CN113836895A - An unsupervised machine reading comprehension method based on large-scale problem self-learning - Google Patents
An unsupervised machine reading comprehension method based on large-scale problem self-learning Download PDFInfo
- Publication number
- CN113836895A CN113836895A CN202111151305.9A CN202111151305A CN113836895A CN 113836895 A CN113836895 A CN 113836895A CN 202111151305 A CN202111151305 A CN 202111151305A CN 113836895 A CN113836895 A CN 113836895A
- Authority
- CN
- China
- Prior art keywords
- model
- data
- training
- domain
- machine reading
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/211—Syntactic parsing, e.g. based on context-free grammar [CFG] or unification grammars
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/58—Use of machine translation, e.g. for multi-lingual retrieval, for server-side translation for client devices or for real-time translation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/088—Non-supervised learning, e.g. competitive learning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Machine Translation (AREA)
Abstract
本发明公开了一种基于大规模问题自学习的无监督机器阅读理解方法,首先将数据分为四种类型:然后按以下步骤进行:S1、对未标注的通用数据使用标准预训练模型进行训练得到预训练语言模型;S2、对已标注的通用数据使用预训练语言模型进行训练得到问题生成器,并生成特定任务通用领域模型;S3、对未标注的域内数据使用问题生成器生成合成的域内数据,然后使用特定任务通用领域模型进行过滤,再对过滤得到的高质量的合成的域内数据集进行训练得到新预训练模型;S4、对已标注的域内数据通过过滤得到的低质量的合成数据集进行混合并标记答案,然后使用新预训练模型进行训练得到最终模型;基于最终模型,输入数据得到机器阅读理解的结果。

The invention discloses an unsupervised machine reading comprehension method based on large-scale problem self-learning. First, the data is divided into four types: and then the following steps are performed: S1. Use a standard pre-training model to train the unlabeled general data Obtain a pre-trained language model; S2, use the pre-trained language model to train the labeled general data to obtain a problem generator, and generate a general domain model for a specific task; S3, use the problem generator for unlabeled in-domain data to generate a synthetic in-domain model Then use the general domain model for specific tasks to filter, and then train the high-quality synthetic intra-domain data set obtained by filtering to obtain a new pre-training model; S4. Low-quality synthetic data obtained by filtering the labeled intra-domain data The final model is obtained by training the new pre-trained model; based on the final model, the input data is used to obtain the results of machine reading comprehension.
Description

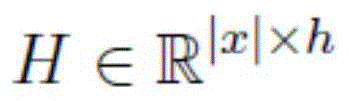



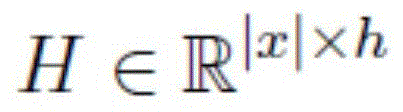







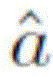

Claims (5)


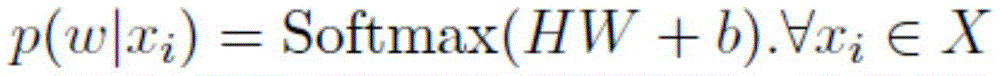

Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2021101731076 | 2021-02-08 | ||
| CN202110173107 | 2021-02-08 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113836895A true CN113836895A (en) | 2021-12-24 |
| CN113836895B CN113836895B (en) | 2025-05-09 |
Family
ID=78967302
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111151305.9A Active CN113836895B (en) | 2021-02-08 | 2021-09-29 | An unsupervised machine reading comprehension method based on large-scale question self-learning |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113836895B (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114996424A (en) * | 2022-06-01 | 2022-09-02 | 吴艳 | Weak supervision cross-domain question-answer pair generation method based on deep learning |
| CN116229185A (en) * | 2023-04-03 | 2023-06-06 | 南京大学 | A Continuous Learning Image Classification Method for Open Environment |
| CN116501859A (en) * | 2023-06-26 | 2023-07-28 | 中国海洋大学 | Paragraph retrieval method, device and medium based on refrigerator field |
| CN116663679A (en) * | 2023-07-25 | 2023-08-29 | 南栖仙策(南京)高新技术有限公司 | Language model training method, device, equipment and storage medium |
| CN116701930A (en) * | 2023-05-29 | 2023-09-05 | 北京零点远景网络科技有限公司 | A blockchain data acquisition method and device based on a multi-architecture NLP pre-training model |
| CN117291245A (en) * | 2023-09-25 | 2023-12-26 | 北京声智科技有限公司 | Model training methods, devices, computer equipment and storage media |
| CN117540021A (en) * | 2023-11-28 | 2024-02-09 | 中关村科学城城市大脑股份有限公司 | Large language model training method, device, electronic equipment and computer readable medium |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090276764A1 (en) * | 2008-05-05 | 2009-11-05 | Ghorbani Ali-Akbar | High-level hypermedia synthesis for adaptive web |
| US20170105683A1 (en) * | 2015-10-16 | 2017-04-20 | General Electric Company | System and method of adaptive interpretation of ecg waveforms |
| CN106844356A (en) * | 2017-01-17 | 2017-06-13 | 中译语通科技(北京)有限公司 | A kind of method that English-Chinese mechanical translation quality is improved based on data selection |
| CN108962224A (en) * | 2018-07-19 | 2018-12-07 | 苏州思必驰信息科技有限公司 | Speech understanding and language model joint modeling method, dialogue method and system |
| CN109992669A (en) * | 2019-04-08 | 2019-07-09 | 浙江大学 | A kind of keyword answering method based on language model and intensified learning |
| CN111079431A (en) * | 2019-10-31 | 2020-04-28 | 北京航天云路有限公司 | Entity relation joint extraction method based on transfer learning |
| CN111444677A (en) * | 2020-02-21 | 2020-07-24 | 平安科技(深圳)有限公司 | Reading model optimization method, device, equipment and medium based on big data |
| CN111611361A (en) * | 2020-04-01 | 2020-09-01 | 西南电子技术研究所(中国电子科技集团公司第十研究所) | Extractive Machine Intelligence Reading Comprehension Question Answering System |
| CN111797194A (en) * | 2020-05-20 | 2020-10-20 | 北京三快在线科技有限公司 | Text risk detection method and device, electronic equipment and storage medium |
| CN112309528A (en) * | 2020-10-27 | 2021-02-02 | 上海交通大学 | A method for generating medical image report based on visual question answering method |
-
2021
- 2021-09-29 CN CN202111151305.9A patent/CN113836895B/en active Active
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090276764A1 (en) * | 2008-05-05 | 2009-11-05 | Ghorbani Ali-Akbar | High-level hypermedia synthesis for adaptive web |
| US20170105683A1 (en) * | 2015-10-16 | 2017-04-20 | General Electric Company | System and method of adaptive interpretation of ecg waveforms |
| CN106844356A (en) * | 2017-01-17 | 2017-06-13 | 中译语通科技(北京)有限公司 | A kind of method that English-Chinese mechanical translation quality is improved based on data selection |
| CN108962224A (en) * | 2018-07-19 | 2018-12-07 | 苏州思必驰信息科技有限公司 | Speech understanding and language model joint modeling method, dialogue method and system |
| CN109992669A (en) * | 2019-04-08 | 2019-07-09 | 浙江大学 | A kind of keyword answering method based on language model and intensified learning |
| CN111079431A (en) * | 2019-10-31 | 2020-04-28 | 北京航天云路有限公司 | Entity relation joint extraction method based on transfer learning |
| CN111444677A (en) * | 2020-02-21 | 2020-07-24 | 平安科技(深圳)有限公司 | Reading model optimization method, device, equipment and medium based on big data |
| CN111611361A (en) * | 2020-04-01 | 2020-09-01 | 西南电子技术研究所(中国电子科技集团公司第十研究所) | Extractive Machine Intelligence Reading Comprehension Question Answering System |
| CN111797194A (en) * | 2020-05-20 | 2020-10-20 | 北京三快在线科技有限公司 | Text risk detection method and device, electronic equipment and storage medium |
| CN112309528A (en) * | 2020-10-27 | 2021-02-02 | 上海交通大学 | A method for generating medical image report based on visual question answering method |
Non-Patent Citations (1)
| Title |
|---|
| 琚心怡;: "基于深层双向Transformer编码器的早期谣言检测", 《信息通信》, no. 5, 15 May 2020 (2020-05-15), pages 17 - 22 * |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114996424A (en) * | 2022-06-01 | 2022-09-02 | 吴艳 | Weak supervision cross-domain question-answer pair generation method based on deep learning |
| CN114996424B (en) * | 2022-06-01 | 2023-05-09 | 吴艳 | Weak supervision cross-domain question-answer pair generation method based on deep learning |
| CN116229185A (en) * | 2023-04-03 | 2023-06-06 | 南京大学 | A Continuous Learning Image Classification Method for Open Environment |
| CN116701930A (en) * | 2023-05-29 | 2023-09-05 | 北京零点远景网络科技有限公司 | A blockchain data acquisition method and device based on a multi-architecture NLP pre-training model |
| CN116501859A (en) * | 2023-06-26 | 2023-07-28 | 中国海洋大学 | Paragraph retrieval method, device and medium based on refrigerator field |
| CN116501859B (en) * | 2023-06-26 | 2023-09-01 | 中国海洋大学 | Paragraph retrieval method, equipment and medium based on refrigerator field |
| CN116663679A (en) * | 2023-07-25 | 2023-08-29 | 南栖仙策(南京)高新技术有限公司 | Language model training method, device, equipment and storage medium |
| CN117291245A (en) * | 2023-09-25 | 2023-12-26 | 北京声智科技有限公司 | Model training methods, devices, computer equipment and storage media |
| CN117540021A (en) * | 2023-11-28 | 2024-02-09 | 中关村科学城城市大脑股份有限公司 | Large language model training method, device, electronic equipment and computer readable medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113836895B (en) | 2025-05-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Gupta et al. | Abstractive summarization: An overview of the state of the art | |
| CN113836895B (en) | An unsupervised machine reading comprehension method based on large-scale question self-learning | |
| US10482115B2 (en) | Providing question and answers with deferred type evaluation using text with limited structure | |
| US8332394B2 (en) | System and method for providing question and answers with deferred type evaluation | |
| US9535898B2 (en) | Natural language question expansion and extraction | |
| US20110125734A1 (en) | Questions and answers generation | |
| Team et al. | Fanar: An arabic-centric multimodal generative ai platform | |
| Cheng et al. | Research on automatic error correction method in English writing based on deep neural network | |
| Kusuma et al. | Automatic question generation with various difficulty levels based on knowledge ontology using a query template | |
| Ahmed et al. | On the application of sentence transformers to automatic short answer grading in blended assessment | |
| Johnsi et al. | Enhancing automated essay scoring by leveraging LSTM networks with hyper-parameter tuned word embeddings and fine-tuned LLMs | |
| Ramesh et al. | Coherence‐based automatic short answer scoring using sentence embedding | |
| Kumar et al. | A novel approach for text generation using RNN for language modeling | |
| Thakkar | Finetuning transformer models to build asag system | |
| Kowsher et al. | Knowledge-base optimization to reduce the response time of bangla chatbot | |
| Kilmen et al. | Shortening psychological scales: semantic similarity matters | |
| Sendra et al. | Enhanced latent semantic analysis by considering mistyped words in automated essay scoring | |
| Ramesh et al. | Coherence based automatic essay scoring using sentence embedding and recurrent neural networks | |
| Bo et al. | Bug question answering with pretrained encoders | |
| Hendricks et al. | Text to model via SysML: Automated generation of dynamical system computational models from unstructured natural language text via enhanced System Modeling Language diagrams | |
| Seneviratne et al. | Inductive logic programming in an agent system for ontological relation extraction | |
| Kulkarni | Named Entity Recognition on Kannada Low Resource Language using Deep Learning Models | |
| Egaña Azpiazu | Exploration of aunnotation strategies for entailment-based Automatic Short Answer Grading | |
| Hodzic | Automated Extraction of Data from Insurance Websites | |
| Abumansour | Check-worthy Arabic Claim Detection across topics for Automated Fact-checking Systems |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right |
Effective date of registration: 20221026 Address after: 310000 Room 303, building 3, No. 399, Qiuyi Road, Changhe street, Binjiang District, Hangzhou City, Zhejiang Province Applicant after: Honglong Technology (Hangzhou) Co.,Ltd. Applicant after: HANGZHOU LINKER TECHNOLOGY CO.,LTD. Address before: 310000 room 31191, 3 / F, building 1, No. 88, Puyan Road, Puyan street, Binjiang District, Hangzhou City, Zhejiang Province Applicant before: Honglong Technology (Hangzhou) Co.,Ltd. |
|
| TA01 | Transfer of patent application right | ||
| CB02 | Change of applicant information |
Country or region after: China Address after: 3rd Floor, Building 4, No. 399 Qiuyi Road, Changhe Street, Binjiang District, Hangzhou City, Zhejiang Province 311000 Applicant after: Qiongjie Intelligent Technology (Hangzhou) Co.,Ltd. Applicant after: HANGZHOU LINKER TECHNOLOGY CO.,LTD. Address before: Room 303, Building 3, No. 399 Qiuyi Road, Changhe Street, Binjiang District, Hangzhou City, Zhejiang Province Applicant before: Honglong Technology (Hangzhou) Co.,Ltd. Country or region before: China Applicant before: HANGZHOU LINKER TECHNOLOGY CO.,LTD. |
|
| CB02 | Change of applicant information | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |