서의 자일라나제 활성은 엔도-메커니즘에 의해 아조-밀 아라비녹실란을 탈중합하며, 자일로-올리고머 형태의 저분자량 염색 단편을 생산한다. 5분 동안 항온처리한 후, 95% EtOH 5용적을 첨가하여 반응을 종결시켰다. 알콜의 첨가는 비-탈중합화 염색 기질을 침전시켜 오직 저분자량 자일로-올리고머만 용액에 잔류하도록 한다. 불용성 물질은 원심분리하여 제거하였다. 상층액 분획으 흡광도를 590nm에서 측정하였고, 분말 g당 자일라나제의 단위를 공지된 활성의 자일라나제 표준물을 사용하여 동일한 검정으로부터의 흡광도 수치에 비교하여 결정하였다. 당해 표준물의 활성은 BCA 검정으로 측정하였다. 표준물의 효소 활성은 기질로서 밀 아라비녹실란을 사용하고 2,2'-바이신크로닌산(BCA)과 환원 말단을 반응시켜 환원 말단의 방출을 측정함으로써 결정하였다. 당해 기질은 0.02% 아지드화나트륨을 함유하는 pH 5.30의 100mM 아세트산나트륨 완충액 중 밀 아라비녹실란(Megazyme P-WAXYM) 1.4% w/w 용액으로서 제조하였다. BCA 시약은 시약 A 50부와 시약 B 1부를 혼합하여 제조하였다(시약 A 및 B는 제조사[Pierce]의 제품, 각각 상품 번호 제23223호 및 제23224호이다). 이들 시약을 사용하기 전 최대 4시간 동안 혼합하였다. 기질 200마이크로리터를 효소 샘플 80마이크로리터와 혼합하여 당해 검정을 수행하였다. 목적하는 온도에서 목적하는 시간 동안 항온처리 한 후, BCA 시약 2.80 밀리리터를 첨가하였다. 내용물을 혼합하고 80℃에서 30분 내지 45분 동안 두었다. 내용물을 냉각시킨 후 큐벳으로 옮겨 560nm에서의 흡광도를 공지된 농도의 자일로스에 비교하여 측정하였다. 효소 희석, 항온처리 시간 및 항온처리 온도의 선택은 당해 분야의 숙련가에 따라 다양할 수 있다. T1 seeds were ground and water soluble proteins were extracted from the powder samples using citrate-phosphate buffer (pH 5.4). The powder suspension was stirred at room temperature for 60 minutes and insoluble material was removed by centrifugation. The xylanase activity of the supernatant fractions was determined using the Azo-WAXY assay (Mccleary, BV "Problems in the measurement of beta-xylanase, beta-glucanase and alpha-amylase in feed enzymes and animal feeds" .In proceedings of Second European Symposium on Feed Enzymes "(W. van Hartingsveldt, M. Hessing, JP van der Jugt, and WAC Somers Eds.), Noordwiijkerhout, Netherlands, 25-27 October, 1995]. Pre-incubated at 37 ° C. To 1 volume of 1 × extract supernatant, 1 volume of substrate (1% azo-mill arabinoxysilane S-AWAXP) was added and then incubated for 5 minutes at 37 ° C. Corn powder extract Xylanase activity in the depolymerized azo-mill arabinoxysilane by the endo-mechanism and produces low molecular weight stained fragments in the form of xylo-oligomers, after incubation for 5 minutes, yielding 95
표 14에 나타낸 실험 결과는 T1 세대 옥수수 종자로부터 제조된 분말 중 재조합 자일라나제 활성의 존재를 입증한다. 12개의 T0 식물(독립적 T-DNA 삽입 결과로부터 유래한)로부터의 종자를 분석하였다. 12개의 형질전환 결과물은 제시된 바와 같이(벡터의 기술에 대한 실시예 47에서 표 13을 참조) 6개의 상이한 벡터로부터 유래한 것이다. 비-형질전환(음성 대조군) 옥수수 분말의 추출물은 측정가능한 자일라나제 활성을 포함하지 않는다(표 15 참조). 이들 12개의 샘플 내에서의 자일라나제 활성은 10 내지 87 단위/분말 그람의 범위였다. The experimental results shown in Table 14 demonstrate the presence of recombinant xylanase activity in powders made from T1 generation corn seeds. Seeds from 12 T0 plants (derived from independent T-DNA insertion results) were analyzed. The twelve transformation results are from six different vectors as shown (see Table 13 in Example 47 for the description of the vector). Extracts of non-transformed (negative control) corn powder do not contain measurable xylanase activity (see Table 15). Xylanase activity in these 12 samples ranged from 10 to 87 units / powder gram.

표 15의 결과는 단일 낟알으로부터 유래한 옥수수 분말 중 자일라나제 활성의 존재를 입증한다. 벡터 11561 및 11559를 포함하는 2개의 T0 식물로부터의 T1 종자를 분석하였다. 이들 벡터는 실시예 47에 기술되어 있다. 2가지의 식물 각각으로부터의 8개의 종자를 분쇄하고 각각의 종자로부터 분말 샘플을 추출하였다. 당해 표는 각각의 추출물의 단일 검정의 결과를 나타낸다. 형질전환 결과물 둘 다에 대한 종자 1, 5 및 8의 추출물의 검정에서 어떠한 자일라나제 활성도 발견되지 않았다. 이들 종자는 무 분리물을 대표한다. 형질전환 결과물 둘 다에 대한 종자 2, 3, 4, 6 및 7은 재조합체 BD7436 유전자의 발현에 기여할 수 있는 측정가능한 자일라나제 활성을 축적하였다. 자일라나제 활성(>10 단위/분말 그람)에 대하여 양성으로 검사된 10개 종자 모두 명백하게 주름이 지거나 수축된 외형을 가졌다. 대조적으로 자일라나제 활성(≤1 단위/분말 그람)에 대하여 음성으로 검사된 6개의 종자는 정상적인 외형을 가졌다. 당해 결과는 재조합체 자일라나제가 종자 발달 및/또는 성숙 중 내인성(아라비노)실란 기질을 탈중합화하였음을 제시한다. The results in Table 15 demonstrate the presence of xylanase activity in corn powders derived from single grains. T1 seeds from two T0 plants comprising vectors 11561 and 11559 were analyzed. These vectors are described in Example 47. Eight seeds from each of the two plants were ground and a powder sample was extracted from each seed. This table shows the results of a single assay of each extract. No xylanase activity was found in the assay of extracts of

실시예 49Example 49
효소를 사용한 옥수수 종자로부터의 증강된 전분 회수Enhanced Starch Recovery from Corn Seeds Using Enzymes
옥수수 습식-제분은 옥수수 낟알 침지, 옥수수 낟알 연마 및 낟알 성분의 분리 단계를 포함한다. 작업대 상단 검정(균열된 옥수수 검정)을 개발하여 옥수수 습식 제분 과정을 모방하였다. Corn wet-milling includes the steps of dipping corn kernels, grinding corn kernels, and separating the kernel components. A work bench top assay (cracked corn assay) was developed to mimic the corn wet milling process.
"균열 옥수수 검정"은 옥수수 습식 제분 과정의 개선된 효율을 초래하는 옥수수 종자로부터의 전분 수율을 증강하는 효소를 동정하기 위해 사용하였다. 효소 전달은 외인성 첨가, 형질전환 옥수수 종자 또는 이들 둘 다의 조합에 의한 것이었다. 옥수수 성분의 분리를 촉진하기 위해 효소를 사용하는 것 외에, 당해 과정으로부터의 SO2의 제거가 또한 나타내어져 있다.A "cracked corn assay" was used to identify enzymes that enhance starch yield from corn seeds resulting in improved efficiency of the corn wet milling process. Enzyme delivery was by exogenous addition, transformed corn seeds or a combination of both. In addition to using enzymes to facilitate the separation of corn components, removal of SO 2 from this process is also shown.
균열 옥수수 검정Crack corn black
종자 1그램을 50℃ 또는 37℃에서 4000, 2000, 1000, 500, 400, 40 또는 0ppm SO2에서 밤새 침지시켰다. 종자를 반으로 절단하여 배를 제거하였다. 각각의 반쪽 종자를 다시 반으로 절단하였다. 각각의 침지된 종자 샘플로부터 침지수를 보존하여 400ppm 내지 0ppm SO2 범위의 최종 농도로 희석하였다. 효소가 있거나 없는 침지수 2밀리리터를 재발아된 종자에 첨가하고 샘플을 50℃ 또는 37℃에서 2 내지 3시간 동안 두었다. 각각의 효소를 샘플 당 10 단위로 첨가하였다. 모든 샘플을 대략 매 15분 마다 격렬히 교반하였다. 2 내지 3시간 후, 샘플을 미라천(mira cloth)을 통해 50ml 원심분리 튜브로 여과하였다. 종자를 물 2ml로 세척하고 샘플을 첫번째 상층액과 함께 수거하였다. 당해 샘플을 3000rpm에서 15분 동안 원심분리하였다. 원심분리 후, 상층액을 쏟아 붓고 펠렛을 37℃에 두어 건조시켰다. 모든 펠렛 중량을 기록하였다. 또한 처리 중 방출된 전분:단백질 비율을 측정하기 위해 샘플에 대한 전분 및 단백질 측정을 수행하였다(데이타는 나타내지 않았음).One gram of seed was soaked overnight at 4000, 2000, 1000, 500, 400, 40 or 0 ppm SO 2 at 50 ° C. or 37 ° C. Seeds were cut in half to remove embryos. Each half seed was cut in half again. Dipping water was preserved from each soaked seed sample and diluted to a final concentration ranging from 400 ppm to 0 ppm SO 2 . Two milliliters of immersion water, with or without enzyme, was added to the regerminated seeds and the sample was left at 50 ° C. or 37 ° C. for 2-3 hours. Each enzyme was added at 10 units per sample. All samples were vigorously stirred approximately every 15 minutes. After 2-3 hours, the samples were filtered through a mira cloth into a 50 ml centrifuge tube. Seeds were washed with 2 ml of water and samples were collected with the first supernatant. The sample was centrifuged at 3000 rpm for 15 minutes. After centrifugation, the supernatant was poured out and the pellet was dried at 37 ° C. All pellet weights were recorded. Starch and protein measurements were also performed on the samples to determine the starch: protein ratio released during treatment (data not shown).
균열 옥수수 검정에서 6GP1 엔도글루카나제를 발현하는 옥수수 식물로부터의 T1 및 T2 종자의 분석Analysis of T1 and T2 Seeds from Corn Plants Expressing 6GP1 Endoglucanase in Cracked Corn Assays
균열 옥수수 검정으로 분석하는 경우, 호열성 엔도글루카나제를 함유하는 형질전환 옥수수(pNOV4819 및 pNOV4823)는 잘 수행되었다. pNOV4819 주로부터의 전분의 회수는 2000ppm SO2에 침지시킨 경우 엔도글루카나제를 발현하는 종자에서 2배 이상 높은 것으로 밝혀졌다. 엔도글루카나제 종자로의 프로테아제 및 셀로바이오하이드롤라제의 첨가는 전분 회수를 대조군 종자의 대략 7배로 증가시켰다. 표 16을 참조한다. When analyzed by the cracked corn assay, transgenic corn (pNOV4819 and pNOV4823) containing thermophilic endoglucanase performed well. The recovery of starch from pNOV4819 strain was found to be more than two times higher in seed expressing endoglucanase when immersed in 2000 ppm SO 2 . Addition of protease and cellobiohydrolase to endoglucanase seeds increased starch recovery approximately 7-fold of control seeds. See Table 16.
내배유의 ER로 표적화된 엔도글루카나제를 함유하는 형질전환 종자(pNOV4823)에서 유사한 결과가 나타났으며, 대조군 종자와 비교시, 다시 전분 회수에 2 내지 7배의 증가를 초래하였다. 표 17을 참조한다. Similar results were seen in transformed seeds containing endoglucanase targeted with ER in endosperm (pNOV4823), which again resulted in a 2-7 fold increase in starch recovery when compared to control seeds. See Table 17.
이들 결과는 엔도글루카나제의 발현이 옥수수 종자의 전분 및 단백질 성분의 분리를 증강함을 확증한다. 추가로, 이는 침지 과정 중 SO2의 감소 또는 제거는 통상적으로 침지된 대조군 종자와 필적할만한 또는 이보다 나은 전분 회수를 야기함을 나타낼 수 있다. 표 18을 참조한다. 습식 제분 과정으로부터의 높은 수준의 SO2의 제거는 부가가치 이득을 제공할 수 있다. These results confirm that expression of endoglucanase enhances the separation of starch and protein components of corn seeds. In addition, this may indicate that the reduction or removal of SO2 during the soaking process typically results in starch recovery comparable to or better than that of the soaked control seeds. See Table 18. Removal of high levels of SO 2 from the wet milling process can provide a value added benefit.

실시예 50Example 50
옥수수 최적화된 브로멜라인에 대한 형질전환 벡터의 작제Construction of Transformation Vectors for Corn Optimized Bromelain
다음과 같이 다양한 표적화 시그날을 갖는 옥수수 내배유 내에서 옥수수 최적화된 브로멜라인을 발현시키기 위해 발현 카세트를 작제하였다:Expression cassettes were constructed to express maize optimized bromelain in maize endosperm with various targeting signals as follows:
pSYN11000(서열번호 73)은 브로멜라인 시그날 서열(MAWKVQVVFLFLFLCVMWASPSAASA)(서열번호 72) 및 PVS로의 표적화 및 PVS 내에서의 체류를 위한 서열 VFAEAIAANSTLVAE의 C-말단 첨가물과 함께 융합시킨 합성 브로멜라인 서열을 포함한다(문헌[참조: Vitale and Raikhel Trends in Plant Science Vol 4 no. 4pg 149-155]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 감마 제인 프로모터 뒤로 클로닝하였다. pSYN11000 (SEQ ID NO: 73) comprises a synthetic Bromelain sequence fused with a Bromelain signal sequence (MAWKVQVVFLFLFLCVMWASPSAASA) (SEQ ID NO: 72) and a C-terminal addition of the sequence VFAEAIAANSTLVAE for targeting to PVS and retention in PVS. (Vitale and Raikhel Trends in
pSYN11587(서열번호 75)은 브로멜라인 시그날 서열(MAWKVQVVFLFLFLCVMWASPSAASA) 및 세포질세망(ER)으로의 표적화 및 ER내에서의 체류를 위한 서열 SEKDEL의 C-말단 첨가물과 함께 합성 브로멜라인 서열을 포함한다(문헌[참조: Munro and Pelham, 1987]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 감마 제인 프로모터 뒤로 클로닝하였다.pSYN11587 (SEQ ID NO: 75) comprises a synthetic bromelain sequence along with a bromelain signal sequence (MAWKVQVVFLFLFLCVMWASPSAASA) and a C-terminal addition of the sequence SEKDEL for targeting to and retention in the cytoplasmic reticulum (ER) ( Munro and Pelham, 1987). This fusion was cloned behind the corn gamma agent promoter for specific expression in endocrine.
pSYN11589(서열번호 74)은 용해성 액포 표적화 서열 SSSSFADSNPIRVTDRAAST(문헌[참조: Neuhaus and Rogers Plant Molecular Biology 38:127-144, 1998])에 융합시킨 브로멜라인 시그날 서열(MAWKVQVVFLFLFLCVMWASPSAASA)(서열번호 72) 및 용해성 액포로 표적화하기 위한 합성 브로멜라인을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 감마 제인 프로모터 뒤로 클로닝하였다.pSYN11589 (SEQ ID NO: 74) is a bromelain signal sequence (MAWKVQVVFLFLFLCVMWASPSAASA) (SEQ ID NO: 72) fused to soluble vacuole targeting sequence SSSSFADSNPIRVTDRAAST (Neuhaus and Rogers Plant Molecular Biology 38: 127-144, 1998) Synthetic bromelain for targeting to vacuoles. This fusion was cloned behind the corn gamma agent promoter for specific expression in endocrine.
pSYN12169(서열번호 76)은 세포질세망으로의 표적화 및 아포플라스트로의 분비를 위한 합성 브로멜라인에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(서열번호 17)을 포함한다(문헌[참조: Torrent et al. 1997]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 감마 제인 프로모터 뒤로 클로닝하였다.pSYN12169 (SEQ ID NO: 76) includes a corn γ-zein N-terminal signal sequence (MRVLLVALALLALAASATS) (SEQ ID NO: 17) fused to synthetic bromelain for targeting to cytoplasmic networks and secretion of apoptoplasm (SEQ ID NO: 17). See Torrent et al. 1997]. This fusion was cloned behind the corn gamma agent promoter for specific expression in endocrine.
pSYN12575(서열번호 77)은 전분체로의 표적화을 위해 합성 브로멜라인으로 융합시킨 waxy 전분체 표적화 펩타이드(문헌[참조: Klosgen et al., 1986])을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 감마 제인 프로모터 뒤로 클로닝하였다. pSYN12575 (SEQ ID NO: 77) includes waxy starch targeting peptides (Klosgen et al., 1986) fused with synthetic bromelain for targeting to starch. This fusion was cloned behind the gamma agent promoter for specific expression in endocrine.
pSM270(서열번호 78)은 용해성 액포 표적화 서열 SSSSFADSNPIRVTDRAAST(문헌[참조: Neuhaus and Rogers Plant Molecular Biology 38:127-144, 1998])에 융합시킨 브로멜라인 N-말단 시그날 서열 및 용해성 액포로의 표적화을 위한 합성 브로멜라인을 포함한다. 당해 융합물을 호분 내에서의 특이적 발현을 위해 호분 특이적 프로모터 P19(미국 특허 제6392123호) 뒤로 클로닝하였다. pSM270 (SEQ ID NO: 78) is used for targeting to a bromline N-terminal signal sequence and soluble vacuole fused to a soluble vacu targeting sequence sequence SSSSFADSNPIRVTDRAAST (Neuhaus and Rogers Plant Molecular Biology 38: 127-144, 1998). Synthetic bromelain. The fusions were cloned behind whistle specific promoter P19 (US Pat. No. 6392123) for specific expression in whistle.
실시예 51Example 51
옥수수 내에서의 브로멜라인의 발현Expression of Bromelain in Corn
종자의 다양한 아세포성 위치에서 발현을 위한 표적화 서열을 갖는 합성 브로멜라인 유전자를 포함하는 벡터로 형질전환한 T1 형질전환 주로부터의 종자를 프로테아제 활성에 대하여 분석하였다. 종자를 Kleco 연마기로 30초 동안 연마하여 옥수수 분말을 제조하였다. 1mM EDTA 및 5mM DTT를 함유하는 pH 4.8의 50mM NaOAc 또는 pH 7.0의 50mM 트리스 완충액을 사용하여 분말 100mg으로부터 효소를 추출하였다. 샘플을 격렬히 교반한 후, 30분 동안 계속 교반하며 4℃에 두었다. 각각의 형질전환 주로부터의 추출물을 제품 책자에 개관된 레소루핀 라벨링된 카세인(Roche, 카탈로그 번호 제1 080 733호)을 사용하여 검정하였다. T2 종자로부터의 분말을 다음의 변형을 가한 문헌[참조: Methods in Enzymology Vol. 244: Pg 557-558]에 개관된 바와 같은 브로멜라인 특이적 검정을 사용하여 검정하였다. 옥수수 종자 분말 100mg을 pH 7.0의 50mM Na2HPO4/50mM NaH2P04 1ml, 1mM EDTA +/- 1μM 류펩틴을 사용하여 15분 동안 4℃에서 추출하였다. 추출물을 14,000rpm에서 5분 동안 4℃에서 원심분리하였다. 추출을 2회 수행하였다. T2 형질전환 주로부터의 분말을 기질로 Z-Arg-Arg-NHMec(Sigma)를 사용하여 브로멜라인 활성에 대하여 검정하였다. 100㎕/옥수수 종자 추출물의 4개의 분취액을 웰 당 pH 7.0의 100mM Na2HPO4/100mM NaH2P04 50㎕, 2mM EDTA, 8mM DTT을 함유하는 96개 웰 평저 플레이트(Corning)에 첨가하였다. 당해 반응은 20μM Z-Arg-Arg-NHMec 50㎕을 첨가하여 출발하였다. 40℃에서 2.5분 간격으로 360nm 여기 및 465nm 방출 필터로 조정한 SpectraFluorPlus(Tecan)를 사용하여 반응률을 관찰하였다. Seeds from the T1 transgenic strains transformed with the vector comprising the synthetic bromelain gene with the targeting sequence for expression at various subcellular locations of the seed were analyzed for protease activity. Seeds were ground for 30 seconds with a Kleco grinder to produce corn powder. The enzyme was extracted from 100 mg of powder using 50 mM NaOAc at pH 4.8 or 50 mM Tris buffer at pH 7.0 containing 1 mM EDTA and 5 mM DTT. The sample was vigorously stirred and then left at 4 ° C. with continued stirring for 30 minutes. Extracts from each transgenic strain were assayed using Lesoruppin labeled casein (Roche, Cat. No. 1 080 733) as outlined in the product booklet. Powders from T2 seeds were subjected to the following modifications. Methods in Enzymology Vol. 244: Pg 557-558], assayed using a bromelain specific assay as outlined in P. 557-558. Corn Seed Powder 100mg pH 7.0 50mM Na 2 HPO 4 / 50mM NaH 2 P0 4 Extracted at 4 ° C. for 15 minutes using 1 ml, 1 mM EDTA +/− 1 μM leupeptin. The extract was centrifuged at 4 ° C. for 5 minutes at 14,000 rpm. Extraction was performed twice. Powders from T2 transgenic strains were assayed for bromelain activity using Z-Arg-Arg-NHMec (Sigma) as substrate. 100㎕ / 4 two aliquots of 100mM Na 2 HPO, pH 7.0 per well of corn seed extract 4 / 100mM NaH 2 P0 4 It was added to a 96 well bottom plate (Corning) containing 50 μl, 2 mM EDTA, 8 mM DTT. The reaction was started by adding 50 μl of 20 μM Z-Arg-Arg-NHMec. The reaction rate was observed using SpectraFluorPlus (Tecan) adjusted with 360 nm excitation and 465 nm emission filters at 2.5 min intervals at 40 ° C.
표 19는 상이한 T1 브로멜라인 결과물로부터의 종자의 분석을 나타낸다. 브로멜라인 발현은 A188 및 JHAF 대조군 주보다 2 내지 7배 높은 것으로 밝혀졌다. T1 형질전환 주를 다시 심고 T2 종자를 수득하였다. T2 종자의 분석은 브로멜라인의 발현을 나타내었다. 도 21은 ER 표적설정된(11587) 및 용해성 액포 표적설정된(11589) 브로멜라인에 대한 T2 종자에서 Z-Arg-Arg-NHMec를 사용한 브로멜라인 활성 검정을 나타낸다. Table 19 shows the analysis of seeds from different T1 bromelain outputs. Bromelain expression was found to be 2-7 times higher than A188 and JHAF control weeks. T1 transformed strains were replanted and T2 seeds obtained. Analysis of T2 seeds showed expression of bromelain. FIG. 21 shows a bromelain activity assay using Z-Arg-Arg-NHMec in T2 seeds for ER targeted (11587) and soluble vacuole targeted (11589) bromelain.
브로멜라인을 발현하는 옥수수 식물로부터의 T2 종자의 분석Analysis of T2 Seeds from Corn Plants Expressing Bromelain
T2 형질전환 브로멜라인 주로부터의 종자, 11587-2를 증강된 전분 회수에 대한 균열 옥수수 검정으로 분석하였다. 외인성으로 첨가된 브로멜라인을 사용한 이전의 실험은 단독으로 검사하고, 기타 효소, 특히 셀룰라제와 함께 검사한 경우, 증가된 전분 회수를 나타내었다. 주 11587-2로부터의 T2 종자는 37C/2000ppm SO2에서 밤새 침지시킨 경우 대조군 종자보다 회수된 전분에 1.3배의 증가를 나타내었다. 보다 중요하게는, 셀룰라제(C8546)를 첨가한 경우, 종자를 37C/2000ppm SO2에서 침지시킨 경우, T2 브로멜라인 주로부터의 전분보다 2배 증가하였다. Seeds from the T2 transgenic bromelain strain, 11587-2, were analyzed in a cracked corn assay for enhanced starch recovery. Previous experiments with exogenously added bromelain have been tested alone and show increased starch recovery when tested with other enzymes, especially cellulase. T2 seeds from 11587-2 showed a 1.3-fold increase in recovered starch over control seeds when soaked overnight at 37C / 2000 ppm SO2. More importantly, the addition of cellulase (C8546) increased twice as much as starch from the T2 bromelain strain when the seeds were soaked at 37 C / 2000 ppm SO2.
형질전환 주는 종자를 37C/400ppm SO2에서 침지시킨 경우, 대조군 종자보다 증가된 전분의 유사한 경향을 나타내었다. 대조군의 1.6배로 증가된 전분 회수가 형질전환 종자에서 나타났으며, 셀룰라제(C8546)의 첨가 없이 2.1배의 전분 증가가 나타났다. 표 20을 참조한다.Transformed strains showed a similar tendency of increased starch than control seeds when the seeds were soaked in 37C / 400 ppm SO2. A 1.6-fold increase in starch recovery was seen in the transgenic seeds and a 2.1-fold increase in starch without the addition of cellulase (C8546). See Table 20.
이들 결과는 이것이 감소된 온도 및 SO2 농도에서 가능한 반면, 또한 브로멜라인을 발현하는 형질 전환 종자를 사용하는 경우, 습식 제분 과정 중 전분 회수를 증가시킴을 나타내는 유의적인 것이다. These results are significant, indicating that this is possible at reduced temperatures and SO 2 concentrations, but also increases starch recovery during the wet milling process when using transgenic seeds expressing bromelain.
실시예 52Example 52
옥수수 최적화된 페룰산 에스테라제에 대한 형질전환 벡터의 작제Construction of Transformation Vectors for Corn Optimized Ferulic Acid Esterase
다음과 같이 다양한 표적화 시그날의 유무하에 옥수수 내배유 내에서 옥수수 최적화된 페룰산 에스테라제를 발현하기 위한 발현 카세트를 작제하였다.Expression cassettes for expressing corn optimized ferulic acid esterase in corn endosperm with or without various targeting signals were constructed as follows.
플라스미드 13036(서열번호 101)은 옥수수 최적화된 페룰산 에스테라제(FAE) 서열(서열번호 99)을 포함한다. 당해 서열을 내배유의 세포질 내에서의 특이적 발현을 위한 임의의 표적 서열 없이 옥수수 감마 제인 프로모터 뒤로 클로닝하였다. Plasmid 13036 (SEQ ID NO: 101) comprises a corn optimized ferulic acid esterase (FAE) sequence (SEQ ID NO: 99). The sequence was cloned behind the corn gamma agent promoter without any target sequence for specific expression in the cytoplasm of endocrine.
플라스미드 13038(서열번호 103)은 세포질 세망으로의 표적화 및 아포플라스트로의 분비를 위해 합성 FAE에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(시그날 서열 17)을 포함한다(문헌[참조: Torrent et al. 1997]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 감마 제인 프로모터 뒤로 클로닝하였다. Plasmid 13038 (SEQ ID NO: 103) comprises a N-terminal signal sequence (MRVLLVALALLALAASATS) (signal sequence 17), a corn γ-agent fused to synthetic FAE for targeting to cytoplasmic reticulum and secretion of apoplasts. Torrent et al. 1997]. This fusion was cloned behind the corn gamma agent promoter for specific expression in endocrine.
플라스미드 13039(서열번호 105)는 전분체로의 표적화을 위해 합성 FAE에 융합시킨 waxy 전분체 표적화 펩타이드(MLAALATSQLVATRAGLGVPDASTFRRGAAQGLRGARASAAAD TLSMRTSARAAPRHQHQQARRGARFPSLVVCASAGA)(문헌[참조: Klosgen et al., 1986])를 포함한다(문헌[참조: Torrent et al. 1997]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 감마 제인 프로모터 뒤로 클로닝하였다. Plasmid 13039 (SEQ ID NO: 105) is a waxy starch targeting peptide (MLAALATSQLVATRAGLGVPDASTFRRGAAQGLRGARASAAAD TLSMRTSARAAPRHQHQQARRGARFPSLVVCASAGA) fused to synthetic FAEs for targeting to starch (see Klosgen et al., Et al., 1986 et al.). al. 1997]. This fusion was cloned behind the gamma agent promoter for specific expression in endocrine.
플라스미드 13347(서열번호 107)은 세포질세망(ER)으로의 표적화 및 그 내에서의 체류를 위해 서열 SEKDEL의 C-말단 첨가물과 함께, 합성 FAE에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS)(시그날 서열 17)을 포함한다(문헌[참조: Munro and Pelham, 1987]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 감마 제인 프로모터 뒤로 클로닝하였다. Plasmid 13347 (SEQ ID NO: 107) is a corn γ-agent N-terminal signal sequence (MRVLLVALALLALAASATS) fused to a synthetic FAE with C-terminal addition of the sequence SEKDEL for targeting to and retention within cytoplasmic reticulum (ER). (Signal sequence 17) (Munro and Pelham, 1987). This fusion was cloned behind the gamma agent promoter for specific expression in endocrine.
애그로박테리움 감염을 통한 옥수수 내로의 형질전환을 위해 모든 발현 카세트를 이원 벡터 pNOV2117로 삽입하였다. 이원 벡터는 만노즈를 갖는 형질전환 세포의 선별을 가능하게 하는 포스포만노즈 이소머라제(PMI) 유전자를 포함하였다. 형질전환 옥수수 식물을 자가-수분 또는 이계교배하였고, 분석을 위해 종자를 수거하였다. All expression cassettes were inserted into the binary vector pNOV2117 for transformation into maize via Agrobacterium infection. The binary vector contained a phosphomannose isomerase (PMI) gene that allows the selection of transformed cells with mannose. Transformed corn plants were self-pollinated or crossbred and seeds were harvested for analysis.
당해 효소의 조합은 개별 효소를 발현하는 식물을 교배시키거나 수개의 발현 카세트를 동일한 이원 벡터 내로 클로닝하여 공형질전환을 가능하게 함으로써 제조할 수 있다.Combinations of these enzymes can be made by crossing plants expressing individual enzymes or by cloning several expression cassettes into the same binary vector to enable cotransformation.



실시예 53Example 53
페룰산 에스테라제에 의한 옥수수 섬유의 가수분해성 분해Hydrolysable Degradation of Corn Fiber by Ferulic Acid Esterase
옥수수 섬유는 옥수수 습식 및 건식 제분의 주요 부산물이다. 섬유 성분은 주로 종자 과피(외피) 및 호분으로부터 유래한 조대 섬유와 소량의 내배유 세포벽으로부터 유래한 미세 섬유로 구성되어 있다. 세포벽의 리그닌, 헤미셀룰로스 및 셀룰로스 성분의 가교결합을 초래하는 페룰산, 하이드록시신남산은 곡물 곡립의 세포 벽에서 높은 농도로 발견된다. 페룰산 가교결합의 효소 분해는 옥수수 섬유의 가수분해의 중요한 단계이며 기타 가수분해 효소에 의한 추가의 효소 분해의 접근가능성을 야기할 수 있다. Corn fiber is a major by-product of corn wet and dry milling. The fiber component mainly consists of coarse fibers derived from seed husks (shells) and whistle and fine fibers derived from small amounts of endocrine cell walls. Ferulic acid, hydroxycinnamic acid, which results in crosslinking of the lignin, hemicellulose and cellulose components of the cell wall, is found in high concentrations in the cell walls of grain grains. Enzymatic degradation of ferulic acid crosslinking is an important step in the hydrolysis of corn fiber and can lead to accessibility of further enzymatic degradation by other hydrolytic enzymes.
페룰산 에스테라제 활성 검정Ferulic Acid Esterase Activity Assay
페룰산 에스테라제, FAE-1(씨. 터모셀룸으로부터의 옥수수 최적화된 합성 유전자)를 이. 콜라이에서 발현시켰다. 세포를 수거하고 -80℃에서 밤새 저장하였다. 수거된 세균을 pH 7.5의 50mM 트리스 완충액에 현탁시켰다. 라이소자임을 200ug/ml의 최종 농도로 첨가하였고, 샘플을 부드럽게 교반하면서 실온에서 10분 동안 항온처리하였다. 당해 샘플을 4000rpm에서 4℃에서 15분 동안 원심분리하였다. 원심분리 후, 상층액을 50ml 들이 원추형 튜브로 옮기고 70℃ 수욕에 30분 동안 두었다. 이어서 샘플을 4000rpm에서 15분 동안 원심분리하였고, 맑아진 상층액을 원추형 튜브로 옮겼다(문헌[참조: Blum et al. J Bacteriology, Mar 2000, pg 1346-1351]).Ferulic acid esterase, FAE-1 (a corn optimized synthetic gene from C. thermocelum). Expressed in E. coli. Cells were harvested and stored overnight at -80 ° C. The harvested bacteria were suspended in 50 mM Tris buffer at pH 7.5. Lysozyme was added at a final concentration of 200 ug / ml and the sample was incubated for 10 minutes at room temperature with gentle stirring. The sample was centrifuged at 4000 rpm for 15 minutes at 4 ° C. After centrifugation, the supernatant was transferred to a 50 ml conical tube and placed in a 70 ° C. water bath for 30 minutes. Samples were then centrifuged at 4000 rpm for 15 minutes and the cleared supernatant was transferred to conical tubes (Blum et al. J Bacteriology,
재조합체 FAE-1을 문헌[참조: Mastihubova et al (2002) Analytical Biochemistry 309 96-101])에 기술된 바와 같이 4-메틸움벨리페릴 페룰산염을 사용하여 활성에 대하여 검사하였다. 재조합체 단백질 FAE-1(104-3)을 10, 100 및 1000배 희석하고 검정하였다. 활성 검정 결과는 도 22에 나타내어져 있다. Recombinant FAE-1 was tested for activity using 4-methylumbeliferyl ferulate as described in Mastihubova et al (2002) Analytical Biochemistry 309 96-101. Recombinant protein FAE-1 (104-3) was diluted 10, 100 and 1000 fold and assayed. Activity assay results are shown in FIG. 22.
옥수수 종자 섬유의 제조Preparation of Corn Seed Fiber
옥수수 과피 조대 섬유를 2000ppm 메타중아황산나트륨(Aldrich)에서 50℃에서 48시간 동안 황색 마치종 옥수수 #2 낟알을 침지시켜 분리하였다. 낟알을 동량 부의 물과 혼합하고 역 방향의 날을 가진 Waring 실험실 중하중 혼합기로 혼합하였다. 혼합기는 다양한 자동 변압기(Staco Energy)로 2분 동안 50% 전압 출력에서 조절하였다. 혼합된 물질을 표준 검사 체 #7(Fisher scientific) 위에서 수돗물로 세척하여 전분 분획으로부터 조대 섬유를 분리하였다. 조대 섬유 및 배아는 4L 들이 비커(Fisher scientific)에서 뜨거운 수돗물로 배아로부터 섬유도를 부유시켜 분리하였다. 이어서 섬유를 에탄올에 적신 후 진공 오븐(Precision)에서 밤새 60℃에서 건조시켰다. 옥수수 낟알 과피로부터 유래한 옥수수 조대 섬유를 제분 배전선 3170(Perten instrument)을 갖춘 실험실 제분기 3100으로 0.5mm 입자 크기로 제분하였다. Corn hull coarse fibers were separated by soaking yellow
옥수수 섬유 가수분해 검정Corn Fiber Hydrolysis Black
조대 섬유(CF)를 pH 5.2의 50mM 시트르산염-인산염 완충액에 30mg/5ml 완충액으로 현탁시켰다. CF 모액을 격렬히 교반하고 40ml 모듈식 저수조(Beckman, 카탈로그 번호 제372790호)로 옮겼다. 당해 용액을 잘 혼합한 후 100ul를 96 웰 플레이트(Corning Inc., 카탈로그 번호 제9017호, 폴리스티렌, 평저)로 옮겼다. 효소를 1-10ul/웰에 첨가하였고 최종 용적을 완충액을 사용하여 110ul로 조절하였다. CF 배경 대조군은 오직 완충액 10ul만 함유하였다. 플레이트를 알루미늄 박으로 밀봉하고 계속 교반하여 18시간 동안 37℃에서 항온처리하였다. 플레이트를 4000rpm에서 15분 동안 원심분리하였다. CF 상층액 1-10ul를 BCA 시약{BCA-시약: 시약 A(Pierce, Prod. #23223), 시약 B(Pierce, Prod. #23224)} 100ul로 재탑재한 96 웰 플레이트로 옮겼다. 최종 용적을 110ul로 조절하였다. 플레이트를 알루미늄 박으로 밀봉하고 85℃에서 30분 동안 두었다. 85℃에서 항온처리한 후, 플레이트를 2500rpm에서 5분 동안 원심분리하였다. 흡광도 수치를 562nm에서 읽었다(Molecular Devices, Spectramax Plus). 샘플을 D-글루코즈 및 D-자일로스(Sigma) 보정 곡선으로 정량화하였다. 검정 결과는 방출된 총 당으로 기록되어 있다. Coarse fibers (CF) were suspended in 30 mg / 5 ml buffer in 50 mM citrate-phosphate buffer at pH 5.2. The CF mother liquor was stirred vigorously and transferred to a 40 ml modular reservoir (Beckman, Cat. No. 372790). After well mixing the solution, 100 ul was transferred to a 96 well plate (Corning Inc., Cat. No. 9017, Polystyrene, Flat). Enzyme was added to 1-10 ul / well and the final volume was adjusted to 110 ul using buffer. The CF background control contained only 10ul of buffer. The plate was sealed with aluminum foil and kept stirring to incubate at 37 ° C. for 18 hours. Plates were centrifuged at 4000 rpm for 15 minutes. 1-10 ul of CF supernatant was transferred to a 96 well plate reloaded with 100 ul of BCA reagent (BCA-Reagent: Reagent A (Pierce, Prod. # 23223), Reagent B (Pierce, Prod. # 23224)). The final volume was adjusted to 110 ul. The plate was sealed with aluminum foil and left at 85 ° C. for 30 minutes. After incubation at 85 ° C., the plates were centrifuged at 2500 rpm for 5 minutes. Absorbance readings were read at 562 nm (Molecular Devices, Spectramax Plus). Samples were quantified with D-glucose and D-Xylose (Sigma) calibration curves. Assay results are reported in total sugars released.
옥수수 종자 섬유 가수분해 검정에서 페룰산 에스테라제에 의해 방출된 총 당의 측정Determination of Total Sugars Released by Ferulic Acid Esterase in Corn Seed Fiber Hydrolysis Assay
재조합체 FAE-1 섬유 가수분해 검정 결과는 총 환원 당에 어떠한 증가도 보여주지 않았다(데이타는 나타내지 않았음). 이들 결과는 예상치 않았던 것인데, 이는 기타 가수분해성 효소를 FAE와 함께 사용하는 경우 총 환원 당의 증가만이 탐지가능함이 문헌에 보고되어 왔기 때문이다(문헌[참조: Yu et al J. Agric. Food Chem. 2003,51, 218- 223]). 도 23은 옥수수 섬유에서 자란 진균 상층액에 대한 FAE-2의 첨가가 총 환원 당을 나타내며 이를 증가시킴을 나타낸다. 이는 FAE가 옥수수 섬유 가수분해에 중요한 역할을 수행함을 제시한다. Recombinant FAE-1 fiber hydrolysis assay results did not show any increase in total reducing sugar (data not shown). These results were unexpected because it has been reported in the literature that only an increase in total reducing sugars is detectable when other hydrolytic enzymes are used with FAE (see Yu et al J. Agric. Food Chem. 2003, 51, 218-223). FIG. 23 shows that the addition of FAE-2 to fungal supernatants grown on corn fiber represents and increases total reducing sugars. This suggests that FAE plays an important role in corn fiber hydrolysis.
도 23은 FAE-2의 진균 상층액(FS9)으로의 첨가와 함께 옥수수 섬유로부터의 총 환원 당의 방출의 증가를 나타내는 옥수수 섬유 가수분해 검정 결과를 나타낸다.FIG. 23 shows the results of a corn fiber hydrolysis assay showing an increase in the release of total reducing sugars from corn fiber with addition of FAE-2 to fungal supernatant (FS9).
FAE-1에 의한 옥수수 종자 섬유로부터 방출된 페룰산의 분석Analysis of Ferulic Acid Released from Corn Seed Fiber by FAE-1
옥수수 섬유에 대한 FAE 활성을 검사한 후 약간 수정된 문헌[참조: Walfron and Parr (1996)(Waldron. KW. Parr AJ 1996 Vol 7 pages 305-312 Phytochem Anal)])에 기술된 바와 같이 페룰산을 방출시켰다. 옥수수 낟알 과피로부터 유래한 옥수수 조대 섬유를 제분 배전선 3170(Perten instrument)을 갖춘 laboratory 제분기 3100으로 0.5mm 입자 크기로 제분하였고 기질로서 10mg/ml의 농도로 사용하였다. 1ml 검정을 24웰 Becton Dickenson MultiwellTM에서 수행하였다. 기질을 재조합체 FAE의 존재 및 부재 하에 18시간 동안 110rpm에서 50℃에서 pH 5.4의 50mM 시트르산염-인산염에서 항온처리하였다. 항온처리 기간 후, 샘플을 13,000rpm에서 10분 동안 원심분리한 후 에틸 아세테이트 추출하였다. 사용한 모든 용매 및 산은 제조사[Fisher Scientific]의 제품이었다. 상층액 0.8ml을 빙아세트산 0.5ml로 산성화하고 동일한 용적의 에틸 아세테이트로 3회 추출하였다. 유기 분획을 혼합하고 스피드 백(speed vac)(Savant)을 사용하여 40℃에서 건조시켰다. 이어서 샘플을 메탄올 100㎕로 현탁시키고 HPLC 분석에 사용하였다. After examining FAE activity on corn fiber, ferulic acid was described as described in a slightly modified literature (Waldron and Parr (1996) (Waldron. KW. Parr AJ 1996
HPLC 크로마토그래피를 다음과 같이 수행하였다. 페룰산(ICN Biomedicals)을 HPLC 분석에서 표준으로 사용하였다(데이타는 나타내지 않았음). Hewlett Packard 시리즈 1100 HPLC 시스템을 사용하여 HPLC 분석을 수행하였다. 당해 과정은 40℃에서 1.0ml 분-1에서 작동된 C18 전체 캡핑된 역상 칼럼(XterraRp18, 150mm X 3.9mm, i.d. 5㎛ 입자 크기)을 사용하여 수행하였다. 32분에 25 내지 70%의 구배(용매 A: H2O, 0.01%b TFA; 용매 B: MeCN, 0.0075%)를 사용하여 페룰산을 용출시켰다. HPLC chromatography was performed as follows. Ferulic acid (ICN Biomedicals) was used as standard in HPLC analysis (data not shown). HPLC analysis was performed using a Hewlett Packard series 1100 HPLC system. The procedure was performed using a C 18 total capped reversed phase column (XterraRp 18 , 150 mm × 3.9 mm,
도 24에 나타낸 바와 같이, 옥수수 섬유로부터 방출된 FA는 FAE-1 10 또는 100ul로 처리한 경우, 대조군보다 2 내지 3배 높았다. 이들 결과는 FAE-1이 옥수수 섬유를 가수분해할 수 있음을 명확히 보여준다. As shown in Figure 24, FA released from corn fiber was 2-3 times higher than the control when treated with FAE-1 10 or 100ul. These results clearly show that FAE-1 can hydrolyze corn fiber.
실시예 54Example 54
옥수수 발현된 글루코아밀라제 및 아밀라제의 발효 중 기능성Functionality during Fermentation of Corn Expressed Glucoamylase and Amylase
당해 실시예는 옥수수-발현된 효소가 첨가된 효소의 부재 하에 그리고 옥수수 슬러리의 조리 과정 없이 옥수수 슬러리 내에서의 전분의 발효를 지원할 것임을 입증한다. 리조푸스 오리재 글루코아밀라제(ROGA)(서열번호 49)를 포함하는 옥수수 낟알을 실시예 32에 기술한 바와 같이 제조하였다. 보리 저-PI α-아밀라제(AMYI)(서열번호 88)를 포함하는 옥수수 낟알은 실시예 46에 기술된 바와 같이 제조하였다. 다음의 물질을 당해 실시예에 사용한다:This example demonstrates that corn-expressed enzymes will support fermentation of starch in corn slurries in the absence of added enzymes and without cooking corn slurries. Corn kernels comprising Rizopus duck glucoamylase (ROGA) (SEQ ID NO: 49) were prepared as described in Example 32. Corn kernels containing barley low-PI α-amylase (AMYI) (SEQ ID NO: 88) were prepared as described in Example 46. The following materials are used in this example:
아스퍼길러스 니거 글루코아밀라제(ANGA)는 제조사[Sigma]로부터 구입하였다.Aspergillus niger glucoamylase (ANGA) was purchased from Sigma.
리조푸스 종 글루코아밀라제(RxGA)는 제조사[Wako]에서 무수 결정질 분말로 구입하였으며 pH 5.2의 10mM 아세트산나트륨, 5mM CaCl2 중 10mg/ml로 제조하였다. Rizopus spp. Glucoamylase (RxGA) was purchased as anhydrous crystalline powder from the manufacturer Wako and prepared at 10 mg / ml in 10 mM sodium acetate, 5 mM CaCl 2 at pH 5.2.
MAMYI 미생물성 제조 AMYI는 pH 5.2의 10mM 아세트산나트륨, 5mM CaCl2 중 대략 0.25mg/ml로 제조하였다. MAMYI Microbial Preparation AMYI was prepared at approximately 0.25 mg / ml in 10 mM sodium acetate, 5 mM CaCl 2 at pH 5.2.
효모는 사카로마이세스 세레비시애였다. Yeast was Saccharomyces cerevisiae.
YE는 수중 효모 추출물의 멸균 5% 용액이었다. YE was a sterile 5% solution of yeast extract in water.
효모 출발자는 총 용적 300ml의 물에 50g 말토덱스트린, 1.5g 효소 추출물, 0.2mg ZnSO4를 포함하였다. 배지를 제조한 후 오토클레이브하여 멸균하였다. 실온으로 냉각시킨 후, 테트라사이클린(에탄올 중 10mg/ml) 1ml, AMG300 글루코아밀라제 100㎕ 및 155mg 활성 무수 효모를 첨가하였다. 이어서 당해 혼합물을 30℃에서 22시간 동안 교반하였다. 문헌[참조: Current Protocols in Molecular Biology]에 기술된 바와 같이, 밤새 교반한 효모 배양액을 물로 1/10으로 희석하였고 A600을 측정하여 효모 수를 측정하였다. Yeast starter contained 50 g maltodextrin, 1.5 g enzyme extract, 0.2 mg ZnSO 4 in a total volume of 300 ml water. The medium was prepared and then autoclaved and sterilized. After cooling to room temperature, 1 ml of tetracycline (10 mg / ml in ethanol), 100 μl of AMG300 glucoamylase and 155 mg active anhydrous yeast were added. The mixture was then stirred at 30 ° C. for 22 hours. As described in Current Protocols in Molecular Biology, yeast cultures stirred overnight were diluted 1/10 with water and the number of yeast was determined by measuring A600.
ROGA 분말: 낟알을 활성 글루코아밀라제를 갖는 것으로 나타난 수개의 T 주로부터 수집하였다. 당해 종자를 Kleco로 연마하고, 모든 분말을 수집하였다. ROGA Powder: Grains were collected from several T strains shown to have active glucoamylase. The seed was ground with Kleco and all powders were collected.
AMYI 분말: 상기한 바와 같이 AMYI를 발현하는 T0 옥수수로부터의 낟알을 수집하고 연마하였다. AMYI Powder: Grain from T0 corn expressing AMYI as described above was collected and polished.
대조군 분말: 유사한 유전적 배경의 낟알을 ROGA 발현 옥수수와 동일한 방식으로 연마하였다. Control Powder: Grains of similar genetic background were ground in the same manner as ROGA expressing corn.
접종 혼합물을 멸균 튜브에서 제조하였다: 이는 1.65ml 당 효모 세포(1x107), 효모 추출물(8.6mg), 테트라사이클린(55㎍)을 함유하였다. 1.65ml를 각각의 발효 튜브에 분말 g 당 첨가하였다. The inoculation mixture was prepared in sterile tubes: it contained yeast cells (1 × 10 7 ), yeast extract (8.6 mg), tetracycline (55 μg) per 1.65 ml. 1.65 ml was added per gram of powder to each fermentation tube.
발효 제제: 분말을 자체중량을 측정한 17 x 100mm 멸균 폴리프로필렌으로 1.8g/튜브에서 칭량하였다. 0.9M H2SO4 50㎕을 5로 발효시키기 전 최종 pH에 이르게 하기 위해 첨가하였다. 접종 혼합물(2.1ml)을 하기한 바와 같이 RXGA, AMYI-P 및 아밀라제 탈염 완충액과 함께 튜브당 첨가하였다. 완충액의 양을 각각의 분말의 함수량을 기초로 하여 조정하여, 총 고체 함량이 각각의 튜브에서 일정하도록 하였다. 당해 튜브를 전체적으로 혼합하고, 칭량하고 플라스틱 자루에 두고 30℃에서 항온처리하였다. Fermentation formulation: The powder was weighed at 1.8 g / tube with self weighing 17 × 100 mm sterile polypropylene. 50 μL of 0.9MH 2 SO 4 was added to reach final pH before fermentation to 5. The inoculation mixture (2.1 ml) was added per tube with RXGA, AMYI-P and amylase desalting buffer as described below. The amount of buffer was adjusted based on the water content of each powder so that the total solids content was constant in each tube. The tubes were mixed throughout, weighed and placed in plastic bags and incubated at 30 ° C.

발효 튜브를 67시간 과정에 걸쳐 일정한 간격으로 칭량하였다. 중량 손실은 발효 중 CO2의 방출과 상응한다. 샘플의 에탄올 함량을 DCL 에탄올 검정 방법에 의해 발효 67시간 후에 결정하였다. 킷트(카탈로그 번호 제229-29호)는 제조사[Diagnostic Chemicals Limited], 캐나다 프린스 에드워드 샬럿타운 소재, D1E 1B0]에서 구입하였다. 샘플(10㎕)을 각각의 발효 튜브로부터 3회 뽑아내어 물 990㎕로 희석하였다. 희석된 샘플 10㎕을 검정 완충액/ADH-NAD 시약의 12.5/1 혼합물 1.25ml와 혼합하였다. 표준(0, 5, 10, 15 & 20% v/v ETOH)을 희석하고 같은 방식으로 검정하였다. 반응물을 37℃에서 10분 동안 항온처리한 후, A340을 읽었다. 표준은 2회 제조하였고, 각각의 발효로부터의 샘플을 3회(초기 희석을 포함하여) 제조하였다. 샘플의 중량은 아래의 표에 상세히 나타낸 바와 같이 시간에 따라 변하였다. 중량 손실은 시간 0 기의 초기 샘플 중량의 퍼센트로 표현되어 있다.Fermentation tubes were weighed at regular intervals over the course of 67 hours. The weight loss corresponds to the release of CO 2 during fermentation. The ethanol content of the samples was determined after 67 hours of fermentation by the DCL ethanol assay method. Kit (Catalog No. 229-29) was purchased from Diagnostic Chemicals Limited, D1E 1B0, Prince Edward Charlottetown, Canada. Samples (10 μl) were extracted three times from each fermentation tube and diluted with 990 μl of water. 10 μl of the diluted sample was mixed with 1.25 ml of a 12.5 / 1 mixture of assay buffer / ADH-NAD reagent. Standards (0, 5, 10, 15 & 20% v / v ETOH) were diluted and assayed in the same manner. The reaction was incubated at 37 ° C. for 10 minutes before reading A340. Standards were prepared twice and samples from each fermentation were made three times (including the initial dilution). The weight of the sample varied over time as detailed in the table below. Weight loss is expressed as a percentage of the initial sample weight at time zero.

이들 데이타는 옥수수 내에서 발현된 ROGA 효소가 효소가 없는 대조군에 비하여 발효율을 증가시킴을 나타낸다. 이는 또한 옥수수 낟알 내에서 발현된 AMYI가 옥수수 내에서의 전분 발효의 잠정적인 활성자임을 나타내는 이전의 데이타를 확증한다. 에탄올 함량은 아래에 상세히 나타내어져 있다. These data indicate that ROGA enzyme expressed in maize increases efficiencies compared to the control without enzyme. This also confirms previous data indicating that AMYI expressed in corn kernels is a potential activator of starch fermentation in corn. Ethanol content is detailed below.

이들 데이타는 또한 옥수수 내에서의 리조푸스 오리재 글루코아밀라제의 발현이 옥수수 내에서의 증가된 전분 발효를 촉진함을 입증한다. 유사하게, 옥수수 내에서의 보리 아밀라제의 발현은 외인성 효소의 첨가 없이 옥수수 전분을 보다 발효가능성이 높게 만든다. These data also demonstrate that the expression of Rifupus duck glucoamylase in corn promotes increased starch fermentation in corn. Similarly, expression of barley amylase in corn makes corn starch more fermentable without the addition of exogenous enzymes.
실시예 55Example 55
셀로바이오하이드롤라제 ICellobiohydrolase I
트리코더마 리세이(Trichoderma reesei) 셀로바이오하이드롤라제 I(CBH I) 유전자를 증폭하고 공개된 데이타베이스 서열(수탁 번호 제E00389호)을 기초로 하여 RT-PCR로 클로닝하였다. cDNA 서열을 SignalP 프로그램을 사용하여 시그날 서열의 존재에 대하여 분석하였고, 이는 17개 아미노산 시그날 서열을 예측하였다. 시그날 서열을 암호화하는 DNA 서열을 당해 서열(서열번호 79)로 나타내어진 바와 같이, PCR에 의해 ATG로 치환하였다. 당해 cDNA 서열을 사용하여 그 이후의 작제물을 제조하였다. 추가의 작제물은 당해 유전자(서열번호 93)의 옥수수 최적화 형을 치환시켜 제조하였다. Trichoderma reesei ) Cellobiohydrolase I (CBH I) gene was amplified and cloned by RT-PCR based on published database sequence (Accession No. E00389). cDNA sequences were analyzed for the presence of signal sequences using the SignalP program, which predicted 17 amino acid signal sequences. The DNA sequence encoding the signal sequence was replaced with ATG by PCR as shown by the sequence (SEQ ID NO: 79). Subsequent constructs were prepared using this cDNA sequence. Additional constructs were prepared by substituting the corn optimized form of the gene (SEQ ID NO: 93).
실시예 56Example 56
셀로바이오하이드롤라제 IICellobiohydrolase II
트리코더마 리세이 셀로바이오하이드롤라제 II(CBH II) 유전자를 증폭하고 공개된 데이타베이스 서열(수탁 번호 제M55080호)을 기초로 하여 RT-PCR로 클로닝하였다. cDNA 서열을 SignalP 프로그램을 사용하여 시그날 서열의 존재에 대하여 분석하였고, 이는 18개 아미노산 시그날 서열을 예측하였다. 시그날 서열을 암호화하는 DNA 서열을 당해 서열(서열번호 81)로 나타내어진 바와 같이, PCR에 의해 ATG로 치환하였다. 당해 cDNA 서열을 사용하여 그 이후의 작제물을 제조하였다. 추가의 작제물은 당해 유전자(서열번호 94)의 옥수수 최적화 형을 치환시켜 제조하였다.Trichoderma Reese Cellobiohydrolase II (CBH II) gene was amplified and cloned by RT-PCR based on published database sequence (Accession No. M55080). cDNA sequences were analyzed for the presence of signal sequences using the SignalP program, which predicted 18 amino acid signal sequences. The DNA sequence encoding the signal sequence was replaced with ATG by PCR as shown by the sequence (SEQ ID NO: 81). Subsequent constructs were prepared using this cDNA sequence. Additional constructs were prepared by substituting the corn optimized form of the gene (SEQ ID NO: 94).
실시예 57Example 57
트리코더마 리시 셀로바이오하이드롤라제 I 및 셀로바이오하이드롤라제 II에 대한 형질전환 벡터의 작제Construction of Transformation Vectors for Tricoderma Rishi Cellobiohydrolase I and Cellobiohydrolase II
천연 N-말단 시그날 서열 무의 트리코더마 리시 셀로바이오하이드롤라제 I(cbhi) cDNA의 클로닝이 실시예 55에 기술되어 있다. 다음과 같이 다양한 표적화 시그날을 갖는 트리코더마 리세이 셀로바이오하이드롤라제 I cDNA를 옥수수 내배유 내에서 발현시키기 위해 발현 카세트를 작제하였다.Cloning of the Tricoderma lishi cellobiohydrolase I ( cbhi ) cDNA of native N-terminal signal sequence Radix is described in Example 55. Expression cassettes were constructed to express Trichoderma reesei cellobiohydrolase I cDNA in corn endosperm with various targeting signals as follows.
플라스미드 12392는 세포질 내에서의 발현을 위해 내배유 내에서의 특이적 발현을 위해 γ 제인 프로모터 뒤로 클로닝한 트리코더마 리시 cbhi cDNA를 포함한다. Plasmid 12392 contains a Trichoderma lishi cbhi cDNA cloned behind the γ zein promoter for expression in the endocrine for expression in the cytoplasm.
플라스미드 12391은 세포질세망으로의 표적화 및 아포플라스트 내로의 분비를 위해 실시예 1에 상기한 바와 같이 트리코더마 리시 cbhi cDNA에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열(MRVLLVALALLALAASATS(시그날 서열 17))을 포함한다(문헌[참조: Torrent et al. 1997]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 감마 제인 프로모터 뒤로 클로닝하였다. Plasmid 12391 contains a corn γ-agent N-terminal signal sequence (MRVLLVALALLALAASATS (signal sequence 17)) fused to a Trichoderma lishi cbhi cDNA as described above in Example 1 for targeting to cytoplasmic networks and secretion into apoplasts . (See Torrent et al. 1997). This fusion was cloned behind the corn gamma agent promoter for specific expression in endocrine.
플라스미드 12392는 세포질세망(ER)로의 표적화 및 그 내에서의 체류를 위해 서열 KDEL의 C-말단 첨가물을 갖는 트리코더마 리시 cbhi cDNA에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다(문헌[참조: Munro and Pelham, 1987]). 당해 융합물을 내배유 내에서의 특이적 발현을 위해 감마 제인 프로모터 뒤로 클로닝하였다. Plasmid 12392 contains an N-terminal signal sequence, a corn γ-zein fused to a Trichoderma lishi cbhi cDNA with a C-terminal addition of the sequence KDEL for targeting to and retention within cytoplasmic reticulum (ER) (see, Munro and Pelham, 1987]. This fusion was cloned behind the gamma agent promoter for specific expression in endocrine.
플라스미드 12656은 전분체로의 효적 설정을 위해 트리코더마 리시 cbhi cDNA에 융합시킨 waxy 전분체 표적화 펩타이드(문헌[참조: Klogen et al., 1986])을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ 제인 프로모터 뒤로 클로닝하였다. Plasmid 12656 includes waxy starch targeting peptides (Klogen et al., 1986) fused to Trichoderma licci cbhi cDNA for efficacy setting into starch. This fusion was cloned behind the corn γ zein promoter for specific expression in endocrine.
애그로박테리움 감염을 통한 옥수수 내로의 형질전환을 위해 모든 발현 카세트를 이원 벡터(pNOV2117)로 삽입하였다. 이원 벡터는 만노즈를 갖는 형질전환 세포의 선별을 가능하게 하는 포스포만노즈 이소머라제(PMI) 유전자를 포함하였다. 형질전환 옥수수 식물을 자가-수분 또는 이계교배하였고, 분석을 위해 종자를 수거하였다. All expression cassettes were inserted into the binary vector (pNOV2117) for transformation into maize via Agrobacterium infection. The binary vector contained a phosphomannose isomerase (PMI) gene that allows the selection of transformed cells with mannose. Transformed corn plants were self-pollinated or crossbred and seeds were harvested for analysis.
추가의 작제물(플라스미드 12652, 12653, 12654 및 12655)을 트리코더마 리시 cbhi cDNA에 대하여 기술한 바와 동일한 방식으로 정교하게 트리코더마 리시 셀로바이오하이드롤라제II(cbhii) cDNA에 융합시킨 상기한 표적화 시그날로 제조하였다. 이들 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 Q 단백질 프로모터(50 Kd γ 제인)(서열번호 98) 뒤로 클로닝하였고, 상기한 바와 같이 옥수수로 형질전환시켰다. 형질전환된 옥수수 식물을 자가-수분 또는 이계교배하였고, 분석을 위해 종자를 수거하였다. Add Preparation of a construct (
당해 효소의 조합은 개별 효소를 발현하는 식물을 교배시키거나 수개의 발현 카세트를 동일한 이원 벡터 내로 클로닝하여 공형질전환을 가능하게 함으로써 제조할 수 있다.Combinations of these enzymes can be made by crossing plants expressing individual enzymes or by cloning several expression cassettes into the same binary vector to enable cotransformation.
실시예 58Example 58
옥수수 내에서의 Cbhi의 발현Expression of Cbhi in Corn
플라스미드 12390, 12391 또는 12392로 형질전환시킨 자가-수분된 옥수수 식물로부터의 T1 종자를 수득하였다. 12390 작제물은 내배유의 세포질세망 내에서의 CbhI의 발현을 표적화하며, 12391 작제물은 내배유의 아포플라스트 내에서의 CbhI의 발현을 표적화하며, 12392 작제물은 내배유의 세포질 내에서의 CbhI의 발현을 표적화한다. T1 seeds from self-pollinated corn plants transformed with plasmid 12390, 12391 or 12392 were obtained. 12390 construct targets expression of CbhI in endocrine cytoplasmic network, 12391 construct targets expression of CbhI in endocrine apoplasts, and 12392 construct expresses expression of CbhI in endocrine cytoplasm To target.
옥수수 분말로부터의 CbhI의 추출 및 검출: CbhI 및 CbhII에 대한 폴리클로날 항체를 확정된 프로토콜에 따라 염소에서 제조하였다. CbhI 형질전환 종자로부터의 분말은 이들을 Autogizer 연마기에서 연마하여 수득하였다. 대략 50mg의 분말을 20mM NaPO4 완충액(pH 7.4) 0.5ml, 150mM NaCl에 재현탁한 후 계속 교반하며 실온에서 15분 동안 항온처리하였다. 이어서 항온처리된 혼합물을 10,000xg에서 10분 동안 회전시켰다. 상층액을 효소 공급원으로서 사용하였다. 당해 추출물 30㎕을 4-12% NuPAGE 겔(invitrogen) 상에 적재하였고, NuPAGE MES 진행 완충액(invitrogen)에서 분리하였다. 단백질을 니트로셀룰로스 막 상에 블롯팅하였고 상기한 특이적 항체 이후 알칼리성 포스파타제를 접합시킨 토끼 항염소 IgG(H+L)를 사용하는 확정된 프로토콜에 따라 웨스턴 블롯 분석을 수행하였다. 알칼리성 포스파타제 활성은 제조사[Moss Inc.]의 즉석사용 BCIP/MBT(plus) 기질과 함께 막을 항온처리하여 검출하였다. Extraction and Detection of CbhI from Corn Powder: Polyclonal antibodies against CbhI and CbhII were prepared in goats according to established protocols. Powders from CbhI transgenic seeds were obtained by grinding them in an Autogizer polisher. Approximately 50 mg of powder was resuspended in 0.5 ml of 20 mM NaPO 4 buffer, pH 7.4, 150 mM NaCl, and then incubated for 15 minutes at room temperature with continued stirring. The incubated mixture was then spun at 10,000 × g for 10 minutes. Supernatant was used as the enzyme source. 30 μl of this extract was loaded on a 4-12% NuPAGE gel (invitrogen) and isolated in NuPAGE MES running buffer (invitrogen). Proteins were blotted onto nitrocellulose membranes and Western blot analysis was performed according to a confirmed protocol using rabbit anti-chlorine IgG (H + L) conjugated with alkaline phosphatase following the specific antibodies described above. Alkaline phosphatase activity was detected by incubating the membrane with a ready-made BCIP / MBT (plus) substrate from Moss Inc.
웨스턴 블롯 분석은 플라스미드 12390으로 형질전환시킨 상이한 결과물로부터의 T1 종자에 대하여 수행하였다. CbhI 단백질의 발현을 비-형질전환 대조군과 비교하였고, 다수의 결과물에서 검출되었다. Western blot analysis was performed on T1 seeds from different results transformed with plasmid 12390. Expression of CbhI protein was compared to non-transformation control and detected in a number of results.
균열된 옥수수 검정을 Cnhi를 발현하는 형질전환 종자를 사용하여, 근본적으로 실시예 49에 기술된 바와 같이 수행하였다. 형질전환 종자로부터의 전분 회수를 측정하였고, 그 결과는 표 24에 진술되어 있다. A cracked maize assay was performed essentially as described in Example 49, using transformed seeds expressing Cnhi. Starch recovery from the transgenic seeds was measured and the results are stated in Table 24.
실시예 59Example 59
엔도글루카나제 I 작제물의 제조Preparation of Endoglucanase I Constructs
트리코더마 리세이 엔도글루카나제 I(EGLI) 유전자를 공개된 데이타베이스 서열{수탁 번호 제M15665호; 문헌[참조: Penttila et al., 1986]}을 기초로 하여 증폭하고 PCR에 의해 클로닝하였다. 오직 게놈 서열만 수득할 수 있기 때문에, 중첩 PCR을 사용하여 2개 인트론을 제거하여 게놈 서열로부터 cDNA를 제조하였다. 수득된 cDNA 서열을 SignalP 프로그램을 사용하여 시그날 서열의 존재에 대하여 분석하였고, 이는 22개 아미노산 시그날 서열을 예측하였다. 시그날 서열을 암호화하는 DNA 서열을 당해 서열(서열번호 83)로 나타내어진 바와 같이, PCR에 의해 ATC로 치환하였다. 당해 cDNA 서열을 사용하여 다음에 기술된 바와 같은 연속한 작제물을 제조하였다. The Trichoderma Reese endoglucanase I (EGLI) gene is disclosed in published database sequences (Accession No. M15665; Based on Penttila et al., 1986, it was amplified and cloned by PCR. Since only genomic sequences can be obtained, cDNA was prepared from genomic sequences by removing two introns using overlapping PCR. The cDNA sequences obtained were analyzed for the presence of signal sequences using the SignalP program, which predicted 22 amino acid signal sequences. The DNA sequence encoding the signal sequence was replaced with ATC by PCR as shown by the sequence (SEQ ID NO: 83). This cDNA sequence was used to prepare a continuous construct as described below.
중첩 PCRNested PCR
중첩 PCR은 2개 이상의 PCR 생성물의 상보적 말단을 융합하기 위해 사용하는 기법(문헌[참조: Ho et al., 1989])이며, 염기쌍(bp) 변화를 가하고, bp를 첨가하거나 bp를 절단하는 데 사용할 수 있다. 의도한 bp 변화의 위치에서, 의도한 변화 및 변화의 각 측면 상의 15bp 서열을 포함하는 전향 및 역 돌연변이 프라이머(Mut-F 및 Mut-R)를 제조한다. 예를 들면, 인트론을 제거하기 위해, 프라이머는 엑손 2의 최초 15bp에 융합된 엑손 1의 최종 15bp로 이루어져야 할 것이다. 또한 증폭시킬 서열의 말단에 어닐링하는 프라이머를 제조한다(예를 들면, ATG 및 종결 코돈 프라이머). 당해 생성물의 PCR 증폭은 독립적 반응에서 ATG/Mut-R 프라이머 쌍 및 Mut-F/종결 프라이머로 진행시킨다. 당해 생성물을 겔 정제하고 프라이머 첨가 없이 PCR에서 함께 융합시킨다. 당해 융합 반응물을 겔에서 분리하고, 올바른 크기의 밴드를 겔 정제 및 클로닝한다. 다중 변화는 추가의 돌연변이성 프라이머 쌍을 첨가하여 동시에 달성할 수 있다.Nested PCR is a technique used to fuse the complementary ends of two or more PCR products (Ho et al., 1989), adding base pair (bp) changes, adding bp or cutting bp Can be used to At the location of the intended bp change, forward and reverse mutant primers (Mut-F and Mut-R) are prepared comprising the 15 bp sequence on each side of the intended change and change. For example, to remove introns, the primer would have to consist of the last 15 bp of
EGLI 식물 발현 작제물EGLI Plant Expression Constructs
다음과 같이 옥수수 내배유 내에서 트리코더마 리세이 EGLI cDNA를 발현하기 위해 발현 카세트를 제조하였다.An expression cassette was prepared to express Trichoderma Reese EGLI cDNA in corn endosperm as follows.
13025는 세포질 국소화 및 내배유 내에서의 특이적 발현을 위해 γ 제인 프로모터 뒤로 클로닝한 티. 리세이 EGLI 유전자를 포함한다. 13025 was cloned after the γ zein promoter for cytoplasmic localization and specific expression in endocrine. Contains the assay EGLI gene.
13026은 세포질세망으로의 표적화 및 아포플라스트 내로의 분비를 위해 티. 리세이 EGLI 유전자에 융합시킨 옥수수 γ-제인 N-말단 시그날 펩타이드(MRLLVALALLALAASATS)를 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 감마 제인 프로모터 뒤로 클로닝하였다. 13026 is used for targeting to cytoplasmic reticulum and secretion into apoplasts. N-terminal signal peptide (MRLLVALALLALAASATS), a corn γ-agent fused to the Risei EGLI gene. This fusion was cloned behind the corn gamma agent promoter for specific expression in endocrine.
13027은 세포질세망(ER)로의 표적화 및 그 내에서의 체류를 위해 서열 KDEL의 C-말단 첨가물을 갖는 티. 리세이 EGLI 유전자에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 감마 제인 프로모터 뒤로 클로닝하였다. 13027 contains a C. terminal addition of the sequence KDEL for targeting to and retention within cytoplasmic reticulum (ER). N-terminal signal sequence, a maize γ-agent fused to the Risei EGLI gene. This fusion was cloned behind the gamma agent promoter for specific expression in endocrine.
13028은 전분체의 내강으로의 효적 설정을 위해 티. 리세이 EGLI 유전자에 융합시킨 옥수수 과립 결합 전분 신타제 I(GBSSI) N-말단 시그날 펩타이드(N-말단 77개 아미노산)를 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ 제인 프로모터 뒤로 클로닝하였다. 13028 is used to establish the efficacy of the starch in the lumen. Corn granules bound starch synthase I (GBSSI) N-terminal signal peptide (N-terminal 77 amino acids) fused to the Risei EGLI gene. This fusion was cloned behind the corn γ zein promoter for specific expression in endocrine.
13029는 전분 과립으로의 표적화을 위해 옥수수 GBSSI 유전자의 전분 결합 도메인(C-말단 301개 아미노산)의 C-말단 첨가와 함께, 티. 리세이 EGLI 유전자에 융합시킨 옥수수 GBSSI N-말단 시그날 펩타이드를 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. 13029, with the C-terminal addition of the starch binding domain (C-terminal 301 amino acids) of the corn GBSSI gene, for targeting to starch granules. Corn GBSSI N-terminal signal peptide fused to the Risei EGLI gene. This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
추가의 발현 카세트는 EGLI(서열번호 95)의 옥수수 최적화 형을 사용하여 제조한다.Additional expression cassettes are prepared using a corn optimized form of EGLI (SEQ ID NO: 95).
EGLI 효소 검정EGLI enzyme assay
EGLI 효소 활성을 말트 베타-글루카나제 검정 킷트(카탈로그 번호 제K-MBGL호)(제조사[Megazyme International Ireland Ltd.])를 사용하여 옥수수 형질전환체에서 측정한다. EGLI 발현자의 효소 활성은 실시예 53에 기술된 바와 같이 옥수수 섬유 가수분해 검정으로 검사한다. EGLI enzyme activity is measured in maize transformants using the Malt beta-glucanase assay kit (Cat. No. K-MBGL) (Megazyme International Ireland Ltd.). Enzymatic activity of the EGLI expresser is examined by a corn fiber hydrolysis assay as described in Example 53.
실시예 60Example 60
β-글루코시다제 2β-
트리코더마 리세이 β-글루코시다제 2(BGL2) 유전자를 서열 수탁번호 제AB003110호를 기초로 하여 RT-PCR로 증폭 및 클로닝하였다(문헌[참조: Takashima et al., 1999]).The Tricoderma Reese β-glucosidase 2 (BGL2) gene was amplified and cloned by RT-PCR based on SEQ ID NO: AB003110 (Takashima et al., 1999).
BGL2 식물 발현 작제물BGL2 Plant Expression Construct
다음과 같이 옥수수 내배유 내에서 트리코더마 리세이 BGL2 cDNA(서열번호 89)를 발현하기 위해 발현 카세트를 제조하였다.An expression cassette was prepared to express Trichoderma Reese BGL2 cDNA (SEQ ID NO: 89) in corn endosperm as follows.
13030은 세포질 국소화 및 내배유 내에서의 특이적 발현을 위해 γ 제인 프로모터 뒤로 클로닝한 티. 리세이 BGL2 유전자를 포함한다. 13030 was cloned behind the γ zein promoter for cytoplasmic localization and specific expression in endocrine. Contains the assay BGL2 gene.
13031은 세포질세망으로의 표적화 및 아포플라스트 내로의 분비를 위해 티. 리세이 BGL2 유전자에 융합시킨 옥수수 γ-제인 N-말단 시그날 펩타이드(MRLLVALALLALAASATS)를 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 감마 제인 프로모터 뒤로 클로닝하였다. 13031 is used for targeting to cytoplasmic reticulum and secretion into apoplasts. N-terminal signal peptide (MRLLVALALLALAASATS), a corn γ-agent fused to the Reese BGL2 gene. This fusion was cloned behind the corn gamma agent promoter for specific expression in endocrine.
13032는 세포질세망으로의 표적화 및 그 내에서의 체류를 위해 서열 KDEL의 C-말단 첨가물을 갖는 티. 리세이 BGL2 유전자에 융합시킨 옥수수 γ-제인 N-말단 시그날 서열을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 감마 제인 프로모터 뒤로 클로닝하였다. 13032 contains a C. terminal addition of the sequence KDEL for targeting to and retention therein. N-terminal signal sequence, a maize γ-agent fused to the Risei BGL2 gene. This fusion was cloned behind the gamma agent promoter for specific expression in endocrine.
13033은 전분체의 내강으로의 효적 설정을 위해 티. 리세이 BGL2 유전자에 융합시킨 옥수수 과립 결합 전분 신타제 I(GBSSI) N-말단 시그날 펩타이드(N-말단 77개 아미노산)을 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ 제인 프로모터 뒤로 클로닝하였다. 13033 is used to establish the efficacy of the starch in the lumen. Corn granules bound starch synthase I (GBSSI) N-terminal signal peptide (N-terminal 77 amino acids) fused to the Reese BGL2 gene. This fusion was cloned behind the corn γ zein promoter for specific expression in endocrine.
13034는 전분 과립으로의 표적화을 위해 옥수수 GBSSI 유전자의 전분 결합 도메인(C-말단 301개 아미노산)의 C-말단 첨가와 함께, 티. 리세이 BGL2 유전자에 융합시킨 옥수수 GBSSI N-말단 시그날 펩타이드를 포함한다. 당해 융합물을 내배유 내에서의 특이적 발현을 위해 옥수수 γ-제인 프로모터 뒤로 클로닝하였다. 13034, with the C-terminal addition of the starch binding domain (C-terminal 301 amino acids) of the corn GBSSI gene, for targeting to starch granules. Corn GBSSI N-terminal signal peptide fused to the Reese BGL2 gene. This fusion was cloned behind the corn γ-zein promoter for specific expression in endocrine.
추가의 발현 카세트는 BGL2(서열번호 96)의 옥수수 최적화 형을 치환하여 제조한다.Additional expression cassettes are prepared by substituting the corn optimized form of BGL2 (SEQ ID NO: 96).
애그로박테리움 감염을 통한 옥수수 내로의 형질전환을 위해 모든 발현 카세트를 이원 벡터(pNOV2117)로 삽입하였다. 이원 벡터는 만노즈를 갖는 형질전환 세포의 선별을 가능하게 하는 포스포만노즈 이소머라제(PMI) 유전자를 포함하였다. 형질전환 옥수수 식물을 자가-수분 또는 이계교배하였고, 분석을 위해 종자를 수거하였다. All expression cassettes were inserted into the binary vector (pNOV2117) for transformation into maize via Agrobacterium infection. The binary vector contained a phosphomannose isomerase (PMI) gene that allows the selection of transformed cells with mannose. Transformed corn plants were self-pollinated or crossbred and seeds were harvested for analysis.
BGL2 효소 검정BGL2 Enzyme Assay
BGL2 효소 검정은 저자 Bauer와 Kelly가 변형한 프로토콜(문헌[참조: Bauer, M.W. and Keely, R.M. 1998. The family 1 β-glucosidases from Pyrococcus furiosus and Agrobacterium faecalis share a common catalytic mechanism. Biochemistry 37: 17170-17178])을 사용하여 형질전환 옥수수에서 측정하였다. 당해 프로토콜은 100℃ 대신 37℃에서 샘플을 항온처리하도록 변형할 수 있다. BGL2-발현자의 효소 활성은 섬유 가수분해 검정으로 검사한다. The BGL2 enzyme assay is a protocol modified by the author Bauer and Kelly (Bauder, MW and Keely, RM 1998. The
실시예 61Example 61
β-글루코시다제 Dβ-glucosidase D
트리코더마 리세이 β-글루코시다제 D(CEL3D) 유전자를 공개된 데이타베이스 서열{수탁 번호 제AY281378호; 문헌[참조: Foreman et al., 2003]}을 기초로 하여 증폭하고 PCR에 의해 클로닝하였다. 오직 게놈 서열만 수득할 수 있기 때문에, 실시예 58에 기술된 바와 같이, 중첩 PCR을 사용하여 인트론을 제거하여 게놈 서열로부터 cDNA를 제조하였다. 수득된 cDNA(서열번호 91)를 연속한 작제물을 위하여 사용할 수 있다. 수득된 cDNA의 옥수수 최적화 형(서열번호 97)을 또한 작제물을 위하여 사용할 수 있다. Trichoderma lysase β-glucosidase D (CEL3D) gene is disclosed in published database sequences (Accession No. AY281378; Amplification was based on Foreman et al., 2003 and cloned by PCR. Since only genomic sequences can be obtained, as described in Example 58, cDNA was prepared from genomic sequences by removing introns using overlapping PCR. The cDNA obtained (SEQ ID NO: 91) can be used for successive constructs. The corn optimized form of the obtained cDNA (SEQ ID NO: 97) can also be used for the construct.
식물 작제물을 제조하고 BGL2를 CEL3D로 대체하여, 실시예 60에 BGL2에 대하여 기술된 바와 같이 β-글루코시다제 검정을 수행할 수 있다. Plant constructs can be prepared and BGL2 replaced with CEL3D to perform the β-glucosidase assay as described for BGL2 in Example 60.
실시예 62Example 62
리파제Lipase
리파제를 암호화하는 cDNA를 수탁 번호 제D85895호, 제AF04488호 및 제AF04489호(문헌[참조: Tsuchiya et al., 1996; Yu et al., 2003])으로부터의 서열 및 실시예 59-60에 기술된 방법론을 사용하여 제조한다.CDNA encoding lipases are described in SEQ ID NOs: D85895, AF04488 and AF04489 (Tsuchiya et al., 1996; Yu et al., 2003) and sequences 59-60 It is prepared using the methodology.
리파제 효소 활성은 형광 리파제 검정 킷트(카탈로그 번호 제M0612호)(제조사[Maker Gene Technologies, Inc.])를 사용하여 형질전환 옥수수에서 측정할 수 있다. 또한 리파제 활성은 형광 기질 1, 2-디올레오일-3-(피렌-1-일)데카노일-rac-글리세롤(M0258)(또한 제조사[Maker Gene Technologies, Inc.] 제품)을 사용하여 생체 내에서 측정할 수 있다. Lipase enzyme activity can be measured in transgenic maize using a fluorescent lipase assay kit (Cat. No. M0612) (Maker Gene Technologies, Inc.). Lipase activity was also determined in vivo using
실시예 63Example 63
벼에서의 피타제의 발현Expression of phytase in rice
벡터 11267 및 11268은 Nov9x 피타제를 암호화하는 이원 벡터를 포함한다. 벡터 둘 다에서의 Nov9x 피타제의 발현은 벼 글루텔린-1- 프로모터(서열번호 67)의 제어 하에 둔다. 벡터 11267 및 11268은 pNOV2117로부터 유래한 것이다. Vectors 11267 and 11268 contain binary vectors encoding Nov9x phytase. Expression of Nov9x phytase in both vectors is under the control of the rice glutelin-1 promoter (SEQ ID NO: 67). Vectors 11267 and 11268 are from pNOV2117.
벡터 11267 내의 Nov9x 피타제 발현 카세트는 벼 글루텔린-1 프로모터, 아포플라스트 표적화 시그날을 갖는 Nov9x 피타제 유전자, PEPC 인트론 및 35S 종결자를 포함한다. 벡터 11267 내의 Nov9x 피타제 암호화 서열의 생성물은 서열번호 110으로 나타내어져 있다. The Nov9x phytase expression cassette in vector 11267 includes a rice glutelin-1 promoter, a Nov9x phytase gene with an apoplast targeting signal, a PEPC intron and a 35S terminator. The product of the Nov9x phytase coding sequence in vector 11267 is shown by SEQ ID NO: 110.
벡터 11268 내의 Nov9x 피타제 발현 카세트는 벼 글루텔린-1 프로모터, ER 체류를 갖는 Nov9x 피타제 유전자(서열번호 111), PEPC 인트론 및 35S 종결자를 포함한다. 벡터 11268 내의 Nov9x 피타제 암호화 서열의 생성물은 서열번호 112로 나타내어져 있다. The Nov9x phytase expression cassette in vector 11268 includes a rice glutelin-1 promoter, a Nov9x phytase gene with ER retention (SEQ ID NO: 111), a PEPC intron and a 35S terminator. The product of the Nov9x phytase coding sequence in vector 11268 is shown as SEQ ID NO: 112.
아포플라스트 표적화 DNA 서열(서열번호 109)을 갖는 11267 Nov9x 피타제. 해독 출발 및 종결 코돈은 밑줄이 그어져 있다. 27-kD 감마-제인 단백질의 시그날 서열을 암호화하는 서열은 볼드체로 나타내어져 있다. 11267 Nov9x phytase with apoplast targeting DNA sequence (SEQ ID NO: 109). Detoxification start and stop codons are underlined. Sequences encoding the signal sequence of the 27-kD gamma-zein protein are shown in bold.

아포플라스트 표적화 유전자 생성물(서열번호 110)을 갖는 11267 Nov9x 피타제. 27-kD 감마-제인 단백질의 시그날 서열은 볼드체로 나타내어져 있다. 11267 Nov9x phytase with apoplast targeting gene product (SEQ ID NO: 110). The signal sequence of the 27-kD gamma-zein protein is shown in bold.

ER 체류 DNA 서열(서열번호 111)을 갖는 11268 Nov9x 피타제. 27-kD 감마-제인 단백질의 시그날 서열을 암호화하는 서열은 볼드체로 나타내어져 있다. SEKDEK 헥사펩타이드 ER 체류 시그날을 암호화하는 서열은 밑줄이 그어져 있다. 11268 Nov9x phytase with ER retention DNA sequence (SEQ ID NO: 111). Sequences encoding the signal sequence of the 27-kD gamma-zein protein are shown in bold. The sequence encoding the SEKDEK hexapeptide ER retention signal is underlined.
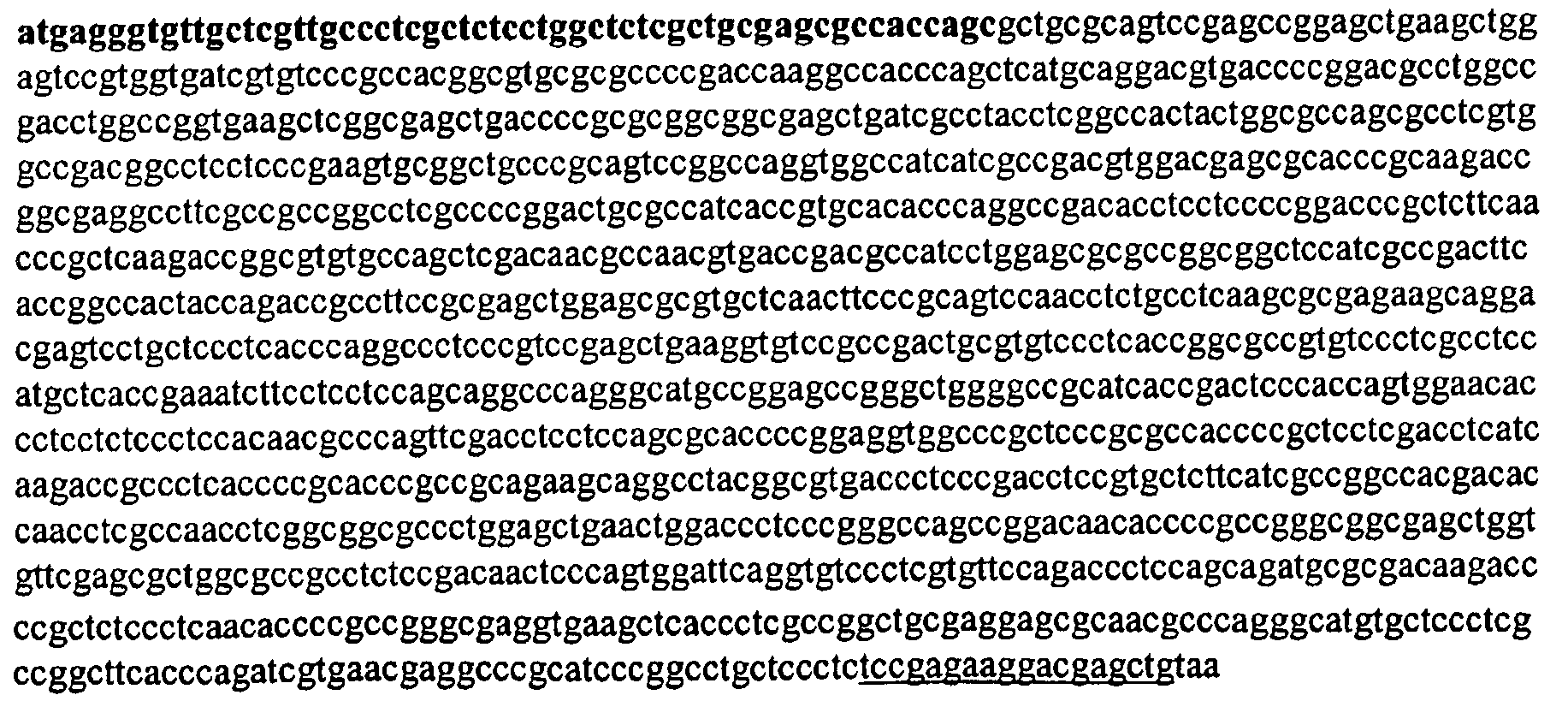
ER 체류 서열을 갖는 11268 Nov9x 피타제, 유전자 생성물(서열번호 112). 27-kD 감마-제인 단백질의 시그날 서열은 볼드체로 나타내어져 있다. ER 체류 시그날은 밑줄이 그어져 있다.11268 Nov9x phytase, gene product with ER retention sequence (SEQ ID NO: 112). The signal sequence of the 27-kD gamma-zein protein is shown in bold. The ER retention signal is underlined.

형질전환 벼 식물의 제조Preparation of Transgenic Rice Plants
벼(오리재 사티바)를 형질전환된 식물 제조를 위해 사용한다. 각종 벼 재배변종식물을 사용할 수 있다(Hiei et al., 1994, Plant Journal 6: 271-282; Dong et al., 1996, Molecular Breeding 2:267- 276; Hiei et al., 1997, Plant Molecular Biology, 35: 205-218]). 또한, 하기한 각종 배지 성분은 농도가 다양할 수 있거나 치환시킬 수 있다. 배발생 반응을 개시하고/거나 MS-CIM 배지(MS 기본 염, 4.3g/리터; B5 비타민(200x), 5ml/리터; 슈크로즈, 30g/리터; 프롤린, 500mg/리터; 글루타민, 500mg/리터; 카세인 가수분해물, 300mg/리터; 2,4-D(1mg/ml), 2ml/리터; 1N KOH로 pH 5.8로 조정; 피타겔, 3g/리터) 상에서 배양하여 성숙한 배아로부터 배양물을 수득한다. 배양 반응의 초기 단계에서의 성숙 배아 또는 수득된 배양물 주를 접종하고 목적하는 벡터 작제물을 포함하는 애그로박테리움 균주 LBA4404와 함께 동시-배양한다. 애그로박테리움은 고체 YPC 배지(100mg/L 스펙티노마이신 및 임의의 기타 적합한 항생제) 상에서 글리세롤 모액으로부터 ~2일 동안 28℃에서 배양한다. 애그로박테리움을 액체 MS-CIM 배지에 재 현탁한다. 애그로박테리움 배양물을 0.2 내지 0.3의 OD600으로 희석하고, 아세토시린곤을 200 uM의 최종 농도로 첨가한다. 애그로박테리움을 아세토시린곤으로 유도한 후 당해 용액을 벼 배양물과 혼합한다. 접종을 위해, 배양물을 세균 현탁액에 침윤시킨다. 액체 세균 현탁액을 제거하고 접종된 배양물을 동시-배양 배지 상에 두고, 22℃에서 2일 동안 항온처리한다. 이어서 배양물을 티카르실린(400mg/리터)을 갖는 MS-CIM 배지로 옮겨 애그로박테리움의 성장을 억제한다. PMI 선별 마커 유전자(문헌[참조: Reed et al., In Vitro Cell. Dev. Biol.-Plant 37: 127-132])를 사용하는 작제물에 대하여, 배양물을 7일 후에 탄수화물 공급원(2% 만노즈, 300mg/리터 티카르실린을 갖는 MS)로서 만노즈를 함유하는 선별 배지로 옮기고, 암실에서 3주 내지 4주 동안 배양한다. 이어서 내성 콜로니를 재생 유도 배지(2,4-D가 없고, 0.5mg/리터 IAA, 1mg/리터 지아틴, 200mg/리터 티카르실린, 2% 만노즈 및 3% 소르비톨을 갖는 MS)로 옮기고 암실에서 14일 동안 배양한다. 이어서 증식중인 콜로니를 다른 원형의 재생 유도 배지로 옮기고 광원 배양실로 옮긴다. 재생된 순을 2주 동안 GA7-1 배지(호르몬이 없고 2% 소르비톨을 갖는 MS)로 옮긴 후 이들이 충분히 크고 적합한 뿌리를 가진 경우, 온실로 옮긴다. 식물을 온실의 토양에 심고 성숙시까지 배양한다. Rice (duck sativa) is used for the production of transformed plants. Various rice cultivars may be used (Hiei et al., 1994, Plant Journal 6: 271-282; Dong et al., 1996, Molecular Breeding 2: 267-276; Hiei et al., 1997, Plant Molecular Biology , 35: 205-218]. In addition, the various media components described below may vary in concentration or may be substituted. Initiate the embryogenic reaction and / or MS-CIM medium (MS base salt, 4.3 g / liter; B5 vitamin (200 ×), 5 ml / liter; sucrose, 30 g / liter; proline, 500 mg / liter; glutamine, 500 mg / liter) ; Casein hydrolysate, 300 mg / liter; 2,4-D (1 mg / ml), 2 ml / liter; adjusted to pH 5.8 with 1N KOH; phytagel, 3 g / liter) to obtain a culture from mature embryos . Mature embryos or obtained culture strains at the initial stage of the culture reaction are inoculated and co-cultured with Agrobacterium strain LBA4404 comprising the desired vector construct. Agrobacterium is incubated at 28 ° C. for ˜2 days from glycerol mother liquor on solid YPC medium (100 mg / L spectinomycin and any other suitable antibiotic). Agrobacterium is resuspended in liquid MS-CIM medium. Agrobacterium culture is diluted with an OD600 of 0.2-0.3 and acetosyringone is added at a final concentration of 200 uM. After Agrobacterium is induced with acetosyringone, the solution is mixed with rice culture. For inoculation, cultures are infiltrated with bacterial suspensions. The liquid bacterial suspension is removed and the inoculated culture is placed on co-culture medium and incubated at 22 ° C. for 2 days. The culture is then transferred to MS-CIM medium with ticarcillin (400 mg / liter) to inhibit the growth of Agrobacterium. For constructs using the PMI selectable marker gene (Reed et al., In Vitro Cell. Dev. Biol.-Plant 37: 127-132), the cultures were subjected to a carbohydrate source (2%) after 7 days. Mannose, MS with 300 mg / liter ticarcillin) is transferred to selection medium containing mannose and incubated in the dark for 3-4 weeks. Resistant colonies were then transferred to regeneration induction medium (MS without 2,4-D, 0.5 mg / liter IAA, 1 mg / liter gelatin, 200 mg / liter ticarcillin, 2% mannose and 3% sorbitol) and dark Incubate for 14 days at. Proliferating colonies are then transferred to another circular regeneration induction medium and transferred to the light source culture chamber. The regenerated shoots are transferred to GA7-1 medium (MS without hormones and with 2% sorbitol) for 2 weeks and then transferred to the greenhouse if they are large enough and have suitable roots. Plants are planted in soil in a greenhouse and incubated until maturity.
실시예 64Example 64
Nov9X 피타제를 발현하는 형질전환 벼 종자의 분석 Analysis of Transgenic Rice Seeds Expressing Nov9X Phytase
벼 종자로부터의 Nov9X 피타제의 정량화를 위한 ELISAELISA for Quantification of Nov9X Phytase from Rice Seeds
형질전환 벼 시에서 발현되는 피타제의 정량화를 ELISA로 검정하였다. 하나(1g)의 벼 종자를 Kleco 종자 연마기에서 분말로 연마하였다. 분말 50mg을 Nov9X 피타제 활성 검정을 위한 실시예에 기술한 아세트산나트륨 완충액에 재현탁하고 면역검정에 필요한 만큼 희석하였다. Nov9X 면역검정은 2개의 폴리클로날 항체를 사용하는 피타제의 검출용 정량적 샌드위치 검정이다. 토끼 항체를 단백질 A를 사용하여 정제하였고, 염소 항체는 이. 콜라이 봉입체에서 제조된 재조합체 피타제(Nov9X) 단백질에 대하여 정제되는 면역친화성을 가졌다. 이들 고도의 특이적 항체를 사용하여, 검정은 형질전환된 식물에서 피타제의 피코그램 수준을 측정할 수 있다. 검정에 대한 3가지의 기본 부분이 있다. 샘플 중의 피타제 단백질을 토끼 항체를 사용하여 고체 상 미세역가 웰 상에서 포획한다. 이어서 고체 상 항체, 피타제 단백질 및 웰에 첨가된 제2의 항체 사이에 "샌드위치"를 형성한다. 세척 단계 후, 결합하지 않은 제2의 항체는 제거하고, 결합한 항체를 알칼리성 포스파타제-라벨링된 항체를 사용하여 검출한다. 효소에 대한 기질을 첨가하고, 색 발현을 각각의 웰의 흡광도를 읽어 측정한다. 표준 곡선은 농도 대 흡광도를 좌표에 나타내기 위해 4개-매개변수 곡선 적합도를 사용한다. Quantification of phytase expressed in transgenic rice was assayed by ELISA. One (1 g) rice seed was ground to powder in a Kleco seed grinder. 50 mg of powder was resuspended in sodium acetate buffer described in the Example for Nov9X Phytase Activity Assay and diluted as needed for immunoassay. Nov9X immunoassay is a quantitative sandwich assay for the detection of phytase using two polyclonal antibodies. Rabbit antibodies were purified using Protein A, goat antibodies were E. coli. It had purified immunoaffinity against recombinant phytase (Nov9X) protein prepared in E. coli inclusions. Using these highly specific antibodies, the assay can measure picogram levels of phytase in transformed plants. There are three basic parts to the test. The phytase protein in the sample is captured on solid phase microtiter wells using rabbit antibodies. A "sandwich" is then formed between the solid phase antibody, the phytase protein and the second antibody added to the wells. After the washing step, the unbound second antibody is removed and the bound antibody is detected using alkaline phosphatase-labeled antibody. Substrates for enzymes are added and color expression is measured by reading the absorbance of each well. The standard curve uses a four-parameter curve fit to plot concentration versus absorbance.
피타제 활성 검정Phytase activity assay
피트산의 가수분해시 방출된 무기 인산염의 추정을 기초로 한, 피타제 활성의 측정은 문헌[참조: Engelen, A.J. et al., J. AOAC, Inter., 84, 629(2001)]의 방법에 따라 37℃에서 수행할 수 있다. 효소 활성의 1 단위는 검정 조건하에서 분당 무기 인산염 1μmol을 유리하는 효소의 양으로 정의된다. 예를 들면, 효소 제제 2.0ml을 1mM CaCl2를 첨가한 pH 5.5의 250mM 아세트산나트륨 완충액 중 9.1mM 피트산나트륨 4.0ml과 함께 37℃에서 60분 동안 항온처리하여, 피타제 활성을 측정할 수 있다. 항온처리 후, 동량 부의 10%(w/v) 몰리브덴산암모늄 및 0.235%(w/v) 바나드산암모늄 모액으로 이루어진 색-종결 시약 4.0ml을 첨가하여 반응을 종결시킨다. 침전물은 원심분리하여 제거하고, 방출된 인삼염은 415nm에서 인산염 표준의 세트에 대하여 분광측정법으로 측정한다. 피타제 활성은 산출된 인산염 표준 곡선을 사용하여 피타제 함유 샘플로부터 수득한 A415nm 흡광도 수치를 삽입하여 계산한다. Determination of phytase activity, based on the estimation of inorganic phosphate released upon hydrolysis of phytic acid, is described by Engelen, A.J. et al., J. AOAC, Inter., 84, 629 (2001)]. One unit of enzyme activity is defined as the amount of enzyme that liberates 1 μmol of inorganic phosphate per minute under assay conditions. For example, 2.0 ml of enzyme preparation can be incubated at 37 ° C. for 60 minutes with 4.0 ml of 9.1 mM sodium phytate in 250 mM sodium acetate buffer at pH 5.5 with 1
당해 과정은 보다 적은 용적을 조정하기 위해 규모를 축소하고 바람직한 용기로 조절할 수 있다. 바람직한 용기에는 유리 검사 튜브 및 플라스틱 미세플레이트가 포함된다. 수욕에서 반응 용기(들)를 부분적으로 침수시키는 것은 효소 반응 중 일정한 온도를 유지하는 데 필수적이다. The process can be scaled down and adjusted to the desired container to adjust for smaller volumes. Preferred containers include glass test tubes and plastic microplates. Partial immersion of the reaction vessel (s) in the water bath is essential to maintain a constant temperature during the enzymatic reaction.
피타제를 발현하는 형질전환 벼의 조리 중 무기 인산염 방출의 검정Assay of Inorganic Phosphate Release in Cooked Transgenic Rice Expressing Phytase
선택된 벼 형질전환 주 및 대조군 야생형 주로부터의 종자 1g의 2가지 샘플을 benchtop Kett TR200 자동 벼 탈피기를 사용하여 탈피하였다. 이어서 1개의 샘플을 Kett 벼 정미기에서 30초 동안 정미하였다. 2 용적의 H2O를 각각의 샘플에 첨가하였고, 튜브를 물이 담긴 비커로 침윤시켜 벼를 조리하였다. 물을 끓이고 10분 동안 총 회전 비등으로 유지하였다. 이어서 "조리된" 벼 종자를 te 슬러리의 총 용적이 6ml에 이르게 하는 수분을 함유한 페이스트로 연마하였다. 당해 슬러리를 15,000xg에서 10분 동안 원심분리하였고, 맑은 상층액을 방출된 내인성 무기 인산염에 대하여 검정하였다. 방출된 인산염의 검정은 무기 인산염과 착화시킨 몰리브덴산염 및 바나드산염 이온의 결과로서 색 형성을 기초로 하며, 피타제 효소 활성에 대한 실시예에 기술된 바와 같이 415nm에서 분광측정법으로 측정한다. 당해 결과는 표 24에 나타내어져 있다. Two samples of 1 g of seed from selected rice transgenic and control wild-type strains were stripped using a benchtop Kett TR200 automatic rice peeler. One sample was then polished for 30 seconds in a Kett rice mill. Two volumes of H 2 O were added to each sample, and the rice was cooked by infiltrating the tube with a beaker containing water. The water was boiled and kept at total rotary boiling for 10 minutes. The “cooked” rice seeds were then ground with a water-containing paste that brought the total volume of the te slurry to 6 ml. The slurry was centrifuged at 15,000 × g for 10 minutes and the clear supernatant was assayed for released endogenous inorganic phosphate. The assay of the released phosphate is based on color formation as a result of molybdate and vanadate ions complexed with inorganic phosphate and is measured spectrophotometrically at 415 nm as described in the Examples for Phytase Enzyme Activity. The results are shown in Table 24.
모든 문헌, 특허 및 특허원은 본원에 참조로 인용되어 있다. 전술한 명세서에 본 발명이 이의 특정한 바람직한 양태에 관하여 기술되어 있지만, 많은 세부 사항은 예시의 목적으로 진술한 것이며, 당해 분야의 숙련가는 본 발명이 부가적 양태에 대한 여지가 있으며 본원에 기술된 특정한 세부 사항은 본 발명의 기본 원리에서 벗어나지 않으면서 상당히 다양할 수 있음을 이해할 것이다.All documents, patents, and patent applications are incorporated herein by reference. Although the invention has been described in the foregoing specification with reference to certain preferred embodiments thereof, many details are set forth for the purpose of illustration, and one of ordinary skill in the art will appreciate that the invention has room for additional aspects and the specifics described herein. It will be appreciated that the details may vary considerably without departing from the basic principles of the invention.
서열 목록Sequence list











































































































































<110> SYNGENTA PARTICIPATIONS AG
<120> Self-processing plants and plant parts
<130> 109846.317
<160> 112
<170> KopatentIn 1.71
<210> 1
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 1
Met Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met Gln Ala
1 5 10 15
Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr Ile Arg
20 25 30
Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile Trp Ile
35 40 45
Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly Tyr Asp
50 55 60
Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly Thr Val
65 70 75 80
Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile Asn Thr
85 90 95
Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile Asn His
100 105 110
Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp Tyr Thr
115 120 125
Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala Asn Tyr
130 135 140
Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly Thr Phe
145 150 155 160
Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln Tyr Trp
165 170 175
Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser Ile Gly
180 185 190
Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala Trp Val
195 200 205
Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly Glu Tyr
210 215 220
Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser Ser Gly
225 230 235 240
Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala Ala Phe
245 250 255
Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn Gly Gly
260 265 270
Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val Ala Asn
275 280 285
His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala Phe Ile
290 295 300
Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr Glu Glu
305 310 315 320
Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His Asp Asn
325 330 335
Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp Glu Met
340 345 350
Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile Thr Tyr
355 360 365
Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val Pro Lys
370 375 380
Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly Gly Trp
385 390 395 400
Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu Ala Pro
405 410 415
Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp Ser Tyr
420 425 430
Cys Gly Val Gly
435
<210> 2
<211> 1308
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 2
atggccaagt acctggagct ggaggagggc ggcgtgatca tgcaggcgtt ctactgggac 60
gtcccgagcg gaggcatctg gtgggacacc atccgccaga agatccccga gtggtacgac 120
gccggcatct ccgcgatctg gataccgcca gcttccaagg gcatgtccgg gggctactcg 180
atgggctacg acccgtacga ctacttcgac ctcggcgagt actaccagaa gggcacggtg 240
gagacgcgct tcgggtccaa gcaggagctc atcaacatga tcaacacggc gcacgcctac 300
ggcatcaagg tcatcgcgga catcgtgatc aaccacaggg ccggcggcga cctggagtgg 360
aacccgttcg tcggcgacta cacctggacg gacttctcca aggtcgcctc cggcaagtac 420
accgccaact acctcgactt ccaccccaac gagctgcacg cgggcgactc cggcacgttc 480
ggcggctacc cggacatctg ccacgacaag tcctgggacc agtactggct ctgggcctcg 540
caggagtcct acgcggccta cctgcgctcc atcggcatcg acgcgtggcg cttcgactac 600
gtcaagggct acggggcctg ggtggtcaag gactggctca actggtgggg cggctgggcg 660
gtgggcgagt actgggacac caacgtcgac gcgctgctca actgggccta ctcctccggc 720
gccaaggtgt tcgacttccc cctgtactac aagatggacg cggccttcga caacaagaac 780
atcccggcgc tcgtcgaggc cctgaagaac ggcggcacgg tggtctcccg cgacccgttc 840
aaggccgtga ccttcgtcgc caaccacgac acggacatca tctggaacaa gtacccggcg 900
tacgccttca tcctcaccta cgagggccag cccacgatct tctaccgcga ctacgaggag 960
tggctgaaca aggacaagct caagaacctg atctggattc acgacaacct cgcgggcggc 1020
tccactagta tcgtgtacta cgactccgac gagatgatct tcgtccgcaa cggctacggc 1080
tccaagcccg gcctgatcac gtacatcaac ctgggctcct ccaaggtggg ccgctgggtg 1140
tacgtcccga agttcgccgg cgcgtgcatc cacgagtaca ccggcaacct cggcggctgg 1200
gtggacaagt acgtgtactc ctccggctgg gtctacctgg aggccccggc ctacgacccc 1260
gccaacggcc agtacggcta ctccgtgtgg tcctactgcg gcgtcggc 1308
<210> 3
<211> 800
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 3
Met Gly His Trp Tyr Lys His Gln Arg Ala Tyr Gln Phe Thr Gly Glu
1 5 10 15
Asp Asp Phe Gly Lys Val Ala Val Val Lys Leu Pro Met Asp Leu Thr
20 25 30
Lys Val Gly Ile Ile Val Arg Leu Asn Glu Trp Gln Ala Lys Asp Val
35 40 45
Ala Lys Asp Arg Phe Ile Glu Ile Lys Asp Gly Lys Ala Glu Val Trp
50 55 60
Ile Leu Gln Gly Val Glu Glu Ile Phe Tyr Glu Lys Pro Asp Thr Ser
65 70 75 80
Pro Arg Ile Phe Phe Ala Gln Ala Arg Ser Asn Lys Val Ile Glu Ala
85 90 95
Phe Leu Thr Asn Pro Val Asp Thr Lys Lys Lys Glu Leu Phe Lys Val
100 105 110
Thr Val Asp Gly Lys Glu Ile Pro Val Ser Arg Val Glu Lys Ala Asp
115 120 125
Pro Thr Asp Ile Asp Val Thr Asn Tyr Val Arg Ile Val Leu Ser Glu
130 135 140
Ser Leu Lys Glu Glu Asp Leu Arg Lys Asp Val Glu Leu Ile Ile Glu
145 150 155 160
Gly Tyr Lys Pro Ala Arg Val Ile Met Met Glu Ile Leu Asp Asp Tyr
165 170 175
Tyr Tyr Asp Gly Glu Leu Gly Ala Val Tyr Ser Pro Glu Lys Thr Ile
180 185 190
Phe Arg Val Trp Ser Pro Val Ser Lys Trp Val Lys Val Leu Leu Phe
195 200 205
Lys Asn Gly Glu Asp Thr Glu Pro Tyr Gln Val Val Asn Met Glu Tyr
210 215 220
Lys Gly Asn Gly Val Trp Glu Ala Val Val Glu Gly Asp Leu Asp Gly
225 230 235 240
Val Phe Tyr Leu Tyr Gln Leu Glu Asn Tyr Gly Lys Ile Arg Thr Thr
245 250 255
Val Asp Pro Tyr Ser Lys Ala Val Tyr Ala Asn Asn Gln Glu Ser Ala
260 265 270
Val Val Asn Leu Ala Arg Thr Asn Pro Glu Gly Trp Glu Asn Asp Arg
275 280 285
Gly Pro Lys Ile Glu Gly Tyr Glu Asp Ala Ile Ile Tyr Glu Ile His
290 295 300
Ile Ala Asp Ile Thr Gly Leu Glu Asn Ser Gly Val Lys Asn Lys Gly
305 310 315 320
Leu Tyr Leu Gly Leu Thr Glu Glu Asn Thr Lys Gly Pro Gly Gly Val
325 330 335
Thr Thr Gly Leu Ser His Leu Val Glu Leu Gly Val Thr His Val His
340 345 350
Ile Leu Pro Phe Phe Asp Phe Tyr Thr Gly Asp Glu Leu Asp Lys Asp
355 360 365
Phe Glu Lys Tyr Tyr Asn Trp Gly Tyr Asp Pro Tyr Leu Phe Met Val
370 375 380
Pro Glu Gly Arg Tyr Ser Thr Asp Pro Lys Asn Pro His Thr Arg Ile
385 390 395 400
Arg Glu Val Lys Glu Met Val Lys Ala Leu His Lys His Gly Ile Gly
405 410 415
Val Ile Met Asp Met Val Phe Pro His Thr Tyr Gly Ile Gly Glu Leu
420 425 430
Ser Ala Phe Asp Gln Thr Val Pro Tyr Tyr Phe Tyr Arg Ile Asp Lys
435 440 445
Thr Gly Ala Tyr Leu Asn Glu Ser Gly Cys Gly Asn Val Ile Ala Ser
450 455 460
Glu Arg Pro Met Met Arg Lys Phe Ile Val Asp Thr Val Thr Tyr Trp
465 470 475 480
Val Lys Glu Tyr His Ile Asp Gly Phe Arg Phe Asp Gln Met Gly Leu
485 490 495
Ile Asp Lys Lys Thr Met Leu Glu Val Glu Arg Ala Leu His Lys Ile
500 505 510
Asp Pro Thr Ile Ile Leu Tyr Gly Glu Pro Trp Gly Gly Trp Gly Ala
515 520 525
Pro Ile Arg Phe Gly Lys Ser Asp Val Ala Gly Thr His Val Ala Ala
530 535 540
Phe Asn Asp Glu Phe Arg Asp Ala Ile Arg Gly Ser Val Phe Asn Pro
545 550 555 560
Ser Val Lys Gly Phe Val Met Gly Gly Tyr Gly Lys Glu Thr Lys Ile
565 570 575
Lys Arg Gly Val Val Gly Ser Ile Asn Tyr Asp Gly Lys Leu Ile Lys
580 585 590
Ser Phe Ala Leu Asp Pro Glu Glu Thr Ile Asn Tyr Ala Ala Cys His
595 600 605
Asp Asn His Thr Leu Trp Asp Lys Asn Tyr Leu Ala Ala Lys Ala Asp
610 615 620
Lys Lys Lys Glu Trp Thr Glu Glu Glu Leu Lys Asn Ala Gln Lys Leu
625 630 635 640
Ala Gly Ala Ile Leu Leu Thr Ser Gln Gly Val Pro Phe Leu His Gly
645 650 655
Gly Gln Asp Phe Cys Arg Thr Thr Asn Phe Asn Asp Asn Ser Tyr Asn
660 665 670
Ala Pro Ile Ser Ile Asn Gly Phe Asp Tyr Glu Arg Lys Leu Gln Phe
675 680 685
Ile Asp Val Phe Asn Tyr His Lys Gly Leu Ile Lys Leu Arg Lys Glu
690 695 700
His Pro Ala Phe Arg Leu Lys Asn Ala Glu Glu Ile Lys Lys His Leu
705 710 715 720
Glu Phe Leu Pro Gly Gly Arg Arg Ile Val Ala Phe Met Leu Lys Asp
725 730 735
His Ala Gly Gly Asp Pro Trp Lys Asp Ile Val Val Ile Tyr Asn Gly
740 745 750
Asn Leu Glu Lys Thr Thr Tyr Lys Leu Pro Glu Gly Lys Trp Asn Val
755 760 765
Val Val Asn Ser Gln Lys Ala Gly Thr Glu Val Ile Glu Thr Val Glu
770 775 780
Gly Thr Ile Glu Leu Asp Pro Leu Ser Ala Tyr Val Leu Tyr Arg Glu
785 790 795 800
<210> 4
<211> 2400
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 4
atgggccact ggtacaagca ccagcgcgcc taccagttca ccggcgagga cgacttcggg 60
aaggtggccg tggtgaagct cccgatggac ctcaccaagg tgggcatcat cgtgcgcctc 120
aacgagtggc aggcgaagga cgtggccaag gaccgcttca tcgagatcaa ggacggcaag 180
gccgaggtgt ggatactcca gggcgtggag gagatcttct acgagaagcc ggacacctcc 240
ccgcgcatct tcttcgccca ggcccgctcc aacaaggtga tcgaggcctt cctcaccaac 300
ccggtggaca ccaagaagaa ggagctgttc aaggtgaccg tcgacggcaa ggagatcccg 360
gtgtcccgcg tggagaaggc cgacccgacc gacatcgacg tgaccaacta cgtgcgcatc 420
gtgctctccg agtccctcaa ggaggaggac ctccgcaagg acgtggagct gatcatcgag 480
ggctacaagc cggcccgcgt gatcatgatg gagatcctcg acgactacta ctacgacggc 540
gagctggggg cggtgtactc cccggagaag accatcttcc gcgtgtggtc cccggtgtcc 600
aagtgggtga aggtgctcct cttcaagaac ggcgaggaca ccgagccgta ccaggtggtg 660
aacatggagt acaagggcaa cggcgtgtgg gaggccgtgg tggagggcga cctcgacggc 720
gtgttctacc tctaccagct ggagaactac ggcaagatcc gcaccaccgt ggacccgtac 780
tccaaggccg tgtacgccaa caaccaggag tctgcagtgg tgaacctcgc ccgcaccaac 840
ccggagggct gggagaacga ccgcggcccg aagatcgagg gctacgagga cgccatcatc 900
tacgagatcc acatcgccga catcaccggc ctggagaact ccggcgtgaa gaacaagggc 960
ctctacctcg gcctcaccga ggagaacacc aaggccccgg gcggcgtgac caccggcctc 1020
tcccacctcg tggagctggg cgtgacccac gtgcacatcc tcccgttctt cgacttctac 1080
accggcgacg agctggacaa ggacttcgag aagtactaca actggggcta cgacccgtac 1140
ctcttcatgg tgccggaggg ccgctactcc accgacccga agaacccgca cacccgaatt 1200
cgcgaggtga aggagatggt gaaggccctc cacaagcacg gcatcggcgt gatcatggac 1260
atggtgttcc cgcacaccta cggcatcggc gagctgtccg ccttcgacca gaccgtgccg 1320
tactacttct accgcatcga caagaccggc gcctacctca acgagtccgg ctgcggcaac 1380
gtgatcgcct ccgagcgccc gatgatgcgc aagttcatcg tggacaccgt gacctactgg 1440
gtgaaggagt accacatcga cggcttccgc ttcgaccaga tgggcctcat cgacaagaag 1500
accatgctgg aggtggagcg cgccctccac aagatcgacc cgaccatcat cctctacggc 1560
gagccgtggg gcggctgggg ggccccgatc cgcttcggca agtccgacgt ggccggcacc 1620
cacgtggccg ccttcaacga cgagttccgc gacgccatcc gcggctccgt gttcaacccg 1680
tccgtgaagg gcttcgtgat gggcggctac ggcaaggaga ccaagatcaa gcgcggcgtg 1740
gtgggctcca tcaactacga cggcaagctc atcaagtcct tcgccctcga cccggaggag 1800
accatcaact acgccgcctg ccacgacaac cacaccctct gggacaagaa ctacctcgcc 1860
gccaaggccg acaagaagaa ggagtggacc gaggaggagc tgaagaacgc ccagaagctc 1920
gccggcgcca tcctcctcac tagtcagggc gtgccgttcc tccacggcgg ccaggacttc 1980
tgccgcacca ccaacttcaa cgacaactcc tacaacgccc cgatctccat caacggcttc 2040
gactacgagc gcaagctcca gttcatcgac gtgttcaact accacaaggg cctcatcaag 2100
ctccgcaagg agcacccggc cttccgcctc aagaacgccg aggagatcaa gaagcacctg 2160
gagttcctcc cgggcgggcg ccgcatcgtg gccttcatgc tcaaggacca cgccggcggc 2220
gacccgtgga aggacatcgt ggtgatctac aacggcaacc tggagaagac cacctacaag 2280
ctcccggagg gcaagtggaa cgtggtggtg aactcccaga aggccggcac cgaggtgatc 2340
gagaccgtgg agggcaccat cgagctggac ccgctctccg cctacgtgct ctaccgcgag 2400
<210> 5
<211> 693
<212> PRT
<213> Sulfolobus solfataricus
<400> 5
Met Glu Thr Ile Lys Ile Tyr Glu Asn Lys Gly Val Tyr Lys Val Val
1 5 10 15
Ile Gly Glu Pro Phe Pro Pro Ile Glu Phe Pro Leu Glu Gln Lys Ile
20 25 30
Ser Ser Asn Lys Ser Leu Ser Glu Leu Gly Leu Thr Ile Val Gln Gln
35 40 45
Gly Asn Lys Val Ile Val Glu Lys Ser Leu Asp Leu Lys Glu His Ile
50 55 60
Ile Gly Leu Gly Glu Lys Ala Phe Glu Leu Asp Arg Lys Arg Lys Arg
65 70 75 80
Tyr Val Met Tyr Asn Val Asp Ala Gly Ala Tyr Lys Lys Tyr Gln Asp
85 90 95
Pro Leu Tyr Val Ser Ile Pro Leu Phe Ile Ser Val Lys Asp Gly Val
100 105 110
Ala Thr Gly Tyr Phe Phe Asn Ser Ala Ser Lys Val Ile Phe Asp Val
115 120 125
Gly Leu Glu Glu Tyr Asp Lys Val Ile Val Thr Ile Pro Glu Asp Ser
130 135 140
Val Glu Phe Tyr Val Ile Glu Gly Pro Arg Ile Glu Asp Val Leu Glu
145 150 155 160
Lys Tyr Thr Glu Leu Thr Gly Lys Pro Phe Leu Pro Pro Met Trp Ala
165 170 175
Phe Gly Tyr Met Ile Ser Arg Tyr Ser Tyr Tyr Pro Gln Asp Lys Val
180 185 190
Val Glu Leu Val Asp Ile Met Gln Lys Glu Gly Phe Arg Val Ala Gly
195 200 205
Val Phe Leu Asp Ile His Tyr Met Asp Ser Tyr Lys Leu Phe Thr Trp
210 215 220
His Pro Tyr Arg Phe Pro Glu Pro Lys Lys Leu Ile Asp Glu Leu His
225 230 235 240
Lys Arg Asn Val Lys Leu Ile Thr Ile Val Asp His Gly Ile Arg Val
245 250 255
Asp Gln Asn Tyr Ser Pro Phe Leu Ser Gly Met Gly Lys Phe Cys Glu
260 265 270
Ile Glu Ser Gly Glu Leu Phe Val Gly Lys Met Trp Pro Gly Thr Thr
275 280 285
Val Tyr Pro Asp Phe Phe Arg Glu Asp Thr Arg Glu Trp Trp Ala Gly
290 295 300
Leu Ile Ser Glu Trp Leu Ser Gln Gly Val Asp Gly Ile Trp Leu Asp
305 310 315 320
Met Asn Glu Pro Thr Asp Phe Ser Arg Ala Ile Glu Ile Arg Asp Val
325 330 335
Leu Ser Ser Leu Pro Val Gln Phe Arg Asp Asp Arg Leu Val Thr Thr
340 345 350
Phe Pro Asp Asn Val Val His Tyr Leu Arg Gly Lys Arg Val Lys His
355 360 365
Glu Lys Val Arg Asn Ala Tyr Pro Leu Tyr Glu Ala Met Ala Thr Phe
370 375 380
Lys Gly Phe Arg Thr Ser His Arg Asn Glu Ile Phe Ile Leu Ser Arg
385 390 395 400
Ala Gly Tyr Ala Gly Ile Gln Arg Tyr Ala Phe Ile Trp Thr Gly Asp
405 410 415
Asn Thr Pro Ser Trp Asp Asp Leu Lys Leu Gln Leu Gln Leu Val Leu
420 425 430
Gly Leu Ser Ile Ser Gly Val Pro Phe Val Gly Cys Asp Ile Gly Gly
435 440 445
Phe Gln Gly Arg Asn Phe Ala Glu Ile Asp Asn Ser Met Asp Leu Leu
450 455 460
Val Lys Tyr Tyr Ala Leu Ala Leu Phe Phe Pro Phe Tyr Arg Ser His
465 470 475 480
Lys Ala Thr Asp Gly Ile Asp Thr Glu Pro Val Phe Leu Pro Asp Tyr
485 490 495
Tyr Lys Glu Lys Val Lys Glu Ile Val Glu Leu Arg Tyr Lys Phe Leu
500 505 510
Pro Tyr Ile Tyr Ser Leu Ala Leu Glu Ala Ser Glu Lys Gly His Pro
515 520 525
Val Ile Arg Pro Leu Phe Tyr Glu Phe Gln Asp Asp Asp Asp Met Tyr
530 535 540
Arg Ile Glu Asp Glu Tyr Met Val Gly Lys Tyr Leu Leu Tyr Ala Pro
545 550 555 560
Ile Val Ser Lys Glu Glu Ser Arg Leu Val Thr Leu Pro Arg Gly Lys
565 570 575
Trp Tyr Asn Tyr Trp Asn Gly Glu Ile Ile Asn Gly Lys Ser Val Val
580 585 590
Lys Ser Thr His Glu Leu Pro Ile Tyr Leu Arg Glu Gly Ser Ile Ile
595 600 605
Pro Leu Glu Gly Asp Glu Leu Ile Val Tyr Gly Glu Thr Ser Phe Lys
610 615 620
Arg Tyr Asp Asn Ala Glu Ile Thr Ser Ser Ser Asn Glu Ile Lys Phe
625 630 635 640
Ser Arg Glu Ile Tyr Val Ser Lys Leu Thr Ile Thr Ser Glu Lys Pro
645 650 655
Val Ser Lys Ile Ile Val Asp Asp Ser Lys Glu Ile Gln Val Glu Lys
660 665 670
Thr Met Gln Asn Thr Tyr Val Ala Lys Ile Asn Gln Lys Ile Arg Gly
675 680 685
Lys Ile Asn Leu Glu
690
<210> 6
<211> 2082
<212> DNA
<213> Sulfolobus solfataricus
<400> 6
atggagacca tcaagatcta cgagaacaag ggcgtgtaca aggtggtgat cggcgagccg 60
ttcccgccga tcgagttccc gctcgagcag aagatctcct ccaacaagtc cctctccgag 120
ctgggcctca ccatcgtgca gcagggcaac aaggtgatcg tggagaagtc cctcgacctc 180
aaggagcaca tcatcggcct cggcgagaag gccttcgagc tggaccgcaa gcgcaagcgc 240
tacgtgatgt acaacgtgga cgccggcgcc tacaagaagt accaggaccc gctctacgtg 300
tccatcccgc tcttcatctc cgtgaaggac ggcgtggcca ccggctactt cttcaactcc 360
gcctccaagg tgatcttcga cgtgggcctc gaggagtacg acaaggtgat cgtgaccatc 420
ccggaggact ccgtggagtt ctacgtgatc gagggcccgc gcatcgagga cgtgctcgag 480
aagtacaccg agctgaccgg caagccgttc ctcccgccga tgtgggcctt cggctacatg 540
atctcccgct actcctacta cccgcaggac aaggtggtgg agctggtgga catcatgcag 600
aaggagggct tccgcgtggc cggcgtgttc ctcgacatcc actacatgga ctcctacaag 660
ctcttcacct ggcacccgta ccgcttcccg gagccgaaga agctcatcga cgagctgcac 720
aagcgcaacg tgaagctcat caccatcgtg gaccacggca tccgcgtgga ccagaactac 780
tccccgttcc tctccggcat gggcaagttc tgcgagatcg agtccggcga gctgttcgtg 840
ggcaagatgt ggccgggcac caccgtgtac ccggacttct tccgcgagga cacccgcgag 900
tggtgggccg gcctcatctc cgagtggctc tcccagggcg tggacggcat ctggctcgac 960
atgaacgagc cgaccgactt ctcccgcgcc atcgagatcc gcgacgtgct ctcctccctc 1020
ccggtgcagt tccgcgacga ccgcctcgtg accaccttcc cggacaacgt ggtgcactac 1080
ctccgcggca agcgcgtgaa gcacgagaag gtgcgcaacg cctacccgct ctacgaggcg 1140
atggccacct tcaagggctt ccgcacctcc caccgcaacg agatcttcat cctctcccgc 1200
gccggctacg ccggcatcca gcgctacgcc ttcatctgga ccggcgacaa caccccgtcc 1260
tgggacgacc tcaagctcca gctccagctc gtgctcggcc tctccatctc cggcgtgccg 1320
ttcgtgggct gcgacatcgg cggcttccag ggccgcaact tcgccgagat cgacaactcg 1380
atggacctcc tcgtgaagta ctacgccctc gccctcttct tcccgttcta ccgctcccac 1440
aaggccaccg acggcatcga caccgagccg gtgttcctcc cggactacta caaggagaag 1500
gtgaaggaga tcgtggagct gcgctacaag ttcctcccgt acatctactc cctcgccctc 1560
gaggcctccg agaagggcca cccggtgatc cgcccgctct tctacgagtt ccaggacgac 1620
gacgacatgt accgcatcga ggacgagtac atggtgggca agtacctcct ctacgccccg 1680
atcgtgtcca aggaggagtc ccgcctcgtg accctcccgc gcggcaagtg gtacaactac 1740
tggaacggcg agatcatcaa cggcaagtcc gtggtgaagt ccacccacga gctgccgatc 1800
tacctccgcg agggctccat catcccgctc gagggcgacg agctgatcgt gtacggcgag 1860
acctccttca agcgctacga caacgccgag atcacctcct cctccaacga gatcaagttc 1920
tcccgcgaga tctacgtgtc caagctcacc atcacctccg agaagccggt gtccaagatc 1980
atcgtggacg actccaagga gatccaggtg gagaagacca tgcagaacac ctacgtggcc 2040
aagatcaacc agaagatccg cggcaagatc aacctcgagt ga 2082
<210> 7
<211> 1818
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 7
atggcggctc tggccacgtc gcagctcgtc gcaacgcgcg ccggcctggg cgtcccggac 60
gcgtccacgt tccgccgcgg cgccgcgcag ggcctgaggg gggcccgggc gtcggcggcg 120
gcggacacgc tcagcatgcg gaccagcgcg cgcgcggcgc ccaggcacca gcaccagcag 180
gcgcgccgcg gggccaggtt cccgtcgctc gtcgtgtgcg ccagcgccgg catgaacgtc 240
gtcttcgtcg gcgccgagat ggcgccgtgg agcaagaccg gaggcctcgg cgacgtcctc 300
ggcggcctgc cgccggccat ggccgcgaac gggcaccgtg tcatggtcgt ctctccccgc 360
tacgaccagt acaaggacgc ctgggacacc agcgtcgtgt ccgagatcaa gatgggagac 420
gggtacgaga cggtcaggtt cttccactgc tacaagcgcg gagtggaccg cgtgttcgtt 480
gaccacccac tgttcctgga gagggtttgg ggaaagaccg aggagaagat ctacgggcct 540
gtcgctggaa cggactacag ggacaaccag ctgcggttca gcctgctatg ccaggcagca 600
cttgaagctc caaggatcct gagcctcaac aacaacccat acttctccgg accatacggg 660
gaggacgtcg tgttcgtctg caacgactgg cacaccggcc ctctctcgtg ctacctcaag 720
agcaactacc agtcccacgg catctacagg gacgcaaaga ccgctttctg catccacaac 780
atctcctacc agggccggtt cgccttctcc gactacccgg agctgaacct ccccgagaga 840
ttcaagtcgt ccttcgattt catcgacggc tacgagaagc ccgtggaagg ccggaagatc 900
aactggatga aggccgggat cctcgaggcc gacagggtcc tcaccgtcag cccctactac 960
gccgaggagc tcatctccgg catcgccagg ggctgcgagc tcgacaacat catgcgcctc 1020
accggcatca ccggcatcgt caacggcatg gacgtcagcg agtgggaccc cagcagggac 1080
aagtacatcg ccgtgaagta cgacgtgtcg acggccgtgg aggccaaggc gctgaacaag 1140
gaggcgctgc aggcggaggt cgggctcccg gtggaccgga acatcccgct ggtggcgttc 1200
atcggcaggc tggaagagca gaagggcccc gacgtcatgg cggccgccat cccgcagctc 1260
atggagatgg tggaggacgt gcagatcgtt ctgctgggca cgggcaagaa gaagttcgag 1320
cgcatgctca tgagcgccga ggagaagttc ccaggcaagg tgcgcgccgt ggtcaagttc 1380
aacgcggcgc tggcgcacca catcatggcc ggcgccgacg tgctcgccgt caccagccgc 1440
ttcgagccct gcggcctcat ccagctgcag gggatgcgat acggaacgcc ctgcgcctgc 1500
gcgtccaccg gtggactcgt cgacaccatc atcgaaggca agaccgggtt ccacatgggc 1560
cgcctcagcg tcgactgcaa cgtcgtggag ccggcggacg tcaagaaggt ggccaccacc 1620
ttgcagcgcg ccatcaaggt ggtcggcacg ccggcgtacg aggagatggt gaggaactgc 1680
atgatccagg atctctcctg gaagggccct gccaagaact gggagaacgt gctgctcagc 1740
ctcggggtcg ccggcggcga gccaggggtt gaaggcgagg agatcgcgcc gctcgccaag 1800
gagaacgtgg ccgcgccc 1818
<210> 8
<211> 606
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 8
Met Ala Ala Leu Ala Thr Ser Gln Leu Val Ala Thr Arg Ala Gly Leu
1 5 10 15
Gly Val Pro Asp Ala Ser Thr Phe Arg Arg Gly Ala Ala Gln Gly Leu
20 25 30
Arg Gly Ala Arg Ala Ser Ala Ala Ala Asp Thr Leu Ser Met Arg Thr
35 40 45
Ser Ala Arg Ala Ala Pro Arg His Gln His Gln Gln Ala Arg Arg Gly
50 55 60
Ala Arg Phe Pro Ser Leu Val Val Cys Ala Ser Ala Gly Met Asn Val
65 70 75 80
Val Phe Val Gly Ala Glu Met Ala Pro Trp Ser Lys Thr Gly Gly Leu
85 90 95
Gly Asp Val Leu Gly Gly Leu Pro Pro Ala Met Ala Ala Asn Gly His
100 105 110
Arg Val Met Val Val Ser Pro Arg Tyr Asp Gln Tyr Lys Asp Ala Trp
115 120 125
Asp Thr Ser Val Val Ser Glu Ile Lys Met Gly Asp Gly Tyr Glu Thr
130 135 140
Val Arg Phe Phe His Cys Tyr Lys Arg Gly Val Asp Arg Val Phe Val
145 150 155 160
Asp His Pro Leu Phe Leu Glu Arg Val Trp Gly Lys Thr Glu Glu Lys
165 170 175
Ile Tyr Gly Pro Val Ala Gly Thr Asp Tyr Arg Asp Asn Gln Leu Arg
180 185 190
Phe Ser Leu Leu Cys Gln Ala Ala Leu Glu Ala Pro Arg Ile Leu Ser
195 200 205
Leu Asn Asn Asn Pro Tyr Phe Ser Gly Pro Tyr Gly Glu Asp Val Val
210 215 220
Phe Val Cys Asn Asp Trp His Thr Gly Pro Leu Ser Cys Tyr Leu Lys
225 230 235 240
Ser Asn Tyr Gln Ser His Gly Ile Tyr Arg Asp Ala Lys Thr Ala Phe
245 250 255
Cys Ile His Asn Ile Ser Tyr Gln Gly Arg Phe Ala Phe Ser Asp Tyr
260 265 270
Pro Glu Leu Asn Leu Pro Glu Arg Phe Lys Ser Ser Phe Asp Phe Ile
275 280 285
Asp Gly Tyr Glu Lys Pro Val Glu Gly Arg Lys Ile Asn Trp Met Lys
290 295 300
Ala Gly Ile Leu Glu Ala Asp Arg Val Leu Thr Val Ser Pro Tyr Tyr
305 310 315 320
Ala Glu Glu Leu Ile Ser Gly Ile Ala Arg Gly Cys Glu Leu Asp Asn
325 330 335
Ile Met Arg Leu Thr Gly Ile Thr Gly Ile Val Asn Gly Met Asp Val
340 345 350
Ser Glu Trp Asp Pro Ser Arg Asp Lys Tyr Ile Ala Val Lys Tyr Asp
355 360 365
Val Ser Thr Ala Val Glu Ala Lys Ala Leu Asn Lys Glu Ala Leu Gln
370 375 380
Ala Glu Val Gly Leu Pro Val Asp Arg Asn Ile Pro Leu Val Ala Phe
385 390 395 400
Ile Gly Arg Leu Glu Glu Gln Lys Gly Pro Asp Val Met Ala Ala Ala
405 410 415
Ile Pro Gln Leu Met Glu Met Val Glu Asp Val Gln Ile Val Leu Leu
420 425 430
Gly Thr Gly Lys Lys Lys Phe Glu Arg Met Leu Met Ser Ala Glu Glu
435 440 445
Lys Phe Pro Gly Lys Val Arg Ala Val Val Lys Phe Asn Ala Ala Leu
450 455 460
Ala His His Ile Met Ala Gly Ala Asp Val Leu Ala Val Thr Ser Arg
465 470 475 480
Phe Glu Pro Cys Gly Leu Ile Gln Leu Gln Gly Met Arg Tyr Gly Thr
485 490 495
Pro Cys Ala Cys Ala Ser Thr Gly Gly Leu Val Asp Thr Ile Ile Glu
500 505 510
Gly Lys Thr Gly Phe His Met Gly Arg Leu Ser Val Asp Cys Asn Val
515 520 525
Val Glu Pro Ala Asp Val Lys Lys Val Ala Thr Thr Leu Gln Arg Ala
530 535 540
Ile Lys Val Val Gly Thr Pro Ala Tyr Glu Glu Met Val Arg Asn Cys
545 550 555 560
Met Ile Gln Asp Leu Ser Trp Lys Gly Pro Ala Lys Asn Trp Glu Asn
565 570 575
Val Leu Leu Ser Leu Gly Val Ala Gly Gly Glu Pro Gly Val Glu Gly
580 585 590
Glu Glu Ile Ala Pro Leu Ala Lys Glu Asn Val Ala Ala Pro
595 600 605
<210> 9
<211> 2223
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 9
atggccaagt acctggagct ggaggagggc ggcgtgatca tgcaggcgtt ctactgggac 60
gtcccgagcg gaggcatctg gtgggacacc atccgccaga agatccccga gtggtacgac 120
gccggcatct ccgcgatctg gataccgcca gcttccaagg gcatgtccgg gggctactcg 180
atgggctacg acccgtacga ctacttcgac ctcggcgagt actaccagaa gggcacggtg 240
gagacgcgct tcgggtccaa gcaggagctc atcaacatga tcaacacggc gcacgcctac 300
ggcatcaagg tcatcgcgga catcgtgatc aaccacaggg ccggcggcga cctggagtgg 360
aacccgttcg tcggcgacta cacctggacg gacttctcca aggtcgcctc cggcaagtac 420
accgccaact acctcgactt ccaccccaac gagctgcacg cgggcgactc cggcacgttc 480
ggcggctacc cggacatctg ccacgacaag tcctgggacc agtactggct ctgggcctcg 540
caggagtcct acgcggccta cctgcgctcc atcggcatcg acgcgtggcg cttcgactac 600
gtcaagggct acggggcctg ggtggtcaag gactggctca actggtgggg cggctgggcg 660
gtgggcgagt actgggacac caacgtcgac gcgctgctca actgggccta ctcctccggc 720
gccaaggtgt tcgacttccc cctgtactac aagatggacg cggccttcga caacaagaac 780
atcccggcgc tcgtcgaggc cctgaagaac ggcggcacgg tggtctcccg cgacccgttc 840
aaggccgtga ccttcgtcgc caaccacgac acggacatca tctggaacaa gtacccggcg 900
tacgccttca tcctcaccta cgagggccag cccacgatct tctaccgcga ctacgaggag 960
tggctgaaca aggacaagct caagaacctg atctggattc acgacaacct cgcgggcggc 1020
tccactagta tcgtgtacta cgactccgac gagatgatct tcgtccgcaa cggctacggc 1080
tccaagcccg gcctgatcac gtacatcaac ctgggctcct ccaaggtggg ccgctgggtg 1140
tacgtcccga agttcgccgg cgcgtgcatc cacgagtaca ccggcaacct cggcggctgg 1200
gtggacaagt acgtgtactc ctccggctgg gtctacctgg aggccccggc ctacgacccc 1260
gccaacggcc agtacggcta ctccgtgtgg tcctactgcg gcgtcggcac atcgattgct 1320
ggcatcctcg aggccgacag ggtcctcacc gtcagcccct actacgccga ggagctcatc 1380
tccggcatcg ccaggggctg cgagctcgac aacatcatgc gcctcaccgg catcaccggc 1440
atcgtcaacg gcatggacgt cagcgagtgg gaccccagca gggacaagta catcgccgtg 1500
aagtacgacg tgtcgacggc cgtggaggcc aaggcgctga acaaggaggc gctgcaggcg 1560
gaggtcgggc tcccggtgga ccggaacatc ccgctggtgg cgttcatcgg caggctggaa 1620
gagcagaagg gccccgacgt catggcggcc gccatcccgc agctcatgga gatggtggag 1680
gacgtgcaga tcgttctgct gggcacgggc aagaagaagt tcgagcgcat gctcatgagc 1740
gccgaggaga agttcccagg caaggtgcgc gccgtggtca agttcaacgc ggcgctggcg 1800
caccacatca tggccggcgc cgacgtgctc gccgtcacca gccgcttcga gccctgcggc 1860
ctcatccagc tgcaggggat gcgatacgga acgccctgcg cctgcgcgtc caccggtgga 1920
ctcgtcgaca ccatcatcga aggcaagacc gggttccaca tgggccgcct cagcgtcgac 1980
tgcaacgtcg tggagccggc ggacgtcaag aaggtggcca ccaccttgca gcgcgccatc 2040
aaggtggtcg gcacgccggc gtacgaggag atggtgagga actgcatgat ccaggatctc 2100
tcctggaagg gccctgccaa gaactgggag aacgtgctgc tcagcctcgg ggtcgccggc 2160
ggcgagccag gggttgaagg cgaggagatc gcgccgctcg ccaaggagaa cgtggccgcg 2220
ccc 2223
<210> 10
<211> 741
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 10
Met Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met Gln Ala
1 5 10 15
Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr Ile Arg
20 25 30
Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile Trp Ile
35 40 45
Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly Tyr Asp
50 55 60
Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly Thr Val
65 70 75 80
Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile Asn Thr
85 90 95
Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile Asn His
100 105 110
Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp Tyr Thr
115 120 125
Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala Asn Tyr
130 135 140
Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly Thr Phe
145 150 155 160
Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln Tyr Trp
165 170 175
Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser Ile Gly
180 185 190
Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala Trp Val
195 200 205
Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly Glu Tyr
210 215 220
Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser Ser Gly
225 230 235 240
Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala Ala Phe
245 250 255
Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn Gly Gly
260 265 270
Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val Ala Asn
275 280 285
His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala Phe Ile
290 295 300
Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr Glu Glu
305 310 315 320
Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His Asp Asn
325 330 335
Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp Glu Met
340 345 350
Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile Thr Tyr
355 360 365
Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val Pro Lys
370 375 380
Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly Gly Trp
385 390 395 400
Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu Ala Pro
405 410 415
Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp Ser Tyr
420 425 430
Cys Gly Val Gly Thr Ser Ile Ala Gly Ile Leu Glu Ala Asp Arg Val
435 440 445
Leu Thr Val Ser Pro Tyr Tyr Ala Glu Glu Leu Ile Ser Gly Ile Ala
450 455 460
Arg Gly Cys Glu Leu Asp Asn Ile Met Arg Leu Thr Gly Ile Thr Gly
465 470 475 480
Ile Val Asn Gly Met Asp Val Ser Glu Trp Asp Pro Ser Arg Asp Lys
485 490 495
Tyr Ile Ala Val Lys Tyr Asp Val Ser Thr Ala Val Glu Ala Lys Ala
500 505 510
Leu Asn Lys Glu Ala Leu Gln Ala Glu Val Gly Leu Pro Val Asp Arg
515 520 525
Asn Ile Pro Leu Val Ala Phe Ile Gly Arg Leu Glu Glu Gln Lys Gly
530 535 540
Pro Asp Val Met Ala Ala Ala Ile Pro Gln Leu Met Glu Met Val Glu
545 550 555 560
Asp Val Gln Ile Val Leu Leu Gly Thr Gly Lys Lys Lys Phe Glu Arg
565 570 575
Met Leu Met Ser Ala Glu Glu Lys Phe Pro Gly Lys Val Arg Ala Val
580 585 590
Val Lys Phe Asn Ala Ala Leu Ala His His Ile Met Ala Gly Ala Asp
595 600 605
Val Leu Ala Val Thr Ser Arg Phe Glu Pro Cys Gly Leu Ile Gln Leu
610 615 620
Gln Gly Met Arg Tyr Gly Thr Pro Cys Ala Cys Ala Ser Thr Gly Gly
625 630 635 640
Leu Val Asp Thr Ile Ile Glu Gly Lys Thr Gly Phe His Met Gly Arg
645 650 655
Leu Ser Val Asp Cys Asn Val Val Glu Pro Ala Asp Val Lys Lys Val
660 665 670
Ala Thr Thr Leu Gln Arg Ala Ile Lys Val Val Gly Thr Pro Ala Tyr
675 680 685
Glu Glu Met Val Arg Asn Cys Met Ile Gln Asp Leu Ser Trp Lys Gly
690 695 700
Pro Ala Lys Asn Trp Glu Asn Val Leu Leu Ser Leu Gly Val Ala Gly
705 710 715 720
Gly Glu Pro Gly Val Glu Gly Glu Glu Ile Ala Pro Leu Ala Lys Glu
725 730 735
Asn Val Ala Ala Pro
740
<210> 11
<211> 1515
<212> DNA
<213> Zea mays
<400> 11
ggagagctat gagacgtatg tcctcaaagc cactttgcat tgtgtgaaac caatatcgat 60
ctttgttact tcatcatgca tgaacatttg tggaaactac tagcttacaa gcattagtga 120
cagctcagaa aaaagttatc tatgaaaggt ttcatgtgta ccgtgggaaa tgagaaatgt 180
tgccaactca aacaccttca atatgttgtt tgcaggcaaa ctcttctgga agaaaggtgt 240
ctaaaactat gaacgggtta cagaaaggta taaaccacgg ctgtgcattt tggaagtatc 300
atctatagat gtctgttgag gggaaagccg tacgccaacg ttatttactc agaaacagct 360
tcaacacaca gttgtctgct ttatgatggc atctccaccc aggcacccac catcacctat 420
ctctcgtgcc tgtttatttt cttgcccttt ctgatcataa aaaaacatta agagtttgca 480
aacatgcata ggcatatcaa tatgctcatt tattaatttg ctagcagatc atcttcctac 540
tctttacttt atttattgtt tgaaaaatat gtcctgcacc tagggagctc gtatacagta 600
ccaatgcatc ttcattaaat gtgaatttca gaaaggaagt aggaacctat gagagtattt 660
ttcaaaatta attagcggct tctattatgt ttatagcaaa ggccaagggc aaaattggaa 720
cactaatgat ggttggttgc atgagtctgt cgattacttg caagaaatgt gaacctttgt 780
ttctgtgcgt gggcataaaa caaacagctt ctagcctctt ttacggtact tgcacttgca 840
agaaatgtga actccttttc atttctgtat gtggacataa tgccaaagca tccaggcttt 900
ttcatggttg ttgatgtctt tacacagttc atctccacca gtatgccctc ctcatactct 960
atataaacac atcaacagca tcgcaattag ccacaagatc acttcgggag gcaagtgcga 1020
tttcgatctc gcagccacct ttttttgttc tgttgtaagt ataccttccc ttaccatctt 1080
tatctgttag tttaatttgt aattgggaag tattagtgga aagaggatga gatgctatca 1140
tctatgtact ctgcaaatgc atctgacgtt atatgggctg cttcatataa tttgaattgc 1200
tccattcttg ccgacaatat attgcaaggt atatgcctag ttccatcaaa agttctgttt 1260
tttcattcta aaagcatttt agtggcacac aatttttgtc catgagggaa aggaaatctg 1320
ttttggttac tttgcttgag gtgcattctt catatgtcca gttttatgga agtaataaac 1380
ttcagtttgg tcataagatg tcatattaaa gggcaaacat atattcaatg ttcaattcat 1440
cgtaaatgtt ccctttttgt aaaagattgc atactcattt atttgagttg caggtgtatc 1500
tagtagttgg aggag 1515
<210> 12
<211> 673
<212> DNA
<213> Zea mays
<400> 12
gatcatccag gtgcaaccgt ataagtccta aagtggtgag gaacacgaaa caaccatgca 60
ttggcatgta aagctccaag aatttgttgt atccttaaca actcacagaa catcaaccaa 120
aattgcacgt caagggtatt gggtaagaaa caatcaaaca aatcctctct gtgtgcaaag 180
aaacacggtg agtcatgccg agatcatact catctgatat acatgcttac agctcacaag 240
acattacaaa caactcatat tgcattacaa agatcgtttc atgaaaaata aaataggccg 300
gacaggacaa aaatccttga cgtgtaaagt aaatttacaa caaaaaaaaa gccatatgtc 360
aagctaaatc taattcgttt tacgtagatc aacaacctgt agaaggcaac aaaactgagc 420
cacgcagaag tacagaatga ttccagatga accatcgacg tgctacgtaa agagagtgac 480
gagtcatata catttggcaa gaaaccatga agctgcctac agccgtctcg gtggcataag 540
aacacaagaa attgtgttaa ttaatcaaag ctataaataa cgctcgcatg cctgtgcact 600
tctccatcac caccactggg tcttcagacc attagcttta tctactccag agcgcagaag 660
aacccgatcg aca 673
<210> 13
<211> 454
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 13
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met
20 25 30
Gln Ala Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr
35 40 45
Ile Arg Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile
50 55 60
Trp Ile Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly
65 70 75 80
Tyr Asp Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly
85 90 95
Thr Val Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile
100 105 110
Asn Thr Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile
115 120 125
Asn His Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp
130 135 140
Tyr Thr Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala
145 150 155 160
Asn Tyr Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly
165 170 175
Thr Phe Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln
180 185 190
Tyr Trp Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser
195 200 205
Ile Gly Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala
210 215 220
Trp Val Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly
225 230 235 240
Glu Tyr Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser
245 250 255
Ser Gly Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala
260 265 270
Ala Phe Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn
275 280 285
Gly Gly Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val
290 295 300
Ala Asn His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala
305 310 315 320
Phe Ile Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr
325 330 335
Glu Glu Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His
340 345 350
Asp Asn Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp
355 360 365
Glu Met Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile
370 375 380
Thr Tyr Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val
385 390 395 400
Pro Lys Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly
405 410 415
Gly Trp Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu
420 425 430
Ala Pro Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp
435 440 445
Ser Tyr Cys Gly Val Gly
450
<210> 14
<211> 460
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 14
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met
20 25 30
Gln Ala Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr
35 40 45
Ile Arg Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile
50 55 60
Trp Ile Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly
65 70 75 80
Tyr Asp Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly
85 90 95
Thr Val Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile
100 105 110
Asn Thr Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile
115 120 125
Asn His Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp
130 135 140
Tyr Thr Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala
145 150 155 160
Asn Tyr Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly
165 170 175
Thr Phe Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln
180 185 190
Tyr Trp Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser
195 200 205
Ile Gly Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala
210 215 220
Trp Val Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly
225 230 235 240
Glu Tyr Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser
245 250 255
Ser Gly Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala
260 265 270
Ala Phe Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn
275 280 285
Gly Gly Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val
290 295 300
Ala Asn His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala
305 310 315 320
Phe Ile Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr
325 330 335
Glu Glu Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His
340 345 350
Asp Asn Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp
355 360 365
Glu Met Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile
370 375 380
Thr Tyr Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val
385 390 395 400
Pro Lys Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly
405 410 415
Gly Trp Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu
420 425 430
Ala Pro Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp
435 440 445
Ser Tyr Cys Gly Val Gly Ser Glu Lys Asp Glu Leu
450 455 460
<210> 15
<211> 518
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 15
Met Leu Ala Ala Leu Ala Thr Ser Gln Leu Val Ala Thr Arg Ala Gly
1 5 10 15
Leu Gly Val Pro Asp Ala Ser Thr Phe Arg Arg Gly Ala Ala Gln Gly
20 25 30
Leu Arg Gly Ala Arg Ala Ser Ala Ala Ala Asp Thr Leu Ser Met Arg
35 40 45
Thr Ser Ala Arg Ala Ala Pro Arg His Gln His Gln Gln Ala Arg Arg
50 55 60
Gly Ala Arg Phe Pro Ser Leu Val Val Cys Ala Ser Ala Gly Ala Met
65 70 75 80
Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met Gln Ala Phe
85 90 95
Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr Ile Arg Gln
100 105 110
Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile Trp Ile Pro
115 120 125
Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly Tyr Asp Pro
130 135 140
Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly Thr Val Glu
145 150 155 160
Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile Asn Thr Ala
165 170 175
His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile Asn His Arg
180 185 190
Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp Tyr Thr Trp
195 200 205
Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala Asn Tyr Leu
210 215 220
Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly Thr Phe Gly
225 230 235 240
Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln Tyr Trp Leu
245 250 255
Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser Ile Gly Ile
260 265 270
Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala Trp Val Val
275 280 285
Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly Glu Tyr Trp
290 295 300
Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser Ser Gly Ala
305 310 315 320
Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala Ala Phe Asp
325 330 335
Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn Gly Gly Thr
340 345 350
Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val Ala Asn His
355 360 365
Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala Phe Ile Leu
370 375 380
Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr Glu Glu Trp
385 390 395 400
Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His Asp Asn Leu
405 410 415
Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp Glu Met Ile
420 425 430
Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile Thr Tyr Ile
435 440 445
Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val Pro Lys Phe
450 455 460
Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly Gly Trp Val
465 470 475 480
Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu Ala Pro Ala
485 490 495
Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp Ser Tyr Cys
500 505 510
Gly Val Gly Thr Ser Ile
515
<210> 16
<211> 820
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 16
Met Leu Ala Ala Leu Ala Thr Ser Gln Leu Val Ala Thr Arg Ala Gly
1 5 10 15
Leu Gly Val Pro Asp Ala Ser Thr Phe Arg Arg Gly Ala Ala Gln Gly
20 25 30
Leu Arg Gly Ala Arg Ala Ser Ala Ala Ala Asp Thr Leu Ser Met Arg
35 40 45
Thr Ser Ala Arg Ala Ala Pro Arg His Gln His Gln Gln Ala Arg Arg
50 55 60
Gly Ala Arg Phe Pro Ser Leu Val Val Cys Ala Ser Ala Gly Ala Met
65 70 75 80
Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met Gln Ala Phe
85 90 95
Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr Ile Arg Gln
100 105 110
Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile Trp Ile Pro
115 120 125
Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly Tyr Asp Pro
130 135 140
Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly Thr Val Glu
145 150 155 160
Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile Asn Thr Ala
165 170 175
His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile Asn His Arg
180 185 190
Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp Tyr Thr Trp
195 200 205
Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala Asn Tyr Leu
210 215 220
Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly Thr Phe Gly
225 230 235 240
Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln Tyr Trp Leu
245 250 255
Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser Ile Gly Ile
260 265 270
Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala Trp Val Val
275 280 285
Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly Glu Tyr Trp
290 295 300
Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser Ser Gly Ala
305 310 315 320
Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala Ala Phe Asp
325 330 335
Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn Gly Gly Thr
340 345 350
Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val Ala Asn His
355 360 365
Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala Phe Ile Leu
370 375 380
Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr Glu Glu Trp
385 390 395 400
Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His Asp Asn Leu
405 410 415
Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp Glu Met Ile
420 425 430
Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile Thr Tyr Ile
435 440 445
Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val Pro Lys Phe
450 455 460
Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly Gly Trp Val
465 470 475 480
Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu Ala Pro Ala
485 490 495
Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp Ser Tyr Cys
500 505 510
Gly Val Gly Thr Ser Ile Ala Gly Ile Leu Glu Ala Asp Arg Val Leu
515 520 525
Thr Val Ser Pro Tyr Tyr Ala Glu Glu Leu Ile Ser Gly Ile Ala Arg
530 535 540
Gly Cys Glu Leu Asp Asn Ile Met Arg Leu Thr Gly Ile Thr Gly Ile
545 550 555 560
Val Asn Gly Met Asp Val Ser Glu Trp Asp Pro Ser Arg Asp Lys Tyr
565 570 575
Ile Ala Val Lys Tyr Asp Val Ser Thr Ala Val Glu Ala Lys Ala Leu
580 585 590
Asn Lys Glu Ala Leu Gln Ala Glu Val Gly Leu Pro Val Asp Arg Asn
595 600 605
Ile Pro Leu Val Ala Phe Ile Gly Arg Leu Glu Glu Gln Lys Gly Pro
610 615 620
Asp Val Met Ala Ala Ala Ile Pro Gln Leu Met Glu Met Val Glu Asp
625 630 635 640
Val Gln Ile Val Leu Leu Gly Thr Gly Lys Lys Lys Phe Glu Arg Met
645 650 655
Leu Met Ser Ala Glu Glu Lys Phe Pro Gly Lys Val Arg Ala Val Val
660 665 670
Lys Phe Asn Ala Ala Leu Ala His His Ile Met Ala Gly Ala Asp Val
675 680 685
Leu Ala Val Thr Ser Arg Phe Glu Pro Cys Gly Leu Ile Gln Leu Gln
690 695 700
Gly Met Arg Tyr Gly Thr Pro Cys Ala Cys Ala Ser Thr Gly Gly Leu
705 710 715 720
Val Asp Thr Ile Ile Glu Gly Lys Thr Gly Phe His Met Gly Arg Leu
725 730 735
Ser Val Asp Cys Asn Val Val Glu Pro Ala Asp Val Lys Lys Val Ala
740 745 750
Thr Thr Leu Gln Arg Ala Ile Lys Val Val Gly Thr Pro Ala Tyr Glu
755 760 765
Glu Met Val Arg Asn Cys Met Ile Gln Asp Leu Ser Trp Lys Gly Pro
770 775 780
Ala Lys Asn Trp Glu Asn Val Leu Leu Ser Leu Gly Val Ala Gly Gly
785 790 795 800
Glu Pro Gly Val Glu Gly Glu Glu Ile Ala Pro Leu Ala Lys Glu Asn
805 810 815
Val Ala Ala Pro
820
<210> 17
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 17
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser
<210> 18
<211> 444
<212> PRT
<213> Thermotoga maritima
<400> 18
Met Ala Glu Phe Phe Pro Glu Ile Pro Lys Ile Gln Phe Glu Gly Lys
1 5 10 15
Glu Ser Thr Asn Pro Leu Ala Phe Arg Phe Tyr Asp Pro Asn Glu Val
20 25 30
Ile Asp Gly Lys Pro Leu Lys Asp His Leu Lys Phe Ser Val Ala Phe
35 40 45
Trp His Thr Phe Val Asn Glu Gly Arg Asp Pro Phe Gly Asp Pro Thr
50 55 60
Ala Glu Arg Pro Trp Asn Arg Phe Ser Asp Pro Met Asp Lys Ala Phe
65 70 75 80
Ala Arg Val Asp Ala Leu Phe Glu Phe Cys Glu Lys Leu Asn Ile Glu
85 90 95
Tyr Phe Cys Phe His Asp Arg Asp Ile Ala Pro Glu Gly Lys Thr Leu
100 105 110
Arg Glu Thr Asn Lys Ile Leu Asp Lys Val Val Glu Arg Ile Lys Glu
115 120 125
Arg Met Lys Asp Ser Asn Val Lys Leu Leu Trp Gly Thr Ala Asn Leu
130 135 140
Phe Ser His Pro Arg Tyr Met His Gly Ala Ala Thr Thr Cys Ser Ala
145 150 155 160
Asp Val Phe Ala Tyr Ala Ala Ala Gln Val Lys Lys Ala Leu Glu Ile
165 170 175
Thr Lys Glu Leu Gly Gly Glu Gly Tyr Val Phe Trp Gly Gly Arg Glu
180 185 190
Gly Tyr Glu Thr Leu Leu Asn Thr Asp Leu Gly Leu Glu Leu Glu Asn
195 200 205
Leu Ala Arg Phe Leu Arg Met Ala Val Glu Tyr Ala Lys Lys Ile Gly
210 215 220
Phe Thr Gly Gln Phe Leu Ile Glu Pro Lys Pro Lys Glu Pro Thr Lys
225 230 235 240
His Gln Tyr Asp Phe Asp Val Ala Thr Ala Tyr Ala Phe Leu Lys Asn
245 250 255
His Gly Leu Asp Glu Tyr Phe Lys Phe Asn Ile Glu Ala Asn His Ala
260 265 270
Thr Leu Ala Gly His Thr Phe Gln His Glu Leu Arg Met Ala Arg Ile
275 280 285
Leu Gly Lys Leu Gly Ser Ile Asp Ala Asn Gln Gly Asp Leu Leu Leu
290 295 300
Gly Trp Asp Thr Asp Gln Phe Pro Thr Asn Ile Tyr Asp Thr Thr Leu
305 310 315 320
Ala Met Tyr Glu Val Ile Lys Ala Gly Gly Phe Thr Lys Gly Gly Leu
325 330 335
Asn Phe Asp Ala Lys Val Arg Arg Ala Ser Tyr Lys Val Glu Asp Leu
340 345 350
Phe Ile Gly His Ile Ala Gly Met Asp Thr Phe Ala Leu Gly Phe Lys
355 360 365
Ile Ala Tyr Lys Leu Ala Lys Asp Gly Val Phe Asp Lys Phe Ile Glu
370 375 380
Glu Lys Tyr Arg Ser Phe Lys Glu Gly Ile Gly Lys Glu Ile Val Glu
385 390 395 400
Gly Lys Thr Asp Phe Glu Lys Leu Glu Glu Tyr Ile Ile Asp Lys Glu
405 410 415
Asp Ile Glu Leu Pro Ser Gly Lys Gln Glu Tyr Leu Glu Ser Leu Leu
420 425 430
Asn Ser Tyr Ile Val Lys Thr Ile Ala Glu Leu Arg
435 440
<210> 19
<211> 1335
<212> DNA
<213> Thermotoga maritima
<400> 19
atggccgagt tcttcccgga gatcccgaag atccagttcg agggcaagga gtccaccaac 60
ccgctcgcct tccgcttcta cgacccgaac gaggtgatcg acggcaagcc gctcaaggac 120
cacctcaagt tctccgtggc cttctggcac accttcgtga acgagggccg cgacccgttc 180
ggcgacccga ccgccgagcg cccgtggaac cgcttctccg acccgatgga caaggccttc 240
gcccgcgtgg acgccctctt cgagttctgc gagaagctca acatcgagta cttctgcttc 300
cacgaccgcg acatcgcccc ggagggcaag accctccgcg agaccaacaa gatcctcgac 360
aaggtggtgg agcgcatcaa ggagcgcatg aaggactcca acgtgaagct cctctggggc 420
accgccaacc tcttctccca cccgcgctac atgcacggcg ccgccaccac ctgctccgcc 480
gacgtgttcg cctacgccgc cgcccaggtg aagaaggccc tggagatcac caaggagctg 540
ggcggcgagg gctacgtgtt ctggggcggc cgcgagggct acgagaccct cctcaacacc 600
gacctcggcc tggagctgga gaacctcgcc cgcttcctcc gcatggccgt ggagtacgcc 660
aagaagatcg gcttcaccgg ccagttcctc atcgagccga agccgaagga gccgaccaag 720
caccagtacg acttcgacgt ggccaccgcc tacgccttcc tcaagaacca cggcctcgac 780
gagtacttca agttcaacat cgaggccaac cacgccaccc tcgccggcca caccttccag 840
cacgagctgc gcatggcccg catcctcggc aagctcggct ccatcgacgc caaccagggc 900
gacctcctcc tcggctggga caccgaccag ttcccgacca acatctacga caccaccctc 960
gccatgtacg aggtgatcaa ggccggcggc ttcaccaagg gcggcctcaa cttcgacgcc 1020
aaggtgcgcc gcgcctccta caaggtggag gacctcttca tcggccacat cgccggcatg 1080
gacaccttcg ccctcggctt caagatcgcc tacaagctcg ccaaggacgg cgtgttcgac 1140
aagttcatcg aggagaagta ccgctccttc aaggagggca tcggcaagga gatcgtggag 1200
ggcaagaccg acttcgagaa gctggaggag tacatcatcg acaaggagga catcgagctg 1260
ccgtccggca agcaggagta cctggagtcc ctcctcaact cctacatcgt gaagaccatc 1320
gccgagctgc gctga 1335
<210> 20
<211> 444
<212> PRT
<213> Thermotoga neapolitana
<400> 20
Met Ala Glu Phe Phe Pro Glu Ile Pro Lys Val Gln Phe Glu Gly Lys
1 5 10 15
Glu Ser Thr Asn Pro Leu Ala Phe Lys Phe Tyr Asp Pro Glu Glu Ile
20 25 30
Ile Asp Gly Lys Pro Leu Lys Asp His Leu Lys Phe Ser Val Ala Phe
35 40 45
Trp His Thr Phe Val Asn Glu Gly Arg Asp Pro Phe Gly Asp Pro Thr
50 55 60
Ala Asp Arg Pro Trp Asn Arg Tyr Thr Asp Pro Met Asp Lys Ala Phe
65 70 75 80
Ala Arg Val Asp Ala Leu Phe Glu Phe Cys Glu Lys Leu Asn Ile Glu
85 90 95
Tyr Phe Cys Phe His Asp Arg Asp Ile Ala Pro Glu Gly Lys Thr Leu
100 105 110
Arg Glu Thr Asn Lys Ile Leu Asp Lys Val Val Glu Arg Ile Lys Glu
115 120 125
Arg Met Lys Asp Ser Asn Val Lys Leu Leu Trp Gly Thr Ala Asn Leu
130 135 140
Phe Ser His Pro Arg Tyr Met His Gly Ala Ala Thr Thr Cys Ser Ala
145 150 155 160
Asp Val Phe Ala Tyr Ala Ala Ala Gln Val Lys Lys Ala Leu Glu Ile
165 170 175
Thr Lys Glu Leu Gly Gly Glu Gly Tyr Val Phe Trp Gly Gly Arg Glu
180 185 190
Gly Tyr Glu Thr Leu Leu Asn Thr Asp Leu Gly Phe Glu Leu Glu Asn
195 200 205
Leu Ala Arg Phe Leu Arg Met Ala Val Asp Tyr Ala Lys Arg Ile Gly
210 215 220
Phe Thr Gly Gln Phe Leu Ile Glu Pro Lys Pro Lys Glu Pro Thr Lys
225 230 235 240
His Gln Tyr Asp Phe Asp Val Ala Thr Ala Tyr Ala Phe Leu Lys Ser
245 250 255
His Gly Leu Asp Glu Tyr Phe Lys Phe Asn Ile Glu Ala Asn His Ala
260 265 270
Thr Leu Ala Gly His Thr Phe Gln His Glu Leu Arg Met Ala Arg Ile
275 280 285
Leu Gly Lys Leu Gly Ser Ile Asp Ala Asn Gln Gly Asp Leu Leu Leu
290 295 300
Gly Trp Asp Thr Asp Gln Phe Pro Thr Asn Val Tyr Asp Thr Thr Leu
305 310 315 320
Ala Met Tyr Glu Val Ile Lys Ala Gly Gly Phe Thr Lys Gly Gly Leu
325 330 335
Asn Phe Asp Ala Lys Val Arg Arg Ala Ser Tyr Lys Val Glu Asp Leu
340 345 350
Phe Ile Gly His Ile Ala Gly Met Asp Thr Phe Ala Leu Gly Phe Lys
355 360 365
Val Ala Tyr Lys Leu Val Lys Asp Gly Val Leu Asp Lys Phe Ile Glu
370 375 380
Glu Lys Tyr Arg Ser Phe Arg Glu Gly Ile Gly Arg Asp Ile Val Glu
385 390 395 400
Gly Lys Val Asp Phe Glu Lys Leu Glu Glu Tyr Ile Ile Asp Lys Glu
405 410 415
Thr Ile Glu Leu Pro Ser Gly Lys Gln Glu Tyr Leu Glu Ser Leu Ile
420 425 430
Asn Ser Tyr Ile Val Lys Thr Ile Leu Glu Leu Arg
435 440
<210> 21
<211> 1335
<212> DNA
<213> Thermotoga neapolitana
<400> 21
atggccgagt tcttcccgga gatcccgaag gtgcagttcg agggcaagga gtccaccaac 60
ccgctcgcct tcaagttcta cgacccggag gagatcatcg acggcaagcc gctcaaggac 120
cacctcaagt tctccgtggc cttctggcac accttcgtga acgagggccg cgacccgttc 180
ggcgacccga ccgccgaccg cccgtggaac cgctacaccg acccgatgga caaggccttc 240
gcccgcgtgg acgccctctt cgagttctgc gagaagctca acatcgagta cttctgcttc 300
cacgaccgcg acatcgcccc ggagggcaag accctccgcg agaccaacaa gatcctcgac 360
aaggtggtgg agcgcatcaa ggagcgcatg aaggactcca acgtgaagct cctctggggc 420
accgccaacc tcttctccca cccgcgctac atgcacggcg ccgccaccac ctgctccgcc 480
gacgtgttcg cctacgccgc cgcccaggtg aagaaggccc tggagatcac caaggagctg 540
ggcggcgagg gctacgtgtt ctggggcggc cgcgagggct acgagaccct cctcaacacc 600
gacctcggct tcgagctgga gaacctcgcc cgcttcctcc gcatggccgt ggactacgcc 660
aagcgcatcg gcttcaccgg ccagttcctc atcgagccga agccgaagga gccgaccaag 720
caccagtacg acttcgacgt ggccaccgcc tacgccttcc tcaagtccca cggcctcgac 780
gagtacttca agttcaacat cgaggccaac cacgccaccc tcgccggcca caccttccag 840
cacgagctgc gcatggcccg catcctcggc aagctcggct ccatcgacgc caaccagggc 900
gacctcctcc tcggctggga caccgaccag ttcccgacca acgtgtacga caccaccctc 960
gccatgtacg aggtgatcaa ggccggcggc ttcaccaagg gcggcctcaa cttcgacgcc 1020
aaggtgcgcc gcgcctccta caaggtggag gacctcttca tcggccacat cgccggcatg 1080
gacaccttcg ccctcggctt caaggtggcc tacaagctcg tgaaggacgg cgtgctcgac 1140
aagttcatcg aggagaagta ccgctccttc cgcgagggca tcggccgcga catcgtggag 1200
ggcaaggtgg acttcgagaa gctggaggag tacatcatcg acaaggagac catcgagctg 1260
ccgtccggca agcaggagta cctggagtcc ctcatcaact cctacatcgt gaagaccatc 1320
ctggagctgc gctga 1335
<210> 22
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 22
agcgaattca tggcggctct ggccacgt 28
<210> 23
<211> 29
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 23
agctaagctt cagggcgcgg ccacgttct 29
<210> 24
<211> 825
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 24
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Gly His Trp Tyr Lys His Gln Arg Ala Tyr Gln Phe
20 25 30
Thr Gly Glu Asp Asp Phe Gly Lys Val Ala Val Val Lys Leu Pro Met
35 40 45
Asp Leu Thr Lys Val Gly Ile Ile Val Arg Leu Asn Glu Trp Gln Ala
50 55 60
Lys Asp Val Ala Lys Asp Arg Phe Ile Glu Ile Lys Asp Gly Lys Ala
65 70 75 80
Glu Val Trp Ile Leu Gln Gly Val Glu Glu Ile Phe Tyr Glu Lys Pro
85 90 95
Asp Thr Ser Pro Arg Ile Phe Phe Ala Gln Ala Arg Ser Asn Lys Val
100 105 110
Ile Glu Ala Phe Leu Thr Asn Pro Val Asp Thr Lys Lys Lys Glu Leu
115 120 125
Phe Lys Val Thr Val Asp Gly Lys Glu Ile Pro Val Ser Arg Val Glu
130 135 140
Lys Ala Asp Pro Thr Asp Ile Asp Val Thr Asn Tyr Val Arg Ile Val
145 150 155 160
Leu Ser Glu Ser Leu Lys Glu Glu Asp Leu Arg Lys Asp Val Glu Leu
165 170 175
Ile Ile Glu Gly Tyr Lys Pro Ala Arg Val Ile Met Met Glu Ile Leu
180 185 190
Asp Asp Tyr Tyr Tyr Asp Gly Glu Leu Gly Ala Val Tyr Ser Pro Glu
195 200 205
Lys Thr Ile Phe Arg Val Trp Ser Pro Val Ser Lys Trp Val Lys Val
210 215 220
Leu Leu Phe Lys Asn Gly Glu Asp Thr Glu Pro Tyr Gln Val Val Asn
225 230 235 240
Met Glu Tyr Lys Gly Asn Gly Val Trp Glu Ala Val Val Glu Gly Asp
245 250 255
Leu Asp Gly Val Phe Tyr Leu Tyr Gln Leu Glu Asn Tyr Gly Lys Ile
260 265 270
Arg Thr Thr Val Asp Pro Tyr Ser Lys Ala Val Tyr Ala Asn Asn Gln
275 280 285
Glu Ser Ala Val Val Asn Leu Ala Arg Thr Asn Pro Glu Gly Trp Glu
290 295 300
Asn Asp Arg Gly Pro Lys Ile Glu Gly Tyr Glu Asp Ala Ile Ile Tyr
305 310 315 320
Glu Ile His Ile Ala Asp Ile Thr Gly Leu Glu Asn Ser Gly Val Lys
325 330 335
Asn Lys Gly Leu Tyr Leu Gly Leu Thr Glu Glu Asn Thr Lys Ala Pro
340 345 350
Gly Gly Val Thr Thr Gly Leu Ser His Leu Val Glu Leu Gly Val Thr
355 360 365
His Val His Ile Leu Pro Phe Phe Asp Phe Tyr Thr Gly Asp Glu Leu
370 375 380
Asp Lys Asp Phe Glu Lys Tyr Tyr Asn Trp Gly Tyr Asp Pro Tyr Leu
385 390 395 400
Phe Met Val Pro Glu Gly Arg Tyr Ser Thr Asp Pro Lys Asn Pro His
405 410 415
Thr Arg Ile Arg Glu Val Lys Glu Met Val Lys Ala Leu His Lys His
420 425 430
Gly Ile Gly Val Ile Met Asp Met Val Phe Pro His Thr Tyr Gly Ile
435 440 445
Gly Glu Leu Ser Ala Phe Asp Gln Thr Val Pro Tyr Tyr Phe Tyr Arg
450 455 460
Ile Asp Lys Thr Gly Ala Tyr Leu Asn Glu Ser Gly Cys Gly Asn Val
465 470 475 480
Ile Ala Ser Glu Arg Pro Met Met Arg Lys Phe Ile Val Asp Thr Val
485 490 495
Thr Tyr Trp Val Lys Glu Tyr His Ile Asp Gly Phe Arg Phe Asp Gln
500 505 510
Met Gly Leu Ile Asp Lys Lys Thr Met Leu Glu Val Glu Arg Ala Leu
515 520 525
His Lys Ile Asp Pro Thr Ile Ile Leu Tyr Gly Glu Pro Trp Gly Gly
530 535 540
Trp Gly Ala Pro Ile Arg Phe Gly Lys Ser Asp Val Ala Gly Thr His
545 550 555 560
Val Ala Ala Phe Asn Asp Glu Phe Arg Asp Ala Ile Arg Gly Ser Val
565 570 575
Phe Asn Pro Ser Val Lys Gly Phe Val Met Gly Gly Tyr Gly Lys Glu
580 585 590
Thr Lys Ile Lys Arg Gly Val Val Gly Ser Ile Asn Tyr Asp Gly Lys
595 600 605
Leu Ile Lys Ser Phe Ala Leu Asp Pro Glu Glu Thr Ile Asn Tyr Ala
610 615 620
Ala Cys His Asp Asn His Thr Leu Trp Asp Lys Asn Tyr Leu Ala Ala
625 630 635 640
Lys Ala Asp Lys Lys Lys Glu Trp Thr Glu Glu Glu Leu Lys Asn Ala
645 650 655
Gln Lys Leu Ala Gly Ala Ile Leu Leu Thr Ser Gln Gly Val Pro Phe
660 665 670
Leu His Gly Gly Gln Asp Phe Cys Arg Thr Thr Asn Phe Asn Asp Asn
675 680 685
Ser Tyr Asn Ala Pro Ile Ser Ile Asn Gly Phe Asp Tyr Glu Arg Lys
690 695 700
Leu Gln Phe Ile Asp Val Phe Asn Tyr His Lys Gly Leu Ile Lys Leu
705 710 715 720
Arg Lys Glu His Pro Ala Phe Arg Leu Lys Asn Ala Glu Glu Ile Lys
725 730 735
Lys His Leu Glu Phe Leu Pro Gly Gly Arg Arg Ile Val Ala Phe Met
740 745 750
Leu Lys Asp His Ala Gly Gly Asp Pro Trp Lys Asp Ile Val Val Ile
755 760 765
Tyr Asn Gly Asn Leu Glu Lys Thr Thr Tyr Lys Leu Pro Glu Gly Lys
770 775 780
Trp Asn Val Val Val Asn Ser Gln Lys Ala Gly Thr Glu Val Ile Glu
785 790 795 800
Thr Val Glu Gly Thr Ile Glu Leu Asp Pro Leu Ser Ala Tyr Val Leu
805 810 815
Tyr Arg Glu Ser Glu Lys Asp Glu Leu
820 825
<210> 25
<211> 2478
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 25
atgagggtgt tgctcgttgc cctcgctctc ctggctctcg ctgcgagcgc caccagcgct 60
ggccactggt acaagcacca gcgcgcctac cagttcaccg gcgaggacga cttcgggaag 120
gtggccgtgg tgaagctccc gatggacctc accaaggtgg gcatcatcgt gcgcctcaac 180
gagtggcagg cgaaggacgt ggccaaggac cgcttcatcg agatcaagga cggcaaggcc 240
gaggtgtgga tactccaggg cgtggaggag atcttctacg agaagccgga cacctccccg 300
cgcatcttct tcgcccaggc ccgctccaac aaggtgatcg aggccttcct caccaacccg 360
gtggacacca agaagaagga gctgttcaag gtgaccgtcg acggcaagga gatcccggtg 420
tcccgcgtgg agaaggccga cccgaccgac atcgacgtga ccaactacgt gcgcatcgtg 480
ctctccgagt ccctcaagga ggaggacctc cgcaaggacg tggagctgat catcgagggc 540
tacaagccgg cccgcgtgat catgatggag atcctcgacg actactacta cgacggcgag 600
ctgggggcgg tgtactcccc ggagaagacc atcttccgcg tgtggtcccc ggtgtccaag 660
tgggtgaagg tgctcctctt caagaacggc gaggacaccg agccgtacca ggtggtgaac 720
atggagtaca agggcaacgg cgtgtgggag gccgtggtgg agggcgacct cgacggcgtg 780
ttctacctct accagctgga gaactacggc aagatccgca ccaccgtgga cccgtactcc 840
aaggccgtgt acgccaacaa ccaggagtct gcagtggtga acctcgcccg caccaacccg 900
gagggctggg agaacgaccg cggcccgaag atcgagggct acgaggacgc catcatctac 960
gagatccaca tcgccgacat caccggcctg gagaactccg gcgtgaagaa caagggcctc 1020
tacctcggcc tcaccgagga gaacaccaag gccccgggcg gcgtgaccac cggcctctcc 1080
cacctcgtgg agctgggcgt gacccacgtg cacatcctcc cgttcttcga cttctacacc 1140
ggcgacgagc tggacaagga cttcgagaag tactacaact ggggctacga cccgtacctc 1200
ttcatggtgc cggagggccg ctactccacc gacccgaaga acccgcacac ccgaattcgc 1260
gaggtgaagg agatggtgaa ggccctccac aagcacggca tcggcgtgat catggacatg 1320
gtgttcccgc acacctacgg catcggcgag ctgtccgcct tcgaccagac cgtgccgtac 1380
tacttctacc gcatcgacaa gaccggcgcc tacctcaacg agtccggctg cggcaacgtg 1440
atcgcctccg agcgcccgat gatgcgcaag ttcatcgtgg acaccgtgac ctactgggtg 1500
aaggagtacc acatcgacgg cttccgcttc gaccagatgg gcctcatcga caagaagacc 1560
atgctggagg tggagcgcgc cctccacaag atcgacccga ccatcatcct ctacggcgag 1620
ccgtggggcg gctggggggc cccgatccgc ttcggcaagt ccgacgtggc cggcacccac 1680
gtggccgcct tcaacgacga gttccgcgac gccatccgcg gctccgtgtt caacccgtcc 1740
gtgaagggct tcgtgatggg cggctacggc aaggagacca agatcaagcg cggcgtggtg 1800
ggctccatca actacgacgg caagctcatc aagtccttcg ccctcgaccc ggaggagacc 1860
atcaactacg ccgcctgcca cgacaaccac accctctggg acaagaacta cctcgccgcc 1920
aaggccgaca agaagaagga gtggaccgag gaggagctga agaacgccca gaagctcgcc 1980
ggcgccatcc tcctcactag tcagggcgtg ccgttcctcc acggcggcca ggacttctgc 2040
cgcaccacca acttcaacga caactcctac aacgccccga tctccatcaa cggcttcgac 2100
tacgagcgca agctccagtt catcgacgtg ttcaactacc acaagggcct catcaagctc 2160
cgcaaggagc acccggcctt ccgcctcaag aacgccgagg agatcaagaa gcacctggag 2220
ttcctcccgg gcgggcgccg catcgtggcc ttcatgctca aggaccacgc cggcggcgac 2280
ccgtggaagg acatcgtggt gatctacaac ggcaacctgg agaagaccac ctacaagctc 2340
ccggagggca agtggaacgt ggtggtgaac tcccagaagg ccggcaccga ggtgatcgag 2400
accgtggagg gcaccatcga gctggacccg ctctccgcct acgtgctcta ccgcgagtcc 2460
gagaaggacg agctgtga 2478
<210> 26
<211> 718
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 26
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Met Glu Thr Ile Lys Ile Tyr Glu Asn Lys Gly Val Tyr
20 25 30
Lys Val Val Ile Gly Glu Pro Phe Pro Pro Ile Glu Phe Pro Leu Glu
35 40 45
Gln Lys Ile Ser Ser Asn Lys Ser Leu Ser Glu Leu Gly Leu Thr Ile
50 55 60
Val Gln Gln Gly Asn Lys Val Ile Val Glu Lys Ser Leu Asp Leu Lys
65 70 75 80
Glu His Ile Ile Gly Leu Gly Glu Lys Ala Phe Glu Leu Asp Arg Lys
85 90 95
Arg Lys Arg Tyr Val Met Tyr Asn Val Asp Ala Gly Ala Tyr Lys Lys
100 105 110
Tyr Gln Asp Pro Leu Tyr Val Ser Ile Pro Leu Phe Ile Ser Val Lys
115 120 125
Asp Gly Val Ala Thr Gly Tyr Phe Phe Asn Ser Ala Ser Lys Val Ile
130 135 140
Phe Asp Val Gly Leu Glu Glu Tyr Asp Lys Val Ile Val Thr Ile Pro
145 150 155 160
Glu Asp Ser Val Glu Phe Tyr Val Ile Glu Gly Pro Arg Ile Glu Asp
165 170 175
Val Leu Glu Lys Tyr Thr Glu Leu Thr Gly Lys Pro Phe Leu Pro Pro
180 185 190
Met Trp Ala Phe Gly Tyr Met Ile Ser Arg Tyr Ser Tyr Tyr Pro Gln
195 200 205
Asp Lys Val Val Glu Leu Val Asp Ile Met Gln Lys Glu Gly Phe Arg
210 215 220
Val Ala Gly Val Phe Leu Asp Ile His Tyr Met Asp Ser Tyr Lys Leu
225 230 235 240
Phe Thr Trp His Pro Tyr Arg Phe Pro Glu Pro Lys Lys Leu Ile Asp
245 250 255
Glu Leu His Lys Arg Asn Val Lys Leu Ile Thr Ile Val Asp His Gly
260 265 270
Ile Arg Val Asp Gln Asn Tyr Ser Pro Phe Leu Ser Gly Met Gly Lys
275 280 285
Phe Cys Glu Ile Glu Ser Gly Glu Leu Phe Val Gly Lys Met Trp Pro
290 295 300
Gly Thr Thr Val Tyr Pro Asp Phe Phe Arg Glu Asp Thr Arg Glu Trp
305 310 315 320
Trp Ala Gly Leu Ile Ser Glu Trp Leu Ser Gln Gly Val Asp Gly Ile
325 330 335
Trp Leu Asp Met Asn Glu Pro Thr Asp Phe Ser Arg Ala Ile Glu Ile
340 345 350
Arg Asp Val Leu Ser Ser Leu Pro Val Gln Phe Arg Asp Asp Arg Leu
355 360 365
Val Thr Thr Phe Pro Asp Asn Val Val His Tyr Leu Arg Gly Lys Arg
370 375 380
Val Lys His Glu Lys Val Arg Asn Ala Tyr Pro Leu Tyr Glu Ala Met
385 390 395 400
Ala Thr Phe Lys Gly Phe Arg Thr Ser His Arg Asn Glu Ile Phe Ile
405 410 415
Leu Ser Arg Ala Gly Tyr Ala Gly Ile Gln Arg Tyr Ala Phe Ile Trp
420 425 430
Thr Gly Asp Asn Thr Pro Ser Trp Asp Asp Leu Lys Leu Gln Leu Gln
435 440 445
Leu Val Leu Gly Leu Ser Ile Ser Gly Val Pro Phe Val Gly Cys Asp
450 455 460
Ile Gly Gly Phe Gln Gly Arg Asn Phe Ala Glu Ile Asp Asn Ser Met
465 470 475 480
Asp Leu Leu Val Lys Tyr Tyr Ala Leu Ala Leu Phe Phe Pro Phe Tyr
485 490 495
Arg Ser His Lys Ala Thr Asp Gly Ile Asp Thr Glu Pro Val Phe Leu
500 505 510
Pro Asp Tyr Tyr Lys Glu Lys Val Lys Glu Ile Val Glu Leu Arg Tyr
515 520 525
Lys Phe Leu Pro Tyr Ile Tyr Ser Leu Ala Leu Glu Ala Ser Glu Lys
530 535 540
Gly His Pro Val Ile Arg Pro Leu Phe Tyr Glu Phe Gln Asp Asp Asp
545 550 555 560
Asp Met Tyr Arg Ile Glu Asp Glu Tyr Met Val Gly Lys Tyr Leu Leu
565 570 575
Tyr Ala Pro Ile Val Ser Lys Glu Glu Ser Arg Leu Val Thr Leu Pro
580 585 590
Arg Gly Lys Trp Tyr Asn Tyr Trp Asn Gly Glu Ile Ile Asn Gly Lys
595 600 605
Ser Val Val Lys Ser Thr His Glu Leu Pro Ile Tyr Leu Arg Glu Gly
610 615 620
Ser Ile Ile Pro Leu Glu Gly Asp Glu Leu Ile Val Tyr Gly Glu Thr
625 630 635 640
Ser Phe Lys Arg Tyr Asp Asn Ala Glu Ile Thr Ser Ser Ser Asn Glu
645 650 655
Ile Lys Phe Ser Arg Glu Ile Tyr Val Ser Lys Leu Thr Ile Thr Ser
660 665 670
Glu Lys Pro Val Ser Lys Ile Ile Val Asp Asp Ser Lys Glu Ile Gln
675 680 685
Val Glu Lys Thr Met Gln Asn Thr Tyr Val Ala Lys Ile Asn Gln Lys
690 695 700
Ile Arg Gly Lys Ile Asn Leu Glu Ser Glu Lys Asp Glu Leu
705 710 715
<210> 27
<211> 712
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 27
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Met Glu Thr Ile Lys Ile Tyr Glu Asn Lys Gly Val Tyr
20 25 30
Lys Val Val Ile Gly Glu Pro Phe Pro Pro Ile Glu Phe Pro Leu Glu
35 40 45
Gln Lys Ile Ser Ser Asn Lys Ser Leu Ser Glu Leu Gly Leu Thr Ile
50 55 60
Val Gln Gln Gly Asn Lys Val Ile Val Glu Lys Ser Leu Asp Leu Lys
65 70 75 80
Glu His Ile Ile Gly Leu Gly Glu Lys Ala Phe Glu Leu Asp Arg Lys
85 90 95
Arg Lys Arg Tyr Val Met Tyr Asn Val Asp Ala Gly Ala Tyr Lys Lys
100 105 110
Tyr Gln Asp Pro Leu Tyr Val Ser Ile Pro Leu Phe Ile Ser Val Lys
115 120 125
Asp Gly Val Ala Thr Gly Tyr Phe Phe Asn Ser Ala Ser Lys Val Ile
130 135 140
Phe Asp Val Gly Leu Glu Glu Tyr Asp Lys Val Ile Val Thr Ile Pro
145 150 155 160
Glu Asp Ser Val Glu Phe Tyr Val Ile Glu Gly Pro Arg Ile Glu Asp
165 170 175
Val Leu Glu Lys Tyr Thr Glu Leu Thr Gly Lys Pro Phe Leu Pro Pro
180 185 190
Met Trp Ala Phe Gly Tyr Met Ile Ser Arg Tyr Ser Tyr Tyr Pro Gln
195 200 205
Asp Lys Val Val Glu Leu Val Asp Ile Met Gln Lys Glu Gly Phe Arg
210 215 220
Val Ala Gly Val Phe Leu Asp Ile His Tyr Met Asp Ser Tyr Lys Leu
225 230 235 240
Phe Thr Trp His Pro Tyr Arg Phe Pro Glu Pro Lys Lys Leu Ile Asp
245 250 255
Glu Leu His Lys Arg Asn Val Lys Leu Ile Thr Ile Val Asp His Gly
260 265 270
Ile Arg Val Asp Gln Asn Tyr Ser Pro Phe Leu Ser Gly Met Gly Lys
275 280 285
Phe Cys Glu Ile Glu Ser Gly Glu Leu Phe Val Gly Lys Met Trp Pro
290 295 300
Gly Thr Thr Val Tyr Pro Asp Phe Phe Arg Glu Asp Thr Arg Glu Trp
305 310 315 320
Trp Ala Gly Leu Ile Ser Glu Trp Leu Ser Gln Gly Val Asp Gly Ile
325 330 335
Trp Leu Asp Met Asn Glu Pro Thr Asp Phe Ser Arg Ala Ile Glu Ile
340 345 350
Arg Asp Val Leu Ser Ser Leu Pro Val Gln Phe Arg Asp Asp Arg Leu
355 360 365
Val Thr Thr Phe Pro Asp Asn Val Val His Tyr Leu Arg Gly Lys Arg
370 375 380
Val Lys His Glu Lys Val Arg Asn Ala Tyr Pro Leu Tyr Glu Ala Met
385 390 395 400
Ala Thr Phe Lys Gly Phe Arg Thr Ser His Arg Asn Glu Ile Phe Ile
405 410 415
Leu Ser Arg Ala Gly Tyr Ala Gly Ile Gln Arg Tyr Ala Phe Ile Trp
420 425 430
Thr Gly Asp Asn Thr Pro Ser Trp Asp Asp Leu Lys Leu Gln Leu Gln
435 440 445
Leu Val Leu Gly Leu Ser Ile Ser Gly Val Pro Phe Val Gly Cys Asp
450 455 460
Ile Gly Gly Phe Gln Gly Arg Asn Phe Ala Glu Ile Asp Asn Ser Met
465 470 475 480
Asp Leu Leu Val Lys Tyr Tyr Ala Leu Ala Leu Phe Phe Pro Phe Tyr
485 490 495
Arg Ser His Lys Ala Thr Asp Gly Ile Asp Thr Glu Pro Val Phe Leu
500 505 510
Pro Asp Tyr Tyr Lys Glu Lys Val Lys Glu Ile Val Glu Leu Arg Tyr
515 520 525
Lys Phe Leu Pro Tyr Ile Tyr Ser Leu Ala Leu Glu Ala Ser Glu Lys
530 535 540
Gly His Pro Val Ile Arg Pro Leu Phe Tyr Glu Phe Gln Asp Asp Asp
545 550 555 560
Asp Met Tyr Arg Ile Glu Asp Glu Tyr Met Val Gly Lys Tyr Leu Leu
565 570 575
Tyr Ala Pro Ile Val Ser Lys Glu Glu Ser Arg Leu Val Thr Leu Pro
580 585 590
Arg Gly Lys Trp Tyr Asn Tyr Trp Asn Gly Glu Ile Ile Asn Gly Lys
595 600 605
Ser Val Val Lys Ser Thr His Glu Leu Pro Ile Tyr Leu Arg Glu Gly
610 615 620
Ser Ile Ile Pro Leu Glu Gly Asp Glu Leu Ile Val Tyr Gly Glu Thr
625 630 635 640
Ser Phe Lys Arg Tyr Asp Asn Ala Glu Ile Thr Ser Ser Ser Asn Glu
645 650 655
Ile Lys Phe Ser Arg Glu Ile Tyr Val Ser Lys Leu Thr Ile Thr Ser
660 665 670
Glu Lys Pro Val Ser Lys Ile Ile Val Asp Asp Ser Lys Glu Ile Gln
675 680 685
Val Glu Lys Thr Met Gln Asn Thr Tyr Val Ala Lys Ile Asn Gln Lys
690 695 700
Ile Arg Gly Lys Ile Asn Leu Glu
705 710
<210> 28
<211> 469
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 28
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Met Ala Glu Phe Phe Pro Glu Ile Pro Lys Ile Gln Phe
20 25 30
Glu Gly Lys Glu Ser Thr Asn Pro Leu Ala Phe Arg Phe Tyr Asp Pro
35 40 45
Asn Glu Val Ile Asp Gly Lys Pro Leu Lys Asp His Leu Lys Phe Ser
50 55 60
Val Ala Phe Trp His Thr Phe Val Asn Glu Gly Arg Asp Pro Phe Gly
65 70 75 80
Asp Pro Thr Ala Glu Arg Pro Trp Asn Arg Phe Ser Asp Pro Met Asp
85 90 95
Lys Ala Phe Ala Arg Val Asp Ala Leu Phe Glu Phe Cys Glu Lys Leu
100 105 110
Asn Ile Glu Tyr Phe Cys Phe His Asp Arg Asp Ile Ala Pro Glu Gly
115 120 125
Lys Thr Leu Arg Glu Thr Asn Lys Ile Leu Asp Lys Val Val Glu Arg
130 135 140
Ile Lys Glu Arg Met Lys Asp Ser Asn Val Lys Leu Leu Trp Gly Thr
145 150 155 160
Ala Asn Leu Phe Ser His Pro Arg Tyr Met His Gly Ala Ala Thr Thr
165 170 175
Cys Ser Ala Asp Val Phe Ala Tyr Ala Ala Ala Gln Val Lys Lys Ala
180 185 190
Leu Glu Ile Thr Lys Glu Leu Gly Gly Glu Gly Tyr Val Phe Trp Gly
195 200 205
Gly Arg Glu Gly Tyr Glu Thr Leu Leu Asn Thr Asp Leu Gly Leu Glu
210 215 220
Leu Glu Asn Leu Ala Arg Phe Leu Arg Met Ala Val Glu Tyr Ala Lys
225 230 235 240
Lys Ile Gly Phe Thr Gly Gln Phe Leu Ile Glu Pro Lys Pro Lys Glu
245 250 255
Pro Thr Lys His Gln Tyr Asp Phe Asp Val Ala Thr Ala Tyr Ala Phe
260 265 270
Leu Lys Asn His Gly Leu Asp Glu Tyr Phe Lys Phe Asn Ile Glu Ala
275 280 285
Asn His Ala Thr Leu Ala Gly His Thr Phe Gln His Glu Leu Arg Met
290 295 300
Ala Arg Ile Leu Gly Lys Leu Gly Ser Ile Asp Ala Asn Gln Gly Asp
305 310 315 320
Leu Leu Leu Gly Trp Asp Thr Asp Gln Phe Pro Thr Asn Ile Tyr Asp
325 330 335
Thr Thr Leu Ala Met Tyr Glu Val Ile Lys Ala Gly Gly Phe Thr Lys
340 345 350
Gly Gly Leu Asn Phe Asp Ala Lys Val Arg Arg Ala Ser Tyr Lys Val
355 360 365
Glu Asp Leu Phe Ile Gly His Ile Ala Gly Met Asp Thr Phe Ala Leu
370 375 380
Gly Phe Lys Ile Ala Tyr Lys Leu Ala Lys Asp Gly Val Phe Asp Lys
385 390 395 400
Phe Ile Glu Glu Lys Tyr Arg Ser Phe Lys Glu Gly Ile Gly Lys Glu
405 410 415
Ile Val Glu Gly Lys Thr Asp Phe Glu Lys Leu Glu Glu Tyr Ile Ile
420 425 430
Asp Lys Glu Asp Ile Glu Leu Pro Ser Gly Lys Gln Glu Tyr Leu Glu
435 440 445
Ser Leu Leu Asn Ser Tyr Ile Val Lys Thr Ile Ala Glu Leu Arg Ser
450 455 460
Glu Lys Asp Glu Leu
465
<210> 29
<211> 469
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 29
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Met Ala Glu Phe Phe Pro Glu Ile Pro Lys Val Gln Phe
20 25 30
Glu Gly Lys Glu Ser Thr Asn Pro Leu Ala Phe Lys Phe Tyr Asp Pro
35 40 45
Glu Glu Ile Ile Asp Gly Lys Pro Leu Lys Asp His Leu Lys Phe Ser
50 55 60
Val Ala Phe Trp His Thr Phe Val Asn Glu Gly Arg Asp Pro Phe Gly
65 70 75 80
Asp Pro Thr Ala Asp Arg Pro Trp Asn Arg Tyr Thr Asp Pro Met Asp
85 90 95
Lys Ala Phe Ala Arg Val Asp Ala Leu Phe Glu Phe Cys Glu Lys Leu
100 105 110
Asn Ile Glu Tyr Phe Cys Phe His Asp Arg Asp Ile Ala Pro Glu Gly
115 120 125
Lys Thr Leu Arg Glu Thr Asn Lys Ile Leu Asp Lys Val Val Glu Arg
130 135 140
Ile Lys Glu Arg Met Lys Asp Ser Asn Val Lys Leu Leu Trp Gly Thr
145 150 155 160
Ala Asn Leu Phe Ser His Pro Arg Tyr Met His Gly Ala Ala Thr Thr
165 170 175
Cys Ser Ala Asp Val Phe Ala Tyr Ala Ala Ala Gln Val Lys Lys Ala
180 185 190
Leu Glu Ile Thr Lys Glu Leu Gly Gly Glu Gly Tyr Val Phe Trp Gly
195 200 205
Gly Arg Glu Gly Tyr Glu Thr Leu Leu Asn Thr Asp Leu Gly Phe Glu
210 215 220
Leu Glu Asn Leu Ala Arg Phe Leu Arg Met Ala Val Asp Tyr Ala Lys
225 230 235 240
Arg Ile Gly Phe Thr Gly Gln Phe Leu Ile Glu Pro Lys Pro Lys Glu
245 250 255
Pro Thr Lys His Gln Tyr Asp Phe Asp Val Ala Thr Ala Tyr Ala Phe
260 265 270
Leu Lys Ser His Gly Leu Asp Glu Tyr Phe Lys Phe Asn Ile Glu Ala
275 280 285
Asn His Ala Thr Leu Ala Gly His Thr Phe Gln His Glu Leu Arg Met
290 295 300
Ala Arg Ile Leu Gly Lys Leu Gly Ser Ile Asp Ala Asn Gln Gly Asp
305 310 315 320
Leu Leu Leu Gly Trp Asp Thr Asp Gln Phe Pro Thr Asn Val Tyr Asp
325 330 335
Thr Thr Leu Ala Met Tyr Glu Val Ile Lys Ala Gly Gly Phe Thr Lys
340 345 350
Gly Gly Leu Asn Phe Asp Ala Lys Val Arg Arg Ala Ser Tyr Lys Val
355 360 365
Glu Asp Leu Phe Ile Gly His Ile Ala Gly Met Asp Thr Phe Ala Leu
370 375 380
Gly Phe Lys Val Ala Tyr Lys Leu Val Lys Asp Gly Val Leu Asp Lys
385 390 395 400
Phe Ile Glu Glu Lys Tyr Arg Ser Phe Arg Glu Gly Ile Gly Arg Asp
405 410 415
Ile Val Glu Gly Lys Val Asp Phe Glu Lys Leu Glu Glu Tyr Ile Ile
420 425 430
Asp Lys Glu Thr Ile Glu Leu Pro Ser Gly Lys Gln Glu Tyr Leu Glu
435 440 445
Ser Leu Ile Asn Ser Tyr Ile Val Lys Thr Ile Leu Glu Leu Arg Ser
450 455 460
Glu Lys Asp Glu Leu
465
<210> 30
<211> 463
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 30
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Met Ala Glu Phe Phe Pro Glu Ile Pro Lys Val Gln Phe
20 25 30
Glu Gly Lys Glu Ser Thr Asn Pro Leu Ala Phe Lys Phe Tyr Asp Pro
35 40 45
Glu Glu Ile Ile Asp Gly Lys Pro Leu Lys Asp His Leu Lys Phe Ser
50 55 60
Val Ala Phe Trp His Thr Phe Val Asn Glu Gly Arg Asp Pro Phe Gly
65 70 75 80
Asp Pro Thr Ala Asp Arg Pro Trp Asn Arg Tyr Thr Asp Pro Met Asp
85 90 95
Lys Ala Phe Ala Arg Val Asp Ala Leu Phe Glu Phe Cys Glu Lys Leu
100 105 110
Asn Ile Glu Tyr Phe Cys Phe His Asp Arg Asp Ile Ala Pro Glu Gly
115 120 125
Lys Thr Leu Arg Glu Thr Asn Lys Ile Leu Asp Lys Val Val Glu Arg
130 135 140
Ile Lys Glu Arg Met Lys Asp Ser Asn Val Lys Leu Leu Trp Gly Thr
145 150 155 160
Ala Asn Leu Phe Ser His Pro Arg Tyr Met His Gly Ala Ala Thr Thr
165 170 175
Cys Ser Ala Asp Val Phe Ala Tyr Ala Ala Ala Gln Val Lys Lys Ala
180 185 190
Leu Glu Ile Thr Lys Glu Leu Gly Gly Glu Gly Tyr Val Phe Trp Gly
195 200 205
Gly Arg Glu Gly Tyr Glu Thr Leu Leu Asn Thr Asp Leu Gly Phe Glu
210 215 220
Leu Glu Asn Leu Ala Arg Phe Leu Arg Met Ala Val Asp Tyr Ala Lys
225 230 235 240
Arg Ile Gly Phe Thr Gly Gln Phe Leu Ile Glu Pro Lys Pro Lys Glu
245 250 255
Pro Thr Lys His Gln Tyr Asp Phe Asp Val Ala Thr Ala Tyr Ala Phe
260 265 270
Leu Lys Ser His Gly Leu Asp Glu Tyr Phe Lys Phe Asn Ile Glu Ala
275 280 285
Asn His Ala Thr Leu Ala Gly His Thr Phe Gln His Glu Leu Arg Met
290 295 300
Ala Arg Ile Leu Gly Lys Leu Gly Ser Ile Asp Ala Asn Gln Gly Asp
305 310 315 320
Leu Leu Leu Gly Trp Asp Thr Asp Gln Phe Pro Thr Asn Val Tyr Asp
325 330 335
Thr Thr Leu Ala Met Tyr Glu Val Ile Lys Ala Gly Gly Phe Thr Lys
340 345 350
Gly Gly Leu Asn Phe Asp Ala Lys Val Arg Arg Ala Ser Tyr Lys Val
355 360 365
Glu Asp Leu Phe Ile Gly His Ile Ala Gly Met Asp Thr Phe Ala Leu
370 375 380
Gly Phe Lys Val Ala Tyr Lys Leu Val Lys Asp Gly Val Leu Asp Lys
385 390 395 400
Phe Ile Glu Glu Lys Tyr Arg Ser Phe Arg Glu Gly Ile Gly Arg Asp
405 410 415
Ile Val Glu Gly Lys Val Asp Phe Glu Lys Leu Glu Glu Tyr Ile Ile
420 425 430
Asp Lys Glu Thr Ile Glu Leu Pro Ser Gly Lys Gln Glu Tyr Leu Glu
435 440 445
Ser Leu Ile Asn Ser Tyr Ile Val Lys Thr Ile Leu Glu Leu Arg
450 455 460
<210> 31
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 31
Met Gly Lys Asn Gly Asn Leu Cys Cys Phe Ser Leu Leu Leu Leu Leu
1 5 10 15
Leu Ala Gly Leu Ala Ser Gly His Gln
20 25
<210> 32
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 32
Met Gly Phe Val Leu Phe Ser Gln Leu Pro Ser Phe Leu Leu Val Ser
1 5 10 15
Thr Leu Leu Leu Phe Leu Val Ile Ser His Ser Cys Arg Ala
20 25 30
<210> 33
<211> 460
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 33
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met
20 25 30
Gln Ala Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr
35 40 45
Ile Arg Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile
50 55 60
Trp Ile Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly
65 70 75 80
Tyr Asp Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly
85 90 95
Thr Val Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile
100 105 110
Asn Thr Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile
115 120 125
Asn His Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp
130 135 140
Tyr Thr Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala
145 150 155 160
Asn Tyr Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly
165 170 175
Thr Phe Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln
180 185 190
Tyr Trp Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser
195 200 205
Ile Gly Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala
210 215 220
Trp Val Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly
225 230 235 240
Glu Tyr Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser
245 250 255
Ser Gly Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala
260 265 270
Ala Phe Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn
275 280 285
Gly Gly Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val
290 295 300
Ala Asn His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala
305 310 315 320
Phe Ile Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr
325 330 335
Glu Glu Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His
340 345 350
Asp Asn Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp
355 360 365
Glu Met Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile
370 375 380
Thr Tyr Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val
385 390 395 400
Pro Lys Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly
405 410 415
Gly Trp Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu
420 425 430
Ala Pro Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp
435 440 445
Ser Tyr Cys Gly Val Gly Ser Glu Lys Asp Glu Leu
450 455 460
<210> 34
<211> 825
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 34
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Gly His Trp Tyr Lys His Gln Arg Ala Tyr Gln Phe
20 25 30
Thr Gly Glu Asp Asp Phe Gly Lys Val Ala Val Val Lys Leu Pro Met
35 40 45
Asp Leu Thr Lys Val Gly Ile Ile Val Arg Leu Asn Glu Trp Gln Ala
50 55 60
Lys Asp Val Ala Lys Asp Arg Phe Ile Glu Ile Lys Asp Gly Lys Ala
65 70 75 80
Glu Val Trp Ile Leu Gln Gly Val Glu Glu Ile Phe Tyr Glu Lys Pro
85 90 95
Asp Thr Ser Pro Arg Ile Phe Phe Ala Gln Ala Arg Ser Asn Lys Val
100 105 110
Ile Glu Ala Phe Leu Thr Asn Pro Val Asp Thr Lys Lys Lys Glu Leu
115 120 125
Phe Lys Val Thr Val Asp Gly Lys Glu Ile Pro Val Ser Arg Val Glu
130 135 140
Lys Ala Asp Pro Thr Asp Ile Asp Val Thr Asn Tyr Val Arg Ile Val
145 150 155 160
Leu Ser Glu Ser Leu Lys Glu Glu Asp Leu Arg Lys Asp Val Glu Leu
165 170 175
Ile Ile Glu Gly Tyr Lys Pro Ala Arg Val Ile Met Met Glu Ile Leu
180 185 190
Asp Asp Tyr Tyr Tyr Asp Gly Glu Leu Gly Ala Val Tyr Ser Pro Glu
195 200 205
Lys Thr Ile Phe Arg Val Trp Ser Pro Val Ser Lys Trp Val Lys Val
210 215 220
Leu Leu Phe Lys Asn Gly Glu Asp Thr Glu Pro Tyr Gln Val Val Asn
225 230 235 240
Met Glu Tyr Lys Gly Asn Gly Val Trp Glu Ala Val Val Glu Gly Asp
245 250 255
Leu Asp Gly Val Phe Tyr Leu Tyr Gln Leu Glu Asn Tyr Gly Lys Ile
260 265 270
Arg Thr Thr Val Asp Pro Tyr Ser Lys Ala Val Tyr Ala Asn Asn Gln
275 280 285
Glu Ser Ala Val Val Asn Leu Ala Arg Thr Asn Pro Glu Gly Trp Glu
290 295 300
Asn Asp Arg Gly Pro Lys Ile Glu Gly Tyr Glu Asp Ala Ile Ile Tyr
305 310 315 320
Glu Ile His Ile Ala Asp Ile Thr Gly Leu Glu Asn Ser Gly Val Lys
325 330 335
Asn Lys Gly Leu Tyr Leu Gly Leu Thr Glu Glu Asn Thr Lys Ala Pro
340 345 350
Gly Gly Val Thr Thr Gly Leu Ser His Leu Val Glu Leu Gly Val Thr
355 360 365
His Val His Ile Leu Pro Phe Phe Asp Phe Tyr Thr Gly Asp Glu Leu
370 375 380
Asp Lys Asp Phe Glu Lys Tyr Tyr Asn Trp Gly Tyr Asp Pro Tyr Leu
385 390 395 400
Phe Met Val Pro Glu Gly Arg Tyr Ser Thr Asp Pro Lys Asn Pro His
405 410 415
Thr Arg Ile Arg Glu Val Lys Glu Met Val Lys Ala Leu His Lys His
420 425 430
Gly Ile Gly Val Ile Met Asp Met Val Phe Pro His Thr Tyr Gly Ile
435 440 445
Gly Glu Leu Ser Ala Phe Asp Gln Thr Val Pro Tyr Tyr Phe Tyr Arg
450 455 460
Ile Asp Lys Thr Gly Ala Tyr Leu Asn Glu Ser Gly Cys Gly Asn Val
465 470 475 480
Ile Ala Ser Glu Arg Pro Met Met Arg Lys Phe Ile Val Asp Thr Val
485 490 495
Thr Tyr Trp Val Lys Glu Tyr His Ile Asp Gly Phe Arg Phe Asp Gln
500 505 510
Met Gly Leu Ile Asp Lys Lys Thr Met Leu Glu Val Glu Arg Ala Leu
515 520 525
His Lys Ile Asp Pro Thr Ile Ile Leu Tyr Gly Glu Pro Trp Gly Gly
530 535 540
Trp Gly Ala Pro Ile Arg Phe Gly Lys Ser Asp Val Ala Gly Thr His
545 550 555 560
Val Ala Ala Phe Asn Asp Glu Phe Arg Asp Ala Ile Arg Gly Ser Val
565 570 575
Phe Asn Pro Ser Val Lys Gly Phe Val Met Gly Gly Tyr Gly Lys Glu
580 585 590
Thr Lys Ile Lys Arg Gly Val Val Gly Ser Ile Asn Tyr Asp Gly Lys
595 600 605
Leu Ile Lys Ser Phe Ala Leu Asp Pro Glu Glu Thr Ile Asn Tyr Ala
610 615 620
Ala Cys His Asp Asn His Thr Leu Trp Asp Lys Asn Tyr Leu Ala Ala
625 630 635 640
Lys Ala Asp Lys Lys Lys Glu Trp Thr Glu Glu Glu Leu Lys Asn Ala
645 650 655
Gln Lys Leu Ala Gly Ala Ile Leu Leu Thr Ser Gln Gly Val Pro Phe
660 665 670
Leu His Gly Gly Gln Asp Phe Cys Arg Thr Thr Asn Phe Asn Asp Asn
675 680 685
Ser Tyr Asn Ala Pro Ile Ser Ile Asn Gly Phe Asp Tyr Glu Arg Lys
690 695 700
Leu Gln Phe Ile Asp Val Phe Asn Tyr His Lys Gly Leu Ile Lys Leu
705 710 715 720
Arg Lys Glu His Pro Ala Phe Arg Leu Lys Asn Ala Glu Glu Ile Lys
725 730 735
Lys His Leu Glu Phe Leu Pro Gly Gly Arg Arg Ile Val Ala Phe Met
740 745 750
Leu Lys Asp His Ala Gly Gly Asp Pro Trp Lys Asp Ile Val Val Ile
755 760 765
Tyr Asn Gly Asn Leu Glu Lys Thr Thr Tyr Lys Leu Pro Glu Gly Lys
770 775 780
Trp Asn Val Val Val Asn Ser Gln Lys Ala Gly Thr Glu Val Ile Glu
785 790 795 800
Thr Val Glu Gly Thr Ile Glu Leu Asp Pro Leu Ser Ala Tyr Val Leu
805 810 815
Tyr Arg Glu Ser Glu Lys Asp Glu Leu
820 825
<210> 35
<211> 460
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 35
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met
20 25 30
Gln Ala Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr
35 40 45
Ile Arg Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile
50 55 60
Trp Ile Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly
65 70 75 80
Tyr Asp Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly
85 90 95
Thr Val Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile
100 105 110
Asn Thr Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile
115 120 125
Asn His Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp
130 135 140
Tyr Thr Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala
145 150 155 160
Asn Tyr Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly
165 170 175
Thr Phe Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln
180 185 190
Tyr Trp Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser
195 200 205
Ile Gly Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala
210 215 220
Trp Val Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly
225 230 235 240
Glu Tyr Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser
245 250 255
Ser Gly Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala
260 265 270
Ala Phe Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn
275 280 285
Gly Gly Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val
290 295 300
Ala Asn His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala
305 310 315 320
Phe Ile Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr
325 330 335
Glu Glu Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His
340 345 350
Asp Asn Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp
355 360 365
Glu Met Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile
370 375 380
Thr Tyr Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val
385 390 395 400
Pro Lys Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly
405 410 415
Gly Trp Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu
420 425 430
Ala Pro Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp
435 440 445
Ser Tyr Cys Gly Val Gly Ser Glu Lys Asp Glu Leu
450 455 460
<210> 36
<211> 718
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 36
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Met Glu Thr Ile Lys Ile Tyr Glu Asn Lys Gly Val Tyr
20 25 30
Lys Val Val Ile Gly Glu Pro Phe Pro Pro Ile Glu Phe Pro Leu Glu
35 40 45
Gln Lys Ile Ser Ser Asn Lys Ser Leu Ser Glu Leu Gly Leu Thr Ile
50 55 60
Val Gln Gln Gly Asn Lys Val Ile Val Glu Lys Ser Leu Asp Leu Lys
65 70 75 80
Glu His Ile Ile Gly Leu Gly Glu Lys Ala Phe Glu Leu Asp Arg Lys
85 90 95
Arg Lys Arg Tyr Val Met Tyr Asn Val Asp Ala Gly Ala Tyr Lys Lys
100 105 110
Tyr Gln Asp Pro Leu Tyr Val Ser Ile Pro Leu Phe Ile Ser Val Lys
115 120 125
Asp Gly Val Ala Thr Gly Tyr Phe Phe Asn Ser Ala Ser Lys Val Ile
130 135 140
Phe Asp Val Gly Leu Glu Glu Tyr Asp Lys Val Ile Val Thr Ile Pro
145 150 155 160
Glu Asp Ser Val Glu Phe Tyr Val Ile Glu Gly Pro Arg Ile Glu Asp
165 170 175
Val Leu Glu Lys Tyr Thr Glu Leu Thr Gly Lys Pro Phe Leu Pro Pro
180 185 190
Met Trp Ala Phe Gly Tyr Met Ile Ser Arg Tyr Ser Tyr Tyr Pro Gln
195 200 205
Asp Lys Val Val Glu Leu Val Asp Ile Met Gln Lys Glu Gly Phe Arg
210 215 220
Val Ala Gly Val Phe Leu Asp Ile His Tyr Met Asp Ser Tyr Lys Leu
225 230 235 240
Phe Thr Trp His Pro Tyr Arg Phe Pro Glu Pro Lys Lys Leu Ile Asp
245 250 255
Glu Leu His Lys Arg Asn Val Lys Leu Ile Thr Ile Val Asp His Gly
260 265 270
Ile Arg Val Asp Gln Asn Tyr Ser Pro Phe Leu Ser Gly Met Gly Lys
275 280 285
Phe Cys Glu Ile Glu Ser Gly Glu Leu Phe Val Gly Lys Met Trp Pro
290 295 300
Gly Thr Thr Val Tyr Pro Asp Phe Phe Arg Glu Asp Thr Arg Glu Trp
305 310 315 320
Trp Ala Gly Leu Ile Ser Glu Trp Leu Ser Gln Gly Val Asp Gly Ile
325 330 335
Trp Leu Asp Met Asn Glu Pro Thr Asp Phe Ser Arg Ala Ile Glu Ile
340 345 350
Arg Asp Val Leu Ser Ser Leu Pro Val Gln Phe Arg Asp Asp Arg Leu
355 360 365
Val Thr Thr Phe Pro Asp Asn Val Val His Tyr Leu Arg Gly Lys Arg
370 375 380
Val Lys His Glu Lys Val Arg Asn Ala Tyr Pro Leu Tyr Glu Ala Met
385 390 395 400
Ala Thr Phe Lys Gly Phe Arg Thr Ser His Arg Asn Glu Ile Phe Ile
405 410 415
Leu Ser Arg Ala Gly Tyr Ala Gly Ile Gln Arg Tyr Ala Phe Ile Trp
420 425 430
Thr Gly Asp Asn Thr Pro Ser Trp Asp Asp Leu Lys Leu Gln Leu Gln
435 440 445
Leu Val Leu Gly Leu Ser Ile Ser Gly Val Pro Phe Val Gly Cys Asp
450 455 460
Ile Gly Gly Phe Gln Gly Arg Asn Phe Ala Glu Ile Asp Asn Ser Met
465 470 475 480
Asp Leu Leu Val Lys Tyr Tyr Ala Leu Ala Leu Phe Phe Pro Phe Tyr
485 490 495
Arg Ser His Lys Ala Thr Asp Gly Ile Asp Thr Glu Pro Val Phe Leu
500 505 510
Pro Asp Tyr Tyr Lys Glu Lys Val Lys Glu Ile Val Glu Leu Arg Tyr
515 520 525
Lys Phe Leu Pro Tyr Ile Tyr Ser Leu Ala Leu Glu Ala Ser Glu Lys
530 535 540
Gly His Pro Val Ile Arg Pro Leu Phe Tyr Glu Phe Gln Asp Asp Asp
545 550 555 560
Asp Met Tyr Arg Ile Glu Asp Glu Tyr Met Val Gly Lys Tyr Leu Leu
565 570 575
Tyr Ala Pro Ile Val Ser Lys Glu Glu Ser Arg Leu Val Thr Leu Pro
580 585 590
Arg Gly Lys Trp Tyr Asn Tyr Trp Asn Gly Glu Ile Ile Asn Gly Lys
595 600 605
Ser Val Val Lys Ser Thr His Glu Leu Pro Ile Tyr Leu Arg Glu Gly
610 615 620
Ser Ile Ile Pro Leu Glu Gly Asp Glu Leu Ile Val Tyr Gly Glu Thr
625 630 635 640
Ser Phe Lys Arg Tyr Asp Asn Ala Glu Ile Thr Ser Ser Ser Asn Glu
645 650 655
Ile Lys Phe Ser Arg Glu Ile Tyr Val Ser Lys Leu Thr Ile Thr Ser
660 665 670
Glu Lys Pro Val Ser Lys Ile Ile Val Asp Asp Ser Lys Glu Ile Gln
675 680 685
Val Glu Lys Thr Met Gln Asn Thr Tyr Val Ala Lys Ile Asn Gln Lys
690 695 700
Ile Arg Gly Lys Ile Asn Leu Glu Ser Glu Lys Asp Glu Leu
705 710 715
<210> 37
<211> 1434
<212> DNA
<213> Thermotoga maritima
<400> 37
atgaaagaaa ccgctgctgc taaattcgaa cgccagcaca tggacagccc agatctgggt 60
accctggtgc cacgcggttc catggccgag ttcttcccgg agatcccgaa gatccagttc 120
gagggcaagg agtccaccaa cccgctcgcc ttccgcttct acgacccgaa cgaggtgatc 180
gacggcaagc cgctcaagga ccacctcaag ttctccgtgg ccttctggca caccttcgtg 240
aacgagggcc gcgacccgtt cggcgacccg accgccgagc gcccgtggaa ccgcttctcc 300
gacccgatgg acaaggcctt cgcccgcgtg gacgccctct tcgagttctg cgagaagctc 360
aacatcgagt acttctgctt ccacgaccgc gacatcgccc cggagggcaa gaccctccgc 420
gagaccaaca agatcctcga caaggtggtg gagcgcatca aggagcgcat gaaggactcc 480
aacgtgaagc tcctctgggg caccgccaac ctcttctccc acccgcgcta catgcacggc 540
gccgccacca cctgctccgc cgacgtgttc gcctacgccg ccgcccaggt gaagaaggcc 600
ctggagatca ccaaggagct gggcggcgag ggctacgtgt tctggggcgg ccgcgagggc 660
tacgagaccc tcctcaacac cgacctcggc ctggagctgg agaacctcgc ccgcttcctc 720
cgcatggccg tggagtacgc caagaagatc ggcttcaccg gccagttcct catcgagccg 780
aagccgaagg agccgaccaa gcaccagtac gacttcgacg tggccaccgc ctacgccttc 840
ctcaagaacc acggcctcga cgagtacttc aagttcaaca tcgaggccaa ccacgccacc 900
ctcgccggcc acaccttcca gcacgagctg cgcatggccc gcatcctcgg caagctcggc 960
tccatcgacg ccaaccaggg cgacctcctc ctcggctggg acaccgacca gttcccgacc 1020
aacatctacg acaccaccct cgccatgtac gaggtgatca aggccggcgg cttcaccaag 1080
ggcggcctca acttcgacgc caaggtgcgc cgcgcctcct acaaggtgga ggacctcttc 1140
atcggccaca tcgccggcat ggacaccttc gccctcggct tcaagatcgc ctacaagctc 1200
gccaaggacg gcgtgttcga caagttcatc gaggagaagt accgctcctt caaggagggc 1260
atcggcaagg agatcgtgga gggcaagacc gacttcgaga agctggagga gtacatcatc 1320
gacaaggagg acatcgagct gccgtccggc aagcaggagt acctggagtc cctcctcaac 1380
tcctacatcg tgaagaccat cgccgagctg cgctccgaga aggacgagct gtga 1434
<210> 38
<211> 477
<212> PRT
<213> Thermotoga maritima
<400> 38
Met Lys Glu Thr Ala Ala Ala Lys Phe Glu Arg Gln His Met Asp Ser
1 5 10 15
Pro Asp Leu Gly Thr Leu Val Pro Arg Gly Ser Met Ala Glu Phe Phe
20 25 30
Pro Glu Ile Pro Lys Ile Gln Phe Glu Gly Lys Glu Ser Thr Asn Pro
35 40 45
Leu Ala Phe Arg Phe Tyr Asp Pro Asn Glu Val Ile Asp Gly Lys Pro
50 55 60
Leu Lys Asp His Leu Lys Phe Ser Val Ala Phe Trp His Thr Phe Val
65 70 75 80
Asn Glu Gly Arg Asp Pro Phe Gly Asp Pro Thr Ala Glu Arg Pro Trp
85 90 95
Asn Arg Phe Ser Asp Pro Met Asp Lys Ala Phe Ala Arg Val Asp Ala
100 105 110
Leu Phe Glu Phe Cys Glu Lys Leu Asn Ile Glu Tyr Phe Cys Phe His
115 120 125
Asp Arg Asp Ile Ala Pro Glu Gly Lys Thr Leu Arg Glu Thr Asn Lys
130 135 140
Ile Leu Asp Lys Val Val Glu Arg Ile Lys Glu Arg Met Lys Asp Ser
145 150 155 160
Asn Val Lys Leu Leu Trp Gly Thr Ala Asn Leu Phe Ser His Pro Arg
165 170 175
Tyr Met His Gly Ala Ala Thr Thr Cys Ser Ala Asp Val Phe Ala Tyr
180 185 190
Ala Ala Ala Gln Val Lys Lys Ala Leu Glu Ile Thr Lys Glu Leu Gly
195 200 205
Gly Glu Gly Tyr Val Phe Trp Gly Gly Arg Glu Gly Tyr Glu Thr Leu
210 215 220
Leu Asn Thr Asp Leu Gly Leu Glu Leu Glu Asn Leu Ala Arg Phe Leu
225 230 235 240
Arg Met Ala Val Glu Tyr Ala Lys Lys Ile Gly Phe Thr Gly Gln Phe
245 250 255
Leu Ile Glu Pro Lys Pro Lys Glu Pro Thr Lys His Gln Tyr Asp Phe
260 265 270
Asp Val Ala Thr Ala Tyr Ala Phe Leu Lys Asn His Gly Leu Asp Glu
275 280 285
Tyr Phe Lys Phe Asn Ile Glu Ala Asn His Ala Thr Leu Ala Gly His
290 295 300
Thr Phe Gln His Glu Leu Arg Met Ala Arg Ile Leu Gly Lys Leu Gly
305 310 315 320
Ser Ile Asp Ala Asn Gln Gly Asp Leu Leu Leu Gly Trp Asp Thr Asp
325 330 335
Gln Phe Pro Thr Asn Ile Tyr Asp Thr Thr Leu Ala Met Tyr Glu Val
340 345 350
Ile Lys Ala Gly Gly Phe Thr Lys Gly Gly Leu Asn Phe Asp Ala Lys
355 360 365
Val Arg Arg Ala Ser Tyr Lys Val Glu Asp Leu Phe Ile Gly His Ile
370 375 380
Ala Gly Met Asp Thr Phe Ala Leu Gly Phe Lys Ile Ala Tyr Lys Leu
385 390 395 400
Ala Lys Asp Gly Val Phe Asp Lys Phe Ile Glu Glu Lys Tyr Arg Ser
405 410 415
Phe Lys Glu Gly Ile Gly Lys Glu Ile Val Glu Gly Lys Thr Asp Phe
420 425 430
Glu Lys Leu Glu Glu Tyr Ile Ile Asp Lys Glu Asp Ile Glu Leu Pro
435 440 445
Ser Gly Lys Gln Glu Tyr Leu Glu Ser Leu Leu Asn Ser Tyr Ile Val
450 455 460
Lys Thr Ile Ala Glu Leu Arg Ser Glu Lys Asp Glu Leu
465 470 475
<210> 39
<211> 1434
<212> DNA
<213> Thermotoga neapolitana
<400> 39
atgaaagaaa ccgctgctgc taaattcgaa cgccagcaca tggacagccc agatctgggt 60
accctggtgc cacgcggttc catggccgag ttcttcccgg agatcccgaa ggtgcagttc 120
gagggcaagg agtccaccaa cccgctcgcc ttcaagttct acgacccgga ggagatcatc 180
gacggcaagc cgctcaagga ccacctcaag ttctccgtgg ccttctggca caccttcgtg 240
aacgagggcc gcgacccgtt cggcgacccg accgccgacc gcccgtggaa ccgctacacc 300
gacccgatgg acaaggcctt cgcccgcgtg gacgccctct tcgagttctg cgagaagctc 360
aacatcgagt acttctgctt ccacgaccgc gacatcgccc cggagggcaa gaccctccgc 420
gagaccaaca agatcctcga caaggtggtg gagcgcatca aggagcgcat gaaggactcc 480
aacgtgaagc tcctctgggg caccgccaac ctcttctccc acccgcgcta catgcacggc 540
gccgccacca cctgctccgc cgacgtgttc gcctacgccg ccgcccaggt gaagaaggcc 600
ctggagatca ccaaggagct gggcggcgag ggctacgtgt tctggggcgg ccgcgagggc 660
tacgagaccc tcctcaacac cgacctcggc ttcgagctgg agaacctcgc ccgcttcctc 720
cgcatggccg tggactacgc caagcgcatc ggcttcaccg gccagttcct catcgagccg 780
aagccgaagg agccgaccaa gcaccagtac gacttcgacg tggccaccgc ctacgccttc 840
ctcaagtccc acggcctcga cgagtacttc aagttcaaca tcgaggccaa ccacgccacc 900
ctcgccggcc acaccttcca gcacgagctg cgcatggccc gcatcctcgg caagctcggc 960
tccatcgacg ccaaccaggg cgacctcctc ctcggctggg acaccgacca gttcccgacc 1020
aacgtgtacg acaccaccct cgccatgtac gaggtgatca aggccggcgg cttcaccaag 1080
ggcggcctca acttcgacgc caaggtgcgc cgcgcctcct acaaggtgga ggacctcttc 1140
atcggccaca tcgccggcat ggacaccttc gccctcggct tcaaggtggc ctacaagctc 1200
gtgaaggacg gcgtgctcga caagttcatc gaggagaagt accgctcctt ccgcgagggc 1260
atcggccgcg acatcgtgga gggcaaggtg gacttcgaga agctggagga gtacatcatc 1320
gacaaggaga ccatcgagct gccgtccggc aagcaggagt acctggagtc cctcatcaac 1380
tcctacatcg tgaagaccat cctggagctg cgctccgaga aggacgagct gtga 1434
<210> 40
<211> 477
<212> PRT
<213> Thermotoga neapolitana
<400> 40
Met Lys Glu Thr Ala Ala Ala Lys Phe Glu Arg Gln His Met Asp Ser
1 5 10 15
Pro Asp Leu Gly Thr Leu Val Pro Arg Gly Ser Met Ala Glu Phe Phe
20 25 30
Pro Glu Ile Pro Lys Val Gln Phe Glu Gly Lys Glu Ser Thr Asn Pro
35 40 45
Leu Ala Phe Lys Phe Tyr Asp Pro Glu Glu Ile Ile Asp Gly Lys Pro
50 55 60
Leu Lys Asp His Leu Lys Phe Ser Val Ala Phe Trp His Thr Phe Val
65 70 75 80
Asn Glu Gly Arg Asp Pro Phe Gly Asp Pro Thr Ala Asp Arg Pro Trp
85 90 95
Asn Arg Tyr Thr Asp Pro Met Asp Lys Ala Phe Ala Arg Val Asp Ala
100 105 110
Leu Phe Glu Phe Cys Glu Lys Leu Asn Ile Glu Tyr Phe Cys Phe His
115 120 125
Asp Arg Asp Ile Ala Pro Glu Gly Lys Thr Leu Arg Glu Thr Asn Lys
130 135 140
Ile Leu Asp Lys Val Val Glu Arg Ile Lys Glu Arg Met Lys Asp Ser
145 150 155 160
Asn Val Lys Leu Leu Trp Gly Thr Ala Asn Leu Phe Ser His Pro Arg
165 170 175
Tyr Met His Gly Ala Ala Thr Thr Cys Ser Ala Asp Val Phe Ala Tyr
180 185 190
Ala Ala Ala Gln Val Lys Lys Ala Leu Glu Ile Thr Lys Glu Leu Gly
195 200 205
Gly Glu Gly Tyr Val Phe Trp Gly Gly Arg Glu Gly Tyr Glu Thr Leu
210 215 220
Leu Asn Thr Asp Leu Gly Phe Glu Leu Glu Asn Leu Ala Arg Phe Leu
225 230 235 240
Arg Met Ala Val Asp Tyr Ala Lys Arg Ile Gly Phe Thr Gly Gln Phe
245 250 255
Leu Ile Glu Pro Lys Pro Lys Glu Pro Thr Lys His Gln Tyr Asp Phe
260 265 270
Asp Val Ala Thr Ala Tyr Ala Phe Leu Lys Ser His Gly Leu Asp Glu
275 280 285
Tyr Phe Lys Phe Asn Ile Glu Ala Asn His Ala Thr Leu Ala Gly His
290 295 300
Thr Phe Gln His Glu Leu Arg Met Ala Arg Ile Leu Gly Lys Leu Gly
305 310 315 320
Ser Ile Asp Ala Asn Gln Gly Asp Leu Leu Leu Gly Trp Asp Thr Asp
325 330 335
Gln Phe Pro Thr Asn Val Tyr Asp Thr Thr Leu Ala Met Tyr Glu Val
340 345 350
Ile Lys Ala Gly Gly Phe Thr Lys Gly Gly Leu Asn Phe Asp Ala Lys
355 360 365
Val Arg Arg Ala Ser Tyr Lys Val Glu Asp Leu Phe Ile Gly His Ile
370 375 380
Ala Gly Met Asp Thr Phe Ala Leu Gly Phe Lys Val Ala Tyr Lys Leu
385 390 395 400
Val Lys Asp Gly Val Leu Asp Lys Phe Ile Glu Glu Lys Tyr Arg Ser
405 410 415
Phe Arg Glu Gly Ile Gly Arg Asp Ile Val Glu Gly Lys Val Asp Phe
420 425 430
Glu Lys Leu Glu Glu Tyr Ile Ile Asp Lys Glu Thr Ile Glu Leu Pro
435 440 445
Ser Gly Lys Gln Glu Tyr Leu Glu Ser Leu Ile Asn Ser Tyr Ile Val
450 455 460
Lys Thr Ile Leu Glu Leu Arg Ser Glu Lys Asp Glu Leu
465 470 475
<210> 41
<211> 1435
<212> DNA
<213> Thermotoga maritima
<400> 41
atgggcagca gccatcatca tcatcatcac agcagcggcc tggtgccgcg cggcagccat 60
atggctagca tgactggtgg acagcaaatg ggtcggatcc ccatggccga gttcttcccg 120
gagatcccga agatccagtt cgagggcaag gagtccacca acccgctcgc cttccgcttc 180
tacgacccga acgaggtgat cgacggcaag ccgctcaagg accacctcaa gttctccgtg 240
gccttctggc acaccttcgt gaacgagggc cgcgacccgt tcggcgaccc gaccgccgag 300
cgcccgtgga accgcttctc cgacccgatg gacaaggcct tcgcccgcgt ggacgccctc 360
ttcgagttct gcgagaagct caacatcgag tacttctgct tccacgaccg cgacatcccc 420
cggagggcaa gaccctccgc gagaccaaca agatcctcga caaggtggtg gagcgcatca 480
aggagcgcat gaaggactcc aacgtgaagc tcctctgggg caccgccaac ctcttctccc 540
acccgcgcta catgcacggc gccgccacca cctgctccgc cgacgtgttc gcctacgccg 600
ccgcccaggt gaagaaggcc ctggagatca ccaaggagct gggcggcgag ggctacgtgt 660
tctggggcgg ccgcgagggc tacgagaccc tcctcaacac cgacctcggc ctggagctgg 720
agaacctcgc ccgcttcctc cgcatggccg tggagtacgc caagaagatc ggcttcaccg 780
gccagttcct catcgagccg aagccgaagg agccgaccaa gcaccagtac gcttcgacgt 840
ggccaccgcc tacgccttcc tcaagaacca cggcctcgac gagtacttca agttcaacat 900
cgaggccaac cacgccaccc tcgccggcca caccttccag cacgagctgc gcatggcccg 960
catcctcggc aagctcggct ccatcgacgc caaccagggc gacctcctcc tcggctggga 1020
caccgaccag ttcccgacca acatctacga caccaccctc gccatgtacg aggtgatcaa 1080
ggccggcggc ttcaccaagg gcggcctcaa cttcgacgcc aaggtgcgcc gcgcctccta 1140
caaggtggag gacctcttca tcggccacat cgccggcatg gacaccttcg ccctcggctt 1200
caagatcgcc tacaagctcg ccaaggacgg cgtgttcgac aagttcatcg aggagaagta 1260
ccgctccttc aaggagggca tcggcaagga gatcgtggag ggcaagaccg acttcgagaa 1320
gctggaggag tacatcatcg acaaggagga catcgagctg ccgtccggca agcaggagta 1380
cctggagtcc ctcctcaact cctacatcgt gaagaccatc gccgagctgc gctga 1435
<210> 42
<211> 478
<212> PRT
<213> Thermotoga maritima
<400> 42
Met Gly Ser Ser His His His His His His Ser Ser Gly Leu Val Pro
1 5 10 15
Arg Gly Ser His Met Ala Ser Met Thr Gly Gly Gln Gln Met Gly Arg
20 25 30
Ile Pro Met Ala Glu Phe Phe Pro Glu Ile Pro Lys Ile Gln Phe Glu
35 40 45
Gly Lys Glu Ser Thr Asn Pro Leu Ala Phe Arg Phe Tyr Asp Pro Asn
50 55 60
Glu Val Ile Asp Gly Lys Pro Leu Lys Asp His Leu Lys Phe Ser Val
65 70 75 80
Ala Phe Trp His Thr Phe Val Asn Glu Gly Arg Asp Pro Phe Gly Asp
85 90 95
Pro Thr Ala Glu Arg Pro Trp Asn Arg Phe Ser Asp Pro Met Asp Lys
100 105 110
Ala Phe Ala Arg Val Asp Ala Leu Phe Glu Phe Cys Glu Lys Leu Asn
115 120 125
Ile Glu Tyr Phe Cys Phe His Asp Arg Asp Ile Ala Pro Glu Gly Lys
130 135 140
Thr Leu Arg Glu Thr Asn Lys Ile Leu Asp Lys Val Val Glu Arg Ile
145 150 155 160
Lys Glu Arg Met Lys Asp Ser Asn Val Lys Leu Leu Trp Gly Thr Ala
165 170 175
Asn Leu Phe Ser His Pro Arg Tyr Met His Gly Ala Ala Thr Thr Cys
180 185 190
Ser Ala Asp Val Phe Ala Tyr Ala Ala Ala Gln Val Lys Lys Ala Leu
195 200 205
Glu Ile Thr Lys Glu Leu Gly Gly Glu Gly Tyr Val Phe Trp Gly Gly
210 215 220
Arg Glu Gly Tyr Glu Thr Leu Leu Asn Thr Asp Leu Gly Leu Glu Leu
225 230 235 240
Glu Asn Leu Ala Arg Phe Leu Arg Met Ala Val Glu Tyr Ala Lys Lys
245 250 255
Ile Gly Phe Thr Gly Gln Phe Leu Ile Glu Pro Lys Pro Lys Glu Pro
260 265 270
Thr Lys His Gln Tyr Asp Phe Asp Val Ala Thr Ala Tyr Ala Phe Leu
275 280 285
Lys Asn His Gly Leu Asp Glu Tyr Phe Lys Phe Asn Ile Glu Ala Asn
290 295 300
His Ala Thr Leu Ala Gly His Thr Phe Gln His Glu Leu Arg Met Ala
305 310 315 320
Arg Ile Leu Gly Lys Leu Gly Ser Ile Asp Ala Asn Gln Gly Asp Leu
325 330 335
Leu Leu Gly Trp Asp Thr Asp Gln Phe Pro Thr Asn Ile Tyr Asp Thr
340 345 350
Thr Leu Ala Met Tyr Glu Val Ile Lys Ala Gly Gly Phe Thr Lys Gly
355 360 365
Gly Leu Asn Phe Asp Ala Lys Val Arg Arg Ala Ser Tyr Lys Val Glu
370 375 380
Asp Leu Phe Ile Gly His Ile Ala Gly Met Asp Thr Phe Ala Leu Gly
385 390 395 400
Phe Lys Ile Ala Tyr Lys Leu Ala Lys Asp Gly Val Phe Asp Lys Phe
405 410 415
Ile Glu Glu Lys Tyr Arg Ser Phe Lys Glu Gly Ile Gly Lys Glu Ile
420 425 430
Val Glu Gly Lys Thr Asp Phe Glu Lys Leu Glu Glu Tyr Ile Ile Asp
435 440 445
Lys Glu Asp Ile Glu Leu Pro Ser Gly Lys Gln Glu Tyr Leu Glu Ser
450 455 460
Leu Leu Asn Ser Tyr Ile Val Lys Thr Ile Ala Glu Leu Arg
465 470 475
<210> 43
<211> 1436
<212> DNA
<213> Thermotoga neapolitana
<400> 43
atgggcagca gccatcatca tcatcatcac agcagcggcc tggtgccgcg cggcagccat 60
atggctagca tgactggtgg acagcaaatg ggtcggatcc ccatggccga gttcttcccg 120
gagatcccga aggtgcagtt cgagggcaag gagtccacca acccgctcgc cttcaagttc 180
tacgacccgg aggagatcat cgacggcaag ccgctcaagg accacctcaa gttctccgtg 240
gccttctggc acaccttcgt gaacgagggc cgcgacccgt tcggcgaccc gaccgccgac 300
cgcccgtgga accgctacac cgacccgatg gacaaggcct tcgcccgcgt ggacgccctc 360
ttcgagttct gcgagaagct caacatcgag tacttctgct tccacgaccg cgacatcccc 420
cggagggcaa gaccctccgc gagaccaaca agatcctcga caaggtggtg gagcgcatca 480
aggagcgcat gaaggactcc aacgtgaagc tcctctgggg caccgccaac ctcttctccc 540
acccgcgcta catgcacggc gccgccacca cctgctccgc cgacgtgttc gcctacgccg 600
ccgcccaggt gaagaaggcc ctggagatca ccaaggagct gggcggcgag ggctacgtgt 660
tctggggcgg ccgcgagggc tacgagaccc tcctcaacac cgacctcggc ttcgagctgg 720
agaacctcgc ccgcttcctc cgcatggccg tggactacgc caagcgcatc ggcttcaccg 780
gccagttcct catcgagccg aagccgaagg agccgaccaa gcaccagtac gacttcgacg 840
tggccaccgc ctacgccttc ctcaagtccc acggcctcga cgagtacttc aagttcaaca 900
tcgaggccaa ccacgccacc ctcgccggcc acaccttcca gcacgagctg cgcatggccc 960
gcatcctcgg caagctcggc tccatcgacg ccaaccaggg cgacctcctc ctcggctggg 1020
acaccgacca gttcccgacc aacgtgtacg acaccaccct cgccatgtac gaggtgatca 1080
aggccggcgg cttcaccaag ggcggcctca acttcgacgc caaggtgcgc cgcgcctcct 1140
acaaggtgga ggacctcttc atcggccaca tcgccggcat ggacaccttc gccctcggct 1200
tcaaggtggc ctacaagctc gtgaaggacg gcgtgctcga caagttcatc gaggagaagt 1260
accgctcctt ccgcgagggc atcggccgcg acatcgtgga gggcaaggtg gacttcgaga 1320
agctggagga gtacatcatc gacaaggaga ccatcgagct gccgtccggc aagcaggagt 1380
acctggagtc cctcatcaac tcctacatcg tgaagaccat cctggagctg cgctga 1436
<210> 44
<211> 478
<212> PRT
<213> Thermotoga neapolitana
<400> 44
Met Gly Ser Ser His His His His His His Ser Ser Gly Leu Val Pro
1 5 10 15
Arg Gly Ser His Met Ala Ser Met Thr Gly Gly Gln Gln Met Gly Arg
20 25 30
Ile Pro Met Ala Glu Phe Phe Pro Glu Ile Pro Lys Val Gln Phe Glu
35 40 45
Gly Lys Glu Ser Thr Asn Pro Leu Ala Phe Lys Phe Tyr Asp Pro Glu
50 55 60
Glu Ile Ile Asp Gly Lys Pro Leu Lys Asp His Leu Lys Phe Ser Val
65 70 75 80
Ala Phe Trp His Thr Phe Val Asn Glu Gly Arg Asp Pro Phe Gly Asp
85 90 95
Pro Thr Ala Asp Arg Pro Trp Asn Arg Tyr Thr Asp Pro Met Asp Lys
100 105 110
Ala Phe Ala Arg Val Asp Ala Leu Phe Glu Phe Cys Glu Lys Leu Asn
115 120 125
Ile Glu Tyr Phe Cys Phe His Asp Arg Asp Ile Ala Pro Glu Gly Lys
130 135 140
Thr Leu Arg Glu Thr Asn Lys Ile Leu Asp Lys Val Val Glu Arg Ile
145 150 155 160
Lys Glu Arg Met Lys Asp Ser Asn Val Lys Leu Leu Trp Gly Thr Ala
165 170 175
Asn Leu Phe Ser His Pro Arg Tyr Met His Gly Ala Ala Thr Thr Cys
180 185 190
Ser Ala Asp Val Phe Ala Tyr Ala Ala Ala Gln Val Lys Lys Ala Leu
195 200 205
Glu Ile Thr Lys Glu Leu Gly Gly Glu Gly Tyr Val Phe Trp Gly Gly
210 215 220
Arg Glu Gly Tyr Glu Thr Leu Leu Asn Thr Asp Leu Gly Phe Glu Leu
225 230 235 240
Glu Asn Leu Ala Arg Phe Leu Arg Met Ala Val Asp Tyr Ala Lys Arg
245 250 255
Ile Gly Phe Thr Gly Gln Phe Leu Ile Glu Pro Lys Pro Lys Glu Pro
260 265 270
Thr Lys His Gln Tyr Asp Phe Asp Val Ala Thr Ala Tyr Ala Phe Leu
275 280 285
Lys Ser His Gly Leu Asp Glu Tyr Phe Lys Phe Asn Ile Glu Ala Asn
290 295 300
His Ala Thr Leu Ala Gly His Thr Phe Gln His Glu Leu Arg Met Ala
305 310 315 320
Arg Ile Leu Gly Lys Leu Gly Ser Ile Asp Ala Asn Gln Gly Asp Leu
325 330 335
Leu Leu Gly Trp Asp Thr Asp Gln Phe Pro Thr Asn Val Tyr Asp Thr
340 345 350
Thr Leu Ala Met Tyr Glu Val Ile Lys Ala Gly Gly Phe Thr Lys Gly
355 360 365
Gly Leu Asn Phe Asp Ala Lys Val Arg Arg Ala Ser Tyr Lys Val Glu
370 375 380
Asp Leu Phe Ile Gly His Ile Ala Gly Met Asp Thr Phe Ala Leu Gly
385 390 395 400
Phe Lys Val Ala Tyr Lys Leu Val Lys Asp Gly Val Leu Asp Lys Phe
405 410 415
Ile Glu Glu Lys Tyr Arg Ser Phe Arg Glu Gly Ile Gly Arg Asp Ile
420 425 430
Val Glu Gly Lys Val Asp Phe Glu Lys Leu Glu Glu Tyr Ile Ile Asp
435 440 445
Lys Glu Thr Ile Glu Leu Pro Ser Gly Lys Gln Glu Tyr Leu Glu Ser
450 455 460
Leu Ile Asn Ser Tyr Ile Val Lys Thr Ile Leu Glu Leu Arg
465 470 475
<210> 45
<211> 1095
<212> PRT
<213> Aspergillus shirousami
<400> 45
Ala Thr Pro Ala Asp Trp Arg Ser Gln Ser Ile Tyr Phe Leu Leu Thr
1 5 10 15
Asp Arg Phe Ala Arg Thr Asp Gly Ser Thr Thr Ala Thr Cys Asn Thr
20 25 30
Ala Asp Gln Lys Tyr Cys Gly Gly Thr Trp Gln Gly Ile Ile Asp Lys
35 40 45
Leu Asp Tyr Ile Gln Gly Met Gly Phe Thr Ala Ile Trp Ile Thr Pro
50 55 60
Val Thr Ala Gln Leu Pro Gln Thr Thr Ala Tyr Gly Asp Ala Tyr His
65 70 75 80
Gly Tyr Trp Gln Gln Asp Ile Tyr Ser Leu Asn Glu Asn Tyr Gly Thr
85 90 95
Ala Asp Asp Leu Lys Ala Leu Ser Ser Ala Leu His Glu Arg Gly Met
100 105 110
Tyr Leu Met Val Asp Val Val Ala Asn His Met Gly Tyr Asp Gly Ala
115 120 125
Gly Ser Ser Val Asp Tyr Ser Val Phe Lys Pro Phe Ser Ser Gln Asp
130 135 140
Tyr Phe His Pro Phe Cys Phe Ile Gln Asn Tyr Glu Asp Gln Thr Gln
145 150 155 160
Val Glu Asp Cys Trp Leu Gly Asp Asn Thr Val Ser Leu Pro Asp Leu
165 170 175
Asp Thr Thr Lys Asp Val Val Lys Asn Glu Trp Tyr Asp Trp Val Gly
180 185 190
Ser Leu Val Ser Asn Tyr Ser Ile Asp Gly Leu Arg Ile Asp Thr Val
195 200 205
Lys His Val Gln Lys Asp Phe Trp Pro Gly Tyr Asn Lys Ala Ala Gly
210 215 220
Val Tyr Cys Ile Gly Glu Val Leu Asp Val Asp Pro Ala Tyr Thr Cys
225 230 235 240
Pro Tyr Gln Asn Val Met Asp Gly Val Leu Asn Tyr Pro Ile Tyr Tyr
245 250 255
Pro Leu Leu Asn Ala Phe Lys Ser Thr Ser Gly Ser Met Asp Asp Leu
260 265 270
Tyr Asn Met Ile Asn Thr Val Lys Ser Asp Cys Pro Asp Ser Thr Leu
275 280 285
Leu Gly Thr Phe Val Glu Asn His Asp Asn Pro Arg Phe Ala Ser Tyr
290 295 300
Thr Asn Asp Ile Ala Leu Ala Lys Asn Val Ala Ala Phe Ile Ile Leu
305 310 315 320
Asn Asp Gly Ile Pro Ile Ile Tyr Ala Gly Gln Glu Gln His Tyr Ala
325 330 335
Gly Gly Asn Asp Pro Ala Asn Arg Glu Ala Thr Trp Leu Ser Gly Tyr
340 345 350
Pro Thr Asp Ser Glu Leu Tyr Lys Leu Ile Ala Ser Ala Asn Ala Ile
355 360 365
Arg Asn Tyr Ala Ile Ser Lys Asp Thr Gly Phe Val Thr Tyr Lys Asn
370 375 380
Trp Pro Ile Tyr Lys Asp Asp Thr Thr Ile Ala Met Arg Lys Gly Thr
385 390 395 400
Asp Gly Ser Gln Ile Val Thr Ile Leu Ser Asn Lys Gly Ala Ser Gly
405 410 415
Asp Ser Tyr Thr Leu Ser Leu Ser Gly Ala Gly Tyr Thr Ala Gly Gln
420 425 430
Gln Leu Thr Glu Val Ile Gly Cys Thr Thr Val Thr Val Gly Ser Asp
435 440 445
Gly Asn Val Pro Val Pro Met Ala Gly Gly Leu Pro Arg Val Leu Tyr
450 455 460
Pro Thr Glu Lys Leu Ala Gly Ser Lys Ile Cys Ser Ser Ser Lys Pro
465 470 475 480
Ala Thr Leu Asp Ser Trp Leu Ser Asn Glu Ala Thr Val Ala Arg Thr
485 490 495
Ala Ile Leu Asn Asn Ile Gly Ala Asp Gly Ala Trp Val Ser Gly Ala
500 505 510
Asp Ser Gly Ile Val Val Ala Ser Pro Ser Thr Asp Asn Pro Asp Tyr
515 520 525
Phe Tyr Thr Trp Thr Arg Asp Ser Gly Ile Val Leu Lys Thr Leu Val
530 535 540
Asp Leu Phe Arg Asn Gly Asp Thr Asp Leu Leu Ser Thr Ile Glu His
545 550 555 560
Tyr Ile Ser Ser Gln Ala Ile Ile Gln Gly Val Ser Asn Pro Ser Gly
565 570 575
Asp Leu Ser Ser Gly Gly Leu Gly Glu Pro Lys Phe Asn Val Asp Glu
580 585 590
Thr Ala Tyr Ala Gly Ser Trp Gly Arg Pro Gln Arg Asp Gly Pro Ala
595 600 605
Leu Arg Ala Thr Ala Met Ile Gly Phe Gly Gln Trp Leu Leu Asp Asn
610 615 620
Gly Tyr Thr Ser Ala Ala Thr Glu Ile Val Trp Pro Leu Val Arg Asn
625 630 635 640
Asp Leu Ser Tyr Val Ala Gln Tyr Trp Asn Gln Thr Gly Tyr Asp Leu
645 650 655
Trp Glu Glu Val Asn Gly Ser Ser Phe Phe Thr Ile Ala Val Gln His
660 665 670
Arg Ala Leu Val Glu Gly Ser Ala Phe Ala Thr Ala Val Gly Ser Ser
675 680 685
Cys Ser Trp Cys Asp Ser Gln Ala Pro Gln Ile Leu Cys Tyr Leu Gln
690 695 700
Ser Phe Trp Thr Gly Ser Tyr Ile Leu Ala Asn Phe Asp Ser Ser Arg
705 710 715 720
Ser Gly Lys Asp Thr Asn Thr Leu Leu Gly Ser Ile His Thr Phe Asp
725 730 735
Pro Glu Ala Gly Cys Asp Asp Ser Thr Phe Gln Pro Cys Ser Pro Arg
740 745 750
Ala Leu Ala Asn His Lys Glu Val Val Asp Ser Phe Arg Ser Ile Tyr
755 760 765
Thr Leu Asn Asp Gly Leu Ser Asp Ser Glu Ala Val Ala Val Gly Arg
770 775 780
Tyr Pro Glu Asp Ser Tyr Tyr Asn Gly Asn Pro Trp Phe Leu Cys Thr
785 790 795 800
Leu Ala Ala Ala Glu Gln Leu Tyr Asp Ala Leu Tyr Gln Trp Asp Lys
805 810 815
Gln Gly Ser Leu Glu Ile Thr Asp Val Ser Leu Asp Phe Phe Lys Ala
820 825 830
Leu Tyr Ser Gly Ala Ala Thr Gly Thr Tyr Ser Ser Ser Ser Ser Thr
835 840 845
Tyr Ser Ser Ile Val Ser Ala Val Lys Thr Phe Ala Asp Gly Phe Val
850 855 860
Ser Ile Val Glu Thr His Ala Ala Ser Asn Gly Ser Leu Ser Glu Gln
865 870 875 880
Phe Asp Lys Ser Asp Gly Asp Glu Leu Ser Ala Arg Asp Leu Thr Trp
885 890 895
Ser Tyr Ala Ala Leu Leu Thr Ala Asn Asn Arg Arg Asn Ser Val Val
900 905 910
Pro Pro Ser Trp Gly Glu Thr Ser Ala Ser Ser Val Pro Gly Thr Cys
915 920 925
Ala Ala Thr Ser Ala Ser Gly Thr Tyr Ser Ser Val Thr Val Thr Ser
930 935 940
Trp Pro Ser Ile Val Ala Thr Gly Gly Thr Thr Thr Thr Ala Thr Thr
945 950 955 960
Thr Gly Ser Gly Gly Val Thr Ser Thr Ser Lys Thr Thr Thr Thr Ala
965 970 975
Ser Lys Thr Ser Thr Thr Thr Ser Ser Thr Ser Cys Thr Thr Pro Thr
980 985 990
Ala Val Ala Val Thr Phe Asp Leu Thr Ala Thr Thr Thr Tyr Gly Glu
995 1000 1005
Asn Ile Tyr Leu Val Gly Ser Ile Ser Gln Leu Gly Asp Trp Glu Thr
1010 1015 1020
Ser Asp Gly Ile Ala Leu Ser Ala Asp Lys Tyr Thr Ser Ser Asn Pro
1025 1030 1035 1040
Pro Trp Tyr Val Thr Val Thr Leu Pro Ala Gly Glu Ser Phe Glu Tyr
1045 1050 1055
Lys Phe Ile Arg Val Glu Ser Asp Asp Ser Val Glu Trp Glu Ser Asp
1060 1065 1070
Pro Asn Arg Glu Tyr Thr Val Pro Gln Ala Cys Gly Glu Ser Thr Ala
1075 1080 1085
Thr Val Thr Asp Thr Trp Arg
1090 1095
<210> 46
<211> 3285
<212> DNA
<213> Aspergillus shirousami
<400> 46
gccaccccgg ccgactggcg ctcccagtcc atctacttcc tcctcaccga ccgcttcgcc 60
cgcaccgacg gctccaccac cgccacctgc aacaccgccg accagaagta ctgcggcggc 120
acctggcagg gcatcatcga caagctcgac tacatccagg gcatgggctt caccgccatc 180
tggatcaccc cggtgaccgc ccagctcccg cagaccaccg cctacggcga cgcctaccac 240
ggctactggc agcaggacat ctactccctc aacgagaact acggcaccgc cgacgacctc 300
aaggccctct cctccgccct ccacgagcgc ggcatgtacc tcatggtgga cgtggtggcc 360
aaccacatgg gctacgacgg cgccggctcc tccgtggact actccgtgtt caagccgttc 420
tcctcccagg actacttcca cccgttctgc ttcatccaga actacgagga ccagacccag 480
gtggaggact gctggctcgg cgacaacacc gtgtccctcc cggacctcga caccaccaag 540
gacgtggtga agaacgagtg gtacgactgg gtgggctccc tcgtgtccaa ctactccatc 600
gacggcctcc gcatcgacac cgtgaagcac gtgcagaagg acttctggcc gggctacaac 660
aaggccgccg gcgtgtactg catcggcgag gtgctcgacg tggacccggc ctacacctgc 720
ccgtaccaga acgtgatgga cggcgtgctc aactacccga tctactaccc gctcctcaac 780
gccttcaagt ccacctccgg ctcgatggac gacctctaca acatgatcaa caccgtgaag 840
tccgactgcc cggactccac cctcctcggc accttcgtgg agaaccacga caacccgcgc 900
ttcgcctcct acaccaacga catcgccctc gccaagaacg tggccgcctt catcatcctc 960
aacgacggca tcccgatcat ctacgccggc caggagcagc actacgccgg cggcaacgac 1020
ccggccaacc gcgaggccac ctggctctcc ggctacccga ccgactccga gctgtacaag 1080
ctcatcgcct ccgccaacgc catccgcaac tacgccatct ccaaggacac cggcttcgtg 1140
acctacaaga actggccgat ctacaaggac gacaccacca tcgccatgcg caagggcacc 1200
gacggctccc agatcgtgac catcctctcc aacaagggcg cctccggcga ctcctacacc 1260
ctctccctct ccggcgccgg ctacaccgcc ggccagcagc tcaccgaggt gatcggctgc 1320
accaccgtga ccgtgggctc cgacggcaac gtgccggtgc cgatggccgg cggcctcccg 1380
cgcgtgctct acccgaccga gaagctcgcc ggctccaaga tatgctcctc ctccaagccg 1440
gccaccctcg actcctggct ctccaacgag gccaccgtgg cccgcaccgc catcctcaac 1500
aacatcggcg ccgacggcgc ctgggtgtcc ggcgccgact ccggcatcgt ggtggcctcc 1560
ccgtccaccg acaacccgga ctacttctac acctggaccc gcgactccgg catcgtgctc 1620
aagaccctcg tggacctctt ccgcaacggc gacaccgacc tcctctccac catcgagcac 1680
tacatctcct cccaggccat catccagggc gtgtccaacc cgtccggcga cctctcctcc 1740
ggcggcctcg gcgagccgaa gttcaacgtg gacgagaccg cctacgccgg ctcctggggc 1800
cgcccgcagc gcgacggccc ggccctccgc gccaccgcca tgatcggctt cggccagtgg 1860
ctcctcgaca acggctacac ctccgccgcc accgagatcg tgtggccgct cgtgcgcaac 1920
gacctctcct acgtggccca gtactggaac cagaccggct acgacctctg ggaggaggtg 1980
aacggctcct ccttcttcac catcgccgtg cagcaccgcg ccctcgtgga gggctccgcc 2040
ttcgccaccg ccgtgggctc ctcctgctcc tggtgcgact cccaggcccc gcagatcctc 2100
tgctacctcc agtccttctg gaccggctcc tacatcctcg ccaacttcga ctcctcccgc 2160
tccggcaagg acaccaacac cctcctcggc tccatccaca ccttcgaccc ggaggccggc 2220
tgcgacgact ccaccttcca gccgtgctcc ccgcgcgccc tcgccaacca caaggaggtg 2280
gtggactcct tccgctccat ctacaccctc aacgacggcc tctccgactc cgaggccgtg 2340
gccgtgggcc gctacccgga ggactcctac tacaacggca acccgtggtt cctctgcacc 2400
ctcgccgccg ccgagcagct ctacgacgcc ctctaccagt gggacaagca gggctccctg 2460
gagatcaccg acgtgtccct cgacttcttc aaggccctct actccggcgc cgccaccggc 2520
acctactcct cctcctcctc cacctactcc tccatcgtgt ccgccgtgaa gaccttcgcc 2580
gacggcttcg tgtccatcgt ggagacccac gccgcctcca acggctccct ctccgagcag 2640
ttcgacaagt ccgacggcga cgagctgtcc gcccgcgacc tcacctggtc ctacgccgcc 2700
ctcctcaccg ccaacaaccg ccgcaactcc gtggtgccgc cgtcctgggg cgagacctcc 2760
gcctcctccg tgccgggcac ctgcgccgcc acctccgcct ccggcaccta ctcctccgtg 2820
accgtgacct cctggccgtc catcgtggcc accggcggca ccaccaccac cgccaccacc 2880
accggctccg gcggcgtgac ctccacctcc aagaccacca ccaccgcctc caagacctcc 2940
accaccacct cctccacctc ctgcaccacc ccgaccgccg tggccgtgac cttcgacctc 3000
accgccacca ccacctacgg cgagaacatc tacctcgtgg gctccatctc ccagctcggc 3060
gactgggaga cctccgacgg catcgccctc tccgccgaca agtacacctc ctccaacccg 3120
ccgtggtacg tgaccgtgac cctcccggcc ggcgagtcct tcgagtacaa gttcatccgc 3180
gtggagtccg acgactccgt ggagtgggag tccgacccga accgcgagta caccgtgccg 3240
caggcctgcg gcgagtccac cgccaccgtg accgacacct ggcgc 3285
<210> 47
<211> 679
<212> PRT
<213> Thermoanaerobacterium thermosaccharolyticum
<400> 47
Val Leu Ser Gly Cys Ser Asn Asn Val Ser Ser Ile Lys Ile Asp Arg
1 5 10 15
Phe Asn Asn Ile Ser Ala Val Asn Gly Pro Gly Glu Glu Asp Thr Trp
20 25 30
Ala Ser Ala Gln Lys Gln Gly Val Gly Thr Ala Asn Asn Tyr Val Ser
35 40 45
Arg Val Trp Phe Thr Leu Ala Asn Gly Ala Ile Ser Glu Val Tyr Tyr
50 55 60
Pro Thr Ile Asp Thr Ala Asp Val Lys Glu Ile Lys Phe Ile Val Thr
65 70 75 80
Asp Gly Lys Ser Phe Val Ser Asp Glu Thr Lys Asp Ala Ile Ser Lys
85 90 95
Val Glu Lys Phe Thr Asp Lys Ser Leu Gly Tyr Lys Leu Val Asn Thr
100 105 110
Asp Lys Lys Gly Arg Tyr Arg Ile Thr Lys Glu Ile Phe Thr Asp Val
115 120 125
Lys Arg Asn Ser Leu Ile Met Lys Ala Lys Phe Glu Ala Leu Glu Gly
130 135 140
Ser Ile His Asp Tyr Lys Leu Tyr Leu Ala Tyr Asp Pro His Ile Lys
145 150 155 160
Asn Gln Gly Ser Tyr Asn Glu Gly Tyr Val Ile Lys Ala Asn Asn Asn
165 170 175
Glu Met Leu Met Ala Lys Arg Asp Asn Val Tyr Thr Ala Leu Ser Ser
180 185 190
Asn Ile Gly Trp Lys Gly Tyr Ser Ile Gly Tyr Tyr Lys Val Asn Asp
195 200 205
Ile Met Thr Asp Leu Asp Glu Asn Lys Gln Met Thr Lys His Tyr Asp
210 215 220
Ser Ala Arg Gly Asn Ile Ile Glu Gly Ala Glu Ile Asp Leu Thr Lys
225 230 235 240
Asn Ser Glu Phe Glu Ile Val Leu Ser Phe Gly Gly Ser Asp Ser Glu
245 250 255
Ala Ala Lys Thr Ala Leu Glu Thr Leu Gly Glu Asp Tyr Asn Asn Leu
260 265 270
Lys Asn Asn Tyr Ile Asp Glu Trp Thr Lys Tyr Cys Asn Thr Leu Asn
275 280 285
Asn Phe Asn Gly Lys Ala Asn Ser Leu Tyr Tyr Asn Ser Met Met Ile
290 295 300
Leu Lys Ala Ser Glu Asp Lys Thr Asn Lys Gly Ala Tyr Ile Ala Ser
305 310 315 320
Leu Ser Ile Pro Trp Gly Asp Gly Gln Arg Asp Asp Asn Thr Gly Gly
325 330 335
Tyr His Leu Val Trp Ser Arg Asp Leu Tyr His Val Ala Asn Ala Phe
340 345 350
Ile Ala Ala Gly Asp Val Asp Ser Ala Asn Arg Ser Leu Asp Tyr Leu
355 360 365
Ala Lys Val Val Lys Asp Asn Gly Met Ile Pro Gln Asn Thr Trp Ile
370 375 380
Ser Gly Lys Pro Tyr Trp Thr Ser Ile Gln Leu Asp Glu Gln Ala Asp
385 390 395 400
Pro Ile Ile Leu Ser Tyr Arg Leu Lys Arg Tyr Asp Leu Tyr Asp Ser
405 410 415
Leu Val Lys Pro Leu Ala Asp Phe Ile Ile Lys Ile Gly Pro Lys Thr
420 425 430
Gly Gln Glu Arg Trp Glu Glu Ile Gly Gly Tyr Ser Pro Ala Thr Met
435 440 445
Ala Ala Glu Val Ala Gly Leu Thr Cys Ala Ala Tyr Ile Ala Glu Gln
450 455 460
Asn Lys Asp Tyr Glu Ser Ala Gln Lys Tyr Gln Glu Lys Ala Asp Asn
465 470 475 480
Trp Gln Lys Leu Ile Asp Asn Leu Thr Tyr Thr Glu Asn Gly Pro Leu
485 490 495
Gly Asn Gly Gln Tyr Tyr Ile Arg Ile Ala Gly Leu Ser Asp Pro Asn
500 505 510
Ala Asp Phe Met Ile Asn Ile Ala Asn Gly Gly Gly Val Tyr Asp Gln
515 520 525
Lys Glu Ile Val Asp Pro Ser Phe Leu Glu Leu Val Arg Leu Gly Val
530 535 540
Lys Ser Ala Asp Asp Pro Lys Ile Leu Asn Thr Leu Lys Val Val Asp
545 550 555 560
Ser Thr Ile Lys Val Asp Thr Pro Lys Gly Pro Ser Trp Tyr Arg Tyr
565 570 575
Asn His Asp Gly Tyr Gly Glu Pro Ser Lys Thr Glu Leu Tyr His Gly
580 585 590
Ala Gly Lys Gly Arg Leu Trp Pro Leu Leu Thr Gly Glu Arg Gly Met
595 600 605
Tyr Glu Ile Ala Ala Gly Lys Asp Ala Thr Pro Tyr Val Lys Ala Met
610 615 620
Glu Lys Phe Ala Asn Glu Gly Gly Ile Ile Ser Glu Gln Val Trp Glu
625 630 635 640
Asp Thr Gly Leu Pro Thr Asp Ser Ala Ser Pro Leu Asn Trp Ala His
645 650 655
Ala Glu Tyr Val Ile Leu Phe Ala Ser Asn Ile Glu His Lys Val Leu
660 665 670
Asp Met Pro Asp Ile Val Tyr
675
<210> 48
<211> 2037
<212> DNA
<213> Thermoanaerobacterium thermosaccharolyticum
<220>
<223> synthetic
<400> 48
gtgctctccg gctgctccaa caacgtgtcc tccatcaaga tcgaccgctt caacaacatc 60
tccgccgtga acggcccggg cgaggaggac acctgggcct ccgcccagaa gcagggcgtg 120
ggcaccgcca acaactacgt gtcccgcgtg tggttcaccc tcgccaacgg cgccatctcc 180
gaggtgtact acccgaccat cgacaccgcc gacgtgaagg agatcaagtt catcgtgacc 240
gacggcaagt ccttcgtgtc cgacgagacc aaggacgcca tctccaaggt ggagaagttc 300
accgacaagt ccctcggcta caagctcgtg aacaccgaca agaagggccg ctaccgcatc 360
accaaggaaa tcttcaccga cgtgaagcgc aactccctca tcatgaaggc caagttcgag 420
gccctcgagg gctccatcca cgactacaag ctctacctcg cctacgaccc gcacatcaag 480
aaccagggct cctacaacga gggctacgtg atcaaggcca acaacaacga gatgctcatg 540
gccaagcgcg acaacgtgta caccgccctc tcctccaaca tcggctggaa gggctactcc 600
atcggctact acaaggtgaa cgacatcatg accgacctcg acgagaacaa gcagatgacc 660
aagcactacg actccgcccg cggcaacatc atcgagggcg ccgagatcga cctcaccaag 720
aactccgagt tcgagatcgt gctctccttc ggcggctccg actccgaggc cgccaagacc 780
gccctcgaga ccctcggcga ggactacaac aacctcaaga acaactacat cgacgagtgg 840
accaagtact gcaacaccct caacaacttc aacggcaagg ccaactccct ctactacaac 900
tccatgatga tcctcaaggc ctccgaggac aagaccaaca agggcgccta catcgcctcc 960
ctctccatcc cgtggggcga cggccagcgc gacgacaaca ccggcggcta ccacctcgtg 1020
tggtcccgcg acctctacca cgtggccaac gccttcatcg ccgccggcga cgtggactcc 1080
gccaaccgct ccctcgacta cctcgccaag gtggtgaagg acaacggcat gatcccgcag 1140
aacacctgga tctccggcaa gccgtactgg acctccatcc agctcgacga gcaggccgac 1200
ccgatcatcc tctcctaccg cctcaagcgc tacgacctct acgactccct cgtgaagccg 1260
ctcgccgact tcatcatcaa gatcggcccg aagaccggcc aggagcgctg ggaggagatc 1320
ggcggctact ccccggccac gatggccgcc gaggtggccg gcctcacctg cgccgcctac 1380
atcgccgagc agaacaagga ctacgagtcc gcccagaagt accaggagaa ggccgacaac 1440
tggcagaagc tcatcgacaa cctcacctac accgagaacg gcccgctcgg caacggccag 1500
tactacatcc gcatcgccgg cctctccgac ccgaacgccg acttcatgat caacatcgcc 1560
aacggcggcg gcgtgtacga ccagaaggag atcgtggacc cgtccttcct cgagctggtg 1620
cgcctcggcg tgaagtccgc cgacgacccg aagatcctca acaccctcaa ggtggtggac 1680
tccaccatca aggtggacac cccgaagggc ccgtcctggt atcgctacaa ccacgacggc 1740
tacggcgagc cgtccaagac cgagctgtac cacggcgccg gcaagggccg cctctggccg 1800
ctcctcaccg gcgagcgcgg catgtacgag atcgccgccg gcaaggacgc caccccgtac 1860
gtgaaggcga tggagaagtt cgccaacgag ggcggcatca tctccgagca ggtgtgggag 1920
gacaccggcc tcccgaccga ctccgcctcc ccgctcaact gggcccacgc cgagtacgtg 1980
atcctcttcg cctccaacat cgagcacaag gtgctcgaca tgccggacat cgtgtac 2037
<210> 49
<211> 579
<212> PRT
<213> Rhizopus oryzae
<400> 49
Ala Ser Ile Pro Ser Ser Ala Ser Val Gln Leu Asp Ser Tyr Asn Tyr
1 5 10 15
Asp Gly Ser Thr Phe Ser Gly Lys Ile Tyr Val Lys Asn Ile Ala Tyr
20 25 30
Ser Lys Lys Val Thr Val Ile Tyr Ala Asp Gly Ser Asp Asn Trp Asn
35 40 45
Asn Asn Gly Asn Thr Ile Ala Ala Ser Tyr Ser Ala Pro Ile Ser Gly
50 55 60
Ser Asn Tyr Glu Tyr Trp Thr Phe Ser Ala Ser Ile Asn Gly Ile Lys
65 70 75 80
Glu Phe Tyr Ile Lys Tyr Glu Val Ser Gly Lys Thr Tyr Tyr Asp Asn
85 90 95
Asn Asn Ser Ala Asn Tyr Gln Val Ser Thr Ser Lys Pro Thr Thr Thr
100 105 110
Thr Ala Thr Ala Thr Thr Thr Thr Ala Pro Ser Thr Ser Thr Thr Thr
115 120 125
Pro Pro Ser Arg Ser Glu Pro Ala Thr Phe Pro Thr Gly Asn Ser Thr
130 135 140
Ile Ser Ser Trp Ile Lys Lys Gln Glu Gly Ile Ser Arg Phe Ala Met
145 150 155 160
Leu Arg Asn Ile Asn Pro Pro Gly Ser Ala Thr Gly Phe Ile Ala Ala
165 170 175
Ser Leu Ser Thr Ala Gly Pro Asp Tyr Tyr Tyr Ala Trp Thr Arg Asp
180 185 190
Ala Ala Leu Thr Ser Asn Val Ile Val Tyr Glu Tyr Asn Thr Thr Leu
195 200 205
Ser Gly Asn Lys Thr Ile Leu Asn Val Leu Lys Asp Tyr Val Thr Phe
210 215 220
Ser Val Lys Thr Gln Ser Thr Ser Thr Val Cys Asn Cys Leu Gly Glu
225 230 235 240
Pro Lys Phe Asn Pro Asp Ala Ser Gly Tyr Thr Gly Ala Trp Gly Arg
245 250 255
Pro Gln Asn Asp Gly Pro Ala Glu Arg Ala Thr Thr Phe Ile Leu Phe
260 265 270
Ala Asp Ser Tyr Leu Thr Gln Thr Lys Asp Ala Ser Tyr Val Thr Gly
275 280 285
Thr Leu Lys Pro Ala Ile Phe Lys Asp Leu Asp Tyr Val Val Asn Val
290 295 300
Trp Ser Asn Gly Cys Phe Asp Leu Trp Glu Glu Val Asn Gly Val His
305 310 315 320
Phe Tyr Thr Leu Met Val Met Arg Lys Gly Leu Leu Leu Gly Ala Asp
325 330 335
Phe Ala Lys Arg Asn Gly Asp Ser Thr Arg Ala Ser Thr Tyr Ser Ser
340 345 350
Thr Ala Ser Thr Ile Ala Asn Lys Ile Ser Ser Phe Trp Val Ser Ser
355 360 365
Asn Asn Trp Ile Gln Val Ser Gln Ser Val Thr Gly Gly Val Ser Lys
370 375 380
Lys Gly Leu Asp Val Ser Thr Leu Leu Ala Ala Asn Leu Gly Ser Val
385 390 395 400
Asp Asp Gly Phe Phe Thr Pro Gly Ser Glu Lys Ile Leu Ala Thr Ala
405 410 415
Val Ala Val Glu Asp Ser Phe Ala Ser Leu Tyr Pro Ile Asn Lys Asn
420 425 430
Leu Pro Ser Tyr Leu Gly Asn Ser Ile Gly Arg Tyr Pro Glu Asp Thr
435 440 445
Tyr Asn Gly Asn Gly Asn Ser Gln Gly Asn Ser Trp Phe Leu Ala Val
450 455 460
Thr Gly Tyr Ala Glu Leu Tyr Tyr Arg Ala Ile Lys Glu Trp Ile Gly
465 470 475 480
Asn Gly Gly Val Thr Val Ser Ser Ile Ser Leu Pro Phe Phe Lys Lys
485 490 495
Phe Asp Ser Ser Ala Thr Ser Gly Lys Lys Tyr Thr Val Gly Thr Ser
500 505 510
Asp Phe Asn Asn Leu Ala Gln Asn Ile Ala Leu Ala Ala Asp Arg Phe
515 520 525
Leu Ser Thr Val Gln Leu His Ala His Asn Asn Gly Ser Leu Ala Glu
530 535 540
Glu Phe Asp Arg Thr Thr Gly Leu Ser Thr Gly Ala Arg Asp Leu Thr
545 550 555 560
Trp Ser His Ala Ser Leu Ile Thr Ala Ser Tyr Ala Lys Ala Gly Ala
565 570 575
Pro Ala Ala
<210> 50
<211> 1737
<212> DNA
<213> Rhizopus oryzae
<400> 50
gcctccatcc cgtcctccgc ctccgtgcag ctcgactcct acaactacga cggctccacc 60
ttctccggca aaatctacgt gaagaacatc gcctactcca agaaggtgac cgtgatctac 120
gccgacggct ccgacaactg gaacaacaac ggcaacacca tcgccgcctc ctactccgcc 180
ccgatctccg gctccaacta cgagtactgg accttctccg cctccatcaa cggcatcaag 240
gagttctaca tcaagtacga ggtgtccggc aagacctact acgacaacaa caactccgcc 300
aactaccagg tgtccacctc caagccgacc accaccaccg ccaccgccac caccaccacc 360
gccccgtcca cctccaccac caccccgccg tcccgctccg agccggccac cttcccgacc 420
ggcaactcca ccatctcctc ctggatcaag aagcaggagg gcatctcccg cttcgccatg 480
ctccgcaaca tcaacccgcc gggctccgcc accggcttca tcgccgcctc cctctccacc 540
gccggcccgg actactacta cgcctggacc cgcgacgccg ccctcacctc caacgtgatc 600
gtgtacgagt acaacaccac cctctccggc aacaagacca tcctcaacgt gctcaaggac 660
tacgtgacct tctccgtgaa gacccagtcc acctccaccg tgtgcaactg cctcggcgag 720
ccgaagttca acccggacgc ctccggctac accggcgcct ggggccgccc gcagaacgac 780
ggcccggccg agcgcgccac caccttcatc ctcttcgccg actcctacct cacccagacc 840
aaggacgcct cctacgtgac cggcaccctc aagccggcca tcttcaagga cctcgactac 900
gtggtgaacg tgtggtccaa cggctgcttc gacctctggg aggaggtgaa cggcgtgcac 960
ttctacaccc tcatggtgat gcgcaagggc ctcctcctcg gcgccgactt cgccaagcgc 1020
aacggcgact ccacccgcgc ctccacctac tcctccaccg cctccaccat cgccaacaaa 1080
atctcctcct tctgggtgtc ctccaacaac tggatacagg tgtcccagtc cgtgaccggc 1140
ggcgtgtcca agaagggcct cgacgtgtcc accctcctcg ccgccaacct cggctccgtg 1200
gacgacggct tcttcacccc gggctccgag aagatcctcg ccaccgccgt ggccgtggag 1260
gactccttcg cctccctcta cccgatcaac aagaacctcc cgtcctacct cggcaactcc 1320
atcggccgct acccggagga cacctacaac ggcaacggca actcccaggg caactcctgg 1380
ttcctcgccg tgaccggcta cgccgagctg tactaccgcg ccatcaagga gtggatcggc 1440
aacggcggcg tgaccgtgtc ctccatctcc ctcccgttct tcaagaagtt cgactcctcc 1500
gccacctccg gcaagaagta caccgtgggc acctccgact tcaacaacct cgcccagaac 1560
atcgccctcg ccgccgaccg cttcctctcc accgtgcagc tccacgccca caacaacggc 1620
tccctcgccg aggagttcga ccgcaccacc ggcctctcca ccggcgcccg cgacctcacc 1680
tggtcccacg cctccctcat caccgcctcc tacgccaagg ccggcgcccc ggccgcc 1737
<210> 51
<211> 439
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 51
Met Ala Lys His Leu Ala Ala Met Cys Trp Cys Ser Leu Leu Val Leu
1 5 10 15
Val Leu Leu Cys Leu Gly Ser Gln Leu Ala Gln Ser Gln Val Leu Phe
20 25 30
Gln Gly Phe Asn Trp Glu Ser Trp Lys Lys Gln Gly Gly Trp Tyr Asn
35 40 45
Tyr Leu Leu Gly Arg Val Asp Asp Ile Ala Ala Thr Gly Ala Thr His
50 55 60
Val Trp Leu Pro Gln Pro Ser His Ser Val Ala Pro Gln Gly Tyr Met
65 70 75 80
Pro Gly Arg Leu Tyr Asp Leu Asp Ala Ser Lys Tyr Gly Thr His Ala
85 90 95
Glu Leu Lys Ser Leu Thr Ala Ala Phe His Ala Lys Gly Val Gln Cys
100 105 110
Val Ala Asp Val Val Ile Asn His Arg Cys Ala Asp Tyr Lys Asp Gly
115 120 125
Arg Gly Ile Tyr Cys Val Phe Glu Gly Gly Thr Pro Asp Ser Arg Leu
130 135 140
Asp Trp Gly Pro Asp Met Ile Cys Ser Asp Asp Thr Gln Tyr Ser Asn
145 150 155 160
Gly Arg Gly His Arg Asp Thr Gly Ala Asp Phe Ala Ala Ala Pro Asp
165 170 175
Ile Asp His Leu Asn Pro Arg Val Gln Gln Glu Leu Ser Asp Trp Leu
180 185 190
Asn Trp Leu Lys Ser Asp Leu Gly Phe Asp Gly Trp Arg Leu Asp Phe
195 200 205
Ala Lys Gly Tyr Ser Ala Ala Val Ala Lys Val Tyr Val Asp Ser Thr
210 215 220
Ala Pro Thr Phe Val Val Ala Glu Ile Trp Ser Ser Leu His Tyr Asp
225 230 235 240
Gly Asn Gly Glu Pro Ser Ser Asn Gln Asp Ala Asp Arg Gln Glu Leu
245 250 255
Val Asn Trp Ala Gln Ala Val Gly Gly Pro Ala Ala Ala Phe Asp Phe
260 265 270
Thr Thr Lys Gly Val Leu Gln Ala Ala Val Gln Gly Glu Leu Trp Arg
275 280 285
Met Lys Asp Gly Asn Gly Lys Ala Pro Gly Met Ile Gly Trp Leu Pro
290 295 300
Glu Lys Ala Val Thr Phe Val Asp Asn His Asp Thr Gly Ser Thr Gln
305 310 315 320
Asn Ser Trp Pro Phe Pro Ser Asp Lys Val Met Gln Gly Tyr Ala Tyr
325 330 335
Ile Leu Thr His Pro Gly Thr Pro Cys Ile Phe Tyr Asp His Val Phe
340 345 350
Asp Trp Asn Leu Lys Gln Glu Ile Ser Ala Leu Ser Ala Val Arg Ser
355 360 365
Arg Asn Gly Ile His Pro Gly Ser Glu Leu Asn Ile Leu Ala Ala Asp
370 375 380
Gly Asp Leu Tyr Val Ala Lys Ile Asp Asp Lys Val Ile Val Lys Ile
385 390 395 400
Gly Ser Arg Tyr Asp Val Gly Asn Leu Ile Pro Ser Asp Phe His Ala
405 410 415
Val Ala His Gly Asn Asn Tyr Cys Val Trp Glu Lys His Gly Leu Arg
420 425 430
Val Pro Ala Gly Arg His His
435
<210> 52
<211> 1320
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 52
atggcgaagc acttggctgc catgtgctgg tgcagcctcc tagtgcttgt actgctctgc 60
ttgggctccc agctggccca atcccaggtc ctcttccagg ggttcaactg ggagtcgtgg 120
aagaagcaag gtgggtggta caactacctc ctggggcggg tggacgacat cgccgcgacg 180
ggggccacgc acgtctggct cccgcagccg tcgcactcgg tggcgccgca ggggtacatg 240
cccggccggc tctacgacct ggacgcgtcc aagtacggca cccacgcgga gctcaagtcg 300
ctcaccgcgg cgttccacgc caagggcgtc cagtgcgtcg ccgacgtcgt gatcaaccac 360
cgctgcgccg actacaagga cggccgcggc atctactgcg tcttcgaggg cggcacgccc 420
gacagccgcc tcgactgggg ccccgacatg atctgcagcg acgacacgca gtactccaac 480
gggcgcgggc accgcgacac gggggccgac ttcgccgccg cgcccgacat cgaccacctc 540
aacccgcgcg tgcagcagga gctctcggac tggctcaact ggctcaagtc cgacctcggc 600
ttcgacggct ggcgcctcga cttcgccaag ggctactccg ccgccgtcgc caaggtgtac 660
gtcgacagca ccgcccccac cttcgtcgtc gccgagatat ggagctccct ccactacgac 720
ggcaacggcg agccgtccag caaccaggac gccgacaggc aggagctggt caactgggcg 780
caggcggtgg gcggccccgc cgcggcgttc gacttcacca ccaagggcgt gctgcaggcg 840
gccgtccagg gcgagctgtg gcgcatgaag gacggcaacg gcaaggcgcc cgggatgatc 900
ggctggctgc cggagaaggc cgtcacgttc gtcgacaacc acgacaccgg ctccacgcag 960
aactcgtggc cattcccctc cgacaaggtc atgcagggct acgcctatat cctcacgcac 1020
ccaggaactc catgcatctt ctacgaccac gttttcgact ggaacctgaa gcaggagatc 1080
agcgcgctgt ctgcggtgag gtcaagaaac gggatccacc cggggagcga gctgaacatc 1140
ctcgccgccg acggggatct ctacgtcgcc aagattgacg acaaggtcat cgtgaagatc 1200
gggtcacggt acgacgtcgg gaacctgatc ccctcagact tccacgccgt tgcccctggc 1260
aacaactact gcgtttggga gaagcacggt ctgagagttc cagcggggcg gcaccactag 1320
<210> 53
<211> 45
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 53
Ala Thr Gly Gly Thr Thr Thr Thr Ala Thr Thr Thr Gly Ser Gly Gly
1 5 10 15
Val Thr Ser Thr Ser Lys Thr Thr Thr Thr Ala Ser Lys Thr Ser Thr
20 25 30
Thr Thr Ser Ser Thr Ser Cys Thr Thr Pro Thr Ala Val
35 40 45
<210> 54
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 54
gccaccggcg gcaccaccac caccgccacc accaccggct ccggcggcgt gacctccacc 60
tccaagacca ccaccaccgc ctccaagacc tccaccacca cctcctccac ctcctgcacc 120
accccgaccg ccgtgtc 137
<210> 55
<211> 300
<212> PRT
<213> Pyrococcus furiosus
<400> 55
Ile Tyr Phe Val Glu Lys Tyr His Thr Ser Glu Asp Lys Ser Thr Ser
1 5 10 15
Asn Thr Ser Ser Thr Pro Pro Gln Thr Thr Leu Ser Thr Thr Lys Val
20 25 30
Leu Lys Ile Arg Tyr Pro Asp Asp Gly Glu Trp Pro Gly Ala Pro Ile
35 40 45
Asp Lys Asp Gly Asp Gly Asn Pro Glu Phe Tyr Ile Glu Ile Asn Leu
50 55 60
Trp Asn Ile Leu Asn Ala Thr Gly Phe Ala Glu Met Thr Tyr Asn Leu
65 70 75 80
Thr Ser Gly Val Leu His Tyr Val Gln Gln Leu Asp Asn Ile Val Leu
85 90 95
Arg Asp Arg Ser Asn Trp Val His Gly Tyr Pro Glu Ile Phe Tyr Gly
100 105 110
Asn Lys Pro Trp Asn Ala Asn Tyr Ala Thr Asp Gly Pro Ile Pro Leu
115 120 125
Pro Ser Lys Val Ser Asn Leu Thr Asp Phe Tyr Leu Thr Ile Ser Tyr
130 135 140
Lys Leu Glu Pro Lys Asn Gly Leu Pro Ile Asn Phe Ala Ile Glu Ser
145 150 155 160
Trp Leu Thr Arg Glu Ala Trp Arg Thr Thr Gly Ile Asn Ser Asp Glu
165 170 175
Gln Glu Val Met Ile Trp Ile Tyr Tyr Asp Gly Leu Gln Pro Ala Gly
180 185 190
Ser Lys Val Lys Glu Ile Val Val Pro Ile Ile Val Asn Gly Thr Pro
195 200 205
Val Asn Ala Thr Phe Glu Val Trp Lys Ala Asn Ile Gly Trp Glu Tyr
210 215 220
Val Ala Phe Arg Ile Lys Thr Pro Ile Lys Glu Gly Thr Val Thr Ile
225 230 235 240
Pro Tyr Gly Ala Phe Ile Ser Val Ala Ala Asn Ile Ser Ser Leu Pro
245 250 255
Asn Tyr Thr Glu Leu Tyr Leu Glu Asp Val Glu Ile Gly Thr Glu Phe
260 265 270
Gly Thr Pro Ser Thr Thr Ser Ala His Leu Glu Trp Trp Ile Thr Asn
275 280 285
Ile Thr Leu Thr Pro Leu Asp Arg Pro Leu Ile Ser
290 295 300
<210> 56
<211> 903
<212> DNA
<213> Pyrococcus furiosus
<400> 56
atctacttcg tggagaagta ccacacctcc gaggacaagt ccacctccaa cacctcctcc 60
accccgccgc agaccaccct ctccaccacc aaggtgctca agatccgcta cccggacgac 120
ggcgagtggc ccggcgcccc gatcgacaag gacggcgacg gcaacccgga gttctacatc 180
gagatcaacc tctggaacat cctcaacgcc accggcttcg ccgagatgac ctacaacctc 240
actagtggcg tgctccacta cgtgcagcag ctcgacaaca tcgtgctccg cgaccgctcc 300
aactgggtgc acggctaccc ggaaatcttc tacggcaaca agccgtggaa cgccaactac 360
gccaccgacg gcccgatccc gctcccgtcc aaggtgtcca acctcaccga cttctacctc 420
accatctcct acaagctcga gccgaagaac ggtctcccga tcaacttcgc catcgagtcc 480
tggctcaccc gcgaggcctg gcgcaccacc ggcatcaact ccgacgagca ggaggtgatg 540
atctggatct actacgacgg cctccagccc gcgggctcca aggtgaagga gatcgtggtg 600
ccgatcatcg tgaacggcac cccggtgaac gccaccttcg aggtgtggaa ggccaacatc 660
ggctgggagt acgtggcctt ccgcatcaag accccgatca aggagggcac cgtgaccatc 720
ccgtacggcg ccttcatctc cgtggccgcc aacatctcct ccctcccgaa ctacaccgag 780
aagtacctcg aggacgtgga gatcggcacc gagttcggca ccccgtccac cacctccgcc 840
cacctcgagt ggtggatcac caacatcacc ctcaccccgc tcgaccgccc gctcatctcc 900
tag 903
<210> 57
<211> 387
<212> PRT
<213> Thermus flavus
<400> 57
Met Tyr Glu Pro Lys Pro Glu His Arg Phe Thr Phe Gly Leu Trp Thr
1 5 10 15
Val Asp Asn Val Asp Arg Asp Pro Phe Gly Asp Thr Val Arg Glu Arg
20 25 30
Leu Asp Pro Val Tyr Val Val His Lys Leu Ala Glu Leu Gly Ala Tyr
35 40 45
Gly Val Asn Leu His Asp Glu Asp Leu Ile Pro Arg Gly Thr Pro Pro
50 55 60
Gln Glu Arg Asp Gln Ile Val Arg Arg Phe Lys Lys Ala Leu Asp Glu
65 70 75 80
Thr Val Leu Lys Val Pro Met Val Thr Ala Asn Leu Phe Ser Glu Pro
85 90 95
Ala Phe Arg Asp Gly Ala Ser Thr Thr Arg Asp Pro Trp Val Trp Ala
100 105 110
Tyr Ala Leu Arg Lys Ser Leu Glu Thr Met Asp Leu Gly Ala Glu Leu
115 120 125
Gly Ala Glu Ile Tyr Met Phe Trp Met Val Arg Glu Arg Ser Glu Val
130 135 140
Glu Ser Thr Asp Lys Thr Arg Lys Val Trp Asp Trp Val Arg Glu Thr
145 150 155 160
Leu Asn Phe Met Thr Ala Tyr Thr Glu Asp Gln Gly Tyr Gly Tyr Arg
165 170 175
Phe Ser Val Glu Pro Lys Pro Asn Glu Pro Arg Gly Asp Ile Tyr Phe
180 185 190
Thr Thr Val Gly Ser Met Leu Ala Leu Ile His Thr Leu Asp Arg Pro
195 200 205
Glu Arg Phe Gly Leu Asn Pro Glu Phe Ala His Glu Thr Met Ala Gly
210 215 220
Leu Asn Phe Asp His Ala Val Ala Gln Ala Val Asp Ala Gly Lys Leu
225 230 235 240
Phe His Ile Asp Leu Asn Asp Gln Arg Met Ser Arg Phe Asp Gln Asp
245 250 255
Leu Arg Phe Gly Ser Glu Asn Leu Lys Ala Gly Phe Phe Leu Val Asp
260 265 270
Leu Leu Glu Ser Ser Gly Tyr Gln Gly Pro Arg His Phe Glu Ala His
275 280 285
Ala Leu Arg Thr Glu Asp Glu Glu Gly Val Trp Thr Phe Val Arg Val
290 295 300
Cys Met Arg Thr Tyr Leu Ile Ile Lys Val Arg Ala Glu Thr Phe Arg
305 310 315 320
Glu Asp Pro Glu Val Lys Glu Leu Leu Ala Ala Tyr Tyr Gln Glu Asp
325 330 335
Pro Ala Thr Leu Ala Leu Leu Asp Pro Tyr Ser Arg Glu Lys Ala Glu
340 345 350
Ala Leu Lys Arg Ala Glu Leu Pro Leu Glu Thr Lys Arg Arg Arg Gly
355 360 365
Tyr Ala Leu Glu Arg Leu Asp Gln Leu Ala Val Glu Tyr Leu Leu Gly
370 375 380
Val Arg Gly
385
<210> 58
<211> 978
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 58
atggggaaga acggcaacct gtgctgcttc tctctgctgc tgcttcttct cgccgggttg 60
gcgtccggcc atcaaatcta cttcgtggag aagtaccaca cctccgagga caagtccacc 120
tccaacacct cctccacccc gccgcagacc accctctcca ccaccaaggt gctcaagatc 180
cgctacccgg acgacggtga gtggcccggc gccccgatcg acaaggacgg cgacggcaac 240
ccggagttct acatcgagat caacctctgg aacatcctca acgccaccgg cttcgccgag 300
atgacctaca acctcactag tggcgtgctc cactacgtgc agcagctcga caacatcgtg 360
ctccgcgacc gctccaactg ggtgcacggc tacccggaaa tcttctacgg caacaagccg 420
tggaacgcca actacgccac cgacggcccg atcccgctcc cgtccaaggt gtccaacctc 480
accgacttct acctcaccat ctcctacaag ctcgagccga agaacggtct cccgatcaac 540
ttcgccatcg agtcctggct cacccgcgag gcctggcgca ccaccggcat caactccgac 600
gagcaggagg tgatgatctg gatctactac gacggcctcc agcccgcggg ctccaaggtg 660
aaggagatcg tggtgccgat catcgtgaac ggcaccccgg tgaacgccac cttcgaggtg 720
tggaaggcca acatcggctg ggagtacgtg gccttccgca tcaagacccc gatcaaggag 780
ggcaccgtga ccatcccgta cggcgccttc atctccgtgg ccgccaacat ctcctccctc 840
ccgaactaca ccgagaagta cctcgaggac gtggagatcg gcaccgagtt cggcaccccg 900
tccaccacct ccgcccacct cgagtggtgg atcaccaaca tcaccctcac cccgctcgac 960
cgcccgctca tctcctag 978
<210> 59
<211> 1920
<212> DNA
<213> Aspergillus niger
<400> 59
atgtccttcc gctccctcct cgccctctcc ggcctcgtgt gcaccggcct cgccaacgtg 60
atctccaagc gcgccaccct cgactcctgg ctctccaacg aggccaccgt ggcccgcacc 120
gccatcctca acaacatcgg cgccgacggc gcctgggtgt ccggcgccga ctccggcatc 180
gtggtggcct ccccgtccac cgacaacccg gactacttct acacctggac ccgcgactcc 240
ggcctcgtgc tcaagaccct cgtggacctc ttccgcaacg gcgacacctc cctcctctcc 300
accatcgaga actacatctc cgcccaggcc atcgtgcagg gcatctccaa cccgtccggc 360
gacctctcct ccggcgccgg cctcggcgag ccgaagttca acgtggacga gaccgcctac 420
accggctcct ggggccgccc gcagcgcgac ggcccggccc tccgcgccac cgccatgatc 480
ggcttcggcc agtggctcct cgacaacggc tacacctcca ccgccaccga catcgtgtgg 540
ccgctcgtgc gcaacgacct ctcctacgtg gcccagtact ggaaccagac cggctacgac 600
ctctgggagg aggtgaacgg ctcctccttc ttcaccatcg ccgtgcagca ccgcgccctc 660
gtggagggct ccgccttcgc caccgccgtg ggctcctcct gctcctggtg cgactcccag 720
gccccggaga tcctctgcta cctccagtcc ttctggaccg gctccttcat cctcgccaac 780
ttcgactcct cccgctccgg caaggacgcc aacaccctcc tcggctccat ccacaccttc 840
gacccggagg ccgcctgcga cgactccacc ttccagccgt gctccccgcg cgccctcgcc 900
aaccacaagg aggtggtgga ctccttccgc tccatctaca ccctcaacga cggcctctcc 960
gactccgagg ccgtggccgt gggccgctac ccggaggaca cctactacaa cggcaacccg 1020
tggttcctct gcaccctcgc cgccgccgag cagctctacg acgccctcta ccagtgggac 1080
aagcagggct ccctcgaggt gaccgacgtg tccctcgact tcttcaaggc cctctactcc 1140
gacgccgcca ccggcaccta ctcctcctcc tcctccacct actcctccat cgtggacgcc 1200
gtgaagacct tcgccgacgg cttcgtgtcc atcgtggaga cccacgccgc ctccaacggc 1260
tccatgtccg agcagtacga caagtccgac ggcgagcagc tctccgcccg cgacctcacc 1320
tggtcctacg ccgccctcct caccgccaac aaccgccgca actccgtggt gccggcctcc 1380
tggggcgaga cctccgcctc ctccgtgccg ggcacctgcg ccgccacctc cgccatcggc 1440
acctactcct ccgtgaccgt gacctcctgg ccgtccatcg tggccaccgg cggcaccacc 1500
accaccgcca ccccgaccgg ctccggctcc gtgacctcca cctccaagac caccgccacc 1560
gcctccaaga cctccacctc cacctcctcc acctcctgca ccaccccgac cgccgtggcc 1620
gtgaccttcg acctcaccgc caccaccacc tacggcgaga acatctacct cgtgggctcc 1680
atctcccagc tcggcgactg ggagacctcc gacggcatcg ccctctccgc cgacaagtac 1740
acctcctccg acccgctctg gtacgtgacc gtgaccctcc cggccggcga gtccttcgag 1800
tacaagttca tccgcatcga gtccgacgac tccgtggagt gggagtccga cccgaaccgc 1860
gagtacaccg tgccgcaggc ctgcggcacc tccaccgcca ccgtgaccga cacctggcgc 1920
<210> 60
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 60
Ser Glu Lys Asp Glu Leu
1 5
<210> 61
<211> 561
<212> DNA
<213> Artificial Sequence
<220>
<223> Xylanase BD7436
<220>
<221> CDS
<222> (1)..(561)
<400> 61
atg gct agc acc ttc tac tgg cat ttg tgg acc gac ggc atc ggc acc 48
Met Ala Ser Thr Phe Tyr Trp His Leu Trp Thr Asp Gly Ile Gly Thr
1 5 10 15
gtg aac gct acc aac ggc agc gac ggc aac tac agc gtg agc tgg agc 96
Val Asn Ala Thr Asn Gly Ser Asp Gly Asn Tyr Ser Val Ser Trp Ser
20 25 30
aac tgc ggc aac ttc gtg gtg ggc aag ggc tgg acc acc ggc agc gct 144
Asn Cys Gly Asn Phe Val Val Gly Lys Gly Trp Thr Thr Gly Ser Ala
35 40 45
acc agg gtg atc aac tac aac gct cat gct ttc agc gtg gtg ggc aac 192
Thr Arg Val Ile Asn Tyr Asn Ala His Ala Phe Ser Val Val Gly Asn
50 55 60
gct tac ttg gct ttg tac ggc tgg acc agg aac agc ttg atc gag tac 240
Ala Tyr Leu Ala Leu Tyr Gly Trp Thr Arg Asn Ser Leu Ile Glu Tyr
65 70 75 80
tac gtg gtg gac agc tgg ggc acc tac agg cca acc ggc acc tac aag 288
Tyr Val Val Asp Ser Trp Gly Thr Tyr Arg Pro Thr Gly Thr Tyr Lys
85 90 95
ggc acc gtg acc agc gac ggc ggc acc tac gac atc tac acc acc acc 336
Gly Thr Val Thr Ser Asp Gly Gly Thr Tyr Asp Ile Tyr Thr Thr Thr
100 105 110
agg acc aac gct cca agc atc gac ggc aac aac acc acc ttc acc caa 384
Arg Thr Asn Ala Pro Ser Ile Asp Gly Asn Asn Thr Thr Phe Thr Gln
115 120 125
ttc tgg agc gtg agg caa agc aag agg cca atc ggc acc aac aac acc 432
Phe Trp Ser Val Arg Gln Ser Lys Arg Pro Ile Gly Thr Asn Asn Thr
130 135 140
atc acc ttc agc aac cat gtg aac gct tgg aag agc aag ggc atg aac 480
Ile Thr Phe Ser Asn His Val Asn Ala Trp Lys Ser Lys Gly Met Asn
145 150 155 160
ttg ggc agc agc tgg agc tac caa gtg ttg gct acc gag ggc tac caa 528
Leu Gly Ser Ser Trp Ser Tyr Gln Val Leu Ala Thr Glu Gly Tyr Gln
165 170 175
agc agc ggc tac agc aac gtg acc gtg tgg tag 561
Ser Ser Gly Tyr Ser Asn Val Thr Val Trp
180 185
<210> 62
<211> 186
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 62
Met Ala Ser Thr Phe Tyr Trp His Leu Trp Thr Asp Gly Ile Gly Thr
1 5 10 15
Val Asn Ala Thr Asn Gly Ser Asp Gly Asn Tyr Ser Val Ser Trp Ser
20 25 30
Asn Cys Gly Asn Phe Val Val Gly Lys Gly Trp Thr Thr Gly Ser Ala
35 40 45
Thr Arg Val Ile Asn Tyr Asn Ala His Ala Phe Ser Val Val Gly Asn
50 55 60
Ala Tyr Leu Ala Leu Tyr Gly Trp Thr Arg Asn Ser Leu Ile Glu Tyr
65 70 75 80
Tyr Val Val Asp Ser Trp Gly Thr Tyr Arg Pro Thr Gly Thr Tyr Lys
85 90 95
Gly Thr Val Thr Ser Asp Gly Gly Thr Tyr Asp Ile Tyr Thr Thr Thr
100 105 110
Arg Thr Asn Ala Pro Ser Ile Asp Gly Asn Asn Thr Thr Phe Thr Gln
115 120 125
Phe Trp Ser Val Arg Gln Ser Lys Arg Pro Ile Gly Thr Asn Asn Thr
130 135 140
Ile Thr Phe Ser Asn His Val Asn Ala Trp Lys Ser Lys Gly Met Asn
145 150 155 160
Leu Gly Ser Ser Trp Ser Tyr Gln Val Leu Ala Thr Glu Gly Tyr Gln
165 170 175
Ser Ser Gly Tyr Ser Asn Val Thr Val Trp
180 185
<210> 63
<211> 561
<212> DNA
<213> Artificial Sequence
<220>
<223> Xylanase BD6002A
<220>
<221> CDS
<222> (1)..(561)
<400> 63
atg gct agc acc gac tac tgg caa aac tgg acc gac ggc ggc ggc acc 48
Met Ala Ser Thr Asp Tyr Trp Gln Asn Trp Thr Asp Gly Gly Gly Thr
1 5 10 15
gtg aac gct acc aac ggc agc gac ggc aac tac agc gtg agc tgg agc 96
Val Asn Ala Thr Asn Gly Ser Asp Gly Asn Tyr Ser Val Ser Trp Ser
20 25 30
aac tgc ggc aac ttc gtg gtg ggc aag ggc tgg acc acc ggc agc gct 144
Asn Cys Gly Asn Phe Val Val Gly Lys Gly Trp Thr Thr Gly Ser Ala
35 40 45
acc agg gtg atc aac tac aac gct ggc gct ttc agc cca agc ggc aac 192
Thr Arg Val Ile Asn Tyr Asn Ala Gly Ala Phe Ser Pro Ser Gly Asn
50 55 60
ggc tac ttg gct ttg tac ggc tgg acc agg aac agc ttg atc gag tac 240
Gly Tyr Leu Ala Leu Tyr Gly Trp Thr Arg Asn Ser Leu Ile Glu Tyr
65 70 75 80
tac gtg gtg gac agc tgg ggc acc tac agg cca acc ggc acc tac aag 288
Tyr Val Val Asp Ser Trp Gly Thr Tyr Arg Pro Thr Gly Thr Tyr Lys
85 90 95
ggc acc gtg acc agc gac ggc ggc acc tac gac atc tac acc acc acc 336
Gly Thr Val Thr Ser Asp Gly Gly Thr Tyr Asp Ile Tyr Thr Thr Thr
100 105 110
agg acc aac gct cca agc atc gac ggc aac aac acc acc ttc acc caa 384
Arg Thr Asn Ala Pro Ser Ile Asp Gly Asn Asn Thr Thr Phe Thr Gln
115 120 125
ttc tgg agc gtg agg caa agc aag agg cca atc ggc acc aac aac acc 432
Phe Trp Ser Val Arg Gln Ser Lys Arg Pro Ile Gly Thr Asn Asn Thr
130 135 140
atc acc ttc agc aac cat gtg aac gct tgg aag agc aag ggc atg aac 480
Ile Thr Phe Ser Asn His Val Asn Ala Trp Lys Ser Lys Gly Met Asn
145 150 155 160
ttg ggc agc agc tgg agc tac caa gtg ttg gct acc gag ggc tac caa 528
Leu Gly Ser Ser Trp Ser Tyr Gln Val Leu Ala Thr Glu Gly Tyr Gln
165 170 175
agc agc ggc tac agc aac gtg acc gtg tgg tag 561
Ser Ser Gly Tyr Ser Asn Val Thr Val Trp
180 185
<210> 64
<211> 186
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 64
Met Ala Ser Thr Asp Tyr Trp Gln Asn Trp Thr Asp Gly Gly Gly Thr
1 5 10 15
Val Asn Ala Thr Asn Gly Ser Asp Gly Asn Tyr Ser Val Ser Trp Ser
20 25 30
Asn Cys Gly Asn Phe Val Val Gly Lys Gly Trp Thr Thr Gly Ser Ala
35 40 45
Thr Arg Val Ile Asn Tyr Asn Ala Gly Ala Phe Ser Pro Ser Gly Asn
50 55 60
Gly Tyr Leu Ala Leu Tyr Gly Trp Thr Arg Asn Ser Leu Ile Glu Tyr
65 70 75 80
Tyr Val Val Asp Ser Trp Gly Thr Tyr Arg Pro Thr Gly Thr Tyr Lys
85 90 95
Gly Thr Val Thr Ser Asp Gly Gly Thr Tyr Asp Ile Tyr Thr Thr Thr
100 105 110
Arg Thr Asn Ala Pro Ser Ile Asp Gly Asn Asn Thr Thr Phe Thr Gln
115 120 125
Phe Trp Ser Val Arg Gln Ser Lys Arg Pro Ile Gly Thr Asn Asn Thr
130 135 140
Ile Thr Phe Ser Asn His Val Asn Ala Trp Lys Ser Lys Gly Met Asn
145 150 155 160
Leu Gly Ser Ser Trp Ser Tyr Gln Val Leu Ala Thr Glu Gly Tyr Gln
165 170 175
Ser Ser Gly Tyr Ser Asn Val Thr Val Trp
180 185
<210> 65
<211> 561
<212> DNA
<213> Artificial Sequence
<220>
<223> Xylanase BD6002B
<220>
<221> CDS
<222> (1)..(561)
<400> 65
atg gcc tcc acc gac tac tgg cag aac tgg acc gac ggc ggc ggc acc 48
Met Ala Ser Thr Asp Tyr Trp Gln Asn Trp Thr Asp Gly Gly Gly Thr
1 5 10 15
gtg aac gcc acc aac ggc tcc gac ggc aac tac tcc gtg tcc tgg tcc 96
Val Asn Ala Thr Asn Gly Ser Asp Gly Asn Tyr Ser Val Ser Trp Ser
20 25 30
aac tgc ggc aac ttc gtg gtg ggc aag ggc tgg acc acc ggc tcc gcc 144
Asn Cys Gly Asn Phe Val Val Gly Lys Gly Trp Thr Thr Gly Ser Ala
35 40 45
acc cgc gtg atc aac tac aac gcc ggc gcc ttc tcc ccg tcc ggc aac 192
Thr Arg Val Ile Asn Tyr Asn Ala Gly Ala Phe Ser Pro Ser Gly Asn
50 55 60
ggc tac ctc gcc ctc tac ggc tgg acc cgc aac tcc ctc atc gag tac 240
Gly Tyr Leu Ala Leu Tyr Gly Trp Thr Arg Asn Ser Leu Ile Glu Tyr
65 70 75 80
tac gtg gtg gac tcc tgg ggc acc tac cgc ccg acc ggc acc tac aag 288
Tyr Val Val Asp Ser Trp Gly Thr Tyr Arg Pro Thr Gly Thr Tyr Lys
85 90 95
ggc acc gtg acc tcc gac ggc ggc acc tac gac atc tac acc acc acc 336
Gly Thr Val Thr Ser Asp Gly Gly Thr Tyr Asp Ile Tyr Thr Thr Thr
100 105 110
cgc acc aac gcc ccg tcc atc gac ggc aac aac acc acc ttc acc cag 384
Arg Thr Asn Ala Pro Ser Ile Asp Gly Asn Asn Thr Thr Phe Thr Gln
115 120 125
ttc tgg tcc gtg cgc cag tcc aag cgc ccg atc ggc acc aac aac acc 432
Phe Trp Ser Val Arg Gln Ser Lys Arg Pro Ile Gly Thr Asn Asn Thr
130 135 140
atc acc ttc tcc aac cac gtg aac gcc tgg aag tcc aag ggc atg aac 480
Ile Thr Phe Ser Asn His Val Asn Ala Trp Lys Ser Lys Gly Met Asn
145 150 155 160
ctc ggc tcc tcc tgg tcc tac cag gtg ctc gcc acc gag ggc tac cag 528
Leu Gly Ser Ser Trp Ser Tyr Gln Val Leu Ala Thr Glu Gly Tyr Gln
165 170 175
tcc tcc ggc tac tcc aac gtg acc gtg tgg tga 561
Ser Ser Gly Tyr Ser Asn Val Thr Val Trp
180 185
<210> 66
<211> 186
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 66
Met Ala Ser Thr Asp Tyr Trp Gln Asn Trp Thr Asp Gly Gly Gly Thr
1 5 10 15
Val Asn Ala Thr Asn Gly Ser Asp Gly Asn Tyr Ser Val Ser Trp Ser
20 25 30
Asn Cys Gly Asn Phe Val Val Gly Lys Gly Trp Thr Thr Gly Ser Ala
35 40 45
Thr Arg Val Ile Asn Tyr Asn Ala Gly Ala Phe Ser Pro Ser Gly Asn
50 55 60
Gly Tyr Leu Ala Leu Tyr Gly Trp Thr Arg Asn Ser Leu Ile Glu Tyr
65 70 75 80
Tyr Val Val Asp Ser Trp Gly Thr Tyr Arg Pro Thr Gly Thr Tyr Lys
85 90 95
Gly Thr Val Thr Ser Asp Gly Gly Thr Tyr Asp Ile Tyr Thr Thr Thr
100 105 110
Arg Thr Asn Ala Pro Ser Ile Asp Gly Asn Asn Thr Thr Phe Thr Gln
115 120 125
Phe Trp Ser Val Arg Gln Ser Lys Arg Pro Ile Gly Thr Asn Asn Thr
130 135 140
Ile Thr Phe Ser Asn His Val Asn Ala Trp Lys Ser Lys Gly Met Asn
145 150 155 160
Leu Gly Ser Ser Trp Ser Tyr Gln Val Leu Ala Thr Glu Gly Tyr Gln
165 170 175
Ser Ser Gly Tyr Ser Asn Val Thr Val Trp
180 185
<210> 67
<211> 2071
<212> DNA
<213> Oryza sativa
<220>
<221> misc_feature
<222> (1)..(2071)
<223> Promoter
<400> 67
tccatgctgt cctactactt gcttcatccc cttctacatt ttgttctggt ttttggcctg 60
catttcggat catgatgtat gtgatttcca atctgctgca atatgaatgg agactctgtg 120
ctaaccatca acaacatgaa atgcttatga ggcctttgct gagcagccaa tcttgcctgt 180
gtttatgtct tcacaggccg aattcctctg ttttgttttt caccctcaat atttggaaac 240
atttatctag gttgtttgtg tccaggccta taaatcatac atgatgttgt cgtattggat 300
gtgaatgtgg tggcgtgttc agtgccttgg atttgagttt gatgagagtt gcttctgggt 360
caccactcac cattatcgat gctcctcttc agcataaggt aaaagtcttc cctgtttacg 420
ttattttacc cactatggtt gcttgggttg gttttttcct gattgcttat gccatggaaa 480
gtcatttgat atgttgaact tgaattaact gtagaattgt atacatgttc catttgtgtt 540
gtacttcctt cttttctatt agtagcctca gatgagtgtg aaaaaaacag attatataac 600
ttgccctata aatcatttga aaaaaatatt gtacagtgag aaattgatat atagtgaatt 660
tttaagagca tgttttccta aagaagtata tattttctat gtacaaaggc cattgaagta 720
attgtagata caggataatg tagacttttt ggacttacac tgctaccttt aagtaacaat 780
catgagcaat agtgttgcaa tgatatttag gctgcattcg tttactctct tgatttccat 840
gagcacgctt cccaaactgt taaactctgt gttttttgcc aaaaaaaaat gcataggaaa 900
gttgctttta aaaaatcata tcaatccatt ttttaagtta tagctaatac ttaattaatc 960
atgcgctaat aagtcactct gtttttcgta ctagagagat tgttttgaac cagcactcaa 1020
gaacacagcc ttaacccagc caaataatgc tacaacctac cagtccacac ctcttgtaaa 1080
gcatttgttg catggaaaag ctaagatgac agcaacctgt tcaggaaaac aactgacaag 1140
gtcataggga gagggagctt ttggaaaggt gccgtgcagt tcaaacaatt agttagcagt 1200
agggtgttgg tttttgctca cagcaataag aagttaatca tggtgtaggc aacccaaata 1260
aaacaccaaa atatgcacaa ggcagtttgt tgtattctgt agtacagaca aaactaaaag 1320
taatgaaaga agatgtggtg ttagaaaagg aaacaatatc atgagtaatg tgtgggcatt 1380
atgggaccac gaaataaaaa gaacattttg atgagtcgtg tatcctcgat gagcctcaaa 1440
agttctctca ccccggataa gaaaccctta agcaatgtgc aaagtttgca ttctccactg 1500
acataatgca aaataagata tcatcgatga catagcaact catgcatcat atcatgcctc 1560
tctcaaccta ttcattccta ctcatctaca taagtatctt cagctaaatg ttagaacata 1620
aacccataag tcacgtttga tgagtattag gcgtgacaca tgacaaatca cagactcaag 1680
caagataaag caaaatgatg tgtacataaa actccagagc tatatgtcat attgcaaaaa 1740
gaggagagct tataagacaa ggcatgactc acaaaaattc atttgccttt cgtgtcaaaa 1800
agaggagggc tttacattat ccatgtcata ttgcaaaaga aagagagaaa gaacaacaca 1860
atgctgcgtc aattatacat atctgtatgt ccatcattat tcatccacct ttcgtgtacc 1920
acacttcata tatcatgagt cacttcatgt ctggacatta acaaactcta tcttaacatt 1980
tagatgcaag agcctttatc tcactataaa tgcacgatga tttctcattg tttctcacaa 2040
aaagcattca gttcattagt cctacaacaa c 2071
<210> 68
<211> 79
<212> PRT
<213> Zea mays
<220>
<221> SIGNAL
<222> (1)..(79)
<223> Maize waxy signal sequence.
<400> 68
Met Leu Ala Ala Leu Ala Thr Ser Gln Leu Val Ala Thr Arg Ala Gly
1 5 10 15
Leu Gly Val Pro Asp Ala Ser Thr Phe Arg Arg Gly Ala Ala Gln Gly
20 25 30
Leu Arg Gly Ala Arg Ala Ser Ala Ala Ala Asp Thr Leu Ser Met Arg
35 40 45
Thr Ser Ala Arg Ala Ala Pro Arg His Gln His Gln Gln Ala Arg Arg
50 55 60
Gly Ala Arg Phe Pro Ser Leu Val Val Cys Ala Ser Ala Gly Ala
65 70 75
<210> 69
<211> 1005
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Bromelain Sequence
<220>
<221> CDS
<222> (1)..(1005)
<223> Synthetic Bromelain
<400> 69
atg gcc tgg aag gtg cag gtg gtg ttc ctc ttc ctc ttc ctc tgc gtg 48
Met Ala Trp Lys Val Gln Val Val Phe Leu Phe Leu Phe Leu Cys Val
1 5 10 15
atg tgg gcc tcc ccg tcc gcc gcc tcc gcg gac gag ccg tcc gac ccg 96
Met Trp Ala Ser Pro Ser Ala Ala Ser Ala Asp Glu Pro Ser Asp Pro
20 25 30
atg atg aag cgc ttc gag gag tgg atg gtg gag tac ggc cgc gtg tac 144
Met Met Lys Arg Phe Glu Glu Trp Met Val Glu Tyr Gly Arg Val Tyr
35 40 45
aag gac aac gac gag aag atg cgc cgc ttc cag atc ttc aag aac aac 192
Lys Asp Asn Asp Glu Lys Met Arg Arg Phe Gln Ile Phe Lys Asn Asn
50 55 60
gtg aac cac atc gag acc ttc aac tcc cgc aac gag aac tcc tac acc 240
Val Asn His Ile Glu Thr Phe Asn Ser Arg Asn Glu Asn Ser Tyr Thr
65 70 75 80
ctc ggc atc aac cag ttc acc gac atg acc aac aac gag ttc atc gcc 288
Leu Gly Ile Asn Gln Phe Thr Asp Met Thr Asn Asn Glu Phe Ile Ala
85 90 95
cag tac acc ggc ggc atc tcc cgc ccg ctc aac atc gag cgc gag ccg 336
Gln Tyr Thr Gly Gly Ile Ser Arg Pro Leu Asn Ile Glu Arg Glu Pro
100 105 110
gtg gtg tcc ttc gac gac gtg gac atc tcc gcc gtg ccg cag tcc atc 384
Val Val Ser Phe Asp Asp Val Asp Ile Ser Ala Val Pro Gln Ser Ile
115 120 125
gac tgg cgc gac tac ggc gcc gtg acc tcc gtg aag aac cag aac ccg 432
Asp Trp Arg Asp Tyr Gly Ala Val Thr Ser Val Lys Asn Gln Asn Pro
130 135 140
tgc ggc gcc tgc tgg gcc ttc gcc gcc atc gcc acc gtg gag tcc atc 480
Cys Gly Ala Cys Trp Ala Phe Ala Ala Ile Ala Thr Val Glu Ser Ile
145 150 155 160
tac aag atc aag aag ggc atc ctc gag ccg ctc tcc gag cag cag gtg 528
Tyr Lys Ile Lys Lys Gly Ile Leu Glu Pro Leu Ser Glu Gln Gln Val
165 170 175
ctc gac tgc gcc aag ggc tac ggc tgc aag ggc ggc tgg gag ttc cgc 576
Leu Asp Cys Ala Lys Gly Tyr Gly Cys Lys Gly Gly Trp Glu Phe Arg
180 185 190
gcc ttc gag ttc atc atc tcc aac aag ggc gtg gcc tcc ggc gcc atc 624
Ala Phe Glu Phe Ile Ile Ser Asn Lys Gly Val Ala Ser Gly Ala Ile
195 200 205
tac ccg tac aag gcc gcc aag ggc acc tgc aag acc gac ggc gtg ccg 672
Tyr Pro Tyr Lys Ala Ala Lys Gly Thr Cys Lys Thr Asp Gly Val Pro
210 215 220
aac tcc gcc tac atc acc ggc tac gcc cgc gtg ccg cgc aac aac gag 720
Asn Ser Ala Tyr Ile Thr Gly Tyr Ala Arg Val Pro Arg Asn Asn Glu
225 230 235 240
tcc tcc atg atg tac gcc gtg tcc aag cag ccg atc acc gtg gcc gtg 768
Ser Ser Met Met Tyr Ala Val Ser Lys Gln Pro Ile Thr Val Ala Val
245 250 255
gac gcc aac gcc aac ttc cag tac tac aag tcc ggc gtg ttc aac ggc 816
Asp Ala Asn Ala Asn Phe Gln Tyr Tyr Lys Ser Gly Val Phe Asn Gly
260 265 270
ccg tgc ggc acc tcc ctc aac cac gcc gtg acc gcc atc ggc tac ggc 864
Pro Cys Gly Thr Ser Leu Asn His Ala Val Thr Ala Ile Gly Tyr Gly
275 280 285
cag gac tcc atc atc tac ccg aag aag tgg ggc gcc aag tgg ggc gag 912
Gln Asp Ser Ile Ile Tyr Pro Lys Lys Trp Gly Ala Lys Trp Gly Glu
290 295 300
gcc ggc tac atc cgc atg gcc cgc gac gtg tcc tcc tcc tcc ggc atc 960
Ala Gly Tyr Ile Arg Met Ala Arg Asp Val Ser Ser Ser Ser Gly Ile
305 310 315 320
tgc ggc atc gcc atc gac ccg ctc tac ccg acc ctc gag gag tag 1005
Cys Gly Ile Ala Ile Asp Pro Leu Tyr Pro Thr Leu Glu Glu
325 330
<210> 70
<211> 334
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 70
Met Ala Trp Lys Val Gln Val Val Phe Leu Phe Leu Phe Leu Cys Val
1 5 10 15
Met Trp Ala Ser Pro Ser Ala Ala Ser Ala Asp Glu Pro Ser Asp Pro
20 25 30
Met Met Lys Arg Phe Glu Glu Trp Met Val Glu Tyr Gly Arg Val Tyr
35 40 45
Lys Asp Asn Asp Glu Lys Met Arg Arg Phe Gln Ile Phe Lys Asn Asn
50 55 60
Val Asn His Ile Glu Thr Phe Asn Ser Arg Asn Glu Asn Ser Tyr Thr
65 70 75 80
Leu Gly Ile Asn Gln Phe Thr Asp Met Thr Asn Asn Glu Phe Ile Ala
85 90 95
Gln Tyr Thr Gly Gly Ile Ser Arg Pro Leu Asn Ile Glu Arg Glu Pro
100 105 110
Val Val Ser Phe Asp Asp Val Asp Ile Ser Ala Val Pro Gln Ser Ile
115 120 125
Asp Trp Arg Asp Tyr Gly Ala Val Thr Ser Val Lys Asn Gln Asn Pro
130 135 140
Cys Gly Ala Cys Trp Ala Phe Ala Ala Ile Ala Thr Val Glu Ser Ile
145 150 155 160
Tyr Lys Ile Lys Lys Gly Ile Leu Glu Pro Leu Ser Glu Gln Gln Val
165 170 175
Leu Asp Cys Ala Lys Gly Tyr Gly Cys Lys Gly Gly Trp Glu Phe Arg
180 185 190
Ala Phe Glu Phe Ile Ile Ser Asn Lys Gly Val Ala Ser Gly Ala Ile
195 200 205
Tyr Pro Tyr Lys Ala Ala Lys Gly Thr Cys Lys Thr Asp Gly Val Pro
210 215 220
Asn Ser Ala Tyr Ile Thr Gly Tyr Ala Arg Val Pro Arg Asn Asn Glu
225 230 235 240
Ser Ser Met Met Tyr Ala Val Ser Lys Gln Pro Ile Thr Val Ala Val
245 250 255
Asp Ala Asn Ala Asn Phe Gln Tyr Tyr Lys Ser Gly Val Phe Asn Gly
260 265 270
Pro Cys Gly Thr Ser Leu Asn His Ala Val Thr Ala Ile Gly Tyr Gly
275 280 285
Gln Asp Ser Ile Ile Tyr Pro Lys Lys Trp Gly Ala Lys Trp Gly Glu
290 295 300
Ala Gly Tyr Ile Arg Met Ala Arg Asp Val Ser Ser Ser Ser Gly Ile
305 310 315 320
Cys Gly Ile Ala Ile Asp Pro Leu Tyr Pro Thr Leu Glu Glu
325 330
<210> 71
<211> 78
<212> DNA
<213> Artificial Sequence
<220>
<223> Bromealin signal sequence
<400> 71
atggcctgga aggtgcaggt ggtgttcctc ttcctcttcc tctgcgtgat gtgggcctcc 60
ccgtccgccg cctccgcc 78
<210> 72
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> Bromealin signal peptide
<400> 72
Met Ala Trp Lys Val Gln Val Val Phe Leu Phe Leu Phe Leu Cys Val
1 5 10 15
Met Trp Ala Ser Pro Ser Ala Ala Ser Ala
20 25
<210> 73
<211> 1050
<212> DNA
<213> Artificial Sequence
<220>
<223> pSYN11000
<400> 73
atggcctgga aggtgcaggt ggtgttcctc ttcctcttcc tctgcgtgat gtgggcctcc 60
ccgtccgccg cctccgcgga cgagccgtcc gacccgatga tgaagcgctt cgaggagtgg 120
atggtggagt acggccgcgt gtacaaggac aacgacgaga agatgcgccg cttccagatc 180
ttcaagaaca acgtgaacca catcgagacc ttcaactccc gcaacgagaa ctcctacacc 240
ctcggcatca accagttcac cgacatgacc aacaacgagt tcatcgccca gtacaccggc 300
ggcatctccc gcccgctcaa catcgagcgc gagccggtgg tgtccttcga cgacgtggac 360
atctccgccg tgccgcagtc catcgactgg cgcgactacg gcgccgtgac ctccgtgaag 420
aaccagaacc cgtgcggcgc ctgctgggcc ttcgccgcca tcgccaccgt ggagtccatc 480
tacaagatca agaagggcat cctcgagccg ctctccgagc agcaggtgct cgactgcgcc 540
aagggctacg gctgcaaggg cggctgggag ttccgcgcct tcgagttcat catctccaac 600
aagggcgtgg cctccggcgc catctacccg tacaaggccg ccaagggcac ctgcaagacc 660
gacggcgtgc cgaactccgc ctacatcacc ggctacgccc gcgtgccgcg caacaacgag 720
tcctccatga tgtacgccgt gtccaagcag ccgatcaccg tggccgtgga cgccaacgcc 780
aacttccagt actacaagtc cggcgtgttc aacggcccgt gcggcacctc cctcaaccac 840
gccgtgaccg ccatcggcta cggccaggac tccatcatct acccgaagaa gtggggcgcc 900
aagtggggcg aggccggcta catccgcatg gcccgcgacg tgtcctcctc ctccggcatc 960
tgcggcatcg ccatcgaccc gctctacccg accctcgagg aggtgttcgc cgaggccatc 1020
gccgccaact ccaccctcgt ggccgagtag 1050
<210> 74
<211> 1067
<212> DNA
<213> Artificial Sequence
<220>
<223> pSYN11589
<400> 74
tggcctggaa ggtgcaggtg gtgttcctct tcctcttcct ctgcgtgatg tgggcctccc 60
cgtccgccgc ctccgcctcc tcctcctcct tcgccgactc caacccgatc cgcccggtga 120
ccgaccgcgc cgcctccacc gacgagccgt ccgacccgat gatgaagcgc ttcgaggagt 180
ggatggtgga gtacggccgc gtgtacaagg acaacgacga gaagatgcgc cgcttccaga 240
tcttcaagaa caacgtgaac cacatcgaga ccttcaactc ccgcaacgag aactcctaca 300
ccctcggcat caaccagttc accgacatga ccaacaacga gttcatcgcc cagtacaccg 360
gcggcatctc ccgcccgctc aacatcgagc gcgagccggt ggtgtccttc gacgacgtgg 420
acatctccgc cgtgccgcag tccatcgact ggcgcgacta cggcgccgtg acctccgtga 480
agaaccagaa cccgtgcggc gcctgctggg ccttcgccgc catcgccacc gtggagtcca 540
tctacaagat caagaagggc atcctcgagc cgctctccga gcagcaggtg ctcgactgcg 600
ccaagggcta cggctgcaag ggcggctggg agttccgcgc cttcgagttc atcatctcca 660
acaagggcgt ggcctccggc gccatctacc cgtacaaggc cgccaagggc acctgcaaga 720
ccgacggcgt gccgaactcc gcctacatca ccggctacgc ccgcgtgccg cgcaacaacg 780
agtcctccat gatgtacgcc gtgtccaagc agccgatcac cgtggccgtg gacgccaacg 840
ccaacttcca gtactacaag tccggcgtgt tcaacggccc gtgcggcacc tccctcaacc 900
acgccgtgac cgccatcggc tacggccagg actccatcat ctacccgaag aagtggggcg 960
ccaagtgggg cgaggccggc tacatccgca tggcccgcga cgtgtcctcc tcctccggca 1020
tctgcggcat cgccatcgac ccgctctacc cgaccctcga ggagtag 1067
<210> 75
<211> 1023
<212> DNA
<213> Artificial Sequence
<220>
<223> pSYN11587 Sequence
<400> 75
atggcctgga aggtgcaggt ggtgttcctc ttcctcttcc tctgcgtgat gtgggcctcc 60
ccgtccgccg cctccgcgga cgagccgtcc gacccgatga tgaagcgctt cgaggagtgg 120
atggtggagt acggccgcgt gtacaaggac aacgacgaga agatgcgccg cttccagatc 180
ttcaagaaca acgtgaacca catcgagacc ttcaactccc gcaacgagaa ctcctacacc 240
ctcggcatca accagttcac cgacatgacc aacaacgagt tcatcgccca gtacaccggc 300
ggcatctccc gcccgctcaa catcgagcgc gagccggtgg tgtccttcga cgacgtggac 360
atctccgccg tgccgcagtc catcgactgg cgcgactacg gcgccgtgac ctccgtgaag 420
aaccagaacc cgtgcggcgc ctgctgggcc ttcgccgcca tcgccaccgt ggagtccatc 480
tacaagatca agaagggcat cctcgagccg ctctccgagc agcaggtgct cgactgcgcc 540
aagggctacg gctgcaaggg cggctgggag ttccgcgcct tcgagttcat catctccaac 600
aagggcgtgg cctccggcgc catctacccg tacaaggccg ccaagggcac ctgcaagacc 660
gacggcgtgc cgaactccgc ctacatcacc ggctacgccc gcgtgccgcg caacaacgag 720
tcctccatga tgtacgccgt gtccaagcag ccgatcaccg tggccgtgga cgccaacgcc 780
aacttccagt actacaagtc cggcgtgttc aacggcccgt gcggcacctc cctcaaccac 840
gccgtgaccg ccatcggcta cggccaggac tccatcatct acccgaagaa gtggggcgcc 900
aagtggggcg aggccggcta catccgcatg gcccgcgacg tgtcctcctc ctccggcatc 960
tgcggcatcg ccatcgaccc gctctacccg accctcgagg agtccgagaa ggacgagctg 1020
tag 1023
<210> 76
<211> 990
<212> DNA
<213> Artificial Sequence
<220>
<223> pSYN12169 Sequence
<400> 76
atgagggtgt tgctcgttgc cctcgctctc ctggctctcg ctgcgagcgc cacctccatg 60
gcggacgagc cgtccgaccc gatgatgaag cgcttcgagg agtggatggt ggagtacggc 120
cgcgtgtaca aggacaacga cgagaagatg cgccgcttcc agatcttcaa gaacaacgtg 180
aaccacatcg agaccttcaa ctcccgcaac gagaactcct acaccctcgg catcaaccag 240
ttcaccgaca tgaccaacaa cgagttcatc gcccagtaca ccggcggcat ctcccgcccg 300
ctcaacatcg agcgcgagcc ggtggtgtcc ttcgacgacg tggacatctc cgccgtgccg 360
cagtccatcg actggcgcga ctacggcgcc gtgacctccg tgaagaacca gaacccgtgc 420
ggcgcctgct gggccttcgc cgccatcgcc accgtggagt ccatctacaa gatcaagaag 480
ggcatcctcg agccgctctc cgagcagcag gtgctcgact gcgccaaggg ctacggctgc 540
aagggcggct gggagttccg cgccttcgag ttcatcatct ccaacaaggg cgtggcctcc 600
ggcgccatct acccgtacaa ggccgccaag ggcacctgca agaccgacgg cgtgccgaac 660
tccgcctaca tcaccggcta cgcccgcgtg ccgcgcaaca acgagtcctc catgatgtac 720
gccgtgtcca agcagccgat caccgtggcc gtggacgcca acgccaactt ccagtactac 780
aagtccggcg tgttcaacgg cccgtgcggc acctccctca accacgccgt gaccgccatc 840
ggctacggcc aggactccat catctacccg aagaagtggg gcgccaagtg gggcgaggcc 900
ggctacatcc gcatggcccg cgacgtgtcc tcctcctccg gcatctgcgg catcgccatc 960
gacccgctct acccgaccct cgaggagtag 990
<210> 77
<211> 1170
<212> DNA
<213> Artificial Sequence
<220>
<223> pSYN12575 Sequence
<400> 77
atgctggcgg ctctggccac gtcgcagctc gtcgcaacgc gcgccggcct gggcgtcccg 60
gacgcgtcca cgttccgccg cggcgccgcg cagggcctga ggggggcccg ggcgtcggcg 120
gcggcggaca cgctcagcat gcggaccagc gcgcgcgcgg cgcccaggca ccagcaccag 180
caggcgcgcc gcggggccag gttcccgtcg ctcgtcgtgt gcgccagcgc cggcgccatg 240
gcggacgagc cgtccgaccc gatgatgaag cgcttcgagg agtggatggt ggagtacggc 300
cgcgtgtaca aggacaacga cgagaagatg cgccgcttcc agatcttcaa gaacaacgtg 360
aaccacatcg agaccttcaa ctcccgcaac gagaactcct acaccctcgg catcaaccag 420
ttcaccgaca tgaccaacaa cgagttcatc gcccagtaca ccggcggcat ctcccgcccg 480
ctcaacatcg agcgcgagcc ggtggtgtcc ttcgacgacg tggacatctc cgccgtgccg 540
cagtccatcg actggcgcga ctacggcgcc gtgacctccg tgaagaacca gaacccgtgc 600
ggcgcctgct gggccttcgc cgccatcgcc accgtggagt ccatctacaa gatcaagaag 660
ggcatcctcg agccgctctc cgagcagcag gtgctcgact gcgccaaggg ctacggctgc 720
aagggcggct gggagttccg cgccttcgag ttcatcatct ccaacaaggg cgtggcctcc 780
ggcgccatct acccgtacaa ggccgccaag ggcacctgca agaccgacgg cgtgccgaac 840
tccgcctaca tcaccggcta cgcccgcgtg ccgcgcaaca acgagtcctc catgatgtac 900
gccgtgtcca agcagccgat caccgtggcc gtggacgcca acgccaactt ccagtactac 960
aagtccggcg tgttcaacgg cccgtgcggc acctccctca accacgccgt gaccgccatc 1020
ggctacggcc aggactccat catctacccg aagaagtggg gcgccaagtg gggcgaggcc 1080
ggctacatcc gcatggcccg cgacgtgtcc tcctcctccg gcatctgcgg catcgccatc 1140
gacccgctct acccgaccct cgaggagtag 1170
<210> 78
<211> 1068
<212> DNA
<213> Artificial Sequence
<220>
<223> pSM270 Sequence
<400> 78
atggcctgga aggtgcaggt ggtgttcctc ttcctcttcc tctgcgtgat gtgggcctcc 60
ccgtccgccg cctccgcctc ctcctcctcc ttcgccgact ccaacccgat ccgcccggtg 120
accgaccgcg ccgcctccac cgacgagccg tccgacccga tgatgaagcg cttcgaggag 180
tggatggtgg agtacggccg cgtgtacaag gacaacgacg agaagatgcg ccgcttccag 240
atcttcaaga acaacgtgaa ccacatcgag accttcaact cccgcaacga gaactcctac 300
accctcggca tcaaccagtt caccgacatg accaacaacg agttcatcgc ccagtacacc 360
ggcggcatct cccgcccgct caacatcgag cgcgagccgg tggtgtcctt cgacgacgtg 420
gacatctccg ccgtgccgca gtccatcgac tggcgcgact acggcgccgt gacctccgtg 480
aagaaccaga acccgtgcgg cgcctgctgg gccttcgccg ccatcgccac cgtggagtcc 540
atctacaaga tcaagaaggg catcctcgag ccgctctccg agcagcaggt gctcgactgc 600
gccaagggct acggctgcaa gggcggctgg gagttccgcg ccttcgagtt catcatctcc 660
aacaagggcg tggcctccgg cgccatctac ccgtacaagg ccgccaaggg cacctgcaag 720
accgacggcg tgccgaactc cgcctacatc accggctacg cccgcgtgcc gcgcaacaac 780
gagtcctcca tgatgtacgc cgtgtccaag cagccgatca ccgtggccgt ggacgccaac 840
gccaacttcc agtactacaa gtccggcgtg ttcaacggcc cgtgcggcac ctccctcaac 900
cacgccgtga ccgccatcgg ctacggccag gactccatca tctacccgaa gaagtggggc 960
gccaagtggg gcgaggccgg ctacatccgc atggcccgcg acgtgtcctc ctcctccggc 1020
atctgcggca tcgccatcga cccgctctac ccgaccctcg aggagtag 1068
<210> 79
<211> 1497
<212> DNA
<213> Trichoderma reesei
<220>
<221> CDS
<222> (1)..(1497)
<223> Trichoderma reesei cellobiohyrodlase I
<400> 79
atg cag tcg gcg tgt act ctc caa tcg gag act cac ccg cct ctg aca 48
Met Gln Ser Ala Cys Thr Leu Gln Ser Glu Thr His Pro Pro Leu Thr
1 5 10 15
tgg cag aaa tgc tcg tct ggt ggc acg tgc act caa cag aca ggc tcc 96
Trp Gln Lys Cys Ser Ser Gly Gly Thr Cys Thr Gln Gln Thr Gly Ser
20 25 30
gtg gtc atc gac gcc aac tgg cgc tgg act cac gct acg aac agc agc 144
Val Val Ile Asp Ala Asn Trp Arg Trp Thr His Ala Thr Asn Ser Ser
35 40 45
acg aac tgc tac gat ggc aac act tgg agc tcg acc cta tgt cct gac 192
Thr Asn Cys Tyr Asp Gly Asn Thr Trp Ser Ser Thr Leu Cys Pro Asp
50 55 60
aac gag acc tgc gcg aag aac tgc tgt ctg gac ggt gcc gcc tac gcg 240
Asn Glu Thr Cys Ala Lys Asn Cys Cys Leu Asp Gly Ala Ala Tyr Ala
65 70 75 80
tcc acg tac gga gtt acc acg agc ggt aac agc ctc tcc att ggc ttt 288
Ser Thr Tyr Gly Val Thr Thr Ser Gly Asn Ser Leu Ser Ile Gly Phe
85 90 95
gtc acc cag tct gcg cag aag aac gtt ggc gct cgc ctt tac ctt atg 336
Val Thr Gln Ser Ala Gln Lys Asn Val Gly Ala Arg Leu Tyr Leu Met
100 105 110
gcg agc gac acg acc tac cag gaa ttc acc ctg ctt ggc aac gag ttc 384
Ala Ser Asp Thr Thr Tyr Gln Glu Phe Thr Leu Leu Gly Asn Glu Phe
115 120 125
tct ttc gat gtt gat gtt tcg cag ctg ccg tgc ggc ttg aac gga gct 432
Ser Phe Asp Val Asp Val Ser Gln Leu Pro Cys Gly Leu Asn Gly Ala
130 135 140
ctc tac ttc gtg tcc atg gac gcg gat ggt ggc gtg agc aag tat ccc 480
Leu Tyr Phe Val Ser Met Asp Ala Asp Gly Gly Val Ser Lys Tyr Pro
145 150 155 160
acc aac acc gct ggc gcc aag tac ggc acg ggg tac tgt gac agc cag 528
Thr Asn Thr Ala Gly Ala Lys Tyr Gly Thr Gly Tyr Cys Asp Ser Gln
165 170 175
tgt ccc cgc gat ctg aag ttc atc aat ggc cag gcc aac gtt gag ggc 576
Cys Pro Arg Asp Leu Lys Phe Ile Asn Gly Gln Ala Asn Val Glu Gly
180 185 190
tgg gag ccg tca tcc aac aac gcg aac acg ggc att gga gga cac gga 624
Trp Glu Pro Ser Ser Asn Asn Ala Asn Thr Gly Ile Gly Gly His Gly
195 200 205
agc tgc tgc tct gag atg gat atc tgg gag gcc aac tcc atc tcc gag 672
Ser Cys Cys Ser Glu Met Asp Ile Trp Glu Ala Asn Ser Ile Ser Glu
210 215 220
gct ctt acc ccc cac cct tgc acg act gtc ggc cag gag atc tgc gag 720
Ala Leu Thr Pro His Pro Cys Thr Thr Val Gly Gln Glu Ile Cys Glu
225 230 235 240
ggt gat ggg tgc ggc gga act tac tcc gat aac aga tat ggc ggc act 768
Gly Asp Gly Cys Gly Gly Thr Tyr Ser Asp Asn Arg Tyr Gly Gly Thr
245 250 255
tgc gat ccc gat ggc tgc gac tgg aac cca tac cgc ctg ggc aac acc 816
Cys Asp Pro Asp Gly Cys Asp Trp Asn Pro Tyr Arg Leu Gly Asn Thr
260 265 270
agc ttc tac ggc cct ggc tct agc ttt acc ctc gat acc acc aag aaa 864
Ser Phe Tyr Gly Pro Gly Ser Ser Phe Thr Leu Asp Thr Thr Lys Lys
275 280 285
ttg acc gtt gtc acc cag ttc gag acg tcg ggt gcc atc aac cga tac 912
Leu Thr Val Val Thr Gln Phe Glu Thr Ser Gly Ala Ile Asn Arg Tyr
290 295 300
tat gtc cag aat ggc gtc act ttc cag cag ccc aac gcc gag ctt ggt 960
Tyr Val Gln Asn Gly Val Thr Phe Gln Gln Pro Asn Ala Glu Leu Gly
305 310 315 320
agt tac tct ggc aac gag ctc aac gat gat tac tgc aca gct gag gag 1008
Ser Tyr Ser Gly Asn Glu Leu Asn Asp Asp Tyr Cys Thr Ala Glu Glu
325 330 335
gca gaa ttc ggc gga tcc tct ttc tca gac aag ggc ggc ctg act cag 1056
Ala Glu Phe Gly Gly Ser Ser Phe Ser Asp Lys Gly Gly Leu Thr Gln
340 345 350
ttc aag aag gct acc tct ggc ggc atg gtt ctg gtc atg agt ctg tgg 1104
Phe Lys Lys Ala Thr Ser Gly Gly Met Val Leu Val Met Ser Leu Trp
355 360 365
gat gat tac tac gcc aac atg ctg tgg ctg gac tcc acc tac ccg aca 1152
Asp Asp Tyr Tyr Ala Asn Met Leu Trp Leu Asp Ser Thr Tyr Pro Thr
370 375 380
aac gag acc tcc tcc aca ccc ggt gcc gtg cgc gga agc tgc tcc acc 1200
Asn Glu Thr Ser Ser Thr Pro Gly Ala Val Arg Gly Ser Cys Ser Thr
385 390 395 400
agc tcc ggt gtc cct gct cag gtc gaa tct cag tct ccc aac gcc aag 1248
Ser Ser Gly Val Pro Ala Gln Val Glu Ser Gln Ser Pro Asn Ala Lys
405 410 415
gtc acc ttc tcc aac atc aag ttc gga ccc att ggc agc acc ggc aac 1296
Val Thr Phe Ser Asn Ile Lys Phe Gly Pro Ile Gly Ser Thr Gly Asn
420 425 430
cct agc ggc ggc aac cct ccc ggc gga aac ccg cct ggc acc acc acc 1344
Pro Ser Gly Gly Asn Pro Pro Gly Gly Asn Pro Pro Gly Thr Thr Thr
435 440 445
acc cgc cgc cca gcc act acc act gga agc tct ccc gga cct acc cag 1392
Thr Arg Arg Pro Ala Thr Thr Thr Gly Ser Ser Pro Gly Pro Thr Gln
450 455 460
tct cac tac ggc cag tgc ggc ggt att ggc tac agc ggc ccc acg gtc 1440
Ser His Tyr Gly Gln Cys Gly Gly Ile Gly Tyr Ser Gly Pro Thr Val
465 470 475 480
tgc gcc agc ggc aca act tgc cag gtc ctg aac cct tac tac tct cag 1488
Cys Ala Ser Gly Thr Thr Cys Gln Val Leu Asn Pro Tyr Tyr Ser Gln
485 490 495
tgc ctg taa 1497
Cys Leu
<210> 80
<211> 498
<212> PRT
<213> Trichoderma reesei
<400> 80
Met Gln Ser Ala Cys Thr Leu Gln Ser Glu Thr His Pro Pro Leu Thr
1 5 10 15
Trp Gln Lys Cys Ser Ser Gly Gly Thr Cys Thr Gln Gln Thr Gly Ser
20 25 30
Val Val Ile Asp Ala Asn Trp Arg Trp Thr His Ala Thr Asn Ser Ser
35 40 45
Thr Asn Cys Tyr Asp Gly Asn Thr Trp Ser Ser Thr Leu Cys Pro Asp
50 55 60
Asn Glu Thr Cys Ala Lys Asn Cys Cys Leu Asp Gly Ala Ala Tyr Ala
65 70 75 80
Ser Thr Tyr Gly Val Thr Thr Ser Gly Asn Ser Leu Ser Ile Gly Phe
85 90 95
Val Thr Gln Ser Ala Gln Lys Asn Val Gly Ala Arg Leu Tyr Leu Met
100 105 110
Ala Ser Asp Thr Thr Tyr Gln Glu Phe Thr Leu Leu Gly Asn Glu Phe
115 120 125
Ser Phe Asp Val Asp Val Ser Gln Leu Pro Cys Gly Leu Asn Gly Ala
130 135 140
Leu Tyr Phe Val Ser Met Asp Ala Asp Gly Gly Val Ser Lys Tyr Pro
145 150 155 160
Thr Asn Thr Ala Gly Ala Lys Tyr Gly Thr Gly Tyr Cys Asp Ser Gln
165 170 175
Cys Pro Arg Asp Leu Lys Phe Ile Asn Gly Gln Ala Asn Val Glu Gly
180 185 190
Trp Glu Pro Ser Ser Asn Asn Ala Asn Thr Gly Ile Gly Gly His Gly
195 200 205
Ser Cys Cys Ser Glu Met Asp Ile Trp Glu Ala Asn Ser Ile Ser Glu
210 215 220
Ala Leu Thr Pro His Pro Cys Thr Thr Val Gly Gln Glu Ile Cys Glu
225 230 235 240
Gly Asp Gly Cys Gly Gly Thr Tyr Ser Asp Asn Arg Tyr Gly Gly Thr
245 250 255
Cys Asp Pro Asp Gly Cys Asp Trp Asn Pro Tyr Arg Leu Gly Asn Thr
260 265 270
Ser Phe Tyr Gly Pro Gly Ser Ser Phe Thr Leu Asp Thr Thr Lys Lys
275 280 285
Leu Thr Val Val Thr Gln Phe Glu Thr Ser Gly Ala Ile Asn Arg Tyr
290 295 300
Tyr Val Gln Asn Gly Val Thr Phe Gln Gln Pro Asn Ala Glu Leu Gly
305 310 315 320
Ser Tyr Ser Gly Asn Glu Leu Asn Asp Asp Tyr Cys Thr Ala Glu Glu
325 330 335
Ala Glu Phe Gly Gly Ser Ser Phe Ser Asp Lys Gly Gly Leu Thr Gln
340 345 350
Phe Lys Lys Ala Thr Ser Gly Gly Met Val Leu Val Met Ser Leu Trp
355 360 365
Asp Asp Tyr Tyr Ala Asn Met Leu Trp Leu Asp Ser Thr Tyr Pro Thr
370 375 380
Asn Glu Thr Ser Ser Thr Pro Gly Ala Val Arg Gly Ser Cys Ser Thr
385 390 395 400
Ser Ser Gly Val Pro Ala Gln Val Glu Ser Gln Ser Pro Asn Ala Lys
405 410 415
Val Thr Phe Ser Asn Ile Lys Phe Gly Pro Ile Gly Ser Thr Gly Asn
420 425 430
Pro Ser Gly Gly Asn Pro Pro Gly Gly Asn Pro Pro Gly Thr Thr Thr
435 440 445
Thr Arg Arg Pro Ala Thr Thr Thr Gly Ser Ser Pro Gly Pro Thr Gln
450 455 460
Ser His Tyr Gly Gln Cys Gly Gly Ile Gly Tyr Ser Gly Pro Thr Val
465 470 475 480
Cys Ala Ser Gly Thr Thr Cys Gln Val Leu Asn Pro Tyr Tyr Ser Gln
485 490 495
Cys Leu
<210> 81
<211> 1365
<212> DNA
<213> Trichoderma reesei
<220>
<221> CDS
<222> (1)..(1365)
<223> trichoderma reesei cellobiohydrolase II
<400> 81
atg gtg cct cta gag gag cgg caa gct tgc tca agc gtc tgg ggc caa 48
Met Val Pro Leu Glu Glu Arg Gln Ala Cys Ser Ser Val Trp Gly Gln
1 5 10 15
tgt ggt ggc cag aat tgg tcg ggt ccg act tgc tgt gct tcc gga agc 96
Cys Gly Gly Gln Asn Trp Ser Gly Pro Thr Cys Cys Ala Ser Gly Ser
20 25 30
aca tgc gtc tac tcc aac gac tat tac tcc cag tgt ctt ccc ggc gct 144
Thr Cys Val Tyr Ser Asn Asp Tyr Tyr Ser Gln Cys Leu Pro Gly Ala
35 40 45
gca agc tca agc tcg tcc acg cgc gcc gcg tcg acg act tca cga gta 192
Ala Ser Ser Ser Ser Ser Thr Arg Ala Ala Ser Thr Thr Ser Arg Val
50 55 60
tcc ccc aca aca tcc cgg tcg agc tcc gcg acg cct cca cct ggt tct 240
Ser Pro Thr Thr Ser Arg Ser Ser Ser Ala Thr Pro Pro Pro Gly Ser
65 70 75 80
acc act acc aga gta cct cca gtc gga tcg gga acc gct acg tat tca 288
Thr Thr Thr Arg Val Pro Pro Val Gly Ser Gly Thr Ala Thr Tyr Ser
85 90 95
ggc aac cct ttt gtt ggg gtc act cct tgg gcc aat gca tat tac gcc 336
Gly Asn Pro Phe Val Gly Val Thr Pro Trp Ala Asn Ala Tyr Tyr Ala
100 105 110
tct gaa gtt agc agc ctc gct att cct agc ttg act gga gcc atg gcc 384
Ser Glu Val Ser Ser Leu Ala Ile Pro Ser Leu Thr Gly Ala Met Ala
115 120 125
act gct gca gca gct gtc gca aag gtt ccc tct ttt atg tgg cta gat 432
Thr Ala Ala Ala Ala Val Ala Lys Val Pro Ser Phe Met Trp Leu Asp
130 135 140
act ctt gac aag acc cct ctc atg gag caa acc ttg gcc gac atc cgc 480
Thr Leu Asp Lys Thr Pro Leu Met Glu Gln Thr Leu Ala Asp Ile Arg
145 150 155 160
acc gcc aac aag aat ggc ggt aac tat gcc gga cag ttt gtg gtg tat 528
Thr Ala Asn Lys Asn Gly Gly Asn Tyr Ala Gly Gln Phe Val Val Tyr
165 170 175
gac ttg ccg gat cgc gat tgc gct gcc ctt gcc tcg aat ggc gaa tac 576
Asp Leu Pro Asp Arg Asp Cys Ala Ala Leu Ala Ser Asn Gly Glu Tyr
180 185 190
tct att gcc gat ggt ggc gtc gcc aaa tat aag aac tat atc gac acc 624
Ser Ile Ala Asp Gly Gly Val Ala Lys Tyr Lys Asn Tyr Ile Asp Thr
195 200 205
att cgt caa att gtc gtg gaa tat tcc gat atc cgg acc ctc ctg gtt 672
Ile Arg Gln Ile Val Val Glu Tyr Ser Asp Ile Arg Thr Leu Leu Val
210 215 220
att gag cct gac tct ctt gcc aac ctg gtg acc aac ctc ggt act cca 720
Ile Glu Pro Asp Ser Leu Ala Asn Leu Val Thr Asn Leu Gly Thr Pro
225 230 235 240
aag tgt gcc aat gct cag tca gcc tac ctt gag tgc atc aac tac gcc 768
Lys Cys Ala Asn Ala Gln Ser Ala Tyr Leu Glu Cys Ile Asn Tyr Ala
245 250 255
gtc aca cag ctg aac ctt cca aat gtt gcg atg tat ttg gac gct ggc 816
Val Thr Gln Leu Asn Leu Pro Asn Val Ala Met Tyr Leu Asp Ala Gly
260 265 270
cat gca gga tgg ctt ggc tgg ccg gca aac caa gac ccg gcc gct cag 864
His Ala Gly Trp Leu Gly Trp Pro Ala Asn Gln Asp Pro Ala Ala Gln
275 280 285
cta ttt gca aat gtt tac aag aat gca tcg tct ccg aga gct ctt cgc 912
Leu Phe Ala Asn Val Tyr Lys Asn Ala Ser Ser Pro Arg Ala Leu Arg
290 295 300
gga ttg gca acc aat gtc gcc aac tac aac ggg tgg aac att acc agc 960
Gly Leu Ala Thr Asn Val Ala Asn Tyr Asn Gly Trp Asn Ile Thr Ser
305 310 315 320
ccc cca tcg tac acg caa ggc aac gct gtc tac aac gag aag ctg tac 1008
Pro Pro Ser Tyr Thr Gln Gly Asn Ala Val Tyr Asn Glu Lys Leu Tyr
325 330 335
atc cac gct att gga cct ctt ctt gcc aat cac ggc tgg tcc aac gcc 1056
Ile His Ala Ile Gly Pro Leu Leu Ala Asn His Gly Trp Ser Asn Ala
340 345 350
ttc ttc atc act gat caa ggt cga tcg gga aag cag cct acc gga cag 1104
Phe Phe Ile Thr Asp Gln Gly Arg Ser Gly Lys Gln Pro Thr Gly Gln
355 360 365
caa cag tgg gga gac tgg tgc aat gtg atc ggc acc gga ttt ggt att 1152
Gln Gln Trp Gly Asp Trp Cys Asn Val Ile Gly Thr Gly Phe Gly Ile
370 375 380
cgc cca tcc gca aac act ggg gac tcg ttg ctg gat tcg ttt gtc tgg 1200
Arg Pro Ser Ala Asn Thr Gly Asp Ser Leu Leu Asp Ser Phe Val Trp
385 390 395 400
gtc aag cca ggc ggc gag tgt gac ggc acc agc gac agc agt gcg cca 1248
Val Lys Pro Gly Gly Glu Cys Asp Gly Thr Ser Asp Ser Ser Ala Pro
405 410 415
cga ttt gac tcc cac tgt gcg ctc cca gat gcc ttg caa ccg gcg cct 1296
Arg Phe Asp Ser His Cys Ala Leu Pro Asp Ala Leu Gln Pro Ala Pro
420 425 430
caa gct ggt gct tgg ttc caa gcc tac ttt gtg cag ctt ctc aca aac 1344
Gln Ala Gly Ala Trp Phe Gln Ala Tyr Phe Val Gln Leu Leu Thr Asn
435 440 445
gca aac cca tcg ttc ctg tag 1365
Ala Asn Pro Ser Phe Leu
450
<210> 82
<211> 454
<212> PRT
<213> Trichoderma reesei
<400> 82
Met Val Pro Leu Glu Glu Arg Gln Ala Cys Ser Ser Val Trp Gly Gln
1 5 10 15
Cys Gly Gly Gln Asn Trp Ser Gly Pro Thr Cys Cys Ala Ser Gly Ser
20 25 30
Thr Cys Val Tyr Ser Asn Asp Tyr Tyr Ser Gln Cys Leu Pro Gly Ala
35 40 45
Ala Ser Ser Ser Ser Ser Thr Arg Ala Ala Ser Thr Thr Ser Arg Val
50 55 60
Ser Pro Thr Thr Ser Arg Ser Ser Ser Ala Thr Pro Pro Pro Gly Ser
65 70 75 80
Thr Thr Thr Arg Val Pro Pro Val Gly Ser Gly Thr Ala Thr Tyr Ser
85 90 95
Gly Asn Pro Phe Val Gly Val Thr Pro Trp Ala Asn Ala Tyr Tyr Ala
100 105 110
Ser Glu Val Ser Ser Leu Ala Ile Pro Ser Leu Thr Gly Ala Met Ala
115 120 125
Thr Ala Ala Ala Ala Val Ala Lys Val Pro Ser Phe Met Trp Leu Asp
130 135 140
Thr Leu Asp Lys Thr Pro Leu Met Glu Gln Thr Leu Ala Asp Ile Arg
145 150 155 160
Thr Ala Asn Lys Asn Gly Gly Asn Tyr Ala Gly Gln Phe Val Val Tyr
165 170 175
Asp Leu Pro Asp Arg Asp Cys Ala Ala Leu Ala Ser Asn Gly Glu Tyr
180 185 190
Ser Ile Ala Asp Gly Gly Val Ala Lys Tyr Lys Asn Tyr Ile Asp Thr
195 200 205
Ile Arg Gln Ile Val Val Glu Tyr Ser Asp Ile Arg Thr Leu Leu Val
210 215 220
Ile Glu Pro Asp Ser Leu Ala Asn Leu Val Thr Asn Leu Gly Thr Pro
225 230 235 240
Lys Cys Ala Asn Ala Gln Ser Ala Tyr Leu Glu Cys Ile Asn Tyr Ala
245 250 255
Val Thr Gln Leu Asn Leu Pro Asn Val Ala Met Tyr Leu Asp Ala Gly
260 265 270
His Ala Gly Trp Leu Gly Trp Pro Ala Asn Gln Asp Pro Ala Ala Gln
275 280 285
Leu Phe Ala Asn Val Tyr Lys Asn Ala Ser Ser Pro Arg Ala Leu Arg
290 295 300
Gly Leu Ala Thr Asn Val Ala Asn Tyr Asn Gly Trp Asn Ile Thr Ser
305 310 315 320
Pro Pro Ser Tyr Thr Gln Gly Asn Ala Val Tyr Asn Glu Lys Leu Tyr
325 330 335
Ile His Ala Ile Gly Pro Leu Leu Ala Asn His Gly Trp Ser Asn Ala
340 345 350
Phe Phe Ile Thr Asp Gln Gly Arg Ser Gly Lys Gln Pro Thr Gly Gln
355 360 365
Gln Gln Trp Gly Asp Trp Cys Asn Val Ile Gly Thr Gly Phe Gly Ile
370 375 380
Arg Pro Ser Ala Asn Thr Gly Asp Ser Leu Leu Asp Ser Phe Val Trp
385 390 395 400
Val Lys Pro Gly Gly Glu Cys Asp Gly Thr Ser Asp Ser Ser Ala Pro
405 410 415
Arg Phe Asp Ser His Cys Ala Leu Pro Asp Ala Leu Gln Pro Ala Pro
420 425 430
Gln Ala Gly Ala Trp Phe Gln Ala Tyr Phe Val Gln Leu Leu Thr Asn
435 440 445
Ala Asn Pro Ser Phe Leu
450
<210> 83
<211> 1317
<212> DNA
<213> Trichoderma reesei
<220>
<221> CDS
<222> (1)..(1317)
<223> Trichoderma reesei endoglucanase I
<400> 83
atg cag caa ccg gga acc agc acc ccc gag gtc cat ccc aag ttg aca 48
Met Gln Gln Pro Gly Thr Ser Thr Pro Glu Val His Pro Lys Leu Thr
1 5 10 15
acc tac aag tgc aca aag tcc ggg ggg tgc gtg gcc cag gac acc tcg 96
Thr Tyr Lys Cys Thr Lys Ser Gly Gly Cys Val Ala Gln Asp Thr Ser
20 25 30
gtg gtc ctt gac tgg aac tac cgc tgg atg cac gac gca aac tac aac 144
Val Val Leu Asp Trp Asn Tyr Arg Trp Met His Asp Ala Asn Tyr Asn
35 40 45
tcg tgc acc gtc aac ggc ggc gtc aac acc acg ctc tgc cct gac gag 192
Ser Cys Thr Val Asn Gly Gly Val Asn Thr Thr Leu Cys Pro Asp Glu
50 55 60
gcg acc tgt ggc aag aac tgc ttc atc gag ggc gtc gac tac gcc gcc 240
Ala Thr Cys Gly Lys Asn Cys Phe Ile Glu Gly Val Asp Tyr Ala Ala
65 70 75 80
tcg ggc gtc acg acc tcg ggc agc agc ctc acc atg aac cag tac atg 288
Ser Gly Val Thr Thr Ser Gly Ser Ser Leu Thr Met Asn Gln Tyr Met
85 90 95
ccc agc agc tct ggc ggc tac agc agc gtc tct cct cgg ctg tat ctc 336
Pro Ser Ser Ser Gly Gly Tyr Ser Ser Val Ser Pro Arg Leu Tyr Leu
100 105 110
ctg gac tct gac ggt gag tac gtg atg ctg aag ctc aac ggc cag gag 384
Leu Asp Ser Asp Gly Glu Tyr Val Met Leu Lys Leu Asn Gly Gln Glu
115 120 125
ctg agc ttc gac gtc gac ctc tct gct ctg ccg tgt gga gag aac ggc 432
Leu Ser Phe Asp Val Asp Leu Ser Ala Leu Pro Cys Gly Glu Asn Gly
130 135 140
tcg ctc tac ctg tct cag atg gac gag aac ggg ggc gcc aac cag tat 480
Ser Leu Tyr Leu Ser Gln Met Asp Glu Asn Gly Gly Ala Asn Gln Tyr
145 150 155 160
aac acg gcc ggt gcc aac tac ggg agc ggc tac tgc gat gct cag tgc 528
Asn Thr Ala Gly Ala Asn Tyr Gly Ser Gly Tyr Cys Asp Ala Gln Cys
165 170 175
ccc gtc cag aca tgg agg aac ggc acc ctc aac act agc cac cag ggc 576
Pro Val Gln Thr Trp Arg Asn Gly Thr Leu Asn Thr Ser His Gln Gly
180 185 190
ttc tgc tgc aac gag atg gat atc ctg gag ggc aac tcg agg gcg aat 624
Phe Cys Cys Asn Glu Met Asp Ile Leu Glu Gly Asn Ser Arg Ala Asn
195 200 205
gcc ttg acc cct cac tct tgc acg gcc acg gcc tgc gac tct gcc ggt 672
Ala Leu Thr Pro His Ser Cys Thr Ala Thr Ala Cys Asp Ser Ala Gly
210 215 220
tgc ggc ttc aac ccc tat ggc agc ggc tac aaa agc tac tac ggc ccc 720
Cys Gly Phe Asn Pro Tyr Gly Ser Gly Tyr Lys Ser Tyr Tyr Gly Pro
225 230 235 240
gga gat acc gtt gac acc tcc aag acc ttc acc atc atc acc cag ttc 768
Gly Asp Thr Val Asp Thr Ser Lys Thr Phe Thr Ile Ile Thr Gln Phe
245 250 255
aac acg gac aac ggc tcg ccc tcg ggc aac ctt gtg agc atc acc cgc 816
Asn Thr Asp Asn Gly Ser Pro Ser Gly Asn Leu Val Ser Ile Thr Arg
260 265 270
aag tac cag caa aac ggc gtc gac atc ccc agc gcc cag ccc ggc ggc 864
Lys Tyr Gln Gln Asn Gly Val Asp Ile Pro Ser Ala Gln Pro Gly Gly
275 280 285
gac acc atc tcg tcc tgc ccg tcc gcc tca gcc tac ggc ggc ctc gcc 912
Asp Thr Ile Ser Ser Cys Pro Ser Ala Ser Ala Tyr Gly Gly Leu Ala
290 295 300
acc atg ggc aag gcc ctg agc agc ggc atg gtg ctc gtg ttc agc att 960
Thr Met Gly Lys Ala Leu Ser Ser Gly Met Val Leu Val Phe Ser Ile
305 310 315 320
tgg aac gac aac agc cag tac atg aac tgg ctc gac agc ggc aac gcc 1008
Trp Asn Asp Asn Ser Gln Tyr Met Asn Trp Leu Asp Ser Gly Asn Ala
325 330 335
ggc ccc tgc agc agc acc gag ggc aac cca tcc aac acc ctg gcc aac 1056
Gly Pro Cys Ser Ser Thr Glu Gly Asn Pro Ser Asn Thr Leu Ala Asn
340 345 350
aac ccc aac acg cac gtc gtc ttc tcc aac atc cgc tgg gga gac att 1104
Asn Pro Asn Thr His Val Val Phe Ser Asn Ile Arg Trp Gly Asp Ile
355 360 365
ggg tct act acg aac tcg act gcg ccc ccg ccc ccg cct gcg tcc agc 1152
Gly Ser Thr Thr Asn Ser Thr Ala Pro Pro Pro Pro Pro Ala Ser Ser
370 375 380
acg acg ttt tcg act aca cgg agg agc tcg acg act tcg agc agc ccg 1200
Thr Thr Phe Ser Thr Thr Arg Arg Ser Ser Thr Thr Ser Ser Ser Pro
385 390 395 400
agc tgc acg cag act cac tgg ggg cag tgc ggt ggc att ggg tac agc 1248
Ser Cys Thr Gln Thr His Trp Gly Gln Cys Gly Gly Ile Gly Tyr Ser
405 410 415
ggg tgc aag acg tgc acg tcg ggc act acg tgc cag tat agc aac gac 1296
Gly Cys Lys Thr Cys Thr Ser Gly Thr Thr Cys Gln Tyr Ser Asn Asp
420 425 430
tac tac tcg caa tgc ctt tag 1317
Tyr Tyr Ser Gln Cys Leu
435
<210> 84
<211> 438
<212> PRT
<213> Trichoderma reesei
<400> 84
Met Gln Gln Pro Gly Thr Ser Thr Pro Glu Val His Pro Lys Leu Thr
1 5 10 15
Thr Tyr Lys Cys Thr Lys Ser Gly Gly Cys Val Ala Gln Asp Thr Ser
20 25 30
Val Val Leu Asp Trp Asn Tyr Arg Trp Met His Asp Ala Asn Tyr Asn
35 40 45
Ser Cys Thr Val Asn Gly Gly Val Asn Thr Thr Leu Cys Pro Asp Glu
50 55 60
Ala Thr Cys Gly Lys Asn Cys Phe Ile Glu Gly Val Asp Tyr Ala Ala
65 70 75 80
Ser Gly Val Thr Thr Ser Gly Ser Ser Leu Thr Met Asn Gln Tyr Met
85 90 95
Pro Ser Ser Ser Gly Gly Tyr Ser Ser Val Ser Pro Arg Leu Tyr Leu
100 105 110
Leu Asp Ser Asp Gly Glu Tyr Val Met Leu Lys Leu Asn Gly Gln Glu
115 120 125
Leu Ser Phe Asp Val Asp Leu Ser Ala Leu Pro Cys Gly Glu Asn Gly
130 135 140
Ser Leu Tyr Leu Ser Gln Met Asp Glu Asn Gly Gly Ala Asn Gln Tyr
145 150 155 160
Asn Thr Ala Gly Ala Asn Tyr Gly Ser Gly Tyr Cys Asp Ala Gln Cys
165 170 175
Pro Val Gln Thr Trp Arg Asn Gly Thr Leu Asn Thr Ser His Gln Gly
180 185 190
Phe Cys Cys Asn Glu Met Asp Ile Leu Glu Gly Asn Ser Arg Ala Asn
195 200 205
Ala Leu Thr Pro His Ser Cys Thr Ala Thr Ala Cys Asp Ser Ala Gly
210 215 220
Cys Gly Phe Asn Pro Tyr Gly Ser Gly Tyr Lys Ser Tyr Tyr Gly Pro
225 230 235 240
Gly Asp Thr Val Asp Thr Ser Lys Thr Phe Thr Ile Ile Thr Gln Phe
245 250 255
Asn Thr Asp Asn Gly Ser Pro Ser Gly Asn Leu Val Ser Ile Thr Arg
260 265 270
Lys Tyr Gln Gln Asn Gly Val Asp Ile Pro Ser Ala Gln Pro Gly Gly
275 280 285
Asp Thr Ile Ser Ser Cys Pro Ser Ala Ser Ala Tyr Gly Gly Leu Ala
290 295 300
Thr Met Gly Lys Ala Leu Ser Ser Gly Met Val Leu Val Phe Ser Ile
305 310 315 320
Trp Asn Asp Asn Ser Gln Tyr Met Asn Trp Leu Asp Ser Gly Asn Ala
325 330 335
Gly Pro Cys Ser Ser Thr Glu Gly Asn Pro Ser Asn Thr Leu Ala Asn
340 345 350
Asn Pro Asn Thr His Val Val Phe Ser Asn Ile Arg Trp Gly Asp Ile
355 360 365
Gly Ser Thr Thr Asn Ser Thr Ala Pro Pro Pro Pro Pro Ala Ser Ser
370 375 380
Thr Thr Phe Ser Thr Thr Arg Arg Ser Ser Thr Thr Ser Ser Ser Pro
385 390 395 400
Ser Cys Thr Gln Thr His Trp Gly Gln Cys Gly Gly Ile Gly Tyr Ser
405 410 415
Gly Cys Lys Thr Cys Thr Ser Gly Thr Thr Cys Gln Tyr Ser Asn Asp
420 425 430
Tyr Tyr Ser Gln Cys Leu
435
<210> 85
<211> 954
<212> DNA
<213> Artificial Sequence
<220>
<223> 6GP1
<220>
<221> CDS
<222> (1)..(954)
<223> 6GP1
<400> 85
atg ggc gtg gac ccg ttc gag cgc aac aag atc ctc ggc cgc ggc atc 48
Met Gly Val Asp Pro Phe Glu Arg Asn Lys Ile Leu Gly Arg Gly Ile
1 5 10 15
aac atc ggc aac gcc ctg gag gcc ccg aac gag ggc gac tgg ggc gtg 96
Asn Ile Gly Asn Ala Leu Glu Ala Pro Asn Glu Gly Asp Trp Gly Val
20 25 30
gtg atc aag gac gag ttc ttc gac atc atc aag gag gcc ggc ttc tcc 144
Val Ile Lys Asp Glu Phe Phe Asp Ile Ile Lys Glu Ala Gly Phe Ser
35 40 45
cac gtg cgc atc ccg atc cgc tgg tcc acc cac gcc tac gcc ttc ccg 192
His Val Arg Ile Pro Ile Arg Trp Ser Thr His Ala Tyr Ala Phe Pro
50 55 60
ccg tac aag atc atg gac cgc ttc ttc aag cgc gtg gac gag gtg atc 240
Pro Tyr Lys Ile Met Asp Arg Phe Phe Lys Arg Val Asp Glu Val Ile
65 70 75 80
aac ggc gcc ctc aag cgc ggc ctc gcc gtg gcc atc aac atc cac cac 288
Asn Gly Ala Leu Lys Arg Gly Leu Ala Val Ala Ile Asn Ile His His
85 90 95
tac gag gag ctc atg aac gac ccg gag gag cac aag gag cgc ttc ctc 336
Tyr Glu Glu Leu Met Asn Asp Pro Glu Glu His Lys Glu Arg Phe Leu
100 105 110
gcc ctc tgg aag cag atc gcc gac cgc tac aag gac tac ccg gag acc 384
Ala Leu Trp Lys Gln Ile Ala Asp Arg Tyr Lys Asp Tyr Pro Glu Thr
115 120 125
ctc ttc ttc gag atc ctc aac gag ccg cac ggc aac ctc acc ccg gag 432
Leu Phe Phe Glu Ile Leu Asn Glu Pro His Gly Asn Leu Thr Pro Glu
130 135 140
aag tgg aac gag ctg ctc gag gag gcc ctc aag gtg atc cgc tcc atc 480
Lys Trp Asn Glu Leu Leu Glu Glu Ala Leu Lys Val Ile Arg Ser Ile
145 150 155 160
gac aag aag cac acc atc atc att ggc acc gca gag tgg gga ggc atc 528
Asp Lys Lys His Thr Ile Ile Ile Gly Thr Ala Glu Trp Gly Gly Ile
165 170 175
tcc gcc ctc gag aag ctc tcc gtg ccg aag tgg gag aag aat tcc atc 576
Ser Ala Leu Glu Lys Leu Ser Val Pro Lys Trp Glu Lys Asn Ser Ile
180 185 190
gtg acc atc cac tac tac aac ccg ttc gag ttc acg cac cag ggc gcc 624
Val Thr Ile His Tyr Tyr Asn Pro Phe Glu Phe Thr His Gln Gly Ala
195 200 205
gag tgg gtg gag ggc tcc gag aag tgg ctt ggc cgc aag tgg ggc tcc 672
Glu Trp Val Glu Gly Ser Glu Lys Trp Leu Gly Arg Lys Trp Gly Ser
210 215 220
ccg gac gac cag aag cac ctc atc gag gag ttc aac ttc atc gag gag 720
Pro Asp Asp Gln Lys His Leu Ile Glu Glu Phe Asn Phe Ile Glu Glu
225 230 235 240
tgg tcc aag aag aac aag cgc ccg atc tac atc ggc gag ttt ggc gcc 768
Trp Ser Lys Lys Asn Lys Arg Pro Ile Tyr Ile Gly Glu Phe Gly Ala
245 250 255
tac cgc aag gcc gac ctc gag tcc cgc atc aag tgg acc tcc ttc gtg 816
Tyr Arg Lys Ala Asp Leu Glu Ser Arg Ile Lys Trp Thr Ser Phe Val
260 265 270
gtg cgt gag atg gag aag cgc cgc tgg tcc tgg gcc tac tgg gag ttc 864
Val Arg Glu Met Glu Lys Arg Arg Trp Ser Trp Ala Tyr Trp Glu Phe
275 280 285
tgc tcc ggc ttc ggc gtg tac gac acc ctc cgc aag acc tgg aac aag 912
Cys Ser Gly Phe Gly Val Tyr Asp Thr Leu Arg Lys Thr Trp Asn Lys
290 295 300
gac ctc ctc gag gcc ctc atc ggc ggc gac tcc atc gag tag 954
Asp Leu Leu Glu Ala Leu Ile Gly Gly Asp Ser Ile Glu
305 310 315
<210> 86
<211> 317
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 86
Met Gly Val Asp Pro Phe Glu Arg Asn Lys Ile Leu Gly Arg Gly Ile
1 5 10 15
Asn Ile Gly Asn Ala Leu Glu Ala Pro Asn Glu Gly Asp Trp Gly Val
20 25 30
Val Ile Lys Asp Glu Phe Phe Asp Ile Ile Lys Glu Ala Gly Phe Ser
35 40 45
His Val Arg Ile Pro Ile Arg Trp Ser Thr His Ala Tyr Ala Phe Pro
50 55 60
Pro Tyr Lys Ile Met Asp Arg Phe Phe Lys Arg Val Asp Glu Val Ile
65 70 75 80
Asn Gly Ala Leu Lys Arg Gly Leu Ala Val Ala Ile Asn Ile His His
85 90 95
Tyr Glu Glu Leu Met Asn Asp Pro Glu Glu His Lys Glu Arg Phe Leu
100 105 110
Ala Leu Trp Lys Gln Ile Ala Asp Arg Tyr Lys Asp Tyr Pro Glu Thr
115 120 125
Leu Phe Phe Glu Ile Leu Asn Glu Pro His Gly Asn Leu Thr Pro Glu
130 135 140
Lys Trp Asn Glu Leu Leu Glu Glu Ala Leu Lys Val Ile Arg Ser Ile
145 150 155 160
Asp Lys Lys His Thr Ile Ile Ile Gly Thr Ala Glu Trp Gly Gly Ile
165 170 175
Ser Ala Leu Glu Lys Leu Ser Val Pro Lys Trp Glu Lys Asn Ser Ile
180 185 190
Val Thr Ile His Tyr Tyr Asn Pro Phe Glu Phe Thr His Gln Gly Ala
195 200 205
Glu Trp Val Glu Gly Ser Glu Lys Trp Leu Gly Arg Lys Trp Gly Ser
210 215 220
Pro Asp Asp Gln Lys His Leu Ile Glu Glu Phe Asn Phe Ile Glu Glu
225 230 235 240
Trp Ser Lys Lys Asn Lys Arg Pro Ile Tyr Ile Gly Glu Phe Gly Ala
245 250 255
Tyr Arg Lys Ala Asp Leu Glu Ser Arg Ile Lys Trp Thr Ser Phe Val
260 265 270
Val Arg Glu Met Glu Lys Arg Arg Trp Ser Trp Ala Tyr Trp Glu Phe
275 280 285
Cys Ser Gly Phe Gly Val Tyr Asp Thr Leu Arg Lys Thr Trp Asn Lys
290 295 300
Asp Leu Leu Glu Ala Leu Ile Gly Gly Asp Ser Ile Glu
305 310 315
<210> 87
<211> 1248
<212> DNA
<213> Hordeum vulgare
<220>
<221> CDS
<222> (1)..(1248)
<223> Barley AmyI amylase
<400> 87
atg gca cac caa gtc ctc ttt cag ggg ttc aac tgg gag tcg tgg aag 48
Met Ala His Gln Val Leu Phe Gln Gly Phe Asn Trp Glu Ser Trp Lys
1 5 10 15
cag agc ggc ggg tgg tac aac atg atg atg ggc aag gtc gac gac atc 96
Gln Ser Gly Gly Trp Tyr Asn Met Met Met Gly Lys Val Asp Asp Ile
20 25 30
gcc gct gcc gga gtc acc cac gtc tgg ctg cca ccg ccg tcg cac tcc 144
Ala Ala Ala Gly Val Thr His Val Trp Leu Pro Pro Pro Ser His Ser
35 40 45
gtc tcc aac gaa ggt tac atg cct ggt cgg ctg tac gac atc gac gcg 192
Val Ser Asn Glu Gly Tyr Met Pro Gly Arg Leu Tyr Asp Ile Asp Ala
50 55 60
tcc aag tac ggc aac gcg gcg gag ctc aag tcg ctc atc ggc gcg ctc 240
Ser Lys Tyr Gly Asn Ala Ala Glu Leu Lys Ser Leu Ile Gly Ala Leu
65 70 75 80
cac ggc aag ggc gtg cag gcc atc gcc gac atc gtc atc aac cac cgc 288
His Gly Lys Gly Val Gln Ala Ile Ala Asp Ile Val Ile Asn His Arg
85 90 95
tgc gcc gac tac aag gat agc cgc ggc atc tac tgc atc ttc gag ggc 336
Cys Ala Asp Tyr Lys Asp Ser Arg Gly Ile Tyr Cys Ile Phe Glu Gly
100 105 110
ggc acc tcc gac ggc cgc ctc gac tgg ggc ccc cac atg atc tgt cgc 384
Gly Thr Ser Asp Gly Arg Leu Asp Trp Gly Pro His Met Ile Cys Arg
115 120 125
gac gac acc aaa tac tcc gat ggc acc gca aac ctc gac acc gga gcc 432
Asp Asp Thr Lys Tyr Ser Asp Gly Thr Ala Asn Leu Asp Thr Gly Ala
130 135 140
gac ttc gcc gcc gcg ccc gac atc gac cac ctc aac gac cgg gtc cag 480
Asp Phe Ala Ala Ala Pro Asp Ile Asp His Leu Asn Asp Arg Val Gln
145 150 155 160
cgc gag ctc aag gag tgg ctc ctc tgg ctc aag agc gac ctc ggc ttc 528
Arg Glu Leu Lys Glu Trp Leu Leu Trp Leu Lys Ser Asp Leu Gly Phe
165 170 175
gac gcg tgg cgc ctt gac ttc gcc agg ggc tac tcg ccg gag atg gcc 576
Asp Ala Trp Arg Leu Asp Phe Ala Arg Gly Tyr Ser Pro Glu Met Ala
180 185 190
aag gtg tac atc gac ggc aca tcc ccg agc ctc gcc gtg gcc gag gtg 624
Lys Val Tyr Ile Asp Gly Thr Ser Pro Ser Leu Ala Val Ala Glu Val
195 200 205
tgg gac aat atg gcc acc ggc ggc gac ggc aag ccc aac tac gac cag 672
Trp Asp Asn Met Ala Thr Gly Gly Asp Gly Lys Pro Asn Tyr Asp Gln
210 215 220
gac gcg cac cgg cag aat ctg gtg aac tgg gtg gac aag gtg ggc ggc 720
Asp Ala His Arg Gln Asn Leu Val Asn Trp Val Asp Lys Val Gly Gly
225 230 235 240
gcg gcc tcg gca ggc atg gtg ttc gac ttc acg acc aaa ggg ata ctg 768
Ala Ala Ser Ala Gly Met Val Phe Asp Phe Thr Thr Lys Gly Ile Leu
245 250 255
aac gct gcc gtg gag ggc gag ctg tgg agg ctg atc gac ccg cag ggg 816
Asn Ala Ala Val Glu Gly Glu Leu Trp Arg Leu Ile Asp Pro Gln Gly
260 265 270
aag gcc ccc ggc gtg atg gga tgg tgg ccg gcc aag gcc gtc acc ttc 864
Lys Ala Pro Gly Val Met Gly Trp Trp Pro Ala Lys Ala Val Thr Phe
275 280 285
gtc gac aac cac gat aca ggc tcc acg cag gcc atg tgg cca ttc ccc 912
Val Asp Asn His Asp Thr Gly Ser Thr Gln Ala Met Trp Pro Phe Pro
290 295 300
tcc gac aag gtc atg cag ggc tac gcg tac atc ctc acc cac ccc ggc 960
Ser Asp Lys Val Met Gln Gly Tyr Ala Tyr Ile Leu Thr His Pro Gly
305 310 315 320
atc cca tgc atc ttc tac gac cat ttc ttc aac tgg ggg ttt aag gac 1008
Ile Pro Cys Ile Phe Tyr Asp His Phe Phe Asn Trp Gly Phe Lys Asp
325 330 335
cag atc gcg gcg ctg gtg gcg atc agg aag cgc aac ggc atc acg gcg 1056
Gln Ile Ala Ala Leu Val Ala Ile Arg Lys Arg Asn Gly Ile Thr Ala
340 345 350
acg agc gct ctg aag atc ctc atg cac gaa gga gat gcc tac gtc gcc 1104
Thr Ser Ala Leu Lys Ile Leu Met His Glu Gly Asp Ala Tyr Val Ala
355 360 365
gag ata gac ggc aag gtg gtg gtg aag atc ggg tcc agg tac gac gtc 1152
Glu Ile Asp Gly Lys Val Val Val Lys Ile Gly Ser Arg Tyr Asp Val
370 375 380
ggg gcg gtg atc ccg gcc ggg ttc gtg acc tcg gca cac ggc aac gac 1200
Gly Ala Val Ile Pro Ala Gly Phe Val Thr Ser Ala His Gly Asn Asp
385 390 395 400
tac gcc gtc tgg gag aag aac ggt gcc gcg gca aca cta caa cgg agc 1248
Tyr Ala Val Trp Glu Lys Asn Gly Ala Ala Ala Thr Leu Gln Arg Ser
405 410 415
<210> 88
<211> 416
<212> PRT
<213> Hordeum vulgare
<400> 88
Met Ala His Gln Val Leu Phe Gln Gly Phe Asn Trp Glu Ser Trp Lys
1 5 10 15
Gln Ser Gly Gly Trp Tyr Asn Met Met Met Gly Lys Val Asp Asp Ile
20 25 30
Ala Ala Ala Gly Val Thr His Val Trp Leu Pro Pro Pro Ser His Ser
35 40 45
Val Ser Asn Glu Gly Tyr Met Pro Gly Arg Leu Tyr Asp Ile Asp Ala
50 55 60
Ser Lys Tyr Gly Asn Ala Ala Glu Leu Lys Ser Leu Ile Gly Ala Leu
65 70 75 80
His Gly Lys Gly Val Gln Ala Ile Ala Asp Ile Val Ile Asn His Arg
85 90 95
Cys Ala Asp Tyr Lys Asp Ser Arg Gly Ile Tyr Cys Ile Phe Glu Gly
100 105 110
Gly Thr Ser Asp Gly Arg Leu Asp Trp Gly Pro His Met Ile Cys Arg
115 120 125
Asp Asp Thr Lys Tyr Ser Asp Gly Thr Ala Asn Leu Asp Thr Gly Ala
130 135 140
Asp Phe Ala Ala Ala Pro Asp Ile Asp His Leu Asn Asp Arg Val Gln
145 150 155 160
Arg Glu Leu Lys Glu Trp Leu Leu Trp Leu Lys Ser Asp Leu Gly Phe
165 170 175
Asp Ala Trp Arg Leu Asp Phe Ala Arg Gly Tyr Ser Pro Glu Met Ala
180 185 190
Lys Val Tyr Ile Asp Gly Thr Ser Pro Ser Leu Ala Val Ala Glu Val
195 200 205
Trp Asp Asn Met Ala Thr Gly Gly Asp Gly Lys Pro Asn Tyr Asp Gln
210 215 220
Asp Ala His Arg Gln Asn Leu Val Asn Trp Val Asp Lys Val Gly Gly
225 230 235 240
Ala Ala Ser Ala Gly Met Val Phe Asp Phe Thr Thr Lys Gly Ile Leu
245 250 255
Asn Ala Ala Val Glu Gly Glu Leu Trp Arg Leu Ile Asp Pro Gln Gly
260 265 270
Lys Ala Pro Gly Val Met Gly Trp Trp Pro Ala Lys Ala Val Thr Phe
275 280 285
Val Asp Asn His Asp Thr Gly Ser Thr Gln Ala Met Trp Pro Phe Pro
290 295 300
Ser Asp Lys Val Met Gln Gly Tyr Ala Tyr Ile Leu Thr His Pro Gly
305 310 315 320
Ile Pro Cys Ile Phe Tyr Asp His Phe Phe Asn Trp Gly Phe Lys Asp
325 330 335
Gln Ile Ala Ala Leu Val Ala Ile Arg Lys Arg Asn Gly Ile Thr Ala
340 345 350
Thr Ser Ala Leu Lys Ile Leu Met His Glu Gly Asp Ala Tyr Val Ala
355 360 365
Glu Ile Asp Gly Lys Val Val Val Lys Ile Gly Ser Arg Tyr Asp Val
370 375 380
Gly Ala Val Ile Pro Ala Gly Phe Val Thr Ser Ala His Gly Asn Asp
385 390 395 400
Tyr Ala Val Trp Glu Lys Asn Gly Ala Ala Ala Thr Leu Gln Arg Ser
405 410 415
<210> 89
<211> 1401
<212> DNA
<213> Artificial Sequence
<220>
<223> Trichoderma reesei ß-Glucosidase 2
<220>
<221> CDS
<222> (1)..(1401)
<223> Trichoderma reesei ß-Glucosidase 2
<400> 89
atg ttg ccc aag gac ttt cag tgg ggg ttc gcc acg gct gcc tac cag 48
Met Leu Pro Lys Asp Phe Gln Trp Gly Phe Ala Thr Ala Ala Tyr Gln
1 5 10 15
atc gag ggc gcc gtc gac cag gac ggc cgc ggc ccc agc atc tgg gac 96
Ile Glu Gly Ala Val Asp Gln Asp Gly Arg Gly Pro Ser Ile Trp Asp
20 25 30
acg ttc tgc gcg cag ccc ggc aag atc gcc gac ggc tcg tcg ggc gtg 144
Thr Phe Cys Ala Gln Pro Gly Lys Ile Ala Asp Gly Ser Ser Gly Val
35 40 45
acg gcg tgc gac tcg tac aac cgc acg gcc gag gac att gcg ctg ctg 192
Thr Ala Cys Asp Ser Tyr Asn Arg Thr Ala Glu Asp Ile Ala Leu Leu
50 55 60
aag tcg ctc ggg gcc aag agc tac cgc ttc tcc atc tcg tgg tcg cgc 240
Lys Ser Leu Gly Ala Lys Ser Tyr Arg Phe Ser Ile Ser Trp Ser Arg
65 70 75 80
atc atc ccc gag ggc ggc cgc ggc gat gcc gtc aac cag gcg ggc atc 288
Ile Ile Pro Glu Gly Gly Arg Gly Asp Ala Val Asn Gln Ala Gly Ile
85 90 95
gac cac tac gtc aag ttc gtc gac gac ctg ctc gac gcc ggc atc acg 336
Asp His Tyr Val Lys Phe Val Asp Asp Leu Leu Asp Ala Gly Ile Thr
100 105 110
ccc ttc atc acc ctc ttc cac tgg gac ctg ccc gag ggc ctg cat cag 384
Pro Phe Ile Thr Leu Phe His Trp Asp Leu Pro Glu Gly Leu His Gln
115 120 125
cgg tac ggg ggg ctg ctg aac cgc acc gag ttc ccg ctc gac ttt gaa 432
Arg Tyr Gly Gly Leu Leu Asn Arg Thr Glu Phe Pro Leu Asp Phe Glu
130 135 140
aac tac gcc cgc gtc atg ttc agg gcg ctg ccc aag gtg cgc aac tgg 480
Asn Tyr Ala Arg Val Met Phe Arg Ala Leu Pro Lys Val Arg Asn Trp
145 150 155 160
atc acc ttc aac gag ccg ctg tgc tcg gcc atc ccg ggc tac ggc tcc 528
Ile Thr Phe Asn Glu Pro Leu Cys Ser Ala Ile Pro Gly Tyr Gly Ser
165 170 175
ggc acc ttc gcc ccc ggc cgg cag agc acc tcg gag ccg tgg acc gtc 576
Gly Thr Phe Ala Pro Gly Arg Gln Ser Thr Ser Glu Pro Trp Thr Val
180 185 190
ggc cac aac atc ctc gtc gcc cac ggc cgc gcc gtc aag gcg tac cgc 624
Gly His Asn Ile Leu Val Ala His Gly Arg Ala Val Lys Ala Tyr Arg
195 200 205
gac gac ttc aag ccc gcc agc ggc gac ggc cag atc ggc atc gtc ctc 672
Asp Asp Phe Lys Pro Ala Ser Gly Asp Gly Gln Ile Gly Ile Val Leu
210 215 220
aac ggc gac ttc acc tac ccc tgg gac gcc gcc gac ccg gcc gac aag 720
Asn Gly Asp Phe Thr Tyr Pro Trp Asp Ala Ala Asp Pro Ala Asp Lys
225 230 235 240
gag gcg gcc gag cgg cgc ctc gag ttc ttc acg gcc tgg ttc gcg gac 768
Glu Ala Ala Glu Arg Arg Leu Glu Phe Phe Thr Ala Trp Phe Ala Asp
245 250 255
ccc atc tac ttg ggc gac tac ccg gcg tcg atg cgc aag cag ctg ggc 816
Pro Ile Tyr Leu Gly Asp Tyr Pro Ala Ser Met Arg Lys Gln Leu Gly
260 265 270
gac cgg ctg ccg acc ttt acg ccc gag gag cgc gcc ctc gtc cac ggc 864
Asp Arg Leu Pro Thr Phe Thr Pro Glu Glu Arg Ala Leu Val His Gly
275 280 285
tcc aac gac ttt tac ggc atg aac cac tac acg tcc aac tac atc cgc 912
Ser Asn Asp Phe Tyr Gly Met Asn His Tyr Thr Ser Asn Tyr Ile Arg
290 295 300
cac cgc agc tcg ccc gcc tcc gcc gac gac acc gtc ggc aac gtc gac 960
His Arg Ser Ser Pro Ala Ser Ala Asp Asp Thr Val Gly Asn Val Asp
305 310 315 320
gtg ctc ttc acc aac aag cag ggc aac tgc atc ggc ccc gag acg cag 1008
Val Leu Phe Thr Asn Lys Gln Gly Asn Cys Ile Gly Pro Glu Thr Gln
325 330 335
tcc ccc tgg ctg cgc ccc tgt gcc gcc ggc ttc cgc gac ttc ctg gtg 1056
Ser Pro Trp Leu Arg Pro Cys Ala Ala Gly Phe Arg Asp Phe Leu Val
340 345 350
tgg atc agc aag agg tac ggc tac ccg ccc atc tac gtg acg gag aac 1104
Trp Ile Ser Lys Arg Tyr Gly Tyr Pro Pro Ile Tyr Val Thr Glu Asn
355 360 365
ggc acg agc atc aag ggc gag agc gac ttg ccc aag gag aag att ctc 1152
Gly Thr Ser Ile Lys Gly Glu Ser Asp Leu Pro Lys Glu Lys Ile Leu
370 375 380
gaa gat gac ttc agg gtc aag tac tat aac gag tac atc cgt gcc atg 1200
Glu Asp Asp Phe Arg Val Lys Tyr Tyr Asn Glu Tyr Ile Arg Ala Met
385 390 395 400
gtt acc gcc gtg gag ctg gac ggg gtc aac gtc aag ggg tac ttt gcc 1248
Val Thr Ala Val Glu Leu Asp Gly Val Asn Val Lys Gly Tyr Phe Ala
405 410 415
tgg tcg ctc atg gac aac ttt gag tgg gcg gac ggc tac gtg acg agg 1296
Trp Ser Leu Met Asp Asn Phe Glu Trp Ala Asp Gly Tyr Val Thr Arg
420 425 430
ttt ggg gtt acg tat gtg gat tat gag aat ggg cag aag cgg ttc ccc 1344
Phe Gly Val Thr Tyr Val Asp Tyr Glu Asn Gly Gln Lys Arg Phe Pro
435 440 445
aag aag agc gca aag agc ttg aag ccg ctg ttt gac gag ctg att gcg 1392
Lys Lys Ser Ala Lys Ser Leu Lys Pro Leu Phe Asp Glu Leu Ile Ala
450 455 460
gcg gcg tga 1401
Ala Ala
465
<210> 90
<211> 466
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 90
Met Leu Pro Lys Asp Phe Gln Trp Gly Phe Ala Thr Ala Ala Tyr Gln
1 5 10 15
Ile Glu Gly Ala Val Asp Gln Asp Gly Arg Gly Pro Ser Ile Trp Asp
20 25 30
Thr Phe Cys Ala Gln Pro Gly Lys Ile Ala Asp Gly Ser Ser Gly Val
35 40 45
Thr Ala Cys Asp Ser Tyr Asn Arg Thr Ala Glu Asp Ile Ala Leu Leu
50 55 60
Lys Ser Leu Gly Ala Lys Ser Tyr Arg Phe Ser Ile Ser Trp Ser Arg
65 70 75 80
Ile Ile Pro Glu Gly Gly Arg Gly Asp Ala Val Asn Gln Ala Gly Ile
85 90 95
Asp His Tyr Val Lys Phe Val Asp Asp Leu Leu Asp Ala Gly Ile Thr
100 105 110
Pro Phe Ile Thr Leu Phe His Trp Asp Leu Pro Glu Gly Leu His Gln
115 120 125
Arg Tyr Gly Gly Leu Leu Asn Arg Thr Glu Phe Pro Leu Asp Phe Glu
130 135 140
Asn Tyr Ala Arg Val Met Phe Arg Ala Leu Pro Lys Val Arg Asn Trp
145 150 155 160
Ile Thr Phe Asn Glu Pro Leu Cys Ser Ala Ile Pro Gly Tyr Gly Ser
165 170 175
Gly Thr Phe Ala Pro Gly Arg Gln Ser Thr Ser Glu Pro Trp Thr Val
180 185 190
Gly His Asn Ile Leu Val Ala His Gly Arg Ala Val Lys Ala Tyr Arg
195 200 205
Asp Asp Phe Lys Pro Ala Ser Gly Asp Gly Gln Ile Gly Ile Val Leu
210 215 220
Asn Gly Asp Phe Thr Tyr Pro Trp Asp Ala Ala Asp Pro Ala Asp Lys
225 230 235 240
Glu Ala Ala Glu Arg Arg Leu Glu Phe Phe Thr Ala Trp Phe Ala Asp
245 250 255
Pro Ile Tyr Leu Gly Asp Tyr Pro Ala Ser Met Arg Lys Gln Leu Gly
260 265 270
Asp Arg Leu Pro Thr Phe Thr Pro Glu Glu Arg Ala Leu Val His Gly
275 280 285
Ser Asn Asp Phe Tyr Gly Met Asn His Tyr Thr Ser Asn Tyr Ile Arg
290 295 300
His Arg Ser Ser Pro Ala Ser Ala Asp Asp Thr Val Gly Asn Val Asp
305 310 315 320
Val Leu Phe Thr Asn Lys Gln Gly Asn Cys Ile Gly Pro Glu Thr Gln
325 330 335
Ser Pro Trp Leu Arg Pro Cys Ala Ala Gly Phe Arg Asp Phe Leu Val
340 345 350
Trp Ile Ser Lys Arg Tyr Gly Tyr Pro Pro Ile Tyr Val Thr Glu Asn
355 360 365
Gly Thr Ser Ile Lys Gly Glu Ser Asp Leu Pro Lys Glu Lys Ile Leu
370 375 380
Glu Asp Asp Phe Arg Val Lys Tyr Tyr Asn Glu Tyr Ile Arg Ala Met
385 390 395 400
Val Thr Ala Val Glu Leu Asp Gly Val Asn Val Lys Gly Tyr Phe Ala
405 410 415
Trp Ser Leu Met Asp Asn Phe Glu Trp Ala Asp Gly Tyr Val Thr Arg
420 425 430
Phe Gly Val Thr Tyr Val Asp Tyr Glu Asn Gly Gln Lys Arg Phe Pro
435 440 445
Lys Lys Ser Ala Lys Ser Leu Lys Pro Leu Phe Asp Glu Leu Ile Ala
450 455 460
Ala Ala
465
<210> 91
<211> 2103
<212> DNA
<213> Artificial Sequence
<220>
<223> Trichoderma reesei ß-Glucosidase D
<220>
<221> CDS
<222> (1)..(2103)
<223> Trichoderma reesei ß-Glucosidase D
<400> 91
atg att ctc ggc tgt gaa agc aca ggt gtc atc tct gcc gtc aaa cac 48
Met Ile Leu Gly Cys Glu Ser Thr Gly Val Ile Ser Ala Val Lys His
1 5 10 15
ttt gtc gcc aac gac cag gag cac gag cgg cga gcg gtc gac tgt ctc 96
Phe Val Ala Asn Asp Gln Glu His Glu Arg Arg Ala Val Asp Cys Leu
20 25 30
atc acc cag cgg gct ctc cgg gag gtc tat ctg cga ccc ttc cag atc 144
Ile Thr Gln Arg Ala Leu Arg Glu Val Tyr Leu Arg Pro Phe Gln Ile
35 40 45
gta gcc cga gat gca agg ccc ggc gca ttg atg aca tcc tac aac aag 192
Val Ala Arg Asp Ala Arg Pro Gly Ala Leu Met Thr Ser Tyr Asn Lys
50 55 60
gtc aat ggc aag cac gtc gct gac agc gcc gag ttc ctt cag ggc att 240
Val Asn Gly Lys His Val Ala Asp Ser Ala Glu Phe Leu Gln Gly Ile
65 70 75 80
ctc cgg act gag tgg aat tgg gac cct ctc att gtc agc gac tgg tac 288
Leu Arg Thr Glu Trp Asn Trp Asp Pro Leu Ile Val Ser Asp Trp Tyr
85 90 95
ggc acc tac acc act att gat gcc atc aaa gcc ggc ctt gat ctc gag 336
Gly Thr Tyr Thr Thr Ile Asp Ala Ile Lys Ala Gly Leu Asp Leu Glu
100 105 110
atg ccg ggc gtt tca cga tat cgc ggc aaa tac atc gag tct gct ctg 384
Met Pro Gly Val Ser Arg Tyr Arg Gly Lys Tyr Ile Glu Ser Ala Leu
115 120 125
cag gcc cgt ttg ctg aag cag tcc act atc gat gag cgc gct cgc cgc 432
Gln Ala Arg Leu Leu Lys Gln Ser Thr Ile Asp Glu Arg Ala Arg Arg
130 135 140
gtg ctc agg ttc gcc cag aag gcc agc cat ctc aag gtc tcc gag gta 480
Val Leu Arg Phe Ala Gln Lys Ala Ser His Leu Lys Val Ser Glu Val
145 150 155 160
gag caa ggc cgt gac ttc cca gag gat cgc gtc ctc aac cgt cag atc 528
Glu Gln Gly Arg Asp Phe Pro Glu Asp Arg Val Leu Asn Arg Gln Ile
165 170 175
tgc ggc agc agc att gtc cta ctg aag aat gag aac tcc atc tta cct 576
Cys Gly Ser Ser Ile Val Leu Leu Lys Asn Glu Asn Ser Ile Leu Pro
180 185 190
ctc ccc aag tcc gtc aag aag gtc gcc ctt gtt ggt tcc cac gtg cgt 624
Leu Pro Lys Ser Val Lys Lys Val Ala Leu Val Gly Ser His Val Arg
195 200 205
cta ccg gct atc tcg gga gga ggc agc gcc tct ctt gtc cct tac tat 672
Leu Pro Ala Ile Ser Gly Gly Gly Ser Ala Ser Leu Val Pro Tyr Tyr
210 215 220
gcc ata tct cta tac gat gcc gtc tct gag gta cta gcc ggt gcc acg 720
Ala Ile Ser Leu Tyr Asp Ala Val Ser Glu Val Leu Ala Gly Ala Thr
225 230 235 240
atc acg cac gag gtc ggt gcc tat gcc cac caa atg ctg ccc gtc atc 768
Ile Thr His Glu Val Gly Ala Tyr Ala His Gln Met Leu Pro Val Ile
245 250 255
gac gca atg atc agc aac gcc gta atc cac ttc tac aac gac ccc atc 816
Asp Ala Met Ile Ser Asn Ala Val Ile His Phe Tyr Asn Asp Pro Ile
260 265 270
gat gtc aaa gac aga aag ctc ctt ggc agt gag aac gta tcg tcg aca 864
Asp Val Lys Asp Arg Lys Leu Leu Gly Ser Glu Asn Val Ser Ser Thr
275 280 285
tcg ttc cag ctc atg gat tac aac aac atc cca acg ctc aac aag gcc 912
Ser Phe Gln Leu Met Asp Tyr Asn Asn Ile Pro Thr Leu Asn Lys Ala
290 295 300
atg ttc tgg ggt act ctc gtg ggc gag ttt atc cct acc gcc acg gga 960
Met Phe Trp Gly Thr Leu Val Gly Glu Phe Ile Pro Thr Ala Thr Gly
305 310 315 320
att tgg gaa ttt ggc ctc agt gtc ttt ggc act gcc gac ctt tat att 1008
Ile Trp Glu Phe Gly Leu Ser Val Phe Gly Thr Ala Asp Leu Tyr Ile
325 330 335
gat aat gag ctc gtg att gaa aat aca aca cat cag acg cgt gga acc 1056
Asp Asn Glu Leu Val Ile Glu Asn Thr Thr His Gln Thr Arg Gly Thr
340 345 350
gcc ttt ttc gga aag gga acg acg gaa aaa gtc gct acc agg agg atg 1104
Ala Phe Phe Gly Lys Gly Thr Thr Glu Lys Val Ala Thr Arg Arg Met
355 360 365
gtg gcc ggc agc acc tac aag ctg cgt ctc gag ttt ggg tct gcc aac 1152
Val Ala Gly Ser Thr Tyr Lys Leu Arg Leu Glu Phe Gly Ser Ala Asn
370 375 380
acg acc aag atg gag acg acc ggt gtt gtc aac ttt ggc ggc ggt gcc 1200
Thr Thr Lys Met Glu Thr Thr Gly Val Val Asn Phe Gly Gly Gly Ala
385 390 395 400
gta cac ctg ggt gcc tgt ctc aag gtc gac cca cag gag atg att gcg 1248
Val His Leu Gly Ala Cys Leu Lys Val Asp Pro Gln Glu Met Ile Ala
405 410 415
cgg gcc gtc aag gcc gca gcc gat gcc gac tac acc atc atc tgc acg 1296
Arg Ala Val Lys Ala Ala Ala Asp Ala Asp Tyr Thr Ile Ile Cys Thr
420 425 430
gga ctc agc ggc gag tgg gag tct gag ggt ttt gac cgg cct cac atg 1344
Gly Leu Ser Gly Glu Trp Glu Ser Glu Gly Phe Asp Arg Pro His Met
435 440 445
gac ctg ccc cct ggt gtg gac acc atg atc tcg caa gtt ctt gac gcc 1392
Asp Leu Pro Pro Gly Val Asp Thr Met Ile Ser Gln Val Leu Asp Ala
450 455 460
gct ccc aat gct gta gtc gtc aac cag tca ggc acc cca gtg aca atg 1440
Ala Pro Asn Ala Val Val Val Asn Gln Ser Gly Thr Pro Val Thr Met
465 470 475 480
agc tgg gct cat aaa gca aag gcc att gtg cag gct tgg tat ggt ggt 1488
Ser Trp Ala His Lys Ala Lys Ala Ile Val Gln Ala Trp Tyr Gly Gly
485 490 495
aac gag aca ggc cac gga atc tcc gat gtg ctc ttt ggc aac gtc aac 1536
Asn Glu Thr Gly His Gly Ile Ser Asp Val Leu Phe Gly Asn Val Asn
500 505 510
ccg tcg ggg aaa ctc tcc cta tcg tgg cca gtc gat gtg aag cac aac 1584
Pro Ser Gly Lys Leu Ser Leu Ser Trp Pro Val Asp Val Lys His Asn
515 520 525
cca gca tat ctc aac tac gcc agc gtt ggt gga cgg gtc ttg tat ggc 1632
Pro Ala Tyr Leu Asn Tyr Ala Ser Val Gly Gly Arg Val Leu Tyr Gly
530 535 540
gag gat gtt tac gtt ggc tac aag ttc tac gac aaa acg gag agg gag 1680
Glu Asp Val Tyr Val Gly Tyr Lys Phe Tyr Asp Lys Thr Glu Arg Glu
545 550 555 560
gtt ctg ttt cct ttt ggg cat ggc ctg tct tac gct acc ttc aag ctc 1728
Val Leu Phe Pro Phe Gly His Gly Leu Ser Tyr Ala Thr Phe Lys Leu
565 570 575
cca gat tct acc gtg agg acg gtc ccc gaa acc ttc cac ccg gac cag 1776
Pro Asp Ser Thr Val Arg Thr Val Pro Glu Thr Phe His Pro Asp Gln
580 585 590
ccc aca gta gcc att gtc aag atc aag aac acg agc agt gtc ccg ggc 1824
Pro Thr Val Ala Ile Val Lys Ile Lys Asn Thr Ser Ser Val Pro Gly
595 600 605
gcc cag gtc ctg cag tta tac att tcg gcc cca aac tcg cct aca cat 1872
Ala Gln Val Leu Gln Leu Tyr Ile Ser Ala Pro Asn Ser Pro Thr His
610 615 620
cgc ccg gtc aag gag ctg cac gga ttc gaa aag gtg tat ctt gaa gct 1920
Arg Pro Val Lys Glu Leu His Gly Phe Glu Lys Val Tyr Leu Glu Ala
625 630 635 640
ggc gag gag aag gag gta caa ata ccc att gac cag tac gct act agc 1968
Gly Glu Glu Lys Glu Val Gln Ile Pro Ile Asp Gln Tyr Ala Thr Ser
645 650 655
ttc tgg gac gag att gag agc atg tgg aag agc gag agg ggc att tat 2016
Phe Trp Asp Glu Ile Glu Ser Met Trp Lys Ser Glu Arg Gly Ile Tyr
660 665 670
gat gtg ctt gta gga ttc tcg agt cag gaa atc tcg ggc aag ggg aag 2064
Asp Val Leu Val Gly Phe Ser Ser Gln Glu Ile Ser Gly Lys Gly Lys
675 680 685
ctg att gtg cct gaa acg cga ttc tgg atg ggg ctg tag 2103
Leu Ile Val Pro Glu Thr Arg Phe Trp Met Gly Leu
690 695 700
<210> 92
<211> 700
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 92
Met Ile Leu Gly Cys Glu Ser Thr Gly Val Ile Ser Ala Val Lys His
1 5 10 15
Phe Val Ala Asn Asp Gln Glu His Glu Arg Arg Ala Val Asp Cys Leu
20 25 30
Ile Thr Gln Arg Ala Leu Arg Glu Val Tyr Leu Arg Pro Phe Gln Ile
35 40 45
Val Ala Arg Asp Ala Arg Pro Gly Ala Leu Met Thr Ser Tyr Asn Lys
50 55 60
Val Asn Gly Lys His Val Ala Asp Ser Ala Glu Phe Leu Gln Gly Ile
65 70 75 80
Leu Arg Thr Glu Trp Asn Trp Asp Pro Leu Ile Val Ser Asp Trp Tyr
85 90 95
Gly Thr Tyr Thr Thr Ile Asp Ala Ile Lys Ala Gly Leu Asp Leu Glu
100 105 110
Met Pro Gly Val Ser Arg Tyr Arg Gly Lys Tyr Ile Glu Ser Ala Leu
115 120 125
Gln Ala Arg Leu Leu Lys Gln Ser Thr Ile Asp Glu Arg Ala Arg Arg
130 135 140
Val Leu Arg Phe Ala Gln Lys Ala Ser His Leu Lys Val Ser Glu Val
145 150 155 160
Glu Gln Gly Arg Asp Phe Pro Glu Asp Arg Val Leu Asn Arg Gln Ile
165 170 175
Cys Gly Ser Ser Ile Val Leu Leu Lys Asn Glu Asn Ser Ile Leu Pro
180 185 190
Leu Pro Lys Ser Val Lys Lys Val Ala Leu Val Gly Ser His Val Arg
195 200 205
Leu Pro Ala Ile Ser Gly Gly Gly Ser Ala Ser Leu Val Pro Tyr Tyr
210 215 220
Ala Ile Ser Leu Tyr Asp Ala Val Ser Glu Val Leu Ala Gly Ala Thr
225 230 235 240
Ile Thr His Glu Val Gly Ala Tyr Ala His Gln Met Leu Pro Val Ile
245 250 255
Asp Ala Met Ile Ser Asn Ala Val Ile His Phe Tyr Asn Asp Pro Ile
260 265 270
Asp Val Lys Asp Arg Lys Leu Leu Gly Ser Glu Asn Val Ser Ser Thr
275 280 285
Ser Phe Gln Leu Met Asp Tyr Asn Asn Ile Pro Thr Leu Asn Lys Ala
290 295 300
Met Phe Trp Gly Thr Leu Val Gly Glu Phe Ile Pro Thr Ala Thr Gly
305 310 315 320
Ile Trp Glu Phe Gly Leu Ser Val Phe Gly Thr Ala Asp Leu Tyr Ile
325 330 335
Asp Asn Glu Leu Val Ile Glu Asn Thr Thr His Gln Thr Arg Gly Thr
340 345 350
Ala Phe Phe Gly Lys Gly Thr Thr Glu Lys Val Ala Thr Arg Arg Met
355 360 365
Val Ala Gly Ser Thr Tyr Lys Leu Arg Leu Glu Phe Gly Ser Ala Asn
370 375 380
Thr Thr Lys Met Glu Thr Thr Gly Val Val Asn Phe Gly Gly Gly Ala
385 390 395 400
Val His Leu Gly Ala Cys Leu Lys Val Asp Pro Gln Glu Met Ile Ala
405 410 415
Arg Ala Val Lys Ala Ala Ala Asp Ala Asp Tyr Thr Ile Ile Cys Thr
420 425 430
Gly Leu Ser Gly Glu Trp Glu Ser Glu Gly Phe Asp Arg Pro His Met
435 440 445
Asp Leu Pro Pro Gly Val Asp Thr Met Ile Ser Gln Val Leu Asp Ala
450 455 460
Ala Pro Asn Ala Val Val Val Asn Gln Ser Gly Thr Pro Val Thr Met
465 470 475 480
Ser Trp Ala His Lys Ala Lys Ala Ile Val Gln Ala Trp Tyr Gly Gly
485 490 495
Asn Glu Thr Gly His Gly Ile Ser Asp Val Leu Phe Gly Asn Val Asn
500 505 510
Pro Ser Gly Lys Leu Ser Leu Ser Trp Pro Val Asp Val Lys His Asn
515 520 525
Pro Ala Tyr Leu Asn Tyr Ala Ser Val Gly Gly Arg Val Leu Tyr Gly
530 535 540
Glu Asp Val Tyr Val Gly Tyr Lys Phe Tyr Asp Lys Thr Glu Arg Glu
545 550 555 560
Val Leu Phe Pro Phe Gly His Gly Leu Ser Tyr Ala Thr Phe Lys Leu
565 570 575
Pro Asp Ser Thr Val Arg Thr Val Pro Glu Thr Phe His Pro Asp Gln
580 585 590
Pro Thr Val Ala Ile Val Lys Ile Lys Asn Thr Ser Ser Val Pro Gly
595 600 605
Ala Gln Val Leu Gln Leu Tyr Ile Ser Ala Pro Asn Ser Pro Thr His
610 615 620
Arg Pro Val Lys Glu Leu His Gly Phe Glu Lys Val Tyr Leu Glu Ala
625 630 635 640
Gly Glu Glu Lys Glu Val Gln Ile Pro Ile Asp Gln Tyr Ala Thr Ser
645 650 655
Phe Trp Asp Glu Ile Glu Ser Met Trp Lys Ser Glu Arg Gly Ile Tyr
660 665 670
Asp Val Leu Val Gly Phe Ser Ser Gln Glu Ile Ser Gly Lys Gly Lys
675 680 685
Leu Ile Val Pro Glu Thr Arg Phe Trp Met Gly Leu
690 695 700
<210> 93
<211> 1496
<212> DNA
<213> Artificial Sequence
<220>
<223> Maize optimized CBHI
<400> 93
tgcagtccgc ctgcaccctc cagtccgaga cccacccgcc gctcacctgg cagaagtgct 60
cctccggcgg cacctgcacc cagcagaccg gctccgtggt gatcgacgcc aactggcgct 120
ggacccacgc caccaactcc tccaccaact gctacgacgg caacacctgg tcctccaccc 180
tctgcccgga caacgagacc tgcgccaaga actgctgcct cgacggcgcc gcctacgcct 240
ccacctacgg cgtgaccacc tccggcaact ccctctccat cggcttcgtg acccagtccg 300
cccagaagaa cgtgggcgcc cgcctctacc tcatggcctc cgacaccacc taccaggagt 360
tcaccctcct cggcaacgag ttctccttcg acgtggacgt gtcccagctc ccgtgcggcc 420
tcaacggcgc cctctacttc gtgtccatgg acgccgacgg cggcgtgtcc aagtacccga 480
ccaacaccgc cggcgccaag tacggcaccg gctactgcga ctcccagtgc ccgcgcgacc 540
tcaagttcat caacggccag gccaacgtgg agggctggga gccgtcctcc aacaacgcca 600
acaccggcat cggcggccac ggctcctgct gctccgagat ggacatctgg gaggccaact 660
ccatctccga ggccctcacc ccgcacccgt gcaccaccgt gggccaggag atctgcgagg 720
gcgacggctg cggcggcacc tactccgaca accgctacgg cggcacctgc gacccggacg 780
gctgcgactg gaacccgtac cgcctcggca acacctcctt ctacggcccg ggctcctcct 840
tcaccctcga caccaccaag aagctcaccg tggtgaccca gttcgagacc tccggcgcca 900
tcaaccgcta ctacgtgcag aacggcgtga ccttccagca gccgaacgcc gagctcggct 960
cctactccgg caacgagctc aacgacgact actgcaccgc cgaggaggcc gagttcggcg 1020
gctcctcctt ctccgacaag ggcggcctca cccagttcaa gaaggccacc tccggcggca 1080
tggtgctcgt gatgtccctc tgggacgact actacgccaa catgctctgg ctcgactcca 1140
cctacccgac caacgagacc tcctccaccc cgggcgccgt gcgcggctcc tgctccacct 1200
cctccggcgt gccggcccag gtggagtccc agtccccgaa cgccaaggtg accttctcca 1260
acatcaagtt cggcccgatc ggctccaccg gcaacccgtc cggcggcaac ccgccgggcg 1320
gcaacccgcc gggcaccacc accacccgcc gcccggccac caccaccggc tcctccccgg 1380
gcccgaccca gtcccactac ggccagtgcg gcggcatcgg ctactccggc ccgaccgtgt 1440
gcgcctccgg caccacctgc caggtgctca acccgtacta ctcccagtgc ctctag 1496
<210> 94
<211> 1365
<212> DNA
<213> Artificial Sequence
<220>
<223> Maize optimized CBHII
<400> 94
atggtgccgc tcgaggagcg ccaggcctgc tcctccgtgt ggggccagtg cggcggccag 60
aactggtccg gcccgacctg ctgcgcctcc ggctccacct gcgtgtactc caacgactac 120
tactcccagt gcctcccggg cgccgcctcc tcctcctcct ccacccgcgc cgcctccacc 180
acctcccgcg tgtccccgac cacctcccgc tcctcctccg ccaccccgcc gccgggctcc 240
accaccaccc gcgtgccgcc ggtgggctcc ggcaccgcca cctactccgg caacccgttc 300
gtgggcgtga ccccgtgggc caacgcctac tacgcctccg aggtgtcctc cctcgccatc 360
ccgtccctca ccggcgccat ggccaccgcc gccgccgccg tggccaaggt gccgtccttc 420
atgtggctcg acaccctcga caagaccccg ctcatggagc agaccctcgc cgacatccgc 480
accgccaaca agaacggcgg caactacgcc ggccagttcg tggtgtacga cctcccggac 540
cgcgactgcg ccgccctcgc ctccaacggc gagtactcca tcgccgacgg cggcgtggcc 600
aagtacaaga actacatcga caccatccgc cagatcgtgg tggagtactc cgacatccgc 660
accctcctcg tgatcgagcc ggactccctc gccaacctcg tgaccaacct cggcaccccg 720
aagtgcgcca acgcccagtc cgcctacctc gagtgcatca actacgccgt gacccagctc 780
aacctcccga acgtggccat gtacctcgac gccggccacg ccggctggct cggctggccg 840
gccaaccagg acccggccgc ccagctcttc gccaacgtgt acaagaacgc ctcctccccg 900
cgcgccctcc gcggcctcgc caccaacgtg gccaactaca acggctggaa catcacctcc 960
ccgccgtcct acacccaggg caacgccgtg tacaacgaga agctctacat ccacgccatc 1020
ggcccgctcc tcgccaacca cggctggtcc aacgccttct tcatcaccga ccagggccgc 1080
tccggcaagc agccgaccgg ccagcagcag tggggcgact ggtgcaacgt gatcggcacc 1140
ggcttcggca tccgcccgtc cgccaacacc ggcgactccc tcctcgactc cttcgtgtgg 1200
gtgaagccgg gcggcgagtg cgacggcacc tccgactcct ccgccccgcg cttcgactcc 1260
cactgcgccc tcccggacgc cctccagccg gccccgcagg ccggcgcctg gttccaggcc 1320
tacttcgtgc agctcctcac caacgccaac ccgtccttcc tctag 1365
<210> 95
<211> 1317
<212> DNA
<213> Artificial Sequence
<220>
<223> Maize optimized EGLI
<400> 95
atgcagcagc cgggcacctc caccccggag gtgcacccga agctcaccac ctacaagtgc 60
accaagtccg gcggctgcgt ggcccaggac acctccgtgg tgctcgactg gaactaccgc 120
tggatgcacg acgccaacta caactcctgc accgtgaacg gcggcgtgaa caccaccctc 180
tgcccggacg aggccacctg cggcaagaac tgcttcatcg agggcgtgga ctacgccgcc 240
tccggcgtga ccacctccgg ctcctccctc accatgaacc agtacatgcc gtcctcctcc 300
ggcggctact cctccgtgtc cccgcgcctc tacctcctcg actccgacgg cgagtacgtg 360
atgctcaagc tcaacggcca ggagctctcc ttcgacgtgg acctctccgc cctcccgtgc 420
ggcgagaacg gctccctcta cctctcccag atggacgaga acggcggcgc caaccagtac 480
aacaccgccg gcgccaacta cggctccggc tactgcgacg cccagtgccc ggtgcagacc 540
tggcgcaacg gcaccctcaa cacctcccac cagggcttct gctgcaacga gatggacatc 600
ctcgagggca actcccgcgc caacgccctc accccgcact cctgcaccgc caccgcctgc 660
gactccgccg gctgcggctt caacccgtac ggctccggct acaagtccta ctacggcccg 720
ggcgacaccg tggacacctc caagaccttc accatcatca cccagttcaa caccgacaac 780
ggctccccgt ccggcaacct cgtgtccatc acccgcaagt accagcagaa cggcgtggac 840
atcccgtccg cccagccggg cggcgacacc atctcctcct gcccgtccgc ctccgcctac 900
ggcggcctcg ccaccatggg caaggccctc tcctccggca tggtgctcgt gttctccatc 960
tggaacgaca actcccagta catgaactgg ctcgactccg gcaacgccgg cccgtgctcc 1020
tccaccgagg gcaacccgtc caacaccctc gccaacaacc cgaacaccca cgtggtgttc 1080
tccaacatcc gctggggcga catcggctcc accaccaact ccaccgcccc gccgccgccg 1140
ccggcctcct ccaccacctt ctccaccacc cgccgctcct ccaccacctc ctcctccccg 1200
tcctgcaccc agacccactg gggccagtgc ggcggcatcg gctactccgg ctgcaagacc 1260
tgcacctccg gcaccacctg ccagtactcc aacgactact actcccagtg cctctag 1317
<210> 96
<211> 1401
<212> DNA
<213> Artificial Sequence
<220>
<223> Maize optimized BGLII
<400> 96
atgctcccga aggacttcca gtggggcttc gccaccgccg cctaccagat cgagggcgcc 60
gtggaccagg acggccgcgg cccgtccatc tgggacacct tctgcgccca gccgggcaag 120
atcgccgacg gctcctccgg cgtgaccgcc tgcgactcct acaaccgcac cgccgaggac 180
atcgccctcc tcaagtccct cggcgccaag tcctaccgct tctccatctc ctggtcccgc 240
atcatcccgg agggcggccg cggcgacgcc gtgaaccagg ccggcatcga ccactacgtg 300
aagttcgtgg acgacctcct cgacgccggc atcaccccgt tcatcaccct cttccactgg 360
gacctcccgg agggcctcca ccagcgctac ggcggcctcc tcaaccgcac cgagttcccg 420
ctcgacttcg agaactacgc ccgcgtgatg ttccgcgccc tcccgaaggt gcgcaactgg 480
atcaccttca acgagccgct ctgctccgcc atcccgggct acggctccgg caccttcgcc 540
ccgggccgcc agtccacctc cgagccgtgg accgtgggcc acaacatcct cgtggcccac 600
ggccgcgccg tgaaggccta ccgcgacgac ttcaagccgg cctccggcga cggccagatc 660
ggcatcgtgc tcaacggcga cttcacctac ccgtgggacg ccgccgaccc ggccgacaag 720
gaggccgccg agcgccgcct cgagttcttc accgcctggt tcgccgaccc gatctacctc 780
ggcgactacc cggcctccat gcgcaagcag ctcggcgacc gcctcccgac cttcaccccg 840
gaggagcgcg ccctcgtgca cggctccaac gacttctacg gcatgaacca ctacacctcc 900
aactacatcc gccaccgctc ctccccggcc tccgccgacg acaccgtggg caacgtggac 960
gtgctcttca ccaacaagca gggcaactgc atcggcccgg agacccagtc cccgtggctc 1020
cgcccgtgcg ccgccggctt ccgcgacttc ctcgtgtgga tctccaagcg ctacggctac 1080
ccgccgatct acgtgaccga gaacggcacc tccatcaagg gcgagtccga cctcccgaag 1140
gagaagatcc tcgaggacga cttccgcgtg aagtactaca acgagtacat ccgcgccatg 1200
gtgaccgccg tggagctcga cggcgtgaac gtgaagggct acttcgcctg gtccctcatg 1260
gacaacttcg agtgggccga cggctacgtg acccgcttcg gcgtgaccta cgtggactac 1320
gagaacggcc agaagcgctt cccgaagaag tccgccaagt ccctcaagcc gctcttcgac 1380
gagctcatcg ccgccgccta g 1401
<210> 97
<211> 2103
<212> DNA
<213> Artificial Sequence
<220>
<223> Maize optimized CEL3D
<400> 97
atgatcctcg gctgcgagtc caccggcgtg atctccgccg tgaagcactt cgtggccaac 60
gaccaggagc acgagcgccg cgccgtggac tgcctcatca cccagcgcgc cctccgcgag 120
gtgtacctcc gcccgttcca gatcgtggcc cgcgacgccc gcccgggcgc cctcatgacc 180
tcctacaaca aggtgaacgg caagcacgtg gccgactccg ccgagttcct ccagggcatc 240
ctccgcaccg agtggaactg ggacccgctc atcgtgtccg actggtacgg cacctacacc 300
accatcgacg ccatcaaggc cggcctcgac ctcgagatgc cgggcgtgtc ccgctaccgc 360
ggcaagtaca tcgagtccgc cctccaggcc cgcctcctca agcagtccac catcgacgag 420
cgcgcccgcc gcgtgctccg cttcgcccag aaggcctccc acctcaaggt gtccgaggtg 480
gagcagggcc gcgacttccc ggaggaccgc gtgctcaacc gccagatctg cggctcctcc 540
atcgtgctcc tcaagaacga gaactccatc ctcccgctcc cgaagtccgt gaagaaggtg 600
gccctcgtgg gctcccacgt gcgcctcccg gccatctccg gcggcggctc cgcctccctc 660
gtgccgtact acgccatctc cctctacgac gccgtgtccg aggtgctcgc cggcgccacc 720
atcacccacg aggtgggcgc ctacgcccac cagatgctcc cggtgatcga cgccatgatc 780
tccaacgccg tgatccactt ctacaacgac ccgatcgacg tgaaggaccg caagctcctc 840
ggctccgaga acgtgtcctc cacctccttc cagctcatgg actacaacaa catcccgacc 900
ctcaacaagg ccatgttctg gggcaccctc gtgggcgagt tcatcccgac cgccaccggc 960
atctgggagt tcggcctctc cgtgttcggc accgccgacc tctacatcga caacgagctc 1020
gtgatcgaga acaccaccca ccagacccgc ggcaccgcct tcttcggcaa gggcaccacc 1080
gagaaggtgg ccacccgccg catggtggcc ggctccacct acaagctccg cctcgagttc 1140
ggctccgcca acaccaccaa gatggagacc accggcgtgg tgaacttcgg cggcggcgcc 1200
gtgcacctcg gcgcctgcct caaggtggac ccgcaggaga tgatcgcccg cgccgtgaag 1260
gccgccgccg acgccgacta caccatcatc tgcaccggcc tctccggcga gtgggagtcc 1320
gagggcttcg accgcccgca catggacctc ccgccgggcg tggacaccat gatctcccag 1380
gtgctcgacg ccgccccgaa cgccgtggtg gtgaaccagt ccggcacccc ggtgaccatg 1440
tcctgggccc acaaggccaa ggccatcgtg caggcctggt acggcggcaa cgagaccggc 1500
cacggcatct ccgacgtgct cttcggcaac gtgaacccgt ccggcaagct ctccctctcc 1560
tggccggtgg acgtgaagca caacccggcc tacctcaact acgcctccgt gggcggccgc 1620
gtgctctacg gcgaggacgt gtacgtgggc tacaagttct acgacaagac cgagcgcgag 1680
gtgctcttcc cgttcggcca cggcctctcc tacgccacct tcaagctccc ggactccacc 1740
gtgcgcaccg tgccggagac cttccacccg gaccagccga ccgtggccat cgtgaagatc 1800
aagaacacct cctccgtgcc gggcgcccag gtgctccagc tctacatctc cgccccgaac 1860
tccccgaccc accgcccggt gaaggagctc cacggcttcg agaaggtgta cctcgaggcc 1920
ggcgaggaga aggaggtgca gatcccgatc gaccagtacg ccacctcctt ctgggacgag 1980
atcgagtcca tgtggaagtc cgagcgcggc atctacgacg tgctcgtggg cttctcctcc 2040
caggagatct ccggcaaggg caagctcatc gtgccggaga cccgcttctg gatgggcctc 2100
tag 2103
<210> 98
<211> 420
<212> DNA
<213> Zea mays
<220>
<223> Q protein promoter
<400> 98
gggctggtaa attacttggg agcaatggta tgcaaatcct ttgcatgtac gcaaaactag 60
ctagttgtca caagttgtat atcgattcgt cgcgtttcaa caactcatgc aacattacaa 120
acaagtaaca caatattaca aagttagttt catacaaagc aagaaaagga caataatact 180
tgacatgtaa agtgaagctt attatacttc ctaatccaac acaaaacaaa aaaaagttgc 240
acaaaggtcc aaaaatccac atcaaccatt aacctatacg taaagtgagt gatgagtcac 300
attatccaac aaatgtttat caatgtggta tcatacaagc attgacatcc cataaatgca 360
agaaattgtg ccaacaaagc tataagtaac cctcatatgt atttgcactc atgcatcaca 420
<210> 99
<211> 1188
<212> DNA
<213> artificial sequence
<220>
<223> synthetic ferulic acid esterase
<400> 99
atggccgcct ccctcccgac catgccgccg tccggctacg accaggtgcg caacggcgtg 60
ccgcgcggcc aggtggtgaa catctcctac ttctccaccg ccaccaactc cacccgcccg 120
gcccgcgtgt acctcccgcc gggctactcc aaggacaaga agtactccgt gctctacctc 180
ctccacggca tcggcggctc cgagaacgac tggttcgagg gcggcggccg cgccaacgtg 240
atcgccgaca acctcatcgc cgagggcaag atcaagccgc tcatcatcgt gaccccgaac 300
accaacgccg ccggcccggg catcgccgac ggctacgaga acttcaccaa ggacctcctc 360
aactccctca tcccgtacat cgagtccaac tactccgtgt acaccgaccg cgagcaccgc 420
gccatcgccg gcctctctat gggcggcggc cagtccttca acatcggcct caccaacctc 480
gacaagttcg cctacatcgg cccgatctcc gccgccccga acacctaccc gaacgagcgc 540
ctcttcccgg acggcggcaa ggccgcccgc gagaagctca agctcctctt catcgcctgc 600
ggcaccaacg actccctcat cggcttcggc cagcgcgtgc acgagtactg cgtggccaac 660
aacatcaacc acgtgtactg gctcatccag ggcggcggcc acgacttcaa cgtgtggaag 720
ccgggcctct ggaacttcct ccagatggcc gacgaggccg gcctcacccg cgacggcaac 780
accccggtgc cgaccccgtc cccgaagccg gccaacaccc gcatcgaggc cgaggactac 840
gacggcatca actcctcctc catcgagatc atcggcgtgc cgccggaggg cggccgcggc 900
atcggctaca tcacctccgg cgactacctc gtgtacaagt ccatcgactt cggcaacggc 960
gccacctcct tcaaggccaa ggtggccaac gccaacacct ccaacatcga gcttcgcctc 1020
aacggcccga acggcaccct catcggcacc ctctccgtga agtccaccgg cgactggaac 1080
acctacgagg agcagacctg ctccatctcc aaggtgaccg gcatcaacga cctctacctc 1140
gtgttcaagg gcccggtgaa catcgactgg ttcaccttcg gcgtgtag 1188
<210> 100
<211> 395
<212> PRT
<213> artificial sequence
<220>
<223> synthetic ferulic acid esterase
<400> 100
Met Ala Ala Ser Leu Pro Thr Met Pro Pro Ser Gly Tyr Asp Gln Val
1 5 10 15
Arg Asn Gly Val Pro Arg Gly Gln Val Val Asn Ile Ser Tyr Phe Ser
20 25 30
Thr Ala Thr Asn Ser Thr Arg Pro Ala Arg Val Tyr Leu Pro Pro Gly
35 40 45
Tyr Ser Lys Asp Lys Lys Tyr Ser Val Leu Tyr Leu Leu His Gly Ile
50 55 60
Gly Gly Ser Glu Asn Asp Trp Phe Glu Gly Gly Gly Arg Ala Asn Val
65 70 75 80
Ile Ala Asp Asn Leu Ile Ala Glu Gly Lys Ile Lys Pro Leu Ile Ile
85 90 95
Val Thr Pro Asn Thr Asn Ala Ala Gly Pro Gly Ile Ala Asp Gly Tyr
100 105 110
Glu Asn Phe Thr Lys Asp Leu Leu Asn Ser Leu Ile Pro Tyr Ile Glu
115 120 125
Ser Asn Tyr Ser Val Tyr Thr Asp Arg Glu His Arg Ala Ile Ala Gly
130 135 140
Leu Ser Met Gly Gly Gly Gln Ser Phe Asn Ile Gly Leu Thr Asn Leu
145 150 155 160
Asp Lys Phe Ala Tyr Ile Gly Pro Ile Ser Ala Ala Pro Asn Thr Tyr
165 170 175
Pro Asn Glu Arg Leu Phe Pro Asp Gly Gly Lys Ala Ala Arg Glu Lys
180 185 190
Leu Lys Leu Leu Phe Ile Ala Cys Gly Thr Asn Asp Ser Leu Ile Gly
195 200 205
Phe Gly Gln Arg Val His Glu Tyr Cys Val Ala Asn Asn Ile Asn His
210 215 220
Val Tyr Trp Leu Ile Gln Gly Gly Gly His Asp Phe Asn Val Trp Lys
225 230 235 240
Pro Gly Leu Trp Asn Phe Leu Gln Met Ala Asp Glu Ala Gly Leu Thr
245 250 255
Arg Asp Gly Asn Thr Pro Val Pro Thr Pro Ser Pro Lys Pro Ala Asn
260 265 270
Thr Arg Ile Glu Ala Glu Asp Tyr Asp Gly Ile Asn Ser Ser Ser Ile
275 280 285
Glu Ile Ile Gly Val Pro Pro Glu Gly Gly Arg Gly Ile Gly Tyr Ile
290 295 300
Thr Ser Gly Asp Tyr Leu Val Tyr Lys Ser Ile Asp Phe Gly Asn Gly
305 310 315 320
Ala Thr Ser Phe Lys Ala Lys Val Ala Asn Ala Asn Thr Ser Asn Ile
325 330 335
Glu Leu Arg Leu Asn Gly Pro Asn Gly Thr Leu Ile Gly Thr Leu Ser
340 345 350
Val Lys Ser Thr Gly Asp Trp Asn Thr Tyr Glu Glu Gln Thr Cys Ser
355 360 365
Ile Ser Lys Val Thr Gly Ile Asn Asp Leu Tyr Leu Val Phe Lys Gly
370 375 380
Pro Val Asn Ile Asp Trp Phe Thr Phe Gly Val
385 390 395
<210> 101
<211> 1188
<212> DNA
<213> artificial sequence
<220>
<223> plasmid 13036
<400> 101
atggccgcct ccctcccgac catgccgccg tccggctacg accaggtgcg caacggcgtg 60
ccgcgcggcc aggtggtgaa catctcctac ttctccaccg ccaccaactc cacccgcccg 120
gcccgcgtgt acctcccgcc gggctactcc aaggacaaga agtactccgt gctctacctc 180
ctccacggca tcggcggctc cgagaacgac tggttcgagg gcggcggccg cgccaacgtg 240
atcgccgaca acctcatcgc cgagggcaag atcaagccgc tcatcatcgt gaccccgaac 300
accaacgccg ccggcccggg catcgccgac ggctacgaga acttcaccaa ggacctcctc 360
aactccctca tcccgtacat cgagtccaac tactccgtgt acaccgaccg cgagcaccgc 420
gccatcgccg gcctctctat gggcggcggc cagtccttca acatcggcct caccaacctc 480
gacaagttcg cctacatcgg cccgatctcc gccgccccga acacctaccc gaacgagcgc 540
ctcttcccgg acggcggcaa ggccgcccgc gagaagctca agctcctctt catcgcctgc 600
ggcaccaacg actccctcat cggcttcggc cagcgcgtgc acgagtactg cgtggccaac 660
aacatcaacc acgtgtactg gctcatccag ggcggcggcc acgacttcaa cgtgtggaag 720
ccgggcctct ggaacttcct ccagatggcc gacgaggccg gcctcacccg cgacggcaac 780
accccggtgc cgaccccgtc cccgaagccg gccaacaccc gcatcgaggc cgaggactac 840
gacggcatca actcctcctc catcgagatc atcggcgtgc cgccggaggg cggccgcggc 900
atcggctaca tcacctccgg cgactacctc gtgtacaagt ccatcgactt cggcaacggc 960
gccacctcct tcaaggccaa ggtggccaac gccaacacct ccaacatcga gcttcgcctc 1020
aacggcccga acggcaccct catcggcacc ctctccgtga agtccaccgg cgactggaac 1080
acctacgagg agcagacctg ctccatctcc aaggtgaccg gcatcaacga cctctacctc 1140
gtgttcaagg gcccggtgaa catcgactgg ttcaccttcg gcgtgtag 1188
<210> 102
<211> 395
<212> PRT
<213> artificial sequence
<220>
<223> plasmid 13036
<400> 102
Met Ala Ala Ser Leu Pro Thr Met Pro Pro Ser Gly Tyr Asp Gln Val
1 5 10 15
Arg Asn Gly Val Pro Arg Gly Gln Val Val Asn Ile Ser Tyr Phe Ser
20 25 30
Thr Ala Thr Asn Ser Thr Arg Pro Ala Arg Val Tyr Leu Pro Pro Gly
35 40 45
Tyr Ser Lys Asp Lys Lys Tyr Ser Val Leu Tyr Leu Leu His Gly Ile
50 55 60
Gly Gly Ser Glu Asn Asp Trp Phe Glu Gly Gly Gly Arg Ala Asn Val
65 70 75 80
Ile Ala Asp Asn Leu Ile Ala Glu Gly Lys Ile Lys Pro Leu Ile Ile
85 90 95
Val Thr Pro Asn Thr Asn Ala Ala Gly Pro Gly Ile Ala Asp Gly Tyr
100 105 110
Glu Asn Phe Thr Lys Asp Leu Leu Asn Ser Leu Ile Pro Tyr Ile Glu
115 120 125
Ser Asn Tyr Ser Val Tyr Thr Asp Arg Glu His Arg Ala Ile Ala Gly
130 135 140
Leu Ser Met Gly Gly Gly Gln Ser Phe Asn Ile Gly Leu Thr Asn Leu
145 150 155 160
Asp Lys Phe Ala Tyr Ile Gly Pro Ile Ser Ala Ala Pro Asn Thr Tyr
165 170 175
Pro Asn Glu Arg Leu Phe Pro Asp Gly Gly Lys Ala Ala Arg Glu Lys
180 185 190
Leu Lys Leu Leu Phe Ile Ala Cys Gly Thr Asn Asp Ser Leu Ile Gly
195 200 205
Phe Gly Gln Arg Val His Glu Tyr Cys Val Ala Asn Asn Ile Asn His
210 215 220
Val Tyr Trp Leu Ile Gln Gly Gly Gly His Asp Phe Asn Val Trp Lys
225 230 235 240
Pro Gly Leu Trp Asn Phe Leu Gln Met Ala Asp Glu Ala Gly Leu Thr
245 250 255
Arg Asp Gly Asn Thr Pro Val Pro Thr Pro Ser Pro Lys Pro Ala Asn
260 265 270
Thr Arg Ile Glu Ala Glu Asp Tyr Asp Gly Ile Asn Ser Ser Ser Ile
275 280 285
Glu Ile Ile Gly Val Pro Pro Glu Gly Gly Arg Gly Ile Gly Tyr Ile
290 295 300
Thr Ser Gly Asp Tyr Leu Val Tyr Lys Ser Ile Asp Phe Gly Asn Gly
305 310 315 320
Ala Thr Ser Phe Lys Ala Lys Val Ala Asn Ala Asn Thr Ser Asn Ile
325 330 335
Glu Leu Arg Leu Asn Gly Pro Asn Gly Thr Leu Ile Gly Thr Leu Ser
340 345 350
Val Lys Ser Thr Gly Asp Trp Asn Thr Tyr Glu Glu Gln Thr Cys Ser
355 360 365
Ile Ser Lys Val Thr Gly Ile Asn Asp Leu Tyr Leu Val Phe Lys Gly
370 375 380
Pro Val Asn Ile Asp Trp Phe Thr Phe Gly Val
385 390 395
<210> 103
<211> 1245
<212> DNA
<213> artificial sequence
<220>
<223> plasmid 13038
<400> 103
atgagggtgt tgctcgttgc cctcgctctc ctggctctcg ctgcgagcgc cacctccatg 60
gccgcctccc tcccgaccat gccgccgtcc ggctacgacc aggtgcgcaa cggcgtgccg 120
cgcggccagg tggtgaacat ctcctacttc tccaccgcca ccaactccac ccgcccggcc 180
cgcgtgtacc tcccgccggg ctactccaag gacaagaagt actccgtgct ctacctcctc 240
cacggcatcg gcggctccga gaacgactgg ttcgagggcg gcggccgcgc caacgtgatc 300
gccgacaacc tcatcgccga gggcaagatc aagccgctca tcatcgtgac cccgaacacc 360
aacgccgccg gcccgggcat cgccgacggc tacgagaact tcaccaagga cctcctcaac 420
tccctcatcc cgtacatcga gtccaactac tccgtgtaca ccgaccgcga gcaccgcgcc 480
atcgccggcc tctctatggg cggcggccag tccttcaaca tcggcctcac caacctcgac 540
aagttcgcct acatcggccc gatctccgcc gccccgaaca cctacccgaa cgagcgcctc 600
ttcccggacg gcggcaaggc cgcccgcgag aagctcaagc tcctcttcat cgcctgcggc 660
accaacgact ccctcatcgg cttcggccag cgcgtgcacg agtactgcgt ggccaacaac 720
atcaaccacg tgtactggct catccagggc ggcggccacg acttcaacgt gtggaagccg 780
ggcctctgga acttcctcca gatggccgac gaggccggcc tcacccgcga cggcaacacc 840
ccggtgccga ccccgtcccc gaagccggcc aacacccgca tcgaggccga ggactacgac 900
ggcatcaact cctcctccat cgagatcatc ggcgtgccgc cggagggcgg ccgcggcatc 960
ggctacatca cctccggcga ctacctcgtg tacaagtcca tcgacttcgg caacggcgcc 1020
acctccttca aggccaaggt ggccaacgcc aacacctcca acatcgagct tcgcctcaac 1080
ggcccgaacg gcaccctcat cggcaccctc tccgtgaagt ccaccggcga ctggaacacc 1140
tacgaggagc agacctgctc catctccaag gtgaccggca tcaacgacct ctacctcgtg 1200
ttcaagggcc cggtgaacat cgactggttc accttcggcg tgtag 1245
<210> 104
<211> 414
<212> PRT
<213> artificial sequence
<220>
<223> plasmid 13038 aa
<400> 104
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Met Ala Ala Ser Leu Pro Thr Met Pro Pro Ser Gly Tyr
20 25 30
Asp Gln Val Arg Asn Gly Val Pro Arg Gly Gln Val Val Asn Ile Ser
35 40 45
Tyr Phe Ser Thr Ala Thr Asn Ser Thr Arg Pro Ala Arg Val Tyr Leu
50 55 60
Pro Pro Gly Tyr Ser Lys Asp Lys Lys Tyr Ser Val Leu Tyr Leu Leu
65 70 75 80
His Gly Ile Gly Gly Ser Glu Asn Asp Trp Phe Glu Gly Gly Gly Arg
85 90 95
Ala Asn Val Ile Ala Asp Asn Leu Ile Ala Glu Gly Lys Ile Lys Pro
100 105 110
Leu Ile Ile Val Thr Pro Asn Thr Asn Ala Ala Gly Pro Gly Ile Ala
115 120 125
Asp Gly Tyr Glu Asn Phe Thr Lys Asp Leu Leu Asn Ser Leu Ile Pro
130 135 140
Tyr Ile Glu Ser Asn Tyr Ser Val Tyr Thr Asp Arg Glu His Arg Ala
145 150 155 160
Ile Ala Gly Leu Ser Met Gly Gly Gly Gln Ser Phe Asn Ile Gly Leu
165 170 175
Thr Asn Leu Asp Lys Phe Ala Tyr Ile Gly Pro Ile Ser Ala Ala Pro
180 185 190
Asn Thr Tyr Pro Asn Glu Arg Leu Phe Pro Asp Gly Gly Lys Ala Ala
195 200 205
Arg Glu Lys Leu Lys Leu Leu Phe Ile Ala Cys Gly Thr Asn Asp Ser
210 215 220
Leu Ile Gly Phe Gly Gln Arg Val His Glu Tyr Cys Val Ala Asn Asn
225 230 235 240
Ile Asn His Val Tyr Trp Leu Ile Gln Gly Gly Gly His Asp Phe Asn
245 250 255
Val Trp Lys Pro Gly Leu Trp Asn Phe Leu Gln Met Ala Asp Glu Ala
260 265 270
Gly Leu Thr Arg Asp Gly Asn Thr Pro Val Pro Thr Pro Ser Pro Lys
275 280 285
Pro Ala Asn Thr Arg Ile Glu Ala Glu Asp Tyr Asp Gly Ile Asn Ser
290 295 300
Ser Ser Ile Glu Ile Ile Gly Val Pro Pro Glu Gly Gly Arg Gly Ile
305 310 315 320
Gly Tyr Ile Thr Ser Gly Asp Tyr Leu Val Tyr Lys Ser Ile Asp Phe
325 330 335
Gly Asn Gly Ala Thr Ser Phe Lys Ala Lys Val Ala Asn Ala Asn Thr
340 345 350
Ser Asn Ile Glu Leu Arg Leu Asn Gly Pro Asn Gly Thr Leu Ile Gly
355 360 365
Thr Leu Ser Val Lys Ser Thr Gly Asp Trp Asn Thr Tyr Glu Glu Gln
370 375 380
Thr Cys Ser Ile Ser Lys Val Thr Gly Ile Asn Asp Leu Tyr Leu Val
385 390 395 400
Phe Lys Gly Pro Val Asn Ile Asp Trp Phe Thr Phe Gly Val
405 410
<210> 105
<211> 1425
<212> DNA
<213> artificial sequence
<220>
<223> plasmid 13039
<400> 105
atgctggcgg ctctggccac gtcgcagctc gtcgcaacgc gcgccggcct gggcgtcccg 60
gacgcgtcca cgttccgccg cggcgccgcg cagggcctga ggggggcccg ggcgtcggcg 120
gcggcggaca cgctcagcat gcggaccagc gcgcgcgcgg cgcccaggca ccagcaccag 180
caggcgcgcc gcggggccag gttcccgtcg ctcgtcgtgt gcgccagcgc cggcgccatg 240
gccgcctccc tcccgaccat gccgccgtcc ggctacgacc aggtgcgcaa cggcgtgccg 300
cgcggccagg tggtgaacat ctcctacttc tccaccgcca ccaactccac ccgcccggcc 360
cgcgtgtacc tcccgccggg ctactccaag gacaagaagt actccgtgct ctacctcctc 420
cacggcatcg gcggctccga gaacgactgg ttcgagggcg gcggccgcgc caacgtgatc 480
gccgacaacc tcatcgccga gggcaagatc aagccgctca tcatcgtgac cccgaacacc 540
aacgccgccg gcccgggcat cgccgacggc tacgagaact tcaccaagga cctcctcaac 600
tccctcatcc cgtacatcga gtccaactac tccgtgtaca ccgaccgcga gcaccgcgcc 660
atcgccggcc tctctatggg cggcggccag tccttcaaca tcggcctcac caacctcgac 720
aagttcgcct acatcggccc gatctccgcc gccccgaaca cctacccgaa cgagcgcctc 780
ttcccggacg gcggcaaggc cgcccgcgag aagctcaagc tcctcttcat cgcctgcggc 840
accaacgact ccctcatcgg cttcggccag cgcgtgcacg agtactgcgt ggccaacaac 900
atcaaccacg tgtactggct catccagggc ggcggccacg acttcaacgt gtggaagccg 960
ggcctctgga acttcctcca gatggccgac gaggccggcc tcacccgcga cggcaacacc 1020
ccggtgccga ccccgtcccc gaagccggcc aacacccgca tcgaggccga ggactacgac 1080
ggcatcaact cctcctccat cgagatcatc ggcgtgccgc cggagggcgg ccgcggcatc 1140
ggctacatca cctccggcga ctacctcgtg tacaagtcca tcgacttcgg caacggcgcc 1200
acctccttca aggccaaggt ggccaacgcc aacacctcca acatcgagct tcgcctcaac 1260
ggcccgaacg gcaccctcat cggcaccctc tccgtgaagt ccaccggcga ctggaacacc 1320
tacgaggagc agacctgctc catctccaag gtgaccggca tcaacgacct ctacctcgtg 1380
ttcaagggcc cggtgaacat cgactggttc accttcggcg tgtag 1425
<210> 106
<211> 474
<212> PRT
<213> artificial sequence
<220>
<223> plasmid 13039 aa
<400> 106
Met Leu Ala Ala Leu Ala Thr Ser Gln Leu Val Ala Thr Arg Ala Gly
1 5 10 15
Leu Gly Val Pro Asp Ala Ser Thr Phe Arg Arg Gly Ala Ala Gln Gly
20 25 30
Leu Arg Gly Ala Arg Ala Ser Ala Ala Ala Asp Thr Leu Ser Met Arg
35 40 45
Thr Ser Ala Arg Ala Ala Pro Arg His Gln His Gln Gln Ala Arg Arg
50 55 60
Gly Ala Arg Phe Pro Ser Leu Val Val Cys Ala Ser Ala Gly Ala Met
65 70 75 80
Ala Ala Ser Leu Pro Thr Met Pro Pro Ser Gly Tyr Asp Gln Val Arg
85 90 95
Asn Gly Val Pro Arg Gly Gln Val Val Asn Ile Ser Tyr Phe Ser Thr
100 105 110
Ala Thr Asn Ser Thr Arg Pro Ala Arg Val Tyr Leu Pro Pro Gly Tyr
115 120 125
Ser Lys Asp Lys Lys Tyr Ser Val Leu Tyr Leu Leu His Gly Ile Gly
130 135 140
Gly Ser Glu Asn Asp Trp Phe Glu Gly Gly Gly Arg Ala Asn Val Ile
145 150 155 160
Ala Asp Asn Leu Ile Ala Glu Gly Lys Ile Lys Pro Leu Ile Ile Val
165 170 175
Thr Pro Asn Thr Asn Ala Ala Gly Pro Gly Ile Ala Asp Gly Tyr Glu
180 185 190
Asn Phe Thr Lys Asp Leu Leu Asn Ser Leu Ile Pro Tyr Ile Glu Ser
195 200 205
Asn Tyr Ser Val Tyr Thr Asp Arg Glu His Arg Ala Ile Ala Gly Leu
210 215 220
Ser Met Gly Gly Gly Gln Ser Phe Asn Ile Gly Leu Thr Asn Leu Asp
225 230 235 240
Lys Phe Ala Tyr Ile Gly Pro Ile Ser Ala Ala Pro Asn Thr Tyr Pro
245 250 255
Asn Glu Arg Leu Phe Pro Asp Gly Gly Lys Ala Ala Arg Glu Lys Leu
260 265 270
Lys Leu Leu Phe Ile Ala Cys Gly Thr Asn Asp Ser Leu Ile Gly Phe
275 280 285
Gly Gln Arg Val His Glu Tyr Cys Val Ala Asn Asn Ile Asn His Val
290 295 300
Tyr Trp Leu Ile Gln Gly Gly Gly His Asp Phe Asn Val Trp Lys Pro
305 310 315 320
Gly Leu Trp Asn Phe Leu Gln Met Ala Asp Glu Ala Gly Leu Thr Arg
325 330 335
Asp Gly Asn Thr Pro Val Pro Thr Pro Ser Pro Lys Pro Ala Asn Thr
340 345 350
Arg Ile Glu Ala Glu Asp Tyr Asp Gly Ile Asn Ser Ser Ser Ile Glu
355 360 365
Ile Ile Gly Val Pro Pro Glu Gly Gly Arg Gly Ile Gly Tyr Ile Thr
370 375 380
Ser Gly Asp Tyr Leu Val Tyr Lys Ser Ile Asp Phe Gly Asn Gly Ala
385 390 395 400
Thr Ser Phe Lys Ala Lys Val Ala Asn Ala Asn Thr Ser Asn Ile Glu
405 410 415
Leu Arg Leu Asn Gly Pro Asn Gly Thr Leu Ile Gly Thr Leu Ser Val
420 425 430
Lys Ser Thr Gly Asp Trp Asn Thr Tyr Glu Glu Gln Thr Cys Ser Ile
435 440 445
Ser Lys Val Thr Gly Ile Asn Asp Leu Tyr Leu Val Phe Lys Gly Pro
450 455 460
Val Asn Ile Asp Trp Phe Thr Phe Gly Val
465 470
<210> 107
<211> 1263
<212> DNA
<213> artificial sequence
<220>
<223> plasmid 13347
<400> 107
atgagggtgt tgctcgttgc cctcgctctc ctggctctcg ctgcgagcgc cacctccatg 60
gccgcctccc tcccgaccat gccgccgtcc ggctacgacc aggtgcgcaa cggcgtgccg 120
cgcggccagg tggtgaacat ctcctacttc tccaccgcca ccaactccac ccgcccggcc 180
cgcgtgtacc tcccgccggg ctactccaag gacaagaagt actccgtgct ctacctcctc 240
cacggcatcg gcggctccga gaacgactgg ttcgagggcg gcggccgcgc caacgtgatc 300
gccgacaacc tcatcgccga gggcaagatc aagccgctca tcatcgtgac cccgaacacc 360
aacgccgccg gcccgggcat cgccgacggc tacgagaact tcaccaagga cctcctcaac 420
tccctcatcc cgtacatcga gtccaactac tccgtgtaca ccgaccgcga gcaccgcgcc 480
atcgccggcc tctctatggg cggcggccag tccttcaaca tcggcctcac caacctcgac 540
aagttcgcct acatcggccc gatctccgcc gccccgaaca cctacccgaa cgagcgcctc 600
ttcccggacg gcggcaaggc cgcccgcgag aagctcaagc tcctcttcat cgcctgcggc 660
accaacgact ccctcatcgg cttcggccag cgcgtgcacg agtactgcgt ggccaacaac 720
atcaaccacg tgtactggct catccagggc ggcggccacg acttcaacgt gtggaagccg 780
ggcctctgga acttcctcca gatggccgac gaggccggcc tcacccgcga cggcaacacc 840
ccggtgccga ccccgtcccc gaagccggcc aacacccgca tcgaggccga ggactacgac 900
ggcatcaact cctcctccat cgagatcatc ggcgtgccgc cggagggcgg ccgcggcatc 960
ggctacatca cctccggcga ctacctcgtg tacaagtcca tcgacttcgg caacggcgcc 1020
acctccttca aggccaaggt ggccaacgcc aacacctcca acatcgagct tcgcctcaac 1080
ggcccgaacg gcaccctcat cggcaccctc tccgtgaagt ccaccggcga ctggaacacc 1140
tacgaggagc agacctgctc catctccaag gtgaccggca tcaacgacct ctacctcgtg 1200
ttcaagggcc cggtgaacat cgactggttc accttcggcg tgtccgagaa ggacgaactc 1260
tag 1263
<210> 108
<211> 420
<212> PRT
<213> artificial sequence
<220>
<223> plasmid 13347
<400> 108
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Met Ala Ala Ser Leu Pro Thr Met Pro Pro Ser Gly Tyr
20 25 30
Asp Gln Val Arg Asn Gly Val Pro Arg Gly Gln Val Val Asn Ile Ser
35 40 45
Tyr Phe Ser Thr Ala Thr Asn Ser Thr Arg Pro Ala Arg Val Tyr Leu
50 55 60
Pro Pro Gly Tyr Ser Lys Asp Lys Lys Tyr Ser Val Leu Tyr Leu Leu
65 70 75 80
His Gly Ile Gly Gly Ser Glu Asn Asp Trp Phe Glu Gly Gly Gly Arg
85 90 95
Ala Asn Val Ile Ala Asp Asn Leu Ile Ala Glu Gly Lys Ile Lys Pro
100 105 110
Leu Ile Ile Val Thr Pro Asn Thr Asn Ala Ala Gly Pro Gly Ile Ala
115 120 125
Asp Gly Tyr Glu Asn Phe Thr Lys Asp Leu Leu Asn Ser Leu Ile Pro
130 135 140
Tyr Ile Glu Ser Asn Tyr Ser Val Tyr Thr Asp Arg Glu His Arg Ala
145 150 155 160
Ile Ala Gly Leu Ser Met Gly Gly Gly Gln Ser Phe Asn Ile Gly Leu
165 170 175
Thr Asn Leu Asp Lys Phe Ala Tyr Ile Gly Pro Ile Ser Ala Ala Pro
180 185 190
Asn Thr Tyr Pro Asn Glu Arg Leu Phe Pro Asp Gly Gly Lys Ala Ala
195 200 205
Arg Glu Lys Leu Lys Leu Leu Phe Ile Ala Cys Gly Thr Asn Asp Ser
210 215 220
Leu Ile Gly Phe Gly Gln Arg Val His Glu Tyr Cys Val Ala Asn Asn
225 230 235 240
Ile Asn His Val Tyr Trp Leu Ile Gln Gly Gly Gly His Asp Phe Asn
245 250 255
Val Trp Lys Pro Gly Leu Trp Asn Phe Leu Gln Met Ala Asp Glu Ala
260 265 270
Gly Leu Thr Arg Asp Gly Asn Thr Pro Val Pro Thr Pro Ser Pro Lys
275 280 285
Pro Ala Asn Thr Arg Ile Glu Ala Glu Asp Tyr Asp Gly Ile Asn Ser
290 295 300
Ser Ser Ile Glu Ile Ile Gly Val Pro Pro Glu Gly Gly Arg Gly Ile
305 310 315 320
Gly Tyr Ile Thr Ser Gly Asp Tyr Leu Val Tyr Lys Ser Ile Asp Phe
325 330 335
Gly Asn Gly Ala Thr Ser Phe Lys Ala Lys Val Ala Asn Ala Asn Thr
340 345 350
Ser Asn Ile Glu Leu Arg Leu Asn Gly Pro Asn Gly Thr Leu Ile Gly
355 360 365
Thr Leu Ser Val Lys Ser Thr Gly Asp Trp Asn Thr Tyr Glu Glu Gln
370 375 380
Thr Cys Ser Ile Ser Lys Val Thr Gly Ile Asn Asp Leu Tyr Leu Val
385 390 395 400
Phe Lys Gly Pro Val Asn Ile Asp Trp Phe Thr Phe Gly Val Ser Glu
405 410 415
Lys Asp Glu Leu
420
<210> 109
<211> 1296
<212> DNA
<213> artificial sequence
<220>
<223> plasmid 11267
<400> 109
atgagggtgt tgctcgttgc cctcgctctc ctggctctcg ctgcgagcgc caccagcgct 60
gcgcagtccg agccggagct gaagctggag tccgtggtga tcgtgtcccg ccacggcgtg 120
cgcgccccga ccaaggccac ccagctcatg caggacgtga ccccggacgc ctggccgacc 180
tggccggtga agctcggcga gctgaccccg cgcggcggcg agctgatcgc ctacctcggc 240
cactactggc gccagcgcct cgtggccgac ggcctcctcc cgaagtgcgg ctgcccgcag 300
tccggccagg tggccatcat cgccgacgtg gacgagcgca cccgcaagac cggcgaggcc 360
ttcgccgccg gcctcgcccc ggactgcgcc atcaccgtgc acacccaggc cgacacctcc 420
tccccggacc cgctcttcaa cccgctcaag accggcgtgt gccagctcga caacgccaac 480
gtgaccgacg ccatcctgga gcgcgccggc ggctccatcg ccgacttcac cggccactac 540
cagaccgcct tccgcgagct ggagcgcgtg ctcaacttcc cgcagtccaa cctctgcctc 600
aagcgcgaga agcaggacga gtcctgctcc ctcacccagg ccctcccgtc cgagctgaag 660
gtgtccgccg actgcgtgtc cctcaccggc gccgtgtccc tcgcctccat gctcaccgaa 720
atcttcctcc tccagcaggc ccagggcatg ccggagccgg gctggggccg catcaccgac 780
tcccaccagt ggaacaccct cctctccctc cacaacgccc agttcgacct cctccagcgc 840
accccggagg tggcccgctc ccgcgccacc ccgctcctcg acctcatcaa gaccgccctc 900
accccgcacc cgccgcagaa gcaggcctac ggcgtgaccc tcccgacctc cgtgctcttc 960
atcgccggcc acgacaccaa cctcgccaac ctcggcggcg ccctggagct gaactggacc 1020
ctcccgggcc agccggacaa caccccgccg ggcggcgagc tggtgttcga gcgctggcgc 1080
cgcctctccg acaactccca gtggattcag gtgtccctcg tgttccagac cctccagcag 1140
atgcgcgaca agaccccgct ctccctcaac accccgccgg gcgaggtgaa gctcaccctc 1200
gccggctgcg aggagcgcaa cgcccagggc atgtgctccc tcgccggctt cacccagatc 1260
gtgaacgagg cccgcatccc ggcctgctcc ctctaa 1296
<210> 110
<211> 431
<212> PRT
<213> artificial sequence
<220>
<223> plasmid 11267 aa sequence
<400> 110
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Ala Gln Ser Glu Pro Glu Leu Lys Leu Glu Ser Val
20 25 30
Val Ile Val Ser Arg His Gly Val Arg Ala Pro Thr Lys Ala Thr Gln
35 40 45
Leu Met Gln Asp Val Thr Pro Asp Ala Trp Pro Thr Trp Pro Val Lys
50 55 60
Leu Gly Glu Leu Thr Pro Arg Gly Gly Glu Leu Ile Ala Tyr Leu Gly
65 70 75 80
His Tyr Trp Arg Gln Arg Leu Val Ala Asp Gly Leu Leu Pro Lys Cys
85 90 95
Gly Cys Pro Gln Ser Gly Gln Val Ala Ile Ile Ala Asp Val Asp Glu
100 105 110
Arg Thr Arg Lys Thr Gly Glu Ala Phe Ala Ala Gly Leu Ala Pro Asp
115 120 125
Cys Ala Ile Thr Val His Thr Gln Ala Asp Thr Ser Ser Pro Asp Pro
130 135 140
Leu Phe Asn Pro Leu Lys Thr Gly Val Cys Gln Leu Asp Asn Ala Asn
145 150 155 160
Val Thr Asp Ala Ile Leu Glu Arg Ala Gly Gly Ser Ile Ala Asp Phe
165 170 175
Thr Gly His Tyr Gln Thr Ala Phe Arg Glu Leu Glu Arg Val Leu Asn
180 185 190
Phe Pro Gln Ser Asn Leu Cys Leu Lys Arg Glu Lys Gln Asp Glu Ser
195 200 205
Cys Ser Leu Thr Gln Ala Leu Pro Ser Glu Leu Lys Val Ser Ala Asp
210 215 220
Cys Val Ser Leu Thr Gly Ala Val Ser Leu Ala Ser Met Leu Thr Glu
225 230 235 240
Ile Phe Leu Leu Gln Gln Ala Gln Gly Met Pro Glu Pro Gly Trp Gly
245 250 255
Arg Ile Thr Asp Ser His Gln Trp Asn Thr Leu Leu Ser Leu His Asn
260 265 270
Ala Gln Phe Asp Leu Leu Gln Arg Thr Pro Glu Val Ala Arg Ser Arg
275 280 285
Ala Thr Pro Leu Leu Asp Leu Ile Lys Thr Ala Leu Thr Pro His Pro
290 295 300
Pro Gln Lys Gln Ala Tyr Gly Val Thr Leu Pro Thr Ser Val Leu Phe
305 310 315 320
Ile Ala Gly His Asp Thr Asn Leu Ala Asn Leu Gly Gly Ala Leu Glu
325 330 335
Leu Asn Trp Thr Leu Pro Gly Gln Pro Asp Asn Thr Pro Pro Gly Gly
340 345 350
Glu Leu Val Phe Glu Arg Trp Arg Arg Leu Ser Asp Asn Ser Gln Trp
355 360 365
Ile Gln Val Ser Leu Val Phe Gln Thr Leu Gln Gln Met Arg Asp Lys
370 375 380
Thr Pro Leu Ser Leu Asn Thr Pro Pro Gly Glu Val Lys Leu Thr Leu
385 390 395 400
Ala Gly Cys Glu Glu Arg Asn Ala Gln Gly Met Cys Ser Leu Ala Gly
405 410 415
Phe Thr Gln Ile Val Asn Glu Ala Arg Ile Pro Ala Cys Ser Leu
420 425 430
<210> 111
<211> 1314
<212> DNA
<213> artificial sequence
<220>
<223> plasmid 11268
<400> 111
atgagggtgt tgctcgttgc cctcgctctc ctggctctcg ctgcgagcgc caccagcgct 60
gcgcagtccg agccggagct gaagctggag tccgtggtga tcgtgtcccg ccacggcgtg 120
cgcgccccga ccaaggccac ccagctcatg caggacgtga ccccggacgc ctggccgacc 180
tggccggtga agctcggcga gctgaccccg cgcggcggcg agctgatcgc ctacctcggc 240
cactactggc gccagcgcct cgtggccgac ggcctcctcc cgaagtgcgg ctgcccgcag 300
tccggccagg tggccatcat cgccgacgtg gacgagcgca cccgcaagac cggcgaggcc 360
ttcgccgccg gcctcgcccc ggactgcgcc atcaccgtgc acacccaggc cgacacctcc 420
tccccggacc cgctcttcaa cccgctcaag accggcgtgt gccagctcga caacgccaac 480
gtgaccgacg ccatcctgga gcgcgccggc ggctccatcg ccgacttcac cggccactac 540
cagaccgcct tccgcgagct ggagcgcgtg ctcaacttcc cgcagtccaa cctctgcctc 600
aagcgcgaga agcaggacga gtcctgctcc ctcacccagg ccctcccgtc cgagctgaag 660
gtgtccgccg actgcgtgtc cctcaccggc gccgtgtccc tcgcctccat gctcaccgaa 720
atcttcctcc tccagcaggc ccagggcatg ccggagccgg gctggggccg catcaccgac 780
tcccaccagt ggaacaccct cctctccctc cacaacgccc agttcgacct cctccagcgc 840
accccggagg tggcccgctc ccgcgccacc ccgctcctcg acctcatcaa gaccgccctc 900
accccgcacc cgccgcagaa gcaggcctac ggcgtgaccc tcccgacctc cgtgctcttc 960
atcgccggcc acgacaccaa cctcgccaac ctcggcggcg ccctggagct gaactggacc 1020
ctcccgggcc agccggacaa caccccgccg ggcggcgagc tggtgttcga gcgctggcgc 1080
cgcctctccg acaactccca gtggattcag gtgtccctcg tgttccagac cctccagcag 1140
atgcgcgaca agaccccgct ctccctcaac accccgccgg gcgaggtgaa gctcaccctc 1200
gccggctgcg aggagcgcaa cgcccagggc atgtgctccc tcgccggctt cacccagatc 1260
gtgaacgagg cccgcatccc ggcctgctcc ctctccgaga aggacgagct gtaa 1314
<210> 112
<211> 437
<212> PRT
<213> artificial sequence
<220>
<223> plasmid 11268 amino acid sequence
<400> 112
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Ala Gln Ser Glu Pro Glu Leu Lys Leu Glu Ser Val
20 25 30
Val Ile Val Ser Arg His Gly Val Arg Ala Pro Thr Lys Ala Thr Gln
35 40 45
Leu Met Gln Asp Val Thr Pro Asp Ala Trp Pro Thr Trp Pro Val Lys
50 55 60
Leu Gly Glu Leu Thr Pro Arg Gly Gly Glu Leu Ile Ala Tyr Leu Gly
65 70 75 80
His Tyr Trp Arg Gln Arg Leu Val Ala Asp Gly Leu Leu Pro Lys Cys
85 90 95
Gly Cys Pro Gln Ser Gly Gln Val Ala Ile Ile Ala Asp Val Asp Glu
100 105 110
Arg Thr Arg Lys Thr Gly Glu Ala Phe Ala Ala Gly Leu Ala Pro Asp
115 120 125
Cys Ala Ile Thr Val His Thr Gln Ala Asp Thr Ser Ser Pro Asp Pro
130 135 140
Leu Phe Asn Pro Leu Lys Thr Gly Val Cys Gln Leu Asp Asn Ala Asn
145 150 155 160
Val Thr Asp Ala Ile Leu Glu Arg Ala Gly Gly Ser Ile Ala Asp Phe
165 170 175
Thr Gly His Tyr Gln Thr Ala Phe Arg Glu Leu Glu Arg Val Leu Asn
180 185 190
Phe Pro Gln Ser Asn Leu Cys Leu Lys Arg Glu Lys Gln Asp Glu Ser
195 200 205
Cys Ser Leu Thr Gln Ala Leu Pro Ser Glu Leu Lys Val Ser Ala Asp
210 215 220
Cys Val Ser Leu Thr Gly Ala Val Ser Leu Ala Ser Met Leu Thr Glu
225 230 235 240
Ile Phe Leu Leu Gln Gln Ala Gln Gly Met Pro Glu Pro Gly Trp Gly
245 250 255
Arg Ile Thr Asp Ser His Gln Trp Asn Thr Leu Leu Ser Leu His Asn
260 265 270
Ala Gln Phe Asp Leu Leu Gln Arg Thr Pro Glu Val Ala Arg Ser Arg
275 280 285
Ala Thr Pro Leu Leu Asp Leu Ile Lys Thr Ala Leu Thr Pro His Pro
290 295 300
Pro Gln Lys Gln Ala Tyr Gly Val Thr Leu Pro Thr Ser Val Leu Phe
305 310 315 320
Ile Ala Gly His Asp Thr Asn Leu Ala Asn Leu Gly Gly Ala Leu Glu
325 330 335
Leu Asn Trp Thr Leu Pro Gly Gln Pro Asp Asn Thr Pro Pro Gly Gly
340 345 350
Glu Leu Val Phe Glu Arg Trp Arg Arg Leu Ser Asp Asn Ser Gln Trp
355 360 365
Ile Gln Val Ser Leu Val Phe Gln Thr Leu Gln Gln Met Arg Asp Lys
370 375 380
Thr Pro Leu Ser Leu Asn Thr Pro Pro Gly Glu Val Lys Leu Thr Leu
385 390 395 400
Ala Gly Cys Glu Glu Arg Asn Ala Gln Gly Met Cys Ser Leu Ala Gly
405 410 415
Phe Thr Gln Ile Val Asn Glu Ala Arg Ile Pro Ala Cys Ser Leu Ser
420 425 430
Glu Lys Asp Glu Leu
435
<110> SYNGENTA PARTICIPATIONS AG
<120> Self-processing plants and plant parts
<130> 109846.317
<160> 112
<170> KopatentIn 1.71
<210> 1
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 1
Met Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met Gln Ala
1 5 10 15
Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr Ile Arg
20 25 30
Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile Trp Ile
35 40 45
Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly Tyr Asp
50 55 60
Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly Thr Val
65 70 75 80
Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile Asn Thr
85 90 95
Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile Asn His
100 105 110
Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp Tyr Thr
115 120 125
Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala Asn Tyr
130 135 140
Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly Thr Phe
145 150 155 160
Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln Tyr Trp
165 170 175
Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser Ile Gly
180 185 190
Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala Trp Val
195 200 205
Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly Glu Tyr
210 215 220
Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser Ser Gly
225 230 235 240
Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala Ala Phe
245 250 255
Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn Gly Gly
260 265 270
Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val Ala Asn
275 280 285
His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala Phe Ile
290 295 300
Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr Glu Glu
305 310 315 320
Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His Asp Asn
325 330 335
Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp Glu Met
340 345 350
Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile Thr Tyr
355 360 365
Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val Pro Lys
370 375 380
Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly Gly Trp
385 390 395 400
Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu Ala Pro
405 410 415
Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp Ser Tyr
420 425 430
Cys Gly Val Gly
435
<210> 2
<211> 1308
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 2
atggccaagt acctggagct ggaggagggc ggcgtgatca tgcaggcgtt ctactgggac 60
gtcccgagcg gaggcatctg gtgggacacc atccgccaga agatccccga gtggtacgac 120
gccggcatct ccgcgatctg gataccgcca gcttccaagg gcatgtccgg gggctactcg 180
atgggctacg acccgtacga ctacttcgac ctcggcgagt actaccagaa gggcacggtg 240
gagacgcgct tcgggtccaa gcaggagctc atcaacatga tcaacacggc gcacgcctac 300
ggcatcaagg tcatcgcgga catcgtgatc aaccacaggg ccggcggcga cctggagtgg 360
aacccgttcg tcggcgacta cacctggacg gacttctcca aggtcgcctc cggcaagtac 420
accgccaact acctcgactt ccaccccaac gagctgcacg cgggcgactc cggcacgttc 480
ggcggctacc cggacatctg ccacgacaag tcctgggacc agtactggct ctgggcctcg 540
caggagtcct acgcggccta cctgcgctcc atcggcatcg acgcgtggcg cttcgactac 600
gtcaagggct acggggcctg ggtggtcaag gactggctca actggtgggg cggctgggcg 660
gtgggcgagt actgggacac caacgtcgac gcgctgctca actgggccta ctcctccggc 720
gccaaggtgt tcgacttccc cctgtactac aagatggacg cggccttcga caacaagaac 780
atcccggcgc tcgtcgaggc cctgaagaac ggcggcacgg tggtctcccg cgacccgttc 840
aaggccgtga ccttcgtcgc caaccacgac acggacatca tctggaacaa gtacccggcg 900
tacgccttca tcctcaccta cgagggccag cccacgatct tctaccgcga ctacgaggag 960
tggctgaaca aggacaagct caagaacctg atctggattc acgacaacct cgcgggcggc 1020
tccactagta tcgtgtacta cgactccgac gagatgatct tcgtccgcaa cggctacggc 1080
tccaagcccg gcctgatcac gtacatcaac ctgggctcct ccaaggtggg ccgctgggtg 1140
tacgtcccga agttcgccgg cgcgtgcatc cacgagtaca ccggcaacct cggcggctgg 1200
gtggacaagt acgtgtactc ctccggctgg gtctacctgg aggccccggc ctacgacccc 1260
gccaacggcc agtacggcta ctccgtgtgg tcctactgcg gcgtcggc 1308
<210> 3
<211> 800
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 3
Met Gly His Trp Tyr Lys His Gln Arg Ala Tyr Gln Phe Thr Gly Glu
1 5 10 15
Asp Asp Phe Gly Lys Val Ala Val Val Lys Leu Pro Met Asp Leu Thr
20 25 30
Lys Val Gly Ile Ile Val Arg Leu Asn Glu Trp Gln Ala Lys Asp Val
35 40 45
Ala Lys Asp Arg Phe Ile Glu Ile Lys Asp Gly Lys Ala Glu Val Trp
50 55 60
Ile Leu Gln Gly Val Glu Glu Ile Phe Tyr Glu Lys Pro Asp Thr Ser
65 70 75 80
Pro Arg Ile Phe Phe Ala Gln Ala Arg Ser Asn Lys Val Ile Glu Ala
85 90 95
Phe Leu Thr Asn Pro Val Asp Thr Lys Lys Lys Glu Leu Phe Lys Val
100 105 110
Thr Val Asp Gly Lys Glu Ile Pro Val Ser Arg Val Glu Lys Ala Asp
115 120 125
Pro Thr Asp Ile Asp Val Thr Asn Tyr Val Arg Ile Val Leu Ser Glu
130 135 140
Ser Leu Lys Glu Glu Asp Leu Arg Lys Asp Val Glu Leu Ile Ilu Glu
145 150 155 160
Gly Tyr Lys Pro Ala Arg Val Ile Met Met Glu Ile Leu Asp Asp Tyr
165 170 175
Tyr Tyr Asp Gly Glu Leu Gly Ala Val Tyr Ser Pro Glu Lys Thr Ile
180 185 190
Phe Arg Val Trp Ser Pro Val Ser Lys Trp Val Lys Val Leu Leu Phe
195 200 205
Lys Asn Gly Glu Asp Thr Glu Pro Tyr Gln Val Val Asn Met Glu Tyr
210 215 220
Lys Gly Asn Gly Val Trp Glu Ala Val Val Glu Gly Asp Leu Asp Gly
225 230 235 240
Val Phe Tyr Leu Tyr Gln Leu Glu Asn Tyr Gly Lys Ile Arg Thr Thr
245 250 255
Val Asp Pro Tyr Ser Lys Ala Val Tyr Ala Asn Asn Gln Glu Ser Ala
260 265 270
Val Val Asn Leu Ala Arg Thr Asn Pro Glu Gly Trp Glu Asn Asp Arg
275 280 285
Gly Pro Lys Ile Glu Gly Tyr Glu Asp Ala Ile Ile Tyr Glu Ile His
290 295 300
Ile Ala Asp Ile Thr Gly Leu Glu Asn Ser Gly Val Lys Asn Lys Gly
305 310 315 320
Leu Tyr Leu Gly Leu Thr Glu Glu Asn Thr Lys Gly Pro Gly Gly Val
325 330 335
Thr Thr Gly Leu Ser His Leu Val Glu Leu Gly Val Thr His Val His
340 345 350
Ile Leu Pro Phe Phe Asp Phe Tyr Thr Gly Asp Glu Leu Asp Lys Asp
355 360 365
Phe Glu Lys Tyr Tyr Asn Trp Gly Tyr Asp Pro Tyr Leu Phe Met Val
370 375 380
Pro Glu Gly Arg Tyr Ser Thr Asp Pro Lys Asn Pro His Thr Arg Ile
385 390 395 400
Arg Glu Val Lys Glu Met Val Lys Ala Leu His Lys His Gly Ile Gly
405 410 415
Val Ile Met Asp Met Val Phe Pro His Thr Tyr Gly Ile Gly Glu Leu
420 425 430
Ser Ala Phe Asp Gln Thr Val Pro Tyr Tyr Phe Tyr Arg Ile Asp Lys
435 440 445
Thr Gly Ala Tyr Leu Asn Glu Ser Gly Cys Gly Asn Val Ile Ala Ser
450 455 460
Glu Arg Pro Met Met Arg Lys Phe Ile Val Asp Thr Val Thr Tyr Trp
465 470 475 480
Val Lys Glu Tyr His Ile Asp Gly Phe Arg Phe Asp Gln Met Gly Leu
485 490 495
Ile Asp Lys Lys Thr Met Leu Glu Val Glu Arg Ala Leu His Lys Ile
500 505 510
Asp Pro Thr Ile Ile Leu Tyr Gly Glu Pro Trp Gly Gly Trp Gly Ala
515 520 525
Pro Ile Arg Phe Gly Lys Ser Asp Val Ala Gly Thr His Val Ala Ala
530 535 540
Phe Asn Asp Glu Phe Arg Asp Ala Ile Arg Gly Ser Val Phe Asn Pro
545 550 555 560
Ser Val Lys Gly Phe Val Met Gly Gly Tyr Gly Lys Glu Thr Lys Ile
565 570 575
Lys Arg Gly Val Val Gly Ser Ile Asn Tyr Asp Gly Lys Leu Ile Lys
580 585 590
Ser Phe Ala Leu Asp Pro Glu Glu Thr Ile Asn Tyr Ala Ala Cys His
595 600 605
Asp Asn His Thr Leu Trp Asp Lys Asn Tyr Leu Ala Ala Lys Ala Asp
610 615 620
Lys Lys Lys Glu Trp Thr Glu Glu Glu Leu Lys Asn Ala Gln Lys Leu
625 630 635 640
Ala Gly Ala Ile Leu Leu Thr Ser Gln Gly Val Pro Phe Leu His Gly
645 650 655
Gly Gln Asp Phe Cys Arg Thr Thr Asn Phe Asn Asp Asn Ser Tyr Asn
660 665 670
Ala Pro Ile Ser Ile Asn Gly Phe Asp Tyr Glu Arg Lys Leu Gln Phe
675 680 685
Ile Asp Val Phe Asn Tyr His Lys Gly Leu Ile Lys Leu Arg Lys Glu
690 695 700
His Pro Ala Phe Arg Leu Lys Asn Ala Glu Glu Ile Lys Lys His Leu
705 710 715 720
Glu Phe Leu Pro Gly Gly Arg Arg Ile Val Ala Phe Met Leu Lys Asp
725 730 735
His Ala Gly Gly Asp Pro Trp Lys Asp Ile Val Val Ile Tyr Asn Gly
740 745 750
Asn Leu Glu Lys Thr Thr Tyr Lys Leu Pro Glu Gly Lys Trp Asn Val
755 760 765
Val Val Asn Ser Gln Lys Ala Gly Thr Glu Val Ile Glu Thr Val Glu
770 775 780
Gly Thr Ile Glu Leu Asp Pro Leu Ser Ala Tyr Val Leu Tyr Arg Glu
785 790 795 800
<210> 4
<211> 2400
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 4
atgggccact ggtacaagca ccagcgcgcc taccagttca ccggcgagga cgacttcggg 60
aaggtggccg tggtgaagct cccgatggac ctcaccaagg tgggcatcat cgtgcgcctc 120
aacgagtggc aggcgaagga cgtggccaag gaccgcttca tcgagatcaa ggacggcaag 180
gccgaggtgt ggatactcca gggcgtggag gagatcttct acgagaagcc ggacacctcc 240
ccgcgcatct tcttcgccca ggcccgctcc aacaaggtga tcgaggcctt cctcaccaac 300
ccggtggaca ccaagaagaa ggagctgttc aaggtgaccg tcgacggcaa ggagatcccg 360
gtgtcccgcg tggagaaggc cgacccgacc gacatcgacg tgaccaacta cgtgcgcatc 420
gtgctctccg agtccctcaa ggaggaggac ctccgcaagg acgtggagct gatcatcgag 480
ggctacaagc cggcccgcgt gatcatgatg gagatcctcg acgactacta ctacgacggc 540
gagctggggg cggtgtactc cccggagaag accatcttcc gcgtgtggtc cccggtgtcc 600
aagtgggtga aggtgctcct cttcaagaac ggcgaggaca ccgagccgta ccaggtggtg 660
aacatggagt acaagggcaa cggcgtgtgg gaggccgtgg tggagggcga cctcgacggc 720
gtgttctacc tctaccagct ggagaactac ggcaagatcc gcaccaccgt ggacccgtac 780
tccaaggccg tgtacgccaa caaccaggag tctgcagtgg tgaacctcgc ccgcaccaac 840
ccggagggct gggagaacga ccgcggcccg aagatcgagg gctacgagga cgccatcatc 900
tacgagatcc acatcgccga catcaccggc ctggagaact ccggcgtgaa gaacaagggc 960
ctctacctcg gcctcaccga ggagaacacc aaggccccgg gcggcgtgac caccggcctc 1020
tcccacctcg tggagctggg cgtgacccac gtgcacatcc tcccgttctt cgacttctac 1080
accggcgacg agctggacaa ggacttcgag aagtactaca actggggcta cgacccgtac 1140
ctcttcatgg tgccggaggg ccgctactcc accgacccga agaacccgca cacccgaatt 1200
cgcgaggtga aggagatggt gaaggccctc cacaagcacg gcatcggcgt gatcatggac 1260
atggtgttcc cgcacaccta cggcatcggc gagctgtccg ccttcgacca gaccgtgccg 1320
tactacttct accgcatcga caagaccggc gcctacctca acgagtccgg ctgcggcaac 1380
gtgatcgcct ccgagcgccc gatgatgcgc aagttcatcg tggacaccgt gacctactgg 1440
gtgaaggagt accacatcga cggcttccgc ttcgaccaga tgggcctcat cgacaagaag 1500
accatgctgg aggtggagcg cgccctccac aagatcgacc cgaccatcat cctctacggc 1560
gagccgtggg gcggctgggg ggccccgatc cgcttcggca agtccgacgt ggccggcacc 1620
cacgtggccg ccttcaacga cgagttccgc gacgccatcc gcggctccgt gttcaacccg 1680
tccgtgaagg gcttcgtgat gggcggctac ggcaaggaga ccaagatcaa gcgcggcgtg 1740
gtgggctcca tcaactacga cggcaagctc atcaagtcct tcgccctcga cccggaggag 1800
accatcaact acgccgcctg ccacgacaac cacaccctct gggacaagaa ctacctcgcc 1860
gccaaggccg acaagaagaa ggagtggacc gaggaggagc tgaagaacgc ccagaagctc 1920
gccggcgcca tcctcctcac tagtcagggc gtgccgttcc tccacggcgg ccaggacttc 1980
tgccgcacca ccaacttcaa cgacaactcc tacaacgccc cgatctccat caacggcttc 2040
gactacgagc gcaagctcca gttcatcgac gtgttcaact accacaaggg cctcatcaag 2100
ctccgcaagg agcacccggc cttccgcctc aagaacgccg aggagatcaa gaagcacctg 2160
gagttcctcc cgggcgggcg ccgcatcgtg gccttcatgc tcaaggacca cgccggcggc 2220
gacccgtgga aggacatcgt ggtgatctac aacggcaacc tggagaagac cacctacaag 2280
ctcccggagg gcaagtggaa cgtggtggtg aactcccaga aggccggcac cgaggtgatc 2340
gagaccgtgg agggcaccat cgagctggac ccgctctccg cctacgtgct ctaccgcgag 2400
<210> 5
<211> 693
<212> PRT
<213> Sulfolobus solfataricus
<400> 5
Met Glu Thr Ile Lys Ile Tyr Glu Asn Lys Gly Val Tyr Lys Val Val
1 5 10 15
Ile Gly Glu Pro Phe Pro Pro Ile Glu Phe Pro Leu Glu Gln Lys Ile
20 25 30
Ser Ser Asn Lys Ser Leu Ser Glu Leu Gly Leu Thr Ile Val Gln Gln
35 40 45
Gly Asn Lys Val Ile Val Glu Lys Ser Leu Asp Leu Lys Glu His Ile
50 55 60
Ile Gly Leu Gly Glu Lys Ala Phe Glu Leu Asp Arg Lys Arg Lys Arg
65 70 75 80
Tyr Val Met Tyr Asn Val Asp Ala Gly Ala Tyr Lys Lys Tyr Gln Asp
85 90 95
Pro Leu Tyr Val Ser Ile Pro Leu Phe Ile Ser Val Lys Asp Gly Val
100 105 110
Ala Thr Gly Tyr Phe Phe Asn Ser Ala Ser Lys Val Ile Phe Asp Val
115 120 125
Gly Leu Glu Glu Tyr Asp Lys Val Ile Val Thr Ile Pro Glu Asp Ser
130 135 140
Val Glu Phe Tyr Val Ile Glu Gly Pro Arg Ile Glu Asp Val Leu Glu
145 150 155 160
Lys Tyr Thr Glu Leu Thr Gly Lys Pro Phe Leu Pro Pro Met Trp Ala
165 170 175
Phe Gly Tyr Met Ile Ser Arg Tyr Ser Tyr Tyr Pro Gln Asp Lys Val
180 185 190
Val Glu Leu Val Asp Ile Met Gln Lys Glu Gly Phe Arg Val Ala Gly
195 200 205
Val Phe Leu Asp Ile His Tyr Met Asp Ser Tyr Lys Leu Phe Thr Trp
210 215 220
His Pro Tyr Arg Phe Pro Glu Pro Lys Lys Leu Ile Asp Glu Leu His
225 230 235 240
Lys Arg Asn Val Lys Leu Ile Thr Ile Val Asp His Gly Ile Arg Val
245 250 255
Asp Gln Asn Tyr Ser Pro Phe Leu Ser Gly Met Gly Lys Phe Cys Glu
260 265 270
Ile Glu Ser Gly Glu Leu Phe Val Gly Lys Met Trp Pro Gly Thr Thr
275 280 285
Val Tyr Pro Asp Phe Phe Arg Glu Asp Thr Arg Glu Trp Trp Ala Gly
290 295 300
Leu Ile Ser Glu Trp Leu Ser Gln Gly Val Asp Gly Ile Trp Leu Asp
305 310 315 320
Met Asn Glu Pro Thr Asp Phe Ser Arg Ala Ile Glu Ile Arg Asp Val
325 330 335
Leu Ser Ser Leu Pro Val Gln Phe Arg Asp Asp Arg Leu Val Thr Thr
340 345 350
Phe Pro Asp Asn Val Val His Tyr Leu Arg Gly Lys Arg Val Lys His
355 360 365
Glu Lys Val Arg Asn Ala Tyr Pro Leu Tyr Glu Ala Met Ala Thr Phe
370 375 380
Lys Gly Phe Arg Thr Ser His Arg Asn Glu Ile Phe Ile Leu Ser Arg
385 390 395 400
Ala Gly Tyr Ala Gly Ile Gln Arg Tyr Ala Phe Ile Trp Thr Gly Asp
405 410 415
Asn Thr Pro Ser Trp Asp Asp Leu Lys Leu Gln Leu Gln Leu Val Leu
420 425 430
Gly Leu Ser Ile Ser Gly Val Pro Phe Val Gly Cys Asp Ile Gly Gly
435 440 445
Phe Gln Gly Arg Asn Phe Ala Glu Ile Asp Asn Ser Met Asp Leu Leu
450 455 460
Val Lys Tyr Tyr Ala Leu Ala Leu Phe Phe Pro Phe Tyr Arg Ser His
465 470 475 480
Lys Ala Thr Asp Gly Ile Asp Thr Glu Pro Val Phe Leu Pro Asp Tyr
485 490 495
Tyr Lys Glu Lys Val Lys Glu Ile Val Glu Leu Arg Tyr Lys Phe Leu
500 505 510
Pro Tyr Ile Tyr Ser Leu Ala Leu Glu Ala Ser Glu Lys Gly His Pro
515 520 525
Val Ile Arg Pro Leu Phe Tyr Glu Phe Gln Asp Asp Asp Asp Met Tyr
530 535 540
Arg Ile Glu Asp Glu Tyr Met Val Gly Lys Tyr Leu Leu Tyr Ala Pro
545 550 555 560
Ile Val Ser Lys Glu Glu Ser Arg Leu Val Thr Leu Pro Arg Gly Lys
565 570 575
Trp Tyr Asn Tyr Trp Asn Gly Glu Ile Ile Asn Gly Lys Ser Val Val
580 585 590
Lys Ser Thr His Glu Leu Pro Ile Tyr Leu Arg Glu Gly Ser Ile Ile
595 600 605
Pro Leu Glu Gly Asp Glu Leu Ile Val Tyr Gly Glu Thr Ser Phe Lys
610 615 620
Arg Tyr Asp Asn Ala Glu Ile Thr Ser Ser Ser Asn Glu Ile Lys Phe
625 630 635 640
Ser Arg Glu Ile Tyr Val Ser Lys Leu Thr Ile Thr Ser Glu Lys Pro
645 650 655
Val Ser Lys Ile Ile Val Asp Asp Ser Lys Glu Ile Gln Val Glu Lys
660 665 670
Thr Met Gln Asn Thr Tyr Val Ala Lys Ile Asn Gln Lys Ile Arg Gly
675 680 685
Lys Ile Asn Leu Glu
690
<210> 6
<211> 2082
<212> DNA
<213> Sulfolobus solfataricus
<400> 6
atggagacca tcaagatcta cgagaacaag ggcgtgtaca aggtggtgat cggcgagccg 60
ttcccgccga tcgagttccc gctcgagcag aagatctcct ccaacaagtc cctctccgag 120
ctgggcctca ccatcgtgca gcagggcaac aaggtgatcg tggagaagtc cctcgacctc 180
aaggagcaca tcatcggcct cggcgagaag gccttcgagc tggaccgcaa gcgcaagcgc 240
tacgtgatgt acaacgtgga cgccggcgcc tacaagaagt accaggaccc gctctacgtg 300
tccatcccgc tcttcatctc cgtgaaggac ggcgtggcca ccggctactt cttcaactcc 360
gcctccaagg tgatcttcga cgtgggcctc gaggagtacg acaaggtgat cgtgaccatc 420
ccggaggact ccgtggagtt ctacgtgatc gagggcccgc gcatcgagga cgtgctcgag 480
aagtacaccg agctgaccgg caagccgttc ctcccgccga tgtgggcctt cggctacatg 540
atctcccgct actcctacta cccgcaggac aaggtggtgg agctggtgga catcatgcag 600
aaggagggct tccgcgtggc cggcgtgttc ctcgacatcc actacatgga ctcctacaag 660
ctcttcacct ggcacccgta ccgcttcccg gagccgaaga agctcatcga cgagctgcac 720
aagcgcaacg tgaagctcat caccatcgtg gaccacggca tccgcgtgga ccagaactac 780
tccccgttcc tctccggcat gggcaagttc tgcgagatcg agtccggcga gctgttcgtg 840
ggcaagatgt ggccgggcac caccgtgtac ccggacttct tccgcgagga cacccgcgag 900
tggtgggccg gcctcatctc cgagtggctc tcccagggcg tggacggcat ctggctcgac 960
atgaacgagc cgaccgactt ctcccgcgcc atcgagatcc gcgacgtgct ctcctccctc 1020
ccggtgcagt tccgcgacga ccgcctcgtg accaccttcc cggacaacgt ggtgcactac 1080
ctccgcggca agcgcgtgaa gcacgagaag gtgcgcaacg cctacccgct ctacgaggcg 1140
atggccacct tcaagggctt ccgcacctcc caccgcaacg agatcttcat cctctcccgc 1200
gccggctacg ccggcatcca gcgctacgcc ttcatctgga ccggcgacaa caccccgtcc 1260
tgggacgacc tcaagctcca gctccagctc gtgctcggcc tctccatctc cggcgtgccg 1320
ttcgtgggct gcgacatcgg cggcttccag ggccgcaact tcgccgagat cgacaactcg 1380
atggacctcc tcgtgaagta ctacgccctc gccctcttct tcccgttcta ccgctcccac 1440
aaggccaccg acggcatcga caccgagccg gtgttcctcc cggactacta caaggagaag 1500
gtgaaggaga tcgtggagct gcgctacaag ttcctcccgt acatctactc cctcgccctc 1560
gaggcctccg agaagggcca cccggtgatc cgcccgctct tctacgagtt ccaggacgac 1620
gacgacatgt accgcatcga ggacgagtac atggtgggca agtacctcct ctacgccccg 1680
atcgtgtcca aggaggagtc ccgcctcgtg accctcccgc gcggcaagtg gtacaactac 1740
tggaacggcg agatcatcaa cggcaagtcc gtggtgaagt ccacccacga gctgccgatc 1800
tacctccgcg agggctccat catcccgctc gagggcgacg agctgatcgt gtacggcgag 1860
acctccttca agcgctacga caacgccgag atcacctcct cctccaacga gatcaagttc 1920
tcccgcgaga tctacgtgtc caagctcacc atcacctccg agaagccggt gtccaagatc 1980
atcgtggacg actccaagga gatccaggtg gagaagacca tgcagaacac ctacgtggcc 2040
aagatcaacc agaagatccg cggcaagatc aacctcgagt ga 2082
<210> 7
<211> 1818
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 7
atggcggctc tggccacgtc gcagctcgtc gcaacgcgcg ccggcctggg cgtcccggac 60
gcgtccacgt tccgccgcgg cgccgcgcag ggcctgaggg gggcccgggc gtcggcggcg 120
gcggacacgc tcagcatgcg gaccagcgcg cgcgcggcgc ccaggcacca gcaccagcag 180
gcgcgccgcg gggccaggtt cccgtcgctc gtcgtgtgcg ccagcgccgg catgaacgtc 240
gtcttcgtcg gcgccgagat ggcgccgtgg agcaagaccg gaggcctcgg cgacgtcctc 300
ggcggcctgc cgccggccat ggccgcgaac gggcaccgtg tcatggtcgt ctctccccgc 360
tacgaccagt acaaggacgc ctgggacacc agcgtcgtgt ccgagatcaa gatgggagac 420
gggtacgaga cggtcaggtt cttccactgc tacaagcgcg gagtggaccg cgtgttcgtt 480
gaccacccac tgttcctgga gagggtttgg ggaaagaccg aggagaagat ctacgggcct 540
gtcgctggaa cggactacag ggacaaccag ctgcggttca gcctgctatg ccaggcagca 600
cttgaagctc caaggatcct gagcctcaac aacaacccat acttctccgg accatacggg 660
gaggacgtcg tgttcgtctg caacgactgg cacaccggcc ctctctcgtg ctacctcaag 720
agcaactacc agtcccacgg catctacagg gacgcaaaga ccgctttctg catccacaac 780
atctcctacc agggccggtt cgccttctcc gactacccgg agctgaacct ccccgagaga 840
ttcaagtcgt ccttcgattt catcgacggc tacgagaagc ccgtggaagg ccggaagatc 900
aactggatga aggccgggat cctcgaggcc gacagggtcc tcaccgtcag cccctactac 960
gccgaggagc tcatctccgg catcgccagg ggctgcgagc tcgacaacat catgcgcctc 1020
accggcatca ccggcatcgt caacggcatg gacgtcagcg agtgggaccc cagcagggac 1080
aagtacatcg ccgtgaagta cgacgtgtcg acggccgtgg aggccaaggc gctgaacaag 1140
gaggcgctgc aggcggaggt cgggctcccg gtggaccgga acatcccgct ggtggcgttc 1200
atcggcaggc tggaagagca gaagggcccc gacgtcatgg cggccgccat cccgcagctc 1260
atggagatgg tggaggacgt gcagatcgtt ctgctgggca cgggcaagaa gaagttcgag 1320
cgcatgctca tgagcgccga ggagaagttc ccaggcaagg tgcgcgccgt ggtcaagttc 1380
aacgcggcgc tggcgcacca catcatggcc ggcgccgacg tgctcgccgt caccagccgc 1440
ttcgagccct gcggcctcat ccagctgcag gggatgcgat acggaacgcc ctgcgcctgc 1500
gcgtccaccg gtggactcgt cgacaccatc atcgaaggca agaccgggtt ccacatgggc 1560
cgcctcagcg tcgactgcaa cgtcgtggag ccggcggacg tcaagaaggt ggccaccacc 1620
ttgcagcgcg ccatcaaggt ggtcggcacg ccggcgtacg aggagatggt gaggaactgc 1680
atgatccagg atctctcctg gaagggccct gccaagaact gggagaacgt gctgctcagc 1740
ctcggggtcg ccggcggcga gccaggggtt gaaggcgagg agatcgcgcc gctcgccaag 1800
gagaacgtgg ccgcgccc 1818
<210> 8
<211> 606
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 8
Met Ala Ala Leu Ala Thr Ser Gln Leu Val Ala Thr Arg Ala Gly Leu
1 5 10 15
Gly Val Pro Asp Ala Ser Thr Phe Arg Arg Gly Ala Ala Gln Gly Leu
20 25 30
Arg Gly Ala Arg Ala Ser Ala Ala Ala Asp Thr Leu Ser Met Arg Thr
35 40 45
Ser Ala Arg Ala Ala Pro Arg His Gln His Gln Gln Ala Arg Arg Gly
50 55 60
Ala Arg Phe Pro Ser Leu Val Val Cys Ala Ser Ala Gly Met Asn Val
65 70 75 80
Val Phe Val Gly Ala Glu Met Ala Pro Trp Ser Lys Thr Gly Gly Leu
85 90 95
Gly Asp Val Leu Gly Gly Leu Pro Pro Ala Met Ala Ala Asn Gly His
100 105 110
Arg Val Met Val Val Ser Pro Arg Tyr Asp Gln Tyr Lys Asp Ala Trp
115 120 125
Asp Thr Ser Val Val Ser Glu Ile Lys Met Gly Asp Gly Tyr Glu Thr
130 135 140
Val Arg Phe Phe His Cys Tyr Lys Arg Gly Val Asp Arg Val Phe Val
145 150 155 160
Asp His Pro Leu Phe Leu Glu Arg Val Trp Gly Lys Thr Glu Glu Lys
165 170 175
Ile Tyr Gly Pro Val Ala Gly Thr Asp Tyr Arg Asp Asn Gln Leu Arg
180 185 190
Phe Ser Leu Leu Cys Gln Ala Ala Leu Glu Ala Pro Arg Ile Leu Ser
195 200 205
Leu Asn Asn Asn Pro Tyr Phe Ser Gly Pro Tyr Gly Glu Asp Val Val
210 215 220
Phe Val Cys Asn Asp Trp His Thr Gly Pro Leu Ser Cys Tyr Leu Lys
225 230 235 240
Ser Asn Tyr Gln Ser His Gly Ile Tyr Arg Asp Ala Lys Thr Ala Phe
245 250 255
Cys Ile His Asn Ile Ser Tyr Gln Gly Arg Phe Ala Phe Ser Asp Tyr
260 265 270
Pro Glu Leu Asn Leu Pro Glu Arg Phe Lys Ser Ser Phe Asp Phe Ile
275 280 285
Asp Gly Tyr Glu Lys Pro Val Glu Gly Arg Lys Ile Asn Trp Met Lys
290 295 300
Ala Gly Ile Leu Glu Ala Asp Arg Val Leu Thr Val Ser Pro Tyr Tyr
305 310 315 320
Ala Glu Glu Leu Ile Ser Gly Ile Ala Arg Gly Cys Glu Leu Asp Asn
325 330 335
Ile Met Arg Leu Thr Gly Ile Thr Gly Ile Val Asn Gly Met Asp Val
340 345 350
Ser Glu Trp Asp Pro Ser Arg Asp Lys Tyr Ile Ala Val Lys Tyr Asp
355 360 365
Val Ser Thr Ala Val Glu Ala Lys Ala Leu Asn Lys Glu Ala Leu Gln
370 375 380
Ala Glu Val Gly Leu Pro Val Asp Arg Asn Ile Pro Leu Val Ala Phe
385 390 395 400
Ile Gly Arg Leu Glu Glu Gln Lys Gly Pro Asp Val Met Ala Ala Ala
405 410 415
Ile Pro Gln Leu Met Glu Met Val Glu Asp Val Gln Ile Val Leu Leu
420 425 430
Gly Thr Gly Lys Lys Lys Phe Glu Arg Met Leu Met Ser Ala Glu Glu
435 440 445
Lys Phe Pro Gly Lys Val Arg Ala Val Val Lys Phe Asn Ala Ala Leu
450 455 460
Ala His His Ile Met Ala Gly Ala Asp Val Leu Ala Val Thr Ser Arg
465 470 475 480
Phe Glu Pro Cys Gly Leu Ile Gln Leu Gln Gly Met Arg Tyr Gly Thr
485 490 495
Pro Cys Ala Cys Ala Ser Thr Gly Gly Leu Val Asp Thr Ile Ile Glu
500 505 510
Gly Lys Thr Gly Phe His Met Gly Arg Leu Ser Val Asp Cys Asn Val
515 520 525
Val Glu Pro Ala Asp Val Lys Lys Val Ala Thr Thr Leu Gln Arg Ala
530 535 540
Ile Lys Val Val Gly Thr Pro Ala Tyr Glu Glu Met Val Arg Asn Cys
545 550 555 560
Met Ile Gln Asp Leu Ser Trp Lys Gly Pro Ala Lys Asn Trp Glu Asn
565 570 575
Val Leu Leu Ser Leu Gly Val Ala Gly Gly Glu Pro Gly Val Glu Gly
580 585 590
Glu Glu Ile Ala Pro Leu Ala Lys Glu Asn Val Ala Ala Pro
595 600 605
<210> 9
<211> 2223
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 9
atggccaagt acctggagct ggaggagggc ggcgtgatca tgcaggcgtt ctactgggac 60
gtcccgagcg gaggcatctg gtgggacacc atccgccaga agatccccga gtggtacgac 120
gccggcatct ccgcgatctg gataccgcca gcttccaagg gcatgtccgg gggctactcg 180
atgggctacg acccgtacga ctacttcgac ctcggcgagt actaccagaa gggcacggtg 240
gagacgcgct tcgggtccaa gcaggagctc atcaacatga tcaacacggc gcacgcctac 300
ggcatcaagg tcatcgcgga catcgtgatc aaccacaggg ccggcggcga cctggagtgg 360
aacccgttcg tcggcgacta cacctggacg gacttctcca aggtcgcctc cggcaagtac 420
accgccaact acctcgactt ccaccccaac gagctgcacg cgggcgactc cggcacgttc 480
ggcggctacc cggacatctg ccacgacaag tcctgggacc agtactggct ctgggcctcg 540
caggagtcct acgcggccta cctgcgctcc atcggcatcg acgcgtggcg cttcgactac 600
gtcaagggct acggggcctg ggtggtcaag gactggctca actggtgggg cggctgggcg 660
gtgggcgagt actgggacac caacgtcgac gcgctgctca actgggccta ctcctccggc 720
gccaaggtgt tcgacttccc cctgtactac aagatggacg cggccttcga caacaagaac 780
atcccggcgc tcgtcgaggc cctgaagaac ggcggcacgg tggtctcccg cgacccgttc 840
aaggccgtga ccttcgtcgc caaccacgac acggacatca tctggaacaa gtacccggcg 900
tacgccttca tcctcaccta cgagggccag cccacgatct tctaccgcga ctacgaggag 960
tggctgaaca aggacaagct caagaacctg atctggattc acgacaacct cgcgggcggc 1020
tccactagta tcgtgtacta cgactccgac gagatgatct tcgtccgcaa cggctacggc 1080
tccaagcccg gcctgatcac gtacatcaac ctgggctcct ccaaggtggg ccgctgggtg 1140
tacgtcccga agttcgccgg cgcgtgcatc cacgagtaca ccggcaacct cggcggctgg 1200
gtggacaagt acgtgtactc ctccggctgg gtctacctgg aggccccggc ctacgacccc 1260
gccaacggcc agtacggcta ctccgtgtgg tcctactgcg gcgtcggcac atcgattgct 1320
ggcatcctcg aggccgacag ggtcctcacc gtcagcccct actacgccga ggagctcatc 1380
tccggcatcg ccaggggctg cgagctcgac aacatcatgc gcctcaccgg catcaccggc 1440
atcgtcaacg gcatggacgt cagcgagtgg gaccccagca gggacaagta catcgccgtg 1500
aagtacgacg tgtcgacggc cgtggaggcc aaggcgctga acaaggaggc gctgcaggcg 1560
gaggtcgggc tcccggtgga ccggaacatc ccgctggtgg cgttcatcgg caggctggaa 1620
gagcagaagg gccccgacgt catggcggcc gccatcccgc agctcatgga gatggtggag 1680
gacgtgcaga tcgttctgct gggcacgggc aagaagaagt tcgagcgcat gctcatgagc 1740
gccgaggaga agttcccagg caaggtgcgc gccgtggtca agttcaacgc ggcgctggcg 1800
caccacatca tggccggcgc cgacgtgctc gccgtcacca gccgcttcga gccctgcggc 1860
ctcatccagc tgcaggggat gcgatacgga acgccctgcg cctgcgcgtc caccggtgga 1920
ctcgtcgaca ccatcatcga aggcaagacc gggttccaca tgggccgcct cagcgtcgac 1980
tgcaacgtcg tggagccggc ggacgtcaag aaggtggcca ccaccttgca gcgcgccatc 2040
aaggtggtcg gcacgccggc gtacgaggag atggtgagga actgcatgat ccaggatctc 2100
tcctggaagg gccctgccaa gaactgggag aacgtgctgc tcagcctcgg ggtcgccggc 2160
ggcgagccag gggttgaagg cgaggagatc gcgccgctcg ccaaggagaa cgtggccgcg 2220
ccc 2223
<210> 10
<211> 741
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 10
Met Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met Gln Ala
1 5 10 15
Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr Ile Arg
20 25 30
Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile Trp Ile
35 40 45
Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly Tyr Asp
50 55 60
Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly Thr Val
65 70 75 80
Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile Asn Thr
85 90 95
Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile Asn His
100 105 110
Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp Tyr Thr
115 120 125
Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala Asn Tyr
130 135 140
Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly Thr Phe
145 150 155 160
Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln Tyr Trp
165 170 175
Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser Ile Gly
180 185 190
Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala Trp Val
195 200 205
Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly Glu Tyr
210 215 220
Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser Ser Gly
225 230 235 240
Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala Ala Phe
245 250 255
Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn Gly Gly
260 265 270
Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val Ala Asn
275 280 285
His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala Phe Ile
290 295 300
Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr Glu Glu
305 310 315 320
Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His Asp Asn
325 330 335
Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp Glu Met
340 345 350
Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile Thr Tyr
355 360 365
Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val Pro Lys
370 375 380
Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly Gly Trp
385 390 395 400
Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu Ala Pro
405 410 415
Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp Ser Tyr
420 425 430
Cys Gly Val Gly Thr Ser Ile Ala Gly Ile Leu Glu Ala Asp Arg Val
435 440 445
Leu Thr Val Ser Pro Tyr Tyr Ala Glu Glu Leu Ile Ser Gly Ile Ala
450 455 460
Arg Gly Cys Glu Leu Asp Asn Ile Met Arg Leu Thr Gly Ile Thr Gly
465 470 475 480
Ile Val Asn Gly Met Asp Val Ser Glu Trp Asp Pro Ser Arg Asp Lys
485 490 495
Tyr Ile Ala Val Lys Tyr Asp Val Ser Thr Ala Val Glu Ala Lys Ala
500 505 510
Leu Asn Lys Glu Ala Leu Gln Ala Glu Val Gly Leu Pro Val Asp Arg
515 520 525
Asn Ile Pro Leu Val Ala Phe Ile Gly Arg Leu Glu Glu Gln Lys Gly
530 535 540
Pro Asp Val Met Ala Ala Ala Ile Pro Gln Leu Met Glu Met Val Glu
545 550 555 560
Asp Val Gln Ile Val Leu Leu Gly Thr Gly Lys Lys Lys Phe Glu Arg
565 570 575
Met Leu Met Ser Ala Glu Glu Lys Phe Pro Gly Lys Val Arg Ala Val
580 585 590
Val Lys Phe Asn Ala Ala Leu Ala His His Ile Met Ala Gly Ala Asp
595 600 605
Val Leu Ala Val Thr Ser Arg Phe Glu Pro Cys Gly Leu Ile Gln Leu
610 615 620
Gln Gly Met Arg Tyr Gly Thr Pro Cys Ala Cys Ala Ser Thr Gly Gly
625 630 635 640
Leu Val Asp Thr Ile Ile Glu Gly Lys Thr Gly Phe His Met Gly Arg
645 650 655
Leu Ser Val Asp Cys Asn Val Val Glu Pro Ala Asp Val Lys Lys Val
660 665 670
Ala Thr Thr Leu Gln Arg Ala Ile Lys Val Val Gly Thr Pro Ala Tyr
675 680 685
Glu Glu Met Val Arg Asn Cys Met Ile Gln Asp Leu Ser Trp Lys Gly
690 695 700
Pro Ala Lys Asn Trp Glu Asn Val Leu Leu Ser Leu Gly Val Ala Gly
705 710 715 720
Gly Glu Pro Gly Val Glu Gly Glu Glu Ile Ala Pro Leu Ala Lys Glu
725 730 735
Asn Val Ala Ala Pro
740
<210> 11
<211> 1515
<212> DNA
<213> Zea mays
<400> 11
ggagagctat gagacgtatg tcctcaaagc cactttgcat tgtgtgaaac caatatcgat 60
ctttgttact tcatcatgca tgaacatttg tggaaactac tagcttacaa gcattagtga 120
cagctcagaa aaaagttatc tatgaaaggt ttcatgtgta ccgtgggaaa tgagaaatgt 180
tgccaactca aacaccttca atatgttgtt tgcaggcaaa ctcttctgga agaaaggtgt 240
ctaaaactat gaacgggtta cagaaaggta taaaccacgg ctgtgcattt tggaagtatc 300
atctatagat gtctgttgag gggaaagccg tacgccaacg ttatttactc agaaacagct 360
tcaacacaca gttgtctgct ttatgatggc atctccaccc aggcacccac catcacctat 420
ctctcgtgcc tgtttatttt cttgcccttt ctgatcataa aaaaacatta agagtttgca 480
aacatgcata ggcatatcaa tatgctcatt tattaatttg ctagcagatc atcttcctac 540
tctttacttt atttattgtt tgaaaaatat gtcctgcacc tagggagctc gtatacagta 600
ccaatgcatc ttcattaaat gtgaatttca gaaaggaagt aggaacctat gagagtattt 660
ttcaaaatta attagcggct tctattatgt ttatagcaaa ggccaagggc aaaattggaa 720
cactaatgat ggttggttgc atgagtctgt cgattacttg caagaaatgt gaacctttgt 780
ttctgtgcgt gggcataaaa caaacagctt ctagcctctt ttacggtact tgcacttgca 840
agaaatgtga actccttttc atttctgtat gtggacataa tgccaaagca tccaggcttt 900
ttcatggttg ttgatgtctt tacacagttc atctccacca gtatgccctc ctcatactct 960
atataaacac atcaacagca tcgcaattag ccacaagatc acttcgggag gcaagtgcga 1020
tttcgatctc gcagccacct ttttttgttc tgttgtaagt ataccttccc ttaccatctt 1080
tatctgttag tttaatttgt aattgggaag tattagtgga aagaggatga gatgctatca 1140
tctatgtact ctgcaaatgc atctgacgtt atatgggctg cttcatataa tttgaattgc 1200
tccattcttg ccgacaatat attgcaaggt atatgcctag ttccatcaaa agttctgttt 1260
tttcattcta aaagcatttt agtggcacac aatttttgtc catgagggaa aggaaatctg 1320
ttttggttac tttgcttgag gtgcattctt catatgtcca gttttatgga agtaataaac 1380
ttcagtttgg tcataagatg tcatattaaa gggcaaacat atattcaatg ttcaattcat 1440
cgtaaatgtt ccctttttgt aaaagattgc atactcattt atttgagttg caggtgtatc 1500
tagtagttgg aggag 1515
<210> 12
<211> 673
<212> DNA
<213> Zea mays
<400> 12
gatcatccag gtgcaaccgt ataagtccta aagtggtgag gaacacgaaa caaccatgca 60
ttggcatgta aagctccaag aatttgttgt atccttaaca actcacagaa catcaaccaa 120
aattgcacgt caagggtatt gggtaagaaa caatcaaaca aatcctctct gtgtgcaaag 180
aaacacggtg agtcatgccg agatcatact catctgatat acatgcttac agctcacaag 240
acattacaaa caactcatat tgcattacaa agatcgtttc atgaaaaata aaataggccg 300
gacaggacaa aaatccttga cgtgtaaagt aaatttacaa caaaaaaaaa gccatatgtc 360
aagctaaatc taattcgttt tacgtagatc aacaacctgt agaaggcaac aaaactgagc 420
cacgcagaag tacagaatga ttccagatga accatcgacg tgctacgtaa agagagtgac 480
gagtcatata catttggcaa gaaaccatga agctgcctac agccgtctcg gtggcataag 540
aacacaagaa attgtgttaa ttaatcaaag ctataaataa cgctcgcatg cctgtgcact 600
tctccatcac caccactggg tcttcagacc attagcttta tctactccag agcgcagaag 660
aacccgatcg aca 673
<210> 13
<211> 454
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 13
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met
20 25 30
Gln Ala Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr
35 40 45
Ile Arg Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile
50 55 60
Trp Ile Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly
65 70 75 80
Tyr Asp Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly
85 90 95
Thr Val Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile
100 105 110
Asn Thr Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile
115 120 125
Asn His Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp
130 135 140
Tyr Thr Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala
145 150 155 160
Asn Tyr Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly
165 170 175
Thr Phe Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln
180 185 190
Tyr Trp Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser
195 200 205
Ile Gly Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala
210 215 220
Trp Val Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly
225 230 235 240
Glu Tyr Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser
245 250 255
Ser Gly Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala
260 265 270
Ala Phe Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn
275 280 285
Gly Gly Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val
290 295 300
Ala Asn His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala
305 310 315 320
Phe Ile Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr
325 330 335
Glu Glu Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His
340 345 350
Asp Asn Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp
355 360 365
Glu Met Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile
370 375 380
Thr Tyr Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val
385 390 395 400
Pro Lys Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly
405 410 415
Gly Trp Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu
420 425 430
Ala Pro Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp
435 440 445
Ser Tyr Cys Gly Val Gly
450
<210> 14
<211> 460
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 14
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala Thr Ser Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met
20 25 30
Gln Ala Phe Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr
35 40 45
Ile Arg Gln Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile
50 55 60
Trp Ile Pro Pro Ala Ser Lys Gly Met Ser Gly Gly Tyr Ser Met Gly
65 70 75 80
Tyr Asp Pro Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly
85 90 95
Thr Val Glu Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile
100 105 110
Asn Thr Ala His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile
115 120 125
Asn His Arg Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp
130 135 140
Tyr Thr Trp Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala
145 150 155 160
Asn Tyr Leu Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly
165 170 175
Thr Phe Gly Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln
180 185 190
Tyr Trp Leu Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser
195 200 205
Ile Gly Ile Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala
210 215 220
Trp Val Val Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly
225 230 235 240
Glu Tyr Trp Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser
245 250 255
Ser Gly Ala Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala
260 265 270
Ala Phe Asp Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn
275 280 285
Gly Gly Thr Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val
290 295 300
Ala Asn His Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala
305 310 315 320
Phe Ile Leu Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr
325 330 335
Glu Glu Trp Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His
340 345 350
Asp Asn Leu Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp
355 360 365
Glu Met Ile Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile
370 375 380
Thr Tyr Ile Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val
385 390 395 400
Pro Lys Phe Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly
405 410 415
Gly Trp Val Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu
420 425 430
Ala Pro Ala Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp
435 440 445
Ser Tyr Cys Gly Val Gly Ser Glu Lys Asp Glu Leu
450 455 460
<210> 15
<211> 518
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 15
Met Leu Ala Ala Leu Ala Thr Ser Gln Leu Val Ala Thr Arg Ala Gly
1 5 10 15
Leu Gly Val Pro Asp Ala Ser Thr Phe Arg Arg Gly Ala Ala Gln Gly
20 25 30
Leu Arg Gly Ala Arg Ala Ser Ala Ala Ala Asp Thr Leu Ser Met Arg
35 40 45
Thr Ser Ala Arg Ala Ala Pro Arg His Gln His Gln Gln Ala Arg Arg
50 55 60
Gly Ala Arg Phe Pro Ser Leu Val Val Cys Ala Ser Ala Gly Ala Met
65 70 75 80
Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met Gln Ala Phe
85 90 95
Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr Ile Arg Gln
100 105 110
Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile Trp Ile Pro
115 120 125
Pro Ala Ser Lys Gly Met Ser Gly Gyr Tyr Ser Met Gly Tyr Asp Pro
130 135 140
Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly Thr Val Glu
145 150 155 160
Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile Asn Thr Ala
165 170 175
His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile Asn His Arg
180 185 190
Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp Tyr Thr Trp
195 200 205
Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala Asn Tyr Leu
210 215 220
Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly Thr Phe Gly
225 230 235 240
Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln Tyr Trp Leu
245 250 255
Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser Ile Gly Ile
260 265 270
Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala Trp Val Val
275 280 285
Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly Glu Tyr Trp
290 295 300
Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser Ser Gly Ala
305 310 315 320
Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala Ala Phe Asp
325 330 335
Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn Gly Gly Thr
340 345 350
Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val Ala Asn His
355 360 365
Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala Phe Ile Leu
370 375 380
Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr Glu Glu Trp
385 390 395 400
Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His Asp Asn Leu
405 410 415
Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp Glu Met Ile
420 425 430
Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile Thr Tyr Ile
435 440 445
Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val Pro Lys Phe
450 455 460
Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly Gly Trp Val
465 470 475 480
Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu Ala Pro Ala
485 490 495
Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp Ser Tyr Cys
500 505 510
Gly Val Gly Thr Ser Ile
515
<210> 16
<211> 820
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 16
Met Leu Ala Ala Leu Ala Thr Ser Gln Leu Val Ala Thr Arg Ala Gly
1 5 10 15
Leu Gly Val Pro Asp Ala Ser Thr Phe Arg Arg Gly Ala Ala Gln Gly
20 25 30
Leu Arg Gly Ala Arg Ala Ser Ala Ala Ala Asp Thr Leu Ser Met Arg
35 40 45
Thr Ser Ala Arg Ala Ala Pro Arg His Gln His Gln Gln Ala Arg Arg
50 55 60
Gly Ala Arg Phe Pro Ser Leu Val Val Cys Ala Ser Ala Gly Ala Met
65 70 75 80
Ala Lys Tyr Leu Glu Leu Glu Glu Gly Gly Val Ile Met Gln Ala Phe
85 90 95
Tyr Trp Asp Val Pro Ser Gly Gly Ile Trp Trp Asp Thr Ile Arg Gln
100 105 110
Lys Ile Pro Glu Trp Tyr Asp Ala Gly Ile Ser Ala Ile Trp Ile Pro
115 120 125
Pro Ala Ser Lys Gly Met Ser Gly Gyr Tyr Ser Met Gly Tyr Asp Pro
130 135 140
Tyr Asp Tyr Phe Asp Leu Gly Glu Tyr Tyr Gln Lys Gly Thr Val Glu
145 150 155 160
Thr Arg Phe Gly Ser Lys Gln Glu Leu Ile Asn Met Ile Asn Thr Ala
165 170 175
His Ala Tyr Gly Ile Lys Val Ile Ala Asp Ile Val Ile Asn His Arg
180 185 190
Ala Gly Gly Asp Leu Glu Trp Asn Pro Phe Val Gly Asp Tyr Thr Trp
195 200 205
Thr Asp Phe Ser Lys Val Ala Ser Gly Lys Tyr Thr Ala Asn Tyr Leu
210 215 220
Asp Phe His Pro Asn Glu Leu His Ala Gly Asp Ser Gly Thr Phe Gly
225 230 235 240
Gly Tyr Pro Asp Ile Cys His Asp Lys Ser Trp Asp Gln Tyr Trp Leu
245 250 255
Trp Ala Ser Gln Glu Ser Tyr Ala Ala Tyr Leu Arg Ser Ile Gly Ile
260 265 270
Asp Ala Trp Arg Phe Asp Tyr Val Lys Gly Tyr Gly Ala Trp Val Val
275 280 285
Lys Asp Trp Leu Asn Trp Trp Gly Gly Trp Ala Val Gly Glu Tyr Trp
290 295 300
Asp Thr Asn Val Asp Ala Leu Leu Asn Trp Ala Tyr Ser Ser Gly Ala
305 310 315 320
Lys Val Phe Asp Phe Pro Leu Tyr Tyr Lys Met Asp Ala Ala Phe Asp
325 330 335
Asn Lys Asn Ile Pro Ala Leu Val Glu Ala Leu Lys Asn Gly Gly Thr
340 345 350
Val Val Ser Arg Asp Pro Phe Lys Ala Val Thr Phe Val Ala Asn His
355 360 365
Asp Thr Asp Ile Ile Trp Asn Lys Tyr Pro Ala Tyr Ala Phe Ile Leu
370 375 380
Thr Tyr Glu Gly Gln Pro Thr Ile Phe Tyr Arg Asp Tyr Glu Glu Trp
385 390 395 400
Leu Asn Lys Asp Lys Leu Lys Asn Leu Ile Trp Ile His Asp Asn Leu
405 410 415
Ala Gly Gly Ser Thr Ser Ile Val Tyr Tyr Asp Ser Asp Glu Met Ile
420 425 430
Phe Val Arg Asn Gly Tyr Gly Ser Lys Pro Gly Leu Ile Thr Tyr Ile
435 440 445
Asn Leu Gly Ser Ser Lys Val Gly Arg Trp Val Tyr Val Pro Lys Phe
450 455 460
Ala Gly Ala Cys Ile His Glu Tyr Thr Gly Asn Leu Gly Gly Trp Val
465 470 475 480
Asp Lys Tyr Val Tyr Ser Ser Gly Trp Val Tyr Leu Glu Ala Pro Ala
485 490 495
Tyr Asp Pro Ala Asn Gly Gln Tyr Gly Tyr Ser Val Trp Ser Tyr Cys
500 505 510
Gly Val Gly Thr Ser Ile Ala Gly Ile Leu Glu Ala Asp Arg Val Leu
515 520 525
Thr Val Ser Pro Tyr Tyr Ala Glu Glu Leu Ile Ser Gly Ile Ala Arg
530 535 540
Gly Cys Glu Leu Asp Asn Ile Met Arg Leu Thr Gly Ile Thr Gly Ile
545 550 555 560
Val Asn Gly Met Asp Val Ser Glu Trp Asp Pro Ser Arg Asp Lys Tyr
565 570 575
Ile Ala Val Lys Tyr Asp Val Ser Thr Ala Val Glu Ala Lys Ala Leu
580 585 590
Asn Lys Glu Ala Leu Gln Ala Glu Val Gly Leu Pro Val Asp Arg Asn
595 600 605
Ile Pro Leu Val Ala Phe Ile Gly Arg Leu Glu Glu Gln Lys Gly Pro
610 615 620
Asp Val Met Ala Ala Ala Ile Pro Gln Leu Met Glu Met Val Glu Asp
625 630 635 640
Val Gln Ile Val Leu Leu Gly Thr Gly Lys Lys Lys Phe Glu Arg Met
645 650 655
Leu Met Ser Ala Glu Glu Lys Phe Pro Gly Lys Val Arg Ala Val Val
660 665 670
Lys Phe Asn Ala Ala Leu Ala His His Ile Met Ala Gly Ala Asp Val
675 680 685
Leu Ala Val Thr Ser Arg Phe Glu Pro Cys Gly Leu Ile Gln Leu Gln
690 695 700
Gly Met Arg Tyr Gly Thr Pro Cys Ala Cys Ala Ser Thr Gly Gly Leu
705 710 715 720
Val Asp Thr Ile Ile Glu Gly Lys Thr Gly Phe His Met Gly Arg Leu
725 730 735
Ser Val Asp Cys Asn Val Val Glu Pro Ala Asp Val Lys Lys Val Ala
740 745 750
Thr Thr Leu Gln Arg Ala Ile Lys Val Val Gly Thr Pro Ala Tyr Glu
755 760 765
Glu Met Val Arg Asn Cys Met Ile Gln Asp Leu Ser Trp Lys Gly Pro
770 775 780
Ala Lys Asn Trp Glu Asn Val Leu Leu Ser Leu Gly Val Ala Gly Gly
785 790 795 800
Glu Pro Gly Val Glu Gly Glu Glu Ile Ala Pro Leu Ala Lys Glu Asn
805 810 815
Val Ala Ala Pro
820
<210> 17
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 17
Met Arg Val Leu Leu Val Ala Leu Ala Leu Leu Ala Leu Ala Ala Ser
1 5 10 15
Ala thr ser
<210> 18
<211> 444
<212> PRT
<213> Thermotoga maritima
<400> 18
Met Ala Glu Phe Phe Pro Glu Ile Pro Lys Ile Gln Phe Glu Gly Lys
1 5 10 15
Glu Ser Thr Asn Pro Leu Ala Phe Arg Phe Tyr Asp Pro Asn Glu Val
20 25 30
Ile Asp Gly Lys Pro Leu Lys Asp His Leu Lys Phe Ser Val Ala Phe
35 40 45
Trp His Thr Phe Val Asn Glu Gly Arg Asp Pro Phe Gly Asp Pro Thr
50 55 60
Ala Glu Arg Pro Trp Asn Arg Phe Ser Asp Pro Met Asp Lys Ala Phe
65 70 75 80
Ala Arg Val Asp Ala Leu Phe Glu Phe Cys Glu Lys Leu Asn Ile Glu
85 90 95
Tyr Phe Cys Phe His Asp Arg Asp Ile Ala Pro Glu Gly Lys Thr Leu
100 105 110
Arg Glu Thr Asn Lys Ile Leu Asp Lys Val Val Glu Arg Ile Lys Glu
115 120 125
Arg Met Lys Asp Ser Asn Val Lys Leu Leu Trp Gly Thr Ala Asn Leu
130 135 140
Phe Ser His Pro Arg Tyr Met His Gly Ala Ala Thr Thr Cys Ser Ala
145 150 155 160
Asp Val Phe Ala Tyr Ala Ala Ala Gln Val Lys Lys Ala Leu Glu Ile
165 170 175
Thr Lys Glu Leu Gly Gly Glu Gly Tyr Val Phe Trp Gly Gly Arg Glu
180 185 190
Gly Tyr Glu Thr Leu Leu Asn Thr Asp Leu Gly Leu Glu Leu Glu Asn
195 200 205
Leu Ala Arg Phe Leu Arg Met Ala Val Glu Tyr Ala Lys Lys Ile Gly
210 215 220
Phe Thr Gly Gln Phe Leu Ile Glu Pro Lys Pro Lys Glu Pro Thr Lys
225 230 235 240
His Gln Tyr Asp Phe Asp Val Ala Thr Ala Tyr Ala Phe Leu Lys Asn
245 250 255
His Gly Leu Asp Glu Tyr Phe Lys Phe Asn Ile Glu Ala Asn His Ala
260 265 270
Thr Leu Ala Gly His Thr Phe Gln His Glu Leu Arg Met Ala Arg Ile
275 280 285
Leu Gly Lys Leu Gly Ser Ile Asp Ala Asn Gln Gly Asp Leu Leu Leu
290 295 300
Gly Trp Asp Thr Asp Gln Phe Pro Thr Asn Ile Tyr Asp Thr Thr Leu
305 310 315 320
Ala Met Tyr Glu Val Ile Lys Ala Gly Gly Phe Thr Lys Gly Gly Leu
325 330 335
Asn Phe Asp Ala Lys Val Arg Arg Ala Ser Tyr Lys Val Glu Asp Leu
340 345 350
Phe Ile Gly His Ile Ala Gly Met Asp Thr Phe Ala Leu Gly Phe Lys
355 360 365
Ile Ala Tyr Lys Leu Ala Lys Asp Gly Val Phe Asp Lys Phe Ile Glu
370 375 380
Glu Lys Tyr Arg Ser Phe Lys Glu Gly Ile Gly Lys Glu Ile Val Glu
385 390 395 400
Gly Lys Thr Asp Phe Glu Lys Leu Glu Glu Tyr Ile Ile Asp Lys Glu
405 410 415
Asp Ile Glu Leu Pro Ser Gly Lys Gln Glu Tyr Leu Glu Ser Leu Leu
420 425 430
Asn Ser Tyr Ile Val Lys Thr Ile Ala Glu Leu Arg
435 440
<210> 19
<211> 1335
<212> DNA
<213> Thermotoga maritima
<400> 19
atggccgagt tcttcccgga gatcccgaag atccagttcg agggcaagga
Claims (234)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020067020881A KR20070007817A (en) | 2006-10-04 | 2004-03-08 | Self-processing plants and plant parts |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020067020881A KR20070007817A (en) | 2006-10-04 | 2004-03-08 | Self-processing plants and plant parts |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20070007817A true KR20070007817A (en) | 2007-01-16 |
Family
ID=38010260
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020067020881A Withdrawn KR20070007817A (en) | 2006-10-04 | 2004-03-08 | Self-processing plants and plant parts |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR20070007817A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107552124A (en) * | 2017-09-21 | 2018-01-09 | 中国农业大学 | A kind of more qualities are fresh to grind rice automatic processing system and method |
-
2004
- 2004-03-08 KR KR1020067020881A patent/KR20070007817A/en not_active Withdrawn
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107552124A (en) * | 2017-09-21 | 2018-01-09 | 中国农业大学 | A kind of more qualities are fresh to grind rice automatic processing system and method |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2004318207B2 (en) | Self-processing plants and plant parts | |
| CN1564866B (en) | Self-processed plants and plant parts | |
| AU2002332666A1 (en) | Self-processing plants and plant parts | |
| US20120054915A1 (en) | Methods for increasing starch content in plant cobs | |
| KR20070007817A (en) | Self-processing plants and plant parts | |
| AU2006225290B2 (en) | Self-processing plants and plant parts | |
| NZ549679A (en) | Self-processing plants and plant parts | |
| US20240392333A1 (en) | Methods and compositions for increasing glucose yield from grain | |
| BR122014007966B1 (en) | Expression cassette comprising an alpha-amylase and a method of obtaining a plant comprising the same | |
| MXPA06010197A (en) | Self-processing plants and plant parts | |
| HK1094710A (en) | Self-processing plants and plant parts | |
| HK1072618A (en) | Self processing plants and plant parts |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20061004 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |