CN113947804A - Target fixation identification method and system based on sight line estimation - Google Patents
Target fixation identification method and system based on sight line estimation Download PDFInfo
- Publication number
- CN113947804A CN113947804A CN202111047180.5A CN202111047180A CN113947804A CN 113947804 A CN113947804 A CN 113947804A CN 202111047180 A CN202111047180 A CN 202111047180A CN 113947804 A CN113947804 A CN 113947804A
- Authority
- CN
- China
- Prior art keywords
- network
- original image
- gaze
- feature
- features
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
Abstract
The invention provides a target gaze identification method and a target gaze identification system based on sight line estimation, and relates to the technical field of target gaze prediction. According to the method, after the face features and the head position features of an original image and a reversed image of the original image are extracted, the face features and the head position features are spliced to obtain two-dimensional features, then a feature map of a watching sight line area is obtained based on the two-dimensional features, and finally a watching thermodynamic diagram is obtained based on the characteristic pyramid network of the watching sight line area and the original image and based on the BoTNet network, so that the identification and detection of the object watching in the image are achieved. The invention is not limited by the application scene, the hardware condition constraint is less, the actual operation is simple and convenient, and the target fixation identification and detection result is accurate.
Description
Technical Field
The invention relates to a target fixation prediction technology, in particular to a target fixation identification method and a target fixation identification system based on sight line estimation.
Background
With the rapid development of computer vision, artificial intelligence technology and digitization technology, eye tracking technology has become the current hot research field, and has wide application in the field of human-computer interaction. In real life, people in the image are required to watch the target through a third visual angle, so that the attention content of people in the scene is known through target watching identification, and the purpose of detecting the watching target of the people in the image is achieved.
Currently, target gaze prediction can be achieved mainly by both face-based and line-of-sight based techniques. The face-based approach refers to prediction by extracting eye features and facial features; generally, eye images and face coordinates in a photo are extracted, then a model is established, characteristics are extracted, and finally target fixation prediction is directly carried out; the sight line based method mainly comprises the steps of deducing the sight line direction of a person through an eye picture or a face picture for prediction, establishing a model, extracting face features or eye features in the picture, and then performing feature splicing to realize target fixation prediction.
However, the face-based target fixation technology requires that the image has a complete face and needs to provide eye position information, otherwise the prediction result is not accurate, so the application scene is limited; in the target fixation technology based on the sight line, an additional module is needed for detecting eyes and estimating the head posture, the operation is complex in practical application, the constraint is more, and the prediction result is not accurate. Therefore, there is a need to provide a new target fixation method to overcome at least the above problems of the prior art.
Disclosure of Invention
Technical problem to be solved
Aiming at the defects of the prior art, the invention provides a target gaze identification method and a target gaze identification system based on sight line estimation, and solves the problem that the target gaze identification result cannot be accurately obtained when the information is insufficient and the hardware equipment is deficient in the prior art.
(II) technical scheme
In order to achieve the purpose, the invention is realized by the following technical scheme:
in a first aspect, the present invention first provides a target gaze identification method based on gaze estimation, where the method includes:
extracting face features and head position features in the original image; the face features comprise face features in the original image and reversed face features of the original image after being reversed;
obtaining two-dimensional features by feature splicing of the face features and the head position features;
acquiring a characteristic diagram of a gaze line area based on the two-dimensional characteristics;
acquiring a fixation thermodynamic diagram by utilizing a characteristic pyramid network based on a BoTNet network based on the fixation sight area characteristic diagram and the original image; the BoTNet network is a network after 3x3 constraint in a ResNet network is replaced by multi-head Self-attachment.
Preferably, the extracting facial features in the original image includes:
and extracting facial features in the original image by using a ResNet model.
Preferably, the extracting facial features in the original image by using the ResNet model includes:
s11, adding or subtracting 0.15 to the eye coordinates in the original image to obtain face coordinates, and then cutting the face coordinates to obtain a face image;
s12, extracting facial features in the original image based on the facial image by using a ResNet model;
and S13, horizontally turning the original image to obtain a turned image of the original image, and extracting the turned facial features of the turned image through the steps S11 and S12.
Preferably, the gaze thermodynamic diagram is acquired by using a feature pyramid network based on a BoTNet network based on the gaze area feature map and the original image; the BoTNet network is a network which replaces 3x3 constraint in a ResNet network by using multi-head Self-attachment and comprises the following steps:
and replacing 3x3 constraint in the ResNet network by using multi-head Self-orientation to obtain a BoTNet network, and sending the gazing sight line area characteristic diagram and the original image into a Heatmap path of a characteristic pyramid network taking the BoTNet network as a main network together to generate a gazing thermodynamic diagram.
Preferably, the method further comprises:
the BoTNet network-based feature pyramid network is trained prior to acquiring the gaze thermodynamic diagram.
In a second aspect, the present invention further provides a gaze recognition system for an object based on gaze estimation, the system comprising:
the feature extraction module is used for extracting facial features and head position features in the original image; the face features comprise face features in the original image and reversed face features of the original image after being reversed;
the feature splicing module is used for splicing the face feature and the head position feature to obtain a two-dimensional feature;
the sight line area characteristic diagram acquisition module is used for acquiring a characteristic diagram of a watching sight line area based on the two-dimensional characteristics;
the gazing thermodynamic diagram acquisition module is used for acquiring a gazing thermodynamic diagram by utilizing a characteristic pyramid network based on a BoTNet network based on the gazing sight line area characteristic diagram and the original image; the BoTNet network is a network after 3x3 constraint in a ResNet network is replaced by multi-head Self-attachment.
Preferably, the extracting facial features in the original image by the feature extraction module includes:
and extracting facial features in the original image by using a ResNet model.
Preferably, the extracting facial features in the original image by the feature extraction module using the ResNet model includes:
s11, adding or subtracting 0.15 to the eye coordinates in the original image to obtain face coordinates, and then cutting the face coordinates to obtain a face image;
s12, extracting facial features in the original image based on the facial image by using a ResNet model;
and S13, horizontally turning the original image to obtain a turned image of the original image, and extracting the turned facial features of the turned image through the steps S11 and S12.
Preferably, the gaze thermodynamic diagram acquisition module acquires a gaze thermodynamic diagram by using a feature pyramid network based on a BoTNet network based on the gaze area feature map and the original image; the BoTNet network is a network which replaces 3x3 constraint in a ResNet network by using multi-head Self-attachment and comprises the following steps:
and replacing 3x3 constraint in the ResNet network by using multi-head Self-orientation to obtain a BoTNet network, and sending the gazing sight line area characteristic diagram and the original image into a Heatmap path of a characteristic pyramid network taking the BoTNet network as a main network together to generate a gazing thermodynamic diagram.
Preferably, the system further comprises:
and the model training module is used for training the BoTNet network-based feature pyramid network before the gazing thermodynamic diagram is acquired.
(III) advantageous effects
The invention provides a target fixation identification method and a target fixation identification system based on sight line estimation. Compared with the prior art, the method has the following beneficial effects:
1. the method comprises the steps of firstly extracting face features and head position features of an original image and a reversed image of the original image, obtaining two-dimensional features by feature splicing the face features and the head position features, then obtaining a feature map of a watching sight line area based on the two-dimensional features, and finally obtaining a watching thermodynamic diagram based on the watching sight line area feature map and the original image by utilizing a feature pyramid network based on a BoTNet network, so that the identification and detection of the object watching in the image are realized. The invention can accurately acquire the recognition and detection result of the object target in the image when the information such as image information, eye position information and the like is insufficient, and does not need additional detection modules such as eyes, head postures and the like. The invention is not limited by the application scene, the hardware condition constraint is less, the actual operation is simple and convenient, and the target fixation identification and detection result is accurate.
2. According to the method, a BoTNet network is obtained by replacing 3x3 constraint in a ResNet network with multi-head Self-orientation, then a characteristic pyramid network taking the BoTNet network as a main network is used as a Heatmap path, the obtained gazing sight line area characteristic diagram and an original image are combined and sent to the Heatmap path together, and finally a gazing thermodynamic diagram is generated. The method utilizes the similarity of an attention mechanism and human visual attention to obtain a target area needing important attention, obtains an attention focus, can obtain more detailed information of the target needing attention, simultaneously inhibits other useless information, can effectively extract features, and enables a target fixation identification result based on sight estimation to be more accurate.
Drawings
In order to more clearly illustrate the embodiments of the present invention or the technical solutions in the prior art, the drawings used in the description of the embodiments or the prior art will be briefly described below, it is obvious that the drawings in the following description are only some embodiments of the present invention, and for those skilled in the art, other drawings can be obtained according to the drawings without creative efforts.
Fig. 1 is a flowchart of a target gaze identification method based on gaze estimation according to an embodiment of the present invention;
FIG. 2 is a block diagram of a ResNet network in an embodiment of the present invention;
FIG. 3 is a schematic view of a gaze area in an embodiment of the present invention;
fig. 4 is a view of the gaze area characteristic when γ takes different values in an embodiment of the present invention;
FIG. 5 is a comparison of the use of a BoTNet network ResNet network in an embodiment of the present invention;
FIG. 6 is a schematic diagram of a feature pyramid network in an embodiment of the invention.
Detailed Description
In order to make the objects, technical solutions and advantages of the embodiments of the present invention clearer, the technical solutions in the embodiments of the present invention are clearly and completely described, and it is obvious that the described embodiments are a part of the embodiments of the present invention, but not all of the embodiments. All other embodiments, which can be derived by a person skilled in the art from the embodiments given herein without making any creative effort, shall fall within the protection scope of the present invention.
The embodiment of the application provides the target gazing identification method and the target gazing identification system based on the sight line estimation, solves the problem that in the prior art, the target gazing identification result cannot be accurately obtained when the information is insufficient and the hardware equipment is deficient, and achieves the purposes of flexibly, conveniently and accurately predicting the target gazing identification and detection result.
In order to solve the technical problems, the general idea of the embodiment of the application is as follows:
in order to solve the problem that in the prior art, when information such as image information, eye position information and the like is insufficient or detection modules such as eye postures and head postures are lacked, the object target fixation recognition and detection results in an image cannot be accurately obtained, the face features and the head position features of an original image and a reversed image of the original image are firstly extracted, the face features and the head position features are spliced through features to obtain two-dimensional features, then a feature map of a fixation sight line area is obtained based on the two-dimensional features, and finally, the fixation thermodynamic map is obtained based on the fixation sight line area feature map and the original image by using a feature pyramid network based on a BoTNet network. The invention is not limited by the application scene, the hardware condition constraint is less, the actual operation is simple and convenient, and the target fixation identification and detection result is accurate.
In order to better understand the technical solution, the technical solution will be described in detail with reference to the drawings and the specific embodiments.
Example 1:
in a first aspect, the present invention first proposes a target gaze identification method based on gaze estimation, and referring to fig. 1, the method includes:
s1, extracting facial features and head position features in the original image; the face features comprise face features in the original image and reversed face features of the original image after being reversed;
s2, obtaining two-dimensional features by feature splicing of the face features and the head position features;
s3, acquiring a characteristic diagram of the gaze area based on the two-dimensional characteristics;
s4, acquiring a fixation thermodynamic diagram by utilizing a characteristic pyramid network based on a BoTNet network based on the fixation sight area characteristic diagram and the original image; the BoTNet network is a network after 3x3 constraint in a ResNet network is replaced by multi-head Self-attachment.
Therefore, the method comprises the steps of firstly extracting the face characteristics and the head position characteristics of the original image and the overturn image of the original image, obtaining the two-dimensional characteristics by characteristic splicing of the face characteristics and the head position characteristics, then obtaining the characteristic diagram of the watching sight line area based on the two-dimensional characteristics, and finally obtaining the watching thermodynamic diagram based on the characteristic pyramid network based on the BoTNet network and the original image, so that the identification and detection of the object watching in the image are realized. The invention can accurately acquire the recognition and detection result of the object target in the image when the information such as image information, eye position information and the like is insufficient, and does not need additional detection modules such as eyes, head postures and the like. The invention is not limited by the application scene, the hardware condition constraint is less, the actual operation is simple and convenient, and the target fixation identification and detection result is accurate.
The following describes the implementation of one embodiment of the present invention in detail with reference to the explanation of specific steps S1-S4.
S1, extracting facial features and head position features in the original image; the face features comprise face features in the original image and reversed face features of the original image after being reversed.
And extracting the face features in the original image and the reversed face features of the reversed image of the original image based on the ResNet model.
The method comprises the steps of obtaining an original image (namely scene content) and eye coordinates in the original image through labeling of an existing data set, obtaining a face image according to the eye coordinates, and finally extracting face features in the original image. In particular, the method comprises the following steps of,
the present embodiment uses a size-focusing dataset as an input source, in which the coordinates of where the person in the image looks (i.e. the real Gaze point coordinates) and the eyes in the image are annotated. Acquiring an original image of a data set, adding or subtracting 0.15 to the coordinates of eyes to obtain the coordinates of a face, and then cutting the face according to the coordinates of the face to obtain a face image; when the original image of the data set is acquired, the original image is horizontally inverted, and then an inverted face image of the face image is obtained by the same operation as described above.
The resolution of both the resulting face image and the inverted face image are adjusted to 224x224, the pixel values of the pixels of these images are read and converted to the tensor form required by the ResNet model, the pixel values are transformed from the range of 0-255 to between 0-1, and then the images are normalized channel by channel (i.e., mean becomes 0 and standard deviation becomes 1) for the three channels rgb to speed up the convergence of the model.
In the present embodiment, the model used to extract facial features is the ResNet model. Inputting a face image into a ResNet model, outputting the face image with the dimension of 2048 after the characteristics are extracted, and converting the dimension into 512 dimensions by using a full connection layer; synchronously, the same operation is carried out on the reversed face image, so that two 512-dimensional features can be obtained, and the two features are spliced to obtain a 1024-dimensional feature.
In this embodiment, the ResNet network is designed to be h (x) ═ f (x) + x, as shown in fig. 2. The above function can be converted to learn a residual function f (x) ═ h (x) — x, and if f (x) ═ 0, an identity map h (x) ═ x is formed, and it is easier to fit the residual. ResNet provides two selection modes, namely identification mapping and residual mapping, if the network reaches the optimal state, the network is continuously deepened, the residual mapping is pushed to be 0, and only the identification mapping is left, so that the network is in the optimal state all the time theoretically, and the performance of the network cannot be reduced along with the increase of the depth.
And extracting head position features in the original image.
And sending the head position into the three full-connection layers to extract the head position characteristics. Specifically, the head position is represented using coordinates of the eye position in the data set. From the size-focusing dataset, the coordinates of the eye in the image have been annotated, assuming that the annotated eye coordinates are H (H)x,hy) Then the head position coordinate is also H (H)x,hy) And is two-dimensional, using three fully connected layers to map it into 256-dimensional feature space. Although high dimensionality can help to learn more features, the amount of computation is also increased, so that a suitable dimensionality can be selected according to actual conditions. In the embodiment, 256-dimensional feature space is selected after comprehensive consideration, that is, 256-dimensional head position features are extracted after the head position is sent into three fully-connected layers.
And S2, obtaining two-dimensional features by feature splicing the face features and the head position features.
And splicing the obtained 256-dimensional head position feature with two 512-dimensional facial features, and then sending the two 512-dimensional facial features into a full connection layer to obtain the 256-dimensional features. And then the 256-dimensional features are processed by Relu activation function and then sent to a full connection layer, and finally the 2-dimensional features are obtained. This 2-dimensional feature is the predicted gaze line of sight.
And S3, acquiring a characteristic diagram of the gaze area based on the two-dimensional characteristics.
If the gaze line of the target person is predicted to be correct, the viewpoint is generally along the gaze line. Usually the target person's gaze field will be reduced to a cone, head position H (H)x,hy) As the apex of the cone. FIG. 3 is a view of the gaze area, see FIG. 3, given a point P (P)x,py) The probability that the point P is the fixation point should be equal to the straight line LHPProportional to the angle theta between the predicted gaze directions, the smaller the angle theta the greater the probability. In the present embodiment, the mapping from the angle to the probability value is described using a cosine function, and the probability distribution with P point as the gaze point is referred to as a gaze line region. The gaze area is thus effectively a probability map, this probabilityThe intensity value of each point on the graph represents the probability value that the point is the point of regard. Specifically, the larger the brightness value is, the larger the probability value is; the smaller the luminance value, the smaller the probability value. Wherein,
straight line LHPThe direction calculation formula of (2) is as follows: g ═ p (p)x-hx,py-hy);
Representing the predicted gaze line as Then the probability calculation formula for point P as the point of regard is as follows:
Then the probability calculation formula for point P as the point of regard is as follows:
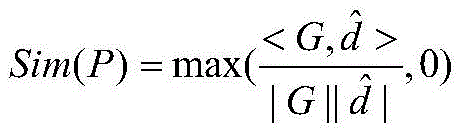
if the predicted gaze direction is correct, it is expected that along the gaze direction, the profile of the probability is sharp; if the predicted gaze direction is wrong, it is desirable that the probability profile is flat along the gaze direction, so the sharpness of the gaze area is controlled using:
Sim(P,γ)=[Sim(P)γ]
wherein gamma is a parameter for controlling the aperture size of the cone, and the larger gamma is, the smaller the aperture of the cone is. Empirically, the values of γ can be set to 5, 3, 1, respectively, see fig. 4, where fig. 4 shows the values of γ set to γ, respectively1=5,γ2=3,γ3Three fixation sight line area characteristic maps in 1 three cases.
S4, acquiring a fixation thermodynamic diagram by utilizing a characteristic pyramid network based on a BoTNet network based on the fixation sight area characteristic diagram and the original image; the BoTNet network is a network after 3x3 constraint in a ResNet network is replaced by multi-head Self-attachment.
The three gaze area feature maps and the original image are combined and sent to a Heatmap path together, and a gaze thermodynamic diagram is finally generated. The gaze line region feature map is a map having a size of 224x224 and the number of channels of 1, and the original image is a map having a size of 224x224 and the number of channels of 3. And splicing the three gaze line area characteristic graphs with the original image to obtain a graph with the size of 224x224 and the number of channels of 6, and reusing the graph as the input of a Heatmap path.
In this embodiment, for the Heatmap path, a feature pyramid network using a BoTNet network as a backbone network is used for target detection. And connecting the last layer of the Heatmap path with a Sigmoid function, thereby calculating the probability value of each point in the thermodynamic diagram and finally obtaining the visual attention diagram. The visual attention map is a thermodynamic map of size 56x56, with the size of the value representing the probability of a point of regard.
Referring to fig. 5, BoTNet replaces 3 × 3 containment with Multi-Head Self-attachment (MHSA) only in ResNet, and does not make any other changes. Since the Attention mechanism is similar to the human visual Attention, the Multi-Head Self-Attention can obtain the target area needing important Attention, and the Attention focus is obtained to obtain more detailed information of the target needing Attention, so that other useless information is suppressed, and therefore, the Multi-Head Self-Attention can be used for replacing the 3 × 3 restriction to more effectively extract the features.
The feature pyramid network can combine shallow features and deep features to make predictions on feature maps with different resolutions respectively, and is a classic method in the field of computer vision. Referring to fig. 6, the construction of the feature pyramid involves a bottom-up path, a top-down path, and a lateral connection.
The bottom-up approach is a feed-forward computation of the backbone network, which computes a feature hierarchy that contains a plurality of feature maps with scaling steps of 2. There will typically be many layers that produce a profile of the same size, it being understood that these layers are at the same network stage. For the constructed feature pyramid, defining a pyramid grade for each stage, and then selecting the output of the last layer of each stage as the reference of the feature map set.
The top-down path illusions that the higher resolution features at the high pyramid level are spatially coarser, but semantically stronger. These functions are then enhanced by the bottom-up path through the cross-connect. Each transverse connection merges a bottom-up path and a top-down path into a feature map of the same spatial size.
And after the characteristic pyramid network is constructed, sending the three gaze area graphs and the original graph into the characteristic pyramid network together to obtain the gaze thermodynamic diagrams of the characters in the image.
To ensure accuracy of target gaze recognition of the model, the method further comprises:
and S5, training the ResNet model and the BoTNet network-based feature pyramid network before obtaining the fixation thermodynamic diagram.
The ResNet model used above and the feature pyramid network with BoTNet as the backbone network were trained using the pytorech framework. During training, the face image, the head position and the original image in the size-Following data set are used as the input of the model, and the fixation thermodynamic diagram is output. In the model training process, in order to guide the model training process to a good direction, two loss functions are used to measure the quality of the model prediction process. The better the model training effect, the smaller the loss function of the whole model. The loss function of the whole model is obtained by adding two loss functions, namely the fixation sight loss and the thermodynamic loss. Specifically, the gaze loss function is:
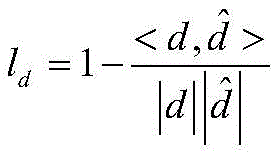
wherein d is the real gaze line obtained by subtracting the eye coordinates from the real gaze point coordinates in the data set, to predict the gaze line of sight, the above-described S2 may be obtained.
to predict the gaze line of sight, the above-described S2 may be obtained.
The thermodynamic diagram loss function is:

wherein HiIs the ithA true thermodynamic diagram (generated by a gaussian kernel from the eye coordinates in the dataset), for the ith predicted thermodynamic diagram, N is the magnitude of the thermodynamic diagram, 56x 56.
for the ith predicted thermodynamic diagram, N is the magnitude of the thermodynamic diagram, 56x 56.
After the values of the two loss functions are obtained respectively, the values corresponding to the two loss functions are added to obtain the loss function of the whole model.
In order to evaluate the prediction effect of the trained model, two evaluation indexes, namely AUC and Minimum angular error (MAng), are used for verifying the prediction effect of the model. Specifically, the AUC is used to estimate the difference between the predicted fixation point and the actual fixation point, and a larger value thereof indicates a better effect of the model, and conversely, the worse value; the MAng is used for measuring the minimum angle between the predicted gazing sight line and the real gazing sight line, and the smaller the value is, the better the model effect is, and the worse the model effect is.
Thus, the whole process of the target fixation identification method based on sight line estimation is completed.
Example 2:
in a second aspect, the present invention also provides a gaze recognition system for an object based on gaze estimation, the system comprising:
the feature extraction module is used for extracting facial features and head position features in the original image; the face features comprise face features in the original image and reversed face features of the original image after being reversed;
the feature splicing module is used for splicing the face feature and the head position feature to obtain a two-dimensional feature;
the sight line area characteristic diagram acquisition module is used for acquiring a characteristic diagram of a watching sight line area based on the two-dimensional characteristics;
the gazing thermodynamic diagram acquisition module is used for acquiring a gazing thermodynamic diagram by utilizing a characteristic pyramid network based on a BoTNet network based on the gazing sight line area characteristic diagram and the original image; the BoTNet network is a network after 3x3 constraint in a ResNet network is replaced by multi-head Self-attachment.
Optionally, the extracting facial features in the original image by the feature extraction module includes:
and extracting facial features in the original image by using a ResNet model.
Optionally, the extracting facial features in the original image by the feature extraction module using the ResNet model includes:
s11, adding or subtracting 0.15 to the eye coordinates in the original image to obtain face coordinates, and then cutting the face coordinates to obtain a face image;
s12, extracting facial features in the original image based on the facial image by using a ResNet model;
and S13, horizontally turning the original image to obtain a turned image of the original image, and extracting the turned facial features of the turned image through the steps S11 and S12.
Optionally, the gaze thermodynamic diagram obtaining module obtains a gaze thermodynamic diagram by using a feature pyramid network based on a BoTNet network based on the gaze area feature diagram and the original image; the BoTNet network is a network which replaces 3x3 constraint in a ResNet network by using multi-head Self-attachment and comprises the following steps:
and replacing 3x3 constraint in the ResNet network by using multi-head Self-orientation to obtain a BoTNet network, and sending the gazing sight line area characteristic diagram and the original image into a Heatmap path of a characteristic pyramid network taking the BoTNet network as a main network together to generate a gazing thermodynamic diagram.
Optionally, the system further includes:
and the model training module is used for training the BoTNet network-based feature pyramid network before the gazing thermodynamic diagram is acquired.
It can be understood that, the target gaze identification system based on gaze estimation provided by the embodiment of the present invention corresponds to the above target gaze identification method based on gaze estimation, and the explanations, examples, and beneficial effects of the relevant contents thereof may refer to the corresponding contents in the target gaze identification method based on gaze estimation, and are not described herein again.
In summary, compared with the prior art, the method has the following beneficial effects:
1. the method comprises the steps of firstly extracting face features and head position features of an original image and a reversed image of the original image, obtaining two-dimensional features by feature splicing the face features and the head position features, then obtaining a feature map of a watching sight line area based on the two-dimensional features, and finally obtaining a watching thermodynamic diagram based on the watching sight line area feature map and the original image by utilizing a feature pyramid network based on a BoTNet network, so that the identification and detection of the object watching in the image are realized. The invention can accurately acquire the recognition and detection result of the object target in the image when the information such as image information, eye position information and the like is insufficient, and does not need additional detection modules such as eyes, head postures and the like. The invention is not limited by the application scene, the hardware condition constraint is less, the actual operation is simple and convenient, and the target fixation identification and detection result is accurate.
2. According to the method, a BoTNet network is obtained by replacing 3x3 constraint in a ResNet network with multi-head Self-orientation, then a characteristic pyramid network taking the BoTNet network as a main network is used as a Heatmap path, the obtained gazing sight line area characteristic diagram and an original image are combined and sent to the Heatmap path together, and finally a gazing thermodynamic diagram is generated. The method utilizes the similarity of an attention mechanism and human visual attention to obtain a target area needing important attention, obtains an attention focus, can obtain more detailed information of the target needing attention, simultaneously inhibits other useless information, can effectively extract features, and enables a target fixation identification result based on sight estimation to be more accurate.
It is noted that, herein, relational terms such as first and second, and the like may be used solely to distinguish one entity or action from another entity or action without necessarily requiring or implying any actual such relationship or order between such entities or actions. Also, the terms "comprises," "comprising," or any other variation thereof, are intended to cover a non-exclusive inclusion, such that a process, method, article, or apparatus that comprises a list of elements does not include only those elements but may include other elements not expressly listed or inherent to such process, method, article, or apparatus. Without further limitation, an element defined by the phrase "comprising an … …" does not exclude the presence of other identical elements in a process, method, article, or apparatus that comprises the element.
The above examples are only intended to illustrate the technical solution of the present invention, but not to limit it; although the present invention has been described in detail with reference to the foregoing embodiments, it will be understood by those of ordinary skill in the art that: the technical solutions described in the foregoing embodiments may still be modified, or some technical features may be equivalently replaced; and such modifications or substitutions do not depart from the spirit and scope of the corresponding technical solutions of the embodiments of the present invention.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111047180.5A CN113947804A (en) | 2021-09-08 | 2021-09-08 | Target fixation identification method and system based on sight line estimation |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111047180.5A CN113947804A (en) | 2021-09-08 | 2021-09-08 | Target fixation identification method and system based on sight line estimation |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN113947804A true CN113947804A (en) | 2022-01-18 |
Family
ID=79328161
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111047180.5A Pending CN113947804A (en) | 2021-09-08 | 2021-09-08 | Target fixation identification method and system based on sight line estimation |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113947804A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114529787A (en) * | 2022-03-30 | 2022-05-24 | 长沙海信智能系统研究院有限公司 | Method and device for detecting checked article and electronic equipment |
| CN117011925A (en) * | 2023-07-05 | 2023-11-07 | 上海大学 | A fixation point detection method based on attention mechanism and depth prior |
| TWI903928B (en) * | 2024-01-24 | 2025-11-01 | 仁寶電腦工業股份有限公司 | Method for operating electronic apparatus based on gaze tracking and electronic apparatus |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108171152A (en) * | 2017-12-26 | 2018-06-15 | 深圳大学 | Deep learning human eye sight estimation method, equipment, system and readable storage medium storing program for executing |
| CN110853073A (en) * | 2018-07-25 | 2020-02-28 | 北京三星通信技术研究有限公司 | Method, device, equipment and system for determining attention point and information processing method |
| CN111507592A (en) * | 2020-04-08 | 2020-08-07 | 山东大学 | An evaluation method for active reformation behaviors for prisoners |
| CN111985341A (en) * | 2020-07-23 | 2020-11-24 | 东北师范大学 | Method and system for capturing visual attention of image and readable storage medium |
-
2021
- 2021-09-08 CN CN202111047180.5A patent/CN113947804A/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108171152A (en) * | 2017-12-26 | 2018-06-15 | 深圳大学 | Deep learning human eye sight estimation method, equipment, system and readable storage medium storing program for executing |
| CN110853073A (en) * | 2018-07-25 | 2020-02-28 | 北京三星通信技术研究有限公司 | Method, device, equipment and system for determining attention point and information processing method |
| CN111507592A (en) * | 2020-04-08 | 2020-08-07 | 山东大学 | An evaluation method for active reformation behaviors for prisoners |
| CN111985341A (en) * | 2020-07-23 | 2020-11-24 | 东北师范大学 | Method and system for capturing visual attention of image and readable storage medium |
Non-Patent Citations (3)
| Title |
|---|
| ARAVIND SRINIVAS 等: "Bottleneck Transformers for Visual Recognition", 《ARXIV:2101.11605V2》, 2 August 2021 (2021-08-02), pages 1 - 8 * |
| DONGZE LIAN 等: "Believe It or Not, We Know What You Are Looking At!", 《ACCV 2018》, 31 December 2019 (2019-12-31), pages 35 - 48 * |
| 梁玮 等: "《计算机视觉》", vol. 1, 31 January 2021, 北京理工大学出版社, pages: 152 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114529787A (en) * | 2022-03-30 | 2022-05-24 | 长沙海信智能系统研究院有限公司 | Method and device for detecting checked article and electronic equipment |
| CN117011925A (en) * | 2023-07-05 | 2023-11-07 | 上海大学 | A fixation point detection method based on attention mechanism and depth prior |
| TWI903928B (en) * | 2024-01-24 | 2025-11-01 | 仁寶電腦工業股份有限公司 | Method for operating electronic apparatus based on gaze tracking and electronic apparatus |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11644898B2 (en) | Eye tracking method and system | |
| US11854243B2 (en) | Gaze correction of multi-view images | |
| US11830230B2 (en) | Living body detection method based on facial recognition, and electronic device and storage medium | |
| CN113591562B (en) | Image processing method, device, electronic equipment and computer readable storage medium | |
| WO2022156626A1 (en) | Image sight correction method and apparatus, electronic device, computer-readable storage medium, and computer program product | |
| WO2019169884A1 (en) | Image saliency detection method and device based on depth information | |
| CN113947804A (en) | Target fixation identification method and system based on sight line estimation | |
| CN111723707A (en) | A gaze point estimation method and device based on visual saliency | |
| CN112528902A (en) | Video monitoring dynamic face recognition method and device based on 3D face model | |
| CN113822174A (en) | Gaze estimation method, electronic device, and storage medium | |
| WO2024198475A1 (en) | Face anti-spoofing recognition method and apparatus, and electronic device and storage medium | |
| CN118736010A (en) | A dynamic visual SLAM method for low-light scenes | |
| CN112446322A (en) | Eyeball feature detection method, device, equipment and computer-readable storage medium | |
| CN112257664A (en) | Image fusion method and device, computer equipment and storage medium | |
| US20230059499A1 (en) | Image processing system, image processing method, and non-transitory computer readable medium | |
| KR20190119212A (en) | System for performing virtual fitting using artificial neural network, method thereof and computer recordable medium storing program to perform the method | |
| CN111582155B (en) | Living body detection method, living body detection device, computer equipment and storage medium | |
| US20250086823A1 (en) | Gaze target detection method and system | |
| KR20230044341A (en) | Method and System for Medical diagnosis of human skin through artificial intelligence | |
| KR102039164B1 (en) | Apparatus for performing virtual fitting using multi-level artificial neural network, method thereof and computer recordable medium storing program to perform the method | |
| CN113988957B (en) | Automatic image scoring method and system based on element recognition | |
| Huang et al. | Dual fusion paired environmental background and face region for face anti-spoofing | |
| CN117218398A (en) | A data processing method and related devices | |
| US20230059407A1 (en) | Image processing system, image processing method, and non-transitory computer readable medium | |
| CN113392865B (en) | Image processing method, device, computer equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |