CN114663910A - Multi-mode learning state analysis system - Google Patents
Multi-mode learning state analysis system Download PDFInfo
- Publication number
- CN114663910A CN114663910A CN202210027041.4A CN202210027041A CN114663910A CN 114663910 A CN114663910 A CN 114663910A CN 202210027041 A CN202210027041 A CN 202210027041A CN 114663910 A CN114663910 A CN 114663910A
- Authority
- CN
- China
- Prior art keywords
- information
- teacher
- acquisition module
- unit
- student
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000004458 analytical method Methods 0.000 title claims abstract description 30
- 238000001514 detection method Methods 0.000 claims abstract description 29
- 230000001815 facial effect Effects 0.000 claims abstract description 20
- 238000012545 processing Methods 0.000 claims abstract description 19
- 238000007781 pre-processing Methods 0.000 claims abstract description 5
- 230000004927 fusion Effects 0.000 claims description 19
- 238000010606 normalization Methods 0.000 claims description 15
- 238000000605 extraction Methods 0.000 claims description 10
- 238000010586 diagram Methods 0.000 claims description 9
- 238000012549 training Methods 0.000 claims description 9
- 238000007500 overflow downdraw method Methods 0.000 claims description 6
- 238000011176 pooling Methods 0.000 claims description 4
- 238000013507 mapping Methods 0.000 claims 2
- 238000013527 convolutional neural network Methods 0.000 description 15
- 238000000034 method Methods 0.000 description 14
- 239000013598 vector Substances 0.000 description 13
- 230000006870 function Effects 0.000 description 6
- 230000008569 process Effects 0.000 description 6
- 230000006399 behavior Effects 0.000 description 4
- 238000004422 calculation algorithm Methods 0.000 description 2
- 230000008921 facial expression Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000003542 behavioural effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 229910052709 silver Inorganic materials 0.000 description 1
- 239000004332 silver Substances 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/29—Geographical information databases
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/10—Services
- G06Q50/20—Education
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Computing Systems (AREA)
- Molecular Biology (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Biophysics (AREA)
- Business, Economics & Management (AREA)
- Databases & Information Systems (AREA)
- Tourism & Hospitality (AREA)
- Probability & Statistics with Applications (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Educational Administration (AREA)
- Educational Technology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Economics (AREA)
- Human Resources & Organizations (AREA)
- Marketing (AREA)
- Primary Health Care (AREA)
- Strategic Management (AREA)
- General Business, Economics & Management (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Remote Sensing (AREA)
- Image Analysis (AREA)
Abstract
Description
技术领域technical field
本发明涉及数字数据处理领域,尤其涉及一种基于多模态学习状态分析系统。The invention relates to the field of digital data processing, in particular to a state analysis system based on multimodal learning.
背景技术Background technique
在传统课堂教育中,老师通过对学生的面部表情和头部姿态,判断学生对学习状态,但由于老师的精力有限,无法及时观察到每位学生的课堂学习状态情况,进而无法根据每位学生的学习情况调整教学策略。In traditional classroom education, the teacher judges the students' learning status through the facial expressions and head posture of the students. However, due to the limited energy of the teacher, it is impossible to observe the classroom learning status of each student in time, and thus cannot analyze the learning status of each student in time. Adjust teaching strategies according to the learning situation.
智慧教学是当前我国教育信息化研究的热词,有学者将其称之为教育信息化发展的新形态、新境界、新阶段,将智慧教学研究提到了相当高的高度。现如今关于学生课堂的学情分析的检测方面,可将检测分为基于人脸识别的方法、基于微表情的识别方法和基于脑电波的检测方法。Smarter teaching is a hot word in current educational informatization research in my country. Some scholars call it a new form, new realm, and new stage of educational informatization development, raising the research on smarter teaching to a very high level. Nowadays, regarding the detection of students' classroom learning situation analysis, the detection can be divided into methods based on face recognition, recognition methods based on micro-expressions and detection methods based on brain waves.
采用上述方法由于只有一个变量,使得检测精度较低。Since there is only one variable in the above method, the detection accuracy is low.
发明内容SUMMARY OF THE INVENTION
本发明的目的在于提供一种基于多模态学习状态分析系统,旨在结合学生的面部表情、老师的位置以及老师的上课语音的数据进行分析,给出可视化的分析结果。可以给出学生专注度的分析,有利于教师制定合适的教学计划,促进老师和学生的课堂交互。The purpose of the present invention is to provide a multi-modal learning state analysis system, which aims to analyze the data of the students' facial expressions, the teacher's position and the teacher's speech in class, and provide a visual analysis result. The analysis of students' concentration can be given, which is helpful for teachers to formulate appropriate teaching plans and promote classroom interaction between teachers and students.
为实现上述目的,本发明提供了一种基于多模态学习状态分析系统,包括图像获取模块、老师位置信息获取模块、老师姿态信息获取模块、学生面部信息获取模块和分析模块,In order to achieve the above purpose, the present invention provides a multi-modal learning state analysis system, including an image acquisition module, a teacher position information acquisition module, a teacher posture information acquisition module, a student facial information acquisition module and an analysis module,
所述图像获取模块,用于收集教室内部的图像数据并进行预处理得到处理图像;The image acquisition module is used for collecting the image data inside the classroom and preprocessing to obtain the processed image;
所述老师位置信息获取模块,用于基于处理图像和Faster R-CNN目标检测模型获得老师的位置信息;The teacher position information acquisition module is used to obtain the teacher's position information based on the processed image and the Faster R-CNN target detection model;
所述老师姿态信息获取模块,用于基于处理图像和Faster R-CNN目标检测模型获得老师的姿态信息;The teacher's attitude information acquisition module is used to obtain the teacher's attitude information based on the processed image and the Faster R-CNN target detection model;
所述学生面部信息获取模块,用于基于处理图像和ERT人脸特征点检测方法获取学生面部信息;Described student facial information acquisition module, is used for acquiring student facial information based on processing image and ERT facial feature point detection method;
所述分析模块,用于基于位置信息、姿态信息和学生面部信息分析学习状态。The analysis module is used to analyze the learning state based on the position information, the posture information and the student's face information.
其中,所述图像获取模块包括获取单元和处理单元,所述获取单元用于收集摄像头的图像数据;Wherein, the image acquisition module includes an acquisition unit and a processing unit, and the acquisition unit is used to collect the image data of the camera;
所述处理单元,用于将图像数据的尺寸标准化,并进行归一化处理,得到处理图像。The processing unit is used for normalizing the size of the image data and performing normalization processing to obtain a processed image.
其中,所述收集摄像头的图像数据的具体方式是,每隔5秒为一帧获取图像。Wherein, the specific method of collecting the image data of the camera is to acquire an image for one frame every 5 seconds.
其中,所述老师位置信息获取模块包括特征图提取单元、候选单元、区域特征图生成单元和老师位置获取单元,Wherein, the teacher position information acquisition module includes a feature map extraction unit, a candidate unit, a region feature map generation unit and a teacher position acquisition unit,
所述特征图提取单元,用于基于处理图像提取原始特征图;The feature map extraction unit is used to extract the original feature map based on the processed image;
所述候选单元,用于将原始特征图输入到候选框提取网络,生成区域候选框;The candidate unit is used to input the original feature map into the candidate frame extraction network to generate a regional candidate frame;
所述区域特征图生成单元,用于将区域候选框映射到所述原始特征图中,并池化为区域特征图;The regional feature map generation unit is used to map the regional candidate frame to the original feature map, and pool it into a regional feature map;
所述老师位置获取单元,用于将区域特征图输入Faster R-CNN目标检测模型中获取老师位置信息。The teacher position obtaining unit is used for inputting the regional feature map into the Faster R-CNN target detection model to obtain teacher position information.
其中,所述老师姿态信息获取模块包括关键点获取单元和归一化单元,所述关键点获取单元,用于基于Faster R-CNN目标检测模型,获取人体姿态关键点信息;Wherein, the teacher attitude information acquisition module includes a key point acquisition unit and a normalization unit, and the key point acquisition unit is used for acquiring human body attitude key point information based on the Faster R-CNN target detection model;
所述归一化单元,用于基于人体姿态关键点信息进行姿态归一化模块处理。The normalization unit is used to perform attitude normalization module processing based on the human body attitude key point information.
其中,所述基于位置信息、姿态信息和学生面部信息分析学习状态的具体步骤是:Wherein, the specific steps of analyzing the learning state based on position information, posture information and student facial information are:
构建并训练基于全连接层的多模态特征融合网络结构;Build and train a multimodal feature fusion network structure based on a fully connected layer;
将位置信息、姿态信息和学生面部信息映射到特征融合空间进行学习状态分析。The location information, pose information and student face information are mapped to the feature fusion space for learning state analysis.
其中,所述基于位置信息、姿态信息和学生面部信息分析学习状态的具体步骤是:Wherein, the specific steps of analyzing the learning state based on position information, posture information and student facial information are:
采用加权融合方法融合位置信息、姿态信息和学生面部信息得到加权融合特征;A weighted fusion method is used to fuse position information, attitude information and student face information to obtain weighted fusion features;
将加权融合特征输入全连接层;Input the weighted fusion features into the fully connected layer;
获得加权融合特征的分类概率分布。Obtain the classification probability distribution of weighted fused features.
本发明的一种基于多模态学习状态分析系统,可以在教室的前后分别放置摄像头,然后通过所述图像获取模块获取图像数据,之后通过Faster R-CNN目标检测模型分别对图像进行处理以得到老师的位置信息和面部信息,然后通过ERT人脸特征点检测方法提取图像数据中的学生面部信息,之后可以综合对学生的学习状态进行评估,从而可以更好地对学生的上课情况进行监管,以提高学生的学习效率。According to the multi-modal learning state analysis system of the present invention, cameras can be placed in the front and rear of the classroom respectively, and then the image data is acquired through the image acquisition module, and then the images are processed respectively through the Faster R-CNN target detection model to obtain The location information and facial information of the teacher, and then the facial information of the students in the image data is extracted by the ERT facial feature point detection method, and then the students' learning status can be evaluated comprehensively, so as to better supervise the students' class situation, to improve students' learning efficiency.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to explain the embodiments of the present invention or the technical solutions in the prior art more clearly, the following briefly introduces the accompanying drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments of the present invention. For those of ordinary skill in the art, other drawings can also be obtained according to these drawings without creative efforts.
图1是本发明的池化流程图。FIG. 1 is a flow chart of the pooling of the present invention.
图2是本发明的老师姿态信息计算流程图。FIG. 2 is a flow chart of the teacher attitude information calculation according to the present invention.
图3是本发明的多模态融合分析学生课堂学习状态图。Fig. 3 is a state diagram of a student's classroom learning by multimodal fusion analysis of the present invention.
图4是本发明的通过三模态卷积神经网络的联合学习可以得到三种基于不同模态的三维模型特征到的流程图。FIG. 4 is a flow chart of the three-dimensional model features based on different modalities that can be obtained through joint learning of a three-modal convolutional neural network according to the present invention.
图5是本发明的一种基于多模态学习状态分析系统的结构图。FIG. 5 is a structural diagram of a state analysis system based on multimodal learning of the present invention.
图6是本发明的图像获取模块的结构图。FIG. 6 is a structural diagram of an image acquisition module of the present invention.
图7是本发明的老师位置信息获取模块的结构图。FIG. 7 is a structural diagram of a teacher position information acquisition module of the present invention.
图8是本发明的老师姿态信息获取模块的结构图。FIG. 8 is a structural diagram of a teacher attitude information acquisition module of the present invention.
1-图像获取模块、2-老师位置信息获取模块、3-老师姿态信息获取模块、4-学生面部信息获取模块、5-分析模块、11-获取单元、12-处理单元、21-特征图提取单元、22-候选单元、23-区域特征图生成单元、24-老师位置获取单元、31-关键点获取单元、32-归一化单元。1-Image acquisition module, 2-Teacher position information acquisition module, 3-Teacher attitude information acquisition module, 4-Student face information acquisition module, 5-Analysis module, 11-Acquisition unit, 12-Processing unit, 21-Feature map extraction Unit, 22-candidate unit, 23-region feature map generation unit, 24-teacher position acquisition unit, 31-key point acquisition unit, 32-normalization unit.
具体实施方式Detailed ways
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。The following describes in detail the embodiments of the present invention, examples of which are illustrated in the accompanying drawings, wherein the same or similar reference numerals refer to the same or similar elements or elements having the same or similar functions throughout. The embodiments described below with reference to the accompanying drawings are exemplary, and are intended to explain the present invention and should not be construed as limiting the present invention.
实施例1Example 1
请参阅图1~图8,本发明提供一种基于多模态学习状态分析系统:Please refer to FIG. 1 to FIG. 8 , the present invention provides a state analysis system based on multimodal learning:
包括图像获取模块1、老师位置信息获取模块2、老师姿态信息获取模块3、学生面部信息获取模块4和分析模块5,Including
所述图像获取模块1,用于收集教室内部的图像数据并进行预处理得到处理图像;The
所述老师位置信息获取模块2,用于基于处理图像和Faster R-CNN目标检测模型获得老师的位置信息;The teacher position
所述老师姿态信息获取模块3,用于基于处理图像和Faster R-CNN目标检测模型获得老师的姿态信息;The teacher attitude
所述学生面部信息获取模块4,用于基于处理图像和ERT人脸特征点检测方法获取学生面部信息;Described student facial
所述分析模块5,用于基于位置信息、姿态信息和学生面部信息分析学习状态。The
在本实施方式中,可以在教室的前后分别放置摄像头,然后通过所述图像获取模块1获取图像数据,之后通过Faster R-CNN目标检测模型分别对图像进行处理以得到老师的位置信息和面部信息,然后通过ERT人脸特征点检测方法提取图像数据中的学生面部信息,之后可以综合对学生的学习状态进行评估,从而可以更好地对学生的上课情况进行监管,以提高学生的学习效率。其中ERT人脸特征点检测方法的公式如下:In this embodiment, cameras can be placed in the front and back of the classroom, and then the image data is acquired by the
ξ(t+1)=ξ(t)+rt(I,ξ(t))ξ (t+1) = ξ (t) +r t (I,ξ (t) )
其中:t表示级联序号,rt(,)表示当前级的回归器。回归器输入人脸图像I和上一级回归器更新后的面部特征点位置坐标,采用的特征可以是灰度值或者其他特征。当获得图像是,算法生成出事位置,改初始位置是预估面部特征点的位置。采用梯度提升算法来最小化误差,得到每一级联回归银子。Among them: t represents the serial number of the cascade, and r t (,) represents the regressor of the current stage. The regressor inputs the face image I and the position coordinates of the facial feature points updated by the previous regressor, and the adopted feature can be gray value or other features. When the image is obtained, the algorithm generates the location of the accident, and the initial location is the location of the estimated facial feature points. The gradient boosting algorithm is used to minimize the error, and each cascaded regression silver is obtained.
进一步的,所述图像获取模块1包括获取单元11和处理单元12,所述获取单元11用于收集摄像头的图像数据;Further, the
所述处理单元12,用于将图像数据的尺寸标准化,并进行归一化处理,得到处理图像。The
所述收集摄像头的图像数据的具体方式是,每隔5秒为一帧获取图像。使得采样频率更加合适,在满足实时性的同时也提高了图像的处理效率。The specific manner of collecting the image data of the camera is to acquire an image for one frame every 5 seconds. The sampling frequency is more suitable, and the image processing efficiency is improved while satisfying the real-time performance.
进一步的,所述老师位置信息获取模块2包括特征图提取单元21、候选单元22、区域特征图生成单元23和老师位置获取单元24,Further, the teacher position
所述特征图提取单元21,用于基于处理图像提取原始特征图;The feature
所述候选单元22,用于将原始特征图输入到候选框提取网络,生成区域候选框;The
所述区域特征图生成单元23,用于将区域候选框映射到所述原始特征图中,并池化为区域特征图;The regional feature
所述老师位置获取单元24,用于将区域特征图输入Faster R-CNN目标检测模型中获取老师位置信息。The teacher
在本实施方式中,提取原始特征图的具体方式是首先将任意大小的上课场景中的老师行为图像缩放置固定大小256*256,然后将256*256大小的图片输入CNN(卷积层)等基础网络,从而特取原始图片的特征图,后续的RPN层和全连接层可以共享该特征图。In this embodiment, the specific method of extracting the original feature map is to first downscale the teacher behavior image in the class scene of any size to a fixed size of 256*256, and then input the 256*256 image into the CNN (convolutional layer), etc. The basic network, so as to take the feature map of the original image, the subsequent RPN layer and the fully connected layer can share the feature map.
第二步:将特征图输入到RPN,生成区域候选框。在特征图上应用华东窗口进行目标区域判定和分类,从而生成区域候选框。RPN首先对共享卷积层输入的特征图做一个卷积操作已得到特征向量,然后将特征向量输入连个全连接层,即边界框回归层和边界框分类层。Step 2: Input the feature map to the RPN to generate a region candidate frame. The East China window is applied to the feature map to determine and classify the target region, thereby generating a region candidate frame. RPN first performs a convolution operation on the feature map input by the shared convolution layer to obtain the feature vector, and then inputs the feature vector into a fully connected layer, namely the bounding box regression layer and the bounding box classification layer.
第三步:对每个区域特征图进行池化(POI Pooling)。输入特征图和候选区域,将候选区域映射到特征图中,并池化为统一大小的区域特征图,在将区域特征图输入全连接,得到分类向量和位置坐标Step 3: Perform POI Pooling on each region feature map. Input the feature map and candidate region, map the candidate region to the feature map, and pool it into a uniform size region feature map, and then input the region feature map into the full connection to obtain the classification vector and position coordinates
第四步:最后将区域特征图输入Faster R-CNN中,根据RPN所提出的候选框,对候选框做进一步地位置精修好额类别回归。Step 4: Finally, input the regional feature map into Faster R-CNN. According to the candidate frame proposed by RPN, further refine the position of the candidate frame and perform category regression.
对于老师上课行为图片中的每个选定区域i,fi定义为来自改区域的平均池化卷积特征,因此图像特征向量的为维数2048.全连接层将fi转换成h维向量。For each selected area i in the teacher's class behavior picture, fi is defined as the average pooled convolution feature from the modified area, so the dimension of the image feature vector is 2048. The fully connected layer converts fi into an h-dimensional vector .
vi=Wvfi+bv v i =W v f i +b v
因此,老师上课时行为图像的完整表示是一组嵌入向量。Therefore, the complete representation of the teacher's behavioral images during class is a set of embedding vectors.
V={v1,...,vk},vi∈RV={v 1 ,...,v k },vi∈R
其中,vi编码一个显著区域i,k是区域个数。Among them, vi encodes a salient region i , and k is the number of regions.
进一步的,所述老师姿态信息获取模块3包括关键点获取单元31和归一化单元32,所述关键点获取单元31,用于基于Faster R-CNN目标检测模型,获取人体姿态关键点信息;Further, the teacher attitude
所述归一化单元32,用于基于人体姿态关键点信息进行姿态归一化模块处理。The
在本实施方式中,Faster R-CNN目标检测模型,获取人体姿态关键点信息,在进行姿态归一化模块处理。In this embodiment, the Faster R-CNN target detection model obtains the key point information of the human body posture, and performs the posture normalization module processing.
在姿态归一化时,对关键点坐标的估算,从而计算变换矩阵。During pose normalization, the estimation of the coordinates of the key points, thereby calculating the transformation matrix.
流程如图2所示。图中,首先基于先前关键点检测网络得到的关键点提取出关键点的坐标。然后选取其中最大值点作为关键点的估计,有了关键点坐标。The process is shown in Figure 2. In the figure, the coordinates of the key points are first extracted based on the key points obtained by the previous key point detection network. Then select the maximum point as the estimation of the key point, and have the coordinates of the key point.
进一步的,所述基于位置信息、姿态信息和学生面部信息分析学习状态的具体步骤是:Further, the concrete steps of analyzing the learning state based on position information, posture information and student face information are:
构建并训练基于全连接层的多模态特征融合网络结构;Build and train a multimodal feature fusion network structure based on a fully connected layer;
将位置信息、姿态信息和学生面部信息映射到特征融合空间进行学习状态分析。The location information, pose information and student face information are mapped to the feature fusion space for learning state analysis.
为了解决单一模态数据对学生课堂学习状态的评估,本文采用了多模态融合的方法,从3个模态分析学生课堂学习状态。总的流程图如图3所示。In order to solve the evaluation of students' classroom learning status by single modal data, this paper adopts the method of multi-modal fusion to analyze students' classroom learning status from three modalities. The overall flow chart is shown in Figure 3.
通过构建并训练基于全连接层的多模态特征融合网络结构,将多维度的多尺度特征映射到特征融合空间,这种特征融合方式的优势主要在于模型能够在训练阶段学习2个并行网络各自的特征参数,并自主完成协调反馈,实现了模型端到端的训练。By building and training a multi-modal feature fusion network structure based on a fully connected layer, the multi-dimensional and multi-scale features are mapped to the feature fusion space. The advantage of this feature fusion method is that the model can learn two parallel networks in the training phase. The characteristic parameters of the model are completed independently, and the coordination feedback is completed, which realizes the end-to-end training of the model.
本文选自Softmax函数将特征向量映射成概率序列,已保留更多特征的原始信息。Softmax计算输出类别y(i)的过程如公式所示。This paper selects the Softmax function to map the feature vector into a probability sequence, and retains the original information of more features. The process of Softmax calculating the output category y (i) is shown in the formula.

式中:ηi为融合后的特征值;k为类别数;P表示y(i)表示类别k的概率值。In the formula: η i is the feature value after fusion; k is the number of categories; P represents y (i) represents the probability value of category k.
第一阶段:关注每张老师图片中老师位置信息特征与学生眼睛偏移量,得到学生是否看老师The first stage: Pay attention to the teacher's position information feature and the student's eye offset in each teacher's picture, and get whether the student is looking at the teacher
第二阶段:将老师行为图像特征区域进行分析,此时应该看黑板还是老师;然后与学生眼睛偏移量进行比较,得出学生此时应该看那里。The second stage: analyze the characteristic area of the teacher's behavior image, whether to look at the blackboard or the teacher at this time; then compare with the student's eye offset to get where the student should look at this time.
第三阶段:将学生的面部特征图与老师行为和位置进行分析,得出相似实施例2The third stage: analyze the student's facial feature map and the teacher's behavior and position, and obtain a
实施例2和实施例1的区别仅在于所述基于位置信息、姿态信息和学生面部信息分析学习状态的具体步骤是:The difference between
采用加权融合方法融合位置信息、姿态信息和学生面部信息得到加权融合特征;A weighted fusion method is used to fuse position information, attitude information and student face information to obtain weighted fusion features;
将加权融合特征输入全连接层;Input the weighted fusion features into the fully connected layer;
获得加权融合特征的分类概率分布。Obtain the classification probability distribution of weighted fused features.
通过三模态卷积神经网络的联合学习可以得到三种基于不同模态的三维模型特征。区别于传统的采用池化操作的特征融合方法,本文中基于统计方法,采用加权融合方法融合三个特征向量,方法的框架如图4所示。Through the joint learning of the three-modal convolutional neural network, three 3D model features based on different modalities can be obtained. Different from the traditional feature fusion method using pooling operation, this paper uses the weighted fusion method to fuse three feature vectors based on the statistical method. The framework of the method is shown in Figure 4.
具体公式:Specific formula:

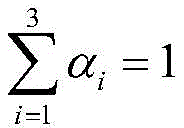
其中:f表示的是在不同模态表特征提取的特征向量;αi表示的是不同模态的权重,对加权融合特征的特征向量输入到全连接层(FC层),全连接层的维度依次为512、256、C,C表示数据集类别的数量。最后通过一个softmax层获得三维模型的分类概率分布。将学习状态分为从容,一般、走神、困难Among them: f represents the feature vector extracted from different modal table features; α i represents the weight of different modalities, the feature vector of the weighted fusion feature is input to the fully connected layer (FC layer), the dimension of the fully connected layer The sequence is 512, 256, C, and C represents the number of dataset categories. Finally, the classification probability distribution of the 3D model is obtained through a softmax layer. Divide the learning state into calm, normal, distracted, and difficult
本文通过相关性损失函数来确保训练过程中多个模态之间可以相互指导,提高网络训练的学习速度,并提高最终特征向量的鲁棒性。In this paper, the correlation loss function is used to ensure that multiple modalities can guide each other during the training process, improve the learning speed of network training, and improve the robustness of the final feature vector.
具体公式如下:The specific formula is as follows:
LC(Mi,Mj)=|ξ(fMi)-ξ(fMj)|2 L C (M i ,M j )=|ξ(f Mi )-ξ(f Mj )| 2
其中:2表示为两个不同特征向量的相关性。f表示的是在不同模态表特征提取的特征向量;M的下标表示第1、2、3个模态的数据;ξ=sigmoid(log(abs()))表示一个归一化激发函数。在训练过程中,相关性损失的值逐渐减小,表明在训练过程中不同模态特征相互指导,这会加快训练的收敛速度,获得更具有鲁棒性的特征向量。以模态M,为例,基于这种相关性损失函数的设计,不同模态网络的最终损失函数如下:where: 2 represents the correlation of two different eigenvectors. f represents the feature vector extracted from different modal tables; the subscript of M represents the data of the 1st, 2nd, and 3rd modalities; ξ=sigmoid(log(abs())) represents a normalized excitation function . During the training process, the value of the correlation loss gradually decreases, indicating that different modal features guide each other during the training process, which will speed up the training convergence speed and obtain more robust feature vectors. Taking modal M as an example, based on the design of this correlation loss function, the final loss functions of different modal networks are as follows:

其中:
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。The above disclosure is only a preferred embodiment of the present invention, and of course, it cannot limit the scope of rights of the present invention. Those of ordinary skill in the art can understand that all or part of the process for realizing the above-mentioned embodiment can be realized according to the rights of the present invention. The equivalent changes required to be made still belong to the scope covered by the invention.
Claims (7)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210027041.4A CN114663910A (en) | 2022-01-11 | 2022-01-11 | Multi-mode learning state analysis system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210027041.4A CN114663910A (en) | 2022-01-11 | 2022-01-11 | Multi-mode learning state analysis system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114663910A true CN114663910A (en) | 2022-06-24 |
Family
ID=82025652
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210027041.4A Pending CN114663910A (en) | 2022-01-11 | 2022-01-11 | Multi-mode learning state analysis system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114663910A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116596347A (en) * | 2023-07-17 | 2023-08-15 | 泰山职业技术学院 | Multi-disciplinary interaction teaching system and teaching method based on cloud platform |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109035089A (en) * | 2018-07-25 | 2018-12-18 | 重庆科技学院 | A kind of Online class atmosphere assessment system and method |
| CN109165552A (en) * | 2018-07-14 | 2019-01-08 | 深圳神目信息技术有限公司 | A kind of gesture recognition method based on human body key point, system and memory |
| CN111652045A (en) * | 2020-04-17 | 2020-09-11 | 西北工业大学太仓长三角研究院 | Classroom teaching quality assessment method and system |
| US20210060787A1 (en) * | 2019-08-29 | 2021-03-04 | Wuyi University | Education assisting robot and control method thereof |
-
2022
- 2022-01-11 CN CN202210027041.4A patent/CN114663910A/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109165552A (en) * | 2018-07-14 | 2019-01-08 | 深圳神目信息技术有限公司 | A kind of gesture recognition method based on human body key point, system and memory |
| CN109035089A (en) * | 2018-07-25 | 2018-12-18 | 重庆科技学院 | A kind of Online class atmosphere assessment system and method |
| US20210060787A1 (en) * | 2019-08-29 | 2021-03-04 | Wuyi University | Education assisting robot and control method thereof |
| CN111652045A (en) * | 2020-04-17 | 2020-09-11 | 西北工业大学太仓长三角研究院 | Classroom teaching quality assessment method and system |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116596347A (en) * | 2023-07-17 | 2023-08-15 | 泰山职业技术学院 | Multi-disciplinary interaction teaching system and teaching method based on cloud platform |
| CN116596347B (en) * | 2023-07-17 | 2023-09-29 | 泰山职业技术学院 | Multi-disciplinary interaction teaching system and teaching method based on cloud platform |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109815826B (en) | Method and device for generating face attribute model | |
| CN110659723B (en) | Data processing method and device based on artificial intelligence, medium and electronic equipment | |
| CN110728209A (en) | Gesture recognition method and device, electronic equipment and storage medium | |
| CN108427921A (en) | A kind of face identification method based on convolutional neural networks | |
| CN106909938B (en) | Perspective-independent behavior recognition method based on deep learning network | |
| Liu et al. | Action recognition based on 3d skeleton and rgb frame fusion | |
| CN111680550B (en) | Emotion information identification method and device, storage medium and computer equipment | |
| CN111783748A (en) | Face recognition method and device, electronic equipment and storage medium | |
| CN113128424A (en) | Attention mechanism-based graph convolution neural network action identification method | |
| CN109508686B (en) | Human behavior recognition method based on hierarchical feature subspace learning | |
| CN113743544A (en) | Cross-modal neural network construction method, pedestrian retrieval method and system | |
| CN113297956A (en) | Gesture recognition method and system based on vision | |
| CN114694174A (en) | A human interaction behavior recognition method based on spatiotemporal graph convolution | |
| CN114724224A (en) | Multi-mode emotion recognition method for medical care robot | |
| CN111967361A (en) | Emotion detection method based on baby expression recognition and crying | |
| CN116975602A (en) | AR interactive emotion recognition method and system based on multi-modal information double fusion | |
| CN112446253A (en) | Skeleton behavior identification method and device | |
| CN115965968A (en) | Small sample target detection and identification method based on knowledge guidance | |
| CN116958027A (en) | Three-dimensional industrial abnormality detection method and device, storage medium and electronic equipment | |
| CN115982652A (en) | A Cross-Modal Sentiment Analysis Method Based on Attention Network | |
| CN114663910A (en) | Multi-mode learning state analysis system | |
| CN114495210A (en) | Posture change face recognition method based on attention mechanism | |
| CN114613011A (en) | Human 3D Skeletal Behavior Recognition Method Based on Graph Attention Convolutional Neural Network | |
| CN114187506A (en) | Remote sensing image scene classification method of viewpoint-aware dynamic routing capsule network | |
| CN114494773A (en) | Part sorting and identifying system and method based on deep learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |