CN114758319A - A near-field vehicle jamming behavior prediction method based on image input - Google Patents
A near-field vehicle jamming behavior prediction method based on image input Download PDFInfo
- Publication number
- CN114758319A CN114758319A CN202210289381.4A CN202210289381A CN114758319A CN 114758319 A CN114758319 A CN 114758319A CN 202210289381 A CN202210289381 A CN 202210289381A CN 114758319 A CN114758319 A CN 114758319A
- Authority
- CN
- China
- Prior art keywords
- vehicle
- lane
- target
- lane line
- jamming
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/20—Analysis of motion
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30248—Vehicle exterior or interior
- G06T2207/30252—Vehicle exterior; Vicinity of vehicle
- G06T2207/30256—Lane; Road marking
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computing Systems (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
- Traffic Control Systems (AREA)
Abstract
本发明涉及一种基于图像输入的近场车辆加塞行为预测方法,该方法包括:(1)采集真实的结构化道路场景中基于前向全景图像的图像序列信息,通过人工方法标注图像序列中车辆目标的位置以及行为信息;(2)构建适用于结构化道路中近场车辆检测与跟踪的近场车辆检测与跟踪模型;(3)构建适用于结构化道路中车道线检测的车道线检测网络及相应的损失函数;(4)基于步骤(2)建立的近场车辆检测与跟踪模型获得的车辆ID与对应目标的边界框位置数据、以及步骤(3)建立的车道线检测网络获得的车道线,获得目标与车道线的相对位置偏差,根据先验规则的制定,得到近场车辆的加塞行为预测结果。与现有技术相比,本发明预测准确度高,效率高。

The invention relates to a near-field vehicle jamming behavior prediction method based on image input. The method includes: (1) collecting image sequence information based on forward panoramic images in a real structured road scene, and manually labeling vehicles in the image sequence The location and behavior information of the target; (2) Build a near-field vehicle detection and tracking model suitable for near-field vehicle detection and tracking in structured roads; (3) Build a lane line detection network suitable for lane line detection in structured roads and the corresponding loss function; (4) the vehicle ID and the bounding box position data of the corresponding target obtained based on the near-field vehicle detection and tracking model established in step (2), and the lane obtained by the lane line detection network established in step (3) line to obtain the relative position deviation of the target and the lane line, and according to the formulation of the prior rules, the prediction result of the jamming behavior of the near-field vehicle is obtained. Compared with the prior art, the present invention has high prediction accuracy and high efficiency.
Description
技术领域technical field
本发明涉及智能驾驶技术领域,尤其是涉及一种基于图像输入的近场车辆加塞行为预测方法。The invention relates to the technical field of intelligent driving, in particular to a near-field vehicle jamming behavior prediction method based on image input.
背景技术Background technique
行为预测属于基于行为识别的进一步发展,而作为计算机视觉领域的基本任务之一,近些年随着深度学习技术的火热发展,行为预测算法也存在制定先验规则的算法以及基于深度神经网络的端到端预测技术。行为识别与预测的方法从最初的基于物理运动特征的方法发展到基于视觉视频输入的SlowFast网络、基于双模态输入动作识别网络TSN以及基于膨胀三维卷积(I3D)的3D卷积神经网络,涌现出许多好的算法技术,这些算法在开放的人类行为识别数据集上的检测效果和性能都很出色,但是针对近场车辆加塞行为预测任务,在实际应用中存在以下缺点:Behavior prediction is a further development based on behavior recognition. As one of the basic tasks in the field of computer vision, with the rapid development of deep learning technology in recent years, behavior prediction algorithms also include algorithms for formulating prior rules and algorithms based on deep neural networks. End-to-end prediction technology. The method of behavior recognition and prediction has developed from the original method based on physical motion features to the SlowFast network based on visual video input, the action recognition network TSN based on bimodal input, and the 3D convolutional neural network based on dilated three-dimensional convolution (I3D). Many good algorithm techniques have emerged. These algorithms have excellent detection effects and performance on open human behavior recognition datasets. However, for the near-field vehicle jamming behavior prediction task, there are the following shortcomings in practical applications:
其一,现有的公开数据集中,缺少针对近场车辆加塞行为预测的自车辆(EgoVehicle)视角数据集,与目标检测数据集相比,在数据的采集、标注中存在很多困难,限制了该技术的进一步发展;First, in the existing public datasets, there is a lack of EgoVehicle perspective datasets for near-field vehicle jamming behavior prediction. the further development of technology;
其二,双模态输入技术中,光流属于手工制作特征,与RGB输入分别训练,不能实现端到端的训练,系统的准确率也有待提高,同时复杂的算法降低系统运行的实时性;Second, in the dual-modal input technology, the optical flow is a hand-made feature, and it is trained separately from the RGB input, which cannot achieve end-to-end training, and the accuracy of the system needs to be improved. At the same time, the complex algorithm reduces the real-time performance of the system;
其三,基于LiDAR的方法硬件成本和使用维护成本较高,同时目前缺少以前向全景图像视频为输入的自车辆(Ego Vehicle)视角行为预测方法。Third, the hardware cost and maintenance cost of the LiDAR-based method are high, and there is currently no method for predicting the behavior of the Ego Vehicle from the perspective of the forward panoramic image and video.
其四,基于深度学习的端到端的方法,存在训练模型的泛化性不好、具体原理不清晰、以及对于移动端的硬件要求较高等问题,较难在实际场景中快速落地。Fourth, the end-to-end method based on deep learning has problems such as poor generalization of the training model, unclear specific principles, and high hardware requirements for mobile terminals, making it difficult to quickly implement in actual scenarios.
发明内容SUMMARY OF THE INVENTION
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于图像输入的近场车辆加塞行为预测方法,其能够以一段时间内车载高清相机提供的前向全景图像视频数据作为输入,利用基于图像输入的目标检测跟踪算法得到自车辆(Ego Vehicle)视角下的前向目标车辆感兴趣区域的感知和跟踪,再对感兴趣区域基于制定先验规则的算法进行行为预测,在保证推理速度的前提下,大大降低了实际部署的软硬件成本,最终得到对临近车辆加塞行为较为准确的预测,为智能驾驶系统规避风险提供了充足的时间,提升了智能驾驶系统整体的安全性。The purpose of the present invention is to provide a near-field vehicle jamming behavior prediction method based on image input in order to overcome the above-mentioned defects in the prior art. The target detection and tracking algorithm based on image input is used to obtain the perception and tracking of the area of interest of the forward target vehicle from the perspective of the ego vehicle. Under the premise of speed, the cost of software and hardware for actual deployment is greatly reduced, and finally a more accurate prediction of the jamming behavior of adjacent vehicles is obtained, which provides sufficient time for the intelligent driving system to avoid risks and improves the overall safety of the intelligent driving system.
本发明的目的可以通过以下技术方案来实现:The object of the present invention can be realized through the following technical solutions:
一种基于图像输入的近场车辆加塞行为预测方法,该方法包括:A near-field vehicle jamming behavior prediction method based on image input, the method comprising:
(1)采集真实的结构化道路场景中基于前向全景图像的图像序列信息,通过人工方法标注图像序列中车辆目标的位置以及行为信息;(1) Collect the image sequence information based on the forward panoramic image in the real structured road scene, and manually mark the position and behavior information of the vehicle target in the image sequence;
(2)构建适用于结构化道路中近场车辆检测与跟踪的近场车辆检测与跟踪模型;(2) Build a near-field vehicle detection and tracking model suitable for near-field vehicle detection and tracking in structured roads;
(3)构建适用于结构化道路中车道线检测的车道线检测网络及相应的损失函数;(3) Construct a lane line detection network and corresponding loss function suitable for lane line detection in structured roads;
(4)基于步骤(2)建立的近场车辆检测与跟踪模型获得的车辆ID与对应目标的边界框位置数据、以及步骤(3)建立的车道线检测网络获得的车道线,获得目标与车道线的相对位置偏差,根据先验规则的制定,得到近场车辆的加塞行为预测结果。(4) Based on the vehicle ID obtained by the near-field vehicle detection and tracking model established in step (2) and the bounding box position data of the corresponding target, and the lane line obtained by the lane line detection network established in step (3), the target and lane are obtained. According to the relative position deviation of the line, according to the formulation of the prior rules, the prediction result of the jamming behavior of the near-field vehicle is obtained.
优选地,步骤(1)具体包括:Preferably, step (1) specifically includes:
(11)对摄像头的内外参进行标定,其中外参包括旋转矩阵R和平移向量T,内参包括内参矩阵K,以及相机畸变系数;(11) Calibrate the internal and external parameters of the camera, wherein the external parameters include a rotation matrix R and a translation vector T, and the internal parameters include an internal parameter matrix K, and the camera distortion coefficient;
(12)利用装有摄像头的数据采集车在真实道路场景中采集视频数据,并记录采集时图像内车辆目标的类别;(12) Use a data collection vehicle equipped with a camera to collect video data in a real road scene, and record the type of vehicle target in the image at the time of collection;
(13)利用标注工具对采集到的视频数据进行标注,标注方式包含车辆目标跟踪ID标注、车辆目标类别标注、目标物体边界框标注、车辆加塞开始、车辆越过车道线中点以及车辆完成加塞行为的关键帧标注、车辆加塞行为类别标注,标注内容至少需要包含近场车辆的位置、关键帧以及加塞行为类别信息。(13) Annotate the collected video data with an annotation tool. The annotation methods include vehicle target tracking ID annotation, vehicle target category annotation, target object bounding box annotation, vehicle jamming start, vehicle crossing the midpoint of the lane line, and vehicle completion jamming behavior The key frame annotations and vehicle jamming behavior category annotations of the , and the annotation content needs to include at least the location, keyframes, and jamming behavior category information of the near-field vehicle.
优选地,步骤(2)具体包括:Preferably, step (2) specifically includes:
(21)构建基于改进的Yolov5的近场车辆目标检测网络,将输入的视频切片作为图像时间序列输入至近场车辆目标检测网络,经过多层卷积与下采样操作,对输入的图像信息进行特征提取与特征编码,得到将图片划分好的多维特征张量;(21) Construct a near-field vehicle target detection network based on the improved Yolov5, input the input video slices as image time series to the near-field vehicle target detection network, and perform multi-layer convolution and downsampling operations to characterize the input image information Extraction and feature encoding to obtain a multi-dimensional feature tensor that divides the image;
(22)构建分类网络,采用非极大抑制操作,最终得到各个目标的位置信息与分类置信度信息,包括对象的分类概率和定位概率;(22) Build a classification network, adopt non-maximum suppression operation, and finally obtain the location information and classification confidence information of each target, including the classification probability and positioning probability of the object;
(23)构建基于改进的Deep-SORT的近场车辆目标跟踪网络,将目标检测得到的目标物体边界框信息以及分类信息作为输入,对视频中多个对象同时定位与追踪并记录ID和轨迹信息,尤其是在有遮挡的条件下减少对象ID的变换,输出目标车辆的跟踪ID、目标类别以及目标物体边界框信息。(23) Build a near-field vehicle target tracking network based on improved Deep-SORT, take the target object bounding box information and classification information obtained by target detection as input, locate and track multiple objects in the video simultaneously, and record ID and trajectory information , especially under the condition of occlusion, reduce the transformation of object ID, and output the tracking ID of the target vehicle, the target category and the bounding box information of the target object.
优选地,步骤(3)具体包括:Preferably, step (3) specifically includes:
(31)构建基于卷积神经网络的车道线特征提取骨干网络,基于浅层残差连接网络输出特征,通过使用较大的感受野,在保证检测效果的同时提高模型的推理速度;(31) Construct a backbone network for lane feature extraction based on convolutional neural network, output features based on shallow residual connection network, and improve the inference speed of the model while ensuring the detection effect by using a larger receptive field;
(32)构建车道线语义分割网络,在网络训练时将多尺度特征上采样到同一尺度,并经过转置卷积,计算语义分割损失,增强骨干网络的视觉特征抽取能力,最终得到增强的基于残差连接的车道线检测骨干网络;(32) Construct a lane line semantic segmentation network, up-sample multi-scale features to the same scale during network training, and through transposed convolution, calculate the semantic segmentation loss, enhance the visual feature extraction ability of the backbone network, and finally obtain an enhanced based on Residual connected lane detection backbone network;
(33)将骨干网络抽取的特征,根据先验指定的图片纵向候选锚框,在全局范围内通过分类器计算候选点,最终得到自车辆所在车道的车道线位置节点;(33) According to the features extracted by the backbone network, according to the longitudinal candidate anchor frame of the picture specified by the prior, the candidate points are calculated by the classifier in the global scope, and finally the lane line position node of the lane where the vehicle is located is obtained;
(34)构建车道线检测网络的损失函数,包括多分类损失、分割损失以及车道结构化损失。(34) Construct the loss function of lane line detection network, including multi-classification loss, segmentation loss and lane structure loss.
优选地,所述的车道线检测网络的损失函数表示为Ltotal:Preferably, the loss function of the lane line detection network is expressed as L total :
Ltotal=Lcls+Lseg+ηLlane L total =L cls +L seg +ηL lane
Lcls为多分类损失、Lseg为分割损失,Llane为车道结构化损失,η为超参数。L cls is the multi-classification loss, L seg is the segmentation loss, L lane is the lane structuring loss, and η is the hyperparameter.
优选地,所述的多分类损失Lcls表示为:Preferably, the multi-class loss L cls is expressed as:

其中,LCE(·)表示交叉熵损失函数,Pi,j,:表示针对第i个车道线、第j个横向锚框的所有(w+1)个车道线单元预测结果,Ti,j,:表示针对第i个车道线、第j个横向锚框的所有(w+1)个车道线单元真实分布,ci,j,:表示Pi,j,:与Ti,j,:的相似度,C与h分别代表车道线类数与车道纵向锚点数,γ与α为超参数。Among them, L CE ( ) represents the cross-entropy loss function, P i,j,: represents the prediction results of all (w+1) lane line units for the i-th lane line and the j-th lateral anchor box, T i, j,: indicates the true distribution of all (w+1) lane line units for the i-th lane line and the j-th lateral anchor box, c i,j,: indicates P i,j,: and T i,j, : similarity, C and h represent the number of lane line classes and the number of longitudinal anchor points of the lane, respectively, and γ and α are hyperparameters.
优选地,所述的车道结构化损失Llane表示为:Preferably, the lane structure loss L lane is expressed as:
Llane=Lsim+λLshp L lane =L sim +λ Lshp
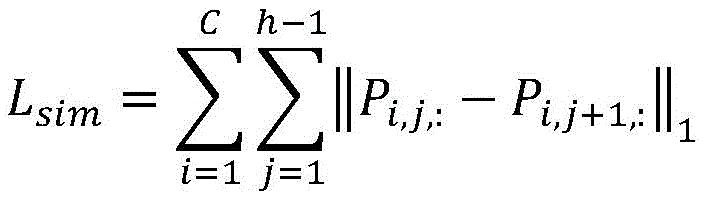

其中,Lsim为相似度损失,Lshp为形状损失,λ为表示损失权重的超参数,Pi,j,k表示第i类车道线在位置为(j,k)处的预测概率,w为每行的划分单元数量。Among them, L sim is the similarity loss, L shp is the shape loss, λ is the hyperparameter representing the loss weight, P i, j, k is the predicted probability of the i-th lane line at the position (j, k), w The number of division cells for each row.
优选地,步骤(4)训练网络与制定先验规则步骤如下:Preferably, the steps of step (4) training the network and formulating a priori rules are as follows:
(41)将采集到的图像序列进行数据预处理,包括:将图像进行随机的水平翻转、裁剪并统一缩放到固定的尺寸,标注数据也进行相应的翻转、裁剪和缩放,在此基础上对得到的图像按通道进行归一化处理;(41) Perform data preprocessing on the collected image sequence, including: randomly flipping, cropping and uniformly scaling the image to a fixed size horizontally, and flipping, cropping and scaling the labeled data accordingly. The obtained image is normalized by channel;
(42)将车道线检测得到的自车辆所在车道的车道线位置节点,采用高鲁棒性回归模型得到自车辆所在车道的车道线拟合模型;(42) Using a highly robust regression model to obtain the lane line fitting model of the lane where the ego vehicle is located by using the lane line position node of the lane where the ego vehicle is located, obtained from the lane line detection;
(43)根据自车辆所在车道的车道线模型建立加塞行为感兴趣区域,并计算目标车辆边界框信息与加塞行为感兴趣区域的位置偏差,并根据目标车辆跟踪ID建立每个目标的加塞行为期望次数与车辆状态符号字典;(43) Establish an area of interest for jamming behavior according to the lane line model of the lane where the ego vehicle is located, calculate the position deviation between the bounding box information of the target vehicle and the area of interest for jamming behavior, and establish the jamming behavior expectation of each target according to the target vehicle tracking ID Dictionary of times and vehicle status symbols;
(44)经过设定加塞行为期望次数阈值结合车辆状态符号判断目标车辆具体的行为,对建立的加塞行为感兴趣区域进行参数更新,迭代后得到理想的网络参数。(44) Determine the specific behavior of the target vehicle by setting the threshold of the expected number of jamming behaviors combined with the vehicle status symbol, update the parameters of the established jamming behavior area of interest, and obtain ideal network parameters after iteration.
优选地,自车辆所在车道的车道线拟合模型为线性模型,且左右车道分别根据车道线预测位置节点拟合得到。Preferably, the lane line fitting model of the lane where the ego vehicle is located is a linear model, and the left and right lanes are respectively obtained by fitting according to the predicted position nodes of the lane lines.
优选地,建立的每个目标的加塞行为期望次数与车辆状态符号字典中键值为目标跟踪ID,值为期望次数与车辆状态符号。Preferably, in the established dictionary of expected times of jamming behavior and vehicle status symbols for each target, the key value is the target tracking ID, and the value is the expected number of times and the vehicle status symbol.
与现有技术相比,本发明具有如下优点:Compared with the prior art, the present invention has the following advantages:
(1)本发明针对目前的神经网络对车辆加塞行为预测不佳的问题提出全新的网络结构,在移动端计算能力有限的前提下大大提升对近场车辆实时行为预测的性能,能方便地部署在现有的智能驾驶系统中,使智能驾驶汽车能对近场车辆加塞行为及时地做出反应,提高行驶过程中的安全性;(1) The present invention proposes a new network structure in view of the problem that the current neural network cannot predict the vehicle jamming behavior, and greatly improves the performance of the near-field vehicle real-time behavior prediction under the premise of limited computing power of the mobile terminal, which can be easily deployed In the existing intelligent driving system, the intelligent driving car can respond to the jamming behavior of the near-field vehicle in time, and improve the safety during driving;
(2)本发明首先抽取变道行为的视频片段与目标的边界框(Bounding Boxe s)信息,筛选出符合前文定义的临近车辆加塞行为的数据集合,最终建立起包含标注与视频数据的“临近物体典型加塞行为数据库”数据集;(2) The present invention first extracts the video clips of the lane-changing behavior and the bounding box (Bounding Boxes) information of the target, filters out the data set that conforms to the above-defined car jamming behavior, and finally establishes a “proximity” containing the annotation and video data. Object Typical Jamming Behavior Database" dataset;
(3)本发明中凭借大的视场、高分辨率获得前向视角图像,包含目标的外观特征以及目标之间的依赖关系,开发了临近车辆检测与跟踪模型和加塞行为预测算法。其中的目标检测模块基于目前最新的One-Stage目标检测算法Yolov5深度改进,在保持一定的检测准确度的基础上有着较高的检测速度;(3) In the present invention, a forward-view image is obtained with a large field of view and high resolution, including the appearance features of the target and the dependencies between the targets, and a near-vehicle detection and tracking model and a jamming behavior prediction algorithm are developed. The target detection module is deeply improved based on the latest One-Stage target detection algorithm Yolov5, and has a high detection speed on the basis of maintaining a certain detection accuracy;
(4)本发明中在输出目标的边界框和类别信息之后,采用Deep-SORT多目标跟踪算法,得到与每个目标ID对应的感兴趣帧序列,考虑到传统的双模态输入网络对系统的计算资源要求较高,为保证算法的实时性,本文不采用光流作为时域特征的抽取,而是采用目标序列作为时空特征输入;(4) In the present invention, after outputting the bounding box and category information of the target, the Deep-SORT multi-target tracking algorithm is used to obtain the frame sequence of interest corresponding to each target ID. In order to ensure the real-time performance of the algorithm, this paper does not use optical flow as the extraction of time-domain features, but uses the target sequence as the input of time-space features;
(5)本发明中在加塞行为预测模块,从加塞行为的特征信息出发,基于制定先验规则的算法与上一步得到的目标序列输出,提出一种可解释的车辆行驶场景下实时高鲁棒性的临近物体加塞行为预测方法。(5) In the present invention, in the jamming behavior prediction module, starting from the characteristic information of jamming behavior, based on the algorithm for formulating a priori rules and the target sequence output obtained in the previous step, an interpretable real-time high robustness in the vehicle driving scene is proposed A method for predicting the jamming behavior of sexual neighbors.
附图说明Description of drawings
图1为本发明一种基于图像输入的近场车辆加塞行为预测方法的流程示意图;1 is a schematic flowchart of a method for predicting a near-field vehicle jamming behavior based on image input according to the present invention;
图2为本发明近场车辆目标检测网络的结构示意图;2 is a schematic structural diagram of a near-field vehicle target detection network according to the present invention;
图3为根据先验规则进行加塞行为预测的算法流程第一部分;Fig. 3 is the first part of the algorithm flow for predicting the jamming behavior according to the a priori rule;
图4为根据先验规则进行加塞行为预测的算法流程第二部分;Fig. 4 is the second part of the algorithm flow for predicting the jamming behavior according to the a priori rule;
图5为根据先验规则进行加塞行为预测的算法流程第三部分。FIG. 5 is the third part of the algorithm flow for predicting the jamming behavior according to the prior rules.
具体实施方式Detailed ways
下面结合附图和具体实施例对本发明进行详细说明。注意,以下的实施方式的说明只是实质上的例示,本发明并不意在对其适用物或其用途进行限定,且本发明并不限定于以下的实施方式。The present invention will be described in detail below with reference to the accompanying drawings and specific embodiments. Note that the description of the following embodiments is merely an illustration in essence, and the present invention is not intended to limit its application or use, and the present invention is not limited to the following embodiments.
实施例Example
本发明行为预测方法主要步骤包括采集真实的结构化道路场景中基于前向全景图像的图像序列信息,通过人工方法标注图像序列中车辆目标的位置以及行为信息;构建适用于结构化道路中近场车辆检测与跟踪的深度卷积神经网络;构建适用于结构化道路中车道线检测的深度神经网络及相应的损失函数;从所建立的近场车辆检测与跟踪模型获得的车辆ID与对应目标的边界框位置数据、以及所建立的车道线检测网络获得的车道线模型,获得目标与车道线的相对位置偏差,根据先验规则的制定,得到近场车辆的加塞行为预测结果。本发明针对目前的神经网络对车辆加塞行为预测不佳的问题提出全新的加塞行为预测算法,在移动端计算能力有限的前提下大大提升对近场车辆实时行为预测的性能,能方便地部署在现有的智能驾驶系统中,使智能驾驶汽车能对近场车辆加塞行为及时地做出反应,提高行驶过程中的安全性。The main steps of the behavior prediction method of the present invention include collecting the image sequence information based on the forward panoramic image in the real structured road scene, marking the position and behavior information of the vehicle target in the image sequence by artificial methods; A deep convolutional neural network for vehicle detection and tracking; construct a deep neural network suitable for lane line detection in structured roads and the corresponding loss function; the vehicle ID obtained from the established near-field vehicle detection and tracking model is related to the corresponding target. The position data of the bounding box and the lane line model obtained by the established lane line detection network are used to obtain the relative position deviation between the target and the lane line. Aiming at the problem that the current neural network cannot predict the vehicle jamming behavior poorly, the present invention proposes a new jamming behavior prediction algorithm, which greatly improves the performance of near-field vehicle real-time behavior prediction under the premise of limited computing capability of the mobile terminal, and can be easily deployed in In the existing intelligent driving system, the intelligent driving car can respond to the jamming behavior of the near-field vehicle in time, so as to improve the safety during driving.
如图1所示,本实施例提供一种基于图像输入的近场车辆加塞行为预测方法,该方法包括:As shown in FIG. 1 , this embodiment provides a near-field vehicle jamming behavior prediction method based on image input, and the method includes:
(1)采集真实的结构化道路场景中基于前向全景图像的图像序列信息,通过人工方法标注图像序列中车辆目标的位置以及行为信息;(1) Collect the image sequence information based on the forward panoramic image in the real structured road scene, and manually mark the position and behavior information of the vehicle target in the image sequence;
(2)构建适用于结构化道路中近场车辆检测与跟踪的近场车辆检测与跟踪模型;(2) Build a near-field vehicle detection and tracking model suitable for near-field vehicle detection and tracking in structured roads;
(3)构建适用于结构化道路中车道线检测的车道线检测网络及相应的损失函数;(3) Construct a lane line detection network and corresponding loss function suitable for lane line detection in structured roads;
(4)基于步骤(2)建立的近场车辆检测与跟踪模型获得的车辆ID与对应目标的边界框位置数据、以及步骤(3)建立的车道线检测网络获得的车道线,获得目标与车道线的相对位置偏差,根据先验规则的制定,得到近场车辆的加塞行为预测结果。(4) Based on the vehicle ID obtained by the near-field vehicle detection and tracking model established in step (2) and the bounding box position data of the corresponding target, and the lane line obtained by the lane line detection network established in step (3), the target and lane are obtained. According to the relative position deviation of the line, according to the formulation of the prior rules, the prediction result of the jamming behavior of the near-field vehicle is obtained.
具体地,步骤(1)具体包括:Specifically, step (1) specifically includes:
(11)对摄像头的内外参进行标定,其中外参包括旋转矩阵R和平移向量T,内参包括内参矩阵K,以及相机畸变系数;(11) Calibrate the internal and external parameters of the camera, wherein the external parameters include a rotation matrix R and a translation vector T, and the internal parameters include an internal parameter matrix K, and the camera distortion coefficient;
(12)利用装有摄像头的数据采集车在真实道路场景中采集视频数据,并记录采集时图像内车辆目标的类别;(12) Use a data collection vehicle equipped with a camera to collect video data in a real road scene, and record the type of vehicle target in the image at the time of collection;
(13)利用标注工具对采集到的视频数据进行标注,标注方式包含车辆目标跟踪ID标注、车辆目标类别标注、目标物体边界框标注、车辆加塞开始、车辆越过车道线中点以及车辆完成加塞行为的关键帧标注、车辆加塞行为类别标注,标注内容至少需要包含近场车辆的位置、关键帧以及加塞行为类别信息,此过程中所要求记录的车辆目标ID是唯一的。(13) Annotate the collected video data with an annotation tool. The annotation methods include vehicle target tracking ID annotation, vehicle target category annotation, target object bounding box annotation, vehicle jamming start, vehicle crossing the midpoint of the lane line, and vehicle completion jamming behavior The key frame annotation and the vehicle jamming behavior category annotation of the vehicle should contain at least the position, key frame and jamming behavior category information of the near-field vehicle. The vehicle target ID required to be recorded in this process is unique.
步骤(2)具体包括:Step (2) specifically includes:
(21)构建基于改进的Yolov5的近场车辆目标检测网络,将输入的视频切片作为图像时间序列输入至近场车辆目标检测网络,经过多层卷积与下采样操作,对输入的图像信息进行特征提取与特征编码,得到将图片划分好的多维特征张量,此部分的近场车辆目标检测网络的网络结构如图2所示,由Backbone、FPN、PAN等结构组成;(21) Construct a near-field vehicle target detection network based on the improved Yolov5, input the input video slices as image time series to the near-field vehicle target detection network, and perform multi-layer convolution and downsampling operations to characterize the input image information Extraction and feature encoding to obtain a multi-dimensional feature tensor that divides the picture. The network structure of the near-field vehicle target detection network in this part is shown in Figure 2, which is composed of Backbone, FPN, PAN and other structures;
(22)构建分类网络,采用非极大抑制操作,最终得到各个目标的位置信息与分类置信度信息,包括对象的分类概率和定位概率;(22) Build a classification network, adopt non-maximum suppression operation, and finally obtain the location information and classification confidence information of each target, including the classification probability and positioning probability of the object;
(23)构建基于改进的Deep-SORT的近场车辆目标跟踪网络,将目标检测得到的目标物体边界框信息以及分类信息作为输入,对视频中多个对象同时定位与追踪并记录ID和轨迹信息,尤其是在有遮挡的条件下减少对象ID的变换,输出目标车辆的跟踪ID、目标类别以及目标物体边界框信息,Deep-SORT网络中的ReID模块经过了经过重新分类处理的新的车辆重识别数据集Compcars训练。(23) Build a near-field vehicle target tracking network based on improved Deep-SORT, take the target object bounding box information and classification information obtained by target detection as input, locate and track multiple objects in the video simultaneously, and record ID and trajectory information , especially under the condition of occlusion to reduce the transformation of object ID, output the tracking ID of the target vehicle, the target category and the bounding box information of the target object, the ReID module in the Deep-SORT network has undergone the reclassification process of the new vehicle weight. Recognition dataset Compcars training.
步骤(3)具体包括:Step (3) specifically includes:
(31)构建基于卷积神经网络的车道线特征提取骨干网络,基于浅层残差连接网络输出特征,通过使用较大的感受野,在保证检测效果的同时提高模型的推理速度,浅层残差连接卷积神经网络输出有四种尺度,分别为112×112×3、56×56×64、28×28×128、14×14×256:(31) Construct a backbone network for lane feature extraction based on convolutional neural network, connect network output features based on shallow residuals, and improve the inference speed of the model while ensuring the detection effect by using a larger receptive field. The output of the differentially connected convolutional neural network has four scales, which are 112×112×3, 56×56×64, 28×28×128, 14×14×256:
(32)构建车道线语义分割网络,在网络训练时将多尺度特征上采样到同一尺度,并经过转置卷积,计算语义分割损失,增强骨干网络的视觉特征抽取能力,最终得到增强的基于残差连接的车道线检测骨干网络,车道线语义分割网络,在网络训练时将多尺度特征上采样到同一尺度,在实际推断过程中不使用;(32) Construct a lane line semantic segmentation network, up-sample multi-scale features to the same scale during network training, and through transposed convolution, calculate the semantic segmentation loss, enhance the visual feature extraction ability of the backbone network, and finally obtain an enhanced based on Residual connected lane line detection backbone network, lane line semantic segmentation network, multi-scale features are upsampled to the same scale during network training, and are not used in the actual inference process;
(33)将骨干网络抽取的特征,根据先验指定的图片纵向候选锚框,在全局范围内通过分类器计算候选点,最终得到自车辆所在车道的车道线位置节点,本实施例中车道线类数C的值为4,纵向候选锚框个数h的值为18;(33) According to the features extracted by the backbone network, according to the a priori specified vertical candidate anchor frame of the picture, the candidate points are calculated by the classifier in the global scope, and finally the lane line position node of the lane where the vehicle is located is obtained. In this embodiment, the lane line The value of the number of classes C is 4, and the value of the number of vertical candidate anchor boxes h is 18;
(34)构建车道线检测网络的损失函数,包括多分类损失、分割损失以及车道结构化损失,车道线检测网络的损失函数表示为Ltotal:(34) Construct the loss function of the lane line detection network, including multi-classification loss, segmentation loss and lane structure loss. The loss function of the lane line detection network is expressed as L total :
Ltotal=Lcls+Lseg+ηLlane L total =L cls +L seg +ηL lane
Lcls为多分类损失、Lseg为分割损失,Llane为车道结构化损失,η为超参数。L cls is the multi-classification loss, L seg is the segmentation loss, L lane is the lane structuring loss, and η is the hyperparameter.
其中,多分类损失Lcls和分割损失Lseg均采用了交叉熵损失函数,分割损失Lseg采用了分类数为2的多分类损失。Among them, the multi-class loss L cls and the segmentation loss L seg both use the cross entropy loss function, and the segmentation loss L seg uses the multi-class loss with 2 classifications.
具体地,多分类损失Lcls表示为:Specifically, the multi-class loss L cls is expressed as:

其中,LCE(·)表示交叉熵损失函数,Pi,j,:表示针对第i个车道线、第j个横向锚框的所有(w+1)个车道线单元预测结果,Ti,j,:表示针对第i个车道线、第j个横向锚框的所有(w+1)个车道线单元真实分布,ci,j,:表示Pi,j,:与Ti,j,:的相似度,C与h分别代表车道线类数与车道纵向锚点数,γ与α为超参数。Among them, L CE ( ) represents the cross-entropy loss function, P i,j,: represents the prediction results of all (w+1) lane line units for the i-th lane line and the j-th lateral anchor box, T i, j,: indicates the true distribution of all (w+1) lane line units for the i-th lane line and the j-th lateral anchor box, c i,j,: indicates P i,j,: and T i,j, : similarity, C and h represent the number of lane line classes and the number of longitudinal anchor points of the lane, respectively, and γ and α are hyperparameters.
车道结构化损失Llane表示为:The lane structuring loss L lane is expressed as:
Llane=Lsim+λLshp L lane =L sim +λL shp


其中,Lsim为相似度损失,Lshp为形状损失,λ为表示损失权重的超参数,Pi,j,k表示第i类车道线在位置为(j,k)处的预测概率,w为每行中的车道线单元数量。Among them, L sim is the similarity loss, L shp is the shape loss, λ is the hyperparameter representing the loss weight, P i, j, k is the predicted probability of the i-th lane line at the position (j, k), w is the number of lane line units in each row.
在被实施例中,η的值为1,γ的值为2,α的值为0.25,λ的值为1.25。In the embodiment, the value of η is 1, the value of γ is 2, the value of α is 0.25, and the value of λ is 1.25.
步骤(4)训练网络与制定先验规则步骤如下:Step (4) The steps of training the network and formulating a priori rules are as follows:
(41)将采集到的图像序列进行数据预处理,包括:将图像进行随机的水平翻转、裁剪并统一缩放到固定的尺寸,标注数据也进行相应的翻转、裁剪和缩放,在此基础上对得到的图像按通道进行归一化处理;(41) Perform data preprocessing on the collected image sequence, including: randomly flipping, cropping and uniformly scaling the image to a fixed size horizontally, and flipping, cropping and scaling the labeled data accordingly. The obtained image is normalized by channel;
(42)将车道线检测得到的自车辆所在车道的车道线位置节点,采用高鲁棒性回归模型得到自车辆所在车道的车道线拟合模型,自车辆所在车道的车道线拟合模型为线性模型,且左右车道分别根据车道线预测位置节点拟合得到;(42) Use the highly robust regression model to obtain the lane line fitting model of the own vehicle's lane by using the lane line position node of the own vehicle's lane detected by the lane line detection, and the lane line fitting model of the own vehicle's lane is linear. model, and the left and right lanes are respectively fitted according to the predicted position nodes of the lane line;
(43)根据自车辆所在车道的车道线模型建立加塞行为感兴趣区域,并计算目标车辆边界框信息与加塞行为感兴趣区域的位置偏差,并根据目标车辆跟踪ID建立每个目标的加塞行为期望次数与车辆状态符号字典,建立的每个目标的加塞行为期望次数与车辆状态符号字典中键值为目标跟踪ID,值为期望次数与车辆状态符号;(43) Establish an area of interest for jamming behavior according to the lane line model of the lane where the ego vehicle is located, calculate the position deviation between the bounding box information of the target vehicle and the area of interest for jamming behavior, and establish the jamming behavior expectation of each target according to the target vehicle tracking ID The dictionary of times and vehicle status symbols, the key value in the established expected times of jamming behavior of each target and the vehicle status symbol dictionary is the target tracking ID, and the value is the expected number of times and the vehicle status symbol;
(44)经过设定加塞行为期望次数阈值结合车辆状态符号判断目标车辆具体的行为,对建立的加塞行为感兴趣区域进行参数更新,迭代后得到理想的网络参数。(44) Determine the specific behavior of the target vehicle by setting the threshold of the expected number of jamming behaviors combined with the vehicle status symbol, update the parameters of the established jamming behavior area of interest, and obtain ideal network parameters after iteration.
根据先验规则的制定,得到近场车辆的加塞行为预测结果的算法具体流程如图3、图4、图5所示。首先在每一个临近车辆在完成检测与跟踪之后,构建以目标跟踪ID为键、初始状态[0,′keep′]为值的目标状态描述符,其中0是计数值,′keep′是历史状态描述子。根据临近车辆检测边界框(Bounding Box)所在区域的不同,判断临近车辆初始车道为左侧车道或者右侧车道;同时,根据车道线检测模块获得的车道线模型适当增加车道线两侧的宽度,设置车辆加塞预测感兴趣区域(Cut-In RoI)。根据临近车辆目标与车辆加塞预测感兴趣区域(Cut-InRoI)相对位置关系,可分为两种位置状态:①临近车辆目标处于横跨该区域边缘时;②临近车辆目标处于该区域内时。后者较为简单,在此时设置目标状态描述符为[2,′follow′]。前者的状态多出现于临近车辆切入与切出两种时刻,在这种条件下可以根据历史状态描述子{′keep′,′cut_in′,′follow′}加以区分。According to the formulation of the prior rules, the specific flow of the algorithm to obtain the prediction result of the jamming behavior of the near-field vehicle is shown in Figure 3, Figure 4, and Figure 5. First, after each adjacent vehicle completes detection and tracking, construct a target state descriptor with the target tracking ID as the key and the initial state [0, 'keep'] as the value, where 0 is the count value and 'keep' is the historical state descriptor. According to the difference of the area where the adjacent vehicle detection bounding box (Bounding Box) is located, it is judged that the initial lane of the adjacent vehicle is the left lane or the right lane; at the same time, according to the lane line model obtained by the lane line detection module, the width on both sides of the lane line is appropriately increased. Set the vehicle jamming prediction region of interest (Cut-In RoI). According to the relative positional relationship between the adjacent vehicle target and the vehicle jamming prediction region of interest (Cut-InRoI), it can be divided into two position states: (1) when the adjacent vehicle target is crossing the edge of the area; (2) when the adjacent vehicle target is in the area. The latter is relatively simple, and the target state descriptor is set to [2, 'follow'] at this time. The former state mostly occurs at the cut-in and cut-out moments of the adjacent vehicle. Under this condition, it can be distinguished according to the historical state descriptor {'keep', 'cut_in', 'follow'}.
如果目标状态描述符为[count<Threshold,′keep′]时,认为前一时刻目标临近车辆处于车道保持状态并有从车道保持向加塞行为发展的潜在趋势,同时为了降低临近车辆加塞行为预警逻辑的误检率,可以适当延迟加塞预警预测时间,只考虑被跟踪足够长时间加塞的目标。具体而言,只有临近车辆检测边界框(Bounding Box)距离加塞预测感兴趣区域(Cut-In RoI)较远的点位于该区域外,同时在加塞预测感兴趣区域(Cut-In RoI)内的边界框关键点(距离另一端点的距离占宽度一定比例α)被检测到的次数超过阈值时,目标状态描述符为[count=count+1,′keep′]保持更新,直到count=Threshold,目标状态描述符更新为[count=Threshold,′cut_in′]。在本项目中设置α=0.4,检测到的加塞次数阈值Threshold=3。此时,当前帧临近车辆的加塞行为从action=′keep′变为action=′cut_in′,临近车辆检测边界框(Bounding Box)与加塞预测感兴趣区域(Cut-In RoI)变为红色预警。If the target state descriptor is [count<Threshold, 'keep'], it is considered that the target adjacent vehicle was in the lane keeping state at the previous moment and there is a potential trend from lane keeping to jamming behavior. At the same time, in order to reduce the warning logic of the jamming behavior of adjacent vehicles If the false detection rate is higher, the prediction time of the jamming warning can be appropriately delayed, and only the targets that have been tracked for a long enough time to be jammed are considered. Specifically, only the points of the adjacent vehicle detection bounding box (Bounding Box) that are far from the cut-in prediction region of interest (Cut-In RoI) are located outside the region, while the points within the cut-in prediction region of interest (Cut-In RoI) are located outside the region. When the number of times the bounding box key point (the distance from the other end point is a certain proportion of the width α) is detected exceeds the threshold, the target state descriptor is [count=count+1, 'keep'] and keeps updating until count=Threshold, The target state descriptor is updated to [count=Threshold, 'cut_in']. In this project, α=0.4 is set, and the threshold of the detected jamming times Threshold=3. At this time, the jamming behavior of adjacent vehicles in the current frame changes from action='keep' to action='cut_in', and the adjacent vehicle detection bounding box (Bounding Box) and jamming prediction region of interest (Cut-In RoI) become red warnings.
如果当前帧目标状态描述符为[count=Threshold,′cut_in′],可以认为该目标正在延续上一帧的加塞行为,故保持目标状态描述符为[count=Threshold,′cut_in′]不变,当前帧临近车辆的加塞行为从action=′cut_in′,临近车辆检测边界框(BoundingBox)与加塞预测感兴趣区域(Cut-In RoI)继续保持红色,提示临近车辆加塞行为正在发生。If the target state descriptor of the current frame is [count=Threshold, 'cut_in'], it can be considered that the target is continuing the jamming behavior of the previous frame, so keep the target state descriptor as [count=Threshold, 'cut_in'] unchanged, The jamming behavior of the adjacent vehicles in the current frame is changed from action='cut_in', the adjacent vehicle detection bounding box (BoundingBox) and the jamming prediction region of interest (Cut-In RoI) continue to remain red, indicating that the jamming behavior of the neighboring vehicles is taking place.
如果当前帧目标状态描述符为[count=Threshold,′cut_in′],但是此时临近车辆检测边界框(Bounding Box)完全进入加塞预测感兴趣区域(Cut-In RoI)内,可以认为该目标已经完成加塞行为,故目标状态描述符更新为[count=Threshold,′follow′],当前帧临近车辆的加塞行为从action′keep′,临近车辆检测边界框(Bounding Box)与加塞预测感兴趣区域(Cut-In RoI)变为绿色,提示临近车辆加塞行为已经完成,当前帧处于安全状态。If the target state descriptor of the current frame is [count=Threshold, 'cut_in'], but at this time, the adjacent vehicle detection bounding box (Bounding Box) completely enters the area of interest (Cut-In RoI) for plugging prediction, it can be considered that the target has been The jamming behavior is completed, so the target state descriptor is updated to [count=Threshold,'follow'], the jamming behavior of the adjacent vehicle in the current frame is from action'keep', the adjacent vehicle detection bounding box (Bounding Box) and the jamming prediction region of interest ( Cut-In RoI) turns green, indicating that the approaching vehicle jamming behavior has been completed and the current frame is in a safe state.
如果当前帧目标状态描述符为pcount=Threshold,′folow′],同时临近车辆检测边界框(Bounding Box)处于横跨加塞预测感兴趣区域(Cut-In RoI)边缘时,可以认为该目标已经完成加塞行为并在离开当前车道,故目标状态描述符更新为[count=Threshold,′keep′],当前帧临近车辆的加塞行为从action=′keep′,临近车辆检测边界框(BoundingBox)与加塞预测感兴趣区域(Cut-In RoI)继续保持绿色,当前帧处于安全状态。If the target state descriptor of the current frame is pcount=Threshold, 'folow'], and the adjacent vehicle detection bounding box (Bounding Box) is at the edge of the crossed prediction region of interest (Cut-In RoI), it can be considered that the target has been completed. The jamming behavior is leaving the current lane, so the target state descriptor is updated to [count=Threshold,'keep'], the jamming behavior of the adjacent vehicles in the current frame is from action='keep', the adjacent vehicle detection bounding box (BoundingBox) and jamming prediction The region of interest (Cut-In RoI) continues to remain green and the current frame is in a safe state.
在任何情况下,如果临近车辆检测边界框(Bounding Box)完全离开加塞预测感兴趣区域(Cut-In RoI)范围,则立刻更新目标状态描述符为[count=0,′keep′],并在下一帧继续重复以上步骤。使用以上算法流程,针对加塞情况有额外的3帧延迟,由于输入流的FPS=30,这个延迟相当于0.1s;真实条件下人类司机在遇到未预见加塞切入情况时,通常至少需要0.7s才能刹车。因此,即使有一个从检测到发送加塞预警的时间延迟,预计也不会造成严重的问题,符合实际的技术要求。In any case, if the adjacent vehicle detection bounding box (Bounding Box) completely leaves the area of interest (Cut-In RoI) for plugging prediction, immediately update the target state descriptor to [count=0, 'keep'], and in the next Continue to repeat the above steps for one frame. Using the above algorithm flow, there is an additional 3 frame delay for the jamming situation. Since the FPS of the input stream is 30, this delay is equivalent to 0.1s; under real conditions, the human driver usually needs at least 0.7s when encountering an unforeseen jamming cut-in situation. to brake. Therefore, even if there is a time delay from the detection of a jamming warning sent, it is not expected to cause serious problems, in line with the actual technical requirements.
经过测试可知,本发明提出的网络分别成功的预测出的临近车辆加塞的行为并预警,同时能够实现加塞完成之后的预警解除,在上述类似的两种场景下均能成功辨别。After testing, it can be seen that the network proposed by the present invention successfully predicts the jamming behavior of adjacent vehicles and gives an early warning, and at the same time can realize the early warning cancellation after the jamming is completed, and can be successfully distinguished in the above two similar scenarios.
总之,本发明提出了一种基于图像输入的的近场车辆加塞行为预测方法,在移动端计算能力有限的前提下大大提升对近场车辆实时行为预测的性能,能方便地部署在现有的智能驾驶系统中,使智能驾驶汽车能对近场车辆加塞行为及时地做出反应,提高行驶过程中的安全性。In a word, the present invention proposes a near-field vehicle jamming behavior prediction method based on image input, which greatly improves the performance of near-field vehicle real-time behavior prediction under the premise of limited computing capability of the mobile terminal, and can be easily deployed in the existing In the intelligent driving system, the intelligent driving car can respond in time to the jamming behavior of vehicles in the near field, and improve the safety during driving.
上述实施方式仅为例举,不表示对本发明范围的限定。这些实施方式还能以其它各种方式来实施,且能在不脱离本发明技术思想的范围内作各种省略、置换、变更。The above-described embodiments are merely examples, and do not limit the scope of the present invention. These embodiments can be implemented in other various forms, and various omissions, substitutions, and changes can be made without departing from the technical idea of the present invention.
Claims (10)



Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210289381.4A CN114758319B (en) | 2022-03-22 | 2022-03-22 | A prediction method for near-field vehicle jamming behavior based on image input |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210289381.4A CN114758319B (en) | 2022-03-22 | 2022-03-22 | A prediction method for near-field vehicle jamming behavior based on image input |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114758319A true CN114758319A (en) | 2022-07-15 |
| CN114758319B CN114758319B (en) | 2025-03-28 |
Family
ID=82327924
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210289381.4A Active CN114758319B (en) | 2022-03-22 | 2022-03-22 | A prediction method for near-field vehicle jamming behavior based on image input |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114758319B (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115950445A (en) * | 2023-01-09 | 2023-04-11 | 江苏大学 | Highway Commercial Vehicle Trajectory Planning Method and Vehicle Electronic Equipment Combining Complex Network Theory and Deep Neural Network |
| CN115984793A (en) * | 2022-12-28 | 2023-04-18 | 北京四维图新科技股份有限公司 | Method, device and equipment for detecting lane markings |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111460984A (en) * | 2020-03-30 | 2020-07-28 | 华南理工大学 | A global lane line detection method based on keypoint and gradient equalization loss |
| EP3806064A1 (en) * | 2018-05-25 | 2021-04-14 | Hangzhou Hikvision Digital Technology Co., Ltd. | Method and apparatus for detecting parking space usage condition, electronic device, and storage medium |
-
2022
- 2022-03-22 CN CN202210289381.4A patent/CN114758319B/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3806064A1 (en) * | 2018-05-25 | 2021-04-14 | Hangzhou Hikvision Digital Technology Co., Ltd. | Method and apparatus for detecting parking space usage condition, electronic device, and storage medium |
| CN111460984A (en) * | 2020-03-30 | 2020-07-28 | 华南理工大学 | A global lane line detection method based on keypoint and gradient equalization loss |
Non-Patent Citations (3)
| Title |
|---|
| CHEN, G (CHEN, GUANG); LU, F (LU, FAN); LI, ZJ (LI, ZHIJUN); LIU, YL (LIU, YINLONG); DONG, JH (DONG, JINHU); ZHAO, JQ (ZHAO, JUNQI: "Pole-Curb Fusion Based Robust and Efficient Autonomous Vehicle Localization System With Branch-and-Bound Global Optimization and Local Grid Map Method", IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY, no. 11, 30 November 2021 (2021-11-30), pages 11283 - 11294, XP011888718, DOI: 10.1109/TVT.2021.3114825 * |
| 俞骏威;张黎明;陈凯;熊璐;余卓平;陈广;: "基于道路消失点的远距离路面微小障碍物检测", 同济大学学报(自然科学版), no. 1, 31 December 2019 (2019-12-31), pages 213 - 216 * |
| 蔡英凤;朱南楠;邰康盛;刘擎超;王海;: "基于注意力机制的车辆行为预测", 江苏大学学报(自然科学版), no. 02, 10 March 2020 (2020-03-10), pages 6 - 11 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115984793A (en) * | 2022-12-28 | 2023-04-18 | 北京四维图新科技股份有限公司 | Method, device and equipment for detecting lane markings |
| CN115950445A (en) * | 2023-01-09 | 2023-04-11 | 江苏大学 | Highway Commercial Vehicle Trajectory Planning Method and Vehicle Electronic Equipment Combining Complex Network Theory and Deep Neural Network |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114758319B (en) | 2025-03-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108921875B (en) | A real-time traffic flow detection and tracking method based on aerial photography data | |
| CN111191583B (en) | Space target recognition system and method based on convolutional neural network | |
| Chabot et al. | Deep manta: A coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image | |
| CN110363104B (en) | A kind of detection method of diesel black smoke vehicle | |
| CN113344932B (en) | A Semi-Supervised Single-Object Video Segmentation Method | |
| CN113408584B (en) | RGB-D multi-modal feature fusion 3D target detection method | |
| CN108875608B (en) | Motor vehicle traffic signal identification method based on deep learning | |
| CN110766098A (en) | Traffic scene small target detection method based on improved YOLOv3 | |
| CN110263786B (en) | A road multi-target recognition system and method based on feature dimension fusion | |
| CN112395951B (en) | Complex scene-oriented domain-adaptive traffic target detection and identification method | |
| US20230142676A1 (en) | Trajectory prediction method and apparatus, device, storage medium and program | |
| CN110659601B (en) | Dense vehicle detection method for remote sensing images based on deep fully convolutional network based on central points | |
| CN108171112A (en) | Vehicle identification and tracking based on convolutional neural networks | |
| CN114973199A (en) | Rail transit train obstacle detection method based on convolutional neural network | |
| CN105335716A (en) | Improved UDN joint-feature extraction-based pedestrian detection method | |
| Dewangan et al. | Towards the design of vision-based intelligent vehicle system: methodologies and challenges | |
| CN111882620A (en) | Road drivable area segmentation method based on multi-scale information | |
| Xiong et al. | Contrastive learning for automotive mmWave radar detection points based instance segmentation | |
| CN112766056A (en) | Method and device for detecting lane line in low-light environment based on deep neural network | |
| CN117058641B (en) | Panoramic driving perception method based on deep learning | |
| CN116524189A (en) | High-resolution remote sensing image semantic segmentation method based on coding and decoding indexing edge characterization | |
| CN115019279A (en) | A contextual feature fusion method based on MobileNet lightweight network | |
| Zhang et al. | GC-Net: Gridding and clustering for traffic object detection with roadside LiDAR | |
| Yang | Research on lane recognition algorithm based on deep learning | |
| CN115019039A (en) | An instance segmentation method and system combining self-supervision and global information enhancement |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |