CN116127098A - Knowledge graph construction method and device - Google Patents
Knowledge graph construction method and device Download PDFInfo
- Publication number
- CN116127098A CN116127098A CN202310147705.5A CN202310147705A CN116127098A CN 116127098 A CN116127098 A CN 116127098A CN 202310147705 A CN202310147705 A CN 202310147705A CN 116127098 A CN116127098 A CN 116127098A
- Authority
- CN
- China
- Prior art keywords
- entity
- knowledge
- graph
- source data
- constructed
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/367—Ontology
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/284—Relational databases
- G06F16/288—Entity relationship models
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/31—Indexing; Data structures therefor; Storage structures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Animal Behavior & Ethology (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Stored Programmes (AREA)
Abstract
本申请公开了一种知识图谱的构建方法、装置。所述方法包括:获取目标知识图谱对应的本体、抽取规则和映射规则,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则;接收查询请求,查询请求中包括第一实体,根据查询请求,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建,查询请求用于在图数据库中查询第一实体的第一相关知识;在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识;将第一相关知识导入图数据库中,进行目标知识图谱的构建。
The present application discloses a method and a device for constructing a knowledge map. The method includes: obtaining ontology corresponding to the target knowledge map, extraction rules and mapping rules, the ontology includes the definition of multiple entities and the definition of related information of multiple entities, and the extraction rule is to extract data from the source data corresponding to the entity A rule, the mapping rule is a rule for mapping the fields in the source data corresponding to the entity to the ontology; receiving a query request, including the first entity in the query request, and determining whether the first entity is in the graph database corresponding to the target knowledge map according to the query request has been constructed, the query request is used to query the first relevant knowledge of the first entity in the graph database; if the first entity has not been constructed, according to the ontology, extraction rules and mapping rules, the source data corresponding to the first entity Perform extraction to determine the first relevant knowledge; import the first relevant knowledge into the graph database to construct the target knowledge map.
Description
技术领域technical field
本申请属于知识图谱技术领域,具体涉及一种知识图谱的构建方法、装置。The present application belongs to the technical field of knowledge graph, and specifically relates to a method and device for constructing a knowledge graph.
背景技术Background technique
近年来,知识图谱(Knowledge Graph)已在工业界和学术界得到了广泛使用。知识图谱以图数据结构来表达和存储知识,采用实体、关系、属性来描述现实世界,一般有两种构建方式:自上而下方式、自下而上方式,无论是自上而下还是自下而上的构建方式,都是对数据源进行全量抽取,转换并加载至知识图谱的过程。In recent years, Knowledge Graph has been widely used in industry and academia. The knowledge map uses the graph data structure to express and store knowledge, and uses entities, relationships, and attributes to describe the real world. There are generally two construction methods: top-down and bottom-up. The bottom-up construction method is a process of fully extracting data sources, converting and loading them into the knowledge map.
但在海量数据下,对数据源进行全量抽取进行知识图谱的构建或更新,可能导致大量的几乎不会被搜索的相关知识占用了大量的空间资源,且进行全量抽取需要的时间较长。However, in the context of massive data, full extraction of data sources to construct or update knowledge graphs may result in a large amount of relevant knowledge that is hardly searchable, occupying a large amount of space resources, and full extraction takes a long time.
发明内容Contents of the invention
本申请实施例提供一种知识图谱的构建方法、装置,能够减少在海量数据下构建知识图谱占用的时间与存储空间。The embodiment of the present application provides a method and device for constructing a knowledge graph, which can reduce the time and storage space occupied by constructing a knowledge graph under massive data.
第一方面,本申请实施例提供了一种知识图谱的构建方法,该方法包括:获取目标知识图谱对应的本体、抽取规则和映射规则;其中,所述本体中包括多个实体的定义与所述多个实体的相关信息的定义,所述抽取规则为从实体对应的源数据中抽取数据的规则,所述映射规则为将实体对应的源数据中的字段映射到本体的规则;接收查询请求,所述查询请求中包括第一实体,根据所述查询请求,确定所述第一实体在所述目标知识图谱对应的图数据库中是否已经被构建,所述查询请求用于在所述图数据库中查询所述第一实体的第一相关知识;在所述第一实体未被构建的情况下,根据所述本体、所述抽取规则和所述映射规则,对所述第一实体对应的源数据进行抽取,确定所述第一相关知识;将所述第一相关知识导入所述图数据库中,进行所述目标知识图谱的构建。In the first aspect, the embodiment of the present application provides a method for constructing a knowledge graph, the method includes: obtaining an ontology, extraction rules, and mapping rules corresponding to the target knowledge graph; wherein, the ontology includes the definitions of multiple entities and the The definition of related information of multiple entities, the extraction rule is a rule for extracting data from the source data corresponding to the entity, and the mapping rule is a rule for mapping the fields in the source data corresponding to the entity to the ontology; receiving the query request , the query request includes the first entity, and according to the query request, it is determined whether the first entity has been constructed in the graph database corresponding to the target knowledge graph, and the query request is used in the graph database Query the first relevant knowledge of the first entity in ; if the first entity has not been constructed, according to the ontology, the extraction rules and the mapping rules, the source corresponding to the first entity Extracting data to determine the first relevant knowledge; importing the first relevant knowledge into the graph database to construct the target knowledge map.
第二方面,本申请实施例提供了一种知识图谱的构建装置,包括:本体预置模块,用于获取目标知识图谱对应的本体、抽取规则和映射规则;其中,所述本体中包括多个实体的定义与所述多个实体的相关信息的定义,所述抽取规则为从实体对应的源数据中抽取数据的规则,所述映射规则为将实体对应的源数据中的字段映射到本体的规则;第一确定模块,用于接收查询请求,所述查询请求中包括第一实体,根据所述查询请求,确定所述第一实体在所述目标知识图谱对应的图数据库中是否已经被构建,所述查询请求用于在所述图数据库中查询所述第一实体的第一相关知识;第二确定模块,用于在所述第一实体未被构建的情况下,根据所述本体、所述抽取规则和所述映射规则,对所述第一实体对应的源数据进行抽取,确定所述第一相关知识;构建模块,用于将所述第一相关知识导入所述图数据库中,进行所述目标知识图谱的构建。In the second aspect, the embodiment of the present application provides a knowledge map construction device, including: an ontology preset module, used to obtain the ontology, extraction rules, and mapping rules corresponding to the target knowledge map; wherein, the ontology includes multiple The definition of the entity and the definition of the relevant information of the multiple entities, the extraction rule is a rule for extracting data from the source data corresponding to the entity, and the mapping rule is a rule for mapping the fields in the source data corresponding to the entity to the ontology Rules; a first determination module, configured to receive a query request, the query request includes a first entity, and according to the query request, determine whether the first entity has been constructed in the graph database corresponding to the target knowledge graph , the query request is used to query the first related knowledge of the first entity in the graph database; the second determination module is used to, if the first entity is not constructed, according to the ontology, The extraction rule and the mapping rule extract the source data corresponding to the first entity to determine the first related knowledge; a building module is used to import the first related knowledge into the graph database, Carry out the construction of the target knowledge map.
第三方面,本申请实施例提供了一种电子设备,该电子设备包括处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如第一方面所述的方法的步骤。In a third aspect, an embodiment of the present application provides an electronic device, the electronic device includes a processor, a memory, and a program or instruction stored in the memory and operable on the processor, and the program or instruction is The processor implements the steps of the method described in the first aspect when executed.
第四方面,本申请实施例提供了一种可读存储介质,所述可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现如第一方面所述的方法的步骤。In a fourth aspect, an embodiment of the present application provides a readable storage medium, on which a program or an instruction is stored, and when the program or instruction is executed by a processor, the steps of the method described in the first aspect are implemented .
第五方面,本申请实施例提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现如第一方面所述的方法。In the fifth aspect, the embodiment of the present application provides a chip, the chip includes a processor and a communication interface, the communication interface is coupled to the processor, and the processor is used to run programs or instructions, so as to implement the first aspect the method described.
在本申请实施例中,通过获取目标知识图谱对应的本体、抽取规则和映射规则,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则;接收查询请求,查询请求中包括第一实体,根据查询请求,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建,查询请求用于在图数据库中查询第一实体的第一相关知识;在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识;将第一相关知识导入图数据库中,进行目标知识图谱的构建。可见,相比于直接对海量数据进行全量抽取得到大量的知识,进行知识图谱的构建,导致几乎不会被搜索的知识占用了大量的空间资源,且不容易进行知识图谱的多次构建,本技术方案能够根据用户的查询请求,对第一实体对应的源数据进行抽取,抽取的数据量更小,节省了知识抽取的时间,相应的,储存该知识时,占用相对更少的空间,且由于获取了本体、抽取规则和映射规则,能够根据每次的查询请求,使用本体、抽取规则和映射规则对每次查询请求需要的知识进行抽取,进而实现知识图谱的多次构建(动态构建),减少了在海量数据下构建知识图谱占用的时间与存储空间。In this embodiment of the application, by obtaining the ontology, extraction rules, and mapping rules corresponding to the target knowledge graph, the ontology includes definitions of multiple entities and definitions of related information of multiple entities, and the extraction rules are obtained from the source data corresponding to entities The rule for extracting data, the mapping rule is the rule for mapping the fields in the source data corresponding to the entity to the ontology; receive the query request, the query request includes the first entity, and determine the graph corresponding to the first entity in the target knowledge map according to the query request Whether the database has been constructed, the query request is used to query the first relevant knowledge of the first entity in the graph database; if the first entity has not been constructed, according to ontology, extraction rules and mapping rules, corresponding to the first entity Extract the source data to determine the first relevant knowledge; import the first relevant knowledge into the graph database to construct the target knowledge graph. It can be seen that, compared to directly extracting a large amount of knowledge from massive data and constructing a knowledge map, knowledge that is hardly searchable takes up a lot of space resources, and it is not easy to construct knowledge maps multiple times. The technical solution can extract the source data corresponding to the first entity according to the user's query request, and the amount of extracted data is smaller, which saves the time for knowledge extraction. Correspondingly, when storing the knowledge, it occupies relatively less space, and Due to the acquisition of ontology, extraction rules and mapping rules, according to each query request, the ontology, extraction rules and mapping rules can be used to extract the knowledge required for each query request, and then multiple constructions of knowledge graphs (dynamic construction) can be realized. , which reduces the time and storage space occupied by building knowledge graphs under massive data.
附图说明Description of drawings
图1是本申请实施例提供的一种知识图谱的构建方法的流程示意图;FIG. 1 is a schematic flow diagram of a method for constructing a knowledge graph provided in an embodiment of the present application;
图2是本申请实施例提供的一种目标知识图谱的示意图;FIG. 2 is a schematic diagram of a target knowledge map provided by an embodiment of the present application;
图3(a)是本申请又一实施例提供的一种使用布隆过滤器的示意图;Figure 3(a) is a schematic diagram of using a Bloom filter provided by another embodiment of the present application;
图3(b)是本申请又一实施例提供的一种使用布隆过滤器的示意图;Figure 3(b) is a schematic diagram of using a Bloom filter provided by another embodiment of the present application;
图4是本申请实施例提供的另一种知识图谱的构建方法的流程示意图;FIG. 4 is a schematic flowchart of another method for constructing a knowledge graph provided in the embodiment of the present application;
图5是根据本申请的实施例提供的知识图谱的构建装置的结构示意图;Fig. 5 is a schematic structural diagram of a knowledge map construction device provided according to an embodiment of the present application;
图6是根据本申请的实施例提供的电子设备的结构示意图。Fig. 6 is a schematic structural diagram of an electronic device provided according to an embodiment of the present application.
具体实施方式Detailed ways
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。The following will clearly and completely describe the technical solutions in the embodiments of the present application with reference to the drawings in the embodiments of the present application. Obviously, the described embodiments are part of the embodiments of the present application, not all of them. Based on the embodiments in this application, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of this application.
本申请的说明书和权利要求书中的术语“第一”、“第二”等是用于区别类似的对象,而不用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便本申请的实施例能够以除了在这里图示或描述的那些以外的顺序实施,且“第一”、“第二”等所区分的对象通常为一类,并不限定对象的个数,例如第一对象可以是一个,也可以是多个。此外,说明书以及权利要求中“和/或”表示所连接对象的至少其中之一,字符“/”,一般表示前后关联对象是一种“或”的关系。The terms "first", "second" and the like in the specification and claims of the present application are used to distinguish similar objects, and are not used to describe a specific sequence or sequence. It should be understood that the terms so used are interchangeable under appropriate circumstances such that the embodiments of the application can be practiced in sequences other than those illustrated or described herein, and that references to "first," "second," etc. distinguish Objects are generally of one type, and the number of objects is not limited. For example, there may be one or more first objects. In addition, "and/or" in the specification and claims means at least one of the connected objects, and the character "/" generally means that the related objects are an "or" relationship.
下面结合附图,通过具体的实施例及其应用场景对本申请实施例提供的知识图谱的构建方法、装置进行详细地说明。The method and device for constructing the knowledge map provided by the embodiments of the present application will be described in detail below through specific embodiments and application scenarios with reference to the accompanying drawings.
图1示出本发明的一个实施例提供的一种知识图谱的构建方法,该方法可以由电子设备执行,该电子设备可以包括:服务器和/或终端设备,其中终端设备可以例如手机终端等。换言之,该方法可以由安装在电子设备的软件或硬件来执行,该方法包括如下步骤:FIG. 1 shows a method for constructing a knowledge map provided by an embodiment of the present invention. The method can be executed by an electronic device, and the electronic device can include: a server and/or a terminal device, where the terminal device can be a mobile terminal, for example. In other words, the method can be executed by software or hardware installed in the electronic device, and the method includes the following steps:
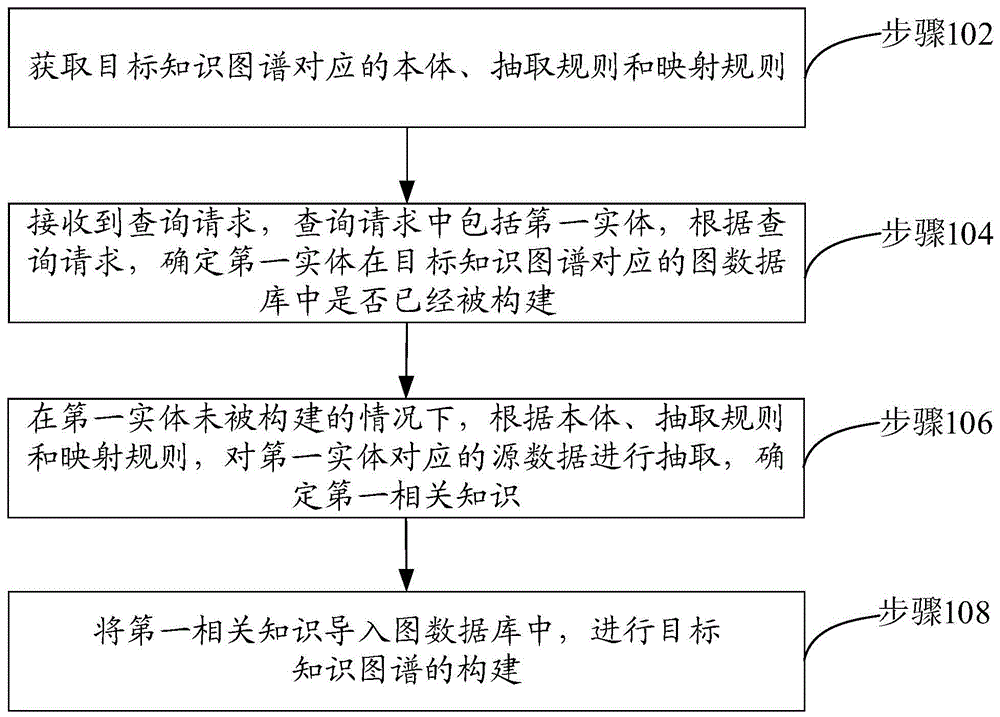
步骤102:获取目标知识图谱对应的本体、抽取规则和映射规则。Step 102: Obtain ontology, extraction rules and mapping rules corresponding to the target knowledge graph.
其中,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则。Among them, the ontology includes the definition of multiple entities and the definition of related information of multiple entities, the extraction rule is the rule for extracting data from the source data corresponding to the entity, and the mapping rule is to map the fields in the source data corresponding to the entity to the ontology the rule of.
实体对应的源数据来自数据库,是结构化数据,当然,实体对应的源数据也可以来自半结构化数据或非结构化数据进行转换,得到的结构化数据。结构化的源数据,例如,可以以一张或多张表的形式存储。The source data corresponding to the entity comes from the database, which is structured data. Of course, the source data corresponding to the entity can also be converted from semi-structured data or unstructured data to obtain structured data. Structured source data, for example, can be stored in the form of one or more tables.
实际应用中,本体中包括多个实体的定义、多个实体的相关信息的定义,该多个实体的相关信息可以包括实体的属性、实体之间的关系信息中的至少一种。由于同一实体在不同的领域下,代表的含义有所不同,随之对该实体的定义及其相关信息的定义有所不同。故在真正实施对知识图谱的构建之前,先获取目标知识图谱对应领域的实体的定义和实体相关信息的定义,即获取目标知识图谱对应的本体。In practical applications, the ontology includes definitions of multiple entities and definitions of related information of multiple entities, and the related information of multiple entities may include at least one of attributes of entities and relationship information between entities. Since the same entity has different meanings in different fields, the definition of the entity and its related information are also different. Therefore, before actually implementing the construction of the knowledge graph, first obtain the definition of entities in the field corresponding to the target knowledge graph and the definition of entity-related information, that is, obtain the ontology corresponding to the target knowledge graph.
本体中实体的定义、实体的相关信息的定义,都是根据领域词典等定义的一般概念,例如,当本体中对狗这个实体进行定义,可以使用“犬科动物”等一般概念定义,而不会在本体中对狗这个实体进行定义时,使用“具有斑点”等有个体性特点的定义。The definition of entities in ontology and the definition of entity-related information are based on general concepts defined by domain dictionaries. For example, when the entity dog is defined in ontology, general concepts such as "canine" can be used instead of When defining the entity dog in the ontology, a definition with individual characteristics such as "has spots" is used.
示例性地,以目标知识图谱包括书、作者这两个实体,实体的相关信息包括实体的属性、实体之间的关系信息为例,本体中包括根据领域词典等定义的书的一般概念、作者的一般概念,即本体中包括书、作者这两个实体的定义。本体中还包括书的属性,例如,书的文学体裁等;作者的属性,例如,作者所处年代等;除此之外,本体中还包括书和作者之间的关系信息,例如,作者创作了书等。Exemplarily, the target knowledge graph includes the two entities of book and author, and the related information of the entity includes the attribute of the entity and the relationship information between the entities. The ontology includes the general concept of the book, author, etc. The general concept of , that is, the ontology includes the definitions of the two entities of book and author. The ontology also includes the attributes of the book, such as the literary genre of the book, etc.; the attributes of the author, such as the age of the author; in addition, the ontology also includes the relationship information between the book and the author, such as the author’s creation Books etc.
接上述示例,映射规则可以是将书这一实体对应的源数据中的《西游记》、长篇小说等字段,分别映射到本体上的书、书的文学体裁等的规则,即映射规则为将实体对应的源数据中的字段映射到本体的规则。Continuing from the above example, the mapping rule can be a rule that maps fields such as "Journey to the West" and novels in the source data corresponding to the book entity to the book on the ontology, the literary genre of the book, etc., that is, the mapping rule is The rules for mapping fields in source data corresponding to entities to ontology.
抽取规则为从实体对应的源数据中抽取数据的规则,可以包括对抽取的源数据进行转换的规则,即转换函数,能够将源数据中的字段换成图数据库中对应的存储字段。接上述示例,图数据库中存储了名为《西游记》这一实体的数据,由于《西游记》别名《西游释厄传》,抽取规则可以包括当源数据中出现《西游释厄传》这一字段时,将《西游释厄传》替换成《西游记》,并对其数据进行储存的规则。抽取规则也可以包括当图数据库中书这一实体的文学体裁以m(短篇小说)、n(长篇小说)等的形式进行储存,当源数据中书这一实体的文学体裁为长篇小说,相应的,将长篇小说转换成n的形式进行储存的规则。且当不设定更新知识图谱的方式时,抽取规则也可以包括抽取周期的规则,电子设备能够根据抽取周期的规则进行数据的抽取,进而实现知识图谱的更新。Extraction rules are rules for extracting data from the source data corresponding to entities, and may include rules for converting the extracted source data, that is, conversion functions, which can replace fields in the source data with corresponding storage fields in the graph database. Following the above example, the data of the entity named "Journey to the West" is stored in the graph database. Since "Journey to the West" is aliased as "Journey to the West", the extraction rules can include when "Journey to the West" appears in the source data. In one field, replace "Journey to the West" with "Journey to the West" and store its data. The extraction rules can also include that when the literary genre of the book entity in the graph database is stored in the form of m (short story), n (long novel), etc., when the literary genre of the book entity in the source data is a novel, the corresponding , the rules for converting novels into the form of n for storage. And when the method of updating the knowledge map is not set, the extraction rules may also include the rules of the extraction period, and the electronic device can extract data according to the rules of the extraction period, thereby realizing the update of the knowledge map.
需要说明的是,上述获取了本体、抽取规则和映射规则,用于抽取能够存入图数据库中知识,但没有在上述过程中使用本体、抽取规则和映射规则对源数据进行抽取,进而实现知识图谱的构建。It should be noted that the above mentioned ontology, extraction rules and mapping rules are used to extract knowledge that can be stored in the graph database, but the ontology, extraction rules and mapping rules are not used in the above process to extract the source data, and then realize the knowledge Graph construction.
相比于直接进行知识图谱的构建,本实施例先获取本体、抽取规则和映射规则,后续根据需求,能够使用本体、抽取规则和映射规则对源数据进行多次抽取,从而实现构建动态的知识图谱。Compared with directly constructing the knowledge map, this embodiment first obtains the ontology, extraction rules and mapping rules, and then according to the requirements, can use the ontology, extraction rules and mapping rules to extract the source data multiple times, so as to realize the construction of dynamic knowledge Atlas.
步骤104:接收到查询请求,查询请求中包括第一实体,根据查询请求,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建。Step 104: A query request is received, and the query request includes the first entity, and according to the query request, it is determined whether the first entity has been constructed in the graph database corresponding to the target knowledge graph.
其中,查询请求用于在图数据库中查询第一实体的第一相关知识。Wherein, the query request is used to query the first relevant knowledge of the first entity in the graph database.
实际应用中,可以为电子设备接收到用户输入的查询请求。查询请求中可以包括用户输入的某个名词,也可以包括用户输入的某句话,本实施例对此不作限定。但当查询请求中包括某句话时,需要有相应的提取装置,该提取装置将某句话中的某个或某些名词提取出来。上述的某个名词、某句话中提取出的某个或某些名词,为查询对应的实体,即第一实体。In practical applications, the electronic device may receive a query request input by a user. The query request may include a noun input by the user, or a sentence input by the user, which is not limited in this embodiment. However, when a certain sentence is included in the query request, a corresponding extracting device is required, and the extracting device extracts one or some nouns in a certain sentence. A certain noun mentioned above, a certain noun or some nouns extracted from a certain sentence are entities corresponding to the query, that is, the first entity.
需要说明的是,本技术方案中第一实体、实体、以及下文提到的第二实体都与本体中实体有所不同,本体中实体是一般的概念,而该第一实体、实体、以及下文提到的第二实体指代的是在文本中具有特定含义或者具有很强指代性的名词,例如人名、地名、机构名称、时间等。示例性的,本体中实体中可以有书这个实体,该第一实体、实体、以及下文提到的第二实体可以为《西游记》这个实体。It should be noted that the first entity, the entity, and the second entity mentioned below in this technical solution are different from the entity in the ontology. The entity in the ontology is a general concept, and the first entity, entity, and the following The second entity mentioned refers to a noun that has a specific meaning or a strong reference in the text, such as a person's name, place name, institution name, time, etc. Exemplarily, among the entities in the ontology, there may be the entity of book, and the first entity, the entity, and the second entity mentioned below may be the entity of "Journey to the West".
根据查询请求,电子设备对图数据库中的实体进行判断,确定第一实体在图数据库中是否已经被构建。实际应用中,电子设备可以通过布隆过滤器Bloom Filter,对图数据库中的实体进行判断,确定第一实体在图数据库中是否已经被构建。According to the query request, the electronic device judges the entities in the graph database to determine whether the first entity has been constructed in the graph database. In practical applications, the electronic device can judge the entities in the graph database through the Bloom Filter to determine whether the first entity has been constructed in the graph database.
步骤106:在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识。Step 106: If the first entity has not been constructed, extract the source data corresponding to the first entity according to ontology, extraction rules and mapping rules, and determine the first related knowledge.
在电子设备对图数据库中的实体进行判断,确定第一实体在图数据库中未被构建时,使用步骤102中获取的本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识。When the electronic device judges the entities in the graph database and determines that the first entity has not been constructed in the graph database, use the ontology, extraction rules and mapping rules obtained in step 102 to extract the source data corresponding to the first entity, Determine the first relevant knowledge.
示例性地,以多个实体的源数据如下表1所示,其中第一实体为“吴承恩”,相关信息包括实体的属性、实体之间关系信息,在本体中定义了作者、作者所处年代(作者的属性)、作品(与作者这一实体存在关系信息)、创作年代(作品的属性)为例。For example, the source data of multiple entities is shown in Table 1 below, where the first entity is "Wu Chengen", and the relevant information includes the attributes of entities and the relationship information between entities. The author and the age of the author are defined in the ontology (the attribute of the author), the work (information about the relationship with the entity of the author), and the year of creation (the attribute of the work) as examples.
表1Table 1
根据映射规则和本体,可以将表1(多个实体的源数据)中“作品”字段的列映射到本体中的作品这一实体上,将源数据中“创作年代”字段的列映射到本体中的创作年代上,将源数据中“作者”字段的列映射到本体中的作者这一实体上,将源数据中“作者所处年代”字段的列映射到本体中的作者所处年代上。According to the mapping rules and the ontology, the column of the "work" field in Table 1 (source data of multiple entities) can be mapped to the entity of the work in the ontology, and the column of the "creation year" field in the source data can be mapped to the ontology In terms of the creation year in the source data, map the column of the "author" field in the source data to the author entity in the ontology, and map the column of the "author's year" field in the source data to the author's year in the ontology .
再根据抽取规则,可以对“吴承恩”(第一实体)对应的源数据进行抽取,确定第一相关知识:“吴承恩”(作者);明代(作者所处年代);“吴承恩”创作下述作品(实体之间关系信息),西游记、明代,禹鼎记、1500年-1582年,杨柳青、明代,舟行、明代,桃源图、明代,射阳先生存稿、明代(作品及其创作年代)。应理解,第一相关知识可以以表等方式表示,上述表示方式仅是为了展示第一相关知识包括的内容,本实施例对第一相关知识的表示方式,不作具体限定。对第一实体对应的源数据进行抽取,确定第一相关知识,相比于相关技术中的全量抽取知识,对第一实体对应的源数据进行抽取,抽取的数据量更小,节省了知识抽取的时间。According to the extraction rules, the source data corresponding to "Wu Chengen" (the first entity) can be extracted to determine the first related knowledge: "Wu Chengen" (author); Ming Dynasty (the author's year); "Wu Chengen" created the following works (Relationship information between entities), Journey to the West, Ming Dynasty, Yu Ding Ji, 1500-1582, Yangliuqing, Ming Dynasty, Zhou Xing, Ming Dynasty, Taoyuan Map, Ming Dynasty, Mr. Sheyang's manuscript, Ming Dynasty (works and creation time) . It should be understood that the first relevant knowledge may be expressed in a form such as a table, and the above representation is only for displaying the content included in the first relevant knowledge, and this embodiment does not specifically limit the representation of the first relevant knowledge. Extract the source data corresponding to the first entity to determine the first relevant knowledge. Compared with the full extraction of knowledge in related technologies, the source data corresponding to the first entity is extracted, and the amount of extracted data is smaller, saving knowledge extraction. time.
步骤108:将第一相关知识导入图数据库中,进行目标知识图谱的构建。Step 108: Import the first relevant knowledge into the graph database to construct the target knowledge graph.
构建的目标知识图谱,接上述示例,参见图2所示,第一实体201的第一相关知识可以包括第一实体的属性202、第一实体相关的实体203和第一实体相关的实体的属性204,以及实体之间的关系信息:“吴承恩”创作西游记、禹鼎记、杨柳青、舟行、桃源图、射阳先生存稿。The constructed target knowledge graph follows the above example, as shown in FIG. 2 , the first relevant knowledge of the
本发明实施例提供的知识图谱的构建方法,通过获取目标知识图谱对应的本体、抽取规则和映射规则,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则;接收查询请求,查询请求中包括第一实体,根据查询请求,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建,查询请求用于在图数据库中查询第一实体的第一相关知识;在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识;将第一相关知识导入图数据库中,进行目标知识图谱的构建。可见,相比于直接对海量数据进行全量抽取得到大量的知识,进行知识图谱的构建,导致几乎不会被搜索的知识占用了大量的空间资源,且不容易进行知识图谱的多次构建,本技术方案能够根据用户的查询请求,对第一实体对应的源数据进行抽取,抽取的数据量更小,节省了知识抽取的时间,相应的,储存该知识时,占用相对更少的空间,且由于获取了本体、抽取规则和映射规则,能够根据每次的查询请求,使用本体、抽取规则和映射规则对每次查询请求需要的知识进行抽取,进而实现知识图谱的多次构建(动态构建),减少了在海量数据下构建知识图谱占用的时间与存储空间。The knowledge map construction method provided by the embodiment of the present invention obtains the ontology, extraction rules, and mapping rules corresponding to the target knowledge map. The ontology includes the definition of multiple entities and the definition of related information of multiple entities. The rules for extracting data from the corresponding source data, the mapping rules are the rules for mapping the fields in the source data corresponding to the entities to the ontology; receive the query request, the query request includes the first entity, and according to the query request, determine the first entity in the target Whether the graph database corresponding to the knowledge graph has been constructed, the query request is used to query the first related knowledge of the first entity in the graph database; if the first entity has not been constructed, according to ontology, extraction rules and mapping rules, The source data corresponding to the first entity is extracted to determine the first relevant knowledge; the first relevant knowledge is imported into the graph database to construct the target knowledge map. It can be seen that, compared to directly extracting a large amount of knowledge from massive data and constructing a knowledge map, knowledge that is hardly searchable takes up a lot of space resources, and it is not easy to construct knowledge maps multiple times. The technical solution can extract the source data corresponding to the first entity according to the user's query request, and the amount of extracted data is smaller, which saves the time for knowledge extraction. Correspondingly, when storing the knowledge, it occupies relatively less space, and Due to the acquisition of ontology, extraction rules and mapping rules, according to each query request, the ontology, extraction rules and mapping rules can be used to extract the knowledge required for each query request, and then multiple constructions of knowledge graphs (dynamic construction) can be realized. , which reduces the time and storage space occupied by building knowledge graphs under massive data.
在一种实现方式中,该方法还包括如下步骤A1-A3:In an implementation manner, the method also includes the following steps A1-A3:
步骤A1:在第二实体对应的源数据产生更新的情况下,根据更新的源数据,确定第二实体在图数据库中是否已经被构建。Step A1: When the source data corresponding to the second entity is updated, determine whether the second entity has been constructed in the graph database according to the updated source data.
实际应用中,可以通过布隆过滤器,确定第二实体在图数据库中是否已经被构建。In practical applications, it may be determined whether the second entity has been constructed in the graph database through a Bloom filter.
需要说明的是,为了能够更准确地判断第二实体在图数据库中是否已经被构建,需要保持第二实体的实体名称与图数据库中实体的实体名称一致。若第二实体的实体名称与图数据库中实体的实体名称不一致,为了使实体的实体名称一致,可以利用抽取规则对第二实体对应的源数据进行实体抽取,对第二实体的实体名称进行转换,得到用于存储到图数据库的实体名称,再判断第二实体在图数据库中是否已经被构建。当然,为了使第二实体的实体名称与图数据库中实体的实体名称一致,也可以进行归一化处理,本实施例对此不作限定。It should be noted that, in order to more accurately determine whether the second entity has been constructed in the graph database, it is necessary to keep the entity name of the second entity consistent with the entity name of the entity in the graph database. If the entity name of the second entity is inconsistent with the entity name of the entity in the graph database, in order to make the entity name of the entity consistent, the entity extraction rule can be used to extract the source data corresponding to the second entity and convert the entity name of the second entity , get the entity name for storing in the graph database, and then judge whether the second entity has been constructed in the graph database. Of course, in order to make the entity name of the second entity consistent with the entity name of the entity in the graph database, normalization processing may also be performed, which is not limited in this embodiment.
步骤A2:在第二实体已经被构建的情况下,根据本体、抽取规则和映射规则,对第二实体对应的源数据进行抽取,确定第二实体的第二相关知识。Step A2: When the second entity has been constructed, extract the source data corresponding to the second entity according to ontology, extraction rules and mapping rules, and determine the second related knowledge of the second entity.
步骤A3:将第二相关知识导入图数据库中,进行知识图谱的更新。Step A3: import the second relevant knowledge into the graph database, and update the knowledge graph.
在根据更新的源数据,确定第二实体在图数据库中已经被构建的情况下,对第二实体对应的源数据进行抽取,第二实体对应的源数据与第一实体对应的源数据来自同一数据库,是结构化数据。According to the updated source data, when it is determined that the second entity has been constructed in the graph database, the source data corresponding to the second entity is extracted, and the source data corresponding to the second entity and the source data corresponding to the first entity come from the same A database is structured data.
对第二实体对应的源数据进行抽取,确定第二相关知识,相比于相关技术中的全量抽取知识,对第二实体对应的源数据进行抽取,抽取的数据量更小,节省了知识抽取的时间。将第二相关知识导入图数据库中,进行目标知识图谱的更新,使第二相关知识覆盖图数据库中已经被构建的更新前的第二实体的相关知识。相比于相关技术中的知识图谱整体更新,导致对知识图谱进行搜索时容易处于知识图谱的更新期间,搜索效果差,本方案的更新需要的时间更短,在对知识图谱进行搜索时,更容易搜索到新的知识,搜索效果更优。Extract the source data corresponding to the second entity to determine the second relevant knowledge. Compared with the full extraction of knowledge in related technologies, the source data corresponding to the second entity is extracted, and the amount of extracted data is smaller, saving knowledge extraction. time. The second related knowledge is imported into the graph database, and the target knowledge graph is updated, so that the second related knowledge covers the related knowledge of the second entity that has been constructed in the graph database before updating. Compared with the overall update of the knowledge map in the related technology, it is easy to be in the update period of the knowledge map when searching the knowledge map, and the search effect is poor. The time required for the update of this scheme is shorter. It is easy to search for new knowledge, and the search effect is better.
在一种实现方式中,对第一实体对应的源数据进行抽取,确定第一相关知识(即步骤106),可具体为以下步骤B1-B3:In an implementation manner, the source data corresponding to the first entity is extracted to determine the first relevant knowledge (that is, step 106), which may specifically include the following steps B1-B3:
步骤B1:获取对多个实体对应的源数据构建的索引表,索引表包括实体名称、实体唯一编码(Identity document,ID)。Step B1: Obtain an index table constructed for source data corresponding to multiple entities, the index table includes entity name, entity unique code (Identity document, ID).
步骤B2:根据第一实体,通过在索引表中检索实体的实体名称,确定实体名称对应的实体ID。Step B2: According to the first entity, by searching the entity name of the entity in the index table, determine the entity ID corresponding to the entity name.
接上述步骤106中的示例,当第一实体为“西游记”,可以在索引表中检索例如“作品”(实体的实体名称),确定“作品”的实体ID。Following the example in step 106 above, when the first entity is "Journey to the West", for example, "work" (entity name of the entity) can be searched in the index table to determine the entity ID of "work".
步骤B3:根据实体ID,确定第一实体对应的以下信息中的一个或多个:实体的属性、相关的实体、实体之间的关系信息。Step B3: According to the entity ID, one or more of the following information corresponding to the first entity is determined: attributes of the entity, related entities, and relationship information between entities.
实际应用中,电子设备获取对多个实体对应的源数据构建的索引表,该索引表中包括实体名称字段和实体ID字段,电子设备接收到第一实体,根据第一实体对应的实体的实体名称字段,可以通过查找实体名称字段和实体ID字段进行索引,能够获取第一实体对应的源数据,再从该源数据中抽取出来以下信息的一个或多个:第一实体的属性、相关的实体、以及第一实体相关实体的属性、第一实体与第一实体相关实体之间的关系信息,即第一相关知识。In practical applications, the electronic device acquires an index table constructed for source data corresponding to multiple entities, the index table includes an entity name field and an entity ID field, the electronic device receives the first entity, and according to the entity of the entity corresponding to the first entity The name field can be indexed by searching the entity name field and the entity ID field to obtain the source data corresponding to the first entity, and then extract one or more of the following information from the source data: attributes of the first entity, related The entity, the attribute of the entity related to the first entity, and the relationship information between the first entity and the entity related to the first entity, that is, the first related knowledge.
同样的,对第二实体对应的源数据进行抽取,确定第二实体的第二相关知识(即步骤A2),也可具体为上述步骤B1-B3中对第一实体的处理。Similarly, extracting the source data corresponding to the second entity and determining the second related knowledge of the second entity (ie step A2) may also specifically be the processing of the first entity in the above steps B1-B3.
由于数据库中的源数据以表的形式存储,可能存在表的数据量较多,也就是说,表的列数较多,或存在多个表的情况,相比于直接历遍全表,本技术方案能够提高抽取第一相关知识或第二相关知识的速度,从而减少抽取知识占用的时间。Since the source data in the database is stored in the form of a table, there may be a large amount of data in the table, that is, the number of columns in the table is large, or there are multiple tables. Compared with directly traversing the entire table, this The technical solution can increase the speed of extracting the first relevant knowledge or the second relevant knowledge, thereby reducing the time taken for knowledge extraction.
在一种实现方式中,根据查询请求,确定第一实体在图数据库中是否已经被构建(即步骤104)之后,还可执行以下步骤:In an implementation manner, after determining whether the first entity has been constructed in the graph database according to the query request (that is, step 104), the following steps may also be performed:
获取第一实体的第一相关知识,显示第一相关知识对应的目标知识图谱。The first related knowledge of the first entity is acquired, and the target knowledge graph corresponding to the first related knowledge is displayed.
根据查询请求,判断第一实体在图数据库中是否已经被构建,得到两种判断结果:According to the query request, it is judged whether the first entity has been constructed in the graph database, and two judgment results are obtained:
第一种判断结果,第一实体在图数据库中已经被构建,相应的,电子设备从图数据库获取第一实体的第一相关知识,显示第一相关知识对应的目标知识图谱。The first judgment result indicates that the first entity has been constructed in the graph database. Correspondingly, the electronic device obtains the first related knowledge of the first entity from the graph database, and displays the target knowledge graph corresponding to the first related knowledge.
第二种判断结果,第一实体在图数据库中没有被构建,相应的,电子设备先对第一实体的第一相关知识对应的知识图谱进行构建,再从图数据库获取第一实体的第一相关知识,显示第一相关知识对应的目标知识图谱。The second judgment result is that the first entity has not been constructed in the graph database. Correspondingly, the electronic device first constructs the knowledge map corresponding to the first related knowledge of the first entity, and then obtains the first entity’s first relevant knowledge from the graph database. Relevant knowledge, displaying the target knowledge graph corresponding to the first relevant knowledge.
在一种实现方式中,该方法还包括如下步骤C3:In an implementation manner, the method also includes the following step C3:
通过布隆过滤器,确定目标实体在所述图数据库中是否已经被构建。Through the Bloom filter, it is determined whether the target entity has been constructed in the graph database.
目标实体为被判断在所述图数据库中是否已经被构建的所述第一实体或所述第二实体。The target entity is the first entity or the second entity judged whether it has been constructed in the graph database.
布隆过滤器,包括一个二进制向量和散列Hash函数。布隆过滤器可以用于确定第一实体或第二实体是否在图数据库的已经构建的实体集合中,且不需要另外储存第一实体、第二实体和已经构建的实体,相比于使用其他的算法,减少了内存的占用。Bloom filter, including a binary vector and hash Hash function. The Bloom filter can be used to determine whether the first entity or the second entity is in the constructed entity collection of the graph database, and does not need to additionally store the first entity, the second entity and the constructed entity, compared to using other The algorithm reduces memory usage.
在一种实现方式中,参见图3(a)、(b)所示,通过布隆过滤器,确定第一实体或第二实体在图数据库中是否已经被构建(即步骤C3),可执行为以下步骤D1-D5:In one implementation, as shown in Fig. 3 (a), (b), through the Bloom filter, it is determined whether the first entity or the second entity has been constructed in the graph database (ie, step C3), which can be executed For the following steps D1-D5:
步骤D1:获取一个长度为n的比特数组,比特数组中每个比特位的值为零。Step D1: Obtain a bit array with a length of n, and the value of each bit in the bit array is zero.
比特数组为一个二进制向量,有0和1两种值。The bit array is a binary vector with two values, 0 and 1.
步骤D2:获取k个散列函数和已构建的实体,k小于n。Step D2: Obtain k hash functions and constructed entities, where k is less than n.
步骤D3:根据k个散列函数,针对每个已构建的实体,确定k个第一比特位置并赋值为一。Step D3: According to k hash functions, for each constructed entity, k first bit positions are determined and assigned a value of one.
一个散列函数对一个已构建的实体映射到一个第一位置并值为1,而获取k个散列函数,是k个散列函数对每一个已构建的实体映射到k个第一位置并值为1。A hash function maps a constructed entity to a first position with a value of 1, and obtaining k hash functions means that k hash functions map each constructed entity to k first positions and The value is 1.
步骤D4:根据k个散列函数,确定每个目标实体的k个第二比特位置。Step D4: Determine k second bit positions of each target entity according to k hash functions.
目标实体为被判断在所述图数据库中是否已经被构建的所述第一实体或所述第二实体。The target entity is the first entity or the second entity judged whether it has been constructed in the graph database.
当k为1时,一个散列函数可以将一个目标实体映射到比特数组中的一个比特位置上(一个第二位置)。由于使用一个散列函数进行映射时,只需判断一个第二位置的值是否为0,当出现已构建的实体与目标实体映射到同一个比特位置上,即出现了目标实体的第二位置的值为1,更容易得出目标实体在图数据库中已经被构建的结论,为了减少通过布隆过滤器进行判断造成失误的可能性,可以获取多个散列函数,k大于1,小于n。When k is 1, a hash function can map a target entity to a bit position (a second position) in the bit array. When using a hash function for mapping, it is only necessary to judge whether the value of a second position is 0, when the constructed entity and the target entity are mapped to the same bit position, that is, the second position of the target entity appears When the value is 1, it is easier to conclude that the target entity has been constructed in the graph database. In order to reduce the possibility of making mistakes through the judgment of the Bloom filter, multiple hash functions can be obtained, and k is greater than 1 and less than n.
步骤D5:根据k个第二比特位置的值,确定目标实体是否已被构建。Step D5: Determine whether the target entity has been constructed according to the values of the k second bit positions.
根据所述k个第二比特位置的值,判断是否存在值为零的第二比特位置,若存在值为零的第二比特位置,则能够确定目标实体在图数据库中未被构建,示例性的,以k为3,n为10为例,其中一种情况见图3(a)所示,已构建的实体310映射到三个第一比特位置311,目标实体320映射到三个第二比特位置321,存在2个值为零的第二比特位置,确定目标实体在图数据库中未被构建。若第二比特位置的值全部为1,则有以下两种情况。According to the values of the k second bit positions, it is judged whether there is a second bit position with a value of zero. If there is a second bit position with a value of zero, it can be determined that the target entity has not been constructed in the graph database. Exemplary Take k as 3 and n as 10 as an example, one of the cases is shown in Figure 3(a), the constructed
第一种情况,目标实体在图数据库中已经被构建。由于目标实体实际上为某一已构建的实体,即目标实体对应的第二比特位置为该某一已构建的实体的第一比特位置,故该第二比特位置对应的值全部为1。In the first case, the target entity has already been constructed in the graph database. Since the target entity is actually a constructed entity, that is, the second bit position corresponding to the target entity is the first bit position of the certain constructed entity, the values corresponding to the second bit position are all 1.
第二种情况,目标实体在图数据库中未被构建。目标实体本应映射到值为零的第二比特位置,但由于目标实体对应的某第二比特位置重复映射到已构建的实体的某第一比特位置,且目标实体对应的k个第二比特位置完全重复映射到已构建的实体的第一比特位置上了,导致第二比特位置的值全部为1,但实际上目标实体在图数据库中未被构建,示例性的,以k为3,n为10为例,其中一种情况见图3(b)所示,由于目标实体320对应的三个第二比特位置321重复映射到已构建的实体的三个第一比特位置311上,导致第二比特位置的值全部为1,但实际上目标实体在图数据库中未被构建。In the second case, the target entity is not constructed in the graph database. The target entity should be mapped to the second bit position with a value of zero, but because a certain second bit position corresponding to the target entity is repeatedly mapped to a certain first bit position of the constructed entity, and the k second bit positions corresponding to the target entity The position is completely mapped to the first bit position of the constructed entity, resulting in the value of the second bit position being all 1, but in fact the target entity has not been constructed in the graph database. For example, k is 3, n is 10 as an example, one of the cases is shown in Figure 3(b), since the three second bit positions 321 corresponding to the
上述第二种情况的发生与k、n有关,为了减少上述第二种情况的发生,需要预先设定k与n。The occurrence of the above-mentioned second situation is related to k and n. In order to reduce the occurrence of the above-mentioned second situation, k and n need to be set in advance.
需要说明的是,若目标实体的k个第二比特位置的值全部为1,相应的,电子设备从图数据库获取目标实体的第一相关知识,当未能从图数据库获取到目标实体的第一相关知识时,执行步骤106到步骤108。It should be noted that if the values of the k second bit positions of the target entity are all 1, correspondingly, the electronic device obtains the first related knowledge of the target entity from the graph database, and when the first related knowledge of the target entity cannot be obtained from the graph database When there is relevant knowledge, execute step 106 to step 108 .
由于布隆过滤器通过计算Hash函数映射位置的值来判断第一实体或第二实体是否在图数据库的已经构建的实体集合中,相比于使用其他的算法,需要的判断时间更短。Since the Bloom filter judges whether the first entity or the second entity is in the constructed entity set of the graph database by calculating the value of the Hash function mapping position, the required judgment time is shorter than other algorithms.
图4是根据本申请另一实施例的一种知识图谱的构建方法的示意性流程图,如图4所示,知识图谱的构建方法可包括以下步骤:Fig. 4 is a schematic flowchart of a method for constructing a knowledge map according to another embodiment of the present application. As shown in Fig. 4, the method for constructing a knowledge map may include the following steps:
步骤401,获取目标知识图谱对应的本体、抽取规则和映射规则。Step 401, obtain ontology, extraction rules and mapping rules corresponding to the target knowledge graph.
其中,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则。Among them, the ontology includes the definition of multiple entities and the definition of related information of multiple entities, the extraction rule is the rule for extracting data from the source data corresponding to the entity, and the mapping rule is to map the fields in the source data corresponding to the entity to the ontology the rule of.
步骤402,接收查询请求,查询请求中包括第一实体。In step 402, a query request is received, and the query request includes the first entity.
步骤403,根据查询请求,通过布隆过滤器,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建。Step 403, according to the query request, determine whether the first entity has been constructed in the graph database corresponding to the target knowledge graph through the Bloom filter.
查询请求用于在图数据库中查询第一实体的第一相关知识。The query request is used to query the first relevant knowledge of the first entity in the graph database.
若是,则执行步骤408,若否,则执行404-步骤408.If yes, then execute step 408, if not, then execute 404-step 408.
步骤404,在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,获取对多个实体对应的源数据构建的索引表,索引表包括实体名称、实体ID。Step 404, if the first entity has not been constructed, according to ontology, extraction rules and mapping rules, obtain an index table constructed for source data corresponding to multiple entities, the index table includes entity name and entity ID.
步骤405,根据第一实体,通过在索引表中检索实体的实体名称,确定实体名称对应的实体ID。Step 405, according to the first entity, by searching the entity name of the entity in the index table, determine the entity ID corresponding to the entity name.
步骤406,根据实体ID,确定第一实体对应的实体的属性、以及相关的实体、实体之间的关系信息。Step 406, according to the entity ID, determine the attributes of the entity corresponding to the first entity, related entities, and relationship information between entities.
步骤407,将第一实体对应的实体的属性、以及相关的实体、实体之间的关系信息导入图数据库中,进行目标知识图谱的构建。Step 407, importing the attribute of the entity corresponding to the first entity, related entities, and relationship information between entities into the graph database to construct the target knowledge graph.
步骤408,在第一实体已经被构建的情况下,获取第一实体的第一相关知识,显示第一相关知识对应的目标知识图谱。Step 408, if the first entity has been constructed, acquire the first relevant knowledge of the first entity, and display the target knowledge graph corresponding to the first relevant knowledge.
上述步骤401到至步骤408的具体过程在上述实施例中已进行详细说明,此处不再赘述。The specific process from step 401 to step 408 has been described in detail in the above embodiment, and will not be repeated here.
采用本申请实施例的技术方案,通过获取目标知识图谱对应的本体、抽取规则和映射规则,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则;接收查询请求,查询请求中包括第一实体,根据查询请求,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建,查询请求用于在图数据库中查询第一实体的第一相关知识;在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识;将第一相关知识导入图数据库中,进行目标知识图谱的构建。可见,相比于直接对海量数据进行全量抽取得到大量的知识,进行知识图谱的构建,导致几乎不会被搜索的知识占用了大量的空间资源,且不容易进行知识图谱的多次构建,本技术方案能够根据用户的查询请求,对第一实体对应的源数据进行抽取,抽取的数据量更小,节省了知识抽取的时间,相应的,储存该知识时,占用相对更少的空间,且由于获取了本体、抽取规则和映射规则,能够根据每次的查询请求,使用本体、抽取规则和映射规则对每次查询请求需要的知识进行抽取,进而实现知识图谱的多次构建(动态构建),减少了在海量数据下构建知识图谱占用的时间与存储空间。By adopting the technical solution of the embodiment of the present application, by obtaining the ontology, extraction rules and mapping rules corresponding to the target knowledge map, the ontology includes definitions of multiple entities and definitions of related information of multiple entities, and the extraction rules are derived from the source corresponding to the entity The rules for extracting data from the data, the mapping rules are the rules for mapping the fields in the source data corresponding to the entities to the ontology; receive the query request, the query request includes the first entity, and according to the query request, determine that the first entity corresponds to the target knowledge map Whether the graph database has been constructed, the query request is used to query the first related knowledge of the first entity in the graph database; if the first entity has not been constructed, according to the ontology, extraction rules and mapping rules, the first The source data corresponding to the entity is extracted to determine the first relevant knowledge; the first relevant knowledge is imported into the graph database to construct the target knowledge map. It can be seen that, compared to directly extracting a large amount of knowledge from massive data and constructing a knowledge map, knowledge that is hardly searchable takes up a lot of space resources, and it is not easy to construct knowledge maps multiple times. The technical solution can extract the source data corresponding to the first entity according to the user's query request, and the amount of extracted data is smaller, which saves the time for knowledge extraction. Correspondingly, when storing the knowledge, it occupies relatively less space, and Due to the acquisition of ontology, extraction rules and mapping rules, according to each query request, the ontology, extraction rules and mapping rules can be used to extract the knowledge required for each query request, and then multiple constructions of knowledge graphs (dynamic construction) can be realized. , which reduces the time and storage space occupied by building knowledge graphs under massive data.
需要说明的是,本申请实施例提供的知识图谱的构建方法,执行主体可以为电子设备,或者该电子设备中的用于执行知识图谱的构建方法的控制模块。本申请实施例中以电子设备执行知识图谱的构建方法为例,说明本申请实施例提供的知识图谱的构建装置。It should be noted that, for the method for constructing a knowledge graph provided in the embodiment of the present application, the execution body may be an electronic device, or a control module in the electronic device for executing the method for constructing a knowledge graph. In the embodiment of the present application, the method for constructing the knowledge graph executed by an electronic device is taken as an example to illustrate the device for constructing the knowledge graph provided in the embodiment of the present application.
图5是根据本发明实施例的知识图谱的构建装置的结构示意图。如图5所示,知识图谱的构建装置包括:本体预置模块510、第一确定模块520、第二确定模块530、构建模块540。Fig. 5 is a schematic structural diagram of an apparatus for constructing a knowledge graph according to an embodiment of the present invention. As shown in FIG. 5 , the device for constructing a knowledge graph includes: an ontology
本体预置模块510,用于获取目标知识图谱对应的本体、抽取规则和映射规则,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则;The ontology
第一确定模块520,用于接收查询请求,查询请求中包括第一实体,根据查询请求,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建,查询请求用于在图数据库中查询第一实体的第一相关知识;The first determining
第二确定模块530,用于在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识;The
构建模块540,用于将第一相关知识导入图数据库中,进行目标知识图谱的构建。A
在一种实现方式中,知识图谱的构建装置还包括:第三确定模块550、第四确定模块560、更新模块570。In an implementation manner, the device for constructing a knowledge graph further includes: a third determination module 550 , a fourth determination module 560 , and an update module 570 .
第三确定模块550,用于在第二实体对应的源数据产生更新的情况下,根据更新的源数据,确定第二实体在图数据库中是否已经被构建;The third determination module 550 is configured to determine whether the second entity has been constructed in the graph database according to the updated source data when the source data corresponding to the second entity is updated;
第四确定模块560,用于在第二实体已经被构建的情况下,根据本体、抽取规则和映射规则,对第二实体对应的源数据进行抽取,确定第二实体的第二相关知识;The fourth determination module 560 is configured to extract the source data corresponding to the second entity according to ontology, extraction rules and mapping rules when the second entity has been constructed, and determine the second relevant knowledge of the second entity;
更新模块570,用于将第二相关知识导入图数据库中,进行目标知识图谱的更新。The update module 570 is configured to import the second relevant knowledge into the graph database to update the target knowledge graph.
在一种实现方式中,第二确定模块540,用于获取对多个实体对应的源数据构建的索引表,索引表包括实体名称、实体ID;根据第一实体,通过在索引表中检索实体的实体名称,确定实体名称对应的实体ID;根据实体ID,确定第一实体对应的以下信息中的一个或多个:实体的属性、相关的实体、实体之间的关系信息。In one implementation, the
在一种实现方式中,第一确定模块520,还用于获取第一实体的第一相关知识,显示第一相关知识对应的目标知识图谱。In one implementation manner, the first determining
在一种实现方式中,判断模块580,还用于通过布隆过滤器,确定目标实体在所述图数据库中是否已经被构建。In an implementation manner, the judging module 580 is further configured to determine whether the target entity has been constructed in the graph database through a Bloom filter.
所述目标实体为被判断在所述图数据库中是否已经被构建的所述第一实体或所述第二实体。The target entity is the first entity or the second entity judged whether it has been constructed in the graph database.
在一种实现方式中,判断模块580,用于获取一个长度为n的比特数组,比特数组中每个比特位的值为零;获取k个散列函数和已创建的实体,k小于n;根据k个散列函数,针对每个已创建的实体,确定k个第一比特位置并赋值为一;根据k个散列函数,确定每个目标实体的k个第二比特位置;根据k个第二比特位置的值,确定目标实体是否已被构建。In one implementation, the judging module 580 is configured to acquire a bit array with a length of n, where the value of each bit in the bit array is zero; acquire k hash functions and created entities, where k is less than n; According to k hash functions, for each created entity, determine k first bit positions and assign a value to one; according to k hash functions, determine k second bit positions of each target entity; according to k The value of the second bit position, which determines whether the target entity has been constructed.
采用本发明实施例提供的知识图谱的构建装置,通过获取目标知识图谱对应的本体、抽取规则和映射规则,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则;接收查询请求,查询请求中包括第一实体,根据查询请求,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建,查询请求用于在图数据库中查询第一实体的第一相关知识;在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识;将第一相关知识导入图数据库中,进行目标知识图谱的构建。可见,相比于直接对海量数据进行全量抽取得到大量的知识,进行知识图谱的构建,导致几乎不会被搜索的知识占用了大量的空间资源,且不容易进行知识图谱的多次构建,本技术方案能够根据用户的查询请求,对第一实体对应的源数据进行抽取,抽取的数据量更小,节省了知识抽取的时间,相应的,储存该知识时,占用相对更少的空间,且由于获取了本体、抽取规则和映射规则,能够根据每次的查询请求,使用本体、抽取规则和映射规则对每次查询请求需要的知识进行抽取,进而实现知识图谱的多次构建(动态构建),减少了在海量数据下构建知识图谱占用的时间与存储空间。Using the knowledge map construction device provided by the embodiment of the present invention, by obtaining the ontology, extraction rules and mapping rules corresponding to the target knowledge map, the ontology includes definitions of multiple entities and definitions of related information of multiple entities, and the extraction rules are from The rule for extracting data from the source data corresponding to the entity, the mapping rule is the rule for mapping the fields in the source data corresponding to the entity to the ontology; receive the query request, the query request includes the first entity, according to the query request, determine the first entity in Whether the graph database corresponding to the target knowledge graph has been constructed, the query request is used to query the first related knowledge of the first entity in the graph database; if the first entity has not been constructed, according to ontology, extraction rules and mapping rules , extract the source data corresponding to the first entity, and determine the first relevant knowledge; import the first relevant knowledge into the graph database, and construct the target knowledge graph. It can be seen that, compared to directly extracting a large amount of knowledge from massive data and constructing a knowledge map, knowledge that is hardly searchable takes up a lot of space resources, and it is not easy to construct knowledge maps multiple times. The technical solution can extract the source data corresponding to the first entity according to the user's query request, and the amount of extracted data is smaller, which saves the time for knowledge extraction. Correspondingly, when storing the knowledge, it occupies relatively less space, and Due to the acquisition of ontology, extraction rules and mapping rules, according to each query request, the ontology, extraction rules and mapping rules can be used to extract the knowledge required for each query request, and then multiple constructions of knowledge graphs (dynamic construction) can be realized. , which reduces the time and storage space occupied by building knowledge graphs under massive data.
本申请实施例中的知识图谱的构建装置可以是装置,也可以是终端中的部件、集成电路、或芯片。该装置可以是移动电子设备,也可以为非移动电子设备。示例性的,移动电子设备可以为手机、平板电脑、笔记本电脑、掌上电脑、车载电子设备、可穿戴设备、超级移动个人计算机(ultra-mobile personal computer,UMPC)、上网本或者个人数字助理(personal digital assistant,PDA)等,非移动电子设备可以为服务器、网络附属存储器(Network Attached Storage,NAS)、个人计算机(personal computer,PC)、电视机(television,TV)、柜员机或者自助机等,本申请实施例不作具体限定。The device for constructing the knowledge graph in the embodiment of the present application may be a device, or a component, an integrated circuit, or a chip in a terminal. The device may be a mobile electronic device or a non-mobile electronic device. Exemplarily, the mobile electronic device may be a mobile phone, a tablet computer, a notebook computer, a handheld computer, a vehicle electronic device, a wearable device, an ultra-mobile personal computer (ultra-mobile personal computer, UMPC), a netbook or a personal digital assistant (personal digital assistant). assistant, PDA), etc., non-mobile electronic devices can be servers, network attached storage (Network Attached Storage, NAS), personal computer (personal computer, PC), television (television, TV), teller machine or self-service machine, etc., this application Examples are not specifically limited.
本申请实施例中的知识图谱的构建装置可以为具有操作系统的装置。该操作系统可以为安卓(Android)操作系统,可以为ios操作系统,还可以为其他可能的操作系统,本申请实施例不作具体限定。The device for constructing the knowledge graph in the embodiment of the present application may be a device with an operating system. The operating system may be an Android (Android) operating system, an ios operating system, or other possible operating systems, which are not specifically limited in this embodiment of the present application.
本申请实施例提供的知识图谱的构建装置能够实现图1至图3的方法实施例中实现的各个过程,为避免重复,这里不再赘述。The knowledge map construction device provided in the embodiment of the present application can implement various processes implemented in the method embodiments in FIG. 1 to FIG. 3 , and will not be repeated here to avoid repetition.
基于相同的技术构思,本申请实施例还提供了一种电子设备,该电子设备用于执行上述的知识图谱的构建方法,图5为实现本申请各个实施例的一种电子设备的结构示意图。电子设备可因配置或性能不同而产生比较大的差异,可以包括处理器(processor)610、通信接口(Communications Interface)620、存储器(memory)630和通信总线640,其中,处理器610,通信接口620,存储器630通过通信总线640完成相互间的通信。处理器610可以调用存储在存储器630上并可在处理器610上运行的计算机程序,以执行下述步骤:Based on the same technical idea, the embodiment of the present application also provides an electronic device, which is used to implement the above-mentioned method for constructing the knowledge graph. FIG. 5 is a schematic structural diagram of an electronic device implementing various embodiments of the present application. Electronic equipment may have relatively large differences due to different configurations or performances, and may include a processor (processor) 610, a communication interface (Communications Interface) 620, a memory (memory) 630, and a
获取目标知识图谱对应的本体、抽取规则和映射规则,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则;接收查询请求,查询请求中包括第一实体,根据查询请求,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建,查询请求用于在图数据库中查询第一实体的第一相关知识;在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识;将第一相关知识导入图数据库中,进行目标知识图谱的构建。Obtain the ontology, extraction rules and mapping rules corresponding to the target knowledge graph. The ontology includes the definition of multiple entities and the definition of related information of multiple entities. The extraction rule is the rule for extracting data from the source data corresponding to the entity. The mapping rule is Map the fields in the source data corresponding to the entity to the rules of the ontology; receive the query request, which includes the first entity, and determine whether the first entity has been constructed in the graph database corresponding to the target knowledge graph according to the query request, and query The request is used to query the first relevant knowledge of the first entity in the graph database; if the first entity has not been constructed, extract the source data corresponding to the first entity according to ontology, extraction rules and mapping rules, and determine the first 1. Relevant knowledge; import the first relevant knowledge into the graph database to construct the target knowledge graph.
采用本发明实施例提供的电子设备,通过获取目标知识图谱对应的本体、抽取规则和映射规则,本体中包括多个实体的定义与多个实体的相关信息的定义,抽取规则为从实体对应的源数据中抽取数据的规则,映射规则为将实体对应的源数据中的字段映射到本体的规则;接收查询请求,查询请求中包括第一实体,根据查询请求,确定第一实体在目标知识图谱对应的图数据库中是否已经被构建,查询请求用于在图数据库中查询第一实体的第一相关知识;在第一实体未被构建的情况下,根据本体、抽取规则和映射规则,对第一实体对应的源数据进行抽取,确定第一相关知识;将第一相关知识导入图数据库中,进行目标知识图谱的构建。可见,相比于直接对海量数据进行全量抽取得到大量的知识,进行知识图谱的构建,导致几乎不会被搜索的知识占用了大量的空间资源,且不容易进行知识图谱的多次构建,本技术方案能够根据用户的查询请求,对第一实体对应的源数据进行抽取,抽取的数据量更小,节省了知识抽取的时间,相应的,储存该知识时,占用相对更少的空间,且由于获取了本体、抽取规则和映射规则,能够根据每次的查询请求,使用本体、抽取规则和映射规则对每次查询请求需要的知识进行抽取,进而实现知识图谱的多次构建(动态构建),减少了在海量数据下构建知识图谱占用的时间与存储空间。Using the electronic device provided by the embodiment of the present invention, by acquiring the ontology, extraction rules, and mapping rules corresponding to the target knowledge map, the ontology includes definitions of multiple entities and definitions of related information of multiple entities, and the extraction rules are from entities corresponding to The rules for extracting data in the source data, the mapping rules are the rules for mapping the fields in the source data corresponding to the entities to the ontology; receive the query request, the query request includes the first entity, and determine the first entity in the target knowledge map according to the query request Whether the corresponding graph database has been constructed, the query request is used to query the first related knowledge of the first entity in the graph database; if the first entity has not been constructed, according to the ontology, extraction rules and mapping rules, the second The source data corresponding to an entity is extracted to determine the first relevant knowledge; the first relevant knowledge is imported into the graph database to construct the target knowledge graph. It can be seen that, compared to directly extracting a large amount of knowledge from massive data and constructing a knowledge map, knowledge that is hardly searchable takes up a lot of space resources, and it is not easy to construct knowledge maps multiple times. The technical solution can extract the source data corresponding to the first entity according to the user's query request, and the amount of extracted data is smaller, which saves the time for knowledge extraction. Correspondingly, when storing the knowledge, it occupies relatively less space, and Due to the acquisition of ontology, extraction rules and mapping rules, according to each query request, the ontology, extraction rules and mapping rules can be used to extract the knowledge required for each query request, thereby realizing multiple constructions of knowledge graphs (dynamic construction) , which reduces the time and storage space occupied by building knowledge graphs under massive data.
具体执行步骤可以参见上述知识图谱的构建方法实施例的各个步骤,且能达到相同的技术效果,为避免重复,这里不再赘述。For specific execution steps, please refer to the various steps in the above embodiment of the method for constructing the knowledge map, and can achieve the same technical effect. To avoid repetition, details will not be repeated here.
需要说明的是,本申请实施例中的电子设备包括:服务器、终端或除终端之外的其他设备。It should be noted that the electronic device in the embodiment of the present application includes: a server, a terminal or other devices except the terminal.
以上电子设备结构并不构成对电子设备的限定,电子设备可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置,例如,输入单元,可以包括图形处理器(Graphics Processing Unit,GPU)和麦克风,显示单元可以采用液晶显示器、有机发光二极管等形式来配置显示面板。用户输入单元包括触控面板以及其他输入设备中的至少一种。触控面板也称为触摸屏。其他输入设备可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆,在此不再赘述。The above electronic device structure does not constitute a limitation to the electronic device, and the electronic device may include more or fewer components than shown in the illustration, or combine certain components, or arrange different components, for example, an input unit may include a graphics processor (Graphics Processing Unit, GPU) and a microphone, the display unit can be configured with a display panel in the form of a liquid crystal display, an organic light-emitting diode, or the like. The user input unit includes at least one of a touch panel and other input devices. A touch panel is also called a touch screen. Other input devices may include, but are not limited to, physical keyboards, function keys (such as volume control buttons, switch buttons, etc.), trackballs, mice, and joysticks, which will not be repeated here.
存储器可用于存储软件程序以及各种数据。存储器可主要包括存储程序或指令的第一存储区和存储数据的第二存储区,其中,第一存储区可存储操作系统、至少一个功能所需的应用程序或指令(比如声音播放功能、图像播放功能等)等。此外,存储器可以包括易失性存储器或非易失性存储器,或者,存储器可以包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(Read-Only Memory,ROM)、可编程只读存储器(Programmable ROM,PROM)、可擦除可编程只读存储器(Erasable PROM,EPROM)、电可擦除可编程只读存储器(Electrically EPROM,EEPROM)或闪存。易失性存储器可以是随机存取存储器(Random Access Memory,RAM),静态随机存取存储器(Static RAM,SRAM)、动态随机存取存储器(Dynamic RAM,DRAM)、同步动态随机存取存储器(Synchronous DRAM,SDRAM)、双倍数据速率同步动态随机存取存储器(Double Data Rate SDRAM,DDRSDRAM)、增强型同步动态随机存取存储器(Enhanced SDRAM,ESDRAM)、同步连接动态随机存取存储器(Synchlink DRAM,SLDRAM)和直接内存总线随机存取存储器(Direct Rambus RAM,DRRAM)。The memory can be used to store software programs as well as various data. The memory may mainly include a first storage area for storing programs or instructions and a second storage area for storing data, wherein the first storage area may store an operating system, application programs or instructions required by at least one function (such as sound playback function, image playback function, etc.) etc. Also, memory may include volatile memory or nonvolatile memory, or memory may include both volatile and nonvolatile memory. Among them, the non-volatile memory can be read-only memory (Read-Only Memory, ROM), programmable read-only memory (Programmable ROM, PROM), erasable programmable read-only memory (Erasable PROM, EPROM), electronically programmable Erase Programmable Read-Only Memory (Electrically EPROM, EEPROM) or Flash. Volatile memory can be random access memory (Random Access Memory, RAM), static random access memory (Static RAM, SRAM), dynamic random access memory (Dynamic RAM, DRAM), synchronous dynamic random access memory (Synchronous DRAM, SDRAM), double data rate synchronous dynamic random access memory (Double Data Rate SDRAM, DDRSDRAM), enhanced synchronous dynamic random access memory (Enhanced SDRAM, ESDRAM), synchronous connection dynamic random access memory (Synchlink DRAM, SLDRAM) and Direct Memory Bus Random Access Memory (Direct Rambus RAM, DRRAM).
处理器可包括一个或多个处理单元;可选的,处理器集成应用处理器和调制解调处理器,其中,应用处理器主要处理涉及操作系统、用户界面和应用程序等的操作,调制解调处理器主要处理无线通信信号,如基带处理器。可以理解的是,上述调制解调处理器也可以不集成到处理器中。The processor may include one or more processing units; optionally, the processor integrates an application processor and a modem processor, wherein the application processor mainly handles operations related to the operating system, user interface, and application programs, and the modem The tone processor mainly processes wireless communication signals, such as a baseband processor. It can be understood that the foregoing modem processor may not be integrated into the processor.
本申请实施例还提供一种可读存储介质,所述可读存储介质上存储有程序或指令,该程序或指令被处理器执行时实现上述知识图谱的构建方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。The embodiment of the present application also provides a readable storage medium, on which a program or instruction is stored, and when the program or instruction is executed by a processor, each process of the above-mentioned knowledge map construction method embodiment is implemented, and can To achieve the same technical effect, in order to avoid repetition, no more details are given here.
其中,所述处理器为上述实施例中所述的电子设备中的处理器。所述可读存储介质,包括计算机可读存储介质,如计算机只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random Access Memory,RAM)、磁碟或者光盘等。Wherein, the processor is the processor in the electronic device described in the above embodiments. The readable storage medium includes computer readable storage medium, such as computer read-only memory (Read-Only Memory, ROM), random access memory (Random Access Memory, RAM), magnetic disk or optical disk, etc.
本申请实施例另提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现上述知识图谱的构建方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。The embodiment of the present application further provides a chip, the chip includes a processor and a communication interface, the communication interface is coupled to the processor, and the processor is used to run programs or instructions to realize the implementation of the above knowledge map construction method Each process of the example, and can achieve the same technical effect, in order to avoid repetition, will not repeat them here.
应理解,本申请实施例提到的芯片还可以称为系统级芯片、系统芯片、芯片系统或片上系统芯片等。It should be understood that the chips mentioned in the embodiments of the present application may also be called system-on-chip, system-on-chip, system-on-a-chip, or system-on-a-chip.
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。此外,需要指出的是,本申请实施方式中的方法和装置的范围不限按示出或讨论的顺序来执行功能,还可包括根据所涉及的功能按基本同时的方式或按相反的顺序来执行功能,例如,可以按不同于所描述的次序来执行所描述的方法,并且还可以添加、省去、或组合各种步骤。另外,参照某些示例所描述的特征可在其他示例中被组合。It should be noted that, in this document, the term "comprising", "comprising" or any other variation thereof is intended to cover a non-exclusive inclusion such that a process, method, article or apparatus comprising a set of elements includes not only those elements, It also includes other elements not expressly listed, or elements inherent in the process, method, article, or device. Without further limitations, an element defined by the phrase "comprising a ..." does not preclude the presence of additional identical elements in the process, method, article, or apparatus comprising that element. In addition, it should be pointed out that the scope of the methods and devices in the embodiments of the present application is not limited to performing functions in the order shown or discussed, and may also include performing functions in a substantially simultaneous manner or in reverse order according to the functions involved. Functions are performed, for example, the described methods may be performed in an order different from that described, and various steps may also be added, omitted, or combined. Additionally, features described with reference to certain examples may be combined in other examples.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本申请各个实施例所述的方法。Through the description of the above embodiments, those skilled in the art can clearly understand that the methods of the above embodiments can be implemented by means of software plus a necessary general-purpose hardware platform, and of course also by hardware, but in many cases the former is better implementation. Based on such an understanding, the technical solution of the present application can be embodied in the form of a software product in essence or the part that contributes to the prior art, and the computer software product is stored in a storage medium (such as ROM/RAM, disk, CD) contains several instructions to enable a terminal (which may be a mobile phone, a computer, a server, an air conditioner, or a network device, etc.) to execute the methods described in various embodiments of the present application.
上面结合附图对本申请的实施例进行了描述,但是本申请并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本申请的启示下,在不脱离本申请宗旨和权利要求所保护的范围情况下,还可做出很多形式,均属于本申请的保护之内。The embodiments of the present application have been described above in conjunction with the accompanying drawings, but the present application is not limited to the above-mentioned specific implementations. The above-mentioned specific implementations are only illustrative and not restrictive. Those of ordinary skill in the art will Under the inspiration of this application, without departing from the purpose of this application and the scope of protection of the claims, many forms can also be made, all of which belong to the protection of this application.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310147705.5A CN116127098A (en) | 2023-02-20 | 2023-02-20 | Knowledge graph construction method and device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310147705.5A CN116127098A (en) | 2023-02-20 | 2023-02-20 | Knowledge graph construction method and device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116127098A true CN116127098A (en) | 2023-05-16 |
Family
ID=86309931
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310147705.5A Pending CN116127098A (en) | 2023-02-20 | 2023-02-20 | Knowledge graph construction method and device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116127098A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116881474A (en) * | 2023-07-17 | 2023-10-13 | 工赋(青岛)科技有限公司 | Query processing system, method and medium based on knowledge graph |
| WO2025043550A1 (en) * | 2023-08-30 | 2025-03-06 | 西门子股份公司 | Method, apparatus and system for querying knowledge graphs, and electronic device and storage medium |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113051382A (en) * | 2021-04-08 | 2021-06-29 | 云南电网有限责任公司电力科学研究院 | Intelligent power failure question-answering method and device based on knowledge graph |
| CN114461744A (en) * | 2020-11-09 | 2022-05-10 | 中移(上海)信息通信科技有限公司 | Knowledge graph construction method and device, electronic equipment and computer storage medium |
-
2023
- 2023-02-20 CN CN202310147705.5A patent/CN116127098A/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114461744A (en) * | 2020-11-09 | 2022-05-10 | 中移(上海)信息通信科技有限公司 | Knowledge graph construction method and device, electronic equipment and computer storage medium |
| CN113051382A (en) * | 2021-04-08 | 2021-06-29 | 云南电网有限责任公司电力科学研究院 | Intelligent power failure question-answering method and device based on knowledge graph |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116881474A (en) * | 2023-07-17 | 2023-10-13 | 工赋(青岛)科技有限公司 | Query processing system, method and medium based on knowledge graph |
| WO2025043550A1 (en) * | 2023-08-30 | 2025-03-06 | 西门子股份公司 | Method, apparatus and system for querying knowledge graphs, and electronic device and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110457439B (en) | One-stop intelligent writing auxiliary method, device and system | |
| US10515147B2 (en) | Using statistical language models for contextual lookup | |
| US9965569B2 (en) | Truncated autosuggest on a touchscreen computing device | |
| CN109190049B (en) | Keyword recommendation method, system, electronic device and computer readable medium | |
| US9342233B1 (en) | Dynamic dictionary based on context | |
| US20170177180A1 (en) | Dynamic Highlighting of Text in Electronic Documents | |
| US20160026616A1 (en) | Presenting dataset of spreadsheet in form based view | |
| US20130339840A1 (en) | System and method for logical chunking and restructuring websites | |
| GB2549362A (en) | Related entity discovery | |
| AU2017216520A1 (en) | Common data repository for improving transactional efficiencies of user interactions with a computing device | |
| JP2011233162A (en) | System, method, and software for assessing ambiguity of medical terms | |
| CN114637831A (en) | Data query method and related equipment based on semantic analysis | |
| CN116127098A (en) | Knowledge graph construction method and device | |
| CN111581363B (en) | Knowledge extraction method, device, equipment and storage medium | |
| CN114936272A (en) | Question answering method and system | |
| CN105550217B (en) | Scene music searching method and scene music searching device | |
| CN113360789A (en) | Interest point data processing method and device, electronic equipment and storage medium | |
| CN114020245A (en) | Page construction method and apparatus, device and medium | |
| CN109933788A (en) | Type determination method, apparatus, apparatus and medium | |
| CN105354506B (en) | The method and apparatus of hidden file | |
| CN110471901B (en) | Data import method and terminal device | |
| CN113157964A (en) | Method and device for searching data set through voice and electronic equipment | |
| CN119597868A (en) | Data question-answering method, system, device and computer program product | |
| CN116127176A (en) | Text recommendation method, device, equipment and storage medium | |
| CN114020867A (en) | Method, device, equipment and medium for expanding search terms |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information |
Country or region after: China Address after: 100080 101 / F, building 14, 27 Jiancai Middle Road, Haidian District, Beijing Applicant after: Percentage Technology Group Co.,Ltd. Address before: 100080 101 / F, building 14, 27 Jiancai Middle Road, Haidian District, Beijing Applicant before: Beijing PERCENT Technology Group Co.,Ltd. Country or region before: China |
|
| CB02 | Change of applicant information |