ES2803560T3 - Polipéptidos de fusión relacionados con omega-hidroxilasa con propiedades mejoradas - Google Patents
Polipéptidos de fusión relacionados con omega-hidroxilasa con propiedades mejoradas Download PDFInfo
- Publication number
- ES2803560T3 ES2803560T3 ES15732504T ES15732504T ES2803560T3 ES 2803560 T3 ES2803560 T3 ES 2803560T3 ES 15732504 T ES15732504 T ES 15732504T ES 15732504 T ES15732504 T ES 15732504T ES 2803560 T3 ES2803560 T3 ES 2803560T3
- Authority
- ES
- Spain
- Prior art keywords
- seq
- fatty acid
- reductase
- hybrid
- cyp153a
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 229920001184 polypeptide Polymers 0.000 title claims abstract description 339
- 108090000765 processed proteins & peptides Proteins 0.000 title claims abstract description 339
- 102000004196 processed proteins & peptides Human genes 0.000 title claims abstract description 339
- 230000004927 fusion Effects 0.000 title claims abstract description 239
- 102000005297 Cytochrome P-450 CYP4A Human genes 0.000 title description 6
- 108010081498 Cytochrome P-450 CYP4A Proteins 0.000 title description 6
- 239000000194 fatty acid Substances 0.000 claims abstract description 548
- 235000014113 dietary fatty acids Nutrition 0.000 claims abstract description 542
- 229930195729 fatty acid Natural products 0.000 claims abstract description 542
- 150000004665 fatty acids Chemical class 0.000 claims abstract description 496
- 230000035772 mutation Effects 0.000 claims abstract description 80
- 238000006243 chemical reaction Methods 0.000 claims abstract description 43
- 125000003275 alpha amino acid group Chemical group 0.000 claims abstract description 31
- 239000000203 mixture Substances 0.000 claims description 132
- 229910052799 carbon Inorganic materials 0.000 claims description 78
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 claims description 76
- 230000014509 gene expression Effects 0.000 claims description 73
- 238000000034 method Methods 0.000 claims description 58
- 238000004113 cell culture Methods 0.000 claims description 45
- 150000007523 nucleic acids Chemical group 0.000 claims description 45
- 108020002982 thioesterase Proteins 0.000 claims description 35
- 102000005488 Thioesterase Human genes 0.000 claims description 33
- 108020001507 fusion proteins Proteins 0.000 claims description 31
- 102000037865 fusion proteins Human genes 0.000 claims description 31
- 244000005700 microbiome Species 0.000 claims description 29
- 229920006395 saturated elastomer Polymers 0.000 claims description 29
- POULHZVOKOAJMA-UHFFFAOYSA-N dodecanoic acid Chemical class CCCCCCCCCCCC(O)=O POULHZVOKOAJMA-UHFFFAOYSA-N 0.000 claims description 23
- 238000000855 fermentation Methods 0.000 claims description 18
- 230000004151 fermentation Effects 0.000 claims description 18
- 230000037361 pathway Effects 0.000 claims description 18
- 239000002994 raw material Substances 0.000 claims description 14
- 238000001727 in vivo Methods 0.000 claims description 10
- 238000012258 culturing Methods 0.000 claims description 5
- 229910052717 sulfur Inorganic materials 0.000 claims description 3
- 210000004027 cell Anatomy 0.000 description 298
- 108090000623 proteins and genes Proteins 0.000 description 106
- 102000040430 polynucleotide Human genes 0.000 description 85
- 108091033319 polynucleotide Proteins 0.000 description 85
- 239000002157 polynucleotide Substances 0.000 description 85
- 102000004190 Enzymes Human genes 0.000 description 61
- 108090000790 Enzymes Proteins 0.000 description 61
- 229940088598 enzyme Drugs 0.000 description 61
- 230000000694 effects Effects 0.000 description 55
- 102000004169 proteins and genes Human genes 0.000 description 51
- 229940053200 antiepileptics fatty acid derivative Drugs 0.000 description 48
- 235000018102 proteins Nutrition 0.000 description 47
- 238000004519 manufacturing process Methods 0.000 description 42
- 239000013598 vector Substances 0.000 description 42
- 235000001014 amino acid Nutrition 0.000 description 39
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 36
- 239000004474 valine Substances 0.000 description 36
- 239000004475 Arginine Substances 0.000 description 30
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 30
- 108020004414 DNA Proteins 0.000 description 29
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Natural products NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 28
- 230000015572 biosynthetic process Effects 0.000 description 28
- 241000196324 Embryophyta Species 0.000 description 26
- 235000004279 alanine Nutrition 0.000 description 26
- 230000002255 enzymatic effect Effects 0.000 description 26
- 239000013604 expression vector Substances 0.000 description 26
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 24
- 101150053185 P450 gene Proteins 0.000 description 24
- 102000039446 nucleic acids Human genes 0.000 description 24
- 108020004707 nucleic acids Proteins 0.000 description 24
- -1 primary alcohols Chemical class 0.000 description 24
- 239000000047 product Substances 0.000 description 24
- 102000004316 Oxidoreductases Human genes 0.000 description 23
- 108090000854 Oxidoreductases Proteins 0.000 description 23
- 238000002703 mutagenesis Methods 0.000 description 23
- 231100000350 mutagenesis Toxicity 0.000 description 23
- 241000588724 Escherichia coli Species 0.000 description 22
- 239000004471 Glycine Substances 0.000 description 22
- 229940024606 amino acid Drugs 0.000 description 21
- 125000003729 nucleotide group Chemical group 0.000 description 21
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 20
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 20
- 150000001413 amino acids Chemical class 0.000 description 20
- 235000009582 asparagine Nutrition 0.000 description 20
- 229960001230 asparagine Drugs 0.000 description 20
- 108091028043 Nucleic acid sequence Proteins 0.000 description 19
- CKLJMWTZIZZHCS-REOHCLBHSA-N aspartic acid group Chemical group N[C@@H](CC(=O)O)C(=O)O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 19
- 230000006870 function Effects 0.000 description 19
- 230000001965 increasing effect Effects 0.000 description 19
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 18
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 18
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 18
- 239000004473 Threonine Substances 0.000 description 18
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 17
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 17
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 17
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 17
- 239000002609 medium Substances 0.000 description 17
- 239000002773 nucleotide Substances 0.000 description 17
- 241000894006 Bacteria Species 0.000 description 16
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 16
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 16
- 101710146995 Acyl carrier protein Proteins 0.000 description 15
- 230000003197 catalytic effect Effects 0.000 description 15
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 14
- 229940009098 aspartate Drugs 0.000 description 14
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 13
- 230000001580 bacterial effect Effects 0.000 description 13
- 229930195712 glutamate Natural products 0.000 description 13
- 125000001909 leucine group Chemical group [H]N(*)C(C(*)=O)C([H])([H])C(C([H])([H])[H])C([H])([H])[H] 0.000 description 13
- 239000013612 plasmid Substances 0.000 description 13
- 125000002987 valine group Chemical group [H]N([H])C([H])(C(*)=O)C([H])(C([H])([H])[H])C([H])([H])[H] 0.000 description 13
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 12
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 12
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 12
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 12
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 12
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 12
- 239000004472 Lysine Substances 0.000 description 12
- 230000001588 bifunctional effect Effects 0.000 description 12
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 12
- 229960000310 isoleucine Drugs 0.000 description 12
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 12
- 239000000463 material Substances 0.000 description 12
- 108020004705 Codon Proteins 0.000 description 11
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 11
- 241000293869 Salmonella enterica subsp. enterica serovar Typhimurium Species 0.000 description 11
- 150000001875 compounds Chemical class 0.000 description 11
- 239000012634 fragment Substances 0.000 description 11
- 239000008103 glucose Substances 0.000 description 11
- 238000010561 standard procedure Methods 0.000 description 11
- 238000006467 substitution reaction Methods 0.000 description 11
- 235000000346 sugar Nutrition 0.000 description 11
- 238000013518 transcription Methods 0.000 description 11
- 230000035897 transcription Effects 0.000 description 11
- 239000002028 Biomass Substances 0.000 description 10
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 10
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 10
- 230000009286 beneficial effect Effects 0.000 description 10
- 230000006872 improvement Effects 0.000 description 10
- 229930182817 methionine Natural products 0.000 description 10
- 241000894007 species Species 0.000 description 10
- 239000000758 substrate Substances 0.000 description 10
- 239000002253 acid Substances 0.000 description 9
- 230000001851 biosynthetic effect Effects 0.000 description 9
- 229910002092 carbon dioxide Inorganic materials 0.000 description 9
- 101150016526 fadE gene Proteins 0.000 description 9
- 239000003550 marker Substances 0.000 description 9
- 238000000746 purification Methods 0.000 description 9
- 102200074510 rs2015352 Human genes 0.000 description 9
- 241000206597 Marinobacter hydrocarbonoclasticus Species 0.000 description 8
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 8
- 235000003704 aspartic acid Nutrition 0.000 description 8
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 8
- 150000002191 fatty alcohols Chemical class 0.000 description 8
- 239000001963 growth medium Substances 0.000 description 8
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 8
- COLNVLDHVKWLRT-QMMMGPOBSA-N phenylalanine group Chemical group N[C@@H](CC1=CC=CC=C1)C(=O)O COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 8
- 230000001105 regulatory effect Effects 0.000 description 8
- 239000000126 substance Substances 0.000 description 8
- 238000003786 synthesis reaction Methods 0.000 description 8
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 description 8
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 8
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 7
- 101710129019 Long-chain acyl-[acyl-carrier-protein] reductase Proteins 0.000 description 7
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 7
- 125000000539 amino acid group Chemical group 0.000 description 7
- 230000003247 decreasing effect Effects 0.000 description 7
- 150000002148 esters Chemical class 0.000 description 7
- 150000002194 fatty esters Chemical class 0.000 description 7
- 238000009396 hybridization Methods 0.000 description 7
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 7
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 7
- 150000002894 organic compounds Chemical class 0.000 description 7
- 230000002018 overexpression Effects 0.000 description 7
- 239000003208 petroleum Substances 0.000 description 7
- 238000012216 screening Methods 0.000 description 7
- 238000012360 testing method Methods 0.000 description 7
- 101150071111 FADD gene Proteins 0.000 description 6
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 6
- 241000187488 Mycobacterium sp. Species 0.000 description 6
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 6
- 241000187562 Rhodococcus sp. Species 0.000 description 6
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 6
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 6
- 150000001335 aliphatic alkanes Chemical class 0.000 description 6
- 230000008827 biological function Effects 0.000 description 6
- 235000010633 broth Nutrition 0.000 description 6
- 150000001720 carbohydrates Chemical class 0.000 description 6
- 235000014633 carbohydrates Nutrition 0.000 description 6
- 238000010367 cloning Methods 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 101150115959 fadR gene Proteins 0.000 description 6
- 230000002068 genetic effect Effects 0.000 description 6
- 230000001939 inductive effect Effects 0.000 description 6
- 239000000543 intermediate Substances 0.000 description 6
- 125000000741 isoleucyl group Chemical group [H]N([H])C(C(C([H])([H])[H])C([H])([H])C([H])([H])[H])C(=O)O* 0.000 description 6
- 230000000813 microbial effect Effects 0.000 description 6
- 238000007254 oxidation reaction Methods 0.000 description 6
- 230000014616 translation Effects 0.000 description 6
- 108010001058 Acyl-CoA Dehydrogenase Proteins 0.000 description 5
- 241000611270 Alcanivorax borkumensis Species 0.000 description 5
- 101100012355 Bacillus anthracis fabH1 gene Proteins 0.000 description 5
- 101100012357 Bacillus subtilis (strain 168) fabHA gene Proteins 0.000 description 5
- 102000002004 Cytochrome P-450 Enzyme System Human genes 0.000 description 5
- 102000018832 Cytochromes Human genes 0.000 description 5
- 108010052832 Cytochromes Proteins 0.000 description 5
- 102000053602 DNA Human genes 0.000 description 5
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 5
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 5
- 241000187492 Mycobacterium marinum Species 0.000 description 5
- 102000004020 Oxygenases Human genes 0.000 description 5
- 108090000417 Oxygenases Proteins 0.000 description 5
- 241001472610 Polaromonas sp. Species 0.000 description 5
- 241001135759 Sphingomonas sp. Species 0.000 description 5
- 101150070497 accC gene Proteins 0.000 description 5
- 125000000217 alkyl group Chemical group 0.000 description 5
- 230000002238 attenuated effect Effects 0.000 description 5
- SECPZKHBENQXJG-UHFFFAOYSA-N cis-palmitoleic acid Natural products CCCCCCC=CCCCCCCCC(O)=O SECPZKHBENQXJG-UHFFFAOYSA-N 0.000 description 5
- 101150090981 fabG gene Proteins 0.000 description 5
- 101150035981 fabH gene Proteins 0.000 description 5
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 5
- 235000011187 glycerol Nutrition 0.000 description 5
- 150000002430 hydrocarbons Chemical class 0.000 description 5
- 238000000338 in vitro Methods 0.000 description 5
- 230000000670 limiting effect Effects 0.000 description 5
- 101150068528 mabA gene Proteins 0.000 description 5
- 239000012925 reference material Substances 0.000 description 5
- NNNVXFKZMRGJPM-KHPPLWFESA-N sapienic acid Chemical compound CCCCCCCCC\C=C/CCCCC(O)=O NNNVXFKZMRGJPM-KHPPLWFESA-N 0.000 description 5
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 5
- 238000013519 translation Methods 0.000 description 5
- 125000000430 tryptophan group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C2=C([H])C([H])=C([H])C([H])=C12 0.000 description 5
- 235000021122 unsaturated fatty acids Nutrition 0.000 description 5
- 150000004670 unsaturated fatty acids Chemical class 0.000 description 5
- 239000002699 waste material Substances 0.000 description 5
- 241000588625 Acinetobacter sp. Species 0.000 description 4
- 102000002735 Acyl-CoA Dehydrogenase Human genes 0.000 description 4
- 241000219195 Arabidopsis thaliana Species 0.000 description 4
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 4
- 241000722910 Burkholderia mallei Species 0.000 description 4
- 108010078791 Carrier Proteins Proteins 0.000 description 4
- 241000010804 Caulobacter vibrioides Species 0.000 description 4
- 241000252867 Cupriavidus metallidurans Species 0.000 description 4
- 241001619535 Hyphomonas neptunium Species 0.000 description 4
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 4
- 108091034117 Oligonucleotide Proteins 0.000 description 4
- 241000930992 Paraburkholderia fungorum Species 0.000 description 4
- 241000190950 Rhodopseudomonas palustris Species 0.000 description 4
- 240000008042 Zea mays Species 0.000 description 4
- 150000001336 alkenes Chemical group 0.000 description 4
- 229940074375 burkholderia mallei Drugs 0.000 description 4
- 238000004422 calculation algorithm Methods 0.000 description 4
- 125000004432 carbon atom Chemical group C* 0.000 description 4
- 238000006473 carboxylation reaction Methods 0.000 description 4
- 238000013461 design Methods 0.000 description 4
- FVTCRASFADXXNN-SCRDCRAPSA-N flavin mononucleotide Chemical compound OP(=O)(O)OC[C@@H](O)[C@@H](O)[C@@H](O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O FVTCRASFADXXNN-SCRDCRAPSA-N 0.000 description 4
- 229940013640 flavin mononucleotide Drugs 0.000 description 4
- FVTCRASFADXXNN-UHFFFAOYSA-N flavin mononucleotide Natural products OP(=O)(O)OCC(O)C(O)C(O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O FVTCRASFADXXNN-UHFFFAOYSA-N 0.000 description 4
- 239000011768 flavin mononucleotide Substances 0.000 description 4
- 230000012010 growth Effects 0.000 description 4
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 230000000155 isotopic effect Effects 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 230000004048 modification Effects 0.000 description 4
- 238000005457 optimization Methods 0.000 description 4
- 230000036961 partial effect Effects 0.000 description 4
- 230000000243 photosynthetic effect Effects 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 235000019231 riboflavin-5'-phosphate Nutrition 0.000 description 4
- 238000000926 separation method Methods 0.000 description 4
- 238000002741 site-directed mutagenesis Methods 0.000 description 4
- 150000008163 sugars Chemical class 0.000 description 4
- 230000009466 transformation Effects 0.000 description 4
- 102000000452 Acetyl-CoA carboxylase Human genes 0.000 description 3
- 108010016219 Acetyl-CoA carboxylase Proteins 0.000 description 3
- 102220557155 Alstrom syndrome protein 1_N61L_mutation Human genes 0.000 description 3
- 241000193830 Bacillus <bacterium> Species 0.000 description 3
- 108010018763 Biotin carboxylase Proteins 0.000 description 3
- 241000193401 Clostridium acetobutylicum Species 0.000 description 3
- 108091026890 Coding region Proteins 0.000 description 3
- 241000195493 Cryptophyta Species 0.000 description 3
- 108010015742 Cytochrome P-450 Enzyme System Proteins 0.000 description 3
- 102100024452 DNA-directed RNA polymerase III subunit RPC1 Human genes 0.000 description 3
- 101100390711 Escherichia coli (strain K12) fhuA gene Proteins 0.000 description 3
- 241000238631 Hexapoda Species 0.000 description 3
- 101000689002 Homo sapiens DNA-directed RNA polymerase III subunit RPC1 Proteins 0.000 description 3
- 101000937642 Homo sapiens Malonyl-CoA-acyl carrier protein transacylase, mitochondrial Proteins 0.000 description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 3
- 102100027329 Malonyl-CoA-acyl carrier protein transacylase, mitochondrial Human genes 0.000 description 3
- 241000206589 Marinobacter Species 0.000 description 3
- 241000192560 Synechococcus sp. Species 0.000 description 3
- 244000025271 Umbellularia californica Species 0.000 description 3
- 235000008674 Umbellularia californica Nutrition 0.000 description 3
- 241000607626 Vibrio cholerae Species 0.000 description 3
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 3
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 3
- 125000002252 acyl group Chemical group 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 125000003118 aryl group Chemical group 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-L aspartate group Chemical group N[C@@H](CC(=O)[O-])C(=O)[O-] CKLJMWTZIZZHCS-REOHCLBHSA-L 0.000 description 3
- 230000036983 biotransformation Effects 0.000 description 3
- 239000006227 byproduct Substances 0.000 description 3
- 102220367838 c.28G>T Human genes 0.000 description 3
- 239000001569 carbon dioxide Substances 0.000 description 3
- 238000012219 cassette mutagenesis Methods 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 230000001413 cellular effect Effects 0.000 description 3
- 230000000052 comparative effect Effects 0.000 description 3
- 235000005822 corn Nutrition 0.000 description 3
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 3
- 235000018417 cysteine Nutrition 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 230000009088 enzymatic function Effects 0.000 description 3
- 210000003527 eukaryotic cell Anatomy 0.000 description 3
- 238000000605 extraction Methods 0.000 description 3
- 101150026389 fabF gene Proteins 0.000 description 3
- 101150072202 fabV gene Proteins 0.000 description 3
- 235000019387 fatty acid methyl ester Nutrition 0.000 description 3
- 125000000524 functional group Chemical group 0.000 description 3
- 238000010353 genetic engineering Methods 0.000 description 3
- WHUUTDBJXJRKMK-VKHMYHEASA-L glutamate group Chemical group N[C@@H](CCC(=O)[O-])C(=O)[O-] WHUUTDBJXJRKMK-VKHMYHEASA-L 0.000 description 3
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 3
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 3
- 229930195733 hydrocarbon Natural products 0.000 description 3
- 238000001802 infusion Methods 0.000 description 3
- 239000007788 liquid Substances 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 108020004999 messenger RNA Proteins 0.000 description 3
- 230000037353 metabolic pathway Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 239000003348 petrochemical agent Substances 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 210000001236 prokaryotic cell Anatomy 0.000 description 3
- 238000010188 recombinant method Methods 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 102220245308 rs1555601006 Human genes 0.000 description 3
- 101150087812 tesA gene Proteins 0.000 description 3
- 230000001131 transforming effect Effects 0.000 description 3
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 3
- 239000002023 wood Substances 0.000 description 3
- 210000005253 yeast cell Anatomy 0.000 description 3
- GGQQNYXPYWCUHG-RMTFUQJTSA-N (3e,6e)-deca-3,6-diene Chemical group CCC\C=C\C\C=C\CC GGQQNYXPYWCUHG-RMTFUQJTSA-N 0.000 description 2
- ZDHCZVWCTKTBRY-UHFFFAOYSA-N 12-hydroxylauric acid Chemical compound OCCCCCCCCCCCC(O)=O ZDHCZVWCTKTBRY-UHFFFAOYSA-N 0.000 description 2
- BZUNJUAMQZRJIP-UHFFFAOYSA-N 15-hydroxypentadecanoic acid Chemical compound OCCCCCCCCCCCCCCC(O)=O BZUNJUAMQZRJIP-UHFFFAOYSA-N 0.000 description 2
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 2
- 241000122231 Acinetobacter radioresistens Species 0.000 description 2
- 108700037654 Acyl carrier protein (ACP) Proteins 0.000 description 2
- 102000048456 Acyl carrier protein (ACP) Human genes 0.000 description 2
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 2
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 2
- 241000995051 Brenda Species 0.000 description 2
- 102220524140 Cadherin-24_R27I_mutation Human genes 0.000 description 2
- 101100173127 Caldanaerobacter subterraneus subsp. tengcongensis (strain DSM 15242 / JCM 11007 / NBRC 100824 / MB4) fabZ gene Proteins 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 2
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 2
- 241000701988 Escherichia virus T5 Species 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 108010074122 Ferredoxins Proteins 0.000 description 2
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- 108010070675 Glutathione transferase Proteins 0.000 description 2
- 102000005720 Glutathione transferase Human genes 0.000 description 2
- 241000223198 Humicola Species 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- 241001465754 Metazoa Species 0.000 description 2
- VZUNGTLZRAYYDE-UHFFFAOYSA-N N-methyl-N'-nitro-N-nitrosoguanidine Chemical compound O=NN(C)C(=N)N[N+]([O-])=O VZUNGTLZRAYYDE-UHFFFAOYSA-N 0.000 description 2
- 101710198130 NADPH-cytochrome P450 reductase Proteins 0.000 description 2
- 101710192343 NADPH:adrenodoxin oxidoreductase, mitochondrial Proteins 0.000 description 2
- 102100036777 NADPH:adrenodoxin oxidoreductase, mitochondrial Human genes 0.000 description 2
- 101710104207 Probable NADPH:adrenodoxin oxidoreductase, mitochondrial Proteins 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 241000158504 Rhodococcus hoagii Species 0.000 description 2
- 240000000111 Saccharum officinarum Species 0.000 description 2
- 235000007201 Saccharum officinarum Nutrition 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 2
- 108010006785 Taq Polymerase Proteins 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- 102220517055 Transcriptional regulator PINT87aa_I11L_mutation Human genes 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- ZSLZBFCDCINBPY-ZSJPKINUSA-N acetyl-CoA Chemical compound O[C@@H]1[C@H](OP(O)(O)=O)[C@@H](COP(O)(=O)OP(O)(=O)OCC(C)(C)[C@@H](O)C(=O)NCCC(=O)NCCSC(=O)C)O[C@H]1N1C2=NC=NC(N)=C2N=C1 ZSLZBFCDCINBPY-ZSJPKINUSA-N 0.000 description 2
- 238000007792 addition Methods 0.000 description 2
- 238000001261 affinity purification Methods 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 125000003368 amide group Chemical group 0.000 description 2
- 238000007845 assembly PCR Methods 0.000 description 2
- 239000012620 biological material Substances 0.000 description 2
- OCKPCBLVNKHBMX-UHFFFAOYSA-N butylbenzene Chemical compound CCCCC1=CC=CC=C1 OCKPCBLVNKHBMX-UHFFFAOYSA-N 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 150000001721 carbon Chemical group 0.000 description 2
- 239000001913 cellulose Substances 0.000 description 2
- 229920002678 cellulose Polymers 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 239000000356 contaminant Substances 0.000 description 2
- 238000011109 contamination Methods 0.000 description 2
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 230000000593 degrading effect Effects 0.000 description 2
- VILAVOFMIJHSJA-UHFFFAOYSA-N dicarbon monoxide Chemical group [C]=C=O VILAVOFMIJHSJA-UHFFFAOYSA-N 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 230000009483 enzymatic pathway Effects 0.000 description 2
- 101150078207 fabA gene Proteins 0.000 description 2
- 230000004129 fatty acid metabolism Effects 0.000 description 2
- 150000002192 fatty aldehydes Chemical class 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 238000000769 gas chromatography-flame ionisation detection Methods 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 230000004077 genetic alteration Effects 0.000 description 2
- 231100000118 genetic alteration Toxicity 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 150000003278 haem Chemical class 0.000 description 2
- 238000003306 harvesting Methods 0.000 description 2
- 108090001018 hexadecanal dehydrogenase (acylating) Proteins 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 2
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 2
- 229930027917 kanamycin Natural products 0.000 description 2
- 229960000318 kanamycin Drugs 0.000 description 2
- 229930182823 kanamycin A Natural products 0.000 description 2
- 150000002576 ketones Chemical group 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 150000002632 lipids Chemical class 0.000 description 2
- 150000007931 macrolactones Chemical class 0.000 description 2
- VNWKTOKETHGBQD-UHFFFAOYSA-N methane Chemical compound C VNWKTOKETHGBQD-UHFFFAOYSA-N 0.000 description 2
- 150000004702 methyl esters Chemical class 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 239000003921 oil Substances 0.000 description 2
- 210000003463 organelle Anatomy 0.000 description 2
- 239000012044 organic layer Substances 0.000 description 2
- 239000011368 organic material Substances 0.000 description 2
- 235000006408 oxalic acid Nutrition 0.000 description 2
- 230000003647 oxidation Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- REIUXOLGHVXAEO-UHFFFAOYSA-N pentadecan-1-ol Chemical compound CCCCCCCCCCCCCCCO REIUXOLGHVXAEO-UHFFFAOYSA-N 0.000 description 2
- 239000011846 petroleum-based material Substances 0.000 description 2
- 238000011176 pooling Methods 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 230000001902 propagating effect Effects 0.000 description 2
- 230000006337 proteolytic cleavage Effects 0.000 description 2
- 238000002708 random mutagenesis Methods 0.000 description 2
- 239000011535 reaction buffer Substances 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 230000000284 resting effect Effects 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 230000001568 sexual effect Effects 0.000 description 2
- 230000037432 silent mutation Effects 0.000 description 2
- UNFWWIHTNXNPBV-WXKVUWSESA-N spectinomycin Chemical compound O([C@@H]1[C@@H](NC)[C@@H](O)[C@H]([C@@H]([C@H]1O1)O)NC)[C@]2(O)[C@H]1O[C@H](C)CC2=O UNFWWIHTNXNPBV-WXKVUWSESA-N 0.000 description 2
- 229960000268 spectinomycin Drugs 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- 239000011593 sulfur Substances 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 230000002123 temporal effect Effects 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 210000001519 tissue Anatomy 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- 241000701447 unidentified baculovirus Species 0.000 description 2
- 229940118696 vibrio cholerae Drugs 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- XKLJLHAPJBUBNL-UHFFFAOYSA-N 12-methyltetradecanoic acid Chemical compound CCC(C)CCCCCCCCCCC(O)=O XKLJLHAPJBUBNL-UHFFFAOYSA-N 0.000 description 1
- ZVRQKBZSJNBTCW-UHFFFAOYSA-N 15-hydroxypentadec-2-enoic acid Chemical compound OCCCCCCCCCCCCC=CC(O)=O ZVRQKBZSJNBTCW-UHFFFAOYSA-N 0.000 description 1
- YSNNTXAJZMWJCI-UHFFFAOYSA-N 16-hydroxyhexadec-2-enoic acid Chemical compound OCCCCCCCCCCCCCC=CC(O)=O YSNNTXAJZMWJCI-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical compound OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 1
- UHPMCKVQTMMPCG-UHFFFAOYSA-N 5,8-dihydroxy-2-methoxy-6-methyl-7-(2-oxopropyl)naphthalene-1,4-dione Chemical compound CC1=C(CC(C)=O)C(O)=C2C(=O)C(OC)=CC(=O)C2=C1O UHPMCKVQTMMPCG-UHFFFAOYSA-N 0.000 description 1
- 102220590902 60S ribosomal protein L4_P56Q_mutation Human genes 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- 241000588624 Acinetobacter calcoaceticus Species 0.000 description 1
- 241000186361 Actinobacteria <class> Species 0.000 description 1
- 102100022089 Acyl-[acyl-carrier-protein] hydrolase Human genes 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 101000935487 Agrobacterium fabrum (strain C58 / ATCC 33970) 3-oxopimeloyl-[acyl-carrier-protein] synthase Proteins 0.000 description 1
- 241000864489 Alcanivorax borkumensis SK2 Species 0.000 description 1
- 241000228212 Aspergillus Species 0.000 description 1
- 241001513093 Aspergillus awamori Species 0.000 description 1
- 241000892910 Aspergillus foetidus Species 0.000 description 1
- 241001225321 Aspergillus fumigatus Species 0.000 description 1
- 241000351920 Aspergillus nidulans Species 0.000 description 1
- 241000228245 Aspergillus niger Species 0.000 description 1
- 240000006439 Aspergillus oryzae Species 0.000 description 1
- 235000002247 Aspergillus oryzae Nutrition 0.000 description 1
- 208000000659 Autoimmune lymphoproliferative syndrome Diseases 0.000 description 1
- 241000193744 Bacillus amyloliquefaciens Species 0.000 description 1
- 101100301559 Bacillus anthracis repS gene Proteins 0.000 description 1
- 241000193752 Bacillus circulans Species 0.000 description 1
- 241001328122 Bacillus clausii Species 0.000 description 1
- 241000193749 Bacillus coagulans Species 0.000 description 1
- 241000193422 Bacillus lentus Species 0.000 description 1
- 241000194107 Bacillus megaterium Species 0.000 description 1
- 241000194103 Bacillus pumilus Species 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 241000193388 Bacillus thuringiensis Species 0.000 description 1
- 208000016444 Benign adult familial myoclonic epilepsy Diseases 0.000 description 1
- 241000193764 Brevibacillus brevis Species 0.000 description 1
- DKPFZGUDAPQIHT-UHFFFAOYSA-N Butyl acetate Natural products CCCCOC(C)=O DKPFZGUDAPQIHT-UHFFFAOYSA-N 0.000 description 1
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 1
- 244000025254 Cannabis sativa Species 0.000 description 1
- 108090000489 Carboxy-Lyases Proteins 0.000 description 1
- 102000004031 Carboxy-Lyases Human genes 0.000 description 1
- 241000195597 Chlamydomonas reinhardtii Species 0.000 description 1
- 241000191382 Chlorobaculum tepidum Species 0.000 description 1
- 241000123346 Chrysosporium Species 0.000 description 1
- 241000193403 Clostridium Species 0.000 description 1
- 241000186566 Clostridium ljungdahlii Species 0.000 description 1
- 101100247969 Clostridium saccharobutylicum regA gene Proteins 0.000 description 1
- 102000005870 Coenzyme A Ligases Human genes 0.000 description 1
- 241000218631 Coniferophyta Species 0.000 description 1
- 241000192700 Cyanobacteria Species 0.000 description 1
- 241001464430 Cyanobacterium Species 0.000 description 1
- 241000159506 Cyanothece Species 0.000 description 1
- XDTMQSROBMDMFD-UHFFFAOYSA-N Cyclohexane Chemical compound C1CCCCC1 XDTMQSROBMDMFD-UHFFFAOYSA-N 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- YAHZABJORDUQGO-NQXXGFSBSA-N D-ribulose 1,5-bisphosphate Chemical compound OP(=O)(O)OC[C@@H](O)[C@@H](O)C(=O)COP(O)(O)=O YAHZABJORDUQGO-NQXXGFSBSA-N 0.000 description 1
- 230000033616 DNA repair Effects 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 108010013369 Enteropeptidase Proteins 0.000 description 1
- 102100029727 Enteropeptidase Human genes 0.000 description 1
- 241000588722 Escherichia Species 0.000 description 1
- 101100412434 Escherichia coli (strain K12) repB gene Proteins 0.000 description 1
- 241000644323 Escherichia coli C Species 0.000 description 1
- 102220597057 Essential MCU regulator, mitochondrial_I11C_mutation Human genes 0.000 description 1
- 108010074860 Factor Xa Proteins 0.000 description 1
- 108010039731 Fatty Acid Synthases Proteins 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 241000223218 Fusarium Species 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 241000193385 Geobacillus stearothermophilus Species 0.000 description 1
- 244000068988 Glycine max Species 0.000 description 1
- 235000010469 Glycine max Nutrition 0.000 description 1
- 101000836620 Homo sapiens Nucleic acid dioxygenase ALKBH1 Proteins 0.000 description 1
- 241001480714 Humicola insolens Species 0.000 description 1
- 102000004867 Hydro-Lyases Human genes 0.000 description 1
- 108090001042 Hydro-Lyases Proteins 0.000 description 1
- 238000012404 In vitro experiment Methods 0.000 description 1
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- 241000186660 Lactobacillus Species 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 235000019738 Limestone Nutrition 0.000 description 1
- 108010011449 Long-chain-fatty-acid-CoA ligase Proteins 0.000 description 1
- 101710175625 Maltose/maltodextrin-binding periplasmic protein Proteins 0.000 description 1
- 239000004165 Methyl ester of fatty acids Substances 0.000 description 1
- 241001074116 Miscanthus x giganteus Species 0.000 description 1
- 102000002568 Multienzyme Complexes Human genes 0.000 description 1
- 108010093369 Multienzyme Complexes Proteins 0.000 description 1
- 108010021466 Mutant Proteins Proteins 0.000 description 1
- 102000008300 Mutant Proteins Human genes 0.000 description 1
- XCOBLONWWXQEBS-KPKJPENVSA-N N,O-bis(trimethylsilyl)trifluoroacetamide Chemical compound C[Si](C)(C)O\C(C(F)(F)F)=N\[Si](C)(C)C XCOBLONWWXQEBS-KPKJPENVSA-N 0.000 description 1
- 241000221960 Neurospora Species 0.000 description 1
- 241000424623 Nostoc punctiforme Species 0.000 description 1
- 102100027051 Nucleic acid dioxygenase ALKBH1 Human genes 0.000 description 1
- XOCNMRWROLNAKC-UHFFFAOYSA-N OC=1C2=CC3=CC4=CC5=CC=CC=C5C=C4C=C3C=C2C=C2C=C3C=C4C=CC=C(C4=CC3=CC12)C(=O)O Chemical compound OC=1C2=CC3=CC4=CC5=CC=CC=C5C=C4C=C3C=C2C=C2C=C3C=C4C=CC=C(C4=CC3=CC12)C(=O)O XOCNMRWROLNAKC-UHFFFAOYSA-N 0.000 description 1
- 241000795633 Olea <sea slug> Species 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 235000021314 Palmitic acid Nutrition 0.000 description 1
- 241001520808 Panicum virgatum Species 0.000 description 1
- 239000001888 Peptone Substances 0.000 description 1
- 108010080698 Peptones Proteins 0.000 description 1
- 241000222385 Phanerochaete Species 0.000 description 1
- 108091000041 Phosphoenolpyruvate Carboxylase Proteins 0.000 description 1
- 241000222350 Pleurotus Species 0.000 description 1
- 241000209504 Poaceae Species 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 241000192138 Prochlorococcus Species 0.000 description 1
- 241000192142 Proteobacteria Species 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 241000589776 Pseudomonas putida Species 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 241000235402 Rhizomucor Species 0.000 description 1
- 241000235403 Rhizomucor miehei Species 0.000 description 1
- 241000191023 Rhodobacter capsulatus Species 0.000 description 1
- 241000316848 Rhodococcus <scale insect> Species 0.000 description 1
- 241001524101 Rhodococcus opacus Species 0.000 description 1
- 241000190932 Rhodopseudomonas Species 0.000 description 1
- 241000190984 Rhodospirillum rubrum Species 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 241000235088 Saccharomyces sp. Species 0.000 description 1
- 241001466077 Salina Species 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 241000235346 Schizosaccharomyces Species 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 108091081024 Start codon Proteins 0.000 description 1
- 101100114425 Streptococcus agalactiae copG gene Proteins 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 241000187398 Streptomyces lividans Species 0.000 description 1
- 241001468239 Streptomyces murinus Species 0.000 description 1
- 241000192707 Synechococcus Species 0.000 description 1
- 241000192589 Synechococcus elongatus PCC 7942 Species 0.000 description 1
- 241000192584 Synechocystis Species 0.000 description 1
- 241000192581 Synechocystis sp. Species 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 241001313706 Thermosynechococcus Species 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 241000222354 Trametes Species 0.000 description 1
- 101710195626 Transcriptional activator protein Proteins 0.000 description 1
- 241000223259 Trichoderma Species 0.000 description 1
- 241000378866 Trichoderma koningii Species 0.000 description 1
- 241000223262 Trichoderma longibrachiatum Species 0.000 description 1
- 241000499912 Trichoderma reesei Species 0.000 description 1
- 241000223261 Trichoderma viride Species 0.000 description 1
- 108020000999 Viral RNA Proteins 0.000 description 1
- 241000235013 Yarrowia Species 0.000 description 1
- 235000007244 Zea mays Nutrition 0.000 description 1
- 241000588901 Zymomonas Species 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- XJLXINKUBYWONI-DQQFMEOOSA-N [[(2r,3r,4r,5r)-5-(6-aminopurin-9-yl)-3-hydroxy-4-phosphonooxyoxolan-2-yl]methoxy-hydroxyphosphoryl] [(2s,3r,4s,5s)-5-(3-carbamoylpyridin-1-ium-1-yl)-3,4-dihydroxyoxolan-2-yl]methyl phosphate Chemical compound NC(=O)C1=CC=C[N+]([C@@H]2[C@H]([C@@H](O)[C@H](COP([O-])(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](OP(O)(O)=O)[C@@H](O3)N3C4=NC=NC(N)=C4N=C3)O)O2)O)=C1 XJLXINKUBYWONI-DQQFMEOOSA-N 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 238000004760 accelerator mass spectrometry Methods 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 108700021044 acyl-ACP thioesterase Proteins 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 238000005273 aeration Methods 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 150000007824 aliphatic compounds Chemical class 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 239000010775 animal oil Substances 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 125000004429 atom Chemical group 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 230000001651 autotrophic effect Effects 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 229940054340 bacillus coagulans Drugs 0.000 description 1
- 229940097012 bacillus thuringiensis Drugs 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 108010051210 beta-Fructofuranosidase Proteins 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N biotin Natural products N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 101150031021 birA gene Proteins 0.000 description 1
- 150000001722 carbon compounds Chemical class 0.000 description 1
- 230000006860 carbon metabolism Effects 0.000 description 1
- 150000004649 carbonic acid derivatives Chemical class 0.000 description 1
- 230000021523 carboxylation Effects 0.000 description 1
- 150000001732 carboxylic acid derivatives Chemical class 0.000 description 1
- 230000001925 catabolic effect Effects 0.000 description 1
- 108020001778 catalytic domains Proteins 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 210000003850 cellular structure Anatomy 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 150000001793 charged compounds Chemical class 0.000 description 1
- 150000005829 chemical entities Chemical class 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 1
- 229960005091 chloramphenicol Drugs 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 238000012411 cloning technique Methods 0.000 description 1
- 239000003245 coal Substances 0.000 description 1
- 239000005515 coenzyme Substances 0.000 description 1
- 238000002742 combinatorial mutagenesis Methods 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 235000021438 curry Nutrition 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- SUYVUBYJARFZHO-RRKCRQDMSA-N dATP Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-RRKCRQDMSA-N 0.000 description 1
- SUYVUBYJARFZHO-UHFFFAOYSA-N dATP Natural products C1=NC=2C(N)=NC=NC=2N1C1CC(O)C(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-UHFFFAOYSA-N 0.000 description 1
- RGWHQCVHVJXOKC-SHYZEUOFSA-J dCTP(4-) Chemical compound O=C1N=C(N)C=CN1[C@@H]1O[C@H](COP([O-])(=O)OP([O-])(=O)OP([O-])([O-])=O)[C@@H](O)C1 RGWHQCVHVJXOKC-SHYZEUOFSA-J 0.000 description 1
- HAAZLUGHYHWQIW-KVQBGUIXSA-N dGTP Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 HAAZLUGHYHWQIW-KVQBGUIXSA-N 0.000 description 1
- NHVNXKFIZYSCEB-XLPZGREQSA-N dTTP Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C1 NHVNXKFIZYSCEB-XLPZGREQSA-N 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 150000002016 disaccharides Chemical class 0.000 description 1
- VCIQTMGWJDEYRX-UHFFFAOYSA-N dodec-1-ene-1,12-diol Chemical compound OCCCCCCCCCCC=CO VCIQTMGWJDEYRX-UHFFFAOYSA-N 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 108010052305 exodeoxyribonuclease III Proteins 0.000 description 1
- 101150015067 fabB gene Proteins 0.000 description 1
- 101150084167 fabZ gene Proteins 0.000 description 1
- 208000016427 familial adult myoclonic epilepsy Diseases 0.000 description 1
- 230000004133 fatty acid degradation Effects 0.000 description 1
- 210000003608 fece Anatomy 0.000 description 1
- 230000008713 feedback mechanism Effects 0.000 description 1
- 239000002921 fermentation waste Substances 0.000 description 1
- 101150077341 fhuA gene Proteins 0.000 description 1
- 239000012467 final product Substances 0.000 description 1
- ZGNITFSDLCMLGI-UHFFFAOYSA-N flubendiamide Chemical compound CC1=CC(C(F)(C(F)(F)F)C(F)(F)F)=CC=C1NC(=O)C1=CC=CC(I)=C1C(=O)NC(C)(C)CS(C)(=O)=O ZGNITFSDLCMLGI-UHFFFAOYSA-N 0.000 description 1
- 230000004907 flux Effects 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 239000010794 food waste Substances 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 239000002803 fossil fuel Substances 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 239000003205 fragrance Substances 0.000 description 1
- 239000000446 fuel Substances 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 125000002791 glucosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 239000011121 hardwood Substances 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 235000008216 herbs Nutrition 0.000 description 1
- 125000000623 heterocyclic group Chemical group 0.000 description 1
- FUZZWVXGSFPDMH-UHFFFAOYSA-N hexanoic acid Chemical compound CCCCCC(O)=O FUZZWVXGSFPDMH-UHFFFAOYSA-N 0.000 description 1
- 125000000487 histidyl group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C([H])=N1 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 238000005805 hydroxylation reaction Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 239000013067 intermediate product Substances 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 239000001573 invertase Substances 0.000 description 1
- 235000011073 invertase Nutrition 0.000 description 1
- 229910052742 iron Inorganic materials 0.000 description 1
- 238000002307 isotope ratio mass spectrometry Methods 0.000 description 1
- 229940039696 lactobacillus Drugs 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 239000002029 lignocellulosic biomass Substances 0.000 description 1
- 239000006028 limestone Substances 0.000 description 1
- 239000010871 livestock manure Substances 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 239000013028 medium composition Substances 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 102000035118 modified proteins Human genes 0.000 description 1
- 108091005573 modified proteins Proteins 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 235000021281 monounsaturated fatty acids Nutrition 0.000 description 1
- 239000010813 municipal solid waste Substances 0.000 description 1
- 239000003345 natural gas Substances 0.000 description 1
- 229930027945 nicotinamide-adenine dinucleotide Natural products 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- TVMXDCGIABBOFY-UHFFFAOYSA-N octane Chemical compound CCCCCCCC TVMXDCGIABBOFY-UHFFFAOYSA-N 0.000 description 1
- JRZJOMJEPLMPRA-UHFFFAOYSA-N olefin Natural products CCCCCCCC=C JRZJOMJEPLMPRA-UHFFFAOYSA-N 0.000 description 1
- 235000021354 omega 7 monounsaturated fatty acids Nutrition 0.000 description 1
- 239000012074 organic phase Substances 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 150000002972 pentoses Chemical class 0.000 description 1
- 235000019319 peptone Nutrition 0.000 description 1
- 239000003209 petroleum derivative Substances 0.000 description 1
- 239000013520 petroleum-based product Substances 0.000 description 1
- 230000010363 phase shift Effects 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- 108010001814 phosphopantetheinyl transferase Proteins 0.000 description 1
- 239000010773 plant oil Substances 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 150000003138 primary alcohols Chemical class 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000004952 protein activity Effects 0.000 description 1
- 108040006686 pyruvate synthase activity proteins Proteins 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 101150044854 repA gene Proteins 0.000 description 1
- 230000000754 repressing effect Effects 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- 239000007320 rich medium Substances 0.000 description 1
- 102200014657 rs121434437 Human genes 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 239000004460 silage Substances 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 239000001488 sodium phosphate Substances 0.000 description 1
- 229910000162 sodium phosphate Inorganic materials 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000002910 solid waste Substances 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 239000010902 straw Substances 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 239000013076 target substance Substances 0.000 description 1
- 101150026728 tesB gene Proteins 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- XLKZJJVNBQCVIX-UHFFFAOYSA-N tetradecane-1,14-diol Chemical compound OCCCCCCCCCCCCCCO XLKZJJVNBQCVIX-UHFFFAOYSA-N 0.000 description 1
- 238000009482 thermal adhesion granulation Methods 0.000 description 1
- 150000007970 thio esters Chemical class 0.000 description 1
- 150000003573 thiols Chemical group 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 239000002351 wastewater Substances 0.000 description 1
- 239000001993 wax Substances 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0071—Oxidoreductases (1.) acting on paired donors with incorporation of molecular oxygen (1.14)
- C12N9/0077—Oxidoreductases (1.) acting on paired donors with incorporation of molecular oxygen (1.14) with a reduced iron-sulfur protein as one donor (1.14.15)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/52—Genes encoding for enzymes or proenzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/18—Carboxylic ester hydrolases (3.1.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
- C12P7/6409—Fatty acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y114/00—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14)
- C12Y114/15—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14) with reduced iron-sulfur protein as one donor, and incorporation of one atom of oxygen (1.14.15)
- C12Y114/15003—Alkane 1-monooxygenase (1.14.15.3)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y301/00—Hydrolases acting on ester bonds (3.1)
- C12Y301/01—Carboxylic ester hydrolases (3.1.1)
- C12Y301/01005—Lysophospholipase (3.1.1.5)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y301/00—Hydrolases acting on ester bonds (3.1)
- C12Y301/02—Thioester hydrolases (3.1.2)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y301/00—Hydrolases acting on ester bonds (3.1)
- C12Y301/02—Thioester hydrolases (3.1.2)
- C12Y301/02014—Oleoyl-[acyl-carrier-protein] hydrolase (3.1.2.14), i.e. ACP-thioesterase
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02E—REDUCTION OF GREENHOUSE GAS [GHG] EMISSIONS, RELATED TO ENERGY GENERATION, TRANSMISSION OR DISTRIBUTION
- Y02E50/00—Technologies for the production of fuel of non-fossil origin
- Y02E50/10—Biofuels, e.g. bio-diesel
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Peptides Or Proteins (AREA)
Abstract
Una variante de polipéptido de fusión híbrida de CYP153A-reductasa que comprende al menos el 90 % de identidad de secuencia con SEQ ID NO: 38 y que tiene al menos una mutación en una posición de aminoácido seleccionada del grupo que consiste en 9, 10, 11, 12, 13, 14, 28, 61, 119, 231, 233, 327, 413, 703, 745, 747, 749, 757, 770, 771 y 784, en donde dicha variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso omega-hidroxilado.
Description
DESCRIPCIÓN
Polipéptidos de fusión relacionados con omega-hidroxilasa con propiedades mejoradas
Campo
La divulgación se refiere a polipéptidos de fusión relacionados con omega-hidroxilasa que dan lugar a una producción mejorada de derivados de ácidos grasos omega-hidroxilados cuando se expresan en células hospedadoras recombinantes. La divulgación se refiere además a microorganismos para expresar los polipéptidos de fusión relacionados con omega-hidroxilasa para la producción de derivados de ácidos grasos omega-hidroxilados.
Antecedentes
Las citocromo P450 monooxigenasas (P450) son un grupo diverso de enzimas. Se clasifican en familias y subfamilias. Cuando comparten una identidad de aminoácidos superior o igual al cuarenta por ciento, pertenecen a la misma familia. Cuando comparten una identidad de aminoácidos superior o igual al cincuenta y cinco por ciento, pertenecen a la misma subfamilia. Las P450 usan ácidos grasos como sustratos y catalizan reacciones de hidroxilación. Las bacterias tienen varios sistemas P450 que participan en la degradación de los alcanos y en la modificación de los ácidos grasos, y se conocen más de 1000 P450 microbianas hasta la fecha. Una subfamilia de P450 particular se conoce como cyp153A, en donde la primera se clonó de Acinetobacter calcoaceticus en 2001. Desde entonces, se han identificado enzimas similares en otras especies que utilizan alcanos tales como Sphingomonas sp. HXN200, Mycobacterium sp. HXN1500 y Alcanivorax borkumensis (Van Bogaert et al. (2011) FEBS Journal 278: 206-221). Varias P450 de la subfamilia de CYP153A bacterianas son alcano omega-hidroxilasas (u-hidroxilasas, también denominadas u-oxigenasas) con alta regioselectividad terminal. Las CYP153A también se han asociado con la síntesis de compuestos alifáticos omega-hidroxilados (u-hidroxilados) industrialmente relevantes, tales como alcoholes primarios, ácidos grasos u-hidroxilados y derivados de ácidos grasos bifuncionales tales como ácidos a,udicarboxílicos y a,u-dioles (Honda Malca et al. (2012) Chem. Commun. 48:5115-5117).
Scheps et al. (2013) Microbial Biotechnology 6: 694-707 desvela la síntesis de ácido dodecanoico u-hidroxi basado en una construcción de fusión de CYP153A diseñada genéticamente.
Sumario
La presente invención proporciona:
- Una variante de polipéptido de fusión híbrida de CYP153A-reductasa que comprende al menos el 90 % de identidad de secuencia con SEQ ID NO: 38 y que tiene al menos una mutación en una posición de aminoácido seleccionada del grupo que consiste en 9, 10, 11, 12, 13, 14, 28, 61, 119, 231, 233, 327, 413, 703, 745, 747, 749, 757, 770, 771 y 784, en donde dicha variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso omega-hidroxilado.
La presente invención también proporciona:
- Una célula hospedadora recombinante que expresa la variante de polipéptido de fusión híbrida de CYP153A-reductasa de la presente invención, que preferentemente expresa adicionalmente un polipéptido de tioesterasa de CE 3.1.2.-, CE 3.1.1.5 o CE 3.1.2.14;
- Un cultivo celular que comprende la célula hospedadora recombinante de la presente invención;
- Un método para producir un ácido graso omega-hidroxilado que tiene un aumento en el título, que comprende:
i. cultivar la célula hospedadora de la presente invención con una fuente de carbono; e
ii) recoger un ácido graso omega-hidroxilado; y
- Un microorganismo recombinante para producir un derivado de ácido graso omega-hidroxilado in vivo cuando se cultiva en un caldo de fermentación en presencia de una fuente de carbono a partir de una materia prima renovable, comprendiendo dicho microorganismo una vía diseñada para expresar al menos dos secuencias de ácido nucleico que codifican un polipéptido que comprende:
(i) una tioesterasa de CE 3.1.2.-, CE 3.1.1.5 o CE 3.1.2.14; e
(ii) una variante de polipéptido de fusión híbrida de CYP153A-reductasa de la presente invención.
La presente divulgación proporciona polipéptidos de fusión relacionados con omega-hidroxilasa y variantes de los mismos que pueden producir derivados de ácidos grasos omega-hidroxilados y bifuncionales en células hospedadoras. De manera más específica, la presente divulgación proporciona variantes de polipéptidos de fusión híbrida de CYP153A-reductasa que producen derivados de ácidos grasos omega-hidroxilados (u-hidroxilados) y bifuncionales, y composiciones de los mismos, que incluyen ácidos grasos u-hidroxilados, ésteres grasos u -hidroxilados, a,u-diácidos, a,u-diésteres, a,u-dioles y productos químicos derivados de los mismos, tales como las macrolactonas. También se proporcionan secuencias específicas de proteína y ácido nucleico de fusión híbrida de
CYP153A-reductasa, así como células hospedadoras recombinantes y cultivos celulares que engloban dichas variantes de polipéptidos de fusión híbrida de CYP153A-reductasa diseñadas genéticamente. La divulgación también proporciona métodos para usar las células hospedadoras que expresan las variantes de polipéptidos de fusión híbrida de CYP153A-reductasa recombinantes para fabricar derivados de ácidos grasos w-hidroxilados y/o bifuncionales, o composiciones de los mismos.
Un aspecto de la divulgación proporciona un polipéptido de fusión híbrida de CYP153A-reductasa que cataliza la conversión de un ácido graso en un ácido graso o derivado de ácido graso w-hidroxilado (w-OH), en donde el polipéptido de fusión híbrida de CYP153A-reductasa tiene al menos aproximadamente el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con la secuencia de polipéptido de SEQ ID NO: 6. Además, se incluyen métodos para expresar el polipéptido de fusión híbrida de CYP153A-reductasa y sus variantes. En un aspecto, el polipéptido de fusión híbrida de CYP153A-reductasa tiene al menos el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con SEQ ID NO: 6 y la expresión del polipéptido de fusión híbrida de CYP153A-reductasa en una célula hospedadora recombinante produce un título más alto de ácidos grasos o derivados de ácidos grasos w-OH, o composiciones de los mismos, en comparación con el título producido por la expresión de una CYP153A de tipo silvestre. En un aspecto, la célula hospedadora recombinante produce un ácido graso w-OH o un derivado de ácido graso w-OH, o una composición del mismo, con un título que es al menos aproximadamente un 10 % superior al título de un ácido graso w-OH o un derivado de ácido graso w-OH, o una composición del mismo, producido por una célula hospedadora que expresa una CYP153A de tipo silvestre correspondiente, cuando se cultiva en medio que contiene una fuente de carbono en condiciones eficaces para expresar el polipéptido de fusión híbrida de CYP153A-reductasa. En otro aspecto, el ácido graso w-OH o el derivado de ácido graso w-OH, o la composición del mismo, se produce extracelularmente.
Otro aspecto de la presente divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa que tiene al menos aproximadamente el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o 99 % de identidad de secuencia con SEQ ID NO: 6 y que tiene al menos una mutación en una posición de aminoácido que incluye la posición 796, 141,231,27, 82, 178, 309, 407, 415, 516 y/o 666, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso w-OH. La variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene una mutación en una cualquiera o más de las siguientes posiciones, incluidas la posición A796V, donde la alanina (A) está sustituida con (es decir, reemplazada con) valina (V); posición V141I, donde la valina está sustituida con isoleucina (I); posición V141Q, donde la valina (V) está sustituida con glutamina (Q); posición V141G, donde la valina (V) está sustituida con glicina (G); posición V141M, donde la valina (V) está sustituida con metionina (M); posición V141L, donde la valina (V) está sustituida con leucina (L); posición V141T, donde la valina (V) sustituida con treonina (T); posición A231T, donde la alanina (A) está sustituida con treonina (T); posición R27L, donde la arginina (R) está sustituida con lisina (L); posición R82D, donde la arginina (R) está sustituida con ácido aspártico (D); posición R178N, donde la arginina (R) está sustituida con asparagina (N); posición N309R, donde la asparagina (N) está sustituida con arginina (R); posición N407A, donde la asparagina (N) está sustituida con alanina (A); posición V415R, donde la valina (V) está sustituida con arginina (R); posición T516V, donde la treonina (T) está sustituida con valina (V); posición P666A, donde la prolina (P) está sustituida con alanina (A); y posición P666D, donde la prolina (P) está sustituida con ácido aspártico (D). Los ejemplos de variantes de polipéptidos de fusión híbrida de CYP153A-reductasa incluyen SEQ ID NO: 8, Se Q ID NO: 10, Se Q ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 20, SEQ ID NO: 22, SEQ ID NO: 24, SEQ ID NO: 26, SEQ ID NO: 28 o SEQ ID NO: 30, SEQ ID NO: 32, SEQ ID NO: 34, SEQ ID NO: 36, SEQ ID NO: 38, SEQ ID NO: 40, SEQ ID NO: 42, SEQ ID NO: 44 y SEQ ID NO: 46. En una realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa es una variante de proteína de fusión de tipo CYP153A-RedRhF híbrida. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa en una célula hospedadora recombinante produce un título más alto de un ácido graso w-OH o derivado de ácido graso w-OH, o composición del mismo, en comparación con el título de un ácido graso w-OH o derivado de ácido graso w-OH, o composición del mismo, producido por la expresión de un polipéptido de fusión híbrida de CYP153A-reductasa en una célula hospedadora correspondiente. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene una mutación en la posición de aminoácido 796, incluyendo A796V. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene una mutación en la posición de aminoácido 231, incluyendo a 231t . En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene una mutación en la posición de aminoácido 141, incluyendo V141I y/o V141T. En el presente documento, la expresión de la variante de polipéptido de fusión híbrida de CYP153A-reductasa con mutaciones A796V, V141I, V141T y/o A231T en una célula hospedadora recombinante produce un título más alto de un ácido graso C12 o C16 w-OH, respectivamente, en comparación con un título de un ácido graso C12 o C16 w-OH producido por la expresión de un polipéptido de fusión híbrida de CYP153A-reductasa.
La divulgación contempla además un cultivo celular con una célula hospedadora recombinante que expresa una variante de polipéptido de fusión híbrida de CYP153A-reductasa como se ha descrito anteriormente. El ácido graso o derivado de ácido graso w-OH, o la composición del mismo, puede incluir uno o más de un ácido graso o derivado de ácido graso C6, C7, Cs, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19 y C20 w-OH. El ácido graso o derivado de ácido graso w-OH, o la composición del mismo, puede incluir un ácido graso o derivado de ácido graso w-OH saturado o insaturado. En otra realización, el ácido graso o derivado de ácido graso w-OH, o la composición del mismo, puede incluir uno o más de un ácido graso o derivado de ácido graso C8:1, Cg:1, Cm1, C111 , C12:1, C13:1, C14:1, C15:1, Cm 1, C171, C18:1, C191 y C201 w-OH insaturado. En otra realización, el ácido graso o derivado de ácido graso w-OH, o la
composición del mismo, puede incluir un ácido graso o derivado de ácido graso C12 y/o C16 y/o C161.
Otro aspecto de la divulgación proporciona un método para producir un ácido graso o derivado de ácido graso w-OH, o una composición del mismo, que tenga un aumento en el título, que incluye cultivar la célula hospedadora que expresa la variante de polipéptido de fusión híbrida de CYP153A-reductasa (descrita anteriormente) con una fuente de carbono; y recoger un ácido graso w-OH o un derivado de ácido graso w-OH. En un aspecto, el ácido graso o derivado de ácido graso w-OH es al menos de aproximadamente el 20 % al 30 % superior al título de un ácido graso o derivado de ácido graso w-OH producido por una célula hospedadora que expresa el polipéptido de fusión híbrida de CYP153A-reductasa. En otro aspecto, el ácido graso o derivado de ácido graso w-OH, o la composición del mismo, se produce a un título de aproximadamente 15 g/l a aproximadamente 25 g/l a partir de una fuente de carbono.
Otro aspecto de la divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa con al menos aproximadamente el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con SEQ ID NO: 32, que tiene una mutación en V141I y A231T, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso o derivado de ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, Cn:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OH, o una composición del mismo. Otro aspecto de la divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa con al menos aproximadamente el 90 %, 91 %, 93 %,
94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con s Eq ID NO: 34, que tiene una mutación en R27L, R82D, V141M, R178N y N407A, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso o derivado de ácido graso C6, C7, C8, C9 C10, C11 C12, C13,
C14, C15, C16, C17, C18, C19 C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OH, o una composición del mismo. Otro aspecto de la divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa con al menos aproximadamente el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o
100 % de identidad de secuencia con SEQ ID NO: 36, que tiene una mutación en P666A, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso o derivado de ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C m , C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OH, o una composición del mismo. Otro aspecto de la divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa con al menos aproximadamente el
90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con SEQ ID NO: 38, que tiene una mutación en A796V, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso o derivado de ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14,
C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OH, o una composición del mismo. Otro aspecto de la divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa con al menos aproximadamente el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o
100 % de identidad de secuencia con SEQ ID NO: 40, que tiene una mutación en A796V, P666D y T516V, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso o derivado de ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C n :1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OH, o una composición del mismo. Otro aspecto de la divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa con al menos aproximadamente el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con
SEQ ID NO: 42, que tiene una mutación en V141I, A231T y A796V, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso o derivado de ácido graso
C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C171, C181, C191 y/o C201 w-OH, o una composición del mismo. Otro aspecto de la divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa con al menos aproximadamente el 90 %, 91 %, 93 %, 94 %,
95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con SEQ ID NO: 44, que tiene una mutación en R27L, R82D, V141M, R178N, N407A y A796V, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso o derivado de ácido graso C6, C7, C8, C9, C10,
C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o
C20:1 w-OH, o una composición del mismo. Otro aspecto de la divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa con al menos aproximadamente el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %,
98 %, 99 % o 100 % de identidad de secuencia con SEQ ID NO: 46, que tiene una mutación en V141T, A231T y A796V, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso o derivado de ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20,
C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OH, o una composición del mismo.
La divulgación contempla además una célula hospedadora recombinante que expresa la variante de polipéptido de fusión híbrida de CYP153A-reductasa como se ha descrito anteriormente. En una realización, la célula hospedadora recombinante expresa una variante de polipéptido de fusión híbrida de CYP153A-reductasa como se ha descrito anteriormente y un polipéptido de tioesterasa de CE 3.1.2.- o CE 3.1.1.5 o CE 3.1.2.14, en donde la célula hospedadora recombinante produce un ácido graso w-OH o una composición del mismo con un título que es al menos un 10 % superior, al menos un 15 % superior, al menos un 20 % superior, al menos un 25 % superior o al menos un 30 % superior al título de un ácido graso w-OH o una composición del mismo producido por una célula hospedadora que expresa un polipéptido de fusión híbrida de CYP153A-reductasa correspondiente, cuando se cultiva en medio que contiene una fuente de carbono en condiciones eficaces para expresar la variante de polipéptido de fusión híbrida de
CYP153A-reductasa. En una realización, el ácido graso w-OH o la composición del mismo se puede producir a un título de aproximadamente 15 g/l a aproximadamente 25 g/l. En otra realización, el ácido graso w-OH o la composición
del mismo se produce extracelularmente.
En un aspecto, la divulgación engloba un microorganismo recombinante para producir un ácido graso o derivado de ácido graso w-OH in vivo cuando se cultiva en un caldo de fermentación en presencia de una fuente de carbono a partir de una materia prima renovable, el microorganismo que tiene una vía diseñada genéticamente para expresar al menos dos secuencias de ácido nucleico que codifican un polipéptido que incluye una tioesterasa de CE 3.1.2.- o CE
3.1.1.5 o 3.1.2.14; y una variante de polipéptido de fusión híbrida de CYP153A-reductasa, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene al menos el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %,
98 %, 99 % o 100 % de identidad de secuencia con una cualquiera de SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO:
12, SEQ ID NO: 14, SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 20, SEQ ID NO: 22, SEQ ID NO: 24, SEQ ID NO:
26, SEQ ID NO: 28, SEQ ID NO: 30, SEQ ID NO: 36, SEQ ID NO: 38, SEQ ID NO: 40, SEQ ID NO: 42, SEQ ID NO:
44 y SEQ ID NO: 46. En una realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa es una variante de proteína de fusión híbrida de CYP153A-RedRhF autosuficiente.
Otro aspecto de la presente divulgación proporciona un cultivo celular que incluye la célula hospedadora recombinante
como se ha descrito anteriormente, en donde el cultivo celular produce un ácido graso w-OH o una composición del mismo. En una realización, el cultivo celular produce un ácido graso w-OH que incluye uno o más de un ácido graso o derivado de ácido graso C6, C7, Cs, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, Cs:1, C9:1, C101 C13:1, C14:1, C15:1, C16:1, C17:1, Cm1, C19:1 y/o C20:1, o composición del mismo. En una realización, el cultivo celular produce un ácido graso C161 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C16 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C121 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C12 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C141 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C14 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso
C181 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C18 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C101 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C10 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C81 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C8 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C201 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C20 w-OH saturado o una composición del mismo. En otra realización más, la célula hospedadora recombinante produce ácidos grasos w-OH saturados o insaturados adicionales o composiciones de los mismos.
Otro aspecto más de la presente divulgación proporciona un método para producir un ácido graso w-OH que tiene un aumento en el título, que incluye cultivar la célula hospedadora (descrito anteriormente) con una fuente de carbono; y cosechar un ácido graso w-OH o una composición del mismo. El método contempla la recogida de un ácido graso w-OH que es un ácido graso o derivado de ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20,
C8:1, C9:1, C10:1, C n :1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, Cm1, C19:1 y/o C20:1, o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C161 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C16 w-OH saturado o una composición del mismo.
En una realización, el ácido graso w-OH recogido es un ácido graso C121 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C12 w-OH saturado o una composición
del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C141 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C14 w-OH saturado o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C181 w-OH insaturado
o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C18 w-OH saturado
o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C101 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C10 w-OH saturado o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C8:1 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso
C8 w-OH saturado o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso
C20:1 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C20 w-OH saturado o una composición del mismo. En otra realización más, se producen ácidos grasos w-OH saturados o insaturados adicionales, o composiciones de los mismos, mediante el método descrito en el presente documento.
Otro aspecto de la presente divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa que tiene al menos aproximadamente el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o 99 % de identidad de secuencia con SEQ ID NO: 38 y que tiene al menos una mutación en una posición de aminoácido que
incluye la posición 9, 10, 11, 12, 13, 14, 27, 28, 56, 61, 111, 119, 140, 149, 154, 157, 162, 164, 204, 231, 233, 244,
254, 271, 273, 302, 309, 327, 407, 413, 477, 480, 481, 527, 544, 546, 557, 567, 591, 648, 649, 703, 706, 707, 708,
709, 710, 719, 720, 736, 741, 745, 747, 749, 757, 770, 771, 784, en donde la variante de polipéptido de fusión híbrida
de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso u>-OH o una composición del mismo. La variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene una mutación en una cualquiera o más de las siguientes posiciones, que incluyen la posición D9N, donde el aspartato (D) está sustituido con (es decir, reemplazado con) asparagina (N); posición D9K, donde el aspartato (D) está sustituido con lisina (K); posición D10Y, donde el ácido aspártico (D) está sustituido con tirosina (Y); posición I11L, donde la isoleucina (I) está sustituida con leucina (L); posición Q12W, donde la glutamina (Q) está sustituida con triptófano (W); posición Q12R, donde la glutamina (Q) está sustituida con arginina (R); posición Q12T, donde la glutamina (Q) está sustituida con treonina (T); posición S13K, donde la serina (S) está sustituida con lisina (K); posición R14F, donde la arginina (R) está sustituida con fenilalanina (F); posición R27L, donde la arginina (R) está sustituida con leucina (L); posición Q28M, donde la glutamina (Q) está sustituida con metionina (M); posición Q28T, donde la glutamina (Q) está sustituida con treonina (T); posición P56Q, donde la prolina (P) está sustituida con glutamina (Q); posición N61L, donde la asparagina (N) está sustituida con leucina (L); posición F111A, donde la fenilalanina (F) está sustituida con alanina (A); posición K119R, donde la lisina (K) está sustituida con arginina (R); posición S140N, donde la serina (S) está sustituida con asparagina (N); posición P149G, donde la prolina (P) está sustituida con glicina (G); posición P149R, donde la prolina (P) está sustituida con arginina (R); posición V154G, donde la valina (V) está sustituida con glicina (G); posición S157R, donde la serina (S) está sustituida con arginina (R); posición V162C, donde la valina (V) está sustituida con cisteína (C) ; posición A164N, donde la alanina (A) está sustituida con asparagina (N); posición G204V, donde la glicina (G) está sustituida con valina (V); posición A231W, donde la alanina (A) está sustituida con triptófano (W); posición A231Y, donde la alanina (A) está sustituida con tirosina (Y); posición A231V, donde la alanina (A) está sustituida con valina (V); posición S233L, donde la serina (S) está sustituida con leucina (L); posición S233V donde la serina (S) está sustituida con valina (V); posición A244R, donde la alanina (A) está sustituida con arginina (R); posición R254G, donde la arginina (R) está sustituida con glicina (G); posición E271D, donde el glutamato (E) está sustituido con aspartato (D) ; posición P273M, donde la prolina (P) está sustituida con metionina (M); posición T302M, donde la treonina (T) está sustituida con metionina (M); posición N309S, donde la asparagina (N) está sustituida con serina (S); posición P327D, donde la prolina (P) está sustituida con aspartato (D); posición N407G, donde la asparagina (N) está sustituida con glicina (G); posición Y413R, donde la tirosina (Y) está sustituida con arginina (R); posición P477G, donde la prolina (P) está sustituida con glicina (G); posición I480G, donde la isoleucina (I) está sustituida con glicina (G); posición G481I, donde la glicina (G) está sustituida con isoleucina (I); posición D527E, donde el aspartato (D) está sustituido con glutamato (E); posición D544N, donde el aspartato (D) está sustituido con asparagina (N); posición P546G, donde la prolina (P) está sustituida con glicina (G); posición E557R, donde el glutamato (E) está sustituido con arginina (R); posición E557W, donde el glutamato (E) está sustituido con triptófano (W); posición E567S, donde el glutamato (E) está sustituido con serina (S); posición E591Q, donde el glutamato (E) está sustituido con glutamina (Q); posición V648L, donde la valina (V) está sustituida con leucina (L); posición S649I, donde la serina (S) está sustituida con isoleucina (I); posición L703G, donde la leucina (L) está sustituida con glicina (G); posición L706E, donde la leucina (L) está sustituida con glutamato (E); posición L706S, donde la leucina (L) está sustituida con serina (S); posición L706H, donde la leucina (L) está sustituida con histidina (H); posición D707E, donde el aspartato (D) está sustituido con glutamato (E); posición P708S, donde la prolina (P) está sustituida con serina (S); posición D709L, donde el aspartato (D) está sustituido con leucina (L); posición V710C, donde la valina (V) está sustituida con cisteína (C); posición V710R, donde la valina (V) está sustituida con arginina (R); posición V710Q, donde la valina (V) está sustituida con glutamina (Q); posición R719W, donde la arginina (R) está sustituida con triptófano (W); posición D720V, donde el aspartato (D) está sustituido con valina (V); posición A736V, donde la alanina (A) está sustituida con valina (V); posición N741G, donde la asparagina (N) está sustituida con glicina (G); posición P745K, donde la prolina (P) está sustituida con lisina (K); posición P745R, donde la prolina (P) está sustituida con arginina (R); posición D747N, donde el aspartato (D) está sustituido con asparagina (N); posición E749L, donde el glutamato (E) está sustituido con leucina (L); posición E749M, donde el glutamato (E) está sustituido con metionina (M); posición E757A, donde el glutamato (E) está sustituido con alanina (A); posición T770G, donde la treonina (T) está sustituida con glicina (G); posición V771F, donde la valina (V) está sustituida con fenilalanina (F); y la posición M784I, donde la metionina (M) está sustituida con isoleucina (I). En una realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa es una variante de proteína de fusión de tipo cyp153A-RedRhF híbrida. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa en una célula hospedadora recombinante produce un título más alto de un ácido graso u>-OH en comparación con el título de un ácido graso u>-OH producido por la expresión de un polipéptido de fusión híbrida de CYPl53A-reductasa en una célula hospedadora correspondiente. En otra realización, el ácido graso u>-OH es una composición de ácido graso u>-OH.
Otro aspecto de la presente divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa que tiene al menos aproximadamente el 90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o 99 % de identidad de secuencia con SEQ ID NO: 38 y que tiene al menos una mutación en una posición de aminoácido que incluye la posición 747, 12, 327, 14, 61, 28, 13, 771, 119, 10, 11, 28, 745, 9, 770, 413, 784, 749, 233, 757 y 703, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso u>-OH. La variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene una mutación en una cualquiera o más de las siguientes posiciones, que incluyen la posición D747N, donde el aspartato (D) está sustituido con asparagina (N); posición Q12W, donde la glutamina (Q) está sustituida con triptófano (W); posición Q12R, donde la glutamina (Q) está sustituida con arginina (R); posición Q12T, donde la glutamina (Q) está sustituida con treonina (T); posición P327D, donde la prolina (P) está sustituida con aspartato (D); posición R14F, donde la arginina (R) está sustituida con fenilalanina (F); posición N61L, donde la asparagina (N) está sustituida con leucina (L); posición Q28M, donde la glutamina (Q) está sustituida con metionina (M); posición S13K, donde la serina (S) está sustituida con lisina
(K); posición V771F, donde la valina (V) está sustituida con fenilalanina (F); posición K119R, donde la lisina (K) está sustituida con arginina (R); posición D10Y, donde el ácido aspártico (D) está sustituido con tirosina (Y); posición II1L, donde la isoleucina (I) está sustituida con leucina (L); posición Q28T, donde la glutamina (Q) está sustituida con treonina (T); posición P745R, donde la prolina (P) está sustituida con arginina (R); posición D9N, donde el aspartato
(D) está sustituido con asparagina (N); posición D9K, donde el aspartato (D) está sustituido con lisina (K); posición T770G, donde la treonina (T) está sustituida con glicina (G); posición Y413R, donde la tirosina (Y) está sustituida con arginina (R); posición M784I, donde la metionina (M) está sustituida con isoleucina (I); posición E749L, donde el glutamato (E) está sustituido con leucina (L); posición S233L, donde la serina (S) está sustituida con leucina (L); posición E757A, donde el glutamato (E) está sustituido con alanina (A); y posición L703G, donde la leucina (L) está sustituida con glicina (G). En una realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa es una variante de proteína de fusión de tipo CYP153A-RedRhF híbrida. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa en una célula hospedadora recombinante produce un título más alto de un ácido graso w-OH en comparación con el título de un ácido graso w-OH producido por la expresión de un polipéptido de fusión híbrida de CYp153A-reductasa en un célula hospedadora correspondiente. En otra realización, las variantes de polipéptidos de fusión híbrida de CYP153A-reductasa (y las secuencias de polinucleótidos correspondientes) incluyen
SEQ ID NO: 47-96. En otra realización, el ácido graso w-OH es una composición de ácido graso w-OH.
En un aspecto, la divulgación engloba un microorganismo recombinante o una célula hospedadora recombinante para producir un ácido graso w-OH o derivado de ácido graso w-OH in vivo cuando se cultiva en un caldo de fermentación en presencia de una fuente de carbono a partir de una materia prima renovable, el microorganismo que tiene una vía diseñada genéticamente para expresar al menos dos secuencias de ácido nucleico que codifican un polipéptido que incluye una tioesterasa de CE 3.1.2.- o CE 3.1.1.5 o 3.1.2.14; y una variante de polipéptido de fusión híbrida de CYP153A-reductasa, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene al menos el
90 %, 91 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con una cualquiera de
SEQ ID NO: 48, SEQ ID NO: 50, SEQ ID NO: 52, SEQ ID NO: 54, SEQ ID NO: 56, SEQ ID NO: 58, SEQ ID NO: 60,
SEQ ID NO: 62, SEQ ID NO: 64, SEQ ID NO: 66, SEQ ID NO: 68, SEQ ID NO: 70, SEQ ID NO: 72, SEQ ID NO: 74,
SEQ ID NO: 76, SEQ ID NO: 78, SEQ ID NO: 80, SEQ ID NO: 82, SEQ ID NO: 84, SEQ ID NO: 86, SEQ ID NO: 88,
SEQ ID NO: 90, SEQ ID NO: 92, SEQ ID NO: 94 y SEQ ID NO: 96. En una realización, la variante de polipéptido de
fusión híbrida de CYP153A-reductasa es una variante de proteína de fusión híbrida de CYP153A-RedRhF autosuficiente.
Otro aspecto de la presente divulgación proporciona un cultivo celular que incluye la célula hospedadora recombinante como se ha descrito anteriormente, en donde el cultivo celular produce un ácido graso w-OH o una composición del mismo. En una realización, el cultivo celular produce un ácido graso w-OH que incluye uno o más de un ácido graso o derivado de ácido graso C6, C7, Cs, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, Cs:1, C9:1, Cm 1, C11M, C12M, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1, o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C161 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C16 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C121 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C12 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C141 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C14 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso
C18:1 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C18 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso Cm1 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C10 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C81 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C8 w-OH saturado o una composición del mismo. En una realización, el cultivo celular produce un ácido graso C201 w-OH insaturado o una composición del mismo. En otra realización, el cultivo celular produce un ácido graso C20 w-OH saturado o una composición del mismo. En otra realización más, la célula hospedadora recombinante produce ácidos grasos w-OH saturados o insaturados adicionales o composiciones de los mismos.
Otro aspecto más de la presente divulgación proporciona un método para producir un ácido graso w-OH que tiene un aumento en el título, que incluye cultivar la célula hospedadora (descrito anteriormente) con una fuente de carbono; y cosechar un ácido graso w-OH o una composición del mismo. En particular, el método engloba producir un ácido graso o derivado de ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1, o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C161 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C16 w-OH saturado o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C121 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C12 w-OH saturado o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C141 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C14 w-OH saturado o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso Cm1 w-OH insaturado o una composición del mismo.
En otra realización, el ácido graso w-OH recogido es un ácido graso C18 w-OH saturado o una composición del mismo.
En una realización, el ácido graso w-OH recogido es un ácido graso Cm1 w-OH insaturado o una composición del
mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso Cío w-OH saturado o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C8 í w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C8 w-OH saturado o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C201 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C20 w-OH saturado o una composición del mismo. En una realización, el ácido graso w-OH recogido es un ácido graso C221 w-OH insaturado o una composición del mismo. En otra realización, el ácido graso w-OH recogido es un ácido graso C22 w-OH saturado o una composición del mismo.
Breve divulgación de los dibujos
La presente divulgación se entiende mejor cuando se lee junto con las figuras adjuntas, que sirven para ilustrar algunas realizaciones preferidas. Se entiende que, sin embargo, la divulgación no se limita a las realizaciones específicas desveladas en las figuras.
La Figura 1 es una descripción esquemática de una vía biosintética a modo de ejemplo para la producción de derivados de ácidos grasos w-hidroxilados tales como, por ejemplo, ácidos grasos C12 w-hidroxilados (FFA C12 w-OH) y/o ácidos grasos Cí 6 í w-hidroxilados (FFA Cí6 í w-OH) como resultado de la expresión de la variante de polipéptido de fusión híbrida de CYP153A-reductasa y un polipéptido de tioesterasa en un microorganismo recombinante. FAB (Fatty Acid Biosynthesis) se refiere a la biosíntesis de ácidos grasos en el microorganismo;
fatBí se refiere a una acil-ACP (Acyl Carrier Protein) tioesterasa de cadena media de Umbellularia californica (Laurel de California); y fatA3 se refiere a una acil-ACP tioesterasa de cadena larga de Arabidopsis thaliana.
La Figura 2 proporciona un ejemplo de la producción de ácidos grasos w-hidroxilados como resultado de la expresión de una variante de polipéptido de fusión híbrida de CYP153A-reductasa. Con el fin de ilustrar la producción de ácidos grasos w-hidroxilados (w-OH) mediante variantes, se empleó una mutagénesis por saturación de sitio. El gráfico representado muestra los mejores resultados de una mutagénesis por saturación de sitio de la posición de aminoácido 141 y 309 de cyp153A (G307A, A796V)-Red450RhF. La figura se refiere a las especies de ácidos grasos totales (FAS (Fatty Acid Species) totales) (véase la barra de color gris oscuro); a ácido hexadecenoico w-hidroxi (C16:1 w-OH) (véase la barra de color gris claro); y el porcentaje de ácidos grasos whidroxi (% de FFA w-OH) (véase la flecha).
Descripción detallada
Visión general
Una forma de eliminar nuestra dependencia de los productos petroquímicos es producir derivados de ácidos grasos tales como los derivados de ácidos grasos w-OH a través de microorganismos ecológicos que sirvan como hospedadores de producción en miniatura. Dichos hospedadores celulares (es decir, células hospedadoras o microorganismos recombinantes) están diseñados genéticamente para producir derivados de ácidos grasos w-OH y derivados de ácidos grasos bifuncionales a partir de fuentes renovables tales como materia prima renovable (por ejemplo, carbohidratos fermentables, biomasa, celulosa, glicerol, CO, CO2, etc.). Estos derivados de ácidos grasos w-OH son las materias primas para productos industriales que incluyen productos químicos especializados, polímeros y fragancias.
La presente divulgación se refiere a polipéptidos de fusión relacionados con la w-hidroxilasa, que incluyen polipéptidos de fusión híbrida de CYP153A-reductasa y variantes de los mismos que producen un título, un rendimiento y/o una productividad altos de composiciones de derivados de ácidos grasos w-OH cuando se expresan en células hospedadoras recombinantes. En el presente documento, la biosíntesis mejorada de derivados de ácidos grasos w-OH se logra transformando las células hospedadoras de manera que expresen un polipéptido de fusión híbrida de CYP153A-reductasa o una variante del mismo, que catalice la reacción de un ácido graso en un ácido graso w-OH tal como, por ejemplo, un ácido graso o derivado de ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18,
C19, C20, C8:1, C9:1, C10:1, C n :1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OH. La d las células hospedadoras recombinantes o las cepas de producción que expresan los polipéptidos de fusión híbrida de CYP153A-reductasa y sus variantes. En un aspecto, la divulgación se refiere a la subfamilia de P450 cyp153A.
Definiciones
Como se usan en la presente memoria descriptiva y las reivindicaciones adjuntas, las formas en singular "un", "una" y
"el" o "la" incluyen los referentes en plural salvo que el contexto indique claramente otra cosa. Por lo tanto, por ejemplo, la referencia a "una célula hospedadora" incluye dos o más de dichas células hospedadoras, la referencia a "un éster graso" incluye uno o más ésteres grasos, o mezclas de ésteres, la referencia a "una secuencia de ácido nucleico" incluye una o más secuencias de ácido nucleico, la referencia a "una enzima" incluye una o más enzimas, y similares.
El término "número de clasificación enzimática (CE)" se refiere a un número que denota una actividad enzimática específica. Los números CE clasifican las enzimas de acuerdo con la reacción que catalizan bajo un sistema de
nomenclatura de enzimas. Los números CE especifican reacciones catalizadas por enzimas. Por ejemplo, si diferentes enzimas de diferentes organismos catalizan la misma reacción, entonces tienen el mismo número CE. Además, diferentes pliegues de proteínas pueden catalizar una reacción idéntica y, por lo tanto, se les asignaría un número CE idéntico (por ejemplo, enzimas isofuncionales no homólogas o NISE, Non-homologous ISofunctional Enzymes). Los números CE son establecidos por el Comité de Nomenclatura de la Unión Internacional de Bioquímica y Biología Molecular (IUBMB, International Union of Biochemistry and Molecular Biology), cuya descripción se encuentra disponible en el sitio web de la Nomenclatura de enzimas IUBMB en la World Wide Web. Por ejemplo, la actividad enzimática de la citocromo P450 monooxigenasa (P450), incluyendo la actividad enzimática de w-hidroxilasa o woxigenasa se clasifica como CE 1.14.15.3. La funcionalidad de las enzimas que pertenecen a la familia de enzimas P450 se conserva en la mayoría de los procariotas de una especie a otra. Por lo tanto, diferentes especies microbianas pueden llevar a cabo la misma actividad enzimática que se clasifica como CE 1.14.15.3. Un ejemplo de una actividad enzimática característica de CE 1.14.15.3 es la actividad enzimática de un polipéptido de fusión híbrida de CYP153A-reductasa o una variante del mismo como se describe en el presente documento (anteriormente).
Las expresiones "ácido graso omega-hidroxilado" o "ácido graso w-hidroxilado" o "ácido graso w-hidroxi" o "ácido graso w-hidroxilo" o "ácido graso w-OH" o "ácido graso wOH" se usan indistintamente en el presente documento y se refieren a un ácido graso que se origina en el metabolismo de los ácidos grasos y que tiene al menos un grupo OH en la posición omega (w). Los ejemplos de dichos ácidos grasos w-hidroxilados son ácidos grasos C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C201. En una realización, dichos ácidos grasos w-hidroxilados son ácidos grasos C80 w-OH, ácidos grasos C100 w-OH, ácidos grasos C120 w-OH, ácidos grasos C140 w-OH, ácidos grasos C160 w-OH, ácidos grasos C180 w-OH, ácidos grasos C200 w-OH, ácidos grasos C81 w-OH, ácidos grasos C101 w-OH, ácidos grasos C121 w-OH, ácidos grasos C141 w-OH, ácidos grasos C161 w-OH, ácidos grasos C181 w-OH, ácidos grasos C201 w-OH, y similares. En un microorganismo, el ácido graso w-hidroxilado puede usarse para producir derivados de ácidos grasos w-hidroxilados tales como ésteres grasos w-hidroxilados, así como derivados de ácidos grasos bifuncionales que incluyen a,wdiácidos, a,w-diésteres y a,w-dioles. En ese sentido, Las expresiones "derivado de ácido graso omega-hidroxilado" y "derivado de ácido graso w-hidroxilado" y "derivado de ácido graso w-hidroxi" y "derivado de ácido graso w-hidroxilo" y "derivado de ácido graso a,w-bifuncional" y "derivado de ácido graso w-OH "se refiere a una entidad química que se originó a partir del metabolismo de los ácidos grasos y que tiene al menos un grupo OH en la posición omega o se deriva de un producto intermedio que tiene al menos un grupo OH en la posición omega. En el presente documento, la "posición omega (w)" se refiere al átomo de carbono terminal de un derivado de ácido graso en el extremo opuesto con respecto a su grupo funcional primario. Dichos derivados de ácidos grasos w-hidroxilados incluyen, pero sin limitación, a,w-diácidos; a,w-diésteres; a,w-dioles y productos químicos derivados de los mismos (por ejemplo, macrolactonas).
Una ''composición de ácido graso w-hidroxilado'' o ''composición de ácido graso w-OH" como se menciona en el presente documento es producida por una célula hospedadora recombinante y normalmente incluye una mezcla de ciertos tipos de ácidos grasos w-hidroxilados con distintas longitudes de cadena y/o características de saturación y/o de ramificación. De manera similar, una célula hospedadora recombinante produce una "composición de derivado de ácido graso w-hidroxilado" y normalmente comprende una mezcla de ciertos tipos de derivados de ácidos grasos whidroxilados con distintas longitudes de cadena y/o características de saturación y/o de ramificación (por ejemplo, ácidos grasos w-hidroxilados con distintas longitudes de cadena y/o características de saturación y/o de ramificación; ésteres grasos w-hidroxilados con distintas longitudes de cadena y/o características de saturación y/o de ramificación; a,w-diácidos de distintas longitudes de cadena y/o características de saturación y/o ramificación; a,w-diésteres de distintas longitudes de cadena y/o características de saturación y/o de ramificación; a,w-dioles de distintas longitudes de cadena y/o características de saturación y/o de ramificación; y similares). En algunos casos, la composición de derivado de ácido graso w-OH incluye principalmente un tipo de derivado de ácido graso w-OH tal como, por ejemplo, 1,12-dodecenodiol, o 1,14-tetradecanodiol, o éster metílico del ácido 16-hidroxi-hexadecanoico, o ácido 16-hidroxihexadecenoico, o ácido 15-hidroxi-pentadecanoico, o ácido 15-hidroxi-pentadecenoico, o ácido 18-hidroxioctacecenoico, o los ésteres metílicos de cualquiera de estos derivados de ácidos grasos, u otros. En otros casos más, la composición de derivado de ácido graso w-OH comprende una mezcla de más de un tipo de derivado de ácido graso w-OH para proporcionar una composición diseñada específicamente (por ejemplo, aproximadamente el 20 % de ácido 12-hidroxi-dodecanoico y aproximadamente el 80 % de ácido 1,14-14-hidroxi-tetradecanoico en la misma composición proporcionaría dicho ejemplo).
La expresión "número de registro" o "número de registro NCBI" o "número de registro GenBank" se refiere a un número que denota una secuencia específica de ácido nucleico. Los números de registro de secuencias mencionados en la presente descripción se obtuvieron de las bases de datos proporcionadas por el NCBI (National Center for Biotechnology Information, Centro Nacional de Información Biotecnológica) mantenido por los Institutos Nacionales de Salud, EE. UU., y de las bases de datos UniProt Knowledgebase (UniProtKB) y Swiss-Prot proporcionadas por el Instituto Suizo de Bioinformática (también denominado número de registro UniProtKB).
Como se usa en el presente documento, el término "nucleótido" se refiere a una unidad monomérica de un polinucleótido que consiste en una base heterocíclica, un azúcar y uno o más grupos fosfato. Las bases naturales (guanina, (G), adenina, (A), citosina, (C), timina, (T) y uracilo (U)) normalmente se derivan de purina o pirimidina, aunque debe entenderse que también se incluyen análogos de bases naturales y no naturales. El azúcar natural es la
pentosa (azúcar de cinco átomos de carbono) desoxirribosa (que forma el ADN) o ribosa (que forma el ARN), aunque debe entenderse que también se incluyen análogos de azúcares naturales y no naturales. Los ácidos nucleicos normalmente están unidos mediante enlaces fosfato para formar ácidos nucleicos o polinucleótidos, aunque se conocen muchos otros enlaces en la técnica (por ejemplo, fosforotioatos, boranofosfatos y similares).
El término "polinucleótido" se refiere a un polímero de ribonucleótidos (ARN) o desoxirribonucleótidos (ADN), que puede ser monocatenario o bicatenario y que puede contener nucleótidos no naturales o modificados. Los términos "polinucleótido", "secuencia de ácido nucleico", y "secuencia de nucleótidos" se usan indistintamente en el presente documento para referirse a una forma polimérica de nucleótidos de cualquier longitud, bien ARN o ADN. Estos términos se refieren a la estructura primaria de la molécula y, por lo tanto, incluyen ADN bicatenario y monocatenario, y ARN bicatenario y monocatenario. Los términos incluyen, como equivalentes, análogos de ARN o ADN hechos de análogos de nucleótidos y polinucleótidos modificados tales como, pero sin limitación, polinucleótidos metilados y/o protegidos terminalmente. El polinucleótido puede estar en cualquier forma, incluyendo, pero sin limitación, de plásmido, vírica, cromosómica, EST, ADNc, ARNm y ARNr.
Como se usa en el presente documento, los términos "polipéptido" y "proteína" se usan indistintamente para referirse a un polímero de restos de aminoácidos. La expresión "polipéptido recombinante" se refiere a un polipéptido que se produce mediante técnicas recombinantes, en donde, en general, el ADN o ARN que codifica la proteína expresada se inserta en un vector de expresión adecuado que, a su vez, se usa para transformar una célula hospedadora para producir el polipéptido. De manera similar, las expresiones "polinucleótido recombinante" o "ácido nucleico recombinante" o "ADN recombinante" se producen mediante técnicas recombinantes que son conocidas por los expertos en la materia.
El término "homólogo" se refiere a un polinucleótido o un polipéptido que comprende una secuencia que es al menos aproximadamente un 50 por ciento (%) idéntica a la secuencia polinucleotídica o polipeptídica correspondiente. Preferentemente, los polinucleótidos o polipéptidos homólogos tienen secuencias de polinucleótidos o secuencias de aminoácidos que tienen al menos aproximadamente un 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o al menos aproximadamente un 99 % de homología con la secuencia de aminoácidos o la secuencia polinucleotídica correspondientes. Como se usan en el presente documento, los términos "homología" de secuencia e "identidad" de secuencia se usan indistintamente. Un experto en la materia conoce los métodos de determinación de la homología entre dos o más secuencias. En resumen, los cálculos de "homología" entre dos secuencias se pueden realizar de la siguiente manera. Se alinean las secuencias con fines comparativos óptimos (por ejemplo, se pueden introducir huecos en una o ambas de una primera y una segunda secuencia de aminoácidos o de ácido nucleico para un alineamiento óptimo, y las secuencias no homólogas se pueden descartar para fines comparativos). En una realización preferida, la longitud de una primera secuencia que se alinea con fines comparativos es al menos aproximadamente un 30 %, preferentemente, al menos aproximadamente un 40 %, más preferentemente, en al menos aproximadamente un 50 %, incluso más preferentemente, al menos aproximadamente un 60 %, e incluso más preferentemente, al menos aproximadamente un 70 %, al menos aproximadamente el 80 %, al menos aproximadamente el 85 %, al menos aproximadamente el 90 %, al menos aproximadamente el 95 %, al menos aproximadamente un 98 % o aproximadamente un 100 % de la longitud de una segunda secuencia. Luego se comparan los restos de aminoácidos o nucleótidos de las posiciones de aminoácidos o posiciones de nucleótidos correspondientes de la primera y segunda secuencias. Cuando una posición en la primera secuencia está ocupada por el mismo resto de aminoácido o nucleótido que la posición correspondiente en la segunda secuencia, entonces las moléculas son idénticas en esa posición. El porcentaje de homología entre las dos secuencias es una función del número de posiciones idénticas compartidas por las secuencias, teniendo en cuenta el número de huecos y la longitud de cada hueco, que es necesario introducir para un alineamiento óptimo de las dos secuencias. Puede realizarse la comparación de secuencias y la determinación del porcentaje de homología entre dos secuencias usando un algoritmo matemático, tal como BLa St (Altschul et al. (1990) J. Mol. Biol. 215(3):403-410). El porcentaje de homología entre dos secuencias de aminoácidos también se puede determinar usando el algoritmo de Needleman y Wunsch, que se ha incorporado al programa GAP en el paquete de software GCG, usando una matriz Blossum 62 o una matriz PAM250, y un peso de separación de 16, 14, 12, 10, 8, 6 o 4 y un peso de longitud de 1, 2, 3, 4, 5 o 6 (Needleman y Wunsch (1970) J. Mol. Biol. 48:444-453). El porcentaje de homología entre dos secuencias de nucleótidos también se puede determinar usando el programa GAP en el paquete de software GCG, usando una matriz NWSgapdna.CMP y un peso de separación de 40, 50, 60, 70 u 80 y un peso de longitud de 1,2, 3, 4, 5 o 6. Un experto en la materia puede realizar cálculos iniciales de homología y ajustar los parámetros del algoritmo en consecuencia. Un conjunto preferido de parámetros (y el que debería usarse si un profesional no estuviera seguro acerca de qué parámetros deben aplicarse para determinar si una molécula está dentro de una limitación de homología de las reivindicaciones) es una matriz de puntuación Blossum 62 con una penalización por hueco de 12, una penalización por hueco extendido de 4 y una penalización por hueco de desplazamiento de fase de 5. Se conocen métodos adicionales de alineamiento de secuencias en las técnicas de biotecnología (véase, por ejemplo, Rosenberg (2005) BMC Bioinformatics 6:278; Altschul et al. (2005) FEBS J. 272(20):5101-5109).
La expresión "se hibrida en condiciones de baja rigurosidad, rigurosidad media, alta rigurosidad o muy alta rigurosidad "describe condiciones de hibridación y lavado. Puede encontrarse orientación para llevar a cabo las reacciones de hibridación en "Current Protocols in Molecular Biology", John Wiley & Sons, N.Y. (1989), 6.3.1 - 6.3.6. En esa referencia, se describen métodos acuosos y no acuosos, y puede usarse cualquier método. Las condiciones de
hibridación específicas citadas en el presente documento son las siguientes: (1) condiciones de hibridación de baja rigurosidad: 6x cloruro de sodio/citrato de sodio (SSC) a aproximadamente 45 °C, seguido de dos lavados en 0,2x SSC, SDS al 0,1 % al menos a 50 °C (la temperatura de los lavados se puede aumentar hasta 55 °C para condiciones de baja rigurosidad); (2) condiciones de hibridación de rigurosidad media: 6x SSC a aproximadamente 45 °C, seguido de uno o más lavados en 0,2x SSC, SDS al 0,1 % a 60 °C; (3) condiciones de hibridación de alta rigurosidad: 6x SSC a aproximadamente 45 °C, seguido de uno o más lavados en 0,2x SSC, SDS al 0,1 % a 65 °C; y (4) condiciones de hibridación de muy alta rigurosidad: fosfato de sodio 0,5 M, SDS al 7 % a 65 °C, seguido de uno o más lavados en 0,2x SSC, SDS al 1 % a 65 °C. Las condiciones de rigurosidad muy alta (4) son las condiciones preferidas a menos que se especifique lo contrario.
Un polipéptido "endógeno" se refiere a un polipéptido codificado por el genoma de la célula primaria (o célula hospedadora). Un polipéptido "exógeno" se refiere a un polipéptido que no está codificado por el genoma de la célula primaria. Una variante de polipéptido o polipéptido mutante es un ejemplo de un polipéptido exógeno. Por lo tanto, una molécula de ácido nucleico que no se produce de manera natural se considera que es exógena con respecto a la célula una vez introducida en la célula. Una molécula de ácido nucleico que se produce de manera natural también puede ser exógena con respecto a una célula particular. Por ejemplo, una secuencia codificante completa aislada de una célula X es un ácido nucleico exógeno con respecto a la célula Y una vez que la secuencia codificante se introduce en la célula Y, incluso si X e Y son el mismo tipo de célula.
El término "sobreexpresado" significa que se hace que un gen se transcriba a una tasa elevada en comparación con la tasa de transcripción endógena para ese gen. En algunos ejemplos, la sobreexpresión incluye adicionalmente una tasa elevada de traducción del gen en comparación con la tasa de traducción endógena para ese gen. En la técnica, se conocen bien métodos de ensayo para la sobreexpresión, por ejemplo, los niveles de ARN transcrito pueden evaluarse usando rtPCR y los niveles de proteína pueden evaluarse usando análisis en gel de SDS page.
El término "heterólogo" significa derivado de un organismo diferente, un tipo de célula diferente o diferentes especies. Como se usa en el presente documento, se refiere a una secuencia nucleotídica, polinucleotídica, polipeptídica o proteica, no presente de manera natural en un organismo dado. Por ejemplo, se puede introducir una secuencia polinucleotídica que es nativa de las cianobacterias en una célula hospedadora de E. coli mediante métodos recombinantes, y que el polinucleótido de las cianobacterias sea entonces heterólogo a la célula de E. coli (por ejemplo, célula recombinante). El término "heterólogo" también puede usarse con referencia a una secuencia nucleotídica, polinucleotídica, polipeptídica o proteica que está presente en una célula hospedadora recombinante en un estado no nativo. Por ejemplo, una secuencia nucleotídica, polinucleotídica, polipeptídica o proteica "heteróloga" puede modificarse con respecto a la secuencia de tipo silvestre presente de manera natural en la célula hospedadora de tipo silvestre correspondiente, por ejemplo, una modificación en el nivel de expresión o en la secuencia de un nucleótido, un polinucleótido, un polipéptido o una proteína.
Como se usa en el presente documento, el término "fragmento" de un polipéptido se refiere a una parte más corta de un polipéptido o de una proteína de longitud completa que varía en tamaño desde dos restos de aminoácidos hasta la secuencia de aminoácidos completa menos un resto de aminoácido. En ciertas realizaciones de la divulgación, un fragmento se refiere a la secuencia de aminoácidos completa de un dominio de un polipéptido o de una proteína (por ejemplo, un dominio de unión al sustrato o un dominio catalítico).
El término "mutagénesis" se refiere a un proceso mediante el que la información genética de un organismo se cambia de manera estable. La mutagénesis de una secuencia de ácido nucleico que codifica una proteína produce una proteína mutante. La mutagénesis también se refiere a cambios en las secuencias de ácido nucleico no codificantes que producen una actividad proteica modificada.
Una "mutación", como se usa en el presente documento, se refiere a un cambio permanente en una posición de ácido nucleico de un gen o en una posición de aminoácido de un polipéptido o de una proteína. Las mutaciones incluyen sustituciones, adiciones, inserciones y eliminaciones. Por ejemplo, una mutación en una posición de aminoácido puede ser una sustitución de un tipo de aminoácido con otro tipo de aminoácido (por ejemplo, una serina (S) puede ser sustituida con una alanina (A); una lisina (L) puede ser sustituida con una treonina (T); etc.). Como tales, un polipéptido o una proteína puede tener una o más mutaciones en las que un aminoácido está sustituido con otro aminoácido.
Como se usa en el presente documento, el término "gen" se refiere a secuencias de ácido nucleico que codifican un producto de ARN o un producto proteico, así como secuencias de ácido nucleico unidas operativamente que afectan a la expresión del ARN o proteína (por ejemplo, dichas secuencias incluyen, pero sin limitación, secuencias promotoras o potenciadoras) o secuencias de ácido nucleico unidas operativamente que codifican secuencias que afectan a la expresión del ARN o proteína (por ejemplo, dichas secuencias incluyen, pero sin limitación, sitios de unión a ribosomas o secuencias de control de la traducción).
Las secuencias de control de la expresión son conocidas en la técnica e incluyen, por ejemplo, promotores, potenciadores, señales de poliadenilación, terminadores de la transcripción, sitios de entrada al ribosoma internos (IRES, Internal Ribosome Entry Sites) y similares, que proporcionan la expresión de la secuencia polinucleotídica en una célula hospedadora. Las secuencias de control de la expresión interactúan específicamente con proteínas
celulares que participan en la transcripción (Maniatis et al., (1987) Science 236:1237-1245). Se describen ejemplos de secuencias de control de la expresión en, por ejemplo, Goeddel, "Gene Expression Technology: Methods in Enzymology", Vol. 185, Academic Press, San Diego, Calif. (1990). En los métodos de la divulgación, una secuencia de control de la expresión está unida operativamente a una secuencia polinucleotídica. Por "unidas operativamente" se entiende que una secuencia polinucleotídica y una secuencia de control de la expresión están conectadas de manera que permiten la expresión génica cuando las moléculas apropiadas (por ejemplo, proteínas activadoras de la transcripción) se unen a la secuencia de control de la expresión. Los promotores unidos operativamente se encuentran en dirección 5' de la secuencia polinucleotídica seleccionada en términos de la dirección de transcripción y traducción. Los potenciadores unidos operativamente se pueden ubicar en dirección 5', dentro o en dirección 3' del polinucleótido seleccionado.
Como se usa en el presente documento, el término "vector" se refiere a una molécula de ácido nucleico capaz de transportar otro ácido nucleico, es decir, una secuencia polinucleotídica, al que se ha unido. Un tipo de vector útil es un episoma (es decir, un ácido nucleico capaz de realizar la replicación extracromosómica). Los vectores útiles son aquellos capaces de realizar la replicación autónoma y/o expresión de los ácidos nucleicos a los que están unidos. Los vectores capaces de dirigir la expresión de los genes a los que están unidos operativamente se denominan en el presente documento "vectores de expresión". En general, los vectores de expresión de utilidad en las técnicas de ADN recombinante suelen estar en forma de "plásmidos", que generalmente se refieren a bucles circulares de ADN bicatenario que, en su forma vectorial, no están unidos al cromosoma. Se proporcionan otros vectores de expresión útiles en forma lineal. También se incluyen otras de dichas formas de vectores de expresión que cumplen funciones equivalentes y que se han dado a conocer en la técnica posteriormente a continuación. En algunas realizaciones, un vector recombinante incluye además un promotor unido operativamente a la secuencia polinucleotídica. En algunas realizaciones, el promotor es un promotor regulado por el desarrollo, un promotor específico de orgánulo, un promotor específico de tejido, un promotor inducible, un promotor constitutivo o un promotor específico de célula. El vector recombinante normalmente comprende al menos una secuencia seleccionada entre una secuencia de control de la expresión acoplada operativamente a la secuencia polinucleotídica; un marcador de selección acoplado operativamente a la secuencia polinucleotídica; una secuencia marcadora acoplada operativamente a la secuencia polinucleotídica; una fracción de purificación acoplada operativamente a la secuencia polinucleotídica; una secuencia de secreción acoplada operativamente a la secuencia polinucleotídica; y una secuencia de direccionamiento acoplada operativamente a la secuencia polinucleotídica. En ciertas realizaciones, la secuencia nucleotídica se incorpora de manera estable en el ADN genómico de la célula hospedadora, y la expresión de la secuencia nucleotídica está bajo el control de una región promotora regulada. Los vectores de expresión como se usan en el presente documento incluyen una secuencia polinucleotídica particular como se describe en el presente documento en una forma adecuada para la expresión de la secuencia polinucleotídica en una célula hospedadora. Los expertos en la materia apreciarán que el diseño del vector de expresión puede depender de factores tales como la elección de la célula hospedadora que se vaya a transformar, el nivel de expresión del polipéptido deseado, etc. Los vectores de expresión descritos en el presente documento se pueden introducir en las células hospedadoras para producir polipéptidos, incluyendo los polipéptidos de fusión, codificados por las secuencias polinucleotídicas como se describe en el presente documento. La expresión de genes que codifican polipéptidos en procariotas, por ejemplo, E. coli, se realiza con mayor frecuencia con vectores que contienen promotores constitutivos o inducibles que dirigen la expresión de polipéptidos de fusión o no fusión. Los vectores de fusión agregan una cantidad de aminoácidos a un polipéptido codificado en los mismos, usualmente al extremo amino o carboxi del polipéptido recombinante. Dichos vectores de fusión normalmente sirven para uno o más de los tres siguientes propósitos, que incluyen para aumentar la expresión del polipéptido recombinante; para aumentar la solubilidad del polipéptido recombinante; y para ayudar en la purificación del polipéptido recombinante actuando como ligando en la purificación por afinidad. Con frecuencia, en los vectores de expresión de fusión, se introduce un sitio de escisión proteolítica en la unión de la fracción de fusión y el polipéptido recombinante. Esto permite la separación del polipéptido recombinante de la fracción de fusión después de la purificación del polipéptido de fusión. En ciertas realizaciones, una secuencia polinucleotídica de la divulgación está unida operativamente a un promotor derivado del bacteriófago T5.
En ciertas realizaciones, la célula hospedadora es una célula de levadura, y el vector de expresión es un vector de expresión de levadura. Los ejemplos de vectores para la expresión en levaduras S. cerevisiae incluyen pYepSec1 (Baldari et al. (1987) EMBO J. 6: 229-234); pMFa (Kurjan et al. (1982) Cell 30:933-943); pJRY88 (Schultz et al. (1987) Gene 54: 113-123); pYES2 (Invitrogen Corp., San Diego, CA) y picZ (Invitrogen Corp., San Diego, CA). En otras realizaciones, la célula hospedadora es una célula de insecto, y el vector de expresión es un vector de expresión de baculovirus. Los vectores de baculovirus disponibles para la expresión de proteínas en células de insecto cultivadas (por ejemplo, células Sf9) incluyen, por ejemplo, la serie pAc (Smith et al. (1983) Mol. Cell Biol. 3: 2156-2165) y la serie pVL (Lucklow et al. (1989) Virology 170: 31-39). En otra realización más, las secuencias polinucleotídicas descritas en el presente documento pueden expresarse en células de mamífero usando un vector de expresión de mamífero. Otros sistemas de expresión adecuados para células procariotas y eucariotas son bien conocidos en la técnica; véase, por ejemplo, Sambrook et al., "Molecular Cloning: A Laboratory Manual", segunda edición, Cold Spring Harbor Laboratory, (1989).
Como se usa en el presente documento, el término "CoA" o "acil-CoA" se refiere a un aciltioéster formado entre el átomo de carbono carbonílico de la cadena de alquilo y el grupo sulfhidrilo de la fracción 4'-fosfopantetionilo de la coenzima A (CoA), que tiene la fórmula R-C(O)S-CoA, donde R es cualquier grupo alquilo que tiene al menos 4 átomos
de carbono.
El término "ACP" significa proteína portadora de acilo. ACP es un vehículo altamente conservado de productos intermedios de acilo durante la biosíntesis de ácidos grasos, en donde la cadena de crecimiento se une durante la síntesis como un éster de tiol en el tiol distal de una fracción 4'-fosfopanteteína. La proteína existe en dos formas, es decir, apo-ACP (inactiva en la biosíntesis de ácidos grasos) y ACP u holo-ACP (activa en la biosíntesis de ácidos grasos). Los términos "ACP" y "holo-ACP" se usan indistintamente en el presente documento y se refieren a la forma activa de la proteína. Una enzima denominada fosfopanteteiniltransferasa participa en la conversión de la apo-ACP inactiva en la holo-ACP activa. De manera más específica, la ACP se expresa en la forma inactiva de apo-ACP y una fracción 4'-fosfopanteteína debe unirse después de la traducción a un resto de serina conservado en la ACP por la acción de la proteína portadora sintasa de holo-acilo (ACPS), una fosfopanteteiniltransferasa, para producir holo-ACP.
Como se usa en el presente documento, el término "acil-ACP" se refiere a un aciltioéster formado entre el carbono carbonílico de una cadena de alquilo y el grupo sulfhidrilo de la fracción fosfopanteteinilo de una proteína portadora de acilo (ACP). En algunas realizaciones, una ACP es un producto intermedio en la síntesis de acil-ACP completamente saturadas. En otras realizaciones, una ACP es un producto intermedio en la síntesis de acil-ACP insaturadas. En algunas realizaciones, la cadena de carbono tendrá aproximadamente 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25 o 26 átomos de carbono.
Como se usa en el presente documento, la expresión "derivado de ácido graso" significa un "ácido graso" o un "derivado de ácido graso", que pueden denominarse "ácido graso o derivado del mismo". El término "ácido graso" significa un ácido carboxílico que tiene la fórmula RCOOH. R representa un grupo alifático, preferentemente, un grupo alquilo. R puede incluir entre aproximadamente 4 y aproximadamente 22 átomos de carbono. Los ácidos grasos pueden estar saturados, monoinsaturados o poliinsaturados. Un "derivado de ácido graso" es un producto creado en parte a partir de la vía biosintética de ácidos grasos del organismo hospedador de producción (por ejemplo, célula hospedadora o microorganismo recombinante). "Derivados de ácidos grasos" incluye productos creados en parte a partir de ACP, acil-ACP o derivados de acil-ACP. Los ejemplos de derivados de ácidos grasos incluyen, por ejemplo, acil-CoA, ácidos grasos, aldehídos grasos, alcoholes de cadena corta y larga, alcoholes grasos, hidrocarburos, ésteres (por ejemplo, ceras, ésteres de ácidos grasos o ésteres grasos), olefinas terminales, olefinas internas, cetonas, así como ácidos grasos u-OH y sus derivados de ácidos grasos u-OH, incluidos los a,ui-diácidos y otros compuestos bifuncionales.
Como se usa en el presente documento, la expresión "vía biosintética de los ácidos grasos" significa una vía biosintética que produce ácidos grasos y derivados de los mismos. La vía biosintética de los ácidos grasos puede incluir enzimas adicionales para producir derivados de ácidos grasos que tengan las características deseadas.
El grupo R de un ácido graso puede ser una cadena lineal o una cadena ramificada. Las cadenas ramificadas pueden tener más de un punto de ramificación y pueden incluir ramificaciones cíclicas. En algunas realizaciones, el ácido graso ramificado es un ácido graso C6, C7, Cs, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C21, C22, C23, C24, C25 o C26 ramificado. En otras realizaciones, el ácido graso ramificado es un ácido graso C6, Cs, C10, C12, C13, C14, C15, C16, C17, C18 o C20 ramificado. En ciertas realizaciones, el grupo hidroxilo (OH) del ácido graso ramificado está en la posición omega (u). En ciertas realizaciones, el ácido graso ramificado es un ácido iso-graso o un ácido anteiso-graso. En realizaciones ilustrativas, el ácido graso ramificado se selecciona entre ácido graso iso-C70-, iso-Cs0-, iso-C90-, iso-C10:0-, iso-C11:0-, iso-C12:0-, iso-C13:0-, iso-C14:0-, iso-C15:0-, iso-C16:0-, iso-C17:0-, iso-C18:0-, iso-C19:0-, iso-C20:0, anteiso-C7:0-, anteiso-C9:0-, anteiso-Cn:0-, anteiso-C13:0-, anteiso- C15:0-, anteiso-C17:0- y anteiso-Cm0 ramificado.
El grupo R de un ácido graso puede estar saturado o insaturado. Si está insaturado, el grupo R puede tener uno o más de un punto de insaturación. En algunas realizaciones, el ácido graso insaturado es un ácido graso monoinsaturado. En ciertas realizaciones, el ácido graso insaturado es un ácido graso Cs1-, C91-, C101-, C111-, C121-, C13:1-, C14:1-, C15:1-, C16:1-, C17:1-, C18:1-, C19:1-, C20:1-, C21:1-, C22:1-, C23:1-, C24:1-, C25:1- o C26:1 insaturado. En ciertas realizaciones, el ácido graso insaturado es Cs:1, Cm1, C12:1, C141 Cm1, C18:1 o C20:1. En otras realizaciones más, el ácido graso insaturado está insaturado en la posición omega-7. En ciertas realizaciones, el ácido graso insaturado tiene un doble enlace cis.
Como se usa en el presente documento, una "célula hospedadora recombinante" o "célula hospedadora diseñada genéticamente" es una célula hospedadora, por ejemplo, un microorganismo que se ha modificado de modo que produce ácidos grasos u-hidroxilados y derivados de ácidos grasos u-hidroxilados, incluidos derivados de ácidos grasos bifuncionales. En algunas realizaciones, la célula hospedadora recombinante incluye uno o más polinucleótidos, cada polinucleótido codifica un polipéptido de fusión híbrida de CYP153A-reductasa o una variante del mismo que tiene actividad de enzima biosintética u-hidroxilasa, en donde la célula hospedadora recombinante produce un ácido graso u-hidroxilado y/o un derivado de ácido graso u-hidroxilado, o una composición del mismo, cuando se cultiva en presencia de una fuente de carbono en condiciones eficaces para expresar los polinucleótidos.
Como se usa en el presente documento, el término "clon" normalmente se refiere a una célula o a un grupo de células descendientes de y esencialmente idénticas genéticamente a un único ancestro común, por ejemplo, las bacterias de una colonia bacteriana clonada surgieron de una sola célula bacteriana.
Como se usa en el presente documento, el término "cultivo" normalmente se refiere a un medio líquido que comprende células viables. En una realización, un cultivo comprende células que se reproducen en un medio de cultivo predeterminado en condiciones controladas, por ejemplo, un cultivo de células hospedadoras recombinantes cultivadas en medios líquidos que comprenden una fuente de carbono seleccionada y/o nitrógeno.
Los términos "cultivar" o "cultivo" se refieren al crecimiento de una población de células (por ejemplo, células microbianas) en condiciones adecuadas en un medio líquido o sólido. En realizaciones particulares, cultivar se refiere a la bioconversión fermentativa de un sustrato hasta la obtención de un producto final. Los medios de cultivo son bien conocidos, y los componentes individuales de dichos medios de cultivo están disponibles en fuentes comerciales, por ejemplo, en los medios DIFCO y en los medios BBL. En un ejemplo no limitante, el medio de nutrientes acuoso es un "medio rico" que comprende fuentes complejas de nitrógeno, sales y carbono, tales como el medio YP, que comprende 10 g/l de peptona y 10 g/l de extracto de levadura de dicho medio. Además, la célula hospedadora puede diseñarse genéticamente para asimilar carbono de manera eficaz y usar materiales celulósicos como fuentes de carbono de acuerdo con los métodos descritos, por ejemplo, en las patentes de EE.UU. n.° 5.000.000; 5.028.539; 5.424.202; 5.482.846; 5.602.030 y WO2010127318. Además, la célula hospedadora se puede diseñar genéticamente para expresar una invertasa a fin de poderse usar la sacarosa como fuente de carbono.
Como se usa en el presente documento, la expresión "en condiciones eficaces para expresar dichas secuencias nucleotídicas heterólogas" significa cualquier condición que permita que una célula hospedadora produzca un derivado de ácido graso deseado (por ejemplo, ácido graso u>-OH y/o derivado de ácido graso u>-OH). Las condiciones adecuadas incluyen, por ejemplo, las condiciones de fermentación.
Como se usa en el presente documento, actividad "modificada" o un "nivel alterado de" actividad de una proteína, por ejemplo, una enzima, en una célula hospedadora recombinante se refiere a una diferencia en una o más características en la actividad determinada en relación con la célula hospedadora primaria o nativa. Por lo general, las diferencias en la actividad se determinan entre una célula hospedadora recombinante, que tiene actividad modificada y la célula hospedadora de tipo silvestre correspondiente (por ejemplo, comparación de un cultivo de una célula hospedadora recombinante con respecto a la célula hospedadora de tipo silvestre). Las actividades modificadas pueden ser el resultado de, por ejemplo, cantidades modificadas de proteína expresadas por una célula hospedadora recombinante (por ejemplo, como resultado del aumento o de la disminución del número de copias de secuencias de ADN que codifican la proteína, aumento o disminución del número de transcripciones de ARNm que codifican la proteína, y/o aumento o disminución de las cantidades de traducción proteica de la proteína a partir del ARNm); cambios en la estructura de la proteína (por ejemplo, cambios en la estructura primaria, tales como, cambios en la secuencia de codificación de la proteína que producen cambios en la especificidad del sustrato, cambios en los parámetros cinéticos observados); y cambios en la estabilidad de la proteína (por ejemplo, aumento o disminución de la degradación de la proteína). En algunas realizaciones, el polipéptido es un mutante o una variante de cualquiera de los polipéptidos descritos en el presente documento. En determinados casos, la secuencia de codificación para los polipéptidos como se describen en el presente documento son de codones optimizados para la expresión en una célula hospedadora en particular. Por ejemplo, para la expresión en E. coli, se pueden optimizar uno o más codones (Grosjean et al. (1982) Gene 18: 199-209).
La expresión "secuencias reguladoras", como se usa en el presente documento, normalmente se refiere a una secuencia de bases en el ADN, unida operativamente a secuencias de ADN que codifican una proteína que finalmente controla la expresión de la proteína. Los ejemplos de secuencias reguladoras incluyen, pero sin limitación, secuencias promotoras de ARN, secuencias de unión de factor de transcripción, secuencias de terminación de la transcripción, moduladores de la transcripción (tales como elementos potenciadores), secuencias de nucleótidos que afectan a la estabilidad del ARN y secuencias reguladoras de la traducción (tales como sitios de unión a ribosomas (por ejemplo, secuencias de Shine-Dalgarno en procariotas o secuencias de Kozak en eucariotas), codones de inicio, codones de terminación).
Como se usa en el presente documento, la expresión "la expresión de dicha secuencia de nucleótidos se modifica con respecto a la secuencia de nucleótidos de tipo silvestre", significa un aumento o una disminución en el nivel de expresión y/o la actividad de una secuencia de nucleótidos endógena o la expresión y/o actividad de una secuencia de nucleótidos que codifica un polipéptido heterólogo o no nativo.
Como se usa en el presente documento, la expresión "la actividad de una variante de secuencia de polipéptido de fusión híbrida de CYP153A-reductasa se modifica en relación con la actividad de una secuencia de polipéptido de fusión híbrida de CYP153A-reductasa" (es decir, un molde de polipéptido) significa un aumento o una disminución del nivel de actividad de una variante de secuencia de polipéptido expresada en comparación con un molde de secuencia de polipéptido expresada. El molde de polipéptido está codificado por un molde de ácido nucleico (es decir, una secuencia de molde de ADN). Un ejemplo de un molde de secuencia de polipéptido es la secuencia de proteína de fusión híbrida de cyp153A-RedRhF, en donde cyp153A se fusiona con un dominio reductasa. Otro ejemplo de un molde de secuencia de polipéptido es SEQ ID NO: 6. Otro ejemplo de un molde de secuencia de polipéptido es SEQ ID NO: 38. Cualquier secuencia de polipéptido puede servir como un molde que incluye variantes.
Como se usa en el presente documento, el término "expresar" con respecto a un polinucleótido es hacer que funcione. Un polinucleótido que codifica un polipéptido (o una proteína), cuando se expresa, se transcribirá o se traducirá para producir ese polipéptido (o esa proteína). Como se usa en el presente documento, el término "sobreexpresar" significa expresar (o hacer que se exprese) un polinucleótido o polipéptido en una célula a una concentración superior a la expresada normalmente en una célula de tipo silvestre correspondiente en las mismas condiciones. En otra realización, el término "sobreexpresar" significa expresar (o hacer que se exprese) un polinucleótido o polipéptido en una célula a una concentración superior la que normalmente se expresa en una célula correspondiente que expresa la secuencia de polinucleótido molde o polipéptido molde en las mismas condiciones. Un ejemplo de una secuencia de polipéptido molde es el polipéptido de fusión híbrida de CYP153A-RedRhF.
La expresión "nivel de expresión alterado" y "nivel de expresión modificado" se usan indistintamente, y significan que un polinucleótido, polipéptido o derivado de ácido graso está presente a una concentración diferente en una célula hospedadora modificada en comparación con su concentración en una célula de tipo silvestre correspondiente en las mismas condiciones.
Como se usa en el presente documento, el término "título" se refiere a la cantidad de ácidos grasos w-OH y/o derivados de ácidos grasos w-OH producidos por unidad de volumen de cultivo de células hospedadoras. En cualquier aspecto de las composiciones y de los métodos descritos en el presente documento, se produce un ácido graso w-OH y/o un derivado de ácido graso w-OH a un título de aproximadamente 25 mg/l, aproximadamente 50 mg/l, aproximadamente 75 mg/l, aproximadamente 100 mg/l, aproximadamente 125 mg/l, aproximadamente 150 mg/l, aproximadamente 175 mg/l, aproximadamente 200 mg/l, aproximadamente 225 mg/l, aproximadamente 250 mg/l, aproximadamente 275 mg/l, aproximadamente 300 mg/l, aproximadamente 325 mg/l, aproximadamente 350 mg/l, aproximadamente 375 mg/l aproximadamente 400 mg/l, aproximadamente 425 mg/l, aproximadamente 450 mg/l, aproximadamente 475 mg/l aproximadamente 500 mg/l, aproximadamente 525 mg/l, aproximadamente 550 mg/l, aproximadamente 575 mg/l aproximadamente 600 mg/l, aproximadamente 625 mg/l, aproximadamente 650 mg/l, aproximadamente 675 mg/l aproximadamente 700 mg/l, aproximadamente 725 mg/l, aproximadamente 750 mg/l, aproximadamente 775 mg/l aproximadamente 800 mg/l, aproximadamente 825 mg/l, aproximadamente 850 mg/l, aproximadamente 875 mg/l aproximadamente 900 mg/l, aproximadamente 925 mg/l, aproximadamente 950 mg/l, aproximadamente 975 mg/l aproximadamente 1000 mg/l, aproximadamente 1050 mg/l, aproximadamente 1075 mg/l, aproximadamente 1100 mg/l, aproximadamente 1125 mg/l, aproximadamente aproximadamente 1175 mg/l, aproximadamente 1200 mg/l, aproximadamente 1225 mg/l, aproximadamente 1250 mg/l, aproximadamente 1275 mg/l, aproximadamente 1300 mg/l, aproximadamente 1325 mg/l, aproximadamente 1350 mg/l, aproximadamente 1375 mg/l, aproximadamente 1400 mg/l, aproximadamente 1425 mg/l, aproximadamente 1450 mg/l, aproximadamente 1475 mg/l, aproximadamente 1500 mg/l, aproximadamente 1525 mg/l, aproximadamente 1550 mg/l, aproximadamente 1575 mg/l, aproximadamente 1600 mg/l, aproximadamente 1625 mg/l, aproximadamente 1650 mg/l, aproximadamente 1675 mg/l, aproximadamente 1700 mg/l, aproximadamente 1725 mg/l, aproximadamente 1750 mg/l, aproximadamente 1775 mg/l, aproximadamente 1800 mg/l, aproximadamente 1825 mg/l, aproximadamente 1850 mg/l, aproximadamente 1875 mg/l, aproximadamente 1900 mg/l, aproximadamente 1925 mg/l, aproximadamente 1950 mg/l, aproximadamente 1975 mg/l, aproximadamente 2000 mg/l (2 g/l), 3 g/l, 5 g/l, 10 g/l, 20 g/l, 30 g/l, 40 g/l, 50 g/l, 60 g/l, 70 g/l, 80 g/l, 90 g/l, 100 g/lo un intervalo limitado por cualquiera de los dos valores anteriores. En otras realizaciones, se produce un ácido graso w-OH y/o un derivado de ácido graso w-OH a un título de más de 100 g/l, más de 200 g/l, más de 300 g/l o superior, tal como 500 g/l, 700 g/l, 1000 g/l, 1200 g/l, 1500 g/l o 2000 g/l. En una realización, el título de un ácido graso w-OH y/o un derivado de ácido graso w-OH producido por una célula hospedadora recombinante de acuerdo con los métodos de la divulgación es de 5 g/l a 200 g/l,, de 10 g/l a 150 g/l, de 20 g/l a 120 g/l, de 25 g/l a 110 g/l y de 30 g/l a 100 g/l.
Como se usa en el presente documento, la expresión "rendimiento de los ácidos grasos w-OH y/o derivados de ácidos grasos w-OH producidos por una célula hospedadora" se refiere a la eficacia con la que una fuente de carbono de entrada se convierte en producto (es decir, ácidos grasos w-OH y/o derivados de ácidos grasos w-OH) en una célula hospedadora. Las células hospedadoras diseñadas genéticamente para producir ácidos grasos w-OH y/o derivados de ácidos grasos w-OH de acuerdo con los métodos de la divulgación tienen un rendimiento de al menos el 3 %, al menos el 4 %, al menos el 5 %, al menos el 6 %, al menos el 7 %, al menos el 8 %, al menos el 9 %, al menos el 10 %, al menos el 11 %, al menos el 12 %, al menos el 13 %, al menos el 14 %, al menos el 15 %, al menos el 16 %, al menos el 17 %, al menos el 18 %, al menos el 19 %, al menos el 20 %, al menos el 21 %, al menos el 22 %, al menos el 23 %, al menos el 24 %, al menos el 25 %, al menos el 26 %, al menos el 27 %, al menos el 28 %, al menos el 29 % o al menos el 30 % o un intervalo delimitado por dos valores cualquiera de los anteriores. En otras realizaciones, se produce un ácido graso w-OH y/o un derivado de ácido graso w-OH con un rendimiento de más del 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 % o superior. Como alternativa, o además, el rendimiento es de aproximadamente el 30 % o inferior, aproximadamente el 27 % o inferior, aproximadamente el 25 % o inferior, o aproximadamente el 22 % o inferior. Por lo tanto, el rendimiento puede estar limitado por dos cualquiera de los criterios de valoración anteriores. Por ejemplo, el rendimiento de un ácido graso w-OH y/o un derivado de ácido graso w-OH producido por la célula hospedadora recombinante de acuerdo con los métodos de la divulgación puede ser del 5 % al 15 %, del 10 % al 25 %, del 10 % al 22 %, del 15 % al 27 %, del 18 % al 22 %, del 20 % al 28 %, del 20 % al 30 %, del 25 % al 40 % o superior. Un ejemplo de un rendimiento preferido de un ácido graso w-OH y/o un derivado de ácido graso w-OH producido por la célula hospedadora recombinante de acuerdo con los métodos de la divulgación es del 10 % al 30 %.
Otro ejemplo de un rendimiento preferido de un ácido graso w-OH y/o un derivado de ácido graso w-OH producido por la célula hospedadora recombinante de acuerdo con los métodos de la divulgación es del 10 % al 40 %. Otro ejemplo de un rendimiento preferido de un ácido graso w-OH y/o un derivado de ácido graso w-OH producido por la célula hospedadora recombinante de acuerdo con los métodos de la divulgación es del 10 % al 50 %.
Como se usa en el presente documento, el término "productividad" se refiere a la cantidad de ácidos grasos w-OH y/o derivados de ácidos grasos w-OH producidos por unidad de volumen de cultivo de células hospedadoras por unidad de tiempo. En cualquier aspecto de las composiciones y de los métodos descritos en el presente documento, la productividad de un ácido graso w-OH y/o un derivado de ácido graso w-OH producido por una célula hospedadora recombinante es de al menos 100 mg/l/hora, al menos 200 mg/l/hora, al menos 300 mg/l/hora, al menos 400 mg/l/hora, al menos 500 mg/l/hora, al menos 600 mg/l/hora, al menos 700 mg/l/hora, al menos 800 mg/l/hora, al menos 900 mg/l/hora, al menos 1000 mg/l/hora, al menos 1100 mg/l/hora, al menos 1200 mg/l/hora, al menos 1300 mg/l/hora, al menos 1400 mg/l/hora, al menos 1500 mg/l/hora, al menos 1600 mg/l/hora, al menos 1700 mg/l/hora, al menos 1800 mg/l/hora, al menos 1900 mg/l/hora, al menos 2000 mg/l/hora, al menos 2100 mg/l/hora, al menos 2200 mg/l/hora, al menos 2300 mg/l/hora, al menos 2400 mg/l/hora o al menos 2500 mg/l/hora. Además, la productividad puede ser de 2500 mg/l/hora o inferior, 2000 mg/l/DO600 o inferior, 1500 mg/l/DO600 o inferior, 120 mg/l/hora o inferior, 1000 mg/l/hora o inferior, 800 mg/l/hora o inferior, o 600 mg/l/hora o inferior. Por lo tanto, la productividad puede estar limitada por dos cualquiera de los criterios de valoración anteriores. Por ejemplo, la productividad puede ser de 3 a 30 mg/l/hora, de 6 a 20 mg/l/hora o de 15 a 30 mg/l/hora. La productividad preferida de un ácido graso w-OH y/o un derivado de ácido graso w-OH producido por una célula hospedadora recombinante de acuerdo con los métodos de la divulgación se selecciona entre de 500 mg/l/hora a 2500 mg/l/hora, o de 700 mg/l/hora a 2000 mg/l/hora.
Las expresiones "especies grasas totales (FAS)" y "producto de ácidos grasos totales" se pueden usar indistintamente en el presente documento con referencia a la cantidad total de ácidos grasos w-OH y ácidos grasos presentes en una muestra evaluada por GC-FID como se describe en la publicación de solicitud de patente internacional WO 2008/119082.
Como se usa en el presente documento, la expresión "tasa de utilización de glucosa" significa la cantidad de glucosa usada por el cultivo por unidad de tiempo, indicada como gramos/litro/hora (g/l/h).
La expresión "fuente de carbono de una materia prima renovable", cuando se usa sola o en referencia a una fuente de alimentación incluye cualquier material biológico (incluidas las materias primas renovables y/o la biomasa y/o los productos de desecho) de los que se deriva el carbono, excepto los productos oleoquímicos (es decir, aceites refinados de plantas y animales tales como ácidos grasos, ésteres de ácidos grasos, TAG, ácidos grasos hidroxi y similares) y productos petroquímicos (es decir, productos químicos derivados del petróleo tales como alcanos, alquenos y similares). Por lo tanto, la expresión "fuente de carbono de una materia prima renovable", como se usa en el presente documento, excluye el carbono derivado de productos oleoquímicos y petroquímicos. En algunas realizaciones, la fuente de carbono incluye azúcares o carbohidratos (por ejemplo, monosacáridos, disacáridos o polisacáridos). En algunas realizaciones, la fuente de carbono es glucosa y/o sacarosa. En otras realizaciones, la fuente de carbono se deriva de una materia prima renovable tal como carbohidratos de maíz, caña de azúcar o biomasa lignocelulósica; o productos de desecho tales como glicerol, gas de escape, gas de síntesis; o la reforma de materiales orgánicos tales como biomasa o gas natural; o es dióxido de carbono que se fija fotosintéticamente. En otras realizaciones, una biomasa se procesa en una fuente de carbono, que es adecuada para la bioconversión. En otras realizaciones más, la biomasa no requiere un procesamiento adicional en una fuente de carbono, sino que puede usarse directamente como fuente de carbono. Una fuente ilustrativa de dicha biomasa es materia vegetal o vegetación, tal como césped. Otra fuente de carbono ilustrativa incluye productos de desecho metabólico, tales como materia animal (por ejemplo, estiércol de vaca). Otras fuentes ilustrativas de carbono incluyen algas y otras plantas marinas. Otra fuente de carbono (incluida la biomasa) incluye productos de desecho de la industria, la agricultura, la silvicultura y los hogares, incluidos, pero sin limitación, desechos de fermentación, biomasa de fermentación, glicerol/glicerina, ensilado, paja, madera, aguas residuales, basura, desechos sólidos manipulados, residuos urbanos celulósicos y restos de comida.
Como se usa en el presente documento, el término "aislado", con respecto a productos tales como ácidos grasos w-OH y sus derivados se refiere a productos que están separados de los componentes celulares, medios de cultivo celular, o precursores químicos o sintéticos. Los ácidos grasos y sus derivados (por ejemplo, ácido graso w-OH y/o derivados de ácidos grasos w-OH) producidos mediante los métodos descritos en el presente documento pueden ser relativamente inmiscibles en el caldo de fermentación, así como en el citoplasma. Por lo tanto, los ácidos grasos y sus derivados pueden acumularse en una fase orgánica, ya sea intracelular o extracelularmente.
Como se usa en el presente documento, Los términos "purificar", "purificado/a" o "purificación" significan la eliminación o el aislamiento de una molécula de su entorno mediante, por ejemplo, aislamiento o separación. Las moléculas "esencialmente purificadas" están al menos aproximadamente un 60 % libres (por ejemplo, al menos aproximadamente un 70 % libres, al menos aproximadamente un 75 % libres, al menos aproximadamente un 85 % libres, al menos aproximadamente un 90 % libres, al menos aproximadamente un 95 % libres, al menos aproximadamente un 97 % libres, al menos aproximadamente un 99 % libres) de otros componentes con los que están asociados. Como se usa en el presente documento, estos términos también se refieren a la eliminación de
contaminantes de una muestra. Por ejemplo, la eliminación de contaminantes puede producir un aumento en el porcentaje de derivados de ácidos grasos tales como ácido graso w-OH y/o derivados de ácidos grasos w-OH en una muestra. Por ejemplo, cuando se produce un derivado de ácido graso en una célula hospedadora recombinante, el derivado de ácido graso puede purificarse mediante la eliminación de proteínas de la célula hospedadora u otros materiales de la célula hospedadora. Después de la purificación, el porcentaje de derivado de ácido graso en la muestra aumenta. Los términos "purificar", "purificado/a" y "purificación" son términos relativos que no requieren una pureza absoluta. Por lo tanto, por ejemplo, cuando se produce un derivado de ácido graso en células hospedadoras recombinantes, un derivado de ácido graso purificado es un derivado de ácido graso que está sustancialmente separado de otros componentes celulares (por ejemplo, ácidos nucleicos, polipéptidos, lípidos, carbohidratos u otros hidrocarburos).
Producción de ácidos grasos y derivados de ácidos grasos omega-hidroxilados
La divulgación proporciona la producción de ácidos grasos w-OH y derivados de ácidos grasos w-OH en una célula hospedadora. La producción de ácido graso w-OH puede potenciarse como resultado de la expresión de una variante de polipéptido de fusión híbrida de CYP153A-reductasa. Las variantes del polipéptidos de fusión híbrida de CYP153A-reductasa producen los derivados y las composiciones de ácido graso w-OH en un título alto. En el presente documento, la variante de polipéptido de fusión híbrida de CYP153A-reductasa participa en una vía biosintética para la producción de derivados de ácidos grasos w-OH; se puede usar sola o en combinación con otras enzimas. Por ejemplo, la variante de polipéptido de fusión híbrida de CYP153A-reductasa se puede usar en una vía biosintética diseñada en donde una enzima tioesterasa (es decir, expresada de forma natural o heteróloga) convierte una acil-ACP en un ácido graso. La variante de polipéptido de fusión híbrida de CYP153A-reductasa puede convertir el ácido graso en un ácido graso w-OH (véase la Figura 1). Enzimas adicionales en la vía pueden convertir los ácidos grasos w-OH en otros derivados de ácidos grasos bifuncionales tales como a,w-diácidos.
De manera más específica, un polipéptido de fusión híbrida de CYP153A-reductasa es una secuencia de polipéptido que tiene al menos el 70 %, 71 %, 72 %, 73 %, 74 %, 75 %, 76 %, 77 %, 78 %, 79 %, 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con SEQ ID NO: 6 y sirve como una secuencia molde para introducir mutaciones con el fin de crear variantes con actividad enzimática mejorada para la producción de ácidos grasos y derivados de ácidos grasos w-OH. El polipéptido de fusión híbrida de CYP153A-reductasa es autosuficiente y posee actividad enzimática w-hidroxilasa que cataliza la reacción de un ácido graso a un ácido graso w-OH. Un ejemplo de un polipéptido de fusión híbrida de CYP153A-reductasa es un polipéptido de fusión híbrida de tipo cyp153A-RedRhF. En una realización, la expresión variante de polipéptido de fusión híbrida de CYP153A-reductasa se refiere a un polipéptido de fusión híbrida de CYP153A-reductasa modificado que tiene al menos una mutación en su secuencia de aminoácidos que incluye, pero sin limitación, una mutación en la posición de aminoácido 796, 141, 231, 27, 82, 178, 309, 407, 415, 516 y 666 o una combinación de los mismos. La expresión de la variante de polipéptido de fusión híbrida de CYP153A-reductasa en células hospedadoras recombinantes produce un título, un rendimiento y/o una productividad mejorados de ácidos grasos w-OH y/o derivados de ácidos grasos w-OH o composiciones de los mismos en comparación con la expresión del polipéptido de fusión híbrida de CYP153A-reductasa en una célula hospedadora correspondiente.
Un ejemplo de una variante de polipéptido de fusión híbrida de CYP153A-reductasa es SEQ ID NO: 38, que tiene una mutación en la posición 796, en donde una alanina se reemplaza con una valina. Esta variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene una secuencia de polipéptido que tiene al menos el 70 %, 71 %, 72 %, 73 %, 74 %, 75 %, 76 %, 77 %, 78 %, 79 %, 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con SEQ ID NO: 38 y además sirve como una secuencia molde para crear mutaciones adicionales o variantes adicionales. De manera similar, Esta variante de polipéptido de fusión híbrida de CYP153A-reductasa es autosuficiente y posee actividad enzimática whidroxilasa que cataliza la reacción de un ácido graso a un ácido graso w-OH. En una realización, la expresión variante de polipéptido de fusión híbrida de CYP153A-reductasa se refiere a un polipéptido de fusión híbrida de CYP153A-reductasa modificado que tiene al menos una mutación adicional en su secuencia de aminoácidos que incluye, pero sin limitación, una mutación en la posición de aminoácido 747, 12, 327, 14, 61, 28, 13, 771, 119, 10, 11, 28, 745, 9, 770, 413, 784, 749, 231, 233, 757 y 703 o una combinación de los mismos. La expresión de la variante de polipéptido de fusión híbrida de CYP153A-reductasa en células hospedadoras recombinantes produce un título, un rendimiento y/o una productividad mejorados de ácidos grasos w-OH y/o derivados de ácidos grasos w-OH en comparación con la expresión del polipéptido de fusión híbrida de CYP153A-reductasa (SEQ ID NO: 6) en una célula hospedadora correspondiente.
Cuando una célula se ha transformado con una variante de polipéptido de fusión híbrida de CYP153A-reductasa, es una célula que expresa la variante de polipéptido de fusión híbrida de CYP153A-reductasa (por ejemplo, una célula recombinante). En una realización, el título y/o el rendimiento de un ácido graso w-OH producido por una célula que expresa la variante de polipéptido de fusión híbrida de CYP153A-reductasa es al menos el doble que el de una célula correspondiente que expresa el polipéptido de fusión híbrida de CYP153A-reductasa. En un hospedador tal como Escherichia coli, los ácidos grasos w-OH pueden convertirse en derivados de ácidos grasos bifuncionales mediante enzimas expresadas de forma natural o heteróloga. En otra realización, el título y/o el rendimiento de un ácido graso w-OH o derivado del mismo producido por una célula que expresa la variante de polipéptido de fusión híbrida de
CYP153A-reductasa es al menos aproximadamente 1 vez, al menos aproximadamente 2 veces, al menos aproximadamente 3 veces, al menos aproximadamente 4 veces, al menos aproximadamente 5 veces, al menos aproximadamente 6 veces, al menos aproximadamente 7 veces, al menos aproximadamente 8 veces, al menos aproximadamente 9 veces o al menos aproximadamente 10 veces superior al de una célula correspondiente que expresa el polipéptido de fusión híbrida de CYP153A-reductasa. En una realización, el título y/o el rendimiento de un ácido graso w-OH o derivado del mismo producido por una célula que expresa la variante de polipéptido de fusión híbrida de CYP153A-reductasa es al menos aproximadamente el 1 por ciento, al menos aproximadamente el 2 por ciento, al menos aproximadamente el 3 por ciento, al menos aproximadamente el 4 por ciento, al menos aproximadamente el 5 por ciento, al menos aproximadamente el 6 por ciento, al menos aproximadamente el 7 por ciento, al menos aproximadamente el 8 por ciento, al menos aproximadamente el 9 por ciento o al menos aproximadamente el 10 por ciento superior al de una célula correspondiente que expresa el polipéptido de fusión híbrida de CYP153A-reductasa. En otra realización, el título y/o el rendimiento de un ácido graso w-OH o derivado del mismo producido en una célula recombinante debido a la expresión de una variante de polipéptido de fusión híbrida de CYP153A-reductasa es al menos aproximadamente el 20 por ciento a al menos aproximadamente el 80 por ciento superior al de una célula correspondiente que expresa el polipéptido de fusión híbrida de CYP153A-reductasa. En algunas realizaciones, el título y/o el rendimiento de un ácido graso w-OH producido por una célula es al menos aproximadamente el 20 por ciento, al menos aproximadamente el 25 por ciento, al menos aproximadamente el 30 por ciento, al menos aproximadamente el 35 por ciento, al menos aproximadamente el 40 por ciento, al menos aproximadamente el 45 por ciento, al menos aproximadamente el 50 por ciento, al menos aproximadamente el 55 por ciento, al menos aproximadamente el 60 por ciento, al menos aproximadamente el 65 por ciento, al menos aproximadamente el 70 por ciento, al menos aproximadamente el 75 por ciento, al menos aproximadamente el 80 por ciento, al menos aproximadamente el 85 por ciento, al menos aproximadamente el 90 por ciento, al menos aproximadamente el 95 por ciento, al menos aproximadamente el 97 por ciento, al menos aproximadamente el 98 por ciento o al menos aproximadamente el 100 por ciento superior al de la célula correspondiente que expresa el polipéptido de fusión híbrida de CYP153A-reductasa.
Por lo tanto, la divulgación proporciona células hospedadoras recombinantes, que se han diseñado genéticamente para expresar una variante de polipéptido de fusión híbrida de CYP153A-reductasa para producir ácidos grasos w-OH o derivados de los mismos. La biosíntesis de los ácidos grasos w-OH se mejora en relación con las células hospedadoras que expresan el polipéptido de fusión híbrida de CYP153A-reductasa, es decir, células hospedadoras que expresan el polipéptido de fusión híbrida de CYP153A-reductasa basado en SEQ ID NO: 6 (es decir, polipéptido molde) u otros polipéptidos con la misma función enzimática. Se puede modificar una variedad de células hospedadoras diferentes para expresar una variante de polipéptido de fusión híbrida de CYP153A-reductasa tal como las descritas en el presente documento, dando lugar a células hospedadoras recombinantes adecuadas para la producción mejorada de ácido graso w-OH y derivados de ácidos grasos w-OH, o composiciones del mismo. Los ejemplos de ácidos grasos w-OH que se producen son ácidos grasos C6, C7, Cs, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1. En una realización, dichos ácidos grasos w-OH son ácidos grasos C80 w-OH, ácidos grasos C100 w-OH, ácidos grasos C120 w-OH, ácidos grasos C140 w-OH, ácidos grasos C160 w-OH, ácidos grasos C180 w-OH, ácidos grasos C200 w-OH, ácidos grasos C81 w-OH, ácidos grasos C101 w-OH, ácidos grasos C121 w-OH, ácidos grasos C141 w-OH, ácidos grasos C161 w-OH, ácidos grasos Cm1 w-OH, ácidos grasos C201 w-OH, y similares. Se entiende que una variedad de células puede proporcionar fuentes de material genético, incluyendo secuencias polinucleotídicas que codifican polipéptidos adecuados para usar en una célula hospedadora recombinante como se describe en el presente documento.
Diseño mediante ingeniería genética de vías y actividades enzimáticas
La síntesis de ácidos grasos es uno de los sistemas más conservados de la maquinaria biosintética bacteriana. El complejo de múltiples enzimas de la ácido graso sintasa (FAS, Fatty Acid Synthase) está presente en todas las bacterias y organismos eucariotas. La mayoría de los genes relacionados con la FAS son indispensables para el crecimiento y la supervivencia de las células. La FAS eucariota y bacteriana conducen esencialmente el mismo tipo de transformación bioquímica. En eucariotas, la FAS se conoce como FASI, y la mayoría de sus dominios catalíticos están codificados por una cadena polipeptídica (no disociable). En procariotas tales como las bacterias, FAS se conoce como FASII y sus enzimas individuales y proteínas portadoras están codificadas por genes separados que codifican proteínas diferenciadas (disociables). Como tal, FASII es un sistema complejo con variaciones significativas y distintas peculiaridades.
La proteína portadora de acilo (ACP) junto con las enzimas en una vía de FAS controlan la longitud, el grado de saturación y de ramificación de los ácidos grasos producidos en un organismo nativo. Las etapas de esta vía son catalizadas por enzimas de las familias de genes de biosíntesis de ácidos grasos (FAB) y acetil-CoA carboxilasa (ACC, Acetyl-CoA Carboxylase). Por ejemplo, las enzimas que pueden incluirse en una vía FAS incluyen AccABCD, FabD, FabH, FabG, FabA, FabZ, FabI, FabK, FabL, FabM, FabB y FabF. Dependiendo del producto deseado, uno o más de estos genes pueden atenuarse o sobreexpresarse. Como tal, Se han diseñado genéticamente procariotas para aumentar la producción de derivados de ácidos grasos a partir de materias primas renovables tales como glucosa u otras fuentes de carbono. En el presente documento, la objetivo principal es aumentar la actividad de las enzimas de control clave que regulan la producción de derivados de ácidos grasos para convertir la cepa bacteriana en una fábrica de microbios para la producción de derivados de ácidos grasos, incluidos ésteres metílicos de ácidos grasos (FAME,
Fatty Acid Methyl Esters), ésteres etílicos de ácidos grasos (FAEE, Fatty Acid Ethyl Esters) y alcoholes grasos (FALC, FAtty AlCohols) (véase, por ejemplo, la patente de EE.UU. n.° 8.283.143).
La presente divulgación identifica polinucleótidos de fusión híbrida de CYP153A-reductasa que codifican polipéptidos de función enzimática para modificar vías enzimáticas para la producción de compuestos deseables tales como ácidos grasos u>-OH y derivados de ácidos grasos u>-OH. Estos polipéptidos, que se identifican en el presente documento por los números de registro de enzimas (números CE), son útiles para diseñar genéticamente vías de ácidos grasos que conducen a la producción de ácidos grasos u>-OH y otras moléculas bifuncionales tales como derivados de ácidos grasos u>-OH como los a,u>-diácidos (véase la Figura 1).
En una realización, en la Figura 1, se representan vías que usan una fuente de carbono derivada de una materia prima renovable como la glucosa para producir derivados de ácidos grasos u>-OP. Un carbohidrato (por ejemplo, la glucosa) es convertido en un acil-tioéster tal como un acil-ACP por el organismo nativo (véase la etapa 1 de la Figura 1). Los polinucleótidos que codifican polipéptidos con actividad enzimática de degradación de ácidos grasos pueden atenuarse opcionalmente dependiendo del producto deseado (véanse el apartado de Ejemplos, más adelante). Son ejemplos no limitantes de dichos polipéptidos la acil-CoA sintetasa (FadD) y la acil-CoA deshidrogenasa (FadE). La Tabla 1 proporciona una lista completa de la actividad enzimática (más adelante) dentro de la vía metabólica, incluyendo distintas enzimas de degradación de ácidos grasos que pueden atenuarse opcionalmente de acuerdo con métodos conocidos en la técnica (véase, por ejemplo, la patente de EE.UU. n.° 8.283.143, mencionada anteriormente).
Por ejemplo, FadR (véase la Tabla 1, más adelante) es un factor regulador clave que participa en la degradación de los ácidos grasos y las vías biosintéticas de los ácidos grasos (Cronan et al., Mol. Microbiol., 29(4). 937-943 (1998)). La enzima FadD de E. coli (véase la Tabla 1, más adelante) y la proteína transportadora de ácidos grasos Fadl son componentes de un sistema de absorción de ácidos grasos. Fadl media el transporte de los ácidos grasos a la célula bacteriana, y FadD media la formación de acil-CoA ésteres. Cuando no hay otra fuente de carbono disponible, los ácidos grasos exógenos son absorbidos por bacterias y convertidos en acil-CoA ésteres, que puede unirse al factor de transcripción FadR y deprimir la expresión de los genes fad que codifican las proteínas responsables del transporte (Fadl), de la activación (FadD) y de la p-oxidación (FadA, FadB y FadE) de los ácidos grasos. Cuando hay fuentes alternativas de carbono disponibles, las bacterias sintetizan ácidos grasos como acil-ACP, que se usan para la síntesis de fosfolípidos, pero no son sustratos para la p-oxidación. Por lo tanto, la acil-CoA y la acil-ACP son fuentes independientes de ácidos grasos que pueden dar lugar a diferentes productos finales (Caviglia et al., J. Biol. Chem., 279(12): 1163-1169 (2004)).
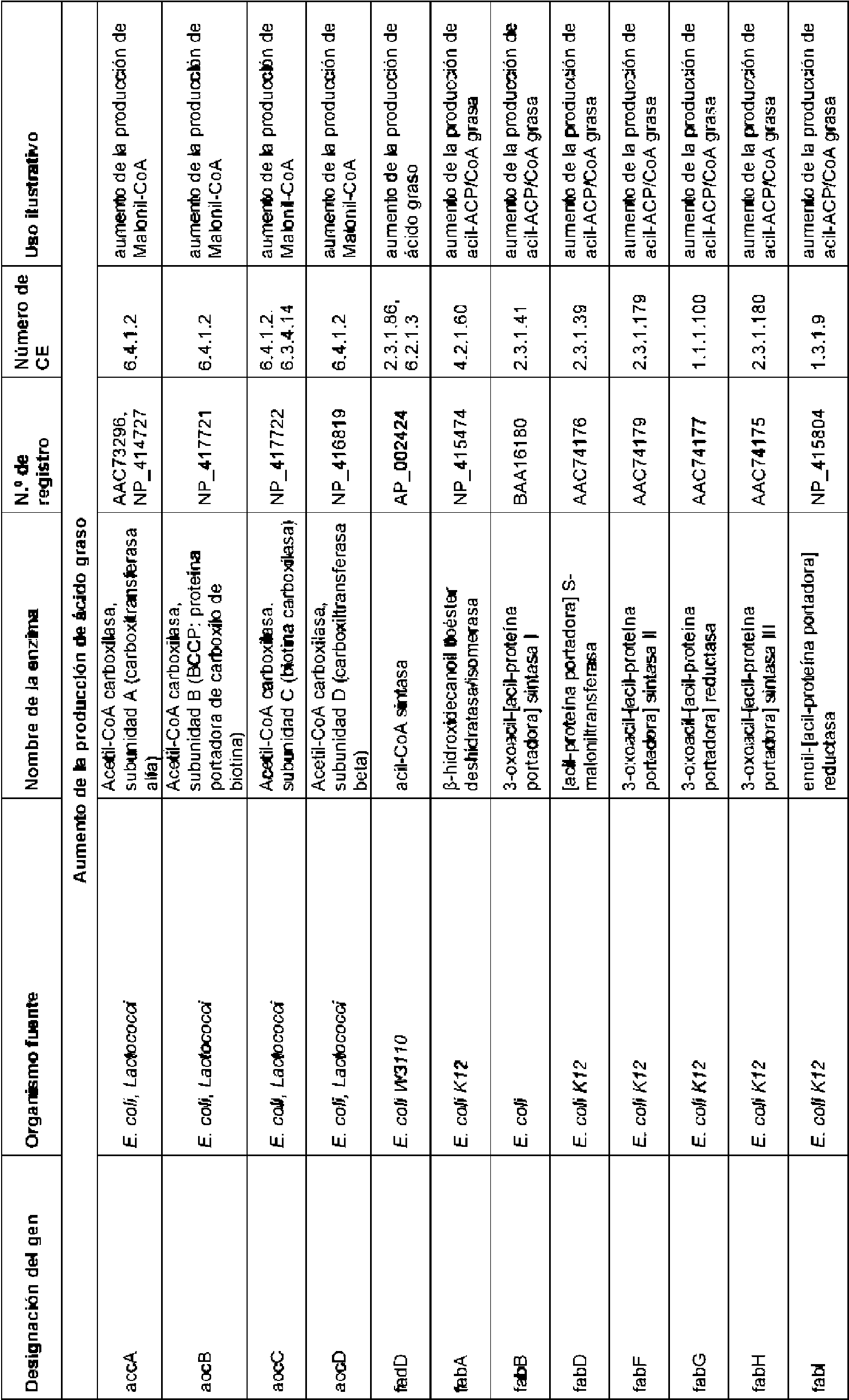


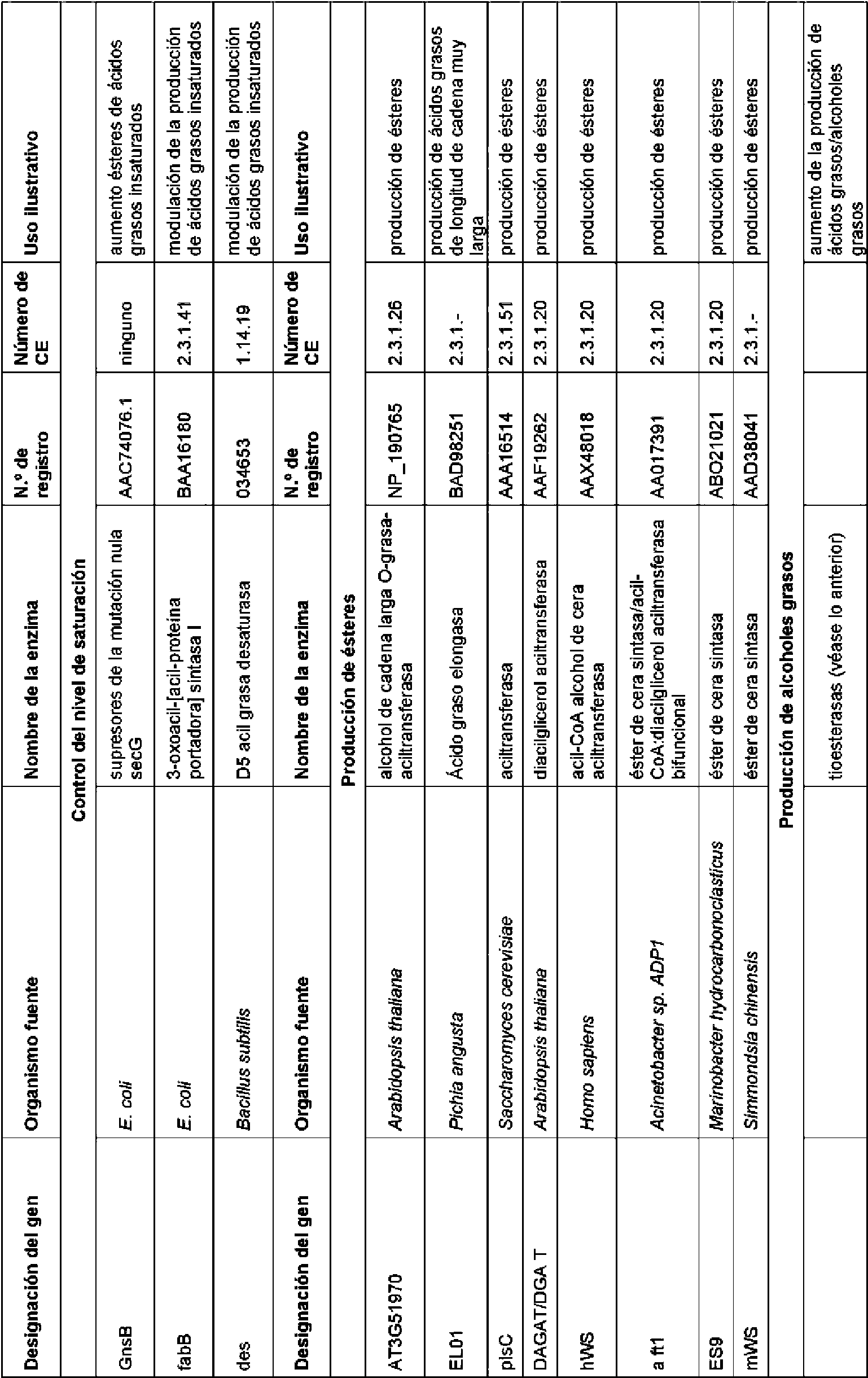
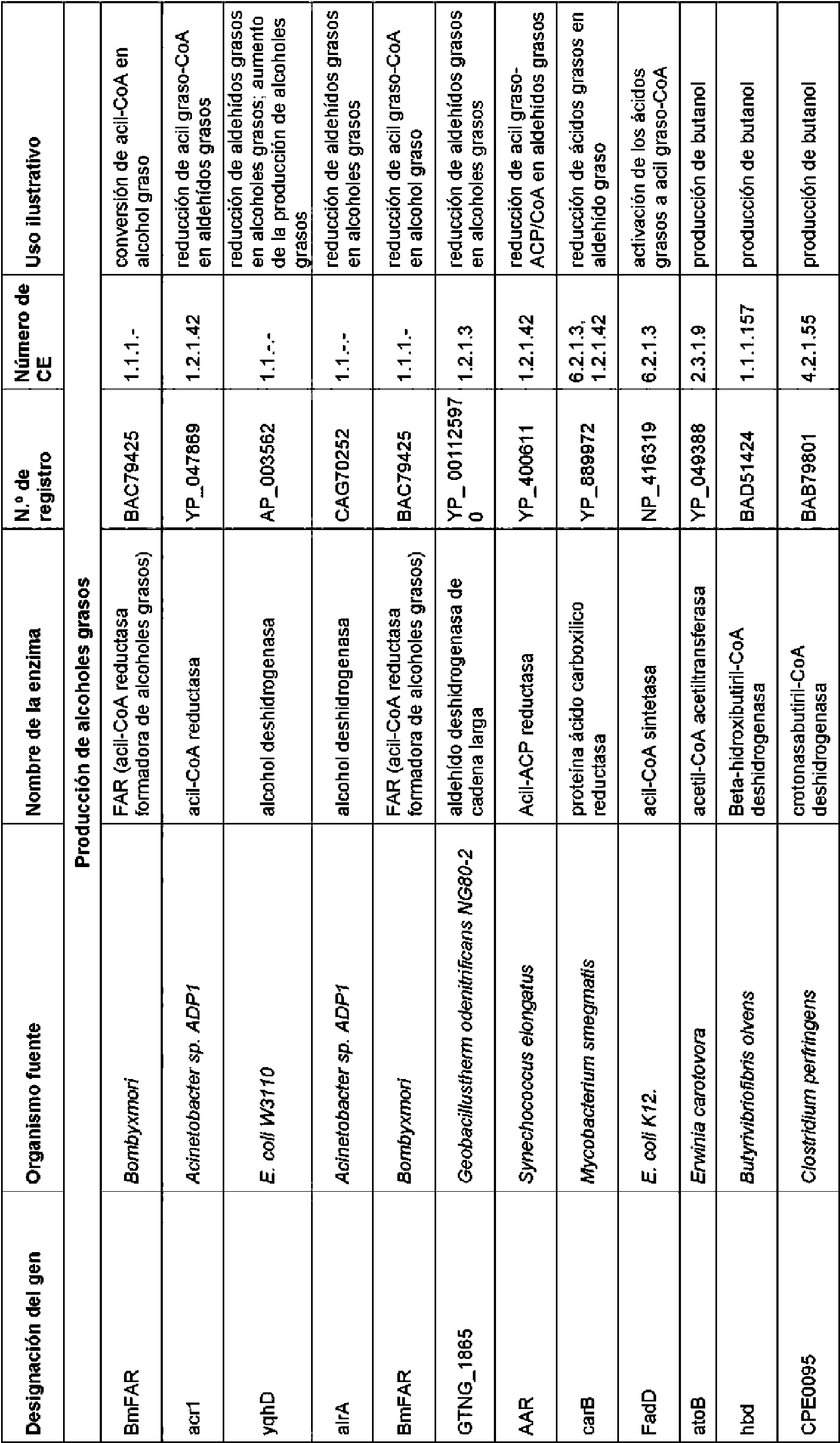

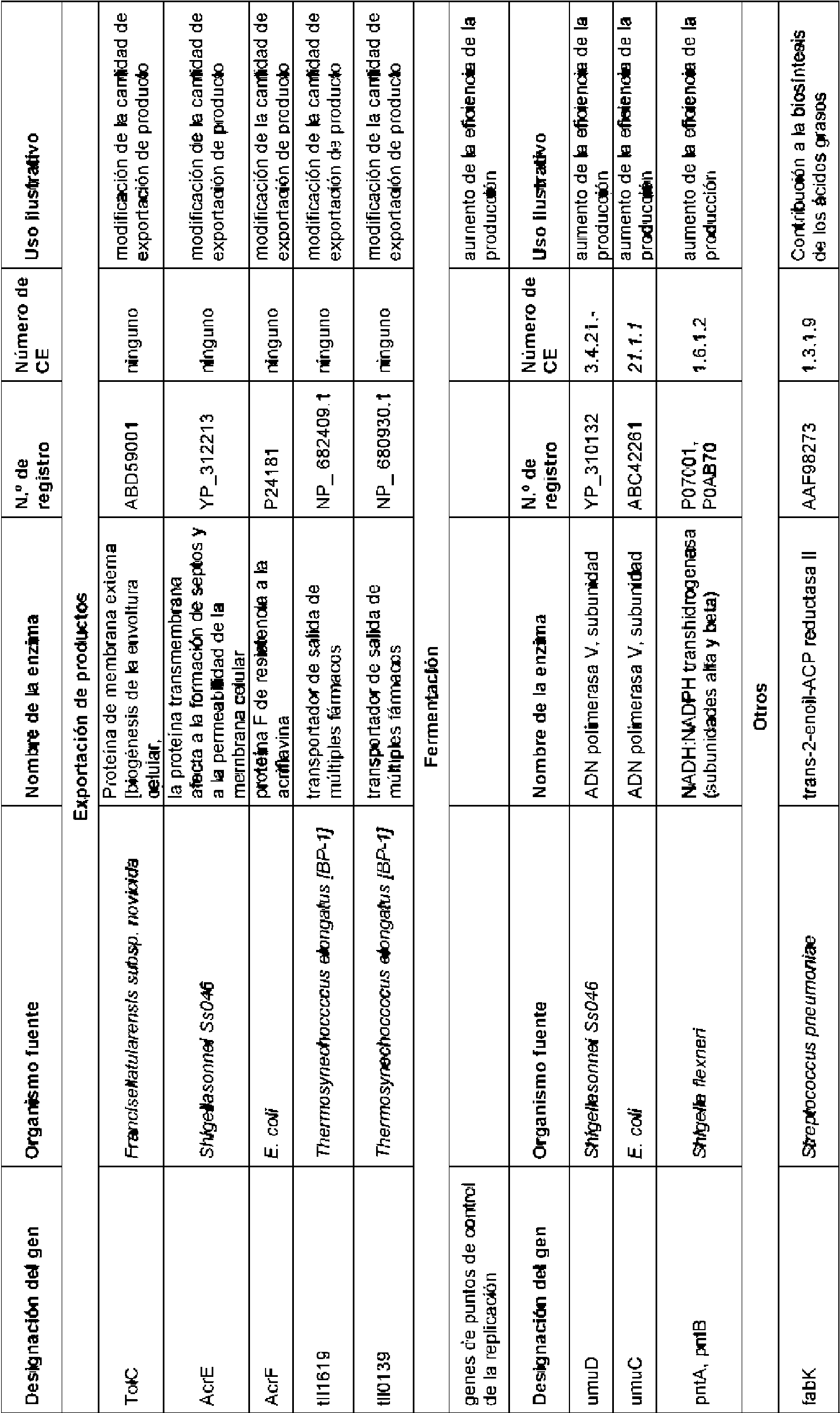

La Figura 1 muestra una vía ilustrativa en la que un acil tioéster tal como una acil-ACP puede convertirse en un ácido graso C12 o C16: 1 (FFA) como un precursor intermedio. En la Etapa 1 de la Figura 1, se emplea una tioesterasa para convertir una acil-ACP en un FFA. En ciertas realizaciones, el gen que codifica una tioesterasa es tesA, 'tesA, tesB, fatBI, fatB2, fatB3, fatAl, o fatA (véase también la Tabla 1, que muestra polipéptidos que tienen la actividad enzimática de una tioesterasa que puede usarse para catalizar esta etapa, descrito anteriormente). En la etapa 2 , se usa un polipéptido de fusión híbrida de C Y P 153A-reductasa o una variante del mismo para generar ácidos grasos w-OP (FFA w-O p ) a partir de ácidos grasos. Se pueden producir otras moléculas bifuncionales en dirección 3 ' de la vía, por ejemplo, a,w-diácidos u otros derivados de ácidos grasos w-OP, dependiendo de las funcionalidades enzimáticas que están presentes en la vía.
Polipéptidos de fusión híbrida de CYP153A-reductasa
Las w-hidroxilasas (o w-oxigenasas) incluyen ciertas di-oxigenasas de hierro de tipo no hemo (por ejemplo, alkB de Pseudomonas putida G Po1) y ciertas oxigenasas P450 de tipo hemo (por ejemplo, w-hidroxilasas tales como cyp153A de Marinobacter aquaeolei). Las P450 son enzimas distribuidas ubicuamente, que poseen una alta complejidad y muestran un amplio campo de actividad. Son proteínas codificadas por una superfamilia de genes que convierten una amplia variedad de sustratos y catalizan una variedad de reacciones químicas. Cyp153A es una subfamilia de P450 del citocromo bacterianas solubles que hidroxilan cadenas de hidrocarburo con alta selectividad por la posición w (van Beilen et al. (2006) Appl. Environ. Microbiol. 72 :59 -65 ). Se ha demostrado in vitro que los miembros de la familia cyp153A hidroxilan selectivamente la posición w de los alcanos, ácidos grasos o alcoholes grasos, por ejemplo, cyp153A6 de Mycobacterium sp. HXN-1500 (Funhoff et al. (2006 ) J. Bacteriol. 188 : 5220 - 5227), cyp153A 16 de Mycobacterium marinum y cyp153A de Polaromonas sp. JS 666 (Scheps et al. (2011 ) Org. Biomol. Chem. 9 : 6727 6733 ), así como cyp153A de Marinobacter aquaeoli (Honda-Malca et al. (2012) Chem. Commun. 48 :5115 -5117). Las Tablas 2A y 2 B que figuran a continuación muestran ejemplos de enzimas y parejas rédox que tienen actividad enzimática de w-hidroxilasa que pueden usarse para producir ácidos grasos w-OP y derivados de ácidos grasos w-OP.
T l 2A E m l i i nzim i -hi r xil P450 E 1 14 15 -3

T l 2B: E m l r r x r l ivi nzim i -hi r xil P4 E 1.14.1 .

Como con todas las P450 del citocromo, las u-hidroxilasas Cyp153A requieren electrones para su actividad catalítica, que se proporcionan a través de proteínas rédox específicas tales como ferredoxina y ferredoxina reductasa. Estas son proteínas diferenciadas que interactúan con cyp153A. Ya se ha creado una oxigenasa cyp153A híbrida autosuficiente (quimérica) (es decir, una oxigenasa que no requiere proteínas diferenciadas de ferredoxina y ferredoxina reductasa para la actividad) fusionando cyp153A de Alcanivorax borkumensis SK2 (Kubota et al. (2005) Biosci. Biotechnol. Biochem. 69:2421-2430; Fujita et al. (2009) Biosci. Biotechnol. Biochem. 73: 1825-1830) con el dominio reductasa de P450RhF, que incluye sitios de unión a mononucleótidos de flavina (FMN) y NADPH y un centro de ferredoxina [2FeS] (Hunter et al. (2005) FEBS Lett. 579:2215-2220). P450RhF pertenece a PFOR fusionado con P450 de clase I (DeMot y Parret (2003) Trends Microbiol. 10: 502). Esta proteína de fusión de cyp153A-RedRhF híbrida se observó en biotransformaciones in vitro para hidroxilar octano en la posición u y también hidroxilar otros compuestos tales como ciclohexano o butilbenceno. Se han creado otras oxigenasas cyp153A híbridas autosuficientes (quiméricas) fusionando cyp153A de Marinobacter aquaeolei con los dominios reductasa de P450RhF y P450-BM3 (Scheps et al. (2013) Microb. Biotechnol. 6:694-707). En las Tablas 2C y 2D que figuran a continuación se muestran ejemplos de proteínas de fusión de P450-reductasa naturales.
- - - -
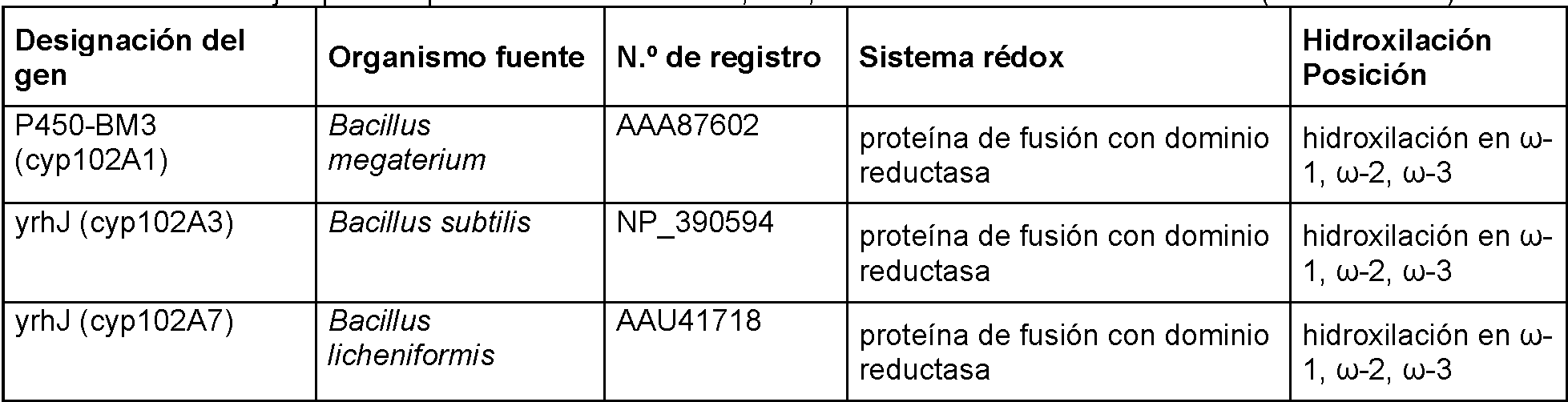
T l 2D: E m l r ín f i n PF R f i n n P4 l I fi i n

Dada su alta selectividad hacia la posición u de las cadenas de hidrocarburo, la familia de oxigenasas cyp153A parecía ser buenos ejemplos de candidatos adecuados para producir derivados de ácidos grasos a,u-bifuncionales a partir de una fuente de carbono renovable. Esto permitiría el desarrollo de procesos viables a nivel comercial para producir estos valiosos compuestos. No obstante, como con otras P450 del citocromo, las proteínas de la familia cyp153A hasta ahora se han aplicado principalmente a experimentos in vitro con enzimas purificadas o lisados de células brutas o en biotransformaciones de células en reposo a las que se añaden derivados de ácidos grasos o hidrocarburos de forma exógena (Kubota et al., Fujita et al., Honda-Malca et al., Scheps et al., mencionados anteriormente). Sin embargo, los procedimientos in vitro que emplean fusión híbrida o las biotransformaciones de células en reposo no conducen a una producción a gran escala y rentable de derivados de ácidos grasos u-hidroxilados. El conocimiento ampliamente aceptado en la técnica es que muchas P450 del citocromo, así como las u-hidroxilasas de tipo alkB no son fáciles de
expresar funcionalmente en microorganismos recombinantes, porque las enzimas suelen estar inactivas y su química ha sido difícil de dilucidar. De hecho, el único trabajo in vivo que usa una fuente de carbono renovable distinta de los derivados de ácidos grasos que se ha intentado hasta ahora empleaba la alquil w-hidroxilasa, y ha logrado solo un título bajo de derivados de ácidos grasos w-hidroxi en una fermentación de alta densidad celular (documento WO2013/024114A2).
La presente divulgación proporciona variantes de proteína de fusión híbrida de CYP153A-reductasa que son capaces de producir eficazmente derivados de ácidos grasos w-hidroxi in vivo a partir de una fuente de carbono renovable. De manera más específica, un gen de Marinobacter aquaeoli que codifica una proteína de fusión híbrida del dominio catalítico de P450 CYP153A (G307A), donde una glicina (G) fue sustituida por una alanina (A) en la posición 307, se fusionó con un gen codificante del dominio reductasa que contenía FMN y Fe/S c-terminal de P450RhF de Rhodococcus sp. NCIMB9784. El polipéptido resultante es un polipéptido de fusión híbrida de CYP153A-RedRhF (SEQ ID NO: 6) con una secuencia de ácido nucleico correspondiente (SEQ ID NO: 5). Cuando esta proteína de fusión híbrida de CYP153A-reductasa se expresó en células de E. coli con una fuente de carbono simple, tal como glucosa, los derivados de ácidos grasos se convirtieron eficazmente en derivados de ácidos grasos w-hidroxi (véase el Ejemplo 1). Otros ejemplos de w-hidroxilasas adecuadas (CE 1.14.15.3) y sus parejas rédox que pueden usarse para generar polipéptidos de fusión híbrida de CYP153A-reductasa similares se enumeran en las Tablas 2A y 2B (anteriores).
Variantes del polipéptido de fusión híbrida de CYP153A-reductasa
La presente divulgación identifica variantes de polipéptidos de fusión híbrida de CYP153A-reductasa que producen un título, un rendimiento y/o una productividad altos de composiciones de derivados de ácidos grasos w-hidroxilados cuando se expresan en células hospedadoras. En ejemplos no limitantes de la presente divulgación (véanse los Ejemplos 1-7, más adelante) el polipéptido de fusión de CYP153A (G307A)-RedRhF híbrida (supra) se usó como molde para diseñar de manera eficaz variantes de polipéptidos de fusión híbrida de CYP153A-reductasa para producir mayores cantidades de ácidos grasos w-OP y derivados de ácidos grasos w-OP. Por ejemplo, dicha variante de polipéptido de fusión de CYP153A-reductasa híbrida puede convertir eficazmente compuestos tales como el ácido dodecanoico en ácido 12-hidroxi-dodecanoico in vivo a partir de una fuente de carbono simple tal como glucosa. Cualquier fuente de carbono simple, por ejemplo, como la derivada de una materia prima renovable es adecuada. Se demostró que las variantes de polipéptidos de fusión híbrida de CYP153A-reductasa diseñadas genéticamente (es decir,las ilustradas a través de una variante de polipéptido de fusión híbrida de CYP153A-RedRhF diseñado genéticamente) pueden convertir eficazmente ácidos grasos in vivo en compuestos deseables específicos que incluyen ácidos grasos w-OP cuando se expresa junto con una tioesterasa en una célula hospedadora tal como E. coli mediante el uso de una fuente de carbono tal como la glucosa de una materia prima renovable (véase el apartado de Ejemplos, más adelante). Siguiendo la presente divulgación, se pueden diseñar otras variantes de polipéptidos de fusión híbrida uniendo un gen mutado, tal como un gen codificante de una proteína CYP153A a un gen mutado codificante de un dominio reductasa c-terminal (véanse las Tablas 2A a 2D, anteriores). En el presente documento, se engloban variaciones, por ejemplo, mutando ambos genes (el dominio P5450 y reductasa) o mutando un gen (el dominio P450 o reductasa). Siguiendo estas instrucciones, se pueden crear variantes de proteínas de fusión similares a partir de otros tipos de w-hidroxilasas.
Por lo tanto, la presente divulgación se refiere a variantes de polipéptidos de fusión híbrida de CYP153A-reductasa que producen un título, un rendimiento y/o una productividad altos de composiciones de derivados de ácidos grasos w-hidroxilados cuando se expresan en células hospedadoras. Las variantes del polipéptido de fusión híbrida de CYP153A-reductasa tienen una o más mutaciones en el dominio CYP153A o dominio de reductasa, o ambos. En una realización, la presente divulgación proporciona una variante de polipéptido de fusión híbrida de CYP153A-reductasa que tiene al menos aproximadamente el 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o 99 % de identidad de secuencia con s Eq ID NO: 6 y que tiene una o más mutaciones en una posición de aminoácido que incluye la posición 27, 82, 141, 178, 231, 309, 407, 415, 516, 666 y/o 796, en donde la variante de polipéptido de fusión híbrida de CYP153A-reductasa cataliza la conversión de un ácido graso en un ácido graso w-OP. De manera más específica, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene una o más de las siguientes mutaciones, que incluyen R27L, donde la arginina (R) está sustituida con lisina (L); posición R82D, donde la arginina (R) está sustituida con ácido aspártico (D); posición V141I, donde la valina está sustituida con isoleucina (I); posición V141Q, donde la valina (V) está sustituida con glutamina (Q); posición V141G, donde la valina (V) está sustituida con glicina (G); posición V141M, donde la valina (V) está sustituida con metionina (M); posición V141L, donde la valina (V) está sustituida con leucina (L); posición V141T, donde la valina (V) está sustituida con treonina (T); posición R178N, donde la arginina (R) está sustituida con asparagina (N); posición A231T, donde la alanina (A) está sustituida con treonina (T); posición N309R, donde la asparagina (N) está sustituida con arginina (R); posición N407A, donde la asparagina (N) está sustituida con alanina (A); posición V415R, donde la valina (V) está sustituida con arginina (R); posición T516V, donde la treonina (T) está sustituida con valina (V); posición P666A, donde la prolina (P) está sustituida con alanina (A); posición P666D, donde la prolina (P) está sustituida con ácido aspártico (D); y posición A796V, donde la alanina (A) está sustituida con valina (V). Los ejemplos de variantes de polipéptidos de fusión híbrida de CYP153A-reductasa incluyen SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 20, SEQ ID NO: 22, SEQ ID NO: 24, SEQ ID NO: 26, SEQ ID NO: 28 o SEQ ID NO: 30, SEQ ID NO: 32, SEQ ID NO: 34, SEQ ID NO: 36, SEQ ID NO: 38, SEQ ID NO: 40, SEQ ID NO: 42, SEQ ID NO: 44 y SEQ ID NO: 46. En una realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa es una variante de proteína de
fusión de tipo CYP153A-RedRhF híbrida. En otra realización, la variante del polipéptido de fusión híbrida de CYP153A-reductasa en una célula hospedadora recombinante produce un título más alto de un derivado de ácido graso w-OP o composición del mismo en comparación con el título de un ácido graso w-OP o composición del mismo producido por la expresión de un polipéptido de fusión híbrida de CYP153A-reductasa en una célula hospedadora correspondiente.
En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene una mutación en la posición de aminoácido 141, incluyendo V141I y/o V141T. En el presente documento, la expresión de la variante de polipéptido de fusión híbrida de CYP153A-reductasa con mutaciones V141I o V141T en una célula hospedadora recombinante produce un título más alto de un ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18,
C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OP respectivamente, en comparación con un título de un ácido graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1,
C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OP producido mediante la expresión de un polipéptido de fusión híbrida de CYP153A-reductasa. En una realización, la variante del polipéptido de fusión híbrida de CYP153A-reductasa tiene mutaciones V141I y A231T (SEQ ID NO: 32) y produce mayores cantidades de ácidos grasos C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C161, C171, C181, C191 y/o C201 w-OP cuando se expresa en una célula hospedadora con una función enzimática de tioesterasa. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene mutaciones R27L, R82D, V141M, R178N y N407A (SEQ iD NO: 34) y produce mayores cantidades de ácidos grasos C6, C7, C8,
C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1,
C191 y/o C201 w-OP cuando se expresa en una célula hospedadora con una función enzimática de tioesterasa. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene la mutación P666A (SEQ ID NO:
36) y produce mayores cantidades de ácidos grasos C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20,
C8:1, C9:1, C10:1, Cn:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OP cuando se expresa en una célula hospedadora con una función enzimática de tioesterasa. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene la mutación A796V (SEQ ID NO: 38) y produce mayores cantidades de ácidos grasos
C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C171, C181, C191 y/o C201 w-OP cuando se expresa en una célula hospedadora con una función enzimática de tioesterasa. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene mutaciones A796V, P666D y T516V (SEQ ID NO: 40) y produce mayores cantidades de ácidos grasos C6, C7, C8, C9, C10, C11,
C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OP cuando se expresa en una célula hospedadora con una función enzimática de tioesterasa. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene mutaciones V141I, A231T y A796V (SEQ ID
NO: 42) y produce mayores cantidades de ácidos grasos C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19,
C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OP cuando se expresa en una célula hospedadora con una función enzimática de tioesterasa. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene mutaciones R27L, R82D, V141M, R178N, N407A y A796V (SEQ ID NO: 44) y produce mayores cantidades de ácidos grasos C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C9:1, C10:1, Cn:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OP cuando se expresa en una célula hospedadora con una función enzimática de tioesterasa. En otra realización, la variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene mutaciones V141T, A231T y A796V (SEQ ID NO: 46) y produce mayores cantidades de ácidos grasos C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1 y/o C20:1 w-OP cuando se expresa en una célula hospedadora con una función enzimática de tioesterasa. En una realización, las variantes de SEQ ID NO: 32, SEQ ID NO: 34, SEQ ID NO: 36, SEQ ID NO: 38,
SEQ ID NO: 40, SEQ ID NO: 42, SEQ ID NO: 44 y SEQ ID NO: 46 produjeron mayores cantidades de ácidos grasos o derivados de ácidos grasos w-OP en comparación con SEQ ID NO: 6. En una realización, estos ácidos grasos w-OP son ácidos grasos Cso w-OP, ácidos grasos C100 w-OP, ácidos grasos C120 w-OP, ácidos grasos C140 w-OP, ácidos grasos C160 w-OP, ácidos grasos C180 w-OP, ácidos grasos C200 w-OP, ácidos grasos C81 w-OP, ácidos grasos C101 w-OP, ácidos grasos C121 w-OP, ácidos grasos C141 w-OP, ácidos grasos C161 w-OP, ácidos grasos C181 w-OP, ácidos grasos C20:1 w-OP y similares.
La divulgación identifica variantes de polinucleótidos y polipéptidos relacionados con la fusión híbrida de CYP153A-reductasa. Las variantes del polipéptidos de fusión híbrida de CYP153A-reductasa incluyen SEQ ID NO: 8, 10, 12, 14,
16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44 y 46. Las variantes de ácido nucleico de fusión híbrida de CYP153A-reductasa (secuencias de ADN) incluyen SEQ ID NO: 7, 9, 11, 13, 15, 17, 19, 21,23, 25, 27, 29, 31, 33, 35,
37, 39, 41, 43, 45 y 47. Sin embargo, se reconocerá que no es necesaria la identidad de secuencia absoluta para las variantes de polinucleótidos de fusión híbrida de CYP153A-reductasa. Por ejemplo, se pueden hacer cambios en una secuencia polinucleotídica particular, y el polipéptido codificado puede cribarse en busca de actividad. Dichos cambios normalmente incluyen mutaciones conservativas y mutaciones silenciosas tales como, por ejemplo, a través de la optimización de codones. Los polinucleótidos modificados o mutados (es decir, mutantes) y las variantes de polipéptidos codificadas pueden cribarse en busca de una función deseada, tal como, una función mejorada en comparación con el polipéptido de tipo silvestre o molde, que incluye, pero sin limitación, una mayor actividad catalítica, mayor estabilidad o menor inhibición (por ejemplo, disminución de la inhibición de retroalimentación), usando métodos conocidos en la técnica. La divulgación identifica actividades enzimáticas implicadas en distintas etapas (es decir, reacciones) de las vías biosintéticas de ácidos grasos descritas en el presente documento de acuerdo con el número de clasificación enzimática (CE), y proporciona polipéptidos ilustrativos (por ejemplo, que funcionan como enzimas específicas y muestran actividad enzimática específica) categorizados por dichos números de CE y polinucleótidos ilustrativos que codifican dichos polipéptidos. Dichos polipéptidos y polinucleótidos ilustrativos, que se identifican en
el presente documento por los números de identificación de secuencia (SEQ ID NO; anteriores), son útiles para diseñar genéticamente vías de ácidos grasos en células hospedadoras como la que se muestra en la Figura 1. Debe entenderse, sin embargo, que los polipéptidos y polinucleótidos descritos en el presente documento son ilustrativos y, por lo tanto, no limitantes. Las secuencias de homólogos de polipéptidos ilustrativos descritos en el presente documento están disponibles para los expertos en la técnica usando bases de datos tales como, por ejemplo, las bases de datos Entrez proporcionadas por el Centro Nacional de Información Biotecnológica (NCBI), las bases de datos ExPasy proporcionadas por el Instituto Suizo de Bioinformática, la base de datos BRENDA proporcionada por la Universidad Técnica de Braunschweig y la base de datos KEGG proporcionada por el Centro de Bioinformática de la Universidad de Kyoto y la Universidad de Tokio, estando todas ellas disponibles en la World Wide Web.
Una variante de polipéptido de fusión híbrida de CYP153A-reductasa para usar en la práctica de la divulgación tiene al menos aproximadamente el 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 20, SEQ ID NO: 22, SEQ ID NO: 24, SEQ ID NO: 26, SEQ ID NO: 28 o SEQ ID NO: 30, SEQ ID NO: 32, SEQ ID NO: 34, SEQ ID NO: 36, SEQ ID NO: 38, SEQ ID NO: 40, SEQ ID NO: 42, SEQ ID NO: 44 y SEQ ID NO: 46. En algunas realizaciones, la variante de polipéptido de fusión híbrida de CYP153A-reductasa se deriva de un polipéptido CYP153A (G307A) de Marinobacter aquaeolei donde una glicina (G) está sustituida por una alanina (A), y se fusiona con un dominio reductasa de P450RhF de Rhodococcus sp. NCIMB9784. El citocromo P450RhF es autosuficiente, muestra un alto grado de promiscuidad del sustrato y cataliza una amplia gama de grupos funcionales. En otras realizaciones, una variante de polipéptido de fusión híbrida de CYP153A-reductasa para usar en la práctica de la divulgación tiene al menos aproximadamente el 75 %, 76 %, 77 %, 78 %, 79 %, 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o al menos el 99 % de identidad de secuencia con SEQ ID NO 6, SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 20, SEQ ID NO: 22, SEQ ID NO: 24, SEQ ID NO: 26, SEQ ID NO: 28 o SEQ ID NO: 30, SEQ ID NO: 32, SEQ ID NO: 34, SEQ ID NO: 36, SEQ ID NO: 38, SEQ ID NO: 40, SEQ ID NO: 42, SEQ ID NO: 44 o SEQ ID NO: 46, y también puede incluir una o más sustituciones que producen características y/o propiedades útiles como se describe en el presente documento. En otras realizaciones, una variante de polipéptido de fusión híbrida de CYP153A-reductasa para usar en la práctica de la divulgación tiene al menos aproximadamente el 100 %, 99 %, 98 %, 97 %, 96 %, 95 %, 94 %, 93 %, 92 %, 91 % o 90 % de identidad de secuencia con SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 20, SEQ ID NO: 22, SEQ ID NO: 24, SEQ ID NO: 26, SEQ ID NO: 28 o SEQ ID NO: 30, SEQ ID NO: 32, SEQ ID NO: 34, SEQ ID NO: 36, SEQ ID NO: 38, SEQ ID NO: 40, SEQ ID NO: 42, SEQ ID NO: 44 o SEQ ID NO: 46. En otras realizaciones más, el dominio catalítico de P450 de la variante de polipéptido de fusión híbrida de CYP153A-reductasa se deriva de un organismo distinto de Marinobacter aquaeolei. Dichos otros organismos incluyen, pero sin limitación, Acinetobacter sp., Mycobacterium marinum, Polaromonas sp., Alcanivorax borkumensis., Burkholderia fungorum, Caulobacter crescentus, Hyphomonas neptunium, Rhodopseudomonas palustris, Sphingomonas sp., Mycobacterium sp. En otras realizaciones más, El dominio reductasa de la variante de polipéptido de fusión híbrida de CYP153A-reductasa se deriva de un organismo distinto de Rhodococcus sp. Dichos otros organismos incluyen, pero sin limitación, Rhodococcus equi, Acinetobacter radioresistens, Burkholderia mallei, Burkholderia mallei, Ralstonia eutropha, Cupriavidus metallidurans.
La divulgación incluye una variante de polinucleótido de fusión híbrida de CYP153A-reductasa que tiene al menos aproximadamente el 75 %, 76 %, 77 %, 78 %, 79 %, 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o al menos el 99 % de identidad de secuencia con SEQ ID NO 5, SEQ ID NO: 7, SEQ ID NO: 9, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 15, SEQ ID NO: 17, SEQ ID NO: 19, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 25, SEQ ID NO: 27, SEQ ID NO: 29, SEQ ID NO: 31, SEQ ID NO: 33, SEQ ID NO: 35, SEQ ID NO: 37, SEQ ID NO: 39, SEQ ID NO: 41, SEQ ID NO: 43, SEQ ID NO: 45 o SEQ ID NO: 47. La secuencia de ácido nucleico codifica una variante de polipéptido de fusión híbrida de CYP153A-reductasa con una o más sustituciones que produce características y/o propiedades mejoradas como se describe en el presente documento. En otra realización relacionada más, una variante de polipéptido de fusión híbrida de CYP153A-reductasa para usar en la práctica de la divulgación está codificada por una secuencia de nucleótidos que tiene al menos aproximadamente el 100 %, 99 %, 98 %, 97 %, 96 %, 95 %, 94 %, 93 %, 92 %, 91 % o 90 % de identidad de secuencia con SEQ ID NO: 7, SEQ ID NO: 9, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 15, SEQ ID NO: 17, SEQ ID NO: 19, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 25, SEQ ID NO: 27, SEQ ID NO: 29, SEQ ID NO: 31, SEQ ID NO: 33, SEQ ID NO: 35, SEQ ID NO: 37, SEQ ID NO: 39, SEQ ID NO: 41, SEQ ID NO: 43, SEQ ID NO: 45 o SEQ ID NO: 47. En otro aspecto, la divulgación se refiere a variantes de polipéptidos de fusión híbrida de CYP153A-reductasa que abarcan una secuencia de aminoácidos codificada por una secuencia de ácido nucleico que se hibrida en condiciones rigurosas sobre sustancialmente la longitud completa de una secuencia de ácido nucleico correspondiente a SEQ ID NO: 7, SEQ ID NO: 9, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 15, SEQ ID NO: 17, SEQ ID NO: 19, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 25, SEQ ID NO: 27, SEQ ID NO: 29, SEQ ID NO: 31, SEQ ID NO: 33, SEQ ID NO: 35, SEQ ID NO: 37, SEQ ID NO: 39, SEQ ID NO: 41, SEQ ID NO: 43, SEQ ID NO: 45 o SEQ ID NO: 47. En algunas realizaciones, la variante de polipéptido de fusión híbrida de CYP153A-reductasa se deriva de Marinobacter aquaeolei. En otras realizaciones, el polipéptido de fusión híbrida de P450 se deriva de Acinetobacter sp., Mycobacterium marinum, Polaromonas sp., Alcanivorax borkumensis., Burkholderia fungorum, Caulobacter crescentus, Hyphomonas neptunium, Rhodopseudomonas palustris, Sphingomonas sp. y Mycobacterium sp.
Variantes adicionales de polipéptidos de fusión híbrida de CYP153A-reductasa
La divulgación identifica variantes adicionales de polinucleótidos y polipéptidos relacionados con la fusión híbrida de CYP153A-reductasa, en donde se usó una variante como molde. La variante molde de polipéptido de fusión híbrida de CYP153A-reductasa se basa en el polipéptido de fusión híbrida de CYP153A (G307A)-RedRhF, e incluye además la mutación A796V (SEQ ID NO: 38). Se construyó una biblioteca de saturación total de proteína de fusión cyp153A-Red450RhF, y se seleccionaron las variantes que mostraron mejoras frente a cyp153A (G307A)-Red450RhF (A796V) (SEQ ID NO: 38) (véase el Ejemplo 7). Las mutaciones G307A y A796V son mutaciones beneficiosas que mejoran la actividad w-hidroxilasa de cyp153A (véase SEQ ID NO: 38). Las variantes del polipéptidos de fusión híbrida de CYP153A-reductasa resultantes se muestran en la Tabla 11 (más adelante). Estas variantes de polipéptidos de fusión híbrida de CYP153A-reductasa produjeron una mayor cantidad de ácidos grasos w-hidroxilados (título de FFA w-OP) en comparación con SEQ ID n O: 38, e incluyen las SEQ ID NO: 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94 y 96. Estas variantes de polipéptidos de fusión híbrida de CYP153A-reductasa pueden producir mayores cantidades de ácidos grasos w-OP, incluidos ácidos grasos y/o derivados de ácidos grasos C6, C7, Cs, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C8:1, C9:1, Cl0:1, Cl1:1, Cl2:1, Cl 3:1, Cl 4:1, Cl 5:1, Cl6:1, Cl 7:1, C18:1, C19:1 y/o C20:1.
Las variantes de ácido nucleico de fusión híbrida de CYP153A-reductasa (secuencias de ADN) incluyen SEQ ID NO: 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93 y 95. Sin embargo, se reconocerá que no es necesaria la identidad de secuencia absoluta para las variantes de polinucleótidos de fusión híbrida de cYP153A-reductasa. Por ejemplo, se pueden hacer cambios en una secuencia polinucleotídica particular, y el polipéptido codificado puede cribarse en busca de actividad. Dichos cambios normalmente incluyen mutaciones conservativas y mutaciones silenciosas tales como, por ejemplo, a través de la optimización de codones. Los polinucleótidos modificados o mutados (es decir, mutantes) y las variantes de polipéptidos codificadas pueden cribarse en busca de una función deseada, tal como, una función mejorada en comparación con el polipéptido de tipo silvestre o molde, que incluye, pero sin limitación, una mayor actividad catalítica, mayor estabilidad o menor inhibición (por ejemplo, disminución de la inhibición de retroalimentación), usando métodos conocidos en la técnica. La divulgación identifica actividades enzimáticas implicadas en distintas etapas (es decir, reacciones) de las vías biosintéticas de ácidos grasos descritas en el presente documento de acuerdo con el número de clasificación enzimática (CE), y proporciona polipéptidos ilustrativos (por ejemplo, que funcionan como enzimas específicas y muestran actividad enzimática específica) categorizados por dichos números de CE y polinucleótidos ilustrativos que codifican dichos polipéptidos. Dichos polipéptidos y polinucleótidos ilustrativos, que se identifican en el presente documento por los números de identificación de secuencia (SEQ ID NO; anteriores), son útiles para diseñar genéticamente vías de ácidos grasos en células hospedadoras como la que se muestra en la Figura 1. Debe entenderse, sin embargo, que los polipéptidos y polinucleótidos descritos en el presente documento son ilustrativos y, por lo tanto, no limitantes. Las secuencias de homólogos de polipéptidos ilustrativos descritos en el presente documento están disponibles para los expertos en la técnica usando bases de datos tales como, por ejemplo, las bases de datos Entrez proporcionadas por el Centro Nacional de Información Biotecnológica (NCBI), las bases de datos ExPasy proporcionadas por el Instituto Suizo de Bioinformática, la base de datos BRENDA proporcionada por la Universidad Técnica de Braunschweig y la base de datos KEGG proporcionada por el Centro de Bioinformática de la Universidad de Kyoto y la Universidad de Tokio, estando todas ellas disponibles en la World Wide Web.
Una variante de polipéptido de fusión híbrida de CYP153A-reductasa para usar en la práctica de la divulgación tiene al menos aproximadamente el 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia con SEQ ID NO: 48, SEQ ID NO: 50, SEQ ID NO: 52, SEQ ID NO: 54, SEQ ID NO: 56, SEQ ID NO: 58, SEQ ID NO: 60, SEQ ID NO: 62, SEQ ID NO: 64, SEQ ID NO: 66, SEQ ID NO: 68 o SEQ ID NO: 70, SEQ ID NO: 72, SEQ ID NO: 74, SEQ ID NO: 76, SEQ ID NO: 78, SEQ ID NO: 80, SEQ ID NO: 82, SEQ ID NO: 84, SEQ ID NO: 86, SEQ ID NO: 88, SEQ ID NO: 90, SEQ ID NO: 92, SEQ ID NO: 94 y SEQ ID NO: 96. En algunas realizaciones, la variante de polipéptido de fusión híbrida de CYP153A-reductasa se deriva de un polipéptido CYP153A (G307A) de Marinobacter aquaeolei donde una glicina (G) se reemplaza con una alanina (A), y se fusiona con un dominio reductasa de P450RhF de Rhodococcus sp. NCIMB9784, e incluye una mutación adicional de A796V donde una alanina (A) se reemplaza con una valina (V). El citocromo P450RhF es autosuficiente, muestra un alto grado de promiscuidad del sustrato y cataliza una amplia gama de grupos funcionales. En otras realizaciones, una variante de polipéptido de fusión híbrida de CYP153A-reductasa para usar en la práctica de la divulgación tiene al menos aproximadamente el 75 %, 76 %, 77 %, 78 %, 79 %, 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o al menos el 99 % de identidad de secuencia con SEQ ID NO 38, SEQ ID NO: 48, SEQ ID NO: 50, SEQ ID NO: 52, SEQ ID NO: 54, SEQ ID NO: 56, SEQ ID NO: 58, SEQ ID NO: 60, SEQ ID NO: 62, SEQ ID NO: 64, SEQ ID NO: 66, SEQ ID NO: 68 o SEQ ID NO: 70, SEQ ID NO: 72, SEQ ID NO: 74, SEQ ID NO: 76, SEQ ID NO: 78, SEQ ID NO: 80, SEQ ID NO: 82, SEQ ID NO: 84, SEQ ID NO: 86, SEQ ID NO: 88, SEQ ID NO: 90, SEQ ID NO: 92, SEQ ID NO: 94 o SEQ ID NO: 96, y también puede incluir una o más sustituciones que producen características y/o propiedades útiles como se describe en el presente documento. Una variante de polipéptido de fusión híbrida de CYP153A-reductasa para usar en la práctica de la divulgación tiene al menos aproximadamente el 100 %, 99 %, 98 %, 97 %, 96 %, 95 %, 94 %, 93 %, 92 %, 91 % o 90 % de identidad de secuencia con SEQ ID NO: 48, SEQ ID NO: 50, SEQ ID NO: 52, SEQ ID NO: 54, SEQ ID NO: 56, SEQ ID NO: 58, SEQ ID NO: 60, SEQ ID NO: 62, SEQ ID NO: 64, SEQ ID NO: 66, SEQ ID NO: 68 o SEQ ID NO: 70, SEQ ID NO: 72, SEQ ID NO: 74, SEQ ID NO: 76, SEQ ID NO: 78, SEQ ID NO: 80, SEQ ID NO: 82, SEQ ID NO: 84, SEQ ID NO: 86, SEQ ID NO: 88, SEQ ID NO:
90, SEQ ID NO: 92, SEQ ID NO: 94 o SEQ ID NO: 96. En otras realizaciones más, el dominio catalítico de P450 de la variante de polipéptido de fusión híbrida de CYP153A-reductasa se deriva de un organismo distinto de Marinobacter aquaeolei. Dichos otros organismos incluyen, pero sin limitación, Acinetobacter sp., Mycobacterium marinum, Polaromonas sp., Alcanivorax borkumensis., Burkholderia fungorum, Caulobacter crescentus, Hyphomonas neptunium, Rhodopseudomonas palustris, Sphingomonas sp., Mycobacterium sp. En otras realizaciones más, El dominio reductasa de la variante de polipéptido de fusión híbrida de CYP153A-reductasa se deriva de un organismo distinto de Rhodococcus sp. Dichos otros organismos incluyen, pero sin limitación, Rhodococcus equi, Acinetobacter radioresistens, Burkholderia mallei, Burkholderia mallei, Ralstonia eutropha, Cupriavidus metallidurans.
La divulgación incluye una variante de polinucleótido de fusión híbrida de CYP153A-reductasa que tiene al menos aproximadamente el 75 %, 76 %, 77 %, 78 %, 79 %, 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o al menos el 99 % de identidad de secuencia con SEQ ID NO 47, SEQ ID NO: 49, SEQ ID NO: 51, SEQ ID NO: 53, SEQ ID NO: 55, SEQ ID NO: 57, SEQ ID NO: 59, SEQ ID NO: 61, SEQ ID NO: 63, SEQ ID NO: 65, SEQ ID NO: 67, SEQ ID NO: 69, SEQ ID NO: 71, SEQ ID NO: 73, SEQ ID NO: 75, SEQ ID NO: 77, SEQ ID NO: 79, SEQ ID NO: 81, SEQ ID NO: 83, SEQ ID NO: 85, SEQ ID NO: 87, SEQ ID NO: 89, SEQ ID NO: 91, SEQ ID NO: 93 o SEQ ID NO: 95. En algunas realizaciones, la secuencia de ácido nucleico codifica una variante de polipéptido de fusión híbrida de CYP153A-reductasa con una o más sustituciones que produce características y/o propiedades mejoradas como se describe en el presente documento. En otra realización relacionada más, una variante de polipéptido de fusión híbrida de CYP153A-reductasa para usar en la práctica de la divulgación está codificada por una secuencia de nucleótidos que tiene al menos aproximadamente el 100 %, 99 %, 98 %, 97 %, 96 %, 95 %, 94 %, 93 %, 92 %, 91 % o 90 % de identidad de secuencia con SEQ ID NO: 47, SEQ ID NO: 49, SEQ ID NO: 51, SEQ ID NO: 53, SEQ ID NO: 55, SEQ ID NO: 57, SEQ ID NO: 59, SEQ ID NO: 61, SEQ ID NO: 63, SEQ ID NO: 65, SEQ ID NO: 67, SEQ ID NO: 69, SEQ ID NO: 71, SEQ ID NO: 73, SEQ ID NO: 75, SEQ ID NO: 77, SEQ ID NO: 79, SEQ ID NO: 81, SEQ ID NO: 83, SEQ ID NO: 85, SEQ ID NO: 87, SEQ ID NO: 89, SEQ ID NO: 91, SEQ ID NO: 93 o SEQ ID NO: 95. En otro aspecto, la divulgación se refiere a variantes de polipéptidos de fusión híbrida de CYP153A-reductasa que abarcan una secuencia de aminoácidos codificada por una secuencia de ácido nucleico que se hibrida en condiciones rigurosas sobre sustancialmente la longitud completa de una secuencia de ácido nucleico correspondiente a SEQ ID NO: 47, SEQ ID NO: 49, SEQ ID NO: 51, SEQ ID NO: 53, SEQ ID NO: 55, SEQ ID NO: 57, SEQ ID NO: 59, SEQ ID NO: 61, SEQ ID NO: 63, SEQ ID NO: 65, SEQ ID NO: 67, SEQ ID NO: 69, SEQ ID NO: 71, SEQ ID NO: 73, SEQ ID NO: 75, SEQ ID NO: 77, SEQ ID NO: 79, SEQ ID NO: 81, SEQ ID NO: 83, SEQ ID NO: 85, SEQ ID NO: 87, SEQ ID NO: 89, SEQ ID NO: 91, SEQ ID NO: 93 o SEQ ID NO: 95. En algunas realizaciones, la variante de polipéptido de fusión híbrida de CYP153A-reductasa se deriva de una especie de Marinobacter aquaeolei. En otras realizaciones, el polipéptido de fusión híbrida de P450 se deriva de Acinetobacter sp., Mycobacterium marinum, Polaromonas sp., Alcanivorax borkumensis., Burkholderia fungorum, Caulobacter crescentus, Hyphomonas neptunium, Rhodopseudomonas palustris, Sphingomonas sp. y Mycobacterium sp.
Secuencias
Las variantes que se muestran en la tabla que se presenta a continuación se basan en la proteína de fusión híbrida de cyp153A16(G307A)-RedRhF del citocromo P450.

(continuación)

(continuación)

(continuación)

Las variantes que se muestran en la tabla que se presenta a continuación se basan en la proteína de fusión híbrida de Citocromo P450 cyp153A (G307A)-Red450RhF (A796V).

(continuación)

(continuación)

Variaciones y mutaciones
Una variante de polipéptido, como se usa en el presente documento, se refiere a un polipéptido que tiene una secuencia de aminoácidos que difiere de un polipéptido de tipo silvestre o molde en al menos un aminoácido. Por ejemplo, la variante (por ejemplo, mutante) puede tener una o más de las siguientes sustituciones conservativas de aminoácidos, incluyendo, pero sin limitación, el reemplazo de un aminoácido alifático, tal como alanina, valina, leucina e isoleucina, con otro aminoácido alifático; el reemplazo de una serina con una treonina; el reemplazo de una treonina con una serina; el reemplazo de un resto ácido, tal como el ácido aspártico y el ácido glutámico, con otro resto ácido;
el reemplazo de un resto portador de un grupo amida, tal como la asparagina y la glutamina, con otro resto portador de un grupo amida; el intercambio de un resto básico, tal como lisina y arginina, con otro resto básico; y el reemplazo de un resto aromático, tal como fenilalanina y tirosina, con otro resto aromático. La variante de polipéptido tiene aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90, 99 o más sustituciones, adiciones, inserciones o eliminaciones de aminoácidos. Algunos fragmentos preferidos de un polipéptido que funcionan como una variante o mutante retienen parte o la totalidad de la función biológica (por ejemplo, actividad enzimática) del polipéptido de tipo silvestre correspondiente. El fragmento retiene al menos el 75 %, al menos el 80 %, al menos el 90 %, al menos el 95 % o al menos el 98 % o más de la función biológica del polipéptido de tipo silvestre o molde correspondiente. En otras realizaciones, el fragmento o mutante retiene aproximadamente el 100 % de la función biológica del polipéptido de tipo silvestre o molde correspondiente. En otras realizaciones, algunos fragmentos presentan una mayor función biológica en comparación con el polipéptido de tipo silvestre o molde correspondiente. Se puede encontrar orientación para determinar qué restos de aminoácidos pueden ser sustituidos, insertados o eliminados sin afectar a la actividad biológica usando programas informáticos bien conocidos en la técnica, por ejemplo, Software LASERGENE (DNASTAR, Inc., Madison, WI). Un fragmento presenta un aumento de la función biológica en comparación con un polipéptido de tipo silvestre o polipéptido molde correspondiente. Por ejemplo, un fragmento puede mostrar al menos un 10 %, al menos un 25 %, al menos un 50 %, al menos un 75 % o al menos un 90 % de mejora en la actividad enzimática en comparación con el polipéptido de tipo silvestre o polipéptido molde correspondiente. El fragmento muestra al menos el 100 %, al menos el 200 % o al menos el 500 % de mejora en la actividad enzimática en comparación con el polipéptido de tipo silvestre o polipéptido molde correspondiente.
Se entiende que los polipéptidos descritos en el presente documento pueden tener sustituciones de aminoácidos conservativas o no esenciales adicionales que no tengan un efecto sustancial sobre la función del polipéptido. Se puede determinar si se tolerará o no una sustitución particular (es decir, si no afectará negativamente a la función biológica deseada, tal como la actividad enzimática u-hidroxilasa), como se conoce en la técnica (véase Bowie et al. (1990) Science, 247: 1306-1310). Una sustitución conservativa de aminoácidos es aquella en la que el resto de aminoácido se reemplaza con un resto de aminoácido que tiene una cadena lateral similar. En la técnica, se han definido familias de restos de aminoácidos que tienen cadenas laterales similares. Estas familias incluyen aminoácidos con cadenas laterales básicas (por ejemplo, lisina, arginina, histidina), cadenas laterales ácidas (por ejemplo, ácido aspártico, ácido glutámico), cadenas laterales polares no cargadas (por ejemplo, glicina, asparagina, glutamina, serina, treonina, tirosina, cisteína), cadenas laterales no polares (por ejemplo, alanina, valina, leucina, isoleucina, prolina, fenilalanina, metionina, triptófano), cadenas laterales beta-ramificadas (por ejemplo, treonina, valina, isoleucina) y cadenas laterales aromáticas (por ejemplo, tirosina, fenilalanina, triptófano, histidina).
Las variantes pueden ser naturales o creadas in vitro. En particular, dichas variantes se pueden crear usando técnicas de ingeniería genética, tales como mutagénesis dirigida, mutagénesis química aleatoria, procedimientos de eliminación de exonucleasa III o técnicas de clonación convencionales. Como alternativa, dichas variantes, mutantes, fragmentos, análogos o derivados se pueden crear mediante síntesis química o procedimientos de modificación. Los métodos para crear variantes son bien conocidos en la técnica. Por ejemplo, las variantes se pueden preparar usando mutagénesis aleatoria y dirigida. La mutagénesis aleatoria y dirigida se conoce, en general, en la técnica (véase, por ejemplo, Arnold (1993) Curr. Opin. Biotech. 4:450-455). La mutagénesis aleatoria se puede lograr usando PCR propensa a errores (véase, por ejemplo, Leung et al. (1989) Technique 1:11-15; y Caldwell et al. (1992) PCR Methods Applic. 2: 28-33). En la PCR propensa a errores, la PCR real se realiza en condiciones en las que la fidelidad de copias de la ADN polimerasa es baja, de modo que se obtiene una alta tasa de mutaciones puntuales a lo largo de toda la longitud del producto de PCR. En resumen, en dichos procedimientos, los ácidos nucleicos que se van a mutagenizar (por ejemplo, una secuencia polinucleotídica que codifica una proteína P450 o un polipéptido de fusión híbrida de P450) se mezclan con cebadores de PCR, tampón de reacción, MgCb, MnCb, Taq polimerasa y una concentración apropiada de dNTP para lograr una alta tasa de mutación puntual a lo largo de toda la longitud del producto de PCR. Por ejemplo, la reacción se puede realizar usando 20 fmoles de ácido nucleico que se va a mutagenizar, 30 pmol de cada cebador de PCR, un tampón de reacción que comprende KCl 50 mM, Tris HCl 10 mM (pH 8,3), gelatina al 0,01 %, MgCb 7 mM, MnCb 0,5 mM, 5 unidades de Taq polimerasa, dGTP 0,2 mM, dATP 0,2 mM, dCTP 1 mM y dTTP 1 mM. La PCR se puede realizar durante 30 ciclos de 94 °C durante 1 minuto, a 45 °C durante 1 min y a 72 °C durante 1 min. Sin embargo, los expertos en la materia apreciarán que estos parámetros pueden variarse según sea apropiado. Los ácidos nucleicos mutagenizados se clonan luego en un vector apropiado, y se evalúan las actividades de los polipéptidos codificados por los ácidos nucleicos mutagenizados. La mutagénesis dirigida se puede realizar usando mutagénesis dirigida a oligonucleótidos para generar mutaciones específicas del sitio en cualquier ADN clonado de interés. La mutagénesis de oligonucleótidos se describe en la técnica (véase, por ejemplo, Reidhaar-Olson et al. (1988) Science 241:53-57). En resumen, en dichos procedimientos, se sintetiza una pluralidad de oligonucleótidos bicatenarios portadores de una o más mutaciones para introducirlos en el ADN clonado, y se insertan en el ADN clonado que se va a mutagenizar (por ejemplo, una secuencia polinucleotídica que codifica un polipéptido P450 o un polipéptido de fusión híbrida de P450). Se recuperan los clones que contienen el ADN mutagenizado y se evalúan las actividades de los polipéptidos que codifican.
Otro método para generar variantes es la PCR de ensamblaje. La PCR de ensamblaje implica el ensamblaje de un producto de PCR a partir de una mezcla de pequeños fragmentos de ADN. Se produce una gran cantidad de diferentes reacciones de PCR en paralelo en el mismo vial, Cebando con los productos de una reacción a los productos de otra reacción (véase la patente de EE.UU. n.° 5.965.408). Otro método más para generar variantes es la mutagénesis por
PCR sexual. En la mutagénesis por PCR sexual, se produce la recombinación homóloga forzada entre moléculas de ADN de diferentes, pero muy relacionadas, secuencias de ADN in vitro como resultado de la fragmentación aleatoria de la molécula de ADN basada en la homología de secuencia. A esto, le sigue la fijación del cruce por extensión del cebador en una reacción de PCR. La mutagénesis por PCR sexual se describe en publicaciones conocidas en la técnica (véase, por ejemplo, Stemmer (1994) Proc. Natl. Acad. Sci. EE.UU. 91:10747-10751). También se pueden crear variantes por mutagénesis in vivo. En algunas realizaciones, se generan mutaciones aleatorias en una secuencia de ácido nucleico propagando la secuencia en una cepa bacteriana, tal como una cepa de E. coli, que porta mutaciones en una o más de las vías de reparación del ADN. Dichas cepas mutantes tienen una tasa de mutación aleatoria más alta que la de una cepa de tipo silvestre. La propagación de una secuencia de ADN (por ejemplo, una secuencia polinucleotídica que codifica un polipéptido de fusión híbrida de P450) en una de estas cepas finalmente generará mutaciones aleatorias dentro del a Dn . Las cepas mutantes adecuadas para usar para la mutagénesis in vivo se describen en la publicación en la técnica (véase, por ejemplo, publicación de solicitud de patente internacional n.° WO1991/016427). Las variantes también se pueden generar usando mutagénesis en casete. En la mutagénesis en casete, una pequeña región de una molécula de ADN bicatenaria se reemplaza con un casete de oligonucleótido sintético que difiere de la secuencia nativa. El oligonucleótido suele contener una secuencia nativa completa y/o parcialmente aleatoria. La mutagénesis de conjunto recursivo también se puede usar para generar variantes. La mutagénesis de conjunto recursivo es un algoritmo para el diseño genético de proteínas (es decir, mutagénesis de proteínas), desarrollado para producir distintas poblaciones de mutantes relacionados fenotípicamente, cuyos miembros difieren en la secuencia de aminoácidos. Este método usa un mecanismo de retroalimentación para controlar series sucesivas de mutagénesis en casete combinatoria (véase, por ejemplo, Arkin et al. (1992) Proc. Natl. Acad. Sci., EE.UU. 89:7811-7815). Las variantes se crean usando mutagénesis de conjunto exponencial. La mutagénesis de conjunto exponencial es un proceso para generar bibliotecas combinatorias con un alto porcentaje de mutantes únicos y funcionales, en donde pequeños grupos de restos son aleatorizados en paralelo para identificar, en cada posición alterada, aminoácidos que conduzcan a proteínas funcionales (véase, por ejemplo, Delegrave et al. (1993) Biotech. Res. 11:1548-1552). En algunas realizaciones, se crean variantes usando procedimientos de barajado en los que porciones de una pluralidad de ácidos nucleicos que codifican polipéptidos distintos se fusionan para crear secuencias de ácido nucleico quimérico que codifican polipéptidos quiméricos (como se describe en, por ejemplo, las patentes de EE.UU. n.° 5.965.408 y 5.939.250).
Células hospedadoras
Las estrategias para aumentar la producción de composiciones de ácido graso u-OP por las células hospedadoras recombinantes incluyen un mayor flujo a través de la vía biosintética de ácidos grasos mediante la expresión de un gen de fusión híbrida de CYP153A-reductasa y un gen de tioesterasa en el hospedador de producción. Como se usa en el presente documento, la expresión célula hospedadora recombinante o célula hospedadora modificada se refiere a una célula hospedadora cuya composición genética ha sido alterada en relación con la célula hospedadora de tipo silvestre correspondiente, por ejemplo, mediante la introducción deliberada de nuevos elementos genéticos y/o la modificación deliberada de elementos genéticos presentes de manera natural en la célula hospedadora. La descendencia de dichas células hospedadoras recombinantes también contiene estos elementos genéticos nuevos y/o modificados. En cualquiera de los aspectos de la divulgación descritos en el presente documento, la célula hospedadora puede seleccionarse entre una célula vegetal, célula de insecto, célula fúngica (por ejemplo, un hongo filamentoso, tal como Candida sp. o una levadura incipiente, tal como Saccharomyces sp.), una célula de algas y una célula bacteriana. En una realización, las células hospedadoras recombinantes son microorganismos recombinantes. Los ejemplos de células hospedadoras que son microorganismos incluyen, pero sin limitación, células del género Escherichia, Bacillus, Lactobacillus, Zymomonas, Rhodococcus, Pseudomonas, Aspergillus, Trichoderma, Neurospora, Fusarium, Humicola, Rhizomucor, Kluyveromyces, Pichia, Mucor, Myceliophtora, Penicillium, Phanerochaete, Pleurotus, Trametes, Chrysosporium, Saccharomyces, Stenotrophamonas, Schizosaccharomyces, Yarrowia o Streptomyces. En algunas realizaciones, la célula hospedadora es una célula bacteriana Gram-positiva. En otras realizaciones, la célula hospedadora es una célula bacteriana Gram-negativa. En algunas realizaciones, La célula hospedadora es una célula de E. coli. En alguna realización, la célula hospedadora es un linfocito B de E. coli, un linfocito C de E. coli, un linfocito K de E. coli o un linfocito W de E. coli. En otras realizaciones, la célula hospedadora es una célula de Bacillus lentus, una célula de Bacillus brevis, una célula de Bacillus stearothermophilus, una célula de Bacillus lichenoformis, una célula de Bacillus alkalophilus, una célula de Bacillus coagulans, una célula de Bacillus circulans, una célula de Bacillus pumilis, una célula de Bacillus thuringiensis, una célula de Bacillus clausii, una célula de Bacillus megaterium, una célula de Bacillus subtilis o una célula de Bacillus amyloliquefaciens. En otras realizaciones, la célula hospedadora es una célula de Trichoderma koningii, una célula de Trichoderma viride, una célula de Trichoderma reesei, una célula de Trichoderma longibrachiatum, una célula de Aspergillus awamori, una célula de Aspergillus fumigates, una célula de Aspergillus foetidus, una célula de Aspergillus nidulans, una célula de Aspergillus niger, una célula de Aspergillus oryzae, una célula de Humicola insolens, una célula de Humicola lanuginose, una célula de Rhodococcusopacus, una célula de Rhizomucormiehei o una célula de Mucormichei. En otras realizaciones más, la célula hospedadora es una célula de Streptomyces lividans o una célula de Streptomyces murinus. En otras realizaciones más, la célula hospedadora es una célula de Actinomycetes. En algunas realizaciones, la célula hospedadora es una célula de Saccharomyces cerevisiae.
En otras realizaciones, la célula hospedadora es una célula vegetal eucariota, una célula de alga, una célula de cianobacteria, una célula de bacteria verde de azufre, una célula de bacteria verde sin azufre, una célula de bacteria
púrpura de azufre, una célula de bacteria púrpura sin azufre, una célula extremófila, una célula de levadura, una célula de hongo, una célula diseñada genéticamente de cualquiera de los organismos descritos en el presente documento o un organismo sintético. En algunas realizaciones, la célula hospedadora depende de la luz o fija el carbono. En algunas realizaciones, la célula hospedadora tiene actividad autótrofa. En algunas realizaciones, la célula hospedadora tiene actividad fotoautótrofa, tal como en presencia de luz. En algunas realizaciones, la célula hospedadora es heterótrofa o mixotrófica en ausencia de luz. En ciertas realizaciones, la célula hospedadora es una célula de Arabidopsis thaliana, Panicum virgatum, Miscanthus giganteus, Zea mays, Botryococcuse braunii, Chlamydomonas reinhardtii, Dunaliela salina, Synechococcus Sp. PCC 7002, Synechococcus Sp. PCC 7942, Synechocystis Sp. PCC 6803, Thermosynechococcus elongates BP-1, Chlorobium tepidum, Chlorojlexus auranticus, Chromatiumm vinosum, Rhodospirillum rubrum, Rhodobacter capsulatus, Rhodopseudomonas palusris, Clostridium ljungdahlii, Clostridium thermocellum, Penicillium chrysogenum, Pichiapastoris, Saccharomyces cerevisiae, Schizosaccharomyces pombe, Pseudomonas fluorescens o Zymomonas mobilis. En una realización, la célula microbiana es de una cianobacteria que incluye, pero sin limitación, Prochlorococcus, Synechococcus, Synechocystis, Cyanothece y Nostoc punctiforme. En otra realización, la célula microbiana es de una especie cianobacteriana específica que incluye, pero sin limitación, Synechococcus elongatus PCC7942, Synechocystis sp. PCC6803 y Synechococcus sp. PCC7001.
Vectores de expresión
En algunas realizaciones, se proporciona una secuencia polinucleotídica (o gen) a la célula hospedadora por medio de un vector recombinante, que incluye un promotor unido operativamente a la secuencia polinucleotídica. En ciertas realizaciones, el promotor es un promotor de desarrollo regulado, específico de orgánulo, específico de tejido, inducible, constitutivo o específico de célula. En algunas realizaciones, el vector recombinante incluye al menos una secuencia seleccionada entre una secuencia de control de la expresión acoplada operativamente a la secuencia polinucleotídica; un marcador de selección acoplado operativamente a la secuencia polinucleotídica; una secuencia marcadora acoplada operativamente a la secuencia polinucleotídica; un resto de purificación acoplado operativamente a la secuencia polinucleotídica; una secuencia de secreción acoplada operativamente a la secuencia polinucleotídica; y una secuencia de dirección acoplada operativamente a la secuencia polinucleotídica. Los vectores de expresión descritos en el presente documento incluyen una secuencia polinucleotídica en una forma adecuada para la expresión de la secuencia polinucleotídica en una célula hospedadora. Los expertos en la materia apreciarán que el diseño del vector de expresión puede depender de factores tales como la elección de la célula hospedadora que se vaya a transformar, del nivel de expresión del polipéptido deseado, y similares. Los vectores de expresión descritos en el presente documento pueden introducirse en células hospedadoras para producir polipéptidos, incluyendo polipéptidos de fusión, codificados por las secuencias de polinucleótidos como se ha descrito anteriormente. La expresión de genes que codifican polipéptidos en procariotas, por ejemplo, E. coli, se realiza con mayor frecuencia con vectores que contienen promotores constitutivos o inducibles que dirigen la expresión de polipéptidos de fusión o no fusión. Los vectores de fusión agregan una cantidad de aminoácidos a un polipéptido codificado en los mismos, usualmente al extremo amino o carboxi del polipéptido recombinante. Dichos vectores de fusión normalmente sirven para uno o más de los tres siguientes propósitos, que incluyen aumentar la expresión del polipéptido recombinante; aumentar la solubilidad del polipéptido recombinante; y ayudar en la purificación del polipéptido recombinante actuando como ligando en la purificación por afinidad. Con frecuencia, en los vectores de expresión de fusión, se introduce un sitio de escisión proteolítica en la unión de la fracción de fusión y el polipéptido recombinante. Esto permite la separación del polipéptido recombinante de la fracción de fusión después de la purificación del polipéptido de fusión. Los ejemplos de dichas enzimas, y sus secuencias de reconocimiento afines, incluyen el factor Xa, la trombina y la enteroquinasa. Los vectores de expresión de fusión ilustrativos incluyen el vector pGEX (Pharmacia Biotech, Inc., Piscataway, NJ; Smith et al. (1988) Gene 67:31-40), vector pMAL (New England Biolabs, Beverly, MA) y vector pRITS (Pharmacia Biotech, Inc., Piscataway, N.J.), que fusionan glutatión S-transferasa (GST), proteína de unión a maltosa E o proteína A, respectivamente, a la proteína recombinante diana.
Los ejemplos de vectores de expresión de E. coli sin fusión, inducibles, incluyen el vector pTrc (Amann et al. (1988) Gene 69: 301-315) y el vector pET 11d (Studier et al., "Gene Expression Technology": Methods in Enzymology 185, Academic Press, San Diego, Calif. (1990) 60-89). La expresión de genes diana a partir del vector pTrc se basa en la transcripción de la ARN polimerasa del hospedador a partir de un promotor de fusión híbrida de trp-lac. La expresión de genes diana a partir del vector pET 11d se basa en la transcripción de un promotor de fusión de T7 gn10-lac mediada por una ARN polimerasa vírica expresada conjuntamente (T7 gn1). Esta polimerasa vírica es suministrada por cepas hospedadoras tales como BL21(DE3) o HMS174(DE3) de un profago A residente que alberga un gen T7 gn1 bajo el control transcripcional del promotor lacUV 5. Los sistemas de expresión adecuados para células tanto procariotas como eucariotas son bien conocidos en la técnica (véase, por ejemplo, Sambrook et al. (1989) "Molecular Cloning: A Laboratory Manual", segunda edición, Cold Spring Harbor Laboratory). Los ejemplos de vectores de expresión de E. coli inducibles no de fusión adecuados incluyen el vector pTrc (Amann et al. (1988) Gene 69:301-315) y el vectgor PET 11d (Studier et al. (1990) "Gene Expression Technology": Methods in Enzymology 185, Academic Press, San Diego, CA, pág. 60-89). En ciertas realizaciones, una secuencia polinucleotídica de la divulgación está unida operativamente a un promotor derivado del bacteriófago T5. En una realización, la célula hospedadora es una célula de levadura. En esta realización, el vector de expresión es un vector de expresión de levadura. Los vectores pueden introducirse en células procariotas o eucariotas mediante una variedad de técnicas reconocidas en la técnica para introducir ácido nucleico foráneo (por ejemplo, ADN) en una célula hospedadora. Se pueden encontrar métodos adecuados para transformar o transfectar células hospedadoras en, por ejemplo, Sambrook et al. (anterior). Para la
transformación estable de células bacterianas, se sabe que (dependiendo del vector de expresión y de la técnica de transformación usada) una cierta fracción de células absorberá y replicará el vector de expresión. Para identificar y seleccionar estos transformantes, se puede introducir un gen que codifique un marcador seleccionable (por ejemplo, resistencia a un antibiótico) en las células hospedadoras junto con el gen de interés. Los marcadores seleccionables incluyen aquellos que confieren resistencia a fármacos tales como, pero sin limitación, ampicilina, kanamicina, cloranfenicol o tetraciclina. Los ácidos nucleicos que codifican un marcador seleccionable pueden introducirse en una célula hospedadora en el mismo vector que el que codifica un polipéptido descrito en el presente documento o pueden introducirse en un vector separado.
Diseño por ingeniería genética de vías opcionales
Las células o los microorganismos hospedadoras de la divulgación incluyen cepas hospedadoras o células hospedadoras que están diseñadas o modificadas genéticamente para contener alteraciones con el fin de probar la eficacia de mutaciones específicas en actividades enzimáticas (es decir,células recombinantes o microorganismos recombinantes). Se pueden usar distintas manipulaciones y alteraciones genéticas opcionales indistintamente de una célula hospedadora a otra, dependiendo de qué vías enzimáticas nativas estén presentes en la célula hospedadora original. En una realización, se puede usar una cepa hospedadora para probar la expresión de una variante de polipéptido de fusión híbrida de CYP153A-reductasa en combinación con otros polipéptidos biosintéticos (por ejemplo, enzimas). Una cepa hospedadora puede englobar una serie de alteraciones genéticas para probar variables específicas, incluyendo, pero sin limitación, condiciones de cultivo, incluidos los componentes de fermentación, fuente de carbono (por ejemplo, materia prima), la temperatura, la presión, las condiciones de contaminación reducida de cultivos y los niveles de oxígeno.
En una realización, una cepa hospedadora engloba una deleción de fadEy fhuA opcional. La acil-CoA deshidrogenasa (FadE) es una enzima que es importante para metabolizar los ácidos grasos. Cataliza la segunda etapa en la utilización de los ácidos grasos (beta-oxidación), que es el proceso de romper las cadenas largas de ácidos grasos (acil-CoA) en moléculas de acetil-CoA. De manera más específica, la segunda etapa del ciclo de p-oxidación de la degradación de los ácidos grasos en las bacterias es la oxidación de acil-CoA a 2-enoil-CoA, que es catalizada por FadE. Cuando E. coli carece de FadE, no puede crecer en los ácidos grasos como fuente de carbono, pero puede crecer en el acetato. La incapacidad para utilizar ácidos grasos de cualquier longitud de cadena coincide con el fenotipo reportado de las cepas de fadE, es decir, cepas mutantes de fadE donde la función de FadE está interrumpida. El gen fadE puede eliminarse o atenuarse opcionalmente para garantizar que las acil-CoA, que pueden ser productos intermedios en una vía de derivados de ácidos grasos, puedan acumularse en la célula de modo que todas las acil-CoA se puedan convertir de manera eficaz en derivados de ácidos grasos. Sin embargo, la atenuación de fadE es opcional cuando se usa el azúcar como fuente de carbono, ya que,en dichas condiciones, la expresión de FadE probablemente inhibida y, por lo tanto, FadE solo puede estar presente en pequeñas cantidades y no puede competir eficazmente con la éster sintasa u otras enzimas por los sustratos de acil-CoA. La FadE se inhibe debido a la represión catabólica. E. coli y muchos otros microbios prefieren consumir azúcar frente a los ácidos grasos, por lo que, cuando ambas fuentes están disponibles, el azúcar se consume primero reprimiendo el regulón de fad (véase D. Clark, J Bacteriol. (1981) 148(2):521-6)). Además, la ausencia de azúcares y la presencia de ácidos grasos induce la expresión de FadE. Los productos intermedios de acil-CoA podrían perderse en la vía de oxidación beta, ya que las proteínas expresadas por el regulón de fad (incluyendo FadE) están reguladas y competirán eficazmente por las acil-CoA. Por lo tanto, puede ser beneficioso tener el gen fadE inactivado o atenuado. Como la mayoría de las fuentes de carbono se basan principalmente en el azúcar, es opcional atenuar FadE. El gen fhuA codifica la proteína TonA, que es un transportador y receptor acoplado a energía en la membrana externa de E. coli (V. Braun (2009) J Bacteriol. 191(11):3431-3436). Su eliminación es opcional. La eliminación de fhuA permite que la célula se vuelva más resistente al ataque de fagos, lo que puede ser beneficioso en ciertas condiciones de fermentación. Por lo tanto, puede ser deseable eliminar fhuA en una célula hospedadora que probablemente esté sujeta a una posible contaminación durante los procesos de fermentación.
En otra realización, la cepa hospedadora (anterior) también abarca la sobreexpresión opcional de uno o más de los siguientes genes, incluyendo fadR, fabA, fabD, fabG, fabH, fabVy/o fabF. Los ejemplos de dichos genes son fadR de Escherichia coli, fabA de Salmonella typhimurium (NP_460041), fabD de Salmonella typhimurium (NP_460164), fabG de Salmonella typhimurium (NP_460165), fabH de Salmonella typhimurium (NP_460163), fabV de Vibrio cholera (YP_001217283) y fabF de Clostridium acetobutylicum (NP_350156). La sobreexpresión de uno o más de estos genes, que codifican enzimas y reguladores en la biosíntesis de ácidos grasos, puede servir para aumentar el título de los compuestos derivados de ácidos grasos que incluyen ácidos grasos u-OP y derivados de los mismos en distintas condiciones de cultivo.
En otra realización, las cepas de E. coli se usan como células hospedadoras para la producción de ácidos grasos u -OH y derivados de los mismos. De manera similar, estas células hospedadoras proporcionan una sobreexpresión opcional de uno o más genes de biosíntesis (es decir, genes que codifican enzimas y reguladores de la biosíntesis de los ácidos grasos) que pueden aumentar o mejorar aún más el título de los compuestos derivados de ácidos grasos como los derivados de ácidos grasos (por ejemplo, ácidos grasos u-OP y a,u-diácidos, etc.) en distintas condiciones de cultivo, incluyendo, pero sin limitación, fadR, fabA, fabD, fabG, fabH, fabV y/o fabF. Los ejemplos de modificaciones genéticas incluyen fadR de Escherichia coli, fabA de Salmonella typhimurium (NP_46004l), fabD de Salmonella
typhimurium (NP_460164), fabG de Salmonella typhimurium (NP_460165), fabH de Salmonella typhimurium (Np_460163), fabVde Vibrio cholera (YP_001217283) y fabFde Clostridium acetobutylicum (NP_350156). En algunas realizaciones, los operones sintéticos portadores de estos genes biosintéticos se pueden diseñar y expresar en células para probar la expresión de P450 en distintas condiciones de cultivo y/o mejorar aún más la producción de los ácidos grasos w-OP y a,w-diácidos. Dichos operones sintéticos contienen uno o más genes biosintéticos. Un operón diseñado genéticamente puede contener genes biosintéticos de ácidos grasos opcionales, incluyendo fabV de Vibrio cholera, fabH de Salmonella typhimurium, fabD de S. typhimurium, fabG de S. typhimurium, fabA de S. typhimurium y/o fabF de Clostridium acetobutylicum que pueden usarse para facilitar la sobreexpresión de derivados de ácidos grasos para probar condiciones de cultivo específicas. Una ventaja de dichos operones sintéticos es que la tasa de producción de derivados de ácidos grasos w-OP puede aumentarse o potenciarse.
En algunas realizaciones, las células o los microorganismos hospedadores que se usan para expresar ACP y enzimas biosintéticas (por ejemplo, w-hidroxilasa, tioesterasa, etc.) expresarán además genes que abarcarán ciertas actividades enzimáticas que podrán aumentar la producción a uno o más derivados de ácidos grasos particulares tales como ácidos grasos w-OP, derivados de ácidos grasos w-OP, a,w-diácidos y similares. En una realización, la célula hospedadora tiene actividad tioesterasa (C.E. 3.1.2.* o C.E. 3.1. 2.14 o C.E. 3.1.1.5) para la producción de ácidos grasos que se puede aumentar sobreexpresando el gen. En otra realización, la célula hospedadora tiene actividad éster sintasa (C.E. 2.3.1.75) para la producción de ésteres grasos. En otra realización, la célula hospedadora tiene actividad acil-ACP reductasa (AAR) (CE 1.2.1.80) y/o actividad alcohol deshidrogenasa (CE 1.11.1.) y/o actividad alcohol graso acil-CoA reductasa (Fa R) (CE 1.1.1.*) y/o actividad ácido carboxílico reductasa (CAR) (CE 1.2.99.6) para la producción de alcoholes grasos. En otra realización, la célula hospedadora tiene actividad acil-ACP reductasa (AAR) (C.E. 1.2.1.80) para la producción de aldehidos grasos. En otra realización, la célula hospedadora tiene actividad acil-ACP reductasa (a A r ) (C.E. 1.2.1.80) y actividad descarbonilasa (ADC) para la producción de alcanos y alquenos. En otra realización, la célula hospedadora tiene actividad acil-CoA reductasa (C.E. 1.2.1.50), actividad acil-CoA sintasa (FadD) (C.E. 2.3.1.86) y actividad tioesterasa (C.E. 3.1.2.* o C.E. 3.1. 2.14 o C.E. 3.11.5) para la producción de alcoholes grasos. En otra realización, la célula hospedadora tiene actividad éster sintasa (C.E. 2.3.1.75), actividad acil-CoA sintasa (FadD) (C.E. 2.3.1.86) y actividad tioesterasa (C.E. 3.1.2.* o C.E. 3.1. 2.14 o C.E. 3.1.1.5) para la producción de ésteres grasos. En otra realización, la célula hospedadora tiene actividad OleA para la producción de cetonas. En otra realización, la célula hospedadora tiene actividad OleBCD para la producción de olefinas internas. En otra realización, la célula hospedadora tiene actividad acil-ACP reductasa (AAR) (C.E. 1.2.1.80) y actividad alcohol deshidrogenasa (C.E. 1.11.1.) para la producción de alcoholes grasos. En otra realización, la célula hospedadora tiene actividad tioesterasa (C.E. 3.1.2.* o C.E. 3.1. 2.14 o C.E. 3.1.1.5) y actividad descarboxilasa para formación de olefinas terminales. La expresión de actividades enzimáticas en microorganismos y células microbianas se enseña en los números de patente de EE.UU. n.° 8.097.439; 8.110.093; 8.110.670; 8.183.028; 8.268.599; 8.283.143; 8.232.924; 8.372.610; y 8.530.221. En otras realizaciones, las células o los microorganismos hospedadores que se usan para expresar ACP y otras enzimas biosintéticas incluirán ciertas actividades enzimáticas nativas que se regulan positivamente o se sobreexpresan para producir uno o más derivados de ácidos grasos particulares, tales como los ácidos grasos w-OP, derivados de ácidos grasos w-OH y a,w-diácidos. En una realización, la célula hospedadora tiene una actividad tioesterasa nativa (C.E. 3.1.2.* o C.E. 3.1.2.14 o C.E. 3.1.1.5) para la producción de ácidos grasos que pueden aumentarse mediante la sobreexpresión del gen de tioesterasa.
La presente divulgación incluye cepas o microorganismos hospedadores que expresan genes que codifican variantes de polipéptidos de fusión híbrida de CYP153A-reductasa y otras enzimas biosintéticas (anteriores). Las células hospedadoras recombinantes producen derivados de ácidos grasos tales como los ácidos grasos w-OP, derivados de ácidos grasos w-OH, a,w-diácidos,y composiciones y mezclas de los mismos. Los derivados de ácidos grasos normalmente se recuperan del medio de cultivo y/o se aíslan de las células hospedadoras. En una realización, los derivados de ácidos grasos se recuperan del medio de cultivo (extracelular). En otra realización, los derivados de ácidos grasos se aíslan de las células hospedadoras (intracelular). En otra realización, los derivados de ácidos grasos se recuperan del medio de cultivo y se aíslan de las células hospedadoras. Los derivados o las composiciones de ácidos grasos producidos por una célula hospedadora pueden analizarse usando métodos conocidos en la técnica, por ejemplo, GC-FID, para determinar la distribución de derivados de ácidos grasos particulares, así como la longitud de las cadenas y el grado de saturación de los componentes de los derivados de ácidos grasos w-OH, tales como los ácidos grasos w-OH, ésteres grasos w-OH, a,w-diácidos y similares.
Cultivo y fermentación
Como se usa en el presente documento, el término fermentación se refiere, en general, a la conversión de materiales orgánicos en sustancias diana por las células hospedadoras, por ejemplo, la conversión de una fuente de carbono por células hospedadoras recombinantes en ácidos grasos w-OH o derivados de los mismos mediante la propagación de un cultivo de las células hospedadoras recombinantes en un medio que comprende la fuente de carbono. Las condiciones permisivas para la producción se refieren a cualquier condición que permita que una célula hospedadora produzca un producto deseado, tales como los ácidos grasos w-OH. De manera similar, la condición o las condiciones en las que se expresa la secuencia polinucleotídica de un vector significa cualquier condición que permita que una célula hospedadora sintetice un polipéptido. Las condiciones adecuadas incluyen, por ejemplo, las condiciones de fermentación. Las condiciones de fermentación pueden incluir muchos parámetros que incluyen, pero sin limitación, intervalos de temperatura, niveles de aireación, tasas de alimentación y composición de los medios. Cada una de
estas condiciones, de forma individual y en combinación, permite que la célula hospedadora crezca. La fermentación puede ser aeróbica, anaeróbica o variaciones de las mismas (tal como microaeróbica). Los medios de cultivo ilustrativos incluyen caldos o geles. En general, el medio incluye una fuente de carbono que puede ser metabolizada directamente por una célula hospedadora. Además, Las enzimas se pueden usar en el medio para facilitar la movilización (por ejemplo, la despolimerización de almidón o celulosa a azúcares fermentables) y el metabolismo posterior de la fuente de carbono.
Para la producción a pequeña escala, las células hospedadoras diseñadas se pueden cultivar en lotes de, por ejemplo, aproximadamente 100 pl, 200 pl, 300 pl, 400 pl, 500 pl, 1 ml, 5 ml, 10 ml, 15 ml, 25 ml, 50 ml, 75 ml, 100 ml, 500 ml, 1 l, 2 l, 5 l o 10 l; fermentarse; e inducirse a expresar una secuencia polinucleotídica deseada, tal como una secuencia polinucleotídica codificante de un polipéptido de fusión híbrida de p450. Para la producción a gran escala, las células hospedadoras modificadas pueden crecer en lotes de aproximadamente 10 L, 100 L, 1000 L, 10,000 L, 100,000 L y 1,000,000 L o más; fermentarse; e inducirse a expresar una secuencia polinucleotídica deseada. Como alternativa, se puede llevar a cabo una fermentación a gran escala alimentada por lotes. Los ácidos grasos u>-OP, los derivados y las composiciones de los mismos, como se describe en el presente documento, se encuentran en el entorno extracelular del cultivo de células hospedadoras recombinantes, y pueden aislarse fácilmente del medio de cultivo. Un ácido graso u>-OP o un derivado del mismo puede ser secretado por la célula hospedadora recombinante, transportada al entorno extracelular o transferida pasivamente al entorno extracelular del cultivo de células hospedadoras recombinantes. Los ácidos grasos u>-OP o sus derivados se aíslan de un cultivo de células hospedadoras recombinantes usando métodos habituales conocidos en la técnica.
Productos derivados de células hospedadoras recombinantes
Como se usa en el presente documento, la fracción de carbono moderno o fM tiene el mismo significado definido por los materiales de referencia estándar del Instituto Nacional de Estándares y Tecnología (NIST, National Institute of Standards and Technology) (SRM, Standard Reference Materials, 4990B y 4990C, conocidos como los estándares de ácidos oxálicos HOxl y HOxlI, respectivamente. La definición fundamental se refiere a 0,95 veces la proporción de isótopos de 14C/12C HOxl (denominada AD 1950). Esto es más o menos equivalente a la madera de antes de la revolución industrial corregida para la desintegración. Para la biosfera viva actual (materia vegetal), fM es de aproximadamente 1,1. Los bioproductos (por ejemplo, los derivados de ácidos grasos que incluyen ácidos grasos u>-OP y derivados producidos de acuerdo con la presente divulgación) incluyen compuestos orgánicos producidos biológicamente. En particular, los derivados de ácidos grasos (por ejemplo, ácidos grasos u>-OP y derivados de los mismos) producidos usando la vía biosintética de los ácidos grasos en el presente documento, no han sido producidos a partir de fuentes renovables y, como tales, son nuevas composiciones de materia. Estos nuevos bioproductos se pueden distinguir de los compuestos orgánicos derivados del carbono petroquímico basándose en la huella isotópica del carbono doble o la datación por 14C. Adicionalmente, la fuente específica de carbono de origen biológico (por ejemplo, glucosa frente a glicerol) puede determinarse mediante la huella isotópica del carbono doble (véase, por ejemplo, la Patente de EE.UU. n.° 7.169.588). La capacidad de distinguir los bioproductos de los compuestos orgánicos a base de petróleo es beneficiosa para rastrear estos materiales en el comercio. Por ejemplo, Los compuestos orgánicos o productos químicos, incluidos los perfiles de isótopos de carbono tanto biológicos como derivados del petróleo, se pueden distinguir de los compuestos orgánicos y de los productos químicos hechos solo de materiales basados en el petróleo. Por consiguiente, los bioproductos del presente documento pueden seguirse o rastrearse en el comercio en función de su perfil único de isótopos de carbono. Los bioproductos se pueden distinguir de los compuestos orgánicos a base de petróleo mediante la comparación de la proporción estable de isótopos de carbono (13C/12C) en cada muestra. La proporción de 13C/12C de un bioproducto dado es una consecuencia de la proporción de 13C/12C en el dióxido de carbono atmosférico en el momento en que se fija el dióxido de carbono. También refleja la vía metabólica exacta. También se producen variaciones regionales. El petróleo, las plantas C3 (de hoja ancha), las plantas C4 (hierbas) y los carbonatos marinos, muestran diferencias significativas en la 13C/12C y en los valores correspondientes de 513C. Además, la materia lipídica de plantas C3 y C4 se analiza de manera diferente a la de los materiales derivados de los componentes de hidratos de carbono de las mismas plantas como consecuencia de la vía metabólica. Dentro de la precisión de la medición, el 13C muestra grandes variaciones debido a los efectos de fraccionamiento isotópico, siendo el más significativo de los cuales para los bioproductos el mecanismo fotosintético. La principal causa de las diferencias en la proporción de isótopos de carbono en las plantas está estrechamente asociada a las diferencias en la vía del metabolismo de carbono fotosintético en las plantas, en particular, teniendo lugar la reacción durante la primera carboxilación (es decir, la fijación inicial del CO2 atmosférico). Dos grandes clases de vegetación son las que incorporan el ciclo fotosintético C3 (o de Calvin-Benson) y las que incorporan el ciclo fotosintético C4 (o de Hatch-Slack). En las plantas C3, la fijación primaria de CO2 o la reacción de carboxilación implica la enzima ribulosa-1,5-difosfato carboxilasa, y el primer producto estable es un compuesto de 3 átomos de carbono. Las plantas C3, tales como de madera dura y las coníferas, son dominantes en las zonas de clima templado. En las plantas C4, una reacción de carboxilación adicional que implica otra enzima, fosfoenol-piruvato carboxilasa, es la reacción de carboxilación primaria. El primer compuesto de carbono estable es un ácido de 4 átomos de carbono que posteriormente se descarboxila. El CO2 así liberado vuelve a fijarse mediante el ciclo C3. Son ejemplos de plantas C4 los pastos tropicales, el maíz y la caña de azúcar. Las plantas tanto C4 como C3 presentan un intervalo de proporciones isotópicas 13C/12C, pero los valores típicos son de aproximadamente -7 a aproximadamente -13 por mil para las plantas C4 y de aproximadamente -19 a aproximadamente -27 por mil para las plantas C3 (véase, por ejemplo, Stuiver et al. (1977) "Radiocarbon" 19:355). El carbón y el petróleo se encuentran generalmente en este
último intervalo. La escala de medición de 13C se definió originalmente por un ajuste a cero con piedra caliza belemnita Pee Dee (PDB, Pee Dee Belemnite), en donde los valores se dan en partes por mil desviaciones con respecto a este material. Los valores de 813 C están en partes por mil (por mil), abreviado, % de c, y se calculan de la siguiente manera:
8x3C (%c) = [(13C/12C) muestra-(13C/12C) patrón]/ (13C/12C) patrón x 1000
Dado que el material de referencia (MR) PDB se ha agotado, se ha desarrollado una serie de MR alternativos en cooperación con el IAEA (International Atomic Energy Agency, organismo internacional de energía atómica), USGS, el NIST y con otros laboratorios de isótopos internacionales seleccionados. Las anotaciones para las desviaciones por mil de PDB es 813 C. Las mediciones se realizan en CO2 mediante espectrometría de masas de proporción estable de alta precisión (IRMS) sobre iones moleculares de las masas 44, 45 y 46. Las composiciones descritas en el presente documento incluyen bioproductos producidos por cualquiera de los métodos descritos en el presente documento, entre ellos, por ejemplo, productos derivados de ácidos grasos. Específicamente, el bioproducto puede tener un 813 C de aproximadamente -28 o superior, de aproximadamente - 27 o superior, -20 o superior, -18 o superior, -15 o superior, -13 o superior, -10 o superior, o -8 o superior. Por ejemplo, el bioproducto puede tener un 813 C de aproximadamente -30 a aproximadamente -15, de aproximadamente -27 a aproximadamente -19, de aproximadamente -25 a aproximadamente -21, de aproximadamente -15 a aproximadamente -5, de aproximadamente -13 a aproximadamente -7, o de aproximadamente -13 a aproximadamente -10. En otros casos, el bioproducto puede tener un 813 C de aproximadamente -10, -11, -12 o -12,3. Los bioproductos producidos de acuerdo con la divulgación del presente documento, también se puede distinguir de los compuestos orgánicos a base de petróleo comparando la cantidad de 14C de cada compuesto. Como el 14C tiene una semivida nuclear de 5.730 años, los combustibles a base de petróleo que contienen carbono más antiguo se pueden distinguir de los bioproductos que contienen carbono más nuevo (véase, por ejemplo, Currie, "Source Apportionment of Atmospheric Particles, Characterization of Environmental Particles", J. Buffle y H. P. van Leeuwen, Eds., 1 de Vol. I de IUPAc Environmental Analytical Chemistry Series (Lewis Publishers, Inc.) 3-74, (1992)). La suposición básica en la datación de radiocarbono es que la constancia de la concentración de 14C en la atmósfera conduce a la constancia de 14C en los organismos vivos. Sin embargo, debido a las pruebas nucleares atmosféricas desde 1950 y a la quema de combustible fósil desde 1850, el 14C ha adquirido una segunda característica temporal geoquímica. Su concentración en el CO2 atmosférico y, por consiguiente, en la biosfera viva, aproximadamente se ha duplicado en el máximo de las pruebas nucleares, a mediados de la década de los 60 del siglo pasado. Desde entonces, ha regresado gradualmente a la tasa de isótopos basales cosmogénicos (atmosféricos) en estado estacionario (14C/12C) de aproximadamente 1,2 x 10'12, con una "semivida" de relajación aproximada de 7-10 años. Esta última semivida no debe tomarse literalmente; si no que, debe usarse la función de entrada nuclear atmosférica/desintegración detallada para trazar la variación del 14C atmosférico y biosférico desde el inicio de la era nuclear. Es esta última característica temporal del 14C biosférico la que mantiene la promesa de la datación anual del carbono biosférico reciente. El 14C puede medirse mediante espectrometría de masas con acelerador (EMA), con los resultados dados en unidades de fracción de carbono moderno (fM). fM está definido por los materiales de referencia estándar (SRM) 4990B y 4990C del Instituto Nacional de Estándares y Tecnología (NlST) usados en el presente documento, la fracción de carbono moderno o fM tiene el mismo significado definido por los materiales de referencia estándar (SRM) 4990B y 4990C del Instituto Nacional de Estándares y Tecnología (NIST, National Institute of Standards and Technology), conocidos como patrones de ácidos oxálicos HOxI y HOxII, respectivamente. La definición fundamental se refiere a 0,95 veces la proporción de isótopos de 14C/12C HOxI (denominada AD 1950). Esto es más o menos equivalente a la madera de antes de la revolución industrial corregida para la desintegración. Para la biosfera viva actual (materia vegetal), fM es de aproximadamente 1,1. Las composiciones descritas en el presente documento incluyen bioproductos que pueden tener una fM14C de al menos aproximadamente 1. Por ejemplo, el bioproducto de la divulgación puede tener una fM14C de al menos aproximadamente 1,01, una fM14C de aproximadamente 1 a aproximadamente 1,5, una fM14C de aproximadamente 1,04 a aproximadamente 1,18, o una fM14C de aproximadamente 1,111 a aproximadamente 1,124.
Otra medida de 14C se conoce como el porcentaje de carbono moderno (pMC). Para un arqueólogo o geólogo que usa dataciones con 14C, AD 1950 es igual a cero años. Esto también representa un pMC de 100. La bomba de carbono en la atmósfera alcanzó casi el doble del nivel normal en 1963 en el pico de las armas termo-nucleares. Su distribución dentro de la atmósfera se ha aproximado desde su aparición, mostrando valores superiores a pMC de 100 para plantas y animales que viven desde AD 1950. Ha disminuido gradualmente con el tiempo y el valor actual está cerca de un pMC de 107,5. Esto significa que un material de biomasa nuevo, tal como de maíz, daría un distintivo de 14C de pMC cercano a 107,5. Los compuestos a base de petróleo tendrán un valor de pMC de cero. La combinación de carbono fósil con carbono actual dará lugar a una dilución del contenido actual de pMC. Suponiendo que un pMC de 107,5 representa el contenido de 14C de los materiales de biomasa actuales y un pMC de 0 representa el contenido de 14C de los productos derivados del petróleo, el valor medido de pMC para ese material reflejará las proporciones de los dos tipos de componentes. Por ejemplo, un material derivado al 100 % de la soja actual daría un distintivo de radiocarbono de un valor de pMC cercano a 107,5. Si ese material se diluyera al 50 % con productos a base de petróleo, daría un distintivo de radiocarbono de un pMC de aproximadamente 54. Se deriva un contenido de carbono con base biológica asignando el 100 % igual a 107,5 pMC y el 0 % igual a 0 pMC. Por ejemplo, una muestra que mide un pMC de 99 dará un contenido de carbono con base biológica equivalente del 93 %. Este valor se conoce como el resultado medio de carbono con base biológica, y supone que todos los componentes de dentro del material analizado se originaron a partir del material biológico actual o del material a base de petróleo. Un bioproducto que comprende uno o más derivados de ácidos grasos como se describe en el presente documento puede tener un pMC de al menos
aproximadamente 50, 60, 70, 75, 80, 85, 90, 95, 96, 97, 98, 99 o 100. En otros casos, un derivado de ácido graso descrito en el presente documento puede tener un pMC de entre aproximadamente 50 y aproximadamente 100; de aproximadamente 60 y aproximadamente 100; de aproximadamente 70 y aproximadamente 100; de aproximadamente 80 y aproximadamente 100; de aproximadamente 85 y aproximadamente 100; de aproximadamente 87 y aproximadamente 98; o de aproximadamente 90 y aproximadamente 95. En otros casos más, un derivado de ácido graso descrito en el presente documento puede tener un pMC de aproximadamente 90, 91, 92, 93, 94 o 94,2.
Ejemplos
Los siguientes ejemplos específicos están destinados a ilustrar la divulgación, y no deben interpretarse como limitantes de la invención de ninguna manera.
Protocolos y Métodos
Cribado de una biblioteca
Todos los protocolos descritos en el presente documento se basan en un sistema de placa de 96 pocillos de bloque maestro de 2 ml (Greiner Bio-One, Monroe, NC o Corning, Ámsterdam, Países Bajos) para cultivos en crecimiento y placas (Costar, Inc.) para extraer especies de ácidos grasos del caldo de cultivo. Los protocolos que se proporcionan a continuación son ejemplos de condiciones de fermentación. Se pueden usar protocolos alternativos para evaluar la producción de especies de ácidos grasos.
Protocolo de cultivo Plim a 32 °C
Se usaron 30 pl de cultivo LB (de un cultivo LB que crecía en una placa de 96 pocillos) para inocular 290 pl de medio Plim (Tabla 2), que luego se incubó durante aproximadamente 16 horas con agitación a 32 °C. Se usaron 40 pl de la semilla durante la noche para inocular 360 pl de medio Plim. Tras crecer a 32 °C durante 2 horas, los cultivos fueron inducidos con IPTG (concentración final de 1 mM) (Tabla 3 a continuación). Los cultivos se incubaron a 32 °C con agitación durante 20 horas si no se indica lo contrario, después de lo que se extrajeron siguiendo el protocolo de extracción convencional detallado a continuación.
Protocolo de cultivo Nlim a 35 °C
Se usaron 40 pl de cultivo LB (de un cultivo LB que crecía en una placa de 96 pocillos) para inocular 360 pl de medio LB (Tabla 3 a continuación), que luego se incubó durante aproximadamente 4 horas con agitación a 32 °C. Se usaron 40 pl de la semilla de LB para inocular 360 pl de medio Nlim. Después de crecer a 32 °C durante 2 h a 35 °C, los cultivos fueron inducidos con IPTG (concentración final de 1 mM) (Tabla 3 a continuación). Los cultivos se incubaron a 35 °C con agitación durante 20 horas si no se indica lo contrario, después de lo que se extrajeron siguiendo el protocolo de extracción convencional detallado a continuación.
Tabla 3: Nombres de medios formulaciones
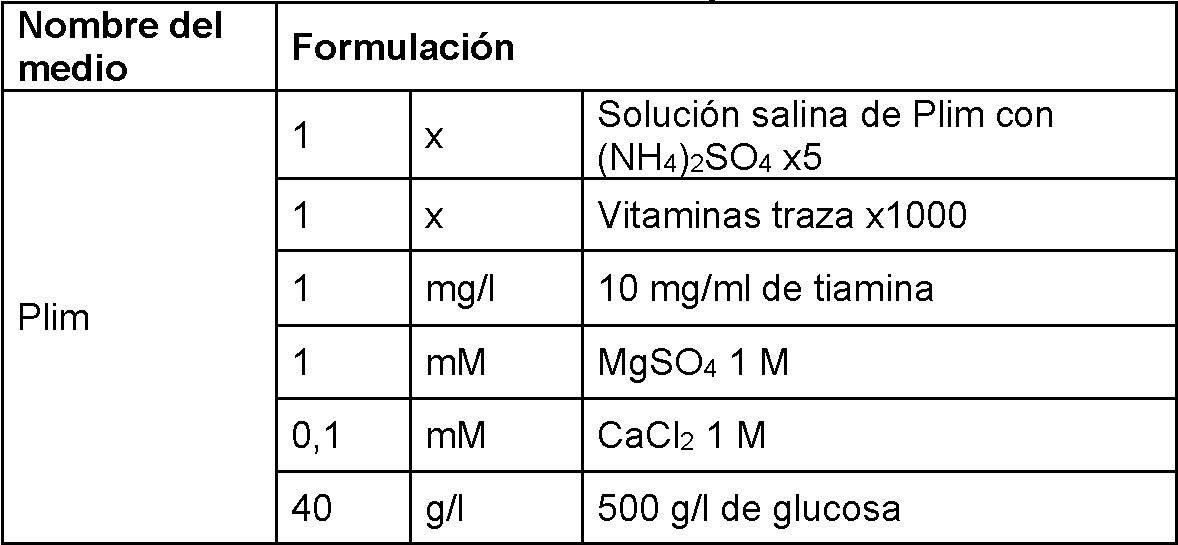
(continuación)
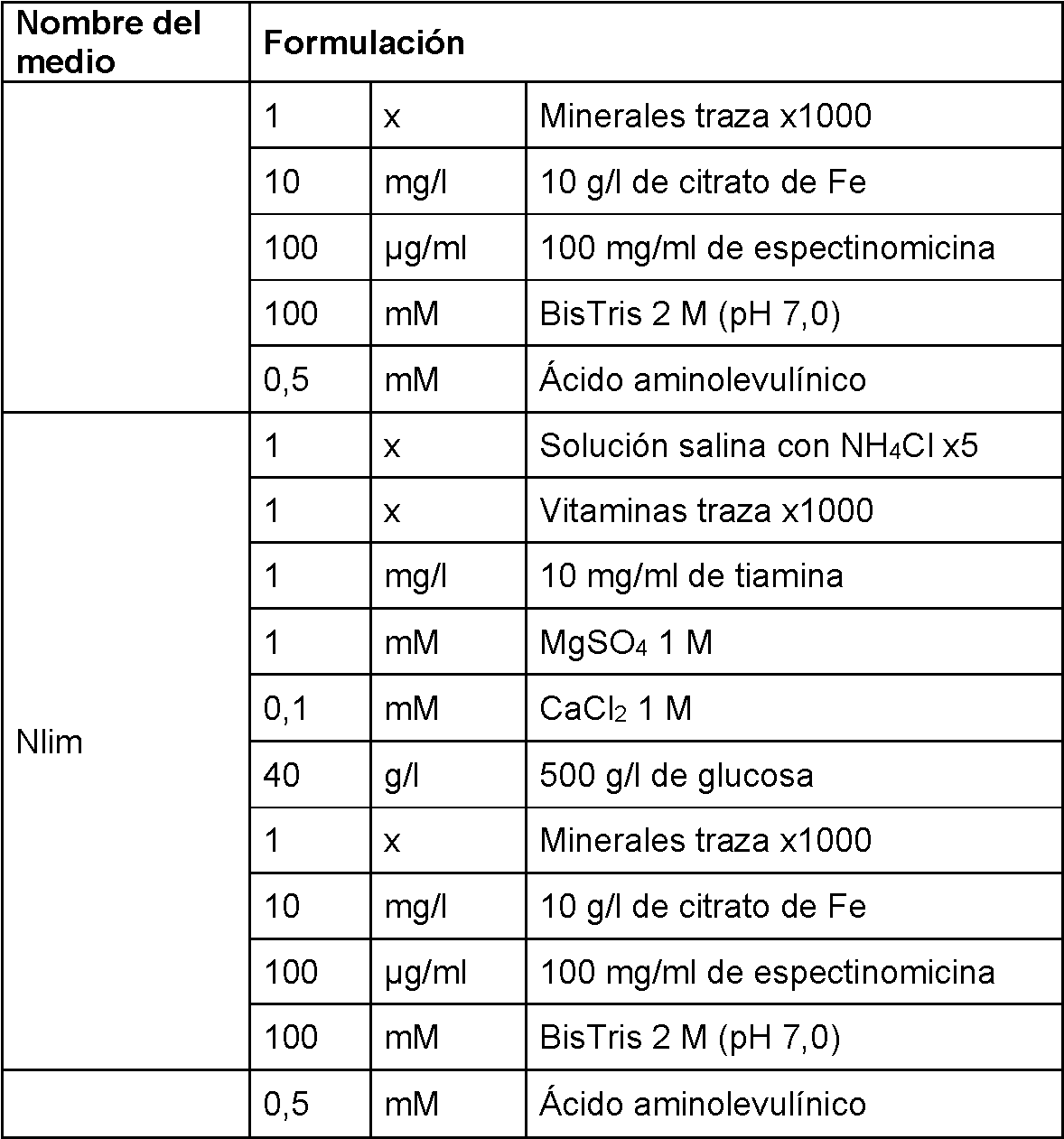
Protocolo convencional de extracción de especies de ácidos grasos
Se añadieron, a cada pocilio que se iba a extraer, 80 |jl de HCl 1 M, seguidos de 400 |jl de acetato de butilo (con 500 mg/l de pentadecanol como patrón interno). Se sellaron las placas de 96 pocillos con calor usando un sellador de placas (calentador A L P S -300 ; Abgene, ThermoScientific, Rockford, IL), y se agitaron durante 15 minutos a 2000 rpm usando el mezclador MIXMATE (Eppendorf, Hamburgo, Alemania). Después de la agitación, las placas se centrifugaron durante 10 minutos a 4500 rpm a temperatura ambiente (Allegra X -15R, rotor S X 4750A, Beckman Coulter, Brea, CA) para separar las capas acuosa y orgánica. Se transfirieron 100 j l de la capa orgánica a una placa de 96 pocillos (polipropileno, Corning, Ámsterdam, Holanda) y se derivatizaron con 100 j l de BSTFA. La placa se selló posteriormente con calor y se almacenó a -20 °C hasta que se evaluó mediante G C -F lD usando el método de FFA w-OH, que se llevó a cabo de la siguiente manera: Se inyectó 1 j l de muestra en una columna analítica (DB-1, espesor de película de 10 m x 180 jm x 0,2 jM , disponible de JW 121- 101A) en un dispositivo Agilent 7890A g C Ultra (Agilent, Santa Clara, CA) con un detector de ionización de llama (FID, Flame lonization Detector) con una división 1-20. El instrumento se configuró para detectar y cuantificar ácidos grasos C10 a C18 y ácidos grasos w-hidroxilados. El protocolo detallado anteriormente representa las condiciones convencionales, que pueden modificarse según sea necesario para optimizar los resultados analíticos.
Construcción de bibliotecas propensas a errores
Se usaron técnicas convencionales conocidas por los expertos en la materia para preparar bibliotecas propensas a errores. En un ejemplo, se preparó la estructura principal del vector usando endonucleasas de restricción en el vector, mientras que se generó la creación de diversidad en la inserción de ADN mediante amplificación por PCR a partir de un molde de ADN en condiciones que favorecían la incorporación de nucleótidos desapareados. En un enfoque, la clonación de la estructura principal del vector y una inserción de ADN con diversidad se realizó usando el Sistema de Clonación INFUSION (Clontech Laboratories, Inc., Mountain View, CA), de acuerdo con el protocolo del fabricante. Construcción de bibliotecas de saturación
Se usaron técnicas convencionales conocidas por los expertos en la materia para preparar bibliotecas de saturación. En un ejemplo, se preparó la estructura principal del vector usando endonucleasas de restricción en el vector, mientras que la creación de diversidad en la inserción de ADN se generó usando cebadores degenerados. En un enfoque, la clonación de la estructura principal del vector y una inserción de ADN con diversidad se realizó usando el Sistema de Clonación INFUSION (Clontech Laboratories, Inc., Mountain View, CA) según el protocolo del fabricante.
Creación de bibliotecas combinadas
Se combinaron las mutaciones identificadas como beneficiosas para proporcionar variantes de polipéptidos de fusión híbrida de CYP153-reductasa (por ejemplo, variantes de proteína híbrida de CYP153A-RedRhF) con mejoras adicionales en la producción de especies derivadas de ácido graso u>-OH. Se usaron técnicas convencionales conocidas por los expertos en la materia para preparar las bibliotecas de combinación. En un ejemplo, se preparó la estructura principal del vector usando endonucleasas de restricción en el vector, mientras que la creación de diversidad en la inserción de ADN se generó usando cebadores para introducir las mutaciones deseadas. Como se ha descrito anteriormente, en un enfoque, la clonación de la estructura principal del vector y una inserción de ADN con diversidad se realizó usando el Sistema de Clonación INFUSION (Clontech Laboratories, Inc., Mountain View, CA), de acuerdo con el protocolo del fabricante. Las bibliotecas de combinación se pueden generar usando el protocolo de transferencia por PCR (tPCR) (Erijman et al. (2011) J. Structural Bio. 175:171-177).
Cribado de bibliotecas
Una vez que se generó la diversidad de las bibliotecas en una biblioteca propenso a errores, de saturación y de combinación, se realizó el cribado usando uno de los métodos descritos anteriormente. Se identificaron dos tipos de aciertos: (1) aumento de la cantidad de ácidos grasos u>-hidroxi (título de FFA u>-OH); y/o (2) aumento de la conversión de los ácidos grasos en ácidos grasos u>-hidroxi. Se identificaron las mutaciones en las variantes de proteína híbrida de CYP153A-RedRhF dentro de cada acierto mediante secuenciación, usando técnicas convencionales comúnmente empleadas por los expertos en la materia. Las Tablas 5, 6 y 7 que figuran a continuación enumeran las mutaciones (los aciertos) que se han identificado como beneficiosas en las bibliotecas de saturación.
Ejemplo 1: Construcción de cepas y plásmidos para el cribado de bibliotecas
Este ejemplo describe las cepas y los plásmidos construidos para la saturación o el cribado de las bibliotecas por mutagénesis combinatoria.
Se creó un gen codificante de una proteína de fusión híbrida hecha de la proteína catalítica P450 CYP153A(G307A) de Marinobacter aquaeoli y el dominio reductasa que contiene FMN y Fe/S c-terminal de P450RhF de Rhodococcus sp. NCIMB9784 de la siguiente manera: Se amplificó el gen cyp165A(G307A)_Maqu a partir de ADN genómico y se fusionó con un dominio reductasa de P450RhF sintético con optimización de codones mediante PCR cruzada. El gen de fusión resultante (SEQ ID NO: 5) se clonó en un derivado de pACYC (es decir, replicón de p15A, marcador de resistencia a la kanamicina) de modo que su transcripción era controlada por el promotor de Ptrc inducible por IPTG. El plásmido se denominó pEP125 (véase la Tabla 4, más adelante).
También se amplificó el gen codificante de la proteína de fusión híbrida de CYP153A(G307A)-Red450RhF a partir de pEP125, y se clonó en un vector derivado de pCL1920 (replicón de SC101, marcador de resistencia a la espectinomicina), de modo que su transcripción era controlada por el promotor de Ptrc inducible por IPTG, y formó un operón con genes codificantes de una tioesterasa vegetal (fatB1), una variante de 3-ceto-acil-ACP sintasa (fabB) y un regulador de la transcripción (fadR). El plásmido se denominó pLC81 (véase la Tabla 4, más adelante).
Se crearon plásmidos adicionales de la siguiente manera: Se sintetizó el gen codificante de una tioesterasa vegetal (fatB1) de Umbellularia californica como ADN con optimización de codones, y se clonó en un vector de derivado de pCL1920 (replicón de SC101, marcador de resistencia a la espectinomicina), de modo que su transcripción era controlada por el promotor de Ptrc inducible por IPTG, y formó un operón con genes codificantes de la acetil-CoA carboxilasa (accDACB), biotina ligasa (birA) y una proteína portadora de acilo. El plásmido se denominó pNH305 (véase la Tabla 4, más adelante). El plásmido pAS033 se creó reemplazando fatB1 en pNH305 con una tioesterasa vegetal sintética con optimización de codones (fatA3) de Arabidopsis thaliana (véase Tabla 4, más adelante). El plásmido pEP146 se creó reemplazando fatB1 en pLC81 con una tioesterasa vegetal sintética con optimización de codones (fatA3) de Arabidopsis thaliana (véase Tabla 4, más adelante). pEP146 también portaba una mutación en la proteína repA codificada por el plásmido.
Las cepas base usadas para la transformación de plásmidos fueron GLP077 y BZ128. En resumen, el genoma de la cepa base GLPH077 se manipuló de la siguiente manera: se eliminó el gen de acil-CoA deshidrogenasa (fadE) y se sobreexpresó un regulador de la transcripción (fadR) y un operón de la biosíntesis de ácidos grasos sintético. En resumen, el genoma de la cepa base BZ128 se manipuló de la siguiente manera: se eliminó el gen fadE (acil-CoA deshidrogenasa) y se sobrexpresaron un operón de la biosíntesis de ácidos grasos sintético, una acil-ACP deshidratasa de ácidos grasos p-hidroxi (fabZ) y una variante de una tioesterasa (tesA). Además, la cepa había sido previamente sometida a transposón, así como a mutagénesis y a cribado de N-metil-N'-nitro-N-nitrosoguanidina (NTG).
T l 4: Pl mi r l ri i li
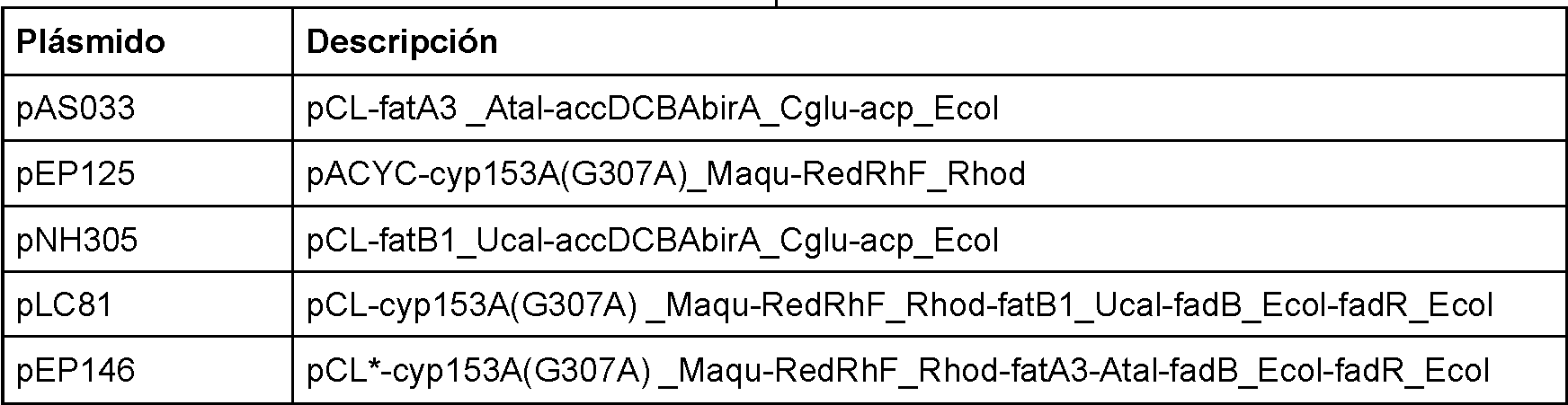
La proteína de fusión híbrida de CYP153A(G307A)-Red450RhF se probó para ver si la expresión en las células hospedadoras podría producir derivados de ácidos grasos w-OP. Un microorganismo que expresaba SEQ ID NO: 5 fue capaz de producir más de 1 g/l de derivados de ácidos grasos w-OP a partir de glucosa. Por lo tanto, se seleccionó esta enzima diseñada genéticamente para futuros estudios de evolución.
Ejemplo 2: Bibliotecas de saturación del dominio catalítico P450 de la proteína de fusión de cyp153A(G307A)-Red450RhF
Se construyó una biblioteca de saturación total del dominio catalítico P450 de la proteína de fusión de cyp153A-Red450RhF, y se cribó en busca de variantes que mostraran mejoras frente a cyp153A(G307A)-Red450RhF (es decir, el polipéptido molde). G307A (es decir, un resto de alanina que reemplaza a una glicina en la posición 307) es una mutación beneficiosa que mejora la actividad w-hidroxilasa de cypl53A (véase Honda Malca et al. (2012) Chem. Commun. 48: 5115). Los criterios de selección para los aciertos fueron (1) aumento de la cantidad de ácidos grasos w-hidroxi (título de FFA wOH); y/o (2) aumento de la conversión de los ácidos grasos en ácidos grasos w-hidroxi.
Se usaron técnicas convencionales conocidas por los expertos en la materia para preparar bibliotecas de saturación. Se usaron los plásmidos pEP125 y pLC81 (véase la Tabla 4, anterior) para crear las bibliotecas de saturación total. Se cribaron tres bibliotecas de saturación: Para la primera biblioteca, pEP125 se transformó junto con pNH305 en la cepa GLPH077, para la segunda biblioteca, pLC81 se transformó en BZ128, y para la tercera biblioteca, pEP125 se transformó junto con pAS.033 en la cepa GLPH077. La primera y segunda biblioteca se cribaron en particular en busca de variantes mejoradas en la formación de ácido dodecanoico w-hidroxi, y la tercera biblioteca se cribó en particular en busca de variantes mejoradas en la formación de ácido hexadecenoico w-hidroxi. Las bibliotecas se cribaron usando uno de los protocolos convencionales descritos anteriormente. Las variantes mejoradas se muestran en las Tablas 5 a 7 que figuran a continuación (más adelante). En particular, las variantes de la posición 141 se identificaron múltiples veces, y se descubrió que eran enzimas significativamente mejoradas tanto para la formación de ácido dodecanoico w-hidroxi como para la formación de ácido hexadecenoico w-hidroxi.
Tabla 5: Sumario de variantes mejoradas de la primera biblioteca de saturación de sitio del dominio catalítico de
FFA w-OH FAS totales % de FFA FIOC % de Ci2:0 w-OH FIOC Aminoácid Codones w-OH en Ci2:0 os
1346,3 2236,6 60,2 1,33 83,1 1,08 V141Q GTG/CAG
1201,1 2149,3 55,9 1,23 84,1 1,10 D134G GAC/GGG
1106,2 2006,9 55,1 1,22 82 1.07 R40H AGG/CAC
1007,9 1839,7 54,8 1,21 86,1 1,12 V141I GTG/ATC
962,5 1791,2 53,7 1,19 81,1 1,06 K41V AAG/GTG
1228,6 2298,6 53,4 1,18 80,2 1.05 M419V ATG/GTC
1046,8 1958,5 53,4 1,18 80,1 1.05 V154A GTG/GCC
990,7 1865,4 53,1 1,17 84,9 1,11 D134G GAC/GGT
1203,1 2313,1 52 1,15 81,6 1.07 D134G GAC/GGG
908,7 1773,2 51,2 1,13 80,3 1.05 I11C ATT/TGC
1020,1 2057 49,6 1,09 81,4 1.06 R205L CGC/TTG
1256 2688,4 46,7 1,03 72,6 0,95 L304W CTC/TGG
883,2 1960,8 45,3 1,00 76,6 1,00
FIOC: Mejora frente al control; El control está en negrita
Tabla 6: Sumario de variantes mejoradas de la segunda biblioteca de saturación de sitio del dominio catalítico de ___________________________________ cyp153A(G307A)-Red450RhF___________________________________ Mutación Mutación 2 FFA w- OH FAS % de FIOC % de C12: o w-OH en FIOC 1 totales totales FFA w- FAS Cl 2: 0
OH
V415R 0 928,10 2880,10 32,23 1,85 33,29 1,96 V415R 0 941,13 2980,97 31,58 1,81 32,98 1,94 V154A 0 694,63 2959,63 23,47 1,35 23,06 1,36 V154A 0 716,00 2963,77 24,16 1,39 23,88 1,40 V154A 0 686,93 2926,97 23,47 1,35 23,40 1,38 V141M E142Q 717,80 2873,73 24,98 1,44 28,51 1,68 V141I 0 749,07 2971,23 25,21 1,45 31,96 1,88 V141I 0 778,87 2886,77 26,98 1,55 34,27 2,02 V141I 0 754,67 2918,90 25,85 1,49 32,85 1,93 V141I R258Y 672,13 2909,13 23,10 1,33 29,24 1,72 V141I 0 810,23 2912,67 27,83 1,60 35,86 2,11 S233R 0 720,13 2838,00 25,37 1,46 30,82 1,81 S233R 0 746,20 2912,97 25,61 1,47 31,15 1,83 S233N 0 735,57 2905,40 25,33 1,46 25,77 1,52 S233N 0 698,80 2915,17 23,97 1,38 24,40 1,44 S233N 0 732,47 2949,93 24,83 1,43 25,29 1,49 S233N 0 725,97 3018,60 24,05 1,38 24,76 1,46 R82D E271F 629,03 2914,83 21,58 1,24 20,90 1,23
R6F R178N 792,33 2845,17 27,85 1,60 28,56 1,68
R6F V141I 833,13 2871,87 29,01 1,67 36,28 2,13
R27L 0 742,57 2857,53 25,99 1,49 26,10 1,54 R178N 0 701,17 2983,60 23,50 1,35 24,98 1,47 Q129R 0 675,07 2847,37 23,71 1,36 27,97 1,65 Q129R 0 812,23 3044,30 26,68 1,53 31,29 1,84 Q129R 0 660,53 2967,23 22,26 1,28 26,24 1,54 P149R S157V 684,03 3011,80 22,71 1,31 23,04 1,36 P149R 0 771,40 2959,70 26,06 1,50 26,12 1,54 P149R 0 731,10 2966,13 24,65 1,42 24,75 1,46 P149R 0 757,97 3014,93 25,14 1,45 25,49 1,50 P149R 0 765,90 2963,50 25,84 1,49 26,16 1,54 P149R 0 734,30 2923,70 25,12 1,44 25,50 1,50 P149R 0 745,00 2993,83 24,88 1,43 25,47 1,50 P136T 0 724,53 2980,20 24,31 1,40 24,97 1,47 P136T 0 729,37 3017,67 24,17 1,39 24,90 1,46 P136T 0 678,33 2850,87 23,79 1,37 24,39 1,43 P136C 0 702,27 2947,23 23,83 1,37 25,36 1,49 P136C 0 689,77 3069,63 22,47 1,29 24,01 1,41 N407A 0 731,50 3042,77 24,04 1,38 24,56 1,44 N407A 0 704,47 3015,93 23,36 1,34 23,75 1,40 M228R 0 344,60 2992,27 11,52 0,66 18,33 1,08 L168V 0 793,20 2938,23 27,00 1,55 27,84 1,64 G161P 0 718,33 2938,47 24,45 1,41 24,28 1,43 G161A 0 639,93 2943,40 21,74 1,25 21,65 1,27 G138F N407A 667,93 2825,43 23,64 1,36 26,09 1,53 F116R V415R 678,77 2854,97 23,78 1,37 24,14 1,42 E142R 0 663,67 2925,83 22,68 1,30 22,86 1,34
(continuación)
Mutación Mutación 2 FFA w- OH FAS % de FIOC % de C : w-OH en FIOC 1 totales totales FFA w- FAS C12: 0
OH
E142R 0 628,03 2930,57 21,43 1,23 21,62 1,27
E142R 0 639,23 2972,03 21,51 1,24 21,86 1,29
D153G 0 787,87 3018,90 26,13 1,50 26,94 1,58
D153G 0 746,20 3039,10 24,55 1,41 25,31 1,49
0 0 543,65 3117,75 17,44 1,00 17,04 1,00
FIOC: Mejora frente al control; El control está en negrita
Tabla 7: Sumario de variantes mejoradas de la tercera biblioteca de saturación de sitio del dominio catalítico de
FFA w- FAS % de FIOC % de C160 w- FIOC % de C161 w- FIOC Aminoác Codones OH totales FFA w- OH en C16:0 OH en C16:1 idos
OH
1298,5 2342,5 55,43 1,53 64,61 1,33 49,02 2,00 N309R AAC/CGG
1095,9 2374,3 46,16 1,28 58,36 1,20 34,41 1,40 V141G GTG/GGG
1564 3448,1 45,36 1,25 62,78 1,29 32,88 1,34 L132T CTC/ACT
1092,9 2391,4 45,70 1,26 60,82 1,25 32,96 1,34 F144R TTC/AGG
1170,5 2529,6 46,27 1,28 62,41 1,28 31,91 1,30 I131L ATT/TTG
1232,9 2685,8 45,90 1,27 55,17 1,13 37,63 1,53 G308W GGC/TGG
931,1 2570,1 36,2 1,00 48,70 1,00 24,53 1,00
FIOC: Mejora frente al control; El control está en negrita
Ejemplo 3: Bibliotecas de saturación parcial de sitio del dominio reductasa de la proteína de fusión de cyp153A (G307A)-Red450RhF
Se construyó una biblioteca de saturación parcial (se mutó cada décimo aminoácido) de los dominios reductasa de la proteína de fusión híbrida de cyp153A-Red450RhF, y se cribó en busca de variantes que mostraran mejoras frente a cyp153A (V141I, A231T, G307A)-Red450RhF (Se Q ID NO: 32), y se identificó una variante en la biblioteca de mutagénesis por saturación de sitio del dominio catalítico P450 cyp153A. Los criterios de selección para los aciertos fueron (1) aumento de la cantidad de ácido dodecanoico u>-hidroxi (título de FFA u>OH); y/o (2) aumento de la conversión de ácido dodecanoico en ácido dodecanoico w-hidroxi.
Se usaron técnicas convencionales conocidas por los expertos en la materia para preparar bibliotecas de saturación. Para la biblioteca, se transformó pLC81 que albergaba cyp153A(V141I, A231T, G307A)-Red450RhF en BZ128. La biblioteca se cribó usando uno de los protocolos convencionales descritos anteriormente. Las variantes mejoradas se muestran en la Tabla 8. En particular, las variantes A796V (SEQ ID: 42) y P666A fueron enzimas significativamente mejores.
Tabla 8: Sumario de variantes mejoradas de la biblioteca de saturación parcial del dominio reductasa de _______________________cyp153A(V1411 A231T G307A)-Red450RhF_______________________ Mutación de FFA w-OH FAS % de FFA FIOC C12: 0 w-OH en FAS C12: FIOC
RhF w-OH 0
P666K 1012,1 2945,5 34,36 1,09 44,08 1,07
P666A 1575,9 2918,7 53,99 1,71 68,35 1,66
T516E 1150,4 2966,2 38,78 1,23 49,01 1,19
V696K 983,4 2955,4 33,27 1,05 43,02 1,05
0 950,3 3004,6 31,63 1,00 41,13 1,00 (continuación)
Mutación de FFA w-OH FAS % de FFA FIOC C12: 0 w-OH en FAS C12: FIOC
RhF w-OH 0
A796V 2458,0 3884,7 63,27 1,81 76,58 1,70
0 1363,7 3905,2 34,92 1,00 44,96 1,00
FIOC: Mejora frente al control; El control está en negrita
Ejemplo 4 : Biblioteca combinatoria del dominio reductasa de la proteína de fusión de cyp153A (G307A)-Red450RhF
Las mutaciones beneficiosas identificadas en la biblioteca de saturación parcial del dominio reductasa (Ejemplo 3) fueron la base de una biblioteca de combinación para mejorar aún más la proteína de fusión de cyp153A(G307A)-Red450RhF. Los criterios de selección fueron (1) aumento de la cantidad de ácido dodecanoico (título de FFA wOH); y/o (2) aumento de la conversión de ácido dodecanoico en ácido dodecanoico.
Se construyó la biblioteca de combinación en pLC81 que albergaba cyp153A (V141I, A231T, G307A)-Red450RhF (SEQ ID: 32) y se transformó en BZ128. Se usaron técnicas convencionales conocidas por los expertos en la materia para preparar bibliotecas de combinación. La biblioteca se cribó usando uno de los protocolos convencionales descritos anteriormente. Las variantes mejoradas se muestran en la Tabla 9 que figura a continuación.
Tabla 9: Sumario de variantes mejoradas de una biblioteca de combinación del dominio reductasa de cyp153A _______________________________ (V141I, A231T, G307A)-Red450RhF_______________________________ Mutación de Mutación de RhF FFA w-OH FAS % de FFA FIOC % de C12: 0 w-OH FIOC P450 w-OH en FAS C12: 0
1411, 231T T516G, P666M, 851 983 86,8 1,29 88,3 1,23 A769V
141I, 231T T516G, P666H, 1557 2214 69,2 1,03 73,1 1,02
A769V
1411, 231T T516V, P666D, 1491 1999 74,5 1,11 76,9 1,07 A769V
1411, 231T P666M, V696T 916,88 1125 81,4 1,21 82,9 1,15
141I, 231T A769V 1528,33 2280 67,1 1,00 71,8 1,00
FIOC: Mejora frente al control; El control está en negrita
Ejemplo 5: Biblioteca combinatoria del dominio catalítico y dominio reductasa de la proteína de fusión de cyp153A (G307A)-Red450RhF
Las mutaciones beneficiosas identificadas en la biblioteca de saturación (Ejemplo 2 y 3) fueron la base de una biblioteca de combinación para mejorar aún más la proteína de fusión de cyp153A(G307A)-Red450RhF. Los criterios de selección fueron (1) aumento de la cantidad de ácido dodecanoico (título de FFA wOH); y/o (2) aumento de la conversión de ácido dodecanoico en ácido dodecanoico. Se construyó la biblioteca de combinación en pLC81 y se transformó en BZ128. Se usaron técnicas convencionales conocidas por los expertos en la materia para preparar bibliotecas de combinación. La biblioteca se cribó usando uno de los protocolos convencionales descritos anteriormente. Las dos mejores variantes mejoradas se muestran en la Tabla 10.
Tabla 10: Mejores variantes mejoradas de una biblioteca combinatoria de cyp153A(G307A)-Red450RhF Mutaciones SEQ ID FFA w-OH* FAS* FFA w-OH C12: 0 w-OH en FAS R27I, R82D, V141M, R178N, N407A 34 2290,3 3665,1 62,4 % 74,1 % R27I, R82D, V141M, R178N, N407A, 44 3499,5 4154,9 84,5 % 93,1 %
A796V
* Título (mg/l) después de 48 h
Ejemplo 6: Mutagénesis por saturación de sitio de las posiciones 141 y 309 de cyp153A (G307A,A796V)-Red450RhF
Se observó que los cambios en la posición 141 influían en la especificidad del sustrato. Por lo tanto, se llevó a cabo
una mutagénesis por saturación de sitio de estas dos posiciones en cyp153A(G307A,A796V)-Red450RhF. Los criterios de selección para los aciertos fueron (1 ) aumento de la cantidad de ácido hexadecenoico; y/o (2) aumento de la conversión de ácido hexadecenoico en ácido hexadecenoico w-hidroxi.
Para la biblioteca, se transformó pEP146 que albergaba cyp153A(G307A,A796V)-Red450RhF (SEQ ID: 38) en BZ128. Se usaron técnicas convencionales conocidas por los expertos en la materia para preparar bibliotecas de saturación de sitio. La biblioteca se cribó usando uno de los protocolos convencionales descritos anteriormente. Las variantes mejoradas se muestran en la Figura 2. En particular, las variantes con V141T (SEQ ID: 46) mostraron el mayor título de ácido hexadecenoico y la mayor conversión de ácido hexadecenoico.
EJEMPLO 7: Bibliotecas de saturación de proteína de fusión de cyp153A(G307A)-Red450RhF A796V)
Se construyó una biblioteca de saturación total de la proteína de fusión de cyp153A-Red450RhF, y se cribó en busca de variantes que mostraran mejoras frente a cyp153A(G307A)-Red450RhF (es decir, el polipéptido molde). G307A (es decir, un resto de alanina que reemplazaba a una glicina en la posición 307) y A796V (es decir, un resto de valina que reemplazaba a una alanina en la posición 796) son mutaciones beneficiosas que mejoran la actividad w-hidroxilasa de cyp153A (véase lo anterior). Los criterios de selección para los aciertos fueron (1) un aumento de la cantidad de ácidos grasos (título de FFA w-OH); y/o (2) un aumento de la conversión de ácidos grasos en ácidos grasos.
Se usaron técnicas convencionales conocidas por los expertos en la materia para preparar la biblioteca de saturación. Se usó el plásmido pEP302 para crear la biblioteca de saturación total, que era un derivado de pEP146 (véase la Tabla 4), en el que se alteró el orden de los genes (fatA3-fadB-fadR-cyp153A(G307A)-Red450RhF(A796V)) y el último gen se expresó desde un promotor separado. La biblioteca se transformó en la cepa stNH1525. En resumen, el genoma de la cepa base stNH1525 se manipuló de la siguiente manera: se eliminó el gen fadE (acil-CoA deshidrogenasa) y se sobreexpresó un operón de la biosíntesis de ácidos grasos sintético. Además, la cepa había sido previamente sometida a transposón, así como a mutagénesis y a cribado de N-metil-N'-nitro-N-nitrosoguanidina (NTG).
Las bibliotecas se cribaron usando uno de los protocolos convencionales descritos anteriormente. Las variantes mejoradas se muestran en la Tabla 11 que figura a continuación, en particular, variantes que mejoraron significativamente la formación de ácido hexadecanoico y ácido hexadecenoico.
Tabla 11: Sumario de variantes mejoradas de la biblioteca de saturación de sitio de cyp153A(G307A)-Red450RhF(A976V)
% de % de
% de Cl6:0
FFA w-OH FAS totales FFA w- FOIC Cl6:1 W-OH en FOIC w -OH FOIC Aminoácidos Codones OH en
Cl6:1 ________ Cl6:0_______________________________ 1201,0 1751,4 68,6 1,8 59,7 2,1 80,1 1,4 D747N AAC 1007,7 1733,3 58,1 1,6 50,6 1,9 79,0 1,4 Q12W TGG 793,2 1366,8 58,0 1,6 54,4 2,0 77,1 1,3 P327D GAT 955.6 1714,9 55,7 1,5 50,6 1,7 74,9 1,3 R14F TTC 678.7 1235,6 54,9 1.4 52,6 1,8 73,1 1,3 N61L TTG 855.8 1629,3 52,5 1.4 44,6 1,6 72,9 1,3 R27L TTG 911,6 1763,5 51,7 1.4 44,7 1,6 72,3 1,2 Q28M ATG 858.1 1678,7 51,1 1.3 46,8 1,6 69,9 1,2 S13K AAG 1247.9 2458,5 50,8 1.3 44,3 1,6 67,8 1,2 V771F TTC 850.2 1686,3 50,4 1.3 42,1 1,5 71,6 1,2 Q12T ACG 810.3 1615,4 50,2 1.3 46,8 1,6 65,0 1,1 K119R CGG 821,1 1639,9 50,1 1.3 43,7 1,6 70,1 1,2 D10Y TAC 807.4 1676,8 48,2 1.3 40,8 1,4 68,7 1,2 Q12R AGG 722.5 1519,4 47,6 1.3 39,3 1,4 68,9 1,2 I11L TTG 748.9 1576,6 47,5 1,2 42,4 1,5 66,3 1,1 Q28T ACG 733.8 1546,2 47,5 1.3 38,7 1,4 68,9 1,2 A231Y TAC 1198.9 2528,5 47,4 1,2 39,9 1,4 67,5 1,2 P745R CGC/CGG 769.8 1647,1 46,7 1,2 38,1 1,4 68,0 1,2 D9N AAT 1133,4 2469,6 45,9 1,2 38,1 1,4 65,6 1,1 T770G GGT
(continuación)
% de
% de % de Cl 6:0
FFA w-OH FAS totales FFA w- FOIC Cl 6:1 W- FOIC w -O H FOIC Aminoácidos Codones OH OH en en
Cl6:1 Cl 6:0
763,7 1672,4 45,7 1,2 39,0 1,4 63,2 1,1 Y413R AGG 1146,2 2514,4 45,6 1,2 37,0 1,3 66,0 1,1 M784I ATC 729,8 1610,4 45,3 1,2 36,5 1,3 65,8 1,1 D9K AAG 1078,0 2390,8 45,1 1,2 35,7 1,3 66,7 1,1 E749L TTG 752,9 1682,8 44,7 1,2 38,1 1,3 63,7 1,1 S233L TTG 940,3 2111,2 44,5 1,2 35,9 1,3 65,4 1,1 E757A GCG 1063,1 2405,5 44,2 1,2 35,5 1,3 65,0 1,1 L703G GGG 632,5 1434,9 44,1 1,2 37,5 1,3 61,5 1,1 N309S TCT 755,7 1715,3 44,1 1,2 35,0 1,3 64,5 1,1 S140N AAC 1070,7 2441,3 43,9 1,2 37,6 1,3 60,9 1,0 L706E GAG 757,3 1753,4 43,2 1,2 33,7 1,2 65,2 1,1 I480G GGT 880,6 2044,0 43,1 1,2 33,6 1,2 65,3 1,1 G481I ATT 989,8 2301,4 43,0 1,1 35,0 1,2 62,5 1,1 R719W TGG 1062,9 2478,7 42,9 1,1 35,7 1,3 61,1 1,0 L706S TCG 906,2 2116,3 42,8 1,1 34,8 1,3 62,5 1,1 E557W TGG 734,0 1717,3 42,7 1,1 34,1 1,3 60,6 1,0 S157R CGG 651,4 1527,0 42,7 1,1 35,9 1,2 61,1 1,1 S233V GTC 710,4 1667,8 42,6 1,1 35,6 1,2 60,6 1,0 A231V GTA 663,4 1558,7 42,6 1,1 33,4 1,1 62,1 1,1 A164N AAC 664,3 1564,2 42,5 1,1 32,3 1,2 64,7 1,1 A244R CGG 711,2 1675,3 42,5 1,1 38,3 1,3 56,0 1,0 T302M ATG 1010,3 2381,5 42,4 1,1 34,1 1,2 62,4 1,1 P708S TCG 1015,6 2394,2 42,4 1,1 32,3 1,1 64,9 1,1 N741G GGG 690,6 1630,5 42,4 1,1 33,3 1,2 63,0 1,1 P149G GGG 656,9 1552,9 42,3 1,1 34,8 1,3 60,9 1,0 V154G GGC 905,2 2139,9 42,3 1,1 33,1 1,2 63,6 1,1 E557R CGG/AGG 946,6 2247,5 42,1 1,1 32,9 1,2 63,4 1,1 V710Q CAG 1159,1 2753,7 42,1 1,1 32,6 1,2 65,7 1,1 E567S TCC 640,8 1522,8 42,1 1,1 34,4 1,3 59,7 1,0 P149R AGG 665,7 1587,4 41,9 1,1 33,0 1,2 61,8 1,1 N407G GGG 1026,9 2465,0 41,7 1,1 31,7 1,1 63,9 1,1 D544N AAC 941,4 2265,1 41,6 1,1 32,5 1,2 62,6 1,1 D709L CTG 721,3 1747,4 41,3 1,1 35,1 1,2 58,3 1,0 G204V GTT 985,6 2393,7 41,2 1,1 31,7 1,1 62,7 1,1 V710C TGT 696,6 1694,0 41,1 1,1 32,3 1,2 61,5 1,1 R254G GGG 664,3 1616,1 41,1 1,1 32,8 1,1 61,1 1,1 P273M ATG 739,2 1801,0 41,0 1,1 33,8 1,2 59,9 1,0 F111A GCG 1042,8 2540,9 41,0 1,1 31,6 1,1 62,5 1,1 E749M ATG 681,8 1661,6 41,0 1,1 30,0 1,1 64,3 1,1 A231W TGG 1017,8 2487,3 40,9 1,1 31,1 1,1 63,2 1,1 P546G GGG 719,6 1760,1 40,9 1,1 32,2 1,2 60,4 1,0 V162C TGC 950,8 2327,9 40,8 1,1 31,8 1,1 61,8 1,1 A736V GTC 945,2 2314,2 40,8 1,1 34,2 1,2 58,5 1,0 L706H CAC 914,2 2241,1 40,8 1,1 31,4 1,1 62,3 1,1 V710R AGG 1055,3 2587,4 40,8 1,1 32,0 1,1 61,2 1,0 D707E GAG 883,4 2168,3 40,7 1,1 32,5 1,2 60,7 1,0 D527E GAG 921,4 2266,5 40,7 1,1 32,9 1,2 60,3 1,0 P745K AAG
Claims (16)
1. Una variante de polipéptido de fusión híbrida de C Y P 153A-reductasa que comprende al menos el 90 % de identidad de secuencia con SEQ ID NO: 38 y que tiene al menos una mutación en una posición de aminoácido seleccionada del grupo que consiste en 9 , 10 , 11 , 12 , 13 , 14, 28 , 61 , 119 , 231 , 233 , 327 , 413 , 703 , 745 , 747 , 749 , 757 , 770 , 771 y 784 , en donde dicha variante de polipéptido de fusión híbrida de C Y P 153A-reductasa cataliza la conversión de un ácido graso en un ácido graso omega-hidroxilado.
2. La variante de polipéptido de fusión híbrida de C Y P 153A-reductasa de la reivindicación 1, en donde la variante de polipéptido de fusión híbrida de C Y P 153A-reductasa es una variante de proteína de fusión híbrida de C Y P 153A-RedRhF.
3. La variante de polipéptido de fusión híbrida de C Y P 153A-reductasa de la reivindicación 1, en donde dicha mutación se selecciona del grupo que consiste en D9N, D9K, D10Y, II1L, Q 12W, Q 12R, Q 12T, S 13K, R 14F, Q28 M, Q28T, N61 L, K119R, A231Y, S 233 L, P327D, Y 413 R, L703G, P745R, D747N, E 749L, E 757A, T 770G, V 771F y M784 I.
4. La variante de polipéptido de fusión híbrida de C Y P 153A-reductasa de la reivindicación 3 , en donde la expresión de dicha variante de polipéptido de fusión híbrida de C Y P 153A-reductasa en una célula hospedadora recombinante produce un título más alto de un ácido graso omega-hidroxilado en comparación con un título de un ácido graso omegahidroxilado producido por la expresión de un polipéptido de fusión híbrida de C Y P 153A-reductasa de SEQ ID NO: 38.
5. La variante de polipéptido de fusión híbrida de C Y P 153A-reductasa de la reivindicación 3 , que comprende una cualquiera de SEQ ID NO: 48 , SEQ ID NO: 50 , SEQ ID NO: 52 , SEQ ID NO: 54 , SEQ ID NO: 56 , SEQ ID NO: 58 , SEQ
ID NO: 60 , SEQ ID NO: 62 , SEQ ID NO: 64 , SEQ ID NO: 66 , SEQ ID NO: 68 , SEQ ID NO: 70 , SEQ ID NO: 72 , SEQ ID NO: 74 , SEQ ID NO: 76 , SEQ ID NO: 78 , SEQ ID NO: 80 , SEQ ID NO: 82 , SEQ  ID NO: 86 , SEQ ID NO: 88 , SEQ ID NO: 90 , SEQ ID NO: 92 , SEQ ID NO: 94 y SEQ ID NO: 96.
ID NO: 86 , SEQ ID NO: 88 , SEQ ID NO: 90 , SEQ ID NO: 92 , SEQ ID NO: 94 y SEQ ID NO: 96.
6. Una célula hospedadora recombinante que expresa la variante de polipéptido de fusión híbrida de C Y P 153A-reductasa de una cualquiera de las reivindicaciones 1 a 5 , que preferentemente expresa adicionalmente un polipéptido de tioesterasa de C E 3.1.2.-, C E 3.1.1.5 o C E 3.1.2.14.
7. La célula hospedadora recombinante de la reivindicación 6 , en donde la célula hospedadora recombinante produce una composición de ácido graso omega-hidroxilado con un título que es al menos un 10 % superior, al menos un 15 % superior, al menos un 20 % superior, al menos un 25 % superior o al menos un 30 % superior al título de una composición de ácido graso omega-hidroxilado producida por una célula hospedadora que expresa un polipéptido de fusión híbrida de C Y P 153A-reductasa correspondiente, cuando se cultiva en medio que contiene una fuente de carbono.
8. La célula hospedadora recombinante de la reivindicación 7 , en donde el ácido graso omega-hidroxilado se produce intracelular o extracelularmente.
9. Un cultivo celular que comprende la célula hospedadora recombinante de una cualquiera de las reivindicaciones 6
8.
10. El cultivo celular de la reivindicación 9 , en donde el ácido graso omega-hidroxilado comprende uno o más de un ácido graso C12, C16 y C161 omega-hidroxilado.
11. El cultivo celular de la reivindicación 10 , en donde el ácido graso omega-hidroxilado comprende
(a) un ácido graso C161 omega-hidroxilado insaturado; o
(b) un ácido graso C12 omega-hidroxilado saturado.(a)
12. Un método para producir un ácido graso omega-hidroxilado que tiene un aumento en el título, que comprende:
i. cultivar la célula hospedadora de la reivindicación 6 con una fuente de carbono; e
ii) recoger un ácido graso omega-hidroxilado.
13. El método de la reivindicación 12, en donde dicho ácido graso omega-hidroxilado es un ácido graso omegahidroxilado saturado o un ácido graso omega-hidroxilado insaturado.
14. Un microorganismo recombinante para producir un derivado de ácido graso omega-hidroxilado in v ivo cuando se cultiva en un caldo de fermentación en presencia de una fuente de carbono a partir de una materia prima renovable, comprendiendo dicho microorganismo una vía diseñada para expresar al menos dos secuencias de ácido nucleico que codifican un polipéptido que comprende:
(i) una tioesterasa de C E 3.1.2.-, C E 3.1.1.5 o C E 3.1.2.14 ; e
(ii) una variante de polipéptido de fusión híbrida de CYP153A-reductasa como se define en una cualquiera de las reivindicaciones 1 a 5.
15. El microorganismo recombinante de la reivindicación 14, en donde dicha variante de polipéptido de fusión híbrida de CYP153A-reductasa es una variante de proteína de fusión híbrida de CYP153A-RedRhF autosuficiente.
16. El microorganismo recombinante de la reivindicación 14, en donde dicha variante de polipéptido de fusión híbrida de CYP153A-reductasa tiene al menos el 90 % de identidad de secuencia con una cualquiera de SEQ ID NO; 48, SEQ ID NO: 50, SEQ ID NO: 52, SEQ ID NO: 54, SEQ ID NO: 56, SEQ ID NO: 58, SEQ ID NO: 60, SEQ ID NO: 62, SEQ ID NO: 64, SEQ ID NO: 66, SEQ ID NO: 68, SEQ ID NO: 70, SEQ ID NO: 72, SEQ ID NO: 74, SEQ ID NO: 76, SEQ ID NO: 78, SEQ ID NO: 80, SEQ ID NO: 82, SEQ ID NO: 84, SEQ ID NO: 86, SEQ ID NO: 88, SEQ ID NO: 90, SEQ ID NO: 92, SEQ ID NO: 94 y SEQ ID NO 96
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201462012970P | 2014-06-16 | 2014-06-16 | |
| PCT/US2015/036078 WO2015195697A1 (en) | 2014-06-16 | 2015-06-16 | Omega-hydroxylase-related fusion polypeptides with improved properties |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2803560T3 true ES2803560T3 (es) | 2021-01-27 |
Family
ID=53491691
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES15732504T Active ES2803560T3 (es) | 2014-06-16 | 2015-06-16 | Polipéptidos de fusión relacionados con omega-hidroxilasa con propiedades mejoradas |
Country Status (14)
| Country | Link |
|---|---|
| US (3) | US11441130B2 (es) |
| EP (2) | EP3690035A3 (es) |
| JP (3) | JP6826435B2 (es) |
| KR (2) | KR102663049B1 (es) |
| CN (3) | CN106604990B (es) |
| AU (2) | AU2015277261B2 (es) |
| BR (1) | BR112016029235B1 (es) |
| CA (1) | CA2951925A1 (es) |
| ES (1) | ES2803560T3 (es) |
| MX (1) | MX372803B (es) |
| MY (2) | MY207981A (es) |
| PL (1) | PL3087179T3 (es) |
| SI (1) | SI3087179T1 (es) |
| WO (1) | WO2015195697A1 (es) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2915229A1 (en) * | 2013-06-14 | 2014-12-18 | REG Life Sciences, LLC | Methods of producing omega-hydroxylated fatty acid derivatives |
| ES2803560T3 (es) | 2014-06-16 | 2021-01-27 | Genomatica Inc | Polipéptidos de fusión relacionados con omega-hidroxilasa con propiedades mejoradas |
| WO2017101987A1 (en) * | 2015-12-15 | 2017-06-22 | REG Life Sciences, LLC | Omega-hydroxylase-related fusion polypeptide variants with improved properties |
| BR112019020784A2 (pt) | 2017-04-03 | 2020-04-28 | Genomatica Inc | variantes de tioesterase com atividade melhorada para a produção de derivados de ácidos graxos de cadeia média |
| EP3844179A4 (en) | 2018-08-31 | 2022-08-31 | Genomatica, Inc. | XYLR MUTANT FOR IMPROVED XYLOSE UTILIZATION OR IMPROVED CO-UTILIZATION OF GLUCOSE AND XYLOSE |
| CN119391659B (zh) * | 2024-10-30 | 2025-10-10 | 天津凯莱英生物科技有限公司 | 多肽连接酶突变体及多肽的制备方法 |
Family Cites Families (58)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA1305083C (en) | 1987-02-18 | 1992-07-14 | Yoshiharu Kimura | Microorganism belonging to genus rhodococcus, and a process for producing alkene derivative and unsaturated fatty acid |
| US5028539A (en) | 1988-08-31 | 1991-07-02 | The University Of Florida | Ethanol production using engineered mutant E. coli |
| US5424202A (en) | 1988-08-31 | 1995-06-13 | The University Of Florida | Ethanol production by recombinant hosts |
| US5000000A (en) | 1988-08-31 | 1991-03-19 | University Of Florida | Ethanol production by Escherichia coli strains co-expressing Zymomonas PDC and ADH genes |
| US5482846A (en) | 1988-08-31 | 1996-01-09 | University Of Florida | Ethanol production in Gram-positive microbes |
| AU7791991A (en) | 1990-04-24 | 1991-11-11 | Stratagene | Methods for phenotype creation from multiple gene populations |
| US5602030A (en) | 1994-03-28 | 1997-02-11 | University Of Florida Research Foundation | Recombinant glucose uptake system |
| US6428767B1 (en) | 1995-05-12 | 2002-08-06 | E. I. Du Pont De Nemours And Company | Method for identifying the source of carbon in 1,3-propanediol |
| US5939250A (en) | 1995-12-07 | 1999-08-17 | Diversa Corporation | Production of enzymes having desired activities by mutagenesis |
| US5965408A (en) | 1996-07-09 | 1999-10-12 | Diversa Corporation | Method of DNA reassembly by interrupting synthesis |
| US7576227B2 (en) | 2002-04-29 | 2009-08-18 | Union Carbide Chemicals & Plastics Technology Corporation | Integrate chemical processes for industrial utilization of seed oils |
| EP1811029A4 (en) | 2004-11-10 | 2008-03-12 | Marine Biotech Inst Co Ltd | PROCESS FOR ISOLATING THE P450 GENE |
| US8110670B2 (en) | 2006-05-19 | 2012-02-07 | Ls9, Inc. | Enhanced production of fatty acid derivatives |
| US20100242345A1 (en) | 2006-05-19 | 2010-09-30 | LS9, Inc | Production of fatty acids & derivatives thereof |
| ES2763624T3 (es) | 2006-05-19 | 2020-05-29 | Genomatica Inc | Producción de ácidos grasos y derivados de los mismos |
| CN101558027B (zh) | 2006-10-13 | 2013-10-16 | 埃莱文斯可更新科学公司 | 通过复分解反应制备α,ω-二羧酸烯烃衍生物的方法 |
| CN106083579A (zh) | 2006-10-13 | 2016-11-09 | 埃莱文斯可更新科学公司 | 通过烯烃复分解由内烯烃合成末端烯烃的方法 |
| US8110093B2 (en) | 2007-03-14 | 2012-02-07 | Ls9, Inc. | Process for producing low molecular weight hydrocarbons from renewable resources |
| EP2594633A1 (en) | 2007-03-28 | 2013-05-22 | LS9, Inc. | Enhanced production of fatty acid derivatives |
| US20080293060A1 (en) | 2007-04-23 | 2008-11-27 | Ls9, Inc. | Methods and Compositions for Identification of Hydrocarbon Response, Transport and Biosynthesis Genes |
| KR101862691B1 (ko) | 2007-05-22 | 2018-05-31 | 알이지 라이프 사이언시스, 엘엘씨 | 탄화수소-생산 유전자와 이들의 이용 방법 |
| JP5324129B2 (ja) | 2007-05-25 | 2013-10-23 | 神戸天然物化学株式会社 | Cyp153による芳香族化合物の製造方法 |
| US20100199548A1 (en) | 2007-07-06 | 2010-08-12 | Ls9, Inc. | Systems and methods for the production of fatty esters |
| FR2921362B1 (fr) | 2007-09-20 | 2012-09-21 | Arkema France | Procede de synthese d'acides gras omega-insatures |
| CA2692266C (en) | 2007-09-27 | 2019-04-16 | Ls9, Inc. | Reduction of the toxic effect of impurities from raw materials by extractive fermentation |
| TWI351779B (en) | 2007-12-03 | 2011-11-01 | Advance Smart Ind Ltd | Apparatus and method for correcting residual capac |
| WO2009085278A1 (en) | 2007-12-21 | 2009-07-09 | Ls9, Inc. | Methods and compositions for producing olefins |
| EP2283121B1 (en) | 2008-05-16 | 2015-02-11 | REG Life Sciences, LLC | Methods and compositions for producing hydrocarbons |
| WO2009142983A1 (en) | 2008-05-23 | 2009-11-26 | Alliant Techsystems Inc. | Broadband patch antenna and antenna system |
| US8273694B2 (en) | 2008-07-28 | 2012-09-25 | Jeffrey A Brown | Synthetic compositions obtained from algae |
| WO2010021711A1 (en) | 2008-08-18 | 2010-02-25 | Ls9, Inc. | Systems and methods for the production of mixed fatty esters |
| MY150586A (en) | 2008-08-28 | 2014-01-30 | Mitsui Chemicals Inc | Olefin production process |
| CA2738938C (en) | 2008-10-07 | 2019-04-30 | Ls9, Inc. | Methods and compositions for producing fatty aldehydes |
| BRPI0920010A2 (pt) | 2008-10-28 | 2016-04-19 | Ls9 Inc | métodos para produzir álcool graxo e surfactante |
| US7989875B2 (en) | 2008-11-24 | 2011-08-02 | Nxp B.V. | BiCMOS integration of multiple-times-programmable non-volatile memories |
| MX368526B (es) | 2008-12-23 | 2019-10-07 | Reg Life Sciences Llc | Metodos y composiciones relacionados con tioesterasa enzima. |
| US8071799B2 (en) | 2009-01-29 | 2011-12-06 | Energy & Environmental Research Center Foundation | Chain-selective synthesis of fuel components and chemical feedstocks |
| CA2758301A1 (en) | 2009-04-10 | 2010-10-14 | Ls9, Inc. | Production of fatty acid derivatives |
| CA2759273C (en) | 2009-04-27 | 2018-01-09 | Ls9, Inc. | Production of fatty acid esters |
| US20120115195A1 (en) | 2009-05-01 | 2012-05-10 | The Regents Of The University Of California | Product of fatty acid esters from biomass polymers |
| EP2910630B1 (en) | 2009-09-25 | 2018-10-24 | REG Life Sciences, LLC | Production of fatty acid derivatives |
| US8809563B2 (en) | 2009-11-09 | 2014-08-19 | Exxonmobil Chemical Patents Inc. | Metathesis catalyst and process for use thereof |
| US8237003B2 (en) | 2009-11-09 | 2012-08-07 | Exxonmobil Chemical Patents Inc. | Metathesis catalyst and process for use thereof |
| US8361769B1 (en) | 2009-11-16 | 2013-01-29 | U.S. Department Of Energy | Regioselective alkane hydroxylation with a mutant CYP153A6 enzyme |
| US20110124071A1 (en) | 2009-11-17 | 2011-05-26 | LS9, Inc | Methods and compositions for producing hydrocarbons |
| US8530221B2 (en) | 2010-01-14 | 2013-09-10 | Ls9, Inc. | Production of branched chain fatty acids and derivatives thereof in recombinant microbial cells |
| US20110250663A1 (en) | 2010-04-08 | 2011-10-13 | Ls9, Inc. | Methods and compositions related to fatty alcohol biosynthetic enzymes |
| EP2576800B1 (en) | 2010-05-28 | 2019-01-30 | Corbion Biotech, Inc. | Method for producing oils from Prototheca |
| US8372610B2 (en) | 2010-09-15 | 2013-02-12 | Ls9, Inc. | Production of odd chain fatty acid derivatives in recombinant microbial cells |
| WO2012071439A1 (en) | 2010-11-22 | 2012-05-31 | The Regents Of The University Of California | Host cells and methods for producing diacid compounds |
| CN110066836A (zh) | 2011-02-02 | 2019-07-30 | 柯碧恩生物技术公司 | 产自重组产油微生物的定制油 |
| EP2729564B1 (en) | 2011-07-06 | 2019-09-18 | Radici Chimica S.p.A. | Biological methods for preparing a fatty dicarboxylic acid |
| DE102011110946A1 (de) | 2011-08-15 | 2016-01-21 | Evonik Degussa Gmbh | Biotechnologisches Syntheseverfahren von omegafunktionalisierten Carbonsäuren und Carbonsäure-Estern aus einfachen Kohlenstoffquellen |
| EP2639308A1 (de) | 2012-03-12 | 2013-09-18 | Evonik Industries AG | Enzymatische omega-Oxidation und -Aminierung von Fettsäuren |
| FR3003577B1 (fr) | 2013-03-19 | 2016-05-06 | Ferropem | Inoculant a particules de surface |
| CA2915229A1 (en) * | 2013-06-14 | 2014-12-18 | REG Life Sciences, LLC | Methods of producing omega-hydroxylated fatty acid derivatives |
| ES2803560T3 (es) | 2014-06-16 | 2021-01-27 | Genomatica Inc | Polipéptidos de fusión relacionados con omega-hidroxilasa con propiedades mejoradas |
| WO2017101987A1 (en) | 2015-12-15 | 2017-06-22 | REG Life Sciences, LLC | Omega-hydroxylase-related fusion polypeptide variants with improved properties |
-
2015
- 2015-06-16 ES ES15732504T patent/ES2803560T3/es active Active
- 2015-06-16 AU AU2015277261A patent/AU2015277261B2/en not_active Ceased
- 2015-06-16 CA CA2951925A patent/CA2951925A1/en active Pending
- 2015-06-16 BR BR112016029235-9A patent/BR112016029235B1/pt active IP Right Grant
- 2015-06-16 PL PL15732504T patent/PL3087179T3/pl unknown
- 2015-06-16 CN CN201580032792.3A patent/CN106604990B/zh active Active
- 2015-06-16 MX MX2016016565A patent/MX372803B/es active IP Right Grant
- 2015-06-16 WO PCT/US2015/036078 patent/WO2015195697A1/en not_active Ceased
- 2015-06-16 JP JP2016573541A patent/JP6826435B2/ja active Active
- 2015-06-16 MY MYPI2022002249A patent/MY207981A/en unknown
- 2015-06-16 EP EP20160184.6A patent/EP3690035A3/en active Pending
- 2015-06-16 SI SI201531270T patent/SI3087179T1/sl unknown
- 2015-06-16 EP EP15732504.4A patent/EP3087179B1/en active Active
- 2015-06-16 MY MYPI2016002190A patent/MY198268A/en unknown
- 2015-06-16 US US15/319,272 patent/US11441130B2/en active Active
- 2015-08-13 KR KR1020227029909A patent/KR102663049B1/ko active Active
- 2015-08-13 CN CN202210284305.4A patent/CN114605558A/zh active Pending
- 2015-08-13 CN CN202511366259.2A patent/CN121203035A/zh active Pending
- 2015-08-13 KR KR1020177001306A patent/KR102439589B1/ko active Active
-
2019
- 2019-10-23 US US16/661,667 patent/US11421206B2/en active Active
- 2019-11-15 JP JP2019206602A patent/JP2020036610A/ja active Pending
-
2021
- 2021-04-12 AU AU2021202194A patent/AU2021202194A1/en not_active Abandoned
- 2021-11-18 JP JP2021187660A patent/JP7564800B2/ja active Active
-
2022
- 2022-08-08 US US17/818,038 patent/US20230167419A1/en active Pending
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7406529B2 (ja) | ω-ヒドロキシル化脂肪酸誘導体を生産する方法 | |
| ES2786633T3 (es) | Enzimas CAR y producción mejorada de alcoholes grasos | |
| JP7564800B2 (ja) | 特性が改良されたオメガ-ヒドロキシラーゼ関連融合ポリペプチド | |
| ES2675224T3 (es) | Acil-ACP reductasa con propiedades mejoradas | |
| JP7458358B2 (ja) | 改良された特性を有するω-ヒドロキシラーゼ関連融合ポリペプチドバリアント | |
| KR102215530B1 (ko) | 개선된 아세틸-coa 카르복실라아제 변이체 | |
| BR112018012193B1 (pt) | Variantes do polipeptídeo de fusão relacionados à ômega-hidroxilase com propriedades melhoradas, célula hospedeira recombinante, método para produzir um derivado de ácido graxo omega hidroxilado, e microorganismo recombinante |