CN114974228B - Rapid voice recognition method based on hierarchical recognition - Google Patents
Rapid voice recognition method based on hierarchical recognition Download PDFInfo
- Publication number
- CN114974228B CN114974228B CN202210571189.4A CN202210571189A CN114974228B CN 114974228 B CN114974228 B CN 114974228B CN 202210571189 A CN202210571189 A CN 202210571189A CN 114974228 B CN114974228 B CN 114974228B
- Authority
- CN
- China
- Prior art keywords
- shallow
- network
- networks
- level
- speech recognition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 23
- 238000012549 training Methods 0.000 claims description 5
- 230000000750 progressive effect Effects 0.000 claims description 3
- 238000012163 sequencing technique Methods 0.000 claims 2
- 238000010586 diagram Methods 0.000 description 3
- 230000009286 beneficial effect Effects 0.000 description 2
- 230000001934 delay Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012935 Averaging Methods 0.000 description 1
- 239000010754 BS 2869 Class F Substances 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000000354 decomposition reaction Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005265 energy consumption Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 210000002569 neuron Anatomy 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Telephonic Communication Services (AREA)
Abstract
Description
技术领域technical field
本发明涉及语音识别领域,尤其涉及一种基于分级识别的快速语音识别方法。The invention relates to the field of voice recognition, in particular to a fast voice recognition method based on hierarchical recognition.
背景技术Background technique
随着算力的不断提升和数据的累计,语音识别系统的效果取得了明显的进步,以CTC和encoder-decoder为代表的端到端建模方法对海量数据的利用更加充分,具有更强的建模能力。在语音识别领域,一种采用卷积增强的Conformer模型由谷歌在2020年提出后,不断刷新语音识别的准确率,已经成为当前语音识别声学建模的常规方法。在海量训练数据下,多层Conformer模型拥有更多的参数量,也被证明具备更强的建模能力。通常12-24层的Conformer模型随着模型层数的增加,在海量训练数据的加持下,建模能力就更强。但是随着参数量的增加,在进行语音识别时,模型推理过程中的计算量就越大,所带来的能耗、延迟和需要的资源也越多,这就限制了大模型在实际场景中的应用。为了使深层Conformer网络能够应用在语音识别任务中,通常会采用减小隐层神经元个数或采用矩阵分解等方法降低参数量和计算量,但是这些方法通常也会带来一定的性能损失。同时,语音识别过程中模型推理的计算复杂度依旧随Conformer层数增加呈现线性增长。With the continuous improvement of computing power and the accumulation of data, the effect of the speech recognition system has made significant progress. The end-to-end modeling method represented by CTC and encoder-decoder makes full use of massive data and has a stronger Modeling ability. In the field of speech recognition, a Conformer model using convolution enhancement was proposed by Google in 2020, which has continuously refreshed the accuracy of speech recognition and has become a conventional method for acoustic modeling of speech recognition. With massive training data, the multi-layer Conformer model has more parameters and has been proven to have stronger modeling capabilities. Usually, the 12-24 layer Conformer model has stronger modeling ability with the increase of the number of model layers and the blessing of massive training data. However, as the number of parameters increases, the greater the amount of calculation in the model reasoning process when performing speech recognition, the more energy consumption, delay, and resources required, which limits the use of large models in actual scenarios. in the application. In order to enable the deep Conformer network to be applied to speech recognition tasks, methods such as reducing the number of neurons in the hidden layer or using matrix decomposition are usually used to reduce the amount of parameters and calculations, but these methods usually also bring certain performance losses. At the same time, the computational complexity of model reasoning in the speech recognition process still increases linearly with the increase in the number of Conformer layers.
发明内容Contents of the invention
本发明的目的在于提供一种基于分级识别的快速语音识别方法,从而解决现有技术中存在的前述问题。The purpose of the present invention is to provide a fast speech recognition method based on hierarchical recognition, so as to solve the aforementioned problems in the prior art.
为了实现上述目的,本发明采用的技术方案如下:In order to achieve the above object, the technical scheme adopted in the present invention is as follows:
一种基于分级识别的快速语音识别方法,包括以下步骤:A fast speech recognition method based on hierarchical recognition, comprising the following steps:
S1、对Conformer模型的深层网络进行划分,将具有R层的深层网络按照从底层到顶层的顺序每隔M层划分为一个的浅层网络,并在每一个所述浅层网络中的最后一层识别网络引出一个抽头使用浅层Decoder进行解码,形成F个具有浅层网络的Conformer模型;其中R和M表示网络层次的数量,F表示具有浅层网络的Conformer模型的数量,F=R/M;S1. Divide the deep network of the Conformer model, divide the deep network with R layers into a shallow network every M layers in the order from the bottom layer to the top layer, and divide the deep network into a shallow network in each of the shallow networks. The layer recognition network leads a tap to be decoded by a shallow Decoder to form F Conformer models with a shallow network; where R and M represent the number of network layers, F represents the number of Conformer models with a shallow network, F=R/ M;
S2、依照所述深层网络中从底层到顶层的顺序,对形成的所述浅层网络进行级别划分和排序,形成具有F个浅层网络的语音识别模型,对输入语音根据所述语音识别模型中所述浅层网络的级别进行逐级识别,判断所述输入语音的难易程度;S2. According to the order from the bottom layer to the top layer in the deep network, classify and sort the formed shallow network to form a speech recognition model with F shallow networks, and input speech according to the speech recognition model The level of the shallow network described in is identified step by step, and the degree of difficulty of the input speech is judged;
S3、根据输入语音通过所述浅层网络的熵,判断所述输入语音的难易程度,判断所述输入语音是否还需要经过下一级别所述浅层网络的计算识别;所述浅层网络输出的熵值越小表示所述浅层网络输出语音识别结果越确定,对于语音识别结果的歧义越小;反之,熵值越大表示所述浅层网络输出的语音识别结果越不确定,对于语音识别结果的歧义越大,需要具有更强建模能力的网络进行识别。S3. According to the entropy of the input speech through the shallow network, judge the difficulty of the input speech, and judge whether the input speech needs to be calculated and recognized by the shallow network at the next level; the shallow network The smaller the entropy value of the output, the more certain the speech recognition result output by the shallow network is, and the smaller the ambiguity of the speech recognition result; conversely, the larger the entropy value is, the more uncertain the speech recognition result output by the shallow network is. The greater the ambiguity of the speech recognition results, the need for a network with stronger modeling capabilities for recognition.
一种基于分级识别的快速语音识别方法,包括以下步骤A fast speech recognition method based on hierarchical recognition, comprising the following steps
S1、对Conformer模型的深层网络进行划分,将具有R层的深层网络按照从底层到顶层的顺序每隔M层划分为一个的浅层网络,并在每一个所述浅层网络中的最后一层识别网络引出一个抽头使用浅层Decoder进行解码,形成F个具有浅层网络的Conformer模型;其中,R和M表示网络层次的数量,F表示具有浅层网络的Conformer模型的数量,F=R/M;S1. Divide the deep network of the Conformer model, divide the deep network with R layers into a shallow network every M layers in the order from the bottom layer to the top layer, and divide the deep network into a shallow network in each of the shallow networks. The layer recognition network leads a tap to be decoded by a shallow Decoder to form F Conformer models with a shallow network; where R and M represent the number of network layers, F represents the number of Conformer models with a shallow network, F=R /M;
S2、依照所述深层网络中从底层到顶层的顺序,对形成的所述浅层网络进行级别划分和排序,形成具有F个浅层网络的语音识别模型,对输入语音根据所述语音识别模型中所述浅层网络的级别进行逐级识别,判断所述输入语音的难易程度;S2. According to the order from the bottom layer to the top layer in the deep network, classify and sort the formed shallow network to form a speech recognition model with F shallow networks, and input speech according to the speech recognition model The level of the shallow network described in is identified step by step, and the degree of difficulty of the input speech is judged;
S3、依照所述浅层网络的级别从小到大的顺序,选择相邻的两个级别的浅层网络,对两个所述浅层网络输出的语音识别结果的一致性进行判断;当相邻的两个所述浅层网络的语音识别结果通过一致性判定时,认为声学建模已经完整;反之则需要具有更强建模能力的网络进行语音识别。S3. According to the order of the levels of the shallow networks from small to large, select two adjacent levels of shallow networks, and judge the consistency of the speech recognition results output by the two shallow networks; when adjacent When the speech recognition results of the two shallow networks pass the consistency judgment, the acoustic modeling is considered complete; otherwise, a network with stronger modeling capabilities is required for speech recognition.
优选的,所述输入语音经过所述浅层网络的熵的计算公式为:Preferably, the formula for calculating the entropy of the input speech through the shallow network is:

其中E表示熵值,L表示语音帧数,N表示输入语音中需要进行语音识别的单元总量,pli表示输入语音中第i个语音识别单元在第l帧进行语音识别的概率。Where E represents the entropy value, L represents the number of speech frames, N represents the total number of units in the input speech that need to be recognized, p li represents the probability that the i-th speech recognition unit in the input speech performs speech recognition in the l frame.
优选的,步骤S3所述的语音难易程度的判断依据为:设定熵的阈值,当第f级别的所述浅层网络输出的熵值小于所述阈值时,确定所述输入语音的难易程度,判定所述输入语音经过第f级别的所述浅层网络输出的语音识别结果为最终结果;否则所述输入语音继续向上通过所述浅层网络逐级进行语音识别,直至所述浅层网络的熵值小于所述阈值或所述浅层网络的级别为第F级;其中f表示所述语音识别模型中所述浅层网络的级别。Preferably, the basis for judging the degree of speech difficulty described in step S3 is: setting the threshold value of entropy, when the entropy value of the output of the shallow layer network at the fth level is less than the threshold value, determine the difficulty of the input speech degree of ease, it is determined that the voice recognition result output by the input voice through the shallow network at level f is the final result; otherwise, the input voice continues to pass through the shallow network for voice recognition step by step until the shallow network The entropy value of the layer network is less than the threshold value or the level of the shallow network is F; where f represents the level of the shallow network in the speech recognition model.
优选的,步骤S3所述的语音难易程度的判断依据为:设定识别结果差异阈值threshold,当两个级别的所述浅层网络的语音识别结果差异小于所述差异阈值,即diff(result1,result2)<threshold时,则认为声学建模已经完整;若两个语音识别结果差异大于所述差异阈值,即diff(result1,result2)≥threshold时,则认为当前的浅层网络构成的语音识别模型对于语音的建模能力不足,继续向上通过所述浅层模型逐级进行语音识别,直至相邻的两个所述浅层网络的语音识别结果通过一致性判断或所述浅层网络的级别为第F级。Preferably, the basis for judging the degree of speech difficulty described in step S3 is: setting the recognition result difference threshold value threshold, when the speech recognition result difference between the two levels of the shallow network is less than the difference threshold value, that is, diff(result1 ,result2)<threshold, it is considered that the acoustic modeling has been completed; if the difference between the two speech recognition results is greater than the difference threshold, that is, when diff(result1,result2)≥threshold, it is considered that the speech recognition composed of the current shallow network The model’s ability to model speech is insufficient, and continue to perform speech recognition step by step through the shallow model until the speech recognition results of two adjacent shallow networks pass the consistency judgment or the level of the shallow network for class F.
优选的,步骤S3中,当相邻的两个所述浅层网络的语音识别结果通过一致性判定时,将当前两个级别的所述浅层网络的语音识别结果通过线性加权作为输出的最终结果。Preferably, in step S3, when the speech recognition results of the two adjacent shallow networks pass the consistency judgment, the speech recognition results of the current two levels of the shallow networks are linearly weighted as the final output result.
优选的,步骤S1中对Conformer模型的深层网络进行划分方式为:对于R层的深层网络,每隔M层引出一个抽头使用一个浅层Decoder进行解码,则共设置F个浅层Decoder,形成F个浅层网络。Preferably, in step S1, the deep network of the Conformer model is divided in the following manner: for the deep network of the R layer, every M layer leads a tap to be decoded using a shallow Decoder, and a total of F shallow Decoders are set to form F a shallow network.
优选的,针对步骤S2中形成的具有浅层网络的语音识别模型,采用R/M个分支对级别递进的浅层网络进行多任务联合训练。Preferably, for the speech recognition model with a shallow network formed in step S2, R/M branches are used to perform multi-task joint training on the shallow network with progressive levels.
优选的,对于具有不同网络深度的模型,在浅层网络中均为共享参数。Preferably, for models with different network depths, all shallow networks share parameters.
本发明的有益效果是:本发明公开了一种基于分级识别的快速语音识别方法,对不同难度的语音进行分流将模型进行逐级拆解,使不同级别的模型能够处理不同难易程度的案例;本发明通过分级推理的方式,解决了大模型建模所需的计算资源受限的问题,大大降低了整体推理的复杂度,在节省计算资源的同时降低服务延迟。The beneficial effects of the present invention are: the present invention discloses a fast speech recognition method based on hierarchical recognition, which splits the speech of different difficulty and disassembles the model step by step, so that the models of different levels can handle cases of different degrees of difficulty ; The present invention solves the problem of limited computing resources required for large model modeling through hierarchical reasoning, greatly reduces the complexity of overall reasoning, and reduces service delays while saving computing resources.
附图说明Description of drawings
图1是分级识别的快速语音识别流程图;Fig. 1 is the fast speech recognition flowchart of hierarchical recognition;
图2是分级识别的快速语音识别结构图;Fig. 2 is the fast speech recognition structural diagram of hierarchical recognition;
图3是分级识别的判断准则结构图;Fig. 3 is a judgment criterion structural diagram of hierarchical recognition;
图4是分级识别的结果度量结构图。Fig. 4 is a structure diagram of the result measurement of hierarchical recognition.
具体实施方式Detailed ways
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings. It should be understood that the specific embodiments described here are only used to explain the present invention, and are not intended to limit the present invention.
一种基于分级识别的快速语音识别方法,将多层Conformer语音模型进行多级划分,从语音模型的角度判断输入的语音识别难度,根据语音识别难度判断语音识别层级;如图1所示,包括以下步骤:A fast speech recognition method based on hierarchical recognition, which divides the multi-layer Conformer speech model into multiple levels, judges the speech recognition difficulty of the input from the perspective of the speech model, and judges the speech recognition level according to the speech recognition difficulty; as shown in Figure 1, including The following steps:
S1、对Conformer模型的深层网络进行划分,将具有R层的深层网络按照从底层到顶层的顺序每隔M层划分为一个的浅层网络,并在每一个所述浅层网络中的最后一层识别网络引出一个抽头使用浅层Decoder进行解码,形成R/M个具有浅层网络的Conformer模型;S1. Divide the deep network of the Conformer model, divide the deep network with R layers into a shallow network every M layers in the order from the bottom layer to the top layer, and divide the deep network into a shallow network in each of the shallow networks. The layer identification network leads a tap to decode with a shallow Decoder to form R/M Conformer models with a shallow network;
具体实施方式为:对于R层的深层网络,每隔M层引出一个抽头使用一个浅层Decoder进行解码,则共设置F个浅层Decoder,其中,R和M表示网络层次的数量,F表示具有浅层网络的Conformer模型的数量,F=R/M。如图2所示,针对12层的Conformer模型,每隔3层连接一个浅层Decoder,从底层到顶层依次设置了4个浅层Decoder,形成4个具有浅层网络的Conformer模型。The specific implementation method is as follows: for the deep network of R layer, every M layer draws a tap and uses a shallow Decoder for decoding, then a total of F shallow Decoders are set, where R and M represent the number of network layers, and F represents the The number of Conformer models of the shallow network, F=R/M. As shown in Figure 2, for the 12-layer Conformer model, a shallow Decoder is connected every 3 layers, and 4 shallow Decoders are set up from the bottom layer to the top layer in order to form 4 Conformer models with shallow networks.
S2、依照所述深层网络中从底层到顶层的顺序,对形成的所述浅层网络进行级别划分和排序,形成具有R/M个浅层网络的语音识别模型,采用R/M个分支语音对级别递进的浅层网络进行多任务联合训练,并且每一个浅层网络内均为共享参数;S2. According to the order from the bottom layer to the top layer in the deep network, classify and sort the formed shallow network, form a speech recognition model with R/M shallow networks, and use R/M branch voices Perform multi-task joint training on shallow networks with progressive levels, and share parameters in each shallow network;
S3、对输入语音根据所述语音识别模型中所述浅层网络的级别进行逐级识别,判断所述输入语音的难易程度;S3. Recognize the input voice step by step according to the level of the shallow network in the voice recognition model, and judge the difficulty of the input voice;
S41、如图3所示,根据语音通过所述浅层网络的熵,判断所述语音的难易程度,判断所述语音是否还需要经过下一级别所述浅层网络的计算识别;S41. As shown in FIG. 3 , judge the degree of difficulty of the speech according to the entropy of the speech passing through the shallow network, and judge whether the speech needs to be calculated and recognized by the shallow network at the next level;
所述语音经过所述浅层网络的熵的计算公式为:The formula for calculating the entropy of the speech passing through the shallow network is:
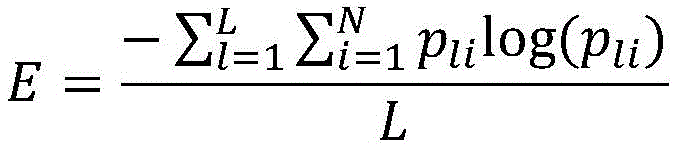
其中E表示熵值,L表示语音帧数,N表示输入语音中需要进行语音识别的单元总量,pli表示输入语音中第i个语音识别单元在第l帧进行语音识别的概率;所述浅层网络输出的熵值越小表示所述浅层网络输出语音识别结果越确定,对于语音识别结果的歧义越小;反之,熵值越大表示所述浅层网络输出的语音识别结果越不确定,对于语音识别结果的歧义越大,需要具有更强建模能力的网络去识别。Wherein E represents the entropy value, L represents the speech frame number, N represents the unit total amount that needs to carry out speech recognition in the input speech, p li represents the i-th speech recognition unit in the input speech and carries out the probability of speech recognition at the l frame; The smaller the entropy value of the shallow network output, the more certain the speech recognition result output by the shallow network is, and the smaller the ambiguity of the speech recognition result; on the contrary, the larger the entropy value is, the less accurate the speech recognition result output by the shallow network is. It is determined that the greater the ambiguity of the speech recognition results, the need for a network with stronger modeling capabilities to recognize.
设定熵的阈值,当第f级别的所述浅层网络输出的熵值小于所述阈值时,确定所述语音的难易程度,判定所述语音经过第f级别的所述浅层网络输出的语音识别结果为最终结果;否则所述语音继续向上通过所述浅层网络逐级进行语音识别,直至所述浅层网络的熵值小于所述阈值或所述浅层网络的级别为第F级;其中f表示所述语音识别模型中所述浅层网络的级别。Setting the threshold value of entropy, when the entropy value of the shallow layer network output of the fth level is less than the threshold value, determine the degree of difficulty of the speech, and determine that the speech is output through the shallow layer network output of the fth level The speech recognition result is the final result; otherwise, the speech continues to pass through the shallow network for speech recognition step by step, until the entropy value of the shallow network is less than the threshold or the level of the shallow network is the Fth level; where f represents the level of the shallow network in the speech recognition model.
利用上述步骤S41所述的语音难度判断方法,仍有可能会出现即便当前浅层网络输出的熵值小于阈值,但是对应输出的语音识别结果仍旧会出现错误的情况;基于此还可以采用以下语音难度判断方法:Using the speech difficulty judgment method described in step S41 above, it is still possible that even if the entropy value of the current shallow network output is less than the threshold value, the corresponding output speech recognition result will still be wrong; based on this, the following speech can also be used Difficulty Judgment Method:
S42、如图4所示,依照所述浅层网络的级别从小到大的顺序,选择相邻的两个级别的浅层网络,对两个所述浅层网络输出的语音识别结果的一致性进行判断;设定识别结果差异阈值threshold,当两个级别的所述浅层网络的语音识别结果差异小于所述差异阈值,即S42. As shown in FIG. 4 , according to the order of the levels of the shallow networks from small to large, select adjacent two levels of shallow networks, and the consistency of the speech recognition results output by the two shallow networks Judging; setting the recognition result difference threshold threshold, when the speech recognition result difference of the two levels of the shallow network is less than the difference threshold, that is
diff(result1,result2)<threshold时,则认为声学建模已经完整,识别结果趋向于收敛,使用当前两个级别的所述浅层网络的语音识别结果通过线性加权作为输出的最终结果;若两个语音识别结果差异大于所述差异阈值,即diff(result1,result2)≥threshold时,则认为当前的浅层网络构成的语音识别模型对于语音的建模能力不足,继续向上通过所述浅层模型逐级进行语音识别,直至相邻的两个所述浅层网络的语音识别结果通过一致性判断或所述浅层网络的级别为第F级。When diff(result1, result2)<threshold, it is considered that the acoustic modeling is complete, and the recognition result tends to converge, and the speech recognition results of the current two levels of the shallow network are used as the final result of the output through linear weighting; if the two When the difference between two speech recognition results is greater than the difference threshold, that is, when diff(result1, result2)≥threshold, it is considered that the speech recognition model formed by the current shallow network is not capable of modeling speech, and continues to pass through the shallow model Carry out speech recognition step by step until the speech recognition results of two adjacent shallow networks pass the consistency judgment or the level of the shallow networks is the Fth level.
利用上述步骤S42所述的语音难度判断方法相较于步骤S41计算量更大一些,因为至少要计算前两级语音识别,但是在识别的准确率上更有保证,同时两级识别结果的加权融合也能起到一定的模型平均的作用,可以提升同样层级所述语音识别模型的解码准确率。Compared with step S41, the calculation amount of the speech difficulty judgment method described in the above step S42 is larger, because at least the first two levels of speech recognition must be calculated, but the accuracy of recognition is more guaranteed, and the weighting of the two levels of recognition results Fusion can also play a certain role in model averaging, which can improve the decoding accuracy of the speech recognition model at the same level.
实施例Example
在实际的语音识别任务中,大多数的语音识别任务都是背景干净、发音清洗的简单案例,针对此种语音识别任务使用浅层网络就可以完成语音识别任务。In actual speech recognition tasks, most of the speech recognition tasks are simple cases with clean background and pronunciation. For such speech recognition tasks, shallow networks can be used to complete speech recognition tasks.
以Conformer模型的深层网络为12层为例,假设选用的检测语音中20%的案例需要用到深层网路进行语音识别,即使使用上述步骤S42中的判断方法,也能节省约80%*50%=40%的计算量,收益较为可观;Taking the 12-layer deep network of the Conformer model as an example, assuming that 20% of the selected speech detection cases need to use the deep network for speech recognition, even if the judgment method in the above step S42 is used, it can save about 80%*50 % = 40% of the calculation amount, the income is considerable;
以Conformer模型的深层网络为24层为例,选用上述检测语音中20%的案例需要用到深层网路进行语音识别,假设其中有20%的案例推理需要用到24层网络,80%案例推理不超过12层网络,那么增加的复杂度不会超过100%*20%=20%计算量,要远小于直接全部案例全部通过24层网络增加的100%计算量。Taking the 24-layer deep network of the Conformer model as an example, 20% of the cases in the above detection speech need to use the deep network for speech recognition. Assume that 20% of the case reasoning needs to use the 24-layer network, and 80% of the case reasoning needs to use the 24-layer network. If the network does not exceed 12 layers, the increased complexity will not exceed 100%*20%=20% of the calculation amount, which is much smaller than the 100% increase in the calculation amount of all cases directly through the 24-layer network.
通过采用本发明公开的上述技术方案,得到了如下有益的效果:By adopting the above-mentioned technical scheme disclosed by the present invention, the following beneficial effects are obtained:
本发明公开了一种基于分级识别的快速语音识别方法,对不同难度的语音进行分流将模型进行逐级拆解,使不同级别的模型能够处理不同难易程度的案例;本发明通过分级推理的方式,解决了大模型建模所需的计算资源受限的问题,大大降低了整体推理的复杂度,在节省计算资源的同时降低服务延迟。The invention discloses a fast speech recognition method based on hierarchical recognition, which divides speech with different difficulties and disassembles the model step by step, so that models of different levels can handle cases with different degrees of difficulty; the present invention uses hierarchical reasoning This method solves the problem of limited computing resources required for large model modeling, greatly reduces the complexity of overall reasoning, and reduces service delays while saving computing resources.
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。The above is only a preferred embodiment of the present invention, it should be pointed out that, for those of ordinary skill in the art, without departing from the principle of the present invention, some improvements and modifications can also be made, and these improvements and modifications can also be made. It should be regarded as the protection scope of the present invention.
Claims (1)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210571189.4A CN114974228B (en) | 2022-05-24 | 2022-05-24 | Rapid voice recognition method based on hierarchical recognition |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210571189.4A CN114974228B (en) | 2022-05-24 | 2022-05-24 | Rapid voice recognition method based on hierarchical recognition |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114974228A CN114974228A (en) | 2022-08-30 |
| CN114974228B true CN114974228B (en) | 2023-04-11 |
Family
ID=82955743
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210571189.4A Active CN114974228B (en) | 2022-05-24 | 2022-05-24 | Rapid voice recognition method based on hierarchical recognition |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114974228B (en) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019095600A (en) * | 2017-11-22 | 2019-06-20 | 日本電信電話株式会社 | Acoustic model learning device, speech recognition device, and method and program for them |
| WO2021023202A1 (en) * | 2019-08-07 | 2021-02-11 | 交叉信息核心技术研究院(西安)有限公司 | Self-distillation training method and device for convolutional neural network, and scalable dynamic prediction method |
| CN113807499A (en) * | 2021-09-15 | 2021-12-17 | 清华大学 | Lightweight neural network model training method, system, device and storage medium |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3467556B2 (en) * | 1992-06-19 | 2003-11-17 | セイコーエプソン株式会社 | Voice recognition device |
| US6795793B2 (en) * | 2002-07-19 | 2004-09-21 | Med-Ed Innovations, Inc. | Method and apparatus for evaluating data and implementing training based on the evaluation of the data |
| US9305554B2 (en) * | 2013-07-17 | 2016-04-05 | Samsung Electronics Co., Ltd. | Multi-level speech recognition |
| CN106844343B (en) * | 2017-01-20 | 2019-11-19 | 上海傲硕信息科技有限公司 | Command result screening device |
| DE102017220266B3 (en) * | 2017-11-14 | 2018-12-13 | Audi Ag | Method for checking an onboard speech recognizer of a motor vehicle and control device and motor vehicle |
| WO2020014899A1 (en) * | 2018-07-18 | 2020-01-23 | 深圳魔耳智能声学科技有限公司 | Voice control method, central control device, and storage medium |
| CN109192194A (en) * | 2018-08-22 | 2019-01-11 | 北京百度网讯科技有限公司 | Voice data mask method, device, computer equipment and storage medium |
| CN110413997B (en) * | 2019-07-16 | 2023-04-07 | 深圳供电局有限公司 | New word discovery method, system and readable storage medium for power industry |
| CN112182154B (en) * | 2020-09-25 | 2023-10-10 | 中国人民大学 | A personalized search model that uses personal word vectors to eliminate keyword ambiguity |
| CN112434163A (en) * | 2020-11-30 | 2021-03-02 | 北京沃东天骏信息技术有限公司 | Risk identification method, model construction method, risk identification device, electronic equipment and medium |
| CN112908301B (en) * | 2021-01-27 | 2024-06-11 | 科大讯飞(上海)科技有限公司 | Voice recognition method, device, storage medium and equipment |
| CN113870845B (en) * | 2021-09-26 | 2025-03-25 | 平安科技(深圳)有限公司 | Speech recognition model training method, device, equipment and medium |
-
2022
- 2022-05-24 CN CN202210571189.4A patent/CN114974228B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019095600A (en) * | 2017-11-22 | 2019-06-20 | 日本電信電話株式会社 | Acoustic model learning device, speech recognition device, and method and program for them |
| WO2021023202A1 (en) * | 2019-08-07 | 2021-02-11 | 交叉信息核心技术研究院(西安)有限公司 | Self-distillation training method and device for convolutional neural network, and scalable dynamic prediction method |
| CN113807499A (en) * | 2021-09-15 | 2021-12-17 | 清华大学 | Lightweight neural network model training method, system, device and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114974228A (en) | 2022-08-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112633010B (en) | Aspect-level emotion analysis method and system based on multi-head attention and graph convolution network | |
| Chen et al. | Leveraging modality-specific representations for audio-visual speech recognition via reinforcement learning | |
| CN110046226B (en) | An image description method based on distributed word vector CNN-RNN network | |
| CN109409307B (en) | Online video behavior detection method based on space-time context analysis | |
| CN107346340A (en) | A kind of user view recognition methods and system | |
| CN110956222B (en) | Method for detecting network for underwater target detection | |
| CN117892175A (en) | A SNN multimodal target recognition method, system, device and medium | |
| CN109783799B (en) | A Relation Extraction Method Based on Semantic Dependency Graph | |
| CN118982658A (en) | An infrared weak target detection method based on improved YOLO v8 | |
| CN115810128A (en) | A Compression Method of Image Classification Model Based on Greedy Strategy | |
| CN113033410B (en) | Domain generalized person re-identification method, system and medium based on automatic data augmentation | |
| CN117115474A (en) | An end-to-end single target tracking method based on multi-stage feature extraction | |
| CN117058156A (en) | A semi-supervised medical image segmentation method | |
| Wang et al. | Autost: Training-free neural architecture search for spiking transformers | |
| CN118350460A (en) | Feature-enhanced cooperative relationship knowledge distillation method for skin tumor image classification | |
| CN107910009B (en) | A method and system for the detection of code element rewriting information hiding based on Bayesian inference | |
| CN114974228B (en) | Rapid voice recognition method based on hierarchical recognition | |
| CN114548090B (en) | A Fast Relation Extraction Method Based on Convolutional Neural Networks and Improved Cascade Labeling | |
| CN119810702A (en) | Video data processing method, device, electronic device and readable storage medium | |
| CN115438658A (en) | Entity recognition method, recognition model training method and related device | |
| CN116303932A (en) | Conversational recommendation method and system for incomplete knowledge graph | |
| Gul et al. | Lplgrad: Optimizing active learning through gradient norm sample selection and auxiliary model training | |
| CN115019366A (en) | Automatic micro-expression classification model training method based on neural process | |
| Nomuunbayar et al. | Pruning method using correlation of weight changes and weight magnitudes in CNN | |
| Yang et al. | Enhancing end-to-end speech recognition models with a joint decoding strategy |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CP03 | Change of name, title or address | ||
| CP03 | Change of name, title or address |
Address after: 805, 8th Floor, Building 6, Courtyard 1, Xitucheng Road, Haidian District, Beijing, 100088 Patentee after: Beijing Xiyu Jizhi Technology Co.,Ltd. Country or region after: China Address before: Room 512A, 5th Floor, No. 23, Zhichun Road, Haidian District, Beijing 100061 Patentee before: Mingri Dream (Beijing) Technology Co.,Ltd. Country or region before: China |
|
| TR01 | Transfer of patent right | ||
| TR01 | Transfer of patent right |
Effective date of registration: 20250219 Address after: 805, 8th Floor, Building 6, Courtyard 1, Xitucheng Road, Haidian District, Beijing, 100088 Patentee after: Beijing Xiyu Jizhi Technology Co.,Ltd. Country or region after: China Patentee after: Shanghai Xiyu Jizhi Technology Co.,Ltd. Address before: 805, 8th Floor, Building 6, Courtyard 1, Xitucheng Road, Haidian District, Beijing, 100088 Patentee before: Beijing Xiyu Jizhi Technology Co.,Ltd. Country or region before: China |