CN114037868A - 图像识别模型的生成方法及装置 - Google Patents
图像识别模型的生成方法及装置 Download PDFInfo
- Publication number
- CN114037868A CN114037868A CN202111302552.4A CN202111302552A CN114037868A CN 114037868 A CN114037868 A CN 114037868A CN 202111302552 A CN202111302552 A CN 202111302552A CN 114037868 A CN114037868 A CN 114037868A
- Authority
- CN
- China
- Prior art keywords
- image recognition
- recognition model
- training
- data set
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G06F18/2155—Generating training patterns; Bootstrap methods, e.g. bagging or boosting characterised by the incorporation of unlabelled data, e.g. multiple instance learning [MIL], semi-supervised techniques using expectation-maximisation [EM] or naïve labelling
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/0002—Inspection of images, e.g. flaw detection
- G06T7/0012—Biomedical image inspection
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10056—Microscopic image
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30004—Biomedical image processing
- G06T2207/30024—Cell structures in vitro; Tissue sections in vitro
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Medical Informatics (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Radiology & Medical Imaging (AREA)
- Quality & Reliability (AREA)
- Image Analysis (AREA)
Abstract
本发明公开了一种图像识别模型的生成方法及装置。其中,该方法包括:利用第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到第二训练数据集中未标注数据的类别,并筛选得到第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集;使用处理后的第三训练数据集训练得到第二图像识别模型。本发明解决了相关技术中采用的TCT玻片信息分析方式存在局限性,无法快速得到比较全面的信息的技术问题。
Description
技术领域
本发明涉及信息处理技术领域,具体而言,涉及一种图像识别模型的生成方法及装置。
背景技术
现有的研究大多数是对宫颈液基薄层细胞检测(Thinprep Cytologic Test,简称TCT)的检测和分类,例如,通过显微镜对物理病理玻片进行观察的方式进行分析,来判定玻片是否存在阳性。然而,需要处理的玻片数量较大,通过人工进行分析处理,容易出现误差,而且,也无法对TCT玻片进行深度分析,导致对玻片的进行分析得到的信息存在很大的局限性。
针对上述人工检测的弊端,也出现了自动化检测,例如,在自动化检测中利用传统算法在图像的纹理颜色形状上提取特征。但是,TCT图像种类过于类似,导致传统算法并不能很好的进行精准识别。
又例如,随着人工智能技术的发展,人们开始使用人工智能技术训练人工智能模型来解决各种问题。具体地,通过使用标注数据训练得到基准神经网络模型,然后使用标注图像数据和未标注图像数据通过基准神经网络进行训练训练得到分类神经网络模型,能够使基准神经网络模型中的特征信息被分类神经网络模型复用,提高了分类神经网络模型的效率。再通过使用分类神经网络模型来挑选信息量较高的未标注图像数据进行标注,并使用更新的标注图像数据重新训练调整基准神经网络模型,直到基准神经网络模型达到预设条件时,将更新的基准神经网络模型作为目标神经网络模型。然而,这种方式使用标注图像数据和未标注图像数据对基准神经网络模型训练得到分类神经网络模型,再使用分类神经网络模型对挑选出的未标注图像数据进行标注,以得到更新后的标准图像数据,并利用更新后的标准图像数据对基准神经网络模型进行更新,这里训练基准神经网络模型的图像数据是固定的,存在一定的局限性。
当前,深度学习在多个领域得到应用。其中,利用深度学习在图像处理上也被广泛应用,例如,使用神经网络在待处理图像上定位出目标对象。与传统的算法相比,深度学习的方法使用大量的数据集,解决了图像中目标识别难的问题。例如,对于细粒度差别的图像,深度学习具有明显的优势。在一些图像分割中已经存在应用,例如,可利用分类网络将图像分类为阳性图像和正常图像,以快速分别阳性图像,从而可以节约时间。然而,在TCT数字图像中,图片像素较大,且不同病变细胞的视觉形态相近,使得简单的神经网络算法难以对其进行分辨。
针对上述的问题,目前尚未提出有效的解决方案。
发明内容
本申请提供了一种图像识别模型的生成方法及装置,以至少解决相关技术中采用的TCT玻片信息分析方式存在局限性,无法快速得到比较全面的信息的技术问题。
根据本发明实施例的一个方面,提供了一种图像识别模型的生成方法,包括:获取第一训练数据集,其中,所述第一训练数据集包含标注数据中的阳性对象;利用所述第一训练数据集对初始网络模型进行训练,得到第一图像识别模型,其中,所述第一图像识别模型使用监督学习方式训练得到,所述第一图像识别模型的应用场景包括以下至少之一:目标检测、图像分割、图像分类;利用所述第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到所述第二训练数据集中未标注数据的类别,并筛选得到所述第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集,其中,所述第二训练数据集包含阴性诊断结果中未进行标注的数据;利用所述第一训练数据集中的标注数据和所述第三训练数据集中的数据对所述初始网络模型进行半监督学习训练,并在第二图像识别模型的应用场景与所述第一图像识别模型的应用场景不一致时,按照预设规则将所述第三训练数据集中的数据标签修改为与所述第二图像识别模型的应用场景对应的图像标签,其中,所述第二图像识别模型的应用场景至少包括:图像分类;使用处理后的所述第三训练数据集训练得到所述第二图像识别模型。
可选地,获取第一训练数据集,包括:获取所述标注数据;对所述标注数据进行筛选以得到所述标注数据中的阳性对象;将所述标注数据中的阳性对象作为所述第一训练数据集。
可选地,获取所述标注数据,包括:采集原始样本;对所述原始样本进行扫描,得到预定数量的训练样本;将所述训练样本发送至一个或多个标注终端,其中,所述训练样本在所述一个或多个标注终端被执行标注操作;获取所述一个或多个标注终端的反馈的标注数据。
可选地,获取所述一个或多个标注终端的反馈的所述标注数据,包括:将所述一个或多个标注终端反馈的标注数据发送至审阅终端,其中,所述一个或多个标注终端反馈的标注数据在所述审阅终端被执行审阅操作;获取经所述审阅终端审阅的标注数据。
可选地,在训练得到所述第二图像识别模型之后,该图像识别模型的生成方法还包括:获取验证数据;利用所述验证数据对所述第二图像识别模型进行验证,得到验证结果;基于所述验证结果判断所述第二图像识别模型是否满足预定条件,得到判断结果;在所述判断结果表示所述第二图像识别模型满足预定条件时,停止训练;在所述判断结果表示所述第二图像识别模型不满足预定条件时,继续对所述第二图像识别模型进行训练,直到验证得到所述第二图像识别模型满足预定条件。
根据本发明实施例的另外一个方面,还提供了一种图像识别模型的生成装置,包括:第一获取模块,用于获取第一训练数据集,其中,所述第一训练数据集包含标注数据中的阳性对象;第二获取模块,用于利用所述第一训练数据集对初始网络模型进行训练,得到第一图像识别模型,其中,所述第一图像识别模型使用监督学习方式训练得到,所述第一图像识别模型的应用场景包括以下至少之一:目标检测、图像分割、图像分类;第三获取模块,用于利用所述第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到所述第二训练数据集中未标注数据的类别,并筛选得到所述第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集,其中,所述第二训练数据集包含阴性诊断结果中未进行标注的数据;修改模块,用于利用所述第一训练数据集中的标注数据和所述第三训练数据集中的数据对所述初始网络模型进行半监督学习训练,并在第二图像识别模型的应用场景与所述第一图像识别模型的应用场景不一致时,按照预设规则将所述第三训练数据集中的数据标签修改为与所述第二图像识别模型的应用场景对应的图像标签,其中,所述第二图像识别模型的应用场景至少包括:图像分类;第四获取模块,用于使用处理后的所述第三训练数据集训练得到所述第二图像识别模型。
可选地,所述第一获取模块,包括:第一获取子模块,用于获取所述标注数据;第二获取子模块,用于对所述标注数据进行筛选以得到所述标注数据中的阳性对象;确定单元,用于将所述标注数据中的阳性对象作为所述第一训练数据集。
可选地,所述第一获取子模块,包括:采集单元,用于采集原始样本;扫描单元,用于对所述原始样本进行扫描,得到预定数量的训练样本;发送单元,用于将所述训练样本发送至一个或多个标注终端,其中,所述训练样本在所述一个或多个标注终端被执行标注操作;获取单元,用于获取所述一个或多个标注终端的反馈的标注数据。
可选地,所述获取单元,包括:发送子单元,用于将所述一个或多个标注终端反馈的标注数据发送至审阅终端,其中,所述一个或多个标注终端反馈的标注数据在所述审阅终端被执行审阅操作;获取子单元,用于获取经所述审阅终端审阅的标注数据。
可选地,所述装置还包括:第五获取模块,用于在训练得到所述第二图像识别模型之后,获取验证数据;验证模块,用于利用所述验证数据对所述第二图像识别模型进行验证,得到验证结果;第六获取模块,用于基于所述验证结果判断所述第二图像识别模型是否满足预定条件,得到判断结果;停止模块,用于在所述判断结果表示所述第二图像识别模型满足预定条件时,停止训练;训练模块,用于在所述判断结果表示所述第二图像识别模型不满足预定条件时,继续对所述第二图像识别模型进行训练,直到验证得到所述第二图像识别模型满足预定条件。
根据本发明实施例的另外一个方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述计算机可读存储介质所在设备执行上述中任一项所述的图像识别模型的生成方法。
根据本发明实施例的另外一个方面,还提供了一种处理器,所述处理器用于运行计算机程序,其中,所述计算机程序运行时执行上述中任一项所述的图像识别模型的生成方法。
在本发明实施例中,获取第一训练数据集,其中,第一训练数据集包含标注数据中的阳性对象;利用第一训练数据集对初始网络模型进行训练,得到第一图像识别模型,其中,第一图像识别模型使用监督学习方式训练得到,第一图像识别模型的应用场景包括以下至少之一:目标检测、图像分割、图像分类;利用第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到第二训练数据集中未标注数据的类别,并筛选得到第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集,其中,第二训练数据集包含阴性诊断结果中未进行标注的数据;利用第一训练数据集中的标注数据和第三训练数据集中的数据对初始网络模型进行半监督学习训练,并在第二图像识别模型的应用场景与第一图像识别模型的应用场景不一致时,按照预设规则将第三训练数据集中的数据标签修改为与第二图像识别模型的应用场景对应的图像标签,其中,第二图像识别模型的应用场景至少包括:图像分类;使用处理后的第三训练数据集训练得到第二图像识别模型。通过本发明实施例提供的图像识别模型的生成方法,实现了对训练图像识别模型的训练数据的扩充,以将假阳性数据也作为训练数据的目的,达到了提高图像识别模型的精准度的技术效果,进而解决了相关技术中采用的TCT玻片信息分析方式存在局限性,无法快速得到比较全面的信息的技术问题。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是根据本发明实施例的图像识别模型的生成方法的流程图;
图2是根据本发明实施例的训练样本的分割示意图;
图3是根据本发明实施例的可选的图像识别模型的生成方法的流程图;
图4是根据本发明实施例的后处理流程图;
图5是根据本发明实施例的图像识别模型的生成装置的示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
实施例1
根据本发明实施例,提供了一种图像识别模型的生成方法的方法实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
图1是根据本发明实施例的图像识别模型的生成方法的流程图,如图1所示,该图像识别模型的生成方法包括如下步骤:
步骤S101,获取第一训练数据集,其中,第一训练数据集包含标注数据中的阳性对象。
在该实施例中,标注数据均为已经添加有标签的样本,即,带有阳性标注结果的图像,该样本用于训练图像识别模型的一部分。
上述第一训练数据为标注样本中的存在异常的样本。例如,被检测出为阳性的样本。在进行宫颈癌筛查时,所有玻片对应的图像诊断结果均为宫颈癌阳性。
步骤S102,利用第一训练数据集对初始网络模型进行训练,得到第一图像识别模型,其中,第一图像识别模型使用监督学习方式训练得到,第一图像识别模型的应用场景包括以下至少之一:目标检测、图像分割、图像分类。
步骤S103,利用第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到第二训练数据集中未标注数据的类别,并筛选得到第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集,其中,第二训练数据集包含阴性诊断结果中未进行标注的数据。
在该实施例中,未标注数据为未添加标注的样本,对于此类未添加标注的样本可预先预测其是否为阳性对象。
其中,需要说明的是,这里的未标注数据均为宫颈癌阴性,即,这里的无标注玻片图像对应的玻片诊断结果均为阴性。
由于预测过程中会存在预测错误的阳性对象,即,假阳性。上述第二训练数据即为对未标注数据进行预测得到的假阳性样本。
步骤S104,利用第一训练数据集中的标注数据和第三训练数据集中的数据对初始网络模型进行半监督学习训练,并在第二图像识别模型的应用场景与第一图像识别模型的应用场景不一致时,按照预设规则将第三训练数据集中的数据标签修改为与第二图像识别模型的应用场景对应的图像标签,其中,第二图像识别模型的应用场景至少包括:图像分类。
假设,第一图像识别模型的场景为图像分割,其标注为图像中的像素区域,如果第二图像识别模型为图像分割模型,可以直接使用这些标注信息,当第二图像识别模型为分类模型时,与第一图像识别模型的应用场景不一致,训练分类模型要用到的标注为类别信息,不能直接使用像素区域信息,所以第三训练数据的标注数据需要进行处理转换成第二训练模型所适用的场景。同样的情况还会发生在第一训练模型为目标检测模型,第二训练模型为图像分类模型的场景下。
步骤S105,使用处理后的第三训练数据集训练得到第二图像识别模型。
在该实施例中,用于训练第二图像识别模型的训练数据包括阳性对象和假阳性对象,从而训练出的图像识别模型精准度更高。
由上可知,在本发明实施例中,可以获取第一训练数据集,其中,第一训练数据集包含标注数据中的阳性对象;利用第一训练数据集对初始网络模型进行训练,得到第一图像识别模型,其中,第一图像识别模型使用监督学习方式训练得到,第一图像识别模型的应用场景包括以下至少之一:目标检测、图像分割、图像分类;利用第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到第二训练数据集中未标注数据的类别,并筛选得到第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集,其中,第二训练数据集包含阴性诊断结果中未进行标注的数据;利用第一训练数据集中的标注数据和第三训练数据集中的数据对初始网络模型进行半监督学习训练,并在第二图像识别模型的应用场景与第一图像识别模型的应用场景不一致时,按照预设规则将第三训练数据集中的数据标签修改为与第二图像识别模型的应用场景对应的图像标签,其中,第二图像识别模型的应用场景至少包括:图像分类;使用处理后的第三训练数据集训练得到第二图像识别模型,进而可以利用图像识别模型对目标样本进行识别,以确定目标样本是否存在阳性,实现了对训练图像识别模型的训练数据的扩充,以将假阳性数据也作为训练数据的目的,达到了提高图像识别模型的精准度的技术效果。
因此,通过本发明实施例提供的图像识别模型的生成方法,解决了相关技术中采用的TCT玻片信息分析方式存在局限性,无法快速得到比较全面的信息的技术问题。
在上述步骤S101中,获取第一训练数据集,包括:获取标注数据;对标注数据进行筛选以得到标注数据中的阳性对象;将标注数据中的阳性对象作为第一训练数据集。
在该实施例中,首先获取标注数据,接着对标注数据进行筛选,从而可以从标注数据中的阳性对象,以获取第一训练数据集。
其中,上述实施例中,获取标注数据,包括:采集原始样本;对原始样本进行扫描,得到预定数量的训练样本;将训练样本发送至一个或多个标注终端,其中,训练样本在一个或多个标注终端被执行标注操作;获取一个或多个标注终端的反馈的标注数据。
在该实施例中,可以先获取原始样本,接着对原始样本进行扫描,从而得到预定数量的训练样本,并将训练样本发送至一个或多个标注终端。
在本发明实施例中,数据标注可以是由多名病理医生或专家进行标准而来。例如,第一轮可通过1名医生进行标注,既给出每个玻片(即,原始样本)的10个感兴趣区域。第二轮可通过2名病理医生进行二级标注,既,对同批次的玻片中感兴趣区域进行背靠背标注,从而可以得到不同病理医生或专家对玻片的标注,提高了客观性。
其中,上述玻片可以为TCT玻片。
在上述实施例中,获取一个或多个标注终端的反馈的标注数据,包括:将一个或多个标注终端反馈的标注数据发送至审阅终端,其中,一个或多个标注终端反馈的标注数据在审阅终端被执行审阅操作;获取经审阅终端审阅的标注数据。
例如,可在第三轮中由一名病理医生或专家进行三级标注,既将每张玻片由第一轮和第二轮的标注框进行合并。在第四轮有专家医生对每张玻片进行最终审核,得到下个阶段使用的标注数据。
需要说明的是,在本发明实施例中,原始样本可以PNG图像,和测试玻片,比如,38403张PNG图像,和1000例测试玻片。这里的数据集可以为第三方检测实验室,收集的多个不同地区的病例玻片,比如,918张。将918张半径为19毫米的玻片进行扫描,扫描物镜倍数可为20倍,扫描层数可为7层,最终得到300000*300000像素的玻片。为了保证数据集的多样性,病理医生对每张玻片挑选了10个(7800-10000)*(4140-10000)的区域图像进行标注。受限于计算力,可将大型区域图像统一按照一定步长切割成2100*2100的PNG图像,且通过观察,2100*2100的包含细胞的个数相对较好。切割步长具体如公式所示:s=2100-m/n,m=mod(l,2100),n=[l/2100]。在上述公式中,l表示图像长度,mod表示余数函数,m表示余数,n表示l除以2100取整,s表示步长。
其中,图2是根据本发明实施例的训练样本的分割示意图,当按照步长切割时,图像边缘存在目标会被切割的情况。经过分析,存在一定量的细胞细胞核并不存在整个细胞中心。因此采用细胞核作为判断整个细胞是否被切割并不是一种较好的方式。本发明实施例中,采用判断目标细胞中心是否在图中的原则对其进行处理,既细胞框的中心所在的图像就为其唯一标注图像。
最后在对玻片的数字图像进行切割后,获得38403张图像。为了保证每一张玻片都含有训练集和验证集,本发明实施例中,将每张玻片都划分出一定数量的图像分别作为训练集和验证集,最终将34910张图像作为训练集,3493张图像作为验证集。
图3是根据本发明实施例的可选的图像识别模型的生成方法的流程图,如图3所示,首先,可以对TCT阳性诊断玻片进行标注得到TCT目标检测标注数据,并利用上述标注数据训练得到目标检测模型(即,第一图像识别模型);接着获取TCT阴性诊断玻片,对其进行分割得到未标注阴性TCT数据;再利用上述目标检测模型对上述未标注阴性TCT数据进行推理,得到未标注数据中预测出假阳性目标与标注数据中的阳性目标一起作为训练数据,得到图像分类模型(即,第二图像识别模型)。
通过该实施例提供的图像识别模型的生成方法,通过深度学习的方法,对数字图像中的细胞进行识别,再通过将细胞级的预测结果转换成玻片级预测,具体是通过半监督模式模块和后处理模块。
其中,通常半监督模型主要将经过目标检测模型预测后的目标框作为新数据,再用该数据对原模型进行提升。在本发明实施例中的半监督模式主要将经过目标检测模型预测后的目标框作为分类模型的新数据。该模式主要分成三部分。第一部分为通过第一数据集训练一个目标检测模型,第二个部分为对阴性玻片进行切割,然后传入检测模型,将检测目标与数据集阳性细胞结合制作成新的分类数据集,第三部分为根据新的分类数据集训练新的分类网络。
此外,在本发明实施例中选取了三种常用的二阶段网络和一种一阶段的网络进行训练测试,分别为Mask-RCNN,Cascade-RCNN[,DetectoRS,和EfficientDet。并且针对Cascade-RCNN和DetectoRs进行了多次实验。为了增强网络鲁棒性,本发明实施例中加入了Albumentations的数据增强方式,Albumentations是一个基于OpenCV图像视觉库实现的数据增强库。其针对不同图像任务提供了简单的接口供研究者使用。同时为了提高网络局部视野,本发明实施例中使用了多尺度图像输入。其中,由于Albumentations图像增强库中影响图像颜色的增强方式对结果影响较大,因此,在本发明实施例中优先选取了CLAHE的方法进行数据增强。
在最终测试中,针对细胞病理图像的预测存在大量的假阳。通过挑选未标注过的纯阴性的玻片,对其进行预测,所测出来的阳性则全部为假阳,再收集该假阳的目标框结合原阳性细胞框制作成分类网络数据集,最后训练出一个分类网络,具体如图3所示。分类网络选取了ResNeXt101进行分类。经过分类网络后,再通过后验方法得到玻片的阴阳判断。
进一步地,由于最终的目标是为了得到一张玻片甚至多张玻片的阴阳判断,所以需要将预测的细胞结果转换至玻片结果。在病理知识理论中,当一个细胞玻片存在一个或者多个阳性细胞时,该玻片就被认定为阳性玻片。该判定条件只适用于人眼观察,不适用于存在假阳情况下的深度学习。因此在结合医生的建议和后验经验后,将多种阳性亚型类别进行固定排序,其优先级为:ASC-US<ASC-H<LSIL<HSIL。具体来说,首先预测得出1000例的每一例玻片的所有阳性细胞坐标和类别得分,其次将其类别得分分别求平均值。在以ASC-US的平均值为排序准则,对1000例玻片进行ASC-US平均值从小到大的排序,然后再以ASC-H为排序准则,对已经经过ASC-US的排序再进行排序,依次用相同的方法对LSIL和HSIL进行相同的操作。图4是根据本发明实施例的后处理流程图,如图4所示,在同一玻片下检出上述四种类别的所有目标图像集合,将由分类网络对其类别再次进行推理,输出值为所有目标为各个类别的可能性。经过依次排序的方法,将各类别的输出值从小到大进行排序,最终形成1000例玻片排序。以1000例玻片中阴性玻片个数作为基数,以其前60%的分位数个数作为划分点,判断该部分的准确度。
需要说明的是,在训练过程中,可选取Albumentations库中常用的数据增强方式,如随机更改亮度、对比、饱和度,使用随机高斯函数对图像进行高斯模糊,随机的Gamma变换,CLAHE等一系列的数据增强方式。
训练部分:统一进行12轮训练,同时使用了阶段降低学习率的方法进行训练,分别在第8和第11轮进行下降,下降为原来的0.1倍。学习率初始值设定为0.005,batch size选取为2,本数据集的RGB均值、方差为[224.889,221.787,232.288]和[48.087,50.326,32.562]其初始归一化后的RGB均值、方差为[123.675,116.28,103.53]和[58.395,57.12,57.375]。初始化训练的图像尺寸为(1333,800)。检测算法中multi scale的尺寸为(1333,800)、(1024,1024)、(1666、1024)、(2048、1600)、(2048,2048)、(2666,800)、(2666,1600)、(2666,2048)。
作为一种可选的实施例,在训练得到第二图像识别模型之后,该图像识别模型的生成方法还包括:获取验证数据;利用验证数据对第二图像识别模型进行验证,得到验证结果;基于验证结果判断第二图像识别模型是否满足预定条件,得到判断结果;在判断结果表示第二图像识别模型满足预定条件时,停止训练;在判断结果表示第二图像识别模型不满足预定条件时,继续对第二图像识别模型进行训练,直到验证得到第二图像识别模型满足预定条件。
在本发明实施例中,针对玻片级检测,采用4个评判指标来作为评判标准,即精度、召回率、准确率以及经过病理专家讨论出符合现实场景的筛阴率指标。具体如下公式所示:精度=TP/(TP+FP),召回率=TP/(TP+FN),准确率:(TP+TN)/(TP+FP+TN+FN),其中,TP表示正确预测阳性的个数,FP表示错误预测阳性的个数,FN表示错误预测阴性的个数,TN表示正确预测阴性的个数。除此之外,针对了临床场景所收集来的信息,给出了针对1000例玻片的一种评判指标。针对1000例玻片,给出排序,按照玻片总数的百分比划分阴阳界限。例如,1000例玻片,含有900个阴性玻片,100个阳性玻片。经过筛阴算法,给出排序,前360张的玻片中只有1张阳性,则我们称其为前40%阴性预测准确率为99.72%。具体如公式所示:pa=M/(a%*N),式中,pa表示前百分之a的阴性预测准确率,M表示预测正确的阴性玻片个数,N表示阴性总玻片数。
经过DetectoRS后的检测网络后,在本发明实施例中选取了383个阴性玻片进行预测,得到62099张假阳图片,结合84985张原数据集标注的阳性分别对ResNet50和ResNeXt101、进行训练,Accuracy结果如表1所示:
表1
| Method | Accuracy |
| ResNet50 | 92.36% |
| ResNeXt101 | 97.60% |
由表可见,ResNeXt101准确率高于ResNet50,因此可选取ResNeXt101为分类网络。Accuracy公式如下所示:Accuracy=(TP+TN)/GT,式中,TP表示预测正确阳性个数,TF表示预测正确阴性个数,GT表示所有标注个数。
此外需要说明的是,图像在经过目标检测和分类网络后,形成一些目标框。然而由于在切割图像时采用带重叠的方式切割图像,会产生目标框重复出现的情况。因此需要对预测出的目标框进行IOU(Intersection over union)去重,IOU公式如下所示: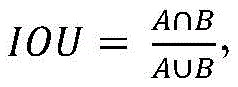 式中,A,B表示两个目标框,∩表示交集,∪表示并集。经过去重后的结果使用后处理方法对玻片进行排序。最终在验证的1000例玻片上进行测试,得出结果表2所示:
式中,A,B表示两个目标框,∩表示交集,∪表示并集。经过去重后的结果使用后处理方法对玻片进行排序。最终在验证的1000例玻片上进行测试,得出结果表2所示:
表2
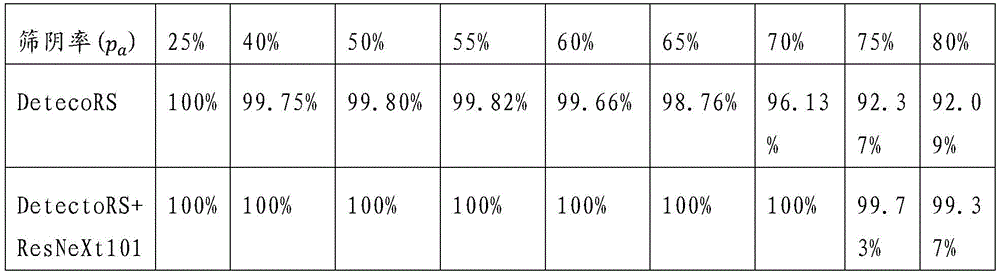
表中第一行百分比的数字表示算法预测出阴性玻片按照阴性可能性从大到小排序,总数的前25%至前85%。第二行和第三行表示两种方法的阴性预测准确率,即pa或筛阴率。由表可看出经过分类网络后即DetectoRS+ResNeXt101方案的效果明显高于仅做目标检测即DetecoRS方案的效果,当其筛阴率为70%时,筛除阴性玻片总计697张,错0张,准确率100.00%;当筛阴率为75%时,筛除阴性玻片总计747张,错2张,准确率99.73%;当其筛阴率为80%时,筛除阴性玻片总计796张,错5张,准确率99.37%;当其筛阴率为85%时,筛除阴性玻片总计846张,错12张,准确率98.58%;整体效果高于仅作目标检测的方案。
实施例2
根据本发明实施例的另外一个方面,还提供了一种图像识别模型的生成装置,图5是根据本发明实施例的图像识别模型的生成装置的示意图,如图5所示,该图像识别模型的生成装置包括:第一获取模块51、第二获取模块52、第三获取模块53、修改模块54以及第四获取模块55。下面对该图像识别模型的生成装置进行说明。
第一获取模块51,用于获取第一训练数据集,其中,第一训练数据集包含标注数据中的阳性对象。
第二获取模块52,用于利用第一训练数据集对初始网络模型进行训练,得到第一图像识别模型,其中,第一图像识别模型使用监督学习方式训练得到,第一图像识别模型的应用场景包括以下至少之一:目标检测、图像分割、图像分类。
第三获取模块53,用于利用第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到第二训练数据集中未标注数据的类别,并筛选得到第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集,其中,第二训练数据集包含阴性诊断结果中未进行标注的数据。
修改模块54,用于利用第一训练数据集中的标注数据和第三训练数据集中的数据对初始网络模型进行半监督学习训练,并在第二图像识别模型的应用场景与第一图像识别模型的应用场景不一致时,按照预设规则将第三训练数据集中的数据标签修改为与第二图像识别模型的应用场景对应的图像标签,其中,第二图像识别模型的应用场景至少包括:图像分类。
第四获取模块55,用于使用处理后的第三训练数据集训练得到第二图像识别模型。
此处需要说明的是,上述第一获取模块51、第二获取模块52、第三获取模块53、修改模块54以及第四获取模块55对应于实施例1中的步骤S101至S105,上述模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例1所公开的内容。需要说明的是,上述模块作为装置的一部分可以在诸如一组计算机可执行指令的计算机系统中执行。
由上可知,在本发明实施例中,首先第一获取模块获取第一训练数据集,其中,第一训练数据集包含标注数据中的阳性对象;接着利用第二获取模块利用第一训练数据集对初始网络模型进行训练,得到第一图像识别模型,其中,第一图像识别模型使用监督学习方式训练得到,第一图像识别模型的应用场景包括以下至少之一:目标检测、图像分割、图像分类;然后利用第三获取模块利用第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到第二训练数据集中未标注数据的类别,并筛选得到第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集,其中,第二训练数据集包含阴性诊断结果中未进行标注的数据;再使用修改模块利用第一训练数据集中的标注数据和第三训练数据集中的数据对初始网络模型进行半监督学习训练,并在第二图像识别模型的应用场景与第一图像识别模型的应用场景不一致时,按照预设规则将第三训练数据集中的数据标签修改为与第二图像识别模型的应用场景对应的图像标签,其中,第二图像识别模型的应用场景至少包括:图像分类;以及使用第四获取模块使用处理后的第三训练数据集训练得到第二图像识别模型。通过本发明实施例提供的图像识别模型的生成装置,实现了对训练图像识别模型的训练数据的扩充,以将假阳性数据也作为训练数据的目的,达到了提高图像识别模型的精准度的技术效果,解决了相关技术中采用的TCT玻片信息分析方式存在局限性,无法快速得到比较全面的信息的技术问题。
可选地,第一获取子模块,包括:采集单元,用于采集原始样本;扫描单元,用于对原始样本进行扫描,得到预定数量的训练样本;发送单元,用于将训练样本发送至一个或多个标注终端,其中,训练样本在一个或多个标注终端被执行标注操作;获取单元,用于获取一个或多个标注终端的反馈的标注数据。
可选地,获取单元,包括:发送子单元,用于将一个或多个标注终端反馈的标注数据发送至审阅终端,其中,一个或多个标注终端反馈的标注数据在审阅终端被执行审阅操作;获取子单元,用于获取经审阅终端审阅的标注数据。
可选地,装置还包括:第五获取模块,用于在训练得到第二图像识别模型之后,获取验证数据;验证模块,用于利用验证数据对第二图像识别模型进行验证,得到验证结果;第六获取模块,用于基于验证结果判断第二图像识别模型是否满足预定条件,得到判断结果;停止模块,用于在判断结果表示第二图像识别模型满足预定条件时,停止训练;训练模块,用于在判断结果表示第二图像识别模型不满足预定条件时,继续对第二图像识别模型进行训练,直到验证得到第二图像识别模型满足预定条件。
实施例3
根据本发明实施例的另外一个方面,还提供了一种计算机可读存储介质,计算机可读存储介质包括存储的计算机程序,其中,在计算机程序被处理器运行时控制计算机可读存储介质所在设备执行上述中任一项的图像识别模型的生成方法。
实施例4
根据本发明实施例的另外一个方面,还提供了一种处理器,处理器用于运行计算机程序,其中,计算机程序运行时执行上述中任一项的图像识别模型的生成方法。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
在本申请所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,可以为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
Claims (10)
1.一种图像识别模型的生成方法,其特征在于,包括:
获取第一训练数据集,其中,所述第一训练数据集包含标注数据中的阳性对象;
利用所述第一训练数据集对初始网络模型进行训练,得到第一图像识别模型,其中,所述第一图像识别模型使用监督学习方式训练得到,所述第一图像识别模型的应用场景包括以下至少之一:目标检测、图像分割、图像分类;
利用所述第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到所述第二训练数据集中未标注数据的类别,并筛选得到所述第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集,其中,所述第二训练数据集包含阴性诊断结果中未进行标注的数据;
利用所述第一训练数据集中的标注数据和所述第三训练数据集中的数据对所述初始网络模型进行半监督学习训练,并在第二图像识别模型的应用场景与所述第一图像识别模型的应用场景不一致时,按照预设规则将所述第三训练数据集中的数据标签修改为与所述第二图像识别模型的应用场景对应的图像标签,其中,所述第二图像识别模型的应用场景至少包括:图像分类;
使用处理后的所述第三训练数据集训练得到所述第二图像识别模型。
2.根据权利要求1所述的方法,其特征在于,获取第一训练数据集,包括:
获取所述标注数据;
对所述标注数据进行筛选以得到所述标注数据中的阳性对象;
将所述标注数据中的阳性对象作为所述第一训练数据集。
3.根据权利要求2所述的方法,其特征在于,获取所述标注数据,包括:
采集原始样本;
对所述原始样本进行扫描,得到预定数量的训练样本;
将所述训练样本发送至一个或多个标注终端,其中,所述训练样本在所述一个或多个标注终端被执行标注操作;
获取所述一个或多个标注终端的反馈的标注数据。
4.根据权利要求3所述的方法,其特征在于,获取所述一个或多个标注终端的反馈的所述标注数据,包括:
将所述一个或多个标注终端反馈的标注数据发送至审阅终端,其中,所述一个或多个标注终端反馈的标注数据在所述审阅终端被执行审阅操作;
获取经所述审阅终端审阅的标注数据。
5.根据权利要求1至4中任一项所述的方法,其特征在于,在训练得到所述第二图像识别模型之后,所述方法还包括:
获取验证数据;
利用所述验证数据对所述第二图像识别模型进行验证,得到验证结果;
基于所述验证结果判断所述第二图像识别模型是否满足预定条件,得到判断结果;
在所述判断结果表示所述第二图像识别模型满足预定条件时,停止训练;
在所述判断结果表示所述第二图像识别模型不满足预定条件时,继续对所述第二图像识别模型进行训练,直到验证得到所述第二图像识别模型满足预定条件。
6.一种图像识别模型的生成装置,其特征在于,包括:
第一获取模块,用于获取第一训练数据集,其中,所述第一训练数据集包含标注数据中的阳性对象;
第二获取模块,用于利用所述第一训练数据集对初始网络模型进行训练,得到第一图像识别模型,其中,所述第一图像识别模型使用监督学习方式训练得到,所述第一图像识别模型的应用场景包括以下至少之一:目标检测、图像分割、图像分类;
第三获取模块,用于利用所述第一图像识别模型对第二训练数据集中未标注数据进行处理,以得到所述第二训练数据集中未标注数据的类别,并筛选得到所述第二训练数据集中未标注数据中类别为阳性的对象,并将其重置为阴性,以得到第三训练数据集,其中,所述第二训练数据集包含阴性诊断结果中未进行标注的数据;
修改模块,用于利用所述第一训练数据集中的标注数据和所述第三训练数据集中的数据对所述初始网络模型进行半监督学习训练,并在第二图像识别模型的应用场景与所述第一图像识别模型的应用场景不一致时,按照预设规则将所述第三训练数据集中的数据标签修改为与所述第二图像识别模型的应用场景对应的图像标签,其中,所述第二图像识别模型的应用场景至少包括:图像分类;
第四获取模块,用于使用处理后的所述第三训练数据集训练得到所述第二图像识别模型。
7.根据权利要求6所述的装置,其特征在于,所述第一获取模块,包括:
第一获取子模块,用于获取所述标注数据;
第二获取子模块,用于对所述标注数据进行筛选以得到所述标注数据中的阳性对象;
确定单元,用于将所述标注数据中的阳性对象作为所述第一训练数据集。
8.根据权利要求7所述的装置,其特征在于,所述第一获取子模块,包括:
采集单元,用于采集原始样本;
扫描单元,用于对所述原始样本进行扫描,得到预定数量的训练样本;
发送单元,用于将所述训练样本发送至一个或多个标注终端,其中,所述训练样本在所述一个或多个标注终端被执行标注操作;
获取单元,用于获取所述一个或多个标注终端的反馈的标注数据。
9.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述计算机可读存储介质所在设备执行上述权利要求1至5中任一项所述的图像识别模型的生成方法。
10.一种处理器,其特征在于,所述处理器用于运行计算机程序,其中,所述计算机程序运行时执行上述权利要求1至5中任一项所述的图像识别模型的生成方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111302552.4A CN114037868B (zh) | 2021-11-04 | 2021-11-04 | 图像识别模型的生成方法及装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111302552.4A CN114037868B (zh) | 2021-11-04 | 2021-11-04 | 图像识别模型的生成方法及装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114037868A true CN114037868A (zh) | 2022-02-11 |
| CN114037868B CN114037868B (zh) | 2022-07-01 |
Family
ID=80136382
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111302552.4A Active CN114037868B (zh) | 2021-11-04 | 2021-11-04 | 图像识别模型的生成方法及装置 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114037868B (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114581715A (zh) * | 2022-03-08 | 2022-06-03 | 赛维森(广州)医疗科技服务有限公司 | 病理玻片数字图像数据集的半监督甄选方法和甄选系统 |
| CN117152746A (zh) * | 2023-10-27 | 2023-12-01 | 南方医科大学 | 一种基于yolov5网络的宫颈细胞分类参数获取方法 |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108416370A (zh) * | 2018-02-07 | 2018-08-17 | 深圳大学 | 基于半监督深度学习的图像分类方法、装置和存储介质 |
| CN109190567A (zh) * | 2018-09-10 | 2019-01-11 | 哈尔滨理工大学 | 基于深度卷积神经网络的异常宫颈细胞自动检测方法 |
| CN110909803A (zh) * | 2019-11-26 | 2020-03-24 | 腾讯科技(深圳)有限公司 | 图像识别模型训练方法、装置和计算机可读存储介质 |
| CN111008643A (zh) * | 2019-10-29 | 2020-04-14 | 平安科技(深圳)有限公司 | 基于半监督学习的图片分类方法、装置和计算机设备 |
| CN111028224A (zh) * | 2019-12-12 | 2020-04-17 | 广西医准智能科技有限公司 | 数据标注、模型训练和图像处理方法、装置及存储介质 |
| US20200320348A1 (en) * | 2019-04-04 | 2020-10-08 | Beijing Jingdong Shangke Information Technology Co., Ltd. | System and method for fashion attributes extraction |
| CN111814832A (zh) * | 2020-06-11 | 2020-10-23 | 上海联影智能医疗科技有限公司 | 一种目标检测方法、装置及存储介质 |
| US20200357516A1 (en) * | 2017-11-21 | 2020-11-12 | Beth Israel Deaconess Medical Center, Inc. | Systems and methods for automatically interpreting images of microbiological samples |
| CN112560964A (zh) * | 2020-12-18 | 2021-03-26 | 深圳赛安特技术服务有限公司 | 基于半监督学习训练中草药病虫害识别模型的方法与系统 |
| CN113222928A (zh) * | 2021-05-07 | 2021-08-06 | 北京大学第一医院 | 一种尿细胞学人工智能尿路上皮癌识别系统 |
| US20210272288A1 (en) * | 2018-08-06 | 2021-09-02 | Shimadzu Corporation | Training Label Image Correction Method, Trained Model Creation Method, and Image Analysis Device |
| WO2021186174A1 (en) * | 2020-03-17 | 2021-09-23 | Seechange Technologies Limited | Machine-learning data handling |
-
2021
- 2021-11-04 CN CN202111302552.4A patent/CN114037868B/zh active Active
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200357516A1 (en) * | 2017-11-21 | 2020-11-12 | Beth Israel Deaconess Medical Center, Inc. | Systems and methods for automatically interpreting images of microbiological samples |
| CN108416370A (zh) * | 2018-02-07 | 2018-08-17 | 深圳大学 | 基于半监督深度学习的图像分类方法、装置和存储介质 |
| US20210272288A1 (en) * | 2018-08-06 | 2021-09-02 | Shimadzu Corporation | Training Label Image Correction Method, Trained Model Creation Method, and Image Analysis Device |
| CN109190567A (zh) * | 2018-09-10 | 2019-01-11 | 哈尔滨理工大学 | 基于深度卷积神经网络的异常宫颈细胞自动检测方法 |
| US20200320348A1 (en) * | 2019-04-04 | 2020-10-08 | Beijing Jingdong Shangke Information Technology Co., Ltd. | System and method for fashion attributes extraction |
| CN111008643A (zh) * | 2019-10-29 | 2020-04-14 | 平安科技(深圳)有限公司 | 基于半监督学习的图片分类方法、装置和计算机设备 |
| CN110909803A (zh) * | 2019-11-26 | 2020-03-24 | 腾讯科技(深圳)有限公司 | 图像识别模型训练方法、装置和计算机可读存储介质 |
| CN111028224A (zh) * | 2019-12-12 | 2020-04-17 | 广西医准智能科技有限公司 | 数据标注、模型训练和图像处理方法、装置及存储介质 |
| WO2021186174A1 (en) * | 2020-03-17 | 2021-09-23 | Seechange Technologies Limited | Machine-learning data handling |
| CN111814832A (zh) * | 2020-06-11 | 2020-10-23 | 上海联影智能医疗科技有限公司 | 一种目标检测方法、装置及存储介质 |
| CN112560964A (zh) * | 2020-12-18 | 2021-03-26 | 深圳赛安特技术服务有限公司 | 基于半监督学习训练中草药病虫害识别模型的方法与系统 |
| CN113222928A (zh) * | 2021-05-07 | 2021-08-06 | 北京大学第一医院 | 一种尿细胞学人工智能尿路上皮癌识别系统 |
Non-Patent Citations (1)
| Title |
|---|
| 马占飞; 杨树英; 郭广丰: "基于ISM特性的检测器生成算法及模型", 《控制与决策》 * |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114581715A (zh) * | 2022-03-08 | 2022-06-03 | 赛维森(广州)医疗科技服务有限公司 | 病理玻片数字图像数据集的半监督甄选方法和甄选系统 |
| CN114581715B (zh) * | 2022-03-08 | 2024-09-24 | 赛维森(广州)医疗科技服务有限公司 | 病理玻片数字图像数据集的半监督甄选方法和甄选系统 |
| CN117152746A (zh) * | 2023-10-27 | 2023-12-01 | 南方医科大学 | 一种基于yolov5网络的宫颈细胞分类参数获取方法 |
| CN117152746B (zh) * | 2023-10-27 | 2024-03-26 | 南方医科大学 | 一种基于yolov5网络的宫颈细胞分类参数获取方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114037868B (zh) | 2022-07-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11681418B2 (en) | Multi-sample whole slide image processing in digital pathology via multi-resolution registration and machine learning | |
| Zhang et al. | Automated semantic segmentation of red blood cells for sickle cell disease | |
| US9684958B2 (en) | Image processing device, program, image processing method, computer-readable medium, and image processing system | |
| CN111814902A (zh) | 目标检测模型训练方法、目标识别方法、装置和介质 | |
| WO2021139258A1 (zh) | 基于图像识别的细胞识别计数方法、装置和计算机设备 | |
| US20100002920A1 (en) | Mitotic Figure Detector and Counter System and Method for Detecting and Counting Mitotic Figures | |
| CN110322438A (zh) | 结核分枝杆菌自动检测模型的训练方法及自动检测系统 | |
| CN112365471A (zh) | 基于深度学习的宫颈癌细胞智能检测方法 | |
| CN113793336B (zh) | 一种检测血细胞的方法、装置、设备及可读存储介质 | |
| Salama et al. | Enhancing medical image quality using neutrosophic fuzzy domain and multi-level enhancement transforms: A comparative study for leukemia detection and classification | |
| CN114037868B (zh) | 图像识别模型的生成方法及装置 | |
| Chidester et al. | Discriminative bag-of-cells for imaging-genomics | |
| CN111414930A (zh) | 深度学习模型训练方法及装置、电子设备及存储介质 | |
| JP6070420B2 (ja) | 画像処理装置及びプログラム | |
| Sabino et al. | Toward leukocyte recognition using morphometry, texture and color | |
| US10146042B2 (en) | Image processing apparatus, storage medium, and image processing method | |
| Vale et al. | Automatic segmentation and classification of blood components in microscopic images using a fuzzy approach | |
| Iqbal et al. | Towards efficient segmentation and classification of white blood cell cancer using deep learning | |
| Taha et al. | Deep learning for malaria diagnosis: Leveraging convolutional neural networks for accurate parasite detection | |
| AU2021103689A4 (en) | A Method for Automatic Detection of Infected Erythrocytes | |
| Kromp et al. | Machine learning framework incorporating expert knowledge in tissue image annotation | |
| CN116152566A (zh) | 一种数据高效的多尺度病理图像分类方法 | |
| Bhanumathi et al. | Underwater fish species classification using Alexnet | |
| WO2020120039A1 (en) | Classification of cell nuclei | |
| Benazzouz et al. | Evidential segmentation scheme of bone marrow images |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |