CN115221157A - Data processing method and apparatus, computer readable storage medium and electronic device - Google Patents
Data processing method and apparatus, computer readable storage medium and electronic device Download PDFInfo
- Publication number
- CN115221157A CN115221157A CN202110418607.1A CN202110418607A CN115221157A CN 115221157 A CN115221157 A CN 115221157A CN 202110418607 A CN202110418607 A CN 202110418607A CN 115221157 A CN115221157 A CN 115221157A
- Authority
- CN
- China
- Prior art keywords
- dimension
- node
- group
- field
- query
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2228—Indexing structures
- G06F16/2246—Trees, e.g. B+trees
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/242—Query formulation
- G06F16/2433—Query languages
- G06F16/244—Grouping and aggregation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/25—Integrating or interfacing systems involving database management systems
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/284—Relational databases
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
技术领域technical field
本公开涉及计算机技术领域,具体而言,涉及一种数据处理方法及装置、计算机可读存储介质和电子设备。The present disclosure relates to the field of computer technology, and in particular, to a data processing method and apparatus, a computer-readable storage medium, and an electronic device.
背景技术Background technique
随着移动互联网、物联网等技术的发展,所积累的数据呈爆炸式增长,大数据时代已经来临。海量数据的收集只是大数据技术的第一步,如何让数据产生价值才是大数据领域的终极目标。Hadoop(海杜普,一个分布式系统基础架构)的出现解决了数据存储问题,但如何对海量数据进行实时查询,却一直未有满意的解决方案。而多数情况下的查询需要对用户的操作做出实时反应,相关技术中查询引擎动辄数分钟甚至数十分钟的响应时间,显然是不能满足需求的。With the development of mobile Internet, Internet of Things and other technologies, the accumulated data has exploded, and the era of big data has arrived. The collection of massive data is only the first step of big data technology. How to make data generate value is the ultimate goal of big data field. The emergence of Hadoop (Hedup, a distributed system infrastructure) has solved the problem of data storage, but there has been no satisfactory solution for how to query massive data in real time. In most cases, the query needs to respond to the user's operation in real time. In the related technology, the query engine often has a response time of several minutes or even tens of minutes, which obviously cannot meet the demand.
在一些数据平台产品、数据分析或者报表业务中,通常需要选择OLAP(OnlineAnalytical Process,联机分析处理)数据查询引擎,Apache Kylin作为一个基于Hadoop大数据平台打造的开源OLAP引擎,采用了多维立方体(Cube,也称之为数据立方体)预计算技术,利用空间换时间的方法,相较与传统的MPP(Massive Parallel Processing,大规模并行处理)架构的OLAP查询引擎,将查询速度提升至亚秒级别,以及很高的并发能力,极大地提高了数据分析的效率。Apache Kylin的出现不仅很好地解决了海量数据快速查询的问题,也避免了手动开发和维护提前计算程序带来的一系列麻烦。In some data platform products, data analysis or report business, it is usually necessary to choose an OLAP (Online Analytical Process) data query engine. As an open source OLAP engine built on the Hadoop big data platform, Apache Kylin uses a multi-dimensional cube (Cube) , also known as data cube) pre-computing technology, using the method of changing space for time, compared with the OLAP query engine of the traditional MPP (Massive Parallel Processing, massively parallel processing) architecture, the query speed is improved to sub-second level, And high concurrency capability, which greatly improves the efficiency of data analysis. The emergence of Apache Kylin not only solves the problem of fast query of massive data, but also avoids a series of troubles caused by manual development and maintenance of advance calculation programs.
在采用以Apache Kylin作为OLAP查询引擎作为技术方案时,面临着复杂Cube的计算问题:超大维度组合的Cube其预计算一般采用Apache spark作为构建引擎,但是大的Cube其计算任务会给计算资源带来不小的压力,不仅会耗费大量的计算资源,并且还会有超高的构建时长,对于一些数据时效性比较高的业务不友好,而且超大的spark计算任务可能会因资源问题出现任务失败,进而导致更多的资源浪费。When Apache Kylin is used as the OLAP query engine as the technical solution, it is faced with the calculation problem of complex cubes: the pre-computing of cubes with super-large dimension combinations generally uses Apache spark as the construction engine, but the computing tasks of large cubes will increase the computing resources. A lot of pressure will not only consume a lot of computing resources, but also have a super high construction time, which is not friendly to some businesses with high data timeliness, and super-large spark computing tasks may fail due to resource problems. , which in turn leads to more waste of resources.
发明内容SUMMARY OF THE INVENTION
本公开实施例提供一种数据处理方法及装置、计算机可读存储介质和电子设备,能够解决上述相关技术中存在Cube构建时长较长且耗费较多计算资源的技术问题。Embodiments of the present disclosure provide a data processing method and apparatus, a computer-readable storage medium, and an electronic device, which can solve the technical problems in the above-mentioned related technologies that Cube construction takes a long time and consumes more computing resources.
本公开实施例提供一种数据处理方法,所述方法包括:获得目标表的历史查询语句中的维度字段及不同维度字段之间的查询共现频次;将维度字段作为节点,根据不同维度字段之间的查询共现频次确定不同节点之间的初阶边权重,形成维度共现图;根据维度共现图中各个节点的度,确定维度共现图中的第一核心节点;获得删除维度共现图中的第一核心节点后的第一连通子图;根据维度共现图及其第一核心节点和第一连通子图,获得维度共现图的分裂树;根据分裂树的目标叶子节点确定维度字段的聚合组;根据维度字段的聚合组构建面向目标表的数据立方体。An embodiment of the present disclosure provides a data processing method, the method includes: obtaining a dimension field in a historical query statement of a target table and a query co-occurrence frequency between different dimension fields; The query co-occurrence frequency between different nodes determines the initial edge weights between different nodes to form a dimension co-occurrence graph; according to the degree of each node in the dimension co-occurrence graph, the first core node in the dimension co-occurrence graph is determined; the deleted dimension co-occurrence graph is obtained. Now the first connected subgraph after the first core node in the figure; according to the dimension co-occurrence graph and its first core node and the first connected sub-graph, a split tree of the dimension co-occurrence graph is obtained; according to the target leaf node of the split tree Determines the aggregation group of the dimension field; builds the data cube for the target table based on the aggregation group of the dimension field.
在本公开的一些示例性实施例中,根据各个关联维度组之间的相关度和合并膨胀率,确定各个关联维度组中满足合并条件的关联维度组对,包括:若关联维度组之间的相关度大于第一相关度阈值;或者若关联维度组之间的相关度大于第二相关度阈值且合并膨胀率小于第一膨胀率阈值;或者若关联维度组之间的相关度大于第三相关度阈值且合并膨胀率小于第二膨胀率阈值,则判定对应的关联维度组为满足合并条件的关联维度组对;其中,第一相关性阈值大于第二相关性阈值,第二相关性阈值大于第三相关性阈值,第一膨胀率阈值大于第二膨胀率阈值。In some exemplary embodiments of the present disclosure, determining pairs of associated dimension groups that satisfy the merging condition in each associated dimension group according to the correlation between the associated dimension groups and the combined expansion rate, including: if the correlation between the associated dimension groups is The correlation is greater than the first correlation threshold; or if the correlation between the associated dimension groups is greater than the second correlation threshold and the combined expansion rate is less than the first expansion rate threshold; or if the correlation between the associated dimension groups is greater than the third correlation degree threshold and the combined expansion rate is less than the second expansion rate threshold, then it is determined that the corresponding associated dimension group is an associated dimension group pair that satisfies the combination condition; wherein, the first correlation threshold is greater than the second correlation threshold, and the second correlation threshold is greater than The third correlation threshold, the first expansion rate threshold is greater than the second expansion rate threshold.
本公开实施例提供一种数据处理装置,所述装置包括:共现频次获得单元,用于获得目标表的历史查询语句中的维度字段及不同维度字段之间的查询共现频次;维度共现图构建单元,用于将维度字段作为节点,根据不同维度字段之间的查询共现频次确定不同节点之间的初阶边权重,形成维度共现图;核心节点确定单元,用于根据维度共现图中各个节点的度,确定维度共现图中的第一核心节点;连通子图获得单元,用于获得删除维度共现图中的第一核心节点后的第一连通子图;图分裂树获得单元,用于根据维度共现图及其第一核心节点和第一连通子图,获得维度共现图的分裂树;字段聚合组确定单元,用于根据分裂树的目标叶子节点确定维度字段的聚合组;数据立方体构建单元,用于根据维度字段的聚合组构建面向目标表的数据立方体。An embodiment of the present disclosure provides a data processing apparatus, the apparatus includes: a co-occurrence frequency obtaining unit, configured to obtain a dimension field in a historical query statement of a target table and a query co-occurrence frequency between different dimension fields; dimension co-occurrence frequency The graph construction unit is used to use the dimension field as a node, and determine the primary edge weights between different nodes according to the query co-occurrence frequency between different dimension fields to form a dimension co-occurrence graph; the core node determination unit is used to co-occur according to dimensions The degree of each node in the graph is to determine the first core node in the dimension co-occurrence graph; the connected subgraph obtaining unit is used to obtain the first connected subgraph after deleting the first core node in the dimension co-occurrence graph; the graph is split The tree obtaining unit is used to obtain the split tree of the dimensional co-occurrence graph according to the dimensional co-occurrence graph and its first core node and the first connected subgraph; the field aggregation group determination unit is used to determine the dimension according to the target leaf node of the split tree The aggregation group of the field; the data cube building unit is used to construct the data cube oriented to the target table based on the aggregation group of the dimension field.
本公开实施例提供了一种计算机可读存储介质,其上存储有计算机程序,程序被处理器执行时实现如上述实施例中所述的数据处理方法。Embodiments of the present disclosure provide a computer-readable storage medium on which a computer program is stored, and when the program is executed by a processor, the data processing method described in the foregoing embodiments is implemented.
本公开实施例提供了一种电子设备,包括:至少一个处理器;存储装置,配置为存储至少一个程序,当至少一个程序被至少一个处理器执行时,使得至少一个处理器实现如上述实施例中的数据处理方法。An embodiment of the present disclosure provides an electronic device, including: at least one processor; and a storage device configured to store at least one program, and when the at least one program is executed by the at least one processor, the at least one processor implements the above embodiments data processing methods in .
在本公开的一些实施例所提供的技术方案中,一方面,通过目标表的历史查询语句进行分析,根据历史查询语句中的维度字段及不同维度字段之间的查询共现频次构建维度共现图,并根据该维度共现图中各个节点的度来确定维度共现图中的第一核心节点,然后获得删除该维度共现图中的第一核心节点后的第一连通子图,根据该维度共现图及其第一核心节点和该第一连通子图对该维度共现图进行分裂,获得该维度共现图的分裂树,由此可以根据该分裂树的目标叶子节点来确定上述历史查询语句中的维度字段的聚合组,当利用该维度字段的聚合组来构建面向该目标表的数据立方体(Cube)时,实现了将大的Cube拆分为聚合组,各个聚合组可以用于构建各个小的Cube,即通过对维度共现图的拆分,压缩了数据规模,降低了Cube构建过程中耗费的计算资源,且能够缩短Cube的构建时长,实现了构建资源和构建时间之间的平衡。同时,由于本公开实施例中的维度共现图是根据目标表的历史查询语句中的维度字段及不同维度字段之间的查询共现频次构建的,因此,通过分裂该维度共现图来实现将一个大的Cube的构建任务拆分为多个小的Cube的构建任务,还能够保证构建的各个小的Cube能够满足实际业务中的查询需求,还不会增加较多的重复计算量。另一方面,通过分析历史查询语句,实现了Cube构建的自动化,简化了用户设计Cube的难度,优化了Cube设计。In the technical solutions provided by some embodiments of the present disclosure, on the one hand, the historical query statement of the target table is used for analysis, and the dimension co-occurrence is constructed according to the dimension fields in the historical query statement and the query co-occurrence frequency between different dimension fields. and determine the first core node in the dimension co-occurrence graph according to the degree of each node in the dimension co-occurrence graph, and then obtain the first connected subgraph after deleting the first core node in the dimension co-occurrence graph, according to The dimensional co-occurrence graph and its first core node and the first connected subgraph are split on the dimensional co-occurrence graph to obtain a split tree of the dimensional co-occurrence graph, which can be determined according to the target leaf node of the split tree The aggregation group of the dimension field in the above historical query statement, when the aggregation group of the dimension field is used to construct the data cube (Cube) oriented to the target table, the large cube is divided into aggregation groups, and each aggregation group can be It is used to build various small cubes, that is, by splitting the dimensional co-occurrence graph, the data scale is compressed, the computing resources consumed in the cube construction process are reduced, the construction time of the cube can be shortened, and the construction resources and construction time can be realized. balance between. At the same time, since the dimension co-occurrence graph in the embodiment of the present disclosure is constructed according to the dimension fields in the historical query statements of the target table and the query co-occurrence frequency between different dimension fields, the dimension co-occurrence graph is split to achieve this. Splitting the construction task of a large cube into multiple small cube construction tasks can also ensure that each small cube constructed can meet the query requirements in the actual business, and will not increase the amount of repeated calculations. On the other hand, by analyzing historical query statements, the automation of cube construction is realized, the difficulty of designing cubes is simplified, and the design of cubes is optimized.
附图说明Description of drawings
图1示意性示出了根据本公开的一实施例的数据处理方法的流程图。FIG. 1 schematically shows a flowchart of a data processing method according to an embodiment of the present disclosure.
图2示意性示出了根据本公开的一实施例的维度共现图的示意图。FIG. 2 schematically shows a schematic diagram of a dimensional co-occurrence graph according to an embodiment of the present disclosure.
图3示意性示出了删除图2中的维度共现图中度最大的节点后的连通子图的示意图。FIG. 3 schematically shows a schematic diagram of a connected subgraph after deleting the node with the largest degree in the dimensional co-occurrence graph in FIG. 2 .
图4示意性示出了删除图3中的连通子图中度最大的节点后的连通子图的示意图。FIG. 4 schematically shows a schematic diagram of a connected subgraph after deleting the node with the largest degree in the connected subgraph in FIG. 3 .
图5示意性示出了根据本公开的一实施例的维度共现图分裂的流程示意图。FIG. 5 schematically shows a flow chart of dimensional co-occurrence graph splitting according to an embodiment of the present disclosure.
图6示意性示出了根据本公开的一实施例的维度共现图的分裂树的结构示意图。FIG. 6 schematically shows a schematic structural diagram of a split tree of a dimensional co-occurrence graph according to an embodiment of the present disclosure.
图7示意性示出了根据本公开的一实施例的对分裂树进行剪枝操作的示意图。FIG. 7 schematically shows a schematic diagram of performing a pruning operation on a split tree according to an embodiment of the present disclosure.
图8示意性示出了根据本公开的另一实施例的数据处理方法的流程图。FIG. 8 schematically shows a flowchart of a data processing method according to another embodiment of the present disclosure.
图9示意性示出了根据本公开的又一实施例的数据处理方法的流程示意图。FIG. 9 schematically shows a schematic flowchart of a data processing method according to yet another embodiment of the present disclosure.
图10示意性示出了应用本公开实施例提供的数据处理方法的系统架构示意图。FIG. 10 schematically shows a schematic diagram of a system architecture to which the data processing method provided by the embodiment of the present disclosure is applied.
图11示意性示出了根据本公开的一实施例的数据处理装置的框图。FIG. 11 schematically shows a block diagram of a data processing apparatus according to an embodiment of the present disclosure.
图12示出了适于用来实现本公开实施例的电子设备的结构示意图。FIG. 12 shows a schematic structural diagram of an electronic device suitable for implementing an embodiment of the present disclosure.
具体实施方式Detailed ways
现在将参考附图更全面地描述示例实施例。然而,示例实施例能够以多种形式实施,且不应被理解为限于在此阐述的实施例;相反,提供这些实施例使得本公开将全面和完整,并将示例实施例的构思全面地传达给本领域的技术人员。在图中相同的附图标记表示相同或类似的部分,因而将省略对它们的重复描述。Example embodiments will now be described more fully with reference to the accompanying drawings. Example embodiments, however, can be embodied in various forms and should not be construed as limited to the embodiments set forth herein; rather, these embodiments are provided so that this disclosure will be thorough and complete, and will fully convey the concept of example embodiments to those skilled in the art. The same reference numerals in the drawings denote the same or similar parts, and thus their repeated descriptions will be omitted.
本公开所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施方式中。在下面的描述中,提供许多具体细节从而给出对本公开的实施方式的充分理解。然而,本领域技术人员将意识到,可以实践本公开的技术方案而省略特定细节中的一个或更多,或者可以采用其它的方法、组元、装置、步骤等。在其它情况下,不详细示出或描述公知方法、装置、实现或者操作以避免模糊本公开的各方面。The features, structures, or characteristics described in this disclosure may be combined in any suitable manner in one or more embodiments. In the following description, numerous specific details are provided in order to give a thorough understanding of the embodiments of the present disclosure. However, those skilled in the art will appreciate that the technical solutions of the present disclosure may be practiced without one or more of the specific details, or other methods, components, devices, steps, etc. may be employed. In other instances, well-known methods, devices, implementations, or operations have not been shown or described in detail to avoid obscuring aspects of the present disclosure.
附图仅为本公开的示意性图解,图中相同的附图标记表示相同或类似的部分,因而将省略对它们的重复描述。附图中所示的一些方框图不一定必须与物理或逻辑上独立的实体相对应。可以采用软件形式来实现这些功能实体,或在至少一个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。The accompanying drawings are merely schematic illustrations of the present disclosure, and the same reference numerals in the drawings denote the same or similar parts, and thus their repeated descriptions will be omitted. Some of the block diagrams shown in the figures do not necessarily necessarily correspond to physically or logically separate entities. These functional entities may be implemented in software, or in at least one hardware module or integrated circuit, or in different networks and/or processor devices and/or microcontroller devices.
附图中所示的流程图仅是示例性说明,不是必须包括所有的内容和步骤,也不是必须按所描述的顺序执行。例如,有的步骤还可以分解,而有的步骤可以合并或部分合并,因此实际执行的顺序有可能根据实际情况改变。The flowcharts shown in the figures are only exemplary illustrations, and do not necessarily include all contents and steps, nor do they have to be performed in the order described. For example, some steps can be decomposed, and some steps can be combined or partially combined, so the actual execution order may be changed according to the actual situation.
本说明书中,用语“一个”、“一”、“该”、“所述”和“至少一个”用以表示存在至少一个要素/组成部分/等;用语“包含”、“包括”和“具有”用以表示开放式的包括在内的意思并且是指除了列出的要素/组成部分/等之外还可存在另外的要素/组成部分/等;用语“第一”、“第二”和“第三”等仅作为标记使用,不是对其对象的数量限制。In this specification, the terms "a", "an", "the", "the" and "at least one" are used to indicate the presence of at least one element/component/etc.; the terms "comprising", "including" and "having" " is used to indicate an open-ended inclusive meaning and to mean that there may be additional elements/components/etc. in addition to the listed elements/components/etc; the terms "first", "second" and "Third" etc. are used only as markers, not as a limit on the number of their objects.
相关技术中,让用户自行去设计Cube的聚合组,当面对非常复杂的业务时,用户需要花费大量的时间去理解业务,再去设计Cube,通常面临比如确定哪些维度组合可以归入一个聚合组;在聚合组中,哪些维度组合可以形成联合维度;RowKey(行键)该怎么设计才能让查询速度更快这样的问题,用户自己设计出的Cube的维度组合非常庞大,并且用户自行设计的Cube并没有利用到历史查询数据,使得设计出的Cube不能较好地满足实际查询需求。In related technologies, users are allowed to design the aggregation group of cubes by themselves. When faced with very complex business, users need to spend a lot of time to understand the business and then design the cube. Usually, they are faced with the task of determining which dimension combinations can be classified into an aggregation. Group; in the aggregation group, which dimension combinations can form a joint dimension; how to design the RowKey (row key) to make the query faster. The dimension combination of the Cube designed by the user is very large, and the user designed it by himself. Cube does not use historical query data, so that the designed Cube cannot meet the actual query requirements well.
此外,要设计一个好的Cube,对开发人员有较高的要求,既要懂数据,也要熟悉业务,同时精通Kylin和Spark原理,而且设计过程也不是一蹴而就,而是通过不停的调整得到最终的结果。因此,自动化Cube设计是一个很有必要的工作。In addition, to design a good Cube, there are high requirements for developers, not only to understand data, but also to be familiar with business, and to be proficient in Kylin and Spark principles, and the design process is not achieved overnight, but through continuous adjustment. final result. Therefore, automating Cube design is a necessary task.
基于上述相关技术中存在的技术问题,本公开实施例提出了一种数据处理方法,以用于至少部分解决上述问题。本公开各实施例提供的方法可以由任意的电子设备来执行,例如服务器,或者终端,或者服务器与终端之间进行交互,本公开对此不做限定。Based on the technical problems existing in the above-mentioned related technologies, an embodiment of the present disclosure proposes a data processing method for at least partially solving the above-mentioned problems. The methods provided by the embodiments of the present disclosure may be executed by any electronic device, such as a server, or a terminal, or the interaction between a server and a terminal, which is not limited in the present disclosure.
本公开实施例中提及的服务器可以是独立的服务器,也可以是多个服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、CDN(Content Delivery Network,内容分发网络)、以及大数据和人工智能平台等基础云计算服务的云服务器。The server mentioned in the embodiments of the present disclosure may be an independent server, a server cluster or a distributed system composed of multiple servers, and may also provide cloud services, cloud databases, cloud computing, cloud functions, cloud storage, network Services, cloud communications, middleware services, domain name services, security services, CDN (Content Delivery Network), and cloud servers for basic cloud computing services such as big data and artificial intelligence platforms.
终端可以是智能手机、平板电脑、笔记本电脑、台式计算机、智能音箱、智能手表等,但并不局限于此。终端以及服务器可以通过有线或无线通信方式进行直接或间接地连接,本公开在此不做限制。The terminal may be a smart phone, a tablet computer, a notebook computer, a desktop computer, a smart speaker, a smart watch, etc., but is not limited thereto. The terminal and the server may be directly or indirectly connected through wired or wireless communication, which is not limited in this disclosure.
下面结合附图对本公开示例实施方式进行详细说明。The exemplary embodiments of the present disclosure will be described in detail below with reference to the accompanying drawings.
图1示意性示出了根据本公开的一实施例的数据处理方法的流程图。如图1所示,本公开实施例提供的方法可以包括以下步骤。FIG. 1 schematically shows a flowchart of a data processing method according to an embodiment of the present disclosure. As shown in FIG. 1 , the method provided by the embodiment of the present disclosure may include the following steps.
在步骤S110中,获得目标表的历史查询语句中的维度字段及不同维度字段之间的查询共现频次。In step S110, the dimension field in the historical query statement of the target table and the query co-occurrence frequency between different dimension fields are obtained.
本公开实施例中,目标表是指待构建Cube的表。目标表可以来自同一数据源。本公开实施例中,数据源可以是Hive(是基于Hadoop的一个数据仓库工具)或者Kafka(一种分布式发布订阅消息系统)等,本公开对此不作限定,在下面的实施例中,均以Hive为例进行举例说明,则同一数据源是指Hive上相同的表或者相同的事实表(Fact Table)和维表(Dimension Table)的组合。当目标表来自不同数据源时,则构建的是面对多个数据源的多个Cube。In the embodiment of the present disclosure, the target table refers to the table of the cube to be constructed. The target table can be from the same data source. In the embodiment of the present disclosure, the data source may be Hive (a data warehouse tool based on Hadoop) or Kafka (a distributed publish-subscribe messaging system), etc., which are not limited in the present disclosure. In the following embodiments, all Taking Hive as an example for illustration, the same data source refers to the same table on Hive or the combination of the same Fact Table and Dimension Table. When the target table comes from different data sources, it builds multiple cubes facing multiple data sources.
其中,事实表是指存储有事实记录的表,如系统日志、销售记录、传感器数值等。维度表或维表,也称为查找表(Lookup Table),是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联;相当于将事实表上经常重复的属性抽取、规范出来用一张表进行管理。常见的维度表有:日期表(存储与日期对应的周、月、季度等属性)、地区表(包含国家、省/州、城市等属性)等。The fact table refers to a table that stores fact records, such as system logs, sales records, sensor values, and so on. A dimension table or dimension table, also known as a lookup table, is a table corresponding to a fact table; it stores the attribute values of the dimension and can be associated with the fact table; it is equivalent to repeating the fact table frequently The attributes are extracted and standardized with a table for management. Common dimension tables include: date table (stores attributes such as week, month, quarter, etc. corresponding to the date), region table (including attributes such as country, province/state, city, etc.), etc.
本公开实施例中,目标表的历史查询语句可以是指用户历史上,在Hive上针对同一数据源进行查询的SQL(Structured Query Language,结构化查询语言)语句,这些历史查询的SQL语句可以存储在查询日志中。In the embodiment of the present disclosure, the historical query statement of the target table may refer to the SQL (Structured Query Language, Structured Query Language) statement used to query the same data source on Hive in the history of the user, and these historical query SQL statements can be stored in the in the query log.
本公开实施例中,维度是观察数据的角度,一般是一组离散的值,例如,时间维度上的每一个独立的日期,商品维度上的每一件独立的商品,设备维度上的每一个独立的设备等。而度量是被聚合的统计值,也就是聚合计算(如做累加、均值、最大值、最小值等)的结果,一般是连续的值,例如,销售额、销售均价、销售商品的总件数等。In this embodiment of the present disclosure, a dimension is an angle from which data is observed, and is generally a set of discrete values, for example, each independent date in the time dimension, each independent commodity in the commodity dimension, and each individual commodity in the device dimension stand-alone equipment, etc. The measure is the aggregated statistical value, that is, the result of the aggregation calculation (such as accumulation, mean, maximum, minimum, etc.), which is generally a continuous value, such as sales, average sales price, and the total number of items sold Wait.
通过对历史查询语句中涉及到的字段进行分析,可以对其进行分类,确定其是否为维度字段,并确定不同维度字段的查询共现频次。其中,查询共现频次是指不同维度字段在该目标表的所有历史查询语句中同时出现在同一历史查询语句中的出现次数。By analyzing the fields involved in the historical query statement, it can be classified to determine whether it is a dimension field, and the query co-occurrence frequency of different dimension fields can be determined. The query co-occurrence frequency refers to the number of times that different dimension fields appear in the same historical query statement in all historical query statements of the target table at the same time.
本公开实施例中,可以借助于SQL Parser(解析器),将历史查询语句中的SQL语句转换得到AST(Abstract Syntax Tree,抽象语法树),然后通过遍历AST的边,可以抽取出所有历史查询语句中所涉及的各SQL语句对应的物理表(是指某个数据源中的一张表)的字段,并对各个字段标注字段类型,例如标注的字段类型可以包括聚合字段(group),过滤字段(filter)和指标字段等。In the embodiment of the present disclosure, an AST (Abstract Syntax Tree) can be obtained by converting the SQL statements in the historical query statements with the help of a SQL Parser, and then all historical queries can be extracted by traversing the edges of the AST The fields of the physical table (referring to a table in a certain data source) corresponding to each SQL statement involved in the statement, and the field type is marked for each field. For example, the marked field type can include aggregate fields (group), filtering Field (filter) and indicator fields, etc.
例如,对于如下的SQL语句:SELECT user_id,user_name,sum(value)as valueFROM user_data WHERE partition_time=20200101GROUP BY user_id,user_name,可以得到如下的结果:For example, for the following SQL statement: SELECT user_id,user_name,sum(value)as valueFROM user_data WHERE partition_time=20200101GROUP BY user_id,user_name, the following results can be obtained:
[(user_data,user_id,(”group”)),[(user_data, user_id, ("group")),
(user_data,user_name,(”group”)),(user_data, user_name, ("group")),
(user_data,partition_time,(”filter”)),(user_data, partition_time, ("filter")),
(user_data,value,(”sum”))](user_data, value, ("sum"))]
即假设历史查询的目标表的表名为user_data(用户数据),则在上述SQL语句中,抽取出字段user_id(用户标识)、user_name(用户名)、partition_time(分割时间)和value(值),其中,字段user_id和user_name的字段类型为聚合字段,字段partition_time的字段类型为过滤字段,字段value的字段类型为指标字段。其中,value字段为指标字段,不会进入查询网络,将user_id、user_name、partition_time等字段确定为维度字段。That is, assuming that the table name of the target table of the historical query is user_data (user data), in the above SQL statement, the fields user_id (user ID), user_name (user name), partition_time (partition time) and value (value) are extracted, The field type of the fields user_id and user_name is an aggregate field, the field type of the field partition_time is a filter field, and the field type of the field value is an indicator field. The value field is an indicator field and will not enter the query network. Fields such as user_id, user_name, and partition_time are determined as dimension fields.
在步骤S120中,将维度字段作为节点,根据不同维度字段之间的查询共现频次确定不同节点之间的初阶边权重,形成维度共现图。In step S120, the dimension field is used as a node, and the primary edge weight between different nodes is determined according to the query co-occurrence frequency between different dimension fields, so as to form a dimension co-occurrence graph.
本公开实施例中,利用上述步骤S110中获得的维度字段及不同维度字段的查询共现频次,可以构建维度共现图。初阶边权重表示连接边的两个节点对应的两个维度字段之间的查询共现频次。In the embodiment of the present disclosure, a dimension co-occurrence graph can be constructed by using the dimension fields obtained in the above step S110 and the query co-occurrence frequencies of different dimension fields. The initial edge weight represents the query co-occurrence frequency between the two dimension fields corresponding to the two nodes connecting the edge.
例如,还是以上述历史查询的目标表user_data为例,根据上述确定的user_id、user_name、partition_time三个维度字段,可以得到如下的节点、边及初阶边权重等信息,由此形成目标表user_data的维度共现图:For example, taking the target table user_data of the above historical query as an example, according to the three dimension fields of user_id, user_name, and partition_time determined above, the following information such as node, edge and primary edge weight can be obtained, thereby forming the target table user_data. Dimensional co-occurrence graph:
[(user_name,user_id,1),[(user_name,user_id,1),
(partition_time,user_id,1),(partition_time, user_id, 1),
(partition_time,user_name,1)](partition_time,user_name,1)]
其中,(user_name,user_id,1)表示user_name和user_id作为两个节点,这两个节点之间存在一条边,且由于user_name和user_id这两个维度字段在上述SQL语句中共同出现了一次,因此,此时这条边的初阶边权重为1。(partition_time,user_id,1)和(partition_time,user_name,1)表达类似的含义。Among them, (user_name, user_id, 1) indicates that user_name and user_id are used as two nodes, and there is an edge between these two nodes, and since the two dimension fields of user_name and user_id appear together in the above SQL statement, therefore, At this time, the initial edge weight of this edge is 1. (partition_time, user_id, 1) and (partition_time, user_name, 1) express similar meanings.
当分析完所有的历史查询语句后,把相同边上的初阶边权重进行累加,即根据各条边连接的两个节点对应的两个维度字段之间的查询共现频次,确定各条边的初阶边权重,便可以得到一个包含所有历史查询语句中所有维度字段的无向带权的维度共现图G。After analyzing all historical query statements, the initial edge weights on the same edge are accumulated, that is, each edge is determined according to the query co-occurrence frequency between the two dimension fields corresponding to the two nodes connected by each edge. Then we can get an undirected weighted dimension co-occurrence graph G containing all dimension fields in all historical query sentences.
在步骤S130中,根据维度共现图中各个节点的度,确定维度共现图中的第一核心节点。In step S130, a first core node in the dimensional co-occurrence graph is determined according to the degrees of each node in the dimensional co-occurrence graph.
本公开实施例中,维度共现图中各个节点的度是指各个节点连接的边的数量,例如假设user_id分别与partition_time、以及user_name连接,则user_id这个维度字段对应的节点的度为2。In the embodiment of the present disclosure, the degree of each node in the dimension co-occurrence graph refers to the number of edges connected to each node. For example, if user_id is connected to partition_time and user_name respectively, the degree of the node corresponding to the dimension field of user_id is 2.
本公开实施例中,可以将维度共现图G中度最大的节点确定为该维度共现图G的第一核心节点。In the embodiment of the present disclosure, the node with the highest degree in the dimensional co-occurrence graph G may be determined as the first core node of the dimensional co-occurrence graph G.
在步骤S140中,获得删除维度共现图中的第一核心节点后的第一连通子图。In step S140, a first connected subgraph after deleting the first core node in the dimension co-occurrence graph is obtained.
本公开实施例中,当获得维度共现图G中度最大的第一核心节点后,可以从该维度共现图中删除该第一核心节点,对应删除该第一核心节点原本与其它各个节点之间连接形成的边,然后判断删除该第一核心节点后的维度共现图中是否还存在节点,若存在节点,则进一步判断这些剩余的任意两个节点之间是否还是连通的,若这些剩余的节点中存在至少两个节点之间不是连通的,则说明删除该第一核心节点后的维度共现图中存在两个或者以上的第一连通子图。在每个第一连通子图中的任意两个节点之间是连通的。In the embodiment of the present disclosure, after obtaining the first core node with the largest degree in the dimensional co-occurrence graph G, the first core node can be deleted from the dimensional co-occurrence graph, corresponding to the deletion of the first core node and other nodes. and then judge whether there are still nodes in the dimensional co-occurrence graph after deleting the first core node. If there are nodes, then further judge whether the remaining two nodes are still connected. If there are at least two nodes in the remaining nodes that are not connected, it means that there are two or more first connected subgraphs in the dimensional co-occurrence graph after the first core node is deleted. There is connectivity between any two nodes in each first connected subgraph.
其中,在一个无向图中,若从节点i到节点j有路径相连,则称节点i和节点j是连通的,i和j均为大于或等于1的正整数。如果图中任意两个节点都是连通的,那么该图被认为是连通的,反之,则认为是非连通的。Among them, in an undirected graph, if there is a path connecting from node i to node j, then node i and node j are said to be connected, and both i and j are positive integers greater than or equal to 1. If any two nodes in the graph are connected, then the graph is considered connected, otherwise, it is considered disconnected.
在步骤S150中,根据维度共现图及其第一核心节点和第一连通子图,获得维度共现图的分裂树。In step S150, a split tree of the dimensional co-occurrence graph is obtained according to the dimensional co-occurrence graph and its first core node and first connected subgraph.
在示例性实施例中,根据维度共现图及其第一核心节点和第一连通子图,获得维度共现图的分裂树,可以包括:组合维度共现图中的节点,形成分裂树的根节点;根据第一连通子图中各个节点的度,确定第一连通子图中的第二核心节点;若删除第一连通子图中的第二核心节点之后,第一连通子图中不存在节点,则组合第一核心节点和第二核心节点作为分裂树的初阶叶子节点。In an exemplary embodiment, obtaining a split tree of the dimensional co-occurrence graph according to the dimensional co-occurrence graph and its first core node and first connected subgraph may include: combining nodes in the dimensional co-occurrence graph to form a split tree The root node; according to the degree of each node in the first connected subgraph, determine the second core node in the first connected subgraph; if the second core node in the first connected subgraph is deleted, the first connected subgraph will not be If there is a node, the first core node and the second core node are combined as the primary leaf node of the split tree.
在示例性实施例中,根据维度共现图及其第一核心节点和第一连通子图,获得维度共现图的分裂树,还可以包括:若删除第一连通子图中的第二核心节点之后,第一连通子图中存在节点,且删除第二核心节点之后的节点之间是连通的,则获得删除第一连通子图中的第二核心节点后的第二连通子图;若分裂树的当前分裂层数小于或等于分裂层数阈值,则根据第二连通子图中各个节点的度,确定第二连通子图中的第三核心节点;若删除第二连通子图中的第三核心节点之后,第二连通子图中不存在节点,则组合第一核心节点、第二核心节点和第三核心节点作为分裂树的初阶叶子节点。对维度共现图进行分裂获得分裂树的具体方式可以参照下图2至图7。In an exemplary embodiment, obtaining a split tree of the dimensional co-occurrence graph according to the dimensional co-occurrence graph and its first core node and the first connected subgraph, may further include: if the second core in the first connected subgraph is deleted After the node, there are nodes in the first connected subgraph, and the nodes after deleting the second core node are connected, then the second connected subgraph after deleting the second core node in the first connected subgraph is obtained; if If the current number of split layers of the split tree is less than or equal to the threshold of the number of split layers, the third core node in the second connected subgraph is determined according to the degree of each node in the second connected subgraph; After the third core node, if there is no node in the second connected subgraph, the first core node, the second core node and the third core node are combined as the primary leaf node of the split tree. For a specific manner of splitting the dimensional co-occurrence graph to obtain a split tree, reference may be made to FIG. 2 to FIG. 7 below.
在步骤S160中,根据分裂树的目标叶子节点确定维度字段的聚合组。In step S160, an aggregation group of dimension fields is determined according to the target leaf node of the split tree.
在示例性实施例中,根据分裂树的目标叶子节点确定维度字段的聚合组,可以包括:获得分裂树中各分支节点的分裂收益;根据分裂树中各分支节点的分裂收益的大小以及叶子节点阈值,对分裂树进行剪枝操作;将分裂树剪枝操作后保留的初阶叶子节点作为目标叶子节点,且目标叶子节点的数量小于或等于叶子节点阈值;将目标叶子节点作为维度字段的聚合组。In an exemplary embodiment, determining the aggregation group of dimension fields according to the target leaf node of the split tree may include: obtaining the split income of each branch node in the split tree; according to the size of the split income of each branch node in the split tree and the leaf node Threshold, prune the split tree; take the initial leaf node retained after the split tree pruning operation as the target leaf node, and the number of target leaf nodes is less than or equal to the leaf node threshold; take the target leaf node as the aggregation of dimension fields Group.
本公开实施例中,叶子节点阈值可以根据实际需求进行设置,本公开对此不做限定。In the embodiment of the present disclosure, the leaf node threshold may be set according to actual requirements, which is not limited in the present disclosure.
在示例性实施例中,分裂树中各分支节点可以包括第一分支节点,第一分支节点可以包括第一父节点的各个第一子节点。其中,获得分裂树中各分支节点的分裂收益,可以包括:获得第一父节点中各个维度字段的维度组合大小;获得第一父节点中各个维度字段之间的查询共现频次;获得根节点中各个维度字段之间的查询共现频次;根据第一父节点中各个维度字段的维度组合大小、第一父节点中各个维度字段之间的查询共现频次和根节点中各个维度字段之间的查询共现频次,获得第一父节点的查询构建代价;获得各个第一子节点中各个维度字段的维度组合大小;获得各个第一子节点中各个维度字段之间的查询共现频次;根据各个第一子节点中各个维度字段的维度组合大小、各个第一子节点中各个维度字段之间的查询共现频次和根节点中各个维度字段之间的查询共现频次,获得各个第一子节点的查询构建代价;根据第一父节点的查询构建代价和各个第一子节点的查询构建代价,获得第一分支节点的分裂收益。计算分裂收益以及根据分裂收益对分裂树进行剪枝操作的具体方式可以参照图7实施例。In an exemplary embodiment, each branch node in the split tree may include a first branch node, and the first branch node may include each first child node of the first parent node. Wherein, obtaining the split income of each branch node in the split tree may include: obtaining the dimension combination size of each dimension field in the first parent node; obtaining the query co-occurrence frequency between each dimension field in the first parent node; obtaining the root node The query co-occurrence frequency between each dimension field in The query co-occurrence frequency of each first child node is obtained, and the query construction cost of the first parent node is obtained; the dimension combination size of each dimension field in each first child node is obtained; the query co-occurrence frequency between each dimension field in each first child node is obtained; The dimension combination size of each dimension field in each first child node, the query co-occurrence frequency between each dimension field in each first child node, and the query co-occurrence frequency between each dimension field in the root node, obtain each first child node The query construction cost of the node; according to the query construction cost of the first parent node and the query construction cost of each first child node, the split income of the first branch node is obtained. For the specific manner of calculating the split income and performing the pruning operation on the split tree according to the split income, reference may be made to the embodiment in FIG. 7 .
在步骤S170中,根据维度字段的聚合组构建面向目标表的数据立方体。In step S170, a data cube oriented to the target table is constructed according to the aggregation group of dimension fields.
本公开实施例中,Cube即多维立方体,也叫数据立方体,是根据维度构建出来的多维空间,包含了要分析的基础数据,聚合数据操作在Cube上进行。其中,对于每一种维度的组合,将度量做聚合运算,然后将运算的结果保存为一个物化视图,称为Cuboid。所有维度组合的Cuboid作为一个整体,被称为Cube。In the embodiment of the present disclosure, a cube is a multi-dimensional cube, also called a data cube, which is a multi-dimensional space constructed according to dimensions, and contains basic data to be analyzed, and aggregated data operations are performed on the cube. Among them, for each combination of dimensions, the measures are aggregated, and then the result of the operation is saved as a materialized view, called Cuboid. A Cuboid that combines all dimensions as a whole is called a Cube.
本公开实施方式提供的数据处理方法,一方面,通过目标表的历史查询语句进行分析,根据历史查询语句中的维度字段及不同维度字段之间的查询共现频次构建维度共现图,并根据该维度共现图中各个节点的度来确定维度共现图中的第一核心节点,然后获得删除该维度共现图中的第一核心节点后的第一连通子图,根据该维度共现图及其第一核心节点和该第一连通子图对该维度共现图进行分裂,获得该维度共现图的分裂树,由此可以根据该分裂树的目标叶子节点来确定上述历史查询语句中的维度字段的聚合组,当利用该维度字段的聚合组来构建面向该目标表的数据立方体(Cube)时,实现了将大的Cube拆分为聚合组,各个聚合组可以用于构建各个小的Cube,即通过对维度共现图的拆分,压缩了数据规模,降低了Cube构建过程中耗费的计算资源,且能够缩短Cube的构建时长,实现了构建资源和构建时间之间的平衡。同时,由于本公开实施例中的维度共现图是根据目标表的历史查询语句中的维度字段及不同维度字段之间的查询共现频次构建的,因此,通过分裂该维度共现图来实现将一个大的Cube的构建任务拆分为多个小的Cube的构建任务,还能够保证构建的各个小的Cube能够满足实际业务中的查询需求,还不会增加较多的重复计算量。另一方面,通过分析历史查询语句,实现了Cube构建的自动化,简化了用户设计Cube的难度,优化了Cube设计。The data processing method provided by the embodiment of the present disclosure, on the one hand, analyzes the historical query statement of the target table, constructs a dimension co-occurrence graph according to the dimension fields in the historical query statement and the query co-occurrence frequency between different dimension fields, and according to The degree of each node in the dimensional co-occurrence graph is used to determine the first core node in the dimensional co-occurrence graph, and then the first connected subgraph after deleting the first core node in the dimensional co-occurrence graph is obtained. According to the dimensional co-occurrence graph The graph and its first core node and the first connected subgraph are split on the dimension co-occurrence graph to obtain a split tree of the dimension co-occurrence graph, so that the above historical query statement can be determined according to the target leaf node of the split tree When using the aggregation group of the dimension field to build a data cube (Cube) oriented to the target table, the large cube is divided into aggregation groups, and each aggregation group can be used to construct various aggregation groups. Small cubes, that is, by splitting the dimensional co-occurrence graph, compresses the data scale, reduces the computing resources consumed in the cube construction process, and can shorten the construction time of the cube, achieving a balance between construction resources and construction time. . At the same time, since the dimension co-occurrence graph in the embodiment of the present disclosure is constructed according to the dimension fields in the historical query statements of the target table and the query co-occurrence frequency between different dimension fields, the dimension co-occurrence graph is split to achieve this. Splitting the construction task of a large cube into multiple small cube construction tasks can also ensure that each small cube constructed can meet the query requirements in the actual business, and will not increase the amount of repeated calculations. On the other hand, by analyzing historical query statements, the automation of cube construction is realized, the difficulty of designing cubes is simplified, and the design of cubes is optimized.
图2示意性示出了根据本公开的一实施例的维度共现图的示意图。FIG. 2 schematically shows a schematic diagram of a dimensional co-occurrence graph according to an embodiment of the present disclosure.
如图2所示,假设历史查询语句中包括维度字段city_name(城市名),city_id(城市标识),user_name,user_id,partition_time,Y(year,年),M(month,月)和D(day,日),并假设partition_time分别与city_name、city_id、user_name、user_id、Y、M和D连接有一条边,且各边的初阶边权重分别为56、106、70、100、300、60和80;user_name和user_id两个节点连接的边的初阶边权重为61,city_name和city_id两个节点连接的边的初阶边权重为200,city_id和Y两个节点连接的边的初阶边权重为77,Y和M两个节点连接的边的初阶边权重为53,D和M两个节点连接的边的初阶边权重为96,city_id和Y两个节点连接的边的初阶边权重为89,Y和D两个节点连接的边的初阶边权重为21。As shown in Figure 2, it is assumed that the historical query statement includes dimension fields city_name (city name), city_id (city ID), user_name, user_id, partition_time, Y (year, year), M (month, month) and D (day, Day), and assume that partition_time has an edge connected to city_name, city_id, user_name, user_id, Y, M, and D, respectively, and the primary edge weights of each edge are 56, 106, 70, 100, 300, 60, and 80; The primary edge weight of the edge connected by the two nodes user_name and user_id is 61, the primary edge weight of the edge connected by the city_name and city_id nodes is 200, and the primary edge weight of the edge connected by the city_id and Y nodes is 77 , the primary edge weight of the edge connected by the two nodes Y and M is 53, the primary edge weight of the edge connected by the two nodes D and M is 96, and the primary edge weight of the edge connected by city_id and the two nodes of Y is 89, the initial edge weight of the edge connecting the two nodes Y and D is 21.
本公开实施例中,在得到了维度共现图G后,可以利用如下的图分解算法对该维度共现图进行图划分,以用于得到一个分裂树:In the embodiment of the present disclosure, after the dimensional co-occurrence graph G is obtained, the following graph decomposition algorithm can be used to divide the dimensional co-occurrence graph to obtain a split tree:
第一步,设置核心节点列表cores和子节点列表children,且初始化核心节点列表为空,即表示为:cores=[],且初始化该子节点列表包括该维度共现图G中的所有维度字段。The first step is to set the core node list cores and the child node list children, and initialize the core node list to be empty, which means: cores=[], and initialize the child node list to include all dimension fields in the co-occurrence graph G of this dimension.
第二步,计算维度共现图G中所有节点的度,并按照度的大小进行倒序排列,将度最大的节点确定为第一核心节点。The second step is to calculate the degrees of all nodes in the dimensional co-occurrence graph G, and arrange them in reverse order according to the size of the degree, and determine the node with the largest degree as the first core node.
第三步,从维度共现图G中删除度最大的第一核心节点,并将第一核心节点放入核心节点列表cores中。The third step is to delete the first core node with the largest degree from the dimension co-occurrence graph G, and put the first core node into the core node list cores.
第四步,判断删除度最大的第一核心节点后的维度共现图G中是否还存在节点,如果没有节点了,则完成该维度共现图的分裂;反之,如果还存在节点,则判断删除第一核心节点后剩余的任意两个节点之间是否连通;如果删除第一核心节点后剩余的任意两个节点之间是连通的,则返回上述第二步,对删除第一核心节点之后的维度共现图G中剩余的所有的节点进行类似上述第二步至第四步的处理,即继续计算删除第一核心节点之后的维度共现图G中剩余的所有的节点的度,并按照度的大小进行倒序排列,将度最大的节点确定为另一个第一核心节点;然后从删除第一核心节点之后的维度共现图G中删除度最大的该另一个第一核心节点,并将该另一个第一核心节点放入核心节点列表cores中,然后判断删除度最大的该另一个第一核心节点后的维度共现图G中是否还存在节点,如果没有节点了,则完成该维度共现图的分裂;反之,如果还存在节点,则判断删除该另一个第一核心节点后剩余的任意两个节点之间是否连通;如果删除该另一个第一核心节点后剩余的任意两个节点之间是连通的,则再次返回上述第二步,对删除该另一个第一核心节点之后的维度共现图G中剩余的所有的节点进行类似上述第二步至第四步的处理,...直至删除某个第一核心节点之后,维度共现图中不存在节点,或者删除某个第一核心节点后维度共现图中剩余的节点之间存在至少两个节点之间不是连通的。The fourth step is to judge whether there are still nodes in the dimensional co-occurrence graph G after the first core node with the largest deletion degree. If there are no nodes, the splitting of the dimensional co-occurrence graph is completed; otherwise, if there are still nodes, judge Whether any two remaining nodes after deleting the first core node are connected; if any two remaining nodes after deleting the first core node are connected, then return to the above second step, after deleting the first core node The remaining nodes in the dimensional co-occurrence graph G of the dimensional co-occurrence graph G are processed similarly to the above-mentioned steps 2 to 4, that is, continue to calculate the degree of all the remaining nodes in the dimensional co-occurrence graph G after the deletion of the first core node, and Arrange in reverse order according to the size of the degree, and determine the node with the largest degree as another first core node; then delete the other first core node with the largest degree from the dimensional co-occurrence graph G after deleting the first core node, and Put the other first core node into the core node list cores, and then judge whether there are still nodes in the dimension co-occurrence graph G behind the other first core node with the largest deletion degree, if there is no node, complete the The splitting of the dimensional co-occurrence graph; on the contrary, if there are still nodes, it is judged whether any two remaining nodes after deleting the other first core node are connected; if any two remaining nodes after deleting the other first core node are connected If the two nodes are connected, then go back to the above second step again, and process all the remaining nodes in the dimensional co-occurrence graph G after the deletion of the other first core node similar to the above second step to fourth step. , ... until a first core node is deleted, there is no node in the dimensional co-occurrence graph, or there are at least two nodes between the remaining nodes in the dimensional co-occurrence graph after a first core node is deleted. connected.
第五步,如果删除第一核心节点后剩余的节点中存在至少两个节点之间是非连通的,则将删除第一核心节点后的维度共现图中的所有第一连通子图G’加入到子节点列表children中。Step 5: If at least two nodes are non-connected in the remaining nodes after deleting the first core node, then add all the first connected subgraphs G' in the dimension co-occurrence graph after deleting the first core node. to the child node list children.
之后,再对子节点列表children中的每个第一连通子图G’进行分裂,分裂的方式可以参考上述维度共现图G,即是以树状的方式进行分裂的,最终可以获得分裂树。After that, split each first connected subgraph G' in the child node list children. The splitting method can refer to the above-mentioned dimensional co-occurrence graph G, that is, splitting in a tree-like manner, and finally a splitting tree can be obtained. .
以其中任意一个第一连通子图G’的分裂为例:Take the splitting of any one of the first connected subgraphs G' as an example:
1),设置核心节点列表cores和子节点列表children,且初始化核心节点列表cores包括上述维度共现图中的第一核心节点,且初始化该子节点列表包括第一连通子图G’中的所有维度字段。1), set the core node list cores and the child node list children, and initialize the core node list cores to include the first core node in the above-mentioned dimension co-occurrence graph, and initialize the child node list to include all dimensions in the first connected subgraph G' field.
2),计算第一连通子图G’中所有节点的度,并按照度的大小进行倒序排列,将度最大的节点确定为第二核心节点。2), calculate the degree of all nodes in the first connected subgraph G', and arrange in reverse order according to the size of the degree, and determine the node with the largest degree as the second core node.
3),从第一连通子图G’中删除度最大的第二核心节点,并将第二核心节点放入核心节点列表cores中。3), delete the second core node with the largest degree from the first connected subgraph G', and put the second core node into the core node list cores.
4),判断删除度最大的第二核心节点后的第一连通子图G’中是否还存在节点,如果没有节点了,则完成该第一连通子图G’的分裂;反之,如果还存在节点,则判断删除第二核心节点后剩余的任意两个节点之间是否连通;如果删除第二核心节点后剩余的任意两个节点之间是连通的,则返回上述步骤2),对删除第二核心节点之后的第一连通子图G’中剩余的所有的节点进行类似上述步骤2)至步骤4)的处理,即继续计算删除第二核心节点之后的第一连通子图G’中剩余的所有的节点的度,并按照度的大小进行倒序排列,将度最大的节点确定为另一个第二核心节点;然后从删除第二核心节点之后的第一连通子图G’中删除度最大的该另一个第二核心节点,并将该另一个第二核心节点放入核心节点列表cores中,然后判断删除度最大的该另一个第二核心节点后的第一连通子图G’中是否还存在节点,如果没有节点了,则完成该第一连通子图G’的分裂;反之,如果还存在节点,则判断删除该另一个第二核心节点后剩余的任意两个节点之间是否连通;如果删除该另一个第二核心节点后剩余的任意两个节点之间是连通的,则再次返回上述步骤2),对删除该另一个第二核心节点之后的第一连通子图G’中剩余的所有的节点进行类似上述步骤2)至步骤4)的处理,...直至删除某个第二核心节点之后,该第一连通子图G’中不存在节点,或者删除某个第二核心节点后该第一连通子图G’中剩余的节点之间存在至少两个节点之间不是连通的。4), judge whether there is a node in the first connected subgraph G' behind the second core node with the largest deletion degree, if there is no node, then complete the splitting of the first connected subgraph G'; otherwise, if there is still node, then determine whether any two remaining nodes after deleting the second core node are connected; if there is connectivity between any two remaining nodes after deleting the second core node, then return to the above step 2), to delete the first node. All the remaining nodes in the first connected subgraph G' after the two core nodes are processed similar to the above steps 2) to 4), that is, continue to calculate the remaining nodes in the first connected subgraph G' after the second core node is deleted. The degrees of all nodes are arranged in reverse order according to the size of the degree, and the node with the largest degree is determined as another second core node; then delete the largest degree from the first connected subgraph G' after deleting the second core node. the other second core node, put the other second core node into the core node list cores, and then judge whether the first connected subgraph G' behind the other second core node with the largest deletion degree is in the first connected subgraph G' There are still nodes. If there are no nodes, the splitting of the first connected subgraph G' is completed; otherwise, if there are nodes, it is determined whether any two remaining nodes are connected after deleting the other second core node. If the connection between any two remaining nodes after deleting this other second core node is connected, then return to above-mentioned step 2) again, to delete the first connected subgraph G' after this other second core node All the remaining nodes are processed similar to the above steps 2) to 4), ... until after deleting a certain second core node, there is no node in the first connected subgraph G', or delete a certain second core node. Between the remaining nodes in the first connected subgraph G' after the core node, at least two nodes are not connected.
5),如果删除第二核心节点后剩余的节点中存在至少两个节点之间是非连通的,则将删除第二核心节点后的该第一连通子图G’中的所有第二连通子图加入到子节点列表children中。5), if there are at least two non-connected nodes in the remaining nodes after deleting the second core node, then all the second connected subgraphs in the first connected subgraph G' after deleting the second core node will be deleted. Add to the child node list children.
之后,再对子节点列表children中的每个第二连通子图进行分裂,分裂的方式可以参考上述维度共现图G和第一连通子图的分裂。After that, each second connected subgraph in the child node list children is split again, and the splitting method can refer to the above-mentioned splitting of the dimensional co-occurrence graph G and the first connected subgraph.
以其中任意一个第二连通子图的分裂为例:Take the splitting of any of the second connected subgraphs as an example:
(1),设置核心节点列表cores和子节点列表children,且初始化核心节点列表cores包括上述维度共现图中的第一核心节点及该第一连通子图对应的第二核心节点,且初始化该子节点列表包括第二连通子图中的所有维度字段。(1), set the core node list cores and the child node list children, and initialize the core node list cores to include the first core node in the above-mentioned dimensional co-occurrence graph and the second core node corresponding to the first connected subgraph, and initialize the child The node list includes all dimension fields in the second connected subgraph.
(2),计算第二连通子图中所有节点的度,并按照度的大小进行倒序排列,将度最大的节点确定为第三核心节点。(2), calculate the degree of all nodes in the second connected subgraph, and arrange them in reverse order according to the size of the degree, and determine the node with the largest degree as the third core node.
(3),从第二连通子图中删除度最大的第三核心节点,并将第三核心节点放入核心节点列表cores中。(3), delete the third core node with the largest degree from the second connected subgraph, and put the third core node into the core node list cores.
(4),判断删除度最大的第三核心节点后的第二连通子图中是否还存在节点,如果没有节点了,则完成该第二连通子图的分裂;反之,如果还存在节点,则判断删除第三核心节点后剩余的任意两个节点之间是否连通;如果删除第三核心节点后剩余的任意两个节点之间是连通的,则返回上述步骤(2),对删除第三核心节点之后的第二连通子图中剩余的所有的节点进行类似上述步骤(2)至步骤(4)的处理,即继续计算删除第三核心节点之后的第二连通子图中剩余的所有的节点的度,并按照度的大小进行倒序排列,将度最大的节点确定为另一个第三核心节点;然后从删除第三核心节点之后的第二连通子图中删除度最大的该另一个第三核心节点,并将该另一个第三核心节点放入核心节点列表cores中,然后判断删除度最大的该另一个第三核心节点后的第二连通子图中是否还存在节点,如果没有节点了,则完成该第二连通子图的分裂;反之,如果还存在节点,则判断删除该另一个第三核心节点后剩余的任意两个节点之间是否连通;如果删除该另一个第三核心节点后剩余的任意两个节点之间是连通的,则再次返回上述步骤(2),对删除该另一个第三核心节点之后的第二连通子图中剩余的所有的节点进行类似上述步骤(2)至步骤(4)的处理,...直至删除某个第三核心节点之后,该第二连通子图中不存在节点,或者删除某个第三核心节点后该第二连通子图中剩余的节点之间存在至少两个节点之间不是连通的。(4), judging whether there are still nodes in the second connected subgraph after the third core node with the largest deletion degree, if there are no nodes, the splitting of the second connected subgraph is completed; otherwise, if there are still nodes, then Determine whether any two remaining nodes after deleting the third core node are connected; if any two nodes remaining after deleting the third core node are connected, then return to the above step (2), to delete the third core node. All the remaining nodes in the second connected subgraph after the node are processed similar to the above steps (2) to (4), that is, continue to calculate all the remaining nodes in the second connected subgraph after deleting the third core node. degree, and arrange them in reverse order according to the size of the degree, and determine the node with the largest degree as another third core node; then delete the other third core node with the largest degree from the second connected subgraph after deleting the third core node. core node, and put the other third core node into the core node list cores, and then judge whether there is a node in the second connected subgraph behind the other third core node with the largest deletion degree, if there is no node , then the splitting of the second connected subgraph is completed; on the contrary, if there are nodes, it is judged whether any two remaining nodes after deleting the other third core node are connected; if the other third core node is deleted After the connection between any two remaining nodes is connected, then return to the above step (2) again, and perform similar steps (2) on all the remaining nodes in the second connected subgraph after the deletion of the other third core node. ) to the processing of step (4), ... until after deleting a certain third core node, there is no node in the second connected subgraph, or after deleting a certain third core node, the second connected subgraph remains There are at least two nodes that are not connected between the nodes.
(5),如果删除第三核心节点后剩余的节点中存在至少两个节点之间是非连通的,则将删除第三核心节点后的该第二连通子图中的所有第三连通子图加入到子节点列表children中。(5), if at least two nodes are disconnected between the remaining nodes after deleting the third core node, then add all third connected subgraphs in the second connected subgraph after deleting the third core node to the to the child node list children.
之后,再对子节点列表children中的每个第三连通子图进行分裂...。After that, split each third connected subgraph in the child node list children... .
在上述分裂过程中,可以判断分裂树的当前分裂层数是否大于分裂层数阈值,如果当前分裂层数大于该分裂层数阈值,则停止分裂;反之,如果当前分裂层数小于或等于该分裂层数阈值,且当前被分裂的图(例如上述维度共现图或者第一连通子图、第二连通子图、第三连通子图)的children不为空,则继续对当前被分裂的图的children中的所有连通子图进行分裂,例如,对维度共现图的各个第一连通子图进行分裂,对第一连通子图的各个第二连通子图进行分裂...,得到各个连通子图的分裂结果。In the above splitting process, it can be judged whether the current split level of the split tree is greater than the split level threshold, and if the current split level is greater than the split level threshold, the splitting is stopped; otherwise, if the current split level is less than or equal to the split level The number of layers threshold, and the children of the currently split graph (such as the above-mentioned dimensional co-occurrence graph or the first connected subgraph, the second connected subgraph, and the third connected subgraph) is not empty, then continue to the current split graph. Split all connected subgraphs in children, for example, split each first connected subgraph of the dimension co-occurrence graph, split each second connected subgraph of the first connected subgraph... to get each connected subgraph The split result of the subgraph.
本公开实施例中,当前分裂层数是指分裂树的当前深度。其中,分裂层数阈值可以根据具体业务来定,例如可以综合考虑维度字段的数量、所需的Cube的数量等,这里假设分类层数阈值设置为6。In this embodiment of the present disclosure, the current number of split layers refers to the current depth of the split tree. Among them, the threshold of the number of split layers can be determined according to the specific business. For example, the number of dimension fields and the number of required cubes can be comprehensively considered. Here, it is assumed that the threshold of the number of classification layers is set to 6.
下面结合图3至图6对上述分裂过程进行举例说明。The above splitting process will be illustrated below with reference to FIG. 3 to FIG. 6 .
根据上图2可知,partition_time为图2所示的维度共现图中度最大的节点,其连接7条边,则删除图2中的第一核心节点partition_time之后,获得如图3所示的两个第一连通子图,即图2所示的维度共现图分裂为:user_name和user_id两个节点及其连接的一条边组成的第一连通子图301,city_name,city_id,Y,M和D四个节点及这四个节点之间连接形成的6条边组成的第一连通子图302。According to Figure 2 above, partition_time is the node with the largest degree in the dimensional co-occurrence graph shown in Figure 2, and it connects 7 edges. After deleting the first core node partition_time in Figure 2, the two nodes shown in Figure 3 are obtained. A first connected subgraph, that is, the dimensional co-occurrence graph shown in Figure 2 is split into: the first connected
对上图3中的连通子图302,可以进一步确定其中度最大的节点为Y,则删除连通第一子图302中的第二核心节点Y之后,获得如图4所示的两个第二连通子图:city_name和city_id两个节点及其连接的一条边组成的第二连通子图401,M和D两个节点及其连接的一条边组成的第二连通子图402。For the
如图5所示,以上述图2至图4为例,分裂过程可以包括以下步骤。As shown in FIG. 5 , taking the above-mentioned FIGS. 2 to 4 as examples, the splitting process may include the following steps.
在步骤S11中,初始化核心节点列表为空,即cores=[],子节点列表children=[partition_time,city_id,tity_name,user_id,user_name,Y,M,D]。In step S11, the initialized core node list is empty, that is, cores=[], and the child node list children=[partition_time, city_id, city_name, user_id, user_name, Y, M, D].
在步骤S12中,将第一核心节点加入核心节点列表,则cores=[partition_time]。In step S12, the first core node is added to the core node list, then cores=[partition_time].
同时,将两个第一连通子图加入子节点列表,则children=[user_id,user_name],[city_id,tity_name,Y,M,D]。At the same time, add the two first connected subgraphs to the child node list, then children=[user_id, user_name], [city_id, city_name, Y, M, D].
在步骤S13中,确定第一连通子图301的第二核心节点为user_id,将第二核心节点user_id加入核心节点列表,则cores=[partition_time,user_id],且子节点列表children=[user_name]。In step S13, it is determined that the second core node of the first connected
在步骤S14中,确定第一连通子图301的另一个第二核心节点为user_name,将另一个第二核心节点user_name加入核心节点列表,则cores=[partition_time,user_id,user_name],且子节点列表children=[]。In step S14, it is determined that another second core node of the first connected
在步骤S15中,确定第一连通子图302的第二核心节点为Y,将第二核心节点Y加入核心节点列表,则cores=[partition_time,Y],且获得第一连通子图302的两个第二连通子图401和402,将这两个第二连通子图402加入子节点列表,则children=([city_id,tity_name],[M,D])。In step S15, it is determined that the second core node of the first connected
在步骤S16中,确定第二连通子图401的第三核心节点为city_id,将第三核心节点city_id加入核心节点列表,则cores=[partition_time,Y,city_id],且子节点列表children=[city_name]。In step S16, it is determined that the third core node of the second connected
在步骤S17中,确定第二连通子图401的另一个第三核心节点为city_name,将该另一个第三核心节点city_name加入核心节点列表,则cores=[partition_time,Y,city_id,city_name],且子节点列表children=[]。In step S17, it is determined that another third core node of the second connected
在步骤S18中,确定第二连通子图402的第三核心节点为M,将第三核心节点M加入核心节点列表,则cores=[partition_time,Y,M],且子节点列表children=[D]。In step S18, it is determined that the third core node of the second connected
在步骤S19中,确定第二连通子图402的另一个第三核心节点为D,将该另一个第三核心节点D加入核心节点列表,则cores=[partition_time,Y,M,D],且子节点列表children=[]。In step S19, it is determined that another third core node of the second connected
通过图5所示的分裂过程,可以得到如图6所示的分裂树。Through the splitting process shown in Figure 5, the splitting tree shown in Figure 6 can be obtained.
该分裂树的根节点600的节点列表nodes中包括[partition_time,city_id,tity_name,user_id,user_name,Y,M,D]。第一分裂层数601中包括的两个分支节点的节点列表nodes分别为[partition_time,user_id,user_name],[partition_time,Y,city_id,tity_name,M,D],即[partition_time,user_id,user_name]和[partition_time,Y,city_id,tity_name,M,D]均为根节点600的子节点。The node list nodes of the root node 600 of the split tree includes [partition_time, city_id, city_name, user_id, user_name, Y, M, D]. The node list nodes of the two branch nodes included in the first split layer 601 are respectively [partition_time, user_id, user_name], [partition_time, Y, city_id, tity_name, M, D], namely [partition_time, user_id, user_name] and [partition_time, Y, city_id, city_name, M, D] are all child nodes of the root node 600 .
第一分裂层数601中的分支节点[partition_time,Y,city_id,tity_name,M,D]作为第二分裂层数602的父节点,第二分裂层数602中包括的两个分支节点的节点列表分别为[partition_time,user_id,user_name],[partition_time,Y,city_id,tity_name,M,D],即[partition_time,user_id,user_name]和[partition_time,Y,city_id,tity_name,M,D]为父节点[partition_time,Y,city_id,tity_name,M,D]的子节点。The branch node [partition_time, Y, city_id, tity_name, M, D] in the first split level 601 is used as the parent node of the second split level 602 , and the node list of the two branch nodes included in the second split level 602 Respectively [partition_time, user_id, user_name], [partition_time, Y, city_id, tity_name, M, D], namely [partition_time, user_id, user_name] and [partition_time, Y, city_id, tity_name, M, D] are the parent nodes [ child nodes of partition_time, Y, city_id, city_name, M, D].
相关技术中,存在数据膨胀的问题:即相关技术中对维度组合进行预计算,而计算维度组合的公式是2^N(N为维度个数,N为大于或等于1的正整数),比如对于一个包含(A,B,C,D)的一个模型,其中D是指标字段,A、B、C三个是维度字段,那么其对应的所有维度组合如下:[(),(A),(B),(C),(A,B),(A,C),(B,C),(A,B,C)],如果当数据模型的维度特别多的时候,比如60或者以上个维度,在这种情况下,维度爆炸是不可接受的,尽管相关技术中提供了维度剪枝的方式,以用于减少维度组合的个数,但是对于比较复杂的业务例如广告,单数据模型的构建任务不可裁剪的组合个数仍高达1000多个以上,在维度组合特别多的情况下,必然会导致结果数据规模急速膨胀。因此,怎么更有效的剪枝,是Cube设计的一个重要问题。In the related art, there is the problem of data expansion: that is, in the related art, the dimension combination is pre-calculated, and the formula for calculating the dimension combination is 2^N (N is the number of dimensions, and N is a positive integer greater than or equal to 1), such as For a model containing (A, B, C, D), where D is the indicator field, and A, B, and C are the dimension fields, then all the corresponding dimensions are combined as follows: [(), (A), (B),(C),(A,B),(A,C),(B,C),(A,B,C)], if the dimension of the data model is very large, such as 60 or more In this case, dimension explosion is unacceptable. Although dimension pruning is provided in the related art to reduce the number of dimension combinations, for more complex businesses such as advertising, the single data model There are still more than 1,000 combinations that cannot be tailored for the construction tasks of . In the case of a particularly large number of dimensional combinations, it will inevitably lead to a rapid expansion of the resulting data scale. Therefore, how to prune more effectively is an important issue in Cube design.
相关技术中,为了降低Cube的复杂度,减少Cuboid数量,虽然提供了一些Cube剪枝算法,但这些Cube剪枝算法都存在一个问题,它们是基于所有的查询请求都是均匀分布在每一种维度组合上这个假设去计算收益率的,这在现实中是不可能的。在实际业务中,用户的查询通常会比较集中在一些维度组合上,其它的维度组合很少甚至没有查询落到上边,如果有些维度组合被预计算了,但是没有查询到;或者是有些维度组合经常被查询,但是没有被预计算出来,这些差距影响了Cube的资源利用率和查询性能。In the related art, in order to reduce the complexity of cubes and reduce the number of cubes, although some cube pruning algorithms are provided, there is a problem with these cube pruning algorithms. They are based on that all query requests are evenly distributed in each This assumption is used to calculate the rate of return on the combination of dimensions, which is impossible in reality. In actual business, users' queries usually focus on some dimension combinations, and other dimension combinations rarely or even no query falls on top, if some dimension combinations are pre-computed, but not queried; or some dimension combinations Frequently queried, but not pre-computed, these gaps affect Cube's resource utilization and query performance.
另外相关技术中的一些剪枝方法并不适合用于维度太多的Cube剪枝,或者另一些剪枝方法存在稳定性问题,即每次计算出来的维度组合完全不同。In addition, some pruning methods in the related art are not suitable for cube pruning with too many dimensions, or other pruning methods have stability problems, that is, the dimension combinations calculated each time are completely different.
获得如图6所示的分裂树后,将其叶子节点作为初阶叶子节点,图6中有些分支节点可能本不需要细分,但是被拆分了,因此,本公开实施例中,通过计算每次分裂后的分裂收益,对其进行剪枝,以获得分裂树的目标叶子节点。After obtaining the split tree shown in Fig. 6, its leaf nodes are used as primary leaf nodes. Some branch nodes in Fig. 6 may not need to be subdivided, but are split. The split income after each split is pruned to obtain the target leaf node of the split tree.
图7示意性示出了根据本公开的一实施例的对分裂树进行剪枝操作的示意图。FIG. 7 schematically shows a schematic diagram of performing a pruning operation on a split tree according to an embodiment of the present disclosure.
如图7所示,假设分裂树中的第一父节点701包括a,b,c三个维度字段,第一分支节点包括第一父节点701的两个第一子节点702,即一个第一子节点702包括a和b两个维度字段,另一个第一子节点702a和c两个维度字段。可以理解的是,可以选择分裂树中的任意一个父节点作为第一父节点,每个父节点相对上一分裂层数为子节点。As shown in FIG. 7 , it is assumed that the first parent node 701 in the split tree includes three dimension fields a, b, and c, and the first branch node includes two first child nodes 702 of the first parent node 701 , that is, a first The child node 702 includes two dimension fields a and b, and another first child node 702 has two dimension fields a and c. It can be understood that any parent node in the split tree can be selected as the first parent node, and each parent node is a child node relative to the previous split level.
假设第一子节点702中a和c两个维度字段作为第二父节点703,进一步包括两个第二子节点704,即包括a维度字段的第二子节点704和包括c维度字段的第二子节点704。It is assumed that the two dimension fields a and c in the first child node 702 are used as the second parent node 703, and further includes two second child nodes 704, namely the second child node 704 including the a dimension field and the second child node including the c dimension field. Child node 704.
本公开实施例中,可以采用如下公式(1)来计算第一分支节点的分裂收益Split_income1:In the embodiment of the present disclosure, the following formula (1) can be used to calculate the split income Split_income1 of the first branch node:
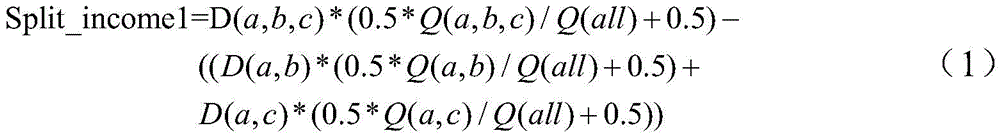
或者,也可以根据如下公式(2)来计算第一分支节点的分裂收益Split_income1:Alternatively, the split income Split_income1 of the first branch node can also be calculated according to the following formula (2):
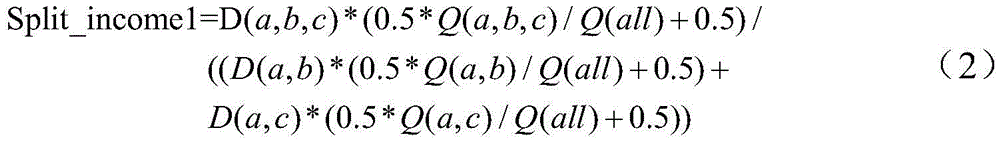
上述公式(1)和(2)中,D(a,b,c)表示第一父节点中的(a,b,c)这三个维度字段组合而成的维度组合的维度组合大小,具体计算可以通过统计目标表的原始数据中该三个维度字段组合而成的记录条数获得,例如通过唯一值获得;Q(a,b,c)表示第一父节点中(a,b,c)这三个维度字段之间的查询共现频次;Q(all)表示根节点中所有维度字段之间的查询共现频次;D(a,b,c)*(0.5*Q(a,b,c)/Q(all)+0.5)考虑了第一父节点的查询代价和构建代价,称之为第一父节点的查询构建代价;D(a,b)表示第一子节点中的(a,b)这两个维度字段组合而成的维度组合的维度组合大小;Q(a,b)表示第一子节点中(a,b)这两个维度字段之间的查询共现频次;(D(a,b)*(0.5*Q(a,b)/Q(all)+0.5),称之为第一子节点的查询构建代价;D(a,c)表示第一子节点中的(a,c)这两个维度字段组合而成的维度组合的维度组合大小;Q(a,c)表示第一子节点中(a,c)这两个维度字段之间的查询共现频次;D(a,c)*(0.5*Q(a,c)/Q(all)+0.5),称之为第一子节点的查询构建代价。In the above formulas (1) and (2), D(a,b,c) represents the dimension combination size of the dimension combination formed by the combination of the three dimension fields (a,b,c) in the first parent node, specifically The calculation can be obtained by counting the number of records combined by the three dimension fields in the original data of the target table, for example, obtained by unique values; Q(a,b,c) means (a,b,c) in the first parent node ) query co-occurrence frequency between these three dimension fields; Q(all) represents the query co-occurrence frequency between all dimension fields in the root node; D(a,b,c)*(0.5*Q(a,b) ,c)/Q(all)+0.5) considers the query cost and construction cost of the first parent node, which is called the query construction cost of the first parent node; D(a,b) represents the ( a,b) The dimension combination size of the dimension combination formed by the combination of these two dimension fields; Q(a,b) represents the query co-occurrence frequency between the two dimension fields (a,b) in the first child node; (D(a,b)*(0.5*Q(a,b)/Q(all)+0.5), which is called the query construction cost of the first child node; D(a,c) represents the cost of the first child node The dimension combination size of the dimension combination formed by the combination of these two dimension fields (a, c); Q(a, c) represents the query co-occurrence between the two dimension fields (a, c) in the first child node Frequency; D(a,c)*(0.5*Q(a,c)/Q(all)+0.5), which is called the query construction cost of the first child node.
本公开实施例中,可以采用如下公式(3)来计算第二分支节点的分裂收益Split_income2:In the embodiment of the present disclosure, the following formula (3) can be used to calculate the split income Split_income2 of the second branch node:
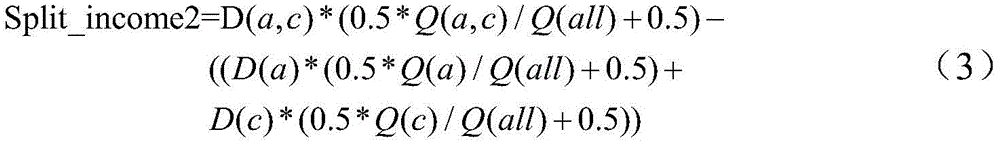
或者,也可以根据如下公式(4)来计算第二分支节点的分裂收益Split_income2:Alternatively, the split income Split_income2 of the second branch node can also be calculated according to the following formula (4):

上述公式(3)和(4)中,D(a,c)表示第二父节点中的(a,c)这两个维度字段组合而成的维度组合的维度组合大小;Q(a,c)表示第二父节点中(a,c)这两个维度字段之间的查询共现频次;D(a,c)*(0.5*Q(a,c)/Q(all)+0.5)称之为第二父节点的查询构建代价;D(a)表示第二子节点中的(a)这个维度字段的维度组合大小;Q(a)表示第二子节点中(a)这个维度字段之间的查询共现频次;(D(a)*(0.5*Q(a)/Q(all)+0.5),称之为第二子节点的查询构建代价;D(c)表示第二子节点中的(c)这个维度字段的维度组合大小;Q(c)表示第二子节点中(c)这个维度字段之间的查询共现频次;D(c)*(0.5*Q(c)/Q(all)+0.5),称之为第二子节点的查询构建代价。In the above formulas (3) and (4), D(a,c) represents the dimension combination size of the dimension combination formed by the combination of the two dimension fields (a,c) in the second parent node; Q(a,c ) represents the query co-occurrence frequency between the two dimension fields (a,c) in the second parent node; D(a,c)*(0.5*Q(a,c)/Q(all)+0.5) is called It is the query construction cost of the second parent node; D(a) represents the dimension combination size of (a) this dimension field in the second child node; Q(a) represents the (a) dimension field in the second child node. The co-occurrence frequency of queries between the In (c) the dimension combination size of this dimension field; Q(c) represents the query co-occurrence frequency between (c) this dimension field in the second child node; D(c)*(0.5*Q(c)/ Q(all)+0.5), which is called the query construction cost of the second child node.
但本公开实施例中对各个分支节点的分裂收益的计算方式并不限于上述公式给出的实例。However, in the embodiment of the present disclosure, the calculation method of the split income of each branch node is not limited to the example given by the above formula.
利用上述计算方式,可以计算该分裂树的所有分支节点的分裂收益,然后按照分裂收益的大小对低收益的分裂进行剪枝,例如,假设上述第一分支节点的分裂收益小于第二分支节点的分裂收益,则删除第一子节点(a,b)和(a,c),直到分裂树的初阶叶子节点数量满足叶子节点阈值,将保留的每一个初阶叶子节点作为目标叶子节点,每一个目标叶子节点表示为Cube的一个聚合组,可以把每个目标叶子节点上的所有维度字段作为单个Cube的维度,从而通过上述分裂过程可以构建出该目标表的多个Cube,即实现了将一个较大的Cube拆分为多个较小的Cube的目的。Using the above calculation method, the split income of all branch nodes of the split tree can be calculated, and then the low-income splits can be pruned according to the size of the split income. For example, it is assumed that the split income of the first branch node is smaller than that of the second branch node To split the income, delete the first child nodes (a, b) and (a, c) until the number of primary leaf nodes of the split tree meets the leaf node threshold, and take each remaining primary leaf node as the target leaf node, and each A target leaf node is represented as an aggregate group of Cubes, and all dimension fields on each target leaf node can be used as the dimensions of a single Cube, so that multiple Cubes of the target table can be constructed through the above splitting process, that is, the The purpose of splitting a larger cube into multiple smaller cubes.
本公开实施例中,叶子节点阈值可以根据实际需要进行设置,本公开对此不做限定。此外,并不限定低收益的具体取值,其可以根据设置的叶子节点阈值来确定。例如,假设当前需要设置4个聚合组,则设置叶子节点阈值为4,那么在上述剪枝过程中,保留分支节点的分裂收益最高的前4个初阶叶子节点作为目标叶子节点即可。In this embodiment of the present disclosure, the leaf node threshold may be set according to actual needs, which is not limited in the present disclosure. In addition, the specific value of the low profit is not limited, and it can be determined according to the set leaf node threshold. For example, assuming that 4 aggregation groups need to be set currently, the leaf node threshold is set to 4, then in the above pruning process, the first 4 primary leaf nodes with the highest splitting benefits of branch nodes can be reserved as the target leaf nodes.
需要说明的是,在上述剪枝过程中,并不要求最后获得的目标叶子节点数量等于叶子节点阈值,只要满足目标叶子节点数量小于或等于叶子节点阈值即可。It should be noted that, in the above-mentioned pruning process, it is not required that the number of target leaf nodes finally obtained is equal to the leaf node threshold, as long as the number of target leaf nodes is less than or equal to the leaf node threshold.
本公开实施方式提供的数据处理方法,通过分析目标表的历史查询语句来构建维度共现图,并通过对该维度共现图进行分裂,获得分裂树的聚合组,根据多个聚合组来构建多个较小的Cube,由此改善了Cube构建过程中的计算资源和构建时长,减少了Cuboid数量。此外,通过上述剪枝操作,进一步降低了聚合组的数量,由此进一步减少了耗费的计算资源,进一步降低了构建时长,同时使得构建出来的Cube满足实际业务需求。同时,实现了自动确定聚合组,不需用户手动设计,由此降低了Cube的设计复杂度,在维度特别多的情况下,减小了Cube的设计难度。In the data processing method provided by the embodiment of the present disclosure, a dimensional co-occurrence graph is constructed by analyzing the historical query statements of the target table, and by splitting the dimensional co-occurrence graph, an aggregation group of the split tree is obtained, and the aggregation group is constructed according to a plurality of aggregation groups. Multiple smaller cubes, thereby improving the computing resources and construction time during the cube construction process, and reducing the number of cubes. In addition, through the above pruning operation, the number of aggregation groups is further reduced, thereby further reducing the consumption of computing resources, further reducing the construction time, and at the same time making the constructed cubes meet actual business needs. At the same time, it realizes the automatic determination of the aggregation group, and does not require the user to design manually, thereby reducing the design complexity of the cube, and in the case of a particularly large number of dimensions, the design difficulty of the cube is reduced.
图8示意性示出了根据本公开的另一实施例的数据处理方法的流程图。如图8所示,与上述其他实施例相比,图8实施例提供的方法进一步还包括以下步骤。FIG. 8 schematically shows a flowchart of a data processing method according to another embodiment of the present disclosure. As shown in FIG. 8 , compared with other above-mentioned embodiments, the method provided in the embodiment of FIG. 8 further includes the following steps.
在步骤S810中,根据维度共现图各条边的初阶边权重,获得维度共现图各条边的目标边权重。In step S810, the target edge weight of each edge of the dimensional co-occurrence graph is obtained according to the primary edge weight of each edge of the dimensional co-occurrence graph.
在示例性实施例中,维度共现图中可以包括第一边及第一边的第一节点和第二节点。其中,根据维度共现图各条边的初阶边权重,获得维度共现图各条边的目标边权重,可以包括:获得第一节点对应的维度字段在历史查询语句中的第一查询频次;获得第二节点对应的维度字段在历史查询语句中的第二查询频次;根据第一查询频次和第二查询频次,确定目标查询频次;根据第一边的初阶边权重和目标查询频次,获得第一边的目标边权重。In an exemplary embodiment, the dimensional co-occurrence graph may include a first edge and first and second nodes of the first edge. Wherein, obtaining the target edge weight of each edge of the dimensional co-occurrence graph according to the initial edge weight of each edge of the dimensional co-occurrence graph may include: obtaining the first query frequency of the dimension field corresponding to the first node in the historical query statement ; obtain the second query frequency of the dimension field corresponding to the second node in the historical query statement; determine the target query frequency according to the first query frequency and the second query frequency; according to the initial edge weight of the first side and the target query frequency, Get the target edge weight for the first edge.
本公开实施例中,可以通过分析维度字段在历史查询语句中的查询共现频次,将一些关联度比较高的维度字段组合到一起,形成联合维度。具体地,可以采用如下步骤来进行维度字段之间的关联度分析:对维度共现图G重新计算边权重,获得目标边权重。In the embodiment of the present disclosure, some dimension fields with relatively high correlation degree can be combined together to form a joint dimension by analyzing the query co-occurrence frequency of dimension fields in historical query sentences. Specifically, the following steps may be used to analyze the degree of association between dimension fields: recalculate the edge weights on the dimension co-occurrence graph G to obtain the target edge weights.
例如,对于维度共现图中的第一边(a,b,w),其中a和b分别为该第一边的第一节点和第二节点,w为该第一边的初阶边权重,则可以利用如下公式计算该第一边的目标边权重w′:For example, for the first edge (a, b, w) in the dimensional co-occurrence graph, where a and b are the first and second nodes of the first edge, respectively, and w is the initial edge weight of the first edge , the target edge weight w' of the first edge can be calculated by the following formula:
w′=w/max(count(a),count(b)) (5)w′=w/max(count(a),count(b)) (5)
上述公式中,count(a)表示第一节点a在历史查询语句中的第一查询频次,即出现的总次数;count(b)表示第二节点b在历史查询语句中的第二查询频次,即出现的总次数。In the above formula, count(a) represents the first query frequency of the first node a in the historical query statement, that is, the total number of occurrences; count(b) represents the second query frequency of the second node b in the historical query statement, the total number of occurrences.
在步骤S820中,将目标边权重低于权重阈值的边移除,获得维度共现图的各个子图。In step S820, the edges whose weights of the target edges are lower than the weight threshold are removed to obtain each subgraph of the dimension co-occurrence graph.
然后,将维度共现图中目标边权重小于权重阈值的边从维度共现图中移除,移除目标边权重低于权重阈值的边之后,可能将该维度共现图拆分为多个子图。Then, the edge with the target edge weight less than the weight threshold in the dimensional co-occurrence graph is removed from the dimensional co-occurrence graph, and after removing the edge with the target edge weight lower than the weight threshold, the dimensional co-occurrence graph may be split into multiple sub-graphs picture.
本公开实施例中,权重阈值可以根据经验设置,取值范围为(0~1),例如这里假设设置为0.6。In the embodiment of the present disclosure, the weight threshold may be set according to experience, and the value range is (0-1), for example, it is assumed to be set to 0.6 here.
在步骤S830中,获得各个子图中的最大团,根据各个最大团中的维度字段形成各个关联维度组。In step S830, the largest clique in each subgraph is obtained, and each associated dimension group is formed according to the dimension field in each largest clique.
之后,在移除目标边权重低于权重阈值的边后的各个子图上利用最大团算法找出图中的最大团,每一个最大团作为一个关联维度组。After that, the maximum clique algorithm is used to find the largest clique in the graph on each subgraph after removing the edge whose target edge weight is lower than the weight threshold, and each largest clique is used as an associated dimension group.
其中,给定各个子图,如果子图存在图,该图中任意两个节点之间存在边,则称该图为该子图的完全子图,该子图的完全子图是该子图的团,该子图的最大团是指该子图的最大完全子图。本公开对采用何种最大团算法不做限定。Among them, given each subgraph, if there is a graph in the subgraph and there is an edge between any two nodes in the graph, then the graph is called the complete subgraph of the subgraph, and the complete subgraph of the subgraph is the subgraph The clique of the subgraph refers to the largest complete subgraph of the subgraph. The present disclosure does not limit which maximal clique algorithm is adopted.
在步骤S840中,获得各个关联维度组之间的相关度和合并膨胀率。In step S840, the degree of correlation and the combined expansion rate between each associated dimension group are obtained.
在示例性实施例中,各个关联维度组可以包括第一关联维度组和第二关联维度组。其中,获得各个关联维度组之间的相关度,可以包括:获得第一关联维度组的维度组合大小和第二关联维度组的维度组合大小;获得第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的乘积结果;合并第一关联维度组和第二关联维度组,获得合并关联维度组;获得合并关联维度组的维度组合大小;根据合并关联维度组的维度组合大小以及第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的乘积结果,获得第一关联维度组和第二关联维度组之间的相关度。In an exemplary embodiment, each associated dimension group may include a first associated dimension group and a second associated dimension group. Wherein, obtaining the correlation between each associated dimension group may include: obtaining the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group; obtaining the dimension combination size of the first associated dimension group and the second associated dimension group. The product result of the dimension combination size of the associated dimension group; merge the first associated dimension group and the second associated dimension group to obtain the merged associated dimension group; obtain the dimension combination size of the merged associated dimension group; according to the combined dimension combination size of the merged associated dimension group and The correlation between the first associated dimension group and the second associated dimension group is obtained by multiplying the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group.
在示例性实施例中,各个关联维度组可以包括第一关联维度组和第二关联维度组。其中,获得各个关联维度组之间的合并膨胀率,可以包括:获得第一关联维度组的维度组合大小和第二关联维度组的维度组合大小;获得第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的求和结果;合并第一关联维度组和第二关联维度组,获得合并关联维度组;获得合并关联维度组的维度组合大小;根据合并关联维度组的维度组合大小以及第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的求和结果,获得第一关联维度组和第二关联维度组之间的合并膨胀率。In an exemplary embodiment, each associated dimension group may include a first associated dimension group and a second associated dimension group. Wherein, obtaining the combined expansion rate between each associated dimension group may include: obtaining the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group; obtaining the dimension combination size of the first associated dimension group and the first associated dimension group. The summation result of the dimension combination size of the two associated dimension groups; merge the first associated dimension group and the second associated dimension group to obtain the merged associated dimension group; obtain the dimension combination size of the merged associated dimension group; according to the dimension combination of the merged associated dimension group The size and the summation result of the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group obtains the combined expansion rate between the first associated dimension group and the second associated dimension group.
在步骤S850中,根据各个关联维度组之间的相关度和合并膨胀率,对各个关联维度组进行合并,获得维度共现图的联合维度(Joint Dimension),联合维度的数量小于或等于联合维度阈值。In step S850, each associated dimension group is merged according to the correlation between the respective associated dimension groups and the combined expansion rate to obtain a joint dimension (Joint Dimension) of the dimension co-occurrence graph, where the number of joint dimensions is less than or equal to the joint dimension threshold.
本公开实施例中,将部分维度字段组合在一起作为联合维度,对联合维度进行预计算,从而可以减少维度组合数量,降低Cube复杂度,减少Cuboid数量。In the embodiment of the present disclosure, some dimension fields are combined together as a joint dimension, and the joint dimension is pre-calculated, thereby reducing the number of dimension combinations, the complexity of cubes, and the number of cubes.
例如将维度字段a、b和c定义为联合维度,就仅会构建Cuboid a b C,而Cuboid ab、b c、a等等Cuboid都不会被生成。For example, if the dimension fields a, b, and c are defined as joint dimensions, only Cuboid a b C will be constructed, and Cuboid ab, b c, a, and so on will not be generated.
在示例性实施例中,根据各个关联维度组之间的相关度和合并膨胀率,对各个关联维度组进行合并,获得维度共现图的联合维度,可以包括:根据各个关联维度组之间的相关度和合并膨胀率,确定各个关联维度组中满足合并条件的关联维度组对;获得关联维度组对中相关度最高的目标关联维度组对;合并目标关联维度组对中的关联维度组,获得目标合并关联维度组,并删除目标关联维度组对中的关联维度组;若目标合并关联维度组和未合并的关联维度组的数量小于或等于联合维度阈值,则将目标合并关联维度组和未合并的关联维度组分别作为维度共现图的联合维度。In an exemplary embodiment, combining each associated dimension group to obtain a joint dimension of the dimension co-occurrence graph according to the correlation degree and the combined expansion rate between the respective associated dimension groups may include: according to the correlation between the respective associated dimension groups Relevance and merger expansion rate, determine the associated dimension group pairs that meet the merger conditions in each associated dimension group; obtain the target associated dimension group pair with the highest correlation in the associated dimension group pair; merge the associated dimension group in the target associated dimension group pair, Obtain the target merged associated dimension group, and delete the associated dimension group in the target associated dimension group pair; if the number of the target merged associated dimension group and the unmerged associated dimension group is less than or equal to the union dimension threshold, the target merged associated dimension group and The unmerged associated dimension groups are respectively used as the joint dimension of the dimension co-occurrence graph.
在示例性实施例中,根据各个关联维度组之间的相关度和合并膨胀率,确定各个关联维度组中满足合并条件的关联维度组对,可以包括:若关联维度组之间的相关度大于第一相关度阈值;或者若关联维度组之间的相关度大于第二相关度阈值且合并膨胀率小于第一膨胀率阈值;或者若关联维度组之间的相关度大于第三相关度阈值且合并膨胀率小于第二膨胀率阈值,则判定对应的关联维度组为满足合并条件的关联维度组对;其中,第一相关性阈值大于第二相关性阈值,第二相关性阈值大于第三相关性阈值,第一膨胀率阈值大于第二膨胀率阈值。In an exemplary embodiment, determining the pair of associated dimension groups in each associated dimension group that satisfies the merging condition according to the degree of correlation and the combined expansion rate of each associated dimension group may include: if the degree of correlation between the associated dimension groups is greater than the first correlation threshold; or if the correlation between the associated dimension groups is greater than the second correlation threshold and the combined expansion rate is less than the first expansion rate threshold; or if the correlation between the associated dimension groups is greater than the third correlation threshold and If the combined expansion rate is less than the second expansion rate threshold, it is determined that the corresponding associated dimension group is an associated dimension group pair that satisfies the combination condition; wherein the first correlation threshold is greater than the second correlation threshold, and the second correlation threshold is greater than the third correlation threshold The first expansion rate threshold is greater than the second expansion rate threshold.
具体地,在得到各个关联维度组后,继续进一步对维度字段进行聚合,例如假设通过上述方法得到了如下的关联维度组的组合groups,并假设目标是将组合中的关联维度组的数量压缩到一个给定的联合维度阈值N(N为大于或等于1的正整数,可以根据实际需要设置,这里假设为4个):Specifically, after each associated dimension group is obtained, continue to further aggregate the dimension fields. For example, it is assumed that the following combination groups of associated dimension groups are obtained through the above method, and it is assumed that the goal is to compress the number of associated dimension groups in the combination to A given joint dimension threshold N (N is a positive integer greater than or equal to 1, which can be set according to actual needs, here it is assumed to be 4):
Groups=[Groups=[
[user_id,user_name],[user_id,user_name],
[partition_time],[partition_time],
[city_id,city_name],[city_id,city_name],
[year],[year],
[month],[month],
[day]][day]]
即假设获得[user_id,user_name],[partition_time],[city_id,city_name],[year],[month],[day]六个关联维度组。然后通过如下的步骤进行计算:That is, it is assumed that six associated dimension groups of [user_id, user_name], [partition_time], [city_id, city_name], [year], [month], [day] are obtained. Then it is calculated by the following steps:
1.1:遍历groups中的所有关联维度组,通过统计目标表的源数据中各个关联维度组的维度组合的唯一值数量,得到各个关联维度组的维度组合大小。1.1: Traverse all associated dimension groups in groups, and obtain the dimension combination size of each associated dimension group by counting the number of unique values of the dimension combination of each associated dimension group in the source data of the target table.
1.2:计算groups中所有关联维度组间的相关度。1.2: Calculate the correlation between all associated dimension groups in groups.
例如,假设第一关联维度组为[user_id,user_name]和第二关联维度组为[partition_time],[user_id,user_name,partition_time]表示合并第一关联维度组和第二关联维度组获得的合并关联维度组,则第一关联维度组和第二关联维度组之间的相关度可以采用如下公式计算Rel:For example, assuming that the first associated dimension group is [user_id, user_name] and the second associated dimension group is [partition_time], [user_id, user_name, partition_time] represents the merged associated dimension obtained by merging the first associated dimension group and the second associated dimension group group, the correlation between the first associated dimension group and the second associated dimension group can be calculated by the following formula: Rel:

上述公式中,D(user_id,user_name)表示第一关联维度组的维度组合大小;D(partition_time))表示第二关联维度组的维度组合大小;(D(user_id,user_name)*D(partition_time))表示第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的乘积结果;D(user_id,user_name,partition_time)表示合并关联维度组的维度组合大小。In the above formula, D(user_id, user_name) represents the dimension combination size of the first associated dimension group; D(partition_time)) represents the dimension combination size of the second associated dimension group; (D(user_id, user_name)*D(partition_time)) Represents the product result of the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group; D(user_id, user_name, partition_time) represents the dimension combination size of the merged associated dimension group.
计算合并关联维度组的维度组合大小相对未合并的第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的合并膨胀率,例如,可以根据如下公式计算合并膨胀率Exp:Calculate the combined expansion rate of the dimension combination size of the merged associated dimension group relative to the dimension combination size of the unmerged first associated dimension group and the dimension combination size of the second associated dimension group. For example, the combined expansion rate Exp can be calculated according to the following formula:
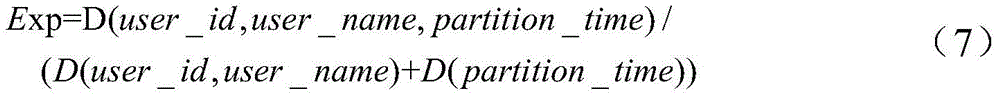
上述公式中,(D(user_id,user_name)+D(partition_time))表示第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的求和结果。In the above formula, (D(user_id, user_name)+D(partition_time)) represents the summation result of the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group.
1.3:通过上述各个关联维度组之间的相关度和合并膨胀率的计算,确定任意两个关联维度组是否满足合并条件,例如假设满足以下条件中的任意一项即判定为对应的两个关联维度组满足合并条件:1.3: Determine whether any two associated dimension groups meet the merging conditions through the calculation of the correlation between the above-mentioned various associated dimension groups and the combined expansion rate. For example, if any one of the following conditions is satisfied, it is determined as the corresponding two associations The dimension group meets the merge condition:
1)相关度大于0.85,即假设第一相关度阈值为0.85,但本公开并不限定于此,第一相关度阈值为大于0且小于1的实数。1) The correlation is greater than 0.85, that is, it is assumed that the first correlation threshold is 0.85, but the present disclosure is not limited thereto, and the first correlation threshold is a real number greater than 0 and less than 1.
2)相关度大于0.75并且合并膨胀率小于10,即假设第二相关度阈值为0.75,且第一膨胀率阈值为10,但本公开并不限定于此,第二相关度阈值为大于0且小于1的实数,第一膨胀率阈值为大于或等于1的实数。2) The correlation is greater than 0.75 and the combined expansion ratio is less than 10, that is, it is assumed that the second correlation threshold is 0.75 and the first expansion ratio threshold is 10, but the present disclosure is not limited to this, and the second correlation threshold is greater than 0 and A real number less than 1, the first expansion rate threshold is a real number greater than or equal to 1.
3)相关度大于0.5并且合并膨胀率小于5,即假设第三相关度阈值为0.5,且第二膨胀率阈值为5,但本公开并不限定于此,第三相关度阈值为大于0且小于1的实数,第二膨胀率阈值为大于或等于1的实数。3) The correlation is greater than 0.5 and the combined expansion ratio is less than 5, that is, it is assumed that the third correlation threshold is 0.5 and the second expansion ratio threshold is 5, but the present disclosure is not limited to this, and the third correlation threshold is greater than 0 and A real number less than 1, the second dilation rate threshold is a real number greater than or equal to 1.
1.4:若存在满足合并条件的两个关联维度组,则将满足合并条件的两个关联维度组作为一个关联维度组对。然后,按照各个关联维度组对的相关度的大小进行倒序排列,将相关度最高的关联维度组对确定为目标关联维度组对,合并目标关联维度组对中的两个关联维度组,将合并为新的关联维度组放入groups中,并删除groups中合并前的两个关联维度组。若不存在满足合并条件的两个关联维度组,则终止合并。1.4: If there are two associated dimension groups that satisfy the merging condition, the two associated dimension groups that satisfy the merging condition are regarded as a pair of associated dimension groups. Then, sort in reverse order according to the correlation degree of each associated dimension group pair, determine the associated dimension group pair with the highest degree of correlation as the target associated dimension group pair, merge the two associated dimension groups in the target associated dimension group pair, and merge Put the new associated dimension group into groups, and delete the two associated dimension groups in groups before merging. If there are no two associated dimension groups that satisfy the merge condition, the merge is terminated.
1.5:若groups中的关联维度组的数量小于或等于给定的联合维度阈值,则终止合并,否则重复上述步骤1.1~1.5。1.5: If the number of associated dimension groups in groups is less than or equal to the given joint dimension threshold, terminate the merge, otherwise repeat steps 1.1 to 1.5 above.
在示例性实施例中,根据维度字段的聚合组构建面向目标表的数据立方体,可以包括:获得历史查询语句中各个字段的行键顺序,字段包括维度字段;根据各个字段的行键顺序、维度共现图的联合维度以及维度字段的聚合组,构建面向目标表的数据立方体。In an exemplary embodiment, constructing a data cube oriented to a target table according to an aggregation group of dimension fields may include: obtaining the row key sequence of each field in the historical query statement, where the fields include dimension fields; The joint dimension of the co-occurrence graph and the aggregated group of dimension fields are used to construct a data cube for the target table.
在示例性实施例中,获得历史查询语句中各个字段的行键顺序,可以包括:获得历史查询语句中不同字段类型的权重参数;获得历史查询语句中的各个字段及其字段类型;根据各个字段的字段类型对应的权重参数以及各个字段在历史查询语句中的查询频次,获得各个字段的字段权重值;根据各个字段的字段权重值,确定各个字段的行键顺序。In an exemplary embodiment, obtaining the row key sequence of each field in the historical query statement may include: obtaining weight parameters of different field types in the historical query statement; obtaining each field and its field type in the historical query statement; The weight parameter corresponding to the field type and the query frequency of each field in the historical query statement, obtain the field weight value of each field; according to the field weight value of each field, determine the row key sequence of each field.
具体地,利用上述历史查询语句分析获得的各个字段,计算各个字段的字段权重值。Specifically, each field obtained by analyzing the above historical query statement is used to calculate the field weight value of each field.
例如,假设对于维度字段中的聚合字段(group),设置一个权重参数,例如假设为4;对于维度字段中的过滤字段(filter),设置一个权重参数,例如假设为2。在其他实施例中,还可以对于指标字段,例如上述的sum设置一个权重参数,例如假设为1。但本公开并不限定于此,可以根据实际需要进行设置,考虑到不同字段类型的字段在实际查询中被使用的频率,可以设置越被经常使用的字段类型的权重参数越大,例如设置聚合字段的权重参数大于过滤字段的权重参数,过滤字段的权重参数大于指标字段的权重参数等等,同时各字段类型之间的权重参数差异不会较大。这样可以得到上述一个历史查询语句中各个字段的字段权重值如下:For example, suppose that for the aggregation field (group) in the dimension field, a weight parameter is set, for example, it is assumed to be 4; for the filter field (filter) in the dimension field, a weight parameter is set, for example, it is assumed to be 2. In other embodiments, a weight parameter may also be set for the indicator field, such as the above-mentioned sum, for example, it is assumed to be 1. However, the present disclosure is not limited to this, and can be set according to actual needs. Considering the frequency of fields of different field types being used in actual queries, the more frequently used field types can be set to have larger weight parameters, such as setting aggregation. The weight parameter of the field is greater than the weight parameter of the filter field, the weight parameter of the filter field is greater than the weight parameter of the indicator field, etc. At the same time, the weight parameters of each field type will not differ greatly. In this way, the field weight values of each field in the above historical query statement can be obtained as follows:
(user_data,user_id,4),(user_data, user_id, 4),
(user_data,user_name,4),(user_data, user_name, 4),
(user_data,partition_time,2),(user_data, partition_time, 2),
(user_data,value,1)(user_data, value, 1)
对于所有历史查询语句中获得的各个字段,将该字段所属的字段类型的权重参数及该字段在所有历史查询语句中查询的查询频次相乘,获得该字段的字段权重值,例如对于字段类型为聚合字段的字段user_id,假设在所有历史查询语句中出现了50次,则字段user_id的字段权重值为200。For each field obtained in all historical query statements, multiply the weight parameter of the field type to which the field belongs and the query frequency of the field in all historical query statements to obtain the field weight value of the field. For example, for the field type of Assuming that the field user_id of the aggregated field appears 50 times in all historical query statements, the field weight of the field user_id is 200.
获得所有历史查询语句中各个字段的字段权重值后,按照字段权重值的大小对各字段进行倒序排列,倒序排列得到的字段的顺序可以直接用于RowKey顺序(行键顺序)的设计。After obtaining the field weight value of each field in all historical query statements, sort each field in reverse order according to the size of the field weight value. The order of the fields obtained in the reverse order can be directly used for the design of the RowKey order (row key order).
本公开实施方式提供的数据处理方法,通过分析目标表的历史查询语句,提取出其中涉及的字段,并标注各字段的字段类型,从中获得维度字段及不同维度字段之间的查询共现频次,将维度字段作为节点,具有查询共现频次的两个维度字段对应的两个节点连接形成边,并将每条边连接的两个节点对应的两个维度字段之间的查询共现频次作为对应边的初阶边权重,由此自动构建出该目标表的维度共现图,一方面,通过对该维度共现图进行分裂,并通过计算各分支节点的分裂收益来执行剪枝操作,可以获得该维度共现图中小于或等于所设置的叶子节点阈值的目标叶子节点,然后将每个目标叶子节点中包含的维度字段组合成一个聚合组,单个聚合组可以用于构建一个相对较小的Cube,从而实现了将一个较大的Cube构建任务拆分为了多个较小Cube构建任务,节约了计算资源,减少了构建时长,同时使得构建出来的Cube更符合实际查询需求,满足实际查询中各查询请求的分布;另一方面,还可以根据各条边连接的两个节点对应的两个维度字段的查询频次来重新计算各条边的目标边权重,将目标边权重低于权重阈值的边移除后,可以获得该维度共现图的多个子图,然后分别获得各个子图的最大团,将每个最大团中的所有维度字段组合形成一个关联维度组,再根据不同关联维度组之间的相关度和合并膨胀率来合并满足合并条件且相关度最高的两个关联维度组,以此形成小于或等于联合维度阈值的联合维度,即实现了将相关度最高的关联维度组进一步组合为联合维度,减小了构建的Cube的大小,降低了占用的存储资源,使得最终构建的Cube满足相关膨胀率的要求。此外,还可以获得不同字段类型的权重参数,根据各字段的查询频次和所属字段类型的权重参数确定各字段的字段权重值,根据字段权重值的大小来设计RowKey顺序,使得设计的RowKey顺序满足实际查询需求。经过上述过程,设计Cube的几个核心参数都有了,包括聚合组的划分、联合维度的设计和RowKey顺序的设计等,由此可以自动构建出Cube。The data processing method provided by the embodiment of the present disclosure extracts the fields involved by analyzing the historical query statements of the target table, and marks the field type of each field, thereby obtaining the dimension field and the query co-occurrence frequency between different dimension fields, Take the dimension field as a node, connect the two nodes corresponding to the two dimension fields with the query co-occurrence frequency to form an edge, and use the query co-occurrence frequency between the two dimension fields corresponding to the two nodes connected by each edge as the corresponding The initial edge weight of the edge, thus automatically constructing the dimension co-occurrence graph of the target table. On the one hand, by splitting the dimension co-occurrence graph, and by calculating the split income of each branch node, the pruning operation can be performed. Obtain the target leaf nodes that are less than or equal to the set leaf node threshold in the co-occurrence graph of the dimension, and then combine the dimension fields contained in each target leaf node into an aggregation group. A single aggregation group can be used to construct a relatively small Cube, so that a large cube construction task can be split into multiple smaller cube construction tasks, which saves computing resources and reduces the construction time. The distribution of each query request in the After removing the edges of , multiple subgraphs of the co-occurrence graph of this dimension can be obtained, and then the maximum cliques of each subgraph are obtained respectively, and all dimension fields in each maximum clique are combined to form an associated dimension group, and then according to different associated dimensions The correlation between the groups and the combined expansion rate are used to combine the two associated dimension groups that meet the combined conditions and have the highest correlation to form a joint dimension less than or equal to the joint dimension threshold, that is, to realize the highest correlation. It is further combined into a joint dimension, which reduces the size of the constructed cube and reduces the occupied storage resources, so that the final constructed cube meets the requirements of the relevant expansion rate. In addition, weight parameters of different field types can also be obtained, the field weight value of each field is determined according to the query frequency of each field and the weight parameter of the field type to which it belongs, and the RowKey order is designed according to the size of the field weight value, so that the designed RowKey order satisfies actual query requirements. After the above process, several core parameters for designing Cubes are available, including the division of aggregation groups, the design of joint dimensions, and the design of RowKey sequences, so that Cubes can be automatically constructed.
图9示意性示出了根据本公开的又一实施例的数据处理方法的流程示意图。如图9所示,本公开实施例提供的方法可以包括以下步骤。FIG. 9 schematically shows a schematic flowchart of a data processing method according to yet another embodiment of the present disclosure. As shown in FIG. 9 , the method provided by the embodiment of the present disclosure may include the following steps.
在步骤S910中,获取目标表的历史查询语句,对历史查询语句进行分析,获得维度字段及不同维度字段之间的查询共现频次。In step S910, the historical query statement of the target table is obtained, the historical query statement is analyzed, and the query co-occurrence frequency between dimension fields and different dimension fields is obtained.
如图9所示,假设系统输入的是用户在Hive上同一数据源(相同的表或者相同的事实表和维表组合)上的历史查询SQL语句的记录,经过对历史查询语句进行分析,获得维度字段及不同维度字段之间的查询共现频次,还可以获得字段及不同字段类型的权重参数,各字段在历史查询语句中的查询频次,维度字段被包括在这些字段中。As shown in Figure 9, it is assumed that the system inputs the records of historical query SQL statements on the same data source (same table or the same combination of fact table and dimension table) on Hive by the user. After analyzing the historical query statements, we obtain The query co-occurrence frequency between dimension fields and different dimension fields can also be obtained. The weight parameters of fields and different field types can also be obtained. The query frequency of each field in historical query statements, and the dimension fields are included in these fields.
在步骤S920中,根据维度字段及不同维度字段之间的查询共现频次,构建维度共现图。In step S920, a dimension co-occurrence graph is constructed according to the dimension field and the query co-occurrence frequency between different dimension fields.
然后,将各维度字段作为各个节点,再根据查询共现频次构建边及确定边的初阶边权重,构建一个带权无向的维度共现图。Then, each dimension field is used as each node, and then the edge is constructed according to the query co-occurrence frequency and the initial edge weight of the edge is determined, and a weighted and undirected dimension co-occurrence graph is constructed.
在步骤S930中,对维度共现图进行分解,获得分裂树。In step S930, the dimension co-occurrence graph is decomposed to obtain a split tree.
采用上述实施例中描述的方式对维度共现图进行分解,获得包括初阶叶子节点的分裂树。The dimensional co-occurrence graph is decomposed in the manner described in the above embodiment to obtain a split tree including primary leaf nodes.
在步骤S940中,对分裂树进行剪枝操作,确定聚合组。In step S940, a pruning operation is performed on the split tree to determine an aggregation group.
采用上述实施例中描述的方式对获得的分裂树进行剪枝操作,根据分裂收益减少一些初阶叶子节点,获得目标叶子节点,将每个目标叶子节点中的所有维度字段组合成单个聚合组。The obtained split tree is pruned in the manner described in the above embodiment, some primary leaf nodes are reduced according to the split income, target leaf nodes are obtained, and all dimension fields in each target leaf node are combined into a single aggregation group.
在步骤S950中,发现维度共现图中的联合维度。In step S950, the joint dimension in the dimension co-occurrence graph is found.
通过上述实施例中重新计算维度共现图的边的初阶边权重,确定目标边权重,根据目标边权重将维度共现图拆分为多个子图,并分别确定每个子图中的一个或者多个最大团,根据这些最大团发现关联度较高且符合膨胀率要求的联合维度。By recalculating the primary edge weights of the edges of the dimensional co-occurrence graph in the above embodiment, the target edge weight is determined, the dimensional co-occurrence graph is divided into multiple subgraphs according to the target edge weight, and one or more subgraphs in each subgraph are determined respectively. Multiple maximal cliques, according to which a joint dimension with a high degree of correlation and meeting the requirements of the expansion rate is found.
在步骤S960中,计算字段的字段权重值,以确定行键顺序。In step S960, the field weight value of the field is calculated to determine the row key sequence.
还可以根据各字段所属字段类型的权重参数及各字段的查询频次,计算获得各字段的字段权重值,根据字段权重值的大小来确定各字段的行键顺序。The field weight value of each field can also be calculated and obtained according to the weight parameter of the field type to which each field belongs and the query frequency of each field, and the row key sequence of each field can be determined according to the size of the field weight value.
在步骤S970中,根据聚合组、联合维度和行键顺序进行数据立方体的设计生成。In step S970, the design and generation of the data cube is performed according to the aggregation group, the joint dimension and the row key sequence.
根据上述步骤中获得的聚合组、联合维度和行键顺序便可以得到一个完整的Cube设计方案。According to the aggregation group, union dimension and row key order obtained in the above steps, a complete Cube design can be obtained.
本公开实施方式提供的数据处理方法,通过分析目标表的历史查询语句,抽取历史查询语句中涉及的所有字段,利用维度字段之间的查询共现频次来构建维度共现图,然后利用最大团算法来发现维度共现图中所有子图的所有最大团,并将每个最大团中的所有节点组成联合维度,进一步提升了维度字段之间的关联度;还可以基于带权无向的查询共现图的图划分算法(上述图分裂过程)对查询共现图进行划分,得到一颗分裂树,通过剪枝得到最终的划分结果即目标叶子节点,该叶子节点可以直接用于Cube的设计,由此可以实现Cube设计的自动化,降低了大规模维度上的Cube构建的设计难度。此外,通过图划分的方法,可以实现将大的Cube拆分为聚合组或者多个小的Cube,且各个小的Cube对应的子任务能满足需求,同时不会增加较多的重复计算量,通过拆分减少了Cube构建过程中占有的计算资源,以及降低了构建时长,实现了构建资源和构建时长之间的平衡。在一些比较复杂的业务中,一般会有十分复杂的数据模型,数据维度通常会比较多,利用本公开实施例提供的方案,可以基于业务需求给出好的Cube设计,使得设计出来的Cube既能满足查询需求,又能保证查询效率和构建效率,同时保证数据的膨胀率在合适的范围内。In the data processing method provided by the embodiment of the present disclosure, by analyzing the historical query statements of the target table, extracting all the fields involved in the historical query statements, using the query co-occurrence frequency between the dimension fields to construct a dimension co-occurrence graph, and then using the maximum cluster Algorithm to find all the largest cliques of all subgraphs in the dimension co-occurrence graph, and combine all nodes in each largest clique into a joint dimension, which further improves the correlation between dimension fields; it can also be based on weighted undirected query The graph division algorithm of co-occurrence graph (the above graph splitting process) divides the query co-occurrence graph to obtain a split tree, and obtains the final division result through pruning, namely the target leaf node, which can be directly used in the design of Cube , which can realize the automation of Cube design and reduce the design difficulty of Cube construction in large-scale dimensions. In addition, through the method of graph division, large cubes can be divided into aggregate groups or multiple small cubes, and the subtasks corresponding to each small cube can meet the needs without increasing the amount of repeated calculations. By splitting, the computing resources occupied in the Cube construction process are reduced, and the construction time is reduced, so as to achieve a balance between construction resources and construction time. In some complex businesses, there are generally very complex data models, and there are usually many data dimensions. Using the solutions provided by the embodiments of the present disclosure, a good cube design can be given based on business requirements, so that the designed cubes not only It can meet the query requirements, and can ensure the query efficiency and construction efficiency, and at the same time ensure that the data expansion rate is within an appropriate range.
在测试中,针对一个61个维度字段、日数据规模在3亿左右的数据,在未使用本公开实施例提供的方案时,通过手动设计Cube、然后通过相关技术提供的优化工具,得到的Cube平均构建时间为120min(分钟)左右,每日预计算后结果数据规模约为600G,而采用本公开实施例提供的方案优化拆分后,将原有Cube拆分为3个Cube,构建平均时间压缩到50min左右,另外整体结果数据占用的存储空间约为200G。在另外几个中等规模Cube优化任务中,也展现了较好地效果。例如如下表1所示:In the test, for a data with 61 dimension fields and a daily data scale of about 300 million, when the solution provided by the embodiment of the present disclosure is not used, the cube is obtained by manually designing the cube and then using the optimization tool provided by the related technology. The average construction time is about 120 minutes (minutes), and the resulting data size after daily pre-calculation is about 600G. After using the solution provided by the embodiment of the present disclosure to optimize the split, the original cube is split into three cubes, and the average construction time is It is compressed to about 50 minutes, and the storage space occupied by the overall result data is about 200G. In several other medium-scale Cube optimization tasks, it also shows good results. For example, as shown in Table 1 below:
表1Table 1
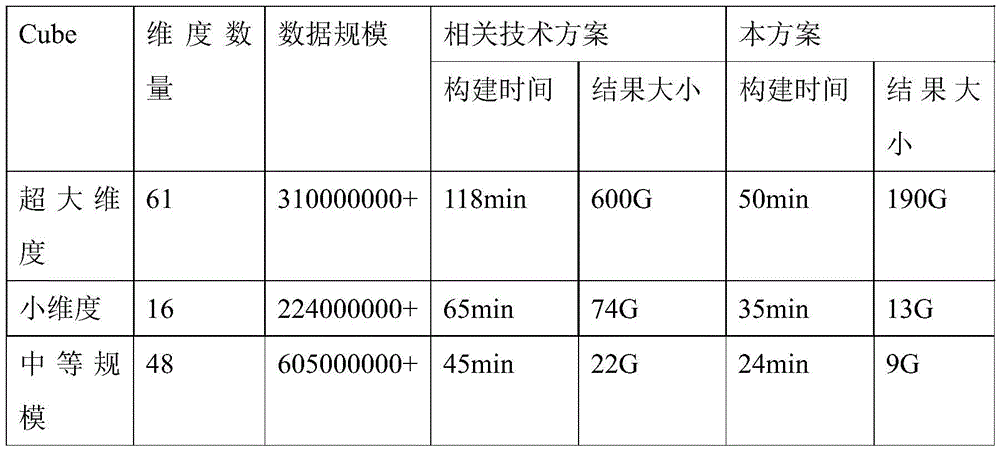
通过上述测试结果可以看出,本公开实施例通过历史查询语句来分析业务,自动生成Cube设计,简化了用户设计难度,优化了Cube设计。通过图分裂的方式,可以对大的Cube进行拆分,可以减少Cube构建时长,同时也可以压缩数据规模。It can be seen from the above test results that the embodiment of the present disclosure analyzes the business through historical query statements, and automatically generates the Cube design, which simplifies the user's design difficulty and optimizes the Cube design. Through graph splitting, large cubes can be split, which can reduce the construction time of cubes and compress the data size.
本公开实施例提供的方法,能应用到OLAP数据查询、数据平台类产品等的优化工作中,可以减少用户的OLAP Cube设计难度,通过分析优化,自动设计Cube,能降低预计算任务时间和资源占用,也可以在一些缓存设计应用中使用,也可以用在通过查询去反向分析业务,对业务数据进行拆分的场景。图10中以基于MapReduce预计算生成Cube并提供低延迟查询的Apache Kylin解决方案为例进行举例说明。The methods provided by the embodiments of the present disclosure can be applied to the optimization work of OLAP data query, data platform products, etc., which can reduce the difficulty of designing OLAP cubes for users, and can automatically design cubes through analysis and optimization, which can reduce the time and resources of pre-computing tasks Occupancy can also be used in some cache design applications, and can also be used in the scenario of reverse analysis of business through query and splitting of business data. Figure 10 takes the Apache Kylin solution that generates cubes based on MapReduce precomputing and provides low-latency queries as an example for illustration.
图10示意性示出了应用本公开实施例提供的数据处理方法的系统架构示意图。首先来看离线构建部分。从图10中可以看出,左侧为数据源1010,默认的数据源可以是ApacheHive(也可以采用Kafka,RDBMS(Relational Database Management System,关系数据库管理系统)等),保存着待分析的用户数据。根据元数据(Metadata)1024的定义,数据立方体构建引擎(Cube Build Engine)1025从数据源1010抽取数据,并构建Cube。构建技术可以为MapReduce。构建后的OLAP数据立方体(OLAP Cube)1030保存在右侧存储引擎中,默认的存储为Apache HBase。FIG. 10 schematically shows a schematic diagram of a system architecture to which the data processing method provided by the embodiment of the present disclosure is applied. First look at the offline build part. As can be seen from Figure 10, the left side is the data source 1010, the default data source can be Apache Hive (or Kafka, RDBMS (Relational Database Management System, relational database management system), etc.), which saves the user data to be analyzed . According to the definition of the metadata (Metadata) 1024, the data cube build engine (Cube Build Engine) 1025 extracts data from the data source 1010, and builds a cube. The construction technology can be MapReduce. The constructed OLAP data cube (OLAP Cube) 1030 is stored in the storage engine on the right, and the default storage is Apache HBase.
完成离线构建后,用户可以从上方的查询系统(例如,第三方APP1040、SQL-Based工具1050)发送SQL进行查询分析。提供了RESTful API(Representational StateTransfer Application Programming Interface,表示状态转移应用程序接口)、JDBC(Java Database Connectivity,Java数据库连接)/ODBC(Open Database Connectivity,开放数据库互连)等接口供用户调用。无论从哪个接口进入,SQL最终都会来到REST服务器(REST Server)1021,再转交给查询引擎(Query Engine)1022进行处理。查询引擎(QueryEngine)1022解析SQL,生成基于关系表的逻辑执行计划,然后将其转译为基于Cube的物理执行计划,基于路由(Routing)1023查询预计算生成的Cube并产生结果。整个过程不会访问原始数据源。如果用户提交的查询语句未预先定义,则会返回一个错误。After the offline construction is completed, the user can send SQL from the upper query system (eg, third-party APP 1040, SQL-Based tool 1050) for query analysis. Provides RESTful API (Representational StateTransfer Application Programming Interface), JDBC (Java Database Connectivity, Java Database Connectivity)/ODBC (Open Database Connectivity, Open Database Connectivity) and other interfaces for users to call. No matter which interface is used to enter, the SQL will eventually come to the REST server (REST Server) 1021, and then be transferred to the Query Engine (Query Engine) 1022 for processing. The query engine (QueryEngine) 1022 parses the SQL, generates a logical execution plan based on the relational table, and then translates it into a physical execution plan based on the cube, and queries the pre-computed generated cube based on the routing (Routing) 1023 and generates a result. The entire process does not access the original data source. If the user-submitted query statement is not predefined, an error is returned.
图10实施例中对数据源、数据立方体构建引擎和Cube存储三个模块提取出了抽象层,这三个模块可以被任意地扩展和替换。例如可以使用Spark替代MapReduce作为Cube的数据立方体构建引擎,使用Cassandra替代HBase作为Cube计算后数据的存储等,使之良好的扩展性,也使用户可以针对自己的业务特点进行深度定制。In the embodiment of FIG. 10, an abstraction layer is extracted for the three modules of the data source, the data cube construction engine and the cube storage, and these three modules can be extended and replaced arbitrarily. For example, Spark can be used instead of MapReduce as the data cube construction engine of Cube, and Cassandra can be used instead of HBase as the storage of data after Cube calculation.
Apache Kylin使用预计算技术解决了数据集大小受限的问题,能更好地支持海量数据集的查询。同样受益于预计算技术,Kylin的查询速度非常快,因为复杂的连接、聚合等操作都在Cube的构建过程中已经完成了。Apache Kylin同样可以使用集群部署方式进行水平扩展。Apache Kylin uses precomputing technology to solve the problem of limited data set size and can better support the query of massive data sets. Also benefiting from the precomputing technology, Kylin's query speed is very fast, because complex joins, aggregations and other operations have been completed during the construction of Cube. Apache Kylin can also be scaled horizontally using cluster deployment.
本公开实施例提供的方法可以采用云技术中的数据库技术。The method provided by the embodiments of the present disclosure may adopt the database technology in the cloud technology.
其中,云技术(Cloud technology)是指在广域网或局域网内将硬件、软件、网络等系列资源统一起来,实现数据的计算、储存、处理和共享的一种托管技术。Among them, cloud technology refers to a kind of hosting technology that unifies a series of resources such as hardware, software, and network in a wide area network or a local area network to realize the calculation, storage, processing and sharing of data.
云技术是基于云计算商业模式应用的网络技术、信息技术、整合技术、管理平台技术、应用技术等的总称,可以组成资源池,按需所用,灵活便利。云计算技术将变成重要支撑。技术网络系统的后台服务需要大量的计算、存储资源,如视频网站、图片类网站和更多的门户网站。伴随着互联网行业的高度发展和应用,将来每个物品都有可能存在自己的识别标志,都需要传输到后台系统进行逻辑处理,不同程度级别的数据将会分开处理,各类行业数据皆需要强大的系统后盾支撑,只能通过云计算来实现。Cloud technology is a general term for network technology, information technology, integration technology, management platform technology, and application technology based on cloud computing business models. Cloud computing technology will become an important support. Background services of technical network systems require a lot of computing and storage resources, such as video websites, picture websites and more portal websites. With the high development and application of the Internet industry, in the future, each item may have its own identification mark, which needs to be transmitted to the back-end system for logical processing. Data of different levels will be processed separately, and all kinds of industry data need to be strong. The system backing support can only be achieved through cloud computing.
数据库(Database),简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作。所谓“数据库”是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。Database, in short, can be regarded as an electronic filing cabinet—a place where electronic files are stored, and users can perform operations such as adding, querying, updating, and deleting data in the files. The so-called "database" is a collection of data that is stored together in a certain way, can be shared with multiple users, has as little redundancy as possible, and is independent of applications.
数据库管理系统(Database Management System,简称DBMS)是为管理数据库而设计的电脑软件系统,一般具有存储、截取、安全保障、备份等基础功能。数据库管理系统可以依据它所支持的数据库模型来作分类,例如关系式、XML(Extensible Markup Language,即可扩展标记语言);或依据所支持的计算机类型来作分类,例如服务器群集、移动电话;或依据所用查询语言来作分类,例如SQL、XQuery;或依据性能冲量重点来作分类,例如最大规模、最高运行速度;亦或其他的分类方式。不论使用哪种分类方式,一些DBMS能够跨类别,例如,同时支持多种查询语言。Database Management System (DBMS for short) is a computer software system designed for database management. It generally has basic functions such as storage, interception, security, and backup. The database management system can be classified according to the database model it supports, such as relational, XML (Extensible Markup Language, Extensible Markup Language); or according to the type of computer it supports, such as server clusters, mobile phones; Or classify according to the query language used, such as SQL, XQuery; or classify according to the focus of performance impulse, such as the largest scale, the highest running speed; or other classification methods. Regardless of the classification method used, some DBMSs are capable of cross-classification, for example, simultaneously supporting multiple query languages.
图11示意性示出了根据本公开的一实施例的数据处理装置的框图。如图11所示,本公开实施例提供的数据处理装置1100可以包括共现频次获得单元1110、维度共现图构建单元1120、核心节点确定单元1130、连通子图获得单元1140、图分裂树获得单元1150、字段聚合组确定单元1160以及数据立方体构建单元1170。FIG. 11 schematically shows a block diagram of a data processing apparatus according to an embodiment of the present disclosure. As shown in FIG. 11 , the
本公开实施例中,共现频次获得单元1110可以用于获得目标表的历史查询语句中的维度字段及不同维度字段之间的查询共现频次。维度共现图构建单元1120可以用于将维度字段作为节点,根据不同维度字段之间的查询共现频次确定不同节点之间的初阶边权重,形成维度共现图。核心节点确定单元1130可以用于根据维度共现图中各个节点的度,确定维度共现图中的第一核心节点。连通子图获得单元1140可以用于获得删除维度共现图中的第一核心节点后的第一连通子图。图分裂树获得单元1150可以用于根据维度共现图及其第一核心节点和第一连通子图,获得维度共现图的分裂树。字段聚合组确定单元1160可以用于根据分裂树的目标叶子节点确定维度字段的聚合组。数据立方体构建单元1170可以用于根据维度字段的聚合组构建面向目标表的数据立方体。In the embodiment of the present disclosure, the co-occurrence frequency obtaining unit 1110 may be configured to obtain the dimension field in the historical query statement of the target table and the query co-occurrence frequency between different dimension fields. The dimension co-occurrence graph construction unit 1120 may be configured to use the dimension field as a node, and determine the primary edge weight between different nodes according to the query co-occurrence frequency between different dimension fields to form a dimension co-occurrence graph. The core node determining unit 1130 may be configured to determine the first core node in the dimensional co-occurrence graph according to the degree of each node in the dimensional co-occurrence graph. The connected subgraph obtaining unit 1140 may be configured to obtain the first connected subgraph after deleting the first core node in the dimensional co-occurrence graph. The graph splitting tree obtaining unit 1150 may be configured to obtain a splitting tree of the dimensional co-occurrence graph according to the dimensional co-occurrence graph and its first core node and first connected subgraph. The field aggregation group determination unit 1160 may be configured to determine the aggregation group of dimension fields according to the target leaf node of the split tree. The data cube building unit 1170 may be configured to build a target table-oriented data cube according to the aggregation group of dimension fields.
本公开实施方式提供的数据处理装置,一方面,通过目标表的历史查询语句进行分析,根据历史查询语句中的维度字段及不同维度字段之间的查询共现频次构建维度共现图,并根据该维度共现图中各个节点的度来确定维度共现图中的第一核心节点,然后获得删除该维度共现图中的第一核心节点后的第一连通子图,根据该维度共现图及其第一核心节点和该第一连通子图对该维度共现图进行分裂,获得该维度共现图的分裂树,由此可以根据该分裂树的目标叶子节点来确定上述历史查询语句中的维度字段的聚合组,当利用该维度字段的聚合组来构建面向该目标表的数据立方体(Cube)时,实现了将大的Cube拆分为聚合组,各个聚合组可以用于构建各个小的Cube,即通过对维度共现图的拆分,压缩了数据规模,降低了Cube构建过程中耗费的计算资源,且能够缩短Cube的构建时长,实现了构建资源和构建时间之间的平衡。同时,由于本公开实施例中的维度共现图是根据目标表的历史查询语句中的维度字段及不同维度字段之间的查询共现频次构建的,因此,通过分裂该维度共现图来实现将一个大的Cube的构建任务拆分为多个小的Cube的构建任务,还能够保证构建的各个小的Cube能够满足实际业务中的查询需求,还不会增加较多的重复计算量。另一方面,通过分析历史查询语句,实现了Cube构建的自动化,简化了用户设计Cube的难度,优化了Cube设计。The data processing device provided by the embodiment of the present disclosure, on the one hand, analyzes the historical query statement of the target table, constructs a dimension co-occurrence graph according to the dimension fields in the historical query statement and the query co-occurrence frequency between different dimension fields, and according to The degree of each node in the dimensional co-occurrence graph is used to determine the first core node in the dimensional co-occurrence graph, and then the first connected subgraph after deleting the first core node in the dimensional co-occurrence graph is obtained. According to the dimensional co-occurrence graph The graph and its first core node and the first connected subgraph are split on the dimension co-occurrence graph to obtain a split tree of the dimension co-occurrence graph, so that the above historical query statement can be determined according to the target leaf node of the split tree When using the aggregation group of the dimension field to build a data cube (Cube) oriented to the target table, the large cube is divided into aggregation groups, and each aggregation group can be used to construct various aggregation groups. Small cubes, that is, by splitting the dimensional co-occurrence graph, compresses the data scale, reduces the computing resources consumed in the cube construction process, and can shorten the construction time of the cube, achieving a balance between construction resources and construction time. . At the same time, since the dimension co-occurrence graph in the embodiment of the present disclosure is constructed according to the dimension fields in the historical query statements of the target table and the query co-occurrence frequency between different dimension fields, the dimension co-occurrence graph is split to achieve this. Splitting the construction task of a large cube into multiple small cube construction tasks can also ensure that each small cube constructed can meet the query requirements in the actual business, and will not increase the amount of repeated calculations. On the other hand, by analyzing historical query statements, the automation of cube construction is realized, the difficulty of designing cubes is simplified, and the design of cubes is optimized.
在示例性实施例中,图分裂树获得单元1150可包括:根节点形成单元,可以用于组合维度共现图中的节点,形成分裂树的根节点;第二核心节点确定单元,可以用于根据第一连通子图中各个节点的度,确定第一连通子图中的第二核心节点;第一初阶叶子节点获得单元,可以用于若删除第一连通子图中的第二核心节点之后,第一连通子图中不存在节点,则组合第一核心节点和第二核心节点作为分裂树的初阶叶子节点。In an exemplary embodiment, the graph splitting tree obtaining unit 1150 may include: a root node forming unit, which may be used to combine nodes in the dimensional co-occurrence graph to form the root node of the splitting tree; a second core node determining unit, which may be used for According to the degree of each node in the first connected subgraph, the second core node in the first connected subgraph is determined; the first preliminary leaf node obtains the unit, which can be used to delete the second core node in the first connected subgraph After that, if there is no node in the first connected subgraph, the first core node and the second core node are combined as the primary leaf node of the split tree.
在示例性实施例中,图分裂树获得单元1150还可包括:第二连通子图获得单元,可以用于若删除第一连通子图中的第二核心节点之后,第一连通子图中存在节点,且删除第二核心节点之后的节点之间是连通的,则获得删除第一连通子图中的第二核心节点后的第二连通子图;第三核心节点确定单元,可以用于若分裂树的当前分裂层数小于或等于分裂层数阈值,则根据第二连通子图中各个节点的度,确定第二连通子图中的第三核心节点;第二初阶叶子节点获得单元,可以用于若删除第二连通子图中的第三核心节点之后,第二连通子图中不存在节点,则组合第一核心节点、第二核心节点和第三核心节点作为分裂树的初阶叶子节点。In an exemplary embodiment, the graph-splitting tree obtaining unit 1150 may further include: a second connected subgraph obtaining unit, which may be configured to, if after deleting the second core node in the first connected subgraph, exist in the first connected subgraph nodes, and the nodes after deleting the second core node are connected, then the second connected subgraph after deleting the second core node in the first connected subgraph is obtained; the third core node determination unit can be used if If the current number of split layers of the split tree is less than or equal to the threshold of the number of split layers, the third core node in the second connected subgraph is determined according to the degree of each node in the second connected subgraph; the second primary leaf node obtains the unit, It can be used to combine the first core node, the second core node and the third core node as the initial stage of the split tree if there is no node in the second connected subgraph after deleting the third core node in the second connected subgraph. leaf node.
在示例性实施例中,字段聚合组确定单元1160可以包括:分裂收益获得单元,可以用于获得分裂树中各分支节点的分裂收益;剪枝操作单元,可以用于根据分裂树中各分支节点的分裂收益的大小以及叶子节点阈值,对分裂树进行剪枝操作;目标叶子节点确定单元,可以用于将分裂树剪枝操作后保留的初阶叶子节点作为目标叶子节点,且目标叶子节点的数量小于或等于叶子节点阈值;聚合组确定单元,可以用于将目标叶子节点作为维度字段的聚合组。In an exemplary embodiment, the field aggregation group determination unit 1160 may include: a division benefit obtaining unit, which may be used to obtain the division revenue of each branch node in the split tree; The size of the split income and the threshold of the leaf node, the pruning operation is performed on the split tree; the target leaf node determination unit can be used to use the primary leaf node retained after the split tree pruning operation as the target leaf node, and the target leaf node The number is less than or equal to the leaf node threshold; the aggregation group determines the unit, which can be used for the aggregation group that uses the target leaf node as the dimension field.
在示例性实施例中,分裂树中各分支节点可以包括第一分支节点,第一分支节点可以包括第一父节点的各个第一子节点。其中,分裂收益获得单元可以包括:第一父节点维度组合大小获得单元,可以用于获得第一父节点中各个维度字段的维度组合大小;第一父节点查询共现频次获得单元,可以用于获得第一父节点中各个维度字段之间的查询共现频次;根节点查询共现频次获得单元,可以用于获得根节点中各个维度字段之间的查询共现频次;第一父节点查询构建代价获得单元,可以用于根据第一父节点中各个维度字段的维度组合大小、第一父节点中各个维度字段之间的查询共现频次和根节点中各个维度字段之间的查询共现频次,获得第一父节点的查询构建代价;第一子节点维度组合大小获得单元,可以用于获得各个第一子节点中各个维度字段的维度组合大小;第一子节点查询共现频次获得单元,可以用于获得各个第一子节点中各个维度字段之间的查询共现频次;第一子节点查询构建代价获得单元,可以用于根据各个第一子节点中各个维度字段的维度组合大小、各个第一子节点中各个维度字段之间的查询共现频次和根节点中各个维度字段之间的查询共现频次,获得各个第一子节点的查询构建代价;第一分支节点分裂收益获得单元,可以用于根据第一父节点的查询构建代价和各个第一子节点的查询构建代价,获得第一分支节点的分裂收益。In an exemplary embodiment, each branch node in the split tree may include a first branch node, and the first branch node may include each first child node of the first parent node. Wherein, the unit for obtaining the split income may include: a unit for obtaining the combined size of the dimensions of the first parent node, which can be used to obtain the combined size of dimensions of each dimension field in the first parent node; a unit for obtaining the co-occurrence frequency by querying the first parent node, which can be used for Obtain the query co-occurrence frequency between each dimension field in the first parent node; the root node query co-occurrence frequency obtaining unit can be used to obtain the query co-occurrence frequency between each dimension field in the root node; the first parent node query construction A cost acquisition unit, which can be used to combine the dimensions of each dimension field in the first parent node, the query co-occurrence frequency between each dimension field in the first parent node, and the query co-occurrence frequency between each dimension field in the root node. , to obtain the query construction cost of the first parent node; the unit for obtaining the dimension combination size of the first child node can be used to obtain the dimension combination size of each dimension field in each first child node; the first child node query co-occurrence frequency to obtain the unit, It can be used to obtain the query co-occurrence frequency between each dimension field in each first sub-node; the first sub-node query construction cost obtaining unit can be used to obtain the unit according to the dimension combination size of each dimension field in each first sub-node, each The query co-occurrence frequency between each dimension field in the first child node and the query co-occurrence frequency between each dimension field in the root node are used to obtain the query construction cost of each first child node; the first branch node splits the revenue to obtain the unit, It can be used to obtain the split benefit of the first branch node according to the query construction cost of the first parent node and the query construction cost of each first child node.
在示例性实施例中,数据处理装置1100还可以包括:目标边权重获得单元,可以用于根据维度共现图各条边的初阶边权重,获得维度共现图各条边的目标边权重;共现图子图获得单元,可以用于将目标边权重低于权重阈值的边移除,获得维度共现图的各个子图;关联维度组获得单元,可以用于获得各个子图中的最大团,根据各个最大团中的维度字段形成各个关联维度组;相关度膨胀率获得单元,可以用于获得各个关联维度组之间的相关度和合并膨胀率;联合维度获得单元,可以用于根据各个关联维度组之间的相关度和合并膨胀率,对各个关联维度组进行合并,获得维度共现图的联合维度,联合维度的数量小于或等于联合维度阈值。In an exemplary embodiment, the
在示例性实施例中,维度共现图中可以包括第一边及第一边的第一节点和第二节点。其中,目标边权重获得单元可以包括:第一查询频次获得单元,可以用于获得第一节点对应的维度字段在历史查询语句中的第一查询频次;第二查询频次获得单元,可以用于获得第二节点对应的维度字段在历史查询语句中的第二查询频次;目标查询频次确定单元,可以用于根据第一查询频次和第二查询频次,确定目标查询频次;第一目标边权重获得单元,可以用于根据第一边的初阶边权重和目标查询频次,获得第一边的目标边权重。In an exemplary embodiment, the dimensional co-occurrence graph may include a first edge and first and second nodes of the first edge. The target edge weight obtaining unit may include: a first query frequency obtaining unit, which can be used to obtain the first query frequency of the dimension field corresponding to the first node in the historical query statement; a second query frequency obtaining unit, which can be used to obtain The second query frequency of the dimension field corresponding to the second node in the historical query statement; the target query frequency determination unit can be used to determine the target query frequency according to the first query frequency and the second query frequency; the first target edge weight obtaining unit , which can be used to obtain the target edge weight of the first edge based on the initial edge weight of the first edge and the target query frequency.
在示例性实施例中,各个关联维度组可以包括第一关联维度组和第二关联维度组。其中,相关度膨胀率获得单元可以包括:关联维度组维度组合大小获得单元,可以用于获得第一关联维度组的维度组合大小和第二关联维度组的维度组合大小;维度组合大小乘积单元,可以用于获得第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的乘积结果;合并关联维度组获得单元,可以用于合并第一关联维度组和第二关联维度组,获得合并关联维度组;合并关联维度组维度组合大小获得单元,可以用于获得合并关联维度组的维度组合大小;关联维度组相关度获得单元,可以用于根据合并关联维度组的维度组合大小以及第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的乘积结果,获得第一关联维度组和第二关联维度组之间的相关度。In an exemplary embodiment, each associated dimension group may include a first associated dimension group and a second associated dimension group. Wherein, the correlation degree expansion rate obtaining unit may include: an associated dimension group dimension combination size obtaining unit, which can be used to obtain the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group; the dimension combination size product unit, can be used to obtain the product result of the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group; the unit for merging associated dimension groups can be used to merge the first associated dimension group and the second associated dimension group, Obtain the merged associated dimension group; merge the associated dimension group dimension combination size obtaining unit, which can be used to obtain the dimension combination size of the merged associated dimension group; the associated dimension group correlation degree obtaining unit can be used to merge the associated dimension group according to the dimension combination size and The correlation between the first associated dimension group and the second associated dimension group is obtained by multiplying the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group.
在示例性实施例中,各个关联维度组可以包括第一关联维度组和第二关联维度组。其中,相关度膨胀率获得单元可以包括:关联维度组维度组合大小获得单元,可以用于获得第一关联维度组的维度组合大小和第二关联维度组的维度组合大小;维度组合大小求和单元,可以用于获得第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的求和结果;合并关联维度组获得单元,可以用于合并第一关联维度组和第二关联维度组,获得合并关联维度组;合并关联维度组维度组合大小获得单元,可以用于获得合并关联维度组的维度组合大小;关联维度组合并膨胀率获得单元,可以用于根据合并关联维度组的维度组合大小以及第一关联维度组的维度组合大小和第二关联维度组的维度组合大小的求和结果,获得第一关联维度组和第二关联维度组之间的合并膨胀率。In an exemplary embodiment, each associated dimension group may include a first associated dimension group and a second associated dimension group. Wherein, the correlation expansion rate obtaining unit may include: an associated dimension group dimension combination size obtaining unit, which may be used to obtain the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group; a dimension combination size summation unit , which can be used to obtain the summation result of the dimension combination size of the first associated dimension group and the dimension combination size of the second associated dimension group; the unit for merging associated dimension groups can be used to merge the first associated dimension group and the second associated dimension group, to obtain the merged associated dimension group; the unit to obtain the size of the combined associated dimension group dimension combination, which can be used to obtain the size of the combined associated dimension group; The combined size and the summation result of the combined dimension size of the first associated dimension group and the dimension combined size of the second associated dimension group are used to obtain the combined expansion rate between the first associated dimension group and the second associated dimension group.
在示例性实施例中,联合维度获得单元可以包括:关联维度组对确定单元,可以用于根据各个关联维度组之间的相关度和合并膨胀率,确定各个关联维度组中满足合并条件的关联维度组对;目标关联维度组对获得单元,可以用于获得关联维度组对中相关度最高的目标关联维度组对;目标合并关联维度组获得单元,可以用于合并目标关联维度组对中的关联维度组,获得目标合并关联维度组,并删除目标关联维度组对中的关联维度组;联合维度确定单元,可以用于若目标合并关联维度组和未合并的关联维度组的数量小于或等于联合维度阈值,则将目标合并关联维度组和未合并的关联维度组分别作为维度共现图的联合维度。In an exemplary embodiment, the joint dimension obtaining unit may include: an association dimension group pair determination unit, which may be configured to determine, according to the correlation between the respective association dimension groups and the merge expansion rate, the associations in the respective association dimension groups that satisfy the merge condition Dimension group pair; target associated dimension group pair acquisition unit, which can be used to obtain the target associated dimension group pair with the highest correlation in the associated dimension group pair; Associated dimension group, obtains the target merged associated dimension group, and deletes the associated dimension group in the target associated dimension group pair; the joint dimension determination unit can be used if the number of the target merged associated dimension group and the unmerged associated dimension group is less than or equal to If the joint dimension threshold is set, the target merged associated dimension group and the unmerged associated dimension group are respectively used as the joint dimension of the dimension co-occurrence graph.
在示例性实施例中,关联维度组对确定单元可以包括:合并条件判定单元,可以用于若关联维度组之间的相关度大于第一相关度阈值;或者若关联维度组之间的相关度大于第二相关度阈值且合并膨胀率小于第一膨胀率阈值;或者若关联维度组之间的相关度大于第三相关度阈值且合并膨胀率小于第二膨胀率阈值,则判定对应的关联维度组为满足合并条件的关联维度组对;其中,第一相关性阈值大于第二相关性阈值,第二相关性阈值大于第三相关性阈值,第一膨胀率阈值大于第二膨胀率阈值。In an exemplary embodiment, the associated dimension group pair determination unit may include: a merging condition determination unit, which may be configured to: if the correlation between the associated dimension groups is greater than the first correlation threshold; or if the correlation between the associated dimension groups is greater than the second correlation threshold and the combined expansion rate is less than the first expansion rate threshold; or if the correlation between the associated dimension groups is greater than the third correlation threshold and the combined expansion rate is less than the second expansion rate threshold, then determine the corresponding associated dimension A group is a pair of associated dimension groups that meet the merging conditions; wherein the first correlation threshold is greater than the second correlation threshold, the second correlation threshold is greater than the third correlation threshold, and the first expansion rate threshold is greater than the second expansion rate threshold.
在示例性实施例中,数据立方体构建单元1170可以包括:行键顺序确定单元,可以用于获得历史查询语句中各个字段的行键顺序,字段包括维度字段;数据立方体生成单元,可以用于根据各个字段的行键顺序、维度共现图的联合维度以及维度字段的聚合组,构建面向目标表的数据立方体。In an exemplary embodiment, the data cube construction unit 1170 may include: a row key sequence determination unit, which may be used to obtain the row key sequence of each field in the historical query statement, the fields including dimension fields; a data cube generation unit, which may be used to The row key order of each field, the joint dimension of the dimension co-occurrence graph, and the aggregation group of dimension fields are used to construct a data cube for the target table.
在示例性实施例中,行键顺序确定单元可以包括:字段类型权重参数获得单元,可以用于获得历史查询语句中不同字段类型的权重参数;字段类型确定单元,可以用于获得历史查询语句中的各个字段及其字段类型;字段权重值获得单元,可以用于根据各个字段的字段类型对应的权重参数以及各个字段在历史查询语句中的查询频次,获得各个字段的字段权重值;行键顺序设计单元,可以用于根据各个字段的字段权重值,确定各个字段的行键顺序。In an exemplary embodiment, the row key sequence determination unit may include: a field type weight parameter obtaining unit, which can be used to obtain weight parameters of different field types in the historical query statement; each field and its field type; the field weight value obtaining unit can be used to obtain the field weight value of each field according to the weight parameter corresponding to the field type of each field and the query frequency of each field in the historical query statement; the row key sequence The design unit can be used to determine the row key sequence of each field according to the field weight value of each field.
本公开实施例的数据处理装置的其它内容可以参照上述实施例。For other contents of the data processing apparatus in the embodiments of the present disclosure, reference may be made to the above-mentioned embodiments.
应当注意,尽管在上文详细描述中提及了用于动作执行的设备的若干单元,但是这种划分并非强制性的。实际上,根据本公开的实施方式,上文描述的两个或更多单元的特征和功能可以在一个单元中具体化。反之,上文描述的一个单元的特征和功能可以进一步划分为由多个单元来具体化。It should be noted that although several units of the apparatus for action performance are mentioned in the above detailed description, this division is not mandatory. Indeed, in accordance with embodiments of the present disclosure, the features and functions of two or more units described above may be embodied in a single unit. Conversely, the features and functions of one unit described above may be further subdivided to be embodied by multiple units.
下面参考图12,其示出了适于用来实现本申请实施例的电子设备的结构示意图。图12示出的电子设备仅仅是一个示例,不应对本申请实施例的功能和使用范围带来任何限制。Referring to FIG. 12 below, it shows a schematic structural diagram of an electronic device suitable for implementing the embodiments of the present application. The electronic device shown in FIG. 12 is only an example, and should not impose any limitations on the functions and scope of use of the embodiments of the present application.
参照图12,本公开实施例提供的电子设备可以包括:处理器1201、通信接口1202、存储器1203和通信总线1204。12 , an electronic device provided by an embodiment of the present disclosure may include: a
其中处理器1201、通信接口1202和存储器1203通过通信总线1204完成相互间的通信。The
可选的,通信接口1202可以为通信模块的接口,如GSM(Global System forMobile communications,全球移动通信系统)模块的接口。处理器1201用于执行程序。存储器1203用于存放程序。程序可以包括计算机程序,该计算机程序包括计算机操作指令。其中,程序中可以包括:游戏客户端的程序。Optionally, the
处理器1201可以是一个中央处理器CPU,或者是特定集成电路ASIC(ApplicationSpecific Integrated Circuit),或者是被配置成实施本公开实施例的一个或多个集成电路。The
存储器1203可以包含高速RAM(random access memory,随机存取存储器)存储器,也可以还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。The
其中,程序可具体用于:获得目标表的历史查询语句中的维度字段及不同维度字段之间的查询共现频次;将维度字段作为节点,根据不同维度字段之间的查询共现频次确定不同节点之间的初阶边权重,形成维度共现图;根据维度共现图中各个节点的度,确定维度共现图中的第一核心节点;获得删除维度共现图中的第一核心节点后的第一连通子图;根据维度共现图及其第一核心节点和第一连通子图,获得维度共现图的分裂树;根据分裂树的目标叶子节点确定维度字段的聚合组;根据维度字段的聚合组构建面向目标表的数据立方体。The program can be specifically used to: obtain the dimension field in the historical query statement of the target table and the query co-occurrence frequency between different dimension fields; take the dimension field as a node, and determine the difference according to the query co-occurrence frequency between different dimension fields The first-order edge weights between nodes form a dimensional co-occurrence graph; according to the degrees of each node in the dimensional co-occurrence graph, determine the first core node in the dimensional co-occurrence graph; obtain and delete the first core node in the dimensional co-occurrence graph After the first connected subgraph; according to the dimension co-occurrence graph and its first core node and the first connected sub-graph, the split tree of the dimension co-occurrence graph is obtained; according to the target leaf node of the split tree, the aggregation group of the dimension field is determined; Aggregate groups of dimension fields build a data cube for the target table.
根据本申请的一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述实施例的各种可选实现方式中提供的方法。According to one aspect of the present application, there is provided a computer program product or computer program comprising computer instructions stored in a computer readable storage medium. The processor of the computer device reads the computer instructions from the computer-readable storage medium, and the processor executes the computer instructions to cause the computer device to perform the methods provided in various optional implementations of the above-described embodiments.
需要理解的是,在本公开附图中的任何元素数量均用于示例而非限制,以及任何命名都仅用于区分,而不具有任何限制含义。It should be understood that any number of elements in the drawings of the present disclosure is for illustration rather than limitation, and any designation is for distinction only and does not have any limiting meaning.
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。Other embodiments of the present disclosure will readily occur to those skilled in the art upon consideration of the specification and practice of the invention disclosed herein. This application is intended to cover any variations, uses, or adaptations of the present disclosure that follow the general principles of the present disclosure and include common knowledge or techniques in the technical field not disclosed by the present disclosure . The specification and examples are to be regarded as exemplary only, with the true scope and spirit of the disclosure being indicated by the following claims.
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。It is to be understood that the present disclosure is not limited to the precise structures described above and illustrated in the accompanying drawings, and that various modifications and changes may be made without departing from the scope thereof. The scope of the present disclosure is limited only by the appended claims.
Claims (15)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110418607.1A CN115221157A (en) | 2021-04-19 | 2021-04-19 | Data processing method and apparatus, computer readable storage medium and electronic device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110418607.1A CN115221157A (en) | 2021-04-19 | 2021-04-19 | Data processing method and apparatus, computer readable storage medium and electronic device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115221157A true CN115221157A (en) | 2022-10-21 |
Family
ID=83605180
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110418607.1A Pending CN115221157A (en) | 2021-04-19 | 2021-04-19 | Data processing method and apparatus, computer readable storage medium and electronic device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115221157A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117171161A (en) * | 2023-07-24 | 2023-12-05 | 杭州未名信科科技有限公司 | Data query method and device |
| US20240346020A1 (en) * | 2023-04-13 | 2024-10-17 | Beijing Zitiao Network Technology Co., Ltd. | Method, apparatus, electronic device and storage media for data aggregation |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001055951A2 (en) * | 2000-01-25 | 2001-08-02 | Cellomics, Inc. | Method and system for automated inference of physico-chemical interaction knowl edge |
| US20070168323A1 (en) * | 2006-01-03 | 2007-07-19 | Microsoft Corporation | Query aggregation |
| CN111930770A (en) * | 2020-07-15 | 2020-11-13 | 北京金山云网络技术有限公司 | Data query method and device and electronic equipment |
| CN112286954A (en) * | 2020-09-25 | 2021-01-29 | 北京邮电大学 | Multi-dimensional data analysis method and system based on hybrid engine |
| CN112286953A (en) * | 2020-09-25 | 2021-01-29 | 北京邮电大学 | Multidimensional data query method, device and electronic device |
-
2021
- 2021-04-19 CN CN202110418607.1A patent/CN115221157A/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001055951A2 (en) * | 2000-01-25 | 2001-08-02 | Cellomics, Inc. | Method and system for automated inference of physico-chemical interaction knowl edge |
| US20070168323A1 (en) * | 2006-01-03 | 2007-07-19 | Microsoft Corporation | Query aggregation |
| CN111930770A (en) * | 2020-07-15 | 2020-11-13 | 北京金山云网络技术有限公司 | Data query method and device and electronic equipment |
| CN112286954A (en) * | 2020-09-25 | 2021-01-29 | 北京邮电大学 | Multi-dimensional data analysis method and system based on hybrid engine |
| CN112286953A (en) * | 2020-09-25 | 2021-01-29 | 北京邮电大学 | Multidimensional data query method, device and electronic device |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240346020A1 (en) * | 2023-04-13 | 2024-10-17 | Beijing Zitiao Network Technology Co., Ltd. | Method, apparatus, electronic device and storage media for data aggregation |
| US12386822B2 (en) * | 2023-04-13 | 2025-08-12 | Beijing Zitiao Network Technology Co., Ltd. | Method, apparatus, electronic device and storage media for recording correspondence relationships between target aggregation paths and aggregation results |
| CN117171161A (en) * | 2023-07-24 | 2023-12-05 | 杭州未名信科科技有限公司 | Data query method and device |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112269792B (en) | Data query method, device, equipment and computer readable storage medium | |
| CN110618983B (en) | Multidimensional analysis and visualization method of industrial big data based on JSON document structure | |
| CN109669934B (en) | A data warehouse system suitable for electric power customer service business and its construction method | |
| Zhao et al. | Modeling MongoDB with relational model | |
| CN110199273B (en) | System and method for loading, aggregating and bulk computing in one scan in a multidimensional database environment | |
| CN103678520B (en) | A kind of multi-dimensional interval query method and its system based on cloud computing | |
| CN104160394B (en) | Scalable analytics platform for semi-structured data | |
| Ribeiro et al. | Data modeling and data analytics: a survey from a big data perspective | |
| CN106874426B (en) | A Real-time Keyword Search Method for RDF Streaming Data Based on Storm | |
| CN109359115B (en) | Distributed storage method, device and system based on graph database | |
| Oussous et al. | NoSQL databases for big data | |
| US10977280B2 (en) | Systems and methods for memory optimization interest-driven business intelligence systems | |
| CN115309789B (en) | Method for generating associated data graph in real time based on intelligent dynamic business object | |
| CN112269797B (en) | Multidimensional query method of satellite remote sensing data on heterogeneous computing platform | |
| Larriba-Pey et al. | Introduction to graph databases | |
| CN111723089A (en) | A method and device for processing data based on columnar storage format | |
| CN116186041A (en) | Data lake index creation method, device, electronic device and computer storage medium | |
| CN113704248A (en) | Block chain query optimization method based on external index | |
| CN115221157A (en) | Data processing method and apparatus, computer readable storage medium and electronic device | |
| CN118885673A (en) | A community search method, system and storage medium based on k-truss nested index | |
| Hashem et al. | An Integrative Modeling of BigData Processing. | |
| Theeten et al. | Chive: Bandwidth optimized continuous querying in distributed clouds | |
| CN115048469A (en) | Data query method and device, electronic equipment and storage medium | |
| CN118708608A (en) | Processing engine selection method, device, computer equipment, and storage medium | |
| HK40074965A (en) | Data processing method and apparatus, computer readable storage medium, and electronic device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 40074965 Country of ref document: HK |
|
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |