JP2008225898A - Conversion device, conversion program, and conversion method - Google Patents
Conversion device, conversion program, and conversion method Download PDFInfo
- Publication number
- JP2008225898A JP2008225898A JP2007063853A JP2007063853A JP2008225898A JP 2008225898 A JP2008225898 A JP 2008225898A JP 2007063853 A JP2007063853 A JP 2007063853A JP 2007063853 A JP2007063853 A JP 2007063853A JP 2008225898 A JP2008225898 A JP 2008225898A
- Authority
- JP
- Japan
- Prior art keywords
- data
- process product
- difference
- product data
- downstream process
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images






















Landscapes
- Stored Programmes (AREA)
Abstract
【課題】上流工程成果物データから下流工程成果物データを変換ルールデータに基づいて生成する。
【解決手段】 PIMデータ51と、変換ルールデータに基づいてPIMデータ51から生成されたPSMデータ61とを記憶するリポジトリデータ21と、PSMデー61タから修正されたPSMデータ62を記憶し、PSMデータ61とPSMデータ62とを比較して差分を差分適用データ33として出力する差分抽出手段12と、PIMデータ51が修正されPIMデータ52が生成されると、変換ルールデータ及び差分適用データ33とに基づいてPIMデータ52からPSMデータ63を生成する差分適用手段15とを備える。
【選択図】図1Downstream process product data is generated from upstream process product data based on conversion rule data.
SOLUTION: PIM data 51, repository data 21 for storing PSM data 61 generated from PIM data 51 based on conversion rule data, and PSM data 62 modified from PSM data 61 are stored. The difference extraction means 12 that compares the data 61 with the PSM data 62 and outputs the difference as difference application data 33, and when the PIM data 51 is modified and the PIM data 52 is generated, Difference application means 15 for generating PSM data 63 from the PIM data 52 based on the above.
[Selection] Figure 1
Description
本発明は、上流工程成果物データから下流工程成果物データを変換ルールデータに基づいて生成する変換装置、変換プログラム及び変換方法に関する。 The present invention relates to a conversion device, a conversion program, and a conversion method for generating downstream process product data from upstream process product data based on conversion rule data.
近年、システム開発において、システム開発対象となるビジネスなどに重点を置いたオブジェクト指向が広く採用されている。オブジェクト指向によるシステム開発においては、関連するデータの集合と、それに対する手続き(メソッド)を「オブジェクト」と呼ばれる一つのまとまりとして管理し、その組み合わせによってソフトウェアを構築する。既に存在するオブジェクトについては、利用に際してその内部構造や動作原理の詳細を知る必要はなく、外部からメッセージを送れば機能するため、特に大規模なソフトウェア開発において有効な考え方であるとされている。 In recent years, in the system development, object orientation with an emphasis on the business to be developed is widely adopted. In object-oriented system development, a set of related data and procedures (methods) for the related data are managed as a single unit called an “object”, and software is constructed by combining them. For objects that already exist, it is not necessary to know the details of the internal structure and the operating principle when using them, and it works if you send a message from the outside, so it is considered to be an effective idea especially in large-scale software development.
このオブジェクト指向において、MDA(Model Driven Architecture:モデル駆動型アーキテクチャ)と呼ばれるシステム開発手法が広く普及している。このMDAでは、概念モデルの作成、PIM(Platform Independent Model)の作成、PSM(Platform Specific Model)の作成を経て、システムの実行コードを得る。ここで、「概念モデル」とは、システムの全体の構造を表すモデルである。「PIM」とは、CPU、OS、ミドルウェア、開発言語などのシステム実装環境であるプラットフォームに依存しないモデルで表された設計データある。「PSM」とは、実際に開発対象となるプラットフォームに対応した(プラットフォームの開発言語と1対1に対応した)モデルで表された設計データである。PIM及びPSMは、システム開発者によって開発又は保守される。 In this object orientation, a system development method called MDA (Model Driven Architecture) is widely used. In this MDA, a system execution code is obtained through creation of a conceptual model, creation of a PIM (Platform Independent Model), and creation of a PSM (Platform Specific Model). Here, the “concept model” is a model representing the overall structure of the system. “PIM” is design data represented by a platform-independent model, which is a system implementation environment such as a CPU, OS, middleware, and development language. “PSM” is design data represented by a model (corresponding to a platform development language one-to-one) corresponding to a platform to be actually developed. PIM and PSM are developed or maintained by system developers.
PIMからPSMへの変換において、図22に示すように、市販のツールや自作した変換ツール(モデルコンパイラ)が利用される。この変換ルールセットには、PIMメタモデルからPSMメタモデルを変換するための複数の変換ルールが含まれており、この変換ルールによって、PIMからPSMを作成することができる。PIMとプラットフォームに対応して設けらた変換ルールによって、プラットフォームに依存しないPIMから、開発環境であるプラットフォームに特化及び最適化されたPSMが得られる。この変換ルールは、プラットフォーム専門家(ベンダー)によって提供される。 In the conversion from PIM to PSM, as shown in FIG. 22, a commercially available tool or a self-made conversion tool (model compiler) is used. This conversion rule set includes a plurality of conversion rules for converting a PIM metamodel to a PSM metamodel, and a PSM can be created from the PIM by using this conversion rule. With the conversion rules provided corresponding to the PIM and the platform, a PSM specialized and optimized for the platform, which is the development environment, can be obtained from the platform-independent PIM. This conversion rule is provided by a platform expert (vendor).
しかし、PIMからPSMへモデル変換された後に、PSM上でモデルの修正を行った場合、再度PIMからPSMへモデル変換されると、修正されたPSMがモデル変換後のPMによって上書きされてしまう問題がある。 However, when a model is modified on PSM after model conversion from PIM to PSM, if the model is converted again from PIM to PSM, the modified PSM is overwritten by the PM after model conversion There is.
具体的には、図23に示すように、まずステップS901において、PIMデータ951から変換ルールに従ってモデル変換され、PSMデータ961が生成される。次に、ステップS902において、開発者等によってPSMデータ961が修正され、PSMデータ962が生成される。
Specifically, as shown in FIG. 23, first, in step S901, model conversion is performed from the
一方、ステップS903において、PIMデータ951に仕様変更等が発生することによって、PIMデータ951’が生成される。ここで、ステップS901で用いられた変換ルールを用いてPIMデータ951’をモデル変換して、PSMデータ963を生成する。この場合、PSMデータ962とPSMデータ963のモデル間で競合が発生してしまう。具体的には、ステップS902で修正されたPSMデータ962に、ステップS904でモデル変換されたPSMデータ963が上書きされる。これにより、ステップS902で修正された修正内容が、PSMデータ963に適用されない問題がある。
On the other hand, in step S903, when a specification change or the like occurs in the
この様な状況の背景として、下流のモデルデータ(ここではPSMデータ)を修正している過程で、上流のモデルデータ(ここではPIMデータ)が仕様変更された場合が考えられる。具体的には、下記の様な状況が考えられる。
(1)複数人で開発している場合:PIMデータの開発者とPSMデータの開発者が平行して開発を行っている
(2)要求変更が頻繁に発生している場合:PIMデータからPSMデータへのモデル変換後に、要求変更によりPIMのモデルが変更されると、後戻り工程が発生
(3)変換ルールの修正:変換ルールが修正された場合、同じPIMデータから変換しても異なるPSMデータが出力される
この様に、システム開発の工程において、上流の成果物と下流の成果物との間で、整合性の取れたシステム開発できる環境の開発が期待されている。
As a background of such a situation, there may be a case where the specification of the upstream model data (here PIM data) is changed in the process of modifying the downstream model data (here PSM data). Specifically, the following situations can be considered.
(1) When developing with multiple people: PIM data developer and PSM data developer are developing in parallel (2) When request changes occur frequently: PIM data to PSM When the PIM model is changed due to a request change after model conversion to data, a backtracking process occurs. (3) Modification of conversion rule: When conversion rules are modified, different PSM data even if converted from the same PIM data In this way, in the system development process, it is expected to develop an environment in which a consistent system can be developed between the upstream product and the downstream product.
この様な状況で、プログラムの改訂のため変更後設計ドキュメントから再度プログラムを自動生成する場合に,元の自動生成部分と追加部分とを区別できるようにし,プログラム編集時の安全性を高めるプログラム作成支援装置がある(例えば、特許文献1)。この特許文献1に記載の装置は、設計ドキュメントから変更後設計ドキュメントへの変更を,論理情報抽出部で抽出した論理情報の差分情報として捉え,元の設計ドキュメントから自動生成したプログラムに対して追加編集した編集後プログラムからプログラム論理情報抽出部によってプログラム論理情報を抽出する。更に、論理情報更新部により,差分情報をもとにプログラム論理情報を更新し,更新結果のプログラム論理情報をもとにプログラム生成部によって変更後のプログラムを自動生成する。
In such a situation, when the program is automatically generated again from the design document after the change due to the revision of the program, it is possible to distinguish the original automatically generated part from the added part, and to create a program that enhances safety when editing the program There is a support device (for example, Patent Document 1). The apparatus described in
又、プログラムの修正箇所を継承したプログラムを自動生成できる修正プログラムを継承したプログラムの自動生成方法がある(例えば、特許文献2)。この特許文献2に記載の方法では、プログラム自動生成部は、設計情報に基づいてプログラムを自動生成する。修正箇所継承部は、設計情報の変更によりコードが追加された場合には、追加された箇所を最新の設計情報に基づいて自動生成された新規のプログラムから検索し、設計情報の変更によりコードが削除された場合には、削除された箇所を、自動生成された前回のプログラムに対し修正が加えられた修正済プログラムから検索する。そして、検索により得られた追加箇所を修正済プログラムに追加し、削除箇所を修正済プログラムから削除する。
In addition, there is an automatic program generation method that inherits a correction program that can automatically generate a program that inherits a correction portion of the program (for example, Patent Document 2). In the method described in
更に、ソフトウェア生産支援システムのプログラム作成工程において、自動生成したプログラムに対して削除・修正・追加など新たに加えたコーディング部分を保持し、既存の財産をより有効に使用して生成効率を向上させるプログラム自動生成方法がある(例えば、特許文献3)。この特許文献3に記載の方法は、仕様変更前の旧バージョン生成プログラムと仕様変更後の新バージョン生成プログラムとを比較しその差分を抽出するステップと、旧バージョン生成プログラムに対して追加・修正・削除コーディングを行ったプログラムと旧バージョン生成プログラムとを比較しその差分を抽出するステップと、それぞれの抽出した差分情報から新バージョン仕様情報を用いて生成したプログラムに対し、追加・修正・削除を行うステップとを備える。
しかし、上記の様な技術では、適切に修正及び差分を反映したプログラムを出力できない問題がある。 However, the above-described technique has a problem that a program that appropriately reflects correction and difference cannot be output.
例えば、特許文献1及び特許文献2に記載の方法では、上流工程の成果物について変更の差分を取って、下流工程の成果物に反映している。これは、既に完成している下流工程に対して上流工程の変更を行うことになり、本来の開発手順からすれば、処理の順序が逆行している。このため、特許文献1に記載の方法では、部分変換、修正後のプログラムに上書きするように部分変換結果のマージなど、煩雑な処理が必要となってしまう。
For example, in the methods described in
又、これらの特許文献1及び特許文献2に記載の方法では、上述したような変換ルールを用いてモデル変換するシステム開発には適切ではない。具体的には、変換ルール自体に変更があった場合、上述した特許文献1及び特許文献2の技術では対応することができない。
In addition, the methods described in
一方、特許文献3に記載の技術では、新バージョン生成プログラムと、旧バージョン生成プログラムの第1の差分と、旧バージョン生成プログラムと旧バージョン修正済プログラムの第2の差分とを抽出し、更に第1の差分と第2の差分とに基づいて新バージョン修正済プログラムを出力する。即ち、特許文献3に記載の技術では、差分の抽出処理が2回発生し、処理が煩雑になってしまう問題がある。
On the other hand, in the technique described in
以上のような状況をふまえ、上流の成果物と下流の成果物との間で、容易に整合性の取れたシステム開発できる環境の開発が期待されている。 Based on the situation as described above, it is expected to develop an environment that allows easy and consistent system development between upstream products and downstream products.
従って本発明の目的は、上流の成果物と下流の成果物との間で、容易に整合性の取れる変換装置、変換プログラム及び変換方法を提供することである。 Accordingly, an object of the present invention is to provide a conversion device, a conversion program, and a conversion method that can easily achieve consistency between an upstream product and a downstream product.
上記課題を解決するために、本発明の第1の特徴は、上流工程成果物データから下流工程成果物データを変換ルールデータに基づいて生成する変換装置に関する。即ち本発明の第1の特徴に係る変換装置は、第1の上流工程成果物データと、変換ルールデータに基づいて第1の上流工程成果物データから生成された第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶手段と、第1の下流工程成果物データから修正された第2の下流工程成果物データを、記憶装置に記憶する修正データ記憶手段と、第1の下流工程成果物データと第2の下流工程成果物データとを比較して、第1の下流工程成果物データと第2の下流工程成果物データとの差分を差分適用データとして出力し、差分適用データを記憶装置に記憶する差分抽出手段と、第1の上流工程成果物データが修正され第2の上流工程成果物データが生成されると、変換ルールデータ及び差分適用データとに基づいて第2の上流工程成果物データから第3の下流工程成果物データを生成する差分適用手段とを備える。 In order to solve the above-described problem, a first feature of the present invention relates to a conversion apparatus that generates downstream process product data from upstream process product data based on conversion rule data. That is, the conversion device according to the first aspect of the present invention includes first upstream process product data and first downstream process product data generated from the first upstream process product data based on the conversion rule data. Are stored in the storage device, the second downstream process product data corrected from the first downstream process product data is stored in the storage device, and the first downstream process. The product data and the second downstream process product data are compared, the difference between the first downstream process product data and the second downstream process product data is output as difference application data, and the difference application data is When the difference extraction means stored in the storage device and the first upstream process product data are corrected and the second upstream process product data are generated, the second upstream is based on the conversion rule data and the difference application data. Process completion And a difference application means for generating a third downstream process artifacts data from the object data.
より具体的には、差分抽出手段は、第1の下流工程成果物データから第1の差分抽出データを生成するとともに、第2の下流工程成果物データから第2の差分抽出データを生成して、第1の差分抽出データ及び第2の差分抽出データを記憶装置に記憶する差分抽出データ生成手段と、記憶装置から第1の差分抽出データ及び第2の差分抽出データを読み出して、第1の差分抽出データを第2の差分抽出データを比較する差分抽出データ比較手段と、差分抽出データ比較手段による比較結果に基づいて差分適用データを出力して、差分適用データを記憶装置に記憶する差分適用データ生成手段とを備えても良い。 More specifically, the difference extraction means generates first difference extraction data from the first downstream process product data, and generates second difference extraction data from the second downstream process product data. , Difference extraction data generating means for storing the first difference extraction data and the second difference extraction data in the storage device, and reading out the first difference extraction data and the second difference extraction data from the storage device, Difference extraction data comparing means for comparing the difference extraction data with the second difference extraction data, and difference application data is output based on the comparison result by the difference extraction data comparison means, and the difference application data is stored in the storage device. Data generation means may be provided.
この様な本発明によれば、下流工程成果物データの変更点を考慮して、変更後の上流工程成果物データから新たな下流工程成果物データが生成されるので、開発による手戻りや競合が発生することなく、容易に整合性の取れたシステムを開発できある。 According to the present invention, since new downstream process product data is generated from the upstream process product data after the change in consideration of the change in the downstream process product data, rework and competition by development. It is possible to easily develop a consistent system without causing any problems.
又、第1及び第2の上流工程成果物データ及び第1及び第2の下流工程成果物データは、木構造で表現可能で、複数の要素で表現される文書データであっても良い。この場合、差分抽出データ生成手段は、第1の下流工程成果物データの各要素について、要素の要素名、要素に関連づけられた属性名及び属性値のリスト、要素の識別子を関連づけた第1の差分抽出データを生成するとともに、第2の下流工程成果物データの各要素について、要素の要素名、ノードに関連づけられた属性名及び属性値のリスト、要素の識別子を関連づけた第2の差分抽出データを生成し、差分抽出データ比較手段は、第1の差分抽出データと第2の差分抽出データのそれぞれについて部分木データを作成し、第1の差分抽出データの部分木データと第2の差分抽出データの部分木データが等しい部分木データを抽出して第1の差分抽出データと第2の差分抽出データのそれぞれから削除し、第1の差分抽出データの部分木データと第2の差分抽出データの部分木データが異なる部分木データに含まれる各要素について、要素名、属性名リスト及び属性値リストが等しい要素を抽出して第1の差分抽出データと第2の差分抽出データのそれぞれから削除し、差分適用データ生成手段は、第1の差分抽出データと第2の差分抽出データのそれぞれに共通する要素の識別子に関連づけられた要素の区分を変更に設定し、第1の差分抽出データに含まれ第2の差分抽出データに含まれない要素の識別子に関連づけられた要素の区分を削除に設定し、第2の差分抽出データに含まれ第1の差分抽出データに含まれない要素の識別子に関連づけられた要素の区分を削除に設定し、要素の識別子及び区分を関連づけた差分適用データを出力して、差分適用データを記憶装置に記憶する。 Further, the first and second upstream process product data and the first and second downstream process product data can be represented by a tree structure and may be document data represented by a plurality of elements. In this case, for each element of the first downstream process product data, the difference extraction data generation means has a first element name associated with the element name, a list of attribute names and attribute values associated with the element, and an element identifier. Second difference extraction in which difference extraction data is generated, and for each element of the second downstream process result data, an element name of the element, a list of attribute names and attribute values associated with the node, and an element identifier The data is generated, and the differential extraction data comparison unit creates partial tree data for each of the first differential extraction data and the second differential extraction data, and the partial tree data and the second difference of the first differential extraction data Extract subtree data having the same subtree data of the extracted data, delete the subtree data from each of the first difference extraction data and the second difference extraction data, and extract the subtree data of the first difference extraction data. For each element included in subtree data having different subtree data of the second difference extraction data and the second difference extraction data, elements having the same element name, attribute name list, and attribute value list are extracted, and the first difference extraction data and second difference extraction data The difference application data generation means sets the element classification associated with the element identifier common to each of the first difference extraction data and the second difference extraction data to change. The element classification associated with the identifier of the element included in the first difference extraction data and not included in the second difference extraction data is set to delete, and the first difference extraction included in the second difference extraction data is set. Set the element classification associated with the element identifier not included in the data to be deleted, output the differential application data associated with the element identifier and classification, and store the differential application data in the storage device That.
予め部分木データを作成して差分を抽出し、部分木データが同じ部分木について各要素毎に比較することにより、効率よく差分適用データを生成することができる。 The difference application data can be efficiently generated by creating the subtree data in advance and extracting the difference, and comparing the subtrees having the same subtree data for each element.
本発明の第2の特徴は、上流工程成果物データから下流工程成果物データを変換ルールデータに基づいて生成する変換装置に関する。即ち本発明の第2の特徴に係る変換装置は、上流工程成果物データと、第1の変換ルールデータに基づいて上流工程成果物データから生成された第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶手段と、第1の下流工程成果物データから修正された第2の下流工程成果物データを、記憶装置に記憶する修正データ記憶手段と、第1の下流工程成果物データと第2の下流工程成果物データとを比較して、第1の下流工程成果物データと第2の下流工程成果物データとの差分を差分適用データとして出力し、差分適用データを記憶装置に記憶する差分抽出手段と、第1の変換ルールデータが修正され第2の変換ルールデータが生成されると、第2の変換ルールデータ及び差分適用データとに基づいて上流工程成果物データから第3の下流工程成果物データを生成する差分適用手段とを備える。 The second feature of the present invention relates to a conversion device that generates downstream process product data from upstream process product data based on conversion rule data. That is, the conversion device according to the second aspect of the present invention stores upstream process product data and first downstream process product data generated from the upstream process product data based on the first conversion rule data. Repository storage means for storing in the device, modified data storage means for storing in the storage device the second downstream process product data corrected from the first downstream process product data, and first downstream process product data Is compared with the second downstream process product data, the difference between the first downstream process product data and the second downstream process product data is output as difference application data, and the difference application data is stored in the storage device. When the difference extraction means to be stored and the first conversion rule data are corrected and the second conversion rule data are generated, the upstream process product data is based on the second conversion rule data and the difference application data. And a difference application means for generating a third downstream process product data.
本発明の第3の特徴は、上流工程成果物データから下流工程成果物データを変換ルールデータに基づいて生成する変換プログラムに関する。即ち本発明の第3の特徴に係る変換プログラムは、第1の上流工程成果物データと、変換ルールデータに基づいて第1の上流工程成果物データから生成された第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶手段と、第1の下流工程成果物データから修正された第2の下流工程成果物データを、記憶装置に記憶する修正データ記憶手段と、第1の下流工程成果物データと第2の下流工程成果物データとを比較して、第1の下流工程成果物データと第2の下流工程成果物データとの差分を差分適用データとして出力し、差分適用データを記憶装置に記憶する差分抽出手段と、第1の上流工程成果物データが修正され第2の上流工程成果物データが生成されると、変換ルールデータ及び差分適用データとに基づいて第2の上流工程成果物データから第3の下流工程成果物データを生成する差分適用手段とをコンピュータに実現させる
本発明の第4の特徴は、上流工程成果物データから下流工程成果物データを変換ルールデータに基づいて生成する変換プログラムに関する。即ち本発明の第4の特徴に係る変換プログラムは、上流工程成果物データと、第1の変換ルールデータに基づいて上流工程成果物データから生成された第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶手段と、第1の下流工程成果物データから修正された第2の下流工程成果物データを、記憶装置に記憶する修正データ記憶手段と、第1の下流工程成果物データと第2の下流工程成果物データとを比較して、第1の下流工程成果物データと第2の下流工程成果物データとの差分を差分適用データとして出力し、差分適用データを記憶装置に記憶する差分抽出手段と、第1の変換ルールデータが修正され第2の変換ルールデータが生成されると、第2の変換ルールデータ及び差分適用データとに基づいて上流工程成果物データから第3の下流工程成果物データを生成する差分適用手段とをコンピュータに実現させる。
A third feature of the present invention relates to a conversion program that generates downstream process product data from upstream process product data based on conversion rule data. In other words, the conversion program according to the third feature of the present invention is the first upstream process product data and the first downstream process product data generated from the first upstream process product data based on the conversion rule data. Are stored in the storage device, the second downstream process product data corrected from the first downstream process product data is stored in the storage device, and the first downstream process. The product data and the second downstream process product data are compared, the difference between the first downstream process product data and the second downstream process product data is output as difference application data, and the difference application data is When the difference extraction means stored in the storage device and the first upstream process product data are corrected and the second upstream process product data are generated, the second upstream is based on the conversion rule data and the difference application data. The fourth feature of the present invention is that the difference application means for generating the third downstream process product data from the process product data is realized in the computer. The fourth feature of the present invention is that the downstream process product data is converted into the conversion rule data from the upstream process product data. The present invention relates to a conversion program generated based on the above. That is, the conversion program according to the fourth aspect of the present invention stores upstream process product data and first downstream process product data generated from the upstream process product data based on the first conversion rule data. Repository storage means for storing in the device, modified data storage means for storing in the storage device the second downstream process product data corrected from the first downstream process product data, and first downstream process product data Is compared with the second downstream process product data, the difference between the first downstream process product data and the second downstream process product data is output as difference application data, and the difference application data is stored in the storage device. When the difference extraction means to be stored and the first conversion rule data are corrected and the second conversion rule data are generated, the upstream process product data is based on the second conversion rule data and the difference application data. From realizing the difference application means for generating a third downstream process artifact data to the computer.
本発明の第5の特徴は、上流工程成果物データから下流工程成果物データを変換ルールデータに基づいて生成する変換方法に関する。即ち本発明の第5の特徴に係る変換プログラムは、第1の上流工程成果物データと、変換ルールデータに基づいて第1の上流工程成果物データから生成された第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶ステップと、第1の下流工程成果物データから修正された第2の下流工程成果物データを、記憶装置に記憶する修正データ記憶ステップと、第1の下流工程成果物データと第2の下流工程成果物データとを比較して、第1の下流工程成果物データと第2の下流工程成果物データとの差分を差分適用データとして出力し、差分適用データを記憶装置に記憶する差分抽出ステップと、第1の上流工程成果物データが修正され第2の上流工程成果物データが生成されると、変換ルールデータ及び差分適用データとに基づいて第2の上流工程成果物データから第3の下流工程成果物データを生成する差分適用ステップとを備える。 A fifth feature of the present invention relates to a conversion method for generating downstream process product data from upstream process product data based on conversion rule data. In other words, the conversion program according to the fifth feature of the present invention is the first upstream process product data and the first downstream process product data generated from the first upstream process product data based on the conversion rule data. Is stored in the storage device, the second downstream process product data corrected from the first downstream process product data is stored in the storage device, and the first downstream process is stored in the storage device. The product data and the second downstream process product data are compared, the difference between the first downstream process product data and the second downstream process product data is output as difference application data, and the difference application data is When the difference extraction step stored in the storage device and the first upstream process product data are corrected to generate the second upstream process product data, the conversion rule data and the difference application data are used. And a difference application step of generating a third downstream process artifacts data from the second upstream process product data.
本発明の第6の特徴は、上流工程成果物データから下流工程成果物データを変換ルールデータに基づいて生成する変換方法に関する。即ち本発明の第6の特徴に係る変換方法は、上流工程成果物データと、第1の変換ルールデータに基づいて上流工程成果物データから生成された第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶ステップと、第1の下流工程成果物データから修正された第2の下流工程成果物データを、記憶装置に記憶する修正データ記憶ステップと、第1の下流工程成果物データと第2の下流工程成果物データとを比較して、第1の下流工程成果物データと第2の下流工程成果物データとの差分を差分適用データとして出力し、差分適用データを記憶装置に記憶する差分抽出ステップと、第1の変換ルールデータが修正され第2の変換ルールデータが生成されると、第2の変換ルールデータ及び差分適用データとに基づいて上流工程成果物データから第3の下流工程成果物データを生成する差分適用ステップとを備える。 A sixth feature of the present invention relates to a conversion method for generating downstream process product data from upstream process product data based on conversion rule data. That is, the conversion method according to the sixth aspect of the present invention stores upstream process product data and first downstream process product data generated from the upstream process product data based on the first conversion rule data. A repository storing step for storing in the device; a modified data storing step for storing in the storage device second downstream process product data modified from the first downstream process product data; and first downstream process product data Is compared with the second downstream process product data, the difference between the first downstream process product data and the second downstream process product data is output as difference application data, and the difference application data is stored in the storage device. When the difference extraction step to be stored and the first conversion rule data are corrected to generate the second conversion rule data, the upstream process result is based on the second conversion rule data and the difference application data. And a difference application step of generating a third downstream process artifacts data from the data.
本発明によれば、上流の成果物と下流の成果物との間で、容易に整合性の取れる変換装置、変換プログラム及び変換方法を提供することができる。 According to the present invention, it is possible to provide a conversion device, a conversion program, and a conversion method that can easily achieve consistency between an upstream product and a downstream product.
次に、図面を参照して、本発明の実施の形態を説明する。以下の図面の記載において、同一又は類似の部分には同一又は類似の符号を付している。 Next, embodiments of the present invention will be described with reference to the drawings. In the following description of the drawings, the same or similar parts are denoted by the same or similar reference numerals.
「PIM」とは、Platform Independent Modelの略で、CPU、OS、ミドルウェア、開発言語などのシステム実装環境であるプラットフォームに依存しないモデルで表された設計データある。PIMは、システム開発者によって開発又は保守される。本発明の最良の実施の形態においては、複数の要素が木構造で記述される文書データであって、上流工程成果物データの一例として、PIMを用いて説明している。 “PIM” is an abbreviation for Platform Independent Model, which is design data represented by a platform-independent model, which is a system implementation environment such as a CPU, OS, middleware, and development language. A PIM is developed or maintained by a system developer. In the best mode of the present invention, document data in which a plurality of elements are described in a tree structure is described using PIM as an example of upstream process product data.
「PSM」とは、Platform Specific Modelの略で、実際に開発対象となるプラットフォームに対応した(プラットフォームの開発言語と1対1に対応した)モデルで表された設計データである。PSMは、システム開発者によって開発又は保守される。本発明の最良の実施の形態においては、複数の要素が木構造で記述される文書データであって、上流工程成果物データから変換ルールで変換される下流工程成果物データの一例として、PIMを用いて説明している。 “PSM” is an abbreviation of Platform Specific Model, and is design data represented by a model corresponding to the platform that is actually the development target (corresponding to the development language of the platform on a one-to-one basis). The PSM is developed or maintained by a system developer. In the best mode of the present invention, PIM is used as an example of downstream process product data that is document data in which a plurality of elements are described in a tree structure and is converted from upstream process product data by a conversion rule. It explains using.
「XMI」とは、XML Metadata Interchangeの略で、分析・設計フェーズで作成したUMLモデルを含むメタデータを交換するストリームフォーマットである。UMLとXML間の双方向の変換に利用する。 “XMI” is an abbreviation for XML Metadata Interchange, and is a stream format for exchanging metadata including UML models created in the analysis / design phase. Used for bidirectional conversion between UML and XML.
「UML」とは、Unified Modeling Languageの略で、オブジェクト指向のソフトウェア開発における、プログラム設計図の統一表記法である。本発明の最良の実施の形態において、PSMデータ及びPIMデータは、UMLのクラス図の形式で記述されている。このUMLのクラス図においては、要素であるクラスを表す四角形、それらの関係を示す結線などで構成される。このクラスを表す四角形には、ステレオタイプ、クラス名、属性、メソッドが表示される。クラスの関係を示す結線は、その関係に応じて複数種の形状を備える。 “UML” is an abbreviation for Unified Modeling Language, which is a unified notation for program design drawings in object-oriented software development. In the preferred embodiment of the present invention, PSM data and PIM data are described in the form of a UML class diagram. In this UML class diagram, the UML class diagram is composed of a quadrangle representing a class as an element, a connection indicating their relationship, and the like. A stereotype, a class name, an attribute, and a method are displayed in a rectangle representing the class. Connections indicating class relationships have a plurality of shapes according to the relationship.
「変換ルール」とは、上流工程成果物データから下流工程成果物データに変換するためのルールデータである。 The “conversion rule” is rule data for converting from upstream process product data to downstream process product data.
「リポジトリ」とは、複数の開発者が参加するシステム開発環境においてソースコードや仕様に関する情報がまとめて保管されているデータである。本発明の最良の実施の形態では、具体的には、図7のことである。 “Repository” is data in which information related to source codes and specifications is stored together in a system development environment in which a plurality of developers participate. Specifically, in the best mode of the present invention, FIG.
(最良の実施の形態の概要)
本発明の最良の実施の形態では、モデルデータの差分を抽出し、不整合なくマージする機能(部分的ラウンドトリップエンジニアリング)を採用している。ラウンドトリップエンジニアリングとは、システム・アーキテクチャや設計を記述する抽象モデルとコード間で双方向変換が可能な機能である。ラウンドトリップエンジニアリングでは、フォワードエンジニアリングとリバースエンジニアリングを反復して行う。ここでフォワードエンジニアリングとは、モデルデータからソースコードを生成することで、リバースエンジニアリングは、ソースコードからモデルを生成することである。
(Outline of the best embodiment)
In the best mode of the present invention, a function (partial round trip engineering) of extracting a difference between model data and merging without inconsistency is adopted. Round-trip engineering is a function that allows bidirectional conversion between an abstract model describing system architecture and design and code. In round trip engineering, forward engineering and reverse engineering are repeated. Here, forward engineering is to generate source code from model data, and reverse engineering is to generate a model from source code.
ここで本発明の最良の実施の形態において採用している部分的(パーシャル)ラウンドトリップエンジニアリングとは、反復型リバースエンジニアリングなしのラウンドトリップエンジニアリングである。部分的ラウンドトリップエンジニアリングに対し、完全ラウンドトリップエンジニアリングがある。完全ラウンドトリップエンジニアリングとは、ラウンドトリップエンジニアリングに更に反復型リバースエンジニアリングを適用した技術である。 Here, the partial (tripal) round-trip engineering employed in the best mode of the present invention is round-trip engineering without iterative reverse engineering. There is full round-trip engineering versus partial round-trip engineering. Complete round trip engineering is a technology that further applies iterative reverse engineering to round trip engineering.
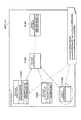
ここで、部分的ラウンドトリップエンジニアリングを、図1を参照して説明する。まずステップS1において、PIMデータ51から変換ルールに従ってモデル変換され、PSMデータ61が生成される。次に、ステップS2において、開発者等によってPSMデータ61が修正され、PSMデータ62が生成される。このとき、PSMデータ61とPSMデータ62との差分データであるPSM差分データ70が自動生成される。
The partial round trip engineering will now be described with reference to FIG. First, in step S1, model conversion is performed from the PIM data 51 according to a conversion rule, and PSM data 61 is generated. Next, in step S2, the PSM data 61 is corrected by a developer or the like, and the PSM data 62 is generated. At this time,
一方、ステップS3において、PIMデータ51に仕様変更等が発生することによって、新たなPIMデータ51’が生成される。ステップS4において、PIMデータ51’とPSM差分データ70とステップS1で用いられた変換ルールを用いてから、PSMデータ63を再生成する。
On the other hand, when a specification change or the like occurs in the PIM data 51 in step S3, new PIM data 51 'is generated. In
これにより、ステップS2における修正が反映され、PIMデータ51における仕様変更も反映されたPSMデータ63が出力される。 As a result, the correction in step S2 is reflected, and the PSM data 63 reflecting the specification change in the PIM data 51 is output.
この様に、本願発明の最良の実施の形態では、時間で変換した三世代のモデルデータ、具体的にはPSMデータ61、PSMデータ62、PSMデータ63の差分を抽出する。具体的には、PIM同士の差分とPSM同士の差分がPSMデータ63に反映される。又、本願発明の最良の実施の形態では、XMLのタグを組み合わせた意味的な情報を差分抽出する。更に、本願発明の最良の実施の形態では、差分対象としないものは、差分対象として扱わないことも可能である。 As described above, in the best mode of the present invention, three generations of model data converted by time, specifically, differences between the PSM data 61, the PSM data 62, and the PSM data 63 are extracted. Specifically, the difference between the PIMs and the difference between the PSMs are reflected in the PSM data 63. In the best mode of the present invention, a difference is extracted between semantic information obtained by combining XML tags. Furthermore, in the best mode of the present invention, it is possible not to treat a difference object as a difference object.
図2乃至図6を参照して、図1に示した各データのクラス構成を説明する。図2乃至図6は、各モデルデータについて、UMLで記述されたクラス図である。
PIMデータ51は、図2に示すようにprocess::Class1クラスC101、process::Class2クラスC102、service::Class3クラスC103及びentity::Class4クラスC104を有する。
PIMデータ51が修正されたPIMデータ51’は、図3に示すようにprocess::Class1クラスC101’、process::Class2クラスC102、service::Class3クラスC103、entity::Class4クラスC104及びprocess::NewPIMClass3C105を有する。図2に記載したPIMデータ51と比べると、PIMデータ51’process::NewPIMClass3クラスC105が追加され、process::NewPIMClass3クラスC105←service::Class3クラスC103への関連が追加され、process::Class1クラスC101’において、newPIMMethod()メソッドが追加されている点が異なる。
The class configuration of each data shown in FIG. 1 will be described with reference to FIGS. 2 to 6 are class diagrams described in UML for each model data.
As shown in FIG. 2, the PIM data 51 includes a process :: Class1 class C101, a process :: Class2 class C102, a service :: Class3 class C103, and an entity :: Class4 class C104.
As shown in FIG. 3, the PIM data 51 ′ in which the PIM data 51 is modified includes process :: Class1 class C101 ′, process :: Class2 class C102, service :: Class3 class C103, entity :: Class4 class C104, and process: : NewPIMClass3C105. Compared with the PIM data 51 described in FIG. 2, the PIM data 51′process :: NewPIMClass3 class C105 is added, the process :: NewPIMClass3 class C105 ← relation to the service :: Class3 class C103 is added, and process :: Class1 The difference is that a newPIMMethod () method is added in class C101 ′.
PIMデータ51から変換されたPSMデータ61は、図4に示すように、process::AbsClassクラスC202、process::Class1クラスC202、process::Class2クラスC203,service::Interface1クラスC204、service::Class3クラスC205及びentity::Class4クラスC206を有する。 As shown in FIG. 4, the PSM data 61 converted from the PIM data 51 includes process :: AbsClass class C202, process :: Class1 class C202, process :: Class2 class C203, service :: Interface1 class C204, service :: It has a Class3 class C205 and an entity :: Class4 class C206.
PSMデータ61から開発者によって修正されたPSMデータ62は、図5に示すように、process::AbsClassクラスC201、process::Class1クラスC202’、service::Interface1クラスC204、service::Class3クラスC205及びentity::Class4クラスC206及びaddNewClassC207を有する。図4に記載したPSMデータ61と比べると、PSMデータ62は、process::Class1クラスC203が削除されてaddNewClassクラスC207が追加され、process::AbsClassクラスC201←AddNewClassクラスC207の汎化が追加され、process::Class1クラスC202’にnewMethodB(string)メソッドが追加されている点が異なる。 As shown in FIG. 5, the PSM data 62 corrected by the developer from the PSM data 61 includes a process :: AbsClass class C201, a process :: Class1 class C202 ′, a service :: Interface1 class C204, and a service :: Class3 class C205. And entity :: Class4 class C206 and addNewClassC207. Compared to the PSM data 61 shown in FIG. 4, the PSM data 62 is obtained by deleting the process :: Class1 class C203 and adding the addNewClass class C207, and adding the generalization of the process :: AbsClass class C201 ← AddNewClass class C207. The process :: Class1 class C202 ′ is different in that a newMethodB (string) method is added.
PIMデータ51’から変換されたPSMデータ63は、図6に示すように、process::AbsClassクラスC201、process::Class1クラスC202’’、service::Interface1クラスC204、service::Class3クラスC205、entity::Class4クラスC206、addNewClassC207及びprocess::NewPIMClass3C208を有する。図4に記載したPSMデータ61と比べると、PSMデータ63は、PIMデータ51からPIMデータ51’に修正された変更点と、PSMデータ61からPSMデータ62に修正された変更点とを備える。PIMデータ51からPIMデータ51’に修正された変更点は、process::Class1クラスC202’’にnewPIMMethod()メソッドが追加され、process::NewPIMClass3クラスC208が追加され、process::AbsClassC201←process::NewPIMClass3クラスC208の汎化が追加されている点である。PSMデータ61からPSMデータ62に修正された変更点は、process::Class1クラスC203が削除されてaddNewClassクラスC207が追加され、process::AbsClassクラスC201←AddNewClassクラスC207の汎化が追加され、process::Class1クラスC202’’にnewMethodB(string)メソッドが追加されている点である。 As shown in FIG. 6, the PSM data 63 converted from the PIM data 51 ′ includes process :: AbsClass class C201, process :: Class1 class C202 ″, service :: Interface1 class C204, service :: Class3 class C205, It has entity :: Class4 class C206, addNewClassC207 and process :: NewPIMClass3C208. Compared with the PSM data 61 described in FIG. 4, the PSM data 63 includes a change point corrected from the PIM data 51 to the PIM data 51 ′ and a change point corrected from the PSM data 61 to the PSM data 62. The changes corrected from the PIM data 51 to the PIM data 51 ′ are that a newPIMMethod () method is added to the process :: Class1 class C202 ″, a process :: NewPIMClass3 class C208 is added, and process :: AbsClassC201 ← process: : NewPIMClass3 Generalization of class C208 is added. The changes from PSM data 61 to PSM data 62 are that process :: Class1 class C203 is deleted and addNewClass class C207 is added, generalization of process :: AbsClass class C201 ← AddNewClass class C207 is added, and process The newMethodB (string) method is added to the :: Class1 class C202 ″.
ここで、PIMデータ、PSMデータ及び変換ルールデータの関係を説明する。例えばオブジェクト指向のシステム開発において、リポジトリデータには、図7に示すような情報が記憶されている。図7に示すリポジトリデータにおいては、PIMメタモデルデータから変換ルールデータR1を用いて、PSMメタモデルデータが生成される。図7に示すように、変換ルールデータR1は、PIMメタモデルデータ及びPSMメタモデルデータに依存する。PIMデータ1及びPIMデータ2は、PIMメタモデルのインスタンスであり、PSMデータ1は、PSMメタモデルのインスタンスである。「メタモデル」とは、例えばPIM又はPSMを記述するためのUMLのモデル要素(クラス、属性、操作、関係など)を定義するモデルである。ここで、sourceであるPIMデータ1から、変換ルールデータR1を用いてtargetであるPSMデータ1を作成する場合、変換インスタンス1が生成されて、リポジトリデータ21に記憶される。この様に変換記録に関するリポジトリデータ21には、変換インスタンス1として、sourceとなるPIMデータの識別子(PIMデータ1)、targetとなるPSMデータの識別子(PSMデータ1)、PSMデータ1の生成時に使用された変換ルールの識別子(変換ルールデータR1)に関する情報が含まれる。
Here, the relationship among PIM data, PSM data, and conversion rule data will be described. For example, in object-oriented system development, information as shown in FIG. 7 is stored in the repository data. In the repository data shown in FIG. 7, PSM metamodel data is generated from the PIM metamodel data using the conversion rule data R1. As shown in FIG. 7, the conversion rule data R1 depends on the PIM metamodel data and the PSM metamodel data.
(変換装置)
図8に示すように、本発明の最良の実施の形態に係る変換装置1は、中央処理制御装置101、ROM(Read Only Memory)102、RAM(Random Access Memory)103及び入出力インタフェース109が、バス110を介して接続されている。入出力インタフェース109には、入力装置104、表示装置105、通信制御装置106、記憶装置107及びリムーバブルディスク108が接続されている。
(Conversion device)
As shown in FIG. 8, the
中央処理制御装置101は、入力装置104からの入力信号に基づいてROM102から変換装置1を起動するためのブートプログラムを読み出して実行し、更に記憶装置107に記憶されたオペレーティングシステムを読み出す。更に中央処理制御装置101は、入力装置104や通信制御装置106などの入力信号に基づいて、各種装置の制御を行ったり、RAM103や記憶装置107などに記憶されたプログラム及びデータを読み出してRAM103にロードするとともに、RAM103から読み出されたプログラムのコマンドに基づいて、データの計算又は加工など、後述する一連の処理を実現する処理装置である。
The central
入力装置104は、操作者が各種の操作を入力するキーボード、マウスなどの入力デバイスにより構成されており、操作者の操作に基づいて入力信号を作成し、入出力インタフェース109及びバス110を介して中央処理制御装置101に送信される。表示装置105は、CRT(Cathode Ray Tube)ディスプレイや液晶ディスプレイなどであり、中央処理制御装置101からバス110及び入出力インタフェース109を介して表示装置105において表示させる出力信号を受信し、例えば中央処理制御装置101の処理結果などを表示する装置である。通信制御装置106は、LANカードやモデムなどの装置であり、変換装置1をインターネットやLANなどの通信ネットワークに接続する装置である。通信制御装置106を介して通信ネットワークと送受信したデータは入力信号又は出力信号として、入出力インタフェース109及びバス110を介して中央処理制御装置101に送受信される。
The
記憶装置107は半導体記憶装置や磁気ディスク装置などであって、中央処理制御装置101で実行されるプログラムやデータが記憶されている。リムーバブルディスク108は、光ディスクやフレキシブルディスクのことであり、ディスクドライブによって読み書きされた信号は、入出力インタフェース109及びバス110を介して中央処理制御装置101に送受信される。
The
本発明の最良の実施の形態に係る変換装置1の記憶装置107には、図9に示すように、変換プログラムが記憶されるとともに、リポジトリデータ21、差分適用PSMデータ22、修正PSMデータ62、差分抽出データ32a、32b、差分適用データ33、差分適用データテーブル34、タグ組み合わせデータテーブル35、画面表示データ36が記憶される。修正PSMデータ62は、PSMデータ62から開発者等によって修正されたPSMデータである。又、変換プログラムが中央処理制御装置101によって実行されることにより、中央処理制御装置101に、フィルタリング手段11、差分抽出手段12、タグ組み合わせデータ生成手段13、画面表示データ生成手段14及び差分適用手段15が中央処理制御装置101に実装される。差分抽出手段12は、差分抽出データ生成手段12a、差分抽出データ比較手段12b、差分適用データ生成手段12cを備える。
As shown in FIG. 9, the
図9に示す図では、記憶装置107a及び107bの二つの記憶装置に各データが記憶されているが、一つの記憶装置に記憶されても良いし、3つ以上の記憶装置に記憶されても良い。
In the diagram shown in FIG. 9, each data is stored in the two
リポジトリデータ21には、PIMデータ(第1の上流工程成果物データ)51、修正後のPIMデータ(第2の上流工程成果物データ)51’、PSMデータ(第1の下流工程成果物データ)61、修正後のPSMデータ62(第2の下流工程成果物データ)及びPSMデータ63が記憶されている。
The
本願発明の最良の実施の形態に係る変換装置1は、PSMデータ61とPSMデータ62との差分と、修正後のPIMデータ51’から差分適用PSMデータ63’を生成する。本発明の最良の実施の形態に係る変換装置1が扱うPIMデータ及びPSMデータは、木構造で表現可能で、複数の要素で表現される文書データの一例である。
The
ここで図9の中央処理制御装置101に実装される各手段について詳述する。
Here, each means mounted on the central
フィルタリング手段11は、PSMデータ61及びPSMデータ62の各データの要素について、比較対象として扱わないデータに対してフィルタリングする手段である。これにより、本発明の最良の実施の形態に係る変換装置1は、PSMデータ61及びPSMデータ62の各要素のうち比較対象として扱う要素のみについて、後述する処理を行うことができる。このフィルタリング手段11は、例えばPSMデータの各要素のうち、所定日付以前に修正された要素など所定条件を満たす要素だけ抽出しても良い。又、フィルタリング手段11は、ユーザの操作によって選択された要素だけ抽出しても良い。
The filtering unit 11 is a unit that filters the data elements that are not handled as comparison targets with respect to the data elements of the PSM data 61 and the PSM data 62. Thereby, the
差分抽出手段12は、PSMデータ61とPSMデータ62とを比較して、PSMデータ61とPSMデータ62との差分を差分適用データ33として出力し、差分適用データ33を記憶装置107bに記憶する。差分抽出手段12は、差分抽出データ生成手段12a、差分抽出データ比較手段12b、差分適用データ生成手段12cを備える。
The
差分抽出データ生成手段12aは、PSMデータ61から第1の差分抽出データ33aを生成するとともに、PSMデータ62から第2の差分抽出データ33bを生成する。差分抽出データ生成手段12aは、第1の差分抽出データ33a及び第2の差分抽出データ33bを記憶装置107bに記憶する。詳述すると、差分抽出データ生成手段12aは、PSMデータ61の各要素について、要素の要素名、要素に関連づけられた属性名及び属性値のリスト、要素の識別子を関連づけた第1の差分抽出データ33aを生成して記憶装置107bに記憶する。更に差分抽出データ生成手段12aは、PSMデータ62の各要素について、要素の要素名、要素に関連づけられた属性名及び属性値のリスト、要素の識別子を関連づけた第2の差分抽出データ33bを生成して記憶装置107bに記憶する。ここで要素の識別子は、xmi.idである。
The difference extraction
図10(a)及び図10(b)を参照して、差分抽出データ32a及び差分抽出データ32bについて詳述する。差分抽出データ32a及び差分抽出データ32bは、各要素について、当該要素がxmi.idを有する場合は図10(a)のデータ構造を有し、当該要素がmi.idを有さない場合は図10(b)に示すデータ構造を有する。
The difference extraction data 32a and the
図10(a)に示す差分抽出データ32は、当該要素がmi.idを有する場合のデータ構造の一例である。差分抽出データ32では、各要素について、要素名、要素に関連づけられた属性の属性名リスト、属性値リスト、当該要素のxmi.id、当該要素の祖先(親要素)のxmi.id及び祖先と当該要素の距離が関連づけられている。属性名リストの属性は、属性値リストの属性値と対応する。具体的には、図11に示す要素E101の場合、差分抽出データ32には、要素名「UML:Class」に、属性名リスト「atrA」、「atrB」、「atrC」及び「xmi.id」、属性値リスト「xx」、「yy」、「zz」及び「0011」、xmi.id「0011」が関連づけられて記憶されている。更に、差分抽出データには、祖先xmi.idとしてデフォルト値の「0000」が設定され、距離としてデフォルト値の「0」が設定される。 The difference extraction data 32 shown in FIG. It is an example of the data structure in the case of having id. In the difference extraction data 32, for each element, an element name, an attribute name list of attributes associated with the element, an attribute value list, xmi. id, xmi. of the ancestor (parent element) of the element The id and ancestor are associated with the distance of the element. The attribute name list attribute corresponds to the attribute value list attribute value. Specifically, in the case of the element E101 shown in FIG. 11, the difference extraction data 32 includes the element name “UML: Class”, the attribute name lists “atrA”, “atrB”, “atrC”, and “xmi.id”. , Attribute value list “xx”, “yy”, “zz” and “0011”, xmi. id “0011” is stored in association with each other. Further, the difference extraction data includes an ancestor xmi. The default value “0000” is set as the id, and the default value “0” is set as the distance.
図10(b)に示す差分抽出データ32は、当該要素がmi.idを有さない場合のデータ構造の一例である。差分抽出データ32では、各要素について、要素名、要素に関連づけられた属性の属性名リスト、属性値リスト、当該要素の祖先のxmi.id及び祖先のxmi.id以下から葉までのパス名、祖先と当該要素の距離が関連づけられている。ここで祖先は、当該要素の親要素、親要素の親要素と、祖先を辿り、xmi.idが付与されている最初の要素のことである。又、パス名は、例えば、祖先のxmi.id以下から葉まで部分木の各要素について、その要素名を連結したものである。このパス名は、この部分木を一意に識別できればどのような形式でも良い。属性名リストの属性は、属性値リストの属性値と対応する。具体的には、図12に示す要素E111の場合、差分抽出データ32には、要素名「UML:XXX」に、属性名リスト「atrA」、「atrB」及び「atrC」、ている。更に、要素名「UML:XXX」の祖先でxmi.idが付与された要素E112のxmi.id及びこの祖先の要素E112と要素E111との距離「2」が関連づけられている。又、差分抽出データ32には、要素E112から葉までの部分木を識別するパス名「abcdefzzxxvv」が関連づけられている。 The difference extraction data 32 shown in FIG. It is an example of a data structure when it does not have id. In the difference extraction data 32, for each element, an element name, an attribute name list of attributes associated with the element, an attribute value list, xmi. id and ancestor xmi. The path name from the id to the leaf, the ancestor and the distance between the elements are associated. Here, the ancestor traces the parent element of the element, the parent element of the parent element, and the ancestor, xmi. It is the first element with id. The path name is, for example, the ancestor xmi. For each element of the subtree from id to the leaf, the element names are concatenated. This path name may have any format as long as this subtree can be uniquely identified. The attribute name list attribute corresponds to the attribute value list attribute value. Specifically, in the case of the element E111 shown in FIG. 12, the difference extraction data 32 includes the element name “UML: XXX” and the attribute name lists “atrA”, “atrB”, and “atrC”. Furthermore, the ancestor of the element name “UML: XXX” is xmi. xmi. of element E112 to which id is assigned. The id and the distance “2” between the ancestor element E112 and the element E111 are associated with each other. The difference extraction data 32 is associated with a path name “abcdefzzxxvv” that identifies the subtree from the element E112 to the leaf.
次に、図13を参照して、差分抽出データ生成手段12aによる差分抽出データ生成処理を説明する。
まず、ステップS101において、PSMデータ61又はPSMデータ62をDOMの木構造データから、ノード(要素)を一つ取得する。ステップS102において、ノードがない場合は、全てのノードについて処理されたことになるので、処理を終了する。ノードがある場合、ステップS103において、取得したノードにxmi.idがあるか否かを判定する。xmi.idがある場合、ステップS104においてノードからxmi.idを取得して差分抽出データにセットする。一方、xmi.idがない場合、ステップS105においてもっとも近い上位のxmi.idを取得して祖先のxmi.idとしてセットする。
次に、ステップS106において、当該要素の要素タグ名を要素名としてセットする。ステップS107において、当該要素に関連づけられた属性の属性名を取得して属性名リストをセットするとともに、属性の属性値を取得して属性値リストをセットする。ステップS108において、当該要素がxmi.idを持つ場合は距離「0」をセットする。当該要素にxmi.idがない場合は、xmi.idを有する上位要素と当該要素との距離をセットする。ステップS108において、当該要素がxmi.idを持つ場合は距離「0」をセットする。当該要素にxmi.idがない場合は、xmi.idを有する上位要素と当該要素との距離をセットする。ステップS109において、当該要素がxmi.idを持つ場合は祖先xmi.id「0000」をセットする。
ステップS110において、当該要素がxmi.idを持つと判断される場合、ステップS101に戻り、次のノードについて処理する。ステップS110において、当該要素がxmi.idを持たないと判断される場合、ステップS111においてノードパスを生成し、ステップS112において、ステップS111で生成されたノードパスを設定する。
Next, with reference to FIG. 13, difference extraction data generation processing by the difference extraction data generation means 12a will be described.
First, in step S101, one node (element) is acquired from the PSM data 61 or the PSM data 62 from the DOM tree structure data. In step S102, if there are no nodes, all nodes have been processed, and the process ends. If there is a node, in step S103, xmi. Determine whether there is an id. xmi. If there is an id, xmi. Get the id and set it in the difference extraction data. On the other hand, xmi. If there is no id, in step S105, the closest higher order xmi. get id to get ancestor xmi. Set as id.
Next, in step S106, the element tag name of the element is set as the element name. In step S107, the attribute name of the attribute associated with the element is acquired and the attribute name list is set, and the attribute value of the attribute is acquired and the attribute value list is set. In step S108, the element is xmi. If it has id, the distance “0” is set. Xmi. If there is no id, xmi. The distance between the upper element having id and the element is set. In step S108, the element is xmi. If it has id, the distance “0” is set. Xmi. If there is no id, xmi. The distance between the upper element having id and the element is set. In step S109, the element is xmi. ancestor xmi. Set id “0000”.
In step S110, the element is xmi. If it is determined that it has id, the process returns to step S101 to process the next node. In step S110, the element is xmi. If it is determined that it does not have an id, a node path is generated in step S111, and the node path generated in step S111 is set in step S112.
図13に示した処理を、PSMデータ61とPSMデータ62のそれぞれについて実行する。以上の処理により、差分抽出データ生成手段12aは、PSMデータ61とPSMデータ62の差分を抽出するために、各要素について、各要素を特徴付けるデータを作成することができる。 The process shown in FIG. 13 is executed for each of the PSM data 61 and the PSM data 62. Through the above processing, the difference extraction data generation means 12a can create data characterizing each element for each element in order to extract the difference between the PSM data 61 and the PSM data 62.
PSMデータ61から差分抽出データ32aが生成され、PSMデータ62から生成された差分抽出データ32bが生成されると、差分抽出データ比較手段12bによって、差分抽出データ32a及び差分抽出データ32bが比較される。
When the difference extraction data 32a is generated from the PSM data 61 and the
差分抽出データ比較手段12bは、記憶装置107bから第1の差分抽出データ33a及び第2の差分抽出データ33bを読み出して、第1の差分抽出データ33aを第2の差分抽出データ33bを比較する。
The difference extraction data comparison unit 12b reads the first difference extraction data 33a and the second difference extraction data 33b from the
より具体的には、差分抽出データ比較手段12bは、第1の差分抽出データ32aと第2の差分抽出データ32bのそれぞれについて部分木データを作成する。差分抽出データ比較手段12bは、第1の差分抽出データ32aの部分木データと第2の差分抽出データ32bの部分木データが等しい部分木データを抽出して第1の差分抽出データ32aと第2の差分抽出データ32bのそれぞれから削除する。差分抽出データ比較手段12bは、第1の差分抽出データ32aの部分木データと第2の差分抽出データ32bの部分木データが異なる部分木データに含まれる各要素について、要素名、属性名リスト及び属性値リストが等しい要素を抽出して第1の差分抽出データ32aと第2の差分抽出データ32bのそれぞれから削除する。
More specifically, the difference extraction data comparison unit 12b creates partial tree data for each of the first difference extraction data 32a and the second
例えば、図14に示す様に、PSMデータ61に関する第1の差分抽出データ32aに含まれた差分抽出データAは、PSMデータ62に関する第2の差分抽出データ32bに含まれた差分抽出データA乃至差分抽出データEのそれぞれと比較される。同様の処理をPSMデータ61の第1の抽出データ32aに含まれた差分抽出データB乃至差分抽出データEについて繰り返す。図15に示すように、PSMデータ61に関する差分抽出データCと、PSMデータ62に関する差分抽出データBが等価の場合、PSMデータ61に関する差分抽出データ32aに含まれる差分抽出データCを、差分抽出データ32aから削除するとともに、PSMデータ62に関する差分抽出データ32bに含まれる差分抽出データBを、差分抽出データ32bから削除する。
For example, as illustrated in FIG. 14, the difference extraction data A included in the first difference extraction data 32 a related to the PSM data 61 is changed from the difference extraction data A to the second
ここで図16を参照して、差分抽出データ比較手段12bによる差分抽出データ比較処理を説明する。
まず、ステップS201において、差分抽出データ32a及び差分抽出データ32bについて、一定の固まりとみなして、PSMデータ61とPSMデータ62について、それぞれ部分木データを作成する。ここで部分木データとは、複数の要素が含まれている状態で、例えばあるノードからから葉までの要素群のデータである。次に、全てのPSMデータ61の差分抽出データとPSMデータ62の差分抽出データについて、ステップS202乃至ステップS207の処理を繰り返す。
ステップS202において、ステップS201で生成されたPSMデータ61の部分木データとPSM62の部分木データを抽出する。ステップS203において、PSMデータ61の差分抽出データ32aの部分木データと、PSMデータ62の差分抽出データ32bの部分木データとが等しいか否かを検討する。ここで、部分木データが等しいとは、部分木に含まれる全ての要素について、要素名、属性名リスト、属性値リスト、xmi.id、祖先xmi.id等の差分抽出データが同一である状態である。等しい場合、ステップS204において、PSMデータ61に関する差分抽出データ32aから当該部分木データに関する差分抽出データを削除するとともに、PSMデータ62に関する差分抽出データ32bから当該部分木データに関する差分抽出データを削除する。
次に、ステップS205において、PSMデータ61に関する差分抽出データ32aの部分木データと、PSMデータ62に関する差分抽出データ32bの部分木データのそれぞれについて、要素に分解する。更に、全てのPSMデータ61に関する各要素と、PSMデータ62に関する各要素について、ステップS206及びステップS207の処理を繰り返す。
ステップS206において、PSMデータ61に関する要素とPSMデータ62に関する要素とを抽出し、PSMデータ61に関する要素とPSMデータ62に関する要素が等しいかを検討する。ここで、要素が等しいとは、要素名、属性名リスト、属性値リスト、xmi.id、祖先xmi.id等の差分抽出データが同一である状態である。等しい場合、ステップS207においてPSMデータ61に関する要素のデータを、差分抽出データ32aから削除するとともに、とPSMデータ62に関する要素のデータを、差分抽出データ32bから削除する。PSMデータ61に関する要素とPSMデータ62の要素が異なる場合は、次のPSMデータ61に関する要素とPSMデータ62の要素について比較する。
Here, with reference to FIG. 16, the difference extraction data comparison process by the difference extraction data comparison means 12b is demonstrated.
First, in step S201, the difference extraction data 32a and the
In step S202, the subtree data of the PSM data 61 and the subtree data of the PSM 62 generated in step S201 are extracted. In step S203, it is examined whether or not the subtree data of the difference extraction data 32a of the PSM data 61 is equal to the subtree data of the
Next, in step S205, each of the subtree data of the difference extraction data 32a related to the PSM data 61 and the subtree data of the
In step S206, the elements related to the PSM data 61 and the elements related to the PSM data 62 are extracted, and it is examined whether the elements related to the PSM data 61 and the elements related to the PSM data 62 are equal. Here, the elements are equal means that the element name, attribute name list, attribute value list, xmi. id, ancestor xmi. In this state, the difference extraction data such as id is the same. If equal, the element data related to the PSM data 61 is deleted from the difference extraction data 32a in step S207, and the element data related to the PSM data 62 is deleted from the
以上の処理により、差分抽出データ比較手段12bは、差分抽出データ32aと差分抽出データ32bを比較して差分を抽出する。又、部分木データの単位で比較することにより、より早く差分を抽出することができる。
Through the above processing, the difference extraction data comparison unit 12b compares the difference extraction data 32a and the
差分適用データ生成手段12cは、差分抽出データ比較手段12bによる比較結果に基づいて差分適用データ33を出力する。差分適用データ生成手段12cは、差分適用データ33を記憶装置107bに記憶する。
The difference application
差分適用データ生成手段12cは、第1の差分抽出データ32aと第2の差分抽出データ32bのそれぞれに共通する要素の識別子に関連づけられた要素の区分を変更に設定する。差分適用データ生成手段12cは、第1の差分抽出データ32aに含まれ第2の差分抽出データ32bに含まれない要素の識別子に関連づけられた要素の区分を削除に設定する。差分適用データ生成手段12cは、第2の差分抽出データ32bに含まれ第1の差分抽出データ32aに含まれない要素の識別子に関連づけられた要素の区分を削除に設定する。差分適用データ生成手段12cは、上記の処理により要素の識別子及び区分を関連づけた差分適用データ33を出力して、差分適用データ33を記憶装置107bに記憶する。
The difference application
差分適用データ33は、図17に示す様なデータ構造を備える。差分適用データ33は、xmi.id(当該要素がxmi.idを持たない場合は、パス名)、更新リスト、区分、距離、祖先xmi.idを備える。更新リストとは、更新前の属性リストと、更新後の属性リストが含まれる。区分は、当該要素について、PSMデータ61とPSMデータ62との間でどのように変化したかを示す区分であって、変更、削除、追加が記載される。距離及び祖先xmi.idは、差分抽出データ32a及び32bに設定されているデータと同様である。差分適用データは、図18に示すようなデータを備える。区分が削除の場合、更新リストにおいては、更新前属性リストのみ記載される。区分が追加の場合、更新リストにおいては更新後属性リストのみ記載される。区分が更新の場合、属性値が変更になったものだけではなく、変更されていない属性についても属性名と属性値が全て書き出される。
The
タグ組み合わせデータ生成手段13は、差分適用データ33をPSMデータ63に適用する際の組み合わせのセットを生成する手段である。タグ組み合わせデータ生成手段13は、差分適用データテーブル34及びタグ組み合わせデータテーブル35を出力する。
The tag combination
差分適用データテーブル34は、図19に示すように、差分適用データ33に記載された各要素と、当該要素を識別するアドレスを関連づけたテーブルである。タグ組み合わせデータテーブル35は、図20に示すように、同時に適用しなければならない差分適用データの組み合わせについて、差分適用データテーブル34のアドレスで表現したテーブルである。例えば、タグ組み合わせデータテーブル35のアドレス2においては、差分適用データテーブル34のアドレス4の「EEEEEEEEE」とアドレス5の「FFFFFFFFF」の各差分適用データを適用しなければならないことを示している。この様に、同時に適用しなければならない差分適用データの組み合わせを保持することにより、PSMデータ63における整合性を保つことができる。
As shown in FIG. 19, the difference application data table 34 is a table in which each element described in the
画面表示データ生成手段14は、タグ組み合わせデータテーブル35に記憶された各組み合わせについて、どのデータをPSMデータ63に適用するかをユーザに選択させるための表示画面P101を表示するためのデータを生成する手段である。表示画面P101は、図21に示すような画面である。図21には、タグ組み合わせデータテーブル35に含まれる各組み合わせについて、適用するか否かをユーザに選択させるチェックボックスが設けられている。 The screen display data generation unit 14 generates data for displaying the display screen P101 for allowing the user to select which data to apply to the PSM data 63 for each combination stored in the tag combination data table 35. Means. The display screen P101 is a screen as shown in FIG. In FIG. 21, a check box for allowing the user to select whether to apply each combination included in the tag combination data table 35 is provided.
差分適用手段15は、PIMデータ51が修正されPIMデータ51’が生成されると、変換ルールデータ及び差分適用データ33とに基づいてPIMデータ51’から差分適用PSMデータ63’を生成する。具体的には差分適用手段15は、まず、PIMデータ51’からPSMデータ63を生成して、リポジトリデータ21に記憶する。更に差分適用手段15は、リポジトリデータ21からPSMデータ63を取得して、PSMデータ63に差分適用データを適用して、差分適用PSMデータ63’を生成する。
When the PIM data 51 is corrected and the PIM data 51 ′ is generated, the
このとき差分適用手段15は、図21に示した表示画面P101において、ユーザによってチェックボックスがチェックされた組み合わせについて、タグ組み合わせデータテーブル35からアドレスを取得し、取得したアドレスをキーとして、差分適用データテーブル34から差分適用データを取得する。差分適用手段15は、取得された差分適用データに基づいて、要素を追加又は削除したり、要素の属性値を変更したりする。
At this time, the
以上、本発明の最良の実施の形態に係る変換装置は、上流工程での改良や変更を下流工程で吸収可能なパーシャルラウンドトリップが実現できる。これにより、上流工程での開発作業と下流工程での開発作業とを平行して進めることができる。更に、開発に係る工数を低減し効率的なシステム開発を実現することができる。 As described above, the conversion device according to the best embodiment of the present invention can realize a partial round trip that can absorb improvements and changes in the upstream process in the downstream process. Thereby, the development work in an upstream process and the development work in a downstream process can be advanced in parallel. Furthermore, it is possible to reduce the man-hours related to development and realize efficient system development.
又、本発明の最良の実施の形態に係る変換装置によれば、上流工程で変更が生じた際の戻り工程の排除と下流工程の変更を吸収することができるので、生産性が向上する。又、最良の実施の形態では、上流工程成果物であるPIMデータに変更が生じた場合について説明したが、上流工程成果物データから下流工程成果物データに変換する際の変換ルールデータに変更が生じた場合についても同様の処理により吸収することができる。 In addition, according to the conversion device according to the best embodiment of the present invention, it is possible to absorb the elimination of the return process and the change of the downstream process when a change occurs in the upstream process, thereby improving productivity. Further, in the best embodiment, the case where the PIM data that is the upstream process product is changed has been described. However, the conversion rule data when the upstream process product data is converted into the downstream process product data is changed. Even if it occurs, it can be absorbed by the same treatment.
更に本発明の最良の実施の形態に係る変換装置によれば、パーシャルラウンドトリップの実現によって、反復工程を実現することができる。従って、システム開発における品質を向上させることができる。 Furthermore, according to the conversion apparatus according to the preferred embodiment of the present invention, the iterative process can be realized by realizing a partial round trip. Therefore, quality in system development can be improved.
(その他の実施の形態)
上記のように、本発明の最良の実施の形態によって記載したが、この開示の一部をなす論述及び図面はこの発明を限定するものであると理解すべきではない。この開示から当業者には様々な代替実施の形態、実施例及び運用技術が明らかとなる。
(Other embodiments)
Although the present invention has been described with reference to the preferred embodiment, it should not be understood that the description and drawings constituting a part of this disclosure limit the present invention. From this disclosure, various alternative embodiments, examples, and operational techniques will be apparent to those skilled in the art.
例えば、本発明の最良の実施の形態に記載した承認支援装置は、図9に示すように一つのハードウェア上に構成されても良いし、その機能や処理数に応じて複数のハードウェア上に構成されても良い。又、既存の変換装置上に実現されても良い。 For example, the approval support apparatus described in the best embodiment of the present invention may be configured on one piece of hardware as shown in FIG. 9, or on a plurality of pieces of hardware according to the functions and the number of processes. It may be configured. Moreover, you may implement | achieve on the existing converter.
又、本発明の最良の実施の形態では、上流工程成果物データがPIMデータ、下流工程成果物データがPSMデータである場合について説明したが、他のデータについても適用可能である。 In the best embodiment of the present invention, the case where the upstream process product data is PIM data and the downstream process product data is PSM data has been described. However, the present invention can also be applied to other data.
本発明はここでは記載していない様々な実施の形態等を含むことは勿論である。従って、本発明の技術的範囲は上記の説明から妥当な特許請求の範囲に係る発明特定事項によってのみ定められるものである。 It goes without saying that the present invention includes various embodiments not described herein. Therefore, the technical scope of the present invention is defined only by the invention specifying matters according to the scope of claims reasonable from the above description.
1…変換装置
11…フィルタリング手段
12…差分抽出手段
12a…差分抽出データ生成手段
12b…差分抽出データ比較手段
12c…差分適用データ生成手段
13…タグ組み合わせデータ生成手段
14…画面表示データ生成手段
15…差分適用手段
21…リポジトリデータ
22…差分適用PSMデータ
32a、32b…差分抽出データ
33…差分適用データ
34…差分適用データテーブル
35…タグ組み合わせデータテーブル
36…画面表示データ
51、51’…PIMデータ
61、62、63…PSMデータ
101…中央処理制御装置
102…ROM
103…RAM
104…入力装置
105…表示装置
106…通信制御装置
107、107a、107b…記憶装置
108…リムーバブルディスク
109…入出力インタフェース
110…バス
DESCRIPTION OF
103 ... RAM
104 ...
Claims (8)
第1の上流工程成果物データと、前記変換ルールデータに基づいて前記第1の上流工程成果物データから生成された前記第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶手段と、
前記第1の下流工程成果物データから修正された第2の下流工程成果物データを、前記記憶装置に記憶する修正データ記憶手段と、
前記第1の下流工程成果物データと前記第2の下流工程成果物データとを比較して、前記第1の下流工程成果物データと前記第2の下流工程成果物データとの差分を差分適用データとして出力し、前記差分適用データを前記記憶装置に記憶する差分抽出手段と、
前記第1の上流工程成果物データが修正され第2の上流工程成果物データが生成されると、前記変換ルールデータ及び前記差分適用データとに基づいて前記第2の上流工程成果物データから前記第3の下流工程成果物データを生成する差分適用手段
とを備えることを特徴とする変換装置。 A conversion device that generates downstream process product data from upstream process product data based on conversion rule data,
Repository storage means for storing, in a storage device, first upstream process product data, and the first downstream process product data generated from the first upstream process product data based on the conversion rule data; ,
Modified data storage means for storing in the storage device second downstream process product data modified from the first downstream process product data;
The first downstream process product data is compared with the second downstream process product data, and the difference between the first downstream process product data and the second downstream process product data is applied as a difference. Difference extraction means for outputting as data and storing the difference application data in the storage device;
When the first upstream process product data is corrected and second upstream process product data is generated, the second upstream process product data is generated based on the conversion rule data and the difference application data. A difference applying means for generating third downstream process result data.
前記第1の下流工程成果物データから第1の差分抽出データを生成するとともに、前記第2の下流工程成果物データから第2の差分抽出データを生成して、前記第1の差分抽出データ及び前記第2の差分抽出データを前記記憶装置に記憶する差分抽出データ生成手段と、
前記記憶装置から前記第1の差分抽出データ及び前記第2の差分抽出データを読み出して、前記第1の差分抽出データを前記第2の差分抽出データを比較する差分抽出データ比較手段と、
前記差分抽出データ比較手段による比較結果に基づいて前記差分適用データを出力して、前記差分適用データを前記記憶装置に記憶する差分適用データ生成手段
とを備えることを特徴とする請求項1に記載の変換装置。 The difference extraction means includes
The first difference extraction data is generated from the first downstream process product data, and the second difference extraction data is generated from the second downstream process product data, and the first difference extraction data and Differential extraction data generating means for storing the second differential extraction data in the storage device;
Differential extraction data comparison means for reading the first differential extraction data and the second differential extraction data from the storage device, and comparing the first differential extraction data with the second differential extraction data;
The difference application data generation means for outputting the difference application data based on a comparison result by the difference extraction data comparison means and storing the difference application data in the storage device. Conversion device.
前記差分抽出データ生成手段は、前記第1の下流工程成果物データの各要素について、前記要素の要素名、前記要素に関連づけられた属性名及び属性値のリスト、前記要素の識別子を関連づけた前記第1の差分抽出データを生成するとともに、前記第2の下流工程成果物データの各要素について、前記要素の要素名、前記ノードに関連づけられた属性名及び属性値のリスト、前記要素の識別子を関連づけた前記第2の差分抽出データを生成し、
前記差分抽出データ比較手段は、前記第1の差分抽出データと前記第2の差分抽出データのそれぞれについて部分木データを作成し、前記第1の差分抽出データの部分木データと前記第2の差分抽出データの部分木データが等しい部分木データを抽出して前記第1の差分抽出データと前記第2の差分抽出データのそれぞれから削除し、前記第1の差分抽出データの部分木データと前記第2の差分抽出データの部分木データが異なる部分木データに含まれる各要素について、前記要素名、前記属性名リスト及び前記属性値リストが等しい前記要素を抽出して前記第1の差分抽出データと前記第2の差分抽出データのそれぞれから削除し、
前記差分適用データ生成手段は、前記第1の差分抽出データと前記第2の差分抽出データのそれぞれに共通する前記要素の識別子に関連づけられた要素の区分を変更に設定し、前記第1の差分抽出データに含まれ前記第2の差分抽出データに含まれない前記要素の識別子に関連づけられた要素の区分を削除に設定し、前記第2の差分抽出データに含まれ前記第1の差分抽出データに含まれない前記要素の識別子に関連づけられた要素の区分を削除に設定し、前記要素の識別子及び前記区分を関連づけた差分適用データを出力して、前記差分適用データを前記記憶装置に記憶する
ことを特徴とする請求項2に記載の変換装置。 The first and second upstream process product data and the first and second downstream process product data are document data that can be expressed in a tree structure and expressed by a plurality of elements,
The difference extraction data generation means associates, for each element of the first downstream process product data, an element name of the element, a list of attribute names and attribute values associated with the element, and an identifier of the element The first difference extraction data is generated, and for each element of the second downstream process result data, an element name of the element, a list of attribute names and attribute values associated with the node, and an identifier of the element Generating the associated second difference extraction data;
The difference extraction data comparison unit creates partial tree data for each of the first difference extraction data and the second difference extraction data, and the partial tree data of the first difference extraction data and the second difference Extract subtree data having the same subtree data of the extracted data, delete the subtree data from each of the first differential extraction data and the second differential extraction data, and extract the partial tree data of the first differential extraction data and the first differential data. For each element included in subtree data having different subtree data of two difference extraction data, the elements having the same element name, attribute name list, and attribute value list are extracted to obtain the first difference extraction data Deleting from each of the second difference extraction data;
The difference application data generation means sets the element classification associated with the element identifier common to each of the first difference extraction data and the second difference extraction data to change, and sets the first difference The element classification associated with the identifier of the element that is included in the extracted data and not included in the second difference extracted data is set to delete, and the first difference extracted data included in the second difference extracted data The element classification associated with the element identifier not included in the element is set to delete, the difference application data associated with the element identifier and the classification is output, and the difference application data is stored in the storage device The conversion device according to claim 2.
上流工程成果物データと、第1の変換ルールデータに基づいて前記上流工程成果物データから生成された前記第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶手段と、
前記第1の下流工程成果物データから修正された第2の下流工程成果物データを、前記記憶装置に記憶する修正データ記憶手段と、
前記第1の下流工程成果物データと前記第2の下流工程成果物データとを比較して、前記第1の下流工程成果物データと前記第2の下流工程成果物データとの差分を差分適用データとして出力し、前記差分適用データを前記記憶装置に記憶する差分抽出手段と、
前記第1の変換ルールデータが修正され第2の変換ルールデータが生成されると、前記第2の変換ルールデータ及び前記差分適用データとに基づいて前記上流工程成果物データから前記第3の下流工程成果物データを生成する差分適用手段
とを備えることを特徴とする変換装置。 A conversion device that generates downstream process product data from upstream process product data based on conversion rule data,
Repository storage means for storing upstream process product data and the first downstream process product data generated from the upstream process product data based on first conversion rule data in a storage device;
Modified data storage means for storing in the storage device second downstream process product data modified from the first downstream process product data;
The first downstream process product data is compared with the second downstream process product data, and the difference between the first downstream process product data and the second downstream process product data is applied as a difference. Difference extraction means for outputting as data and storing the difference application data in the storage device;
When the first conversion rule data is corrected and the second conversion rule data is generated, the third downstream from the upstream process product data based on the second conversion rule data and the difference application data. A conversion device comprising: difference application means for generating process product data.
第1の上流工程成果物データと、前記変換ルールデータに基づいて前記第1の上流工程成果物データから生成された前記第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶手段と、
前記第1の下流工程成果物データから修正された第2の下流工程成果物データを、前記記憶装置に記憶する修正データ記憶手段と、
前記第1の下流工程成果物データと前記第2の下流工程成果物データとを比較して、前記第1の下流工程成果物データと前記第2の下流工程成果物データとの差分を差分適用データとして出力し、前記差分適用データを前記記憶装置に記憶する差分抽出手段と、
前記第1の上流工程成果物データが修正され第2の上流工程成果物データが生成されると、前記変換ルールデータ及び前記差分適用データとに基づいて前記第2の上流工程成果物データから前記第3の下流工程成果物データを生成する差分適用手段
とをコンピュータに実現させることを特徴とする変換プログラム。 A conversion program for generating downstream process product data from upstream process product data based on conversion rule data,
Repository storage means for storing, in a storage device, first upstream process product data, and the first downstream process product data generated from the first upstream process product data based on the conversion rule data; ,
Modified data storage means for storing in the storage device second downstream process product data modified from the first downstream process product data;
Comparing the difference between the first downstream process product data and the second downstream process product data by comparing the first downstream process product data and the second downstream process product data Difference extraction means for outputting as data and storing the difference application data in the storage device;
When the first upstream process product data is modified and second upstream process product data is generated, the second upstream process product data is generated based on the conversion rule data and the difference application data. A conversion program for causing a computer to realize difference application means for generating third downstream process result data.
上流工程成果物データと、第1の変換ルールデータに基づいて前記上流工程成果物データから生成された前記第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶手段と、
前記第1の下流工程成果物データから修正された第2の下流工程成果物データを、前記記憶装置に記憶する修正データ記憶手段と、
前記第1の下流工程成果物データと前記第2の下流工程成果物データとを比較して、前記第1の下流工程成果物データと前記第2の下流工程成果物データとの差分を差分適用データとして出力し、前記差分適用データを前記記憶装置に記憶する差分抽出手段と、
前記第1の変換ルールデータが修正され第2の変換ルールデータが生成されると、前記第2の変換ルールデータ及び前記差分適用データとに基づいて前記上流工程成果物データから前記第3の下流工程成果物データを生成する差分適用手段
とをコンピュータに実現させることを特徴とする変換プログラム。 A conversion program for generating downstream process product data from upstream process product data based on conversion rule data,
Repository storage means for storing upstream process product data and the first downstream process product data generated from the upstream process product data based on the first conversion rule data in a storage device;
Modified data storage means for storing in the storage device second downstream process product data modified from the first downstream process product data;
The first downstream process product data is compared with the second downstream process product data, and the difference between the first downstream process product data and the second downstream process product data is applied as a difference. Difference extraction means for outputting as data and storing the difference application data in the storage device;
When the first conversion rule data is corrected and second conversion rule data is generated, the third downstream from the upstream process product data based on the second conversion rule data and the difference application data. A conversion program for causing a computer to realize difference application means for generating process product data.
第1の上流工程成果物データと、前記変換ルールデータに基づいて前記第1の上流工程成果物データから生成された前記第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶ステップと、
前記第1の下流工程成果物データから修正された第2の下流工程成果物データを、前記記憶装置に記憶する修正データ記憶ステップと、
前記第1の下流工程成果物データと前記第2の下流工程成果物データとを比較して、前記第1の下流工程成果物データと前記第2の下流工程成果物データとの差分を差分適用データとして出力し、前記差分適用データを前記記憶装置に記憶する差分抽出ステップと、
前記第1の上流工程成果物データが修正され第2の上流工程成果物データが生成されると、前記変換ルールデータ及び前記差分適用データとに基づいて前記第2の上流工程成果物データから前記第3の下流工程成果物データを生成する差分適用ステップ
とを備えることを特徴とする変換方法。 A conversion method for generating downstream process product data from upstream process product data based on conversion rule data,
A repository storage step of storing, in a storage device, first upstream process product data and the first downstream process product data generated from the first upstream process product data based on the conversion rule data; ,
A modified data storage step of storing in the storage device second downstream process product data modified from the first downstream process product data;
The first downstream process product data is compared with the second downstream process product data, and the difference between the first downstream process product data and the second downstream process product data is applied as a difference. A difference extraction step for outputting as data and storing the difference application data in the storage device;
When the first upstream process product data is corrected and second upstream process product data is generated, the second upstream process product data is generated based on the conversion rule data and the difference application data. A difference applying step of generating third downstream process result data.
上流工程成果物データと、第1の変換ルールデータに基づいて前記上流工程成果物データから生成された前記第1の下流工程成果物データとを記憶装置に記憶するリポジトリ記憶ステップと、
前記第1の下流工程成果物データから修正された第2の下流工程成果物データを、前記記憶装置に記憶する修正データ記憶ステップと、
前記第1の下流工程成果物データと前記第2の下流工程成果物データとを比較して、前記第1の下流工程成果物データと前記第2の下流工程成果物データとの差分を差分適用データとして出力し、前記差分適用データを前記記憶装置に記憶する差分抽出ステップと、
前記第1の変換ルールデータが修正され第2の変換ルールデータが生成されると、前記第2の変換ルールデータ及び前記差分適用データとに基づいて前記上流工程成果物データから前記第3の下流工程成果物データを生成する差分適用ステップ
とを備えることを特徴とする変換方法。 A conversion method for generating downstream process product data from upstream process product data based on conversion rule data,
A repository storage step of storing upstream process product data and the first downstream process product data generated from the upstream process product data based on first conversion rule data in a storage device;
A modified data storage step of storing in the storage device second downstream process product data modified from the first downstream process product data;
The first downstream process product data is compared with the second downstream process product data, and the difference between the first downstream process product data and the second downstream process product data is applied as a difference. A difference extraction step of outputting as data and storing the difference application data in the storage device;
When the first conversion rule data is corrected and the second conversion rule data is generated, the third downstream from the upstream process product data based on the second conversion rule data and the difference application data. A difference application step for generating process product data.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007063853A JP2008225898A (en) | 2007-03-13 | 2007-03-13 | Conversion device, conversion program, and conversion method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007063853A JP2008225898A (en) | 2007-03-13 | 2007-03-13 | Conversion device, conversion program, and conversion method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2008225898A true JP2008225898A (en) | 2008-09-25 |
Family
ID=39844442
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007063853A Withdrawn JP2008225898A (en) | 2007-03-13 | 2007-03-13 | Conversion device, conversion program, and conversion method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2008225898A (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010198494A (en) * | 2009-02-26 | 2010-09-09 | Panasonic Corp | Software development support tool |
| JP2011048796A (en) * | 2009-08-28 | 2011-03-10 | Fujitsu Computer Technologies Ltd | Semantic model generation program and semantic model generation device |
| WO2011052148A1 (en) * | 2009-10-30 | 2011-05-05 | 日本電気株式会社 | System model management support system, system model management support method and program |
| WO2016085213A1 (en) * | 2014-11-27 | 2016-06-02 | 주식회사 엘지씨엔에스 | Computer-executable model reverse engineering method and apparatus |
| CN107148615A (en) * | 2014-11-27 | 2017-09-08 | 乐金信世股份有限公司 | Computer executable model reverse engineering approach and device |
| JP2020057385A (en) * | 2018-09-28 | 2020-04-09 | ディスペース デジタル シグナル プロセッシング アンド コントロール エンジニアリング ゲゼルシャフト ミット ベシュレンクテル ハフツングdspace digital signal processing and control engineering GmbH | How to modify a model to create source code |
-
2007
- 2007-03-13 JP JP2007063853A patent/JP2008225898A/en not_active Withdrawn
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010198494A (en) * | 2009-02-26 | 2010-09-09 | Panasonic Corp | Software development support tool |
| JP2011048796A (en) * | 2009-08-28 | 2011-03-10 | Fujitsu Computer Technologies Ltd | Semantic model generation program and semantic model generation device |
| WO2011052148A1 (en) * | 2009-10-30 | 2011-05-05 | 日本電気株式会社 | System model management support system, system model management support method and program |
| JP5605370B2 (en) * | 2009-10-30 | 2014-10-15 | 日本電気株式会社 | System model management support system, system model management support method and program |
| WO2016085213A1 (en) * | 2014-11-27 | 2016-06-02 | 주식회사 엘지씨엔에스 | Computer-executable model reverse engineering method and apparatus |
| CN107148615A (en) * | 2014-11-27 | 2017-09-08 | 乐金信世股份有限公司 | Computer executable model reverse engineering approach and device |
| JP2020057385A (en) * | 2018-09-28 | 2020-04-09 | ディスペース デジタル シグナル プロセッシング アンド コントロール エンジニアリング ゲゼルシャフト ミット ベシュレンクテル ハフツングdspace digital signal processing and control engineering GmbH | How to modify a model to create source code |
| JP7396846B2 (en) | 2018-09-28 | 2023-12-12 | ディスペース ゲー・エム・ベー・ハー | How to change the model to create source code |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8826225B2 (en) | Model transformation unit | |
| Cicchetti et al. | A metamodel independent approach to difference representation. | |
| US9465590B2 (en) | Code generation framework for application program interface for model | |
| US7526753B2 (en) | System and method for creating, managing and using code segments | |
| JP4613214B2 (en) | Software automatic configuration device | |
| US8589877B2 (en) | Modeling and linking documents for packaged software application configuration | |
| US20090089746A1 (en) | Method and System for Generating Application Data Editors | |
| US20120266131A1 (en) | Automatic program generation device, method, and computer program | |
| CN102955697B (en) | Based on the component base construction method of AOP | |
| CN101263454A (en) | An Extensible XML Format and Object Model for Localization Data | |
| JP6479184B2 (en) | Computer-executable model reverse engineering method and apparatus | |
| US8234570B2 (en) | Harvesting assets for packaged software application configuration | |
| Durai et al. | A novel approach with an extensive case study and experiment for automatic code generation from the XMI schema Of UML models | |
| JP2008225898A (en) | Conversion device, conversion program, and conversion method | |
| CN117453713A (en) | SQL statement generation methods, equipment and storage media for multiple types of databases | |
| JPH10254689A (en) | Application configuration design support method for client / server system | |
| US7490098B2 (en) | Apparatus, system, and method for processing hierarchical data in disparate data repositories | |
| JP4724387B2 (en) | Program conversion program, program conversion apparatus, and program conversion method | |
| CN102193802A (en) | Method for converting models with model subsets of same base class structure | |
| CN100504863C (en) | The Method of Mutual Transformation Between Graph and XML Document Based on BPEL | |
| Giachetti et al. | Integration of domain-specific modelling languages and UML through UML profile extension mechanism. | |
| CN114296726B (en) | A code generation method, device, computer equipment and storage medium | |
| CN101288072A (en) | Migration and transformation of data structures | |
| JPH07129382A (en) | Spiral object-oriented software development support system and software development method | |
| Van Den Brand et al. | A generic solution for syntax-driven model co-evolution |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A300 | Application deemed to be withdrawn because no request for examination was validly filed |
Free format text: JAPANESE INTERMEDIATE CODE: A300 Effective date: 20100601 |