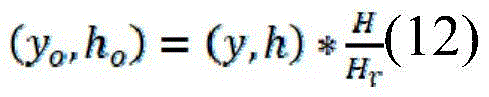Detailed Description
For a more clear understanding of the technical features, objects and effects of the present invention, embodiments of the present invention will now be described in detail with reference to the accompanying drawings.
As shown in fig. 1, the active ship name identification method for inland river maritime video monitoring of the present invention includes the following steps:
s1, detecting the ship in the video and determining the type of the ship: when the ships are container ships, bulk cargo ships and oil carriers, the semantic part is used for detection, the part of the ship with the name of the ship is detected while the ship is detected, and when the ships are passenger ships and law enforcement ships, the semantic part is not detected;
the concrete contents are as follows: s101, inputting the ship instance and the hull part instance generated by the ship area suggestion network and the hull part area suggestion network respectively, wherein the instances comprise a bounding box coordinate bbox, namely: bounding box, and the corresponding feature sequence, said bbox containing the top left corner point coordinates and width and height, i.e.: x, y, w, h;
the concrete contents are as follows: inputting the picture, obtaining a feature map through a convolution feature extraction network, sending the feature map into a RegionProposalNetwork, namely an RPN network to obtain a detection result, filtering a repeated result through a Non Maximum Suppression, namely NMS, intercepting a feature segment at a corresponding position on the feature map according to coordinate information of the result, and processing the feature segment into a new feature map with the same size after passing through a RegionOfInterest, namely a RoI Pooling layer.
S102, calculating the correlation between the ship examples and the ship hull examples, wherein correlation coefficients among the examples are calculated to obtain a correlation matrix, and the correlation matrix is summed according to the coordinate axis direction and multiplied to a corresponding example characteristic sequence to finish the correlation calculation between the ship examples and the ship hull examples;
the concrete contents are as follows: inputting the pictures, outputting the detection results of the ships and the ship bodies after the pictures are subjected to a network of ship detection, classification and ship body part detection, wherein the detection results comprise the position coordinates of the targets: x, y, w, h and characteristic diagrams with uniform size after the RoI Pooling, IoU of the ship example coordinate frame and the ship body part example coordinate frame are sequentially calculated, finally a correlation matrix of the ship and the ship body part is obtained, the correlation matrix is summed according to rows or columns and then multiplied by the characteristic diagrams of the ship or the ship body part, and correlation coefficient weighting is completed.
S103, the example is proposed to be sent to a final classification and coordinate regression network in the area weighted by the correlation coefficient, and the coordinate frame and the classification result of the ship and the ship body are obtained.
S2, detecting the ship or the ship part in the step S1 by using an OCR text detection and recognition frame, and recognizing existing text information;
the concrete contents are as follows: the original size of the image is (W, H), the size of the image input into the ship detection, classification and hull part detection network after scaling is (Wr, Hr), the bbox in the output result is (x, y, w, h), and the position coordinate bbox (x) of the target in the original image iso、yo、wo、ho) The calculation methods of (A) are as follows:
the computing method restores a position bboxo of the target in the original image, and corresponding parts are intercepted from the original image according to a bboxo coordinate to serve as original output of the second step; and performing text detection on the input image, and intercepting a corresponding area on the input image according to a text detection result to perform text recognition.
S3, determining the real name of the ship by using a designed text filtering algorithm based on an edit distance rule, wherein the specific contents are as follows:
a. when a plurality of recognition results exist, sequentially calculating the edit distance of each recognition result: and calculating the editing distance score of each recognition result according to a set editing distance threshold, wherein the ship name with a recognition error is judged when the editing distance is lower than the similar result of the threshold, and the ship name is closest to the real ship name when the editing distance is higher than the similar result of the threshold.
b. And when the edit distance of the two results is 0, namely the two recognition results are completely the same, determining the name of the ship.
The preferred embodiment of the present invention comprises the following three steps:
s1, detecting the ships in the video and determining the types of the ships, if the ships are container ships, bulk cargo ships, oil tankers and the like, detecting the ship parts possibly with names while detecting the ships by utilizing a semantic part detection technology, and if the ships are passenger ships, law enforcement ships and the like, not detecting the semantic part;
s2, detecting the ship or the ship part detected in the first step by using an OCR text detection and recognition framework, and recognizing text information existing in the ship or the ship part;
s3, determining the real name of the ship by using the designed text filtering algorithm based on the edit distance rule
As shown in fig. 2, the network structure diagram of ship detection, classification and hull part detection, the first step in the general structure of the present invention is: firstly, inputting and respectively generating a plurality of ship examples and ship body part examples through a ship area suggestion network and a ship body part area suggestion network, wherein each example comprises a bounding box coordinate bbox (bounding box) and a corresponding characteristic sequence, wherein the bbox comprises (x, y, w, h), namely the coordinate of the upper left corner point of the bbox and the width and the height, then calculating the correlation between each ship example and the ship body part example, calculating the correlation coefficient among all the examples to obtain a correlation matrix, summing according to the coordinate axis direction and multiplying the correlation matrix onto the corresponding example characteristic sequence to finish the correlation calculation of each ship example and the ship body part example. And finally, sending the area suggestion examples weighted by the correlation coefficients into a final classification and coordinate regression network to obtain a final coordinate frame and classification results of the ship and the ship body.
As shown in fig. 3, the proposed neural networks in the ship and hull regions have the same structure, and are all composed of a feature extraction network, an RPN (region pro temporal network) and roi (region of interest) Pooling, an input picture is passed through the convolution feature extraction network to obtain a feature map, the feature map is sent into the RPN network to obtain a detection result, the repetition result is filtered through nms (non max mapping), a feature segment of a corresponding position on the feature map is intercepted according to coordinate information of the filtered detection result, and the feature segments can be processed into new feature maps of the same size after passing through a roup layer.
1) Feature extraction
The structure parameters of the feature extraction network in the area recommendation neural network are shown in table 1, wherein conv represents convolution layers, two parameters in brackets represent the sizes of convolution kernels and the number of channels respectively, maxpool represents a maximum pooling layer, wherein a ReLU layer is arranged behind each convolution layer, and is ignored in the table because of element-wise operation, and the length and the width of a feature map obtained through the feature extraction network are 1/16 of an input picture.
TABLE 1 feature extraction network parameter Table
| Network layer name
|
Structural parameters
|
| Layer1
|
conv(3*3,64)conv(3*3,64)maxpool(2*2)
|
| Layer2
|
conv(3*3,128)conv(3*3,128)maxpool(2*2)
|
| Layer3
|
conv(3*3,256)conv(3*3,256)conv(1*1,256)maxpool(2*2)
|
| Layer4
|
conv(3*3,512)conv(3*3,512)conv(1*1,512)maxpool(2*2)
|
| Layer5
|
conv(3*3,512)conv(3*3,512)conv(1*1,512) |
2) RPN network
As shown in fig. 4, the RPN structure in the area-proposed neural network is preset with 9 different sizes of bbox for each point, respectively unit length: {128, 256, 512}, aspect ratio: {1:1, 1:2, 2:1} are combined two by two. After the first 3 × 3 convolutional layer, the length and width of the feature map are unchanged, the number of channels is 256, then two branches have different calculation tasks, the upper 1 × 1 convolutional layer is added with Softmax to calculate the possibility of whether an object or a background is contained in each rectangular frame, and the lower 1 × 1 convolutional layer is used for calculating the bbox coordinate (x, y, w, h) of the target, so that the real position of the object can be obtained.
3) NMS algorithm
The principle of NMS in area proposal neural networks is as algorithm 1:
the calculation process of IoU (interaction of Union) is as follows: for a given bboxA(xa,ya,wa,ha),bboxB(xb,yb,wb,hb) First, the coordinates (x) of the upper left corner and the lower right corner of the overlapped area of the two bboxs are calculated1,y1),(x2,y2) As shown in formulas (1), (2):
x1=max(xa,xb),y1=max(ya,yb) (1)
x2=min(xa+wa,xb+wb),y2=min(ya+ha,yb+hb) (2)
obtaining coordinates of two corner points of the overlapped region to calculate the area S of the overlapped regioniAs in formula (3):
Si=max(x2-x1,0)*max(y2-y1,0) (3)
the next two bbox union region areas SuI.e. bboxA,bboxBIs subtracted from the sum of the areas ofiIf formula (4), IoU is the ratio of Si to Su, as shown in formula (5):
Su=waha+wbhb-Si (4)
the significance of NMS is to filter out the results with redundancy and relatively poor confidence and position, reduce the workload of subsequent RoIPooling, and avoid a large amount of repeated calculation during the subsequent accurate calculation of target classification and positioning.
4)RoIPooling
As shown in fig. 5, the rohpooling principle in the area-suggested neural network divides feature maps of different sizes into smaller segments according to a set output size, where the output is 2 × 2 in the figure, the output size set in an actual network is 7 × 7, and when a corresponding dimension cannot be divided exactly, the extra lines (columns) are allocated to a first segment of the corresponding dimension, for example, the divided feature segments are surrounded by black borders in the figure, and then the maximum value is obtained in each black border to obtain a value corresponding to an output position.
The RoIPooling has the advantages that the previous feature maps with different sizes are changed into the uniform size through calculation, the subsequent parameter setting of the neural network responsible for target correlation calculation and final classification and regression is facilitated, and the calculation speed of the network is improved.
And calculating the correlation between the ship and the hull part example, wherein the correlation calculation steps of the ship and the hull part detection example are as follows:
after the input image passes through a network of ship detection, classification and hull part detection, the output ship and hull detection results comprise position coordinates (x, y, w, h) of the target and a characteristic diagram with uniform size after RoIPooling. IoU of each ship example coordinate frame and the hull part example coordinate frame are calculated in turn, a threshold value gamma of IoU is set to be 0.9 in an experiment, and if IoU is smaller than gamma, the correlation coefficient CC of the corresponding examples of two bboxs is calculatedijSetting the characteristic diagram to be zero, otherwise, unfolding the characteristic diagrams corresponding to the two examples into a one-dimensional sequence and splicing, and sending the spliced characteristic sequence into a full-connection layer neural network to obtain a correlation coefficient CCijThe correlation matrix size is related to the number of the detection results of the network of ship detection, classification and hull portion detection, for example, there are n ship detection results and m hull detection results, and then the dimension of the correlation matrix is m × n.
The correlation matrix is summed up in rows or columns and then multiplied by the signature of the corresponding vessel or hull section to complete the weighting of the correlation coefficients. After weighting, when final classification and bbox regression calculation are carried out, the ship example also comprises the information of the ship body part, and the ship body part also comprises the information of the ship example, so that the information interaction of the two branches is realized.
The regression and classification of coordinates of ships and ship body parts adopt the same structure, as shown in fig. 6, fc represents a full connection layer, wherein a ReLU layer is attached to the front two common fc layers, the last fc layer is responsible for the accurate regression of the coordinates of targets, the lower fc layer and the softmax layer are responsible for the classification of the targets, the ship classification comprises 6 categories of container ships, bulk cargo ships, oil tankers, transport ships, passenger ships and law enforcement ships, and the ship classification comprises two categories of a bow and a cabin.
And calculating the loss of the detection of the ship and the hull part, wherein the loss of the detection of the ship and the hull part is divided into two parts, namely the loss of the suggested output of the area of the ship and the hull part and the loss of final bbox regression and classification.
1) Suggested output loss of ship and hull part area
The loss of the ship and hull part region recommendation output comprises the loss of the region recommendation classified as foreground and background and the loss of the region recommendation coordinate frame offset calculation, and the formula (6):
wherein C is
iSuggesting an output contextual classification probability, C, for the ith region
i *Denotes a supervised value of the classification, and B
i、B
i *The processing is relatively complex, in order to enable the model to sensitively perceive the slight difference of the bbox when calculating the target position and improve the detection accuracy, the second group of output of the regional proposal network and the corresponding label are processed, as shown in formula (7), wherein (x, y, w, h) are the bbox coordinates of the output of the regional proposal network, (x, y, w, h) are the bbox coordinates of the output of the regional proposal network
a,y
a,w
a,h
a) Width and height (x) of initial anchor of position coordinate corresponding to current output
*,y
*,w
*,h
*) Representing a true value of the target position for supervision; nc, N
bRespectively represent the coincidence with C
iNot less than 0.7 or C
iC of less than or equal to 0.3
iNumber of (2) and C
iNot less than 0.7 or C
iLess than or equal to 0.3 and
b of 1
iIn order to ensure the balance between the front loss and the rear loss in the training process, the number of the super parameters mu is set to 10.
And L in the formula (6)cAnd LbThe specific calculation method of (3) is as follows:
2) loss of final output
The final output loss of the model includes a target classification loss and a target coordinate regression loss, as in equation (10), v is a hyper-parameter that ensures the balance of the two losses, and is set to 5 in the experiment.
The acquisition work of the detection data sets of the ship and the ship body part is completed in the Yangtze river Wuhan navigation section, and all the acquisition and marking work is completed in 2020.5-2020.7. The data set contained 221 pictures, labeled with labelme, and contained 235 boats, 174 bow sections and 202 stern sections.
To ensure the robustness of the model, the model is pre-trained using the Pascal-Part dataset, and then the model is trained on the detection dataset of the ship and the hull Part based on the training parameters of the Pascal-Part dataset, because the number of pictures in the dataset is limited, all data are used for training, and the hyper-parameters of the two times of training are as shown in table 2:
TABLE 2 Ship and hull part detection training parameter settings
| epoch
|
150
|
| optimizer
|
SGD
|
| learning rate
|
1.00E-03
|
| momentum
|
0.9
|
| Weightdecay
|
1.00E-06 |
The AP (average precision) of the model was trained as shown in Table 3:
TABLE 3 detection of Average Precision for ships and hull parts
| Detecting a target type
|
IoU=0.5
|
IoU=0.75
|
| Ship with a detachable cover
|
99.4%
|
94.9%
|
| Hull section
|
99.1%
|
75.3% |
In addition, in order to test the filtering effect of the hull part detection on the interference of the non-ship-name texts, the number of the non-ship-name texts which can be filtered when the hull part area is used as the input of text detection is counted by adopting 20 unlabelled picture tests, as shown in table 4:
TABLE 4 Hull segment test Effect statistics on non-Ship-name text Filtering
| Number of text instances
|
Filtered number of non-ship name texts
|
Number of unfiltered non-ship name texts
|
Number of ship names
|
| 193
|
153
|
5
|
35 |
Before entering the second step formally, the algorithm process firstly processes the detection results of the first step ship detection, classification and ship body part detection network, because the size of the input picture is reduced proportionally in order to improve the overall efficiency of the first step, the output result of the first step is naturally the position of the target on the scaled picture, and in the second step, in order to ensure the definition of the text area in the picture and improve the identification accuracy, the part of the related target is planned to be cut from the most original high-resolution picture, so the dimension reduction of bbox in the detection result of the first step is needed, and the specific steps are as follows: assuming that the original image size is (W, H), the image size input into the ship detection, classification and hull part detection network after scaling is (Wr, Hr), bbox in the output result is (x, y, W, H), the calculation method of the position coordinates bbox (xo, yo, wo, ho) of the target in the original image is as in formulas (11), (12):
restoring the position bbox of the target in the original image according to the methodoThen, according to bboxoThe coordinates intercept the corresponding portion in the original image as the original output of the second step. The method at the second stage is a standard two-stage method, namely, text detection is carried out on the input image, and corresponding areas are intercepted on the input image according to the text detection result and then text recognition is carried out.
The ship name potential area text detection is carried out through the following steps:
1) network architecture
The text detection network is an image segmentation network constructed based on the Unet idea, and as shown in the overall structure shown in FIG. 7, an input image enters the network and then sequentially passes through layers 0 to 4, and the width and height of an output feature map of each layer are half of those of the previous layer.
And then, sequentially carrying out upsampling on the ConvTp layer from the input feature map of the layer4 at the lowest end, carrying out element-wise addition on the ConvTp layer and the output feature of the layer3, and carrying out element-wise addition from bottom to top until the layer0, wherein the structure of the ConvTp layer is Conv (1 x 1), BN (), ReLU (), ConvTranspose (), BN (), and the output channel of Conv (1 x 1) is half of the number of input channels, so that the element-wise addition between the output of the ConvTp layer and the output of the downsampling layer can be ensured. And then, the output of each stage of upsampling is respectively expanded to the width and height sizes output by layer0 by using a method of nearby value interpolation, and then the output is spliced from the channel dimension and sent to a final classifier for pixel classification of different scales.
And finally, based on the segmentation results of three different scales, obtaining the most total segmentation result by using a pixel set expansion algorithm, wherein bbox generates the minimum bounding rectangle according to the pixel set of each text region.
2) Down-sampling network structure
The structure of each downsampling layer of the ship name potential region text detection network is shown in a table 5, the first two parameters of a Conv convolution layer respectively represent the number of input channels and output channels, k represents the size of a convolution kernel, s represents the convolution step length, and p represents the edge filling dimension; in particular, the feature map passes through the red font layer to realize down-sampling, and the rightmost digit represents the number of times that the corresponding part is repeatedly overlapped, so that the feature map is folded due to the convenience of reading.
Table 5 ship name potential area text detection network downsampling layer structure
3) Multi-scale classifier and supervision method
In order to accurately detect the boundary of the text region, a multi-scale progressive pixel classifier which gradually expands outwards from the text center region is designed. For example, in the Multi-scalecosisifier in fig. 7, after interpolation, expansion and concatenation of output results at each stage, the output results pass through a Conv (3 × 3,256) convolution layer (which also includes BN (), ReLU (), which is simply omitted in the figure), and then enter three branches respectively, the three branches are of the same structure, 1 × 1 convolution is performed and then classified by using a Sigmoid function, and the results P1, P2, and P3 are output respectively, where P1 is responsible for distinguishing text and non-text regions, and P2 and P3 are responsible for distinguishing text and text regions with contracted boundaries, so as to generate accurate text region boundaries in the following.
From bottom to top, the three segmentation branches are thermodynamic diagrams generated by shrinking the original label by 40%, 20% and 0% in the original text region by the bbox center respectively.
As shown in FIG. 8, the calculation method of supervising the shrinkage of the text region of the thermodynamic diagram is to assume that black bbox in the diagram is the original text region in the label, and coordinates of four vertexes in the coordinate system are respectively black (x) in the diagram1,y1),(x2,y2),(x3,y3),(x4,y4)。
First, the coordinates (x) of the center point of bbox are requiredc,yc) The central point coordinate calculation formula is as shown in formulas (13) and (14):
then, the distances between the center point and the four vertices in the X and Y directions are respectively obtained as (X)1,y1) For example, formulas (15), (16):
dx1=xc-x1 (15)
dy1=yc-y1 (16)
find dx1、dy1Then, the first vertex coordinate (x) of bbox shrunk by a certain ratio from the center can be obtained1shrink,y1shrink) As in formulas (17), (18):
x1shrink=xc-(1-r)dx1 (17)
y1shrink=yc-(1-r)dy1 (18)
wherein the letter r represents the shrinkage rate of the bbox, the value of r is modified to calculate the bbox of the classifier used for supervising different scales, and finally, a corresponding thermodynamic diagram is generated according to the bbox coordinate.
In conjunction with the development of natural scene text inspection algorithms in recent years, DiceLoss was chosen as the loss function, as in equation (19):
wherein P isi,x,yAn output P representing the ith orderiThe value at the coordinate point (x, y) of (a)I.e. predicted value, Gi,x,ySupervised thermodynamic diagram G representing the ith orderiThe value at the coordinate point (x, y) of (a), i.e., the true value.
First order output P1Is responsible for distinguishing text and non-text regions, so the first-order loss calculation strategy is to evaluate P from the global1The classification capability of (2); in order to improve the calculation efficiency, an OHEM (Online Hard sample mining) algorithm is added in the first-order loss calculation process, and the proportion of positive and negative samples is set to be 1:3, as shown in formula (20):
Lc=1-D(P1*M,G1*M) (20)
where M represents the thermodynamic diagram generated upon addition of an OHEM.
Output P of 2 nd and 3 rd order2、P3The method is responsible for distinguishing the text and the text area after the boundary contraction, and the key point is that the original text area is originally a part of area which becomes the assignment after the contraction of a positive value, so when the loss of the two-order output is calculated, the part which is judged as the non-text area in the first-order output is set to be omitted, and the formula (21):
wherein W is according to P1Outputting a screened thermodynamic diagram, wherein the selection principle is as shown in formula (22):
in summary, the Loss function Loss of the text detection of the ship name potential area is as shown in formula (23), where λ is a hyper-parameter for balancing losses of the terms, and is set to 0.7 in the experiment.
Loss=λLc+(1-λ)Ls (23)
4) Pixel set expansion algorithm
In order to obtain an accurate segmentation result according to the multi-scale output result, the pixel set expansion algorithm combines the results of the multi-scale classifiers step by step to obtain a final text region segmentation result, and calculates the minimum circumscribed rectangle of each text region according to the segmentation thermodynamic diagram, wherein the flow of the pixel set expansion algorithm is as algorithm 2.
5) Data collection and annotation
Data of text detection of a ship name potential area are shot in the Wuhan navigation section of the Yangtze river for many times from 2019 to the present, currently, 1220 images are provided, 2542 text detection examples are labeled, and the division ratio of a training set to a testing set is 4: 1.
And in labelme used by the marking tool, the area where the text is located is marked by adopting a four-point method, and the marking information is the coordinates of four vertexes of the text area in the picture.
6) Experiment of
Firstly, to ensure accuracy and robustness, an ICDAR2017 MLT text detection data set was selected for model pre-training, and the specific experimental settings are as shown in table 6:
TABLE 6 text detection Pre-training parameter settings
| epoch
|
600
|
| optimizer
|
SGD
|
| learning rate
|
1.00E-03
|
| momentum
|
0.99
|
| weight decay
|
5.00E-04
|
| lr step
|
0.1(200,400) |
Subsequently, training is performed on the ship name potential region text detection data set on the basis of model pre-training parameters, and the specific experimental settings are as shown in table 7:
TABLE 7 Ship name potential region text detection training parameter settings
In addition, the performance of several excellent natural scene text detection methods was tested and compared with the present invention, as shown in table 8, and for ensuring fairness, training tests were performed on the ship name potential region text detection data set based on the parameters of all methods trained on the public data set.
Table 8 experimental accuracy (IoU ═ 0.5)
| Method
|
Recall
|
Precision
|
H-mean
|
| DBNet
|
0.776
|
0.946
|
0.847
|
| DRRG
|
0.781
|
0.877
|
0.826
|
| FCENet
|
0.773
|
0.822
|
0.797
|
| Mask RCNN
|
0.89
|
0.836
|
0.862
|
| PANet
|
0.628
|
0.869
|
0.729
|
| Our menthod
|
0.861
|
0.868
|
0.864 |
It can be seen from the above table that although the present invention is not optimal, it is not inferior to the existing text detection algorithm.
The steps of text detection result identification are as follows:
1) principle of construction
As shown in fig. 9, the text recognition network has an overall structure, the input is a segment cut from the original image according to the output of the text detection model, feature extraction is performed through ResNet31, then the feature map is separated from the channel dimension and sent to the LSTM encoder in a sequence form, and the decoder combines the output of the encoder and the information calculated by the attention mechanism to sequentially output the recognition result.
The encoder and the decoder are both of two-layer 512 hiddenenstate LSTM circulating network structures, and after the feature maps are separated along the channel dimension, the feature maps are firstly subjected to vertical maximum pooling (Vertical Max-Pooling) compression dimension and then sent to the encoder for encoding. In training, the input of the decoder is the character sequence of the label; at inference, the input to the decoder is the output of the last tense.
In order to improve the accuracy, two-dimensional attention calculated by combining the decoder hiddenenstate and the feature map extracted by the CNN is introduced, the feature map is subjected to convolution by 3 x 3, meanwhile, the hiddenenstate of the current time state of the decoder is subjected to convolution by 1 x 1, the hiddenenstate and the feature map are added along the channel dimension, then the two-dimensional attention feature map is obtained through attention calculation, the two-dimensional attention map and the CNN feature map are subjected to weighted summation along the channel dimension, and finally the weighted feature map is subjected to summation and dimension reduction along the channel dimension. After being spliced with the hiddenenstate of the current time state of the decoder, the weighted feature after dimensionality reduction is converted into the dimension of a label dictionary through a full connection layer, and the output of the current time state is determined by Softmax layer classification.
2) Data generation
In order to improve the accuracy, a ship name identification data set is expanded by adopting a method of manual data generation. Firstly, 2754 Chinese ship names, 3226 English ship names and pinyin ship names are collected by a web crawler method, more than 3 million training pictures and 5980 test pictures are artificially generated by using an image synthesis technology, and a SynthText label dictionary is used.
3) Experiment of the invention
To ensure the robustness of the model, the model is first trained on the synthttext data set, with specific parameters as shown in table 9:
table 9 SynthText recognition training parameter settings
Then, based on the training parameters of SynthText, a ship name recognition experiment is carried out, and the specific parameters are as shown in table 10:
TABLE 10 Ship name recognition training parameter settings
After training, the model identification accuracy is as shown in table 11:
TABLE 11 Ship name recognition accuracy
| Accuracy rate of ship name identification
|
Character recognition accuracy
|
| 95.42%
|
99.19% |
The text filtering algorithm comprises the following specific steps:
as shown in fig. 10, in the flowchart of the text filtering algorithm, if there are a plurality of recognition results, the edit distance of each recognition result is calculated in sequence, if there are two results with edit distance of 0, that is, the two recognition results are completely the same, it is determined that the ship name is the ship name to be found, otherwise, the edit distance score of each recognition result is calculated according to the set edit distance threshold.
While the present invention has been described with reference to the embodiments shown in the drawings, the present invention is not limited to the embodiments, which are illustrative and not restrictive, and it will be apparent to those skilled in the art that various changes and modifications can be made therein without departing from the spirit and scope of the invention as defined in the appended claims.