KR102128158B1 - Emotion recognition apparatus and method based on spatiotemporal attention - Google Patents
Emotion recognition apparatus and method based on spatiotemporal attention Download PDFInfo
- Publication number
- KR102128158B1 KR102128158B1 KR1020180053306A KR20180053306A KR102128158B1 KR 102128158 B1 KR102128158 B1 KR 102128158B1 KR 1020180053306 A KR1020180053306 A KR 1020180053306A KR 20180053306 A KR20180053306 A KR 20180053306A KR 102128158 B1 KR102128158 B1 KR 102128158B1
- Authority
- KR
- South Korea
- Prior art keywords
- emotion
- features
- feature
- spatial
- value
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images









Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/16—Devices for psychotechnics; Testing reaction times ; Devices for evaluating the psychological state
- A61B5/165—Evaluating the state of mind, e.g. depression, anxiety
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/72—Signal processing specially adapted for physiological signals or for diagnostic purposes
- A61B5/7235—Details of waveform analysis
- A61B5/7246—Details of waveform analysis using correlation, e.g. template matching or determination of similarity
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Psychiatry (AREA)
- Public Health (AREA)
- Surgery (AREA)
- Veterinary Medicine (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Pathology (AREA)
- Biomedical Technology (AREA)
- Heart & Thoracic Surgery (AREA)
- Medical Informatics (AREA)
- Molecular Biology (AREA)
- Animal Behavior & Ethology (AREA)
- Physiology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Signal Processing (AREA)
- Child & Adolescent Psychology (AREA)
- Developmental Disabilities (AREA)
- Educational Technology (AREA)
- Hospice & Palliative Care (AREA)
- Psychology (AREA)
- Social Psychology (AREA)
- Image Analysis (AREA)
Abstract
감정 인식 장치 및 방법을 공개한다. 본 발명의 감정 인식 장치 및 방법은 다수의 프레임을 포함하는 이미지 시퀀스로부터 3차원 특징을 획득함과 동시에 각 프레임에 대한 시공간 특징을 추출하여 시공간 가중치로 획득하고, 3차원 특징에 시공간 가중치를 가중함으로써, 별도의 관심 영역을 설정하지 않더라도 정확한 감정을 판별할 수 있다.Disclosure of emotion recognition device and method. The apparatus and method for recognizing emotions of the present invention acquire 3D features from an image sequence including a plurality of frames, and at the same time extract space-time features for each frame, obtain them with space-time weights, and weight space-time weights on the 3D features. , Even if a separate region of interest is not set, accurate emotions can be determined.
Description
본 발명은 감정 인식 장치 및 방법에 관한 것으로, 특히 시공간 주의 기반 감정 인식 장치 및 방법에 관한 것이다.The present invention relates to an apparatus and method for recognizing emotions, and more particularly to an apparatus and method for recognizing emotions based on space-time attention.
감정 인식은 대화형 시스템에서 중요한 이슈 중 하나이다. 대화형 시스템은 기존의 명령 입력 방식이 아닌 사용자와의 상호 대화를 통해 사용자의 요구 사항을 판별한다. 이때, 감정 인식 기술이 적용되면, 사용자의 요구 사항을 더욱 정확하게 판별할 수 있다는 장점이 있다.Emotion recognition is an important issue in interactive systems. The interactive system determines the user's requirements through interaction with the user instead of the conventional command input method. At this time, when the emotion recognition technology is applied, there is an advantage that the user's requirements can be more accurately determined.
또한 감정 인식은 통증이나 심리적 고통 탐지와 같이 의료 분야 등에 적용될 수 있으며 그 외에도 다양한 분야에 적용될 수 있다.In addition, emotion recognition can be applied to medical fields such as pain and psychological pain detection, and can be applied to various other fields.
기존의 감정 인식에 대한 연구는 대부분 감정을 공포, 분노, 행복, 혐오, 슬픔, 놀람과 같은 기지정된 개수(예를 들면 6가지)로 지정된 기본 감정에 따라 이산된 범주로 분류하는 범주형 감정 인식 방식이 대부분이었다. 그러나 범주형 감정 인식은 지정된 감정으로만 분류하여 인식함에 따라 분류되지 않는 감정의 영역이 존재될 뿐만 아니라, 인식 가능한 감정의 종류가 제한되는 한계가 있다.Most of the existing studies on emotion recognition recognize categorical emotions that classify emotions into discrete categories according to the basic emotions designated by a predetermined number (for example, six) such as fear, anger, happiness, disgust, sadness, and surprise. Most of the way. However, as categorical emotion recognition is classified and recognized only as a specified emotion, there is a limitation in that not only an area of emotion that is not classified exists, but also a type of recognizable emotion is limited.
도1 은 사람의 감정을 나타내는 이미지의 일예를 나타낸다.1 shows an example of an image representing a person's emotions.
도1 은 (a) 내지 (d)는 Ekman이 정의한 4 가지 유형의 놀람에 대한 표정 이미지로서, (a)는 놀랄만한 질문(questioning surprise), (b)는 깜짝 놀람(astonished surprise), (c)는 어리둥절한 놀람(dazed surprise)을 나타내고, (d)는 완전히 놀람(full surprise)을 표현하고 있다.1 is (a) to (d) are expression images of four types of surprises defined by Ekman, (a) is a surprising question (questioning surprise), (b) is a surprise surprise (astonished surprise), (c) ) Represents a dazed surprise, and (d) represents a full surprise.
도1 에 도시된 바와 같이, 놀람에도 다양한 놀람이 존재할 수 있으나, 기존의 범주형 감정 인식은 모두 놀람으로만 분류될 뿐, 미묘한 감정의 차이를 인식할 수 없다는 한계가 있다. 이에 감정을 연속되는 2개의 영역(domain)에 따라 2차원으로 표현하는 방안이 제안되었다.As illustrated in FIG. 1, various surprises may exist in surprises, but all existing categorical emotion recognition is classified only as surprises, and there is a limitation that subtle emotion differences cannot be recognized. Accordingly, a method of expressing emotion in two dimensions according to two consecutive domains has been proposed.
도2 는 연속하는 2차원 그래프로 나타나는 감정의 일예를 나타낸다.Fig. 2 shows an example of emotion represented by a continuous two-dimensional graph.
도2 에서 2차원의 각 축은 각성(Arousal) 및 유인가(Valence)를 나타내고, 각성축은 활동적인지 비활동적의 수준을 나타내고, 유인가축은 긍정적 또는 부정적인 수준을 나타낸다. 도2 에서 도시된 바와 같이, 연속되는 2차원으로 감정을 묘사하는 방식은 기존 범주형에 비해 더 복잡하고 미묘한 감정을 표현할 수 있다.In FIG. 2, each axis of the 2D represents arousal and valence, the arousal axis represents a level of being active or inactive, and the axis of arousal represents a positive or negative level. As shown in FIG. 2, the method of describing emotions in two-dimensional series can express more complex and subtle emotions than the conventional categorical type.
한편 최근에는 감정 인식 기법에 신경망(neural network)를 적용하여 감정 인식의 정확도를 향상시키고 있다. 그러나 기존의 감정 인식 기법은 대부분 단일 이미지로부터 감정을 인식하도록 연구가 수행되어, 시간에 따른 이미지 시퀀스(image sequence)로부터 사람의 감정을 정확하게 인식하는 방법에 대한 연구가 부족한 실정이다. 실제 사람의 감정은 시간의 흐름에 따라 서서히 연속되어 변화되므로, 연속되는 이미지 시퀀스를 이용하여 감정을 인식하는 경우, 단일 이미지보다 더욱 정확하게 감정을 인식할 수 있다.Meanwhile, recently, a neural network is applied to the emotion recognition technique to improve the accuracy of emotion recognition. However, most of the existing emotion recognition techniques have been conducted to recognize emotions from a single image, so there is a lack of research on how to accurately recognize human emotions from image sequences over time. Since the emotions of a real person are gradually and continuously changed with the passage of time, emotions can be recognized more accurately than a single image when emotions are recognized using a sequence of images.
또한 기존의 감정 인식은 도1 에 도시된 바와 같이, 사람의 얼굴 이미지에서 감정 표출이 강하게 나타나는 것으로 예상되는 관심 영역을 미리 지정하고, 지정된 관심 영역에 대해 분석을 수행한다. 그러나 일부의 관심 영역만을 활성화하여 표정을 추정하고, 감정을 인식함에 따라 다양한 얼굴 이미지에 대해 최적의 성능으로 감정을 인식할 수 없다는 한계가 있다.In addition, as shown in FIG. 1, in the conventional emotion recognition, a region of interest in which emotion expression is expected to appear strongly in a human face image is previously designated, and analysis is performed on the designated region of interest. However, there is a limitation in that emotions cannot be recognized with optimal performance for various facial images as the facial expressions are estimated by activating only a region of interest and the emotions are recognized.
본 발명의 목적은 얼굴 이미지 시퀀스로부터 시간적, 공간적 주의에 기반하여 감정을 인식할 수 있는 감정 인식 장치 및 방법을 제공하는데 있다.An object of the present invention is to provide an apparatus and method for recognizing emotion based on temporal and spatial attention from a face image sequence.
본 발명의 다른 목적은 얼굴 이미지 시퀀스에 관심 영역을 지정하지 않고도 감정을 인식할 수 있는 감정 인식 장치 및 방법을 제공하는데 있다.Another object of the present invention is to provide an apparatus and method for recognizing emotions capable of recognizing emotions without specifying a region of interest in a face image sequence.
본 발명의 또 다른 목적은 얼굴 이미지 시퀀스로부터 2차원 및 3차원 특징을 각각 추출하고, 추출된 2차원 및 3차원 특징을 이용하여 감정을 정확하게 인식할 수 있는 감정 인식 장치 및 방법을 제공하는데 있다.Another object of the present invention is to provide a device and a method for recognizing emotions by extracting 2D and 3D features from a face image sequence, respectively, and accurately recognizing emotions using the extracted 2D and 3D features.
상기 목적을 달성하기 위한 본 발명의 일 예에 따른 감정 인식 장치는 기지정된 3차원 패턴 인식 기법에 따라 미리 학습되어, 이미지 시퀀스의 시간적으로 연속하는 T개(여기서 T는 자연수)의 프레임을 3차원의 단일 이미지로서 패턴 인식하여 3D 특징을 추출하는 3D 특징 추출부; 기지정된 2차원 패턴 인식 기법에 따라 미리 학습되어, 상기 T개의 프레임 각각으로부터 패턴 인식을 통해 T개의 공간적 특징을 추출하고, 획득된 T개의 공간적 특징 사이의 시공간 특징을 추가하여 시공간 가중치를 획득하는 시공간 특징 추출부; 상기 시공간 가중치를 상기 3D 특징에 가중하여 감정 특징을 획득하고, 기지정된 3차원 패턴 인식 기법에 따라 미리 학습되어, 상기 감정 특징으로부터 미리 지정된 범위 이내의 값을 갖는 감정값을 추출하는 감정값 추출부; 및 감정값에 대비한 감정이 미리 저장되어, 상기 감정값 추출부에서 획득된 상기 감정값에 대응하는 감정을 판별하는 감정 판별부를 포함한다.In order to achieve the above object, the emotion recognition apparatus according to an embodiment of the present invention is pre-learned according to a predetermined 3D pattern recognition technique, and 3D temporally continuous T frames (where T is a natural number) of an image sequence A 3D feature extraction unit that extracts a 3D feature by recognizing a pattern as a single image of the; Spatio-temporal, which is pre-trained according to a known 2D pattern recognition technique, extracts T spatial features through pattern recognition from each of the T frames, and adds spatio-temporal features between the obtained T spatial features to obtain spatio-temporal weights Feature extraction unit; The emotion value extraction unit extracts an emotion value having a value within a predetermined range from the emotion feature by learning the emotion value by weighting the space-time weight to the 3D feature and learning in advance according to a known 3D pattern recognition technique. ; And an emotion discrimination unit that stores emotions prepared for the emotion values in advance, and determines emotions corresponding to the emotion values obtained from the emotion value extraction unit.
상기 3D 특징 추출부는 미리 학습된 3D CNN(3D Convolutional Neural Networks)을 포함하여, 상기 3D 특징을 추출할 수 있다.The 3D feature extraction unit may extract 3D features, including 3D Cvo (3D Convolutional Neural Networks) previously learned.
상기 시공간 특징 추출부는 미리 학습된 2D CNN(2D Convolutional Neural Networks)을 포함하여, 상기 T개의 프레임 각각에 대한 상기 T개의 공간적 특징을 추출하는 공간 인코더; 미리 학습된 ConvLSTM(Convolutional Long Short-Term Memory)을 포함하여, 상기 T개의 공간적 특징 사이의 시공간 특징을 추출하는 시간 디코더; 및 상기 시간 디코더에서 추출된 시공간 특징을 기지정된 방식으로 정규화하여, 상기 시공간 가중치를 획득하는 정규화부를 포함할 수 있다.The space-time feature extraction unit includes a pre-trained 2D CNN (2D Convolutional Neural Networks), a spatial encoder for extracting the T spatial features for each of the T frames; A temporal decoder for extracting the spatio-temporal feature between the T spatial features, including a pre-trained convolutional long short-term memory (ConvLSTM); And a normalization unit that normalizes the spatiotemporal features extracted from the time decoder in a predetermined manner to obtain the spatiotemporal weights.
상기 공간 인코더는 상기 2D CNN가 각각 다수의 필터를 포함하는 컨볼루션 레이어, ReLU(Rectified Linear Unit) 레이어 및 맥스 풀링(Max-Pooling) 레이어를 포함하여 상기 공간적 특징의 공간 해상도를 상기 프레임의 공간 해상도보다 낮도록 축소할 수 있다.The spatial encoder includes the convolutional layer, the rectified linear unit (ReLU) layer, and the Max-Pooling layer, each of which includes a plurality of filters, and the spatial resolution of the spatial feature of the frame. It can be reduced to lower.
상기 시간 디코더는 상기 ConvLSTM가 다수의 ConvLSTM 레이어를 포함하여, 순차적 디콘볼루션을 수행함으로써, 상기 공간적 특징의 축소된 공간 해상도를 복구할 수 있다.In the temporal decoder, the ConvLSTM includes a plurality of ConvLSTM layers to perform sequential deconvolution to recover the reduced spatial resolution of the spatial feature.
상기 정규화기는 소프트 맥스 함수를 이용하여, 상기 시공간 특징을 정규화할 수 있다.The normalizer may normalize the spatiotemporal features using a soft max function.
상기 감정값 추출부는 상기 3D 특징과 상기 시공간 가중치를 하다마드 곱셈하여 상기 감정 특징을 획득하는 특징 결합부; 및 미리 학습된 3D CNN을 포함하여 상기 감정 특징으로부터 감정을 대표하는 감정값을 추출하는 감정값 획득부를 포함할 수 있다.The emotion value extracting unit combines the 3D feature and the space-time weight by Hadamard to obtain the emotion feature; And an emotion value acquiring unit for extracting an emotion value representing emotion from the emotion feature, including a previously learned 3D CNN.
상기 목적을 달성하기 위한 본 발명의 다른 예에 따른 감정 인식 방법은 기지정된 3차원 패턴 인식 기법에 따라 미리 학습되어, 이미지 시퀀스의 시간적으로 연속하는 T개(여기서 T는 자연수)의 프레임을 3차원의 단일 이미지로서 패턴 인식하여 3D 특징을 추출하는 단계; 기지정된 2차원 패턴 인식 기법에 따라 미리 학습되어, 상기 T개의 프레임 각각으로부터 패턴 인식을 통해 T개의 공간적 특징을 추출하고, 획득된 T개의 공간적 특징 사이의 시공간 특징을 추가하여 시공간 가중치를 획득하는 단계; 상기 시공간 가중치를 상기 3D 특징에 가중하여 감정 특징을 획득하는 단계; 기지정된 3차원 패턴 인식 기법에 따라 미리 학습되어, 상기 감정 특징으로부터 미리 지정된 범위 이내의 값을 갖는 감정값을 추출하는 단계; 및 상기 감정값에 대응하는 감정을 판별하는 단계를 포함한다.The emotion recognition method according to another example of the present invention for achieving the above object is pre-learned according to a known three-dimensional pattern recognition technique, and three-dimensionally sequential T consecutive frames of the image sequence (where T is a natural number) Extracting 3D features by recognizing a pattern as a single image; Pre-learning according to a known two-dimensional pattern recognition technique, extracting T spatial features through pattern recognition from each of the T frames, and adding space-time features between the obtained T spatial features to obtain space-time weights ; Obtaining emotional features by weighting the space-time weights with the 3D features; Learning in advance according to a predetermined 3D pattern recognition technique, and extracting an emotion value having a value within a predetermined range from the emotion feature; And determining an emotion corresponding to the emotion value.
따라서, 본 발명의 감정 인식 장치 및 방법은 이미지 시퀀스로부터 2차원 및 3차원 특징을 각각 획득하고, 획득된 2차원 및 3차원 특징을 함께 이용하여 정확하게 감정을 인식할 수 있다. 또한 시간적 및 공간적 주의에 기반하여 감정을 인식할 뿐만 아니라, 감정을 인식하기 위한 영역을 별도로 지정하지 않고도 감정을 연속적인 유인가를 기반으로 정확하게 인식할 수 있다.Accordingly, the apparatus and method for recognizing emotions of the present invention can acquire 2D and 3D features from an image sequence, respectively, and accurately recognize emotions using the obtained 2D and 3D features together. In addition, not only can emotions be recognized based on temporal and spatial attention, but emotions can be accurately recognized based on successive accreditation without specifying a region for recognizing emotions.
도1 은 사람의 감정을 나타내는 이미지의 일예를 나타낸다.
도2 는 연속하는 2차원 그래프로 나타나는 감정의 일예를 나타낸다.
도3 은 본 발명의 일 실시예에 따른 감정 인식 장치의 개략적 구성을 나타낸다.
도4 는 도3 의 시공간 특징 추출부의 상세 구성의 일예를 나타낸다.
도5 는 도3 의 감정 인식 장치의 학습 방법을 설명하기 위한 도면이다.
도6 은 본 발명의 일 실시예에 따른 감정 인식 방법을 나타낸다.
도7 은 본 실시예의 시공간 가중치를 시각화한 도면이다.
도8 및 도9 는 각각 2 종류의 RECOLA 데이터 세트와 AV + EC 데이터 세트에 대해 본 실시예에 따른 감정 인식 방법을 적용하여 획득되는 감정값과 검증값을 비교한 결과를 나타낸다.1 shows an example of an image representing a person's emotions.
Fig. 2 shows an example of emotion represented by a continuous two-dimensional graph.
3 shows a schematic configuration of an emotion recognition device according to an embodiment of the present invention.
4 shows an example of a detailed configuration of the space-time feature extraction unit of FIG. 3.
5 is a diagram for explaining a learning method of the emotion recognition device of FIG. 3.
6 shows an emotion recognition method according to an embodiment of the present invention.
7 is a diagram visualizing the spatiotemporal weight of the present embodiment.
8 and 9 show the results of comparing emotion values and verification values obtained by applying the emotion recognition method according to the present embodiment to the two types of RECOLA data sets and AV + EC data sets, respectively.
본 발명과 본 발명의 동작상의 이점 및 본 발명의 실시에 의하여 달성되는 목적을 충분히 이해하기 위해서는 본 발명의 바람직한 실시예를 예시하는 첨부 도면 및 첨부 도면에 기재된 내용을 참조하여야만 한다. In order to fully understand the present invention, the operational advantages of the present invention, and the objects achieved by the practice of the present invention, reference should be made to the accompanying drawings and the contents described in the accompanying drawings, which illustrate preferred embodiments of the present invention.
이하, 첨부한 도면을 참조하여 본 발명의 바람직한 실시예를 설명함으로써, 본 발명을 상세히 설명한다. 그러나, 본 발명은 여러 가지 상이한 형태로 구현될 수 있으며, 설명하는 실시예에 한정되는 것이 아니다. 그리고, 본 발명을 명확하게 설명하기 위하여 설명과 관계없는 부분은 생략되며, 도면의 동일한 참조부호는 동일한 부재임을 나타낸다. Hereinafter, the present invention will be described in detail by explaining preferred embodiments of the present invention with reference to the accompanying drawings. However, the present invention may be implemented in various different forms, and is not limited to the described embodiments. And, in order to clearly describe the present invention, parts irrelevant to the description are omitted, and the same reference numerals in the drawings indicate the same members.
명세서 전체에서, 어떤 부분이 어떤 구성요소를 "포함"한다고 할 때, 이는 특별히 반대되는 기재가 없는 한 다른 구성요소를 제외하는 것이 아니라, 다른 구성요소를 더 포함할 수 있는 것을 의미한다. 또한, 명세서에 기재된 "...부", "...기", "모듈", "블록" 등의 용어는 적어도 하나의 기능이나 동작을 처리하는 단위를 의미하며, 이는 하드웨어나 소프트웨어 또는 하드웨어 및 소프트웨어의 결합으로 구현될 수 있다. Throughout the specification, when a part “includes” a certain component, it means that the component may further include other components, not to exclude other components, unless otherwise stated. In addition, terms such as "... unit", "... group", "module", and "block" described in the specification mean a unit that processes at least one function or operation, which is hardware or software or hardware. And software.
도3 은 본 발명의 일 실시예에 따른 감정 인식 장치의 개략적 구성을 나타내고, 도4 는 도3 의 시공간 특징 추출부의 상세 구성의 일예를 나타낸다.3 shows a schematic configuration of an emotion recognition apparatus according to an embodiment of the present invention, and FIG. 4 shows an example of a detailed configuration of the spatiotemporal feature extraction unit of FIG. 3.
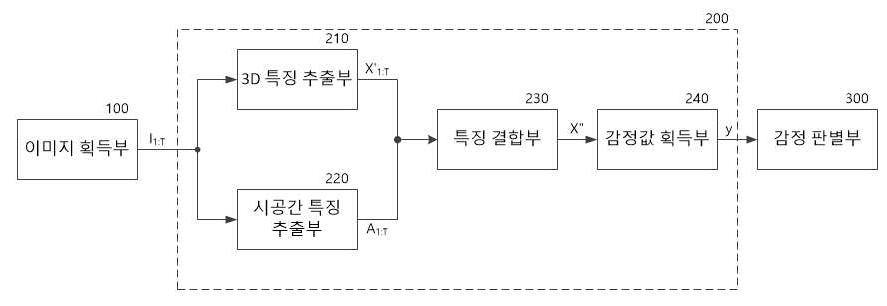
도3 을 참조하면, 본 실시예에 따른 감정 인식 장치는 감정을 인식해야 하는 대상이 포함된 이미지 시퀀스를 획득하는 이미지 획득부(100), 이미지 획득부(100)에서 전달된 이미지 시퀀스로부터 감정값을 추출하는 감정 추출부(200) 및 추출된 감정값에 따라 이미지에 포함된 대상의 감정을 판별하는 감정 판별부(300)를 포함한다.Referring to FIG. 3, in the emotion recognition apparatus according to the present embodiment, an emotion value is obtained from an
우선 이미지 획득부(100)는 감정을 인식해야 하는 대상이 포함된 이미지 시퀀스를 획득한다. 특히 본 실시예에서 이미지 획득부(100)는 단일 이미지가 아닌, 연속된 T(여기서 T는 자연수)개의 프레임(If)(여기서 f는 프레임 인덱스로서 자연수)을 포함하는 이미지 시퀀스(I1:T = {I1, I2, …, IT})를 획득한다. 여기서 이미지 시퀀스(I1:T)의 각 프레임에는 감정을 인식할 수 있도록 대상의 얼굴이 포함된다.First, the
그리고 이미지 획득부(100)는 획득된 이미지 시퀀스를 감정 추출부(200)로 전달한다. 이때 이미지 획득부(100)는 획득된 이미지 시퀀스에 포함된 프레임의 개수가 T개를 초과하는 경우, 이미지 시퀀스에서 대상의 감정을 인식하고자 하는 시점의 프레임이 포함된 T개의 프레임을 분리하여 감정 추출부(200)로 전달할 수 있다. 예를 들면 이미지 획득부(100)는 100개의 프레임을 포함하는 이미지 시퀀스에서 제11 내지 제20 프레임(I11 ~ I20)를 별도로 분리(T가 10 인 것으로 가정)하여, 감정 추출부(200)로 전달할 수 있다.In addition, the
또한 이미지 시퀀스로부터 대상의 연속적인 감정 변화를 인식하고자 하는 경우에는, 이미지 시퀀스에서 순차적으로 T개의 프레임을 분리하여, 감정 추출부(200)로 전달할 수 있다. 일예로 제1 내지 제10 프레임(I1 ~ I10)을 전달하고, 이후 제2 내지 제11 프레임(I2 ~ I11)을 전달할 수 있다.In addition, when it is desired to recognize a continuous emotion change of an object from an image sequence, T frames may be sequentially separated from the image sequence and transmitted to the
감정 추출부(200)는 이미지 획득부(100)에서 전달된 이미지 시퀀스(I1:T)로부터 감정값을 추출한다. 특히 본 실시예에서 감정 추출부(200)는 이미지 시퀀스(I1:T)에 대해 미리 학습된 2차원(2D) 및 3차원(3D) 패턴 인식 기법을 이용하여 이미지 시퀀스(I1:T)의 특징을 추출하고, 추출된 특징을 결합하여 감정값을 추출한다.The
도3 에 도시된 바와 같이, 감정 추출부(200)는 3D 특징 추출부(210), 시공간 특징 추출부(220), 특징 결합부(230) 및 감정값 획득부(240)를 포함할 수 있다.As illustrated in FIG. 3, the
3D 특징 추출부(210)는 대상의 감정을 판별하기 위해 이미지 획득부(100)에서 전달된 2차원의 이미지 시퀀스(I1:T)의 프레임({I1, I2, …, IT}) 전체를 3차원의 단일 객체로서 패턴 인식하여 3D 특징(X'1:T)을 추출한다. 즉 시간의 흐름에 따라 누적된 다수의 2차원 프레임을 포함하는 이미지 시퀀스(I1:T)를 3차원 이미지로 인식하여, 3차원의 이미지 시퀀스(I1:T)를 미리 지정된 패턴 인식 기법에 따라 분석함으로써 3D 특징(X'1:T)을 추출한다. 본 실시예에서는 3D 특징 추출부(210)가 시간에 따라 연속하는 T개의 프레임({I1, I2, …, IT})을 포함하는 이미지 시퀀스(I1:T)로부터 감정 인식을 위한 3D 특징(X'1:T)을 추출하므로, 단일 이미지로부터 감정 인식을 위한 2D 특징을 추출하는 방식에 비해, 상대적으로 정확한 특징을 추출할 수 있다. 즉 대상의 감정을 매우 정확하게 판별할 수 있도록 한다.The 3D
3D 특징 추출부(210)는 일예로 미리 학습된 3차원 콘볼루션 신경망(3D Convolutional Neural Networks: 이하 3D CNN)으로 구현될 수 있다.The 3D
시공간 특징 추출부(220)는 이미지 획득부(100)에서 전달된 T개의 2차원 프레임({I1, I2, …, IT}) 각각으로부터 시공간 주의(Spatiotemporal Attention)에 기반하여 특징을 추출한다. 특히 본 실시예에서 시공간 특징 추출부(220)는 이미지 시퀀스(I1:T)의 시공간 주의 기반 특징을 추출함으로써, 이미지 시퀀스(I1:T)에 대해 별도의 관심 영역을 지정하지 않더라도 T개의 프레임({I1, I2, …, IT})내의 각 영역별 중요도에 따른 가중치를 획득할 수 있도록 한다.The spatiotemporal
즉 본 실시예에 따른 감정 인식 장치는, 도1 과 같이 각 프레임({I1, I2, …, IT})에서 사람의 얼굴에서 감정이 강하게 표출되는 영역(눈, 입)을 별도로 지정하지 않더라도, 시공간 특징 추출부(220)가 각 프레임의 영역별 감정 표출의 중요도를 시공간 주의에 기반하여 특징으로 추출하고, 추출된 특징을 시공간 가중치(A1:T)로서 3D 특징(X'1:T)에 부가함으로써 최적의 감정 인식 성능을 제공할 수 있다.That is, the emotion recognition apparatus according to the present embodiment separately designates regions (eyes and mouths) in which emotions are strongly expressed on a person's face in each frame ({I 1 , I 2 , …, I T }) as shown in FIG. 1. Even if not, the spatiotemporal
이를 위해, 시공간 특징 추출부(220)는 도4 와 같이 구성될 수 있다.To this end, the spatiotemporal
도4 를 참조하면, 시공간 특징 추출부(220)는 공간 주의(Spatial Attention) 기반 특징을 추출하기 위한 공간 인코더(221), 시공간 주의(Spatiotemporal Attention) 기반 특징을 추출하기 위한 시간 디코더(223) 및 추출된 특징을 지정된 범위 이내의 가중치로 변환하는 정규화하는 정규화기(225)를 포함한다.Referring to FIG. 4, the spatiotemporal
공간 인코더(221)는 이미지 시퀀스(I1:T)의 T개의 2차원 프레임({I1, I2, …, IT}) 각각에 대해 공간적 특징(X1:T)을 추출하여 출력한다. 공간 인코더(221)는 지정된 2차원 패턴 인식 기법에 의해 미리 학습되어, T개의 프레임({I1, I2, …, IT}) 각각의 공간적 패턴을 인식함으로써, 2차원의 공간적 특징(X1:T)을 추출한다.The
공간 인코더(221)는 일예로 미리 학습된 2차원 콘볼루션 신경망(2D Convolutional Neural Networks: 이하 2D CNN)으로 구현될 수 있다. 2D CNN은 2차원의 이미지에서 특징을 추출하기 위해 주로 이용되는 인공 신경망의 하나이다.The
공간 인코더(221)는 이미지 획득부(100)로부터 T개의 프레임({I1, I2, …, IT})을 순차적으로 인가받아 공간적 특징({X1, X2, …, XT})을 순차적으로 출력하도록 구성될 수 있으나, 시간을 줄이기 위해 T개의 프레임({I1, I2, …, IT})을 동시에 인가받아 특징을 추출할 수 있도록 병렬로 구성될 수도 있다. 공간 인코더(221)가 병렬로 구성되는 경우, 모든 공간 인코더는 가중치 및 바이어스 값이 동일하게 공유되는 사이어미즈(Siamese) 네트워크로 구성된다.The
또한 공간 인코더(221)가 학습되는 과정에서 T개의 프레임({I1, I2, …, IT})이 순차적으로 인가되더라도, T개의 프레임({I1, I2, …, IT})에 대한 공간적 특징({X1, X2, …, XT})이 모두 출력되기 이전에는 공간 인코더(221)의 가중치 및 바이어스 값이 가변되지 않아야 하며, T개의 프레임({I1, I2, …, IT})에 대한 공간적 특징({X1, X2, …, XT})이 모두 출력된 이후, 공간 인코더(221)의 가중치 및 바이어스 값이 가변될 수 있다. 이는 본 실시예에 따른 감정 인식 장치가 T개의 프레임({I1, I2, …, IT})을 포함하는 이미지 시퀀스(I1:T)를 감정 인식을 위한 단위로 처리하기 때문이다.Also, even if T frames ({I 1 , I 2 , …, I T }) are sequentially applied in the course of learning the
한편, 본 실시예에서 2D CNN으로 구현되는 공간 인코더(221)는 일예로 연속되는 3 X 3 컨볼루션 레이어와 ReLU(Rectified Linear Unit) 레이어 및 2 X 2 스트라이드(stride)의 맥스 풀링(Max-Pooling) 레이어를 포함하도록 구성될 수 있다. 여기서 3 X 3 컨볼루션 레이어와 ReLU 레이어 및 맥스 풀링 레이어는 각각 기지정된 개수의 필터를 포함할 수 있다. 일예로, 3 X 3 컨볼루션 레이어는 32개의 필터를 포함할 수 있고, ReLU 레이어는 64개의 필터를 포함할 수 있으며, 맥스 풀링 레이어는 128개의 필터를 포함하도록 구성될 수 있다.On the other hand, in this embodiment, the
공간 인코더(221)가 3 X 3 컨볼루션 레이어와 ReLU 레이어 및 맥스 풀링 레이어를 포함하는 것은 이미지 시퀀스(I1:T)로부터 공간적 특징(X1:T)을 추출할 때, 매개 변수의 수를 줄임으로써 오버 피팅(overfitting) 문제를 방지하기 위함이다.The
시간 디코더(223)는 공간 인코더(221)에서 획득된 공간적 특징(X1:T)에 대해 시공간 주의 기반 특징을 추출한다.The
공간 인코더(221)가 2D CNN으로 구현되는 경우, 이미지 시퀀스(I1:T)의 T개의 프레임({I1, I2, …, IT}) 각각에서의 공간적 특징, 즉 영역별 특징을 추출할 수 있다. 그러나 공간 인코더(221)가 T개의 프레임({I1, I2, …, IT})을 개별적으로 특징을 추출함으로써, 시간적으로 연속하는 T개의 프레임({I1, I2, …, IT}) 사이의 시간적 특징이 반영되지 않는 한계가 있다.When the
이에 본 실시예에서 시간 디코더(223)는 시공간 주의 기반 특징을 추출함으로써, 공간적 특징(X1:T)에 시간적 특징이 더 부가되도록 한다. 시간 디코더(223)는 지정된 패턴 인식 기법에 의해 미리 학습되어, 공간적 특징({X1, X2, …, XT})에 포함된 공간 패턴 특징을 가능한 유지하면서, 공간적 특징({X1, X2, …, XT}) 중 시간적으로 서로 인접한 공간적 특징 사이의 시간적 특징을 추가로 추출한다.Accordingly, in this embodiment, the
시간 디코더(223)는 일예로 미리 학습된 ConvLSTM(Convolutional Long Short-Term Memory)으로 구현될 수 있다. ConvLSTM 또한 인공 신경망의 하나로서, 순환 신경망(Recurrent Neural Network: RNN)이 장기간(Long Term) 특징을 반영할 수 있도록 개선한 LSTM(Long Short-Term Memory)을 더욱 개선하여 공간적 특징을 더 반영할 수 있도록 하였다.The
여기서 시간 디코더(223)가 시간적 특징을 반영할 수 있는 LSTM이 아닌 ConvLSTM을 이용하는 것은 공간 인코더(221)에서 획득된 공간적 특징(X1:T)을 가능한 유지할 수 있도록 하기 위함이다.Here, the

수학식 1은 시간 디코더(223)에서 ConvLSTM이 수행하는 기능을 수학식으로 표현한 것이다. 수학식 1에서 it, ft, ot, ct 및 ht 는 각각 시간 t에서 입력 게이트(input gate), 망각 게이트(forget gate), 출력 게이트(output gate), 활성화 셀(activation cell) 및 셀 출력(cell output)을 나타낸다. 그리고 σ(·)와 tanh(·)는 각각 시그모이드(sigmoid) 함수와 쌍곡 탄젠트 함수(hyperbolic tangent)를 나타내며, *는 컨볼루션 연산자이고, ⊙는 하다마드(Hadamard) 곱셈 연산자를 나타낸다. 그리고 W*은 다른 게이트를 연결하는 필터 행렬이고, b*는 각 게이트에 상응하는 바이어스 벡터를 나타낸다.
수학식 1에 나타난 바와 같이 ConvLSTM은 입력 대 상태 및 상태 대 상태 천이 시에 모두 컨볼루션 구조를 갖고 있어, 시간적 특징을 추출할 수 있을 뿐만 아니라 공간적 특징을 유지할 수 있다.As shown in
또한 시간 디코더(223)는 순차적 디콘볼루션(deconvolution)을 통해 인가된 공간적 특징(X1:T)의 공간 해상도를 점차적으로 확대한다. 즉 시간 디코더(223)는 공간적 특징(X1:T)의 공간 구조를 유지하면서 각 프레임 간의 시간 상관에 따른 특징을 추출한다.In addition, the
이를 위해 시간 디코더(223)는 다수개의 ConvLSTM 레이어를 포함할 수 있으며, ConvLSTM 레이어 각각은 기지정된 개수의 필터를 포함할 수 있다. 도4 에서는 일예로 2개의 ConvLSTM 레이어가 각각 64개 및 32개의 필터를 포함하는 경우를 도시하였다.To this end, the
정규화기(225)는 시간 디코더(223)에서 출력되는 시공간 특징을 수학식 2에 따른 공간적 소프트 맥스(spatial softmax) 함수를 사용하여 정규화한다.The

수학식 2에서 Ht-1은 히든 상태(hidden state)를 나타내고, Wi는 위치 소프트맥스의 i번째 요소에 매핑되는 가중치이고, j는 위치를 나타낸다.In Equation 2, H t-1 represents a hidden state, W i is a weight mapped to the i-th element of the location softmax, and j represents a location.
정규화기(225)에 의해 시간 디코더(223)에서 출력되는 시공간 특징은 정규화되어 시공간 가중치(A1:T)로서 출력된다. 일예로 정규화기(225)는 시공간 가중치(A1:T)의 합이 1이되도록 정규화할 수 있다.The spatiotemporal features output from the
특징 결합부(230)는 3D 특징(X'1:T)과 시공간 가중치(A1:T)를 수학식 3에 따라 결합하여, 감정 특징(X")을 획득한다.The
![]()
![]()
수학식 3에서 3D 특징(X'1:T)은 대상의 감정을 판별하기 위한 특징이고, 정규화기(225)에 의해 정규화된 시공간 가중치(A1:T)는 3D 특징(X'1:T)의 대응하는 각 영역에 대한 중요도를 지정하는 가중치로서 기능한다.In Equation 3, the 3D feature (X' 1:T ) is a feature for determining the emotion of the object, and the space-time weight (A 1:T ) normalized by the
감정값 획득부(240)는 감정 특징(X")에 대해 다시 3차원 특징을 추출하여 감정값(y)를 획득한다. The emotion
감정값 획득부(240)는 일예로 3D 특징 추출부(210)와 유사하게 미리 학습된 3D CNN으로 구현될 수 있다. 그리고 본 실시예에서 감정값 획득부(240)는 감정값을 -1 에서 1 사이의 스칼라 값(scalar value)(y ∈ [-1, 1])으로 획득되도록 특징을 추출할 수 있으나, 이에 한정되지 않는다.The emotion
감정값 획득부(240) 또한 효율적인 감정값을 획득하기 위해 다수개의 레이어로 구성될 수 있다. 일예로 감정값 획득부(240)는 다수개(예를 들면 4개)의 3D CNN 레이어와 다수개(예를 들면 3개)의 3D 맥스 풀링 레이어 및 다수개(예를 들면 2개)의 완전 연결 레이어(fully-connected layer)를 포함할 수 있다. 그리고 다수개의 3D CNN 레이어는 일예로 각각 32, 64, 128 및 256개의 필터를 포함할 수 있다.The emotion
한편, 완전 연결 레이어는 단일 출력 채널을 갖고, 선형 회귀 레이어를 이용하여 감정값(y)을 획득할 수 있다.Meanwhile, the fully connected layer has a single output channel, and an emotion value y may be obtained using a linear regression layer.
감정 판별부(300)는 감정값 획득부(240)에서 획득된 감정값(y)을 미리 저장된 감정값별 감정 기준에 대입함으로써, 대상의 감정을 판별한다. 상기에서 감정값(y)가 -1 에서 1 사이의 스칼라 값인 것으로 가정하였으므로, 감정값별 감정 기준은 각 감정에 대한 감정값이 -1 에서 1 사이의 연속되는 범위값으로 설정될 수 있다. 따라서, 감정 판별부(300)는 인가된 감정값(y)에 대응하는 감정을 용이하게 판별할 수 있다.The
본 실시예에서는 일예로 도2 에 도시된 2차원 감정 그래프의 각성(Arousal)과 유인가(Valence)의 2개의 축 중 유인가에 대응하는 감정값(y)을 추출한다. 그러나 이는 일예로서 경우에 따라 감정 추출부(200)는 각성에 대응하는 감정값을 추출하도록 구성될 수도 있으며, 각성 및 유인가 양쪽에 대응하는 감정값을 추출하도록 구성될 수도 있다.In this embodiment, as an example, the emotion value y corresponding to the validity among the two axes of the arousal and the validity of the two-dimensional emotion graph shown in FIG. 2 is extracted. However, this is an example, and in some cases, the
본 실시예에서 3D 특징 추출부(210)와 시공간 특징 추출부(220)의 공간 인코더(221) 및 시간 디코더(222), 그리고 감정값 획득부(240)는 각각 지정된 딥-러닝 알고리즘에 따라 미리 학습된 인공 신경망이다.In this embodiment, the
그리고 감정 추출부(200)에 인가되는 이미지 시퀀스(I1:T)의 T개의 프레임({I1, I2, …, IT})과 각 특징(X1:T, X'1:T, X", A1:T)는 백터 행렬(vector matrix)로 표현될 수 있다.Then, T frames ({I 1 , I 2 , …, I T }) of the image sequence (I 1: T ) applied to the
결과적으로 본 실시예에 따른 감정 인식 장치는 연속되는 T개의 프레임({I1, I2, …, IT})을 포함하는 이미지 시퀀스(I1:T)로부터 3차원으로 감정을 판별하기 위한 3D 특징(X'1:T)을 추출하고, 이와 동시에 T개의 프레임({I1, I2, …, IT}) 각각의 시공간 주의에 기반한 특징을 추출하여 T개의 프레임({I1, I2, …, IT}) 각각의 영역별 가중치(A1:T)를 획득한다. 그리고 3D 특징(X'1:T)에 영역별 가중치(A1:T)를 가중하여 감정 특징(X")을 획득하고, 감정 특징(X")으로부터 감정값(y)를 추출함으로써, 이미지 시퀀스(I1:T)에 별도의 관심 영역을 설정하지 않고서도 대상의 감정을 매우 정확하게 추출 및 판별할 수 있도록 한다.As a result, the emotion recognition apparatus according to the present embodiment is for determining emotion in three dimensions from an image sequence (I 1: T ) including consecutive T frames ({I 1 , I 2 , …, I T }). 3D feature (X '1: T) extract, and at the same time the T-frame ({I 1, I 2, ..., I T}) extracts features based on the respective space-time attention to the T-frame ({I 1, I 2 , …, I T }) Obtain weights (A 1: T ) for each region. Then, by weighting each region's weight (A 1:T ) on the 3D feature (X' 1:T ), the emotion feature (X") is obtained, and the emotion value (y) is extracted from the emotion feature (X") to obtain an image. It is possible to extract and discriminate the emotion of an object very accurately without setting a separate region of interest in the sequence (I 1: T ).
도5 는 도3 의 감정 인식 장치의 학습 방법을 설명하기 위한 도면이다.5 is a diagram for explaining a learning method of the emotion recognition device of FIG. 3.
도3 및 도4 를 참조하여, 도5 의 학습 방법을 설명하면, 이미지 획득부(100)는 미리 감정값이 판별된 다수의 프레임을 포함하는 이미지 시퀀스 중 T개의 프레임({I1, I2, …, IT})씩 순차적으로 감정 추출부(200)로 전달한다.Referring to FIGS. 3 and 4, when the learning method of FIG. 5 is described, the
감정 추출부(200)를 학습시키기 위해서는 다수의 이미지 시퀀스 또는 다수의 프레임이 필요하므로, 여기서는 일예로 이미지 시퀀스가 3500개의 프레임을 포함하는 경우를 도시하였다.In order to train the
그리고 이미지 획득부(100)는 이미지 시퀀스에서 순차적으로 T개씩의 프레임을 분리하여 전달하며, 이때 이미지 획득부(100)는 제1 내지 제10 프레임(I1 ~ IT)을 전달하고, 이후 제2 내지 제11 프레임(I2 ~ IT+1)을 전달하는 방식으로 전달할 수 있다.In addition, the
감정 추출부(200)의 3D 특징 추출부(210)는 T개의 프레임({I1, I2, …, IT})이 포함된 이미지 시퀀스(I1:T) 전체에 대해 3D 특징(X'1:T)을 추출한다. 이와 함께 시공간 특징 추출부(220)의 공간 인코더(221)와 시간 디코더(223) 및 정규화기(225)가 T개의 프레임({I1, I2, …, IT}) 각각에 대해 공간적 특징(X1:T)을 추출하고, 추출된 공간적 특징(X1:T)에 대해 다시 시공간 특징을 추출하여 정규화함으로써, 시공간 가중치(A1:T)를 획득한다.The 3D
한편, 감정 추출부(200)의 특징 결합부(230)는 3D 특징(X'1:T)에 시공간 가중치(A1:T)를 가중하여, 감정 특징(X")을 획득하고, 감정값 획득부(240)는 획득된 감정 특징(X")에 대해 다시 3차원 측징을 추출하여, 기지정된 범위(여기서는 일예로 -1 ~ 1) 이내의 스칼라 값을 갖는 감정값(y)를 획득한다.On the other hand, the
여기서 3D 특징 추출부(210)와 공간 인코더(221)와 시간 디코더(223) 및 감정값 획득부(240)이 모두 학습되지 않은 인공 신경망이므로, 추출되는 3D 특징(X'1:T)과 공간적 특징(X1:T), 시공간 가중치(A1:T) 및 감정값(y)은 모두 상당한 오차를 포함한 상태이다.Here, since the 3D
이에 획득된 감정값(y)을 해당 프레임에서 미리 판별되어 저장된 감정값과 비교하여 오차를 분석한다. 도5 의 오른쪽 그래프는 학습용으로 3500개의 프레임을 포함하는 이미지 시퀀스에서 프레임별로 획득된 감정값(y)과 미리 저장된 감정값을 나타낸다. 여기서는 감정값이 유인가 점수(Valence Score)인 경우를 나타내었으며, 청색 선은 각 프레임에 대해 획득된 감정값(y)를 나타내고, 적색 선은 미리 저장된 감정값을 나타낸다. 즉 x 축에 해당하는 특정 프레임에서 청색 선과 적색 선 사이의 차이가 오차이다.The obtained emotion value y is determined in advance in the corresponding frame and compared with the stored emotion value to analyze the error. The graph on the right of FIG. 5 represents the emotion value y obtained for each frame and the previously stored emotion value in an image sequence including 3500 frames for learning. Here, the case where the emotion value is a valence score is shown, the blue line represents the emotion value (y) obtained for each frame, and the red line represents the previously stored emotion value. That is, the difference between the blue line and the red line in a specific frame corresponding to the x-axis is an error.
감정 추출부(200)는 분석된 오차가 감소하도록 3D 특징 추출부(210)와 공간 인코더(221)와 시간 디코더(223) 및 감정값 획득부(240)의 가중치 및 바이어스 벡터등을 조절하여 학습시킨다. 이때 오차는 이미지 시퀀스(I1:T)를 처리하는 순서의 역순으로 감정값 획득부(240)로부터 시간 디코더(223)와 공간 인코더(221) 및 3D 특징 추출부(210)로 전파되어, 점차로 오차를 줄이도록 학습된다.The
그리고 감정 추출부(200)는 다시 이미지 획득부(100)로부터 T개의 프레임을 인가받아, 감정값(y)을 획득하여 오차를 판별함으로써, 반복적으로 학습한다. 결과적으로 다수의 프레임을 포함하는 이미지 시퀀스에 대해 반복적으로 감정값(y)을 획득하고, 획득된 감정값(y)의 오차가 감소되도록 함으로써, 감정 인식 장치가 학습될 수 있다.Then, the
도6 은 본 발명의 일 실시예에 따른 감정 인식 방법을 나타낸다.6 shows an emotion recognition method according to an embodiment of the present invention.
도3 및 도4 를 참조하여 도6 의 감정 인식 방법을 설명하면, 우선 이미지 획득부(100)가 T개 프레임({I1, I2, …, IT})을 포함하는 이미지 시퀀스(I1:T)를 획득하여 감정 추출부(200)로 전달한다(S10).Referring to FIGS. 3 and 4, the emotion recognition method of FIG. 6, first, the
이에 감정 추출부(200)의 3D 특징 추출부(210)는 T개의 프레임({I1, I2, …, IT})이 포함된 이미지 시퀀스(I1:T) 전체에 대해 3D 특징(X'1:T)을 추출한다(S20). 3D 특징 추출부(210)는 일예로 3D CNN으로 구현될 수 있으며, 이에 T개의 2차원 프레임({I1, I2, …, IT})에서 3D 특징(X'1:T)을 추출할 수 있다.Accordingly, the 3D
이와 동시에 감정 추출부(200)의 시공간 특징 추출부(220)는 T개 프레임({I1, I2, …, IT}) 각각에 대해 우선 공간적 특징(X1:T = {X1, X2, …, XT})을 추출한다(S30). 시공간 특징 추출부(220)는 일예로 2D CNN을 이용하여, T개 프레임({I1, I2, …, IT}) 각각의 공간적 특징({X1, X2, …, XT})을 추출할 수 있다. 이때, 시공간 특징 추출부(220)는 오버 피팅 문제를 방지하기 위해, 2D CNN으로 컨볼루현 레이어와 ReLU 레이어 및 맥스 풀링 레이어를 포함하여, 공간 해상도를 축소시킬 수 있다.At the same time, the spatiotemporal
그리고 추출된 공간적 특징(X1:T)을 가능한 유지하면서 시간적 특징을 더하기 위해, 시공간 특징을 추출한다(S40). 시공간 특징 추출부(220)는 공간적 특징(X1:T)을 유지하면서 시간적 특징을 더 추출하기 위해 일예로 ConvLSTM을 이용한다. 이때 시공간 특징 추출부(220)는 다수개의 ConvLSTM 레이어를 포함하여, 순차적 디콘볼루션함으로써, 축소된 공간 해상도를 다시 확대할 수 있다.Then, in order to add temporal features while maintaining the extracted spatial features (X 1: T ) as possible, space-time features are extracted (S40 ). The spatio-temporal
그리고 감정 추출부(200)는 추출된 시공간 특징을 미리 지정된 방식으로 정규화하여, 시공간 가중치(A1:T)를 획득한다(S50).Then, the
그리고 감정 추출부(200)의 특징 결합부(230)는 3D 특징(X'1:T)에 시공간 가중치(A1:T)를 가중하여, 감정 특징(X")을 획득한다(S60). 3D 특징(X'1:T)에 시공간 가중치(A1:T)가 가중됨으로써, T개의 프레임({I1, I2, …, IT})으로부터 추출된 3D 특징(X'1:T)의 각 시공간 영역별 가중치가 상이하게 가중될 수 있다.Then, the
이는 별도의 관심 영역이 지정되지 않더라도, 감정 추출부(200)가 T개의 프레임({I1, I2, …, IT}) 각각에서 영역별 중요도를 결정할 수 있음을 의미한다.This means that even if a separate region of interest is not specified, the
그리고 감정 추출부(200)의 감정값 획득부(240)는 감정 특징(X")에 대해 다시 3차원 특징을 추출하여, 기지정된 범위 이내의 스칼라 값을 갖는 감정값(y)를 획득한다(S70). 감정값 획득부(240) 또한 일예로 3D CNN으로 구현될 수 있으며, 여기서 획득된 감정값(y)는 이미지 시퀀스(I1:T)에 포함된 대상의 감정을 대표하는 값이다. 감정값 획득부(240)는 감정값을 획득하기 위해, 3D CNN 레이어와 3D 맥스 풀링 레이어 및 완전 연결 레이어를 포함할 수 있다.Then, the emotion
감정 판별부(300)는 미리 저장된 감정값별 대한 감정에 획득된 감정값(y)를 대입하여 비교함으로써, 대상의 감정을 판별한다(S80).The
이하에서는 본 실시예에 따른 감정 인식 장치 및 방법의 성능을 기존의 감정 인식 방법과 비교하여 설명한다.Hereinafter, the performance of the emotion recognition apparatus and method according to the present embodiment will be described in comparison with an existing emotion recognition method.
여기서는 본 실시예에 따른 감정 인식 장치 및 방법의 성능을 정량적으로 평가하기 위해, 평균 제곱근 오차(Root Mean Square Error: RMSE)와 피어슨 상관 계수(Pearson Correlation Coefficient)(CC) 및 일치 상관 계수(Concordance Correlation Coefficient)(CCC)의 3가지 측정 기준을 이용하였다.Here, in order to quantitatively evaluate the performance of the emotion recognition apparatus and method according to the present embodiment, the Root Mean Square Error (RMSE), the Pearson Correlation Coefficient (CC), and the Concordance Correlation Coefficient) (CCC) was used.
이중 일치 상관 계수(CCC)는 수학식 4에 따라 두 변수 사이의 일치성을 측정한다.The double coincidence correlation coefficient (CCC) measures the correspondence between two variables according to Equation (4).

수학식 4에서 ρ는 피어슨 상관 계수이고, σx 2와 σy 2는 예측 및 측정값의 분산이며, μx와 μy는 예측 및 측정값의 평균을 나타낸다.In Equation 4, ρ is the Pearson correlation coefficient, σ x 2 and σ y 2 are variances of the prediction and measurement values, and μ x and μ y represent the average of the prediction and measurement values.
그리고 성능 검증을 위한 데이터로 2015년 및 2016년 Audio/Visual Emotion recognition Challenges (이하 AV + EC)에서 채택된 RECOLA 데이터 세트와 2017년 AV + EC의 데이터 세트를 이용하였다.Also, RECOLA data set adopted in 2015/2016 Audio/Visual Emotion recognition Challenges (hereinafter AV + EC) and data set of AV + EC in 2017 were used as data for performance verification.
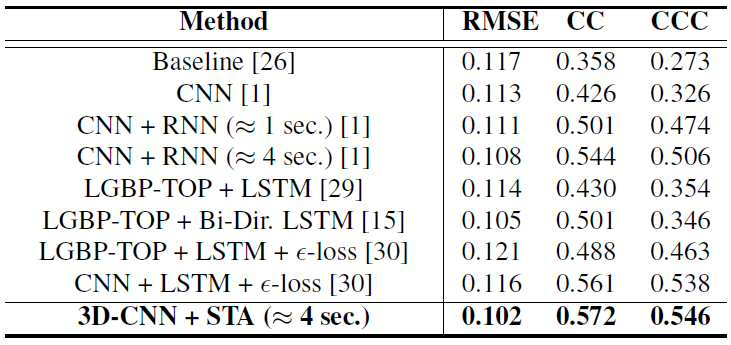
표1 은 2D CNN을 이용한 경우와 3D CNN을 이용한 경우 및 본 실시예에 따른 3D CNN과 시공간 주의(STA)를 함께 이용한 감정 인식 방법에 대한 측정 결과를 나타낸다.Table 1 shows the measurement results for the case of using the 2D CNN and the case of using the 3D CNN and the emotion recognition method using the 3D CNN and the spatiotemporal attention (STA) according to the present embodiment.

표1 의 3번째 행에 나타난 바와 같이, 본 실시예에 따른 감정 인식 방법은 3D CNN과 시공간 주의(STA)를 함께 이용함에 따라 평균 제곱근 오차(RMSE)가 줄어들었으며, 피어슨 상관 계수(CC) 및 일치 상관 계수(CCC)가 각각 0.062 및 0.053만큼 증가되었음을 알 수 있다.As shown in the third row of Table 1, the method of recognizing emotion according to the present embodiment reduces the mean square root error (RMSE) by using 3D CNN and space-time attention (STA) together, and the Pearson correlation coefficient (CC) and It can be seen that the coincidence correlation coefficient (CCC) was increased by 0.062 and 0.053, respectively.
도7 은 본 실시예의 시공간 가중치를 시각화한 도면이다.7 is a diagram visualizing the spatiotemporal weight of the present embodiment.
도7 은 RECOLA 데이터 세트에 대해 시공간 특징 추출부(220)가 시공간 특징을 추출하여 획득된 시공간 가중치(A1:T)를 색상별로 구분하여 시각화한 도면이다. 도7 에서 붉은 색 영역이 가중치가 높은 영역을 나타내고, 파란색 영역은 가중치가 낮은 영역을 나타낸다.FIG. 7 is a view visualizing the spatial and temporal weights (A 1: T ) obtained by extracting the spatiotemporal feature by color and the color space by extracting the spatiotemporal feature for the RECOLA data set. In FIG. 7, the red area indicates a high weighted area, and the blue area indicates a low weighted area.
상기한 바와 같이, 본 발명의 실시예에서 시공간 특징 추출부(220)는 다수의 프레임({I1, I2, …, IT})에 대해 공간적 특징을 추출하고, 추출된 공간적 특징을 유지하면서 시간적 특징을 더 추출함으로써, 시공간 주의 기반 특징을 추출한다. 즉 시공간 가중치(A1:T)를 획득한다. 이로 인해, 시공간 특징 추출부(220)는 도7 에 도시된 바와 같이, 별도의 관심 영역이 지정되지 않더라도, 학습된 바에 따라 다수의 프레임({I1, I2, …, IT}) 각각에서 감정 인식을 위한 각 영역의 가중치를 차등화시킬 수 있다.As described above, in the embodiment of the present invention, the spatiotemporal
도7 로부터 시공간 특징 추출부(220)가 눈과 입 주위의 영역을 감정을 추정하기 위해 중요한 영역으로 스스로 판별하였음을 알 수 있다.It can be seen from FIG. 7 that the spatio-temporal
도8 및 도9 는 각각 2 종류의 RECOLA 데이터 세트와 AV + EC 데이터 세트에 대해 본 실시예에 따른 감정 인식 방법을 적용하여 획득되는 감정값과 검증값을 비교한 결과를 나타낸다.8 and 9 show the results of comparing emotion values and verification values obtained by applying the emotion recognition method according to the present embodiment to the two types of RECOLA data sets and AV + EC data sets, respectively.
도8 및 도9 에서 적색 선은 검증값(ground truth)를 나타내고, 청색 선은 감정값(y)를 나타낸다. 도8 및 도9 에 도시된 바와 같이, 본 발명의 실시예에 따른 감정 인식 방법에 의해 획득된 감정값(y)는 검증값과 유사하게 변동됨을 확인할 수 있다.8 and 9, the red line represents the ground truth, and the blue line represents the emotion value y. 8 and 9, it can be confirmed that the emotion value y obtained by the emotion recognition method according to the embodiment of the present invention fluctuates similarly to the verification value.
그리고 표2 및 표3 에서는 각각 RECOLA 데이터 세트와 AV + EC 데이터 세트에 대한 본 실시예에 따른 감정 인식 결과를 다른 감정 인식 방법과 비교하였다.In Table 2 and Table 3, the emotion recognition results according to the present embodiment for the RECOLA data set and the AV + EC data set were compared with other emotion recognition methods, respectively.

상기 표2 및 표3 에 나타난 바와 같이, 본 실시예에 따른 감정 인식 방법은 기존의 다른 감정 인식 방법에 비해, 가장 낮은 평균 제곱근 오차(RMSE)를 나타내는 반면, 피어슨 상관 계수(CC) 및 일치 상관 계수(CCC)는 가장 높게 나타남을 확인할 수 있다. 즉 감정 인식 성능이 매우 우수함을 확인할 수 있다.As shown in Tables 2 and 3, the emotion recognition method according to the present embodiment shows the lowest mean square root error (RMSE) compared to other conventional emotion recognition methods, while the Pearson correlation coefficient (CC) and coincidence correlation It can be seen that the coefficient (CCC) is highest. That is, it can be confirmed that the emotion recognition performance is very excellent.
본 발명에 따른 방법은 컴퓨터에서 실행 시키기 위한 매체에 저장된 컴퓨터 프로그램으로 구현될 수 있다. 여기서 컴퓨터 판독가능 매체는 컴퓨터에 의해 액세스 될 수 있는 임의의 가용 매체일 수 있고, 또한 컴퓨터 저장 매체를 모두 포함할 수 있다. 컴퓨터 저장 매체는 컴퓨터 판독가능 명령어, 데이터 구조, 프로그램 모듈 또는 기타 데이터와 같은 정보의 저장을 위한 임의의 방법 또는 기술로 구현된 휘발성 및 비휘발성, 분리형 및 비분리형 매체를 모두 포함하며, ROM(판독 전용 메모리), RAM(랜덤 액세스 메모리), CD(컴팩트 디스크)-ROM, DVD(디지털 비디오 디스크)-ROM, 자기 테이프, 플로피 디스크, 광데이터 저장장치 등을 포함할 수 있다.The method according to the present invention may be implemented as a computer program stored in a medium for execution on a computer. The computer readable medium herein can be any available medium that can be accessed by a computer, and can also include any computer storage medium. Computer storage media includes both volatile and nonvolatile, removable and non-removable media implemented in any method or technology for storage of information such as computer readable instructions, data structures, program modules or other data, and ROM (readable) Dedicated memory), RAM (random access memory), CD (compact disk)-ROM, DVD (digital video disk)-ROM, magnetic tape, floppy disk, optical data storage, and the like.
본 발명은 도면에 도시된 실시예를 참고로 설명되었으나 이는 예시적인 것에 불과하며, 본 기술 분야의 통상의 지식을 가진 자라면 이로부터 다양한 변형 및 균등한 타 실시예가 가능하다는 점을 이해할 것이다.Although the present invention has been described with reference to the embodiments shown in the drawings, these are merely exemplary, and those skilled in the art will understand that various modifications and other equivalent embodiments are possible therefrom.
따라서, 본 발명의 진정한 기술적 보호 범위는 첨부된 청구범위의 기술적 사상에 의해 정해져야 할 것이다.Therefore, the true technical protection scope of the present invention should be defined by the technical spirit of the appended claims.
100: 이미지 획득부 200: 감정 추출부
300: 감정 판별부 210: 3D 특징 추출부
220: 시공간 특징 추출부 230: 특징 결합부
240: 감정값 획득부 221: 공간 인코더
223: 시간 디코더 225: 정규화부100: image acquisition unit 200: emotion extraction unit
300: emotion discrimination unit 210: 3D feature extraction unit
220: space-time feature extraction unit 230: feature coupling unit
240: emotion value acquisition unit 221: spatial encoder
223: time decoder 225: normalization
Claims (14)
기지정된 2차원 패턴 인식 기법에 따라 미리 학습되어, 상기 T개의 프레임 각각으로부터 패턴 인식을 통해 T개의 공간적 특징을 추출하고, 획득된 T개의 공간적 특징 사이의 시공간 특징을 추가하여 시공간 가중치를 획득하는 시공간 특징 추출부;
상기 시공간 가중치를 상기 3D 특징에 가중하여 감정 특징을 획득하고, 기지정된 3차원 패턴 인식 기법에 따라 미리 학습되어, 상기 감정 특징으로부터 미리 지정된 범위 이내의 값을 갖는 감정값을 추출하는 감정값 추출부; 및
감정값에 대비한 감정이 미리 저장되어, 상기 감정값 추출부에서 획득된 상기 감정값에 대응하는 감정을 판별하는 감정 판별부; 를 포함하는 감정 인식 장치.A 3D feature extraction unit that is pre-learned according to a known 3D pattern recognition technique and extracts 3D features by pattern recognition of T consecutive frames of an image sequence (where T is a natural number) as a single 3D image;
Spatio-temporal, which is pre-trained according to a known 2D pattern recognition technique, extracts T spatial features through pattern recognition from each of the T frames, and adds spatio-temporal features between the obtained T spatial features to obtain spatio-temporal weights Feature extraction unit;
The emotion value extraction unit extracts an emotion value having a value within a predetermined range from the emotion feature by learning the emotion value by weighting the space-time weight to the 3D feature and learning in advance according to a known 3D pattern recognition technique. ; And
An emotion discrimination unit that stores emotions prepared for emotion values in advance, and determines emotions corresponding to the emotion values obtained by the emotion value extraction unit; Emotion recognition device comprising a.
미리 학습된 3D CNN(3D Convolutional Neural Networks)을 포함하여, 상기 3D 특징을 추출하는 감정 인식 장치.The method of claim 1, wherein the 3D feature extraction unit
Emotion recognition device for extracting the 3D features, including pre-trained 3D CNN (3D Convolutional Neural Networks).
미리 학습된 2D CNN(2D Convolutional Neural Networks)을 포함하여, 상기 T개의 프레임 각각에 대한 상기 T개의 공간적 특징을 추출하는 공간 인코더;
미리 학습된 ConvLSTM(Convolutional Long Short-Term Memory)을 포함하여, 상기 T개의 공간적 특징 사이의 시공간 특징을 추출하는 시간 디코더; 및
상기 시간 디코더에서 추출된 시공간 특징을 기지정된 방식으로 정규화하여, 상기 시공간 가중치를 획득하는 정규화부; 를 포함하는 감정 인식 장치.The method of claim 1, wherein the space-time feature extraction unit
A spatial encoder for extracting the T spatial features for each of the T frames, including pre-trained 2D Convolutional Neural Networks (CNN);
A temporal decoder for extracting the spatio-temporal feature between the T spatial features, including a pre-trained convolutional long short-term memory (ConvLSTM); And
A normalization unit to normalize the spatiotemporal features extracted from the time decoder in a predetermined manner to obtain the spatiotemporal weights; Emotion recognition device comprising a.
상기 2D CNN가 각각 다수의 필터를 포함하는 컨볼루션 레이어, ReLU(Rectified Linear Unit) 레이어 및 맥스 풀링(Max-Pooling) 레이어를 포함하여 상기 공간적 특징의 공간 해상도를 상기 프레임의 공간 해상도보다 낮도록 축소하는 감정 인식 장치.The method of claim 3, wherein the spatial encoder
The 2D CNN includes a convolutional layer including a plurality of filters, a ReLU (Rectified Linear Unit) layer, and a Max-Pooling layer to reduce the spatial resolution of the spatial feature to be lower than the spatial resolution of the frame. Emotion recognition device.
상기 ConvLSTM가 다수의 ConvLSTM 레이어를 포함하여, 순차적 디콘볼루션을 수행함으로써, 상기 공간적 특징의 축소된 공간 해상도를 복구하는 감정 인식 장치.The method of claim 4, wherein the time decoder
The ConvLSTM includes a plurality of ConvLSTM layers, and performs sequential deconvolution to restore the reduced spatial resolution of the spatial feature.
소프트 맥스 함수를 이용하여, 상기 시공간 특징을 정규화하는 감정 인식 장치.The method of claim 5, wherein the normalization unit
An emotion recognition device that normalizes the spatiotemporal features using a soft max function.
상기 3D 특징과 상기 시공간 가중치를 하다마드 곱셈하여 상기 감정 특징을 획득하는 특징 결합부; 및
미리 학습된 3D CNN을 포함하여 상기 감정 특징으로부터 감정을 대표하는 감정값을 추출하는 감정값 획득부; 를 포함하는 감정 인식 장치.The method of claim 6, wherein the emotion value extraction unit
A feature combining unit for multiplying the 3D feature and the spatiotemporal weight to obtain the emotional feature; And
An emotion value acquiring unit for extracting emotion values representing emotions from the emotion features, including 3D CNNs learned in advance; Emotion recognition device comprising a.
상기 감정값을 기지정된 범위 이내의 스칼라 값으로 획득하는 감정 인식 장치.The method of claim 7, wherein the emotion value acquisition unit
An emotion recognition device that acquires the emotion value as a scalar value within a predetermined range.
감정을 각성(Arousal) 및 유인가(Valence)를 2개의 축으로 하여 2차원으로 표현하는 감정 모델에서 상기 유인가의 값을 나타내는 감정 인식 장치.The method of claim 7, wherein the emotional value
An emotion recognition device that indicates the value of the validity in an emotion model that expresses emotion in two dimensions with two axes, Arousal and Valence.
다수의 프레임을 포함하는 이미지 시퀀스에서 시간적으로 연속하는 상기 T개의 프레임을 분리하여 출력하는 이미지 획득부; 를 더 포함하는 감정 인식 장치.According to claim 1, The emotion recognition device
An image acquiring unit for separating and sequentially outputting the T frames consecutively in an image sequence including a plurality of frames; Emotion recognition device further comprising.
기지정된 3차원 패턴 인식 기법에 따라 미리 학습되어, 이미지 시퀀스의 시간적으로 연속하는 T개(여기서 T는 자연수)의 프레임을 3차원의 단일 이미지로서 패턴 인식하여 3D 특징을 추출하는 단계;
기지정된 2차원 패턴 인식 기법에 따라 미리 학습되어, 상기 T개의 프레임 각각으로부터 패턴 인식을 통해 T개의 공간적 특징을 추출하고, 획득된 T개의 공간적 특징 사이의 시공간 특징을 추가하여 시공간 가중치를 획득하는 단계;
상기 시공간 가중치를 상기 3D 특징에 가중하여 감정 특징을 획득하는 단계;
기지정된 3차원 패턴 인식 기법에 따라 미리 학습되어, 상기 감정 특징으로부터 미리 지정된 범위 이내의 값을 갖는 감정값을 추출하는 단계; 및
상기 감정값에 대응하는 감정을 판별하는 단계; 를 포함하는 감정 인식 방법.As a method for recognizing emotions performed in a space-time attention-based emotion recognition device,
Extracting 3D features by pattern-recognizing T consecutive frames of the image sequence (where T is a natural number) as a single 3D image by learning in advance according to a predetermined 3D pattern recognition technique;
Pre-learning according to a known two-dimensional pattern recognition technique, extracting T spatial features through pattern recognition from each of the T frames, and adding space-time features between the obtained T spatial features to obtain space-time weights ;
Obtaining emotional features by weighting the space-time weights with the 3D features;
Learning in advance according to a predetermined 3D pattern recognition technique, and extracting an emotion value having a value within a predetermined range from the emotion feature; And
Determining an emotion corresponding to the emotion value; Emotion recognition method comprising a.
미리 학습된 3D CNN(3D Convolutional Neural Networks)을 이용하여 상기 3D 특징을 추출하는 감정 인식 방법.The method of claim 11, wherein the step of extracting the 3D feature
Emotion recognition method for extracting the 3D features using 3D CNN (3D Convolutional Neural Networks) previously learned.
미리 학습된 2D CNN(2D Convolutional Neural Networks)을 이용하여 상기 T개의 프레임 각각에 대한 상기 T개의 공간적 특징을 추출하는 단계;
미리 학습된 ConvLSTM(Convolutional Long Short-Term Memory)을 이용하여 상기 T개의 공간적 특징 사이의 시공간 특징을 추출하는 단계; 및
추출된 시공간 특징을 기지정된 방식으로 정규화하여, 상기 시공간 가중치를 획득하는 단계; 를 포함하는 감정 인식 방법.The method of claim 11, wherein the step of obtaining the space-time weight
Extracting the T spatial features for each of the T frames using pre-trained 2D CNNs (2D Convolutional Neural Networks);
Extracting the spatiotemporal feature between the T spatial features using a previously learned Convlutional Long Short-Term Memory (ConvLSTM); And
Normalizing the extracted spatiotemporal features in a predetermined manner to obtain the spatiotemporal weights; Emotion recognition method comprising a.
미리 학습된 3D CNN을 포함하여 상기 감정 특징으로부터 감정을 대표하는 감정값을 추출하는 감정 인식 방법.The method of claim 11, wherein the step of extracting the emotion value
An emotion recognition method for extracting emotion values representing emotions from the emotion features including 3D CNNs learned in advance.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180053306A KR102128158B1 (en) | 2018-05-09 | 2018-05-09 | Emotion recognition apparatus and method based on spatiotemporal attention |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180053306A KR102128158B1 (en) | 2018-05-09 | 2018-05-09 | Emotion recognition apparatus and method based on spatiotemporal attention |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20190128933A KR20190128933A (en) | 2019-11-19 |
| KR102128158B1 true KR102128158B1 (en) | 2020-06-29 |
Family
ID=68771202
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020180053306A Active KR102128158B1 (en) | 2018-05-09 | 2018-05-09 | Emotion recognition apparatus and method based on spatiotemporal attention |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102128158B1 (en) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102546600B1 (en) * | 2020-11-30 | 2023-06-22 | 연세대학교 산학협력단 | Emotion recognition apparatus and method based on multimodal fusion |
| CN112699815A (en) * | 2020-12-30 | 2021-04-23 | 常州码库数据科技有限公司 | Dynamic expression recognition method and system based on space-time motion enhancement network |
| CN112766172B (en) * | 2021-01-21 | 2024-02-02 | 北京师范大学 | A facial continuous expression recognition method based on temporal attention mechanism |
| KR20220114351A (en) * | 2021-02-08 | 2022-08-17 | 전남대학교산학협력단 | A method and apparatus for pain assessment based on a photoplethysmographic based spectrogram and convolutional neural network |
| CN114424940B (en) * | 2022-01-27 | 2025-04-25 | 广州万企共赢科技管理有限公司 | Emotion recognition method and system based on multimodal spatiotemporal feature fusion |
| CN115512418A (en) * | 2022-09-29 | 2022-12-23 | 太保科技有限公司 | Question-answer emotion assessment method and device based on action units AU and micro-expressions |
| CN115530841B (en) * | 2022-11-03 | 2025-08-12 | 浙江大学 | Noninvasive myocardial transmembrane potential reconstruction and abnormal point positioning method |
| CN116712048A (en) * | 2023-05-18 | 2023-09-08 | 智慧眼科技股份有限公司 | Blood pressure measurement methods, devices and related equipment |
| CN118506580B (en) * | 2024-07-11 | 2025-01-17 | 长春大学 | Traffic flow prediction method based on multi-factor graph neural network and differential decomposition |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101818129B1 (en) | 2017-04-25 | 2018-01-12 | 동국대학교 산학협력단 | Device and method for pedestrian recognition using convolutional neural network |
| JP2018055470A (en) | 2016-09-29 | 2018-04-05 | 国立大学法人神戸大学 | Facial expression recognition method, facial expression recognition apparatus, computer program, and advertisement management system |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101265466B1 (en) | 2011-08-05 | 2013-05-16 | 충남대학교산학협력단 | Emotion recognition apparatus using facial expression, emotion recognition method using the same, and recording medium thereof |
| US9576190B2 (en) * | 2015-03-18 | 2017-02-21 | Snap Inc. | Emotion recognition in video conferencing |
| KR102036955B1 (en) * | 2016-03-25 | 2019-10-25 | 한국과학기술원 | Method for recognizing subtle facial expression using deep learning based analysis of micro facial dynamics and apparatus therefor |
| KR101910158B1 (en) * | 2016-12-09 | 2018-12-19 | 동국대학교 산학협력단 | Device and method for classifying open and close eyes based on convolutional neural network |
-
2018
- 2018-05-09 KR KR1020180053306A patent/KR102128158B1/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018055470A (en) | 2016-09-29 | 2018-04-05 | 国立大学法人神戸大学 | Facial expression recognition method, facial expression recognition apparatus, computer program, and advertisement management system |
| KR101818129B1 (en) | 2017-04-25 | 2018-01-12 | 동국대학교 산학협력단 | Device and method for pedestrian recognition using convolutional neural network |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20190128933A (en) | 2019-11-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102128158B1 (en) | Emotion recognition apparatus and method based on spatiotemporal attention | |
| US12322175B2 (en) | System and method for detecting fabricated videos | |
| KR102734298B1 (en) | Method and apparatus for recognizing object, and method and apparatus for learning recognizer | |
| Chen et al. | Convolution neural network for automatic facial expression recognition | |
| Guo et al. | Facial expression recognition: a review | |
| CN110659665B (en) | A model construction method and image recognition method and device for different-dimensional features | |
| CN112784763A (en) | Expression recognition method and system based on local and overall feature adaptive fusion | |
| KR102546600B1 (en) | Emotion recognition apparatus and method based on multimodal fusion | |
| CN113076905B (en) | A Method of Emotion Recognition Based on Context Interaction Relationship | |
| CN113011357A (en) | Depth fake face video positioning method based on space-time fusion | |
| Salunke et al. | A new approach for automatic face emotion recognition and classification based on deep networks | |
| Kantarcı et al. | Thermal to visible face recognition using deep autoencoders | |
| CN110427881B (en) | Cross-library micro-expression recognition method and device based on face local area feature learning | |
| CN113627391A (en) | Cross-mode electroencephalogram signal identification method considering individual difference | |
| Diyasa et al. | Multi-face Recognition for the Detection of Prisoners in Jail using a Modified Cascade Classifier and CNN | |
| Jamil et al. | Face recognition using neural networks | |
| Monisha et al. | Enhanced automatic recognition of human emotions using machine learning techniques | |
| Liu et al. | Audio-visual speech recognition using a two-step feature fusion strategy | |
| Subarna et al. | Real time facial expression recognition based on deep convolutional spatial neural networks | |
| Tibermacine et al. | Enhanced EEG classification via Riemannian normalizing flows and deep neural networks | |
| Devi et al. | A novel face recognition system based on combining eigenfaces with fisher faces using wavelets | |
| Punithavathi et al. | Suicide Ideation Detection of Covid Patients Using Machine Learning Algorithm. | |
| Zuobin et al. | Effective feature fusion for pattern classification based on intra-class and extra-class discriminative correlation analysis | |
| Kumar et al. | Vgg 16 based human emotion classification using thermal images through transfer learning | |
| Sharvesh et al. | EmoSense: Deep Analysis of Real-Time Facial Expression for Multi-Class Emotions |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| PA0109 | Patent application |
Patent event code: PA01091R01D Comment text: Patent Application Patent event date: 20180509 |
|
| PA0201 | Request for examination | ||
| PG1501 | Laying open of application | ||
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20191202 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20200622 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20200623 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20200623 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration | ||
| PR1001 | Payment of annual fee |
Payment date: 20240614 Start annual number: 5 End annual number: 5 |