JP2005065191A - Movie metadata automatic creation device and movie metadata automatic creation program - Google Patents
Movie metadata automatic creation device and movie metadata automatic creation program Download PDFInfo
- Publication number
- JP2005065191A JP2005065191A JP2003296393A JP2003296393A JP2005065191A JP 2005065191 A JP2005065191 A JP 2005065191A JP 2003296393 A JP2003296393 A JP 2003296393A JP 2003296393 A JP2003296393 A JP 2003296393A JP 2005065191 A JP2005065191 A JP 2005065191A
- Authority
- JP
- Japan
- Prior art keywords
- moving image
- metadata
- data
- phrase
- speech recognition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images










Landscapes
- Television Signal Processing For Recording (AREA)
Abstract
【課題】 動画像に対して自動的にメタデータを付与する動画メタデータ自動作成装置を提供する。
【解決手段】 音声データを含む動画像データを入力する動画像入力手段と、動画像データから音声データとこの音声データが記録された動画像データ上の時間情報を抽出する音声分離手段と、動画像上の空間位置を特定する語句とメタデータとなる語句とが予め登録された音声認識用辞書と、音声認識用辞書を参照して、音声データを認識することにより、該音声データから動画像上の空間位置を特定する語句とメタデータとなる語句とを分離して抽出し、それぞれを文字データに変換する音声認識手段と、動画像上の空間位置と、メタデータとなる語句の文字データと、時間情報とを関連付けてメタデータとして記憶するメタデータ記憶手段とを備える。
【選択図】 図1
PROBLEM TO BE SOLVED: To provide a moving image metadata automatic creation device for automatically assigning metadata to a moving image.
A moving image input unit that inputs moving image data including audio data, an audio separating unit that extracts audio data from the moving image data, and time information on the moving image data in which the audio data is recorded, and a moving image A speech recognition dictionary in which a phrase for specifying a spatial position on an image and a phrase to become metadata are registered in advance, and a speech image is recognized from the speech data by referring to the speech recognition dictionary. The speech recognition means for separating and extracting the phrase that identifies the spatial position above and the phrase that serves as metadata, and converting them into character data, the spatial position on the moving image, and the character data of the phrase that serves as metadata And metadata storage means for associating and storing time information as metadata.
[Selection] Figure 1
Description
本発明は、動画像に対して自動的にメタデータを付与する動画メタデータ自動作成装置及び動画メタデータ自動作成プログラムに関する。 The present invention relates to a moving picture metadata automatic creation apparatus and a moving picture metadata automatic creation program for automatically assigning metadata to a moving image.
デジタルビデオカメラの低価格化ならびに、生活のIT化が進み、これまでの文字・写真に続き、動画像が身近な存在となってきた。撮影した動画像を検索したり、データとして後々有効活用したりするには、動画上になんらかのインデックスをつけ、それによって整理および管理することが考えられる。現状におけるインデックス付けは、自動で入る日付や時間などのデータに頼るか、動画像を再生しながら、人手を介して手動で挿入する方法が一般的である。そのため、従来は以下に示す(1)〜(5)の方法で、自動的にインデックスを付けることが試みられていた。 The price of digital video cameras and the use of IT in daily life have progressed, and moving images have become familiar, following text and photographs so far. In order to search for a captured moving image or to use it effectively as data later, it is conceivable that some kind of index is provided on the moving image to organize and manage it. In general, indexing is generally performed by relying on automatically entered data such as date and time, or by manually inserting the data while reproducing a moving image. Therefore, conventionally, attempts have been made to automatically index by the following methods (1) to (5).
(1)動画像を構成する各フレームの平均色情報を動画像の特徴情報として用いる方法(非特許文献1)。また、古くから、各フレームのヒストグラムを特徴情報として用いる方法がある。
(2)任意の動画像シーンを人間の言葉で検索させる方法(非特許文献2)。この方法は、予めオブジェクト間の位置関係や動きや変化を人間の言葉に対応付けておく。そして、この人間の言葉に対応した、位置関係や動きや変化をした動画像中のオブジェクトを半自動で切り出すことにより、任意の動画像シーンを人間の言葉で検索する。
(3)映像情報の映像情報に対応する音響情報を特徴分析してこれを音響の特徴パラメータ時系列に変換する「音響キーワードによる映像検索方法および装置」(特許文献1)。映像検索キーとなるべきキーワード音響を特徴分析してこれをキーワード音響の特徴パラメータ時系列に変換し、両者を比較することにより、音響情報に含まれる音響をキーワードとして映像情報を検索する。
(4)音声認識技術を活用して確認した映像内の音声と、その映像に関する議事録・原稿・プレゼンテーション資料などのテキストコンテンツを照合することで、議事録の文やプレゼンテーション資料のスライドごとに映像の先頭からの時間情報を付与したメタデータを自動的に作成することができる「議会映像検索システム」(非特許文献3)。
(5)音声認識してメタデータを自動作成することで、文字検索が可能となる「映像ナレッジマネジメントシステム」(非特許文献4)。
(2) A method of searching for an arbitrary moving image scene using human words (Non-Patent Document 2). In this method, the positional relationship, movement, and change between objects are associated with human language in advance. Then, an arbitrary moving image scene is searched with human words by semi-automatically extracting an object in the moving image having a positional relationship, movement or change corresponding to the human language.
(3) “Video search method and apparatus using acoustic keywords” in which acoustic information corresponding to the video information of the video information is subjected to feature analysis and converted into an acoustic feature parameter time series (Patent Document 1). The keyword sound to be the video search key is subjected to feature analysis, converted into a keyword sound feature parameter time series, and the two are compared to search for the video information using the sound included in the sound information as a keyword.
(4) By comparing the audio in the video confirmed using voice recognition technology with text content such as the minutes, manuscripts, and presentation materials related to the video, the video for each slide of the minutes and presentation materials “Parliamentary video search system” (Non-patent Document 3) that can automatically create metadata to which time information from the head of the video is added.
(5) “Video knowledge management system” (Non-Patent Document 4) that enables text search by automatically recognizing and generating metadata.
ところで、「検索する」という用途で考えると、インデックスは、検索対象となる“文字情報”と時間軸上の位置を示す“時間情報”を持っていればよく、従来技術でも十分であると言えるが、動画像の利用用途は、撮影して、そのまま見るというものだけではなく、編集し、教材などへ利用されることが多くなってきている。最近では、インデックスに、動画像の文字情報+時間情報というシンプルな情報を持つだけではなく、文字情報+時間情報+空間情報を持ったものがあり、動画上に矢印などの記号や文字をメモのように貼り付け、再生することが可能となるものもでてきた。このような装置を用いると、動画像の情報に加え、文字の情報が参照できるため、スポーツ、学問、マニュアルなどの各種教材や、業務上で有効利用が期待されている。また、一時停止やスロー再生といった再生時の制御情報を動画にオブジェクトとして組み込み、映像提供者が閲覧者により多くの情報を伝えるといった方法も実現されてきている。
しかしながら、従来の技術では、“文字情報”と“時間情報”のみの取得を念頭においたものであるため、動画の新たな使い方における空間情報を持ったインデックスやオブジェクトであるメタデータを動画像に対して自動的に挿入することはできないという問題がある。したがって、人手を介する煩雑な編集作業が必要となってしまい、作業効率が悪化するという問題もある。
By the way, considering the use of “search”, the index only needs to have “character information” to be searched and “time information” indicating the position on the time axis, and it can be said that the conventional technology is sufficient. However, moving images are used not only for taking pictures and watching them as they are, but also for editing and using them for teaching materials. Recently, there are indexes that have not only simple information such as moving image character information + time information but also character information + time information + space information. Some of them can be pasted and played back. When such an apparatus is used, information on characters can be referred to in addition to information on moving images, so that it is expected to be used effectively in various teaching materials such as sports, academics, manuals, and business. In addition, a method has been realized in which control information at the time of playback such as pause or slow playback is incorporated as an object in a moving image, and a video provider conveys more information to a viewer.
However, in the conventional technology, since only “text information” and “time information” are acquired in mind, the index or object metadata with spatial information in the new usage of moving images is used as a moving image. However, there is a problem that it cannot be automatically inserted. Therefore, a complicated editing work with manual intervention is required, and there is a problem that work efficiency deteriorates.
本発明は、このような事情に鑑みてなされたもので、動画像に対して自動的にメタデータを付与することができる動画メタデータ自動作成装置及び動画メタデータ自動作成プログラムを提供することを目的とする。 The present invention has been made in view of such circumstances, and provides a moving picture metadata automatic creation apparatus and a moving picture metadata automatic creation program capable of automatically assigning metadata to a moving image. Objective.
請求項1に記載の発明は、音声データを含む動画像データを入力する動画像入力手段と、前記動画像データから音声データとこの音声データが記録された動画像データ上の時間情報を抽出する音声分離手段と、動画像上の空間位置を特定する語句とメタデータとなる語句とが予め登録された音声認識用辞書と、前記音声認識用辞書を参照して、前記音声データを認識することにより、該音声データから動画像上の空間位置を特定する語句とメタデータとなる語句とを分離して抽出し、それぞれを文字データに変換する音声認識手段と、前記動画像上の空間位置と、前記メタデータとなる語句の文字データと、前記時間情報とを関連付けてメタデータとして記憶するメタデータ記憶手段とを備えたことを特徴とする。 According to the first aspect of the present invention, moving image input means for inputting moving image data including audio data, audio data and time information on the moving image data recorded with the audio data are extracted from the moving image data. Recognizing the speech data by referring to the speech separation means, a speech recognition dictionary in which a phrase specifying a spatial position on a moving image and a phrase to be metadata are registered in advance, and the speech recognition dictionary Thus, a speech recognition means for separating and extracting a phrase for specifying a spatial position on a moving image and a phrase to be metadata from the speech data, and converting each of them into character data, and a spatial position on the moving image And a metadata storage means for associating and storing the character data of the word to be the metadata and the time information as metadata.
請求項2に記載の発明は、前記動画像上の空間位置の特定は、前記動画像上の空間位置を特定する語句と画面上の位置データが予め定義された位置変換テーブルを参照することにより行うことを特徴とする。 According to the second aspect of the present invention, the spatial position on the moving image is identified by referring to a position conversion table in which words and phrases specifying the spatial position on the moving image and position data on the screen are defined in advance. It is characterized by performing.
請求項3に記載の発明は、前記位置変換テーブルを画面上の分割数の指定により作成し、前記音声認識用辞書に登録する手段をさらに備えたことを特徴とする。
The invention according to
請求項4に記載の発明は、前記位置変換テーブルは、前記動画像データを画像認識することにより得られた認識結果に基づいて作成することを特徴とする。
The invention according to
請求項5に記載の発明は、前記メタデータ記憶手段は、前記メタデータを文字データファイルとして記憶することを特徴とする。
The invention according to
請求項6に記載の発明は、音声データを含む動画像データを入力する動画像入力手段と、前記動画像データから音声データとこの音声データが記録された動画像データ上の時間情報を抽出する音声分離手段と、動画像の再生を制御する語句が予め登録された音声認識用辞書と、前記音声認識用辞書を参照して、前記音声データを認識することにより、該音声データから動画像の再生を制御する語句を抽出し、文字データに変換する音声認識手段と、前記動画像の再生を制御する文字データと、前記時間情報とを関連付けてメタデータとして記憶するメタデータ記憶手段とを備えたことを特徴とする。 According to the sixth aspect of the present invention, moving image input means for inputting moving image data including audio data, audio data and time information on the moving image data recorded with the audio data are extracted from the moving image data. Referencing the speech data by referring to the speech separation means, the speech recognition dictionary in which words and phrases for controlling the playback of the motion image are registered in advance, and the speech recognition dictionary, the motion data can be extracted from the speech data. Voice recognition means for extracting a phrase for controlling reproduction and converting it into character data, character data for controlling reproduction of the moving image, and metadata storage means for associating and storing the time information as metadata. It is characterized by that.
請求項7に記載の発明は、音声データを含む動画像データを入力する動画像入力処理と、前記動画像データから音声データとこの音声データが記録された動画像データ上の時間情報を抽出する音声分離処理と、動画像上の空間位置を特定する語句とメタデータとなる語句とが予め登録された音声認識用辞書と、前記音声認識用辞書を参照して、前記音声データを認識することにより、該音声データから動画像上の空間位置を特定する語句とメタデータとなる語句とを分離して抽出し、それぞれを文字データに変換する音声認識処理と、前記動画像上の空間位置と、前記メタデータとなる語句の文字データと、前記時間情報とを関連付けてメタデータとして記憶するメタデータ記憶処理とをコンピュータに行わせることを特徴とする。
The invention according to
請求項8に記載の発明は、音声データを含む動画像データを入力する動画像入力処理と、前記動画像データから音声データとこの音声データが記録された動画像データ上の時間情報を抽出する音声分離処理と、動画像の再生を制御する語句が予め登録された音声認識用辞書と、前記音声認識用辞書を参照して、前記音声データを認識することにより、該音声データから動画像の再生を制御する語句を抽出し、文字データに変換する音声認識処理と、前記動画像の再生を制御する文字データと、前記時間情報とを関連付けてメタデータとして記憶するメタデータ記憶処理とをコンピュータに行わせることを特徴とする。 According to an eighth aspect of the present invention, moving image input processing for inputting moving image data including audio data, audio data and time information on the moving image data recorded with the audio data are extracted from the moving image data. By referring to the voice recognition dictionary in which words and phrases for controlling playback of the moving image are registered in advance, and the voice recognition dictionary, the voice data is recognized, thereby moving the moving image from the voice data. A computer recognizes a speech recognition process that extracts a phrase that controls reproduction and converts it into character data, a character data that controls reproduction of the moving image, and a metadata storage process that associates and stores the time information as metadata. It is made to carry out.
本発明によれば、指定した時間及び画面上で指定した位置にメモなどの文字やマーキングなどを付与することができる。例えば、撮影中に「左上」などの言葉を発話すると、動画像の時間的該当位置の空間的該当位置にインデックスを付与することができるという効果が得られる。また、指定した時間に一時停止やスロー再生といった再生の制御を実行するオブジェクトを付与することができる。したがって、メタデータを自動生成することで、従来は編集作業として撮影後に手動で行っていた作業を、撮影中にすることができ、作業効率を向上させることができる。また、画像再生時に文字やマークの表示や動画の制御が自動で行われる動画を作成できるため、撮影側が閲覧側により多くの情報を与えることができる。また、動画像上の空間(位置)情報及び動画像上の時間軸とメタデータを関連付けるようにしたため、指定した空間位置にインデックス等を付与することができるとともに、動画像の検索等が可能となり、必要なデータ(動画位置)に迅速にアクセスすることができる。また、画面上の分割数を設定することで、位置を変換するテーブルを自動作成でき、辞書に反映できるため、空間位置の単語列を辞書に登録する手間を省くことができる。さらに、文字データファイル(例えば報告書など)を自動的に動画像とリンクさせて作成することができるため、動画像の整理・管理が容易になるという効果が得られる。 According to the present invention, characters such as memos, markings, and the like can be given at a designated time and a designated position on the screen. For example, when a word such as “upper left” is spoken during shooting, an effect is obtained that an index can be assigned to a spatially relevant position of a temporally relevant position of a moving image. In addition, an object for executing playback control such as pause or slow playback can be given at a specified time. Therefore, by automatically generating metadata, a work that has been manually performed after photographing as a conventional editing work can be performed during photographing, and work efficiency can be improved. In addition, since a moving image in which characters and marks are displayed and moving images are automatically controlled during image reproduction can be created, the photographing side can give more information to the browsing side. In addition, since the space (position) information on the moving image and the time axis on the moving image are associated with the metadata, an index can be added to the designated spatial position, and the search of the moving image can be performed. The necessary data (video position) can be quickly accessed. Also, by setting the number of divisions on the screen, a table for converting the position can be automatically created and reflected in the dictionary, so that it is possible to save the trouble of registering the word string at the spatial position in the dictionary. Furthermore, since a character data file (for example, a report) can be automatically linked to a moving image and created, an effect of facilitating the organization and management of moving images can be obtained.
以下、本発明の一実施形態による動画メタデータ自動作成装置を図面を参照して説明する。図1は同実施形態における動画メタデータ自動作成装置の概略構成を示すブロック図である。この図において、符号1は、メタデータ自動作成装置である。符号2は、動画像記録装置であり、動画像の記録装置として用いる、ビデオカメラやデジタルカメラ、小型パソコン、カメラ付き携帯電話などで構成される。符号12は、動画編集部であり動画像記録装置2から動画像を取り込むとともに、音声認識結果からメタデータを作成する。符号17は、辞書中の単語列と、画面上の位置と変換するための位置変換テーブルである。符号20は、動画像から音声部分を取り出す音声分離部である。符号21は、音声を認識して文字に変換するとともに、音声認識をする際に利用する認識用の辞書22を作成および管理する音声認識部である。
Hereinafter, an automatic moving image metadata creation apparatus according to an embodiment of the present invention will be described with reference to the drawings. FIG. 1 is a block diagram showing a schematic configuration of a moving image metadata automatic creation apparatus according to the embodiment. In this figure,
次に、図1を参照して、装置の動作の概略を説明する。まず、利用者は、動画像のメタデータとしたい単語列を並べ、メタデータ自動作成装置1の音声認識部21で管理する、認識用の辞書22を作成する。
Next, an outline of the operation of the apparatus will be described with reference to FIG. First, a user arranges word strings to be used as moving image metadata, and creates a
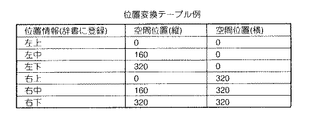
次に、利用者は、辞書22中の、画面上の位置を示す単語列(右上、左下など)を画面上の位置(ピクセルなど)に変換するための位置変換テーブル17を作成する。このテーブルは、画面を何分割するか指定することで、自動的に作成し、辞書に追加することや、画像認識装置を併用して自動的に作成するようにしてもよく、辞書22の名称と関連付けされる。
Next, the user creates a position conversion table 17 for converting a word string (upper right, lower left, etc.) indicating a position on the screen in the
次に、動画像記録装置2を用い、動画像を撮影する。このとき、辞書22に登録した単語、及び、システム側が持つ辞書に登録されている単語を撮影者が意識的に発話する。例えば、会議の記録シーンにおいて、議題とそれをインデックスとして貼り付けたい位置を発話する。また、個人のプロフィール作成シーンにおいては、名前とそれをインデックスとして貼り付けたい位置を発話する。また、再生時に自動的に一時停止をしたいシーンにおいては、「一時停止」と発話する。
Next, a moving image is photographed using the moving
次に、撮影した動画像をメタデータ自動作成装置1の動画編集部12により、取り込む。これを受けて、メタデータ自動作成装置1は、音声分離部20により、動画像から音声データのみを抽出する。そして、メタデータ自動作成装置1は、音声認識部21により、音声データを認識する。この時点で、音声認識結果を保存した文字データファイル(動画の整理用の書類など)が必要な場合は、音声認識結果を用いて作成する。
Next, the captured moving image is captured by the moving
次に、メタデータ自動作成装置1は、動画編集部12により、動画像の該当する箇所のメタデータ(インデックスやまたは動画制御用のオブジェクト)を作成し、保存用のデータベースに作成した文字データファイルやメタデータを貼付した動画像を格納する。
Next, the automatic
この動作を実施することにより、利用者は、メタデータをインデックスやオブジェクトとして貼った動画像や、自動生成された文字データファイルを閲覧できるようになる。 By performing this operation, the user can browse a moving image in which metadata is pasted as an index or an object, or an automatically generated character data file.
次に、図2を参照して、図1に示すメタデータ自動作成装置1の詳細な構成を説明する。この図において、図1に示す装置と同一の部分には同一の符号を付し、その説明を省略する。符号11は、動画像記録装置2との間で動画像転送を可能にする入出力インターフェイスである。符号13は、動画像記録装置2から動画像を取り込む動画像取り込み部である。符号14は、音声認識結果からインデックスおよびオブジェクトとなるメタデータ作成するメタデータ作成部である。符号15は、辞書ファイル名から、該当する位置変換テーブル17を検索するとともに、認識結果をもとにインデックスとなるメタデータを作成するインデックス作成部である。符号16は、認識結果をもとに、動画制御のためのオブジェクトとなるメタデータを作成する動画制御部である。符号18は、画面分割数によって、空間位置を表す単語列を自動的に選択し、位置変換テーブル17を作成するとともに音声認識用辞書22に空間位置を示す単語列として登録する画面分割部である。符号19は、認識用の辞書22を作成および管理する辞書管理部である。符号23は、音声認識した結果を元に、指定された様式の文字データファイルを作成する文字データファイル作成部である。符号24は、動画像などを格納するデータベースの管理や、他システムとの連携を行うファイル管理部である。符号25は、作成した動画像などを保存する保存用データベース(DB)である。符号31は、ビデオカメラや各種機器のカメラ部分から構成される映像入力部である。符号32は、内蔵マイクまたは外付けマイクで構成される音声入力部である。符号33は、映像入力部31と音声入力部32からの信号を入力をし、動画像を生成する動画像作成部である。符号3は、指定された時間の画像を認識し、位置変換テーブル17を作成する画像認識装置である。
Next, the detailed configuration of the metadata
次に、図2を参照して、動画撮影前準備(画面分割部18により、空間位置を表す単語列を自動取得する場合)の動作を説明する。まず、音声認識に利用する音声認識用辞書22を辞書管理部19によりシステム内に取り込む(図2の(A))。辞書には、位置を示す単語(「右上」、「左下」など)・インデックスの種別(「メモ」、「矢印」など)・コンテンツ(「表示させたい言葉」)・動画制御情報(「一時停止」、「スロー」)を定義する。これは、利用者が作成した辞書でも、システム側が提供する辞書でもどちらでもかまわない。
Next, with reference to FIG. 2, the operation of preparation before moving image shooting (when the word string representing the spatial position is automatically acquired by the screen dividing unit 18) will be described. First, the
続いて、利用者から画面の分割数を取得し、画面分割部18により、空間位置を表す単語列を自動的に選択し、位置変換テーブル17を作成する(図2の(B))。利用者は、画面の分割数を指定(例えば6分割)する。画面分割部18は、あらかじめ分割数に応じた単語列を有する。そして、辞書管理部19は、該当する音声認識用辞書22に空間位置を示す単語列として登録する(図2の(C))。これにより図6に示す位置変換テーブル17が作成され、音声認識用辞書22に位置情報を示す単語列が登録される(手動で辞書に登録してもよい)。
Subsequently, the number of screen divisions is acquired from the user, and a word string representing a spatial position is automatically selected by the
次に、図2、3を参照して、メタデータを自動作成(画像認識装置を利用しない場合)する動作を説明する。ここでは、画面左上に「ポイント」というメモのインデックスを画像に貼り付け、任意のタイミングで一時停止オブジェクトを付与する動作を例にして説明する。 Next, with reference to FIGS. 2 and 3, an operation for automatically creating metadata (when the image recognition apparatus is not used) will be described. Here, a description will be given by taking as an example an operation of pasting a memo index of “point” on the image at the upper left of the screen and adding a pause object at an arbitrary timing.
まず、利用者は、動画像記録装置2の映像入力部(カメラ)31と音声入力部(マイク)32からの入力を動画像作成部33で合成し、動画像を作成する(図2(1))。このとき、利用者は、インデックスをつけたいタイミングで、「左上、メモ、ポイント」と発話し、オブジェクトをつけたいタイミングで「一時停止」と発話する。
First, the user composes the input from the video input unit (camera) 31 and the audio input unit (microphone) 32 of the moving
続いて、利用者は、動画撮影後、動画像記録装置2とメタデータ自動作成装置1の各々の入出力インターフェイス11,34を接続し、動画像の転送を可能な状態にする(図2(2))。これを受けて、メタデータ自動作成装置1は、動画編集部12の動画取り込み部13により、撮影した動画像を取り込む(図2(3)、ステップS1)。
Subsequently, after shooting the moving image, the user connects the input /
次に、メタデータ自動作成装置1は、音声分離部20により、動画像から音声データのみを抽出する(図2(4)、(5)、ステップS2)。そして、音声認識部21により、あらかじめ作成されている音声認識用辞書22を基に抽出した音声データを認識(ステップS3)し、その結果として、撮影者の発話内容の文字情報を取得するとともに、音声認識時のファイルの時間情報(例えば、ファイルの先頭から何秒後か、といった時間的な位置を特定できる情報)を取得する。文字データファイル作成部により、音声認識結果を用いて、図8に示す文字データファイルを作成する(図2(6))。
Next, the metadata
次に、メタデータ自動作成装置1は、動画編集部12のメタデータ作成部14により、インデックス作成部15または、動画制御部16を呼ぶ(図2(7)、ステップS5)。どちらを呼ぶかの判断は、取得した文字情報と、辞書を照らし合わせて判断する、またはインデックス用とオブジェクト用で辞書を区別し、辞書名を取得して判断する。
Next, the metadata
次に、呼ばれたインデックス作成部15は、音声認識に用いられた辞書名をもとに、位置変換テーブル17を検索する(図2(8)、ステップS8)。そして、インデックス作成部15は、音声認識結果の文字情報をステップS8で検索した位置変換テーブル17に照らし合わせて、空間位置を確定し、図8に示すインデックスとなるメタデータを作成する(図2(9)、ステップS9、S10)。一方、呼ばれた動画制御部16は、音声認識結果の文字データをもとに、図9に示す動画制御のためのオブジェクトとなるメタデータを作成する(図2(10)、ステップS6)。 Next, the called index creating unit 15 searches the position conversion table 17 based on the dictionary name used for speech recognition (FIG. 2 (8), step S8). Then, the index creating unit 15 confirms the spatial position by comparing the character information of the speech recognition result with the position conversion table 17 searched in step S8, and creates metadata as an index shown in FIG. 8 (FIG. 2). (9), steps S9, S10). On the other hand, the called moving image control unit 16 creates metadata as an object for moving image control shown in FIG. 9 based on the character data of the voice recognition result (FIG. 2 (10), step S6).
次に、メタデータ自動作成装置1は、動画編集部12のメタデータ作成部14により、ステップS6またはS10で作成したインデックスまたはオブジェクトとなるメタデータを動画像に貼付する(図2(11)、ステップS7)。そして、ファイル管理部24は、生成したメタデータを貼付した動画像や文字データファイルを保存用データベース25へ格納する(図2(12))。
Next, in the metadata
次に、図4を参照して、画像認識装置3を利用した場合のメタデータ自動作成動作を説明する。ここでは、図3に示す動作と異なる部分についてのみ説明する。図4に示す動作は、図3に示すステップS1〜S5と同様な動作を実施する。そして、インデックス作成と判断された場合(ステップS5でYES)に、画像認識装置3は、取得した時間情報(例えば、先頭から20秒後)の時間の画像を認識し、同じタイミングで取得した文字情報(図10)をもとに、図11に示す位置変換テーブル17を作成する(ステップS8a)。そして、インデックス作成部15は、音声認識結果の文字情報を、ステップS8aで作成した位置変換テーブル17に照らし合わせて(ステップS8b)、空間位置を確定し(ステップS9a)、インデックスとなるメタデータを作成する(ステップS10)。
Next, with reference to FIG. 4, an automatic metadata creation operation when the
このように、撮影時に発話した空間的および時間的位置にインデックスやオブジェクトが貼られた動画像を閲覧することができるようになる。 In this way, it is possible to view a moving image in which indexes and objects are pasted at spatial and temporal positions spoken during shooting.
次に、図5を参照して、画面の分割数を指定する場合の動作を説明する。前述したように音声認識を用いて、撮影した動画像から空間情報を持ったメタデータを取得するには、音声認識結果(文字)をピクセルなどの画面上の空間位置を示す情報に変換する必要がある。前述の説明では、この変換は位置変換テーブル17の参照によって実現している。この位置変換テーブル17の作成方法として、画面分割と画像認識の2つを示したが、ここでは、画面分割方法について説明する。 Next, with reference to FIG. 5, the operation when the number of screen divisions is designated will be described. As described above, in order to obtain metadata with spatial information from a captured moving image using voice recognition, it is necessary to convert the voice recognition result (character) into information indicating the spatial position on the screen, such as pixels. There is. In the above description, this conversion is realized by referring to the position conversion table 17. Two methods of screen division and image recognition have been shown as methods for creating the position conversion table 17. Here, the screen division method will be described.
まず、ステップS1〜S4は、図3に示す動作と同一であるため、説明を省略し、ここでは、図3に示す動作と異なる部分のみ説明する。ここでは、例として、機器利用マニュアルビデオ作成する場面において、機器の全体像を撮影した状態から各操作ポイント(電源ボタン等)にズームインすると分割数が変更される動作を説明する。 First, since steps S1 to S4 are the same as the operations shown in FIG. 3, the description thereof will be omitted, and only the portions different from the operations shown in FIG. 3 will be described here. Here, as an example, an operation will be described in which the number of divisions is changed when zooming in on each operation point (power button, etc.) from a state in which an entire image of the device is captured in a scene where device-based manual video is created.
まず、利用者は、動画像を撮影する場合に、操作ポイントにズームインするとともに、「操作ポイント」と発話する(これにより、分割数を変更する)。そして、「右上、メモ、このボタンが電源ボタンです」というようにインデックスを貼りたい箇所とその内容を発話する。利用者は、撮影後、動画像記録装置2とメタデータ自動作成装置1を接続し、音声認識する。ここまでの動作は、前述した動作と同じである。
First, when shooting a moving image, the user zooms in on the operation point and speaks “operation point” (this changes the number of divisions). Then, utter the location and contents of the index to be pasted, such as “Upper right, memo, this button is the power button”. After shooting, the user connects the moving
次に、メタデータ自動作成装置1は、音声認識結果から画面分割数を特定し、位置変換テーブル17を選定する。画面分割数は、操作ポイントのとき、9分割、全体表示のとき、4分割というように指定がされている。メタデータ自動作成装置1は、位置変換テーブル17の変更が発生するまで、この位置変換テーブルを用いてインデックス等のメタデータを自動作成する(ステップS11〜S14)。
Next, the metadata
このように、分割数(数字)の発話、撮影対象物や動画の利用用途等の発話、カメラのズームイン・ズームアウト操作、画像認識の利用(例えば撮影する対象物によって分割数を変える場合など)など、動画像撮影中の任意のタイミングにおいてシステム側で分割数を決定することができる。 In this way, utterance of the number of divisions (numbers), utterances such as the usage of the object to be photographed and moving images, zooming in / out of the camera, use of image recognition (for example, changing the number of divisions depending on the object to be photographed) For example, the number of divisions can be determined on the system side at any timing during moving image shooting.
次に、前述したメタデータ自動作成装置1の使用例を説明する。
(a)マニュアルビデオ
機材などのマニュアルに適用することで、マニュアル本では分かりにくい場合なども動画を使うことで、より分かり易くなる。例えば、「右上のボタン」と発話するとボタン上に○印をする、注意箇所や使ってはいけない使い方などの指示、画面認識を併用し、該当位置にマークなどをすることも可能となる。
(b)ヘルプデスクの省力化
よくある質問に対して、対処方法を撮影したマークやメモをいれた画像を提供することで、質問側の満足度確保と回答側の省力化を図ることができる。
(c)授業の復習ビデオ
授業シーンを撮影しておいて、「ここが重要」、「試験に出る」という発話に対して自動的にメモを貼ることで授業後に復習することなどが可能となる。
(d)商品等紹介ビデオ
モデルルームなど、現場に行かなければ見られないものや、名所などの紹介に適用することができる。例えば、「右下がポイント」と発話すると、ドアやキッチンなどのセールスポイントにマーク、「中央 ○○岬」と名所の名前を発話するとその位置にタイトルとマークを付与することができる。
(e)家庭向けの使い方
旅行中のビデオで「画面中央がエッフェル塔」というように名所などにマークや文字を貼ることや、運動会で、「A君のゴールシーン、一時停止」というように再生時に決定的なシーンを見逃さないなど、家庭内において煩雑な編集作業をしなくてもよくなる。
(f)スポーツトレーニングなどの教材ビデオ
人間の部位にマークをつける。例えば、撮影中に「頭がうごかないように」や「ひざの角度に注意」などと発話すると、画面認識を使って「頭」や「ひざ」に○印等のマーキングや、文字をメモのようにはることができる。
Next, a usage example of the metadata
(A) Manual video By applying it to manuals such as equipment, it becomes easier to understand by using moving images even if it is difficult to understand with manual books. For example, when the user speaks the “upper right button”, it is possible to place a mark on the corresponding position by using a circle on the button, instructions such as caution points and usage that should not be used, and screen recognition.
(B) Labor-saving at the help desk By providing images with marks and memos taken of how to deal with frequently asked questions, it is possible to secure satisfaction on the question side and save labor on the answer side. .
(C) Review video of the class By taking a video of the class scene, it is possible to review after the class by automatically putting notes on the utterances of “This is important” and “Exiting the exam”. .
(D) Product introduction video This can be applied to the introduction of things such as model rooms that cannot be seen without going to the site, and famous places. For example, if you say “Points in the lower right”, you can mark sales points such as doors and kitchens, and if you say “Central Cape XX” and the name of a famous place, you can add a title and mark to that position.
(E) How to use for home Use a video while traveling, such as “Eiffel Tower is at the center of the screen”, mark or character on a famous place, or play at a sports day as “A's goal scene, pause” Sometimes it is not necessary to perform complicated editing work at home, such as not overlooking a decisive scene.
(F) Video materials for sports training, etc. Mark human parts. For example, if you say `` Do not move your head '' or `` Be careful about the angle of your knees '' during shooting, you can use screen recognition to mark your head and knees with a mark such as a circle, Can be done.
このような例に適用させることで、自動的に編集後のような映像を作成でき、編集作業を大幅に軽減できるため、動画像の利用シーンを広げること可能となる。 By applying to such an example, it is possible to automatically create a video as it is after editing and greatly reduce the editing work, so that it is possible to widen the use scene of moving images.
以上説明したように、動画像から音声を分離し、音声認識により、画面上の位置を示す単語(空間情報)およびインデックス種別とそれに伴うコンテンツを示す単語(文字情報)、または動画制御オブジェクトを示す単語(文字情報)を取得するとともに、同時に動画ファイルにおける時間軸上の位置を示す時間情報を取得し、取得した空間情報を、予め作成済みの位置変換テーブルにより、単語から画面上の空間位置(ピクセル等)に変換するようにしたため、自動的に文字情報+時間情報+空間情報を持った動画像メタデータを作成することが可能となる。 As described above, the voice is separated from the moving image, and the word (spatial information) indicating the position on the screen and the index type and the word (character information) indicating the content associated therewith or the moving image control object are shown by the voice recognition. While acquiring a word (character information) and simultaneously acquiring time information indicating a position on the time axis in the moving image file, the acquired spatial information is converted from a word to a spatial position ( Therefore, it is possible to automatically create moving image metadata having character information + time information + spatial information.
なお、図2における処理部の部を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することにより動画メタデータ自動作成処理を行ってもよい。なお、ここでいう「コンピュータシステム」とは、OSや周辺機器等のハードウェアを含むものとする。また、「コンピュータシステム」は、ホームページ提供環境(あるいは表示環境)を備えたWWWシステムも含むものとする。また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムが送信された場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリ(RAM)のように、一定時間プログラムを保持しているものも含むものとする。 The program for realizing the processing unit in FIG. 2 is recorded on a computer-readable recording medium, and the program recorded on the recording medium is read into a computer system and executed to automatically execute moving image metadata. A creation process may be performed. Here, the “computer system” includes an OS and hardware such as peripheral devices. The “computer system” includes a WWW system having a homepage providing environment (or display environment). The “computer-readable recording medium” refers to a storage device such as a flexible medium, a magneto-optical disk, a portable medium such as a ROM and a CD-ROM, and a hard disk incorporated in a computer system. Further, the “computer-readable recording medium” refers to a volatile memory (RAM) in a computer system that becomes a server or a client when a program is transmitted via a network such as the Internet or a communication line such as a telephone line. In addition, those holding programs for a certain period of time are also included.
また、上記プログラムは、このプログラムを記憶装置等に格納したコンピュータシステムから、伝送媒体を介して、あるいは、伝送媒体中の伝送波により他のコンピュータシステムに伝送されてもよい。ここで、プログラムを伝送する「伝送媒体」は、インターネット等のネットワーク(通信網)や電話回線等の通信回線(通信線)のように情報を伝送する部を有する媒体のことをいう。また、上記プログラムは、前述した部の一部を実現するためのものであっても良い。さらに、前述した部をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるもの、いわゆる差分ファイル(差分プログラム)であっても良い。 The program may be transmitted from a computer system storing the program in a storage device or the like to another computer system via a transmission medium or by a transmission wave in the transmission medium. Here, the “transmission medium” for transmitting the program refers to a medium having a section for transmitting information, such as a network (communication network) such as the Internet or a communication line (communication line) such as a telephone line. The program may be for realizing a part of the above-described unit. Furthermore, what can implement | achieve the part mentioned above in combination with the program already recorded on the computer system, and what is called a difference file (difference program) may be sufficient.
1・・・メタデータ自動作成装置
11・・・入出力インターフェイス
12・・・動画編集部
13・・・動画像取り込み部
14・・・メタデータ作成部
15・・・インデックス作成部
16・・・動画制御部
17・・・位置変換テーブル
18・・・画面分割部
19・・・辞書管理部
20・・・音声分離部
21・・・音声認識部
22・・・音声認識用辞書
23・・・文字データファイル作成部
24・・・ファイル管理部
25・・・保存用データベース
2・・・動画像記録装置
31・・・映像入力部
32・・・音声入力部
33・・・動画像作成部
34・・・入出力インターフェイス
3・・・画像認識装置
DESCRIPTION OF
Claims (8)
前記動画像データから音声データとこの音声データが記録された動画像データ上の時間情報を抽出する音声分離手段と、
動画像上の空間位置を特定する語句とメタデータとなる語句とが予め登録された音声認識用辞書と、
前記音声認識用辞書を参照して、前記音声データを認識することにより、該音声データから動画像上の空間位置を特定する語句とメタデータとなる語句とを分離して抽出し、それぞれを文字データに変換する音声認識手段と、
前記動画像上の空間位置と、前記メタデータとなる語句の文字データと、前記時間情報とを関連付けてメタデータとして記憶するメタデータ記憶手段と
を備えたことを特徴とする動画メタデータ自動作成装置。 Moving image input means for inputting moving image data including audio data;
Audio separation means for extracting audio data and time information on the video data recorded with the audio data from the video data;
A speech recognition dictionary in which a phrase specifying a spatial position on a moving image and a phrase serving as metadata are registered in advance;
By referring to the voice recognition dictionary and recognizing the voice data, a phrase specifying a spatial position on a moving image and a phrase serving as metadata are separated and extracted from the voice data. Voice recognition means for converting to data,
Automatic creation of moving image metadata, comprising: metadata storage means for associating a spatial position on the moving image, character data of a word and phrase serving as metadata, and the time information, and storing them as metadata apparatus.
前記動画像データから音声データとこの音声データが記録された動画像データ上の時間情報を抽出する音声分離手段と、
動画像の再生を制御する語句が予め登録された音声認識用辞書と、
前記音声認識用辞書を参照して、前記音声データを認識することにより、該音声データから動画像の再生を制御する語句を抽出し、文字データに変換する音声認識手段と、
前記動画像の再生を制御する文字データと、前記時間情報とを関連付けてメタデータとして記憶するメタデータ記憶手段と
を備えたことを特徴とする動画メタデータ自動作成装置。 Moving image input means for inputting moving image data including audio data;
Audio separation means for extracting audio data and time information on the video data recorded with the audio data from the video data;
A speech recognition dictionary in which words and phrases for controlling reproduction of moving images are registered in advance;
A speech recognition means for extracting the words controlling the reproduction of moving images from the speech data by referring to the speech recognition dictionary and converting the speech data into character data;
An apparatus for automatically creating moving image metadata, comprising: metadata storage means for storing character data for controlling reproduction of the moving image and the time information in association with each other.
前記動画像データから音声データとこの音声データが記録された動画像データ上の時間情報を抽出する音声分離処理と、
動画像上の空間位置を特定する語句とメタデータとなる語句とが予め登録された音声認識用辞書と、
前記音声認識用辞書を参照して、前記音声データを認識することにより、該音声データから動画像上の空間位置を特定する語句とメタデータとなる語句とを分離して抽出し、それぞれを文字データに変換する音声認識処理と、
前記動画像上の空間位置と、前記メタデータとなる語句の文字データと、前記時間情報とを関連付けてメタデータとして記憶するメタデータ記憶処理と
をコンピュータに行わせることを特徴とする動画メタデータ自動作成プログラム。 Moving image input processing for inputting moving image data including audio data;
Audio separation processing for extracting audio data and time information on the video data recorded with the audio data from the video data;
A speech recognition dictionary in which a phrase specifying a spatial position on a moving image and a phrase serving as metadata are registered in advance;
By referring to the voice recognition dictionary and recognizing the voice data, a phrase specifying a spatial position on a moving image and a phrase serving as metadata are separated and extracted from the voice data. Voice recognition processing to convert to data,
Moving image metadata, characterized by causing a computer to perform metadata storage processing for associating the spatial position on the moving image, the character data of the word and phrase serving as metadata, and the time information and storing them as metadata. Automatic creation program.
前記動画像データから音声データとこの音声データが記録された動画像データ上の時間情報を抽出する音声分離処理と、
動画像の再生を制御する語句が予め登録された音声認識用辞書と、
前記音声認識用辞書を参照して、前記音声データを認識することにより、該音声データから動画像の再生を制御する語句を抽出し、文字データに変換する音声認識処理と、
前記動画像の再生を制御する文字データと、前記時間情報とを関連付けてメタデータとして記憶するメタデータ記憶処理と
をコンピュータに行わせることを特徴とする動画メタデータ自動作成プログラム。
Moving image input processing for inputting moving image data including audio data;
Audio separation processing for extracting audio data and time information on the video data recorded with the audio data from the video data;
A speech recognition dictionary in which words and phrases for controlling reproduction of moving images are registered in advance;
A speech recognition process of referring to the speech recognition dictionary and extracting the words controlling the reproduction of moving images from the speech data by recognizing the speech data, and converting them into character data;
An automatic moving image metadata creation program that causes a computer to perform a character storage process for storing character data for controlling reproduction of the moving image and the time information as metadata in association with each other.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003296393A JP2005065191A (en) | 2003-08-20 | 2003-08-20 | Movie metadata automatic creation device and movie metadata automatic creation program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003296393A JP2005065191A (en) | 2003-08-20 | 2003-08-20 | Movie metadata automatic creation device and movie metadata automatic creation program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2005065191A true JP2005065191A (en) | 2005-03-10 |
Family
ID=34372317
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003296393A Pending JP2005065191A (en) | 2003-08-20 | 2003-08-20 | Movie metadata automatic creation device and movie metadata automatic creation program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2005065191A (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007101945A (en) * | 2005-10-05 | 2007-04-19 | Fujifilm Corp | Video data processing apparatus with audio, video data processing method with audio, and video data processing program with audio |
| GB2443027A (en) * | 2006-10-19 | 2008-04-23 | Sony Comp Entertainment Europe | Storing meta-data with recordings of dialogue to allow additional interpretations without the need for re-recording different languages |
| JP2009088644A (en) * | 2007-09-27 | 2009-04-23 | Funai Electric Co Ltd | Recording and reproducing apparatus |
| JP2020509504A (en) * | 2017-03-20 | 2020-03-26 | 深▲せん▼前海達闥雲端智能科技有限公司Cloudminds (Shenzhen) Robotics Systems Co., Ltd. | Image tagging method, apparatus, and electronic device |
| US11386658B2 (en) | 2018-04-20 | 2022-07-12 | Fujifilm Business Innovation Corp. | Information processing apparatus and non-transitory computer readable medium |
| US11606629B2 (en) | 2018-07-26 | 2023-03-14 | Fujifilm Business Innovation Corp. | Information processing apparatus and non-transitory computer readable medium storing program |
-
2003
- 2003-08-20 JP JP2003296393A patent/JP2005065191A/en active Pending
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007101945A (en) * | 2005-10-05 | 2007-04-19 | Fujifilm Corp | Video data processing apparatus with audio, video data processing method with audio, and video data processing program with audio |
| GB2443027A (en) * | 2006-10-19 | 2008-04-23 | Sony Comp Entertainment Europe | Storing meta-data with recordings of dialogue to allow additional interpretations without the need for re-recording different languages |
| GB2443027B (en) * | 2006-10-19 | 2009-04-01 | Sony Comp Entertainment Europe | Apparatus and method of audio processing |
| US8825483B2 (en) | 2006-10-19 | 2014-09-02 | Sony Computer Entertainment Europe Limited | Apparatus and method for transforming audio characteristics of an audio recording |
| JP2009088644A (en) * | 2007-09-27 | 2009-04-23 | Funai Electric Co Ltd | Recording and reproducing apparatus |
| JP2020509504A (en) * | 2017-03-20 | 2020-03-26 | 深▲せん▼前海達闥雲端智能科技有限公司Cloudminds (Shenzhen) Robotics Systems Co., Ltd. | Image tagging method, apparatus, and electronic device |
| US11321583B2 (en) | 2017-03-20 | 2022-05-03 | Cloudminds Robotics Co., Ltd. | Image annotating method and electronic device |
| US11386658B2 (en) | 2018-04-20 | 2022-07-12 | Fujifilm Business Innovation Corp. | Information processing apparatus and non-transitory computer readable medium |
| US11606629B2 (en) | 2018-07-26 | 2023-03-14 | Fujifilm Business Innovation Corp. | Information processing apparatus and non-transitory computer readable medium storing program |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8385588B2 (en) | Recording audio metadata for stored images | |
| CN110968736B (en) | Video generation method and device, electronic equipment and storage medium | |
| JP4175390B2 (en) | Information processing apparatus, information processing method, and computer program | |
| Moore et al. | Collecting, transcribing, analyzing and presenting plurilingual interactional data | |
| US9298704B2 (en) | Language translation of visual and audio input | |
| US9524282B2 (en) | Data augmentation with real-time annotations | |
| JP3895892B2 (en) | Multimedia information collection management device and storage medium storing program | |
| JP5123591B2 (en) | Idea support device, idea support system, idea support program, and idea support method | |
| US20130094697A1 (en) | Capturing, annotating, and sharing multimedia tips | |
| WO2024108981A1 (en) | Video editing method and apparatus | |
| US9525841B2 (en) | Imaging device for associating image data with shooting condition information | |
| JP4803147B2 (en) | Imaging apparatus, image generation method, and program | |
| KR101634068B1 (en) | Method and device for generating educational contents map | |
| CN101527772A (en) | Digital camera and information recording method | |
| JP2005065191A (en) | Movie metadata automatic creation device and movie metadata automatic creation program | |
| CN109376145A (en) | Establishment method, establishment device and storage medium of film and television dialogue database | |
| KR20110080712A (en) | Video retrieval method using voice recognition of mobile communication terminal and system and text conversion device of video voice | |
| JP2017021672A (en) | Search device | |
| KR101783872B1 (en) | Video Search System and Method thereof | |
| KR20230008687A (en) | Method and apparatus for automatic picture labeling and recording in smartphone | |
| US20140297678A1 (en) | Method for searching and sorting digital data | |
| CN111933131B (en) | Voice recognition method and device | |
| JP2002288178A (en) | Multimedia information collection management device and program | |
| KR101843135B1 (en) | Video processing method, apparatus and computer program | |
| JP2004185424A (en) | Presentation recording device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20060301 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20070615 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20070626 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20071023 |