CN115994230A - A smart file construction method integrating artificial intelligence and knowledge graph technology - Google Patents
A smart file construction method integrating artificial intelligence and knowledge graph technology Download PDFInfo
- Publication number
- CN115994230A CN115994230A CN202211709138.XA CN202211709138A CN115994230A CN 115994230 A CN115994230 A CN 115994230A CN 202211709138 A CN202211709138 A CN 202211709138A CN 115994230 A CN115994230 A CN 115994230A
- Authority
- CN
- China
- Prior art keywords
- data
- text
- image
- model
- recognition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images









Classifications
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Character Discrimination (AREA)
Abstract
Description
技术领域technical field
本发明涉及本发明涉及计算机技术领域,尤其涉及一种融合人工智能和知识图谱技术的智慧档案构建方法。The present invention relates to the field of computer technology, in particular to a method for constructing smart archives that integrates artificial intelligence and knowledge graph technology.
背景技术Background technique
随着数字经济的深化发展,档案数据愈发呈现海量、多源、异构的特点,这对现有档案馆建设模式提出了巨大挑战,但同时也为发展新的档案信息管理和服务方法提供了机遇。智慧档案馆由此从传统档案馆、数字档案馆的基础上逐步演化而来。当前人工智能可划分为感知智能和认知智能两大领域,前者主要集中在对图像、文本、语音和视频数据的内容解析上,而后者则涉及知识推理、因果分析等认知能力,知识图谱即被认为是认知智能的重要组成技术。因此,构建基于人工智能和知识图谱技术的智慧档案馆,为海量多源异构数据的解析和归档整理以及从档案数据中发掘知识服务提供了新的思路。With the deepening development of the digital economy, archival data is increasingly characterized by massive, multi-source, and heterogeneous features. This poses a huge challenge to the existing archives construction model, but it also provides opportunities for the development of new archival information management and service methods. opportunity. Smart archives have gradually evolved from traditional archives and digital archives. At present, artificial intelligence can be divided into two fields: perceptual intelligence and cognitive intelligence. The former mainly focuses on the content analysis of image, text, voice and video data, while the latter involves cognitive abilities such as knowledge reasoning and causal analysis. It is considered to be an important component technology of cognitive intelligence. Therefore, the construction of a smart archive based on artificial intelligence and knowledge graph technology provides a new idea for the analysis and archiving of massive multi-source heterogeneous data and the discovery of knowledge services from archive data.
发明内容Contents of the invention
本发明所要解决的技术问题是针对现有档案馆发展模式中数智化发展程度不足,难以应对档案数据愈发呈现海量多源异构特点的问题,本专利提出一种融合人工智能和知识图谱技术的智慧档案构建方法,该方法首先以深度学习技术为支撑,构建多源异构档案数据结构化解析服务,然后基于知识图谱技术从解析结果中构建出多种图谱能力,并作为可交互的知识服务提供给档案馆用户。The technical problem to be solved by the present invention is to solve the problem that the development of digital intelligence in the existing archives development model is insufficient, and it is difficult to deal with the problem that the archival data is increasingly characterized by massive multi-source heterogeneity. This patent proposes a fusion of artificial intelligence and knowledge graph. A technology-based smart archive construction method. This method first uses deep learning technology as a support to construct a multi-source heterogeneous archive data structured analysis service, and then builds a variety of graph capabilities from the analysis results based on knowledge graph technology, and serves as an interactive Knowledge services are provided to users of archives.
本发明为解决上述技术问题采用以下技术方案:The present invention adopts the following technical solutions for solving the problems of the technologies described above:
一种融合人工智能及知识图谱技术的智慧档案构建方法,包含数据存储、AI学习引擎、基础AI模型、业务模型、知识图谱和前端功能界面6个模块,用于接收并处理文档、图像和视频3种类型的数字档案格式文件;A smart file construction method that integrates artificial intelligence and knowledge graph technology, including 6 modules: data storage, AI learning engine, basic AI model, business model, knowledge graph and front-end functional interface, used to receive and process documents, images and videos 3 types of digital archive format files;
具体地,依托多种AI学习引擎提供的深度学习模型构建能力,构建了多种基础AI模型,分别为文档、图像和视频不同类型数据中关键信息的识别与解析提供支撑,以多种基础AI模型为基础,结合智慧档案领域的具体需求,构建了多种适用于该领域的业务模型,以实现对多源异构档案数据的充分解析能力;Specifically, relying on the deep learning model construction capabilities provided by multiple AI learning engines, a variety of basic AI models have been constructed to provide support for the identification and analysis of key information in different types of data such as documents, images, and videos. Based on the model, combined with the specific needs of the field of smart archives, a variety of business models suitable for this field have been constructed to achieve sufficient analysis capabilities for multi-source heterogeneous archive data;
步骤1,基于深度学习技术对文档、图像、音视频多源异构数据构建关键信息解析模型,实现对多源异构档案数据的结构化解析;
步骤2,经过解析得到的结果数据以一种轻量级数据交换格式JSON和数据表的格式呈现;Step 2, the result data obtained after parsing is presented in a lightweight data exchange format JSON and data table format;
步骤3,基于知识图谱及其可视化技术将解析结果进行进一步的整合,形成多种图谱知识服务能力提供给用户,进而有效提高用户发掘利用档案馆资源的效率。Step 3: Based on the knowledge map and its visualization technology, the analysis results are further integrated to form a variety of map knowledge service capabilities for users, thereby effectively improving the efficiency of users in discovering and utilizing archive resources.
作为本发明一种融合人工智能及知识图谱技术的智慧档案构建方法的进一步优选方案,文档数据的结构化解析流程,具体如下:As a further preferred solution of the smart file construction method of the present invention that integrates artificial intelligence and knowledge graph technology, the structured analysis process of document data is as follows:
步骤A1,文档数据在经过预处理后首先进行印章检测与行文本检测,对印章图形进行分离以及对红头、标题、正文段落等区域进行定位,随后对检测存在行文本的目标区域进行文本识别;Step A1, after the document data is preprocessed, it first performs seal detection and line text detection, separates the seal graphics and locates areas such as red heads, titles, text paragraphs, etc., and then performs text recognition on the target area where line text is detected;
步骤A2,将文本识别结果进行汇总整理成段落后,即形成了文档的具体正文内容;Step A2, after summarizing the text recognition results into paragraphs, the specific text content of the document is formed;
步骤A3,从识别结果中提取该文档的一系列关键字段,包含全宗号、文号、收文单位、落款,形成结构化文档信息,完成后续检索与信息挖掘。Step A3, extracting a series of key fields of the document from the recognition result, including the full case number, document number, receiving unit, and signature, to form structured document information, and complete subsequent retrieval and information mining.
作为本发明一种融合人工智能及知识图谱技术的智慧档案构建方法的进一步优选方案,视频数据的结构化解析流程,具体如下:As a further preferred solution of the smart file construction method of the present invention that integrates artificial intelligence and knowledge graph technology, the structured analysis process of video data is as follows:
步骤B1,关键帧抽取:Step B1, key frame extraction:
步骤B11,对视频进行关键帧的检测和抽取;Step B11, detecting and extracting key frames from the video;
步骤B12,基于哈希感知算法实现了镜头切分算法,将视频流切分为了图像数据;In step B12, the shot segmentation algorithm is implemented based on the hash-aware algorithm, and the video stream is divided into image data;
步骤B13,将关键帧抽取模块更具体地划分为字幕检测、知名人物人脸检测和语音活动检测等3种子模块,分别用于从视频流中抽取字幕帧、人脸帧或语音活动时间段;Step B13, the key frame extraction module is more specifically divided into three sub-modules such as subtitle detection, famous person face detection and voice activity detection, which are respectively used to extract subtitle frames, human face frames or voice activity time segments from the video stream;
步骤B14,对于提取出的关键帧,分别送入后续相应的处理模块进行下一步的分析;In step B14, the extracted key frames are respectively sent to subsequent corresponding processing modules for further analysis;
步骤B2,人脸识别:通过串联若干人脸图像处理子模块实现了对领导人出席活动照片中相关领导人的识别,以及对证件、票据、风景、建筑等图像进行分类的能力;基于目标检测算法YOLO模型对图像进行人脸检测,并使用一种将人脸图像变换为特征向量的算法FaceNet工具对检测存在人脸的目标区域提取人脸编码,接着将其与领导人人脸库中的预存数据进行相似度对比,即可确定图像中是否存在用户关注的领导人;Step B2, face recognition: by connecting several face image processing sub-modules in series, it realizes the recognition of relevant leaders in the photos of leaders attending events, and the ability to classify images such as certificates, bills, landscapes, buildings, etc.; based on target detection The algorithm YOLO model detects the face of the image, and uses an algorithm FaceNet tool that converts the face image into a feature vector to extract the face code from the target area where the face is detected, and then compares it with the leader's face database. By comparing the pre-stored data for similarity, it is possible to determine whether there is a leader that the user cares about in the image;
步骤B3,字幕OCR:包含场景文本检测CTPN、文本识别Densenet,用于实现对视频画面中字幕区域的定位、排序、识别以及整理,从视频中提取出具体的新闻事件或会议报道信息;利用基于一种基于卷积神经网络的文本分类算法TextCNN实现的文本分类模型识别该视频内容的主题,形成热点话题标签;Step B3, subtitle OCR: including scene text detection CTPN and text recognition Densenet, used to realize the positioning, sorting, identification and arrangement of the subtitle area in the video screen, and extract specific news events or conference report information from the video; use based on A text classification model implemented by TextCNN, a convolutional neural network-based text classification algorithm, identifies the subject of the video content and forms hot topic tags;
步骤B4,语音识别:Step B4, speech recognition:
步骤B41,将视频流转换为音频流,通过语音活动检测VAD算法提取音频流中的语音段;Step B41, the video stream is converted into an audio stream, and the voice segment in the audio stream is extracted by a voice activity detection VAD algorithm;
步骤B42,通过基于链式时延神经网络ChainTDNN网络模型的语音识别模型将音频识别为对应的音素序列,Step B42, the audio is recognized as a corresponding phoneme sequence by the speech recognition model based on the chain-type time-delay neural network ChainTDNN network model,
步骤B43,基于三元文法模型3-gram的语言模型对音素序列进行解码,获得可供用户阅读的文本结果。In step B43, the phoneme sequence is decoded based on the language model of the trigram 3-gram, and a text result that can be read by the user is obtained.
作为本发明一种融合人工智能及知识图谱技术的智慧档案构建方法的进一步优选方案,图像档案数据的结构化解析流程,具体如下:As a further preferred solution of a smart file construction method that integrates artificial intelligence and knowledge graph technology in the present invention, the structured analysis process of image file data is as follows:
步骤C1,对用户上传的图片资料进行一系列预处理措施之后,对其进行人脸检测;其中,一系列预处理措施包含对文件格式、图像尺寸、颜色编码进行统一;Step C1, after performing a series of preprocessing measures on the image data uploaded by the user, perform face detection on it; wherein, a series of preprocessing measures include unifying the file format, image size, and color coding;
步骤C2,若检测到人脸则基于Facenet技术对目标区域进行向量化处理,得到人脸编码,并将得到的人脸编码与领导人数据库中事先存储好的领导人人脸标准编码数据进行相似度对比,以判断该图片中是否出现了用户关注的领导人;Step C2, if a face is detected, vectorize the target area based on Facenet technology to obtain a face code, and perform similarity between the obtained face code and the pre-stored leader face standard code data in the leader database Degree comparison to determine whether there is a leader followed by the user in the picture;
步骤C3,若成功识别出领导人,则输出领导人列表;而若未成功识别领导人,则转至进行图像物体分类模块,进行如下5种档案馆常见图片标签:证件、票据、建筑、风景和其他,以方便对图片进行归档。Step C3, if the leader is successfully identified, output the list of leaders; and if the leader is not successfully identified, then go to the image object classification module, and perform the following five common image tags in archives: certificates, bills, buildings, landscapes and others for easy archiving of pictures.
作为本发明一种融合人工智能及知识图谱技术的智慧档案构建方法的进一步优选方案,文档数据的预处理包含倾角检测与修正、印章检测与去除、灰度化、二值化以及噪点去除;As a further preferred solution of the smart file construction method of the present invention that integrates artificial intelligence and knowledge graph technology, the preprocessing of document data includes inclination detection and correction, seal detection and removal, grayscale, binarization, and noise removal;
其中,(1)倾角检测与修正:Among them, (1) inclination detection and correction:
采用Hough变换对档案馆图片数据进行校正;Hough变换主要采用了极坐标转换的方式,将常规的笛卡尔坐标系中的点(x,y)映射到Hough空间中的点(ρ,θ),其中:The Hough transform is used to correct the image data of the archives; the Hough transform mainly adopts the method of polar coordinate transformation, mapping the point (x, y) in the conventional Cartesian coordinate system to the point (ρ, θ) in the Hough space, in:
ρ=x·cosθ+y·sinθρ=x·cosθ+y·sinθ
Hough变换会对图像上的每个边缘点计算其所有可能的(ρ,θ)值,将这些极坐标点连成一条曲线,当足够多的曲线在Hough空间中相交于某一点(ρ,θ)时,可认为(ρ,θ)对应于图像空间位置中一条直线,对其进行位置映射后,即可得到原始图像中直线的位置和倾斜角度,由此得到校正之后的坐标点(x’,y’);The Hough transform will calculate all possible (ρ, θ) values for each edge point on the image, and connect these polar coordinate points into a curve. When enough curves intersect at a certain point (ρ, θ) in Hough space ), it can be considered that (ρ, θ) corresponds to a straight line in the image space position, and after position mapping, the position and inclination angle of the straight line in the original image can be obtained, and the corrected coordinate point (x' ,y');
(2)印章检测与去除:(2) Seal detection and removal:
采用基于YOLO的目标检测技术,提取文档中可能出现的印章的圆心坐标、半径、坐标框以及所在页码,接着通过基于通道阈值的方式,去除该区域的印章图形;Using YOLO-based target detection technology, extract the center coordinates, radius, coordinate frame and page number of the stamp that may appear in the document, and then remove the stamp graphics in this area by means of channel threshold;
(3)灰度化:将彩色图像转换为黑白图像再进行处理,有效地去除数据中的冗余信息,即为灰度化,图像由常规的三通道图通过加权平均算法转换为单通道图即为灰度图,计算公式如下所示:(3) Grayscale: convert the color image into a black and white image and then process it to effectively remove redundant information in the data, that is, grayscale. The image is converted from a conventional three-channel image to a single-channel image through a weighted average algorithm It is a grayscale image, and the calculation formula is as follows:
Gray(x,y)=0.229*R(x,y)+0.587*G(x,y)+0.114*B(x,y)Gray(x,y)=0.229*R(x,y)+0.587*G(x,y)+0.114*B(x,y)
其中,Gray(x,y)、R(x,y)、G(x,y)、B(x,y)分别为像素点的灰度值、红色、绿色和蓝色值;Among them, Gray(x,y), R(x,y), G(x,y), B(x,y) are the gray value, red, green and blue value of the pixel respectively;
(6)二值化:将灰度图做二值化处理,即通过设置阈值的方式将图像的像素划分为两部分,一部分像素的灰度值大于阈值,而另一部分像素的灰度值则小于阈值;(6) Binarization: binarize the grayscale image, that is, divide the pixels of the image into two parts by setting a threshold, the grayscale value of some pixels is greater than the threshold value, and the grayscale value of the other part of pixels is less than the threshold;
根据灰度值判断为1的像素构成的区域即被认为是可识别的字符图形;The area composed of pixels judged to be 1 according to the gray value is considered to be a recognizable character graphic;
采用迭代阈值分割的方法将待处理文档的灰度图进行二值化处理,首先将二值化阈值的初始值设定为图像灰度值的平均值,接着通过若干轮的迭代来找到恰当的终值,再对灰度图进行二值化的划分;The grayscale image of the document to be processed is binarized by the method of iterative threshold segmentation. First, the initial value of the binarization threshold is set as the average value of the grayscale value of the image, and then the appropriate threshold is found through several rounds of iterations. The final value, and then binarize the grayscale image;
(7)噪点去除:采用数学形态学滤波将待处理图像中的噪点进行去除,可有效提高文档的识别准确率。(7) Noise removal: The noise in the image to be processed is removed by mathematical morphology filtering, which can effectively improve the recognition accuracy of the document.
(8)作为本发明一种融合人工智能及知识图谱技术的智慧档案构建方法的进一步优选方案,对档案文件的OCR分为行文本检测与行文本识别两步:采用了基于可微分二值化DB的文本检测方法以及基于CRNN网络的文本识别方法;(8) As a further preferred solution of the smart archive construction method that integrates artificial intelligence and knowledge graph technology in the present invention, the OCR of archive files is divided into two steps: line text detection and line text recognition: using a method based on differentiable binarization DB text detection method and text recognition method based on CRNN network;
文本检测方法:通过文本检测模块,获取到文档中存在文字区域的坐标,并以边界框的形式进行标记,方便了后续的文本识别步骤;采用了基于分割的DB算法,以文本行作为分割目标,并给予分割结果构建文本框,进而得到了行文本字框;在实现上采用了基于卷积神经网络的文本分类算法ResNet34_vd为主干网络的特征提取层,后接特征图金字塔FPN层确保捕获特征的多样性和稳健性,并以3层卷积网络作为模型的特征预测组件;Text detection method: through the text detection module, the coordinates of the text area in the document are obtained, and marked in the form of a bounding box, which facilitates the subsequent text recognition steps; the DB algorithm based on segmentation is adopted, and the text line is used as the segmentation target , and give the segmentation result to build a text box, and then get a line text box; in the implementation, the text classification algorithm ResNet34_vd based on the convolutional neural network is used as the feature extraction layer of the backbone network, followed by the feature map pyramid FPN layer to ensure the capture of features The diversity and robustness of the model, and a 3-layer convolutional network as the feature prediction component of the model;
(3)文本识别方法:将目标字框内存在的字符图形识别为对应的文本字符串的功能:采用基于卷积循环神经网络CRNN网络作为本模块的主干网络实现,采用一种适用于移动端设备的轻量级神经网络架构MobileNetV3网络进行初步的特征提取,接着以若干层双向长短时记忆BiLSTM网络输出每个字符位置上输出的标签概率分布,并通过连接时序分类CTC算法对输出分布进行优化训练。(3) Text recognition method: the function of recognizing the character graphics existing in the target word box as the corresponding text string: using the CRNN network based on the convolutional cyclic neural network as the backbone network of this module, and using a mobile terminal The lightweight neural network architecture MobileNetV3 network of the device performs preliminary feature extraction, and then uses several layers of bidirectional long-short-term memory BiLSTM network to output the label probability distribution output at each character position, and optimizes the output distribution through the connection time series classification CTC algorithm train.
作为本发明一种融合人工智能及知识图谱技术的智慧档案构建方法的进一步优选方案,通过文本处理模块以及文档信息抽取业务模型,将字符串列表转换为方便用户阅读的自然段落,并从中自动抽取出关键字段,形成结构化的文本信息解析结果;As a further preferred solution of the smart file construction method that integrates artificial intelligence and knowledge graph technology in the present invention, through the text processing module and the document information extraction business model, the list of character strings is converted into natural paragraphs that are easy for users to read, and automatically extracted Key fields are extracted to form a structured text information analysis result;
其中,(1)规则抽取:通过对具体档案文件的理解,系统要事先设置若干关键字段;Among them, (1) rule extraction: through the understanding of specific archives, the system needs to set several key fields in advance;
(2)字符推算:另外,档案文档中也有若干字段可以通过分析版面特征来进行判断;(2) Character calculation: In addition, there are also several fields in the archive document that can be judged by analyzing the layout features;
(3)整合输出:最后将上述系统流程给出的结果进行汇总,并将相同字段的结果进行整合。(3) Integration output: Finally, summarize the results given by the above system flow, and integrate the results of the same fields.
作为本发明一种融合人工智能及知识图谱技术的智慧档案构建方法的进一步优选方案,在步骤3中,知识图谱的构建过程,具体分为实体识别、关系抽取、实体对齐和知识推理共4个子模块;As a further preferred solution of the smart file construction method that integrates artificial intelligence and knowledge graph technology in the present invention, in step 3, the knowledge graph construction process is specifically divided into four sub-sections: entity recognition, relationship extraction, entity alignment, and knowledge reasoning. module;
实体识别层:实体是知识图谱的基础,实体识别是构建知识图谱的基础任务,好的实体识别结果能显著提升知识图谱构建结果的质量;基于深度学习网络的实体识别模型,可以实现仅使用少量的人工标注数据构建训练集,并使用BERT模型提取句向量后训练以BiLSTM+CRF为主干网络的实体识别模型;Entity recognition layer: Entities are the basis of knowledge graphs, and entity recognition is the basic task of building knowledge graphs. Good entity recognition results can significantly improve the quality of knowledge graph construction results; entity recognition models based on deep learning networks can achieve using only a small amount of Construct a training set from manually labeled data, and use the BERT model to extract sentence vectors to train an entity recognition model with BiLSTM+CRF as the backbone network;
关系抽取层:根据已经识别出的实体结果以及全文数据,进一步提取出实体之间的关系;将全文数据进行分词处理后送入CBoW模型提取出词向量,接着送入BiLSTM模型提取上下文关联语义特征编码,模型引入注意力机制,根据样本数据自动调整样本节点相互之间的注意力权重参数,形成实体节点之间的关系信息;Relationship extraction layer: According to the identified entity results and full-text data, the relationship between entities is further extracted; the full-text data is word-segmented and sent to the CBoW model to extract word vectors, and then sent to the BiLSTM model to extract context-related semantic features Coding, the model introduces the attention mechanism, automatically adjusts the attention weight parameters between the sample nodes according to the sample data, and forms the relationship information between the entity nodes;
实体对齐层:系统将全文数据、摘要以及主题、关键字、领导人、时间、来源、类型等属性数据进行充分利用,送入BERT模型转化为向量表示;在档案样本数据之间分别计算实体全文余弦相似度以及实体摘要余弦相似度,并通过综合两种相似度以判断档案样本数据之间的语义相似度;将多个相似度指标输入到由SENet层搭建的多特征融合模型中输出实体对齐的结果;全部档案数据经过实体对齐模型的预测后,即可形成对齐实体的集合;将关系抽取层给出的实体及其关系使用对齐实体集合完成对齐;Entity alignment layer: The system makes full use of full-text data, abstracts, and attribute data such as topics, keywords, leaders, time, sources, types, etc., and sends them into the BERT model to convert them into vector representations; the full-text entities are calculated separately between the archive sample data Cosine similarity and entity summary cosine similarity, and by combining the two similarities to judge the semantic similarity between archive sample data; input multiple similarity indicators into the multi-feature fusion model built by the SENet layer to output entity alignment The result; all the archive data can form a set of aligned entities after being predicted by the entity alignment model; the entities and their relationships given by the relationship extraction layer are aligned using the aligned entity set;
知识推理层:经过前面实体识别层、关系抽取层和实体对齐层的处理,数据已经形成了<头实体-关系-尾实体>结构的三元组;知识图谱构建系统还需进行知识推理,以丰富、充实实体之间的关系,解决实体之间依靠原始数据构建出的关系较为稀疏的问题。Knowledge reasoning layer: After the processing of the previous entity recognition layer, relationship extraction layer and entity alignment layer, the data has formed a triplet of <head entity-relationship-tail entity> structure; the knowledge map construction system also needs to carry out knowledge reasoning to Enrich and enrich the relationship between entities, and solve the problem that the relationship between entities based on original data is relatively sparse.
本发明采用以上技术方案与现有技术相比,具有以下技术效果:Compared with the prior art, the present invention adopts the above technical scheme and has the following technical effects:
本专利提出了融合人工智能和知识图谱技术的新型智慧档案构建方法,以深度学习技术为支撑,依托多种AI学习引擎提供的深度学习模型构建能力,构建了多种基础AI模型,分别为文档、图像和视频不同类型数据中关键信息的识别与解析提供支撑,并以这些基础AI模型为基础,结合智慧档案领域的具体需求,构建了多种适用于该领域的业务模型,以实现对多源异构档案数据的充分解析能力;构建多源异构档案数据结构化解析服务,然后基于知识图谱技术从解析结果中构建出多种图谱能力,并作为可交互的知识服务提供给档案馆用户。This patent proposes a new smart file construction method that integrates artificial intelligence and knowledge graph technology. Supported by deep learning technology and relying on the deep learning model construction capabilities provided by various AI learning engines, a variety of basic AI models are constructed. , image and video data to provide support for the identification and analysis of key information in different types of data, and based on these basic AI models, combined with the specific needs of the field of smart archives, a variety of business models suitable for this field have been constructed to achieve multi-to-many Sufficient analytical capabilities for source heterogeneous archival data; construct multi-source heterogeneous archival data structured analysis services, and then construct various graph capabilities from the analysis results based on knowledge graph technology, and provide them to archive users as interactive knowledge services .
附图说明Description of drawings
图1是本发明一种融合人工智能和知识图谱技术的智慧档案构建方法流程图;Fig. 1 is a flow chart of a method for constructing smart archives that integrates artificial intelligence and knowledge graph technology according to the present invention;
图2是本发明文档结构化解析流程图;Fig. 2 is a flow chart of document structure parsing in the present invention;
图3是本发明视频结构化解析流程图;Fig. 3 is a flow chart of video structured analysis in the present invention;
图4是本发明结合人脸识别和物体分类的图像解析流程图;Fig. 4 is the image analysis flowchart of the present invention combining face recognition and object classification;
图5是本发明知识图谱及其可视化处理流程;Fig. 5 is the knowledge graph and its visualization processing flow of the present invention;
图6是本发明知识图谱的构建流程;Fig. 6 is the construction process of the knowledge map of the present invention;
图7是本发明文档解析功能用户界面;Fig. 7 is the document analysis function user interface of the present invention;
图8是本发明视频解析功能用户界面;Fig. 8 is the video analysis function user interface of the present invention;
图9是本发明图像解析功能用户界面;Fig. 9 is the image analysis function user interface of the present invention;
图10是本发明知识图谱展示界面。Fig. 10 is the knowledge map display interface of the present invention.
具体实施方式Detailed ways
下面结合附图对本发明的技术方案做进一步的详细说明:Below in conjunction with accompanying drawing, technical scheme of the present invention is described in further detail:
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。In order to make the purpose, technical solutions and advantages of the embodiments of the present invention more clear, the technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the drawings in the embodiments of the present invention. Apparently, the described embodiments are some, but not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of the present invention.
如图1至10所示,本专利的目的是解决数字经济深化发展的背景下,现有档案馆发展中数智化发展程度不足,难以应对海量多源异构档案数据的整理与利用的难题。本专利提出融合人工智能和知识图谱技术的新型智慧档案构建方法。首先,基于深度学习技术针对文档、图像、音视频等多源异构数据构建关键信息解析模型,实现针对多源异构档案数据的结构化解析能力;经过解析得到的结果数据以JSON和数据表的格式呈现,然后再基于知识图谱技术将这些解析结果进行进一步的整合,形成多种图谱知识服务能力提供给用户,可以有效提高用户发掘利用档案馆资源的效率。As shown in Figures 1 to 10, the purpose of this patent is to solve the problem of insufficient development of digital intelligence in the development of existing archives under the background of the deepening development of the digital economy, and it is difficult to deal with the problem of collation and utilization of massive multi-source heterogeneous archive data . This patent proposes a new smart file construction method that integrates artificial intelligence and knowledge graph technology. First, build a key information analysis model for multi-source heterogeneous data such as documents, images, audio and video based on deep learning technology, and realize the structured analysis capability for multi-source heterogeneous archive data; format, and then further integrate these analytical results based on knowledge graph technology to form a variety of graph knowledge service capabilities for users, which can effectively improve the efficiency of users in discovering and utilizing archive resources.
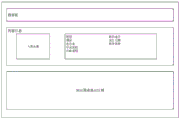
融合人工智能和知识图谱技术的智慧档案构建方法的整体结结构,如图1所示,具体步骤如下:The overall structure of the smart file construction method that integrates artificial intelligence and knowledge graph technology is shown in Figure 1. The specific steps are as follows:
由图1可知,本专利提出的融合人工智能和知识图谱技术的智慧档案构建方法,主要有数据存储、AI学习引擎、基础AI模型、业务模型、知识图谱和前端功能界面等6大模块组成,可接收并处理文档、图像和视频3种类型的数字档案格式文件。其中,对文档的处理主要针对档案数据中最常见的公文和报刊文档,对图像的处理结合了人脸识别和物体分类两类能力,而对视频文件的处理则主要针对新闻报道类视频以进行结构化解析。具体地,本专利所提出的方法首先依托多种AI学习引擎提供的深度学习模型构建能力,构建了多种基础AI模型,分别为文档、图像和视频不同类型数据中关键信息的识别与解析提供支撑;进一步地,以上述多种基础AI模型为基础,结合智慧档案领域的具体需求,本专利设计并构建了多种适用于该领域的业务模型,以实现对多源异构档案数据的充分解析能力。As can be seen from Figure 1, the smart archive construction method proposed by this patent that integrates artificial intelligence and knowledge graph technology mainly consists of six modules: data storage, AI learning engine, basic AI model, business model, knowledge graph, and front-end functional interface. It can receive and process three types of digital archive format files: document, image and video. Among them, the processing of documents is mainly aimed at the most common official documents and newspaper documents in the archival data. The processing of images combines the capabilities of face recognition and object classification, while the processing of video files is mainly aimed at news report videos. Structured analysis. Specifically, the method proposed in this patent first relies on the deep learning model construction capabilities provided by multiple AI learning engines to build a variety of basic AI models, which provide information for the identification and analysis of key information in different types of data such as documents, images, and videos. Support; further, based on the above-mentioned various basic AI models, combined with the specific needs of the field of smart archives, this patent designs and builds a variety of business models applicable to this field, in order to fully realize the multi-source heterogeneous archive data analytical ability.
文档数据的结构化解析流程如图2所示。文档数据在经过预处理后首先进行印章检测与行文本检测,对印章图形进行分离以及对红头、标题、正文段落等区域进行定位,随后对检测存在行文本的目标区域进行文本识别。将文本识别结果进行汇总整理成段落后,即形成了文档的具体正文内容。另外还需从识别结果中提取该文档的一系列关键字段,如全宗号、文号、收文单位、落款等,形成结构化文档信息,方便后续检索与信息挖掘。The structured parsing process of document data is shown in Figure 2. After the document data is preprocessed, it first performs seal detection and line text detection, separates the seal graphics and locates areas such as red heads, titles, and text paragraphs, and then performs text recognition on the target area where line text is detected. After summarizing the text recognition results into paragraphs, the specific text content of the document is formed. In addition, a series of key fields of the document need to be extracted from the recognition results, such as the full case number, document number, receiving unit, signature, etc., to form structured document information to facilitate subsequent retrieval and information mining.
档案馆通过收集领导人活动报道、会议新闻、政策宣传等音视频资料,可以对本市党政动态、当下热点新闻等进行及时跟踪。本系统在获取到音视频资料后,可以对数据基于新闻事件进行切片,快速定位到视频中的具体事件片段。为了获取新闻事件的具体内容,系统需要从视频画面中提取相应的字幕信息,从视频语音中识别出旁白播报信息,以构成该则新闻的播报内容。接着可以通过对识别得到的文本进行分类,得到该则新闻的内容分类标签。最后为获取得到新闻事件中有哪些领导人出席会议活动,除了从识别文本结果中进行关键词提取以外,本系统还引入了人脸检测、编码与识别技术,通过比对数据库中事先存储的领导人编码,可以提取出视频画面中出现的领导人。The archives can track the city's party and government dynamics and current hot news in a timely manner by collecting audio and video materials such as leaders' activity reports, conference news, and policy propaganda. After the system obtains audio and video materials, it can slice the data based on news events and quickly locate specific event segments in the video. In order to obtain the specific content of the news event, the system needs to extract the corresponding subtitle information from the video screen, and recognize the narration broadcast information from the video voice to form the broadcast content of the news. Then, the content classification label of the news can be obtained by classifying the recognized text. Finally, in order to obtain which leaders attended the meeting activities in the news event, in addition to extracting keywords from the recognition text results, this system also introduces face detection, coding and recognition technology, by comparing the leaders stored in the database in advance People coding can extract the leaders appearing in the video.
由图3可知,视频解析模块的工作流程如下:As can be seen from Figure 3, the workflow of the video parsing module is as follows:
(1)关键帧抽取:为了便于提取视频数据中的各项关键信息,系统首先需要知道这些关键信息出现的时间信息(即定位“关键帧”),才能进一步对画面上的信息进行处理。因此,视频信息结构化模块的第一个步骤就是对视频进行关键帧的检测和抽取。本系统基于哈希感知算法实现了镜头切分算法,将视频流切分为了图像数据。为了不同的检测目标,可以将关键帧抽取模块更具体地划分为字幕检测、知名人物人脸检测和语音活动检测等3种子模块,分别用于从视频流中抽取字幕帧、人脸帧或语音活动时间段。对于提取出的关键帧,分别送入后续相应的处理模块进行下一步的分析。(1) Key frame extraction: In order to facilitate the extraction of various key information in the video data, the system first needs to know the time information of these key information (that is, locate the "key frame") before further processing the information on the screen. Therefore, the first step of the video information structure module is to detect and extract key frames of the video. This system implements the lens segmentation algorithm based on the hash perception algorithm, and divides the video stream into image data. For different detection targets, the key frame extraction module can be more specifically divided into three sub-modules: subtitle detection, famous person face detection and voice activity detection, which are used to extract subtitle frames, face frames or voice from video streams respectively. Active time period. The extracted key frames are respectively sent to subsequent corresponding processing modules for further analysis.
(2)人脸识别:本模块通过串联若干人脸图像处理子模块实现了对领导人出席活动照片中相关领导人的识别,以及对证件、票据、风景、建筑等图像进行分类的能力。首先基于YOLO(YouOnlyLookOnce,一种目标检测算法)模型对图像进行人脸检测,并使用一种将人脸图像变换为特征向量的算法Facenet工具对检测存在人脸的目标区域提取人脸编码,接着将其与领导人人脸库中的预存数据进行相似度对比,即可确定图像中是否存在用户关注的领导人。(2) Face recognition: This module realizes the recognition of relevant leaders in the photos of leaders attending activities by connecting several face image processing sub-modules in series, and the ability to classify images such as certificates, bills, landscapes, and buildings. First, face detection is performed on the image based on the YOLO (YouOnlyLookOnce, a target detection algorithm) model, and an algorithm Facenet tool that converts the face image into a feature vector is used to extract the face code for the target area where the face is detected, and then By comparing the similarity with the pre-stored data in the leader's face database, it can be determined whether there is a leader that the user cares about in the image.
(3)字幕OCR:本模块由场景文本检测CTPN、文本识别Densenet等子模块所组成,可以实现对视频画面中字幕区域的定位、排序、识别以及整理,可以从视频中提取出具体的新闻事件或会议报道信息。进一步可以利用基于基于卷积神经网络的文本分类算法TextCNN实现的文本分类模型识别该视频内容的主题,形成热点话题标签。(3) Subtitle OCR: This module is composed of scene text detection CTPN, text recognition Densenet and other sub-modules, which can realize the positioning, sorting, identification and arrangement of the subtitle area in the video screen, and can extract specific news events from the video or conference coverage information. Further, the text classification model based on the convolutional neural network-based text classification algorithm TextCNN can be used to identify the subject of the video content and form hot topic tags.
(4)语音识别:本模块首先将视频流转换为音频流,通过语音活动检测VAD算法提取音频流中的语音段,通过基于链式时延神经网络ChainTDNN网络模型的语音识别模型将音频识别为对应的音素序列,接着使用基于3-gram的语言模型对音素序列进行解码,获得可供用户阅读的文本结果。此外还可以加入一些后处理子模块,如基于BiLSTM网络的标点恢复模型,进一步提升文本结果的可读性。(4) Speech recognition: This module first converts the video stream into an audio stream, extracts the speech segment in the audio stream through the voice activity detection VAD algorithm, and recognizes the audio as The corresponding phoneme sequence is then decoded using a 3-gram-based language model to obtain a text result that can be read by the user. In addition, some post-processing sub-modules can be added, such as the punctuation recovery model based on the BiLSTM network, to further improve the readability of the text results.
对图像档案数据进行解析的流程步骤如图4所示,本项目系统对用户上传的图片资料进行一系列预处理措施(对文件格式、图像尺寸、颜色编码进行统一等)之后,对其进行人脸检测。若检测到人脸则基于Facenet技术对目标区域进行向量化处理,得到人脸编码,并将得到的人脸编码与领导人数据库中事先存储好的领导人人脸标准编码数据进行相似度对比,以判断该图片中是否出现了用户关注的领导人。成功识别出领导人,则输出领导人列表;而若未成功识别领导人,则转至进行图像物体分类模块,进行如下5种档案馆常见图片标签:证件、票据、建筑、风景和其他,以方便对图片进行归档。The process steps of analyzing the image file data are shown in Figure 4. After a series of preprocessing measures (unification of file format, image size, color coding, etc.) face detection. If a face is detected, the target area is vectorized based on Facenet technology to obtain a face code, and the obtained face code is compared with the pre-stored leader face standard code data in the leader database. To determine whether there is a leader followed by the user in the picture. If the leader is successfully identified, the list of leaders will be output; if the leader is not successfully identified, then go to the image object classification module to perform the following five common image tags in archives: certificates, bills, buildings, landscapes, and others. Easy to archive pictures.
如图5所示,本档案馆基于前文设计的对图像、文档、音视频资料的信息抽取模块,设计了将提取出的结构化信息融合为图形网络的档案数据知识图谱服务平台,解决了档案馆用户处理多源异构数据的难题。知识图谱构建系统需要对多种数据进行相应的预处理,从图像、文档和视频数据中提取出文本内容、文本摘要、热点话题、关键字、报道时间、涉及的领导人等结构化信息。这些处理过程已经在上文中分别介绍过。接着系统会对这些结构化数据做命名实体识别,进一步提取出领导人、机构单位、地名、专有名词等实体,并建立各个实体之间的关系。实际意义相近的实体可能在名称上相差较大,因此需要计算实体之间的相似度,并对实体进行融合归一化处理。最后对实体以及实体之间的关系进行推理、扩展和补全,完成档案馆多源异构数据知识图谱的构建过程。As shown in Figure 5, based on the information extraction module for images, documents, and audio and video materials designed above, the archives design a knowledge map service platform for archives data that integrates the extracted structured information into a graphic network, solving the problem of archives Library users deal with the difficulties of multi-source heterogeneous data. The knowledge map construction system needs to preprocess a variety of data accordingly, and extract structured information such as text content, text summaries, hot topics, keywords, reporting time, and involved leaders from image, document, and video data. These processes have been introduced separately above. Then the system will perform named entity recognition on these structured data, further extract leaders, institutional units, place names, proper nouns and other entities, and establish the relationship between each entity. Entities with similar actual meanings may have large differences in names, so it is necessary to calculate the similarity between entities and perform fusion and normalization processing on the entities. Finally, infer, expand and complete the entities and the relationships between entities, and complete the construction process of the multi-source heterogeneous data knowledge map of the archives.
由于文档样式的多样性,以及在数字化处理过程中可能产生各种问题,对文档数据进行解析以前,需要进行预处理,对数据的格式进行规范化,降低系统解析错误的概率。具体来说对文档数据的预处理模块由以下几个子模块组成:倾角检测与修正、印章检测与去除、灰度化、二值化以及噪点去除等。Due to the diversity of document styles and various problems that may arise during digital processing, before analyzing document data, preprocessing is required to standardize the format of the data to reduce the probability of system analysis errors. Specifically, the preprocessing module for document data consists of the following submodules: inclination detection and correction, seal detection and removal, grayscale, binarization, and noise removal, etc.
(1)倾角检测与修正:档案馆中存储的文档资料数据,难免会存在图像倾角不正的情况,一定程度上影响了文本内容识别质量。因此,图像的预处理阶段首先需要对图像进行角度修正。本系统采用Hough变换对档案馆图片数据进行校正;Hough变换主要采用了极坐标转换的方式,将常规的笛卡尔坐标系中的点(x,y)映射到Hough空间中的点(ρ,θ),其中:(1) Inclination detection and correction: The document data stored in the archives will inevitably have incorrect image inclination, which affects the quality of text content recognition to a certain extent. Therefore, the image preprocessing stage first needs to correct the angle of the image. This system adopts Hough transform to correct the image data of the archives; Hough transform mainly adopts the method of polar coordinate conversion, and maps the point (x, y) in the conventional Cartesian coordinate system to the point (ρ, θ) in the Hough space ),in:
ρ=x·cosθ+y·sinθρ=x·cosθ+y·sinθ
由于在做Hough变换之前需要对文档图像进行边缘检测,因此Hough变换会对图像上的每个边缘点计算其所有可能的(ρ,θ)值,将这些极坐标点连成一条曲线,当足够多的曲线在Hough空间中相交于某一点(ρ,θ)时,可认为(ρ,θ)对应于图像空间位置中一条直线,对其进行位置映射后,即可得到原始图像中直线的位置和倾斜角度,由此得到校正之后的坐标点(x’,y’);Since the edge detection of the document image is required before the Hough transform, the Hough transform will calculate all possible (ρ, θ) values for each edge point on the image, and connect these polar coordinate points into a curve, when enough When many curves intersect at a certain point (ρ, θ) in Hough space, it can be considered that (ρ, θ) corresponds to a straight line in the image space position, and after position mapping, the position of the straight line in the original image can be obtained and the tilt angle, thus obtaining the corrected coordinate point (x', y');
(2)印章检测与去除:档案资料中常出现的印章图形会覆盖部分字符形成遮挡,对文字识别不利。因此系统中需要对印章部分进行自动检测与去除。智慧档案馆系统采用基于YOLO的目标检测技术,提取文档中可能出现的印章的圆心坐标、半径、坐标框以及所在页码,接着通过基于通道阈值的方式,去除该区域的印章图形。以常见的红色印章为例,在目标区域内提取红色通道,得到红色通道的灰度值,用过三角法计算灰度图的统计直方图的最大距离,即可确定图像分割的最佳阈值,再通过该阈值来去除红色印章。(2) Seal detection and removal: The seal graphics that often appear in archives will cover part of the characters to form a block, which is not good for character recognition. Therefore, it is necessary to automatically detect and remove the stamp part in the system. The smart archive system uses YOLO-based target detection technology to extract the center coordinates, radius, coordinate frame and page number of the seal that may appear in the document, and then removes the seal graphics in this area based on the channel threshold. Taking the common red stamp as an example, extract the red channel in the target area to obtain the gray value of the red channel, and use the triangulation method to calculate the maximum distance of the statistical histogram of the gray image to determine the optimal threshold for image segmentation. Then pass the threshold to remove the red stamp.
(3)灰度化:系统后台模型并不会直接输入彩色图像,而是将彩色图像转换为黑白图像再进行处理,这样可以有效地去除数据中的冗余信息。这个过程即为灰度化,图像由常规的三通道图通过加权平均算法转换为单通道图(也称为灰度图),计算公式如下所示:(3) Grayscale: The background model of the system does not directly input color images, but converts color images into black and white images for processing, which can effectively remove redundant information in the data. This process is grayscale. The image is converted from a conventional three-channel image to a single-channel image (also called a grayscale image) through a weighted average algorithm. The calculation formula is as follows:
Gray(x,y)=0.229*R(x,y)+0.587*G(x,y)+0.114*B(x,y)Gray(x,y)=0.229*R(x,y)+0.587*G(x,y)+0.114*B(x,y)
其中,Gray(x,y)、R(x,y)、G(x,y)、B(x,y)分别为像素点的灰度值、红色、绿色和蓝色值。Among them, Gray(x, y), R(x, y), G(x, y), B(x, y) are the gray value, red, green and blue value of the pixel, respectively.
(4)二值化:为了使得灰度图中的各类特征显得更为明显,系统进一步将灰度图做二值化处理,即通过设置阈值的方式将图像的像素划分为两部分,一部分像素的灰度值大于阈值,而另一部分像素的灰度值则小于阈值。灰度值判断为1的像素构成的区域即被认为是可识别的字符图形。本系统采用迭代阈值分割的方法对待处理文档的灰度图进行二值化处理,首先将图像灰度值的平均值设定为二值化阈值的初始值,接着通过若干轮的迭代来找到恰当的终值,再对灰度图进行二值化的划分。(4) Binarization: In order to make the various features in the grayscale image more obvious, the system further performs binary processing on the grayscale image, that is, divides the pixels of the image into two parts by setting a threshold, and one part The gray value of the pixel is greater than the threshold, while the gray value of another part of the pixel is smaller than the threshold. The area formed by pixels whose gray value is determined to be 1 is considered to be a recognizable character graphic. This system adopts the iterative threshold segmentation method to binarize the gray image of the document to be processed. First, the average value of the image gray value is set as the initial value of the binarization threshold, and then through several rounds of iterations to find the appropriate threshold value. The final value, and then binarize the grayscale image.
(5)噪点去除:部分档案由于年代久远,在进行数字化前已存在明显的折痕或污损现象,扫描得到的图像整体或部分分辨率较低,不利于后续的OCR处理。本系统采用数学形态学滤波将待处理图像中的噪点去除,可有效提高文档的识别准确率。(5) Noise removal: Due to the age of some archives, there are obvious creases or stains before digitization, and the overall or partial resolution of the scanned image is low, which is not conducive to subsequent OCR processing. This system uses mathematical morphology filtering to remove the noise in the image to be processed, which can effectively improve the accuracy of document recognition.
对档案文件的OCR可以分为行文本检测与行文本识别两步。本系统采用了基于可微分二值化算法DB的文本检测方法以及基于CRNN网络的文本识别方法。The OCR of archive files can be divided into two steps: line text detection and line text recognition. This system adopts the text detection method based on the differentiable binarization algorithm DB and the text recognition method based on the CRNN network.
针对文档数据的OCR与字幕OCR有所不同。二者最大的区别在于,文档普遍有多行文本,而字幕往往大多数情况下只有单行文本。OCR for document data is different from subtitle OCR. The biggest difference between the two is that documents generally have multiple lines of text, while subtitles usually only have a single line of text in most cases.
(1)文本检测:通过文本检测模块,系统可以获取到文档中存在文字区域的坐标,并可以以边界框的形式进行标记,方便了后续的文本识别步骤。本系统采用了基于分割的DB算法,以文本行作为分割目标,并给予分割结果构建文本框,进而得到了行文本字框。在实现上采用了基于ResNet34_vd为主干网络的特征提取层,后接特征图金字塔(FPN)层确保捕获特征的多样性和稳健性,并以3层卷积网络作为模型的特征预测组件。(2)文本识别:本模块实现了将目标字框内存在的字符图形识别为对应的文本字符串的功能。采用基于卷积循环神经网络(ConvolutionalRecurrentNeuralNetwork,CRNN)网络作为本模块的主干网络实现,采用一种适用于移动端设备的轻量级神经网络架构MobileNetV3网络进行初步的特征提取,接着以若干层双向长短时记忆BiLSTM网络输出每个字符位置上输出的标签概率分布,并通过连接时序分类CTC算法对输出分布进行优化训练;该模型自然地融合了卷积神经网络和循环神经网络各自的优势,充分分析了待识别图像的空间图形特征和上下文语义联系,并且解决了行文本图像与字符串序列之间的自动标签对齐问题。这种模型设计自然地融合了卷积神经网络和循环神经网络各自的优势,充分分析了待识别图像的空间图形特征和上下文语义联系,并且解决了行文本图像与字符串序列之间的自动标签对齐问题。(1) Text detection: Through the text detection module, the system can obtain the coordinates of the text area in the document, and can mark it in the form of a bounding box, which facilitates the subsequent text recognition steps. This system adopts the DB algorithm based on segmentation, takes the text line as the segmentation target, and constructs a text box based on the segmentation result, and then obtains the text box of the line. In the implementation, the feature extraction layer based on ResNet34_vd is used as the backbone network, followed by the Feature Map Pyramid (FPN) layer to ensure the diversity and robustness of the captured features, and a 3-layer convolutional network is used as the feature prediction component of the model. (2) Text recognition: This module realizes the function of recognizing the character graphics existing in the target word box as corresponding text strings. Using a convolutional recurrent neural network (Convolutional Recurrent Neural Network, CRNN) network as the backbone network of this module, a lightweight neural network architecture MobileNetV3 network suitable for mobile devices is used for preliminary feature extraction, and then several layers of bidirectional length The time-memory BiLSTM network outputs the label probability distribution output at each character position, and optimizes the output distribution by connecting the time series classification CTC algorithm; this model naturally integrates the respective advantages of convolutional neural networks and cyclic neural networks, and fully analyzes The spatial graphic features and contextual semantic connections of the image to be recognized are obtained, and the problem of automatic label alignment between the line text image and the string sequence is solved. This model design naturally combines the respective advantages of convolutional neural networks and cyclic neural networks, fully analyzes the spatial graphic features and contextual semantic connections of images to be recognized, and solves the problem of automatic labeling between line text images and string sequences Alignment issues.
上一步OCR模块识别得到的是若干字符串列表。接下来需要通过一些文本处理模块以及文档信息抽取业务模型,将字符串列表转换为方便用户阅读的自然段落,并从中自动抽取出关键字段,形成结构化的文本信息解析结果。(1)规则抽取:通过对具体档案文件的理解,系统要事先设置好若干关键字段,如“印发单位”“收文单位”“文号”“落款”等;(2)字符推算:另外,档案文档中也有若干字段可以通过分析版面特征来进行判断,如“红头”“正标题”“正文”等;(3)整合输出:最后将上述系统流程给出的结果进行汇总,并将相同字段的结果进行整合。What the OCR module identified in the previous step is a list of several character strings. Next, some text processing modules and document information extraction business models need to be used to convert the list of strings into natural paragraphs that are easy for users to read, and automatically extract key fields from them to form a structured text information analysis result. (1) Rule extraction: Through the understanding of specific archives, the system must set up several key fields in advance, such as "issuer", "receiver", "document number", "signature", etc.; (2) Character calculation: In addition, There are also several fields in the archive document that can be judged by analyzing the layout characteristics, such as "red head", "headline", "text", etc.; (3) Integrated output: finally, summarize the results given by the above system process, and combine the same fields results are integrated.
本档案馆系统对文档数据的处理功能界面如图7所示。点击“选择文件”上传待处理的文档数据,目前系统支持对PDF、JPEG、PNG以及TIF格式文件的处理。等待文档上传完成之后,页面下方即出现文档正文内容,用户可在此处对文档进行实时浏览。本系统的文档浏览功能基于PDF.js库开发,与网页原生iFrame标签相比,PDF.js更加稳定、美观,并且可以实现页面缩放、实时渲染等额外功能。点击“开始分析”调用后台服务对文档进行实时解析。解析结果显示在页面的右侧,以表格的形式分别显示出从文档中提取出的关键字段信息。如图7所示,在正文显示区域,系统根据后台解析得到的坐标结果,基于PDF.js的渲染功能对文档的不同段落区域标注了字框,使得用户可以清楚直观地区分文档中的不同内容,方便快速定位到想要浏览的目标区域。The functional interface of the archives system for processing document data is shown in Figure 7. Click "Select File" to upload the document data to be processed. Currently, the system supports the processing of files in PDF, JPEG, PNG and TIF formats. After the upload of the document is completed, the text of the document will appear at the bottom of the page, where users can browse the document in real time. The document browsing function of this system is developed based on the PDF.js library. Compared with the native iFrame tag of the web page, PDF.js is more stable and beautiful, and can realize additional functions such as page zooming and real-time rendering. Click "Start Analysis" to call the background service to analyze the document in real time. The parsing result is displayed on the right side of the page, and the key field information extracted from the document is displayed in the form of a table. As shown in Figure 7, in the text display area, the system marks the different paragraphs of the document with boxes based on the coordinate results obtained by the background analysis based on the rendering function of PDF.js, so that users can clearly and intuitively distinguish different contents in the document , so that you can quickly locate the target area you want to browse.
档案馆系统的视频解析界面如图8所示。点击“上传”按钮上传视频文件。显示文件上传完成后,点击“开始分析”对该文件进行解析。如图8所示,本模块已实现对视频中多项关键数据的结构化提取功能。系统自动截取了与视频内容最相关的画面作为封面,一般会选取存在相关领导人或出现新闻标题字幕的画面进行截取,便于用户快速了解本视频文件的主要内容。而在截图下方,界面也展示了视频的关键信息,如热点话题分类、内容摘要以及识别到的领导人姓名等。若视频中存在多条新闻报道,系统也会对其进行自动划分,方便用户分别浏览不同的报道。原始视频数据经过上述3个重点模块处理后,将提取到的关键信息保存为JSON格式,包含了领导人信息、热点话题分类、视频内容摘要等字段。为了充分利用解析结果,智慧档案馆系统会基于这些JSON数据进一步构建知识图谱,将原本孤立的数据整合为彼此关联的信息图再呈现给用户,方便用户从整体的角度了解已有数据。The video analysis interface of the archives system is shown in Figure 8. Click the "Upload" button to upload the video file. After the file upload is displayed, click "Start Analysis" to analyze the file. As shown in Figure 8, this module has realized the structured extraction function of multiple key data in the video. The system automatically intercepts the screen most relevant to the video content as the cover, and generally selects screens with relevant leaders or news titles and subtitles to capture, so that users can quickly understand the main content of the video file. Below the screenshot, the interface also displays the key information of the video, such as classification of hot topics, content summary, and the names of recognized leaders. If there are multiple news reports in the video, the system will also automatically divide them, so that users can browse different reports separately. After the original video data is processed by the above three key modules, the extracted key information is saved in JSON format, including fields such as leader information, hot topic classification, and video content summary. In order to make full use of the analysis results, the smart archive system will further build a knowledge map based on these JSON data, integrate the original isolated data into an interrelated information map and present it to users, so that users can understand the existing data from a holistic perspective.
知识图谱的构建过程具体可以细分为实体识别、关系抽取、实体对齐和知识推理共4个子模块。The construction process of the knowledge map can be subdivided into four sub-modules: entity recognition, relationship extraction, entity alignment and knowledge reasoning.
(1)实体识别层:实体是知识图谱的基础,实体识别是构建知识图谱的基础任务,好的实体识别结果能显著提升知识图谱构建结果的质量。本模块实现了基于深度学习网络的实体识别模型,可以实现仅使用少量的人工标注数据构建训练集,并使用BERT模型提取句向量后训练以双向长短时记忆BiLSTM+条件随机场CRF为主干网络的实体识别模型;。(1) Entity recognition layer: Entities are the basis of knowledge graphs, and entity recognition is the basic task of building knowledge graphs. Good entity recognition results can significantly improve the quality of knowledge graph construction results. This module implements an entity recognition model based on a deep learning network, which can use only a small amount of manually labeled data to construct a training set, and use the BERT model to extract sentence vectors and then train entities with bidirectional long-short-term memory BiLSTM+ conditional random field CRF as the backbone network recognition model; .
(2)关系抽取层:根据已经识别出的实体结果以及全文数据,系统会进一步提取出实体之间的关系。将全文数据进行分词处理后送入连续词袋模型CBoW模型提取出词向量,接着送入BiLSTM模型提取上下文关联语义特征编码,模型引入注意力机制,根据样本数据自动调整样本节点之间相互的注意力权重参数,形成实体节点之间的关系信息。(2) Relationship extraction layer: According to the identified entity results and full-text data, the system will further extract the relationship between entities. Segment the full-text data and send it to the continuous bag-of-words model CBoW model to extract word vectors, and then send it to the BiLSTM model to extract context-related semantic feature codes. The model introduces an attention mechanism to automatically adjust the mutual attention between sample nodes according to the sample data. The force weight parameter forms the relationship information between entity nodes.
(3)实体对齐层:系统将全文数据、摘要以及主题、关键字、领导人、时间、来源、类型等属性数据进行充分利用,送入基于变换器的双向编码器表示BERT模型转化为向量表示。在档案样本数据之间分别计算实体全文余弦相似度以及实体摘要余弦相似度,并通过综合两种相似度以判断档案样本数据之间的语义相似度。接着,将多个相似度指标输入到由一种原先用于图像识别的神经网络结构SENet(Squeeze-and-ExcitationNetworks)层搭建的多特征融合模型中输出实体对齐的结果。全部档案数据经过实体对齐模型的预测后,即可形成对齐实体的集合。最后将关系抽取层给出的实体及其关系使用对齐实体集合完成对齐。(3) Entity alignment layer: the system makes full use of full-text data, abstracts, and attribute data such as topics, keywords, leaders, time, sources, types, etc., and sends them to a transformer-based bidirectional encoder to represent BERT models and convert them into vector representations . The entity full-text cosine similarity and the entity abstract cosine similarity are calculated respectively between the archive sample data, and the semantic similarity between the archive sample data is judged by combining the two similarities. Then, multiple similarity indicators are input into a multi-feature fusion model built by a neural network structure SENet (Squeeze-and-Excitation Networks) layer originally used for image recognition to output the result of entity alignment. After all the archive data are predicted by the entity alignment model, a set of aligned entities can be formed. Finally, the entities and their relationships given by the relationship extraction layer are aligned using the aligned entity set.
(4)知识推理层:经过前面实体识别层、关系抽取层和实体对齐层的处理,数据已经形成了<头实体-关系-尾实体>结构的三元组。此时,知识图谱构建系统还需进行知识推理,以丰富、充实实体之间的关系,解决实体之间依靠原始数据构建出的关系较为稀疏的问题。(4) Knowledge reasoning layer: After the processing of the previous entity recognition layer, relationship extraction layer and entity alignment layer, the data has formed a triplet of <head entity-relationship-tail entity> structure. At this time, the knowledge graph construction system also needs to perform knowledge reasoning to enrich and enrich the relationship between entities, and solve the problem that the relationship between entities based on the original data is relatively sparse.
基于已解析的文档、视频、图像数据,档案馆系统构建了知识图谱,并绘制成信息图呈现在用户界面上。知识图谱模块的处理流程如图5所示。其中,对于系统构建出的单领导人、多领导人以及热点话题3种档案知识图谱,系统前端对它们做可视化处理,分别转化为“领导人事件关系轴”“领导人伴随事件关系轴”“事件图谱”共3种信息图,用户界面样式如图10,其中前两者为时间轴形式,展现目标领导人的基本信息和近期动态汇编,或领导人之间共同出席会议活动的情况。而后者为某一特定热点话题下领导人动态、会议活动、政策宣传等事件的汇编。这些信息图都是可互动的,用户可以点击浏览事件详情,也可以在事件之间进行跳转,方便用户对相关事项做更加详尽的了解。Based on the parsed document, video, and image data, the archives system constructs a knowledge map, and draws it into an information map and presents it on the user interface. The processing flow of the knowledge map module is shown in Figure 5. Among them, for the three types of archival knowledge graphs constructed by the system: single leader, multi-leader and hot topic, the front end of the system visualizes them and transforms them into "leader event relationship axis" and "leader accompanying event relationship axis" respectively. There are 3 kinds of information graphs in "Event Graph". The user interface style is shown in Figure 10. Among them, the first two are in the form of time axis, showing the basic information of the target leader and the recent dynamic compilation, or the joint attendance of the leaders in the meeting activities. The latter is a compilation of leaders' dynamics, conference activities, policy promotion and other events under a specific hot topic. These infographics are all interactive, users can click to browse event details, and can also jump between events, which is convenient for users to have a more detailed understanding of related matters.
(1)领导人事件关系轴:主要呈现单个领导人的相关信息。输入领导人姓名作为关键词,来检索领导人的基本信息,包括他在近期的一系列出席会议和各类活动的资料。这些信息都是以时间轴的顺序进行展示,可以很方便快捷地让用户浏览他想要了解的信息。这里的图谱按时间线展示了S市某领导人的近期主要活动汇编,同时呈现了各个活动发生的时间、地点、以及关联人物等重要信息。(1) Leader event relationship axis: It mainly presents the relevant information of a single leader. Enter the leader's name as a keyword to retrieve the basic information of the leader, including his recent attendance at a series of meetings and various activities. The information is displayed in the order of the time axis, which allows the user to browse the information he wants to know very conveniently and quickly. The map here shows a compilation of recent major activities of a leader of City S according to the timeline, and also presents important information such as the time, place, and related people of each activity.
(2)领导人伴随事件关系轴:主要呈现多位领导人之间共同出席的会议和活动的资料汇编。这些信息同样以时间轴的顺序展示。(2) Leader-accompanied-event relationship axis: It mainly presents the compilation of materials on meetings and activities attended by multiple leaders. The information is also displayed in the order of the time axis.
(3)事件图谱:系统可以基于热点话题标签来检索热点话题下的政策文件或事件报道,在这里不仅仅罗列出了本事件的一系列详情信息,还可以在事件详情的下方显示关联事件图谱。(3) Event graph: The system can retrieve policy documents or event reports under hot topics based on hot topic tags. Not only a series of detailed information about this event is listed here, but related events can also be displayed below the event details Atlas.
Claims (8)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211709138.XA CN115994230A (en) | 2022-12-29 | 2022-12-29 | A smart file construction method integrating artificial intelligence and knowledge graph technology |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211709138.XA CN115994230A (en) | 2022-12-29 | 2022-12-29 | A smart file construction method integrating artificial intelligence and knowledge graph technology |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115994230A true CN115994230A (en) | 2023-04-21 |
Family
ID=85994772
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211709138.XA Pending CN115994230A (en) | 2022-12-29 | 2022-12-29 | A smart file construction method integrating artificial intelligence and knowledge graph technology |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115994230A (en) |
Cited By (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116090560A (en) * | 2023-04-06 | 2023-05-09 | 北京大学深圳研究生院 | Knowledge graph establishment method, device and system based on teaching materials |
| CN116665523A (en) * | 2023-05-15 | 2023-08-29 | 广州大学 | Braille reading device |
| CN116719783A (en) * | 2023-08-09 | 2023-09-08 | 江苏中威科技软件系统有限公司 | Method for extracting metadata specification of office-entering OFD archive file and filling archive copybook |
| CN116738009A (en) * | 2023-08-09 | 2023-09-12 | 北京谷器数据科技有限公司 | A method for archiving and backtracking data |
| CN116935396A (en) * | 2023-06-16 | 2023-10-24 | 北京化工大学 | OCR college entrance guide intelligent acquisition method based on CRNN algorithm |
| CN116955639A (en) * | 2023-04-24 | 2023-10-27 | 浙商期货有限公司 | Futures industry chain knowledge graph construction method, device and computer equipment |
| CN116993376A (en) * | 2023-08-14 | 2023-11-03 | 深圳数拓科技有限公司 | An intelligent data interaction method and system for unmanned restaurants |
| CN117094394A (en) * | 2023-10-16 | 2023-11-21 | 之江实验室 | Method and system for constructing astronomical multimodal knowledge graph based on paper PDF |
| CN117235279A (en) * | 2023-09-04 | 2023-12-15 | 上海歆广数据科技有限公司 | Critical task development framework integrating large voice model and knowledge graph |
| CN117251613A (en) * | 2023-09-18 | 2023-12-19 | 深圳市畅飞扬信息系统有限公司 | An artificial intelligence-based family file management method and system |
| CN118395124A (en) * | 2024-05-31 | 2024-07-26 | 广东烟草梅州市有限公司 | Collaborative analysis method of archival data based on deep learning |
| CN118551837A (en) * | 2024-07-29 | 2024-08-27 | 广州机智云物联网科技有限公司 | Knowledge intelligent generation system based on multi-dimensional data of Internet of things |
| CN118551800A (en) * | 2024-05-21 | 2024-08-27 | 北京普巴大数据有限公司 | Artificial Intelligence Knowledge Management System |
| CN118587725A (en) * | 2024-08-07 | 2024-09-03 | 广东亚齐信息技术股份有限公司 | A digital product intelligent quality inspection and acceptance system and method |
| CN118798349A (en) * | 2024-09-13 | 2024-10-18 | 江西农业大学 | A method and device for constructing a red soil acidification knowledge graph |
| CN119131803A (en) * | 2024-09-12 | 2024-12-13 | 北京建筑大学 | A dual-modal image-text fusion target recognition method and system |
| CN119336994A (en) * | 2024-10-22 | 2025-01-21 | 深圳市英卡科技有限公司 | A tablet computer learning and training system and method based on artificial intelligence |
| CN119336854A (en) * | 2024-12-18 | 2025-01-21 | 成都索贝数码科技股份有限公司 | An intelligent arrangement method for audio-visual archives based on event knowledge graph |
| CN119380456A (en) * | 2024-12-26 | 2025-01-28 | 山西档务通档案管理有限公司 | A security early warning system for intelligent archives management room based on the Internet of Things |
| CN119545610A (en) * | 2024-11-04 | 2025-02-28 | 黄山学院 | An intelligent lighting control method and system for a smart nursing home |
| CN119669872A (en) * | 2025-02-21 | 2025-03-21 | 湖南理工职业技术学院 | An information-based accounting archive management method and system |
| CN119885274A (en) * | 2024-12-31 | 2025-04-25 | 河南大有文化发展有限公司 | Intelligent archives integrated safety management system |
| CN120067325A (en) * | 2025-04-28 | 2025-05-30 | 福建亿榕信息技术有限公司 | File management method and system based on multi-mode data analysis technology |
| CN120216669A (en) * | 2025-03-28 | 2025-06-27 | 武汉大学 | A method and system for intelligent retrieval of archive data based on multimodal large model |
| CN120687623A (en) * | 2025-06-24 | 2025-09-23 | 泰州市人民医院 | A digital archive call management method and system based on artificial intelligence |
| CN120705189A (en) * | 2025-08-28 | 2025-09-26 | 浙江万维空间信息技术有限公司 | A natural resource archive retrieval and utilization method combining large models and knowledge graph technology |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111860389A (en) * | 2020-07-27 | 2020-10-30 | 北京易真学思教育科技有限公司 | Data processing method, electronic device and computer readable medium |
| CN112004111A (en) * | 2020-09-01 | 2020-11-27 | 南京烽火星空通信发展有限公司 | News video information extraction method for global deep learning |
| CN114004962A (en) * | 2021-11-02 | 2022-02-01 | 国网江苏省电力有限公司泰州供电分公司 | OCR (optical character recognition) method for invoice of electric power business hall |
-
2022
- 2022-12-29 CN CN202211709138.XA patent/CN115994230A/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111860389A (en) * | 2020-07-27 | 2020-10-30 | 北京易真学思教育科技有限公司 | Data processing method, electronic device and computer readable medium |
| CN112004111A (en) * | 2020-09-01 | 2020-11-27 | 南京烽火星空通信发展有限公司 | News video information extraction method for global deep learning |
| CN114004962A (en) * | 2021-11-02 | 2022-02-01 | 国网江苏省电力有限公司泰州供电分公司 | OCR (optical character recognition) method for invoice of electric power business hall |
Non-Patent Citations (1)
| Title |
|---|
| 易黎等: ""基于深度学习的档案知识图谱构建研究"", 《中国档案》, 29 November 2022 (2022-11-29), pages 33 - 35 * |
Cited By (38)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116090560A (en) * | 2023-04-06 | 2023-05-09 | 北京大学深圳研究生院 | Knowledge graph establishment method, device and system based on teaching materials |
| CN116955639A (en) * | 2023-04-24 | 2023-10-27 | 浙商期货有限公司 | Futures industry chain knowledge graph construction method, device and computer equipment |
| CN116665523A (en) * | 2023-05-15 | 2023-08-29 | 广州大学 | Braille reading device |
| CN116935396A (en) * | 2023-06-16 | 2023-10-24 | 北京化工大学 | OCR college entrance guide intelligent acquisition method based on CRNN algorithm |
| CN116935396B (en) * | 2023-06-16 | 2024-02-23 | 北京化工大学 | OCR college entrance guide intelligent acquisition method based on CRNN algorithm |
| CN116738009A (en) * | 2023-08-09 | 2023-09-12 | 北京谷器数据科技有限公司 | A method for archiving and backtracking data |
| CN116719783B (en) * | 2023-08-09 | 2023-10-20 | 江苏中威科技软件系统有限公司 | Method for extracting metadata specification of office-entering OFD archive file and filling archive copybook |
| CN116738009B (en) * | 2023-08-09 | 2023-11-21 | 北京谷器数据科技有限公司 | Method for archiving and backtracking data |
| CN116719783A (en) * | 2023-08-09 | 2023-09-08 | 江苏中威科技软件系统有限公司 | Method for extracting metadata specification of office-entering OFD archive file and filling archive copybook |
| CN116993376A (en) * | 2023-08-14 | 2023-11-03 | 深圳数拓科技有限公司 | An intelligent data interaction method and system for unmanned restaurants |
| CN116993376B (en) * | 2023-08-14 | 2024-03-12 | 深圳数拓科技有限公司 | An intelligent data interaction method and system for unmanned restaurants |
| CN117235279A (en) * | 2023-09-04 | 2023-12-15 | 上海歆广数据科技有限公司 | Critical task development framework integrating large voice model and knowledge graph |
| CN117235279B (en) * | 2023-09-04 | 2024-03-19 | 上海峻思寰宇数据科技有限公司 | Critical task development system integrating large language model and knowledge graph |
| CN117251613A (en) * | 2023-09-18 | 2023-12-19 | 深圳市畅飞扬信息系统有限公司 | An artificial intelligence-based family file management method and system |
| CN117094394A (en) * | 2023-10-16 | 2023-11-21 | 之江实验室 | Method and system for constructing astronomical multimodal knowledge graph based on paper PDF |
| CN117094394B (en) * | 2023-10-16 | 2024-01-30 | 之江实验室 | Astronomical multi-mode knowledge graph construction method and system based on paper PDF |
| CN118551800A (en) * | 2024-05-21 | 2024-08-27 | 北京普巴大数据有限公司 | Artificial Intelligence Knowledge Management System |
| CN118551800B (en) * | 2024-05-21 | 2024-11-29 | 北京普巴大数据有限公司 | Artificial Intelligence Knowledge Management System |
| CN118395124A (en) * | 2024-05-31 | 2024-07-26 | 广东烟草梅州市有限公司 | Collaborative analysis method of archival data based on deep learning |
| CN118551837A (en) * | 2024-07-29 | 2024-08-27 | 广州机智云物联网科技有限公司 | Knowledge intelligent generation system based on multi-dimensional data of Internet of things |
| CN118587725A (en) * | 2024-08-07 | 2024-09-03 | 广东亚齐信息技术股份有限公司 | A digital product intelligent quality inspection and acceptance system and method |
| CN118587725B (en) * | 2024-08-07 | 2024-10-01 | 广东亚齐信息技术股份有限公司 | Digital achievement intelligent quality inspection and acceptance system and method |
| CN119131803B (en) * | 2024-09-12 | 2025-08-01 | 北京建筑大学 | Dual-mode image-text fusion target identification method and system |
| CN119131803A (en) * | 2024-09-12 | 2024-12-13 | 北京建筑大学 | A dual-modal image-text fusion target recognition method and system |
| CN118798349B (en) * | 2024-09-13 | 2025-01-28 | 江西农业大学 | A method and device for constructing a red soil acidification knowledge graph |
| CN118798349A (en) * | 2024-09-13 | 2024-10-18 | 江西农业大学 | A method and device for constructing a red soil acidification knowledge graph |
| CN119336994A (en) * | 2024-10-22 | 2025-01-21 | 深圳市英卡科技有限公司 | A tablet computer learning and training system and method based on artificial intelligence |
| CN119545610A (en) * | 2024-11-04 | 2025-02-28 | 黄山学院 | An intelligent lighting control method and system for a smart nursing home |
| CN119336854A (en) * | 2024-12-18 | 2025-01-21 | 成都索贝数码科技股份有限公司 | An intelligent arrangement method for audio-visual archives based on event knowledge graph |
| CN119380456A (en) * | 2024-12-26 | 2025-01-28 | 山西档务通档案管理有限公司 | A security early warning system for intelligent archives management room based on the Internet of Things |
| CN119885274A (en) * | 2024-12-31 | 2025-04-25 | 河南大有文化发展有限公司 | Intelligent archives integrated safety management system |
| CN119669872A (en) * | 2025-02-21 | 2025-03-21 | 湖南理工职业技术学院 | An information-based accounting archive management method and system |
| CN119669872B (en) * | 2025-02-21 | 2025-05-02 | 湖南理工职业技术学院 | An information-based accounting archive management method and system |
| CN120216669A (en) * | 2025-03-28 | 2025-06-27 | 武汉大学 | A method and system for intelligent retrieval of archive data based on multimodal large model |
| CN120067325A (en) * | 2025-04-28 | 2025-05-30 | 福建亿榕信息技术有限公司 | File management method and system based on multi-mode data analysis technology |
| CN120067325B (en) * | 2025-04-28 | 2025-09-30 | 福建亿榕信息技术有限公司 | File management method and system based on multi-mode data analysis technology |
| CN120687623A (en) * | 2025-06-24 | 2025-09-23 | 泰州市人民医院 | A digital archive call management method and system based on artificial intelligence |
| CN120705189A (en) * | 2025-08-28 | 2025-09-26 | 浙江万维空间信息技术有限公司 | A natural resource archive retrieval and utilization method combining large models and knowledge graph technology |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN115994230A (en) | A smart file construction method integrating artificial intelligence and knowledge graph technology | |
| CN111476067B (en) | Character recognition method and device for image, electronic equipment and readable storage medium | |
| CN110363194B (en) | NLP-based intelligent marking method, device, equipment and storage medium | |
| CN113221735B (en) | Method, device and related equipment for restoring paragraph structure of scanned documents based on multimodality | |
| CN113642536B (en) | Data processing method, computer device and readable storage medium | |
| CN114445744A (en) | Education video automatic positioning method, device and storage medium | |
| CN118013372A (en) | Method, system and device for asset identification based on multimodal data heterogeneous Transformer | |
| CN112925905B (en) | Method, device, electronic equipment and storage medium for extracting video subtitles | |
| CN113807218B (en) | Layout analysis method, device, computer equipment and storage medium | |
| CN113780276A (en) | A text detection and recognition method and system combined with text classification | |
| CN118968380B (en) | A video review method based on multimodal large model | |
| CN118467778B (en) | Video information summary generation method, device, electronic device and storage medium | |
| CN114821620B (en) | Text content extraction and recognition method based on vertical merging of line text boxes | |
| CN114022923A (en) | Intelligent collecting and editing system | |
| CN113762036B (en) | Video processing method, apparatus, electronic device, and computer-readable storage medium | |
| CN114330247A (en) | Automatic insurance clause analysis method based on image recognition | |
| CN117391201A (en) | Question and answer methods, devices and electronic equipment | |
| CN117793483A (en) | Video tag extraction methods, systems, equipment and media | |
| CN117009595A (en) | Text paragraph acquisition method and device, storage medium, and program product | |
| CN117033308B (en) | Multi-mode retrieval method and device based on specific range | |
| Srividhya et al. | Deep learning based Telugu video text detection using video coding over digital transmission | |
| CN113486171B (en) | Image processing method and device and electronic equipment | |
| Chen et al. | Scene text recognition based on deep learning: A brief survey | |
| Mosannafat et al. | Farsi text detection and localization in videos and images | |
| Jing et al. | Optical character recognition of medical records based on deep learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |