CN115687939A - Mask text matching method and medium based on multi-task learning - Google Patents
Mask text matching method and medium based on multi-task learning Download PDFInfo
- Publication number
- CN115687939A CN115687939A CN202211071421.4A CN202211071421A CN115687939A CN 115687939 A CN115687939 A CN 115687939A CN 202211071421 A CN202211071421 A CN 202211071421A CN 115687939 A CN115687939 A CN 115687939A
- Authority
- CN
- China
- Prior art keywords
- text
- mask
- matched
- text matching
- loss
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims abstract description 48
- 238000012549 training Methods 0.000 claims abstract description 21
- 238000004590 computer program Methods 0.000 claims abstract description 9
- 239000013598 vector Substances 0.000 claims description 43
- 230000006870 function Effects 0.000 claims description 31
- 238000012545 processing Methods 0.000 claims description 22
- 238000004458 analytical method Methods 0.000 claims description 5
- 230000011218 segmentation Effects 0.000 claims description 5
- 230000004913 activation Effects 0.000 claims description 4
- 238000000605 extraction Methods 0.000 abstract description 7
- 239000011159 matrix material Substances 0.000 abstract description 4
- 230000008569 process Effects 0.000 description 11
- 238000004422 calculation algorithm Methods 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 238000003058 natural language processing Methods 0.000 description 5
- 238000004364 calculation method Methods 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 238000005065 mining Methods 0.000 description 2
- 238000003062 neural network model Methods 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 238000013528 artificial neural network Methods 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 235000013399 edible fruits Nutrition 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
Images



Landscapes
- Machine Translation (AREA)
Abstract
本发明公开一种基于多任务学习的Mask文本匹配方法及介质。方法步骤包括:1)获取至少两个待匹配文本;2)对所述待匹配文本进行特征提取,得到每个待匹配文本的文本字词特征;3)建立基于BERT的文本匹配模型;4)将所有待匹配文本的文本字词特征输入到文本匹配模型,获得不同待匹配文本的匹配结果。介质包括计算机程序。本发明提出了结合数据特点构建Mask矩阵简化模型的思路,在简化模型的同时也能放大待匹配文本之间的差异,使最终模型训练的泛化能力增强。

The invention discloses a Mask text matching method and medium based on multi-task learning. The method steps include: 1) obtaining at least two texts to be matched; 2) performing feature extraction on the texts to be matched to obtain the text word features of each text to be matched; 3) establishing a text matching model based on BERT; 4) Input the text word features of all texts to be matched into the text matching model to obtain matching results of different texts to be matched. The media includes a computer program. The present invention proposes the idea of constructing a simplified model of the Mask matrix in combination with data characteristics, which can enlarge the difference between texts to be matched while simplifying the model, and enhance the generalization ability of the final model training.
Description
技术领域technical field
本发明涉及自然语言处理领域,具体是一种基于多任务学习的Mask文本匹配方法及介质。The invention relates to the field of natural language processing, in particular to a mask text matching method and medium based on multi-task learning.
背景技术Background technique
文本匹配方法旨在判断两个自然句之间的语义是否等价,是自然语言处理领域一个重要研究方向。文本匹配研究同时也具有很高的商业价值,在信息检索、智能客服等领域发挥重要作用。Text matching method aims to judge whether the semantic equivalence between two natural sentences is an important research direction in the field of natural language processing. Text matching research also has high commercial value and plays an important role in information retrieval, intelligent customer service and other fields.
近年来,神经网络模型虽然在一些标准的问题匹配评上已经取得与人类相仿甚至超越人类的准确性,但是在处理真实应用场景问题时,这些模型鲁棒性较差,在非常简单(人类很容易判断)的问题上无法做出正确判断,造成了极差的产品体验和经济损失。In recent years, although neural network models have achieved similar or even better accuracy than humans in some standard question matching evaluations, these models are less robust when dealing with real application scenarios. It is impossible to make a correct judgment on the issue of easy judgment), resulting in extremely poor product experience and economic losses.
当前大多数文本匹配任务在与训练集同分布的测试集上进行测试,效果不错,但实际却夸大了模型能力,缺乏对模型细粒度优势和劣势的真实测评,因为从工业实际的一些信息检索、智能客服场景看,很难保证应用场景与模型开发同分布。因此,本发明关注文本匹配模型在真实应用场景中的鲁棒性,从词汇、句法、语用等多个维度出发,发现当前文本匹配算法模型的不足之处,推动语义匹配技术在智能交互等工业领域的发展。Most of the current text matching tasks are tested on the test set with the same distribution as the training set, and the effect is good, but the model ability is actually exaggerated, and the real evaluation of the fine-grained advantages and disadvantages of the model is lacking, because some information retrieval from the actual industry , In terms of intelligent customer service scenarios, it is difficult to guarantee the same distribution of application scenarios and model development. Therefore, the present invention focuses on the robustness of the text matching model in real application scenarios, and discovers the shortcomings of the current text matching algorithm model from multiple dimensions such as vocabulary, syntax, and pragmatics, and promotes the application of semantic matching technology in intelligent interaction, etc. The development of the industrial field.
传统文本匹配方法有BoW、VSM、TF-IDF、BM25、Jaccord、SimHash等算法,如BM25算法通过网络字段对查询字段的覆盖程度来计算两者间的匹配得分,得分越高的文本与查询的匹配度更好,主要解决词汇层面的匹配问题,或者说词汇层面的相似度问题,而实际上,基于词汇重合度的匹配算法有很大的局限性,原因包括:词义局限,“的士”和“出租车”虽然字面上不相似,但实际为同一种交通工具;“苹果”在不同的语境下表示不同的东西,或为水果或为公司;结构局限,“机器学习”和“学习机器”虽然词汇完全重合,但表达的意思不同;知识局限,“秦始皇打Dota”,这句话虽从词法和句法上看均没问题,但结合知识看这句话是不对的,以上表明,对于文本匹配任务,不能只停留在字面匹配层面,更需要语义层面的匹配。Traditional text matching methods include algorithms such as BoW, VSM, TF-IDF, BM25, Jaccord, and SimHash. For example, the BM25 algorithm calculates the matching score between the two through the coverage of the network field on the query field. The matching degree is better, and it mainly solves the matching problem at the vocabulary level, or the similarity problem at the vocabulary level. In fact, the matching algorithm based on the coincidence degree of vocabulary has great limitations. The reasons include: the limitation of word meaning, "taxi" Although it is not similar to "taxi" in words, it is actually the same means of transportation; "apple" means different things in different contexts, either for fruit or for a company; due to structural limitations, "machine learning" and "learning Although the vocabulary of "machine" completely overlaps, the meanings expressed are different; knowledge is limited, "Qin Shihuang played Dota", although this sentence has no problem in terms of grammar and syntax, it is wrong to look at this sentence in combination with knowledge. The above shows that, For text matching tasks, we should not only stay at the level of literal matching, but also need to match at the semantic level.
深度语义匹配方法,随着深度学习在计算机视觉、语音识别和推荐系统领域中的成功运用,近年来有很多研究致力于将深度神经网络模型应用于自然语言处理任务,以降低特征工程的成本。基于神经网络训练出的Word Embedding进行文本匹配计算,训练方式简洁,所得的词向量表示的语义可计算性进一步加强,但是只利用无标注数据训练得到的Word Embedding在文本匹配度计算的实用效果上和主题模型技术相差不大,他们本质都是基于共现信息的训练,除此另外,Word Embedding本身没有解决短语、句子的语义表示问题,也没有解决匹配的非对称性问题。Deep semantic matching method, with the successful application of deep learning in the fields of computer vision, speech recognition, and recommendation systems, in recent years, many studies have devoted themselves to applying deep neural network models to natural language processing tasks to reduce the cost of feature engineering. The Word Embedding trained based on the neural network is used for text matching calculation. The training method is simple, and the semantic computability of the obtained word vector representation is further enhanced. However, the Word Embedding obtained by only using unlabeled data training has a practical effect on the text matching degree calculation. It is not much different from the topic model technology. They are essentially based on the training of co-occurrence information. In addition, Word Embedding itself does not solve the semantic representation of phrases and sentences, nor does it solve the asymmetry problem of matching.
当前文本匹配算法主要还是基于BERT的预训练语言模型,尽可能的提高文本向量语义信息。但经过预训练模型得到的文本向量,在某些场景里面并不能很好的识别文本的差异,比如:“人民币怎么换港币”与“港币怎么换人民币”两个句子在内容上差异比较小,但意思却大相径庭,因此如果单单依靠预训练模型得到文本向量,很难将从词汇、句法、语用等维度捕捉文本的差异。The current text matching algorithm is mainly based on the pre-trained language model of BERT, which improves the semantic information of the text vector as much as possible. However, the text vector obtained by the pre-trained model cannot recognize the differences in the text well in some scenarios. For example, the difference in content between the sentences "How to exchange RMB for Hong Kong dollars" and "How to exchange Hong Kong dollars for RMB" is relatively small. But the meanings are very different. Therefore, if you only rely on the pre-trained model to get the text vector, it is difficult to capture the differences in the text from the dimensions of vocabulary, syntax, and pragmatics.
可见,当前文本匹配算法存在以下缺陷:It can be seen that the current text matching algorithm has the following defects:
1)基于统计的语言模型无法表达丰富的语义信息,在一些差异比较小的短文本匹配场景很难捕捉文本之间的差异。1) The language model based on statistics cannot express rich semantic information, and it is difficult to capture the differences between texts in some short text matching scenarios with relatively small differences.
2)基于词向量和attention等算法模型需要较多的标注数据,且模型结构复杂,也没有进一步挖掘及利用文本本身的结构特征,例如句法结构、词性等。2) Algorithmic models based on word vectors and attention require a lot of labeled data, and the model structure is complex, and there is no further mining and utilization of the structural features of the text itself, such as syntactic structure and parts of speech.
3)基于预训练的文本匹配模型比较关注预训练的输出结果,并根据预训练模型的输出结果设计更复杂的网络结构做分类,没有将文本本身的结构特征与预训练模型相结合,这样其实损失了一些比较有用的先验信息。3) The text matching model based on pre-training pays more attention to the output results of pre-training, and designs a more complex network structure for classification according to the output results of the pre-training model, without combining the structural features of the text itself with the pre-training model. Some useful prior information is lost.
发明内容Contents of the invention
本发明的目的是提供一种基于多任务学习的Mask文本匹配方法,包括以下步骤:The object of the present invention is to provide a kind of Mask text matching method based on multi-task learning, comprising the following steps:
1)获取至少两个待匹配文本;1) Obtain at least two texts to be matched;
2)对所述待匹配文本进行特征提取,得到每个待匹配文本的文本字词特征;2) feature extraction is carried out to described text to be matched, obtain the text word feature of each text to be matched;
3)建立基于BERT的文本匹配模型;3) Establish a text matching model based on BERT;
4)将所有待匹配文本的文本字词特征输入到文本匹配模型,获得不同待匹配文本的匹配结果。4) Input the text word features of all texts to be matched into the text matching model to obtain matching results of different texts to be matched.
进一步,对所述待匹配目标文本进行特征提取的步骤包括:分词处理、词性标注、命名实体识别、语义角色标注、依存句法分析。Further, the step of extracting features from the target text to be matched includes: word segmentation processing, part-of-speech tagging, named entity recognition, semantic role tagging, and dependency syntax analysis.
进一步,所述目标文本字词特征包括词性特征、命名实体特征、语义角色特征和依存句法关系特征中的一个或多个。Further, the word features of the target text include one or more of part-of-speech features, named entity features, semantic role features, and dependency syntactic relationship features.
进一步,所述基于BERT的文本匹配模型包括embedding输入层、多头注意力层、前向传播层和输出层。Further, the BERT-based text matching model includes an embedding input layer, a multi-head attention layer, a forward propagation layer and an output layer.
进一步,获得不同待匹配文本的匹配结果的步骤包括:Further, the steps of obtaining matching results of different texts to be matched include:
a)利用embedding输入层对文本字词特征进行转换,得到embedding输入X,并将embedding输入X转换为特征分量Q=XWQ、特征分量K=XWK、特征分量V=XWV;WQ、WK、WV为不同特征分量对应的权重;a) Utilize the embedding input layer to convert the text word features to obtain the embedding input X, and convert the embedding input X to feature components Q=XW Q , feature components K=XW K , feature components V=XW V ; W Q , W K , W V are the weights corresponding to different feature components;
b)利用多头注意力层对embedding输入X的特征分量进行处理,得到多头注意力层处理结果MultiHead(Q,K,V),即:b) Use the multi-head attention layer to process the feature components of the embedding input X, and obtain the multi-head attention layer processing result MultiHead(Q, K, V), namely:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO (1)MultiHead (Q, K, V) = Concat (head 1 , . . . , head h ) W O (1)
式中,WO为权重;In the formula, W O is the weight;
其中,参数headi如下所示:Among them, the parameter head i is as follows:
headi=Attention(QWi Q,KWi k,VWi v),i=1,2,...,h (2)head i = Attention(QW i Q , KW i k , VW i v ), i=1, 2, . . . , h (2)
Attention(QWi Q,KWi k,VWi v)=Mask*Attention(Q,K,V) (3)Attention(QW i Q , KW i k , VW i v )=Mask*Attention(Q, K, V) (3)

式中,softmax为激活函数;dk表示词向量的维度,为了防止softmax的输入值太大,导致导数为接近0。Mask表示掩码;Attention(QWi Q,KWi k,VWi v)、Attention(Q,K,V)为中间参量;h为大于0的整数;In the formula, softmax is the activation function; d k represents the dimension of the word vector. In order to prevent the input value of softmax from being too large, the derivative is close to 0. Mask represents a mask; Attention(QW i Q , KW i k , VW i v ), Attention(Q, K, V) are intermediate parameters; h is an integer greater than 0;
c)利用前向传播层对多头注意力层处理结果MultiHead(Q,K,V)进行处理,得到前向传播层处理结果x,即:c) Use the forward propagation layer to process the processing result MultiHead (Q, K, V) of the multi-head attention layer, and obtain the processing result x of the forward propagation layer, namely:
x=norm(X+MultiHead(Q,K,V)) (5)x=norm(X+MultiHead(Q, K, V)) (5)
d)利用输出层对前向传播层处理结果x进行处理,得到基于BERT的文本匹配模型输出,作为不同待匹配文本的匹配结果;d) process the result x of the forward propagation layer by using the output layer, and obtain the output of the BERT-based text matching model as the matching result of different texts to be matched;
基于BERT的文本匹配模型输出如下所示:The output of the BERT-based text matching model is as follows:
FFN(x)=max(0,xW1+b1)W2+b2 (6)FFN(x)=max(0, xW 1 +b 1 )W 2 +b 2 (6)
式中,W1、W2为权重;b1、b2为偏置;FFN(x)为输出。In the formula, W 1 and W 2 are weights; b 1 and b 2 are biases; FFN(x) is the output.
进一步,所述embedding输入X=x1+x2;Further, the embedding input X=x 1 +x 2 ;
其中,输入分量x1和输入分量x2分别如下所示:Among them, the input component x1 and the input component x2 are as follows:
X1=Etok+Eseg+Epos (7)X 1 =E tok +E seg +E pos (7)
x2=embedding1(pos)+embedding2(ner)+embedding3(seg) (8)x 2 =embedding1(pos)+embedding2(ner)+embedding3(seg) (8)
式中,Etok、Eseg、Epos分别表示文本字词特征的Token Embedding编码、PositionEmbeddings编码和SegmentEmbeddings编码;embedding1、embedding2、embedding3表示词性、命名实体、语义角色的embedding层;pos、ner、seg表示输入文本的词性、命名体、语义角色编码。In the formula, E tok , E seg , and E pos respectively represent Token Embedding encoding, PositionEmbeddings encoding and SegmentEmbeddings encoding of text word features; embedding1, embedding2, and embedding3 represent the embedding layer of part of speech, named entity, and semantic role; pos, ner, and seg Represents the part-of-speech, nomenclature, and semantic role encoding of the input text.
进一步,所述掩码Mask为0-1变量,不同待匹配文本的词相同位置的掩码Mask=1,不同待匹配文本的词不同位置Mask=0。Further, the mask Mask is a 0-1 variable, and Mask=1 for the same position of words in different texts to be matched, and Mask=0 for different positions of words in different texts to be matched.
进一步,所述基于BERT的文本匹配模型的输出包括序列输出和向量输出;所述向量输出为分类向量,所述序列输出为词性标注向量。所述分类向量包括语义相同和语义不同。Further, the output of the BERT-based text matching model includes a sequence output and a vector output; the vector output is a classification vector, and the sequence output is a part-of-speech tagging vector. The classification vectors include semantic sameness and semantic difference.
进一步,所述基于BERT的文本匹配模型经过了预训练;Further, the BERT-based text matching model has been pre-trained;
预训练结束的标准为损失函数Loss收敛;The criterion for the end of pre-training is the convergence of the loss function Loss;
损失函数Loss如下所示:The loss function Loss is as follows:
Loss=Lossnll+Losspos-tag (9)Loss=Loss nll + Loss pos-tag (9)
式中,Lossnll为分类向量损失函数;Losspos-tag为词性标注的损失函数;In the formula, Loss nll is the classification vector loss function; Loss pos-tag is the loss function of part-of-speech tagging;
其中,分类向量损失函数Lossnll如下所示:Among them, the classification vector loss function Loss nll is as follows:

式中,n为训练样本数;j表示第j个样本;Z表示分类的类别数;c表示第c个类别;hj,c表示第j个样本属于第c个类别的概率;yj,c表示第j个样本是否属于第c个类别;yj,c=1表示第j个样本属于第c个类别;yj,c=0表示第j个样本不属于第c个类别;In the formula, n is the number of training samples; j is the jth sample; Z is the number of categories; c is the cth category; h j, c is the probability that the jth sample belongs to the cth category; y j, c indicates whether the j-th sample belongs to the c-th category; y j, c = 1 indicates that the j-th sample belongs to the c-th category; y j, c = 0 indicates that the j-th sample does not belong to the c-th category;
词性标注损失函数Losspos-tag如下所示:The part-of-speech tagging loss function Loss pos-tag is as follows:

式中,P1、P2、P3、Pn为一个样本对应的第1种、第2种、第n种可能词性标注序列的得分;Preal-path为一个样本对应的真实词性标注序列的得分。In the formula, P 1 , P 2 , P 3 , P n are the scores of the first, second, and nth possible part-of-speech tagging sequences corresponding to a sample; P real-path is the real part-of-speech tagging sequence corresponding to a sample score.
一种计算机可读存储介质,所述计算机可读介质存储有计算机程序;A computer-readable storage medium storing a computer program;
所述计算机程序被处理器执行时,实现权利要求1至9任一项所述方法的步骤。When the computer program is executed by a processor, the steps of the method described in any one of
本发明的技术效果是毋庸置疑的,本发明解决了在智能交互、自然语言理解,相似句抽取等场景中难以捕捉文本之间的差异的问题。The technical effect of the present invention is unquestionable, and the present invention solves the problem that it is difficult to capture the differences between texts in scenarios such as intelligent interaction, natural language understanding, and similar sentence extraction.
本发明针对短文本匹配模型复杂,参数大的问题,提出了结合数据特点构建Mask矩阵简化模型的思路,在简化模型的同时也能放大待匹配文本之间的差异,使最终模型训练的泛化能力增强。Aiming at the problem of complex short text matching models and large parameters, the present invention proposes the idea of constructing a simplified model of the Mask matrix in combination with data characteristics. While simplifying the model, it can also enlarge the difference between the texts to be matched, so that the final model training can be generalized Enhanced capabilities.
考虑到文本匹配之前的差异比较小,这个差异能体现在词性、句法结构的语言特征上,本发明在输入端,通过句法、实体等特征做embedding,增加了模型输入的语义信息。Considering that the difference before text matching is relatively small, this difference can be reflected in the language features of part of speech and syntactic structure. At the input end, the present invention uses syntax, entity and other features as embedding to increase the semantic information of the model input.
一般的文本匹配主要利用句向量做匹配,本发明引入多任务学习,从词粒度学习待匹配文本词性之间的差异,从而增强了模型的泛化能力。General text matching mainly uses sentence vectors for matching. The present invention introduces multi-task learning to learn the difference between parts of speech of text to be matched from word granularity, thereby enhancing the generalization ability of the model.
附图说明Description of drawings
图1为文本匹配流程图;Fig. 1 is a flow chart of text matching;
图2为文本特征挖掘流程图;Fig. 2 is a flow chart of text feature mining;
图3为Mask掩码原理图。Figure 3 is a schematic diagram of the Mask mask.
具体实施方式Detailed ways
下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。The present invention will be further described below in conjunction with the examples, but it should not be understood that the scope of the subject of the present invention is limited to the following examples. Without departing from the above-mentioned technical ideas of the present invention, various replacements and changes made according to common technical knowledge and conventional means in this field shall be included in the protection scope of the present invention.
实施例1:Example 1:
参见图1至图3,一种基于多任务学习的Mask文本匹配方法,包括以下步骤:Referring to Figures 1 to 3, a mask text matching method based on multi-task learning includes the following steps:
1)获取至少两个待匹配文本;1) Obtain at least two texts to be matched;
2)对所述待匹配文本进行特征提取,得到每个待匹配文本的文本字词特征;2) feature extraction is carried out to described text to be matched, obtain the text word feature of each text to be matched;
3)建立基于BERT的文本匹配模型;3) Establish a text matching model based on BERT;
4)将所有待匹配文本的文本字词特征输入到文本匹配模型,获得不同待匹配文本的匹配结果,匹配结果包括语义相似、语义不相似。4) Input the text word features of all texts to be matched into the text matching model to obtain matching results of different texts to be matched, and the matching results include semantic similarity and semantic dissimilarity.
对所述待匹配目标文本进行特征提取的步骤包括:分词处理、词性标注、命名实体识别、语义角色标注、依存句法分析等一系列自然语言处理操作,本发明所提出的方法借助哈工大社会计算与信息检索研究中心研发的“语言技术平台(LTP)”所提供的自然语言处理技术进行上述操作。The step of feature extraction for the target text to be matched includes: word segmentation processing, part-of-speech tagging, named entity recognition, semantic role tagging, dependency syntax analysis and a series of natural language processing operations. The method proposed in the present invention relies on the social computing and The natural language processing technology provided by the "Language Technology Platform (LTP)" developed by the Information Retrieval Research Center performs the above operations.
本方法采用哈工大语言技术平台提供的命名实体识别技术和迭代的启发式方法进行命名实体识别。后者是通过合并相连名词获取最大化名词短语,其中名词的词性只能是{ni,nh,ns,nz,j},分别代表机构名、人名、地理名、其他专有名词和缩略词。This method uses the named entity recognition technology provided by the language technology platform of Harbin Institute of Technology and the iterative heuristic method for named entity recognition. The latter is to obtain the maximum noun phrase by merging connected nouns, in which the part of speech of nouns can only be {ni, nh, ns, nz, j}, which respectively represent organization names, personal names, geographical names, other proper nouns and acronyms .
所述目标文本字词特征包括词性特征、命名实体特征、语义角色特征和依存句法关系特征中的一个或多个。The word features of the target text include one or more of part-of-speech features, named entity features, semantic role features and dependent syntactic relationship features.
所述基于BERT的文本匹配模型包括embedding输入层、多头注意力层、前向传播层和输出层。The BERT-based text matching model includes an embedding input layer, a multi-head attention layer, a forward propagation layer and an output layer.
获得不同待匹配文本的匹配结果的步骤包括:The steps for obtaining matching results of different texts to be matched include:
1)利用embedding输入层对文本字词特征进行转换,得到embedding输入X,并将embedding输入X转换为特征分量Q=XWQ、特征分量K=XWK、特征分量V=XWV;WQ、WK、WV为不同特征分量对应的权重;1) Use the embedding input layer to convert the text word features to obtain the embedding input X, and convert the embedding input X to feature components Q=XW Q , feature components K=XW K , feature components V=XW V ; W Q , W K , W V are the weights corresponding to different feature components;
2)利用多头注意力层对embedding输入X的特征分量进行处理,得到多头注意力层处理结果MultiHead(Q,K,V),即:2) Use the multi-head attention layer to process the feature components of the embedding input X, and obtain the multi-head attention layer processing result MultiHead(Q, K, V), namely:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO (1)MultiHead (Q, K, V) = Concat (head 1 , . . . , head h ) W O (1)
式中,WO为权重;In the formula, W O is the weight;
其中,参数headi如下所示:Among them, the parameter head i is as follows:
headi=Attention(QWi Q,KWi k,VWi v),i=1,2,...,h (2)head i = Attention(QW i Q , KW i k , VW i v ), i=1, 2, . . . , h (2)
Attention(QWi Q,KWi k,VWi v)=Mask*Attention(Q,K,V) (3)Attention(QW i Q , KW i k , VW i v )=Mask*Attention(Q, K, V) (3)

式中,softmax为激活函数;dk表示词向量的维度,为了防止softmax的输入值太大,导致导数为接近0。Mask表示掩码;Attention(QWi Q,KWi k,VWi v)、Attention(Q,K,V)为中间参量;h为大于0的整数;In the formula, softmax is the activation function; d k represents the dimension of the word vector. In order to prevent the input value of softmax from being too large, the derivative is close to 0. Mask represents a mask; Attention(QW i Q , KW i k , VW i v ), Attention(Q, K, V) are intermediate parameters; h is an integer greater than 0;
3)利用前向传播层对多头注意力层处理结果MultiHead(Q,K,V)进行处理,得到前向传播层处理结果x,即:3) Use the forward propagation layer to process the processing result MultiHead (Q, K, V) of the multi-head attention layer, and obtain the processing result x of the forward propagation layer, namely:
x=norm(X+MultiHead(Q,K,V)) (5)x=norm(X+MultiHead(Q, K, V)) (5)
4)利用输出层对前向传播层处理结果x进行处理,得到基于BERT的文本匹配模型输出,作为不同待匹配文本的匹配结果;4) Utilize the output layer to process the result x of the forward propagation layer to obtain the output of the BERT-based text matching model as the matching result of different texts to be matched;
基于BERT的文本匹配模型输出如下所示:The output of the BERT-based text matching model is as follows:
FFN(x)=max(0,xW1+b1)W2+b2 (6)FFN(x)=max(0, xW 1 +b 1 )W 2 +b 2 (6)
式中,W1、W2为权重;b1、b2为偏置。FFN(x)为输出。In the formula, W 1 and W 2 are weights; b 1 and b 2 are biases. FFN(x) is the output.
所述embedding输入输入X=x1+x2;The embedding input input X=x 1 +x 2 ;
其中,输入分量x1和输入分量x2分别如下所示:Among them, the input component x1 and the input component x2 are as follows:
X1=Etok+Eseg+Epos (7)X 1 =E tok +E seg +E pos (7)
x2=embedding1(pos)+embedding2(ner)+embedding3(seg) (8)x 2 =embedding1(pos)+embedding2(ner)+embedding3(seg) (8)
式中,Etok、Eseg、Epos分别表示文本字词特征的Token Embedding编码、PositionEmbeddings编码和SegmentEmbeddings编码;embedding1、embedding2、embedding3表示词性、命名实体、语义角色的embedding层;pos、ner、seg表示输入文本的词性、命名体、语义角色编码。In the formula, E tok , E seg , and E pos represent the Token Embedding encoding, PositionEmbeddings encoding, and SegmentEmbeddings encoding of the text word feature respectively; embedding1, embedding2, and embedding3 represent the embedding layer of part of speech, named entity, and semantic role; pos, ner, and seg Represents the part-of-speech, nomenclature, and semantic role encoding of the input text.
所述掩码Mask为0-1变量,不同待匹配文本的词相同位置的掩码Mask=1,不同待匹配文本的词不同位置Mask=0。The mask Mask is a 0-1 variable, and Mask=1 for the same position of words in different texts to be matched, and Mask=0 for different positions of words in different texts to be matched.
所述基于BERT的文本匹配模型的输出包括序列输出和向量输出;所述向量输出为分类向量,所述序列输出为词性标注向量。所述分类向量包括语义相同和语义不同。The output of the BERT-based text matching model includes a sequence output and a vector output; the vector output is a classification vector, and the sequence output is a part-of-speech tagging vector. The classification vectors include semantic sameness and semantic difference.
所述基于BERT的文本匹配模型经过了预训练;The BERT-based text matching model has been pre-trained;
预训练结束的标准为损失函数Loss收敛;The criterion for the end of pre-training is the convergence of the loss function Loss;
损失函数Loss如下所示:The loss function Loss is as follows:
Loss=Lossnll+Losspos-tag (9)Loss=Loss nll + Loss pos-tag (9)
式中,Lossnll为分类向量损失函数;Losspos-tag为词性标注的损失函数;In the formula, Loss nll is the classification vector loss function; Loss pos-tag is the loss function of part-of-speech tagging;
其中,分类向量损失函数Lossnll如下所示:Among them, the classification vector loss function Loss nll is as follows:

式中,n为训练样本数;j表示第j个样本;Z表示分类的类别数;c表示第c个类别;hj,c表示第j个样本属于第c个类别的概率;yj,c表示第j个样本是否属于第c个类别;yj,c=1表示第j个样本属于第c个类别;yj,c=0表示第j个样本不属于第c个类别;In the formula, n is the number of training samples; j is the jth sample; Z is the number of categories; c is the cth category; h j, c is the probability that the jth sample belongs to the cth category; y j, c indicates whether the j-th sample belongs to the c-th category; y j, c = 1 indicates that the j-th sample belongs to the c-th category; y j, c = 0 indicates that the j-th sample does not belong to the c-th category;
词性标注损失函数Losspos-tag计算原理如下:The calculation principle of the part-of-speech tagging loss function Loss pos-tag is as follows:
对于任何样本,词性标注的类别序列可能是:For any sample, the class sequence for part-of-speech tagging might be:
词性标注序列1:START N-B N-I N-E O OPart-of-speech tagging sequence 1: START N-B N-I N-E O O
词性标注序列2:START N-B N-E O O OPart-of-speech tagging sequence 2: START N-B N-E O O O
词性标注序列3:START O N-B N-E O OPart-of-speech tagging sequence 3: START O N-B N-E O O
词性标注序列4:START V-B V-I V-E O OPart-of-speech tagging sequence 4: START V-B V-I V-E O O
……
词性标注序列n:START N-B N-E V-B V-E OPart-of-speech tagging sequence n: START N-B N-E V-B V-E O
每种可能的路径都有分数为Pi,共有N个路径,则总的得分为:Each possible path has a score P i , and there are N paths in total, then the total score is:
Ptotal=P1+P2+P3+...+Pn P total =P 1 +P 2 +P 3 +...+P n
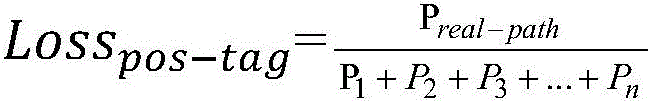
在训练过程中,模型的参数值将随着训练过程的迭代不断更新,使得真实路径所占的比值越来越大。During the training process, the parameter values of the model will be continuously updated with the iterations of the training process, so that the proportion of the real path will become larger and larger.
一种计算机可读存储介质,所述计算机可读介质存储有计算机程序;A computer-readable storage medium storing a computer program;
所述计算机程序被处理器执行时,实现权利要求1至9任一项所述方法的步骤。When the computer program is executed by a processor, the steps of the method described in any one of
实施例2:Example 2:
参见图1至图3,一种基于多任务学习的Mask文本匹配方法,包括以下内容:See Figures 1 to 3, a mask text matching method based on multi-task learning, including the following:
1)文本通过语言分析工具处理,可以得到词性、命名实体、语义角色、依存句法关系等特征。1) The text is processed by language analysis tools, and features such as parts of speech, named entities, semantic roles, and dependent syntactic relationships can be obtained.
2)根据输入的待匹配文本,比较文本对之间的差异,标记出词位置相同的位置和词不同的位置,词相同位置在Mask矩阵中设为0,否则设为1。2) According to the input text to be matched, compare the differences between the text pairs, and mark the positions with the same word position and the positions with different words. The same word position is set to 0 in the Mask matrix, otherwise it is set to 1.
BERT的embedding输入可以表示为Token Embedding、Segmentation Embedding和Position Embedding合成x1:The embedding input of BERT can be expressed as Token Embedding, Segmentation Embedding and Position Embedding synthesis x 1 :
X1=Eword=Etok+Eseg+Epos X 1 =E word =E tok +E seg +E pos
其他语言特征通过embedding层可以表示为x2:Other language features can be expressed as x 2 through the embedding layer:
x2=embedding1(pos)+embedding2(ner)+embedding3(seg)x 2 =embedding1(pos)+embedding2(ner)+embedding3(seg)
最终的输入x=x1+x2 Final input x=x 1 +x 2
将输入X转化为Q,K,V:Convert input X to Q, K, V:
Q=XWQ,K=XWK,V=XWV Q=XW Q , K=XW K , V=XW V
注意力计算公式:Attention calculation formula:

这里为了让模型关注待匹配文本不一致的地方,我们在数据处理阶段通过简单处理即可得到Mask矩阵,所以模型不需要关注全量的attention,只需要关注文本不一致的字符的attention即可:Here, in order to let the model pay attention to the inconsistency of the text to be matched, we can obtain the Mask matrix through simple processing in the data processing stage, so the model does not need to pay attention to the full amount of attention, but only needs to pay attention to the attention of the characters with inconsistent text:
Attention=Mask*Attention(Q,K,V)Attention=Mask*Attention(Q, K, V)
多头注意力层:Multi-head attention layer:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO MultiHead (Q, K, V) = Concat (head 1 , . . . , head h ) W O
其中:in:
headi=Attention(QWi Q,KWi k,VWi v),i=1,2,...,hhead i = Attention(QW i Q , KW i k , VW i v ), i=1, 2, . . . , h
前向传播层:Forward propagation layer:
FFN(x)=max(0,xW1+b1)W2+b2 FFN(x)=max(0, xW 1 +b 1 )W 2 +b 2
然后输出为:Then the output is:
x=norm(X+MultiHead(Q,K,V))x=norm(X+MultiHead(Q,K,V))
最终encoder的输出:The output of the final encoder:
Y=FFN(x)Y=FFN(x)
该输出包含序列输出和向量输出,本实施例将向量输出作为分类向量,序列输出作为第二个任务词性标注向量,针对分类向量,我们可以得到第一个损失函数LossKL为:The output includes a sequence output and a vector output. In this embodiment, the vector output is used as a classification vector, and the sequence output is used as the second task part-of-speech tagging vector. For the classification vector, we can obtain the first loss function Loss KL as:

词性标注的损失函数为:Losspos-tag,最终损失函数将是:The loss function of part-of-speech tagging is: Loss pos-tag , and the final loss function will be:
Loss=Lossnll+Losspos-tag Loss=Loss nll + Loss pos-tag
实施例3:Example 3:
一种基于多任务学习的Mask文本匹配方法,包括以下步骤:A kind of Mask text matching method based on multi-task learning, comprises the following steps:
1)获取至少两个待匹配文本;1) Obtain at least two texts to be matched;
2)对所述待匹配文本进行特征提取,得到每个待匹配文本的文本字词特征;2) feature extraction is carried out to described text to be matched, obtain the text word feature of each text to be matched;
3)建立基于BERT的文本匹配模型;3) Establish a text matching model based on BERT;
4)将所有待匹配文本的文本字词特征输入到文本匹配模型,获得不同待匹配文本的匹配结果。4) Input the text word features of all texts to be matched into the text matching model to obtain matching results of different texts to be matched.
实施例4:Example 4:
一种基于多任务学习的Mask文本匹配方法,主要内容见实施例3,其中,对所述待匹配目标文本进行特征提取的步骤包括:分词处理、词性标注、命名实体识别、语义角色标注、依存句法分析。A mask text matching method based on multi-task learning, the main content is shown in embodiment 3, wherein the step of feature extraction of the target text to be matched includes: word segmentation processing, part-of-speech tagging, named entity recognition, semantic role tagging, dependency Syntax analysis.
实施例5:Example 5:
一种基于多任务学习的Mask文本匹配方法,主要内容见实施例3,其中,所述目标文本字词特征包括词性特征、命名实体特征、语义角色特征和依存句法关系特征中的一个或多个。A Mask text matching method based on multi-task learning, the main content is shown in embodiment 3, wherein the target text word features include one or more of part-of-speech features, named entity features, semantic role features and dependent syntactic relationship features .
实施例6:Embodiment 6:
一种基于多任务学习的Mask文本匹配方法,主要内容见实施例3,其中,所述基于BERT的文本匹配模型包括embedding输入层、多头注意力层、前向传播层和输出层。A mask text matching method based on multi-task learning, the main content is shown in embodiment 3, wherein the BERT-based text matching model includes an embedding input layer, a multi-head attention layer, a forward propagation layer and an output layer.
实施例7:Embodiment 7:
一种基于多任务学习的Mask文本匹配方法,主要内容见实施例3,其中,获得不同待匹配文本的匹配结果的步骤包括:A kind of Mask text matching method based on multi-task learning, see embodiment 3 for main content, wherein, the step of obtaining the matching result of different text to be matched comprises:
1)利用embedding输入层对文本字词特征进行转换,得到embedding输入X,并将embedding输入X转换为特征分量Q=XWQ、特征分量K=XWK、特征分量V=XWV;WQ、WK、WV为不同特征分量对应的权重;1) Use the embedding input layer to convert the text word features to obtain the embedding input X, and convert the embedding input X to feature components Q=XW Q , feature components K=XW K , feature components V=XW V ; W Q , W K , W V are the weights corresponding to different feature components;
2)利用多头注意力层对embedding输入X的特征分量进行处理,得到多头注意力层处理结果MultiHead(Q,K,V),即:2) Use the multi-head attention layer to process the feature components of the embedding input X, and obtain the multi-head attention layer processing result MultiHead(Q, K, V), namely:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO (1)MultiHead (Q, K, V) = Concat (head 1 , . . . , head h ) W O (1)
式中,WO为权重;In the formula, W O is the weight;
其中,参数headi如下所示:Among them, the parameter head i is as follows:
headi=Attention(QWi Q,KWi k,VWi v),i=1,2,...,h (2)head i = Attention(QW i Q , KW i k , VW i v ), i=1, 2, . . . , h (2)
Attention(QWi Q,KWi k,VWi v)=Mask*Attention(Q,K,V) (3)Attention(QW i Q , KW i k , VW i v )=Mask*Attention(Q, K, V) (3)

式中,softmax为激活函数;dk表示词向量的维度;Mask表示掩码;Attention(QWi Q,KWi k,VWi v)、Attention(Q,K,V)为中间参量;h为大于0的整数;In the formula, softmax is the activation function; d k represents the dimension of the word vector; Mask represents the mask; Attention(QW i Q , KW i k , VW i v ), Attention(Q, K, V) are intermediate parameters; h is an integer greater than 0;
3)利用前向传播层对多头注意力层处理结果MultiHead(Q,K,V)进行处理,得到前向传播层处理结果x,即:3) Use the forward propagation layer to process the processing result MultiHead (Q, K, V) of the multi-head attention layer, and obtain the processing result x of the forward propagation layer, namely:
x=norm(X+MultiHead(Q,K,V)) (5)x=norm(X+MultiHead(Q, K, V)) (5)
4)利用输出层对前向传播层处理结果x进行处理,得到基于BERT的文本匹配模型输出,作为不同待匹配文本的匹配结果;4) Utilize the output layer to process the result x of the forward propagation layer to obtain the output of the BERT-based text matching model as the matching result of different texts to be matched;
基于BERT的文本匹配模型输出如下所示:The output of the BERT-based text matching model is as follows:
FFN(x)=max(0,xW1+b1)W2+b2 (6)FFN(x)=max(0, xW 1 +b 1 )W 2 +b 2 (6)
式中,W1、W2为权重;b1、b2为偏置;FFN(x)为输出。In the formula, W 1 and W 2 are weights; b 1 and b 2 are biases; FFN(x) is the output.
实施例8:Embodiment 8:
一种基于多任务学习的Mask文本匹配方法,主要内容见实施例3,其中,所述embedding输入X=x1+x2;A kind of Mask text matching method based on multi-task learning, main content see embodiment 3, wherein, described embedding input X=x 1 +x 2 ;
其中,输入分量x1和输入分量x2分别如下所示:Among them, the input component x1 and the input component x2 are as follows:
X1=Etok+Eseg+Epos (7)X 1 =E tok +E seg +E pos (7)
x2=embedding1(pos)+embedding2(ner)+embedding3(seg) (8)x 2 =embedding1(pos)+embedding2(ner)+embedding3(seg) (8)
式中,Etok、Eseg、Epos分别表示文本字词特征的Token Embedding编码、PositionEmbeddings编码和SegmentEmbeddings编码;embedding1、embedding2、embedding3表示词性、命名实体、语义角色的embedding层;pos、ner、seg表示输入文本的词性、命名体、语义角色编码。In the formula, E tok , E seg , and E pos respectively represent Token Embedding encoding, PositionEmbeddings encoding and SegmentEmbeddings encoding of text word features; embedding1, embedding2, and embedding3 represent the embedding layer of part of speech, named entity, and semantic role; pos, ner, and seg Represents the part-of-speech, nomenclature, and semantic role encoding of the input text.
实施例9:Embodiment 9:
一种基于多任务学习的Mask文本匹配方法,主要内容见实施例3,其中,所述掩码Mask为0-1变量,不同待匹配文本的词相同位置的掩码Mask=1,不同待匹配文本的词不同位置Mask=0。A kind of Mask text matching method based on multi-task learning, see embodiment 3 for main content, wherein, described mask Mask is 0-1 variable, the mask Mask=1 of the word same position of different text to be matched, different to be matched Mask=0 at different positions of words in the text.
实施例10:Example 10:
一种基于多任务学习的Mask文本匹配方法,主要内容见实施例3,其中,所述基于BERT的文本匹配模型的输出包括序列输出和向量输出;所述向量输出为分类向量,所述序列输出为词性标注向量;所述分类向量包括语义相同和语义不同。A kind of Mask text matching method based on multi-task learning, see embodiment 3 for main content, wherein, the output of the text matching model based on BERT comprises sequence output and vector output; The vector output is a classification vector, and the sequence output is a part-of-speech tagging vector; the classification vector includes the same semantics and different semantics.
实施例11:Example 11:
一种基于多任务学习的Mask文本匹配方法,主要内容见实施例3,其中,所述基于BERT的文本匹配模型经过了预训练;A kind of Mask text matching method based on multi-task learning, main content sees embodiment 3, wherein, described text matching model based on BERT has been through pre-training;
预训练结束的标准为损失函数Loss收敛;The criterion for the end of pre-training is the convergence of the loss function Loss;
损失函数Loss如下所示:The loss function Loss is as follows:
Loss=Lossnll+Losspos-tag (9)Loss=Loss nll + Loss pos-tag (9)
式中,Lossnll为分类向量损失函数;Losspos-tag为词性标注的损失函数;In the formula, Loss nll is the classification vector loss function; Loss pos-tag is the loss function of part-of-speech tagging;
其中,分类向量损失函数Lossnll如下所示:Among them, the classification vector loss function Loss nll is as follows:

式中,n为训练样本数;j表示第j个样本;Z表示分类的类别数;c表示第c个类别;hj,c表示第j个样本属于第c个类别的概率;yj,c表示第j个样本是否属于第c个类别;yj,c=1表示第j个样本属于第c个类别;yj,c=0表示第j个样本不属于第c个类别;In the formula, n is the number of training samples; j is the jth sample; Z is the number of categories; c is the cth category; h j, c is the probability that the jth sample belongs to the cth category; y j, c indicates whether the j-th sample belongs to the c-th category; y j, c = 1 indicates that the j-th sample belongs to the c-th category; y j, c = 0 indicates that the j-th sample does not belong to the c-th category;
词性标注损失函数Losspos-tag如下所示:The part-of-speech tagging loss function Loss pos-tag is as follows:

式中,P1、P2、P3、Pn为一个样本对应的第1种、第2种、第n种可能词性标注序列的得分;Preal-path为一个样本对应的真实词性标注序列的得分。In the formula, P 1 , P 2 , P 3 , P n are the scores of the first, second, and nth possible part-of-speech tagging sequences corresponding to a sample; P real-path is the real part-of-speech tagging sequence corresponding to a sample score.
实施例12:Example 12:
一种计算机可读存储介质,所述计算机可读介质存储有计算机程序;所述计算机程序被处理器执行时,实现实施例1-11所述方法的步骤。A computer-readable storage medium, where the computer-readable medium stores a computer program; when the computer program is executed by a processor, the steps of the method described in Embodiments 1-11 are implemented.
Claims (10)



Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211071421.4A CN115687939B (en) | 2022-09-02 | 2022-09-02 | A Mask text matching method and medium based on multi-task learning |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211071421.4A CN115687939B (en) | 2022-09-02 | 2022-09-02 | A Mask text matching method and medium based on multi-task learning |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN115687939A true CN115687939A (en) | 2023-02-03 |
| CN115687939B CN115687939B (en) | 2024-09-24 |
Family
ID=85061022
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211071421.4A Active CN115687939B (en) | 2022-09-02 | 2022-09-02 | A Mask text matching method and medium based on multi-task learning |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115687939B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116522165A (en) * | 2023-06-27 | 2023-08-01 | 武汉爱科软件技术股份有限公司 | Public opinion text matching system and method based on twin structure |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113239700A (en) * | 2021-04-27 | 2021-08-10 | 哈尔滨理工大学 | Text semantic matching device, system, method and storage medium for improving BERT |
| CN113642330A (en) * | 2021-07-19 | 2021-11-12 | 西安理工大学 | Entity recognition method of rail transit specification based on catalog topic classification |
| WO2022121251A1 (en) * | 2020-12-11 | 2022-06-16 | 平安科技(深圳)有限公司 | Method and apparatus for training text processing model, computer device and storage medium |
-
2022
- 2022-09-02 CN CN202211071421.4A patent/CN115687939B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022121251A1 (en) * | 2020-12-11 | 2022-06-16 | 平安科技(深圳)有限公司 | Method and apparatus for training text processing model, computer device and storage medium |
| CN113239700A (en) * | 2021-04-27 | 2021-08-10 | 哈尔滨理工大学 | Text semantic matching device, system, method and storage medium for improving BERT |
| CN113642330A (en) * | 2021-07-19 | 2021-11-12 | 西安理工大学 | Entity recognition method of rail transit specification based on catalog topic classification |
Non-Patent Citations (4)
| Title |
|---|
| 刘祥龙 等: "《飞桨PaddlePaddle深度学习实战》", 31 August 2020, 北京:机械工业出版社 * |
| 吕洋 等: ""基于数据挖掘算法的汉英机器翻译二元语义模式规则"", 《微型电脑应用》, vol. 37, no. 11, 20 November 2021 (2021-11-20) * |
| 月来客栈: ""This post is you need(上卷)——层层剥开Transformer"", pages 1 - 57, Retrieved from the Internet <URL:https://zhuanlan.zhihu.com/p/420820453> * |
| 李广 等: ""融合多角度特征的文本匹配模型"", 《计算机系统应用》, 17 May 2022 (2022-05-17) * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116522165A (en) * | 2023-06-27 | 2023-08-01 | 武汉爱科软件技术股份有限公司 | Public opinion text matching system and method based on twin structure |
| CN116522165B (en) * | 2023-06-27 | 2024-04-02 | 武汉爱科软件技术股份有限公司 | Public opinion text matching system and method based on twin structure |
Also Published As
| Publication number | Publication date |
|---|---|
| CN115687939B (en) | 2024-09-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112733533B (en) | Multi-modal named entity recognition method based on BERT model and text-image relation propagation | |
| Wang et al. | A novel network with multiple attention mechanisms for aspect-level sentiment analysis | |
| CN113868432B (en) | A method and system for automatically constructing a knowledge graph for steel manufacturing enterprises | |
| CN110781680A (en) | Semantic Similarity Matching Method Based on Siamese Network and Multi-Head Attention Mechanism | |
| CN115033670A (en) | Cross-modal image-text retrieval method with multi-granularity feature fusion | |
| CN112183094B (en) | Chinese grammar debugging method and system based on multiple text features | |
| CN114926150B (en) | A digital intelligent audit method and device for transformer technical compliance assessment | |
| Xiao et al. | Joint entity and relation extraction with a hybrid transformer and reinforcement learning based model | |
| CN112905736B (en) | An unsupervised text sentiment analysis method based on quantum theory | |
| CN108256968A (en) | A kind of electric business platform commodity comment of experts generation method | |
| Khare et al. | Multi-modal embeddings using multi-task learning for emotion recognition | |
| CN116049406A (en) | Cross-domain emotion classification method based on contrast learning | |
| CN112597306A (en) | Travel comment suggestion mining method based on BERT | |
| Zhang et al. | Modeling the clause-level structure to multimodal sentiment analysis via reinforcement learning | |
| CN114881042A (en) | Chinese emotion analysis method based on graph convolution network fusion syntax dependence and part of speech | |
| CN116029305A (en) | Chinese attribute-level emotion analysis method, system, equipment and medium based on multitask learning | |
| CN114048286A (en) | Automatic fact verification method fusing graph converter and common attention network | |
| CN114579707B (en) | Aspect-level emotion analysis method based on BERT neural network and multi-semantic learning | |
| Wu et al. | One improved model of named entity recognition by combining BERT and BiLSTM-CNN for domain of Chinese railway construction | |
| CN115687939B (en) | A Mask text matching method and medium based on multi-task learning | |
| CN118469006B (en) | Knowledge graph construction method, device, medium and chip for electric power operation text | |
| Zhang et al. | Sentiment analysis of chinese reviews based on BiTCN-attention model | |
| Zhang et al. | BGAT: Aspect-based sentiment analysis based on bidirectional GRU and graph attention network | |
| Gao et al. | Few-shot fake news detection via prompt-based tuning | |
| CN114707508B (en) | Event detection method based on multi-hop neighbor information fusion based on graph structure |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |