CN114958700A - Escherichia coli engineering bacterium and application thereof - Google Patents
Escherichia coli engineering bacterium and application thereof Download PDFInfo
- Publication number
- CN114958700A CN114958700A CN202210510742.3A CN202210510742A CN114958700A CN 114958700 A CN114958700 A CN 114958700A CN 202210510742 A CN202210510742 A CN 202210510742A CN 114958700 A CN114958700 A CN 114958700A
- Authority
- CN
- China
- Prior art keywords
- ala
- leu
- glu
- val
- gly
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 241000894006 Bacteria Species 0.000 title claims abstract description 58
- 241000588724 Escherichia coli Species 0.000 title claims abstract description 54
- 239000013612 plasmid Substances 0.000 claims abstract description 91
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 56
- GHVNFZFCNZKVNT-UHFFFAOYSA-N decanoic acid Chemical compound CCCCCCCCCC(O)=O GHVNFZFCNZKVNT-UHFFFAOYSA-N 0.000 claims abstract description 38
- 241000672609 Escherichia coli BL21 Species 0.000 claims abstract description 31
- 238000012224 gene deletion Methods 0.000 claims abstract description 24
- 230000009466 transformation Effects 0.000 claims abstract description 17
- WXBXVVIUZANZAU-UHFFFAOYSA-N 2E-decenoic acid Natural products CCCCCCCC=CC(O)=O WXBXVVIUZANZAU-UHFFFAOYSA-N 0.000 claims abstract description 14
- WXBXVVIUZANZAU-CMDGGOBGSA-N trans-2-decenoic acid Chemical compound CCCCCCC\C=C\C(O)=O WXBXVVIUZANZAU-CMDGGOBGSA-N 0.000 claims abstract description 13
- 239000005632 Capric acid (CAS 334-48-5) Substances 0.000 claims abstract description 9
- 239000002773 nucleotide Substances 0.000 claims description 55
- 125000003729 nucleotide group Chemical group 0.000 claims description 55
- 238000006243 chemical reaction Methods 0.000 claims description 43
- 108090000790 Enzymes Proteins 0.000 claims description 40
- QHBZHVUGQROELI-UHFFFAOYSA-N Royal Jelly acid Natural products OCCCCCCCC=CC(O)=O QHBZHVUGQROELI-UHFFFAOYSA-N 0.000 claims description 40
- KUPHXIFBKAORGY-UHFFFAOYSA-N 2-amino-3-iodo-4-methylbenzoic acid Chemical compound CC1=CC=C(C(O)=O)C(N)=C1I KUPHXIFBKAORGY-UHFFFAOYSA-N 0.000 claims description 38
- 238000012408 PCR amplification Methods 0.000 claims description 37
- 238000011144 upstream manufacturing Methods 0.000 claims description 37
- 239000012634 fragment Substances 0.000 claims description 29
- 102000004190 Enzymes Human genes 0.000 claims description 28
- 230000001580 bacterial effect Effects 0.000 claims description 28
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 claims description 27
- 238000000034 method Methods 0.000 claims description 25
- 239000007788 liquid Substances 0.000 claims description 23
- GYSCBCSGKXNZRH-UHFFFAOYSA-N 1-benzothiophene-2-carboxamide Chemical compound C1=CC=C2SC(C(=O)N)=CC2=C1 GYSCBCSGKXNZRH-UHFFFAOYSA-N 0.000 claims description 20
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 claims description 20
- 238000010276 construction Methods 0.000 claims description 15
- 101710120269 Acyl-CoA thioester hydrolase YbgC Proteins 0.000 claims description 14
- 238000000137 annealing Methods 0.000 claims description 13
- 238000004925 denaturation Methods 0.000 claims description 13
- 230000036425 denaturation Effects 0.000 claims description 13
- 238000012257 pre-denaturation Methods 0.000 claims description 13
- 230000000284 resting effect Effects 0.000 claims description 13
- 108010001058 Acyl-CoA Dehydrogenase Proteins 0.000 claims description 12
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 claims description 11
- 230000003115 biocidal effect Effects 0.000 claims description 10
- 239000000243 solution Substances 0.000 claims description 10
- 229960005322 streptomycin Drugs 0.000 claims description 10
- 229960000723 ampicillin Drugs 0.000 claims description 9
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 claims description 9
- 102000003960 Ligases Human genes 0.000 claims description 8
- 108090000364 Ligases Proteins 0.000 claims description 8
- 238000012216 screening Methods 0.000 claims description 8
- 108700020831 3-Hydroxyacyl-CoA Dehydrogenase Proteins 0.000 claims description 7
- 229930027917 kanamycin Natural products 0.000 claims description 7
- 229960000318 kanamycin Drugs 0.000 claims description 7
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 claims description 7
- 229930182823 kanamycin A Natural products 0.000 claims description 7
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 claims description 7
- 229920000053 polysorbate 80 Polymers 0.000 claims description 7
- 230000006698 induction Effects 0.000 claims description 6
- 239000008057 potassium phosphate buffer Substances 0.000 claims description 6
- 239000002994 raw material Substances 0.000 claims description 6
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 claims description 5
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 claims description 5
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 claims description 5
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 claims description 5
- 239000005642 Oleic acid Substances 0.000 claims description 5
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 claims description 5
- 238000010367 cloning Methods 0.000 claims description 5
- 150000002148 esters Chemical class 0.000 claims description 5
- 239000008103 glucose Substances 0.000 claims description 5
- 230000001939 inductive effect Effects 0.000 claims description 5
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 claims description 5
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 claims description 5
- 230000006798 recombination Effects 0.000 claims description 5
- 238000005215 recombination Methods 0.000 claims description 5
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 claims description 4
- 238000001976 enzyme digestion Methods 0.000 claims description 4
- 238000012546 transfer Methods 0.000 claims description 4
- 239000003292 glue Substances 0.000 claims description 3
- 238000002360 preparation method Methods 0.000 claims description 3
- 239000002904 solvent Substances 0.000 claims description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 claims description 2
- 238000012258 culturing Methods 0.000 claims description 2
- 239000012533 medium component Substances 0.000 claims description 2
- 239000002244 precipitate Substances 0.000 claims description 2
- 239000011780 sodium chloride Substances 0.000 claims description 2
- 239000001963 growth medium Substances 0.000 claims 4
- 230000001131 transforming effect Effects 0.000 claims 3
- RGJOEKWQDUBAIZ-IBOSZNHHSA-N CoASH Chemical compound O[C@@H]1[C@H](OP(O)(O)=O)[C@@H](COP(O)(=O)OP(O)(=O)OCC(C)(C)[C@@H](O)C(=O)NCCC(=O)NCCS)O[C@H]1N1C2=NC=NC(N)=C2N=C1 RGJOEKWQDUBAIZ-IBOSZNHHSA-N 0.000 claims 2
- 125000002252 acyl group Chemical group 0.000 claims 2
- RGJOEKWQDUBAIZ-UHFFFAOYSA-N coenzime A Natural products OC1C(OP(O)(O)=O)C(COP(O)(=O)OP(O)(=O)OCC(C)(C)C(O)C(=O)NCCC(=O)NCCS)OC1N1C2=NC=NC(N)=C2N=C1 RGJOEKWQDUBAIZ-UHFFFAOYSA-N 0.000 claims 2
- 239000005516 coenzyme A Substances 0.000 claims 2
- 229940093530 coenzyme a Drugs 0.000 claims 2
- KDTSHFARGAKYJN-UHFFFAOYSA-N dephosphocoenzyme A Natural products OC1C(O)C(COP(O)(=O)OP(O)(=O)OCC(C)(C)C(O)C(=O)NCCC(=O)NCCS)OC1N1C2=NC=NC(N)=C2N=C1 KDTSHFARGAKYJN-UHFFFAOYSA-N 0.000 claims 2
- 229920000136 polysorbate Polymers 0.000 claims 2
- 108020002982 thioesterase Proteins 0.000 claims 2
- 101710153103 Long-chain-fatty-acid-CoA ligase FadD13 Proteins 0.000 claims 1
- 238000012790 confirmation Methods 0.000 claims 1
- 239000002609 medium Substances 0.000 claims 1
- 238000005406 washing Methods 0.000 claims 1
- 108700026220 vif Genes Proteins 0.000 abstract 1
- 108020004414 DNA Proteins 0.000 description 35
- 229940023064 escherichia coli Drugs 0.000 description 28
- 239000000047 product Substances 0.000 description 20
- 230000004927 fusion Effects 0.000 description 18
- 238000000246 agarose gel electrophoresis Methods 0.000 description 14
- 239000000499 gel Substances 0.000 description 13
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 11
- 230000029087 digestion Effects 0.000 description 10
- 150000002185 fatty acyl-CoAs Chemical class 0.000 description 10
- 238000011084 recovery Methods 0.000 description 9
- -1 trimethylsilanol phosphate Chemical compound 0.000 description 9
- 238000000855 fermentation Methods 0.000 description 8
- 230000004151 fermentation Effects 0.000 description 8
- 108010049041 glutamylalanine Proteins 0.000 description 8
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 8
- 241000880493 Leptailurus serval Species 0.000 description 7
- 230000014759 maintenance of location Effects 0.000 description 7
- 108010061238 threonyl-glycine Proteins 0.000 description 7
- RQHLMGCXCZUOGT-ZPFDUUQYSA-N Asp-Leu-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RQHLMGCXCZUOGT-ZPFDUUQYSA-N 0.000 description 6
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 6
- OKARHJKJTKFQBM-ACZMJKKPSA-N Gln-Ser-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OKARHJKJTKFQBM-ACZMJKKPSA-N 0.000 description 6
- DWUKOTKSTDWGAE-BQBZGAKWSA-N Gly-Asn-Arg Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DWUKOTKSTDWGAE-BQBZGAKWSA-N 0.000 description 6
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 6
- 108010050848 glycylleucine Proteins 0.000 description 6
- 238000004519 manufacturing process Methods 0.000 description 6
- 239000003550 marker Substances 0.000 description 6
- 108010012581 phenylalanylglutamate Proteins 0.000 description 6
- 102000004169 proteins and genes Human genes 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 241000194107 Bacillus megaterium Species 0.000 description 5
- 102000005297 Cytochrome P-450 CYP4A Human genes 0.000 description 5
- 108010081498 Cytochrome P-450 CYP4A Proteins 0.000 description 5
- ILWHFUZZCFYSKT-AVGNSLFASA-N Glu-Lys-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ILWHFUZZCFYSKT-AVGNSLFASA-N 0.000 description 5
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 5
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 5
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 5
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 5
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 5
- 108010005233 alanylglutamic acid Proteins 0.000 description 5
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 5
- 150000001413 amino acids Chemical group 0.000 description 5
- 108010060035 arginylproline Proteins 0.000 description 5
- 108010093581 aspartyl-proline Proteins 0.000 description 5
- 230000015572 biosynthetic process Effects 0.000 description 5
- 230000002950 deficient Effects 0.000 description 5
- 108010045126 glycyl-tyrosyl-glycine Proteins 0.000 description 5
- 108010005942 methionylglycine Proteins 0.000 description 5
- 239000000203 mixture Substances 0.000 description 5
- 108010084572 phenylalanyl-valine Proteins 0.000 description 5
- 238000011027 product recovery Methods 0.000 description 5
- 108010080629 tryptophan-leucine Proteins 0.000 description 5
- JUWQNWXEGDYCIE-YUMQZZPRSA-N Arg-Gln-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O JUWQNWXEGDYCIE-YUMQZZPRSA-N 0.000 description 4
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 4
- ZUVMUOOHJYNJPP-XIRDDKMYSA-N Arg-Trp-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZUVMUOOHJYNJPP-XIRDDKMYSA-N 0.000 description 4
- NAPNAGZWHQHZLG-ZLUOBGJFSA-N Asp-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N NAPNAGZWHQHZLG-ZLUOBGJFSA-N 0.000 description 4
- PWAIZUBWHRHYKS-MELADBBJSA-N Asp-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)O)N)C(=O)O PWAIZUBWHRHYKS-MELADBBJSA-N 0.000 description 4
- DYFJZDDQPNIPAB-NHCYSSNCSA-N Glu-Arg-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O DYFJZDDQPNIPAB-NHCYSSNCSA-N 0.000 description 4
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 4
- GVNNAHIRSDRIII-AJNGGQMLSA-N Ile-Lys-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N GVNNAHIRSDRIII-AJNGGQMLSA-N 0.000 description 4
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 4
- PJYSOYLLTJKZHC-GUBZILKMSA-N Leu-Asp-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(N)=O PJYSOYLLTJKZHC-GUBZILKMSA-N 0.000 description 4
- 241000206597 Marinobacter hydrocarbonoclasticus Species 0.000 description 4
- WYBVBIHNJWOLCJ-UHFFFAOYSA-N N-L-arginyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCCN=C(N)N WYBVBIHNJWOLCJ-UHFFFAOYSA-N 0.000 description 4
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 4
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 4
- 102000004316 Oxidoreductases Human genes 0.000 description 4
- 108090000854 Oxidoreductases Proteins 0.000 description 4
- WFHRXJOZEXUKLV-IRXDYDNUSA-N Phe-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 WFHRXJOZEXUKLV-IRXDYDNUSA-N 0.000 description 4
- KNYPNEYICHHLQL-ACRUOGEOSA-N Phe-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 KNYPNEYICHHLQL-ACRUOGEOSA-N 0.000 description 4
- YUPRIZTWANWWHK-DZKIICNBSA-N Phe-Val-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N YUPRIZTWANWWHK-DZKIICNBSA-N 0.000 description 4
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 4
- COYSIHFOCOMGCF-WPRPVWTQSA-N Val-Arg-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-WPRPVWTQSA-N 0.000 description 4
- COYSIHFOCOMGCF-UHFFFAOYSA-N Val-Arg-Gly Natural products CC(C)C(N)C(=O)NC(C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-UHFFFAOYSA-N 0.000 description 4
- ROLGIBMFNMZANA-GVXVVHGQSA-N Val-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N ROLGIBMFNMZANA-GVXVVHGQSA-N 0.000 description 4
- MHAHQDBEIDPFQS-NHCYSSNCSA-N Val-Glu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C MHAHQDBEIDPFQS-NHCYSSNCSA-N 0.000 description 4
- 108010087924 alanylproline Proteins 0.000 description 4
- 108010013835 arginine glutamate Proteins 0.000 description 4
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 4
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 4
- 108010025801 glycyl-prolyl-arginine Proteins 0.000 description 4
- 239000013600 plasmid vector Substances 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 229950010481 5-aminolevulinic acid hydrochloride Drugs 0.000 description 3
- ZGXJTSGNIOSYLO-UHFFFAOYSA-N 88755TAZ87 Chemical compound NCC(=O)CCC(O)=O ZGXJTSGNIOSYLO-UHFFFAOYSA-N 0.000 description 3
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 3
- DVWVZSJAYIJZFI-FXQIFTODSA-N Ala-Arg-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O DVWVZSJAYIJZFI-FXQIFTODSA-N 0.000 description 3
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 3
- FOWHQTWRLFTELJ-FXQIFTODSA-N Ala-Asp-Met Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O)N FOWHQTWRLFTELJ-FXQIFTODSA-N 0.000 description 3
- RAAWHFXHAACDFT-FXQIFTODSA-N Ala-Met-Asn Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CC(N)=O)C(O)=O RAAWHFXHAACDFT-FXQIFTODSA-N 0.000 description 3
- DGLQWAFPIXDKRL-UBHSHLNASA-N Ala-Met-Phe Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N DGLQWAFPIXDKRL-UBHSHLNASA-N 0.000 description 3
- 108010011667 Ala-Phe-Ala Proteins 0.000 description 3
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 3
- VSPLYCLMFAUZRF-GUBZILKMSA-N Arg-Cys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N VSPLYCLMFAUZRF-GUBZILKMSA-N 0.000 description 3
- SKTGPBFTMNLIHQ-KKUMJFAQSA-N Arg-Glu-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SKTGPBFTMNLIHQ-KKUMJFAQSA-N 0.000 description 3
- RKQRHMKFNBYOTN-IHRRRGAJSA-N Arg-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N RKQRHMKFNBYOTN-IHRRRGAJSA-N 0.000 description 3
- OOIMKQRCPJBGPD-XUXIUFHCSA-N Arg-Ile-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O OOIMKQRCPJBGPD-XUXIUFHCSA-N 0.000 description 3
- OISWSORSLQOGFV-AVGNSLFASA-N Arg-Met-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CCCN=C(N)N OISWSORSLQOGFV-AVGNSLFASA-N 0.000 description 3
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 3
- IARGXWMWRFOQPG-GCJQMDKQSA-N Asn-Ala-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IARGXWMWRFOQPG-GCJQMDKQSA-N 0.000 description 3
- JJGRJMKUOYXZRA-LPEHRKFASA-N Asn-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O JJGRJMKUOYXZRA-LPEHRKFASA-N 0.000 description 3
- YVXRYLVELQYAEQ-SRVKXCTJSA-N Asn-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N YVXRYLVELQYAEQ-SRVKXCTJSA-N 0.000 description 3
- YRTOMUMWSTUQAX-FXQIFTODSA-N Asn-Pro-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O YRTOMUMWSTUQAX-FXQIFTODSA-N 0.000 description 3
- ZNYKKCADEQAZKA-FXQIFTODSA-N Asn-Ser-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O ZNYKKCADEQAZKA-FXQIFTODSA-N 0.000 description 3
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 3
- YQPSDMUGFKJZHR-QRTARXTBSA-N Asn-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)N)N YQPSDMUGFKJZHR-QRTARXTBSA-N 0.000 description 3
- SDHFVYLZFBDSQT-DCAQKATOSA-N Asp-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N SDHFVYLZFBDSQT-DCAQKATOSA-N 0.000 description 3
- VAWNQIGQPUOPQW-ACZMJKKPSA-N Asp-Glu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VAWNQIGQPUOPQW-ACZMJKKPSA-N 0.000 description 3
- IJHUZMGJRGNXIW-CIUDSAMLSA-N Asp-Glu-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IJHUZMGJRGNXIW-CIUDSAMLSA-N 0.000 description 3
- XJQRWGXKUSDEFI-ACZMJKKPSA-N Asp-Glu-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O XJQRWGXKUSDEFI-ACZMJKKPSA-N 0.000 description 3
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 3
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 3
- HKEZZWQWXWGASX-KKUMJFAQSA-N Asp-Leu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 HKEZZWQWXWGASX-KKUMJFAQSA-N 0.000 description 3
- NZWDWXSWUQCNMG-GARJFASQSA-N Asp-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)C(=O)O NZWDWXSWUQCNMG-GARJFASQSA-N 0.000 description 3
- BKOIIURTQAJHAT-GUBZILKMSA-N Asp-Pro-Pro Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 BKOIIURTQAJHAT-GUBZILKMSA-N 0.000 description 3
- WOACHWLUOFZLGJ-GUBZILKMSA-N Gln-Arg-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O WOACHWLUOFZLGJ-GUBZILKMSA-N 0.000 description 3
- RGAOLBZBLOJUTP-GRLWGSQLSA-N Gln-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CCC(=O)N)N RGAOLBZBLOJUTP-GRLWGSQLSA-N 0.000 description 3
- JNENSVNAUWONEZ-GUBZILKMSA-N Gln-Lys-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O JNENSVNAUWONEZ-GUBZILKMSA-N 0.000 description 3
- WHVLABLIJYGVEK-QEWYBTABSA-N Gln-Phe-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WHVLABLIJYGVEK-QEWYBTABSA-N 0.000 description 3
- BPDVTFBJZNBHEU-HGNGGELXSA-N Glu-Ala-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 BPDVTFBJZNBHEU-HGNGGELXSA-N 0.000 description 3
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 3
- ZCOJVESMNGBGLF-GRLWGSQLSA-N Glu-Ile-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZCOJVESMNGBGLF-GRLWGSQLSA-N 0.000 description 3
- JHSRJMUJOGLIHK-GUBZILKMSA-N Glu-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N JHSRJMUJOGLIHK-GUBZILKMSA-N 0.000 description 3
- CBWKURKPYSLMJV-SOUVJXGZSA-N Glu-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CBWKURKPYSLMJV-SOUVJXGZSA-N 0.000 description 3
- AIJAPFVDBFYNKN-WHFBIAKZSA-N Gly-Asn-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN)C(=O)N AIJAPFVDBFYNKN-WHFBIAKZSA-N 0.000 description 3
- IWAXHBCACVWNHT-BQBZGAKWSA-N Gly-Asp-Arg Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IWAXHBCACVWNHT-BQBZGAKWSA-N 0.000 description 3
- TZOVVRJYUDETQG-RCOVLWMOSA-N Gly-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN TZOVVRJYUDETQG-RCOVLWMOSA-N 0.000 description 3
- NPSWCZIRBAYNSB-JHEQGTHGSA-N Gly-Gln-Thr Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NPSWCZIRBAYNSB-JHEQGTHGSA-N 0.000 description 3
- LRQXRHGQEVWGPV-NHCYSSNCSA-N Gly-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN LRQXRHGQEVWGPV-NHCYSSNCSA-N 0.000 description 3
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 3
- IXHQLZIWBCQBLQ-STQMWFEESA-N Gly-Pro-Phe Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IXHQLZIWBCQBLQ-STQMWFEESA-N 0.000 description 3
- GJHWILMUOANXTG-WPRPVWTQSA-N Gly-Val-Arg Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GJHWILMUOANXTG-WPRPVWTQSA-N 0.000 description 3
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 3
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 3
- FJCGVRRVBKYYOU-DCAQKATOSA-N His-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N FJCGVRRVBKYYOU-DCAQKATOSA-N 0.000 description 3
- 108700039609 IRW peptide Proteins 0.000 description 3
- WUEIUSDAECDLQO-NAKRPEOUSA-N Ile-Ala-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)O)N WUEIUSDAECDLQO-NAKRPEOUSA-N 0.000 description 3
- LLZLRXBTOOFODM-QSFUFRPTSA-N Ile-Asp-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N LLZLRXBTOOFODM-QSFUFRPTSA-N 0.000 description 3
- CYHJCEKUMCNDFG-LAEOZQHASA-N Ile-Gln-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)NCC(=O)O)N CYHJCEKUMCNDFG-LAEOZQHASA-N 0.000 description 3
- WUKLZPHVWAMZQV-UKJIMTQDSA-N Ile-Glu-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N WUKLZPHVWAMZQV-UKJIMTQDSA-N 0.000 description 3
- SLQVFYWBGNNOTK-BYULHYEWSA-N Ile-Gly-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N SLQVFYWBGNNOTK-BYULHYEWSA-N 0.000 description 3
- XHBYEMIUENPZLY-GMOBBJLQSA-N Ile-Pro-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O XHBYEMIUENPZLY-GMOBBJLQSA-N 0.000 description 3
- KXUKTDGKLAOCQK-LSJOCFKGSA-N Ile-Val-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O KXUKTDGKLAOCQK-LSJOCFKGSA-N 0.000 description 3
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 3
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 3
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 3
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 3
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 3
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 3
- JLWZLIQRYCTYBD-IHRRRGAJSA-N Leu-Lys-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JLWZLIQRYCTYBD-IHRRRGAJSA-N 0.000 description 3
- NJMXCOOEFLMZSR-AVGNSLFASA-N Leu-Met-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O NJMXCOOEFLMZSR-AVGNSLFASA-N 0.000 description 3
- QMKFDEUJGYNFMC-AVGNSLFASA-N Leu-Pro-Arg Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QMKFDEUJGYNFMC-AVGNSLFASA-N 0.000 description 3
- PWPBLZXWFXJFHE-RHYQMDGZSA-N Leu-Pro-Thr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O PWPBLZXWFXJFHE-RHYQMDGZSA-N 0.000 description 3
- VDIARPPNADFEAV-WEDXCCLWSA-N Leu-Thr-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O VDIARPPNADFEAV-WEDXCCLWSA-N 0.000 description 3
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 3
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 3
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 3
- SJNZALDHDUYDBU-IHRRRGAJSA-N Lys-Arg-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(O)=O SJNZALDHDUYDBU-IHRRRGAJSA-N 0.000 description 3
- WGLAORUKDGRINI-WDCWCFNPSA-N Lys-Glu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGLAORUKDGRINI-WDCWCFNPSA-N 0.000 description 3
- DAOSYIZXRCOKII-SRVKXCTJSA-N Lys-His-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(O)=O DAOSYIZXRCOKII-SRVKXCTJSA-N 0.000 description 3
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 3
- TWPCWKVOZDUYAA-KKUMJFAQSA-N Lys-Phe-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O TWPCWKVOZDUYAA-KKUMJFAQSA-N 0.000 description 3
- LNMKRJJLEFASGA-BZSNNMDCSA-N Lys-Phe-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LNMKRJJLEFASGA-BZSNNMDCSA-N 0.000 description 3
- LKDXINHHSWFFJC-SRVKXCTJSA-N Lys-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N LKDXINHHSWFFJC-SRVKXCTJSA-N 0.000 description 3
- RNAGAJXCSPDPRK-KKUMJFAQSA-N Met-Glu-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 RNAGAJXCSPDPRK-KKUMJFAQSA-N 0.000 description 3
- BQHLZUMZOXUWNU-DCAQKATOSA-N Met-Pro-Glu Chemical compound CSCC[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N BQHLZUMZOXUWNU-DCAQKATOSA-N 0.000 description 3
- LUYURUYVNYGKGM-RCWTZXSCSA-N Met-Pro-Thr Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUYURUYVNYGKGM-RCWTZXSCSA-N 0.000 description 3
- CIDICGYKRUTYLE-FXQIFTODSA-N Met-Ser-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O CIDICGYKRUTYLE-FXQIFTODSA-N 0.000 description 3
- LBSWWNKMVPAXOI-GUBZILKMSA-N Met-Val-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O LBSWWNKMVPAXOI-GUBZILKMSA-N 0.000 description 3
- 108010079364 N-glycylalanine Proteins 0.000 description 3
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- 235000016496 Panda oleosa Nutrition 0.000 description 3
- 240000000220 Panda oleosa Species 0.000 description 3
- WMGVYPPIMZPWPN-SRVKXCTJSA-N Phe-Asp-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N WMGVYPPIMZPWPN-SRVKXCTJSA-N 0.000 description 3
- JSGWNFKWZNPDAV-YDHLFZDLSA-N Phe-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 JSGWNFKWZNPDAV-YDHLFZDLSA-N 0.000 description 3
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 3
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 3
- FUVBEZJCRMHWEM-FXQIFTODSA-N Pro-Asn-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FUVBEZJCRMHWEM-FXQIFTODSA-N 0.000 description 3
- XUSDDSLCRPUKLP-QXEWZRGKSA-N Pro-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 XUSDDSLCRPUKLP-QXEWZRGKSA-N 0.000 description 3
- NXEYSLRNNPWCRN-SRVKXCTJSA-N Pro-Glu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXEYSLRNNPWCRN-SRVKXCTJSA-N 0.000 description 3
- XQSREVQDGCPFRJ-STQMWFEESA-N Pro-Gly-Phe Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XQSREVQDGCPFRJ-STQMWFEESA-N 0.000 description 3
- XYSXOCIWCPFOCG-IHRRRGAJSA-N Pro-Leu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XYSXOCIWCPFOCG-IHRRRGAJSA-N 0.000 description 3
- RFWXYTJSVDUBBZ-DCAQKATOSA-N Pro-Pro-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 RFWXYTJSVDUBBZ-DCAQKATOSA-N 0.000 description 3
- DGDCSVGVWWAJRS-AVGNSLFASA-N Pro-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 DGDCSVGVWWAJRS-AVGNSLFASA-N 0.000 description 3
- 108010003201 RGH 0205 Proteins 0.000 description 3
- SRTCFKGBYBZRHA-ACZMJKKPSA-N Ser-Ala-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SRTCFKGBYBZRHA-ACZMJKKPSA-N 0.000 description 3
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 3
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 3
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 3
- DKKGAAJTDKHWOD-BIIVOSGPSA-N Ser-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)C(=O)O DKKGAAJTDKHWOD-BIIVOSGPSA-N 0.000 description 3
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 3
- GVMUJUPXFQFBBZ-GUBZILKMSA-N Ser-Lys-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GVMUJUPXFQFBBZ-GUBZILKMSA-N 0.000 description 3
- QUGRFWPMPVIAPW-IHRRRGAJSA-N Ser-Pro-Phe Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QUGRFWPMPVIAPW-IHRRRGAJSA-N 0.000 description 3
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 3
- UTSWGQNAQRIHAI-UNQGMJICSA-N Thr-Arg-Phe Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 UTSWGQNAQRIHAI-UNQGMJICSA-N 0.000 description 3
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 3
- WYLAVUAWOUVUCA-XVSYOHENSA-N Thr-Phe-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O WYLAVUAWOUVUCA-XVSYOHENSA-N 0.000 description 3
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 3
- VTMGKRABARCZAX-OSUNSFLBSA-N Thr-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O VTMGKRABARCZAX-OSUNSFLBSA-N 0.000 description 3
- QYDKSNXSBXZPFK-ZJDVBMNYSA-N Thr-Thr-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYDKSNXSBXZPFK-ZJDVBMNYSA-N 0.000 description 3
- HOJPPPKZWFRTHJ-PJODQICGSA-N Trp-Arg-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N HOJPPPKZWFRTHJ-PJODQICGSA-N 0.000 description 3
- HIZDHWHVOLUGOX-BPUTZDHNSA-N Trp-Ser-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O HIZDHWHVOLUGOX-BPUTZDHNSA-N 0.000 description 3
- LGEYOIQBBIPHQN-UWJYBYFXSA-N Tyr-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 LGEYOIQBBIPHQN-UWJYBYFXSA-N 0.000 description 3
- WVRUKYLYMFGKAN-IHRRRGAJSA-N Tyr-Glu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 WVRUKYLYMFGKAN-IHRRRGAJSA-N 0.000 description 3
- PSALWJCUIAQKFW-ACRUOGEOSA-N Tyr-Phe-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N PSALWJCUIAQKFW-ACRUOGEOSA-N 0.000 description 3
- RWOKVQUCENPXGE-IHRRRGAJSA-N Tyr-Ser-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RWOKVQUCENPXGE-IHRRRGAJSA-N 0.000 description 3
- XTAUQCGQFJQGEJ-NHCYSSNCSA-N Val-Gln-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XTAUQCGQFJQGEJ-NHCYSSNCSA-N 0.000 description 3
- PWCJARIQERIIGF-BZSNNMDCSA-N Val-Met-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N PWCJARIQERIIGF-BZSNNMDCSA-N 0.000 description 3
- WANVRBAZGSICCP-SRVKXCTJSA-N Val-Pro-Met Chemical compound CSCC[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C)C(O)=O WANVRBAZGSICCP-SRVKXCTJSA-N 0.000 description 3
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 3
- 108010047495 alanylglycine Proteins 0.000 description 3
- 108010070783 alanyltyrosine Proteins 0.000 description 3
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 3
- 108010059459 arginyl-threonyl-phenylalanine Proteins 0.000 description 3
- 108010062796 arginyllysine Proteins 0.000 description 3
- 108010047857 aspartylglycine Proteins 0.000 description 3
- 108010092854 aspartyllysine Proteins 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 230000000052 comparative effect Effects 0.000 description 3
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 3
- 108010087823 glycyltyrosine Proteins 0.000 description 3
- 239000007924 injection Substances 0.000 description 3
- 238000002347 injection Methods 0.000 description 3
- 108010053037 kyotorphin Proteins 0.000 description 3
- 108010034529 leucyl-lysine Proteins 0.000 description 3
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 3
- 108010017391 lysylvaline Proteins 0.000 description 3
- 238000001819 mass spectrum Methods 0.000 description 3
- 108010056582 methionylglutamic acid Proteins 0.000 description 3
- POULHZVOKOAJMA-UHFFFAOYSA-N methyl undecanoic acid Natural products CCCCCCCCCCCC(O)=O POULHZVOKOAJMA-UHFFFAOYSA-N 0.000 description 3
- 230000037361 pathway Effects 0.000 description 3
- 108010089198 phenylalanyl-prolyl-arginine Proteins 0.000 description 3
- 108010051242 phenylalanylserine Proteins 0.000 description 3
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 3
- 108010079317 prolyl-tyrosine Proteins 0.000 description 3
- 238000012163 sequencing technique Methods 0.000 description 3
- 108010051110 tyrosyl-lysine Proteins 0.000 description 3
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 2
- 102000002735 Acyl-CoA Dehydrogenase Human genes 0.000 description 2
- DKJPOZOEBONHFS-ZLUOBGJFSA-N Ala-Ala-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O DKJPOZOEBONHFS-ZLUOBGJFSA-N 0.000 description 2
- FJVAQLJNTSUQPY-CIUDSAMLSA-N Ala-Ala-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN FJVAQLJNTSUQPY-CIUDSAMLSA-N 0.000 description 2
- UGLPMYSCWHTZQU-AUTRQRHGSA-N Ala-Ala-Tyr Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 UGLPMYSCWHTZQU-AUTRQRHGSA-N 0.000 description 2
- LWUWMHIOBPTZBA-DCAQKATOSA-N Ala-Arg-Lys Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O LWUWMHIOBPTZBA-DCAQKATOSA-N 0.000 description 2
- ZIBWKCRKNFYTPT-ZKWXMUAHSA-N Ala-Asn-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZIBWKCRKNFYTPT-ZKWXMUAHSA-N 0.000 description 2
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 2
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 2
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 2
- IVKWMMGFLAMMKJ-XVYDVKMFSA-N Ala-His-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N IVKWMMGFLAMMKJ-XVYDVKMFSA-N 0.000 description 2
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 2
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 2
- RUXQNKVQSKOOBS-JURCDPSOSA-N Ala-Phe-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RUXQNKVQSKOOBS-JURCDPSOSA-N 0.000 description 2
- YCRAFFCYWOUEOF-DLOVCJGASA-N Ala-Phe-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 YCRAFFCYWOUEOF-DLOVCJGASA-N 0.000 description 2
- DCVYRWFAMZFSDA-ZLUOBGJFSA-N Ala-Ser-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DCVYRWFAMZFSDA-ZLUOBGJFSA-N 0.000 description 2
- RMAWDDRDTRSZIR-ZLUOBGJFSA-N Ala-Ser-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RMAWDDRDTRSZIR-ZLUOBGJFSA-N 0.000 description 2
- SYIFFFHSXBNPMC-UWJYBYFXSA-N Ala-Ser-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N SYIFFFHSXBNPMC-UWJYBYFXSA-N 0.000 description 2
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 2
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 2
- XAXMJQUMRJAFCH-CQDKDKBSSA-N Ala-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 XAXMJQUMRJAFCH-CQDKDKBSSA-N 0.000 description 2
- VYSRNGOMGHOJCK-GUBZILKMSA-N Arg-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N VYSRNGOMGHOJCK-GUBZILKMSA-N 0.000 description 2
- OTUQSEPIIVBYEM-IHRRRGAJSA-N Arg-Asn-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OTUQSEPIIVBYEM-IHRRRGAJSA-N 0.000 description 2
- PBSOQGZLPFVXPU-YUMQZZPRSA-N Arg-Glu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PBSOQGZLPFVXPU-YUMQZZPRSA-N 0.000 description 2
- NVCIXQYNWYTLDO-IHRRRGAJSA-N Arg-His-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N NVCIXQYNWYTLDO-IHRRRGAJSA-N 0.000 description 2
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 2
- YBZMTKUDWXZLIX-UWVGGRQHSA-N Arg-Leu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YBZMTKUDWXZLIX-UWVGGRQHSA-N 0.000 description 2
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 2
- OGSQONVYSTZIJB-WDSOQIARSA-N Arg-Leu-Trp Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCN=C(N)N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O OGSQONVYSTZIJB-WDSOQIARSA-N 0.000 description 2
- RIQBRKVTFBWEDY-RHYQMDGZSA-N Arg-Lys-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RIQBRKVTFBWEDY-RHYQMDGZSA-N 0.000 description 2
- GSUFZRURORXYTM-STQMWFEESA-N Arg-Phe-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 GSUFZRURORXYTM-STQMWFEESA-N 0.000 description 2
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 2
- PDQBXRSOSCTGKY-ACZMJKKPSA-N Asn-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PDQBXRSOSCTGKY-ACZMJKKPSA-N 0.000 description 2
- GNKVBRYFXYWXAB-WDSKDSINSA-N Asn-Glu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O GNKVBRYFXYWXAB-WDSKDSINSA-N 0.000 description 2
- NKLRWRRVYGQNIH-GHCJXIJMSA-N Asn-Ile-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O NKLRWRRVYGQNIH-GHCJXIJMSA-N 0.000 description 2
- GZXOUBTUAUAVHD-ACZMJKKPSA-N Asn-Ser-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GZXOUBTUAUAVHD-ACZMJKKPSA-N 0.000 description 2
- IPPFAOCLQSGHJV-WFBYXXMGSA-N Asn-Trp-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O IPPFAOCLQSGHJV-WFBYXXMGSA-N 0.000 description 2
- NJIKKGUVGUBICV-ZLUOBGJFSA-N Asp-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O NJIKKGUVGUBICV-ZLUOBGJFSA-N 0.000 description 2
- XDGBFDYXZCMYEX-NUMRIWBASA-N Asp-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N)O XDGBFDYXZCMYEX-NUMRIWBASA-N 0.000 description 2
- YDJVIBMKAMQPPP-LAEOZQHASA-N Asp-Glu-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O YDJVIBMKAMQPPP-LAEOZQHASA-N 0.000 description 2
- WSXDIZFNQYTUJB-SRVKXCTJSA-N Asp-His-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O WSXDIZFNQYTUJB-SRVKXCTJSA-N 0.000 description 2
- KQBVNNAPIURMPD-PEFMBERDSA-N Asp-Ile-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O KQBVNNAPIURMPD-PEFMBERDSA-N 0.000 description 2
- XMKXONRMGJXCJV-LAEOZQHASA-N Asp-Val-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XMKXONRMGJXCJV-LAEOZQHASA-N 0.000 description 2
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 2
- 101100480629 Bacillus subtilis (strain 168) tatAy gene Proteins 0.000 description 2
- SDXQKJAWASHMIZ-CIUDSAMLSA-N Cys-Glu-Met Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O SDXQKJAWASHMIZ-CIUDSAMLSA-N 0.000 description 2
- GUKYYUFHWYRMEU-WHFBIAKZSA-N Cys-Gly-Asp Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O GUKYYUFHWYRMEU-WHFBIAKZSA-N 0.000 description 2
- 101100022866 Escherichia coli (strain K12) menI gene Proteins 0.000 description 2
- JFSNBQJNDMXMQF-XHNCKOQMSA-N Gln-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O JFSNBQJNDMXMQF-XHNCKOQMSA-N 0.000 description 2
- AJDMYLOISOCHHC-YVNDNENWSA-N Gln-Gln-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AJDMYLOISOCHHC-YVNDNENWSA-N 0.000 description 2
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 2
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 2
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 2
- MFORDNZDKAVNSR-SRVKXCTJSA-N Gln-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O MFORDNZDKAVNSR-SRVKXCTJSA-N 0.000 description 2
- KUBFPYIMAGXGBT-ACZMJKKPSA-N Gln-Ser-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KUBFPYIMAGXGBT-ACZMJKKPSA-N 0.000 description 2
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 2
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 2
- FYBSCGZLICNOBA-XQXXSGGOSA-N Glu-Ala-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FYBSCGZLICNOBA-XQXXSGGOSA-N 0.000 description 2
- RSUVOPBMWMTVDI-XEGUGMAKSA-N Glu-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCC(O)=O)C)C(O)=O)=CNC2=C1 RSUVOPBMWMTVDI-XEGUGMAKSA-N 0.000 description 2
- NLKVNZUFDPWPNL-YUMQZZPRSA-N Glu-Arg-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O NLKVNZUFDPWPNL-YUMQZZPRSA-N 0.000 description 2
- AKJRHDMTEJXTPV-ACZMJKKPSA-N Glu-Asn-Ala Chemical compound C[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AKJRHDMTEJXTPV-ACZMJKKPSA-N 0.000 description 2
- CYHBMLHCQXXCCT-AVGNSLFASA-N Glu-Asp-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CYHBMLHCQXXCCT-AVGNSLFASA-N 0.000 description 2
- CLROYXHHUZELFX-FXQIFTODSA-N Glu-Gln-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CLROYXHHUZELFX-FXQIFTODSA-N 0.000 description 2
- PXHABOCPJVTGEK-BQBZGAKWSA-N Glu-Gln-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O PXHABOCPJVTGEK-BQBZGAKWSA-N 0.000 description 2
- HTTSBEBKVNEDFE-AUTRQRHGSA-N Glu-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N HTTSBEBKVNEDFE-AUTRQRHGSA-N 0.000 description 2
- CUXJIASLBRJOFV-LAEOZQHASA-N Glu-Gly-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUXJIASLBRJOFV-LAEOZQHASA-N 0.000 description 2
- HPJLZFTUUJKWAJ-JHEQGTHGSA-N Glu-Gly-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HPJLZFTUUJKWAJ-JHEQGTHGSA-N 0.000 description 2
- YDJOULGWHQRPEV-SRVKXCTJSA-N Glu-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N YDJOULGWHQRPEV-SRVKXCTJSA-N 0.000 description 2
- VGUYMZGLJUJRBV-YVNDNENWSA-N Glu-Ile-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O VGUYMZGLJUJRBV-YVNDNENWSA-N 0.000 description 2
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 2
- UJMNFCAHLYKWOZ-DCAQKATOSA-N Glu-Lys-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O UJMNFCAHLYKWOZ-DCAQKATOSA-N 0.000 description 2
- FGSGPLRPQCZBSQ-AVGNSLFASA-N Glu-Phe-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O FGSGPLRPQCZBSQ-AVGNSLFASA-N 0.000 description 2
- JDAYMLXPUJRSDJ-XIRDDKMYSA-N Glu-Trp-Arg Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 JDAYMLXPUJRSDJ-XIRDDKMYSA-N 0.000 description 2
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 2
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 2
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 2
- FKJQNJCQTKUBCD-XPUUQOCRSA-N Gly-Ala-His Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O FKJQNJCQTKUBCD-XPUUQOCRSA-N 0.000 description 2
- MHHUEAIBJZWDBH-YUMQZZPRSA-N Gly-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN MHHUEAIBJZWDBH-YUMQZZPRSA-N 0.000 description 2
- PMNHJLASAAWELO-FOHZUACHSA-N Gly-Asp-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PMNHJLASAAWELO-FOHZUACHSA-N 0.000 description 2
- YZACQYVWLCQWBT-BQBZGAKWSA-N Gly-Cys-Arg Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YZACQYVWLCQWBT-BQBZGAKWSA-N 0.000 description 2
- LHRXAHLCRMQBGJ-RYUDHWBXSA-N Gly-Glu-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)CN LHRXAHLCRMQBGJ-RYUDHWBXSA-N 0.000 description 2
- CUYLIWAAAYJKJH-RYUDHWBXSA-N Gly-Glu-Tyr Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CUYLIWAAAYJKJH-RYUDHWBXSA-N 0.000 description 2
- YFGONBOFGGWKKY-VHSXEESVSA-N Gly-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)CN)C(=O)O YFGONBOFGGWKKY-VHSXEESVSA-N 0.000 description 2
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 2
- VEPBEGNDJYANCF-QWRGUYRKSA-N Gly-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN VEPBEGNDJYANCF-QWRGUYRKSA-N 0.000 description 2
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 2
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 2
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 2
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 2
- GWCJMBNBFYBQCV-XPUUQOCRSA-N Gly-Val-Ala Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O GWCJMBNBFYBQCV-XPUUQOCRSA-N 0.000 description 2
- ZVXMEWXHFBYJPI-LSJOCFKGSA-N Gly-Val-Ile Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZVXMEWXHFBYJPI-LSJOCFKGSA-N 0.000 description 2
- DCRODRAURLJOFY-XPUUQOCRSA-N His-Ala-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)NCC(O)=O DCRODRAURLJOFY-XPUUQOCRSA-N 0.000 description 2
- SKOKHBGDXGTDDP-MELADBBJSA-N His-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N SKOKHBGDXGTDDP-MELADBBJSA-N 0.000 description 2
- BRQKGRLDDDQWQJ-MBLNEYKQSA-N His-Thr-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O BRQKGRLDDDQWQJ-MBLNEYKQSA-N 0.000 description 2
- MCGOGXFMKHPMSQ-AVGNSLFASA-N His-Val-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 MCGOGXFMKHPMSQ-AVGNSLFASA-N 0.000 description 2
- AXNGDPAKKCEKGY-QPHKQPEJSA-N Ile-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N AXNGDPAKKCEKGY-QPHKQPEJSA-N 0.000 description 2
- CAHCWMVNBZJVAW-NAKRPEOUSA-N Ile-Pro-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)O)N CAHCWMVNBZJVAW-NAKRPEOUSA-N 0.000 description 2
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 2
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 2
- 239000005639 Lauric acid Substances 0.000 description 2
- CZCSUZMIRKFFFA-CIUDSAMLSA-N Leu-Ala-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O CZCSUZMIRKFFFA-CIUDSAMLSA-N 0.000 description 2
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 2
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 2
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 2
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 2
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 2
- GLBNEGIOFRVRHO-JYJNAYRXSA-N Leu-Gln-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GLBNEGIOFRVRHO-JYJNAYRXSA-N 0.000 description 2
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 2
- HQUXQAMSWFIRET-AVGNSLFASA-N Leu-Glu-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HQUXQAMSWFIRET-AVGNSLFASA-N 0.000 description 2
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 2
- HGFGEMSVBMCFKK-MNXVOIDGSA-N Leu-Ile-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O HGFGEMSVBMCFKK-MNXVOIDGSA-N 0.000 description 2
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 2
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 2
- ZRHDPZAAWLXXIR-SRVKXCTJSA-N Leu-Lys-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O ZRHDPZAAWLXXIR-SRVKXCTJSA-N 0.000 description 2
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 2
- WFCKERTZVCQXKH-KBPBESRZSA-N Leu-Tyr-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O WFCKERTZVCQXKH-KBPBESRZSA-N 0.000 description 2
- RDFIVFHPOSOXMW-ACRUOGEOSA-N Leu-Tyr-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RDFIVFHPOSOXMW-ACRUOGEOSA-N 0.000 description 2
- DFXQCCBKGUNYGG-GUBZILKMSA-N Lys-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCCN DFXQCCBKGUNYGG-GUBZILKMSA-N 0.000 description 2
- DCRWPTBMWMGADO-AVGNSLFASA-N Lys-Glu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DCRWPTBMWMGADO-AVGNSLFASA-N 0.000 description 2
- DUTMKEAPLLUGNO-JYJNAYRXSA-N Lys-Glu-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DUTMKEAPLLUGNO-JYJNAYRXSA-N 0.000 description 2
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 2
- DTUZCYRNEJDKSR-NHCYSSNCSA-N Lys-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN DTUZCYRNEJDKSR-NHCYSSNCSA-N 0.000 description 2
- UQRZFMQQXXJTTF-AVGNSLFASA-N Lys-Lys-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O UQRZFMQQXXJTTF-AVGNSLFASA-N 0.000 description 2
- SPNKGZFASINBMR-IHRRRGAJSA-N Lys-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCCN)N SPNKGZFASINBMR-IHRRRGAJSA-N 0.000 description 2
- OZVXDDFYCQOPFD-XQQFMLRXSA-N Lys-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N OZVXDDFYCQOPFD-XQQFMLRXSA-N 0.000 description 2
- ULNXMMYXQKGNPG-LPEHRKFASA-N Met-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N ULNXMMYXQKGNPG-LPEHRKFASA-N 0.000 description 2
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 2
- CGUYGMFQZCYJSG-DCAQKATOSA-N Met-Lys-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O CGUYGMFQZCYJSG-DCAQKATOSA-N 0.000 description 2
- YLDSJJOGQNEQJK-AVGNSLFASA-N Met-Pro-Leu Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O YLDSJJOGQNEQJK-AVGNSLFASA-N 0.000 description 2
- RDLSEGZJMYGFNS-FXQIFTODSA-N Met-Ser-Asp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RDLSEGZJMYGFNS-FXQIFTODSA-N 0.000 description 2
- CQRGINSEMFBACV-WPRPVWTQSA-N Met-Val-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O CQRGINSEMFBACV-WPRPVWTQSA-N 0.000 description 2
- 101100390398 Mus musculus Ptk2 gene Proteins 0.000 description 2
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 2
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 2
- 108010065395 Neuropep-1 Proteins 0.000 description 2
- MECSIDWUTYRHRJ-KKUMJFAQSA-N Phe-Asn-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O MECSIDWUTYRHRJ-KKUMJFAQSA-N 0.000 description 2
- FIRWJEJVFFGXSH-RYUDHWBXSA-N Phe-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 FIRWJEJVFFGXSH-RYUDHWBXSA-N 0.000 description 2
- MMYUOSCXBJFUNV-QWRGUYRKSA-N Phe-Gly-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N MMYUOSCXBJFUNV-QWRGUYRKSA-N 0.000 description 2
- VZFPYFRVHMSSNA-JURCDPSOSA-N Phe-Ile-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=CC=C1 VZFPYFRVHMSSNA-JURCDPSOSA-N 0.000 description 2
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 2
- MMPBPRXOFJNCCN-ZEWNOJEFSA-N Phe-Tyr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MMPBPRXOFJNCCN-ZEWNOJEFSA-N 0.000 description 2
- KUSYCSMTTHSZOA-DZKIICNBSA-N Phe-Val-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N KUSYCSMTTHSZOA-DZKIICNBSA-N 0.000 description 2
- OYEUSRAZOGIDBY-JYJNAYRXSA-N Pro-Arg-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OYEUSRAZOGIDBY-JYJNAYRXSA-N 0.000 description 2
- CJZTUKSFZUSNCC-FXQIFTODSA-N Pro-Asp-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 CJZTUKSFZUSNCC-FXQIFTODSA-N 0.000 description 2
- DIFXZGPHVCIVSQ-CIUDSAMLSA-N Pro-Gln-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DIFXZGPHVCIVSQ-CIUDSAMLSA-N 0.000 description 2
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 2
- BAKAHWWRCCUDAF-IHRRRGAJSA-N Pro-His-Lys Chemical compound C([C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@H]1NCCC1)C1=CN=CN1 BAKAHWWRCCUDAF-IHRRRGAJSA-N 0.000 description 2
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 2
- XQPHBAKJJJZOBX-SRVKXCTJSA-N Pro-Lys-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O XQPHBAKJJJZOBX-SRVKXCTJSA-N 0.000 description 2
- LGMBKOAPPTYKLC-JYJNAYRXSA-N Pro-Phe-Arg Chemical compound C([C@@H](C(=O)N[C@@H](CCCNC(=N)N)C(O)=O)NC(=O)[C@H]1NCCC1)C1=CC=CC=C1 LGMBKOAPPTYKLC-JYJNAYRXSA-N 0.000 description 2
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 2
- COAHUSQNSVFYBW-FXQIFTODSA-N Ser-Asn-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O COAHUSQNSVFYBW-FXQIFTODSA-N 0.000 description 2
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 2
- CNIIKZQXBBQHCX-FXQIFTODSA-N Ser-Asp-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O CNIIKZQXBBQHCX-FXQIFTODSA-N 0.000 description 2
- BNFVPSRLHHPQKS-WHFBIAKZSA-N Ser-Asp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O BNFVPSRLHHPQKS-WHFBIAKZSA-N 0.000 description 2
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 2
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 2
- RQXDSYQXBCRXBT-GUBZILKMSA-N Ser-Met-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RQXDSYQXBCRXBT-GUBZILKMSA-N 0.000 description 2
- QPPYAWVLAVXISR-DCAQKATOSA-N Ser-Pro-His Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O QPPYAWVLAVXISR-DCAQKATOSA-N 0.000 description 2
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 2
- PQEQXWRVHQAAKS-SRVKXCTJSA-N Ser-Tyr-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=C(O)C=C1 PQEQXWRVHQAAKS-SRVKXCTJSA-N 0.000 description 2
- RKDFEMGVMMYYNG-WDCWCFNPSA-N Thr-Gln-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O RKDFEMGVMMYYNG-WDCWCFNPSA-N 0.000 description 2
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 2
- KAJRRNHOVMZYBL-IRIUXVKKSA-N Thr-Tyr-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAJRRNHOVMZYBL-IRIUXVKKSA-N 0.000 description 2
- REJRKTOJTCPDPO-IRIUXVKKSA-N Thr-Tyr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O REJRKTOJTCPDPO-IRIUXVKKSA-N 0.000 description 2
- KVEWWQRTAVMOFT-KJEVXHAQSA-N Thr-Tyr-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O KVEWWQRTAVMOFT-KJEVXHAQSA-N 0.000 description 2
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 2
- RNDWCRUOGGQDKN-UBHSHLNASA-N Trp-Ser-Asp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RNDWCRUOGGQDKN-UBHSHLNASA-N 0.000 description 2
- IELISNUVHBKYBX-XDTLVQLUSA-N Tyr-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 IELISNUVHBKYBX-XDTLVQLUSA-N 0.000 description 2
- ZWZOCUWOXSDYFZ-CQDKDKBSSA-N Tyr-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 ZWZOCUWOXSDYFZ-CQDKDKBSSA-N 0.000 description 2
- WZQZUVWEPMGIMM-JYJNAYRXSA-N Tyr-Gln-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O WZQZUVWEPMGIMM-JYJNAYRXSA-N 0.000 description 2
- CDBXVDXSLPLFMD-BPNCWPANSA-N Tyr-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDBXVDXSLPLFMD-BPNCWPANSA-N 0.000 description 2
- QPOUERMDWKKZEG-HJPIBITLSA-N Tyr-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 QPOUERMDWKKZEG-HJPIBITLSA-N 0.000 description 2
- TYFLVOUZHQUBGM-IHRRRGAJSA-N Tyr-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TYFLVOUZHQUBGM-IHRRRGAJSA-N 0.000 description 2
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 2
- UDLYXGYWTVOIKU-QXEWZRGKSA-N Val-Asn-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UDLYXGYWTVOIKU-QXEWZRGKSA-N 0.000 description 2
- VLOYGOZDPGYWFO-LAEOZQHASA-N Val-Asp-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VLOYGOZDPGYWFO-LAEOZQHASA-N 0.000 description 2
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 2
- XKVXSCHXGJOQND-ZOBUZTSGSA-N Val-Asp-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N XKVXSCHXGJOQND-ZOBUZTSGSA-N 0.000 description 2
- DLYOEFGPYTZVSP-AEJSXWLSSA-N Val-Cys-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N DLYOEFGPYTZVSP-AEJSXWLSSA-N 0.000 description 2
- CVIXTAITYJQMPE-LAEOZQHASA-N Val-Glu-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CVIXTAITYJQMPE-LAEOZQHASA-N 0.000 description 2
- SDSCOOZQQGUQFC-GVXVVHGQSA-N Val-His-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N SDSCOOZQQGUQFC-GVXVVHGQSA-N 0.000 description 2
- DAVNYIUELQBTAP-XUXIUFHCSA-N Val-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N DAVNYIUELQBTAP-XUXIUFHCSA-N 0.000 description 2
- LGXUZJIQCGXKGZ-QXEWZRGKSA-N Val-Pro-Asn Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)N)C(=O)O)N LGXUZJIQCGXKGZ-QXEWZRGKSA-N 0.000 description 2
- VIKZGAUAKQZDOF-NRPADANISA-N Val-Ser-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O VIKZGAUAKQZDOF-NRPADANISA-N 0.000 description 2
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 2
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 2
- CEKSLIVSNNGOKH-KZVJFYERSA-N Val-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](C(C)C)N)O CEKSLIVSNNGOKH-KZVJFYERSA-N 0.000 description 2
- MNSSBIHFEUUXNW-RCWTZXSCSA-N Val-Thr-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N MNSSBIHFEUUXNW-RCWTZXSCSA-N 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 2
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 2
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 2
- 108010027371 asparaginyl-leucyl-prolyl-arginine Proteins 0.000 description 2
- 230000003197 catalytic effect Effects 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 108010016616 cysteinylglycine Proteins 0.000 description 2
- 239000012154 double-distilled water Substances 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 2
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 2
- 108010015792 glycyllysine Proteins 0.000 description 2
- 108010037850 glycylvaline Proteins 0.000 description 2
- 108010025306 histidylleucine Proteins 0.000 description 2
- 108010092114 histidylphenylalanine Proteins 0.000 description 2
- 108010027338 isoleucylcysteine Proteins 0.000 description 2
- 108010003700 lysyl aspartic acid Proteins 0.000 description 2
- 108010009298 lysylglutamic acid Proteins 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 108010034507 methionyltryptophan Proteins 0.000 description 2
- VLKZOEOYAKHREP-UHFFFAOYSA-N n-Hexane Chemical compound CCCCCC VLKZOEOYAKHREP-UHFFFAOYSA-N 0.000 description 2
- 239000008188 pellet Substances 0.000 description 2
- 239000002504 physiological saline solution Substances 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 2
- 108010077112 prolyl-proline Proteins 0.000 description 2
- 229940109850 royal jelly Drugs 0.000 description 2
- 108010048818 seryl-histidine Proteins 0.000 description 2
- 108010071207 serylmethionine Proteins 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- 108700004896 tripeptide FEG Proteins 0.000 description 2
- 108010035534 tyrosyl-leucyl-alanine Proteins 0.000 description 2
- 108010003137 tyrosyltyrosine Proteins 0.000 description 2
- 108010073969 valyllysine Proteins 0.000 description 2
- QHBZHVUGQROELI-SOFGYWHQSA-N (E)-10-hydroxydec-2-enoic acid Chemical compound OCCCCCCC\C=C\C(O)=O QHBZHVUGQROELI-SOFGYWHQSA-N 0.000 description 1
- WOJJIRYPFAZEPF-YFKPBYRVSA-N 2-[[(2s)-2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]propanoyl]amino]acetate Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)CNC(=O)CN WOJJIRYPFAZEPF-YFKPBYRVSA-N 0.000 description 1
- 102000052553 3-Hydroxyacyl CoA Dehydrogenase Human genes 0.000 description 1
- YLTKNGYYPIWKHZ-ACZMJKKPSA-N Ala-Ala-Glu Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O YLTKNGYYPIWKHZ-ACZMJKKPSA-N 0.000 description 1
- WYPUMLRSQMKIJU-BPNCWPANSA-N Ala-Arg-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WYPUMLRSQMKIJU-BPNCWPANSA-N 0.000 description 1
- PJNSIUPOXFBHDM-GUBZILKMSA-N Ala-Arg-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O PJNSIUPOXFBHDM-GUBZILKMSA-N 0.000 description 1
- MCKSLROAGSDNFC-ACZMJKKPSA-N Ala-Asp-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MCKSLROAGSDNFC-ACZMJKKPSA-N 0.000 description 1
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 1
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 1
- DAEFQZCYZKRTLR-ZLUOBGJFSA-N Ala-Cys-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O DAEFQZCYZKRTLR-ZLUOBGJFSA-N 0.000 description 1
- IFTVANMRTIHKML-WDSKDSINSA-N Ala-Gln-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O IFTVANMRTIHKML-WDSKDSINSA-N 0.000 description 1
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 1
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 1
- PAIHPOGPJVUFJY-WDSKDSINSA-N Ala-Glu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PAIHPOGPJVUFJY-WDSKDSINSA-N 0.000 description 1
- GGNHBHYDMUDXQB-KBIXCLLPSA-N Ala-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)N GGNHBHYDMUDXQB-KBIXCLLPSA-N 0.000 description 1
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 1
- BTBUEVAGZCKULD-XPUUQOCRSA-N Ala-Gly-His Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CN=CN1 BTBUEVAGZCKULD-XPUUQOCRSA-N 0.000 description 1
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 1
- DVJSJDDYCYSMFR-ZKWXMUAHSA-N Ala-Ile-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O DVJSJDDYCYSMFR-ZKWXMUAHSA-N 0.000 description 1
- TZDNWXDLYFIFPT-BJDJZHNGSA-N Ala-Ile-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O TZDNWXDLYFIFPT-BJDJZHNGSA-N 0.000 description 1
- YHKANGMVQWRMAP-DCAQKATOSA-N Ala-Leu-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YHKANGMVQWRMAP-DCAQKATOSA-N 0.000 description 1
- WUHJHHGYVVJMQE-BJDJZHNGSA-N Ala-Leu-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WUHJHHGYVVJMQE-BJDJZHNGSA-N 0.000 description 1
- CHFFHQUVXHEGBY-GARJFASQSA-N Ala-Lys-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N CHFFHQUVXHEGBY-GARJFASQSA-N 0.000 description 1
- XRUJOVRWNMBAAA-NHCYSSNCSA-N Ala-Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 XRUJOVRWNMBAAA-NHCYSSNCSA-N 0.000 description 1
- DHBKYZYFEXXUAK-ONGXEEELSA-N Ala-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 DHBKYZYFEXXUAK-ONGXEEELSA-N 0.000 description 1
- RNHKOQHGYMTHFR-UBHSHLNASA-N Ala-Phe-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 RNHKOQHGYMTHFR-UBHSHLNASA-N 0.000 description 1
- CYBJZLQSUJEMAS-LFSVMHDDSA-N Ala-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C)N)O CYBJZLQSUJEMAS-LFSVMHDDSA-N 0.000 description 1
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 1
- GMGWOTQMUKYZIE-UBHSHLNASA-N Ala-Pro-Phe Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 GMGWOTQMUKYZIE-UBHSHLNASA-N 0.000 description 1
- XKXAZPSREVUCRT-BPNCWPANSA-N Ala-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=C(O)C=C1 XKXAZPSREVUCRT-BPNCWPANSA-N 0.000 description 1
- BVLPIIBTWIYOML-ZKWXMUAHSA-N Ala-Val-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BVLPIIBTWIYOML-ZKWXMUAHSA-N 0.000 description 1
- CLOMBHBBUKAUBP-LSJOCFKGSA-N Ala-Val-His Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N CLOMBHBBUKAUBP-LSJOCFKGSA-N 0.000 description 1
- RYRQZJVFDVWURI-SRVKXCTJSA-N Arg-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N RYRQZJVFDVWURI-SRVKXCTJSA-N 0.000 description 1
- HPKSHFSEXICTLI-CIUDSAMLSA-N Arg-Glu-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HPKSHFSEXICTLI-CIUDSAMLSA-N 0.000 description 1
- MZRBYBIQTIKERR-GUBZILKMSA-N Arg-Glu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MZRBYBIQTIKERR-GUBZILKMSA-N 0.000 description 1
- OGUPCHKBOKJFMA-SRVKXCTJSA-N Arg-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N OGUPCHKBOKJFMA-SRVKXCTJSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- YQGZIRIYGHNSQO-ZPFDUUQYSA-N Arg-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N YQGZIRIYGHNSQO-ZPFDUUQYSA-N 0.000 description 1
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 1
- KXOPYFNQLVUOAQ-FXQIFTODSA-N Arg-Ser-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KXOPYFNQLVUOAQ-FXQIFTODSA-N 0.000 description 1
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 1
- ICRHGPYYXMWHIE-LPEHRKFASA-N Arg-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ICRHGPYYXMWHIE-LPEHRKFASA-N 0.000 description 1
- OQPAZKMGCWPERI-GUBZILKMSA-N Arg-Ser-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OQPAZKMGCWPERI-GUBZILKMSA-N 0.000 description 1
- ASQKVGRCKOFKIU-KZVJFYERSA-N Arg-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ASQKVGRCKOFKIU-KZVJFYERSA-N 0.000 description 1
- DRDWXKWUSIKKOB-PJODQICGSA-N Arg-Trp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O DRDWXKWUSIKKOB-PJODQICGSA-N 0.000 description 1
- QEYJFBMTSMLPKZ-ZKWXMUAHSA-N Asn-Ala-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O QEYJFBMTSMLPKZ-ZKWXMUAHSA-N 0.000 description 1
- NNMUHYLAYUSTTN-FXQIFTODSA-N Asn-Gln-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O NNMUHYLAYUSTTN-FXQIFTODSA-N 0.000 description 1
- MSBDSTRUMZFSEU-PEFMBERDSA-N Asn-Glu-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MSBDSTRUMZFSEU-PEFMBERDSA-N 0.000 description 1
- JREOBWLIZLXRIS-GUBZILKMSA-N Asn-Glu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JREOBWLIZLXRIS-GUBZILKMSA-N 0.000 description 1
- DDPXDCKYWDGZAL-BQBZGAKWSA-N Asn-Gly-Arg Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N DDPXDCKYWDGZAL-BQBZGAKWSA-N 0.000 description 1
- IKLAUGBIDCDFOY-SRVKXCTJSA-N Asn-His-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O IKLAUGBIDCDFOY-SRVKXCTJSA-N 0.000 description 1
- SPCONPVIDFMDJI-QSFUFRPTSA-N Asn-Ile-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O SPCONPVIDFMDJI-QSFUFRPTSA-N 0.000 description 1
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 1
- UBGGJTMETLEXJD-DCAQKATOSA-N Asn-Leu-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O UBGGJTMETLEXJD-DCAQKATOSA-N 0.000 description 1
- HMUKKNAMNSXDBB-CIUDSAMLSA-N Asn-Met-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O HMUKKNAMNSXDBB-CIUDSAMLSA-N 0.000 description 1
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 1
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 1
- MJIJBEYEHBKTIM-BYULHYEWSA-N Asn-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MJIJBEYEHBKTIM-BYULHYEWSA-N 0.000 description 1
- KRXIWXCXOARFNT-ZLUOBGJFSA-N Asp-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O KRXIWXCXOARFNT-ZLUOBGJFSA-N 0.000 description 1
- SLHOOKXYTYAJGQ-XVYDVKMFSA-N Asp-Ala-His Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 SLHOOKXYTYAJGQ-XVYDVKMFSA-N 0.000 description 1
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 1
- PSLSTUMPZILTAH-BYULHYEWSA-N Asp-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O PSLSTUMPZILTAH-BYULHYEWSA-N 0.000 description 1
- NHSDEZURHWEZPN-SXTJYALSSA-N Asp-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CC(=O)O)N NHSDEZURHWEZPN-SXTJYALSSA-N 0.000 description 1
- PYXXJFRXIYAESU-PCBIJLKTSA-N Asp-Ile-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PYXXJFRXIYAESU-PCBIJLKTSA-N 0.000 description 1
- UMHUHHJMEXNSIV-CIUDSAMLSA-N Asp-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UMHUHHJMEXNSIV-CIUDSAMLSA-N 0.000 description 1
- MYOHQBFRJQFIDZ-KKUMJFAQSA-N Asp-Leu-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYOHQBFRJQFIDZ-KKUMJFAQSA-N 0.000 description 1
- HJCGDIGVVWETRO-ZPFDUUQYSA-N Asp-Lys-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC(O)=O)C(O)=O HJCGDIGVVWETRO-ZPFDUUQYSA-N 0.000 description 1
- SARSTIZOZFBDOM-FXQIFTODSA-N Asp-Met-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O SARSTIZOZFBDOM-FXQIFTODSA-N 0.000 description 1
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 1
- QSFHZPQUAAQHAQ-CIUDSAMLSA-N Asp-Ser-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O QSFHZPQUAAQHAQ-CIUDSAMLSA-N 0.000 description 1
- JJQGZGOEDSSHTE-FOHZUACHSA-N Asp-Thr-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JJQGZGOEDSSHTE-FOHZUACHSA-N 0.000 description 1
- GXHDGYOXPNQCKM-XVSYOHENSA-N Asp-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O GXHDGYOXPNQCKM-XVSYOHENSA-N 0.000 description 1
- PDIYGFYAMZZFCW-JIOCBJNQSA-N Asp-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N)O PDIYGFYAMZZFCW-JIOCBJNQSA-N 0.000 description 1
- XWKBWZXGNXTDKY-ZKWXMUAHSA-N Asp-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O XWKBWZXGNXTDKY-ZKWXMUAHSA-N 0.000 description 1
- KJJASVYBTKRYSN-FXQIFTODSA-N Cys-Pro-Asp Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CS)N)C(=O)N[C@@H](CC(=O)O)C(=O)O KJJASVYBTKRYSN-FXQIFTODSA-N 0.000 description 1
- JLZCAZJGWNRXCI-XKBZYTNZSA-N Cys-Thr-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O JLZCAZJGWNRXCI-XKBZYTNZSA-N 0.000 description 1
- 108010023922 Enoyl-CoA hydratase Proteins 0.000 description 1
- 102000011426 Enoyl-CoA hydratase Human genes 0.000 description 1
- 241001198387 Escherichia coli BL21(DE3) Species 0.000 description 1
- XEYMBRRKIFYQMF-GUBZILKMSA-N Gln-Asp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XEYMBRRKIFYQMF-GUBZILKMSA-N 0.000 description 1
- ICDIMQAMJGDHSE-GUBZILKMSA-N Gln-His-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O ICDIMQAMJGDHSE-GUBZILKMSA-N 0.000 description 1
- GIVHPCWYVWUUSG-HVTMNAMFSA-N Gln-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N GIVHPCWYVWUUSG-HVTMNAMFSA-N 0.000 description 1
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 1
- ZZLDMBMFKZFQMU-NRPADANISA-N Gln-Val-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O ZZLDMBMFKZFQMU-NRPADANISA-N 0.000 description 1
- OGMQXTXGLDNBSS-FXQIFTODSA-N Glu-Ala-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O OGMQXTXGLDNBSS-FXQIFTODSA-N 0.000 description 1
- SRZLHYPAOXBBSB-HJGDQZAQSA-N Glu-Arg-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SRZLHYPAOXBBSB-HJGDQZAQSA-N 0.000 description 1
- SYDJILXOZNEEDK-XIRDDKMYSA-N Glu-Arg-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SYDJILXOZNEEDK-XIRDDKMYSA-N 0.000 description 1
- RDPOETHPAQEGDP-ACZMJKKPSA-N Glu-Asp-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RDPOETHPAQEGDP-ACZMJKKPSA-N 0.000 description 1
- NTBDVNJIWCKURJ-ACZMJKKPSA-N Glu-Asp-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NTBDVNJIWCKURJ-ACZMJKKPSA-N 0.000 description 1
- OXEMJGCAJFFREE-FXQIFTODSA-N Glu-Gln-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O OXEMJGCAJFFREE-FXQIFTODSA-N 0.000 description 1
- QJCKNLPMTPXXEM-AUTRQRHGSA-N Glu-Glu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O QJCKNLPMTPXXEM-AUTRQRHGSA-N 0.000 description 1
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 1
- WTMZXOPHTIVFCP-QEWYBTABSA-N Glu-Ile-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 WTMZXOPHTIVFCP-QEWYBTABSA-N 0.000 description 1
- NWOUBJNMZDDGDT-AVGNSLFASA-N Glu-Leu-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NWOUBJNMZDDGDT-AVGNSLFASA-N 0.000 description 1
- UGSVSNXPJJDJKL-SDDRHHMPSA-N Glu-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N UGSVSNXPJJDJKL-SDDRHHMPSA-N 0.000 description 1
- GMVCSRBOSIUTFC-FXQIFTODSA-N Glu-Ser-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMVCSRBOSIUTFC-FXQIFTODSA-N 0.000 description 1
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 1
- HQTDNEZTGZUWSY-XVKPBYJWSA-N Glu-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)NCC(O)=O HQTDNEZTGZUWSY-XVKPBYJWSA-N 0.000 description 1
- GZUKEVBTYNNUQF-WDSKDSINSA-N Gly-Ala-Gln Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GZUKEVBTYNNUQF-WDSKDSINSA-N 0.000 description 1
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 1
- UPOJUWHGMDJUQZ-IUCAKERBSA-N Gly-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UPOJUWHGMDJUQZ-IUCAKERBSA-N 0.000 description 1
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 1
- NZAFOTBEULLEQB-WDSKDSINSA-N Gly-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN NZAFOTBEULLEQB-WDSKDSINSA-N 0.000 description 1
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 1
- KTSZUNRRYXPZTK-BQBZGAKWSA-N Gly-Gln-Glu Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KTSZUNRRYXPZTK-BQBZGAKWSA-N 0.000 description 1
- HFXJIZNEXNIZIJ-BQBZGAKWSA-N Gly-Glu-Gln Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFXJIZNEXNIZIJ-BQBZGAKWSA-N 0.000 description 1
- ZQIMMEYPEXIYBB-IUCAKERBSA-N Gly-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN ZQIMMEYPEXIYBB-IUCAKERBSA-N 0.000 description 1
- HQRHFUYMGCHHJS-LURJTMIESA-N Gly-Gly-Arg Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N HQRHFUYMGCHHJS-LURJTMIESA-N 0.000 description 1
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 1
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 1
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 1
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 1
- YABRDIBSPZONIY-BQBZGAKWSA-N Gly-Ser-Met Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O YABRDIBSPZONIY-BQBZGAKWSA-N 0.000 description 1
- RIYIFUFFFBIOEU-KBPBESRZSA-N Gly-Tyr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 RIYIFUFFFBIOEU-KBPBESRZSA-N 0.000 description 1
- DUAWRXXTOQOECJ-JSGCOSHPSA-N Gly-Tyr-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O DUAWRXXTOQOECJ-JSGCOSHPSA-N 0.000 description 1
- FNXSYBOHALPRHV-ONGXEEELSA-N Gly-Val-Lys Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN FNXSYBOHALPRHV-ONGXEEELSA-N 0.000 description 1
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 1
- DZMVESFTHXSSPZ-XVYDVKMFSA-N His-Ala-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DZMVESFTHXSSPZ-XVYDVKMFSA-N 0.000 description 1
- SOFSRBYHDINIRG-QTKMDUPCSA-N His-Arg-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CN=CN1)N)O SOFSRBYHDINIRG-QTKMDUPCSA-N 0.000 description 1
- NELVFWFDOKRTOR-SDDRHHMPSA-N His-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O NELVFWFDOKRTOR-SDDRHHMPSA-N 0.000 description 1
- IIVZNQCUUMBBKF-GVXVVHGQSA-N His-Gln-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CN=CN1 IIVZNQCUUMBBKF-GVXVVHGQSA-N 0.000 description 1
- AKEDPWJFQULLPE-IUCAKERBSA-N His-Glu-Gly Chemical compound N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O AKEDPWJFQULLPE-IUCAKERBSA-N 0.000 description 1
- VJJSDSNFXCWCEJ-DJFWLOJKSA-N His-Ile-Asn Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O VJJSDSNFXCWCEJ-DJFWLOJKSA-N 0.000 description 1
- VFBZWZXKCVBTJR-SRVKXCTJSA-N His-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N VFBZWZXKCVBTJR-SRVKXCTJSA-N 0.000 description 1
- DQZCEKQPSOBNMJ-NKIYYHGXSA-N His-Thr-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DQZCEKQPSOBNMJ-NKIYYHGXSA-N 0.000 description 1
- VSZALHITQINTGC-GHCJXIJMSA-N Ile-Ala-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(=O)O)C(=O)O)N VSZALHITQINTGC-GHCJXIJMSA-N 0.000 description 1
- YKRYHWJRQUSTKG-KBIXCLLPSA-N Ile-Ala-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKRYHWJRQUSTKG-KBIXCLLPSA-N 0.000 description 1
- IDAHFEPYTJJZFD-PEFMBERDSA-N Ile-Asp-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N IDAHFEPYTJJZFD-PEFMBERDSA-N 0.000 description 1
- PDTMWFVVNZYWTR-NHCYSSNCSA-N Ile-Gly-Lys Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](CCCCN)C(O)=O PDTMWFVVNZYWTR-NHCYSSNCSA-N 0.000 description 1
- PMMMQRVUMVURGJ-XUXIUFHCSA-N Ile-Leu-Pro Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O PMMMQRVUMVURGJ-XUXIUFHCSA-N 0.000 description 1
- RCMNUBZKIIJCOI-ZPFDUUQYSA-N Ile-Met-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RCMNUBZKIIJCOI-ZPFDUUQYSA-N 0.000 description 1
- XQLGNKLSPYCRMZ-HJWJTTGWSA-N Ile-Phe-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(=O)O)N XQLGNKLSPYCRMZ-HJWJTTGWSA-N 0.000 description 1
- PBWMCUAFLPMYPF-ZQINRCPSSA-N Ile-Trp-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PBWMCUAFLPMYPF-ZQINRCPSSA-N 0.000 description 1
- AUIYHFRUOOKTGX-UKJIMTQDSA-N Ile-Val-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N AUIYHFRUOOKTGX-UKJIMTQDSA-N 0.000 description 1
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 1
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 1
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 1
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 1
- MJOZZTKJZQFKDK-GUBZILKMSA-N Leu-Ala-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(N)=O MJOZZTKJZQFKDK-GUBZILKMSA-N 0.000 description 1
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 1
- UCOCBWDBHCUPQP-DCAQKATOSA-N Leu-Arg-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O UCOCBWDBHCUPQP-DCAQKATOSA-N 0.000 description 1
- DLFAACQHIRSQGG-CIUDSAMLSA-N Leu-Asp-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O DLFAACQHIRSQGG-CIUDSAMLSA-N 0.000 description 1
- ULXYQAJWJGLCNR-YUMQZZPRSA-N Leu-Asp-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O ULXYQAJWJGLCNR-YUMQZZPRSA-N 0.000 description 1
- XVSJMWYYLHPDKY-DCAQKATOSA-N Leu-Asp-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O XVSJMWYYLHPDKY-DCAQKATOSA-N 0.000 description 1
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 1
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 1
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 1
- CFZZDVMBRYFFNU-QWRGUYRKSA-N Leu-His-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)NCC(O)=O CFZZDVMBRYFFNU-QWRGUYRKSA-N 0.000 description 1
- DBSLVQBXKVKDKJ-BJDJZHNGSA-N Leu-Ile-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O DBSLVQBXKVKDKJ-BJDJZHNGSA-N 0.000 description 1
- AUBMZAMQCOYSIC-MNXVOIDGSA-N Leu-Ile-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O AUBMZAMQCOYSIC-MNXVOIDGSA-N 0.000 description 1
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 1
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 1
- LZHJZLHSRGWBBE-IHRRRGAJSA-N Leu-Lys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O LZHJZLHSRGWBBE-IHRRRGAJSA-N 0.000 description 1
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 1
- JDBQSGMJBMPNFT-AVGNSLFASA-N Leu-Pro-Val Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O JDBQSGMJBMPNFT-AVGNSLFASA-N 0.000 description 1
- IZPVWNSAVUQBGP-CIUDSAMLSA-N Leu-Ser-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IZPVWNSAVUQBGP-CIUDSAMLSA-N 0.000 description 1
- YWFZWQKWNDOWPA-XIRDDKMYSA-N Leu-Trp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O YWFZWQKWNDOWPA-XIRDDKMYSA-N 0.000 description 1
- BGGTYDNTOYRTTR-MEYUZBJRSA-N Leu-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(C)C)N)O BGGTYDNTOYRTTR-MEYUZBJRSA-N 0.000 description 1
- FBNPMTNBFFAMMH-AVGNSLFASA-N Leu-Val-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-AVGNSLFASA-N 0.000 description 1
- FBNPMTNBFFAMMH-UHFFFAOYSA-N Leu-Val-Arg Natural products CC(C)CC(N)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-UHFFFAOYSA-N 0.000 description 1
- RVOMPSJXSRPFJT-DCAQKATOSA-N Lys-Ala-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVOMPSJXSRPFJT-DCAQKATOSA-N 0.000 description 1
- NFLFJGGKOHYZJF-BJDJZHNGSA-N Lys-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN NFLFJGGKOHYZJF-BJDJZHNGSA-N 0.000 description 1
- NTEVEUCLFMWSND-SRVKXCTJSA-N Lys-Arg-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O NTEVEUCLFMWSND-SRVKXCTJSA-N 0.000 description 1
- VQXAVLQBQJMENB-SRVKXCTJSA-N Lys-Glu-Met Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O VQXAVLQBQJMENB-SRVKXCTJSA-N 0.000 description 1
- YPLVCBKEPJPBDQ-MELADBBJSA-N Lys-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N YPLVCBKEPJPBDQ-MELADBBJSA-N 0.000 description 1
- PLOUVAYOMTYJRG-JXUBOQSCSA-N Lys-Thr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PLOUVAYOMTYJRG-JXUBOQSCSA-N 0.000 description 1
- OPJRECCCQSDDCZ-TUSQITKMSA-N Lys-Trp-Trp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O OPJRECCCQSDDCZ-TUSQITKMSA-N 0.000 description 1
- XYLSGAWRCZECIQ-JYJNAYRXSA-N Lys-Tyr-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCC(O)=O)C(O)=O)CC1=CC=C(O)C=C1 XYLSGAWRCZECIQ-JYJNAYRXSA-N 0.000 description 1
- VWPJQIHBBOJWDN-DCAQKATOSA-N Lys-Val-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O VWPJQIHBBOJWDN-DCAQKATOSA-N 0.000 description 1
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 1
- MCNGIXXCMJAURZ-VEVYYDQMSA-N Met-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCSC)N)O MCNGIXXCMJAURZ-VEVYYDQMSA-N 0.000 description 1
- IZLCDZDNZFEDHB-DCAQKATOSA-N Met-Cys-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N IZLCDZDNZFEDHB-DCAQKATOSA-N 0.000 description 1
- OXHSZBRPUGNMKW-DCAQKATOSA-N Met-Gln-Arg Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OXHSZBRPUGNMKW-DCAQKATOSA-N 0.000 description 1
- UYAKZHGIPRCGPF-CIUDSAMLSA-N Met-Glu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCSC)N UYAKZHGIPRCGPF-CIUDSAMLSA-N 0.000 description 1
- CHQWUYSNAOABIP-ZPFDUUQYSA-N Met-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCSC)N CHQWUYSNAOABIP-ZPFDUUQYSA-N 0.000 description 1
- FYRUJIJAUPHUNB-IUCAKERBSA-N Met-Gly-Arg Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N FYRUJIJAUPHUNB-IUCAKERBSA-N 0.000 description 1
- MHQXIBRPDKXDGZ-ZFWWWQNUSA-N Met-Gly-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)CNC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 MHQXIBRPDKXDGZ-ZFWWWQNUSA-N 0.000 description 1
- RXWPLVRJQNWXRQ-IHRRRGAJSA-N Met-His-His Chemical compound C([C@H](NC(=O)[C@@H](N)CCSC)C(=O)N[C@@H](CC=1N=CNC=1)C(O)=O)C1=CNC=N1 RXWPLVRJQNWXRQ-IHRRRGAJSA-N 0.000 description 1
- BJPQKNHZHUCQNQ-SRVKXCTJSA-N Met-Pro-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCSC)N BJPQKNHZHUCQNQ-SRVKXCTJSA-N 0.000 description 1
- DBMLDOWSVHMQQN-XGEHTFHBSA-N Met-Ser-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DBMLDOWSVHMQQN-XGEHTFHBSA-N 0.000 description 1
- HOTNHEUETJELDL-BPNCWPANSA-N Met-Tyr-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCSC)N HOTNHEUETJELDL-BPNCWPANSA-N 0.000 description 1
- QAVZUKIPOMBLMC-AVGNSLFASA-N Met-Val-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C QAVZUKIPOMBLMC-AVGNSLFASA-N 0.000 description 1
- 108010066427 N-valyltryptophan Proteins 0.000 description 1
- 108010047562 NGR peptide Proteins 0.000 description 1
- 235000021314 Palmitic acid Nutrition 0.000 description 1
- ULECEJGNDHWSKD-QEJZJMRPSA-N Phe-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 ULECEJGNDHWSKD-QEJZJMRPSA-N 0.000 description 1
- JNRFYJZCMHHGMH-UBHSHLNASA-N Phe-Ala-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 JNRFYJZCMHHGMH-UBHSHLNASA-N 0.000 description 1
- IWRZUGHCHFZYQZ-UFYCRDLUSA-N Phe-Arg-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 IWRZUGHCHFZYQZ-UFYCRDLUSA-N 0.000 description 1
- MGECUMGTSHYHEJ-QEWYBTABSA-N Phe-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 MGECUMGTSHYHEJ-QEWYBTABSA-N 0.000 description 1
- APJPXSFJBMMOLW-KBPBESRZSA-N Phe-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 APJPXSFJBMMOLW-KBPBESRZSA-N 0.000 description 1
- UXQFHEKRGHYJRA-STQMWFEESA-N Phe-Met-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O UXQFHEKRGHYJRA-STQMWFEESA-N 0.000 description 1
- RBRNEFJTEHPDSL-ACRUOGEOSA-N Phe-Phe-Lys Chemical compound C([C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 RBRNEFJTEHPDSL-ACRUOGEOSA-N 0.000 description 1
- LTAWNJXSRUCFAN-UNQGMJICSA-N Phe-Thr-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LTAWNJXSRUCFAN-UNQGMJICSA-N 0.000 description 1
- OLHDPZMYUSBGDE-GUBZILKMSA-N Pro-Arg-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O OLHDPZMYUSBGDE-GUBZILKMSA-N 0.000 description 1
- QBFONMUYNSNKIX-AVGNSLFASA-N Pro-Arg-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O QBFONMUYNSNKIX-AVGNSLFASA-N 0.000 description 1
- VJLJGKQAOQJXJG-CIUDSAMLSA-N Pro-Asp-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VJLJGKQAOQJXJG-CIUDSAMLSA-N 0.000 description 1
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 1
- UEHYFUCOGHWASA-HJGDQZAQSA-N Pro-Glu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 UEHYFUCOGHWASA-HJGDQZAQSA-N 0.000 description 1
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 1
- ULIWFCCJIOEHMU-BQBZGAKWSA-N Pro-Gly-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 ULIWFCCJIOEHMU-BQBZGAKWSA-N 0.000 description 1
- VWXGFAIZUQBBBG-UWVGGRQHSA-N Pro-His-Gly Chemical compound C([C@@H](C(=O)NCC(=O)[O-])NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 VWXGFAIZUQBBBG-UWVGGRQHSA-N 0.000 description 1
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 1
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 1
- ABSSTGUCBCDKMU-UWVGGRQHSA-N Pro-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 ABSSTGUCBCDKMU-UWVGGRQHSA-N 0.000 description 1
- VGVCNKSUVSZEIE-IHRRRGAJSA-N Pro-Phe-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O VGVCNKSUVSZEIE-IHRRRGAJSA-N 0.000 description 1
- LEIKGVHQTKHOLM-IUCAKERBSA-N Pro-Pro-Gly Chemical compound OC(=O)CNC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 LEIKGVHQTKHOLM-IUCAKERBSA-N 0.000 description 1
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 1
- KIDXAAQVMNLJFQ-KZVJFYERSA-N Pro-Thr-Ala Chemical compound C[C@@H](O)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](C)C(O)=O KIDXAAQVMNLJFQ-KZVJFYERSA-N 0.000 description 1
- 241000241413 Propolis Species 0.000 description 1
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 1
- XWCYBVBLJRWOFR-WDSKDSINSA-N Ser-Gln-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O XWCYBVBLJRWOFR-WDSKDSINSA-N 0.000 description 1
- BRGQQXQKPUCUJQ-KBIXCLLPSA-N Ser-Glu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRGQQXQKPUCUJQ-KBIXCLLPSA-N 0.000 description 1
- GZBKRJVCRMZAST-XKBZYTNZSA-N Ser-Glu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZBKRJVCRMZAST-XKBZYTNZSA-N 0.000 description 1
- OHKFXGKHSJKKAL-NRPADANISA-N Ser-Glu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OHKFXGKHSJKKAL-NRPADANISA-N 0.000 description 1
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 1
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 1
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 1
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 1
- IAOHCSQDQDWRQU-GUBZILKMSA-N Ser-Val-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IAOHCSQDQDWRQU-GUBZILKMSA-N 0.000 description 1
- KBLYJPQSNGTDIU-LOKLDPHHSA-N Thr-Glu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O KBLYJPQSNGTDIU-LOKLDPHHSA-N 0.000 description 1
- AQAMPXBRJJWPNI-JHEQGTHGSA-N Thr-Gly-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AQAMPXBRJJWPNI-JHEQGTHGSA-N 0.000 description 1
- UBDDORVPVLEECX-FJXKBIBVSA-N Thr-Gly-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O UBDDORVPVLEECX-FJXKBIBVSA-N 0.000 description 1
- XTCNBOBTROGWMW-RWRJDSDZSA-N Thr-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N XTCNBOBTROGWMW-RWRJDSDZSA-N 0.000 description 1
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 1
- RRRRCRYTLZVCEN-HJGDQZAQSA-N Thr-Leu-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O RRRRCRYTLZVCEN-HJGDQZAQSA-N 0.000 description 1
- RFKVQLIXNVEOMB-WEDXCCLWSA-N Thr-Leu-Gly Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N)O RFKVQLIXNVEOMB-WEDXCCLWSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- KZURUCDWKDEAFZ-XVSYOHENSA-N Thr-Phe-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O KZURUCDWKDEAFZ-XVSYOHENSA-N 0.000 description 1
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 1
- WKGAAMOJPMBBMC-IXOXFDKPSA-N Thr-Ser-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WKGAAMOJPMBBMC-IXOXFDKPSA-N 0.000 description 1
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 1
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 1
- LGEPIBQBGZTBHL-SXNHZJKMSA-N Trp-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N LGEPIBQBGZTBHL-SXNHZJKMSA-N 0.000 description 1
- VPRHDRKAPYZMHL-SZMVWBNQSA-N Trp-Leu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 VPRHDRKAPYZMHL-SZMVWBNQSA-N 0.000 description 1
- OOEUVMFKKZYSRX-LEWSCRJBSA-N Tyr-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OOEUVMFKKZYSRX-LEWSCRJBSA-N 0.000 description 1
- KSVMDJJCYKIXTK-IGNZVWTISA-N Tyr-Ala-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 KSVMDJJCYKIXTK-IGNZVWTISA-N 0.000 description 1
- DXYWRYQRKPIGGU-BPNCWPANSA-N Tyr-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DXYWRYQRKPIGGU-BPNCWPANSA-N 0.000 description 1
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 1
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 1
- KEANSLVUGJADPN-LKTVYLICSA-N Tyr-His-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CC=C(C=C2)O)N KEANSLVUGJADPN-LKTVYLICSA-N 0.000 description 1
- YKCXQOBTISTQJD-BZSNNMDCSA-N Tyr-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N YKCXQOBTISTQJD-BZSNNMDCSA-N 0.000 description 1
- VTCKHZJKWQENKX-KBPBESRZSA-N Tyr-Lys-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O VTCKHZJKWQENKX-KBPBESRZSA-N 0.000 description 1
- SYFHQHYTNCQCCN-MELADBBJSA-N Tyr-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O SYFHQHYTNCQCCN-MELADBBJSA-N 0.000 description 1
- OBKOPLHSRDATFO-XHSDSOJGSA-N Tyr-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OBKOPLHSRDATFO-XHSDSOJGSA-N 0.000 description 1
- YFOCMOVJBQDBCE-NRPADANISA-N Val-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N YFOCMOVJBQDBCE-NRPADANISA-N 0.000 description 1
- RUCNAYOMFXRIKJ-DCAQKATOSA-N Val-Ala-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN RUCNAYOMFXRIKJ-DCAQKATOSA-N 0.000 description 1
- HNWQUBBOBKSFQV-AVGNSLFASA-N Val-Arg-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N HNWQUBBOBKSFQV-AVGNSLFASA-N 0.000 description 1
- CVUDMNSZAIZFAE-TUAOUCFPSA-N Val-Arg-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N CVUDMNSZAIZFAE-TUAOUCFPSA-N 0.000 description 1
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 1
- QPZMOUMNTGTEFR-ZKWXMUAHSA-N Val-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N QPZMOUMNTGTEFR-ZKWXMUAHSA-N 0.000 description 1
- UDNYEPLJTRDMEJ-RCOVLWMOSA-N Val-Asn-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N UDNYEPLJTRDMEJ-RCOVLWMOSA-N 0.000 description 1
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 1
- COSLEEOIYRPTHD-YDHLFZDLSA-N Val-Asp-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 COSLEEOIYRPTHD-YDHLFZDLSA-N 0.000 description 1
- FRUYSSRPJXNRRB-GUBZILKMSA-N Val-Cys-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N FRUYSSRPJXNRRB-GUBZILKMSA-N 0.000 description 1
- FBVUOEYVGNMRMD-NAKRPEOUSA-N Val-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N FBVUOEYVGNMRMD-NAKRPEOUSA-N 0.000 description 1
- NXRAUQGGHPCJIB-RCOVLWMOSA-N Val-Gly-Asn Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O NXRAUQGGHPCJIB-RCOVLWMOSA-N 0.000 description 1
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 1
- OPGWZDIYEYJVRX-AVGNSLFASA-N Val-His-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N OPGWZDIYEYJVRX-AVGNSLFASA-N 0.000 description 1
- LKUDRJSNRWVGMS-QSFUFRPTSA-N Val-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LKUDRJSNRWVGMS-QSFUFRPTSA-N 0.000 description 1
- VXDSPJJQUQDCKH-UKJIMTQDSA-N Val-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N VXDSPJJQUQDCKH-UKJIMTQDSA-N 0.000 description 1
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 1
- RFKJNTRMXGCKFE-FHWLQOOXSA-N Val-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC(C)C)C(O)=O)=CNC2=C1 RFKJNTRMXGCKFE-FHWLQOOXSA-N 0.000 description 1
- JAKHAONCJJZVHT-DCAQKATOSA-N Val-Lys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N JAKHAONCJJZVHT-DCAQKATOSA-N 0.000 description 1
- MGVYZTPLGXPVQB-CYDGBPFRSA-N Val-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N MGVYZTPLGXPVQB-CYDGBPFRSA-N 0.000 description 1
- VNGKMNPAENRGDC-JYJNAYRXSA-N Val-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=CC=C1 VNGKMNPAENRGDC-JYJNAYRXSA-N 0.000 description 1
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 1
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 1
- MIKHIIQMRFYVOR-RCWTZXSCSA-N Val-Pro-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C(C)C)N)O MIKHIIQMRFYVOR-RCWTZXSCSA-N 0.000 description 1
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 1
- PMKQKNBISAOSRI-XHSDSOJGSA-N Val-Tyr-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N PMKQKNBISAOSRI-XHSDSOJGSA-N 0.000 description 1
- RTJPAGFXOWEBAI-SRVKXCTJSA-N Val-Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RTJPAGFXOWEBAI-SRVKXCTJSA-N 0.000 description 1
- 108010081404 acein-2 Proteins 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 1
- 108010044940 alanylglutamine Proteins 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 230000003078 antioxidant effect Effects 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 239000012159 carrier gas Substances 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 150000001875 compounds Chemical group 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 108010054813 diprotin B Proteins 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 150000004665 fatty acids Chemical class 0.000 description 1
- 239000012467 final product Substances 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 238000004817 gas chromatography Methods 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 108010080575 glutamyl-aspartyl-alanine Proteins 0.000 description 1
- 108010008237 glutamyl-valyl-glycine Proteins 0.000 description 1
- 108010059898 glycyl-tyrosyl-lysine Proteins 0.000 description 1
- 108010020688 glycylhistidine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 239000001307 helium Substances 0.000 description 1
- 229910052734 helium Inorganic materials 0.000 description 1
- SWQJXJOGLNCZEY-UHFFFAOYSA-N helium atom Chemical compound [He] SWQJXJOGLNCZEY-UHFFFAOYSA-N 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 239000005457 ice water Substances 0.000 description 1
- 230000003832 immune regulation Effects 0.000 description 1
- 238000011419 induction treatment Methods 0.000 description 1
- 238000009776 industrial production Methods 0.000 description 1
- 239000002054 inoculum Substances 0.000 description 1
- 239000013067 intermediate product Substances 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 210000002429 large intestine Anatomy 0.000 description 1
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 1
- 108010000761 leucylarginine Proteins 0.000 description 1
- 108010057821 leucylproline Proteins 0.000 description 1
- 108010012058 leucyltyrosine Proteins 0.000 description 1
- 239000012160 loading buffer Substances 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 235000021281 monounsaturated fatty acids Nutrition 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 description 1
- IPCSVZSSVZVIGE-UHFFFAOYSA-N n-hexadecanoic acid Natural products CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- 230000035790 physiological processes and functions Effects 0.000 description 1
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 1
- 108010025826 prolyl-leucyl-arginine Proteins 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 108010053725 prolylvaline Proteins 0.000 description 1
- 229940069949 propolis Drugs 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 239000012488 sample solution Substances 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 238000002444 silanisation Methods 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000001308 synthesis method Methods 0.000 description 1
- 150000007970 thio esters Chemical class 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 238000011282 treatment Methods 0.000 description 1
- PQDJYEQOELDLCP-UHFFFAOYSA-N trimethylsilane Chemical compound C[SiH](C)C PQDJYEQOELDLCP-UHFFFAOYSA-N 0.000 description 1
- 108010015666 tryptophyl-leucyl-glutamic acid Proteins 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images











Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0006—Oxidoreductases (1.) acting on CH-OH groups as donors (1.1)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/195—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria
- C07K14/24—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria from Enterobacteriaceae (F), e.g. Citrobacter, Serratia, Proteus, Providencia, Morganella, Yersinia
- C07K14/245—Escherichia (G)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/70—Vectors or expression systems specially adapted for E. coli
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/001—Oxidoreductases (1.) acting on the CH-CH group of donors (1.3)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0071—Oxidoreductases (1.) acting on paired donors with incorporation of molecular oxygen (1.14)
- C12N9/0073—Oxidoreductases (1.) acting on paired donors with incorporation of molecular oxygen (1.14) with NADH or NADPH as one donor, and incorporation of one atom of oxygen 1.14.13
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1025—Acyltransferases (2.3)
- C12N9/1029—Acyltransferases (2.3) transferring groups other than amino-acyl groups (2.3.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/88—Lyases (4.)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
- C12P7/6409—Fatty acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y101/00—Oxidoreductases acting on the CH-OH group of donors (1.1)
- C12Y101/01—Oxidoreductases acting on the CH-OH group of donors (1.1) with NAD+ or NADP+ as acceptor (1.1.1)
- C12Y101/01035—3-Hydroxyacyl-CoA dehydrogenase (1.1.1.35)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y103/00—Oxidoreductases acting on the CH-CH group of donors (1.3)
- C12Y103/08—Oxidoreductases acting on the CH-CH group of donors (1.3) with flavin as acceptor (1.3.8)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y106/00—Oxidoreductases acting on NADH or NADPH (1.6)
- C12Y106/02—Oxidoreductases acting on NADH or NADPH (1.6) with a heme protein as acceptor (1.6.2)
- C12Y106/02004—NADPH-hemoprotein reductase (1.6.2.4), i.e. NADP-cytochrome P450-reductase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y301/00—Hydrolases acting on ester bonds (3.1)
- C12Y301/02—Thioester hydrolases (3.1.2)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y402/00—Carbon-oxygen lyases (4.2)
- C12Y402/01—Hydro-lyases (4.2.1)
- C12Y402/01017—Enoyl-CoA hydratase (4.2.1.17), i.e. crotonase
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Landscapes
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Medicinal Chemistry (AREA)
- Biophysics (AREA)
- Gastroenterology & Hepatology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
Abstract
Description
本申请为申请号202110211118.9、申请日2021.02.25、发明名称“一种突变酶CYP153AM228L及其在合成10-羟基-2-癸烯酸中的应用”的分案申请。This application is a divisional application with the application number of 202110211118.9, the application date of 2021.02.25, and the title of the invention "A mutant enzyme CYP153AM228L and its application in the synthesis of 10-hydroxy-2-decenoic acid".
技术领域technical field
本发明涉及一种大肠杆菌工程菌及应用,属于生物发酵技术领域。The invention relates to an Escherichia coli engineering bacteria and application, and belongs to the technical field of biological fermentation.
背景技术Background technique
10-羟基-2-癸烯酸(10-hydroxy-2-decenoic acid,10-HDA)是一种含有羟基的单不饱和脂肪酸,分子式为C10H18O3。迄今为止,自然界中仅从蜂王浆及蜂胶中发现,因此又称王浆酸。研究表明10-HDA具有抗菌、免疫调节及抗氧化,抗肿瘤,降低血糖等多种重要的生理功能,具有极高的医药和保健价值,应用前景十分广泛。该化合物结构如下:10-hydroxy-2-decenoic acid (10-HDA) is a monounsaturated fatty acid containing hydroxyl, and the molecular formula is C 10 H 18 O 3 . So far, only royal jelly and propolis are found in nature, so it is also called royal jelly acid. Studies have shown that 10-HDA has many important physiological functions such as antibacterial, immune regulation, antioxidant, anti-tumor, and lowering blood sugar. The compound structure is as follows:
鉴于10-HDA广泛而重要的应用价值,寻找10-HDA高效方便、低成本生产方法的研究被广泛重视。目前10-HDA的获得方法主要有物理提取法、化学合成法。其中物理提取法来In view of the extensive and important application value of 10-HDA, the research to find efficient, convenient and low-cost production methods for 10-HDA has been widely paid attention to. At present, the main methods for obtaining 10-HDA are physical extraction and chemical synthesis. of which physical extraction

源单一,蜂王浆中10-HDA含量仅为1.4%-2.4%,因此产量小,无法满足市场需求。而化学合成法虽然可以满足产业需求,但其操作步骤较冗繁,且化学试剂具有一定的毒性。因而探索10-HDA高效方便、低成本的合成方法,对其大规模开发和利用具有重要的理论和应用价值。近年来微生物发酵合成法生产10-HDA 已经成为研究者及该行业的新目标。The source is single, and the content of 10-HDA in royal jelly is only 1.4%-2.4%, so the output is small and cannot meet the market demand. Although the chemical synthesis method can meet the needs of the industry, its operation steps are cumbersome and the chemical reagents have certain toxicity. Therefore, exploring an efficient, convenient and low-cost synthesis method for 10-HDA has important theoretical and application value for its large-scale development and utilization. In recent years, the production of 10-HDA by microbial fermentation synthesis has become a new target of researchers and the industry.
中国专利文献CN109897870A(申请号:201910088897.0)公开了一种以癸酸为原料利用大肠杆菌工程菌制备10-羟基-2癸烯酸的方法,该专利文献利用癸酸一步生成10-HDA。Chinese patent document CN109897870A (application number: 201910088897.0) discloses a method for preparing 10-hydroxy-2 decenoic acid by using decanoic acid as a raw material and using Escherichia coli engineering bacteria. The patent document utilizes decanoic acid to generate 10-HDA in one step.
发明内容SUMMARY OF THE INVENTION
针对现有技术的不足,本发明提供了一种大肠杆菌工程菌及应用。Aiming at the deficiencies of the prior art, the present invention provides an Escherichia coli engineering bacteria and its application.
本申请利用两步法生成10-HDA,且本申请利用的脂酰CoA脱氢酶基因PpFadE、脂酰CoA合成酶基因MaMACS、酰辅酶A硫酯酶基因ctydiI与中国专利文献CN109897870A(申请号:201910088897.0)中脂酰CoA脱氢酶基因MCAD、脂酰CoA合成酶基因FadK、酰辅酶A硫酯酶基因ydiI并非相同基因,本申请中的烷烃羟化酶CYP153A是将228位的氨基酸由M变为L。The application utilizes a two-step method to generate 10-HDA, and the fatty acyl-CoA dehydrogenase gene PpFadE, the fatty acyl-CoA synthase gene MaMACS, the acyl-CoA thioesterase gene ctydiI and the Chinese patent document CN109897870A (application number: 201910088897.0), the fatty acyl-CoA dehydrogenase gene MCAD, the fatty acyl-CoA synthase gene FadK, and the acyl-CoA thioesterase gene ydiI are not the same genes, and the alkane hydroxylase CYP153A in this application is to change the amino acid at position 228 from M. for L.
本发明针对现有单独一个工程菌构建的合成途径,10-HDA合成效率极低,不能达到工业化水平的情况下,本发明在前期研究的基础上,进一步优化表达元件及10-HDA合成途径,提供一种两步法以癸酸为原料利用大肠杆菌工程菌生产制备10-羟基-2-癸烯酸的方法。The present invention is aimed at the existing synthetic route constructed by a single engineering bacterium, and the 10-HDA synthesis efficiency is extremely low and cannot reach the industrialized level. Provided is a two-step method for producing 10-hydroxy-2-decenoic acid by using decanoic acid as a raw material and utilizing Escherichia coli engineering bacteria.
本发明的技术方案如下:The technical scheme of the present invention is as follows:
一种大肠杆菌基因缺失菌BL21ΔFadB、R、J,所述大肠杆菌基因缺失菌种为大肠杆菌BL21中敲除了FadB基因、FadR基因和FadJ基因得到。An Escherichia coli gene-deficient strain BL21ΔFadB, R, J is obtained by knocking out FadB gene, FadR gene and FadJ gene in Escherichia coli BL21.
所述Δ符号为从大肠的基因组上敲除了某个基因,FadB为烯酰CoA水合酶,FadR是一种蛋白操纵子,FadJ为3-羟酰辅酶A脱氢酶;这三种酶的存在对本发明的两步法催化癸酸产10-HDA起阻碍作用,所以敲除了。The Δ symbol means that a gene has been knocked out from the genome of the large intestine, FadB is enoyl-CoA hydratase, FadR is a protein operon, and FadJ is 3-hydroxyacyl-CoA dehydrogenase; the presence of these three enzymes The two-step method of the present invention catalyzes the production of 10-HDA from decanoic acid, so it is knocked out.
大肠杆菌基因缺失菌BL21ΔFadB、R、J在制备10-羟基-2-癸烯酸中的应用。Application of Escherichia coli gene deletion bacteria BL21ΔFadB, R, J in the preparation of 10-hydroxy-2-decenoic acid.
上述大肠杆菌基因缺失菌BL21ΔFadB、R、J的构建方法,包括如下步骤:The construction method of the above-mentioned Escherichia coli gene deletion bacteria BL21ΔFadB, R, J, comprises the following steps:
Ⅰ利用RED重组法敲除基因,构建基因缺失ΔFadRB菌种(以下称为ΔFadRΔFadB菌种);该菌种的构建方法参见中国专利文献CN110684794A;Ⅰ. Knock out the gene using RED recombination method, and construct gene deletion ΔFadRB strain (hereinafter referred to as ΔFadRΔFadB strain); for the construction method of this strain, refer to Chinese patent document CN110684794A;
Ⅱ利用RED重组法敲除基因,构建大肠杆菌基因缺失菌BL21ΔFadB、R、J,具体包括构建FadJ敲除框(以下将FadJ敲除框缩写为Jk);将FadJ敲除框转化进pkd46-ΔFadRΔFadB感受态细胞中,制得大肠杆菌基因缺失菌BL21ΔFadB、R、J。Ⅱ Use the RED recombination method to knock out the gene and construct the E. coli gene-deficient bacteria BL21ΔFadB, R, and J, including the construction of the FadJ knockout box (the FadJ knockout box is abbreviated as Jk below); the FadJ knockout box is transformed into pkd46-ΔFadRΔFadB In competent cells, Escherichia coli gene deletion bacteria BL21ΔFadB, R, J were obtained.
根据本发明优选的,步骤Ⅱ中构建FadR敲除框,包括如下步骤:Preferably according to the present invention, constructing the FadR knockout frame in step II includes the following steps:
以大肠杆菌BL21基因组为模板,扩增3-羟酰辅酶A脱氢酶基因的上游同源臂FadJ1,上游引物的核苷酸序列如SEQ ID NO.25所示,下游引物的核苷酸序列如SEQ IDNO.26所示;以大肠杆菌BL21基因组为模板,扩增3-羟酰辅酶A脱氢酶基因的下游同源臂FadJ2,上游引物的核苷酸序列如SEQ ID NO.27所示,下游引物的核苷酸序列如SEQ IDNO.28所示;以pkd3质粒为模板,扩增FRT-RKan—FRT基因片段,上游引物的核苷酸序列如SEQ ID NO.29所示,下游引物的核苷酸序列如SEQ ID NO.30所示;然后将FadJl、FRT-RKan-FRT与FadJ2基因片段多片段无缝克隆,扩增FadJ1-Kan-FadJ2的敲除框片段,上游引物的核苷酸序列如SEQ ID NO.31所示,下游引物的核苷酸序列如SEQ ID NO.32所示,纯化胶回收获得FadJ敲除框(以下将FadJ敲除框缩写为Jk)。Using the genome of Escherichia coli BL21 as a template, the upstream homology arm FadJ1 of the 3-hydroxyacyl-CoA dehydrogenase gene was amplified. The nucleotide sequence of the upstream primer is shown in SEQ ID NO.25, and the nucleotide sequence of the downstream primer As shown in SEQ ID NO.26; using Escherichia coli BL21 genome as a template, amplify the downstream homology arm FadJ2 of 3-hydroxyacyl-CoA dehydrogenase gene, and the nucleotide sequence of the upstream primer is shown in SEQ ID NO.27 , the nucleotide sequence of the downstream primer is shown in SEQ ID NO.28; the pkd3 plasmid is used as a template to amplify the FRT-RKan-FRT gene fragment, the nucleotide sequence of the upstream primer is shown in SEQ ID NO.29, the downstream primer The nucleotide sequence is shown in SEQ ID NO.30; then FadJ1, FRT-RKan-FRT and FadJ2 gene fragment multi-fragment seamless cloning, amplifying the knockout frame fragment of FadJ1-Kan-FadJ2, the core of the upstream primer The nucleotide sequence is shown in SEQ ID NO. 31, the nucleotide sequence of the downstream primer is shown in SEQ ID NO. 32, and the FadJ knockout box is recovered from the purified gel (hereinafter, the FadJ knockout box is abbreviated as Jk).
进一步优选的,PCR扩增体系如下,总体系50μL:Further preferably, the PCR amplification system is as follows, and the total system is 50 μL:
100μM上游引物2.0μL,100μM下游引物2.0μL,模板2.0μL,5U/μL phanta酶25μL,ddH2O19μL;100μM upstream primer 2.0μL, 100μM downstream primer 2.0μL, template 2.0μL, 5U/μL phanta enzyme 25μL, ddH2O 19μL;
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸1min15s,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 1 min 15 s, 30 cycles; extension at 72 °C for 5 min.
根据本发明优选的,步骤Ⅱ中FadJ敲除框转化入pkd46-ΔFadRΔFadB重组菌,最终获得Preferably according to the present invention, in step II, the FadJ knockout box is transformed into the pkd46-ΔFadRΔFadB recombinant bacteria, and finally obtain
大肠杆菌基因缺失菌BL21ΔFadB、R、J,包括如下步骤:Escherichia coli gene deletion bacteria BL21ΔFadB, R, J, including the following steps:
a、将质粒pkd46转化进ΔFadRΔFadB感受态细胞中,获得的pkd46-ΔFadRΔFadB重组菌,制备pkd46-ΔFadRΔFadB感受态细胞,再用质量浓度为10%的甘油保存制备的pkd46-ΔFadRΔFadB感受态细胞;a. The plasmid pkd46 was transformed into ΔFadRΔFadB competent cells, and the obtained pkd46-ΔFadRΔFadB recombinant bacteria were prepared to prepare pkd46-ΔFadRΔFadB competent cells, and then the prepared pkd46-ΔFadRΔFadB competent cells were stored in 10% glycerol;
b、将FadJ敲除框Jk转化进pkd46-ΔFadRΔFadB感受态细胞中,验证pkd46-Jk-BL21重组菌确认敲除框转入后,42℃消除pkd46,筛选后得到Jk-ΔFadRΔFadB重组菌;b. Transform the FadJ knockout box Jk into pkd46-ΔFadRΔFadB competent cells, and verify that the pkd46-Jk-BL21 recombinant strain confirms that after the knockout frame is transferred, pkd46 is eliminated at 42°C, and the Jk-ΔFadRΔFadB recombinant strain is obtained after screening;
c、将Jk-ΔFadRΔFadB重组菌制备感受态转化pcp20质粒,42℃消除Jk抗性以及pcp20质粒,获得ΔFadRBJ重组菌,即为大肠杆菌基因缺失菌BL21ΔFadB、R、J。c. The Jk-ΔFadRΔFadB recombinant strain was prepared to be competent to transform the pcp20 plasmid, and the Jk resistance and the pcp20 plasmid were eliminated at 42°C to obtain the ΔFadRBJ recombinant strain, which is the E. coli gene deletion strain BL21ΔFadB, R, J.
一种以癸酸为原料利用大肠杆菌工程菌静息细胞制备10-羟基-2-癸烯酸的方法,包括如下步骤:A method for preparing 10-hydroxy-2-decenoic acid by using decanoic acid as a raw material and utilizing Escherichia coli engineering bacteria resting cells, comprising the following steps:
(1)构建优化后重组质粒pCDFDuet-1-MaMACS-PpFadE、优化后重组质粒pET21b-CYP153A M228L-CPRBM3、优化后重组质粒pET28a-SUMO-ctYdiI;(1) Construction of the optimized recombinant plasmid pCDFDuet-1-MaMACS-PpFadE, the optimized recombinant plasmid pET21b-CYP153A M228L-CPR BM3 , and the optimized recombinant plasmid pET28a-SUMO-ctYdiI;
所述CYP153A-CPRBM3融合酶的表达基因核苷酸序列如SEQ ID NO.13所示;CYP153AM228L-CPRBM3融合酶的表达基因核苷酸序列如SEQ ID NO.14所示;脂酰CoA合成酶基因MaMACS的核苷酸序列如SEQ ID NO.15所示;脂酰CoA脱氢酶基因PpFadE的核苷酸序列如SEQ ID NO.16所示;酯酰辅酶A硫酯酶基因ctYdiI的核苷酸序列如SEQ ID NO.17所示;The nucleotide sequence of the expression gene of the CYP153A-CPR BM3 fusion enzyme is shown in SEQ ID NO.13; the nucleotide sequence of the expression gene of the CYP153AM228L-CPR BM3 fusion enzyme is shown in SEQ ID NO.14; fatty acyl CoA synthesis The nucleotide sequence of the enzyme gene MaMACS is shown in SEQ ID NO.15; the nucleotide sequence of the fatty acyl-CoA dehydrogenase gene PpFadE is shown in SEQ ID NO.16; the nucleus of the acyl-CoA thioesterase gene ctYdiI The nucleotide sequence is shown in SEQ ID NO.17;
所述CYP153A M228L是将CYP153A酶第228位的氨基酸由M突变为L。The CYP153A M228L is a mutation of the amino acid at position 228 of the CYP153A enzyme from M to L.
(2)利用步骤(1)制得的重组质粒pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI转化到的大肠杆菌敲除菌种,构建大肠杆菌BL21ΔFadB、R、J,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI,将重组质粒pET21b-CYP153AM228L-CPRBM3转化到大肠杆菌BL21中,构建大肠杆菌BL21 pET21b-CYP153AM228L-CPRBM3,两种工程菌经筛选,诱导培养,制得诱导细胞;(2) Use the recombinant plasmids pCDFDuet-1-MaMACS-PpFadE and pET28a-SUMO-ctYdiI obtained in step (1) to transform the E. coli knockout strains to construct E. coli BL21ΔFadB, R, J, pCDFDuet-1-MaMACS -PpFadE, pET28a-SUMO-ctYdiI, the recombinant plasmid pET21b-CYP153AM228L-CPR BM3 was transformed into Escherichia coli BL21 to construct Escherichia coli BL21 pET21b-CYP153AM228L-CPR BM3 , two engineered bacteria were screened, induced and cultured to obtain induced cells ;
(3)将步骤(2)制得的诱导细胞经转化培养基培养,制得静息细胞,然后向大肠杆菌BL21ΔFadB、R、J,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI静息细胞中加入癸酸培养制得反式-2-癸烯酸;将反应液中加入大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3静息细胞,培养制得10-羟基-2-癸烯酸。(3) The induced cells obtained in step (2) were cultured in the transformation medium to obtain resting cells, and then rested in Escherichia coli BL21ΔFadB, R, J, pCDFDuet-1-MaMACS-PpFadE, pET28a-SUMO-ctYdiI Add decanoic acid to the cells and culture to obtain trans-2-decenoic acid; add Escherichia coli BL21 pET21b-CYP153A M228L-CPR BM3 resting cells to the reaction solution, and culture to obtain 10-hydroxy-2-decenoic acid.
根据本发明优选的,所述步骤(1)中,构建重组质粒pCDFDuet-1-MaMACS-PpFadE,包括如下步骤:Preferably according to the present invention, in the step (1), the construction of the recombinant plasmid pCDFDuet-1-MaMACS-PpFadE includes the following steps:
以大肠杆菌DH5a基因组为模板,扩增脂酰CoA合成酶基因MaMACS,上游引物的核苷酸序列如SEQ ID NO.7所示,下游引物的核苷酸序列如SEQ ID NO.8所示,然后将pCDFDuet-1质粒用BamH I、Hind III进行双酶切,经连接酶连接,制得重组质粒pCDFDuet-1-MaMACS;Using Escherichia coli DH5a genome as a template, amplify the fatty acyl-CoA synthase gene MaMACS, the nucleotide sequence of the upstream primer is shown in SEQ ID NO.7, and the nucleotide sequence of the downstream primer is shown in SEQ ID NO.8, Then, the pCDFDuet-1 plasmid was double digested with BamH I and Hind III, and then ligated with ligase to obtain the recombinant plasmid pCDFDuet-1-MaMACS;
PCR扩增体系如下,总体系25μL:The PCR amplification system is as follows, the total system is 25 μL:
100μM上游引物1.0μL,100μM下游引物1.0μL,模板1.0μL,5U/μL phanta酶12.5μL,ddH2O 9.5μL;100 μM upstream primer 1.0 μL, 100 μM downstream primer 1.0 μL, template 1.0 μL, 5U/μL phanta enzyme 12.5 μL, ddH 2 O 9.5 μL;
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸50s,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 50 s, 30 cycles; extension at 72 °C for 5 min.
以大肠杆菌DH5a基因组为模板,扩增脂酰CoA脱氢酶基因PpFadE,上游引物的核苷酸序列如SEQ ID NO.9所示,下游引物的核苷酸序列如SEQ ID NO.10所示,然后将pCDFDuet-1-MaMACS质粒用Nde I、Ava I进行双酶切,经连接酶连接,制得重组质粒pCDFDuet-1-MaMACS-PpFadE;Using Escherichia coli DH5a genome as a template, amplify the fatty acyl-CoA dehydrogenase gene PpFadE, the nucleotide sequence of the upstream primer is shown in SEQ ID NO.9, and the nucleotide sequence of the downstream primer is shown in SEQ ID NO.10 , and then the pCDFDuet-1-MaMACS plasmid was double digested with Nde I and Ava I, and ligated by ligase to obtain the recombinant plasmid pCDFDuet-1-MaMACS-PpFadE;
PCR扩增体系如下,总体系25μL:The PCR amplification system is as follows, the total system is 25 μL:
100μM上游引物1.0μL,100μM下游引物1.0μL,模板1.0μL,5U/μL phanta酶12.5μL,ddH2O 9.5μL;100 μM upstream primer 1.0 μL, 100 μM downstream primer 1.0 μL, template 1.0 μL, 5U/μL phanta enzyme 12.5 μL, ddH 2 O 9.5 μL;
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸40S,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 40 s, 30 cycles; extension at 72 °C for 5 min.
根据本发明优选的,所述步骤(1)中,构建重组质粒pET28a-SUMO-ctYdiI,包括如下步骤:Preferably according to the present invention, in the step (1), the construction of the recombinant plasmid pET28a-SUMO-ctYdiI includes the following steps:
以大肠杆菌DH5a基因组为模板,扩增酯酰辅酶A硫酯酶基因ctydiI,上游引物的核苷酸序列如SEQ ID NO.11所示,下游引物的核苷酸序列如SEQ ID NO.12所示,然后将pET28a-SUMO质粒和酯酰辅酶A硫酯酶基因ctydiI分别用BamHI和Xho I分别进行双酶切,经连接酶连接,制得重组质粒pET28a-SUMO-ctYdiI;Using Escherichia coli DH5a genome as a template, amplify the acyl-CoA thioesterase gene ctydiI, the nucleotide sequence of the upstream primer is shown in SEQ ID NO.11, and the nucleotide sequence of the downstream primer is shown in SEQ ID NO.12. Then, the pET28a-SUMO plasmid and the acyl-CoA thioesterase gene ctydiI were double digested with BamHI and Xho I, respectively, and ligated with ligase to prepare the recombinant plasmid pET28a-SUMO-ctYdiI;
PCR扩增体系如下,总体系25μL:The PCR amplification system is as follows, the total system is 25 μL:
100μM上游引物1.0μL,100μM下游引物1.0μL,模板1.0μL,5U/μL phanta酶12.5μL,ddH2O 9.5μL。100 μM upstream primer 1.0 μL, 100 μM downstream primer 1.0 μL, template 1.0 μL, 5U/μL phanta enzyme 12.5 μL, ddH 2 O 9.5 μL.
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸15s,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 15 s, 30 cycles; extension at 72 °C for 5 min.
根据本发明优选的,所述步骤(2)中,筛选为将转化后的大肠杆菌工程菌接入含有相应浓度50μg/mL卡那霉素、100μg/mL氨苄霉素和40μg/mL链霉素的LB液体培养基中,在35~40℃振荡筛选培养至菌液OD600为0.8~1.2。Preferably according to the present invention, in the step (2), the screening is to insert the transformed Escherichia coli engineering bacteria into the corresponding concentrations of 50 μg/mL kanamycin, 100 μg/mL ampicillin and 40 μg/mL streptomycin In the LB liquid medium, shake screening and culture at 35-40 °C until the OD 600 of the bacterial liquid is 0.8-1.2.
根据本发明优选的,所述步骤(2)中,诱导培养为将筛选培养的菌液降温至18~20℃适应0.5~1小时后,然后分别加入IPTG至浓度为0.5~0.8mM、加入油酸至质量百分比浓度为0.4~0.8%、加入吐温80至质量百分比浓度为0.2~0.5%,继续诱导培养18~20小时,分离细胞,制得诱导细胞。According to the preferred embodiment of the present invention, in the step (2), the induction culture is to cool the screened and cultured bacterial liquid to 18-20°C for 0.5-1 hour, then add IPTG to a concentration of 0.5-0.8mM, add oil Acid to reach a mass percentage concentration of 0.4-0.8%, add
进一步优选的,所述步骤(2)中,诱导培养条件为将筛选培养的菌液降温至20℃适应1小时后,分别加入IPTG使培养基中IPTG浓度为0.5mM、加入油酸使培养基中质量百分比浓度为0.6%、加入吐温80使培养基中吐温80的质量百分比浓度为0.3%,继续诱导培养18小时,分离细胞,制得诱导细胞。Further preferably, in the step (2), the inductive culture condition is to cool the bacterial liquid of the screening culture to 20 ° C for 1 hour, then add IPTG to make the IPTG concentration in the medium be 0.5mM, and add oleic acid to make the medium. The medium mass percentage concentration was 0.6%,
进一步优选的,所述步骤(2)中,诱导培养条件为将筛选培养的菌液降温至20℃适应1小时后,加入终浓度0.5mM的FeCl3、0.5mM终浓度5-ALA继续诱导培养18小时,分离细胞,制得诱导细胞。Further preferably, in the step (2), the induction culture condition is to cool the screened and cultured bacterial liquid to 20°C for 1 hour, then add FeCl 3 with a final concentration of 0.5mM and 5-ALA with a final concentration of 0.5mM to continue the induction culture. After 18 hours, cells were isolated and induced cells were prepared.
进一步优选的,所述步骤(2)中,分离细胞为在5000rpm条件下离心15min,收集沉淀,然后用质量百分比浓度为0.85%的盐水洗涤。Further preferably, in the step (2), the cells are separated by centrifugation at 5000 rpm for 15 minutes, the precipitate is collected, and then washed with saline with a concentration of 0.85% by mass.
根据本发明优选的,所述步骤(3)中的转化培养基组份包括如下:Preferably according to the present invention, the transformation medium components in the step (3) include the following:
甘油按质量分数计0.8~1.2%,葡萄糖按质量分数计0.3~0.5%,卡那抗生素为40-60μg/mL、氨苄抗生素90-110μg/mL、链霉素抗生素30-50μg/mL,余量溶剂为pH7.4的浓度100mM的磷酸钾缓冲液。Glycerol is 0.8-1.2% by mass fraction, glucose is 0.3-0.5% by mass fraction, kana antibiotic is 40-60 μg/mL, ampicillin antibiotic 90-110 μg/mL, streptomycin antibiotic 30-50 μg/mL, the balance The solvent was potassium phosphate buffer at a concentration of 100 mM at pH 7.4.
进一步优选的,甘油按质量百分数计1%,葡萄糖按质量百分数计0.4%,卡那抗生素50μg/mL、氨苄抗生素100μg/mL、链霉素抗生素40μg/mL,余量溶剂为pH7.4的浓度100mM的磷酸钾缓冲液。Further preferably, glycerol is 1% by mass percentage, glucose is 0.4% by mass percentage, kana antibiotic 50 μg/mL,
根据本发明优选的,步骤(3)中静息细胞中加入癸酸至浓度为0.3-0.7g/L,在28-37℃条件下反应7-10h,制得反式-2-癸烯酸;将反应液中加入大肠杆菌BL21 pET21b-CYP153AM228L-CPRBM3静息细胞,在28-37℃条件下反应10-24h,制得10-羟基-2-癸烯酸。Preferably according to the present invention, in step (3), decanoic acid is added to the resting cells to a concentration of 0.3-0.7g/L, and the reaction is carried out at 28-37°C for 7-10h to obtain trans-2-decenoic acid ; Add Escherichia coli BL21 pET21b-CYP153AM228L-CPR BM3 resting cells to the reaction solution, and react at 28-37°C for 10-24h to obtain 10-hydroxy-2-decenoic acid.
进一步优选的,所述步骤(3)中,癸酸转化浓度为0.5g/L。Further preferably, in the step (3), the conversion concentration of capric acid is 0.5 g/L.
更优选的,步骤(3)中静息细胞中加入癸酸至浓度为0.5g/L,在30℃条件下反应9h,制得反式-2-癸烯酸;将反应液中加入大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3静息细胞,在30℃条件下反应20h,制得10-羟基-2-癸烯酸。More preferably, in step (3), capric acid is added to the resting cells to a concentration of 0.5 g/L, and the reaction is carried out at 30° C. for 9 h to obtain trans-2-decenoic acid; Escherichia coli is added to the reaction solution. BL21 pET21b-CYP153A M228L-CPR BM3 resting cells were reacted at 30 °C for 20 h to obtain 10-hydroxy-2-decenoic acid.
根据本发明优选的,所述步骤(3)中,转化培养条件为在29~31℃条件下培养8小时。According to a preferred embodiment of the present invention, in the step (3), the transformation culture conditions are cultured at 29-31° C. for 8 hours.
根据本发明优选的,所述步骤(3)中,癸酸溶解于二甲基亚砜。Preferably according to the present invention, in the step (3), capric acid is dissolved in dimethyl sulfoxide.
有益效果beneficial effect
1、本发明构建重组质粒pCDFDuet-1-MaMACS-PpFadE、重组质粒pET21b-CYP153AM228L-CPRBM3、重组质粒pET28a-SUMO-ctYdiI,实现10-羟基-2-癸烯酸表达元件的高效表达,并经过特殊诱导处理后,利用工程菌大肠杆菌BL21ΔFadB、R、J,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI静息细胞以癸酸为原料发酵生产反式-2-癸烯酸,继而将上述反应液中加入工程菌大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3静息细胞继续反应,最终获得以癸酸为原料发酵生10-羟基-2-癸烯酸,从而实现以低值癸酸经过两步法生产高附加值10-羟基-2-癸烯酸的过程0.5g/L癸酸经摇瓶发酵,产生0.273g/L的10-羟基-2-癸烯酸,转化率为54.6%。1. The present invention constructs the recombinant plasmid pCDFDuet-1-MaMACS-PpFadE, the recombinant plasmid pET21b-CYP153AM228L-CPR BM3 , and the recombinant plasmid pET28a-SUMO-ctYdiI to realize the high-efficiency expression of the 10-hydroxy-2-decenoic acid expression element, and through After special induction treatment, the engineering bacteria Escherichia coli BL21ΔFadB, R, J, pCDFDuet-1-MaMACS-PpFadE, pET28a-SUMO-ctYdiI resting cells were fermented to produce trans-2-decenoic acid with capric acid as raw material, and then the The engineering bacteria Escherichia coli BL21 pET21b-CYP153A M228L-CPR BM3 resting cells were added to the above-mentioned reaction solution to continue the reaction, and finally 10-hydroxy-2-decenoic acid was obtained by fermenting raw decanoic acid as a raw material, so as to realize the process with low-value decanoic acid. Two-step production process of high value-added 10-hydroxy-2-decenoic acid 0.5g/L decanoic acid was fermented in shake flasks to produce 0.273g/L of 10-hydroxy-2-decenoic acid with a conversion rate of 54.6% .
2、本发明通过优化10-羟基-2-癸烯酸表达途径,并优化途径中的各个表达元件,转化过程中的相关条件,显著提高10-羟基-2-癸烯酸的转化率,从而使10-羟基-2-癸烯酸的工业化生产成为可能。2. The present invention significantly improves the conversion rate of 10-hydroxy-2-decenoic acid by optimizing the expression pathway of 10-hydroxy-2-decenoic acid, and optimizing each expression element in the pathway and the relevant conditions in the transformation process, thereby It makes the industrial production of 10-hydroxy-2-decenoic acid possible.
附图说明Description of drawings
图1为重组质粒结构示意图;Fig. 1 is a schematic diagram of a recombinant plasmid structure;
图中:A为重组质粒pET21b-CYP153A M228L-CPRBM3、B为重组质粒pCDFDuet-1-MaMACS-PpFadE、C为重组质粒pET28a-SUMO-ctYdiI。In the figure: A is the recombinant plasmid pET21b-CYP153A M228L-CPR BM3 , B is the recombinant plasmid pCDFDuet-1-MaMACS-PpFadE, and C is the recombinant plasmid pET28a-SUMO-ctYdiI.
图2为PCR扩增CYP153A、CPRBM3基因产物琼脂糖凝胶电泳图;Fig. 2 is the agarose gel electrophoresis picture of PCR amplification of CYP153A and CPR BM3 gene products;
图中M为marker,第一排为CYP153A基因,第二排为CPRBM3基因。In the figure, M is the marker, the first row is the CYP153A gene, and the second row is the CPR BM3 gene.
图3为PCR扩增重组质粒pET21b-CYP153A M228L-CPRBM3的目的基因条带的琼脂糖凝胶电泳图;Fig. 3 is the agarose gel electrophoresis image of the target gene band of the recombinant plasmid pET21b-CYP153A M228L-CPR BM3 amplified by PCR;
图中M为marker,图中1-4均为重组质粒pET21b-CYP153A M228L-CPRBM3线性化的条带。M in the figure is the marker, and 1-4 in the figure are the linearized bands of the recombinant plasmid pET21b-CYP153A M228L-CPR BM3 .
图4为PCR扩增ctYdiI产物琼脂糖凝胶电泳图;Fig. 4 is agarose gel electrophoresis image of PCR amplification ctYdiI product;
图中M为marker,1-5为ctydiI基因的条带。In the figure, M is the marker, and 1-5 are the bands of the ctydiI gene.
图5为Nde I,Xho I双酶切质粒pET21b质粒图;Fig. 5 is Nde I, Xho I double digestion plasmid pET21b plasmid map;
图中,泳道M为Marker;泳道1-6为酶切结果。In the figure, lane M is Marker; lanes 1-6 are the results of enzyme cleavage.
图6为pET28a-SUMO、ctYdiI双酶切脂糖凝胶电泳图;Fig. 6 is pET28a-SUMO, ctYdiI double digestion lipose gel electrophoresis image;
第一块胶图为pET28a-SUMO双酶切基因序列,图中1-3均为pET28a-SUMO双酶切后的条带;第二胶图为ctYdiI双酶切基因条带,图中1-3均为ctYdiI双酶切后的条带。The first gel map is the sequence of the pET28a-SUMO double-enzyme-digested gene, and 1-3 in the figure are the bands after pET28a-SUMO double-enzyme digestion; 3 are the bands after double digestion with ctYdiI.
图7为SDS-PAGE蛋白胶图;Figure 7 is an SDS-PAGE protein gel image;
第一块胶为BL21ΔFadB、R、J,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI蛋白表达情况,图中MaMACS为59KD、PpFadE为45KD、ctYdiI为27KD;第二块胶为大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3的蛋白表达情况,CYP153A M228L-CPRBM3蛋白为117KD。The first glue is BL21ΔFadB, R, J, pCDFDuet-1-MaMACS-PpFadE, pET28a-SUMO-ctYdiI protein expression, MaMACS is 59KD, PpFadE is 45KD, ctYdiI is 27KD; the second glue is Escherichia coli BL21 The protein expression of pET21b-CYP153A M228L-CPRBM3, CYP153A M228L-CPRBM3 protein is 117KD.
图8为癸酸产10-羟基-2-癸烯酸的色谱图;Fig. 8 is the chromatogram of decanoic acid producing 10-hydroxy-2-decenoic acid;
图中保留时间8.395min为磷酸三甲基硅醇,保留时间10.426min为反式-2-癸烯酸TMS衍生物,保留时间11.564min为月桂酸TMS衍生物,保留时间12.744min为10-羟基癸酸TMS衍生物,保留时间为13.092min为10-羟基-2癸烯酸TMS衍生物,保留时间为14.292min为棕榈酸TMS衍生物,保留时间15.564min为(Z)-油酸TMS衍生物,所述TMS为三甲基硅烷。In the figure, the retention time of 8.395min is trimethylsilanol phosphate, the retention time of 10.426min is trans-2-decenoic acid TMS derivative, the retention time of 11.564min is lauric acid TMS derivative, and the retention time of 12.744min is 10-hydroxyl Decanoic acid TMS derivative, retention time of 13.092min is 10-hydroxy-2-decenoic acid TMS derivative, retention time of 14.292min is palmitic acid TMS derivative, retention time of 15.564min is (Z)-oleic acid TMS derivative , the TMS is trimethylsilane.
图9为中间产物反式-2-癸烯酸的质谱图。Figure 9 is a mass spectrum of the intermediate product trans-2-decenoic acid.
图10为终产物10-羟基-2-癸烯酸质谱图。Figure 10 is the mass spectrum of the final product 10-hydroxy-2-decenoic acid.
图11为菌落PCR验证ΔFadRΔFadB敲除FadJ产物琼脂糖凝胶电泳图;Figure 11 is an agarose gel electrophoresis image of colony PCR to verify ΔFadRΔFadB knockout FadJ product;
图中,泳道M为Marker;泳道1-2为FadJ基因条带,泳道3-8为FadJ敲除框融合片段基因条带。In the figure, lane M is Marker; lanes 1-2 are FadJ gene bands, and lanes 3-8 are FadJ knockout box fusion fragment gene bands.
具体实施方式Detailed ways
下面结合实施例对本发明的内容作进一步阐述,但本发明保护范围并不仅局限于此。实施例中未作详细说明的操作方法均为本领域技术人员公知的常规操作方法。The content of the present invention will be further described below in conjunction with the embodiments, but the protection scope of the present invention is not limited to this. The operation methods not described in detail in the examples are conventional operation methods known to those skilled in the art.
本发明中所用的试剂及药品均为普通市售产品。The reagents and medicines used in the present invention are all common commercial products.
实施例1Example 1
海杆菌(Marinobacter aquaeolei)的烷烃羟化酶CYP153A与巨大芽孢杆菌(Bacillus megaterium)P450NADH还原酶的融合酶基因,即CYP153A-CPRBM3融合酶基因、CYP153AM228L-CPRBM3融合酶基因,脂酰CoA脱氢酶基因PpFadE、脂酰CoA合成酶基因MaMACS、酯酰辅酶A硫酯酶基因ctydiI的PCR扩增。The fusion enzyme gene of alkane hydroxylase CYP153A of Marinobacter aquaeolei and Bacillus megaterium P450NADH reductase, namely CYP153A-CPR BM3 fusion enzyme gene, CYP153AM228L-CPR BM3 fusion enzyme gene, fatty acyl CoA dehydrogenase PCR amplification of the enzyme gene PpFadE, the fatty acyl-CoA synthase gene MaMACS, and the acyl-CoA thioesterase gene ctydiI.
根据海杆菌(Marinobacter aquaeolei)的烷烃羟化酶CYP153A与巨大芽孢杆菌(Bacillus megaterium)P450NADH还原酶的融合酶基因,即CYP153A基因、CPRBM3基因、CYP153AM228L-CPRBM3融合酶基因、脂酰CoA脱氢酶基因PpFadE、脂酰CoA合成酶基因MaMACS、酯酰辅酶A硫酯酶基因ctydiI设计PCR扩增引物,上游引物的核苷酸序列分别如SEQ IDNO.1、3、5、7、9、11所示,下游引物的核苷酸序列如SEQ ID NO.2、4、6、8、10、12所示;According to the fusion enzyme genes of alkane hydroxylase CYP153A of Marinobacter aquaeolei and Bacillus megaterium P450NADH reductase, namely CYP153A gene, CPR BM3 gene, CYP153AM228L-CPR BM3 fusion enzyme gene, fatty acyl CoA dehydrogenase Enzyme gene PpFadE, fatty acyl-CoA synthase gene MaMACS, ester acyl-CoA thioesterase gene ctydiI design PCR amplification primers, and the nucleotide sequences of the upstream primers are respectively SEQ ID NO.1, 3, 5, 7, 9, 11 As shown, the nucleotide sequences of the downstream primers are shown in SEQ ID NO. 2, 4, 6, 8, 10, and 12;
其中,海杆菌(Marinobacter aquaeolei)的烷烃羟化酶CYP153A与巨大芽孢杆菌(Bacillus megaterium)P450NADH还原酶的融合酶基因,即CYP153A-CPRBM3、CYP153AM228L-CPRBM3融合酶基因,脂酰CoA脱氢酶基因PpFadE、脂酰CoA合成酶基因PpFadE、酯酰辅酶A硫酯酶基因ctYdiI的核苷酸序列分别如SEQ ID NO.13、14、15、16、17所示,对应表达的氨基酸序列如SEQ ID NO.18、19、20、21、22所示,CYP153A M228L的核苷酸序列如SEQ ID NO.23所示,CYP153A M228L的氨基酸序列如SEQ ID NO.24所示。Among them, the fusion enzyme gene of alkane hydroxylase CYP153A of Marinobacter aquaeolei and Bacillus megaterium P450NADH reductase, namely CYP153A-CPRBM3, CYP153AM228L-CPRBM3 fusion enzyme gene, fatty acyl-CoA dehydrogenase gene PpFadE , the nucleotide sequences of fatty acyl-CoA synthase gene PpFadE, ester acyl-CoA thioesterase gene ctYdiI are respectively shown in SEQ ID NO.13, 14, 15, 16, 17, and the corresponding expressed amino acid sequence is as SEQ ID NO. 18, 19, 20, 21, 22, the nucleotide sequence of CYP153A M228L is shown in SEQ ID NO.23, and the amino acid sequence of CYP153A M228L is shown in SEQ ID NO.24.
所述构建重组质粒pET21b-CYP153A-CPRBM3,包括如下步骤:The described construction of the recombinant plasmid pET21b-CYP153A-CPR BM3 includes the following steps:
以经过密码子优化的海杆菌(Marinobacter aquaeolei)的烷烃羟化酶CYP153A与巨大芽孢杆菌(Bacillus megaterium)P450NADH还原酶的融合酶基因为模板进行PCR扩增,CYP153A的上游引物的核苷酸序列如SEQ ID NO.1所示,下游引物的核苷酸序列如SEQ IDNO.2所示,CPRBM3的上游引物的核苷酸序列如SEQ ID NO.3所示,下游引物的核苷酸序列如SEQ ID NO.4所示,然后将pET21b质粒用Nde I和Xho I进行双酶切,经多片段无缝克隆试剂盒连接,制得重组质粒pET21b-CYP153A-CPRBM3;Using the fusion enzyme gene of alkane hydroxylase CYP153A of Marinobacter aquaeolei and Bacillus megaterium (Bacillus megaterium) P450NADH reductase as template to carry out PCR amplification, the nucleotide sequence of the upstream primer of CYP153A is as follows Shown in SEQ ID NO.1, the nucleotide sequence of the downstream primer is shown in SEQ ID NO.2, the nucleotide sequence of the upstream primer of CPR BM3 is shown in SEQ ID NO.3, and the nucleotide sequence of the downstream primer is shown in SEQ ID NO.3. As shown in SEQ ID NO.4, the pET21b plasmid was then double digested with Nde I and Xho I, and connected by a multi-segment seamless cloning kit to obtain a recombinant plasmid pET21b-CYP153A-CPR BM3 ;
PCR扩增体系如下,总体系25μL:The PCR amplification system is as follows, the total system is 25 μL:
100μM上游引物1.0μL,100μM下游引物1.0μL,模板1.0μL,5U/μL phanta酶(一种高保真酶)12.5μL,ddH2O 9.5μL;100 μM upstream primer 1.0 μL, 100 μM downstream primer 1.0 μL, template 1.0 μL, 5U/μL phanta enzyme (a high-fidelity enzyme) 12.5 μL, ddH 2 O 9.5 μL;
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸CYP153A 45s、CPRBM355s,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 45 s for CYP153A and CPR BM3 for 55 s, 30 cycles; extension at 72 °C for 5 min.
PCR产物回收:PCR product recovery:
PCR扩增结束后通过1%的琼脂糖凝胶电泳分析片段长短,结果如图2所示,根据片段大小切下目的条带,使用上海生工生物工程股份有限公司的DNA胶回收试剂盒回收PCR产物。After PCR amplification, the length of the fragment was analyzed by 1% agarose gel electrophoresis. The results are shown in Figure 2. The target band was cut out according to the size of the fragment and recovered using the DNA gel recovery kit from Shanghai Sangon Bioengineering Co., Ltd. PCR product.
所述构建重组质粒pET21b-CYP153A M228L-CPRBM3,包括如下步骤:The described construction of the recombinant plasmid pET21b-CYP153A M228L-CPR BM3 includes the following steps:
以构建好的pET21b-CYP153A-CPRBM3融合酶基因为模板进行PCR扩增,CYP153AM228L-CPRBM3的上游引物的核苷酸序列如SEQ ID NO.5所示,下游引物的核苷酸序列如SEQ ID NO.6所示;然后利用Dpn I酶去除原始模板后,转化到感受态细胞Escherichiacoli BL21中使其环化,得到重组质粒pET21b-CYP153A M228L-CPRBM3。Using the constructed pET21b-CYP153A-CPR BM3 fusion enzyme gene as a template to carry out PCR amplification, the nucleotide sequence of the upstream primer of CYP153AM228L-CPR BM3 is as shown in SEQ ID NO.5, and the nucleotide sequence of the downstream primer is as shown in SEQ ID NO.5 ID No. 6; then, after removing the original template with Dpn I enzyme, it was transformed into the competent cell Escherichiacoli BL21 to make it circular, and the recombinant plasmid pET21b-CYP153A M228L-CPR BM3 was obtained .
PCR扩增体系如下,总体系25μL:The PCR amplification system is as follows, the total system is 25 μL:
100μM上游引物1.0μL,100μM下游引物1.0μL,模板1.0μL,5U/μL phanta酶(一种高保真酶)12.5μL,ddH2O 9.5μL;100 μM upstream primer 1.0 μL, 100 μM downstream primer 1.0 μL, template 1.0 μL, 5U/μL phanta enzyme (a high-fidelity enzyme) 12.5 μL, ddH 2 O 9.5 μL;
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸100s,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 100 s, 30 cycles; extension at 72 °C for 5 min.
PCR产物回收:PCR product recovery:
PCR扩增结束后通过1%的琼脂糖凝胶电泳分析片段长短,结果如图3所示,得到pET21b-CYP153A M228L-CPRBM3的质粒见图1中A,根据片段大小切下目的条带,使用上海生工生物工程股份有限公司的DNA胶回收试剂盒回收PCR产物。After PCR amplification, the length of the fragment was analyzed by 1% agarose gel electrophoresis. The results are shown in Figure 3. The plasmid of pET21b-CYP153A M228L-CPR BM3 is shown in Figure 1, A, and the target band was cut according to the size of the fragment. PCR products were recovered using a DNA gel recovery kit from Shanghai Sangon Bioengineering Co., Ltd.
DpnI酶切模板DpnI digestion template
DpnI酶切体系:DpnI digestion system:
PCR产物 44μLPCR product 44μL
DpnI 1μL
10X QuickCut Buffer 5μL10X QuickCut Buffer 5μL
反应条件:37℃反应2h。Reaction conditions: 37°C for 2h.
反应完成后70℃15min失活DpnI。DpnI was inactivated at 70°C for 15 min after the completion of the reaction.
所述构建重组质粒pCDFDuet-1-MaMACS,包括如此步骤:The described construction of the recombinant plasmid pCDFDuet-1-MaMACS includes the following steps:
以大肠杆菌DH5a基因组为模板,扩增脂酰CoA合成酶基因MaMACS,上游引物的核苷酸序列如SEQ ID NO.7所示,下游引物的核苷酸序列如SEQ ID NO.8所示,然后将pCDFDuet-1质粒用Hind III、BamH I进行双酶切,经连接酶连接,制得重组质粒pCDFDuet-1-MaMACS;Using Escherichia coli DH5a genome as a template, amplify the fatty acyl-CoA synthase gene MaMACS, the nucleotide sequence of the upstream primer is shown in SEQ ID NO.7, and the nucleotide sequence of the downstream primer is shown in SEQ ID NO.8, Then the pCDFDuet-1 plasmid was double digested with Hind III and BamH I, and then ligated with ligase to obtain the recombinant plasmid pCDFDuet-1-MaMACS;
PCR扩增体系如下,总体系25μL:The PCR amplification system is as follows, the total system is 25 μL:
100μM上游引物1.0μL,100μM下游引物1.0μL,模板1.0μL,5U/μL phanta酶(一种高保真酶)12.5μL,ddH2O 9.5μL;100 μM upstream primer 1.0 μL, 100 μM downstream primer 1.0 μL, template 1.0 μL, 5U/μL phanta enzyme (a high-fidelity enzyme) 12.5 μL, ddH 2 O 9.5 μL;
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸50s,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 50 s, 30 cycles; extension at 72 °C for 5 min.
PCR产物回收:PCR product recovery:
PCR扩增结束后通过1%的琼脂糖凝胶电泳分析片段长短,根据片段大小切下目的条带,使用上海生工生物工程股份有限公司的DNA胶回收试剂盒回收PCR产物。After PCR amplification, the length of the fragment was analyzed by 1% agarose gel electrophoresis, and the target band was cut out according to the size of the fragment, and the PCR product was recovered using a DNA gel recovery kit from Shanghai Sangon Bioengineering Co., Ltd.
所述构建重组质粒pCDFDuet-1-MaMACS-PpFadE,包括如下步骤:The described construction of the recombinant plasmid pCDFDuet-1-MaMACS-PpFadE includes the following steps:
以大肠杆菌DH5a基因组为模板,扩增脂酰CoA脱氢酶基因PpFadE,上游引物的核苷酸序列如SEQ ID NO.9所示,下游引物的核苷酸序列如SEQ ID NO.10所示,然后将pCDFDuet-1-MaMACS质粒用Nde I、Ava I进行双酶切,经连接酶连接,制得重组质粒pCDFDuet-1-MaMACS-PpFadE;Take Escherichia coli DH5a genome as a template, amplify fatty acyl CoA dehydrogenase gene PpFadE, the nucleotide sequence of the upstream primer is as shown in SEQ ID NO.9, and the nucleotide sequence of the downstream primer is as shown in SEQ ID NO.10 , and then the pCDFDuet-1-MaMACS plasmid was double digested with Nde I and Ava I, and ligated by ligase to obtain the recombinant plasmid pCDFDuet-1-MaMACS-PpFadE;
PCR扩增体系如下,总体系25μL:The PCR amplification system is as follows, the total system is 25 μL:
100μM上游引物1.0μL,100μM下游引物1.0μL,模板1.0μL,5U/μL phanta酶12.5μL,ddH2O 9.5μL;100 μM upstream primer 1.0 μL, 100 μM downstream primer 1.0 μL, template 1.0 μL, 5U/μL phanta enzyme 12.5 μL, ddH 2 O 9.5 μL;
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸40s,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 40 s, 30 cycles; extension at 72 °C for 5 min.
PCR产物回收:PCR product recovery:
PCR扩增结束后通过1%的琼脂糖凝胶电泳分析片段长短,根据片段大小切下目的条带,使用上海生工生物工程股份有限公司的DNA胶回收试剂盒回收PCR产物。After PCR amplification, the length of the fragment was analyzed by 1% agarose gel electrophoresis, and the target band was cut out according to the size of the fragment, and the PCR product was recovered using a DNA gel recovery kit from Shanghai Sangon Bioengineering Co., Ltd.
所述构建重组质粒pET28a-SUMO-ctYdiI,包括如下步骤:The described construction of recombinant plasmid pET28a-SUMO-ctYdiI includes the following steps:
扩增酯酰辅酶A硫酯酶基因ctydiI,上游引物的核苷酸序列如SEQ ID NO.11所示,下游引物的核苷酸序列如SEQ ID NO.12所示,然后将pET28a-SUMO质粒和酯酰辅酶A硫酯酶基因ctydiI分别用BamH I和Xho I分别进行双酶切,经连接酶连接,制得重组质粒pET28a-SUMO-ctYdiI;Amplify the acyl-CoA thioesterase gene ctydiI, the nucleotide sequence of the upstream primer is shown in SEQ ID NO.11, and the nucleotide sequence of the downstream primer is shown in SEQ ID NO.12, and then the pET28a-SUMO plasmid And the acyl-CoA thioesterase gene ctydiI was double digested with BamH I and Xho I respectively, and ligated by ligase to obtain the recombinant plasmid pET28a-SUMO-ctYdiI;
PCR扩增体系如下,总体系25μL:The PCR amplification system is as follows, the total system is 25 μL:
100μM上游引物1.0μL,100μM下游引物1.0μL,模板1.0μL,5U/μL phanta酶12.5μL,ddH2O 9.5μL;100 μM upstream primer 1.0 μL, 100 μM downstream primer 1.0 μL, template 1.0 μL, 5U/μL phanta enzyme 12.5 μL, ddH 2 O 9.5 μL;
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸15s,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 15 s, 30 cycles; extension at 72 °C for 5 min.
PCR产物回收:PCR product recovery:
PCR扩增结束后通过1%的琼脂糖凝胶电泳分析片段长短,结果如图4所示,根据片段大小切下目的条带,使用上海生工生物工程股份有限公司的DNA胶回收试剂盒回收PCR产物。After PCR amplification, the length of the fragment was analyzed by 1% agarose gel electrophoresis. The results are shown in Figure 4. The target band was cut out according to the size of the fragment and recovered using the DNA gel recovery kit from Shanghai Sangon Bioengineering Co., Ltd. PCR product.
实施例2Example 2
重组质粒载体pET21b、pCDFDuet-1、pCDFDuet-1-MaMACS、pET28a-SUMO及基因ctYdiI的酶切Recombinant plasmid vector pET21b, pCDFDuet-1, pCDFDuet-1-MaMACS, pET28a-SUMO and gene ctYdiI digestion
提取pET21b质粒并对其进行双酶切反应,反应体系如下:The pET21b plasmid was extracted and subjected to double digestion reaction. The reaction system was as follows:


反应条件:37℃反应6h。Reaction conditions: 37°C for 6h.
pET21b质粒载体双酶切后经1%琼脂糖凝胶电泳纯化图5,并使用DNA胶回收试剂盒进行目的片段回收。The pET21b plasmid vector was double digested and purified by 1% agarose gel electrophoresis as shown in Figure 5, and the target fragment was recovered using a DNA gel recovery kit.
提取pCDFDuet-1质粒并对其进行双酶切反应,反应体系如下:The pCDFDuet-1 plasmid was extracted and subjected to double-enzyme digestion reaction. The reaction system was as follows:

反应条件:37℃反应6h。Reaction conditions: 37°C for 6h.
pCDFDuet-1质粒载体双酶切后经1%琼脂糖凝胶电泳纯化,并使用DNA胶回收试剂盒进行目的片段回收。The pCDFDuet-1 plasmid vector was double digested and purified by 1% agarose gel electrophoresis, and the target fragment was recovered using a DNA gel recovery kit.
提取pCDFDuet-1-MaMACS质粒并对其进行双酶切反应,反应体系如下:The pCDFDuet-1-MaMACS plasmid was extracted and subjected to double digestion reaction. The reaction system was as follows:

反应条件:37℃反应6h。Reaction conditions: 37°C for 6h.
pCDFDuet-1-MaMACS质粒载体双酶切后经1%琼脂糖凝胶电泳纯化,并使用DNA胶回收试剂盒进行目的片段回收。The pCDFDuet-1-MaMACS plasmid vector was double digested and purified by 1% agarose gel electrophoresis, and the target fragment was recovered using a DNA gel recovery kit.
提取pET28a-SUMO质粒及酯酰CoA硫酯酶ctYdiI PCR产物进行双酶切反应,反应体系如下:The pET28a-SUMO plasmid and the acyl-CoA thioesterase ctYdiI PCR product were extracted and subjected to double digestion reaction. The reaction system was as follows:

反应条件:37℃反应6h。Reaction conditions: 37°C for 6h.
pET28a-SUMO质粒及酯酰CoA硫酯酶ctYdiI PCR产物经双酶切后经1%琼脂糖凝胶电泳纯化图6,并使用DNA胶回收试剂盒进行目的片段回收。The pET28a-SUMO plasmid and the acyl-CoA thioesterase ctYdiI PCR product were double digested and purified by 1% agarose gel electrophoresis as shown in Figure 6, and the target fragment was recovered using a DNA gel recovery kit.
实施例3Example 3
重组质粒pET21b-CYP153A-CPRBM3多片段无缝克隆、重组质粒pET28a-SUMO-ctYdiI连接Recombinant plasmid pET21b-CYP153A-CPR BM3 multi-fragment seamless cloning, recombinant plasmid pET28a-SUMO-ctYdiI ligation
将经过双酶切的pET21b质粒与CYP153A、CPRBM3 PCR产物连接,连接反应体系如下:The pET21b plasmid that has undergone double digestion is connected with the CYP153A, CPR BM3 PCR products, and the ligation reaction system is as follows:

将上述连接反应体系充分混匀后离心数秒,将管壁液滴收到管底,37℃连接30min,得重组质粒pET21b-CYP153A-CPRBM3。The above-mentioned ligation reaction system was thoroughly mixed, centrifuged for several seconds, the droplets on the tube wall were collected at the bottom of the tube, and ligated at 37°C for 30 min to obtain the recombinant plasmid pET21b-CYP153A-CPR BM3 .
将经过酶切的pCDFDuet-1质粒与MaMACS PCR产物连接,连接反应体系如下:The digested pCDFDuet-1 plasmid was ligated with the MaMACS PCR product, and the ligation reaction system was as follows:
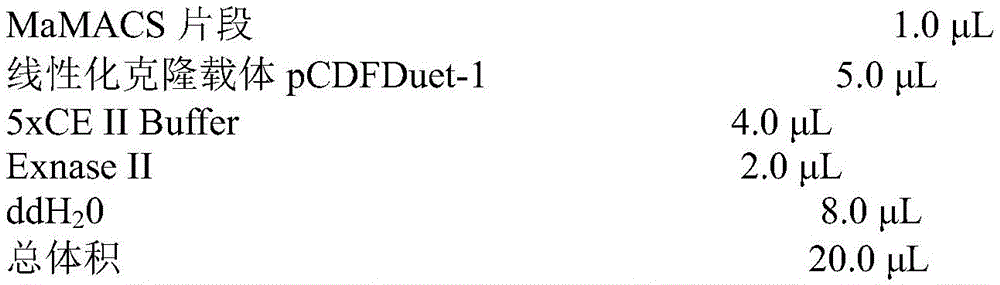
将上述连接反应体系充分混匀后离心数秒,将管壁液滴收到管底,37℃反应37min,得重组质粒pCDFDuet-1-MaMACS。The above-mentioned ligation reaction system was thoroughly mixed, centrifuged for several seconds, the droplets on the tube wall were collected at the bottom of the tube, and the reaction was carried out at 37° C. for 37 minutes to obtain the recombinant plasmid pCDFDuet-1-MaMACS.
将经过酶切的pCDFDuet-1-MaMACS质粒与PpFadE PCR产物连接,连接反应体系如下:The digested pCDFDuet-1-MaMACS plasmid was ligated with the PpFadE PCR product, and the ligation reaction system was as follows:

将上述连接反应体系充分混匀后离心数秒,将管壁液滴收到管底,37℃反应37min,得重组质粒pCDFDuet-1-MaMACS-PpFadE见图1中B。The above ligation reaction system was fully mixed, centrifuged for several seconds, the tube wall was dropped to the bottom of the tube, and the reaction was carried out at 37°C for 37 minutes to obtain the recombinant plasmid pCDFDuet-1-MaMACS-PpFadE as shown in Figure 1B.
将经过双酶切的pET28a-SUMO质粒与ctYdiI PCR产物连接,连接反应体系如下:The double digested pET28a-SUMO plasmid was ligated with the ctYdiI PCR product, and the ligation reaction system was as follows:

将上述连接反应体系充分混匀后离心数秒,将管壁液滴收到管底,22℃连接2小时,得重组质粒pET28a-SUMO-ctYdiI见图1中C。After fully mixing the above ligation reaction system, centrifuge for a few seconds, drop the tube wall to the bottom of the tube, and connect at 22°C for 2 hours to obtain the recombinant plasmid pET28a-SUMO-ctYdiI as shown in C in Figure 1.
实施例4Example 4
重组质粒pET21b-CYP153A-CPRBM3、重组质粒pET21b-CYP153A M228L-CPRBM3、重组质粒pCDFDuet-1-MaMACS-PpFadE、重组质粒pET28a-SUMO-ctYdiI的转化:Transformation of recombinant plasmid pET21b-CYP153A-CPR BM3 , recombinant plasmid pET21b-CYP153A M228L-CPR BM3 , recombinant plasmid pCDFDuet-1-MaMACS-PpFadE, recombinant plasmid pET28a-SUMO-ctYdiI:
(1)感受态细胞的制备(1) Preparation of competent cells
①挑取大肠杆菌BL21(DE3)单菌落(或挑取保存菌种)接种至10ml液体LB培养基,37℃、210rpm过夜培养;①Pick a single colony of Escherichia coli BL21(DE3) (or pick a preserved strain) and inoculate it into 10ml of liquid LB medium, and cultivate overnight at 37°C and 210rpm;
②取5ml菌液接种于500ml LB培养基中,37℃、210rpm培养至菌液OD600为0.375左右;② Take 5ml of bacterial liquid and inoculate it in 500ml of LB medium, and cultivate at 37°C and 210rpm until the bacterial liquid OD 600 is about 0.375;
③将菌液放置于冰水混合物上10min,同时预冷50ml离心管;③Place the bacterial liquid on the ice-water mixture for 10min, and pre-cool a 50ml centrifuge tube at the same time;
④将菌液转移到离心管中,4℃,3700rpm离心10min收集菌体;④ Transfer the bacterial liquid to a centrifuge tube, centrifuge at 4°C and 3700 rpm for 10 min to collect the bacterial cells;
⑤每个离心管中加入10mL预冷的0.1M CaCl2溶液,重悬菌体,再加入30mL预冷的0.1M CaCl2溶液,颠倒混匀,冰上静置20min;⑤ Add 10 mL of pre-cooled 0.1M CaCl 2 solution to each centrifuge tube, resuspend the cells, then add 30 mL of pre-cooled 0.1 M CaCl 2 solution, invert and mix, and let stand on ice for 20 min;
⑥4℃,3700rpm离心10min收集菌体,按照与步骤④中菌液的体积比为3:125的比例加入预冷的含有15%甘油的0.1M的CaCl2溶液,重悬菌体,得感受态细胞;⑥ 4 ℃, 3700rpm centrifugation for 10min to collect the bacteria, add pre-cooled 0.1M CaCl 2 solution containing 15% glycerol according to the volume ratio of the bacteria liquid in
⑦将感受态细胞分装,并于-80℃冻存。⑦ Distribute the competent cells and freeze them at -80℃.
同理制备大肠杆菌基因缺失菌BL21(ΔFadB、R、J)的感受态细胞。Competent cells of Escherichia coli gene deletion strain BL21 (ΔFadB, R, J) were prepared in the same way.
大肠杆菌基因缺失菌BL21ΔFadB、R、J的构建方法,包括如下步骤:The construction method of Escherichia coli gene deletion bacteria BL21ΔFadB, R, J, including the following steps:
Ⅰ利用RED重组法敲除基因,构建基因缺失ΔFadRB菌种,以下称为ΔFadRΔFadB菌种;该菌种的构建方法参见中国专利文献CN110684794A(申请号:201911038194.3)。Ⅰ Knock out the gene by RED recombination method to construct a gene-deficient ΔFadRB strain, hereinafter referred to as a ΔFadRΔFadB strain; the construction method of this strain is referred to in Chinese patent document CN110684794A (application number: 201911038194.3).
Ⅱ构建FadJ敲除框,具体步骤如下:Ⅱ Constructing the FadJ knockout box, the specific steps are as follows:
以大肠杆菌BL21基因组为模板,扩增3-羟酰辅酶A脱氢酶基因的上游同源臂FadJ1,上游引物的核苷酸序列如SEQ ID NO.25所示,下游引物的核苷酸序列如SEQ IDNO.26所示;以大肠杆菌BL21基因组为模板,扩增3-羟酰辅酶A脱氢酶基因的下游同源臂FadJ2,上游引物的核苷酸序列如SEQ ID NO.27所示,下游引物的核苷酸序列如SEQ IDNO.28所示;以pkd3质粒为模板,扩增FRT-RKan—FRT基因片段,上游引物的核苷酸序列如SEQ ID NO.29所示,下游引物的核苷酸序列如SEQ ID NO.30所示;然后将FadJl、FRT-RKan-FRT与FadJ2基因片段多片段无缝克隆,扩增FadJ1-Kan-FadJ2的敲除框片段,上游引物的核苷酸序列如SEQ ID NO.31所示,下游引物的核苷酸序列如SEQ ID NO.32所示,纯化胶回收获得FadJ敲除框(以下将FadJ敲除框缩写为Jk);Using the genome of Escherichia coli BL21 as a template, the upstream homology arm FadJ1 of the 3-hydroxyacyl-CoA dehydrogenase gene was amplified. The nucleotide sequence of the upstream primer is shown in SEQ ID NO.25, and the nucleotide sequence of the downstream primer As shown in SEQ ID NO.26; using Escherichia coli BL21 genome as a template, amplify the downstream homology arm FadJ2 of 3-hydroxyacyl-CoA dehydrogenase gene, and the nucleotide sequence of the upstream primer is shown in SEQ ID NO.27 , the nucleotide sequence of the downstream primer is shown in SEQ ID NO.28; the pkd3 plasmid is used as a template to amplify the FRT-RKan-FRT gene fragment, the nucleotide sequence of the upstream primer is shown in SEQ ID NO.29, the downstream primer The nucleotide sequence is shown in SEQ ID NO.30; then FadJ1, FRT-RKan-FRT and FadJ2 gene fragment multi-fragment seamless cloning, amplifying the knockout frame fragment of FadJ1-Kan-FadJ2, the core of the upstream primer The nucleotide sequence is shown in SEQ ID NO.31, the nucleotide sequence of the downstream primer is shown in SEQ ID NO.32, and the FadJ knockout frame is recovered from the purification gel (hereinafter, the FadJ knockout frame is abbreviated as Jk);
PCR扩增体系如下,总体系50μL:The PCR amplification system is as follows, the total system is 50 μL:
100μM上游引物2.0μL,100μM下游引物2.0μL,模板2.0μL,5U/μL phanta酶25μL,ddH2O19μL;100μM upstream primer 2.0μL, 100μM downstream primer 2.0μL, template 2.0μL, 5U/μL phanta enzyme 25μL, ddH2O 19μL;
PCR扩增条件如下:PCR amplification conditions are as follows:
95℃预变性3min;95℃变性15s,60℃退火15s,72℃延伸1min15s,循环30次;72℃延伸5min。Pre-denaturation at 95 °C for 3 min; denaturation at 95 °C for 15 s, annealing at 60 °C for 15 s, extension at 72 °C for 1 min 15 s, 30 cycles; extension at 72 °C for 5 min.
Ⅲ将步骤Ⅱ制备的FadJ敲除框转化入pkd46-ΔFadRΔFadB重组菌,最终获得大肠杆菌基因缺失菌BL21ΔFadB、R、J,具体步骤如下:Ⅲ Transform the FadJ knockout box prepared in step Ⅱ into pkd46-ΔFadRΔFadB recombinant bacteria, and finally obtain Escherichia coli gene deletion bacteria BL21ΔFadB, R, J, and the specific steps are as follows:
a、将质粒pkd46转化进ΔFadRΔFadB感受态细胞中,获得的pkd46-ΔFadRΔFadB重组菌,制备pkd46-ΔFadRΔFadB感受态细胞,再用质量浓度为10%的甘油保存制备的pkd46-ΔFadRΔFadB感受态细胞;a. The plasmid pkd46 was transformed into ΔFadRΔFadB competent cells, and the obtained pkd46-ΔFadRΔFadB recombinant bacteria were prepared to prepare pkd46-ΔFadRΔFadB competent cells, and then the prepared pkd46-ΔFadRΔFadB competent cells were stored in 10% glycerol;
b、将FadJ敲除框Jk转化进pkd46-ΔFadRΔFadB感受态细胞中,验证pkd46-Jk-BL21重组菌确认敲除框转入后,42℃消除pkd46,筛选后得到Jk-ΔFadRΔFadB重组菌;b. Transform the FadJ knockout box Jk into pkd46-ΔFadRΔFadB competent cells, and verify that the pkd46-Jk-BL21 recombinant strain confirms that after the knockout frame is transferred, pkd46 is eliminated at 42°C, and the Jk-ΔFadRΔFadB recombinant strain is obtained after screening;
c、将Jk-ΔFadRΔFadB重组菌制备感受态转化pcp20质粒,42℃消除Jk抗性以及pcp20质粒,获得ΔFadRBJ重组菌,即大肠杆菌基因缺失菌BL21ΔFadB、R、J。c. The Jk-ΔFadRΔFadB recombinant strain was prepared and transformed into the pcp20 plasmid, and the Jk resistance and pcp20 plasmid were eliminated at 42°C to obtain the ΔFadRBJ recombinant strain, namely the E. coli gene-deficient strain BL21ΔFadB, R, J.
图11为菌落PCR验证ΔFadRΔFadB敲除FadJ产物琼脂糖凝胶电泳图;Figure 11 is an agarose gel electrophoresis image of colony PCR to verify ΔFadRΔFadB knockout FadJ product;
图中,泳道M为Marker;泳道1-2为FadJ基因条带,泳道3-8为FadJ敲除框融合片段基因条带。In the figure, lane M is Marker; lanes 1-2 are FadJ gene bands, and lanes 3-8 are FadJ knockout box fusion fragment gene bands.
(2)重组质粒的转化(2) Transformation of recombinant plasmids
①将10μL重组质粒pET21b-CYP153A M228L-CPRBM3加入到100μL新鲜制备的大肠杆菌BL21感受态细胞中,轻轻混匀,冰浴30min;10μL重组质粒pET21b-CYP153A-CPRBM3加入到100μL新鲜制备的大肠杆菌BL21感受态细胞中,轻轻混匀,冰浴30min;将10μL重组质粒pCDFDuet-1-MaMACS-PpFadE、重组质粒pET28a-SUMO-ctYdiI同时加入到100μL新鲜制备的大肠杆菌基因缺失菌BL21ΔFadB、R、J的感受态细胞中。
②42℃热激90s,然后迅速置于冰浴中冷却3min;② Heat shock at 42°C for 90s, then quickly cool in an ice bath for 3min;
③将上述感受态细胞接入到500μL LB培养基,37℃,200rpm振荡培养60min;③ The above-mentioned competent cells were inserted into 500 μL LB medium, 37 ° C, 200 rpm shaking culture for 60 min;
④取上述菌液200μL,涂布于带有100mg/mL、50mg/mL、40mg/mL氨苄青霉素、卡娜霉素、链霉素的LB固体培养基;4. get 200 μL of above-mentioned bacterial liquid, spread on the LB solid medium with 100mg/mL, 50mg/mL, 40mg/mL ampicillin, kanamycin, streptomycin;
⑤37℃培养箱中正置30min,待菌液被吸干后,倒置平板于37℃培养12-16h。⑤Incubate in a 37℃ incubator for 30min, after the bacterial liquid is sucked dry, invert the plate and incubate at 37℃ for 12-16h.
(3)阳性克隆的鉴定:(3) Identification of positive clones:
①蛋白表达及可溶性鉴定①Protein expression and solubility identification
取上述菌液900μL,并加入终浓度为0.32mM的IPTG,诱导表达4h,12000rpm离心1min,收集菌体,加入2倍上样缓冲液,重悬菌体,100℃水浴变性10min,用SDS-PAGE检测蛋白表达,结果如图7所示,显示为阳性克隆。Take 900 μL of the above bacterial solution, add IPTG with a final concentration of 0.32 mM, induce expression for 4 h, centrifuge at 12,000 rpm for 1 min, collect the bacterial cells, add 2 times the loading buffer, resuspend the bacterial cells, denature them in a water bath at 100 °C for 10 min, and use SDS- The protein expression was detected by PAGE, and the results were shown in Figure 7, which were shown as positive clones.
②菌样测序②Bacteria sample sequencing
将用以上两种方法鉴定后的阳性克隆,送至测序公司进行测序,进一步证明构建的阳性克隆的正确性,获得大肠杆菌BL21ΔFadB、R、J,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI;大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3;大肠杆菌BL21pET21b-CYP153A-CPRBM3;The positive clones identified by the above two methods were sent to a sequencing company for sequencing to further prove the correctness of the constructed positive clones. ctYdiI; Escherichia coli BL21 pET21b-CYP153A M228L-CPR BM3 ; Escherichia coli BL21 pET21b-CYP153A-CPR BM3 ;
实施例5Example 5
大肠杆菌BL21ΔFadB、R、J,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI及大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3融合酶工程菌发酵Fermentation of E. coli BL21ΔFadB, R, J, pCDFDuet-1-MaMACS-PpFadE, pET28a-SUMO-ctYdiI and E. coli BL21 pET21b-CYP153A M228L-CPR BM3 fusion enzyme engineering bacteria
(1)菌种活化:将实施例4中的大肠杆菌BL21ΔFadB、R、J,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI以1%的接种量接种至50mL的含有卡那霉素和链霉素的液体LB培养基中,在37℃、200rpm振荡培养12h;(1) Strain activation: Escherichia coli BL21ΔFadB, R, J, pCDFDuet-1-MaMACS-PpFadE, pET28a-SUMO-ctYdiI in Example 4 were inoculated into 50 mL containing kanamycin and In liquid LB medium of streptomycin, shake culture at 37°C and 200rpm for 12h;
(2)菌体转接:取上述活化菌株3mL接入300mL含有卡那霉素和链霉素的液体培养基中,37℃、200rpm振荡培养至菌液OD600为1.0时,降温至20℃适应1小时后,加入IPTG使培养基中IPTG浓度为0.5mM、加入油酸使培养基中油酸质量百分比浓度为0.6%、加入吐温80使培养基中吐温80的质量百分比浓度为0.3%,过夜诱导培养;(2) Bacterial transfer: Take 3 mL of the above-mentioned activated strain and insert it into 300 mL of liquid medium containing kanamycin and streptomycin, and shake at 37 ° C and 200 rpm until the OD600 of the bacterial liquid is 1.0, then cool to 20 ° C to adapt After 1 hour, adding IPTG to make the IPTG concentration in the medium be 0.5 mM, adding oleic acid to make the oleic acid mass percent concentration in the medium 0.6%, adding
(3)收集菌体:取上述菌液300mL,5000rpm,4℃离心15min,收集菌体;(3) Collecting the bacterial cells: take 300 mL of the above bacterial liquid, centrifuge at 5000 rpm for 15 min at 4°C, and collect the bacterial cells;
(4)用0.85%生理盐水洗涤沉淀三次,并用转化培养基重悬菌体制备菌悬液。转化培养基包含100mM磷酸钾缓冲液(pH7.4),质量浓度1%的甘油,质量浓度0.4%的葡萄糖,50μg/mL的卡那抗生素、40μg/mL的链霉素,总体积为30mL,分别加入0.5g/L的癸酸进行反应。30℃反应20h并在9h取样。(4) Wash the pellet three times with 0.85% physiological saline, and resuspend the bacteria in the transformation medium to prepare a bacterial suspension. The transformation medium contains 100 mM potassium phosphate buffer (pH 7.4), 1% glycerol, 0.4% glucose, 50 μg/mL kana antibiotic, 40 μg/mL streptomycin, and the total volume is 30 mL, 0.5g/L capric acid was added respectively to carry out the reaction. React at 30°C for 20h and sample at 9h.
大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3融合酶工程菌发酵Escherichia coli BL21 pET21b-CYP153A M228L-CPR BM3 fusion enzyme engineering bacteria fermentation
(1)菌种活化:将实施例4中的大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3以1%的接种量接种至50mL的含有氨苄青霉素的液体LB培养基中,在37℃、200rpm振荡培养12h;(1) Activation of strains: E. coli BL21 pET21b-CYP153A M228L-CPR BM3 in Example 4 was inoculated into 50 mL of liquid LB medium containing ampicillin at an inoculum of 1%, and cultured with shaking at 37° C. and 200 rpm. 12h;
(2)菌体转接:取上述活化菌株3mL接入300mL含有氨苄青霉素的液体培养基中,37℃、200rpm振荡培养至菌液OD600为1.0时,降温至20℃适应1小时后,加入加入IPTG使培养基中IPTG浓度为0.5mM、加入终浓度0.5mM的FeCl3、0.5mM终浓度5-ALA(5-氨基乙酰丙酸盐酸盐)继续诱导培养18小时,分离细胞,制得诱导细胞;(2) Bacterial transfer: Take 3 mL of the above-mentioned activated bacterial strain and insert it into 300 mL of liquid medium containing ampicillin, shake at 37 ° C and 200 rpm until the OD600 of the bacterial liquid is 1.0, cool down to 20 ° C and adapt to 1 hour, add IPTG The IPTG concentration in the medium was 0.5 mM, FeCl 3 with a final concentration of 0.5 mM, and 5-ALA (5-aminolevulinic acid hydrochloride) with a final concentration of 0.5 mM were added to induce and culture for 18 hours. cell;
(3)收集菌体:取上述菌液300mL,5000rpm,4℃离心15min,收集菌体;(3) Collecting the bacterial cells: take 300 mL of the above bacterial liquid, centrifuge at 5000 rpm for 15 min at 4°C, and collect the bacterial cells;
(4)用0.85%生理盐水洗涤沉淀三次,并用转化培养基重悬菌体制备菌悬液。转化培养基包含100mM磷酸钾缓冲液(pH7.4),菌体重悬后体积为3mL,将其加入到上一步反应完成的反应体系中,30℃反应20h取样。反应终止后加入1mL 0.4mol/L HCl终止反应,加入0.1g/L月桂酸作为内标。(4) Wash the pellet three times with 0.85% physiological saline, and resuspend the bacteria in the transformation medium to prepare a bacterial suspension. The transformation medium contained 100 mM potassium phosphate buffer (pH 7.4), and the volume of the bacteria was 3 mL after resuspending, which was added to the reaction system completed in the previous step, and sampled at 30° C. for 20 h. After the reaction was terminated, 1 mL of 0.4 mol/L HCl was added to terminate the reaction, and 0.1 g/L of lauric acid was added as an internal standard.
发酵液硅烷化处理:取1mL发酵液于1.5mL离心管中,每个样品用1.5mL乙酸乙酯萃取样品溶液中的脂肪酸(每次750μL),旋流混合器混合60s,室温下4000r/m离心10min。取提取液蒸发干燥,干燥后的样品重新溶解在0.5mL乙酸乙酯(色谱纯)、0.5mL正己烷(色谱纯)中,100μL BSTFA-TMCS(99:1,v/v)衍生化试剂加入后室温放置5min,在70℃的烤箱中孵育50min。Fermentation broth silanization treatment: take 1 mL of fermentation broth into a 1.5 mL centrifuge tube, extract the fatty acids in the sample solution with 1.5 mL of ethyl acetate for each sample (750 μL each time), mix with a cyclone mixer for 60 s, at room temperature 4000 r/m Centrifuge for 10 min. The extract was evaporated to dryness, and the dried sample was redissolved in 0.5 mL of ethyl acetate (chromatographically pure), 0.5 mL of n-hexane (chromatically pure), and 100 μL of BSTFA-TMCS (99:1, v/v) derivatization reagent was added After 5 min at room temperature, incubate in an oven at 70 °C for 50 min.
气相质谱检测生成产物:气相色谱以氦气为载气,恒流模式,进样体积1μL,分流进样,分流比为1:5,进样温度250℃,50℃保持1min,以15℃/min升至250℃,保持10min。产物色谱图如图8、图9、图10所示。Gas mass spectrometry detection of generated products: gas chromatography with helium as carrier gas, constant flow mode, injection volume of 1 μL, split injection, split ratio of 1:5, injection temperature of 250 °C, maintained at 50 °C for 1 min, at 15 °C / min to 250 °C and hold for 10 min. The product chromatograms are shown in Figure 8, Figure 9, and Figure 10.
通过对产物的色谱图、质谱图计算分析,得出癸酸经过两步法生产高附加值10-羟基-2-癸烯酸的过程0.5g/L癸酸经摇瓶发酵,产生0.273g/L的10-羟基-2-癸烯酸,转化率为54.6%Through the calculation and analysis of the chromatogram and mass spectrum of the product, it was concluded that decanoic acid produced 10-hydroxy-2-decenoic acid with high added value through a two-step method. L of 10-hydroxy-2-decenoic acid with a conversion of 54.6%
对比例1Comparative Example 1
与实施例5重组菌发酵的不同之处在于,用实施例4获得的大肠杆菌BL21pET21b-CYP153A-CPRBM3代替大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3,其他均相同,实验结果得出0.5g/L癸酸经摇瓶发酵,产生0.077g/L的10-羟基-2-癸烯酸,转化率为15.4%The difference from the fermentation of the recombinant bacteria in Example 5 is that the E. coli BL21pET21b-CYP153A-CPR BM3 obtained in Example 4 was used to replace the E. coli BL21 pET21b-CYP153A M228L-CPR BM3 . L decanoic acid was fermented in shake flasks to produce 0.077 g/L of 10-hydroxy-2-decenoic acid with a conversion rate of 15.4%
对比例2Comparative Example 2
重组质粒pET21b-CYP153A M228L-CPRBM3、重组质粒pCDFDuet-1-MaMACS-PpFadE、重组质粒pET28a-SUMO-ctYdiI的转化与实施例4的不同之处在于,同理制备大肠杆菌基因缺失菌BL21(ΔFadB、R)的感受态细胞,将重组质粒pCDFDuet-1-MaMACS-PpFadE、重组质粒pET28a-SUMO-ctYdiI转化入新鲜制备的大肠杆菌基因缺失菌BL21ΔFadB、R的感受态细胞中,获得大肠杆菌BL21ΔFadB、R,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI;其他均相同。The difference between the transformation of the recombinant plasmid pET21b-CYP153A M228L-CPR BM3 , the recombinant plasmid pCDFDuet-1-MaMACS-PpFadE, and the recombinant plasmid pET28a-SUMO-ctYdiI and Example 4 is that the E. coli gene deletion bacteria BL21 (ΔFadB , R) competent cells, the recombinant plasmid pCDFDuet-1-MaMACS-PpFadE, recombinant plasmid pET28a-SUMO-ctYdiI was transformed into the competent cells of freshly prepared Escherichia coli gene deletion bacteria BL21ΔFadB, R, to obtain Escherichia coli BL21ΔFadB, R, pCDFDuet-1-MaMACS-PpFadE, pET28a-SUMO-ctYdiI; others are the same.
将获得的大肠杆菌BL21ΔFadB、R,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI及大肠杆菌BL21 pET21b-CYP153A M228L-CPRBM3融合酶工程菌发酵,发酵方法同实施例5相同,实验结果得出大肠杆菌BL21ΔFadB、R,pCDFDuet-1-MaMACS-PpFadE、pET28a-SUMO-ctYdiI催化癸酸并不能产生反式-2-癸烯酸,所以也就无法产生10-羟基-2癸烯酸。The obtained Escherichia coli BL21ΔFadB, R, pCDFDuet-1-MaMACS-PpFadE, pET28a-SUMO-ctYdiI and Escherichia coli BL21 pET21b-CYP153A M228L-CPR BM3 fusion enzyme engineering bacteria were fermented, and the fermentation method was the same as in Example 5, and the experimental results obtained Escherichia coli BL21ΔFadB, R, pCDFDuet-1-MaMACS-PpFadE, pET28a-SUMO-ctYdiI catalyzed decanoic acid and could not produce trans-2-decenoic acid, so 10-hydroxy-2-decenoic acid could not be produced.
本实验以癸酸为底物,利用两步法生物级联催化生成10-HDA,前期实验室以癸酸为底物一步法合成10-HAD,本申请通过优化获得的脂酰CoA脱氢酶基因PpFadE、脂酰CoA合成酶基因MaMACS、酰辅酶A硫酯酶基因ctydiI构建的合成途径与专利文献CN109897870A中脂酰CoA脱氢酶基因MCAD、脂酰CoA合成酶基因FadK、酰辅酶A硫酯酶基因ydiI并非相同基因,本文中的P450融合酶是将228位的氨基酸由M变为L,通过催化元件的替换以及生物合成方式的变化,可以显著提高10-HDA产量。In this experiment, decanoic acid was used as the substrate, and 10-HDA was generated by two-step biological cascade catalysis. In the previous laboratory, 10-HAD was synthesized by one-step method with decanoic acid as the substrate. The fatty acyl-CoA dehydrogenase obtained by optimization in this application The synthetic pathway constructed by gene PpFadE, fatty acyl-CoA synthase gene MaMACS, acyl-CoA thioesterase gene ctydiI and patent document CN109897870A fatty acyl-CoA dehydrogenase gene MCAD, fatty acyl-CoA synthase gene FadK, acyl-CoA thioester The enzyme gene ydiI is not the same gene. The P450 fusion enzyme in this paper changes the amino acid at position 228 from M to L. The production of 10-HDA can be significantly improved by the replacement of catalytic elements and the change of biosynthesis.
由实施例5与对比例2的实验结果可以看出本发明使用大肠杆菌基因缺失菌BL21ΔFadB、R、J作为重组质粒pCDFDuet-1-MaMACS-PpFadE、重组质粒pET28a-SUMO-ctYdiI的转化宿主菌,催化癸酸产生反式-2-癸烯酸具有特异性,与大肠杆菌BL21 pET21b-CYP153AM228L-CPRBM3融合酶工程菌结合两步法合成10-羟基-2癸烯酸,最终10-羟基-2-癸烯酸的转化率达54.6%显著优于大肠杆菌基因缺失菌BL21ΔFadB、R作为宿主菌的作用效果。From the experimental results of Example 5 and Comparative Example 2, it can be seen that the present invention uses Escherichia coli gene deletion bacteria BL21ΔFadB, R, and J as the transformation host bacteria of recombinant plasmid pCDFDuet-1-MaMACS-PpFadE and recombinant plasmid pET28a-SUMO-ctYdiI, Catalytic decanoic acid to produce trans-2-decenoic acid with specificity, combined with Escherichia coli BL21 pET21b-CYP153AM228L-CPR BM3 fusion enzyme engineering bacteria to synthesize 10-hydroxy-2-decenoic acid in two steps, and finally 10-hydroxy-2 -The conversion rate of decenoic acid reached 54.6%, which was significantly better than the effect of E. coli gene deletion bacteria BL21ΔFadB, R as the host bacteria.
SEQUENCE LISTINGSEQUENCE LISTING
<110> 齐鲁工业大学<110> Qilu University of Technology
<120> 一种大肠杆菌工程菌及应用<120> A kind of Escherichia coli engineering bacteria and its application
<160> 32<160> 32
<170> PatentIn version 3.5<170> PatentIn version 3.5
<210> 1<210> 1
<211> 42<211> 42
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 1<400> 1
taagaaggag atatacatat gatgccgacg ttaccacgta cc 42taagaaggag atatacatat gatgccgacg ttaccacgta cc 42
<210> 2<210> 2
<211> 39<211> 39
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 2<400> 2
tgccgcccat actattaggt gtcagtttaa ccattaagc 39tgccgcccat actattaggt gtcagtttaa ccattaagc 39
<210> 3<210> 3
<211> 28<211> 28
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 3<400> 3
acctaatagt atgggcggca ttccttca 28acctaatagt atgggcggca ttccttca 28
<210> 4<210> 4
<211> 41<211> 41
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 4<400> 4
gtggtggtgg tggtgctcga gttacccagc ccacacgtct t 41gtggtggtgg tggtgctcga gttacccagc ccacacgtct t 41
<210> 5<210> 5
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 5<400> 5
cgcaccggcc aagcgatcgc tcc 23cgcaccggcc aagcgatcgc tcc 23
<210> 6<210> 6
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 6<400> 6
ggagcgatcg cttggccggt gcg 23ggagcgatcg cttggccggt gcg 23
<210> 7<210> 7
<211> 30<211> 30
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 7<400> 7
atgtcagata ccaccaccgc atttaccgtt 30atgtcagata ccaccaccgc atttaccgtt 30
<210> 8<210> 8
<211> 25<211> 25
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 8<400> 8
atgtcagata ccaccaccgc attta 25atgtcagata ccaccaccgc attta 25
<210> 9<210> 9
<211> 32<211> 32
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 9<400> 9
atggattttg cctatagtcc gaaagttcag gc 32atggattttg cctatagtcc gaaagttcag gc 32
<210> 10<210> 10
<211> 32<211> 32
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 10<400> 10
ttccggttga aatgctgcgc tcaggtcgtt aa 32ttccggttga aatgctgcgc tcaggtcgtt aa 32
<210> 11<210> 11
<211> 41<211> 41
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 11<400> 11
agagaacaga ttggtggatc cggatccatg atttggcagc g 41agagaacaga ttggtggatc cggatccatg atttggcagc g 41
<210> 12<210> 12
<211> 41<211> 41
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 12<400> 12
gtggtggtgg tggtgctcga gctcgagtta cacaacggcg g 41gtggtggtgg tggtgctcga gctcgagtta cacaacggcg g 41
<210> 13<210> 13
<211> 3195<211> 3195
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 13<400> 13
atgccgacgt taccacgtac ctttgatgac attcagtctc gcttaatcaa tgctacaagt 60atgccgacgt taccacgtac ctttgatgac attcagtctc gcttaatcaa tgctacaagt 60
cgtgtggttc caatgcagcg tcagattcag ggtctgaaat ttctgatgag tgccaaacgc 120cgtgtggttc caatgcagcg tcagattcag ggtctgaaat ttctgatgag tgccaaacgc 120
aaaacctttg gtccacgtcg cccaatgccg gaatttgtgg aaacacctat cccggatgtt 180aaaacctttg gtccacgtcg cccaatgccg gaatttgtgg aaacacctat cccggatgtt 180
aatacattag ccttagagga cattgatgtg agtaatccgt ttctgtatcg ccagggccag 240aatacattag ccttagagga cattgatgtg agtaatccgt ttctgtatcg ccagggccag 240
tggcgcgcat attttaaacg cttacgcgat gaagctccag ttcattatca gaaaaatagc 300tggcgcgcat attttaaacg cttacgcgat gaagctccag ttcattatca gaaaaatagc 300
ccatttggtc cgttttggag cgtgacccgc tttgaggaca ttctgtttgt ggataaatca 360ccatttggtc cgttttggag cgtgacccgc tttgaggaca ttctgtttgt ggataaatca 360
catgatctgt ttagcgccga accacagatc atcttaggtg atcctccgga aggcctgtca 420catgatctgt ttagcgccga accacagatc atcttaggtg atcctccgga aggcctgtca 420
gtggaaatgt ttattgcgat ggaccctcct aaacatgatg tgcagcgctc tagtgttcag 480gtggaaatgt ttattgcgat ggaccctcct aaacatgatg tgcagcgctc tagtgttcag 480
ggtgtggttg cccctaaaaa tctgaaagaa atggaaggcc tgattcgtag tcgtacgggc 540ggtgtggttg cccctaaaaa tctgaaagaa atggaaggcc tgattcgtag tcgtacgggc 540
gatgtgttag attcattacc gacggataaa ccgtttaatt gggttcctgc ggtgagcaaa 600gatgtgttag attcattacc gacggataaa ccgtttaatt gggttcctgc ggtgagcaaa 600
gaactgacgg gtagaatgct ggctacctta ctggattttc cgtatgaaga acgtcataaa 660gaactgacgg gtagaatgct ggctacctta ctggattttc cgtatgaaga acgtcataaa 660
ctggttgaat ggagcgatcg catggccggt gcggcaagtg ctacgggcgg cgaatttgcg 720ctggttgaat ggagcgatcg catggccggt gcggcaagtg ctacgggcgg cgaatttgcg 720
gatgaaaatg ctatgtttga tgatgcggca gatatggcac gctctttttc tcgcctgtgg 780gatgaaaatg ctatgtttga tgatgcggca gatatggcac gctctttttc tcgcctgtgg 780
cgcgataaag aagcccgccg tgcagcaggc gaagaaccgg gctttgattt aatctcactg 840cgcgataaag aagcccgccg tgcagcaggc gaagaaccgg gctttgattt aatctcactg 840
ctacagtcta ataaagaaac caaggatctg atcaatcgtc ctatggaatt tattggcaat 900ctacagtcta ataaagaaac caaggatctg atcaatcgtc ctatggaatt tattggcaat 900
ctgaccctgc tgattgtggg cggtaatgat acgacccgca atagcatgtc aggcggctta 960ctgaccctgc tgattgtggg cggtaatgat acgacccgca atagcatgtc aggcggctta 960
gttgccatga atgaatttcc tcgtgaattt gaaaaactga aagccaaacc ggaactgatt 1020gttgccatga atgaatttcc tcgtgaattt gaaaaactga aagccaaacc ggaactgatt 1020
ccgaatatgg tgagcgaaat tattcgttgg cagacaccac tggcctatat gcgccgcatt 1080ccgaatatgg tgagcgaaat tattcgttgg cagacaccac tggcctatat gcgccgcatt 1080
gccaaacagg atgttgaact gggcggtcag accatcaaaa aaggtgatcg cgttgttatg 1140gccaaacagg atgttgaact gggcggtcag accatcaaaa aaggtgatcg cgttgttatg 1140
tggtatgcct caggtaatcg cgatgaacgt aaatttgata atccggatca gtttattatc 1200tggtatgcct caggtaatcg cgatgaacgt aaatttgata atccggatca gtttattatc 1200
gatcgtaaag atgcacgcaa tcacatgtct tttggctatg gtgttcatcg ctgtatgggt 1260gatcgtaaag atgcacgcaa tcacatgtct tttggctatg gtgttcatcg ctgtatgggt 1260
aatcgtctgg ccgaattaca gctgcgtatt ctgtgggaag aaatcttaaa acgctttgat 1320aatcgtctgg ccgaattaca gctgcgtatt ctgtgggaag aaatcttaaa acgctttgat 1320
aatatcgaag ttgtggaaga accagaacgt gtgcagagca attttgttcg cggctatagc 1380aatatcgaag ttgtggaaga accagaacgt gtgcagagca attttgttcg cggctatagc 1380
cgcttaatgg ttaaactgac acctaatagt atgggcggca ttccttcacc aagccgagag 1440cgcttaatgg ttaaactgac acctaatagt atgggcggca ttccttcacc aagccgagag 1440
cagtcagcta aaaaagagcg caaaaccgta gaaaacgctc ataatacgcc gcttcttgtg 1500cagtcagcta aaaaagagcg caaaaccgta gaaaacgctc ataatacgcc gcttcttgtg 1500
ctatacggtt caaatatggg aacagccgaa ggaacggcgc gtgatttagc ggatattgcg 1560ctatacggtt caaatatggg aacagccgaa ggaacggcgc gtgatttagc ggatattgcg 1560
atgagcaaag gattcgcacc gcaagtcgca acgcttgatt cccacgcagg aaaccttccg 1620atgagcaaag gattcgcacc gcaagtcgca acgcttgatt cccacgcagg aaaccttccg 1620
cgtgaaggag ctgttttaat tgtaacggct tcttataacg gtcatcctcc tgataacgca 1680cgtgaaggag ctgttttaat tgtaacggct tcttataacg gtcatcctcc tgataacgca 1680
aaggaatttg ttgactggtt agaccaagcg tctgctgatg aagtaaaagg cgtgcgctac 1740aaggaatttg ttgactggtt agaccaagcg tctgctgatg aagtaaaagg cgtgcgctac 1740
tccgtatttg gatgcggtga taaaaactgg gcgacaacgt atcaaaaagt gcctgctttt 1800tccgtatttg gatgcggtga taaaaactgg gcgacaacgt atcaaaaagt gcctgctttt 1800
attgatgaaa ctcttgccgc taaaggggca gaaaacatag ctgaacgcgg tgaagcagat 1860attgatgaaa ctcttgccgc taaaggggca gaaaacatag ctgaacgcgg tgaagcagat 1860
gcaagcgacg actttgaagg cacatacgaa gaatggcgtg aacacatgtg gagtgactta 1920gcaagcgacg actttgaagg cacatacgaa gaatggcgtg aacacatgtg gagtgactta 1920
gcagcctact ttaacttaga cattgaaaac agcgaagaaa atgcgtctac gctttcactt 1980gcagcctact ttaacttaga cattgaaaac agcgaagaaa atgcgtctac gctttcactt 1980
caatttgtcg acagcgctgc ggacatgccg cttgcgaaaa tgcaccgtgc gttttcagca 2040caatttgtcg acagcgctgc ggacatgccg cttgcgaaaa tgcaccgtgc gttttcagca 2040
aacgtcgtag caagcaaaga gcttcaaaag ccaggcagtg cacgaagcac gcgtcatctt 2100aacgtcgtag caagcaaaga gcttcaaaag ccaggcagtg cacgaagcac gcgtcatctt 2100
gaaattgaac ttccaaaaga agcttcttat caagaaggag atcatttagg tgttattcct 2160gaaattgaac ttccaaaaga agcttcttat caagaaggag atcatttagg tgttattcct 2160
cgcaactatg aaggaatagt aaatcgtgta gcaacaagat ttggtctaga tgcatcacag 2220cgcaactatg aaggaatagt aaatcgtgta gcaacaagat ttggtctaga tgcatcacag 2220
caaatccgtt tggaagctga agaagaaaaa ttagctcatt tgccactcgg taaaacagta 2280caaatccgtt tggaagctga agaagaaaaa ttagctcatt tgccactcgg taaaacagta 2280
tcagtagaag agcttctgca atacgtggag cttcaagatc ctgttacgcg cacgcagctt 2340tcagtagaag agcttctgca atacgtggag cttcaagatc ctgttacgcg cacgcagctt 2340
cgcgcaatgg ctgctaaaac agtctgcccg ccgcataaag tagagcttga agtcttgctt 2400cgcgcaatgg ctgctaaaac agtctgcccg ccgcataaag tagagcttga agtcttgctt 2400
gaaaagcagg cgtacaaaga acaagtgctg gcaaaacgtt taacaatgct tgaactgctt 2460gaaaagcagg cgtacaaaga acaagtgctg gcaaaacgtt taacaatgct tgaactgctt 2460
gaaaaatatc cggcgtgtga aatggaattc agcgaattta tcgcacttct tccaagcatg 2520gaaaaatatc cggcgtgtga aatggaattc agcgaattta tcgcacttct tccaagcatg 2520
cgtccgcgct attactcaat ttcttcatca cctcgtgtcg atgaaaaaca agcaagcatc 2580cgtccgcgct attactcaat ttcttcatca cctcgtgtcg atgaaaaaca agcaagcatc 2580
acggtcagcg ttgtttcagg agaagcgtgg agcggatacg gagaatacaa aggaattgca 2640acggtcagcg ttgtttcagg agaagcgtgg agcggatacg gagaatacaa aggaattgca 2640
tcgaactatc ttgccaatct gcaagaagga gatacgatta cgtgctttgt ttccacaccg 2700tcgaactatc ttgccaatct gcaagaagga gatacgatta cgtgctttgt ttccacaccg 2700
cagtcaggat ttacgctgcc aaaaggccct gaaacaccac ttatcatggt aggaccggga 2760cagtcaggat ttacgctgcc aaaaggccct gaaacaccac ttatcatggt aggaccggga 2760
acaggcgtcg cgccgtttag aggctttgtg caggctcgca agcagttaaa agaacaagga 2820acaggcgtcg cgccgtttag aggctttgtg caggctcgca agcagttaaa agaacaagga 2820
cagtcgcttg gagaagcgca tttatacttt ggctgccgtt cacctcatga agattatctg 2880cagtcgcttg gagaagcgca tttatacttt ggctgccgtt cacctcatga agattatctg 2880
tatcaaaaag agcttgaaaa cgcccaaaat gaaggcatca ttacgcttca taccgctttt 2940tatcaaaaag agcttgaaaa cgcccaaaat gaaggcatca ttacgcttca taccgctttt 2940
tctcgcgtac caaatcagcc gaaaacatac gttcaacacg tgatggaaca agacggcaag 3000tctcgcgtac caaatcagcc gaaaacatac gttcaacacg tgatggaaca agacggcaag 3000
aaattgattg aacttcttga ccaaggagcg cacttctata tttgcggaga cggaagccaa 3060aaattgattg aacttcttga ccaaggagcg cacttctata tttgcggaga cggaagccaa 3060
atggcacctg acgttgaagc aacgcttatg aaaagctatg ctgaagttca ccaagtgagt 3120atggcacctg acgttgaagc aacgcttatg aaaagctatg ctgaagttca ccaagtgagt 3120
gaagcagacg ctcgcttatg gctgcagcag ctagaagaaa agggccgata cgcaaaagac 3180gaagcagacg ctcgcttatg gctgcagcag ctagaagaaa agggccgata cgcaaaagac 3180
gtgtgggctg ggtaa 3195gtgtggggctg ggtaa 3195
<210> 14<210> 14
<211> 3195<211> 3195
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 14<400> 14
atgccgacgt taccacgtac ctttgatgac attcagtctc gcttaatcaa tgctacaagt 60atgccgacgt taccacgtac ctttgatgac attcagtctc gcttaatcaa tgctacaagt 60
cgtgtggttc caatgcagcg tcagattcag ggtctgaaat ttctgatgag tgccaaacgc 120cgtgtggttc caatgcagcg tcagattcag ggtctgaaat ttctgatgag tgccaaacgc 120
aaaacctttg gtccacgtcg cccaatgccg gaatttgtgg aaacacctat cccggatgtt 180aaaacctttg gtccacgtcg cccaatgccg gaatttgtgg aaacacctat cccggatgtt 180
aatacattag ccttagagga cattgatgtg agtaatccgt ttctgtatcg ccagggccag 240aatacattag ccttagagga cattgatgtg agtaatccgt ttctgtatcg ccagggccag 240
tggcgcgcat attttaaacg cttacgcgat gaagctccag ttcattatca gaaaaatagc 300tggcgcgcat attttaaacg cttacgcgat gaagctccag ttcattatca gaaaaatagc 300
ccatttggtc cgttttggag cgtgacccgc tttgaggaca ttctgtttgt ggataaatca 360ccatttggtc cgttttggag cgtgacccgc tttgaggaca ttctgtttgt ggataaatca 360
catgatctgt ttagcgccga accacagatc atcttaggtg atcctccgga aggcctgtca 420catgatctgt ttagcgccga accacagatc atcttaggtg atcctccgga aggcctgtca 420
gtggaaatgt ttattgcgat ggaccctcct aaacatgatg tgcagcgctc tagtgttcag 480gtggaaatgt ttattgcgat ggaccctcct aaacatgatg tgcagcgctc tagtgttcag 480
ggtgtggttg cccctaaaaa tctgaaagaa atggaaggcc tgattcgtag tcgtacgggc 540ggtgtggttg cccctaaaaa tctgaaagaa atggaaggcc tgattcgtag tcgtacgggc 540
gatgtgttag attcattacc gacggataaa ccgtttaatt gggttcctgc ggtgagcaaa 600gatgtgttag attcattacc gacggataaa ccgtttaatt gggttcctgc ggtgagcaaa 600
gaactgacgg gtagaatgct ggctacctta ctggattttc cgtatgaaga acgtcataaa 660gaactgacgg gtagaatgct ggctacctta ctggattttc cgtatgaaga acgtcataaa 660
ctggttgaat ggagcgatcg cttggccggt gcggcaagtg ctacgggcgg cgaatttgcg 720ctggttgaat ggagcgatcg cttggccggt gcggcaagtg ctacgggcgg cgaatttgcg 720
gatgaaaatg ctatgtttga tgatgcggca gatatggcac gctctttttc tcgcctgtgg 780gatgaaaatg ctatgtttga tgatgcggca gatatggcac gctctttttc tcgcctgtgg 780
cgcgataaag aagcccgccg tgcagcaggc gaagaaccgg gctttgattt aatctcactg 840cgcgataaag aagcccgccg tgcagcaggc gaagaaccgg gctttgattt aatctcactg 840
ctacagtcta ataaagaaac caaggatctg atcaatcgtc ctatggaatt tattggcaat 900ctacagtcta ataaagaaac caaggatctg atcaatcgtc ctatggaatt tattggcaat 900
ctgaccctgc tgattgtggg cggtaatgat acgacccgca atagcatgtc aggcggctta 960ctgaccctgc tgattgtggg cggtaatgat acgacccgca atagcatgtc aggcggctta 960
gttgccatga atgaatttcc tcgtgaattt gaaaaactga aagccaaacc ggaactgatt 1020gttgccatga atgaatttcc tcgtgaattt gaaaaactga aagccaaacc ggaactgatt 1020
ccgaatatgg tgagcgaaat tattcgttgg cagacaccac tggcctatat gcgccgcatt 1080ccgaatatgg tgagcgaaat tattcgttgg cagacaccac tggcctatat gcgccgcatt 1080
gccaaacagg atgttgaact gggcggtcag accatcaaaa aaggtgatcg cgttgttatg 1140gccaaacagg atgttgaact gggcggtcag accatcaaaa aaggtgatcg cgttgttatg 1140
tggtatgcct caggtaatcg cgatgaacgt aaatttgata atccggatca gtttattatc 1200tggtatgcct caggtaatcg cgatgaacgt aaatttgata atccggatca gtttattatc 1200
gatcgtaaag atgcacgcaa tcacatgtct tttggctatg gtgttcatcg ctgtatgggt 1260gatcgtaaag atgcacgcaa tcacatgtct tttggctatg gtgttcatcg ctgtatgggt 1260
aatcgtctgg ccgaattaca gctgcgtatt ctgtgggaag aaatcttaaa acgctttgat 1320aatcgtctgg ccgaattaca gctgcgtatt ctgtgggaag aaatcttaaa acgctttgat 1320
aatatcgaag ttgtggaaga accagaacgt gtgcagagca attttgttcg cggctatagc 1380aatatcgaag ttgtggaaga accagaacgt gtgcagagca attttgttcg cggctatagc 1380
cgcttaatgg ttaaactgac acctaatagt atgggcggca ttccttcacc aagccgagag 1440cgcttaatgg ttaaactgac acctaatagt atgggcggca ttccttcacc aagccgagag 1440
cagtcagcta aaaaagagcg caaaaccgta gaaaacgctc ataatacgcc gcttcttgtg 1500cagtcagcta aaaaagagcg caaaaccgta gaaaacgctc ataatacgcc gcttcttgtg 1500
ctatacggtt caaatatggg aacagccgaa ggaacggcgc gtgatttagc ggatattgcg 1560ctatacggtt caaatatggg aacagccgaa ggaacggcgc gtgatttagc ggatattgcg 1560
atgagcaaag gattcgcacc gcaagtcgca acgcttgatt cccacgcagg aaaccttccg 1620atgagcaaag gattcgcacc gcaagtcgca acgcttgatt cccacgcagg aaaccttccg 1620
cgtgaaggag ctgttttaat tgtaacggct tcttataacg gtcatcctcc tgataacgca 1680cgtgaaggag ctgttttaat tgtaacggct tcttataacg gtcatcctcc tgataacgca 1680
aaggaatttg ttgactggtt agaccaagcg tctgctgatg aagtaaaagg cgtgcgctac 1740aaggaatttg ttgactggtt agaccaagcg tctgctgatg aagtaaaagg cgtgcgctac 1740
tccgtatttg gatgcggtga taaaaactgg gcgacaacgt atcaaaaagt gcctgctttt 1800tccgtatttg gatgcggtga taaaaactgg gcgacaacgt atcaaaaagt gcctgctttt 1800
attgatgaaa ctcttgccgc taaaggggca gaaaacatag ctgaacgcgg tgaagcagat 1860attgatgaaa ctcttgccgc taaaggggca gaaaacatag ctgaacgcgg tgaagcagat 1860
gcaagcgacg actttgaagg cacatacgaa gaatggcgtg aacacatgtg gagtgactta 1920gcaagcgacg actttgaagg cacatacgaa gaatggcgtg aacacatgtg gagtgactta 1920
gcagcctact ttaacttaga cattgaaaac agcgaagaaa atgcgtctac gctttcactt 1980gcagcctact ttaacttaga cattgaaaac agcgaagaaa atgcgtctac gctttcactt 1980
caatttgtcg acagcgctgc ggacatgccg cttgcgaaaa tgcaccgtgc gttttcagca 2040caatttgtcg acagcgctgc ggacatgccg cttgcgaaaa tgcaccgtgc gttttcagca 2040
aacgtcgtag caagcaaaga gcttcaaaag ccaggcagtg cacgaagcac gcgtcatctt 2100aacgtcgtag caagcaaaga gcttcaaaag ccaggcagtg cacgaagcac gcgtcatctt 2100
gaaattgaac ttccaaaaga agcttcttat caagaaggag atcatttagg tgttattcct 2160gaaattgaac ttccaaaaga agcttcttat caagaaggag atcatttagg tgttattcct 2160
cgcaactatg aaggaatagt aaatcgtgta gcaacaagat ttggtctaga tgcatcacag 2220cgcaactatg aaggaatagt aaatcgtgta gcaacaagat ttggtctaga tgcatcacag 2220
caaatccgtt tggaagctga agaagaaaaa ttagctcatt tgccactcgg taaaacagta 2280caaatccgtt tggaagctga agaagaaaaa ttagctcatt tgccactcgg taaaacagta 2280
tcagtagaag agcttctgca atacgtggag cttcaagatc ctgttacgcg cacgcagctt 2340tcagtagaag agcttctgca atacgtggag cttcaagatc ctgttacgcg cacgcagctt 2340
cgcgcaatgg ctgctaaaac agtctgcccg ccgcataaag tagagcttga agtcttgctt 2400cgcgcaatgg ctgctaaaac agtctgcccg ccgcataaag tagagcttga agtcttgctt 2400
gaaaagcagg cgtacaaaga acaagtgctg gcaaaacgtt taacaatgct tgaactgctt 2460gaaaagcagg cgtacaaaga acaagtgctg gcaaaacgtt taacaatgct tgaactgctt 2460
gaaaaatatc cggcgtgtga aatggaattc agcgaattta tcgcacttct tccaagcatg 2520gaaaaatatc cggcgtgtga aatggaattc agcgaattta tcgcacttct tccaagcatg 2520
cgtccgcgct attactcaat ttcttcatca cctcgtgtcg atgaaaaaca agcaagcatc 2580cgtccgcgct attactcaat ttcttcatca cctcgtgtcg atgaaaaaca agcaagcatc 2580
acggtcagcg ttgtttcagg agaagcgtgg agcggatacg gagaatacaa aggaattgca 2640acggtcagcg ttgtttcagg agaagcgtgg agcggatacg gagaatacaa aggaattgca 2640
tcgaactatc ttgccaatct gcaagaagga gatacgatta cgtgctttgt ttccacaccg 2700tcgaactatc ttgccaatct gcaagaagga gatacgatta cgtgctttgt ttccacaccg 2700
cagtcaggat ttacgctgcc aaaaggccct gaaacaccac ttatcatggt aggaccggga 2760cagtcaggat ttacgctgcc aaaaggccct gaaacaccac ttatcatggt aggaccggga 2760
acaggcgtcg cgccgtttag aggctttgtg caggctcgca agcagttaaa agaacaagga 2820acaggcgtcg cgccgtttag aggctttgtg caggctcgca agcagttaaa agaacaagga 2820
cagtcgcttg gagaagcgca tttatacttt ggctgccgtt cacctcatga agattatctg 2880cagtcgcttg gagaagcgca tttatacttt ggctgccgtt cacctcatga agattatctg 2880
tatcaaaaag agcttgaaaa cgcccaaaat gaaggcatca ttacgcttca taccgctttt 2940tatcaaaaag agcttgaaaa cgcccaaaat gaaggcatca ttacgcttca taccgctttt 2940
tctcgcgtac caaatcagcc gaaaacatac gttcaacacg tgatggaaca agacggcaag 3000tctcgcgtac caaatcagcc gaaaacatac gttcaacacg tgatggaaca agacggcaag 3000
aaattgattg aacttcttga ccaaggagcg cacttctata tttgcggaga cggaagccaa 3060aaattgattg aacttcttga ccaaggagcg cacttctata tttgcggaga cggaagccaa 3060
atggcacctg acgttgaagc aacgcttatg aaaagctatg ctgaagttca ccaagtgagt 3120atggcacctg acgttgaagc aacgcttatg aaaagctatg ctgaagttca ccaagtgagt 3120
gaagcagacg ctcgcttatg gctgcagcag ctagaagaaa agggccgata cgcaaaagac 3180gaagcagacg ctcgcttatg gctgcagcag ctagaagaaa agggccgata cgcaaaagac 3180
gtgtgggctg ggtaa 3195gtgtggggctg ggtaa 3195
<210> 15<210> 15
<211> 1653<211> 1653
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 15<400> 15
atgtcagata ccaccaccgc atttaccgtt ccagcggttg ccaaagcagt tgccgcagcc 60atgtcagata ccaccaccgc atttaccgtt ccagcggttg ccaaagcagt tgccgcagcc 60
attccggatc gcgaactgat tattcagggt gatcgtcgct atacctatcg tcaggttatt 120attccggatc gcgaactgat tattcagggt gatcgtcgct atacctatcg tcaggttatt 120
gaacgctcaa atagattagc tgcatattta cattcacagg gcttaggctg tcataccgaa 180gaacgctcaa atagattagc tgcatattta cattcacagg gcttaggctg tcataccgaa 180
cgcgaagcct tagcaggtca tgaagttggc caggatctgc tgggcctgta tgcatataat 240cgcgaagcct tagcaggtca tgaagttggc caggatctgc tgggcctgta tgcatataat 240
ggcaatgaat ttgtggaagc cttactgggt gcctttgcag ctagggtggc cccgtttaat 300ggcaatgaat ttgtggaagc cttactgggt gcctttgcag ctagggtggc cccgtttaat 300
gtgaattttc gctatgttaa atcagaatta cattatctgt tagccgatag tgaagcaacc 360gtgaattttc gctatgttaa atcagaatta cattatctgt tagccgatag tgaagcaacc 360
gccctgattt atcatgcagc ctttgccccg cgtgtggcag aaattctgcc ggaactgccg 420gccctgattt atcatgcagc ctttgccccg cgtgtggcag aaattctgcc ggaactgccg 420
cgtctgcgcg tgctgattca gattgcagat gaatcaggta atgaattact ggatggtgca 480cgtctgcgcg tgctgattca gattgcagat gaatcaggta atgaattact ggatggtgca 480
gttgattatg aagatgcctt agcaagcgtg agcgcccagc cgccgccggt tcgtcattgt 540gttgattatg aagatgcctt agcaagcgtg agcgcccagc cgccgccggt tcgtcattgt 540
ccggatgatc tgtatgttct gtataccggc ggtaccaccg gtatgccgaa aggcgtttta 600ccggatgatc tgtatgttct gtataccggc ggtaccaccg gtatgccgaa aggcgtttta 600
tggcgtcagc atgatatttt tatgacctct tttggcggtc gtaatctgat gaccggcgaa 660tggcgtcagc atgatatttt tatgacctct tttggcggtc gtaatctgat gaccggcgaa 660
cctagctcta gtattgatga aattgttcag cgcgcagcct caggtccggg taccaaatta 720cctagctcta gtattgatga aattgttcag cgcgcagcct caggtccggg taccaaatta 720
atgattctgc cgccgttaat tcatggtgcc gcacagtgga gtgttatgac cgcaattacc 780atgattctgc cgccgttaat tcatggtgcc gcacagtgga gtgttatgac cgcaattacc 780
accggccaga ccgtggtgtt tccgaccgtt gtggatcatc tggatgcaga agatgtggtt 840accggccaga ccgtggtgtt tccgaccgtt gtggatcatc tggatgcaga agatgtggtt 840
cgtaccattg aacgtgaaaa agttatggtt gtgaccgtgg tgggcgatgc aatggcacgt 900cgtaccattg aacgtgaaaa agttatggtt gtgaccgtgg tgggcgatgc aatggcacgt 900
ccgttagttg ccgcaattga aaaaggtatt gccgatgtgt cttcactagc cgtggtagcc 960ccgttagttg ccgcaattga aaaaggtatt gccgatgtgt cttcactagc cgtggtagcc 960
aatggcggcg ccctgctgac cccgtttgtt aaacagcgtc tgattgaagt gctgccgaat 1020aatggcggcg ccctgctgac cccgtttgtt aaacagcgtc tgattgaagt gctgccgaat 1020
gcagtggttg tggatggtgt tggctcaagc gaaaccggtg cacagatgca tcacatgtct 1080gcagtggttg tggatggtgt tggctcaagc gaaaccggtg cacagatgca tcacatgtct 1080
acccccggcg ccgtggcaac cggtaccttt aatgcaggtc cggatacctt tgttgccgca 1140acccccggcg ccgtggcaac cggtaccttt aatgcaggtc cggatacctt tgttgccgca 1140
gaggacctga gcgccatttt accgccgggc catgaaggca tgggctggtt agcccagcgc 1200gaggacctga gcgccatttt accgccgggc catgaaggca tgggctggtt agcccagcgc 1200
ggctatgttc cgttaggcta taaaggcgat gcagccaaaa ccgccaaaac ctttccggtt 1260ggctatgttc cgttaggcta taaaggcgat gcagccaaaa ccgccaaaac ctttccggtt 1260
attgatggcg tgcgctatgc agttccgggt gatcgcgcac gtcatcatgc agatggtcat 1320attgatggcg tgcgctatgc agttccgggt gatcgcgcac gtcatcatgc agatggtcat 1320
attgaactgc tgggtcgcga tagtgtttgt attaatagcg gcggcgaaaa aatttttgtg 1380attgaactgc tgggtcgcga tagtgtttgt attaatagcg gcggcgaaaa aatttttgtg 1380
gaagaagtgg aaaccgcaat tgcctcacat ccggcagttg ccgatgtggt tgtggcaggt 1440gaagaagtgg aaaccgcaat tgcctcacat ccggcagttg ccgatgtggt tgtggcaggt 1440
cgtccgagtg aacgctgggg tcaggaagtt gttgcagttg tggccctgag cgatggtgca 1500cgtccgagtg aacgctgggg tcaggaagtt gttgcagttg tggccctgag cgatggtgca 1500
gcagtggatg caggcgaact gattgcacat gcctctaatt ccctggctcg ctataaactg 1560gcagtggatg caggcgaact gattgcacat gcctctaatt ccctggctcg ctataaactg 1560
ccgaaagcca ttgtgtttcg cccggttatt gaacgctctc cgagcggtaa agccgattat 1620ccgaaagcca ttgtgtttcg cccggttatt gaacgctctc cgagcggtaa agccgattat 1620
cgttgggcac gcgaacaggc agttaatggt taa 1653cgttgggcac gcgaacaggc agttaatggt taa 1653
<210> 16<210> 16
<211> 1227<211> 1227
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 16<400> 16
gattttgcct atagtccgaa agttcaggca ttacgtgaac gtgtgaccgc ctttatggat 60gattttgcct atagtccgaa agttcaggca ttacgtgaac gtgtgaccgc ctttatggat 60
gcacatgtgt atccagccga agcagtgttt gaacgccagg ttgccgaagg tgatcgctgg 120gcacatgtgt atccagccga agcagtgttt gaacgccagg ttgccgaagg tgatcgctgg 120
cagccgaccg ccattatgga agaactgaaa gccaaagcac gcgccgaagg cctgtggaat 180cagccgaccg ccattatgga agaactgaaa gccaaagcac gcgccgaagg cctgtggaat 180
ctgtttctgc cggaatcaga atatggtgca ggtctgtcta atctggaata tgcaccgtta 240ctgtttctgc cggaatcaga atatggtgca ggtctgtcta atctggaata tgcaccgtta 240
gcagaaatta tgggccgtag cttactgggc ccggaaccgt ttaattgtag tgccccggat 300gcagaaatta tgggccgtag cttactgggc ccggaaccgt ttaattgtag tgccccggat 300
accggtaata tggaagtttt agttcgctat ggtagcgaag cccagaaacg tcagtggtta 360accggtaata tggaagtttt agttcgctat ggtagcgaag cccagaaacg tcagtggtta 360
gaaccgttac tgcgcggtga aattcgtagt gcctttgcaa tgaccgaacc ggatgttgca 420gaaccgttac tgcgcggtga aattcgtagt gcctttgcaa tgaccgaacc ggatgttgca 420
tctagcgatg ccaccaatat ggcagcaacc gcaattcgcg atggcgatca gtgggttatt 480tctagcgatg ccaccaatat ggcagcaacc gcaattcgcg atggcgatca gtgggttatt 480
aatggtcgca aatggtggac ctcaggcgcc tgtgatccgc gttgtaaagt gatgattttt 540aatggtcgca aatggtggac ctcaggcgcc tgtgatccgc gttgtaaagt gatgattttt 540
atgggcttaa gcgatccgga aggcccgcgt catcagcagc attcaatggt gctggttccg 600atgggcttaa gcgatccgga aggcccgcgt catcagcagc attcaatggt gctggttccg 600
accgatacgc caggtgttaa aattgtgcgt ccgctgccgg tgtttggcta tgatgatgcc 660accgatacgc caggtgttaa aattgtgcgt ccgctgccgg tgtttggcta tgatgatgcc 660
ccgcatggtc atgccgaagt gctgtttgaa aatgttcgtg ttccgtatga aaatgttatt 720ccgcatggtc atgccgaagt gctgtttgaa aatgttcgtg ttccgtatga aaatgttatt 720
ttaggcgaag gtcgcggctt tgaaattgca cagggtcgtc tggggcctgg tcgtattcat 780ttaggcgaag gtcgcggctt tgaaattgca cagggtcgtc tggggcctgg tcgtattcat 780
cattgtatgc gctctattgg catggcagaa cgcgcattag aactgatgtg taaacgctca 840cattgtatgc gctctattgg catggcagaa cgcgcattag aactgatgtg taaacgctca 840
gttgaacgta ccgcctttgg tcgtccgtta gcacgtctgg gcggtaatgt ggataaaatt 900gttgaacgta ccgcctttgg tcgtccgtta gcacgtctgg gcggtaatgt ggataaaatt 900
gcagattctc gcatggaaat tgatatggca cgcttactga ccttaaaagc cgcctatatg 960gcagattctc gcatggaaat tgatatggca cgcttactga ccttaaaagc cgcctatatg 960
atggataccg tgggtaataa agttgcacgc tctgaaattg cacagattaa agttgtggcc 1020atggataccg tgggtaataa agttgcacgc tctgaaattg cacagattaa agttgtggcc 1020
ccgaatgtgg ccctgaatgt tattgatcgt gccattcaga ttcatggcgg cgcaggcgtg 1080ccgaatgtgg ccctgaatgt tattgatcgt gccattcaga ttcatggcgg cgcaggcgtg 1080
agcggcgatt ttccgttagc ctatatgtat gccatgcagc gtaccctgcg tttagcagat 1140agcggcgatt ttccgttagc ctatatgtat gccatgcagc gtaccctgcg tttagcagat 1140
ggtccggatg aagttcatcg cgcagccatt ggcaaatatg aaattggtaa atatgttccg 1200ggtccggatg aagttcatcg cgcagccatt ggcaaatatg aaattggtaa atatgttccg 1200
gttgaaatgc tgcgctcagg tcgttaa 1227gttgaaatgc tgcgctcagg tcgttaa 1227
<210> 17<210> 17
<211> 423<211> 423
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 17<400> 17
ggatccatga tttggcagcg caccgccacc ctggatgcac tgaatgcaat gggtgcgaat 60ggatccatga tttggcagcg caccgccacc ctggatgcac tgaatgcaat gggtgcgaat 60
aatatggtgg gcctgctgga tattcgcttt acccgtctgg atgataatga aattgaagca 120aatatggtgg gcctgctgga tattcgcttt acccgtctgg atgataatga aattgaagca 120
accatgccgg ttgatcatcg tacccatcaa cctttcggtt tactgcatgg cggcgcaagc 180accatgccgg ttgatcatcg tacccatcaa cctttcggtt tactgcatgg cggcgcaagc 180
gtggtgttag ccgaaacctt aggtagtgtt gcaggctatc tgtgtaccga aggcgaacag 240gtggtgttag ccgaaacctt aggtagtgtt gcaggctatc tgtgtaccga aggcgaacag 240
aatattgtgg gcttagaagt taatgccaat catttacgct cagtgcgtag cggtcgcgtg 300aatattgtgg gcttagaagt taatgccaat catttacgct cagtgcgtag cggtcgcgtg 300
cgcggcgtgt gtcgcgcagt tcatgtgggt cgtcgtcatc aggtttggca gattgaaatt 360cgcggcgtgt gtcgcgcagt tcatgtgggt cgtcgtcatc aggtttggca gattgaaatt 360
tttgatgaac aggatcgctt atgttgtagc tctcgtctga ccaccgccgt tgtgtaactc 420tttgatgaac aggatcgctt atgttgtagc tctcgtctga ccaccgccgt tgtgtaactc 420
gag 423gag 423
<210> 18<210> 18
<211> 1064<211> 1064
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 18<400> 18
Met Pro Thr Leu Pro Arg Thr Phe Asp Asp Ile Gln Ser Arg Leu IleMet Pro Thr Leu Pro Arg Thr Phe Asp Asp Ile Gln Ser Arg Leu Ile
1 5 10 151 5 10 15
Asn Ala Thr Ser Arg Val Val Pro Met Gln Arg Gln Ile Gln Gly LeuAsn Ala Thr Ser Arg Val Val Pro Met Gln Arg Gln Ile Gln Gly Leu
20 25 30 20 25 30
Lys Phe Leu Met Ser Ala Lys Arg Lys Thr Phe Gly Pro Arg Arg ProLys Phe Leu Met Ser Ala Lys Arg Lys Thr Phe Gly Pro Arg Arg Pro
35 40 45 35 40 45
Met Pro Glu Phe Val Glu Thr Pro Ile Pro Asp Val Asn Thr Leu AlaMet Pro Glu Phe Val Glu Thr Pro Ile Pro Asp Val Asn Thr Leu Ala
50 55 60 50 55 60
Leu Glu Asp Ile Asp Val Ser Asn Pro Phe Leu Tyr Arg Gln Gly GlnLeu Glu Asp Ile Asp Val Ser Asn Pro Phe Leu Tyr Arg Gln Gly Gln
65 70 75 8065 70 75 80
Trp Arg Ala Tyr Phe Lys Arg Leu Arg Asp Glu Ala Pro Val His TyrTrp Arg Ala Tyr Phe Lys Arg Leu Arg Asp Glu Ala Pro Val His Tyr
85 90 95 85 90 95
Gln Lys Asn Ser Pro Phe Gly Pro Phe Trp Ser Val Thr Arg Phe GluGln Lys Asn Ser Pro Phe Gly Pro Phe Trp Ser Val Thr Arg Phe Glu
100 105 110 100 105 110
Asp Ile Leu Phe Val Asp Lys Ser His Asp Leu Phe Ser Ala Glu ProAsp Ile Leu Phe Val Asp Lys Ser His Asp Leu Phe Ser Ala Glu Pro
115 120 125 115 120 125
Gln Ile Ile Leu Gly Asp Pro Pro Glu Gly Leu Ser Val Glu Met PheGln Ile Ile Leu Gly Asp Pro Pro Glu Gly Leu Ser Val Glu Met Phe
130 135 140 130 135 140
Ile Ala Met Asp Pro Pro Lys His Asp Val Gln Arg Ser Ser Val GlnIle Ala Met Asp Pro Pro Lys His Asp Val Gln Arg Ser Ser Val Gln
145 150 155 160145 150 155 160
Gly Val Val Ala Pro Lys Asn Leu Lys Glu Met Glu Gly Leu Ile ArgGly Val Val Ala Pro Lys Asn Leu Lys Glu Met Glu Gly Leu Ile Arg
165 170 175 165 170 175
Ser Arg Thr Gly Asp Val Leu Asp Ser Leu Pro Thr Asp Lys Pro PheSer Arg Thr Gly Asp Val Leu Asp Ser Leu Pro Thr Asp Lys Pro Phe
180 185 190 180 185 190
Asn Trp Val Pro Ala Val Ser Lys Glu Leu Thr Gly Arg Met Leu AlaAsn Trp Val Pro Ala Val Ser Lys Glu Leu Thr Gly Arg Met Leu Ala
195 200 205 195 200 205
Thr Leu Leu Asp Phe Pro Tyr Glu Glu Arg His Lys Leu Val Glu TrpThr Leu Leu Asp Phe Pro Tyr Glu Glu Arg His Lys Leu Val Glu Trp
210 215 220 210 215 220
Ser Asp Arg Met Ala Gly Ala Ala Ser Ala Thr Gly Gly Glu Phe AlaSer Asp Arg Met Ala Gly Ala Ala Ser Ala Thr Gly Gly Glu Phe Ala
225 230 235 240225 230 235 240
Asp Glu Asn Ala Met Phe Asp Asp Ala Ala Asp Met Ala Arg Ser PheAsp Glu Asn Ala Met Phe Asp Asp Ala Ala Asp Met Ala Arg Ser Phe
245 250 255 245 250 255
Ser Arg Leu Trp Arg Asp Lys Glu Ala Arg Arg Ala Ala Gly Glu GluSer Arg Leu Trp Arg Asp Lys Glu Ala Arg Arg Ala Ala Gly Glu Glu
260 265 270 260 265 270
Pro Gly Phe Asp Leu Ile Ser Leu Leu Gln Ser Asn Lys Glu Thr LysPro Gly Phe Asp Leu Ile Ser Leu Leu Gln Ser Asn Lys Glu Thr Lys
275 280 285 275 280 285
Asp Leu Ile Asn Arg Pro Met Glu Phe Ile Gly Asn Leu Thr Leu LeuAsp Leu Ile Asn Arg Pro Met Glu Phe Ile Gly Asn Leu Thr Leu Leu
290 295 300 290 295 300
Ile Val Gly Gly Asn Asp Thr Thr Arg Asn Ser Met Ser Gly Gly LeuIle Val Gly Gly Asn Asp Thr Thr Arg Asn Ser Met Ser Gly Gly Leu
305 310 315 320305 310 315 320
Val Ala Met Asn Glu Phe Pro Arg Glu Phe Glu Lys Leu Lys Ala LysVal Ala Met Asn Glu Phe Pro Arg Glu Phe Glu Lys Leu Lys Ala Lys
325 330 335 325 330 335
Pro Glu Leu Ile Pro Asn Met Val Ser Glu Ile Ile Arg Trp Gln ThrPro Glu Leu Ile Pro Asn Met Val Ser Glu Ile Ile Arg Trp Gln Thr
340 345 350 340 345 350
Pro Leu Ala Tyr Met Arg Arg Ile Ala Lys Gln Asp Val Glu Leu GlyPro Leu Ala Tyr Met Arg Arg Ile Ala Lys Gln Asp Val Glu Leu Gly
355 360 365 355 360 365
Gly Gln Thr Ile Lys Lys Gly Asp Arg Val Val Met Trp Tyr Ala SerGly Gln Thr Ile Lys Lys Gly Asp Arg Val Val Met Trp Tyr Ala Ser
370 375 380 370 375 380
Gly Asn Arg Asp Glu Arg Lys Phe Asp Asn Pro Asp Gln Phe Ile IleGly Asn Arg Asp Glu Arg Lys Phe Asp Asn Pro Asp Gln Phe Ile Ile
385 390 395 400385 390 395 400
Asp Arg Lys Asp Ala Arg Asn His Met Ser Phe Gly Tyr Gly Val HisAsp Arg Lys Asp Ala Arg Asn His Met Ser Phe Gly Tyr Gly Val His
405 410 415 405 410 415
Arg Cys Met Gly Asn Arg Leu Ala Glu Leu Gln Leu Arg Ile Leu TrpArg Cys Met Gly Asn Arg Leu Ala Glu Leu Gln Leu Arg Ile Leu Trp
420 425 430 420 425 430
Glu Glu Ile Leu Lys Arg Phe Asp Asn Ile Glu Val Val Glu Glu ProGlu Glu Ile Leu Lys Arg Phe Asp Asn Ile Glu Val Val Glu Glu Pro
435 440 445 435 440 445
Glu Arg Val Gln Ser Asn Phe Val Arg Gly Tyr Ser Arg Leu Met ValGlu Arg Val Gln Ser Asn Phe Val Arg Gly Tyr Ser Arg Leu Met Val
450 455 460 450 455 460
Lys Leu Thr Pro Asn Ser Met Gly Gly Ile Pro Ser Pro Ser Arg GluLys Leu Thr Pro Asn Ser Met Gly Gly Ile Pro Ser Pro Ser Arg Glu
465 470 475 480465 470 475 480
Gln Ser Ala Lys Lys Glu Arg Lys Thr Val Glu Asn Ala His Asn ThrGln Ser Ala Lys Lys Glu Arg Lys Thr Val Glu Asn Ala His Asn Thr
485 490 495 485 490 495
Pro Leu Leu Val Leu Tyr Gly Ser Asn Met Gly Thr Ala Glu Gly ThrPro Leu Leu Val Leu Tyr Gly Ser Asn Met Gly Thr Ala Glu Gly Thr
500 505 510 500 505 510
Ala Arg Asp Leu Ala Asp Ile Ala Met Ser Lys Gly Phe Ala Pro GlnAla Arg Asp Leu Ala Asp Ile Ala Met Ser Lys Gly Phe Ala Pro Gln
515 520 525 515 520 525
Val Ala Thr Leu Asp Ser His Ala Gly Asn Leu Pro Arg Glu Gly AlaVal Ala Thr Leu Asp Ser His Ala Gly Asn Leu Pro Arg Glu Gly Ala
530 535 540 530 535 540
Val Leu Ile Val Thr Ala Ser Tyr Asn Gly His Pro Pro Asp Asn AlaVal Leu Ile Val Thr Ala Ser Tyr Asn Gly His Pro Pro Asp Asn Ala
545 550 555 560545 550 555 560
Lys Glu Phe Val Asp Trp Leu Asp Gln Ala Ser Ala Asp Glu Val LysLys Glu Phe Val Asp Trp Leu Asp Gln Ala Ser Ala Asp Glu Val Lys
565 570 575 565 570 575
Gly Val Arg Tyr Ser Val Phe Gly Cys Gly Asp Lys Asn Trp Ala ThrGly Val Arg Tyr Ser Val Phe Gly Cys Gly Asp Lys Asn Trp Ala Thr
580 585 590 580 585 590
Thr Tyr Gln Lys Val Pro Ala Phe Ile Asp Glu Thr Leu Ala Ala LysThr Tyr Gln Lys Val Pro Ala Phe Ile Asp Glu Thr Leu Ala Ala Lys
595 600 605 595 600 605
Gly Ala Glu Asn Ile Ala Glu Arg Gly Glu Ala Asp Ala Ser Asp AspGly Ala Glu Asn Ile Ala Glu Arg Gly Glu Ala Asp Ala Ser Asp Asp
610 615 620 610 615 620
Phe Glu Gly Thr Tyr Glu Glu Trp Arg Glu His Met Trp Ser Asp LeuPhe Glu Gly Thr Tyr Glu Glu Trp Arg Glu His Met Trp Ser Asp Leu
625 630 635 640625 630 635 640
Ala Ala Tyr Phe Asn Leu Asp Ile Glu Asn Ser Glu Glu Asn Ala SerAla Ala Tyr Phe Asn Leu Asp Ile Glu Asn Ser Glu Glu Asn Ala Ser
645 650 655 645 650 655
Thr Leu Ser Leu Gln Phe Val Asp Ser Ala Ala Asp Met Pro Leu AlaThr Leu Ser Leu Gln Phe Val Asp Ser Ala Ala Asp Met Pro Leu Ala
660 665 670 660 665 670
Lys Met His Arg Ala Phe Ser Ala Asn Val Val Ala Ser Lys Glu LeuLys Met His Arg Ala Phe Ser Ala Asn Val Val Ala Ser Lys Glu Leu
675 680 685 675 680 685
Gln Lys Pro Gly Ser Ala Arg Ser Thr Arg His Leu Glu Ile Glu LeuGln Lys Pro Gly Ser Ala Arg Ser Thr Arg His Leu Glu Ile Glu Leu
690 695 700 690 695 700
Pro Lys Glu Ala Ser Tyr Gln Glu Gly Asp His Leu Gly Val Ile ProPro Lys Glu Ala Ser Tyr Gln Glu Gly Asp His Leu Gly Val Ile Pro
705 710 715 720705 710 715 720
Arg Asn Tyr Glu Gly Ile Val Asn Arg Val Ala Thr Arg Phe Gly LeuArg Asn Tyr Glu Gly Ile Val Asn Arg Val Ala Thr Arg Phe Gly Leu
725 730 735 725 730 735
Asp Ala Ser Gln Gln Ile Arg Leu Glu Ala Glu Glu Glu Lys Leu AlaAsp Ala Ser Gln Gln Ile Arg Leu Glu Ala Glu Glu Glu Lys Leu Ala
740 745 750 740 745 750
His Leu Pro Leu Gly Lys Thr Val Ser Val Glu Glu Leu Leu Gln TyrHis Leu Pro Leu Gly Lys Thr Val Ser Val Glu Glu Leu Leu Gln Tyr
755 760 765 755 760 765
Val Glu Leu Gln Asp Pro Val Thr Arg Thr Gln Leu Arg Ala Met AlaVal Glu Leu Gln Asp Pro Val Thr Arg Thr Gln Leu Arg Ala Met Ala
770 775 780 770 775 780
Ala Lys Thr Val Cys Pro Pro His Lys Val Glu Leu Glu Val Leu LeuAla Lys Thr Val Cys Pro Pro His Lys Val Glu Leu Glu Val Leu Leu
785 790 795 800785 790 795 800
Glu Lys Gln Ala Tyr Lys Glu Gln Val Leu Ala Lys Arg Leu Thr MetGlu Lys Gln Ala Tyr Lys Glu Gln Val Leu Ala Lys Arg Leu Thr Met
805 810 815 805 810 815
Leu Glu Leu Leu Glu Lys Tyr Pro Ala Cys Glu Met Glu Phe Ser GluLeu Glu Leu Leu Glu Lys Tyr Pro Ala Cys Glu Met Glu Phe Ser Glu
820 825 830 820 825 830
Phe Ile Ala Leu Leu Pro Ser Met Arg Pro Arg Tyr Tyr Ser Ile SerPhe Ile Ala Leu Leu Pro Ser Met Arg Pro Arg Tyr Tyr Ser Ile Ser
835 840 845 835 840 845
Ser Ser Pro Arg Val Asp Glu Lys Gln Ala Ser Ile Thr Val Ser ValSer Ser Pro Arg Val Asp Glu Lys Gln Ala Ser Ile Thr Val Ser Val
850 855 860 850 855 860
Val Ser Gly Glu Ala Trp Ser Gly Tyr Gly Glu Tyr Lys Gly Ile AlaVal Ser Gly Glu Ala Trp Ser Gly Tyr Gly Glu Tyr Lys Gly Ile Ala
865 870 875 880865 870 875 880
Ser Asn Tyr Leu Ala Asn Leu Gln Glu Gly Asp Thr Ile Thr Cys PheSer Asn Tyr Leu Ala Asn Leu Gln Glu Gly Asp Thr Ile Thr Cys Phe
885 890 895 885 890 895
Val Ser Thr Pro Gln Ser Gly Phe Thr Leu Pro Lys Gly Pro Glu ThrVal Ser Thr Pro Gln Ser Gly Phe Thr Leu Pro Lys Gly Pro Glu Thr
900 905 910 900 905 910
Pro Leu Ile Met Val Gly Pro Gly Thr Gly Val Ala Pro Phe Arg GlyPro Leu Ile Met Val Gly Pro Gly Thr Gly Val Ala Pro Phe Arg Gly
915 920 925 915 920 925
Phe Val Gln Ala Arg Lys Gln Leu Lys Glu Gln Gly Gln Ser Leu GlyPhe Val Gln Ala Arg Lys Gln Leu Lys Glu Gln Gly Gln Ser Leu Gly
930 935 940 930 935 940
Glu Ala His Leu Tyr Phe Gly Cys Arg Ser Pro His Glu Asp Tyr LeuGlu Ala His Leu Tyr Phe Gly Cys Arg Ser Pro His Glu Asp Tyr Leu
945 950 955 960945 950 955 960
Tyr Gln Lys Glu Leu Glu Asn Ala Gln Asn Glu Gly Ile Ile Thr LeuTyr Gln Lys Glu Leu Glu Asn Ala Gln Asn Glu Gly Ile Ile Thr Leu
965 970 975 965 970 975
His Thr Ala Phe Ser Arg Val Pro Asn Gln Pro Lys Thr Tyr Val GlnHis Thr Ala Phe Ser Arg Val Pro Asn Gln Pro Lys Thr Tyr Val Gln
980 985 990 980 985 990
His Val Met Glu Gln Asp Gly Lys Lys Leu Ile Glu Leu Leu Asp GlnHis Val Met Glu Gln Asp Gly Lys Lys Leu Ile Glu Leu Leu Asp Gln
995 1000 1005 995 1000 1005
Gly Ala His Phe Tyr Ile Cys Gly Asp Gly Ser Gln Met Ala ProGly Ala His Phe Tyr Ile Cys Gly Asp Gly Ser Gln Met Ala Pro
1010 1015 1020 1010 1015 1020
Asp Val Glu Ala Thr Leu Met Lys Ser Tyr Ala Glu Val His GlnAsp Val Glu Ala Thr Leu Met Lys Ser Tyr Ala Glu Val His Gln
1025 1030 1035 1025 1030 1035
Val Ser Glu Ala Asp Ala Arg Leu Trp Leu Gln Gln Leu Glu GluVal Ser Glu Ala Asp Ala Arg Leu Trp Leu Gln Gln Leu Glu Glu
1040 1045 1050 1040 1045 1050
Lys Gly Arg Tyr Ala Lys Asp Val Trp Ala GlyLys Gly Arg Tyr Ala Lys Asp Val Trp Ala Gly
1055 1060 1055 1060
<210> 19<210> 19
<211> 1064<211> 1064
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 19<400> 19
Met Pro Thr Leu Pro Arg Thr Phe Asp Asp Ile Gln Ser Arg Leu IleMet Pro Thr Leu Pro Arg Thr Phe Asp Asp Ile Gln Ser Arg Leu Ile
1 5 10 151 5 10 15
Asn Ala Thr Ser Arg Val Val Pro Met Gln Arg Gln Ile Gln Gly LeuAsn Ala Thr Ser Arg Val Val Pro Met Gln Arg Gln Ile Gln Gly Leu
20 25 30 20 25 30
Lys Phe Leu Met Ser Ala Lys Arg Lys Thr Phe Gly Pro Arg Arg ProLys Phe Leu Met Ser Ala Lys Arg Lys Thr Phe Gly Pro Arg Arg Pro
35 40 45 35 40 45
Met Pro Glu Phe Val Glu Thr Pro Ile Pro Asp Val Asn Thr Leu AlaMet Pro Glu Phe Val Glu Thr Pro Ile Pro Asp Val Asn Thr Leu Ala
50 55 60 50 55 60
Leu Glu Asp Ile Asp Val Ser Asn Pro Phe Leu Tyr Arg Gln Gly GlnLeu Glu Asp Ile Asp Val Ser Asn Pro Phe Leu Tyr Arg Gln Gly Gln
65 70 75 8065 70 75 80
Trp Arg Ala Tyr Phe Lys Arg Leu Arg Asp Glu Ala Pro Val His TyrTrp Arg Ala Tyr Phe Lys Arg Leu Arg Asp Glu Ala Pro Val His Tyr
85 90 95 85 90 95
Gln Lys Asn Ser Pro Phe Gly Pro Phe Trp Ser Val Thr Arg Phe GluGln Lys Asn Ser Pro Phe Gly Pro Phe Trp Ser Val Thr Arg Phe Glu
100 105 110 100 105 110
Asp Ile Leu Phe Val Asp Lys Ser His Asp Leu Phe Ser Ala Glu ProAsp Ile Leu Phe Val Asp Lys Ser His Asp Leu Phe Ser Ala Glu Pro
115 120 125 115 120 125
Gln Ile Ile Leu Gly Asp Pro Pro Glu Gly Leu Ser Val Glu Met PheGln Ile Ile Leu Gly Asp Pro Pro Glu Gly Leu Ser Val Glu Met Phe
130 135 140 130 135 140
Ile Ala Met Asp Pro Pro Lys His Asp Val Gln Arg Ser Ser Val GlnIle Ala Met Asp Pro Pro Lys His Asp Val Gln Arg Ser Ser Val Gln
145 150 155 160145 150 155 160
Gly Val Val Ala Pro Lys Asn Leu Lys Glu Met Glu Gly Leu Ile ArgGly Val Val Ala Pro Lys Asn Leu Lys Glu Met Glu Gly Leu Ile Arg
165 170 175 165 170 175
Ser Arg Thr Gly Asp Val Leu Asp Ser Leu Pro Thr Asp Lys Pro PheSer Arg Thr Gly Asp Val Leu Asp Ser Leu Pro Thr Asp Lys Pro Phe
180 185 190 180 185 190
Asn Trp Val Pro Ala Val Ser Lys Glu Leu Thr Gly Arg Met Leu AlaAsn Trp Val Pro Ala Val Ser Lys Glu Leu Thr Gly Arg Met Leu Ala
195 200 205 195 200 205
Thr Leu Leu Asp Phe Pro Tyr Glu Glu Arg His Lys Leu Val Glu TrpThr Leu Leu Asp Phe Pro Tyr Glu Glu Arg His Lys Leu Val Glu Trp
210 215 220 210 215 220
Ser Asp Arg Leu Ala Gly Ala Ala Ser Ala Thr Gly Gly Glu Phe AlaSer Asp Arg Leu Ala Gly Ala Ala Ser Ala Thr Gly Gly Glu Phe Ala
225 230 235 240225 230 235 240
Asp Glu Asn Ala Met Phe Asp Asp Ala Ala Asp Met Ala Arg Ser PheAsp Glu Asn Ala Met Phe Asp Asp Ala Ala Asp Met Ala Arg Ser Phe
245 250 255 245 250 255
Ser Arg Leu Trp Arg Asp Lys Glu Ala Arg Arg Ala Ala Gly Glu GluSer Arg Leu Trp Arg Asp Lys Glu Ala Arg Arg Ala Ala Gly Glu Glu
260 265 270 260 265 270
Pro Gly Phe Asp Leu Ile Ser Leu Leu Gln Ser Asn Lys Glu Thr LysPro Gly Phe Asp Leu Ile Ser Leu Leu Gln Ser Asn Lys Glu Thr Lys
275 280 285 275 280 285
Asp Leu Ile Asn Arg Pro Met Glu Phe Ile Gly Asn Leu Thr Leu LeuAsp Leu Ile Asn Arg Pro Met Glu Phe Ile Gly Asn Leu Thr Leu Leu
290 295 300 290 295 300
Ile Val Gly Gly Asn Asp Thr Thr Arg Asn Ser Met Ser Gly Gly LeuIle Val Gly Gly Asn Asp Thr Thr Arg Asn Ser Met Ser Gly Gly Leu
305 310 315 320305 310 315 320
Val Ala Met Asn Glu Phe Pro Arg Glu Phe Glu Lys Leu Lys Ala LysVal Ala Met Asn Glu Phe Pro Arg Glu Phe Glu Lys Leu Lys Ala Lys
325 330 335 325 330 335
Pro Glu Leu Ile Pro Asn Met Val Ser Glu Ile Ile Arg Trp Gln ThrPro Glu Leu Ile Pro Asn Met Val Ser Glu Ile Ile Arg Trp Gln Thr
340 345 350 340 345 350
Pro Leu Ala Tyr Met Arg Arg Ile Ala Lys Gln Asp Val Glu Leu GlyPro Leu Ala Tyr Met Arg Arg Ile Ala Lys Gln Asp Val Glu Leu Gly
355 360 365 355 360 365
Gly Gln Thr Ile Lys Lys Gly Asp Arg Val Val Met Trp Tyr Ala SerGly Gln Thr Ile Lys Lys Gly Asp Arg Val Val Met Trp Tyr Ala Ser
370 375 380 370 375 380
Gly Asn Arg Asp Glu Arg Lys Phe Asp Asn Pro Asp Gln Phe Ile IleGly Asn Arg Asp Glu Arg Lys Phe Asp Asn Pro Asp Gln Phe Ile Ile
385 390 395 400385 390 395 400
Asp Arg Lys Asp Ala Arg Asn His Met Ser Phe Gly Tyr Gly Val HisAsp Arg Lys Asp Ala Arg Asn His Met Ser Phe Gly Tyr Gly Val His
405 410 415 405 410 415
Arg Cys Met Gly Asn Arg Leu Ala Glu Leu Gln Leu Arg Ile Leu TrpArg Cys Met Gly Asn Arg Leu Ala Glu Leu Gln Leu Arg Ile Leu Trp
420 425 430 420 425 430
Glu Glu Ile Leu Lys Arg Phe Asp Asn Ile Glu Val Val Glu Glu ProGlu Glu Ile Leu Lys Arg Phe Asp Asn Ile Glu Val Val Glu Glu Pro
435 440 445 435 440 445
Glu Arg Val Gln Ser Asn Phe Val Arg Gly Tyr Ser Arg Leu Met ValGlu Arg Val Gln Ser Asn Phe Val Arg Gly Tyr Ser Arg Leu Met Val
450 455 460 450 455 460
Lys Leu Thr Pro Asn Ser Met Gly Gly Ile Pro Ser Pro Ser Arg GluLys Leu Thr Pro Asn Ser Met Gly Gly Ile Pro Ser Pro Ser Arg Glu
465 470 475 480465 470 475 480
Gln Ser Ala Lys Lys Glu Arg Lys Thr Val Glu Asn Ala His Asn ThrGln Ser Ala Lys Lys Glu Arg Lys Thr Val Glu Asn Ala His Asn Thr
485 490 495 485 490 495
Pro Leu Leu Val Leu Tyr Gly Ser Asn Met Gly Thr Ala Glu Gly ThrPro Leu Leu Val Leu Tyr Gly Ser Asn Met Gly Thr Ala Glu Gly Thr
500 505 510 500 505 510
Ala Arg Asp Leu Ala Asp Ile Ala Met Ser Lys Gly Phe Ala Pro GlnAla Arg Asp Leu Ala Asp Ile Ala Met Ser Lys Gly Phe Ala Pro Gln
515 520 525 515 520 525
Val Ala Thr Leu Asp Ser His Ala Gly Asn Leu Pro Arg Glu Gly AlaVal Ala Thr Leu Asp Ser His Ala Gly Asn Leu Pro Arg Glu Gly Ala
530 535 540 530 535 540
Val Leu Ile Val Thr Ala Ser Tyr Asn Gly His Pro Pro Asp Asn AlaVal Leu Ile Val Thr Ala Ser Tyr Asn Gly His Pro Pro Asp Asn Ala
545 550 555 560545 550 555 560
Lys Glu Phe Val Asp Trp Leu Asp Gln Ala Ser Ala Asp Glu Val LysLys Glu Phe Val Asp Trp Leu Asp Gln Ala Ser Ala Asp Glu Val Lys
565 570 575 565 570 575
Gly Val Arg Tyr Ser Val Phe Gly Cys Gly Asp Lys Asn Trp Ala ThrGly Val Arg Tyr Ser Val Phe Gly Cys Gly Asp Lys Asn Trp Ala Thr
580 585 590 580 585 590
Thr Tyr Gln Lys Val Pro Ala Phe Ile Asp Glu Thr Leu Ala Ala LysThr Tyr Gln Lys Val Pro Ala Phe Ile Asp Glu Thr Leu Ala Ala Lys
595 600 605 595 600 605
Gly Ala Glu Asn Ile Ala Glu Arg Gly Glu Ala Asp Ala Ser Asp AspGly Ala Glu Asn Ile Ala Glu Arg Gly Glu Ala Asp Ala Ser Asp Asp
610 615 620 610 615 620
Phe Glu Gly Thr Tyr Glu Glu Trp Arg Glu His Met Trp Ser Asp LeuPhe Glu Gly Thr Tyr Glu Glu Trp Arg Glu His Met Trp Ser Asp Leu
625 630 635 640625 630 635 640
Ala Ala Tyr Phe Asn Leu Asp Ile Glu Asn Ser Glu Glu Asn Ala SerAla Ala Tyr Phe Asn Leu Asp Ile Glu Asn Ser Glu Glu Asn Ala Ser
645 650 655 645 650 655
Thr Leu Ser Leu Gln Phe Val Asp Ser Ala Ala Asp Met Pro Leu AlaThr Leu Ser Leu Gln Phe Val Asp Ser Ala Ala Asp Met Pro Leu Ala
660 665 670 660 665 670
Lys Met His Arg Ala Phe Ser Ala Asn Val Val Ala Ser Lys Glu LeuLys Met His Arg Ala Phe Ser Ala Asn Val Val Ala Ser Lys Glu Leu
675 680 685 675 680 685
Gln Lys Pro Gly Ser Ala Arg Ser Thr Arg His Leu Glu Ile Glu LeuGln Lys Pro Gly Ser Ala Arg Ser Thr Arg His Leu Glu Ile Glu Leu
690 695 700 690 695 700
Pro Lys Glu Ala Ser Tyr Gln Glu Gly Asp His Leu Gly Val Ile ProPro Lys Glu Ala Ser Tyr Gln Glu Gly Asp His Leu Gly Val Ile Pro
705 710 715 720705 710 715 720
Arg Asn Tyr Glu Gly Ile Val Asn Arg Val Ala Thr Arg Phe Gly LeuArg Asn Tyr Glu Gly Ile Val Asn Arg Val Ala Thr Arg Phe Gly Leu
725 730 735 725 730 735
Asp Ala Ser Gln Gln Ile Arg Leu Glu Ala Glu Glu Glu Lys Leu AlaAsp Ala Ser Gln Gln Ile Arg Leu Glu Ala Glu Glu Glu Lys Leu Ala
740 745 750 740 745 750
His Leu Pro Leu Gly Lys Thr Val Ser Val Glu Glu Leu Leu Gln TyrHis Leu Pro Leu Gly Lys Thr Val Ser Val Glu Glu Leu Leu Gln Tyr
755 760 765 755 760 765
Val Glu Leu Gln Asp Pro Val Thr Arg Thr Gln Leu Arg Ala Met AlaVal Glu Leu Gln Asp Pro Val Thr Arg Thr Gln Leu Arg Ala Met Ala
770 775 780 770 775 780
Ala Lys Thr Val Cys Pro Pro His Lys Val Glu Leu Glu Val Leu LeuAla Lys Thr Val Cys Pro Pro His Lys Val Glu Leu Glu Val Leu Leu
785 790 795 800785 790 795 800
Glu Lys Gln Ala Tyr Lys Glu Gln Val Leu Ala Lys Arg Leu Thr MetGlu Lys Gln Ala Tyr Lys Glu Gln Val Leu Ala Lys Arg Leu Thr Met
805 810 815 805 810 815
Leu Glu Leu Leu Glu Lys Tyr Pro Ala Cys Glu Met Glu Phe Ser GluLeu Glu Leu Leu Glu Lys Tyr Pro Ala Cys Glu Met Glu Phe Ser Glu
820 825 830 820 825 830
Phe Ile Ala Leu Leu Pro Ser Met Arg Pro Arg Tyr Tyr Ser Ile SerPhe Ile Ala Leu Leu Pro Ser Met Arg Pro Arg Tyr Tyr Ser Ile Ser
835 840 845 835 840 845
Ser Ser Pro Arg Val Asp Glu Lys Gln Ala Ser Ile Thr Val Ser ValSer Ser Pro Arg Val Asp Glu Lys Gln Ala Ser Ile Thr Val Ser Val
850 855 860 850 855 860
Val Ser Gly Glu Ala Trp Ser Gly Tyr Gly Glu Tyr Lys Gly Ile AlaVal Ser Gly Glu Ala Trp Ser Gly Tyr Gly Glu Tyr Lys Gly Ile Ala
865 870 875 880865 870 875 880
Ser Asn Tyr Leu Ala Asn Leu Gln Glu Gly Asp Thr Ile Thr Cys PheSer Asn Tyr Leu Ala Asn Leu Gln Glu Gly Asp Thr Ile Thr Cys Phe
885 890 895 885 890 895
Val Ser Thr Pro Gln Ser Gly Phe Thr Leu Pro Lys Gly Pro Glu ThrVal Ser Thr Pro Gln Ser Gly Phe Thr Leu Pro Lys Gly Pro Glu Thr
900 905 910 900 905 910
Pro Leu Ile Met Val Gly Pro Gly Thr Gly Val Ala Pro Phe Arg GlyPro Leu Ile Met Val Gly Pro Gly Thr Gly Val Ala Pro Phe Arg Gly
915 920 925 915 920 925
Phe Val Gln Ala Arg Lys Gln Leu Lys Glu Gln Gly Gln Ser Leu GlyPhe Val Gln Ala Arg Lys Gln Leu Lys Glu Gln Gly Gln Ser Leu Gly
930 935 940 930 935 940
Glu Ala His Leu Tyr Phe Gly Cys Arg Ser Pro His Glu Asp Tyr LeuGlu Ala His Leu Tyr Phe Gly Cys Arg Ser Pro His Glu Asp Tyr Leu
945 950 955 960945 950 955 960
Tyr Gln Lys Glu Leu Glu Asn Ala Gln Asn Glu Gly Ile Ile Thr LeuTyr Gln Lys Glu Leu Glu Asn Ala Gln Asn Glu Gly Ile Ile Thr Leu
965 970 975 965 970 975
His Thr Ala Phe Ser Arg Val Pro Asn Gln Pro Lys Thr Tyr Val GlnHis Thr Ala Phe Ser Arg Val Pro Asn Gln Pro Lys Thr Tyr Val Gln
980 985 990 980 985 990
His Val Met Glu Gln Asp Gly Lys Lys Leu Ile Glu Leu Leu Asp GlnHis Val Met Glu Gln Asp Gly Lys Lys Leu Ile Glu Leu Leu Asp Gln
995 1000 1005 995 1000 1005
Gly Ala His Phe Tyr Ile Cys Gly Asp Gly Ser Gln Met Ala ProGly Ala His Phe Tyr Ile Cys Gly Asp Gly Ser Gln Met Ala Pro
1010 1015 1020 1010 1015 1020
Asp Val Glu Ala Thr Leu Met Lys Ser Tyr Ala Glu Val His GlnAsp Val Glu Ala Thr Leu Met Lys Ser Tyr Ala Glu Val His Gln
1025 1030 1035 1025 1030 1035
Val Ser Glu Ala Asp Ala Arg Leu Trp Leu Gln Gln Leu Glu GluVal Ser Glu Ala Asp Ala Arg Leu Trp Leu Gln Gln Leu Glu Glu
1040 1045 1050 1040 1045 1050
Lys Gly Arg Tyr Ala Lys Asp Val Trp Ala GlyLys Gly Arg Tyr Ala Lys Asp Val Trp Ala Gly
1055 1060 1055 1060
<210> 20<210> 20
<211> 550<211> 550
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 20<400> 20
Met Ser Asp Thr Thr Thr Ala Phe Thr Val Pro Ala Val Ala Lys AlaMet Ser Asp Thr Thr Thr Ala Phe Thr Val Pro Ala Val Ala Lys Ala
1 5 10 151 5 10 15
Val Ala Ala Ala Ile Pro Asp Arg Glu Leu Ile Ile Gln Gly Asp ArgVal Ala Ala Ala Ile Pro Asp Arg Glu Leu Ile Ile Gln Gly Asp Arg
20 25 30 20 25 30
Arg Tyr Thr Tyr Arg Gln Val Ile Glu Arg Ser Asn Arg Leu Ala AlaArg Tyr Thr Tyr Arg Gln Val Ile Glu Arg Ser Asn Arg Leu Ala Ala
35 40 45 35 40 45
Tyr Leu His Ser Gln Gly Leu Gly Cys His Thr Glu Arg Glu Ala LeuTyr Leu His Ser Gln Gly Leu Gly Cys His Thr Glu Arg Glu Ala Leu
50 55 60 50 55 60
Ala Gly His Glu Val Gly Gln Asp Leu Leu Gly Leu Tyr Ala Tyr AsnAla Gly His Glu Val Gly Gln Asp Leu Leu Gly Leu Tyr Ala Tyr Asn
65 70 75 8065 70 75 80
Gly Asn Glu Phe Val Glu Ala Leu Leu Gly Ala Phe Ala Ala Arg ValGly Asn Glu Phe Val Glu Ala Leu Leu Gly Ala Phe Ala Ala Arg Val
85 90 95 85 90 95
Ala Pro Phe Asn Val Asn Phe Arg Tyr Val Lys Ser Glu Leu His TyrAla Pro Phe Asn Val Asn Phe Arg Tyr Val Lys Ser Glu Leu His Tyr
100 105 110 100 105 110
Leu Leu Ala Asp Ser Glu Ala Thr Ala Leu Ile Tyr His Ala Ala PheLeu Leu Ala Asp Ser Glu Ala Thr Ala Leu Ile Tyr His Ala Ala Phe
115 120 125 115 120 125
Ala Pro Arg Val Ala Glu Ile Leu Pro Glu Leu Pro Arg Leu Arg ValAla Pro Arg Val Ala Glu Ile Leu Pro Glu Leu Pro Arg Leu Arg Val
130 135 140 130 135 140
Leu Ile Gln Ile Ala Asp Glu Ser Gly Asn Glu Leu Leu Asp Gly AlaLeu Ile Gln Ile Ala Asp Glu Ser Gly Asn Glu Leu Leu Asp Gly Ala
145 150 155 160145 150 155 160
Val Asp Tyr Glu Asp Ala Leu Ala Ser Val Ser Ala Gln Pro Pro ProVal Asp Tyr Glu Asp Ala Leu Ala Ser Val Ser Ala Gln Pro Pro Pro
165 170 175 165 170 175
Val Arg His Cys Pro Asp Asp Leu Tyr Val Leu Tyr Thr Gly Gly ThrVal Arg His Cys Pro Asp Asp Leu Tyr Val Leu Tyr Thr Gly Gly Thr
180 185 190 180 185 190
Thr Gly Met Pro Lys Gly Val Leu Trp Arg Gln His Asp Ile Phe MetThr Gly Met Pro Lys Gly Val Leu Trp Arg Gln His Asp Ile Phe Met
195 200 205 195 200 205
Thr Ser Phe Gly Gly Arg Asn Leu Met Thr Gly Glu Pro Ser Ser SerThr Ser Phe Gly Gly Arg Asn Leu Met Thr Gly Glu Pro Ser Ser Ser
210 215 220 210 215 220
Ile Asp Glu Ile Val Gln Arg Ala Ala Ser Gly Pro Gly Thr Lys LeuIle Asp Glu Ile Val Gln Arg Ala Ala Ser Gly Pro Gly Thr Lys Leu
225 230 235 240225 230 235 240
Met Ile Leu Pro Pro Leu Ile His Gly Ala Ala Gln Trp Ser Val MetMet Ile Leu Pro Pro Leu Ile His Gly Ala Ala Gln Trp Ser Val Met
245 250 255 245 250 255
Thr Ala Ile Thr Thr Gly Gln Thr Val Val Phe Pro Thr Val Val AspThr Ala Ile Thr Thr Gly Gln Thr Val Val Phe Pro Thr Val Val Asp
260 265 270 260 265 270
His Leu Asp Ala Glu Asp Val Val Arg Thr Ile Glu Arg Glu Lys ValHis Leu Asp Ala Glu Asp Val Val Arg Thr Ile Glu Arg Glu Lys Val
275 280 285 275 280 285
Met Val Val Thr Val Val Gly Asp Ala Met Ala Arg Pro Leu Val AlaMet Val Val Thr Val Val Gly Asp Ala Met Ala Arg Pro Leu Val Ala
290 295 300 290 295 300
Ala Ile Glu Lys Gly Ile Ala Asp Val Ser Ser Leu Ala Val Val AlaAla Ile Glu Lys Gly Ile Ala Asp Val Ser Ser Leu Ala Val Val Ala
305 310 315 320305 310 315 320
Asn Gly Gly Ala Leu Leu Thr Pro Phe Val Lys Gln Arg Leu Ile GluAsn Gly Gly Ala Leu Leu Thr Pro Phe Val Lys Gln Arg Leu Ile Glu
325 330 335 325 330 335
Val Leu Pro Asn Ala Val Val Val Asp Gly Val Gly Ser Ser Glu ThrVal Leu Pro Asn Ala Val Val Val Asp Gly Val Gly Ser Ser Glu Thr
340 345 350 340 345 350
Gly Ala Gln Met His His Met Ser Thr Pro Gly Ala Val Ala Thr GlyGly Ala Gln Met His His Met Ser Thr Pro Gly Ala Val Ala Thr Gly
355 360 365 355 360 365
Thr Phe Asn Ala Gly Pro Asp Thr Phe Val Ala Ala Glu Asp Leu SerThr Phe Asn Ala Gly Pro Asp Thr Phe Val Ala Ala Glu Asp Leu Ser
370 375 380 370 375 380
Ala Ile Leu Pro Pro Gly His Glu Gly Met Gly Trp Leu Ala Gln ArgAla Ile Leu Pro Pro Gly His Glu Gly Met Gly Trp Leu Ala Gln Arg
385 390 395 400385 390 395 400
Gly Tyr Val Pro Leu Gly Tyr Lys Gly Asp Ala Ala Lys Thr Ala LysGly Tyr Val Pro Leu Gly Tyr Lys Gly Asp Ala Ala Lys Thr Ala Lys
405 410 415 405 410 415
Thr Phe Pro Val Ile Asp Gly Val Arg Tyr Ala Val Pro Gly Asp ArgThr Phe Pro Val Ile Asp Gly Val Arg Tyr Ala Val Pro Gly Asp Arg
420 425 430 420 425 430
Ala Arg His His Asp Ala Gly His Ile Glu Leu Leu Gly Arg Asp SerAla Arg His His Asp Ala Gly His Ile Glu Leu Leu Gly Arg Asp Ser
435 440 445 435 440 445
Val Cys Ile Asn Ser Gly Gly Glu Lys Ile Phe Val Glu Glu Val GluVal Cys Ile Asn Ser Gly Gly Glu Lys Ile Phe Val Glu Glu Val Glu
450 455 460 450 455 460
Thr Ala Ile Ala Ser His Pro Ala Val Ala Asp Val Val Val Ala GlyThr Ala Ile Ala Ser His Pro Ala Val Ala Asp Val Val Val Ala Gly
465 470 475 480465 470 475 480
Arg Pro Ser Glu Arg Trp Gly Gln Glu Val Val Ala Val Val Ala LeuArg Pro Ser Glu Arg Trp Gly Gln Glu Val Val Ala Val Val Ala Leu
485 490 495 485 490 495
Ser Asp Gly Ala Ala Val Asp Ala Gly Glu Leu Ile Ala His Ala SerSer Asp Gly Ala Ala Val Asp Ala Gly Glu Leu Ile Ala His Ala Ser
500 505 510 500 505 510
Asn Ser Leu Ala Arg Tyr Lys Leu Pro Lys Ala Ile Val Phe Arg ProAsn Ser Leu Ala Arg Tyr Lys Leu Pro Lys Ala Ile Val Phe Arg Pro
515 520 525 515 520 525
Val Ile Glu Arg Ser Pro Ser Gly Lys Ala Asp Tyr Arg Trp Ala ArgVal Ile Glu Arg Ser Pro Ser Gly Lys Ala Asp Tyr Arg Trp Ala Arg
530 535 540 530 535 540
Glu Gln Ala Val Asn GlyGlu Gln Ala Val Asn Gly
545 550545 550
<210> 21<210> 21
<211> 408<211> 408
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 21<400> 21
Asp Phe Ala Tyr Ser Pro Lys Val Gln Ala Leu Arg Glu Arg Val ThrAsp Phe Ala Tyr Ser Pro Lys Val Gln Ala Leu Arg Glu Arg Val Thr
1 5 10 151 5 10 15
Ala Phe Met Asp Ala His Val Tyr Pro Ala Glu Ala Val Phe Glu ArgAla Phe Met Asp Ala His Val Tyr Pro Ala Glu Ala Val Phe Glu Arg
20 25 30 20 25 30
Gln Val Ala Glu Gly Asp Arg Trp Gln Pro Thr Ala Ile Met Glu GluGln Val Ala Glu Gly Asp Arg Trp Gln Pro Thr Ala Ile Met Glu Glu
35 40 45 35 40 45
Leu Lys Ala Lys Ala Arg Ala Glu Gly Leu Trp Asn Leu Phe Leu ProLeu Lys Ala Lys Ala Arg Ala Glu Gly Leu Trp Asn Leu Phe Leu Pro
50 55 60 50 55 60
Glu Ser Glu Tyr Gly Ala Gly Leu Ser Asn Leu Glu Tyr Ala Pro LeuGlu Ser Glu Tyr Gly Ala Gly Leu Ser Asn Leu Glu Tyr Ala Pro Leu
65 70 75 8065 70 75 80
Ala Glu Ile Met Gly Arg Ser Leu Leu Gly Pro Glu Pro Phe Asn CysAla Glu Ile Met Gly Arg Ser Leu Leu Gly Pro Glu Pro Phe Asn Cys
85 90 95 85 90 95
Ser Ala Pro Asp Thr Gly Asn Met Glu Val Leu Val Arg Tyr Gly SerSer Ala Pro Asp Thr Gly Asn Met Glu Val Leu Val Arg Tyr Gly Ser
100 105 110 100 105 110
Glu Ala Gln Lys Arg Gln Trp Leu Glu Pro Leu Leu Arg Gly Glu IleGlu Ala Gln Lys Arg Gln Trp Leu Glu Pro Leu Leu Arg Gly Glu Ile
115 120 125 115 120 125
Arg Ser Ala Phe Ala Met Thr Glu Pro Asp Val Ala Ser Ser Asp AlaArg Ser Ala Phe Ala Met Thr Glu Pro Asp Val Ala Ser Ser Asp Ala
130 135 140 130 135 140
Thr Asn Met Ala Ala Thr Ala Ile Arg Asp Gly Asp Gln Trp Val IleThr Asn Met Ala Ala Thr Ala Ile Arg Asp Gly Asp Gln Trp Val Ile
145 150 155 160145 150 155 160
Asn Gly Arg Lys Trp Trp Thr Ser Gly Ala Cys Asp Pro Arg Cys LysAsn Gly Arg Lys Trp Trp Thr Ser Gly Ala Cys Asp Pro Arg Cys Lys
165 170 175 165 170 175
Val Met Ile Phe Met Gly Leu Ser Asp Pro Glu Gly Pro Arg His GlnVal Met Ile Phe Met Gly Leu Ser Asp Pro Glu Gly Pro Arg His Gln
180 185 190 180 185 190
Gln His Ser Met Val Leu Val Pro Thr Asp Thr Pro Gly Val Lys IleGln His Ser Met Val Leu Val Pro Thr Asp Thr Pro Gly Val Lys Ile
195 200 205 195 200 205
Val Arg Pro Leu Pro Val Phe Gly Tyr Asp Asp Ala Pro His Gly HisVal Arg Pro Leu Pro Val Phe Gly Tyr Asp Asp Ala Pro His Gly His
210 215 220 210 215 220
Ala Glu Val Leu Phe Glu Asn Val Arg Val Pro Tyr Glu Asn Val IleAla Glu Val Leu Phe Glu Asn Val Arg Val Pro Tyr Glu Asn Val Ile
225 230 235 240225 230 235 240
Leu Gly Glu Gly Arg Gly Phe Glu Ile Ala Gln Gly Arg Leu Gly ProLeu Gly Glu Gly Arg Gly Phe Glu Ile Ala Gln Gly Arg Leu Gly Pro
245 250 255 245 250 255
Gly Arg Ile His His Cys Met Arg Ser Ile Gly Met Ala Glu Arg AlaGly Arg Ile His His Cys Met Arg Ser Ile Gly Met Ala Glu Arg Ala
260 265 270 260 265 270
Leu Glu Leu Met Cys Lys Arg Ser Val Glu Arg Thr Ala Phe Gly ArgLeu Glu Leu Met Cys Lys Arg Ser Val Glu Arg Thr Ala Phe Gly Arg
275 280 285 275 280 285
Pro Leu Ala Arg Leu Gly Gly Asn Val Asp Lys Ile Ala Asp Ser ArgPro Leu Ala Arg Leu Gly Gly Asn Val Asp Lys Ile Ala Asp Ser Arg
290 295 300 290 295 300
Met Glu Ile Asp Met Ala Arg Leu Leu Thr Leu Lys Ala Ala Tyr MetMet Glu Ile Asp Met Ala Arg Leu Leu Thr Leu Lys Ala Ala Tyr Met
305 310 315 320305 310 315 320
Met Asp Thr Val Gly Asn Lys Val Ala Arg Ser Glu Ile Ala Gln IleMet Asp Thr Val Gly Asn Lys Val Ala Arg Ser Glu Ile Ala Gln Ile
325 330 335 325 330 335
Lys Val Val Ala Pro Asn Val Ala Leu Asn Val Ile Asp Arg Ala IleLys Val Val Ala Pro Asn Val Ala Leu Asn Val Ile Asp Arg Ala Ile
340 345 350 340 345 350
Gln Ile His Gly Gly Ala Gly Val Ser Gly Asp Phe Pro Leu Ala TyrGln Ile His Gly Gly Ala Gly Val Ser Gly Asp Phe Pro Leu Ala Tyr
355 360 365 355 360 365
Met Tyr Ala Met Gln Arg Thr Leu Arg Leu Ala Asp Gly Pro Asp GluMet Tyr Ala Met Gln Arg Thr Leu Arg Leu Ala Asp Gly Pro Asp Glu
370 375 380 370 375 380
Val His Arg Ala Ala Ile Gly Lys Tyr Glu Ile Gly Lys Tyr Val ProVal His Arg Ala Ala Ile Gly Lys Tyr Glu Ile Gly Lys Tyr Val Pro
385 390 395 400385 390 395 400
Val Glu Met Leu Arg Ser Gly ArgVal Glu Met Leu Arg Ser Gly Arg
405 405
<210> 22<210> 22
<211> 237<211> 237
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 22<400> 22
Met Ser Asp Ser Glu Val Asn Gln Glu Ala Lys Pro Glu Val Lys ProMet Ser Asp Ser Glu Val Asn Gln Glu Ala Lys Pro Glu Val Lys Pro
1 5 10 151 5 10 15
Glu Val Lys Pro Glu Thr His Ile Asn Leu Lys Val Ser Asp Gly SerGlu Val Lys Pro Glu Thr His Ile Asn Leu Lys Val Ser Asp Gly Ser
20 25 30 20 25 30
Ser Glu Ile Phe Phe Lys Ile Lys Lys Thr Thr Pro Leu Arg Arg LeuSer Glu Ile Phe Phe Lys Ile Lys Lys Thr Thr Pro Leu Arg Arg Leu
35 40 45 35 40 45
Met Glu Ala Phe Ala Lys Arg Gln Gly Lys Glu Met Asp Ser Leu ArgMet Glu Ala Phe Ala Lys Arg Gln Gly Lys Glu Met Asp Ser Leu Arg
50 55 60 50 55 60
Phe Leu Tyr Asp Gly Ile Arg Ile Gln Ala Asp Gln Thr Pro Glu AspPhe Leu Tyr Asp Gly Ile Arg Ile Gln Ala Asp Gln Thr Pro Glu Asp
65 70 75 8065 70 75 80
Leu Asp Met Glu Asp Asn Asp Ile Ile Glu Ala His Arg Glu Gln IleLeu Asp Met Glu Asp Asn Asp Ile Ile Glu Ala His Arg Glu Gln Ile
85 90 95 85 90 95
Gly Gly Ser Gly Ser Met Ile Trp Gln Arg Thr Ala Thr Leu Asp AlaGly Gly Ser Gly Ser Met Ile Trp Gln Arg Thr Ala Thr Leu Asp Ala
100 105 110 100 105 110
Leu Asn Ala Met Gly Ala Asn Asn Met Val Gly Leu Leu Asp Ile ArgLeu Asn Ala Met Gly Ala Asn Asn Met Val Gly Leu Leu Asp Ile Arg
115 120 125 115 120 125
Phe Thr Arg Leu Asp Asp Asn Glu Ile Glu Ala Thr Met Pro Val AspPhe Thr Arg Leu Asp Asp Asn Glu Ile Glu Ala Thr Met Pro Val Asp
130 135 140 130 135 140
His Arg Thr His Gln Pro Phe Gly Leu Leu His Gly Gly Ala Ser ValHis Arg Thr His Gln Pro Phe Gly Leu Leu His Gly Gly Ala Ser Val
145 150 155 160145 150 155 160
Val Leu Ala Glu Thr Leu Gly Ser Val Ala Gly Tyr Leu Cys Thr GluVal Leu Ala Glu Thr Leu Gly Ser Val Ala Gly Tyr Leu Cys Thr Glu
165 170 175 165 170 175
Gly Glu Gln Asn Ile Val Gly Leu Glu Val Asn Ala Asn His Leu ArgGly Glu Gln Asn Ile Val Gly Leu Glu Val Asn Ala Asn His Leu Arg
180 185 190 180 185 190
Ser Val Arg Ser Gly Arg Val Arg Gly Val Cys Arg Ala Val His ValSer Val Arg Ser Gly Arg Val Arg Gly Val Cys Arg Ala Val His Val
195 200 205 195 200 205
Gly Arg Arg His Gln Val Trp Gln Ile Glu Ile Phe Asp Glu Gln AspGly Arg Arg His Gln Val Trp Gln Ile Glu Ile Phe Asp Glu Gln Asp
210 215 220 210 215 220
Arg Leu Cys Cys Ser Ser Arg Leu Thr Thr Ala Val ValArg Leu Cys Cys Ser Ser Arg Leu Thr Thr Ala Val Val
225 230 235225 230 235
<210> 23<210> 23
<211> 1410<211> 1410
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 23<400> 23
atgccgacgt taccacgtac ctttgatgac attcagtctc gcttaatcaa tgctacaagt 60atgccgacgt taccacgtac ctttgatgac attcagtctc gcttaatcaa tgctacaagt 60
cgtgtggttc caatgcagcg tcagattcag ggtctgaaat ttctgatgag tgccaaacgc 120cgtgtggttc caatgcagcg tcagattcag ggtctgaaat ttctgatgag tgccaaacgc 120
aaaacctttg gtccacgtcg cccaatgccg gaatttgtgg aaacacctat cccggatgtt 180aaaacctttg gtccacgtcg cccaatgccg gaatttgtgg aaacacctat cccggatgtt 180
aatacattag ccttagagga cattgatgtg agtaatccgt ttctgtatcg ccagggccag 240aatacattag ccttagagga cattgatgtg agtaatccgt ttctgtatcg ccagggccag 240
tggcgcgcat attttaaacg cttacgcgat gaagctccag ttcattatca gaaaaatagc 300tggcgcgcat attttaaacg cttacgcgat gaagctccag ttcattatca gaaaaatagc 300
ccatttggtc cgttttggag cgtgacccgc tttgaggaca ttctgtttgt ggataaatca 360ccatttggtc cgttttggag cgtgacccgc tttgaggaca ttctgtttgt ggataaatca 360
catgatctgt ttagcgccga accacagatc atcttaggtg atcctccgga aggcctgtca 420catgatctgt ttagcgccga accacagatc atcttaggtg atcctccgga aggcctgtca 420
gtggaaatgt ttattgcgat ggaccctcct aaacatgatg tgcagcgctc tagtgttcag 480gtggaaatgt ttattgcgat ggaccctcct aaacatgatg tgcagcgctc tagtgttcag 480
ggtgtggttg cccctaaaaa tctgaaagaa atggaaggcc tgattcgtag tcgtacgggc 540ggtgtggttg cccctaaaaa tctgaaagaa atggaaggcc tgattcgtag tcgtacgggc 540
gatgtgttag attcattacc gacggataaa ccgtttaatt gggttcctgc ggtgagcaaa 600gatgtgttag attcattacc gacggataaa ccgtttaatt gggttcctgc ggtgagcaaa 600
gaactgacgg gtagaatgct ggctacctta ctggattttc cgtatgaaga acgtcataaa 660gaactgacgg gtagaatgct ggctacctta ctggattttc cgtatgaaga acgtcataaa 660
ctggttgaat ggagcgatcg cttggccggt gcggcaagtg ctacgggcgg cgaatttgcg 720ctggttgaat ggagcgatcg cttggccggt gcggcaagtg ctacgggcgg cgaatttgcg 720
gatgaaaatg ctatgtttga tgatgcggca gatatggcac gctctttttc tcgcctgtgg 780gatgaaaatg ctatgtttga tgatgcggca gatatggcac gctctttttc tcgcctgtgg 780
cgcgataaag aagcccgccg tgcagcaggc gaagaaccgg gctttgattt aatctcactg 840cgcgataaag aagcccgccg tgcagcaggc gaagaaccgg gctttgattt aatctcactg 840
ctacagtcta ataaagaaac caaggatctg atcaatcgtc ctatggaatt tattggcaat 900ctacagtcta ataaagaaac caaggatctg atcaatcgtc ctatggaatt tattggcaat 900
ctgaccctgc tgattgtggg cggtaatgat acgacccgca atagcatgtc aggcggctta 960ctgaccctgc tgattgtggg cggtaatgat acgacccgca atagcatgtc aggcggctta 960
gttgccatga atgaatttcc tcgtgaattt gaaaaactga aagccaaacc ggaactgatt 1020gttgccatga atgaatttcc tcgtgaattt gaaaaactga aagccaaacc ggaactgatt 1020
ccgaatatgg tgagcgaaat tattcgttgg cagacaccac tggcctatat gcgccgcatt 1080ccgaatatgg tgagcgaaat tattcgttgg cagacaccac tggcctatat gcgccgcatt 1080
gccaaacagg atgttgaact gggcggtcag accatcaaaa aaggtgatcg cgttgttatg 1140gccaaacagg atgttgaact gggcggtcag accatcaaaa aaggtgatcg cgttgttatg 1140
tggtatgcct caggtaatcg cgatgaacgt aaatttgata atccggatca gtttattatc 1200tggtatgcct caggtaatcg cgatgaacgt aaatttgata atccggatca gtttattatc 1200
gatcgtaaag atgcacgcaa tcacatgtct tttggctatg gtgttcatcg ctgtatgggt 1260gatcgtaaag atgcacgcaa tcacatgtct tttggctatg gtgttcatcg ctgtatgggt 1260
aatcgtctgg ccgaattaca gctgcgtatt ctgtgggaag aaatcttaaa acgctttgat 1320aatcgtctgg ccgaattaca gctgcgtatt ctgtgggaag aaatcttaaa acgctttgat 1320
aatatcgaag ttgtggaaga accagaacgt gtgcagagca attttgttcg cggctatagc 1380aatatcgaag ttgtggaaga accagaacgt gtgcagagca attttgttcg cggctatagc 1380
cgcttaatgg ttaaactgac acctaatagt 1410cgcttaatgg ttaaactgac acctaatagt 1410
<210> 24<210> 24
<211> 470<211> 470
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 24<400> 24
Met Pro Thr Leu Pro Arg Thr Phe Asp Asp Ile Gln Ser Arg Leu IleMet Pro Thr Leu Pro Arg Thr Phe Asp Asp Ile Gln Ser Arg Leu Ile
1 5 10 151 5 10 15
Asn Ala Thr Ser Arg Val Val Pro Met Gln Arg Gln Ile Gln Gly LeuAsn Ala Thr Ser Arg Val Val Pro Met Gln Arg Gln Ile Gln Gly Leu
20 25 30 20 25 30
Lys Phe Leu Met Ser Ala Lys Arg Lys Thr Phe Gly Pro Arg Arg ProLys Phe Leu Met Ser Ala Lys Arg Lys Thr Phe Gly Pro Arg Arg Pro
35 40 45 35 40 45
Met Pro Glu Phe Val Glu Thr Pro Ile Pro Asp Val Asn Thr Leu AlaMet Pro Glu Phe Val Glu Thr Pro Ile Pro Asp Val Asn Thr Leu Ala
50 55 60 50 55 60
Leu Glu Asp Ile Asp Val Ser Asn Pro Phe Leu Tyr Arg Gln Gly GlnLeu Glu Asp Ile Asp Val Ser Asn Pro Phe Leu Tyr Arg Gln Gly Gln
65 70 75 8065 70 75 80
Trp Arg Ala Tyr Phe Lys Arg Leu Arg Asp Glu Ala Pro Val His TyrTrp Arg Ala Tyr Phe Lys Arg Leu Arg Asp Glu Ala Pro Val His Tyr
85 90 95 85 90 95
Gln Lys Asn Ser Pro Phe Gly Pro Phe Trp Ser Val Thr Arg Phe GluGln Lys Asn Ser Pro Phe Gly Pro Phe Trp Ser Val Thr Arg Phe Glu
100 105 110 100 105 110
Asp Ile Leu Phe Val Asp Lys Ser His Asp Leu Phe Ser Ala Glu ProAsp Ile Leu Phe Val Asp Lys Ser His Asp Leu Phe Ser Ala Glu Pro
115 120 125 115 120 125
Gln Ile Ile Leu Gly Asp Pro Pro Glu Gly Leu Ser Val Glu Met PheGln Ile Ile Leu Gly Asp Pro Pro Glu Gly Leu Ser Val Glu Met Phe
130 135 140 130 135 140
Ile Ala Met Asp Pro Pro Lys His Asp Val Gln Arg Ser Ser Val GlnIle Ala Met Asp Pro Pro Lys His Asp Val Gln Arg Ser Ser Val Gln
145 150 155 160145 150 155 160
Gly Val Val Ala Pro Lys Asn Leu Lys Glu Met Glu Gly Leu Ile ArgGly Val Val Ala Pro Lys Asn Leu Lys Glu Met Glu Gly Leu Ile Arg
165 170 175 165 170 175
Ser Arg Thr Gly Asp Val Leu Asp Ser Leu Pro Thr Asp Lys Pro PheSer Arg Thr Gly Asp Val Leu Asp Ser Leu Pro Thr Asp Lys Pro Phe
180 185 190 180 185 190
Asn Trp Val Pro Ala Val Ser Lys Glu Leu Thr Gly Arg Met Leu AlaAsn Trp Val Pro Ala Val Ser Lys Glu Leu Thr Gly Arg Met Leu Ala
195 200 205 195 200 205
Thr Leu Leu Asp Phe Pro Tyr Glu Glu Arg His Lys Leu Val Glu TrpThr Leu Leu Asp Phe Pro Tyr Glu Glu Arg His Lys Leu Val Glu Trp
210 215 220 210 215 220
Ser Asp Arg Leu Ala Gly Ala Ala Ser Ala Thr Gly Gly Glu Phe AlaSer Asp Arg Leu Ala Gly Ala Ala Ser Ala Thr Gly Gly Glu Phe Ala
225 230 235 240225 230 235 240
Asp Glu Asn Ala Met Phe Asp Asp Ala Ala Asp Met Ala Arg Ser PheAsp Glu Asn Ala Met Phe Asp Asp Ala Ala Asp Met Ala Arg Ser Phe
245 250 255 245 250 255
Ser Arg Leu Trp Arg Asp Lys Glu Ala Arg Arg Ala Ala Gly Glu GluSer Arg Leu Trp Arg Asp Lys Glu Ala Arg Arg Ala Ala Gly Glu Glu
260 265 270 260 265 270
Pro Gly Phe Asp Leu Ile Ser Leu Leu Gln Ser Asn Lys Glu Thr LysPro Gly Phe Asp Leu Ile Ser Leu Leu Gln Ser Asn Lys Glu Thr Lys
275 280 285 275 280 285
Asp Leu Ile Asn Arg Pro Met Glu Phe Ile Gly Asn Leu Thr Leu LeuAsp Leu Ile Asn Arg Pro Met Glu Phe Ile Gly Asn Leu Thr Leu Leu
290 295 300 290 295 300
Ile Val Gly Gly Asn Asp Thr Thr Arg Asn Ser Met Ser Gly Gly LeuIle Val Gly Gly Asn Asp Thr Thr Arg Asn Ser Met Ser Gly Gly Leu
305 310 315 320305 310 315 320
Val Ala Met Asn Glu Phe Pro Arg Glu Phe Glu Lys Leu Lys Ala LysVal Ala Met Asn Glu Phe Pro Arg Glu Phe Glu Lys Leu Lys Ala Lys
325 330 335 325 330 335
Pro Glu Leu Ile Pro Asn Met Val Ser Glu Ile Ile Arg Trp Gln ThrPro Glu Leu Ile Pro Asn Met Val Ser Glu Ile Ile Arg Trp Gln Thr
340 345 350 340 345 350
Pro Leu Ala Tyr Met Arg Arg Ile Ala Lys Gln Asp Val Glu Leu GlyPro Leu Ala Tyr Met Arg Arg Ile Ala Lys Gln Asp Val Glu Leu Gly
355 360 365 355 360 365
Gly Gln Thr Ile Lys Lys Gly Asp Arg Val Val Met Trp Tyr Ala SerGly Gln Thr Ile Lys Lys Gly Asp Arg Val Val Met Trp Tyr Ala Ser
370 375 380 370 375 380
Gly Asn Arg Asp Glu Arg Lys Phe Asp Asn Pro Asp Gln Phe Ile IleGly Asn Arg Asp Glu Arg Lys Phe Asp Asn Pro Asp Gln Phe Ile Ile
385 390 395 400385 390 395 400
Asp Arg Lys Asp Ala Arg Asn His Met Ser Phe Gly Tyr Gly Val HisAsp Arg Lys Asp Ala Arg Asn His Met Ser Phe Gly Tyr Gly Val His
405 410 415 405 410 415
Arg Cys Met Gly Asn Arg Leu Ala Glu Leu Gln Leu Arg Ile Leu TrpArg Cys Met Gly Asn Arg Leu Ala Glu Leu Gln Leu Arg Ile Leu Trp
420 425 430 420 425 430
Glu Glu Ile Leu Lys Arg Phe Asp Asn Ile Glu Val Val Glu Glu ProGlu Glu Ile Leu Lys Arg Phe Asp Asn Ile Glu Val Val Glu Glu Pro
435 440 445 435 440 445
Glu Arg Val Gln Ser Asn Phe Val Arg Gly Tyr Ser Arg Leu Met ValGlu Arg Val Gln Ser Asn Phe Val Arg Gly Tyr Ser Arg Leu Met Val
450 455 460 450 455 460
Lys Leu Thr Pro Asn SerLys Leu Thr Pro Asn Ser
465 470465 470
<210> 25<210> 25
<211> 45<211> 45
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 25<400> 25
tcgagctccg tcgacaagct tatggaaatg acatcagcgt ttacc 45tcgagctccg tcgacaagct tatggaaatg acatcagcgt ttacc 45
<210> 26<210> 26
<211> 38<211> 38
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 26<400> 26
gtccacggag aattcatctc taatgctgtg ctgacgcc 38gtccacggag aattcatctc taatgctgtg ctgacgcc 38
<210> 27<210> 27
<211> 22<211> 22
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 27<400> 27
ctgtactgga agccgcttat gg 22ctgtactgga agccgcttat gg 22
<210> 28<210> 28
<211> 44<211> 44
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 28<400> 28
gtggtggtgg tggtgctcga gttattgcag gtcagttgca gttg 44gtggtggtgg tggtgctcga gttattgcag gtcagttgca gttg 44
<210> 29<210> 29
<211> 25<211> 25
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 29<400> 29
gagatgaatt ctccgtggac ctgca 25gagatgaatt ctccgtggac ctgca 25
<210> 30<210> 30
<211> 39<211> 39
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 30<400> 30
ataagcggct tccagtacag ggtaccgagc tcggatccg 39ataagcggct tccagtacag ggtaccgagc tcggatccg 39
<210> 31<210> 31
<211> 24<211> 24
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 31<400> 31
atggaaatga catcagcgtt tacc 24atggaaatga catcagcgtt tacc 24
<210> 32<210> 32
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 32<400> 32
ttattgcagg tcagttgcag ttg 23ttattgcagg tcagttgcag ttg 23
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210510742.3A CN114958700A (en) | 2021-02-25 | 2021-02-25 | Escherichia coli engineering bacterium and application thereof |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210510742.3A CN114958700A (en) | 2021-02-25 | 2021-02-25 | Escherichia coli engineering bacterium and application thereof |
| CN202110211118.9A CN113106109B (en) | 2021-02-25 | 2021-02-25 | Mutant enzyme CYP153A M228L and application thereof in synthesis of 10-hydroxy-2-decenoic acid |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110211118.9A Division CN113106109B (en) | 2021-02-25 | 2021-02-25 | Mutant enzyme CYP153A M228L and application thereof in synthesis of 10-hydroxy-2-decenoic acid |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114958700A true CN114958700A (en) | 2022-08-30 |
Family
ID=76710132
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210510742.3A Pending CN114958700A (en) | 2021-02-25 | 2021-02-25 | Escherichia coli engineering bacterium and application thereof |
| CN202110211118.9A Active CN113106109B (en) | 2021-02-25 | 2021-02-25 | Mutant enzyme CYP153A M228L and application thereof in synthesis of 10-hydroxy-2-decenoic acid |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110211118.9A Active CN113106109B (en) | 2021-02-25 | 2021-02-25 | Mutant enzyme CYP153A M228L and application thereof in synthesis of 10-hydroxy-2-decenoic acid |
Country Status (1)
| Country | Link |
|---|---|
| CN (2) | CN114958700A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116790685A (en) * | 2023-08-21 | 2023-09-22 | 山东福瑞达生物股份有限公司 | A biosynthetic method for preparing royal jelly acid and its application in skin care |
| CN120005789A (en) * | 2025-02-19 | 2025-05-16 | 齐鲁工业大学(山东省科学院) | A genetically engineered bacterium with high decanoic acid tolerance and its construction method and application |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115806923B (en) * | 2022-10-12 | 2024-11-15 | 齐鲁工业大学(山东省科学院) | An engineered bacterium containing acyl-CoA oxidase gene and its application in preparing 10-hydroxy-2-decenoic acid |
| CN115806924B (en) * | 2022-10-12 | 2025-10-10 | 齐鲁工业大学(山东省科学院) | A genetically engineered bacterium and its application in preparing 10-hydroxy-2-decenoic acid |
| CN116024110B (en) * | 2022-10-12 | 2025-12-12 | 齐鲁工业大学(山东省科学院) | An engineered bacterium containing acyl-CoA dehydrogenase and its application method |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140349353A1 (en) * | 2012-01-09 | 2014-11-27 | The Research Foundation For The State University Of New York | Engineered strain of escherichia coli for production of poly-r-3-hydroxyalkanoate polymers with defined monomer unit composition and methods based thereon |
| US20180201961A1 (en) * | 2012-09-10 | 2018-07-19 | Wisconsin Alumni Research Foundation | Production of polyhydroxyalkanoates with a defined composition from an unrelated carbon source |
| CN109897870A (en) * | 2019-01-30 | 2019-06-18 | 齐鲁工业大学 | A method of 10-HAD is prepared using colibacillus engineering using capric acid as raw material |
| CN110684794A (en) * | 2019-10-29 | 2020-01-14 | 齐鲁工业大学 | A method for preparing α, β unsaturated fatty acid by taking fatty acid as raw material and utilizing Escherichia coli engineering bacteria |
-
2021
- 2021-02-25 CN CN202210510742.3A patent/CN114958700A/en active Pending
- 2021-02-25 CN CN202110211118.9A patent/CN113106109B/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140349353A1 (en) * | 2012-01-09 | 2014-11-27 | The Research Foundation For The State University Of New York | Engineered strain of escherichia coli for production of poly-r-3-hydroxyalkanoate polymers with defined monomer unit composition and methods based thereon |
| US20180201961A1 (en) * | 2012-09-10 | 2018-07-19 | Wisconsin Alumni Research Foundation | Production of polyhydroxyalkanoates with a defined composition from an unrelated carbon source |
| CN109897870A (en) * | 2019-01-30 | 2019-06-18 | 齐鲁工业大学 | A method of 10-HAD is prepared using colibacillus engineering using capric acid as raw material |
| CN110684794A (en) * | 2019-10-29 | 2020-01-14 | 齐鲁工业大学 | A method for preparing α, β unsaturated fatty acid by taking fatty acid as raw material and utilizing Escherichia coli engineering bacteria |
Non-Patent Citations (3)
| Title |
|---|
| FAKHRUL IKHMA MOHD FADZIL 等: "Low Carbon Concentration Feeding Improves Medium-Chain-Length Polyhydroxyalkanoate Production in Escherichia coli Strains With Defective b-Oxidation", FRONTIERS IN BIOENGINEERING AND BIOTECHNOLOGY * |
| 孙淑慧: "生物合成10-HDA关键酶分子的克隆及工程菌构建研究", 中国优秀硕士论文库基础科学辑 * |
| 王芬 等: "大肠杆菌合成反式2-癸烯酸工程菌的构建及全细胞催化条件的研究", 中国硕士学位论文 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116790685A (en) * | 2023-08-21 | 2023-09-22 | 山东福瑞达生物股份有限公司 | A biosynthetic method for preparing royal jelly acid and its application in skin care |
| CN116790685B (en) * | 2023-08-21 | 2023-12-01 | 山东福瑞达生物股份有限公司 | A biosynthetic method for preparing royal jelly acid and its application in skin care |
| CN120005789A (en) * | 2025-02-19 | 2025-05-16 | 齐鲁工业大学(山东省科学院) | A genetically engineered bacterium with high decanoic acid tolerance and its construction method and application |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113106109A (en) | 2021-07-13 |
| CN113106109B (en) | 2022-06-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114958700A (en) | Escherichia coli engineering bacterium and application thereof | |
| CN113136377B (en) | A kind of glycanase and its application in the biosynthesis of ligustrazine | |
| CN113583925B (en) | Method for preparing patchouli alcohol by fermenting metabolic engineering escherichia coli | |
| CN109897870B (en) | A method for preparing 10-hydroxy-2-decenoic acid by using decanoic acid as raw material and utilizing Escherichia coli engineering bacteria | |
| CN110396507B (en) | L-pantolactone dehydrogenase from Cnuibacter physcomitrellae | |
| CN115806924B (en) | A genetically engineered bacterium and its application in preparing 10-hydroxy-2-decenoic acid | |
| CN114075524B (en) | Ferulic acid production engineering bacteria, its establishment method and its application | |
| CN106047837B (en) | Serratia lipase mutant, recombinant expression transformant, enzyme preparation and application | |
| WO2023155864A1 (en) | Caffeic acid o-methyltransferase mutant and use thereof | |
| CN111454918B (en) | A kind of alkenol reductase mutant and its application in the preparation of (R)-citronellal | |
| WO2020048523A1 (en) | Baicalein- and wild baicalein-synthesizing microorganism, preparation method for same, and applications thereof | |
| CN114350630B (en) | L-pantolactone dehydrogenase, mutants and applications thereof | |
| CN112662709A (en) | Method for synthesizing (R) -citronellol by double-enzyme coupling | |
| WO2022148377A1 (en) | Host cell of heterologous synthetic flavonoid compound, and use thereof | |
| CN112442490B (en) | Invertase and application thereof in production of S-equol | |
| CN108265041A (en) | A kind of expression of small molecule thioesterase and application | |
| CN111454998B (en) | A kind of biopreparation method of chiral hydroxy acid ester | |
| CN113106075B (en) | Cytochrome oxidase mutant and application thereof | |
| CN110684794A (en) | A method for preparing α, β unsaturated fatty acid by taking fatty acid as raw material and utilizing Escherichia coli engineering bacteria | |
| CN110791466B (en) | Recombinant bacterium for synthesizing butanetriol oleate as well as construction method and application thereof | |
| CN113583983A (en) | Fusion protein or variant thereof and application thereof in preparation of calcifediol | |
| CN113151205B (en) | Alcohol dehydrogenase mutant and application thereof in synthesis of cyclic terpene ketone | |
| CN112410353A (en) | fkbS gene, genetic engineering bacterium containing fkbS gene, and preparation method and application of fkbS gene | |
| CN103865940A (en) | L-isoleucine hydroxylase gene as well as genetically engineered bacterium and application of L-isoleucine hydroxylase gene | |
| CN114958933A (en) | Method for preparing sulforaphene by using myrosinase Emyr |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information | ||
| CB02 | Change of applicant information |
Country or region after: China Address after: 250300 No. 3501 University Road, Changqing District, Jinan City, Shandong Province Applicant after: Qilu University of Technology (Shandong Academy of Sciences) Address before: 250300 No. 3501 University Road, Changqing District, Jinan City, Shandong Province Applicant before: Qilu University of Technology Country or region before: China |