CN114913465A - Action prediction method based on time sequence attention model - Google Patents
Action prediction method based on time sequence attention model Download PDFInfo
- Publication number
- CN114913465A CN114913465A CN202210610980.1A CN202210610980A CN114913465A CN 114913465 A CN114913465 A CN 114913465A CN 202210610980 A CN202210610980 A CN 202210610980A CN 114913465 A CN114913465 A CN 114913465A
- Authority
- CN
- China
- Prior art keywords
- attention
- frame
- module
- model
- action
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/80—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level
- G06V10/806—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level of extracted features
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/46—Extracting features or characteristics from the video content, e.g. video fingerprints, representative shots or key frames
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/20—Movements or behaviour, e.g. gesture recognition
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/172—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a picture, frame or field
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Health & Medical Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Medical Informatics (AREA)
- Databases & Information Systems (AREA)
- Biophysics (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Psychiatry (AREA)
- Social Psychology (AREA)
- Human Computer Interaction (AREA)
- Signal Processing (AREA)
- Image Analysis (AREA)
Abstract
本发明公开了一种基于时序注意力模型的动作预测方法,基于深度学习,搭建时序注意力模型,该模型通过self‑attention模块对来自视频的图像帧数据进行特征解析,并融合时序模型,递归式地整合时空上下文信息,并通过自监督方式进行推理并拟合,从而可预测长期的未来动作;引入虚拟帧结构,将复杂的预测任务简化为针对虚拟帧的动作分类任务,进而最大程度发挥现有模型整合信息与分类的能力,更有效地能够解决现有算法检测准确性低、预测时长短等问题。
The invention discloses an action prediction method based on a time series attention model. Based on deep learning, a time series attention model is built. The model uses a self-attention module to perform feature analysis on image frame data from a video, and integrates the time series model, recursively. It integrates the spatiotemporal context information, and conducts inference and fitting in a self-supervised manner, so that long-term future actions can be predicted; the virtual frame structure is introduced to simplify the complex prediction task into an action classification task for virtual frames, so as to maximize the performance The ability of existing models to integrate information and classification can more effectively solve the problems of low detection accuracy and short prediction time of existing algorithms.
Description
技术领域technical field
本发明涉及计算机视觉图像处理领域,特别涉及一种基于时序注意力模型的动作预测方法。The invention relates to the field of computer vision image processing, in particular to an action prediction method based on a time series attention model.
背景技术Background technique
人体动作预测是计算机视觉与人工智能领域的新兴任务,其应用场景包括且不限于,自动驾驶中的行人轨迹预测、家用辅助机器人、游戏VR感知等。同时,针对居家养老的视频检测而言,能够对人体进行未来动作的预测在预防摔倒与紧急救助等场景下有着重要作用。人体动作预测要求算法模型超越当前的时空视觉分类建模,从而预测未来动作的多模态分布。不同于动作识别任务可以规避时间推理而合理地整合完整上下文信息,动作预测任务要求对过去的动作进行建模而对下一动作进行预测,使得人体动作预测任务十分复杂困难,而长期的时空上下文进行建模是该任务的核心。Human motion prediction is an emerging task in the field of computer vision and artificial intelligence. Its application scenarios include, but are not limited to, pedestrian trajectory prediction in autonomous driving, home assistance robots, and game VR perception. At the same time, for the video detection of home care, the ability to predict the future movements of the human body plays an important role in scenarios such as fall prevention and emergency rescue. Human action prediction requires algorithmic models to go beyond current spatiotemporal visual classification modeling to predict the multimodal distribution of future actions. Unlike the action recognition task, which can avoid temporal reasoning and reasonably integrate complete context information, the action prediction task requires modeling past actions and predicting the next action, which makes the human action prediction task very complicated and difficult, and the long-term spatiotemporal context. Modeling is at the heart of this task.
典型的长期时空上下文建模方式包括对采样的帧图像或片段进行特征提取,再利用基于聚类、递归或注意力机制的模型进行特征聚合,并直接输出预测动作的分类结果。大多数此类模型仅在时间范围内聚合特征,而缺少考虑对视频帧的时间序列演化进行建模,因而往往无法预测准确。Typical long-term spatiotemporal context modeling methods include extracting features from sampled frame images or segments, then using models based on clustering, recursion, or attention mechanism to perform feature aggregation, and directly output the classification results of predicted actions. Most of these models aggregate features only over time, and lack consideration for modeling the time-series evolution of video frames, so they are often inaccurate in predictions.
另一种方案是基于时序LSTM模型对短期动作进行预测(如下一帧发生的动作),该类方案使用递归的方式整合上一帧信息并预测下一帧信息,不断向前推理从而实现预测。但由于长期预测过程中模型产生的误差不断积累,这种方案在长期预测的场景下失去作用,无法满足居家养老场景中以预测为核心的需求功能。Another scheme is to predict short-term actions (such as the actions that occur in the next frame) based on the time-series LSTM model. This kind of scheme integrates the information of the previous frame and predicts the information of the next frame in a recursive way, and continuously forwards the reasoning to achieve the prediction. However, due to the accumulation of errors generated by the model during the long-term forecasting process, this solution is ineffective in the long-term forecasting scenario, and cannot meet the forecast-centered demand function in the home-based care scenario.
最新的方案利用注意力机制的长期感知能力,构建Transformer模型对视频数据进行分析并预测下一步动作,该类方案能够很好地整合上下文信息,同步地对帧信息进行整合预测,并采用自监督的方式最大程度地消除长期预测过程中模型产生的误差,能够较好地实现预测功能。但注意力模型要求较大算力(如大规模GPU集群运算),计算复杂度随处理的数据量以平方的速率增长,因而难以处理大批视频数据,且难以部署到产品中。受限于此,这种方案同样难以进行更长期预测。The latest scheme uses the long-term perception ability of the attention mechanism to build a Transformer model to analyze video data and predict the next action. This type of scheme can well integrate context information, synchronously integrate and predict frame information, and use self-supervision. The method can eliminate the errors generated by the model in the long-term forecasting process to the greatest extent, and can better realize the forecasting function. However, the attention model requires large computing power (such as large-scale GPU cluster computing), and the computational complexity increases at a square rate with the amount of data processed, so it is difficult to process a large amount of video data and deploy it into products. Due to this limitation, this scheme is also difficult to make longer-term predictions.
另一方面,深度学习模型的性能很大程度取决于所用的训练数据对特定任务的拟合程度,而由于缺少相关场景数据用于模型训练,现有动作预测方案并不能直接应用到居家养老中来。On the other hand, the performance of deep learning models largely depends on the fit of the training data used to specific tasks. Due to the lack of relevant scene data for model training, existing action prediction schemes cannot be directly applied to home care. Come.
综上所述,人体动作预测的现有技术方案仍存在预测时长短、预测精度不足、计算量大等缺陷,且受限与特殊应用场景,无法满足居家养老场景中的预防摔倒与紧急救助需求。In summary, the existing technical solutions for human motion prediction still have shortcomings such as short prediction time, insufficient prediction accuracy, and large amount of calculation, and are limited and special application scenarios, which cannot meet the fall prevention and emergency rescue in home care scenarios. need.
发明内容SUMMARY OF THE INVENTION
为了解决上述问题,本发明提供了一种基于时序注意力模型的动作预测方法,利用时序注意力模型,可对视频数据进行分析,预测精度高。In order to solve the above problems, the present invention provides an action prediction method based on a time-series attention model, which can analyze video data with high prediction accuracy by using the time-series attention model.
为此,本发明的技术方案是:一种基于时序注意力模型的动作预测方法,包括以下步骤:To this end, the technical solution of the present invention is: an action prediction method based on a time series attention model, comprising the following steps:
1)视频数据采样:选用带每帧对应动作标注的稠密视频流作为训练视频,在视频流数据中采样一定帧数的图像;1) Video data sampling: select the dense video stream with the corresponding action annotation of each frame as the training video, and sample images of a certain number of frames in the video stream data;
2)图像预处理:对步骤1)中采样的图像进行归一化处理,再对图像进行缩放、裁剪、翻转处理;2) Image preprocessing: normalize the image sampled in step 1), and then scale, crop, and flip the image;
3)时序注意力模型的建立与训练:时序注意力模型包括编码器、解码器以及预测分类器三部分;3) Establishment and training of time series attention model: The time series attention model includes three parts: encoder, decoder and prediction classifier;
①编码阶段,利用transformer模型对图像的强大解析能力,使用预训练VisionTransformer(ViT)模型对帧图像进行编码;Vision Transformer模型包括PatchEmbedding(PE)模块、Self-Attention(SA)模块、前馈网络(FFN)模块以及残差连接几部分;① In the encoding stage, the powerful image analysis ability of the transformer model is used, and the pre-trained Vision Transformer (ViT) model is used to encode the frame image; the Vision Transformer model includes PatchEmbedding (PE) module, Self-Attention (SA) module, feedforward network ( FFN) module and residual connection parts;
Self-Attention模块通过注意力机制计算各个分块两两之间的权重并进一步进行特征融合;使用多层线性层将X映射到高维度空间,分别表示为:The Self-Attention module calculates the weights between each block through the attention mechanism and further performs feature fusion; uses multi-layer linear layers to map X to the high-dimensional space, which are expressed as:
Q=Wq*XQ=Wq*X
K=Wk*XK=Wk*X
V=Wv*XV=Wv*X
其中X为输入图像,Q是查询矩阵,K是关键字矩阵,V是值矩阵,Wq、Wk、Wv分别表示Q、K、V所对应的学习参数,通过Q、K可计算得到各个分块两两之间的关系,即注意力图Am,再通过注意力图Am与V即可计算得到每个分块的权重;Where X is the input image, Q is the query matrix, K is the keyword matrix, V is the value matrix, and Wq, Wk, and Wv represent the learning parameters corresponding to Q, K, and V, respectively. Each block can be calculated by Q and K. The relationship between the two, that is, the attention map Am, and then the weight of each block can be calculated through the attention maps Am and V;
Am=SoftMax((Q*K)/sqrt(D)Am=SoftMax((Q*K)/sqrt(D)
其中SoftMax指对于计算结果使用指数归一化,D表示Q、K、V的特征通道数,sqrt表示开方操作;Among them, SoftMax refers to the use of exponential normalization for the calculation results, D represents the number of characteristic channels of Q, K, and V, and sqrt represents the square root operation;
Self-Attention模块计算得到特征F1可表示为:The feature F1 calculated by the Self-Attention module can be expressed as:
F1=Am*V;F1=Am*V;
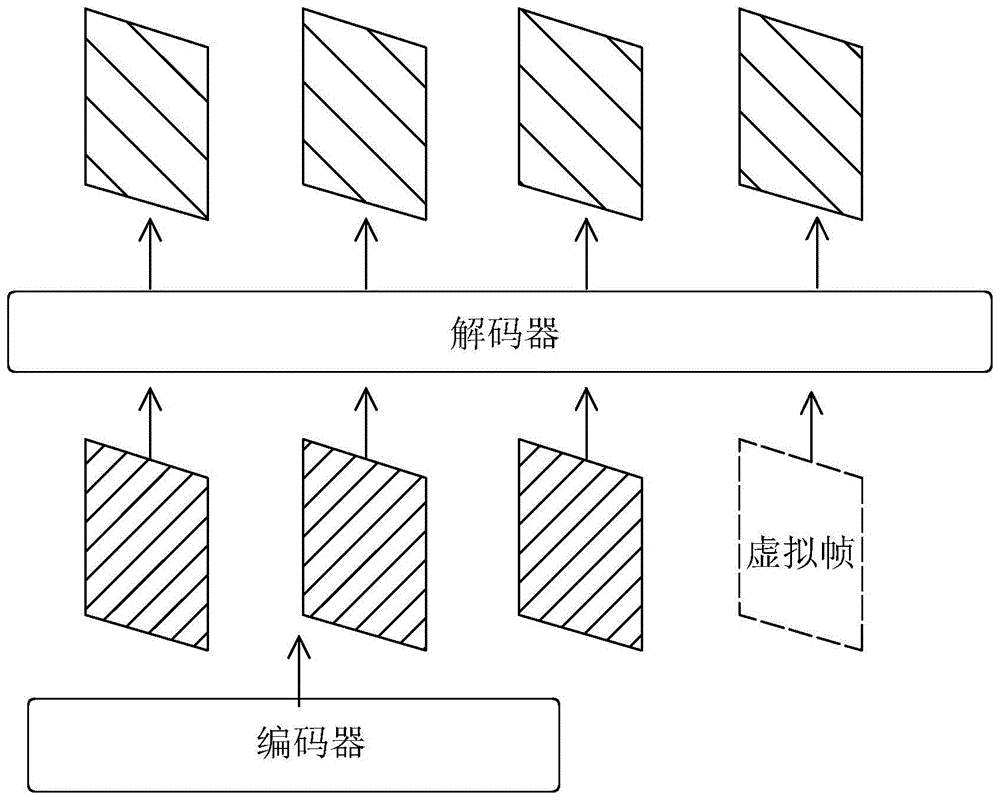
②解码阶段:解码器包括Multi-Head Self-Attention模块、虚拟帧结构以及时序推理结构;②Decoding stage: The decoder includes a Multi-Head Self-Attention module, a virtual frame structure, and a time-series inference structure;
I)Multi-Head Self-Attention模块:解码过程中的输入为编码后的帧图像的高维特征表示;所计算的特征为解码过程中帧与帧之间的时空上下文信息;1) Multi-Head Self-Attention module: the input in the decoding process is the high-dimensional feature representation of the encoded frame image; the calculated feature is the spatiotemporal context information between the frame and the frame in the decoding process;
Multi-Head机制的引入如下:The introduction of the Multi-Head mechanism is as follows:
Q=[Q1,Q2,...,Qh],Qh=Wq_h*XQ=[Q1,Q2,...,Qh],Qh=Wq_h*X
K=[K1,K2,...,Kh],Kh=Wk_h*XK=[K1,K2,...,Kh],Kh=Wk_h*X
V=[V1,V2,...,Vh],Vh=Wv_h*XV=[V1,V2,...,Vh],Vh=Wv_h*X
II)位置编码:引入帧位置编码与注意力图编码,以增强帧图像特征;帧位置编码,将帧图像按先后顺序编号并通过标准embedding层编码为高维特征Pe;II) Position coding: introduce frame position coding and attention map coding to enhance frame image features; frame position coding, number the frame images in sequence and encode them into high-dimensional features Pe through the standard embedding layer;
注意力图编码将步骤①计算得到的注意力图Am通过标准多层感知器进行编码,得到高维特征Ae,The attention map encoding encodes the attention map Am calculated in step ① through a standard multi-layer perceptron to obtain high-dimensional features Ae,
则解码器的初始输入为:Then the initial input of the decoder is:
Input=Pe+FeInput=Pe+Fe
其中,Fe为编码阶段的最终输出;Among them, Fe is the final output of the encoding stage;
设定第一层Transformer的计算过程为:Set the calculation process of the first layer Transformer as:
TF_1=FFN(MHSA(Input))TF_1=FFN(MHSA(Input))
MHSA是Multi-Head Self-Attention模块的计算过程,FFN为前馈网络模块的计算过程;MHSA is the calculation process of the Multi-Head Self-Attention module, and FFN is the calculation process of the feedforward network module;
则第n层Transformer的计算过程为:Then the calculation process of the nth layer Transformer is:
TF_n=FFN(MHSA(TF_n-1+Ae))TF_n=FFN(MHSA(TF_n-1+Ae))
如上所述,Ae为来自第n-1层Transformer的注意力图编码;As mentioned above, Ae encodes the attention map from the n-1th layer Transformer;
III)虚拟帧结构,将初始化的虚拟帧等同于真实帧图像特征,并根据预测目的赋予其对应的位置编码,再一同输送到多头注意力模型中进行解码;III) virtual frame structure, the initialized virtual frame is equal to the real frame image feature, and the corresponding position code is given to it according to the prediction purpose, and then sent to the multi-head attention model for decoding;
定义该虚拟帧为Vf,则引入虚拟帧结构后解码器初始输入为:Define the virtual frame as Vf, then the initial input of the decoder after introducing the virtual frame structure is:
Input=Pe+Concatenate(Fe,Vf)Input=Pe+Concatenate(Fe,Vf)
其中Concatenate()为标准拼接操作;Among them, Concatenate() is the standard splicing operation;
IV)时序推理结构:IV) Temporal reasoning structure:
将完整的T帧图像特征序列划分为互不重合的序列片段,每个片段包含t帧序列,再分别输入到多头注意力模型中,即多头注意力模型的输入序列长度被限制为t;通过递归的推理方式可以将完整的序列循环解码,最终得到所需的解码特征;Divide the complete T-frame image feature sequence into non-overlapping sequence segments, each segment contains t-frame sequences, and then input them into the multi-head attention model respectively, that is, the length of the input sequence of the multi-head attention model is limited to t; The recursive reasoning method can cyclically decode the complete sequence, and finally obtain the required decoding features;
③预测分类器:通过标准MLP将解码得到的帧图像特征的通道数映射为具体动作类别数,取通道最大值作为分类结果。③ Prediction classifier: The number of channels of the decoded frame image features is mapped to the number of specific action categories by standard MLP, and the maximum value of the channel is taken as the classification result.
优选地,步骤1)中的视频数据采样,具体包括以下步骤:Preferably, the video data sampling in step 1) specifically includes the following steps:
a.获取视频流的动作分割块:根据每帧的动作标签将完整的视频流按一个完整动作分割为不同的子视频流,即视频数据中包含一个完整动作的多个子视频流,截取其中一个子视频流及其对应动作作为所需预测的目标;a. Obtain the action segmentation block of the video stream: According to the action label of each frame, the complete video stream is divided into different sub-video streams according to a complete action, that is, the video data contains multiple sub-video streams of a complete action, and intercept one of them. sub-video streams and their corresponding actions as the target of the desired prediction;
b.根据子视频流向前采样,得到已观测到的数据,用于输送到网络中进行分析预测;设定所截取的子视频流从S时刻开始,到E时刻结束,设定模型需要在动作发生前A秒进行动作预测,所使用的数据为O秒内的视频流,则截取从St=E-O时刻到Et=S-A时刻的视频流作为输入数据,并从中采样T帧图像及对应的动作标注作为模型输入。b. Sampling forward according to the sub-video stream to obtain the observed data, which is used to transmit it to the network for analysis and prediction; set the intercepted sub-video stream from time S to time E, and set the model to be in action Action prediction is performed A seconds before the occurrence, and the data used is the video stream within 0 seconds, then the video stream from the time St=E-O to the time Et=S-A is intercepted as the input data, and T frame images and corresponding action annotations are sampled from them. as model input.
优选地,步骤2)中图像预处理时,按帧图像RGB三个通道各自的均值与标准差对将图像进行标准化操作,即将[0,255]范围的色彩值归一化到[0,1]范围;图像缩放时,将帧图像的长宽分别随机缩放到[248,280]像素大小的范围;图像裁剪时,将帧图像随机裁剪到224×224像素大小;并随机地将帧图像进行水平翻转。Preferably, during image preprocessing in step 2), the image is normalized according to the mean and standard deviation of the three channels of the RGB of the frame image, that is, the color values in the range of [0,255] are normalized to the range of [0,1] ; When the image is zoomed, the length and width of the frame image are randomly scaled to the range of [248, 280] pixels; when the image is cropped, the frame image is randomly cropped to the size of 224×224 pixels; and the frame image is randomly flipped horizontally.
优选地,所述Patch Embedding模块将一张图像划分为大小一致的16×16分块,并将分块内的像素压平;即通过卷积核大小与步长均为16的二维卷积实现,且包括一个层级归一化模块LayerNorm,即表示为:Preferably, the Patch Embedding module divides an image into 16×16 blocks of the same size, and flattens the pixels in the blocks; It is implemented and includes a layer normalization module LayerNorm, which is expressed as:
PE(X)=LayerNorm(Conv(X))PE(X)=LayerNorm(Conv(X))
其中Conv表示卷积核大小与步长均为16的二维卷积。where Conv represents a two-dimensional convolution with a convolution kernel size and stride of 16.
优选地,所述前馈网络模块由一个多层感知器构成,多层感知器包括两个线性层线性层以及一个Relu激活函数。Preferably, the feedforward network module is composed of a multi-layer perceptron, and the multi-layer perceptron includes two linear layers and a Relu activation function.
优选地,所述Vision Transformer模型的计算过程为:Preferably, the calculation process of the Vision Transformer model is:
X=PE(X)X=PE(X)
F1=SA(X)F1=SA(X)
Af=F1+XAf=F1+X
Fe=FFN(Af)+AfFe=FFN(Af)+Af
其中:X为输入图像,PE是Patch Embedding模块的计算过程,SA是Self-Attention模块的计算过程,FFN为前馈网络模块的计算过程。Among them: X is the input image, PE is the calculation process of the Patch Embedding module, SA is the calculation process of the Self-Attention module, and FFN is the calculation process of the feedforward network module.
优选地,时序推理结构中还包括记忆模块,设置记忆单元用于储存Self-Attention模块计算过程中的K与V,并传递到下一递归过程中,即在第n次递归计算的Self-Attention过程中引入:Preferably, the time series reasoning structure also includes a memory module, and the memory unit is set to store K and V in the calculation process of the Self-Attention module, and pass them to the next recursive process, that is, the Self-Attention calculated in the nth recursive calculation Introduced in the process:
K_n=Concatenate(K_n-1,Wk*X)K_n=Concatenate(K_n-1,Wk*X)
V_n=Concatenate(V_n-1,Wv*X)V_n=Concatenate(V_n-1,Wv*X)
K_n-1、V_n-1即来自上一次递归计算过程中的K与V。K_n-1 and V_n-1 are K and V from the last recursive calculation process.
与现有技术相比,本发明的有益效果是:Compared with the prior art, the beneficial effects of the present invention are:
1、通过self-attention模块对来自视频的图像帧数据进行特征解析,并融合时序模型,递归式地整合时空上下文信息,并通过自监督方式进行推理并拟合,从而可预测长期的未来动作。1. The self-attention module analyzes the image frame data from the video, and integrates the time series model, recursively integrates the spatiotemporal context information, and conducts inference and fitting through a self-supervised method, so that long-term future actions can be predicted.
2、引入虚拟帧的概念,在递归式推理的过程中,将虚拟帧与真实上下文信息进行整合处理,进而输出对应的动作分类;虚拟帧的引入使得模型能够专注于信息整合与分类,将复杂的预测任务简化为对虚拟帧的动作分类任务,能够极大幅度发挥模型的学习能力。2. Introduce the concept of virtual frame. In the process of recursive reasoning, the virtual frame and the real context information are integrated and processed, and then the corresponding action classification is output; the introduction of virtual frame enables the model to focus on information integration and classification. The prediction task is simplified to the action classification task of virtual frames, which can greatly exert the learning ability of the model.
3、结合注意力模型的长期信息捕捉能力,并通过递归式的推理方式,在整合上下文信息的同时使得模型计算复杂度随处理的数据量线性增长,更有效地能够解决现有算法检测准确性低、预测时长短,难部署且无法用于居家养老场景等问题。3. Combined with the long-term information capture ability of the attention model, and through recursive reasoning, while integrating context information, the computational complexity of the model increases linearly with the amount of processed data, which can more effectively solve the detection accuracy of existing algorithms. Low, forecast time is short, difficult to deploy and cannot be used for home care scenarios.
4、采集居家养老场景下的动作数据,并针对动作预测的需求进行相关人体标注,从而将时序注意力模型拟合到居家养老的场景中,最大程度发挥算法的性能。4. Collect the action data in the home care scenario, and mark the relevant human body according to the needs of action prediction, so as to fit the time series attention model to the home care scene, and maximize the performance of the algorithm.
附图说明Description of drawings
以下结合附图和本发明的实施方式来作进一步详细说明Further detailed description will be given below in conjunction with the accompanying drawings and the embodiments of the present invention
图1为本发明的算法整体结构图;Fig. 1 is the overall structure diagram of the algorithm of the present invention;
图2为本发明的时序推理结构图;Fig. 2 is the sequence reasoning structure diagram of the present invention;
图3为本发明的视频采样示意图。FIG. 3 is a schematic diagram of video sampling according to the present invention.
具体实施方式Detailed ways
参见附图。本实施例所述针对居家养老场景的视频未来动作预测方法,基于深度神经网络,设计一个时序注意力模型,可对视频数据进行分析,该时序注意力模型通过self-attention模块对来自视频的图像帧数据进行特征解析,并融合时序模型,递归式地整合时空上下文信息,并通过自监督方式进行推理并拟合,从而可预测长期的未来动作。See attached image. The video future action prediction method for home care scenarios described in this embodiment is based on a deep neural network, and a time series attention model is designed to analyze video data. The time series attention model uses the self-attention module to analyze the images from the video. Frame data is analyzed for features, and time series models are integrated to recursively integrate spatiotemporal context information, and inference and fitting are performed in a self-supervised manner, so that long-term future actions can be predicted.
具体包括以下步骤:Specifically include the following steps:
一、视频数据采样及图像预处理1. Video data sampling and image preprocessing
1.视频数据采样:训练所用数据形式为带每帧对应动作标注的稠密视频流,首先需要从视频流数据中采样一定帧数图像,具体操作如下:1. Video data sampling: The data used for training is a dense video stream with corresponding action annotations for each frame. First, a certain number of frames of images need to be sampled from the video stream data. The specific operations are as follows:
1.1获取视频流的动作分割块。根据每帧的动作标签将完整的视频流按一个完整动作分割为不同的子视频流,得到视频数据中包含一个完整动作的多个子视频流,截取其中一个子视频流及其对应动作作为所需预测的目标。1.1 Obtain the action segmentation block of the video stream. According to the action tag of each frame, the complete video stream is divided into different sub-video streams according to a complete action, and multiple sub-video streams containing a complete action are obtained in the video data, and one sub-video stream and its corresponding action are intercepted as the required predicted target.
1.2根据子视频流向前采样得到已观测到的数据,用于输送到网络中进行分析预测。设定所截取的子视频流从S时刻开始,到E时刻结束。设定模型需要在动作发生前A秒进行动作预测,所使用的数据为O秒内的视频流,则截取从St=E-O时刻到Et=S-A时刻的视频流作为输入数据,并从中采样T帧图像及对应的动作标注作为模型输入。1.2 The observed data is obtained by forward sampling according to the sub-video stream, and is used for transmission to the network for analysis and prediction. It is assumed that the intercepted sub-video stream starts at time S and ends at time E. Set the model to perform motion prediction A seconds before the action occurs, the data used is the video stream within 0 seconds, then intercept the video stream from the time St=E-O to the time Et=S-A as the input data, and sample T frames from it Images and corresponding action annotations are used as model inputs.
采样方式可以是随机分布采样、前置分布采样(选取输入视频流的前T帧)、后置分布采样(选取输入视频流的后T帧)。使用后置分布采样作为默认采样方式,因为该段视频帧最接近所需预测的动作。The sampling method may be random distribution sampling, pre-distributed sampling (selecting the first T frames of the input video stream), and post-distribution sampling (selecting the last T frames of the input video stream). Post-distribution sampling is used as the default sampling method, as this video frame is closest to the desired predicted action.
2.图像预处理:2. Image preprocessing:
2.1图像归一化:按帧图像RGB三个通道各自的均值与标准差对将图像进行标准化操作,即将[0,255]范围的色彩值归一化到[0,1]范围。2.1 Image normalization: Normalize the image according to the mean and standard deviation of the three RGB channels of the frame image, that is, normalize the color values in the range of [0, 255] to the range of [0, 1].
2.2图像数据增强。图像的数据增强是为了扩充数据集的多样性,这能够很好地避免模型过拟合,使其在测试集上有更好的泛化能力。2.2 Image data enhancement. The data augmentation of the image is to expand the diversity of the dataset, which can well avoid overfitting of the model and make it have better generalization ability on the test set.
1)图像缩放:将帧图像的长宽分别随机缩放到[248,280]像素大小的范围。1) Image scaling: Randomly scale the length and width of the frame image to the range of [248, 280] pixel size.
2)图像裁剪:将帧图像随机裁剪到224×224像素大小。2) Image cropping: randomly crop the frame image to 224×224 pixel size.
3)随机翻转:随机地将帧图像进行水平翻转。3) Random flip: randomly flip the frame image horizontally.
二、时序注意力模型的建立与训练2. Establishment and training of temporal attention model
时序注意力模型的作用是分析已观测的视频数据,并结合虚拟帧结构进行动作预测,包括编码器、解码器以及预测分类器三部分。The role of the temporal attention model is to analyze the observed video data and combine the virtual frame structure for action prediction, including three parts: encoder, decoder and prediction classifier.
1.编码阶段,利用transformer模型对图像的强大解析能力,使用预训练VisionTransformer(ViT)模型对帧图像进行编码。ViT模型包括Patch Embedding(PE)模块、Self-Attention(SA)模块、前馈网络Feed Forward Network(FFN)模块以及残差连接几部分。1. In the encoding phase, the pre-trained VisionTransformer (ViT) model is used to encode the frame image by using the powerful analytical ability of the transformer model to the image. The ViT model includes Patch Embedding (PE) module, Self-Attention (SA) module, Feed Forward Network (FFN) module and residual connection.
设定X为输入图像,则Vision Transformer模型的特征提取过程可表示为:Set X as the input image, the feature extraction process of the Vision Transformer model can be expressed as:
X=PE(X)X=PE(X)
Af=SA(X)+XAf=SA(X)+X
Fe=FFN(Af)+AfFe=FFN(Af)+Af
其中:X为输入图像,PE()是Patch Embedding模块的输出结果,SA()是Self-Attention模块的输出结果,FFN()为前馈网络模块的输出结果,Fe为编码阶段的最终输出。Among them: X is the input image, PE() is the output of the Patch Embedding module, SA() is the output of the Self-Attention module, FFN() is the output of the feedforward network module, and Fe is the final output of the encoding stage.
Patch Embedding(PE)模块将一张图像划分为大小一致的16×16分块,并将分块内的像素压平,具体通过卷积核大小与步长均为16的二维卷积实现,且包括一个层级归一化模块LayerNorm,即表示为:The Patch Embedding (PE) module divides an image into 16×16 blocks of the same size, and flattens the pixels in the blocks. And includes a level normalization module LayerNorm, which is expressed as:
PE(X)=LayerNorm(Conv(X))PE(X)=LayerNorm(Conv(X))
其中Conv表示卷积核大小与步长均为16的二维卷积。where Conv represents a two-dimensional convolution with a convolution kernel size and stride of 16.
Self-Attention(SA)模块通过注意力机制计算各个分块两两之间的权重并进一步进行特征融合。具体步骤为:The Self-Attention (SA) module calculates the weights between each block through the attention mechanism and further performs feature fusion. The specific steps are:
使用多层Linear Layer将X映射到高维度空间,分别表示为:Use a multi-layer Linear Layer to map X to a high-dimensional space, which are expressed as:
Q=Wq*XQ=Wq*X
K=Wk*XK=Wk*X
V=Wv*XV=Wv*X
其中Wq、Wk、Wv分别表示Q(query)、K(key)、V(value)所对应的学习参数,通过Q、K可计算得到各个分块两两之间的关系,即注意力图Attention Map,简称Am,再通过注意力图Am与V即可计算得到每个分块的权重。Among them, Wq, Wk, and Wv represent the learning parameters corresponding to Q(query), K(key), and V(value) respectively. The relationship between each block can be calculated through Q and K, that is, the Attention Map , referred to as Am, and then the weight of each block can be calculated through the attention maps Am and V.
Am=SoftMax((Q*K)/sqrt(D)Am=SoftMax((Q*K)/sqrt(D)
其中SoftMax指对于计算结果使用指数归一化,D表示Q、K、V的特征通道数,sqrt表示开方操作。Among them, SoftMax refers to the use of exponential normalization for the calculation results, D represents the number of characteristic channels of Q, K, and V, and sqrt represents the square root operation.
权重计算:Self-Attention模块计算得到特征F1可表示为:Weight calculation: The feature F1 calculated by the Self-Attention module can be expressed as:
F1=Am*V;F1=Am*V;
则Self-Attention模块的计算过程可表示为F1=SA(X)Then the calculation process of the Self-Attention module can be expressed as F1=SA(X)
前馈网络Feed ForwardNetwork(FFN)模块由一个多层感知器(MLP)构成,MLP包括两个线性层Linear Layer以及一个Relu激活函数,是现有深度学习网络的一个基本标准组成单元The Feed Forward Network (FFN) module is composed of a multi-layer perceptron (MLP). The MLP includes two linear layers and a Relu activation function. It is a basic standard component of existing deep learning networks.
残差连接。在上述此基础上为SA模块与FFN模块加上残差连接,即得到ViT的完整计算过程:Residual connections. On the basis of the above, add the residual connection to the SA module and the FFN module, that is, to obtain the complete calculation process of ViT:
X=PE(X)X=PE(X)
F1=SA(X)F1=SA(X)
Af=F1+XAf=F1+X
Fe=FFN(Af)+AfFe=FFN(Af)+Af
其中:X为输入图像,PE()是Patch Embedding模块的计算过程,SA()是Self-Attention模块的计算过程,FFN()为前馈网络模块的计算过程。Among them: X is the input image, PE() is the calculation process of the Patch Embedding module, SA() is the calculation process of the Self-Attention module, and FFN() is the calculation process of the feedforward network module.
由计算过程可知,初始图像在经过PE时分辨率下降到16×16,而经过SA与FFN时形状不变。为了加强网络学习能力,ViT将SA与FFN多层叠加以加深网络。最终经过一个标准池化层,得到帧图像的高维特征表示。It can be seen from the calculation process that the resolution of the initial image drops to 16×16 when it passes through PE, but its shape remains unchanged when it passes through SA and FFN. In order to strengthen the network learning ability, ViT superimposes SA and FFN in multiple layers to deepen the network. Finally, after a standard pooling layer, the high-dimensional feature representation of the frame image is obtained.
2.解码阶段。解码器为本发明时序注意力模型的核心组件,包括Multi-HeadSelf-Attention模块、虚拟帧结构以及时序推理结构。2. Decoding stage. The decoder is the core component of the time series attention model of the present invention, including a Multi-HeadSelf-Attention module, a virtual frame structure and a time series inference structure.
2.1Multi-Head Self-Attention模块及位置编码。2.1Multi-Head Self-Attention module and position encoding.
Multi-Head Self-Attention模块的计算过程与编码过程的Transformer结构相似,关键区别在于,编码过程的输入为图像的分块Patch,而解码过程中的输入为编码后的帧图像的高维特征表示。所计算的特征也从编码过程中图像信息变为解码过程中帧与帧之间的时空上下文信息。The calculation process of the Multi-Head Self-Attention module is similar to the Transformer structure of the encoding process. The key difference is that the input of the encoding process is the patch of the image, while the input of the decoding process is the high-dimensional feature representation of the encoded frame image. . The computed features also change from image information during encoding to frame-to-frame contextual information during decoding.
Multi-Head机制的引入如下:The introduction of the Multi-Head mechanism is as follows:
Q=[Q1,Q2,...,Qh],Qh=Wq_h*XQ=[Q1,Q2,...,Qh],Qh=Wq_h*X
K=[K1,K2,...,Kh],Kh=Wk_h*XK=[K1,K2,...,Kh],Kh=Wk_h*X
V=[V1,V2,...,Vh],Vh=Wv_h*XV=[V1,V2,...,Vh],Vh=Wv_h*X
其余部分计算与编码过程的SA模块计算一致。The rest of the calculation is consistent with the SA module calculation of the encoding process.
位置编码:由于注意力机制对帧与帧之间的顺序结构不敏感,因此为了网络能够学习到帧图像的位置信息,并据此整合时空上下文进行动作预测,特引入帧位置编码与Attention Map编码,以增强帧图像特征。Position coding: Since the attention mechanism is not sensitive to the order structure between frames, in order for the network to learn the position information of the frame image and integrate the spatiotemporal context for action prediction, frame position coding and Attention Map coding are introduced. , to enhance frame image features.
帧位置编码position encoding:将帧图像按先后顺序编号并通过标准embedding层编码为高维特征Pe。Frame position encoding position encoding: The frame images are numbered in sequence and encoded into high-dimensional features Pe through the standard embedding layer.
注意力图Attention Map编码attention encoding:将上一层计算得到的注意力图Am通过标准多层感知器进行编码为高维特征。在编码步骤中的到的帧图像高维特征表示为Ae,则解码器的初始输入为:Attention Map Attention Map Encoding Attention encoding: The attention map Am calculated by the previous layer is encoded into high-dimensional features through a standard multi-layer perceptron. The high-dimensional feature of the frame image obtained in the encoding step is represented as Ae, then the initial input of the decoder is:
Input=Pe+FeInput=Pe+Fe
设定第一层Transformer的计算过程为:Set the calculation process of the first layer Transformer as:
TF_1=FFN(MHSA(Input))TF_1=FFN(MHSA(Input))
MHSA即Multi-Head Self-Attention模块的计算过程,此处与SA()区分开来;则第n层Transformer的计算过程为:MHSA is the calculation process of the Multi-Head Self-Attention module, which is distinguished from SA() here; the calculation process of the nth layer Transformer is:
TF_n=FFN(MHSA(TF_n-1+Ae))TF_n=FFN(MHSA(TF_n-1+Ae))
如上所述,Ae为来自第n-1层Transformer的注意力图编码。As mentioned above, Ae encodes the attention map from the n-1th layer Transformer.
2.2虚拟帧结构。不同于已有方案,本实施例引入虚拟帧的概念,将虚拟帧与真实上下文信息进行整合处理,最终输出虚拟帧对应的动作分类从而达到预测目的。虚拟帧的引入使得时序注意力模型能够专注于信息整合与分类,将复杂的预测任务简化为对虚拟帧的动作分类任务。具体操作为将初始化的虚拟帧等同于真实帧图像特征,并根据预测目的(要预测第几帧的动作)赋予其对应的位置编码,再一同输送到多头注意力模块中进行解码。2.2 Virtual frame structure. Different from the existing solution, this embodiment introduces the concept of virtual frame, integrates the virtual frame and real context information, and finally outputs the action classification corresponding to the virtual frame to achieve the purpose of prediction. The introduction of virtual frames enables the temporal attention model to focus on information integration and classification, and simplifies complex prediction tasks into action classification tasks for virtual frames. The specific operation is to equate the initialized virtual frame with the real frame image features, and assign its corresponding position code according to the prediction purpose (the action of the frame to be predicted), and then send it to the multi-head attention module for decoding.
定义该虚拟帧为Vf,则引入虚拟帧结构后解码器初始输入为:Define the virtual frame as Vf, then the initial input of the decoder after introducing the virtual frame structure is:
Input=Pe+Concatenate(Fe,Vf)Input=Pe+Concatenate(Fe,Vf)
其中Concatenate为标准拼接操作。Among them, Concatenate is a standard splicing operation.
2.3时序推理结构。由于注意力模型的复杂度随处理的数据量以平方的速率增长,难以处理大批视频数据。本发明设计时序推理结构,通过递归式的推理方式,在整合上下文信息的同时使得模型计算复杂度随处理的数据量线性增长。2.3 Temporal reasoning structure. Since the complexity of the attention model grows at a quadratic rate with the amount of data processed, it is difficult to process large amounts of video data. The present invention designs a time-series reasoning structure, and through a recursive reasoning method, while integrating context information, the computational complexity of the model increases linearly with the amount of processed data.
首先将完整的T帧图像特征序列(包括虚拟帧)划分为互不重合的序列片段,每个片段包含t帧序列,再分别输入到多头注意力模型中,即多头注意力模型的输入序列长度被限制为t。通过递归的推理方式可以将完整的序列循环解码,最终得到所需的解码特征。First, the complete T-frame image feature sequence (including virtual frames) is divided into non-overlapping sequence segments, each segment contains t-frame sequence, and then respectively input into the multi-head attention model, that is, the length of the input sequence of the multi-head attention model is limited to t. Through recursive reasoning, the complete sequence can be cyclically decoded, and finally the required decoding features can be obtained.
从SA模块的计算过程可知,随着t增长,模型复杂度以平方的速率增长。而当t固定时,模型复杂度随着T线性增长。从而极大扩大了模型整体可处理的数据量。It can be seen from the calculation process of the SA module that as t increases, the model complexity increases at a square rate. And when t is fixed, the model complexity grows linearly with T. This greatly expands the overall amount of data that the model can handle.
由于序列片段之间不相重合,因此为了在递归推理的过程中不损失上下文信息,本实施例引入记忆模块,具体为设置记忆单元用于储存SA计算过程中的K与V,并传递到下一递归过程中,即在第n次递归计算的SA过程中引入:Since the sequence segments do not overlap, in order not to lose context information during the recursive reasoning process, a memory module is introduced in this embodiment. Specifically, a memory unit is set to store K and V in the SA calculation process, and transmit them to the next In a recursive process, that is, it is introduced in the SA process of the nth recursive calculation:
K_n=Concatenate(K_n-1,Wk*X)K_n=Concatenate(K_n-1,Wk*X)
V_n=Concatenate(V_n-1,Wv*X)V_n=Concatenate(V_n-1,Wv*X)
其中:K_n-1、V_n-1即来自上一次递归计算过程中的K与V,其余部分计算与标准SA模块计算一致。Among them: K_n-1, V_n-1 are K and V from the last recursive calculation process, and the rest of the calculation is consistent with the standard SA module calculation.
3.预测分类器。预测分类器为深度学习模型中的标准分类器,即通过标准MLP将解码得到的帧图像特征的通道数映射为具体动作类别数,取通道最大值作为分类结果。3. Predictive classifier. The prediction classifier is a standard classifier in the deep learning model, that is, the number of channels of the decoded frame image feature is mapped to the number of specific action categories through standard MLP, and the maximum value of the channel is taken as the classification result.
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。The above are only the preferred embodiments of the present invention, and the protection scope of the present invention is not limited to the above-mentioned embodiments, and all technical solutions under the idea of the present invention belong to the protection scope of the present invention. It should be pointed out that for those skilled in the art, some improvements and modifications without departing from the principle of the present invention should also be regarded as the protection scope of the present invention.
Claims (7)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210610980.1A CN114913465A (en) | 2022-05-31 | 2022-05-31 | Action prediction method based on time sequence attention model |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210610980.1A CN114913465A (en) | 2022-05-31 | 2022-05-31 | Action prediction method based on time sequence attention model |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114913465A true CN114913465A (en) | 2022-08-16 |
Family
ID=82771002
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210610980.1A Withdrawn CN114913465A (en) | 2022-05-31 | 2022-05-31 | Action prediction method based on time sequence attention model |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114913465A (en) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115309736A (en) * | 2022-10-10 | 2022-11-08 | 北京航空航天大学 | Anomaly detection method for time series data based on self-supervised learning multi-head attention network |
| CN115527272A (en) * | 2022-10-13 | 2022-12-27 | 上海师范大学 | Construction method of pedestrian trajectory prediction model |
| CN115530788A (en) * | 2022-09-17 | 2022-12-30 | 贵州大学 | Arrhythmia classification method based on self-attention mechanism |
| CN115661596A (en) * | 2022-10-28 | 2023-01-31 | 哈尔滨工业大学 | Short video positive energy evaluation method, device and equipment based on 3D convolution and Transformer |
| CN116129330A (en) * | 2023-03-14 | 2023-05-16 | 阿里巴巴(中国)有限公司 | Video-based image processing, behavior recognition, segmentation and detection methods and equipment |
| CN116168329A (en) * | 2023-03-27 | 2023-05-26 | 南京大学 | Video motion detection method, equipment and medium based on key frame screening pixel block |
| CN116310653A (en) * | 2023-04-03 | 2023-06-23 | 厦门大学 | A Self-Supervised 3D Action Prediction Method Based on Past Completion and Future Trends |
| CN119672486A (en) * | 2024-11-07 | 2025-03-21 | 中国测绘科学研究院 | Crop recognition model construction method and system compatible with arbitrary time-series remote sensing images |
| CN116310653B (en) * | 2023-04-03 | 2026-02-13 | 厦门大学 | A self-supervised 3D motion prediction method based on past completion rate and future trends |
-
2022
- 2022-05-31 CN CN202210610980.1A patent/CN114913465A/en not_active Withdrawn
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115530788A (en) * | 2022-09-17 | 2022-12-30 | 贵州大学 | Arrhythmia classification method based on self-attention mechanism |
| CN115309736A (en) * | 2022-10-10 | 2022-11-08 | 北京航空航天大学 | Anomaly detection method for time series data based on self-supervised learning multi-head attention network |
| CN115527272A (en) * | 2022-10-13 | 2022-12-27 | 上海师范大学 | Construction method of pedestrian trajectory prediction model |
| CN115661596A (en) * | 2022-10-28 | 2023-01-31 | 哈尔滨工业大学 | Short video positive energy evaluation method, device and equipment based on 3D convolution and Transformer |
| CN116129330A (en) * | 2023-03-14 | 2023-05-16 | 阿里巴巴(中国)有限公司 | Video-based image processing, behavior recognition, segmentation and detection methods and equipment |
| CN116129330B (en) * | 2023-03-14 | 2023-11-28 | 阿里巴巴(中国)有限公司 | Video-based image processing, behavior recognition, segmentation and detection methods and equipment |
| CN116168329A (en) * | 2023-03-27 | 2023-05-26 | 南京大学 | Video motion detection method, equipment and medium based on key frame screening pixel block |
| CN116310653A (en) * | 2023-04-03 | 2023-06-23 | 厦门大学 | A Self-Supervised 3D Action Prediction Method Based on Past Completion and Future Trends |
| CN116310653B (en) * | 2023-04-03 | 2026-02-13 | 厦门大学 | A self-supervised 3D motion prediction method based on past completion rate and future trends |
| CN119672486A (en) * | 2024-11-07 | 2025-03-21 | 中国测绘科学研究院 | Crop recognition model construction method and system compatible with arbitrary time-series remote sensing images |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114913465A (en) | Action prediction method based on time sequence attention model | |
| CN110781838B (en) | Multi-mode track prediction method for pedestrians in complex scene | |
| Zhao et al. | Real-time and light-weighted unsupervised video object segmentation network | |
| CN110225341A (en) | A kind of code flow structure image encoding method of task-driven | |
| CN109446923A (en) | Depth based on training characteristics fusion supervises convolutional neural networks Activity recognition method | |
| CN110309732A (en) | Activity recognition method based on skeleton video | |
| CN111523378A (en) | A human behavior prediction method based on deep learning | |
| CN114613004B (en) | Light-weight on-line detection method for human body actions | |
| CN112587129A (en) | Human body action recognition method and device | |
| Desai et al. | Next frame prediction using ConvLSTM | |
| CN116091978A (en) | Video description method based on advanced semantic information feature coding | |
| CN118202388A (en) | Attention-based deep point cloud compression method | |
| WO2023174256A1 (en) | Data compression method and related device | |
| US20240296592A1 (en) | Adaptive deep-learning based probability prediction method for point cloud compression | |
| Ma et al. | Convolutional transformer network for fine-grained action recognition | |
| CN113971826B (en) | Dynamic emotion recognition method and system for estimating continuous titer and arousal level | |
| CN116721132A (en) | A multi-target tracking method, system and equipment for factory-cultured fish | |
| Zhao et al. | Research on human behavior recognition in video based on 3DCCA | |
| CN114926900A (en) | Human body action online detection method with separated foreground and background | |
| CN120147749B (en) | A method to accelerate 3D object detection using pruning and distillation | |
| CN119888260A (en) | Target tracking model training method, multi-target video labeling method and device | |
| CN113033283A (en) | Improved video classification system | |
| CN119091496A (en) | A behavior recognition method, device, system, and storage medium | |
| CN118799567A (en) | Semantic segmentation network training method, image semantic segmentation method and device | |
| CN116597503A (en) | Classroom behavior detection method based on space-time characteristics |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| WW01 | Invention patent application withdrawn after publication |
Application publication date: 20220816 |
|
| WW01 | Invention patent application withdrawn after publication |