以下に、本願の開示する検索処理プログラム、検索処理方法及び情報処理装置の実施例を図面に基づいて詳細に説明する。なお、以下の実施例により本願の開示する検索処理プログラム、検索処理方法及び情報処理装置が限定されるものではない。
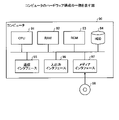
図1は、情報処理システムのシステム構成図である。情報処理システム1は、図1に示すように、Hadoopクラスタ10、HDFS(Hadoop Distributed File System)クライアント20及びジョブクライアント30を有する。
HDFSクライアント20は、Hadoopクラスタ10に対してデータ管理の指示を行う情報処理端末である。HDFSクライアント20は、ネットワークを介してHadoopクラスタ10のマスタサーバ11と接続される。HDFSクライアント20は、利用者からのデータ管理の指示の入力を入力装置(不図示)から受ける。そして、HDFSクライアント20は、利用者からの入力に応じたデータ管理の処理命令をHDFS API(Application Programing Interface)を介してマスタサーバ11へ送信する。
ジョブクライアント30は、Hadoopクラスタ10に対してジョブ管理の指示を行う情報処理端末である。ジョブクライアント30は、ネットワークを介してHadoopクラスタ10のマスタサーバ11と接続される。ジョブクライアント30は、MapReduceプログラムを有する。ジョブクライアント30は、利用者からのジョブ管理の指示の入力を入力装置(不図示)から受ける。そして、ジョブクライアント30は、利用者からの入力に応じたジョブ管理の処理命令をマスタサーバ11へ送信する。
これら、HDFSクライアント20及びジョブクライアント30は、同じ情報処理装置に配置されてもよいし、異なる情報処理装置に配置されてもよい。また、HDFSクライアント20及びジョブクライアント30の機能は、Hadoopクラスタ10の中に配置されてもよい。
Hadoopクラスタ10は、マスタサーバ11及びスレーブサーバ12を有する。図1では、3台のスレーブサーバ12を図示したが、スレーブサーバ12の数に特に制限は無い。マスタサーバ11は、各スレーブサーバ12とネットワークで接続される。さらに、マスタサーバ11は、HDFSクライアント20及びジョブクライアント30とネットワークで接続される。また、各スレーブサーバ12は、それぞれ相互にネット―ワークで接続される。
図2は、マスタサーバ及びスレーブサーバの詳細を表すブロック図である。以下では、図2を参照して、マスタサーバ11及びスレーブサーバ12について説明する。ここで、図1では構成の概略を図示するため、主要構成に絞りいくつかの構成を省略して記載したが、マスタサーバ11及びスレーブサーバ12は、より詳しくは図2に示す構成を有する。
マスタサーバ11は、RDFストア110、HDFS111、ネームノード112、メタデータDB(Data Base)113及びジョブトラッカー114を有する。さらに、マスタサーバ11は、第1生成部115、第2生成部116、RDFコントローラ117、SPARQL処理部118及びMapReduce処理部119を有する。
HDFS111は、複数のサーバと連携して見た目上1つのファイルシステムと見せる仮想ファイルシステムである。HDFS111は、ファイルをブロックサイズと呼ばれる単位で分割することでファイル管理を行う。ブロックサイズはデフォルトで64MBである。HDFS111は、排他制御機能を有さない。また、HDFS111では、ファイルの新規作成及び追加は可能であるが、修正は許可されない。HDFS111の1つのブロックに対して1つのMapタスクが作成される。
RDFデータは、例えば、図3に示すようにツリー形式で表すことができる。図3は、RDFデータをツリー形式で表した一例の図である。図3における、矢印の始点に配置された楕円で囲われたデータが主語にあたる。また、矢印の終点に配置された楕円で囲われたデータが述語にあたる。さらに、矢印上に記載されたデータが述語にあたる。
また、RDFデータは、図4に示すように表形式で表すこともできる。図4は、RDFデータを表形式で表した一例の図である。図3に示したツリー形式のRDFデータを表形式で表した図が、図4にあたる。図4における、id(Identifier)は各トリプルに与えられた識別子を表す。また、Subjectはトリプルにおける主語を表し、predicateは述語を表し、objectは目的語を表す。このようにして各トリプルに割り当てられた識別子に対応させて、そのトリプルの主語、述語及びオブジェクトが表形式における1行(横列)に対応させて登録される。
RDFストア110は、例えば、図4に示すような表形式のRDFデータを保持することができる。このRDFストア110に格納されたRDFデータを入力としてHDFS111へ保存することで、後述するMapReduce処理でHDFS111内のデータを操作することが可能となる。
図2に戻って説明を続ける。RDFコントローラ117は、RDFストア110に格納されたRDFデータの管理を行う。例えば、RDFコントローラ117は、読み出し要求や格納要求を受けて、指定されたRDFデータの読み出し又は格納をRDFストア110に対して行う。また、RDFコントローラ117は、RDFストア110に格納されたRDFデータのHDFS111への保存の指示を受けて、RDFストア110に格納されRFDデータを入力としてHDFS111に保存させる。
第1生成部115は、識別子対応表の生成の指示をHDFSクライアント20から受ける。そして、第1生成部115は、RDFストア110に登録された全てのRDFデータの主語、述語及び目的語の取得をRDFコントローラ117に指示する。その後、第1生成部115は、RDFストア110に登録された全てのRDFデータの主語、述語及び目的語をRDFコントローラ117から取得する。
次に、第1生成部115は、取得した主語、述語及び目的語のそれぞれの重複を除いて集計する。そして、第1生成部115は、集計した主語、述語及び目的語を用いて、「主語、述語」、「述語、目的語」及び「主語、目的語」の全ての通りの組み合わせを生成する。これらの組を以下では、「valueパターン」という。このRDFデータの主語、述語及び目的語が、「3要素」の一例にあたり、valueパターンに含まれる2つの値が、「2要素」の一例にあたる。
次に、第1生成部115は、生成したvalueパターンの中に、実際の各RDFデータの主語、述語及び目的語の組の中に含まれないvalueパターンが存在するか否かを判定する。実際の各RDFデータの主語、述語及び目的語の組の中に含まれないvalueパターンが存在する場合、第1生成部115は、各RDFデータの主語、述語及び目的語の中に含まれないvalueパターン以外のvalueパターンを抽出する。
第1生成部115は、抽出したvalueパターンのそれぞれにパターン識別子を割り当てる。この識別子は、valueパターンより小さいデータサイズである。データサイズとは、メモリを占有する上でのサイズである。そして、第1生成部115は、各valueパターンと割り当てたパターン識別子との対応を表す識別子対応表を作成する。このとき、第1生成部115は、実際の各RDFデータの主語、述語及び目的語の組の中に含まれないvalueパターンについては、不存在を表す情報を付加して識別子対応表へ登録する。図5は、識別子対応表の一例を表す図である。
ここでは、図4に示したRDFデータを基に識別子対応表を作成する場合で説明する。また、述語と目的語の組み合わせのvalueパターンを生成する場合を例に説明する。
第1生成部115は、図4に示されるRDFデータにおける述語201を重複を除いて集計する。この場合、第1生成部115は、「likes」及び「loves」という2語を述語として取得する。また、第1生成部115は、図4に示されるRDFデータにおける目的語202を重複を除いて集計する。この場合、第1生成部115は、「A」、「C」、「D」及び「F」という4語を述語として取得する。そして、第1生成部115は、取得した述語及び目的語の全ての組み合わせを生成する。この場合、第1生成部115は、「likes A」、「likes C」、「likes D」、「likes F」、「loves A」、「loves C」、「loves D」及び「loves F」をvalueバターンとして生成する。そして、第1生成部115は、「likes A」及び「loves D」が図4に示すRDFデータに含まれないと判定する。その後、第1生成部115は、実際に存在するValueパターンにパターン識別子を割り当て、実際には存在しないvalueパターンに対しては不存在を示す情報を対応させて、図4に示す識別子対応表211及び212を生成する。図5では、「likes」を述語として含むvalueパターンを表す識別子対応表211と「loves」を述語として含むvalueパターンを表す識別子対応表212とを分けて記載した。さらに、第1生成部115は、存在しないvalueパターンである「likes A」及び「loves D」に不存在を表すNA(Not Applicable)を付加して識別子対応表211及び212にそれぞれ登録する。
その後、第1生成部115は、生成した識別子対応表をRDFコントローラ117へ送信し、RDFストア110への格納を指示する。さらに、第1生成部115は、識別子対応表の生成完了を第2生成部116に通知する。この識別子対応表が、「第1の表」の一例にあたる。
第2生成部116は、識別子対応表の生成完了の通知を第1生成部115から受ける。そして、第2生成部116は、識別子対応表の取得要求をRDFコントローラ117へ送信する。その後、第2生成部116は、第1生成部115により作成された全ての識別子対応表をRDFコントローラ117から取得する。
次に、第2生成部116は、RDFストア110に登録された各RDFデータの取得要求をRDFコントローラ117へ送信する。そして、第2生成部116は、RDFコントローラ117から取得した各RDFデータの主語、述語及び目的語を確認し、それぞれの組み合のvalueパターンに対応するパターン識別子を識別子対応表から取得する。その後、第2生成部116は、各RDFデータのトリプルの対応表に、RDFデータ毎の取得したパターン識別子を付加した識別子付RDFデータ表を生成する。
図6は、識別子付RDFデータ表の一例を表す図である。図6における「vp-id」は、パターン識別子を表す。そして、パターン識別子221は、主語と述語との組み合わせのvalueパターンに対応する。パターン識別子222は、述語と目的語との組み合わせのvalueパターンに対応する。パターン識別子223は、主語と目的語との組み合わせのvalueパターンに対応する。
第2生成部116は、例えば、図4の1行目のRDFデータの主語、述語及び目的語として「A」、「likes」及び「D」を取得する。そして、第2生成部116は、取得した各値から「A likes」、「likes D」及び「A D」というvalueパターンを取得する。その後、第2生成部116は、取得したvalueパターンに対応するパターン識別子を取得する。例えば、第2生成部116は、図5の識別子対応表211から「likes D」のパターン識別子である「0002」を取得する。同様に、第2生成部116は、「A likes」及び「A D」のパターン識別子として「2001」及び「4001」を取得する。その後、第2生成部116は、各パターン識別子を1行目のRDFデータに対応させて登録する。
その後、第2生成部116は、生成した識別子付RDFデータ表をRDFコントローラ117へ送信し、RDFストア110に格納させる。この識別子付RDFデータ表が、「第2の表」の一例にあたる。
ネームノード112は、RDFストア110に格納された識別子付RDFデータ表の取得要求をRDFコントローラ117に通知する。そして、ネームノード112は、RDFストア110に格納された識別子付RDFデータ表をRDFコントローラ117から取得する。ここで、識別子付RDFデータ表のデータを分散配置する場合、ネームノード112は、RDFコントローラ117と連携してRDFストア110に格納されたデータを取り扱うが、他の形式のデータを取り扱う場合にはRDFストア110から直接データを取得してもよい。
ネームノード112は、識別子付RDFデータ表の一部の行データを含むブロックの格納先のデータノード121を決定する。ここで、図2では、分かり易いように、スレーブサーバ12を1つ記載したが、実際には図1のように複数のスレーブサーバ12が配置されており、ネームノード112は、各スレーブサーバ12のデータノード121の中から各ブロックの配置先を選択する。
そして、ネームノード112は、識別子付RDFデータ表の一部の行データを含むブロックを選択したデータノード121へ送信し配置する。ここで、ネームノード112は、複数のブロックを1つのデータノード121へ送信してもよい。この各ネームノード112へのブロックの配置が、「複数の処理装置に分割して配置」することの一例にあたる。さらに、ネームノード112は、各ブロックの保存先のデータノード121の情報をメタデータDB113に登録する。
ここで、分散配置において、ネームノード112は、1つのデータブロックを複製して複数のデータノード121に配置する。例えば、ネームノード112は、1つのデータブロックを複製して3つにする。これにより、あるデータノード121に障害が発生した場合に、他のデータノード121に格納された同一のブロックを用いることができるようになり、Hadoopクラスタ10の耐障害性が確保される。このネームノード112が、「配置部」の一例にあたる。
SPARQL処理部118は、SPARQLクエリの入力をジョブクライアント30から受ける。そして、SPARQL処理部118は、取得したSPARQLクエリを解析してMapReduce処理に変換する。さらに、SPARQL処理部118は、識別子対応表の取得要求をRDFコントローラ117に通知する。その後、SPARQL処理部118は、RDFストア110に格納された識別子対応表をRDFコントローラ117から取得する。次に、SPARQL処理部118は、識別子対応表を参照して、取得したクエリの要素に対応するvalueパターンが存在するか否かを判定する。取得したクエリの要素に対応するvalueパターンが存在しなければ、SPARQL処理部118は、そのようなvalueパターンのマッチング結果は0件としてジョブクライアント30に検索結果を返す。
一方、取得したクエリの要素に対応するvalueパターンが存在する場合、SPARQL処理部118は、取得したクエリの要素のvalueパターンに割り当てられたパターン識別子を取得する。次に、SPARQL処理部118は、MAPReduce処理において、文字列を取得したパターン識別子に置き換える。その後、SPARQL処理部118は、パターン識別子を含むMapReduce処理をMapReduce処理部119に出力する。
その後、SPARQL処理部118は、MapReduce処理の実行結果の入力をMapReduce処理部119から受ける。そして、SPARQL処理部118は、取得したMapReduce処理の実行結果をSPARQLクエリの実行結果としてジョブクライアント30へ送信する。このSPARQL処理部118が、「出力部」の一例にあたる。
MapReduce処理部119は、パターン識別子を含むMapReduce処理の入力をSPARQL処理部118から受ける。このMapReduce処理には、元のSPARQL処理に含まれる個々の検索処理に対応する複数のMapReduce処理が含まれる。そこで、MapReduce処理部119は、受信したMapReduce処理に含まれる個々のMapReduce処理を取得する。そして、MapReduce処理部119は、取得した各MapReduce処理の実行をジョブトラッカー114に指示する。この場合、検索に用いる文字列がパターン識別子に置き換えられているので、MapReduce処理部119は、パターン識別子を用いたMapReduce処理の実行をジョブトラッカー114に指示する。
その後、MapReduce処理部119は、MapReduce処理の実行結果の入力をジョブトラッカー114から受ける。そして、MapReduce処理部119は、MapReduce処理の実行結果をSPARQL処理部118へ出力する。
ジョブトラッカー114は、各MapReduce処理の実行の指示をMapReduce処理部119から受ける。次に、ジョブトラッカー114は、メタデータDB113に格納された各ブロックが配置されたデータノード121を確認し、各MapReduce処理を実行させるデータノード121を決定する。そして、ジョブトラッカー114は、1つのブロックに対して1つのMapタスクを生成して割り当てる。その後、ジョブトラッカー114は、各Mapタスクを対応するブロックを保持するデータノード121を有するスレーブサーバ12のタスクトラッカー123へ送信する。このように、各Mapタスクが対象とするブロックを有するスレーブサーバ12に対して、それぞれのMapタスクが割り振られることにより、通信コストを最小化することができる。
その後、ジョブトラッカー114は、各スレーブサーバ12のタスクトラッカー123からジョブの実行結果を受信する。そして、ジョブトラッカー114は、ジョブの実行結果をまとめたMapReduce処理の実行結果をMapReduce処理部119へ出力する。
次に、スレーブサーバ12について説明する。スレーブサーバ12は、図2に示すように、データノード121、HDFS122、タスクトラッカー123及びMapReduce処理部124を有する。
HDFS122は、HDFS111と同様にデフォルト64MBのサイズのブロック単位でデータを管理する。各スレーブサーバ12のそれぞれのHDFS122は、全体で1つの仮想ファイルシステムを形成する。
データノード121は、識別子付RDFデータ表の一部の行データを含むブロックをネームノード112から受信する。ここで、データノード121は、複数のブロックを受信してもよい。そして、データノード121は、取得したブロックを自装置のHDFS122へ格納する。すなわち、HDFS122には、識別子付RDFデータ表の全行のうちの一部の行のデータが格納される。
タスクトラッカー123は、自装置が有するブロックに対応するMapタスクをジョブトラッカー114から受信する。そして、タスクトラッカー123は、Mapタスクで指示されたMap処理の実行をMapReduce処理部124に指示する。その後、タスクトラッカー123は、Mapタスクにしたがって実行されたMapReduce処理の実行結果の入力をMapReduce処理部124から受ける。そして、タスクトラッカー123は、Mapタスク毎の実行結果をジョブトラッカー114へ送信する。
MapReduce処理部124は、タスクトラッカー123から取得したMapタスクにしたがってMapReduce処理を実行する。ここで、図7を参照して、MapReduce処理について説明する。図7は、MapReduce処理の概要を表す図である。ここでは、MapReduce処理部124A~124Cが動作する場合で説明する。さらに、ここでは、MapReduce処理部124Aがブロック301~303に対する処理を行い、MapReduce処理部124B及び124Cは他のブロックを処理する。各ブロックのデータは、key=valueの形式を有するデータを含む。図7において括弧でくくられた2つの文字は、先頭の文字がkeyを表し、2番目の文字がvalueを表す。さらに、ここでは、MapReduce処理としてvalueがXのデータをカウントする処理を実行する場合で説明する。
MapReduce処理部124Aは、ブロック301~303の各データを入力として、入力をmap関数に与えて内部で処理した結果を新たなkey=valueの形式のデータとして出力する。ここでは、MapReduce処理部124Aは、ValueがXであるデータを出力する。この場合、MapReduce処理部124Aは、ブロック301から(K1,X)及び(K4,X)を抽出し、ブロック302から(K2,X)及び(K3,X)を抽出し、ブロック303から(K2,X)及び(K5,X)を抽出する。この処理がMap処理にあたる。Map処理は、ブロック301~303毎に行われる。
同様に、MapReduce処理部124Bは、処理対象とするブロックからvalueがXであるものを抽出する。この場合、MapReduce処理部124Bは、(K1,X)、(K4,X)、(K5,X)、(K1,X)及び(K6,X)を抽出する。また、MapReduce処理部124Cも同様に処理対象とするブロックからvalueがXであるものを抽出する。
次に、MapReduce処理部124A~124Cは、抽出した各データを分類してそれぞれを、MapReduce処理部124A~124Cのうちの決められた送信先へ送信する。例えば、図7では、keyがK1及びK2のデータがMapReduce処理部124Aへまとめられる。また、keyがK3及びK4のデータがMapReduce処理部124Bへまとめられる。また、keyがK5及びK6のデータがMapReduce処理部124Cへまとめられる。次に、各MapReduce処理部124A~124Cは、自己に集められたデータを並び替える。ここでは、MapReduce処理部124A~124Cは、key毎にまとまるようにデータを並び替える。すなわち、MapReduce処理部124A~124Cは、おなじkeyを有するkey=value形式のデータ同士を集約する。これらの処理をシャッフル及びソート処理と言う。
次に、MapReduce処理部124A~124Cは、シャッフル及びソート処理が完了したデータを取得し、取得したデータをReduce関数の内部で処理した結果をkey=value形式のデータとして出力する。ここでは、MapReduce処理部124A~124Cは、Reduce関数として同じkeyを有するデータ毎に集計を行う。図7では、MapReduce処理部124Aは、(K1,X)が3つあることを表すデータとして(K1,3)を出力する。また、MapReduce処理部124Aは、(K2,X)が2つあることを表すデータとして(K2,2)を出力する。MapReduce処理部124Bは、keyがK3又はK4であるデータの集計結果を出力する。MapReduce処理部124Cは、keyがK5又はK6であるデータの集計結果を出力する。この処理をReduce処理と言う。Reduce処理は、利用者が編集可能である。ここでは、Reduce処理として、同じkeyを有するデータの集計を行う処理を行ったが、他の処理に変更することも可能である。例えば、SPARQLクエリに対応する結果を返す場合、Reduce処理を、valueがXであり、そのXに対応する値をkeyとするデータをそのまま出力する処理にしてもよい。
MapReduce処理部124は、Mapタスク実行部241及びReduceタスク実行部242を有する。Mapタスク実行部241は、Map処理及びシャッフル及びソート処理を行う。
Mapタスク実行部241は、タスクトラッカー123から実行の指示を受けたMapタスクを取得する。そして、Mapタスク実行部241は、Map処理を実行する。この場合、Mapタスク実行部241は、パラメータ識別子を用いたMapタスクを受信する。そこで、Mapタスク実行部241は、例えば、図8に示すようにパラメータ識別子を用いてMap処理を実行する。図8は、実施例1に係るパラメータ識別子を用いた場合のMapReduce処理の概要を表す図である。図8に記載された識別子付RDFデータ表411及び421のそれぞれが異なるMapReduce処理部124で処理される場合で説明する。
例えば、図8では、Mapタスク実行部241は、太枠で囲われた1002というパラメータ識別子をvalueとするデータを抽出するMapタスクを取得する。ここで、図8では、分かり易いように1002に対応するvalueパターンを記載したが、実際のMapタスクにはvalueパターンは含まれなくてもよい。
Mapタスク実行部241は、識別子付RDFデータ表411又は421からMap処理を行う対象とするデータを取得してkey=value形式のデータに変換しそのデータを入力とする。ここでは、Mapタスク実行部241は、主語とkeyとし述語及び目的語の組み合わせのvalueパターンをvalueとするデータを入力とする。
そして、各Mapタスク実行部241は、入力のデータからvalueを表すパターン識別子が1002であるデータ412又は422を抽出する。そして、各Mapタスク実行部241は、抽出したデータ412又は422に対してシャッフル及びソート処理を実行する。ここでは、各Mapタスク実行部241は、keyがBであるデータを一方に集め、それ以外のデータを他方に集める。このkey毎に各スレーブサーバ12にデータを集める処理が、「3要素のいずれか1つの要素を基準に集約」する処理の一例にあたる。
さらに、各Mapタスク実行部241は、keyを基準に収集したデータをソートしてデータ413又は423を生成する。そして、各Mapタスク実行部241は、データ413又は423をReduceタスク実行部242へ出力する。このMapタスク実行部241が、「検索部」の一例にあたる。
Reduceタスク実行部242は、Reduce処理を行う。例えば図8に示すように、各Reduceタスク実行部242は、データ413又は423の入力をそれぞれ対応するMapタスク実行部241から受ける。次に、各Reduceタスク実行部242は、取得したデータ413又は423から同じkeyを有するデータの数を集計する。そして、各Reduceタスク実行部242は、Reduce処理の結果414又は424をタスクトラッカー123へ出力する。ここで、図8の結果414及び424におけるcはカウント値を表す。このReduceタスク実行部242による同じkeyを有するデータの数を集計が、「予め決められた処理の実行」の一例にあたる。
次に、図9を参照して、実施例1に係る識別子表及び識別子付RDFデータ表の生成処理の流れについて説明する。図9は、実施例1に係る識別子表及び識別子付RDFデータ表の生成処理のフローチャートである。以下では、HDFS111との間のデータの送受信におけるRDFコントローラ117の仲介動作を省略する。
第1生成部115は、RDFストア110に格納されたRDFデータから全ての主語、述語及び目的語の重複を除いて取得する。そして、第1生成部115は、取得した主語、述語及び目的語を2つずつ組み合わせて、valueパターンを抽出する(ステップS1)。
次に、第1生成部115は、抽出したvalueパターンの中にRDFストア110に格納された実際のRDFデータの中に存在しないvalueパターンがあるか否かを判定する(ステップS2)。実際には存在しないvalueパターンが無い場合(ステップS2:否定)、第1生成部115は、ステップS4へ進む。
実際には存在しないvalueパターンがある場合(ステップS2:肯定)、第1生成部115は、抽出したvalueパターンの中から実際には存在しないvalueパターンを除いて、実際に存在するvalueパターンを抽出する(ステップS3)。
次に、第1生成部115は、実際に存在するvalueパターンに識別子を割り当て、各valueパターンに対応するパターン識別子を表す識別子対応表を生成する(ステップS4)。その後、第1生成部115は、生成した識別子対応表のRDFストア110への格納をRDFコントローラ117に行わせ、識別子対表の生成完了を第2生成部116に通知する。
識別子対表の生成完了の通知を受けた第2生成部116は、RDFストア110に含まれる全てのRDFデータ及び識別子対応表をRDFストア110から取得する。次に、第2生成部116は、各RDFデータの主語と述語とを組み合わせたvalueパターン、述語と目的語とを組わせたvalueパターン及び主語と目的語とを組わせたvalueパターンを取得する。そして、第2生成部116は、取得したvalueパターンに対応するパターン識別子を識別子対応表から取得する。次に、第2生成部116は、トリプルの対応を表す対応表における各RDFデータに取得したパターン識別子を付加して識別子付RDFデータ表を生成する(ステップS5)。その後、第2生成部116は、生成した識別子付RDFデータ表をRDFストア110に格納する。ここで、本実施例では、第1生成部115からの通知を受けた第2生成部116が、自動的に識別子付RDFデータの生成を行うように説明したが、これは他の手順でもよい。例えば、第2生成部116は、ジョブクライアント30を用いた利用者からの指示を受けて、その指示の入力をトリガとして識別子付RDFデータの生成を行ってもよい。
ネームノード112は、識別子付RDFデータ表をRDFストア110から取得する。次に、ネームノード112は、識別子付RDFデータ表に登録されたデータを含む各ブロックを配置するデータノード121を決定する。そして、ネームノード112は、識別子付RDFデータ表の一部の行データを含む各ブロックを、配置先として決定したそれぞれのデータノード121へ送信し、データの分散配置を実行する(ステップS6)。
次に、図10を参照して、実施例1に係るMapReduce処理の流れについて説明する。図10は、実施例1に係るMapReduce処理のフローチャートである。
SPARQL処理部118は、SPARQLクエリの実行命令の入力をジョブクライアント30から受ける。そして、SPARQL処理部118は、SPARQLクエリを実行する(ステップS11)。
次に、SPARQL処理部118は、SPARQLクエリをMapReduce処理のジョブへ変換する(ステップS12)。
次に、SPARQL処理部118は、HDFS111から識別子対応表を取得する。そして、SPARQL処理部118は、投入されたクエリを構文解析(パース)して識別子対応表に登録されたvalueパターンに該当するvalueパターンがあるか否かを判定する(ステップS13)。該当するvalueパターンが無い場合(ステップS13:否定)、SPARQL処理部118は、そのようなvalueパターンのマッチング結果は0件であるという検索結果をジョブクライアント30に返してSPARQLクエリの実行処理を終了する。実際には、SPARQL処理部118は、パースした段階で識別子対応表に登録されたvalueパターンに該当するvalueパターンがあるか否かが分かる。
これに対して、該当するvalueパターンがある場合(ステップS13:肯定)、SPARQL処理部118は、パターン識別子を参照してMapReduce処理を実行する。
MapReduce処理部119は、SPARQL処理部118からの指示を受けて、パターン識別子を参照してMapReduce処理の実行をジョブトラッカー114に指示する。ジョブトラッカー114は、メタデータDB113を確認し、MapReduce処理を行わせるスレーブサーバ12を選択する。そして、ジョブトラッカー114は、MapReduce処理をブロック単位のMapタスクに分割し、選択したスレーブサーバ12へ送信する。タスクトラッカー123は、Mapタスクをジョブトラッカー114から受信する。そして、タスクトラッカー123は、取得したMapタスクの実行をMapReduce処理部124に指示する。MapReduce処理部124は、Mapタスクの実行の指示をタスクトラッカー123から受ける。そして、Mapタスク実行部241は、HDFS122に格納された識別符号付RDFデータを用いて、Mapタスクで指定されたMap処理を実行する(ステップS14)。
次に、Mapタスク実行部241は、Map処理の処理結果をkey毎にまとまるようシャッフルして各スレーブサーバ12のMapタスク実行部241に振り分ける。さらに、Mapタスク実行部241は、シャッフルにより自装置に振り分けられたデータをkey毎にまとまるようにソートする(ステップS15)。そして、Mapタスク実行部241は、ソートしたデータをReduceタスク実行部242へ出力する。
Reduceタスク実行部242は、Mapタスク実行部241から取得したデータに対して予め指定されたReduce処理を実行する(ステップS16)。例えば、Reduceタスク実行部242は、データをkey毎に集計する。
その後、Reduceタスク実行部242は、MapReduce処理の結果をタスクトラッカー123へ出力する。タスクトラッカー123は、入力されたMapReduce処理の結果をマスタサーバ11のジョブトラッカー114へ送信する。ジョブトラッカー114は、各スレーブサーバ12から送信されたMapReduce処理の結果を収集する。そして、ジョブトラッカー114は、MapReduce処理の結果を結合する。そして、ジョブトラッカー114は、結合したMapReduce処理の結果をMapReduce処理部119を介してSPARQL処理部118へ送信する。SPARQL処理部118は、結合されたMapReduce処理の結果を受信し、受信したデータをRDF形式に変換する(ステップS17)。その後、SPARQL処理部118は、RDF形式に変換したMapReduce処理の結果をSPARQLクエリの実行結果としてジョブクライアント30へ送信する。
以上に説明したように、本実施例に係るHadoopクラスタは、グラフデータに含まれる3要素のうちの2要素の組み合わせであるvalueパターンに識別子を割り当てし、その識別子を用いてMapReduce処理を実行する。これにより、MapReduce処理においてグラフデータの検索を行う場合に、データ領域が小さい識別子を用いて検索を行うことができ、検索時のマッチングを高速に行うことができる。
さらに、本実施例に係るHadoopクラスタは、実際のRDFデータの中には存在しないvalueパターンを除いて識別子対応表を作成する。これにより、存在しないRDFデータを用いた処理を省くことができ、検索速度がさらに向上する。例えば、RDFデータに存在しないvalueパターンを用いた検索操作の指示を受けた場合、本実施例に係るHadoopクラスタは、MapReduce処理を行わずに結果を返すことができる。
次に実施例2について説明する。本実施例に係るHadoopクラスタは、検索の対象とするデータとしてvalueパターンと対応するkeyとが登録された分割データ表を用いることが実施例1と異なる。本実施例に係るHadoopクラスタ10も図1及び2で表される。以下の説明では、実施例1と同様の各部の機能については説明を省略する。
第2生成部116は、RDFコントローラ117を介してR全てのRDFデータ及び識別対応表をRDFストア110から取得する。次に、第2生成部116は、各RDFデータの主語、述語及び目的語のうち2つの組み合わせた値を取得し、識別子対応表からその組み合わせの値と一致するvalueパターンに対応する識別子を取得する。そして、第2生成部116は、主語、述語及び目的語のうちの2つを組み合わせ毎に、valueパターンに対応するパターン識別子と、主語、述語及び目的語のうちvalueパターンに含まれる2要素以外の残りの1要素とを対応させて分割データ表を生成する。
図11は、分割データ表の一例を表す図である。本実施例に係る第2生成部116は、図11に示すようにkeyの種類多一致するデータ毎にパターン識別情報とkeyとを一致させる分割データ表501~503を生成する。
具体的には、第2生成部116は、述語と目的語との組み合わせを表すvalueパターンに対応するパターン識別子と主語との対応を表す分割データ表501を生成する。また、第2生成部116は、主語と述語との組み合わせを表すvalueパターンに対応するパターン識別子と目的語との対応を表す分割データ表502を生成する。また、分割データ表502は、主語と目的語との組み合わせを表すvalueパターンに対応するパターン識別子と述語との対応を表す分割データ表503を生成する。そして、第2生成部116は、RDFコントローラ117を介してRDFストア110に生成した分割データ表501~503を格納させる。
ネームノード112は、分割データ表の一部の行データを含むブロックを各データノード121へ送信する。データノード121は、分割データ表の一部の行データを含むブロックをHDFS122に格納する。
Mapタスク実行部241は、Mapタスクの実行指示をタスクトラッカー123から受信する。そして、Mapタスク実行部241は、Mapタスクで使用するテーブルを選択する。例えば、Mapタスクが述語と目的語とを組み合わせたvalueパターン用いるMap処理の場合、Mapタスク実行部241は、述語と目的語とを組み合わせたvalueパターンが登録された分割データ表を選択する。図11を用いた場合を例に説明すると、例えば、主語と述語との組み合わせのvalueパターンを用いたMap処理の場合、Mapタスク実行部241は、分割データ表501を選択する。
そして、Mapタスク実行部241は、HDFS122に格納された各ブロックに対して、タスクトラッカー123から実行の指示を受けたMapタスクを実行する。その後、Mapタスク実行部241は、Map処理、並びに、シャッフル及びソート処理を実行した結果をReduceタスク実行部242へ出力する。
ここで、図12を参照して、実施例2に係るMapタスク実行部241によるMap処理の流れについて説明する。図12は、実施例2に係るパラメータ識別子を用いた場合のMapReduce処理の概要を表す図である。ここでは、図12に記載された分割データ表511及び521のそれぞれが異なるMapReduce処理部124で処理される場合で説明する。
例えば、図12では、Mapタスク実行部241は、太枠で囲われたパラメータ識別子である1002をvalueとして抽出するMapタスクを取得する。次に、Mapタスク実行部241は、分割データ表511又は521からMap処理を行う対象とするデータを取得する。この場合、分割データ表511及び521のデータは既にkey=valueの形式であるので、各Mapタスク実行部241は、分割データ表511又は521のデータをそのまま入力とすることができる。
そして、各Mapタスク実行部241は、入力されたデータからvalueにあたるパターン識別子が1002であるデータ512又は522を抽出する。次に、各Mapタスク実行部241は、抽出したデータ512又は522に対してシャッフル及びソート処理を実行しデータ513及び523を取得する。
Reduceタスク実行部242は、Map処理、並びに、シャッフル及びソート処理の結果をMapタスク実行部241から取得する。そして、Reduceタスク実行部242は、取得したデータに対してReduce処理を行う。
ここで、図12を参照して、実施例2に係るReduceタスク実行部242によるReduce処理の流れについて説明する。各Reduceタスク実行部242は、データ513又は523の入力をそれぞれ対応するMapタスク実行部241から受ける。次に、各Reduceタスク実行部242は、取得したデータ513又は523から同じkeyを有するデータの数を集計する。そして、各Reduceタスク実行部242は、Reduce処理の結果514又は524をタスクトラッカー123へ出力する。
以上に説明したように、本実施例に係るHadoopクラスタは、valueパターンに対応する識別子とその識別子に対応するkeyとの対応を表す分割データ表を用いてMapReduec処理を実行する。本実施例に係るHadoopクラスタは、Map処理の目的に応じて分割データ表を選択する。各分割データ表は実施例1で用いた識別子付RDFデータ表よりもサイズが小さいため、実施例1に比べてメモリの消費量を抑えることができ、且つ、表のスキャンを迅速に行うことができる。
ここで、以上の各実施例では、Hadoopクラスタを用いて説明したが、システムの構成はこれに限らず、3つの要素を有するデータを2つの要素に対する処理に対して用いるシステムであれば他のシステム構成でもよい。また、以上の各実施例ではRDFデータを用いて説明したが、グラフデータで有れば他のデータを用いても同様の処理を行うことができ、同様の効果を得ることができる。
(ハードウェア構成)
上述してきた各実施例に係るマスタサーバ11及びスレーブサーバ12は、例えば図13に示すようなハードウェア構成を有するコンピュータで実現できる。図13は、コンピュータのハードウェア構成の一例を表す図である。コンピュータ90は、CPU(Central Processing Unit)91、RAM(Random Access Memory)92、ROM(Read Only Memory)93及びHDD(Hard Disk Drive)94を有する。さらに、コンピュータ90は、通信インターフェイス(I/F:Interface)95、入出力インターフェイス(I/F)96、及びメディアインターフェイス(I/F)97を有する。
CPU91は、ROM93またはHDD94に格納されたプログラムに基づいて動作し、各部の制御を行う。ROM93は、コンピュータ90の起動時にCPU91によって実行されるブートプログラムや、コンピュータ90のハードウェアに依存するプログラム等を格納する。
HDD94は、CPU91によって実行されるプログラム、及び、かかるプログラムによって使用されるデータ等を格納する。通信インターフェイス95は、ネットワークを介して他の機器からデータを受信してCPU91へ送り、CPU91が生成したデータをネットワークを介して他の機器へ送信する。
CPU91は、入出力インターフェイス96を介して、ディスプレイやプリンタ等の出力装置、及び、キーボードやマウス等の入力装置を制御する。CPU91は、入出力インターフェイス96を介して、入力装置からデータを取得する。また、CPU91は、生成したデータを入出力インターフェイス96を介して出力装置へ出力する。
メディアインターフェイス97は、記録媒体98に格納されたプログラムまたはデータを読み取り、RAM92を介してCPU91に提供する。CPU91は、かかるプログラムを、メディアインターフェイス97を介して記録媒体98からRAM92上にロードし、ロードしたプログラムを実行する。記録媒体98は、例えばDVD(Digital Versatile Disc)、PD(Phase change rewritable Disk)等の光学記録媒体、MO(Magneto-Optical disk)等の光磁気記録媒体、テープ媒体、磁気記録媒体、または半導体メモリ等である。
例えば、コンピュータ90のRAM92及びHDD94は、HDFS111及び122、並びに、メタデータDB113の機能を実現する。さらに、コンピュータ90のCPU91は、RAM92上にロードされたプログラムを実行することにより、ネームノード112、ジョブトラッカー114、第1生成部115、第2生成部116の機能と実現する。また、コンピュータ90のCPU91は、RDFコントローラ117、SPARQL処理部118及びMapReduce処理部119の機能を実現する。さらに、コンピュータ90のCPU91は、データノード121、タスクトラッカー123及びMapReduce処理部124の機能を実現する。
コンピュータ90のCPU91は、これらのプログラムをHDD94から読み取って実行するが、他の例として、記録媒体98からプログラムを読みとってもよいし、他の装置からネットワークを介してこれらのプログラムを取得してもよい。
ここで、以上の説明では、SPARQL処理部118が、SPARQLクエリで指定された検索対象のvalueパターンに対応するパターン識別子を識別子対応表から取得しする場合で説明したが、この処理はスレーブサーバ12側で実行することも可能である。例えば、スレーブサーバ12のMapReduce処理部124が、検索対象のvalueパターンに対応するパターン識別子を識別子対応表から取得して、取得したパターン識別子を用いてMapReduce処理を実行してもよい。
次に、実施例3について説明する。HadoopによるMapReduce処理では、入力データと最終の出力データは共にHDFSに格納される。さらに、HadoopによるMapReduce処理では、Map処理において、生成される中間ファイルも、一時的にHDFSに格納される。そのため、Map処理において、HDFSに対する中間ファイルの入出力が行われる。HDFSは、HDDやSSD(Solid State Drive)に配置されるファイルシステムであり、演算処理に比べて読み書きにかかる時間が大きい。そのため、HadoopによるMapReduce処理を行う場合、遅延が発生するおそれがある。
そこで、MapReduce処理を行う際に、メモリ上のデータを用いて処理を行うインメモリ処理を用いることで、HDFSへのアクセスを減らして、処理速度を向上させる方法が考えられる。例えば、分散型のインメモリ処理として、Spark(登録商標)を用いた処理が存在する。Sparkを用いることで、インメモリでMapReduceを行うことができる。
Sparkでは、ストレージとして、HadoopのHDFSが利用される。そのため、Sparkを用いた場合にも、入力データ及び最終の出力データは、HDFSに格納される。一方、Map処理における中間データはRDD(Resilient Distributed Dataset)形式でメモリ上に保持され、HDFSに格納されることなく連続的に処理される。そのため、深層学習などにおいて処理結果を用いてMap処理を繰り返す場合などでは、HadoopによるMapReduce処理よりも処理速度をより向上させることが可能である。
しかしながら、Sparkのような分散型のインメモリ処理を用いてメインメモリでデータ処理を完結させる場合、識別子対応表をメモリ上に展開する構成では、識別子対応表のサイズが大きいとメモリ上に展開することが困難である。その場合、メモリ内でMap処理に割り当てるメモリ容量が不足するため、処理速度が低下するおそれがある。
そこで、本実施例に係る情報処理システムでは、識別子対応表を分割することでメモリ上に展開する識別子対応表を小さくする。以下では、Sparkを用いたMapReduce処理における分割した識別子対応表の使用について主に説明する。図14は、実施例3に係るマスタサーバ及びスレーブサーバの詳細を表すブロック図である。以下の説明では、実施例1と同様の各部の動作は説明を省略する。
図14に示すように、マスタサーバ11は、実施例1の各部に加えてSpark処理部131を有する。また、スレーブサーバ12は、実施例1の各部に加えてSSD125及びメモリ126を有する。さらに、本実施例に係るスレーブサーバ12のMapReduce処理部124は、Mapタスク実行部241及びReduceタスク実行部242に加えて、メモリ管理部243を有する。
第1生成部115は、識別子対応表の生成の指示をHDFSクライアント20から受ける。そして、第1生成部115は、RDFストア110に登録された全てのRDFデータの主語、述語及び目的語の取得をRDFコントローラ117に指示する。その後、第1生成部115は、RDFストア110に登録された全てのRDFデータの主語、述語及び目的語をRDFコントローラ117から取得する。
次に、第1生成部115は、取得した主語、述語及び目的語のそれぞれの重複を除いて集計する。そして、第1生成部115は、集計した主語、述語及び目的語を用いて、全ての通りの組み合わせのvalueバターンを生成する。次に、第1生成部115は、実際の各RDFデータの主語、述語及び目的語の組み合わせに含まれないvalueパターン以外のvalueパターンを抽出して、識別子を割り当てる。そして、第1生成部115は、実際の各RDFデータの主語、述語及び目的語の組の中に含まれないvalueパターンについては、不存在を表す情報を付加して、各valueパターンと割り当てたパターン識別子との対応を表す識別子対応表を作成する。
この段階では、第1生成部115は、図15に示す識別子対応表213が生成される。図15は、分割前の識別子対応表の一例を表す図である。この識別子対応表213には、述語と目的語とを組み合わせたValueバターンを表す領域214、主語と述語とを組み合わせたvalueバターンを表す領域215、主語と目的語とを組み合わせたValueバターンを表す領域216が含まれる。
ここで、例えば、「select ? s where {?s likes C}」といったSPARQLクエリでは、述語と目的語とを組み合わせたvalueパターンが検索される。すなわち、このSPARQLクエリでは、識別子対応表213の中の領域215及び216は、検索対象としなくてもよい。このように、検索が、対応する主語を検出する主語基準の検索なのか、対応する目的語を検出する目的語基準の検索なのか、又は、対応する述語を検出する述語基準の検索なのかにより、識別子対応表213において実際に必要となる領域が異なる。
そして、第1生成部115は、識別子対応表213を分割して、図16に示す主語基準の検索用の分割識別子対応表231、目的語基準の検索用の分割識別子対応表232及び述語基準の検索用の分割識別子対応表233を生成する。図16は、分割識別子対応表の一例を表す図である。
その後、第1生成部115は、生成した分割識別子対応表231~233をRDFコントローラ117へ送信し、RDFストア110への格納を指示する。さらに、第1生成部115は、識別子対応表の生成完了を第2生成部116に通知する。これにより、RDFコントローラ117によって、RDFストア110へ、分割識別子対応表231~233が格納される。
SPARQL処理部118は、SPARQLクエリの入力をジョブクライアント30から受ける。そして、SPARQL処理部118は、取得したSPARQLクエリを解析してMapReduce処理に変換する。その後、SPARQL処理部118は、パターン識別子を含むMapReduce処理をSpark処理部131に出力する。さらに、SPARQL処理部118は、分割識別子対応表231~233の送信要求をネームノード112に通知する。
ネームノード112は、分割識別子対応表231~233の送信要求の通知をSPARQL処理部118から受信する。そして、ネームノード112は、RDFストア110から分割識別子対応表231~233を取得し、データノード121へ送信する。また、ネームノード112は、識別子付RDFデータ表の一部の行データを含むブロックを選択したデータノード121へ送信し配置する。
Spark処理部131は、Sparkを用いて実行するMapReduce処理の入力をSPARQL処理部118から受ける。次に、Spark処理部131は、受信したMapReduce処理に含まれる個々のMapReduce処理を取得する。そして、Spark処理部131は、取得したMapReduce処理の実行をジョブトラッカー114に指示する。さらに、深層学習などにおいて実行結果を用いてMapReduce処理が繰り返し行われる場合、Spark処理部131は、繰り返しの手順を管理して、ジョブトラッカー114にメモリ126の上でのMapReduce処理の繰り返しの実行を指示する。
その後、Spark処理部131は、MapReduce処理の実行結果の入力をジョブトラッカー114から受ける。そして、Spark処理部131は、MapReduce処理の実行結果をSPARQL処理部118へ出力する。この場合のSpark処理部131は、Sparkにおける「Driver」にあたる。
データノード121は、識別子付RDFデータ表の一部の行データを含むブロックをネームノード112から受信する。ここで、データノード121は、複数のブロックを受信してもよい。そして、データノード121は、取得したブロックを自装置のHDFS122へ格納する。
また、データノード121は、分割識別子対応表231~233をネームノード112から受信する。そして、データノード121は、取得した分割識別子対応表231~233を次装置のHDFS122へ格納する。
本実施例に係るMapReduce処理部124は、Mapタスク実行部241、Reduceタスク実行部242及びメモリ管理部243を有する。MapReduce処理部124は、Mapタスクをタスクトラッカー123から取得し、Sparkを用いたMapReduce処理を実行する。この場合のMapReduce処理部124は、Sparkにおける「Exector」にあたる。以下にSparkを用いたMapReduce処理の詳細を説明する。
メモリ管理部243は、タスクトラッカー123から取得したMapタスクで指定された検索するvalueパターンを取得する。そして、メモリ管理部243は、そのvalueパターンによる検索が、主語基準の検索、目的語基準の検索、又は、述語基準の検索のいずれにあたるかを特定する。そして、メモリ管理部243は、分割識別子対応表231~233のうち特定した種類の検索に対応する表をSSD125から取得する。ここでは、主語基準の検索を行う場合で説明する。すなわち、メモリ管理部243は、主語基準の検索用の分割識別子対応表231をSSD125から取得する。そして、メモリ管理部243は、取得した分割識別子対応表231をRDDに変換する。その後、メモリ管理部243は、RDDに変換した分割識別子対応表231をメモリ126上に展開する。
また、メモリ管理部243は、HDFS122に格納された識別子付RDFデータ表の一部の行データを含むブロックを取得する。そして、メモリ管理部243は、取得したブロックをRDDに変換する。その後、メモリ管理部243は、RDDに変換したブロックをメモリ126上に展開する。RDDは、不変で並列実行可能な分割されたコレクションである。RDDは、メモリ上に保持することが可能で、耐障害性、データ局所性などの特徴を有する。
その後、メモリ管理部243は、Reduceタスク実行部242からReduce処理の完了の通知を受けると、MapReduce処理の実行結果をメモリ126から取得する。そして、メモリ管理部243は、取得したMapReduce処理の実行結果をRDDの形式からHDFS111への格納用のデータ形式に直してHDFS122へ格納する。すなわち、HDFS122には、MapReduce処理に使用するデータが格納された識別子付RDFデータ表及びMapReduce処理の実行結果が格納される。
Mapタスク実行部241は、タスクトラッカー123から実行の指示を受けたSparkを用いたMapタスクにおけるMap処理を実行する。具体的には、Mapタスク実行部241は、Mapタスクで指定された検索対象となるvalueパターンを取得する。そして、Mapタスク実行部241は、取得したvalueパターンでメモリ126上の分割識別子対応表231を検索して、valueパターンに対応するパラメータ識別子を取得する。
次に、Mapタスク実行部241は、識別子付RDFデータ表からMap処理を行う対象とするデータを取得してkey=value形式のデータに変換しそのデータを入力とする。次に、Mapタスク実行部241は、RDDに変換された入力データの中からvalueが取得したパターン識別子と一致するデータを抽出する。次に、Mapタスク実行部241は、抽出したデータに対してシャッフル及びソート処理を実行する。そして、各Mapタスク実行部241は、シャッフル及びソート処理を実行したデータをReduceタスク実行部242へ出力する。
ここで、Mapタスク実行部241は、以上の処理の際に生成される中間データはRDD形式でメモリ126上に保持しつつ、以上の処理を連続的に実行する。特に、深層学習などにおいてMapReduce処理の実行結果を繰り返し用いて処理を行う場合、Mapタスク実行部241は、メモリ126に対するデータの読み出し及び書き込みにより連続的に繰り返し処理を実行することができる。
Reduceタスク実行部242は、Reduce処理を行う。Reduce処理は、Reduceの設計者が予め決めた処理を実行することができる。例えば、Reduceタスク実行部242は、値の合計や集約などの処理を行う。その後、Reduceタスク実行部242は、MapReduce処理の実行結果をメモリ126に格納する。さらに、Reduceタスク実行部242は、Reduce処理の完了をメモリ管理部243及びタスクトラッカー123へ通知する。
タスクトラッカー123は、Reduce処理の完了の通知をReduceタスク実行部242から受ける。そして、タスクトラッカー123は、MapReduce処理の実行結果をHDFS122から取得し、ジョブトラッカー114へ送信する。
ここで、以上の説明では、スレーブサーバ12が保持するSSD125に分割識別子対応表231~233を格納する構成で説明したが、分割識別子対応表231~233の配置場所に特に制限は無い。例えば、マスタサーバ11に分割識別子対応表231~233を配置して、スレーブサーバ12のメモリ管理部243が、マスタサーバ11から分割識別子対応表231~233を取得する構成であってもよい。
次に、図17を参照して、実施例3に係るパラメータ識別子を用いた場合のMapReduce処理の概要を説明する。図17は、実施例3に係るMapReduce処理の概要を表す図である。ここでは、図17に記載された識別子付RDFデータ表611及び621のそれぞれが異なるMapReduce処理部124で処理される場合で説明する。
例えば、図17では、Mapタスク実行部241は、SPARQLクエリが「select ?s where{?s loves C.}という構文で表されるデータ抽出をSparkを用いて行うMapタスクを取得する。メモリ管理部243は、識別子付RDFデータ表611及び621、並びに、分割識別子対応表231をRDDに変換してメモリ126上に格納する。
Mapタスク実行部241は、RDDに変換されメモリ上に格納された分割識別子対応表231から、「loves C」に対応するパターン識別子として1002を取得する。そして、Mapタスク実行部241は、RDDに変換された識別子付RDFデータ表411又は421からMap処理を行う対象とするデータを取得してkey=value形式のデータに変換しそのデータを入力とする。ここでは、Mapタスク実行部241は、主語とkeyとし述語及び目的語の組み合わせのvalueパターンをvalueとするデータを入力とする。
そして、各Mapタスク実行部241は、入力のデータからvalueを表すパターン識別子が1002であるデータ612又は622を抽出してメモリ126上に格納する。そして、各Mapタスク実行部241は、抽出したデータ612又は622に対してシャッフル及びソート処理を実行し処理結果をメモリ126上に格納する。ここでは、各Mapタスク実行部241は、keyがBであるデータを一方に集め、それ以外のデータを他方に集める。さらに、各Mapタスク実行部241は、keyを基準に収集したデータをソートしてデータ613又は623を生成しメモリ126上に格納する。
Reduceタスク実行部242は、データ613又は623の入力をメモリ126から取得する。次に、Reduceタスク実行部242は、取得したデータ613又は623から同じkeyを有するデータの数を集計する。そして、Reduceタスク実行部242は、Reduce処理の結果614又は624をメモリ126上に格納する。ここで、図17の結果614及び624におけるcはカウント値を表す。
次に、図18を参照して、実施例3に係る識別子表及び識別子付RDFデータ表の生成処理の流れについて説明する。図18は、実施例3に係る識別子表及び識別子付RDFデータ表の生成処理のフローチャートである。以下では、HDFS111との間のデータの送受信におけるRDFコントローラ117の仲介動作を省略する。
第1生成部115は、RDFストア110に格納されたRDFデータから全ての主語、述語及び目的語の重複を除いて取得する。そして、第1生成部115は、取得した主語、述語及び目的語を2つずつ組み合わせて、valueパターンを抽出する(ステップS101)。
次に、第1生成部115は、抽出したvalueパターンの中にRDFストア110に格納された実際のRDFデータの中に存在しないvalueパターンがあるか否かを判定する(ステップS102)。実際には存在しないvalueパターンが無い場合(ステップS102:否定)、第1生成部115は、ステップS104へ進む。
実際には存在しないvalueパターンがある場合(ステップS102:肯定)、第1生成部115は、抽出したvalueパターンの中から実際には存在しないvalueパターンを除いて、実際に存在するvalueパターンを抽出する(ステップS103)。
次に、第1生成部115は、実際に存在するvalueパターンに識別子を割り当て、各valueパターンに対応するパターン識別子を表す識別子対応表を生成する(ステップS104)。
次に、第1生成部115は、生成した識別子対応表を主語基準の検索用、述語基準の検索用、目的語基準の検索用に分割して分割識別子対応表231~233を作成する。次に、第1生成部115は、分割識別子対応表231~233をRDFストア110に格納する(ステップS105)。さらに、第1生成部115は、分割識別子対応表231~233の生成完了を第2生成部116に通知する。
分割識別子対表231~233の生成完了の通知を受けた第2生成部116は、RDFストア110に含まれる全てのRDFデータ及び識別子対応表をRDFストア110から取得する。次に、第2生成部116は、各RDFデータの主語と述語とを組み合わせたvalueパターン、述語と目的語とを組わせたvalueパターン及び主語と目的語とを組わせたvalueパターンを取得する。そして、第2生成部116は、取得したvalueパターンに対応するパターン識別子を分割識別子対応表231~233から取得する。次に、第2生成部116は、トリプルの対応を表す対応表における各RDFデータに取得したパターン識別子を付加して識別子付RDFデータ表を生成する(ステップS106)。
ネームノード112は、識別子付RDFデータ表をRDFストア110から取得する。次に、ネームノード112は、識別子付RDFデータ表に登録されたデータを含む各ブロックを配置するデータノード121を決定する。そして、ネームノード112は、識別子付RDFデータ表の一部の行データを含む各ブロックを、配置先として決定したそれぞれのデータノード121へ送信し、データの分散配置を実行する(ステップS107)。
次に、図19を参照して、実施例3に係るMapReduce処理の流れについて説明する。図19は、実施例3に係るMapReduce処理のフローチャートである。
SPARQL処理部118は、SPARQLクエリの実行命令の入力をジョブクライアント30から受ける。そして、SPARQL処理部118は、SPARQLクエリを実行する(ステップS201)。
次に、SPARQL処理部118は、SPARQLクエリをMapReduce処理のジョブへ変換する(ステップS202)。
次に、SPARQL処理部118は、HDFS111から識別子対応表を取得する。そして、SPARQL処理部118は、投入されたクエリを構文解析(パース)して識別子対応表に登録されたvalueパターンに該当するvalueパターンがあるか否かを判定する(ステップS203)。該当するvalueパターンが無い場合(ステップS203:否定)、SPARQL処理部118は、そのようなvalueパターンのマッチング結果は0件であるという検索結果をジョブクライアント30に返してSPARQLクエリの実行処理を終了する。
これに対して、該当するvalueパターンがある場合(ステップS203:肯定)、SPARQL処理部118は、MapReduce処理を実行する。Spark処理部131は、SPARQL処理部118からの指示を受けて、MapReduce処理の実行をジョブトラッカー114に指示する。ジョブトラッカー114は、メタデータDB113を確認し、MapReduce処理を行わせるスレーブサーバ12を選択する。そして、ジョブトラッカー114は、MapReduce処理をブロック単位のMapタスクに分割し、選択したスレーブサーバ12へ送信する。タスクトラッカー123は、Mapタスクをジョブトラッカー114から受信する。そして、タスクトラッカー123は、取得したMapタスクの実行をMapReduce処理部124に指示する。MapReduce処理部124は、Mapタスクの実行の指示をタスクトラッカー123から受ける。そして、メモリ管理部243は、分割識別子対応表231~233の中からMapタスクで実行する検索基準に応じた表を取得する(ステップS204)。ここでは、分割識別子対応表231を選択した場合で説明する。
次に、メモリ管理部243は、選択した分割識別子対応表231及びHDFS122bに格納された識別子付RDFデータ表をRDDに変換してメモリ126上に展開する(ステップS205)。
Mapタスク実行部241は、メモリ126上に展開された分割識別子対応表231及び識別子付RDFデータ表を用いて、Mapタスクで指定されたMap処理を実行する(ステップS206)。
次に、Mapタスク実行部241は、Map処理の処理結果をkey毎にまとまるようシャッフルして各スレーブサーバ12のMapタスク実行部241に振り分ける。さらに、Mapタスク実行部241は、シャッフルにより自装置に振り分けられたデータをkey毎にまとまるようにソートする(ステップS207)。そして、Mapタスク実行部241は、ソートしたデータをメモリ126に格納する。
Reduceタスク実行部242は、Mapタスク実行部241によりメモリ126に格納されたデータに対して予め指定されたReduce処理を実行する(ステップS208)。
その後、Reduceタスク実行部242は、MapReduce処理の結果をメモリ126に格納する。メモリ管理部243は、メモリ126に格納されたMapReduce処理の実行結果を取得してHDFS111への格納用のデータ形式に変換してHDFS122に格納する。タスクトラッカー123は、HDFS122に格納されたMapReduce処理の実行結果をマスタサーバ11のジョブトラッカー114へ送信する。ジョブトラッカー114は、各スレーブサーバ12から送信されたMapReduce処理の実行結果を収集する。そして、ジョブトラッカー114は、MapReduce処理の実行結果を結合する。そして、ジョブトラッカー114は、結合したMapReduce処理の実行結果をMapReduce処理部119を介してSPARQL処理部118へ送信する。SPARQL処理部118は、結合されたMapReduce処理の実行結果を受信し、受信したデータをRDF形式に変換する(ステップS209)。その後、SPARQL処理部118は、RDF形式に変換したMapReduce処理の結果をSPARQLクエリの実行結果としてジョブクライアント30へ送信する。
ここで、本実施例では、分散型のインメモリ処理としてSparkを用いる場合で説明したが、他の分散型のインメモリ処理を用いてもよい。また、情報処理システム1は、分散型のインメモリ処理を用いるMapReduce処理と実施例1で説明した分散型のインメモリ処理を用いないMapReduce処理とを選択的に実行できる構成にしてもよい。さらに、本実施例では、実施例1で説明したMapReduce処理に対してSparkを用いる構成で説明したが、実施例2の構成に適用することもできる。
以上に説明したように、本実施例に係るHadoopクラスタは、Sparkを用いたMapReduce処理を実行する際に、検索対象に応じて作成された識別子対応表のいずれかを用いる。これにより、メモリへの読み込み量を削減して処理に割り当てるメモリ容量を十分に確保することで、処理速度が低下を回避することができる。また、識別子対応表に含まれるエントリ数が少なくなるため、グラフデータの検索効率を向上させることができる。さらに、分散型のインメモリ処理によりMapReduce処理を実行することにより、MapReduce処理の効率を向上させることができる。
上述してきた各実施例に係るマスタサーバ11及びスレーブサーバ12は、例えば図13に示すようなハードウェア構成を有するコンピュータで実現できる。Spark処理部131は、マスタサーバ11がコンピュータ90で実現される場合、CPU91及びメモリ92によりその機能が実現される。また、MapReduce処理部124は、スレーブサーバ12がコンピュータ90で実現される場合、CPU91及びメモリ92によりその機能が実現される。