CN116152289A - A tracking method, related device, equipment and storage medium of a target object - Google Patents
A tracking method, related device, equipment and storage medium of a target object Download PDFInfo
- Publication number
- CN116152289A CN116152289A CN202111371200.4A CN202111371200A CN116152289A CN 116152289 A CN116152289 A CN 116152289A CN 202111371200 A CN202111371200 A CN 202111371200A CN 116152289 A CN116152289 A CN 116152289A
- Authority
- CN
- China
- Prior art keywords
- offset
- bounding box
- tracking
- target object
- feature map
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images
















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/20—Analysis of motion
- G06T7/246—Analysis of motion using feature-based methods, e.g. the tracking of corners or segments
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/70—Determining position or orientation of objects or cameras
- G06T7/73—Determining position or orientation of objects or cameras using feature-based methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Biophysics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Image Analysis (AREA)
Abstract
本申请公开了一种基于人工智能技术实现的目标对象跟踪方法,具体涉及图像识别领域,应用场景至少包括各类终端,如:手机、电脑、车载终端等。本申请包括若前一个图像帧中检测出目标对象,则从当前图像帧中提取原始检测图像;通过特征提取网络获取目标特征图;针对每个特征图,根据特征图中设置的锚点获取锚点框;基于锚点框所对应的特征,通过对象检测网络获取可选边界框参数;确定T组边界框参数;根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果。本申请还提供了装置、设备及存储介质。本申请不仅降低了数据处理量,提升目标跟踪效率,而且在图像检测过程中达到更好的识别效果,从而有利于提升目标跟踪的准确性。
The present application discloses a target object tracking method based on artificial intelligence technology, which specifically relates to the field of image recognition. The application scenarios include at least various terminals, such as mobile phones, computers, and vehicle-mounted terminals. This application includes if the target object is detected in the previous image frame, extracting the original detection image from the current image frame; obtaining the target feature map through the feature extraction network; for each feature map, obtaining the anchor according to the anchor point set in the feature map Point frame; based on the features corresponding to the anchor point frame, obtain optional bounding box parameters through the object detection network; determine the T group of bounding box parameters; determine the tracking result for the target object in the current image frame according to the T group of bounding box parameters. The present application also provides devices, equipment and storage media. The present application not only reduces the amount of data processing and improves the efficiency of target tracking, but also achieves better recognition effect in the process of image detection, thereby helping to improve the accuracy of target tracking.
Description
技术领域technical field
本申请涉及计算机视觉技术,尤其涉及一种目标对象的跟踪方法、相关装置、设备以及存储介质。The present application relates to computer vision technology, and in particular to a method for tracking a target object, related devices, equipment and storage media.
背景技术Background technique
目标跟踪是计算机视觉中的一个重要研究方向,有着广泛的应用。随着计算机技术的发展,出现越来越多的用户和计算机之间进行交互的场景。在交互的场景中,通常需要对目标对象进行定位跟踪,然后再依据跟踪到的目标对象执行不同的交互动作。Object tracking is an important research direction in computer vision and has a wide range of applications. With the development of computer technology, more and more scenarios of interaction between users and computers appear. In an interactive scene, it is usually necessary to locate and track the target object, and then perform different interactive actions based on the tracked target object.
目前,通常采用传统的跟踪算法对目标对象进行跟踪。例如,使用核相关滤波(kernel correlation filter,KCF)算法实现目标跟踪。KCF算法的优势在于速度非常快,因此,该算能够支持在大部分的移动端运行,其推理时间可以达到毫秒级别。At present, traditional tracking algorithms are usually used to track the target object. For example, a kernel correlation filter (kernel correlation filter, KCF) algorithm is used to implement target tracking. The advantage of the KCF algorithm is that it is very fast. Therefore, the algorithm can support running on most mobile terminals, and its inference time can reach the millisecond level.
然而,发明人发现现有方案中至少存在如下问题,KCF算法难以识别出物体的形变。假设初始图像帧中有一个正方形的物体,在后续的跟踪中该物体变换为矩形,此时,KCF算法很难自适应的去把一个正方形修正为矩形,因此,导致目标跟踪的准确性较低。However, the inventors have found that there are at least the following problems in the existing solutions, the KCF algorithm is difficult to identify the deformation of the object. Assuming that there is a square object in the initial image frame, the object is transformed into a rectangle in the subsequent tracking. At this time, it is difficult for the KCF algorithm to adaptively correct a square into a rectangle. Therefore, the accuracy of target tracking is low. .
发明内容Contents of the invention
本申请实施例提供了一种目标对象的跟踪方法、相关装置、设备以及存储介质。一方面,降低了数据处理量,提升目标跟踪效率。另一方面,在图像检测过程中达到更好的识别效果,从而有利于提升目标跟踪的准确性。Embodiments of the present application provide a method for tracking a target object, a related device, equipment, and a storage medium. On the one hand, it reduces the amount of data processing and improves the efficiency of target tracking. On the other hand, a better recognition effect is achieved in the image detection process, which is beneficial to improve the accuracy of target tracking.
有鉴于此,本申请一方面提供一种目标对象的跟踪方法,包括:In view of this, on the one hand, the present application provides a method for tracking a target object, including:
若在当前图像帧的前一个图像帧中检测出目标对象,则根据前一个图像帧所对应的目标边界框,从当前图像帧中提取原始检测图像,其中,原始检测图像包括目标对象;If the target object is detected in the previous image frame of the current image frame, an original detection image is extracted from the current image frame according to the target bounding box corresponding to the previous image frame, wherein the original detection image includes the target object;
基于原始检测图像,通过特征提取网络获取目标特征图,其中,目标特征图包括K个特征点,且目标特征图被划分为N个特征图,每个特征图中设置有一个锚点,K为大于1的整数,N为大于或等于1且小于K的整数;Based on the original detection image, the target feature map is obtained through the feature extraction network, where the target feature map includes K feature points, and the target feature map is divided into N feature maps, each feature map is set with an anchor point, and K is An integer greater than 1, N is an integer greater than or equal to 1 and less than K;
针对每个特征图,根据特征图中设置的锚点获取锚点框;For each feature map, get the anchor point box according to the anchor point set in the feature map;
针对每个特征图,基于锚点框所对应的特征,通过对象检测网络获取至少一组可选边界框参数,其中,每组可选边界框参数包括可选边界框的坐标参数以及尺寸参数;For each feature map, based on the features corresponding to the anchor box, at least one set of optional bounding box parameters is obtained through the object detection network, wherein each set of optional bounding box parameters includes coordinate parameters and size parameters of the optional bounding box;
根据每个特征图的至少一组可选边界框参数确定T组边界框参数,其中,每组边界框参数包括边界框的坐标参数以及尺寸参数,T为大于或等于1的整数;Determine T groups of bounding box parameters according to at least one group of optional bounding box parameters of each feature map, wherein each group of bounding box parameters includes coordinate parameters and size parameters of the bounding box, and T is an integer greater than or equal to 1;
根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果。Determine the tracking result for the target object in the current image frame according to T groups of bounding box parameters.
本申请另一方面提供一种目标对象的跟踪方法,包括:Another aspect of the present application provides a method for tracking a target object, including:
若在当前图像帧的前一个图像帧中检测出目标对象,则根据前一个图像帧所对应的目标边界框,从当前图像帧中提取原始检测图像,其中,原始检测图像包括目标对象;If the target object is detected in the previous image frame of the current image frame, an original detection image is extracted from the current image frame according to the target bounding box corresponding to the previous image frame, wherein the original detection image includes the target object;
基于原始检测图像,通过特征提取网络获取目标特征图;Based on the original detection image, the target feature map is obtained through the feature extraction network;
基于目标特征图,通过对象检测网络获取第一偏移量以及第二偏移量,其中,第一偏移量为左上偏移量,且第二偏移量为右下偏移量,或,第一偏移量为右上偏移量,且第二偏移量为左下偏移量;Based on the target feature map, the first offset and the second offset are obtained through the object detection network, wherein the first offset is the upper left offset, and the second offset is the lower right offset, or, The first offset is an upper right offset, and the second offset is a lower left offset;
根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果。According to the first offset and the second offset, a tracking result for the target object in the current image frame is determined.
本申请另一方面提供一种目标对象跟踪装置,包括:Another aspect of the present application provides a target object tracking device, including:
获取模块,用于若在当前图像帧的前一个图像帧中检测出目标对象,则根据前一个图像帧所对应的目标边界框,从当前图像帧中提取原始检测图像,其中,原始检测图像包括目标对象;The acquisition module is used to extract the original detection image from the current image frame according to the target bounding box corresponding to the previous image frame if the target object is detected in the previous image frame of the current image frame, wherein the original detection image includes target;
获取模块,还用于基于原始检测图像,通过特征提取网络获取目标特征图,其中,目标特征图包括K个特征点,且目标特征图被划分为N个特征图,每个特征图中设置有一个锚点,K为大于1的整数,N为大于或等于1且小于K的整数;The acquisition module is also used to acquire the target feature map through the feature extraction network based on the original detection image, wherein the target feature map includes K feature points, and the target feature map is divided into N feature maps, and each feature map is set with An anchor point, K is an integer greater than 1, N is an integer greater than or equal to 1 and less than K;
获取模块,还用于针对每个特征图,根据特征图中设置的锚点获取锚点框;The obtaining module is also used for obtaining an anchor point frame according to the anchor point set in the feature map for each feature map;
获取模块,还用于针对每个特征图,基于锚点框所对应的特征,通过对象检测网络获取至少一组可选边界框参数,其中,每组可选边界框参数包括可选边界框的坐标参数以及尺寸参数;The obtaining module is further configured to obtain at least one set of optional bounding box parameters through the object detection network based on the features corresponding to the anchor point boxes for each feature map, wherein each set of optional bounding box parameters includes optional bounding box parameters Coordinate parameters and size parameters;
确定模块,用于根据每个特征图的至少一组可选边界框参数确定T组边界框参数,其中,每组边界框参数包括边界框的坐标参数以及尺寸参数,T为大于或等于1的整数;A determining module, configured to determine T groups of bounding box parameters according to at least one set of optional bounding box parameters of each feature map, wherein each group of bounding box parameters includes coordinate parameters and size parameters of the bounding box, and T is greater than or equal to 1 integer;
跟踪模块,用于根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果。A tracking module, configured to determine a tracking result for the target object in the current image frame according to T groups of bounding box parameters.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,目标对象跟踪装置还包括识别模块;In a possible design, in an implementation manner of another aspect of the embodiments of the present application, the target object tracking device further includes an identification module;
识别模块,用于若在当前图像帧的前一个图像帧中未检测出目标对象,则对当前图像帧进行对象识别;The recognition module is used to perform object recognition on the current image frame if no target object is detected in the previous image frame of the current image frame;
识别模块,还用于若未获取到当前图像帧的前一个图像帧,则对当前图像帧进行对象识别。The recognition module is also used for performing object recognition on the current image frame if the previous image frame of the current image frame is not obtained.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,In a possible design, in an implementation manner of another aspect of the embodiments of the present application,
获取模块,具体用于对原始检测图像进行尺寸调整,得到待处理图像;The acquisition module is specifically used to adjust the size of the original detection image to obtain the image to be processed;
若待处理图像的尺寸与预设尺寸匹配失败,则对待处理图像进行填充,得到满足预设尺寸的目标检测图像;If the size of the image to be processed fails to match the preset size, the image to be processed is filled to obtain a target detection image that meets the preset size;
基于目标检测图像,通过特征提取网络输出目标特征图。Based on the target detection image, the target feature map is output through the feature extraction network.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,每组可选边界框参数还包括置信度参数,至少一组可选边界框参数包括多组可选边界框参数;In a possible design, in an implementation of another aspect of the embodiments of the present application, each set of optional bounding box parameters further includes a confidence parameter, and at least one set of optional bounding box parameters includes multiple sets of optional bounding box parameters. Bounding box parameters;
确定模块,具体用于针对每个特征图,从多组可选边界框参数中选择具有最大置信度参数的可选边界框参数,其中,每组可选边界框参数用于确定一个可选边界框;The determination module is specifically used for selecting an optional bounding box parameter with the maximum confidence parameter from multiple sets of optional bounding box parameters for each feature map, wherein each set of optional bounding box parameters is used to determine an optional bounding box parameter frame;
针对每个特征图,根据具有最大置信度参数的可选边界框参数,确定初始可选边界框;For each feature map, determine an initial optional bounding box according to the optional bounding box parameter with the maximum confidence parameter;
针对每个特征图,遍历其余的可选边界框,若存在可选边界框与初始可选边界框之间的重叠面积大于或等于面积阈值,则删除可选边界框,直至得到剩余的可选边界框,其中,其余的可选边界框表示除了初始可选边界框之外的可选边界框;For each feature map, traverse the remaining optional bounding boxes. If the overlapping area between the optional bounding box and the initial optional bounding box is greater than or equal to the area threshold, delete the optional bounding box until the remaining optional bounding boxes are obtained. bounding boxes, where the remaining optional bounding boxes represent optional bounding boxes in addition to the initial optional bounding box;
针对每个特征图,将剩余的可选边界框所对应的可选边界框参数作为边界框参数。For each feature map, the optional bounding box parameters corresponding to the remaining optional bounding boxes are used as bounding box parameters.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,In a possible design, in an implementation manner of another aspect of the embodiments of the present application,
跟踪模块,具体用于根据T组边界框参数确定T个边界框;A tracking module, specifically for determining T bounding boxes according to T groups of bounding box parameters;
根据T个边界框确定最左侧顶点、最右侧顶点、最上侧顶点以及最下侧顶点;Determine the leftmost vertex, the rightmost vertex, the uppermost vertex, and the lowermost vertex according to the T bounding boxes;
根据最左侧顶点、最右侧顶点、最上侧顶点以及最下侧顶点,确定左上顶点坐标、左下顶点坐标、右上顶点坐标以及右下顶点坐标;Determine the coordinates of the upper left vertex, the lower left vertex, the upper right vertex, and the lower right vertex according to the leftmost vertex, the rightmost vertex, the uppermost vertex, and the lowermost vertex;
根据左上顶点坐标、左下顶点坐标、右上顶点坐标以及右下顶点坐标,确定针对目标对象的跟踪结果。According to the coordinates of the upper left vertex, the lower left vertex, the upper right vertex and the lower right vertex, the tracking result for the target object is determined.
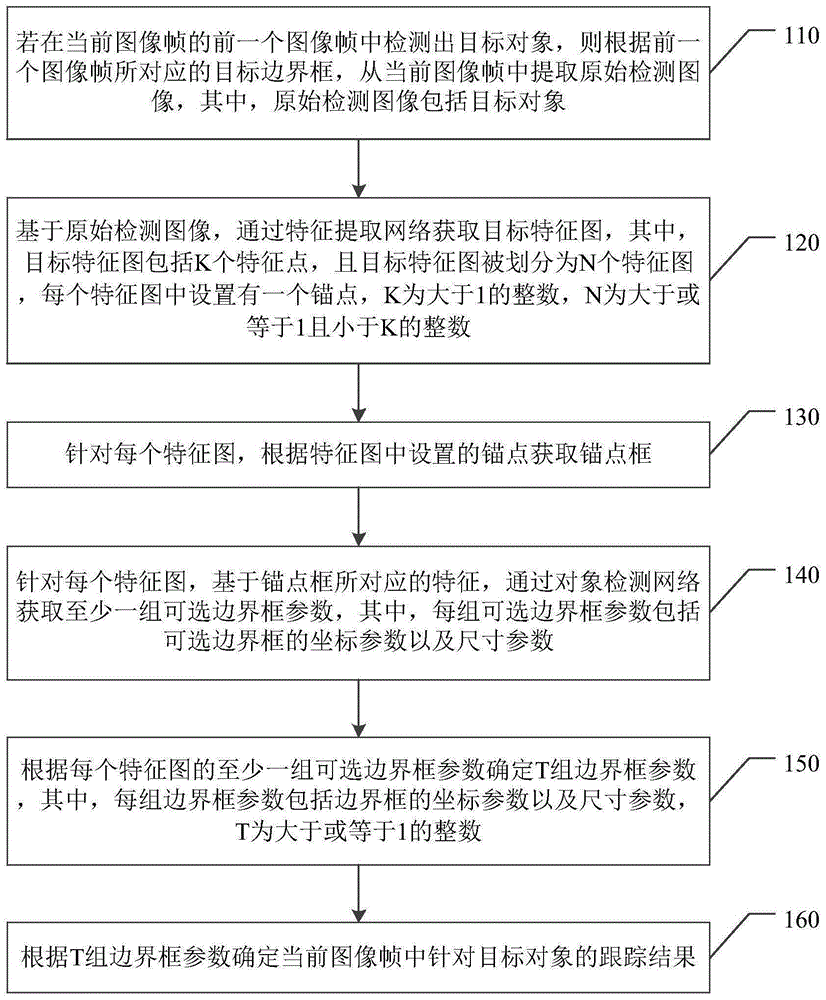
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,目标对象跟踪装置还包括训练模块;In a possible design, in an implementation of another aspect of the embodiments of the present application, the target object tracking device further includes a training module;
获取模块,还用于获取图像样本,其中,图像样本包括目标对象;The obtaining module is also used to obtain image samples, wherein the image samples include the target object;
获取模块,还用于基于图像样本,通过特征提取网络获取样本特征图,其中,样本特征图包括K个特征点,样本特征图被划分为N个待训练特征图,每个待训练特征图中设置有一个锚点;The acquisition module is also used to obtain the sample feature map through the feature extraction network based on the image sample, wherein the sample feature map includes K feature points, the sample feature map is divided into N feature maps to be trained, and each feature map to be trained set has an anchor;
获取模块,还用于针对每个待训练特征图,根据待训练特征图中设置的锚点获取锚点框;The obtaining module is also used for obtaining the anchor point frame according to the anchor point set in the feature map to be trained for each feature map to be trained;
获取模块,还用于针对每个待训练特征图,基于锚点框所对应的特征以及真实边界框参数,通过对象检测网络获取至少一组可选边界框参数,其中,每组可选边界框参数包括待训练边界框的坐标参数以及尺寸参数;The obtaining module is also used to obtain at least one set of optional bounding box parameters through the object detection network based on the features corresponding to the anchor box and the real bounding box parameters for each feature map to be trained, wherein each set of optional bounding boxes The parameters include coordinate parameters and size parameters of the bounding box to be trained;
确定模块,还用于针对每个待训练特征图,从至少一组可选边界框参数中确定预测边界框参数;The determination module is also used to determine the predicted bounding box parameters from at least one set of optional bounding box parameters for each feature map to be trained;
训练模块,用于针对每个待训练特征图,根据预测边界框参数以及真实边界框参数,采用损失函数对特征提取网络以及对象检测网络的模型参数进行更新。The training module is used for updating the model parameters of the feature extraction network and the object detection network by using a loss function according to the predicted bounding box parameters and the real bounding box parameters for each feature map to be trained.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,目标对象跟踪装置还包括检测模块;In a possible design, in an implementation manner of another aspect of the embodiments of the present application, the target object tracking device further includes a detection module;
检测模块,用于采用预设跟踪算法对当前图像帧进行检测,得到目标对象的第一中心位置参数,其中,预设跟踪算法为核相关滤波算法、在线实时跟踪算法、背景感知相关滤波算法或多实例在线学习算法;The detection module is used to detect the current image frame using a preset tracking algorithm to obtain the first center position parameter of the target object, wherein the preset tracking algorithm is a kernel correlation filtering algorithm, an online real-time tracking algorithm, a background perception correlation filtering algorithm or Multi-instance online learning algorithm;
跟踪模块,具体用于根据T组边界框参数,确定目标对象的第二中心位置参数;The tracking module is specifically used to determine the second center position parameter of the target object according to the T group of bounding box parameters;
根据第一中心位置参数以及第二中心位置参数,确定当前图像帧中针对目标对象的跟踪结果。According to the first center position parameter and the second center position parameter, a tracking result for the target object in the current image frame is determined.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,目标对象为人手;In a possible design, in an implementation manner of another aspect of the embodiment of the present application, the target object is a human hand;
目标对象跟踪装置还包括启动模块、生成模块以及触发模块;The target object tracking device also includes a starting module, a generating module and a triggering module;
启动模块,用于响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;The starting module is used to start the camera device of the terminal device in response to the operation on the video shooting control;
获取模块,还用于通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;The acquisition module is also used to collect M consecutive image frames through the camera device, where M is an integer greater than or equal to 1;
获取模块,还用于根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果之后,获取连续M个图像帧中针对人手的跟踪结果;The acquisition module is also used to obtain the tracking results for the human hand in consecutive M image frames after determining the tracking results for the target object in the current image frame according to the T group of bounding box parameters;
生成模块,用于根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,生成针对人手的移动轨迹;A generating module, configured to generate a moving track for the human hand according to the tracking results corresponding to the consecutive M image frames and the tracking results corresponding to the current image frame;
触发模块,用于若移动轨迹与预设轨迹匹配成功,则触发与预设轨迹对应的功能。The trigger module is configured to trigger the function corresponding to the preset track if the moving track matches the preset track successfully.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,目标对象为人手;In a possible design, in an implementation manner of another aspect of the embodiment of the present application, the target object is a human hand;
启动模块,还用于响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;The starting module is also used to start the camera device of the terminal device in response to the operation on the video shooting control;
获取模块,还用于通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;The acquisition module is also used to collect M consecutive image frames through the camera device, where M is an integer greater than or equal to 1;
获取模块,还用于根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果之后,获取连续M个图像帧中针对人手的跟踪结果;The acquisition module is also used to obtain the tracking results for the human hand in consecutive M image frames after determining the tracking results for the target object in the current image frame according to the T group of bounding box parameters;
获取模块,还用于根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,获取轨迹长度;The obtaining module is also used to obtain the track length according to the tracking results corresponding to the consecutive M image frames and the tracking results corresponding to the current image frame;
触发模块,还用于若轨迹长度大于或等于长度阈值,则触发与预设轨迹对应的功能。The trigger module is also used to trigger the function corresponding to the preset track if the track length is greater than or equal to the length threshold.
本申请另一方面提供一种目标对象跟踪装置,包括:Another aspect of the present application provides a target object tracking device, including:
获取模块,用于若在当前图像帧的前一个图像帧中检测出目标对象,则根据前一个图像帧所对应的目标边界框,从当前图像帧中提取原始检测图像,其中,原始检测图像包括目标对象;The acquisition module is used to extract the original detection image from the current image frame according to the target bounding box corresponding to the previous image frame if the target object is detected in the previous image frame of the current image frame, wherein the original detection image includes target;
获取模块,还用于基于原始检测图像,通过特征提取网络获取目标特征图;The acquisition module is also used to acquire the target feature map through the feature extraction network based on the original detection image;
获取模块,还用于基于目标特征图,通过对象检测网络获取第一偏移量以及第二偏移量,其中,第一偏移量为左上偏移量,且第二偏移量为右下偏移量,或,第一偏移量为右上偏移量,且第二偏移量为左下偏移量;The obtaining module is also used to obtain the first offset and the second offset through the object detection network based on the target feature map, wherein the first offset is the upper left offset, and the second offset is the lower right offset, or, the first offset is the upper right offset, and the second offset is the lower left offset;
跟踪模块,用于根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果。The tracking module is configured to determine a tracking result for the target object in the current image frame according to the first offset and the second offset.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,目标对象跟踪装置还包括识别模块;In a possible design, in an implementation manner of another aspect of the embodiments of the present application, the target object tracking device further includes an identification module;
识别模块,用于若在当前图像帧的前一个图像帧中未检测出目标对象,则对当前图像帧进行对象识别;The recognition module is used to perform object recognition on the current image frame if no target object is detected in the previous image frame of the current image frame;
识别模块,还用于若未获取到当前图像帧的前一个图像帧,则对当前图像帧进行对象识别。The recognition module is also used for performing object recognition on the current image frame if the previous image frame of the current image frame is not obtained.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,In a possible design, in an implementation manner of another aspect of the embodiments of the present application,
获取模块,具体用于对原始检测图像进行尺寸调整,得到待处理图像;The acquisition module is specifically used to adjust the size of the original detection image to obtain the image to be processed;
若待处理图像的尺寸与预设尺寸匹配失败,则对待处理图像进行填充,得到满足预设尺寸的目标检测图像;If the size of the image to be processed fails to match the preset size, the image to be processed is filled to obtain a target detection image that meets the preset size;
基于目标检测图像,通过特征提取网络输出目标特征图。Based on the target detection image, the target feature map is output through the feature extraction network.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,第一偏移量为左上偏移量,且第二偏移量为右下偏移量,其中,左上偏移量包括左上顶点距离初始左上顶点的横向偏移量以及纵向偏移量,右下偏移量包括右下顶点距离初始右下顶点的横向偏移量以及纵向偏移量;In a possible design, in an implementation manner of another aspect of the embodiments of the present application, the first offset is an upper-left offset, and the second offset is a lower-right offset, wherein, The upper left offset includes the horizontal offset and vertical offset from the upper left vertex to the initial upper left vertex, and the lower right offset includes the horizontal offset and vertical offset from the lower right vertex to the initial lower right vertex;
目标对象跟踪装置还包括训练模块;The target object tracking device also includes a training module;
获取模块,还用于获取图像样本,其中,图像样本包括目标对象;The obtaining module is also used to obtain image samples, wherein the image samples include the target object;
获取模块,还用于基于图像样本,通过特征提取网络获取样本特征图;The obtaining module is also used to obtain the sample feature map through the feature extraction network based on the image sample;
获取模块,还用于基于样本特征图,通过对象检测网络获取左上预测偏移量以及右下预测偏移量;The obtaining module is also used to obtain the upper left prediction offset and the lower right prediction offset through the object detection network based on the sample feature map;
训练模块,用于基于样本特征图,根据左上预测偏移量、右下预测偏移量、左上真实偏移量以及右下真实偏移量,采用损失函数对特征提取网络以及对象检测网络的模型参数进行更新。The training module is used to use the loss function to model the feature extraction network and the object detection network based on the sample feature map, according to the upper left predicted offset, the lower right predicted offset, the upper left real offset and the lower right real offset The parameters are updated.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,第一偏移量为右上偏移量,且第二偏移量为左下偏移量,其中,右上偏移量包括右上顶点距离初始右上顶点的横向偏移量以及纵向偏移量,左下偏移量包括左下顶点距离初始左下顶点的横向偏移量以及纵向偏移量;In a possible design, in an implementation of another aspect of the embodiments of the present application, the first offset is an upper-right offset, and the second offset is a lower-left offset, where the upper-right The offset includes the horizontal offset and vertical offset from the upper right vertex to the initial upper right vertex, and the lower left offset includes the horizontal offset and vertical offset from the lower left vertex to the initial lower left vertex;
获取模块,还用于获取图像样本,其中,图像样本包括目标对象;The obtaining module is also used to obtain image samples, wherein the image samples include the target object;
获取模块,还用于基于图像样本,通过特征提取网络获取样本特征图;The obtaining module is also used to obtain the sample feature map through the feature extraction network based on the image sample;
获取模块,还用于基于样本特征图,通过对象检测网络获取右上预测偏移量以及左下预测偏移量;The obtaining module is also used to obtain the upper-right prediction offset and the lower-left prediction offset through the object detection network based on the sample feature map;
训练模块,还用于基于样本特征图,根据右上预测偏移量、左下预测偏移量、右上真实偏移量以及左下真实偏移量,采用损失函数对特征提取网络以及对象检测网络的模型参数进行更新。The training module is also used to use the loss function to modify the model parameters of the feature extraction network and the object detection network based on the sample feature map, according to the upper right predicted offset, the lower left predicted offset, the upper right real offset and the lower left real offset to update.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,目标对象跟踪装置还包括检测模块;In a possible design, in an implementation manner of another aspect of the embodiments of the present application, the target object tracking device further includes a detection module;
检测模块,用于采用预设跟踪算法对当前图像帧进行检测,得到目标对象的第一中心位置参数,其中,预设跟踪算法为核相关滤波算法、在线实时跟踪算法、背景感知相关滤波算法或多实例在线学习算法;The detection module is used to detect the current image frame using a preset tracking algorithm to obtain the first center position parameter of the target object, wherein the preset tracking algorithm is a kernel correlation filtering algorithm, an online real-time tracking algorithm, a background perception correlation filtering algorithm or Multi-instance online learning algorithm;
跟踪模块,具体用于根据第一偏移量以及第二偏移量,确定目标对象的第二中心位置参数;The tracking module is specifically configured to determine the second center position parameter of the target object according to the first offset and the second offset;
根据第一中心位置参数以及第二中心位置参数,确定当前图像帧中针对目标对象的跟踪结果。According to the first center position parameter and the second center position parameter, a tracking result for the target object in the current image frame is determined.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,目标对象为人手;In a possible design, in an implementation manner of another aspect of the embodiment of the present application, the target object is a human hand;
目标对象跟踪装置还包括启动模块、生成模块以及触发模块;The target object tracking device also includes a starting module, a generating module and a triggering module;
启动模块,用于响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;The starting module is used to start the camera device of the terminal device in response to the operation on the video shooting control;
获取模块,还用于通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;The acquisition module is also used to collect M consecutive image frames through the camera device, where M is an integer greater than or equal to 1;
获取模块,还用于根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果之后,获取连续M个图像帧中针对人手的跟踪结果;The acquisition module is also used to obtain the tracking results for the human hand in consecutive M image frames after determining the tracking results for the target object in the current image frame according to the first offset and the second offset;
生成模块,用于根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,生成针对人手的移动轨迹;A generating module, configured to generate a moving track for the human hand according to the tracking results corresponding to the consecutive M image frames and the tracking results corresponding to the current image frame;
触发模块,用于若移动轨迹与预设轨迹匹配成功,则触发与预设轨迹对应的功能。The trigger module is configured to trigger the function corresponding to the preset track if the moving track matches the preset track successfully.
在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中,目标对象为人手;In a possible design, in an implementation manner of another aspect of the embodiment of the present application, the target object is a human hand;
启动模块,还用于响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;The starting module is also used to start the camera device of the terminal device in response to the operation on the video shooting control;
获取模块,还用于通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;The acquisition module is also used to collect M consecutive image frames through the camera device, where M is an integer greater than or equal to 1;
获取模块,还用于根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果之后,获取连续M个图像帧中针对人手的跟踪结果;The acquisition module is also used to obtain the tracking results for the human hand in consecutive M image frames after determining the tracking results for the target object in the current image frame according to the first offset and the second offset;
获取模块,还用于根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,获取轨迹长度;The obtaining module is also used to obtain the track length according to the tracking results corresponding to the consecutive M image frames and the tracking results corresponding to the current image frame;
触发模块,还用于若轨迹长度大于或等于长度阈值,则触发与预设轨迹对应的功能。The trigger module is also used to trigger the function corresponding to the preset track if the track length is greater than or equal to the length threshold.
本申请另一方面提供一种计算机设备,包括:存储器、处理器以及总线系统;Another aspect of the present application provides a computer device, including: a memory, a processor, and a bus system;
其中,存储器用于存储程序;Among them, the memory is used to store programs;
处理器用于执行存储器中的程序,处理器用于根据程序代码中的指令执行上述各方面的方法;The processor is used to execute the program in the memory, and the processor is used to execute the methods in the above aspects according to the instructions in the program code;
总线系统用于连接存储器以及处理器,以使存储器以及处理器进行通信。The bus system is used to connect the memory and the processor so that the memory and the processor can communicate.
本申请另一方面提供一种终端设备,包括:存储器、处理器以及总线系统;Another aspect of the present application provides a terminal device, including: a memory, a processor, and a bus system;
其中,存储器用于存储程序;Among them, the memory is used to store programs;
处理器用于执行存储器中的程序,处理器用于根据程序代码中的指令执行上述各方面的方法;The processor is used to execute the program in the memory, and the processor is used to execute the methods in the above aspects according to the instructions in the program code;
总线系统用于连接存储器以及处理器,以使存储器以及处理器进行通信。The bus system is used to connect the memory and the processor so that the memory and the processor can communicate.
本申请的另一方面提供了一种计算机可读存储介质,计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述各方面的方法。Another aspect of the present application provides a computer-readable storage medium. Instructions are stored in the computer-readable storage medium. When the computer-readable storage medium is run on a computer, it causes the computer to execute the methods in the above aspects.
本申请的另一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述各方面所提供的方法。Another aspect of the present application provides a computer program product or computer program, where the computer program product or computer program includes computer instructions, and the computer instructions are stored in a computer-readable storage medium. The processor of the computer device reads the computer instruction from the computer-readable storage medium, and the processor executes the computer instruction, so that the computer device executes the method provided by the above aspects.
从以上技术方案可以看出,本申请实施例具有以下优点:It can be seen from the above technical solutions that the embodiments of the present application have the following advantages:
本申请实施例中,提供了一种目标对象的跟踪方法,首先获取当前图像帧,然后判断在当前图像帧的前一个图像帧中是否检测出目标对象,若是,则根据前一个图像帧的目标边界框,从当前图像帧中提取原始检测图像。接下来,通过特征提取网络获取原始检测图像的目标特征图,进而可通过对象检测网络获取目标特征图对应的T组边界框参数,最后,结合T组边界框参数确定当前图像帧中针对目标对象的跟踪结果。通过上述方式,一方面,从当前图像帧中提取包含有目标对象的原始检测图像用于后续检测,相比于直接对整个当前图像帧进行检测,降低了数据处理量,与此同时,将目标特征图拆分为多个特征图分别进行检测,能够把跟踪看成是一个小规模的检测问题,从而解决被跟踪物体尺度变化和位移变化的问题,提升目标跟踪效率。另一方面,采用对象检测网络对原始检测图像进行边界框检测,相比于传统跟踪算法,能够基于学习到的目标对象的特征,在图像检测过程中达到更好的识别效果,从而有利于提升目标跟踪的准确性。In the embodiment of the present application, a method for tracking a target object is provided. Firstly, the current image frame is obtained, and then it is judged whether the target object is detected in the previous image frame of the current image frame. Bounding box, extract the original detection image from the current image frame. Next, the target feature map of the original detection image is obtained through the feature extraction network, and then the T group of bounding box parameters corresponding to the target feature map can be obtained through the object detection network. Finally, combined with the T group of bounding box parameters to determine the target object in the current image frame tracking results. Through the above method, on the one hand, the original detection image containing the target object is extracted from the current image frame for subsequent detection. Compared with directly detecting the entire current image frame, the amount of data processing is reduced. At the same time, the target The feature map is split into multiple feature maps for detection separately, and tracking can be regarded as a small-scale detection problem, so as to solve the problem of scale change and displacement change of the tracked object and improve the efficiency of target tracking. On the other hand, using the object detection network to detect the bounding box of the original detection image, compared with the traditional tracking algorithm, can achieve better recognition effect in the image detection process based on the characteristics of the learned target object, which is conducive to improving Accuracy of object tracking.
附图说明Description of drawings
图1为本申请实施例中目标对象跟踪方法的一个场景示意图;FIG. 1 is a schematic diagram of a scene of a target object tracking method in an embodiment of the present application;
图2为本申请实施例中目标对象跟踪方法的另一个场景示意图;FIG. 2 is a schematic diagram of another scene of the target object tracking method in the embodiment of the present application;
图3为本申请实施例中目标对象跟踪方法的一个流程示意图;FIG. 3 is a schematic flow diagram of a target object tracking method in an embodiment of the present application;
图4为本申请实施例中基于锚点机制实现对象检测的一个示意图;FIG. 4 is a schematic diagram of object detection based on the anchor point mechanism in the embodiment of the present application;
图5为本申请实施例中基于帧间控制进行目标对象跟踪的一个示意图;FIG. 5 is a schematic diagram of target object tracking based on inter-frame control in an embodiment of the present application;
图6为本申请实施例中对原始检测图像进行尺寸调整的一个示意图;Fig. 6 is a schematic diagram of adjusting the size of the original detection image in the embodiment of the present application;
图7为本申请实施例中基于锚点机制生成跟踪结果的一个示意图;FIG. 7 is a schematic diagram of tracking results generated based on the anchor point mechanism in the embodiment of the present application;
图8为本申请实施例中融合得到跟踪结果的一个示意图;Fig. 8 is a schematic diagram of the tracking result obtained by fusion in the embodiment of the present application;
图9为本申请实施例中基于运动轨迹触发应用功能的一个示意图;FIG. 9 is a schematic diagram of triggering application functions based on motion trajectories in the embodiment of the present application;
图10为本申请实施例中基于移动距离触发应用功能的一个示意图;FIG. 10 is a schematic diagram of triggering an application function based on a moving distance in an embodiment of the present application;
图11为本申请实施例中目标对象跟踪方法的另一个流程示意图;FIG. 11 is another schematic flowchart of the target object tracking method in the embodiment of the present application;
图12为本申请实施例中基于单一边框实现对象检测的一个示意图;FIG. 12 is a schematic diagram of object detection based on a single border in the embodiment of the present application;
图13为本申请实施例中基于单一边框实现对象检测的另一个示意图;FIG. 13 is another schematic diagram of object detection based on a single border in the embodiment of the present application;
图14为本申请实施例中目标对象跟踪装置的一个示意图;FIG. 14 is a schematic diagram of a target object tracking device in an embodiment of the present application;
图15为本申请实施例中目标对象跟踪装置的另一个示意图;Fig. 15 is another schematic diagram of the target object tracking device in the embodiment of the present application;
图16为本申请实施例中终端设备的一个结构示意图。FIG. 16 is a schematic structural diagram of a terminal device in an embodiment of the present application.
具体实施方式Detailed ways
本申请实施例提供了一种目标对象的跟踪方法、相关装置、设备以及存储介质。一方面,降低了数据处理量,提升目标跟踪效率。另一方面,在图像检测过程中达到更好的识别效果,从而有利于提升目标跟踪的准确性。Embodiments of the present application provide a method for tracking a target object, a related device, equipment, and a storage medium. On the one hand, it reduces the amount of data processing and improves the efficiency of target tracking. On the other hand, a better recognition effect is achieved in the image detection process, which is beneficial to improve the accuracy of target tracking.
本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“对应于”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。The terms "first", "second", "third", "fourth", etc. (if any) in the specification and claims of the present application and the above drawings are used to distinguish similar objects, and not necessarily Used to describe a specific sequence or sequence. It is to be understood that the data so used are interchangeable under appropriate circumstances such that the embodiments of the application described herein, for example, can be practiced in sequences other than those illustrated or described herein. Furthermore, the terms "comprising" and "corresponding to" and any variations thereof, are intended to cover a non-exclusive inclusion, for example, a process, method, system, product or device comprising a sequence of steps or elements need not be limited to the expressly listed Instead, other steps or elements not explicitly listed or inherent to the process, method, product or apparatus may be included.
目标跟踪是计算机视觉(computer vision,CV)领域的一个重要分支,是模式识别、图像处理和机器学习等学科的交叉研究,有着广泛的应用,例如,视频监控、虚拟现实、人机交互、图像理解以及无人驾驶等。本申请提供了一种目标对象的跟踪方法,能够兼顾跟踪效率和跟踪准确性,适用于移动端应用。Object tracking is an important branch of computer vision (CV), which is an interdisciplinary study of pattern recognition, image processing and machine learning, and has a wide range of applications, such as video surveillance, virtual reality, human-computer interaction, image Understanding and unmanned driving, etc. The present application provides a method for tracking a target object, which can take into account both tracking efficiency and tracking accuracy, and is suitable for mobile terminal applications.
以跟踪的目标对象为人手为例,作为人手相关算法移动端应用的基础,包括人手关键点检测,人手手势识别,人手三维姿态估计等。在当前的短视频和小视频时代,用户在使用时,经常会有很多手势交互的动作用以来触发各种特效挂件和其他的玩法。因此,开发一种移动端高速且准确的跟踪算法十分重要。对于一些应用产品而言,可能需要适配的手机从低端机到高端机有很广泛的分布,需要在最低端的手机上能够达到实时跟踪的效果,且尽可能少的占用手机的计算资源和提高手机的续航。基于这个前提,既要实现速度快且稳定性好的跟踪算法,又要能够做到低延时和低功耗,从而能够很好地嵌入到终端设备的跟踪系统,提升整体的稳定性和用户体验。Taking the human hand as the target object to be tracked as an example, as the basis for the mobile terminal application of the human hand correlation algorithm, it includes key point detection of the human hand, gesture recognition of the human hand, and 3D pose estimation of the human hand, etc. In the current short video and small video era, users often have a lot of gesture interaction actions to trigger various special effects pendants and other gameplays when using it. Therefore, it is very important to develop a high-speed and accurate tracking algorithm for mobile terminals. For some application products, there may be a wide distribution of mobile phones that need to be adapted from low-end phones to high-end phones. It is necessary to achieve real-time tracking effects on the lowest-end mobile phones and occupy as little computing resources and resources as possible. Improve the battery life of the mobile phone. Based on this premise, it is necessary to implement a fast and stable tracking algorithm, but also to achieve low latency and low power consumption, so that it can be well embedded into the tracking system of the terminal device and improve the overall stability and user experience. experience.
本申请提出了一种目标对象的跟踪方法,该方法应用于目标对象跟踪系统,目标对象跟踪系统包括终端设备,或者,目标对象跟踪系统包括终端设备以及服务器。本申请以运行于终端设备为例进行说明,终端设备上部署有客户端。客户端可以通过浏览器的形式运行于终端设备上,也可以通过独立的应用程序(application,APP)的形式运行于终端设备上等,对于客户端的具体展现形式,此处不做限定。终端设备可以是智能手机、平板电脑、笔记本电脑、掌上电脑、个人电脑、智能电视、智能手表、车载设备、可穿戴设备等,但并不局限于此。The present application proposes a method for tracking a target object. The method is applied to a target object tracking system. The target object tracking system includes a terminal device, or the target object tracking system includes a terminal device and a server. This application is described by taking running on a terminal device as an example, and a client is deployed on the terminal device. The client can run on the terminal device in the form of a browser, or can run on the terminal device in the form of an independent application program (APP), etc. The specific display form of the client is not limited here. The terminal device may be a smart phone, a tablet computer, a laptop computer, a handheld computer, a personal computer, a smart TV, a smart watch, a vehicle device, a wearable device, etc., but is not limited thereto.
示例性地,在单人交互场景中可实现目标跟踪,为了便于说明,请参阅图1,图1为本申请实施例中目标对象跟踪方法的一个场景示意图,如图所示,在终端设备上显示有互动提示,用户可跟随互动提示执行相应的动作。由终端设备通过摄像头采集视频,并对视频中的图像帧进行分析,达到跟踪人手的目的。Exemplarily, target tracking can be realized in a single-person interaction scene. For the convenience of description, please refer to FIG. 1. FIG. 1 is a schematic diagram of a scene of a target object tracking method in an embodiment of the present application. There are interactive prompts displayed, and users can follow the interactive prompts to perform corresponding actions. The terminal device collects the video through the camera, and analyzes the image frames in the video to achieve the purpose of tracking the human hand.
示例性地,在多人交互场景中可实现目标跟踪,为了便于说明,请参阅图2,图2为本申请实施例中目标对象跟踪方法的另一个场景示意图,如图所示,在终端设备上显示有互动提示,用户甲和用户乙可分别跟随互动提示执行相应的动作。由终端设备通过摄像头采集视频,并对视频中的图像帧进行分析,达到跟踪人手的目的。Exemplarily, target tracking can be realized in a multi-person interaction scene. For the convenience of description, please refer to FIG. 2. FIG. 2 is a schematic diagram of another scene of the target object tracking method in the embodiment of the present application. There are interactive prompts displayed on the screen, and user A and user B can respectively follow the interactive prompts to perform corresponding actions. The terminal device collects the video through the camera, and analyzes the image frames in the video to achieve the purpose of tracking the human hand.
本申请提出了一种目标对象的跟踪方法具体涉及到人工智能(artificialintelligence,AI)领域中的CV技术和机器学习(machine learning,ML)技术。其中,CV是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,CV研究相关的理论和技术,试图建立能够从图像或者多维数据中获取信息的AI系统。CV技术通常包括图像处理、图像识别、图像语义理解、图像检索、光学字符识别(optical character recognition,OCR)、视频处理、视频语义理解、视频内容/行为识别、三维物体重建、3D技术、虚拟现实、增强现实、同步定位与地图构建、自动驾驶、智慧交通等技术,还包括常见的人脸识别、指纹识别等生物特征识别技术。ML是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。ML是AI的核心,是使计算机具有智能的根本途径,其应用遍及AI的各个领域。ML和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习等技术。The present application proposes a method for tracking a target object, which specifically relates to CV technology and machine learning (machine learning, ML) technology in the field of artificial intelligence (AI). Among them, CV is a science that studies how to make machines "see". Furthermore, it refers to the use of cameras and computers instead of human eyes to identify, track and measure targets, and further graphics processing to make computers It is processed into an image that is more suitable for human observation or sent to the instrument for detection. As a scientific discipline, CV studies related theories and technologies, trying to build AI systems that can obtain information from images or multidimensional data. CV technology usually includes image processing, image recognition, image semantic understanding, image retrieval, optical character recognition (OCR), video processing, video semantic understanding, video content/behavior recognition, 3D object reconstruction, 3D technology, virtual reality , augmented reality, simultaneous positioning and map construction, autonomous driving, smart transportation and other technologies, as well as common biometric recognition technologies such as face recognition and fingerprint recognition. ML is a multi-field interdisciplinary subject, involving probability theory, statistics, approximation theory, convex analysis, algorithm complexity theory and other disciplines. Specializes in the study of how computers simulate or implement human learning behaviors to acquire new knowledge or skills, and reorganize existing knowledge structures to continuously improve their performance. ML is the core of AI and the fundamental way to make computers intelligent, and its application pervades all fields of AI. ML and deep learning usually include techniques such as artificial neural networks, belief networks, reinforcement learning, transfer learning, inductive learning, and teaching-based learning.
其中,AI是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,AI是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。AI也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。Among them, AI is the theory, method, technology and application system that uses digital computers or machines controlled by digital computers to simulate, extend and expand human intelligence, perceive the environment, acquire knowledge and use knowledge to obtain the best results. In other words, AI is a synthesis of computer science that attempts to understand the nature of intelligence and produce a new class of intelligent machines that respond in ways similar to human intelligence. AI is to study the design principles and implementation methods of various intelligent machines, so that the machines have the functions of perception, reasoning and decision-making.
AI技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。AI基础技术一般包括如传感器、专用AI芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。AI软件技术主要包括CV技术、语音处理技术、自然语言处理技术以及机器学习/深度学习、自动驾驶、智慧交通等几大方向。AI technology is a comprehensive subject that involves a wide range of fields, including both hardware-level technology and software-level technology. AI basic technologies generally include technologies such as sensors, dedicated AI chips, cloud computing, distributed storage, big data processing technology, operation/interaction systems, and mechatronics. AI software technology mainly includes CV technology, speech processing technology, natural language processing technology, machine learning/deep learning, automatic driving, intelligent transportation and other major directions.
随着AI技术研究和进步,AI技术在多个领域展开研究和应用,例如常见的智能家居、智能穿戴设备、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、机器人、智能医疗、智能客服、车联网、自动驾驶、智慧交通等,相信随着技术的发展,AI技术将在更多的领域得到应用,并发挥越来越重要的价值。With the research and progress of AI technology, AI technology has been researched and applied in many fields, such as common smart home, smart wearable devices, virtual assistants, smart speakers, smart marketing, unmanned driving, automatic driving, drones, robots , smart medical care, smart customer service, Internet of Vehicles, autonomous driving, smart transportation, etc. I believe that with the development of technology, AI technology will be applied in more fields and play an increasingly important role.
结合上述介绍,本申请实施例提供的方案涉及AI的CV和ML等技术,下面将对本申请中目标对象的跟踪方法进行介绍,请参阅图3,本申请实施例中目标对象跟踪方法的一个实施例包括:In combination with the above introduction, the solution provided by the embodiment of this application involves technologies such as AI CV and ML. The following will introduce the tracking method of the target object in this application. Please refer to Figure 3, an implementation of the target object tracking method in the embodiment of this application Examples include:
110、若在当前图像帧的前一个图像帧中检测出目标对象,则根据前一个图像帧所对应的目标边界框,从当前图像帧中提取原始检测图像,其中,原始检测图像包括目标对象;110. If the target object is detected in the previous image frame of the current image frame, extract an original detection image from the current image frame according to the target bounding box corresponding to the previous image frame, wherein the original detection image includes the target object;
在一个或多个实施例中,目标对象跟踪装置获取当前图像帧以及当前图像帧的前一个图像帧,并判断前一个图像帧中是否检测出目标对象(例如,人手),如果检测出目标对象,则可以基于前一个图像帧的跟踪结果(即,目标边界框)确定当前图像帧中目标对象的大致范围。In one or more embodiments, the target object tracking device acquires the current image frame and the previous image frame of the current image frame, and determines whether a target object (for example, a human hand) is detected in the previous image frame, and if the target object is detected , then the approximate range of the target object in the current image frame can be determined based on the tracking result (ie, the target bounding box) of the previous image frame.
具体地,假设目标边界框的尺寸为500×500,在一种实现方式中,以目标边界框的中心点为中心,取出一个800×800的区域作为原始检测图像。在另一种实现方式中,可基于目标边界框所在的位置和尺寸,结合目标对象的移动速度和移动方向,预估一个区域作为原始检测图像,此处不做限定。Specifically, assuming that the size of the target bounding box is 500×500, in one implementation, an 800×800 region is taken as the original detection image centered on the center point of the target bounding box. In another implementation, based on the location and size of the target bounding box, combined with the moving speed and moving direction of the target object, an area may be estimated as the original detection image, which is not limited here.
需要说明的是,目标对象跟踪装置可部署于终端设备,或,部署于由终端设备和服务器组成的系统,本申请以部署于目标对象跟踪装置部署于终端设备为例进行说明。It should be noted that the target object tracking device can be deployed on a terminal device, or deployed in a system composed of a terminal device and a server. This application takes the deployment of the target object tracking device on a terminal device as an example for illustration.
120、基于原始检测图像,通过特征提取网络获取目标特征图,其中,目标特征图包括K个特征点,且目标特征图被划分为N个特征图,每个特征图中设置有一个锚点,K为大于1的整数,N为大于或等于1且小于K的整数;120. Based on the original detection image, obtain a target feature map through a feature extraction network, wherein the target feature map includes K feature points, and the target feature map is divided into N feature maps, and each feature map is set with an anchor point, K is an integer greater than 1, and N is an integer greater than or equal to 1 and less than K;
在一个或多个实施例中,可采用训练好的特征提取网络,对原始检测图像进行特征提取,由此得到目标特征图。以目标特征图的尺寸为40×40为例,则目标特征图包括1600个特征点。通过特征提取网络提取原始检测图像的特征,即得到目标特征图。将目标特征图划分为N个特征图(例如,N等于9),并对每个特征图分别进行检测。In one or more embodiments, a trained feature extraction network may be used to perform feature extraction on the original detection image, thereby obtaining a target feature map. Taking the size of the target feature map as 40×40 as an example, the target feature map includes 1600 feature points. The features of the original detection image are extracted through the feature extraction network, and the target feature map is obtained. Divide the target feature map into N feature maps (for example, N is equal to 9), and perform detection on each feature map separately.
130、针对每个特征图,根据特征图中设置的锚点获取锚点框;130. For each feature map, obtain an anchor frame according to the anchor points set in the feature map;
在一个或多个实施例中,在每个特征图中心位置设置一个锚点(anchor),根据锚点即可得到锚点框,即可得到N个锚点框。In one or more embodiments, an anchor point (anchor) is set at the center of each feature map, and an anchor point frame can be obtained according to the anchor point, and N anchor point frames can be obtained.
140、针对每个特征图,基于锚点框所对应的特征,通过对象检测网络获取至少一组可选边界框参数,其中,每组可选边界框参数包括可选边界框的坐标参数以及尺寸参数;140. For each feature map, based on the features corresponding to the anchor box, obtain at least one set of optional bounding box parameters through the object detection network, where each set of optional bounding box parameters includes coordinate parameters and dimensions of the optional bounding box parameter;
在一个或多个实施例中,对于每个特征图而言,将其中锚点框所选特征作为对象检测网络的输入,由此得到至少一组可选边界框参数(例如,9组可选边界框参数),其中,每组可选边界框参数包括可选边界框的坐标参数以及尺寸参数。In one or more embodiments, for each feature map, the selected features of the anchor box are used as the input of the object detection network, thereby obtaining at least one set of optional bounding box parameters (for example, 9 sets of optional Bounding box parameters), where each set of optional bounding box parameters includes coordinate parameters and size parameters of an optional bounding box.
具体地,为了便于理解,请参阅图4,图4为本申请实施例中基于锚点机制实现对象检测的一个示意图,如图所示,目标特征图被划分为9个特征图(即,3×3的网格),每个特征图中心位置设置一个锚点,根据锚点即可得到锚点框。将锚点框选中的特征作为对象检测网络的输入,由对象检测网络输出至少一组可选边界框参数,例如,输出9组可选边界框参数,每组可选边界框参数包括可选边界框的坐标参数以及尺寸参数。Specifically, for ease of understanding, please refer to FIG. 4. FIG. 4 is a schematic diagram of object detection based on the anchor point mechanism in the embodiment of the present application. As shown in the figure, the target feature map is divided into 9 feature maps (ie, 3 ×3 grid), an anchor point is set at the center of each feature map, and the anchor point box can be obtained according to the anchor point. The features selected by the anchor box are used as the input of the object detection network, and the object detection network outputs at least one set of optional bounding box parameters, for example, output 9 sets of optional bounding box parameters, and each set of optional bounding box parameters includes optional boundaries Coordinate parameters and size parameters of the box.
150、根据每个特征图的至少一组可选边界框参数确定T组边界框参数,其中,每组边界框参数包括边界框的坐标参数以及尺寸参数,T为大于或等于1的整数;150. Determine T groups of bounding box parameters according to at least one group of optional bounding box parameters of each feature map, where each group of bounding box parameters includes coordinate parameters and size parameters of the bounding box, and T is an integer greater than or equal to 1;
在一个或多个实施例中,对于每个特征图而言,从至少一组可选边界框参数中选择符合要求的可选边界框参数作为输出的边界框参数。最终,基于N个特征图总共得到T组边界框参数,类似地,每组边界框参数包括边界框的坐标参数以及尺寸参数。In one or more embodiments, for each feature map, optional bounding box parameters that meet requirements are selected from at least one set of optional bounding box parameters as output bounding box parameters. Finally, a total of T groups of bounding box parameters are obtained based on the N feature maps. Similarly, each group of bounding box parameters includes the coordinate parameters and size parameters of the bounding box.
160、根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果。160. Determine a tracking result for the target object in the current image frame according to T groups of bounding box parameters.
在一个或多个实施例中,根据T组边界框参数即可确定目标对象在原始检测图像中的位置,进而可确定目标对象在当前图像帧中的跟踪结果。其中,跟踪结果可表示为一个包含目标对象的边界框。如果当前图像帧中未检测到目标对象,跟踪结果可表示为未跟踪到目标对象。In one or more embodiments, the position of the target object in the original detection image can be determined according to the T group of bounding box parameters, and then the tracking result of the target object in the current image frame can be determined. Among them, the tracking result can be represented as a bounding box containing the target object. If the target object is not detected in the current image frame, the tracking result may represent that the target object is not tracked.
本申请提供的特征提取网络和对象检测网络总共约占50千字节(kilobyte,KB)的存储空间,可实现1.4M浮点操作/秒(floating point operations per second,FLOPs)。相对于超实时性单目标跟踪网络(Siamese Region Proposal Network,Siamese RPN)等算,有3到4个数量级的加速,在低端机上(例如,A53机器)的耗时能够压缩到1毫秒以内,极大了加速了移动端的跟踪算法,并且有效的为下游算法预留了更多的功耗和时间。The feature extraction network and object detection network provided in this application occupy a storage space of about 50 kilobytes (KB) in total, and can achieve 1.4M floating point operations per second (FLOPs). Compared with the ultra-real-time single target tracking network (Siamese Region Proposal Network, Siamese RPN) and other calculations, there are 3 to 4 orders of magnitude acceleration, and the time consumption on low-end machines (for example, A53 machines) can be compressed to within 1 millisecond. It greatly accelerates the tracking algorithm of the mobile terminal, and effectively reserves more power consumption and time for the downstream algorithm.
本申请实施例中,提供了一种目标对象的跟踪方法。通过上述方式,一方面,从当前图像帧中提取包含有目标对象的原始检测图像用于后续检测,相比于直接对整个当前图像帧进行检测,降低了数据处理量,与此同时,将目标特征图拆分为多个特征图分别进行检测,能够把跟踪看成是一个小规模的检测问题,从而解决被跟踪物体尺度变化和位移变化的问题,提升目标跟踪效率。另一方面,采用对象检测网络对原始检测图像进行边界框检测,相比于传统跟踪算法,能够基于学习到的目标对象的特征,在图像检测过程中达到更好的识别效果,从而有利于提升目标跟踪的准确性。In an embodiment of the present application, a method for tracking a target object is provided. Through the above method, on the one hand, the original detection image containing the target object is extracted from the current image frame for subsequent detection. Compared with directly detecting the entire current image frame, the amount of data processing is reduced. At the same time, the target The feature map is split into multiple feature maps for detection separately, and tracking can be regarded as a small-scale detection problem, so as to solve the problem of scale change and displacement change of the tracked object and improve the efficiency of target tracking. On the other hand, using the object detection network to detect the bounding box of the original detection image, compared with the traditional tracking algorithm, can achieve better recognition effect in the image detection process based on the characteristics of the learned target object, which is conducive to improving Accuracy of object tracking.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,还可以包括:Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, another optional embodiment provided by the embodiment of the present application may further include:
若在当前图像帧的前一个图像帧中未检测出目标对象,则对当前图像帧进行对象识别;If the target object is not detected in the previous image frame of the current image frame, object recognition is performed on the current image frame;
若未获取到当前图像帧的前一个图像帧,则对当前图像帧进行对象识别。If the previous image frame of the current image frame is not acquired, object recognition is performed on the current image frame.
在一个或多个实施例中,介绍了一种基于帧间控制实现目标跟踪的方式。由前述实施例可知,如果当前图像帧属于视频中的第一帧图像,那么可采用检测算法检测当前图像帧中是否存在目标对象。In one or more embodiments, a method for implementing target tracking based on inter-frame control is introduced. It can be known from the foregoing embodiments that if the current image frame belongs to the first image frame in the video, a detection algorithm may be used to detect whether there is a target object in the current image frame.
具体地,为了便于理解,请参阅图5,图5为本申请实施例中基于帧间控制进行目标对象跟踪的一个示意图,如图所示,假设当前图像帧存在前一个图像帧,在步骤A1中,基于帧间控制判断前一个图像帧是否检测出目标对象,若上一帧存在目标对象对应的边界框,则执行步骤A2,即进行目标对象的跟踪。若上一帧存在目标对象对应的边界框,则执行步骤A3,即采用检测算法检测当前图像帧进行目标对象的检测,根据检测到的目标对象重置跟踪器。重置跟踪器是指清空跟踪器中的参数,基于检测结果更新跟踪器中的参数。Specifically, for ease of understanding, please refer to FIG. 5. FIG. 5 is a schematic diagram of target object tracking based on inter-frame control in the embodiment of the present application. As shown in the figure, assuming that the current image frame has a previous image frame, in step A1 In , it is judged based on inter-frame control whether the target object is detected in the previous image frame, and if there is a bounding box corresponding to the target object in the previous frame, step A2 is performed, that is, the target object is tracked. If there is a bounding box corresponding to the target object in the previous frame, perform step A3, that is, use a detection algorithm to detect the current image frame to detect the target object, and reset the tracker according to the detected target object. Resetting the tracker refers to clearing the parameters in the tracker and updating the parameters in the tracker based on the detection results.
其中,跟踪器包括包括特征提取网络和对象检测网络,此外,跟踪器还可以包括跟踪算法,例如,KCF算法等。Wherein, the tracker includes a feature extraction network and an object detection network. In addition, the tracker may also include a tracking algorithm, such as a KCF algorithm.
其次,本申请实施例中,提供了一种基于帧间控制实现目标跟踪的方式,通过上述方式,仅对上一帧为空的图像进行检测,避免对每帧图像都进行检测,从而能够减少图像检测所消耗的算力和资源。Secondly, in the embodiment of the present application, a method of realizing target tracking based on inter-frame control is provided. Through the above method, only the image that was empty in the previous frame is detected, and detection of each frame image is avoided, thereby reducing Computing power and resources consumed by image detection.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,基于原始检测图像,通过特征提取网络获取目标特征图,具体可以包括:Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, in another optional embodiment provided by the embodiment of the present application, based on the original detection image, the target feature map is obtained through a feature extraction network, which may specifically include:
对原始检测图像进行尺寸调整,得到待处理图像;Adjust the size of the original detection image to obtain the image to be processed;
若待处理图像的尺寸与预设尺寸匹配失败,则对待处理图像进行填充,得到满足预设尺寸的目标检测图像;If the size of the image to be processed fails to match the preset size, the image to be processed is filled to obtain a target detection image that meets the preset size;
基于目标检测图像,通过特征提取网络输出目标特征图。Based on the target detection image, the target feature map is output through the feature extraction network.
在一个或多个实施例中,介绍了一种对原始检测图像进行尺寸变换的方式。由前述实施例可知,原始检测图像是从当前图像帧中取出一部分图像,基于此,可对原始检测图像进行调整尺寸(resize)和填充(padding)处理,得到统一尺寸且保真的目标检测图像。In one or more embodiments, a method for performing size transformation on an original detected image is introduced. It can be seen from the foregoing embodiments that the original detection image is a part of the image taken from the current image frame. Based on this, the original detection image can be resized and filled (padding) to obtain a uniform size and fidelity target detection image .
具体地,请参阅图6,图6为本申请实施例中对原始检测图像进行尺寸调整的一个示意图,如图所示,假设原始检测图像的尺寸为450×1200,将原始检测图像的长度和宽度分别缩为原来的1/3,即得到待处理图像,其中,待处理图像为150×400。假设预设尺寸为400×400,在待处理图像的尺寸与预设尺寸匹配失败的情况下,将采用填充的方式对待处理图像进行处理,由此得到满足预设尺寸的目标检测图像。将目标检测图像作为特征提取网络的输入,通过特征提取网络输出目标特征图。Specifically, please refer to FIG. 6. FIG. 6 is a schematic diagram of adjusting the size of the original detection image in the embodiment of the present application. As shown in the figure, assuming that the size of the original detection image is 450×1200, the length of the original detection image and The width is respectively reduced to 1/3 of the original, that is, the image to be processed is obtained, wherein the image to be processed is 150×400. Assuming that the preset size is 400×400, if the size of the image to be processed fails to match the preset size, the image to be processed will be processed by padding to obtain a target detection image that meets the preset size. The target detection image is used as the input of the feature extraction network, and the target feature map is output through the feature extraction network.
可以理解的是,特征提取网络包括卷积层、池化层和全连接层,本申请不对网络层的数量进行限定。It can be understood that the feature extraction network includes a convolutional layer, a pooling layer, and a fully connected layer, and this application does not limit the number of network layers.
其次,本申请实施例中,提供了一种对原始检测图像进行尺寸变换的方式,通过上述方式,一方面能缩小原始检测图像的尺寸,从而减少数据处理量,有利于提升跟踪效率,节省终端设备的算力。另一方面,通过填充能够实现图像的保真,达到更好的检测效果。Secondly, in the embodiment of the present application, a method of resizing the original detection image is provided. Through the above method, on the one hand, the size of the original detection image can be reduced, thereby reducing the amount of data processing, which is conducive to improving tracking efficiency and saving terminals. The computing power of the device. On the other hand, the fidelity of the image can be achieved by filling to achieve a better detection effect.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,每组可选边界框参数还包括置信度参数,至少一组可选边界框参数包括多组可选边界框参数;Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, in another optional embodiment provided by the embodiment of the present application, each set of optional bounding box parameters further includes a confidence parameter, and at least one set of optional bounding box parameters Box parameters include multiple sets of optional bounding box parameters;
根据每个特征图的至少一组可选边界框参数确定T组边界框参数,具体可以包括:Determine T groups of bounding box parameters according to at least one set of optional bounding box parameters of each feature map, which may specifically include:
针对每个特征图,从多组可选边界框参数中选择具有最大置信度参数的可选边界框参数,其中,每组可选边界框参数用于确定一个可选边界框;For each feature map, select an optional bounding box parameter with a maximum confidence parameter from multiple sets of optional bounding box parameters, wherein each set of optional bounding box parameters is used to determine an optional bounding box;
针对每个特征图,根据具有最大置信度参数的可选边界框参数,确定初始可选边界框;For each feature map, determine an initial optional bounding box according to the optional bounding box parameter with the maximum confidence parameter;
针对每个特征图,遍历其余的可选边界框,若存在可选边界框与初始可选边界框之间的重叠面积大于或等于面积阈值,则删除可选边界框,直至得到剩余的可选边界框,其中,其余的可选边界框表示除了初始可选边界框之外的可选边界框;For each feature map, traverse the remaining optional bounding boxes. If the overlapping area between the optional bounding box and the initial optional bounding box is greater than or equal to the area threshold, delete the optional bounding box until the remaining optional bounding boxes are obtained. bounding boxes, where the remaining optional bounding boxes represent optional bounding boxes in addition to the initial optional bounding box;
针对每个特征图,将剩余的可选边界框所对应的可选边界框参数作为边界框参数。For each feature map, the optional bounding box parameters corresponding to the remaining optional bounding boxes are used as bounding box parameters.
在一个或多个实施例中,介绍了一种采用非极大值抑制(non maximumsuppression,NMS)筛选出边界框的方式。由前述实施例可知,对于每个特征图而言,可包括多组可选边界框参数,一组可选边界框参数对应于一个可选边界框,且可选边界框参数还包括置信度参数。In one or more embodiments, a method of filtering out bounding boxes using non maximum suppression (NMS) is introduced. As can be seen from the foregoing embodiments, for each feature map, multiple sets of optional bounding box parameters may be included, a set of optional bounding box parameters corresponds to an optional bounding box, and the optional bounding box parameters also include confidence parameters .
具体地,以N个特征图中的任意一个特征图为例,假设针对特征图得到9组可选边界框参数,即存在9个可选边界框。首先,从这9个可选边界框中取出具有最大置信度参数的可选边界框作为初始可选边界框,遍历其余的8个可选边界框,分别判断每个可选边界框与初始可选边界框之间的重叠面积(即,交并比)是否大于或等于面积阈值,对于大于或等于面积阈值的可选边界框,直接删除,保留剩下的可选边界框。基于此,从剩下的可选边界框中再选择最大置信度参数的可选边界框作为初始可选边界框,然后重复上述过程,最终得到剩余的可选边界框。Specifically, taking any one of the N feature maps as an example, it is assumed that 9 sets of optional bounding box parameters are obtained for the feature map, that is, there are 9 optional bounding boxes. First, the optional bounding box with the largest confidence parameter is taken from the nine optional bounding boxes as the initial optional bounding box, and the remaining eight optional bounding boxes are traversed to determine the difference between each optional bounding box and the initial optional bounding box. Whether the overlapping area (that is, the intersection ratio) between the selected bounding boxes is greater than or equal to the area threshold, for the optional bounding boxes greater than or equal to the area threshold, delete them directly, and keep the remaining optional bounding boxes. Based on this, the optional bounding box with the maximum confidence parameter is selected from the remaining optional bounding boxes as the initial optional bounding box, and then the above process is repeated to finally obtain the remaining optional bounding boxes.
由此,将剩余的可选边界框作为该特征图输出的边界框,并得到相应的边界框参数。Thus, the remaining optional bounding boxes are used as the bounding boxes of the feature map output, and the corresponding bounding box parameters are obtained.
再次,本申请实施例中,提供了一种采用NMS筛选出边界框的方式,通过上述方式,能够准确地筛选出包含目标对象的边界框,从而提升检测的可靠性。Again, in the embodiment of the present application, a method of screening out bounding boxes by using NMS is provided. Through the above-mentioned method, the bounding boxes containing the target object can be accurately screened out, thereby improving the reliability of detection.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果,具体可以包括:Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, in another optional embodiment provided by the embodiment of the present application, the tracking result for the target object in the current image frame is determined according to the T group of bounding box parameters, specifically Can include:
根据T组边界框参数确定T个边界框;Determine T bounding boxes according to T groups of bounding box parameters;
根据T个边界框确定最左侧顶点、最右侧顶点、最上侧顶点以及最下侧顶点;Determine the leftmost vertex, the rightmost vertex, the uppermost vertex, and the lowermost vertex according to the T bounding boxes;
根据最左侧顶点、最右侧顶点、最上侧顶点以及最下侧顶点,确定左上顶点坐标、左下顶点坐标、右上顶点坐标以及右下顶点坐标;Determine the coordinates of the upper left vertex, the lower left vertex, the upper right vertex, and the lower right vertex according to the leftmost vertex, the rightmost vertex, the uppermost vertex, and the lowermost vertex;
根据左上顶点坐标、左下顶点坐标、右上顶点坐标以及右下顶点坐标,确定针对目标对象的跟踪结果。According to the coordinates of the upper left vertex, the lower left vertex, the upper right vertex and the lower right vertex, the tracking result for the target object is determined.
在一个或多个实施例中,介绍了一种基于多个边界框确定跟踪结果的方式。由前述实施例可知,将目标特征图划分为N个特征图之后,可针对每个特征图得到其对应的边界框,结合各个边界框构建一个最终的边界框作为针对目标对象的跟踪结果。In one or more embodiments, a way of determining tracking results based on a plurality of bounding boxes is presented. It can be seen from the foregoing embodiments that after the target feature map is divided into N feature maps, its corresponding bounding box can be obtained for each feature map, and a final bounding box is constructed by combining each bounding box as the tracking result for the target object.
具体地,为了便于理解,请参阅图7,图7为本申请实施例中基于锚点机制生成跟踪结果的一个示意图,如图所示,假设目标特征图被划分为9个特征图,每个特征图均检测到一个边界框,即T等于N。从这T个边界框中确定最左侧顶点(即,图示中的A点)、最右侧顶点(即,图示中的B点)、最上侧顶点(即,图示中的C点)以及最下侧顶点(即,图示中的D点)。基于此,根据最左侧顶点、最右侧顶点、最上侧顶点以及最下侧顶点可构建一个矩形框,从而得到左上顶点(即,图示中的E点)坐标、左下顶点(即,图示中的F点)坐标、右上顶点(即,图示中的G点)坐标以及右下顶点(即,图示中的H点)坐标。由此,得到针对目标对象的跟踪结果。Specifically, for ease of understanding, please refer to FIG. 7. FIG. 7 is a schematic diagram of the tracking results generated based on the anchor point mechanism in the embodiment of the present application. As shown in the figure, it is assumed that the target feature map is divided into 9 feature maps, each Each feature map detects a bounding box, that is, T is equal to N. Determine the leftmost vertex (i.e., point A in the illustration), the rightmost vertex (i.e., point B in the illustration), and the uppermost vertex (i.e., point C in the illustration) from these T bounding boxes ) and the lowermost vertex (ie, point D in the illustration). Based on this, a rectangular frame can be constructed according to the leftmost vertex, the rightmost vertex, the uppermost vertex, and the lowermost vertex, so as to obtain the coordinates of the upper left vertex (that is, point E in the illustration), and the coordinates of the lower left vertex (that is, point E in the figure) point F in the illustration), coordinates of the upper right vertex (that is, point G in the illustration), and coordinates of the lower right apex (that is, point H in the illustration). Thus, a tracking result for the target object is obtained.
再次,本申请实施例中,提供了一种基于多个边界框确定跟踪结果的方式,通过上述方式,能够综合T个边界框的结果生成一个更准确的边界框,从而实现目标跟踪。Again, in the embodiment of the present application, a method of determining a tracking result based on multiple bounding boxes is provided. Through the above method, the results of T bounding boxes can be integrated to generate a more accurate bounding box, thereby realizing target tracking.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,还可以包括:Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, another optional embodiment provided by the embodiment of the present application may further include:
获取图像样本,其中,图像样本包括目标对象;acquiring an image sample, wherein the image sample includes a target object;
基于图像样本,通过特征提取网络获取样本特征图,其中,样本特征图包括K个特征点,样本特征图被划分为N个待训练特征图,每个待训练特征图中设置有一个锚点;Based on the image sample, a sample feature map is obtained through a feature extraction network, wherein the sample feature map includes K feature points, the sample feature map is divided into N feature maps to be trained, and an anchor point is set in each feature map to be trained;
针对每个待训练特征图,根据待训练特征图中设置的锚点获取锚点框;For each feature map to be trained, an anchor frame is obtained according to the anchor points set in the feature map to be trained;
针对每个待训练特征图,基于锚点框所对应的特征以及真实边界框参数,通过对象检测网络获取至少一组可选边界框参数,其中,每组可选边界框参数包括待训练边界框的坐标参数以及尺寸参数;For each feature map to be trained, based on the features corresponding to the anchor box and the real bounding box parameters, at least one set of optional bounding box parameters is obtained through the object detection network, wherein each set of optional bounding box parameters includes the bounding box to be trained The coordinate parameters and size parameters of ;
针对每个待训练特征图,从至少一组可选边界框参数中确定预测边界框参数;For each feature map to be trained, determine predicted bounding box parameters from at least one set of optional bounding box parameters;
针对每个待训练特征图,根据预测边界框参数以及真实边界框参数,采用损失函数对特征提取网络以及对象检测网络的模型参数进行更新。For each feature map to be trained, a loss function is used to update the model parameters of the feature extraction network and the object detection network according to the predicted bounding box parameters and the real bounding box parameters.
在一个或多个实施例中,介绍了一种训练对象检测网络的方式。由前述实施例可知,可获取包含有目标对象(例如,人手)的图像样本,在图像样本中可标注出目标对象所在的框。将图像样本作为特征提取网络的输入,由此输出样本特征图。类似地,将样本特征图划分为N个待训练特征图(例如,3×3的待训练特征图),并对每个待训练特征图分别进行检测。每个待训练特征图中心位置可设置一个锚点,并得到对应的锚点框,基于该锚点框可取出锚点框所对应的特征。In one or more embodiments, a way of training an object detection network is presented. It can be seen from the foregoing embodiments that an image sample containing a target object (for example, a human hand) can be obtained, and a frame where the target object is located can be marked in the image sample. The image sample is used as the input of the feature extraction network, and thus the sample feature map is output. Similarly, the sample feature map is divided into N feature maps to be trained (for example, 3×3 feature maps to be trained), and each feature map to be trained is detected separately. An anchor point can be set at the center position of each feature map to be trained, and a corresponding anchor point frame can be obtained, based on the anchor point frame, the feature corresponding to the anchor point frame can be extracted.
在训练对象检测网络的过程中,可采用边框回归(bounding box regression)的方法来回归每个锚点对应的锚点框。基于此,将锚点框所对应的特征以及真实边界框(ground truth)参数作为对象检测网络的输入,由此输出至少一组可选边界框参数,从至少一组可选边界框参数中确定预测边界框参数。In the process of training the object detection network, the method of bounding box regression can be used to regress the anchor box corresponding to each anchor point. Based on this, the features corresponding to the anchor box and the ground truth parameters are used as the input of the object detection network, thereby outputting at least one set of optional bounding box parameters, determined from at least one set of optional bounding box parameters Predict bounding box parameters.
具体地,假设锚点框的参数为(Px,Py,Pw,Ph),真实边界框参数为(Gx,Gy,Gw,Gh),预测边界框参数为(G'x,G'y,G'w,G'h),由此,需要寻找一种映射f,使得:Specifically, assume that the parameters of the anchor box are (Px, Py, Pw, Ph), the parameters of the real bounding box are (Gx, Gy, Gw, Gh), and the parameters of the predicted bounding box are (G'x, G'y, G 'w,G'h), thus, it is necessary to find a mapping f such that:
f(Px,Py,Pw,Ph)=(G'x,G'y,G'w,G'h);f(Px,Py,Pw,Ph)=(G'x,G'y,G'w,G'h);
并使得:and makes:
(G'x,G'y,G'w,G'h)≈(Gx,Gy,Gw,Gh);(G'x,G'y,G'w,G'h)≈(Gx,Gy,Gw,Gh);
将锚点框变换为预测边界框的过程为先平移,再缩放尺度。可采用Smooth L1损失函数或者L2损失函数,分别计算预测值跟真实值之间的损失值,其中,真实值是指基于真实边界框参数和锚点框的参数确定的平移量和尺度缩放量。最终,结合损失值之和,对特征提取网络以及对象检测网络的模型参数进行更新。The process of transforming the anchor box into the predicted bounding box is first translated and then scaled. The Smooth L1 loss function or L2 loss function can be used to calculate the loss value between the predicted value and the real value, respectively, where the real value refers to the translation and scaling determined based on the parameters of the real bounding box and the parameters of the anchor box. Finally, combined with the sum of the loss values, the model parameters of the feature extraction network and the object detection network are updated.
再次,本申请实施例中,提供了一种训练对象检测网络的方式,通过上述方式,采用回归锚点框的思路对对象检测网络进行训练,训练过程较为简易。Thirdly, in the embodiment of the present application, a method of training the object detection network is provided. Through the above method, the method of regressing the anchor frame is used to train the object detection network, and the training process is relatively simple.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,还可以包括:Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, another optional embodiment provided by the embodiment of the present application may further include:
采用预设跟踪算法对当前图像帧进行检测,得到目标对象的第一中心位置参数,其中,预设跟踪算法为核相关滤波算法、在线实时跟踪算法、背景感知相关滤波算法或多实例在线学习算法;Use a preset tracking algorithm to detect the current image frame to obtain the first center position parameter of the target object, wherein the preset tracking algorithm is a kernel correlation filtering algorithm, an online real-time tracking algorithm, a context-aware correlation filtering algorithm or a multi-instance online learning algorithm ;
根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果,具体可以包括:Determine the tracking result for the target object in the current image frame according to the T group of bounding box parameters, which may specifically include:
根据T组边界框参数,确定目标对象的第二中心位置参数;Determine the second center position parameter of the target object according to the T group of bounding box parameters;
根据第一中心位置参数以及第二中心位置参数,确定当前图像帧中针对目标对象的跟踪结果。According to the first center position parameter and the second center position parameter, a tracking result for the target object in the current image frame is determined.
在一个或多个实施例中,介绍了一种结合预设跟踪算法实现融合定位的方式。由前述实施例可知,预设跟踪算法能够快速地实现目标跟踪,能够在目标对象快速运动的情况下进行跟踪。但由于预设跟踪算法的准确性较低,因此,可将预设跟踪算法得到的跟踪结果作为对象检测网络输出结果的运动补偿。In one or more embodiments, a manner of implementing fusion positioning combined with a preset tracking algorithm is introduced. It can be known from the foregoing embodiments that the preset tracking algorithm can quickly realize target tracking, and can perform tracking when the target object moves rapidly. However, since the accuracy of the preset tracking algorithm is low, the tracking result obtained by the preset tracking algorithm can be used as the motion compensation of the output result of the object detection network.
具体地,为了便于理解,请参阅图8,图8为本申请实施例中融合得到跟踪结果的一个示意图,如图所示,F1用于指示采用预设跟踪算法确定的边界框。F2用于指示采用预设跟踪算法确定边界框的中心点。F3用于指示基于T组边界框参数确定的边界框。F4用于指示基于T组边界框参数确定边界框的中心点。Specifically, for ease of understanding, please refer to FIG. 8 . FIG. 8 is a schematic diagram of a tracking result obtained through fusion in an embodiment of the present application. As shown in the figure, F1 is used to indicate a bounding box determined by a preset tracking algorithm. F2 is used to indicate that a preset tracking algorithm is used to determine the center point of the bounding box. F3 is used to indicate the bounding box determined based on the T set of bounding box parameters. F4 is used to indicate to determine the center point of the bounding box based on the T set of bounding box parameters.
假设F2所指示的中心点对应的第一中心位置参数为(x1,y1),F4所指示的中心点对应的第二中心位置参数为(x2,y2),且假设第一中心位置参数的权重设置为0.2,第二中心位置参数的权重设置为0.8,基于此,结合第一中心位置参数和第二中心位置参数,确定最终得到的边界框中心位置参数为(x3,y3),即:Assume that the first center position parameter corresponding to the center point indicated by F2 is (x1, y1), the second center position parameter corresponding to the center point indicated by F4 is (x2, y2), and assume that the weight of the first center position parameter It is set to 0.2, and the weight of the second center position parameter is set to 0.8. Based on this, combined with the first center position parameter and the second center position parameter, the final center position parameter of the bounding box is determined to be (x3, y3), namely:
x3=0.2*x1+0.8*x2;x3=0.2*x1+0.8*x2;
y3=0.2*y1+0.8*y2;y3=0.2*y1+0.8*y2;
可见,预设跟踪算法相当于为对象检测网络输出结果做了一个偏移。It can be seen that the preset tracking algorithm is equivalent to making an offset for the output of the object detection network.
需要说明的是,预设跟踪算法包含但不仅限于核相关滤波(kernel correlationfilter,KCF)算法,简单在线实时跟踪(simple online and realtime tracking,SORT)算法,背景感知相关滤波(background-aware correlation filters,BACF)算法以及多实例在线学习(multi instance learning,MIL)算法等。It should be noted that the preset tracking algorithms include but not limited to kernel correlation filter (kernel correlation filter, KCF) algorithm, simple online and realtime tracking (simple online and realtime tracking, SORT) algorithm, background-aware correlation filters (background-aware correlation filters, BACF) algorithm and multi-instance online learning (multi instance learning, MIL) algorithm.
其次,本申请实施例中,提供了一种结合预设跟踪算法实现融合定位的方式,通过上述方式,考虑到在目标对象快速运动的情况下,容易出现目标跟丢的情形,因此,需要频繁地调用检测功能,从而导致终端设备的功耗变高。因此,结合预设跟踪算法能够快速地定位到目标对象的位置,减少检测功能的调用频率,有利于减低终端设备的功耗。Secondly, in the embodiment of the present application, a method for realizing fusion positioning combined with a preset tracking algorithm is provided. Through the above method, considering that the target object is prone to being lost in the case of fast movement, it is necessary to frequently The detection function is invoked frequently, resulting in higher power consumption of the terminal device. Therefore, combined with the preset tracking algorithm, the position of the target object can be quickly located, the calling frequency of the detection function is reduced, and the power consumption of the terminal device is reduced.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,目标对象为人手;Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, in another optional embodiment provided by the embodiment of the present application, the target object is a human hand;
还可以包括:Can also include:
响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;In response to the operation of the video capture control, activate the camera device of the terminal device;
通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;Collecting M consecutive image frames through the camera device, where M is an integer greater than or equal to 1;
根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果之后,还可以包括:After determining the tracking result for the target object in the current image frame according to the T group of bounding box parameters, it may also include:
获取连续M个图像帧中针对人手的跟踪结果;Obtain the tracking results for human hands in consecutive M image frames;
根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,生成针对人手的移动轨迹;According to the tracking results corresponding to the consecutive M image frames and the tracking results corresponding to the current image frame, a moving track for the human hand is generated;
若移动轨迹与预设轨迹匹配成功,则触发与预设轨迹对应的功能。If the moving track matches the preset track successfully, the function corresponding to the preset track is triggered.
在一个或多个实施例中,介绍了一种基于运动轨迹触发相应功能的方式。由前述实施例可知,终端设备可通过摄像头装置采集视频,并对视频中的图像帧进行分析,进而提取人手的运动轨迹。In one or more embodiments, a manner of triggering a corresponding function based on a motion trajectory is introduced. It can be seen from the above-mentioned embodiments that the terminal device can collect video through the camera device, and analyze the image frames in the video, and then extract the movement track of the human hand.
具体地,为了便于理解,请参阅图9,图9为本申请实施例中基于运动轨迹触发应用功能的一个示意图,如图所示,以目标对象为人手作为示例。当用户点击“启动摄像头”的控件时,即触发针对视频拍摄控件的操作,于是,终端设备开启摄像头装置并采集视频。假设通过摄像头装置采集到连续M个图像帧,并通过连续M个图像帧中每一帧的跟踪结果,可获取人手移动轨迹,由此,可将人手移动轨迹与预设轨迹匹配进行匹配。Specifically, for ease of understanding, please refer to FIG. 9 . FIG. 9 is a schematic diagram of triggering an application function based on a motion trajectory in an embodiment of the present application. As shown in the figure, the target object is a human hand as an example. When the user clicks on the control of "starting the camera", an operation on the video shooting control is triggered, and then the terminal device starts the camera device and collects the video. Assuming that M consecutive image frames are collected by the camera device, and the tracking result of each frame in the M consecutive image frames can be used to obtain the moving trajectory of the human hand, so that the moving trajectory of the human hand can be matched with the preset trajectory.
如果移动轨迹与预设轨迹匹配成功,则触发与预设轨迹对应的功能,例如,为用提供相应的奖励,或,显示相应的特效,或,开启某一项特定功能等,此处不做限定。If the moving track matches the preset track successfully, the function corresponding to the preset track will be triggered, for example, providing corresponding rewards for users, or displaying corresponding special effects, or enabling a specific function, etc., which will not be done here limited.
其次,本申请实施例中,提供了一种基于运动轨迹触发相应功能的方式,通过上述方式,在短视频编辑或短视频特效等产品中,基于对人手的跟踪结果可确定运动轨迹,根据运动轨迹可触发相应的功能。可见,本申请提供的方案能够很好的泛化到各类移动端物体的跟踪任务中,针对不同姿态,角度和遮挡的对象具有较为鲁棒的处理,从而达到提升用户体验的目的。Secondly, in the embodiment of the present application, a method of triggering corresponding functions based on the motion trajectory is provided. Through the above method, in products such as short video editing or short video special effects, the motion trajectory can be determined based on the tracking result of the human hand. According to the motion The trace triggers the corresponding function. It can be seen that the solution provided by this application can be well generalized to various mobile object tracking tasks, and it can handle objects with different postures, angles and occlusions more robustly, so as to achieve the purpose of improving user experience.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,还可以包括:Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, another optional embodiment provided by the embodiment of the present application may further include:
响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;In response to the operation of the video capture control, activate the camera device of the terminal device;
通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;Collecting M consecutive image frames through the camera device, where M is an integer greater than or equal to 1;
根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果之后,还可以包括:After determining the tracking result for the target object in the current image frame according to the T group of bounding box parameters, it may also include:
获取连续M个图像帧中针对人手的跟踪结果;Obtain the tracking results for human hands in consecutive M image frames;
根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,获取轨迹长度;Obtain the trajectory length according to the tracking results corresponding to the consecutive M image frames and the tracking results corresponding to the current image frame;
若轨迹长度大于或等于长度阈值,则触发与预设轨迹对应的功能。If the track length is greater than or equal to the length threshold, the function corresponding to the preset track is triggered.
在一个或多个实施例中,介绍了一种基于移动距离触发相应功能的方式。由前述实施例可知,终端设备可通过摄像头装置采集视频,并对视频中的图像帧进行分析,进而提取人手的运动轨迹。In one or more embodiments, a manner of triggering a corresponding function based on a moving distance is introduced. It can be seen from the above-mentioned embodiments that the terminal device can collect video through the camera device, and analyze the image frames in the video, and then extract the movement track of the human hand.
具体地,为了便于理解,请参阅图10,图10为本申请实施例中基于移动距离触发应用功能的一个示意图,如图所示,以目标对象为人手作为示例。当用户点击“启动摄像头”的控件时,即触发针对视频拍摄控件的操作,于是,终端设备开启摄像头装置并采集视频。假设通过摄像头装置采集到连续M个图像帧,并通过连续M个图像帧中每一帧的跟踪结果,可确定一条连续的运动轨迹,由此,可计算出该运动轨迹的轨迹长度。Specifically, for ease of understanding, please refer to FIG. 10 . FIG. 10 is a schematic diagram of triggering an application function based on a moving distance in an embodiment of the present application. As shown in the figure, the target object is a human hand as an example. When the user clicks on the control of "starting the camera", an operation on the video shooting control is triggered, and then the terminal device starts the camera device and collects the video. Assume that M consecutive image frames are collected by the camera device, and a continuous motion trajectory can be determined through the tracking results of each frame in the M consecutive image frames, and thus the trajectory length of the motion trajectory can be calculated.
如果轨迹长度大于或等于长度阈值,则触发与预设轨迹对应的功能,例如,为用提供相应的奖励,或,显示相应的特效,或,开启某一项特定功能等,此处不做限定。If the track length is greater than or equal to the length threshold, the function corresponding to the preset track will be triggered, for example, providing corresponding rewards for users, or displaying corresponding special effects, or enabling a specific function, etc., which are not limited here .
其次,本申请实施例中,提供了一种基于移动距离触发相应功能的方式,通过上述方式,在短视频编辑或短视频特效等产品中,基于对人手的跟踪结果可确定移动距离,根据移动距离可触发相应的功能。可见,本申请提供的方案能够很好的泛化到各类移动端物体的跟踪任务中,针对不同姿态,角度和遮挡的对象具有较为鲁棒的处理,从而达到提升用户体验的目的。Secondly, in the embodiment of the present application, a method of triggering corresponding functions based on the moving distance is provided. Through the above method, in products such as short video editing or short video special effects, the moving distance can be determined based on the tracking result of the human hand. The distance triggers the corresponding function. It can be seen that the solution provided by this application can be well generalized to various mobile object tracking tasks, and it can handle objects with different postures, angles and occlusions more robustly, so as to achieve the purpose of improving user experience.
结合上述介绍,下面将对本申请中目标对象的跟踪方法进行介绍,请参阅图11,本申请实施例中目标对象跟踪方法的另一个实施例包括:In combination with the above introduction, the following will introduce the target object tracking method in this application, please refer to Figure 11, another embodiment of the target object tracking method in the embodiment of this application includes:
210、若在当前图像帧的前一个图像帧中检测出目标对象,则根据前一个图像帧所对应的目标边界框,从当前图像帧中提取原始检测图像,其中,原始检测图像包括目标对象;210. If the target object is detected in the previous image frame of the current image frame, extract an original detection image from the current image frame according to the target bounding box corresponding to the previous image frame, wherein the original detection image includes the target object;
在一个或多个实施例中,如前述实施例中步骤110所描述的内容,此处不再赘述。In one or more embodiments, the content described in
220、基于原始检测图像,通过特征提取网络获取目标特征图;220. Based on the original detection image, the target feature map is obtained through a feature extraction network;
在一个或多个实施例中,如前述实施例中步骤320所描述的内容,此处不再赘述。In one or more embodiments, the content described in
230、基于目标特征图,通过对象检测网络获取第一偏移量以及第二偏移量,其中,第一偏移量为左上偏移量,且第二偏移量为右下偏移量,或,第一偏移量为右上偏移量,且第二偏移量为左下偏移量;230. Based on the target feature map, obtain a first offset and a second offset through an object detection network, wherein the first offset is an upper left offset, and the second offset is a lower right offset, Or, the first offset is an upper-right offset and the second offset is a lower-left offset;
在一个或多个实施例中,将目标特征图作为对象检测网络,可通过对象检测网络输出第一偏移量以及第二偏移量。In one or more embodiments, the target feature map is used as an object detection network, and the object detection network can output the first offset and the second offset.
示例性地,一种情况为,第一偏移量为左上偏移量,第二偏移量为右下偏移量,其中,左上偏移量包括左上顶点距离初始左上顶点的横向偏移量以及纵向偏移量,右下偏移量包括右下顶点距离初始右下顶点的横向偏移量以及纵向偏移量。Exemplarily, in one case, the first offset is the upper left offset, and the second offset is the lower right offset, wherein the upper left offset includes the lateral offset between the upper left vertex and the initial upper left vertex And the vertical offset, the lower right offset includes the horizontal offset and the vertical offset from the lower right vertex to the initial lower right vertex.
示例性地,另一种情况为,第一偏移量为右上偏移量,第二偏移量为左下偏移量,其中,右上偏移量包括右上顶点距离初始右上顶点的横向偏移量以及纵向偏移量,左下偏移量包括左下顶点距离初始左下顶点的横向偏移量以及纵向偏移量。Exemplarily, another situation is that the first offset is the upper right offset, and the second offset is the lower left offset, wherein the upper right offset includes the lateral offset between the upper right vertex and the initial upper right vertex And the vertical offset, the lower left offset includes the horizontal offset and the vertical offset from the lower left vertex to the initial lower left vertex.
240、根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果。240. Determine a tracking result for the target object in the current image frame according to the first offset and the second offset.
在一个或多个实施例中,根据第一偏移量(x1,y1)以及初始顶点的坐标参数(n1,m1),得到一组边界框参数(x1,y1,n1,m1)。类似地,根据第二偏移量(x2,y2)以及对角初始顶点的坐标参数(n2,m2),得到另一组边界框参数(x2,y2,n2,m2)。In one or more embodiments, a set of bounding box parameters (x1, y1, n1, m1) is obtained according to the first offset (x1, y1) and the coordinate parameters (n1, m1) of the initial vertex. Similarly, another set of bounding box parameters (x2, y2, n2, m2) is obtained according to the second offset (x2, y2) and the coordinate parameters (n2, m2) of the initial vertex of the diagonal.
示例性地,两个对角顶点可以是左上顶点和右下顶点,下面将结合图示进行说明。Exemplarily, the two diagonal vertices may be an upper left vertex and a lower right vertex, which will be described below with reference to figures.
具体地,为了便于理解,请参阅图12,图12为本申请实施例中基于单一边框实现对象检测的一个示意图,如图所示,基于原始检测图像可得到相应的目标特征图,将目标特征图输入至对象检测网络,通过对象检测网络输出a点的偏移量(即,左上偏移量)和b点的偏移量(即,右下偏移量)。其中,左上偏移量包括左上顶点(即,a点)距离初始左上顶点(即,c点)的横向偏移量(即,x1)以及纵向偏移量(即,y1),右下偏移量包括右下顶点(即,b点)距离初始右下顶点(即,d点)的横向偏移量(即,x2)以及纵向偏移量(即,y2)。Specifically, for ease of understanding, please refer to FIG. 12. FIG. 12 is a schematic diagram of object detection based on a single border in the embodiment of the present application. As shown in the figure, the corresponding target feature map can be obtained based on the original detection image, and the target feature The graph is input to the object detection network, and the offset of point a (ie, the upper left offset) and the offset of point b (ie, the lower right offset) are output through the object detection network. Among them, the upper left offset includes the horizontal offset (ie, x1) and the vertical offset (ie, y1) of the upper left vertex (ie, point a) from the initial upper left vertex (ie, point c), and the lower right offset The amount includes a horizontal offset (ie, x2 ) and a vertical offset (ie, y2 ) from the lower right vertex (ie, point b) to the initial lower right vertex (ie, point d).
基于此,可构建如图12所示的二维坐标系,根据左上偏移量(x1,y1)以及初始左上顶点的坐标参数(n1,m1),得到一组边界框参数(x1,y1,n1,m1)。类似地,根据右下偏移量(x2,y2)以及初始右下顶点的坐标参数(n2,m2),得到另一组边界框参数(x2,y2,n2,m2)。Based on this, a two-dimensional coordinate system as shown in Figure 12 can be constructed, and a set of bounding box parameters (x1, y1, n1, m1). Similarly, according to the lower right offset (x2, y2) and the coordinate parameters (n2, m2) of the initial lower right vertex, another set of bounding box parameters (x2, y2, n2, m2) is obtained.
示例性地,两个对角顶点可以是右上顶点和左下顶点,下面将结合图示进行说明。Exemplarily, the two diagonal vertices may be an upper right vertex and a lower left vertex, which will be described below with reference to figures.
具体地,为了便于理解,请参阅图13,图13为本申请实施例中基于单一边框实现对象检测的另一个示意图,如图所示,基于原始检测图像可得到相应的目标特征图,将目标特征图输入至对象检测网络,通过对象检测网络输出a点的偏移量(即,左下偏移量)和b点的偏移量(即,右上偏移量)。其中,左下偏移量包括左下顶点(即,a点)距离初始左下顶点(即,c点)的横向偏移量(即,x1)以及纵向偏移量(即,y1),右上偏移量包括右上顶点(即,b点)距离初始右上顶点(即,d点)的横向偏移量(即,x2)以及纵向偏移量(即,y2)。Specifically, for ease of understanding, please refer to FIG. 13. FIG. 13 is another schematic diagram of object detection based on a single border in the embodiment of the present application. As shown in the figure, the corresponding target feature map can be obtained based on the original detection image, and the target The feature map is input to the object detection network, and the offset of point a (ie, the lower left offset) and the offset of point b (ie, the upper right offset) are output through the object detection network. Among them, the lower left offset includes the horizontal offset (ie, x1) and vertical offset (ie, y1) from the lower left vertex (ie, point a) to the initial lower left vertex (ie, point c), and the upper right offset It includes a horizontal offset (ie, x2) and a vertical offset (ie, y2) from the upper right vertex (ie, point b) to the initial upper right vertex (ie, point d).
基于此,可构建如图13所示的二维坐标系,根据左下偏移量(x1,y1)以及初始左下顶点的坐标参数(n1,m1),得到一组边界框参数(x1,y1,n1,m1)。类似地,根据右上偏移量(x2,y2)以及初始右上顶点的坐标参数(n2,m2),得到另一组边界框参数(x2,y2,n2,m2)。Based on this, a two-dimensional coordinate system as shown in Figure 13 can be constructed, and a set of bounding box parameters (x1, y1, n1, m1). Similarly, according to the upper right offset (x2, y2) and the coordinate parameters (n2, m2) of the initial upper right vertex, another set of bounding box parameters (x2, y2, n2, m2) is obtained.
本申请实施例中,提供了一种目标对象的跟踪方法。通过上述方式,只需对角顶点的偏移量即可确定边界框的位置,从而能够简化模型学习的复杂度,因此,可进一步的降低模型的复杂度,进而达到加速跟踪的效果。In an embodiment of the present application, a method for tracking a target object is provided. Through the above method, the position of the bounding box can be determined only by the offset of the diagonal vertices, which can simplify the complexity of model learning. Therefore, the complexity of the model can be further reduced, and the effect of accelerated tracking can be achieved.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,第一偏移量为左上偏移量,且第二偏移量为右下偏移量,其中,左上偏移量包括左上顶点距离初始左上顶点的横向偏移量以及纵向偏移量,右下偏移量包括右下顶点距离初始右下顶点的横向偏移量以及纵向偏移量;Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, in another optional embodiment provided by the embodiment of the present application, the first offset is the upper left offset, and the second offset is the right Lower offset, where the upper left offset includes the horizontal offset and vertical offset from the upper left vertex to the initial upper left vertex, and the lower right offset includes the horizontal offset and vertical offset from the lower right vertex to the initial lower right vertex Offset;
还可以包括:Can also include:
获取图像样本,其中,图像样本包括所述目标对象;acquiring an image sample, wherein the image sample includes the target object;
基于图像样本,通过特征提取网络获取样本特征图;Based on the image sample, the sample feature map is obtained through the feature extraction network;
基于样本特征图,通过对象检测网络获取左上预测偏移量以及右下预测偏移量;Based on the sample feature map, the upper left prediction offset and the lower right prediction offset are obtained through the object detection network;
基于样本特征图,根据左上预测偏移量、右下预测偏移量、左上真实偏移量以及右下真实偏移量,采用损失函数对特征提取网络以及对象检测网络的模型参数进行更新。Based on the sample feature map, according to the upper left predicted offset, the lower right predicted offset, the upper left real offset and the lower right real offset, the model parameters of the feature extraction network and the object detection network are updated using a loss function.
在一个或多个实施例中,介绍了一种训练对象检测网络的方式。由前述实施例可知,需要对对象检测网络进行训练,使其能够拟合出更准确的结果。可以理解的是,特征提取网络以及对象检测网络采用联合训练的方式。In one or more embodiments, a way of training an object detection network is presented. It can be known from the foregoing embodiments that the object detection network needs to be trained so that it can fit more accurate results. It can be understood that the feature extraction network and the object detection network adopt a joint training method.
具体地,下面将以一个图像样本为例进行介绍,在实际训练中,采用类似方式对其他图像样本进行处理。图像样本中存在目标对象,且,可以通过人工标注的方式圈出包含有目标对象的边界框。将图像样本输入至特征提取网络,由特征提取网络输出样本特征图。基于此,将样本特征图作为对象检测网络的输入,即可得到左上预测偏移量以及右下预测偏移量。由于已预先在图像样本中标定了边界框,因此,可在样本特征图中确定左上真实偏移量以及右下真实偏移量。Specifically, an image sample will be used as an example for introduction below. In actual training, other image samples are processed in a similar manner. There is a target object in the image sample, and the bounding box containing the target object can be circled by manual labeling. The image sample is input to the feature extraction network, and the feature extraction network outputs the sample feature map. Based on this, the upper left prediction offset and the lower right prediction offset can be obtained by using the sample feature map as the input of the object detection network. Since the bounding box has been pre-marked in the image sample, the upper-left true offset and the lower-right true offset can be determined in the sample feature map.
基于此,可采用如下方式计算同一个顶点(例如,左上顶点或右下顶点)在位置上的损失值:Based on this, the loss value of the position of the same vertex (for example, upper left vertex or lower right vertex) can be calculated as follows:

其中,L表示损失值。n表示图像样本的总数。yi表示第i个图像样本对应真实偏移量(左上真实偏移量或右下真实偏移量)中的横向偏移量或纵向偏移量。f(xi)表示第i个图像样本对应预测偏移量(左上预测偏移量或右下预测偏移量)中的横向偏移量或纵向偏移量。Among them, L represents the loss value. n represents the total number of image samples. y i represents the horizontal offset or vertical offset in the i-th image sample corresponding to the real offset (the upper left real offset or the lower right real offset). f( xi ) represents the horizontal offset or the vertical offset in the i-th image sample corresponding to the predicted offset (upper-left predicted offset or lower-right predicted offset).
最后,结合损失值对特征提取网络以及对象检测网络的模型参数进行更新。Finally, the model parameters of the feature extraction network and the object detection network are updated in combination with the loss value.
再次,本申请实施例中,提供了一种训练对象检测网络的方式,通过上述方式,一方面,可采用L1损失回归左上顶点和右下顶点的偏移量,L1损失有利于优化小扰动,且回归偏移量较回归类似尺寸而言,更为简单和有效。另一方面,易于构造训练样本,可以大量的生成样本用于训练整个模型。本方案可泛化到移动端绝大多数跟踪任务。Again, in the embodiment of the present application, a method of training the object detection network is provided. Through the above method, on the one hand, the L1 loss can be used to return the offset of the upper left vertex and the lower right vertex. The L1 loss is conducive to optimizing small disturbances. And regressing offsets is simpler and more effective than regressing similar sizes. On the other hand, it is easy to construct training samples, and a large number of samples can be generated for training the entire model. This scheme can be generalized to most tracking tasks on mobile terminals.
可选地,在上述图3对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,第一偏移量为右上偏移量,且第二偏移量为左下偏移量,其中,右上偏移量包括右上顶点距离初始右上顶点的横向偏移量以及纵向偏移量,左下偏移量包括左下顶点距离初始左下顶点的横向偏移量以及纵向偏移量;Optionally, on the basis of the various embodiments corresponding to FIG. 3 above, in another optional embodiment provided by the embodiment of the present application, the first offset is the upper right offset, and the second offset is the lower left An offset, wherein the upper right offset includes a horizontal offset and a vertical offset from the upper right vertex to the initial upper right vertex, and the lower left offset includes a horizontal offset and a vertical offset from the lower left vertex to the initial lower left vertex;
还可以包括:Can also include:
获取图像样本,其中,图像样本包括所述目标对象;acquiring an image sample, wherein the image sample includes the target object;
基于图像样本,通过特征提取网络获取样本特征图;Based on the image sample, the sample feature map is obtained through the feature extraction network;
基于样本特征图,通过对象检测网络获取右上预测偏移量以及左下预测偏移量;Based on the sample feature map, the upper right prediction offset and the lower left prediction offset are obtained through the object detection network;
基于样本特征图,根据右上预测偏移量、左下预测偏移量、右上真实偏移量以及左下真实偏移量,采用损失函数对特征提取网络以及对象检测网络的模型参数进行更新。Based on the sample feature map, according to the upper right predicted offset, the lower left predicted offset, the upper right real offset and the lower left real offset, the model parameters of the feature extraction network and the object detection network are updated using a loss function.
在一个或多个实施例中,介绍了一种训练对象检测网络的方式。由前述实施例可知,图像样本中存在目标对象,可通过人工标注的方式圈出包含有目标对象的边界框。将图像样本输入至特征提取网络,由此得到样本特征图。基于此,将样本特征图作为对象检测网络的输入,即可得到右上预测偏移量以及左下预测偏移量。由于已预先在图像样本中标定了边界框,因此,可在样本特征图中确定右上真实偏移量以及左下真实偏移量。In one or more embodiments, a way of training an object detection network is presented. It can be known from the foregoing embodiments that there is a target object in the image sample, and the bounding box containing the target object can be circled by manual labeling. The image samples are input to the feature extraction network, and thus the sample feature maps are obtained. Based on this, the upper-right prediction offset and the lower-left prediction offset can be obtained by using the sample feature map as the input of the object detection network. Since the bounding box has been pre-marked in the image sample, the upper-right true offset and the lower-left true offset can be determined in the sample feature map.
基于此,可采用如下方式计算同一个顶点(例如,左下顶点或右上顶点)在位置上的损失值:Based on this, the loss value of the same vertex (for example, lower left vertex or upper right vertex) in position can be calculated as follows:
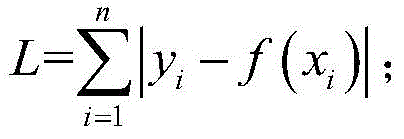
其中,L表示损失值。n表示图像样本的总数。yi表示第i个图像样本对应真实偏移量(左下真实偏移量或右上真实偏移量)中的横向偏移量或纵向偏移量。f(xi)表示第i个图像样本对应预测偏移量(左下预测偏移量或右上预测偏移量)中的横向偏移量或纵向偏移量。Among them, L represents the loss value. n represents the total number of image samples. y i represents the horizontal offset or the vertical offset in the i-th image sample corresponding to the real offset (lower left real offset or upper right real offset). f( xi ) represents the horizontal offset or the vertical offset in the i-th image sample corresponding to the predicted offset (lower left predicted offset or upper right predicted offset).
最后,结合损失值对特征提取网络以及对象检测网络的模型参数进行更新。Finally, the model parameters of the feature extraction network and the object detection network are updated in combination with the loss value.
再次,本申请实施例中,提供了一种训练对象检测网络的方式,通过上述方式,一方面,可采用L1损失回归右上顶点和左下顶点的偏移量,L1损失有利于优化小扰动,且回归偏移量较回归类似尺寸而言,更为简单和有效。另一方面,易于构造训练样本,可以大量的生成样本用于训练整个模型。本方案可泛化到移动端绝大多数跟踪任务。Again, in the embodiment of the present application, a method of training the object detection network is provided. Through the above method, on the one hand, the L1 loss can be used to return the offset of the upper right vertex and the lower left vertex. The L1 loss is conducive to optimizing small disturbances, and Regressing offsets is simpler and more efficient than regressing similar dimensions. On the other hand, it is easy to construct training samples, and a large number of samples can be generated for training the entire model. This scheme can be generalized to most tracking tasks on mobile terminals.
可选地,在上述图11对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,还可以包括:Optionally, on the basis of the above-mentioned embodiments corresponding to FIG. 11 , another optional embodiment provided by the embodiment of the present application may further include:
采用预设跟踪算法对当前图像帧进行检测,得到目标对象的第一中心位置参数,其中,预设跟踪算法为核相关滤波算法、在线实时跟踪算法、背景感知相关滤波算法或多实例在线学习算法;Use a preset tracking algorithm to detect the current image frame to obtain the first center position parameter of the target object, wherein the preset tracking algorithm is a kernel correlation filtering algorithm, an online real-time tracking algorithm, a context-aware correlation filtering algorithm or a multi-instance online learning algorithm ;
根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果,包括:According to the first offset and the second offset, determine the tracking result for the target object in the current image frame, including:
根据第一偏移量以及第二偏移量,确定目标对象的第二中心位置参数;Determine a second center position parameter of the target object according to the first offset and the second offset;
根据第一中心位置参数以及第二中心位置参数,确定当前图像帧中针对目标对象的跟踪结果。According to the first center position parameter and the second center position parameter, a tracking result for the target object in the current image frame is determined.
在一个或多个实施例中,介绍了一种结合预设跟踪算法实现融合定位的方式。由前述实施例可知,预设跟踪算法能够快速地实现目标跟踪,能够在目标对象快速运动的情况下进行跟踪。但由于预设跟踪算法的准确性较低,因此,可将预设跟踪算法得到的跟踪结果作为对象检测网络输出结果的运动补偿。In one or more embodiments, a manner of implementing fusion positioning combined with a preset tracking algorithm is introduced. It can be known from the foregoing embodiments that the preset tracking algorithm can quickly realize target tracking, and can perform tracking when the target object moves rapidly. However, since the accuracy of the preset tracking algorithm is low, the tracking result obtained by the preset tracking algorithm can be used as the motion compensation of the output result of the object detection network.
具体地,为了便于理解,请再次参阅图8,如图所示,F1用于指示采用预设跟踪算法确定的边界框。F2用于指示采用预设跟踪算法确定边界框的中心点。F3用于指示基于第一偏移量以及第二偏移量确定的边界框。F4用于指示基于第一偏移量以及第二偏移量确定边界框的中心点。Specifically, for ease of understanding, please refer to FIG. 8 again. As shown in the figure, F1 is used to indicate a bounding box determined by using a preset tracking algorithm. F2 is used to indicate that a preset tracking algorithm is used to determine the center point of the bounding box. F3 is used to indicate the bounding box determined based on the first offset and the second offset. F4 is used to indicate to determine the center point of the bounding box based on the first offset and the second offset.
假设F2所指示的中心点对应的第一中心位置参数为(x1,y1),F4所指示的中心点对应的第二中心位置参数为(x2,y2),且假设第一中心位置参数的权重设置为0.2,第二中心位置参数的权重设置为0.8,基于此,结合第一中心位置参数和第二中心位置参数,确定最终得到的边界框中心位置参数为(x3,y3),即:Assume that the first center position parameter corresponding to the center point indicated by F2 is (x1, y1), the second center position parameter corresponding to the center point indicated by F4 is (x2, y2), and assume that the weight of the first center position parameter It is set to 0.2, and the weight of the second center position parameter is set to 0.8. Based on this, combined with the first center position parameter and the second center position parameter, the final center position parameter of the bounding box is determined to be (x3, y3), namely:
x3=0.2*x1+0.8*x2;x3=0.2*x1+0.8*x2;
y3=0.2*y1+0.8*y2;y3=0.2*y1+0.8*y2;
可见,预设跟踪算法相当于为对象检测网络输出结果做了一个偏移。It can be seen that the preset tracking algorithm is equivalent to making an offset for the output of the object detection network.
需要说明的是,预设跟踪算法包含但不仅限于KCF算法,SORT算法,BACF算法以及MIL算法等。It should be noted that the preset tracking algorithms include but not limited to KCF algorithm, SORT algorithm, BACF algorithm and MIL algorithm.
其次,本申请实施例中,提供了一种结合预设跟踪算法实现融合定位的方式,通过上述方式,考虑到在目标对象快速运动的情况下,容易出现目标跟丢的情形,因此,需要频繁地调用检测功能,从而导致终端设备的功耗变高。因此,结合预设跟踪算法能够快速地定位到目标对象的位置,减少检测功能的调用频率,有利于减低终端设备的功耗。Secondly, in the embodiment of the present application, a method for realizing fusion positioning combined with a preset tracking algorithm is provided. Through the above method, considering that the target object is prone to being lost in the case of fast movement, it is necessary to frequently The detection function is invoked frequently, resulting in higher power consumption of the terminal device. Therefore, combined with the preset tracking algorithm, the position of the target object can be quickly located, the calling frequency of the detection function is reduced, and the power consumption of the terminal device is reduced.
可选地,在上述图11对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,目标对象为人手;Optionally, on the basis of the above-mentioned embodiments corresponding to FIG. 11 , in another optional embodiment provided by the embodiment of the present application, the target object is a human hand;
还可以包括:Can also include:
响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;In response to the operation of the video capture control, activate the camera device of the terminal device;
通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;Collecting M consecutive image frames through the camera device, where M is an integer greater than or equal to 1;
根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果之后,还可以包括:After determining the tracking result for the target object in the current image frame according to the first offset and the second offset, it may further include:
获取连续M个图像帧中针对人手的跟踪结果;Obtain the tracking results for human hands in consecutive M image frames;
根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,生成针对人手的移动轨迹;According to the tracking results corresponding to the consecutive M image frames and the tracking results corresponding to the current image frame, a moving track for the human hand is generated;
若移动轨迹与预设轨迹匹配成功,则触发与预设轨迹对应的功能。If the moving track matches the preset track successfully, the function corresponding to the preset track is triggered.
在一个或多个实施例中,介绍了一种基于运动轨迹触发相应功能的方式。由前述实施例可知,终端设备可通过摄像头装置采集视频,并对视频中的图像帧进行分析,进而提取人手的运动轨迹。In one or more embodiments, a manner of triggering a corresponding function based on a motion trajectory is introduced. It can be seen from the above-mentioned embodiments that the terminal device can collect video through the camera device, and analyze the image frames in the video, and then extract the movement track of the human hand.
具体地,为了便于理解,请再次参阅图9,如图所示,以目标对象为人手作为示例。当用户点击“启动摄像头”的控件时,即触发针对视频拍摄控件的操作,于是,终端设备开启摄像头装置并采集视频。假设通过摄像头装置采集到连续M个图像帧,并通过连续M个图像帧中每一帧的跟踪结果,可获取人手移动轨迹,由此,可将人手移动轨迹与预设轨迹匹配进行匹配。Specifically, for ease of understanding, please refer to FIG. 9 again. As shown in the figure, the target object is a human hand as an example. When the user clicks on the control of "starting the camera", an operation on the video shooting control is triggered, and then the terminal device starts the camera device and collects the video. Assuming that M consecutive image frames are collected by the camera device, and the tracking result of each frame in the M consecutive image frames can be used to obtain the moving trajectory of the human hand, so that the moving trajectory of the human hand can be matched with the preset trajectory.
如果移动轨迹与预设轨迹匹配成功,则触发与预设轨迹对应的功能,例如,为用提供相应的奖励,或,显示相应的特效,或,开启某一项特定功能等,此处不做限定。If the moving track matches the preset track successfully, the function corresponding to the preset track will be triggered, for example, providing corresponding rewards for users, or displaying corresponding special effects, or enabling a specific function, etc., which will not be done here limited.
其次,本申请实施例中,提供了一种基于运动轨迹触发相应功能的方式,通过上述方式,在短视频编辑或短视频特效等产品中,基于对人手的跟踪结果可确定运动轨迹,根据运动轨迹可触发相应的功能。可见,本申请提供的方案能够很好的泛化到各类移动端物体的跟踪任务中,针对不同姿态,角度和遮挡的对象具有较为鲁棒的处理,从而达到提升用户体验的目的。Secondly, in the embodiment of the present application, a method of triggering corresponding functions based on the motion trajectory is provided. Through the above method, in products such as short video editing or short video special effects, the motion trajectory can be determined based on the tracking result of the human hand. According to the motion The trace triggers the corresponding function. It can be seen that the solution provided by this application can be well generalized to various mobile object tracking tasks, and it can handle objects with different postures, angles and occlusions more robustly, so as to achieve the purpose of improving user experience.
可选地,在上述图11对应的各个实施例的基础上,本申请实施例提供的另一个可选实施例中,还可以包括:Optionally, on the basis of the above-mentioned embodiments corresponding to FIG. 11 , another optional embodiment provided by the embodiment of the present application may further include:
响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;In response to the operation of the video capture control, activate the camera device of the terminal device;
通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;Collecting M consecutive image frames through the camera device, where M is an integer greater than or equal to 1;
根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果之后,还可以包括:After determining the tracking result for the target object in the current image frame according to the first offset and the second offset, it may further include:
获取连续M个图像帧中针对人手的跟踪结果;Obtain the tracking results for human hands in consecutive M image frames;
根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,获取轨迹长度;Obtain the trajectory length according to the tracking results corresponding to the consecutive M image frames and the tracking results corresponding to the current image frame;
若轨迹长度大于或等于长度阈值,则触发与预设轨迹对应的功能。If the track length is greater than or equal to the length threshold, the function corresponding to the preset track is triggered.
在一个或多个实施例中,介绍了一种基于移动距离触发相应功能的方式。由前述实施例可知,终端设备可通过摄像头装置采集视频,并对视频中的图像帧进行分析,进而提取人手的运动轨迹。In one or more embodiments, a manner of triggering a corresponding function based on a moving distance is introduced. It can be seen from the above-mentioned embodiments that the terminal device can collect video through the camera device, and analyze the image frames in the video, and then extract the movement track of the human hand.
具体地,为了便于理解,请再次参阅图10,如图所示,以目标对象为人手作为示例。当用户点击“启动摄像头”的控件时,即触发针对视频拍摄控件的操作,于是,终端设备开启摄像头装置并采集视频。假设通过摄像头装置采集到连续M个图像帧,并通过连续M个图像帧中每一帧的跟踪结果,可确定一条连续的运动轨迹,由此,可计算出该运动轨迹的轨迹长度。Specifically, for ease of understanding, please refer to FIG. 10 again. As shown in the figure, the target object is a human hand as an example. When the user clicks on the control of "starting the camera", an operation on the video shooting control is triggered, and then the terminal device starts the camera device and collects the video. Assume that M consecutive image frames are collected by the camera device, and a continuous motion trajectory can be determined through the tracking results of each frame in the M consecutive image frames, and thus the trajectory length of the motion trajectory can be calculated.
如果轨迹长度大于或等于长度阈值,则触发与预设轨迹对应的功能,例如,为用提供相应的奖励,或,显示相应的特效,或,开启某一项特定功能等,此处不做限定。If the track length is greater than or equal to the length threshold, the function corresponding to the preset track will be triggered, for example, providing corresponding rewards for users, or displaying corresponding special effects, or enabling a specific function, etc., which are not limited here .
其次,本申请实施例中,提供了一种基于移动距离触发相应功能的方式,通过上述方式,在短视频编辑或短视频特效等产品中,基于对人手的跟踪结果可确定移动距离,根据移动距离可触发相应的功能。可见,本申请提供的方案能够很好的泛化到各类移动端物体的跟踪任务中,针对不同姿态,角度和遮挡的对象具有较为鲁棒的处理,从而达到提升用户体验的目的。Secondly, in the embodiment of the present application, a method of triggering corresponding functions based on the moving distance is provided. Through the above method, in products such as short video editing or short video special effects, the moving distance can be determined based on the tracking result of the human hand. The distance triggers the corresponding function. It can be seen that the solution provided by this application can be well generalized to various mobile object tracking tasks, and it can handle objects with different postures, angles and occlusions more robustly, so as to achieve the purpose of improving user experience.
下面对本申请中的目标对象跟踪装置进行详细描述,请参阅图14,图14为本申请实施例中目标对象跟踪装置的一个实施例示意图,目标对象跟踪装置30包括:The following is a detailed description of the target object tracking device in this application. Please refer to FIG. 14. FIG. 14 is a schematic diagram of an embodiment of the target object tracking device in the embodiment of the present application. The target
获取模块310,用于若在当前图像帧的前一个图像帧中检测出目标对象,则根据前一个图像帧所对应的目标边界框,从当前图像帧中提取原始检测图像,其中,原始检测图像包括目标对象;The acquiring
获取模块310,还用于基于原始检测图像,通过特征提取网络获取目标特征图,其中,目标特征图包括K个特征点,且目标特征图被划分为N个特征图,每个特征图中设置有一个锚点,K为大于1的整数,N为大于或等于1且小于K的整数;The obtaining
获取模块310,还用于针对每个特征图,根据特征图中设置的锚点获取锚点框;The obtaining
获取模块310,还用于针对每个特征图,基于锚点框所对应的特征,通过对象检测网络获取至少一组可选边界框参数,其中,每组可选边界框参数包括可选边界框的坐标参数以及尺寸参数;The acquiring
确定模块320,用于根据每个特征图的至少一组可选边界框参数确定T组边界框参数,其中,每组边界框参数包括边界框的坐标参数以及尺寸参数,T为大于或等于1的整数;The determining
跟踪模块330,用于根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果。The
可选地,在上述图14所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置30的另一实施例中,目标对象跟踪装置30还包括识别模块340;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 14 , in another embodiment of the target
识别模块340,用于若在当前图像帧的前一个图像帧中未检测出目标对象,则对当前图像帧进行对象识别;The
识别模块340,还用于若未获取到当前图像帧的前一个图像帧,则对当前图像帧进行对象识别。The
可选地,在上述图14所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置30的另一实施例中,Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 14 , in another embodiment of the target
获取模块310,具体用于对原始检测图像进行尺寸调整,得到待处理图像;The
若待处理图像的尺寸与预设尺寸匹配失败,则对待处理图像进行填充,得到满足预设尺寸的目标检测图像;If the size of the image to be processed fails to match the preset size, the image to be processed is filled to obtain a target detection image that meets the preset size;
基于目标检测图像,通过特征提取网络输出目标特征图。Based on the target detection image, the target feature map is output through the feature extraction network.
可选地,在上述图14所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置30的另一实施例中,每组可选边界框参数还包括置信度参数,至少一组可选边界框参数包括多组可选边界框参数;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 14 , in another embodiment of the target
确定模块320,具体用于针对每个特征图,从多组可选边界框参数中选择具有最大置信度参数的可选边界框参数,其中,每组可选边界框参数用于确定一个可选边界框;The determining
针对每个特征图,根据具有最大置信度参数的可选边界框参数,确定初始可选边界框;For each feature map, determine an initial optional bounding box according to the optional bounding box parameter with the maximum confidence parameter;
针对每个特征图,遍历其余的可选边界框,若存在可选边界框与初始可选边界框之间的重叠面积大于或等于面积阈值,则删除可选边界框,直至得到剩余的可选边界框,其中,其余的可选边界框表示除了初始可选边界框之外的可选边界框;For each feature map, traverse the remaining optional bounding boxes. If the overlapping area between the optional bounding box and the initial optional bounding box is greater than or equal to the area threshold, delete the optional bounding box until the remaining optional bounding boxes are obtained. bounding boxes, where the remaining optional bounding boxes represent optional bounding boxes in addition to the initial optional bounding box;
针对每个特征图,将剩余的可选边界框所对应的可选边界框参数作为边界框参数。For each feature map, the optional bounding box parameters corresponding to the remaining optional bounding boxes are used as bounding box parameters.
可选地,在上述图14所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置30的另一实施例中,Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 14 , in another embodiment of the target
跟踪模块330,具体用于根据T组边界框参数确定T个边界框;
根据T个边界框确定最左侧顶点、最右侧顶点、最上侧顶点以及最下侧顶点;Determine the leftmost vertex, the rightmost vertex, the uppermost vertex, and the lowermost vertex according to the T bounding boxes;
根据最左侧顶点、最右侧顶点、最上侧顶点以及最下侧顶点,确定左上顶点坐标、左下顶点坐标、右上顶点坐标以及右下顶点坐标;Determine the coordinates of the upper left vertex, the lower left vertex, the upper right vertex, and the lower right vertex according to the leftmost vertex, the rightmost vertex, the uppermost vertex, and the lowermost vertex;
根据左上顶点坐标、左下顶点坐标、右上顶点坐标以及右下顶点坐标,确定针对目标对象的跟踪结果。According to the coordinates of the upper left vertex, the lower left vertex, the upper right vertex and the lower right vertex, the tracking result for the target object is determined.
可选地,在上述图14所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置30的另一实施例中,目标对象跟踪装置30还包括训练模块350;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 14 , in another embodiment of the target
获取模块310,还用于获取图像样本,其中,图像样本包括目标对象;The acquiring
获取模块310,还用于基于图像样本,通过特征提取网络获取样本特征图,其中,样本特征图包括K个特征点,样本特征图被划分为N个待训练特征图,每个待训练特征图中设置有一个锚点;The
获取模块310,还用于针对每个待训练特征图,根据待训练特征图中设置的锚点获取锚点框;The obtaining
获取模块310,还用于针对每个待训练特征图,基于锚点框所对应的特征以及真实边界框参数,通过对象检测网络获取至少一组可选边界框参数,其中,每组可选边界框参数包括待训练边界框的坐标参数以及尺寸参数;The
确定模块320,还用于针对每个待训练特征图,从至少一组可选边界框参数中确定预测边界框参数;The
训练模块350,用于针对每个待训练特征图,根据预测边界框参数以及真实边界框参数,采用损失函数对特征提取网络以及对象检测网络的模型参数进行更新。The
可选地,在上述图14所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置30的另一实施例中,目标对象跟踪装置30还包括检测模块360;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 14 , in another embodiment of the target
检测模块360,用于采用预设跟踪算法对当前图像帧进行检测,得到目标对象的第一中心位置参数,其中,预设跟踪算法为核相关滤波算法、在线实时跟踪算法、背景感知相关滤波算法或多实例在线学习算法;The
跟踪模块330,具体用于根据T组边界框参数,确定目标对象的第二中心位置参数;The
根据第一中心位置参数以及第二中心位置参数,确定当前图像帧中针对目标对象的跟踪结果。According to the first center position parameter and the second center position parameter, a tracking result for the target object in the current image frame is determined.
可选地,在上述图14所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置30的另一实施例中,目标对象为人手;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 14 , in another embodiment of the target
目标对象跟踪装置30还包括启动模块370、生成模块380以及触发模块390;The target
启动模块370,用于响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;The starting
获取模块310,还用于通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;The acquiring
获取模块310,还用于根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果之后,获取连续M个图像帧中针对人手的跟踪结果;The obtaining
生成模块380,用于根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,生成针对人手的移动轨迹;The
触发模块390,用于若移动轨迹与预设轨迹匹配成功,则触发与预设轨迹对应的功能。The triggering
可选地,在上述图14所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置30的另一实施例中,目标对象为人手;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 14 , in another embodiment of the target
启动模块370,还用于响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;The starting
获取模块310,还用于通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;The acquiring
获取模块310,还用于根据T组边界框参数确定当前图像帧中针对目标对象的跟踪结果之后,获取连续M个图像帧中针对人手的跟踪结果;The obtaining
获取模块310,还用于根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,获取轨迹长度;The obtaining
触发模块390,还用于若轨迹长度大于或等于长度阈值,则触发与预设轨迹对应的功能。The
下面对本申请中的目标对象跟踪装置进行详细描述,请参阅图15,图15为本申请实施例中目标对象跟踪装置的另一个实施例示意图,目标对象跟踪装置40包括:The following is a detailed description of the target object tracking device in this application. Please refer to FIG. 15. FIG. 15 is a schematic diagram of another embodiment of the target object tracking device in the embodiment of the present application. The target
获取模块410,用于若在当前图像帧的前一个图像帧中检测出目标对象,则根据前一个图像帧所对应的目标边界框,从当前图像帧中提取原始检测图像,其中,原始检测图像包括目标对象;The acquiring
获取模块410,还用于基于原始检测图像,通过特征提取网络获取目标特征图;The obtaining
获取模块410,还用于基于目标特征图,通过对象检测网络获取第一偏移量以及第二偏移量,其中,第一偏移量为左上偏移量,且第二偏移量为右下偏移量,或,第一偏移量为右上偏移量,且第二偏移量为左下偏移量;The obtaining
跟踪模块420,用于根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果。The
可选地,在上述图15所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置40的另一实施例中,目标对象跟踪装置40还包括识别模块430;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 15 , in another embodiment of the target
识别模块430,用于若在当前图像帧的前一个图像帧中未检测出目标对象,则对当前图像帧进行对象识别;The
识别模块430,还用于若未获取到当前图像帧的前一个图像帧,则对当前图像帧进行对象识别。The
可选地,在上述图15所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置40的另一实施例中,Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 15 , in another embodiment of the target
获取模块410,具体用于对原始检测图像进行尺寸调整,得到待处理图像;The
若待处理图像的尺寸与预设尺寸匹配失败,则对待处理图像进行填充,得到满足预设尺寸的目标检测图像;If the size of the image to be processed fails to match the preset size, the image to be processed is filled to obtain a target detection image that meets the preset size;
基于目标检测图像,通过特征提取网络输出目标特征图。Based on the target detection image, the target feature map is output through the feature extraction network.
可选地,在上述图15所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置40的另一实施例中,第一偏移量为左上偏移量,且第二偏移量为右下偏移量,其中,左上偏移量包括左上顶点距离初始左上顶点的横向偏移量以及纵向偏移量,右下偏移量包括右下顶点距离初始右下顶点的横向偏移量以及纵向偏移量;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 15 , in another embodiment of the target
目标对象跟踪装置40还包括训练模块440;The target
获取模块410,还用于获取图像样本,其中,图像样本包括目标对象;The acquiring
获取模块410,还用于基于图像样本,通过特征提取网络获取样本特征图;The obtaining
获取模块410,还用于基于样本特征图,通过对象检测网络获取左上预测偏移量以及右下预测偏移量;The obtaining
训练模块440,用于基于样本特征图,根据左上预测偏移量、右下预测偏移量、左上真实偏移量以及右下真实偏移量,采用损失函数对特征提取网络以及对象检测网络的模型参数进行更新。The
可选地,在上述图15所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置40的另一实施例中,第一偏移量为右上偏移量,且第二偏移量为左下偏移量,其中,右上偏移量包括右上顶点距离初始右上顶点的横向偏移量以及纵向偏移量,左下偏移量包括左下顶点距离初始左下顶点的横向偏移量以及纵向偏移量;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 15 , in another embodiment of the target
获取模块410,还用于获取图像样本,其中,图像样本包括目标对象;The acquiring
获取模块410,还用于基于图像样本,通过特征提取网络获取样本特征图;The obtaining
获取模块410,还用于基于样本特征图,通过对象检测网络获取右上预测偏移量以及左下预测偏移量;The obtaining
训练模块440,还用于基于样本特征图,根据右上预测偏移量、左下预测偏移量、右上真实偏移量以及左下真实偏移量,采用损失函数对特征提取网络以及对象检测网络的模型参数进行更新。The
可选地,在上述图15所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置40的另一实施例中,目标对象跟踪装置40还包括检测模块450;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 15 , in another embodiment of the target
检测模块450,用于采用预设跟踪算法对当前图像帧进行检测,得到目标对象的第一中心位置参数,其中,预设跟踪算法为核相关滤波算法、在线实时跟踪算法、背景感知相关滤波算法或多实例在线学习算法;The
跟踪模块420,具体用于根据第一偏移量以及第二偏移量,确定目标对象的第二中心位置参数;The
根据第一中心位置参数以及第二中心位置参数,确定当前图像帧中针对目标对象的跟踪结果。According to the first center position parameter and the second center position parameter, a tracking result for the target object in the current image frame is determined.
可选地,在上述图15所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置40的另一实施例中,目标对象为人手;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 15 , in another embodiment of the target
目标对象跟踪装置40还包括启动模块460、生成模块470以及触发模块480;The target
启动模块460,用于响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;The starting
获取模块410,还用于通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;The
获取模块410,还用于根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果之后,获取连续M个图像帧中针对人手的跟踪结果;The
生成模块470,用于根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,生成针对人手的移动轨迹;The
触发模块480,用于若移动轨迹与预设轨迹匹配成功,则触发与预设轨迹对应的功能。The triggering
可选地,在上述图15所对应的实施例的基础上,本申请实施例提供的目标对象跟踪装置40的另一实施例中,目标对象为人手;Optionally, on the basis of the above-mentioned embodiment corresponding to FIG. 15 , in another embodiment of the target
启动模块460,还用于响应针对视频拍摄控件的操作,启动终端设备的摄像头装置;The starting
获取模块410,还用于通过摄像头装置采集连续M个图像帧,其中,M为大于或等于1的整数;The
获取模块410,还用于根据第一偏移量以及第二偏移量,确定当前图像帧中针对目标对象的跟踪结果之后,获取连续M个图像帧中针对人手的跟踪结果;The
获取模块410,还用于根据连续M个图像帧对应的跟踪结果以及当前图像帧对应的跟踪结果,获取轨迹长度;The obtaining
触发模块480,还用于若轨迹长度大于或等于长度阈值,则触发与预设轨迹对应的功能。The
本申请实施例还提供了另一种目标对象跟踪装置,如图16所示,为了便于说明,仅示出了与本申请实施例相关的部分,具体技术细节未揭示的,请参照本申请实施例方法部分。该终端设备可以为包括手机、平板电脑、个人数字助理(Personal Digital Assistant,PDA)、销售终端设备(Point of Sales,POS)、车载电脑等任意终端设备,以终端设备为手机为例:The embodiment of the present application also provides another target object tracking device, as shown in Figure 16, for the convenience of description, only the parts related to the embodiment of the present application are shown, and the specific technical details are not disclosed, please refer to the implementation of this application Example methods section. The terminal device may be any terminal device including a mobile phone, a tablet computer, a personal digital assistant (PDA), a point of sales (POS), a vehicle-mounted computer, etc., taking the terminal device as a mobile phone as an example:
图16示出的是与本申请实施例提供的终端设备相关的手机的部分结构的框图。参考图16,手机包括:射频(Radio Frequency,RF)电路710、存储器720、输入单元730、显示单元740、传感器750、音频电路760、无线保真(wireless fidelity,WiFi)模块770、处理器780、以及电源790等部件。本领域技术人员可以理解,图16中示出的手机结构并不构成对手机的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。FIG. 16 is a block diagram showing a partial structure of a mobile phone related to the terminal device provided by the embodiment of the present application. Referring to FIG. 16 , the mobile phone includes: a radio frequency (Radio Frequency, RF)
下面结合图16对手机的各个构成部件进行具体的介绍:The following is a specific introduction to each component of the mobile phone in conjunction with Figure 16:
RF电路710可用于收发信息或通话过程中,信号的接收和发送,特别地,将基站的下行信息接收后,给处理器780处理;另外,将设计上行的数据发送给基站。通常,RF电路710包括但不限于天线、至少一个放大器、收发信机、耦合器、低噪声放大器(Low NoiseAmplifier,LNA)、双工器等。此外,RF电路710还可以通过无线通信与网络和其他设备通信。上述无线通信可以使用任一通信标准或协议,包括但不限于全球移动通讯系统(GlobalSystem of Mobile communication,GSM)、通用分组无线服务(General Packet RadioService,GPRS)、码分多址(Code Division Multiple Access,CDMA)、宽带码分多址(Wideband Code Division Multiple Access,WCDMA)、长期演进(Long Term Evolution,LTE)、电子邮件、短消息服务(Short Messaging Service,SMS)等。The
存储器720可用于存储软件程序以及模块,处理器780通过运行存储在存储器720的软件程序以及模块,从而执行手机的各种功能应用以及数据处理。存储器720可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器720可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。The
输入单元730可用于接收输入的数字或字符信息,以及产生与手机的用户设置以及功能控制有关的键信号输入。具体地,输入单元730可包括触控面板731以及其他输入设备732。触控面板731,也称为触摸屏,可收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触控面板731上或在触控面板731附近的操作),并根据预先设定的程式驱动相应的连接装置。可选的,触控面板731可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器780,并能接收处理器780发来的命令并加以执行。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型实现触控面板731。除了触控面板731,输入单元730还可以包括其他输入设备732。具体地,其他输入设备732可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。The
显示单元740可用于显示由用户输入的信息或提供给用户的信息以及手机的各种菜单。显示单元740可包括显示面板741,可选的,可以采用液晶显示器(Liquid CrystalDisplay,LCD)、有机发光二极管(Organic Light-Emitting Diode,OLED)等形式来配置显示面板741。进一步的,触控面板731可覆盖显示面板741,当触控面板731检测到在其上或附近的触摸操作后,传送给处理器780以确定触摸事件的类型,随后处理器780根据触摸事件的类型在显示面板741上提供相应的视觉输出。虽然在图16中,触控面板731与显示面板741是作为两个独立的部件来实现手机的输入和输入功能,但是在某些实施例中,可以将触控面板731与显示面板741集成而实现手机的输入和输出功能。The
手机还可包括至少一种传感器750,比如光传感器、运动传感器以及其他传感器。具体地,光传感器可包括环境光传感器及接近传感器,其中,环境光传感器可根据环境光线的明暗来调节显示面板741的亮度,接近传感器可在手机移动到耳边时,关闭显示面板741和/或背光。作为运动传感器的一种,加速计传感器可检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向,可用于识别手机姿态的应用(比如横竖屏切换、相关游戏、磁力计姿态校准)、振动识别相关功能(比如计步器、敲击)等;至于手机还可配置的陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。The handset may also include at least one
音频电路760、扬声器761,传声器762可提供用户与手机之间的音频接口。音频电路760可将接收到的音频数据转换后的电信号,传输到扬声器761,由扬声器761转换为声音信号输出;另一方面,传声器762将收集的声音信号转换为电信号,由音频电路760接收后转换为音频数据,再将音频数据输出处理器780处理后,经RF电路710以发送给比如另一手机,或者将音频数据输出至存储器720以便进一步处理。The
WiFi属于短距离无线传输技术,手机通过WiFi模块770可以帮助用户收发电子邮件、浏览网页和访问流式媒体等,它为用户提供了无线的宽带互联网访问。虽然图16示出了WiFi模块770,但是可以理解的是,其并不属于手机的必须构成,完全可以根据需要在不改变发明的本质的范围内而省略。WiFi is a short-distance wireless transmission technology. The mobile phone can help users send and receive emails, browse web pages, and access streaming media through the
处理器780是手机的控制中心,利用各种接口和线路连接整个手机的各个部分,通过运行或执行存储在存储器720内的软件程序和/或模块,以及调用存储在存储器720内的数据,执行手机的各种功能和处理数据,从而对手机进行整体监控。可选的,处理器780可包括一个或多个处理单元;可选的,处理器780可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器780中。The
手机还包括给各个部件供电的电源790(比如电池),可选的,电源可以通过电源管理系统与处理器780逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。The mobile phone also includes a power supply 790 (such as a battery) for supplying power to various components. Optionally, the power supply can be logically connected to the
尽管未示出,手机还可以包括摄像头、蓝牙模块等,在此不再赘述。Although not shown, the mobile phone may also include a camera, a Bluetooth module, etc., which will not be repeated here.
上述实施例中由终端设备所执行的步骤可以基于该图16所示的终端设备结构。The steps performed by the terminal device in the foregoing embodiments may be based on the structure of the terminal device shown in FIG. 16 .
本申请实施例中还提供一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行如前述各个实施例描述的方法。Embodiments of the present application also provide a computer-readable storage medium, where a computer program is stored in the computer-readable storage medium, and when the computer program is run on a computer, the computer executes the methods described in the foregoing embodiments.
本申请实施例中还提供一种包括程序的计算机程序产品,当其在计算机上运行时,使得计算机执行前述各个实施例描述的方法。Embodiments of the present application also provide a computer program product including a program, which when run on a computer, causes the computer to execute the methods described in the foregoing embodiments.
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。Those skilled in the art can clearly understand that for the convenience and brevity of the description, the specific working process of the above-described system, device and unit can refer to the corresponding process in the foregoing method embodiment, which will not be repeated here.
在本申请所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。In the several embodiments provided in this application, it should be understood that the disclosed system, device and method can be implemented in other ways. For example, the device embodiments described above are only illustrative. For example, the division of the units is only a logical function division. In actual implementation, there may be other division methods. For example, multiple units or components can be combined or May be integrated into another system, or some features may be ignored, or not implemented. In another point, the mutual coupling or direct coupling or communication connection shown or discussed may be through some interfaces, and the indirect coupling or communication connection of devices or units may be in electrical, mechanical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and the components shown as units may or may not be physical units, that is, they may be located in one place, or may be distributed to multiple network units. Part or all of the units can be selected according to actual needs to achieve the purpose of the solution of this embodiment.
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。In addition, each functional unit in each embodiment of the present application may be integrated into one processing unit, each unit may exist separately physically, or two or more units may be integrated into one unit. The above-mentioned integrated units can be implemented in the form of hardware or in the form of software functional units.
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(read-only memory,ROM)、随机存取存储器(random access memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。If the integrated unit is realized in the form of a software function unit and sold or used as an independent product, it can be stored in a computer-readable storage medium. Based on this understanding, the technical solution of the present application is essentially or part of the contribution to the prior art or all or part of the technical solution can be embodied in the form of a software product, and the computer software product is stored in a storage medium , including several instructions to make a computer device (which may be a personal computer, a server, or a network device, etc.) execute all or part of the steps of the methods described in the various embodiments of the present application. The aforementioned storage medium includes: U disk, mobile hard disk, read-only memory (read-only memory, ROM), random access memory (random access memory, RAM), magnetic disk or optical disk and other various media that can store program codes. .
以上所述,以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。As mentioned above, the above embodiments are only used to illustrate the technical solutions of the present application, and are not intended to limit them; although the present application has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand that: it can still understand the foregoing The technical solutions described in each embodiment are modified, or some of the technical features are equivalently replaced; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the various embodiments of the application.
Claims (20)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111371200.4A CN116152289A (en) | 2021-11-18 | 2021-11-18 | A tracking method, related device, equipment and storage medium of a target object |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111371200.4A CN116152289A (en) | 2021-11-18 | 2021-11-18 | A tracking method, related device, equipment and storage medium of a target object |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116152289A true CN116152289A (en) | 2023-05-23 |
Family
ID=86349299
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111371200.4A Pending CN116152289A (en) | 2021-11-18 | 2021-11-18 | A tracking method, related device, equipment and storage medium of a target object |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116152289A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN118447071A (en) * | 2023-12-29 | 2024-08-06 | 荣耀终端有限公司 | Image processing method and electronic device |
| CN119444047A (en) * | 2024-10-17 | 2025-02-14 | 广州融大信息科技有限公司 | AI Intelligent Logistics Warehousing System |
| WO2025138522A1 (en) * | 2023-12-27 | 2025-07-03 | 深圳市鸿合创新信息技术有限责任公司 | Hand tracking method and apparatus, and electronic device and storage medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104299243A (en) * | 2014-09-28 | 2015-01-21 | 南京邮电大学 | Target tracking method based on Hough forests |
| CN109584276A (en) * | 2018-12-04 | 2019-04-05 | 北京字节跳动网络技术有限公司 | Critical point detection method, apparatus, equipment and readable medium |
| CN110322473A (en) * | 2019-07-09 | 2019-10-11 | 四川大学 | Target based on significant position is anti-to block tracking |
| CN111754541A (en) * | 2020-07-29 | 2020-10-09 | 腾讯科技(深圳)有限公司 | Target tracking method, device, equipment and readable storage medium |
| CN113628250A (en) * | 2021-08-27 | 2021-11-09 | 北京澎思科技有限公司 | Target tracking method and device, electronic equipment and readable storage medium |
-
2021
- 2021-11-18 CN CN202111371200.4A patent/CN116152289A/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104299243A (en) * | 2014-09-28 | 2015-01-21 | 南京邮电大学 | Target tracking method based on Hough forests |
| CN109584276A (en) * | 2018-12-04 | 2019-04-05 | 北京字节跳动网络技术有限公司 | Critical point detection method, apparatus, equipment and readable medium |
| CN110322473A (en) * | 2019-07-09 | 2019-10-11 | 四川大学 | Target based on significant position is anti-to block tracking |
| CN111754541A (en) * | 2020-07-29 | 2020-10-09 | 腾讯科技(深圳)有限公司 | Target tracking method, device, equipment and readable storage medium |
| CN113628250A (en) * | 2021-08-27 | 2021-11-09 | 北京澎思科技有限公司 | Target tracking method and device, electronic equipment and readable storage medium |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025138522A1 (en) * | 2023-12-27 | 2025-07-03 | 深圳市鸿合创新信息技术有限责任公司 | Hand tracking method and apparatus, and electronic device and storage medium |
| CN118447071A (en) * | 2023-12-29 | 2024-08-06 | 荣耀终端有限公司 | Image processing method and electronic device |
| CN119444047A (en) * | 2024-10-17 | 2025-02-14 | 广州融大信息科技有限公司 | AI Intelligent Logistics Warehousing System |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111652121B (en) | An expression transfer model training method, expression transfer method and device | |
| CN110765967B (en) | A kind of action recognition method and related device based on artificial intelligence | |
| CN112232425B (en) | Image processing method, device, storage medium and electronic equipment | |
| CN110738211B (en) | Object detection method, related device and equipment | |
| CN109325967B (en) | Target tracking method, device, medium, and apparatus | |
| JP6824433B2 (en) | Camera posture information determination method, determination device, mobile terminal and computer program | |
| CN111209423B (en) | Image management method and device based on electronic album and storage medium | |
| CN113821720A (en) | A behavior prediction method, device and related products | |
| CN110766081B (en) | Interface image detection method, model training method and related device | |
| CN113723378B (en) | Model training method and device, computer equipment and storage medium | |
| CN112203115B (en) | Video identification method and related device | |
| CN116543076B (en) | Image processing method, device, electronic equipment and storage medium | |
| CN116152289A (en) | A tracking method, related device, equipment and storage medium of a target object | |
| CN117011929B (en) | Head posture estimation method, device, equipment and storage medium | |
| CN112184548A (en) | Image super-resolution method, device, device and storage medium | |
| CN113536876A (en) | Image recognition method and related device | |
| CN113050860B (en) | Control identification method and related device | |
| US20240331245A1 (en) | Video processing method, video processing apparatus, and storage medium | |
| CN111753813B (en) | Image processing method, device, equipment and storage medium | |
| CN113849142B (en) | Image display method, device, electronic equipment and computer readable storage medium | |
| CN112818733B (en) | Information processing method, device, storage medium and terminal | |
| CN114743024A (en) | Image identification method, device and system and electronic equipment | |
| CN110750193B (en) | Scene topology determination method and device based on artificial intelligence | |
| HK40087207A (en) | Target object tracking method, related apparatus, device, and storage medium | |
| HK40047829A (en) | Control identification method and related apparatus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 40087207 Country of ref document: HK |