CN114818717A - Chinese named entity recognition method and system fusing vocabulary and syntax information - Google Patents
Chinese named entity recognition method and system fusing vocabulary and syntax information Download PDFInfo
- Publication number
- CN114818717A CN114818717A CN202210575509.3A CN202210575509A CN114818717A CN 114818717 A CN114818717 A CN 114818717A CN 202210575509 A CN202210575509 A CN 202210575509A CN 114818717 A CN114818717 A CN 114818717A
- Authority
- CN
- China
- Prior art keywords
- word
- vector
- information
- word set
- syntactic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/049—Temporal neural networks, e.g. delay elements, oscillating neurons or pulsed inputs
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Data Mining & Analysis (AREA)
- Biophysics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Machine Translation (AREA)
Abstract
本发明公开一种融合词汇和句法信息的中文命名实体识别方法及系统,包括以下步骤:步骤1、将原始输入文本映射为字向量,使用改进后的词集匹配算法引入外部词汇信息,并整合在每个字的输入表示中;步骤2、根据字的输入表示,利用双向LSTM抽取上下文信息;步骤3、使用NLP工具从原始输入文本中获取词性标签和句法成分,并且使用健值记忆网络构造句法向量,再通过门控机制对上下文向量与句法向量进行加权融合,获得特征向量;步骤4、将特征向量输入标签预测层的CRF中,实现中文命名实体识别。本发明能够解决中文命名实体中实体边界信息不足的问题和融合输入文本的句法信息。

The invention discloses a Chinese named entity recognition method and system integrating lexical and syntactic information. In the input representation of each word; step 2, according to the input representation of the word, use bidirectional LSTM to extract context information; step 3, use NLP tools to obtain part-of-speech tags and syntactic components from the original input text, and use the key value memory network to construct Syntax vector, and then weighted fusion of context vector and syntax vector through the gating mechanism to obtain feature vector; Step 4, input the feature vector into the CRF of the label prediction layer to realize Chinese named entity recognition. The invention can solve the problem of insufficient entity boundary information in Chinese named entities and fuse the syntactic information of the input text.
Description
技术领域technical field
本发明涉及自然语言处理的信息抽取领域,特别是指一种融合词汇和句法信息的中文命名实体识别方法及系统。The invention relates to the field of information extraction of natural language processing, in particular to a Chinese named entity recognition method and system integrating lexical and syntactic information.
背景技术Background technique
名实体识别(Named entity recognition,NER)旨在识别文本中的实体并将其分为不同的类别如:人名、地名、机构名等。NER是NLP中的一项重要任务,已广泛应用于关系抽取、问答、机器翻译、知识库构建等领域,因此NER的研究和突破具有十分重要的意义。Named entity recognition (NER) aims to identify entities in text and classify them into different categories such as person names, place names, institution names, etc. NER is an important task in NLP and has been widely used in relation extraction, question answering, machine translation, knowledge base construction and other fields. Therefore, the research and breakthrough of NER is of great significance.
而中文与英文的命名实体识别又有所不同,英文中每一个词都可以表达完整的语义信息;而在中文中,大多数情况只有一个词或短语才能表达完整的意思,且中文不存在明显的词汇边界符和首字母大写等特征,使得实体边界识别较为困难。但词语实体边界通常与实体边界相同,所以词语边界信息在中文命名实体识别(Chinese named entityrecognition,CNER)上起着重要作用。The named entity recognition in Chinese and English is different. Every word in English can express complete semantic information; while in Chinese, in most cases, only one word or phrase can express the complete meaning, and there is no obvious meaning in Chinese. The characteristics of lexical boundary characters and capitalization of the first letter make it difficult to identify the entity boundary. But word-entity boundaries are usually the same as entity boundaries, so word-boundary information plays an important role in Chinese named entity recognition (CNER).
面对词语边界识别困难的问题,可以通过引入外部特征来解决。在这些特征中,词汇信息和句法信息等都有重要的意义,能够帮助CNER模型找到对应的实体。现有CNER模型中使用外部特征时,极少进行区分和处理,而特征中的噪声可能会影响模型的性能。因此,寻找一种合适的方法将外部特征信息整合到CNER模型上仍然是一个难题。大多数情况下,人们希望CNER模型可以包含多种额外特征。因此,需要对设计一种有效的机制来对这些特征加权组合,限制噪声信息。Facing the difficulty of word boundary recognition, it can be solved by introducing external features. Among these features, lexical information and syntactic information have important meanings, which can help the CNER model to find the corresponding entities. When external features are used in existing CNER models, they are rarely differentiated and processed, and noise in the features may affect the performance of the model. Therefore, it is still a difficult problem to find a suitable method to integrate the external feature information into the CNER model. Most of the time, it is expected that the CNER model can contain multiple additional features. Therefore, it is necessary to design an effective mechanism to weight the combination of these features to limit the noise information.
同时,现有的SoftLexion词集匹配方法依赖于数据集中的静态词频统计,以词频来衡量不同词语对中文命名实体识别任务的作用。考虑到不同数据集规模大小不同,在小规模数据集上存在着词频过低的问题,词频在有些时候不能较好的反映出词语的重要性。因此,可以寻找一种较为合理的方法,来合理衡量词集中词语的权重。At the same time, the existing SoftLexion word set matching method relies on static word frequency statistics in the data set, and uses word frequency to measure the effect of different words on the Chinese named entity recognition task. Considering the different scales of different data sets, there is a problem of too low word frequency in small-scale data sets, and word frequency sometimes cannot reflect the importance of words well. Therefore, a more reasonable method can be found to reasonably measure the weight of the words in the vocabulary.
发明内容SUMMARY OF THE INVENTION
本发明的主要目的在于克服现有技术中的上述缺陷,提出一种融合词汇和句法信息的中文命名实体识别方法及系统,对词汇(lexical)、句法(Syntactic)信息进行融合(fusion)(简称为LSF-CNER模型),具体为将外部词汇信息和输入文本的句法信息使用门控单元进行融合,并且在模型中引入注意力机制,构建中文命名实体识别模型,有望提高中文命名实体识别的准确率。本发明主要解决的问题体现在以下两个方面:一方面,将输入文本序列的每个字进行改进后的词集匹配算法,将匹配完成后的静态词集向量和动态词集向量以及最初的字向量进行拼接,从而在字向量中融入外部词汇信息,可以解决中文文本词语边界特征不足的问题。另一方面,使用NLP工具抽取输入文本的句法信息,通过门控机制和双向LSTM抽取的上下文向量进行整合,丰富了特征向量的表示,融合了更深层次的句法信息。The main purpose of the present invention is to overcome the above-mentioned defects in the prior art, and to propose a method and system for Chinese named entity recognition that fuses lexical and syntactic information, and fuses lexical and syntactic information (abbreviated as “fusion”). It is the LSF-CNER model), which is to fuse the external vocabulary information and the syntactic information of the input text using the gating unit, and introduce an attention mechanism into the model to build a Chinese named entity recognition model, which is expected to improve the accuracy of Chinese named entity recognition. Rate. The problems mainly solved by the present invention are embodied in the following two aspects: on the one hand, each word of the input text sequence is subjected to an improved word set matching algorithm, and the static word set vector and dynamic word set vector after the matching is completed and the initial The word vector is spliced, so that the external vocabulary information is integrated into the word vector, which can solve the problem of insufficient boundary features of Chinese text words. On the other hand, NLP tools are used to extract the syntactic information of the input text, and the context vector extracted by the gating mechanism and the bidirectional LSTM is integrated, which enriches the representation of the feature vector and integrates deeper syntactic information.
本发明采用如下技术方案:The present invention adopts following technical scheme:
一方面,一种融合词汇和句法信息的中文命名实体识别方法,包括:On the one hand, a Chinese named entity recognition method integrating lexical and syntactic information, including:
步骤1、将原始输入文本映射为字向量,使用改进后的词集匹配算法引入外部词汇信息,并整合在每个字的输入表示中;Step 1. Map the original input text into word vectors, use the improved word set matching algorithm to introduce external vocabulary information, and integrate it into the input representation of each word;
步骤2、根据字的输入表示,利用双向LSTM抽取上下文信息;Step 2. According to the input representation of the word, use bidirectional LSTM to extract context information;
步骤3、使用NLP工具从原始输入文本中获取词性标签和句法成分,并且使用健值记忆网络构造句法向量,再通过门控机制对上下文向量与句法向量进行加权融合,获得特征向量;Step 3. Use NLP tools to obtain part-of-speech tags and syntactic components from the original input text, and use a key-value memory network to construct a syntactic vector, and then perform a weighted fusion of the context vector and the syntactic vector through a gating mechanism to obtain a feature vector;
步骤4、将特征向量输入标签预测层的CRF中,实现中文命名实体识别。
优选的,所述步骤1,具体包括:Preferably, the step 1 specifically includes:
步骤1.1,将输入的文本视为一个句子,用序列表示为x=(x1,x2,..,xn);其中,xi表示在长度为n的句子x中第i个字;为了更好的利用词汇信息,将每个字匹配字典的结果分为如下“BIES”四个词集:Step 1.1, treat the input text as a sentence, which is represented by a sequence as x=(x 1 , x 2 ,..,x n ); where x i represents the i-th word in the sentence x of length n; In order to make better use of vocabulary information, the results of each word matching dictionary are divided into the following four word sets "BIES":
(1)词集B(xi)包含所有在x上以xi开头的词语;(1) Word set B( xi ) contains all words starting with x i on x;
(2)词集I(xi)包含所有在x上xi为中间的词语;(2) The word set I(x i ) contains all words with xi being the middle on x;
(3)词集E(xi)包含所有在x以xi为结尾的词语;(3) The word set E(x i ) contains all words ending in x i in x;
(4)词集S(xi)包含所有xi为单字的词语;(4) The word set S(x i ) contains all words whose xi is a single character;
步骤1.2,得到每个字对应的“BIES”词集后,将每个词集压缩为一个固定维数的向量;改进的词集匹配算法包含静态词集算法和动态词集算法,静态词集算法为了保证计算效率,使用词语出现的频率来代表对应的权重,单个词集的静态词集向量计算方法如下:Step 1.2, after obtaining the "BIES" word set corresponding to each word, compress each word set into a fixed-dimensional vector; the improved word set matching algorithm includes static word set algorithm and dynamic word set algorithm, static word set In order to ensure the calculation efficiency, the algorithm uses the frequency of word occurrence to represent the corresponding weight. The calculation method of the static word set vector for a single word set is as follows:
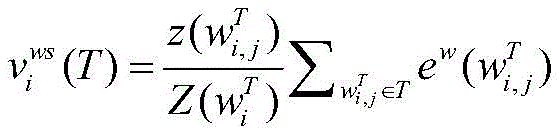
其中,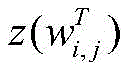





为了更好的保留信息,将四个静态词集表示为一个整体,通过拼接整合成一个固定维度的向量:In order to better retain the information, the four static word sets are represented as a whole and integrated into a fixed-dimensional vector by splicing:

其中,τi表示字xi对应的静态词集向量;Among them, τ i represents the static word set vector corresponding to the word xi ;
动态词集算法使用注意力机制来衡量字符和匹配词之间的信息,计算不同匹配词的注意力权重,增强有用的词汇并抑制作用不明显的词汇,如下:The dynamic word set algorithm uses the attention mechanism to measure the information between characters and matching words, calculates the attention weight of different matching words, enhances useful words and suppresses insignificant words, as follows:
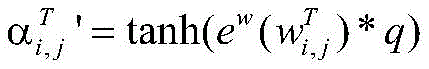
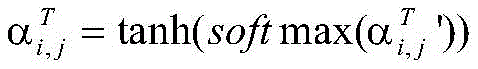
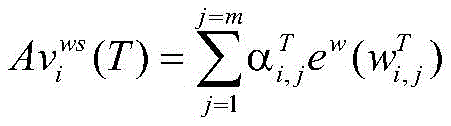
其中,
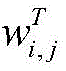


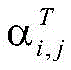

通过注意力权重进行加权求和得到动态词集向量,将四个动态词集表示为一个整体并压缩为一个固定维度的向量:The dynamic word set vector is obtained by the weighted summation of the attention weight, and the four dynamic word sets are represented as a whole and compressed into a fixed-dimensional vector:

其中,Aτi表示为字xi对应的动态词集向量;Among them, Aτ i is represented as the dynamic word set vector corresponding to the word x i ;
步骤1.3,为了充分考虑两个词集中每个词语的重要性,对对动态词集向量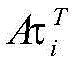




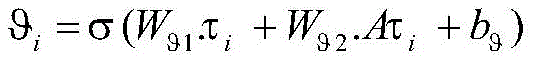
其中,

将字向量、静态词集向量τi和动态词集向量Aτi组合在一起,作为最终包含外部词汇信息的输入表示:The word vector, the static word set vector τ i and the dynamic word set vector Aτ i are combined together as the final input representation containing the external vocabulary information:

其中,


优选的,所述步骤2,具体包括:Preferably, the step 2 specifically includes:
序列编码层采用双向LSTM来获取每个字的上下文向量,所述双向LSTM为前向LSTM和反向LSTM的结合;使用
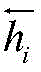

优选的,所述步骤3,具体包括:Preferably, the step 3 specifically includes:
步骤3.1,使用Stanford CoreNLP工具对原始文本进行分词,并使用BerkelyNeural Parse工具抽取输入文本的词性标签和句法成分信息两种句法信息;其中词性标签表示单个字的标签信息,句法成分表示文本跨度的结构分组信息;Step 3.1, use the Stanford CoreNLP tool to segment the original text, and use the BerkelyNeural Parse tool to extract two kinds of syntactic information: the part-of-speech tag and the syntactic component information of the input text; the part-of-speech tag represents the label information of a single word, and the syntactic component represents the structure of the text span group information;
步骤3.2,对于输入序列中的每个xi,将它的上下文特征和句法信息映射到键值记忆网络KVMN中的键和值上,分别表示为

步骤3.3,使用两个嵌入矩阵将ki,j和vi,j分别映射到


其中,hi是xi从序列编码层中获得的隐藏向量;
将权重γi,j应用到对应的句法信息vi,j上,如下:Apply the weight γ i,j to the corresponding syntactic information v i,j as follows:
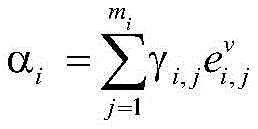
其中,αi为KVMN模型对应xi的加权句法信息;因此,KVMN可以保证语法信息根据其对应的上下文特征进行加权,从而对重要信息进行区分和使用;Among them, α i is the weighted syntactic information of the KVMN model corresponding to xi ; therefore, KVMN can ensure that the syntactic information is weighted according to its corresponding context features, thereby distinguishing and using important information;
步骤3.4,为了更好的利用KVMN编码过的句法信息,对句法向量αi和上下文向量hi动态加权组合,使用评估函数λi来衡量上下文向量hi和句法向量αi对句子的贡献:Step 3.4, in order to make better use of the syntactic information encoded by KVMN, dynamically weight the syntactic vector α i and the context vector hi , and use the evaluation function λ i to measure the contribution of the context vector hi and the syntactic vector α i to the sentence:
λi=σ(Wλ1.hi+Wλ2.αi+bλ)λ i =σ(W λ1 .h i +W λ2 .α i +b λ )
其中,Wλ1和Wλ2是可训练矩阵;bλ是偏置项;σ表示sigmoid激活函数;Among them, W λ1 and W λ2 are trainable matrices; b λ is the bias term; σ represents the sigmoid activation function;
再将句法向量αi和上下文向量hi组合在一起:Then combine the syntax vector α i and the context vector hi together:

其中,l是向量维度与hi匹配的1向量,而最后得到的Oi就是融合了上下文信息和句法信息的特征向量。Among them, l is a 1 vector whose dimension matches h i , and the final O i is a feature vector that combines contextual information and syntactic information.
优选的,所述步骤4,具体包括:Preferably, the
对于输入序列x=(x1,x2,..,xn),给定预测序列y=(y1,y2,y3,...,yn),计算得出预测序列的得分,如下:For the input sequence x=(x 1 ,x 2 ,..,x n ), given the predicted sequence y=(y 1 ,y 2 ,y 3 ,...,y n ), calculate the score for the predicted sequence ,as follows:

其中,M是转移矩阵,

使用softmax函数来计算预测序列y产生的概率p(y|x),如下:Use the softmax function to calculate the probability p(y|x) generated by the predicted sequence y as follows:

其中,Yx为解空间,表示y所有的可能预测序列的集合;

在训练过程中,最大化正确预测序列的似然概率log(p(x,y)),如下:During the training process, the likelihood probability log(p(x,y)) of the correctly predicted sequence is maximized, as follows:

经过不断的迭代训练、反向传播后,得到的y*就是利用CRF序列标注的结果,即最后模型的输出:After continuous iterative training and backpropagation, the obtained y * is the result of using the CRF sequence annotation, that is, the output of the final model:

训练过程不断最大化目标函数
另一方面,一种融合词汇和句法信息的中文命名实体识别系统,包括:On the other hand, a Chinese named entity recognition system that fuses lexical and syntactic information, including:
输入表示获取模块,用于将原始输入文本映射为字向量,使用改进后的词集匹配算法引入外部词汇信息,并整合在每个字的输入表示中;The input representation acquisition module is used to map the original input text into word vectors, and use the improved word set matching algorithm to introduce external vocabulary information and integrate it into the input representation of each word;
上下文向量获取模块,用于根据字的输入表示,利用双向LSTM抽取上下文信息;The context vector acquisition module is used to extract context information using bidirectional LSTM according to the input representation of the word;
上下文信息和句法信息融合模块,用于使用NLP工具从原始输入文本中获取词性标签和句法成分,并且使用健值记忆网络构造句法向量,再通过门控机制对上下文向量与句法向量进行加权融合,获得特征向量;The context information and syntactic information fusion module is used to obtain part-of-speech tags and syntactic components from the original input text using NLP tools, and use the key-value memory network to construct syntactic vectors, and then perform weighted fusion of the context vectors and syntactic vectors through the gating mechanism. get the feature vector;
序列标注模块,用于将特征向量输入标签预测层的CRF中,实现中文命名实体识别。The sequence labeling module is used to input the feature vector into the CRF of the label prediction layer to realize Chinese named entity recognition.
由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:As can be seen from the above description of the present invention, compared with the prior art, the present invention has the following beneficial effects:
本发明通过改进的词集匹配算法在字向量中引入外部词汇信息,并且在句法信息层中整合上下文向量和句法向量,以解决中文命名实体中实体边界信息不足的问题和融合输入文本的句法信息。The invention introduces external vocabulary information into the word vector through an improved word set matching algorithm, and integrates the context vector and the syntax vector in the syntactic information layer, so as to solve the problem of insufficient entity boundary information in Chinese named entities and fuse the syntactic information of the input text. .
附图说明Description of drawings
图1为本发明实施例的融合词汇和句法信息的中文命名实体识别方法的流程图;Fig. 1 is the flow chart of the Chinese named entity recognition method of the fusion vocabulary and syntactic information of the embodiment of the present invention;
图2为本发明实施例的融合词汇和句法信息的中文命名实体识别方法的模型图;Fig. 2 is the model diagram of the Chinese named entity recognition method of fusing vocabulary and syntactic information according to the embodiment of the present invention;
图3为本发明实施例的“中国语言学”对应的词典匹配方法;3 is a dictionary matching method corresponding to "Chinese linguistics" according to an embodiment of the present invention;
图4为本发明实施例的句法信息获取图;FIG. 4 is a diagram for obtaining syntax information according to an embodiment of the present invention;
图5为本发明实施例的融合词汇和句法信息的中文命名实体识别系统的结构框图。FIG. 5 is a structural block diagram of a Chinese named entity recognition system integrating lexical and syntactic information according to an embodiment of the present invention.
具体实施方式Detailed ways
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。The present invention will be further described below in conjunction with specific embodiments. It should be understood that these examples are only used to illustrate the present invention and not to limit the scope of the present invention. In addition, it should be understood that after reading the content taught by the present invention, those skilled in the art can make various changes or modifications to the present invention, and these equivalent forms also fall within the scope defined by the appended claims of the present application.
参见图1所示,本发明一种融合词汇和句法信息的中文命名实体识别方法,包括:Referring to Fig. 1, a Chinese named entity recognition method integrating lexical and syntactic information of the present invention includes:
步骤1、将原始输入文本映射为字向量,使用改进后的词集匹配算法引入外部词汇信息,并整合在每个字的输入表示中;Step 1. Map the original input text into word vectors, use the improved word set matching algorithm to introduce external vocabulary information, and integrate it into the input representation of each word;
步骤2、根据字的输入表示,利用双向LSTM抽取上下文信息;Step 2. According to the input representation of the word, use bidirectional LSTM to extract context information;
步骤3、使用NLP工具从原始输入文本中获取词性标签和句法成分,并且使用健值记忆网络构造句法向量,再通过门控机制对上下文向量与句法向量进行加权融合,获得特征向量;Step 3. Use NLP tools to obtain part-of-speech tags and syntactic components from the original input text, and use a key-value memory network to construct a syntactic vector, and then perform a weighted fusion of the context vector and the syntactic vector through a gating mechanism to obtain a feature vector;
步骤4、将特征向量输入标签预测层的CRF中,实现中文命名实体识别。
具体的,本发明方法的模型图参见图2所示,该模型分为四个部分:输入表示层、序列编码层、句法信息层和标签预测层。Specifically, the model diagram of the method of the present invention is shown in FIG. 2 , and the model is divided into four parts: input representation layer, sequence coding layer, syntax information layer and label prediction layer.
本发明一种融合词汇和句法信息的中文命名实体识别方法的具体实施步骤如下:The specific implementation steps of a Chinese named entity recognition method integrating vocabulary and syntactic information of the present invention are as follows:
(1)包含外部词汇信息的输入表示的获取(1) Acquisition of input representations containing external lexical information
本发明提出了一种的词集匹配方法,该方法在SoftLexicon基础上引入了注意力机制,并将匹配到的静态和动态词集信息相结合,然后使用门控机制将静态词集信息与动态词集信息相融合。The present invention proposes a word set matching method, which introduces an attention mechanism on the basis of SoftLexicon, combines the matched static and dynamic word set information, and then uses a gate control mechanism to match the static word set information with the dynamic word set information. word set information fusion.
1.1)静态词集算法1.1) Static word set algorithm
中文NER模型中,原始输入文本的句子被视为一个序列x=(x1,x2,..,xn)。其中,xi表示在长度为n的句子x中第i个字。为了更好的利用词汇信息,将每个字匹配字典的结果分为四个词集:In the Chinese NER model, the sentence of the original input text is regarded as a sequence x=(x 1 ,x 2 ,..,x n ). where x i represents the ith word in a sentence x of length n. In order to make better use of vocabulary information, the results of each word matching dictionary are divided into four word sets:
a、词集B(xi)包含所有在x上以xi开头的词语;a. Word set B( xi ) contains all words starting with x i on x;
b、词集I(xi)包含所有在x上xi为中间的词语;b. The word set I( xi ) contains all the words with xi being the middle on x;
c、词集E(xi)包含所有在x以xi为结尾的词语;c. The word set E(x i ) contains all the words ending in x i in x;
d、词集S(xi)包含所有xi为单字的词语。d. The word set S( xi ) contains all words with xi being a single character.
这四个词集统称为“BIES”,分别表示为:These four word sets are collectively referred to as "BIES" and are represented as:

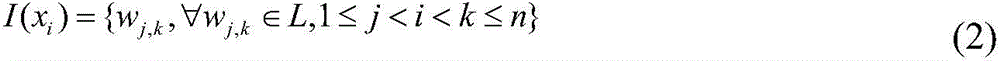


其中,L表示外部词典;wj,k表示一个在外部词典中存在,在序列中以wj为开头以wk为结尾的词语。当输入层的输入为“中国语言学”时,对应的字典匹配方法如图3所示。Among them, L represents the external dictionary; w j, k represents a word that exists in the external dictionary and starts with w j and ends with w k in the sequence. When the input of the input layer is "Chinese linguistics", the corresponding dictionary matching method is shown in Figure 3.
得到每个字对应的“BIES”词集后,再将每个词集压缩为一个固定维数的向量。静态词集算法在处理速度上优于使用注意力机制的动态词集算法为了保证计算效率,使用词语出现的频率来代表对应的权重。由于一个词语的频率是一个静态值,词语频率的高低可以反应词语的重要性,这可以加快词语权重的计算。对于字xi,对应词集T为


其中,
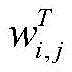
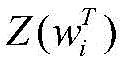
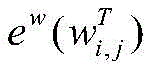

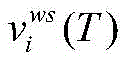

1.2)动态词集算法1.2) Dynamic word set algorithm
注意力机制可以为不同的词语分配不同的权重,为少数关键词语分配较大的权重,为不相关的词语分配较少的权重。动态词集算法使用注意力机制来衡量字符和匹配词之间的信息,计算不同匹配词的重要性,增强有用的词汇并抑制作用不明显的词汇。对于字xi,对应词集T为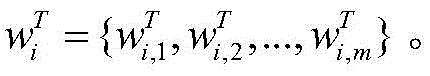





其中,q是与
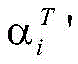



其中,
1.3)门控机制1.3) Gating mechanism
为了充分考虑各个词集中每个词语的重要性,对动态词集向量
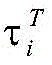



其中,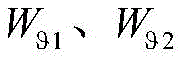



其中,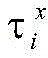



(2)上下文向量的获取(2) Acquisition of context vector
长短时记忆网络(LSTM)是循环神经网络的一种变体,在NLP任务上得到了广泛的使用,例如NER,文本分类、情感分析。LSTM引入细胞状态,利用输入门、遗忘门和输出门来维护和控制信息,有效克服了RNN模型由于长距离依赖而引起的梯度爆炸和梯度损失。LSTM模型的数学表达式如下:Long Short-Term Memory Network (LSTM) is a variant of Recurrent Neural Network and is widely used in NLP tasks such as NER, text classification, sentiment analysis. LSTM introduces cell state and uses input gate, forget gate and output gate to maintain and control information, which effectively overcomes the gradient explosion and gradient loss caused by long-distance dependence of RNN model. The mathematical expression of the LSTM model is as follows:
it=σ(Wi[ht-1,τt]+bi) (15)i t =σ(W i [h t-1 ,τ t ]+b i ) (15)
ft=σ(Wf[ht-1,τt]+bf) (16)f t =σ(W f [h t-1 ,τ t ]+b f ) (16)
ot=σ(Wo[ht-1,τt]+bo) (17)o t =σ(W o [h t-1 ,τ t ]+b o ) (17)


ht=ot*tanh(ct) (20)h t =o t *tanh(c t ) (20)
其中,σ表示sigmoid激活函数,tanh表示双曲正切函数;τt表示单位输入;it,ft,ot分别表示输入门,遗忘门和输出门;Wi,Wf,Wo分别表示输入门,遗忘门和输出门的权重;bi,bf,bo分别表示输入门、遗忘门和输出门的偏置;
为了同时使用字的上下文信息,本文的模型使用双向LSTM来获取每个字的上下文向量,它是前向LSTM和反向LSTM的结合。使用
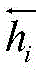

(3)上下文信息和句法信息的融合(3) Fusion of contextual information and syntactic information
上下文信息由序列编码层的双向LSTM输出,句法信息首先通过NLP工具对输入序列进行抽取,然后使用键值记忆网络进行映射,最后使用门控机制进行两种信息的整合。The context information is output by the bidirectional LSTM of the sequence encoding layer, and the syntactic information is first extracted from the input sequence by NLP tools, then mapped by the key-value memory network, and finally integrated by the gating mechanism.
3.1)句法信息获取3.1) Syntax information acquisition
本发明使用Stanford CoreNLP工具先对文本进行分词,然后使用Berkely NeuralParse工具抽取词性标签和句法成分两种句法信息。其中词性标签表示单个字的标签信息,句法成分表示文本跨度的结构分组信息。以“解放大道路面积水”为例,图4表示了例句中的词性标签和句法成分。对于输入序列x=(x1,x2,..,xn)中的每个xi,按照以下步骤提取上下文特征和句法信息。The present invention uses the Stanford CoreNLP tool to firstly segment the text, and then uses the Berkely NeuralParse tool to extract two kinds of syntactic information: part-of-speech tags and syntactic components. The part-of-speech tag represents the tag information of a single word, and the syntactic component represents the structural grouping information of the text span. Taking the example of "liberating water in the area of the road", Figure 4 shows the part-of-speech tags and syntactic components in the example sentence. For each x i in the input sequence x = (x 1 , x 2 , .., x n ), the following steps are followed to extract contextual features and syntactic information.
3.1.1)词性标签:将每个xi作为中心词,使用±1个词的窗口提取xi两侧的上下文词及其词性标签。如图4(a)所示,对于字“道”,得到的上下文特征为(解放,大道,路面),使用这些词和对应的词性标签的组合作为NER任务的词性信息,即对应的句法信息为(解放_NN,大道_NN,路面_NN)。3.1.1) Part-of-speech tags: take each xi as the central word, and use a ±1-word window to extract the context words and their part-of-speech tags on both sides of xi . As shown in Figure 4(a), for the word "dao", the obtained context features are (liberation, avenue, road), and the combination of these words and the corresponding part-of-speech tags is used as the part-of-speech information of the NER task, that is, the corresponding syntactic information is (liberation_NN, avenue_NN, pavement_NN).
3.1.2)句法成分:从xi的句法树的叶子节点开始,沿着树向上搜索找到第一个句法节点,然后将该节点下的所有词语作为上下文特征,将词语及对应句法标签的组合作为NER任务的句法成分信息。如图4(b)所示,对于字“道”,向上搜索节点,句法节点“NP”包含两个词语“解放”和“大道”。因此,上下文特征为(解放,大道),并将上下文特征与“NP”标签组合作为NER任务的句法成分信息,即对应的句法信息为(解放_NP,大道_NP)。3.1.2) Syntactic components: starting from the leaf node of the syntax tree of x i , search up the tree to find the first syntax node, then use all words under the node as context features, and combine the words and the corresponding syntax labels. as syntactic component information for NER tasks. As shown in Figure 4(b), for the word "Dao", the node is searched upward, and the syntactic node "NP" contains two words "Jiefang" and "Dao". Therefore, the context feature is (Jiefang, Dao), and the context feature is combined with the "NP" label as the syntactic component information of the NER task, that is, the corresponding syntactic information is (Jiefang_NP, Dao_NP).
3.2)KVMN构建3.2) KVMN build
由于工具提取的句法信息存在一定的噪声信息,如果不恰当的利用这些噪声,可能会影响模型的性能。KVMN的变体已被证明在结合上下文特征方面是有效的,并提供了一种适当的方式来利用上下文特征及其对应的依存类型。Since there is a certain amount of noise in the syntactic information extracted by the tool, if these noises are not used properly, the performance of the model may be affected. Variants of KVMN have been shown to be effective in incorporating contextual features and provide an appropriate way to exploit contextual features and their corresponding dependency types.
在构建KVMN过程中,首先获得输入序列x=(x1,x2,..,xn)对应的解析结果。对于输入序列中的每个xi,将它的上下文特征和句法信息映射到KVMN中的键和值上,分别表示为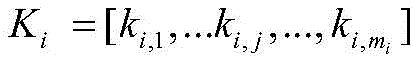




其中,hi是xi从序列编码层中获得的隐藏向量。将权重γi,j应用到对应的句法信息vi,j上:where hi is the hidden vector of xi obtained from the sequence encoding layer. Apply the weight γ i,j to the corresponding syntactic information v i,j :

其中,αi为KVMN模型对应xi的加权句法信息。因此,KVMN可以保证语法信息根据其对应的上下文特征进行加权,从而对重要信息进行区分和使用。Among them, α i is the weighted syntactic information of the KVMN model corresponding to xi . Therefore, KVMN can ensure that grammatical information is weighted according to its corresponding contextual features, thereby distinguishing and using important information.
3.3)门控机制3.3) Gating mechanism
为了更好的利用KVMN编码过的句法信息,对句法向量αi和上下文向量hi动态加权组合。使用评估函数λi来衡量上下文向量hi和句法向量αi对句子的贡献:In order to make better use of the syntactic information encoded by KVMN, the syntactic vector α i and the context vector h i are dynamically weighted and combined. The evaluation function λ i is used to measure the contribution of the context vector h i and the syntactic vector α i to the sentence:
λi=σ(Wλ1.hi+Wλ2.αi+bλ) (23)λ i =σ(W λ1 .h i +W λ2 .α i +b λ ) (23)
其中,Wλ1、Wλ2是可训练矩阵,bλ是偏置项。然后,将句法向量αi和上下文向量hi组合在一起:Among them, W λ1 and W λ2 are trainable matrices, and b λ is the bias term. Then, the syntactic vector α i and the context vector h i are combined together:

其中,Oi是KVMN对应xi的输出,l是向量维度与hi匹配的1向量,*是矩阵点乘计算,⊕是向量拼接。Among them, O i is the output of KVMN corresponding to x i , l is a 1 vector whose vector dimension matches hi i , * is the matrix dot product calculation, and ⊕ is the vector splicing.
(4)使用CRF进行序列标注(4) Sequence annotation using CRF
与HMM相比,CRF对HMM的独立性假设没有严格性要求,可以有效地利用序列和外部观测信息,避免了标签偏差和只直接假设标签产生的差异化。CRF可以捕获更多的依赖性:例如,“I-ORG”标签不能在“B-LOC”之后。在CNER,CRF的输入是从句法信息层学习到的上下文特征向量Oi。对于输入序列x=(x1,x2,..,xn),记Pi,j表示句子中第i个字的第j个标签的概率得分。对于预测序列y=(y1,y2,y3,...,yn),计算得出预测序列的得分:Compared with HMM, CRF does not have strict requirements on the independence assumption of HMM, and can effectively use sequence and external observation information, avoiding label bias and differentiation caused by only directly assuming labels. CRF can capture more dependencies: for example, "I-ORG" tag cannot come after "B-LOC". In CNER, the input of CRF is the context feature vector O i learned from the syntactic information layer. For the input sequence x=(x 1 , x 2 , .., x n ), let P i,j denote the probability score of the j th label of the ith word in the sentence. For the predicted sequence y=(y 1 , y 2 , y 3 ,...,y n ), calculate the score for the predicted sequence:

其中,M是转移矩阵,Mi,j表示从标签i到标签j的转移分数;y0和yn+1分别表示开始和结束标签。使用softmax函数来计算预测序列y产生的概率:where M is the transition matrix, M i,j represents the transition score from label i to label j; y 0 and yn +1 represent the start and end labels, respectively. Use the softmax function to calculate the probability that the predicted sequence y will be produced:

其中,Yx表示y所有的可能预测序列。在训练过程中,最大化正确预测序列的似然概率:where Y x represents all possible prediction sequences for y. During training, maximize the likelihood of correctly predicting the sequence:

在训练结束后,预测序列得到的分数为:After training, the predicted sequence gets a score of:

(5)效果评估(5) Effect evaluation
为了验证本发明方法的效果,同时与其它模型进行比较,本文使用了三个中文命名实体数据集进行实验,包括:Weibo数据集、Resume数据集和MSRA数据集。实验指标采用准确率、召回率和F1值。In order to verify the effect of the method of the present invention and compare with other models, this paper uses three Chinese named entity datasets for experiments, including: Weibo dataset, Resume dataset and MSRA dataset. The experimental metrics are precision, recall and F1 value.
Weibo数据集是来自社交网络微博的信息,包括人名、地名、机构名、地缘政治实体四种实体。MSRA数据集是来自于新闻领域的数据集,只有训练集和测试集,其中包含人名,地名和机构三种实体类型。Resume数据集是来自新浪金融的简历信息,包含城市、教育机构、地名、人名、机构名、专有名词、专业背景和工作头衔七种实体类型。每个数据集的情况如表1所示。The Weibo dataset is information from social network Weibo, including four types of entities: person names, place names, institution names, and geopolitical entities. The MSRA dataset is a dataset from the news domain, with only a training set and a test set, which contain three entity types: person name, place name and institution. The Resume dataset is resume information from Sina Finance, including seven entity types: city, educational institution, place name, person name, institution name, proper noun, professional background and job title. The conditions of each dataset are shown in Table 1.
表1数据集详细信息Table 1 Dataset Details

为了验证本章方法的有效性,本发明以下列3个模型作为基线进行对比:In order to verify the effectiveness of the method in this chapter, the present invention uses the following three models as baselines for comparison:
(1)Lattice-LSTM:引入了一个词语细胞结构,对于当前的字符,融合以该字符结束的所有词信息;(1) Lattice-LSTM: A word cell structure is introduced, and for the current character, all word information ending with this character is fused;
(2)FLAT:基于transformer结构进行改进,设计了巧妙的位置编码来融合lattice结构,并改进了绝对位置编码让其更适合NER任务;(2) FLAT: Based on the improvement of the transformer structure, a clever positional encoding is designed to integrate the lattice structure, and the absolute positional encoding is improved to make it more suitable for NER tasks;
(3)SoftLexicon:在输入表示层中简单利用词汇的方法,可移植性比较高。(3) SoftLexicon: The method of simply using vocabulary in the input presentation layer has high portability.
评估标准如下:The evaluation criteria are as follows:
实验的评价指标使用准确率(Precision)、召回率(Recall)和F1值(F1 score)。其中,Precision为所有识别实体词中正确的比例;Recall表示识别正确的实体占数据集中所有实体的比例。因为正确率和准确率成反比,F1为它们的调和平均值。评价函数为:The evaluation indicators of the experiment use the precision rate (Precision), recall rate (Recall) and F1 value (F1 score). Among them, Precision is the correct proportion of all recognized entity words; Recall represents the proportion of correctly recognized entities in all entities in the dataset. Since accuracy and accuracy are inversely proportional, F1 is their harmonic mean. The evaluation function is:



模型所使用的超参数如表2所示:The hyperparameters used by the model are shown in Table 2:
表2超参数配置Table 2 Hyperparameter configuration

三个基线模型和本发明的模型分别在各个数据集上的实验结果如表3所示,每个数据集下最好的结果加粗显示。The experimental results of the three baseline models and the model of the present invention on each data set are shown in Table 3, and the best results under each data set are shown in bold.
表3不同数据集的实验结果Table 3 Experimental results on different datasets

如表3结果所示,在Weibo、Resume数据集上,本文提出的LSF-CNER优于其它方法。As shown in Table 3, on the Weibo and Resume datasets, the LSF-CNER proposed in this paper outperforms other methods.
在噪声较多,格式不定的Weibo数据集上,LSF-CNER取得了较好的效果,相较于SoftLexicon,F1值提升了0.71%。On the Weibo dataset with more noise and indeterminate format, LSF-CNER achieves better results. Compared with SoftLexicon, the F1 value is improved by 0.71%.
在Resume这种格式相对固定,噪声比较少的数据集上,相较于SoftLexicon,LSF-CNER的F1值提升了0.11%。Compared with SoftLexicon, the F1 value of LSF-CNER is improved by 0.11% on a dataset with a relatively fixed format and less noise such as Resume.
在文本正式,数据较多的MSRA数据集上,相较于SoftLexicon,LSF-CNER的F1值下降了0.01%,说明模型已经过拟合了。原因是,SoftLexicon已经能够很好的拟合较大规模的MSRA和Resume数据集,添加特征信息不能显著的提升模型效果。由于在小规模数据集上,缺少特征信息,因而能够使用句法和词汇信息来提升模型性能。On the MSRA dataset with formal text and more data, compared with SoftLexicon, the F1 value of LSF-CNER dropped by 0.01%, indicating that the model has been overfitted. The reason is that SoftLexicon has been able to fit the larger-scale MSRA and Resume datasets well, and adding feature information cannot significantly improve the model effect. Due to the lack of feature information on small-scale datasets, syntactic and lexical information can be used to improve model performance.
进一步,为了验证LSF-CNER模型的泛用性。将词语的词汇信息,与BERT词向量结合在一起,作为输入表示层的输出送入序列编码层。表4为与BERT结合的实验结果,其中给出的是F1值。本文提出的方法在不同数据集上的F1平均值结果相比BERT-Tagger提升了4.68%;相比BERT+BiLSTM+CRF提升2.48%;相比SoftLexicon+BERT提升了0.89%。尤其在Weibo数据集中,本文方法的提升较为显著。Further, in order to verify the generality of the LSF-CNER model. The lexical information of the word is combined with the BERT word vector, and is sent to the sequence encoding layer as the output of the input representation layer. Table 4 shows the experimental results in combination with BERT, in which the F1 value is given. Compared with BERT-Tagger, the F1 average result of the method proposed in this paper is improved by 4.68%; compared with BERT+BiLSTM+CRF, it is improved by 2.48%; compared with SoftLexicon+BERT, it is improved by 0.89%. Especially in the Weibo dataset, the improvement of the method in this paper is more significant.
表4与预训练语言模型结合的实验结果(%)Table 4 Experimental results (%) combined with pre-trained language models

从实验结果可知,与预训练模型结合,能够较好的提高输入表示层的效果。本文方法在Resume数据集、Weibo数据集和MSRA数据集优于传统的CNER方法。这验证了融合词汇信息和语法信息是有效的。It can be seen from the experimental results that combining with the pre-training model can better improve the effect of the input representation layer. The method in this paper outperforms traditional CNER methods in Resume dataset, Weibo dataset and MSRA dataset. This verifies that fusing lexical information and grammatical information is effective.
为了分别研究动态词集合和句法信息这两部分对实体识别任务的贡献,本文在Resume数据集上进行消融实验,将模型设置为五种情况进行了消融实验。In order to study the contribution of the dynamic word set and syntactic information to the entity recognition task respectively, this paper conducts ablation experiments on the Resume dataset, and sets the model to five cases for ablation experiments.
(1)BERT+LSTM+CRF:初始模型,不包括外部词汇信息和句法信息;(1) BERT+LSTM+CRF: initial model, excluding external lexical information and syntactic information;
(2)SoftLexicon+BERT:包含外部词汇信息;(2) SoftLexicon+BERT: Contains external vocabulary information;
(3)SoftLexicon+Attention+BERT:在SoftLexicon基础上引入注意力机制,动态调整词集中不同词语的权重;(3) SoftLexicon+Attention+BERT: An attention mechanism is introduced on the basis of SoftLexicon to dynamically adjust the weights of different words in the word set;
(4)Syntactic+BERT:包含句法信息,但不包含外部词汇信息;(4) Syntactic+BERT: contains syntactic information, but does not contain external lexical information;
(5)LSF+BERT:包含句法信息,和改进后的词集信息。(5) LSF+BERT: Contains syntactic information and improved word set information.
表5消融实验结果(%)Table 5 Ablation experiment results (%)
如表5所示,当在SoftLexicon+BERT模型中引入注意力机制调整词集向量权重时,其平均F1值提升了0.16%;当在BERT+BiLSTM+CRF模型中引入句法信息时,其平均F1值提升了0.46%;当同时包含句法信息和静动态词集信息时,其平均F1值相比SoftLexicon+BERT提升了0.48%。从以上实验结果可以看出:静动态词集信息和句法信息对模型性能提升均有帮助;两者同时存在使中文命名实体识别精度进一步提升。这说明,动态调整词集中词语权重和引入句法信息有助于帮助句子识别不同词语的重要程度,进而提高中文命名实体精度。As shown in Table 5, when the attention mechanism is introduced into the SoftLexicon+BERT model to adjust the weight of the word set vector, its average F1 value is improved by 0.16%; when syntactic information is introduced into the BERT+BiLSTM+CRF model, its average F1 value The value is improved by 0.46%; when both syntactic information and static dynamic vocabulary information are included, the average F1 value is improved by 0.48% compared with SoftLexicon+BERT. It can be seen from the above experimental results that both the static and dynamic vocabulary information and the syntactic information are helpful for the performance improvement of the model; the coexistence of the two can further improve the recognition accuracy of Chinese named entities. This shows that dynamically adjusting the weight of words in the vocabulary and introducing syntactic information can help sentences identify the importance of different words, thereby improving the accuracy of Chinese named entities.
综上所述,本发明提出了一种融合词汇和句法信息的中文命名实体识别方法。新的词集匹配方法将静动态词集信息整合在输入表示层上,然后使用门控机制将序列编码层的输出和句法信息进行动态加权,不仅考虑了中文命名实体的潜在边界,而且还考虑了句子中潜在的句法信息,两种信息以更平衡的方式融合,提高模型的表达效果。在三个CNER数据集的实验结果表明,与主流方法相比,新方法具有良好的性能。To sum up, the present invention proposes a Chinese named entity recognition method integrating lexical and syntactic information. The new word set matching method integrates static dynamic word set information on the input representation layer, and then uses a gating mechanism to dynamically weight the output and syntactic information of the sequence encoding layer, not only considering the potential boundaries of Chinese named entities, but also considering The potential syntactic information in the sentence is taken into account, and the two kinds of information are fused in a more balanced way to improve the expression effect of the model. The experimental results on three CNER datasets show that the new method has good performance compared with the mainstream methods.
参见图5所示,本发明还包括一种融合词汇和句法信息的中文命名实体识别系统,包括:Referring to Fig. 5, the present invention also includes a Chinese named entity recognition system integrating lexical and syntactic information, including:
输入表示获取模块501,用于将原始输入文本映射为字向量,使用改进后的词集匹配算法引入外部词汇信息,并整合在每个字的输入表示中;The input representation acquisition module 501 is used to map the original input text into a word vector, use the improved word set matching algorithm to introduce external vocabulary information, and integrate it into the input representation of each word;
上下文向量获取模块502,用于根据字的输入表示,利用双向LSTM抽取上下文信息;a context vector acquisition module 502, used for extracting context information by using bidirectional LSTM according to the input representation of the word;
上下文信息和句法信息融合模块503,用于使用NLP工具从原始输入文本中获取词性标签和句法成分,并且使用健值记忆网络构造句法向量,再通过门控机制对上下文向量与句法向量进行加权融合,获得特征向量;The context information and syntactic
序列标注模块504,用于将特征向量输入标签预测层的CRF中,实现中文命名实体识别The sequence labeling module 504 is used to input the feature vector into the CRF of the label prediction layer to realize Chinese named entity recognition
一种融合词汇和句法信息的中文命名实体识别系统的具体实现同一种融合词汇和句法信息的中文命名实体识别方法,本实施例不再重复说明。The specific implementation of a Chinese named entity recognition system integrating lexical and syntactic information is the same as a Chinese named entity recognition method integrating lexical and syntactic information, which will not be repeated in this embodiment.
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。The above are only specific embodiments of the present invention, but the design concept of the present invention is not limited to this, and any non-substantial modification of the present invention by using this concept should be regarded as an act of infringing the protection scope of the present invention.
Claims (6)






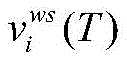

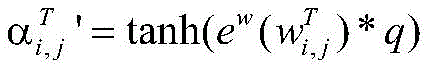






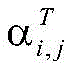








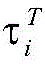


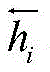


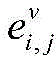








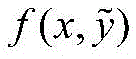

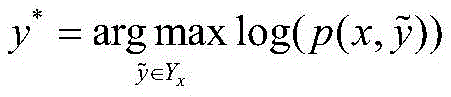

Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210575509.3A CN114818717B (en) | 2022-05-25 | 2022-05-25 | Chinese named entity recognition method and system integrating vocabulary and syntax information |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210575509.3A CN114818717B (en) | 2022-05-25 | 2022-05-25 | Chinese named entity recognition method and system integrating vocabulary and syntax information |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114818717A true CN114818717A (en) | 2022-07-29 |
| CN114818717B CN114818717B (en) | 2024-08-20 |
Family
ID=82517680
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210575509.3A Active CN114818717B (en) | 2022-05-25 | 2022-05-25 | Chinese named entity recognition method and system integrating vocabulary and syntax information |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114818717B (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115270803A (en) * | 2022-09-30 | 2022-11-01 | 北京道达天际科技股份有限公司 | Entity extraction method based on BERT and fused with N-gram characteristics |
| CN115545033A (en) * | 2022-10-18 | 2022-12-30 | 昆明理工大学 | Chinese Domain Text Named Entity Recognition Method Fused with Lexical Category Representation |
| CN115774993A (en) * | 2022-12-29 | 2023-03-10 | 广东南方网络信息科技有限公司 | Conditional error identification method and device based on syntactic analysis |
| CN117077672A (en) * | 2023-07-05 | 2023-11-17 | 哈尔滨理工大学 | A Chinese named entity recognition method based on vocabulary enhancement and TCN-BILSTM model |
| CN117521639A (en) * | 2024-01-05 | 2024-02-06 | 湖南工商大学 | A text detection method combining academic text structure |
| CN119204018A (en) * | 2024-10-17 | 2024-12-27 | 江西师范大学 | Chinese named entity recognition method based on sequence interaction and syntax integration |
| CN119398054A (en) * | 2024-10-25 | 2025-02-07 | 西安电子科技大学 | Chinese entity recognition model and method based on vocabulary enhancement and character external information |
| CN119990117A (en) * | 2025-01-13 | 2025-05-13 | 南京亚思通信息技术有限公司 | Military text recognition method, device and medium |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109726389A (en) * | 2018-11-13 | 2019-05-07 | 北京邮电大学 | A kind of Chinese missing pronoun complementing method based on common sense and reasoning |
| WO2021082366A1 (en) * | 2019-10-28 | 2021-05-06 | 南京师范大学 | Interactive and iterative learning-based intelligent construction method for geographical name tagging corpus |
| CN112883732A (en) * | 2020-11-26 | 2021-06-01 | 中国电子科技网络信息安全有限公司 | Method and device for identifying Chinese fine-grained named entities based on associative memory network |
| CN113095074A (en) * | 2021-03-22 | 2021-07-09 | 北京工业大学 | Word segmentation method and system for Chinese electronic medical record |
| CN113609859A (en) * | 2021-08-04 | 2021-11-05 | 浙江工业大学 | Special equipment Chinese named entity recognition method based on pre-training model |
| CN114528840A (en) * | 2022-01-21 | 2022-05-24 | 深圳大学 | Chinese entity identification method, terminal and storage medium fusing context information |
-
2022
- 2022-05-25 CN CN202210575509.3A patent/CN114818717B/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109726389A (en) * | 2018-11-13 | 2019-05-07 | 北京邮电大学 | A kind of Chinese missing pronoun complementing method based on common sense and reasoning |
| WO2021082366A1 (en) * | 2019-10-28 | 2021-05-06 | 南京师范大学 | Interactive and iterative learning-based intelligent construction method for geographical name tagging corpus |
| CN112883732A (en) * | 2020-11-26 | 2021-06-01 | 中国电子科技网络信息安全有限公司 | Method and device for identifying Chinese fine-grained named entities based on associative memory network |
| CN113095074A (en) * | 2021-03-22 | 2021-07-09 | 北京工业大学 | Word segmentation method and system for Chinese electronic medical record |
| CN113609859A (en) * | 2021-08-04 | 2021-11-05 | 浙江工业大学 | Special equipment Chinese named entity recognition method based on pre-training model |
| CN114528840A (en) * | 2022-01-21 | 2022-05-24 | 深圳大学 | Chinese entity identification method, terminal and storage medium fusing context information |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115270803A (en) * | 2022-09-30 | 2022-11-01 | 北京道达天际科技股份有限公司 | Entity extraction method based on BERT and fused with N-gram characteristics |
| CN115545033A (en) * | 2022-10-18 | 2022-12-30 | 昆明理工大学 | Chinese Domain Text Named Entity Recognition Method Fused with Lexical Category Representation |
| CN115545033B (en) * | 2022-10-18 | 2025-12-19 | 昆明理工大学 | Chinese field text named entity recognition method integrating vocabulary category characterization |
| CN115774993A (en) * | 2022-12-29 | 2023-03-10 | 广东南方网络信息科技有限公司 | Conditional error identification method and device based on syntactic analysis |
| CN115774993B (en) * | 2022-12-29 | 2023-09-08 | 广东南方网络信息科技有限公司 | Condition type error identification method and device based on syntactic analysis |
| CN117077672B (en) * | 2023-07-05 | 2024-04-26 | 哈尔滨理工大学 | Chinese naming entity recognition method based on vocabulary enhancement and TCN-BILSTM model |
| CN117077672A (en) * | 2023-07-05 | 2023-11-17 | 哈尔滨理工大学 | A Chinese named entity recognition method based on vocabulary enhancement and TCN-BILSTM model |
| CN117521639B (en) * | 2024-01-05 | 2024-04-02 | 湖南工商大学 | A text detection method combining academic text structure |
| CN117521639A (en) * | 2024-01-05 | 2024-02-06 | 湖南工商大学 | A text detection method combining academic text structure |
| CN119204018A (en) * | 2024-10-17 | 2024-12-27 | 江西师范大学 | Chinese named entity recognition method based on sequence interaction and syntax integration |
| CN119204018B (en) * | 2024-10-17 | 2025-03-25 | 江西师范大学 | Chinese named entity recognition method based on sequence interaction and syntactic integration |
| CN119398054A (en) * | 2024-10-25 | 2025-02-07 | 西安电子科技大学 | Chinese entity recognition model and method based on vocabulary enhancement and character external information |
| CN119398054B (en) * | 2024-10-25 | 2025-10-28 | 西安电子科技大学 | Chinese entity recognition model and method based on vocabulary enhancement and character external information |
| CN119990117A (en) * | 2025-01-13 | 2025-05-13 | 南京亚思通信息技术有限公司 | Military text recognition method, device and medium |
| CN119990117B (en) * | 2025-01-13 | 2025-08-01 | 南京亚思通信息技术有限公司 | Military text recognition method, device and medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114818717B (en) | 2024-08-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12222970B2 (en) | Generative event extraction method based on ontology guidance | |
| CN114818717B (en) | Chinese named entity recognition method and system integrating vocabulary and syntax information | |
| CN115033659B (en) | Clause-level automatic abstract model system based on deep learning and abstract generation method | |
| CN112541356B (en) | Method and system for recognizing biomedical named entities | |
| CN107729309B (en) | Deep learning-based Chinese semantic analysis method and device | |
| CN106202010B (en) | Method and apparatus based on deep neural network building Law Text syntax tree | |
| CN111966812B (en) | An automatic question answering method and storage medium based on dynamic word vector | |
| CN115392259B (en) | Microblog text sentiment analysis method and system based on confrontation training fusion BERT | |
| CN114547230B (en) | Intelligent administrative law enforcement case information extraction and case identification method | |
| US20240111956A1 (en) | Nested named entity recognition method based on part-of-speech awareness, device and storage medium therefor | |
| CN108460013A (en) | A kind of sequence labelling model based on fine granularity vocabulary representation model | |
| CN111666758A (en) | Chinese word segmentation method, training device and computer readable storage medium | |
| Xiao et al. | User preference mining based on fine-grained sentiment analysis | |
| CN114969304A (en) | Case public opinion multi-document generation type abstract method based on element graph attention | |
| CN111966797B (en) | Method for machine reading and understanding by using word vector introduced with semantic information | |
| CN113761890A (en) | A Multi-level Semantic Information Retrieval Method Based on BERT Context Awareness | |
| CN112818698A (en) | Fine-grained user comment sentiment analysis method based on dual-channel model | |
| CN114742069A (en) | Code similarity detection method and device | |
| CN111191464A (en) | Semantic similarity calculation method based on combined distance | |
| CN112905736A (en) | Unsupervised text emotion analysis method based on quantum theory | |
| CN115510230A (en) | A Mongolian Sentiment Analysis Method Based on Multidimensional Feature Fusion and Comparative Enhancement Learning Mechanism | |
| CN114510569A (en) | News Classification Method of Chemical Emergencies Based on ChineseBERT Model and Attention Mechanism | |
| CN114330350A (en) | Named entity identification method and device, electronic equipment and storage medium | |
| CN118395987A (en) | BERT-based landslide hazard assessment named entity identification method of multi-neural network | |
| CN117910466A (en) | Chinese social media few-sample standing detection method based on theme enhancement |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |