CN116051710A - A shader architecture with texture unit and cache multiplexing - Google Patents
A shader architecture with texture unit and cache multiplexing Download PDFInfo
- Publication number
- CN116051710A CN116051710A CN202211553464.6A CN202211553464A CN116051710A CN 116051710 A CN116051710 A CN 116051710A CN 202211553464 A CN202211553464 A CN 202211553464A CN 116051710 A CN116051710 A CN 116051710A
- Authority
- CN
- China
- Prior art keywords
- texture
- cache
- data
- vertex
- architecture
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T15/00—3D [Three Dimensional] image rendering
- G06T15/04—Texture mapping
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Computer Graphics (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Image Generation (AREA)
Abstract
本发明公开了一种纹理单元与cache复用的shader架构。本发明中,所述多口cache内部通过将整个内存空间的数据根据地址低位映射到不同的单口cache内,如图3所示,从而提供了多个读接口。多个口的请求通过地址合并单元合并,分别将每个口的请求映射到内部的某个单口cache上。在所有的口请求数据都返回后,多口cache将数据输出。本发明中,提出了一种纹理单元与cache复用的统一着色器架构。本架构的好处是:顶点染色器和像素染色器架构一致;不需要额外的单元处理不同的请求,节约了片内资源;采用多口cache的设计,提高了并行多个处理单元的请求效率。
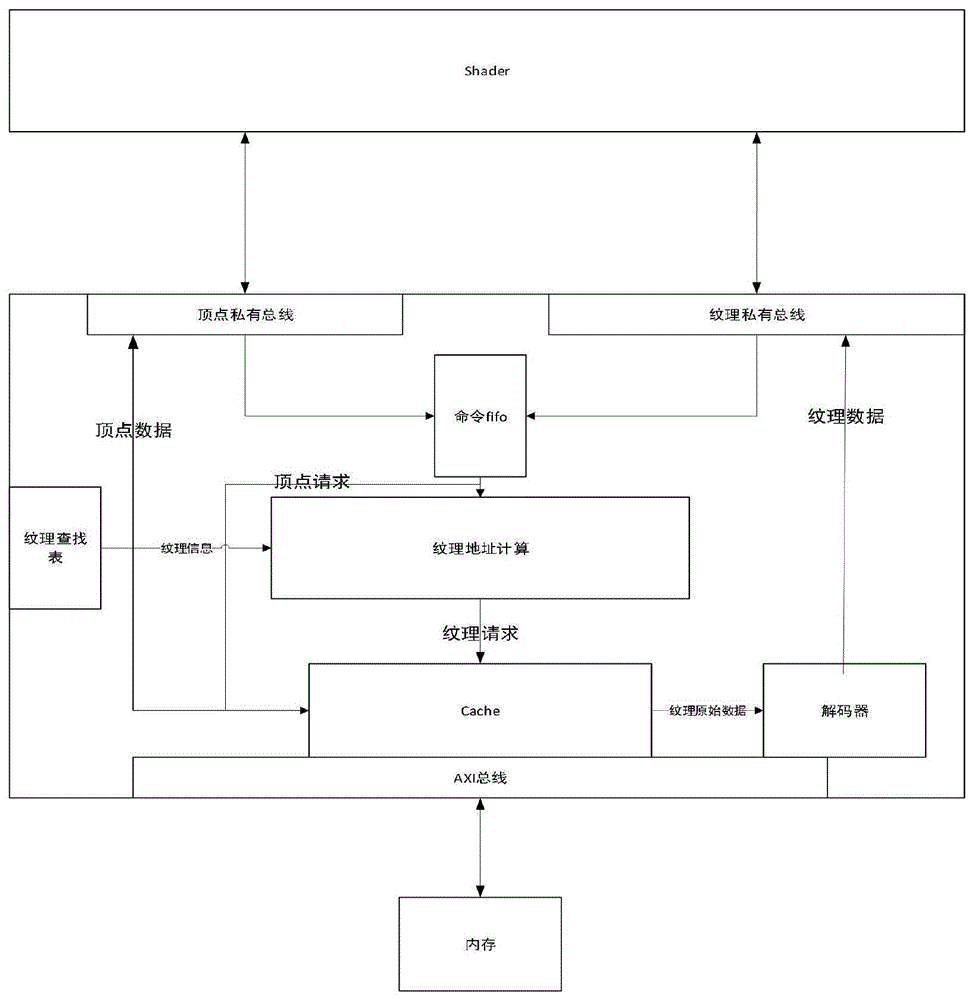
The invention discloses a shader architecture in which texture units and caches are multiplexed. In the present invention, the multi-port cache internally maps the data of the entire memory space to different single-port caches according to the lower bits of the address, as shown in FIG. 3 , thereby providing multiple read interfaces. The requests of multiple ports are merged by the address merging unit, and the requests of each port are mapped to an internal single-port cache. After all the port request data are returned, the multi-port cache outputs the data. In the present invention, a unified shader architecture in which texture units and caches are multiplexed is proposed. The advantages of this architecture are: the architecture of the vertex shader and the pixel shader is consistent; no additional units are required to process different requests, which saves on-chip resources; the multi-port cache design improves the request efficiency of multiple parallel processing units.
Description
技术领域technical field
本发明属于计算机图形学技术领域,具体为一种纹理单元与cache复用的shader架构。The invention belongs to the technical field of computer graphics, and specifically relates to a shader architecture for multiplexing texture units and caches.
背景技术Background technique
着色器(shader)是用来实现图像渲染的,用来替代固定渲染管线的可编辑程序。其中VertexShader(顶点着色器)主要负责顶点的几何关系等的运算,需要访问顶点信息;PixelShader(像素着色器)主要负责片源颜色等的计算,需要访问纹理信息。顶点数据通常使用cache来管理访问,而纹理信息需要额外的纹理单元(textureunit)对请求进行管理。在通常的架构中,cache和纹理单元是独立的两个模块。Shaders are used to implement image rendering, and are used to replace editable programs with fixed rendering pipelines. Among them, the VertexShader (vertex shader) is mainly responsible for the calculation of the geometric relationship of the vertex, and needs to access the vertex information; the PixelShader (pixel shader) is mainly responsible for the calculation of the source color, etc., and needs to access the texture information. Vertex data usually uses a cache to manage access, while texture information requires an additional texture unit (texture unit) to manage requests. In the usual architecture, cache and texture unit are two independent modules.
美国申请公布专利US202217583151A,提出了一种图形处理系统,包括几何处理逻辑、光栅化以及染色器(纹理)。几何处理逻辑使用cache缓存顶点数据,而纹理单元直接从内存获取纹理数据。The US application published patent US202217583151A proposes a graphics processing system, including geometry processing logic, rasterization, and a shader (texture). Geometry processing logic uses cache to cache vertex data, while texture units get texture data directly from memory.
但是此方案提供了一种图形处理系统架构,但是仅像素着色器是可编程的,几何阶段使用固定流水线,并且几何阶段的缓存与像素着色器不共享。But this scheme provides a graphics processing system architecture, but only the pixel shader is programmable, the geometry stage uses a fixed pipeline, and the cache of the geometry stage is not shared with the pixel shader.
发明内容Contents of the invention
本发明的目的在于:为了解决上述提出的问题,提供一种纹理单元与cache复用的shader架构。The object of the present invention is to provide a shader architecture in which texture units and caches are multiplexed in order to solve the above-mentioned problems.
本发明采用的技术方案如下:一种纹理单元与cache复用的shader架构,所述纹理单元与cache复用的shader架构包括:纹理单元、shader架构所述纹理单元与shader架构之间采用私有总线连接。The technical scheme adopted in the present invention is as follows: a shader architecture for multiplexing texture units and cache, the shader architecture for multiplexing texture units and cache includes: texture unit, shader architecture A private bus is used between the texture unit and the shader architecture connect.
在一优选的实施方式中,所述纹理单元与cache复用的shader架构的运行流程包括以下步骤:In a preferred implementation manner, the operation flow of the shader architecture multiplexed by the texture unit and the cache includes the following steps:
S1:在顶点染色阶段,通过顶点总线请求顶点数据;S1: In the vertex coloring stage, request vertex data through the vertex bus;
S2:在像素染色阶段,通过纹理总线请求纹理数据。S2: In the pixel coloring stage, texture data is requested through the texture bus.
在一优选的实施方式中,所述步骤S1中,在顶点染色阶段,染色器通过顶点私有总线请求使用地址直接请求顶点数据。顶点请求发给纹理单元后,直接透传到cache。Cache直接通过顶点私有总线将数据返回给染色器。In a preferred embodiment, in the step S1, in the vertex coloring stage, the shader directly requests vertex data through the vertex private bus request address. After the vertex request is sent to the texture unit, it is directly transparently transmitted to the cache. Cache directly returns data to the shader through the vertex private bus.
在一优选的实施方式中,所述步骤S2中,在像素染色阶段,染色器通过像素私有总线使用纹理坐标和纹理id请求纹理数据。纹理请求发给纹理单元后,首先根据纹理id从纹理查找表中获取纹理信息;然后根据纹理信息和纹理坐标,将请求转换为地址,从cache取回数据;取回数据后根据纹理信息进行解码,最终通过总线返回给染色器。In a preferred embodiment, in the step S2, in the pixel coloring stage, the shader requests texture data by using texture coordinates and texture ids through a pixel private bus. After the texture request is sent to the texture unit, first obtain the texture information from the texture lookup table according to the texture id; then convert the request into an address according to the texture information and texture coordinates, and retrieve the data from the cache; after retrieving the data, decode according to the texture information , and finally returned to the shader through the bus.
在一优选的实施方式中,所述多口cache内部通过将整个内存空间的数据根据地址低位映射到不同的单口cache内,如图3所示,从而提供了多个读接口。多个口的请求通过地址合并单元合并,分别将每个口的请求映射到内部的某个单口cache上。在所有的口请求数据都返回后,多口cache将数据输出。In a preferred embodiment, the multi-port cache internally maps the data of the entire memory space into different single-port caches according to the lower bits of the address, as shown in FIG. 3 , thereby providing multiple read interfaces. The requests of multiple ports are merged by the address merging unit, and the requests of each port are mapped to an internal single-port cache. After all the port request data are returned, the multi-port cache outputs the data.
综上所述,由于采用了上述技术方案,本发明的有益效果是:In summary, owing to adopting above-mentioned technical scheme, the beneficial effect of the present invention is:
本发明中,提出了一种纹理单元与cache复用的统一着色器架构。本架构的好处是:顶点染色器和像素染色器架构一致;不需要额外的单元处理不同的请求,节约了片内资源;采用多口cache的设计,提高了并行多个处理单元的请求效率。In the present invention, a unified shader architecture in which texture units and caches are multiplexed is proposed. The advantages of this architecture are: the vertex shader and pixel shader have the same architecture; no additional units are required to process different requests, which saves on-chip resources; the multi-port cache design improves the request efficiency of multiple parallel processing units.
附图说明Description of drawings
图1为本发明的系统框架图;Fig. 1 is a system frame diagram of the present invention;
图2为本发明中多口cache架构图;Fig. 2 is a multi-port cache architecture diagram in the present invention;
图3为本发明中cache内存映射图。FIG. 3 is a cache memory map in the present invention.
具体实施方式Detailed ways
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
参照图1-3,Referring to Figure 1-3,
实施例:Example:
一种纹理单元与cache复用的shader架构,所述纹理单元与cache复用的shader架构包括:纹理单元、shader架构所述纹理单元与shader架构之间采用私有总线连接。A shader architecture multiplexing a texture unit and a cache, the shader architecture multiplexing a texture unit and a cache includes: a texture unit, shader architecture The texture unit and the shader architecture are connected by a private bus.
所述纹理单元与cache复用的shader架构的运行流程包括以下步骤:The operation flow of the shader architecture multiplexed by the texture unit and the cache includes the following steps:
S1:在顶点染色阶段,通过顶点总线请求顶点数据;S1: In the vertex coloring stage, request vertex data through the vertex bus;
S2:在像素染色阶段,通过纹理总线请求纹理数据。S2: In the pixel coloring stage, texture data is requested through the texture bus.
所述步骤S1中,在顶点染色阶段,染色器通过顶点私有总线请求使用地址直接请求顶点数据。顶点请求发给纹理单元后,直接透传到cache。Cache直接通过顶点私有总线将数据返回给染色器。In the step S1, in the vertex coloring stage, the shader directly requests vertex data through the vertex private bus request address. After the vertex request is sent to the texture unit, it is directly transparently transmitted to the cache. Cache directly returns data to the shader through the vertex private bus.
所述步骤S2中,在像素染色阶段,染色器通过像素私有总线使用纹理坐标和纹理id请求纹理数据。纹理请求发给纹理单元后,首先根据纹理id从纹理查找表中获取纹理信息;然后根据纹理信息和纹理坐标,将请求转换为地址,从cache取回数据;取回数据后根据纹理信息进行解码,最终通过总线返回给染色器。In the step S2, in the pixel coloring stage, the shader requests texture data through the pixel private bus using texture coordinates and texture id. After the texture request is sent to the texture unit, first obtain the texture information from the texture lookup table according to the texture id; then convert the request into an address according to the texture information and texture coordinates, and retrieve the data from the cache; after retrieving the data, decode according to the texture information , and finally returned to the shader through the bus.
所述多口cache内部通过将整个内存空间的数据根据地址低位映射到不同的单口cache内,如图3所示,从而提供了多个读接口。多个口的请求通过地址合并单元合并,分别将每个口的请求映射到内部的某个单口cache上。在所有的口请求数据都返回后,多口cache将数据输出。The multi-port cache internally maps the data of the entire memory space into different single-port caches according to the lower bits of the address, as shown in FIG. 3 , thereby providing multiple read interfaces. The requests of multiple ports are merged by the address merging unit, and the requests of each port are mapped to an internal single-port cache. After all the port request data are returned, the multi-port cache outputs the data.
本发明中,提出了一种纹理单元与cache复用的统一着色器架构。本架构的好处是:顶点染色器和像素染色器架构一致;不需要额外的单元处理不同的请求,节约了片内资源;采用多口cache的设计,提高了并行多个处理单元的请求效率。In the present invention, a unified shader architecture in which texture units and caches are multiplexed is proposed. The advantages of this architecture are: the vertex shader and pixel shader have the same architecture; no additional units are required to process different requests, which saves on-chip resources; the multi-port cache design improves the request efficiency of multiple parallel processing units.
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。It should be noted that in this article, relational terms such as first and second are only used to distinguish one entity or operation from another entity or operation, and do not necessarily require or imply that there is a relationship between these entities or operations. There is no such actual relationship or order between them. Furthermore, the term "comprises", "comprises" or any other variation thereof is intended to cover a non-exclusive inclusion such that a process, method, article, or apparatus comprising a set of elements includes not only those elements, but also includes elements not expressly listed. other elements of or also include elements inherent in such a process, method, article, or device. Without further limitations, an element defined by the phrase "comprising a ..." does not exclude the presence of additional identical elements in the process, method, article or apparatus comprising said element.
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。The above embodiments are only used to illustrate the technical solutions of the present invention, rather than to limit them; although the present invention has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand that: it can still be described in the foregoing embodiments Modifications are made to the recorded technical solutions, or equivalent replacements are made to some of the technical features; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the embodiments of the present invention.
Claims (5)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211553464.6A CN116051710A (en) | 2022-12-06 | 2022-12-06 | A shader architecture with texture unit and cache multiplexing |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211553464.6A CN116051710A (en) | 2022-12-06 | 2022-12-06 | A shader architecture with texture unit and cache multiplexing |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116051710A true CN116051710A (en) | 2023-05-02 |
Family
ID=86113783
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211553464.6A Pending CN116051710A (en) | 2022-12-06 | 2022-12-06 | A shader architecture with texture unit and cache multiplexing |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116051710A (en) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6972769B1 (en) * | 2004-09-02 | 2005-12-06 | Nvidia Corporation | Vertex texture cache returning hits out of order |
| US20140362101A1 (en) * | 2013-06-10 | 2014-12-11 | Sony Computer Entertainment Inc. | Fragment shaders perform vertex shader computations |
| CN106683158A (en) * | 2016-12-12 | 2017-05-17 | 中国航空工业集团公司西安航空计算技术研究所 | Modeling structure of GPU texture mapping non-blocking memory Cache |
| CN110930493A (en) * | 2019-11-21 | 2020-03-27 | 中国航空工业集团公司西安航空计算技术研究所 | GPU texel parallel acquisition method |
| CN112884875A (en) * | 2021-03-19 | 2021-06-01 | 腾讯科技(深圳)有限公司 | Image rendering method and device, computer equipment and storage medium |
-
2022
- 2022-12-06 CN CN202211553464.6A patent/CN116051710A/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6972769B1 (en) * | 2004-09-02 | 2005-12-06 | Nvidia Corporation | Vertex texture cache returning hits out of order |
| US20140362101A1 (en) * | 2013-06-10 | 2014-12-11 | Sony Computer Entertainment Inc. | Fragment shaders perform vertex shader computations |
| CN106683158A (en) * | 2016-12-12 | 2017-05-17 | 中国航空工业集团公司西安航空计算技术研究所 | Modeling structure of GPU texture mapping non-blocking memory Cache |
| CN110930493A (en) * | 2019-11-21 | 2020-03-27 | 中国航空工业集团公司西安航空计算技术研究所 | GPU texel parallel acquisition method |
| CN112884875A (en) * | 2021-03-19 | 2021-06-01 | 腾讯科技(深圳)有限公司 | Image rendering method and device, computer equipment and storage medium |
Non-Patent Citations (1)
| Title |
|---|
| JOSE-MARIA ARNAU ET AL: "Parallel Frame Rendering: Trading Responsiveness for Energy on a Mobile GPU", 31 December 2013 (2013-12-31), pages 86 - 91 * |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8514235B2 (en) | System and method for managing the computation of graphics shading operations | |
| US9519947B2 (en) | Architecture and instructions for accessing multi-dimensional formatted surface memory | |
| US9275491B2 (en) | GPU work creation and stateless graphics in OPENGL | |
| CN105630441B (en) | A kind of GPU system based on unified staining technique | |
| US9406149B2 (en) | Selecting and representing multiple compression methods | |
| US10699427B2 (en) | Method and apparatus for obtaining sampled positions of texturing operations | |
| US8558836B2 (en) | Scalable and unified compute system | |
| EP3964949B1 (en) | Graphics processing method and apparatus | |
| US8022958B2 (en) | Indexes of graphics processing objects in graphics processing unit commands | |
| US7880745B2 (en) | Systems and methods for border color handling in a graphics processing unit | |
| US8271734B1 (en) | Method and system for converting data formats using a shared cache coupled between clients and an external memory | |
| US20110078406A1 (en) | Unified Addressing and Instructions for Accessing Parallel Memory Spaces | |
| US20130271465A1 (en) | Sort-Based Tiled Deferred Shading Architecture for Decoupled Sampling | |
| US9256536B2 (en) | Method and apparatus for providing shared caches | |
| CN108022269A (en) | A kind of modeling structure of GPU compressed textures storage Cache | |
| CN109064535B (en) | Hardware acceleration implementation method for texture mapping in GPU | |
| US10013735B2 (en) | Graphics processing unit with bayer mapping | |
| CN102047315B (en) | The computing system of easily extensible and integration | |
| US20140111512A1 (en) | Buffer clearing apparatus and method for computer graphics | |
| US9779471B2 (en) | Transparent pixel format converter | |
| CN116051710A (en) | A shader architecture with texture unit and cache multiplexing | |
| US9632785B2 (en) | Instruction source specification | |
| US11232622B2 (en) | Data flow in a distributed graphics processing unit architecture | |
| KR20220019791A (en) | Texture mapping hardware accelerator based on dual buffer architecture | |
| US20220036498A1 (en) | Methods and apparatus for mapping source location for input data to a graphics processing unit |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |