DE102009007272A1 - New nucleic acid sequence, which encodes a polypeptide with alcohol dehydrogenase activity, comprising e.g. nucleic acid sequence that hybridizes under stringent conditions with specific nucleic acid sequence, useful to produce polypeptide - Google Patents
New nucleic acid sequence, which encodes a polypeptide with alcohol dehydrogenase activity, comprising e.g. nucleic acid sequence that hybridizes under stringent conditions with specific nucleic acid sequence, useful to produce polypeptide Download PDFInfo
- Publication number
- DE102009007272A1 DE102009007272A1 DE102009007272A DE102009007272A DE102009007272A1 DE 102009007272 A1 DE102009007272 A1 DE 102009007272A1 DE 102009007272 A DE102009007272 A DE 102009007272A DE 102009007272 A DE102009007272 A DE 102009007272A DE 102009007272 A1 DE102009007272 A1 DE 102009007272A1
- Authority
- DE
- Germany
- Prior art keywords
- nucleic acid
- sequence
- acid sequence
- polypeptide
- adh
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 150000007523 nucleic acids Chemical group 0.000 title claims abstract description 87
- 229920001184 polypeptide Polymers 0.000 title claims abstract description 71
- 108090000765 processed proteins & peptides Proteins 0.000 title claims abstract description 69
- 102000004196 processed proteins & peptides Human genes 0.000 title claims abstract description 68
- 230000000694 effects Effects 0.000 title claims abstract description 62
- 108010021809 Alcohol dehydrogenase Proteins 0.000 title claims abstract description 56
- 102000007698 Alcohol dehydrogenase Human genes 0.000 title claims abstract description 53
- 108091028043 Nucleic acid sequence Proteins 0.000 title claims abstract description 49
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 43
- 239000013598 vector Substances 0.000 claims abstract description 40
- 230000014509 gene expression Effects 0.000 claims abstract description 30
- 239000003054 catalyst Substances 0.000 claims abstract description 19
- 230000000295 complement effect Effects 0.000 claims abstract description 10
- 239000000523 sample Substances 0.000 claims abstract description 5
- 238000003259 recombinant expression Methods 0.000 claims abstract description 4
- 238000000034 method Methods 0.000 claims description 41
- 238000002360 preparation method Methods 0.000 claims description 17
- 238000007254 oxidation reaction Methods 0.000 claims description 11
- 238000002703 mutagenesis Methods 0.000 claims description 10
- 231100000350 mutagenesis Toxicity 0.000 claims description 10
- 150000001299 aldehydes Chemical class 0.000 claims description 9
- 230000003647 oxidation Effects 0.000 claims description 9
- 150000001298 alcohols Chemical class 0.000 claims description 8
- 150000002576 ketones Chemical class 0.000 claims description 8
- 230000008569 process Effects 0.000 claims description 6
- BVKZGUZCCUSVTD-UHFFFAOYSA-N carbonic acid Chemical class OC(O)=O BVKZGUZCCUSVTD-UHFFFAOYSA-N 0.000 claims description 5
- 238000010367 cloning Methods 0.000 abstract description 10
- 101710088194 Dehydrogenase Proteins 0.000 abstract description 2
- AEMRFAOFKBGASW-UHFFFAOYSA-M Glycolate Chemical compound OCC([O-])=O AEMRFAOFKBGASW-UHFFFAOYSA-M 0.000 abstract 1
- 102000004190 Enzymes Human genes 0.000 description 77
- 108090000790 Enzymes Proteins 0.000 description 77
- 229940088598 enzyme Drugs 0.000 description 74
- MNQZXJOMYWMBOU-VKHMYHEASA-N D-glyceraldehyde Chemical compound OC[C@@H](O)C=O MNQZXJOMYWMBOU-VKHMYHEASA-N 0.000 description 43
- 210000004027 cell Anatomy 0.000 description 31
- 238000006243 chemical reaction Methods 0.000 description 27
- XJLXINKUBYWONI-DQQFMEOOSA-N [[(2r,3r,4r,5r)-5-(6-aminopurin-9-yl)-3-hydroxy-4-phosphonooxyoxolan-2-yl]methoxy-hydroxyphosphoryl] [(2s,3r,4s,5s)-5-(3-carbamoylpyridin-1-ium-1-yl)-3,4-dihydroxyoxolan-2-yl]methyl phosphate Chemical compound NC(=O)C1=CC=C[N+]([C@@H]2[C@H]([C@@H](O)[C@H](COP([O-])(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](OP(O)(O)=O)[C@@H](O3)N3C4=NC=NC(N)=C4N=C3)O)O2)O)=C1 XJLXINKUBYWONI-DQQFMEOOSA-N 0.000 description 23
- 229930027945 nicotinamide-adenine dinucleotide Natural products 0.000 description 22
- -1 polyol compounds Chemical class 0.000 description 21
- 238000006722 reduction reaction Methods 0.000 description 19
- 108020004414 DNA Proteins 0.000 description 18
- RXKJFZQQPQGTFL-UHFFFAOYSA-N dihydroxyacetone Chemical compound OCC(=O)CO RXKJFZQQPQGTFL-UHFFFAOYSA-N 0.000 description 18
- 239000000758 substrate Substances 0.000 description 18
- 230000009467 reduction Effects 0.000 description 17
- 238000010369 molecular cloning Methods 0.000 description 15
- 108020004707 nucleic acids Proteins 0.000 description 15
- 102000039446 nucleic acids Human genes 0.000 description 15
- 150000001413 amino acids Chemical group 0.000 description 14
- 150000001875 compounds Chemical class 0.000 description 14
- 239000000243 solution Substances 0.000 description 14
- 108010050375 Glucose 1-Dehydrogenase Proteins 0.000 description 13
- 235000001014 amino acid Nutrition 0.000 description 13
- 239000013612 plasmid Substances 0.000 description 13
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 12
- 230000002829 reductive effect Effects 0.000 description 12
- MNQZXJOMYWMBOU-GSVOUGTGSA-N L-(-)-glyceraldehyde Chemical compound OC[C@H](O)C=O MNQZXJOMYWMBOU-GSVOUGTGSA-N 0.000 description 11
- 125000004432 carbon atom Chemical group C* 0.000 description 11
- 239000000287 crude extract Substances 0.000 description 11
- 238000012360 testing method Methods 0.000 description 11
- 230000009261 transgenic effect Effects 0.000 description 11
- 241000588724 Escherichia coli Species 0.000 description 10
- 239000000872 buffer Substances 0.000 description 9
- 229940120503 dihydroxyacetone Drugs 0.000 description 9
- 230000009466 transformation Effects 0.000 description 9
- 241000589232 Gluconobacter oxydans Species 0.000 description 8
- BAWFJGJZGIEFAR-NNYOXOHSSA-N NAD zwitterion Chemical compound NC(=O)C1=CC=C[N+]([C@H]2[C@@H]([C@H](O)[C@@H](COP([O-])(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](O)[C@@H](O3)N3C4=NC=NC(N)=C4N=C3)O)O2)O)=C1 BAWFJGJZGIEFAR-NNYOXOHSSA-N 0.000 description 8
- 230000002255 enzymatic effect Effects 0.000 description 8
- 238000004519 manufacturing process Methods 0.000 description 8
- 229950006238 nadide Drugs 0.000 description 8
- 239000000047 product Substances 0.000 description 8
- 150000003254 radicals Chemical class 0.000 description 8
- 238000011069 regeneration method Methods 0.000 description 8
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 7
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 7
- 238000000338 in vitro Methods 0.000 description 7
- 235000018102 proteins Nutrition 0.000 description 7
- 102000004169 proteins and genes Human genes 0.000 description 7
- 230000008929 regeneration Effects 0.000 description 7
- 125000004209 (C1-C8) alkyl group Chemical group 0.000 description 6
- UHOVQNZJYSORNB-UHFFFAOYSA-N Benzene Chemical compound C1=CC=CC=C1 UHOVQNZJYSORNB-UHFFFAOYSA-N 0.000 description 6
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 6
- 241000282414 Homo sapiens Species 0.000 description 6
- YXFVVABEGXRONW-UHFFFAOYSA-N Toluene Chemical compound CC1=CC=CC=C1 YXFVVABEGXRONW-UHFFFAOYSA-N 0.000 description 6
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 6
- 229960000723 ampicillin Drugs 0.000 description 6
- 239000008103 glucose Substances 0.000 description 6
- 239000000203 mixture Substances 0.000 description 6
- BOPGDPNILDQYTO-NNYOXOHSSA-N nicotinamide-adenine dinucleotide Chemical compound C1=CCC(C(=O)N)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OC[C@@H]2[C@H]([C@@H](O)[C@@H](O2)N2C3=NC=NC(N)=C3N=C2)O)O1 BOPGDPNILDQYTO-NNYOXOHSSA-N 0.000 description 6
- 239000003960 organic solvent Substances 0.000 description 6
- 239000005515 coenzyme Substances 0.000 description 5
- 230000001419 dependent effect Effects 0.000 description 5
- 108020001507 fusion proteins Proteins 0.000 description 5
- 102000037865 fusion proteins Human genes 0.000 description 5
- 244000005700 microbiome Species 0.000 description 5
- 229920005862 polyol Polymers 0.000 description 5
- 150000003077 polyols Chemical class 0.000 description 5
- 230000035484 reaction time Effects 0.000 description 5
- 238000011084 recovery Methods 0.000 description 5
- 102100038837 2-Hydroxyacid oxidase 1 Human genes 0.000 description 4
- 244000063299 Bacillus subtilis Species 0.000 description 4
- 235000014469 Bacillus subtilis Nutrition 0.000 description 4
- 102000016938 Catalase Human genes 0.000 description 4
- 108010053835 Catalase Proteins 0.000 description 4
- 108090000317 Chymotrypsin Proteins 0.000 description 4
- 102000053602 DNA Human genes 0.000 description 4
- 241001198387 Escherichia coli BL21(DE3) Species 0.000 description 4
- 241000238631 Hexapoda Species 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 238000004113 cell culture Methods 0.000 description 4
- 229960002376 chymotrypsin Drugs 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 239000012634 fragment Substances 0.000 description 4
- 238000004817 gas chromatography Methods 0.000 description 4
- 108010062584 glycollate oxidase Proteins 0.000 description 4
- 125000005842 heteroatom Chemical group 0.000 description 4
- 230000001590 oxidative effect Effects 0.000 description 4
- 229910052760 oxygen Inorganic materials 0.000 description 4
- 238000000746 purification Methods 0.000 description 4
- 238000001228 spectrum Methods 0.000 description 4
- 238000001890 transfection Methods 0.000 description 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 3
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- WFDIJRYMOXRFFG-UHFFFAOYSA-N Acetic anhydride Chemical compound CC(=O)OC(C)=O WFDIJRYMOXRFFG-UHFFFAOYSA-N 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 241000713333 Mouse mammary tumor virus Species 0.000 description 3
- 239000002202 Polyethylene glycol Substances 0.000 description 3
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 3
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 3
- 241000187747 Streptomyces Species 0.000 description 3
- 125000002252 acyl group Chemical group 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 239000003125 aqueous solvent Substances 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 238000004587 chromatography analysis Methods 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 229910052736 halogen Inorganic materials 0.000 description 3
- 150000002367 halogens Chemical group 0.000 description 3
- 125000004475 heteroaralkyl group Chemical group 0.000 description 3
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 3
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 229910052698 phosphorus Inorganic materials 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 238000002708 random mutagenesis Methods 0.000 description 3
- 230000006798 recombination Effects 0.000 description 3
- 238000005215 recombination Methods 0.000 description 3
- 230000001172 regenerating effect Effects 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- 229910052717 sulfur Inorganic materials 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- BUHVIAUBTBOHAG-FOYDDCNASA-N (2r,3r,4s,5r)-2-[6-[[2-(3,5-dimethoxyphenyl)-2-(2-methylphenyl)ethyl]amino]purin-9-yl]-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound COC1=CC(OC)=CC(C(CNC=2C=3N=CN(C=3N=CN=2)[C@H]2[C@@H]([C@H](O)[C@@H](CO)O2)O)C=2C(=CC=CC=2)C)=C1 BUHVIAUBTBOHAG-FOYDDCNASA-N 0.000 description 2
- IVWWFWFVSWOTLP-YVZVNANGSA-N (3'as,4r,7'as)-2,2,2',2'-tetramethylspiro[1,3-dioxolane-4,6'-4,7a-dihydro-3ah-[1,3]dioxolo[4,5-c]pyran]-7'-one Chemical compound C([C@@H]1OC(O[C@@H]1C1=O)(C)C)O[C@]21COC(C)(C)O2 IVWWFWFVSWOTLP-YVZVNANGSA-N 0.000 description 2
- 125000006552 (C3-C8) cycloalkyl group Chemical group 0.000 description 2
- RYHBNJHYFVUHQT-UHFFFAOYSA-N 1,4-Dioxane Chemical compound C1COCCO1 RYHBNJHYFVUHQT-UHFFFAOYSA-N 0.000 description 2
- NMSBTWLFBGNKON-UHFFFAOYSA-N 2-(2-hexadecoxyethoxy)ethanol Chemical compound CCCCCCCCCCCCCCCCOCCOCCO NMSBTWLFBGNKON-UHFFFAOYSA-N 0.000 description 2
- HGINCPLSRVDWNT-UHFFFAOYSA-N Acrolein Chemical compound C=CC=O HGINCPLSRVDWNT-UHFFFAOYSA-N 0.000 description 2
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 2
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 2
- 108700028369 Alleles Proteins 0.000 description 2
- ATRRKUHOCOJYRX-UHFFFAOYSA-N Ammonium bicarbonate Chemical compound [NH4+].OC([O-])=O ATRRKUHOCOJYRX-UHFFFAOYSA-N 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- 102000012410 DNA Ligases Human genes 0.000 description 2
- 108010061982 DNA Ligases Proteins 0.000 description 2
- 241000238557 Decapoda Species 0.000 description 2
- 108090000204 Dipeptidase 1 Proteins 0.000 description 2
- 239000001856 Ethyl cellulose Substances 0.000 description 2
- ZZSNKZQZMQGXPY-UHFFFAOYSA-N Ethyl cellulose Chemical compound CCOCC1OC(OC)C(OCC)C(OCC)C1OC1C(O)C(O)C(OC)C(CO)O1 ZZSNKZQZMQGXPY-UHFFFAOYSA-N 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 108090000698 Formate Dehydrogenases Proteins 0.000 description 2
- 241000589236 Gluconobacter Species 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 2
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 2
- 241000320412 Ogataea angusta Species 0.000 description 2
- 108091034117 Oligonucleotide Proteins 0.000 description 2
- 241000589517 Pseudomonas aeruginosa Species 0.000 description 2
- 241001240958 Pseudomonas aeruginosa PAO1 Species 0.000 description 2
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 2
- 244000300264 Spinacia oleracea Species 0.000 description 2
- 235000009337 Spinacia oleracea Nutrition 0.000 description 2
- 108010056079 Subtilisins Proteins 0.000 description 2
- 102000005158 Subtilisins Human genes 0.000 description 2
- 101710137500 T7 RNA polymerase Proteins 0.000 description 2
- 241000499912 Trichoderma reesei Species 0.000 description 2
- 102100026383 Vasopressin-neurophysin 2-copeptin Human genes 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- 101150067366 adh gene Proteins 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- 108010048916 alcohol dehydrogenase (acceptor) Proteins 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 239000001099 ammonium carbonate Substances 0.000 description 2
- 235000012501 ammonium carbonate Nutrition 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 125000003118 aryl group Chemical group 0.000 description 2
- 125000004429 atom Chemical group 0.000 description 2
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical group [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 2
- 239000011942 biocatalyst Substances 0.000 description 2
- 239000012620 biological material Substances 0.000 description 2
- 238000006555 catalytic reaction Methods 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 239000013522 chelant Substances 0.000 description 2
- 239000000460 chlorine Substances 0.000 description 2
- 229910052801 chlorine Inorganic materials 0.000 description 2
- 238000004140 cleaning Methods 0.000 description 2
- 230000009918 complex formation Effects 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 239000013078 crystal Substances 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- ZUOUZKKEUPVFJK-UHFFFAOYSA-N diphenyl Chemical compound C1=CC=CC=C1C1=CC=CC=C1 ZUOUZKKEUPVFJK-UHFFFAOYSA-N 0.000 description 2
- 229920001249 ethyl cellulose Polymers 0.000 description 2
- 235000019325 ethyl cellulose Nutrition 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 229910052731 fluorine Inorganic materials 0.000 description 2
- 238000013467 fragmentation Methods 0.000 description 2
- 238000006062 fragmentation reaction Methods 0.000 description 2
- 238000004108 freeze drying Methods 0.000 description 2
- 101150019455 gdh gene Proteins 0.000 description 2
- MNQZXJOMYWMBOU-UHFFFAOYSA-N glyceraldehyde Chemical compound OCC(O)C=O MNQZXJOMYWMBOU-UHFFFAOYSA-N 0.000 description 2
- 150000002390 heteroarenes Chemical class 0.000 description 2
- 238000009396 hybridization Methods 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 239000002773 nucleotide Substances 0.000 description 2
- 125000003729 nucleotide group Chemical group 0.000 description 2
- 230000002018 overexpression Effects 0.000 description 2
- 125000004430 oxygen atom Chemical group O* 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 210000001938 protoplast Anatomy 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 238000012163 sequencing technique Methods 0.000 description 2
- 229910052710 silicon Inorganic materials 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 230000000707 stereoselective effect Effects 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 210000001519 tissue Anatomy 0.000 description 2
- LWIHDJKSTIGBAC-UHFFFAOYSA-K tripotassium phosphate Chemical compound [K+].[K+].[K+].[O-]P([O-])([O-])=O LWIHDJKSTIGBAC-UHFFFAOYSA-K 0.000 description 2
- 238000002604 ultrasonography Methods 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- 125000003837 (C1-C20) alkyl group Chemical group 0.000 description 1
- YBYIRNPNPLQARY-UHFFFAOYSA-N 1H-indene Natural products C1=CC=C2CC=CC2=C1 YBYIRNPNPLQARY-UHFFFAOYSA-N 0.000 description 1
- MJJYBIKJATXOSF-UHFFFAOYSA-N 2,3-dihydroxy-4-methylpent-3-enal Chemical compound CC(C)=C(O)C(O)C=O MJJYBIKJATXOSF-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- 125000003682 3-furyl group Chemical group O1C([H])=C([*])C([H])=C1[H] 0.000 description 1
- 125000004575 3-pyrrolidinyl group Chemical group [H]N1C([H])([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000001397 3-pyrrolyl group Chemical group [H]N1C([H])=C([*])C([H])=C1[H] 0.000 description 1
- 125000001541 3-thienyl group Chemical group S1C([H])=C([*])C([H])=C1[H] 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- 125000000339 4-pyridyl group Chemical group N1=C([H])C([H])=C([*])C([H])=C1[H] 0.000 description 1
- RXGJTUSBYWCRBK-UHFFFAOYSA-M 5-methylphenazinium methyl sulfate Chemical compound COS([O-])(=O)=O.C1=CC=C2[N+](C)=C(C=CC=C3)C3=NC2=C1 RXGJTUSBYWCRBK-UHFFFAOYSA-M 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- HBAQYPYDRFILMT-UHFFFAOYSA-N 8-[3-(1-cyclopropylpyrazol-4-yl)-1H-pyrazolo[4,3-d]pyrimidin-5-yl]-3-methyl-3,8-diazabicyclo[3.2.1]octan-2-one Chemical class C1(CC1)N1N=CC(=C1)C1=NNC2=C1N=C(N=C2)N1C2C(N(CC1CC2)C)=O HBAQYPYDRFILMT-UHFFFAOYSA-N 0.000 description 1
- 241000589220 Acetobacter Species 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- 241000589158 Agrobacterium Species 0.000 description 1
- 101100122189 Arabidopsis thaliana GLO5 gene Proteins 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 101000950981 Bacillus subtilis (strain 168) Catabolic NAD-specific glutamate dehydrogenase RocG Proteins 0.000 description 1
- 239000002028 Biomass Substances 0.000 description 1
- WKBOTKDWSSQWDR-UHFFFAOYSA-N Bromine atom Chemical compound [Br] WKBOTKDWSSQWDR-UHFFFAOYSA-N 0.000 description 1
- 241000589876 Campylobacter Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 241000863012 Caulobacter Species 0.000 description 1
- ZAMOUSCENKQFHK-UHFFFAOYSA-N Chlorine atom Chemical compound [Cl] ZAMOUSCENKQFHK-UHFFFAOYSA-N 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 108020005199 Dehydrogenases Proteins 0.000 description 1
- 238000009007 Diagnostic Kit Methods 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 101100240657 Emericella nidulans (strain FGSC A4 / ATCC 38163 / CBS 112.46 / NRRL 194 / M139) swoF gene Proteins 0.000 description 1
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 1
- 101000886933 Geobacillus stearothermophilus Glycerol dehydrogenase Proteins 0.000 description 1
- 101000892220 Geobacillus thermodenitrificans (strain NG80-2) Long-chain-alcohol dehydrogenase 1 Proteins 0.000 description 1
- 102000016901 Glutamate dehydrogenase Human genes 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 102000005744 Glycoside Hydrolases Human genes 0.000 description 1
- 108010031186 Glycoside Hydrolases Proteins 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 229930194542 Keto Natural products 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- HEBKCHPVOIAQTA-IMJSIDKUSA-N L-arabinitol Chemical compound OC[C@H](O)C(O)[C@@H](O)CO HEBKCHPVOIAQTA-IMJSIDKUSA-N 0.000 description 1
- 102000003855 L-lactate dehydrogenase Human genes 0.000 description 1
- 108700023483 L-lactate dehydrogenases Proteins 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 241000186660 Lactobacillus Species 0.000 description 1
- 101100536883 Legionella pneumophila subsp. pneumophila (strain Philadelphia 1 / ATCC 33152 / DSM 7513) thi5 gene Proteins 0.000 description 1
- 101710175625 Maltose/maltodextrin-binding periplasmic protein Proteins 0.000 description 1
- 241000589339 Methylobacterium organophilum Species 0.000 description 1
- 241000699666 Mus <mouse, genus> Species 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 241000186359 Mycobacterium Species 0.000 description 1
- 108010007843 NADH oxidase Proteins 0.000 description 1
- 108010002998 NADPH Oxidases Proteins 0.000 description 1
- 102000004722 NADPH Oxidases Human genes 0.000 description 1
- 241000588653 Neisseria Species 0.000 description 1
- 101100240662 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gtt-1 gene Proteins 0.000 description 1
- 101150043338 Nmt1 gene Proteins 0.000 description 1
- 108700020497 Nucleopolyhedrovirus polyhedrin Proteins 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 241000235061 Pichia sp. Species 0.000 description 1
- 241000589774 Pseudomonas sp. Species 0.000 description 1
- 241000589614 Pseudomonas stutzeri Species 0.000 description 1
- 239000012564 Q sepharose fast flow resin Substances 0.000 description 1
- 241000232299 Ralstonia Species 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- 241000316848 Rhodococcus <scale insect> Species 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 125000000641 acridinyl group Chemical group C1(=CC=CC2=NC3=CC=CC=C3C=C12)* 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 125000004423 acyloxy group Chemical group 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 125000004183 alkoxy alkyl group Chemical group 0.000 description 1
- 125000004453 alkoxycarbonyl group Chemical group 0.000 description 1
- 125000000217 alkyl group Chemical group 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 1
- 235000011130 ammonium sulphate Nutrition 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 125000005428 anthryl group Chemical group [H]C1=C([H])C([H])=C2C([H])=C3C(*)=C([H])C([H])=C([H])C3=C([H])C2=C1[H] 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 125000003710 aryl alkyl group Chemical group 0.000 description 1
- 150000005840 aryl radicals Chemical class 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 230000002210 biocatalytic effect Effects 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 239000004305 biphenyl Substances 0.000 description 1
- 235000010290 biphenyl Nutrition 0.000 description 1
- GDTBXPJZTBHREO-UHFFFAOYSA-N bromine Substances BrBr GDTBXPJZTBHREO-UHFFFAOYSA-N 0.000 description 1
- 229910052794 bromium Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 150000001728 carbonyl compounds Chemical class 0.000 description 1
- 239000012159 carrier gas Substances 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 238000000975 co-precipitation Methods 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000001816 cooling Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000002425 crystallisation Methods 0.000 description 1
- 230000008025 crystallization Effects 0.000 description 1
- 125000001995 cyclobutyl group Chemical group [H]C1([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 125000001511 cyclopentyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000001559 cyclopropyl group Chemical group [H]C1([H])C([H])([H])C1([H])* 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000007850 degeneration Effects 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 230000030609 dephosphorylation Effects 0.000 description 1
- 238000006209 dephosphorylation reaction Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 150000002170 ethers Chemical class 0.000 description 1
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 125000005456 glyceride group Chemical group 0.000 description 1
- 125000003147 glycosyl group Chemical group 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 239000001307 helium Substances 0.000 description 1
- 229910052734 helium Inorganic materials 0.000 description 1
- SWQJXJOGLNCZEY-UHFFFAOYSA-N helium atom Chemical compound [He] SWQJXJOGLNCZEY-UHFFFAOYSA-N 0.000 description 1
- 125000003187 heptyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 125000001072 heteroaryl group Chemical group 0.000 description 1
- 125000004051 hexyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000000126 in silico method Methods 0.000 description 1
- 125000003454 indenyl group Chemical group C1(C=CC2=CC=CC=C12)* 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- 239000011630 iodine Substances 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 125000005647 linker group Chemical group 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 210000001161 mammalian embryo Anatomy 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- HEBKCHPVOIAQTA-UHFFFAOYSA-N meso ribitol Natural products OCC(O)C(O)C(O)CO HEBKCHPVOIAQTA-UHFFFAOYSA-N 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 1
- 125000004108 n-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000004123 n-propyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000001624 naphthyl group Chemical group 0.000 description 1
- 125000002347 octyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 150000002894 organic compounds Chemical class 0.000 description 1
- 229910052762 osmium Inorganic materials 0.000 description 1
- SYQBFIAQOQZEGI-UHFFFAOYSA-N osmium atom Chemical compound [Os] SYQBFIAQOQZEGI-UHFFFAOYSA-N 0.000 description 1
- 229910000489 osmium tetroxide Inorganic materials 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 125000001147 pentyl group Chemical group C(CCCC)* 0.000 description 1
- 125000004934 phenanthridinyl group Chemical group C1(=CC=CC2=NC=C3C=CC=CC3=C12)* 0.000 description 1
- 125000005561 phenanthryl group Chemical group 0.000 description 1
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000035479 physiological effects, processes and functions Effects 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 229910000160 potassium phosphate Inorganic materials 0.000 description 1
- 235000011009 potassium phosphates Nutrition 0.000 description 1
- 238000011533 pre-incubation Methods 0.000 description 1
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 1
- 125000004943 pyrimidin-6-yl group Chemical group N1=CN=CC=C1* 0.000 description 1
- 125000002943 quinolinyl group Chemical group N1=C(C=CC2=CC=CC=C12)* 0.000 description 1
- 239000011541 reaction mixture Substances 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 125000003198 secondary alcohol group Chemical group 0.000 description 1
- 150000003333 secondary alcohols Chemical class 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- APSBXTVYXVQYAB-UHFFFAOYSA-M sodium docusate Chemical compound [Na+].CCCCC(CC)COC(=O)CC(S([O-])(=O)=O)C(=O)OCC(CC)CCCC APSBXTVYXVQYAB-UHFFFAOYSA-M 0.000 description 1
- 239000011877 solvent mixture Substances 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 238000011916 stereoselective reduction Methods 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 125000004434 sulfur atom Chemical group 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000011830 transgenic mouse model Methods 0.000 description 1
- 238000011824 transgenic rat model Methods 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 230000009452 underexpressoin Effects 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P41/00—Processes using enzymes or microorganisms to separate optical isomers from a racemic mixture
- C12P41/002—Processes using enzymes or microorganisms to separate optical isomers from a racemic mixture by oxidation/reduction reactions
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0006—Oxidoreductases (1.) acting on CH-OH groups as donors (1.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/02—Preparation of oxygen-containing organic compounds containing a hydroxy group
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/24—Preparation of oxygen-containing organic compounds containing a carbonyl group
Landscapes
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Zoology (AREA)
- Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Analytical Chemistry (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
Abstract
Description
Die vorliegende Erfindung ist auf Nukleinsäuren und die durch sie codierten Polypeptide gerichtet, wobei die Polypeptide eine Alkoholdehydrogenase-Aktivität aufweisen. Die Polypeptide bzw. Nukleinsäuren stammen aus Gluconobacter oxydans bzw. sind von ihnen abgeleitet. Weiterhin richtet sich die vorliegende Erfindung auf Expressionssysteme, Primer, Verfahren zur Herstellung von verbesserten Nukleinsäuren bzw. durch sie codierte Polypeptide sowie deren Verwendung zur Herstellung von enantiomerenangereicherten Alkoholen, Hydroxyketonen oder auch Hydroxyaldehyden. Ebenfalls ist die Erfindung auf Ganzzellkatalysatoren, die die entsprechende Alkoholdehydrogenase (ADH) enthalten sowie gekoppelte Reaktionssysteme zur Herstellung der enantiomerenangereicherten Produkte gerichtet.The The present invention is directed to nucleic acids and by they are directed to encoded polypeptides, wherein the polypeptides are a Have alcohol dehydrogenase activity. The polypeptides or nucleic acids originate from Gluconobacter oxydans or are derived from them. Furthermore, the present is directed Invention on expression systems, primers, methods of preparation of improved nucleic acids or encoded by them Polypeptides and their use for the preparation of enantiomerically enriched Alcohols, hydroxyketones or hydroxyaldehydes. Also the invention is directed to whole cell catalysts containing the corresponding Alcohol dehydrogenase (ADH) and coupled reaction systems directed to the preparation of the enantiomerically enriched products.
Eine Vielzahl biologischer Reaktionen wird von Alkoholdehydrogenasen katalysiert, wobei Alkoholsubstrate zu den entsprechenden Ketonen oder Aldehyden oxidiert werden, bzw. auch die entgegengerichtete Reduktion vom Aldehyd oder Keton zum Alkohol katalysiert wird. Die beschriebenen Reaktionen sind in der Regel reversibel und laufen in Gegenwart von Nicotinamid-Adenin-Dinucleotid (NAD+/NADH) oder Nicotinamid-Adenin-Dinucleotidphosphat (NADP+/NADPH) als Coenzym (Cofaktor) ab.A variety of biological reactions is catalyzed by alcohol dehydrogenases, whereby alcohol substrates are oxidized to the corresponding ketones or aldehydes, as well as the opposite reduction of aldehyde or ketone to the alcohol is catalyzed. The described reactions are usually reversible and proceed in the presence of nicotinamide adenine dinucleotide (NAD + / NADH) or nicotinamide adenine dinucleotide phosphate (NADP + / NADPH) as coenzyme (cofactor).
Neben
der herausragenden Bedeutung von Alkoholdehydrogenasen in biologischen
Prozessen gelten diese Enzyme auch als interessante Katalysatoren
für die organisch-chemische Synthese zur Herstellung von Alkoholen,
Ketonen oder Aldehyden. Die Gewinnung optisch aktiver organischer
Verbindungen, z. B. Alkohole, Hydroxy-Aldehyde oder Hydroxyketone,
auf biokatalytischem Wege gewinnt zunehmend an Bedeutung. Von besonderem
Interesse sind Biokatalysatoren, die regioselektive Umsetzungen
ermöglichen. Als ein Weg zur großtechnischen Synthese
dieser Verbindungen hat sich der gekoppelte Einsatz zweier Dehydrogenasen
unter Cofaktorregenerierung oder auch die substrat-gekoppelte Coenzymregenerierung
erwiesen (als aktuelle, umfassende Übersicht zum Stand
der Technik, siehe:
Für einen technischen Einsatz von ADHs limitierend sind die Substratspektren der beschriebenen Enzyme. Jedes Enzym setzt nur ein begrenztes Spektrum an Verbindungen um, zudem weisen die Enzyme charakteristische Regio- und Stereoselektivitäten auf, die die Verwendung ebenfalls limitieren. Darüberhinaus liegt generell nur ein geringer Anteil an Alkoholdehydrogenasen in der für technische Einsatzzwecke benötigten rekombinanten Form vor.For A technical use of ADHs is limited by the substrate spectra the enzymes described. Each enzyme has only a limited spectrum compounds, and the enzymes have characteristic regions and stereoselectivities, which the use also limit. In addition, there is generally only a minor Proportion of alcohol dehydrogenases in the for technical applications required recombinant form.
Deshalb
besteht ein großes Interesse an der Auffindung weiterer
Alkohol-Dehydrogenasen mit neuen enzymatischen Eigenschaften, insbesondere
zur regio- und stereoselektiven Umsetzung von Polyol-Verbindungen.
Es ist gut bekannt, dass Mikroorganismen in der Lage sind, Hydroxylgruppen
eines Polyols zu oxidieren, allerdings werden üblicherweise
sekundäre Alkoholgruppen oxidiert. So wird Glycerol beispielsweise
von Organismen der Gattung Gluconobacter oder Acetobacter zu Dihydroxyaceton
oxidiert (
Von besonderem Interesse als Produkte sind dabei Glyceraldehyd (Formelschema 1) oder Homologe, die durch Oxidation der entsprechenden Polyole (Formelschema 2; R = aromatische oder aliphatische Seitenkette) gebildet werden können.From Of particular interest as products are glyceraldehyde (formula scheme 1) or homologs by oxidation of the corresponding polyols (Scheme 2, R = aromatic or aliphatic side chain) can be formed.

Glyceraldehyd
ist eine industriell wichtige Verbindung, die chemisch beispielsweise
durch Osmiumtetraoxide-katalysierte Umsetzung von Acrolein hergestellt
wird; Osmium allerdings ist toxisch und die Wiedergewinnung aus
der Produktlösung stellt ein großes technologisches
Problem dar. Ein Enzym-katalysierter Prozess, der zu Glyceraldehyd
führt, ist von Upjohn Co. (
Aufgabe der vorliegenden Erfindung ist es daher, eine Nukleinsäuresequenz anzugeben, welche für Alkoholdehydrogenasen codiert, die die Nachteile der im Stand der Technik vorhandenen Enzyme zu überwinden vermögen. Insbesondere sollten solche Alkoholdehydrogenasen auch Polyole regioselektiv oxidieren bzw. Hydroxyketone bzw.task Therefore, it is the object of the present invention to provide a nucleic acid sequence which codes for alcohol dehydrogenases, the to overcome the disadvantages of the enzymes present in the prior art capital. In particular, such alcohol dehydrogenases should also oxidize regioselectively polyols or hydroxyketones or
Hydroxyaldehyde stereoselektiv reduzieren. Bevorzugt werden insbesondere solche Enzyme, die NAD- oder NADP-abhängig sind, da für diese Coenzyme Regenerierungsmethoden gut bekannt sind. Weiterhin sollten die Alkoholdehydrogenasen den bekannten Enzymen im Hinblick auf ökonomische Gesichtspunkte, insbesondere hinsichtlich Stabilität, Aktivität und/oder Selektivität überlegen sein.hydroxyaldehydes reduce stereoselectively. Particularly preferred are those Enzymes that are NAD- or NADP-dependent, because of These coenzyme regeneration methods are well known. Farther should the alcohol dehydrogenases the known enzymes in terms on economic aspects, in particular with regard to Superior stability, activity and / or selectivity be.
Weiterhin ist es die Aufgabe der Erfindung, ein Verfahren zur Expression von Alkoholdehydrogenasen anzugeben, welche die Nachteile der im Stand der Technik vorhandenen Enzyme zu überwinden vermögen.Farther It is the object of the invention to provide a method for the expression of Indicate alcohol dehydrogenases, which have the disadvantages of the stand the technology to overcome existing enzymes.
Diese
Aufgabe wird hinsichtlich der Nukleinsäuresequenz erfindungsgemäß gelöst
durch eine:
Nukleinsäuresequenz, die für
ein Polypeptid mit Alkoholdehydrogenaseaktivität codiert,
ausgewählt aus der Gruppe:
- a) einer Nukleinsäuresequenz mit der in Sequenz GO-ADH dargestellten Sequenz,
- b) einer Nukleinsäuresequenz, die unter stringenten Bedingungen mit der Nukleinsäuresequenz gemäß Sequenz GO-ADH oder der dazu komplementären Sequenz hybridisiert,
- c) einer Nukleinsäuresequenz, die eine Homologie von mindestens 50%, bevorzugt mindestens mindestens 75%, noch bevorzugter von mindestens 80% und besonders bevorzugt von über 90% zur Sequenz GO-ADH oder zu der zur Sequenz GO-ADH komplementären Sequenz aufweist.
Nucleic acid sequence coding for a polypeptide having alcohol dehydrogenase activity selected from the group:
- a) a nucleic acid sequence having the sequence shown in sequence GO-ADH,
- b) a nucleic acid sequence which hybridizes under stringent conditions with the nucleic acid sequence according to sequence GO-ADH or the sequence complementary thereto,
- c) a nucleic acid sequence which has a homology of at least 50%, preferably at least 75%, more preferably at least 80%, and most preferably more than 90% to the sequence GO-ADH or to the sequence complementary to the sequence GO-ADH.
Hinsichtlich
des Verfahrens wird die Aufgabe gelöst durch ein:
Verfahren
zur Herstellung eines verbesserten rekombinanten Polypeptids mit
Alkoholdehydrogenaseaktivität ausgehend von Nukleinsäuresequenzen
ausgewählt aus der Gruppe:
- a) einer Nukleinsäuresequenz mit der in Sequenz GO-ADH dargestellten Sequenz,
- b) einer Nukleinsäuresequenz, die unter stringenten Bedingungen mit der Nukleinsäuresequenz gemäß Sequenz GO-ADH oder der dazu komplementären Sequenz hybridisiert,
- c) einer Nukleinsäuresequenz, die eine Homologie von mindestens 50%, bevorzugt mindestens mindestens 75%, noch bevorzugter von mindestens 80% und besonders bevorzugt von über 90% zur Sequenz GO-ADH oder zu der zur Sequenz GO-ADH komplementären Sequenz aufweist, dadurch gekennzeichnet, dass man
- a) eine Nukleinsäuresequenzen gemäß Anspruch 1 einer Mutagenese unterwirft,
- b) die aus a) erhältliche Nukleinsäuresequenz in einen geeigneten Vektor kloniert und dieses in ein geeignetes Expressionsystem transferiert und
- c) die gebildeten Polypeptide mit verbesserter Aktivität und/oder Selektivität und/oder Stabilität detektiert und isoliert.
A method for producing an improved recombinant polypeptide having alcohol dehydrogenase activity starting from nucleic acid sequences selected from the group:
- a) a nucleic acid sequence having the sequence shown in sequence GO-ADH,
- b) a nucleic acid sequence which hybridizes under stringent conditions with the nucleic acid sequence according to sequence GO-ADH or the sequence complementary thereto,
- c) a nucleic acid sequence which has a homology of at least 50%, preferably at least 75%, more preferably at least 80% and particularly preferably more than 90% to the sequence GO-ADH or to the sequence complementary to the sequence GO-ADH marked that one
- a) subjecting a nucleic acid sequence according to claim 1 to a mutagenesis,
- b) the nucleic acid sequence obtainable from a) is cloned into a suitable vector and this is transferred into a suitable expression system and
- c) detecting and isolating the polypeptides formed with improved activity and / or selectivity and / or stability.
Durch die erfindungsgemäße Nukleinsäuresequenz sowie das erfindungsgemäße Verfahren gelingt die Lösung der beschriebenen Aufgaben in überraschend einfacher, dafür aber nicht minder vorteilhafter Art und Weise. Mit den angegebenen Nukleinsäurensequenzen können rekombinante Alkoholdehydrogenasen des Typs aus Gluconobacter oxydans gewonnen werden, die sich in hohen Ausbeuten in Wirtsorganismen, wie z. B. Escherichia coli, exprimieren lassen und welche in einer hohen Aktivität auch sterisch anspruchsvolle Polyole mit hoher Selektivität zu den entsprechenden enantiomerenangereicherten Verbindungen umsetzen können. Auch die Stabilität der so gewonnenen Alkoholdehydrogenasen läßt einen Einsatz im technischen Maßstab unter ökonomischen Gesichtspunkten als besonders vorteilhaft erscheinen. So kann mit den durch die Nukleinsäuren codierten Polypeptiden mit Alkoholdehydrogenase-Aktivität aus racemischem Glyceraldehyd stereoselektiv das D-Enantiomere reduziert werden und damit enantiomerenangereicherter L-Glyceraldehyd gewonnen werden.By the nucleic acid sequence according to the invention as well as the inventive method succeeds Solution of the described tasks in surprising simple, but not less advantageous in nature and Wise. With the indicated nucleic acid sequences can recombinant alcohol dehydrogenases of the type from Gluconobacter oxydans are obtained in high yields in host organisms, such as z. B. Escherichia coli, express and which in a high Activity also sterically demanding polyols with high Selectivity to the corresponding enantiomerically enriched Can implement connections. Also the stability the thus obtained alcohol dehydrogenases leaves a Use on an industrial scale under economic Aspects appear to be particularly advantageous. So can with the polypeptides encoded by the nucleic acids Alcohol dehydrogenase activity from racemic glyceraldehyde stereoselectively reduced the D-enantiomers and thus enantiomerically enriched L-glyceraldehyde are recovered.
Das
erfindungsgemäße Enzym katalysiert bevorzugt folgende
Reaktion (Formelschema 1): ![]()
![]()
Daneben werden auch Ketone reduziert bzw. sekundäre Alkohole oxidiert.Besides Ketones are also reduced or secondary alcohols are oxidized.
Eine detaillierte Analyse der Dehydrogenase-Gene des Bakteriums Gluconobacter oxydans hat gezeigt, dass dieser Organismus NAD(P)-abhängige Enzyme enthält, die überraschenderweise Glycerol nicht zu Dehydroxyaceton, sondern durch Oxidation der endständigen Hydroxylgruppe zu Glyceraldehyd umsetzen. Ähnliche Gensequenzen liegen auch in Pseudomonas aeruginosa oder Hypocrea jecorina vor. Wegen der guten Aktivität des rekombinanten Enzyms aus G. oxydans wird im Folgenden hauptsächlich dieses Enzym beschrieben. Bei der Charakterisierung dieses Enzym hat sich zudem gezeigt, dass die Reduktion von Glyceraldehyd mit diesem Enzym stereoselektiv verläuft. Wird das Racemat von Glyceraldehyd eingesetzt, wird nur das D-Enantiomer reduziert, wobei bei vollständigem Ablauf dieser Reaktion enantiomerenreiner L-Glyceraldehyd gewonnen werden kann (Formelschema 4). Technologisch hat diese Reaktion den Vorteil, dass die Regenerierung des Conzyms NADPH in vorteilhafter Weise beispielsweise mit Glucose und Glucose-Dehydrogenase erfolgen kann.A detailed analysis of the dehydrogenase genes of the bacterium Gluconobacter oxydans has shown that this organism is NAD (P) -dependent Contains enzymes that surprisingly glycerol not to dehydroxyacetone, but by oxidation of the terminal React hydroxyl group to glyceraldehyde. Similar gene sequences are also present in Pseudomonas aeruginosa or Hypocrea jecorina. Because of the good activity of the recombinant enzyme G. oxydans will be mainly this enzyme in the following described. In addition, the characterization of this enzyme has demonstrated that the reduction of glyceraldehyde with this enzyme is stereoselective runs. If the racemate of glyceraldehyde is used, only the D-enantiomer is reduced, with complete Sequence of this reaction enantiomerically pure L-glyceraldehyde won can be (equation 4). Technologically, this reaction has the Advantage that the regeneration of the Conzyms NADPH in an advantageous For example, done with glucose and glucose dehydrogenase can.

In der vorliegenden Erfindung werden neben den Nukleinsäuresequenzen der Sequenz GO-ADH also auch solche aufgezeigt, die unter stringenten Bedingungen mit den erfindungsgemäßen Nukleinsäuresequenz oder deren Komplementär hybridisieren bzw. weitere, die durch geeignete Mutageneseverfahren verbessert wurden. Insbesondere sind solche Nukleinsäuren mit umfasst, welche Allele oder funktionelle Varianten der erfindungsgemäßen Nukleinsäuresequenzen darstellen. Funktionelle Varianten weisen bevorzugt eine Homologie von mindestens 50%, bevorzugt mindestens 66%, mehr bevorzugt von mindestens 70% weiter bevorzugt von mindestens 80% und besonders bevorzugt von über 90% zur Sequenz GO-ADH auf.In The present invention, in addition to the nucleic acid sequences the sequence GO-ADH also shows those that are under stringent Conditions with the nucleic acid sequence according to the invention or their complementary hybridize or others, by suitable mutagenesis methods have been improved. In particular are includes such nucleic acids, which are alleles or functional Variants of the nucleic acid sequences according to the invention represent. Functional variants preferably have a homology of at least 50%, preferably at least 66%, more preferably from at least 70% more preferably at least 80% and especially preferably more than 90% to the sequence GO-ADH.
So weist beispielsweise die Sequenz PA-ADH aus Pseudomonas aeruginosa eine Übereinstimmung mit der Sequenz GO-ADH von 66% auf und codiert ebenfalls für ein Peptid mit entsprechender Alkoholdehydrogenaseaktivität.So has, for example, the sequence PA-ADH from Pseudomonas aeruginosa a match with the sequence GO-ADH of 66% and also encodes a peptide with corresponding Alcohol dehydrogenase activity.
Die
Vorgehensweise zur Verbesserung der erfindungsgemäßen
Nukleinsäuresequenzen durch Mutagenese-Methoden ist dem
Fachmann hinlänglich bekannt. Als Mutagenese-Methoden kommen
alle dem Fachmann für diesen Zweck zur Verfügung
stehenden Methoden in Frage. Insbesondere sind dies die Sättigungsmutagenese,
die Random-Mutagenesis, in vitro-Rekombinations-Methoden sowie Site-Directed-Mutagenesis (
Die erhaltenen neuen Nukleinsäuresequenzen werden nach den nachfolgend angegebenen Methoden in einen Wirtsorgansmus kloniert und die so exprimierten Polypeptide mit geeigneten Screening-Methoden detektiert und anschließend isoliert.The obtained new nucleic acid sequences are according to the following methods are cloned into a host organism and the polypeptides thus expressed detected by suitable screening methods and then isolated.
Die Information aus der Sequenz GO-ADH kann zu Erzeugung von Primern genutzt werden, um direkt allele Formen mittels PCR, z. B. in anderen Gluconobacter species-Stämmen zu identifizieren und zu klonieren. Darüber hinaus können aufgrund der Sequenzinformation Sonden zum Auffinden weiterer natürlich vorkommender funktioneller Varianten der erfindungsgemäßen Nukleinsäuren und damit der entsprechenden codierten Enzymvarianten benutzt werden. Ausgehend von der Sequenz GO-ADH oder von dazu allelen oder natürlich vorkommenden funktionellen Varianten kann z. B. über PCR unter Verwendung einer fehlerhaft arbeitenden DNA-Polymerase eine Bank künstlich erzeugter funktioneller Enzymvarianten erhalten werden.The Information from the sequence GO-ADH can be used to generate primers be used to directly allelic forms by PCR, z. In others To identify and identify Gluconobacter species strains clone. In addition, due to the sequence information Probes to find other naturally occurring functional Variants of the nucleic acids according to the invention and thus the corresponding coded enzyme variants are used. Starting from the sequence GO-ADH or from alleles or natural occurring functional variants may, for. B. via PCR using a defective DNA polymerase Bank of artificially generated functional enzyme variants obtained become.
Der
Ausdruck ”unter stringenten Bedingungen” wird
hierin wie bei Sambrook et al. (
Die erfindungsgemäßen Polypeptide sind in technischen Prozessen aufgrund der schon angedeuteten Regio- und Stereoselektivität und dem erweiterten Substratspektrum sehr gut einzusetzen.The polypeptides of the invention are in technical Processes due to the already indicated regio- and stereoselectivity and the extended substrate spectrum.
Mit umfasst sind damit auch die allelen oder funktionellen Varianten der erfindungsgemäßen Polypeptide. Unter einer funktionellen Variante im Sinne dieser Erfindung wird eine Alkoholdehydrogenase mit einer Aminosäuresequenzhomologie zur Sequenz GO-ADH von wenigstens 75%, bevorzugt wenigstens 77%, mehr bevorzugt von über 85% ganz bevorzugt von über 90% verstanden.With This includes allelic or functional variants the polypeptides of the invention. Under one functional variant in the context of this invention is an alcohol dehydrogenase with an amino acid sequence homology to the sequence GO-ADH of at least 75%, preferably at least 77%, more preferably from above 85% very preferred of over 90% understood.
So zeigt beispielsweise das durch die Sequenz PA-ADH codierte Polypeptid eine Homologie auf Aminosäurebasis zu dem durch die Sequenz GO-ADH codierten Polypeptid von 77%. Das durch PA-ADH codierte Polypeptid zeigt eine im Wesentlichen vergleichbare Alkoholdehydrogenaseaktivität, wie die durch die Sequenz GO-ADH codierten Polypeptide. Durch Mutagenese (s. o.) können Aminosäureaustausche in die erfindungsgemäßen Polypeptide eingefügt werden, wobei jedoch die Aktivität und/oder die Selektivität und/oder die Stabilität des Polypeptids nicht wesentlich reduziert werden darf.So shows, for example, the polypeptide encoded by the sequence PA-ADH an amino acid-based homology to that through the sequence GO-ADH coded polypeptide of 77%. The polypeptide encoded by PA-ADH shows a substantially comparable alcohol dehydrogenase activity, such as the polypeptides encoded by the sequence GO-ADH. By mutagenesis (see above) can amino acid substitutions in the inventive Polypeptides are added, but the activity and / or selectivity and / or stability of the polypeptide may not be significantly reduced.
So können beispielsweise Aminosäuren, die sich nicht im aktiven Zentrum befinden und von denen nicht erwartet wird, dass der Austausch durch eine Aminosäure der gleichen Gruppe zu einer wesentlich veränderten dreidimensionalen Struktur führt, durch eine Aminosäure der gleichen Gruppe ausgetauscht werden. Beispielsweise kann erwartet werden, dass bestimmte Aminosäuren aus der Gruppe mit nicht-polaren Seitenketten (z. B. Alanin durch Valin) untereinander ausgetauscht werden können, ohne das dies einen (wesentlichen) Einfluss auf eine katalytische bzw. biochemische Funktion des Enzyms im Sinne der Erfindung hätte. Auf der Basis seines Fachwissens kann der Fachmann entsprechende Schlussfolgerungen auch für den Austausch anderen Aminosäurearten, zum Beispiel den Ersatz saurer Aminosäuren durch andere saure Aminosäuren erstellen.So For example, amino acids that are not are located in the active center and are not expected to the replacement by an amino acid of the same group to a significantly changed three-dimensional structure leads, by an amino acid of the same group be replaced. For example, it can be expected that certain Amino acids from the group with non-polar side chains (eg alanine by valine) can be interchanged, without this having a (significant) impact on a catalytic or biochemical function of the enzyme in the context of the invention would have. On Based on his expertise, the expert can make appropriate conclusions also for replacing other amino acid types, for example, the replacement of acidic amino acids by others create acidic amino acids.
Die erfindungsgemäßen Polypeptide mit Alkoholdehydrogenaseaktivität können darüber hinaus posttranslationale Modifikationen, wie z. B. Glycosylierungen oder Phosphorylierungen, aufweisen.The polypeptides of the invention having alcohol dehydrogenase activity can also posttranslational modifications, such as As glycosylations or phosphorylations have.
In
einer anderen bevorzugten Ausführungsform enthalten die
erfindungsgemäßen Polypeptide darüber
hinaus mindestens einen heterologen Aminosäureabschnitt,
der diese Polypeptide als Fusionsproteine kennzeichnet. Heterologe
Bestandteile des erfindungsgemäßen Fusionsproteins
können beispielsweise Tags (z. B. His-Tag, Flag-Tag, Maltose-binding
Protein) sein, die bei der Aufreinigung der erfindungsgemäßen
Fusionsproteine eingesetzt werden können. In anderen Ausführungsformen
können die heterologen Bestandteile eine eigene enzymatische
Aktivität aufweisen. In einem derartigen Fall sind die
beiden enzymatischen Komponenten vorzugsweise durch einen Linker
wie einen flexiblen 6–10 Aminosäure langen Glycin
oder Glycin-Serin Linker verbunden, um die Funktionalität
der Komponenten zu gewährleisten. Wie hier verwendet, kann
der Begriff ”heterolog" einerseits bedeuten, dass die Komponenten
des Fusionsproteins natürlicherweise nicht zusammen kovalent
verbunden vorkommen, andererseits, dass die Komponenten aus verschiedenen
Spezies stammen. Fusionsproteine werden üblicherweise durch
rekombinante DNA-Technologie hergestellt (siehe
In einer weiteren Ausgestaltung bezieht sich die vorliegende Erfindung auf rekombinante Expressionssysteme oder rekombinante Plasmide/Vektoren aufweisend eine oder mehrere der erfindungsgemäßen Nukleinsäuren. Unter einem Expressionssystem ist ein System zur rekombinanten Expression der erfindungsgemäßen Nukleinsäuren und damit zur rekombinanten Herstellung der erfindungsgemäßen Polypeptide zu verstehen.In In another embodiment, the present invention relates on recombinant expression systems or recombinant plasmids / vectors comprising one or more of the invention Nucleic acids. Under an expression system is a system for recombinant expression of the invention Nucleic acids and thus for the recombinant production of Understand polypeptides of the invention.
Diese Herstellung kann bevorzugt in mit entsprechenden Nukleinsäuresequenzen oder Vektoren (s. u.) transformierten oder transfizierten (die Begriffe ”Transformation” und ”Transfektion” werden gemäß dieser Erfindung sinngleich verwendet) Mikroorganismen oder anderen Wirten erfolgen. Geeignete Wirtszellen schließen Zellen von einzelligen Mikroorganismen wie bakterielle Zellen ein. Als Mikroorganismen sind diesbezüglich Prokaryonten, wie E. coli, Bacillus subtilis oder Pseudomonas sp. Ferner können Bakterien der Genera/Spezies Lactobacillus, Bacillus, Rhodococus, Campylobacter, Caulobacter, Mycobacterium, Streptomyces, Neisseria, Ralstonia, sowie Agrobacterium für die Expression der erfindungsgemäßen Nukleinsäuresequenzen eingesetzt werden. Entsprechende Stämme sind im Stand der Technik verfügbar und können, zumindest teilweise, über die internationalen Hinterlegungsstellen wie die ATCC oder die DMSZ bezogen werden. Gleichfalls können Eukaryonten, wie Säugerzellen, Insektenzellen oder Pflanzenzellen oder Organismen wie z. B. Hefen wie Hansenula polymorpha, Pichia sp., Saccharomyces cerevisiae, für die rekombinante Herstellung der Polypeptide eingesetzt werden.This preparation may preferably be carried out in microorganisms or other hosts transformed or transfected with appropriate nucleic acid sequences or vectors (see below) (the terms "transformation" and "transfection" are used identically according to this invention). Suitable host cells include cells of unicellular microorganisms such as bacterial cells. As microorganisms in this regard are prokaryotes, such as E. coli, Bacillus subtilis or Pseudomonas sp. Furthermore, bacteria of the genera / species Lactobacillus, Bacillus, Rhodococcus, Campylobacter, Caulobacter, Mycobacterium, Streptomyces, Neisseria, Ralstonia, as well as Agrobacterium for the expression of the nucleic acid according to the invention be used. Corresponding strains are available in the art and can be obtained, at least in part, from international depositaries such as ATCC or DMSZ. Likewise, eukaryotes, such as mammalian cells, insect cells or plant cells or organisms such. B. yeasts such as Hansenula polymorpha, Pichia sp., Saccharomyces cerevisiae, are used for the recombinant production of the polypeptides.
Die
Klonierung wird nach Verfahren durchgeführt, die dem Fachmann
wohlbekannt sind (
Ferner kann die rekombinante Herstellung der erfindungsgemäßen Polypeptide in einem nicht-menschlichen Wirt erfolgen. Geeignete eukaryontische Zellen schließen CHO-Zellen, HeLa-Zellen und andere ein.Further can the recombinant production of the inventive Polypeptides are made in a non-human host. suitable eukaryotic cells include CHO cells, HeLa cells and others.
Die
oben beschriebene Transformation bzw. Transfektion kann nach bekannten
Methoden erfolgen, z. B. durch Calciumphosphat-Copräzipitation,
Lipofektion, Elektroporation, PEG/DMSO-Methode, Partikelbeschuß oder
virale/bakteriophage Infektion. Die erfindungsgemäße
Zelle kann die rekombinante Nukleinsäure in extrachromosomaler
oder chromosomal integrierter Form enthalten. Transfektions- und
Transformations-Protokolle sind dem Fachmann bekannt (
In einer weiteren bevorzugten Ausführungsform ist der Wirt ein transgenes nicht-menschliches Tier. Transgene nicht-menschliche Tiere können nach im Stand der Technik bekannten Verfahren hergestellt werden. Das erfindungsgemäße transgene nicht-menschliche Tier kann bevorzugt verschiedene genetische Konstitutionen aufweisen. Es kann (i) das Gen einer erfindungsgemäßen Nukleinsäuresequenz konstitutiv oder induzierbar überexprimieren, (ii) das endogene Gen einer erfindungsgemäßen Nukleinsäuresequenz in inaktivierter Form enthalten, (iii) das endogene Gen einer erfindungsgemäßen Nukleinsäuresequenz vollständig oder teilweise durch ein mutiertes Gen einer erfindungsgemäßen Nukleinsäuresequenz ersetzt enthalten, (iv) eine konditionale und gewebsspezifische Überexpression oder Unterexpression des Gens einer erfindungsgemäßen Nukleinsäuresequenz aufweisen oder (v) einen konditionalen und gewebsspezifischen Knock-out des Gens einer erfindungsgemäßen Nukleinsäuresequenz aufweisen. Vorzugsweise enthält das transgene Tier zusätzlich ein exogenes Gen einer erfindungsgemäßen Nukleinsäuresequenz unter Kontrolle eines die Überexpression erlaubenden Promotors. Alternativ kann das endogene Gen einer erfindungsgemäßen Nukleinsäuresequenz durch Aktivierung oder/und Austausch des eigenen Promotors überexprimiert werden. Vorzugsweise weist der endogene Promotor des Gens einer erfindungsgemäßen Nukleinsäuresequenz eine genetische Veränderung auf, die zu einer erhöhten Expression des Gens führt. Die genetische Veränderung des endogenen Promotors umfasst dabei sowohl eine Mutation einzelner Basen als auch Deletions- und Insertionsmutationen.In Another preferred embodiment is the host a transgenic non-human animal. Transgenic non-human Animals may be by methods known in the art getting produced. The transgenic invention non-human animal may prefer different genetic constitutions exhibit. It can be (i) the gene of a Overexpress nucleic acid sequence constitutively or inducibly, (ii) the endogenous gene of a gene of the invention Containing nucleic acid sequence in inactivated form, (iii) the endogenous gene of a nucleic acid sequence according to the invention completely or partially by a mutated gene of a Nucleic acid sequence of the invention (iv) conditional and tissue-specific overexpression or underexpression of the gene of a gene according to the invention Have nucleic acid sequence or (v) a conditional and tissue-specific knock-out of the gene of an inventive Having nucleic acid sequence. Preferably contains the transgenic animal additionally an exogenous gene of an inventive Nucleic acid sequence under control of overexpression permitting promoter. Alternatively, the endogenous gene of a Nucleic acid sequence by activation and / or replacement of the own promoter are overexpressed. Preferably the endogenous promoter of the gene of a Nucleic acid sequence a genetic change which leads to an increased expression of the gene. The genetic modification of the endogenous promoter comprises thereby both a mutation of individual bases as well as deletion and Insertion mutations.
In
einer besonders bevorzugten Ausführungsform des erfindungsgemäßen
Wirts ist dieser ein transgener Nager, vorzugsweise eine transgene
Maus, ein transgenes Kaninchen, eine transgene Ratte, oder ein transgenes
Schaf, eine transgene Kuh, eine transgene Ziege oder ein transgenes
Schwein. Mäuse haben gegenüber anderen Tieren
zahlreiche Vorteile. Sie sind leicht zu halten und ihre Physiologie
gilt als Modellsystem für die des Menschen. Die Herstellung
solcher Gen-manipulierten Tiere ist dem Fachmann hinreichend bekannt
und wird nach üblichen Verfahren durchgeführt
(s. h. z. B.
Die
codierenden Nukleinsäuresequenzen können in herkömmliche
Plasmide/Vektoren kloniert und nach Transfektion von Mikroorganismen
oder anderen Wirtszellen mit solchen Vektoren in Zellkultur exprimiert werden.
Als Plasmide oder Vektoren kommen im Prinzip alle dem Fachmann für
diesen Zweck zur Verfügung stehende Ausführungsformen
in Frage. Derartige Plasmide und Vektoren können z. B.
von Studier und Mitarbeiter (
Plasmide,
mit denen das in dieser Erfindung beschrieben Genkonstrukt in bevorzugter
Weise in den Wirtsorganismus kloniert werden kann, sind: pUC18 (Roche
Biochemicals), pKK-177-3H (Roche Biochemicals), pBTac2 (Roche Biochemicals),
pKK223-3 (Amersham Pharmacia Biotech), pKK-233-3 (Stratagene) oder pET
(Novagen). Geeignete Vektoren sind z. B. auch pET-21a(+) für
E. coli, aber auch andere Expressionsvektoren für prokaryontische
Einzeller sowie Vektoren für Eukaryoten, wie z. B. Hefen
und Insekten- oder Säugerzellen, können verwendet
werden. Als geeignete Vektoren für Hefen haben sich z.
B. der pREP-Vektor oder der pINT-Vektor erwiesen. Für die
Expression in Insektenzellen sind z. B. Baculovirus-Vektoren wie
in
Die
Vektoren können neben den üblichen Markern, wie
z. B. Antibiotika-Resistenzgenen, weitere funktionelle Nukleotidsequenzen
zur Regulation, insbesondere zur Repression oder Induktion der Expression
des ADH-Gens und/oder eines Reportergens enthalten. Als Promotoren
werden bevorzugt regulierbare schwache Promotoren, wie z. B. der
rha-Promotor oder der nmt1–Promotor, oder regulierbare
starke Promotoren, wie z. B. der lac-, ara-, lambda-, pL-, T7- oder
T3-Promotor, benutzt. Die codierenden DNA-Fragmente müssen
in den Vektoren von einem Promotor aus transkribierbar sein. Weitere
bewährte Promotoren sind z. B. der Baculovirus-Polyhedrin-Promotor
für die Expression in Insektenzellen (s. z. B.
Die erfindungsgemäßen Expressionsvektoren können weitere funktionale Sequenzbereiche, wie z. B. einen Replikationsstartpunkt, Operatoren, oder Terminationssignale enthalten.The Expression vectors according to the invention can additional functional sequence regions, such. B. an origin of replication, Operators, or contain termination signals.
In einer weiteren Ausgestaltung bezieht sich die vorliegende Erfindung auf Teilsequenzen der erfindungsgemäßen Nukleinsäuresequenzen, wobei diese Teilsequenzen, bevorzugt aus mindestens 5 oder 10, bevorzugt 50, mehr bevorzugt 100, ganz bevorzugt 150 aufeinanderfolgenden Nukleotiden, besonders bevorzugt aus mindestens 300 aufeinanderfolgenden Nukleotiden der erfindungsgemäßen Nukleinsäuren bestehen. Insbesondere sind dies Primer zur Herstellung der erfindungsgemäßen Nukleinsäuresequenzen mittels PCR oder LCR oder Sonden zur Gewinnung der erfindungsgemäßen Nukleinsäuresequenzen. Die Primer sind abgeleitet aus dem 3'- bzw. 5'-Ende der erfindungsgemäßen Nukleinsäuresequenzen. Bevorzugt weisen sie zusätzlich gängige Schnittstellen, wie z. B. NdeI- am 5'-Ende sowie am 3'-Ende eine BamHI-Schnittstelle, auf.In In another embodiment, the present invention relates to partial sequences of the nucleic acid sequences according to the invention, these subsequences, preferably from at least 5 or 10, are preferred 50, more preferably 100, most preferably 150 consecutive Nucleotides, more preferably from at least 300 consecutive Nucleotides of the nucleic acids according to the invention consist. In particular, these are primers for the preparation of the invention Nucleic acid sequences by PCR or LCR or probes for obtaining the nucleic acid sequences according to the invention. The primers are derived from the 3'- or 5'-end of the invention Nucleic acid sequences. Preferably, they additionally have common Interfaces, such. B. NdeI at the 5 'end and at the 3' end one BamHI interface, on.
In einer weiteren Ausgestaltung bezieht sich die vorliegende Erfindung auf ein Verfahren zur Herstellung von verbesserten rec-Polypeptiden (rekombinante Polypeptide) mit Alkoholdehydrogenaseaktivität ausgehend von erfindungsgemäßen Nukleinsäuresequenzen, wobei man
- a) die Nukleinsäuresequenzen einer Mutagenese unterwirft,
- b) die aus a) erhältlichen Nukleinsäuresequenzen in einen geeigneten Vektor kloniert und diesen in ein geeignetes Expressionsystem transferiert und
- c) die gebildeten Polypeptide mit verbesserter Aktivität und/oder Selektivität und/oder Stabilität detektiert und isoliert.
- a) subjecting the nucleic acid sequences to mutagenesis,
- b) cloning the nucleic acid sequences obtainable from a) into a suitable vector and transferring it into a suitable expression system, and
- c) detecting and isolating the polypeptides formed with improved activity and / or selectivity and / or stability.
Ebenfalls einen Gegenstand der Erfindung bilden rec-Polypeptide oder diese codierende Nukleinsäuresequenzen, welche nach einem wie eben beschriebenen Verfahren erhältlich sind.Also an object of the invention are rec polypeptides or these encoding nucleic acid sequences, which according to a just described methods are available.
Die Herstellung der zur Erzeugung der verbesserten rec-Polypeptide benötigten Nukleinsäuresequenzen und deren Expression in Wirten wird im weiteren Verlauf der Beschreibung angesprochen und gilt hier entsprechend.The preparation of the required for the production of improved rec-polypeptides nucleic acid sequences and their expression in hosts will be addressed in the further course of the description and applies here ent speaking.
Ebenfalls Gegenstand der Erfindung sind Mutanten der Alkoholdehydrogenase mit geänderter Coenzym-Spezifität, insbesondere solche Mutanten, die NAD an Stelle von NADP akzeptieren.Also The invention relates to mutants of alcohol dehydrogenase with altered coenzyme specificity, in particular such mutants accepting NAD instead of NADP.
In einer nächsten Ausgestaltung richtet sich die vorliegende Erfindung auf die Verwendung der erfindungsgemäßen (rec-)Polypeptide zur Herstellung von enantiomerenangereicherten Alkoholen, Hydroxyketonen oder Hydroxyaldehyden. Die Umsetzung entsprechender Substrate zu enantiomerenangereicherten Produkten mit Hilfe von Alkoholdehydrogenasen ist dem Fachmann grundsätzlich bekannt (siehe oben angegebene Literaturstellen).In In a next embodiment, the present invention is directed Invention on the use of the invention (rec) polypeptides for the preparation of enantiomerically enriched Alcohols, hydroxyketones or hydroxyaldehydes. The implementation of appropriate Substrates to enantiomerically enriched products with the help of Alcohol dehydrogenases is known in principle to the person skilled in the art (see above references).
Beispiele
für enantiomerenangereicherte Verbindungen, die aus den
entsprechenden Vorstufen hergestellt werden können, sind
dem Fachmann ebenfalls geläufig. Sie lassen sich an Hand
folgender allgemeiner Reaktionsgleichung erläutern: ![]()
(C1-C20)-Alkyl, (C1-C8)-Alkoxy, HO-(C1-C8)-Alkyl, (C2-C8)-Alkoxyalkyl,
(C1-C8)-Alkoxycarbonyl,
(C6-C18)-Aryl, (C7-C19)-Aralkyl, (C3-C18)-Heteroaryl,
(C4-C19)-Heteroaralkyl,
(C1-C8)-Alkyl-(C6-C18)-Aryl, (C1-C8)-Alkyl-(C3-C18)-Heteroaryl,
(C3-C8)-Cycloalkyl,
(C1-C8)-Alkyl-(C3-C8)-Cycloalkyl,
(C3-C8)-Cycloalkyl-(C1-C8)-Alkyl, oder
R1 und R2 bilden eine
(C3-C5)-Alkylenbrücke.Examples of enantiomerically enriched compounds which can be prepared from the corresponding precursors are also familiar to the person skilled in the art. They can be explained by the following general equation: ![]()
(C 1 -C 20 ) -alkyl, (C 1 -C 8 ) -alkoxy, HO- (C 1 -C 8 ) -alkyl, (C 2 -C 8 ) -alkoxyalkyl,
(C 1 -C 8 ) -alkoxycarbonyl, (C 6 -C 18 ) -aryl, (C 7 -C 19 ) -aralkyl, (C 3 -C 18 ) -heteroaryl,
(C 4 -C 19 ) heteroaralkyl, (C 1 -C 8 ) -alkyl (C 6 -C 18 ) -aryl, (C 1 -C 8 ) -alkyl (C 3 -C 18 ) -heteroaryl,
(C 3 -C 8 ) -cycloalkyl, (C 1 -C 8 ) -alkyl (C 3 -C 8 ) -cycloalkyl, (C 3 -C 8 ) -cycloalkyl (C 1 -C 8 ) -alkyl, or R 1 and R 2 form a (C 3 -C 5 ) -alkylene bridge.
Besonders bevorzugte Substrate für die erfindungsgemäßen Alkohol-Dehydrogenasen sind R2 = OH, NH2, SH oder andere Heteroatom-haltige Gruppen. Glyceraldehyd ist eine bevorzugte Verbindung. Weitere Substrate sind ebenfalls Ketoesterverbindungen, insbesondere α-, β-, γ-Ketoesterverbindungen.Particularly preferred substrates for the alcohol dehydrogenases according to the invention are R 2 = OH, NH 2 , SH or other heteroatom-containing groups. Glyceraldehyde is a preferred compound. Further substrates are also ketoester compounds, in particular α-, β-, γ-keto ester compounds.
Eine weitere Ausgestaltung der Erfindung betrifft die Verwendung der erfindungsgemäßen Nukleinsäuresequenzen zur Herstellung von Ganzzellkatalysatoren bzw. die Verwendung der erfindungsgemäßen Nukleinsäuresequenzen zur Mutagenese.A Another embodiment of the invention relates to the use of Nucleic acid sequences of the invention for the preparation of whole-cell catalysts or the use of the Nucleic acid sequences of the invention for mutagenesis.
Ebenfalls
Gegenstand der Erfindung ist ein Ganzzellkatalysator, aufweisend
ein kloniertes Gen codierend für ein erfindungsgemäßes
Polypeptid mit Alkoholdehydrogenase-Aktivität und ein kloniertes
Gen für ein Enzym, das zur Regenerierung von NADPH oder – bei
Vorliegen von NAD-abhängigen Mutanten – NADH geeignet
ist, insbesondere eine Formiat-Dehydrogenase, eine Glucose-Dehydrogenase
oder ein NADP- oder NAD-regenerierendes Enzym wie die NAD(P)H-Oxidase,
Lactat-Dehydrogenase oder Glutamat-Dehydrogenase. Der Vorteil eines
Ganzzellkatalysators ist die gleichzeitige Expression beider Polypeptidsysteme
(Alkohol-Dehydrogenase und ein Enzym zur Coenzym-Regenerierung),
womit nur noch ein rec-Organismus für die Reaktion angezogen
werden muss. Um die Expression der Polypeptide im Hinblick auf ihre Umsetzungsgeschwindigkeiten
abzustimmen, können die entsprechend codierenden Nukleinsäuresequenzen
auf unterschiedlichen Plasmiden mit unterschiedlichen Kopienzahlen
untergebracht werden und/oder unterschiedlich starke Promotoren
für eine unterschiedlich starke Expression der Nukleinsäuresequenzen
verwendet werden. Bei derart abgestimmten Enzymsystemen tritt vorteilhafterweise
eine Akkumulation einer ggf. inhibierend wirkenden Zwischenverbindung
nicht auf und die betrachtete Reaktion kann in einer optimalen Gesamtgeschwindigkeit
ablaufen. Dies ist dem Fachmann jedoch hinlänglich bekannt
(
Die
erfindungsgemäßen Nukleinsäuresequenzen
lassen sich also vorzugsweise zur Herstellung von rec-Polypeptiden
einsetzen. Durch rekombinante Techniken, die dem Fachmann hinlänglich
bekannt sind, gelangt man zu Organismen, welche in der Lage sind,
das betrachtete Polypeptid in für einen technischen Prozess
ausreichender Menge zur Verfügung zu stellen. Die Herstellung
der erfindungsgemäßen rec-Polypeptide erfolgt
nach dem Fachmann bekannten gentechnologischen Verfahren (
Darüber hinaus betrifft die vorliegende Erfindung in einem nächsten Aspekt ein gekoppeltes enzymatisches Reaktionssystem aufweisend eine cofaktorabhängige enzymatische Transformation einer Vorstufe (Substrat) mit einem erfindungsgemäßen Polypeptid und eine enzymatische Regeneration des Cofaktors (NAD(P)H). Die enzymatische Regeneration des Cofaktors sollte vorteilhafterweise mit den oben im Zusammenhang mit dem Ganzellkatalysator besprochenen Enzymen vonstatten gehen, sie kann jedoch auch elektrochemisch oder durch chemische Oxidation ohne den Einsatz von Enzymen durchgeführt werden. Als Reaktionssystem kann jedes Gefäß verstanden werden, in dem die erfindungsgemäße Reaktion durchgeführt werden kann, also Reaktoren jeder Art (Schlaufenreaktor, Rührkessel, Enzymmembranreaktor etc.), oder Diagnosekits in jedweder Form. Bei Verwendung einer Formiatdehydrogenase erfolgt die Cofaktor-Regenerierung unter Einsatz von Ameisensäure bzw. deren Salze als Reduktionsmittel. Alternativ können aber auch andere enzymatische oder substratbasierende cofaktoregenerierenden Systeme (z. B. NADH-Oxidase, Glucosedehydrogenase) eingesetzt werden.About that In addition, the present invention relates in a next Aspect having a coupled enzymatic reaction system a cofactor dependent enzymatic transformation of a Precursor (substrate) with an inventive Polypeptide and an enzymatic regeneration of the cofactor (NAD (P) H). The enzymatic regeneration of the cofactor should advantageously with those discussed above in the context of the whole cell catalyst Enzymes, but it can also be electrochemical or performed by chemical oxidation without the use of enzymes become. As a reaction system, each vessel can be understood be performed in which the reaction of the invention reactors of any kind (loop reactor, stirred tank, Enzyme membrane reactor, etc.), or diagnostic kits in any form. at Use of a formate dehydrogenase is the cofactor regeneration using formic acid or salts thereof as reducing agent. Alternatively, however, other enzymatic or substrate-based cofactor-generating systems (eg NADH oxidase, glucose dehydrogenase) be used.
Eine abschließende Verwendung der erfindungsgemäßen (rec-)Polypeptide mit Alkoholdehydrogenase-Aktivität bzw. des erfindungsgemäßen Ganzellkatalysators betrifft deren Einsatz in einem Verfahren zur stereoselektiven Reduktion von Aldehyden. Für die Umsetzung der Aldehyde eignen sich wässrige Lösungsmittel, die entsprechend gepuffert sind.A final use of the invention (rec) polypeptides with alcohol dehydrogenase activity or the whole-cell catalyst according to the invention their use in a process for stereoselective reduction of aldehydes. For the implementation of aldehydes are suitable aqueous solvents buffered accordingly are.
Bevorzugt
wird die Reduktion bei einer Temperatur zwischen 10 und 80°C,
besonders bevorzugt zwischen 20 und 50°C ausgeführt
(siehe dazu
Für
die Anwendung kann das betrachtete Polypeptid in nativer Form als
homogen aufgereinigte Verbindungen oder als rekombinant hergestelltes
Enzym verwendet werden. Weiterhin kann das (rec-)Polypeptid auch
als Bestandteil eines intakten Gastorganismus eingesetzt werden
oder in Verbindung mit der aufgeschlossenen und beliebig hoch aufgereinigten
Zellmasse des Wirtsorganismus. Möglich ist ebenfalls die
Verwendung der Enzyme in immobilisierter Form (
Für die Umsetzung von Ketonen mit den erfindungsgemäßen Polypeptiden geht man vorzugsweise wie folgt vor. Die Polypeptide werden in der gewünschte Form (frei, immobilisiert, in Wirtsorganismen oder als Ganzzellkatalysator) in die wässrige Lösung gegeben. Unter Einhaltung der optimalen Temperatur- bzw. des optimalen pH-Wertbereiches wird das Keton, ggf. der Cofaktor und ggf. die den Cofaktor regenerierenden Mittel zu dieser Mischung gegeben. Nach der erfolgten Umsetzung kann der gewonnene Alkohol nach dem Fachmann bekannten Verfahren (Kristallisation, Extraktion, Chromatographie) aus der Reaktionsmischung isoliert werden.The reaction of ketones with the polypeptides according to the invention is preferably carried out as follows. The polypeptides are added in the desired form (free, immobilized, in host organisms or as a whole cell catalyst) to the aqueous solution. While maintaining the optimum temperature or the optimum pH range, the ketone, if appropriate the cofactor and, if appropriate, the cofactor regenerating agent are added to this mixture. After the reaction has taken place, the alcohol obtained can be isolated from the reaction mixture by methods known to those skilled in the art (crystallization, extraction, chromatography).
Folgendes Schema 5 zeigt die Reaktionsgleichung der Umsetzung von racemischem Glyceraldehyd zu L-Glyceraldehyd durch ADH-katalysierte Reduktion.following Scheme 5 shows the reaction equation of the reaction of racemic Glyceraldehyde to L-glyceraldehyde by ADH-catalyzed reduction.
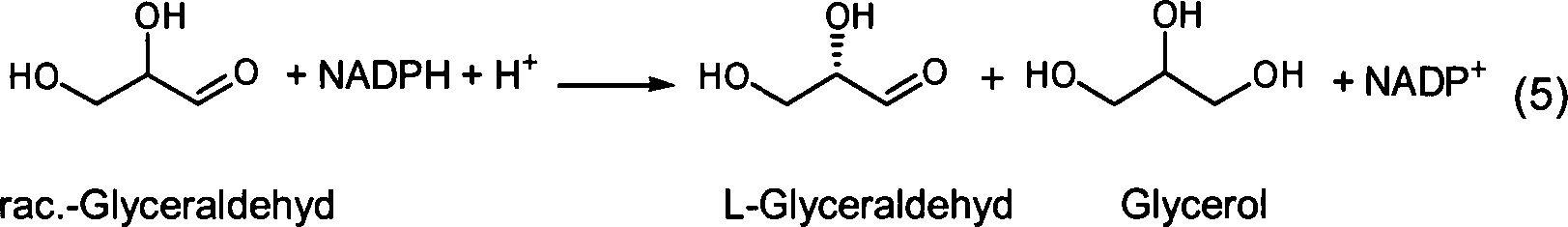
Es konnte überraschend gezeigt werden, dass die erfindungsgemäßen exprimierbaren Proteine eine enzymatische Alkohol-Dehydrogenase-Aktivität besitzen. Insbesondere aliphatische Hydroxyaldehyde oder Aldehyde mit Polyol-Struktur werden von der erfindungsgemäßen Alkoholdehydrogenase reduziert (siehe experimenteller Teil).It could surprisingly be shown that the inventive expressible proteins have an enzymatic alcohol dehydrogenase activity have. In particular, aliphatic hydroxyaldehydes or aldehydes with polyol structure are of the inventive Alcohol dehydrogenase reduced (see experimental part).
Weiterhin zeichnet sich die erfindungsgemäße Alkoholdehydrogenase durch ihre ausgezeichnete Regioselektivität aus. So wird Glyceraldehyd mit guter Aktivität reduziert, während die strukturanaloge Verbindung Dihydroxyaceton praktisch nicht umgesetzt wird. Des Weiteren zeichnet sich die beanspruchte Alkoholdehydrogenase durch ihre ausgezeichnete Stereoselektivität aus. So wird D-Glyceraldehyd mit sehr guter Aktivität umgesetzt, das L-Enantiomere dagegen nicht. Diese Stereoselektivität bleibt auch erhalten, wenn als Substrat die racemische Mischung eingesetzt wird. Das Enzym reduziert aus diesem Gemisch nur die D-Komponente. Diese Umsetzung kann vollständig ablaufen, so dass als Produkt der vollständigen Reduktion hoch enantiomerenangereichteres L-Glyceraldehyd in der Reaktionslösung verbleibt, es können damit ee-Werte > 99% erreicht werden.Farther the alcohol dehydrogenase according to the invention is characterized by their excellent regioselectivity. So will Glyceraldehyde reduced with good activity while the structurally analogous compound dihydroxyacetone practically unreacted becomes. Furthermore, the claimed alcohol dehydrogenase is distinguished by their excellent stereoselectivity. So will D-glyceraldehyde reacted with very good activity, the L enantiomers are not. This stereoselectivity remains also obtained when used as substrate the racemic mixture becomes. The enzyme reduces only the D component from this mixture. This implementation can be completed, so that as Product of complete reduction highly enantiomer-enriched L-glyceraldehyde remains in the reaction solution, it can thus ee values> 99% be achieved.
Unter optisch angereicherten (enantiomerenangereicherten, enantiomer angereicherten) Verbindungen wird im Rahmen der Erfindung das Vorliegen einer optischen Antipode im Gemisch mit der anderen in > 50 mol-% verstanden.Under optically enriched (enantiomerically enriched, enantiomerically enriched) Compounds in the context of the invention, the presence of an optical Antipode in mixture with the other in> 50 mol% understood.
Unter dem Begriff Nukleinsäuresequenzen werden alle Arten von einzelsträngiger oder doppelsträngiger DNA als auch RNA oder Gemische derselben subsumiert. Die erfindungsgemäße Nukleinsäuresequenz kann demnach ein DNA- oder ein RNA-Molekül sein. Bevorzugt ist, dass das Nukleinsäuremolekül ein cDNA- oder ein mRNA-Molekül ist. Erfindungsgemäß kann das DNA-Molekül desweiteren ein genomisches DNA-Molekül sein.Under The term nucleic acid sequences are used to describe all types of single-stranded or double-stranded DNA as also subsumes RNA or mixtures thereof. The inventive Nucleic acid sequence can therefore be a DNA or an RNA molecule be. It is preferred that the nucleic acid molecule is a cDNA or an mRNA molecule. According to the invention the DNA molecule furthermore a genomic DNA molecule be.
Der Begriff ”komplementär” bedeutet erfindungsgemäß, dass sich die Komplementarität über den gesamten Bereich des erfindungsgemäßen Nukleinsäuremoleküls ohne Lücken erstreckt. Mit anderen Worten ist es erfindungsgemäß bevorzugt, dass die Komplementarität sich zu 100% über den gesamten Bereich der erfindungsgemäßen Sequenz, d. h. vom dargestellten 5'-Ende bis zum dargestellten 3'-Ende erstreckt.Of the Term "complementary" means according to the invention, that complementarity over the whole Area of the nucleic acid molecule according to the invention extends without gaps. In other words, it is preferred according to the invention that the complementarity is 100% above the entire region of the sequence according to the invention, d. H. extends from the illustrated 5 'end to the illustrated 3' end.
Die Verbesserung der Aktivität und/oder Selektivität und/oder Stabilität bedeutet erfindungsgemäß, dass die Polypeptide aktiver und/oder selektiver bzw. unter den verwendeten Reaktionsbedingungen stabiler sind. Während die Aktivität und die Stabilität der Enzyme für die technische Anwendung naturgemäß möglichst hoch sein sollte, ist in Bezug auf die Selektivität dann von einer Verbesserung die Rede, wenn entweder die Substratselektivität abnimmt, die Enantioselektivität der Enzyme jedoch gesteigert ist.The Improvement of activity and / or selectivity and / or stability means according to the invention that the polypeptides are more active and / or more selective or among those used Reaction conditions are more stable. While the activity and the stability of the enzymes for the technical Naturally, the application should be as high as possible should be in terms of selectivity then one Improve speech if either the substrate selectivity decreases, but the enantioselectivity of the enzymes increased is.
Der Ausdruck ”Homologie” (oder Identität) wie hierin verwendet, kann durch die Gleichung H (%) = [1 – V/X] × 100 definiert werden, worin H Homologie bedeutet, X die Gesamtzahl an Nukleobasen/Aminosäuren der Vergleichssequenz ist und V die Anzahl an unterschiedlichen Nukleobasen/Aminosäuren der zu betrachtenden Sequenz bezogen auf die Vergleichssequenz ist. Auf jeden Fall sind mit dem Begriff Nukleinsäuresequenzen, welche für Polypeptide codieren, alle Sequenzen umfasst, die nach Maßgabe der Degeneration des genetischen Codes möglich erscheinen.Of the Expression "homology" (or identity) As used herein, by the equation H (%) = [1-V / X] × 100 where H is homology, X is the total number Nucleobases / amino acids of the comparison sequence is and V the number of different nucleobases / amino acids the sequence to be considered is based on the comparison sequence. In any case, with the term nucleic acid sequences, which encode polypeptides comprising all sequences, according to the degeneration of the genetic code appear possible.
Als (C1-C8)-Alkylreste sind anzusehen Methyl, Ethyl, n-Propyl, Isopropyl, n-Butyl, Isobutyl, sec-Butyl, tert-Butyl, Pentyl, Hexyl, Heptyl oder Octyl samt aller ihrer Bindungsisomeren. Ein (C1-C20)-Alkylrest ist im Rahmen der erfindungsgemäßen Definition ein entsprechender Rest mit 1 bis max. 20 C-Atomen. Ein (C3-C20)-Alkylrest ist im Rahmen der erfindungsgemäßen Definition ein entsprechender Rest mit 3 bis max. 20 C-Atomen. Der Rest (C1-C8)-Alkoxy entspricht dem Rest (C1-C8)-Alkyl mit der Maßgabe, dass dieser über ein Sauerstoffatom gebunden ist. Als (C2-C8)-Alkoxyalkyl sind Reste gemeint, bei denen die Alkylkette durch mindestens eine Sauerstoffunktion unterbrochen ist, wobei nicht zwei Sauerstoffatome miteinander verbunden sein können. Die Anzahl der Kohlenstoffatome gibt die Gesamtzahl der im Rest enthaltenen Kohlenstoffatome an. Eine (C3-C5)-Alkylenbrücke ist eine Kohlenstoffkette mit drei bis fünf C-Atomen, wobei diese Kette über zwei verschiedene C-Atome an das betrachtete Molekül gebunden ist.Suitable (C 1 -C 8 ) -alkyl radicals are methyl, ethyl, n-propyl, isopropyl, n-butyl, isobutyl, sec-butyl, tert-butyl, pentyl, hexyl, heptyl or octyl together with all their bonding isomers. A (C 1 -C 20 ) -alkyl radical is in the Rah men of the definition according to the invention a corresponding radical with 1 to max. 20 C atoms. A (C 3 -C 20 ) -alkyl radical is within the scope of the definition according to the invention a corresponding radical having 3 to max. 20 C atoms. The radical (C 1 -C 8 ) -alkoxy corresponds to the radical (C 1 -C 8 ) -alkyl with the proviso that it is bonded via an oxygen atom. By (C 2 -C 8 ) alkoxyalkyl are meant residues in which the alkyl chain is interrupted by at least one oxygen function, whereby two oxygen atoms can not be linked together. The number of carbon atoms indicates the total number of carbon atoms contained in the radical. A (C 3 -C 5 ) -alkylene bridge is a carbon chain with three to five carbon atoms, which chain is bound to the molecule under consideration via two different carbon atoms.
Die eben beschriebenen Reste können einfach oder mehrfach mit Halogenen und/oder (C1-C8)-Alkoxycarbonyl und/oder N-, O-, P-, S-, Si-atomhaltigen Resten substituiert sein. Dies sind insbesondere Alkylreste der oben genannten Art, welche eines oder mehrere dieser Heteroatome in ihrer Kette aufweisen bzw. welche über eines dieser Heteroatome an das Molekül gebunden sind.The radicals just described may be monosubstituted or polysubstituted by halogens and / or (C 1 -C 8 ) alkoxycarbonyl and / or N, O, P, S, Si atom-containing radicals. These are in particular alkyl radicals of the abovementioned type which have one or more of these heteroatoms in their chain or which are bonded to the molecule via one of these heteroatoms.
Unter (C3-C8)-Cycloalkyl versteht man Cyclopropyl, Cyclobutyl, Cyclopentyl, Cyclohexyl bzw. Cycloheptylreste etc. Diese können mit einem oder mehreren Halogenen und/oder N-, O-, P-, S-, Si-atomhaltige Reste substituiert sein und/oder N-, O-, P-, S-Atome im Ring aufweisen, wie z. B. 1-, 2-, 3-, 4-Piperidyl, 1-, 2-, 3-Pyrrolidinyl, 2-, 3-Tetrahydrofuryl, 2-, 3-, 4-Morpholinyl.By (C 3 -C 8 ) -cycloalkyl is meant cyclopropyl, cyclobutyl, cyclopentyl, cyclohexyl or cycloheptyl radicals, etc. These may be with one or more halogens and / or N, O, P, S, Si atom-containing radicals be substituted and / or have N, O, P, S atoms in the ring, such as. 1-, 2-, 3-, 4-piperidyl, 1-, 2-, 3-pyrrolidinyl, 2-, 3-tetrahydrofuryl, 2-, 3-, 4-morpholinyl.
Ein (C3-C8)-Cycloalkyl-(C1-C8)-Alkylrest bezeichnet einen wie oben dargestellten Cycloalkylrest, welcher über einen wie oben angegebenen Alkylrest an das Molekül gebunden ist.A (C 3 -C 8 ) -cycloalkyl (C 1 -C 8 ) -alkyl radical denotes a cycloalkyl radical as described above which is bonded to the molecule via an alkyl radical as indicated above.
(C1-C8)-Alkoxycarbonyl bedeutet im Rahmen der Erfindung einen wie oben definierten Alkylrest mit max. 8 C-Atomen, welcher über eine O(C=O)-Funktion gebunden ist.(C 1 -C 8 ) -alkoxycarbonyl in the context of the invention means an alkyl radical as defined above with max. 8 C atoms, which is bound via an O (C = O) function.
(C1-C8)-Acyloxy bedeutet im Rahmen der Erfindung einen wie oben definierten Alkylrest mit max. 8 C-Atomen, welcher über eine (C=O)O-Funktion gebunden ist.(C 1 -C 8 ) -Acyloxy in the context of the invention means an alkyl radical as defined above with max. 8 C atoms, which is bound via a (C = O) O function.
(C1-C8)-Acyl bedeutet im Rahmen der Erfindung einen wie oben definierten Alkylrest mit max. 8 C-Atomen, welcher über eine (C=O)-Funktion gebunden ist.(C 1 -C 8 ) acyl means in the context of the invention an alkyl radical as defined above with max. 8 C atoms, which is bound via a (C = O) function.
Unter einem (C6-C18)-Arylrest wird ein aromatischer Rest mit 6 bis 18 C-Atomen verstanden. Insbesondere zählen hierzu Verbindungen wie Phenyl-, Naphthyl-, Anthryl-, Phenanthryl-, Biphenylreste oder an das betreffende Molekül annelierte Systeme der vorbeschriebenen Art, wie z. B. Indenylsysteme, welche ggf. mit ((C1-C8)-Alkyl, (C1-C8)-Alkoxy, (C2-C8)-Alkoxyalkyl, NH(C1-C8)-Alkyl, N((C1-C8)-Alkyl)2, OH, O(C1-C8)-Alkyl, NO2, NH(C1-C8)-Acyl, N((C1-C8)-Acyl)2, F, Cl, CF3, (C1-C8)-Acyl, (C1-C8)-Acyloxy, (C7-C19)-Aralkylrest, (C4-C19)-Heteroaralkyl substituiert sein können.By a (C 6 -C 18 ) -aryl radical is meant an aromatic radical having 6 to 18 C atoms. In particular, these include compounds such as phenyl, naphthyl, anthryl, phenanthryl, biphenyl or to the molecule in question annelierte systems of the type described, such as. Indenyl systems which optionally have (C 1 -C 8 ) -alkyl, (C 1 -C 8 ) -alkoxy, (C 2 -C 8 ) -alkoxyalkyl, NH (C 1 -C 8 ) -alkyl, N ((C 1 -C 8 ) -alkyl) 2 , OH, O (C 1 -C 8 ) -alkyl, NO 2 , NH (C 1 -C 8 ) -acyl, N ((C 1 -C 8 ) Acyl) 2 , F, Cl, CF 3 , (C 1 -C 8 ) acyl, (C 1 -C 8 ) acyloxy, (C 7 -C 19 ) aralkyl, (C 4 -C 19 ) heteroaralkyl may be substituted.
Ein (C7-C19)-Aralkylrest ist ein über einen (C1-C8)-Alkylrest an das Molekül gebundener (C6-C18)-Arylrest.A (C 7 -C 19 ) -aralkyl radical is a (C 6 -C 18 ) -aryl radical bonded to the molecule via a (C 1 -C 8 ) -alkyl radical.
Ein (C3-C18)-Heteroarylrest bezeichnet im Rahmen der Erfindung ein fünf-, sechs- oder siebengliedriges aromatisches Ringsystem aus 3 bis 18 C-Atomen, welches Heteroatome wie z. B. Stickstoff, Sauerstoff oder Schwefel im Ring aufweist. Als solche Heteroaromaten werden insbesondere Reste angesehen, wie 1-, 2-, 3-Furyl, wie 1-, 2-, 3-Pyrrolyl, 1-, 2-, 3-Thienyl, 2-, 3-, 4-Pyridyl, 2-, 3-, 4-, 5-, 6-, 7-Indolyl, 3-, 4-, 5-Pyrazolyl, 2-, 4-, 5-Imidazolyl, Acridinyl, Chinolinyl, Phenanthridinyl, 2-, 4-, 5-, 6-Pyrimidinyl. Die Heteroaromaten können in gleicher Weise wie die oben genannten (C6-C18)-Arylreste substituiert sein.In the context of the invention, a (C 3 -C 18 ) -heteroaryl radical denotes a five-, six- or seven-membered aromatic ring system comprising 3 to 18 C atoms, which heteroatoms such. B. nitrogen, oxygen or sulfur in the ring. As such heteroaromatics, especially radicals are considered, such as 1-, 2-, 3-furyl, such as 1-, 2-, 3-pyrrolyl, 1-, 2-, 3-thienyl, 2-, 3-, 4-pyridyl, 2-, 3-, 4-, 5-, 6-, 7-indolyl, 3-, 4-, 5-pyrazolyl, 2-, 4-, 5-imidazolyl, acridinyl, quinolinyl, phenanthridinyl, 2-, 4- , 5-, 6-pyrimidinyl. The heteroaromatics may be substituted in the same way as the abovementioned (C 6 -C 18 ) aryl radicals.
Unter einem (C4-C19)-Heteroaralkyl wird ein dem (C7-C19)-Aralkylrest entsprechendes heteroaromatisches System verstanden.By (C 4 -C 19 ) heteroaralkyl is meant a heteroaromatic system corresponding to the (C 7 -C 19 ) aralkyl radical.
Als Halogene (Hal) kommen Fluor, Chlor, Brom und Iod in Frage.When Halogens (Hal) are fluorine, chlorine, bromine and iodine in question.
Unter dem Begriff wässriges Lösungsmittel wird Wasser oder ein hauptsächlich aus Wasser bestehendes Lösungsmittelgemisch mit wasserlöslichen organischen Lösungsmitteln wie z. B. Alkoholen, insbesondere Methanol oder Ethanol, oder Ethern, wie THF oder Dioxan, verstandenUnder The term aqueous solvent becomes water or a solvent mixture consisting mainly of water with water-soluble organic solvents such as As alcohols, especially methanol or ethanol, or ethers, like THF or dioxane, understood
Die Gewinnung und biochemische Charakterisierung eines Enzyms, mit dem optisch aktive Verbindungen wie Glyceraldehyd gewonnen werden können, ist am Beispiel der Glycerol-Dehydrogenase aus Gluconobacter oxydans im folgenden beschrieben.The Obtaining and biochemical characterization of an enzyme with which optically active compounds such as glyceraldehyde can be obtained, is the example of glycerol dehydrogenase from Gluconobacter oxydans described below.
Beispiele:Examples:
Beispiel 1: Auffindung, Sequenzierung und Klonierung des Glyceraldehyd-umsetzenden ADH-Gens aus Gluconobacter oxydansExample 1: Detection, Sequencing and cloning the glyceraldehyde-converting ADH gene from Gluconobacter oxydans
Ausgehend von der Proteinsequenz der GlyDH aus Hypocrea jecorina wurde ein in silico Screening nach Alkohol-Dehydrogenase (ADH)-Genen mit dem Genom von G. oxydans durchgeführt. Nach Klonierung und Expression verschiedener ADH-Gene wurden photometrische Aktivitätstests mit enzymhaltigem Rohextrakt durchgeführt. Ein wichtiges Kriterium für die Bewertung der ADHs war die Substratselektivität, d. h. erfindungsgemäß geeignete Enzyme sollten Glyceraldehyd (GA) deutlich besser umsetzen als die strukturanaloge Verbindung Dihydroxyaceton (DHA). Daher wurden alle rekombinanten Enzyme sowohl mit GA als auch mit DHA getestet, die Testansätze enthielten dabei pro 1 ml: 100 mM TEA-Puffer pH 7,0; 0, 24 mM NADH oder NADPH; 10 mM DHA bzw. GA und 10 μl Enzym (Rohzellextrakt). Überraschenderweise konnte bei diesen Tests ein Protein gefunden werden, das Glyceraldehyd mit guter Aktivität umsetzt, während Dihydroxyaceton praktisch nicht akzeptiert wird. Im photometrischen Test wurden gefunden: Glyceraldehyd-Reduktion mit NADPH: 67 U/ml; Glyceraldehyd-Reduktion mit NADH: 0,5 U/ml; Dihydroxyaceton-Reduktion mit NADPH: 1,5 U/ml; Dihydroxyaceton-Reduktion mit NADH: 0 U/ml. Die Ergebnisse zeigen zudem, dass es sich um ein NADPH-abhängiges Enzym handelt, NADH zeigt nur eine vernachläßigbare Aktivität. Da bei dieser Reaktion ein Aldehyd zu einem Alkohol reduziert wird, muss es sich bei dem katalysierenden Enzym um eine Alkohol-Dehydrogenase (ADH) handeln. Abgeleitet aus dem Namen des sie ursprünglich exprimierenden Bakteriums wurde sie GO-ADH genannt.outgoing from the protein sequence of GlyDH from Hypocrea jecorina was one in silico screening for alcohol dehydrogenase (ADH) genes with the Genome performed by G. oxydans. After cloning and Expression of various ADH genes were photometric activity tests carried out with enzyme-containing crude extract. An important Criterion for the evaluation of the ADHs was the substrate selectivity, d. H. According to the invention suitable enzymes should Glyceraldehyde (GA) much better than the structurally analogous compound Dihydroxyacetone (DHA). Therefore, all recombinant enzymes were both tested with GA as well as with DHA containing test approaches per 1 ml: 100 mM TEA buffer pH 7.0; 0, 24 mM NADH or NADPH; 10 mM DHA or GA and 10 μl enzyme (crude cell extract). Surprisingly In these tests, a protein could be found, the glyceraldehyde with good activity, while dihydroxyacetone practically not accepted. The photometric test found: Glyceraldehyde reduction with NADPH: 67 U / ml; Glyceraldehyde-reduction with NADH: 0.5 U / ml; Dihydroxyacetone reduction with NADPH: 1.5 U / ml; Dihydroxyacetone reduction with NADH: 0 U / ml. The results show moreover, that it is an NADPH-dependent enzyme, NADH shows only a negligible activity. Since in this reaction an aldehyde is reduced to an alcohol, it must be the catalysing enzyme to an alcohol dehydrogenase (ADH) act. Derived from the name of her originally it was called GO-ADH.
Beispiel 2: Heterologe Expression von GO-ADHExample 2: Heterologous expression of GO-ADH
Zur Expression der GO-ADH wurden E. coli BL21(DE3)-Zellen mit dem Vektor pGOADH transformiert und in Ampicillin-haltigem LB-Medium kultiviert. Die Zellen wurden bis zu einer optischen Dichte (bei 600 nm) von 0,5 bei 37°C inkubiert und die Expression der GO-ADH bei Erreichen der genannten optischen Dichte mit 0,3 mM IPTG-Lösung induziert. Daraufhin wurde die Zellsuspension für 18 Stunden bei 25°C inkubiert, um die optimale Ausbeute an GO-ADH zu erzielen.to Expression of GO-ADH were E. coli BL21 (DE3) cells with the vector pGOADH transformed and cultured in ampicillin-containing LB medium. The cells were grown to an optical density (at 600 nm) of 0.5 incubated at 37 ° C and the expression of GO-ADH at Achieve the stated optical density with 0.3 mM IPTG solution induced. Thereupon the cell suspension became for 18 hours incubated at 25 ° C to give the optimal yield of GO-ADH to achieve.
Beispiel 3: Untersuchung des Substratspektrums der rekombinanten AlkoholdehydrogenaseExample 3: Investigation of the substrate spectrum recombinant alcohol dehydrogenase
In einem ersten Schritt erfolgt die Herstellung von Rohextrakt, enthaltend die rekombinante Alkoholdehydrogenase aus Gluconobacter oxydans, durch Zellaufschluss des Stamms E. coli BL21(DE3) pGOADH. Dazu werden 52 g des Zellpellets mit 120 ml Tris-HCl-Puffer (pH 7,5; 100 mM) versetzt und darin resuspendiert, so dass eine Biomassenkonzentration von ca. 433 g/L vorliegt. Anschließend wird 1 ml dieser Suspension unter Kühlung für 2 × 2 min mittels Ultraschall aufgeschlossen. Nach Abzentrifugation (14.000 rpm; 10 min) wird ein Überstand erhalten, der anschließend als Enzymlösung (Rohextrakt) für die Aktivitätsbestimmung und präparativen Versuche verwendet wird. Die photometrische Aktivitätsbestimmung kann in oxidativer und reduktiver Richtung erfolgen, für die Reduktion werden eingesetzt: 100 mM TEA-Puffer pH 7; 0, 24 mM NADPH; 10 mM Substrat (Glyceraldehyd oder andere Keto-Verbindungen); 10 μl Enzym (Rohextrakt). Für die Oxidationsreaktion werden eingesetzt: 100 mM Kaliumphosphat pH 9,7; 2 mM NADP; 100 mM Substrat (Glycerol oder andere Alkohole); 30 mM Ammoniumsulfat; 10 μl Enzym (Rohextrakt). Die Reaktion wird in einer 1 cm-Küvette durchgeführt, dazu werden die Komponenten in der Küvette gemischt, die Küvette ins Photometer gestellt und die Datenaufnahme gestartet. Die Enzymlösung wird erst direkt vor Messbeginn zugegeben. Die Aktivität des Enzyms wird durch Änderung der photometrisch bestimmten Konzentration von NADPH in einem bestimmten Zeitintervall bestimmt. Die Messung erfolgt bei einer Temperatur von 30°C für die Reduktion und einer Temperatur von 37°C für die Oxidation, einer Wellenlänge von 340 nm und mit einer Messzeit von 1 min.In a first step is the preparation of crude extract containing the recombinant alcohol dehydrogenase from Gluconobacter oxydans, by cell disruption of the strain E. coli BL21 (DE3) pGOADH. To do this 52 g of the cell pellet with 120 ml Tris-HCl buffer (pH 7.5, 100 mM) and resuspended therein, leaving a biomass concentration of about 433 g / L is present. Subsequently, 1 ml of this Suspension under cooling for 2 × 2 min unlocked by ultrasound. After centrifugation (14,000 rpm; 10 min), a supernatant is obtained, which is subsequently as enzyme solution (crude extract) for activity determination and preparative experiments. The photometric Activity determination can be more oxidative and reductive Direction, for the reduction are used: 100 mM TEA buffer pH 7; 0, 24 mM NADPH; 10 mM substrate (glyceraldehyde or other keto compounds); 10 μl of enzyme (crude extract). For the oxidation reaction are used: 100 mM potassium phosphate pH 9.7; 2mM NADP; 100 mM substrate (glycerol or other alcohols); 30 mM ammonium sulfate; 10 μl of enzyme (crude extract). The reaction is performed in a 1 cm cuvette, to the components in the cuvette are mixed, the cuvette placed in the photometer and the data recording started. The enzyme solution is added just before the measurement begins. The activity of the enzyme is determined by changing the photometrically Concentration of NADPH determined in a given time interval. The measurement is carried out at a temperature of 30 ° C for the reduction and a temperature of 37 ° C for the oxidation, a wavelength of 340 nm and with a Measuring time of 1 min.
Die Umsetzungen können sowohl mit Rohextrakt-Protein als auch mit partiell oder vollständig gereinigtem Enzympräparat durchgeführt werden. Zur Reinigung kann der Rohextrakt mit Anionenaustausch-Chromatographie partiell gereinigt werden (Reinigung an Q-Sepharose FF-Material, äquilibriert mit 0,1 M TEA-Puffer (pH 8,0), Elution mit einen Gradienten von 0–0,6 M NaCl). Eine einfache Methode zur nahezu vollständigen Reinigung geht von einem Enzym aus, das am N-Terminus einen sog. His-Tag (Hexahistidin) trägt. Ein solches modifiziertes Enzym kann in einfacher Weise an eine Nickel-NTA-Säule (Qiagen) gebunden (äquilibriert mit 50 mM TEA-Puffer pH 7) und dann mit einem Imidazol-Gradienten (von 0 auf 500 mM) eluiert werden. Der His-Tag und die nachfolgende Elution ermöglichen eine sehr effiziente Reinigung des Enzyms, man erhält mit diesem Reinigungsschritt ein praktisch homogenes Enzympräparat.The Reactions can be made with both crude extract protein as well with partially or completely purified enzyme preparation be performed. For purification, the crude extract be partially purified with anion exchange chromatography (purification on Q-Sepharose FF material equilibrated with 0.1 M TEA buffer (pH 8.0), eluting with a gradient of 0-0.6 M NaCl). A simple method for almost complete cleaning is based on an enzyme that has a so-called His-tag (hexahistidine) at the N-terminus wearing. Such a modified enzyme can be simpler Manner bound to a nickel-NTA column (Qiagen) (equilibrated with 50 mM TEA buffer pH 7) and then with an imidazole gradient (from 0 to 500 mM). His-tag and the following Elution allow a very efficient cleaning of the Enzyme, you get a practical with this purification step homogeneous enzyme preparation.
Die Ergebnisse sind in U/mg Enzymprotein anbei in Tabelle 1 (Oxidation) und Tab. 2 (Reduktion) dargestellt. Neben den in der Tab. 2 aufgeführten Aldehyden und Ketonen wird auch der geschützte Glyceraldehyd, das Isopropyliden-Glyceraldehyd, mit guter Aktivität akzeptiert.The results are in U / mg enzyme protein attached in Table 1 (oxidation) and Tab. 2 (reduction) posed. In addition to the aldehydes and ketones listed in Tab. 2, the protected glyceraldehyde, the isopropylidene-glyceraldehyde, is also accepted with good activity.
Tab. 1: Aktivität der GO-ADH bei Oxidation verschiedener Substrate. Eingesetzt wurde ein Enzympräparat mit N-terminalem His-Tag, das durch Chromatographie an Ni-NTA hoch gereinigt wurde. Die Bestimmung des Rohextraktproteingehalts in der Enzymlösung gemäß der Methode nach Bradford ergab dabei einen Proteingehalt von 4,3 mg pro ml Enzymlösung.Tab. 1: Activity of GO-ADH in oxidation of various substrates. An enzyme preparation with N-terminal His-tag was used, which was highly purified by chromatography on Ni-NTA. The determination of the Crude extract protein content in the enzyme solution according to the Bradford's method yielded a protein content of 4.3 mg per ml of enzyme solution.



Tab. 2: Aktivität der GO-ADH bei Reduktion verschiedener Substrate Eingesetzt wurde ein Enzympräparat mit N-terminalem His-Tag, das durch Chromatographie an Ni-NTA hoch gereinigt wurde. Die Bestimmung des Rohextraktproteingehalts in der Enzymlösung gemäß der Methode nach Bradford ergab dabei einen Proteingehalt von 1,2 mg pro ml Enzymlösung.Tab. 2: Activity of GO-ADH in the reduction of various substrates An enzyme preparation with N-terminal His-tag was used, which was highly purified by chromatography on Ni-NTA. The determination of the Crude extract protein content in the enzyme solution according to the Bradford's method yielded a protein content of 1.2 mg per ml of enzyme solution.



Beispiel 4: Abhängigkeit der Aktivität der rekombinanten Alkoholdehydrogenase vom pH-WertExample 4: Dependency of Activity of recombinant alcohol dehydrogenase of pH
Zur
Bestimmung der Abhängigkeit der Aktivität der
rekombinanten GO-ADH vom pH-Wert wurden die Enzymaktivitäten
photometrisch mit dem in Beispiel 3 beschriebenen oxidativen bzw.
reduktiven Test, wobei hier lediglich Puffer bei verschiedenen pH-Werten
eingesetzt wurden. Die Auswertungen ergaben (
Beispiel 5: Abhängigkeit der Aktivität der rekombinanten Alkoholdehydrogenase von der TemperaturExample 5: Dependence of Activity of the recombinant alcohol dehydrogenase of the temperature
Zur
Bestimmung der Abhängigkeit der Aktivität der
rekombinanten GO-ADH von der Temperatur wurden die Enzymaktivitäten
photometrisch mit dem in Beispiel 3 beschriebenen reduktiven Test
gemessen, lediglich die Temperatur wurde im Bereich von 5 bis 60°C
variiert.
Beispiel 6: Temperaturstabilität der rekombinanten AlkoholdehydrogenaseExample 6: Temperature stability recombinant alcohol dehydrogenase
Zur
Bestimmung der Temperaturstabilität der rekombinanten GO-ADH
wurde das Enzym bei verschiedenen Temperaturen zwischen 5 und 58°C
für 10 min vorinkubiert und danach die Restaktivität
mit dem reduktiven Standardtest (s. Beispiel 3) mit Glyceraldehyd
und NADPH bestimmt.
Beispiel 7: Lagerstabilität der rekombinanten AlkoholdehydrogenaseExample 7: Storage stability of recombinant alcohol dehydrogenase
Rohextrakt
der rekombinanten Alkoholdehydrogenase wurde bei 22°C,
4°C und –20°C gelagert und die Restaktivität
nach bestimmten Zeitintervallen mit dem in Beispiel 3 beschriebenen
Standardtest (Glyceraldehyd und NADPH) bestimmt.
Beispiel 8: Verwendung der rekombinanten Alkoholdehydrogenase: Gewinnung von enantiomerenen-angereichertem Glyceraldehyd durch Racematspaltung mit isolierten EnzymenExample 8: Use of the recombinant Alcohol dehydrogenase: recovery of enantiomeric-enriched Glyceraldehyde by racemate resolution with isolated enzymes
Es
wurden 50 mM racemischer Glyceraldehyd, 100 U/ml GO-ADH, 100 mM
Glucose, 2 U/ml GDH und 0,5 mM NADP in 100 mM TEA pH 7 in einem
Gesamtvolumen von 1 ml eingesetzt. Die Umsetzung fand bei 20°C
statt. Die Reduktion von GA wurde über 3 Stunden beobachtet,
in bestimmten Zeitintervallen wurden Proben entnommen und die Konzentration
der beiden Glyceraldehyd-Enantiomeren gaschromatographisch bestimmt
(GC-Bestimmungsmethode s. Beispiel 9). Eine Cofaktorregenerierung
fand mit Hilfe der GDH statt. In
Beispiel 9: Gewinnung von enantiomerenen-angereichertem Glyceraldehyd mit einem GanzzellkatalysatorExample 9: Recovery of Enantiomer Enriched Glyceraldehyde with a whole cell catalyst
Konstruktion eines rekombinanten E. coli-Stamm für die Ganzzell-Katalyse: Als Ganzzell-Katalysator wurde ein rekombinanter E-coli-Stamm konstruiert, der sowohl das Gen für die GO-ADH als auch ein Gen für ein Enzym enthält, dessen Genprodukt die Regenerierung von NADPH übernehmen kann. Als Regenerierungsenzym wurde die Glucose-Dehydrogenase (GDH) aus Bacillus subtilis eingesetzt. Für die Coexpression von GO-ADH und GDH wurde der Expressionsvektor pETDuet-1 (Novagen) gewählt. Dieser Vektor enthält neben einem Ampicillin-Resistenzgen zwei multiple Klonierungsstellen, denen jeweils ein T7-Promotor sowie eine ribosomale Bindungsstelle vorausgeht. Der T7-Terminator sitzt am Ende der zweiten multiplen Klonierungsstelle. Der Vektor ist für die Coexpression zweier Gene optimal geeignet.construction of a recombinant E. coli strain for whole-cell catalysis: As a whole-cell catalyst, a recombinant E coli strain was constructed, which is both the gene for the GO-ADH and a gene for a Contains enzyme whose gene product is the regeneration of NADPH can take over. As Regenerierungsenzym was the Glucose dehydrogenase (GDH) from Bacillus subtilis used. For the co-expression of GO-ADH and GDH became the expression vector pETDuet-1 (Novagen). This vector contains two multiple cloning sites besides an ampicillin resistance gene, each a T7 promoter and a ribosomal binding site precedes. The T7 terminator sits at the end of the second multiple Cloning site. The vector is for coexpression optimally suited for two genes.
Für das gdh-Gen wurden Primer konstruiert, die dem Gen die Restriktionsschnittstellen EcoRI und NotI an den Enden anfügen sollten. Diese Primer wurden in einer PCR eingesetzt. Das aufgereinigte PCR-Produkt sowie der Vektor pETDuet-1 wurden anschließend einer Restriktion mit den Restriktionsenzymen EcoRI und NotI unterzogen. Der geschnittene Vektor wurde mit alkalischer Phosphatase aus Shrimps dephosphoryliert. Beide DNA-Fragmente wurden nach Ligation mit T4 DNA Ligase mit dem kompetenten Expressionsstamm E. coli XL1-Blue transformiert. Nach Anzucht einiger Klone erfolgte die Isolierung der Plasmide mit nachfolgender Restriktion und gelelektrophoretischer Analyse. Die gdh-Sequenz einer der erhaltenen Klone wurde durch Sequenzanalyse bestätigt.For the gdh gene was constructed primers that restricted the gene EcoRI and NotI should be added at the ends. These primers were used in a PCR. The purified PCR product as well the vector pETDuet-1 was subsequently restricted subjected to the restriction enzymes EcoRI and NotI. The cut Vector was dephosphorylated with shrimp alkaline phosphatase. Both DNA fragments were ligated with the T4 DNA ligase after ligation competent expression strain E. coli XL1-Blue transformed. To Cultivation of some clones was followed by isolation of the plasmids with the following Restriction and gel electrophoretic analysis. The gdh sequence one of the obtained clones was confirmed by sequence analysis.
Anschließend
erfolgten Restriktionsansätze dieses Plasmids und dem goadh-Fragment,
dem mittels PCR die Enden NdeI und KpnI angefügt wurden,
mit den Restriktionsenzymen NdeI und KpnI. Nach der Dephosphorylierung
des Vektors mit alkalischer Phosphatase aus Shrimps erfolgten die
Ligation der beiden DNA-Fragmente mit T4 DNA Ligase und die Transformation
mit kompetenten E. coli XL1-Blue-Zellen. Von den nach Selektion
auf LBamp-Platten resultierenden Kolonien wurden einige Klone ausgewählt
und in jeweils 5 ml LBamp-Medium über Nacht angezogen.
Aus den Kulturen wurde die Plasmid-DNA isoliert, welche nach Restriktion
auf einem Agarosegel elektrophoretisch aufgetrennt wurde. Die Sequenzierung
eines der erhaltenen Klone bestätigte die korrekte Gensequenz.
Für die Expression wurde der Vektor pAW-21 mit kompetenten E. coli BL21(DE3)-Zellen transformiert. Eine Einzelkolonie wurde in 5 ml LBamp-Medium überimpft und über Nacht bei 37°C geschüttelt. Anschließend wurde 1%-ig in 30 ml LBamp-Medium überimpft, bei 37°C geschüttelt und nach Erreichen einer OD600 von 0,5 mit 1 mM IPTG die Genexpression induziert. Nach 20-stündigem Schütteln bei 25°C wurden die Zellen geerntet.For the expression became the vector pAW-21 with competent E. coli BL21 (DE3) cells transformed. A single colony was inoculated into 5 ml of LBamp medium and shaken overnight at 37 ° C. Subsequently 1% was inoculated in 30 ml LBamp medium, shaken at 37 ° C and after reaching a OD600 of 0.5 with 1 mM IPTG induced gene expression. After 20 hours Shaking at 25 ° C, the cells were harvested.
Zellanzucht: E. coli BL21 (DE3) pAW21: Eine Einzelkolonie von einer Agarplatte (LB/100 mg/L Ampicillin) wird gepickt und in 5 ml LB-Medium (100 mg Ampicillin/L) über Nacht bei 37°C angezogen. Ein Erlenmeyerkolben mit 30 mL LB-Mediums (100 mg Amp./L) wird mit 300 μL dieser Kultur angeimpft und über das Wochenende bei Raumtemperatur inkubiert. 500 mL LB-Medium (100 mg/L Ampicillin) in einem 2-L-Erlenmeyerkolben werden mit 5 mL der Kultur angeimpft und bei 37°C bis OD580 = 0.56 angezogen, dann mit 1 mM IPTG induziert und bei 25°C über 16 Stunden geschüttelt. Nach Zentrifugation bei 4°C (30 min, 3200 G) werden 3.61 g Zellen erhalten, die bei –20°C gelagert werden. Messungen zur Aktivität der Enzyme GDH und GO-ADH in den Ganzzellkatalysatoren: 80 mg Zellen werden in 320 μL TEA-Puffer (50 mM, pH 7.0) suspendiert, per Ultraschall (3 × 60 sec., 50% Cycle, 50% Intensität, je 60 sec. Pause) auf Eis aufgeschlossen. Die Aktivität der löslichen Proteine wird nach Standard-Tests am Photometer ermittelt, es wurden 151 U/ml für die GO-ADH (Test mit rac. Glyceraldehyd/NADPH) und 89 U/ml für die Glcucose-Dehydrogenase (Test mit 5 mMGlucose, 0,25 mM NAD) ermittelt. Der Bradford-Test ergab einen Proteingehalt von 15.6 mg/mL.Cell Culture: E. coli BL21 (DE3) pAW21: A single colony from an agar plate (LB / 100 mg / L ampicillin) is picked and grown in 5 ml LB medium (100 mg ampicillin / L) overnight at 37 ° C. An Erlenmeyer flask containing 30 mL LB medium (100 mg Amp./L) is inoculated with 300 μL of this culture and incubated over the weekend at room temperature. 500 mL LB medium (100 mg / L ampicillin) in a 2 L Erlenmey are inoculated with 5 ml of the culture and grown at 37 ° C to OD580 = 0.56, then induced with 1 mM IPTG and shaken at 25 ° C for 16 hours. After centrifugation at 4 ° C (30 min, 3200 G) 3.61 g of cells are obtained, which are stored at -20 ° C. Measurements of the Activity of the Enzymes GDH and GO-ADH in the Whole Cell Catalysts: 80 mg cells are suspended in 320 μL TEA buffer (50 mM, pH 7.0) by ultrasound (3 × 60 sec., 50% cycle, 50% intensity, 60 sec. each break) on ice. The activity of the soluble proteins is determined according to standard tests on the photometer, there were 151 U / ml for the GO-ADH (test with rac. Glyceraldehyd / NADPH) and 89 U / ml for the glucose dehydrogenase (test with 5 mM glucose, 0.25 mM NAD). The Bradford test showed a protein content of 15.6 mg / mL.
Racematspaltung unter Verwendung des Ganzzell-Katalysators (rekombinante E. coli-Zellen): Zur Gewinnung von enantiomeren-angereichertem Glyceraldehyd wurden eingesetzt: 100 mM Ammoniumcarbonat-Puffer, mit konz. HCl auf pH 8.0 eingestellt; 300 mM Glyceraldehyd, 180 mM Glucose, wobei nach 80 Std 12,6 mM nachdosiert wurden; 56 g/L Zellen BL21 pAW21 (Zellfeuchtgewicht). Durchführung: In 30 ml Puffer werden 300 mM racemisches Glyceraldehyd und 180 mM Glucose vorgelegt, mit 1.7 g Ganzzellkatalysator versetzt und bei Raumtemperatur (22°C) unter Lichtausschluss gerührt. Regelmäßig werden Proben entnommen, derivatisiert und per Gaschromatographie vermessen, gleichzeitig wurde der pH-Wert regelmäßig kontrolliert. Die GC-Analytik zeigt bei 71,5 Std Reaktionsdauer einen ee-Wert für das L-Enantiomere des Glyceraldehyds von 97.4%. Nach 75 Stunden Reaktionsdauer wurden 10 ml Ammoniumcarbonat-Lösung sowie 100 mg Glucose nachdosiert. Eine Probe nach 80 Std. Reaktionsdauer zeigte am GC, dass nur noch das L-Enantiomere nachweisbar war. Die Reaktionslösung wurde zentrifugiert (10 min, 20000 G), der klare Überstand (ca. 38 ml) wird abgenommen und bei –20°C gelagert. Für die GC-Analytik wurden die Proben jeweils nach folgender Methode aufbereitet: Es wurden 120 μL Probe entnommen und zentrifugiert, 100 μL Überstand wurden derivatisiert mit 150 μL Ethylacetat, 150 μL 1,4-Dioxan, 100 μL Essigsäureanhydrid und 10 μL Pyridin; die Lösung wird direkt injiziert. Die Konzentration der beiden Glyceraldehyd-Enantiomere wurde unter folgenden Bedingungen bestimmt: Säule: CP-Chirasil-DEX CB (Varian), Trennung bei 108°C (isotherm), Trägergas: Helium (200 ml/min), Injektionsvolumen: 8 μl. Unter diesen Bedingungen eluieren die verschiedenen Glyceralde-Verbindungen zu folgenden Zeiten: Peakpaar 1: D-Glyceraldehyd = 7,5 min, L-Glyceraldehyd = 7,6 min; Peakpaar 2: D-Glyceraldehyd = 10,2 min, L-Glyceraldehyd = 10,8 min; Peakpaar 3: D-Glyceraldehyd = 11,9 min, L-Glyceraldehyd = 14,10 min. Bei diesen drei Produktpeaks handelt es sich um die verschiedenartig derivatisierten Glyceraldehyde (in 1- oder 2-Position mono-derivatisiert oder an 1- und 2-Position di-derivatisiert).resolution using the whole-cell catalyst (recombinant E. coli cells): To obtain enantiomerically-enriched glyceraldehyde were used: 100 mM ammonium carbonate buffer, with conc. HCl to pH 8.0 set; 300 mM glyceraldehyde, 180 mM glucose, taking after Were re-dosed with 12.6 mM for 80 h; 56 g / L cells BL21 pAW21 (wet cell weight). Procedure: 300 mM racemic buffer in 30 ml Glyceraldehyde and 180 mM glucose presented, mixed with 1.7 g of whole-cell catalyst and stirred at room temperature (22 ° C) with exclusion of light. Regularly samples are taken, derivatized and measured by gas chromatography, at the same time became the pH regularly checked. The GC analysis shows at 71.5 hr reaction time, an ee value for the L-enantiomer of glyceraldehyde of 97.4%. After 75 hours of reaction were 10 ml of ammonium carbonate solution and 100 mg of glucose are added. A sample after 80 hrs reaction time showed on the GC that only the L-enantiomer was detectable. The reaction solution was centrifuged (10 min, 20,000 g), the clear supernatant (about 38 ml) is removed and stored at -20 ° C. For the GC analysis, the samples were each according to the following Method prepared: 120 μL samples were taken and centrifuged, 100 μL supernatant were derivatized with 150 μL ethyl acetate, 150 μL 1,4-dioxane, 100 μL Acetic anhydride and 10 μL of pyridine; the solution becomes directly injected. The concentration of the two glyceraldehyde enantiomers was determined under the following conditions: Column: CP-Chirasil-DEX CB (Varian), separation at 108 ° C (isothermal), carrier gas: Helium (200 ml / min), injection volume: 8 μl. Under these Conditions elute the various glycerides compounds following times: Peak Pair 1: D-Glyceraldehyde = 7.5 min, L-Glyceraldehyde = 7.6 min; Peak Pair 2: D-Glyceraldehyde = 10.2 min, L-Glyceraldehyde = 10.8 min; Peak Pair 3: D-Glyceraldehyde = 11.9 min, L-Glyceraldehyde = 14.10 min. These three product peaks are the variously derivatized glyceraldehydes (in the 1- or 2-position mono-derivatized or di-derivatized at 1- and 2-positions).
Die
Beschreibung der FigurenDescription of the figures
Es folgt ein Sequenzprotokoll nach WIPO St. 25.It follows Sequence listing according to WIPO St. 25. Dieses kann von der amtlichen Veröffentlichungsplattform des DPMA heruntergeladen werden.This can of the official publication platform of the DPMA become.
ZITATE ENTHALTEN IN DER BESCHREIBUNGQUOTES INCLUDE IN THE DESCRIPTION
Diese Liste der vom Anmelder aufgeführten Dokumente wurde automatisiert erzeugt und ist ausschließlich zur besseren Information des Lesers aufgenommen. Die Liste ist nicht Bestandteil der deutschen Patent- bzw. Gebrauchsmusteranmeldung. Das DPMA übernimmt keinerlei Haftung für etwaige Fehler oder Auslassungen.This list The documents listed by the applicant have been automated generated and is solely for better information recorded by the reader. The list is not part of the German Patent or utility model application. The DPMA takes over no liability for any errors or omissions.
Zitierte PatentliteraturCited patent literature
- - US 4353987 [0007] US 4353987 [0007]
- - EP 1444367 [0031] EP 1444367 [0031]
- - WO 91/08216 [0035] WO 91/08216 [0035]
- - EP 127839 [0037, 0038] EP 127839 [0037, 0038]
- - EP 549721 [0037] - EP 549721 [0037]
- - DE 19920712 [0049] - DE 19920712 [0049]
Zitierte Nicht-PatentliteraturCited non-patent literature
- - W. Hummel, Adv. Biochem. Engineering/Biotechnology 1997, 58, 145–184 [0003] - W. Hummel, Adv. Biochem. Engineering / Biotechnology 1997, 58, 145-184 [0003]
- - Prescott, S. C. und Dunn, C. G. (1959) Industrial Microbiology, McGraw Hill Book Co., Inc., New York, ”The Acetic Acid Bacteria and sone of Their Biochemical Activities”, pp. 428–469 [0005] Prescott, SC and Dunn, CG (1959) Industrial Microbiology, McGraw Hill Book Co., Inc., New York, "The Acetic Acid Bacteria and Sone of Their Biochemical Activities", p. 428-469 [0005]
- - Eigen, M. und Gardiner, W., Evolutionary molecular engineering based an RNA replication, Pure Appl. Chem. 1984, 56, 967–978 [0019] Eigen, M. and Gardiner, W., Evolutionary molecular engineering based on RNA replication, Pure Appl. Chem. 1984, 56, 967-978 [0019]
- - Chen, K. und Arnold, F., Enzyme engineering for nonaqueous solvents: random mutagenesis to enhance activity of subtilisin E in polar organic media. Bio/Technology 1991, 9, 1073–1077 [0019] - Chen, K. and Arnold, F., Enzymes engineering for nonaqueous solvents: random mutagenesis to enhance the activity of subtilisin E in polar organic media. Bio / Technology 1991, 9, 1073-1077 [0019]
- - Horwitz, M. und Loeb, L., Promoters Selected From Random DNA-Sequences, Proc Natl Acad Sci USA 83, 1986, 7405–7409 [0019] Horwitz, M. and Loeb, L., Promoters Selected From Random DNA Sequences, Proc Natl Acad Sci USA 83, 1986, 7405-7409 [0019]
- - Dube, D. und L. Loeb, Mutants Generated By The Insertion Of Random Oligonucleotides Into The Active-Site Of The Beta-Lactamase Gene, Biochemistry 1989, 28, 5703–5707 [0019] - Dube, D. and L. Loeb, Mutants Generated By The Insertion Of Random Oligonucleotides Into The Active Site Of The Beta-Lactamase Gene, Biochemistry 1989, 28, 5703-5707 [0019]
- - Stemmer, P. C., Rapid evolution of a Protein in vitro by DNA shuffling, Nature 1994, 370, 389–391 und Stemmer, P. C., DNA shuffling by random fragmentation and reassembly: In vitro recombination for molecular evolution. Proc Natl Acad Sci USA 91, 1994, 10747–10751 [0019] - Stemmer, PC, Rapid evolution of a protein in vitro by DNA shuffling, Nature 1994, 370, 389-391 and Stemmer, PC, DNA shuffling by random fragmentation and reassembly: In vitro recombination for molecular evolution. Proc Natl Acad Sci USA 91, 1994, 10747-10751 [0019]
- - Sambrook, J.; Fritsch, E. F. und Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York [0022] - Sambrook, J .; Fritsch, EF and Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York [0022]
- - Sambrook et al. [0028] - Sambrook et al. [0028]
- - Sambrook, J.; Fritsch, E. F. und Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York [0031] - Sambrook, J .; Fritsch, EF and Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York [0031]
- - Chan and Cohen. 1979. High Frequency Transformation of Bacillus subtilis Protoplasts by Palsmid DNA. Mol Gen Genet. 168(1): 111–5 [0033] - Chan and Cohen. 1979. High Frequency Transformation of Bacillus subtilis Protoplasts by Palsmid DNA. Mol Gen Genet. 168 (1): 111-5 [0033]
- - Kieser et al.. 2000. Practical Streptomyces Genetics. The John Innes Foundation Norwich. [0033] - Kieser et al. 2000. Practical Streptomyces Genetics. The John Innes Foundation Norwich. [0033]
- - Sambrook et al.. 1989. Molecular Cloning. A Laboratory Manual. In: second ed.. Cold Spring Harbor Laboratory Press. Cold Spring Harbor. NY. [0033] - Sambrook et al. 1989. Molecular Cloning. A Laboratory Manual. In: second ed. Cold Spring Harbor Laboratory Press. Cold Spring Harbor. NY. [0033]
- - Irani and Rowe. 1997. Enhancement of transformation in Pseudomonas aeruginosa PAO1 by Mg2+ and heat. Biotechniques 22: 54–56 [0033] - Irani and Rowe. 1997. Enhancement of transformation in Pseudomonas aeruginosa PAO1 by Mg2 + and heat. Biotechniques 22: 54-56 [0033]
- - Hogan, B., Beddington, R., Costantini, F. und Lacy, E. (1994), Manipulating the Mouse-Embryo [0035] - Hogan, B., Beddington, R., Costantini, F. and Lacy, E. (1994), Manipulating the Mouse Embryo [0035]
- - A Laboratory Manual, 2. Aufl., Cold Spring Harbor Laboratory, Cold Spring Harbor, NY [0035] A Laboratory Manual, 2nd Ed., Cold Spring Harbor Laboratory, Cold Spring Harbor, NY. [0035]
- - Studier, W. F.; Rosenberg A. H.; Dunn J. J.; Dubendroff J. W.;, Use of the T7 RNA polymerase to direct expression of cloned genes, Methods Enzymol. 1990, 185, 61–89 [0036] - Studier, WF; Rosenberg AH; Dunn JJ; Dubendroff JW; Use of the T7 RNA polymerase to direct expression of cloned genes, Methods Enzymol. 1990, 185, 61-89 [0036]
- - Glover, D. M. (1985), DNA cloning: a practical approach, Vol. I–III, IRL Press Ltd., Oxford [0036] Glover, DM (1985), DNA cloning: a practical approach, Vol. I-III, IRL Press Ltd., Oxford [0036]
- - Rodriguez, R. L. und Denhardt, D. T (eds) (1988), Vectors: a survey of molecular cloning vectors and their uses, 179–204, Butterworth, Stoneham [0036] Rodriguez, RL and Denhardt, D.T. (eds) (1988), Vectors: a survey of molecular cloning vectors and their uses, 179-204, Butterworth, Stoneham [0036]
- - Goeddel, D. V., Systems for heterologous gene expression, Methods Enzymol. 1990, 185, 3–7 [0036] - Goeddel, DV, Systems for heterologous gene expression, Methods Enzymol. 1990, 185, 3-7 [0036]
- - Sambrook, J.; Fritsch, E. F. und Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York [0036] - Sambrook, J .; Fritsch, EF and Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd Ed., Cold Spring Harbor Laboratory Press, New York [0036]
- - Mouse Mammary Tumour Virus; Lee et al. (1981) Nature, 294 (5838), 228–232 [0038] - Mouse Mammary Tumor Virus; Lee et al. (1981) Nature, 294 (5838), 228-232 [0038]
- - Gellissen, G.; Piontek, M.; Dahlems, U.; Jenzelewski, V.; Gavagan, J. W.; DiCosimo, R.; Anton, D. L.; Janowicz, Z. A. (1996), Recombinant Hansenula polymorpha as a biocatalyst. Coexpression of the spinach glycolate oxidase (GO) and the S. cerevisiae catalase T (CTT1) gene, Appl. Microbiol. Biotechnol. 46, 46–54; Farwick, M.; London, M.; Dohmen, J.; Dahlems, U.; Gellissen, G.; Strasser, A. W. [0049] Gellissen, G .; Piontek, M .; Dahlems, U .; Jenzelewski, V .; Gavagan, JW; DiCosimo, R .; Anton, DL; Janowicz, ZA (1996), Recombinant Hansenula polymorpha as a biocatalyst. Coexpression of the spinach glycolate oxidase (GO) and the S. cerevisiae catalase T (CTT1) gene, Appl. Microbiol. Biotechnol. 46, 46-54; Farwick, M .; London, M .; Dohmen, J .; Dahlems, U .; Gellissen, G .; Strasser, AW [0049]
- - Sambrook, J.; Fritsch, E. F. und Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York [0050] - Sambrook, J .; Fritsch, EF and Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York [0050]
- - Balbas, P. und Bolivar, F. (1990), Design and construction of expression plasmid vectors in E. coli, Methods Enzymol. 185, 14–37 [0050] Balbas, P. and Bolivar, F. (1990), Design and construction of expression plasmid vectors in E.coli, Methods Enzymol. 185, 14-37 [0050]
- - Rodriguez, R. L. und Denhardt, D. T (eds) (1988), Vectors: a survey of molecular cloning vectors and their uses, 205–225, Butterworth, Stoneham [0050] Rodriguez, RL and Denhardt, D.T. (eds) (1988), Vectors: a survey of molecular cloning vectors and their uses, 205-225, Butterworth, Stoneham [0050]
- - Triglia T.; Peterson, M. G. und Kemp, D. J. (1988), A procedure for in vitro amplification of DNA segments that lie outside the boundaries of known sequences, Nucleic Acids Res. 16, 8186 [0050] - Triglia T .; Peterson, MG and Kemp, DJ (1988), A procedure for in vitro amplification of DNA segments that lie outside the boundaries of known sequences, Nucleic Acids Res. 16, 8186 [0050]
- - Sambrook, J.; Fritsch, E. F. und Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York [0050] - Sambrook, J .; Fritsch, EF and Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York [0050]
- - Rodriguez, R. L. und Denhardt, D. T (eds) (1988), Vectors: a survey of molecular cloning vectors and their uses, Butterworth, Stoneham [0050] Rodriguez, RL and Denhardt, D.T. (eds) (1988), Vectors: a survey of molecular cloning vectors and their uses, Butterworth, Stoneham [0050]
- - Sharma B. P.; Bailey L. F. und Messing R. A. (1982), Immobilisierte Biomaterialien – Techniken und Anwendungen, Angew. Chem. 94, 836–852 [0054] - Sharma BP; Bailey LF and Messing RA (1982), Immobilized Biomaterials - Techniques and Applications, Angew. Chem. 94, 836-852 [0054]
- - Paradkar, V. M.; Dordick, J. S. (1994), Aqueous-Like Activity of Chymotrypsin Dissolved in Nearly Anhydrous Organic Solvents, J. Am. Chem. Soc. 116, 5009–5010; Mori, T. [0054] - Paradkar, VM; Dordick, JS (1994), Aqueous-Like Activity of Chymotrypsin Dissolved in Nearly Anhydrous Organic Solvents, J. Am. Chem. Soc. 116, 5009-5010; Mori, T. [0054]
- - Okahata, Y. (1997), A variety of lipi-coated glycoside hydrolases as effective glycosyl transfer catalysts in homogeneous organic solvents, Tetrahedron Lett. 38, 1971–1974 [0054] Okahata, Y. (1997), A variety of lipidated glycoside hydrolases as effective glycosyl transfer catalysts in homogeneous organic solvents, Tetrahedron Lett. 38, 1971-1974 [0054]
- - Otamiri, M.; Adlercreutz, P.; Matthiasson, B. (1992), Complex formation between chymotrypsin and ethyl cellulose as a means to solubilize the enzyme in active form in toluene, Biocatalysis 6, 291–305 [0054] - Otamiri, M .; Adlercreutz, P .; Matthiasson, B. (1992), Complex formation between chymotrypsin and ethyl cellulose as a means to solubilize the enzyme in active form in toluene, Biocatalysis 6, 291-305 [0054]
- - Kamiya, N.; Okazaki, S.-Y.; Goto, M. (1997), Surfactant-horseradish peroxidase complex catalytically active in anhydrous benzene, Biotechnol. Tech. 11, 375–378 [0054] - Kamiya, N .; Okazaki, S.-Y .; Goto, M. (1997), surfactant horseradish peroxidase complex catalytically active in anhydrous benzene, Biotechnol. Tech. 11, 375-378 [0054]
- - E. Katchalski-Katzir, D. M. Kraemer, J. Mol. Catal. B: Enzym. (2000), 10, 157 [0054] E. Katchalski-Katzir, DM Kraemer, J. Mol. Catal. B: enzyme. (2000), 10, 157 [0054]
- - Petty, K. J. (1996), Metal-chelate affinity chromatography In: Ausubel, F. M. et al. eds. Current Protocols in Molecular Biology, Vol. 2, New York: John Wiley and Sons [0054] - Petty, KJ (1996), metal-chelate affinity chromatography In: Ausubel, FM et al. eds. Current Protocols in Molecular Biology, Vol. 2, New York: John Wiley and Sons [0054]
- - St. Clair, N.; Wang, Y.-F.; Margolin, A. L. (2000), Cofactor-bound cross-linked enzyme crystals (CLEC) of alcohol dehydrogenase, Angew. Chem. Int. Ed. 39, 380–383 [0054] - St. Clair, N .; Wang, Y.-F .; Margolin, AL (2000), Cofactor-bound cross-linked enzyme crystals (CLEC) of alcohol dehydrogenase, Angew. Chem. Int. Ed. 39, 380-383 [0054]
Claims (13)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE102009007272A DE102009007272A1 (en) | 2009-02-03 | 2009-02-03 | New nucleic acid sequence, which encodes a polypeptide with alcohol dehydrogenase activity, comprising e.g. nucleic acid sequence that hybridizes under stringent conditions with specific nucleic acid sequence, useful to produce polypeptide |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE102009007272A DE102009007272A1 (en) | 2009-02-03 | 2009-02-03 | New nucleic acid sequence, which encodes a polypeptide with alcohol dehydrogenase activity, comprising e.g. nucleic acid sequence that hybridizes under stringent conditions with specific nucleic acid sequence, useful to produce polypeptide |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| DE102009007272A1 true DE102009007272A1 (en) | 2010-08-05 |
Family
ID=42308967
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| DE102009007272A Withdrawn DE102009007272A1 (en) | 2009-02-03 | 2009-02-03 | New nucleic acid sequence, which encodes a polypeptide with alcohol dehydrogenase activity, comprising e.g. nucleic acid sequence that hybridizes under stringent conditions with specific nucleic acid sequence, useful to produce polypeptide |
Country Status (1)
| Country | Link |
|---|---|
| DE (1) | DE102009007272A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102010039833A1 (en) * | 2010-08-26 | 2012-03-01 | Symrise Ag | Whole-cell biotransformation of fatty acids to the fatty aldehydes truncated by one carbon atom |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4353987A (en) | 1981-06-11 | 1982-10-12 | The Upjohn Company | Process for preparing glyceraldehyde from glycerol with methanol dehydrogenase |
| EP0127839A2 (en) | 1983-05-27 | 1984-12-12 | THE TEXAS A&M UNIVERSITY SYSTEM | Method for producing a recombinant baculovirus expression vector |
| WO1991008216A1 (en) | 1989-12-01 | 1991-06-13 | Genpharm International, Inc. | Production of recombinant polypeptides by bovine species and transgenic methods |
| EP0549721A1 (en) | 1990-09-17 | 1993-07-07 | Texas A & M Univ Sys | Multiple promoter baculovirus expression system and defective particle production. |
| DE19920712A1 (en) | 1999-05-05 | 2000-11-09 | Rhein Biotech Proz & Prod Gmbh | Process for producing a recombinant protein |
| EP1444367A1 (en) | 2001-11-15 | 2004-08-11 | Degussa AG | Reca-negative and rhab-negative microorganism |
-
2009
- 2009-02-03 DE DE102009007272A patent/DE102009007272A1/en not_active Withdrawn
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4353987A (en) | 1981-06-11 | 1982-10-12 | The Upjohn Company | Process for preparing glyceraldehyde from glycerol with methanol dehydrogenase |
| EP0127839A2 (en) | 1983-05-27 | 1984-12-12 | THE TEXAS A&M UNIVERSITY SYSTEM | Method for producing a recombinant baculovirus expression vector |
| WO1991008216A1 (en) | 1989-12-01 | 1991-06-13 | Genpharm International, Inc. | Production of recombinant polypeptides by bovine species and transgenic methods |
| EP0549721A1 (en) | 1990-09-17 | 1993-07-07 | Texas A & M Univ Sys | Multiple promoter baculovirus expression system and defective particle production. |
| DE19920712A1 (en) | 1999-05-05 | 2000-11-09 | Rhein Biotech Proz & Prod Gmbh | Process for producing a recombinant protein |
| EP1444367A1 (en) | 2001-11-15 | 2004-08-11 | Degussa AG | Reca-negative and rhab-negative microorganism |
Non-Patent Citations (30)
| Title |
|---|
| A Laboratory Manual, 2. Aufl., Cold Spring Harbor Laboratory, Cold Spring Harbor, NY |
| Balbas, P. und Bolivar, F. (1990), Design and construction of expression plasmid vectors in E. coli, Methods Enzymol. 185, 14-37 |
| Chan and Cohen. 1979. High Frequency Transformation of Bacillus subtilis Protoplasts by Palsmid DNA. Mol Gen Genet. 168(1): 111-5 |
| Chen, K. und Arnold, F., Enzyme engineering for nonaqueous solvents: random mutagenesis to enhance activity of subtilisin E in polar organic media. Bio/Technology 1991, 9, 1073-1077 |
| Dube, D. und L. Loeb, Mutants Generated By The Insertion Of Random Oligonucleotides Into The Active-Site Of The Beta-Lactamase Gene, Biochemistry 1989, 28, 5703-5707 |
| E. Katchalski-Katzir, D. M. Kraemer, J. Mol. Catal. B: Enzym. (2000), 10, 157 |
| Eigen, M. und Gardiner, W., Evolutionary molecular engineering based an RNA replication, Pure Appl. Chem. 1984, 56, 967-978 |
| Gellissen, G.; Piontek, M.; Dahlems, U.; Jenzelewski, V.; Gavagan, J. W.; DiCosimo, R.; Anton, D. L.; Janowicz, Z. A. (1996), Recombinant Hansenula polymorpha as a biocatalyst. Coexpression of the spinach glycolate oxidase (GO) and the S. cerevisiae catalase T (CTT1) gene, Appl. Microbiol. Biotechnol. 46, 46-54; Farwick, M.; London, M.; Dohmen, J.; Dahlems, U.; Gellissen, G.; Strasser, A. W. |
| Glover, D. M. (1985), DNA cloning: a practical approach, Vol. I-III, IRL Press Ltd., Oxford |
| Goeddel, D. V., Systems for heterologous gene expression, Methods Enzymol. 1990, 185, 3-7 |
| Hogan, B., Beddington, R., Costantini, F. und Lacy, E. (1994), Manipulating the Mouse-Embryo |
| Horwitz, M. und Loeb, L., Promoters Selected From Random DNA-Sequences, Proc Natl Acad Sci USA 83, 1986, 7405-7409 |
| Irani and Rowe. 1997. Enhancement of transformation in Pseudomonas aeruginosa PAO1 by Mg2+ and heat. Biotechniques 22: 54-56 |
| Kamiya, N.; Okazaki, S.-Y.; Goto, M. (1997), Surfactant-horseradish peroxidase complex catalytically active in anhydrous benzene, Biotechnol. Tech. 11, 375-378 |
| Kieser et al.. 2000. Practical Streptomyces Genetics. The John Innes Foundation Norwich. |
| Mouse Mammary Tumour Virus; Lee et al. (1981) Nature, 294 (5838), 228-232 |
| Okahata, Y. (1997), A variety of lipi-coated glycoside hydrolases as effective glycosyl transfer catalysts in homogeneous organic solvents, Tetrahedron Lett. 38, 1971-1974 |
| Otamiri, M.; Adlercreutz, P.; Matthiasson, B. (1992), Complex formation between chymotrypsin and ethyl cellulose as a means to solubilize the enzyme in active form in toluene, Biocatalysis 6, 291-305 |
| Paradkar, V. M.; Dordick, J. S. (1994), Aqueous-Like Activity of Chymotrypsin Dissolved in Nearly Anhydrous Organic Solvents, J. Am. Chem. Soc. 116, 5009-5010; Mori, T. |
| Petty, K. J. (1996), Metal-chelate affinity chromatography In: Ausubel, F. M. et al. eds. Current Protocols in Molecular Biology, Vol. 2, New York: John Wiley and Sons |
| Prescott, S. C. und Dunn, C. G. (1959) Industrial Microbiology, McGraw Hill Book Co., Inc., New York, "The Acetic Acid Bacteria and sone of Their Biochemical Activities", pp. 428-469 |
| Rodriguez, R. L. und Denhardt, D. T (eds) (1988), Vectors: a survey of molecular cloning vectors and their uses, 179-204, Butterworth, Stoneham |
| Rodriguez, R. L. und Denhardt, D. T (eds) (1988), Vectors: a survey of molecular cloning vectors and their uses, 205-225, Butterworth, Stoneham |
| Sambrook, J.; Fritsch, E. F. und Maniatis, T. (1989), Molecular cloning: a laboratory manual, 2nd ed., Cold Spring Harbor Laboratory Press, New York |
| Sharma B. P.; Bailey L. F. und Messing R. A. (1982), Immobilisierte Biomaterialien - Techniken und Anwendungen, Angew. Chem. 94, 836-852 |
| St. Clair, N.; Wang, Y.-F.; Margolin, A. L. (2000), Cofactor-bound cross-linked enzyme crystals (CLEC) of alcohol dehydrogenase, Angew. Chem. Int. Ed. 39, 380-383 |
| Stemmer, P. C., Rapid evolution of a Protein in vitro by DNA shuffling, Nature 1994, 370, 389-391 und Stemmer, P. C., DNA shuffling by random fragmentation and reassembly: In vitro recombination for molecular evolution. Proc Natl Acad Sci USA 91, 1994, 10747-10751 |
| Studier, W. F.; Rosenberg A. H.; Dunn J. J.; Dubendroff J. W.;, Use of the T7 RNA polymerase to direct expression of cloned genes, Methods Enzymol. 1990, 185, 61-89 |
| Triglia T.; Peterson, M. G. und Kemp, D. J. (1988), A procedure for in vitro amplification of DNA segments that lie outside the boundaries of known sequences, Nucleic Acids Res. 16, 8186 |
| W. Hummel, Adv. Biochem. Engineering/Biotechnology 1997, 58, 145-184 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102010039833A1 (en) * | 2010-08-26 | 2012-03-01 | Symrise Ag | Whole-cell biotransformation of fatty acids to the fatty aldehydes truncated by one carbon atom |
| US10017790B2 (en) | 2010-08-26 | 2018-07-10 | Symrise Ag | Whole-cell biotransformation of fatty acids to obtain fatty aldehydes shortened by one carbon atom |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR100760106B1 (en) | (R) -2-octanol dehydrogenase, a method for producing the enzyme, DNA encoding the enzyme and a method for producing alcohol using the same | |
| US20070243594A1 (en) | Oxidoreductase from Pichia Capsulata | |
| KR101354546B1 (en) | Oxidoreductases for the stereoselective reduction of keto compounds | |
| DE602004012918T2 (en) | Carbonyl reductase, genes and methods for their expression, and use thereof for the preparation of optically active alcohols | |
| JP2002345479A (en) | Novel (R) -2,3-butanediol dehydrogenase, method for producing the same, and method for producing optically active alcohol using the same | |
| TWI601825B (en) | Process for the enantioselective enzymatic reduction of intermediates | |
| JPWO2001061014A1 (en) | (R)-2-octanol dehydrogenase, method for producing said enzyme, DNA encoding said enzyme, and method for producing alcohol using said DNA | |
| DE10140088A1 (en) | Lactobacillus NADH oxidase | |
| DE10218689A1 (en) | ADH from Rhodococcus erythropolis | |
| JP2004357639A (en) | (2S, 3S) -2,3-butanediol dehydrogenase | |
| EP3222712A1 (en) | Alcohol dehydrogenase from pichia pastoris and use thereof | |
| EP1974045B1 (en) | Process for the enzymatic preparation of citronellal | |
| EP1326984B1 (en) | Cytochrome p450 monooxygenases consisting of thermophilic bacteria | |
| EP1437401B1 (en) | Oxidoreductase | |
| EP2126065B1 (en) | Isoforms of pig liver esterase | |
| DE102009007272A1 (en) | New nucleic acid sequence, which encodes a polypeptide with alcohol dehydrogenase activity, comprising e.g. nucleic acid sequence that hybridizes under stringent conditions with specific nucleic acid sequence, useful to produce polypeptide | |
| DE102005043152A1 (en) | Alcohol dehydrogenase from Nocardia globerula and its use | |
| DE60202227T2 (en) | New enone reductases isolated from Kluyveromyces lactis, methods for their preparation and methods for the selective reduction of carbon-carbon double bonds of alpha, beta-unsaturated ketones using the reductases | |
| WO2007014544A2 (en) | Stereoselective synthesis of chiral diols | |
| WO2022156857A1 (en) | Process for preparing 2,4-dihydroxybutyrate or l-threonine using a microbial metabolic pathway | |
| DE10112401A1 (en) | Alcohol dehydrogenase and its use | |
| WO2003095635A2 (en) | Nucleotide sequence coding for a mannitol 2-dehydrogenase and method for the production of d-mannitol | |
| JP2008502334A (en) | Production method of optically active alcohol using whole cell catalyst | |
| EP2205726A1 (en) | Method for the oxidation of methyl groups in aliphatic hydrocarbons using an enzyme system with the activity of a monooxygenase | |
| WO2007134817A1 (en) | Biocatalysts and process for the preparation of organic compounds |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| R082 | Change of representative |
Representative=s name: MICHALSKI HUETTERMANN & PARTNER PATENTANWAELTE, DE |
|
| R081 | Change of applicant/patentee |
Owner name: EVOCATAL GMBH, DE Free format text: FORMER OWNER: EVOCATAL GMBH, 40225 DUESSELDORF, DE Effective date: 20131007 |
|
| R082 | Change of representative |
Representative=s name: MICHALSKI HUETTERMANN & PARTNER PATENTANWAELTE, DE Effective date: 20131007 |
|
| R005 | Application deemed withdrawn due to failure to request examination |