JP7560627B2 - Information processing system, information processing method, and program - Google Patents
Information processing system, information processing method, and program Download PDFInfo
- Publication number
- JP7560627B2 JP7560627B2 JP2023132705A JP2023132705A JP7560627B2 JP 7560627 B2 JP7560627 B2 JP 7560627B2 JP 2023132705 A JP2023132705 A JP 2023132705A JP 2023132705 A JP2023132705 A JP 2023132705A JP 7560627 B2 JP7560627 B2 JP 7560627B2
- Authority
- JP
- Japan
- Prior art keywords
- inquiry
- answer
- narrowing
- response
- attributes
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000010365 information processing Effects 0.000 title claims description 96
- 238000003672 processing method Methods 0.000 title claims description 4
- 230000004044 response Effects 0.000 claims description 308
- 238000000034 method Methods 0.000 claims description 248
- 230000008569 process Effects 0.000 claims description 238
- 230000003466 anti-cipated effect Effects 0.000 claims description 88
- 238000012545 processing Methods 0.000 description 343
- 238000000605 extraction Methods 0.000 description 119
- 238000010586 diagram Methods 0.000 description 52
- 230000010354 integration Effects 0.000 description 34
- 239000000284 extract Substances 0.000 description 17
- FFBHFFJDDLITSX-UHFFFAOYSA-N benzyl N-[2-hydroxy-4-(3-oxomorpholin-4-yl)phenyl]carbamate Chemical compound OC1=C(NC(=O)OCC2=CC=CC=C2)C=CC(=C1)N1CCOCC1=O FFBHFFJDDLITSX-UHFFFAOYSA-N 0.000 description 14
- 230000006870 function Effects 0.000 description 11
- 230000014509 gene expression Effects 0.000 description 10
- 230000009118 appropriate response Effects 0.000 description 8
- 230000004048 modification Effects 0.000 description 8
- 238000012986 modification Methods 0.000 description 8
- 101000607335 Homo sapiens Serine/threonine-protein kinase ULK1 Proteins 0.000 description 7
- 102100039988 Serine/threonine-protein kinase ULK1 Human genes 0.000 description 7
- 238000007781 pre-processing Methods 0.000 description 7
- 101150028385 ATG2 gene Proteins 0.000 description 6
- 101100410782 Arabidopsis thaliana PXG1 gene Proteins 0.000 description 6
- 101100164184 Candida albicans (strain SC5314 / ATCC MYA-2876) SPO72 gene Proteins 0.000 description 6
- 101100380548 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) apg-2 gene Proteins 0.000 description 6
- 101150033568 ats1 gene Proteins 0.000 description 6
- 238000011161 development Methods 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 238000003384 imaging method Methods 0.000 description 6
- 238000012546 transfer Methods 0.000 description 6
- 101100075174 Arabidopsis thaliana LPAT1 gene Proteins 0.000 description 5
- 101100410783 Arabidopsis thaliana PXG2 gene Proteins 0.000 description 5
- 238000004891 communication Methods 0.000 description 5
- 238000004904 shortening Methods 0.000 description 5
- 102220480414 Adhesion G-protein coupled receptor D1_S13A_mutation Human genes 0.000 description 4
- 101100272041 Arabidopsis thaliana ATS3 gene Proteins 0.000 description 4
- 101000887051 Homo sapiens Ubiquitin-like-conjugating enzyme ATG3 Proteins 0.000 description 4
- 102100039930 Ubiquitin-like-conjugating enzyme ATG3 Human genes 0.000 description 4
- 238000001914 filtration Methods 0.000 description 4
- 102220637010 Actin-like protein 7A_S10T_mutation Human genes 0.000 description 3
- 230000009471 action Effects 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 102220646157 Actin-like protein 7A_S12A_mutation Human genes 0.000 description 2
- 238000013473 artificial intelligence Methods 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 238000010079 rubber tapping Methods 0.000 description 2
- 102220646098 Actin-like protein 7A_S11A_mutation Human genes 0.000 description 1
- 238000007792 addition Methods 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000013528 artificial neural network Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 239000002365 multiple layer Substances 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
Images





























Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本発明は、情報処理システム、情報処理方法及びプログラムに関する。 The present invention relates to an information processing system, an information processing method, and a program.
従来、ユーザの発話を音声認識し、問い合せに対して自動応答を行う技術が知られている。
例えば、特許文献1に記載された音声自動質問応答装置では、音声認識エンジンを用いて自由発話型式の質問等を音声認識し、音声認識結果を談話解析等することで補正して、質問内容の適切な認識を図ることとしている。
2. Description of the Related Art Conventionally, there is known a technique for recognizing a user's speech and automatically responding to an inquiry.
For example, in the automatic voice question answering device described in
しかしながら、従来の技術においては、音声によって入力された問い合わせを基に回答を特定しようとしても、問い合わせに含まれる情報が不十分であること等から、適切な回答を導き出すことができない場合があった。
また、自由発話された問い合わせを汎用的な音声認識エンジンを用いて音声認識した場合、問い合わせ内容を適切に音声認識できない可能性があった。
また、音声認識処理及び回答を特定する処理に長時間を要する場合があり、問い合わせに対して、速やかに回答することができない可能性があった。
さらに、問い合わせを行う発話者が用いる表現は多様であることから、このような表現の多様性に対し、システム側の対応能力が十分ではない場合があった。
これらのいずれかの理由または複数の理由が複合的に生じた場合、音声による問い合わせに対し、適切な自動応答を行うことが困難となる。
なお、このような課題は、音声による問い合わせを音声認識する場合に限らず、チャット等のテキスト入力による問い合わせにおいても生じる可能性がある。
However, in conventional technology, even if an attempt was made to identify an answer based on an inquiry input by voice, there were cases in which an appropriate answer could not be derived due to insufficient information contained in the inquiry, etc.
Furthermore, when a freely spoken inquiry is subjected to speech recognition using a general-purpose speech recognition engine, there is a possibility that the content of the inquiry cannot be properly recognized.
Furthermore, the voice recognition process and the process of identifying an answer may take a long time, which may make it impossible to respond to an inquiry promptly.
Furthermore, since speakers making inquiries use a wide variety of expressions, the system may not be able to adequately handle such a wide variety of expressions.
If any one of these reasons or a combination of multiple reasons occurs, it becomes difficult to provide an appropriate automatic response to a voice inquiry.
It should be noted that such a problem may arise not only in the case of voice recognition of a voice inquiry, but also in the case of an inquiry by text input such as a chat.
本発明の課題は、問い合わせに対し、より適切な自動応答を行う技術を提供することである。 The objective of the present invention is to provide a technology that provides a more appropriate automatic response to inquiries.
上記目的を達成するため、本発明の一態様の情報処理システムは、
1または複数の情報処理装置を含む情報処理システムであって、
想定された問い合わせに関する第1の属性情報を記憶する第1属性情報記憶手段と、
前記想定された問い合わせに対する回答に関する第2の属性情報を記憶する第2属性情報記憶手段と、
問い合わせの内容を取得する問い合わせ内容取得手段と、
前記問い合わせの内容が有する属性情報と、前記第1の属性情報及び前記第2の属性情報とに基づいて、前記問い合わせに対する回答を含む応答を特定する応答特定手段と、
を備えることを特徴とする。
In order to achieve the above object, an information processing system according to one aspect of the present invention comprises:
An information processing system including one or more information processing devices,
a first attribute information storage means for storing first attribute information relating to an anticipated inquiry;
a second attribute information storage means for storing second attribute information relating to a response to the anticipated inquiry;
An inquiry content acquisition means for acquiring the content of an inquiry;
a response specifying means for specifying a response including an answer to the inquiry based on attribute information included in the content of the inquiry, the first attribute information, and the second attribute information;
The present invention is characterized by comprising:
また、上記目的を達成するため、本発明の他の態様の情報処理システムは、
1または複数の情報処理装置を含む情報処理システムであって、
問い合わせのための発話が音声認識処理された音声認識結果を取得する音声認識手段と、
前記音声認識手段による音声認識結果が表す意味内容から、前記問い合わせに適合する回答の候補を言語処理によって特定する言語処理手段と、
前記音声認識手段による音声認識結果から前記問い合わせに含まれる単語を抽出し、前記問い合わせに含まれる単語に基づく属性情報と、前記問い合わせに対する回答に基づく属性情報との関連性に基づいて、前記問い合わせに適合する回答の候補を特定する属性処理手段と、
前記言語処理手段によって特定された前記回答の候補と、前記属性処理手段によって特定された前記回答の候補とに基づいて、前記問い合わせに対する回答を含む応答を特定する応答特定手段と、
を備えることを特徴とする。
In order to achieve the above object, an information processing system according to another aspect of the present invention comprises:
An information processing system including one or more information processing devices,
A speech recognition means for acquiring a speech recognition result obtained by subjecting a speech for a query to speech recognition processing;
a language processing means for specifying answer candidates matching the inquiry by language processing based on the meaning of the speech recognition result by the speech recognition means;
an attribute processing means for extracting words contained in the query from a speech recognition result by the speech recognition means, and for identifying answer candidates matching the query based on attribute information based on the words contained in the query and attribute information based on an answer to the query;
a response identifying means for identifying a response including an answer to the inquiry based on the answer candidates identified by the language processing means and the answer candidates identified by the attribute processing means;
The present invention is characterized by comprising:
また、上記目的を達成するため、本発明の他の態様の情報処理システムは、
1または複数の情報処理装置を含む情報処理システムであって、
想定された問い合わせに関する第1の属性情報と、前記想定された問い合わせに対する回答に関する第2の属性情報とに基づいて、前記想定された問い合わせに対する回答に対応付けられた1または複数の属性によって構成される探索用データを生成する探索用データ生成手段と、
問い合わせの内容を取得する問い合わせ内容取得手段と、
前記問い合わせの内容が有する属性情報と、前記探索用データとに基づいて、前記問い合わせの内容に対する回答を含む応答を特定する応答特定手段と、
を備えることを特徴とする。
In order to achieve the above object, an information processing system according to another aspect of the present invention comprises:
An information processing system including one or more information processing devices,
a search data generating means for generating search data composed of one or more attributes associated with the answer to the anticipated inquiry based on first attribute information related to the anticipated inquiry and second attribute information related to the answer to the anticipated inquiry;
An inquiry content acquisition means for acquiring the content of an inquiry;
a response specifying means for specifying a response including an answer to the content of the inquiry based on attribute information of the content of the inquiry and the search data;
The present invention is characterized by comprising:
また、上記目的を達成するため、本発明の他の態様の情報処理システムは、
1または複数の情報処理装置を含む情報処理システムであって、
問い合わせのための発話が音声認識処理された音声認識結果を取得する音声認識手段と、
想定された問い合わせに関する第1の属性情報と、前記想定された問い合わせに対する回答に関する第2の属性情報と、前記第1の属性情報及び前記第2の属性情報に関連する拡大された属性情報とを要素として含むフィルタによって、前記音声認識手段による音声認識結果が有する属性情報をフィルタ処理するフィルタ処理手段と、
前記フィルタ処理手段によるフィルタ処理結果に基づいて、前記問い合わせのための発話に対する回答を含む応答を特定する応答特定手段と、
を備えることを特徴とする。
In order to achieve the above object, an information processing system according to another aspect of the present invention comprises:
An information processing system including one or more information processing devices,
A speech recognition means for acquiring a speech recognition result obtained by subjecting a speech for a query to speech recognition processing;
a filter processing means for filtering attribute information included in a speech recognition result by said speech recognition means using a filter including, as elements, first attribute information related to an expected inquiry, second attribute information related to a response to said expected inquiry, and expanded attribute information related to said first attribute information and said second attribute information;
a response identifying means for identifying a response including a response to the utterance for inquiry based on a filtering result by the filtering means;
The present invention is characterized by comprising:
本発明によれば、問い合わせに対し、より適切な自動応答を行う技術を提供することができる。 The present invention provides a technology that provides a more appropriate automatic response to inquiries.
以下、本発明の実施形態について、図面を用いて説明する。
[第1実施形態]
本実施形態に係る情報処理システムは、問い合わせのための発話を音声認識処理し、音声認識結果が表す発話の内容を言語処理することによって、問い合わせに適合する回答の候補を特定する特定処理(言語処理を用いた特定処理)と、問い合わせのための発話の音声認識結果に含まれる単語が表す属性と、想定された問い合わせ及び想定された問い合わせに対して用意されている回答に基づく属性との関連性を判定し、属性の関連性によって、発話された問い合わせに適合する回答の候補を特定する特定処理(属性の関連性に基づく特定処理)とを実行する。そして、本実施形態に係る情報処理システムは、言語処理を用いた特定処理によって特定された回答の候補と、属性の関連性に基づく特定処理によって特定された回答の候補とに基づいて、問い合わせに対する最終的な回答を特定し、問い合わせに対して応答(回答を含む対話)を出力する。
したがって、本実施形態に係る情報処理システムによれば、発話に対する自動応答を行う際に、処理時間を短縮しつつ、より適切な応答内容を特定することが可能となる。
Hereinafter, an embodiment of the present invention will be described with reference to the drawings.
[First embodiment]
The information processing system according to the present embodiment performs a process of identifying answer candidates that match the inquiry (a process of identifying using language processing) by performing speech recognition processing on an utterance for making a query, and a process of determining the relevance between attributes represented by words included in the speech recognition result of the utterance for making a query and attributes based on an expected query and answers prepared for the expected query, and performs a process of identifying answer candidates that match the uttered query based on the relevance of the attributes (a process of identifying based on the relevance of the attributes).The information processing system according to the present embodiment then identifies a final answer to the query based on the answer candidates identified by the process of identifying using language processing and the answer candidates identified by the process of identifying based on the relevance of the attributes, and outputs a response (a dialogue including the answer) to the query.
Therefore, according to the information processing system according to the present embodiment, when an automatic response is made to a speech, it is possible to specify more appropriate response content while shortening the processing time.
また、本願発明においては、問い合わせ及び回答の内容を特定の目的(即ち、特定の適用対象)に特化して実装するものとしており、その結果、この目的に応じた適切な問い合わせ及び回答の組み合わせを用意することができる。そして、用意された問い合わせ及び回答に対して、後述するように、属性の分類、属性の拡大、抽出フィルタの生成等の処理を、問い合わせの発話が行われることに先行して実施することができる。したがって、問い合わせの発話が行われた際に、高速に回答を特定することが可能となっている。 Furthermore, in the present invention, the contents of the queries and answers are implemented to be specialized for a specific purpose (i.e., a specific target), and as a result, an appropriate combination of queries and answers can be prepared according to this purpose. Then, as described below, processing such as attribute classification, attribute expansion, and extraction filter generation can be performed on the prepared queries and answers before the query is spoken. Therefore, when a query is spoken, it is possible to quickly identify the answer.
なお、本実施形態において、発話された問い合わせに対する回答として特定される事項(即ち、自動応答の結果)は、回答を行う能力を備えた担当者または回答自体を表すコンテンツ(例えば、テキスト、ビデオ、音声のコンテンツあるいはWebページ等)であるものとし、発話された問い合わせに対する回答として特定された担当者が、自身の知識をベースに問い合わせに回答したり、回答として特定されたコンテンツがユーザ(問い合わせを行った発話者)に提供されたりするものとする。
以下、本実施形態に係る情報処理システムを具体的に説明する。
In this embodiment, the item identified as the answer to the spoken inquiry (i.e., the result of the automatic response) is a person capable of providing an answer or content representing the answer itself (e.g., text, video, audio content, or a web page, etc.), and the person identified as the answer to the spoken inquiry will answer the inquiry based on their own knowledge, and the content identified as the answer will be provided to the user (the speaker who made the inquiry).
The information processing system according to this embodiment will be specifically described below.
図1は、本実施形態に係る情報処理システム1の構成を示す模式図である。
図1に示すように、情報処理システム1は、複数の端末装置10と、サーバ20とを含んで構成され、複数の端末装置10とサーバ20とは、ネットワーク30を介して互いに通信可能に構成されている。
図1に示す情報処理システム1は、本発明に係る情報処理システムを、ネットワークを介して音声による問い合わせを受け付けるコールセンター等の業務システムに適用した例を示しており、音声による問い合わせに対し、自動応答を行うものである。
FIG. 1 is a schematic diagram showing the configuration of an
As shown in FIG. 1, the
An
端末装置10は、スマートフォンあるいはPC(Personal Computer)等の情報処理装置によって構成される。また、端末装置10は、問い合わせを行うユーザによって使用され、ユーザによる問い合わせ内容を表す音声の入力を受け付け、入力された音声のデータをサーバ20に送信する。また、端末装置10は、サーバ20から送信された問い合わせに対する回答(回答を行う能力を備えた担当者または回答自体を表すコンテンツ(例えば、テキスト、ビデオ、音声のコンテンツあるいはWebページ等))をユーザに対して出力する。
The
サーバ20は、PCあるいはサーバコンピュータ等の情報処理装置によって構成される。サーバ20は、端末装置10から送信される問い合わせ内容を表す音声のデータを受信し、音声認識処理を実行して、問い合わせ内容を表すテキストデータ(音声認識結果)を取得する。本実施形態において、サーバ20は、異なる種類の音声認識処理を並列的に実行することにより、複数の音声認識結果を取得する。具体的には、サーバ20は、入力された音声データ全体をテキストデータに変換するディクテーションを目的とした音声認識処理と、音声データに含まれる特定の単語を抽出してテキストデータに変換する単語抽出の音声認識処理とを並列的に実行する。ただし、サーバ20が1つの音声認識処理(例えば、ディクテーションの音声認識処理)を実行し、1つの音声認識結果を処理(例えば、単語抽出処理等)することにより、複数の音声認識結果を取得することとしてもよい。
The
また、サーバ20は、取得した音声認識結果に基づいて、言語処理を用いた回答の候補を特定する。即ち、サーバ20は、ユーザの発話を音声認識したテキストデータを自然言語処理によって意味内容を抽出し、予め用意されている回答(ここでは、回答を行う担当者または回答自体を表すコンテンツ)の中から、発話された問い合わせの内容に適合する可能性が高い回答の候補を特定する。なお、以下、言語処理を用いて特定された回答の候補を適宜「言語処理による回答の候補」と称する。
Furthermore, the
また、サーバ20は、音声認識処理によって問い合わせのための発話から所定の単語を抽出し、発話に含まれる単語が表す属性と、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性との関連性を基に、回答の候補を特定する。即ち、サーバ20は、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性を表す単語の類似語を取得することにより、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性を拡大し、拡大された属性(即ち、オリジナルの属性を表す単語及びその類似語)をフィルタとして、問い合わせのための発話に含まれる単語が拡大された属性のいずれかに一致するか否かを判定する。そして、サーバ20は、拡大された属性において、問い合わせのための発話に含まれる単語と一致したものが対応している回答の候補を特定する。なお、以下、属性の関連性を基に特定された回答の候補を適宜「属性の関連性に基づく回答の候補」と称する。
The
このように、本実施形態においては、問い合わせの発話に含まれる単語が表す属性と、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性との関連性を基に、回答の候補を特定している。そのため、問い合わせの発話に含まれる単語が表す属性と、想定された問い合わせが備える属性との関連性(即ち、発話された問い合わせの内容と想定された問い合わせの内容との一致性)のみを基に、用意されている回答を特定する場合に比べ、発話された問い合わせに適合する回答を特定できる可能性が高いものとなる。
また、本実施形態においては、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性を拡大し、拡大された属性(即ち、オリジナルの属性を表す単語及びその類似語)をフィルタとして、問い合わせのための発話に含まれる単語との一致を判定している。そのため、問い合わせの発話に近い内容、及び、想定された問い合わせ及び想定された問い合わせに対して用意されている回答に近い内容の範囲まで、関連性の特定対象を拡大することができるため、問い合わせの意図を広く汲んで、発話された問い合わせに適合する回答を特定することができる。
In this manner, in this embodiment, answer candidates are identified based on the relevance between the attributes represented by the words included in the inquiry utterance and the attributes of the expected inquiry and the answers prepared for the expected inquiry. Therefore, it is more likely that an answer that matches the uttered inquiry can be identified than when a prepared answer is identified based only on the relevance between the attributes represented by the words included in the inquiry utterance and the attributes of the expected inquiry (i.e., the consistency between the content of the uttered inquiry and the content of the expected inquiry).
In addition, in this embodiment, the attributes of the anticipated inquiry and the answers prepared for the anticipated inquiry are expanded, and the expanded attributes (i.e., words expressing the original attributes and their similar words) are used as a filter to determine whether the expanded attributes match the words included in the inquiry utterance. Therefore, it is possible to expand the scope of the identified relevance to the range of contents close to the inquiry utterance and contents close to the anticipated inquiry and the answers prepared for the anticipated inquiry, and it is possible to identify an answer that matches the uttered inquiry while taking into account the intention of the inquiry in a broad sense.
さらに、サーバ20は、特定された言語処理による回答の候補及び属性の関連性に基づく回答の候補を統合して回答を特定する処理を実行し、発話された問い合わせに対する最終的な回答を特定する。本実施形態においては、言語処理による回答の候補として、一定の確度を有するもの(例えば、言語処理による特定結果のスコアが閾値以上のもの等)が特定されている場合、言語処理による回答の候補を優先し、言語処理による回答の候補の確度が低い場合、属性の関連性に基づく回答の候補を選択するものとする。そして、サーバ20は、特定した最終的な回答を音声またはテキストデータとして端末装置10に送信する。
これにより、問い合わせの発話が行われた際に、高速に、より高精度な音声認識結果を取得して、適切な回答を特定することが可能となっている。
Furthermore, the
This makes it possible to obtain highly accurate speech recognition results quickly when a query is spoken, and to identify an appropriate response.
なお、本実施形態において、想定された問い合わせ及び想定された問い合わせに対して用意されている回答に属性を設定する場合、想定された問い合わせ及び想定された問い合わせに対して用意されている回答のデータにタグあるいはハッシュタグを設定すること等が可能である。
また、問い合わせに対する回答として、回答を行う能力を備えた担当者が特定されることを可能にするため、サーバ20には、回答を行う能力を備えた担当者との通話を行うための電話ネットワークを適宜接続することができる。
In this embodiment, when setting attributes to an anticipated inquiry and a response prepared for the anticipated inquiry, it is possible to set a tag or a hashtag to the data of the anticipated inquiry and the response prepared for the anticipated inquiry.
In addition, in order to enable a person capable of responding to an inquiry to be identified, a telephone network can be appropriately connected to the
[ハードウェア構成]
図2は、端末装置10またはサーバ20を構成する情報処理装置800のハードウェア構成を示す模式図である。
図2に示すように、情報処理装置800は、CPU(Central Processing Unit)811と、ROM(Read Only Memory)812と、RAM(Random Access Memory)813と、バス814と、入力部815と、出力部816と、記憶部817と、通信部818と、ドライブ819と、撮像部820と、を備えている。
[Hardware configuration]
FIG. 2 is a schematic diagram showing a hardware configuration of an
As shown in FIG. 2, the
CPU811は、ROM812に記録されているプログラム、または、記憶部817からRAM813にロードされたプログラムに従って各種の処理を実行する。
RAM813には、CPU811が各種の処理を実行する上において必要なデータ等も適宜記憶される。
The
The
CPU811、ROM812及びRAM813は、バス814を介して相互に接続されている。バス814には、入力部815、出力部816、記憶部817、通信部818及びドライブ819が接続されている。
The
入力部815は、情報処理装置800に対する各種情報の入力を受け付ける。本実施形態において、入力部815は、マウスやキーボード等によって表示画面を介した操作入力を受け付ける操作入力部815aと、マイク等によって音声の入力を受け付ける音声入力部815bとを備えている。
出力部816は、ディスプレイやスピーカ等で構成され、画像や音声を出力する。
記憶部817は、ハードディスクあるいはDRAM(Dynamic Random Access Memory)等で構成され、各サーバで管理される各種データを記憶する。
通信部818は、ネットワークを介して他の装置との間で行う通信を制御する。
The
The
The
The
ドライブ819には、磁気ディスク、光ディスク、光磁気ディスク、あるいは半導体メモリ等よりなる、リムーバブルメディア831が適宜装着される。ドライブ819によってリムーバブルメディア831から読み出されたプログラムは、必要に応じて記憶部817にインストールされる。
撮像部820は、レンズ及び撮像素子等を備えた撮像装置によって構成され、被写体のデジタル画像を撮像する。
なお、上記ハードウェア構成は、情報処理装置800の基本的構成であり、一部のハードウェアを備えない構成としたり、付加的なハードウェアを備えたり、ハードウェアの実装形態を変更したりすることができる。例えば、情報処理装置800は、撮像部820を備えない構成としたり、音声認識処理を高速に実行するためのDSP(Digital Signal Processor)を備えたりすることができる。また、情報処理装置800は、入力部815をタッチセンサによって構成し、出力部816のディスプレイに重ねて配置することにより、タッチパネルを備える構成とすることも可能である。
The
The above hardware configuration is the basic configuration of the
[機能的構成]
次に、端末装置10の機能的構成について説明する。
図3は、端末装置10の機能的構成を示すブロック図である。
図3に示すように、端末装置10のCPU811においては、発話受付部51と、発話データ送信部52と、応答受信部53と、応答出力部54と、が機能する。
[Functional configuration]
Next, the functional configuration of the
FIG. 3 is a block diagram showing the functional configuration of the
As shown in FIG. 3, in the
発話受付部51は、情報処理システム1を利用するユーザが問い合わせのために行う発話を受け付ける。発話受付部51が受け付けた発話は、音声データとして保持される。
発話データ送信部52は、発話受付部51によって受け付けられた問い合わせのための発話(音声データ)をサーバ20に送信する。
応答受信部53は、発話データ送信部52が送信した問い合わせのための発話に対し、サーバ20から送信された応答(Webページデータ、音声データ、ビデオデータまたはテキストデータ)を受信する。
応答出力部54は、応答受信部53が受信した問い合わせに対する応答を音声または画面表示によって出力する。
The
The speech
The
The
次に、サーバ20の機能的構成について説明する。
図4は、サーバ20の機能的構成を示すブロック図である。
図4に示すように、情報処理装置800のCPU811においては、発話データ受信部151と、前処理部152と、音声認識処理部153と、言語処理部154と、絞込み処理部155と、統合処理部156と、が機能する。また、情報処理装置800の記憶部817には、音声認識辞書データベース(音声認識辞書DB)171と、単語辞書データベース(単語辞書DB)172と、応答内容データベース(応答内容DB)173と、コネクタデータベース(コネクタDB)174と、が形成される。
なお、本実施形態においては、音声認識処理を実行する音声認識エンジンとして、入力された音声データ全体をテキストデータに変換するディクテーションを目的としたものと、音声データに含まれる特定の単語を抽出してテキストデータに変換する単語抽出の音声認識処理を目的としたものとが用いられる。
Next, the functional configuration of the
FIG. 4 is a block diagram showing the functional configuration of the
4, in a
In this embodiment, the voice recognition engines used to perform voice recognition processing include one for the purpose of dictation, which converts the entire input voice data into text data, and one for the purpose of word extraction voice recognition processing, which extracts specific words contained in the voice data and converts them into text data.
音声認識辞書DB171には、複数の音声認識エンジンそれぞれが使用する各種辞書及びモデル(音響モデル、言語モデル及び発音辞書等)のデータが記憶されている。例えば、音声認識辞書DB171には、音声の特徴量と音素モデルとが対応付けて格納された音響モデル、文字列あるいは単語列が言語として用いられるパターンを統計処理した結果が格納された言語モデル、及び、言語モデルの単語と音響モデルの音素とが対応付けて格納された発音辞書のデータが記憶されている。 The voice recognition dictionary DB171 stores data on various dictionaries and models (such as acoustic models, language models, and pronunciation dictionaries) used by each of the multiple voice recognition engines. For example, the voice recognition dictionary DB171 stores data on an acoustic model in which voice features and phoneme models are stored in association with each other, a language model in which the results of statistical processing of patterns in which character strings or word strings are used as a language are stored, and a pronunciation dictionary in which words in a language model and phonemes in an acoustic model are stored in association with each other.
単語辞書DB172には、抽出対象となる単語が予め登録された単語抽出用の辞書が記憶されている。単語辞書DB172の各単語には、読み(発音)が付されており、単語抽出の音声認識処理が実行される場合、読み(発音)の情報を基に、予め登録された単語が抽出される。これにより、音声認識の精度と速度の向上を図ることができる。
応答内容DB173には、想定された問い合わせ内容を表すテキストデータと、想定された問い合わせ内容に含まれる単語(問い合わせ内容の属性を表す単語)と、想定された問い合わせに対して用意されている回答を識別する情報(ここでは、問い合わせに対処するオペレータ名または回答を表すコンテンツの名称)とが対応付けられた応答内容テーブルのデータが記憶されている。
The
The response content DB173 stores response content table data in which text data representing the anticipated inquiry content, words contained in the anticipated inquiry content (words representing attributes of the inquiry content), and information identifying an answer prepared for the anticipated inquiry (here, the name of the operator handling the inquiry or the name of the content representing the answer) are associated with each other.
図5は、応答内容テーブルの一例を示す模式図である。
なお、図5において、「・・・」で示される欄は、何らかのデータが存在すること、または、データが存在しないことを意味している(以下、他の図面においても同様であるものとする)。
図5に示すように、応答内容テーブルには、想定された問い合わせ内容を表す文章(テキストデータ)と、想定された問い合わせ内容の属性(単語)と、想定された問い合わせに対して用意されている回答を識別する情報(オペレータ名または回答を表すコンテンツの名称)と、想定された問い合わせに対して用意されている回答に付与された番号とが対応付けて格納されている。例えば、図5の応答内容テーブルの第2行には、想定された問い合わせ内容として「自動振込の登録の手続きをしたいのですが。」という文章が格納され、この問い合わせ内容の属性として、「自動振込」及び「登録」という単語が格納されている。また、この問い合わせに対して用意されている回答を識別する情報として「オペレータA」が格納されている。なお、「オペレータA」には「#1」の番号が付与されている。また、例えば、図5の応答内容テーブルの第10行には、想定された問い合わせ内容として「新規に口座を開設したい。」という文章が格納され、この問い合わせ内容の属性として、「新規」、「口座」及び「開設」という単語が格納されている。また、この問い合わせに対して用意されている回答を識別する情報として「開設ガイダンス」(動画ファイル名)が格納されている。なお、「開設ガイダンス」には「#101」の番号が付与されている。
FIG. 5 is a schematic diagram illustrating an example of a response content table.
In FIG. 5, the cells marked with "..." indicate that some data is present or that no data is present (this also applies to the other drawings below).
As shown in FIG. 5, the response content table stores a sentence (text data) representing the expected inquiry content, an attribute (word) of the expected inquiry content, information identifying a response prepared for the expected inquiry (an operator name or a content name representing the response), and a number assigned to the response prepared for the expected inquiry, in association with each other. For example, in the second row of the response content table in FIG. 5, a sentence "I would like to register for automatic transfer" is stored as the expected inquiry content, and the words "automatic transfer" and "registration" are stored as the attributes of the inquiry content. In addition, "operator A" is stored as information identifying the response prepared for this inquiry. Note that "operator A" is assigned the number "#1". In addition, for example, in the tenth row of the response content table in FIG. 5, a sentence "I would like to open a new account" is stored as the expected inquiry content, and the words "new", "account", and "open" are stored as the attributes of the inquiry content. In addition, "opening guidance" (movie file name) is stored as information identifying the response prepared for this inquiry. The "Opening Guidance" is given the number "#101."
コネクタDB174には、想定された問い合わせ内容の属性を表す単語と、想定された問い合わせに対して用意されている回答の属性(ここでは、オペレータの専門分野や回答実績、あるいは、回答を表すコンテンツが属する分類等)を表す単語とが対応付けられたコネクタテーブルのデータが記憶されている。なお、以下、想定された問い合わせ内容の属性を「タイプAの属性」、想定された問い合わせに対して用意されている回答の属性を「タイプB」の属性と適宜称する。本実施形態において、コネクタDB174には、想定された問い合わせ内容の属性(タイプAの属性)として、想定された問い合わせ内容に明示的に含まれる単語(明示的な属性)に加え、想定された問い合わせ内容自体の意味、回答の名称等、明示化されていない単語(暗示的な属性)が格納されている。これらの単語は名寄せや類似語統一を行い、それぞれ唯一の単語(オリジナルの単語またはオリジナルの属性)としておく。なお、他のテーブル等を作成する場合にも、名寄せや類似語統一を行う場合には、コネクタテーブルの生成時と同様のルールが用いられる。また、コネクタテーブルを基に生成される各種データ(後述する「応答特定属性テーブル」、「応答グループ特定属性テーブル」、「拡大属性テーブル」及び「抽出フィルタ」)は、RAM813の一領域に記憶されると共に、適宜、コネクタDB174に記憶される。
The
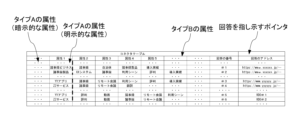
図6は、コネクタテーブルの一例を示す模式図である。
図6に示すように、コネクタテーブルには、1組の想定された問い合わせ及び想定された問い合わせに対して用意されている回答毎に、想定された問い合わせ内容の属性を表す単語(タイプAの属性)と、想定された問い合わせに対して用意されている回答の属性を表す単語(タイプBの属性)とが、対応付けて格納されている。例えば、図6に示すコネクタテーブルの第2行には、想定された問い合わせ内容の属性(タイプAの属性)として、「自動振込」及び「登録」という単語が格納されていると共に、想定された問い合わせに対して用意されている回答の属性(タイプBの属性)として、「クレジットカード」、「デビットカード」、「キャッシュカード」、「自動引落」、「振込」・・・、という単語が格納されている。なお、コネクタテーブルにおいて、タイプAの内の暗示的な属性が、各エントリの左端側に格納されている。コネクタテーブルの1行のデータは、1組の想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性として予め設定されたオリジナルの属性を示している。
FIG. 6 is a schematic diagram showing an example of a connector table.
As shown in FIG. 6, the connector table stores, for each pair of expected inquiries and responses prepared for the expected inquiries, words representing the attributes of the expected inquiry (type A attributes) and words representing the attributes of the responses prepared for the expected inquiries (type B attributes) in association with each other. For example, in the second row of the connector table shown in FIG. 6, the words "automatic transfer" and "registration" are stored as attributes of the expected inquiry (type A attributes), and the words "credit card", "debit card", "cash card", "automatic withdrawal", "transfer", etc. are stored as attributes of responses prepared for the expected inquiries (type B attributes). In the connector table, the implicit attributes of type A are stored on the left side of each entry. Data in one row of the connector table indicates original attributes that are preset as attributes of a pair of expected inquiries and responses prepared for the expected inquiries.
本実施形態においては、問い合わせの内容から適切な回答を特定するために、「属性の拡大」及び、拡大された属性に基づく回答の「絞込み」が行われる。「属性の拡大」を実現するため、オリジナルの単語(オリジナルの属性)を想定された問い合わせに対して用意されている回答を一意に特定可能な属性を表す単語(応答特定属性)と、想定された問い合わせに対して用意されている回答のグループを特定可能な属性を表す単語(応答グループ特定属性)との2つに分類して、それぞれの単語(属性)を類似語に拡大し、必要であれば拡大された単語(属性)も含むすべての単語(属性)をネットワークを介して取得される類似語に拡大する(後述する「拡大属性テーブル」を生成する)、という手法が用いられる。そして、これらの手法で拡大された属性を参照し、問い合わせのための発話に含まれる単語をフィルタリングして、適切な回答が特定される。
コネクタテーブル、応答特定属性及び応答グループ特定属性(具体的には、後述する「応答特定属性テーブル」及び「応答グループ特定属性テーブル」)、拡大属性テーブル、単語抽出用のフィルタ(具体的には、後述する「抽出フィルタ」)を問い合わせが行われることに先立って用意しておくことで、問い合わせの発話が行われた際に、高速に回答を特定することが可能となっている。なお、応答特定属性テーブル、応答グループ特定属性テーブル、拡大属性テーブル及び単語抽出用のフィルタ等、応答内容テーブルにおける「想定された問い合わせに対して用意されている回答」を特定するために用いられるデータを適宜「探索用データ」と称する。
In this embodiment, in order to specify an appropriate answer from the contents of the inquiry, "attribute expansion" and "narrowing down" answers based on the expanded attributes are performed. In order to realize "attribute expansion", the following method is used: original words (original attributes) are classified into two types: words representing attributes that can uniquely specify answers prepared for the expected inquiry (response specific attributes), and words representing attributes that can specify a group of answers prepared for the expected inquiry (response group specific attributes), and each word (attribute) is expanded to a similar word, and if necessary, all words (attributes) including the expanded word (attribute) are expanded to a similar word acquired via a network (generating an "expanded attribute table" to be described later). Then, the attributes expanded by these methods are referred to, and words included in the utterance for the inquiry are filtered to specify an appropriate answer.
By preparing the connector table, the response specific attribute and the response group specific attribute (specifically, the "response specific attribute table" and the "response group specific attribute table" described later), the extended attribute table, and the filter for extracting words (specifically, the "extraction filter" described later) before an inquiry is made, it is possible to quickly identify the answer when the inquiry is uttered. Note that data used to identify "answers prepared for expected inquiries" in the response content table, such as the response specific attribute table, the response group specific attribute table, the extended attribute table, and the filter for extracting words, are appropriately referred to as "search data".
発話データ受信部151は、端末装置10から送信された問い合わせのための発話(音声データ)を受信する。
前処理部152は、発話データ受信部151によって受信された音声データ(問い合わせのための発話)に対し、雑音除去等の前処理を実行する。
The speech
The
音声認識処理部153は、前処理が実行された後の音声データに対し、複数の音声認識エンジンによって、並列的に音声認識処理を実行する。音声認識処理によって取得された各音声認識結果は、言語処理部154及び絞込み処理部155に出力される。図4に示すように、音声認識処理部153は、第1音声認識部153-1~第n音声認識部153-n(nは2以上の整数)を備えることができ、第1音声認識部153-1~第n音声認識部153-nは、それぞれ異なる音声認識エンジンを用いて音声認識処理を実行することができる。第1音声認識部153-1~第n音声認識部153-nにおいて、いずれの音声認識エンジンを用いた音声認識処理を実行するか、及び、第1音声認識部153-1~第n音声認識部153-nの数をいくつとするかについては、サーバ20の処理目的や情報処理能力等の具体的な実装条件に応じて決定することができる。ただし、本実施形態においては、サーバ20は、入力された音声データ全体をテキストデータに変換するディクテーションを目的とした音声認識処理と、音声データに含まれる特定の単語を抽出してテキストデータに変換する単語抽出の音声認識処理とを並列的に実行するものとする。
なお、音声認識処理部153は、フィラー除去等の補助的な処理を適宜実行することとしてもよい。
The speech
The
言語処理部154は、音声認識処理部153によって取得されたディクテーション結果のテキストデータに対し、言語処理による意味内容の抽出を実行し、予め用意されている回答(ここでは、回答を行う担当者または回答自体を表すコンテンツ)の中から、発話された内容の回答に適合する可能性が高い回答(回答を行う担当者または回答自体を表すコンテンツ)の候補を特定する。このとき、言語処理部154は、意味内容から特定される回答の候補に対し、問い合わせの回答としての適合性の高さ(確度)をスコア化し、スコアが最も高いものを言語処理による回答の候補とすることができる。
The
絞込み処理部155は、音声認識処理部153によって取得された単語抽出の音声認識結果(即ち、発話から抽出された単語)と、抽出フィルタに含まれる単語とが一致するか否かを判定し、一致する場合、抽出フィルタに含まれる一致した単語を基に、予め用意されている回答(回答を行う担当者または回答自体を表すコンテンツ)の絞込みを行う。これにより、属性の関連性に基づく回答の候補が特定される。なお、絞込み処理部155は、本実施形態で用いられるコネクタテーブル、応答特定属性テーブル及び応答グループ特定属性テーブル、拡大属性テーブル、抽出フィルタを、ユーザによる問い合わせの発話が入力されることに先立って生成する。
The narrowing down processing
図7は、抽出フィルタ生成の一例を示す模式図である。
なお、ここでは、説明の便宜のため、図7において具体的なデータが示されている欄にのみ注目し、「・・・」で示される欄のデータは考慮しないものとする(図8においても同様とする)。
図7に示すように、抽出フィルタを生成する場合、初めに、コネクタテーブルを参照し、応答特定属性の単語を抽出して、各回答に付与された番号と対応付けたテーブル形式のデータ(以下、「応答特定属性テーブル」と称する。)を生成する。また、コネクタテーブルを参照し、応答グループ特定属性の単語を抽出して、属性毎に回答に付与された番号群を対応付けたテーブル形式のデータ(以下、「応答グループ特定属性テーブル」と称する。)を生成する。さらに、応答特定属性テーブルに含まれる単語及び応答グループ特定属性テーブルに含まれる単語を類似語で拡大する。例えば、その単語に対して予め用意された類似語群のデータや、インターネット等を介して外部から取得される類似語として使用可能な単語のデータ(例えば、オントロジーを参照して取得される類似概念を表す単語のデータ等)で拡大する。さらに、応答特定属性テーブル及び応答グループ特定属性テーブルに含まれるオリジナルの単語と、その単語の類似語とを対応付けたテーブル形式のデータ(以下、「拡大属性テーブル」と称する。)を生成する。そして、拡大属性テーブルに含まれる単語列からなる抽出フィルタを生成する。
FIG. 7 is a schematic diagram showing an example of generating an extraction filter.
For ease of explanation, attention will be paid only to the columns in FIG. 7 in which specific data is shown, and data in columns indicated with "..." will not be taken into consideration (the same applies to FIG. 8).
As shown in FIG. 7, when generating an extraction filter, first, a connector table is referred to, words of response specific attributes are extracted, and table-format data (hereinafter referred to as a "response specific attribute table") is generated in which the words are associated with the numbers assigned to each answer. Also, the connector table is referred to, words of response group specific attributes are extracted, and table-format data (hereinafter referred to as a "response group specific attribute table") is generated in which the numbers assigned to the answers are associated with each attribute. Furthermore, the words included in the response specific attribute table and the words included in the response group specific attribute table are expanded with synonyms. For example, the words are expanded with data of a group of synonyms prepared in advance for the words, or data of words that can be used as synonyms obtained from the outside via the Internet, etc. (for example, data of words representing similar concepts obtained by referring to an ontology). Furthermore, table-format data (hereinafter referred to as an "expanded attribute table") is generated in which original words included in the response specific attribute table and the response group specific attribute table are associated with synonyms of the words. Then, an extraction filter is generated consisting of a string of words included in the expanded attribute table.
なお、新たな回答の候補を追加する場合、その回答の候補が備える属性を表す単語と既存のオリジナルの属性を表す単語との名寄せや類似語統一を行い、オリジナルの属性を表す単語を更新する。そして、既存のオリジナルの属性を表す単語も含めて、オリジナルの属性を表す単語が応答特定属性テーブルに含まれていなければ、その属性を表す単語及び回答の候補を応答特定属性テーブルに追加し、応答特定属性テーブルに既に含まれている場合、その属性を表す単語及び回答の候補を応答特定属性テーブルから削除し、「応答グループ特定属性テーブル」に追加する。 When adding a new answer candidate, the words representing the attributes of the answer candidate are matched with the words representing the existing original attributes and synonyms are unified, and the words representing the original attributes are updated. Then, if the words representing the original attributes, including the words representing the existing original attributes, are not included in the response specific attribute table, the words representing those attributes and the answer candidate are added to the response specific attribute table, and if they are already included in the response specific attribute table, the words representing those attributes and the answer candidate are deleted from the response specific attribute table and added to the "response group specific attribute table."
図8は、抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する過程の一例を示す模式図である。
例えば、下記発話例(1)~(3)の発話が行われたとする。
発話例(1)「ネットで資産運用できますか。」
発話例(2)「定期預金をカードローンに使うことはできますか。」
発話例(3)「住宅ローンの残高の確認はどうすればいいですか。」
FIG. 8 is a schematic diagram showing an example of a process for identifying answer candidates based on attribute relevance using an extraction filter.
For example, assume that the following utterances (1) to (3) are made.
Example utterance (1): "Can I manage my assets online?"
Example utterance (2): "Can I use my fixed-term deposit for a card loan?"
Example utterance (3): "How can I check the remaining balance of my mortgage?"
このとき、各発話例の発話から、以下のように属性を表す単語が抽出されたものとする。
発話例(1)「ネット」(類似語)、「資産運用」(オリジナルの単語)
発話例(2)「定期預金」(オリジナルの単語)、「カードローン」(オリジナルの単語)
発話例(3)「住宅ローン」(オリジナルの単語)、「残高」(オリジナルの単語)
At this time, it is assumed that words expressing attributes are extracted from each example utterance as follows:
Example utterance (1): "Internet" (similar word), "asset management" (original word)
Example utterance (2): "Fixed term deposit" (original word), "Card loan" (original word)
Example utterance (3): "Mortgage" (original word), "Balance" (original word)
発話例(1)の場合、「ネット」及び「資産運用」が抽出フィルタに含まれる単語と一致し、類似語である「ネット」に対応するオリジナルの単語である「インターネット」が応答特定属性テーブルに含まれることから、想定された問い合わせに対して用意されている回答を一意に特定することができる。即ち、発話例(1)の場合、応答特定属性テーブルからオペレータB(#2)が特定され、属性の関連性に基づく回答の候補とされる。 In the case of utterance example (1), "net" and "asset management" match the words included in the extraction filter, and the original word "internet" that corresponds to the synonym "net" is included in the response specific attribute table, so the answer prepared for the anticipated inquiry can be uniquely identified. That is, in the case of utterance example (1), operator B (#2) is identified from the response specific attribute table and becomes a candidate for the answer based on the relevance of attributes.
発話例(2)の場合、「定期預金」及び「カードローン」が抽出フィルタに含まれる単語と一致し、オリジナルの単語である「定期預金」及び「カードローン」が共に、応答グループ特定属性テーブルに含まれる。このとき、「定期預金」によって#3、#4、#5の回答(即ち、オペレータB,C,D)が特定される。また、「カードローン」によって#2、#4の回答(即ち、オペレータB,D)が特定される。特定された回答のグループの論理積により、オペレータD(#4)が特定され、属性の関連性に基づく回答の候補とされる。なお、この例では、回答が1つに絞込まれているが、応答グループ特定属性テーブルに含まれる単語のみが抽出された場合、複数の回答が候補となる可能性がある。このような場合には、複数の回答の候補をユーザに提示する応答を行うこととしてもよく、例えば、「オペレータBとオペレータDがお答えできます。」との応答を出力し、ユーザの発話によって、回答を一意に選択することとしてもよい。また、複数の回答が候補となっている場合に、回答を一意に特定するためのさらなる発話を求める応答を出力してもよい。 In the case of the utterance example (2), "fixed term deposit" and "card loan" match the words included in the extraction filter, and both of the original words "fixed term deposit" and "card loan" are included in the response group specific attribute table. At this time, the answers of #3, #4, and #5 (i.e., operators B, C, and D) are identified by "fixed term deposit". Also, the answers of #2 and #4 (i.e., operators B and D) are identified by "card loan". Operator D (#4) is identified by the logical product of the group of identified answers, and is set as a candidate answer based on the relevance of attributes. In this example, the answers are narrowed down to one, but if only words included in the response group specific attribute table are extracted, multiple answers may be candidates. In such a case, a response may be made that presents multiple answer candidates to the user. For example, a response such as "Operator B and Operator D can answer" may be output, and a unique answer may be selected by the user's utterance. Also, if multiple answers are candidates, a response may be output that requests further utterances to uniquely identify the answer.
発話例(3)の場合、「住宅ローン」及び「残高」が抽出フィルタに含まれる単語と一致し、オリジナルの単語である「住宅ローン」及び「残高」が共に、応答グループ特定属性テーブルに含まれる。このとき、「住宅ローン」によって#2、#4の回答(即ち、オペレータB,D)が特定される。また、「残高」によって#4、#5の回答(即ち、オペレータD,E)が特定される。特定された回答のグループの論理積により、オペレータD(#4)が特定され、属性の関連性に基づく回答の候補とされる。 In the case of example utterance (3), "mortgage" and "balance" match the words included in the extraction filter, and the original words "mortgage" and "balance" are both included in the response group identification attribute table. In this case, "mortgage" identifies the answers in #2 and #4 (i.e., operators B and D). Also, "balance" identifies the answers in #4 and #5 (i.e., operators D and E). Operator D (#4) is identified by the logical product of the groups of identified answers, and is made a candidate answer based on the relevance of attributes.
図4に戻り、統合処理部156は、特定された言語処理による回答の候補及び属性の関連性に基づく回答の候補を統合して特定する処理を実行し、発話された問い合わせに対する最終的な回答を特定する。このとき、上述したように、統合処理部156は、言語処理による回答の候補として、一定の確度を有するもの(例えば、言語処理による特定結果のスコアが閾値以上のもの等)が特定されている場合、言語処理による回答の候補を優先し、言語処理による回答の候補の確度が低い場合、属性の関連性に基づく回答の候補を選択するものとする。そして、統合処理部156は、特定した最終的な回答を音声またはテキストデータとして端末装置10に送信する。なお、言語処理による回答の候補が一定の確度を有するものではなく、属性の関連性に基づく回答の候補も特定されない場合、統合処理部156は、回答が特定できない旨の応答を出力するよう決定する。
なお、サーバ20において用いられる応答内容テーブル、コネクタテーブル及び抽出フィルタは、ユーザによる発話を受け付ける前(即ち、自動応答処理が実行される前)に、予め用意され、サーバ20に実装される。
Returning to FIG. 4, the
The response content table, connector table, and extraction filter used in the
[具体的機能構成例]
図9は、本実施形態における情報処理システム1の具体的機能構成例を示す模式図である。
図9に示すように、音声認識処理部153がディクテーション及び単語抽出の音声認識処理を行う場合、音声認識処理部153において、第1音声認識部153-1と、第2音声認識部153-2とが形成される。
[Specific functional configuration example]
FIG. 9 is a schematic diagram showing an example of a specific functional configuration of the
As shown in FIG. 9, when the voice
第1音声認識部153-1は、ディクテーション音声認識部501と、第1認識結果特定部502と、第1認識結果出力部503と、を備えている。
ディクテーション音声認識部501は、ディクテーションを行うための音声認識エンジンにより音声データを処理し、入力された音声データ全体をテキストデータに変換する。
第1認識結果特定部502は、ディクテーション音声認識部501の処理結果から、音声認識結果を一意に特定する。例えば、第1認識結果特定部502は、ディクテーション音声認識部501によって取得された音声認識結果の候補の中から、音声認識処理の過程で付与されるスコアに基づいて、最も確度が高いものを音声認識結果として特定する。
第1認識結果出力部503は、第1認識結果特定部502によって特定された音声認識結果を言語処理部154に出力する。
The first speech recognition unit 153 - 1 includes a dictation speech recognition unit 501 , a first recognition
The dictation voice recognition unit 501 processes voice data using a voice recognition engine for dictation, and converts the entire input voice data into text data.
The first recognition
The first recognition
第2音声認識部153-2は、単語抽出音声認識部511と、第2認識結果特定部512と、第2認識結果出力部513と、を備えている。
単語抽出音声認識部511は、単語抽出の音声認識処理(ここでは、ルールグラマーの音声認識処理またはDNN(Deep Neural Network)を用いた音声認識処理とする。)を行うための音声認識エンジンにより音声データを処理し、音声データに含まれる特定の単語を抽出してテキストデータに変換する。
第2認識結果特定部512は、単語抽出音声認識部511の処理結果から、音声認識結果を一意に特定する。例えば、第2認識結果特定部512は、単語抽出音声認識部511によって取得された音声認識結果の候補において、同音異字語の中から、単語辞書DB172に登録されている単語を音声認識結果として特定する。
第2認識結果出力部513は、第2認識結果特定部512によって特定された音声認識結果を絞込み処理部155に出力する。
なお、第1音声認識部153-1及び第2音声認識部153-2における音声認識処理を1つのディクテーション音声認識処理(例えば、ディクテーション音声認識部501による音声認識処理)で実行し、以降の処理を上述のように並列的に実行することとしてもよい。この場合、単語辞書DB172は、ディクテーション音声認識処理の結果であるテキストデータから単語を抽出するために用いられる。
The second speech recognition unit 153 - 2 includes a word extraction speech recognition unit 511 , a second recognition
The word extraction speech recognition unit 511 processes the speech data using a speech recognition engine for performing speech recognition processing for word extraction (here, this is assumed to be rule grammar speech recognition processing or speech recognition processing using DNN (Deep Neural Network)), extracts specific words contained in the speech data, and converts them into text data.
The second recognition
The second recognition
The speech recognition processes in the first speech recognition unit 153-1 and the second speech recognition unit 153-2 may be executed as one dictation speech recognition process (for example, speech recognition process by the dictation speech recognition unit 501), and the subsequent processes may be executed in parallel as described above. In this case, the
[動作]
次に、情報処理システム1の動作を説明する。
[自動応答処理]
図10Aは、情報処理システム1が実行する自動応答処理の流れを示すフローチャートである。
自動応答処理は、サーバ20において、自動応答処理の実行を指示する操作が行われることに対応して開始される。
なお、自動応答処理が実行される(即ち、ユーザによる問い合わせの発話が入力される)ことに先立ち、コネクタテーブル、応答特定属性テーブル及び応答グループ特定属性テーブル、拡大属性テーブル、抽出フィルタ(探索用データ)が予め生成されている(図10B参照)。
[Action]
Next, the operation of the
[Auto-Response Processing]
FIG. 10A is a flowchart showing the flow of the automatic response process executed by the
The automatic response process is started in response to an operation of the
In addition, before the automatic response process is executed (i.e., the user inputs an inquiry), the connector table, the response specific attribute table, the response group specific attribute table, the extended attribute table, and the extraction filter (search data) are generated in advance (see Figure 10B).
自動応答処理が開始されると、ステップS1において、端末装置10の発話受付部51は、ユーザによる発話が入力されたか否かの判定を行う。
ユーザによる発話が入力されていない場合、ステップS1においてNOと判定されて、ステップS1の処理が繰り返される。
一方、ユーザによる発話が入力された場合、ステップS1においてYESと判定されて、処理はステップS2に移行する。
When the automatic response process is started, in step S1, the
If no speech has been input by the user, the result of the determination in step S1 is NO, and the process of step S1 is repeated.
On the other hand, if a speech by the user has been input, a YES determination is made in step S1, and the process proceeds to step S2.
ステップS2において、端末装置10の発話データ送信部52は、入力されたユーザによる発話の音声データをサーバ20に送信する。送信された音声データは、サーバ20の発話データ受信部151によって受信される。
ステップS3において、サーバ20の前処理部152は、受信された音声データに対し、雑音除去等の前処理を実行する。
In step S2, the speech
In step S3, the
ステップS4において、サーバ20の音声認識処理部153は、前処理が実行された後の音声データに対し、複数の音声認識エンジンによって、並列的に音声認識処理(S41-1~S43-1及びS41-2~S43-2)を実行する。
具体的には、ステップS41-1において、サーバ20のディクテーション音声認識部501は、ディクテーションを行うための音声認識エンジンにより音声データを処理し、入力された音声データ全体をテキストデータに変換する。
In step S4, the speech
Specifically, in step S41-1, the dictation speech recognition unit 501 of the
ステップS42-1において、第1認識結果特定部502は、ディクテーション音声認識部501の処理結果から、音声認識結果を一意に特定する。
ステップS43-1において、第1認識結果出力部503は、第1認識結果特定部502によって特定された音声認識結果を言語処理部154に出力する。
ステップS43-1の後、処理はステップS5に移行する。
In step S42-1, the first recognition
In step S 43 - 1 , the first recognition
After step S43-1, the process proceeds to step S5.
また、ステップS41-2において、単語抽出音声認識部511は、単語抽出の音声認識処理(ここでは、ルールグラマーの音声認識処理またはDNNを用いた音声認識処理とする。)を行うための音声認識エンジンにより音声データを処理し、音声データに含まれる特定の単語を抽出してテキストデータに変換する。
ステップS42-2において、第2認識結果特定部512は、単語抽出音声認識部511の処理結果から、音声認識結果を一意に特定する。
ステップS43-2において、第2認識結果出力部513は、第2認識結果特定部512によって特定された音声認識結果を絞込み処理部155に出力する。
ステップS43-2の後、処理はステップS6に移行する。
Furthermore, in step S41-2, the word extraction speech recognition unit 511 processes the speech data using a speech recognition engine for performing word extraction speech recognition processing (here, this is rule grammar speech recognition processing or speech recognition processing using DNN), extracts specific words contained in the speech data, and converts them into text data.
In step S42-2, the second recognition
In step S 43 - 2 , the second recognition
After step S43-2, the process proceeds to step S6.
ステップS5において、言語処理部154は、音声認識処理部153によって取得されたディクテーション結果のテキストデータに対し、言語処理による意味内容の抽出を実行し、予め用意されている回答(回答を行う担当者または回答自体を表すコンテンツ)の中から、発話された内容の回答に適合する可能性が高い回答(回答を行う担当者または回答自体を表すコンテンツ)の候補を特定する。ステップS5における言語処理による回答の候補の特定結果は、統合処理部156に出力される。
In step S5, the
ステップS6において、絞込み処理部155は、音声認識処理部153によって取得された単語抽出の音声認識結果(即ち、発話から抽出された単語)と、抽出フィルタに含まれる単語とが一致するか否かを判定し、一致する場合、抽出フィルタに含まれる一致した単語を基に、予め用意されている回答の絞り込みを行う。即ち、絞込み処理部155は、抽出フィルタに含まれる単語から、拡大属性テーブルの属性を表す単語を特定し、さらに、特定した属性を表す単語から、応答特定属性テーブル及び応答グループ特定属性テーブルに含まれる回答の番号(即ち、コネクタテーブルに含まれる回答の番号)を特定する。そして、絞込み処理部155は、特定された回答の番号を基に、応答内容テーブルを参照して、具体的な回答の絞込みを行う。これにより、属性の関連性に基づく回答の候補が特定される。ステップS6における属性の関連性に基づく回答の候補の特定結果は、統合処理部156に出力される。
ステップS5及びステップS6の後、処理はステップS7に移行する。
In step S6, the narrowing down processing
After steps S5 and S6, the process proceeds to step S7.
ステップS7において、統合処理部156は、言語処理による回答の候補が特定できているか否か(例えば、言語処理による特定結果のスコアが閾値以上であるか否か)の判定を行う。
言語処理による回答の候補が特定できている場合、ステップS7においてYESと判定されて、処理はステップS9に移行する。
一方、言語処理による回答の候補が特定できていない場合、ステップS7においてNOと判定されて、処理はステップS8に移行する。
ステップS8において、統合処理部156は、特定された属性の関連性に基づく回答の候補を対象として回答を特定する処理を実行し、発話された問い合わせに対する応答(属性の関連性に基づく回答の候補または回答が特定できない旨の応答)を決定する。
In step S7, the
If answer candidates have been identified through language processing, a YES determination is made in step S7, and the process proceeds to step S9.
On the other hand, if answer candidates have not been identified through language processing, a NO determination is made in step S7, and the process proceeds to step S8.
In step S8, the
ステップS9において、統合処理部156は、問い合わせに対する応答を音声またはテキストデータとして出力(端末装置10に送信)する。このとき、統合処理部156は、問い合わせに対する応答として、言語処理による回答の候補が特定されている場合、特定された言語処理による回答の候補を出力し、言語処理による回答の候補が特定されていない場合、属性の関連性に基づく回答の候補または回答が特定できない旨の応答を出力する。ステップS9において送信された応答のデータは、端末装置10の応答受信部53によって受信され、応答出力部54によって、音声または画像表示によって出力される。なお、ステップS9において出力される問い合わせに対する応答は、一意に特定された回答や回答が特定できない旨を応答する場合の他、複数の回答の候補を一意に特定するための発話を促す応答や、複数の回答の候補を出力する応答としてもよい。
In step S9, the
ステップS10において、統合処理部156は、自動応答処理の終了条件に合致しているか否かの判定を行う。自動応答処理の終了条件としては、例えば、発話された問い合わせに対して、一意に回答を特定して応答を出力したことや、ユーザによって問い合わせを終了する操作が行われたこと等を定義することができる。
問合せ処理の終了条件に合致していない場合、ステップS10においてNOと判定されて、処理はステップS1に移行する。
一方、自動応答処理の終了条件に合致している場合、ステップS10においてYESと判定されて、自動応答処理は終了する。
In step S10, the
If the end condition for the inquiry process is not met, a NO result is obtained in step S10, and the process proceeds to step S1.
On the other hand, if the end condition for the automatic response process is met, the answer in step S10 is YES, and the automatic response process ends.
[抽出フィルタ生成処理]
図10Bは、情報処理システム1が実行する抽出フィルタ生成処理の流れを示すフローチャートである。
抽出フィルタ生成処理は、サーバ20において、抽出フィルタ生成処理の実行を指示する操作が行われることに対応して開始される。抽出フィルタ生成処理によって、一連の探索用データが生成される。
抽出フィルタ生成処理が開始されると、ステップS21において、絞込み処理部155は、想定された問い合わせ内容及び想定された問い合わせに対して用意されている回答の属性を取得する。これらの属性は、想定された問い合わせ内容及び想定された問い合わせに対して用意されている回答に含まれる単語あるいは予め設定された属性等から取得できる。
[Extraction filter generation process]
FIG. 10B is a flowchart showing the flow of the extraction filter generation process executed by the
The extraction filter generation process is started in response to an operation for instructing execution of the extraction filter generation process being performed in the
When the extraction filter generation process is started, in step S21, the narrowing-
ステップS22において、絞込み処理部155は、属性を表す単語の名寄せ及び類似語統一を行う。
ステップS23において、絞込み処理部155は、想定された問い合わせ内容の属性を表す単語(タイプAの属性)と、想定された問い合わせに対して用意されている回答の属性を表す単語(タイプBの属性)とを対応付けて、コネクタテーブルを生成する。
In step S22, the narrowing-
In step S23, the narrowing-
ステップS24において、絞込み処理部155は、コネクタテーブルにおけるオリジナルの単語(オリジナルの属性)を、想定された問い合わせに対して用意されている回答を一意に特定可能な属性を表す単語(応答特定属性)と、想定された問い合わせに対して用意されている回答のグループを特定可能な属性を表す単語(応答グループ特定属性)との2つに分類する。
In step S24, the narrowing-
ステップS25において、絞込み処理部155は、分類された応答特定属性及び応答グループ特定属性に基づいて、応答特定属性テーブル及び応答グループ特定属性テーブルを生成する。
ステップS26において、絞込み処理部155は、応答特定属性テーブルに含まれる単語及び応答グループ特定属性テーブルに含まれる単語を類似語に拡大する。
In step S25, the narrowing-
In step S26, the narrowing-
ステップS27において、絞込み処理部155は、応答特定属性テーブル及び応答グループ特定属性テーブルに含まれるオリジナルの単語と、その単語の類似語とを対応付けた拡大属性テーブルを生成する。
ステップS28において、絞込み処理部155は、拡大属性テーブルに含まれる単語列からなる抽出フィルタを生成する。
ステップS28の後、抽出フィルタ生成処理は終了する。
In step S27, the narrowing-
In step S28, the narrowing-
After step S28, the extraction filter generation process ends.
以上のように、本実施形態における情報処理システム1においては、問い合わせの発話に含まれる単語が表す属性と、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性との関連性を基に、回答の候補を特定する。また、コネクタテーブル、応答特定属性テーブル及び応答グループ特定属性テーブル、拡大属性テーブル、抽出フィルタ(探索用データ)を問い合わせが行われることに先立って用意している。即ち、想定された問い合わせ内容の属性として、想定された問い合わせ内容に明示的に含まれる単語(明示的な属性)と、想定された問い合わせ内容自体の意味、回答の名称等、明示化されていない単語(暗示的な属性)とが用いられ、想定された問い合わせに対して用意されている回答が備える属性と併せて、コネクタテーブルを生成する。また、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性を類似語に拡大し、オリジナルの属性を表す単語及びその類似語で構成される抽出フィルタを生成する。また、音声認識処理によって問い合わせのための発話から所定の単語を抽出し、発話から抽出された単語と、抽出フィルタに含まれる単語とが一致するか否かを判定する。そして、情報処理システム1は、発話から抽出された単語と、抽出フィルタに含まれる単語とが一致する場合、抽出フィルタに含まれる一致した単語を基に、予め用意されている回答(回答を行う担当者または回答自体を表すコンテンツ)の絞込みを行う。これにより、属性の関連性に基づく回答の候補を特定する。また、情報処理システム1は、発話を音声認識処理したディクテーション結果のテキストデータに対し、言語処理による意味内容の抽出を実行し、予め用意されている回答(回答を行う担当者または回答自体を表すコンテンツ)の中から、発話された内容の回答に適合する可能性が高い回答(回答を行う担当者または回答自体を表すコンテンツ)の候補を特定する。さらに、情報処理システム1は、特定された言語処理による回答の候補及び属性の関連性に基づく回答の候補を統合して特定する処理を実行し、発話された問い合わせに対する最終的な回答を特定する。
As described above, in the
このような処理により、情報処理システム1においては、発話された問い合わせに対して、言語処理に基づく特定方法のみならず、属性を表す単語の一致性に基づく特定方法を用いて、問い合わせに対する回答を特定することができる。
したがって、発話に対する自動応答を行う際に、処理時間を短縮しつつ、より適切な応答内容を特定することが可能となる。
また、問い合わせの発話に含まれる単語が表す属性と、想定された問い合わせが備える属性との関連性(即ち、発話された問い合わせの内容と想定された問い合わせの内容との一致性)のみを基に、用意されている回答を特定する場合に比べ、発話された問い合わせに適合する回答を特定できる可能性が高いものとなる。
また、問い合わせに対する回答を特定する処理で用いられるコネクタテーブル、応答特定属性テーブル及び応答グループ特定属性テーブル、拡大属性テーブル、抽出フィルタ(探索用データ)を、問い合わせが行われることに先立って用意しているため、問い合わせの発話が行われた際に、高速に回答を特定することが可能となる。
Through this processing, the
Therefore, when an automatic response to a speech is made, it is possible to specify more appropriate response content while shortening the processing time.
In addition, it is more likely that an answer that matches the spoken inquiry can be identified than when a prepared answer is identified based only on the correlation between the attributes expressed by the words contained in the utterance of the inquiry and the attributes of the expected inquiry (i.e., the consistency between the content of the uttered inquiry and the content of the expected inquiry).
In addition, the connector table, response specific attribute table, response group specific attribute table, extended attribute table, and extraction filter (search data) used in the process of identifying an answer to an inquiry are prepared before an inquiry is made, making it possible to identify an answer quickly when an inquiry is spoken.
また、属性を表す単語の一致性を判定する際に、想定された問い合わせ及び想定された問い合わせに対して用意されている回答に基づく属性を表す単語を拡大して抽出フィルタを生成し、問い合わせのための発話の音声認識結果に含まれる単語が表す属性との一致性を判定する。
したがって、表現のゆらぎや趣旨が類似する単語が用いられた場合等、想定されていない表現が用いられた場合であっても、発話された問い合わせに適合する回答を容易に特定することが可能となる。即ち、問い合わせの発話に近い内容、及び、想定された問い合わせ及び想定された問い合わせに対して用意されている回答に近い内容の範囲まで、関連性の特定対象を拡大することができるため、問い合わせの意図を広く汲んで、発話された問い合わせに適合する回答を特定することができる。
In addition, when determining the consistency of words expressing attributes, an extraction filter is generated by expanding words expressing attributes based on an expected inquiry and answers prepared for the expected inquiry, and a consistency with the attributes expressed by words included in the speech recognition results of the utterance for the inquiry is determined.
Therefore, even if an unexpected expression is used, such as when there is a variation in expression or when words with similar meanings are used, it is possible to easily identify an answer that matches the uttered inquiry. That is, since the scope of the identified relevance can be expanded to include contents close to the utterance of the inquiry, and contents close to anticipated inquiries and answers prepared for the anticipated inquiries, it is possible to identify an answer that matches the uttered inquiry while taking into account the broad intent of the inquiry.
[第2実施形態]
次に、本発明の第2実施形態について説明する。
第1実施形態においては、回答として特定される事項は、回答を行う能力を備えた担当者または回答自体を表すコンテンツ(例えば、テキスト、ビデオ、音声のコンテンツあるいはWebページ等)であるものとした。また、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性を、回答を一意に特定する応答特定属性と、回答をグループとして特定する応答グループ特定属性とに分類して、これらの属性を対応付けてデータ化し、さらに、属性を拡大することにより、発話中の単語をフィルタリングして、問い合わせに対する回答を特定するものとした。
[Second embodiment]
Next, a second embodiment of the present invention will be described.
In the first embodiment, the matter identified as the answer is a person capable of answering or content representing the answer itself (for example, text, video, audio content, or a web page, etc.). In addition, attributes of the anticipated inquiry and the answers prepared for the anticipated inquiry are classified into response-specific attributes that uniquely identify the answer and response group-specific attributes that identify the answers as a group, and these attributes are associated with each other and converted into data. Furthermore, by expanding the attributes, the words being spoken are filtered to identify the answer to the inquiry.
これに対し、本実施形態においては、第1実施形態での、担当者の回答または回答を表すコンテンツ全体の内の特定部分(例えば、テキスト、ビデオ、音声のコンテンツあるいはWebページ等の内の特定部分、一例として、パラグラフ、セクション、動画の時間帯あるいはWebページの内の特定箇所等)も回答として特定される対象としている。また、本実施形態においては、属性の関連性に基づく特定処理として、異なる機能を有する複数の処理(以下、適宜「絞込み処理」と称する。)を並列的に実行し、これら並列的な処理による特定結果及び言語処理を用いた特定処理による特定結果を統合して応答の内容(回答または回答の特定に有効な属性の発話を誘導する対話の内容)を特定する。例えば、絞込み処理の1つとして、オリジナルのコネクタテーブルに含まれる属性を表す単語全体を対象として、最新の発話に含まれる単語によって回答の絞込みを行う絞込み処理1を実行する。絞込み処理1では、オリジナルのコネクタテーブルに含まれる属性を表す単語全体を最新の1回の発話で絞込んだ結果が出力される。また、絞込み処理の他の1つとして、過去の所定回の発話によってオリジナルのコネクタテーブルに含まれる属性を表す単語が絞込まれた結果を対象として、最新の発話に含まれる単語によって絞込みを行う絞込み処理2を実行する。絞込み処理2では、オリジナルのコネクタテーブルに含まれる属性を表す単語を過去の所定回の発話で絞込んだ結果が出力される。また、絞込み処理のさらに他の1つとして、絞込み処理2とは異なる過去の所定回の発話(例えば、問い合わせが行われて以降の過去の全ての発話)によってオリジナルのコネクタテーブルに含まれる属性を表す単語が絞込まれた結果を対象として、最新の発話に含まれる単語によって絞込みを行う絞込み処理3を実行する。絞込み処理3では、オリジナルのコネクタテーブルに含まれる属性を表す単語を絞込み処理2とは異なる過去の所定回の発話(例えば、問い合わせが行われて以降の過去の全ての発話)で絞込んだ結果が出力される。そして、これら絞込み処理1~3による特定結果及び言語処理を用いた特定処理による特定結果を、予め設定された選択条件に基づいて選択することにより統合し、問い合わせに対する応答の内容(回答または回答の特定に有効な属性の発話を誘導する対話の内容)が特定される。
In contrast, in this embodiment, the answer of the person in charge in the first embodiment or a specific part of the entire content representing the answer (for example, a specific part of text, video, audio content, or a web page, for example, a paragraph, a section, a time period of a video, or a specific part of a web page) is also targeted for identification as an answer. In addition, in this embodiment, as an identification process based on the relevance of attributes, multiple processes having different functions (hereinafter referred to as "narrowing processes") are executed in parallel, and the identification results of these parallel processes and the identification results of the identification process using language processing are integrated to identify the content of the response (the content of the dialogue that induces the answer or the utterance of an attribute effective for identifying the answer). For example, as one of the narrowing processes, a
本実施形態においては、言語処理を用いた特定処理と共に、絞込み処理1~3を併用し、さらに、絞込み処理1~3が自律的にユーザとの対話(自動的な対話)を可能とする構造となっているため、適切な回答が特定される可能性がより高いものとなる。
本実施形態における情報処理システム1のシステム構成、情報処理装置のハードウェア構成、端末装置10及びサーバ20の機能的構成等の主要な部分は、第1実施形態と同様であるため、異なる部分を主として説明する。
In this embodiment, narrowing-
The main parts of the system configuration of the
図11は、本実施形態における処理の概念を示す模式図である。
図11に示すように、本実施形態に係る情報処理システム1では、並列的に実行される絞込み処理1~3処理による特定結果及び言語処理を用いた特定処理による特定結果を統合して応答の内容を特定する。このとき、絞込み処理1~3では、オリジナルのコネクタテーブル、オリジナルのコネクタテーブルから生成された応答特定属性テーブル及び応答グループ特定属性テーブル(以下、「コネクタテーブル類」と称する。)を起点として、絞込み処理1によってコネクタテーブル類が絞込まれた結果である絞込みテーブル類1、絞込み処理2によって絞込みテーブル類1が絞込まれた結果である絞込みテーブル類2、絞込み処理3によって絞込みテーブル類2が絞込まれた結果である絞込みテーブル類3を生成することにより、属性の関連性に基づく回答の候補を特定する。ただし、絞込みテーブル類3については、ユーザによる一連の問い合わせが4回以上となった場合、絞込みテーブル類3の出力結果が次回の問い合わせに対する絞込み処理3の入力となり、回帰的に絞込み処理3による絞込みが行われる。絞込みテーブル類1~3には、絞込み処理1~3の結果である絞込みテーブル1~3がそれぞれ含まれている。絞込みテーブル1~3は、絞込み処理1~3によって絞込まれた単語それぞれが、いずれの回答(具体的には、回答の番号)と関連性を有するかを示すテーブル形式のデータである。絞込みテーブル1~3においては、例えば、絞込み処理1~3によって絞込まれた単語それぞれについて、回答の番号と関連性を有する「1」、関連性を有しない「0」が格納されている。また、回答の候補が一意に特定されない場合には、絞込みテーブル1~3に含まれる属性が、回答を現在よりも絞込むことができる属性に更新した後、次段の絞込み処理の入力として受け渡される(入力が置換される)。
FIG. 11 is a schematic diagram showing the concept of processing in this embodiment.
As shown in FIG. 11, in the
なお、図11において、コネクタテーブル類に含まれる応答特定属性テーブルを「応答特定属性テーブルATS0」、応答グループ特定属性テーブルを「応答グループ特定属性テーブルATG0」、絞込みテーブル類1に含まれる応答特定属性テーブルを「応答特定属性テーブルATS1」、応答グループ特定属性テーブルを「応答グループ特定属性テーブルATG1」、絞込みテーブル類2に含まれる応答特定属性テーブルを「応答特定属性テーブルATS2」、応答グループ特定属性テーブルを「応答グループ特定属性テーブルATG2」、絞込みテーブル類3に含まれる応答特定属性テーブルを「応答特定属性テーブルATS3」、応答グループ特定属性テーブルを「応答グループ特定属性テーブルATG3」と称している。以下の説明において、適宜同様の表記を用いるものとする。 In FIG. 11, the response specific attribute table included in the connector tables is called "response specific attribute table ATS0", the response group specific attribute table is called "response group specific attribute table ATG0", the response specific attribute table included in the narrowing down tables 1 is called "response specific attribute table ATS1", the response group specific attribute table is called "response group specific attribute table ATG1", the response specific attribute table included in the narrowing down tables 2 is called "response specific attribute table ATS2", the response group specific attribute table is called "response group specific attribute table ATG2", the response specific attribute table included in the narrowing down tables 3 is called "response specific attribute table ATS3", and the response group specific attribute table is called "response group specific attribute table ATG3". Similar notations will be used as appropriate in the following explanation.
[機能的構成]
本実施形態において、端末装置10の機能的構成は、図3に示す第1実施形態の機能的構成と同様である。
また、サーバ20の機能的構成は、図4に示す第1実施形態の機能的構成に対し、コネクタDB174の記憶内容、絞込み処理部155及び統合処理部156が実行する処理の内容が異なっている。
コネクタDB174には、想定された問い合わせ内容の属性を表す単語と、想定された問い合わせに対して用意されている回答の属性(ここでは、回答を行う能力を備えた担当者の回答、あるいは、回答を表すコンテンツ全体及び回答を表すコンテンツの部分の属性)を表す単語とが対応付けられたコネクタテーブルのデータが記憶されている。
[Functional configuration]
In this embodiment, the functional configuration of the
Furthermore, the functional configuration of the
Connector DB174 stores data of a connector table in which words representing attributes of anticipated inquiry content are associated with words representing attributes of answers prepared for the anticipated inquiries (here, answers from personnel capable of providing an answer, or attributes of the entire content representing the answer and parts of the content representing the answer).
図12Aは、本実施形態におけるコネクタテーブルの一例を示す模式図である。
図12Aに示すように、コネクタテーブルには、第1実施形態と同様に、1組の想定された問い合わせ及び想定された問い合わせに対して用意されている回答毎に、想定された問い合わせ内容の属性を表す単語(タイプAの属性)と、想定された問い合わせに対して用意されている回答の属性を表す単語(タイプBの属性)とが、対応付けて格納されている。
FIG. 12A is a schematic diagram showing an example of a connector table in this embodiment.
As shown in FIG. 12A, in the connector table, as in the first embodiment, for each pair of anticipated inquiries and answers prepared for the anticipated inquiries, words representing the attributes of the anticipated inquiry content (type A attributes) and words representing the attributes of the answers prepared for the anticipated inquiries (type B attributes) are stored in association with each other.
本実施形態において、コネクタDB174には、想定された問い合わせ内容の属性(タイプAの属性)として、想定された問い合わせ内容に明示的に含まれる単語(明示的な属性)に加え、想定された問い合わせ内容自体の意味、回答の名称等、明示化されていない単語(暗示的な属性)が格納されている。これらの単語は名寄せや類似語統一を行い、それぞれ唯一の単語(オリジナルの単語、オリジナルの属性)としておく。 In this embodiment, connector DB174 stores, as attributes of the expected inquiry content (type A attributes), not only words explicitly included in the expected inquiry content (explicit attributes), but also words that are not explicitly stated (implicit attributes), such as the meaning of the expected inquiry content itself and the name of the answer. These words are matched and synonymized, and each is made into a unique word (original word, original attribute).
また、本実施形態において、回答を表すコンテンツの属性(タイプBの属性)として、回答を表すコンテンツ全体が属する分類と、回答を表すコンテンツを構成する部分が属する分類とが設定されており、これら全体及び部分について、属性を表す単語がコネクタテーブルに格納されている。回答を表すコンテンツを構成する部分は、回答を表すコンテンツ全体において、区分して属性を設定することができる部分を任意に選択することができるが、例えば、パラグラフ、セクションあるいは動画の時間帯等で区分された部分とすることができる。
なお、図12Aにおいて、「回答のアドレス」は、回答を表すコンテンツのURL(Uniform Resource Locator)あるいはサーバ内のアドレス等、ネットワークにおけるデータの所在地を示している。
In this embodiment, a category to which the entire content representing the answer belongs and a category to which the part constituting the content representing the answer belongs are set as attributes of the content representing the answer (attributes of type B), and words representing attributes for the entire content and the part are stored in the connector table. The part constituting the content representing the answer can be any part of the entire content representing the answer that can be divided and set with attributes, and can be, for example, a part divided by paragraph, section, or time period of a video.
In FIG. 12A, "answer address" indicates the location of data on a network, such as the URL (Uniform Resource Locator) of the content representing the answer or an address within a server.
本実施形態においても、第1実施形態と同様に、コネクタテーブルを参照して、問い合わせの内容から適切な回答を特定するために、「属性の拡大」及び、拡大された属性に基づく回答の「絞込み」が行われる。「属性の拡大」を実現するため、第1実施形態と同様に、(1)コネクタテーブルにおいて、想定された問い合わせ内容に明示的に含まれる単語(明示的な属性)に加え、想定された問い合わせ内容自体の意味、回答の名称等、明示化されていない単語(暗示的な属性)が格納される、という手法や、コネクタテーブルから応答特定属性テーブルを生成する際に、(2)属性を表す単語を基に予め設定された類似語に拡大する、(3)属性を表す単語をネットワークを介して取得される類似語に拡大する、という手法が用いられる。そして、これらの手法で拡大された属性を参照し、問い合わせのための発話に含まれる単語をフィルタリングして、必要な場合には、情報処理システム1が、絞込みに有効なオリジナルの属性を特定することにより、発話を誘導する対話を行いつつ、適切な回答が特定される。
In this embodiment, as in the first embodiment, in order to identify an appropriate answer from the content of the inquiry, the connector table is referred to to "expand the attributes" and the answers are "narrowed down" based on the expanded attributes. In order to realize "expanding the attributes", as in the first embodiment, the following techniques are used: (1) in addition to words (explicit attributes) explicitly included in the expected content of the inquiry, words (implicit attributes) that are not explicitly included, such as the meaning of the expected content of the inquiry itself and the name of the answer, are stored in the connector table; and when generating a response specific attribute table from the connector table, (2) the words representing the attributes are expanded to similar words set in advance, and (3) the words representing the attributes are expanded to similar words acquired via a network. Then, the attributes expanded by these techniques are referred to, and the words included in the utterance for the inquiry are filtered, and if necessary, the
絞込み処理部155は、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性の類似語を取得する。例えば、絞込み処理部155は、属性を表す単語に対して予め用意された類似語群のデータや、インターネット等を介して外部から取得される類似語として使用可能な単語のデータ(例えば、オントロジーを参照して取得される類似概念を表す単語のデータ等)を取得する。
The narrowing-
そして、絞込み処理部155は、想定された問い合わせ及び想定された問い合わせに対して用意されている回答が備える属性(タイプA及びタイプBの属性)を表す単語(コネクタテーブルに格納されたオリジナルの属性を表す単語)と、類似語として取得された単語(オリジナルの属性の類似語)とを集合させて、想定された問い合わせ及び想定された問い合わせに対して用意されている回答との関連性を抽出するための抽出フィルタを生成する。
このとき、絞込み処理部155は、抽出フィルタを生成するためにコネクタテーブルに含まれる単語が拡大された属性から、応答特定属性テーブルATS0及び応答グループ特定属性テーブルATG0を生成する。これら応答特定属性テーブルATS0及び応答グループ特定属性テーブルATG0は、コネクタテーブルと共に、コネクタテーブル類を構成する。
Then, the narrowing-
At this time, the narrowing-
また、絞込み処理部155は、絞込み処理1において、コネクタテーブル類に含まれる属性を表す単語を、最新の発話に含まれる単語を基に絞込み、絞込まれた属性を表す単語と、回答の番号との関連性を示す情報(例えば、「1」は関連性あり、「0」は関連性なし)を要素とする絞込みテーブル1を生成する。具体的には、絞込み処理部155は、コネクタテーブルを参照し、最新の発話に含まれる単語が関連する回答の候補のいずれかと関連している単語によって、絞込みテーブル1を生成する。なお、コネクタテーブルは、発話により絞込まれる前の絞込みテーブルとしての意義を有している。
In addition, in the narrowing down
図12Bは、絞込みテーブル1の一例を示す模式図である。
図12Bにおいて、絞込みテーブル1には、コネクタテーブルに含まれる属性を表す単語のうち、最新の発話に含まれる単語が関連する回答の候補のいずれかと関連している単語と、各単語が回答の番号それぞれと関連性を有するか否かを示す情報(関連性を有することを示す「1」または関連性を有しないことを示す「0」)とが、対応付けて格納されている。
例えば、図12Bにおいて、絞込みテーブル1における属性を表す単語「議事録製品」については#1、#2、#Xの回答とは関連性を有することを示す「1」が格納されている。また、他の属性を表す単語「XXシステム」については#1の回答とは関連性を有しないことを示す「0」が格納されている。
FIG. 12B is a schematic diagram showing an example of the narrowing-down table 1. As shown in FIG.
In FIG. 12B, narrowing-down table 1 stores, in correspondence with each other, words representing attributes contained in the connector table that are related to one of the candidate answers to which the words contained in the most recent utterance relate, along with information indicating whether each word is related to each of the answer numbers ("1" indicating related or "0" indicating not related).
12B, for the word "minutes product" representing an attribute in the narrowing-down table 1, "1" is stored, indicating that it is related to
絞込みテーブル1に格納されている回答の候補の番号は、最新の発話に含まれる単語が関連するものに絞込まれているため、絞込みテーブル1は、最新の発話によって絞込まれた回答の候補を示す情報となる。また、絞込みテーブル1には、回答の候補と関連している属性を表す単語が併せて格納されているため、次の発話によって回答の候補を絞込むために必要な情報を含むものとなっている。
なお、このとき、絞込み処理部155は、絞込みテーブル1に含まれる属性から、応答特定属性テーブルATS1及び応答グループ特定属性テーブルATG1を生成する。これら応答特定属性テーブルATS1及び応答グループ特定属性テーブルATG1は、絞込みテーブル1と共に、絞込みテーブル類1を構成する。
The numbers of the answer candidates stored in the narrowing-down table 1 are narrowed down to those related to the words included in the latest utterance, so the narrowing-down table 1 is information showing the answer candidates narrowed down by the latest utterance. In addition, the narrowing-down table 1 also stores words representing attributes related to the answer candidates, so it contains information necessary to narrow down the answer candidates by the next utterance.
At this time, the narrowing-
絞込み処理部155は、絞込み処理1において生成された絞込みテーブル1に基づいて、最新の発話に含まれる単語によって、回答の候補を一意に特定できるか否かを判定する。回答の候補を一意に特定できる場合、その回答の候補が属性の関連性に基づく回答の候補を決定するために用いられる。
The narrowing down processing
また、絞込み処理部155は、絞込み処理1において生成された絞込みテーブル1に基づいて、最新の発話に含まれる単語によって、回答の候補を一意に特定できない場合、ユーザから、回答をさらに絞込み可能な属性(即ち、回答の特定に有効な属性)の発話を誘導する対話を行う。具体的には、絞込み処理部155は、絞込みテーブル1における列の要素に「1」を含む属性のうち、回答を現在よりも絞込むことができる属性(即ち、回答を一意に特定可能な属性または回答の候補が現在よりも減少する属性)を、絞込みのための情報としてユーザに提示する属性に採用する。また、絞込み処理部155は、絞込みテーブル1に含まれる属性を、回答を現在よりも絞込むことができるものに更新する。即ち、絞込み処理部155は、絞込みテーブル1において、最新の発話に含まれる単語が関連する回答の候補の全てと関連している単語(即ち、回答の特定に有効でない属性)を除外し、最新の発話に含まれる単語が関連する回答の候補の一部と関連している単語(即ち、回答の特定に有効な属性)を残して、絞込みテーブル1を更新する。具体的には、絞込み処理部155は、絞込みテーブル1において、最新の発話に含まれる単語と関連性を有する回答のグループを特定し、特定された回答のグループに対応するテーブルの要素が全て“1”である列の属性を削除し、それ以外の属性で要素に“1”が1つでもある列の属性を残すことで、絞込みテーブル1を更新する。また、絞込みテーブル1の更新に合わせて、絞込みテーブル類1の応答特定属性テーブルATS1及び応答グループ特定属性テーブルATG1も更新され、更新された絞込みテーブル類1は、絞込み処理2の入力として受け渡される。
このような処理により、システムから回答を絞込むために有効な属性の発話をユーザに促すことができる。
In addition, when the narrowing-
By performing such processing, the user can be prompted to speak attributes that are effective for narrowing down answers from the system.
また、絞込み処理部155は、絞込み処理2において、絞込みテーブル類1を入力とし、更新された絞込みテーブル1に含まれる属性を表す単語を、最新の発話に含まれる単語を基に絞込み、絞込まれた属性を表す単語と、回答の番号との関連性を示す情報(例えば、「1」は関連性あり、「0」は関連性なし)を要素とする絞込みテーブル2を生成する。具体的には、絞込み処理部155は、絞込みテーブル1を参照し、最新の発話に含まれる単語が関連する回答の候補のいずれかと関連している単語によって、絞込みテーブル2を生成する。
In addition, in the narrowing down
図12Cは、絞込みテーブル2の一例を示す模式図である。
図12Cにおいて、絞込みテーブル2には、絞込みテーブル1に含まれる属性を表す単語のうち、最新の発話に含まれる単語が関連する回答の候補のいずれかと関連している単語と、各単語が回答の番号それぞれと関連性を有するか否かを示す情報(関連性を有することを示す「1」または関連性を有しないことを示す「0」)とが、対応付けて格納されている。
例えば、図12Cにおいて、絞込みテーブル2における属性を表す単語「XXシステム」については#2、#Xの回答とは関連性を有することを示す「1」が格納されている。また、他の属性を表す単語「リモート会議」については#2の回答とは関連性を有しないことを示す「0」が格納されている。
FIG. 12C is a schematic diagram showing an example of the narrowing-down table 2. As shown in FIG.
In FIG. 12C , narrowing-down table 2 stores, in correspondence with each other, words representing attributes included in narrowing-down table 1 that are related to one of the candidate answers to which the words included in the most recent utterance relate, along with information indicating whether each word is related to each of the answer numbers ("1" indicating related or "0" indicating not related).
12C, for the word "XX system" representing an attribute in the narrowing-down table 2, "1" is stored, indicating that it is related to the answer of #2, #X. Also, for the word "remote conference" representing another attribute, "0" is stored, indicating that it is not related to the answer of #2.
絞込みテーブル2に格納されている回答の候補の番号は、最新の発話及び前回の発話に含まれる単語が関連するものに絞込まれているため、絞込みテーブル2は、最新の発話及び前回の発話によって絞込まれた回答の候補を示す情報となる。また、絞込みテーブル2には、回答の候補と関連している属性を表す単語が併せて格納されているため、次の発話によって回答の候補を絞込むために必要な情報を含むものとなっている。
なお、このとき、絞込み処理部155は、絞込みテーブル2に含まれる属性から、応答特定属性テーブルATS2及び応答グループ特定属性テーブルATG2を生成する。これら応答特定属性テーブルATS2及び応答グループ特定属性テーブルATG2は、絞込みテーブル2と共に、絞込みテーブル類2を構成する。
The numbers of the answer candidates stored in the narrowing-down table 2 are narrowed down to those related to the words included in the latest utterance and the previous utterance, so the narrowing-down table 2 is information showing the answer candidates narrowed down by the latest utterance and the previous utterance. In addition, the narrowing-down table 2 also stores words that represent attributes related to the answer candidates, so it contains information necessary to narrow down the answer candidates by the next utterance.
At this time, the narrowing-
また、絞込み処理部155は、絞込み処理2において生成された絞込みテーブル2に基づいて、最新の発話に含まれる単語によって、回答の候補を一意に特定できるか否かを判定する。回答の候補を一意に特定できる場合、その回答の候補が属性の関連性に基づく回答の候補を決定するために用いられる。
The narrowing-
また、絞込み処理部155は、絞込み処理2において生成された絞込みテーブル2に基づいて、最新の発話に含まれる単語によって、回答の候補を一意に特定できない場合、ユーザから、回答をさらに絞込み可能な属性(即ち、回答の特定に有効な属性)の発話を誘導する対話を行う。具体的には、絞込み処理部155は、絞込みテーブル2における列の要素に「1」を含む属性のうち、回答を現在よりも絞込むことができる属性(即ち、回答を一意に特定可能な属性または回答の候補が現在よりも減少する属性)を、絞込みのための情報としてユーザに提示する属性に採用する。また、絞込み処理部155は、絞込みテーブル2に含まれる属性を、回答を現在よりも絞込むことができるものに更新する。即ち、絞込み処理部155は、絞込みテーブル2において、最新の発話に含まれる単語が関連する回答の候補の全てと関連している単語(即ち、回答の特定に有効でない属性)を除外し、最新の発話に含まれる単語が関連する回答の候補の一部と関連している単語(即ち、回答の特定に有効な属性)を残して、絞込みテーブル2を更新する。具体的には、絞込み処理部155は、絞込みテーブル2において、最新の発話に含まれる単語と関連性を有する回答のグループを特定し、特定された回答のグループに対応するテーブルの要素が全て“1”である列の属性を削除し、それ以外の属性で要素に“1”が1つでもある列の属性を残すことで、絞込みテーブル2を更新する。このとき、最新の発話に含まれる単語も除外して絞込みテーブル2が更新される。また、絞込みテーブル2の更新に合わせて、絞込みテーブル類2の応答特定属性テーブルATS2及び応答グループ特定属性テーブルATG2も更新され、更新された絞込みテーブル類2は、絞込み処理3の入力として受け渡される。
このような処理により、システムから回答を絞込むために有効な属性の発話をユーザに促すことができる。
In addition, when the narrowing-
By performing such processing, the user can be prompted to speak attributes that are effective for narrowing down answers from the system.
また、絞込み処理部155は、絞込み処理3において、問い合わせの開始から3回目の発話までは、絞込みテーブル類2を入力とし、更新された絞込みテーブル2に含まれる属性を表す単語を、最新の発話に含まれる単語を基に絞込み、絞込まれた属性を表す単語と、回答の番号との関連性を示す情報(例えば、「1」は関連性あり、「0」は関連性なし)を要素とする絞込みテーブル3を生成する。具体的には、絞込み処理部155は、絞込みテーブル2を参照し、最新の発話に含まれる単語が関連する回答の候補のいずれかと関連している単語によって、絞込みテーブル3を生成する。
In addition, in the narrowing down
また、絞込み処理部155は、絞込み処理3において、問い合わせの開始から4回目の発話以降は、前回の絞込み処理3において更新された絞込みテーブル類3を入力とし、更新された絞込みテーブル3に含まれる属性を表す単語を、最新の発話に含まれる単語を基に絞込み、絞込まれた属性を表す単語と、回答の番号との関連性を示す情報(例えば、「1」は関連性あり、「0」は関連性なし)を要素とする絞込みテーブル3を生成する。具体的には、絞込み処理部155は、絞込みテーブル2を参照し、最新の発話に含まれる単語が関連する回答の候補のいずれかと関連している単語によって、絞込みテーブル3を生成する。
In addition, in the narrowing down
図12Dは、絞込みテーブル3の一例を示す模式図である。
図12Dにおいて、絞込みテーブル3には、入力された絞込みテーブル2または絞込みテーブル3に含まれる属性を表す単語を、最新の発話に含まれる単語が関連する回答の候補の一部と関連している単語に絞込んだ結果である属性を表す単語と、各単語が回答の番号それぞれと関連性を有するか否かを示す情報(関連性を有することを示す「1」または関連性を有しないことを示す「0」)とが、対応付けて格納されている。
例えば、図12Dにおいて、絞込みテーブル3における属性を表す単語「リモート会議」については#Xの回答と関連性を有することを示す「1」が格納されている。
FIG. 12D is a schematic diagram showing an example of the narrowing-down table 3. As shown in FIG.
In FIG. 12D, narrowing-down table 3 stores, in correspondence with each other, words representing attributes that are the result of narrowing down the words representing attributes contained in the input narrowing-down table 2 or narrowing-down table 3 to words that are related to some of the answer candidates to which the words contained in the most recent utterance are related, along with information indicating whether each word is related to each answer number ("1" indicating related or "0" indicating not related).
For example, in FIG. 12D, for the word "remote conference" representing an attribute in narrowing-down table 3, "1" is stored, indicating that it is related to the answer of #X.
絞込みテーブル3に格納されている回答の候補の番号は、問い合わせの開始から最新の発話までに含まれる単語が関連するものに絞込まれているため、絞込みテーブル3は、問い合わせの開始から最新の発話によって絞込まれた回答の候補を示す情報となる。また、絞込みテーブル3には、回答の候補と関連している属性を表す単語が併せて格納されているため、次の発話によって回答の候補を絞込むために必要な情報を含むものとなっている。
なお、このとき、絞込み処理部155は、絞込みテーブル3に含まれる属性から、応答特定属性テーブルATS3及び応答グループ特定属性テーブルATG3を生成する。これら応答特定属性テーブルATS3及び応答グループ特定属性テーブルATG3は、絞込みテーブル3と共に、絞込みテーブル類3を構成する。
The numbers of the answer candidates stored in the narrowing-down table 3 are narrowed down to those related to the words contained from the start of the inquiry to the latest utterance, so the narrowing-down table 3 is information showing the answer candidates narrowed down by the latest utterance from the start of the inquiry. In addition, the narrowing-down table 3 also stores words representing attributes related to the answer candidates, so it contains information necessary to narrow down the answer candidates by the next utterance.
At this time, the narrowing-
また、絞込み処理部155は、絞込み処理3において生成された絞込みテーブル3に基づいて、最新の発話に含まれる単語によって、回答の候補を一意に特定できるか否かを判定する。回答の候補を一意に特定できる場合、その回答の候補が属性の関連性に基づく回答の候補を決定するために用いられる。
The narrowing-
また、絞込み処理部155は、絞込み処理3において生成された絞込みテーブル3に基づいて、最新の発話に含まれる単語によって、回答の候補を一意に特定できない場合、ユーザから、回答をさらに絞込み可能な属性(即ち、回答の特定に有効な属性)の発話を誘導する対話を行う。具体的には、絞込み処理部155は、絞込みテーブル3における列の要素に「1」を含む属性のうち、回答を現在よりも絞込むことができる属性(即ち、回答を一意に特定可能な属性または回答の候補が現在よりも減少する属性)を、絞込みのための情報としてユーザに提示する属性に採用する。また、絞込み処理部155は、絞込みテーブル3に含まれる属性を、回答を現在よりも絞込むことができるものに更新する。即ち、絞込み処理部155は、絞込みテーブル3において、最新の発話に含まれる単語が関連する回答の候補の全てと関連している単語(即ち、回答の特定に有効でない属性)を除外し、最新の発話に含まれる単語が関連する回答の候補の一部と関連している単語(即ち、回答の特定に有効な属性)を残して、絞込みテーブル3を更新する。具体的には、絞込み処理部155は、絞込みテーブル3において、最新の発話に含まれる単語と関連性を有する回答のグループを特定し、特定された回答のグループに対応するテーブルの要素が全て“1”である列の属性を削除し、それ以外の属性で要素に“1”が1つでもある列の属性を残すことで、絞込みテーブル3を更新する。このとき、最新の発話に含まれる単語も除外して絞込みテーブル3が更新される。また、絞込みテーブル3の更新に合わせて、絞込みテーブル類3の応答特定属性テーブルATS3及び応答グループ特定属性テーブルATG3も更新され、更新された絞込みテーブル類3は、絞込み処理3の入力とされる。
このような処理により、システムから回答を絞込むために有効な属性の発話をユーザに促すことができる。
In addition, when the narrowing-
By performing such processing, the user can be prompted to speak attributes that are effective for narrowing down answers from the system.
絞込み処理部155は、絞込み処理1、絞込み処理2及び絞込み処理3を並行して実行し、絞込み処理1~3によって絞込みテーブル1~3を逐次生成及び更新する。そして、絞込み処理部155は、絞込み処理1~3による回答の候補の特定結果を統合処理部156に出力する。なお、絞込み処理1は、問い合わせにおける初回の発話から実行され、絞込み処理2は、問い合わせにおける2回目の発話(システムから回答を絞込むために行った初回の対話に対する発話)から実行され、絞込み処理3は、問い合わせにおける3回目の発話(システムから回答を絞込むために行った2回目の対話に対する発話)から実行される。
The narrowing down processing
ここで、絞込み処理1~3において、絞込みテーブル1~3の生成(または更新)及び絞込み処理2,3の入力となる絞込みテーブルの置換(受け渡し)については、発話毎に回答を絞込むことが可能な種々の形態を取ることが可能であるが、一例として、本実施形態では、以下のような手順を定めている。
(1)絞込みテーブル1は、最新の発話において、抽出フィルタによって単語が抽出された場合、絞込み処理1によってコネクタテーブルに含まれる単語を絞込むことにより、逐次生成される。回答が一意に特定されず、絞込みテーブル1が更新された場合、絞込み処理2の入力は、更新された絞込みテーブル1に置換される。
(2)絞込みテーブル1は、最新の発話において、抽出フィルタによって単語が抽出されなかった場合、更新されない。
Here, in the narrowing down
(1) Narrowing table 1 is generated sequentially when a word is extracted by an extraction filter in the latest utterance by narrowing down the words contained in the connector table by narrowing down
(2) Narrowing table 1 is not updated if no words are extracted by the extraction filter in the latest utterance.
(3)絞込みテーブル2は、初期化された直後(絞込みテーブル類1~3がリセットされた直後)の発話に対しては、生成されない(絞込み処理2が実行されない)。
(4)絞込みテーブル2は、初期化された直後以外の発話に対しては、前回の発話に対する絞込み処理1の出力である絞込みテーブル類1において、最新の発話で抽出された単語に合致する属性があれば、絞込み処理2によって絞込みテーブル1に含まれる単語を絞込むことにより生成される。回答が一意に特定されず、絞込みテーブル2が更新された場合、絞込み処理3の入力は、更新された絞込みテーブル2に置換される。
(5)絞込みテーブル2は、初期化された直後以外の発話に対しては、前回の発話に対する絞込み処理1の出力である絞込みテーブル類1において、最新の発話で抽出された単語に合致する属性がなければ、生成されない。
(3) Narrowing table 2 is not generated (narrowing
(4) For utterances other than those immediately after initialization, if there is an attribute in the narrowing-down tables 1, which are the output of the narrowing-down
(5) For utterances other than those immediately after initialization, the narrowing-down table 2 will not be generated if there are no attributes in the narrowing-down tables 1, which are the output of the narrowing-down
(6)絞込みテーブル3は、初期化された直後(絞込みテーブル類1~3がリセットされた後)の発話に対しては、生成されない(絞込み処理3が実行されない)。
(7)絞込みテーブル3は、初期化されてから2回目(絞込みテーブル類1~3がリセットされた後の後)の発話に対しては、生成されない(絞込み処理3が実行されない)。
(8)絞込みテーブル3は、初期化された直後及び初期化されてから2回目以外の発話に対しては、前回の発話に対する絞込み処理2の出力である絞込みテーブル類2において、最新の発話で抽出された単語に合致する属性があれば、絞込み処理2によって絞込みテーブル2に含まれる単語を絞込むことにより生成される。回答が一意に特定されず、絞込みテーブル3が更新された場合、引き続き、問い合わせのための発話が行われるときには、絞込み処理3の入力は、更新された絞込みテーブル3に置換される。
(9)絞込みテーブル3は、初期化された直後及び初期化されてから2回目以外の発話に対しては、前回の発話に対する絞込み処理2の出力である絞込みテーブル類2または前回の発話に対する絞込み処理3の出力である絞込みテーブル類3において、最新の発話で抽出された単語に合致する属性がなければ、生成されない。
(6) Narrowing table 3 is not generated (narrowing
(7) Narrowing table 3 is not generated (narrowing
(8) For an utterance other than immediately after initialization or the second time since initialization, if there is an attribute in the narrowing-down tables 2, which are the output of the narrowing-down
(9) For an utterance other than immediately after initialization or the second utterance after initialization, the narrowing-down table 3 will not be generated if there is no attribute matching the word extracted in the latest utterance in the narrowing-down tables 2 which are the output of the narrowing-down
図13は、抽出フィルタ生成の一例を示す模式図である。
なお、ここでは、説明の便宜のため、図13において具体的なデータが示されている欄にのみ注目し、「・・・」で示される欄のデータは考慮しないものとする(図14においても同様とする)。
また、図13に示す例では、説明の便宜のため、回答を表すコンテンツ全体の属性を対象として図示しているが、回答を表すコンテンツの部分の属性についても、同様に取り扱うことができる。
FIG. 13 is a schematic diagram showing an example of generating an extraction filter.
For ease of explanation, attention will be paid only to the columns in FIG. 13 in which specific data is shown, and data in columns indicated with "..." will not be taken into consideration (the same applies to FIG. 14).
In addition, in the example shown in FIG. 13, for convenience of explanation, the attributes of the entire content representing the answer are illustrated as the target, but the attributes of a portion of the content representing the answer can also be handled in the same manner.
図13に示すように、抽出フィルタが生成される場合、初めに、絞込み処理部155は、コネクタDB174を参照し、想定された問い合わせに対して用意されている回答を一意に特定可能な属性を表す単語を抽出して、各回答に付与された番号と対応付けたテーブル形式のデータ(応答特定属性テーブルATS0)を生成する。また、絞込み処理部155は、コネクタDB174を参照し、想定された問い合わせに対して用意されている回答(全体または部分)のグループを特定可能な属性を表す単語を抽出して、属性毎に回答に付与された番号群を対応付けたテーブル形式のデータ(応答グループ特定属性テーブルATG0)を生成する。さらに、絞込み処理部155は、応答特定属性テーブルATS0に含まれる単語及び応答グループ特定属性テーブルATG0に含まれる単語の類似語を取得し、応答特定属性テーブルATS0及び応答グループ特定属性テーブルATG0に含まれるオリジナルの単語と、その単語の類似語とを対応付けたテーブル形式のデータ(拡大属性テーブル)を生成する。そして、絞込み処理部155は、拡大属性テーブルに含まれる単語列からなる抽出フィルタを生成する。
As shown in FIG. 13, when an extraction filter is generated, the narrowing down processing
図14Aは、抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する過程の一例を示す模式図である。
また、図14Bは、問い合わせのための発話が複数回入力された場合の絞込みテーブル1~3の変化の一例を示す模式図である。
なお、図14Aにおいては、抽出フィルタによって抽出された単語から、コネクタテーブル類に含まれる応答特定属性テーブルATS0及び応答グループ特定属性テーブルATG0を介して回答の候補が特定される場合の例を示しているが、絞込みテーブル類1~3においても、応答特定属性テーブルATS1~3及び応答グループ特定属性テーブルATG1~3を介して同様に回答の候補が特定される。
例えば、問い合わせを開始する発話として、下記発話例(1)の発話が行われたとする。
発話例(1)「議事録製品について知りたい。」
FIG. 14A is a schematic diagram showing an example of a process for identifying answer candidates based on attribute relevance using an extraction filter.
FIG. 14B is a schematic diagram showing an example of changes in the narrowing-down tables 1 to 3 when an inquiry utterance is input multiple times.
Note that FIG. 14A shows an example in which answer candidates are identified from words extracted by the extraction filter via the response specific attribute table ATS0 and response group specific attribute table ATG0 included in the connector tables, but answer candidates are similarly identified in the narrowing down tables 1 to 3 via the response specific attribute tables ATS1 to 3 and response group specific attribute tables ATG1 to 3.
For example, assume that the following utterance example (1) is made as an utterance to start an inquiry.
Example utterance (1): "I would like to know about meeting minutes products."
このとき、発話例(1)の発話から、以下のように属性を表す単語が抽出されたものとする。
抽出単語:「議事録製品」(オリジナルの単語)
In this case, it is assumed that words expressing attributes are extracted from the utterance of the utterance example (1) as follows:
Extracted words: "Minutes product" (original words)
発話例(1)の場合、「議事録製品」が抽出フィルタに含まれる単語と一致し、オリジナルの単語である「議事録製品」が、応答グループ特定属性テーブルATG0に含まれる。このとき、「議事録製品」によって#1、#2、#Xの回答が特定され、絞込み処理1によって絞込みテーブル1が生成される(図14Bの「発話例(1)の結果」参照)。具体的には、特定された回答のグループ#1、#2、#Xにおいて、各回答に対応付けられている属性が取得される。そして、取得された属性を表す単語と、各回答の番号との関連性を表す情報を要素とする絞込みテーブル1、応答特定属性テーブルATS1及び応答グループ特定属性テーブルATG1が生成される。
In the case of utterance example (1), "minutes product" matches the words included in the extraction filter, and the original word "minutes product" is included in the response group specific attribute table ATG0. At this time, answers #1, #2, and #X are identified by "minutes product", and narrowing down
この場合、回答を一意に特定することができないため、絞込みテーブル1を参照し、絞込みテーブル1における列の要素に「1」を含む属性のうち、回答を現在よりも絞込むことができる属性(即ち、回答を一意に特定可能な属性または回答の候補が現在よりも減少する属性)を、絞込みのための情報としてユーザに提示する属性に採用する。また、絞込みテーブル1において、最新の発話に含まれる単語が関連する回答の候補の全てと関連している単語(即ち、回答の特定に有効でない属性)を除外し、最新の発話に含まれる単語が関連する回答の候補の一部と関連している単語(即ち、回答の特定に有効な属性)を残して、絞込みテーブル1が更新される。これにより、ユーザから、回答の特定に有効な属性の発話を誘導する対話が実行される。
具体的には、絞込みテーブル1を参照すると、#1、#2、#Xの回答は、「XXシステム」、「リモート会議」のいずれかが発話されれば、回答を現在よりも絞込むことができるため、ユーザに対して、「「XXシステム」、「リモート会議」を話して頂ければお答えすることができます。」との発話が出力される。
In this case, since the answer cannot be uniquely identified, the narrowing down table 1 is referred to, and among the attributes whose column elements in the narrowing down table 1 contain "1", attributes that can narrow down the answers more than at present (i.e., attributes that can uniquely identify the answer or attributes that reduce the number of answer candidates from the current number) are adopted as attributes to be presented to the user as information for narrowing down. In addition, in the narrowing down table 1, words that are related to all of the answer candidates related to the words included in the latest utterance (i.e., attributes that are not effective in identifying the answer) are excluded, and the narrowing down table 1 is updated while leaving words that are related to some of the answer candidates related to the words included in the latest utterance (i.e., attributes that are effective in identifying the answer). As a result, a dialogue is executed that induces the user to speak of attributes that are effective in identifying the answer.
Specifically, referring to Narrowing Table 1, the answers to #1, #2, and #X can be narrowed down more than the current answers if either "XX system" or "remote conference" is spoken, so the following utterance is output to the user: "We can answer if you say 'XX system' or 'remote conference'."
情報処理システム1が、回答の特定に有効な属性の発話を誘導する対話を行うことに対応して、ユーザが発話を行うと、この発話に含まれる単語を基に、絞込み処理1,2が実行され、絞込みテーブル1,2が生成される。この結果、回答の候補がさらに絞込まれる。
例えば、情報処理システム1が、回答の特定に有効な属性の発話を誘導する対話を行った後、2回目の発話として、ユーザが、下記追加発話例のような発話を行ったとする。
追加発話例(1)「XXシステムに興味あり」
When the
For example, assume that after the
Additional utterance example (1): "I'm interested in the XX system."
追加発話例(1)においては、「XXシステム」が抽出フィルタに含まれる単語と一致する。
追加発話例(1)に対し、絞込み処理1では、上述の「議事録製品」の場合と同様の処理が実行される。
一方、絞込み処理2では、オリジナルの単語である「XXシステム」が、応答グループ特定属性テーブルATG1に含まれる。このとき、「議事録製品」によって#2、#Xの回答が特定され、絞込み処理2によって絞込みテーブル2が生成される(図14Bの「追加発話例(1)の結果」参照)。具体的には、特定された回答のグループ#2、#Xにおいて、各回答に対応付けられている属性が取得される。そして、取得された属性を表す単語と、各回答の番号との関連性を表す情報を要素とする絞込みテーブル2、応答特定属性テーブルATS2及び応答グループ特定属性テーブルATG2が生成される。
In the additional utterance example (1), "XX system" matches the words included in the extraction filter.
In the
On the other hand, in the narrowing down
この場合、回答を一意に特定することができないため、絞込みテーブル2を参照し、絞込みテーブル2における列の要素に「1」を含む属性のうち、回答を現在よりも絞込むことができる属性(即ち、回答を一意に特定可能な属性または回答の候補が現在よりも減少する属性)を、絞込みのための情報としてユーザに提示する属性に採用する。また、絞込みテーブル2において、最新の発話に含まれる単語が関連する回答の候補の全てと関連している単語(即ち、回答の特定に有効でない属性)を除外し、最新の発話に含まれる単語が関連する回答の候補の一部と関連している単語(即ち、回答の特定に有効な属性)を残して、絞込みテーブル2が更新される。
これにより、ユーザから、回答の特定に有効な属性の発話を誘導する対話が実行される。
具体的には、絞込みテーブル2を参照すると、#2、#Xの回答は、「リモート会議」が発話されれば、回答を一意に絞込むことができるため、ユーザに対して、「「リモート会議」を話して頂ければお答えすることができます。」との発話が出力される。
In this case, since the answer cannot be uniquely specified, the narrowing down table 2 is referred to, and among the attributes whose column elements in the narrowing down table 2 contain "1", attributes that can narrow down the answers more than at present (i.e., attributes that can uniquely specify the answer or attributes that reduce the number of answer candidates more than at present) are adopted as attributes to be presented to the user as information for narrowing down. In addition, in the narrowing down table 2, words that are associated with all of the answer candidates related to the words included in the latest utterance (i.e., attributes that are not effective in specifying the answer) are excluded, and the narrowing down table 2 is updated by leaving words that are associated with some of the answer candidates related to the words included in the latest utterance (i.e., attributes that are effective in specifying the answer).
This allows a dialogue to be executed that prompts the user to speak about attributes that are effective in identifying an answer.
Specifically, by referring to Narrowing Table 2, the answers to #2 and #X can be uniquely narrowed down if "remote conference" is spoken, so the following speech is output to the user: "If you say 'remote conference', we can answer that question."
情報処理システム1が、回答の特定に有効な属性の発話を誘導する対話を行うことに対応して、ユーザが発話を行うと、この発話に含まれる単語を基に、絞込み処理1~3が実行され、絞込みテーブル1~3が生成される。この結果、絞込みテーブル3において、回答の候補が一意に絞込まれる。
例えば、情報処理システム1が、回答の特定に有効な属性の発話を誘導する対話を行った後、3回目の発話として、ユーザが、下記追加発話例のような発話を行ったとする。
追加発話例(2)「リモート会議ってなに?」
When the
For example, assume that after the
Additional utterance example (2) "What is a remote meeting?"
追加発話例(2)においては、「リモート会議」が抽出フィルタに含まれる単語と一致する。
追加発話例(2)に対し、絞込み処理1,2では、上述の「議事録製品」及び「XXシステム」の場合と同様の処理が実行される。
一方、絞込み処理3では、オリジナルの単語である「リモート会議」が、応答グループ特定属性テーブルATG2に含まれる。このとき、「リモート会議」によって#Xの回答が特定され、絞込み処理3によって絞込みテーブル3が生成される(図14Bの「追加発話例(2)の結果」参照)。この結果、ここで示す例においては、絞込みテーブル3において、回答の候補が一意に絞込まれることとなる。
In the additional utterance example (2), "remote conference" matches the word included in the extraction filter.
For the additional utterance example (2), in the narrowing down
On the other hand, in the narrowing-down
統合処理部156は、特定された言語処理による回答の候補及び絞込み処理1~3の結果を統合して特定する処理を実行し、発話された問い合わせに対する応答内容(最終的な回答または回答の特定に有効な属性の発話を誘導する対話の内容)最終的な回答を特定する。本実施形態において、統合処理部156は、以下のような選択基準によって最終的な回答を特定する。
The
即ち、統合処理部156は、
(i)言語処理による回答の候補として、一定の確度を有するもの(例えば、言語処理による特定結果のスコアが閾値以上のもの等)が特定されている場合、言語処理による回答の候補を最終的な回答として選択する。
(ii)言語処理による回答の候補として、一定の確度を有するものが特定されていない場合、属性の関連性に基づく回答の候補として、絞込みテーブル1、絞込みテーブル2、あるいは、絞込みテーブル3が1つの回答に絞込まれている場合には、その絞込まれた回答を最終的な回答として選択する。
(iii)属性の関連性に基づく回答の候補が(ii)の結果以外の場合、言語処理による回答の候補が絞込みテーブル1、絞込みテーブル2、あるいは、絞込みテーブル3における回答の候補に含まれていれば、言語処理による回答の候補を最終的な回答として選択する。
(iv)属性の関連性に基づく回答の候補が(iii)の結果以外の場合、最新の発話に対して、絞込み効果があった絞込みテーブル類(即ち、回答を絞込むことができた絞込み処理1~3の結果)を参照して、絞込みの効果のある属性(回答の候補が現在よりも減少する属性)を含む次のユーザの発話を促すメッセージを生成し、それを応答とする。ただし、最新の発話に対して、絞込み効果があった絞込みテーブル類が複数存在する場合、番号がより大きい絞込み処理の出力である応答グループ特定属性テーブルを参照する。
That is, the
(i) If a candidate answer based on language processing is identified that has a certain degree of accuracy (for example, a score of the identified result based on language processing is above a threshold), the candidate answer based on language processing is selected as the final answer.
(ii) When no candidate answer with a certain degree of certainty has been identified through language processing, if candidate answers based on attribute relevance are narrowed down to one answer in narrowing down table 1, narrowing down table 2, or narrowing down table 3, that narrowed down answer is selected as the final answer.
(iii) If the answer candidate based on the attribute relevance is other than the result of (ii), if the answer candidate generated by language processing is included in the answer candidates in narrowing down table 1, narrowing down table 2, or narrowing down table 3, the answer candidate generated by language processing is selected as the final answer.
(iv) If the answer candidate based on the attribute relevance is not the result of (iii), refer to the narrowing down tables that had a narrowing down effect on the latest utterance (i.e., the results of narrowing down
[動作]
次に、情報処理システム1の動作を説明する。
[自動探索処理]
図15は、情報処理システム1が実行する自動探索処理の流れを示すフローチャートである。
自動探索処理は、サーバ20において、自動探索処理の実行を指示する操作が行われることに対応して開始される。
図15に示すフローチャートにおいて、ステップS1~ステップS5の処理は、図10Aに示す第1実施形態の自動応答処理と同様である。
なお、本実施形態においては、自動探索処理の実行に先立ち、絞込み処理1で用いられるコネクタテーブル及び応答特定属性テーブルATS0及び応答グループ特定属性テーブルATG0(コネクタテーブル類)が設定される。
[Action]
Next, the operation of the
[Automatic search process]
FIG. 15 is a flowchart showing the flow of the automatic search process executed by the
The automatic search process is started in response to an operation being performed on the
In the flowchart shown in FIG. 15, the processes in steps S1 to S5 are similar to the automatic response process in the first embodiment shown in FIG. 10A.
In this embodiment, prior to the execution of the automatic search process, the connector table, response specific attribute table ATS0, and response group specific attribute table ATG0 (connector tables) used in the narrowing down
ステップS6Aにおいて、絞込み処理部155は、絞込み処理1~3を並列的に実行し、それぞれの特定結果を統合処理部156に出力する。
ステップS7Aにおいて、統合処理部156は、言語処理による回答の候補を特定できたか否か(一定の確度を有する回答の候補を特定できたか否か)の判定を行う。
言語処理による回答の候補を特定できた場合、ステップS7AにおいてYESと判定されて、処理はステップS13Aに移行する。
一方、言語処理による回答の候補を特定できていない場合、ステップS7AにおいてNOと判定されて、処理はステップS8Aに移行する。
In step S 6 A, narrowing-
In step S7A, the
If answer candidates can be identified through language processing, a YES determination is made in step S7A, and the process proceeds to step S13A.
On the other hand, if answer candidates have not been identified through language processing, a NO determination is made in step S7A, and the process proceeds to step S8A.
ステップS8Aにおいて、統合処理部156は、絞込み処理1~3の結果を基に、予め設定された選択基準によって回答の候補を特定する。
ステップS9Aにおいて、統合処理部156は、絞込み処理1~3によって回答の候補を一意に特定できたか否かの判定を行う。
絞込み処理1~3によって回答の候補を一意に特定できた場合、ステップS9AにおいてYESと判定されて、処理はステップS13Aに移行する。
一方、絞込み処理1~3によって回答の候補を一意に特定できていない場合、ステップS9AにおいてNOと判定されて、処理はステップS10Aに移行する。
In step S8A, the
In step S9A, the
If answer candidates can be uniquely identified through narrowing down
On the other hand, if answer candidates have not been uniquely identified through narrowing down
ステップS10Aにおいて、絞込み処理部155は、絞込みテーブル類1~3を更新する。これにより、絞込みテーブル類1~3に含まれる属性が、回答を現在よりも絞込むことができるものに更新される。なお、最新の発話に含まれる単語によって、絞込みテーブル1~3が絞込まれていない(回答の候補が現在よりも減少していない)場合、その絞込みテーブルが属する絞込みテーブル類は更新されない(ステップS10Aの処理はスキップされる)。
ステップS11Aにおいて、絞込み処理部155は、属性の発話を誘導する対話内容を決定する。
ステップS12Aにおいて、絞込み処理部155は、更新された絞込みテーブル類を他の絞込み処理の入力として置換(受け渡し)する。なお、最新の発話に含まれる単語によって、絞込みテーブル1~3が絞込まれていない(回答の候補が現在よりも減少していない)場合、その絞込みテーブルが属する絞込みテーブル類は他の絞り込み処理の入力として置換(受け渡し)されない(ステップS12Aの処理はスキップされる)。
In step S10A, the narrowing-
In step S11A, the narrowing-
In step S12A, the narrowing-
ステップS13Aにおいて、統合処理部156は、問い合わせに対する応答を音声またはテキストデータとして出力(端末装置10に送信)する。このとき、統合処理部156は、問い合わせに対する応答として、言語処理による回答の候補が特定されている場合、特定された言語処理による回答の候補を出力し、言語処理による回答の候補が特定されていない場合、属性の関連性に基づく回答の候補または属性の発話を誘導する対話内容を出力する。ステップS13Aにおいて送信された応答のデータは、端末装置10の応答受信部53によって受信され、応答出力部54によって、音声または画像表示によって出力される。なお、このとき、複数の回答の候補に絞込まれている場合、これら複数の回答の候補を最終的な回答として出力することとしてもよい。
In step S13A, the
ステップS14Aにおいて、統合処理部156は、自動応答処理の終了条件に合致しているか否かの判定を行う。自動応答処理の終了条件としては、例えば、発話された問い合わせに対して、一意に回答を特定して応答を出力したことや、ユーザによって問い合わせを終了する操作が行われたこと等を定義することができる。
問合せ処理の終了条件に合致していない場合、ステップS14AにおいてNOと判定されて、処理はステップS1に移行する。
一方、自動応答処理の終了条件に合致している場合、ステップS14AにおいてYESと判定されて、自動探索処理は終了する。
In step S14A, the
If the end condition for the inquiry process is not met, a negative determination is made in step S14A, and the process proceeds to step S1.
On the other hand, if the end condition for the automatic response process is met, a YES determination is made in step S14A, and the automatic search process ends.
以上のように、本実施形態に係る情報処理システム1においては、属性の関連性に基づく回答の候補を選択するための処理として、異なる機能を有する複数の絞込み処理1~3を並列的に実行し、これら並列的な処理による特定結果及び言語処理を用いた特定処理による特定結果を統合して応答の内容を特定する。そして、1度の問い合わせのための発話によって回答を特定することができない場合に、情報処理システム1は、回答の特定に有効な属性を自動的に絞込み、ユーザによる有意な発話を誘導する対話を自律的に行う。
これにより、属性の関連性に基づく回答の候補として、適切な回答が特定される可能性を高めることができる。
As described above, in the
This can increase the likelihood that an appropriate answer will be identified as an answer candidate based on attribute relevance.
また、本実施形態に係る情報処理システム1においては、回答を表すコンテンツ全体を回答として特定される対象とする他、コンテンツの部分(例えば、パラグラフ、セクションあるいは動画の時間帯等)を回答として特定される対象としている。
これにより、想定された問い合わせに対して用意されている回答のコンテンツの一部として、適切な回答が含まれている場合にも、その一部を回答として特定することができるため、適切な回答が特定される可能性をさらに高めることができる。
したがって、情報処理システム1によれば、発話に対する自動応答を行う際に、処理時間を短縮しつつ、より適切な応答内容を特定することが可能となる。
In addition, in the
This makes it possible to identify a part of an appropriate answer, even if the appropriate answer is included as part of the content of the answer prepared for an anticipated inquiry, as the answer, thereby further increasing the possibility of identifying an appropriate answer.
Therefore, according to the
[第3実施形態]
次に、本発明の第3実施形態について説明する。
本実施形態に係る情報処理システム1は、第1実施形態の情報処理システム1において、言語処理による回答の候補の特定を実行しないと共に、想定された問い合わせが備える属性から生成された問い合わせ用抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する第1の特定処理と、想定された問い合わせに対して用意されている回答が備える属性から生成された回答用抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する第2の特定処理と、を並列的に実行し、第1の特定処理または第2の特定処理で特定された回答を最終的な回答として出力するものである。
[Third embodiment]
Next, a third embodiment of the present invention will be described.
The
本実施形態における情報処理システム1のシステム構成、情報処理装置のハードウェア構成、端末装置10の機能的構成等の主要な部分は、第1実施形態と同様であるため、異なる部分を主として説明する。
以下、第1実施形態と異なる部分であるサーバ20の機能的構成及び自動応答処理のフローチャートを主として説明する。
The main parts of the system configuration of the
The following mainly describes the functional configuration of the
[機能的構成]
図16は、本実施形態におけるサーバ20の機能的構成を示すブロック図である。
また、図17は、本実施形態における情報処理システム1の具体的機能構成例を示す模式図である。
応答内容DB173には、想定された問い合わせ内容を表すテキストデータ(ここでは、担当者の氏名)と、想定された問い合わせに対して用意されている回答(ここでは、担当者の電話番号)とが対応付けられた応答内容テーブルのデータが格納されている。
[Functional configuration]
FIG. 16 is a block diagram showing the functional configuration of the
FIG. 17 is a schematic diagram showing a specific example of the functional configuration of the
The response content DB173 stores data in a response content table that corresponds text data (here, the name of the person in charge) representing the anticipated inquiry content with responses (here, the telephone number of the person in charge) prepared for the anticipated inquiry.
図18は、本実施形態における応答内容テーブルの一例を示す模式図である。
図18に示すように、本実施形態の応答内容テーブルには、想定された問い合わせ内容を表すテキストデータ(担当者の氏名)と、想定された問い合わせに対して用意された回答(担当者の電話番号)と、想定された問い合わせに付与された番号と、想定された問い合わせに対して用意されている回答に付与された番号とが対応付けて格納されている。
FIG. 18 is a schematic diagram showing an example of a response content table in this embodiment.
As shown in FIG. 18, the response content table of this embodiment stores, in association with each other, text data (name of person in charge) representing the anticipated inquiry content, a response prepared for the anticipated inquiry (phone number of the person in charge), a number assigned to the anticipated inquiry, and a number assigned to the response prepared for the anticipated inquiry.
コネクタDB174には、想定された問い合わせに対応する第1のコネクタテーブルのデータと、想定された問い合わせに対して用意されている回答に対応する第2のコネクタテーブルのデータとが記憶されている。
図19は、第1のコネクタテーブルの一例を示す模式図であり、図20は、第2のコネクタテーブルの一例を示す模式図である。
The
FIG. 19 is a schematic diagram showing an example of the first connector table, and FIG. 20 is a schematic diagram showing an example of the second connector table.
図19に示すように、第1のコネクタテーブルには、想定された問い合わせに付与された番号と、想定された問い合わせを表すテキストデータ(即ち、担当者の氏名)と、想定された問い合わせの属性を表す単語(担当者の呼び名等)と、想定された問い合わせに対して用意された回答(担当者の電話番号)に付与された番号とが、対応付けて格納されている。例えば、図19に示す第1のコネクタテーブルの第2行には、想定された問い合わせを表す「河野三郎」(氏名)について、想定された問い合わせの属性として、「河野」(苗字)という単語が格納されている。 As shown in FIG. 19, the first connector table stores, in association with each other, a number assigned to an anticipated inquiry, text data representing the anticipated inquiry (i.e., the name of the person in charge), a word representing an attribute of the anticipated inquiry (such as the name of the person in charge), and a number assigned to a response prepared to the anticipated inquiry (the person in charge's telephone number). For example, the second row of the first connector table shown in FIG. 19 stores the word "Kono" (surname) as an attribute of the anticipated inquiry for "Kono Saburo" (name) representing the anticipated inquiry.
また、図20に示すように、第2のコネクタテーブルには、想定された問い合わせ(即ち、担当者)毎に、応答の能力・担当(部署、役職、担当商品等)の属性を表す単語と、想定された問い合わせに対して用意されている回答に付与された番号とが、対応付けて格納されている。例えば、図20に示す第2のコネクタテーブルの第2行には、想定された問い合わせに対して用意されている回答の属性を表す単語(本社/開発部/開発課/・・・/XX商品/・・・)と、想定された問い合わせに対して用意されている回答に付与された番号とが格納されている。 As shown in FIG. 20, the second connector table stores, for each anticipated inquiry (i.e., person in charge), a word representing the response ability and attributes of the person in charge (department, position, product in charge, etc.) in association with a number assigned to the answer prepared for the anticipated inquiry. For example, the second row of the second connector table shown in FIG. 20 stores a word representing the attributes of the answer prepared for the anticipated inquiry (head office/development department/development section/.../XX product/...) and a number assigned to the answer prepared for the anticipated inquiry.
図16及び図17に戻り、本実施形態におけるサーバ20は、言語処理による回答の候補を特定しないことから、言語処理部154及び統合処理部156を備えていない。また、本実施形態におけるサーバ20は、ディクテーションの音声認識処理を実行することなく、2つの単語抽出の音声認識処理を並列に実行するため、図9に示す第1実施形態のディクテーション音声認識部501に代えて、単語抽出音声認識部501Aが備えられている。
Returning to Figures 16 and 17, the
ここで、2つの単語抽出の音声認識処理の一方は、想定された問い合わせに含まれる単語を抽出するための音声認識処理であり、他方は、想定された問い合わせに対して用意されている回答に含まれる単語を抽出するための音声認識処理である。
したがって、図17において、単語抽出音声認識部501Aが参照する単語辞書DB172の辞書データには、想定された問い合わせに含まれる単語が登録されており、単語抽出音声認識部511が参照する単語辞書DB172の辞書データには、想定された問い合わせに対して用意されている回答に含まれる単語が登録されている。
Here, one of the two word extraction speech recognition processes is a speech recognition process for extracting words contained in an anticipated inquiry, and the other is a speech recognition process for extracting words contained in a prepared response to the anticipated inquiry.
Therefore, in FIG. 17 , the dictionary data of
また、図16及び図17における絞込み処理部155は、想定された問い合わせが備える属性から生成された問い合わせ用抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する第1の特定処理を実行し、想定された問い合わせに対して用意されている回答が備える属性から生成された回答用抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する第2の特定処理を実行する。
そして、絞込み処理部155によって実行された第1の特定処理及び第2の特定処理の結果から、質問に対する回答が一意に特定され、最終的な回答とされる。
In addition, the narrowing-
Then, from the results of the first and second identification processes executed by the narrowing-
図21は、問い合わせ用抽出フィルタ生成の一例を示す模式図である。
なお、ここでは、説明の便宜のため、図20において具体的なデータが示されている欄にのみ注目し、「・・・」で示される欄のデータは考慮しないものとする(図22~図25においても同様とする)。
図21に示すように、問い合わせ用抽出フィルタを生成する場合、初めに、絞込み処理部155は、コネクタDB174の第1のコネクタテーブルを参照し、応答特定属性の単語を抽出して、各回答に付与された番号と対応付けたテーブル形式のデータ(応答特定属性テーブル)を生成する。また、絞込み処理部155は、コネクタDB174の第1のコネクタテーブルを参照し、応答グループ特定属性の単語を抽出して、属性毎に回答に付与された番号群を対応付けたテーブル形式のデータ(応答グループ特定属性テーブル)を生成する。さらに、絞込み処理部155は、応答特定属性テーブルに含まれる単語及び応答グループ特定属性テーブルに含まれる単語を類似語で拡大する。例えば、その単語に対して予め用意された類似語群のデータや、インターネット等を介して外部から取得される類似語として使用可能な単語のデータ(例えば、オントロジーを参照して取得される類似概念を表す単語のデータ等)で拡大する。さらに、絞込み処理部155は、応答特定属性テーブル及び応答グループ特定属性テーブルに含まれるオリジナルの単語と、その単語の類似語とを対応付けたテーブル形式のデータ(拡大属性テーブル)を生成する。そして、絞込み処理部155は、拡大属性テーブルに含まれる単語列からなる問い合わせ用抽出フィルタを生成する。
FIG. 21 is a schematic diagram showing an example of generating a query extraction filter.
For ease of explanation, attention will be paid only to the columns in Figure 20 in which specific data is shown, and data in columns marked with "..." will not be taken into consideration (the same applies to Figures 22 to 25).
As shown in FIG. 21, when generating an inquiry extraction filter, the narrowing down processing
また、図22は、回答用抽出フィルタ生成の一例を示す模式図である。
本実施形態において、回答用抽出フィルタは、想定された問い合わせが備える属性から生成される問い合わせ用抽出フィルタとは別に、想定された問い合わせに対して用意されている回答が備える属性から生成される。
図22に示すように、回答用抽出フィルタが生成される場合、初めに、絞込み処理部155は、コネクタDB174の第2のコネクタテーブルを参照し、応答特定属性の単語を抽出して、各回答に付与された番号と対応付けたテーブル形式のデータ(応答特定属性テーブル)を生成する。また、絞込み処理部155は、コネクタDB174の第2のコネクタテーブルを参照し、応答グループ特定属性の単語を抽出して、属性毎に回答に付与された番号群を対応付けたテーブル形式のデータ(応答グループ特定属性テーブル)を生成する。さらに、絞込み処理部155は、応答特定属性テーブルに含まれる単語及び応答グループ特定属性テーブルに含まれる単語を類似語で拡大する。例えば、その単語に対して予め用意された類似語群のデータや、インターネット等を介して外部から取得される類似語として使用可能な単語のデータ(例えば、オントロジーを参照して取得される類似概念を表す単語のデータ等)で拡大する。さらに、絞込み処理部155は、応答特定属性テーブル及び応答グループ特定属性テーブルに含まれるオリジナルの単語と、その単語の類似語とを対応付けたテーブル形式のデータ(拡大属性テーブル)を生成する。そして、絞込み処理部155は、拡大属性テーブルに含まれる単語列からなる回答用抽出フィルタを生成する。
FIG. 22 is a schematic diagram showing an example of generating an answer extraction filter.
In this embodiment, an answer extraction filter is generated from attributes of answers prepared for anticipated inquiries, separate from an inquiry extraction filter generated from attributes of anticipated inquiries.
As shown in FIG. 22, when an answer extraction filter is generated, the narrowing down processing
図23は、問い合わせ用抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する過程の一例を示す模式図である。また、図24は、回答用抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する過程の一例を示す模式図である。
例えば、下記発話例(1)~(3)の発話が行われたとする。
発話例(1)「営業の山田さんをお願いします。」
発話例(2)「開発のカワノさんをお願いします。」
発話例(3)「XX商品が分かる技術の人をお願いします。」
Fig. 23 is a schematic diagram showing an example of a process for identifying answer candidates based on attribute relevance using a query extraction filter. Fig. 24 is a schematic diagram showing an example of a process for identifying answer candidates based on attribute relevance using a response extraction filter.
For example, assume that the following utterances (1) to (3) are made.
Example utterance (1): "I'd like to speak to Yamada-san from sales, please."
Example utterance (2): "I'd like to speak to Kawano-san from development, please."
Example utterance (3): "I'd like someone with technical skills who understands the XX product."
このとき、各発話例の発話から、以下のように属性を表す単語が抽出されたものとする。
発話例(1)「山田」(問い合わせ用抽出フィルタより)、「営業」(回答用抽出フィルタより)
発話例(2)「カワノ」(問い合わせ用抽出フィルタより)、「開発」(回答用抽出フィルタより)
発話例(3)「XX商品」(回答用抽出フィルタより)、「技術」(回答用抽出フィルタより)
At this time, it is assumed that words expressing attributes are extracted from each example utterance as follows:
Example utterance (1): "Yamada" (from the inquiry extraction filter), "Sales" (from the answer extraction filter)
Example utterance (2): "Kawano" (from the inquiry extraction filter), "development" (from the answer extraction filter)
Example utterance (3): "XX product" (from the answer extraction filter), "technology" (from the answer extraction filter)
発話例(1)の場合、「山田」が問い合わせ用抽出フィルタに含まれる単語と一致し、「営業」が回答用抽出フィルタに含まれる単語と一致し、「山田」から#2、#3の回答が特定されると共に、「営業」から#3、#4の回答が特定される。即ち、発話例(1)の場合、第1の特定処理及び第2の特定処理の結果の論理積から#2の回答(山田太郎)が特定され、最終的な回答とされる。 In the case of utterance example (1), "Yamada" matches the words contained in the inquiry extraction filter, and "sales" matches the words contained in the answer extraction filter, so answers #2 and #3 are identified from "Yamada," and answers #3 and #4 are identified from "sales." That is, in the case of utterance example (1), answer #2 (Yamada Taro) is identified from the logical product of the results of the first and second identification processes, and is taken as the final answer.
発話例(2)の場合、「カワノ」が問い合わせ用抽出フィルタに含まれる単語と一致し、「開発」が回答用抽出フィルタに含まれる単語と一致し、「カワノ」及び「開発」のいずれからも#1の回答が特定される。即ち、発話例(2)の場合、第1の特定処理または第2の特定処理の結果から#1の回答(河野三郎)が特定され、最終的な回答とされる。
In the case of utterance example (2), "Kawano" matches the words contained in the inquiry extraction filter, and "development" matches the words contained in the answer extraction filter, so
発話例(3)の場合、問い合わせ用抽出フィルタに含まれる単語とは属性が一致せず、「XX商品」及び「技術」が回答用抽出フィルタに含まれる単語と一致し、「XX商品」から#1、#3の回答が特定されると共に、「技術」から#1の回答が特定される。即ち、発話例(3)の場合、第2の特定処理の結果から#1の回答(河野三郎)が特定され、最終的な回答とされる。
In the case of utterance example (3), the attributes do not match the words contained in the inquiry extraction filter, but "XX product" and "technology" match the words contained in the answer extraction filter, and answers #1 and #3 are identified from "XX product," while
[動作]
次に、情報処理システム1の動作を説明する。
図25は、情報処理システム1が実行する自動応答処理の流れを示すフローチャートである。
自動応答処理は、サーバ20において、自動応答処理の実行を指示する操作が行われることに対応して開始される。
本実施形態における自動応答処理は、図10Aに示す第1実施形態の自動応答処理に対し、ステップS41-1の処理がステップS41-1Aに変更され、ステップS41-2の処理がステップS41-2Aに変更されていると共に、ステップS5~ステップS9の処理がステップS105~ステップS107に変更されている点が異なっている。
[Action]
Next, the operation of the
FIG. 25 is a flowchart showing the flow of the automatic response process executed by the
The automatic response process is started in response to an operation of the
The automatic response processing in this embodiment differs from the automatic response processing in the first embodiment shown in FIG. 10A in that the processing of step S41-1 is changed to step S41-1A, the processing of step S41-2 is changed to step S41-2A, and the processing of steps S5 to S9 is changed to steps S105 to S107.
即ち、ステップS4において、サーバ20の音声認識処理部153は、前処理が実行された後の音声データに対し、複数の音声認識エンジンによって、並列的に音声認識処理(S41-1A~S43-1及びS41-2A~S43-2)を実行する。
具体的には、ステップS41-1Aにおいて、単語抽出音声認識部501Aは、単語抽出の音声認識処理(ここでは、ルールグラマーの音声認識処理またはDNNを用いた音声認識処理とする。)を行うための音声認識エンジンにより音声データを処理し、音声データに含まれる特定の単語を抽出してテキストデータに変換する。なお、ステップS41-1Aにおける音声認識処理は、想定された問い合わせに含まれる単語を抽出するための音声認識処理であり、想定された問い合わせに含まれる単語が予め登録された単語抽出用の辞書を参照して、音声認識処理が実行される。
That is, in step S4, the speech
Specifically, in step S41-1A, the word extraction
また、ステップS41-2Aにおいて、単語抽出音声認識部511は、単語抽出の音声認識処理(ここでは、ルールグラマーの音声認識処理またはDNNを用いた音声認識処理とする。)を行うための音声認識エンジンにより音声データを処理し、音声データに含まれる特定の単語を抽出してテキストデータに変換する。なお、ステップS41-2Aにおける音声認識処理は、想定された問い合わせに対して用意されている回答に含まれる単語を抽出するための音声認識処理であり、想定された問い合わせに対して用意されている回答に含まれる単語が予め登録された単語抽出用の辞書を参照して、音声認識処理が実行される。
ステップS43-1及びステップS43-2の後、処理はステップS105に移行する。
In step S41-2A, the word extraction speech recognition unit 511 processes the speech data using a speech recognition engine for performing speech recognition processing for word extraction (here, this is assumed to be speech recognition processing using a rule grammar or speech recognition processing using a DNN), extracts specific words contained in the speech data, and converts them into text data. Note that the speech recognition processing in step S41-2A is a speech recognition processing for extracting words contained in answers prepared for anticipated inquiries, and the speech recognition processing is performed by referring to a word extraction dictionary in which words contained in answers prepared for anticipated inquiries are registered in advance.
After steps S43-1 and S43-2, the process proceeds to step S105.
ステップS105において、絞込み処理部155は、第1の特定処理及び第2の特定処理を実行し、発話された問い合わせに対する最終的な回答を特定する。即ち、絞込み処理部155は、音声認識処理部153-1によって取得された単語抽出の音声認識結果(即ち、想定された問い合わせに含まれる単語)と、問い合わせ用抽出フィルタに含まれる単語とが一致するか否かを判定し、一致する場合、問い合わせ用抽出フィルタに含まれる一致した単語を基に、予め用意されている回答の絞込みを行う。また、絞込み処理部155は、音声認識処理部153-2によって取得された単語抽出の音声認識結果(即ち、想定された問い合わせに対して用意されている回答に含まれる単語)と、回答用抽出フィルタに含まれる単語とが一致するか否かを判定し、一致する場合、回答用抽出フィルタに含まれる一致した単語を基に、予め用意されている回答の絞込みを行う。そして、絞込み処理部155は、第1の特定処理及び第2の特定処理の絞込み結果を基に、発話された問い合わせに対する最終的な回答を特定する。
In step S105, the narrowing down processing
ステップS106において、統合処理部156は、特定した最終的な回答を音声またはテキストデータとして端末装置10に送信する。送信された回答のデータは、端末装置10の応答受信部53によって受信され、応答出力部54によって、音声または画像表示によって出力される。なお、ステップS106において出力される応答は、一意に特定された回答を応答する場合の他、複数の回答の候補を一意に特定するための発話を促す応答や、複数の回答の候補を出力する応答としてもよい。
In step S106, the
ステップS107において、統合処理部156は、自動応答処理の終了条件に合致しているか否かの判定を行う。自動応答処理の終了条件としては、例えば、発話された問い合わせに対して、一意に回答を特定して応答を出力したことや、ユーザによって問い合わせを終了する操作が行われたこと等を定義することができる。
問合せ処理の終了条件に合致していない場合、ステップS107においてNOと判定されて、処理はステップS1に移行する。
一方、自動応答処理の終了条件に合致している場合、ステップS107においてYESと判定されて、自動応答処理は終了する。
In step S107, the
If the end condition for the inquiry process is not met, a negative determination is made in step S107, and the process proceeds to step S1.
On the other hand, if the end condition for the automatic response process is met, the answer in step S107 is YES, and the automatic response process ends.
以上のように、本実施形態における情報処理システム1においては、想定された問い合わせが備える属性から生成された問い合わせ用抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する第1の特定処理と、想定された問い合わせに対して用意されている回答が備える属性から生成された回答用抽出フィルタを用いて、属性の関連性に基づく回答の候補を特定する第2の特定処理と、を並列的に実行し、第1の特定処理または第2の特定処理で特定された回答を最終的な回答として出力する。
そのため、言語処理による回答の候補の特定を実行することなく、想定された問い合わせの内容及び想定された問い合わせに対して用意されている回答の属性から、問い合わせに対する回答を特定することができる。
したがって、発話に対する自動応答を行う際に、処理時間を短縮しつつ、より適切な応答内容を特定することが可能となる。
As described above, in the
Therefore, it is possible to identify an answer to a query from the content of the anticipated query and the attributes of the answers prepared for the anticipated query, without performing language processing to identify answer candidates.
Therefore, when an automatic response to a speech is made, it is possible to specify more appropriate response content while shortening the processing time.
[変形例1]
上述の各実施形態において、探索用データとして、複数のテーブルを生成する場合を例に挙げて説明したが、これに限られない。
即ち、探索用データの形式は特に限定されるものではなく、データ(属性を表す単語や回答の番号等)間の関係を辿って回答を特定できるものであれば、1つのテーブルによって構成したり、ポインタ等によって関係を規定されたデータ群によって構成したりすることが可能である。
[Modification 1]
In each of the above-described embodiments, a case has been described in which a plurality of tables are generated as search data, but the present invention is not limited to this.
In other words, the format of the search data is not particularly limited, and as long as it is possible to identify an answer by tracing the relationships between data (such as words representing attributes or answer numbers), it is possible for the data to be composed of a single table or a group of data whose relationships are defined by pointers, etc.
[変形例2]
第2実施形態において、絞込み処理2は、最新の発話及び前回の発話を基に、属性の関連性に基づく回答の候補を特定するものとして説明したが、これに限られない。
即ち、絞込み処理2は、最新の発話及び最新の発話に先行する過去の任意の回数の発話を基に、属性の関連性に基づく回答の候補を特定することが可能である。
これにより、絞込み処理2において反映させる過去の発話の回数を、統計的なデータあるいは情報処理システム1が適用される用途等に応じて、適切に設定することが可能となる。
また、絞込み処理2として、最新の発話及び最新の発話に先行する異なる回数の過去の所定回の発話を基に、属性の関連性に基づく回答の候補を特定する複数の処理(即ち、複数層の絞込み処理2)を並列的に実行することができる。
これにより、ユーザによる問い合わせのための発話の方向性が変化したり、ユーザがシステムからの誘導に則さない単語を発話したりした場合にも、直近の所定回の発話による絞込み結果(絞込みテーブル)を活用して、絞込み処理を継続することができる。
そのため、ユーザの意図を適確に反映させて回答を絞込むことが可能となるため、ユーザの選好性に対応して、問い合わせに対する適切な回答を早期に特定することができる。
[Modification 2]
In the second embodiment, the narrowing-down
That is, the narrowing-down
This makes it possible to appropriately set the number of past utterances reflected in the narrowing-down
In addition, as narrowing-down
This makes it possible to continue the narrowing down process by utilizing the narrowing down results (narrowing down table) based on the most recent predetermined number of utterances, even if the direction of the user's inquiry changes or if the user speaks words that do not conform to the guidance from the system.
Therefore, it is possible to narrow down the answers by accurately reflecting the user's intention, so that an appropriate answer to the inquiry can be identified quickly in accordance with the user's preferences.
[変形例3]
第1実施形態及び第2実施形態において、音声認識処理部153は、第1音声認識部153-1~第n音声認識部153-nを備え、複数の音声認識処理を並列的に実行する場合を例に挙げて説明したが、これに限られない。例えば、音声認識処理部153が、1つの音声認識エンジン(例えば、汎用のディクテーションを行う音声認識エンジン等)によって音声認識処理された結果を出力し、この音声認識結果に対して、言語処理による回答の候補を特定する処理と、属性の関連性に基づく回答の候補を特定する処理とを並列的に実行することとしてもよい。例えば、1つの音声認識結果に対して、第2実施形態の絞込み処理1~3及び言語処理による回答の候補を特定する処理を並列的に実行することができる。
また、1つの音声認識結果に対して、言語処理による回答の候補及び属性の関連性に基づく回答の候補を特定することに加え、回答の特定に有効な属性の発話を誘導する対話の内容(メッセージ)を特定することも可能である。
このとき、ユーザによる問い合わせのための発話に対し、AI(Artificial Intelligence)を用いて、回答または回答の特定に有効な属性の発話を誘導する対話を応答することとしてもよい。
この場合、処理負荷の増大を抑制しつつ、単独の音声認識処理による処理結果よりも有用な情報を得ることができる。
なお、このとき用いられる音声認識処理の種類としては、汎用のディクテーションを目的とするものの他、特定分野向けのディクテーションを目的とするものや、単語抽出による音声認識を行うもの等、種々の音声認識処理を用いることが可能である。
[Modification 3]
In the first and second embodiments, the voice
In addition to identifying candidate answers based on language processing and candidate answers based on attribute relevance for one speech recognition result, it is also possible to identify the content (message) of the dialogue that induces the utterance of attributes that are effective in identifying an answer.
At this time, in response to a user's inquiry utterance, AI (Artificial Intelligence) may be used to respond with a dialogue that induces the user to utter an answer or an utterance of an attribute that is effective in identifying an answer.
In this case, it is possible to obtain more useful information than the processing result obtained by a single voice recognition process while suppressing an increase in the processing load.
The types of voice recognition processing that can be used at this time include general-purpose dictation, dictation for a specific field, and voice recognition through word extraction.
[変形例4]
第2実施形態において、ユーザの発話に対して、抽出フィルタを用いた単語抽出の音声認識処理を実行し、抽出された単語を基に、絞込み処理1~3によって、属性の関連性に基づく回答の候補を絞込む場合を例に挙げて説明したが、これに限られない。
即ち、ユーザが回答を絞込むための単語を含む発話を行い、音声認識によって単語を入力する形態以外にも、画面操作によって単語を入力する形態を用いることができる。
例えば、絞込み処理1に入力する問い合わせのための単語を画面操作によって入力したり、絞込み処理1あるいは絞込み処理2で絞込まれた回答の候補をさらに絞込むための単語を画面操作によって入力したりすることができる。
画面操作によって単語を入力する形態としては、端末装置10のディスプレイ(出力部816)において、ウィンドウ内に回答の候補と関連性を有する単語(属性を表す単語)をスクロール表示(移動させて表示)し、ユーザがマウスクリックあるいはタップ操作等によって単語を選択する形態とすることが可能である。また、画面操作によって単語を入力する他の形態としては、端末装置10のディスプレイ(出力部816)において、ウィンドウ内に回答の候補と関連性を有する単語(属性を表す単語)をプルダウンメニュー等によって一覧表示し、ユーザがマウスクリックあるいはタップ操作等によって単語を選択する形態や、単語をテーブル形式で一覧表示し、各単語に付されたチェックボックスをユーザがオンとすることにより単語を選択する形態とすること等が可能である。
[Modification 4]
In the second embodiment, an example was given in which a voice recognition process for extracting words using an extraction filter is performed on a user's speech, and based on the extracted words, narrowing down answer candidates based on attribute relevance are narrowed down by narrowing down
That is, in addition to a mode in which the user speaks including words for narrowing down answers and the words are input by voice recognition, a mode in which the words are input by operating the screen can also be used.
For example, words for an inquiry to be entered into narrowing-down
A form in which words are input by operating the screen can be a form in which words (words representing attributes) related to answer candidates are scrolled (moved and displayed) in a window on the display (output unit 816) of the
なお、絞込み処理1で選択対象となる単語として、コネクタテーブル類に含まれる各テーブルに格納されている単語を表示することができる。また、絞込み処理2あるいは絞込み処理3で選択対象となる単語として、絞込みテーブル類1あるいは絞込みテーブル類2に含まれる各テーブルに格納されている単語(即ち、絞込み処理によって絞込まれた後の単語)を表示することができる。
画面操作によって単語を入力する場合、ユーザは、画面に表示された候補となる単語をヒントに、回答を特定するために有効な単語を選択することができる。
なお、回答の候補と関連性を有する単語(属性を表す単語)を上述のいずれかの形態で画面に表示し、ユーザがいずれかの単語を発話することで、単語を選択することも可能である。
さらに、画面操作によって単語を入力する形態の他、キーボード操作等によって単語を入力する形態とすることも可能である。
この場合、ユーザが任意のテキスト(単語あるいは文章等)を入力することに対応して、入力されたテキストに含まれる単語を抽出することで、属性の関連性に基づく回答の候補を絞込むことができる。
Note that the words stored in each table included in the connector tables can be displayed as the words to be selected in the narrowing-down
When inputting words by operating the screen, the user can select effective words for identifying the answer using candidate words displayed on the screen as a hint.
It is also possible to display words (words representing attributes) related to answer candidates on the screen in any of the above-mentioned formats, and for the user to select a word by speaking any of the words.
Furthermore, in addition to inputting words by operating the screen, it is also possible to input words by operating a keyboard or the like.
In this case, in response to the user inputting any text (such as a word or a sentence), the words contained in the input text can be extracted, thereby narrowing down answer candidates based on the relevance of attributes.
[変形例5]
上述の実施形態及び変形例において、問い合わせを音声によって受け付ける場合について説明したが、これに限られない。
即ち、チャットによる問い合わせ等、問い合わせをテキストデータによって受け付けることも可能である。
したがって、上述の実施形態及び変形例において、音声による問い合わせを音声認識処理する構成については、問い合わせの内容を表すテキストデータを取得する構成で、適宜置換することが可能である。
[Modification 5]
In the above embodiment and modified examples, the case where an inquiry is received by voice has been described, but the present invention is not limited to this.
That is, it is also possible to accept inquiries by text data, such as inquiries by chat.
Therefore, in the above-described embodiment and modified examples, the configuration for performing voice recognition processing on a voice inquiry can be appropriately replaced with a configuration for acquiring text data representing the contents of the inquiry.
以上のように構成される情報処理システム1は、コネクタDB174と、音声認識処理部153と、絞込み処理部155及び統合処理部156と、を備える。
コネクタDB174は、想定された問い合わせに関する第1の属性情報を記憶する。
コネクタDB174は、想定された問い合わせに対する回答に関する第2の属性情報を記憶する。
音声認識処理部153は、問い合わせの内容を取得する。
絞込み処理部155及び統合処理部156は、音声認識処理による音声認識結果が有する属性情報と、第1の属性情報及び第2の属性情報とに基づいて、問い合わせに対する回答を含む応答(回答または対話のメッセージ)を特定する。
これにより、想定された問い合わせの内容及び想定された問い合わせに対して用意されている回答の属性から、問い合わせに対する回答を特定することができる。
したがって、問い合わせに対する自動応答を行う際に、処理時間を短縮しつつ、より適切な応答内容を特定することが可能となる。
The
The
The
The
The narrowing down processing
This makes it possible to identify a response to an inquiry from the content of the anticipated inquiry and the attributes of the response prepared for the anticipated inquiry.
Therefore, when an automatic response to an inquiry is made, it is possible to shorten the processing time and specify more appropriate response content.
音声認識処理部153は、問い合わせのための発話が音声認識処理された音声認識結果を取得する。
これにより、音声による問い合わせが行われた場合に、処理時間を短縮しつつ、より適切な応答内容を特定することが可能となる。
The voice
This makes it possible to shorten the processing time and specify more appropriate response content when an inquiry is made by voice.
絞込み処理部155は、音声認識処理による音声認識結果が有する属性情報と、第1の属性情報及び第2の属性情報と、第1の属性情報及び第2の属性情報から拡大された属性を表す拡大属性情報とに基づいて、問い合わせに対する回答を含む応答を特定する。
これにより、表現のゆらぎや趣旨が類似する単語が用いられた場合等、想定されていない表現が用いられた場合であっても、発話された問い合わせに適合する回答を容易に特定することが可能となる。
The narrowing-
This makes it possible to easily identify an answer that matches the spoken inquiry even when unexpected expressions are used, such as when there is variation in expression or when words with similar meanings are used.
また、情報処理システム1は、音声認識処理部153と、言語処理部154と、絞込み処理部155と、統合処理部156と、を備える。
音声認識処理部153は、問い合わせのための発話が音声認識処理された音声認識結果を取得する。
言語処理部154は、音声認識処理部153による音声認識結果が表す意味内容から、問い合わせに適合する回答の候補を言語処理によって特定する。
絞込み処理部155は、音声認識処理部153による音声認識結果から問い合わせに含まれる単語を抽出し、問い合わせに含まれる単語に基づく属性情報と、問い合わせに対する回答に基づく属性情報との関連性に基づいて、問い合わせに適合する回答の候補を特定する。
統合処理部156は、言語処理部154によって特定された回答の候補と、絞込み処理部155によって特定された回答の候補とに基づいて、問い合わせに対する回答を含む応答を特定する。
これにより、言語処理に基づく特定方法のみならず、属性を表す単語の一致性に基づく特定方法を用いて、問い合わせに対する回答を特定することができる。
したがって、発話に対する自動応答を行う際に、処理時間を短縮しつつ、より適切な応答内容を特定することが可能となる。
The
The voice
The
The narrowing-
The
This makes it possible to identify an answer to a query using not only an identification method based on language processing, but also an identification method based on the consistency of words expressing attributes.
Therefore, when an automatic response to a speech is made, it is possible to specify more appropriate response content while shortening the processing time.
絞込み処理部155は、問い合わせに対する回答に基づく属性情報と、問い合わせに対する回答に基づく属性情報から拡大された属性を表す拡大属性情報とに基づいて、問い合わせに対する回答を含む応答を特定する。
これにより、表現のゆらぎや趣旨が類似する単語が用いられた場合等、想定されていない表現が用いられた場合であっても、発話された問い合わせに適合する回答を容易に特定することが可能となる。
The narrowing-
This makes it possible to easily identify an answer that matches the spoken inquiry even when unexpected expressions are used, such as when there is variation in expression or when words with similar meanings are used.
統合処理部156は、言語処理部154によって取得された回答の候補の確度が設定された閾値以上の場合、言語処理部154によって取得された回答の候補を回答とし、言語処理部154によって取得された回答の候補の確度が設定された閾値未満の場合、絞込み処理部155によって特定された回答の候補を回答とする。
これにより、問い合わせの発話が行われた際に、高速に、より高精度な音声認識結果を取得して、適切な回答を特定することが可能となる。
When the accuracy of the answer candidate acquired by the
This makes it possible, when a query is spoken, to quickly obtain a more accurate speech recognition result and identify an appropriate answer.
また、情報処理システム1は、音声認識処理部153と、絞込み処理部155と、統合処理部156と、を備える。
絞込み処理部155は、想定された問い合わせに関する第1の属性情報と、想定された問い合わせに対する回答に関する第2の属性情報とに基づいて、想定された問い合わせに対する回答に対応付けられた1または複数の属性によって構成される探索用データを生成する。
音声認識処理部153は、問い合わせの内容を取得する。
絞込み処理部155及び統合処理部156は、問い合わせの内容が有する属性情報と、探索用データとに基づいて、問い合わせの内容に対する回答を含む応答を特定する。
これにより、問い合わせが行われた際に、探索用データを用いて、高速に回答を特定することが可能となる。
The
The narrowing-
The
The narrowing down processing
This allows for rapid identification of an answer when an inquiry is made using the search data.
音声認識処理部153は、問い合わせのための発話が音声認識処理された音声認識結果を取得する。
これにより、音声による問い合わせが行われた場合に、探索用データを用いて、高速に回答を特定することが可能となる。
The voice
This makes it possible to quickly identify an answer when a voice inquiry is made using the search data.
探索用データは、問い合わせの内容が取得される以前に用意され、問い合わせの内容が取得されることにより、生成されている探索用データを参照して、問い合わせの内容に対する回答が特定される。
これにより、問い合わせが行われることに先立って、探索用データが用意されるため、問い合わせの発話が行われた際に、高速に回答を特定することが可能となる。
The search data is prepared before the content of the inquiry is acquired, and when the content of the inquiry is acquired, the generated search data is referenced to identify an answer to the content of the inquiry.
As a result, since the search data is prepared before a query is made, it becomes possible to quickly identify an answer when a query is made.
探索用データは、回答を一意に特定可能な属性を表す応答特定情報と、複数の回答の候補を特定可能な属性を表す応答グループ特定情報とを含む。
これにより、問い合わせのための発話に含まれる単語が回答を一意に特定可能な属性を表すものであるか、複数の回答の候補を特定可能な属性を表すものであるかに応じて、適切に回答を特定する処理を行うことができる。
The search data includes response identifying information that indicates an attribute that can uniquely identify a response, and response group identifying information that indicates an attribute that can identify a plurality of answer candidates.
This allows the process of identifying an appropriate answer to be performed depending on whether the words contained in the query utterance represent attributes that can uniquely identify an answer or represent attributes that can identify multiple answer candidates.
探索用データは、応答特定情報及び応答グループ特定情報に含まれる属性から拡大された属性を表す拡大属性情報を含む。
これにより、表現のゆらぎや趣旨が類似する単語が用いられた場合等、想定されていない表現が用いられた場合であっても、発話された問い合わせに適合する回答を容易に特定することが可能となる。
The search data includes expanded attribute information that represents attributes expanded from attributes included in the response specifying information and the response group specifying information.
This makes it possible to easily identify an answer that matches the spoken inquiry even when unexpected expressions are used, such as when there is variation in expression or when words with similar meanings are used.
絞込み処理部155は、音声認識処理部153によって取得された問い合わせの内容によって、問い合わせに対する複数の回答が特定される場合に、探索用データに含まれる想定された問い合わせに対する回答に対応付けられた1または複数の属性を、問い合わせの内容に対する回答が一意に特定される属性、または、問い合わせの内容に対する回答がより少なく特定される属性に絞込む。
絞込み処理部155は、絞込まれた属性に基づいて、応答として、問い合わせの内容に対する回答を特定するための追加の問い合わせの内容を誘導する対話を実行する。
これにより、ユーザが、適切な内容の問い合わせを行わなかった場合にも、さらなる問い合わせを受け付けて、適切な回答を特定することが可能となる。
When the content of an inquiry acquired by the voice
The narrowing-
This makes it possible to accept further inquiries and identify appropriate answers even if the user does not make an appropriate inquiry.
絞込み処理部155は、オリジナルの探索用データ全体を対象として、最新の問い合わせの内容に対する回答の特定を行う第1の絞込み処理と、オリジナルの探索用データから属性が絞込まれた探索用データを対象として、過去の所定回の問い合わせの内容に基づく回答の特定を行う第2の絞込み処理と、を並列的に実行する。
これにより、属性の関連性に基づく回答の候補として、適切な回答が特定される可能性を高めることができる。
The narrowing down processing
This can increase the likelihood that an appropriate answer will be identified as an answer candidate based on attribute relevance.
絞込み処理部155は、第2の絞込み処理とは異なる回数の過去の所定回の問い合わせの内容に基づく回答の特定を行う第3の絞込み処理を、第1の絞込み処理及び第2の絞込み処理と並列的に実行する。
これにより、ユーザによる問い合わせの内容の方向性が変化したり、ユーザがシステムからの誘導に則さない内容の問い合わせを行ったりした場合にも、直近の所定回の問い合わせによる絞込み結果(絞込みテーブル)を活用して、絞込み処理を継続することができる。
そのため、ユーザの意図を適確に反映させて回答を絞込むことが可能となるため、ユーザの選好性に対応して、問い合わせに対する適切な回答を早期に特定することができる。
The narrowing-
This makes it possible to continue the narrowing down process by utilizing the narrowing down results (narrowing down table) from the most recent specified number of inquiries, even if the direction of the user's inquiry changes or if the user makes an inquiry that does not conform to the guidance from the system.
Therefore, it is possible to narrow down the answers by accurately reflecting the user's intention, so that an appropriate answer to the inquiry can be identified quickly in accordance with the user's preferences.
絞込み処理部155は、オリジナルの探索用データに含まれる属性を表す単語またはオリジナルの探索用データから絞込まれた属性を表す単語を画面に表示し、画面に表示された単語を選択することにより、問い合わせの内容に対する回答を絞込む。
これにより、ユーザは、画面に表示された候補となる単語をヒントに、回答を特定するために有効な単語を選択することができる。
The narrowing-
This allows the user to select effective words for identifying the answer using the candidate words displayed on the screen as a hint.
また、情報処理システム1は、音声認識処理部153と、絞込み処理部155と、を備える。
音声認識処理部153は、問い合わせのための発話が音声認識処理された音声認識結果を取得する。
絞込み処理部155は、想定された問い合わせに関する第1の属性情報と、想定された問い合わせに対する回答に関する第2の属性情報と、第1の属性情報及び第2の属性情報に関連する拡大された属性情報とを要素として含むフィルタによって、音声認識処理部153による音声認識結果が有する属性情報をフィルタ処理する。
絞込み処理部155は、フィルタ処理結果に基づいて、問い合わせのための発話に対する回答を含む応答を特定する。
これにより、問い合わせのための発話から属性を表す単語を高速に抽出して、属性の関連性に基づく回答の候補を特定することが可能となる。
The
The voice
The narrowing-
The narrowing-
This makes it possible to quickly extract words expressing attributes from a query utterance and identify answer candidates based on the relevance of attributes.
絞込み処理部155は、問い合わせのための発話から抽出された単語に関連する第1の属性情報または第2の属性情報を特定し、第1の属性情報または第2の属性情報に対応付けられた想定された問い合わせに対する回答を、問い合わせのための発話に対する回答として特定する。
これにより、問い合わせのための発話に含まれる単語に関連する回答を容易に特定することが可能となる。
The narrowing-
This makes it possible to easily identify answers related to words included in the query utterance.
なお、本発明は、上述の実施形態に限定されるものではなく、本発明の目的を達成できる範囲での変形、改良等は本発明に含まれるものである。
例えば、上述の実施形態において、情報処理システム1を複数の情報処理装置を含むシステムとして構成する例について説明したが、これに限られない。即ち、情報処理システム1が備える機能を単体の情報処理装置に備えることにより、本発明を実現することとしてもよい。
The present invention is not limited to the above-described embodiment, and modifications and improvements within the scope of the present invention that can achieve the object of the present invention are included in the present invention.
For example, in the above embodiment, an example in which the
また、サーバ20の機能を複数のサーバに分散して実装したり、端末装置10にサーバの機能の一部を実装したり、端末装置10の機能の一部をサーバに実装したりすることとしてもよい。
例えば、上述の各実施形態において、音声認識処理をサーバ20において実行するものとしたが、音声認識処理を端末装置10で実行することとしてもよいし、他のシステム等で実行された音声認識結果を取得(受信等)して処理に用いることとしてもよい。
また、上述の各実施形態において、探索用データは、応答内容テーブルの更新あるいは運用結果に基づく属性を表す単語の更新(追加、修正、削除等)に応じて、逐次更新することができる。
Furthermore, the functions of the
For example, in each of the above-described embodiments, the voice recognition processing is executed in the
In addition, in each of the above-described embodiments, the search data can be updated sequentially in response to updates to the response content table or updates (addition, modification, deletion, etc.) to words expressing attributes based on the operation results.
また、上述の実施形態及び変形例に記載された構成を適宜組み合わせて、本発明を実施することが可能である。
上述した一連の処理は、ハードウェアにより実行させることもできるし、ソフトウェアにより実行させることもできる。
換言すると、図3,4,9,16,17の機能的構成は例示に過ぎず、特に限定されない。即ち、上述した一連の処理を全体として実行できる機能が情報処理システム1に備えられていれば足り、この機能を実現するためにどのような機能ブロックを用いるのかは特に図3,4,9,16,17の例に限定されない。
また、1つの機能ブロックは、ハードウェア単体で構成してもよいし、ソフトウェア単体で構成してもよいし、それらの組み合わせで構成してもよい。
Furthermore, the present invention can be implemented by appropriately combining the configurations described in the above-mentioned embodiments and modifications.
The above-described series of processes can be executed by hardware or software.
In other words, the functional configurations of Figures 3, 4, 9, 16, and 17 are merely examples and are not particularly limited. In other words, it is sufficient for the
Furthermore, one functional block may be configured as a single piece of hardware, a single piece of software, or a combination of both.
一連の処理をソフトウェアにより実行させる場合には、そのソフトウェアを構成するプログラムが、コンピュータ等にネットワークや記録媒体からインストールされる。
コンピュータは、専用のハードウェアに組み込まれているコンピュータであってもよい。また、コンピュータは、各種のプログラムをインストールすることで、各種の機能を実行することが可能なコンピュータ、例えば汎用のパーソナルコンピュータであってもよい。
When the series of processes is executed by software, the program constituting the software is installed into a computer or the like from a network or a recording medium.
The computer may be a computer built into dedicated hardware, or may be a computer capable of executing various functions by installing various programs, such as a general-purpose personal computer.
プログラムを記憶する記憶媒体は、装置本体とは別に配布されるリムーバブルメディア、あるいは、装置本体に予め組み込まれた記憶媒体等で構成される。リムーバブルメディアは、例えば、磁気ディスク、光ディスク、光磁気ディスクあるいはフラッシュメモリ等により構成される。光ディスクは、例えば、CD-ROM(Compact Disk-Read Only Memory),DVD(Digital Versatile Disk),Blu-ray Disc(登録商標)等により構成される。光磁気ディスクは、MD(Mini-Disk)等により構成される。フラッシュメモリは、例えば、USB(Universal Serial Bus)メモリあるいはSDカードにより構成される。また、装置本体に予め組み込まれた記憶媒体は、例えば、プログラムが記憶されているROM、ハードディスクあるいはフラッシュメモリ等で構成される。 The storage medium that stores the program is composed of removable media distributed separately from the device body, or storage media that is pre-installed in the device body. Removable media is composed of, for example, a magnetic disk, optical disk, magneto-optical disk, or flash memory. Optical disks are composed of, for example, CD-ROMs (Compact Disk-Read Only Memory), DVDs (Digital Versatile Disks), Blu-ray Discs (registered trademark), etc. Magneto-optical disks are composed of, for example, MDs (Mini-Disks), etc. Flash memory is composed of, for example, USB (Universal Serial Bus) memory or SD cards. Storage media that is pre-installed in the device body is composed of, for example, a ROM in which the program is stored, a hard disk, or flash memory, etc.
なお、本明細書において、記録媒体に記録されるプログラムを記述するステップは、その順序に沿って時系列的に行われる処理はもちろん、必ずしも時系列的に処理されなくとも、並列的あるいは個別に実行される処理をも含むものである。
また、本明細書において、システムの用語は、複数の装置や複数の手段等より構成される全体的な装置を意味するものとする。
In this specification, the steps of describing a program to be recorded on a recording medium include not only processes that are performed chronologically according to the order, but also processes that are not necessarily performed chronologically but are executed in parallel or individually.
In addition, in this specification, the term "system" refers to an overall device that is composed of a plurality of devices, a plurality of means, etc.
1 情報処理システム、10 端末装置、20 サーバ、30 ネットワーク、800 情報処理装置、811 CPU、812 ROM、813 RAM、814 バス、815 入力部、815a 操作入力部、815b 音声入力部、816 出力部、817 記憶部、818 通信部、819 ドライブ、820 撮像部、831 リムーバブルメディア、51 発話受付部、52 発話データ送信部、53 応答受信部、54 応答出力部、151 発話データ受信部、152 前処理部、153 音声認識処理部、153-1 第1音声認識部、153-2 第2音声認識部、154 言語処理部、155 絞込み処理部、156 統合処理部、171 音声認識辞書データベース(音声認識辞書DB)、172 単語辞書データベース(単語辞書DB)、173 応答内容データベース(応答内容DB)、174 コネクタデータベース(コネクタDB)、501 ディクテーション音声認識部、502 第1認識結果特定部、503 第1認識結果出力部、511 単語抽出音声認識部、512 第2認識結果特定部、513 第2認識結果出力部 1 Information processing system, 10 Terminal device, 20 Server, 30 Network, 800 Information processing device, 811 CPU, 812 ROM, 813 RAM, 814 Bus, 815 Input unit, 815a Operation input unit, 815b Voice input unit, 816 Output unit, 817 Storage unit, 818 Communication unit, 819 Drive, 820 Imaging unit, 831 Removable media, 51 Speech reception unit, 52 Speech data transmission unit, 53 Response reception unit, 54 Response output unit, 151 Speech data reception unit, 152 Preprocessing unit, 153 Speech recognition processing unit, 153-1 First speech recognition unit, 153-2 Second speech recognition unit, 154 Language processing unit, 155 Narrowing processing unit, 156 Integration processing unit, 171 Speech recognition dictionary database (speech recognition dictionary DB), 172 Word dictionary database (word dictionary DB), 173 response content database (response content DB), 174 connector database (connector DB), 501 dictation speech recognition unit, 502 first recognition result identification unit, 503 first recognition result output unit, 511 word extraction speech recognition unit, 512 second recognition result identification unit, 513 second recognition result output unit
Claims (4)
想定された問い合わせに関する第1の属性情報と、前記想定された問い合わせに対する回答に関する第2の属性情報とに基づいて、前記想定された問い合わせに対する回答に対応付けられた1または複数の属性によって構成される探索用データを生成する探索用データ生成手段と、
問い合わせの内容を取得する問い合わせ内容取得手段と、
前記問い合わせの内容が有する属性情報と、前記探索用データとに基づいて、前記問い合わせの内容に対する回答を含む応答を特定する応答特定手段と、
を備え、
前記問い合わせの内容が有する属性情報、前記第1の属性情報及び前記第2の属性情報は単語で表され、
前記応答特定手段は、
オリジナルの前記探索用データ全体を対象として、最新の前記問い合わせの内容に対する回答の特定を行う第1の絞込み処理と、
オリジナルの前記探索用データから属性が絞込まれた前記探索用データを対象として、過去の所定回の前記問い合わせの内容に基づく回答の特定を行う第2の絞込み処理と、
を並列的に実行することを特徴とする情報処理システム。 An information processing system including one or more information processing devices,
a search data generating means for generating search data composed of one or more attributes associated with the answer to the anticipated inquiry based on first attribute information related to the anticipated inquiry and second attribute information related to the answer to the anticipated inquiry;
An inquiry content acquisition means for acquiring the content of an inquiry;
a response specifying means for specifying a response including an answer to the content of the inquiry based on attribute information of the content of the inquiry and the search data;
Equipped with
the attribute information of the content of the inquiry, the first attribute information, and the second attribute information are expressed by words ;
The response identification means
a first narrowing-down process for identifying an answer to the latest inquiry from the entire original search data;
a second narrowing process for identifying an answer based on the content of the inquiry made a predetermined number of times in the past, using the search data whose attributes have been narrowed down from the original search data;
An information processing system characterized by executing the above in parallel .
想定された問い合わせに関する第1の属性情報と、前記想定された問い合わせに対する回答に関する第2の属性情報とに基づいて、前記想定された問い合わせに対する回答に対応付けられた1または複数の属性によって構成される探索用データを生成する探索用データ生成ステップと、
問い合わせの内容を取得する問い合わせ内容取得ステップと、
前記問い合わせの内容が有する属性情報と、前記探索用データとに基づいて、前記問い合わせの内容に対する回答を含む応答を特定する応答特定ステップと、
を含み、
前記問い合わせの内容が有する属性情報、前記第1の属性情報及び前記第2の属性情報は単語で表され、
前記応答特定ステップでは、
オリジナルの前記探索用データ全体を対象として、最新の前記問い合わせの内容に対する回答の特定を行う第1の絞込み処理と、
オリジナルの前記探索用データから属性が絞込まれた前記探索用データを対象として、過去の所定回の前記問い合わせの内容に基づく回答の特定を行う第2の絞込み処理と、
が並列的に実行されることを特徴とする情報処理方法。 An information processing method executed in an information processing system including one or more information processing devices,
a search data generating step of generating search data composed of one or more attributes associated with the answer to the anticipated inquiry based on first attribute information related to the anticipated inquiry and second attribute information related to the answer to the anticipated inquiry;
An inquiry content acquisition step of acquiring the content of the inquiry;
a response identifying step of identifying a response including an answer to the content of the inquiry based on attribute information of the content of the inquiry and the search data;
Including,
the attribute information of the content of the inquiry, the first attribute information, and the second attribute information are expressed by words;
In the response identification step,
a first narrowing-down process for identifying an answer to the latest inquiry from the entire original search data;
a second narrowing process for identifying an answer based on the content of the inquiry made a predetermined number of times in the past, using the search data whose attributes have been narrowed down from the original search data;
4. An information processing method comprising the steps of :
想定された問い合わせに関する第1の属性情報と、前記想定された問い合わせに対する回答に関する第2の属性情報とに基づいて、前記想定された問い合わせに対する回答に対応付けられた1または複数の属性によって構成される探索用データを生成する探索用データ生成機能と、
問い合わせの内容を取得する問い合わせ内容取得機能と、
前記問い合わせの内容が有する属性情報と、前記探索用データとに基づいて、前記問い合わせの内容に対する回答を含む応答を特定する応答特定機能と、
を実現させ、
前記問い合わせの内容が有する属性情報、前記第1の属性情報及び前記第2の属性情報は単語で表され、
前記応答特定機能は、
オリジナルの前記探索用データ全体を対象として、最新の前記問い合わせの内容に対する回答の特定を行う第1の絞込み処理と、
オリジナルの前記探索用データから属性が絞込まれた前記探索用データを対象として、過去の所定回の前記問い合わせの内容に基づく回答の特定を行う第2の絞込み処理と、
を並列的に実行することを特徴とするプログラム。 On the computer,
a search data generation function that generates search data composed of one or more attributes associated with the answer to the anticipated inquiry based on first attribute information related to the anticipated inquiry and second attribute information related to the answer to the anticipated inquiry;
An inquiry content acquisition function for acquiring the content of an inquiry;
a response identification function that identifies a response including an answer to the content of the inquiry based on attribute information of the content of the inquiry and the search data;
Realize this,
the attribute information of the content of the inquiry, the first attribute information, and the second attribute information are expressed by words ;
The response identification function is
a first narrowing-down process for identifying an answer to the latest inquiry from the entire original search data;
a second narrowing process for identifying an answer based on the content of the inquiry made a predetermined number of times in the past, using the search data whose attributes have been narrowed down from the original search data;
A program characterized by executing the above in parallel .
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023132705A JP7560627B2 (en) | 2022-03-21 | 2023-08-16 | Information processing system, information processing method, and program |
| JP2024163036A JP2024169607A (en) | 2022-03-21 | 2024-09-19 | Information processing system, information processing method, and program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022044800A JP7334293B1 (en) | 2022-03-21 | 2022-03-21 | Information processing system, information processing method and program |
| JP2023132705A JP7560627B2 (en) | 2022-03-21 | 2023-08-16 | Information processing system, information processing method, and program |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022044800A Division JP7334293B1 (en) | 2022-03-21 | 2022-03-21 | Information processing system, information processing method and program |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024163036A Division JP2024169607A (en) | 2022-03-21 | 2024-09-19 | Information processing system, information processing method, and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2023159261A JP2023159261A (en) | 2023-10-31 |
| JP7560627B2 true JP7560627B2 (en) | 2024-10-02 |
Family
ID=87764019
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022044800A Active JP7334293B1 (en) | 2022-03-21 | 2022-03-21 | Information processing system, information processing method and program |
| JP2023132705A Active JP7560627B2 (en) | 2022-03-21 | 2023-08-16 | Information processing system, information processing method, and program |
| JP2024163036A Pending JP2024169607A (en) | 2022-03-21 | 2024-09-19 | Information processing system, information processing method, and program |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022044800A Active JP7334293B1 (en) | 2022-03-21 | 2022-03-21 | Information processing system, information processing method and program |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024163036A Pending JP2024169607A (en) | 2022-03-21 | 2024-09-19 | Information processing system, information processing method, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (3) | JP7334293B1 (en) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006031467A (en) | 2004-07-16 | 2006-02-02 | Fujitsu Ltd | Response generation program, response generation method, and response generation apparatus |
| JP2019003319A (en) | 2017-06-13 | 2019-01-10 | 株式会社野村総合研究所 | Interactive business support system and interactive business support program |
| JP2019139746A (en) | 2018-02-09 | 2019-08-22 | 株式会社日立製作所 | Information search system and method |
| JP2019207648A (en) | 2018-05-30 | 2019-12-05 | 株式会社野村総合研究所 | Interactive business assistance system |
| JP2019207647A (en) | 2018-05-30 | 2019-12-05 | 株式会社野村総合研究所 | Interactive business assistance system |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108804456B (en) * | 2017-04-28 | 2023-04-18 | 微软技术许可有限责任公司 | Chat sessions based on object-specific knowledge base |
| JP7163757B2 (en) * | 2018-12-21 | 2022-11-01 | コニカミノルタ株式会社 | Conversation processing system, information processing device and program |
| JP2020187470A (en) * | 2019-05-13 | 2020-11-19 | 富士通株式会社 | Network analysis device and network analysis method |
-
2022
- 2022-03-21 JP JP2022044800A patent/JP7334293B1/en active Active
-
2023
- 2023-08-16 JP JP2023132705A patent/JP7560627B2/en active Active
-
2024
- 2024-09-19 JP JP2024163036A patent/JP2024169607A/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006031467A (en) | 2004-07-16 | 2006-02-02 | Fujitsu Ltd | Response generation program, response generation method, and response generation apparatus |
| JP2019003319A (en) | 2017-06-13 | 2019-01-10 | 株式会社野村総合研究所 | Interactive business support system and interactive business support program |
| JP2019139746A (en) | 2018-02-09 | 2019-08-22 | 株式会社日立製作所 | Information search system and method |
| JP2019207648A (en) | 2018-05-30 | 2019-12-05 | 株式会社野村総合研究所 | Interactive business assistance system |
| JP2019207647A (en) | 2018-05-30 | 2019-12-05 | 株式会社野村総合研究所 | Interactive business assistance system |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2023159261A (en) | 2023-10-31 |
| JP2023138894A (en) | 2023-10-03 |
| JP7334293B1 (en) | 2023-08-28 |
| JP2024169607A (en) | 2024-12-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11740863B2 (en) | Search and knowledge base question answering for a voice user interface | |
| US11037553B2 (en) | Learning-type interactive device | |
| US20230350929A1 (en) | Method and system for generating intent responses through virtual agents | |
| WO2020228173A1 (en) | Illegal speech detection method, apparatus and device and computer-readable storage medium | |
| US7676369B2 (en) | Conversation control apparatus, conversation control method, and programs therefor | |
| EP1366490B1 (en) | Hierarchichal language models | |
| WO2022252636A1 (en) | Artificial intelligence-based answer generation method and apparatus, device, and storage medium | |
| US11563852B1 (en) | System and method for identifying complaints in interactive communications and providing feedback in real-time | |
| EP1901283A2 (en) | Automatic generation of statistical laguage models for interactive voice response applacation | |
| US8010343B2 (en) | Disambiguation systems and methods for use in generating grammars | |
| US10872601B1 (en) | Natural language processing | |
| KR102100214B1 (en) | Method and appratus for analysing sales conversation based on voice recognition | |
| KR102186641B1 (en) | Method for examining applicant through automated scoring of spoken answer based on artificial intelligence | |
| US20240378386A1 (en) | Identifying high effort statements for call center summaries | |
| US11615787B2 (en) | Dialogue system and method of controlling the same | |
| US11355122B1 (en) | Using machine learning to correct the output of an automatic speech recognition system | |
| US20230298615A1 (en) | System and method for extracting hidden cues in interactive communications | |
| CN118194875B (en) | Intelligent voice service management system and method driven by natural language understanding | |
| CN118861258A (en) | Corpus-based voice question-answering method, device, electronic device, and storage medium | |
| JP7560627B2 (en) | Information processing system, information processing method, and program | |
| US20240127804A1 (en) | Transcript tagging and real-time whisper in interactive communications | |
| KR20210009266A (en) | Method and appratus for analysing sales conversation based on voice recognition | |
| US20240144921A1 (en) | Domain specific neural sentence generator for multi-domain virtual assistants | |
| Berkol et al. | Advancing human-machine interaction: Speech and natural language processing | |
| de Vries et al. | “You Can Do It!”—Crowdsourcing Motivational Speech and Text Messages |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20230816 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20240531 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240604 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240805 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240820 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240919 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7560627 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |