KR101250051B1 - Speech signals analysis method and apparatus for correcting pronunciation - Google Patents
Speech signals analysis method and apparatus for correcting pronunciation Download PDFInfo
- Publication number
- KR101250051B1 KR101250051B1 KR1020110092057A KR20110092057A KR101250051B1 KR 101250051 B1 KR101250051 B1 KR 101250051B1 KR 1020110092057 A KR1020110092057 A KR 1020110092057A KR 20110092057 A KR20110092057 A KR 20110092057A KR 101250051 B1 KR101250051 B1 KR 101250051B1
- Authority
- KR
- South Korea
- Prior art keywords
- voice signal
- pronunciation
- histogram
- voice
- speech
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/04—Segmentation; Word boundary detection
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/022—Blocking, i.e. grouping of samples in time; Choice of analysis windows; Overlap factoring
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/06—Transformation of speech into a non-audible representation, e.g. speech visualisation or speech processing for tactile aids
- G10L21/10—Transforming into visible information
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Data Mining & Analysis (AREA)
- Quality & Reliability (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Electrically Operated Instructional Devices (AREA)
Abstract
발음 교정을 위한 음성 신호 분석 방법 및 장치를 공개한다. 본 발명은 입력된 음성을 음소 단위 이하의 지정된 시간 구간 단위로 구분하고, 각 시간 구간 단위의 절대값의 평균값의 분포를 측정하여 히스토그램으로 디스플레이 한다. 따라서 지정된 문장 및 지정된 단어를 기초로 발음을 교정하는 종래의 기술과 달리 입력되는 음성에 대한 제약이 없으며, 컴퓨터 뿐만 아니라 스마트폰과 같은 휴대 장치에서 용이하게 구현될 수 있다. 이에 사용자는 시간이나 장소에 구애받지 않고 용이하게 발음을 교정할 수 있다.Disclosed are a voice signal analysis method and apparatus for pronunciation correction. The present invention divides the input voice into a designated time interval unit of phoneme units or less, measures the distribution of the average value of absolute values of each time interval unit, and displays the histogram. Therefore, unlike the conventional technology of correcting a pronunciation based on a specified sentence and a specified word, there is no restriction on an input voice, and it can be easily implemented in a portable device such as a smartphone as well as a computer. The user can easily correct the pronunciation regardless of time or place.
Description
본 발명은 음성 신호 분석 방법 및 장치에 관한 것으로 특히 발음 교정을 위한 음성 신호 분석 방법 및 장치에 관한 것이다.
The present invention relates to a voice signal analysis method and apparatus, and more particularly, to a voice signal analysis method and apparatus for pronunciation correction.
정보의 교류가 많아짐에 따라 현대 사회는 사람과 사람 사이의 커뮤니케이션이 이전보다 더욱 중요해졌다. 정보 통신 기술의 발전으로 인해 커뮤니케이션의 수단이 다양화 되었으나, 사람의 음성을 전달하는 대화는 여전히 가장 중요한 커뮤니케이션 방법이다. 그리고 음성을 이용하여 커뮤니케이션을 하는 경우에도 고려되어야 할 여러 가지 항목이 있으며, 이러한 고려 대상 항목 중 중요한 하나는 발음이다.As information exchanges increase, the communication between people becomes more important than ever before in modern society. The development of information and communication technology has diversified the means of communication, but the dialogue that conveys human voice is still the most important communication method. In addition, there are various items to be considered even when communicating using voice, and an important one of these items is pronunciation.
발음은 언어를 음성으로 표현한 것으로서 언어의 종류 및 개인에 따라 발음의 특성에도 차이가 있다. 기본적으로 동일한 언어에 대한 발음 특성은 개인차를 고려하더라도 서로가 정확한 의사 전달이 가능하도록 표현되어야 한다.Pronunciation is a voice of a language, and there are differences in the characteristics of the pronunciation according to the type and individual of the language. Basically, the pronunciation characteristics of the same language should be expressed to enable accurate communication with each other even considering individual differences.
그러나 모든 사람이 언어 특성에 따른 정확한 발음을 구사하지는 못하며, 이러한 문제로 인하여 동일한 말을 여러번 반복해야 하거나, 잘못된 의사 전달이 되는 경우가 종종 발생한다. 이러한 실질적인 문제 이외에도 발음이 정확하지 않은 사람은 타인에게 좋지 않은 인상을 남길수 있으므로 개인의 이미지 관리에도 문제가 될 수 있다.However, not everyone speaks the correct pronunciation according to language characteristics, and this problem often causes the same word to be repeated many times or incorrect communication occurs. In addition to these practical problems, an incorrect pronunciation can leave a bad impression on others, which can be a problem in personal image management.
이에 정확한 발음을 구사할 수 있도록 발음을 교정하는 다양한 방법이 제시되었으나, 대부분의 발음 교정 방법은 다수의 사람들로부터 발음이 정확하다고 평가받은 다른 사람의 발음을 따라하거나, 발음이 어려운 특정 단어나 문장을 반복하여 말하는 것과 같이 정량적으로 분석되지 않는 감각적인 방법이 대부분이었다. 즉 발음이 정확하다고 평가 받는 사람의 발음 특성을 모른채 단순히 반복적인 따라하는 방법이 주로 이용되었다. 이러한 발음 교정 방법은 개인의 청취 능력이 선행되어야 할 뿐만 아니라 다양한 발음에 대해 공통적으로 적용하기 어렵다는 문제가 있다.
Various methods for correcting pronunciation have been suggested to use the correct pronunciation. However, most of the pronunciation correction methods repeat a specific word or sentence that is difficult to pronounce or repeats the pronunciation of another person whose pronunciation is judged to be correct. As I said, most of the sensory methods were not quantitatively analyzed. In other words, iteratively followed the method of repeating repeatedly without knowing the pronunciation characteristics of the person evaluated as correct. This pronunciation correction method has a problem that not only the listening ability of the individual must be preceded but also difficult to apply to various pronunciations in common.
본 발명의 목적은 정량적으로 발음을 측정하여 시각적으로 발음 특성을 표시함으로서 발음을 교정할 수 있도록 하는 음성 신호 분석 방법을 제공하는데 있다.An object of the present invention is to provide a voice signal analysis method that can correct pronunciation by measuring the pronunciation quantitatively and visually displaying the pronunciation characteristics.
본 발명의 다른 목적은 상기 음성 신호 분석 방법을 이용하여 사용자의 발음을 교정할 수 있도록 하는 음성 신호 분석 장치를 제공하는데 있다.
Another object of the present invention is to provide a voice signal analysis apparatus that can correct a user's pronunciation using the voice signal analysis method.
상기 목적을 달성하기 위한 음성 신호 분석 방법은 어음 형태의 음성 신호가 인가되고, 상기 음성 신호가 지정된 시간 구간 단위로 분할되어 복수개의 구간별 음성 신호가 획득되는 단계, 상기 복수개의 구간별 음성 신호 각각의 절대값의 평균값이 계산되어 복수개의 평균값이 계산되는 단계, 상기 복수개의 평균값의 분포에 따라 히스토그램이 생성되는 단계, 및 상기 히스토그램에 나타난 피크의 개수에 따라 발음의 명확성이 판별되는 단계를 구비하는 것을 특징으로 한다.In the speech signal analysis method for achieving the above object, a speech signal in the form of speech is applied, and the speech signal is divided into predetermined time interval units to obtain a plurality of speech signals for each section, each of the speech signals for each of the plurality of sections. Calculating an average value of the absolute values of and calculating a plurality of average values, generating a histogram according to the distribution of the plurality of average values, and determining clarity of pronunciation according to the number of peaks shown in the histogram. It is characterized by.
상기 목적을 달성하기 위한 복수개의 구간별 음성 신호가 획득되는 단계는 인가된 상기 음성 신호가 미리 설정된 주파수로 샘플링되어 디지털 음성 신호로 변환되는 단계, 및 상기 디지털 음성 신호가 음소의 발음 시간 보다 짧은 시간 구간 단위로 분할되어 상기 복수개의 구간별 음성 신호가 획득되는 단계를 구비하는 것을 특징으로 한다.Acquiring a plurality of section-specific speech signals to achieve the above object includes: sampling the applied speech signal at a predetermined frequency and converting the speech signal into a digital speech signal, and the digital speech signal having a shorter time than a phoneme pronunciation time. And dividing the signal into intervals to obtain the plurality of intervals.
상기 목적을 달성하기 위한 복수개의 평균값이 계산되는 단계는 상기 복수개의 구간별 음성 신호 각각의 절대값의 평균값이 수학식 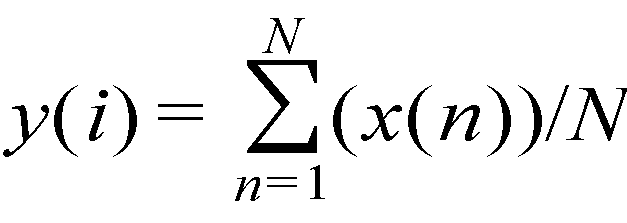
상기 목적을 달성하기 위한 히스토그램이 생성되는 단계는 상기 복수개의 평균값에서 최대값과 최소값이 획득되는 단계, 상기 최대값과 상기 최소값 사이의 범위가 지정된 개수로 균등하게 구분되는 단계, 및 균등하게 구분된 영역 각각에 상기 복수개의 평균값 중 대응하는 크기의 평균값의 개수가 표시되는 히스토그램이 생성되는 단계를 구비하는 것을 특징으로 한다.Generating a histogram for achieving the object may include obtaining a maximum value and a minimum value from the plurality of average values, equally dividing the range between the maximum value and the minimum value into a specified number, and evenly dividing the same. And generating a histogram displaying the number of average values of a corresponding size among the plurality of average values in each of the regions.
상기 목적을 달성하기 위한 발음의 명확성이 판별되는 단계는 상기 히스토그램에 나타난 피크의 개수가 확인되는 단계, 상기 피크의 개수가 하나이면, 발음이 불명확한 것으로 판정되는 단계, 및 상기 피크의 개수가 복수개이면, 발음이 명확한 것으로 판정되는 단계를 구비하는 것을 특징으로 한다.The step of determining the clarity of the pronunciation to achieve the object comprises the steps of checking the number of peaks shown in the histogram, if the number of peaks is one, determining that the pronunciation is unclear, and the number of the peaks is a plurality In this case, it is characterized in that it comprises a step of determining that the pronunciation is clear.
상기 다른 목적을 달성하기 위한 음성 신호 분석 장치는 외부에서 음성을 인가받아, 전기적 신호인 음성 신호로 변환하여 전송하는 음성 입력부, 상기 음성 신호를 지정된 시간 구간 단위로 분할하여 복수개의 구간별 음성 신호를 획득하고, 상기 복수개의 구간별 음성 신호 각각의 절대값의 평균값 분포에 따라 히스토그램을 생성한 후, 생성된 상기 히스토그램의 피크 개수에 따라 상기 음성 신호의 발음의 명확성을 판별하는 제어부, 및 상기 히스토그램을 디스플레이하는 출력부를 구비하는 것을 특징으로 한다.The voice signal analyzing apparatus for achieving the another object includes a voice input unit for receiving a voice from outside and converting the voice signal into an electrical signal, and transmitting the voice signal by dividing the voice signal in units of a predetermined time interval. A control unit for acquiring a histogram according to an average value distribution of absolute values of each of the plurality of speech signals for each section, and determining clarity of pronunciation of the speech signal according to the number of peaks of the generated histogram, and the histogram And an output unit for displaying.
상기 목적을 달성하기 위한 제어부는 상기 음성 신호를 인가받고, 상기 음성 신호를 미리 설정된 주파수로 샘플링하여 디지털 음성 신호로 변환하는 음성 신호 처리부를 더 구비하는 것을 특징으로 한다.The controller may further include a voice signal processor configured to receive the voice signal, sample the voice signal at a predetermined frequency, and convert the voice signal into a digital voice signal.
상기 목적을 달성하기 위한 제어부는 상기 디지털 음성 신호를 음소의 발음 시간 보다 짧은 시간 구간 단위로 분할하여 상기 복수개의 구간별 음성 신호를 획득하는 것을 특징으로 한다.The control unit for achieving the above object is characterized by obtaining a plurality of speech signals for each of the sections by dividing the digital speech signal by a time interval unit shorter than the phonetic pronunciation time.
상기 목적을 달성하기 위한 제어부는 상기 복수개의 구간별 음성 신호 각각의 절대값의 평균값에서 최대값과 최소값을 획득하고, 상기 최대값과 상기 최소값 사이의 범위를 지정된 개수로 균등하게 구분한 후, 균등하게 구분된 영역 각각에 상기 복수개의 절대값의 평균값 중 대응하는 크기의 평균값의 개수에 따라 히스토그램을 생성하는 것을 특징으로 한다.The control unit for achieving the object obtains the maximum value and the minimum value from the average value of the absolute value of each of the plurality of voice signals for each section, and evenly divided the range between the maximum value and the minimum value by a specified number, and then equally A histogram is generated in each of the divided regions according to the number of average values of corresponding magnitudes among the average values of the plurality of absolute values.
상기 목적을 달성하기 위한 제어부는 상기 히스토그램에 나타난 피크의 개수를 확인하여, 상기 피크의 개수가 하나이면 발음이 불명확한 것으로 판정하고, 상기 피크의 개수가 복수개이면 발음이 명확한 것으로 판정하는 것을 특징으로 한다.The control unit for achieving the above object checks the number of peaks shown in the histogram, determines that the pronunciation is unclear if the number of peaks is one, and determines that the pronunciation is clear when the number of the peaks is plural. do.
상기 목적을 달성하기 위한 음성 신호 분석 장치는 사용자로부터 명령을 입력받는 입력부를 더 구비하는 것을 특징으로 한다.Voice signal analysis apparatus for achieving the above object is characterized in that it further comprises an input unit for receiving a command from the user.
상기 목적을 달성하기 위한 음성 신호 분석 장치는 스마트폰인 것을 특징으로 한다.
Voice signal analysis device for achieving the above object is characterized in that the smartphone.
따라서, 본 발명의 음성 신호 분석 방법 및 장치는 입력된 음성을 지정된 시간 구간 단위로 구분하고, 각 시간 구간 단위의 절대값의 평균값의 분포를 측정하여 히스토그램으로 디스플레이 할 수 있다. 그러므로 지정된 문장 및 지정된 단어를 기초로 발음을 교정하는 종래의 기술과 달리 입력되는 음성에 대한 제약이 없으며, 컴퓨터 뿐만 아니라 스마트폰과 같은 휴대 장치에서 용이하게 구현될 수 있다. 이에 사용자는 시간이나 장소에 구애받지 않고 용이하게 발음을 교정할 수 있다.
Therefore, the voice signal analysis method and apparatus of the present invention may classify the input voice into a designated time interval unit, measure a distribution of an average value of absolute values of each time interval unit, and display the histogram. Therefore, unlike the conventional technology of correcting a pronunciation based on a specified sentence and a specified word, there is no restriction on the input voice, and it can be easily implemented in a portable device such as a smartphone as well as a computer. The user can easily correct the pronunciation regardless of time or place.
도1 은 음성신호 파형의 일예를 나타낸다.
도2 는 본 발명에 따른 음성 신호 분석 방법의 일예를 나타낸다.
도3 및 도4 는 어음 세기 평균치 분포 곡선의 예를 나타낸다.
도5 는 본 발명에 따른 음성 신호 분석 장치의 일예를 나타낸다.
도6 는 본 발명에 따른 음성 신호 분석 장치의 일예를 나타낸다.
도7 은 도6 의 스마트폰을 이용한 발음 교정 방법의 일예를 나타낸다.1 shows an example of an audio signal waveform.
2 shows an example of a voice signal analysis method according to the present invention.
3 and 4 show examples of the note intensity distribution curve.
5 shows an example of an apparatus for analyzing voice signals according to the present invention.
6 shows an example of an apparatus for analyzing voice signals according to the present invention.
7 illustrates an example of a pronunciation correction method using the smartphone of FIG. 6.
본 발명과 본 발명의 동작상의 이점 및 본 발명의 실시에 의하여 달성되는 목적을 충분히 이해하기 위해서는 본 발명의 바람직한 실시예를 예시하는 첨부 도면 및 첨부 도면에 기재된 내용을 참조하여야만 한다. In order to fully understand the present invention, operational advantages of the present invention, and objects achieved by the practice of the present invention, reference should be made to the accompanying drawings and the accompanying drawings which illustrate preferred embodiments of the present invention.
이하, 첨부한 도면을 참조하여 본 발명의 바람직한 실시예를 설명함으로서, 본 발명을 상세히 설명한다. 그러나, 본 발명은 여러 가지 상이한 형태로 구현될 수 있으며, 설명하는 실시예에 한정되는 것이 아니다. 그리고, 본 발명을 명확하게 설명하기 위하여 설명과 관계없는 부분은 생략되며, 도면의 동일한 참조부호는 동일한 부재임을 나타낸다. Hereinafter, the present invention will be described in detail with reference to the preferred embodiments of the present invention with reference to the accompanying drawings. However, the present invention can be implemented in various different forms, and is not limited to the embodiments described. In order to clearly describe the present invention, parts that are not related to the description are omitted, and the same reference numerals in the drawings denote the same members.
명세서 전체에서, 어떤 부분이 어떤 구성요소를 “포함”한다고 할 때, 이는 특별히 반대되는 기재가 없는 한 다른 구성요소를 제외하는 것이 아니라, 다른 구성요소를 더 포함할 수 있는 것을 의미한다. 또한, 명세서에 기재된 “...부”, “...기”, “모듈”, “블록” 등의 용어는 적어도 하나의 기능이나 동작을 처리하는 단위를 의미하며, 이는 하드웨어나 소프트웨어 또는 하드웨어 및 소프트웨어의 결합으로 구현될 수 있다.
Throughout the specification, when an element is referred to as " including " an element, it does not exclude other elements unless specifically stated to the contrary. The terms "part", "unit", "module", "block", and the like described in the specification mean units for processing at least one function or operation, And a combination of software.
도1 은 음성신호 파형의 일예를 나타낸다.1 shows an example of an audio signal waveform.
한국어 발음의 음절(音節)은 기본적으로 초성 자음과 중성 모음 및 종성 자음으로 구성되며, 경우에 따라서는 중성 모음만으로 구성되거나, 초성 자음과 중성 모음, 중성 모음과 종성 자음만으로 구성된다.The syllables of Korean pronunciation are basically composed of a consonant consonant, a neutral vowel, and a consonant consonant. In some cases, the syllable consists of only a consonant consonant, or a consonant consonant, a vowel consonant, and a consonant consonant.
도1 에 도시된 음성신호(音聲信號) 파형은 한국어 발음의 일 음절에 대한 음성신호 파형으로서 초성 자음과 중성 모음만으로 구성된 음성 신호의 파형이다. 도1 을 살펴보면, 초성 자음 구간(0 ~ 70 msec)의 음성 에너지가 중성 모음 구간(70 ~ 300 msec)의 음성 에너지에 비해 매우 작게 나타난다는 것을 확인할 수 있다. 그리고 본 발명의 발명자들은 발음의 정확성이 높은 사람일수록 초성 자음과 중성 모음의 신호 파형의 세기가 현저하게 다르다는 것을 발견하였다. 다시 말해 초성 자음과 중성 모음의 음성 에너지 차가 크면, 더욱 정확한 발음이 가능해진다.
The sound signal waveform shown in FIG. 1 is a sound signal waveform for one syllable of Korean pronunciation and is a waveform of an audio signal composed of only consonants and neutral vowels. Referring to FIG. 1, it can be seen that the voice energy of the initial consonant interval (0 to 70 msec) is very small compared to the voice energy of the neutral vowel interval (70 to 300 msec). In addition, the inventors of the present invention found that the higher the accuracy of pronunciation, the remarkably different intensities of the signal waveforms of the initial consonant and the neutral vowel. In other words, if the difference between the voice energy between the consonant and the vowels is large, more accurate pronunciation is possible.
도2 는 본 발명에 따른 음성 신호 분석 방법의 일예를 나타낸다.2 shows an example of a voice signal analysis method according to the present invention.
도2 를 참조하여 본 발명의 음성 신호 분석 방법은 먼저 음성 신호를 인가받는다(S11). 음성 신호는 마이크를 통해 실시간으로 인가받아 저장할 수도 있으며, 미리 저장된 음성 신호를 데이터 형태로 인가받을 수도 있다. 2, the voice signal analysis method of the present invention first receives a voice signal (S11). The voice signal may be authorized and stored in real time through a microphone, or the pre-stored voice signal may be applied in the form of data.
입력된 음성 신호(어음 신호)를 미리 지정된 구간 단위로 분할한다(S12). 음성 신호는 어절(語節) 및 음절 단위로 구분할 수 있으며, 하나의 음절을 발음하는데 소요되는 시간은 통상 300msec ~ 500msec 이다. 본 발명에서는 하나의 음절에서도 자음과 모음과 같은 음소(音素) 이하의 단위로 음성 신호의 에너지를 분석하기 때문에 1 음소가 발음되는 시간 이내의 구간 단위로 음성 신호를 분할한다. 본 발명에서는 일예로 1msec 를 음성 신호의 분할 단위로 설정하였다. 그러나 상기한 바와 같이 1 음소가 발음되는 시간 이내의 구간이면, 다른 시간 구간을 분할 단위로 설정할 수 있다. 측정에 의해 1 음소가 발음되는 시간은 대략 10msec 이내로 분석되었으며, 따라서 음성 신호를 분할하기 위한 시간 구간 단위는 1 ~ 10msec 단위로 설정할 수 있다. 다만 8msec 이상으로 시간 구간 단위가 설정되는 경우, 음소의 구분이 불명확해 질수 있으므로, 시간 구간 단위가 8msec 보다 작게 설정되는 것이 바람직하다.The input voice signal (voice signal) is divided into units of a predetermined section (S12). The speech signal may be divided into words and syllable units, and the time required to pronounce one syllable is typically 300msec to 500msec. In the present invention, since a single syllable analyzes the energy of a speech signal in units of phonemes or less, such as consonants and vowels, the speech signal is divided into interval units within a time when one phoneme is pronounced. In the present invention, for example, 1msec is set as the division unit of the voice signal. However, as described above, if one phoneme is a section within a time when a phoneme is pronounced, another time section may be set in division units. The time when one phoneme is pronounced by the measurement is within about 10 msec. Therefore, the time interval unit for dividing the voice signal may be set in units of 1 to 10 msec. However, when the time interval unit is set to 8msec or more, the division of phonemes may become unclear, so it is preferable that the time interval unit is set smaller than 8msec.
음성 신호를 시간 구간 단위로 분할하였으면, 분할된 구간별 음성 신호의 절대값의 평균값을 계산한다(S13). 구간별 음성 신호의 절대값의 평균값은 수학식 1과 같이 계산 될 수 있다.When the speech signal is divided in units of time sections, an average value of absolute values of the divided speech signals is calculated (S13). The average value of the absolute value of the speech signal for each section may be calculated as in Equation 1.
수학식 1에서 x(n)은 측정된 디지털화된 음성 신호를 나타낸다. 그리고 N은 설정된 구간(여기서는 1 msec)별 샘플링된 디지털 음성 신호의 개수이다. 여기서 n과 N은 자연수이다. 예를 들어 음성 신호가 16 kHz 의 속도로 샘플링 된다면, 음성 신호는 1초당 16000회 샘플링 되므로, 샘플링된 디지털 음성 신호의 개수(N)는 16000/10= 1600 이다. 그리고 y(i)는 i(여기서 i는 자연수)번째 시간 구간에서 측정된 음성 신호(x(n))의 절대값의 평균값을 나타낸다. 만일 음성 신호가 10초 동안 측정되고, 설정된 단위 시간 구간이 1ms 이면, 시간 구간별 음성 신호의 절대값의 평균값(y(i))의 개수는 모두 10000/1 = 10000개가 되며, i는 1 ~ 10000 의 값을 가질 수 있다. 그리고 음성 신호의 절대값의 평균값(y(i))은 통상적으로 20*log10(y(i)) 공식에 의해 데시벨(dB) 단위로 변환된다.In Equation 1, x (n) represents the measured digitized speech signal. N is the number of sampled digital voice signals for each set interval (here 1 msec). Where n and N are natural numbers. For example, if a speech signal is sampled at a rate of 16 kHz, the speech signal is sampled 16000 times per second, so the number N of the sampled digital speech signals is 16000/10 = 1600. Y (i) represents an average value of absolute values of the speech signal x (n) measured in the i th time interval, where i is a natural number. If the voice signal is measured for 10 seconds and the set unit time interval is 1 ms, the average number y (i) of the absolute value of the voice signal for each time interval is 10000/1 = 10000, and i is 1 to 1 It may have a value of 10000. The average value y (i) of the absolute value of the speech signal is typically converted in decibels (dB) by the
입력된 음성 신호 전체 구간에 대해 절대값의 평균값(y(i))이 계산되면, 계산된 절대값의 평균값(y(i))의 최대값 및 최소값을 획득한다(S14). 그리고 획득된 최대값 및 최소값을 사이를 지정된 개수로 균등하게 구분한다(S15). 본 발명에서는 최대값과 최소값 사이에 구분되는 개수를 일예로서 100개로 설정하여 설명한다. 그러나 구분 개수는 100개로 한정되지 않고 다양하게 설정될 수 있다.When the average value y (i) of absolute values is calculated for the entire input voice signal section, the maximum and minimum values of the calculated average value y (i) of the absolute value are obtained (S14). Then, the obtained maximum value and the minimum value are equally divided between the specified number (S15). In the present invention, the number divided between the maximum value and the minimum value is set as an example to 100. However, the number of divisions is not limited to 100, but may be variously set.
최대값 및 최소값 사이가 균등하게 구분되면, 구분된 영역별로 대응하는 절대값의 평균값(y(i))의 개수를 나타내는 히스토그램(histogram)을 산출한다(S16). 산출된 히스토그램은 구분된 구간별 어음 세기 평균치 분포를 나타내는 히스토그램이다. If the difference between the maximum value and the minimum value is equally divided, a histogram indicating the number of average values y (i) of the corresponding absolute values for each divided area is calculated (S16). The calculated histogram is a histogram representing an average distribution of speech intensity for each section.
히스토그램이 산출되면, 산출된 히스토그램에 피크의 개수를 판별한다(S17). 피크의 개수가 복수개이면, 발음이 명확한 것으로 판정한다(S18). 이는 상기한 바와 같이 자음과 모음의 에너지 차가 현격한 것이므로, 자음과 모음을 명확히 구분하여 발음한 것으로 파악할 수 있기 때문이다. 그러나 피크의 개수가 하나이면, 자음과 모음의 구분이 명확하지 않은 것이므로 발음이 불명확한 것으로 판정한다(S19). 즉 히스토그램상의 피크 개수에 따라 발음의 명확성을 판별할 수 있도록 한다.When the histogram is calculated, the number of peaks is determined in the calculated histogram (S17). If the number of peaks is plural, it is determined that the pronunciation is clear (S18). This is because the energy difference between the consonant and the vowel is remarkable as described above, and it can be understood that the consonant and the vowel are clearly distinguished and pronounced. However, if the number of peaks is one, the distinction between consonants and vowels is not clear, and it is determined that the pronunciation is unclear (S19). In other words, the clarity of the pronunciation can be determined according to the number of peaks on the histogram.
음성 신호의 샘플링 주파수가 낮으면, 디지털 음성 신호의 개수가 적어지게 되므로, 유효한 히스토그램을 산출하기 어렵게 된다. 반면 음성 신호의 샘플링 주파수가 높으면, 디지털 음성 신호의 개수가 증가한다. 그러나 디지털 음성 신호의 개수가 증가하더라도, 히스토그램의 형태는 크게 변화하지 않는다. 본 발명에서 필요로 하는 것은 히스토그램에서 피크의 개수를 찾는 것이므로, 매우 정밀한 히스토그램을 필요로 하는 것이 아니다. 또한 디지털 음성 신호의 개수가 많아지게 되면, 계산해야하는 데이터의 양이 증가하는 것이므로 불필요하게 계산량이 증가되는 것은 바람직하지 않다. 이에 샘플링 주파수로서 8kHz ~ 45kHz를 이용하면, 효율적으로 히스토그램을 도출할 수 있음을 측정을 통해 확인하였다.When the sampling frequency of the voice signal is low, the number of digital voice signals decreases, making it difficult to calculate a valid histogram. On the other hand, when the sampling frequency of the voice signal is high, the number of digital voice signals increases. However, even if the number of digital voice signals increases, the shape of the histogram does not change significantly. Since the present invention requires finding the number of peaks in the histogram, it does not require a very accurate histogram. In addition, when the number of digital voice signals increases, the amount of data to be calculated increases, so it is not desirable to increase the amount of calculation unnecessarily. Using 8kHz ~ 45kHz as the sampling frequency, it was confirmed through the measurement that the histogram can be efficiently derived.
또한 상기에서는 획득된 최대값과 최소값 사이를 지정된 개수로 균등분할 하는 것으로 설명하였으나, 획득된 최대값 및 최소값에 무관하게 미리 설정된 범위를 지정된 개수로 균등하게 구분할 수도 있다. 사람이 발성할 수 있는 극한적으로 작은 소리와 큰소리의 차이는 최대 120 dB 로 알려져 있다. 즉 음성의 dB SPL (음압레벨)이 최소 0 dB에서 최대 120 dB 이므로 계산된 절대값의 평균값(y(i))의 최대값 및 최소값에 무관하게, 사람이 발성할 수 있는 소리 범위인 0 dB에서 최대 120 dB를 단순히 dB 단위로 120개로 분할할 수도 있다. 즉 음성 신호의 절대값의 평균값(y(i))이 20 * log10(y(i)) 공식에 의해 dB 단위로 변환되면서 자연스럽게 0~120 dB SPL 단위로 활용할 수 있다.In addition, although the above description is made to equally divide the obtained maximum value and the minimum value into a predetermined number, the predetermined range may be equally divided into the specified number regardless of the obtained maximum value and the minimum value. The difference between the extremely small and loud sounds that a person can speak is known up to 120 dB. That is, the dB SPL (sound pressure level) of speech is 0 dB to 120 dB, so 0 dB, the sound range that can be spoken by humans, regardless of the maximum and minimum values of the average value (y (i)) of the absolute value calculated. You can also divide the maximum 120 dB into 120 units in dB. That is, the average value y (i) of the absolute value of the speech signal is converted into dB unit by the formula of 20 * log10 (y (i)), so it can be naturally used in 0 ~ 120 dB SPL unit.
분할 영역의 개수가 적어지면 그 만큼 히스토그램의 선명도가 감소된다. 그러나 상기한 바와 같이 본 발명에서는 히스토그램의 개략적인 형태가 나타나면, 히스토그램의 선명도는 크게 중요하지 않으므로, 사람이 발성할 수 있는 소리 범위인 0 dB에서 최대 120 dB를 단순히 2dB 단위로 60개로 분할하여도 된다. 즉 본 발명에서 분할 영역의 개수는 60 ~ 120개로 설정되는 것이 바람직하다.As the number of divided regions decreases, the sharpness of the histogram decreases accordingly. However, in the present invention as described above, when the histogram shows a rough shape, the sharpness of the histogram is not very important, so even if the human voice can divide up to 60 dB from 0 dB to 120 dB in 2 dB units, do. That is, in the present invention, the number of divided regions is preferably set to 60 to 120.
그러나 상기에서는 계산된 절대값의 평균값(y(i))의 최대값 및 최소값을 기초로 구분하고, 일반적으로 음성 신호의 최대값 및 최소값은 실제 100dB의 차이를 넘기지 못한다. 이에 상기에서는 계산된 절대값의 평균값(y(i))의 최대값 및 최소값 사이를 100개로 균등 분할하였으며, 경우에 따라서는 50개로 분할 할 수도 있다.
However, the above classification is based on the calculated maximum and minimum values of the average value y (i) of the absolute values, and in general, the maximum and minimum values of the speech signal may not exceed a difference of 100 dB. In the above, the average value y (i) of the calculated absolute value is equally divided between the maximum value and the minimum value of 100, and in some cases, the value may be divided into 50.
도3 및 도4 는 어음 세기 평균치 분포 곡선의 예를 나타낸다.3 and 4 show examples of the note intensity distribution curve.
도3 발음이 좋은 경우의 어음 세기 평균치 분포 곡선을 나타내며, 도4 는 발음이 부정확한 경우의 어음 세기 평균치 분포 곡선을 나타낸다. 상기한 바와 같이, 발음의 정확성이 높은 사람일수록 초성 자음과 중성 모음의 신호 파형의 세기가 현저하게 다르다. 따라서 음성 신호의 절대값의 평균값(y(i))의 분포가 도3 과 같이 세기 별로 확연히 구분되는 쌍봉 형태로 나타나게 된다. 그러나 발음이 부정확한 경우에는 초성 자음과 중성 모음의 신호 파형의 세기가 명확하게 구분되지 못하여, 도4 에 도시된 바와 같이 단봉 형태의 일반적인 가우시안 분포 형태(Gaussian distribution)를 나타내게 된다.Fig. 3 shows a distribution curve of speech intensity average values when the pronunciation is good, and Fig. 4 shows a distribution curve of speech intensity average values when the pronunciation is incorrect. As described above, the higher the accuracy of pronunciation, the more distinctly the intensity of the signal waveforms of the initial consonant and the neutral vowel. Therefore, the distribution of the average value y (i) of the absolute value of the voice signal is represented in the form of a double peak clearly distinguished by intensity as shown in FIG. However, if the pronunciation is incorrect, the intensity of the signal waveforms of the consonant consonants and the neutral vowels cannot be clearly distinguished, and thus shows a general Gaussian distribution in the form of a single peak as shown in FIG.
따라서 발음을 교정하고자 하는 사람은 음성을 입력하고, 상기한 음성 신호 분석 방법으로 분석되어 시각화된 히스토그램을 보고 자신의 발음 상태를 확인하여 발음을 교정할 수 있게 된다. 그리고 본 발명에 따른 음성 신호 분석 방법은 문장이나 어절이 아닌 음절 및 음소를 기반하여 발음을 분석하여 시각적으로 확인 할 수 있도록 하므로, 본 발명의 음성 신호 분석 방법을 이용하여 발음을 교정하고자 특정 단어나 문장에 구애받지 않고 자유롭게 입력되는 음성으로부터 발음 상태를 확인 할 수 있도록 한다. 이는 기존의 발음 교정 방식에서 특정 단어나 문장이 지정되고, 지정된 문장이나 단어에 대해서만 발음이 교정을 제시할 수 있었던 것에 비해 본 발명이 더 큰 범용성을 가질 수 있음을 나타낸다.
Therefore, a person who wants to correct a pronunciation can input a voice, analyze the voice signal analysis method, and view histogram visualized to check his / her pronunciation state to correct the pronunciation. And the voice signal analysis method according to the present invention enables to visually confirm by analyzing the pronunciation based on the syllables and phonemes, not sentences or words, to correct the pronunciation using the voice signal analysis method of the present invention Regardless of the sentence, you can check the pronunciation state from the voice input freely. This indicates that a specific word or sentence is designated in the existing pronunciation correction method, and that the present invention can have greater generality than the pronunciation can provide correction only for the specified sentence or word.
도5 는 본 발명에 따른 음성 신호 분석 장치의 일예를 나타낸다.5 shows an example of an apparatus for analyzing voice signals according to the present invention.
음성 신호 분석 장치(10)는 음성 입력부(110), 음성 신호 처리부(120), 제어부(130), 입력부(140) 및 출력부(150)를 구비한다. 음성 입력부(110)는 마이크(Microphone)로 구현될 수 있으며, 외부에서 인가되는 음성을 아날로그 음성 신호로 변환하여 음성 신호 처리부(120)로 전달한다. 음성 신호 처리부(120)는 아날로그 음성 신호를 인가받아 지정된 샘플링 속도로 샘플링하여 디지털 음성 신호로 변환한다. 변환된 디지털 음성 신호는 제어부(130)로 전송되고, 제어부(130)는 상기한 음성 신호 분석 방법에 따라 음성 신호를 분석하여 히스토그램을 산출한다. 출력부(150)는 디스플레이 장치로 구현될 수 있으며, 제어부(130)에서 인가되는 히스도그램을 디스플레이한다. 또한 출력부(150)는 스피커와 같은 음성 신호 출력 장치를 더 구비하여 디지털 음성 신호를 인가받아 음성을 출력할 수 있다. 이 경우 사용자는 자신이 음성 입력부(110)로 입력한 음성을 청취할 수 있게 된다. 입력부(140)는 사용자의 명령을 인가받아 제어부(130)로 전송한다. 입력부(140)는 키보드, 마우스 등으로 구현될 수 있으며, 경우에 따라서는 출력부(150)의 디스플레이 장치와 결합된 터치스크린으로서 구현될 수도 있다.The voice
상기에서는 음성 처리부(120)와 제어부(130)가 별도로 도시되어 있으나, 음성 처리부(120)는 제어부(130)에 포함될 수 있다.Although the
상기한 음성 신호 분석 장치는 개인용 컴퓨터를 비롯하여 휴대용 임베디드 시스템, 스마트 폰과 같은 모바일 시스템으로 구현 가능하며, 특히 스마트 폰의 경우에는 이미 하드웨어적인 구성요소가 모두 구비되어 있으므로 소프트웨어인 어플리케이션을 제공하는 것만으로도 간단하게 발음 교정을 음성 신호 분석 장치로 활용할 수 있다.
The voice signal analysis device may be implemented as a mobile computer such as a personal computer, a portable embedded system, or a smart phone. In particular, since the smart phone is already equipped with all hardware components, it is only necessary to provide an application that is software. In addition, pronunciation correction can be utilized as a voice signal analysis device.
도6 는 본 발명에 따른 음성 신호 분석 장치의 일예를 나타낸다.6 shows an example of an apparatus for analyzing voice signals according to the present invention.
도6 에서는 음성 신호 분석 장치가 스마트 폰으로 구현된 것을 나타낸다. 6 shows that the voice signal analysis device is implemented as a smart phone.
도6 에 도시된 바와 같이 스마트폰(20)은 터치스크린(210), 마이크(220) 및 스피커(230)를 구비한다. 터치스크린(210)은 도5 의 입력부(140)와 출력부(150)가 결합된 형태이며, 스피커(230) 또한 출력부(150)에 포함된다. 그리고 마이크(220)는 도5 의 음성 입력부(110)에 대응한다. 음성 처리부(120)와 제어부(130)는 스마트폰(20) 내부에 구비된 MPU(Micro Process Unit)으로서 구현될 수 있다. 스마트폰(20)에는 발음 교정 어플리케이션이 설치되고, 터치스크린(210)을 통해 사용자가 발음 교정 어플리케이션을 실행함에 의해 스마트폰(20)은 발음 교정을 위한 음성 신호 분석 장치로 활용할 수 있게 된다.
As shown in FIG. 6, the
도7 은 도6 의 스마트폰을 이용한 발음 교정 방법의 일예를 나타낸다.7 illustrates an example of a pronunciation correction method using the smartphone of FIG. 6.
스마트폰 사용자는 먼저 스마트폰(20)의 터치스크린(210)에 디스플레이된 메뉴들 중에서 발음 교정 프로그램을 선택하여 실행한다(S21). 발음 교정 프로그램이 실행되면, 사용자는 스마트폰(20)에 구비된 마이크(220)를 통해 음성을 입력한다. 이때 사용자가 입력하는 음성은 미리 지정된 단어나 문장을 입력할 필요가 없이 사용자가 원하는 말을 할 수 있다. 그러나 사용자는 음성 신호로서 어음을 입력해야한다. 이는 본 발명이 발음 교정 방업을 위한 음성 신호 처리 방법을 기반으로 하고 있으며, 본 발명에 따른 음성 신호 처리 방법은 음절 내의 음소 간의 신호 파형의 차를 이용하므로, 무의미한 음성이 아니라 자음과 모음이 합쳐진 음절이 입력되어야 한다. 따라서 음성은 어음으로서 입력되어야 한다.The smartphone user first selects and executes a pronunciation correction program from the menus displayed on the
사용자로부터 음성이 입력되면 스마트폰(20)의 MPU는 상기한 음성 신호 분석 방법에 따라 분석하여 히스토그램을 산출한다(S23). 그리고 산출된 히스토그램은 터치스크린(210)을 통해 디스플레이 된다. 사용자는 디스플레이된 히스토그램을 기초로 자신의 발음 상태가 양호한지 판단한다(S24). 만일 발음 상태가 양호하다면, 발음 교정 어플리케이션을 종료하고, 발음 상태가 양호하지 않다면, 다시 음성을 입력하여 발음 교정을 계속 수행할 수 있다. 그리고 사용자는 발음 상태의 여부에 무관하게 언제든지 발음 교정 어플리케이션을 종료할 수 있다.When a voice is input from the user, the MPU of the
비록 상기에서는 사용자가 입력한 음성에 대한 히스토그램만이 터치스크린을 통해 디스플레이 되는 것으로 설명하였으나, 도3 과 같이 정확한 발음에 대한 히스토그램을 사용자 음성에 대한 히스토그램과 함께 디스플레이하여 사용자의 발음의 부정확도를 시각적으로 보여줌으로서 발음 교정 의지를 고취시킬 수 있다.
Although only the histogram for the voice input by the user has been described on the touch screen, the histogram for the correct pronunciation is displayed together with the histogram for the user's voice as shown in FIG. 3 to visualize the inaccuracy of the user's pronunciation. In this way, you can inspire pronunciation correction.
본 발명에 따른 장치는 컴퓨터로 읽을 수 있는 기록매체에 컴퓨터가 읽을 수 있는 코드로서 구현하는 것이 가능하다. 컴퓨터가 읽을 수 있는 기록매체는 컴퓨터 시스템에 의하여 읽혀질 수 있는 데이터가 저장되는 모든 종류의 기록장치를 포함한다. 기록매체의 예로는 ROM, RAM, CD-ROM, 자기 테이프, 플로피 디스크, 광데이터 저장장치 등이 있으며, 또한 캐리어 웨이브(예를 들어 인터넷을 통한 전송)의 형태로 구현되는 것도 포함한다. 또한 컴퓨터가 읽을 수 있는 기록매체는 네트워크로 연결된 컴퓨터 시스템에 분산되어 분산방식으로 컴퓨터가 읽을 수 있는 코드가 저장되고 실행될 수 있다.
The device according to the invention can be embodied as computer readable code on a computer readable recording medium. A computer-readable recording medium includes all kinds of recording apparatuses in which data that can be read by a computer system is stored. Examples of the recording medium include a ROM, a RAM, a CD-ROM, a magnetic tape, a floppy disk, an optical data storage device, and the like, and a carrier wave (for example, transmission via the Internet). The computer readable recording medium can also be distributed over network coupled computer systems so that the computer readable code is stored and executed in a distributed fashion.
본 발명은 도면에 도시된 실시예를 참고로 설명되었으나 이는 예시적인 것에 불과하며, 본 기술 분야의 통상의 지식을 가진 자라면 이로부터 다양한 변형 및 균등한 타 실시예가 가능하다는 점을 이해할 것이다. While the present invention has been particularly shown and described with reference to exemplary embodiments thereof, it is evident that many alternatives, modifications and variations will be apparent to those skilled in the art.
따라서, 본 발명의 진정한 기술적 보호 범위는 첨부된 등록청구범위의 기술적 사상에 의해 정해져야 할 것이다.
Therefore, the true technical protection scope of the present invention will be defined by the technical spirit of the appended claims.
Claims (16)
상기 복수개의 구간별 음성 신호 각각의 절대값의 평균값이 계산되어 복수개의 평균값이 계산되는 단계;
상기 복수개의 평균값의 분포에 따라 히스토그램이 생성되는 단계; 및
상기 히스토그램에 나타난 피크의 개수에 따라 발음의 명확성이 판별되는 단계를 구비하고,
상기 히스토그램이 생성되는 단계는
상기 복수개의 평균값에서 최대값과 최소값이 획득되는 단계;
상기 최대값과 상기 최소값 사이의 범위가 지정된 개수로 균등하게 구분되는 단계; 및
균등하게 구분된 영역 각각에 상기 복수개의 평균값 중 대응하는 크기의 평균값의 개수가 표시되는 히스토그램이 생성되는 단계를 구비하는 것을 특징으로 하는 음성 신호 분석 방법
A speech signal in the form of speech is applied, and the speech signal is divided into predetermined time intervals to obtain a plurality of speech signals for each section;
Calculating a plurality of average values by calculating an average value of absolute values of each of the plurality of sound signals for each section;
Generating a histogram according to the distribution of the plurality of average values; And
Clarity of pronunciation is determined according to the number of peaks shown in the histogram,
The step of generating the histogram
Obtaining a maximum value and a minimum value from the plurality of average values;
Dividing the range between the maximum value and the minimum value evenly into a specified number; And
Generating a histogram in which the number of average values of corresponding magnitudes among the plurality of average values is displayed in each of the evenly divided regions.
인가된 상기 음성 신호가 샘플링 주파수로 샘플링되어 디지털 음성 신호로 변환되는 단계; 및
상기 디지털 음성 신호가 음소의 발음 시간 보다 짧은 시간 구간 단위로 분할되어 상기 복수개의 구간별 음성 신호가 획득되는 단계를 구비하는 것을 특징으로 하는 음성 신호 분석 방법.
The method of claim 1, wherein the acquiring of the plurality of interval speech signals is performed.
The applied voice signal is sampled at a sampling frequency and converted into a digital voice signal; And
And dividing the digital voice signal into units of time intervals shorter than a phoneme pronunciation time to obtain the plurality of voice signals for each of the plurality of sections.
8kHz ~ 45kHz 범위의 주파수인 것을 특징으로 하는 음성 신호 분석 방법.
The method of claim 2, wherein the sampling frequency is
Speech signal analysis method characterized in that the frequency in the range of 8kHz ~ 45kHz.
1msec ~ 10msec 범위의 시간 구간인 것을 특징으로 하는 음성 신호 분석 방법.
The method of claim 3, wherein the time interval unit
Speech signal analysis method characterized in that the time interval of 1msec ~ 10msec range.
상기 복수개의 구간별 음성 신호 각각의 절대값의 평균값이
수학식

(여기서, x(n)은 측정된 디지털화된 음성 신호, y(i)는 i(여기서 i는 자연수)번째 시간 구간에서 측정된 음성 신호(x(n))의 절대값의 평균값, N은 설정된 구간별 샘플링된 디지털 음성 신호의 개수)
에 의해 계산되고,
상기 복수개의 구간별 음성 신호 각각의 절대값의 평균값은
수학식
y(i)=20*log10(y(i))
에 의해 선형 단위에서 데시벨(dB) 단위로 단위 변환 되는 것을 특징으로 하는 음성 신호 분석 방법.
The method of claim 1, wherein the calculating of the plurality of average values
The average value of the absolute value of each of the plurality of audio signals for each section is
Equation
(Where x (n) is the measured digitized speech signal, y (i) is the average value of the absolute value of the speech signal x (n) measured in the i time interval, where i is a natural number, and N is set). Number of digital audio signals sampled per section)
Lt; / RTI >
The average value of the absolute values of each of the plurality of audio signals for each section is
Equation
y (i) = 20 * log 10 (y (i))
Voice signal analysis method characterized in that the unit conversion in linear units to decibels (dB) by.
상기 히스토그램에 나타난 피크의 개수가 확인되는 단계;
상기 피크의 개수가 하나이면, 발음이 불명확한 것으로 판정되는 단계; 및
상기 피크의 개수가 복수개이면, 발음이 명확한 것으로 판정되는 단계를 구비하는 것을 특징으로 하는 음성 신호 분석 방법.
The method of claim 1, wherein the clarity of the pronunciation is determined.
Confirming the number of peaks shown in the histogram;
If the number of peaks is one, determining that the pronunciation is unclear; And
And if the number of peaks is plural, determining that the pronunciation is clear.
상기 음성 신호를 지정된 시간 구간 단위로 분할하여 복수개의 구간별 음성 신호를 획득하고, 상기 복수개의 구간별 음성 신호 각각의 절대값의 평균값 분포에 따라 히스토그램을 생성한 후, 생성된 상기 히스토그램의 피크 개수에 따라 상기 음성 신호의 발음의 명확성을 판별하는 제어부; 및
상기 히스토그램을 디스플레이하는 출력부;를 구비하고,
상기 제어부는
상기 음성 신호를 인가받고, 상기 음성 신호를 샘플링 주파수로 샘플링하여 디지털 음성 신호로 변환하는 음성 신호 처리부를 더 구비하여, 상기 디지털 음성 신호를 음소의 발음 시간 보다 짧은 시간 구간 단위로 분할하여 상기 복수개의 구간별 음성 신호를 획득하고,
상기 복수개의 구간별 음성 신호 각각의 절대값의 평균값에서 최대값과 최소값을 획득하고, 상기 최대값과 상기 최소값 사이의 범위를 지정된 개수로 균등하게 구분한 후, 균등하게 구분된 영역 각각에 상기 복수개의 평균값 중 대응하는 크기의 평균값의 개수에 따라 히스토그램을 생성하는 것을 특징으로 하는 음성 신호 분석 장치.
A voice input unit which receives voice from the outside and converts the voice signal into an electrical signal and transmits the voice signal;
After dividing the speech signal into units of a designated time interval, a speech signal for a plurality of sections is obtained, a histogram is generated according to an average value distribution of absolute values of each of the plurality of sections, and then the number of peaks of the generated histogram. A control unit for determining the clarity of the pronunciation of the voice signal according to; And
An output unit for displaying the histogram;
The control unit
The voice signal processor may be further configured to receive the voice signal, sample the voice signal at a sampling frequency, and convert the voice signal into a digital voice signal. Acquire a speech signal for each section,
Obtaining the maximum value and the minimum value from the average value of the absolute value of each of the plurality of voice signals for each section, and evenly divided the range between the maximum value and the minimum value by a specified number, and then the plurality of equally divided areas in each And a histogram is generated according to the number of average values of corresponding magnitudes among the average values of the two dogs.
8kHz ~ 45kHz 범위의 주파수인 것을 특징으로 하는 음성 신호 분석 장치.
The method of claim 8, wherein the sampling frequency is
Voice signal analysis device, characterized in that the frequency in the range of 8kHz ~ 45kHz.
1msec ~ 10msec 범위의 시간 구간인 것을 특징으로 하는 음성 신호 분석 장치.
The method of claim 8, wherein the time interval unit is
Voice signal analysis device, characterized in that the time interval of 1msec ~ 10msec range.
상기 히스토그램에 나타난 피크의 개수를 확인하여, 상기 피크의 개수가 하나이면 발음이 불명확한 것으로 판정하고, 상기 피크의 개수가 복수개이면 발음이 명확한 것으로 판정하는 것을 특징으로 하는 음성 신호 분석 장치.
The method of claim 8, wherein the control unit
And checking the number of peaks shown in the histogram, determining that the pronunciation is unclear when the number of peaks is one, and determining that the pronunciation is clear when the number of the peaks is plural.
사용자로부터 명령을 입력받는 입력부를 더 구비하는 것을 특징으로 하는 음성 신호 분석 장치.
The apparatus of claim 8, wherein the voice signal analysis device is
Voice signal analysis device further comprises an input unit for receiving a command from the user.
스마트폰인 것을 특징으로 하는 음성 신호 분석 장치.The apparatus of claim 8, wherein the voice signal analysis device is
Voice signal analysis device, characterized in that the smartphone.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020110092057A KR101250051B1 (en) | 2011-09-09 | 2011-09-09 | Speech signals analysis method and apparatus for correcting pronunciation |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020110092057A KR101250051B1 (en) | 2011-09-09 | 2011-09-09 | Speech signals analysis method and apparatus for correcting pronunciation |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20130028472A KR20130028472A (en) | 2013-03-19 |
| KR101250051B1 true KR101250051B1 (en) | 2013-04-03 |
Family
ID=48178984
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020110092057A Expired - Fee Related KR101250051B1 (en) | 2011-09-09 | 2011-09-09 | Speech signals analysis method and apparatus for correcting pronunciation |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101250051B1 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015107984A1 (en) * | 2014-01-14 | 2015-07-23 | アルプス電気株式会社 | Vehicle communication device |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR19980034074A (en) * | 1996-11-05 | 1998-08-05 | 구자홍 | Voice signal feature extraction method and apparatus |
| JP2006195449A (en) * | 2004-12-15 | 2006-07-27 | Yamaha Corp | Device, method, and program for deciding voice quality |
| JP2007079389A (en) * | 2005-09-16 | 2007-03-29 | Yamaha Motor Co Ltd | Speech analysis method and speech analysis apparatus |
| KR20100111544A (en) * | 2009-04-07 | 2010-10-15 | 권용득 | System for proofreading pronunciation using speech recognition and method therefor |
-
2011
- 2011-09-09 KR KR1020110092057A patent/KR101250051B1/en not_active Expired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR19980034074A (en) * | 1996-11-05 | 1998-08-05 | 구자홍 | Voice signal feature extraction method and apparatus |
| JP2006195449A (en) * | 2004-12-15 | 2006-07-27 | Yamaha Corp | Device, method, and program for deciding voice quality |
| JP2007079389A (en) * | 2005-09-16 | 2007-03-29 | Yamaha Motor Co Ltd | Speech analysis method and speech analysis apparatus |
| KR20100111544A (en) * | 2009-04-07 | 2010-10-15 | 권용득 | System for proofreading pronunciation using speech recognition and method therefor |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20130028472A (en) | 2013-03-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11056097B2 (en) | Method and system for generating advanced feature discrimination vectors for use in speech recognition | |
| JP4264841B2 (en) | Speech recognition apparatus, speech recognition method, and program | |
| Yağanoğlu | Real time wearable speech recognition system for deaf persons | |
| Strömbergsson | Today's Most Frequently Used F0 Estimation Methods, and Their Accuracy in Estimating Male and Female Pitch in Clean Speech. | |
| EP2806415B1 (en) | Voice processing device and voice processing method | |
| Daudet et al. | Portable mTBI assessment using temporal and frequency analysis of speech | |
| JP6373621B2 (en) | Speech evaluation device, speech evaluation method, program | |
| US9514738B2 (en) | Method and device for recognizing speech | |
| JP2014066779A (en) | Voice recognition device and method, and semiconductor integrated circuit device | |
| JP2010060846A (en) | Synthesized speech evaluation system and synthesized speech evaluation method | |
| US9269352B2 (en) | Speech recognition with a plurality of microphones | |
| Harrison | Variability of formant measurements | |
| KR20210071713A (en) | Speech Skill Feedback System | |
| JP4587854B2 (en) | Emotion analysis device, emotion analysis program, program storage medium | |
| KR101250051B1 (en) | Speech signals analysis method and apparatus for correcting pronunciation | |
| CN107610691A (en) | English vowel sounding error correction method and device | |
| Omar et al. | Feature fusion techniques based training MLP for speaker identification system | |
| Heinrich et al. | The influence of alcoholic intoxication on the short-time energy function of speech | |
| JP4839970B2 (en) | Prosody identification apparatus and method, and speech recognition apparatus and method | |
| JP6183147B2 (en) | Information processing apparatus, program, and method | |
| Amino et al. | Speaker characteristics that appear in vowel nasalisation and their change over time | |
| Hillenbrand et al. | Perception of sinewave vowels | |
| JP2017068153A (en) | Semiconductor device, system, electronic apparatus, and voice recognition method | |
| JP2011158515A (en) | Device and method for recognizing speech | |
| KR20080065775A (en) | Speech education system for speech education |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| PA0109 | Patent application |
St.27 status event code: A-0-1-A10-A12-nap-PA0109 |
|
| PA0201 | Request for examination |
St.27 status event code: A-1-2-D10-D11-exm-PA0201 |
|
| R17-X000 | Change to representative recorded |
St.27 status event code: A-3-3-R10-R17-oth-X000 |
|
| D13-X000 | Search requested |
St.27 status event code: A-1-2-D10-D13-srh-X000 |
|
| D14-X000 | Search report completed |
St.27 status event code: A-1-2-D10-D14-srh-X000 |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| E13-X000 | Pre-grant limitation requested |
St.27 status event code: A-2-3-E10-E13-lim-X000 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-3-3-R10-R18-oth-X000 |
|
| PG1501 | Laying open of application |
St.27 status event code: A-1-1-Q10-Q12-nap-PG1501 |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
St.27 status event code: A-1-2-D10-D22-exm-PE0701 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
St.27 status event code: A-2-4-F10-F11-exm-PR0701 |
|
| PR1002 | Payment of registration fee |
St.27 status event code: A-2-2-U10-U11-oth-PR1002 Fee payment year number: 1 |
|
| PG1601 | Publication of registration |
St.27 status event code: A-4-4-Q10-Q13-nap-PG1601 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-5-5-R10-R18-oth-X000 |
|
| FPAY | Annual fee payment |
Payment date: 20160318 Year of fee payment: 4 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 4 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-4-4-P10-P22-nap-X000 |
|
| FPAY | Annual fee payment |
Payment date: 20170303 Year of fee payment: 5 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 5 |
|
| FPAY | Annual fee payment |
Payment date: 20180305 Year of fee payment: 6 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 6 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-4-4-P10-P22-nap-X000 |
|
| FPAY | Annual fee payment |
Payment date: 20190304 Year of fee payment: 7 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 7 |
|
| FPAY | Annual fee payment |
Payment date: 20200302 Year of fee payment: 8 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 8 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 9 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 10 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 11 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-5-5-R10-R18-oth-X000 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 12 |
|
| PC1903 | Unpaid annual fee |
St.27 status event code: A-4-4-U10-U13-oth-PC1903 Not in force date: 20250328 Payment event data comment text: Termination Category : DEFAULT_OF_REGISTRATION_FEE |
|
| H13 | Ip right lapsed |
Free format text: ST27 STATUS EVENT CODE: N-4-6-H10-H13-OTH-PC1903 (AS PROVIDED BY THE NATIONAL OFFICE); TERMINATION CATEGORY : DEFAULT_OF_REGISTRATION_FEE Effective date: 20250328 |
|
| PC1903 | Unpaid annual fee |
St.27 status event code: N-4-6-H10-H13-oth-PC1903 Ip right cessation event data comment text: Termination Category : DEFAULT_OF_REGISTRATION_FEE Not in force date: 20250328 |