KR102298901B1 - Method and Apparatus for Emotional Voice Conversion using Multitask Learning with Text-to-Speech - Google Patents
Method and Apparatus for Emotional Voice Conversion using Multitask Learning with Text-to-Speech Download PDFInfo
- Publication number
- KR102298901B1 KR102298901B1 KR1020200027051A KR20200027051A KR102298901B1 KR 102298901 B1 KR102298901 B1 KR 102298901B1 KR 1020200027051 A KR1020200027051 A KR 1020200027051A KR 20200027051 A KR20200027051 A KR 20200027051A KR 102298901 B1 KR102298901 B1 KR 102298901B1
- Authority
- KR
- South Korea
- Prior art keywords
- speech
- mel spectrogram
- style
- text
- language
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000006243 chemical reaction Methods 0.000 title claims abstract description 69
- 230000002996 emotional effect Effects 0.000 title claims abstract description 43
- 238000000034 method Methods 0.000 title claims abstract description 30
- 238000001228 spectrum Methods 0.000 claims abstract description 11
- 230000008451 emotion Effects 0.000 claims description 42
- 238000012545 processing Methods 0.000 claims description 12
- 238000013528 artificial neural network Methods 0.000 claims description 9
- 230000008569 process Effects 0.000 claims description 9
- 238000011426 transformation method Methods 0.000 claims description 6
- 239000000284 extract Substances 0.000 claims description 5
- 230000009466 transformation Effects 0.000 description 16
- 238000013459 approach Methods 0.000 description 7
- 238000010586 diagram Methods 0.000 description 6
- 230000007246 mechanism Effects 0.000 description 4
- 230000002123 temporal effect Effects 0.000 description 4
- 238000002474 experimental method Methods 0.000 description 3
- 230000007935 neutral effect Effects 0.000 description 3
- 238000012549 training Methods 0.000 description 3
- 238000000844 transformation Methods 0.000 description 3
- 241000282414 Homo sapiens Species 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 230000000877 morphologic effect Effects 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000001755 vocal effect Effects 0.000 description 2
- 238000000737 ABX test Methods 0.000 description 1
- ORILYTVJVMAKLC-UHFFFAOYSA-N Adamantane Natural products C1C(C2)CC3CC1CC2C3 ORILYTVJVMAKLC-UHFFFAOYSA-N 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000002457 bidirectional effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/005—Language recognition
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Machine Translation (AREA)
Abstract
텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 방법 및 장치가 제시된다. 본 발명에서 제안하는 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 방법은 입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램(Mel spectrogram) 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)일 경우, 음성 변환(Voice Conversion; VC)을 수행하는 단계, 입력 음성의 페어가 원-핫(one-hot) 대표 텍스트 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)일 경우, 텍스트 음성 변환(Text-to-Speech; TTS)을 수행하는 단계, 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 단계 및 디코딩된 멜 스펙트로그램으로부터 전처리부를 통해 선형 스펙트럼을 획득하는 단계를 포함한다.A method and apparatus for emotional speech conversion using multitask learning along with text-to-speech conversion are presented. The emotional speech conversion method using multi-task learning together with text-to-speech conversion proposed in the present invention is a log Mel spectrogram of a language in which a pair of input speech delivers language content and a log Mel spectrogram of a style reference speech ( Mel spectrogram), performing voice conversion (Voice Conversion; VC), when the pair of input voices is a log Mel spectrogram of a one-hot representative text and style reference voice, The step of performing text-to-speech (TTS), the log Mel spectrogram of the language conveying the language content and the one-hot representative text are all mapped in the same space and then converted to a Mel spectrogram. and obtaining a linear spectrum from the decoded Mel spectrogram through a preprocessor.
Description
본 발명은 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 방법 및 장치에 관한 것이다.The present invention relates to a method and apparatus for emotional speech conversion using multitask learning together with text-to-speech conversion.
음성은 전달해야 할 것 - 언어 내용 - 그리고 전달 방법 - 스타일의 구성으로 간주될 수 있다. 음성 변환(Voice Conversion; VC)은 언어 내용을 유지하면서 음성 스타일을 변경하는 작업이다. 변환 과정에서 언어 내용이 손실되거나 스타일 정보가 변경되지 않을 수 있어 어려운 과제다.Speech can be considered as a construct of what is to be conveyed - the content of the language - and the method of delivery - of the style. Voice Conversion (VC) is the operation of changing the voice style while maintaining the language content. This is a difficult task because language content may be lost or style information may not change during the conversion process.
종래기술에서 음성 변환은 프레임 기반 접근방식을 사용하여 수행되었다. 출처와 대상 음성을 고려할 때 두 음성 사이의 정렬을 얻은 다음, 출처 음성의 음향 특성이 대상 음성으로 변환된다. 가우시안 혼합 모델(Gaussian Mixture Model; GMM), 심층 신경망(Deep Neural Network; DNN), 반복 신경망(Recurrent Neural Network; RNN)과 같이 모델 음향 기능에 다양한 방법이 적용되었다. 최근의 종래기술에서 주목하는 시퀀스 대 시퀀스(sequence-to-sequence; seq2seq) 모델의 성공 역시 음성 변환에 적용된다. seq2seq 음성 변환모델을 교육하는 동안 틀린 발음, 학습 불안정성과 같은 문제가 관찰되었다. 이러한 종래기술에서는 디코더 출력의 각 단계에 텍스트 감독을 추가하여 음성 변환의 품질을 개선한다. 그러나 이 접근법은 인간 또는 동적 시간 래핑(Dynamic Time Wrapping; DTW)에 의한 명확한 정렬이 필요하기 때문에 한계가 있다. In the prior art, speech conversion was performed using a frame-based approach. When considering the source and target voices, an alignment between the two voices is obtained, and then the acoustic properties of the source voice are transformed into the target voice. Various methods have been applied to the model acoustic function, such as Gaussian Mixture Model (GMM), Deep Neural Network (DNN), and Recurrent Neural Network (RNN). The success of the sequence-to-sequence (seq2seq) model, which is noteworthy in the recent prior art, is also applied to speech conversion. Problems such as incorrect pronunciation and learning instability were observed while training the seq2seq speech transformation model. In this prior art, the quality of speech conversion is improved by adding text supervision to each step of the decoder output. However, this approach has limitations because it requires explicit alignment by humans or Dynamic Time Wrapping (DTW).
전통적으로 프레임 기반 모델은 VC를 해결하는 데 사용되어 왔다. 출처와 대상 음성을 고려할 때, 이들의 정렬은 DTW에 의해 발견된다. 그런 다음 정렬된 프레임의 음향 특성 간 변환을 모델링한다. 최근 seq2seq 모델이 VC에서 제안되었다. 이러한 모델에서 모델은 명확한 시간적 정렬 없이 주의 메커니즘에 의한 정렬과 프레임 변환을 공동으로 학습한다. 그러나 변환된 음성이 언어 정보를 잃을 수 있기 때문에 VC의 성능은 충분하지 않다. 예를 들어 같은 단어가 반복적으로 생성되거나, 일부 단어가 삭제되거나, 잘못 발음되는 경우가 있다. 이러한 음성현상을 방지하기 위해 텍스트 감독을 VC에 추가하지만, 명시적인 정렬이 필요하다. 이전 작업과 달리, 언어 정보를 VC로 안내하기 위해 TTS를 사용했다. 이 접근법에는 명시적인 정렬이 필요하지 않다. Traditionally, frame-based models have been used to solve VCs. Given the source and target voices, their alignment is found by DTW. We then model the transformation between the acoustic properties of the aligned frames. Recently, the seq2seq model has been proposed in VC. In such a model, the model jointly learns the alignment and frame transformation by the attention mechanism without clear temporal alignment. However, the performance of VC is not sufficient because the converted voice may lose language information. For example, the same word may be repeatedly generated, or some words may be deleted or mispronounced. To prevent this speech phenomenon, we add text supervision to the VC, but we need explicit alignment. Unlike previous work, TTS was used to guide language information to the VC. This approach does not require explicit alignment.
한편, 감성적 음성 변환은 주로 프레임 기반 변환 또는 규칙 기반 접근을 수행하였다. DTW는 정확한 정렬과 규칙 기반 접근방식이 음성 변환 모델링에 제한을 갖도록 보장하지 않기 때문에 이러한 접근방식은 한계가 있다. 명시적 정렬에 의존하지 않는 모델을 사용하여 개선할 수 있다.On the other hand, emotional voice transformation mainly performed frame-based transformation or rule-based approach. This approach is limited because DTW does not guarantee that the exact alignment and rule-based approaches have limitations on speech transformation modeling. This can be improved by using a model that does not rely on explicit alignment.
본 발명이 이루고자 하는 기술적 과제는 텍스트 음성 변환(TTS)을 이용한 멀티태스크 학습을 이용하는 음성 변환 방법 및 장치를 제공하는데 있다. 제안하는 감정적 음성 변환 방법 및 장치를 통해 전체 네트워크는 VC와 TTS의 손실을 최소화하도록 학습되고, VC는 더 많은 언어 정보를 포착하고 멀티태스크 학습에 의해 학습 안정성을 보존하고자 한다. An object of the present invention is to provide a speech conversion method and apparatus using multi-task learning using text-to-speech (TTS). Through the proposed emotional speech conversion method and apparatus, the whole network is trained to minimize the loss of VC and TTS, and the VC tries to capture more language information and preserve learning stability by multi-task learning.
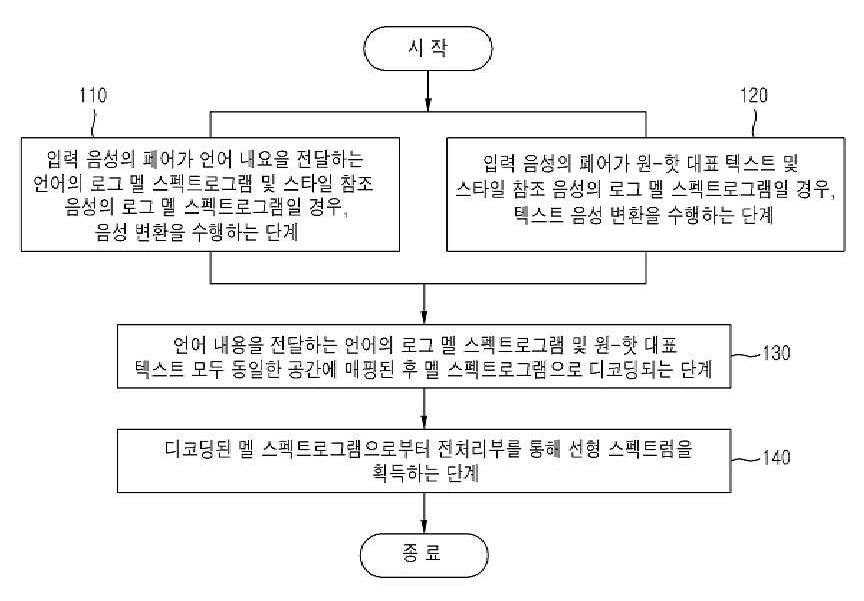
일 측면에 있어서, 본 발명에서 제안하는 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 방법은 입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램(Mel spectrogram) 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)일 경우, 음성 변환(Voice Conversion; VC)을 수행하는 단계, 입력 음성의 페어가 원-핫(one-hot) 대표 텍스트 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)일 경우, 텍스트 음성 변환(Text-to-Speech; TTS)을 수행하는 단계, 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 단계 및 디코딩된 멜 스펙트로그램으로부터 전처리부를 통해 선형 스펙트럼을 획득하는 단계를 포함한다. In one aspect, the emotional speech conversion method using multi-task learning together with text-to-speech conversion proposed in the present invention is a log Mel spectrogram of a language in which a pair of input speech conveys language content and a style reference speech. In case of log Mel spectrogram, performing Voice Conversion (VC), the input voice pair is one-hot representative text and log Mel spectrogram of the style reference voice (Mel) spectrogram), performing text-to-speech (TTS), log Mel spectrogram and one-hot representative text of the language conveying language content, all mapped in the same space Then, decoding into a Mel spectrogram and obtaining a linear spectrum from the decoded Mel spectrogram through a preprocessor.
입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 스타일 참조 음성의 로그 멜 스펙트로그램일 경우, 음성 변환을 수행하는 단계는 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램을 컨텐츠 인코더를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램을 스타일 인코더를 통해 임베딩한다. If the pair of input speech is a log Mel spectrogram of a language conveying language content and a log Mel spectrogram of a style reference voice, the step of performing speech conversion is a log Mel spectrogram of the language conveying the language content using a content encoder. and embedding the log Mel spectrogram of the style reference voice through the style encoder.
입력 음성의 페어가 원-핫 대표 텍스트 및 스타일 참조 음성의 로그 멜 스펙트로그램일 경우, 텍스트 음성 변환을 수행하는 단계는 원-핫 대표 텍스트를 텍스트 인코더를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램을 스타일 인코더를 통해 임베딩한다 When the pair of input voices is a log melt spectrogram of a one-hot representative text and a style reference voice, the step of performing text-to-speech is to embed the one-hot representative text through a text encoder, and log Mel spectrogram of the style reference voice. Embed the gram through the style encoder
언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 단계는 각 디코딩 단계에서 스타일 참조 음성의 로그 멜 스펙트로그램에서 추출한 스타일 벡터를 어텐션(attention) RNN과 디코더 RNN에 연결한다. The log Mel spectrogram and one-hot representative text of the language conveying the language content are both mapped to the same space and then decoded into the Mel spectrogram in each decoding step from the log Mel spectrogram of the style reference voice. The extracted style vector is connected to the attention RNN and the decoder RNN.
언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 단계는 텍스트 인코더, 어텐션 RNN, 디코더 RNN 및 전처리부를 통해 텍스트 음성 변환을 수행하는 경우, 어텐션 RNN의 모든 반복에 컨텍스트 벡터가 활용된다. The log Mel spectrogram and one-hot representative text of the language conveying the language content are both mapped to the same space and then decoded into a Mel spectrogram through a text encoder, attention RNN, decoder RNN and preprocessor. When performing speech transformation, the context vector is utilized for every iteration of the attention RNN.
스타일 참조 음성을 고려할 때 스타일 인코더는 감정 정보만을 추출하고 언어적 내용을 제거하며, 언어적 내용에 관계없이 감정을 추출하도록 설계되어 복수의 입력 스타일 도메인을 처리하고, 추출된 감정이 디코더에 주입되면 다양한 감정을 생성함으로써 다대 다의 감정적 음성 변환을 처리한다. When considering the style reference voice, the style encoder only extracts emotion information and removes the linguistic content, is designed to extract the emotion regardless of the linguistic content, processes multiple input style domains, and when the extracted emotion is injected into the decoder It handles many-to-many emotional speech transformations by generating a variety of emotions.
또 다른 일 측면에 있어서, 본 발명에서 제안하는 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 장치는 입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램(Mel spectrogram) 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)인지 또는 원-핫(one-hot) 대표 텍스트 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)인지에 따라 스타일 인코더, 컨텐츠 인코더 및 텍스트 인코더를 통해 음성 변환 또는 텍스트 음성 변환을 수행하는 변환부, 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 신경망 네트워크 및 디코딩된 멜 스펙트로그램으로부터 선형 스펙트럼을 획득하는 전처리부를 포함한다.In another aspect, the emotional speech conversion apparatus using multi-task learning together with text-to-speech conversion proposed in the present invention refers to a log Mel spectrogram and style of a language in which a pair of input speech conveys language content. Speech conversion through style encoder, content encoder and text encoder depending on whether it is a log Mel spectrogram of speech or a log Mel spectrogram of a one-hot representative text and style reference speech. Alternatively, a conversion unit that performs text-to-speech conversion, a neural network network that is decoded into a Mel spectrogram after all of the log Mel spectrogram and one-hot representative text of the language that delivers the language content are mapped in the same space and decoded It includes a preprocessor that acquires a linear spectrum from the Mel spectrogram.
본 발명의 실시예들에 따르면 텍스트 음성 변환을 이용한 멀티태스크 학습을 이용하는 감정적 음성 변환 방법 및 장치를 통해 전체 네트워크는 VC와 TTS의 손실을 최소화하도록 학습하고, VC는 더 많은 언어 정보를 포착하고 멀티태스크 학습에 의해 학습 안정성을 보존할 수 있다.According to embodiments of the present invention, through the emotional speech conversion method and apparatus using multitask learning using text-to-speech conversion, the entire network learns to minimize the loss of VC and TTS, and the VC captures more language information and multitasks. Learning stability can be preserved by task learning.
도 1은 본 발명의 일 실시예에 따른 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 방법을 설명하기 위한 흐름도이다.
도 2는 본 발명의 일 실시예에 따른 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 장치의 구성을 나타내는 도면이다.
도 3은 본 발명의 일 실시예에 따른 스타일 인코더의 혼잡 행렬을 나타내는 도면이다.
도 4는 본 발명의 일 실시예에 따른 음성 변환 결과의 예시를 나타내는 도면이다. 1 is a flowchart illustrating an emotional speech conversion method using multi-task learning together with text-to-speech conversion according to an embodiment of the present invention.
2 is a diagram showing the configuration of an emotional speech conversion apparatus using multi-task learning together with text-to-speech conversion according to an embodiment of the present invention.
3 is a diagram illustrating a congestion matrix of a style encoder according to an embodiment of the present invention.
4 is a diagram illustrating an example of a voice conversion result according to an embodiment of the present invention.
본 발명에서는 텍스트 음성 변환(Text-to-Speech; TTS)을 사용하는 접근법을 채택하고 있다. TTS는 텍스트 또는 음성 정보를 음성 파형으로 변환하는 작업이며, 풍부한 seq2seq 기반 연구가 활발하게 진행되었다. TTS는 음성 변환(Voice Conversion; VC)과 매우 관련이 깊은 작업이다. VC와 TTS는 입력 도메인만 다를 뿐, 음성 정보를 음향 형상으로 변환하는 디코더의 역할은 매우 동일하다. TTS의 임베딩 공간은 음성정보와 높은 상관관계가 있으며, VC는 멀티태스크 학습을 통해 TTS와 가까운 임베딩 공간을 학습할 것으로 기대된다. 본 발명에서는 성능 향상을 위해 TTS를 VC에 음성 정보를 제공하는 데 활용한다. The present invention adopts an approach using text-to-speech (TTS). TTS is the task of converting text or voice information into voice waveforms, and abundant seq2seq-based research has been actively conducted. TTS is a work closely related to voice conversion (VC). VC and TTS differ only in the input domain, but the role of the decoder for converting voice information into an acoustic shape is very the same. The embedding space of TTS has a high correlation with voice information, and VC is expected to learn an embedding space close to TTS through multi-task learning. In the present invention, TTS is used to provide voice information to VC to improve performance.
본 발명의 실시예에 따르면, 이러한 작업을 감정적 음성 변환으로 확장한다. 스타일 참조 음성을 고려할 때 스타일 인코더는 감정 정보만을 추출하고 언어적 내용을 제거한다. 스타일 인코더는 언어적 내용에 관계없이 감정을 추출하도록 설계되어 있어 복수의 입력 스타일 도메인을 처리할 수 있다. 또한 추출된 감정이 디코더에 주입되면 다양한 감정을 생성할 수 있다. 따라서 제안된 모델은 다대 다의 감정적 음성 변환을 처리할 수 있다. According to an embodiment of the present invention, this task is extended to emotional speech transformation. When considering the style reference voice, the style encoder only extracts emotional information and removes the linguistic content. Style encoders are designed to extract emotions regardless of their linguistic content, so they can handle multiple input style domains. In addition, when the extracted emotions are injected into the decoder, various emotions can be generated. Therefore, the proposed model can handle many-to-many emotional speech transformation.
본 발명의 실시예에 따른 모델의 기여는 다음과 같다: TTS를 이용한 멀티태스킹 학습은 VC의 성능을 향상시킬 수 있다. 다수의 감정적 음성 변환은 처음에 seq2seq 모델에 의해 수행되었다. 스타일 참조 음성은 음성 변환의 대상 영역을 결정할 수 있다. The contribution of the model according to the embodiment of the present invention is as follows: Multitasking learning using TTS can improve the performance of VC. A number of emotional speech transformations were initially performed by the seq2seq model. The style reference voice may determine a target region for voice transformation.
다대 다의 VC는 출처 도메인의 개수와 대상 도메인의 개수를 가리킨다. 종래기술에서 Cycle-GAN은 데이터세트가 아닌 아닌 스피커(speaker)를 대상 스피커로 변환했고, 그 반대로도 변환했다. i-벡터 기반 VC 시스템은 학습 세트에 없는 스피커의 언어적 특징을 생성하기 위해 제안된다. 다른 다대 다의 VC 방식과 비교했을 때, 제안 모델은 스피커의 정서적 지식을 전달할 수 있고 다른 감정들 간의 변환을 가능하게 한다.The many-to-many VC indicates the number of source domains and the number of target domains. In the prior art, Cycle-GAN converts a non-dataset speaker into a target speaker, and vice versa. An i-vector based VC system is proposed to generate linguistic features of speakers that are not in the training set. Compared with other many-to-many VC schemes, the proposed model can convey the emotional knowledge of the speaker and enable conversion between different emotions.
TTS는 음성 영역에서 가장 활발한 연구 분야 중 하나이다. 다양한 종류의 Seq2seq 모델이 제안되었으며 표현적 합성도 연구되었다. 스타일 인코더에서 추출한 스타일 벡터는 입력된 감정이 네트워크에 주입되어 감정적 음성을 생성한다. 본 발명에서, 감정 라벨은 학습 중에 활용되지 않으며, 어떠한 감정 라벨도 네트워크의 입력으로 명시적으로 받아들여지지 않는다. 이하, 본 발명의 실시 예를 첨부된 도면을 참조하여 상세하게 설명한다. TTS is one of the most active research areas in the speech domain. Various kinds of Seq2seq models have been proposed and their expressive synthesis has also been studied. The style vector extracted from the style encoder generates emotional voice by injecting the input emotion into the network. In the present invention, emotion labels are not utilized during learning, and no emotion labels are explicitly accepted as input to the network. Hereinafter, embodiments of the present invention will be described in detail with reference to the accompanying drawings.
도 1은 본 발명의 일 실시예에 따른 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 방법을 설명하기 위한 흐름도이다. 1 is a flowchart illustrating an emotional speech conversion method using multi-task learning together with text-to-speech conversion according to an embodiment of the present invention.
음성 변환(VC)은 언어적 내용을 보존하면서 사람의 목소리를 다른 스타일로 바꾸는 작업이다. VC에 관한 종래의 최첨단 기술은 언어 정보를 호도할 수 있는 시퀀스 대 시퀀스(seq2seq) 모델을 기반으로 한다. 텍스트 감시를 사용하여 이를 극복하려는 시도가 있었고, seq2seq 모델을 사용할 경우의 이점을 잃게 되는 명확한 정렬이 요구된다. 본 발명에서는 텍스트 음성 변환(TTS)를 이용한 멀티태스크 학습을 이용하는 음성 변환을 제시한다. seq2seq 기반 TTS의 임베딩(embedding)은 텍스트에 대한 풍부한 정보를 가지고 있다. TTS 디코더의 역할은 내장 공간을 VC와 같은 음성으로 변환하는 것이다. 제안된 모델에서, 전체 네트워크는 VC와 TTS의 손실을 최소화하도록 학습된다. VC는 더 많은 언어 정보를 포착하고 멀티태스크 학습에 의해 학습 안정성을 보존할 것으로 기대된다. VC의 실험은 한국의 남성 정서적 텍스트 음성 데이터세트에서 수행되었으며, 멀티태스크 학습은 VC에서 언어적 내용을 유지하는 데 도움이 된다는 것을 보여준다.Voice transformation (VC) is the operation of changing a human voice into a different style while preserving the linguistic content. The prior state-of-the-art technology for VC is based on a sequence-to-sequence (seq2seq) model that can mislead linguistic information. Attempts have been made to overcome this by using text monitoring, which requires a clear alignment that loses the benefits of using the seq2seq model. In the present invention, speech conversion using multi-task learning using text-to-speech (TTS) is presented. The embedding of seq2seq-based TTS has rich information about the text. The role of the TTS decoder is to convert the built-in space into VC-like speech. In the proposed model, the entire network is trained to minimize the loss of VC and TTS. VC is expected to capture more language information and preserve learning stability by multi-task learning. Experiments in VC were performed on the male emotional text-to-speech dataset in Korea, and show that multi-task learning helps preserve verbal content in VC.
제안하는 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 방법은 입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램(Mel spectrogram) 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)일 경우, 음성 변환(Voice Conversion; VC)을 수행하는 단계(110), 입력 음성의 페어가 원-핫(one-hot) 대표 텍스트 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)일 경우, 텍스트 음성 변환(Text-to-Speech; TTS)을 수행하는 단계(120), 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 단계(130) 및 디코딩된 멜 스펙트로그램으로부터 전처리부를 통해 선형 스펙트럼을 획득하는 단계(140)를 포함한다. The proposed method for emotional speech conversion using multitask learning with text-to-speech conversion is the log Mel spectrogram of the language in which the pair of input speech conveys the language content and the log Mel spectrogram of the style reference speech. If , performing voice conversion (Voice Conversion; VC)
단계(110)에서, 입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램(Mel spectrogram) 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)일 경우, 음성 변환(Voice Conversion; VC)을 수행한다. 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램을 컨텐츠 인코더를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램을 스타일 인코더를 통해 임베딩한다. In
단계(120)에서, 입력 음성의 페어가 원-핫(one-hot) 대표 텍스트 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)일 경우, 텍스트 음성 변환(Text-to-Speech; TTS)을 수행한다. 원-핫 대표 텍스트를 텍스트 인코더를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램을 스타일 인코더를 통해 임베딩한다. In
단계(130)에서, 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩된다. 각 디코딩 단계에서 스타일 참조 음성의 로그 멜 스펙트로그램에서 추출한 스타일 벡터를 어텐션(attention) RNN과 디코더 RNN에 연결한다. 이때, 텍스트 인코더, 어텐션 RNN, 디코더 RNN 및 전처리부를 통해 텍스트 음성 변환을 수행하는 경우, 어텐션 RNN의 모든 반복에 컨텍스트 벡터가 활용된다. In
단계(140)에서, 디코딩된 멜 스펙트로그램으로부터 전처리부를 통해 선형 스펙트럼을 획득한다. In
본 발명의 실시예에 따르면, 스타일 참조 음성을 고려할 때 스타일 인코더는 감정 정보만을 추출하고 언어적 내용을 제거하며, 언어적 내용에 관계없이 감정을 추출하도록 설계되어 복수의 입력 스타일 도메인을 처리하고, 추출된 감정이 디코더에 주입되면 다양한 감정을 생성함으로써 다대 다의 감정적 음성 변환을 처리한다. According to an embodiment of the present invention, when considering a style reference voice, the style encoder is designed to extract only emotion information and remove linguistic content, and is designed to extract emotions regardless of linguistic content to process a plurality of input style domains, When the extracted emotion is injected into the decoder, it processes many-to-many emotional speech conversion by generating various emotions.
더욱 상세하게는, 제안된 감정적 음성 변환 방법은 단일 모델에서 VC와 TTS를 수행할 수 있다. 네트워크는 입력 페어(pair)가 (xc, xs)일 때 VC로, 또는 입력 페어가 (yt, xs)일 때 TTS로 플레이된다. 여기서 xc, yt, xs는 언어 내용을 전달하는 언어의 로그 멜 스펙토그램(Mel spectrogram), 원-핫(one-hot) 대표 텍스트, 스타일 참조 음성의 로그 멜 스펙토그램이다. xc와 yt 모두 동일한 공간 hl에 매핑된 후, 멜 스펙토그램 m으로 디코딩된다. 각 디코딩 단계에서 xs에서 추출한 스타일 벡터 hs를 어텐션 RNN과 디코더 RNN에 연결한다. 선형 스펙트럼 l는 전처리부에 의해 획득된다. 자세한 네트워크 아키텍처는 도 2 및 아래의 등식을 참조하여 설명한다. More specifically, the proposed emotional speech transformation method can perform VC and TTS in a single model. The network is played with VC when the input pair is (x c , x s ) or TTS when the input pair is (y t , x s ). Here, x c , y t , and x s are the log Mel spectrogram of the language that conveys the language content, the one-hot representative text, and the log Mel spectogram of the style reference voice. Both x c and y t are mapped to the same space h l and then decoded into Mel spectogram m. In each decoding step, the style vector h s extracted from x s is connected to the attention RNN and the decoder RNN. A linear spectrum l is obtained by the preprocessor. A detailed network architecture will be described with reference to FIG. 2 and the equation below.
도 2는 본 발명의 일 실시예에 따른 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 장치의 구성을 나타내는 도면이다. 2 is a diagram showing the configuration of an emotional speech conversion apparatus using multi-task learning together with text-to-speech conversion according to an embodiment of the present invention.
제안하는 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 장치는 변환부(210), 신경망 네트워크(220), 전처리부(230)를 포함한다. The apparatus for emotional speech conversion using multitask learning together with the proposed text-to-speech conversion includes a
변환부(210)는 입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램(Mel spectrogram)(xc) 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)인지 또는 원-핫(one-hot) 대표 텍스트(yt) 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)(xs)인지에 따라 스타일 인코더(211), 컨텐츠 인코더(212) 및 텍스트 인코더(213)를 통해 음성 변환 또는 텍스트 음성 변환을 수행한다. The
변환부(210)는 입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램(xc) 및 스타일 참조 음성의 로그 멜 스펙트로그램(xs)일 경우, 음성 변환을 수행한다. 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램(xc)을 컨텐츠 인코더(212)를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램(xs)을 스타일 인코더(211)를 통해 임베딩한다. When the pair of input voices is a log Mel spectrogram (x c ) of a language transmitting language content and a log Mel spectrogram (x s ) of a style reference voice, it performs voice conversion. The log Mel spectrogram (x c ) of the language delivering the language content is embedded through the content encoder 212 , and the log Mel spectrogram (x s ) of the style reference voice is embedded through the style encoder 211 .
변환부(210)는 입력 음성의 페어가 원-핫 대표 텍스트(yt) 및 스타일 참조 음성의 로그 멜 스펙트로그램(xs)일 경우, 텍스트 음성 변환을 수행한다. 원-핫 대표 텍스트(yt)를 텍스트 인코더(213)를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램(xs)을 스타일 인코더(211)를 통해 임베딩한다. The
신경망 네트워크(220)는 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램(xc) 및 원-핫(one-hot) 대표 텍스트(yt) 모두 동일한 공간에 매핑된 후 멜 스펙트로그램(m)으로 디코딩된다. 신경망 네트워크(220)는 각 디코딩 단계에서 스타일 참조 음성의 로그 멜 스펙트로그램에서 추출한 스타일 벡터를 어텐션(attention) RNN(221)과 디코더 RNN(222)에 연결한다. The
전처리부(230)는 디코딩된 멜 스펙트로그램(m)으로부터 선형 스펙트럼(l)을 획득한다. 선형 스펙트럼(l)은 보코더(Vocoder)(240)를 거쳐 변환된 음성(xo)을 출력한다. The preprocessor 230 obtains a linear spectrum l from the decoded Mel spectrogram m. The linear spectrum (l) outputs a converted voice (x o ) through a vocoder (240).
본 발명의 실시예에 따르면, 스타일 참조 음성을 고려할 때 스타일 인코더는 감정 정보만을 추출하고 언어적 내용을 제거하며, 언어적 내용에 관계없이 감정을 추출하도록 설계되어 복수의 입력 스타일 도메인을 처리하고, 추출된 감정이 디코더에 주입되면 다양한 감정을 생성함으로써 다대 다의 감정적 음성 변환을 처리한다. According to an embodiment of the present invention, when considering a style reference voice, the style encoder is designed to extract only emotion information and remove linguistic content, and is designed to extract emotions regardless of linguistic content to process a plurality of input style domains, When the extracted emotion is injected into the decoder, it processes many-to-many emotional speech conversion by generating various emotions.
더욱 상세하게는, 제안된 감정적 음성 변환 장치 단일 모델에서 VC와 TTS를 수행할 수 있다. 네트워크는 입력 페어(pair)가 (xc, xs)일 때 VC로, 또는 입력 페어가 (yt, xs)일 때 TTS로 플레이된다. 여기서 xc, yt, xs는 언어 내용을 전달하는 언어의 로그 멜 스펙토그램(Mel spectrogram), 원-핫(one-hot) 대표 텍스트, 스타일 참조 음성의 로그 멜 스펙토그램이다. xc와 yt 모두 동일한 공간 hl에 매핑된 후, 멜 스펙토그램 m으로 디코딩된다. 각 디코딩 단계에서 xs에서 추출한 스타일 벡터 hs를 어텐션 RNN과 디코더 RNN에 연결한다. 선형 스펙트럼 l는 전처리부에 의해 획득된다. More specifically, VC and TTS can be performed in a single model of the proposed emotional speech conversion device. The network is played with VC when the input pair is (x c , x s ) or TTS when the input pair is (y t , x s ). Here, x c , y t , and x s are the log Mel spectrogram of the language that conveys the language content, the one-hot representative text, and the log Mel spectogram of the style reference voice. Both x c and y t are mapped to the same space h l and then decoded into Mel spectogram m. In each decoding step, the style vector h s extracted from x s is connected to the attention RNN and the decoder RNN. A linear spectrum l is obtained by the preprocessor.

여기서 ht, hc, hs는 각각 텍스트 인코더(213), 컨텐츠 인코더(212), 스타일 인코더(211)의 임베딩이다. hatt (t) 및 hdec (t)는 시간 단계 t에서 주의 RNN과 디코더 RNN의 숨겨진 표현이다. m, l, c(t) 및 o(t)는 시간 단계 t에서의 로그 멜 스펙트로그램, 대상의 로그 선형 스펙트로그램, 주의 메커니즘에 의해 달성된 컨텍스트 벡터, 시간 단계 t에서의 주의 RNN 출력이다. XOR은 익스클러시브(exclusive) OR 연산자를 의미한다.Here, h t , h c , and h s are embeddings of the text encoder 213 , the content encoder 212 , and the style encoder 211 , respectively. h att (t) and h dec (t) are the hidden representations of the attention RNN and the decoder RNN at time step t. m, l, c (t) and o (t) are the log Mel spectrogram at time step t, the log linear spectrogram of the object, the context vector achieved by the attention mechanism, and the attention RNN output at time step t. XOR stands for an exclusive OR operator.
텍스트 인코더, 디코더, 어텐션 RNN 및 전처리부를 포함한 TTS 부분의 경우, 전체적인 아키텍처는 타코트론(Tacotron)을 기반으로 하며, 어텐션 RNN의 모든 반복에 컨텍스트 벡터 c(t)가 활용되고, 잔여 연결은 Convolution Bank + Highway + bi-GRU(CBHG) 연결에 추가된다.For the TTS part including the text encoder, decoder, attention RNN and preprocessor, the overall architecture is based on the tacotron, the context vector c (t) is utilized for every iteration of the attention RNN, and the residual concatenation is the Convolution Bank + Highway + bi-GRU (CBHG) connections are added.
텍스트 인코더는 캐릭터 임베딩 계층, 프리넷(prenet), CBHG로 구성되며, 여기서 프리넷은 FC ReLU-Dropout 계층 2개로 구성된다. LSTM 스택은 컨텐츠 인코더에 사용되며, 시간적 감소가 로컬 시간 정보를 잃을 수 있기 때문에 시간적 해상도의 감소는 없었다. 이는 hc의 길이가 xc와 같다는 의미이다. 스타일 인코더의 경우 xs는 LSTM의 마지막 단계에 이어 완전히 연결된 계층을 임베딩하여 고정 치수가 있는 hs에 매핑되어 치수를 감소시킨다. 주의 모듈은 주의 RNN과 주의 메커니즘으로 구성된다. 주의 RNN은 hs, c(t-1), m(t-1)을 입력으로 취한다. 그리고 나서 그것의 출력 o(t)와 hl은 컨텍스트 벡터 c(t)를 생성하기 위한 주의 메커니즘에 사용된다.The text encoder consists of a character embedding layer, prenet, and CBHG, where the prenet consists of two FC ReLU-Dropout layers. The LSTM stack is used for content encoders, and there was no decrease in temporal resolution because temporal reduction could result in loss of local temporal information. This means that the length of h c is equal to x c . For the style encoder, x s is mapped to h s with fixed dimensions by embedding a fully connected layer following the last step in LSTM to reduce dimensions. The attention module consists of the attention RNN and the attention mechanism. Note RNNs take h s , c (t-1) , m (t-1) as inputs. Then its outputs o (t) and h l are used in the attention mechanism to generate the context vector c (t).
학습 손실은 Im-mgtI+II-IgtI이며, 여기서 mgt와 lgt는 그라운드 트루(ground truth) 로그 멜 스펙트로그램 및 로그 선형 스펙트로그램이다.The learning loss is Im-mgtI+II-IgtI, where mgt and lgt are the ground truth log Mel spectrogram and log linear spectrogram.
본 발명의 실시예에 따르면, mKETTS(Korean Emotional Text-to-speech) 데이터 세트를 구축했다. 예를 들어, 실험을 위해 측정된 30세의 한 남자는 7개의 다른 감정(중립, 행복, 슬픔, 분노, 두려움, 놀라움, 혐오감)으로 3,000개의 문장을 발음했기 때문에, 전체 발언 수는 2만 1천 개에 이른다. 모든 문장의 텍스트는 감정 전반에 걸쳐 동일하다. 모든 녹음은 소리 없이 조용한 스튜디오에서 진행되어 44.1 kHz의 샘플링 속도로 기록되어 있다. 정적을 다듬은 후의 전체 시간은 29.2시간이다.According to an embodiment of the present invention, a Korean Emotional Text-to-speech (mKETTS) data set was constructed. For example, a 30-year-old man measured for the experiment pronounced 3,000 sentences with 7 different emotions (neutral, happy, sad, anger, fear, surprise, disgust), so the total number of utterances was 21 1 up to a thousand The text of every sentence is the same throughout the emotion. All recordings were made in a quiet, silent studio and recorded at a sampling rate of 44.1 kHz. The total time after refinement of the stillness is 29.2 hours.
사전 처리의 경우, 각 파형의 첫 번째와 끝의 정적을 음성 활동 감지(VAD) 알고리즘을 사용하여 다듬고 16kHz로 다시 샘플링한다. 그런 다음 로그 멜 스펙트로그램은 윈도우 크기 50ms, 시프트 12.5ms, nfft 2048, 80 멜 빈스(Mel bins) 및 해닝(Hanning) 윈도우로 추출한다. 그 크기는 [0, 1]로 표준화되었다. 텍스트 인코더는 문자 기반 표현을 사용하기 때문에, 한국 문자는 온셋(onset), 뉴클리스(nucleus), 코다(coda)로 분해된 후 원-핫(one-hot) 표현으로 변환된다.For pre-processing, the static at the beginning and end of each waveform is trimmed using a voice activity detection (VAD) algorithm and resampled at 16 kHz. Then, the log Mel spectrogram is extracted with a window size of 50 ms, a shift of 12.5 ms, nfft 2048, 80 Mel bins and Hanning windows. The size was normalized to [0, 1]. Since the text encoder uses a character-based representation, Korean characters are decomposed into onset, nucleus, and coda, and then converted into a one-hot representation.
자세한 파라미터 설정은 다음과 같다. 본 발명의 실시예에 따르면, 256자 임베딩, 32차원 hs를 사용했다. 초기 학습율은 아담 최적기의 경우 1e-3이었다. 경사 클립핑(gradient clipping)은 1로 사용되었으며, m은 감소 계수 5로 생성되었다. 배치 사이즈는 32였고, Bahdanau attention이 사용되었다. 컨텐츠 인코더는 양방향 LSTM와 스타일 인코더에 두 층을 사용하였으며, 컨텐츠 인코더는 단방향 LSTM의 두 층으로 구성되어 있다. 마지막 단계의 출력은 컨텐츠 인코더에만 사용된다. 컨텐츠 인코더와 스타일 인코더의 파라미터는 공유되지 않는다. 학습 단계에서는 예측 산출물의 누적 손실을 방지하기 위해 티처 포싱(teacher forcing)을 사용하였다. 미니 배치를 만들 때 각 샘플은 샘플의 가장 긴 길이로 제로-페이딩(zero-padding) 된다. 그 후, 제로-페이딩된 영역의 손실도 추론 안정성을 위해 역전사된다. 모든 반복에 대해, 네트워크의 작업은 무작위로 VC 또는 TTS로 결정된다. 각 샘플에 대해 출처와 대상 감정은 다르게 선택된다.Detailed parameter settings are as follows. According to an embodiment of the present invention, 256-character embeddings, 32-dimensional hs were used. The initial learning rate was 1e-3 for the Adam optimum. Gradient clipping was used as 1, and m was created with a reduction factor of 5. The batch size was 32, and Bahdanau attention was used. The content encoder uses two layers for the bidirectional LSTM and the style encoder, and the content encoder consists of two layers for the unidirectional LSTM. The output of the last step is only used by the content encoder. The parameters of the content encoder and the style encoder are not shared. In the learning phase, teacher forcing was used to prevent the cumulative loss of prediction products. When making a mini-batch, each sample is zero-padded to the longest length of the sample. Then, the loss of the zero-faded region is also reverse transcribed for speculation stability. For every iteration, the network's operation is randomly determined by VC or TTS. For each sample, the source and target emotions are chosen differently.
제안된 모델의 언어적 일관성을 검증하기 위해 세 가지 다른 모델을 교육하고 평가하였다. VCTS는 앞서 설명된 바와 같이 TTS와 VC를 결합한 모델이다. VC는 TTS 경로가 없는 음성 변환기를 말한다. TTS는 VC 경로를 포함하지 않는 TTS 모델을 말한다. VCTTS-V는 VCTTS를 이용한 음성 변환 추론 모델이며, VCTTS-T는 VCTTS의 TTS 경로가 활성화되었을 때의 모델이다.To verify the linguistic consistency of the proposed model, three different models were trained and evaluated. VCTS is a model that combines TTS and VC as described above. VC refers to a voice converter without a TTS path. TTS refers to a TTS model that does not include a VC path. VCTTS-V is a speech transformation inference model using VCTTS, and VCTTS-T is a model when the TTS pathway of VCTTS is activated.
단어 오류율(WER)은 제안된 모델이 어떻게 변환된 언어의 일관성을 향상시키는지를 측정하기 위해 계산되었다. 사실, 형태소는 한국어의 인식 단위로 간주되기 때문에 단어 대신에 사용되었다. 구글 클라우드 음성-텍스트 API는 변환된 음성들을 기록했고, 녹취록은 KoNLPy의 Komoran 형태학 분석기에 의해 일련의 형태소로 나뉘었다. 이후, 실제 기록과 자동 인식된 기록의 두 가지 형태소 순서 사이의 평균 WER을 계산하여 표 1에 표시하였다. 그 결과 VCTTS-V가 VC보다 우수하고, TTS의 WER가 VCTTS-T보다 우수했다. The word error rate (WER) was calculated to measure how the proposed model improves the consistency of the transformed language. In fact, morphemes are used in place of words because they are considered the recognition units of Korean. The Google Cloud speech-to-text API recorded the converted speeches, and the transcripts were broken down into a series of morphemes by KoNLPy's Komoran morphological analyzer. Then, the average WER between the two morphological sequences of the actual record and the automatically recognized record was calculated and displayed in Table 1. As a result, VCTTS-V was superior to VC, and WER of TTS was superior to VCTTS-T.
<표 1> <Table 1>

학습이 끝난 뒤 8명의 원어민이 주관적인 평가에 참여했다. 20개의 문장이 VCTTS-V 모델에 의해 생성되었다. xc의 감정은 중립으로 설정되었고 대상 감정은 행복으로 설정되었고 xs의 문장은 고정되었다. 어떤 모델이 어떤 음성을 생성하는지 피실험자들은 결코 알지 못한다는 것을 맹목적으로 시험한다. 주제들은 그것의 명료성을 1부터 5까지 평가하도록 요청 받았다. 또한, 두 모델 간의 선호도 ABX 테스트가 실시되었다. 어떤 모델이 어떤 샘플을 생성하는지 정보가 없는 두 개의 음성이 주어졌을 때, 주제들은 더 명확한 음성을 선택하도록 요청 받았다. 실험 대상자들은 두 샘플이 유사하다고 인식되면 어떤 것도 선택할 수 없다. 결과는 표 2와 같다. 그것은 VCTTV-V가 높은 MOS와 ABX 선호 점수를 가지고 있다는 것을 보여주는데, 이것은 VC와 TTS의 멀티태스크 학습이 언어 정보를 유지하는 데 도움이 된다는 것을 의미한다. After learning, 8 native speakers participated in the subjective evaluation. Twenty sentences were generated by the VCTTS-V model. The emotion of x c was set to neutral, the target emotion was set to happiness, and the sentence of x s was fixed. Blindly test that subjects never know which model produces which voice. Subjects were asked to rate their clarity on a scale of 1 to 5. In addition, a preference ABX test between the two models was conducted. Given two voices with no information about which model generated which sample, subjects were asked to choose the clearer voice. Subjects are not allowed to choose either one if the two samples are perceived to be similar. The results are shown in Table 2. It shows that VCTTV-V has high MOS and ABX preference scores, which means that multitask learning of VC and TTS helps retain language information.
<표 2><Table 2>

도 3은 본 발명의 일 실시예에 따른 스타일 인코더의 혼잡 행렬을 나타내는 도면이다. 3 is a diagram illustrating a congestion matrix of a style encoder according to an embodiment of the present invention.
감정적 음성 변환을 조사하기 위해 위에서 언급한 VCTTS 모델을 추론에 사용한다. 학습이 끝난 후, 무작위로 각 감정당 20개의 샘플을 선택했고, 그 샘플들은 모델에 공급된다. 그러면 샘플당 hs를 얻을 수 있으며, 각 표본 간의 코사인 유사성을 측정하여 도 3에 나타내었다. 모든 감정 페어 간의 코사인 유사성의 평균값도 표시된다.To investigate emotional speech transformation, the above-mentioned VCTTS model is used for inference. After training, 20 samples were randomly selected for each emotion, and the samples were fed to the model. Then, h s per sample can be obtained, and the cosine similarity between each sample is measured and shown in FIG. 3 . The average value of cosine similarity between all emotion pairs is also displayed.
도 3에서, 같은 감정의 표본은 코사인 유사성이 매우 높은 반면, 사선 이외의 감정 페어는 유사성이 낮다는 것을 보여준다. 그것은 스타일 인코더가 언어적 내용에 상관없이 감정 스타일을 추출할 수 있다는 것을 암시한다. 대각선 감정 페어를 제외하고도 감정 페어(역겨움-분노)는 비교적 높은 유사성을 나타내는데, 이는 이 두 감정의 내재가 다른 감정보다 더 가깝다는 것을 의미한다. (슬픔-두려움) 페어에서도 같은 음성이 관찰된다. In FIG. 3 , it is shown that the sample of the same emotion has a very high cosine similarity, whereas the emotion pair other than the diagonal line has a low similarity. It implies that the style encoder can extract emotional styles regardless of linguistic content. Even with the exception of the diagonal emotion pair, the emotion pair (disgust-anger) shows a relatively high degree of similarity, which means that the immanence of these two emotions is closer than the other emotions. The same voice is observed in the (sad-fear) pair.
도 4는 본 발명의 일 실시예에 따른 음성 변환 결과의 예시를 나타내는 도면이다.4 is a diagram illustrating an example of a voice conversion result according to an embodiment of the present invention.
감성적 음성 변환은 언어적 내용을 유지하면서 감정을 반영해야 한다. 도 4에서는 음성 변환의 예시를 나타낸다. 중립적인 음성이 주어질 때, 주어진 xs는 6가지 다른 감정으로 변모한다. xs의 내용은 이 실험 동안 고정되어 있다. 도 4의 첫째 행은 입력 음성의 로그 멜 스펙트로그램이며, 두 번째 행에서 일곱 번째 행까지 변환 음성의 로그 멜 스펙트로그램이다. 스펙트로그램의 전체적인 형태는 입력과 유사한 반면, 시간 이동, 주파수 이동, 일시 정지 시간 등의 일부 변경이 이루어졌다는 것을 알 수 있다. 단일 모델 내에서, 그것은 다수의 언어 도메인을 생성할 수 있다.Emotional speech transformations must reflect emotions while preserving the verbal content. 4 shows an example of voice conversion. When given a neutral voice, a given x s transforms into six different emotions. The content of x s is fixed during this experiment. The first row of FIG. 4 is the log Mel spectrogram of the input voice, and the second to the seventh row is the log Mel spectrogram of the converted voice. While the overall shape of the spectrogram is similar to the input, it can be seen that some changes such as time shift, frequency shift, and pause time have been made. Within a single model, it can create multiple language domains.
이상에서 설명된 장치는 하드웨어 구성요소, 소프트웨어 구성요소, 및/또는 하드웨어 구성요소 및 소프트웨어 구성요소의 조합으로 구현될 수 있다. 예를 들어, 실시예들에서 설명된 장치 및 구성요소는, 예를 들어, 프로세서, 콘트롤러, ALU(arithmetic logic unit), 디지털 신호 프로세서(digital signal processor), 마이크로컴퓨터, FPA(field programmable array), PLU(programmable logic unit), 마이크로프로세서, 또는 명령(instruction)을 실행하고 응답할 수 있는 다른 어떠한 장치와 같이, 하나 이상의 범용 컴퓨터 또는 특수 목적 컴퓨터를 이용하여 구현될 수 있다. 처리 장치는 운영 체제(OS) 및 상기 운영 체제 상에서 수행되는 하나 이상의 소프트웨어 애플리케이션을 수행할 수 있다. 또한, 처리 장치는 소프트웨어의 실행에 응답하여, 데이터를 접근, 저장, 조작, 처리 및 생성할 수도 있다. 이해의 편의를 위하여, 처리 장치는 하나가 사용되는 것으로 설명된 경우도 있지만, 해당 기술분야에서 통상의 지식을 가진 자는, 처리 장치가 복수 개의 처리 요소(processing element) 및/또는 복수 유형의 처리 요소를 포함할 수 있음을 알 수 있다. 예를 들어, 처리 장치는 복수 개의 프로세서 또는 하나의 프로세서 및 하나의 콘트롤러를 포함할 수 있다. 또한, 병렬 프로세서(parallel processor)와 같은, 다른 처리 구성(processing configuration)도 가능하다.The device described above may be implemented as a hardware component, a software component, and/or a combination of the hardware component and the software component. For example, devices and components described in the embodiments may include, for example, a processor, a controller, an arithmetic logic unit (ALU), a digital signal processor, a microcomputer, a field programmable array (FPA), It may be implemented using one or more general purpose or special purpose computers, such as a programmable logic unit (PLU), microprocessor, or any other device capable of executing and responding to instructions. The processing device may execute an operating system (OS) and one or more software applications running on the operating system. The processing device may also access, store, manipulate, process, and generate data in response to execution of the software. For convenience of understanding, although one processing device is sometimes described as being used, one of ordinary skill in the art will recognize that the processing device includes a plurality of processing elements and/or a plurality of types of processing elements. It can be seen that can include For example, the processing device may include a plurality of processors or one processor and one controller. Other processing configurations are also possible, such as parallel processors.
소프트웨어는 컴퓨터 프로그램(computer program), 코드(code), 명령(instruction), 또는 이들 중 하나 이상의 조합을 포함할 수 있으며, 원하는 대로 동작하도록 처리 장치를 구성하거나 독립적으로 또는 결합적으로(collectively) 처리 장치를 명령할 수 있다. 소프트웨어 및/또는 데이터는, 처리 장치에 의하여 해석되거나 처리 장치에 명령 또는 데이터를 제공하기 위하여, 어떤 유형의 기계, 구성요소(component), 물리적 장치, 가상 장치(virtual equipment), 컴퓨터 저장 매체 또는 장치에 구체화(embody)될 수 있다. 소프트웨어는 네트워크로 연결된 컴퓨터 시스템 상에 분산되어서, 분산된 방법으로 저장되거나 실행될 수도 있다. 소프트웨어 및 데이터는 하나 이상의 컴퓨터 판독 가능 기록 매체에 저장될 수 있다.The software may comprise a computer program, code, instructions, or a combination of one or more thereof, which configures a processing device to operate as desired or is independently or collectively processed You can command the device. The software and/or data may be any kind of machine, component, physical device, virtual equipment, computer storage medium or device, to be interpreted by or to provide instructions or data to the processing device. may be embodied in The software may be distributed over networked computer systems, and stored or executed in a distributed manner. Software and data may be stored in one or more computer-readable recording media.
실시예에 따른 방법은 다양한 컴퓨터 수단을 통하여 수행될 수 있는 프로그램 명령 형태로 구현되어 컴퓨터 판독 가능 매체에 기록될 수 있다. 상기 컴퓨터 판독 가능 매체는 프로그램 명령, 데이터 파일, 데이터 구조 등을 단독으로 또는 조합하여 포함할 수 있다. 상기 매체에 기록되는 프로그램 명령은 실시예를 위하여 특별히 설계되고 구성된 것들이거나 컴퓨터 소프트웨어 당업자에게 공지되어 사용 가능한 것일 수도 있다. 컴퓨터 판독 가능 기록 매체의 예에는 하드 디스크, 플로피 디스크 및 자기 테이프와 같은 자기 매체(magnetic media), CD-ROM, DVD와 같은 광기록 매체(optical media), 플롭티컬 디스크(floptical disk)와 같은 자기-광 매체(magneto-optical media), 및 롬(ROM), 램(RAM), 플래시 메모리 등과 같은 프로그램 명령을 저장하고 수행하도록 특별히 구성된 하드웨어 장치가 포함된다. 프로그램 명령의 예에는 컴파일러에 의해 만들어지는 것과 같은 기계어 코드뿐만 아니라 인터프리터 등을 사용해서 컴퓨터에 의해서 실행될 수 있는 고급 언어 코드를 포함한다. The method according to the embodiment may be implemented in the form of program instructions that can be executed through various computer means and recorded in a computer-readable medium. The computer-readable medium may include program instructions, data files, data structures, etc. alone or in combination. The program instructions recorded on the medium may be specially designed and configured for the embodiment, or may be known and available to those skilled in the art of computer software. Examples of the computer readable recording medium include magnetic media such as hard disks, floppy disks and magnetic tapes, optical media such as CD-ROMs and DVDs, and magnetic media such as floppy disks. - includes magneto-optical media, and hardware devices specially configured to store and execute program instructions, such as ROM, RAM, flash memory, and the like. Examples of program instructions include not only machine language codes such as those generated by a compiler, but also high-level language codes that can be executed by a computer using an interpreter or the like.
이상과 같이 실시예들이 비록 한정된 실시예와 도면에 의해 설명되었으나, 해당 기술분야에서 통상의 지식을 가진 자라면 상기의 기재로부터 다양한 수정 및 변형이 가능하다. 예를 들어, 설명된 기술들이 설명된 방법과 다른 순서로 수행되거나, 및/또는 설명된 시스템, 구조, 장치, 회로 등의 구성요소들이 설명된 방법과 다른 형태로 결합 또는 조합되거나, 다른 구성요소 또는 균등물에 의하여 대치되거나 치환되더라도 적절한 결과가 달성될 수 있다.As described above, although the embodiments have been described with reference to the limited embodiments and drawings, various modifications and variations are possible from the above description by those skilled in the art. For example, the described techniques are performed in a different order than the described method, and/or the described components of the system, structure, apparatus, circuit, etc. are combined or combined in a different form than the described method, or other components Or substituted or substituted by equivalents may achieve an appropriate result.
그러므로, 다른 구현들, 다른 실시예들 및 특허청구범위와 균등한 것들도 후술하는 특허청구범위의 범위에 속한다.Therefore, other implementations, other embodiments, and equivalents to the claims are also within the scope of the following claims.
Claims (12)
입력 음성의 페어가 원-핫(one-hot) 대표 텍스트 및 스타일 참조 음성의 로그 멜 스펙트로그램(Mel spectrogram)일 경우, 텍스트 음성 변환(Text-to-Speech; TTS)을 수행하는 단계;
언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 단계; 및
디코딩된 멜 스펙트로그램으로부터 전처리부를 통해 선형 스펙트럼을 획득하는 단계
를 포함하고,
입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 스타일 참조 음성의 로그 멜 스펙트로그램일 경우, 음성 변환을 수행하는 단계는,
언어 내용을 전달하는 언어의 로그 멜 스펙트로그램을 컨텐츠 인코더를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램을 스타일 인코더를 통해 임베딩하는
감정적 음성 변환 방법. performing voice conversion (Voice Conversion; VC) when the pair of input voices is a log Mel spectrogram of a language transmitting language content and a log Mel spectrogram of a style reference voice;
performing text-to-speech (TTS) when the pair of input speech is a log Mel spectrogram of a one-hot representative text and a style reference speech;
A log Mel spectrogram and a one-hot representative text of a language conveying language content are both mapped to the same space and then decoded into a Mel spectrogram; and
Obtaining a linear spectrum from the decoded Mel spectrogram through a preprocessor
including,
When the pair of input voices is a log Mel spectrogram of a language conveying language content and a log Mel spectrogram of a style reference voice, the step of performing voice conversion includes:
Embedding the log Mel spectrogram of the language that conveys the language content through the content encoder, and embedding the log Mel spectrogram of the style reference voice through the style encoder.
Emotional speech transformation method.
입력 음성의 페어가 원-핫 대표 텍스트 및 스타일 참조 음성의 로그 멜 스펙트로그램일 경우, 텍스트 음성 변환을 수행하는 단계는,
원-핫 대표 텍스트를 텍스트 인코더를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램을 스타일 인코더를 통해 임베딩하는
감정적 음성 변환 방법.According to claim 1,
When the pair of input speech is a log Mel spectrogram of one-hot representative text and style reference speech, the step of performing text-to-speech conversion includes:
Embedding the one-hot representative text through the text encoder and embedding the log Mel spectrogram of the style reference voice through the style encoder
Emotional speech transformation method.
언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 단계는,
각 디코딩 단계에서 스타일 참조 음성의 로그 멜 스펙트로그램에서 추출한 스타일 벡터를 어텐션(attention) RNN과 디코더 RNN에 연결하는
감정적 음성 변환 방법. According to claim 1,
The log Mel spectrogram and one-hot representative text of the language conveying language content are both mapped to the same space and then decoded into a Mel spectrogram,
At each decoding step, the style vector extracted from the log Mel spectrogram of the style reference voice is connected to the attention RNN and the decoder RNN.
Emotional speech transformation method.
언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 단계는,
텍스트 인코더, 어텐션 RNN, 디코더 RNN 및 전처리부를 통해 텍스트 음성 변환을 수행하는 경우, 어텐션 RNN의 모든 반복에 컨텍스트 벡터가 활용되는
감정적 음성 변환 방법. According to claim 1,
The log Mel spectrogram and one-hot representative text of the language conveying language content are both mapped to the same space and then decoded into a Mel spectrogram,
When text-to-speech is performed through a text encoder, attention RNN, decoder RNN, and preprocessor, the context vector is utilized for every iteration of the attention RNN.
Emotional speech transformation method.
스타일 참조 음성을 고려할 때 스타일 인코더는 감정 정보만을 추출하고 언어적 내용을 제거하며, 언어적 내용에 관계없이 감정을 추출하도록 설계되어 복수의 입력 스타일 도메인을 처리하고, 추출된 감정이 디코더에 주입되면 다양한 감정을 생성함으로써 다대 다의 감정적 음성 변환을 처리하는
감정적 음성 변환 방법. According to claim 1,
When considering the style reference voice, the style encoder only extracts emotion information and removes the linguistic content, is designed to extract the emotion regardless of the linguistic content, processes multiple input style domains, and when the extracted emotion is injected into the decoder processing many-to-many emotional speech by generating a variety of emotions
Emotional speech transformation method.
언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 원-핫(one-hot) 대표 텍스트 모두 동일한 공간에 매핑된 후 멜 스펙트로그램으로 디코딩되는 신경망 네트워크; 및
디코딩된 멜 스펙트로그램으로부터 선형 스펙트럼을 획득하는 전처리부
를 포함하고,
변환부는,
입력 음성의 페어가 언어 내용을 전달하는 언어의 로그 멜 스펙트로그램 및 스타일 참조 음성의 로그 멜 스펙트로그램일 경우, 음성 변환을 수행하고,
언어 내용을 전달하는 언어의 로그 멜 스펙트로그램을 컨텐츠 인코더를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램을 스타일 인코더를 통해 임베딩하는
감정적 음성 변환 장치. Whether a pair of input voices is a log Mel spectrogram of a language and a log Mel spectrogram of a style-referenced voice conveying the linguistic content, or a one-hot representative text and a log-mel spectrogram of a style-referenced voice. a conversion unit that performs speech-to-speech or text-to-speech conversion through a style encoder, a content encoder, and a text encoder according to whether it is a log Mel spectrogram;
A neural network in which both log Mel spectrogram and one-hot representative text of a language conveying language content are mapped to the same space and then decoded into Mel spectrogram; and
A preprocessor that acquires a linear spectrum from the decoded Mel spectrogram
including,
conversion unit,
If the pair of input voices is a log Mel spectrogram of a language conveying language content and a log Mel spectrogram of a style reference voice, perform voice conversion;
Embedding the log Mel spectrogram of the language that conveys the language content through the content encoder, and embedding the log Mel spectrogram of the style reference voice through the style encoder.
Emotional Speech Transducer.
변환부는,
입력 음성의 페어가 원-핫 대표 텍스트 및 스타일 참조 음성의 로그 멜 스펙트로그램일 경우, 텍스트 음성 변환을 수행하고,
원-핫 대표 텍스트를 텍스트 인코더를 통해 임베딩하고, 스타일 참조 음성의 로그 멜 스펙트로그램을 스타일 인코더를 통해 임베딩하는
감정적 음성 변환 장치. 8. The method of claim 7,
conversion unit,
If the pair of input speech is a log Mel spectrogram of one-hot representative text and style reference speech, perform text-to-speech conversion;
Embedding the one-hot representative text through the text encoder and embedding the log Mel spectrogram of the style reference voice through the style encoder
Emotional Speech Transducer.
신경망 네트워크는,
각 디코딩 단계에서 스타일 참조 음성의 로그 멜 스펙트로그램에서 추출한 스타일 벡터를 어텐션(attention) RNN과 디코더 RNN에 연결하는
감정적 음성 변환 장치. 8. The method of claim 7,
The neural network is
At each decoding step, the style vector extracted from the log Mel spectrogram of the style reference voice is connected to the attention RNN and the decoder RNN.
Emotional Speech Transducer.
신경망 네트워크는,
텍스트 인코더, 어텐션 RNN, 디코더 RNN 및 전처리부를 통해 텍스트 음성 변환이 수행되는 경우, 어텐션 RNN의 모든 반복에 컨텍스트 벡터가 활용되는
감정적 음성 변환 장치. 8. The method of claim 7,
The neural network is
When text-to-speech is performed through a text encoder, attention RNN, decoder RNN, and preprocessor, the context vector is utilized for every iteration of the attention RNN.
Emotional Speech Transducer.
스타일 참조 음성을 고려할 때 스타일 인코더는 감정 정보만을 추출하고 언어적 내용을 제거하며, 언어적 내용에 관계없이 감정을 추출하도록 설계되어 복수의 입력 스타일 도메인을 처리하고, 추출된 감정이 디코더에 주입되면 다양한 감정을 생성함으로써 다대 다의 감정적 음성 변환을 처리하는
감정적 음성 변환 장치.8. The method of claim 7,
When considering the style reference voice, the style encoder only extracts emotion information and removes the linguistic content, is designed to extract the emotion regardless of the linguistic content, processes multiple input style domains, and when the extracted emotion is injected into the decoder processing many-to-many emotional speech by generating a variety of emotions
Emotional Speech Transducer.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190146665 | 2019-11-15 | ||
| KR20190146665 | 2019-11-15 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20210059586A KR20210059586A (en) | 2021-05-25 |
| KR102298901B1 true KR102298901B1 (en) | 2021-09-07 |
Family
ID=76145694
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020200027051A Active KR102298901B1 (en) | 2019-11-15 | 2020-03-04 | Method and Apparatus for Emotional Voice Conversion using Multitask Learning with Text-to-Speech |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102298901B1 (en) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022235138A1 (en) | 2021-05-07 | 2022-11-10 | 주식회사 엘지화학 | Crosslinked structure-containing olefin polymer porous support, crosslinked structure-containing separator comprising same for lithium secondary battery, manufacturing method therefor, and lithium secondary battery comprising same separator |
| CN113345412A (en) * | 2021-05-31 | 2021-09-03 | 平安科技(深圳)有限公司 | Speech synthesis method, apparatus, device and storage medium |
| CN114299915B (en) * | 2021-11-09 | 2024-12-17 | 腾讯科技(深圳)有限公司 | Speech synthesis method and related equipment |
| CN114299917B (en) * | 2022-01-04 | 2025-10-24 | 南京邮电大学 | StyleGAN emotional speech conversion method based on fundamental frequency difference compensation |
| CN117636842B (en) * | 2024-01-23 | 2024-04-02 | 北京天翔睿翼科技有限公司 | Voice synthesis system and method based on prosody emotion migration |
| CN117688344B (en) * | 2024-02-04 | 2024-05-07 | 北京大学 | Multi-mode fine granularity trend analysis method and system based on large model |
| CN118135990B (en) * | 2024-05-06 | 2024-11-05 | 厦门立马耀网络科技有限公司 | End-to-end text speech synthesis method and system combining autoregressive |
-
2020
- 2020-03-04 KR KR1020200027051A patent/KR102298901B1/en active Active
Non-Patent Citations (3)
| Title |
|---|
| Carl Robinson et al., ‘Sequence-to-sequence modelling of F0 for speech emotion conversion’, ICASSP 2019, pp.6830~6834, 12 May 2019.* |
| Mingyang Zhang et al., ‘Joint training framework for text-to-speech and voice conversion using multi-source Tacotron and WaveNet’, arXiv:1903.12389v2, [eess.AS], 7 April 2019.* |
| Younggun Lee rt al., ‘Emotional end-to-end neural speech synthesizer’, arXiv:1711.05447v2, [cs.SD], 28 November 2017.* |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20210059586A (en) | 2021-05-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102298901B1 (en) | Method and Apparatus for Emotional Voice Conversion using Multitask Learning with Text-to-Speech | |
| KR102862271B1 (en) | Two-level speech prosody transfer | |
| KR102668866B1 (en) | Method and computer readable storage medium for performing text-to-speech synthesis using machine learning | |
| US11881210B2 (en) | Speech synthesis prosody using a BERT model | |
| KR102265972B1 (en) | Method and apparatus for voice translation using a multilingual text-to-speech synthesis model | |
| KR102769179B1 (en) | Synthetic data augmentation using voice conversion and speech recognition models | |
| Kim et al. | Emotional voice conversion using multitask learning with text-to-speech | |
| CN108573693B (en) | Text-to-speech system and method, and storage medium therefor | |
| Wang et al. | Tacotron: Towards end-to-end speech synthesis | |
| Wang et al. | Tacotron: A fully end-to-end text-to-speech synthesis model | |
| JP7228998B2 (en) | speech synthesizer and program | |
| CN111954903A (en) | Multi-Speaker Neural Text-to-Speech Synthesis | |
| US20180047385A1 (en) | Hybrid phoneme, diphone, morpheme, and word-level deep neural networks | |
| JP2018146803A (en) | Voice synthesizer and program | |
| JP6585022B2 (en) | Speech recognition apparatus, speech recognition method and program | |
| CN113870828B (en) | Audio synthesis method, device, electronic device and readable storage medium | |
| Aziz et al. | End to end text to speech synthesis for malay language using tacotron and tacotron 2 | |
| KR102528019B1 (en) | A TTS system based on artificial intelligence technology | |
| CN117153175A (en) | Audio processing methods, devices, equipment, media and products | |
| KR20220004272A (en) | Cyclic Learning Method and Apparatus for Speech Emotion Recognition and Synthesis | |
| Win et al. | Myanmar text-to-speech system based on tacotron-2 | |
| KR102532253B1 (en) | A method and a TTS system for calculating a decoder score of an attention alignment corresponded to a spectrogram | |
| JP7357518B2 (en) | Speech synthesis device and program | |
| Zhe et al. | Incorporating speaker’s speech rate features for improved voice cloning | |
| KR102503066B1 (en) | A method and a TTS system for evaluating the quality of a spectrogram using scores of an attention alignment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
Patent event code: PA01091R01D Comment text: Patent Application Patent event date: 20200304 |
|
| PA0201 | Request for examination | ||
| PG1501 | Laying open of application | ||
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20210527 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20210826 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20210901 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20210901 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration | ||
| PR1001 | Payment of annual fee |
Payment date: 20240823 Start annual number: 4 End annual number: 4 |