CN115688026A - Model training method, text classification method and related equipment for audit field - Google Patents
Model training method, text classification method and related equipment for audit field Download PDFInfo
- Publication number
- CN115688026A CN115688026A CN202211400670.3A CN202211400670A CN115688026A CN 115688026 A CN115688026 A CN 115688026A CN 202211400670 A CN202211400670 A CN 202211400670A CN 115688026 A CN115688026 A CN 115688026A
- Authority
- CN
- China
- Prior art keywords
- audit
- data
- model
- training
- original
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images





Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
技术领域technical field
本申请涉及审计技术领域,尤其涉及一种用于审计领域的模型训练方法、文本分类方法及相关设备。The present application relates to the technical field of auditing, in particular to a model training method, a text classification method and related equipment used in the auditing field.
背景技术Background technique
预训练语言模型的出发点是一个通用的语言模型,具有语义的解析能力,可以理解为一个处理语言的神经中枢。从第一个预训练语言模型BERT发布至今,已经在多个热门任务下得到应用。无论是工业界还是科研界,对预训练模型的使用方式逐渐灵活,能从预训练模型中拆解出适合任务的部分并组装到本领域的实际任务模型中,以使其在本领域中更好地发挥作用。但是,目前预训练模型在审计领域的应用并不多,如何训练得到适合审计领域的分类模型是亟待解决的问题。The starting point of the pre-trained language model is a general language model with semantic analysis capabilities, which can be understood as a nerve center for language processing. Since the release of the first pre-trained language model BERT, it has been applied in many popular tasks. Whether it is industry or scientific research, the use of pre-training models is becoming more and more flexible. Parts suitable for tasks can be disassembled from pre-training models and assembled into actual task models in this field, so that they can be more effective in this field. work well. However, there are not many applications of pre-training models in the audit field at present, and how to train a classification model suitable for the audit field is an urgent problem to be solved.
发明内容Contents of the invention
有鉴于此,本申请的目的在于提出一种用于审计领域的模型训练方法、文本分类方法及相关设备。In view of this, the purpose of this application is to propose a model training method, text classification method and related equipment used in the field of auditing.
基于上述目的,本申请的第一方面提供了一种用于审计领域的模型训练方法,包括:Based on the above purpose, the first aspect of the present application provides a model training method for the field of auditing, including:
获取原始审计数据;Obtain raw audit data;
对所述原始审计数据进行预处理,得到原始训练数据;Preprocessing the original audit data to obtain original training data;
基于所述原始训练数据对神经网络模型进行预训练,得到预训练审计模型;Pre-training the neural network model based on the original training data to obtain a pre-training audit model;
对所述原始审计数据进行标注,得到训练样本数据;Marking the original audit data to obtain training sample data;
基于所述训练样本数据对所述预训练审计模型进行训练,得到审计文本分类模型。The pre-trained audit model is trained based on the training sample data to obtain an audit text classification model.
可选的,所述对所述原始审计数据进行预处理,包括:对所述原始审计数据进行数据去重、格式转换和数据填充。Optionally, the preprocessing of the original audit data includes: performing data deduplication, format conversion and data filling on the original audit data.
可选的,所述对所述原始审计数据进行标注,得到训练样本数据,包括;Optionally, the labeling of the original audit data to obtain training sample data includes;
对所述原始审计数据进行数据清洗操作;Perform data cleaning operations on the original audit data;
基于预设的审计分类标签对经过数据清洗操作的原始审计数据进行标注,得到所述训练样本数据。The original audit data after the data cleaning operation is marked based on the preset audit classification labels to obtain the training sample data.
可选的,所述基于所述训练样本数据对所述预训练审计模型进行训练,包括:Optionally, the training of the pre-trained audit model based on the training sample data includes:
在所述预训练审计模型上叠加softmax层,得到初始分类模型;Superimposing a softmax layer on the pre-trained audit model to obtain an initial classification model;
通过所述训练样本数据对所述初始分类模型进行训练,得到所述审计模型进行训练。The initial classification model is trained by using the training sample data to obtain the audit model for training.
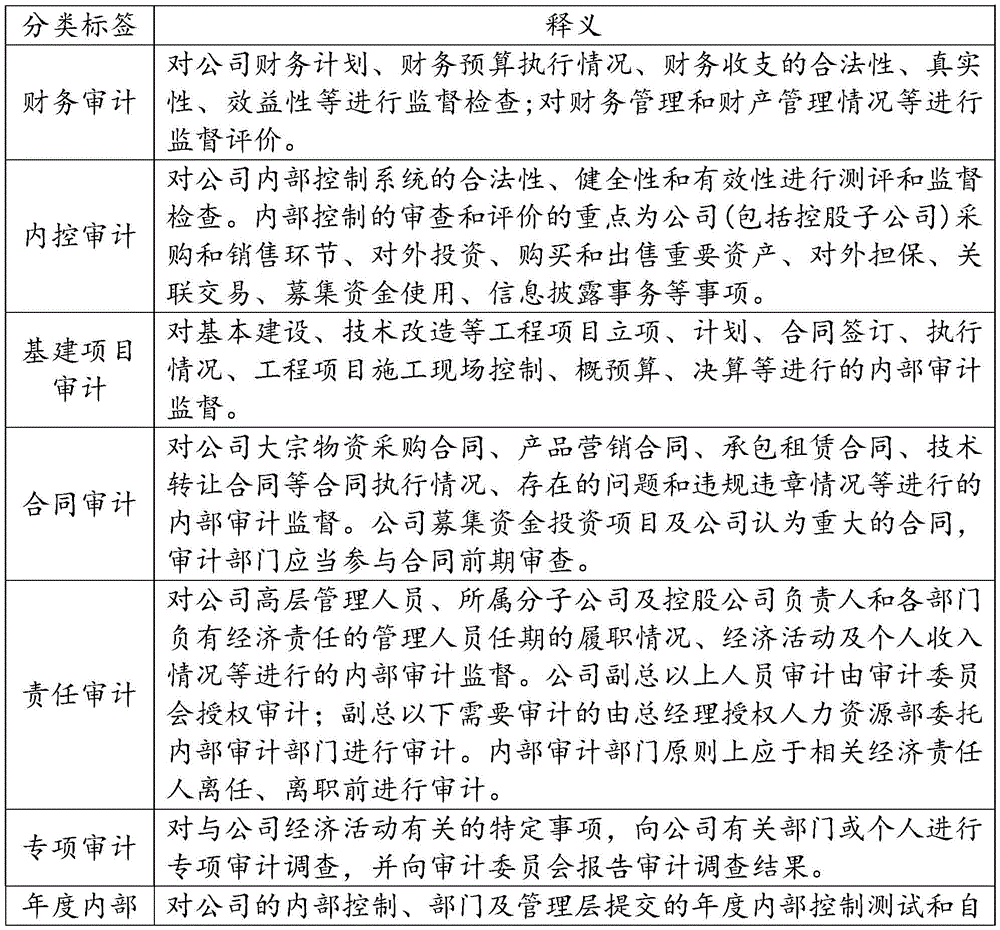
可选的,所述预设的审计分类标签至少包括财务审计、内控审计、基建项目审计、合同审计、责任审计、专项审计、年度内部控制测试与自我评价审计和其它审计。Optionally, the preset audit classification tags include at least financial audit, internal control audit, infrastructure project audit, contract audit, responsibility audit, special audit, annual internal control test and self-evaluation audit and other audits.
本申请的第二方面提供了一种应用第一方面所述的审计文本分类模型进行文本分类的方法,包括:The second aspect of the present application provides a method for text classification using the audit text classification model described in the first aspect, including:
获取待分类审计数据;Obtain audit data to be classified;
将所述待分类审计数据输入至所述审计文本分类模型,经由所述审计文本分类模型输入所述待分类审计数据对应的审计类型。The audit data to be classified is input into the audit text classification model, and the audit type corresponding to the audit data to be classified is input via the audit text classification model.
本申请的第三方面提供了一种用于审计领域的模型训练装置,包括:The third aspect of the present application provides a model training device for the field of auditing, including:
第一获取模块,被配置为获取原始审计数据;The first acquisition module is configured to acquire original audit data;
预处理模块,被配置为对所述原始审计数据进行预处理,得到原始训练数据;A preprocessing module configured to preprocess the original audit data to obtain original training data;
第一训练模块,被配置为基于所述原始训练数据对神经网络模型进行预训练,得到预训练审计模型;The first training module is configured to pre-train the neural network model based on the original training data to obtain a pre-trained audit model;
标注模块,被配置为对所述原始审计数据进行标注,得到训练样本数据;An annotation module configured to annotate the original audit data to obtain training sample data;
第二训练模块,被配置为基于所述训练样本数据对所述预训练审计模型进行训练,得到审计文本分类模型。The second training module is configured to train the pre-trained audit model based on the training sample data to obtain an audit text classification model.
本申请的第四方面提供了一种应用第三方面所述的审计文本分类模型进行文本分类的装置,包括:The fourth aspect of the present application provides a device for text classification using the audit text classification model described in the third aspect, including:
第二获取模块,被配置为获取待分类审计数据;The second acquisition module is configured to acquire audit data to be classified;
分类模块,被配置为将所述待分类审计数据输入至所述审计文本分类模型,经由所述审计文本分类模型输入所述待分类审计数据对应的审计类型。The classification module is configured to input the audit data to be classified into the audit text classification model, and input the audit type corresponding to the audit data to be classified via the audit text classification model.
本申请还提供了一种电子设备,包括存储器、处理器及存储在所述存储器上并可由所述处理器执行的计算机程序,所述处理器在执行所述计算机程序时实现如上所述的方法。The present application also provides an electronic device, including a memory, a processor, and a computer program stored on the memory and executable by the processor, and the processor implements the above-mentioned method when executing the computer program .
本申请还提供了一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令用于使计算机执行如上所述的方法。The present application also provides a non-transitory computer-readable storage medium, where the non-transitory computer-readable storage medium stores computer instructions, and the computer instructions are used to cause a computer to execute the above method.
从上面所述可以看出,本申请提供的用于审计领域的模型训练方法、文本分类方法及相关设备,对获取的原始审计数据进行预处理得到原始训练数据,采用原始训练数据对神经网络模型进行预训练,得到审计领域的预训练审计模型,为审计领域文本分类提供基础。对原始审计数据进行标注,形成训练样本数据,采用训练样本数据对预训练审计模型进行训练,对预训练审计模型的参数进行微调,以得到审计文本分类模型,通过审计文本分类模型对待分类的审计数据进行精确的文本分类。本申请通过两次训练过程得到审计领域的文本分类模型,通过预训练和微调的方式对神经网络模型的参数进行训练,提升神经网络模型在审计领域的适用性,使其输出较为准确的审计类型。It can be seen from the above that the model training method, text classification method and related equipment used in the audit field provided by the application preprocess the acquired original audit data to obtain the original training data, and use the original training data to train the neural network model. Perform pre-training to obtain a pre-trained audit model in the audit field, which provides a basis for text classification in the audit field. Label the original audit data to form training sample data, use the training sample data to train the pre-training audit model, fine-tune the parameters of the pre-training audit model to obtain the audit text classification model, and use the audit text classification model to treat classified audit data for precise text classification. This application obtains the text classification model in the audit field through two training processes, and trains the parameters of the neural network model through pre-training and fine-tuning to improve the applicability of the neural network model in the audit field, so that it can output more accurate audit types .
附图说明Description of drawings
为了更清楚地说明本申请或相关技术中的技术方案,下面将对实施例或相关技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the technical solutions in the present application or related technologies, the following will briefly introduce the accompanying drawings that need to be used in the description of the embodiments or related technologies. Obviously, the accompanying drawings in the following description are only for this application Embodiments, for those of ordinary skill in the art, other drawings can also be obtained based on these drawings without any creative effort.
图1为本申请实施例的用于审计领域的模型训练方法的流程示意图;Fig. 1 is a schematic flow diagram of a model training method for the audit field according to an embodiment of the present application;
图2为本申请实施例的应用审计文本分类模型进行文本分类的方法的流程示意图;FIG. 2 is a schematic flow diagram of a method for text classification using an audit text classification model according to an embodiment of the present application;
图3为本申请实施例的用于审计领域的模型训练装置的结构示意图;FIG. 3 is a schematic structural diagram of a model training device used in the audit field according to an embodiment of the present application;
图4为本申请实施例的应用审计文本分类模型进行文本分类的装置的结构示意图;4 is a schematic structural diagram of a device for text classification using an audit text classification model according to an embodiment of the present application;
图5为本申请实施例的电子设备结构示意图。FIG. 5 is a schematic structural diagram of an electronic device according to an embodiment of the present application.
具体实施方式Detailed ways
为使本申请的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本申请进一步详细说明。In order to make the purpose, technical solutions and advantages of the present application clearer, the present application will be further described in detail below in conjunction with specific embodiments and with reference to the accompanying drawings.
需要说明的是,除非另外定义,本申请实施例使用的技术术语或者科学术语应当为本申请所属领域内具有一般技能的人士所理解的通常意义。本申请实施例中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。It should be noted that, unless otherwise defined, the technical terms or scientific terms used in the embodiments of the present application shall have the usual meanings understood by those skilled in the art to which the present application belongs. "First", "second" and similar words used in the embodiments of the present application do not indicate any order, quantity or importance, but are only used to distinguish different components. "Comprising" or "comprising" and similar words mean that the elements or items appearing before the word include the elements or items listed after the word and their equivalents, without excluding other elements or items. Words such as "connected" or "connected" are not limited to physical or mechanical connections, but may include electrical connections, whether direct or indirect. "Up", "Down", "Left", "Right" and so on are only used to indicate the relative positional relationship. When the absolute position of the described object changes, the relative positional relationship may also change accordingly.
以下结合附图来详细说明本申请的实施例。Embodiments of the present application will be described in detail below in conjunction with the accompanying drawings.
本申请提供了一种用于审计领域的模型训练方法,参考图1,包括以下步骤:This application provides a model training method for the audit field, referring to Figure 1, including the following steps:
步骤102、获取原始审计数据。
具体的,原始审计数据可以通过网络爬取或从现有数据库中获取,本实施例对于具体获取方式不做限定。原始审计数据包括审计单位、被审计单位、审计问题等等。Specifically, the original audit data can be acquired through web crawling or from an existing database, and this embodiment does not limit the specific acquisition method. The original audit data includes the audit unit, the audited unit, audit questions and so on.
步骤104、对所述原始审计数据进行预处理,得到原始训练数据。Step 104: Perform preprocessing on the original audit data to obtain original training data.
获取的原始审计数据存在重复、缺失或格式不统一的问题,需要对原始审计数据进行预处理,得到原始训练数据,以对后续神经网络模型的训练提供基础数据。The obtained original audit data has the problem of duplication, missing or inconsistent format. It is necessary to preprocess the original audit data to obtain the original training data to provide basic data for the training of the subsequent neural network model.
步骤106、基于所述原始训练数据对神经网络模型进行预训练,得到预训练审计模型。
本步骤中的神经网络模型为BERT(Bidirectional Encoder Representationfrom Transformers)模型,BERT模型是一个预训练的语言表征模型。该模型有以下主要优点:1)采用MLM(masked language model)对双向的Transformers进行预训练,以生成深层的双向语言表征;2)预训练后,只需要添加一个额外的输出层进行微调,就可以在各种各样的下游任务中取得最优化的表现。但是,未经预训练的BERT模型并不适合于审计领域,需要通过审计领域的原始训练数据对BERT模型进行预训练,让SJ-BERT模型隐式地学习到了审计领域的语法语义知识,以便后续将学到的知识迁移到下游任务,形成预训练审计模型SJ-BERT。本步骤中的SJ-BERT为预训练大模型,所述预训练大模型是指通过自监督学习从大规模数据中获得与具体任务无关的预训练模型。大模型的模型参数量和神经网络的层数比普通深度学习模型大。得到了预训练审计模型之后才能进一步通过微调得到最终的审计文本分类模型。The neural network model in this step is the BERT (Bidirectional Encoder Representation from Transformers) model, and the BERT model is a pre-trained language representation model. The model has the following main advantages: 1) MLM (masked language model) is used to pre-train bidirectional Transformers to generate deep bidirectional language representations; 2) After pre-training, only an additional output layer needs to be added for fine-tuning, and the Optimal performance can be achieved in a variety of downstream tasks. However, the BERT model without pre-training is not suitable for the audit field. It is necessary to pre-train the BERT model through the original training data in the audit field, so that the SJ-BERT model implicitly learns the grammatical and semantic knowledge of the audit field, so that subsequent Transfer the learned knowledge to downstream tasks to form a pre-trained audit model SJ-BERT. The SJ-BERT in this step is a pre-trained large model, and the pre-trained large model refers to a pre-trained model that is not related to specific tasks obtained from large-scale data through self-supervised learning. The amount of model parameters of the large model and the number of layers of the neural network are larger than those of ordinary deep learning models. After the pre-trained audit model is obtained, the final audit text classification model can be further obtained through fine-tuning.
步骤108、对所述原始审计数据进行标注,得到训练样本数据。原始审计数据为无标签数据,通过对原始审计数据进行打标签,以使每一个原始审计数据均对应一个固定类型的标签,全部标注完成后,得到训练样本数据。Step 108: Mark the original audit data to obtain training sample data. The original audit data is unlabeled data. By labeling the original audit data, each original audit data corresponds to a fixed type of label. After all the labels are completed, the training sample data is obtained.
步骤110、基于所述训练样本数据对所述预训练审计模型进行训练,得到审计文本分类模型。Step 110: Train the pre-trained audit model based on the training sample data to obtain an audit text classification model.
通过带有标签的训练样本数据对SJ-BERT进行训练,也即对SJ-BERT模型的参数进行微调,微调后SJ-BERT模型能够输出较为准确的文本类型,微调之后的模型为审计文本模型。SJ-BERT is trained through labeled training sample data, that is, the parameters of the SJ-BERT model are fine-tuned. After fine-tuning, the SJ-BERT model can output more accurate text types, and the fine-tuned model is the audit text model.
基于上述步骤102至步骤110,对获取的原始审计数据进行预处理得到原始训练数据,采用原始训练数据对神经网络模型进行预训练,得到审计领域的预训练审计模型,为审计领域文本分类提供基础。对原始审计数据进行标注,形成训练样本数据,采用训练样本数据对预训练审计模型进行训练,对预训练审计模型的参数进行微调,以得到审计文本分类模型,通过审计文本分类模型对待分类的审计数据进行精确的文本分类。本申请通过两次训练过程得到审计领域的文本分类模型,通过预训练和微调的方式对神经网络模型的参数进行训练,提升神经网络模型在审计领域的适用性,使其输出较为准确的审计类型。Based on the
在一些实施例中,所述对所述原始审计数据进行预处理,包括:对所述原始审计数据进行数据去重、格式转换和数据填充。获取的原始审计数据存在重复、缺失或格式不统一的问题,需要对其进行预处理,具体的预处理包括数据去重、格式转换和数据填充。通过数据去重除去原始审计数据中的重复数据,过滤掉不必要的数据,减少后续的数据处理量。格式转换是将原始审计数据中的数据格式进行统一,由于原始审计数据的来源不同,其中的数据格式不完全相同,为了方便后续的数据标注和模型训练,需要对原始审计数据的格式进行统一。由于原始审计数据存在数据缺失的现象,通过匹配规则或人工的方式对缺失的数据进行填充,以进一步完善原始审计数据。In some embodiments, the preprocessing of the original audit data includes: performing data deduplication, format conversion and data filling on the original audit data. The obtained original audit data has the problem of duplication, missing or inconsistent format, and it needs to be preprocessed. The specific preprocessing includes data deduplication, format conversion and data filling. Data deduplication is used to remove duplicate data in the original audit data, filter out unnecessary data, and reduce the amount of subsequent data processing. Format conversion is to unify the data format in the original audit data. Since the source of the original audit data is different, the data format is not exactly the same. In order to facilitate subsequent data labeling and model training, it is necessary to unify the format of the original audit data. Due to the lack of data in the original audit data, the missing data is filled by matching rules or manually to further improve the original audit data.
在一些实施例中,所述对所述原始审计数据进行标注,得到训练样本数据,包括:In some embodiments, the labeling of the original audit data to obtain training sample data includes:
对所述原始审计数据进行数据清洗操作;Perform data cleaning operations on the original audit data;
基于预设的审计分类标签对经过数据清洗操作的原始审计数据进行标注,得到所述训练样本数据。The original audit data after the data cleaning operation is marked based on the preset audit classification labels to obtain the training sample data.
本实施例中的数据清洗操作与上述实施例中的预处理操作相同,此处不再赘述。审计领域的技术人员基于本领域的常规审计类型制定审计分类标签,再根据审计分类标签对原始审计数据进行标注,技术人员通过AI平台对原始审计数据进行人工标注,标注的格式为标签+分隔符+审计数据。其中,审计分类标签至少包括财务审计、内控审计、基建项目审计、合同审计、责任审计、专项审计、年度内部控制测试与自我评价审计和其它审计,上述审计分类标签的释义如下表1所示。The data cleaning operation in this embodiment is the same as the preprocessing operation in the above embodiment, and will not be repeated here. The technicians in the audit field formulate audit classification labels based on the conventional audit types in this field, and then mark the original audit data according to the audit classification labels. The technicians manually mark the original audit data through the AI platform, and the label format is label + separator + Audit data. Among them, the audit classification labels include at least financial audit, internal control audit, infrastructure project audit, contract audit, responsibility audit, special audit, annual internal control test and self-evaluation audit, and other audits. The interpretation of the above audit classification labels is shown in Table 1 below.
表1审计分类标签及释义Table 1 Audit classification labels and interpretation

在一些实施例中,所述基于所述训练样本数据对所述预训练审计模型进行训练,包括:In some embodiments, the training of the pre-trained audit model based on the training sample data includes:
在所述预训练审计模型上叠加softmax层,得到初始分类模型;Superimposing a softmax layer on the pre-trained audit model to obtain an initial classification model;
通过所述训练样本数据对所述初始分类模型进行训练,得到所述审计文本分类模型。The initial classification model is trained through the training sample data to obtain the audit text classification model.
具体的,预训练审计模型SJ-BERT的输出包括4种类型,分别为:last_hidden_state:表示最后一个隐藏层的序列的输出;pooler_output:标志[CLS]的输出;hidden_states:表示一个元组,它的第一个元素是embedding,其余元素是各层的输出;attentions:表示一个元组,它的元素是每一层的注意力权重,用于计算自注意力头的加权平均值。在所述预训练审计模型上叠加softmax层得到初始分类模型,也即将SJ-BERT输出pooler_output中的[CLS]作为softmax层的输入,经由softmax层输出模型的分类结果。采用训练样本数据对初始分类模型进行训练,以使叠加了softmax层的SJ-BERT模型学习分类过程。训练时,将训练样本数据划分为训练数据和测试数据,示例性的,划分比例可以为9:1,具体的模型参数表如表2所示。训练结束后,得到审计文本分类模型,通过审计文本分类模型能够对待分类的审计数据进行文本类型的分类,辅助审计领域技术人员对待分类审计数据进行分类,大大的提高了分类效率,为审计人员后续工作提供基础数据。Specifically, the output of the pre-trained audit model SJ-BERT includes 4 types, namely: last_hidden_state: indicates the output of the sequence of the last hidden layer; pooler_output: the output of the flag [CLS]; hidden_states: indicates a tuple, its The first element is embedding, and the remaining elements are the output of each layer; attentions: Represents a tuple whose elements are the attention weights of each layer, which are used to calculate the weighted average of the self-attention heads. Superimpose the softmax layer on the pre-trained audit model to obtain the initial classification model, that is, the [CLS] in the SJ-BERT output pooler_output is used as the input of the softmax layer, and the classification result of the model is output through the softmax layer. The training sample data is used to train the initial classification model, so that the SJ-BERT model superimposed with the softmax layer learns the classification process. During training, the training sample data is divided into training data and test data. Exemplarily, the division ratio may be 9:1. The specific model parameter table is shown in Table 2. After the training, the audit text classification model is obtained. The audit text classification model can be used to classify the text types of the audit data to be classified, and assist the technicians in the audit field to classify the classified audit data, which greatly improves the classification efficiency and provides auditors with follow-up The job provides the underlying data.
表2模型参数表Table 2 Model parameter list
本申请还提供了一种应用如上实施例所述的审计文本分类模型进行文本分类的方法,参考图2,包括:The present application also provides a method for text classification using the audit text classification model described in the above embodiment, referring to Figure 2, including:
步骤202、获取待分类审计数据,待分类审计数据可以是当前获取到的审计数据,或审计人员当前需要进行分类的审计数据,审计数据具体可以为审计报告或一段审计文本等等。
步骤204、将所述待分类审计数据输入至所述审计文本分类模型,经由所述审计文本分类模型输入所述待分类审计数据对应的审计类型。将待分类审计数据输入至审计文本分类模型中,通过模型进行嵌入,并依次在模型的各个神经层内进行传输,通过审计文本分类模型的输出层输出待分类审计数据对应的文本类型。例如,将待分类审计数据输出至审计文本分类模型中,经由模型输出的文本标签类型为财务审计。Step 204: Input the audit data to be classified into the audit text classification model, and input the audit type corresponding to the audit data to be classified via the audit text classification model. The audit data to be classified is input into the audit text classification model, embedded through the model, and transmitted in each neural layer of the model in turn, and the text type corresponding to the audit data to be classified is output through the output layer of the audit text classification model. For example, the audit data to be classified is output to the audit text classification model, and the text label type output through the model is financial audit.
需要说明的是,本申请实施例的方法可以由单个设备执行,例如一台计算机或服务器等。本实施例的方法也可以应用于分布式场景下,由多台设备相互配合来完成。在这种分布式场景的情况下,这多台设备中的一台设备可以只执行本申请实施例的方法中的某一个或多个步骤,这多台设备相互之间会进行交互以完成所述的方法。It should be noted that the method in the embodiment of the present application may be executed by a single device, such as a computer or a server. The method of this embodiment can also be applied in a distributed scenario, and is completed by cooperation of multiple devices. In the case of such a distributed scenario, one of the multiple devices may only perform one or more steps in the method of the embodiment of the present application, and the multiple devices will interact with each other to complete all described method.
需要说明的是,上述对本申请的一些实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于上述实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。It should be noted that some embodiments of the present application are described above. Other implementations are within the scope of the following claims. In some cases, the actions or steps recited in the claims can be performed in an order different from those in the above-described embodiments and still achieve desirable results. In addition, the processes depicted in the accompanying figures do not necessarily require the particular order shown, or sequential order, to achieve desirable results. Multitasking and parallel processing are also possible or may be advantageous in certain embodiments.
本申请还提供了一种用于审计领域的模型训练装置。The present application also provides a model training device used in the field of auditing.
参考图3,所述用于审计领域的模型训练装置,包括:Referring to Fig. 3, the model training device for the audit field includes:
第一获取模块302,被配置为获取原始审计数据;The first obtaining
预处理模块304,被配置为对所述原始审计数据进行预处理,得到原始训练数据;The
第一训练模块306,被配置为基于所述原始训练数据对神经网络模型进行预训练,得到预训练审计模型;The
标注模块308,被配置为对所述原始审计数据进行标注,得到训练样本数据;The
第二训练模块310,被配置为基于所述训练样本数据对所述预训练审计模型进行训练,得到审计文本分类模型。The
基于上述用于审计领域的模型训练装置,对获取的原始审计数据进行预处理得到原始训练数据,采用原始训练数据对神经网络模型进行预训练,得到审计领域的预训练审计模型,为审计领域文本分类提供基础。对原始审计数据进行标注,形成训练样本数据,采用训练样本数据对预训练审计模型进行训练,对预训练审计模型的参数进行微调,以得到审计文本分类模型,通过审计文本分类模型对待分类的审计数据进行精确的文本分类。本申请通过两次训练过程得到审计领域的文本分类模型,通过预训练和微调的方式对神经网络模型的参数进行训练,提升神经网络模型在审计领域的适用性,使其输出较为准确的审计类型。Based on the above-mentioned model training device used in the audit field, the obtained original audit data is preprocessed to obtain the original training data, and the original training data is used to pre-train the neural network model to obtain the pre-trained audit model in the audit field, which is the audit field text Classification provides the basis. Label the original audit data to form training sample data, use the training sample data to train the pre-training audit model, fine-tune the parameters of the pre-training audit model to obtain the audit text classification model, and use the audit text classification model to treat classified audit data for precise text classification. This application obtains the text classification model in the audit field through two training processes, and trains the parameters of the neural network model through pre-training and fine-tuning to improve the applicability of the neural network model in the audit field, so that it can output more accurate audit types .
在一些实施例中,所述预处理模块304,还被配置为对所述原始审计数据进行数据去重、格式转换和数据填充。In some embodiments, the
在一些实施例中,所述标注模块308,还被配置为对所述原始审计数据进行数据清洗操作;In some embodiments, the
基于预设的审计分类标签对经过数据清洗操作的原始审计数据进行标注,得到所述训练样本数据。The original audit data after the data cleaning operation is marked based on the preset audit classification labels to obtain the training sample data.
在一些实施例中,所述第二训练模块310,还被配置为在所述预训练审计模型上叠加softmax层,得到初始分类模型;In some embodiments, the
通过所述训练样本数据对所述初始分类模型进行训练,得到所述审计文本分类模型。The initial classification model is trained through the training sample data to obtain the audit text classification model.
在一些实施例中,所述预设的审计分类标签至少包括财务审计、内控审计、基建项目审计、合同审计、责任审计、专项审计、年度内部控制测试与自我评价审计和其它审计。In some embodiments, the preset audit classification tags include at least financial audit, internal control audit, infrastructure project audit, contract audit, responsibility audit, special audit, annual internal control test and self-evaluation audit and other audits.
本申请还提供了一种应用审计文本分类模型进行文本分类的装置。The present application also provides a device for classifying text by applying the audit text classifying model.
参考图4,应用审计文本分类模型进行文本分类的装置,包括:Referring to Fig. 4, the device for applying the audit text classification model to perform text classification includes:
第二获取模块402,被配置为获取待分类审计数据;The second obtaining
分类模块404,被配置为将所述待分类审计数据输入至所述审计文本分类模型,经由所述审计文本分类模型输入所述待分类审计数据对应的审计类型。The
为了描述的方便,描述以上装置时以功能分为各种模块分别描述。当然,在实施本申请时可以把各模块的功能在同一个或多个软件和/或硬件中实现。For the convenience of description, when describing the above devices, functions are divided into various modules and described separately. Of course, when implementing the present application, the functions of each module can be realized in one or more pieces of software and/or hardware.
上述实施例的装置用于实现前述任一实施例中相应的用于审计领域的模型训练方法或应用审计文本分类模型进行文本分类的方法,并且具有相应的方法实施例的有益效果,在此不再赘述。The device of the above-mentioned embodiment is used to implement the corresponding model training method for the audit field or the method of applying the audit text classification model for text classification in any of the above-mentioned embodiments, and has the beneficial effects of the corresponding method embodiments, and it is not mentioned here Let me repeat.
基于同一发明构思,与上述任意实施例方法相对应的,本申请还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上任意一实施例所述的用于审计领域的模型训练方法或应用审计文本分类模型进行文本分类的方法。Based on the same inventive concept, and corresponding to the method in any of the above embodiments, the present application also provides an electronic device, including a memory, a processor, and a computer program stored in the memory and operable on the processor, the processor When the program is executed, the model training method for the audit field or the method for text classification using the audit text classification model described in any one of the above embodiments is realized.
图5示出了本实施例所提供的一种更为具体的电子设备硬件结构示意图,该设备可以包括:处理器1010、存储器1020、输入/输出接口1030、通信接口1040和总线1050。其中处理器1010、存储器1020、输入/输出接口1030和通信接口1040通过总线1050实现彼此之间在设备内部的通信连接。FIG. 5 shows a schematic diagram of a more specific hardware structure of an electronic device provided by this embodiment. The device may include: a
处理器1010可以采用通用的CPU(Central Processing Unit,中央处理器)、微处理器、应用专用集成电路(Application Specific Integrated Circuit,ASIC)、或者一个或多个集成电路等方式实现,用于执行相关程序,以实现本说明书实施例所提供的技术方案。The
存储器1020可以采用ROM(Read Only Memory,只读存储器)、RAM(Random AccessMemory,随机存取存储器)、静态存储设备,动态存储设备等形式实现。存储器1020可以存储操作系统和其他应用程序,在通过软件或者固件来实现本说明书实施例所提供的技术方案时,相关的程序代码保存在存储器1020中,并由处理器1010来调用执行。The
输入/输出接口1030用于连接输入/输出模块,以实现信息输入及输出。输入输出/模块可以作为组件配置在设备中(图中未示出),也可以外接于设备以提供相应功能。其中输入设备可以包括键盘、鼠标、触摸屏、麦克风、各类传感器等,输出设备可以包括显示器、扬声器、振动器、指示灯等。The input/
通信接口1040用于连接通信模块(图中未示出),以实现本设备与其他设备的通信交互。其中通信模块可以通过有线方式(例如USB、网线等)实现通信,也可以通过无线方式(例如移动网络、WIFI、蓝牙等)实现通信。The
总线1050包括一通路,在设备的各个组件(例如处理器1010、存储器1020、输入/输出接口1030和通信接口1040)之间传输信息。
需要说明的是,尽管上述设备仅示出了处理器1010、存储器1020、输入/输出接口1030、通信接口1040以及总线1050,但是在具体实施过程中,该设备还可以包括实现正常运行所必需的其他组件。此外,本领域的技术人员可以理解的是,上述设备中也可以仅包含实现本说明书实施例方案所必需的组件,而不必包含图中所示的全部组件。It should be noted that although the above device only shows the
上述实施例的电子设备用于实现前述任一实施例中相应的用于审计领域的模型训练方法或应用审计文本分类模型进行文本分类的方法,并且具有相应的方法实施例的有益效果,在此不再赘述。The electronic device of the above-mentioned embodiment is used to implement the corresponding model training method for the audit field or the method of applying the audit text classification model for text classification in any of the above-mentioned embodiments, and has the beneficial effects of the corresponding method embodiments, here No longer.
基于同一发明构思,与上述任意实施例方法相对应的,本申请还提供了一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令用于使所述计算机执行如上任一实施例所述的用于审计领域的模型训练方法或应用审计文本分类模型进行文本分类的方法。Based on the same inventive concept, the present application also provides a non-transitory computer-readable storage medium corresponding to the method in any of the above-mentioned embodiments, the non-transitory computer-readable storage medium stores computer instructions, and the computer instructions use The purpose is to make the computer execute the model training method for the audit field or the method for text classification using the audit text classification model as described in any one of the above embodiments.
本实施例的计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。The computer-readable medium in this embodiment includes permanent and non-permanent, removable and non-removable media, and information storage can be realized by any method or technology. Information may be computer readable instructions, data structures, modules of a program, or other data. Examples of computer storage media include, but are not limited to, phase change memory (PRAM), static random access memory (SRAM), dynamic random access memory (DRAM), other types of random access memory (RAM), read only memory (ROM), Electrically Erasable Programmable Read-Only Memory (EEPROM), Flash memory or other memory technology, Compact Disc Read-Only Memory (CD-ROM), Digital Versatile Disc (DVD) or other optical storage, Magnetic tape cartridge, tape magnetic disk storage or other magnetic storage device or any other non-transmission medium that can be used to store information that can be accessed by a computing device.
上述实施例的存储介质存储的计算机指令用于使所述计算机执行如上任一实施例所述的用于审计领域的模型训练方法或应用审计文本分类模型进行文本分类的方法,并且具有相应的方法实施例的有益效果,在此不再赘述。The computer instructions stored in the storage medium of the above-mentioned embodiments are used to make the computer execute the model training method for the audit field or the method for text classification using the audit text classification model as described in any of the above embodiments, and has a corresponding method The beneficial effects of the embodiment will not be repeated here.
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本申请的范围(包括权利要求)被限于这些例子;在本申请的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本申请实施例的不同方面的许多其它变化,为了简明它们没有在细节中提供。Those of ordinary skill in the art should understand that: the discussion of any of the above embodiments is exemplary only, and is not intended to imply that the scope of the application (including claims) is limited to these examples; under the thinking of the application, the above embodiments or Combinations of technical features in different embodiments are also possible, steps may be implemented in any order, and there are many other variations of the different aspects of the embodiments of the application as described above, which are not provided in detail for the sake of brevity.
另外,为简化说明和讨论,并且为了不会使本申请实施例难以理解,在所提供的附图中可以示出或可以不示出与集成电路(IC)芯片和其它部件的公知的电源/接地连接。此外,可以以框图的形式示出装置,以便避免使本申请实施例难以理解,并且这也考虑了以下事实,即关于这些框图装置的实施方式的细节是高度取决于将要实施本申请实施例的平台的(即,这些细节应当完全处于本领域技术人员的理解范围内)。在阐述了具体细节(例如,电路)以描述本申请的示例性实施例的情况下,对本领域技术人员来说显而易见的是,可以在没有这些具体细节的情况下或者这些具体细节有变化的情况下实施本申请实施例。因此,这些描述应被认为是说明性的而不是限制性的。In addition, for simplicity of illustration and discussion, and so as not to obscure the embodiments of the present application, well-known power/connections associated with integrated circuit (IC) chips and other components may or may not be shown in the provided figures. ground connection. Furthermore, devices may be shown in block diagram form in order to avoid obscuring the embodiments of the present application, and this also takes into account the fact that details regarding the implementation of these block diagram devices are highly dependent on the implementation of the embodiments of the present application to be implemented. platform (ie, the details should be well within the purview of those skilled in the art). Where specific details (eg, circuits) have been set forth to describe exemplary embodiments of the present application, it will be apparent to those skilled in the art that other embodiments may be implemented without or with variations from these specific details. Implement the embodiment of the present application below. Accordingly, these descriptions should be regarded as illustrative rather than restrictive.
尽管已经结合了本申请的具体实施例对本申请进行了描述,但是根据前面的描述,这些实施例的很多替换、修改和变型对本领域普通技术人员来说将是显而易见的。例如,其它存储器架构(例如,动态RAM(DRAM))可以使用所讨论的实施例。Although the application has been described in conjunction with specific embodiments thereof, many alternatives, modifications and variations of those embodiments will be apparent to those of ordinary skill in the art from the foregoing description. For example, other memory architectures such as dynamic RAM (DRAM) may use the discussed embodiments.
本申请实施例旨在涵盖落入所附权利要求的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本申请实施例的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本申请的保护范围之内。The embodiments of the present application are intended to embrace all such alternatives, modifications and variations that fall within the broad scope of the appended claims. Therefore, any omissions, modifications, equivalent replacements, improvements, etc. within the spirit and principles of the embodiments of the present application shall be included within the protection scope of the present application.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211400670.3A CN115688026A (en) | 2022-11-09 | 2022-11-09 | Model training method, text classification method and related equipment for audit field |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211400670.3A CN115688026A (en) | 2022-11-09 | 2022-11-09 | Model training method, text classification method and related equipment for audit field |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115688026A true CN115688026A (en) | 2023-02-03 |
Family
ID=85050335
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211400670.3A Pending CN115688026A (en) | 2022-11-09 | 2022-11-09 | Model training method, text classification method and related equipment for audit field |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115688026A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117076595A (en) * | 2023-09-12 | 2023-11-17 | 中国平安财产保险股份有限公司 | Text processing methods, devices, equipment and storage media based on artificial intelligence |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111966831A (en) * | 2020-08-18 | 2020-11-20 | 创新奇智(上海)科技有限公司 | Model training method, text classification device and network model |
| CN112560486A (en) * | 2020-11-25 | 2021-03-26 | 国网江苏省电力有限公司电力科学研究院 | Power entity identification method based on multilayer neural network, storage medium and equipment |
| CN112749562A (en) * | 2020-12-31 | 2021-05-04 | 合肥工业大学 | Named entity identification method, device, storage medium and electronic equipment |
| CN113722421A (en) * | 2020-05-25 | 2021-11-30 | 中移(苏州)软件技术有限公司 | Contract auditing method and system and computer readable storage medium |
| WO2022227207A1 (en) * | 2021-04-30 | 2022-11-03 | 平安科技(深圳)有限公司 | Text classification method, apparatus, computer device, and storage medium |
-
2022
- 2022-11-09 CN CN202211400670.3A patent/CN115688026A/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113722421A (en) * | 2020-05-25 | 2021-11-30 | 中移(苏州)软件技术有限公司 | Contract auditing method and system and computer readable storage medium |
| CN111966831A (en) * | 2020-08-18 | 2020-11-20 | 创新奇智(上海)科技有限公司 | Model training method, text classification device and network model |
| CN112560486A (en) * | 2020-11-25 | 2021-03-26 | 国网江苏省电力有限公司电力科学研究院 | Power entity identification method based on multilayer neural network, storage medium and equipment |
| CN112749562A (en) * | 2020-12-31 | 2021-05-04 | 合肥工业大学 | Named entity identification method, device, storage medium and electronic equipment |
| WO2022227207A1 (en) * | 2021-04-30 | 2022-11-03 | 平安科技(深圳)有限公司 | Text classification method, apparatus, computer device, and storage medium |
Non-Patent Citations (1)
| Title |
|---|
| 赵雅欣;郑明洪;石林鑫;向菲;江金洋;尹心;: "面向电力审计领域的两阶段短文本分类方法研究", 西南大学学报(自然科学版), no. 10, 20 October 2020 (2020-10-20) * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117076595A (en) * | 2023-09-12 | 2023-11-17 | 中国平安财产保险股份有限公司 | Text processing methods, devices, equipment and storage media based on artificial intelligence |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP4006909A1 (en) | Method, apparatus and device for quality control and storage medium | |
| WO2019095782A1 (en) | Data sample label processing method and apparatus | |
| CN114443899A (en) | Video classification method, device, equipment and medium | |
| CN112528642B (en) | Automatic implicit chapter relation recognition method and system | |
| CN111611797B (en) | Method, device and equipment for marking prediction data based on Albert model | |
| CN112883188B (en) | A method, device, electronic device and storage medium for sentiment classification | |
| CN113255328B (en) | Language model training methods and application methods | |
| CN111897955A (en) | Codec-based comment generation method, device, device and storage medium | |
| CN111079944B (en) | Transfer learning model explanation implementation method and device, electronic equipment, storage medium | |
| CN114357284A (en) | Crowdsourcing task personalized recommendation method and system based on deep learning | |
| CN119832582A (en) | Multi-mode file testing method and system based on large model and automatic test | |
| CN112487803A (en) | Contract auditing method and device based on deep learning and electronic equipment | |
| CN115688026A (en) | Model training method, text classification method and related equipment for audit field | |
| US11886827B1 (en) | General intelligence for tabular data | |
| CN108446262A (en) | A kind of list generates, analysis method and device | |
| CN115712723A (en) | Training method of matching model, method for obtaining matching degree, matching method and device | |
| CN115438153A (en) | Training method and device for intention matching degree analysis model | |
| CN111061870B (en) | Article quality evaluation method and device | |
| CN114662454A (en) | Method and device for generating oil and gas documents | |
| CN119396859A (en) | Large language model data analysis method, device, computer equipment and storage medium | |
| CN114881141B (en) | Event type analysis method and related equipment | |
| CN113705206B (en) | Emotion prediction model training method, device, equipment and storage medium | |
| CN113139382A (en) | Named entity identification method and device | |
| CN115982272A (en) | Data labeling method, device and computer storage medium for urban big data management | |
| CN117540714A (en) | Method and device for detecting single meter quantity, electronic equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |