CN115910066A - Intelligent dispatching command and operation system for regional power distribution network - Google Patents
Intelligent dispatching command and operation system for regional power distribution network Download PDFInfo
- Publication number
- CN115910066A CN115910066A CN202211118157.5A CN202211118157A CN115910066A CN 115910066 A CN115910066 A CN 115910066A CN 202211118157 A CN202211118157 A CN 202211118157A CN 115910066 A CN115910066 A CN 115910066A
- Authority
- CN
- China
- Prior art keywords
- voice
- recognition
- intelligent
- unit
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images

Classifications
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y04—INFORMATION OR COMMUNICATION TECHNOLOGIES HAVING AN IMPACT ON OTHER TECHNOLOGY AREAS
- Y04S—SYSTEMS INTEGRATING TECHNOLOGIES RELATED TO POWER NETWORK OPERATION, COMMUNICATION OR INFORMATION TECHNOLOGIES FOR IMPROVING THE ELECTRICAL POWER GENERATION, TRANSMISSION, DISTRIBUTION, MANAGEMENT OR USAGE, i.e. SMART GRIDS
- Y04S10/00—Systems supporting electrical power generation, transmission or distribution
- Y04S10/50—Systems or methods supporting the power network operation or management, involving a certain degree of interaction with the load-side end user applications
Landscapes
- Machine Translation (AREA)
Abstract
Description
技术领域technical field
本发明属于区域配电网生产运营技术领域,具体涉及一种用于区域配电网的智能调度指挥与运营系统。The invention belongs to the technical field of production and operation of regional distribution networks, and in particular relates to an intelligent dispatching command and operation system for regional distribution networks.
背景技术Background technique
随着配电网规模的进一步扩大及网架日趋复杂,对配电网的运行管理水平要求越来越高。配电网能否正常运行直接影响企业的用户水平和供电质量,是评价公司履责能力的主要因素。With the further expansion of the distribution network scale and the increasingly complex grid structure, the requirements for the operation and management level of the distribution network are getting higher and higher. The normal operation of the distribution network directly affects the user level and power supply quality of the enterprise, and is the main factor in evaluating the company's ability to fulfill its responsibilities.
配网生产运营中心作为配网业务枢纽,第一,涉及的信息化系统越来越多。信息化系统之间孤岛现象严重。第二,配网生产运营点多面广,生产运营需要同时与多处现场进行重复的流程性对接,造成配网生产运营业务“枢纽拥堵”效应。第三,生产运营系统海量数据信息有待进一步挖掘。第四,现有生产运营辅助系统采用传统专家系统构建,知识获取和维护采用人工编辑,扩展性差,知识推理自动化、智能化程度不够。第五,生产运营系统智能交互方式单一,效率低下,缺少语音、触摸等交互方式。因此迫切要求配网生产运营业务效率提升,流程再造。As a distribution network business hub, the distribution network production and operation center, first, involves more and more information systems. The island phenomenon among information systems is serious. Second, the production and operation points of the distribution network are many and wide, and the production and operation need to carry out repeated process docking with multiple sites at the same time, resulting in the "hub congestion" effect of the distribution network production and operation business. Third, the massive data information of the production and operation system needs to be further excavated. Fourth, the existing production and operation auxiliary system is constructed using traditional expert systems, and manual editing is used for knowledge acquisition and maintenance. The scalability is poor, and the degree of automation and intelligence of knowledge reasoning is not enough. Fifth, the intelligent interaction mode of the production operation system is single, inefficient, and lacks voice, touch and other interactive modes. Therefore, it is urgent to improve the efficiency of distribution network production and operation business and process reengineering.
发明内容Contents of the invention
本发明的主要目的在于提供用于区域配电网的智能调度指挥与运营系统,其将人工智能与生产运营系统进行融合,实现生产运营业务的智能感知、分析、控制与交互,真正意义上实现智慧生产运营的转型发展,智能分析即是依赖深度学习技术,智能研判电网故障,辅助生产运营员开展智能决策,实现复杂故障的快速精准研判;智能控制即是根据分析研判结果智能控制电网运行方式与电网设备状态,全面提升电网控制能力;智能交互即是通过综合展示、智能信息推送、智能语音交互等技术手段实现与生产运营员、抢修作业人员、运维人员与用户的信息交互。The main purpose of the present invention is to provide an intelligent dispatching command and operation system for the regional distribution network, which integrates artificial intelligence with the production and operation system to realize the intelligent perception, analysis, control and interaction of the production and operation business, and truly realize the For the transformation and development of smart production and operation, intelligent analysis relies on deep learning technology to intelligently judge power grid faults, assist production operators to carry out intelligent decision-making, and realize fast and accurate judgment of complex faults; intelligent control is to intelligently control the operation mode of the power grid based on the analysis and judgment results and the status of power grid equipment, and comprehensively improve the control ability of the power grid; intelligent interaction is to realize information interaction with production operators, emergency repair operators, operation and maintenance personnel and users through comprehensive display, intelligent information push, intelligent voice interaction and other technical means.
为达到以上目的,本发明提供一种用于区域配电网的智能调度指挥与运营系统,用于保障配电网的生产运营系统的安全运行,包括智能语音导航模块、计划调度指令票自动生成模块、信息监控诊断模块和智能交接班识别模块,其中:In order to achieve the above objectives, the present invention provides an intelligent dispatching command and operation system for regional distribution network, which is used to ensure the safe operation of the production and operation system of the distribution network, including intelligent voice navigation module, automatic generation of planning dispatching instruction tickets module, information monitoring and diagnosis module and intelligent shift identification module, among which:
(基于混合智能与人机耦合技术的)智能语音导航模块包括语音识别引擎单元和语义解析引擎单元,语音识别引擎单元用于将人的语音直接转换成相应的文本,以便处理模块进行理解和产生相应的操作,从而实现人与机器之间的自然语音交互,并且基于深度全序列卷积神经网络框架,将音频流数据实时转换成文字流数据的识别结果;语义解析引擎单元用于将语音识别引擎单元获得的识别结果进行语义解析(使人机交互过程更为顺畅);(Based on hybrid intelligence and human-machine coupling technology) intelligent voice navigation module includes a voice recognition engine unit and a semantic analysis engine unit, the voice recognition engine unit is used to directly convert human voice into corresponding text, so that the processing module can understand and generate Corresponding operations, so as to realize the natural voice interaction between human and machine, and based on the deep full sequence convolutional neural network framework, the audio stream data is converted into the recognition result of the text stream data in real time; the semantic analysis engine unit is used for speech recognition Semantic analysis of the recognition results obtained by the engine unit (to make the human-computer interaction process smoother);
计划调度指令票自动生成模块基于信息抽取自动生成计划调度指令票,计划调度指令票自动生成模块包括学习阶段单元和抽取阶段单元;The planning scheduling instruction ticket automatic generation module automatically generates the planning scheduling instruction ticket based on information extraction, and the planning scheduling instruction ticket automatic generation module includes the learning phase unit and the extraction phase unit;
信息监控诊断模块基于文本识别单元和语音合成单元对生产运营系统的信息进行智能监控、诊断和预警;The information monitoring and diagnosis module performs intelligent monitoring, diagnosis and early warning of the information of the production and operation system based on the text recognition unit and the speech synthesis unit;
智能交接班识别模块用于将用户的声纹进行识别并且融合到生产运营系统,通过声纹注册和分析实现基于声纹的身份认证,进而通过声纹识别交接班的用户。The intelligent shift recognition module is used to identify the user's voiceprint and integrate it into the production and operation system, realize voiceprint-based identity authentication through voiceprint registration and analysis, and then identify the shift-over user through voiceprint.
作为上述技术方案的进一步优选的技术方案,语音识别引擎单元包括中文标点智能预测单元、文件格式智能转化单元、前端语音处理单元和后端识别处理单元,其中;As a further preferred technical solution of the above technical solution, the speech recognition engine unit includes a Chinese punctuation intelligent prediction unit, a file format intelligent conversion unit, a front-end speech processing unit and a back-end recognition processing unit, wherein;
中文标点智能预测单元用于通过语言模型,对语音识别引擎单元识别获得的识别结果进行对话语音的智能预测,从而提供智能断句和标点符号的预测;The Chinese punctuation intelligent prediction unit is used to perform intelligent prediction of dialogue speech on the recognition result obtained by the recognition of the speech recognition engine unit through the language model, thereby providing prediction of intelligent sentence segmentation and punctuation marks;
文件格式智能转化单元对识别结果中出现的包括数字、日期和时间的参数进行格式化并且生成规整的文本;The file format intelligent conversion unit formats the parameters including numbers, dates and times appearing in the recognition results and generates regular text;
前端语音处理单元通过信号处理的方法对输入的语音进行检测、降噪预处理,以便得到最匹配语音识别引擎单元处理的语音,前端语音处理单元包括端点检测子单元和噪音消除子单元,端点检测子单元用于对输入的音频流形式的语音进行分析,确定用户说话的起始和终止的,当检测到用户开始说话,语音开始流向语音识别引擎单元,直到检测到用户说话结束;The front-end speech processing unit detects the input speech and pre-processes the noise reduction by means of signal processing, so as to obtain the speech that best matches the speech recognition engine unit. The front-end speech processing unit includes an endpoint detection subunit and a noise elimination subunit. The endpoint detection The subunit is used to analyze the voice in the form of the input audio stream to determine the start and end of the user's speech. When it is detected that the user starts to speak, the voice starts to flow to the speech recognition engine unit until the end of the user's speech is detected;
后端识别处理单元包括个性化语音识别子单元、置信度输出子单元、多结果识别子单元、说话人自适应子单元和语义上下文自修正子单元,个性化语音识别子单元基于用户的语音特征,搜集并上传使用率高的词语(热词),从业务角度建立个性化的词条语言模型,以调整识别参数、修改上传热词的权重和持续优化识别;置信度输出子单元用于在在返回识别结果时携带该识别结果的置信度,从而通过置信度结果进行分析和后续处理;多结果识别子单元在识别过程中,通过置信度输出子单元的结果向应用程序返回满足条件的多个识别结果,而不是唯一的结果,提供可能的识别结果列表,并按置信度结果从高到低进行排列;说话人自适应子单元用于当用户与语音识别引擎单元进行多次会话过程中,在线提取通话的语音特征,自动调整识别参数,使识别效果得到持续优化;语义上下文自修正子单元用于结合上下文动态修正,根据语音识别结果以及上下文对进行动态修正,使结果更符合当前语境;The back-end recognition processing unit includes a personalized speech recognition subunit, a confidence output subunit, a multi-result recognition subunit, a speaker adaptive subunit, and a semantic context self-correction subunit. The personalized speech recognition subunit is based on the user's voice characteristics , collect and upload words (hot words) with high usage rate, and establish a personalized entry language model from a business perspective to adjust recognition parameters, modify the weight of uploaded hot words and continuously optimize recognition; the confidence output subunit is used in The confidence of the recognition result is carried when the recognition result is returned, so that the analysis and subsequent processing can be carried out through the confidence result; during the recognition process, the multi-result recognition subunit returns the multi-results that meet the conditions to the application program through the result of the confidence output subunit A recognition result, not the only result, provides a list of possible recognition results, and arranges them from high to low according to the confidence results; the speaker adaptive subunit is used when the user conducts multiple conversations with the speech recognition engine unit , extracting the voice features of the call online, automatically adjusting the recognition parameters, so that the recognition effect can be continuously optimized; the semantic context self-correction subunit is used for dynamic correction in combination with the context, and dynamically corrects the result according to the speech recognition result and the context to make the result more in line with the current language territory;
语义解析引擎单元包括规则理解单元和模型理解单元,规则理解单元用于进行规则的匹配,模型理解单元包括语义模型训练子单元、语义特征提取子单元、语义相似度评估子单元,语义模型训练子单元用于对文本进行建模,将语义表达相似的文本映射到语义空间中相近的向量;语义特征提取子单元用于对文本信息进行特征提取,在完成语义模型训练子单元的训练后,通过提取模型特定的隐层向量获得;语义相似度评估子单元用于评估利用深度学习提取的用户句向量与库中离线提取的句向量相似度。The semantic analysis engine unit includes a rule understanding unit and a model understanding unit. The rule understanding unit is used for matching rules. The model understanding unit includes a semantic model training subunit, a semantic feature extraction subunit, a semantic similarity evaluation subunit, and a semantic model training subunit. The unit is used to model the text, and the text with similar semantic expression is mapped to the similar vector in the semantic space; the semantic feature extraction subunit is used to extract the feature of the text information, after completing the training of the semantic model training subunit, through The hidden layer vector specific to the extraction model is obtained; the semantic similarity evaluation subunit is used to evaluate the similarity between the user sentence vector extracted by deep learning and the sentence vector extracted offline in the library.
作为上述技术方案的进一步优选的技术方案,对于学习阶段单元:As a further preferred technical solution of the above technical solution, for the learning stage unit:
在学习阶段设有带标注的数据集,每一个样本包含文字单元序列和标注序列,如下所示:In the learning phase, there is a labeled data set, each sample contains a sequence of text units and a sequence of labels, as follows:
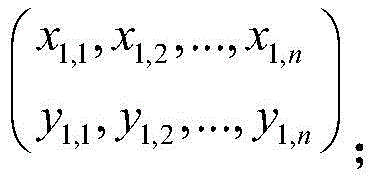
其中,表示第i个样本,前面x部分表示第i个样本的文字单元序列,后面y部分表示第i个样本的标注序列;Among them, represents the i-th sample, the front x part represents the text unit sequence of the i-th sample, and the following y part represents the label sequence of the i-th sample;
根据已有的标注构建一个学习模型,并且用一个条件概率分布进行表示;Construct a learning model based on existing annotations and represent it with a conditional probability distribution;
抽取阶段单元通过不同的模型作为分类器,从而获得不通过的文本信息的抽取方式,并且将各个分类器获得的抽取数据进行相互校正。The extraction stage unit uses different models as classifiers, so as to obtain the extraction methods of text information that do not pass, and correct the extracted data obtained by each classifier.
作为上述技术方案的进一步优选的技术方案,文本识别单元在文本识别中引入上下文序列信息,通过时序关系的神经网络进行识别。As a further preferred technical solution of the above technical solution, the text recognition unit introduces contextual sequence information into the text recognition, and performs recognition through a neural network of temporal relationships.
作为上述技术方案的进一步优选的技术方案,对于语音合成单元:As a further preferred technical solution of the above technical solution, for the speech synthesis unit:
全语种语义模型,基于多国语言融合的无监督文本预训练模型,提取文本语义信息,并且统一的预训练模型基础上构建各语种独立情况的文本预测信息分支;Full-language semantic model, based on the unsupervised text pre-training model of multi-language fusion, extracts text semantic information, and builds independent text prediction information branches for each language based on the unified pre-training model;
发音体系模型,通过半监督聚类方法自动构建统一单元的发音词典,将语言相关技术模块化的方法,在语言资源有限的条件下得以实现合成系统快速定制;Pronunciation system model, which automatically constructs a unified unit pronunciation dictionary through the semi-supervised clustering method, and modularizes language-related technologies, enabling rapid customization of the synthesis system under the condition of limited language resources;
基于听感量化编码的多语种混合模型,对语音中的不同属性信息进行听感量化编码,并且对语音的声学参数进行预测Based on the multilingual mixed model of auditory quantization coding, the auditory quantization coding is performed on different attribute information in speech, and the acoustic parameters of speech are predicted
基于生成对抗网络的高质量语音生成模型,通过对频谱包络的整体结构进行建模和对频谱包络的局部细节建模进行高音质多语种语音合成。Based on the high-quality speech generation model of generative confrontation network, high-quality multilingual speech synthesis is performed by modeling the overall structure of the spectral envelope and the local details of the spectral envelope.
作为上述技术方案的进一步优选的技术方案,智能交接班识别模块包括模型训练阶段单元和模型预测阶段单元:As a further preferred technical solution of the above technical solution, the intelligent shift recognition module includes a model training phase unit and a model prediction phase unit:
模型训练阶段单元用于使用音视频同步、且有语音文字标注的数据集,进行模型的训练;The model training phase unit is used to train the model using audio and video synchronization and data sets with voice and text annotations;
模型预测阶段单元对模型的应用,输入多人混叠的语音与特定目标人的唇动视频,识别出文字序列,同时分离出与唇动视频内容相符的说话人语音。The application of the model in the model prediction stage unit inputs the voices of multiple people and the lip movement video of a specific target person, recognizes the text sequence, and at the same time separates the speaker's voice that matches the content of the lip movement video.
为达到以上目的,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现所述用于区域配电网的智能调度指挥与运营系统。In order to achieve the above object, the present invention also provides an electronic device, including a memory, a processor, and a computer program stored on the memory and operable on the processor. Intelligent dispatching command and operation system of distribution network.
为达到以上目的,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现所述用于区域配电网的智能调度指挥与运营系统。In order to achieve the above object, the present invention also provides a non-transitory computer-readable storage medium, on which a computer program is stored, and when the computer program is executed by a processor, the intelligent dispatching command and operation for the regional distribution network is realized. system.
本发明的有益效果为:The beneficial effects of the present invention are:
第一,有利于进一步提高电网运行特性的认知水平。基于视频采集、OCR文本识别等技术,实现SOE信息的智能监控、诊断和预警,实现重合失败、重合成功、跳闸未重合、接地故障等四类状态的自诊断。并通过TTS播报技术,将重要信息在生产运营指挥中心播报出来,确保重要信息无遗漏。First, it is conducive to further improving the cognitive level of power grid operation characteristics. Based on technologies such as video collection and OCR text recognition, it realizes intelligent monitoring, diagnosis and early warning of SOE information, and realizes self-diagnosis of four types of states, including reclosing failure, reclosing success, trip non-reclosing, and ground fault. And through TTS broadcasting technology, important information is broadcasted in the production operation command center to ensure that no important information is missed.
第二,有利于进一步提高生产运营控制效率和任务完成效率。基于模拟点击、语义理解和文本解析等技术,实现停电计划调度指令票自动生成,提升调度票的生成效率和调度任务的完成效率,进一步减少了计划停电与故障停电时间,提升了电网的自愈水平。同时,基于语音实现生产运营系统的智能语音控制和导航,提升生产运营系统的控制效率。Second, it is conducive to further improving the efficiency of production operation control and task completion. Based on technologies such as simulated clicks, semantic understanding, and text parsing, the automatic generation of power outage planning dispatching order tickets is realized, which improves the efficiency of dispatching ticket generation and completion of dispatching tasks, further reduces the time of planned power outages and fault power outages, and improves the self-healing of the power grid level. At the same time, the intelligent voice control and navigation of the production operation system is realized based on voice, and the control efficiency of the production operation system is improved.
第三,有利于进一步提升生产运营系统的安全性水平。实现基于声纹识别技术的生产运营系统声纹鉴权功能,明确生产运营员的操作权限,确保交接班顺利,建设安全、高效等智能生产运营系统。Third, it is conducive to further improving the security level of the production and operation system. Realize the voiceprint authentication function of the production operation system based on voiceprint recognition technology, clarify the operation authority of production operators, ensure smooth shift handover, and build a safe and efficient intelligent production operation system.
附图说明Description of drawings
图1是本发明的用于区域配电网的智能调度指挥与运营系统的示意图。Fig. 1 is a schematic diagram of an intelligent dispatching command and operation system for a regional distribution network according to the present invention.
具体实施方式Detailed ways
以下描述用于揭露本发明以使本领域技术人员能够实现本发明。以下描述中的优选实施例只作为举例,本领域技术人员可以想到其他显而易见的变型。在以下描述中界定的本发明的基本原理可以应用于其他实施方案、变形方案、改进方案、等同方案以及没有背离本发明的精神和范围的其他技术方案。The following description serves to disclose the present invention to enable those skilled in the art to carry out the present invention. The preferred embodiments described below are only examples, and those skilled in the art can devise other obvious variations. The basic principles of the present invention defined in the following description can be applied to other embodiments, variations, improvements, equivalents and other technical solutions without departing from the spirit and scope of the present invention.
在本发明的优选实施例中,本领域技术人员应注意,本发明所涉及的配电网等可被视为现有技术。In the preferred embodiment of the present invention, those skilled in the art should note that the distribution network and the like involved in the present invention can be regarded as prior art.
优选实施例。preferred embodiment.
本发明公开了一种用于区域配电网的智能调度指挥与运营系统,用于保障配电网的生产运营系统的安全运行,包括智能语音导航模块、计划调度指令票自动生成模块、信息监控诊断模块和智能交接班识别模块,其中:The invention discloses an intelligent dispatching command and operation system for a regional distribution network, which is used to ensure the safe operation of the production and operation system of the distribution network. Diagnosis module and intelligent shift identification module, in which:
(基于混合智能与人机耦合技术的)智能语音导航模块包括语音识别引擎单元和语义解析引擎单元,语音识别引擎单元用于将人的语音直接转换成相应的文本,以便处理模块进行理解和产生相应的操作,从而实现人与机器之间的自然语音交互,并且基于深度全序列卷积神经网络框架,将音频流数据实时转换成文字流数据的识别结果;语义解析引擎单元用于将语音识别引擎单元获得的识别结果进行语义解析(使人机交互过程更为顺畅);(Based on hybrid intelligence and human-machine coupling technology) intelligent voice navigation module includes a voice recognition engine unit and a semantic analysis engine unit, the voice recognition engine unit is used to directly convert human voice into corresponding text, so that the processing module can understand and generate Corresponding operations, so as to realize the natural voice interaction between human and machine, and based on the deep full sequence convolutional neural network framework, the audio stream data is converted into the recognition result of the text stream data in real time; the semantic analysis engine unit is used for speech recognition Semantic analysis of the recognition results obtained by the engine unit (to make the human-computer interaction process smoother);
计划调度指令票自动生成模块基于信息抽取自动生成计划调度指令票,计划调度指令票自动生成模块包括学习阶段单元和抽取阶段单元(基于信息抽取技术,自动生成计划调度指令票。将停电计划信息的详情页中,5个关键字段信息的内容进行解析,根据解析的内容,按照模版生成调度指令票);The automatic planning scheduling instruction ticket generation module is based on information extraction to automatically generate the planning scheduling instruction ticket. The planning scheduling instruction ticket automatic generation module includes the learning stage unit and the extraction stage unit (based on the information extraction technology to automatically generate the planning scheduling instruction ticket. The power outage plan information In the details page, the contents of the five key fields are analyzed, and according to the analyzed content, a scheduling instruction ticket is generated according to the template);
信息监控诊断模块基于文本识别单元和语音合成单元对生产运营系统的信息进行智能监控、诊断和预警(基于OCR文本识别技术、NLP技术和语音外呼技术,实现SOE信息的智能监控、诊断和预警。基于SOE的文本信息和关系,实现故障自诊断;包括事故信息、异常信息、变位信息、告知信息等;同时结合SOE信息的上下文,自动诊断重合失败、重合成功、跳闸未重合、接地故障四类异常。同时,当系统判别到需要关注的故障信息,会在生产运营室中通过语音合成进行播报,并将报文原始信息(时间、内容)、信息的分类等,通过调用平湖供电局内网的短信平台,完成信息发送给外网服务器。外网服务器收到短信报警内容,并解析成对应文本,自动拨打外呼给现场操作人员和总指挥长,并记录电话是否拨通。同时,生产运营人员大屏监护时,可用OCR识别出大屏文字,与生产运营员的讲话内容匹配后,系统语音播报“一致”,否则播报“不一致”);The information monitoring and diagnosis module performs intelligent monitoring, diagnosis and early warning on the information of the production and operation system based on the text recognition unit and the speech synthesis unit (based on OCR text recognition technology, NLP technology and voice outbound technology to realize intelligent monitoring, diagnosis and early warning of SOE information .Based on SOE text information and relationships, realize fault self-diagnosis; including accident information, abnormal information, displacement information, notification information, etc.; combined with the context of SOE information, automatic diagnosis of reclosing failure, reclosing success, trip non-reclosing, ground fault Four types of abnormalities. At the same time, when the system identifies fault information that needs attention, it will broadcast in the production operation room through speech synthesis, and the original information (time, content) and classification of the information, etc. The short message platform of the Internet sends the information to the external network server. The external network server receives the alarm content of the short message and parses it into the corresponding text, automatically dials the outbound call to the on-site operator and the commander-in-chief, and records whether the call is dialed. At the same time, When the production and operation personnel are monitoring the large screen, OCR can be used to recognize the text on the large screen. After matching the content of the production operator's speech, the system voice will broadcast "consistent", otherwise it will broadcast "inconsistent");
智能交接班识别模块用于将用户的声纹进行识别并且融合到生产运营系统,通过声纹注册和分析实现基于声纹的身份认证,进而通过声纹识别交接班的用户(生产运营人员在登陆系统时,需要说出指定口令;系统会根据口令的声纹识别,来鉴定是否有权限操作。在交接班时系统会根据声纹识别,判断两个交接员的身份,并提示交接成功)。The intelligent shift recognition module is used to identify the user's voiceprint and integrate it into the production and operation system, realize voiceprint-based identity authentication through voiceprint registration and analysis, and then use the voiceprint to identify the user of the shift (production and operation personnel log in When using the system, you need to say the specified password; the system will identify whether you have permission to operate according to the voiceprint recognition of the password. During the shift change, the system will judge the identity of the two handover personnel based on the voiceprint recognition, and prompt the handover is successful).
具体的是,语音识别引擎单元包括中文标点智能预测单元、文件格式智能转化单元、前端语音处理单元和后端识别处理单元,其中;Specifically, the speech recognition engine unit includes a Chinese punctuation intelligent prediction unit, a file format intelligent conversion unit, a front-end speech processing unit and a back-end recognition processing unit, wherein;
ASR(语音识别引擎单元)是一种实现从“声音”到“文字”转换的技术,通过将人的语音直接转换成相应的文本以便计算机进行理解和产生相应的操作,并最终实现人与机器之间的自然语音交互。基于深度全序列卷积神经网络框架,将音频流数据实时转换成文字流数据结果。ASR (Speech Recognition Engine Unit) is a technology that realizes the conversion from "sound" to "text", by directly converting human speech into corresponding text so that the computer can understand and generate corresponding operations, and finally realize the human and machine Natural voice interaction between. Based on the deep full sequence convolutional neural network framework, the audio stream data is converted into text stream data in real time.
针对语音识别应用中面临的方言口音、背景噪声等问题,基于实际业务系统中所收集的涵盖不同方言和不同类型背景噪声的海量语音数据,通过先进的区分性训练方法进行语音建模,使语音识别器在复杂应用环境下均有良好的效果表现。Aiming at problems such as dialect accents and background noise in speech recognition applications, based on the massive speech data collected in the actual business system covering different dialects and different types of background noise, speech modeling is carried out through advanced discriminative training methods, so that speech The recognizer has good performance in complex application environments.
中文标点智能预测单元用于通过语言模型,对语音识别引擎单元识别获得的识别结果进行对话语音的智能预测,从而提供智能断句和标点符号的预测;The Chinese punctuation intelligent prediction unit is used to perform intelligent prediction of dialogue speech on the recognition result obtained by the recognition of the speech recognition engine unit through the language model, thereby providing prediction of intelligent sentence segmentation and punctuation marks;
文件格式智能转化单元对识别结果中出现的包括数字、日期和时间的参数进行格式化并且生成规整的文本;The file format intelligent conversion unit formats the parameters including numbers, dates and times appearing in the recognition results and generates regular text;
前端语音处理单元通过信号处理的方法对输入的语音进行检测、降噪预处理,以便得到最匹配语音识别引擎单元处理的语音,前端语音处理单元包括端点检测子单元和噪音消除子单元,端点检测子单元用于对输入的音频流形式的语音进行分析,确定用户说话的起始和终止的,当检测到用户开始说话,语音开始流向语音识别引擎单元,直到检测到用户说话结束;The front-end speech processing unit detects the input speech and pre-processes the noise reduction by means of signal processing, so as to obtain the speech that best matches the speech recognition engine unit. The front-end speech processing unit includes an endpoint detection subunit and a noise elimination subunit. The endpoint detection The subunit is used to analyze the voice in the form of the input audio stream to determine the start and end of the user's speech. When it is detected that the user starts to speak, the voice starts to flow to the speech recognition engine unit until the end of the user's speech is detected;
后端识别处理单元包括个性化语音识别子单元、置信度输出子单元、多结果识别子单元、说话人自适应子单元和语义上下文自修正子单元,个性化语音识别子单元基于用户的语音特征,搜集并上传使用率高的词语(热词),从业务角度建立个性化的词条语言模型,以调整识别参数、修改上传热词的权重和持续优化识别;置信度输出子单元用于在在返回识别结果时携带该识别结果的置信度,从而通过置信度结果进行分析和后续处理;多结果识别子单元在识别过程中,通过置信度输出子单元的结果向应用程序返回满足条件的多个识别结果,而不是唯一的结果,提供可能的识别结果列表,并按置信度结果从高到低进行排列;说话人自适应子单元用于当用户与语音识别引擎单元进行多次会话过程中,在线提取通话的语音特征,自动调整识别参数,使识别效果得到持续优化;语义上下文自修正子单元用于结合上下文动态修正,根据语音识别结果以及上下文对进行动态修正,使结果更符合当前语境;The back-end recognition processing unit includes a personalized speech recognition subunit, a confidence output subunit, a multi-result recognition subunit, a speaker adaptive subunit, and a semantic context self-correction subunit. The personalized speech recognition subunit is based on the user's voice characteristics , collect and upload words (hot words) with high usage rate, and establish a personalized entry language model from a business perspective to adjust recognition parameters, modify the weight of uploaded hot words and continuously optimize recognition; the confidence output subunit is used in The confidence of the recognition result is carried when the recognition result is returned, so that the analysis and subsequent processing can be carried out through the confidence result; during the recognition process, the multi-result recognition subunit returns the multi-results that meet the conditions to the application program through the result of the confidence output subunit A recognition result, not the only result, provides a list of possible recognition results, and arranges them from high to low according to the confidence results; the speaker adaptive subunit is used when the user conducts multiple conversations with the speech recognition engine unit , extracting the voice features of the call online, automatically adjusting the recognition parameters, so that the recognition effect can be continuously optimized; the semantic context self-correction subunit is used for dynamic correction in combination with the context, and dynamically corrects the result according to the speech recognition result and the context to make the result more in line with the current language territory;
语义解析引擎单元包括规则理解单元和模型理解单元,规则理解单元用于进行规则的匹配,模型理解单元包括语义模型训练子单元、语义特征提取子单元、语义相似度评估子单元,语义模型训练子单元用于对文本进行建模,将语义表达相似的文本映射到语义空间中相近的向量;语义特征提取子单元用于对文本信息进行特征提取,在完成语义模型训练子单元的训练后,通过提取模型特定的隐层向量获得;语义相似度评估子单元用于评估利用深度学习提取的用户句向量与库中离线提取的句向量相似度。The semantic analysis engine unit includes a rule understanding unit and a model understanding unit. The rule understanding unit is used for matching rules. The model understanding unit includes a semantic model training subunit, a semantic feature extraction subunit, a semantic similarity evaluation subunit, and a semantic model training subunit. The unit is used to model the text, and the text with similar semantic expression is mapped to the similar vector in the semantic space; the semantic feature extraction subunit is used to extract the feature of the text information, after completing the training of the semantic model training subunit, through The hidden layer vector specific to the extraction model is obtained; the semantic similarity evaluation subunit is used to evaluate the similarity between the user sentence vector extracted by deep learning and the sentence vector extracted offline in the library.
进一步的是,对于学习阶段单元:Further, for learning phase units:
在学习阶段设有带标注的数据集,每一个样本包含文字单元序列和标注序列,如下所示:In the learning phase, there is a labeled data set, each sample contains a sequence of text units and a sequence of labels, as follows:

其中,表示第i个样本,前面x部分表示第i个样本的文字单元序列,后面y部分表示第i个样本的标注序列;Among them, represents the i-th sample, the front x part represents the text unit sequence of the i-th sample, and the following y part represents the label sequence of the i-th sample;
根据已有的标注构建一个学习模型,并且用一个条件概率分布进行表示;Construct a learning model based on existing annotations and represent it with a conditional probability distribution;
抽取阶段单元通过不同的模型作为分类器,从而获得不通过的文本信息的抽取方式,并且将各个分类器获得的抽取数据进行相互校正。The extraction stage unit uses different models as classifiers, so as to obtain the extraction methods of text information that do not pass, and correct the extracted data obtained by each classifier.
更具体的是,文本识别单元在文本识别中引入上下文序列信息,通过时序关系的神经网络进行识别。More specifically, the text recognition unit introduces contextual sequence information in text recognition, and recognizes through the neural network of temporal relations.
文本信息抽取常用的模型有:隐马尔科夫模型、最大熵马尔科夫模型、条件随机场、表决感知机模型。这些模型是上述一般文本信息抽取的具体实现。Commonly used models for text information extraction are: hidden Markov model, maximum entropy Markov model, conditional random field, and voting perceptron model. These models are concrete implementations of the general text information extraction mentioned above.
首先,将每一个标注看作是独立于序列以及序列的其它标注的,对于每一个文字单元序列及其标注,可以得到这样一个条件概率分布;First, each label is regarded as independent of the sequence and other labels of the sequence. For each text unit sequence and its labels, such a conditional probability distribution can be obtained;
这样的一个条件概率分布实际上是一个分类器模型,得到样本序列的各单元序列的最佳标注。Such a conditional probability distribution is actually a classifier model, which obtains the best annotation of each unit sequence of the sample sequence.
在此基础上,利用不同的模型作为分类器,可以得到不同的文本信息抽取方法。On this basis, using different models as classifiers, different text information extraction methods can be obtained.
例如,用最大熵模型作为分类器,并且假设不同的标注之间具有一阶马尔可夫性;For example, use the maximum entropy model as a classifier, and assume that there is a first-order Markov property between different labels;
每一个条件概率分布又是一个新的分类器模型,但是这个分类器是基于前一个标注确定的条件下的分类器,此时模型就成为最大熵马尔科夫模型。Each conditional probability distribution is a new classifier model, but this classifier is based on the classifier under the conditions determined by the previous label. At this time, the model becomes the maximum entropy Markov model.
需要注意的是,最大熵马尔科夫模型是一个局部模型,因为标注之间具有一阶马尔可夫性,用局部数据进行训练,而在抽取全局信息时,效果可能不会很好,会产生标注偏差问题。因此可以用一些复杂的全局模型来解决标注偏差问题。其中,最常用的全局模型就是条件随机场。条件概率分布式中的各个标注会依赖除自身之外的其他标注,条件随机场可以精确的描述全局的标注情况,在精度上由于最大熵马尔科夫模型,但是训练时间也更多。It should be noted that the maximum entropy Markov model is a local model, because there is a first-order Markov property between labels, and local data is used for training, but when extracting global information, the effect may not be very good, and it will produce Labeling bias problem. Therefore, some complex global models can be used to solve the labeling bias problem. Among them, the most commonly used global model is the conditional random field. Each label in the conditional probability distribution will depend on other labels except itself. The conditional random field can accurately describe the global labeling situation. The accuracy is due to the maximum entropy Markov model, but the training time is also more.
更进一步的是,对于语音合成单元:Even further, for the speech synthesis unit:
全语种语义模型,基于多国语言融合的无监督文本预训练模型,提取文本语义信息,并且统一的预训练模型基础上构建各语种独立情况的文本预测信息分支(基于多国语言融合的BERT无监督文本预训练模型,提取文本语义信息,降低文本人工标注难度和数量。具体的,在小语种构建问题上,通过多语言融合的海量文本BERT预训练方式提取语义变化信息,改善文本输入表征能力偏弱的情况。BERT全称为Bidirectional EncoderRepresentations from Transformers,是一种预训练语言表示的方式。在多种NLP任务上取得了业界领先效果。在本项目小语种构建问题上有较高的适应性,可通过多语言融合的海量文本预训练方式提取语义变化信息,改善文本输入能力偏弱的现实,提升语音合成表现效果。并在统一的BERT预训练模型基础上构建各语种独立情况的文本预测信息分支,如中文多音字、日语调核、阿拉伯语元音恢复等问题,实现共享信息的multi-task任务学习);Full-language semantic model, based on the unsupervised text pre-training model of multi-language fusion, extracts text semantic information, and builds a text prediction information branch for each language independently based on the unified pre-training model (BERT unsupervised text based on multi-language fusion The pre-training model extracts text semantic information and reduces the difficulty and quantity of manual text labeling. Specifically, on the issue of small language construction, the multi-language fusion massive text BERT pre-training method extracts semantic change information and improves the weak representation ability of text input The full name of BERT is Bidirectional EncoderRepresentations from Transformers, which is a way of pre-training language representation. It has achieved industry-leading results in a variety of NLP tasks. It has high adaptability to the problem of small language construction in this project. The massive text pre-training method of multi-language integration extracts semantic change information, improves the reality of weak text input ability, and improves the performance of speech synthesis. On the basis of the unified BERT pre-training model, the text prediction information branch of each language independent situation is constructed. Such as Chinese polyphonic characters, Japanese tune-up, Arabic vowel recovery and other issues, to achieve multi-task task learning of shared information);
发音体系模型,通过半监督聚类方法自动构建统一单元的发音词典,将语言相关技术模块化的方法,在语言资源有限的条件下得以实现合成系统快速定制;Pronunciation system model, which automatically constructs a unified unit pronunciation dictionary through the semi-supervised clustering method, and modularizes language-related technologies, enabling rapid customization of the synthesis system under the condition of limited language resources;
Global Phone的构建过程以International Phonetic Alphabet(IPA)为基础,根据物理发音规律覆设计覆盖全部发音体系,包含孤立语、黏着语、屈折语以及区分音节显赫语言(有调、无调)、音节非显赫语言(有重音、无重音)等各种主要语系里语音发音类型。通过Global Phone预先定义并在数据充足语言上人工确认标注,The construction process of Global Phone is based on International Phonetic Alphabet (IPA). According to the laws of physical pronunciation, the design covers all pronunciation systems, including isolated language, agglutinative language, inflectional language, and distinguishing syllable prominent language (toned, atonal), non-syllable Speech pronunciation types in various major language families such as prominent languages (accented, unaccented). Pre-defined by Global Phone and manually confirmed annotations in data-rich languages,
为在有限时间内实现多语种语音合成,提出一种基于Global Phone的多语种合成统一框架,通过VAE半监督聚类方法自动构建统一单元的发音词典,将语言相关技术模块化的方法,在语言资源有限的条件下得以实现合成系统快速定制,解决了小语种或方言等资源受限语种的语音系统需求。In order to achieve multilingual speech synthesis in a limited time, a unified framework for multilingual synthesis based on Global Phone is proposed. The pronunciation dictionary of a unified unit is automatically constructed through the VAE semi-supervised clustering method, and the language-related technology is modularized. In the language Under the condition of limited resources, the rapid customization of the synthesis system can be realized, which solves the needs of the speech system of resource-limited languages such as minority languages or dialects.
首先将系统模块分为语言相关和语言无关两大模块,其中语言无关模块主要包括语音合成引擎和语音识别引擎的通用模块,在多语种语音系统的研发过程中,关注合成系统各功能子模块中不同语言之间的相似性,站在一个统一的视角观察言语现象。Firstly, the system modules are divided into language-related and language-independent modules. The language-independent module mainly includes the general modules of speech synthesis engine and speech recognition engine. The similarities between different languages allow us to observe speech phenomena from a unified perspective.
语言相关模块主要和文本处理和音库处理相关,包括语音单元定义及分类、文本规整、字音转换、语料设计、分词、韵律结构预测、语音数据库标注等所有语音合成需要的模块,语音识别可共享其中的语音单元定义及分类、文本规整、字音转换、语料设计、语音数据处理等。在词典、词性、韵律层级等语种相关信息构建中,使用Global Phone统一框架,用同一套体系对小语种语言统一建模,降低单一语种的构建难度。Language-related modules are mainly related to text processing and sound library processing, including speech unit definition and classification, text regularization, word-to-sound conversion, corpus design, word segmentation, prosodic structure prediction, speech database annotation, and other modules required for speech synthesis, among which speech recognition can be shared Definition and classification of speech units, text regularization, word-to-sound conversion, corpus design, speech data processing, etc. In the construction of language-related information such as dictionaries, parts of speech, and prosodic levels, the Global Phone unified framework is used to uniformly model small languages with the same system, reducing the difficulty of building a single language.
Global Phone的构建过程以International Phonetic Alphabet(IPA)为基础,辅音根据发音部位、发音方法做主要区分;元音以发音位置的高低、前后、圆唇/不圆唇三点作为主要区分维度,以时长、鼻化,松紧作为次要区分维度,构建各语种统一的Global Phone体系。对于有调语言,根据调类、调值、调域进行统一的Global tone标注。The construction process of Global Phone is based on the International Phonetic Alphabet (IPA). Consonants are mainly distinguished according to the pronunciation position and pronunciation method; Duration, nasalization, and tightness are used as secondary distinguishing dimensions to build a unified Global Phone system in various languages. For languages with tones, a unified Global tone label is carried out according to the tone class, tone value, and tone domain.
在数据资源和专家资源不足的语种上通过已标注数据支持下的半监督VAE聚类,自动学习面向资源不足小语种的统一体系下的音库发音序列和发音词典,最终实现一套通用的Global Phone多语言发音统一构建方法。In languages with insufficient data resources and expert resources, semi-supervised VAE clustering supported by labeled data can automatically learn the sound bank pronunciation sequence and pronunciation dictionary under the unified system for small languages with insufficient resources, and finally realize a set of general Global Phone multilingual pronunciation unified construction method.
基于听感量化编码的多语种混合模型,对语音中的不同属性信息进行听感量化编码,并且对语音的声学参数进行预测;Based on the multilingual mixed model of auditory quantitative coding, the auditory quantitative coding is performed on different attribute information in the speech, and the acoustic parameters of the speech are predicted;
由于小语种数据录音采集较为困难,需要在一开始就考虑多语种多人多风格数据的混用问题。采用基于听感量化编码的声学模型构建语音合成系统,首先对语音中的不同属性信息进行听感量化编码,然后对语音的声学参数进行预测。具体地,通过人工定义多人混合语音的说话人、语种、情感风格等属性编码,并引入残差编码描述发音人在录制语音数据时由于情绪、环境、时间差异等不同状态下发音上的变化信息,结合文本信息,通过全连接前馈(feed-forward,FF)网络和长短时记忆网络(LSTM-RNN)实现对语音声学参数的预测。针对语料较少的新发音人,计划采用迁移学习方法,以提高少数据量下的语音合成效果。Since it is difficult to collect data recordings in small languages, it is necessary to consider the mixed use of multi-lingual, multi-person and multi-style data from the very beginning. The speech synthesis system is constructed by using the acoustic model based on auditory quantization coding. First, the auditory quantization coding is performed on different attribute information in the speech, and then the acoustic parameters of the speech are predicted. Specifically, by manually defining the speaker, language, emotional style and other attribute codes of multi-person mixed speech, and introducing residual codes to describe the changes in the pronunciation of speakers due to different states such as emotions, environments, and time differences when recording voice data Information, combined with text information, realizes the prediction of speech acoustic parameters through a fully connected feed-forward (FF) network and a long-short-term memory network (LSTM-RNN). For new speakers with less corpus, it is planned to adopt the transfer learning method to improve the effect of speech synthesis with a small amount of data.
假设多人多语种混合数据集中。传统语音合成声学建模方法是用神经网络直接对建模。为了实现对语音合成说话人、语种、说话风格等的控对语音中的信息进行分解,定义了四种听感量化编码:说话人编码、语种编码、情感风格编码、残差编码。然后显示地对语音中的说话人、语种、情感风格进行听感量化编码,并直接对这些听感量化编码和声学参数的联合分布进行建模;Assume that there are multiple people and multilingual mixed data sets. The traditional acoustic modeling method for speech synthesis is to use neural network to model directly. In order to decompose the information in the speech by controlling the speaker, language, and speaking style of the speech synthesis, four kinds of auditory quantization coding are defined: speaker coding, language coding, emotional style coding, and residual coding. Then explicitly quantify the speaker, language, and emotional style in the speech, and directly model the joint distribution of these quantized codes and acoustic parameters;
整个模型使用神经网络进行实现,主要包含两部分:(1)主网络部分,在给定文本和听感量化编码时预测声学参数,通过所有数据共享同一个主网络,使模型能够学习到不同说话人、语种、风格编码对合成语音的影响;(2)旁支网络,在给定文本、语种、说话人时,对情感编码进行预测,同样使用神经网络进行实现。The whole model is implemented using a neural network, which mainly includes two parts: (1) the main network part, which predicts the acoustic parameters when given text and auditory quantization encoding, and shares the same main network with all data, so that the model can learn different speech The impact of person, language, and style coding on synthesized speech; (2) collateral network, when given text, language, and speaker, predicts the emotional coding, which is also implemented using neural networks.
在模型训练时,说话人、语种给定,情感量化编码通过人工标记进行定义。残差编码描述的是发音人在录制语音数据时由于情绪、环境、时间差异等不同状态下发音上的变化信息,无法人工标记,为此将每个句子使用一个单独残差编码表示,残差编码随机初始化,通过模型训练进行更新。整个模型使用最小均方误差准则进行训练,使用随机梯度下降算法进行梯度更新。During model training, the speaker and language are given, and the emotional quantization coding is defined by manual marking. Residual coding describes the changes in the pronunciation of the speaker due to emotions, environments, time differences, etc. when recording voice data, which cannot be manually marked. Therefore, each sentence is represented by a separate residual coding. The residual The encoding is initialized randomly and updated through model training. The entire model is trained using the minimum mean square error criterion and gradient updates are performed using a stochastic gradient descent algorithm.
针对语料较少的新语种和新发音人,本项目提出使用迁移学习的方法,提高少数据量下的语音合成效果。首先将训好的多人混合模型的权重作为新发音人模型的初始化,然后使用新发音人的少量数据进行微调,从而达到少数据量、新发音人的快速建模。For new languages and new speakers with less corpus, this project proposes the use of transfer learning methods to improve the effect of speech synthesis with a small amount of data. Firstly, the weight of the trained multi-person mixed model is used as the initialization of the new speaker model, and then fine-tuning is performed using a small amount of data of the new speaker, so as to achieve fast modeling of the new speaker with a small amount of data.
基于生成对抗网络的高质量语音生成模型,通过对频谱包络的整体结构进行建模和对频谱包络的局部细节建模进行高音质多语种语音合成。Based on the high-quality speech generation model of generative confrontation network, high-quality multilingual speech synthesis is performed by modeling the overall structure of the spectral envelope and the local details of the spectral envelope.
为构建高音质多语种语音合成系统,计划将语音的频谱建模分为两个阶段:1)对频谱包络的整体结构进行建模;2)对频谱包络的局部细节建模。拟使用GAN模型,在声学模型预测出频谱包络的整体框架条件下,采用语种无关的方式对频谱包络的局部细节进行建模。具体地,使用卷积神经网络构建声学模型预测频谱到自然语音频谱包络的映射,使用GAN准则进行模型训练。GAN中的生成网络以噪声、文本特征和低维梅尔倒谱作为输入,预测谱包络特征;判别网络以文本特征作为条件,对生成网络预测的谱包络和自然的谱包络进行判别。最终实现在特定语种发音人数据量有限的情况下,通过跨语种GAN模型恢复谱包络中的精细结构,提升语音的主观质量。In order to build a high-quality multilingual speech synthesis system, it is planned to divide the spectral modeling of speech into two stages: 1) modeling the overall structure of the spectral envelope; 2) modeling the local details of the spectral envelope. The GAN model is proposed to model the local details of the spectral envelope in a language-independent manner under the condition that the acoustic model predicts the overall framework of the spectral envelope. Specifically, a convolutional neural network is used to construct an acoustic model to predict the mapping from the spectrum to the spectrum envelope of natural speech, and the GAN criterion is used for model training. The generation network in GAN uses noise, text features and low-dimensional Mel cepstrum as input to predict spectral envelope features; the discriminant network uses text features as conditions to distinguish between the spectral envelope predicted by the generative network and the natural spectral envelope . Finally, in the case of a limited amount of speaker data in a specific language, the fine structure in the spectral envelope can be restored through the cross-language GAN model, and the subjective quality of speech can be improved.
频谱包络的整体框架决定的是语音的发音正确性,频谱络的具体细节决定的是语音的音质高低。梅尔倒谱是从谱包络中提取的去相关的特征,其低维表示的是谱包络的整体结构,高维描述的是谱包络的局部细节。在语音合成中,梅尔倒谱的高维对音质影响很大,自然语音梅尔倒谱和合成语音的梅尔倒谱的全局方差中,梅尔倒谱的低维全局方差具有相似的分布,而高维部分全局方差的差别较大,合成语音的高维梅尔倒谱通常过平滑,导致语音音质受损。这表明目前统计参数语音合成中对频谱包络的整体结构建模已经较为准确,而对频谱包络的局部细节建模具有较大的缺陷。考虑到GAN模型生成的样本相比传统基于最大似然准则训练的生成式模型更加接近自然样本,提出使用GAN模型,在给定频谱包络的整体框架时,对频谱包络的局部细节进行建模。由于CNN对于局部结构具有较强的建模能力,以及语音谱包络特征在时间和频率轴上都具有重要的局部结构,本项目选择CNN作为GAN模型的判别网络和生成网络,选择谱包络特征作为预测样本。给定语音的谱包络特征s,对应的文本特征c,以及对应的低维梅尔倒谱特征m,不直接对给定文本时谱包络特征的条件分布P(s|c)进行建模,而是对给定文本特征和低维梅尔倒谱特征时,谱包络的条件分布P(s|c,m)进行建模;The overall framework of the spectral envelope determines the correctness of speech pronunciation, and the specific details of the spectral envelope determine the sound quality of the speech. The Mel cepstrum is a decorrelated feature extracted from the spectral envelope. Its low dimension represents the overall structure of the spectral envelope, and its high dimension describes the local details of the spectral envelope. In speech synthesis, the high dimension of the Mel cepstrum has a great influence on the sound quality. In the global variance of the Mel cepstrum of the natural speech and the Mel cepstrum of the synthetic speech, the low-dimensional global variance of the Mel cepstrum has a similar distribution. , while the global variance of the high-dimensional part has a large difference, and the high-dimensional Mel cepstrum of the synthesized speech is usually too smooth, resulting in impaired speech quality. This shows that the overall structure modeling of the spectrum envelope in the current statistical parametric speech synthesis is relatively accurate, but the local detail modeling of the spectrum envelope has relatively large defects. Considering that the samples generated by the GAN model are closer to natural samples than the traditional generative model based on maximum likelihood training, it is proposed to use the GAN model to construct the local details of the spectral envelope when the overall framework of the spectral envelope is given. mold. Since CNN has a strong modeling ability for local structures, and the speech spectral envelope features have important local structures on the time and frequency axes, this project chooses CNN as the discriminant network and generation network of the GAN model, and selects the spectral envelope features as prediction samples. Given the spectral envelope feature s of the speech, the corresponding text feature c, and the corresponding low-dimensional Mel cepstrum feature m, the conditional distribution P(s|c) of the time spectral envelope feature of the given text is not directly constructed Instead, the conditional distribution P(s|c,m) of the spectral envelope is modeled when given text features and low-dimensional Mel cepstral features;
GAN中的生成网络以噪声、文本特征和低维梅尔倒谱作为输入,预测谱包络特征;判别网络以文本特征作为条件,对生成网络预测的谱包络和自然的谱包络进行判别。The generation network in GAN uses noise, text features and low-dimensional Mel cepstrum as input to predict spectral envelope features; the discriminant network uses text features as conditions to distinguish between the spectral envelope predicted by the generative network and the natural spectral envelope .
在训练阶段,使用自然的梅尔倒谱低维和文本作为条件输入,测试过程中,由于没有梅尔倒谱参数,需要用另一个模型对其进行预测,可以使用传统的统计建模方法或者是基于GAN的建模方法。本项目计划使用RNN-LSTM模型对梅尔倒谱的低维参数进行建模。然后以文本特征和梅尔倒谱低维作为条件,使用GAN模型预测谱包络参数。最后结合传统统计参数语音合成系统预测的时长和基频,合成最终的语音。这一频谱生成过程可以看做是一种两级生成方法,首先由基于MSE准则训练的模型预测出低维梅尔倒谱参数,确定频谱包络的基本框架,然后使用GAN模型预测出谱包络中的精细结构。通过这一两级生成模型预计将显著提升语音的生成质量,提升体验效果。In the training phase, the natural Mel cepstrum low-dimensional and text are used as conditional input. During the test process, since there is no Mel cepstrum parameter, another model needs to be used to predict it. Traditional statistical modeling methods or GAN-based modeling approach. This project plans to use the RNN-LSTM model to model the low-dimensional parameters of the Mel cepstrum. The GAN model is then used to predict spectral envelope parameters conditioned on text features and Mel cepstrum low-dimensionality. Finally, the final speech is synthesized by combining the duration and fundamental frequency predicted by the traditional statistical parameter speech synthesis system. This spectrum generation process can be regarded as a two-stage generation method. First, the low-dimensional Mel cepstrum parameters are predicted by the model trained based on the MSE criterion, the basic framework of the spectrum envelope is determined, and then the spectrum envelope is predicted using the GAN model. fine structure in the network. Through this two-level generation model, it is expected to significantly improve the quality of speech generation and improve the experience effect.
优选地,智能交接班识别模块包括模型训练阶段单元和模型预测阶段单元:Preferably, the intelligent shift recognition module includes a model training phase unit and a model prediction phase unit:
模型训练阶段单元用于使用音视频同步、且有语音文字标注的数据集,进行模型的训练;The model training phase unit is used to train the model using audio and video synchronization and data sets with voice and text annotations;
模型预测阶段单元对模型的应用,输入多人混叠的语音与特定目标人的唇动视频,识别出文字序列,同时分离出与唇动视频内容相符的说话人语音。The application of the model in the model prediction stage unit inputs the voices of multiple people and the lip movement video of a specific target person, recognizes the text sequence, and at the same time separates the speaker's voice that matches the content of the lip movement video.
对模型训练步骤、测试步骤具体实施为:The specific implementation of the model training steps and testing steps is as follows:
步一:数据预处理Step 1: Data Preprocessing
数据预处理主要包含图像的预处理、语音的预处理、以及文字标注的预处理。图像的预处理为检测视频中说话人的人脸特征点,根据特征点将人脸缩放到同一尺度,然后以嘴部中心点为中心,取固定大小的嘴部区域图像,获取嘴部图像视频序列,本例中获取的嘴部区域图像大小为80*80,通道数为RGB三通道,视频的帧率为25fps;语音的预处理分为两种:(1)识别的语音特征提取为滑窗提取语音的40维fbank特征,本例中设置的窗长为25ms,帧移为10ms,(2)分离的语音特征提取为对语音信号做短时傅里叶变换(STFT),形成2通道的频谱图;文字标注的预处理为使用force alignment将文字发音音素对齐到语音信号上,每4帧语音信号对应到一个triphone上,这样实际上文字标注被转化为triphone标注,标注帧率为25fps,与视频帧率同步,是音频帧率的四分之一。Data preprocessing mainly includes image preprocessing, voice preprocessing, and text annotation preprocessing. The preprocessing of the image is to detect the face feature points of the speaker in the video, scale the face to the same scale according to the feature points, and then take the mouth area image of a fixed size with the center point of the mouth as the center to obtain the mouth image video In this example, the size of the mouth area image obtained in this example is 80*80, the number of channels is RGB three-channel, and the frame rate of the video is 25fps; the voice preprocessing is divided into two types: (1) The recognized voice feature extraction is sliding The window extracts the 40-dimensional fbank feature of the speech. In this example, the window length is set to 25ms, and the frame shift is 10ms. (2) The separated speech feature is extracted by performing short-time Fourier transform (STFT) on the speech signal to form 2 channels The spectrogram of the text annotation; the preprocessing of the text annotation is to use force alignment to align the phonemes of the text pronunciation to the speech signal, and every 4 frames of the speech signal correspond to a triphone, so that the text annotation is actually converted into a triphone annotation, and the annotation frame rate is 25fps , synchronized with the video frame rate, is a quarter of the audio frame rate.
步二:语音识别模型与分离模型的联合训练Step 2: Joint training of speech recognition model and separation model
在获取足够的训练数据之后,会分别搭建语音识别神经网络模型与唇语识别神经网络模型,进行多模态语音识别与分离的联合训练。After obtaining enough training data, a neural network model for speech recognition and a neural network model for lip language recognition will be built separately for joint training of multimodal speech recognition and separation.
采用的多模态语音识别与分离神经网络模型的输入是固定时长为3s的音视频。The input of the multimodal speech recognition and separation neural network model is the audio and video with a fixed duration of 3s.
音频特征输入是100fps的40维语音帧fbank特征向量序列,3s时长共有300*40的fbank特征图,经过特征提取模块后会在时间维度下采样4倍,得到的75*512维语音特征向量序列;视频图像输入是25fps的图像序列,图像大小为80*80的RGB三通道图像,3s时长共有75*3*80*80大小的图像序列,经过特征提取模块后得到75*512维视频特征向量序列;多模态信息融合模块将两个模块提取出的512维语音特征向量与512维图像特征向量进行融合,融合可以采用特征拼接,再通过一个小的融合神经网络,生成新的75*512维的融合特征向量。The audio feature input is a 100fps 40-dimensional speech frame fbank feature vector sequence. There are 300*40 fbank feature maps in 3s. After the feature extraction module, it will be sampled 4 times in the time dimension to obtain a 75*512-dimensional speech feature vector sequence. ;The video image input is a 25fps image sequence, the image size is an 80*80 RGB three-channel image, and there are 75*3*80*80 image sequences in 3s duration, and a 75*512-dimensional video feature vector is obtained after the feature extraction module Sequence; the multimodal information fusion module fuses the 512-dimensional speech feature vector extracted by the two modules with the 512-dimensional image feature vector. The fusion can use feature splicing, and then generate a new 75*512 through a small fusion neural network. Dimensional fused feature vectors.
多模态识别任务将该75*512维融合特征直接送入识别模块,经过softmax分类,与标注的triphone音素label一一对应,使用的损失函数为CrossEntry Loss。For the multi-modal recognition task, the 75*512-dimensional fusion feature is directly sent to the recognition module, and after softmax classification, it corresponds to the marked triphone phoneme label one by one, and the loss function used is CrossEntry Loss.
而多模态语音分离任务使用的是U_Net网络结构,其模型的原始输入为3s语音信号经过STFT变换,形成2*298*257的频谱图。U_Net结构会对该特征图进行先下采样再上采样的操作,其中下采样与上采样模块中对应大小一致的中间特征图会有特征拼接操作;在中间最小的特征向量上,会将之前75*512维的融合特征向量拼接进来,形成中间条件,指导U_Net进行频谱图重建。重建后的频谱图与label频谱图做L2 Loss,梯度反传不仅更新U_Net模块,同样更新特征融合模块、音频特征提取模块与视频特征提取模块,与多模态识别的CrossEntry Loss形成联合训练效果。The multimodal speech separation task uses the U_Net network structure, and the original input of the model is a 3s speech signal undergoing STFT transformation to form a 2*298*257 spectrogram. The U_Net structure will first downsample and then upsample the feature map. The intermediate feature map with the same size in the downsampling and upsampling modules will have a feature splicing operation; on the smallest feature vector in the middle, the previous 75 *The 512-dimensional fusion feature vectors are spliced in to form intermediate conditions and guide U_Net to perform spectral map reconstruction. The reconstructed spectrogram and the label spectrogram are used for L2 Loss. Gradient backpropagation not only updates the U_Net module, but also updates the feature fusion module, audio feature extraction module, and video feature extraction module to form a joint training effect with the CrossEntry Loss of multimodal recognition.
此步训练过程中,任务类型类似于Multi_task,同步进行语音分离与识别,两项任务同步进行,但使用的是同样的融合特征,让特征提取与融合模块学习到更加紧密的多模态联合信息。最后对L2 Loss和CrossEntry Loss进行加权求和,形成最终Loss,通过梯度反传优化算法训练整个网络。During this step of training, the task type is similar to Multi_task, and the speech separation and recognition are performed synchronously. The two tasks are performed synchronously, but the same fusion features are used, so that the feature extraction and fusion modules can learn closer multi-modal joint information. . Finally, L2 Loss and CrossEntry Loss are weighted and summed to form the final Loss, and the entire network is trained through the gradient backpropagation optimization algorithm.
步三:模型测试与使用Step 3: Model testing and use
在模型训练完毕后,即可进行多模态语音分离与识别的测试使用。使用过程中对语音和图像的预处理与训练过程中一致,此处不再赘述。首先将音视频特征通过融合模块形成融合特征,再通过识别模块在别成triphone音素状态后,将音素状态通过维特比算法解码成文字序列,达到最终的识别效果。融合特征同样可以拼接到分离重建的U_Net网络中间特征上,重建出分离的频谱图,将频谱图经过ISTFT变换后即可恢复成分离后的语音信号。After the model is trained, it can be tested for multi-modal speech separation and recognition. The preprocessing of speech and images during use is the same as during training, and will not be repeated here. First, the audio and video features are formed into a fusion feature through the fusion module, and then the phoneme state is decoded into a text sequence through the Viterbi algorithm after identifying the triphone phoneme state through the recognition module to achieve the final recognition effect. The fusion features can also be spliced to the intermediate features of the separated and reconstructed U_Net network to reconstruct a separated spectrogram, and the spectrogram can be restored into a separated speech signal after ISTFT transformation.
本发明还公开了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现所述用于区域配电网的智能调度指挥与运营系统。The invention also discloses an electronic device, which includes a memory, a processor, and a computer program stored on the memory and operable on the processor. Intelligent dispatch command and operation system.
本发明还公开了一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现所述用于区域配电网的智能调度指挥与运营系统。The invention also discloses a non-transitory computer-readable storage medium, on which a computer program is stored, and when the computer program is executed by a processor, the intelligent dispatching command and operation system for the regional power distribution network is realized.
值得一提的是,本发明专利申请涉及的配电网等技术特征应被视为现有技术,这些技术特征的具体结构、工作原理以及可能涉及到的控制方式、空间布置方式采用本领域的常规选择即可,不应被视为本发明专利的发明点所在,本发明专利不做进一步具体展开详述。It is worth mentioning that the distribution network and other technical features involved in the patent application of the present invention should be regarded as prior art. Conventional selection is sufficient, and should not be regarded as the invention point of the patent of the present invention, and the patent of the present invention will not be further elaborated in detail.
对于本领域的技术人员而言,依然可以对前述各实施例所记载的技术方案进行修改,或对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围。For those skilled in the art, it is still possible to modify the technical solutions described in the foregoing embodiments, or to perform equivalent replacements for some of the technical features. Any modifications made within the spirit and principles of the present invention, Equivalent replacements, improvements, etc., should all be included in the protection scope of the present invention.
Claims (8)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211118157.5A CN115910066A (en) | 2022-09-15 | 2022-09-15 | Intelligent dispatching command and operation system for regional power distribution network |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211118157.5A CN115910066A (en) | 2022-09-15 | 2022-09-15 | Intelligent dispatching command and operation system for regional power distribution network |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115910066A true CN115910066A (en) | 2023-04-04 |
Family
ID=86475022
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211118157.5A Pending CN115910066A (en) | 2022-09-15 | 2022-09-15 | Intelligent dispatching command and operation system for regional power distribution network |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115910066A (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116229377A (en) * | 2023-05-06 | 2023-06-06 | 成都三合力通科技有限公司 | Personnel control alarm system and method |
| CN116863233A (en) * | 2023-07-13 | 2023-10-10 | 福州大学 | An intelligent identification method for high-resistance ground fault in distribution network based on image classification |
| CN117194648A (en) * | 2023-11-07 | 2023-12-08 | 福建神威系统集成有限责任公司 | Intelligent charging pile management platform software method and system |
| CN117370818A (en) * | 2023-12-05 | 2024-01-09 | 四川发展环境科学技术研究院有限公司 | Intelligent diagnosis method and intelligent environment-friendly system for water supply and drainage pipe network based on artificial intelligence |
| CN118262706A (en) * | 2024-04-22 | 2024-06-28 | 广东电网有限责任公司东莞供电局 | An artificial intelligence distribution network dispatching system based on speech recognition |
| CN119358939A (en) * | 2024-10-25 | 2025-01-24 | 应急管理部大数据中心 | An intelligent emergency command and dispatch system and method |
| CN119601009A (en) * | 2024-12-09 | 2025-03-11 | 小哆智能科技(北京)有限公司 | A method and system for joint recognition of speech and lip movement based on multimodal self-supervised learning |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111326143A (en) * | 2020-02-28 | 2020-06-23 | 科大讯飞股份有限公司 | Voice processing method, device, equipment and storage medium |
| CN111583916A (en) * | 2020-05-19 | 2020-08-25 | 科大讯飞股份有限公司 | Voice recognition method, device, equipment and storage medium |
| CN113792538A (en) * | 2021-08-27 | 2021-12-14 | 北京科东电力控制系统有限责任公司 | Method and device for quickly generating operation ticket of power distribution network |
| CN114171021A (en) * | 2021-11-29 | 2022-03-11 | 国网江苏省电力有限公司南京供电分公司 | Distribution network virtual scheduling system and method based on artificial intelligence |
| CN114529862A (en) * | 2021-11-11 | 2022-05-24 | 国网浙江省电力有限公司平湖市供电公司 | Intelligent monitoring method for SOE information |
| CN114627873A (en) * | 2021-11-11 | 2022-06-14 | 国网浙江省电力有限公司平湖市供电公司 | Spoken language text generation method for voice recognition |
| CN114945058A (en) * | 2022-04-29 | 2022-08-26 | 国网浙江省电力有限公司杭州市临安区供电公司 | Power inquiry system and method based on virtual agent |
-
2022
- 2022-09-15 CN CN202211118157.5A patent/CN115910066A/en active Pending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111326143A (en) * | 2020-02-28 | 2020-06-23 | 科大讯飞股份有限公司 | Voice processing method, device, equipment and storage medium |
| CN111583916A (en) * | 2020-05-19 | 2020-08-25 | 科大讯飞股份有限公司 | Voice recognition method, device, equipment and storage medium |
| CN113792538A (en) * | 2021-08-27 | 2021-12-14 | 北京科东电力控制系统有限责任公司 | Method and device for quickly generating operation ticket of power distribution network |
| CN114529862A (en) * | 2021-11-11 | 2022-05-24 | 国网浙江省电力有限公司平湖市供电公司 | Intelligent monitoring method for SOE information |
| CN114627873A (en) * | 2021-11-11 | 2022-06-14 | 国网浙江省电力有限公司平湖市供电公司 | Spoken language text generation method for voice recognition |
| CN114171021A (en) * | 2021-11-29 | 2022-03-11 | 国网江苏省电力有限公司南京供电分公司 | Distribution network virtual scheduling system and method based on artificial intelligence |
| CN114945058A (en) * | 2022-04-29 | 2022-08-26 | 国网浙江省电力有限公司杭州市临安区供电公司 | Power inquiry system and method based on virtual agent |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116229377A (en) * | 2023-05-06 | 2023-06-06 | 成都三合力通科技有限公司 | Personnel control alarm system and method |
| CN116229377B (en) * | 2023-05-06 | 2023-08-04 | 成都三合力通科技有限公司 | A system and method for personnel control and alarm |
| CN116863233A (en) * | 2023-07-13 | 2023-10-10 | 福州大学 | An intelligent identification method for high-resistance ground fault in distribution network based on image classification |
| CN116863233B (en) * | 2023-07-13 | 2025-05-27 | 福州大学 | An intelligent identification method for high-resistance grounding fault in distribution network based on image classification |
| CN117194648A (en) * | 2023-11-07 | 2023-12-08 | 福建神威系统集成有限责任公司 | Intelligent charging pile management platform software method and system |
| CN117194648B (en) * | 2023-11-07 | 2024-03-26 | 福建神威系统集成有限责任公司 | Intelligent charging pile management platform software method and system |
| CN117370818A (en) * | 2023-12-05 | 2024-01-09 | 四川发展环境科学技术研究院有限公司 | Intelligent diagnosis method and intelligent environment-friendly system for water supply and drainage pipe network based on artificial intelligence |
| CN117370818B (en) * | 2023-12-05 | 2024-02-09 | 四川发展环境科学技术研究院有限公司 | Intelligent diagnosis method and intelligent environment-friendly system for water supply and drainage pipe network based on artificial intelligence |
| CN118262706A (en) * | 2024-04-22 | 2024-06-28 | 广东电网有限责任公司东莞供电局 | An artificial intelligence distribution network dispatching system based on speech recognition |
| CN118262706B (en) * | 2024-04-22 | 2025-03-11 | 广东电网有限责任公司东莞供电局 | Artificial intelligence distribution network scheduling system based on voice recognition |
| CN119358939A (en) * | 2024-10-25 | 2025-01-24 | 应急管理部大数据中心 | An intelligent emergency command and dispatch system and method |
| CN119601009A (en) * | 2024-12-09 | 2025-03-11 | 小哆智能科技(北京)有限公司 | A method and system for joint recognition of speech and lip movement based on multimodal self-supervised learning |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN115910066A (en) | Intelligent dispatching command and operation system for regional power distribution network | |
| CN113470662B (en) | Generating and using text-to-speech data for keyword detection system and speaker adaptation in speech recognition system | |
| CN118471201B (en) | Efficient self-adaptive hotword error correction method and system for speech recognition engine | |
| CN113205792A (en) | Mongolian speech synthesis method based on Transformer and WaveNet | |
| EP4409568B1 (en) | Contrastive siamese network for semi-supervised speech recognition | |
| CN112397054A (en) | Power dispatching voice recognition method | |
| CN113257221B (en) | Voice model training method based on front-end design and voice synthesis method | |
| CN114420169B (en) | Emotion recognition method and device and robot | |
| KR20250048367A (en) | Data processing system and method for speech recognition model, speech recognition method | |
| CN105810191A (en) | Prosodic information-combined Chinese dialect identification method | |
| CN112331207B (en) | Service content monitoring method, device, electronic equipment and storage medium | |
| CN114512121A (en) | Speech synthesis method, model training method and device | |
| Romana et al. | Automatic disfluency detection from untranscribed speech | |
| CN115223537B (en) | Voice synthesis method and device for air traffic control training scene | |
| CN113362803B (en) | ARM side offline speech synthesis method, ARM side offline speech synthesis device and storage medium | |
| CN120632013B (en) | Intelligent Dialogue Scene Analysis Method Based on AI Large Model | |
| CN114529862A (en) | Intelligent monitoring method for SOE information | |
| WO2025183882A1 (en) | Using synthetic data to improve word error rate of differentially private asr models | |
| Das et al. | A survey on audio-visual speech recognition system | |
| Rangarajan et al. | Exploiting prosodic features for dialog act tagging in a discriminative modeling framework | |
| CN114596852A (en) | An on-site call management voice assistant system, management method, medium and terminal | |
| Xu et al. | Braille-to-Speech Generator: Audio Generation Based on Joint Fine-Tuning of CLIP and Fastspeech2 | |
| Kuriakose et al. | Dip Into: A Novel Method for Visual Speech Recognition using Deep Learning | |
| CN119400169B (en) | Speech translation method, electronic device, and computer-readable storage medium | |
| Jiang et al. | ControlAudio: Tackling Text-Guided, Timing-Indicated and Intelligible Audio Generation via Progressive Diffusion Modeling |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |