CN114548274A - Multi-modal interaction-based rumor detection method and system - Google Patents
Multi-modal interaction-based rumor detection method and system Download PDFInfo
- Publication number
- CN114548274A CN114548274A CN202210163061.4A CN202210163061A CN114548274A CN 114548274 A CN114548274 A CN 114548274A CN 202210163061 A CN202210163061 A CN 202210163061A CN 114548274 A CN114548274 A CN 114548274A
- Authority
- CN
- China
- Prior art keywords
- text
- features
- visual
- detected
- attention
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/353—Clustering; Classification into predefined classes
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/243—Classification techniques relating to the number of classes
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Databases & Information Systems (AREA)
- Machine Translation (AREA)
Abstract
本发明提供了一种基于多模态交互的谣言检测方法及系统,包括:获取若干条待检测推文;提取每条待检测推文的序列增强文本特征;提取每条待检测推文的序列增强视觉特征;基于序列增强文本特征和序列增强视觉特征,使用交互使用注意力机制,获得带有文本注意力的视觉特征和带有视觉注意力的文本特征,并基于带有文本注意力的视觉特征和带有视觉注意力的文本特征,生成视觉特征和文本特征;将带有文本注意力的视觉特征、带有视觉注意力的文本特征、视觉特征和文本特征进行特征融合,基于融合后的特征,得到每条待检测推文是否为谣言的结果。能够有效地融合待检测推文中的多模态数据并生成联合表示,提高了谣言检测的精度。

The present invention provides a method and system for detecting rumors based on multimodal interaction, including: acquiring several tweets to be detected; extracting sequence enhancement text features of each tweet to be detected; extracting the sequence of each tweet to be detected Enhance visual features; enhance text features based on sequences and enhance visual features based on sequences, use attention mechanism interactively, obtain visual features with text attention and text features with visual attention, and based on visual features with text attention features and text features with visual attention to generate visual features and text features; feature fusion of visual features with text attention, text features with visual attention, visual features and text features, based on the fusion feature to get the result of whether each tweet to be detected is a rumor. It can effectively fuse the multimodal data in the tweets to be detected and generate a joint representation, which improves the accuracy of rumor detection.
Description
技术领域technical field
本发明属于自然语言处理技术领域,尤其涉及一种基于多模态交互的谣言检测方法及系统。The invention belongs to the technical field of natural language processing, and in particular relates to a rumor detection method and system based on multimodal interaction.
背景技术Background technique
本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。The statements in this section merely provide background information related to the present invention and do not necessarily constitute prior art.
伴随着硬件技术的提升与网络技术的进步,社交媒体获得了前所未有的发展,已经成为人们日常生活中不可或缺的一部分。社交媒体因其低成本、容易访问与传播速度迅速等特点,使其成为重要的新闻来源并对传统媒体起到支撑作用。社交媒体上的信息已被用于市场营销、公共事件讨论和舆情分析、谣言检测等多个领域。用户在社交媒体平台便捷的发布观点、获取新闻、相互交流。与此同时,假新闻与谣言也通过社交媒体迅速传播,误导公众甚至造成恶劣的社会影响。鉴于人工检测花销巨大且检测速度较慢,自动谣言检测方法就显得尤为重要。With the improvement of hardware technology and the advancement of network technology, social media has achieved unprecedented development and has become an indispensable part of people's daily life. Social media is an important source of news and supports traditional media because of its low cost, easy access and rapid dissemination. Information on social media has been used in various fields such as marketing, public event discussion and public opinion analysis, and rumor detection. Users can easily post opinions, get news, and communicate with each other on social media platforms. At the same time, fake news and rumors spread rapidly through social media, misleading the public and even causing bad social impact. In view of the high cost and slow detection speed of manual detection, automatic rumor detection methods are particularly important.
以往的研究集中于使用手工特征或基于深度学习的单模态特征进行谣言检测,缺点在于忽略了推文中多模态数据的互补性。相较于推文中的文本内容,推文中的视频、图像等视觉元素更能吸引读者的注意力。因此,也有一部分方法综合分析推文中的多模态内容进行谣言检测。但是,这些方法大部分在异质模态空间融合数据,无法避免多模态数据间的数值性差异,难以捕捉异质模态数据间依赖关系。Previous studies focused on using handcrafted features or deep learning-based unimodal features for rumor detection, with the disadvantage of ignoring the complementarity of multimodal data in tweets. Compared to the text content in the tweet, visual elements such as video and images in the tweet can attract the reader's attention more. Therefore, there are also some methods that comprehensively analyze the multimodal content in tweets for rumor detection. However, most of these methods fuse data in heterogeneous modal space, which cannot avoid numerical differences between multi-modal data and are difficult to capture the dependencies between heterogeneous modal data.
发明内容SUMMARY OF THE INVENTION
为了解决上述背景技术中存在的技术问题,本发明提供一种基于多模态交互的谣言检测方法及系统,能够有效地融合待检测推文中的多模态数据并生成联合表示,提高了谣言检测的精度。In order to solve the technical problems existing in the above background art, the present invention provides a method and system for rumor detection based on multimodal interaction, which can effectively fuse multimodal data in tweets to be detected and generate a joint representation, thereby improving rumor detection. accuracy.
为了实现上述目的,本发明采用如下技术方案:In order to achieve the above object, the present invention adopts the following technical solutions:
本发明的第一个方面提供一种基于多模态交互的谣言检测方法,其包括:A first aspect of the present invention provides a rumor detection method based on multimodal interaction, which includes:
获取若干条包含文本内容与视觉内容的待检测推文;Get several tweets to be detected that contain textual content and visual content;
基于每条待检测推文的文本内容,提取每条待检测推文的序列增强文本特征;Based on the text content of each tweet to be detected, extract the sequence enhanced text features of each tweet to be detected;
基于每条待检测推文的视觉内容,提取每条待检测推文的序列增强视觉特征;Based on the visual content of each tweet to be detected, extract the sequence enhanced visual features of each tweet to be detected;
基于序列增强文本特征和序列增强视觉特征,使用交互使用注意力机制,获得带有文本注意力的视觉特征和带有视觉注意力的文本特征,并基于带有文本注意力的视觉特征和带有视觉注意力的文本特征,生成视觉特征和文本特征;Based on sequence-enhanced text features and sequence-enhanced visual features, using interactive attention mechanism, obtain visual features with text attention and text features with visual attention, and based on visual features with text attention and with Text features for visual attention, generating visual features and text features;
将带有文本注意力的视觉特征、带有视觉注意力的文本特征、视觉特征和文本特征进行特征融合,得到融合后的特征;Fusion of visual features with text attention, text features with visual attention, visual features and text features to obtain the fused features;
基于融合后的特征,得到每条待检测推文是否为谣言的结果。Based on the fused features, the result of whether each tweet to be detected is a rumor is obtained.
进一步的,所述生成视觉特征和文本特征的具体方法为:Further, the specific method for generating visual features and text features is:
以带有视觉注意力的文本特征为输入矩阵,以带有文本注意力的视觉特征为目标矩阵,通过Transformer映射得到视觉特征;Take the text feature with visual attention as the input matrix, take the visual feature with text attention as the target matrix, and obtain the visual feature through Transformer mapping;
以带有文本注意力的视觉特征为输入矩阵,以带有视觉注意力的文本特征为目标矩阵,通过Transformer映射得到文本特征。Taking the visual features with text attention as the input matrix, and taking the text features with visual attention as the target matrix, the text features are obtained through Transformer mapping.
进一步的,所述特征融合的具体方法为:Further, the specific method of the feature fusion is:
将带有文本注意力的视觉特征与视觉特征拼接后,通过由全连接层组成的融合识别块,得到第一早期融合结果;After splicing visual features with text attention and visual features, the first early fusion result is obtained through a fusion recognition block composed of fully connected layers;
将带有视觉注意力的文本特征与文本特征拼接后,通过由全连接层组成的融合识别块,得到第二早期融合结果;After splicing the text features with visual attention and text features, the second early fusion result is obtained through the fusion recognition block composed of fully connected layers;
将第一早期融合结果和第二早期融合结果通过分配权重融合,得到融合后的特征。The first early fusion result and the second early fusion result are fused by assigning weights to obtain the fused features.
进一步的,所述提取每条待检测推文的序列增强文本特征的具体方法为:Further, the specific method for extracting the sequence-enhanced text feature of each tweet to be detected is:
对每条待检测推文的文本内容进行文本预处理,基于预处理后的文本内容,得到每条待检测推文的初级文本特征表示;Perform text preprocessing on the text content of each tweet to be detected, and obtain the primary text feature representation of each tweet to be detected based on the preprocessed text content;
基于每条待检测推文的初级文本特征表示,得到每条待检测推文的具有上下文信息的文本特征;Based on the primary text feature representation of each tweet to be detected, the text features with contextual information of each tweet to be detected are obtained;
使用自注意力机制增强具有上下文信息的文本特征,得到序列增强后的文本特征。The self-attention mechanism is used to enhance the text features with contextual information, and the sequence-enhanced text features are obtained.
进一步的,所述文本预处理包括:删除每条待检测推文中的停用词、用户句柄和标点符号。Further, the text preprocessing includes: deleting stop words, user handles and punctuation marks in each tweet to be detected.
进一步的,所述提取每条待检测推文的序列增强视觉特征的具体方法为:Further, the specific method for extracting the sequence enhancement visual feature of each tweet to be detected is:
对每条待检测推文的视觉内容进行图像预处理,基于预处理后的视觉内容,得到每条待检测推文的区域特征;Perform image preprocessing on the visual content of each tweet to be detected, and obtain the regional features of each tweet to be detected based on the preprocessed visual content;
基于每条待检测推文的区域特征,通过序列注意力块,得到序列增强视觉特征。Based on the regional features of each tweet to be detected, the sequence-enhanced visual features are obtained through sequential attention blocks.
进一步的,所述图像预处理包括:图像尺寸调整、随机水平翻转和像素值标准化。Further, the image preprocessing includes: image size adjustment, random horizontal flipping and pixel value normalization.
本发明的第二个方面提供一种基于多模态交互的谣言检测系统,其包括:A second aspect of the present invention provides a rumor detection system based on multimodal interaction, which includes:
数据获取模块,其被配置为:获取若干条包含文本内容与视觉内容的待检测推文;a data acquisition module, which is configured to: acquire several tweets to be detected that contain textual content and visual content;
序列增强文本特征提取模块,其被配置为:基于每条待检测推文的文本内容,提取每条待检测推文的序列增强文本特征;a sequence-enhanced text feature extraction module, which is configured to: extract the sequence-enhanced text feature of each tweet to be detected based on the text content of each tweet to be detected;
序列增强视觉特征提取模块,其被配置为:基于每条待检测推文的视觉内容,提取每条待检测推文的序列增强视觉特征;a sequence-enhanced visual feature extraction module, which is configured to: extract the sequence-enhanced visual feature of each tweet to be detected based on the visual content of each tweet to be detected;
交互模块,其被配置为:基于序列增强文本特征和序列增强视觉特征,使用交互使用注意力机制,获得带有文本注意力的视觉特征和带有视觉注意力的文本特征,并基于带有文本注意力的视觉特征和带有视觉注意力的文本特征,生成视觉特征和文本特征;an interaction module, which is configured to: enhance text features based on sequences and enhance visual features based on sequences, use an attention mechanism interactively, obtain visual features with text attention and text features with visual attention, and based on text features with text Visual features of attention and text features with visual attention, generating visual features and text features;
特征融合模块,其被配置为:将带有文本注意力的视觉特征、带有视觉注意力的文本特征、视觉特征和文本特征进行特征融合,得到融合后的特征;a feature fusion module, which is configured to: fuse visual features with text attention, text features with visual attention, visual features and text features to obtain fused features;
检测模块,其被配置为:基于融合后的特征,得到每条待检测推文是否为谣言的结果。A detection module, which is configured to: obtain a result of whether each tweet to be detected is a rumor based on the fused features.
本发明的第三个方面提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述所述的一种基于多模态交互的谣言检测方法中的步骤。A third aspect of the present invention provides a computer-readable storage medium on which a computer program is stored, and when the program is executed by a processor, implements the steps in the above-mentioned method for detecting rumors based on multimodal interaction .
本发明的第四个方面提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述所述的一种基于多模态交互的谣言检测方法中的步骤。A fourth aspect of the present invention provides a computer device, comprising a memory, a processor, and a computer program stored in the memory and executable on the processor, the processor implementing the above-mentioned one when executing the program Steps in a multimodal interaction-based rumor detection method.
与现有技术相比,本发明的有益效果是:Compared with the prior art, the beneficial effects of the present invention are:
本发明提供了一种基于多模态交互的谣言检测方法,其获得时序增强的单模态特征,并对不同模态数据进行跨模态映射,能够有效降低异质性差异带来的影响;并采用交互注意力机制捕捉多模态数据之间的依赖关系,提高了谣言检测的精度。The present invention provides a rumor detection method based on multi-modal interaction, which obtains single-modal features with enhanced time series, and performs cross-modal mapping on different modal data, which can effectively reduce the impact of heterogeneity differences; And the interactive attention mechanism is used to capture the dependencies between multimodal data, which improves the accuracy of rumor detection.
附图说明Description of drawings
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。The accompanying drawings forming a part of the present invention are used to provide further understanding of the present invention, and the exemplary embodiments of the present invention and their descriptions are used to explain the present invention, and do not constitute an improper limitation of the present invention.
图1是本发明实施例一的方法流程图;Fig. 1 is the method flow chart of the first embodiment of the present invention;
图2是本发明实施例一的文本特征提取流程图;2 is a flowchart of text feature extraction according to
图3是本发明实施例一的微博数据集上的早期检测性能对比图;3 is a comparison diagram of early detection performance on the microblog data set according to
图4是本发明实施例一的推特数据集上的早期检测性能对比图。FIG. 4 is a comparison diagram of early detection performance on the Twitter data set according to
具体实施方式Detailed ways
下面结合附图与实施例对本发明作进一步说明。The present invention will be further described below with reference to the accompanying drawings and embodiments.
应该指出,以下详细说明都是例示性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。It should be noted that the following detailed description is exemplary and intended to provide further explanation of the invention. Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs.
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。It should be noted that the terminology used herein is for the purpose of describing specific embodiments only, and is not intended to limit the exemplary embodiments according to the present invention. As used herein, unless the context clearly dictates otherwise, the singular is intended to include the plural as well, furthermore, it is to be understood that when the terms "comprising" and/or "including" are used in this specification, it indicates that There are features, steps, operations, devices, components and/or combinations thereof.
实施例一Example 1
本实施例提供了一种基于多模态交互的谣言检测方法,如图1所示,具体包括以下步骤:This embodiment provides a rumor detection method based on multimodal interaction, as shown in FIG. 1 , which specifically includes the following steps:
步骤1、获取若干条包含文本内容与视觉内容的待检测推文。
获取的若干条待检测推文可以表示为Tw={T,V},其中,T与V分别表示所有待检测推文中的文本内容与视觉内容(图片)。即,每条待检测推文都包括多模态内容(文本内容与视觉内容)。The acquired several tweets to be detected can be expressed as Tw={T, V}, where T and V respectively represent the text content and visual content (pictures) in all the tweets to be detected. That is, each tweet to be detected includes multimodal content (textual content and visual content).
其中,所有待检测推文中的文本内容T={T1,T2,...,TN},Ti∈T表示第i条待检测推文的文本内容,N表示获取的待检测推文的总数,Ti={t1,t2,...,tL}表示第i条待检测推文的字符序列,L表示序列的长度;所有待检测推文中的视觉内容V={V1,V2,...,VN},Vi∈V表示第i条待检测推文的视觉内容。Among them, the text content T={T 1 , T 2 ,...,T N } in all the tweets to be detected, T i ∈ T represents the text content of the i-th tweet to be detected, and N represents the acquired tweet to be detected. The total number of texts, T i ={t 1 ,t 2 ,...,t L } represents the character sequence of the i-th tweet to be detected, L represents the length of the sequence; the visual content in all tweets to be detected V={ V 1 , V 2 ,...,V N }, V i ∈ V represents the visual content of the i-th tweet to be detected.
作为一种实施方式,待检测推文可以来源于微博。As an implementation manner, the tweet to be detected may originate from Weibo.
步骤2、将若干条待检测推文输入融合使用文本内容与视觉内容的多模态谣言检测模型(TIMF模型),检测出每条待检测推文是否为谣言,即TIMF模型的输出为谣言检测的结果:谣言(N)或非谣言(NR)。具体包括以下步骤:
步骤201、如图2所示,基于每条待检测推文的文本内容Ti={t1,t2,...,tL},提取每条待检测推文的序列增强文本特征FT={t1,t2,...,tm},即将所有待检测推文的文本内容输入文本块,可表示为函数FT=fT(Ti;θT),其中,FT表示文本块输出的文本特征,θT表示文本块的参数:Step 201: As shown in FIG. 2, based on the text content T i ={t 1 ,t 2 ,...,t L } of each tweet to be detected, extract the sequence enhanced text feature F of each tweet to be detected T ={t 1 ,t 2 ,...,t m }, that is, input the text content of all tweets to be detected into the text block, which can be expressed as a function F T =f T (T i ; θ T ), where F T represents the text features of the text block output, and θ T represents the parameters of the text block:
(1)对每条待检测推文的文本内容Ti={t1,t2,...,tL}进行文本预处理,基于预处理后的文本内容,得到每条待检测推文的初级文本特征表示H={h(0),h(1),...,h(L1)},包括:(1) Perform text preprocessing on the text content T i ={t 1 ,t 2 ,...,t L } of each tweet to be detected, and obtain each tweet to be detected based on the preprocessed text content The primary text feature representation H={h(0),h(1),...,h(L 1 )}, including:
①删除每条待检测推文中的停用词、用户句柄和标点符号;①Remove stop words, user handles and punctuation marks in each tweet to be detected;
②调用Bert tokenizer对处理后的文本进行分词,得到每条待检测推文的初级文本特征表示H={h(0),h(1),...,h(L1)}。② Call Bert tokenizer to segment the processed text, and obtain the primary text feature representation H={h(0), h(1),..., h(L 1 )} of each tweet to be detected.
具体的,采用微调的预训练Bert模型提取文本特征,基于Transformer(Trm)与Attention机制的Bert模型为各种NLP任务中最优秀的模型之一,并且Bert因其预定义长度的原因使其更加适合微博之类的短文本。Bert的输入由三部分组成:Token Embedding、Segment Embedding和Position Embedding,使用E(toki),E(segi),E(posi)分别表示字符的向量表示、句子的索引和字符的位置索引。Specifically, the fine-tuned pre-trained Bert model is used to extract text features. The Bert model based on Transformer (Trm) and Attention mechanism is one of the best models in various NLP tasks, and Bert is more because of its predefined length. Suitable for short texts like Weibo. Bert's input consists of three parts: Token Embedding, Segment Embedding and Position Embedding, using E(tok i ), E(seg i ), E(pos i ) to represent the vector representation of the character, the index of the sentence and the position index of the character respectively .
Bert的输入BI={I(0),I(1),...,I(L)},I(i)为预处理后的每条待检测推文的第i个字符的元素相加组成,即I(i)=E(toki)+E(segi)+E(posi),其中E(toki),E(segi),E(posi)分别表示字符的向量表示、句子的索引和字符的位置索引,在图2中,cls与sep是添加到句子开头与句子结尾的标记,用于表示句子的开始与结束,ti代表第i个字符的向量表示,A代表句子索引,由于本发明中的Bert任务是特征提取而非问答,因此使用A指代所有的字符属于一个句子,L代表句子中的字符个数。之后使用微调之后的Bert提取文本内容的初级文本特征表示H={h(0),h(1),...,h(L1)},即Bert's input BI={I(0),I(1),...,I(L)}, I(i) is the element addition of the i-th character of each tweet to be detected after preprocessing Composition, that is, I(i)=E(tok i )+E(seg i )+E(pos i ), where E(tok i ), E(seg i ), E(pos i ) represent the vector representations of characters, respectively , the index of the sentence and the position index of the character. In Figure 2, cls and sep are the markers added to the beginning and end of the sentence to indicate the beginning and end of the sentence, ti represents the vector representation of the i-th character, and A represents Sentence index. Since the Bert task in the present invention is feature extraction rather than question answering, A is used to indicate that all characters belong to a sentence, and L is used to indicate the number of characters in the sentence. Then use the fine-tuned Bert to extract the primary text feature representation of the text content H={h(0), h(1), ..., h(L 1 )}, i.e.
H=Bertft(BI)H=Bert ft (BI)
(2)为了能够更好的捕捉全局信息,将每条待检测推文的初级文本特征表示H={h(0),h(1),...,h(L1)}输入序列注意力块(SA module),序列注意力块由Bi-GRU与Self-Attention两部分组成。(2) In order to better capture the global information, the primary text feature of each tweet to be detected is represented by H={h(0), h(1),...,h(L 1 )} input sequence attention Force block (SA module), the sequence attention block consists of Bi-GRU and Self-Attention.
基于每条待检测推文的初级文本特征表示H={h(0),h(1),...,h(L1)},采用Bi-GRU提取每条待检测推文的文本特征的时间属性,以得到具有上下文信息的文本特征表示G={g(0),g(1),...,g(L1)}Based on the primary text feature representation H={h(0),h(1),...,h(L 1 )} of each tweet to be detected, use Bi-GRU to extract the text features of each tweet to be detected to obtain the text feature representation with context information G={g(0), g(1),...,g(L 1 )}
G=Bi-GRU(H)G=Bi-GRU(H)
使用自注意力机制(Self-Attention机制)可以增强具有上下文信息的文本特征,并结合相加标准化操作(Add&Norm)和全连接层(Full Connected Layer(2)),得到序列增强后的文本特征FT={t1,t2,...,tm}:The self-attention mechanism (Self-Attention mechanism) can enhance the text features with contextual information, and combine the additive normalization operation (Add&Norm) and the fully connected layer (Full Connected Layer(2)) to obtain the sequence-enhanced text feature F. T = {t 1 ,t 2 ,...,t m }:
qi=wq×g(i),ki=wk×g(i),pi=wp×g(i)q i =w q ×g(i), ki =w k ×g( i ),pi =w p ×g(i)

att_G={att_g(0),att_g(1),...,att_g(L1)}att_G={att_g(0),att_g(1),...,att_g(L 1 )}
F'T=Add&Norm(G,att_G)F' T =Add&Norm(G,att_G)
FT=σ(wfcgF′T+bfc)F T =σ(w fc gF′ T +b fc )
其中,qi,ki,vi代表注意力机制中的线性变换矩阵(中间矩阵),wq,wk,wv代表权重矩阵,g(i)为具有上下文信息的文本特征表示中的第i个特征值,wfc表示全连接层的权重矩阵,bfc表示全连接层(Full Connected Layer)的偏置矩阵,σ表示激活函数ReLU。Among them, q i , k i , v i represent the linear transformation matrix (intermediate matrix) in the attention mechanism, w q , w k , w v represent the weight matrix, and g(i) is the text feature representation with context information. The i-th eigenvalue, w fc represents the weight matrix of the fully connected layer, b fc represents the bias matrix of the fully connected layer (Full Connected Layer), and σ represents the activation function ReLU.
步骤202、基于每条待检测推文的视觉内容Vi,提取每条待检测推文的序列增强视觉特征FV={v1,v2,...,vm},即将所有待检测推文的视觉内容输入视觉块,可表示为函数FV=fV(Vi;θV),其中FV表示视觉模块输出的视觉特征,θV表示视觉模块的参数:Step 202: Based on the visual content V i of each tweet to be detected, extract the sequence enhanced visual feature F V ={v 1 ,v 2 ,..., vm } of each tweet to be detected, that is, all the tweets to be detected are extracted. The visual content of the tweet is input to the visual block, which can be expressed as a function F V = f V (V i ; θ V ), where F V represents the visual features output by the visual module, and θ V represents the parameters of the visual module:
(1)对每条待检测推文的视觉内容进行图像预处理,具体的,图像尺寸调整,即将图像大小统一调整为224×224;为了扩大训练样本数量并且提高模型的泛化性能,采用随机水平翻转操作对图像进行增广;在[0-1]的范围内进行像素值标准化。(1) Perform image preprocessing on the visual content of each tweet to be detected, specifically, image size adjustment, that is, uniformly adjust the image size to 224×224; in order to expand the number of training samples and improve the generalization performance of the model, random The horizontal flip operation augments the image; normalizes pixel values in the range [0-1].
(2)采用在ImageNet上预训练的ResNet50模型提取预处理后的视觉内容的区域特征res_FV={v′1,v′2,...,v′m},更改最后的全连接层使得输出的序列长度与文本特征保持一致。(2) Use the ResNet50 model pre-trained on ImageNet to extract the pre-processed visual content regional features res_F V ={v′ 1 , v′ 2 ,...,v′ m }, and change the last fully connected layer so that The output sequence length is consistent with the text features.
res_FV=ResNetft(V)res_F V = ResNet ft (V)
(3)与文本模块类似,使用SA module获取序列增强视觉特征FV={v1,v2,...,vm}:(3) Similar to the text module, use the SA module to obtain sequence-enhanced visual features F V = {v 1 , v 2 , ..., v m }:
FV=SA(res_FV)F V =SA(res_F V )
步骤203、将序列增强文本特征和序列增强视觉特征输入多模态融合块,得到谣言检测的结果,可表示为函数Step 203: Input the sequence-enhanced text feature and the sequence-enhanced visual feature into the multimodal fusion block to obtain the result of rumor detection, which can be expressed as a function
Result=fF({FV,FT};θF)Result=f F ({F V , F T }; θ F )
其中,Result表示模块的输出(R或者NR),θF表示多模态融合块的参数。Among them, Result represents the output of the module (R or NR), and θ F represents the parameters of the multimodal fusion block.
(1)跨模态特征映射(1) Cross-modal feature mapping
(101)不同模态的数据间或多或少的存在数值性差异与依赖关系,为了取得更好的融合效果,需要进行跨模态的特征映射以捕捉异质模态数据间的依赖关系并减小数值性差异,首先,对于异质模态数据,序列增强文本特征FT={t1,t2,...,tm}和序列增强视觉特征FV={v1,v2,...,vm},使用交互使用注意力机制(Attention(1)),获得带有文本注意力的视觉特征(101) There are more or less numerical differences and dependencies between the data of different modalities. In order to achieve a better fusion effect, cross-modal feature mapping is required to capture the dependencies between heterogeneous modal data and reduce Small numerical differences, first, for heterogeneous modal data, sequence augmented text features F T = {t 1 , t 2 , ..., t m } and sequence augmented visual features F V = {v 1 , v 2 , ..., v m }, using an interactive attention mechanism (Attention(1)) to obtain visual features with textual attention

qi=tanh(wq·ti+bq)q i =tanh(w q ·t i +b q )
ki=tanh(wk·vi+bk) k i =tanh(w k ·vi +b k )
pi=tanh(wp·vi+bp)p i =tanh( w p ·vi +b p )

同理,使用交互使用注意力机制(Attention(2))可得到带有视觉注意力的文本特征
(102)采用Transformer进行跨模态特征序列映射,Transformer本质上是一个编-解码框架,在NLP领域中主要被用来处理序列-序列(Sequence to Sequence)问题。它由六个编码层和六个解码层组成。将其用作异质模态特征序列映射的媒介。由于经过上述SA-module已经得到序列增强后的特征矩阵。因此对于第一Transformer(Transformer(1)),以带有视觉注意力的文本特征作为输入得到生成视觉特征gen_FV=Transformer{src:att_FT,tgt:att_FV},其中src代表源域,tgt代表目标域。生成视觉特征由源视觉特征att_FT作为输入矩阵,以att_FV为目标矩阵,通过Transformer映射得来,因此缩小了源视觉特征与生成视觉特征之间的异质性差异且进一步捕捉了异质模态数据之间的依赖关系,可以得到更好的融合效果。(102) Using Transformer for cross-modal feature sequence mapping, Transformer is essentially an encoding-decoding framework, and is mainly used to deal with the Sequence to Sequence problem in the NLP field. It consists of six encoding layers and six decoding layers. Use it as a medium for heterogeneous modal feature sequence mapping. The feature matrix after sequence enhancement has been obtained through the above SA-module. Therefore, for the first Transformer (Transformer(1)), the text feature with visual attention is used as input to obtain the generated visual feature gen_F V =Transformer{src:att_F T ,tgt:att_F V }, where src represents the source domain, tgt Represents the target domain. The generated visual feature uses the source visual feature att_FT as the input matrix, and att_F V as the target matrix, which is obtained by Transformer mapping, thus reducing the heterogeneity difference between the source visual feature and the generated visual feature and further capturing the heterogeneous model. The dependency between state data can get better fusion effect.
同理,可得到以带有文本注意力的视觉特征作为第二Transformer(Transformer(2))输入的生成文本特征gen_FT。具体的,以带有文本注意力的视觉特征为输入矩阵,以带有视觉注意力的文本特征为目标矩阵,通过Transformer映射得到文本特征。Similarly, the generated text feature gen_FT can be obtained by taking the visual feature with text attention as the input of the second Transformer (Transformer(2)). Specifically, the visual features with text attention are used as the input matrix, and the text features with visual attention are used as the target matrix, and the text features are obtained through Transformer mapping.
(2)融合(2) Fusion
早期融合包含三个全连接层(第一全连接层Fc-1,第二全连接层Fc-2,第三全连接层Fc-3),并在全连接层之间添加了Dropout层(第一Dropout层Dropout-1和第二Dropout层Dropout-2)以防止过拟合。将源特征与生成特征拼接后送入全连接层中得到早期融合结果:The early fusion consists of three fully connected layers (the first fully connected layer Fc-1, the second fully connected layer Fc-2, and the third fully connected layer Fc-3), and a dropout layer is added between the fully connected layers (the first fully connected layer Fc-1). A Dropout layer Dropout-1 and a second Dropout layer Dropout-2) to prevent overfitting. The source feature and the generated feature are spliced and sent to the fully connected layer to obtain the early fusion result:
将带有文本注意力的视觉特征与视觉特征拼接后,通过由全连接层组成的融合识别模块,得到第一早期融合结果,其中EF指代早期融合:After splicing visual features with text attention and visual features, the first early fusion result is obtained through a fusion recognition module composed of fully connected layers, where EF refers to early fusion:
Result-1=EF{att_FV,gen_FV}Result-1=EF{att_F V ,gen_F V }
将带有视觉注意力的文本特征与文本特征拼接后,通过由全连接层组成的融合识别模块,得到第二早期融合结果:After splicing the text features with visual attention and text features, the second early fusion result is obtained through the fusion recognition module composed of fully connected layers:
Result-2=EF{att_FT,gen_FT}Result-2=EF{ att_FT , gen_FT }
晚期融合通过分配权重融合来自早期融合的结果,将第一早期融合结果和第二早期融合结果通过分配权重融合,其中LF指代晚期融合,得到融合后的特征,即晚期融合结果:The late fusion fuses the results from the early fusion by assigning weights, and fuses the first early fusion result and the second early fusion result by assigning weights, where LF refers to the late fusion, and the fused features are obtained, that is, the late fusion result:
Result=LF{Result-1,Result-2}Result=LF{Result-1,Result-2}
使用交叉熵定义了模块的损失,并用Y来表示事件标签,Result(i)代表第i条推文的预测结果:The loss of the module is defined using cross-entropy, and Y is the event label, and Result(i) is the prediction result of the i-th tweet:
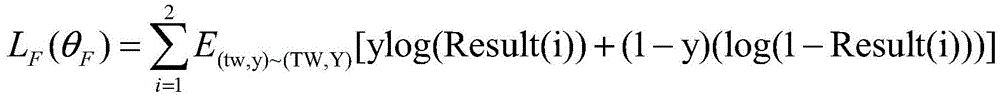
通过寻求最佳参数
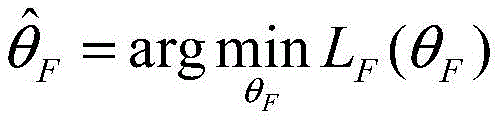
本发明能够有效的综合分析待检测文本中的多模态内容;能够将多模态内容映射到同一数据域中生成有效的联合表示;并且在模态缺失与早期数据量较少的情况下也有较好的检测效果。The invention can effectively and comprehensively analyze the multimodal content in the text to be detected; it can map the multimodal content to the same data domain to generate an effective joint representation; better detection effect.
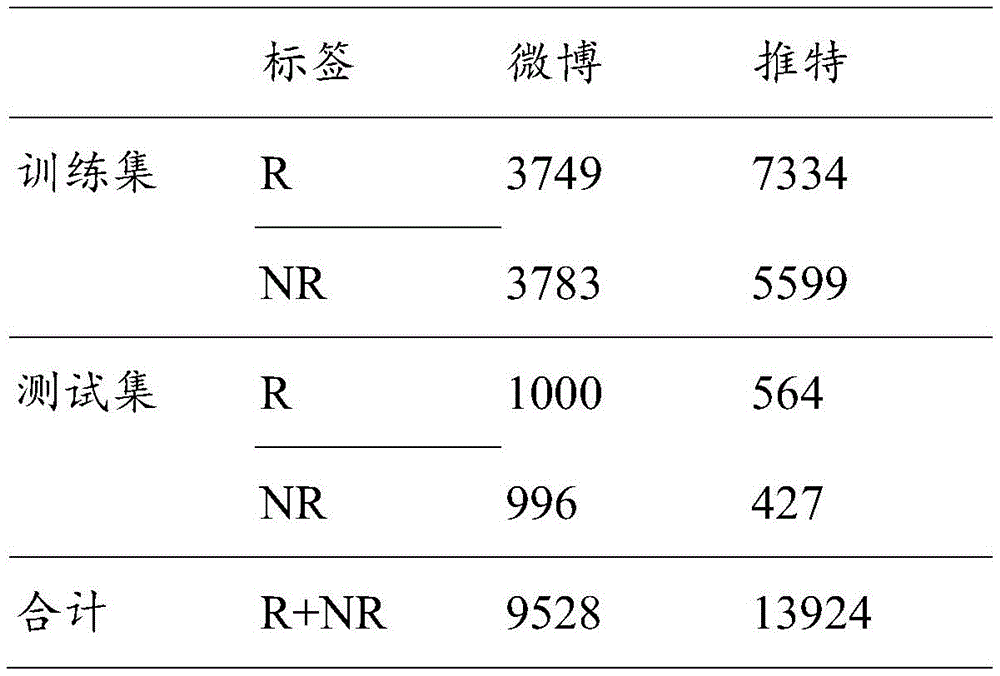
拟议的模型分别在微博数据集和推特数据集上进行了验证。微博数据集是多模态数据集,其中的谣言推文通过抓取2012年5月至2016年1月所有经过验证的虚假谣言帖子得来。该数据集具有客观基础事实标签。其中的非谣言推文取自经过权威新闻机构核实过的推文数据。推特数据集来源于MediaEval的一部分任务,用于检测推特上的虚假内容,删除了其中没有任何文本或图像的推文。The proposed model is validated on the Weibo dataset and Twitter dataset, respectively. The Weibo dataset is a multimodal dataset in which rumor tweets are obtained by crawling all verified fake rumor posts from May 2012 to January 2016. This dataset has objective ground truth labels. The non-rumor tweets included are drawn from tweet data verified by authoritative news organizations. The Twitter dataset was derived from a part of MediaEval’s mission to detect fake content on Twitter, removing tweets that didn’t have any text or images in them.
表1、数据集详情Table 1. Data set details
如表2所示,对本发明中的TIMF模型进行了相应的消融实验,它们是TIMF中的各个模块和简化变体。As shown in Table 2, the corresponding ablation experiments are performed on the TIMF model in the present invention, which are various modules and simplified variants in TIMF.
其中,Visual:仅使用视觉模块中的预训练的ResNet50模型在单模态视觉内容上进行验证;Visual-SA:使用包含了SA-module的完整视觉模块在单模态视觉内容上进行验证;Texual:仅使用文本模块中的微调Bert模型在单模态文本内容上进行验证;Texual-SA:使用包含了SA-module的完整文本模块在单模态文本内容上进行验证;EF-1:仅使用视觉源特征与视觉生成特征融合的早期识别模型;EF-2:仅使用文本源特征与文本生成特征融合的早期识别模型;TMIF:本文中拟议的完整模型。Accuracy:准确率;Precision:精准度;Recall:召回率;F1:F1指标。Among them, Visual: use only the pre-trained ResNet50 model in the vision module to verify on single-modal visual content; Visual-SA: use the complete vision module including SA-module to verify on single-modal visual content; Texual : Validation on unimodal text content using only the fine-tuned Bert model in the text module; Texual-SA: Validation on unimodal text content using the full text module including the SA-module; EF-1: Validating only on unimodal text content Early recognition model fused with visual source features and visual generative features; EF-2: Early recognition model using only text source features fused with text generative features; TMIF: The full model proposed in this paper. Accuracy: precision; Precision: precision; Recall: recall; F1: F1 indicator.
表2、消融实验Table 2. Ablation experiment

如表3所示,将本发明中的TIMF模型与相关工作中的代表性算法进行了对比,其中K表示知识信息,S表示社会语境。考虑到任务设置的差异,采用了这些模型的主要网络结构,并针对于任务进行了必要的调整。其中,att-RNN是2017年在期刊The 25th ACMinternational conference on Multimedia中提出的一种多模态谣言检测模型(Multimodal fusion with recurrent neural networks for rumor detection onmicroblogs)提出的,它的输入是推文中的文本、视觉以及社会语境信息;EANN是2018年在期刊The 24th acm sigkdd international conference on knowledge discovery&datamining中提出的一种谣言检测网络(Eann:Event adversarial neural networks formulti-modal fake news detection),删除了其中的时间鉴别器,仅保留多模态特征提取器和假新闻检测器两部分;MAVE是2019年在期刊The world wide web conference中提出的一种多模态变分自动编码器(Mvae:Multimodal variational autoencoder for fakenews detection),对于任务,使用其完整的结构,包括编码器、解码器和检测器三部分;MFN是2018年在期刊Pacific-Asia conference on knowledge discovery and data mining中提出的一种无监督谣言检测模型(Call attention to rumors:Deep attention basedrecurrent neural networks for early rumor detection),对于任务,使用Text-CNN捕捉不同粒度的文本特征,使用预训练的VGG-19模型捕捉图像特征,最后使用注意力机制和潜在主体记忆网络生成联合表示;MKEMN是2019年在期刊Proceedings of the 27th ACMInternational Conference on Multimedia中提出的谣言检测方法(Multi-modalknowledge-aware event memory network for social media rumor detection),使用其完整的结构融合来自文本、图像与知识信息三种模态的信息用于谣言检测。As shown in Table 3, the TIMF model in the present invention is compared with the representative algorithms in related work, where K represents knowledge information and S represents social context. Taking into account the differences in task settings, the main network structures of these models are adopted and the necessary adjustments are made for the tasks. Among them, att-RNN is proposed by a multimodal rumor detection model (Multimodal fusion with recurrent neural networks for rumor detection onmicroblogs) proposed in the journal The 25th ACMinternational conference on Multimedia in 2017, and its input is the text in the tweet , visual and social context information; EANN is a rumor detection network (Eann: Event adversarial neural networks formulti-modal fake news detection) proposed in the journal The 24th acm sigkdd international conference on knowledge discovery&datamining in 2018, delete the Temporal discriminator, retaining only two parts: multimodal feature extractor and fake news detector; MAVE is a multimodal variational autoencoder (Mvae: Multimodal variational autoencoder proposed in the journal The world wide web conference in 2019). for fakenews detection), for the task, use its complete structure, including encoder, decoder and detector; MFN is an unsupervised rumor proposed in the journal Pacific-Asia conference on knowledge discovery and data mining in 2018 Detection model (Call attention to rumors: Deep attention based recurrent neural networks for early rumor detection), for tasks, use Text-CNN to capture text features of different granularities, use pre-trained VGG-19 model to capture image features, and finally use attention mechanism and latent subject memory network generation joint representation; MKEMN is a rumor detection method (Multi-modalknowledge-aware event memory network for social media rumor detection) proposed in the journal Proceedings of the 27th ACM International Conference on Multimedia in 2019, using its complete The structure fuses information from three modalities of text, image and knowledge information for rumor detection.
表3、与相关算法的对比实验Table 3. Comparative experiments with related algorithms

如图3、图4所示,对本发明中的TIMF模型的早期检测性能进行了对比研究,为此,固定20%的测试样本,通过逐步增加训练样本来观察模型的早期检测能力。As shown in FIG. 3 and FIG. 4 , a comparative study on the early detection performance of the TIMF model in the present invention is carried out. Therefore, 20% of the test samples are fixed, and the early detection ability of the model is observed by gradually increasing the training samples.
实施例二
本实施例提供了一种基于多模态交互的谣言检测系统,其具体包括如下模块:This embodiment provides a rumor detection system based on multimodal interaction, which specifically includes the following modules:
数据获取模块,其被配置为:获取若干条包含文本内容与视觉内容的待检测推文;a data acquisition module, which is configured to: acquire several tweets to be detected that contain textual content and visual content;
序列增强文本特征提取模块,其被配置为:基于每条待检测推文的文本内容,提取每条待检测推文的序列增强文本特征;a sequence-enhanced text feature extraction module, which is configured to: extract the sequence-enhanced text feature of each tweet to be detected based on the text content of each tweet to be detected;
序列增强视觉特征提取模块,其被配置为:基于每条待检测推文的视觉内容,提取每条待检测推文的序列增强视觉特征;a sequence-enhanced visual feature extraction module, which is configured to: extract the sequence-enhanced visual feature of each tweet to be detected based on the visual content of each tweet to be detected;
交互模块,其被配置为:基于序列增强文本特征和序列增强视觉特征,使用交互使用注意力机制,获得带有文本注意力的视觉特征和带有视觉注意力的文本特征,并基于带有文本注意力的视觉特征和带有视觉注意力的文本特征,生成视觉特征和文本特征;an interaction module, which is configured to: enhance text features based on sequences and enhance visual features based on sequences, use an attention mechanism interactively, obtain visual features with text attention and text features with visual attention, and based on text features with text Visual features of attention and text features with visual attention, generating visual features and text features;
特征融合模块,其被配置为:将带有文本注意力的视觉特征、带有视觉注意力的文本特征、视觉特征和文本特征进行特征融合,得到融合后的特征;a feature fusion module, which is configured to: fuse visual features with text attention, text features with visual attention, visual features and text features to obtain fused features;
检测模块,其被配置为:基于融合后的特征,得到每条待检测推文是否为谣言的结果。A detection module, which is configured to: obtain a result of whether each tweet to be detected is a rumor based on the fused features.
此处需要说明的是,本实施例中的各个模块与实施例一中的各个步骤一一对应,其具体实施过程相同,此处不再累述。It should be noted here that each module in this embodiment corresponds to each step in
实施例三
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述实施例一所述的一种基于多模态交互的谣言检测方法中的步骤。This embodiment provides a computer-readable storage medium on which a computer program is stored, and when the program is executed by a processor, implements the steps in the multimodal interaction-based rumor detection method described in the first embodiment above .
实施例四Embodiment 4
本实施例提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例一所述的一种基于多模态交互的谣言检测方法中的步骤。This embodiment provides a computer device, including a memory, a processor, and a computer program stored in the memory and running on the processor, where the processor implements the one described in the first embodiment when the processor executes the program. Steps in a multimodal interaction-based rumor detection method.
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。As will be appreciated by one skilled in the art, embodiments of the present invention may be provided as a method, system, or computer program product. Accordingly, the invention may take the form of a hardware embodiment, a software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present invention may take the form of a computer program product embodied on one or more computer-usable storage media having computer-usable program code embodied therein, including but not limited to disk storage, optical storage, and the like.
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present invention is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the invention. It will be understood that each flow and/or block in the flowchart illustrations and/or block diagrams, and combinations of flows and/or blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to the processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing device to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing device produce Means for implementing the functions specified in a flow or flow of a flowchart and/or a block or blocks of a block diagram.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory result in an article of manufacture comprising instruction means, the instructions The apparatus implements the functions specified in the flow or flow of the flowcharts and/or the block or blocks of the block diagrams.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded on a computer or other programmable data processing device to cause a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process such that The instructions provide steps for implementing the functions specified in the flow or blocks of the flowcharts and/or the block or blocks of the block diagrams.
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(RandomAccessMemory,RAM)等。Those of ordinary skill in the art can understand that all or part of the processes in the methods of the above embodiments can be implemented by instructing relevant hardware through a computer program, and the program can be stored in a computer-readable storage medium. During execution, the processes of the embodiments of the above-mentioned methods may be included. The storage medium may be a magnetic disk, an optical disk, a read-only memory (Read-Only Memory, ROM), or a random access memory (Random Access Memory, RAM) or the like.
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。The above descriptions are only preferred embodiments of the present invention, and are not intended to limit the present invention. For those skilled in the art, the present invention may have various modifications and changes. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present invention shall be included within the protection scope of the present invention.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210163061.4A CN114548274B (en) | 2022-02-22 | 2022-02-22 | A rumor detection method and system based on multimodal interaction |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210163061.4A CN114548274B (en) | 2022-02-22 | 2022-02-22 | A rumor detection method and system based on multimodal interaction |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114548274A true CN114548274A (en) | 2022-05-27 |
| CN114548274B CN114548274B (en) | 2025-04-29 |
Family
ID=81677022
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210163061.4A Active CN114548274B (en) | 2022-02-22 | 2022-02-22 | A rumor detection method and system based on multimodal interaction |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114548274B (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115545039A (en) * | 2022-09-27 | 2022-12-30 | 三峡大学 | A multi-modal rumor detection method and system |
| CN115563573A (en) * | 2022-08-15 | 2023-01-03 | 浙江工商大学 | Information detection method based on modal dynamic feature fusion and cross-modal relationship extraction |
| CN115712869A (en) * | 2022-11-14 | 2023-02-24 | 河海大学 | Multi-modal rumor detection method and system based on layered attention network |
| CN115809327A (en) * | 2023-02-08 | 2023-03-17 | 四川大学 | Real-time social network rumor detection method for multi-mode fusion and topics |
| CN116340887A (en) * | 2023-05-29 | 2023-06-27 | 山东省人工智能研究院 | Multimodal fake news detection method and system |
| CN118395209A (en) * | 2024-06-28 | 2024-07-26 | 东营科技职业学院 | False news identification method and system based on artificial intelligence |
Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111079444A (en) * | 2019-12-25 | 2020-04-28 | 北京中科研究院 | Network rumor detection method based on multi-modal relationship |
| CN112580636A (en) * | 2020-12-30 | 2021-03-30 | 杭州电子科技大学 | Image aesthetic quality evaluation method based on cross-modal collaborative reasoning |
| CN112905827A (en) * | 2021-02-08 | 2021-06-04 | 中国科学技术大学 | Cross-modal image-text matching method and device and computer readable storage medium |
| CN113239926A (en) * | 2021-06-17 | 2021-08-10 | 北京邮电大学 | Multi-modal false information detection model based on countermeasures |
| CN113469214A (en) * | 2021-05-20 | 2021-10-01 | 中国科学院自动化研究所 | False news detection method and device, electronic equipment and storage medium |
| WO2021232589A1 (en) * | 2020-05-21 | 2021-11-25 | 平安国际智慧城市科技股份有限公司 | Intention identification method, apparatus and device based on attention mechanism, and storage medium |
| CN113704547A (en) * | 2021-08-26 | 2021-11-26 | 合肥工业大学 | Multi-mode label recommendation method based on one-way supervision attention |
| CN113761377A (en) * | 2021-09-13 | 2021-12-07 | 中国科学院新疆理化技术研究所 | False information detection method, device, electronic device and storage medium based on multi-feature fusion of attention mechanism |
| CN113780350A (en) * | 2021-08-10 | 2021-12-10 | 上海电力大学 | Image description method based on ViLBERT and BilSTM |
| CN113806564A (en) * | 2021-09-22 | 2021-12-17 | 齐鲁工业大学 | Multi-mode informativeness tweet detection method and system |
| CN113822224A (en) * | 2021-10-12 | 2021-12-21 | 中国人民解放军国防科技大学 | Rumor detection method and device integrating multi-modal learning and multi-granularity structure learning |
| CN113934882A (en) * | 2021-09-29 | 2022-01-14 | 北京中科睿鉴科技有限公司 | A Fine-Grained Multimodal Fake News Detection Method |
| US11238289B1 (en) * | 2021-01-04 | 2022-02-01 | Institute Of Automation, Chinese Academy Of Sciences | Automatic lie detection method and apparatus for interactive scenarios, device and medium |
-
2022
- 2022-02-22 CN CN202210163061.4A patent/CN114548274B/en active Active
Patent Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111079444A (en) * | 2019-12-25 | 2020-04-28 | 北京中科研究院 | Network rumor detection method based on multi-modal relationship |
| WO2021232589A1 (en) * | 2020-05-21 | 2021-11-25 | 平安国际智慧城市科技股份有限公司 | Intention identification method, apparatus and device based on attention mechanism, and storage medium |
| CN112580636A (en) * | 2020-12-30 | 2021-03-30 | 杭州电子科技大学 | Image aesthetic quality evaluation method based on cross-modal collaborative reasoning |
| US11238289B1 (en) * | 2021-01-04 | 2022-02-01 | Institute Of Automation, Chinese Academy Of Sciences | Automatic lie detection method and apparatus for interactive scenarios, device and medium |
| CN112905827A (en) * | 2021-02-08 | 2021-06-04 | 中国科学技术大学 | Cross-modal image-text matching method and device and computer readable storage medium |
| CN113469214A (en) * | 2021-05-20 | 2021-10-01 | 中国科学院自动化研究所 | False news detection method and device, electronic equipment and storage medium |
| CN113239926A (en) * | 2021-06-17 | 2021-08-10 | 北京邮电大学 | Multi-modal false information detection model based on countermeasures |
| CN113780350A (en) * | 2021-08-10 | 2021-12-10 | 上海电力大学 | Image description method based on ViLBERT and BilSTM |
| CN113704547A (en) * | 2021-08-26 | 2021-11-26 | 合肥工业大学 | Multi-mode label recommendation method based on one-way supervision attention |
| CN113761377A (en) * | 2021-09-13 | 2021-12-07 | 中国科学院新疆理化技术研究所 | False information detection method, device, electronic device and storage medium based on multi-feature fusion of attention mechanism |
| CN113806564A (en) * | 2021-09-22 | 2021-12-17 | 齐鲁工业大学 | Multi-mode informativeness tweet detection method and system |
| CN113934882A (en) * | 2021-09-29 | 2022-01-14 | 北京中科睿鉴科技有限公司 | A Fine-Grained Multimodal Fake News Detection Method |
| CN113822224A (en) * | 2021-10-12 | 2021-12-21 | 中国人民解放军国防科技大学 | Rumor detection method and device integrating multi-modal learning and multi-granularity structure learning |
Non-Patent Citations (4)
| Title |
|---|
| JIANDONG LV 等: ""TMIF: transformer‑based multi‑modal interactive fusion for automatic rumor detection"", 《MULTIMEDIA SYSTEMS》, vol. 29, 31 March 2022 (2022-03-31), pages 2979 - 2989 * |
| 夏鑫林;许亮;: "基于注意力机制的谣言检测算法研究", 现代计算机, no. 08, 31 March 2020 (2020-03-31) * |
| 金志威;曹娟;王博;王蕊;张勇东;: "融合多模态特征的社会多媒体谣言检测技术研究", 南京信息工程大学学报(自然科学版), no. 06, 30 November 2017 (2017-11-30) * |
| 陶霄 等: ""基于注意力与多模态混合融合的谣言检测方法"", 《计算机工程》, vol. 47, no. 12, 31 December 2021 (2021-12-31), pages 72 * |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115563573A (en) * | 2022-08-15 | 2023-01-03 | 浙江工商大学 | Information detection method based on modal dynamic feature fusion and cross-modal relationship extraction |
| CN115545039A (en) * | 2022-09-27 | 2022-12-30 | 三峡大学 | A multi-modal rumor detection method and system |
| CN115712869A (en) * | 2022-11-14 | 2023-02-24 | 河海大学 | Multi-modal rumor detection method and system based on layered attention network |
| CN115809327A (en) * | 2023-02-08 | 2023-03-17 | 四川大学 | Real-time social network rumor detection method for multi-mode fusion and topics |
| CN115809327B (en) * | 2023-02-08 | 2023-05-05 | 四川大学 | A real-time social network rumor detection method based on multi-modal fusion and topic |
| CN116340887A (en) * | 2023-05-29 | 2023-06-27 | 山东省人工智能研究院 | Multimodal fake news detection method and system |
| CN116340887B (en) * | 2023-05-29 | 2023-09-01 | 山东省人工智能研究院 | Multi-mode false news detection method and system |
| CN118395209A (en) * | 2024-06-28 | 2024-07-26 | 东营科技职业学院 | False news identification method and system based on artificial intelligence |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114548274B (en) | 2025-04-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Sabat et al. | Hate speech in pixels: Detection of offensive memes towards automatic moderation | |
| CN111126069B (en) | Social media short text named entity identification method based on visual object guidance | |
| CN114548274A (en) | Multi-modal interaction-based rumor detection method and system | |
| US11822590B2 (en) | Method and system for detection of misinformation | |
| CN116383517B (en) | Multimodal rumor detection method and system with enhanced dynamic propagation features | |
| CN108984530A (en) | A kind of detection method and detection system of network sensitive content | |
| WO2020199904A1 (en) | Video description information generation method, video processing method, and corresponding devices | |
| CN113449085A (en) | Multi-mode emotion classification method and device and electronic equipment | |
| CN116341519B (en) | Method, device and storage medium for extracting event causal relationships based on background knowledge | |
| US12321831B1 (en) | Automated detection of content generated by artificial intelligence | |
| CN114579876A (en) | False information detection method, device, equipment and medium | |
| Kathuria et al. | Real time sentiment analysis on twitter data using deep learning (Keras) | |
| CN116258147A (en) | A multi-modal comment sentiment analysis method and system based on heterogeneous graph convolution | |
| CN116049597A (en) | Pre-training method, device and electronic equipment for multi-task model of webpage | |
| CN113627550A (en) | Image-text emotion analysis method based on multi-mode fusion | |
| CN114661951A (en) | Video processing method and device, computer equipment and storage medium | |
| CN117131923A (en) | A backdoor attack method and related devices for cross-modal learning | |
| He et al. | Deep learning in natural language generation from images | |
| Shalabi et al. | Image-text out-of-context detection using synthetic multimodal misinformation | |
| CN117350301A (en) | A public opinion event monitoring method based on multi-modal fusion large model | |
| Rastogi et al. | Sentiment analysis methods and applications–a review | |
| CN118864983A (en) | Image classification and recognition method and device | |
| Wang et al. | An interactive attention mechanism fusion network for aspect-based multimodal sentiment analysis | |
| CN112035670B (en) | Multi-modal rumor detection method based on image emotional tendency | |
| WO2023137903A1 (en) | Reply statement determination method and apparatus based on rough semantics, and electronic device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information |
Country or region after: China Address after: 250353 University Road, Changqing District, Ji'nan, Shandong Province, No. 3501 Applicant after: Qilu University of Technology (Shandong Academy of Sciences) Address before: 250353 University Road, Changqing District, Ji'nan, Shandong Province, No. 3501 Applicant before: Qilu University of Technology Country or region before: China |
|
| CB02 | Change of applicant information | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |