CN114882409A - Intelligent violent behavior detection method and device based on multi-mode feature fusion - Google Patents
Intelligent violent behavior detection method and device based on multi-mode feature fusion Download PDFInfo
- Publication number
- CN114882409A CN114882409A CN202210509347.3A CN202210509347A CN114882409A CN 114882409 A CN114882409 A CN 114882409A CN 202210509347 A CN202210509347 A CN 202210509347A CN 114882409 A CN114882409 A CN 114882409A
- Authority
- CN
- China
- Prior art keywords
- fusion
- feature
- modal
- voice
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/41—Higher-level, semantic clustering, classification or understanding of video scenes, e.g. detection, labelling or Markovian modelling of sport events or news items
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/80—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level
- G06V10/806—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level of extracted features
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/46—Extracting features or characteristics from the video content, e.g. video fingerprints, representative shots or key frames
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Computing Systems (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Biophysics (AREA)
- Mathematical Physics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Multimedia (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Probability & Statistics with Applications (AREA)
- Image Analysis (AREA)
Abstract
Description
技术领域technical field
本发明属于视频内容分析技术领域,具体涉及一种基于多模态特征融合的智能暴力行为检测方法及装置。The invention belongs to the technical field of video content analysis, and in particular relates to an intelligent violent behavior detection method and device based on multimodal feature fusion.
背景技术Background technique
近年来,随着互联网技术的不断发展,加上视频大数据技术的助力,各种各样的视频开始出现在日常工作以及生活,从而导致视频数量呈现指数级式增长。在为人们带来极大的便利,促进了社会的发展的同时,这些视频中也充斥着大量暴力、低俗、恐怖内容,给不成熟的未成年身心成长造成了不良影响。目前,如何高效准确地识别出这些不良元素,保护未成年人的身心健康,成为了一个刻不容缓的问题。另外,要找出海量视频中包含的不良元素,仅靠传统的人力内容审查方式,显然是非常耗时耗力的。因此,以检测特定视频内容为功能的智能分析系统应运而生,聚焦研究视频暴力行为自动检测技术,该技术不仅可以用于互联网视频内容审查,也可以应用于智能安防中敏感场所的视频监控。In recent years, with the continuous development of Internet technology and the help of video big data technology, various videos have begun to appear in daily work and life, resulting in an exponential increase in the number of videos. While bringing great convenience to people and promoting the development of society, these videos are also filled with a lot of violent, vulgar, and terrifying content, which has adversely affected the physical and mental growth of immature minors. At present, how to efficiently and accurately identify these undesirable elements and protect the physical and mental health of minors has become an urgent issue. In addition, it is obviously very time-consuming and labor-intensive to find out the bad elements contained in the massive videos, only relying on the traditional human content review method. Therefore, an intelligent analysis system with the function of detecting specific video content came into being, focusing on the automatic detection technology of video violence, which can be used not only for Internet video content review, but also for video surveillance in sensitive places in intelligent security.
到目前为止,视频暴力行为检测方法还依赖于处理单一的模式,即音频或视频。虽然最近的研究已经考虑了多模式的方法,但大部分研究仅通过在特征级别上简单融合视频和音频情感信息,忽略了不同模式之间的交互信息,以及单一模式的优势。在大多数情况下,视觉信息作为直观信号,可以准确地识别和定位事件,但是在大部分场景下,音频信号可以区分视觉上地模糊事件。因此,这些说明了开发一个多模态方法的重要性和可行性。通过研究一个多模态视频暴力行为检测方法,可以应付多变的复杂环境,提升暴力行为检测方法地泛化能力和平均检测精度。So far, video violence detection methods have relied on processing a single modality, either audio or video. Although recent studies have considered multimodal approaches, most of them ignore the interaction information between different modalities and the advantages of a single modality by simply fusing video and audio emotional information at the feature level. In most cases, visual information acts as an intuitive signal to accurately identify and localize events, but in most scenarios, audio signals can distinguish visually obscured events. Therefore, these illustrate the importance and feasibility of developing a multimodal approach. By studying a multi-modal video violent behavior detection method, it can cope with the changing and complex environment, and improve the generalization ability and average detection accuracy of the violent behavior detection method.
发明内容SUMMARY OF THE INVENTION
针对上述问题,本发明提出了一种基于多模态特征融合的智能暴力行为检测方法,装置及系统。In view of the above problems, the present invention proposes an intelligent violent behavior detection method, device and system based on multimodal feature fusion.
为了实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现,In order to achieve the above-mentioned technical purpose and achieve the above-mentioned technical effect, the present invention is achieved through the following technical solutions:
第一方面,本发明提供了一种基于多模态特征融合的智能暴力行为检测方法,包括:In a first aspect, the present invention provides an intelligent violent behavior detection method based on multimodal feature fusion, including:
获取待检测的图像特征数据、语音特征数据和光流特征数据;Obtain the image feature data, voice feature data and optical flow feature data to be detected;
将图像特征数据和语音特征数据进行跨模态融合,得到图像融合特征和第一语音融合特征;Perform cross-modal fusion of the image feature data and the voice feature data to obtain the image fusion feature and the first voice fusion feature;
将光流特征数据和语音特征数据进行跨模态融合,得到光流融合特征和第二语音融合特征;Perform cross-modal fusion of optical flow feature data and speech feature data to obtain optical flow fusion features and second speech fusion features;
将所述图像融合特征、第一语音融合特征和光流融合特征、第二语音融合特征输入预训练好的多模态融合的深度神经网络模型,得到输出的暴力行为检测结果;Inputting the image fusion feature, the first speech fusion feature, the optical flow fusion feature, and the second speech fusion feature into a pre-trained multimodal fusion deep neural network model to obtain an output violent behavior detection result;
其中,所述多模态融合深度神经网络模型的训练方法包括:利用带标签的图像特征数据、语音特征数据和光流特征数据对多模态融合深度神经网络模型进行训练,并通过最小化损失函数
在一些实施例中,所述获取待检测的图像特征数据,语音特征数据和光流特征数据包括:In some embodiments, the acquiring the image feature data to be detected, the voice feature data and the optical flow feature data include:
利用I3D网络作为图像数据的提取器,进行图像帧特征的提取,得到待检测的图像特征数据;Use the I3D network as an extractor of image data to extract image frame features to obtain image feature data to be detected;
利用VGGish网络作为语音数据的提取器,进行语音数据特征提取,得到待检测的语音特征数据;Use the VGGish network as the extractor of the voice data to extract the features of the voice data to obtain the voice feature data to be detected;
利用I3D网络作为光流数据的提取器,并使用TV-L1算法在GPU上计算光流图,得到待检测的光流特征数据。The I3D network is used as the optical flow data extractor, and the TV-L1 algorithm is used to calculate the optical flow graph on the GPU to obtain the optical flow feature data to be detected.
在一些实施例中,所述将图像特征数据和语音特征数据进行跨模态融合,包括:In some embodiments, the cross-modal fusion of the image feature data and the voice feature data includes:
将图像特征数据和语音特征数据进行拼接,得到融合特征;Splicing image feature data and voice feature data to obtain fusion features;
通过跨模态注意力机制层计算所述的融合特征的相关性,得到基于注意力机制的输出融合特征;By calculating the correlation of the fusion features across the modal attention mechanism layer, the output fusion features based on the attention mechanism are obtained;
将基于注意力机制的输出融合特征进行拆分,得到图像融合特征和第一语音融合特征。The output fusion feature based on the attention mechanism is split to obtain the image fusion feature and the first speech fusion feature.
在一些实施例中,所述将光流特征数据和语音特征数据进行跨模态融合,包括:In some embodiments, the cross-modal fusion of optical flow feature data and speech feature data includes:
将光流特征数据和语音特征数据进行拼接,得到融合特征;Splicing optical flow feature data and speech feature data to obtain fusion features;
通过跨模态注意力机制层计算所述的融合特征的相关性,得到基于注意力机制的输出融合特征;By calculating the correlation of the fusion features across the modal attention mechanism layer, the output fusion features based on the attention mechanism are obtained;
将基于注意力机制的输出融合特征进行拆分,得到光流融合特征和第二语音融合特征。The output fusion features based on the attention mechanism are split to obtain optical flow fusion features and second speech fusion features.
在一些实施例中,所述多模态融合深度神经网络模型包括顺次相连的3个多模态融合模块和全连接层;所述多模态融合层包括跨模态模块、双向长短期记忆递归神经网络层和池化层;所述跨模态模块包括跨模态注意力层和图卷积层;所述跨模态注意力层包括顺次相连的线性层、Softmax层、归一化层和线性层。In some embodiments, the multi-modal fusion deep neural network model includes three multi-modal fusion modules connected in sequence and a fully connected layer; the multi-modal fusion layer includes cross-modal modules, bidirectional long short-term memory A recurrent neural network layer and a pooling layer; the cross-modality module includes a cross-modal attention layer and a graph convolutional layer; the cross-modal attention layer includes sequentially connected linear layers, Softmax layers, normalization layers layers and linear layers.
在一些实施例中,所述跨模态模块表示为:In some embodiments, the cross-modal module is represented as:

Mi=Linear(Mq)M i =Linear(M q )
Ms=Softmax(Mi,dim=1)M s =Softmax(M i , dim=1)
Mn=Norm(Ms,dim=2)M n =Norm(M s , dim=2)
Out=Linear(Mn)Out=Linear(M n )
Out′=GCN(Out)Out'=GCN(Out)
Out1,Out2=Split(Out′)Out 1 , Out 2 =Split(Out')
其中,M1和M2分别表示跨模态模块的两个输入的特征向量,
在一些实施例中,损失函数

其中,yi是真实暴力事件的离散分布,y′i是所述多模态特征融合模型的输出视频标签预测值的离散分布,N是输入样本的数量。Among them, yi is the discrete distribution of real violent events, y′ i is the discrete distribution of the predicted value of the output video tag of the multimodal feature fusion model, and N is the number of input samples.
第二方面,本发明提供了一种基于多模态特征融合的智能暴力行为检测装置,包括:In a second aspect, the present invention provides an intelligent violent behavior detection device based on multimodal feature fusion, including:
数据预处理模块,用于获取待检测的图像特征数据,语音特征数据和光流特征数据;The data preprocessing module is used to obtain the image feature data, voice feature data and optical flow feature data to be detected;
特征融合模块,用于将图像特征数据和语音特征数据进行跨模态融合,以及将光流特征数据和语音特征数据进行跨模态融合获取图像融合特征、第一语音融合特征和光流融合特征、第二语音融合特征;The feature fusion module is used for cross-modal fusion of image feature data and voice feature data, and cross-modal fusion of optical flow feature data and voice feature data to obtain image fusion features, first voice fusion features and optical flow fusion features, The second speech fusion feature;
暴力行为检测模块,用于将所述图像融合特征、第一语音融合特征和光流融合特征、第二语音融合特征输入预训练好的多模态融合的深度神经网络模型,得到输出的暴力行为检测结果。The violent behavior detection module is used to input the image fusion feature, the first speech fusion feature, the optical flow fusion feature, and the second speech fusion feature into the pre-trained multimodal fusion deep neural network model, and obtain the output violent behavior detection result.
第三方面,本发明提供了一种基于多模态特征融合的智能暴力行为检测系统,包括:存储介质和处理器;In a third aspect, the present invention provides an intelligent violent behavior detection system based on multimodal feature fusion, including: a storage medium and a processor;
所述存储介质用于存储指令;the storage medium is used for storing instructions;
所述处理器用于根据所述指令进行操作以执行第一方面中任一项所述方法的步骤。The processor is configured to operate in accordance with the instructions to perform the steps of the method of any one of the first aspects.
第四方面,提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述方法的步骤。In a fourth aspect, a storage medium is provided on which a computer program is stored, and when the computer program is executed by a processor, the steps of the method in the first aspect are implemented.
与现有技术相比,本发明的有益效果:Compared with the prior art, the beneficial effects of the present invention:
本发明提出了一种基于多模态特征融合的智能暴力行为检测方法,并提出了用于联合优化多模态融合和暴力行为检测的多模态融合深度神经网络模型,这为传统的多模态暴力行为检测方法提供了显著改进,本发明能够有效的提取暴力行为事件中的音频、光流和图像帧信息。本法发明利用跨模态模块组合不同地模态特征,建模不同模态之间地关系,以生成区分力更强的视频特征。本发明有效地将图像特征数据,语音特征数据以及光流特征数据进行跨模态融合,同时保留独立的单模态信息,形成了语音融合特征,视觉融合特征,光流融合特征,通过三个融合特征进行视频暴力事件检测,提高了暴力行为检测的平均准确率。The invention proposes an intelligent violent behavior detection method based on multimodal feature fusion, and proposes a multimodal fusion deep neural network model for jointly optimizing multimodal fusion and violent behavior detection, which is the traditional multimodal fusion. The state violent behavior detection method provides significant improvement, and the present invention can effectively extract audio, optical flow and image frame information in violent behavior events. The method of the invention utilizes cross-modal modules to combine different modal features to model the relationship between different modalities, so as to generate video features with stronger discrimination. The present invention effectively fuses image feature data, voice feature data and optical flow feature data across modalities, while retaining independent single-modality information, forming a voice fusion feature, a visual fusion feature, and an optical flow fusion feature. Fusion features are used for video violent event detection, which improves the average accuracy of violent behavior detection.
附图说明Description of drawings
为了使本发明的内容更容易被清楚地理解,下面根据具体实施例并结合附图,对本发明作进一步详细的说明,其中:In order to make the content of the present invention easier to be understood clearly, the present invention will be described in further detail below according to specific embodiments and in conjunction with the accompanying drawings, wherein:
图1是本发明的一种基于多模态特征融合的智能暴力行为检测方法的流程图;Fig. 1 is a kind of flow chart of the intelligent violent behavior detection method based on multimodal feature fusion of the present invention;
图2是本发明的一种基于多模态特征融合的智能暴力行为检测方法的框架图;2 is a frame diagram of a method for detecting intelligent violent behavior based on multimodal feature fusion of the present invention;
图3是本发明的一种基于多模态特征融合的智能暴力行为检测方法所用的跨模态模型示意图。FIG. 3 is a schematic diagram of a cross-modal model used in a method for detecting intelligent violent behavior based on multi-modal feature fusion of the present invention.
具体实施方式Detailed ways
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明的保护范围。In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the embodiments. It should be understood that the specific embodiments described herein are only used to explain the present invention, and are not used to limit the protection scope of the present invention.
下面结合附图对本发明的应用原理作详细的描述。The application principle of the present invention will be described in detail below with reference to the accompanying drawings.
在本发明的描述中,若干的含义是一个以上,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。In the description of the present invention, the meaning of several means one or more, the meaning of multiple means two or more, greater than, less than, exceeding, etc. are understood as not including this number, above, below, within, etc. are understood as including this number. If it is described that the first and the second are only for the purpose of distinguishing technical features, it cannot be understood as indicating or implying relative importance, or indicating the number of the indicated technical features or the order of the indicated technical features. relation.
本发明的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。In the description of the present invention, reference to the terms "one embodiment," "some embodiments," "exemplary embodiment," "example," "specific example," or "some examples" or the like is meant to be used in conjunction with the embodiment. A particular feature, structure, material or characteristic described or exemplified is included in at least one embodiment or example of the present invention. In this specification, schematic representations of the above terms do not necessarily refer to the same embodiment or example. Furthermore, the particular features, structures, materials or characteristics described may be combined in any suitable manner in any one or more embodiments or examples.
实施例1Example 1
一种基于多模态特征融合的智能暴力行为检测方法,包括:An intelligent violent behavior detection method based on multimodal feature fusion, comprising:
获取待检测的图像特征数据、语音特征数据和光流特征数据;Obtain the image feature data, voice feature data and optical flow feature data to be detected;
将图像特征数据和语音特征数据进行跨模态融合,得到图像融合特征和第一语音融合特征;Perform cross-modal fusion of the image feature data and the voice feature data to obtain the image fusion feature and the first voice fusion feature;
将光流特征数据和语音特征数据进行跨模态融合,得到光流融合特征和第二语音融合特征;Perform cross-modal fusion of optical flow feature data and speech feature data to obtain optical flow fusion features and second speech fusion features;
将所述图像融合特征、第一语音融合特征和光流融合特征、第二语音融合特征输入预训练好的多模态融合的深度神经网络模型,得到输出的暴力行为检测结果;Inputting the image fusion feature, the first speech fusion feature, the optical flow fusion feature, and the second speech fusion feature into a pre-trained multimodal fusion deep neural network model to obtain an output violent behavior detection result;
其中,所述多模态融合深度神经网络模型的训练方法包括:利用带标签的图像特征数据、语音特征数据和光流特征数据对多模态融合深度神经网络模型进行训练,并通过最小化损失函数
本发明实施例中提供了一种基于多模态特征融合的智能暴力行为检测方法,如图2所示,具体包括以下步骤:An embodiment of the present invention provides an intelligent violent behavior detection method based on multimodal feature fusion, as shown in FIG. 2 , which specifically includes the following steps:
步骤1:获取待检测的图像特征数据,语音特征数据和光流特征数据,具体描述如下:Step 1: Obtain the image feature data, voice feature data and optical flow feature data to be detected, which are specifically described as follows:
我们将多模态数据样本和相应的标签定义为I=(V,A,O)和y,其中V是未修剪图像帧,A是语音,O是光流,y∈{0,1},y=1表示I涵盖暴力事件。We define multimodal data samples and corresponding labels as I = (V, A, O) and y, where V is the untrimmed image frame, A is speech, O is optical flow, y ∈ {0, 1}, y=1 means I covers violent events.
步骤1.1:利用I3D网络作为图像帧数据V的提取器FV,进行图像帧特征的提取,得到待检测的图像特征数据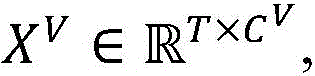
步骤1.2:利用VGGish网络作为语音数据A的提取器FA,进行语音数据特征提取,得到待检测的语音特征数据
步骤1.3:利用I3D网络作为光流数据O的提取器FO,并使用TV-L1算法在GPU上计算光流图,得到待检测的光流特征数据
步骤2:将所述图像特征数据XV和语音特征数据XA进行跨模态融合,如图3所示,具体描述如下:Step 2: Perform cross-modal fusion of the image feature data X V and the voice feature data X A , as shown in Figure 3, and the specific description is as follows:
步骤2.1:将图像特征数据XV和语音特征数据XA进行拼接,获得融合数据
步骤2.2:通过跨模态注意力机制层计算所述的融合数据的相关性,获得基于注意力机制的输出融合特征
步骤2.3:将基于注意力机制的输出融合特征XM进行拆分,获取图像融合特征

步骤3:将所述光流特征数据XO和语音特征数据XA进行跨模态融合,如图3所示,具体描述如下:Step 3: Perform cross-modal fusion of the optical flow feature data X O and the voice feature data X A , as shown in Figure 3, and the specific description is as follows:
步骤3.1:将光流特征数据XO和语音特征数据XA进行拼接,获得融合数据
步骤3.2:通过跨模态注意力机制层计算所述的融合数据的相关性,获得基于注意力机制的输出融合特征
步骤3.3:将基于注意力机制的输出融合特征XM进行拆分,获取光流融合特征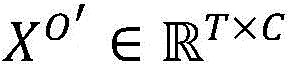

步骤4:构建多模态融合深度神经网络模型,如图2所示,包括顺次相连的3个多模态融合模块(MFB)和全连接层(FC),其中3个多模态融合块的输出通道参数分别设置为:128,64,32。对于每一个多模态融合模块又包含多个跨模态模块、双向长短期记忆递归神经网络层(BiGRU)和池化层(Pool)。如图3所示,对于每个跨模态模块又包括跨模态注意力层(Cross-Modal Attention)和图卷积层(GCN)。所述跨模态注意力层包括顺次相连的线性层(Linear),Softmax层,归一化层(Norm)和线性层(Linear)。对于跨模态模块接受两个输入:特征图


Mi=Linear(Mq) (2)M i =Linear(M q ) (2)
Ms=Softmax(Mi,dim=1) (3)M s =Softmax(M i , dim=1) (3)
Mn=Norm(Ms,dim=2) (4)M n =Norm(M s , dim=2) (4)
Out=Linear(Mn) (5)Out=Linear(M n ) (5)
Out′=GCN(Out) (6)Out′=GCN(Out) (6)
Out1,Out2=Split(Out′) (7)Out 1 , Out 2 =Split(Out') (7)
其中,M1和M2分别表示跨模态模块的两个输入的特征向量,
假定图卷积层(GCN)有l个输出通道和k个输入通道,于是需要利用kl卷积操作实现通道数目的转换,则图卷积运算公式为:Assuming that the graph convolution layer (GCN) has l output channels and k input channels, so the kl convolution operation needs to be used to convert the number of channels, the graph convolution operation formula is:

其中



因为normalized Gaussian和softmax操作是等价的,所以公式(9)等同与公式(10):Since the normalized Gaussian and softmax operations are equivalent, equation (9) is equivalent to equation (10):

其中Aij表示节点vi和节点vj之间的相关性。where A ij represents the correlation between node v i and node v j .
在每个图卷积操作之后,都有Relu的附加操作,其目的是在图卷积中加入非线性,因为使用图卷积来解决的现实世界的问题都是非线性的,而卷积运算是线性运算,所以必须使用一个如ReLU的激活函数来加入非线性的性质。After each graph convolution operation, there is an additional operation of Relu, whose purpose is to add nonlinearity to the graph convolution, because the real-world problems solved by using graph convolution are nonlinear, and the convolution operation is Linear operation, so an activation function such as ReLU must be used to add nonlinear properties.
BiGRU层:在BiGRU层中采用双向长短期记忆递归神经网络层(BiGRU)从全局的角度对暴力视频时序信息进行提取,公式化函数为:X=BiGRU(x)。其中x为BiGRU层的输入向量,X为输出向量,作为下一层的输入。BiGRU layer: In the BiGRU layer, a bidirectional long short-term memory recurrent neural network layer (BiGRU) is used to extract the timing information of violent videos from a global perspective. The formula function is: X=BiGRU(x). where x is the input vector of the BiGRU layer, and X is the output vector, which is used as the input of the next layer.
池化层(Pool):对输入的特征图进行压缩,一方面使其特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征。池化层(Pool)可以在保持最重要的信息的同时降低特征图的维度。Pooling layer (Pool): Compress the input feature map, on the one hand, make the feature map smaller and simplify the network computational complexity; on the other hand, perform feature compression to extract the main features. Pooling layers (Pool) can reduce the dimensionality of feature maps while maintaining the most important information.
步骤5,所述的多模态融合深度神经网络模型的训练方法,具体步骤如下:Step 5, the training method of the multimodal fusion deep neural network model, the specific steps are as follows:
步骤5.1,随机初始化所有多模态融合深度神经网络模型的参数和权重值;Step 5.1, randomly initialize the parameters and weights of all multimodal fusion deep neural network models;
步骤5.2,将带标签的图像特征数据,语音特征数据和光流特征数据作为多模态融合的深度神经网络模型的输入,经过前向传播步骤,最后达到全连接层FC进行检测,得到暴力行为检测结果,也就是输出一个包含预测的概率值的向量。由于权重是随机分配给第一个训练样例的,因此输出概率也是随机的;Step 5.2, take the labeled image feature data, speech feature data and optical flow feature data as the input of the multi-modal fusion deep neural network model, go through the forward propagation step, and finally reach the fully connected layer FC for detection, and obtain the violent behavior detection. As a result, a vector containing the predicted probability values is output. Since the weights are randomly assigned to the first training example, the output probabilities are also random;
步骤5.3,计算全连接层FC的损失函数

其中,yi是真实暴力事件的离散分布。y′i是所述多模态特征融合模型的输出视频标签预测值的离散分布,N是输入样本的数量。

步骤5.4,使用反向传播计算网络中所有权重的误差梯度。并使用梯度下降更新所有滤波器值、权重和参数值,以最大限度地减少输出损失,也就是损失函数的值尽量降低。权重根据它们对损失的贡献进行调整。当再次输入相同的骨架数据时,输出概率可能更接近目标矢量。这意味着网络已经学会了通过调整其权重和滤波器来正确分类该特定骨架,从而减少输出损失。滤波器数量,滤波器大小,网络结构等参数在步骤5.1之前都已经固定,并且在训练过程中不会改变,只更新滤波器矩阵和连接权值。Step 5.4, compute the error gradient for all weights in the network using backpropagation. And use gradient descent to update all filter values, weights and parameter values to minimize the output loss, that is the value of the loss function as low as possible. The weights are adjusted according to their contribution to the loss. When the same skeleton data is input again, the output probability may be closer to the target vector. This means that the network has learned to correctly classify that particular skeleton by adjusting its weights and filters, reducing the output loss. Parameters such as the number of filters, filter size, and network structure are all fixed before step 5.1, and will not change during the training process, only the filter matrix and connection weights are updated.
步骤5.5,对训练集中的所有骨架数据重复步骤5.2-5.4,直到训练次数达到设定的迭代次数。完成上述步骤对训练集数据通过构建的时空注意力的卷积神经网络进行训练学习,这实际上意味着多模态融合深度神经网络模型的所有权重和参数都已经过优化,可正确检测暴力事件。Step 5.5, repeat steps 5.2-5.4 for all skeleton data in the training set, until the training times reach the set number of iterations. After completing the above steps, the training set data is trained and learned through the constructed spatiotemporal attention convolutional neural network, which actually means that all the weights and parameters of the multi-modal fusion deep neural network model have been optimized, which can correctly detect violent events .
步骤6,用已经训练完成的多模态融合深度神经网络模型对测试样本进行识别,并输出暴力行为检测的结果。Step 6, using the trained multimodal fusion deep neural network model to identify the test sample, and output the result of violent behavior detection.
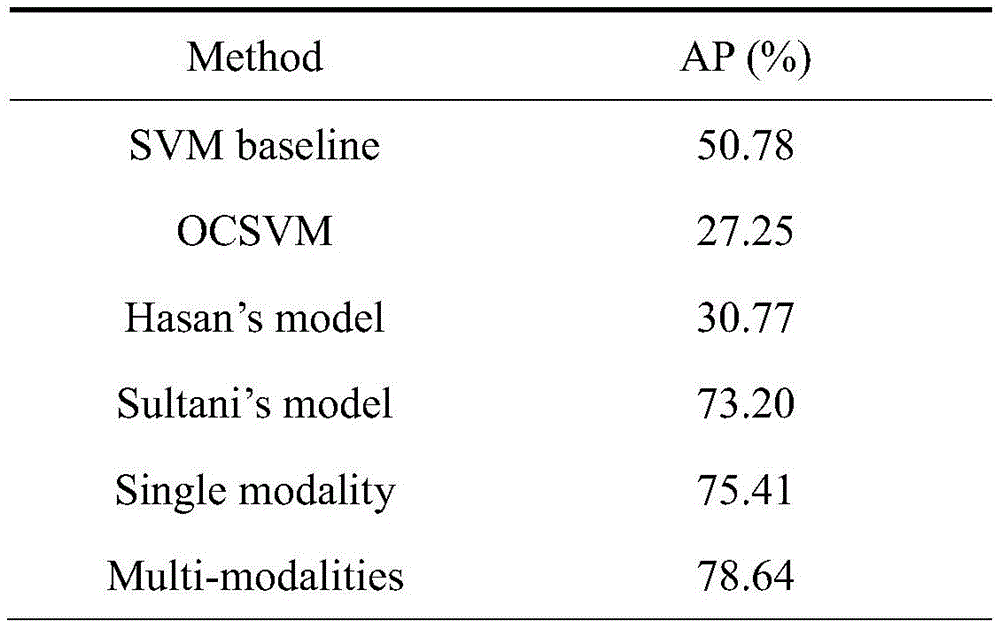
为了验证所述多模态融合深度神经网络模型的优势,本实验将其与公开的几个基线方法在XD-Violence多模态暴力检测数据集上进行实验,选择平均精度((AveragePrecision,AP)作为实验评估指标。In order to verify the advantages of the multimodal fusion deep neural network model, in this experiment, it and several publicly available baseline methods are tested on the XD-Violence multimodal violence detection dataset, and the average precision ((AveragePrecision, AP) as an experimental evaluation indicator.
表1展示了在XD-Violence数据集上,本实施例中提出的一种基于多模态特征融合的智能暴力行为检测方法和其他基线方法的比较结果,在这里多模态融合深度神经网络模型,记为Ours。本实施例中提出的一种基于多模态特征融合的智能暴力行为检测方法,它将两个阶段(多模态建模和检测网络)连接在一起并共同优化它们,生成区分力更强的视频特征,使用基于注意力机制的特征融合模块,交互式地学习了不同的模态融合特征,因此获得了更好的实验结果。Table 1 shows the comparison results of a multi-modal feature fusion-based intelligent violent behavior detection method proposed in this example and other baseline methods on the XD-Violence dataset, where the multi-modal fusion deep neural network model , denoted as Ours. An intelligent violent behavior detection method based on multi-modal feature fusion proposed in this embodiment connects two stages (multi-modal modeling and detection network) and jointly optimizes them to generate a more discriminative Video features, using the attention mechanism-based feature fusion module, interactively learns different modal fusion features, thus obtaining better experimental results.
表1本发明方法和其它公开方法在XD-Violence数据集上的识别结果Table 1 The recognition results of the method of the present invention and other disclosed methods on the XD-Violence dataset

需要说明的是,对于方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明实施例并不受所描述的动作顺序的限制,因为依据本发明实施例,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作并不一定是本发明实施例所必须的。It should be noted that, for the sake of simple description, the method embodiments are described as a series of action combinations, but those skilled in the art should know that the embodiments of the present invention are not limited by the described action sequences, because According to embodiments of the present invention, certain steps may be performed in other sequences or simultaneously. Secondly, those skilled in the art should also know that the embodiments described in the specification are all preferred embodiments, and the actions involved are not necessarily required by the embodiments of the present invention.
实施例2Example 2
对于本发明实施例中提供了一种基于多模态特征融合的智能暴力行为检测装置,包括以下模块:For the embodiment of the present invention, an intelligent violent behavior detection device based on multimodal feature fusion is provided, including the following modules:
数据预处理模块,用于获取待检测的图像特征数据,语音特征数据和光流特征数据;The data preprocessing module is used to obtain the image feature data, voice feature data and optical flow feature data to be detected;
特征融合模块,用于将图像特征数据和语音特征数据进行跨模态融合,以及将光流特征数据和语音特征数据进行跨模态融合获取图像融合特征、第一语音融合特征和光流融合特征、第二语音融合特征;The feature fusion module is used for cross-modal fusion of image feature data and voice feature data, and cross-modal fusion of optical flow feature data and voice feature data to obtain image fusion features, first voice fusion features and optical flow fusion features, The second speech fusion feature;
暴力行为检测模块,用于将所述图像融合特征、第一语音融合特征和光流融合特征、第二语音融合特征输入预训练好的多模态融合的深度神经网络模型,得到输出的暴力行为检测结果。The violent behavior detection module is used to input the image fusion feature, the first speech fusion feature, the optical flow fusion feature, and the second speech fusion feature into the pre-trained multimodal fusion deep neural network model, and obtain the output violent behavior detection result.
实施例3Example 3
基于与实施例1相同的发明构思,本发明实施例中提供了一种基于多模态特征融合的智能暴力行为检测装置,包括:存储介质和处理器;Based on the same inventive concept as
所述存储介质用于存储指令;the storage medium is used for storing instructions;
所述处理器用于根据所述指令进行操作以执行第一方面中所述方法的步骤。The processor is configured to operate in accordance with the instructions to perform the steps of the method of the first aspect.
实施例4Example 4
一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述方法的步骤。A storage medium having a computer program stored thereon, the computer program implementing the steps of the method of the first aspect when executed by a processor.
综上所述,本发明提出的一种基于多模态特征融合的智能暴力行为检测方法,解决了视频暴力行为检测过程中多模态数据的融合问题,通过深度学习技术提取音频、光流和图像帧特征,然后,构建多模态融合的深度神经网络模型,从中计算多模态融合特征和单模态特征。该方法可以融合视频中的多种模态,提高暴力检测的准确性,准确率高达80.59%。To sum up, an intelligent violent behavior detection method based on multi-modal feature fusion proposed by the present invention solves the problem of multi-modal data fusion in the process of video violent behavior detection, and extracts audio, optical flow and Image frame features, and then, a multimodal fusion deep neural network model is constructed, from which multimodal fusion features and single-modality features are calculated. The method can fuse multiple modalities in the video and improve the accuracy of violence detection, with an accuracy rate of up to 80.59%.
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。As will be appreciated by those skilled in the art, the embodiments of the present application may be provided as a method, a system, or a computer program product. Accordingly, the present application may take the form of an entirely hardware embodiment, an entirely software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present application may take the form of a computer program product embodied on one or more computer-usable storage media (including, but not limited to, disk storage, CD-ROM, optical storage, etc.) having computer-usable program code embodied therein.
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present application is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the present application. It will be understood that each flow and/or block in the flowchart illustrations and/or block diagrams, and combinations of flows and/or blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to the processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing device to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing device produce Means for implementing the functions specified in a flow or flow of a flowchart and/or a block or blocks of a block diagram.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory result in an article of manufacture comprising instruction means, the instructions The apparatus implements the functions specified in the flow or flow of the flowcharts and/or the block or blocks of the block diagrams.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded on a computer or other programmable data processing device to cause a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process such that The instructions provide steps for implementing the functions specified in the flow or blocks of the flowcharts and/or the block or blocks of the block diagrams.
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。The basic principles and main features of the present invention and the advantages of the present invention have been shown and described above. Those skilled in the art should understand that the present invention is not limited by the above-mentioned embodiments, and the descriptions in the above-mentioned embodiments and the description are only to illustrate the principle of the present invention. Without departing from the spirit and scope of the present invention, the present invention will have Various changes and modifications fall within the scope of the claimed invention. The claimed scope of the present invention is defined by the appended claims and their equivalents.
Claims (10)





Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210509347.3A CN114882409B (en) | 2022-05-11 | 2022-05-11 | An intelligent violent behavior detection method and device based on multimodal feature fusion |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210509347.3A CN114882409B (en) | 2022-05-11 | 2022-05-11 | An intelligent violent behavior detection method and device based on multimodal feature fusion |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114882409A true CN114882409A (en) | 2022-08-09 |
| CN114882409B CN114882409B (en) | 2025-02-14 |
Family
ID=82675377
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210509347.3A Active CN114882409B (en) | 2022-05-11 | 2022-05-11 | An intelligent violent behavior detection method and device based on multimodal feature fusion |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114882409B (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115861878A (en) * | 2022-11-24 | 2023-03-28 | 松立控股集团股份有限公司 | Anomaly event detection method for panoramic security monitoring city based on iterative refinement |
| CN116883894A (en) * | 2023-06-29 | 2023-10-13 | 南湖实验室 | Video violence behavior detection method, system and equipment for multi-mode information fusion |
| CN117237259A (en) * | 2023-11-14 | 2023-12-15 | 华侨大学 | Compressed video quality enhancement method and device based on multi-modal fusion |
| CN120234654A (en) * | 2025-05-29 | 2025-07-01 | 中天智领(北京)科技有限公司 | Spatial interaction accurate recognition method and system based on multimodal fusion |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108899050A (en) * | 2018-06-14 | 2018-11-27 | 南京云思创智信息科技有限公司 | Speech signal analysis subsystem based on multi-modal Emotion identification system |
| CN110647804A (en) * | 2019-08-09 | 2020-01-03 | 中国传媒大学 | Violent video identification method, computer system and storage medium |
| WO2021184026A1 (en) * | 2021-04-08 | 2021-09-16 | Innopeak Technology, Inc. | Audio-visual fusion with cross-modal attention for video action recognition |
-
2022
- 2022-05-11 CN CN202210509347.3A patent/CN114882409B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108899050A (en) * | 2018-06-14 | 2018-11-27 | 南京云思创智信息科技有限公司 | Speech signal analysis subsystem based on multi-modal Emotion identification system |
| CN110647804A (en) * | 2019-08-09 | 2020-01-03 | 中国传媒大学 | Violent video identification method, computer system and storage medium |
| WO2021184026A1 (en) * | 2021-04-08 | 2021-09-16 | Innopeak Technology, Inc. | Audio-visual fusion with cross-modal attention for video action recognition |
Non-Patent Citations (1)
| Title |
|---|
| 吴晓雨等: "多模态特征融合与多任务学习的特种视频分类", 光学精密工程, no. 05, 13 May 2020 (2020-05-13) * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115861878A (en) * | 2022-11-24 | 2023-03-28 | 松立控股集团股份有限公司 | Anomaly event detection method for panoramic security monitoring city based on iterative refinement |
| CN116883894A (en) * | 2023-06-29 | 2023-10-13 | 南湖实验室 | Video violence behavior detection method, system and equipment for multi-mode information fusion |
| CN117237259A (en) * | 2023-11-14 | 2023-12-15 | 华侨大学 | Compressed video quality enhancement method and device based on multi-modal fusion |
| CN117237259B (en) * | 2023-11-14 | 2024-02-27 | 华侨大学 | Compressed video quality enhancement method and device based on multi-modal fusion |
| CN120234654A (en) * | 2025-05-29 | 2025-07-01 | 中天智领(北京)科技有限公司 | Spatial interaction accurate recognition method and system based on multimodal fusion |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114882409B (en) | 2025-02-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10650042B2 (en) | Image retrieval with deep local feature descriptors and attention-based keypoint descriptors | |
| CN115457395B (en) | Lightweight remote sensing target detection method based on channel attention and multi-scale feature fusion | |
| CN114882409A (en) | Intelligent violent behavior detection method and device based on multi-mode feature fusion | |
| CN104573669B (en) | Image object detection method | |
| CN110390340B (en) | Feature coding model, training method and detection method of visual relation detection model | |
| CN116933051A (en) | Multi-mode emotion recognition method and system for modal missing scene | |
| CN112966074A (en) | Emotion analysis method and device, electronic equipment and storage medium | |
| CN117036843B (en) | Target detection model training method, target detection method and device | |
| CN114140708A (en) | Video processing method, apparatus, and computer-readable storage medium | |
| CN116310850B (en) | Remote sensing image target detection method based on improved RetinaNet | |
| CN114511710A (en) | Image target detection method based on convolutional neural network | |
| CN115204301A (en) | Video text matching model training method and device and video text matching method and device | |
| CN114898339B (en) | Training method, device, equipment and storage medium of driving behavior prediction model | |
| CN117876299A (en) | Multi-mode industrial anomaly detection method and system based on teacher-student network architecture | |
| CN117217807B (en) | A non-performing asset valuation method based on multi-modal high-dimensional features | |
| CN120050096A (en) | Industrial Internet intrusion detection method based on diffusion model | |
| CN117292297B (en) | Video emotion description method based on hierarchical emotion feature coding | |
| CN119577651A (en) | Behavior detection method, device, system, computer equipment and storage medium | |
| CN119128676A (en) | A multimodal emotion recognition method and device | |
| CN111786999A (en) | An intrusion detection method, device, device and storage medium | |
| CN114529969B (en) | Expression recognition method and system | |
| CN117011219A (en) | Article quality testing methods, devices, equipment, storage media and program products | |
| CN117115886A (en) | Cross-scenario adaptation method and device for living body detection model | |
| CN113496231B (en) | Classification model training method, image classification method, device, equipment and medium | |
| CN120707974B (en) | An Unsupervised Persistent Anomaly Detection Method and System Based on Multimodal Cue Memory |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |