CN114075285B - Humanized monoclonal antibody against human CD38 and application thereof - Google Patents
Humanized monoclonal antibody against human CD38 and application thereof Download PDFInfo
- Publication number
- CN114075285B CN114075285B CN202010841602.5A CN202010841602A CN114075285B CN 114075285 B CN114075285 B CN 114075285B CN 202010841602 A CN202010841602 A CN 202010841602A CN 114075285 B CN114075285 B CN 114075285B
- Authority
- CN
- China
- Prior art keywords
- ser
- thr
- val
- lys
- gly
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 title claims abstract description 45
- 102000052645 human CD38 Human genes 0.000 title description 6
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 claims abstract description 39
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 19
- 150000001413 amino acids Chemical class 0.000 claims description 11
- 108020004707 nucleic acids Proteins 0.000 claims description 10
- 102000039446 nucleic acids Human genes 0.000 claims description 10
- 150000007523 nucleic acids Chemical class 0.000 claims description 10
- 208000034578 Multiple myelomas Diseases 0.000 claims description 9
- 239000003814 drug Substances 0.000 claims description 8
- 239000013598 vector Substances 0.000 claims description 8
- 238000004519 manufacturing process Methods 0.000 claims description 4
- 230000000694 effects Effects 0.000 abstract description 20
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 abstract description 19
- 206010028980 Neoplasm Diseases 0.000 abstract description 16
- 230000004540 complement-dependent cytotoxicity Effects 0.000 abstract description 16
- 108010027122 ADP-ribosyl Cyclase 1 Proteins 0.000 abstract description 7
- 102000018667 ADP-ribosyl Cyclase 1 Human genes 0.000 abstract description 7
- 230000002147 killing effect Effects 0.000 abstract description 3
- 210000004027 cell Anatomy 0.000 description 52
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 14
- 239000000427 antigen Substances 0.000 description 14
- 108091007433 antigens Proteins 0.000 description 14
- 102000036639 antigens Human genes 0.000 description 14
- 238000000034 method Methods 0.000 description 13
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 12
- 230000027455 binding Effects 0.000 description 12
- 108010048818 seryl-histidine Proteins 0.000 description 12
- 108010065920 Insulin Lispro Proteins 0.000 description 10
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 10
- 108010078144 glutaminyl-glycine Proteins 0.000 description 10
- 108010017391 lysylvaline Proteins 0.000 description 10
- 201000000050 myeloid neoplasm Diseases 0.000 description 10
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 9
- 108010051242 phenylalanylserine Proteins 0.000 description 9
- 238000001890 transfection Methods 0.000 description 9
- 238000011282 treatment Methods 0.000 description 9
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 8
- 241000880493 Leptailurus serval Species 0.000 description 8
- 241000699670 Mus sp. Species 0.000 description 8
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 8
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 8
- 229960002204 daratumumab Drugs 0.000 description 8
- 108010015792 glycyllysine Proteins 0.000 description 8
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 7
- 241001529936 Murinae Species 0.000 description 7
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 7
- 238000001514 detection method Methods 0.000 description 7
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 7
- 238000001727 in vivo Methods 0.000 description 7
- 230000003442 weekly effect Effects 0.000 description 7
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 6
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 6
- OLGCWMNDJTWQAG-GUBZILKMSA-N Asn-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(N)=O OLGCWMNDJTWQAG-GUBZILKMSA-N 0.000 description 6
- UDSVWSUXKYXSTR-QWRGUYRKSA-N Asn-Gly-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UDSVWSUXKYXSTR-QWRGUYRKSA-N 0.000 description 6
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 6
- 108020004414 DNA Proteins 0.000 description 6
- DGKBSGNCMCLDSL-BYULHYEWSA-N Gly-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN DGKBSGNCMCLDSL-BYULHYEWSA-N 0.000 description 6
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 6
- KOYUSMBPJOVSOO-XEGUGMAKSA-N Gly-Tyr-Ile Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KOYUSMBPJOVSOO-XEGUGMAKSA-N 0.000 description 6
- LPBWRHRHEIYAIP-KKUMJFAQSA-N His-Tyr-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O LPBWRHRHEIYAIP-KKUMJFAQSA-N 0.000 description 6
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 6
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 6
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 6
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 6
- LKEKWDJCJSPXNI-IRIUXVKKSA-N Thr-Glu-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LKEKWDJCJSPXNI-IRIUXVKKSA-N 0.000 description 6
- IVDFVBVIVLJJHR-LKXGYXEUSA-N Thr-Ser-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IVDFVBVIVLJJHR-LKXGYXEUSA-N 0.000 description 6
- BGWSLEYVITZIQP-DCPHZVHLSA-N Trp-Phe-Ala Chemical compound C[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O BGWSLEYVITZIQP-DCPHZVHLSA-N 0.000 description 6
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 6
- GGXUDPQWAWRINY-XEGUGMAKSA-N Tyr-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GGXUDPQWAWRINY-XEGUGMAKSA-N 0.000 description 6
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 6
- 108010008355 arginyl-glutamine Proteins 0.000 description 6
- 230000014509 gene expression Effects 0.000 description 6
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 6
- 108010038320 lysylphenylalanine Proteins 0.000 description 6
- 238000003998 size exclusion chromatography high performance liquid chromatography Methods 0.000 description 6
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 5
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 5
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 5
- SPLBRAKYXGOFSO-UNQGMJICSA-N Pro-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@@H]2CCCN2)O SPLBRAKYXGOFSO-UNQGMJICSA-N 0.000 description 5
- 210000001744 T-lymphocyte Anatomy 0.000 description 5
- UDNVOQMPQBEITB-MEYUZBJRSA-N Thr-His-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O UDNVOQMPQBEITB-MEYUZBJRSA-N 0.000 description 5
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 5
- XVHAUVJXBFGUPC-RPTUDFQQSA-N Thr-Tyr-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XVHAUVJXBFGUPC-RPTUDFQQSA-N 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 230000000295 complement effect Effects 0.000 description 5
- 239000002609 medium Substances 0.000 description 5
- 239000013641 positive control Substances 0.000 description 5
- 239000006228 supernatant Substances 0.000 description 5
- 230000004614 tumor growth Effects 0.000 description 5
- IESDGNYHXIOKRW-YXMSTPNBSA-N (2s)-2-[[(2s)-1-[(2s)-6-amino-2-[[(2s,3r)-2-amino-3-hydroxybutanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IESDGNYHXIOKRW-YXMSTPNBSA-N 0.000 description 4
- DIBLBAURNYJYBF-XLXZRNDBSA-N (2s)-2-[[(2s)-2-[[2-[[(2s)-6-amino-2-[[(2s)-2-amino-3-methylbutanoyl]amino]hexanoyl]amino]acetyl]amino]-3-phenylpropanoyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@H](NC(=O)CNC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 DIBLBAURNYJYBF-XLXZRNDBSA-N 0.000 description 4
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 4
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 4
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 4
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 4
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 4
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 4
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 4
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 4
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 4
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 4
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 4
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 4
- GEEXORWTBTUOHC-FXQIFTODSA-N Cys-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N GEEXORWTBTUOHC-FXQIFTODSA-N 0.000 description 4
- ZXCAQANTQWBICD-DCAQKATOSA-N Cys-Lys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N ZXCAQANTQWBICD-DCAQKATOSA-N 0.000 description 4
- DHNWZLGBTPUTQQ-QEJZJMRPSA-N Gln-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N DHNWZLGBTPUTQQ-QEJZJMRPSA-N 0.000 description 4
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 4
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 4
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 4
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 4
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 4
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 4
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 4
- MFYLRRCYBBJYPI-JYJNAYRXSA-N Glu-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O MFYLRRCYBBJYPI-JYJNAYRXSA-N 0.000 description 4
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 4
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 4
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 4
- IKAIKUBBJHFNBZ-LURJTMIESA-N Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CN IKAIKUBBJHFNBZ-LURJTMIESA-N 0.000 description 4
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 4
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 4
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 4
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 4
- WMKXFMUJRCEGRP-SRVKXCTJSA-N His-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N WMKXFMUJRCEGRP-SRVKXCTJSA-N 0.000 description 4
- FOCSWPCHUDVNLP-PMVMPFDFSA-N His-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC4=CN=CN4)N FOCSWPCHUDVNLP-PMVMPFDFSA-N 0.000 description 4
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 4
- FADXGVVLSPPEQY-GHCJXIJMSA-N Ile-Cys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FADXGVVLSPPEQY-GHCJXIJMSA-N 0.000 description 4
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 4
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 4
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 4
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 4
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 4
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 4
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 4
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 4
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 4
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 4
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 4
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 4
- CTJUSALVKAWFFU-CIUDSAMLSA-N Lys-Ser-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N CTJUSALVKAWFFU-CIUDSAMLSA-N 0.000 description 4
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 4
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 4
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 4
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 4
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 4
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 4
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 4
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 4
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 4
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 4
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 4
- IIEOLPMQYRBZCN-SRVKXCTJSA-N Phe-Ser-Cys Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O IIEOLPMQYRBZCN-SRVKXCTJSA-N 0.000 description 4
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 4
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 4
- VPFGPKIWSDVTOY-SRVKXCTJSA-N Pro-Glu-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O VPFGPKIWSDVTOY-SRVKXCTJSA-N 0.000 description 4
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 4
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 4
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 4
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 4
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 4
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 4
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 4
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 4
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 4
- 238000011579 SCID mouse model Methods 0.000 description 4
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 4
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 4
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 4
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 4
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 4
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 4
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 4
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 4
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 4
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 4
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 4
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 4
- RCOUFINCYASMDN-GUBZILKMSA-N Ser-Val-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O RCOUFINCYASMDN-GUBZILKMSA-N 0.000 description 4
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 4
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 4
- KWQBJOUOSNJDRR-XAVMHZPKSA-N Thr-Cys-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N)O KWQBJOUOSNJDRR-XAVMHZPKSA-N 0.000 description 4
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 4
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 4
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 4
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 4
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 4
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 4
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 4
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 4
- DQDXHYIEITXNJY-BPUTZDHNSA-N Trp-Gln-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N DQDXHYIEITXNJY-BPUTZDHNSA-N 0.000 description 4
- SCCKSNREWHMKOJ-SRVKXCTJSA-N Tyr-Asn-Ser Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O SCCKSNREWHMKOJ-SRVKXCTJSA-N 0.000 description 4
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 4
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 4
- NHOVZGFNTGMYMI-KKUMJFAQSA-N Tyr-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NHOVZGFNTGMYMI-KKUMJFAQSA-N 0.000 description 4
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 4
- GNWUWQAVVJQREM-NHCYSSNCSA-N Val-Asn-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GNWUWQAVVJQREM-NHCYSSNCSA-N 0.000 description 4
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 4
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 4
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 4
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 4
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 4
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 4
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 4
- HPANGHISDXDUQY-ULQDDVLXSA-N Val-Lys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N HPANGHISDXDUQY-ULQDDVLXSA-N 0.000 description 4
- KRAHMIJVUPUOTQ-DCAQKATOSA-N Val-Ser-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KRAHMIJVUPUOTQ-DCAQKATOSA-N 0.000 description 4
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 4
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 4
- 108010081404 acein-2 Proteins 0.000 description 4
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 4
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 4
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 4
- 108010089804 glycyl-threonine Proteins 0.000 description 4
- 108010037850 glycylvaline Proteins 0.000 description 4
- 108010018006 histidylserine Proteins 0.000 description 4
- 238000011534 incubation Methods 0.000 description 4
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 4
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 4
- 108010064235 lysylglycine Proteins 0.000 description 4
- 230000003211 malignant effect Effects 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 239000002773 nucleotide Substances 0.000 description 4
- 125000003729 nucleotide group Chemical group 0.000 description 4
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 4
- 210000004180 plasmocyte Anatomy 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 108010070643 prolylglutamic acid Proteins 0.000 description 4
- 108010053725 prolylvaline Proteins 0.000 description 4
- 108090000623 proteins and genes Proteins 0.000 description 4
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 4
- 108010026333 seryl-proline Proteins 0.000 description 4
- 239000011780 sodium chloride Substances 0.000 description 4
- 108010080629 tryptophan-leucine Proteins 0.000 description 4
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 4
- 108010027345 wheylin-1 peptide Proteins 0.000 description 4
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 3
- FAEFJTCTNZTPHX-ACZMJKKPSA-N Asn-Gln-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FAEFJTCTNZTPHX-ACZMJKKPSA-N 0.000 description 3
- DINOVZWPTMGSRF-QXEWZRGKSA-N Asp-Pro-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O DINOVZWPTMGSRF-QXEWZRGKSA-N 0.000 description 3
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 3
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 3
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 3
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 3
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 3
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 3
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 3
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 3
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 3
- URHJPNHRQMQGOZ-RHYQMDGZSA-N Leu-Thr-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O URHJPNHRQMQGOZ-RHYQMDGZSA-N 0.000 description 3
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 3
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 3
- LOGFVTREOLYCPF-RHYQMDGZSA-N Lys-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN LOGFVTREOLYCPF-RHYQMDGZSA-N 0.000 description 3
- RMOKGALPSPOYKE-KATARQTJSA-N Lys-Thr-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMOKGALPSPOYKE-KATARQTJSA-N 0.000 description 3
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 3
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 3
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 3
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 3
- QNJZOAHSYPXTAB-VEVYYDQMSA-N Thr-Asn-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O QNJZOAHSYPXTAB-VEVYYDQMSA-N 0.000 description 3
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 3
- IQPWNQRRAJHOKV-KATARQTJSA-N Thr-Ser-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN IQPWNQRRAJHOKV-KATARQTJSA-N 0.000 description 3
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 3
- ZMYCLHFLHRVOEA-HEIBUPTGSA-N Thr-Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ZMYCLHFLHRVOEA-HEIBUPTGSA-N 0.000 description 3
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 3
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 3
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 3
- 230000000259 anti-tumor effect Effects 0.000 description 3
- 238000012258 culturing Methods 0.000 description 3
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 3
- 239000006185 dispersion Substances 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 239000002158 endotoxin Substances 0.000 description 3
- 239000000945 filler Substances 0.000 description 3
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 3
- 239000011544 gradient gel Substances 0.000 description 3
- 208000019691 hematopoietic and lymphoid cell neoplasm Diseases 0.000 description 3
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 3
- 230000003834 intracellular effect Effects 0.000 description 3
- 238000011068 loading method Methods 0.000 description 3
- 239000013642 negative control Substances 0.000 description 3
- 239000008194 pharmaceutical composition Substances 0.000 description 3
- 239000013612 plasmid Substances 0.000 description 3
- 239000000047 product Substances 0.000 description 3
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 3
- 235000018102 proteins Nutrition 0.000 description 3
- 102000004169 proteins and genes Human genes 0.000 description 3
- 108020003175 receptors Proteins 0.000 description 3
- 102000005962 receptors Human genes 0.000 description 3
- 208000002491 severe combined immunodeficiency Diseases 0.000 description 3
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 3
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 3
- 210000001519 tissue Anatomy 0.000 description 3
- 108010073969 valyllysine Proteins 0.000 description 3
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 2
- SRNWOUGRCWSEMX-UHFFFAOYSA-N Adenosine diphosphate ribose Natural products C1=NC=2C(N)=NC=NC=2N1C(C(C1O)O)OC1COP(O)(=O)OP(O)(=O)OCC1OC(O)C(O)C1O SRNWOUGRCWSEMX-UHFFFAOYSA-N 0.000 description 2
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 2
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 2
- MDNAVFBZPROEHO-UHFFFAOYSA-N Ala-Lys-Val Natural products CC(C)C(C(O)=O)NC(=O)C(NC(=O)C(C)N)CCCCN MDNAVFBZPROEHO-UHFFFAOYSA-N 0.000 description 2
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 2
- XRNXPIGJPQHCPC-RCWTZXSCSA-N Arg-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)O)C(O)=O XRNXPIGJPQHCPC-RCWTZXSCSA-N 0.000 description 2
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 2
- GXMSVVBIAMWMKO-BQBZGAKWSA-N Asn-Arg-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N GXMSVVBIAMWMKO-BQBZGAKWSA-N 0.000 description 2
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 2
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 2
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 2
- MFDPBZAFCRKYEY-LAEOZQHASA-N Asp-Val-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFDPBZAFCRKYEY-LAEOZQHASA-N 0.000 description 2
- ZUNMTUPRQMWMHX-LSJOCFKGSA-N Asp-Val-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O ZUNMTUPRQMWMHX-LSJOCFKGSA-N 0.000 description 2
- VIRYODQIWJNWNU-NRPADANISA-N Cys-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N VIRYODQIWJNWNU-NRPADANISA-N 0.000 description 2
- ZGERHCJBLPQPGV-ACZMJKKPSA-N Cys-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N ZGERHCJBLPQPGV-ACZMJKKPSA-N 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 108010087819 Fc receptors Proteins 0.000 description 2
- 102000009109 Fc receptors Human genes 0.000 description 2
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 2
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 2
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 2
- JJKKWYQVHRUSDG-GUBZILKMSA-N Glu-Ala-Lys Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O JJKKWYQVHRUSDG-GUBZILKMSA-N 0.000 description 2
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 2
- CLROYXHHUZELFX-FXQIFTODSA-N Glu-Gln-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CLROYXHHUZELFX-FXQIFTODSA-N 0.000 description 2
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 2
- 208000009329 Graft vs Host Disease Diseases 0.000 description 2
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 2
- QQFSKBMCAKWHLG-UHFFFAOYSA-N Ile-Phe-Pro-Pro Chemical compound C1CCC(C(=O)N2C(CCC2)C(O)=O)N1C(=O)C(NC(=O)C(N)C(C)CC)CC1=CC=CC=C1 QQFSKBMCAKWHLG-UHFFFAOYSA-N 0.000 description 2
- 108060003951 Immunoglobulin Proteins 0.000 description 2
- DBVWMYGBVFCRBE-CIUDSAMLSA-N Leu-Asn-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DBVWMYGBVFCRBE-CIUDSAMLSA-N 0.000 description 2
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 2
- AMSSKPUHBUQBOQ-SRVKXCTJSA-N Leu-Ser-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N AMSSKPUHBUQBOQ-SRVKXCTJSA-N 0.000 description 2
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 2
- FGMHXLULNHTPID-KKUMJFAQSA-N Lys-His-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CN=CN1 FGMHXLULNHTPID-KKUMJFAQSA-N 0.000 description 2
- SQXZLVXQXWILKW-KKUMJFAQSA-N Lys-Ser-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQXZLVXQXWILKW-KKUMJFAQSA-N 0.000 description 2
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 2
- 241000699666 Mus <mouse, genus> Species 0.000 description 2
- WFDAEEUZPZSMOG-SRVKXCTJSA-N Phe-Cys-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O WFDAEEUZPZSMOG-SRVKXCTJSA-N 0.000 description 2
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 2
- QSKCKTUQPICLSO-AVGNSLFASA-N Pro-Arg-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O QSKCKTUQPICLSO-AVGNSLFASA-N 0.000 description 2
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 2
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 2
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- QGMLKFGTGXWAHF-IHRRRGAJSA-N Ser-Arg-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QGMLKFGTGXWAHF-IHRRRGAJSA-N 0.000 description 2
- FTVRVZNYIYWJGB-ACZMJKKPSA-N Ser-Asp-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FTVRVZNYIYWJGB-ACZMJKKPSA-N 0.000 description 2
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 2
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 2
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 2
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 2
- PPNPDKGQRFSCAC-CIUDSAMLSA-N Ser-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPNPDKGQRFSCAC-CIUDSAMLSA-N 0.000 description 2
- PJIQEIFXZPCWOJ-FXQIFTODSA-N Ser-Pro-Asp Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O PJIQEIFXZPCWOJ-FXQIFTODSA-N 0.000 description 2
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 2
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 2
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 2
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 2
- CYVQBKQYQGEELV-NKIYYHGXSA-N Thr-His-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O CYVQBKQYQGEELV-NKIYYHGXSA-N 0.000 description 2
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 2
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 2
- CYCGARJWIQWPQM-YJRXYDGGSA-N Thr-Tyr-Ser Chemical compound C[C@@H](O)[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CO)C([O-])=O)CC1=CC=C(O)C=C1 CYCGARJWIQWPQM-YJRXYDGGSA-N 0.000 description 2
- AUZADXNWQMBZOO-JYJNAYRXSA-N Tyr-Pro-Arg Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CC=C(O)C=C1 AUZADXNWQMBZOO-JYJNAYRXSA-N 0.000 description 2
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 2
- OXVPMZVGCAPFIG-BQFCYCMXSA-N Val-Gln-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N OXVPMZVGCAPFIG-BQFCYCMXSA-N 0.000 description 2
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 2
- QPJSIBAOZBVELU-BPNCWPANSA-N Val-Tyr-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N QPJSIBAOZBVELU-BPNCWPANSA-N 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 230000006907 apoptotic process Effects 0.000 description 2
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- 210000000988 bone and bone Anatomy 0.000 description 2
- 239000007853 buffer solution Substances 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 210000004443 dendritic cell Anatomy 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 206010012601 diabetes mellitus Diseases 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 201000010099 disease Diseases 0.000 description 2
- 238000010828 elution Methods 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 230000002349 favourable effect Effects 0.000 description 2
- 239000012634 fragment Substances 0.000 description 2
- 239000012737 fresh medium Substances 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 108010050848 glycylleucine Proteins 0.000 description 2
- 208000024908 graft versus host disease Diseases 0.000 description 2
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 2
- 210000004408 hybridoma Anatomy 0.000 description 2
- 208000026278 immune system disease Diseases 0.000 description 2
- 102000018358 immunoglobulin Human genes 0.000 description 2
- 239000012535 impurity Substances 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 230000035755 proliferation Effects 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 210000000130 stem cell Anatomy 0.000 description 2
- 230000004083 survival effect Effects 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 230000001225 therapeutic effect Effects 0.000 description 2
- 230000001988 toxicity Effects 0.000 description 2
- 231100000419 toxicity Toxicity 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- 108010079202 tyrosyl-alanyl-cysteine Proteins 0.000 description 2
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 2
- 230000035899 viability Effects 0.000 description 2
- UEJJHQNACJXSKW-UHFFFAOYSA-N 2-(2,6-dioxopiperidin-3-yl)-1H-isoindole-1,3(2H)-dione Chemical compound O=C1C2=CC=CC=C2C(=O)N1C1CCC(=O)NC1=O UEJJHQNACJXSKW-UHFFFAOYSA-N 0.000 description 1
- BGFTWECWAICPDG-UHFFFAOYSA-N 2-[bis(4-chlorophenyl)methyl]-4-n-[3-[bis(4-chlorophenyl)methyl]-4-(dimethylamino)phenyl]-1-n,1-n-dimethylbenzene-1,4-diamine Chemical compound C1=C(C(C=2C=CC(Cl)=CC=2)C=2C=CC(Cl)=CC=2)C(N(C)C)=CC=C1NC(C=1)=CC=C(N(C)C)C=1C(C=1C=CC(Cl)=CC=1)C1=CC=C(Cl)C=C1 BGFTWECWAICPDG-UHFFFAOYSA-N 0.000 description 1
- IVLXQGJVBGMLRR-UHFFFAOYSA-N 2-aminoacetic acid;hydron;chloride Chemical compound Cl.NCC(O)=O IVLXQGJVBGMLRR-UHFFFAOYSA-N 0.000 description 1
- SRNWOUGRCWSEMX-KEOHHSTQSA-N ADP-beta-D-ribose Chemical compound C([C@H]1O[C@H]([C@@H]([C@@H]1O)O)N1C=2N=CN=C(C=2N=C1)N)OP(O)(=O)OP(O)(=O)OC[C@H]1O[C@@H](O)[C@H](O)[C@@H]1O SRNWOUGRCWSEMX-KEOHHSTQSA-N 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 206010002556 Ankylosing Spondylitis Diseases 0.000 description 1
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 1
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 1
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 description 1
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 description 1
- 208000025324 B-cell acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 1
- 208000003950 B-cell lymphoma Diseases 0.000 description 1
- 208000019838 Blood disease Diseases 0.000 description 1
- 208000011691 Burkitt lymphomas Diseases 0.000 description 1
- 229940124295 CD38 monoclonal antibody Drugs 0.000 description 1
- BHPQYMZQTOCNFJ-UHFFFAOYSA-N Calcium cation Chemical compound [Ca+2] BHPQYMZQTOCNFJ-UHFFFAOYSA-N 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 208000011231 Crohn disease Diseases 0.000 description 1
- 101710112752 Cytotoxin Proteins 0.000 description 1
- 206010063045 Effusion Diseases 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 1
- 206010018364 Glomerulonephritis Diseases 0.000 description 1
- WVTIBGWZUMJBFY-GUBZILKMSA-N Glu-His-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O WVTIBGWZUMJBFY-GUBZILKMSA-N 0.000 description 1
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 1
- UCZXXMREFIETQW-AVGNSLFASA-N Glu-Tyr-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O UCZXXMREFIETQW-AVGNSLFASA-N 0.000 description 1
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 1
- SLQVFYWBGNNOTK-BYULHYEWSA-N Ile-Gly-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N SLQVFYWBGNNOTK-BYULHYEWSA-N 0.000 description 1
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 1
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 1
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 1
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 1
- 241001424413 Lucia Species 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 239000012515 MabSelect SuRe Substances 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- BAWFJGJZGIEFAR-NNYOXOHSSA-O NAD(+) Chemical compound NC(=O)C1=CC=C[N+]([C@H]2[C@@H]([C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](O)[C@@H](O3)N3C4=NC=NC(N)=C4N=C3)O)O2)O)=C1 BAWFJGJZGIEFAR-NNYOXOHSSA-O 0.000 description 1
- 208000025696 NK cell deficiency Diseases 0.000 description 1
- 206010029350 Neurotoxicity Diseases 0.000 description 1
- 101710160107 Outer membrane protein A Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 102100024616 Platelet endothelial cell adhesion molecule Human genes 0.000 description 1
- 229940079156 Proteasome inhibitor Drugs 0.000 description 1
- 201000004681 Psoriasis Diseases 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 208000001647 Renal Insufficiency Diseases 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- 108091027981 Response element Proteins 0.000 description 1
- XWCYBVBLJRWOFR-WDSKDSINSA-N Ser-Gln-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O XWCYBVBLJRWOFR-WDSKDSINSA-N 0.000 description 1
- QGAHMVHBORDHDC-YUMQZZPRSA-N Ser-His-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CN=CN1 QGAHMVHBORDHDC-YUMQZZPRSA-N 0.000 description 1
- WEQAYODCJHZSJZ-KKUMJFAQSA-N Ser-His-Tyr Chemical compound C([C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CN=CN1 WEQAYODCJHZSJZ-KKUMJFAQSA-N 0.000 description 1
- VAIWUNAAPZZGRI-IHPCNDPISA-N Ser-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CO)N VAIWUNAAPZZGRI-IHPCNDPISA-N 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 206010042971 T-cell lymphoma Diseases 0.000 description 1
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 description 1
- 206010044221 Toxic encephalopathy Diseases 0.000 description 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- YMUQBRQQCPQEQN-CXTHYWKRSA-N Tyr-Ile-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N YMUQBRQQCPQEQN-CXTHYWKRSA-N 0.000 description 1
- 208000025865 Ulcer Diseases 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 239000012491 analyte Substances 0.000 description 1
- 208000007502 anemia Diseases 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 230000009830 antibody antigen interaction Effects 0.000 description 1
- 239000012131 assay buffer Substances 0.000 description 1
- 208000006673 asthma Diseases 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 102000015736 beta 2-Microglobulin Human genes 0.000 description 1
- 108010081355 beta 2-Microglobulin Proteins 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 229960001467 bortezomib Drugs 0.000 description 1
- GXJABQQUPOEUTA-RDJZCZTQSA-N bortezomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)B(O)O)NC(=O)C=1N=CC=NC=1)C1=CC=CC=C1 GXJABQQUPOEUTA-RDJZCZTQSA-N 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 229910001424 calcium ion Inorganic materials 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 108010021331 carfilzomib Proteins 0.000 description 1
- 229960002438 carfilzomib Drugs 0.000 description 1
- BLMPQMFVWMYDKT-NZTKNTHTSA-N carfilzomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)[C@]1(C)OC1)NC(=O)CN1CCOCC1)CC1=CC=CC=C1 BLMPQMFVWMYDKT-NZTKNTHTSA-N 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000022534 cell killing Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 238000012054 celltiter-glo Methods 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 230000019771 cognition Effects 0.000 description 1
- 210000004087 cornea Anatomy 0.000 description 1
- 230000016396 cytokine production Effects 0.000 description 1
- 206010052015 cytokine release syndrome Diseases 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 239000002619 cytotoxin Substances 0.000 description 1
- 230000007890 cytotoxin activity Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 235000013355 food flavoring agent Nutrition 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 230000036449 good health Effects 0.000 description 1
- 208000014951 hematologic disease Diseases 0.000 description 1
- 230000002489 hematologic effect Effects 0.000 description 1
- 238000011134 hematopoietic stem cell transplantation Methods 0.000 description 1
- 208000018706 hematopoietic system disease Diseases 0.000 description 1
- 208000007475 hemolytic anemia Diseases 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 230000015788 innate immune response Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 201000006370 kidney failure Diseases 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 229960004942 lenalidomide Drugs 0.000 description 1
- GOTYRUGSSMKFNF-UHFFFAOYSA-N lenalidomide Chemical compound C1C=2C(N)=CC=CC=2C(=O)N1C1CCC(=O)NC1=O GOTYRUGSSMKFNF-UHFFFAOYSA-N 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 108010057952 lysyl-phenylalanyl-lysine Proteins 0.000 description 1
- 230000002101 lytic effect Effects 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 108010082117 matrigel Proteins 0.000 description 1
- 210000003519 mature b lymphocyte Anatomy 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 201000006417 multiple sclerosis Diseases 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 230000007135 neurotoxicity Effects 0.000 description 1
- 231100000228 neurotoxicity Toxicity 0.000 description 1
- 238000006386 neutralization reaction Methods 0.000 description 1
- QOTXBMGJKFVZRD-HISDBWNOSA-O nicotinic acid-adenine dinucleotide phosphate Chemical compound [N+]1([C@@H]2O[C@@H]([C@H]([C@H]2O)O)COP(O)(=O)OP(O)(=O)OC[C@H]2O[C@H]([C@@H]([C@@H]2O)OP(O)(O)=O)N2C=3N=CN=C(C=3N=C2)N)=CC=CC(C(O)=O)=C1 QOTXBMGJKFVZRD-HISDBWNOSA-O 0.000 description 1
- 230000009437 off-target effect Effects 0.000 description 1
- 238000010979 pH adjustment Methods 0.000 description 1
- 238000012856 packing Methods 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 108010024607 phenylalanylalanine Proteins 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 230000008092 positive effect Effects 0.000 description 1
- 239000003207 proteasome inhibitor Substances 0.000 description 1
- 235000004252 protein component Nutrition 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000012827 research and development Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000000284 resting effect Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 210000004872 soft tissue Anatomy 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 201000000596 systemic lupus erythematosus Diseases 0.000 description 1
- 229960003433 thalidomide Drugs 0.000 description 1
- 206010043554 thrombocytopenia Diseases 0.000 description 1
- 210000001541 thymus gland Anatomy 0.000 description 1
- 230000000451 tissue damage Effects 0.000 description 1
- 231100000827 tissue damage Toxicity 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 230000010474 transient expression Effects 0.000 description 1
- 108091007466 transmembrane glycoproteins Proteins 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 231100000397 ulcer Toxicity 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
Images











Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2896—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against molecules with a "CD"-designation, not provided for elsewhere
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
- A61P11/06—Antiasthmatics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
- A61P17/06—Antipsoriatics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/02—Drugs for skeletal disorders for joint disorders, e.g. arthritis, arthrosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/08—Drugs for skeletal disorders for bone diseases, e.g. rachitism, Paget's disease
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
- A61P7/06—Antianaemics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/51—Complete heavy chain or Fd fragment, i.e. VH + CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/734—Complement-dependent cytotoxicity [CDC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Pharmacology & Pharmacy (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Engineering & Computer Science (AREA)
- Immunology (AREA)
- Physical Education & Sports Medicine (AREA)
- Rheumatology (AREA)
- Pulmonology (AREA)
- Orthopedic Medicine & Surgery (AREA)
- Urology & Nephrology (AREA)
- Pain & Pain Management (AREA)
- Dermatology (AREA)
- Diabetes (AREA)
- Hematology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biomedical Technology (AREA)
- Neurology (AREA)
- Neurosurgery (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
Abstract
The invention provides a monoclonal antibody combined with CD38 antigen and application thereof. The humanized monoclonal antibody provided by the invention can specifically recognize CD38 antigen, has better affinity, and simultaneously has antibody-dependent cell-mediated cytotoxicity (ADCC) activity and complement-dependent cytotoxicity (CDC) activity, thereby killing CD38+ cells. The application also provides application of the monoclonal antibody or the variant in preventing and/or treating tumors.
Description
Technical Field
The invention belongs to the field of biological medicine, and in particular relates to a humanized monoclonal antibody combined with human CD38 protein and application thereof.
Background
Multiple Myeloma (MM) is a malignant blood tumor with abnormal proliferation of plasma cells, and can affect the generation of leucocytes, erythrocytes and stem cells in bone marrow, resulting in anemia; bone destruction, bone damage and soft tissue damage; causing symptoms such as repeated infection and renal insufficiency. The incidence rate of the traditional Chinese medicine is increased year by year, the incidence rate of global multiple myeloma in 2019 accounts for 1.8 percent of all tumors, accounts for 10 to 15 percent of blood tumors, and is discharged at the 2 nd position of the blood tumors. As people continuously deepen cognition on multiple myeloma, research and development efforts are continuously increased, new medicines, diagnosis and treatment means are more and more abundant, especially, immune modulators (such as thalidomide and lenalidomide), proteasome inhibitors (such as bortezomib and carfilzomib), autologous hematopoietic stem cell transplantation (ASCT), monoclonal antibodies (such as Daratumumab) and other medicines are clinically applied, and the total survival time (OS) of MM patients is obviously improved in the past two decades, and compliance is also obviously improved; however, due to the presence of myeloma stem cells and minimal residual lesions in patients, multiple myeloma is not completely cured at present, and almost all patients eventually relapse. However, current treatment regimens for relapsed/refractory myeloma (RRMM) are limited and patient survival outcomes are poor; therefore, the treatment of RRMM has become a focus of attention for researchers at home and abroad.
The prior art shows that the immunophenotype of plasma cells includes: cd138+, cd38+, cd19+, cd56-. Typically, CD38 is expressed by hematopoietic cells and solid tissue, most of the medullary thymus cells are CD38+, resting and circulating T and B cells are CD38-, and activated cells are CD38+. CD38 protein is one of the antigens expressed on malignant plasma cells and is expressed in a variety of malignant blood disease cells including, but not limited to, multiple myeloma cells, B-cell chronic lymphocytic leukemia cells, B-cell acute lymphocytic leukemia cells.
CD38, a single-chain transmembrane glycoprotein, is 45kDa in length and comprises a short amino-terminal intracellular region, a transmembrane region and a long carboxy-terminal extracellular region, which has the functions of enzyme activity, receptor and adhesion in addition to being a phenotypic marker of cell differentiation. CD38, an extracellular enzyme, catalyzes the conversion of nicotinamide adenine dinucleotide (NAD+) to adenosine diphosphate ribose (ADPR) and nicotinic adenine dinucleotide phosphate (NAADP), a process involved in the mobilization of intracellular calcium ions. As a receptor, CD38 plays a role in the immune process, mediating cytokine production, proliferation of T lymphocytes and protecting mature B lymphocytes and dendritic cells from apoptosis. CD38 is also involved in cell-to-cell adhesion, which makes the pattern of migration of cells with different levels of CD38 expression into tissues different. In addition, the adhesion function of CD38 is tightly linked to the receptor function, CD31 is a natural ligand for CD38, and human T lymphocytes adhere to endothelial cells through CD38-CD31 interactions. CD38 is mainly expressed in T cells, dendritic cells, natural Killer (NK) cells, hematopoietic stem cells, and also expressed in pancreatic cells, cornea cells, and the like. Most importantly, the high expression of CD38 in myeloma cells makes CD38 an attractive therapeutic target for MM.
anti-CD 38 antibodies have been reported in the literature, for example, lande R, et al, cell immunol.220 (1), 30-8 (2002), ausiello CM, et al, tissue antibodies.56 (6), 539-47 (2000), and Cotner T, et al, lnt J immunol.3 (3), 255-68 (1981). Patent CN110144008A discloses an antibody capable of binding to CD38 protein, having a good affinity, capable of killing CD38 by antibody-dependent cell-mediated cytotoxicity ADCC, complement-dependent cytotoxicity CDC and/or apoptosis + And (3) cells. Patent WO2020/052546A1 also discloses a series of murine, chimeric or humanized antibodies comprising CDR regions of an anti-CD 38 antibody, as well as pharmaceutical compositions comprising an anti-CD 38 antibody or antigen binding fragment thereof and their use as medicaments.
Although CAR-T and ADC products for multiple myeloma have shown some good results in terms of efficacy in recent years, their drawbacks are not negligible. Such as off-target effects, excessive T cell activation, induction of cytokine release syndrome, and neurotoxicity of CAR-T products; the ADC product has complex production process, poor in-vivo stability of molecules and off-target toxicity of small molecules; BCMA targets are less mature than CD38 targets. Combining clinical therapeutic effects of darimumab and clinical study data of sarcolisa and MOR202, monoclonal antibodies to the CD38 target remain a very good choice for the treatment of multiple myeloma and relapsed/refractory myeloma.
Therefore, the development of monoclonal antibodies with high selectivity, high affinity and high drug property aiming at CD38 targets continues to be a problem to be solved.
Disclosure of Invention
The invention provides a humanized monoclonal antibody combined with CD38 protein and application thereof. The humanized monoclonal antibody combined with the CD38 protein has higher affinity, and can kill tumor cells and inhibit tumor growth through antibody-dependent cell-mediated cytotoxicity ADCC and complement-dependent cytotoxicity CDC functions, thereby achieving the purposes of tumor prevention and treatment.
In one aspect, the invention provides a series of monoclonal antibodies that bind to CD38 protein.
Specifically, the monoclonal antibody binding to CD38 protein comprises:
(1) An HCDR variant comprising a heavy chain complementarity determining region having any one or more of heavy chains HCDR1, HCDR2 and HCDR3 of sequences SEQ ID No. 1, SEQ ID No. 2 and SEQ ID No. 3, respectively, or having a3, 2 or 1 amino acid difference from heavy chain HCDR1, HCDR2 or HCDR3 of SEQ ID No. 1, SEQ ID No. 2 or SEQ ID No. 3, respectively;
and/or (2) a light chain complementarity determining region comprising any one or more of the light chains LCDR1, LCDR2, and LCDR3 shown in SEQ ID NO. 4, SEQ ID NO. 5, and SEQ ID NO. 6, respectively, or an LCDR variant having a3, 2, or 1 amino acid difference from the light chain LCDR1, LCDR2, or LCDR3 shown in SEQ ID NO. 4, SEQ ID NO. 5, or SEQ ID NO. 6, respectively.
Further specifically, the monoclonal antibody that binds to CD38 protein comprises:
(1) A heavy chain variable region variant comprising a heavy chain variable region as set forth in SEQ ID NO. 7 or SEQ ID NO. 8, or having a3, 2 or 1 amino acid difference from the heavy chain variable region set forth in SEQ ID NO. 7 and SEQ ID NO. 8;
and/or (2) a light chain variable region comprising a light chain variable region as set forth in SEQ ID NO. 9 or SEQ ID NO. 10, or a light chain variable region variant having a3, 2 or 1 amino acid difference from the light chain variable regions set forth in SEQ ID NO. 9 and SEQ ID NO. 10.
Further specifically, the monoclonal antibody that binds to CD38 protein comprises:
(1) A heavy chain with a sequence shown as SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13 or SEQ ID NO. 14;
and/or (2) a light chain having a sequence shown as SEQ ID NO. 15 or SEQ ID NO. 16.
Further specifically, the monoclonal antibody that binds to CD38 protein comprises:
(1) A heavy chain with a sequence shown as SEQ ID NO. 11 and a light chain with a sequence shown as SEQ ID NO. 15;
or (2) a heavy chain having a sequence shown as SEQ ID NO. 12 and a light chain having a sequence shown as SEQ ID NO. 15;
or (3) a heavy chain having a sequence shown as SEQ ID NO. 13 and a light chain having a sequence shown as SEQ ID NO. 16;
or (4) a heavy chain having a sequence shown as SEQ ID NO. 14 and a light chain having a sequence shown as SEQ ID NO. 16.
In another aspect, the invention provides a series of nucleic acid molecules encoding said monoclonal antibodies that bind to CD38 protein.
In particular, the nucleic acid molecules comprise one or more codon optimized nucleic acid molecules.
In another aspect, the invention provides a series of vectors comprising one or more nucleic acid molecules as described herein.
In particular, the vectors include, but are not limited to, plasmids, viruses, phages.
In another aspect, the invention provides a series of host cells comprising or producing said monoclonal antibodies that bind to CD38 protein.
In another aspect, the invention provides a method of producing the monoclonal antibody or variant thereof, comprising culturing a host cell as described herein under conditions such that the monoclonal antibody or variant thereof is expressed.
In particular, the host cells include, but are not limited to, microorganisms, plants or animal cells, into which the vectors of the present invention can be introduced by methods known to those skilled in the art, such as electroporation, lipofectine transfection, lipofectamine transfection, and the like.
In another aspect, the invention provides a pharmaceutical composition comprising a monoclonal antibody or variant thereof, the nucleic acid molecule, the vector and/or the cell of the invention, and optionally a pharmaceutically acceptable adjuvant.
Specifically, the pharmaceutically acceptable adjuvants include, but are not limited to: diluents, excipients, fillers, wetting agents, disintegrants, flavoring agents and binders.
In a further aspect, the invention provides the use of said monoclonal antibody or variant thereof, said nucleic acid molecule, said vector and/or said cell in the manufacture of a medicament, kit and/or device for the prevention and/or treatment of a CD38 positive disease or condition.
In particular, the CD38 positive disease or disorder includes an immune disease or hematological tumor.
Further specifically, the immune diseases include rheumatoid arthritis, systemic lupus erythematosus, immune-mediated thrombocytopenia symptoms, hemolytic anemia, ankylosing spondylitis, multiple sclerosis, psoriasis, crohn's disease, glomerulonephritis, asthma and the like.
Further specifically, the hematological neoplasm includes leukemia, B-cell lymphoma, T-cell lymphoma, NK cell lymphoma, plasma cell malignancy, and myeloma.
Preferably, the hematological neoplasm is multiple myeloma.
In another aspect, the invention provides a method of preventing and/or treating a tumor, said method comprising administering to a subject in need thereof the monoclonal antibody or variant thereof, the nucleic acid molecule, the vector, the host cell and/or the pharmaceutical composition, kit and/or device of the invention.
Compared with the prior art, the invention has the following positive and beneficial effects:
(1) The present invention provides a series of monoclonal antibodies that bind to the CD38 antigen, said monoclonal antibodies being humanized monoclonal antibodies.
(2) The monoclonal antibody provided by the invention is a high-expression sequence, has high expression quantity and less impurities, is easy to purify and collect, reduces the purification and collection cost, and is favorable for large-scale production and application.
(3) The monoclonal antibody provided by the invention has good thermal stability and solution stability, and is convenient to store.
(4) The monoclonal antibody provided by the invention can specifically identify the human CD38 antigen, and has high affinity.
(5) The monoclonal antibody provided by the invention has better capability of combining with CD38 antigen, and has effective antibody-dependent cell-mediated cytotoxicity (ADCC) activity and complement-dependent cytotoxicity (CDC) activity.
(6) The monoclonal antibody provided by the invention has better anti-tumor activity in vivo.
Drawings
FIG. 1 shows SDS-PAGE 4-12% gradient gel electrophoresis of monoclonal antibodies RB0021-S1, RB0021-S2, RB0021-S3, and RB 0021-S4.
FIG. 2 is a SEC-HPLC chromatogram of monoclonal antibody RB 0021-S1.
FIG. 3 is a SEC-HPLC chromatogram of monoclonal antibodies RB 0021-S2.
FIG. 4 is a SEC-HPLC chromatogram of monoclonal antibodies RB 0021-S3.
FIG. 5 is a SEC-HPLC chromatogram of monoclonal antibodies RB 0021-S4.
FIG. 6 is a graph showing the results of detection of the binding capacity of monoclonal antibodies RB0021-S1, RB0021-S2, RB0021-S3, and RB0021-S4 to cell surface antigens.
FIG. 7 is a graph showing the results of detection of ADCC activities of monoclonal antibodies RB0021-S1, RB0021-S2, RB0021-S3, and RB 0021-S4.
FIG. 8 is a graph showing the results of detection of CDC activities of monoclonal antibodies RB0021-S1, RB0021-S2, RB0021-S3, and RB 0021-S4.
FIG. 9 is a statistical plot of the mean tumor volume results of mice tested for monoclonal antibody in vivo activity.
FIG. 10 is a statistical plot of the average tumor weight results of monoclonal antibody in vivo activity test mice.
FIG. 11 is a schematic diagram of tumor of mice with monoclonal antibody in vivo activity.
Detailed Description
The present invention will be described in further detail with reference to the following examples, which are not intended to limit the present invention, but are merely illustrative of the present invention. The experimental methods used in the following examples are not specifically described, but the experimental methods in which specific conditions are not specified in the examples are generally carried out under conventional conditions, and the materials, reagents, etc. used in the following examples are commercially available unless otherwise specified.
Terminology
In order that the invention may be more readily understood, certain technical and scientific terms are defined below. Unless defined otherwise herein, all other technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this disclosure belongs.
The three-letter and one-letter codes for amino acids used in the present invention are as described in J.biol. Chem,243, p3558 (1968).
The antibody disclosed by the invention refers to an immunoglobulin, and is a tetrapeptide chain structure formed by linking two identical heavy chains and two identical light chains through inter-chain disulfide bonds. The immunoglobulin heavy chain constant region differs in amino acid composition and sequence, and thus, in antigenicity. Accordingly, immunoglobulins can be assigned to five classes, or isotypes, i.e., igM, igD, igG, igA, igE, with their respective heavy chains being μ, δ, γ, α, ε chains, respectively. The Ig of the same class can be further classified into different subclasses according to the amino acid composition of the hinge region and the number and position of disulfide bonds of the heavy chain, for example, igG can be classified into IgG1, igG2, igG3 and IgG4. Light chains are classified by the difference in constant regions as either kappa chains or lambda chains. Each of the five classes of Ig may have either a kappa chain or a lambda chain.
The sequences of the heavy and light chains of antibodies, near the N-terminus, vary widely, being the variable region (Fv region); the remaining amino acid sequence near the C-terminus is relatively stable and is a constant region. The variable region includes 3 hypervariable regions (HVRs) and 4 Framework Regions (FR) that are relatively conserved in sequence. The 3 hypervariable regions determine the specificity of the antibody, also known as Complementarity Determining Regions (CDRs). Each light chain variable region (VL or LCVR) and heavy chain variable region (VH or HCVR) consists of 3 CDR regions and 4 FR regions, arranged in order from amino-terminus to carboxy-terminus: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4. The 3 CDR regions of the light chain refer to LCDR1, LCDR2 and LCDR3 and the 3 CDR regions of the heavy chain refer to HCDR1, HCDR2 and HCDR3.
The term "complementarity determining region" (CDR) refers to one of 6 hypervariable regions within the variable domain of an antibody that contribute primarily to antigen binding. Typically there are three CDRs (HCDR 1, HCDR2, HCDR 3) in each heavy chain variable region and three CDRs (LCDR 1, LCDR2, LCDR 3) in each light chain variable region. The amino acid sequence boundaries of the CDRs are determined using the "Kabat numbering convention" (see Kabat et al (1991)).
The term "monoclonal antibody" refers to an antibody obtained from a population of substantially homogeneous antibodies, i.e., the individual antibodies comprising the population are identical and/or bind to identical epitopes, except for possible variant antibodies. Unlike polyclonal antibody preparations, which typically include different antibodies directed against different determinants, each monoclonal antibody of a monoclonal antibody preparation is directed against a single determinant on the antigen. Thus, the method is applicable to a variety of applications. "monoclonal" refers to the properties of the antibody obtained from a substantially homogeneous population of antibodies and should not be construed as requiring production of the antibody by any particular method. The monoclonal antibodies of the present invention can be prepared by a variety of techniques known to those skilled in the art, including, but not limited to, hybridoma methods, recombinant DNA methods, phage display methods, transgenic methods, and the like.
The monoclonal antibody disclosed by the invention is a humanized monoclonal antibody.
The term "murine monoclonal antibody" is herein a monoclonal antibody raised against human CD38 according to the knowledge and skill in the art. The preparation is performed by injecting a test subject with a CD38 antigen and then isolating hybridomas expressing antibodies having the desired sequence or functional properties. In a preferred embodiment of the invention, the murine CD38 antibody or antigen binding fragment thereof may further comprise a murine kappa, lambda chain or variant light chain constant region or further comprise a murine IgG1, igG2, igG3 or variant heavy chain constant region.
The term "humanized monoclonal antibody" refers to an antibody produced by grafting murine CDR sequences into the framework of human antibody variable regions, i.e., different types of human germline antibody framework sequences, which overcomes the heterologous response induced by chimeric antibodies carrying a large number of murine protein components. To avoid a decrease in immunogenicity while at the same time causing a decrease in activity, the human antibody variable region framework sequences may be subjected to minimal reverse mutation (or back mutation) to maintain activity.
The monoclonal antibodies that bind to CD38 protein of the present invention include combinations of heavy and light chains as set forth in table 1 below.
TABLE 1 sequence characterization of monoclonal antibodies that bind CD38 protein


The terms "specific binding", "selective binding" refer to binding of an antibody to an epitope on a predetermined antigen. Typically, the antibody is present at about less than 10 -8 M, e.g. less than about 10 -9 M、10 -10 M、10 -11 Affinity (KD) binding of M or less. Where "KD" refers to the dissociation equilibrium constant of a particular antibody-antigen interaction.
The term "ADCC" is antibody-dependent cell-mediated cytotoxicity (anti bodydependent cell-mediated cytotoxicity, ADCC), generally refers to the recognition of an Fc fragment coated on a target antigen by cells with killing activity through its surface-expressed Fc receptor (FcR), whereby effector cells of the immune system actively lyse the target cells whose membrane surface antigens have been bound by specific antibodies.
The term "CDC" is complement dependent cytotoxicity (complement dependent cytotoxicity, CDC), generally refers to the cytotoxic effect of complement participation, i.e. activation of the classical pathway of complement by binding of specific antibodies to the corresponding antigen on the surface of the cell membrane, forming complexes which exert a lytic effect on the target cells.
The term "Daudi cell" generally refers to a cell line derived from Burkitt's lymphoma. Although Daudi cells have an intracellular heavy chain of class I, they have no expression of class I human leukocyte antigen (human leukocyte antigen, HLA) molecules on their surface because of the defect in the gene encoding the beta 2-microglobulin (beta 2 m) resulting in the protein lacking translatable mRNA.
The term "Jurkat-Lucia NFAT-CD16 cells" is genetically engineered from a human T lymphocyte Jurkat cell line. The cell line stably expressed the luciferases reporter gene from Lucia under the control of the minimal promoter and 6 NFAT response elements, as well as the cell surface Fc receptor CD16a (fcyriiia; V158 high affinity allograft). Jurkat cells naturally express the NFAT functional signaling pathway.
The term "NCI-H929 cell" refers to a cell line established in the malignant effusion of a myeloma patient, a human myeloma cell whose cell surface expresses the CD38 antigen.
The term "NOD/SCID mice", i.e., non-obese diabetic/severe combined immunodeficiency mice, is an immunodeficient mouse that is backcrossed with a non-obese diabetic mouse (NOD/Lt) strain (TL, BL, NK cell deficiency) on the basis of the SCID (severe combined immunodeficiency) mice. NOD/SCID mice have both innate immunity and T and B lymphocyte deficiencies, and various tumor cells can be implanted with less rejection and Graft Versus Host Disease (GVHD), so NOD/SCID mice are increasingly becoming a useful tool for hematological experimental research.
EXAMPLE 1 monoclonal antibody preparation
The DNA nucleotide sequence of the RB0021-S1 heavy chain is:
CAAGTGACACTGAAAGAGAGCGGCCCTACACTGGTGAAGCCCACCCAGACACTGACACTGACATGCACCACCAGCGGCTACACATTCACCTCCCACGGCATCAACTGGGTGAGACAGCCCCCCGGCAAGGCCCTCGAGTGGATCGGCTACATCTACATCGGCAACGGCTACACCGAGTACAACGAGAAGTTCAAGGGAAGAGCTACACTGACCAGCGACACCAGCAAGAATCAAGCCGTGCTGACCATGACCAACATGGACCCCGTGGATACCGCCACCTACTTCTGCGCTAGATCCCACTACGACAGCTCCAGCTGGTTTGCTTACTGGGGCCAAGGCACACTGGTGACCGTGAGCTCCGCCAGCACCAAGGGACCTAGCGTGTTTCCTCTGGCCCCTTCTAGCAAGAGCACAAGCGGAGGAACAGCCGCTCTGGGCTGTCTGGTGAAAGACTACTTTCCCGAGCCCGTGACCGTGTCTTGGAATTCAGGAGCCCTGACCAGCGGAGTGCACACATTTCCAGCCGTGCTGCAGAGCAGCGGACTGTATAGCCTGAGCAGCGTGGTGACCGTGCCTTCTTCTTCTCTGGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGTCTTGCGACAAGACCCACACTTGCCCCCCTTGTCCAGCTCCAGAACTCCTGGGAGGACCTAGCGTGTTCCTGTTCCCTCCCAAGCCTAAGGACACCCTGATGATCAGCCGGACCCCAGAAGTGACTTGCGTGGTGGTGGACGTGTCCCACGAAGACCCCGAGGTCAAGTTCAATTGGTACGTGGACGGAGTGGAGGTGCACAACGCTAAGACCAAGCCCAGGGAGGAGCAGTACAACAGCACCTACAGGGTGGTGTCCGTGCTGACAGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCAGCCCCTATCGAGAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGAGAGCCTCAGGTGTACACCCTGCCCCCTAGCAGAGACGAGCTGACCAAGAACCAGGTGTCCCTGACTTGCCTCGTGAAGGGCTTCTACCCCAGCGATATCGCCGTGGAGTGGGAATCTAACGGTCAGCCAGAGAACAACTACAAGACCACCCCCCCAGTGCTGGACAGCGACGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAAAGCCGCTGGCAGCAGGGCAACGTGTTCTCTTGCAGCGTGATGCACGAGGCCCTGCACAACCACTACACCCAGAAGAGCCTGAGCCTGAGCCCAGGAAAG
the DNA nucleotide sequence of the RB0021-S2 heavy chain is:
CAAGTGACACTGAAAGAGAGCGGCCCTACACTGGTGAAGCCCACCCAGACACTGACACTGACATGCACCACCAGCGGCTACACATTCACCTCCCACGGCATCAACTGGGTGAGACAGCCCCCCGGCAAGGCCCTCGAGTGGATCGGCTACATCTACATCGGCAACGGCTACACCGAGTACAACGAGAAGTTCAAGGGAAGAGCTACACTGACCAGCGACACCAGCAAGAATCAAGCCGTGCTGACCATGACCAACATGGACCCCGTGGATACCGCCACCTACTTCTGCGCTAGATCCCACTACGACAGCTCCAGCTGGTTTGCTTACTGGGGCCAAGGCACACTGGTGACCGTGAGCTCCGCCAGCACCAAGGGACCTAGCGTGTTTCCTCTGGCCCCTTCTAGCAAGAGCACAAGCGGAGGAACAGCCGCTCTGGGCTGTCTGGTGAAAGACTACTTTCCCGAGCCCGTGACCGTGTCTTGGAATTCAGGAGCCCTGACCAGCGGAGTGCACACATTTCCAGCCGTGCTGCAGAGCAGCGGACTGTATAGCCTGAGCAGCGTGGTGACCGTGCCTTCTTCTTCTCTGGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGTCTTGCGACAAGACCCACACTTGCCCCCCTTGTCCAGCTCCAGAACTCCTGGGAGGACCTAGCGTGTTCCTGTTCCCTCCCAAGCCTAAGGACACCCTGATGATCAGCCGGACCCCAGAAGTGACTTGCGTGGTGGTGGACGTGTCCCACGAAGACCCCGAGGTCAAGTTCAATTGGTACGTGGACGGAGTGGAGGTGCACAACGCTAAGACCAAGCCCAGGGAGGAGCAGTACAACAGCACCTACAGGGTGGTGTCCGTGCTGACAGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCAGCCCCTATCGAGAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGAAAGCCTCAGGTGTACACCCTGCCCCCTAGCAGAGACGAGCTGACCAAGAACCAGGTGTCCCTGACTTGCCTCGTGAAGGGCTTCTACCCCAGCGATATCGCCGTGGAGTGGGAATCTAACGGTCAGCCAGAGAACAACTACAAGACCACCCCCCCAGTGCTGGACAGCGACGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAAAGCCGCTGGCAGCAGGGCAACGTGTTCTCTTGCAGCGTGATGCACGAGGCCCTGCACAACCACTACACCCAGAAGAGCCTGAGCCTGAGCCCAGGAAAG
the DNA nucleotide sequence of the RB0021-S3 heavy chain is:
CAAGTGCAGCTGGTGCAGAGCGGCGCTGAGGTGAAGAAACCCGGCAGCAGCGTGAAGGTGAGCTGCAAGACCAGCGGCTACACCTTCACCAGCCACGGCATCAACTGGGTGAGACAAGCCCCCGGCCAAGGACTGGAGTGGATCGGCTACATCTACATCGGCAACGGCTACACCGAGTACAACGAGAAGTTCAAGGGAAGAGCCACACTGACCTCCGACACAAGCACCAGCACCGCCTACATGGAGCTGAGCTCTCTGAGGAGCGAGGACACCGCCGTGTATTTCTGCGCTAGAAGCCACTACGACAGCAGCAGCTGGTTCGCTTACTGGGGACAAGGCACACTGGTGACCGTGTCCAGCGCCAGCACCAAGGGACCTAGCGTGTTTCCTCTGGCCCCTTCTAGCAAGAGCACAAGCGGAGGAACAGCCGCTCTGGGCTGTCTGGTGAAAGACTACTTTCCCGAGCCCGTGACCGTGTCTTGGAATTCAGGAGCCCTGACCAGCGGAGTGCACACATTTCCAGCCGTGCTGCAGAGCAGCGGACTGTATAGCCTGAGCAGCGTGGTGACCGTGCCTTCTTCTTCTCTGGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGTCTTGCGACAAGACCCACACTTGCCCCCCTTGTCCAGCTCCAGAACTCCTGGGAGGACCTAGCGTGTTCCTGTTCCCTCCCAAGCCTAAGGACACCCTGATGATCAGCCGGACCCCAGAAGTGACTTGCGTGGTGGTGGACGTGTCCCACGAAGACCCCGAGGTCAAGTTCAATTGGTACGTGGACGGAGTGGAGGTGCACAACGCTAAGACCAAGCCCAGGGAGGAGCAGTACAACAGCACCTACAGGGTGGTGTCCGTGCTGACAGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCAGCCCCTATCGAGAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGAGAGCCTCAGGTGTACACCCTGCCCCCTAGCAGAGACGAGCTGACCAAGAACCAGGTGTCCCTGACTTGCCTCGTGAAGGGCTTCTACCCCAGCGATATCGCCGTGGAGTGGGAATCTAACGGTCAGCCAGAGAACAACTACAAGACCACCCCCCCAGTGCTGGACAGCGACGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAAAGCCGCTGGCAGCAGGGCAACGTGTTCTCTTGCAGCGTGATGCACGAGGCCCTGCACAACCACTACACCCAGAAGAGCCTGAGCCTGAGCCCAGGAAAG
the DNA nucleotide sequence of the RB0021-S4 heavy chain is:
CAAGTGCAGCTGGTGCAGAGCGGCGCTGAGGTGAAGAAACCCGGCAGCAGCGTGAAGGTGAGCTGCAAGACCAGCGGCTACACCTTCACCAGCCACGGCATCAACTGGGTGAGACAAGCCCCCGGCCAAGGACTGGAGTGGATCGGCTACATCTACATCGGCAACGGCTACACCGAGTACAACGAGAAGTTCAAGGGAAGAGCCACACTGACCTCCGACACAAGCACCAGCACCGCCTACATGGAGCTGAGCTCTCTGAGGAGCGAGGACACCGCCGTGTATTTCTGCGCTAGAAGCCACTACGACAGCAGCAGCTGGTTCGCTTACTGGGGACAAGGCACACTGGTGACCGTGTCCAGCGCCAGCACCAAGGGACCTAGCGTGTTTCCTCTGGCCCCTTCTAGCAAGAGCACAAGCGGAGGAACAGCCGCTCTGGGCTGTCTGGTGAAAGACTACTTTCCCGAGCCCGTGACCGTGTCTTGGAATTCAGGAGCCCTGACCAGCGGAGTGCACACATTTCCAGCCGTGCTGCAGAGCAGCGGACTGTATAGCCTGAGCAGCGTGGTGACCGTGCCTTCTTCTTCTCTGGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGTCTTGCGACAAGACCCACACTTGCCCCCCTTGTCCAGCTCCAGAACTCCTGGGAGGACCTAGCGTGTTCCTGTTCCCTCCCAAGCCTAAGGACACCCTGATGATCAGCCGGACCCCAGAAGTGACTTGCGTGGTGGTGGACGTGTCCCACGAAGACCCCGAGGTCAAGTTCAATTGGTACGTGGACGGAGTGGAGGTGCACAACGCTAAGACCAAGCCCAGGGAGGAGCAGTACAACAGCACCTACAGGGTGGTGTCCGTGCTGACAGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCAGCCCCTATCGAGAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGAAAGCCTCAGGTGTACACCCTGCCCCCTAGCAGAGACGAGCTGACCAAGAACCAGGTGTCCCTGACTTGCCTCGTGAAGGGCTTCTACCCCAGCGATATCGCCGTGGAGTGGGAATCTAACGGTCAGCCAGAGAACAACTACAAGACCACCCCCCCAGTGCTGGACAGCGACGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAAAGCCGCTGGCAGCAGGGCAACGTGTTCTCTTGCAGCGTGATGCACGAGGCCCTGCACAACCACTACACCCAGAAGAGCCTGAGCCTGAGCCCAGGAAAG
the nucleotide sequences of the RB0021-S1 and RB0021-S2 light chain DNA are:
GATGTGGTGATGACCCAGAGCCCCGACTCTCTGGCCGTGTCTCTGGGAGAGAGAGCCACCATCAACTGCAGATCCAGCCAGAGCCCCGAGCACAGCAACGGCAACACCTATCTGCACTGGTATCAGCAGAAGCCCGGCCAGCCTCCCAAGCTGCTGATCTACAAGGTGTCCAATAGATTCAGCGGCGTGCCCGACAGATTCAGCGGATCCGGCAGCGGCACCGATTTCACACTGACCATCAGCTCTCTGCAAGCCGAAGACGTGGCCGTGTACTTCTGCAGCCAAGGCACACACTTCCCTTTCACCTTCGGCCAAGGCACCAAGGTGGAGATTAAGAGAACCGTGGCCGCTCCTAGCGTGTTCATCTTCCCTCCCAGCGACGAGCAGCTGAAAAGCGGAACAGCCAGCGTCGTCTGCCTGCTGAATAACTTCTACCCCCGGGAGGCCAAAGTCCAGTGGAAAGTGGACAACGCCCTGCAGAGCGGAAACTCTCAGGAGAGCGTGACCGAGCAGGACAGCAAGGACAGCACCTACAGCCTGAGCAGCACACTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGTACGCTTGCGAGGTCACACACCAGGGACTGTCTAGCCCAGTGACCAAGAGCTTCAACCGCGGCGAGTGTTGA
the nucleotide sequences of the RB0021-S3 and RB0021-S4 light chain DNA are:
GACGTGCAGATGACCCAGTCCCCTAGCAGCGTGAGCGCTTCCGTGGGAGACAGAGTGACCATCACATGCAGAAGCAGCCAGAGCCCCGAGCATAGCAACGGCAACACCTATCTGCACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTCATCTACAAGGTGTCCAATAGATTCAGCGGCGTGCCCTCCAGATTCAGCGGATCCGGCAGCGGCACCGATTTCACACTGACCATCAGCTCTCTGCAGCCCGAGGACTTCGCCACCTACTTTTGCTCCCAAGGCACCCACTTCCCCTTCACCTTCGGCCAAGGCACCAAGGTGGAGATCAAGAGAACCGTGGCCGCTCCTAGCGTGTTCATCTTCCCTCCCAGCGACGAGCAGCTGAAAAGCGGAACAGCCAGCGTCGTCTGCCTGCTGAATAACTTCTACCCCCGGGAGGCCAAAGTCCAGTGGAAAGTGGACAACGCCCTGCAGAGCGGAAACTCTCAGGAGAGCGTGACCGAGCAGGACAGCAAGGACAGCACCTACAGCCTGAGCAGCACACTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGTACGCTTGCGAGGTCACACACCAGGGACTGTCTAGCCCAGTGACCAAGAGCTTCAACCGCGGCGAGTGTTGA
cloning different antibody nucleotide sequences into pcDNA3.1 expression vector, and preparing transfection by using large drawing plasmid of large drawing kit for controlling endotoxin, OPM-293 CD05 medium culture 293F cell. Cell count the day before transfection, density 2.59 x 10 6 Per mL, 98.1% viability, cells were diluted to 1.5 x 10 with fresh medium 6 Culture was continued with/mL. Cell count on day of transfection, density 3.01 x 10 6 Per mL, 98.8% viability, cells were diluted to 2.78 x 10 with fresh medium 6 /mL. 1/10 of the transfection volume of OPM-293 CD05 medium (Ao Pu Mai, cat# 81075-001) was taken, 1:1 heavy and light chain plasmids were added to 1.5. Mu.g/mL transfection volume, followed by 3-fold additionPlasmid amount of PEI, incubated at room temperature for 15min. Adding the incubation mixture into the treated cells, and mixing the cells uniformly while adding the incubation mixture. Placing into a shaking table for culturing at 37deg.C, 90rpm and 8% CO 2 . OPM-CHO PFF05 feed (O Pu Mai, cat. FB 1279-001) was added on the first and fourth days after transfection, respectively, and supernatants were collected on day 6 after transfection.
EXAMPLE 2 purification and detection of monoclonal antibodies
1. Affinity chromatography
The filler Mabselect Sure was rinsed with 0.5M NaOH, 0.1M NaOH, each for 1 hour to time endotoxin, and the filler was equilibrated with 20mM PB,150mM NaCl (pH 7.2). The supernatant of transient expression of RB0021 PC (Daratumumab), RB0021-S1, RB0021-S2, RB0021-S3 and RB0021-S4 was filtered and loaded at a flow rate of 1mL/min, after loading, the supernatant was washed with 20mM PB,150mM NaCl to UV280 peak level, then 20mM PB,1M NaCl (pH 6.5) to peak level, finally 20mM Cit-Na3Cit (pH 3.5) was used for elution and 1M Tris (pH 9.0) was used for neutralization.
2. Cationic chromatography
The packing SP-HP was rinsed with 0.5M NaOH, and the endotoxin was equilibrated with 20mM PB (pH 6.0) at 2 hours of each treatment with 0.1M NaOH. Samples of RB0021 PC (Daratumumab), RB0021-S1, RB0021-S2, RB0021-S3 and RB0021-S4 obtained by affinity chromatography are subjected to pH adjustment to 6.0, the samples are subjected to dilution adjustment, the conductance is less than 3 mu S/cm, the sample loading is performed, the flow rate is controlled to be 1mL/min, 20mM PB (pH 6.0) buffer solution is used for washing to reach a UV280 baseline after the sample loading is finished, and then 20mM PB and 1M NaCl (pH 6.0) are used for performing linear gradient elution (0-30% B and 20 CV), and the eluted samples are collected according to peaks. Table 2 below shows the statistics of the final monoclonal antibodies.
Table 2 statistical table of monoclonal antibody data


As shown in Table 2, under the condition of low transient dye expression level, the monoclonal antibody with higher monomer quality and similar acid-base variant compared with the control group can be obtained, and the denaturation temperature, namely TM value of the monoclonal antibody obtained by the invention is higher than that of the control group, so that the monoclonal antibody has better thermal stability; meanwhile, the monoclonal antibody has higher isoelectric point, and is favorable for stable storage in buffer solution.
3. Detection and analysis
SDS-PAGE 4-12% gradient gel and SEC-HPLC analysis of protein purity.
Wherein, FIG. 1 is a gradient gel electrophoresis chart of monoclonal antibodies RB0021-S1, RB0021-S2, RB0021-S3, RB0021-S4 SDS-PAGE 4-12%, and FIG. 2, FIG. 3, FIG. 4, FIG. 5 are respectively RB0021-S1, RB0021-S2, RB0021-S3, RB0021-S4 SEC-HPLC chromatograms. As can be seen from FIGS. 1 to 5, the electrophoresis patterns of RB0021-S1, RB0021-S2, RB0021-S3 and RB0021-S4 are single bands and are single peaks, which indicates that the monoclonal antibody obtained by the invention has high expression level and less impurity.
Table 3 below shows the dispersion index of the monoclonal antibodies obtained by SEC detection.
TABLE 3 dispersion index of monoclonal antibodies


As shown in Table 3, compared with the control, the monoclonal antibody of the invention has better dispersion index at three different concentrations of large, medium and small, which indicates that the monoclonal antibody has better solution stability.
EXAMPLE 3 monoclonal antibody affinity assay
Biacore affinity assay was performed using GE 8K, HBS-EP+ as assay buffer, at 25℃and ligand dilution to 5. Mu.g/mL, immobilization at a flow rate of 10. Mu.L/min for 20s onto Protein A chip. Analyte CD38 was diluted gradient to 0,0.111,0.333,1,3,9 (. Times.3), 27, 81nM at 30. Mu.L/min, bound for 300s, dissociated for 300s, regenerated with 10mM Glycine-HCl (pH 1.5) at 100. Mu.L/min for 30s and repeated once. The measured affinity data are shown in table 4 below:
table 4 affinity data
| Antibodies to | affinity(human) |
| RB0021 PC(Daratumumab) | 8.86E-08 |
| RB0021-S1 | 1.17E-09 |
| RB0021-S2 | 1.17E-09 |
| RB0021-S3 | 1.04E-09 |
| RB0021-S4 | 1.04E-09 |
As can be seen from Table 4, the monoclonal antibodies of the present invention specifically recognize human CD38 protein, and have higher affinity for CD38 protein than the monoclonal antibodies of the control group.
Example 4 binding to cell surface antigen
Daudi cells cultured in RPMI1640+10% FBS medium were added to 96-well plates, the supernatant was discarded, 100. Mu.L/well of gradient diluted antibody-resuspended cell pellet (positive control for RB0021 PC, negative control for Isotype control) was added, the supernatant was discarded, 100. Mu.L/well of pre-diluted secondary antibody (FITC) resuspended cells was added, and after incubation at 2-8℃for 0.5 hours, detection was performed on a flow cytometer.
TABLE 5 binding data to cell surface antigens

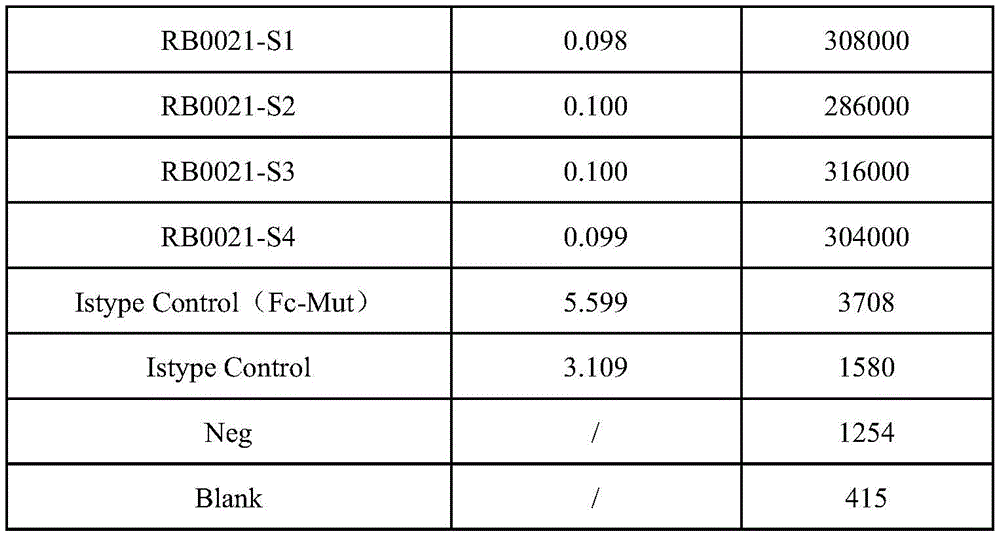
As can be seen from Table 5, the monoclonal antibodies of the present invention have a better ability to bind to cell surface CD38 antigen.
Example 5 antibody-dependent cell-mediated cytotoxicity (ADCC) Activity
Will be 1 x 10 5 NCI-H929 cells were added to 96-well plates, 40. Mu.L of gradient diluted antibody (positive control RB0021 PC, negative control Isotype control) was added, 37℃and 5% CO 2 Incubating for 1 hour; and then 2 x 10 5 Jurkat-Lucia-NFAT-CD16 cells were plated in 96-well plates. 37 ℃,5% CO 2 After 6 hours of incubation, 50. Mu.L of Quanti-LUC was added, and after 5 minutes of reaction at room temperature, the fluorescent signal was read.
TABLE 6 ADCC Activity assay data
| Sample ID | EC50(μg/mL) | Top MFI |
| RB0021 PC(Daratumumab) | 0.017 | 57161 |
| RB0021-S1 | 0.018 | 65759 |
| RB0021-S2 | 0.011 | 45150 |
| RB0021-S3 | 0.011 | 47332 |
| RB0021-S4 | 0.014 | 56729 |
| Istype Control | 0.375 | 2118 |
As can be seen from Table 6, the EC50 values of the monoclonal antibodies RB0021-S2, RB0021-S3 and RB0021-S4 of the invention are obviously lower than those of the control group, and the EC50 values of the monoclonal antibodies RB0021-S1 are basically the same as those of the control group, so that the ADCC activity of the monoclonal antibodies RB0021-S2, RB0021-S3 and RB0021-S4 EC50 of the invention is superior to that of the control group, and the ADCC activity of the RB0021-S1 is similar to that of the control group. Therefore, the monoclonal antibody of the present invention has potent ADCC activity.
EXAMPLE 6 complement dependent cytotoxin Activity (CDC)
Daudi cells cultured in RPMI1640+10% FBS medium were added to 96-well plates, 40. Mu.L of gradient diluted antibody was added, and 40. Mu.L of pre-diluted complement, 37℃and 5% CO were added 2 Culturing for 6 hours. RB0021 PC (Daratumumab) was used as positive control and Isotype control was used as negative controlControl, with Cell Titer-Glo TM Reagent detects cell killing.
TABLE 7 CDC Activity assay data

As can be seen from Table 7, the monoclonal antibodies RB0021-S2 and RB0021-S4 of the invention were significantly superior to the control for Complement Dependent Cytotoxin (CDC) activity of Daudi cells.
EXAMPLE 7 in vivo Activity assay
Will be 1 x 10 7 Each mL of NCI-H929 cells was inoculated subcutaneously into the right armpit of 5-6 week NOD/SCID mice at 0.2 mL/after mixing matrigel in equal volumes. The tumor volume to be averaged was 150mm 3 When the tumor is left and right, tumor-bearing animals with vigorous tumor growth, no ulcer and good health condition are selected for grouping and starting administration. Mice were divided into 11 groups (n=13) such that the average tumor sizes of all groups were similar and dosing was started by tail vein injection (day 0), twice weekly. Group 1 (FIGS. 11G1-22, G1-32, G1-47, G1-48, G1-73, G1-93) received 45mg/kg of negative control antibody treatment twice weekly; group 2 (FIGS. 11G2-9, G2-10, G2-39, G2-74, G2-88, G2-92) received 5mg/kg of positive control antibody (Daratumumab) twice weekly; group 3 (FIG. 11G3-36, G3-38, G3-76, G3-77, G3-85, G3-86) received 45mg/kg of positive control antibody (Daratumumab) twice weekly. Group 4 (FIG. 11G4-1, G4-17, G4-43, G4-64, G4-66, G4-82) received 5mg/kg of RB0021-S1 antibody twice a week; group 5 (FIG. 11G5-3, G5-4, G5-19, G5-30, G5-44, G5-91) received 45mg/kg of RB0021-S1 antibody twice a week. Group 6 (FIG. 11G6-5, G6-50, G6-51, G6-60, G6-80, G6-100) received 5mg/kg of RB0021-S2 antibody, administered twice weekly; group 7 (FIG. 11G7-6, G7-18, G7-23, G7-28, G7-67, G7-75) received 45mg/kg of RB0021-S2 antibody twice a week. Group 8 (FIG. 11G8-27, G8-40, G8-54, G8-55, G8-57, G8-78) received 5mg/kg of RB0021-S3 antibody twice a week; group 9 (FIGS. 11G9-21, G9-24, G9-37, G9-83, G9-84, G9-90) received 45mg/kg of RB0021-S3 antibody, administered twice weekly. Group 10 (FIG. 11G10-16, G10-42, G10-61, G10-63, G10-69, G10-79) received 5mg/kg of RB0021-S4 antibody twice a week; group 11 (FIGS. 11G11-7, G11-12, G11-13, G11-26, G11-70, G11-81) received 45mg/kg of RB0021-S4 antibody, administered twice a week. Tumor volumes at different time points were determined using the following formula: tumor volume (mm) 3 ) =1/2×long diameter×short diameter 2 The anti-tumor efficacy is judged according to the tumor growth condition. Body weight was measured twice weekly to monitor toxicity and all treatments were well tolerated.
The inhibition of tumor growth by the different treatments is different, fig. 9 shows the average tumor volume statistics of mice, fig. 10 shows the average tumor weight statistics of mice, and as can be seen from fig. 9 and 10, the anti-CD 38 monoclonal antibodies of the invention show potent anti-tumor efficacy in vivo, both superior to that of the control monoclonal antibody, wherein the RB0021-S1 antibody given 45mg/kg and the RB0021-S4 antibody given 45mg/kg can significantly inhibit tumor growth (P < 0.05).
The foregoing examples illustrate only a few embodiments of the invention and are described in detail herein without thereby limiting the scope of the invention. It should be noted that it will be apparent to those skilled in the art that several variations and modifications can be made without departing from the spirit of the invention, which are all within the scope of the invention. Accordingly, the scope of protection of the present invention is to be determined by the appended claims.
Sequence listing
<110> Ruiyang (su state) biotechnology Co., ltd
<120> anti-human CD38 humanized monoclonal antibody and use thereof
<130> 20200813
<160> 16
<170> SIPOSequenceListing 1.0
<210> 1
<211> 5
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 1
Ser His Gly Ile Asn
1 5
<210> 2
<211> 17
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 2
Tyr Ile Tyr Ile Gly Asn Gly Tyr Thr Glu Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 3
<211> 11
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 3
Ser His Tyr Asp Ser Ser Ser Trp Phe Ala Tyr
1 5 10
<210> 4
<211> 16
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 4
Arg Ser Ser Gln Ser Pro Glu His Ser Asn Gly Asn Thr Tyr Leu His
1 5 10 15
<210> 5
<211> 7
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 5
Lys Val Ser Asn Arg Phe Ser
1 5
<210> 6
<211> 9
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 6
Ser Gln Gly Thr His Phe Pro Phe Thr
1 5
<210> 7
<211> 120
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 7
Gln Val Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Thr Ser Gly Tyr Thr Phe Thr Ser His
20 25 30
Gly Ile Asn Trp Val Arg Gln Pro Pro Gly Lys Ala Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Ile Gly Asn Gly Tyr Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ser Asp Thr Ser Lys Asn Gln Ala Val
65 70 75 80
Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Ser His Tyr Asp Ser Ser Ser Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 8
<211> 120
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 8
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Ser His
20 25 30
Gly Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Ile Gly Asn Gly Tyr Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ser Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser His Tyr Asp Ser Ser Ser Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 9
<211> 113
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 9
Asp Val Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Arg Ser Ser Gln Ser Pro Glu His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Pro
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Phe Cys Ser Gln Gly
85 90 95
Thr His Phe Pro Phe Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg
<210> 10
<211> 113
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 10
Asp Val Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ser Ser Gln Ser Pro Glu His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Lys Ala
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Phe Cys Ser Gln Gly
85 90 95
Thr His Phe Pro Phe Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg
<210> 11
<211> 450
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 11
Gln Val Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Thr Ser Gly Tyr Thr Phe Thr Ser His
20 25 30
Gly Ile Asn Trp Val Arg Gln Pro Pro Gly Lys Ala Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Ile Gly Asn Gly Tyr Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ser Asp Thr Ser Lys Asn Gln Ala Val
65 70 75 80
Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Ser His Tyr Asp Ser Ser Ser Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 12
<211> 450
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 12
Gln Val Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Thr Ser Gly Tyr Thr Phe Thr Ser His
20 25 30
Gly Ile Asn Trp Val Arg Gln Pro Pro Gly Lys Ala Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Ile Gly Asn Gly Tyr Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ser Asp Thr Ser Lys Asn Gln Ala Val
65 70 75 80
Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Ser His Tyr Asp Ser Ser Ser Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Lys Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 13
<211> 450
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 13
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Ser His
20 25 30
Gly Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Ile Gly Asn Gly Tyr Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ser Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser His Tyr Asp Ser Ser Ser Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 14
<211> 450
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 14
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Ser His
20 25 30
Gly Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Ile Gly Asn Gly Tyr Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ser Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser His Tyr Asp Ser Ser Ser Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Lys Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 15
<211> 219
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 15
Asp Val Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Arg Ser Ser Gln Ser Pro Glu His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Pro
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Phe Cys Ser Gln Gly
85 90 95
Thr His Phe Pro Phe Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 16
<211> 219
<212> PRT
<213> Artificial sequence (artificial sequence)
<400> 16
Asp Val Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ser Ser Gln Ser Pro Glu His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Lys Ala
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Phe Cys Ser Gln Gly
85 90 95
Thr His Phe Pro Phe Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
Claims (8)
1. A monoclonal antibody that binds to CD38 protein, said monoclonal antibody that binds to CD38 protein comprising:
(1) Heavy chain variable regions comprising heavy chains HCDR1, HCDR2 and HCDR3 having sequences shown in SEQ ID NO. 1, SEQ ID NO. 2 and SEQ ID NO. 3, respectively;
and (2) light chain variable regions comprising light chains LCDR1, LCDR2 and LCDR3 having sequences as set forth in SEQ ID NO. 4, SEQ ID NO. 5 and SEQ ID NO. 6, respectively.
2. The monoclonal antibody of claim 1, wherein the monoclonal antibody comprises:
(1) A heavy chain variable region variant comprising a heavy chain variable region as set forth in SEQ ID NO. 7 or SEQ ID NO. 8, or a heavy chain variable region variant having a3, 2 or 1 amino acid difference in the non-CDR region from the heavy chain variable region set forth in SEQ ID NO. 7 and SEQ ID NO. 8;
and (2) a light chain variable region variant comprising a light chain variable region as set forth in SEQ ID NO. 9 or SEQ ID NO. 10, or having a3, 2 or 1 amino acid difference in the non-CDR regions from the light chain variable region as set forth in SEQ ID NO. 9 and SEQ ID NO. 10.
3. The monoclonal antibody of claim 1 or2, wherein the monoclonal antibody comprises:
(1) A heavy chain with a sequence shown as SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13 or SEQ ID NO. 14;
and (2) a light chain having a sequence shown as SEQ ID NO. 15 or SEQ ID NO. 16.
4. The monoclonal antibody of claim 3, wherein the monoclonal antibody comprises:
(1) A heavy chain with a sequence shown as SEQ ID NO. 11 and a light chain with a sequence shown as SEQ ID NO. 15;
or (2) a heavy chain having a sequence shown as SEQ ID NO. 12 and a light chain having a sequence shown as SEQ ID NO. 15;
or (3) a heavy chain having a sequence shown as SEQ ID NO. 13 and a light chain having a sequence shown as SEQ ID NO. 16;
or (4) a heavy chain having a sequence shown as SEQ ID NO. 14 and a light chain having a sequence shown as SEQ ID NO. 16.
5. A nucleic acid molecule encoding the monoclonal antibody of any one of claims 1-4.
6. A vector comprising the nucleic acid molecule of claim 5.
7. A cell comprising or producing the monoclonal antibody of any one of claims 1-4.
8. Use of the monoclonal antibody of any one of claims 1-4, the nucleic acid molecule of claim 5, the vector of claim 6 and the cell of claim 7 in the manufacture of a medicament or kit for treating multiple myeloma.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010841602.5A CN114075285B (en) | 2020-08-20 | 2020-08-20 | Humanized monoclonal antibody against human CD38 and application thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010841602.5A CN114075285B (en) | 2020-08-20 | 2020-08-20 | Humanized monoclonal antibody against human CD38 and application thereof |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114075285A CN114075285A (en) | 2022-02-22 |
| CN114075285B true CN114075285B (en) | 2023-05-30 |
Family
ID=80281691
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010841602.5A Active CN114075285B (en) | 2020-08-20 | 2020-08-20 | Humanized monoclonal antibody against human CD38 and application thereof |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114075285B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114516918B (en) * | 2022-03-04 | 2022-09-27 | 四川大学华西医院 | Antibody and application thereof |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103492583A (en) * | 2010-11-02 | 2014-01-01 | Abbvie公司 | Dual variable domain immunoglobulins and uses thereof |
| WO2019154421A1 (en) * | 2018-02-12 | 2019-08-15 | 杭州尚健生物技术有限公司 | Cd38 protein antibody and application thereof |
| CN110139674A (en) * | 2016-10-05 | 2019-08-16 | 豪夫迈·罗氏有限公司 | The method for preparing antibody drug conjugate |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1914242A1 (en) * | 2006-10-19 | 2008-04-23 | Sanofi-Aventis | Novel anti-CD38 antibodies for the treatment of cancer |
-
2020
- 2020-08-20 CN CN202010841602.5A patent/CN114075285B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103492583A (en) * | 2010-11-02 | 2014-01-01 | Abbvie公司 | Dual variable domain immunoglobulins and uses thereof |
| CN110139674A (en) * | 2016-10-05 | 2019-08-16 | 豪夫迈·罗氏有限公司 | The method for preparing antibody drug conjugate |
| WO2019154421A1 (en) * | 2018-02-12 | 2019-08-15 | 杭州尚健生物技术有限公司 | Cd38 protein antibody and application thereof |
Non-Patent Citations (2)
| Title |
|---|
| Daratumumab, a Novel Therapeutic Human CD38 Monoclonal Antibody, Induces Killing of Multiple Myeloma and Other Hematological Tumors;Michel de Weers;《The Journal of Immunology》;第186卷(第3期);第1840–1848页 * |
| 抗CD38 单克隆抗体治疗多发性骨髓瘤研究进展;高欣;《现代肿瘤医学》;第第27 卷卷(第第09 期期);第1617-1620页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114075285A (en) | 2022-02-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102629503B1 (en) | Fusion protein containing TGF-β receptor and pharmaceutical use thereof | |
| JP6514774B2 (en) | Anti-CTLA4 monoclonal antibody or antigen-binding fragment thereof, pharmaceutical composition and use | |
| KR102588359B1 (en) | Antibodies to TIGIT | |
| CN106967172B (en) | The anti-PD-1 bifunctional antibody of anti-CTLA 4-, its medical composition and its use | |
| CN110066338B (en) | Bispecific IgG antibodies as T cell engagers | |
| AU2019452936B2 (en) | Bispecific antibody, preparation method therefor and application thereof | |
| CN107955072B (en) | PD-1 antibodies | |
| JP7262597B2 (en) | Bispecific antibodies and methods of making and using the same | |
| JP2023106392A (en) | Cd3 antigen binding fragment and application thereof | |
| US20250179172A1 (en) | Cd5 antibody and use thereof | |
| RS66372B1 (en) | ANTI-PD1 MONOCLONAL ANTIBODY, ITS PHARMACEUTICAL COMPOSITION AND ITS USE | |
| CN108124445A (en) | CTLA4 antibody, its medical composition and its use | |
| CN112500485B (en) | anti-B7-H3 antibody and application thereof | |
| CN117321087A (en) | Multispecific protein containing nkp46 binding site and cancer antigen binding site fused to cytokines for NK cell engagement | |
| CN116848147A (en) | CD19 humanized antibodies and their applications | |
| WO2023125888A1 (en) | Gprc5d antibody and application thereof | |
| CN114075285B (en) | Humanized monoclonal antibody against human CD38 and application thereof | |
| WO2023280297A1 (en) | Cd19 antibody and application thereof | |
| US20220267442A1 (en) | METHODS AND COMPOSITIONS FOR TARGETING TGF-ß SIGNALING IN CD4+ HELPER T CELLS FOR CANCER IMMUNOTHERAPY | |
| CN120239710A (en) | Anti-CCR8 antibodies and uses thereof | |
| KR102393776B1 (en) | Humanized antibody specific for CD22 and chimeric antigen receptor using the same | |
| CN113853389B (en) | Bispecific antibodies that specifically bind to GPNMB and CD3 and their uses | |
| TW202241955A (en) | Garp protein antibody and application thereof | |
| CN114829399A (en) | Methods of depleting hematopoietic stem/progenitor cells (HSC/HP) in a patient using bispecific antibodies | |
| CN120230216B (en) | Anti-LAIR 1 antibodies and uses thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |