CN114549919A - 目标识别模型的训练方法、识别方法、装置、设备 - Google Patents
目标识别模型的训练方法、识别方法、装置、设备 Download PDFInfo
- Publication number
- CN114549919A CN114549919A CN202011248507.0A CN202011248507A CN114549919A CN 114549919 A CN114549919 A CN 114549919A CN 202011248507 A CN202011248507 A CN 202011248507A CN 114549919 A CN114549919 A CN 114549919A
- Authority
- CN
- China
- Prior art keywords
- target
- image data
- recognition
- classification
- result
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Molecular Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Evolutionary Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Probability & Statistics with Applications (AREA)
- Image Analysis (AREA)
Abstract
本发明实施例公开了一种目标识别模型的训练方法、识别方法、装置、设备及存储介质。首先获取图像数据;然后根据预设的多层分类网络中的每层分类网络以及预设的与每层分类网络对应的补偿模型对图像数据进行计算,得到至少一种第一分类结果;之后根据第一分类结果从图像数据中确定与第一分类结果对应的第一目标图像数据;之后基于预设的神经网络对第一目标图像数据进行计算,得到第一识别结果;最后根据第一分类结果和第一识别结果对包括多层分类网络和神经网络的模型进行训练,得到目标识别模型,以用于对图像数据进行识别得到识别结果。解决了现有的图形堡垒软件的目标识别过程中,效率较低的问题,提高了工作效率与准确率。
Description
技术领域
本发明涉及目标识别领域,尤其涉及一种目标识别模型的训练方法、识别方法、装置、设备及存储介质。
背景技术
堡垒机是为了保障网络和数据不受来自外部和内部用户的入侵和破坏,而运用各种技术手段监控和记录运维人员对网络内的服务器、网络设备、安全设备、数据库等设备的操作行为的系统,以便集中报警、及时处理及审计定责。
但是,在现有的传统图形堡垒软件的目标识别过程中,主要是通过采集用户操作流程视频与操作日志,再使用人工观察来进行检测操作的软件,但是由于采用的是人机结合的检查方式,这种方法的检测效率受到人的因素限制,效率不高。
因此,在现有的图形堡垒软件的目标识别过程中,存在效率较低的问题。
发明内容
本发明实施例提供了一种目标识别模型的训练方法、识别方法、装置、设备及存储介质,解决了数据传输过程中存在的无法确定处理时延的问题,提高了处理过程中时延的确定性。
为了解决上述技术问题,本发明:
第一方面,提供了一种目标识别模型的训练方法,该方法包括:
获取图像数据;
根据预设的多层分类网络中的每层分类网络以及预设的与每层分类网络对应的补偿模型对图像数据进行计算,得到至少一种第一分类结果;
根据第一分类结果从图像数据中确定与第一分类结果对应的第一目标图像数据;
基于预设的神经网络对第一目标图像数据进行计算,得到第一识别结果;
根据第一分类结果和第一识别结果对包括多层分类网络和神经网络的模型进行训练,得到目标识别模型。
在第一方面的一些实现方式中,图像数据包括目标软件的图像信息;基于预设的神经网络对第一目标图像数据进行计算,得到第一识别结果,包括:
将第一目标图像数据划分为预设数量的候选区域;
对每个候选区域包括的第二目标图像数据进行目标检测,确定存在目标软件的至少一个目标候选区域;
对每个目标候选区域包括的第三目标图像数据进行类别识别,确定目标候选区域中包括目标软件的类别概率;
根据每个目标候选区域的类别概率确定图像数据的第一识别结果,其中,第一识别结果包括目标软件在图像数据中的位置信息。
在第一方面的一些实现方式中,该方法还包括:
对每个候选区域包括的第二目标图像数据进行目标检测,确定候选区域中目标软件的存在概率;
当存在概率满足阈值时,确定候选区域为存在目标软件的目标候选区域。
在第一方面的一些实现方式中,该方法还包括:
根据每个目标候选区域的存在概率和类别概率确定图像数据的第一识别结果。
在第一方面的一些实现方式中,根据第一分类结果和第一识别结果对包括多层分类网络和神经网络的模型进行训练,得到目标识别模型,包括:
根据第一分类结果对多层分类网络进行训练,以及根据第一识别结果对神经网络进行训练;
根据训练后的多层分类网络输出的第二分类结果与预先存储的与图像数据对应的预设分类结果确定分类损失值;
根据训练后的神经网络输出的第二识别结果与预先存储的与图像数据对应的预设识别结果确定识别损失值;
当分类损失值和识别损失值满足预设条件时,将包括训练后的多层分类网络和训练后的神经网络的模型作为目标识别模型。
第二方面,提供了一种目标的识别方法,该识别方法包括:
获取图像数据;
使用目标识别模型对图像数据进行计算,得到识别结果,其中,目标识别模型是基于第一方面,以及第一方面的一些实现方式中的目标识别模型的训练方法得到的。
第三方面,提供了一种目标识别模型的训练装置,该装置包括:
获取模块,用于获取图像数据;
处理模块,用于根据预设的多层分类网络中的每层分类网络以及预设的与每层分类网络对应的补偿模型对图像数据进行计算,得到至少一种第一分类结果;
处理模块,还用于根据第一分类结果从图像数据中确定与第一分类结果对应的第一目标图像数据;
处理模块,还用于基于预设的神经网络对第一目标图像数据进行计算,得到第一识别结果;
处理模块,还用于根据第一分类结果和第一识别结果对包括多层分类网络和神经网络的模型进行训练,得到目标识别模型。
在第三方面的一些实现方式中,图像数据包括目标软件的图像信息;处理模块,还用于将第一目标图像数据划分为预设数量的候选区域;对每个候选区域包括的第二目标图像数据进行目标检测,确定存在目标软件的至少一个目标候选区域;对每个目标候选区域包括的第三目标图像数据进行类别识别,确定目标候选区域中包括目标软件的类别概率;根据每个目标候选区域的类别概率确定图像数据的第一识别结果,其中,第一识别结果包括目标软件在图像数据中的位置信息。
在第三方面的一些实现方式中,处理模块,还用于对每个候选区域包括的第二目标图像数据进行目标检测,确定候选区域中目标软件的存在概率;当存在概率满足阈值时,确定候选区域为存在目标软件的目标候选区域。
在第三方面的一些实现方式中,处理模块,还用于根据每个目标候选区域的存在概率和类别概率确定图像数据的第一识别结果。
在第三方面的一些实现方式中,处理模块,还用于根据第一分类结果对多层分类网络进行训练,以及根据第一识别结果对神经网络进行训练;根据训练后的多层分类网络输出的第二分类结果与预先存储的与图像数据对应的预设分类结果确定分类损失值;根据训练后的神经网络输出的第二识别结果与预先存储的与图像数据对应的预设识别结果确定识别损失值;当分类损失值和识别损失值满足预设条件时,将包括训练后的多层分类网络和训练后的神经网络的模型作为目标识别模型。
第四方面,提供了一种目标的识别装置,该装置包括:
获取模块,用于获取图像数据;
处理模块,用于使用目标识别模型对图像数据进行计算,得到识别结果,其中,目标识别模型是基于第一方面,以及第一方面的一些实现方式中的目标识别模型的训练方法得到的。
第五方面,提供了一种电子设备,该设备包括:处理器以及存储有计算机程序指令的存储器;
处理器执行计算机程序指令时实现第一方面,以及第一方面的一些实现方式中的目标识别模型的训练方法,或者,实现第二方面的目标的识别方法。
第六方面,提供了一种计算机存储介质,其特征在于,计算机存储介质上存储有计算机程序指令,计算机程序指令被处理器执行实现第一方面,以及第一方面的一些实现方式中的目标识别模型的训练方法,或者,实现第二方面的目标的识别方法。
本发明实施例提供了一种目标识别模型的训练方法、识别方法、装置、设备及存储介质。首先获取图像数据;之后根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿参数对所述图像数据进行计算,得到至少一种第一分类结果;然后根据所述第一分类结果从所述图像数据中确定与所述第一分类结果对应的第一目标图像数据;紧接着基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果;最后根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为本发明实施例中,先结合预设的多层分类网络和预设的与所述每层分类网络对应的补偿参数对图像数据进行场景识别,解决图形堡垒检测软件类别较多,且不同场景差异较大、相同场景下类别视觉内容较为相似的情况,提高了识别的精度。然后再将已经确定场景类别的图像数据基于预设的神经网络进行识别,得到识别结果。最后再根据场景识别的结果以及预设神经网络的识别结果训练包括多层分类网络和神经网络的模型,最终得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为整个过程不需要审计人员进行参数设置,所以减少了堡垒机审计人员的工作量,解决了现有的图形堡垒软件的目标识别过程中,效率较低的问题,提高了工作效率与准确率。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图作简单地介绍,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种目标识别模型的训练方法的流程示意图;
图2是本发明实施例提供的一种场景分类框架示意图;
图3是本发明实施例提供的一种图像数据划分示意图;
图4是本发明实施例提供的一种目标的识别方法的流程示意图;
图5是本发明实施例提供的一种目标识别模型的训练装置的示意图;
图6是本发明实施例提供的一种目标的识别装置的示意图;
图7是本发明实施例提供的一种计算设备的结构图。
具体实施方式
下面将详细描述本发明的各个方面的特征和示例性实施例,为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细描述。应理解,此处所描述的具体实施例仅被配置为解释本发明,并不被配置为限定本发明。对于本领域技术人员来说,本发明可以在不需要这些具体细节中的一些细节的情况下实施。下面对实施例的描述仅仅是为了通过示出本发明的示例来提供对本发明更好的理解。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
堡垒机是为了保障网络和数据不受来自外部和内部用户的入侵和破坏,而运用各种技术手段监控和记录运维人员对网络内的服务器、网络设备、安全设备、数据库等设备的操作行为的系统,以便集中报警、及时处理及审计定责。
传统图形堡垒软件目标识别的过程中,是获取堡垒机上的录屏视频,基于录屏视频,对视频帧进行软件场景(例如:浏览器)分类,输出目标软件场景类别信息,再对不同的场景类别采用目标检测方法来得到不同场景下的软件名称(浏览器场景下包括360浏览器、浏览器等)与软件位置,对堡垒机的操作软件进行监控识别,以防止工作人员做出违规的操作。基于深度场景分类和目标检测联合优化的图形堡垒软件目标识别是将场景分类、目标检测以及联合优化等技术结合起来的端到端的识别方法。输出信息包括:软件位置、软件名。
但是,在目前的常用方法中,主要是通过采集用户操作流程视频与操作日志,使用人工观察来检测操作人员进行操作的软件,但是由于采用的是人机结合的检查方式,该方法的检测效率受到人的因素限制,效率不高。近几年随着技术的发展,通过采用图像识别的方法进行图形堡垒软件自动识别可以有效提高检测效率,目前主要有以下两类识别方法。
第一类是基于传统图像识别检测方法,该类方法包括图像预处理、图像分割、图像拼接、盲图像复原和图像分类识别等处理方法。主要分为预处理、提取目标区域、图像分类与识别三个步骤:
Step1:对图形堡垒软件图片进行去噪与增强等预处理;
将存在部分重叠的目标软件图像序列进行配准,并通过融合处理得到的一幅新的完整的、宽视角场景图像;
对于退化图像尝试利用图像降质的先验知识和退化过程建立退化模型,采用一定的方法从观察到的退化图像中尽可能地恢复出原始图像的本来面目。
Step2:将图像根据区域特性(灰度、颜色、纹理等)提取出要识别的目标软件区域。
Step3:提取目标区域的图像特征并采用无监督、监督和半监督等方法进行分类与识别。
但是该类传统的图像识别算法中,图像的特征提取与分类两步是分开进行的。这就使得人需要手工构建、选择针对目标的特征。在面临复杂陌生问题时,人往往无法设计出足够优秀的特征。并且最关键的是,人设计出的特征往往是肤浅的,针对于诸如梯度、颜色、纹理等某一方面的浅层特征。这就使得传统的图像识别算法有很大的局限性,性能提高空间有限。
第二类是基于深度学习的目标检测识别方法,目前基于深度学习的目标检测主要分为两种思路,一种是以Faster-RCNN为代表的两步法,即先通过浅层网络生成候选目标矩形区域,再通过深层网络对候选区域精调。另一种是以单阶段目标检测(Single ShotMultiBox Detector,SSD)/只需一眼检测(You Only Look Once,YOLO)为代表的一步法,即直接通过图像回归出目标物体坐标。一步法是一个可以一次性预测多个检测框Box位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。两步法并没有选择滑窗或提取proposal的方式训练网络,而是直接选用整图训练模型。
虽然基于深度学习的目标检测方法可以提取到物体的深层高级别特征,但是针对图形堡垒不同场景类别所在区域视觉差异较大(浏览器与编辑器)且相同场景下的各个类别区域整体视觉内容较为相似(在浏览器中的ie、360等浏览器),直接使用基于深度学习的检测方法显著增加物体检测分类任务难度,且准确率较低。
由此可以看出,在上述的两类识别方法,虽然改进了传统的软件识别方法,但是在图形堡垒软件识别中还是存在检测率较低的问题,主要局限性如下:
(1)传统的图像识别算法,需要人为构建目标特征,人为设计出的特征往往是针对于诸如梯度、颜色、纹理等某一方面的浅层特征。这就使得传统的图像识别算法有很大的局限性,性能提高空间有限。
(2)由于图形堡垒不同场景类别所在区域视觉差异较大(浏览器与编辑器)且相同场景下的各个类别区域整体视觉内容较为相似(在浏览器中的因特网浏览器ie、360等浏览器),如果对于不同场景类别的软件图片不加以区分直接进行视觉方差较大的基于深度学习的检测方法会显著增加物体检测分类任务难度,且准确率较低。
因此,综上所述,在现有的图形堡垒软件的目标识别过程中,存在效率较低的问题。
针对上述现有技术的不足,以推动基于深度学习的图形堡垒软件识别的工程应用为目的,本发明实施例提供了一种目标识别模型的训练方法、识别方法、装置、设备及存储介质。首先获取图像数据;之后根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿参数对所述图像数据进行计算,得到至少一种第一分类结果;然后根据所述第一分类结果从所述图像数据中确定与所述第一分类结果对应的第一目标图像数据;紧接着基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果;最后根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为本发明实施例中,先结合预设的多层分类网络和预设的与所述每层分类网络对应的补偿参数对图像数据进行场景识别,解决图形堡垒检测软件类别较多,且不同场景差异较大、相同场景下类别视觉内容较为相似的情况,提高了识别的精度。然后再将已经确定场景类别的图像数据基于预设的神经网络进行识别,得到识别结果。最后再根据场景识别的结果以及预设神经网络的识别结果训练包括多层分类网络和神经网络的模型,最终得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为整个过程不需要审计人员进行参数设置,所以减少了堡垒机审计人员的工作量,解决了现有的图形堡垒软件的目标识别过程中,效率较低的问题,提高了工作效率与准确率。
下面结合附图对本发明实施例提供的技术方案进行描述。
图1是本发明实施例提供的一种目标识别模型的训练方法的流程示意图。该方法的执行主体可以是处理器。
如图1所示,目标识别模型的训练方法可以包括:
S101:获取图像数据。
具体的,该图像数据可以是堡垒机录制的录屏视频中的图像数据,因此该图像数据包括目标软件的图像信息。
S102:根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿模型对所述图像数据进行计算,得到至少一种第一分类结果。
在该步骤中,是因为考虑到图形堡垒软件图片不同场景类别所在区域视觉差异较大且相同场景下的各个类别区域整体视觉内容较为相似,所以可以先对获取的图像数据先进行分类,得到至少一种第一分类结果。
具体的,在该步骤中,首先可以将获取的图像数据作为输入X,该输入的特征的长宽分别可以为H′、W′,通道数可以为C′,通过一系列卷积等一般变换Ftr后得到一个特征通道数为C的特征U。与传统的CNN不一样的是,在本发明的一个实施例中,通过三个计算过程来重标定前面得到的特征得到新的特征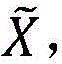 以使得标定后的特征得以根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿参数对所述图像数据进行计算,得到至少一种第一分类结果。
以使得标定后的特征得以根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿参数对所述图像数据进行计算,得到至少一种第一分类结果。
计算过程1:Squeeze操作Fsq(·):将一个通道(channel)上整个空间特征编码为一个1×1×C的全局特征。
计算过程2:Excitation操作Fex(·,W):抓取通道(channel)之间的关系。
计算过程3:Scale操作Fscale(·,·):将归一化后的权重加权到每个通道的特征上,得到更有辨别能力的新的特征
在得到新特征之后,可以根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿模型对新的特征 进行计算,得到至少一种第一分类结果。
进行计算,得到至少一种第一分类结果。
该补偿模型与多层分类网络中的每层分类网络相结合,形成了一种场景分类框架,用以对获取的图像数据进行计算得到第一分类结果,该第一分类结果具体指的是一种场景结果。
在一个实施例中,根据该场景分类框架计算得到第一分类结果的过程如图2所示,补偿模型对多层分类网络中每层分类网络产生的特征图都进行增强或抑制,最终输出与获取的图像数据对应的第一分类结果,即,场景结果。
S103:根据第一分类结果从图像数据中确定与第一分类结果对应的第一目标图像数据。
在该过程中,根据对图像数据进行场景分类得到的第一目标数据为属于一类场景的图像数据,以解决不同场景下的图像数据差异较大的问题。
S104:基于预设的神经网络对第一目标图像数据进行计算,得到第一识别结果。
在该过程中,可以将所述第一目标图像数据划分为预设数量的候选区域,如图3所示,可以将输入的图像划分为M*N个单元格,每个单元格给定B个不同规格的候选框,候选框如剪头1所指,候选框经由卷积层网络提取出来,因此,每幅图像候选框数量为M*N*B,该候选框又可以称为候选区域。需要说明的是,此处的M,N,B的实际数值可以根据实际情况进行调节。
之后对每个所述候选区域包括的第二目标图像数据进行目标检测,确定所述候选区域中目标软件的存在概率;当存在概率满足阈值时,确定候选区域为存在目标软件的至少一个目标候选区域。
在一个具体的实施例中,在确定存在目标软件的至少一个目标候选区域的过程中,可以对每个所述候选区域包括的第二目标图像数据进行目标检测,预测每个候选区域中存在目标软件的置信度Conf(Object),将不存在目标软件的候选区域的置信度置为零。其中,该置信度具体是指上述存在概率,该置信度可以用公式(1)进行表示。
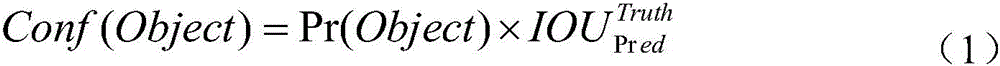
其中,Conf(Object)为候选区域中存在目标软件的置信度,Pr(Object)表示是否有目标落入候选区域对应的单元格中。 为预测框(Pred)与真实框(Truth)交并比,该预测框是指目标候选区域,且该目标候选区域包括有位置信息,真实框是指目标软件的真实位置区域,因此,该交并比可以表示预测框的中目标软件的存在概率。
为预测框(Pred)与真实框(Truth)交并比,该预测框是指目标候选区域,且该目标候选区域包括有位置信息,真实框是指目标软件的真实位置区域,因此,该交并比可以表示预测框的中目标软件的存在概率。
当该候选区域的置信度Conf(Object)大于预设阈值时,该候选区域即为存在目标软件的目标候选区域。
此外,还需要说明的是,Pr(Object)的具体表示可以如公式(2)所示,若有目标落入候选框对应的单元格中,则该单元格就负责检测该目标,Pr(Object)为1,否则为0。
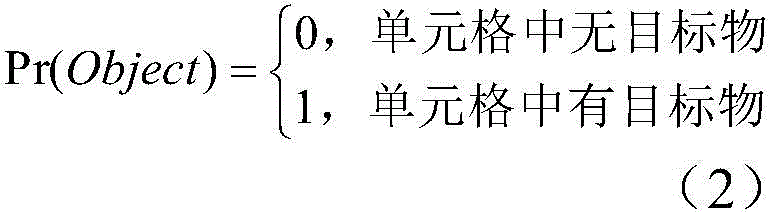
之后对每个目标候选区域包括的第三目标图像数据进行类别识别,确定目标候选区域中包括目标软件的类别概率。
具体的,在确定包括目标软件的类别概率的具体过程中,可以对包括目标软件的目标候选区域进行物体检测,以确定每个目标候选区域特定软件类别的置信分数,然后根据该置信分数确定目标候选区域中包括目标软件的类别概率。确定该置信分数的过程可以如公式(3)所示。
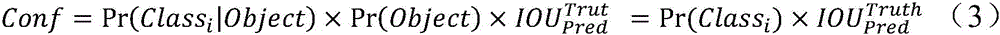
其中,Conf为目标候选区域中包括目标软件的类别概率,Pr(Classi|Object)为每个目标候选区域包含目标软件的概率,Pr(Object)表示是否有目标落入候选区域对应的单元格中, 为预测框(Pred)与真实框(Truth)交并比,该框可以指区域。计算得到的该置信分数具体可以代表目标软件出现在目标候选区域中的概率和目标候选区域的位置信息和物体目标的合适度。
为预测框(Pred)与真实框(Truth)交并比,该框可以指区域。计算得到的该置信分数具体可以代表目标软件出现在目标候选区域中的概率和目标候选区域的位置信息和物体目标的合适度。
因为每个目标候选区域中所包括的信息包括有目标软件的类别概率以及边界框的位置,因此,结合公式(1)(2)和(3),每个目标候选区域可以用公式(4)表示。
[X,Y,W,H,Conf(Object),Conf] (4)
在公式(4)中,X,Y为目标候选区域中心相对于所在单元格边界的偏移,W,H为目标候选区域的宽和高相对于获取的图像数据的宽和高之比,Conf(Object)为候选区域中存在目标软件的置信度,Conf为目标候选区域中包括目标软件的类别概率。
因为每幅图像的候选区域数量为M*N*B,所以对于输入的每幅图片,最终网络输出的向量公式可以如公式(5)所示,该向量公式是指第一识别结果。
M*N*B[X,Y,W,H,Conf(Object),Conf] (5)
其中,M,N是指输入的图像划分的M*N个单元格,B是指的每个单元格给定B个不同规格的初始候选框,X,Y为目标候选区域中心相对于所在单元格边界的偏移,Conf(Object)为候选区域中存在目标软件的置信度,Conf为目标候选区域中包括目标软件的类别概率。
S105:根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型。
在该步骤中,根据所述第一分类结果对所述多层分类网络进行训练,以及根据所述第一识别结果对所述神经网络进行训练;然后根据训练后的多层分类网络输出的第二分类结果与预先存储的与所述图像数据对应的预设分类结果确定分类损失值;以及根据训练后的神经网络输出的第二识别结果与预先存储的与所述图像数据对应的预设识别结果确定识别损失值;当所述分类损失值和所述识别损失值满足预设条件时,将包括训练后的多层分类网络和训练后的神经网络的模型作为目标识别模型。
在根据第一分类结果对所述多层分类网络进行训练的过程中,在一个实施例中,选择使用交叉熵损失函数进行训练,分类损失值LOSSSEN可以如公式(6)所示:
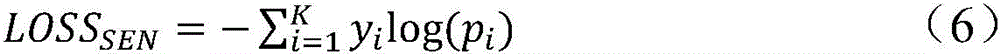
其中,其中:K是软件场景种类数量;y是标签,如果类别是i,则yi=1,否则等于0;pi是神经网络的输出的类别是i的概率。
根据所述第一识别结果对所述神经网络进行训练的过程中,根据第一识别结果与预先存储的与所述图像数据对应的预设识别结果确定的识别损失值损失LOSSY如公式(7)所示:

其中,S2=M*N表示网格数,B表示每个单元格预测框的个数。λcoord=5,λnoobj=0.5, 取值为0和1,即表示单元格内是否有目标。LOSSY为总方误差(sum-squared error)来当作位置预测的损失函数,xi,yi为预测位置,即第一识别结果,
取值为0和1,即表示单元格内是否有目标。LOSSY为总方误差(sum-squared error)来当作位置预测的损失函数,xi,yi为预测位置,即第一识别结果,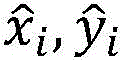 表示真实位置,即所述图像数据对应的预设识别结果。
表示真实位置,即所述图像数据对应的预设识别结果。 表示用根号总方误差作为宽度和高度的损失函数,wi,hi为预测宽度高度,
表示用根号总方误差作为宽度和高度的损失函数,wi,hi为预测宽度高度, 表示真实宽度,真实高度。
表示真实宽度,真实高度。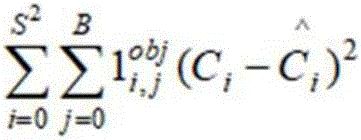 和
和 是对置信度confidence用均方误差作为的损失函数,Ci为预测置信度,
是对置信度confidence用均方误差作为的损失函数,Ci为预测置信度,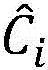 表示真实置信度。
表示真实置信度。

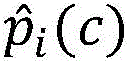
在一个实施例中,在根据第一分类结果对多层分类网络进行训练,以及根据第一识别结果对神经网络进行训练的过程中,可以使用根据LOSSSEN和LOSSY构成的新损失值LOSS,即,如公式(8)所示,对包括多层分类网络和神经网络的模型进行训练,当该LOSS满足预设条件时,将包括训练后的多层分类网络和训练后的神经网络的模型作为目标识别模型,以用于检测图像数据中目标软件的位置和/或种类,该预设条件具体可以指LOSS小于预设阈值。
LOSS=LOSSSEN+LOSSY (8)
本发明实施例提供的目标识别模型的训练方法。首先获取图像数据;之后根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿参数对所述图像数据进行计算,得到至少一种第一分类结果;然后根据所述第一分类结果从所述图像数据中确定与所述第一分类结果对应的第一目标图像数据;紧接着基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果;最后根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为本发明实施例中,先结合预设的多层分类网络和预设的与所述每层分类网络对应的补偿参数对图像数据进行场景识别,解决图形堡垒检测软件类别较多,且不同场景差异较大、相同场景下类别视觉内容较为相似的情况,提高了识别的精度。然后再将已经确定场景类别的图像数据基于预设的神经网络进行识别,得到识别结果。最后再根据场景识别的结果以及预设神经网络的识别结果训练包括多层分类网络和神经网络的模型,最终得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为整个过程不需要审计人员进行参数设置,所以减少了堡垒机审计人员的工作量,解决了现有的图形堡垒软件的目标识别过程中,效率较低的问题,提高了工作效率与准确率。
图4是本发明实施例提供的一种目标的识别方法的流程示意图。如图4所示,目标的识别方法包括:
S401:获取图像数据;
S402:使用目标识别模型对所述图像数据进行计算,得到识别结果。
其中,该目标识别模型是基于图1中的目标识别模型的训练方法得到的。
本发明实施例提供的目标的识别方法,预先根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿参数对获取的图像数据进行计算,得到至少一种第一分类结果;然后根据所述第一分类结果从所述图像数据中确定与所述第一分类结果对应的第一目标图像数据;紧接着基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果;最后根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型,再根据该目标识别模型对获取的图像数据进行识别得到识别结果。因为本发明实施例中,先结合预设的多层分类网络和预设的与所述每层分类网络对应的补偿参数对图像数据进行场景识别,解决图形堡垒检测软件类别较多,且不同场景差异较大、相同场景下类别视觉内容较为相似的情况,提高了识别的精度。然后再将已经确定场景类别的图像数据基于预设的神经网络进行识别,得到识别结果。最后再根据场景识别的结果以及预设神经网络的识别结果训练包括多层分类网络和神经网络的模型,最终得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为整个过程不需要审计人员进行参数设置,所以减少了堡垒机审计人员的工作量,解决了现有的图形堡垒软件的目标识别过程中,效率较低的问题,提高了工作效率与准确率。
与图1中目标识别模型的训练方法的流程示意图相对应,本发明实施例还提供了一种目标识别模型的训练装置。图5是本发明实施例提供的一种目标识别模型的训练装置的示意图,如图5所示,目标识别模型的训练装置可以包括:
获取模块501,用于获取图像数据。
处理模块502,用于根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿模型对所述图像数据进行计算,得到至少一种第一分类结果。
处理模块502,还用于根据所述第一分类结果从所述图像数据中确定与所述第一分类结果对应的第一目标图像数据;基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果;根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型。
在一个实施例中,图像数据包括目标软件的图像信息。
处理模块502,还用于将所述第一目标图像数据划分为预设数量的候选区域;对每个所述候选区域包括的第二目标图像数据进行目标检测,确定存在目标软件的至少一个目标候选区域;对每个所述目标候选区域包括的第三目标图像数据进行类别识别,确定所述目标候选区域中包括所述目标软件的类别概率;根据每个所述目标候选区域的类别概率确定所述图像数据的第一识别结果,其中,所述第一识别结果包括所述目标软件在所述图像数据中的位置信息。
处理模块502,还用于对每个所述候选区域包括的第二目标图像数据进行目标检测,确定所述候选区域中目标软件的存在概率;当所述存在概率满足阈值时,确定所述候选区域为存在目标软件的目标候选区域。
处理模块502,还用于根据每个所述目标候选区域的存在概率和类别概率确定所述图像数据的第一识别结果。
处理模块502,还用于根据所述第一分类结果对所述多层分类网络进行训练,以及根据所述第一识别结果对所述神经网络进行训练;根据训练后的多层分类网络输出的第二分类结果与预先存储的与所述图像数据对应的预设分类结果确定分类损失值;根据训练后的神经网络输出的第二识别结果与预先存储的与所述图像数据对应的预设识别结果确定识别损失值;当所述分类损失值和所述识别损失值满足预设条件时,将包括训练后的多层分类网络和训练后的神经网络的模型作为所述目标识别模型。
可以理解的是,图5所示的目标识别模型的训练装置中的各个模块具有实现图1中各个步骤的功能,并能达到其相应的技术效果,为简洁描述,在此不再赘述。
本发明实施例提供的目标识别模型的训练装置。首先获取图像数据;之后根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿参数对所述图像数据进行计算,得到至少一种第一分类结果;然后根据所述第一分类结果从所述图像数据中确定与所述第一分类结果对应的第一目标图像数据;紧接着基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果;最后根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为本发明实施例中,先结合预设的多层分类网络和预设的与所述每层分类网络对应的补偿参数对图像数据进行场景识别,解决图形堡垒检测软件类别较多,且不同场景差异较大、相同场景下类别视觉内容较为相似的情况,提高了识别的精度。然后再将已经确定场景类别的图像数据基于预设的神经网络进行识别,得到识别结果。最后再根据场景识别的结果以及预设神经网络的识别结果训练包括多层分类网络和神经网络的模型,最终得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为整个过程不需要审计人员进行参数设置,所以减少了堡垒机审计人员的工作量,解决了现有的图形堡垒软件的目标识别过程中,效率较低的问题,提高了工作效率与准确率。
与图4中目标的识别方法的流程示意图相对应,本发明实施例还提供了一种目标的识别装置。图6是本发明实施例提供的一种目标的识别装置的示意图,如图6所示,目标的识别装置可以包括:
获取模块601,用于获取图像数据。
处理模块602,用于使用目标识别模型对所述图像数据进行计算,得到识别结果,其中,所述目标识别模型是基于图1中目标识别模型的训练方法得到的。
本发明实施例提供的目标的识别装置,预先根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿参数对获取的图像数据进行计算,得到至少一种第一分类结果;然后根据所述第一分类结果从所述图像数据中确定与所述第一分类结果对应的第一目标图像数据;紧接着基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果;最后根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型,再根据该目标识别模型对获取的图像数据进行识别得到识别结果。因为本发明实施例中,先结合预设的多层分类网络和预设的与所述每层分类网络对应的补偿参数对图像数据进行场景识别,解决图形堡垒检测软件类别较多,且不同场景差异较大、相同场景下类别视觉内容较为相似的情况,提高了识别的精度。然后再将已经确定场景类别的图像数据基于预设的神经网络进行识别,得到识别结果。最后再根据场景识别的结果以及预设神经网络的识别结果训练包括多层分类网络和神经网络的模型,最终得到目标识别模型,以用于对图像数据进行识别得到识别结果。因为整个过程不需要审计人员进行参数设置,所以减少了堡垒机审计人员的工作量,解决了现有的图形堡垒软件的目标识别过程中,效率较低的问题,提高了工作效率与准确率。
图7是本发明实施例提供的一种计算设备的硬件架构的结构图。如图7所示,计算设备700包括输入设备701、输入接口702、中央处理器703、存储器704、输出接口705、以及输出设备707。其中,输入接口702、中央处理器703、存储器704、以及输出接口705通过总线710相互连接,输入设备701和输出设备706分别通过输入接口702和输出接口705与总线710连接,进而与计算设备700的其他组件连接。
具体地,输入设备701接收来自外部的输入信息,并通过输入接口702将输入信息传送到中央处理器703;中央处理器703基于存储器704中存储的计算机可执行指令对输入信息进行处理以生成输出信息,将输出信息临时或者永久地存储在存储器704中,然后通过输出接口705将输出信息传送到输出设备706;输出设备706将输出信息输出到计算设备700的外部供用户使用。
也就是说,图7所示的计算设备也可以被实现为目标识别模型的训练设备,或者,目标的识别设备,该计算设备可以包括:处理器以及存储有计算机可执行指令的存储器;该处理器在执行计算机可执行指令时可以实现本发明实施例提供的目标识别模型的训练方法,或者,实现本发明实施例提供的目标的识别方法。
本发明实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序指令;该计算机程序指令被处理器执行时实现本发明实施例提供的目标识别模型的训练方法,或者,实现本发明实施例提供的目标的识别方法。
需要明确的是,本发明并不局限于上文所描述并在图中示出的特定配置和处理。为了简明起见,这里省略了对已知方法的详细描述。在上述实施例中,描述和示出了若干具体的步骤作为示例。但是,本发明的方法过程并不限于所描述和示出的具体步骤,本领域的技术人员可以在领会本发明的精神后,作出各种改变、修改和添加,或者改变步骤之间的顺序。
以上所述的结构框图中所示的功能块可以实现为硬件、软件、固件或者它们的组合。当以硬件方式实现时,其可以例如是电子电路、专用集成电路(Application SpecificIntegrated Circuit,ASIC)、适当的固件、插件、功能卡等等。当以软件方式实现时,本发明的元素是被用于执行所需任务的程序或者代码段。程序或者代码段可以存储在机器可读介质中,或者通过载波中携带的数据信号在传输介质或者通信链路上传送。“机器可读介质”可以包括能够存储或传输信息的任何介质。机器可读介质的例子包括电子电路、半导体存储器设备、只读存储器(Read-Only Memory,ROM)、闪存、可消除的只读存储器(ErasableRead Only Memory,EROM)、软盘、只读光盘(Compact Disc Read-Only Memory,CD-ROM)、光盘、硬盘、光纤介质、射频(Radio Frequency,RF)链路,等等。代码段可以经由诸如因特网、内联网等的计算机网络被下载。
还需要说明的是,本发明中提及的示例性实施例,基于一系列的步骤或者装置描述一些方法或系统。但是,本发明不局限于上述步骤的顺序,也就是说,可以按照实施例中提及的顺序执行步骤,也可以不同于实施例中的顺序,或者若干步骤同时执行。
上面参考根据本公开的实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图描述了本公开的各方面。应当理解,流程图和/或框图中的每个方框以及流程图和/或框图中各方框的组合可以由计算机程序指令实现。这些计算机程序指令可被提供给通用计算机、专用计算机、或其它可编程数据处理装置的处理器,以产生一种机器,使得经由计算机或其它可编程数据处理装置的处理器执行的这些指令使能对流程图和/或框图的一个或多个方框中指定的功能/动作的实现。这种处理器可以是但不限于是通用处理器、专用处理器、特殊应用处理器或者现场可编程逻辑电路。还可理解,框图和/或流程图中的每个方框以及框图和/或流程图中的方框的组合,也可以由执行指定的功能或动作的专用硬件来实现,或可由专用硬件和计算机指令的组合来实现。
以上所述,仅为本发明的具体实施方式,所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的系统、模块和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。应理解,本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。
Claims (10)
1.一种目标识别模型的训练方法,其特征在于,所述方法包括:
获取图像数据;
根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿模型对所述图像数据进行计算,得到至少一种第一分类结果;
根据所述第一分类结果从所述图像数据中确定与所述第一分类结果对应的第一目标图像数据;
基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果;
根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型。
2.根据权利要求1所述的方法,其特征在于,所述图像数据包括目标软件的图像信息;所述基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果,包括:
将所述第一目标图像数据划分为预设数量的候选区域;
对每个所述候选区域包括的第二目标图像数据进行目标检测,确定存在目标软件的至少一个目标候选区域;
对每个所述目标候选区域包括的第三目标图像数据进行类别识别,确定所述目标候选区域中包括所述目标软件的类别概率;
根据每个所述目标候选区域的类别概率确定所述图像数据的第一识别结果,其中,所述第一识别结果包括所述目标软件在所述图像数据中的位置信息。
3.根据权利要求2所述的方法,其特征在于,所述方法还包括:
对每个所述候选区域包括的第二目标图像数据进行目标检测,确定所述候选区域中目标软件的存在概率;
当所述存在概率满足阈值时,确定所述候选区域为存在目标软件的目标候选区域。
4.根据根据权利要求3所述的方法,其特征在于,所述方法还包括:
根据每个所述目标候选区域的存在概率和类别概率确定所述图像数据的第一识别结果。
5.根据权利要求1所述的方法,其特征在于,根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型,包括:
根据所述第一分类结果对所述多层分类网络进行训练,以及根据所述第一识别结果对所述神经网络进行训练;
根据训练后的多层分类网络输出的第二分类结果与预先存储的与所述图像数据对应的预设分类结果确定分类损失值;
根据训练后的神经网络输出的第二识别结果与预先存储的与所述图像数据对应的预设识别结果确定识别损失值;
当所述分类损失值和所述识别损失值满足预设条件时,将包括训练后的多层分类网络和训练后的神经网络的模型作为所述目标识别模型。
6.一种目标的识别方法,其特征在于,所述识别方法包括:
获取图像数据;
使用目标识别模型对所述图像数据进行计算,得到识别结果,其中,所述目标识别模型是基于权利要求1至5中任意一项所述的目标识别模型的训练方法得到的。
7.一种目标识别模型的训练装置,其特征在于,所述装置包括:
获取模块,用于获取图像数据;
处理模块,用于根据预设的多层分类网络中的每层分类网络以及预设的与所述每层分类网络对应的补偿模型对所述图像数据进行计算,得到至少一种第一分类结果;
所述处理模块,还用于根据所述第一分类结果从所述图像数据中确定第一目标图像数据;
所述处理模块,还用于基于预设的神经网络对所述第一目标图像数据进行计算,得到第一识别结果;
所述处理模块,还用于根据所述第一分类结果和所述第一识别结果对包括所述多层分类网络和所述神经网络的模型进行训练,得到目标识别模型。
8.一种目标识别的装置,其特征在于,所述装置包括:
获取模块,用于获取图像数据;
处理模块,用于使用目标识别模型对所述图像数据进行计算,得到识别结果,其中,所述目标识别模型是基于权利要求1至5中任意一项所述的目标识别模型的训练方法得到的。
9.一种电子设备,其特征在于,所述电子设备包括:处理器以及存储有计算机程序指令的存储器;
所述处理器执行所述计算机程序指令时实现如权利要求1-5任意一项所述的目标识别模型的训练方法,或者,实现如权利要求6所述的目标的识别方法。
10.一种计算机存储介质,其特征在于,所述计算机存储介质上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现如权利要求1-5任意一项所述的目标识别模型的训练方法,或者,实现如权利要求6所述的目标的识别方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011248507.0A CN114549919A (zh) | 2020-11-10 | 2020-11-10 | 目标识别模型的训练方法、识别方法、装置、设备 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011248507.0A CN114549919A (zh) | 2020-11-10 | 2020-11-10 | 目标识别模型的训练方法、识别方法、装置、设备 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114549919A true CN114549919A (zh) | 2022-05-27 |
Family
ID=81659902
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011248507.0A Pending CN114549919A (zh) | 2020-11-10 | 2020-11-10 | 目标识别模型的训练方法、识别方法、装置、设备 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114549919A (zh) |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104519361A (zh) * | 2014-12-12 | 2015-04-15 | 天津大学 | 一种基于空时域局部二值模式的视频隐写分析方法 |
| CN110598586A (zh) * | 2019-08-27 | 2019-12-20 | 电子科技大学 | 一种目标检测方法及系统 |
| CN111275082A (zh) * | 2020-01-14 | 2020-06-12 | 中国地质大学(武汉) | 一种基于改进端到端神经网络的室内物体目标检测方法 |
| WO2020134102A1 (zh) * | 2018-12-29 | 2020-07-02 | 北京沃东天骏信息技术有限公司 | 物品识别方法、装置、售货系统和存储介质 |
| CN111523596A (zh) * | 2020-04-23 | 2020-08-11 | 北京百度网讯科技有限公司 | 目标识别模型训练方法、装置、设备以及存储介质 |
| CN111783812A (zh) * | 2019-11-18 | 2020-10-16 | 北京沃东天骏信息技术有限公司 | 违禁图像识别方法、装置和计算机可读存储介质 |
| CN111860510A (zh) * | 2020-07-29 | 2020-10-30 | 浙江大华技术股份有限公司 | 一种x光图像目标检测方法及装置 |
-
2020
- 2020-11-10 CN CN202011248507.0A patent/CN114549919A/zh active Pending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104519361A (zh) * | 2014-12-12 | 2015-04-15 | 天津大学 | 一种基于空时域局部二值模式的视频隐写分析方法 |
| WO2020134102A1 (zh) * | 2018-12-29 | 2020-07-02 | 北京沃东天骏信息技术有限公司 | 物品识别方法、装置、售货系统和存储介质 |
| CN110598586A (zh) * | 2019-08-27 | 2019-12-20 | 电子科技大学 | 一种目标检测方法及系统 |
| CN111783812A (zh) * | 2019-11-18 | 2020-10-16 | 北京沃东天骏信息技术有限公司 | 违禁图像识别方法、装置和计算机可读存储介质 |
| CN111275082A (zh) * | 2020-01-14 | 2020-06-12 | 中国地质大学(武汉) | 一种基于改进端到端神经网络的室内物体目标检测方法 |
| CN111523596A (zh) * | 2020-04-23 | 2020-08-11 | 北京百度网讯科技有限公司 | 目标识别模型训练方法、装置、设备以及存储介质 |
| CN111860510A (zh) * | 2020-07-29 | 2020-10-30 | 浙江大华技术股份有限公司 | 一种x光图像目标检测方法及装置 |
Non-Patent Citations (3)
| Title |
|---|
| ALESSANDRO PARISI: "《人工智能在网络安全中的应用》", 30 September 2020, 东南大学出版社, pages: 107 * |
| 李娜: "《文物数字化色彩复原的关键方法研究》", 30 June 2020, 西安电子科技大学出版社, pages: 24 * |
| 查红彬: "《视觉信息处理研究前沿》", 31 December 2019, 上海交通大学出版社, pages: 253 * |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12197544B2 (en) | Method and system for defending against adversarial sample in image classification includes denoising by an adversarial denoising network, and data processing terminal | |
| WO2019140767A1 (zh) | 安检识别系统及其控制方法 | |
| CN109918969A (zh) | 人脸检测方法及装置、计算机装置和计算机可读存储介质 | |
| CN113177929B (zh) | 一种基于全卷积网络的海面溢油检测方法及其系统和应用 | |
| CN103870818B (zh) | 一种烟雾检测方法和装置 | |
| CN108647649A (zh) | 一种视频中异常行为的检测方法 | |
| CN103440645A (zh) | 一种基于自适应粒子滤波和稀疏表示的目标跟踪算法 | |
| CN113240623A (zh) | 一种路面病害检测方法及装置 | |
| CN110298297A (zh) | 火焰识别方法和装置 | |
| CN119477886B (zh) | 一种基于机器学习的建筑物裂缝监测方法和系统 | |
| CN106056079A (zh) | 一种图像采集设备及人脸五官的遮挡检测方法 | |
| CN114332559A (zh) | 一种基于自适应跨模态融合机制和深度注意力网络的rgb-d显著性目标检测方法 | |
| CN113177439B (zh) | 一种行人翻越马路护栏检测方法 | |
| CN119672613B (zh) | 一种基于云计算的监控视频信息智能处理系统 | |
| CN117911862A (zh) | 基于MDALF-Net的输电线路施工机械巡检方法 | |
| CN117152673A (zh) | 一种视觉图像异常行为检测方法 | |
| Chen et al. | Fresh tea sprouts detection via image enhancement and fusion SSD | |
| CN114694090B (zh) | 一种基于改进PBAS算法与YOLOv5的校园异常行为检测方法 | |
| CN112633142A (zh) | 一种输电线路违章建筑物识别方法及相关装置 | |
| CN119516225B (zh) | 一种基于施工图像的建筑进度评估方法 | |
| CN114743212A (zh) | 配网工程现场人员安全行为检测方法、系统、设备和介质 | |
| CN114120234A (zh) | 电力作业施工梯子搬运检测方法、系统及存储介质 | |
| CN118674967B (zh) | 基于ai技术的拖轮人员安全操作行为监管系统及方法 | |
| CN120374980A (zh) | 基于RandLA-Net的电力廊道点云语义分割方法及系统 | |
| CN113989742A (zh) | 一种基于多尺度特征融合的核电站厂区行人检测方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |