CN113869154B - Video actor segmentation method according to language description - Google Patents
Video actor segmentation method according to language description Download PDFInfo
- Publication number
- CN113869154B CN113869154B CN202111081527.8A CN202111081527A CN113869154B CN 113869154 B CN113869154 B CN 113869154B CN 202111081527 A CN202111081527 A CN 202111081527A CN 113869154 B CN113869154 B CN 113869154B
- Authority
- CN
- China
- Prior art keywords
- feature
- frame
- sentence
- level
- video
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computing Systems (AREA)
- General Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Probability & Statistics with Applications (AREA)
- Image Analysis (AREA)
Abstract
本发明公开了一种根据语言描述的视频动作者分割方法,所述方法利用级联跨模态注意力模块,利用剪辑级视觉特征粗略地关注语言查询的信息词,再利用帧级视觉特征来微调单词的注意力,微调目标帧中语言的权重,可以在丰富的视频信息中辨别分割出正例,并通过对比学习挖掘难负例,可以学习从视频中识别目标演员,还可以在不同的视频中区分它,显着提高帧内匹配和分割的准确率。The invention discloses a video actor segmentation method according to language description. The method utilizes cascaded cross-modal attention modules, uses clip-level visual features to roughly focus on the information words of language queries, and then uses frame-level visual features to Fine-tune the attention of words, fine-tune the weight of the language in the target frame, can identify and segment positive examples in the rich video information, and mine difficult negative examples through comparative learning, can learn to identify the target actor from the video, and can also be used in different Distinguish it in the video, significantly improving the accuracy of intra-frame matching and segmentation.
Description
技术领域technical field
本发明涉及视频识别技术领域,具体涉及一种根据语言描述的视频动作者分割方法。The invention relates to the technical field of video recognition, in particular to a method for segmenting video actors according to language description.
背景技术Background technique
近年来,视频理解任务受到了广泛关注,尤其是涉及自然语言处理的问题。在这个领域,已经取得了在语言选择性时间动作定位、视频字幕生成和根据句子描述对视频中动作者和动作分割任务的巨大成就。在现实场景中,一个视频包含多个在做动作的动作者是很常见的。因此,通过语言查询在空间和时间上选择性地细粒度地定位一个特定的动作者及其动作成为计算机更好地理解视频的一项重要任务。Video understanding tasks have received a lot of attention in recent years, especially those involving natural language processing. In this field, great achievements have been made in the tasks of language-selective temporal action localization, video caption generation, and segmentation of actors and actions in videos based on sentence descriptions. In real-world scenarios, it is common for a video to contain multiple actors in action. Therefore, selectively fine-grained localization of a specific actor and its actions in space and time through linguistic queries becomes an important task for computers to better understand videos.
在相关任务中广泛使用的框架,例如视频/图像对象接地,是通过一些检测方法生成视频/图像中的区域提议,然后将文本特征与提议的视觉特征进行匹配以选择最佳的对象提议作为匹配的对象。为了提高匹配两个异构特征的性能,以前的工作首先利用双向LSTM和自注意力机制来生成语言特征,然后使用加权文本特征来处理视觉特征,最后进行文本-视觉特征匹配。但这种自注意力机制学到的语言注意力实际上是训练数据的平均解,而不是专注于某个视频的个性解。这样,在推理过程中,无论输入视频是什么,都确定了关注的语言特征,因为视频是包含丰富内容的高级语义空间,因此很难掌握视频的最具判别力的特征。因而,视频决定了语言查询中的关键,捕获信息性单词和学习视觉感知的判别语言表示对于语言引导的视频动作者-动作分割任务至关重要。A widely used framework in related tasks, such as video/image object grounding, is to generate region proposals in videos/images by some detection methods, and then match text features with proposed visual features to select the best object proposal as a match Object. To improve the performance of matching two heterogeneous features, previous work first utilized bidirectional LSTM and self-attention mechanism to generate linguistic features, then used weighted text features to process visual features, and finally performed text-visual feature matching. But the linguistic attention learned by this self-attention mechanism is actually an average solution of the training data, rather than focusing on the individual solutions of a certain video. In this way, during inference, regardless of the input video, the linguistic features of interest are identified, and since video is a high-level semantic space containing rich content, it is difficult to grasp the most discriminative features of video. Video thus determines the key in language queries, capturing informative words and learning discriminative language representations for visual perception are crucial for language-guided video actor-action segmentation tasks.
如何设计视觉感知的语言编码器和生成判别性语言,从而对视频中的动作者及其动作进行分割,还需进一步优化分割方法,提高帧内匹配和分割的准确率。How to design a visual perception language encoder and generate discriminative language, so as to segment the actors and their actions in the video, it is necessary to further optimize the segmentation method and improve the accuracy of intra-frame matching and segmentation.
发明内容SUMMARY OF THE INVENTION
为了克服上述问题,本发明提供一种根据语言描述对视频动作者及其动作进行分割的方法,其中,利用级联跨模态注意力机制的协作优化网络,显著提高了匹配和分割的准确性。利用两个视角的视觉特征从粗到细地关注语言,生成具有辨别力的视觉感知的语言特征,另外,配备对比学习的方法,设计难负例挖掘策略,有利于网络从负例中识别正例,并进一步提高性能,从而完成本发明。In order to overcome the above problems, the present invention provides a method for segmenting video actors and their actions based on language descriptions, wherein the cooperative optimization network using cascaded cross-modal attention mechanisms significantly improves the accuracy of matching and segmentation . Using visual features from two perspectives to focus on language from coarse to fine, to generate language features with discriminative visual perception. In addition, it is equipped with a comparative learning method to design a mining strategy for difficult negative examples, which is beneficial for the network to identify positive examples from negative examples. example, and further improve the performance, thereby completing the present invention.
本发明第一方面的目的在于提供一种根据语言描述的视频动作者分割方法,所述方法利用级联跨模态注意力模块进行,生成具有辨别力的句子查询特征,提高匹配和分割的准确性。The purpose of the first aspect of the present invention is to provide a video actor segmentation method according to language description, the method utilizes cascaded cross-modal attention modules to generate discriminative sentence query features, and improves the accuracy of matching and segmentation. sex.
所述级联跨模态注意力模块包括剪辑级特征注意力单元和帧级特征注意力单元。The cascaded cross-modal attention module includes a clip-level feature attention unit and a frame-level feature attention unit.
所述剪辑级特征注意力单元采用句子嵌入s和目标帧j的剪辑级特征vc作为输入。The clip-level feature attention unit takes as input the sentence embedding s and the clip-level feature vc of the target frame j.
所述剪辑级特征注意力单元利用剪辑级特征vc对语言特征进行粗略加权,分别得到:The clip-level feature attention unit uses the clip-level feature vc to roughly weight the language features, and obtain:

F1=Att1·ψ(vc)+φ(s)F 1 =Att 1 ·ψ( vc )+φ(s)
其中,T为矩阵转置;σsoftmax是softmax激活函数;Att1为剪辑特征vc和句子嵌入s的注意力图;F1为粗加权的句子特征;剪辑特征vc经过卷积层

对于视频V,剪辑级特征vc由下式进行编码:For video V, the clip-level features vc are encoded by:

其中,
所述帧级特征注意力单元处理所述粗略加权的句子特征F1和帧级特征vf,得到微调的句子特征F2:The frame-level feature attention unit processes the roughly weighted sentence features F 1 and frame-level features v f to obtain fine-tuned sentence features F 2 :

F2=Att2·ψ′(vf)+F1 F 2 =Att 2 ·ψ′(v f )+F 1
其中,Att2为帧级特征vf和粗加权的句子特征F1的注意力图;F2表示微调的句子特征,其每一列表示一个单词的向量;

所述帧级特征vf利用ResNet-101网络进行提取,优选地,提取帧级特征前,在COCO数据集上进行预训练,并在A2D数据集训练分割上进行微调;The frame-level features v f are extracted by using the ResNet-101 network. Preferably, before extracting the frame-level features, pre-training is performed on the COCO dataset, and fine-tuning is performed on the A2D dataset training segmentation;
所述帧级特征为从帧j到帧i的扭曲特征和原始特征vi的线性加权组合,具体如下式所示:The frame-level feature is a linear weighted combination of the warped feature from frame j to frame i and the original feature v i , as shown in the following formula:

其中,vi为对目标帧i的ResNet-101编码特征,β是权重系数,i为目标帧,j为参考帧,2K为参考帧的帧数(即在目标帧前向取K帧,后向取K帧,对目标帧特征进行补偿),vj→i为从参考帧j到目标帧i的扭曲特征;Among them, vi is the ResNet-101 coding feature for the target frame i , β is the weight coefficient, i is the target frame, j is the reference frame, 2K is the number of frames of the reference frame (that is, take K frames in the front of the target frame, and then Take K frames to compensate the target frame features), v j→i is the distortion feature from the reference frame j to the target frame i;
所述vj→i为:The vj→i is:
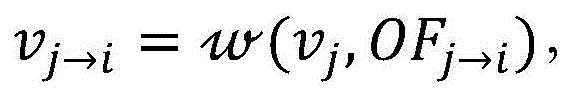
其中,vj是参考帧j的ResNet-101编码特征;OFj→i为参考帧j和目标帧i之间的光流;
加权的单词特征ht经过一个全连接层,得到句子查询特征q:The weighted word feature h t goes through a fully connected layer to obtain the sentence query feature q:
mt=FC(ht)m t =FC(h t )
αt=σsoftmax(mt)α t =σ softmax (m t )

其中,ht为F2特征的第t列,表示第t个单词的向量;FC(ht)为一个全连接层;mt为ht经过一个全连接层的中间向量;αt为第t个单词的加权系数。Among them, h t is the t-th column of the F 2 feature, representing the vector of the t-th word; FC(h t ) is a fully connected layer; m t is the intermediate vector of h t through a fully-connected layer; α t is the th Weighting coefficients for t words.
本发明第二方面还提供了一种计算机可读存储介质,存储有根据语言描述的视频动作者分割的训练程序,所述程序被处理器执行时,使得处理器执行所述根据语言描述的视频动作者分割方法的步骤。A second aspect of the present invention also provides a computer-readable storage medium, which stores a training program for segmentation of video actors according to language description, and when the program is executed by a processor, causes the processor to execute the video according to language description. The steps of the actor segmentation method.
本发明中所述的根据语言描述的视频动作者分割方法可借助软件加必需的通用硬件平台的方式来实现,所述软件存储在计算机可读存储介质(包括ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机、计算机、服务器、网络设备等)执行本发明所述方法。The language-described video actor segmentation method described in the present invention can be implemented by means of software plus a necessary general hardware platform, and the software is stored in a computer-readable storage medium (including ROM/RAM, magnetic disk, optical disk) , including several instructions to make a terminal device (which may be a mobile phone, a computer, a server, a network device, etc.) execute the method of the present invention.
本发明第三方面还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有根据语言描述的视频动作者分割的训练程序,所述程序被处理器执行时,使得处理器执行所述根据语言描述的视频动作者分割方法的步骤。A third aspect of the present invention also provides a computer device, comprising a memory and a processor, wherein the memory stores a training program for segmentation of video actors according to language description, and when the program is executed by the processor, the processor executes the Describe the steps of a video actor segmentation method according to language description.
本发明所具有的有益效果包括:The beneficial effects of the present invention include:
(1)本发明中提供的方法,利用剪辑级视觉特征粗略地关注语言查询的信息词,再利用帧级视觉特征来微调单词的注意力,微调目标帧中语言的权重,显着提高帧内匹配和分割的准确率。(1) The method provided in the present invention uses clip-level visual features to roughly pay attention to the information words of language queries, and then uses frame-level visual features to fine-tune the attention of words, fine-tune the weight of the language in the target frame, and significantly improve the intra-frame Matching and segmentation accuracy.
(2)本发明中提供的方法可以在丰富的视频信息中辨别分割出正例,并通过对比学习挖掘难负例,可以学习从视频中识别目标演员,还可以在不同的视频中区分它。(2) The method provided in the present invention can identify and segment positive examples in rich video information, and mine difficult negative examples through comparative learning, can learn to identify the target actor from the video, and can also distinguish it in different videos.
(3)利用本发明中的视觉特征编码器,提取剪辑级特征、帧级特征和正例、负例的视觉特征,得到句子查询特征q,通过对比学习区分正负例、正例和难负例,加强了级联跨模态注意力模块的判别能力。(3) Using the visual feature encoder in the present invention to extract clip-level features, frame-level features, and visual features of positive and negative examples to obtain sentence query features q, and distinguish positive and negative examples, positive examples, and difficult negative examples through comparative learning , which strengthens the discriminative ability of cascaded cross-modal attention modules.
附图说明Description of drawings
图1示出根据本发明一种根据语言描述的视频动作者分割方法的网络结构示意图;1 shows a schematic diagram of the network structure of a video actor segmentation method described by language according to the present invention;
图2示出本发明实施例1中一种根据语言描述的视频动作者分割方法在A2D数据集上应用的效果图。FIG. 2 shows an effect diagram of a method for segmentation of video actors according to language description applied to an A2D data set in Embodiment 1 of the present invention.
具体实施方式Detailed ways
下面通过附图和实施方式对本发明进一步详细说明。通过这些说明,本发明的特点和优点将变得更为清楚明确。其中,尽管在附图中示出了实施方式的各种方面,但是除非特别指出,不必按比例绘制附图。The present invention will be further described in detail below through the accompanying drawings and embodiments. The features and advantages of the present invention will become more apparent from these descriptions. Therein, although various aspects of the embodiments are shown in the drawings, the drawings are not necessarily drawn to scale unless otherwise indicated.
本发明提供了一种根据语言描述的视频动作者分割方法,所述方法利用级联跨模态注意力模块进行,生成具有辨别力的句子查询特征,提高匹配和分割的准确性。The present invention provides a video actor segmentation method according to language description, which utilizes cascaded cross-modal attention modules to generate discriminative sentence query features and improves the accuracy of matching and segmentation.
所述级联跨模态注意力模块包括剪辑级特征注意力单元和帧级特征注意力单元。The cascaded cross-modal attention module includes a clip-level feature attention unit and a frame-level feature attention unit.
本发明中,由于视频剪辑特征是包含所有信息的全局特征,因此,首先利用剪辑级视觉特征注意力单元粗略地关注语言查询的信息词,如反映运动和时间变化的词。然后,利用帧级特征注意力单元来微调单词的注意力,微调特定帧中句子的权重,例如,反应外观的属性,显著提高帧内匹配和分割的准确率。所述方法中,利用剪辑级特征注意力单元和帧级特征注意力单元学习基于给定视频的判别语言表示。In the present invention, since the video clip feature is a global feature containing all information, first, the clip-level visual feature attention unit is used to roughly focus on the informative words of the language query, such as words reflecting motion and temporal changes. Then, frame-level feature attention units are used to fine-tune word attention, fine-tuning the weights of sentences in specific frames, e.g., to reflect appearance properties, significantly improve the accuracy of intra-frame matching and segmentation. In the method, a clip-level feature attention unit and a frame-level feature attention unit are used to learn a discriminative language representation based on a given video.
所述级联跨模态注意力模块中,剪辑级特征注意力单元采用句子嵌入s和目标帧i的剪辑级特征vc作为输入,得到粗加权的句子特征F1。In the cascaded cross-modal attention module, the clip-level feature attention unit takes the sentence embedding s and the clip-level feature vc of the target frame i as input, and obtains the coarsely weighted sentence feature F 1 .
本发明中,所述剪辑级特征vc利用双流I3D编码器进行提取,优选地,提取剪辑级特征前,利用ImageNet和Kinetics对双流I3D编码器进行预训练。In the present invention, the clip-level feature vc is extracted by using a dual-stream I3D encoder. Preferably, ImageNet and Kinetics are used to pre-train the dual-stream I3D encoder before extracting the clip-level feature.
所述双流I3D编码器具体如文献“Carreira J,Zisserman A.Quo vadis,actionrecognition a new model and the kinetics dataset[C]//proceedings of the IEEEConference on Computer Vision and Pattern Recognition,2017:6299-6308.”中所述。The dual-stream I3D encoder is specifically described in the document "Carreira J, Zisserman A. Quo vadis, actionrecognition a new model and the kinetics dataset[C]//proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6299-6308." described in.
所述ImageNet具体如文献“Russakovsky O,Deng J,Su H,et al.Imagenet largescale Visual recognition challenge[J].International journal of computervision,2015,115(3):211-252.”中所述。The ImageNet is specifically described in the document "Russakovsky O, Deng J, Su H, et al. Imagenet largescale Visual recognition challenge [J]. International journal of computervision, 2015, 115(3): 211-252.".
所述Kinetics具体如文献“Kay W,Carreira J,Simonyan K,et al.The kineticshuman action video dataset[J].arXiV preprint arXiv:1705.06950,2017.”中所述。The Kinetics are specifically described in the document "Kay W, Carreira J, Simonyan K, et al. The kineticshuman action video dataset[J]. arXiV preprint arXiv: 1705.06950, 2017.".
对于视频V,剪辑级特征vc由下式进行编码:For video V, the clip-level features vc are encoded by:

其中,
所述I3D网络的Mixed-4f层具体如文献“Carreira J,Zisserman A.Quo vadis,action recognition a new model and the kinetics dataset[C]//proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition,2017:6299-6308.”中所述。The Mixed-4f layer of the I3D network is specifically described in the document "Carreira J, Zisserman A. Quo vadis, action recognition a new model and the kinetics dataset [C]//proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6299 -6308."
本发明中,先将目标帧i的视觉特征vj送入两个卷积层(

所述

其中,T为矩阵转置,σsoftmax为softmax函数,Att为衡量空间位置对每个单词的注意力图。Among them, T is the matrix transpose, σ softmax is the softmax function, and Att is the attention map that measures the spatial position of each word.
所述Att乘以ψ(vj),再加上φ(s)以得到视觉加权的句子特征:The Att is multiplied by ψ(v j ), plus φ(s) to obtain visually weighted sentence features:
F=Att·ψ(vj)+φ(s)F=Att·ψ(v j )+φ(s)
其中,F为视觉加权的句子特征。where F is the visually weighted sentence feature.
在本发明中,所述剪辑级特征注意力单元利用剪辑级特征vc对语言特征进行粗略加权,分别得到:In the present invention, the clip-level feature attention unit uses the clip-level feature vc to roughly weight the language features, and obtain respectively:

F1=Att1·ψ(vc)+φ(s)F 1 =Att 1 ·ψ( vc )+φ(s)
其中,T为矩阵转置,σsoftmax是softmax函数,Att1为剪辑特征vc和句子嵌入s的注意力图,F1为粗加权的句子特征。where T is the matrix transpose, σ softmax is the softmax function, Att 1 is the attention map of the clip feature vc and sentence embedding s, and F 1 is the coarsely weighted sentence feature.
本发明中,所述帧级特征注意力单元处理所述粗略加权的句子特征F1和帧级特征vf,得到微调的句子特征F2。In the present invention, the frame-level feature attention unit processes the roughly weighted sentence feature F 1 and the frame-level feature v f to obtain a fine-tuned sentence feature F 2 .
所述帧级特征vf利用ResNet-101网络进行提取,优选地,提取帧级特征前,ResNet-101网络在COCO数据集上进行预训练,并在A2D数据集训练分割上进行微调。The frame-level features v f are extracted by using the ResNet-101 network. Preferably, before extracting the frame-level features, the ResNet-101 network is pre-trained on the COCO dataset, and fine-tuned on the A2D dataset training segmentation.
所述ResNet-101网络具体如文献“He K,Zhang X,Ren S,et al.Deep residuallearning for image recognition[C]//Proceedings of the IEEE conference oncomputer vision and pattern recognition.2016:770-778.”中所述;所述COCO数据集具体如文献“Lin T Y,Maire M,Belongie S,et al.Microsoft coco:Common objects incontext[C]//European conference on computer vision.Springer,Cham,2014:740-755.”中所述;所述A2D数据集具体如文献“Xu C,Hsieh S H,Xiong C,et al.Can humansfly action understanding with multiple classes of actors[C]//Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition.2015:2264-2273.”中所述。The ResNet-101 network is specifically described in the document "He K, Zhang X, Ren S, et al. Deep residual learning for image recognition [C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778." Described in; the COCO dataset is specifically described in the document "Lin T Y, Maire M, Belongie S, et al. Microsoft coco: Common objects incontext [C]//European conference on computer vision. Springer, Cham, 2014: 740- 755.”; the A2D dataset is specifically described in the document “Xu C, Hsieh S H, Xiong C, et al. Can humans fly action understanding with multiple classes of actors[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 2264-2273.".
本发明中,为了增强特征图,计算目标帧i附近2K帧个参考帧j之间的光流,即在目标帧i前向取K帧,后向取K帧,作为参考帧,并基于光流将附近2K帧的ResNet-101编码特征扭曲到目标帧上,其中,K为帧数,具体根据下式进行:In the present invention, in order to enhance the feature map, the optical flow between 2K frames and reference frames j near the target frame i is calculated, that is, K frames are taken in the forward direction of the target frame i, and K frames are taken in the backward direction, as reference frames, and based on the light The stream warps the ResNet-101 encoded features of the nearby 2K frames onto the target frame, where K is the number of frames, according to the following formula:

其中,vj是参考帧j的ResNet-101编码特征;OFj→i为参考帧j和目标帧i之间的光流;
所述帧级特征为从帧j到帧i的扭曲特征和原始特征vi的线性加权组合,具体如下式所示:The frame-level feature is a linear weighted combination of the warped feature from frame j to frame i and the original feature v i , as shown in the following formula:

其中,vi为对目标帧i的ResNet-101编码特征,β是权重系数,i为目标帧,j为参考帧,2K为参考帧帧数,即在目标帧前向取K帧,后向取K帧,对目标帧特征进行补偿。通过这种方式,帧级特征vf被附近的帧级特征增强。Among them, vi is the ResNet-101 encoding feature of the target frame i , β is the weight coefficient, i is the target frame, j is the reference frame, 2K is the number of reference frames, that is, take K frames in the forward direction of the target frame, and backward Take K frames to compensate the target frame features. In this way, the frame-level features vf are enhanced by nearby frame-level features.
本发明中,将增强后的帧级特征vf直接放入区域提议网络(RPN)中以生成提议。由于目标帧已被其附近帧补偿,因此可以更容易地检测到移动物体。优选地,所述区域提议网络(RPN)具体如文献“He K,Gkioxari G,Dollár P,et al.Mask r-cnn[C]//Proceedingsof the IEEE international conference on computer vision.2017:2961-2969.”中所述述,优选地,所述区域提议网络(RPN)在COCO数据集上进行预训练,在A2D数据集训练分支割上进行微调得到。In the present invention, the enhanced frame-level features vf are directly put into the Region Proposal Network (RPN) to generate proposals. Since the target frame has been compensated by its nearby frames, moving objects can be detected more easily. Preferably, the Regional Proposal Network (RPN) is as detailed in the document "He K, Gkioxari G, Dollár P, et al. Mask r-cnn [C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969 .", preferably, the Region Proposal Network (RPN) is pre-trained on the COCO dataset and fine-tuned on the A2D dataset training branch cut.
所述帧级特征注意力单元处理所述粗略加权的句子特征F1和帧级特征vf,得到微调的句子特征F2:The frame-level feature attention unit processes the roughly weighted sentence features F 1 and frame-level features v f to obtain fine-tuned sentence features F 2 :

F2=Att2·ψ′(vf)+F1 F 2 =Att 2 ·ψ′(v f )+F 1
其中,Att2为帧级特征vf和粗加权的句子特征F1的注意力图;F2表示微调后的句子特征;

加权的单词特征ht经过一个全连接层,得到句子查询特征q:The weighted word feature h t goes through a fully connected layer to obtain the sentence query feature q:
mt=FC(ht)m t =FC(h t )
αt=σsoftmax(mt)α t =σ softmax (m t )

其中,ht为F2特征的第t列,表示第t个单词的向量;FC(ht)为一个全连接层,其具体如文献“Krizhevsky A,Sutskever I,Hinton G E.ImageNet Classification with DeepConvolutional Neural Networks[C]//Advances in Neural Information ProcessingSystems.2012.”中所述;mt为ht经过一个全连接层的中间向量;αt为第t个单词的加权系数;et为第t个单词的嵌入特征,具体如文献“MIKOLOV T,SUTSKEVER I,CHEN K,etal.Distributed representations of words and phrases and theircompositionality[C]//Advances in neural information processing systems,2013:3111-3119.”中所述。Among them, h t is the t-th column of the F 2 feature, representing the vector of the t-th word; FC(h t ) is a fully connected layer, which is as detailed in the document "Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Described in DeepConvolutional Neural Networks[C]//Advances in Neural Information ProcessingSystems.2012."; m t is the intermediate vector of h t after a fully connected layer; α t is the weighting coefficient of the t-th word; e t is the th-th word Embedding features of t words, as in the document "MIKOLOV T, SUTSKEVER I, CHEN K, etal. Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems, 2013: 3111-3119." said.
在本发明的一种优选实施方式中,在训练时,所述根据语言描述的视频动作者分割方法还包括利用句子查询特征q进行对比学习,用以区分正例和难负例。所述正例为目标帧上,与真值IoU(交并比)大于0.5的且IoU值最大的区域提议。所述难负例为目标帧上,与真值的IoU小于0.5的区域提议。所述IoU具体如文献“He K,Gkioxari G,Dollár P,etal.Mask r-cnn[C]//Proceedings of the IEEE international conference oncomputer vision.2017:2961-2969.”中所述In a preferred embodiment of the present invention, during training, the method for segmenting video actors based on language description further includes using sentence query feature q to perform comparative learning to distinguish positive examples from difficult negative examples. The positive example is the region proposal with the highest IoU value on the target frame, and the true value IoU (intersection-union ratio) is greater than 0.5. The hard negative example is the region proposal on the target frame with an IoU less than 0.5 with the ground truth. The IoU is specifically described in the document "He K, Gkioxari G, Dollár P, etal.Mask r-cnn[C]//Proceedings of the IEEE international conference oncomputer vision.2017:2961-2969."
注意到仅利用同目标帧内的难负例不足以学习句子查询特征q从视频区域提议中匹配到想要结果的能力,本发明中设计了难负例挖掘策略,分为两部分。第一部分,从包含目标帧的视频内挖掘难负例:从视频内的其他关键帧上,找到与当前帧真值不同的区域提议(即IoU小于0.5的区域提议)做为难负例。第二部分,从不同的视频上挖掘难负例:当难负例不足时,不断地找到包含同样动作者-动作标签的视频,从这些视频的关键帧上找到与该动作者-动作标签不同的区域提议作为难负例。测试时,从目标帧上的区域提议中,找到与得到的句子查询特征q相似度得分最高的区域提议即为匹配的结果。Noting that only using hard negative examples in the same target frame is not enough to learn the ability of sentence query feature q to match the desired result from the video region proposal, a hard negative example mining strategy is designed in the present invention, which is divided into two parts. The first part, mining hard negative examples from the video containing the target frame: from other key frames in the video, find the region proposals that are different from the ground truth of the current frame (that is, the region proposals with IoU less than 0.5) as hard negative examples. The second part, mining hard negative examples from different videos: when the hard negative examples are insufficient, continuously find videos that contain the same actor-action label, and find the key frames of these videos that are different from the actor-action label The region proposed as a hard negative example. During testing, from the region proposals on the target frame, finding the region proposal with the highest similarity score with the obtained sentence query feature q is the matching result.
本发明中,需要从包含丰富信息的视频中分割出能够与句子查询特征q相匹配的动作者及其动作,因此,所述方法中利用句子查询特征q进行对比学习,挖掘难负例,来加强q和区域提议之间的匹配能力。In the present invention, it is necessary to segment the actors and their actions that can match the sentence query feature q from the video containing rich information. Therefore, in the method, the sentence query feature q is used for comparative learning, and the difficult negative examples are mined to obtain Strengthen the matching ability between q and region proposals.
本发明中,对于句子嵌入s经过剪辑级特征注意力单元和帧级特征注意力单元处理后,得到微调的句子特征F2后,再与词嵌入加权得到句子查询特征q。所述r+为正例的视觉特征,rl -为负例的视觉特征,其中,l=1,2,...,L,其中L为负例的个数,L为大于等于1的整数,优选为5-50的整数,更优选为15-35,如为25。句子查询特征q的损失函数为:In the present invention, after the sentence embedding s is processed by the clip-level feature attention unit and the frame-level feature attention unit, the fine - tuned sentence feature F2 is obtained, and then the sentence query feature q is obtained by weighting with the word embedding. The r + is the visual feature of the positive example, and r l - is the visual feature of the negative example, wherein, l=1, 2,...,L, where L is the number of negative examples, and L is greater than or equal to 1 Integer, preferably an integer of 5-50, more preferably 15-35, such as 25. The loss function of the sentence query feature q is:

其中,T为矩阵转置。where T is the matrix transpose.
其中,损失函数Loss利用了(L+1)元组来优化从L个负例中识别出正例,减轻了网络收敛到局部最优的可能。Among them, the loss function Loss utilizes (L+1) tuples to optimize the identification of positive examples from L negative examples, reducing the possibility of the network converging to a local optimum.
所述正例的视觉特征r+或负例的视觉特征rl -利用RPN网络进行提取,即区域提议网络,生成区域提议,其骨干网络为ResNet-101网络。优选地,提取特征前,所述ResNet-101网络和区域提议网络(RPN)在COCO数据集上进行预训练,并在A2D数据集训练分支上进行微调。所述区域提议具有目标特征o和位置特征l。The visual feature r + of the positive example or the visual feature r l- of the negative example is extracted by using the RPN network, that is, the region proposal network, to generate region proposals, and its backbone network is the ResNet-101 network. Preferably, before extracting features, the ResNet-101 network and the region proposal network (RPN) are pre-trained on the COCO dataset and fine-tuned on the A2D dataset training branch. The region proposal has object feature o and location feature l.
所述目标特征o为经过RPN网络ROI-Aligned模块后的特征,优选地,与句子查询特征q的维度一致,如均为1024维的向量。所述ROI-Aligned模块具体如“Kaiming He,GeorgiaGkioxari,Piotr Dollár,Ross Girshick.Mask r-cnn[C]//Proceedings of the IEEEinternational conference on computer vision.2017:2961-2969.”中所述。The target feature o is the feature after passing through the ROI-Aligned module of the RPN network, preferably, the dimension of the sentence query feature q is consistent, such as a 1024-dimensional vector. The ROI-Aligned module is specifically described in "Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.".
所述位置特征l为:The location feature l is:

其中,(xtl,ytl)和(xbr,ybr)分别是区域提议的左上角和右下角的点的坐标,而w,h,W,H分别是区域提议的宽度、高度、目标帧的宽度和高度。where (x tl , y tl ) and (x br , y br ) are the coordinates of the upper-left and lower-right corners of the region proposal, respectively, and w, h, W, and H are the width, height, and target of the region proposal, respectively The width and height of the frame.
所述正例的视觉特征r+或负例的视觉特征rl -通过将位置特征l连接到目标特征o,然后将连接后的特征传递给全连接层以获得与文本表示具有相同维度的正例的视觉特征r+或负例的视觉特征rl -,具体如下式所示:The visual feature r of the positive example + or the visual feature r l of the negative example - by concatenating the location feature l to the target feature o, and then passing the concatenated feature to a fully connected layer to obtain a positive image with the same dimension as the text representation The visual feature r + of the example or the visual feature r l - of the negative example, as shown in the following formula:
r=σtanh(W([o;l]))r=σ tanh (W([o;l]))
其中,r为正例的视觉特征r+或负例的视觉特征rl -,为C维目标级特征,[;]表示连接操作,W为要学习的参数矩阵,σtanh为tanh激活函数。Among them, r is the visual feature r + of the positive example or the visual feature r l - of the negative example, which is the C-dimensional target-level feature, [;] represents the connection operation, W is the parameter matrix to be learned, and σ tanh is the tanh activation function.
所述tanh激活函数具体如文献“LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.”中所述。The tanh activation function is specifically described in the document "LeCun Y, Bottou L, Bengio Y, et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE, 1998, 86(11): 2278-2324." described in.
本发明中,经过句子查询特征q和正/难负例进行对比学习后,得到训练好的网络后,选择与文本特征相似度最高的区域提议,并将所选区域提议的视觉特征r+输入到分割分支中以生成结果掩码。本发明中的分割分支采用的是mask r-cnn的分割分支,其具体如文献“He K,Gkioxari G,Dollár P,et al.Mask r-cnn[C]//Proceedings of the IEEEinternational conference on computer vision.2017:2961-2969.”中所述,生成的掩码包含整个实体并有一个很好的边缘。本发明中的根据语言描述分割视频动作者及其动作的方法的网络结构示意图如图1所示。In the present invention, after comparing and learning the sentence query feature q and positive/difficult negative examples, after obtaining a trained network, select the region proposal with the highest similarity with the text feature, and input the visual feature r + of the selected region proposal into the in the split branch to generate the resulting mask. The segmentation branch in the present invention adopts the segmentation branch of mask r-cnn, which is specifically as in the document "He K, Gkioxari G, Dollár P, et al.Mask r-cnn [C]//Proceedings of the IEEE international conference on computer Vision.2017:2961-2969.", the generated mask contains the entire entity and has a nice edge. A schematic diagram of the network structure of the method for segmenting video actors and their actions according to language descriptions in the present invention is shown in FIG. 1 .
本发明第二方面还提供了一种计算机可读存储介质,存储有根据语言描述的视频动作者分割的训练程序,所述程序被处理器执行时,使得处理器执行所述根据语言描述的视频动作者分割方法的步骤。A second aspect of the present invention also provides a computer-readable storage medium, which stores a training program for segmentation of video actors according to language description, and when the program is executed by a processor, causes the processor to execute the video according to language description. The steps of the actor segmentation method.
本发明中所述的根据语言描述的视频动作者分割方法可借助软件加必需的通用硬件平台的方式来实现,所述软件存储在计算机可读存储介质(包括ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机、计算机、服务器、网络设备等)执行本发明所述方法。The language-described video actor segmentation method described in the present invention can be implemented by means of software plus a necessary general hardware platform, and the software is stored in a computer-readable storage medium (including ROM/RAM, magnetic disk, optical disk) , including several instructions to make a terminal device (which may be a mobile phone, a computer, a server, a network device, etc.) execute the method of the present invention.
本发明第三方面还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有根据语言描述的视频动作者分割的训练程序,所述程序被处理器执行时,使得处理器执行所述根据语言描述的视频动作者分割方法的步骤。A third aspect of the present invention also provides a computer device, comprising a memory and a processor, wherein the memory stores a training program for segmentation of video actors according to language description, and when the program is executed by the processor, the processor executes the Describe the steps of a video actor segmentation method according to language description.
本发明中提供的根据语言描述的视频动作者分割方法,首先利用剪辑级视觉特征粗略地关注语言查询的信息词,然后利用帧级视觉特征来微调单词的注意力,显着提高帧内匹配和分割的准确率。并且,该分割方法中,可以在包含内容丰富的视频中识别出正例,通过难负例挖掘策略并引入了对比学习,它不仅可以学习从视频中识别目标演员,还可以在不同的视频中区分它。这样,使其跨模型检索具有更强的判别能力。此外,采用专门的分割网络来分割在匹配中得到的区域,这使得生成的掩码具有更好的完整性和更好的边缘。The video actor segmentation method according to the language description provided in the present invention firstly uses the clip-level visual features to roughly pay attention to the informative words of the language query, and then uses the frame-level visual features to fine-tune the attention of the words, which significantly improves the intra-frame matching and segmentation accuracy. Moreover, in this segmentation method, positive examples can be identified in videos that contain rich content, through the hard negative example mining strategy and the introduction of contrastive learning, it can not only learn to identify target actors from videos, but also in different videos. differentiate it. In this way, it has stronger discriminative ability for cross-model retrieval. Furthermore, a dedicated segmentation network is employed to segment the regions obtained in the matching, which makes the generated masks with better completeness and better edges.
实施例Example
以下通过具体实例进一步描述本发明,不过这些实例仅仅是范例性的,并不对本发明的保护范围构成任何限制。The present invention is further described below through specific examples, but these examples are only exemplary and do not constitute any limitation to the protection scope of the present invention.
实施例1Example 1
(1)使用I3D网络在数据集ImageNet和数据集Kinetics上进行训练,利用得到的I3D网络的Mixed-4f层的输出作为I3D编码器。(1) Use the I3D network to train on the dataset ImageNet and the dataset Kinetics, and use the output of the Mixed-4f layer of the obtained I3D network as the I3D encoder.
所述数据集ImageNet具体如文献“Olga Russakovsky,Jia Deng,Hao Su,Jonathan Krause,Sanjeev Satheesh,Sean Ma,Zhiheng Huang,Andrej Karpathy,AdityaKhosla,Michael Bernstein,et al.2015.Imagenet large scale visual recognitionchallenge.International journal of computer vision 115,3(2015),211–252”中所述。The dataset ImageNet is specifically described in the document "Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, AdityaKhosla, Michael Bernstein, et al. 2015. Imagenet large scale visual recognition challenge. International Journal of computer vision 115, 3(2015), 211–252”.
所述数据集Kinetics具体如文献“Will Kay,Joao Carreira,Karen Simonyan,Brian Zhang,Chloe Hillier,Sudheendra Vijayanarasimhan,Fabio Viola,Tim Green,Trevor Back,Paul Natsev,et al.2017.The kinetics human action videodataset.arXiv preprint arXiv:1705.06950(2017)”中所述。The data set Kinetics is specifically described in the document "Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. The kinetics human action videodataset. arXiv preprint arXiv:1705.06950 (2017)”.
给定视频V(具体如图1或图2中的视频帧所示),剪辑特征vc由下式编码得到:Given a video V (specifically as shown in the video frame in Figure 1 or Figure 2), the clip feature v c is encoded by the following formula:

其中,
(2)ResNet-101网络在COCO数据集上进行了预训练后,在A2D数据集训练分割上进行微调。所述ResNet-101网络具体如文献“He K,Zhang X,Ren S,et al.Deep residuallearning for image recognition[C]//Proceedings of the IEEE conference oncomputer vision and pattern recognition.2016:770-778.”中所述;所述COCO数据集具体如文献“Lin T Y,Maire M,Belongie S,et al.Microsoft coco:Common objects incontext[C]//European conference on computer vision.Springer,Cham,2014:740-755.”中所述;所述A2D数据集具体如文献“Xu C,Hsieh S H,Xiong C,et al.Can humansfly action understanding with multiple classes of actors[C]//Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition.2015:2264-2273.”中所述。(2) The ResNet-101 network is fine-tuned on the A2D dataset training split after pre-training on the COCO dataset. The ResNet-101 network is specifically described in the document "He K, Zhang X, Ren S, et al. Deep residual learning for image recognition [C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778." Described in; the COCO dataset is specifically described in the document "Lin T Y, Maire M, Belongie S, et al. Microsoft coco: Common objects incontext [C]//European conference on computer vision. Springer, Cham, 2014: 740- 755.”; the A2D dataset is specifically described in the document “Xu C, Hsieh S H, Xiong C, et al. Can humans fly action understanding with multiple classes of actors[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 2264-2273.".
计算目标帧i附近14个参考帧j之间的光流(目标帧i前向7帧和后向7帧为参考帧j),并基于光流将上述附近14帧参考帧j的ResNet-101编码特征扭曲到目标帧上,具体通过下式完成:Calculate the optical flow between 14 reference frames j near the target frame i (the forward 7 frames and the backward 7 frames of the target frame i are the reference frame j), and based on the optical flow, the ResNet-101 of the above 14 nearby reference frames j is calculated. The encoded features are warped onto the target frame by the following formula:

其中,vj是对参考帧j的ResNet-101编码特征,OFj→i为参考帧j和目标帧i之间的光流,
帧级特征vf为从帧j到帧i的扭曲特征和原始特征vi的线性加权组合,具体如下式所示,其中,vi为对目标帧i的ResNet-101编码特征:The frame-level feature v f is the linear weighted combination of the warped feature from frame j to frame i and the original feature v i , as shown in the following formula, where v i is the ResNet-101 encoding feature for the target frame i:

其中,β是权重系数为0.1,K设定为7。参考帧j为目标帧i的前面7帧和后面7帧,视频采样帧率为24fps。通过从帧j到帧i的扭曲特征和原始特征vi的线性加权组合,使得帧级特征vf被附近的帧级特征增强。然后将增强后的特征直接放入区域提议网络(RPN)中以生成提议,所述区域提议网络(RPN)具体如文献“Girshick R.Fast r-cnn[C]//Proceedingsof the IEEE international conference on computer vision.2015:1440-1448.”中所述,所述区域提议网络(RPN)在COCO数据集上进行预训练,在A2D数据集训练分支割上进行微调得到。由于目标帧i已被其附近的帧补偿,因此可以更容易地检测到移动物体。where β is a weight coefficient of 0.1 and K is set to 7. The reference frame j is the first 7 frames and the last 7 frames of the target frame i, and the video sampling frame rate is 24fps. The frame-level feature vf is enhanced by nearby frame-level features by a linearly weighted combination of the warped features from frame j to frame i and the original feature vi . The enhanced features are then directly put into a Region Proposal Network (RPN) to generate proposals, which is as detailed in the document "Girshick R. Fast r-cnn[C]//Proceedings of the IEEE international conference on As described in computer vision. 2015: 1440-1448.", the region proposal network (RPN) is pre-trained on the COCO dataset and fine-tuned on the A2D dataset training branch cut. Since the target frame i has been compensated by its nearby frames, moving objects can be detected more easily.
其中,vf为16×16×1024维矩阵。Among them, v f is a 16×16×1024-dimensional matrix.
(3)利用剪辑级特征注意力单元将剪辑级特征vc对语言特征进行粗略加权,将目标帧i的剪辑级特征vc送入卷积层

所述卷积层
通过组合单词嵌入et形成句子嵌入s,接着将其放入一个1024维的全连接层中以生成句子特征φ(s)。其中,t∈[1,n],且t为整数,n为单词总数。et为第t个单词的嵌入特征,是一个300维的向量,由Google News数据集训练的word2vec模型得到,具体如文献“Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words andphrases and their compositionality[C].//In Advances in neural informationprocessing systems 2013.3111-3119.”中所述得到;所述Google News数据集具体如文献“A.S.Das,M.Datar,A.Garg,and S.Rajaram,“Google news personalization:scalableonline collaborative filtering,”in Proceedings of the 16th internationalconference on World Wide Web.ACM,2007,pp.271-280.”中所述。φ(·)是一个全连接层,其作用为将300维的信息变换到1024维,与视觉特征
剪辑级特征注意力单元利用剪辑级特征vc对语言特征进行粗略加权,分别得到:The clip-level feature attention unit uses the clip-level feature vc to roughly weight the language features, and obtain:

F1=Att1·ψ(vc)+φ(s)F 1 =Att 1 ·ψ( vc )+φ(s)
其中,σsoftmax是softmax激活函数,Att1为剪辑特征vc和句子嵌入s的注意力图,其维度为20×1024,其中每一个元素(a,b)表示第b个位置的视觉特征对第a个单词的影响,F1为粗加权的句子特征,其维度为20×1024,表示经过全局特征加权后的单词的特征。所述softmax激活函数具体如文献“LeCun Y,Bottou L,Bengio Y,et al.Gradient-basedlearning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.”中所述。Among them, σ softmax is the softmax activation function, Att 1 is the attention map of clip feature v c and sentence embedding s, and its dimension is 20×1024, where each element (a, b) represents the visual feature of the bth position. The influence of a word, F 1 is the coarsely weighted sentence feature, and its dimension is 20×1024, which represents the feature of the word after the global feature weighting. The softmax activation function is specifically described in the document "LeCun Y, Bottou L, Bengio Y, et al.Gradient-basedlearning applied to document recognition[J].Proceedings of the IEEE, 1998, 86(11): 2278-2324." said.
将上述粗略加权的句子特征F1和帧级特征vf输入到帧级特征注意力单元,得到微调的句子特征F2:Input the above roughly weighted sentence feature F 1 and frame-level feature v f to the frame-level feature attention unit to obtain the fine-tuned sentence feature F 2 :

F2=Att2·ψ′(vf)+F1 F 2 =Att 2 ·ψ′(v f )+F 1
其中,Att2为帧级特征vf和粗加权的句子特征F1的注意力图,F2表示微调的句子特征。
(4)将所述微调的句子特征F2的加权单词ht嵌入,得到句子查询特征q:(4) Embed the weighted word h t of the fine-tuned sentence feature F 2 to obtain the sentence query feature q:
mt=FC(ht)m t =FC(h t )
αt=σsoftmax(mt)α t =σ softmax (m t )

其中,ht为F2特征的第t列,表示第t个单词的向量;FC(ht)为一个全连接层;mt为ht经过一个全连接层的中间向量;αt为第t个单词的加权系数。Among them, h t is the t-th column of the F 2 feature, representing the vector of the t-th word; FC(h t ) is a fully connected layer; m t is the intermediate vector of h t through a fully-connected layer; α t is the th Weighting coefficients for t words.
(5)针对视频V,句子嵌入s,经上述步骤(1)-(4)得到句子查询特征q(如步骤4中所示),其中1个正例视觉特征为r+,25个负例视觉特征为rl -,其中,l=1,2,...,25。(5) For the video V, the sentence embedding s, the sentence query feature q (as shown in step 4) is obtained through the above steps (1)-(4), of which 1 positive example visual feature is r + , 25 negative examples The visual features are r l − , where l=1, 2, . . . , 25.
损失函数为:The loss function is:

其中,T为矩阵转置。where T is the matrix transpose.
(6)所述正例的视觉特征r+或负例的视觉特征rl -利用ResNet-101网络(所述ResNet-101网络具体如文献“He K,Zhang X,Ren S,et al.Deep residual learning forimage recognition[C].//In Proceedings of the IEEE conference on computervision and pattern recognition.2016,770-778.”中所述)进行提取。提取特征前,该网络在COCO数据集(所述COCO数据集具体如文献“Lin T,Maire M,Belongie S,etal.Microsoft coco:Common objects in context[C].//In European conference oncomputer vision.2014.740-755.”中所述)上进行预训练,并在A2D数据集(所述A2D数据集具体如文献“Xu C,Hsieh S,Xiong,C,etal.Can humans fly action understanding withmultiple classes of actors[C].//In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition.2015.2264-2273.”中所述)训练分割上进行微调,生成区域提议。区域提议的特征o为微调后的ResNet-01输出的该区域的目标特征,特征l为位置特征。(6) The visual feature r + of the positive example or the visual feature r l of the negative example — uses the ResNet-101 network (the ResNet-101 network is specifically described in the document “He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C].//In Proceedings of the IEEE conference on computervision and pattern recognition. 2016, 770-778.”) for extraction. Before extracting features, the network is in the COCO dataset (specifically, the COCO dataset is described in the document "Lin T, Maire M, Belongie S, et al. Microsoft coco: Common objects in context[C].//In European conference on computer vision. 2014.740-755.”) and pre-trained on the A2D dataset (the A2D dataset is specifically described in the document “Xu C, Hsieh S, Xiong, C, et al. Can humans fly action understanding with multiple classes of actors [C].//In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.2264-2273.”) fine-tune on training segmentation to generate region proposals. The feature o of the region proposal is the target feature of the region output by the fine-tuned ResNet-01, and the feature l is the position feature.
所述目标特征o为经过RPN网络ROI-Aligned模块后的特征,具体为1024维的向量(与句子查询特征q的维度一致)。The target feature o is the feature after passing through the ROI-Aligned module of the RPN network, and is specifically a 1024-dimensional vector (consistent with the dimension of the sentence query feature q).
所述位置特征l为:The location feature l is:

其中,(xtl,ytl)和(xbr,ybr)分别是区域提议的左上角和右下角的点的坐标,而w,h,W,H分别是区域提议的宽度、高度、目标帧的宽度和高度。where (x tl , y tl ) and (x br , y br ) are the coordinates of the upper-left and lower-right corners of the region proposal, respectively, and w, h, W, and H are the width, height, and target of the region proposal, respectively The width and height of the frame.
所述正例的视觉特征r+或负例的视觉特征rl -是通过将位置特征l连接到目标特征o,然后将连接后的特征传递给全连接层以获得与文本表示具有相同维度的正例的视觉特征r+或负例的视觉特征rl -,具体如下式所示:The visual feature r + of the positive example or the visual feature r l − of the negative example is obtained by concatenating the location feature l to the target feature o, and then passing the concatenated feature to a fully connected layer to obtain a The visual feature r + of the positive example or the visual feature r l - of the negative example, as shown in the following formula:
r=σtanh(W([o;l]))r=σ tanh (W([o;l]))
其中,r为正例的视觉特征r+或负例的视觉特征rl -,为C维目标级特征,[;]表示连接操作,σtanh为tanh激活函数。Among them, r is the visual feature r + of the positive example or the visual feature r l - of the negative example, which is the C-dimensional target-level feature, [;] represents the connection operation, and σ tanh is the tanh activation function.
所述tanh激活函数具体如文献“LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.”中所述。The tanh activation function is specifically described in the document "LeCun Y, Bottou L, Bengio Y, et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE, 1998, 86(11): 2278-2324." described in.
使正例的视觉特征r+或负例的视觉特征rl -与句子查询特征q进行对比学习,能够与q匹配的即为所需分割的正例,得到与文本特征相似度最高的区域提议,并将所选区域提议的视觉特征r+输入到mask r-cnn的分割分支中以生成结果掩码,得到分割后的最终结果。The visual feature r + of the positive example or the visual feature r l - of the negative example is compared with the sentence query feature q, and the positive example that can match q is the positive example to be segmented, and the region proposal with the highest similarity to the text feature is obtained. , and input the visual feature r + proposed by the selected region into the segmentation branch of mask r-cnn to generate the resulting mask, and get the final result after segmentation.
图2中为实施例1中方法在A2D数据集上的效果图,其中第一行中的文字为输入的句子,第二行中的图片序列为输入的视频,第三行为本实施例得到的分割结果,第四行为数据集给出的真实的分割图。从图2中可以看出,利用本发明中提供的根据语言描述分割的视频动作者分割方法能够从视频帧中完整的分割出目标动作者,分割结果与数据集给出的真实的分割图接近度很高。Figure 2 is the effect diagram of the method in Embodiment 1 on the A2D data set, in which the text in the first row is the input sentence, the picture sequence in the second row is the input video, and the third row is obtained in this embodiment. The segmentation result, the real segmentation map given by the fourth row dataset. As can be seen from Fig. 2, the target actor can be completely segmented from the video frame by using the video actor segmentation method according to the language description provided in the present invention, and the segmentation result is close to the real segmentation map given by the data set degree is very high.
以上结合具体实施方式和/或范例性实例以及附图对本发明进行了详细说明,不过这些说明并不能理解为对本发明的限制。本领域技术人员理解,在不偏离本发明精神和范围的情况下,可以对本发明技术方案及其实施方式进行多种等价替换、修饰或改进,这些均落入本发明的范围内。本发明的保护范围以所附权利要求为准。The present invention has been described in detail above with reference to specific embodiments and/or exemplary examples and accompanying drawings, but these descriptions should not be construed as limiting the present invention. Those skilled in the art understand that, without departing from the spirit and scope of the present invention, various equivalent replacements, modifications or improvements can be made to the technical solutions of the present invention and the embodiments thereof, which all fall within the scope of the present invention. The scope of protection of the present invention is determined by the appended claims.
Claims (10)














Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111081527.8A CN113869154B (en) | 2021-09-15 | 2021-09-15 | Video actor segmentation method according to language description |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111081527.8A CN113869154B (en) | 2021-09-15 | 2021-09-15 | Video actor segmentation method according to language description |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113869154A CN113869154A (en) | 2021-12-31 |
| CN113869154B true CN113869154B (en) | 2022-09-02 |
Family
ID=78996032
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111081527.8A Active CN113869154B (en) | 2021-09-15 | 2021-09-15 | Video actor segmentation method according to language description |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113869154B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114494297B (en) * | 2022-01-28 | 2022-12-06 | 杭州电子科技大学 | Adaptive video target segmentation method for processing multiple priori knowledge |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101411195B (en) * | 2003-09-07 | 2012-07-04 | 微软公司 | Encoding and decoding of interlaced video |
| CN108829677A (en) * | 2018-06-05 | 2018-11-16 | 大连理工大学 | A kind of image header automatic generation method based on multi-modal attention |
| US10839223B1 (en) * | 2019-11-14 | 2020-11-17 | Fudan University | System and method for localization of activities in videos |
| CN112466326A (en) * | 2020-12-14 | 2021-03-09 | 江苏师范大学 | Speech emotion feature extraction method based on transform model encoder |
| CN112650886A (en) * | 2020-12-28 | 2021-04-13 | 电子科技大学 | Cross-modal video time retrieval method based on cross-modal dynamic convolution network |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10395118B2 (en) * | 2015-10-29 | 2019-08-27 | Baidu Usa Llc | Systems and methods for video paragraph captioning using hierarchical recurrent neural networks |
-
2021
- 2021-09-15 CN CN202111081527.8A patent/CN113869154B/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101411195B (en) * | 2003-09-07 | 2012-07-04 | 微软公司 | Encoding and decoding of interlaced video |
| CN108829677A (en) * | 2018-06-05 | 2018-11-16 | 大连理工大学 | A kind of image header automatic generation method based on multi-modal attention |
| US10839223B1 (en) * | 2019-11-14 | 2020-11-17 | Fudan University | System and method for localization of activities in videos |
| CN112466326A (en) * | 2020-12-14 | 2021-03-09 | 江苏师范大学 | Speech emotion feature extraction method based on transform model encoder |
| CN112650886A (en) * | 2020-12-28 | 2021-04-13 | 电子科技大学 | Cross-modal video time retrieval method based on cross-modal dynamic convolution network |
Non-Patent Citations (3)
| Title |
|---|
| 【VideoQA最新论文阅读】第一篇视频问答综述Video Question Answering: a Survey of Models and Datasets;Leokadia Rothschild;《https://blog.csdn.net/m0_46413065/article/details/113828037》;20210216;第1-36页 * |
| CVPR 2020 | 细粒度文本视频跨模态检索;AI科技评论;《https://zhuanlan.zhihu.com/p/115890991》;20200324;第1-6页 * |
| 视频显著性检测研究进展;丛润民等;《软件学报》;20180208(第08期);全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113869154A (en) | 2021-12-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114022432B (en) | Insulator defect detection method based on improved yolov5 | |
| Gao et al. | Reading scene text with fully convolutional sequence modeling | |
| CN111462126B (en) | Semantic image segmentation method and system based on edge enhancement | |
| CN113569865B (en) | Single sample image segmentation method based on class prototype learning | |
| CN114723760B (en) | Portrait segmentation model training method and device, and portrait segmentation method and device | |
| CN103984943B (en) | A kind of scene text recognition methods based on Bayesian probability frame | |
| CN113902925A (en) | A method and system for semantic segmentation based on deep convolutional neural network | |
| Pourmirzaei et al. | Using self-supervised auxiliary tasks to improve fine-grained facial representation | |
| CN108537754B (en) | Face image restoration system based on deformation guide picture | |
| CN111914698A (en) | Method and system for segmenting human body in image, electronic device and storage medium | |
| CN114565913A (en) | Text recognition method and device, equipment, medium and product thereof | |
| CN116645694B (en) | Text-object retrieval method based on dynamic self-evolution information extraction and alignment | |
| CN113139966B (en) | Hierarchical cascade video target segmentation method based on Bayesian memory | |
| Wang et al. | Multiscale deep alternative neural network for large-scale video classification | |
| CN114255456A (en) | Natural scene text detection method and system based on attention mechanism feature fusion and enhancement | |
| CN116363361B (en) | Automatic driving method based on real-time semantic segmentation network | |
| CN114743002A (en) | Video object segmentation method based on weakly supervised learning | |
| CN116403015A (en) | Unsupervised target re-identification method and system based on perception-assisted learning Transformer model | |
| Wang et al. | Hierarchical kernel interaction network for remote sensing object counting | |
| CN115147607A (en) | Anti-noise zero-sample image classification method based on convex optimization theory | |
| CN116453232A (en) | Face living body detection method, training method and device of face living body detection model | |
| Wang et al. | Exploring fine-grained sparsity in convolutional neural networks for efficient inference | |
| CN113869154B (en) | Video actor segmentation method according to language description | |
| Yang et al. | Cost-effective adversarial attacks against scene text recognition | |
| Cai et al. | Vehicle detection based on visual saliency and deep sparse convolution hierarchical model |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |