Detailed Description
Reference will now be made in detail to the exemplary embodiments, examples of which are illustrated in the accompanying drawings. The following description refers to the accompanying drawings in which the same numbers in different drawings represent the same or similar elements unless otherwise indicated. The embodiments described in the following exemplary embodiments do not represent all embodiments consistent with the present application. Rather, they are merely examples of apparatus and methods consistent with certain aspects of the application, as detailed in the appended claims.
Speech technology is changing our way of life and work in recent years, and for some embedded devices speech is the dominant way for human-computer interaction. For example, voice is recognized as text and is applicable to various scenes such as voice chat, voice input, voice search, voice ordering, voice instruction, voice question answering, and the like. The key technology of speech recognition is a speech recognition system, and the speech recognition by the speech recognition system can be specifically described as follows:
fig. 1 is an application scenario diagram provided in an embodiment of the present application. As shown in fig. 1, the application scenario includes: a terminal device 11 and a server 12;
the terminal device 11 may be an electronic device provided with a microphone, such as a smart phone, an Ipad, an intelligent wearable device, and a home appliance. When a user performs voice chat, voice input, voice search, voice ordering, voice instruction sending and voice question and answer sending to the household appliance, the voice collecting device on the terminal device 11 collects the voice of the user to obtain the voice to be recognized, and sends the voice to the server 12 for voice recognition, and the server 12 feeds back the voice recognition result to the terminal device 11.
The server 12 may be a single server or a server cluster including a plurality of servers, which is not limited in this embodiment. The server 12 is provided with a voice recognition system 121, configured to perform voice recognition on a voice to be recognized, so as to obtain a voice recognition result corresponding to the voice to be recognized.
Specifically, the speech recognition system 121 includes a preprocessing module 1211, an acoustic model 1212, a language model 1213, and a decoder 1214;
the preprocessing module 1211 is configured to preprocess the voice to be recognized, and input the preprocessed voice to be recognized into the acoustic model 1212, so as to obtain a plurality of candidate texts corresponding to the voice to be recognized and an acoustic score corresponding to each candidate text. Wherein the pretreatment comprises: denoising, framing and feature extraction.
A language model 1213 is used to determine the linguistic score corresponding to each candidate text.
A decoder 1214, configured to re-score each candidate text, that is, perform weighting according to the acoustic score and the language score corresponding to each candidate text and respective weights of the acoustic score and the language score, to obtain a final score of each candidate text, and determine, according to the final scores corresponding to multiple candidate texts, the candidate text corresponding to the highest final score as the speech recognition result.
In the related art, the weights corresponding to the acoustic score and the language score are manually set according to experience values and are not changed in the whole training process, that is, the weights corresponding to the acoustic score and the language score are fixed values in the whole training process, so that the accuracy of the re-scoring language model obtained through training when re-scoring is performed on the voice data to be recognized is low, and the accuracy of the finally obtained voice recognition result is low.
In view of the above technical problems, the inventors of the present application propose the following technical idea: in the training process of the re-scoring language model, the weights corresponding to the scores of the candidate texts in the candidate texts of each voice sample in the first voice training data are dynamically optimized based on the Bayesian optimization algorithm, so that the accuracy of the re-scoring language model obtained through training when the voice data to be recognized are re-scored is improved, and the accuracy of the finally obtained voice recognition result is improved.
In addition, the related art also has the following problems: in a voice recognition task, the difficulty in acquiring text marking data corresponding to voice is high, so that marking data are few, models used in a re-scoring process also need to be trained by the marking data, the effect of the re-scoring process is limited due to the lack of the voice and the corresponding text data, and a large amount of voice data lack some ways to directly act on the re-scoring process. However, the individual voice data is easy to obtain, and the voice data which is not marked in the part is utilized by the application to bring certain effect promotion to some subtasks in the voice recognition task, for example, in a re-scoring process in the voice recognition, the voice recognition gives a plurality of text candidate sets in the final process, and then the best matching result is selected by a certain scoring method.
The following describes the technical solution of the present application and how to solve the above technical problems in detail by specific embodiments. These several specific embodiments may be combined with each other below, and details of the same or similar concepts or processes may not be repeated in some embodiments. Embodiments of the present application will be described below with reference to the accompanying drawings.
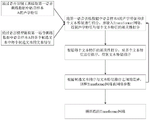
Fig. 2 is a flowchart of a training method of a re-scoring language model according to an embodiment of the present disclosure. As shown in fig. 2, the method for training the re-scoring language model includes the following steps:
step S201, acquiring first voice training data and a voice test data set; the first voice training data includes a plurality of voice samples.
The execution subject of the method of the present embodiment may be a server as shown in fig. 1.
In this embodiment, the server may obtain a plurality of first voice training data from the voice sample library. The speech sample library contains a large number of speech samples, wherein one part of the speech samples have artificially labeled text data, and the other part of the speech samples have no artificially labeled text data. In this embodiment, a voice sample without an artificial labeling text is used as the first voice training data, and a voice sample with an artificial labeling text is used as the voice test data set, that is, the voice test data set includes a plurality of voice test data and their corresponding labeling texts. The manually marked text data refers to words which are manually marked as being identical to the semanteme of the first voice training data.
The voice sample library may be obtained from an open-source voice sample set, or may be a voice database constructed by the user, which is not limited in this embodiment.
Illustratively, for a customer service scene, a question input by a user through voice in the customer service scene and a reply sentence input by a customer service person through voice in the customer service scene can be obtained as voice samples. Aiming at the scene of controlling the household appliance, a voice instruction input by a user can be obtained and used as a voice sample. For a voice search scene, a search sentence input by a user through voice can be obtained as a voice sample. For a voice chat scene, a chat sentence input by a user through voice can be obtained as a voice sample.
It should be understood that, for different application scenarios, the present embodiment may acquire the voice data in the application scenario as a voice sample to establish a voice database, and all application scenarios applicable to voice recognition are within the scope of the present embodiment.
Step S202, a plurality of candidate texts corresponding to the first voice training data and a plurality of scores corresponding to the candidate texts are determined.
Specifically, in this step, for each speech sample in the first speech training data, a plurality of candidate texts corresponding to each speech sample and a plurality of scores corresponding to each candidate text are determined. Wherein the plurality of scores includes an acoustic score, a linguistic score, and a re-score.
In this embodiment, each candidate text in the multiple candidate texts is text data with the same or similar semantics as each speech sample in the first speech training data, and the accuracy of the semantics of each speech sample in the first speech training data represented by each candidate text is different.
Optionally, the plurality of scores corresponding to each candidate text includes an acoustic score, a linguistic score and a re-score; determining a plurality of candidate texts corresponding to the first voice training data and a plurality of scores corresponding to the candidate texts comprises: determining a plurality of candidate texts corresponding to the voice samples in the first voice training data and acoustic scores, language scores and reprinting scores corresponding to the candidate texts; the weights of the scores are corresponding weights of the language scores or the re-scores; the acoustic score is used for representing the probability of the possible words corresponding to the voice sample, the language score is used for representing the probability of the candidate text according with the natural language, the re-scoring is obtained by re-scoring the candidate text through a pre-re-scoring model, and the pre-re-scoring model is obtained by training the recurrent neural network according to the second voice sample; the second voice training data comprises a plurality of voice samples and labeled texts.
The second speech training data may be obtained from a speech sample library, that is: and dividing the voice sample without the manually marked text in the voice sample library into two parts, wherein one part is used as second voice training data, and the other part is used as voice testing data.
Wherein the acoustic score, the linguistic score, and the re-score may be obtained by:
b1, inputting each voice sample in the first voice training data into a voice recognition model to obtain a plurality of candidate texts corresponding to each voice sample in the first voice training data and an acoustic score corresponding to each candidate text; the speech recognition model is a model trained from second speech training data.
Fig. 3 is an exemplary diagram for obtaining a plurality of candidate texts of a speech sample in first speech training data according to an embodiment of the present application. As shown in fig. 3, a speech recognition model is obtained by training using a Kaldi speech recognition tool, and then each speech sample in the first speech training data is decoded by the speech recognition model to obtain a plurality of candidate texts corresponding to each speech sample. Here, the plurality of candidate texts corresponding to each speech sample in the first speech training data may be understood as weak supervised data.
In step b1, the speech recognition model includes an acoustic model and a pre-language model. How to identify the speech recognition model to obtain a plurality of candidate texts corresponding to each speech sample in the first speech training data and an acoustic score corresponding to each candidate text will be described in detail below:
before each voice sample in the first voice training data is input into the voice recognition model, framing processing needs to be carried out on each voice sample to obtain a plurality of voice frames; and aiming at each voice frame in the plurality of voice frames, extracting the voice characteristics of each voice frame to obtain the acoustic characteristics corresponding to each voice frame. And inputting the acoustic characteristics corresponding to each of the plurality of speech frames of each speech sample into an acoustic model, so as to perform acoustic characteristic recognition on the acoustic characteristics corresponding to each speech frame through the acoustic model, and obtain a plurality of likelihood words corresponding to each speech frame and the probability corresponding to each likelihood word. Taking a section of voice sample as an example, performing framing processing on the section of voice sample to obtain M voice frames, and after performing acoustic feature extraction on each voice frame in the M voice frames, obtaining M acoustic features. Then, inputting the M acoustic features into an acoustic model, and obtaining a plurality of likelihood words corresponding to each acoustic feature in the M acoustic features and a probability of each likelihood word.
And then, inputting the plurality of possible words corresponding to each voice frame and the probability corresponding to each possible word into a pre-language model, so that the pre-language model combines the plurality of possible words of each voice frame in the plurality of voice frames according to a grammar rule to obtain a plurality of word sequences, wherein the plurality of word sequences are a plurality of candidate texts. The probability of each candidate text may be derived from the probability of each word sequence. Alternatively, the probability of each word sequence may be obtained according to a product of probabilities of a plurality of possible words of each word sequence, and the acoustic score corresponding to each candidate text may be obtained according to a product of probabilities of a plurality of word sequences corresponding to each candidate text.
Optionally, when the acoustic feature of each speech frame is extracted for each speech frame in the plurality of speech frames, the extracted acoustic feature may be a Mel-frequency cepstrum coefficient (MFCC) feature, a Linear Prediction Coefficient (LPC) feature, a Linear Prediction Cepstrum Coefficient (LPCC) feature, a Line Spectral Frequency (LSF) feature, a Discrete Wavelet Transform (DWT) feature, or a Perceptual Linear Prediction (PLP) feature.
B2, scoring each candidate text in the candidate texts through a language model to obtain a language score corresponding to each candidate text; the language model is a model trained from a plurality of text data.
The language model is obtained by training a large amount of text data and is used for estimating the probability that a section of text conforms to the natural language. The language model may be an N-gram model.
The N-gram model is a probabilistic-based discriminant model whose input is a sentence (sequential sequence of words) and whose output is the probability of the sentence, i.e., the joint probability of the words. The basic idea of the N-gram model is to assume the Nth wordIs only related to the first N-1 words but not to any other words, the probability of the whole sentence is the product of the probabilities of the respective words. Such as a segment of text S consisting of w1,w2,w3...,wnIf the n words are needed to judge whether the section of the characters accords with the natural language, the joint probability of the section of the characters can be calculated according to the following formula (1):
p(S)=p(w1w2...wn)=p(w1)p(w2|w1)...p(wn|wn-1...w2w1); (1)
the larger the joint probability value calculated according to the formula (1), the higher the probability that the text corresponds to the natural language.
Wherein, the segment of characters accords with the natural language, which means whether the segment of characters accords with the grammar rule. Due to the same pronunciation, the candidate texts may be parsed into different sentences, namely a plurality of candidate texts, and the N-gram model is to find out the candidate text which best meets the grammar rule from the candidate texts as a speech recognition result. For example, "what is african of your west africa? "and" what you are doing now "are more consistent with the natural language and grammar rules, so the N-gram model will take the latter candidate as the final speech recognition result.
Wherein the language recognition accuracy of the language model in step b2 is higher than that of the pre-language model in step b 1.
B3, inputting each candidate text into a pre-scoring model to obtain a scoring score corresponding to each candidate text; the pre-duplication scoring model is obtained by training the recurrent neural network according to the voice samples in the second voice training data and the corresponding artificial labeling texts thereof.
In this embodiment, for a plurality of candidate texts corresponding to each voice sample in the first voice training data, each candidate text in the plurality of candidate texts is re-scored through a pre-re-scoring model, so as to obtain a re-score corresponding to each candidate text. Before this step, the recurrent neural network needs to be trained according to each voice sample in the second voice training data and the corresponding labeled text thereof, so as to obtain a pre-scoring model. The training process of the pre-scoring model is as follows:
specifically, training the recurrent neural network according to each voice sample in the second voice training data and the corresponding labeled text thereof to obtain a pre-scoring model, including:
and b31, inputting each voice sample in the second voice training data into the recurrent neural network to obtain the score of the training text corresponding to each voice sample.
The score of the training text corresponding to each voice sample in the second voice training data is used for representing the similarity between the training text corresponding to each voice sample and the labeled text. Because the labeled text corresponding to each voice sample in the second voice training data is an artificially labeled text, the labeled text can be regarded as a text capable of correctly expressing the semantics of each voice sample in the second voice training data, that is, a correct text. The score of the labeled text corresponding to each speech sample in the second speech training data may be set to be full, e.g., 100%. And the score of the training text may be any value less than 100%.
And b32, adjusting the network parameters of the recurrent neural network according to the difference between the score of the training text corresponding to each voice sample and the score of the labeled text.
Specifically, step b32 includes: determining an objective function value according to the difference between the score of the training text corresponding to each voice sample and the score of the labeled text; and performing back propagation according to the objective function value to adjust the network parameters of the recurrent neural network.
Wherein, the network parameters of the recurrent neural network comprise: and (4) weighting. Illustratively, when the recurrent neural network includes an input layer, a hidden layer and an output layer, the input layer and the hidden layer are connected by a first weight, and the hidden layer and the output layer are connected by a second weight, then adjusting the network parameters of the recurrent neural network refers to adjusting the first weight between the input layer and the hidden layer and the second weight between the hidden layer and the output layer.
Optionally, the network parameters of the recurrent neural network may be adjusted according to a gradient descent method. For the gradient descent method, reference is made to the description of the related art, and the present embodiment will not be described in detail here.
And b33, continuing to train the recurrent neural network according to the adjusted network parameters until the training is finished, and obtaining a pre-scoring model.
Wherein, the judgment condition of training end includes: the objective function value is smaller than a preset threshold value, or the iterative training times reach preset times. The objective function value may be determined according to a difference between the score of the training text corresponding to each voice sample and the labeled text.
After the trained pre-reprinting model is obtained, each candidate text in the multiple candidate texts can be input into the pre-reprinting model, and then the corresponding reprint of each candidate text can be obtained.
And S203, determining the weights of a plurality of scores in the current iteration training of the to-be-trained Transformer network through a Bayesian optimization algorithm according to the voice test data set.
In this step, the weights of the plurality of scores include a weight of the acoustic score, a weight of the linguistic score, and a weight of the re-score, wherein a sum of the weight of the linguistic score and the weight of the re-score is 1. The language scoring weight or the re-scoring weight is dynamically and iteratively optimized through a Bayes optimization algorithm. After determining the weight of the linguistic score or the weight of the re-scoring, the weighted scores of the linguistic score and the re-scoring can be calculated according to the weight of the linguistic score or the weight of the re-scoring, the weighted scores of the weighted scores and the acoustic scores are continuously calculated to obtain the target score, and then the target score is applied to the training process of the transform network. Alternatively, the weights of the weighted score and the acoustic score can be set according to actual needs, but it should be noted that the sum of the weights of the weighted score and the acoustic score is 1.
Optionally, determining, according to the voice test data set, the weights of the scores in the current iteration training of the transform network to be trained by using a bayesian optimization algorithm, including: and according to the voice test data set, optimizing the weights of the scores in the previous round of iterative training of the to-be-trained Transformer network through a Bayesian optimization algorithm to obtain the weights of the scores in the current round of iterative training of the to-be-trained Transformer network.
The principle of the Bayesian Optimization (BOA) algorithm is to determine the next search point by using the information of the previous search point, and to solve the black box optimization problem with low dimension. The idea of the algorithm is to generate an initial candidate solution set, then find the next possible extremum point according to the points, add the point to the set, and repeat the steps until the iteration is terminated. And finally, finding out extreme points from the points to be used as the solution of the problem. Therefore, the weights of the scores can be used as search points, a next search point is continuously searched based on Bayesian optimization to be used as the weight of the next round of iterative training, and when the weights of the scores reach an optimal value, the iterative training is finished, so that the weight scoring language model is obtained. As an optional implementation manner, when the weights of the multiple scores reach an optimal value, if the trained Transformer network is tested and the voice recognition performance is poor, the trained Transformer network may be continued to be trained on the basis of the optimal weights of the multiple scores until the voice recognition performance of the trained Transformer network is better.
Further, according to the voice test data set, optimizing the weights of the scores during the previous iteration training of the transform network to be trained through a Bayesian optimization algorithm to obtain the weights of the scores during the current iteration training of the transform network to be trained, including:
and step c1, determining the word error rate of the voice test data according to the voice test data and the Transformer network obtained by the previous iteration training.
Optionally, step c1 specifically includes:
and c11, testing the Transformer network obtained by the previous iteration training according to the voice test data to obtain a test text.
In this embodiment, each pair of the fransformer networks performs one round of iterative training, and the voice test data is input into the fransformer networks after the iterative training of this round, and the test text is determined according to the output of the fransformer networks after the iterative training of this round.
And c12, determining the word error rate of the voice test data according to the difference between the test text and the labeled text corresponding to the voice test data.
The word error rate refers to comparing the words in the test text with the words in the standard text, counting the number of letters that need to be inserted (Insertion), deleted (Deletion), and replaced (Deletion) to be the same as the number of words in the standard text, and dividing the number of letters by the total number of words in the standard text to obtain the word error rate.
Step c2, taking the weights of the scores in the previous round of iterative training as sampling points of the objective function, taking the word error rate of the voice test data as a function value of the objective function, and fitting the objective function according to Gaussian process regression to obtain Gaussian distribution of the objective function; the Gaussian distribution of the objective function is used for representing the probability distribution of the objective function at any numerical point in a preset numerical interval.
The preset value interval here may be a value between 0 and 1.
Fig. 4 is a schematic diagram of a gaussian distribution of an objective function provided in an embodiment of the present application. As shown in fig. 4, the solid line is the average of the estimated objective function values at each point. As can be seen from the figure, there are currently 3 sample points that have been searched, indicated by the solid black dots. The area between the two dotted lines is the range of variation of the function value at each point, and fluctuates in an interval that is centered on the mean, i.e., the solid line, and is proportional to the standard deviation. At the sample points searched, the solid line passes through the sample points searched, and the variance is minimal, and at sample points far from the search the variance is greater, i.e. the function value estimate at the sample points far from is less reliable.
And c3, constructing an acquisition function according to the Gaussian distribution of the target function.
Specifically, the acquisition function may be constructed according to the mean and variance of the gaussian distribution of the objective function, that is, the estimation of the probability that each point is an extreme point of the function reflects the degree to which each point is worth searching, and the extreme point of the function is the next search point.
And step c4, determining the weights of the scores during the current iteration training of the Transformer network to be trained according to the sampling points corresponding to the maximum values of the acquisition functions.
Fig. 5 is a schematic diagram of an acquisition function provided in the embodiment of the present application. As shown in fig. 5, the point where the small rectangular square is located is the extreme point of the collection function, i.e. the next searched sampling point.
It is noted that in the first bayesian optimization process, the linguistic score or the weight of the re-scoring needs to be initialized. Optionally, the linguistic score or weight for the re-scoring may be set to 0.5.
The dynamic optimization of the weights of the multiple scores by a bayesian optimization algorithm can be summarized as follows:
fig. 6 is an exemplary diagram of adjusting weights of a plurality of scores by a bayesian optimization algorithm provided in an embodiment of the present application. As shown in fig. 6, the weights of the scores are initialized, for example, the weight λ 1 of the first round of iterative training of language score or reprinting is initialized to 0.5 as the first sample point, then the target score of the first round of iterative training is calculated according to the initialized weight λ 1, and f (x) the word error rate is calculated based on the difference between Top1 of the reordering result and the real text after the plurality of candidate texts are reordered based on the target score of the first round of iterative training. And then, obtaining a Gaussian distribution p (f) (x) of a fitted target function f (x) through Gaussian process regression, wherein the p (f) (x) represents that the Gaussian process regression is modeled according to the existing sampling points (namely the existing lambda) and corresponding function values, fitting the target function f (x), then constructing an acquisition function u (x) according to the mean value and the variance of the fitted p (f) (x), determining the next sampling point lambda n according to the maximum value of the acquisition function, and the next sampling point lambda n participates in the next round of iterative training of the Transformer network. 3. The whole optimization process is a process of simulating an objective function f (x) through the existing sampling points, selecting the next sampling point according to u (x), and calculating to obtain a function value f (x) and continuously updating p (f (x)).
And S204, performing the iteration training of the current round on the Transformer network according to the candidate texts and the scores and the weights of the scores of the candidate texts in the iteration training of the current round, and repeating the steps until the training of the Transformer network reaches the convergence condition to obtain the repeated scoring language model.
Optionally, step S204 specifically includes:
and d1, pre-training the Transformer network according to the candidate texts, the scores of the candidate texts, the weight of the iterative training of the scores in the current round and the first voice training data to obtain the pre-trained Transformer network.
Optionally, step d1 specifically includes:
and d11, determining the weighted sum of the scores of the candidate texts according to the scores corresponding to the candidate texts and the weights of the scores in the iterative training of the current round, and obtaining the target score of the iterative training of the current round.
Illustratively, when the plurality of scores corresponding to each candidate text includes an acoustic score, a linguistic score and a weight score, step d11 may be expressed as the following formula (2):
p=p1·λ1+p2·λ2+p3·λ3; (2)
in the formula (2), p is a target score corresponding to each candidate text; p is a radical of formula1An acoustic score corresponding to each candidate text; lambda [ alpha ]1Weights corresponding to the acoustic scores; p is a radical of formula2A language score corresponding to each candidate text; lambda [ alpha ]2Scoring a corresponding weight for the language; p is a radical of3Scoring the corresponding repetition of each candidate text; lambda [ alpha ]3The corresponding weight is re-assigned.
The embodiment sets the corresponding weight of the acoustic score as a fixed value and matches lambda2Or λ3And (6) optimizing.
And d12, pre-training the Transformer network according to the first voice training data and the target score of the iterative training in the current round to obtain the pre-trained Transformer network.
Further, step d12 specifically includes:
and d121, extracting acoustic features of the voice samples in the first voice training data to obtain acoustic features corresponding to the voice samples in the first voice training data.
Alternatively, the acoustic features of the first speech training data may be extracted by a speech recognition tool. Alternatively, the speech recognition tool may be a kaldi tool. The acoustic features refer to physical quantities representing acoustic characteristics of speech, and are also a general term for acoustic representation of various elements of sound, such as energy concentration areas representing tone colors, formant frequencies, formant intensities and band views, and duration, fundamental frequency, average speech power and the like representing prosodic characteristics of speech. For example, the acoustic features may be Mel-frequency cepstral coefficient (MFCC) features, Linear Prediction Coefficient (LPC) features, Linear Prediction Cepstral Coefficient (LPCC) features, Line Spectral Frequency (LSF) features, Discrete Wavelet Transform (DWT) features, or Perceptual Linear Prediction (PLP) features.
And d122, extracting text features of the candidate texts corresponding to the voice samples to obtain a plurality of text features corresponding to the voice samples, wherein each text feature corresponds to one candidate text.
Optionally, the text features of each candidate text may be extracted through the BERT language model, so as to obtain the text features corresponding to each candidate text. Taking a speech sample as an example, assuming that a speech sample corresponds to N candidate texts, in this step, a text feature is extracted for each candidate text in the N candidate texts, so as to obtain N text features corresponding to the speech sample, where each text feature in the N text features corresponds to one candidate text of the speech sample.
And d123, training the transform network according to the acoustic features and the text features corresponding to the voice samples in the first voice training data to obtain correlation scores between the acoustic features and the text features corresponding to the voice samples in the first voice training data.
Combining the acoustic features corresponding to each voice sample with each text feature in the plurality of text features, and inputting the combined acoustic features and each text feature into a Transformer network for training.
In the example in the adapting step d122, for a segment of voice sample, in this step, the acoustic features corresponding to the voice sample are combined with each text feature in the N text features to obtain N combined features, and the N combined features are input into the Transformer network, so that the Transformer network learns the correlation or similarity between the acoustic features and the N text features.
And d124, sequencing the plurality of text features according to the correlation scores between the acoustic features corresponding to the voice samples in the first voice training data and the plurality of text features to obtain text feature sequencing.
And d125, determining the network parameters of the Transformer network according to the difference between the sequence of the candidate texts and the sequence of the text features, so as to obtain the pre-trained Transformer network.
Before step d125, a re-ranking of the candidate texts needs to be determined as a ranking of the candidate texts in step d 125. The reordering of the candidate texts and the target score of each candidate text are used as training data of the Transformer network. The process of generating training data for a Transformer network is described below with reference to the accompanying drawings:
fig. 7 is an exemplary diagram of generating training data of a transform network according to an embodiment of the present application. As shown in fig. 7, first, each candidate text in the multiple candidate texts is scored according to the language rules by the language model to obtain a linguistic score, and each candidate text in the multiple candidate texts is re-scored according to the language rules by the pre-re-scoring model to obtain a re-score. And then, taking the average value of the language score and the re-scoring as the weak supervision signal characteristic, and weighting the weak supervision signal characteristic and the acoustic score to obtain the target score of each candidate text. After the target score corresponding to each candidate text in the multiple candidate texts is obtained, the multiple candidate texts may be ranked according to the sequence from high to low of the target score corresponding to each candidate text, so as to obtain the re-ranking of the multiple candidate texts.
Determining an objective function value according to the difference between the ordering of the candidate texts and the ordering of the text features; and performing back propagation according to the objective function value to adjust the network parameters of the Transformer network.
Optionally, the network parameters of the Transformer network may be adjusted according to a gradient descent method.
The following describes the training process of the scoring model with reference to the accompanying drawings:
fig. 8 is an exemplary diagram of a training process of a pre-trained Transformer network according to an embodiment of the present application. As shown in fig. 8, first, acoustic features of a speech sample a in first speech training data are extracted by a speech recognition tool, and a text feature of each candidate text in a plurality of candidate texts of the speech sample a in the first speech training data is extracted by a language model; and then combining the acoustic features of the voice sample A in the first voice training data with the plurality of text features, inputting the combined acoustic features and the plurality of text features into a transform network to obtain a relevance score of the acoustic features and each text feature, and sequencing the plurality of text features according to the relevance score of each text feature to obtain the sequencing of the plurality of text features. And then, according to the difference between the sequence of the candidate texts and the sequence of the text features, adjusting the network parameters of the Transformer network after the current training to obtain the network parameters of the Transformer network after the next training, and repeating the training step until the training is finished to obtain the pre-trained Transformer network.
The pre-trained transform network obtained in the step is essentially obtained by training according to the voice sample without the label, and the accuracy of voice recognition is low. Therefore, the embodiment may also adopt step d2 to fine tune the pre-trained Transformer network based on the second speech training data with the artificial annotation text (finetune).
And d2, fine tuning the pre-trained Transformer network according to the second voice training data to obtain a fine-tuned Transformer network.
Optionally, step d2 specifically includes:
and d21, inputting the voice sample in the second voice training data into the pre-trained Transformer network to obtain the predicted text corresponding to the voice sample in the second voice training data.
This step d21 may be performed simultaneously with step S201, i.e. simultaneously acquiring the first voice training data, the voice test data set and the second voice training data. Step S201 may be executed first, and then the second speech training data is obtained in the fine tuning process to execute step d 2.
And d22, adjusting the network parameters of the Transformer network according to the difference between the labeled text and the predicted text corresponding to the voice sample in the second voice training data to obtain the fine-tuned Transformer network.
Specifically, in this step, an objective function value is determined according to a difference between a target score of a labeled text corresponding to each voice sample in the second voice training data and a score of a predicted text; and performing back propagation according to the objective function value so as to update the network parameters of the Transformer network.
The network parameters of the transform network comprise: network weight. Optionally, the network parameters of the Transformer network may be updated according to a gradient descent method.
Step d3, repeating the pre-training and fine-tuning steps for N times to obtain a Transformer network of the iterative training of the current round; n is an integer which is greater than or equal to 1 and is less than the total iterative training times of the Transformer network.
Optionally, in this step, pre-training and fine-tuning the Transformer network once may be performed according to the first voice training data and the multiple scores corresponding to each of the multiple candidate texts of each voice sample in the first voice training data; then, testing the once-trained Transformer network once according to the voice test data to obtain a test text; according to the difference between the labeled text and the test text of the voice test data, adjusting the weight of a plurality of scores corresponding to each candidate text, which is a round of training process; and then, continuing to train the Transformer network according to the weight of the plurality of scores optimized in each round. After multiple rounds of training, if the trained Transformer network converges, a re-scoring model can be obtained.
The embodiment comprises the steps of acquiring first voice training data and a voice test data set; the first voice training data comprises a plurality of voice samples; determining a plurality of candidate texts corresponding to the first voice training data and a plurality of scores corresponding to the candidate texts; determining the weights of a plurality of scores in the current iteration training of the Transformer network to be trained through a Bayesian optimization algorithm according to the voice test data set; and performing iteration training on the Transformer network in the current iteration training according to the candidate texts and the scores and the weights of the scores of the candidate texts in the current iteration training, and repeating the steps until the training of the Transformer network reaches a convergence condition to obtain a re-scoring language model. As the weights of the scores are determined by the Bayesian optimization algorithm for each iteration training of the transform network to be trained, the weights of the scores for each iteration training can be dynamically adjusted, so that the target scores determined according to the weights of the scores are more accurate later, namely the accuracy of the candidate texts automatically calibrated by the first voice training data without manually labeled texts is higher, the accuracy of scoring can be improved, and the accuracy of voice recognition is further improved.
In addition, in the embodiment, firstly, weak supervision data is used for preliminary pre-training, and then, existing voice samples with small parts of manually labeled texts are used for fine tuning, so that the first voice training data without manually labeled texts are fully utilized and applied to the training process of the re-grading model. Thereby solving the problem of lack of voice text labels.
Optionally, in this embodiment, the first speech training data and the multiple scores corresponding to each candidate text of the multiple candidate texts of each speech sample in the first speech training data may also be used to perform one training on the Transformer network, where the one training includes multiple pre-training and one fine-tuning; then, testing the once-trained Transformer network once according to the voice test data to obtain a test text; according to the difference between the labeled text and the test text of the voice test data, adjusting the weight of a plurality of scores corresponding to each candidate text, which is a round of training process; and then, continuing to train the Transformer network according to the weight of the plurality of scores optimized in each round. After multiple rounds of training, if the trained Transformer network is converged, a re-scoring model can be obtained.
After the re-scoring language model is obtained through training according to the training method of the re-scoring language model, the re-scoring language model can be arranged in a voice recognition system, and voice recognition is carried out on the voice to be recognized through the voice recognition system. The speech recognition method is described in detail below with reference to the accompanying drawings:
fig. 9 is a flowchart of a speech recognition method according to an embodiment of the present application. As shown in fig. 9, the speech recognition method includes the following steps:
step 901, obtaining voice data to be recognized.
Step 902, inputting the voice data to be recognized into a voice recognition system to obtain a voice recognition result; the speech recognition result includes a ranking of the plurality of candidate texts.
The voice recognition system comprises a voice recognition model and a re-scoring language model, the voice recognition model is used for outputting a plurality of candidate texts and scores of the candidate texts according to voice data to be recognized, the re-scoring language model is used for re-scoring each candidate text in the candidate texts and sequencing the candidate texts according to the re-scoring of the candidate texts to obtain sequencing of the candidate texts, and the re-scoring language model is trained according to a training method of the re-scoring language model.
The execution subject of the speech recognition method of the present embodiment may be a speech recognition system.
In an optional implementation manner, the voice system may be disposed in the server, after the voice to be recognized is collected by the voice collector on the terminal device, the voice to be recognized is sent to the server, and the server invokes the voice recognition system to perform voice recognition on the voice to be recognized, so as to obtain a voice recognition result, and returns the voice recognition result to the terminal device.
In another optional implementation manner, the voice system may also be disposed in the terminal device, and when the voice to be recognized is collected by the voice collector on the terminal device, the voice recognition system in the terminal device may be directly called to perform voice recognition, so as to obtain a voice recognition result, and the voice recognition result is displayed on the terminal device.
The voice data to be recognized may be voice to be converted into text selected by the user through the terminal device.
In some instant messaging applications or manual customer service scenes, when a user triggers a voice-to-text operation for a section of voice, the terminal device can send the section of voice to the server, and the server calls the voice recognition system to perform voice recognition on the voice to be recognized to obtain a voice recognition result and returns the voice recognition result to the terminal device. Or the terminal device calls a voice recognition system in the terminal device to perform voice recognition on the voice to be recognized, so that a voice recognition result is obtained, and the voice recognition result is displayed.
In the automatic customer service scene, when a user inputs a section of voice through the terminal equipment, the terminal equipment can send the section of voice to the server, the server calls the voice recognition system to perform voice recognition on the voice to be recognized to obtain a voice recognition result, corresponding answer dialogues are matched according to the voice recognition result, the answer dialogues are returned to the terminal equipment, and the terminal equipment displays the answer dialogues. Or the terminal device calls a voice recognition system in the terminal device to perform voice recognition on the voice to be recognized to obtain a voice recognition result, matches a corresponding answer word according to the voice recognition result, and returns the answer word to the terminal device for display.
On the basis of the foregoing re-scoring language model training method embodiment, fig. 10 is a schematic structural diagram of a re-scoring language model training device provided in this application embodiment. As shown in fig. 10, the re-scoring language model training apparatus includes: the system comprises an acquisition module 101, a determination module 102 and a training module 103; the acquiring module 101 is configured to acquire first voice training data and a voice test data set; the first voice training data comprises a plurality of voice samples; a determining module 102, configured to determine a plurality of candidate texts corresponding to the first speech training data and a plurality of scores corresponding to the candidate texts; determining the weight of the scores in the current iteration training of the transform network to be trained through a Bayesian optimization algorithm according to the voice test data set; the training module 103 is configured to perform iterative training on the Transformer network in a current round according to the candidate texts, the scores of the candidate texts and the weights of the iterative training in the current round of the scores, and repeat the above steps until the training of the Transformer network reaches a convergence condition, so as to obtain a re-scoring language model.
Optionally, the determining module 102 determines, according to the voice test data set, the weights of the scores in the current iteration training of the to-be-trained Transformer network through a bayesian optimization algorithm, and specifically includes: and optimizing the weights of the scores in the previous iteration training of the to-be-trained Transformer network through a Bayesian optimization algorithm according to the voice test data set to obtain the weights of the scores in the current iteration training of the to-be-trained Transformer network.
Optionally, the determining module 102 optimizes, according to the voice test data set, the weights of the multiple scores during a previous iteration training of the transform network to be trained through a bayesian optimization algorithm, to obtain the weights of the multiple scores during a current iteration training of the transform network to be trained, which specifically includes: determining the word error rate of the voice test data according to the voice test data and a Transformer network obtained by the previous iteration training; taking the weights of the scores during the previous round of iterative training as sampling points of an objective function, taking the word error rate of the voice test data as a function value of the objective function, and fitting the objective function according to Gaussian process regression to obtain Gaussian distribution of the objective function; the Gaussian distribution of the target function is used for representing the probability distribution of the target function at any numerical point in a preset numerical interval; constructing an acquisition function according to the Gaussian distribution of the target function; and determining the weights of the scores in the current iteration training of the to-be-trained Transformer network according to the sampling points corresponding to the maximum values of the acquisition functions.
Optionally, the determining module 102 determines the word error rate of the voice test data according to the voice test data and a Transformer network obtained through a previous iteration training, and specifically includes: testing the Transformer network obtained by the previous iteration training according to the voice test data to obtain a test text; and determining the word error rate of the voice test data according to the difference between the test text and the labeled text corresponding to the voice test data.
Optionally, the training module 103 performs iterative training on the transform network in a current round according to the candidate texts, the scores of the candidate texts, and the weight of the iterative training in the current round of the scores, specifically including: pre-training the Transformer network according to the candidate texts, the scores of the candidate texts, the weight of the iterative training of the scores in the current round and the first voice training data to obtain a pre-trained Transformer network; fine-tuning the pre-trained Transformer network according to second voice training data to obtain a fine-tuned Transformer network; the second voice training data comprises a plurality of voice samples and labeled texts; repeating the pre-training and fine-tuning steps for N times to obtain a Transformer network of the current iteration training; and N is an integer which is greater than or equal to 1 and is less than the total iterative training times of the Transformer network.
Optionally, the training module 103 pre-trains the Transformer network according to the multiple candidate texts, the multiple scores of the candidate texts, the weight of the iterative training of the scores in the current round, and the first voice training data, to obtain a pre-trained Transformer network, which specifically includes: determining the weighted sum of the scores of the candidate texts according to the scores corresponding to the candidate texts and the weights of the scores in the iterative training of the current round, so as to obtain the target score of the iterative training of the current round; and pre-training the Transformer network according to the first voice training data and the target score of the current iteration training to obtain the pre-trained Transformer network.
Optionally, the training module 103 pre-trains the Transformer network according to the first voice training data and the target score of the current iteration training to obtain a pre-trained Transformer network, and specifically includes: extracting acoustic features of voice samples in the first voice training data to obtain acoustic features corresponding to the voice samples in the first voice training data; extracting text features of the candidate texts corresponding to the voice sample to obtain a plurality of text features corresponding to the voice sample, wherein each text feature corresponds to one candidate text; training a transform network according to the acoustic features and the text features corresponding to the voice samples in the first voice training data to obtain correlation scores between the acoustic features and the text features corresponding to the voice samples in the first voice training data; sorting the plurality of text features according to the relevance scores between the acoustic features corresponding to the voice samples in the first voice training data and the plurality of text features to obtain text feature sorting; and determining the network parameters of the Transformer network according to the difference between the sequence of the candidate texts and the sequence of the text features to obtain the pre-trained Transformer network.
Optionally, the training module 103 performs fine tuning on the pre-trained transform network according to second voice training data to obtain a fine-tuned transform network, which specifically includes: inputting the voice sample in the second voice training data into the pre-trained Transformer network to obtain a predicted text corresponding to the voice sample in the second voice training data; and adjusting the network parameters of the Transformer network according to the difference between the labeled text and the predicted text corresponding to the voice sample in the second voice training data to obtain the fine-tuned Transformer network.
Optionally, the determining module 102 determines a plurality of candidate texts and a plurality of scores corresponding to the candidate texts, where the determining includes: determining a plurality of candidate texts corresponding to the voice samples in the first voice training data and acoustic scores, linguistic scores and reprinting scores corresponding to the candidate texts; the weight of the scores is the corresponding weight of the language score or the re-scoring; wherein the acoustic score is used for representing the probability of the likelihood word corresponding to the voice sample, and the language score is used for representing the probability of the candidate text conforming to the natural language; the acoustic score and the language score are respectively and correspondingly weighted; the re-scoring is obtained by re-scoring the candidate text through a pre-re-scoring model, and the pre-re-scoring model is obtained by training a recurrent neural network according to a second voice sample; the second voice training data comprises a plurality of voice samples and labeled text.
The re-scoring language model training device provided by the embodiment of the application can be used for executing the technical scheme of the re-scoring language model training method in the embodiment, the implementation principle and the technical effect are similar, and the implementation principle and the technical effect are not repeated herein.
Based on the above embodiment of the speech recognition method, fig. 11 is a schematic structural diagram of a speech recognition apparatus provided in the embodiment of the present application. As shown in fig. 11, the speech recognition apparatus includes: an acquisition module 111 and a voice recognition module 112; the acquiring module 111 is configured to acquire voice data to be recognized; the voice recognition module 112 is configured to input the voice data to be recognized into a voice recognition system, so as to obtain a voice recognition result; the speech recognition result comprises a ranking of a plurality of candidate texts; the voice recognition system comprises a voice recognition model and a re-scoring language model, wherein the voice recognition model is used for outputting a plurality of candidate texts and scores of the candidate texts according to the voice data to be recognized, the re-scoring language model is used for re-scoring each candidate text in the candidate texts and ranking the candidate texts according to the re-scoring of the candidate texts to obtain the ranking of the candidate texts, and the re-scoring language model is trained according to a re-scoring language model training method.
The speech recognition device provided in the embodiment of the present application may be used to implement the technical solution of the speech recognition method in the foregoing embodiments, and the implementation principle and the technical effect are similar, which are not described herein again.
On the basis of the above embodiments of the training method and the speech recognition method of the re-scoring module, fig. 12 is a schematic structural diagram of a speech recognition system provided in the embodiments of the present application. As shown in fig. 12, the speech recognition system includes: a speech recognition model 121, configured to output a plurality of candidate texts and a score of each candidate text according to the speech data to be recognized; the re-scoring language model 122 obtained by training with the training method of the re-scoring language model in the above embodiment is used for re-scoring each candidate text in the multiple candidate texts and outputting a ranking result of ranking the multiple candidate texts according to the re-scoring of the multiple candidate texts.
Optionally, the system further includes: and the voice acquisition device 123 is configured to acquire voice data to be recognized, and input the voice data to be recognized into the voice recognition model.
It should be noted that the division of the modules of the above apparatus is only a logical division, and the actual implementation may be wholly or partially integrated into one physical entity, or may be physically separated. And these modules can all be implemented in the form of software invoked by a processing element; or can be implemented in the form of hardware; and part of the modules can be realized in the form of calling software by the processing element, and part of the modules can be realized in the form of hardware. For example, the training module 103 may be a separate processing element, or may be integrated into a chip of the apparatus, or may be stored in a memory of the apparatus in the form of program code, and a processing element of the apparatus calls and executes the functions of the training module 84. Other modules are implemented similarly. In addition, all or part of the modules can be integrated together or can be independently realized. The processing element here may be an integrated circuit with signal processing capabilities. In implementation, each step of the above method or each module above may be implemented by an integrated logic circuit of hardware in a processor element or an instruction in the form of software.
Fig. 13 is a schematic structural diagram of an electronic device according to an embodiment of the present application. As shown in fig. 13, the electronic device may include: transceiver 131, processor 132, memory 133.
Processor 132 executes computer-executable instructions stored in memory, which cause processor 132 to perform aspects of the embodiments described above. The processor 132 may be a general-purpose processor including a central processing unit CPU, a Network Processor (NP), and the like; but also a digital signal processor DSP, an application specific integrated circuit ASIC, a field programmable gate array FPGA or other programmable logic device, discrete gate or transistor logic, discrete hardware components.
A memory 133 is coupled to and in communication with processor 132 via the system bus, memory 133 storing computer program instructions.
The transceiver 131 may be used to obtain the speech to be recognized and return the speech recognition result.
The system bus may be a Peripheral Component Interconnect (PCI) bus, an Extended Industry Standard Architecture (EISA) bus, or the like. The system bus may be divided into an address bus, a data bus, a control bus, and the like. For ease of illustration, only one thick line is shown, but this does not mean that there is only one bus or one type of bus. The transceiver is used to enable communication between the database access device and other computers (e.g., clients, read-write libraries, and read-only libraries). The memory may include Random Access Memory (RAM) and may also include non-volatile memory (non-volatile memory).
The electronic device provided by the embodiment of the present application may be the terminal device or the server of the foregoing embodiment.
The embodiment of the application also provides a chip for running the instruction, and the chip is used for executing the technical scheme of the re-scoring language model training method or the voice recognition method in the embodiment.
The embodiment of the present application further provides a computer-readable storage medium, where the computer-readable storage medium stores computer instructions, and when the computer instructions are run on a computer, the computer is enabled to execute the technical solution of the above-described re-scoring language model training method or the above-described speech recognition method.
The embodiments of the present application further provide a computer program product, where the computer program product includes a computer program stored in a computer-readable storage medium, and at least one processor can read the computer program from the computer-readable storage medium, and when the computer program is executed by the at least one processor, the technical solution of the re-scoring language model training method or the speech recognition method in the foregoing embodiments can be implemented.
Other embodiments of the present application will be apparent to those skilled in the art from consideration of the specification and practice of the invention disclosed herein. This application is intended to cover any variations, uses, or adaptations of the invention following, in general, the principles of the application and including such departures from the present disclosure as come within known or customary practice within the art to which the invention pertains. It is intended that the specification and examples be considered as exemplary only, with a true scope and spirit of the application being indicated by the following claims.
It will be understood that the present application is not limited to the precise arrangements described above and shown in the drawings and that various modifications and changes may be made without departing from the scope thereof. The scope of the application is limited only by the appended claims.