JP7578209B1 - Image generation system, image generation method, and image generation program - Google Patents
Image generation system, image generation method, and image generation program Download PDFInfo
- Publication number
- JP7578209B1 JP7578209B1 JP2024065475A JP2024065475A JP7578209B1 JP 7578209 B1 JP7578209 B1 JP 7578209B1 JP 2024065475 A JP2024065475 A JP 2024065475A JP 2024065475 A JP2024065475 A JP 2024065475A JP 7578209 B1 JP7578209 B1 JP 7578209B1
- Authority
- JP
- Japan
- Prior art keywords
- video
- data
- generation
- scenario
- information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images









































Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T13/00—Animation
- G06T13/20—3D [Three Dimensional] animation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N5/00—Details of television systems
- H04N5/222—Studio circuitry; Studio devices; Studio equipment
- H04N5/262—Studio circuits, e.g. for mixing, switching-over, change of character of image, other special effects ; Cameras specially adapted for the electronic generation of special effects
- H04N5/272—Means for inserting a foreground image in a background image, i.e. inlay, outlay
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N5/00—Details of television systems
- H04N5/222—Studio circuitry; Studio devices; Studio equipment
- H04N5/262—Studio circuits, e.g. for mixing, switching-over, change of character of image, other special effects ; Cameras specially adapted for the electronic generation of special effects
- H04N5/278—Subtitling
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N5/00—Details of television systems
- H04N5/76—Television signal recording
- H04N5/91—Television signal processing therefor
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N5/00—Details of television systems
- H04N5/76—Television signal recording
- H04N5/91—Television signal processing therefor
- H04N5/92—Transformation of the television signal for recording, e.g. modulation, frequency changing; Inverse transformation for playback
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Processing Or Creating Images (AREA)
- Studio Circuits (AREA)
Abstract
【課題】ユーザからの入力クエリに応じて動画データを取得する。
【解決手段】本開示に係る映像生成システムは、動画生成に関する入力クエリをユーザから取得する取得部と、前記入力クエリに基づいて、動画生成に関するシナリオデータを生成するシナリオ生成部と、前記シナリオデータに基づいて、3Dデータを構成するためのコードを生成するコード生成部と、前記コードに基づいて、動画データを取得する動画データ取得部と、を備える。
【選択図】図3
The present invention obtains video data in response to a query input by a user.
[Solution] The video generation system disclosed herein comprises an acquisition unit that acquires an input query related to video generation from a user, a scenario generation unit that generates scenario data related to video generation based on the input query, a code generation unit that generates code for constructing 3D data based on the scenario data, and a video data acquisition unit that acquires video data based on the code.
[Selected figure] Figure 3
Description
本開示は、映像生成システム、映像生成方法及び映像生成プログラムに関する。 This disclosure relates to an image generation system, an image generation method, and an image generation program.
映像(「動画」ともいう)を自動で生成する技術が提供されている。例えば、2次元的な線画から仮想人物の3次元姿勢を推定し、動画を生成する技術が提供されている(例えば特許文献1)。 Technology has been provided for automatically generating images (also called "videos"). For example, technology has been provided for estimating the three-dimensional posture of a virtual person from a two-dimensional line drawing and generating a video (for example, Patent Document 1).
しかしながら、従来技術には、改善の余地がある。例えば、従来技術では、動画を生成するために2次元的な線画、すなわち画像が必要となり、2次元的な線画といった画像を用意することはユーザの負担が大きく、ユーザが画像を用意できない場合等、動画を生成することが難しい。そのため、ユーザの負担が少なく、ユーザビリティが高い動画生成サービスを提供することが望まれており、例えばユーザからの入力クエリに応じて動画データを取得することが望まれている。 However, there is room for improvement in the conventional technology. For example, in the conventional technology, two-dimensional line drawings, i.e., images, are required to generate videos, and preparing images such as two-dimensional line drawings places a large burden on the user, making it difficult to generate videos when the user is unable to prepare images. For this reason, it is desirable to provide a video generation service that places less burden on the user and has high usability, and it is desirable, for example, to obtain video data in response to a query input by the user.
そこで、本開示では、ユーザからの入力クエリに応じて動画データを取得することができる映像生成システム、映像生成方法及び映像生成プログラムを提案する。 Therefore, this disclosure proposes a video generation system, a video generation method, and a video generation program that can acquire video data in response to a query input by a user.
上記の課題を解決するために、本開示に係る一形態の映像生成システムは、動画生成に関する入力クエリをユーザから取得する取得部と、前記入力クエリに基づいて、動画生成に関するシナリオデータを生成するシナリオ生成部と、前記シナリオデータに基づいて、3Dデータを構成するためのコードを生成するコード生成部と、前記コードに基づいて、動画データを取得する動画データ取得部と、を備える。 In order to solve the above problems, a video generation system according to one embodiment of the present disclosure includes an acquisition unit that acquires an input query related to video generation from a user, a scenario generation unit that generates scenario data related to video generation based on the input query, a code generation unit that generates code for constructing 3D data based on the scenario data, and a video data acquisition unit that acquires video data based on the code.
以下に、本開示の実施形態について図面に基づいて詳細に説明する。なお、この実施形態により本願にかかる映像生成システム、映像生成方法及び映像生成プログラムが限定されるものではない。また、以下の各実施形態において、同一の部位には同一の符号を付することにより重複する説明を省略する。 Embodiments of the present disclosure will be described in detail below with reference to the drawings. Note that the image generation system, image generation method, and image generation program according to the present application are not limited to these embodiments. In addition, in the following embodiments, the same components are designated by the same reference numerals, and duplicated descriptions will be omitted.
以下に示す項目順序に従って本開示を説明する。
1.実施形態
1-1.本開示の映像生成システムの構成概要
1-2.本開示の映像生成システムによる処理
1-3.ユーザインタフェース
1-4.処理例
1-4-1.音生成例
1-4-2.テキストロゴ生成例
1-4-3.再学習例
1-4-4.USD更新例
1-4-5.評価例
1-4-6.複数カットの選択例
1-4-7.時間情報の利用例
1-4-8.言語化の度合いに応じた応答例
1-4-9.定性的な値の利用例
1-4-10.入力途中でのレンダリング処理例
1-4-11.編集時の確認作業例
1-4-12.範囲選択に応じた処理例
1-4-13.被写界深度に応じた処理例
1-4-14.確認作業時の再生処理例
1-4-15.強調表示例
1-4-16.カット間の関係提示例
1-4-17.オブジェクトの選択例
1-4-18.3Dモデル利用例
1-4-19.参考データの利用例
1-4-20.3Dデータを有する利点例
1-5.ユーザから見た処理フロー例
1-6.AIモデルについて
2.その他の実施形態
2-1.その他の構成例
2-2.その他
3.本開示に係る効果
4.ハードウェア構成
The present disclosure will be described in the following order.
1. Embodiment 1-1. Overview of the configuration of the video generation system of the present disclosure 1-2. Processing by the video generation system of the present disclosure 1-3. User interface 1-4. Processing examples 1-4-1. Sound generation example 1-4-2. Text logo generation example 1-4-3. Re-learning example 1-4-4. USD update example 1-4-5. Evaluation example 1-4-6. Selection example of multiple cuts 1-4-7. Use example of time information 1-4-8. Response example according to degree of verbalization 1-4-9. Use example of qualitative values 1-4-10. Rendering processing example during input 1-4-11. Confirmation work example during editing 1-4-12. Processing example according to range selection 1-4-13. Processing example according to depth of field 1-4-14. Playback processing example during confirmation work 1-4-15. Highlighting example 1-4-16. Example of presenting relationships between cuts 1-4-17. Example of selecting objects 1-4-18. Example of using 3D models 1-4-19. Example of using reference data 1-4-20. Example of advantages of having 3D data 1-5. Example of processing flow from the user's perspective 1-6. About AI models 2. Other embodiments 2-1. Other configuration examples 2-2. Others 3. Effects of the
<1.実施形態>
<1-1.本開示の映像生成システムの構成概要>
図1は、本開示の映像生成システムの一例を示す図である。映像生成システム1は、映像生成モジュール100、情報取得モジュール200、センサ部300、及びクライアントUI表示部400を有する。なお、図1では各々の構成を1つだけ図示するが、映像生成システム1には、複数の映像生成モジュール100、複数の情報取得モジュール200、複数のセンサ部300、及び複数のクライアントUI表示部400が含まれてもよい。
1. Embodiment
1-1. Overview of the configuration of the image generation system of the present disclosure
Fig. 1 is a diagram showing an example of an image generation system according to the present disclosure. The
まず、映像生成処理を行う映像生成モジュール100の構成について説明する。映像生成モジュール100は、入力テキスト解析部110、センサ解析部120、プロンプト等生成部130、映像生成部140、サウンド生成部150、テキスト/ロゴ生成部160、コンポジット編集部170、評価部180、クライアントUIモジュール190等を有する。
First, the configuration of the
入力テキスト解析部110は、入力されたテキストを解析する。例えば、入力テキスト解析部110は、情報取得モジュール200から入力されたテキストを解析する。センサ解析部120は、入力されたセンサ情報を解析する。例えば、センサ解析部120は、情報取得モジュール200から取得したセンサ情報を解析する。
The input text analysis unit 110 analyzes the input text. For example, the input text analysis unit 110 analyzes the text input from the
プロンプト等生成部130は、後述する機械学習モデルであるAI(Artificial Intelligence)モデル(単に「モデル」ともいう)に入力するプロンプト等を含む映像(動画)の生成のために必要となる各種情報を生成する。例えば、プロンプト等生成部130は、ユーザの入力と予め保存されたプロンプト(のテンプレート等)とを用いてプロンプトを生成する。なお、プロンプトは、AIモデルへ入力する情報(モデル入力情報)の一例に過ぎず、AIモデルへ入力するモデル入力情報はプロンプトに限らず、任意の形式のモデル入力情報が採用可能であり、「プロンプト等生成部」は「モデル入力情報等生成部」と読み替えてもよい。図1では、プロンプト等生成部130は、シナリオ向け生成部131、映像向け生成部132、サウンド向け生成部133、テキスト/ロゴ向け生成部134を有する。
The prompt etc. generation unit 130 generates various information required for generating a video (video) including a prompt etc. to be input to an AI (Artificial Intelligence) model (also simply referred to as a "model"), which is a machine learning model described later. For example, the prompt etc. generation unit 130 generates a prompt using a user's input and a pre-stored prompt (template, etc.). Note that a prompt is merely one example of information to be input to an AI model (model input information), and the model input information to be input to an AI model is not limited to a prompt, and any form of model input information can be adopted, and the "prompt etc. generation unit" may be read as a "model input information etc. generation unit." In FIG. 1, the prompt etc. generation unit 130 has a scenario-oriented
シナリオ向け生成部131は、シナリオの生成に関連する各種情報を生成する。シナリオ向け生成部131は、シナリオを出力するモデルに入力する入力情報を生成する。例えば、シナリオ向け生成部131は、入力クエリに基づいて、動画生成に関するシナリオデータを生成するシナリオ生成部である。例えば、シナリオ向け生成部131は、入力クエリに基づいて、シナリオデータを生成するためにシナリオ生成部が用いるシナリオ生成用情報を出力する第1の出力部である。
The scenario-oriented
映像向け生成部132は、映像の生成に関連する各種情報を生成する。映像向け生成部132は、3D(三次元)データを構成するためのコードを出力するモデルに入力する入力情報を生成する。例えば、映像向け生成部132は、シナリオデータに基づいて、3Dデータを構成するためのコードを生成するコード生成部である。例えば、映像向け生成部132は、シナリオデータに基づいて、3Dデータを構成するためのコードを生成するためにコード生成部が用いるコード生成用情報を出力する第2の出力部である。
The
サウンド向け生成部133は、サウンド情報(音情報)の生成に関連する各種情報を生成する。サウンド向け生成部133は、サウンドを出力するモデルに入力する入力情報を生成する。テキスト/ロゴ向け生成部134は、テキスト及びロゴの生成に関連する各種情報を生成する。テキスト/ロゴ向け生成部134は、テキスト及びロゴのうち少なくとも1つを出力するモデルに入力する入力情報を生成する。
The sound-oriented
映像生成部140は、映像の生成に関する処理を実行する。映像生成部140は、コードに基づいて、動画データを取得する動画取得部である。映像生成部140は、プロンプト等生成部130で生成された各種情報を用いて映像を生成する。例えば、映像生成部140は、コードに基づいて、動画データを生成する動画生成部である。なお、映像生成部140は、任意の態様により動画データを取得してもよい。例えば、映像生成部140は、動画データの生成に用いられるデータを、動画データ生成のサービスを提供する外部のサービス提供装置(ベンダー等)に送信し、そのサービス提供装置が生成した動画データを、そのサービス提供装置から受信することにより、動画データを取得してもよい。図1では、映像生成部140は、USD生成部141、レンダリング部142、映像リファイン部143を有する。
The
USD生成部141は、USD(Universal Scene Description)に関連する各種情報を生成する。例えば、USD生成部141は、映像向け生成部132での映像向けプロンプト生成で得られたプロンプトを用いて、Large Language Model(以下「LLM」ともいう)などのAIモデルにより、USD-Pythonなどを生成する。
The USD generation unit 141 generates various information related to the USD (Universal Scene Description). For example, the USD generation unit 141 uses a prompt obtained by the video prompt generation in the
レンダリング部142は、レンダリングに関連する各種処理を実行する。レンダリング部142は、USD生成部141により生成されたUSDをレンダリングする処理を実行する。
The
映像リファイン部143は、映像をリファインするための各種処理を実行する。レンダリング部142は、生成された映像を、映像リファインの処理によりクオリティを高くする。例えば、映像リファイン部143は、動画データの画質を改善する画質改善処理を実行する画質改善部である。
The
サウンド生成部150は、サウンド(音)を生成する処理を実行する。サウンド生成部150は、サウンド向け生成部133でのサウンド向けのプロンプト生成で得られたプロンプトを用いて、Contrastive Learning ModelなどのAIモデルにより、BGM(background music)、SE(Sound Effect)、ナレーション、セリフなどのサウンド情報を生成する。
The
テキスト/ロゴ生成部160は、テキスト及びロゴのうち少なくとも1つを生成する処理を実行する。テキスト/ロゴ生成部160は、テキスト/ロゴ向け生成部134により生成された情報を用いてテキスト及びロゴのうち少なくとも1つを生成する。
The text/
映像生成モジュール100は、上述した構成により、あらかじめ保存されたプロンプトとユーザの入力を合わせてシナリオ生成のためのプロンプトを生成する。映像生成モジュール100は、生成されたプロンプトをLLMなどのAIモデルに入力することで、シナリオを生成する。また、映像生成モジュール100は、生成されたシナリオより、映像、サウンド、テキスト/ロゴを生成するためのプロンプトを生成する。映像生成モジュール100は、映像、サウンド、テキスト/ロゴを生成するためのプロンプト、シナリオ等を用いて、映像生成、サウンド生成、テキスト/ロゴ生成を実施する。
With the above-described configuration, the
コンポジット編集部170は、編集に関連する処理を実行する。例えば、コンポジット編集部170は、生成された映像、サウンド、テキスト/ロゴを一つにまとめ(合成し)、一つの映像とする処理を実行する。
The
評価部180は、各種の対象を評価する評価処理を実行する。評価部180は、上述した構成により生成された情報の評価を行う。例えば、評価部180は、シナリオデータと動画データのうち少なくとも1つの評価を示す情報を生成する。
The
クライアントUIモジュール190は、クライアント側のUI(User Interface)での出力に関連する処理を実行する。例えば、クライアントUIモジュール190は、クライアント側のUIでの出力に関連する各種情報を生成する。この場合、クライアントUIモジュール190は、ユーザ側で表示されるUIを生成する処理を実行する。クライアントUIモジュール190は、クライアントUI表示部400に表示させる各種情報を生成する。
The
また、情報取得モジュール200は、各種情報を取得する。情報取得モジュール200は、入力テキスト取得部210、センサ取得部220等を有する。入力テキスト取得部210は、キーボード320やマイク330により入力されたテキスト情報を取得する。例えば、入力テキスト取得部210は、ユーザがキーボード320やマイク330により入力したテキスト情報を取得する。例えば、入力テキスト取得部210は、動画生成に関する入力クエリをユーザから取得する取得部である。
In addition, the
センサ取得部220は、カメラ340やモーションキャプチャなどのセンサにより検知された情報(「センサ情報」ともいう)を取得する。情報取得モジュール200は、取得した各種情報を、映像生成モジュール100へ提供(送信)する。なお、情報取得モジュール200は、映像生成モジュール100と一体であってもよい。
The
センサ部300は、各種のセンサを有する。センサ部300は、ユーザの入力をセンシングする。センサ部300は、ユーザによる操作を受け付ける。例えば、センサ部300は、ユーザから動画編集に関する操作を受け付ける受付部である。例えば、センサ部300は、マウス310、キーボード320、マイク330、カメラ340、慣性計測装置であるIMU350等を有する。このように、センサ部300は、マウス310、キーボード320の他に、マイク330、カメラ340、IMU350を備えるユーザ端末(スマートフォン等)やモーションキャプチャなどのセンサなどを含み、ユーザの入力をセンシングする。
The
クライアントUI表示部400は、クライアント(ユーザ)に提示するための各種情報を表示する。クライアントUI表示部400は、クライアントUIモジュール190により生成されたUIをクライアントのディスプレイ(表示装置)に表示する。例えば、クライアントUI表示部400は、シナリオデータに基づいたストーリーボードを表示させる表示制御部である。ストーリーボードは、動画のカット毎に動画データを表示するように構成される。
The client
映像生成システム1は、図2に示すようなハードウェア構成であってもよい。図2は、本開示の映像生成システムに係るハードウェア構成の一例を示す図である。図2では、映像生成システム1は、クラウド側のコンピュータ10、クライアント側のコンピュータ20、カメラ等の各種のセンサを含むカメラ/センサ30等をハードウェア構成として有する。また、映像生成システム1には、学習データ等の情報リソース40、AIモデル50をコンピュータ10に提供する情報提供装置(コンピュータ)が含まれてもよい。
The
なお、図2に示すハードウェア構成は、一例に過ぎず、映像生成システム1は、所望の処理が実行可能であれば、任意のハードウェア構成が採用可能である。例えば、コンピュータ10とコンピュータ20とは一体であってもよい。また、情報リソース40やAIモデル50はコンピュータ10内部に保存されてもよい。
The hardware configuration shown in FIG. 2 is merely an example, and the
コンピュータ10は、CPU(Central Processing Unit)11、GPU(Graphics Processing Unit)12、通信装置13、メモリ/ストレージ14を備える。例えば、コンピュータ10は、図1中の映像生成モジュール100及び情報取得モジュール200に対応する。コンピュータ10は、映像生成サービスを提供するサービス提供装置(サーバ装置)であってもよい。CPU11及びGPU12は、いわゆるプロセッサであり、例えば映像生成等の各種の処理に関連する計算処理(演算処理)を実行する。
The
通信装置13は、コンピュータ20、情報提供装置等との間で情報を送受信するための通信機能を有する通信装置であり、例えば、通信回路、NIC(Network Interface Card)等であってもよい。通信装置13は、所定のネットワーク(インターネット等)を介してコンピュータ20、情報提供装置等の他の装置と通信を行う。例えば、通信装置13は、所定のネットワークと有線または無線で接続され、コンピュータ20、情報提供装置等の他の装置との間で情報の送受信を行う。
The communication device 13 is a communication device having a communication function for transmitting and receiving information between the
メモリ/ストレージ14は、各種の情報を記憶する記憶装置である。メモリ/ストレージ14は、例えば、RAM(Random Access Memory)、フラッシュメモリ(Flash Memory)等の半導体メモリ素子、または、ハードディスク、光ディスク等の記憶装置である。メモリ/ストレージ14は、CPU11及びGPU12等のプロセッサが処理に用いる各種情報を記憶する。メモリ/ストレージ14は、情報リソース40、AIモデル50等を記憶してもよい。
The memory/storage 14 is a storage device that stores various types of information. For example, the memory/storage 14 is a semiconductor memory element such as a random access memory (RAM) or a flash memory, or a storage device such as a hard disk or an optical disk. The memory/storage 14 stores various types of information used for processing by processors such as the CPU 11 and the GPU 12. The memory/storage 14 may also store
コンピュータ20は、CPU21、GPU22、通信装置23、メモリ/ストレージ24、IOインタフェース25を備える。例えば、コンピュータ20は、図1中のクライアントUI表示部400に対応する。コンピュータ20は、映像生成サービスを利用するユーザが利用する端末装置(PC(Personal Computer)、スマートフォン等の携帯デバイス等)であってもよい。CPU21及びGPU22は、いわゆるプロセッサであり、例えば映像表示等の各種の処理に関連する計算処理(演算処理)を実行する。なお、上記は一例に過ぎず、コンピュータ20は、所望の処理が可能であれば任意の構成が採用可能である。例えば、コンピュータ20は、ASIC(Application Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)等の回路により映像表示等の各種の処理に関連する計算処理(演算処理)を実行してもよい。また、コンピュータ20は、メモリ(メモリ/ストレージ24等)にプログラムを保存する代わりに、プロセッサの回路内にプログラムを直接組み込むよう構成されても構わない。この場合、プロセッサは回路内に組み込まれたプログラムを読み出し実行することで機能を実現する。なお、本実施形態の各プロセッサは、プロセッサごとに単一の回路として構成される場合に限らず、複数の独立した回路を組み合わせて1つのプロセッサとして構成し、その機能を実現するようにしてもよい。また、コンピュータ10もコンピュータ20と同様に、所望の処理が可能であれば任意の構成が採用可能である。
The
通信装置23は、コンピュータ10、センサ30等との間で情報を送受信するための通信機能を有する通信装置であり、例えば、通信回路、NIC等であってもよい。通信装置23は、所定のネットワーク(インターネット等)を介してコンピュータ10、センサ30等の他の装置と通信を行う。例えば、通信装置23は、所定のネットワークと有線または無線で接続され、コンピュータ10、センサ30等の他の装置との間で情報の送受信を行う。
The
メモリ/ストレージ24は、各種の情報を記憶する記憶装置である。メモリ/ストレージ24は、例えば、RAM、フラッシュメモリ等の半導体メモリ素子、または、ハードディスク、光ディスク等の記憶装置である。メモリ/ストレージ24は、CPU21及びGPU22等のプロセッサが処理に用いる各種情報を記憶する。
The memory/storage 24 is a storage device that stores various types of information. For example, the memory/storage 24 is a semiconductor memory element such as a RAM or a flash memory, or a storage device such as a hard disk or an optical disk. The memory/storage 24 stores various types of information used for processing by processors such as the
IOインタフェース25は、入出力のインタフェース装置である。コンピュータ20は、IOインタフェース25を介して、センサ30からの入力を受信する。例えば、コンピュータ20は、IOインタフェース25を介して、キーボードやマウス等の入力デバイスからの入力を受信する。また、コンピュータ20は、IOインタフェース25を介して、ディスプレイ(表示装置)、スピーカー(音声出力装置)から情報を出力させる。例えば、コンピュータ20は、IOインタフェース25を介して、ディスプレイ及びスピーカーにより映像を再生する。
The IO interface 25 is an input/output interface device. The
カメラ等の各種のセンサ30は、ユーザの入力をセンシングする。カメラ等の各種のセンサ30は、ユーザによる操作を受け付ける。例えば、センサ30は、図1中のセンサ部300に対応する。また、情報リソース40は、学習データ等の様々な情報を含む。例えば、情報リソース40は、LLM等の各種のAIモデルの学習に用いられる学習データを含む。AIモデル50は、LLM等の映像生成に関連する処理に用いられるAIモデルの情報を含む。例えば、AIモデル50は、後述するモデルM1~M3等の各種のAIモデルの情報を含む。なお、上述したように、映像生成システム1は、図2に示す構成以外の構成をとってもよい。
The
<1-2.本開示の映像生成システムによる処理>
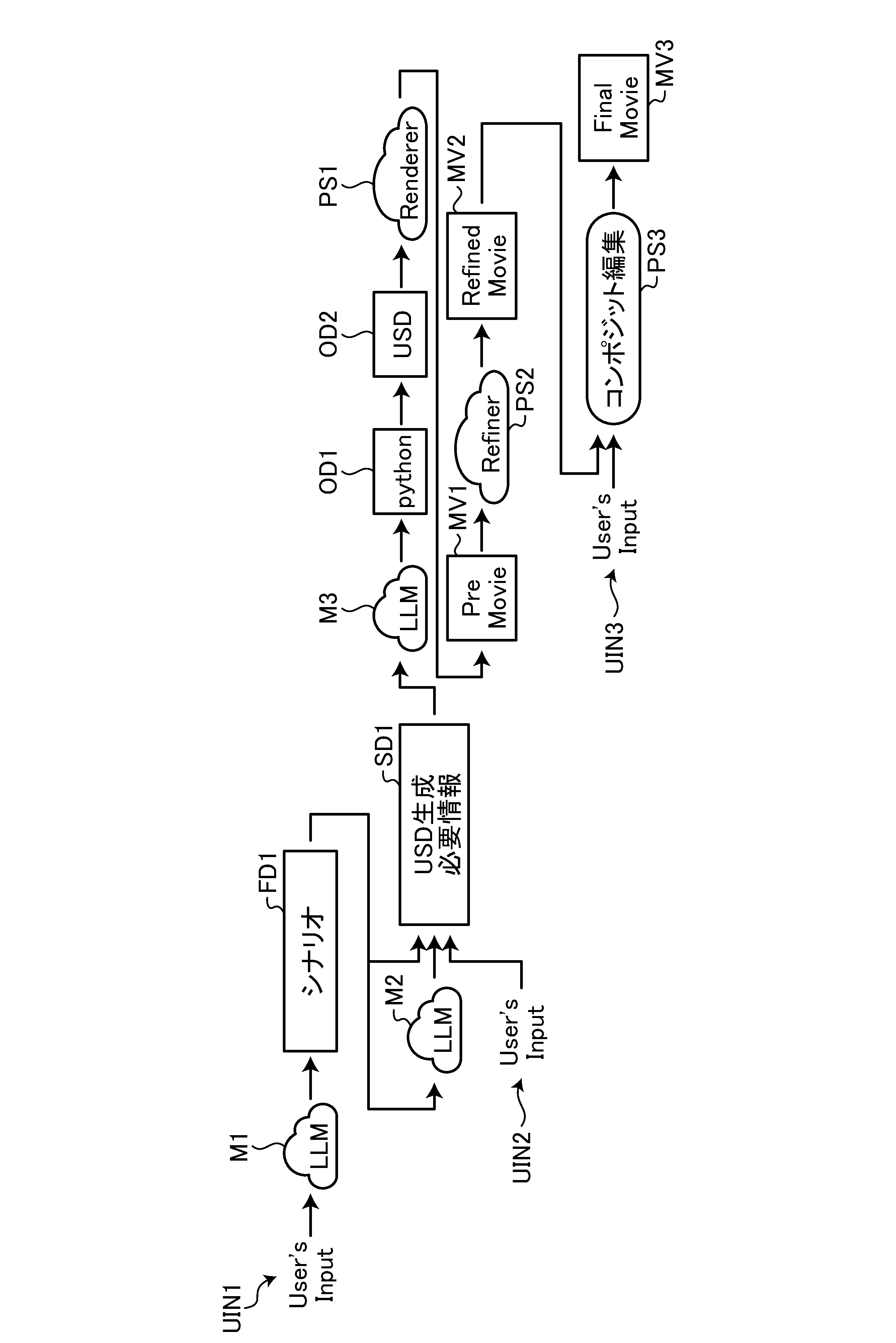
ここから、映像生成システムによる処理について説明する。まず、図3に示す映像生成処理の流れの一例について説明する。図3は、本開示の映像生成処理の流れの一例を示す図である。なお、以下で映像生成システム1を処理主体として説明する処理は、映像生成システム1に含まれる装置構成に応じて、その処理を実行可能ないずれの装置が行ってもよい。
1-2. Processing by the image generation system of the present disclosure
From here, the processing by the video generation system will be described. First, an example of the flow of the video generation processing shown in Fig. 3 will be described. Fig. 3 is a diagram showing an example of the flow of the video generation processing of the present disclosure. Note that the processing described below with the
図3では「User's Input」と表記するユーザ入力情報UIN1は、ユーザが映像生成のために入力した情報(「入力クエリ」ともいう)に対応する。なお、入力クエリは、テキスト(文字情報)に限らず、任意の情報が採用可能である。入力クエリは、テキスト、画像、音声、3Dデータのうち少なくとも1つを含む任意の情報であってもよい。 User input information UIN1, denoted as "User's Input" in FIG. 3, corresponds to information input by the user for image generation (also referred to as "input query"). Note that the input query is not limited to text (character information) and any information can be used. The input query may be any information including at least one of text, image, audio, and 3D data.
映像生成システム1は、ユーザ入力情報UIN1を用いて、図3では「LLM」と表記するモデルM1の入力として用いられるシナリオ生成用情報(「第1の入力情報」ともいう)を生成するが、この点については後述する。例えば、モデルM1は、第1の入力情報の入力に応じてシナリオデータを出力する第1のモデルである。モデルM1は、入力に応じて所望の出力が可能であれば、LLM(大規模言語モデル)等の任意のAIモデルが採用可能である。なお、モデルM1等のAIモデルに関しては後述する。
The
映像生成システム1は、モデルM1に第1の入力情報を入力し、モデルM1にシナリオデータであるシナリオFD1を出力させることにより、シナリオFD1を生成する。そして、映像生成システム1は、シナリオFD1、シナリオFD1を入力とするモデルM2の出力、及びユーザ入力情報UIN2等を用いて、モデルM3の入力として用いられるコード生成用情報(「第2の入力情報」ともいう)であるUSD生成必要情報SD1を生成する。例えば、モデルM3は、第2の入力情報の入力に応じてコードを出力する第2のモデルである。モデルM3は、入力に応じて所望の出力が可能であれば、LLM(大規模言語モデル)等の任意のAIモデルが採用可能である。
The
なお、図3では、USD生成必要情報SD1を1つのみ図示するが、例えば生成するUSDファイルの数に応じてUSD生成必要情報SD1は複数あってもよい。例えば、USD生成必要情報SD1は、図18に示すようなデータ構造に対応して生成するUSDファイルの数に応じてUSD生成必要情報SD1は複数あってもよい。 Note that, although only one piece of information SD1 required for generating USD is illustrated in FIG. 3, there may be multiple pieces of information SD1 required for generating USD, for example, depending on the number of USD files to be generated. For example, there may be multiple pieces of information SD1 required for generating USD, depending on the number of USD files to be generated corresponding to the data structure shown in FIG. 18.
例えば、モデルM2は、シナリオデータの入力に応じて、そのシナリオデータに対応するテンプレート等を出力するモデルであってもよい。モデルM2は、入力に応じて所望の出力が可能であれば、任意のAIモデルが採用可能である。例えば、ユーザ入力情報UIN2は、映像生成での制約条件の指定等を行うための情報であってもよい。なお、映像生成システム1は、シナリオFD1とテンプレート入力情報とを用いて第2の入力情報を生成してもよいがこの点については後述する。
For example, model M2 may be a model that outputs a template or the like corresponding to scenario data in response to the input of that scenario data. Any AI model can be adopted for model M2 as long as it is capable of providing the desired output in response to the input. For example, user input information UIN2 may be information for specifying constraint conditions for image generation. Note that
映像生成システム1は、モデルM3にUSD生成必要情報SD1を入力し、モデルM3に図3では「python」と表記するパイソンコードOD1を出力させることにより、パイソンコードOD1を生成する。例えば、パイソンコードOD1は実行によりUSD形式のデータ(「USDファイル」ともいう)を生成する(プログラム)コードである。なお、パイソンは一例に過ぎず、コードは所望の3DCG用のデータを生成可能であれば、パイソンに限らず任意の形式のコードが採用可能である。また、USDは一例に過ぎず、3DCG用のデータであれば、FBX(Film Box)等任意の形式が採用可能である。映像生成システム1は、パイソンコードOD1を実行し、図3では「USD」と表記するUSDファイルOD2を生成する。
The
映像生成システム1は、図3では「Renderer」と表記するレンダリング処理PS1を実行することにより、図3では「PreMovie」と表記する動画データMV1を生成する。例えば、動画データMV1は、後述するリファイン処理PS2を実行する前のデータ(「第1の動画データ」ともいう)である。
The
映像生成システム1は、図3では「Refiner」と表記するリファイン処理PS2を実行することにより、図3では「RefinedMovie」と表記する動画データMV2を生成する。例えば、リファイン処理PS2は、動画データの画質を改善する画質改善処理である。動画データMV2は、リファイン処理PS2により第1の動画データである動画データMV1が更新された後のデータ(「第2の動画データ」ともいう)である。
The
映像生成システム1は、動画データMV2、ユーザ入力情報UIN3等を用いてコンポジット編集PS3を実行することにより、図3では「FinalMovie」と表記する動画データMV3を生成する。例えば、コンポジット編集PS3は、ユーザ入力情報UIN3が示すユーザの編集指示に応じて、動画データMV2を更新(編集)する処理を実行することにより、動画データMV2が更新された動画データMV3を生成する。
The
なお、図3に示す映像生成処理の流れは一例に過ぎず、映像生成システム1は、ユーザの入力クエリから動画データを生成可能であれば、任意の処理態様が採用可能である。例えば、図3では、モデルM1がコード(パイソンコード)を出力する場合を一例として説明したが、モデルM1は、USDファイル等の3DCG用のデータを出力するモデルであってもよい。また、映像生成システム1は、図3に示す処理に限らず、様々な態様の映像生成処理を行ってもよい。この点の一例について図4を用いて説明する。図4は、本開示の映像生成処理の流れの他の一例を示す図である。図4は、音生成必要情報SD2及びテキストロゴ必要情報SD3を生成し、それらを用いて映像生成処理を行う点等で図3と相違する。なお、図3で説明した内容と同様の点については適宜説明を省略する。
Note that the flow of the image generation process shown in FIG. 3 is merely an example, and the
図4では、映像生成システム1は、シナリオFD1、シナリオFD1を入力とするモデルM2の出力、及びユーザ入力情報UIN2等を用いて、図3では「AI」と表記するモデルM4の入力として用いられる音生成用情報である音生成必要情報SD2を生成する。例えば、モデルM4は、音生成必要情報SD2及び動画データMV2の入力に応じて各種の音データを出力するモデルである。モデルM4は、入力に応じて所望の出力が可能であれば、任意のAIモデルが採用可能である。なお、モデルM4は、音生成必要情報SD2のみを入力とするモデルであってもよい。
In FIG. 4, the
映像生成システム1は、モデルM4に音生成必要情報SD2を入力し、モデルM4にBGM(BackGround Music)用の音データAD1、SE用の音データAD2、Narration用の音データAD3等を出力させることにより、映像に対応する音データを生成する。また、映像生成システム1は、ユーザ入力情報UIN4を用いて、音データAD1、AD2、AD3を生成してもよい。例えば、モデルM4が音データAD1、AD2、AD3を1つの音データとして出力する場合、映像生成システム1は、ユーザ入力情報UIN4での指定に基づいて、モデルM4が出力した1つの音データから、音データAD1、AD2、AD3を抽出して、音データAD1、AD2、AD3を生成してもよい。
The
図4では、映像生成システム1は、シナリオFD1、シナリオFD1を入力とするモデルM2の出力、及びユーザ入力情報UIN2等を用いて、モデルM5の入力として用いられるテキストロゴ生成用情報であるテキストロゴ生成必要情報SD3を生成する。例えば、モデルM5は、テキストロゴ生成必要情報SD3の入力に応じてテキスト及びロゴのうち少なくとも1つを出力するモデルである。モデルM5は、入力に応じて所望の出力が可能であれば、任意のAIモデルが採用可能である。
In FIG. 4, the
映像生成システム1は、モデルM5にテキストロゴ生成必要情報SD3を入力し、モデルM5にText用のテキストロゴデータDI1、Logo用のテキストロゴデータDI2等を出力させることにより、映像に対応するテキストロゴデータを生成する。
映像生成システム1は、動画データMV2、音データAD1、AD2、AD3、テキストロゴデータDI1、DI2、ユーザ入力情報UIN3等を用いてコンポジット編集PS3を実行することにより、動画データMV3を生成する。例えば、コンポジット編集PS3は、動画データMV2、音データAD1、AD2、AD3、テキストロゴデータDI1、DI2等を一つにまとめ(合成し)、一つの映像とした動画データMV3を生成する処理を実行する。
The
上述した図3及び図4は、初期状態としてシナリオやUSD生成必要情報、USD、PreMovie、RefinedMovie等がない状態での処理の一例を示す。上述したように、映像生成システム1は、ユーザの入力クエリに基づき、シナリオを生成するためのプロンプトを生成し、自然言語モデルへプロンプトを提供してシナリオを生成し、シナリオに記載のテキスト情報より、動画を構成するコード出力のためのプロンプトを生成し、自然言語モデルへプロンプトを提供して、動画を構成するコードを生成し、動画を生成する。このように、映像生成システム1では、動画を作る際、ユーザの作りたいものや目的を入力すると、3DCGの知識や映像制作の知識がなくても効果的な映像のストーリーボードと動画が生成される。また、映像生成システム1では、ストーリーボードにすることで、その後に編集しやすくなる。なおこれらの点についての詳細は後述する。
The above-mentioned Figures 3 and 4 show an example of processing in an initial state where there is no scenario, information required for generating USD, USD, PreMovie, RefinedMovie, etc. As described above, the
また、映像生成システム1は、映像生成に関連する各種の処理を行ってもよい。例えば、映像生成システム1は、生成した情報を対象として評価処理を行ってもよい。この点について、図5を用いて、評価処理の流れの一例について説明する。図5は、本開示の評価処理の流れの一例を示す図である。
The
図5では、映像生成システム1は、シナリオFD1、USD生成必要情報SD1、音生成必要情報SD2、テキストロゴ生成必要情報SD3のうち少なくとも1つを入力し、モデルM10に、入力された情報についての評価を示す評価テキスト情報EV1を出力させることにより、生成した情報に対する評価を行う。例えば、モデルM10は、情報の入力に応じて、その入力された情報の評価を出力するモデルである。例えば、モデルM10は、シナリオFD1の入力に応じて、その入力されたシナリオFD1の評価を示す評価テキストを出力する。なお、モデルM10は、シナリオFD1、USD生成必要情報SD1、音生成必要情報SD2、テキストロゴ生成必要情報SD3ごとに入力を受け付けるモデルであってもよいし、これらの情報を組み合わせた入力を受け付けるモデルであってもよい。また、モデルM10は、映像を示す情報(キャプション等)の入力に応じて、その入力された情報に対応する映像の評価を出力するモデルであってもよい。
In FIG. 5, the
ここから、上述した処理の流れについて、映像生成システム1が実行する各処理の具体例について記載する。なお、上述した内容と同様の点について適宜説明を省略する。
From here, specific examples of each process executed by the
例えば、映像生成システム1は、図6に示すように、シナリオ生成用情報(第1の入力情報)を生成する。図6は、シナリオ生成用情報の生成処理の一例を示す図である。図6では、映像生成システム1は、コンテンツCT1にユーザが入力したユーザ入力情報IDT1、IDT2をユーザの入力情報として取得する。コンテンツCT1は、「どういう動画を作りたいですか?」という質問事項、及び「スタイル」という質問事項の各々に対するユーザの入力情報を受け付けるためのコンテンツである。
For example, the
例えば、クライアントUI表示部400は、コンテンツCT1を表示し、センサ部300は、ユーザ入力情報IDT1、IDT2をユーザ入力情報として受け付ける。例えば、ユーザ入力情報IDT1、IDT2は、図3及び図4中のユーザ入力情報UIN1に対応する。
For example, the client
図6では、クライアントUI表示部400は、「どういう動画を作りたいですか?」という質問事項を表示する。センサ部300は、「どういう動画を作りたいですか?」という質問事項に対しては、「15秒のスニーカーのCM動画」というユーザ入力情報IDT1を受け付ける。また、クライアントUI表示部400は、「スタイル」という質問事項を表示する。センサ部300は、「スタイル」という質問事項に対しては「映画風」というユーザ入力情報IDT2を受け付ける。
In FIG. 6, the client
なお、映像生成システム1は、ユーザの入力情報を任意の態様により受け付けてもよく、複数の候補からユーザの選択を受け付けてもよい。例えば、映像生成システム1は、ユーザがキーボードやマイクから入力した情報をテキスト情報にして、ユーザの入力情報として受け付けてもよい。また、映像生成システム1は、自由文だけでなく、動画全体の秒数、スタイル、カメラワークなどの設定値、画像、動画などの他ファイルをユーザの入力情報として受け付けてもよい。
The
映像生成システム1は、ユーザ入力情報IDT1、IDT2、及びテンプレート入力情報であるテンプレートTP1を用いて、シナリオ生成用情報(第1の入力情報)であるプロンプトPT1を生成する。例えば、テンプレートTP1は、予め設定されたものであってもよいし、複数のテンプレート候補から選択されてもよい。例えば、映像生成システム1は、複数のテンプレート候補のうち、ユーザの入力情報に対応するテンプレートを選択してもよい。例えば、映像生成システム1は、ユーザ入力情報IDT1、IDT2が示す内容に基づいて、複数のテンプレート候補のうち、映画風の広告に関連するテンプレートTP1を選択してもよい。
The
例えば、映像生成システム1は、テンプレートTP1にユーザ入力情報IDT1、IDT2を反映することにより、プロンプトPT1を生成する。図6では、映像生成システム1は、制約条件のスタイルの項目に入力情報IDT2が示す「映画風」を追加し、入力文に入力情報IDT1が示す「15秒のスニーカーのCM動画」を追加することにより、プロンプトPT1を生成する。このように、映像生成システム1は、ユーザの入力情報により、シナリオを生成するためのプロンプトを生成する。なお、ユーザの入力情報は、一画面で入力されてもよいし、いくつかの質問に答えることにより入力されてもよいが、これらの点の例について後述する。
For example, the
また、映像生成システム1は、図7に示すように、シナリオデータを生成する。図7は、シナリオデータの生成処理の一例を示す図である。図7では、映像生成システム1は、プロンプトPT1を用いて、シナリオデータSN1を生成する。例えば、シナリオデータSN1は、図3及び図4中のシナリオFD1に対応する。シナリオデータSN1には、オープニングシーン、スニーカーを履くシーン等のシーンごとにその秒数、カットの説明などの情報が含まれる。
The
例えば、映像生成システム1は、LLM等であるモデルM1にプロンプトPT1を入力し、モデルM1にシナリオデータSN1を出力させることにより、シナリオデータSN1を生成する。このように、映像生成システム1は、生成したプロンプトをAI(LLMなど)に入力することにより、シナリオを生成する。なお、図7に示す情報(「シナリオ情報」ともいう)以外にも、シナリオデータSN1には、環境、登場人物、モーション、カメラワーク、ライティング、カラーなどの情報も含まれる。例えば、シナリオ生成には特徴が出るように、ユーザのこれまでの経験学習データや特定の監督や人の学習データを、モデルM1等にRAG(Retrieval-Augmented Generation)やファインチューンングで入れることで、映像生成システム1は、様々なシナリオバリエーションを生成することが可能となる。
For example, the
また、映像生成システム1は、図8に示すように、コード生成用情報(第2の入力情報)を生成する。図8は、コード生成用情報の生成処理の一例を示す図である。映像生成システム1は、シナリオデータSN1、及びテンプレート入力情報であるテンプレートTP2を用いて、コード生成用情報(第2の入力情報)であるプロンプトPT2を生成する。例えば、テンプレートTP2は、予め設定されたものであってもよいし、複数のテンプレート候補から選択されてもよい。例えば、映像生成システム1は、複数のテンプレート候補のうち、シナリオに対応するテンプレートを選択してもよい。例えば、映像生成システム1は、シナリオデータSN1が示す内容に基づいて、複数のテンプレート候補のうち、CMに関連するテンプレートTP2を選択してもよい。
The
例えば、映像生成システム1は、テンプレートTP2にシナリオデータSN1を反映することにより、プロンプトPT2を生成する。図8では、映像生成システム1は、入力文にシナリオデータSN1が示す情報を追加することにより、プロンプトPT2を生成する。このように、映像生成システム1は、AIにより生成されたシナリオにより、映像向けのプロンプトを生成する。
For example, the
例えば、図8は、人に関するシナリオからUSD-Pythonに変換するためのプロンプト生成の一例を示す。USD-Pythonへの変換は変換の形式の一例に過ぎず、変換はUSD-Pythonに限らずに、任意の変換の形式であってもよい。例えば、変換の形式は、Blender向けPython、またUSDなどの形式であってもよい。また、映像生成システム1は、人、環境、カメラワークなどの対象ごとに個別にプロンプトを生成してもよいし、まとめてプロンプトを生成してもよい。また、生成するプロンプトには、使用するアセットのパスやモーションのパスがされてもよいし、アセット/モーションのAI生成アルゴリズムに投げる(入力する)ためのソースコードやAPI(Application Programming Interface)が記載されてもよい。
For example, FIG. 8 shows an example of prompt generation for converting a scenario related to a person into USD-Python. Conversion into USD-Python is merely one example of a conversion format, and the conversion is not limited to USD-Python and may be any conversion format. For example, the conversion format may be Python for Blender, USD, or other formats. Furthermore, the
そして、映像生成システム1は、生成したプロンプトをAI(LLMなど)に入力することでUSD-Pythonファイルを生成する。なお、ファイルの形式はpython形式に限らず、USDなど他の形式でファイルが生成されてもよい。そして、映像生成システム1は、USDファイル等、レンダリングできる形式に変換し、レンダリングを実行することにより、PreMovie(mp4等の映像ファイル)を生成する。
Then, the
なお、映像生成システム1は、PreMovieを用いてコンポジット編集を行ってもよいが、図9に示すように、PreMovieに画質改善処理の一例であるリファイナ処理を行ってもよい。図9は、画質改善処理の一例を示す図である。図9では、映像生成システム1は、PreMovieである第1の動画IN1を入力として、RefinedMovieである第2の動画OT1を出力するDiffusionモデルであるモデルM11を用いたリファイナ処理により、第1の動画IN1から第2の動画OT1を生成する。
The
なお、リファイナ処理に用いられるAIモデル(モデルM11等)は、Diffusionモデルに限らず、LDM(Latent Diffusion Model)、LCM(Latent Consistency Model)などの任意のAIモデルが採用可能である。また、リファイナ処理には、AnimateDiff(時間方向安定化)、ControlNet(ラインアート制御)等の技術が用いられてもよい。このようなリファイナ処理により、映像生成システム1は、登場人物、背景、プロップ(小道具)などの一貫性を保ったまま、映像のクオリティを向上させることができる。
The AI model (such as model M11) used in the refiner process is not limited to the diffusion model, and any AI model such as the latent diffusion model (LDM) or latent consistency model (LCM) can be used. In addition, techniques such as AnimateDiff (time directional stabilization) and ControlNet (line art control) may be used in the refiner process. Through this refiner process, the
また、リファイナ処理には、動画だけでなくプロンプトを用いてもよい。例えば、モデルM11は、第1の動画IN1に加えて、プロンプトIN2を入力としてもよい。例えば、モデルM11は、プロンプトIN2により30代女性等の対象が指定された場合、第1の動画IN1中の30代女性の箇所を改善した第2の動画OT1を出力する。これにより、映像生成システム1は、第1の動画IN1のうちプロンプトIN2により指定された対象について画質等が改善された第2の動画OT1を生成する。
In addition, the refiner process may use prompts in addition to videos. For example, the model M11 may input prompt IN2 in addition to the first video IN1. For example, when a target such as a woman in her 30s is specified by prompt IN2, the model M11 outputs a second video OT1 in which the parts of the first video IN1 that represent the woman in her 30s have been improved. This allows the
上述した映像生成システム1の処理により、ユーザからは入力後にシナリオ(ストリーボード)と各カットの動画が生成されているように見え、その間の処理はシステム内に閉じている。これらの処理は、ユーザの入力テキストから一気にシナリオから全てのカット、リファイナ処理まで生成されることもありうるし、処理の途中で好みの選択などユーザの入力が行われてもよい。例えば、映像生成システム1においては、大筋のみを書いたシナリオを何パターンか生成後、ユーザが選択し、選択された大筋のシナリオを基に詳細シナリオと動画生成処理が実行されてもよい。また、映像生成システム1においては、シナリオ生成後、映像生成の前で生成される映像の登場人物を何パターンか生成し、ユーザが1つを選択後、動画をレンダリング処理やリファイナ処理を実行してもよい。
From the user's perspective, the above-mentioned processing of the
シナリオの構成要素として、カットの動画や代表とする画像(動画の1フレーム目など)、カットの説明、登場人物(ビジュアル、設定など)、各登場人物のモーション、ライティング、カメラワーク、背景の環境情報、カット間のトランジション、セリフ、ナレーションなどがありうる。これらはユーザに提示するものもあれば、ユーザに提示はせずに処理のために持つものもある。シナリオはカットごとに時系列に並んでいる。 The components of a scenario may include videos of cuts, a representative image (such as the first frame of a video), a description of the cut, characters (visuals, setting, etc.), the motions of each character, lighting, camera work, background environmental information, transitions between cuts, dialogue, narration, etc. Some of these are presented to the user, while others are not presented to the user and are kept for processing purposes. The scenario is arranged in chronological order by cut.
現在、Pika、Runway Gen-2、Lumiere、Stable Video Diffusionなどの様々な既存動画生成サービスが提供されている。これらは画像から空間方向や時間方向のベクトルを動かすDiffusionモデルを使い、動画を生成している。これらは、2Dの画像だけを使い映像を生成している。一方、映像生成システム1は、内部に3Dの情報を保持している。例えば、既存動画生成サービスでは動画内の指定した(X,Y)領域のみ修正することは可能であるが、服の色味だけ変化させたいのにモーションも変わってしまうという課題がある。一方で、映像生成システム1の場合、内部に3Dの情報を保持しているため、モーションのみ、ライティングのみ、人の服の色のみなどの狙った部分のみの修正が可能となる。
Currently, various existing video generation services are provided, such as Pika, Runway Gen-2, Lumiere, and Stable Video Diffusion. These generate videos using a diffusion model that moves vectors in the spatial and temporal directions from an image. These generate videos using only 2D images. On the other hand,
また、既存動画生成サービスはカットごとの動画を生成するのみであり、ユーザが各カットの一貫性を自ら担保する必要があるが、映像生成システム1はシナリオ(ストリーボード)から動画生成、修正まで一貫して実施することが可能であり、映像の出演者や背景、カラーグレーディングなど一貫性を持った動画生成をすることが可能である。
In addition, existing video generation services only generate videos for each cut, and users must ensure the consistency of each cut themselves. However,
<1-3.ユーザインタフェース>
ここから、映像生成システム1を利用するユーザに対するユーザインタフェース(UI)について記載する。なお、上述した内容と同様の点については適宜説明を省略する。
<1-3. User interface>
From here, we will describe the user interface (UI) for users who use the
映像生成システム1は、図10に示すように、コンテンツCT11をユーザに提供する。図10は、ユーザインタフェースの一例を示す図である。コンテンツCT11は、ユーザの入力情報を受け付けるための表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT11を表示する。ユーザは、コンテンツCT11を介して、どんな動画を作るかを指示するテキスト(図10では「Prompt」の欄)及びスタイルの選択(図10では「Style」の欄)をユーザの入力情報として入力する。このように、ユーザは、テキスト及びスタイルの選択をユーザの入力情報として入力する。例えば、ユーザは、コンテンツCT11に含まれる例文等を参考に「Prompt」の欄に文字情報を入力する。例えば、ユーザは、「Style」の欄の下向きの三角形を押す(クリック等)すること等により、表示される複数のスタイル候補から使用するスタイルを選択する。
As shown in FIG. 10, the
ユーザの入力情報の入力が完了したユーザは、図10中の「Ask AI Director」と表記されたボタンを選択することにより、映像生成システム1にユーザの入力情報に応じた動画生成を指示する。これにより、映像生成システム1は、ユーザの入力情報に応じた動画の生成処理を実行する。
When the user has completed inputting the user's input information, the user selects the button labeled "Ask AI Director" in FIG. 10 to instruct the
映像生成システム1は、図14に示すように、生成した動画に関するコンテンツCT15をユーザに提供する。図14は、ユーザインタフェースの一例を示す図である。コンテンツCT15は、生成した動画に対するユーザの操作(指示)を受け付けるためのストーリーボード画面(コンテンツ)である。図14に示すように、コンテンツCT15は、生成した動画のカット毎に動画データを表示するストーリーボード画面である。例えば、クライアントUI表示部400は、コンテンツCT15を表示する。このように、映像生成システム1は、ユーザの入力情報に応じて、ストーリーボードと映像が出力されるUIを提供する。ユーザは、ストーリーボード画面にて、各カットの動画、内容、ナレーション、セリフ、カメラワーク、BGM、ライティング、カラーなどの設定をする。
As shown in FIG. 14, the
なお、映像生成システム1は、ユーザに質問を行いながら、ユーザによるユーザの入力情報を受け付けてもよい。例えば、映像生成システム1は、図10中の「Ask AI Director」と表記されたボタンを選択した場合、図11~図13に示すように、ユーザとの会話(対話)によりユーザの入力情報を受け付ける。図11~図13は、ユーザインタフェースの一例を示す図である。図11中のコンテンツCT12は、図10で入力されたユーザの入力情報に対応して生成したサンプルを提示して、ユーザにイメージに近いものがあるかを質問する表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT12を表示する。
The
図12中のコンテンツCT13は、図11中のコンテンツCT12で提示したサンプルにイメージに合うものがないとのユーザの回答(入力情報)に応じて、詳細なターゲット等を要求(質問)する表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT13を表示する。
Content CT13 in FIG. 12 is a display screen (content) that requests (asks) detailed targets, etc. in response to the user's response (input information) that none of the samples presented in content CT12 in FIG. 11 match the image. For example, the client
図13中のコンテンツCT14は、ターゲット等を具体的に指定したユーザの回答(入力情報)に対応して再度生成したサンプルを提示して、ユーザにイメージに近いものがあるかを質問する表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT14を表示する。図13では、ユーザがマウスカーソルを4つのサンプルのうち左端のサンプル動画に合わせてクリック等の指定操作を行うことにより、4つのサンプルのうち左端のサンプル動画がイメージに近い動画であると、ユーザが指定した場合を示す。これにより、映像生成システム1は、4つのサンプルのうち左端のサンプル動画を指定するユーザの入力情報に応じた動画の生成処理を実行する。
Content CT14 in FIG. 13 is a display screen (content) that presents samples that have been regenerated in response to a user's answer (input information) that specifically specifies a target, etc., and asks the user whether there is one that is close to the image. For example, the client
この場合、映像生成システム1は、図14に示すように、生成した動画に関するコンテンツCT15をユーザに提供する。例えば、クライアントUI表示部400は、コンテンツCT15を表示する。このように、映像生成システム1は、初期入力内容で、ストーリーボードと動画を生成するにあたり、必要な情報が足りない場合はユーとの会話(対話)により必要な情報を収集しながら、詳細を詰めていってもよい。
In this case, the
また、映像生成システム1は、図15及び図16に示すように、ユーザに作りたい動画に関する短文を入力させ、その短文を基に動画のストーリーをいくつか生成し、気に入ったものをユーザに選択させてもよい。図15及び図16は、ユーザインタフェースの一例を示す図である。
As shown in Figs. 15 and 16, the
映像生成システム1は、図15に示すように、コンテンツCT21をユーザに提供する。コンテンツCT21は、ユーザの入力情報を受け付けるための表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT21を表示する。ユーザは、コンテンツCT21を介して、どんな動画を作りたいかを示す文章(短文)をユーザの入力情報として入力する。例えば、ユーザは、コンテンツCT21中の入力欄に文字情報を入力する。
As shown in FIG. 15, the
ユーザの入力情報の入力が完了したユーザは、コンテンツCT21中の入力欄の右端の「開始」と表記されたボタンを選択することにより、映像生成システム1にユーザの入力情報に応じた動画のストーリーの生成を指示する。これにより、映像生成システム1は、ユーザの入力情報に応じた動画のストーリーの生成処理を実行する。
When the user has finished inputting the user's input information, the user selects the button marked "Start" on the right side of the input field in content CT21 to instruct
映像生成システム1は、図16に示すように、生成した動画のストーリーに関するコンテンツCT22をユーザに提供する。図16中のコンテンツCT22は、図15で入力されたユーザの入力情報に対応して生成した動画のストーリーのサンプルを提示する表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT22を表示する。例えば、ユーザは、動画のストーリーのサンプルのうち、気に入ったものがあれば、そのサンプルの表示領域の右端の「続ける」と表記されたボタンを選択することにより、映像生成システム1に選択したサンプルに対応する動画生成を指示する。
As shown in FIG. 16, the
なお、映像生成システム1は、ユーザが気に入ったものがなければ別パターンを再度生成する。例えば、ユーザは、動画のストーリーのサンプルのうち、気に入ったものが無ければ、短文の表示領域の右端の「続ける」と表記されたボタンを選択することにより、映像生成システム1に別パターンの動画のストーリーのサンプルを再度生成することを指示する。これにより、映像生成システム1は、別パターンの動画のストーリーのサンプルを生成する。
If the user does not like any of the video story samples, the
<1-4.処理例>
ここから、上述した具体例以外に、映像生成システム1が実行する各処理の具体例について記載する。なお、上述した内容と同様の点について適宜説明を省略する。以下では、上述した映像生成システム1の処理における音等の生成処理、評価処理等についての具体例を説明する。なお、上述した内容と同様の点については適宜説明を省略する。
<1-4. Processing example>
From here, in addition to the specific examples described above, specific examples of each process executed by the
<1-4-1.音生成例>
例えば、映像生成システム1は、図17に示すように、音生成用情報(図3及び図4中の音生成必要情報SD2に対応)を生成する。図17は、音生成用情報の生成処理の一例を示す図である。映像生成システム1は、シナリオデータSN1、及びテンプレート入力情報であるテンプレートTP3を用いて、音生成用情報であるプロンプトPT3を生成する。例えば、テンプレートTP3は、予め設定されたものであってもよいし、複数のテンプレート候補から選択されてもよい。例えば、映像生成システム1は、複数のテンプレート候補のうち、シナリオに対応するテンプレートを選択してもよい。例えば、映像生成システム1は、シナリオデータSN1が示す内容に基づいて、複数のテンプレート候補のうち、CMに関連するテンプレートTP3を選択してもよい。
<1-4-1. Sound generation example>
For example, the
例えば、映像生成システム1は、テンプレートTP3にシナリオデータSN1を反映することにより、プロンプトPT3を生成する。図17では、映像生成システム1は、入力文にシナリオデータSN1が示す情報を追加することにより、プロンプトPT3を生成する。例えば、映像生成システム1は、シナリオにより合うサウンド(BGM等)を生成するために、シナリオの中からキーとなるフレーズをいくつか抽出するためのプロンプトを生成する。映像生成システム1は、生成したプロンプトをAI(LLM等)に入力することで、サウンド生成に必要なキーワードやテキスト情報を取得してもよい。
For example, the
映像生成システム1は、生成したプロンプトPT3を用いて、音データを生成する。例えば、映像生成システム1は、生成された動画とストーリーボード(シナリオデータSN1等)に記載のテキスト情報に基づき、BGMやSE、ナレーション、セリフなどのサウンド(音データ)を生成する。また、映像生成システム1は、セリフやナレーション等、既に必要な言葉(文字情報)がシナリオ内に抜き出されている場合は、プロンプトを生成せずに、その言葉(文字情報)をセリフやナレーション等の音データとして保存してもよい。
The
例えば、映像生成システム1は、得られたサウンド生成のための必要情報(音生成用情報)、動画、ユーザが入力した音声データ(音源、ユーザの声や鼻歌など)より音データを生成する。なお、映像生成システム1は、BGMやSEに関しては、text to music generationの様なTransformer(モデル)を利用し、テキストや動画からサウンドを生成してもよい。また、映像生成システム1は、text to music estimationの様なContrastive Learningされた音源を自然文から検索してもよい。
For example, the
また、映像生成システム1は、セリフやナレーションに関しては、その言葉自体と、シナリオから得られた人物像に関するテキスト情報を元に、text to speech(DiffusionモデルやFlow Matchingなど)で音声を生成してもよい。また、映像生成システム1は、生成された動画と音声をつなげる際、音声の開始終了時間、音量等を示すため、動画内もしくは音声ファイル内にメタ情報を組み込んでもよい。
In addition, for lines and narration, the
<1-4-2.テキストロゴ生成例>
例えば、映像生成システム1は、テキストロゴ生成用情報(図3及び図4中のテキストロゴ生成必要情報SD3に対応)を生成する。映像生成システム1は、生成したストーリーボード(シナリオデータSN1等)に基づき、映像上に表示されるテキストやロゴ情報(キャプション、タイトル、ロゴ、説明文等)を生成する。
<1-4-2. Example of text logo generation>
For example,
例えば、生成されたシナリオ内に、表示するテキスト文章が明確に記載されている場合もあるが、明確に記載されていない場合は、映像生成システム1は、テキスト情報(テキストロゴデータ等)を生成するためのプロンプトを生成し、AI(LLMなど)に投げてテキスト情報を生成する。また、映像生成システム1は、ユーザが表示するテキストを自ら入力した場合、ユーザが入力したその情報をテキスト情報(テキストロゴデータ等)として用いてもよい。
For example, the text sentence to be displayed may be clearly stated in the generated scenario, but if it is not clearly stated, the
また、テキスト表示のフォントやサイズ位置は、任意の方法により決定される。例えば、映像生成システム1は、Diffusionモデル、VAE(Variational Auto-Encoder)、GAN(Generative Adversarial Networks)、DALL E、StyleGAN、StyleGAN2、Pix2Pix、TransGAN、LLMなどの任意のAIを用いて、テキスト表示のフォントやサイズ位置を決定してもよい。また、テキスト表示のフォントやサイズ位置は、ユーザが自ら手動で設定してもよい。
The font, size, and position of the text display may be determined by any method. For example, the
ロゴやイメージに関しては、ユーザが画像や動画をjpeg形式やmp4形式等で入力してもよい。また、ロゴやイメージに関しては、映像生成システム1は、画像生成のためのプロンプトを生成し、Diffusionモデル、VAE、GAN、DALL E、StyleGAN、StyleGAN2、Pix2Pix、TransGAN、LLMなどの任意のAIに投げてロゴ情報を生成してもよい。
Regarding logos and images, the user may input images or videos in jpeg or mp4 format, etc. Also, regarding logos and images, the
また、映像生成システム1は、テキストやロゴ情報と動画をつなげる際、テキストやロゴの開始終了時間や位置、大きさを明確(メタ情報)に示すため、動画内もしくはテキストやロゴ自体にメタ情報を組み込んでもよい。
In addition, when linking text or logo information with a video, the
<1-4-3.再学習例>
また、映像生成システム1は、シナリオや映像を生成する際、取り替え可能な特定の学習データに基づき、その学習データにしか出せないシナリオや映像を生成してもよい。例えば、これまで制作した映像や画像を基に学習データとして再学習する事が可能である。RAGやファインチューンングで再学習することで、生成されるシナリオや映像を変化させることができる。すなわち、映像生成システム1は、過去に制作したユーザ個人のデータ(履歴)を再学習することも可能であるし、特定の映画監督の作品を学習データとして再学習したモデルで生成することも可能である。
<1-4-3. Re-learning example>
Furthermore, when generating a scenario or image, the
また、その学習データは、個人のPC上で再学習させることも可能であるし、サーバ上で再学習させることも可能である。学習データは、LLMやDiffusionモデルなど数多くのモデルを学習させるための学習データとなる。全体のシナリオはA監督を用いてシナリオ生成したいが、映像のカラーは別のB監督を用いてカラーグレーディングを生成したい場合等においては、映像生成システム1は、特定の部分に関して別の学習データで再学習してもよい。
The learning data can also be re-learned on an individual's PC or on a server. The learning data is used to train a number of models, such as the LLM and Diffusion model. In cases such as when it is desired to generate an overall scenario using director A, but to generate color grading for the video color using a different director B, the
<1-4-4.USD更新例>
上述したように、映像生成システム1は、ユーザの入力情報と生成されたストーリーボードのテキスト情報に基づき、既存動画の元となる3DCGアセットやレンダリング方法などを修正する。そして、映像生成システム1は、新しく動画を構成するコード出力のためのプロンプトを出力し、自然言語モデルへプロンプトを提供して、動画を構成するコードを出力し、動画を生成する。これにより、映像生成システム1は、ユーザが3DCGや映像制作の知識がなくても、ユーザの入力に合わせて映像を修正することができる。
<1-4-4. USD update example>
As described above, the
映像生成システム1では、映像(動画)を生成した後、シナリオ情報、映像の情報などはテキストや動画として保存されている。そのため、ユーザはこれらの情報を入力情報(テキストやセンサなど)で修正することが可能である。
After generating a video (video),
例えば、映像生成システム1では、USDファイルは図18に示すように、アセットやモーションごとにわかれて保存される。図18は、USDファイルの一例を示す図である。例えば、図18に示すデータ構造において、上位の階層のUSDには下位の階層のUSDへのパス(ファイルパス)が含まれてもよい。
For example, in the
例えば、全体USDには、環境アセットUSD、人アセットUDS、カメラUSD等へのパスが含まれる。また、環境アセットUSDには、建物アセットUSD、PropアセットUSDへのパスが含まれる。また、建物アセットUSDには、建物自体のメッシュ情報等が含まれる。また、人アセットUSDには、人のメッシュ情報、モーションUSDへのパスが含まれる。このように、USDファイル等の3DCG用のデータ(3Dデータ)は、複数のデータセットを含んでもよい。なお、図18に示すUSDファイルの構成(データ構造)は一例に過ぎず、任意の構成が採用可能であり、全体が一塊(1つのデータセット)のUSD(USDファイル)として構成されてもよい。 For example, the entire USD includes paths to the environment assets USD, human assets UDS, camera USD, etc. The environment assets USD also include paths to the building assets USD and prop assets USD. The building assets USD also include mesh information of the building itself, etc. The human assets USD also include paths to human mesh information and motion USD. In this way, data for 3DCG (3D data) such as a USD file may include multiple data sets. Note that the configuration (data structure) of the USD file shown in FIG. 18 is merely an example, and any configuration can be adopted, and the entire USD (USD file) may be configured as one block (one data set).
修正が行われる際は、図19に示すような処理フローにより、映像生成システム1がユーザの修正情報をAI(LLMなど)で解析し、USDを取り替えるかUSDの一部を修正するかにより、処理が変わる。また、修正後はレンダリング処理とリファイン処理が実行される。図19は、映像生成システムが実行する処理手順を示すフローチャートである。具体例には、図19は、USDファイルの書き換えに関する処理手順を示すフローチャートである。
When modifications are made, the
まず、映像生成システム1は、ユーザの修正情報入力を受け付ける(ステップS101)。例えば、センサ部300は、ユーザによる修正を指示する入力情報を受け付ける。映像生成システム1は、AIにて入力を解析する(ステップS102)。例えば、映像生成モジュール100は、各種モデル等を用いてユーザによる修正を指示する入力情報の内容を解析する。
First, the
映像生成システム1は、既存USDファイルの形式を認識する(ステップS103)。例えば、映像生成モジュール100は、修正前の状態におけるUSDファイルの形式を認識する。映像生成システム1は、USDの一部を修正するか否かを判定する(ステップS104)。例えば、映像生成モジュール100は、ユーザによる修正を指示する入力情報の内容及び既存USDファイルの形式に基づいて、USDの一部を修正するか否かを判定する。
The
映像生成システム1は、USDの一部を修正する場合(ステップS104:Yes)、修正用USD-Python生成のためのプロンプトを生成する(ステップS105)。例えば、映像生成モジュール100は、USDの一部を修正する場合、修正用USD-Python生成のためテンプレート等を用いて、修正用USD-Python生成のためのプロンプトを生成する。
When a portion of the USD is to be modified (step S104: Yes), the
映像生成システム1は、AI(LLM等)にてUSD-Pythonを生成する(ステップS106)。例えば、映像生成モジュール100は、USD-Pythonを生成するためのモデルに、プロンプトを入力することにより、USD-Pythonを生成する。
The
映像生成システム1は、修正対象USDファイルを置き換える(ステップS107)。例えば、映像生成モジュール100は、生成したUSD-Pythonを修正対象USDファイルに反映することにより、修正対象USDファイルを置き換える。このように、映像生成システム1は、USDファイルの複数のデータセットのうち少なくとも1つを更新する。例えば、映像生成システム1は、USDファイルの複数のデータセットのうち一部を更新する処理を実行する。
The
映像生成システム1は、更新後のUSDファイルを用いてレンダリング処理を実行する(ステップS108)。例えば、映像生成モジュール100は、書き換え後、すなわち修正後のUSDファイルを用いてレンダリング処理を実行する。
The
一方、映像生成システム1は、USDの一部を修正しない場合(ステップS104:No)、作成用USD-Python生成のためのプロンプトを生成する(ステップS109)。例えば、映像生成モジュール100は、USDの一部を修正しない、すなわちUSDを新たに作成(生成)する場合、作成用USD-Python生成のためテンプレート等を用いて、作成用USD-Python生成のためのプロンプトを生成する。
On the other hand, if the
映像生成システム1は、AI(LLM等)にてUSD-Python及びUSDを生成する(ステップS110)。例えば、映像生成モジュール100は、USD-Pythonを生成するためのモデルに、プロンプトを入力することにより、USD-Python及びUSDを生成する。
The
映像生成システム1は、修正対象USDファイルと置き換える(ステップS111)。例えば、映像生成モジュール100は、生成したUSDを、修正対象USDファイルと置き換える。このように、映像生成システム1は、USDファイルを更新する処理を実行する。例えば、映像生成システム1は、USDファイルの複数のデータセット全体を更新する処理を実行する。そして、映像生成システム1は、ステップS108の処理を実行する。例えば、映像生成モジュール100は、置き換え後、すなわち修正後のUSDファイルを用いてレンダリング処理を実行する。
The
ここで上述した修正に関するユーザインタフェース(UI)について記載する。映像生成システム1は、図20に示すように、コンテンツCT31をユーザに提供する。図20は、ユーザインタフェースの一例を示す図である。コンテンツCT31は、ストーリーボード等、生成した動画に関する情報を提示し、ユーザの修正指示を受け付けるための表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT31を表示する。
Now, the user interface (UI) related to the above-mentioned modifications will be described. As shown in FIG. 20, the
ユーザは、コンテンツCT31を介して、生成された動画に対しての修正を指示する情報を入力する。例えば、ユーザが動画の特定の部分をクリックし、テキストで修正内容を入力した場合、映像生成システム1は、USDを更新し、修正内容が反映された動画に更新(変更)する。
The user inputs information instructing corrections to be made to the generated video via content CT31. For example, when the user clicks on a specific part of the video and inputs corrections in text, the
図20では、ユーザが一番上のカット(サムネイル)画像を選択し、「子供がスキップしてお母さんによっていく」という修正を指示した場合を示す。この場合、映像生成システム1は、生成した動画のうち、一番上のカット(サムネイル)画像に対応する部分を、「子供がスキップしてお母さんによっていく」という修正指示を基にUSDを更新し、修正内容が反映された動画を生成する。
Figure 20 shows a case where the user selects the top cut (thumbnail) image and instructs a modification to "child skips and runs to mother." In this case, the
なお、上記のUIは一例に過ぎず、映像生成システム1は、様々な態様によりユーザの修正指示を受け付けてもよい。例えば、映像生成システム1は、図21に示すように、コンテンツCT32をユーザに提供し、ユーザの修正指示を受け付けてもよい。図21は、ユーザインタフェースの一例を示す図である。コンテンツCT32は、ユーザの修正指示を受け付けるための表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT32を表示する。
Note that the above UI is merely an example, and the
また、映像生成システム1は、図22に示すように、コンテンツCT33をユーザに提供し、ユーザの修正指示を受け付けてもよい。図22は、ユーザインタフェースの一例を示す図である。コンテンツCT33は、ユーザの修正指示を受け付けるための表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT33を表示する。
Also, as shown in FIG. 22, the
ユーザは、コンテンツCT32またはコンテンツCT33を介して、生成された動画に対しての修正を指示する情報を入力する。これにより、映像生成システム1は、ユーザからの修正指示を受け付けて、修正指示を基にUSDを更新し、修正内容が反映された動画を生成する。例えば、ユーザは動画中に出てくる人物や物を選択し、選択した対象に関するモーションの設定をテキストで編集することができる。また、ユーザは選択した対象のアセットを変更することができる。また、ユーザはカメラワークについてもテキストで編集することができる。また、ユーザは上記以外にも、動画の背景や照明の設定をテキストで編集することができる。
The user inputs information instructing corrections to the generated video via content CT32 or content CT33. As a result, the
なお、上記では動画の一例として説明したが、映像生成システム1は、ユーザの修正指示に基づいて、サウンド情報(BGM、SE、ナレーション、セリフなど)やテキストロゴ情報などに対しての修正処理を実行してもよい。
Although the above description is given as an example of a moving image, the
<1-4-5.評価例>
また、映像生成システム1は、評価処理を実行する。例えば、映像生成システム1は、モデルM10等のAIモデルを用いてシナリオデータについての評価テキストを生成する。例えば、映像生成システム1は、シナリオデータについて生成した評価テキストを基に、ユーザが行う編集(修正等)の指示を基に、シナリオデータを再度生成してもよい。映像生成システム1は、生成した評価テキストを提示する。これにより、ユーザは評価を見ながら映像制作を行うことができる。
<1-4-5. Evaluation example>
Furthermore, the
例えば、映像生成システム1は、シナリオデータについての評価テキストをユーザに提示し、提示した評価テキストを確認したユーザからシナリオデータに対する編集の指示を受け付ける。映像生成システム1は、ユーザから受け付けた編集の指示を基に、シナリオデータを生成する。例えば、映像生成システム1は、ユーザから受け付けた編集の指示を基に、シナリオデータの内容を変更(更新)する。映像生成システム1は、評価テキストを基に生成されたシナリオデータを基に、コードを生成する。映像生成システム1は、評価テキストを基に生成されたコードを用いて動画データを生成する。
For example, the
なお、映像生成システム1は、評価テキストを基にシナリオデータまたはコードのうち少なくとも1つを自動で生成(更新)してもよい。例えば、映像生成システム1は、シナリオデータについての評価テキストが示す内容に対応するようにシナリオデータの内容を変更してもよい。例えば、映像生成システム1は、シナリオデータについての評価テキストがある登場人物の向きが良くないことを示す場合、その登場人物の向きを変更したシナリオデータを生成する。なお、上記は一例に過ぎず、映像生成システム1は、評価テキストを適宜用いて、シナリオデータまたはコードのうち少なくとも1つを生成してもよい。
The
映像生成システム1では、映像(動画)を生成した後、シナリオ情報、映像の情報、音情報、テキスト/ロゴ情報などはテキストや動画ファイル、サウンドファイル、画像ファイルなどで保存されている。そのため、映像生成システム1は、これらの情報を用いた評価処理を行うことが可能である。映像生成システム1は、ユーザの入力情報と生成されたストーリーボードのテキスト情報、評価テキストに基づき、既存動画の元となる3DCGアセットやレンダリング方法などを修正し、新しく動画を構成するコード出力のためのプロンプトを出力し、自然言語モデルへプロンプトを提供して、動画を構成するコードを出力し、動画を生成する。例えば、映像生成システム1は、ユーザの入力情報と生成されたストーリーボードのテキスト情報に基づき、評価テキスト(図5中の評価テキスト情報EV1に対応)を生成するためのプロンプトを出力し、自然言語モデルへプロンプトを提供して評価テキストを生成してもよい。例えば、映像生成システム1は、シナリオの評価については、シナリオ情報を基に評価のためのプロンプトを生成しAI(LLM等)に入力することで、シナリオの評価を示す評価テキストを生成してもよい。
In the
また、映像生成システム1は、映像の構成の評価については、動画の1フレームをAI(Contrastive Captioner Model、Image Captioning Modelなど)に入力することで動画のキャプションを取得する。そして、映像生成システム1は、取得したキャプションとシナリオ文をAI(LLM等)に入力することで、映像の構成の評価を示す評価テキストを生成する。例えば、映像生成システム1は、取得したキャプションとシナリオ文をAI(LLM等)で比較することでキャプション通りの画になっているかを評価してもよい。また、映像生成システム1は、ユーザが評価をして欲しいと希望する評価者像の指定を受け付けてもよい。例えば、映像生成システム1は、マーケット戦略、コピーライター、映像監督、特定の人などの視点で評価を行ってもよい。
In addition, when evaluating the composition of a video, the
<1-4-6.複数カットの選択例>
ここから、編集処理についていくつか例示を記載する。従来技術では、ストーリーボード上では複数カットを同時に修正できないという課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、図23に示すように、複数のカットを選択して編集処理(修正処理)を行ってもよい。図23は、編集処理の一例を示す図である。具体例には、図23は、複数カットの選択に基づく編集処理の一例を示す図である。
<1-4-6. Example of multiple cut selection>
From here, some examples of the editing process will be described. In the conventional technology, there is a problem that multiple cuts cannot be simultaneously corrected on a storyboard. In this way, the conventional technology has a problem regarding usability, and there is room for improvement in usability. Therefore, the
映像生成システム1は、図23に示すように、コンテンツCT41をユーザに提供し、ユーザの複数カットの選択に応じた修正指示を受け付けてもよい。コンテンツCT41は、カットCU1~CU4等の複数のカット(シーン)を含む動画に対するユーザの修正指示を受け付けるための表示画面(コンテンツ)である。例えば、クライアントUI表示部400は、コンテンツCT41を表示する。
As shown in FIG. 23, the
ユーザは、コンテンツCT41を介して、カットCU1~CU4のうち、複数のカットを選択し、選択した複数のカットに対しての修正を指示する情報を入力する。例えば、ユーザは、コンテンツCT41中のカットCU1~CU4のうち、カットCU1~CU3が表示された範囲を選択する操作(線で囲む操作等)を行うことやカットCU1~CU3の各々をクリックすること等により、カットCU1~CU3を選択する。 The user selects multiple cuts from among cuts CU1 to CU4 via content CT41, and inputs information instructing corrections to the selected multiple cuts. For example, the user selects cuts CU1 to CU3 by performing an operation to select the range in which cuts CU1 to CU3 are displayed (such as by surrounding it with a line) among cuts CU1 to CU4 in content CT41, or by clicking on each of cuts CU1 to CU3.
そして、ユーザは、カットCU1~CU3を選択した後に、修正指示を示すプロンプト(文字情報等)を、ユーザの入力情報として入力することにより、映像生成システム1にカットCU1~CU3を対象とした修正を指示する。映像生成システム1は、ユーザからの修正指示に応じて、カットCU1~CU3を対象とした修正を実行する。これにより、ユーザは、複数のカットを選択し、プロンプトを入力することで選択されたカットの構成やカット内容を修正することができる。例えば、各カットのシナリオ情報には、カットの内容、登場人物、カット撮影時間帯などが含まれており、映像生成システム1は、ユーザの入力情報とシナリオ情報をAI(LLMなど)に与えることで、シナリオを再生成する。なお、映像生成システム1は、ユーザの修正指示の内容に基づいて、任意の修正処理を実行する。例えば、映像生成システム1は、必要に応じて映像のUSDファイルを更新してもよいし、USDファイルはそのままでカットの順番のみを変更してもよい。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
After selecting cuts CU1 to CU3, the user inputs a prompt (text information, etc.) indicating a correction instruction as user input information, thereby instructing the
<1-4-7.時間情報の利用例>
従来技術では、特定のカットの修正後、その修正の影響を受ける他のシーンが修正(変更)されないという課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、図24に示すように、時間情報を用いて編集処理を行ってもよい。図24は、編集処理の一例を示す図である。具体例には、図24は、時間情報に応じて決定した修正内容に基づく編集処理の一例を示す図である。例えば、映像生成システム1は、各カットにAIが生成した日付時間情報(「時間情報」または「日付情報」ともいう)を入れておき、その情報を基に映像のカット割りや修正内容を決定する。
<1-4-7. Examples of using time information>
In the conventional technology, there is a problem that after a specific cut is corrected, other scenes affected by the correction are not corrected (changed). Thus, the conventional technology has a problem with usability, and there is room for improvement in usability. Therefore, the
図24では、映像生成システム1は、各カットにそのカットに対応する日付時間情報(時間情報)を対応付けて管理する。例えば、カットCU11には2023年12月21日10時31分を示す時間情報TI11が対応付けられる。また、カットCU12には2023年12月21日10時41分を示す時間情報TI12が対応付けられる。このように、カットCU11及びカットCU12は、時間的に近い(近接した)カットである。この場合、映像生成システム1は、カットCU11が修正された場合、その修正をカットCU12にも反映する。動画データの各カットには時間情報(日付情報)が対応付けられている。
In FIG. 24, the
例えば、映像生成システム1は、カットCU11での人物Xの服装が修正された場合、カットCU11での人物Xの服装と同じようにカットCU12での人物Xの服装も修正する。例えば、映像生成システム1は、各カット間の時間情報を比較し、修正されたカット(「修正対象カット」ともいう)との時間差が所定の範囲内であるカット(「影響カット」ともいう)がある場合、修正対象カットでの修正内容に基づく修正を、その影響カットにも反映すると決定する。
For example, when the clothing of person X in cut CU11 is modified, the
そして、映像生成システム1は、修正対象カットでの修正内容に基づく修正を影響カットに対して実行する。なお、このカット間の影響に基づく影響カットの修正(変更)については、映像生成システム1は、人アセットのみに限らず、環境アセット(天候、ライティング、時間経過で変化するろうそく等のプロップ等)にも行ってもよい。
Then, the
例えば、カットCU21には2023年12月21日10時31分を示す時間情報TI21が対応付けられる。また、カットCU22には2023年12月21日18時41分を示す時間情報TI22が対応付けられる。このように、カットCU21及びカットCU22は、時間的に遠い(離間した)カットである。この場合、映像生成システム1は、カットCU21が修正された場合、その修正をカットCU22には反映しない。
For example, cut CU21 is associated with time information TI21 indicating 10:31 on December 21, 2023. Also, cut CU22 is associated with time information TI22 indicating 18:41 on December 21, 2023. In this way, cut CU21 and cut CU22 are cuts that are distant in time (separate). In this case, when cut CU21 is modified, the
例えば、映像生成システム1は、カットCU21での人物Xの服装が修正された場合、カットCU21での人物Xの服装の修正に応じて、カットCU22での人物Xの服装は修正しない。例えば、映像生成システム1は、各カット間の時間情報を比較し、修正されたカット(修正対象カット)との時間差が所定の範囲内であるカット(影響カット)がない場合、修正対象カットでの修正内容に基づく修正を他のカットには反映しないと決定する。
For example, when the clothing of person X in cut CU21 is modified, the
例えば、映像生成システム1は、シナリオ生成時に、各カットに日付時間情報もAI(LLMなど)で生成しておき、各カットのメタ情報として保存しておく。この日付時間情報は前後のカットとの関係性を考えるためや、季節などを把握するために利用される。生成された架空の日付時間情報は、各カットの内容や各カット間の関係性を保つために入れておく。例えば、映像生成システム1は、雪が降っている朝のショットだとすると、1月24日午前6時30分などとする。また、例えば、映像生成システム1は、前後のカットの関係性が強いショットだとすると、1月24日午前6時30分と1月24日午前7時など同日の近い時間帯とする。
For example, when generating a scenario, the
例えば、映像生成システム1は、季節や時間に応じてユーザの着ている服、太陽のライティング設定、空気のモヤなどを変化させる。また、対象カットと前のカットの日付時間情報が近い場合、対象カットを変更すると前後のカットも影響を受ける。例えば、同じ人物が別カットに出演し、対象カットと時間が近い場合、対象カットの服を変更すると別カットの服も変更される。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
For example, the
<1-4-8.言語化の度合いに応じた応答例>
従来技術では、修正内容をユーザが具体的に言語化できない場合、ユーザの意図に沿った修正が難しいという課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、以下に示すような処理により、修正内容をユーザが具体的に言語化できない場合であっても、ユーザの意図に沿った修正を可能にしてもよい。
<1-4-8. Response examples according to the degree of verbalization>
In the conventional technology, when the user cannot specifically verbalize the content of the correction, it is difficult to make corrections according to the user's intention. Thus, the conventional technology has problems with usability, and there is room for improvement in usability. Therefore, the
例えば、映像生成システム1は、入力された文章に応じて、返答方式を変化させてもよい。映像生成システム1は、図25に示すように、ユーザの指示の抽象度、言語化の度合いに応じて応答を異ならせてもよい。図25は、編集処理の一例を示す図である。具体例には、図25は、言語化の度合いに応じた編集処理の一例を示す図である。
For example, the
図25中の応答例AP1は、「見るユーザが日常を感じる映像にしてください」といった目的ベースの修正指示をユーザが行った場合を示す。この場合、映像生成システム1は、具体的な指示の文章を添えて映像を生成する。例えば、映像生成システム1は、「見るユーザが日常を感じる映像にしてください」といった目的ベースの修正指示に対して、「手を自然な角度で下に下げ、体の向きに合わせて動かします。」という文章を添えて、その文章を基に修正した映像をディスプレイ等に表示することにより、ユーザに対して提示する。
Response example AP1 in FIG. 25 shows a case where a user issues a purpose-based correction instruction such as "Please make the video so that the viewer feels like they are in an everyday situation." In this case,
また、図25中の応答例AP2は、「両腕を自然な状態にして下さい」といった抽象的な文章の修正指示をユーザが行った場合を示す。この場合、映像生成システム1は、具体的な文章を複数提示し、ユーザに選択させる。例えば、映像生成システム1は、「手を下に下ろして、空上の向きに合わせて動かします」、「手で頭をかいて、その後手を下ろします」、「ポケットに手を入れます」等の複数の文章をディスプレイ等に表示することにより、ユーザに対して提示する。そして、映像生成システム1は、複数の文章のうちユーザが選択した文章を基に修正した映像をディスプレイ等に表示することにより、ユーザに対して提示する。
Response example AP2 in FIG. 25 shows a case where the user instructs to correct an abstract sentence such as "Keep both arms in a natural position." In this case, the
図25中の応答例AP3は、「2秒で右前の車の方を見るようにして下さい」といった具体的な文書の修正指示をユーザが行った場合を示す。この場合、映像生成システム1は、ユーザが入力した文章通りに変更(修正)した映像をディスプレイ等に表示することにより、ユーザに対して提示する。例えば、目的ベースの文章、抽象的な文章、具体的な文章の違いは、AI(LLMなど)により判断され、映像生成システム1は、それに応じて生成するプロンプトを変えてAI(LLMなど)に処理を投げてもよい。
Response example AP3 in FIG. 25 shows a case where the user gives a specific instruction to correct a sentence, such as "Please look at the car in front of you on the right in 2 seconds." In this case, the
例えば、映像生成システム1は、センサ用いてモーションやカメラの動きをユーザに指定させてもよい。映像生成システム1は、図26に示すように、Webカメラ等の任意のセンサから得たモーション情報を映像に重畳表示(重ねて表示)し、ユーザの修正を受け付けてもよい。図26は、編集処理の一例を示す図である。具体例には、図26は、映像への重畳表示による編集処理の一例を示す図である。
For example, the
例えば、映像生成システム1は、モバイルモーションキャプチャ、Webカメラ等の任意のセンサから得たモーション情報MTを映像MV11に重畳させて表示し、ユーザの修正指示を受け付ける。このように、映像生成システム1は、顔表情等を含むモーション情報を現在の映像の上に重ねて表示することにより、現在の映像とモーション情報との差異を可視化した状態を基に、ユーザの修正指示を受け付ける。例えば、4秒のカットであれば、常に4秒のカットが再生され続け、ユーザは気に入るまで何度も自分でモーション情報を変更することができる。例えば、ユーザが気に入ったモーション情報がある場合、映像生成システム1は、自然なモーション情報を最終生成して映像のモーションを変更してもよい。
For example, the
ユーザのモーションはモバイルモーションキャプチャ、Webカメラなどでトラッキングされる。また、ユーザはどの人物のモーションを修正するかは、事前にUIからマウスで選択してもよい。映像中の頭と体の大きさや向きより、重ねる自分のモーション表示部分の大きさと位置向きを決定する。細かい大きさと位置向きの調整は、ユーザがマウスとキーボードで入力して調整してもよい。モーションの録画は、上記画像に記載したカットが繰り返し際される方法もありうるし、スタートボタンを押してから体勢を整えるまでの数秒後に録画が開始する方法もありうる。また、撮影後、ユーザがモーション生成ボタンを押すことで、入力したモーションが指定した登場人物に適応されてもよい。 The user's motion is tracked using a mobile motion capture device, a web camera, etc. The user may also select in advance from the UI with the mouse which character's motion they wish to modify. The size and position of the portion of the user's motion to be superimposed is determined based on the size and orientation of the head and body in the video. The user may adjust the size, position, and orientation in detail using the mouse and keyboard. Motion may be recorded by repeating the cuts shown in the image above, or by starting recording several seconds after the start button is pressed and the user adjusts their position. After filming, the user may press the motion generation button, and the input motion may be applied to the specified character.
また、撮影したモーション自体は不自然であることもありうるので、映像生成システム1は、撮影したモーションをmotion to motionのAIを用い、モーション推定や生成などを行い、より自然なモーションに変換してから登場人物のモーションに適応してもよい。また、映像生成システム1は、入力したモーションと自然文を用い、モーションを推定したり生成したりしてもよい。例えば、映像生成システム1は、モーションを入力後、ユーザが入力した「こんな感じで活き活きとした動きにする」などの自然文と共にAI(LLM、text&motion to motion生成のモデルなど)に処理を投げてもよい。
In addition, since the captured motion itself may be unnatural, the
また、ユーザは、自身の手をカメラと見立てて動かして、カメラワークを変更してもよい。例えば、映像生成システム1は、ユーザの手の動きをWebカメラ等のセンサで取得する。映像生成システム1は、図27に示すように、変更したカメラワークを枠として映像に重ねて提示(重畳表示)する。図27は、編集処理の一例を示す図である。具体例には、図27は、映像へのカメラワークの重畳表示の一例を示す図である。
The user may also change the camerawork by moving their hand as if it were a camera. For example, the
例えば、映像生成システム1は、変更前のカメラワークを示す枠CW1と変更後のカメラワークを示す枠CW2とを映像MV12に重畳させて表示する。そして、映像生成システム1は、ユーザが変更後のカメラワークを用いることを指示した場合、その変更後のカメラワークを基にレンダリング処理を実行する。このように、ユーザが変更後のカメラワークをOKとして、その変更後のカメラワークに映像がレンダリングされる。
For example, the
また、ユーザは、自身の携帯端末(スマートフォン等)のIMUやImageSLAM等を用いてカメラワークを指定してもよい。例えば、映像生成システム1は、AR(Augmented Reality)でメインキャラクターを実空間(現実の机の上等)に配置して提示してもよい。映像生成システム1は、変更したカメラワークを図27に示す場合と同様に映像に枠を重ねて表示する。
The user may also specify the camerawork using an IMU or ImageSLAM of the user's mobile device (such as a smartphone). For example, the
上記のように、映像生成システム1では、ユーザが手やスマホの動きを使い、モーションやカメラの動きを決めてもよい。例えば、ユーザが手の動きでカメラワークを決める際、もう一方の手で指定した人物を想定し、左手(カメラ)と右手(人物)の距離から、カメラの相対的な位置を決めてもよい。また、映像生成システム1は、ユーザが手やカメラの入力で変更したカメラワークを枠として映像に重ねて表示するが、その後、ユーザがマウス操作で枠やその動きを微調整してもよい。また、入力したカメラワークは手で入れているため不自然な動きである可能性もあるため、映像生成システム1は、motion to motion生成モデル、text&motion to motion生成モデル等を用いて、自然なカメラワークに修正してもよい。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
As described above, in the
<1-4-9.定性的な値の利用例>
従来技術では、現状や変更履歴をシステムとしてどのように判断するのかという点については考慮されていない場合があった。例えば、「もう少し後ろに立って」や「もう少し明るくして」など、現状と比較して調整したいという場合等があり、システム的にどのように現状を理解(把握)するかについては課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、以下に示すような処理により、現状や変更履歴を適切に判断可能にしてもよい。
<1-4-9. Examples of using qualitative values>
In the conventional technology, there are cases where consideration is not given to how the system determines the current state and the change history. For example, there are cases where a user wants to make adjustments by comparing with the current state, such as "stand a little further back" or "make it a little brighter," and there is a problem with how the system understands (grasps) the current state. Thus, the conventional technology has a problem with usability, and there is room for improvement in usability. Therefore, the
例えば、映像生成システム1は、動き速度、明るさなど各ポイントを、定量的な数値として保持しておき、その値を比較して映像を修正してもよい。映像生成システム1は、図28に示すように、定性的な値を用いて編集処理を行ってもよい。図28は、編集処理の一例を示す図である。具体例には、図28は、定性的な値に応じて決定した修正内容に基づく編集処理の一例を示す図である。
For example, the
図28では、値情報VL21は映像MV21に対応づけられた定量的な値を示す。例えば、値情報VL21は、町全体の明るさ、人の歩行スピード、人の顔を動かすスピード、人の位置、車のスピード、車の位置等の定性的な値を含み、映像MV21のカット等に対応づけられる値を示す。このように、映像生成システム1は、変更されうる値は全て定量的な値として保持しておき、その値と比較して映像を変更する。
In FIG. 28, value information VL21 indicates a quantitative value associated with video MV21. For example, value information VL21 includes qualitative values such as the brightness of the entire town, people's walking speed, the speed at which people's faces move, people's positions, car speeds, and car positions, and indicates values associated with cuts in video MV21. In this way,
図28では、映像MV21について、ユーザが「顔をもう少しゆっくり動かして」という修正指示を行い、映像生成システム1は、映像MV21の顔を動かすスピードを遅くした映像MV22を生成する。映像生成システム1は、「顔をもう少しゆっくり動かして」という修正指示を基に、映像MV21の値情報VL21のうち人の顔を動かすスピードの値を「21」から「10」に減少させた値情報VL22の映像MV22を生成する。
In FIG. 28, the user gives a modification instruction for video MV21, "move your face a little slower," and
図28では、値情報VL22は修正後の映像MV22に対応づけられた定量的な値を示す。例えば、値情報VL22は、町全体の明るさ、人の歩行スピード、人の顔を動かすスピード、人の位置、車のスピード、車の位置等の定性的な値を含み、映像MV22のカット等に対応づけられる値を示す。 In FIG. 28, value information VL22 indicates quantitative values associated with the corrected video MV22. For example, value information VL22 indicates values associated with cuts in video MV22, including qualitative values such as the brightness of the entire town, people's walking speed, the speed at which people's faces move, people's positions, car speeds, and car positions, etc.
このように、映像生成システム1は、定性的な値を用いて映像の編集処理を行ってもよい。例えば、映像生成システム1は、動き速度、明るさなど各ポイント(項目)について、定量的な数値として保持しておき、その値を比較して映像を修正する。上述したように、定性的な値を保持しておく街全体の明るさ、人の歩行スピードなどの分類は、事前に設定された項目である。例えば、映像生成システム1は、各々を自然言語からAI(LLMなど)を使って設定修正してもよいし、設定値を直接修正してもよい。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
In this way, the
また、それぞれの値の取得方法の一例を以下に示すが、取得方法は以下に限らず他の取得方法であってもよい。例えば、映像生成システム1は、ライティングについては、3DCG内のライトの設定値(位置、回転、強さ、色など)を取得する。また、映像生成システム1は、カラーグレーディングについては、コンポジット編集で設定された、ホワイトバランス、色温度、色かぶり補正、彩度、露光量、コントラスト、ハイライト、シャドウ、白レベル、黒レベル、カラー、LUT設定などを取得する。また、映像生成システム1は、歩行スピードについては、対象の3Dモデルの腰のボーンの位置移動速度を取得する。また、映像生成システム1は、顔を動かすスピードについては、頭のボーンの回転速度を取得する。また、映像生成システム1は、位置については、3Dモデルの位置を取得する。
An example of a method for acquiring each value is shown below, but the acquisition method is not limited to the following and may be another method. For example, for lighting, the
<1-4-10.入力途中でのレンダリング処理例>
従来技術では、レンダリング時間を待つのがユーザにとって大変(ユーザビリティが低い)という課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、以下に示すような処理により、レンダリングに関するユーザビリティを向上させてもよい。
<1-4-10. Example of rendering process during input>
The conventional technology has an issue in that it is difficult for the user to wait for the rendering time (low usability). Thus, the conventional technology has an issue with usability, and there is room for improvement in usability. Therefore, the
例えば、映像生成システム1は、テキスト入力途中からレンダリング処理を開始してもよい。映像生成システム1は、図29に示すように、ユーザの入力途中でレンダリング処理を行ってもよい。図29は、編集処理の一例を示す図である。具体例には、図29は、入力途中でのレンダリング処理に基づく編集処理の一例を示す図である。
For example, the
図29では、映像生成システム1は、ユーザが「手で頭を掻いて」というテキストTX31の入力に応じて、レンダリング処理等を実行し映像MV31を表示する。例えば、テキストTX31中の末尾の「|」はユーザが修正指示を入力途中であることを示す。映像生成システム1は、文章として理解できるようになったら一旦バックグラウンドで処理を開始する。例えば、映像生成システム1は、「手で頭を掻いて」までを入力した時点で、バックグラウンドでレンダリング処理等を開始する。このように、映像生成システム1は、ユーザがテキストを入力している途中でレンダリング処理を開始してもよい。
In FIG. 29, the
図29では、ユーザは、テキストTX31から「手をおろして」というテキストTX32に文章を変更する。例えば、テキストTX32中の末尾の「|」はユーザが修正指示を入力途中であることを示す。映像生成システム1は、テキストTX31からテキストTX32の変更に応じて、処理を実行する。例えば、映像生成システム1は、文章が変更されたら、その時点で行っている処理を止めて再度処理をやり直す。例えば、映像生成システム1は、テキストTX31を基に行っていた処理を終了し、テキストTX32を基に、レンダリング処理等を実行し映像MV32を表示する。
In FIG. 29, the user changes the sentence from text TX31 to text TX32, which reads "Put your hands down." For example, the "|" at the end of text TX32 indicates that the user is in the middle of inputting a correction instruction. The
図29では、ユーザは、テキストTX32から「手をおろして、自然な感じで」というテキストTX33に変更して、文章として完成させ、開始ボタン等を押すこと等により処理の実行を指示する。映像生成システム1は、始まっているバックグラウンド処理を終わらせて、テキストTX33を基にレンダリング処理等が実行された映像MV33を表示する。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
In FIG. 29, the user changes text TX32 to text TX33, "Keep your hands down, in a natural way," completes the sentence, and instructs execution of processing by pressing a start button or the like. The
<1-4-11.編集時の確認作業例>
従来技術では、編集時の確認作業についてはユーザビリティが低いなどの課題があり改善の余地があった。そこで、映像生成システム1は、図30に示すように、編集時の確認作業を行ってもよい。図30は、編集処理の一例を示す図である。具体例には、図30は、編集時の確認作業の一例を示す図である。
<1-4-11. Example of confirmation work when editing>
In the conventional technology, there is a problem that the usability is low in the confirmation work at the time of editing, and there is a room for improvement. Therefore, the
図30中の確認作業CP1は、モーションやカメラワークなどの時間軸方向の変化を見る必要がある場合の確認作業の一例を示す。例えば、確認作業CP1では、ユーザは理想に近い動画を選ぶことを繰り返す。また、図30中の確認作業CP2は、時間軸方向の変化を見る必要がある場合以外の確認作業の一例を示す。例えば、確認作業CP2では、ユーザは理想に近い画像を選ぶことを繰り返す。 Checking task CP1 in FIG. 30 shows an example of a checking task when it is necessary to check changes in the time axis direction, such as motion or camera work. For example, in checking task CP1, the user repeatedly selects a video that is close to ideal. Checking task CP2 in FIG. 30 shows an example of a checking task other than when it is necessary to check changes in the time axis direction. For example, in checking task CP2, the user repeatedly selects an image that is close to ideal.
例えば、映像生成システム1は、全てのカットの画像をレンダリングした後、編集したいものから動画のレンダリングを実施してもよい。例えば、映像生成システム1は、生成した動画をユーザに提示し、入力情報の編集を行うかどうかをユーザに判断させてもよい。例えば、確認作業CP1、CP2等に示すように、ユーザの入力情報に対してバリエーションをもたせた数パターンの動画の生成結果をユーザに提示する場合、複数の動画をレンダリングするための待ち時間が生じるという課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。
For example, the
そこで、映像生成システム1は、その待ち時間を低減するために、時間軸方向の変化を見る必要がある確認作業以外の作業(確認作業CP2に対応)については、動画中の1フレームないしは数フレームのみをレンダリングし、画像としてユーザに候補を提示する。これにより、映像生成システム1は、レンダリング待ち時間を低減することができる。
Therefore, in order to reduce this waiting time, for tasks other than the confirmation task that requires viewing changes along the time axis (corresponding to confirmation task CP2), the
また、映像生成システム1は、ユーザがモーションやカメラワークの編集作業を行う場合は動画による候補提示を行う。例えば、レンダリングに用いる動画中の数フレームを選択する方法として、単純に動画の先頭と最後の2フレームのみをレンダリングする方法、USDファイル内のアニメーションの変化量が大きいフレームを数フレームレンダリングする方法、AIに全てのフレームの中でハイライトとして表示すべきフレームを選択させる方法などが挙げられる。例えば、映像生成システム1では、複数枚画像をレンダリングした場合はユーザがマウスカーソルをホバーすることでパラパラ漫画のような形で生成結果を確認することができる。
Furthermore, when the user edits the motion or camerawork, the
また、映像生成システム1は、動画生成については、候補選択用の画像生成を終えた段階で、順次、各パターンの動画生成を開始することで動画プレビュー時の待ち時間を軽減することができる。パターンごとの動画生成の順番については、ランダムな順番で生成する方法の他に、ユーザがUI上のボタンを押すことでレンダリング順番を選ぶ方法、マウスカーソルが画像上にホバーされた時間が長い順番にレンダリングする方法などが挙げられる。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
In addition, when generating videos, the
ここで、上述した確認作業に関する処理フローの一例について図31を用いて説明する。図31は、映像生成システムが実行する処理手順を示すフローチャートである。具体例には、図31は、編集処理に関する処理手順を示すフローチャートである。 Here, an example of a processing flow related to the above-mentioned confirmation work will be described with reference to FIG. 31. FIG. 31 is a flowchart showing the processing procedure executed by the video production system. As a specific example, FIG. 31 is a flowchart showing the processing procedure related to editing processing.
図31では、映像生成システム1は、ユーザの設定からUSDファイルを数パターン生成する(ステップS201)。映像生成システム1は、すべてのパターンのUSDファイルの画像書き出しが終了している場合(ステップS202:Yes)、ファイルの画像書き出しについての処理(例えばステップS202~S204)を終了する。
In FIG. 31, the
映像生成システム1は、すべてのパターンのUSDファイルの画像書き出しが終了していない場合(ステップS202:No)、書き出しが完了していないUSDファイルの画像を書き出す(ステップS203)。映像生成システム1は、書き出した画像をUI上に表示する(ステップS204)。その後、映像生成システム1は、ステップS205以降の処理を開始するとともに、ファイルの画像書き出しが終了するまでステップS202~S204の処理を繰り返す。
If image writing of all patterns of USD files has not been completed (step S202: No), the
映像生成システム1は、すべてのパターンのUSDファイルの動画書き出しが終了している場合(ステップS205:Yes)、ファイルの動画書き出しについての処理(例えばステップS205~S207)を終了する。
When video export of all patterns of USD files has been completed (step S205: Yes), the
映像生成システム1は、すべてのパターンのUSDファイルの動画書き出しが終了していない場合(ステップS205:No)、書き出しが完了していないUSDファイルの動画を書き出す(ステップS206)。映像生成システム1は、書き出した動画をUI上に表示する(ステップS207)。その後、映像生成システム1は、ファイルの動画書き出しが終了するまでステップS205~S207の処理を繰り返す。
If video export of all patterns of USD files has not been completed (step S205: No), the
<1-4-12.範囲選択に応じた処理例>
従来技術では、映像(動画)生成について経験(知見)が無い人(「素人」ともいう)が動画を作ろうとした場合、何が良くて何が悪いのかを判断することが難しく、判断を誤る場合も多いという課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、図32に示すように、生成された動画について評価を行ってもよい。図32は、範囲選択に応じた評価処理の一例を示す図である。
<1-4-12. Examples of processing according to range selection>
In the conventional technology, when a person (also called an "amateur") who has no experience (knowledge) in video (moving image) generation tries to create a video, it is difficult for the person to judge what is good and what is bad, and the person often makes an erroneous judgment. Thus, the conventional technology has a problem regarding usability, and there is room for improvement in usability. Therefore, the
図32では、映像生成システム1は、範囲選択に応じた評価処理を行う。図32中の映像MV40は、ユーザ入力に応じて生成された動画を示す。図32中の映像MV41は、ユーザが評価してほしい範囲として人の部分を指定し、その範囲に対する映像生成システム1による評価を示すテキストTX41が重畳表示された状態を示す。図32では、映像生成システム1は、ユーザが指定した人の部分に対して、「この人の顔の表情を見せたほうがユーザーに感情が伝わりやすい」というテキストTX41が示す評価(修正案の提示)を行う。
In FIG. 32, the
図32中の映像MV42は、映像生成システム1による評価を示すテキストTX42がさらに重畳表示された状態を示す。図32では、映像生成システム1は、ユーザが指定した人の部分に対して、「演出の観点だと顔を真正面から捉えた方が良い」というテキストTX42が示す評価を行う。
Video MV42 in FIG. 32 shows a state in which text TX42 indicating an evaluation by
例えば、テキストTX42が示す評価をユーザが良いと思い、映像生成システム1は、その評価に基づく修正指示のユーザから受け付ける。そして、映像生成システム1は、テキストTX42が示す評価に対応する複数の候補動画MV43、MV44、MV45を生成し、表示する。これにより、映像生成システム1は、テキストTX42が示す評価に対応する複数の候補動画MV43、MV44、MV45をユーザに提示する。
For example, if the user thinks that the evaluation indicated by text TX42 is good,
例えば、ユーザはマウスで範囲を指定し、映像生成システム1は、指定された範囲に対する評価を行いユーザとの対話(議論)を開始する。映像生成システム1は、マウスでの範囲選択に応じて、その範囲を対象としてAIによる評価を開始する。例えば、映像生成システム1は、ユーザが修正を指示するまでの間、N秒に1回の評価(修正案の提示)を行う。ユーザが良いと思ったところで、マウスでクリックすることにより、映像生成システム1は、それまでの対話(議論)を踏まえた修正候補を複数提示する。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
For example, a user specifies a range with a mouse, and
<1-4-13.被写界深度に応じた処理例>
従来技術では、環境アセットのポリゴン数が高かったり、テクスチャの解像度が高かったりしてアセットが重い場合、レンダリングに要する時間の増大を抑制することが難しいという課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、図33に示すように、被写界深度に応じた処理を行ってもよい。図33は、被写界深度に応じた処理の一例を示す概念図である。
<1-4-13. Example of processing according to depth of field>
In the conventional technology, when the number of polygons in the environmental asset is high or the texture resolution is high, and the asset is heavy, it is difficult to suppress the increase in the time required for rendering. Thus, the conventional technology has a problem regarding usability, and there is room for improvement in usability. Therefore, the
図33では、映像生成システム1は、被写界深度に応じて、被写体の前後所定の範囲内については高ポリゴン数、高解像度テクスチャにし、被写体の前後所定の範囲内については低ポリゴン数、低解像度テクスチャにする。図33では、高ポリゴン数、高解像度テクスチャの対象物(被写体に近い丸)を濃いハッチングで示し、低ポリゴン数、低解像度テクスチャの対象物(被写体から遠い丸)を薄いハッチングで示す。このように、映像生成システム1は、被写界深度に応じて、ポリゴン数やテクスチャ解像度を変更する。映像生成システム1は、以下のような式(1)~(3)により、被写界深度を算出する。
In FIG. 33, the


![]()
![]()
式(1)は、前方被写界深度(mm)を算出する関数である。映像生成システム1は、式(1)を用いて、前方被写界深度を算出する。例えば、図33では、が前方被写界深度は、被写体の前方側(カメラに近づく側)に対応する。また、式(2)は、後方被写界深度(mm)を算出する関数である。映像生成システム1は、式(2)を用いて、後方被写界深度を算出する。例えば、図33では、が後方被写界深度は、被写体の後方側(カメラから離れる側)に対応する。式(3)は、被写界深度を算出する関数である。像生成システム1は、式(3)を用いて、前方被写界深度と後方被写界深度とを足し合わせることにより、被写界深度を算出する。
Equation (1) is a function for calculating the front depth of field (mm). The
例えば、映像生成システム1は、前方被写界深度よりカメラに近い部分、後方被写界深度よりカメラから遠い部分に関して、レンダリング前にポリゴン数やテクスチャ解像度を落としたものに差し替えておく。例えば、映像生成システム1は、被写界深度的にボケを作る場合、ポリゴン数やテクスチャ解像度を小さく(低く)する。このように、映像生成システム1は、焦点距離、F値、被写体距離等の基準に、ポリゴン数やテクスチャ解像度を決定する。例えば、映像生成システム1は、上記の決定をUSDファイル生成時に行ってもよい。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
For example, the
<1-4-14.確認作業時の再生処理例>
従来技術では、生成された動画を全て再生して確認する場合、確認作業に要する時間の増大を抑制することが難しいという課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、確認作業時に適した再生を行ってもよい。映像生成システム1は、ユーザの操作に応じて再生の態様を変更してもよい。例えば、映像生成システム1は、ユーザの操作に応じて、パラパラ漫画のような態様で動画を再生してもよい。
<1-4-14. Example of playback process during confirmation work>
In the conventional technology, when all the generated videos are played back for review, it is difficult to suppress an increase in the time required for the reviewing work. Thus, the conventional technology has a problem regarding usability, and there is room for improvement in usability. Therefore, the
映像生成システム1は、ユーザによるクリックやマウスホイール回転ごとに所定の秒数(例えば0.5秒)だけ動画の再生を進めてもよい。例えば、映像生成システム1は、マウスやマウスホイールの動きや位置に応じて、カット内のコマ送りをする。映像生成システム1は、図34に示すように、マウスの位置に対応する秒数だけ動画の再生を進めてもよい。
The
図34では、映像生成システム1は、コンテンツCT41をユーザに提供し、ユーザによる動画を進める度合い(秒数、フレーム数等)の指示を受け付けてもよい。コンテンツCT41は、ユーザによるユーザの動画を進める度合いを受け付けるための表示画面(コンテンツ)である。コンテンツCT41は、動画に重畳させて、動画を進める秒数を指定するための情報を配置する。図34では、0~3.5秒の間で指定可能であり、左から右に行くほど動画を進める秒数が大きくなる場合を示す。例えば、クライアントUI表示部400は、コンテンツCT41を表示する。
In FIG. 34, the
ユーザは、コンテンツCT41を介して、動画を再生する際に動画を進める秒数を指定する情報を入力する。図34では、ユーザはマウスを操作して、マウスカーソルMSを1.0と表示された領域に位置させることに動画を進める秒数を1.0秒に指定する。この場合、映像生成システム1は、ユーザからの動画を進める秒数の指定に応じて、動画を1.0秒の間隔で再生を進める。なお、ユーザはマウスを操作して、マウスカーソルMSを1.0と表示された領域に位置させ、クリックすること等により、動画を進める秒数を1.0秒に指定してもよい。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
Through content CT41, the user inputs information specifying the number of seconds to advance the video when playing the video. In FIG. 34, the user operates the mouse to position the mouse cursor MS in the area marked 1.0 to specify 1.0 seconds as the number of seconds to advance the video. In this case, the
<1-4-15.強調表示例>
従来技術では、動画のうち編集等により変更された生成された部分が分かりづらい場合があり、確認作業に要する時間の増大を抑制することが難しいという課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、図35に示すように、強調表示を行ってもよい。図35は、変更部分の強調表示の一例を示す図である。例えば、映像生成システム1は、前回の生成結果と変化された部分を強調表示する。図35では映像中の女性が変更された場合を一例として説明する。
<1-4-15. Highlighting example>
In the conventional technology, it may be difficult to understand the parts of the video that have been changed by editing or the like, and it is difficult to prevent the increase in time required for the confirmation work. However, there are problems with usability and there is room for improvement in usability. Therefore, the
図35中の映像MV51は、第1の強調表示態様を示す。映像MV51は、変更された箇所以外を暗くする(明度を下げる等)ことにより、変更された箇所を強調表示する態様を示す。映像生成システム1は、映像MV51を生成し、映像MV51を表示することにより、編集等により変更された部分を強調表示する。
Video MV51 in FIG. 35 shows a first highlighting mode. Video MV51 shows a mode in which the changed parts are highlighted by darkening parts other than the changed parts (reducing brightness, etc.).
また、図35中の映像MV52は、第2の強調表示態様を示す。映像MV52は、変更された箇所をハイライトする(色を付ける等)ことにより、変更された箇所を強調表示する態様を示す。映像生成システム1は、映像MV52を生成し、映像MV52を表示することにより、編集等により変更された部分を強調表示する。このように、映像MV51、MV52は、人の部分が変更された場合にその部分を強調表示する場合を示す。
Video MV52 in FIG. 35 shows a second highlighting mode. Video MV52 shows a mode in which the changed parts are highlighted (by adding color, etc.).
図35中の映像MV53は、第3の強調表示態様を示す。映像MV53は、変更があった時間をシークバー上に示すことにより、変更された箇所を強調表示する態様を示す。映像生成システム1は、変更があった時間に対応する位置に色付けした点HL531及び点HL532が配置されたシークバーを含む映像MV53を生成し、映像MV53を表示することにより、編集等により変更された部分を強調表示する。
Video MV53 in FIG. 35 shows a third highlighting mode. Video MV53 shows a mode in which the changed portion is highlighted by indicating the time when the change occurred on the seek bar.
図35中の映像MV54は、第4の強調表示態様を示す。映像MV54は、変更があった時間をシークバー上に示すことにより、変更された箇所を強調表示する態様を示す。映像生成システム1は、変更があった時間帯に対応する範囲に位置に色付けしたバーHL54が配置されたシークバーを含む映像MV54を生成し、映像MV54を表示することにより、編集等により変更された部分を強調表示する。
Video MV54 in FIG. 35 shows a fourth highlighting mode. Video MV54 shows a mode in which the changed portion is highlighted by indicating the time when the change occurred on the seek bar.
上述したように、ユーザが動画生成に関わる設定を行い動画の再生成を行った際には、生成された動画の確認作業が必要になる。複数の生成結果を提示するようなUIでは、それぞれの動画をひとつずつ確認する動作のユーザ負担が大きい。そこで、動画の確認作業の負担を軽減するために、映像生成システム1は、前回の動画生成の結果との差分をユーザに提示する。例えば、映像生成システム1は、動画中で変更のあった箇所のみを強調表示したり、動画中で変更のあった時間をシークバー上に表示したりしてユーザに提示する。これにより、ユーザは変更があった箇所のみを確認できるようになり、映像生成システム1は、確認作業の負担を軽減させることができる。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
As described above, when a user configures settings related to video generation and regenerates a video, the generated video needs to be checked. In a UI that presents multiple generation results, the user has to check each video one by one, which places a heavy burden on the user. Therefore, in order to reduce the burden of checking the videos, the
例えば、動画中で変化した箇所を取り出す方法として、生成したUSDファイルから差分を検出する方法、レンダリング済みの動画と過去にレンダリングした動画を1フレームごとに比較して差分を検出する方法等が挙げられる。例えば、生成したUSDファイルから差分を検出する方法では、USDファイルを都度生成して動画レンダリングを行っている特性を活かし、映像生成システム1は、ユーザが動画生成に関する設定を更新する前後で生成されたUSDファイルの内容を比較し、変化があったオブジェクトや変化があった時間を検出する。また、例えば、レンダリング済みの動画と過去にレンダリングした動画を1フレームごとに比較して差分を検出する方法では、映像生成システム1は、ユーザが動画生成に関する設定を更新する前後で生成された動画を1フレームごとに比較して、変化があったピクセルおよび変化があった時間を検出する。
For example, methods for extracting changed parts of a video include detecting differences from a generated USD file, and detecting differences by comparing a rendered video with a previously rendered video frame by frame. For example, in a method for detecting differences from a generated USD file, taking advantage of the characteristic of generating USD files each time and performing video rendering, the
<1-4-16.カット間の関係提示例>
従来技術では、カットごとに修正した場合、前後カットとの関係が分からなくなる場合があるという課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、図36に示すように、カット間の関係の提示を行ってもよい。図36は、カット間の関係の提示の一例を示す図である。
<1-4-16. Example of showing the relationship between cuts>
In the conventional technology, there is a problem that when each cut is corrected, the relationship between the previous and next cuts may become unclear. Thus, the conventional technology has a problem with usability, and there is room for improvement in usability. Therefore, the
図36では、カットCU61が修正されたカット(「対象カット」ともいう)である場合を示す。対象カットであるカットCU61よりも前のカットCU60には、そのカットが対象カットよりも前のカットであることを示す前関係バーTR60が重畳表示される。例えば、前関係バーTR60は、右側を底辺として左側に延びる三角形である。前関係バーTR60は、対象カットとの時間が離れているほど左側に長く伸びる態様で表示される。 Figure 36 shows a case where cut CU61 is a modified cut (also called the "target cut"). A previous relationship bar TR60 is superimposed on cut CU60 that precedes cut CU61, the target cut, to indicate that the cut precedes the target cut. For example, the previous relationship bar TR60 is a triangle with its base on the right and extending to the left. The previous relationship bar TR60 is displayed in such a way that it extends further to the left the further away it is from the target cut.
また、対象カットであるカットCU61よりも後のカットCU62には、そのカットが対象カットよりも後のカットであることを示す後関係バーTR62が重畳表示される。例えば、後関係バーTR62は、左側を底辺として右側に延びる三角形である。対象カットであるカットCU61よりも後のカットCU62のさらに後のカットCU63には、そのカットが対象カットよりも後のカットであることを示す後関係バーTR63が重畳表示される。例えば、後関係バーTR63は、左側を底辺として右側に延びる三角形である。 In addition, a subsequent relationship bar TR62 is superimposed on cut CU62 that is after cut CU61, the target cut, indicating that the cut is a cut that comes after the target cut. For example, the subsequent relationship bar TR62 is a triangle that extends to the right with its base on the left side. A subsequent relationship bar TR63 is superimposed on cut CU63 that is after cut CU62 that is after cut CU61, the target cut, indicating that the cut is a cut that comes after the target cut. For example, the subsequent relationship bar TR63 is a triangle that extends to the right with its base on the left side.
後関係バーTR62、TR63は、対象カットとの時間が離れているほど左側に長く延びる態様で表示される。図36では、カットCU62よりもカットCU63の方がさらに後であるため、後関係バーTR62よりも後関係バーTR63の方が、右側へ長く延びる態様で表示される。なお、三角形での表示態様は表示態様の一例に過ぎず、時間の前後関係及びその量が提示可能であれば、任意の表示態様が採用可能である。 The later relationship bars TR62, TR63 are displayed in such a way that the further they extend to the left the further they are from the target cut. In FIG. 36, cut CU63 is later than cut CU62, so later relationship bar TR63 is displayed in such a way that it extends further to the right than later relationship bar TR62. Note that the triangular display mode is only one example of a display mode, and any display mode can be used as long as the time relationship and its amount can be presented.
映像生成システム1は、ユーザの操作に応じて、カットCU60~CU63を含む動画を再生する。例えば、映像生成システム1は、ユーザの操作に応じて、カットCU60を表示する際は、前関係バーTR60を重畳表示する。例えば、映像生成システム1は、ユーザの操作に応じて、カットCU62を表示する際は、後関係バーTR62を重畳表示する。例えば、映像生成システム1は、ユーザの操作に応じて、カットCU63を表示する際は、後関係バーTR63を重畳表示する。これにより、映像生成システム1は、対象カットの前後のカットを再生する際、対象カットからの離れた量を提示する。このように、映像生成システム1は、対象カットの前後も再生する場合、対象カットからの離れた秒数に応じて、その量及び方向を示す情報を画面上に重畳表示することで、そのカットが対象カットから前後のどちらに、どの程度離れているかをユーザに認識させることができる。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
The
<1-4-17.オブジェクトの選択例>
従来技術では、編集時のオブジェクトの選択がユーザにとって大変(ユーザビリティが低い)という課題がある。このように、従来技術には、ユーザビリティに関する課題があり、ユーザビリティの改善の余地がある。そこで、映像生成システム1は、図37に示すように、オブジェクトの選択を行ってもよい。図37は、オブジェクトの選択の一例を示す図である。
<1-4-17. Example of object selection>
The conventional technology has an issue that it is difficult for a user to select an object during editing (low usability). Thus, the conventional technology has an issue regarding usability, and there is room for improvement in usability. Therefore, the
図37の映像MV71では、ユーザはマウスを操作して、3人のうち右側の人が含まれる範囲にマウスカーソルMS71を位置させることに右側の人を選択する。この場合、映像生成システム1は、マウスカーソルMS71を位置する右側の人を対象オブジェクトとして選択する操作を受け付ける。例えば、映像生成システム1は、マウスカーソルMS71を位置する右側の人に対応するセグメンテーション(範囲)を、ユーザが選択した範囲として特定する。
In video MV71 of FIG. 37, the user operates the mouse to select the right-hand person of the three people by positioning the mouse cursor MS71 in a range that includes the right-hand person. In this case,
図37の映像MV72では、ユーザはマウスを操作して、3人のうち中央の人が含まれる範囲にマウスカーソルMS72を位置させることに中央の人を選択する。この場合、映像生成システム1は、マウスカーソルMS72を位置する中央の人を対象オブジェクトとして選択する操作を受け付ける。例えば、映像生成システム1は、マウスカーソルMS72を位置する中央の人に対応するセグメンテーション(範囲)を、ユーザが選択した範囲として特定する。
In video MV72 of FIG. 37, the user operates the mouse to select the central person by positioning the mouse cursor MS72 in a range that includes the central person among the three people. In this case,
図37の映像MV73では、ユーザはマウスを操作して、3人のうち左側の人が含まれる範囲にマウスカーソルMS73を位置させることに左側の人を選択する。この場合、映像生成システム1は、マウスカーソルMS73を位置する左側の人を対象オブジェクトとして選択する操作を受け付ける。例えば、映像生成システム1は、マウスカーソルMS73を位置する左側の人に対応するセグメンテーション(範囲)を、ユーザが選択した範囲として特定する。
In video MV73 of FIG. 37, the user operates the mouse to select the left person of the three people by positioning the mouse cursor MS73 in a range that includes the left person. In this case,
このように、映像生成システム1は、対象オブジェクトの選択を、セグメンテーションで認識された範囲で認識する。これにより、ユーザは、クリックだけで指定したいオブジェクトを選択することができる。例えば、動画中に表示されるオブジェクトに対して、ユーザがモーション、アセットの変更を行う際には、変更対象のオブジェクトを選択する必要がある。動画中に表示されるオブジェクトの一覧から変更対象を選ぶようなUIよりも、動画中のオブジェクトを直接クリックできれば、ユーザはより直感的に変更対象のオブジェクトを選択することができる。動画中のオブジェクトのクリック範囲は、動画1フレームごとに各オブジェクトのピクセル領域をセグメンテーションすることにより実現できる。
In this way, the
オブジェクトのクリック範囲を求める方法については、以下のような方法であってもよい。例えば、動画のフレームごとのオブジェクトとカメラの情報がUSD上にあるため、そのフレームにおいてカメラから見たあるピクセルがどのオブジェクトを指しているかのマッピングが可能であるため、映像生成システム1は、そこから逆算してユーザが動画上でクリックした座標と編集対象のオブジェクトのマッピングが可能になる。
The click range of an object may be calculated in the following manner. For example, because object and camera information for each frame of a video is stored in the USD, it is possible to map which object a pixel seen from the camera in that frame points to, and the
オブジェクトのクリック範囲を求める方法としては、動画1フレームごとに、カメラから逆算したピクセルごとのオブジェクトのセグメンテーションで選んだ人と、対象USDを紐づける方法等が挙げられる。例えば、動画自体にx,y(座標等)のこの領域には何が位置するかの情報を含ませる。例えば、映像生成システム1は、図38に示すように、オブジェクトの選択を行ってもよい。
Methods for determining the click range of an object include linking the target USD to a person selected by segmenting the object pixel by pixel calculated backwards from the camera for each frame of the video. For example, the video itself may contain information about what is located in a particular area of x, y (coordinates, etc.). For example, the
図38中のフレームFRは、カメラからレンダリングされた動画の1フレームを示す。図38中のUSDデータOBは、USD上の3Dオブジェクトとカメラを示す。3Dオブジェクトとカメラの情報がUSDに含まれるため、映像生成システム1は、カメラ(図38中のカメラCM等)から見たあるピクセルが3Dオブジェクト上のどの場所を指すのかをマッピングすることができる。そのため、映像生成システム1は、ユーザが動画上でクリックした座標とオブジェクトのマッピングが可能となる。上述した処理により、映像生成システム1は、ユーザビリティを向上させることができる。
Frame FR in FIG. 38 shows one frame of a video rendered from a camera. USD data OB in FIG. 38 shows a 3D object and a camera on the USD. Because information on the 3D object and the camera is included in the USD, the
<1-4-18.3Dモデル利用例>
上述した処理は一例に過ぎず、映像生成システム1は、上述した処理以外にも様々な処理を実行してもよい。この点について、以下いくつかの実施例を記載する。
<1-4-18. Example of using 3D model>
The above-described process is merely an example, and the
例えば、映像生成システム1は、登場人物やプロップ(商品など)を取り込む処理を行ってもよい。映像生成システム1における登場人物やプロップ(商品など)の取り込み方法としては、例えば指定して動画内に登場させたい、3Dモデルや三面図を登録しそれを動画内で使ってもよい。例えば、映像生成システム1は、ユーザにより入力された3Dモデルを登録し、動画内で使ってもよい。例えば、映像生成システム1においては、様々な角度で撮影した商品の写真を入れることが可能であってもよい。この場合、映像生成システム1は、NeRF(Neural Radiance Fields)等の技術を用いて、様々な角度で撮影した商品の写真から、その商品の3Dモデルを生成し、動画内で使ってもよい。
For example, the
例えば、映像生成システム1は、動画データのうち、変更の対象とする対象物を指定するユーザの操作を受け付け、ユーザの操作が示す対象物の3Dデータが変更されたコードを生成する。例えば、映像生成システム1は、動画中のある登場人物(「登場人物A」ともいう)が変更対象物としてユーザに指定され、登録された3Dモデルから別の登場人物(「登場人物B」ともいう)が変更後の登場人物としてユーザが選択した場合、動画中の登場人物Aの3Dデータが登場人物Bの3Dデータに変更されたコードを生成する。これにより、映像生成システム1は、動画中の登場人物Aが、登録された3Dモデルが示す登場人物Bに変更された動画データを生成することができる。
For example, the
なお、上述した処理は一例に過ぎず、映像生成システム1は、任意の処理によりユーザの操作が示す対象物の3Dデータが変更されたコードを生成してもよい。例えば、映像生成システム1は、動画データのうち、ユーザの操作が示す対象物の3Dデータ自体に変更を行うことにより、変更されたコードを生成してもよい。例えば、映像生成システム1は、動画データのうち、ユーザの操作が示す対象物の3Dデータの外形(身長等)の変更を行うことにより、変更されたコードを生成してもよい。また、映像生成システム1は、登録した人やプロップに関しては、レンダリング後、リファイナ処理を部分的に行わなくてもよい。また、映像生成システム1においては、登場人物やプロップなどに関しては、映像生成サービス内でマーケットプレイスを用意し販売しても良い。
Note that the above-mentioned process is merely an example, and the
<1-4-19.参考データの利用例>
また、映像生成システム1は、以前作成した(動画)プロジェクトにより、動画とストーリーを参考にしてもよい。映像生成システム1は、図39に示すように、以前作成したプロジェクトの続編を使いたい時、そのプロジェクトを参考データとして入力を受け付けてもよい。図39は、参考データを用いた処理の一例を示す図である。
<1-4-19. Examples of using reference data>
Furthermore, the
例えば、映像生成システム1は、コンテンツCT51にユーザが入力した他のプロジェクトの参考に関するユーザの入力情報を取得する。コンテンツCT51は、他のプロジェクトを参考にするか否かをチェックマークで指定する項目、及び参考にするプロジェクトをチェックマークで指定する項目、参考にするプロジェクトのうちどの情報を参考にするかをチェックマークで指定する項目等についてのユーザの入力情報を受け付けるためのコンテンツである。
For example, the
例えば、クライアントUI表示部400は、コンテンツCT51を表示し、センサ部300は、ユーザ入力情報を受け付ける。図39では、ユーザは「他のプロジェクトを参考にする」にチェックマークを入れ、他のプロジェクトを参考にすることを選択する。また、ユーザは「商品X CM動画」にチェックマークを入れ、商品XのCM動画のプロジェクトを参考にすることを選択する。
For example, the client
また、ユーザは「登場人物」及び「ビジュアルスタイル」にチェックマークを入れ、商品XのCM動画のプロジェクトのうち、登場人物及びビジュアルスタイルを参考にすることを選択する。また、ユーザは「ストーリー」、「コンテンツスタイル」及び「BGM」にチェックマークを入れておらず、商品XのCM動画のプロジェクトのうち、ストーリー、コンテンツスタイル及びBGMについては参考にしないことを選択する。 The user also checks "Characters" and "Visual Style," choosing to use the characters and visual style of the commercial video project for Product X as a reference. The user also does not check "Story," "Content Style," or "BGM," choosing not to use the story, content style, or BGM of the commercial video project for Product X as a reference.
映像生成システム1は、コンテンツCT51で受け付けたユーザ入力情報を用いて、シナリオ生成用情報(第1の入力情報)であるプロンプトPT51を生成する。なお、図39では説明を省略するが、映像生成システム1は、図6に示すテンプレートTP1のようなテンプレート入力情報を用いて、プロンプトPT51を生成してもよい。
The
例えば、映像生成システム1は、商品XのCM動画のプロジェクトのうち、登場人物及びビジュアルスタイルを反映することにより、プロンプトPT51を生成する。図39では、映像生成システム1は、商品XのCM動画での登場人物“Mike”を使い、商品XのCM動画でのビジュアルスタイル“映画風”を使う事を指定する制約を含むプロンプトPT51を生成する。このように、映像生成システム1は、ユーザの選択に応じて、過去のプロジェクトを参考データに基づいて、シナリオを生成するためのプロンプトを生成する。これにより、映像生成システム1は、動画中の登場人物Aが、ユーザが指定した過去のプロジェクトに基づいて動画データを生成することができる。
For example, the
<1-4-20.3Dデータを有する利点例>
映像生成システム1は、3Dデータを内部に有するため、以下のような機能や利点を有する。映像生成システム1は、生成する映像(動画)については以下のような機能や利点を有する。例えば、映像生成システム1は、物理シミュレーションにより、より自然な映像を作ることができる。例えば、映像生成システム1は、台の上にものを乗っけたり、跳ね返ったり、転がったり、自然な布の揺れを再現したりすることができる。
<1-4-20. Examples of advantages of having 3D data>
Since the
例えば、映像生成システム1は、ライティングとオブジェクト素材に応じて、光の反射具合をリアルに再現することができる。反射しやすいボンネットや鏡の時は、その手前にいる人やものが反射光の影響で明るくなる。反射しにくい布の時は、その手前にいる人やものが反射光をあまり受けない。
For example, the
例えば、映像生成システム1は、ライティングとオブジェクトが固定出来るので、時系列的な破綻が生じる可能性を低減させることができる。例えば、映像生成システム1は、ライティングの位置を映像中に変化させても、破綻なく表現することができる。例えば、映像生成システム1は、簡易光源を設定することで、リアルタイムに映像を出力できる。この場合、映像生成システム1は、リファイナ処理を行わなくてもよい。
For example, because the
例えば、映像生成システム1は、商品データや登場人物を3Dデータとして入れることで、商品自体を忠実に映像内で再現することができる。例えば、映像生成システム1は、デプス、グローバル位置、ノーマルなどがわかるため、リファイナ処理時に破綻が生じる可能性を低減させることができる。例えば、映像生成システム1は、スピーカーなど音のなる3次元位置を固定できるため、音に対してのインタラクションを作りやすい。例えば、映像生成システム1は、Differed Renderingのようなライティング処理をすることで、レンダリング時間を削減することができる。
For example, by inputting product data and characters as 3D data, the
また、映像生成システム1は、映像(動画)の編集(修正)については以下のような機能や利点を有する。例えば、映像生成システム1は、カメラの位置、角度、カメラワークを大幅に修正した時でも、周りの環境やライティングなどの一貫性を保つことができる。例えば、映像生成システム1は、動画内で3次元的に位置角度を指定することができる。
In addition, the
例えば、映像生成システム1は、ある程度動画が生成された後であっても、登場人物のみ、プロップのみなど特定のモノだけを変更し、その他の部分は映像を保つことができる。例えば、映像生成システム1は、キャラクターをリアルな人型から二頭身キャラクターに変更することができる。例えば、映像生成システム1は、設置している看板を黒板タイプからプラスチックボードに変更することができる。例えば、映像生成システム1は、商品パッケージの中のロゴの一部のみを変更することができる。
For example, even after a certain amount of video has been generated, the
例えば、映像生成システム1は、3次元で撮影シーンをみることで、動画のフレームには映らない箇所の映像を修正することができる。例えば、映像生成システム1は、映っていない箇所に光源を設置することができる。例えば、映像生成システム1は、映っていない箇所に人やモノを設置して、動画フレーム内に影だけを表示することができる。例えば、映像生成システム1は、映っていないところに人等を置いて、映っている人が映っていない人の目を見てなどの指定をすることができる。
For example, by viewing the captured scene in three dimensions, the
また、映像生成システム1は、上記以外の点については以下のような機能や利点を有する。例えば、映像生成システム1は、AR、VR(Virtual Reality)、SRD(Spatial Reality Display)、3Dディスプレイなどの3Dデバイスのコンテンツに容易に変換することができる。
In addition to the above, the
<1-5.ユーザから見た処理フロー例>
次に、図40を用いて、ユーザから見た処理フローの一例として、ユーザ操作に応じた映像生成システム1による情報処理の手順について説明する。図40は、ユーザ操作に応じた処理の流れを示すフローチャートである。
<1-5. Example of processing flow from the user's perspective>
Next, a procedure of information processing by the
図40に示すように、映像生成システム1では、ユーザがプロジェクト作成ボタンを押下する(ステップS1)。そして、映像生成システム1では、ユーザが動画生成のための必要情報入力を行う(ステップS2)。例えば、ユーザは、動画作成の目的、動画を通して伝えたいメッセージ、ターゲットユーザ、伝えたい商品/サービスの機能特徴、動画の長さ、アスペクト比等を含む情報の入力を行う。
As shown in FIG. 40, in the
そして、映像生成システム1では、ユーザがストーリーボード、動画、音、テキストロゴ作成ボタンを押下する(ステップS3)。例えば、映像生成システム1は、ユーザ操作に応じて、一気に全て(例えば動画データまで)生成してもよいし、ストーリーボードを提示して、ユーザはからの指示に応じたある程度修正してから、動画、音、テキストロゴを生成してもよい。
Then, in the
そして、映像生成システム1は、ユーザ操作に応じて、ストーリーボード、動画、音、テキストロゴの修正を行う(ステップS4)。例えば、映像生成システム1は、それぞれをユーザの好きな順番に修正を受け付けてもよい。
Then, the
そして、映像生成システム1は、ユーザ操作に応じて、エクスポートを行う(ステップS5)。例えば、映像生成システム1は、ユーザ操作に応じて、mp4、avi、movなどの動画ファイル形式でのエクスポートを行ってもよい。また、例えば、映像生成システム1は、Premiere pro、after effect、davinci resolveなど、任意の動画編集ソフトウェアのファイル形式でのエクスポートを行ってもよい。
Then, the
<1-6.AIモデルについて>
なお、上述した各処理で用いられるAIモデルの各々については、各箇所で記載した例示に限らず、入力に応じて、所望の情報を出力可能であれば、その内部構造は任意の構造が採用可能である。AIモデルの入力、出力及び内部構造については、所望の情報を出力可能であれば、任意の組合せが採用可能である。
<1-6. About the AI model>
In addition, each of the AI models used in each of the above-mentioned processes is not limited to the examples described in each section, and any internal structure can be adopted as long as it is possible to output desired information in response to the input. Any combination of input, output, and internal structure of the AI model can be adopted as long as it is possible to output desired information.
AIモデルの入力は、テキスト、画像、音声、3Dデータ等であってもよく、それらの組合せであってもよい。また、AIモデルの出力は、テキスト、画像、音声、3Dデータ等であってもよい。なお、上述した入力及び出力は一例に過ぎず、上述したAIモデルは、任意の入力及び出力であってもよい。 The input of the AI model may be text, images, audio, 3D data, etc., or a combination thereof. The output of the AI model may be text, images, audio, 3D data, etc. Note that the above-mentioned inputs and outputs are merely examples, and the above-mentioned AI model may have any input and output.
また、AIモデルの内部構造は、入力及び出力の組合せに応じて、任意の構造が採用可能である。すなわち、AIモデルの内部構造は、入力に対して、所望の出力が可能であればどのような構造であってもよい。 The internal structure of the AI model can be any structure depending on the combination of input and output. In other words, the internal structure of the AI model can be any structure that can produce the desired output for the input.
例えば、AIモデルは、Transformerに関する構造を有してもよい。例えば、AIモデルは、Transformerに関する構造を有し、テキスト、時系列データ等、データ内での前後関係等のコンテキストを考慮した処理を行ってもよい。例えば、AIモデルは、自己注意機構(self-attention mechanism)を有してもよい。例えば、AIモデルは、Single-Head Attention、Multi-head Attention等の任意のアテンション機構を有してもよい。なお、AIモデルは、アテンション機構を有しなくてもよい。 For example, the AI model may have a structure related to Transformer. For example, the AI model may have a structure related to Transformer and perform processing that takes into account context such as the context within data, such as text and time-series data. For example, the AI model may have a self-attention mechanism. For example, the AI model may have any attention mechanism, such as Single-Head Attention or Multi-head Attention. Note that the AI model does not have to have an attention mechanism.
AIモデルは、入力から特徴を抽出する機構を有してもよい。例えば、AIモデルは、エンコーダを有してもよい。AIモデルは、抽出された特徴を基に、情報を生成する機構を有してもよい。例えば、AIモデルは、デコーダを有してもよい。 The AI model may have a mechanism for extracting features from an input. For example, the AI model may have an encoder. The AI model may have a mechanism for generating information based on the extracted features. For example, the AI model may have a decoder.
AIモデルは、CNN(Convolutional Neural Network)に関する構造を有してもよい。例えば、AIモデルは、画像を対象とする処理を行う場合、CNNに関する構造を有してもよい。例えば、AIモデルは、畳み込み層、プーリング層、全結合層等のうち少なくとも1つを有してもよい。 The AI model may have a structure related to a CNN (Convolutional Neural Network). For example, when performing processing on an image, the AI model may have a structure related to a CNN. For example, the AI model may have at least one of a convolutional layer, a pooling layer, a fully connected layer, etc.
なお、上述した内部構造は一例に過ぎず、上述したAIモデルは、任意の内部構造を有してもよい。例えば、AIモデルは、スキップ接続(skip connection)を有してもよい。また、AIモデルは、Diffusionモデルに関する構造を有してもよい。 Note that the above-mentioned internal structure is merely an example, and the above-mentioned AI model may have any internal structure. For example, the AI model may have a skip connection. In addition, the AI model may have a structure related to a diffusion model.
また、上述したAIモデルは、任意の学習処理により生成(学習)されてもよい。AIモデルは、任意の機械学習の手法を用いて学習された機械学習モデルであってもよい。例えば、AIモデルは、いわゆるFoundation Model(基盤モデル)を基に、その基盤モデルを特定のタスク(例えばシナリオデータ生成、コード生成等)に適用するようにファインチューニングされて生成されたモデルであってもよい。例えば、上述したLLMのようなAIモデルは、基盤モデルを特定のタスクに適用するようにファインチューニングされて生成されたモデルであってもよい。 The AI model described above may be generated (learned) by any learning process. The AI model may be a machine learning model learned using any machine learning method. For example, the AI model may be a model generated based on a so-called Foundation Model by fine-tuning the Foundation Model to apply it to a specific task (e.g., scenario data generation, code generation, etc.). For example, an AI model such as the LLM described above may be a model generated by fine-tuning the Foundation Model to apply it to a specific task.
ここでいう基盤モデルは、様々なタスクに適用可能なように、例えば多種多様なタスクを実行可能になるように学習されたモデルである。例えば、基盤モデルは、大量のラベル無しデータセットで事前学習させたニューラルネットワークである。なお、基盤モデルは、Transformerベースのアーキテクチャ等の任意の構造を有してもよい。例えば、基盤モデルは、正解ラベルのないデータを使用した自己教師あり学習により生成される。上記のように、基盤モデルは、幅広い下流タスクに適応できるようにファインチューニングされる。 The base model here is a model that has been trained to be applicable to various tasks, for example to be able to perform a wide variety of tasks. For example, the base model is a neural network that has been pre-trained with a large amount of unlabeled data set. Note that the base model may have any structure, such as a Transformer-based architecture. For example, the base model is generated by self-supervised learning using data without correct answer labels. As described above, the base model is fine-tuned so that it can be adapted to a wide range of downstream tasks.
例えば、シナリオデータ生成のタスクに適用される場合、基盤モデルがシナリオデータ生成のタスクに適応できるようにファインチューニングされ、シナリオデータ生成のタスクに適用したAIモデル(モデルM1等)が生成される。また、例えば、コード生成のタスクに適用される場合、基盤モデルがコード生成のタスクに適応できるようにファインチューニングされ、コード生成のタスクに適用したAIモデル(モデルM3等)が生成される。また、例えば、音データ生成のタスクに適用される場合、基盤モデルが音データ生成のタスクに適応できるようにファインチューニングされ、音データ生成のタスクに適用したAIモデル(モデルM4等)が生成される。また、例えば、テキストロゴ生成のタスクに適用される場合、基盤モデルがテキストロゴ生成のタスクに適応できるようにファインチューニングされ、テキストロゴ生成のタスクに適用したAIモデル(モデルM5等)が生成される。 For example, when applied to a task of scenario data generation, the base model is fine-tuned so that it can be adapted to the task of scenario data generation, and an AI model (model M1, etc.) applied to the task of scenario data generation is generated. Also, when applied to a task of code generation, the base model is fine-tuned so that it can be adapted to the task of code generation, and an AI model (model M3, etc.) applied to the task of code generation is generated. Also, when applied to a task of sound data generation, the base model is fine-tuned so that it can be adapted to the task of sound data generation, and an AI model (model M4, etc.) applied to the task of sound data generation is generated. Also, when applied to a task of text logo generation, the base model is fine-tuned so that it can be adapted to the task of text logo generation, and an AI model (model M5, etc.) applied to the task of text logo generation is generated.
例えば、シナリオデータ生成のタスクに適用したAIモデル(モデルM1等)は、そのAIモデルに対応する入力情報と、その入力情報を入力した場合の正解の出力となるシナリオデータ(「正解情報」ともいう)とを組合せを含む学習データを用いて学習される。なお、入力情報、正解情報等の学習データは、人が作成したデータであってもよいし、学習データを生成するコンピュータが自動で生成したデータであってもよい。例えば、正解情報となるシナリオデータ等は、人が作成したデータであってもよい。以下、モデルM1を一例として簡単に説明する。例えば、モデルM1は、学習データ中の各入力情報が入力された場合に、その各入力情報に対応する正解情報を出力するように学習される。例えば、モデルM1は、バックプロパゲーション(誤差逆伝播法)等の手法により、ある入力情報が入力された場合のモデルM1における出力と、その入力情報に対応する正解情報との誤差が少なくなるようにパラメータ(接続係数)が調整(補正)されることにより学習される。また、コード生成のタスクに適用したAIモデル(モデルM3等)、音データ生成のタスクに適用したAIモデル(モデルM4等)、テキストロゴ生成のタスクに適用したAIモデル(モデルM5等)、評価のタスクに適用したAIモデル(モデルM10等)、画像改善処理のタスクに適用したAIモデル(モデルM11等)等の他のAIモデルについても同様の学習処理により学習されてもよい。 For example, an AI model (such as model M1) applied to a task of generating scenario data is trained using training data that includes a combination of input information corresponding to the AI model and scenario data (also called "correct answer information") that is the correct output when the input information is input. The training data, such as the input information and the correct answer information, may be data created by a person, or may be data automatically generated by a computer that generates the training data. For example, the scenario data that is the correct answer information may be data created by a person. Below, model M1 will be briefly described as an example. For example, model M1 is trained to output correct answer information corresponding to each input information when each piece of input information in the training data is input. For example, model M1 is trained by adjusting (correcting) parameters (connection coefficients) using a method such as backpropagation (error backpropagation method) so that the error between the output of model M1 when certain input information is input and the correct answer information corresponding to that input information is reduced. In addition, other AI models such as an AI model applied to a code generation task (e.g., model M3), an AI model applied to a sound data generation task (e.g., model M4), an AI model applied to a text logo generation task (e.g., model M5), an AI model applied to an evaluation task (e.g., model M10), and an AI model applied to an image improvement processing task (e.g., model M11) may also be trained using a similar learning process.
なお、上述した学習処理は一例に過ぎず、上述したAIモデルは、そのAIモデルの入力、出力及び内部構造に応じて任意の学習処理により学習される。例えば、AIモデルは、GAN(Generative Adversarial Network)等のように、教師なし学習の手法により学習されてもよい。また、AIモデルは、フェデレーテッドラーニング等のようにデータを集約せずに分散した状態で学習されてもよい。この場合、各映像生成サービスの装置(サーバ等)において、そのサービスで収集したローカルモデルを生成し、各映像生成サービスの装置(サーバ等)が生成したローカルモデルの情報(パラメータ等)を集約するサーバ(集約サーバ)がローカルモデルの情報を用いてグローバルモデルを生成してもよい。この場合、映像生成システム1は、集約サーバが生成したグローバルモデルを集約サーバから受信し、受信したグローバルモデルをAIモデルとして処理に用いてもよい。
Note that the above-mentioned learning process is merely an example, and the above-mentioned AI model is learned by any learning process according to the input, output, and internal structure of the AI model. For example, the AI model may be learned by an unsupervised learning method such as GAN (Generative Adversarial Network). The AI model may also be learned in a distributed state without aggregating data such as federated learning. In this case, a local model collected by each video generation service device (server, etc.) may be generated in the service, and a server (aggregation server) that aggregates information (parameters, etc.) of the local models generated by each video generation service device (server, etc.) may generate a global model using the information of the local model. In this case, the
このように、上述したAIモデルは、いずれのコンピュータが生成(学習)してもよい。すなわち、AIモデルを生成する学習処理は、映像生成システム1のいずれかの装置(コンピュータ等)が行ってもよいし、映像生成システム1外の装置が行ってもよい。例えば、映像生成システム1外の装置が上述したAIモデルのうち少なくとも1つを生成する場合、映像生成システム1は、映像生成システム1外の装置からそのAIモデルを取得し、取得したAIモデルを用いて処理を行う。
In this way, the AI models described above may be generated (learned) by any computer. In other words, the learning process to generate the AI models may be performed by any device (computer, etc.) of the
<2.その他の実施形態>
上述した各実施形態に係る処理は、上記各実施形態や変形例以外にも種々の異なる形態(変形例)にて実施されてよい。
2. Other embodiments
The processing according to each of the above-described embodiments may be implemented in various different forms (variations) other than the above-described embodiments and variations.
<2-1.その他の構成例>
上記の映像生成システム1の構成は一例に過ぎず、映像生成システム1における機能の分割は任意の態様が採用可能である。すなわち、上述した構成は一例であり、上述した映像生成に関するサービスを提供可能であれば、映像生成システム1は、どのような機能の分割態様であってもよく、どのような構成であってもよい。例えば、映像生成システム1は、上述した処理を行う1つの装置(コンピュータ等)により構成されてもよい。この場合、映像生成システム1の1つの装置が、映像生成モジュール100、情報取得モジュール200、センサ部300、及びクライアントUI表示部400の機能を有してもよい。例えば、映像生成システム1が提供する映像生成サービスは、ユーザが利用する端末装置(コンピュータ20等)上で動作するツール(AI Assist Creation Tool)等のプログラムとしてユーザに提供されてもよい。
<2-1. Other configuration examples>
The above-described configuration of the
<2-2.その他>
また、上記各実施形態において説明した各処理のうち、自動的に行われるものとして説明した処理の全部または一部を手動的に行うこともでき、あるいは、手動的に行われるものとして説明した処理の全部または一部を公知の方法で自動的に行うこともできる。この他、上記文書中や図面中で示した処理手順、具体的名称、各種のデータやパラメータを含む情報については、特記する場合を除いて任意に変更することができる。例えば、各図に示した各種情報は、図示した情報に限られない。
<2-2. Others>
Furthermore, among the processes described in the above embodiments, all or part of the processes described as being performed automatically can be performed manually, or all or part of the processes described as being performed manually can be performed automatically by a known method. In addition, the information including the processing procedures, specific names, various data and parameters shown in the above documents and drawings can be changed arbitrarily unless otherwise specified. For example, the various information shown in each drawing is not limited to the illustrated information.
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。 In addition, each component of each device shown in the figure is a functional concept, and does not necessarily have to be physically configured as shown in the figure. In other words, the specific form of distribution and integration of each device is not limited to that shown in the figure, and all or part of them can be functionally or physically distributed and integrated in any unit depending on various loads, usage conditions, etc.
また、上述してきた各実施形態及び変形例は、処理内容を矛盾させない範囲で適宜組み合わせることが可能である。 Furthermore, the above-mentioned embodiments and variations can be combined as appropriate to the extent that they do not cause any contradiction in the processing content.
また、本明細書に記載された効果はあくまで例示であって限定されるものでは無く、他の効果があってもよい。 Furthermore, the effects described in this specification are merely examples and are not limiting, and other effects may also be present.
<3.本開示に係る効果>
上述のように、本開示に係る映像生成システム(実施形態では映像生成システム1)は、取得部(実施形態では入力テキスト取得部210)と、シナリオ生成部(実施形態ではシナリオ向け生成部131)と、コード生成部(実施形態では映像向け生成部132)と、動画データ取得部(実施形態では映像生成部140)とを備える。取得部は、動画生成に関する入力クエリをユーザから取得する。シナリオ生成部は、入力クエリに基づいて、動画生成に関するシナリオデータを生成する。コード生成部は、シナリオデータに基づいて、3Dデータを構成するためのコードを生成する。動画データ取得部は、コードに基づいて、動画データを取得する。
3. Effects of the Present Disclosure
As described above, the video generation system (
このように、本開示に係る映像生成システムは、ユーザからの入力クエリに基づいて生成したシナリオデータに基づいて、3Dデータを構成するためのコードを生成し、コードに基づいて、動画データを取得することにより、ユーザからの入力クエリに応じて動画データを取得することができる。 In this way, the video generation system according to the present disclosure generates code for constructing 3D data based on scenario data generated based on a query input from a user, and obtains video data based on the code, thereby obtaining video data in response to a query input from a user.
また、映像生成システムは、画質改善部(実施形態では映像リファイン部143)を備える。画質改善部は、動画データの画質を改善する画質改善処理を実行する。このように、映像生成システムは、動画データの画質を改善することにより、高品質な動画を取得することができる。 The video generation system also includes an image quality improvement unit (in this embodiment, an image refinement unit 143). The image quality improvement unit executes an image quality improvement process that improves the image quality of the video data. In this way, the video generation system can obtain high-quality videos by improving the image quality of the video data.
また、画質改善部は、テキストプロンプトに基づいて画質改善処理を実行することにより、動画データの画質を改善する。このように、映像生成システムは、テキストプロンプトに基づいて動画データの画質を改善することにより、高品質な動画を取得することができる。 The image quality improvement unit also improves the image quality of the video data by performing an image quality improvement process based on the text prompt. In this way, the video generation system can obtain high-quality video by improving the image quality of the video data based on the text prompt.
また、画質改善部は、動画データのうち画質改善処理の対象を指定するテキストプロンプトに基づいて、画質改善処理を実行する。このように、映像生成システムは、指定された対象について動画データの画質を改善することにより、高品質な動画を取得することができる。 The image quality improvement unit also performs image quality improvement processing based on a text prompt that specifies the target of the image quality improvement processing in the video data. In this way, the video production system can obtain high-quality video by improving the image quality of the video data for the specified target.
また、画質改善部は、改善が必要と判断された対象を指定するテキストプロンプトに基づいて、画質改善処理を実行する。このように、映像生成システムは、改善が必要と判断された対象について動画データの画質を改善することにより、高品質な動画を取得することができる。 The image quality improvement unit also performs image quality improvement processing based on a text prompt that specifies the target determined to require improvement. In this way, the video generation system can obtain high-quality video by improving the image quality of the video data for the target determined to require improvement.
また、映像生成システムは、表示制御部(実施形態ではクライアントUI表示部400)を備える。表示制御部は、シナリオデータに基づいたストーリーボードを表示させる。このように、映像生成システムは、シナリオデータに基づいたストーリーボードを表示させることにより、ユーザにとって利便性が高い態様で情報を提示することができる。
The video generation system also includes a display control unit (client
また、ストーリーボードは、動画のカット毎に動画データを表示するように構成される。このように、映像生成システムは、ストーリーボードが動画のカット毎に動画データを表示するように構成されることにより、ユーザにとって利便性が高い態様で情報を提示することができる。 The storyboard is also configured to display video data for each cut of the video. In this way, the video production system is able to present information in a manner that is highly convenient for the user, by configuring the storyboard to display video data for each cut of the video.
また、映像生成システムは、サウンド生成部(実施形態ではサウンド生成部150)を備える。サウンド生成部は、シナリオデータと動画データとに基づいて、動画データに対応するサウンドデータを生成する。このように、映像生成システムは、動画データに対応するサウンドデータを生成することで、音を含む動画を取得することができる。
The video generation system also includes a sound generation unit (
また、映像生成システムは、テキスト生成部(実施形態ではテキスト/ロゴ生成部160)を備える。テキスト生成部は、シナリオデータに基づいて、動画データにより表示される映像上に表示させるテキストを示すテキストデータを生成する。このように、映像生成システムは、動画データに対応するテキストデータを生成することで、テキストを含む動画を取得することができる。 The video generation system also includes a text generation unit (in this embodiment, a text/logo generation unit 160). The text generation unit generates text data indicating text to be displayed on the video displayed by the video data, based on the scenario data. In this way, the video generation system can obtain a video including text by generating text data corresponding to the video data.
また、映像生成システムは、ロゴ生成部(実施形態ではテキスト/ロゴ生成部160)を備える。ロゴ生成部は、シナリオデータに基づいて、動画データにより表示される映像上に表示させるロゴを示すロゴデータを生成する。このように、映像生成システムは、動画データに対応するロゴデータを生成することで、ロゴを含む動画を取得することができる。 The video generation system also includes a logo generation unit (in this embodiment, a text/logo generation unit 160). The logo generation unit generates logo data indicating a logo to be displayed on a video displayed by the video data, based on the scenario data. In this way, the video generation system can obtain a video including a logo by generating logo data corresponding to the video data.
また、入力クエリは、テキスト、画像、音声、3Dデータのうち少なくとも1つを含む。このように、映像生成システムは、入力クエリがテキスト、画像、音声、3Dデータのうち少なくとも1つを含むことにより、ユーザからの入力クエリに応じて動画データを取得することができる。 The input query also includes at least one of text, images, audio, and 3D data. In this way, the video generation system can obtain video data in response to the input query from the user by the input query including at least one of text, images, audio, and 3D data.
また、映像生成システムは、第1の出力部(実施形態ではシナリオ向け生成部131)を備える。第1の出力部は、入力クエリに基づいて、シナリオデータを生成するためにシナリオ生成部が用いるシナリオ生成用情報を出力する。シナリオ生成部は、シナリオ生成用情報に基づいてシナリオデータを生成する。このように、映像生成システムは、入力クエリに基づいて生成されたシナリオ生成用情報に基づいてシナリオデータを生成することにより、ユーザからの入力クエリに応じて動画データを取得することができる。 The video generation system also includes a first output unit (in this embodiment, a scenario-oriented generation unit 131). The first output unit outputs scenario generation information used by the scenario generation unit to generate scenario data based on the input query. The scenario generation unit generates scenario data based on the scenario generation information. In this way, the video generation system can acquire video data in response to an input query from a user by generating scenario data based on the scenario generation information generated based on the input query.
また、第1の出力部は、入力クエリに基づいて、シナリオデータを生成するための第1のプロンプトを、シナリオ生成用情報として生成する。シナリオ生成部は、第1のプロンプトに基づいてシナリオデータを生成する。このように、映像生成システムは、第1のプロンプトに基づいてシナリオデータを生成することにより、ユーザからの入力クエリに応じて動画データを取得することができる。 The first output unit also generates a first prompt for generating scenario data based on the input query as scenario generation information. The scenario generation unit generates scenario data based on the first prompt. In this way, the video generation system can obtain video data in response to the input query from the user by generating scenario data based on the first prompt.
また、第1の出力部は、入力クエリに基づいて、シナリオデータを生成するための第1のモデルの入力として用いられる第1の入力情報をシナリオ生成用情報として生成する。シナリオ生成部は、入力クエリを用いて生成された第1の入力情報を、第1のモデルに入力し、第1のモデルにシナリオデータを出力させることにより、シナリオデータを生成する。このように、映像生成システムは、第1のモデルを用いてシナリオデータを生成することにより、ユーザからの入力クエリに応じて動画データを取得することができる。 Furthermore, the first output unit generates, based on the input query, first input information used as an input of a first model for generating scenario data as scenario generation information. The scenario generation unit inputs the first input information generated using the input query to the first model and causes the first model to output scenario data, thereby generating scenario data. In this way, the video generation system can obtain video data in response to an input query from a user by generating scenario data using the first model.
また、映像生成システムは、第2の出力部(実施形態では映像向け生成部132)を備える。第2の出力部は、シナリオデータに基づいて、3Dデータを構成するためのコードを生成するためにコード生成部が用いるコード生成用情報を出力する。コード生成部は、コード生成用情報に基づいてコードを生成する。このように、映像生成システムは、シナリオデータに基づいて生成されたコード生成用情報に基づいてコードを生成することにより、ユーザからの入力クエリに応じて動画データを取得することができる。
The video generation system also includes a second output unit (
また、第2の出力部は、シナリオデータに基づいて、3Dデータを構成するためのコードを出力するための第2のプロンプトを、コード生成用情報として生成する。シナリオ生成部は、第2のプロンプトに基づいてコードを生成する。このように、映像生成システムは、第2のプロンプトに基づいてコードを生成することにより、ユーザからの入力クエリに応じて動画データを取得することができる。 The second output unit also generates, as code generation information, a second prompt for outputting a code for constructing 3D data based on the scenario data. The scenario generation unit generates the code based on the second prompt. In this way, the video generation system can acquire video data in response to an input query from a user by generating a code based on the second prompt.
また、第2の出力部は、入力クエリに基づいて、コードを生成するための第2のモデルの入力として用いられる第2の入力情報をコード生成用情報として生成する。シナリオ生成部は、シナリオデータを用いて生成された第2の入力情報を、第2のモデルに入力し、第2のモデルにコードを出力させることにより、コードを生成する。このように、映像生成システムは、第2のモデルを用いてコードを生成することにより、ユーザからの入力クエリに応じて動画データを取得することができる。 Furthermore, the second output unit generates, based on the input query, second input information used as an input of a second model for generating code as information for code generation. The scenario generation unit generates code by inputting the second input information generated using the scenario data to the second model and causing the second model to output code. In this way, the video generation system can obtain video data in response to an input query from a user by generating code using the second model.
また、映像生成システムは、受付部(実施形態ではセンサ部300)を備える。受付部は、ユーザから動画編集に関する操作を受け付ける。コード生成部は、操作に基づいた編集により、コードを生成する。このように、映像生成システムは、ユーザから動画編集の操作に応じてコードを生成することにより、ユーザの編集に対応する映像を適切に取得することができる。
The video generation system also includes a reception unit (
また、受付部は、センサを用いてモーションまたはカメラの動きを指定する操作を受け付ける。コード生成部は、操作が示すモーションまたはカメラの動きに対応するコードを生成する。このように、映像生成システムは、ユーザからモーションまたはカメラの動きを指定する操作に応じてコードを生成することにより、ユーザの編集に対応する映像を適切に取得することができる。 The receiving unit also receives an operation specifying a motion or camera movement using a sensor. The code generating unit generates a code corresponding to the motion or camera movement indicated by the operation. In this way, the video generation system can appropriately acquire video corresponding to the user's editing by generating a code in response to a user's operation specifying a motion or camera movement.
また、受付部は、動画データのうち、複数のカットを選択する操作を受け付ける。コード生成部は、操作が示す複数のカットに対応する部分が変更されたコードを生成する。このように、映像生成システムは、ユーザから複数のカットを選択するに応じてコードを生成することにより、ユーザの編集に対応する映像を適切に取得することができる。 The receiving unit also receives an operation to select multiple cuts from the video data. The code generating unit generates code in which the portions corresponding to the multiple cuts indicated by the operation have been modified. In this way, the video generating system can appropriately acquire video corresponding to the user's editing by generating code in response to the user selecting multiple cuts.
また、動画データの各カットには日付情報が対応付けられている。コード生成部は、動画データの各カットの日付情報に基づいて、操作が示す編集の内容を決定する。このように、映像生成システムは、動画データの各カットの日付情報に基づいて、編集の内容を決定することにより、ユーザの編集に対応する映像を適切に取得することができる。 Furthermore, date information is associated with each cut of the video data. The code generation unit determines the content of the edit indicated by the operation based on the date information of each cut of the video data. In this way, the video generation system can appropriately acquire video corresponding to the user's editing by determining the content of the edit based on the date information of each cut of the video data.
また、受付部は、動画データのうち、変更の対象とする対象物を指定する操作を受け付ける。コード生成部は、操作が示す対象物の3Dデータが変更されたコードを生成する。このように、映像生成システムは、ユーザから変更の対象として指定された3Dデータが変更されたコードを生成することにより、ユーザの編集に対応する映像を適切に取得することができる。 The receiving unit also receives an operation to specify an object of the video data to be changed. The code generating unit generates a code in which the 3D data of the object specified by the operation has been changed. In this way, the video generating system can appropriately acquire video corresponding to the user's edits by generating a code in which the 3D data specified by the user as the object to be changed has been changed.
また、映像生成システムは、評価部(実施形態では評価部180)を備える。評価部は、シナリオデータと動画データのうち少なくとも1つの評価を示す情報を生成する。このように、映像生成システムは、シナリオデータと動画データのうち少なくとも1つの評価を示す情報を生成することにより、生成した情報に対して評価を行うことができる。
The video generation system also includes an evaluation unit (
また、コード生成部は、評価に基づいて、コードを生成する。このように、映像生成システムは、評価に基づいて、コードを生成することにより、評価に応じて適切に情報を取得することができる。 The code generation unit also generates a code based on the evaluation. In this way, the video generation system can appropriately acquire information according to the evaluation by generating a code based on the evaluation.
また、シナリオ生成部は、評価に基づいて、シナリオデータを生成する。このように、映像生成システムは、評価に基づいて、シナリオデータを生成することにより、評価に応じて適切に情報を取得することができる。 The scenario generation unit also generates scenario data based on the evaluation. In this way, the video generation system can acquire information appropriately according to the evaluation by generating scenario data based on the evaluation.
また、シナリオ生成部は、評価に基づき生成されたシナリオデータに基づいて、コードを生成する。このように、映像生成システムは、評価に基づき生成されたシナリオデータに基づいて、コードを生成することにより、評価に応じて適切に情報を取得することができる。 The scenario generation unit also generates a code based on the scenario data generated based on the evaluation. In this way, the video generation system can appropriately acquire information according to the evaluation by generating a code based on the scenario data generated based on the evaluation.
<4.ハードウェア構成>
上述してきた各実施形態に係る映像生成モジュール100、情報取得モジュール200及びクライアントUI表示部400等を有する情報処理装置(情報機器)は、例えば図41に示すような構成のコンピュータ1000によって実現される。図41は、情報処理装置の機能を実現するコンピュータ1000の一例を示すハードウェア構成図である。以下、実施形態に係る映像生成モジュール100を例に挙げて説明する。コンピュータ1000は、CPU1100、RAM1200、ROM(Read Only Memory)1300、HDD(Hard Disk Drive)1400、通信インターフェイス1500、及び入出力インターフェイス1600を有する。コンピュータ1000の各部は、バス1050によって接続される。
4. Hardware Configuration
An information processing device (information equipment) having the
CPU1100は、ROM1300又はHDD1400に格納されたプログラムに基づいて動作し、各部の制御を行う。例えば、CPU1100は、ROM1300又はHDD1400に格納されたプログラムをRAM1200に展開し、各種プログラムに対応した処理を実行する。
The
ROM1300は、コンピュータ1000の起動時にCPU1100によって実行されるBIOS(Basic Input Output System)等のブートプログラムや、コンピュータ1000のハードウェアに依存するプログラム等を格納する。
The ROM 1300 stores boot programs such as the Basic Input Output System (BIOS) that is executed by the
HDD1400は、CPU1100によって実行されるプログラム、及び、かかるプログラムによって使用されるデータ等を非一時的に記録する、コンピュータが読み取り可能な記録媒体である。具体的には、HDD1400は、プログラムデータ1450の一例である本開示に係る映像生成プログラムを記録する記録媒体である。 HDD1400 is a computer-readable recording medium that non-temporarily records programs executed by CPU1100 and data used by such programs. Specifically, HDD1400 is a recording medium that records the image generation program according to the present disclosure, which is an example of program data 1450.
通信インターフェイス1500は、コンピュータ1000が外部ネットワーク1550(例えばインターネット)と接続するためのインターフェイスである。例えば、CPU1100は、通信インターフェイス1500を介して、他の機器からデータを受信したり、CPU1100が生成したデータを他の機器へ送信したりする。
The
入出力インターフェイス1600は、入出力デバイス1650とコンピュータ1000とを接続するためのインターフェイスである。例えば、CPU1100は、入出力インターフェイス1600を介して、キーボードやマウス等の入力デバイスからデータを受信する。また、CPU1100は、入出力インターフェイス1600を介して、ディスプレイやスピーカーやプリンタ等の出力デバイスにデータを送信する。また、入出力インターフェイス1600は、所定の記録媒体(メディア)に記録されたプログラム等を読み取るメディアインターフェイスとして機能してもよい。メディアとは、例えばDVD(Digital Versatile Disc)、PD(Phase change rewritable Disk)等の光学記録媒体、MO(Magneto-Optical disk)等の光磁気記録媒体、テープ媒体、磁気記録媒体、または半導体メモリ等である。
The input/
例えば、コンピュータ1000が実施形態に係る映像生成モジュール100として機能する場合、コンピュータ1000のCPU1100は、RAM1200上にロードされた映像生成プログラムを実行することにより、制御部1301等の機能を実現する。また、HDD1400には、本開示に係る映像生成プログラムや、記憶部1302内のデータが格納される。なお、CPU1100は、プログラムデータ1450をHDD1400から読み取って実行するが、他の例として、外部ネットワーク1550を介して、他の装置からこれらのプログラムを取得してもよい。
For example, when computer 1000 functions as
なお、本技術は以下のような構成も取ることができる。
(1)
動画生成に関する入力クエリをユーザから取得する取得部と、
前記入力クエリに基づいて、動画生成に関するシナリオデータを生成するシナリオ生成部と、
前記シナリオデータに基づいて、3Dデータを構成するためのコードを生成するコード生成部と、
前記コードに基づいて、動画データを取得する動画データ取得部と、
を備える映像生成システム。
(2)
前記動画データの画質を改善する画質改善処理を実行する画質改善部、
を更に備える(1)に記載の映像生成システム。
(3)
前記画質改善部は、
テキストプロンプトに基づいて前記画質改善処理を実行することにより、前記動画データの画質を改善する
(2)に記載の映像生成システム。
(4)
前記画質改善部は、
前記動画データのうち前記画質改善処理の対象を指定するテキストプロンプトに基づいて、前記画質改善処理を実行する
(2)または(3)に記載の映像生成システム。
(5)
前記画質改善部は、
改善が必要と判断された前記対象を指定するテキストプロンプトに基づいて、前記画質改善処理を実行する
(4)に記載の映像生成システム。
(6)
前記シナリオデータに基づいたストーリーボードを表示させる表示制御部、
を更に備える(1)~(5)のいずれか1つに記載の映像生成システム。
(7)
前記ストーリーボードは、動画のカット毎に前記動画データを表示するように構成される
(6)に記載の映像生成システム。
(8)
前記シナリオデータと前記動画データとに基づいて、前記動画データに対応するサウンドデータを生成するサウンド生成部、
を更に備える(1)~(7)のいずれか1つに記載の映像生成システム。
(9)
前記シナリオデータに基づいて、前記動画データにより表示される映像上に表示させるテキストを示すテキストデータを生成するテキスト生成部、
を更に備える(1)~(8)のいずれか1つに記載の映像生成システム。
(10)
前記シナリオデータに基づいて、前記動画データにより表示される映像上に表示させるロゴを示すロゴデータを生成するロゴ生成部、
を更に備える(1)~(9)のいずれか1つに記載の映像生成システム。
(11)
前記入力クエリは、テキスト、画像、音声、3Dデータのうち少なくとも1つを含む
(1)~(10)のいずれか1つに記載の映像生成システム。
(12)
前記入力クエリに基づいて、前記シナリオデータを生成するために前記シナリオ生成部が用いるシナリオ生成用情報を出力する第1の出力部、
を更に備え、
前記シナリオ生成部は、
前記シナリオ生成用情報に基づいて前記シナリオデータを生成する
(1)~(11)のいずれか1つに記載の映像生成システム。
(13)
前記第1の出力部は、
前記入力クエリに基づいて、前記シナリオデータを生成するための第1のプロンプトを、前記シナリオ生成用情報として生成し、
前記シナリオ生成部は、
前記第1のプロンプトに基づいて前記シナリオデータを生成する
(12)に記載の映像生成システム。
(14)
前記第1の出力部は、
前記入力クエリに基づいて、前記シナリオデータを生成するための第1のモデルの入力として用いられる第1の入力情報を前記シナリオ生成用情報として生成し、
前記シナリオ生成部は、
前記入力クエリを用いて生成された前記第1の入力情報を、前記第1のモデルに入力し、前記第1のモデルに前記シナリオデータを出力させることにより、前記シナリオデータを生成する
(12)または(13)に記載の映像生成システム。
(15)
前記シナリオデータに基づいて、前記3Dデータを構成するためのコードを生成するために前記コード生成部が用いるコード生成用情報を出力する第2の出力部、
を更に備え、
前記コード生成部は、
前記コード生成用情報に基づいて前記コードを生成する
(1)~(14)のいずれか1つに記載の映像生成システム。
(16)
前記第2の出力部は、
前記シナリオデータに基づいて、前記3Dデータを構成するためのコードを出力するための第2のプロンプトを、前記コード生成用情報として生成し、
前記シナリオ生成部は、
前記第2のプロンプトに基づいて前記コードを生成する
(15)に記載の映像生成システム。
(17)
前記第2の出力部は、
前記入力クエリに基づいて、前記コードを生成するための第2のモデルの入力として用いられる第2の入力情報を前記コード生成用情報として生成し、
前記シナリオ生成部は、
前記シナリオデータを用いて生成された前記第2の入力情報を、前記第2のモデルに入力し、前記第2のモデルに前記コードを出力させることにより、前記コードを生成する
(15)または(16)に記載の映像生成システム。
(18)
ユーザから動画編集に関する操作を受け付ける受付部、
を更に備え、
前記コード生成部は、
前記操作に基づいた編集により、前記コードを生成する
(1)~(17)のいずれか1つに記載の映像生成システム。
(19)
前記受付部は、
センサを用いてモーションまたはカメラの動きを指定する前記操作を受け付け、
前記コード生成部は、
前記操作が示す前記モーションまたは前記カメラの動きに対応する前記コードを生成する
(18)に記載の映像生成システム。
(20)
前記受付部は、
前記動画データのうち、複数のカットを選択する前記操作を受け付け、
前記コード生成部は、
前記操作が示す前記複数のカットに対応する部分が変更された前記コードを生成する
(18)または(19)に記載の映像生成システム。
(21)
前記動画データの各カットには日付情報が対応付けられており、
前記コード生成部は、
前記動画データの各カットの日付情報に基づいて、前記操作が示す前記編集の内容を決定する
(18)~(20)のいずれか1つに記載の映像生成システム。
(22)
前記受付部は、
前記動画データのうち、変更の対象とする対象物を指定する前記操作を受け付け、
前記コード生成部は、
前記操作が示す前記対象物の3Dデータが変更された前記コードを生成する
(18)~(21)のいずれか1つに記載の映像生成システム。
(23)
前記3Dデータは、複数のデータセットを含み、
前記コード生成部は、
前記操作に基づいた編集により、前記複数のデータセットのうち少なくとも1つに対応する前記コードを生成する
(18)~(22)のいずれか1つにに記載の映像生成システム。
(24)
前記コード生成部は、
前記操作が示す編集内容に応じて、前記複数のデータセットのうち一部を更新する処理と前記複数のデータセット全体を更新する処理とのうちのいずれかを実行する
(23)に記載の映像生成システム。
(25)
前記シナリオデータと前記動画データのうち少なくとも1つの評価を示す情報を生成する評価部、
を更に備える(1)~(24)のいずれか1つに記載の映像生成システム。
(26)
前記コード生成部は、
前記評価に基づいて、前記コードを生成する
(25)に記載の映像生成システム。
(27)
前記シナリオ生成部は、
前記評価に基づいて、前記シナリオデータを生成する
(25)または(26)に記載の映像生成システム。
(28)
前記コード生成部は、
前記評価に基づき生成された前記シナリオデータに基づいて、前記コードを生成する
(27)に記載の映像生成システム。
(29)
動画生成に関する入力クエリをユーザから取得することと、
前記入力クエリに基づいて、動画生成に関するシナリオデータを生成することと、
前記シナリオデータに基づいて、3Dデータを構成するためのコードを生成することと、
前記コードに基づいて、動画データを取得することと
を含む映像生成方法。
(30)
動画生成に関する入力クエリをユーザから取得することと、
前記入力クエリに基づいて、動画生成に関するシナリオデータを生成することと、
前記シナリオデータに基づいて、3Dデータを構成するためのコードを生成することと、
前記コードに基づいて、動画データを取得することと
をコンピュータに実行させる映像生成プログラム。
The present technology can also be configured as follows.
(1)
An acquisition unit that acquires an input query regarding video generation from a user;
a scenario generation unit that generates scenario data related to video generation based on the input query;
a code generating unit that generates a code for constructing 3D data based on the scenario data;
a video data acquisition unit that acquires video data based on the code;
An image generation system comprising:
(2)
an image quality improvement unit that executes an image quality improvement process to improve the image quality of the video data;
The image generation system according to (1) further comprising:
(3)
The image quality improvement unit includes:
The image generation system according to any one of claims 2 to 6, further comprising: a display unit for displaying an image of the moving image data based on a text prompt;
(4)
The image quality improvement unit includes:
The image generation system according to (2) or (3), further comprising: a text prompt that specifies a target of the image quality improvement process in the video data;
(5)
The image quality improvement unit includes:
The image generation system according to
(6)
a display control unit that displays a storyboard based on the scenario data;
The image generation system according to any one of (1) to (5), further comprising:
(7)
The video production system according to (6), wherein the storyboard is configured to display the video data for each cut of the video.
(8)
a sound generating unit that generates sound data corresponding to the video data based on the scenario data and the video data;
The image generation system according to any one of (1) to (7), further comprising:
(9)
a text generating unit that generates text data indicating text to be displayed on a video displayed based on the video data, based on the scenario data;
The image generation system according to any one of (1) to (8), further comprising:
(10)
a logo generating unit that generates logo data indicating a logo to be displayed on a video image displayed based on the moving image data, based on the scenario data;
The image generation system according to any one of (1) to (9), further comprising:
(11)
The image generation system according to any one of (1) to (10), wherein the input query includes at least one of text, image, audio, and 3D data.
(12)
a first output unit that outputs scenario generation information used by the scenario generation unit to generate the scenario data based on the input query;
Further comprising:
The scenario generation unit includes:
The image generation system according to any one of (1) to (11), further comprising: generating the scenario data based on the scenario generation information.
(13)
The first output section is
generating a first prompt for generating the scenario data based on the input query as the scenario generation information;
The scenario generation unit includes:
The image production system according to any one of claims 12 to 17, further comprising: a display unit configured to display a display screen of the image production system according to the first prompt;
(14)
The first output section is
generating, based on the input query, first input information to be used as an input of a first model for generating the scenario data, as the scenario generation information;
The scenario generation unit includes:
The image generation system according to (12) or (13), further comprising: inputting the first input information generated using the input query into the first model; and causing the first model to output the scenario data, thereby generating the scenario data.
(15)
a second output unit that outputs code generation information used by the code generation unit to generate a code for configuring the 3D data based on the scenario data;
Further comprising:
The code generation unit
The image generation system according to any one of (1) to (14), further comprising: generating the code based on the code generation information.
(16)
The second output section is
generating, as the code generation information, a second prompt for outputting a code for configuring the 3D data based on the scenario data;
The scenario generation unit includes:
The image production system of any one of
(17)
The second output section is
generating second input information as the code generation information based on the input query, the second input information being used as an input of a second model for generating the code;
The scenario generation unit includes:
The video generation system according to (15) or (16), wherein the code is generated by inputting the second input information generated using the scenario data into the second model and causing the second model to output the code.
(18)
a reception unit that receives operations related to video editing from a user;
Further comprising:
The code generation unit
The image generation system according to any one of (1) to (17), further comprising: generating the code by editing based on the operation.
(19)
The reception unit is
Accepting the operation specifying a motion or camera movement using a sensor;
The code generation unit
The image generation system according to claim 18, further comprising: generating the code corresponding to the motion or camera movement indicated by the operation.
(20)
The reception unit is
accepting the operation of selecting a plurality of cuts from the video data;
The code generation unit
The video generation system according to (18) or (19), further comprising: generating the code in which the portions corresponding to the plurality of cuts indicated by the operation have been changed.
(21)
Date information is associated with each cut of the video data,
The code generation unit
The video production system according to any one of (18) to (20), further comprising: determining the content of the editing indicated by the operation based on date information of each cut of the video data.
(22)
The reception unit is
accepting the operation of designating an object to be changed from among the video data;
The code generation unit
The image generation system according to any one of (18) to (21), further comprising: generating the code in which 3D data of the object indicated by the operation has been changed.
(23)
the 3D data comprises a plurality of data sets;
The code generation unit
The image generation system according to any one of (18) to (22), further comprising: generating the code corresponding to at least one of the plurality of data sets by editing based on the operation.
(24)
The code generation unit
The video generation system according to any one of the above (23) and (24), further comprising: a process for updating a part of the plurality of data sets; and a process for updating the entirety of the plurality of data sets, depending on the editing content indicated by the operation.
(25)
an evaluation unit that generates information indicating an evaluation of at least one of the scenario data and the video data;
The image generation system according to any one of (1) to (24), further comprising:
(26)
The code generation unit
The image generation system according to any one of claims 25 to 30, further comprising: generating the code based on the evaluation.
(27)
The scenario generation unit includes:
The image generation system according to (25) or (26), further comprising: generating the scenario data based on the evaluation.
(28)
The code generation unit
The image generation system according to any one of claims 27 to 31, further comprising: generating the code based on the scenario data generated based on the evaluation.
(29)
Obtaining an input query for video generation from a user;
generating scenario data related to movie generation based on the input query;
generating a code for constructing 3D data based on the scenario data; and
and acquiring video data based on the code.
(30)
Obtaining an input query for video generation from a user;
generating scenario data related to movie generation based on the input query;
generating a code for constructing 3D data based on the scenario data; and
and acquiring video data based on said code.
1 映像生成システム
100 映像生成モジュール
110 入力テキスト解析部
120 センサ解析部
130 プロンプト等生成部
131 シナリオ向け生成部
132 映像向け生成部
133 サウンド向け生成部
134 テキスト/ロゴ向け生成部
140 映像生成部
141 USD生成部
142 レンダリング部
143 映像リファイン部
150 サウンド生成部
160 テキスト/ロゴ生成部
170 コンポジット編集部
180 評価部
190 クライアントUIモジュール
200 情報取得モジュール
210 入力テキスト取得部
220 センサ取得部
300 センサ部
400 クライアントUI表示部
1
Claims (30)
前記入力クエリに基づいて、動画生成に関するシナリオデータを生成するシナリオ生成部と、
前記シナリオデータに基づいて、3Dデータを構成し、シーン及びオブジェクトのうち少なくとも1つを定義するための編集可能なコンピュータプログラムであるコードを生成するコード生成部と、
前記コードに基づいて、動画データを取得する動画データ取得部と、
を備える映像生成システム。 An acquisition unit that acquires an input query regarding video generation from a user;
a scenario generation unit that generates scenario data related to video generation based on the input query;
a code generation unit that generates code, which is an editable computer program, for configuring 3D data and defining at least one of a scene and an object based on the scenario data;
a video data acquisition unit that acquires video data based on the code;
An image generation system comprising:
を更に備える請求項1に記載の映像生成システム。 an image quality improvement unit that executes an image quality improvement process to improve the image quality of the video data;
The video production system of claim 1 further comprising:
テキストプロンプトに基づいて前記画質改善処理を実行することにより、前記動画データの画質を改善する
請求項2に記載の映像生成システム。 The image quality improvement unit includes:
The image generation system of claim 2 , further comprising: a display unit configured to display a display image of the video data based on the display image of the video data;
前記動画データのうち前記画質改善処理の対象を指定するテキストプロンプトに基づいて、前記画質改善処理を実行する
請求項2に記載の映像生成システム。 The image quality improvement unit includes:
The video production system according to claim 2 , wherein the image quality improvement process is performed based on a text prompt that specifies a target of the image quality improvement process in the video data.
改善が必要と判断された前記対象を指定するテキストプロンプトに基づいて、前記画質改善処理を実行する
請求項4に記載の映像生成システム。 The image quality improvement unit includes:
The image production system of claim 4 , further comprising: a text prompt that specifies the object determined to require improvement, and the image quality improvement process is performed based on the text prompt that specifies the object determined to require improvement.
を更に備える請求項1に記載の映像生成システム。 a display control unit that displays a storyboard based on the scenario data;
The video production system of claim 1 further comprising:
請求項6に記載の映像生成システム。 The video production system according to claim 6 , wherein the storyboard is configured to display the video data for each cut of the video.
を更に備える請求項1に記載の映像生成システム。 a sound generating unit that generates sound data corresponding to the video data based on the scenario data and the video data;
The video production system of claim 1 further comprising:
を更に備える請求項1に記載の映像生成システム。 a text generating unit that generates text data indicating text to be displayed on a video displayed based on the video data, based on the scenario data;
The video production system of claim 1 further comprising:
を更に備える請求項1に記載の映像生成システム。 a logo generating unit that generates logo data indicating a logo to be displayed on a video image displayed based on the moving image data, based on the scenario data;
The video production system of claim 1 further comprising:
請求項1に記載の映像生成システム。 The video generation system of claim 1 , wherein the input query includes at least one of text, image, audio, and 3D data.
を更に備え、
前記シナリオ生成部は、
前記シナリオ生成用情報に基づいて前記シナリオデータを生成する
請求項1に記載の映像生成システム。 a first output unit that outputs scenario generation information used by the scenario generation unit to generate the scenario data based on the input query;
Further comprising:
The scenario generation unit includes:
The image production system according to claim 1 , wherein the scenario data is generated based on the scenario generation information.
前記入力クエリに基づいて、前記シナリオデータを生成するための第1のプロンプトを、前記シナリオ生成用情報として生成し、
前記シナリオ生成部は、
前記第1のプロンプトに基づいて前記シナリオデータを生成する
請求項12に記載の映像生成システム。 The first output section is
generating a first prompt for generating the scenario data based on the input query as the scenario generation information;
The scenario generation unit includes:
The image production system of claim 12 , further comprising: a display unit configured to display a screen displaying the screen image data based on the first prompt;
前記入力クエリに基づいて、前記シナリオデータを生成するための第1のモデルの入力として用いられる第1の入力情報を前記シナリオ生成用情報として生成し、
前記シナリオ生成部は、
前記入力クエリを用いて生成された前記第1の入力情報を、前記第1のモデルに入力し、前記第1のモデルに前記シナリオデータを出力させることにより、前記シナリオデータを生成する
請求項12に記載の映像生成システム。 The first output section is
generating, based on the input query, first input information to be used as an input of a first model for generating the scenario data, as the scenario generation information;
The scenario generation unit includes:
The image generation system according to claim 12, wherein the scenario data is generated by inputting the first input information generated using the input query into the first model and causing the first model to output the scenario data.
を更に備え、
前記コード生成部は、
前記コード生成用情報に基づいて前記コードを生成する
請求項1に記載の映像生成システム。 a second output unit that outputs code generation information used by the code generation unit to generate a code for configuring the 3D data based on the scenario data;
Further comprising:
The code generation unit
The video generation system according to claim 1 , wherein the code is generated based on the information for code generation.
前記シナリオデータに基づいて、前記3Dデータを構成するためのコードを出力するための第2のプロンプトを、前記コード生成用情報として生成し、
前記シナリオ生成部は、
前記第2のプロンプトに基づいて前記コードを生成する
請求項15に記載の映像生成システム。 The second output section is
generating, as the code generation information, a second prompt for outputting a code for configuring the 3D data based on the scenario data;
The scenario generation unit includes:
The video production system of claim 15 further comprising: generating the code based on the second prompt.
前記入力クエリに基づいて、前記コードを生成するための第2のモデルの入力として用いられる第2の入力情報を前記コード生成用情報として生成し、
前記シナリオ生成部は、
前記シナリオデータを用いて生成された前記第2の入力情報を、前記第2のモデルに入力し、前記第2のモデルに前記コードを出力させることにより、前記コードを生成する
請求項15に記載の映像生成システム。 The second output section is
generating second input information as the code generation information based on the input query, the second input information being used as an input of a second model for generating the code;
The scenario generation unit includes:
The video generation system according to claim 15 , wherein the code is generated by inputting the second input information generated using the scenario data into the second model and causing the second model to output the code.
を更に備え、
前記コード生成部は、
前記操作に基づいた編集により、前記コードを生成する
請求項1に記載の映像生成システム。 a reception unit that receives operations related to video editing from a user;
Further comprising:
The code generation unit
The video generation system according to claim 1 , wherein the code is generated by editing based on the operation.
センサを用いてモーションまたはカメラの動きを指定する前記操作を受け付け、
前記コード生成部は、
前記操作が示す前記モーションまたは前記カメラの動きに対応する前記コードを生成する
請求項18に記載の映像生成システム。 The reception unit is
Accepting the operation specifying a motion or camera movement using a sensor;
The code generation unit
The image generation system of claim 18 , further comprising: generating the code corresponding to the motion or camera movement indicated by the operation.
前記動画データのうち、複数のカットを選択する前記操作を受け付け、
前記コード生成部は、
前記操作が示す前記複数のカットに対応する部分が変更された前記コードを生成する
請求項18に記載の映像生成システム。 The reception unit is
accepting the operation of selecting a plurality of cuts from the video data;
The code generation unit
The video production system according to claim 18 , further comprising: generating the code in which portions corresponding to the plurality of cuts indicated by the operation have been changed.
前記コード生成部は、
前記動画データの各カットの日付情報に基づいて、前記操作が示す前記編集の内容を決定する
請求項18に記載の映像生成システム。 Date information is associated with each cut of the video data,
The code generation unit
The video production system according to claim 18 , further comprising: determining the content of the editing operation indicated by the operation based on date information of each cut of the video data.
前記動画データのうち、変更の対象とする対象物を指定する前記操作を受け付け、
前記コード生成部は、
前記操作が示す前記対象物の3Dデータが変更された前記コードを生成する
請求項18に記載の映像生成システム。 The reception unit is
accepting the operation of designating an object to be changed from among the video data;
The code generation unit
The image generation system according to claim 18 , further comprising: generating the code in which 3D data of the object indicated by the operation has been changed.
前記コード生成部は、
前記操作に基づいた編集により、前記複数のデータセットのうち少なくとも1つに対応する前記コードを生成する
請求項18に記載の映像生成システム。 the 3D data comprises a plurality of data sets;
The code generation unit
The video production system of claim 18 , further comprising: generating the code corresponding to at least one of the plurality of data sets through editing based on the operation.
前記操作が示す編集内容に応じて、前記複数のデータセットのうち一部を更新する処理と前記複数のデータセット全体を更新する処理とのうちのいずれかを実行する
請求項23に記載の映像生成システム。 The code generation unit
The video generation system according to claim 23 , further comprising: a process for updating a part of the plurality of data sets, or a process for updating all of the plurality of data sets, depending on editing content indicated by the operation.
を更に備える請求項1に記載の映像生成システム。 an evaluation unit that generates information indicating an evaluation of at least one of the scenario data and the video data;
The video production system of claim 1 further comprising:
前記評価に基づいて、前記コードを生成する
請求項25に記載の映像生成システム。 The code generation unit
The video production system of claim 25 , further comprising: generating said code based on said evaluation.
前記評価に基づいて、前記シナリオデータを生成する
請求項25に記載の映像生成システム。 The scenario generation unit includes:
The image generation system according to claim 25 , further comprising: generating the scenario data based on the evaluation.
前記評価に基づき生成された前記シナリオデータに基づいて、前記コードを生成する
請求項27に記載の映像生成システム。 The code generation unit
The image generation system according to claim 27, further comprising: generating the code based on the scenario data generated based on the evaluation.
前記入力クエリに基づいて、動画生成に関するシナリオデータを生成することと、
前記シナリオデータに基づいて、3Dデータを構成し、シーン及びオブジェクトのうち少なくとも1つを定義するための編集可能なコンピュータプログラムであるコードを生成することと、
前記コードに基づいて、動画データを取得することと
を含む映像生成方法。 Obtaining an input query for video generation from a user;
generating scenario data related to movie generation based on the input query;
generating, based on the scenario data, code that is an editable computer program for constructing 3D data and defining at least one of a scene and an object ;
and acquiring video data based on the code.
前記入力クエリに基づいて、動画生成に関するシナリオデータを生成することと、
前記シナリオデータに基づいて、3Dデータを構成し、シーン及びオブジェクトのうち少なくとも1つを定義するための編集可能なコンピュータプログラムであるコードを生成することと、
前記コードに基づいて、動画データを取得することと
をコンピュータに実行させる映像生成プログラム。 Obtaining an input query for video generation from a user;
generating scenario data related to movie generation based on the input query;
generating, based on the scenario data, code that is an editable computer program for constructing 3D data and defining at least one of a scene and an object ;
and acquiring video data based on said code.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024065475A JP7578209B1 (en) | 2024-04-15 | 2024-04-15 | Image generation system, image generation method, and image generation program |
| PCT/JP2025/008918 WO2025220361A1 (en) | 2024-04-15 | 2025-03-11 | Video generation system, video generation method, and video generation program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024065475A JP7578209B1 (en) | 2024-04-15 | 2024-04-15 | Image generation system, image generation method, and image generation program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP7578209B1 true JP7578209B1 (en) | 2024-11-06 |
| JP2025162283A JP2025162283A (en) | 2025-10-27 |
Family
ID=93332394
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024065475A Active JP7578209B1 (en) | 2024-04-15 | 2024-04-15 | Image generation system, image generation method, and image generation program |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7578209B1 (en) |
| WO (1) | WO2025220361A1 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN119206016A (en) * | 2024-11-28 | 2024-12-27 | 成都信息工程大学 | A method for rendering extreme rainstorm weather based on generative artificial intelligence |
| CN119251345A (en) * | 2024-12-04 | 2025-01-03 | 美众(天津)科技有限公司 | A virtual hair replacement method and system for diffusion model combined with Transformer architecture |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110249953A1 (en) | 2010-04-09 | 2011-10-13 | Microsoft Corporation | Automated story generation |
| WO2023002659A1 (en) | 2021-07-21 | 2023-01-26 | ソニーグループ株式会社 | Information processing device, information processing method, and program |
| KR102508765B1 (en) | 2022-05-06 | 2023-03-14 | (주) 스튜디오 애니 | User-customized meta content providing system based on artificial neural network and method therefor |
-
2024
- 2024-04-15 JP JP2024065475A patent/JP7578209B1/en active Active
-
2025
- 2025-03-11 WO PCT/JP2025/008918 patent/WO2025220361A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110249953A1 (en) | 2010-04-09 | 2011-10-13 | Microsoft Corporation | Automated story generation |
| WO2023002659A1 (en) | 2021-07-21 | 2023-01-26 | ソニーグループ株式会社 | Information processing device, information processing method, and program |
| KR102508765B1 (en) | 2022-05-06 | 2023-03-14 | (주) 스튜디오 애니 | User-customized meta content providing system based on artificial neural network and method therefor |
Non-Patent Citations (4)
| Title |
|---|
| Dan Kondratyuk ほか1名,VideoPoet: A large language model for zero-shot video generation,Google Research Blog,2023年12月19日,p.1-10,[令和6年7月5日検索],インターネット <URL:https://research.google/blog/videopoet-a-large-language-model-for-zero-shot-video-generation/> |
| Dan Kondratyuk,VideoPoet: A Large Language Model for Zero-Shot Video Generation,2024年03月22日,p.1-19,<URL:https://arxiv.org/pdf/2312.14125>,[令和6年5月2日検索],インターネット |
| チャエン,ChatGPTにストーリーを書いてもらい、生成AIで短編映像を作成する方法,PC Watch,2024年01月11日,<URL: https://pc.watch.impress.co.jp/docs/topic/feature/1559847.html>,[令和6年5月7日検索],インターネット |
| 画像生成AIイラスト[画質を上げるプロンプト]&[画質に美しさ与えるプロンプト]呪文の書き方21選,2023年05月24日,<URL:https://nagi.blog/generativeai-prompt-imagequality/>,[令和6年5月2日検索],インターネット |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN119206016A (en) * | 2024-11-28 | 2024-12-27 | 成都信息工程大学 | A method for rendering extreme rainstorm weather based on generative artificial intelligence |
| CN119251345A (en) * | 2024-12-04 | 2025-01-03 | 美众(天津)科技有限公司 | A virtual hair replacement method and system for diffusion model combined with Transformer architecture |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2025162283A (en) | 2025-10-27 |
| WO2025220361A1 (en) | 2025-10-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11809688B1 (en) | Interactive prompting system for multimodal personalized content generation | |
| US8730231B2 (en) | Systems and methods for creating personalized media content having multiple content layers | |
| CN110012237B (en) | Video generation method and system based on interactive guidance and cloud-enhanced rendering | |
| JP7578209B1 (en) | Image generation system, image generation method, and image generation program | |
| CN114363712A (en) | AI digital person video generation method, device and equipment based on templated editing | |
| KR20210119438A (en) | Systems and methods for face reproduction | |
| KR102180576B1 (en) | Method and apparatus for providing re-programmed interactive content based on user playing | |
| KR100960504B1 (en) | Method and system for creating digital storyboard with emotional expression | |
| KR102854560B1 (en) | Method and electronic device for image augmentation | |
| CN113542624A (en) | Method and device for generating commodity object explanation video | |
| CN118674839B (en) | Animation generation method, device, electronic equipment, storage medium and program product | |
| CN116225234A (en) | Interaction method and cloud server | |
| CN101401130B (en) | Apparatus and method for providing a sequence of video frames, apparatus and method for providing a scene model, scene model, apparatus and method for creating a menu structure and computer program | |
| US9396574B2 (en) | Choreography of animated crowds | |
| Jo et al. | CollageVis: Rapid Previsualization Tool for Indie Filmmaking using Video Collages | |
| Queiroz et al. | A framework for generic facial expression transfer | |
| JP2006221489A (en) | Cg animation manufacturing system | |
| Eisert et al. | Hybrid human modeling: making volumetric video animatable | |
| US8773441B2 (en) | System and method for conforming an animated camera to an editorial cut | |
| KR20060040118A (en) | Custom 3D animation production method and device and its distribution system | |
| CN121239924B (en) | A method and apparatus for generating comic videos based on interactive annotation | |
| KR100965622B1 (en) | Method and apparatus for generating emotional character and animation | |
| Jones et al. | Foundation Flash Cartoon Animation | |
| WO2025225484A1 (en) | Information processing system, information processing method, and information processing program | |
| WO2026001246A1 (en) | Video generation method and related apparatus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20240419 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20240419 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240514 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240701 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240716 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240906 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240924 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20241007 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7578209 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |