CN114882886A - CTC simulation training voice recognition processing method, storage medium and electronic equipment - Google Patents
CTC simulation training voice recognition processing method, storage medium and electronic equipment Download PDFInfo
- Publication number
- CN114882886A CN114882886A CN202210452691.3A CN202210452691A CN114882886A CN 114882886 A CN114882886 A CN 114882886A CN 202210452691 A CN202210452691 A CN 202210452691A CN 114882886 A CN114882886 A CN 114882886A
- Authority
- CN
- China
- Prior art keywords
- statement
- flow
- ctc
- recognition
- online
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09B—EDUCATIONAL OR DEMONSTRATION APPLIANCES; APPLIANCES FOR TEACHING, OR COMMUNICATING WITH, THE BLIND, DEAF OR MUTE; MODELS; PLANETARIA; GLOBES; MAPS; DIAGRAMS
- G09B9/00—Simulators for teaching or training purposes
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/10—Speech classification or search using distance or distortion measures between unknown speech and reference templates
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/30—Distributed recognition, e.g. in client-server systems, for mobile phones or network applications
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Business, Economics & Management (AREA)
- Educational Administration (AREA)
- Educational Technology (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
Abstract
The invention discloses a CTC simulation training voice recognition processing method, a storage medium and electronic equipment, wherein the method comprises the following steps: acquiring dynamic parameters of a rail transit emergency disposal flow, and forming a plurality of groups of flow statements according to the dynamic parameters of the emergency disposal flow; acquiring audio data sent by a calling object on line, converting the audio data into sentence texts by adopting a voice recognizer to obtain on-line recognition sentences, and returning the on-line recognition sentences in real time; and matching the plurality of sets of flow statements with the online identification statement so as to obtain the flow statement with the confidence coefficient larger than the preset threshold value from the plurality of sets of flow statements. The method can combine the characteristics of the flow voice event, realize the standardized language machine check of the fault emergency disposal training and improve the accuracy of the system voice recognition.
Description
Technical Field
The invention relates to the technical field of voice recognition, in particular to a CTC simulation practical training voice recognition processing method, a storage medium and electronic equipment.
Background
At present, standard phrase assessment aiming at fault emergency disposal training of railway dispatching commanders is mainly based on artificial subjective judgment, the mode has higher requirement on the service level of teachers, the training efficiency is low, the training period and the training cost are invisibly increased, and the judgment modes of different teachers have certain difference and are influenced by more interference factors, so the mode of manual assessment lacks universality and universality.
At present, although the voice recognition technology is mature, a vertical engine in a railway field is not determined in a mainstream voice recognition library, and the recognition effect of railway special terms such as train number, speed limit value, station name and the like is far from meeting practical requirements, so that the normal circulation of a process voice event is influenced, and the user experience is reduced. Because the voice recognition technology relates to a plurality of disciplines such as acoustics, linguistics, signal processing, computer disciplines and the like, the autonomous development difficulty coefficient is high, the engineering quantity is large, the effect is difficult to expect, and the autonomous development difficulty coefficient is influenced by factors such as railway network information safety and the like, and part of training environments are not connected to the Internet and need to have offline recognition capability.
Therefore, in the railway field, an effective solution of machine assessment process standard expressions which have online and offline voice recognition capabilities and can improve the system voice recognition accuracy is still lacked.
Disclosure of Invention
The present invention is directed to solving, at least to some extent, one of the technical problems in the related art. Therefore, the first purpose of the invention is to provide a CTC simulation training speech recognition processing method, so as to realize online and offline speech recognition capability, combine the characteristics of flow speech events, realize standardized language machine assessment of fault emergency treatment training and improve the speech recognition accuracy of the system.
A second object of the present invention is to provide a computer-readable storage medium.
A third object of the present invention is to provide an electronic apparatus.
In order to achieve the purpose, the invention is realized by the following technical scheme:
a CTC simulation training voice recognition processing method comprises the following steps: acquiring dynamic parameters of a rail transit emergency disposal flow, and forming a plurality of groups of flow statements according to the dynamic parameters of the emergency disposal flow; acquiring audio data sent by a calling object on line, converting the audio data into a sentence text by adopting a voice recognizer to obtain an on-line recognition sentence, and returning the on-line recognition sentence in real time; and matching the plurality of sets of flow statements with the online identification statement so as to obtain the flow statements with the confidence degrees larger than the preset threshold value from the plurality of sets of flow statements.
Optionally, when the speech recognizer returns the online recognition statement in real time, the method further includes: and the speech recognizer dynamically corrects the online recognition statement according to the conversation context and the sentence up-down relation of the conversation content.
Optionally, after the audio data is collected and before the audio data is converted, the method further includes: and detecting the current network connection state, and if the current network connection state is in a disconnection state, switching the current online voice recognition mode to a voice offline recognition mode so as to perform offline recognition processing on the acquired audio data through the voice offline recognition mode.
Optionally, the speech recognizer is a third-party speech recognition device, the third-party speech recognition device is configured with a public cloud, and before the audio data is uploaded to the speech recognizer for conversion, the method further includes: uploading hot words to the public cloud, and performing online voice dictation basic parameter setting on the voice recognizer, wherein the hot words comprise at least one of a train number, flow statement keywords and a railway special name word library, and the online voice dictation basic parameters comprise at least one of punctuation addition parameters, language area parameters, text return format parameters and engine type parameters.
Optionally, before matching the plurality of sets of flow statements with the online identification statement, the method further includes: and carrying out online preprocessing on the flow statement.
Optionally, the online preprocessing of the flow statement includes at least one of the following processing modes: when the flow statement contains a plurality of train numbers, carrying out multi-train statement segmentation; deleting items of content repetition or un-replaced items of the dynamic parameters of the emergency disposal flow in the plurality of sets of flow statements; replacing characters which do not accord with the dispatching command standard expression in the flow statement with Chinese characters; changing the train number to meet the standard reading requirement; and deleting the symbols which do not accord with the dispatching command standard in the flow statement.
Optionally, after performing online preprocessing on the flow statement, the method further includes: acquiring the word number of each group of flow sentences and the word number of online identification sentences; determining the number difference and the number difference rate of each group of flow sentences and online identification sentences according to the number of words of each group of flow sentences and the number of words of the online identification sentences, and screening a plurality of groups of flow sentences of which the number differences and the number difference rates both meet preset conditions from each group of flow sentences to obtain a first flow sentence set, wherein the preset conditions are expressed by the following formulas:

wherein Y is the word number of the online identification statement, A is the word number difference, and R is the word number difference rate.
Optionally, after obtaining the first flow statement set, the method further includes: calculating the single-double word matching rate of each group of flow statements in the first flow statement set and the online identification statement; and screening a plurality of groups of flow statements with the single-word and double-word matching rate larger than a first preset value from the first flow statement set to obtain a second flow statement set.
Optionally, after obtaining the second flow statement set, the method further includes: calculating the Distance-editing similarity between each group of flow statements in the second flow statement set and the online identification statement by adopting a Levenshtein-Distance algorithm; and screening a plurality of groups of flow statements with the distance-editing similarity larger than a second preset value from the second flow statement set to obtain a third flow statement set.
Optionally, the step of obtaining the flow statements with the confidence degrees larger than the preset threshold value by matching among the plurality of sets of flow statements includes: calculating the matching degree of each group of flow sentences in the third flow sentence set and the pinyin set single characters of the online identification sentences; and determining the confidence of each group of flow statements according to the single-double word matching rate, the distance-editing similarity and the pinyin set single word matching degree of each group of flow statements and the online recognition statements in the third flow statement set, and screening the flow statements with the confidence greater than a preset threshold value from the third flow statement set as the best matching flow statements.
Optionally, before performing offline recognition processing on the acquired audio data in a voice offline recognition manner, the method further includes: and dynamically constructing an offline command word grammar file, wherein the offline command word grammar file is applied to offline recognition processing of the acquired audio data.
Optionally, the step of dynamically constructing the offline command word grammar file includes: receiving a voice event, identifying the voice event to obtain a corresponding text statement, and performing offline preprocessing on the text statement to obtain a dynamic parameter field, wherein the voice event comprises a flow voice event and/or a car control event; and acquiring a grammar file template, and replacing corresponding parameters in the grammar file template by adopting the dynamic parameter field so as to dynamically construct an offline command word grammar file.
Optionally, the step of performing offline preprocessing on the text statement to obtain a dynamic parameter field includes: performing two times of preprocessing on the text statement, wherein the first preprocessing is to perform Chinese character replacement processing and invalid statement deletion processing on the text statement, and the second preprocessing is to perform statement segmentation on the text statement after the first preprocessing to obtain a plurality of statement arrays; and packaging the preprocessed statement arrays into a plurality of rule items comprising rule names and rule contents, and connecting the rule names in the rule items in series into a sequence according to the original text statement semantics to obtain the dynamic parameter field.
Optionally, the step of performing sentence segmentation on the text sentence preprocessed for the first time includes: judging whether the current text sentence contains the number of the train number, if not, dividing and storing the text sentence by taking 16 characters as a group; if the number of the train number is included, the number part of the train number is extracted, and the rest characters are divided and stored according to 16 characters as a group.
Optionally, the dynamic parameter replacement term in the grammar file template includes at least one of a self-identification header, a grammar name, a slot statement and a dynamic parameter reservation term, and the dynamic parameter reservation term includes at least one of a newly added slot statement, a grammar body, a station name and a train number.
Optionally, the step of performing offline recognition processing on the acquired audio data in the voice offline recognition mode includes: storing the collected audio data in an audio buffer queue, calling the audio data from the audio buffer queue, and performing command word matching on the audio data by adopting the voice recognizer to obtain an offline recognition statement through analysis; replacing the off-line recognition statement with a flow statement standard format according to the dynamically constructed off-line command word grammar file,
optionally, after storing the collected audio data in an audio buffer queue, before retrieving the audio data from the audio buffer queue, the method further includes: and performing offline voice recognition basic parameter setting on the voice recognizer, wherein the offline voice recognition basic parameters comprise resource storage paths and/or matching result return types.
In order to achieve the above object, a second aspect of the present invention provides a computer-readable storage medium, on which a computer program is stored, where the computer program, when executed by a processor, implements the CTC simulation training speech recognition processing method described above.
In order to achieve the above object, a third aspect of the present invention provides an electronic device, which includes a processor and a memory, where the memory stores a computer program, and when the computer program is executed by the processor, the CTC simulation training speech recognition processing method is implemented.
The invention has at least the following technical effects:
(1) the invention carries out voice recognition optimization processing aiming at two voice recognition modes of on-line and off-line according to different network configuration conditions, thereby meeting the requirements of different use scenes and providing a plurality of man-machine interaction modes for users.
(2) The method dynamically constructs the off-line command word grammar file according to the process content and the scene information, thereby satisfying the identification of the process sentences and the off-line vehicle control commands in different processes and different scenes, being free from the influence of network factors, and having the characteristics of high response speed and high speech recognition precision.
(3) The invention is based on the voice recognition technology, converts voice content of conversation with other roles in the process of dispatcher simulated fault handling into text information through recognition and processing, and carries out voice/vehicle control event circulation through a CTC simulated training platform so as to complete the standard language assessment of machine automation.
(4) In the aspect of on-line voice dictation, the voice recognition effect is optimized mainly through two aspects of uploading hot words and recognition result matching processing, and the best matching process sentence and confidence coefficient are calculated by comparing the text similarity through single-double word matching, a distance-editing algorithm, pinyin set single word matching and the like in the stage of recognition result matching processing, so that the method has the characteristics of flexible recognition mode and high fault tolerance rate.
(5) According to the invention, according to the service of a third-party speech recognition library, the characteristics of the process speech event are combined, the accuracy of system speech recognition can be effectively improved through an optimization processing algorithm, the problem that process sentences are difficult to recognize can be effectively solved, the software development cost can be reduced, the system intelligence level is improved, and the product competitiveness is enhanced.
Additional aspects and advantages of the invention will be set forth in part in the description which follows and, in part, will be obvious from the description, or may be learned by practice of the invention.
Drawings
Fig. 1 is a flow chart of speech recognition processing information of a CTC simulation training platform according to an embodiment of the present invention;
fig. 2 is a flowchart of a CTC simulation training speech recognition processing method according to an embodiment of the present invention;
FIG. 3 is a flowchart of a CTC simulation training speech online identification processing method according to a specific example of the present invention;
fig. 4 is a flowchart illustrating processing of an online speech dictation recognition result according to an embodiment of the present invention;
FIG. 5 is a flowchart illustrating a dynamic construction of an offline command word grammar file according to an embodiment of the present invention;
fig. 6 is a flowchart of a CTC simulation training speech offline recognition processing method according to a specific example of the present invention.
Detailed Description
Reference will now be made in detail to the present embodiments, examples of which are illustrated in the accompanying drawings, wherein like reference numerals refer to the same or similar elements or elements having the same or similar functions throughout. The embodiments described below with reference to the drawings are illustrative and intended to be illustrative of the invention and are not to be construed as limiting the invention.
As described in the background art, in the railway field, an effective solution of machine assessment process standard expressions which have online and offline voice recognition capabilities and can improve the system voice recognition accuracy is still lacking. Therefore, this embodiment proposes a CTC (central Traffic control System, dispatch Centralized control System) simulation training speech recognition processing method, which is applied to a CTC simulation training platform, and a speech recognition processing information flow diagram of the CTC simulation training platform is shown in fig. 1. The SimFAS is simulation FAS radio station software carried by the invention and used for simulating communication between a dispatcher and other roles, the SCU (student machine) sends process content and scene related information to the SimFAS and is used for constructing an offline grammar file, matching an online recognition result, setting a call role button and prompting a process flow state, the SimFAS starts Mic recording equipment, acquires user speech content, performs speech recognition processing according to the user speech content, calculates a process statement most similar to the user speech content through algorithm processing of a recognition result by calling a third-party speech real-time dictation/offline command word interface, displays the recognition result to the user through a human-computer interface, and transmits the recognition result and confidence back to the SCU for the flow and automatic evaluation of speech events and vehicle control events in the process.
The CTC simulation training speech recognition processing method, the storage medium, and the electronic device according to the embodiment are described below with reference to the drawings.
Fig. 2 is a flowchart of a CTC simulation training speech recognition processing method according to an embodiment of the present invention. As shown in fig. 2, the method includes:
step S1: acquiring dynamic parameters of a rail transit emergency disposal flow, and forming a plurality of groups of flow statements according to the dynamic parameters of the emergency disposal flow.
Because different dispatching stations govern different stations and the section picture, CTC operation, equipment state, access state, fault information and train running state in the CTC simulation training platform change along with time, corresponding parameters in a grammar file template can be replaced according to the dynamic change of emergency disposal flow parameters to obtain a plurality of sets of flow statements after parameter replacement, and the plurality of sets of flow statements and keywords thereof are stored in a two-dimensional array and used for matching subsequent on-line identification statements.
Step S2: and collecting audio data sent by the calling object on line, converting the audio data into sentence texts by adopting a voice recognizer to obtain on-line recognition sentences, and returning the on-line recognition sentences in real time.
When the speech recognizer returns the online recognition statement in real time, the method further comprises the following steps: the speech recognizer dynamically corrects the online recognition sentences according to the conversation context and the sentence up-down relation of the conversation content.
After the audio data is collected, and before the audio data is converted, the method further comprises: and detecting the current network connection state, and if the current network connection state is in a disconnection state, switching the current online voice recognition mode to a voice offline recognition mode so as to perform offline recognition processing on the acquired audio data in the voice offline recognition mode.
It should be noted that, the speech recognizer is a third-party speech recognition device (such as a science fiction flight speech recognition device), the third-party speech recognition device is configured with a public cloud, and before uploading the audio data to the speech recognizer for conversion, the method further includes: uploading hot words to a public cloud, and performing online voice dictation basic parameter setting on a voice recognizer, wherein the hot words comprise at least one of a train number, flow statement keywords and a railway special name word library, and the online voice dictation basic parameters comprise at least one of punctuation addition parameters, language area parameters, text return format parameters and engine type parameters.
In this embodiment, the audio data sent by the call object may be collected online, and then a public cloud interface of a third-party speech recognition device, such as a scientific news fly speech recognition device, is invoked to convert the natural language audio data into a sentence text, obtain an online recognition sentence, and return the online recognition sentence in real time.
As a specific example, the CTC simulation training speech online identification processing method of the present embodiment will be described in detail with reference to fig. 3 and steps S21-S29.
Step S21, starting a recording device, collecting audio data in a PCM (Pulse Code Modulation) format with 16k sampling rate and 16bit single sound channel, and storing the audio data in an audio buffer queue;
step S22, detecting the network connection state, if detecting the network connection failure, switching to the speech off-line recognition mode, ending the calling process, if detecting the network connection success, then proceeding the next step;
step S23, the train number, the flow statement keywords and the railway special name word library are used as hot words and uploaded to the science news flying public cloud;
step S24, setting basic parameters of on-line voice dictation, such as punctuation addition, language area, return format and engine type;
step S25, a group of audio data is taken out from the audio buffer queue, a science news audio writing interface is called, and the audio data is converted into text information based on a natural language processing technology;
step S26, after the audio data are uploaded successfully, acquiring uplink flow for detecting the network connection state;
step S27, judging whether an intermediate recognition result is returned or not according to the flag bit, if the condition is true, reading and analyzing a Json file returned by the voice dictation, and acquiring downlink flow, otherwise, performing the next step;
step S28, judging the end state of the identification process, if the user actively hangs up or automatically hangs up when the silence overtime happens, then proceeding the next step, otherwise, entering step S25 again;
and step S29, writing the last frame of empty audio after the recognition is finished, and acquiring and analyzing the final recognition result to obtain the online recognition statement.
Further, before matching the plurality of sets of flow statements with the online identification statement, the method further includes online preprocessing the flow statements, that is, processing the contents of the flow statements as shown in fig. 4.
Wherein, the on-line preprocessing of the flow statement comprises at least one of the following processing modes: when the flow statement contains a plurality of train numbers, carrying out multi-train statement segmentation; deleting items of content repetition or un-replaced items of the dynamic parameters of the emergency disposal flow in the plurality of sets of flow statements; replacing characters which do not accord with the dispatching command standard expression in the flow statement with Chinese characters; changing the train number to meet the standard reading requirement; and deleting the symbols which do not accord with the dispatching command standard in the flow statement.
Specifically, since the dispatcher can only call one train at a time, a voice/control event including a plurality of calling train numbers needs to be divided into separate sentences, such as "driver G102# G107, please stop immediately" divided into "driver G107, please stop immediately" and "driver G102, please stop immediately. In addition, deleting repeated content and un-replaced items of dynamic parameters in the flow statement array, and replacing special meaning characters in the flow statement and the keywords with Chinese characters according to the requirement of the scheduling command standard expression, such as replacing FG with inverse high. In this embodiment, it is also necessary to replace all the numbers in the flow sentence with the chinese characters, and delete the symbols included in the sentence by using the regular expression, so as to avoid affecting the matching rate, and make the train number support two reading methods, such as "a driver who is higher by one and nine times, please stop immediately" and "a driver who is higher by one and nine times, please stop immediately".
Step S3: and matching the plurality of sets of flow statements with the online identification statement so as to obtain the flow statement with the confidence coefficient larger than the preset threshold value from the plurality of sets of flow statements.
Specifically, after the online preprocessing of the flow statement, the method further includes: acquiring the word number of each group of flow sentences and the word number of online identification sentences; determining the number difference and the number difference rate of each group of flow sentences and online identification sentences according to the number of words of each group of flow sentences and the number of words of the online identification sentences, and screening a plurality of groups of flow sentences of which the number differences and the number difference rates both meet preset conditions from each group of flow sentences to obtain a first flow sentence set, wherein the preset conditions are expressed by the following formulas:

wherein Y is the word number of the online identification statement, A is the word number difference, and R is the word number difference rate.
As shown in FIG. 4, the present embodiment matches the length limit (word count) for a flow statementLength matching limits). For example, if X is the number of words in the flow sentence and Y is the number of words in the recognition result, the difference in the number of words is a ═ X-Y |, and the rate of the difference in the number of words is And then screening a plurality of sets of flow sentences of which A and R both meet the preset conditions from the sets of flow sentences.
And then screening a plurality of sets of flow sentences of which A and R both meet the preset conditions from the sets of flow sentences.
In one embodiment of the invention, after obtaining the first set of flow statements, the method further comprises: calculating the single-double word matching rate of each group of flow statements in the first flow statement set and the online recognition statements; and screening a plurality of groups of flow statements with the single-word and double-word matching rate larger than a first preset value from the first flow statement set to obtain a second flow statement set.
Specifically, the single word matching rate is set as Δ S, the double word matching rate is set as Δ D, and then the single and double word matching rate Δ M of the flow statement and the online recognition statement is calculated as:

wherein, if the number of the same words of the single character is M, and the number of the same words of the double character is N, then:


thus, it is possible to obtain:

in this embodiment, the first preset value may be set to 0.7, that is, the contents of the flow statements with Δ M greater than or equal to 0.7 in the first flow statement set are similar to the contents of the online identification statements, then the partial flow statements are screened out for the next operation, and if all the flow statements Δ M is less than 0.7, the online identification statements are output in place of the standard format of the return flow statements.
In one embodiment of the invention, after obtaining the second set of flow statements, the method further comprises: calculating the Distance-editing similarity between each group of flow statements in the second flow statement set and the online identification statement by adopting a Levenshtein-Distance (Distance-editing) algorithm; and screening a plurality of groups of flow statements with the distance-editing similarity larger than a second preset value from the second flow statement set to obtain a third flow statement set.
Specifically, since the single-double word matching method can only calculate the word similarity of two character strings, even if the sentence is inverted, the matching rate is still not affected, and the relevance and the coherence of words in the sentence are easily ignored, therefore, the distance-editing algorithm is introduced in the embodiment to calculate the minimum editing operation times between the sentences, the problem of 'homonymy and disagreement' can be avoided, and the ambiguity between the matched sentences is further reduced.
For example, let character string str1 be "red band appears on the upper line between north and east stations without tin in Suzhou of the major tune", character string str2 be "red band appears on the upper line between north and east stations without tin in Suzhou of the major tune", and record the number of times it takes to convert str1 to str2 with two-dimensional array x [ i, j ], the basic steps of the algorithm are as follows:
(1) if the length of str1 or str2 is 0, the shortest editing distance returns the length of another character string;
(2) constructing an x [ i, j ] array matrix for storing the conversion operation times among character strings, wherein the minimum time for converting str1 into str2 is matrix [19] [20 ];
(3) initializing an x [ i, j ] array matrix, wherein the first row and the first column are incremented by 0, as shown in table 1 below:
TABLE 1 str1 and str2 character comparison table


(4) Starting with the first character "Note" of str2, matrix [1] [1] to matrix [20] [1] are compared, and if the two characters are equal, matrix [ i ] [0] and matrix [1] [ i-1] are added by 1, and matrix [ i-1] [0] is added by 0, then:
matrix[i][1]=Min(matrix[i][0],matrix[1][i-1],matrix[i-1][0]) (6)
if the two characters are not equal:
matrix[i][1]=Min(matrix[i][0],matrix[1][i-1],matrix[i-1][0])+1 (7)
(5) after completing the 19-column scanning in sequence, the shortest edit distance matrix [19] [20] is obtained to be 5, which is specifically shown in the following table 2:
TABLE 2 Str1 and Str2 shortest edit distance operation Table


(6) Then the distance-edit similarity of two strings str1 and str2 is:

in this embodiment, the second preset value may be set to 0.7 to filter the flow statements with a large difference between the relevance and the coherence between the statements, if the flow statement array is not empty, the next step is performed, otherwise, the online recognition statement is output in place of the standard format of the return flow statement.
In an embodiment of the present invention, the step of obtaining a flow statement with a confidence level greater than a preset threshold from a plurality of sets of flow statements by matching includes: calculating the matching degree of each group of flow sentences in the third flow sentence set and the pinyin set single characters of the online recognition sentences; and determining the confidence coefficient of each group of flow statements according to the single-double word matching rate, the distance-editing similarity and the pinyin set single word matching degree of each group of flow statements and the online recognition statements in the third flow statement set, and screening the flow statements with the confidence coefficient larger than a preset threshold value from the third flow statement set as the best matching flow statements.
Specifically, the similarity between the flow statement and the online recognition statement processed by the Levenshtein-Distance algorithm is high, but the matching degree between the single and double words and the Distance-editing algorithm is reduced due to the influence of the homophone, so that the problem that the final result has matching errors or low confidence coefficient is possibly caused, therefore, the homophone error can be compensated by the pinyin single word matching processing, and the specific processing method comprises the following steps:
(1) converting the flow statement, the keywords thereof and the online identification statement into a pinyin set and storing the pinyin set;
(2) searching a flow sentence keyword pinyin set in the online recognition sentence pinyin set, if the flow sentence keyword pinyin set exists, retaining the flow sentence, and if the flow sentence keyword pinyin set does not exist, rejecting the flow sentence keyword pinyin set; after the calculation is finished, if the flow statement array is empty, namely the third flow statement set is empty, replacing the online identification statement with the standard format of the return flow statement and outputting, and if not, performing the next step;
(3) sequentially calculating the matching degree delta P of the single characters in the pinyin set of the flow sentence and the online recognition sentence;
(4) the single-double word matching rate delta M, the distance-editing similarity delta T and the pinyin set single word matching degree delta P are weighted and averaged to obtain the matching degree, namely confidence coefficient delta Z as follows:

and if the number of the flow statement array items in the third flow statement set is not 0, outputting confidence and outputting the flow statement with the highest matching degree, otherwise, replacing the on-line recognition statement with the standard format of the return flow statement and outputting the flow statement for flow circulation and automatic evaluation.
Fig. 3 is a flowchart of a CTC simulation training voice online identification processing method, and fig. 4 is a flowchart of an online voice dictation identification result processing method. As shown in fig. 3 and 4, in this embodiment, the emphasis of online speech dictation is on hotword and recognition result processing, uploading the hotword is helpful to improve the recognition rate of the proper noun, and the recognition result processing calculates the closest flow standard term through a similarity matching algorithm, so that the problem of disordered recognition content can be solved, and the recognition effect is greatly improved. In addition, when the dispatcher calls out, the recording device is started firstly, the audio data is cached, then whether the network state is normal or not is detected, the situation that the communication fails and recognition cannot be conducted can be avoided, then the hotword extracted from the flow statement is uploaded to the cloud of the science university communication Fei, the uploading flow and the downloading flow need to be obtained in the recognition process to detect the connection state, and the calling mode of other interfaces is similar to the voice offline recognition mode. The identification result is divided into an intermediate result and a final result, the intermediate result is real-time identification content dynamically corrected according to the context and is only used for displaying process identification content to a user, the final result is an identification statement obtained last time after the call is ended, the closest flow statement is calculated through a similarity algorithm, and if the identification content is not similar to all the flow statements, the identification content replaced by the flow standard format is output.
It should be noted that, because the recognition effect of the science news flight voice dictation service on the relevant proper nouns of the railway is not good, after the online voice recognition is finished, the invention adopts the method combination of the methods of flow statement preprocessing, word number length limiting rule, single-double word matching, edit-distance algorithm, pinyin set single word matching and the like to calculate the flow statement with the highest similarity to the online recognition statement, if the calculated flow statement array capacity is not empty, the flow statement with the highest matching rate and the confidence thereof are taken out and output to the student computer SCU, otherwise, the online recognition statement is replaced by the flow standard format and output, so that the SCU performs flow circulation and automatic evaluation according to the output result of the simulated FAS radio station software SimFAS.
Further, as described above, when it is detected that the current network connection state is in the disconnection state, the current online speech recognition mode may be switched to the speech offline recognition mode, so as to perform offline recognition processing on the acquired audio data in the speech offline recognition mode.
In an embodiment of the present invention, before performing offline recognition processing on the acquired audio data by an offline speech recognition method, the method further includes: and dynamically constructing an offline command word grammar file, wherein the offline command word grammar file is applied to offline recognition processing of the acquired audio data.
Specifically, as described above, since different stations under different jurisdictions of different dispatching desks and the section picture, CTC operation, device state, access state, fault information and train operation state in the CTC simulation training platform change with time, an offline command word grammar file needs to be dynamically constructed according to the parameter replacement result and scene information of the emergency handling process, so as to support the voice recognition of the process voice event, the train control event and the process external train control operation.
As shown in fig. 5, the step of dynamically constructing the offline command word grammar file includes:
step S10: the method comprises the steps of receiving a voice event, identifying the voice event to obtain a corresponding text statement, and performing offline preprocessing on the text statement to obtain a dynamic parameter field, wherein the voice event comprises a process voice event and/or a car control event.
In this embodiment, the step of performing offline preprocessing on the text statement to obtain the dynamic parameter field includes: and performing two times of preprocessing on the text sentences, wherein the first preprocessing comprises performing Chinese character replacement processing and invalid sentence deletion processing on the text sentences, and the second preprocessing comprises performing sentence segmentation on the text sentences after the first preprocessing to obtain a plurality of sentence arrays.
The step of sentence segmentation of the text sentence after the first preprocessing comprises the following steps: judging whether the current text sentence contains the train number, if not, dividing and storing the text sentence by taking 16 characters as a group; if the number of the train number is included, the number part of the train number is extracted, and the rest characters are divided and stored according to 16 characters as a group.
Furthermore, the preprocessed statement arrays can be packaged into a plurality of rule items comprising rule names and rule contents, and the rule names in the rule items are connected in series into a sequence according to the original text statement semantics, so as to obtain the dynamic parameter field.
Specifically, the flow voice event and the vehicle control event sentence can be preprocessed for the first time according to the characteristics of scheduling command phrases, so that the accuracy of offline voice recognition is improved, and the processing mode is as follows:
(1) the special meaning letters of the railway are replaced by Chinese characters, such as: s1LQ is replaced with a "last exit";
(2) replacing kilometer values in kilometers with Chinese characters, such as: 800 in K1805+800 is replaced with "eight hundred";
(3) the train speed limit numerical value is replaced by Chinese characters, such as: 160 is replaced by 'one hundred six';
(4) the numbers are replaced by Chinese characters, such as: 2 is replaced by 'two';
(5) removing special symbols in the sentences, and eliminating repeated invalid sentences containing parameters and the like.
Further, the text sentence after the first preprocessing can be preprocessed for the second time, for example, the content of the flow sentence is divided according to the rule defined by the command word grammar file of the departure line of science news, and the processing modes include two types:
(1) the text sentence content does not contain the train number, and the whole sentence is segmented and stored by taking 16 characters as groups;
(2) the text sentence content contains the train number, and the train number part is extracted, wherein the train number needs to support two reading methods, such as: "G1974" can be read as "one nine seven four higher" or "one nine four corners higher", and the rest is stored by dividing the 16 characters into groups.
Furthermore, a plurality of sentence arrays after two times of preprocessing can be packaged into a plurality of rules (consisting of rule names and rule contents), the rule names of the same sentence before division are connected in series into a sequence through rule reference, and a grammar file body is formed by the plurality of rules and the sequence. In the embodiment, in the process of dynamically constructing the off-line command word grammar file, the software resource consumption can be reduced by multiplexing the rule names with the same rule content, and the grammar constructing efficiency is improved. The specific treatment process is as follows:
(1) suppose the sentence is: "G1805 driver, the adjacent train has limited speed, permit the driver of the vehicle-mounted machinist the non-intersection side get-off check. "
(2) The sentence division process is that,
high one-eight-zero five, high one-eight-hole five "
② secondary driver, adjacent train limited speed and permitted vehicle-mounted "
Checking off the side and getting off the vehicle when the mechanic does not meet "
(3) Is packaged into a plurality of rule items,
[ phi < voice11 >: one-eight-zero-five higher | one-eight-hole-five higher;
< voice 12 >: the secondary driver, the adjacent train has limited speed and permits to carry on the train;
(iii) < voice 13 >: the mechanic does not meet the checking of the vehicle on the side and off the vehicle;
(4) the above 3 rules are concatenated into a sequence by rule reference,
<voicetext1>:<voice11><voice 12><voice 13>;
step S20: and acquiring a grammar file template, and replacing corresponding parameters in the grammar file template by adopting dynamic parameter fields to dynamically construct an offline command word grammar file.
The dynamic parameter replacement items in the grammar file template comprise at least one of a self-identification head, a grammar name, a slot statement and a dynamic parameter retention word, and the dynamic parameter retention word comprises at least one of a newly added slot statement, a grammar main body, a station name and a train number.
In this embodiment, the parameter fields in the grammar file template may be sequentially replaced with the dynamic parameter fields obtained in step S10 to complete the dynamic construction of the offline command word grammar file, so as to prepare for the offline speech recognition described below.
In one embodiment of the present invention, the step of performing offline recognition processing on the collected audio data in a voice offline recognition manner includes: storing the collected audio data into an audio buffer queue, calling the audio data from the audio buffer queue, and performing command word matching on the audio data by adopting a voice recognizer to obtain an offline recognition statement by analysis; and replacing the offline recognition statement with a flow statement standard format according to the dynamically constructed offline command word grammar file.
After the collected audio data are stored in the audio buffer queue and before the audio data are called from the audio buffer queue, the method further comprises the following steps: and the speech recognizer sets basic parameters for off-line speech recognition, wherein the basic parameters for off-line speech recognition comprise a resource storage path and/or a matching result return type.
Specifically, the audio data can be collected, then the science popularization communication interface is called to obtain the offline recognition statement, and contents such as kilometer posts, speed limit values, train numbers, special characters and the like in the offline recognition statement are replaced into a flow standard format.
As a specific example, the CTC simulation training speech offline recognition processing method of the present embodiment will be described in detail with reference to fig. 6 and steps S31-S36.
Step S31, selecting and constructing different grammar files according to the calling object, calling a train driver to construct a train control grammar, and calling other roles such as a station attendant to construct a flow statement grammar;
step S32, starting a recording device, collecting PCM format audio data with 16k sampling rate and 16bit single sound channel, and storing the data in an audio buffer queue;
step S33, setting basic parameters of off-line speech recognition, such as resource storage path, result return type, etc.;
step S34, a group of audio data is taken out from the audio buffer queue, then a science news audio writing interface is called, and the speech recognizer matches command words based on grammar rules and speech characteristic information;
step S35, judging the end state of the identification process, if the user actively hangs up or automatically hangs up when the silence overtime happens, then proceeding the next step, otherwise, entering step S34 again;
and step S36, writing the last frame of empty audio after the recognition is finished, acquiring and analyzing the recognition result to obtain an offline recognition statement, and replacing the offline recognition statement with a flow statement standard format.
In this embodiment, since the off-line speech recognition method performs path matching according to the grammar network and the speech feature information, the grammar network is a necessary condition for off-line speech recognition. In addition, because different fault handling flow statement contents are different, dynamic parameter calculation results are different in different scenes, and syntax files cannot be kept consistent due to reasons such as changes of flow statement contents in a flow circulation process, the SimFAS constructs the dynamic syntax files according to the flow statements and scene information sent by the SCU in this embodiment.
In the off-line voice recognition process, when a dispatcher calls, the recording equipment is started firstly, audio data are cached, then scientific communication fly interfaces such as user verification, grammar construction and parameter setting are called in sequence to complete preparation work, the cached audio is read continuously and written into a dictation interface until the dispatcher actively hangs up or is silent for 3 seconds and automatically hangs up, a matching result of the voice recognizer is obtained through a result return interface, and finally the recognition result is replaced by a flow standard format for interface display and flow circulation.
In summary, the invention can perform speech recognition optimization processing aiming at two speech recognition modes of online and offline according to different network configuration conditions, thereby meeting the requirements of different use scenes and providing a plurality of man-machine interaction modes for users; the invention can also dynamically construct an offline command word grammar file according to the process content and the scene information, thereby satisfying the identification of process sentences and offline vehicle control commands in different processes and different scenes, being free from the influence of network factors, and having the characteristics of high response speed and high voice identification precision; the invention can also be based on a voice recognition technology, the voice content which is conversed with other roles in the process of the simulated fault handling of the dispatcher is recognized and processed to be converted into text information, and voice/vehicle control event circulation is carried out through a CTC simulated training platform, so that the standard language assessment of the machine automation can be conveniently completed; in addition, the invention optimizes the voice recognition effect mainly through two aspects of the upper hot word and recognition result matching processing in the aspect of on-line voice dictation, for example, the text similarity comparison is carried out in the modes of single-double word matching, distance-editing algorithm, pinyin set single word matching and the like in the stage of recognition result matching processing, and the optimal matching flow statement and confidence coefficient are calculated, so that the invention has the characteristics of flexible recognition mode and high fault-tolerant rate; and the invention can also effectively improve the accuracy of system speech recognition by optimizing the processing algorithm according to the service of a third-party speech recognition library and combining the characteristics of the process speech event, can effectively solve the problem that the process statement is difficult to recognize, can reduce the software development cost, improve the intelligent level of the system and enhance the product competitiveness.
Further, the present invention also provides a computer readable storage medium, on which a computer program is stored, and when the computer program is executed by a processor, the CTC simulation practical training speech recognition processing method is implemented.
Furthermore, the invention also provides electronic equipment which comprises a processor and a memory, wherein the memory is stored with a computer program, and when the computer program is executed by the processor, the CTC simulation practical training voice recognition processing method is realized.
It is noted that, herein, relational terms such as first and second, and the like may be used solely to distinguish one entity or action from another entity or action without necessarily requiring or implying any actual such relationship or order between such entities or actions. Also, the terms "comprises," "comprising," or any other variation thereof, are intended to cover a non-exclusive inclusion, such that a process, method, article, or apparatus that comprises a list of elements does not include only those elements but may include other elements not expressly listed or inherent to such process, method, article, or apparatus. Without further limitation, an element defined by the phrase "comprising an … …" does not exclude the presence of other identical elements in a process, method, article, or apparatus that comprises the element.
While the present invention has been described in detail with reference to the preferred embodiments, it should be understood that the above description should not be taken as limiting the invention. Various modifications and alterations to this invention will become apparent to those skilled in the art upon reading the foregoing description. Accordingly, the scope of the invention should be determined from the following claims.
Claims (19)
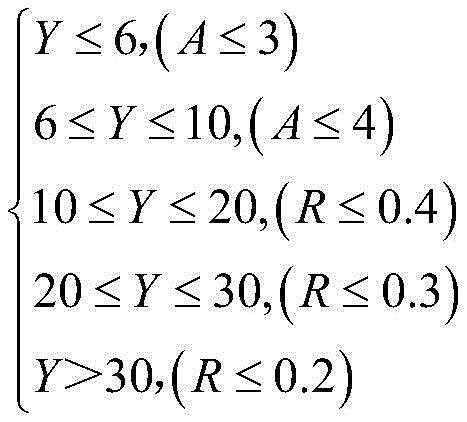
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210452691.3A CN114882886B (en) | 2022-04-27 | 2022-04-27 | CTC simulation training speech recognition processing method, storage medium and electronic device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210452691.3A CN114882886B (en) | 2022-04-27 | 2022-04-27 | CTC simulation training speech recognition processing method, storage medium and electronic device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114882886A true CN114882886A (en) | 2022-08-09 |
| CN114882886B CN114882886B (en) | 2024-10-01 |
Family
ID=82672430
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210452691.3A Active CN114882886B (en) | 2022-04-27 | 2022-04-27 | CTC simulation training speech recognition processing method, storage medium and electronic device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114882886B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116092342A (en) * | 2022-11-18 | 2023-05-09 | 四川大学 | A method and system for automatic response and quality assessment of controller simulation training |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102862587A (en) * | 2012-08-20 | 2013-01-09 | 泉州市铁通电子设备有限公司 | Method and equipment for analyzing rolling stock and locomotive inter-control voice of railways |
| EP2798634A1 (en) * | 2011-12-29 | 2014-11-05 | Intel Corporation | Speech recognition utilizing a dynamic set of grammar elements |
| CN109204007A (en) * | 2018-08-29 | 2019-01-15 | 江西理工大学 | A kind of unpiloted suspension type magnetic suspension train and its control method |
| US20190332915A1 (en) * | 2018-04-26 | 2019-10-31 | Wipro Limited | Method and system for interactively engaging a user of a vehicle |
| US20190371295A1 (en) * | 2017-03-21 | 2019-12-05 | Beijing Didi Infinity Technology And Development Co., Ltd. | Systems and methods for speech information processing |
| CN111326147A (en) * | 2018-12-12 | 2020-06-23 | 北京嘀嘀无限科技发展有限公司 | Voice recognition method and device, electronic equipment and storage medium |
| CN112017642A (en) * | 2019-05-31 | 2020-12-01 | 华为技术有限公司 | Method, device and equipment for speech recognition and computer readable storage medium |
| CN112435664A (en) * | 2020-11-11 | 2021-03-02 | 郑州捷安高科股份有限公司 | Evaluation system and method based on voice recognition and electronic equipment |
-
2022
- 2022-04-27 CN CN202210452691.3A patent/CN114882886B/en active Active
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2798634A1 (en) * | 2011-12-29 | 2014-11-05 | Intel Corporation | Speech recognition utilizing a dynamic set of grammar elements |
| CN102862587A (en) * | 2012-08-20 | 2013-01-09 | 泉州市铁通电子设备有限公司 | Method and equipment for analyzing rolling stock and locomotive inter-control voice of railways |
| US20190371295A1 (en) * | 2017-03-21 | 2019-12-05 | Beijing Didi Infinity Technology And Development Co., Ltd. | Systems and methods for speech information processing |
| US20190332915A1 (en) * | 2018-04-26 | 2019-10-31 | Wipro Limited | Method and system for interactively engaging a user of a vehicle |
| CN109204007A (en) * | 2018-08-29 | 2019-01-15 | 江西理工大学 | A kind of unpiloted suspension type magnetic suspension train and its control method |
| CN111326147A (en) * | 2018-12-12 | 2020-06-23 | 北京嘀嘀无限科技发展有限公司 | Voice recognition method and device, electronic equipment and storage medium |
| CN112017642A (en) * | 2019-05-31 | 2020-12-01 | 华为技术有限公司 | Method, device and equipment for speech recognition and computer readable storage medium |
| CN112435664A (en) * | 2020-11-11 | 2021-03-02 | 郑州捷安高科股份有限公司 | Evaluation system and method based on voice recognition and electronic equipment |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116092342A (en) * | 2022-11-18 | 2023-05-09 | 四川大学 | A method and system for automatic response and quality assessment of controller simulation training |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114882886B (en) | 2024-10-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114547329B (en) | Method for establishing pre-trained language model, semantic parsing method and device | |
| US11380327B2 (en) | Speech communication system and method with human-machine coordination | |
| CN113361266B (en) | Text error correction method, electronic device and storage medium | |
| US10418032B1 (en) | System and methods for a virtual assistant to manage and use context in a natural language dialog | |
| CN114547274B (en) | Multi-turn question and answer method, device and equipment | |
| US7636657B2 (en) | Method and apparatus for automatic grammar generation from data entries | |
| CN111177324B (en) | Method and device for intent classification based on speech recognition results | |
| CA2437620C (en) | Hierarchichal language models | |
| JP4105841B2 (en) | Speech recognition method, speech recognition apparatus, computer system, and storage medium | |
| CN114120985B (en) | Soothing interaction method, system, device and storage medium for intelligent voice terminal | |
| CN116450799B (en) | Intelligent dialogue method and equipment applied to traffic management service | |
| CN114333838A (en) | Method and system for correcting voice recognition text | |
| WO2025000835A1 (en) | Instruction execution method and apparatus based on language model, and storage medium | |
| CN116092342A (en) | A method and system for automatic response and quality assessment of controller simulation training | |
| CN118968978A (en) | A human-computer interaction method, device and electronic device based on semantic analysis | |
| CN112148845A (en) | Method and device for inputting verbal resources of robot, electronic equipment and storage medium | |
| JP2004094257A (en) | Method and apparatus for generating question of decision tree for speech processing | |
| CN114882886A (en) | CTC simulation training voice recognition processing method, storage medium and electronic equipment | |
| CN115620732A (en) | A human-computer interaction method, system, electronic device, storage medium and vehicle | |
| CN114547068A (en) | Data generation method, device, equipment and computer readable storage medium | |
| HK40070308A (en) | Ctc simulation training speech recognition processing method, storage medium and electronic equipment | |
| CN113591441B (en) | Voice editing method and device, storage medium and electronic device | |
| CN114218424B (en) | Voice interaction method and system for tone word insertion based on wav2vec | |
| HK40070308B (en) | Ctc simulation training speech recognition processing method, storage medium and electronic equipment | |
| Komatani et al. | Efficient dialogue strategy to find users’ intended items from information query results |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 40070308 Country of ref document: HK |
|
| GR01 | Patent grant | ||
| GR01 | Patent grant |