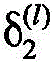Disclosure of Invention
The purpose of the invention is as follows: aiming at the problems in the prior art, the invention discloses a large-scale MIMO detection method, a device and a storage medium, which solve the problem that the performance loss of the existing MIMO detection method based on the approximate expectation propagation algorithm is serious in related channels.
The technical scheme is as follows: in order to achieve the purpose, the invention adopts the following technical scheme: a large-scale MIMO detection method comprises the following steps:
obtaining a received signal vector, a channel matrix and a noise variance according to the obtained received signal, channel information and noise information;
inputting the received signal vector, the channel matrix and the noise variance data into a trained approximate expected propagation network model to obtain an estimated value of a transmitting signal;
the approximate expected propagation network model training process comprises:
constructing an approximate expected propagation network based on the deep learning network, wherein each layer of the approximate expected propagation network corresponds to each iterative process of the EPA algorithm; introducing learnable linear correction parameters at each network layer to correct second-order coefficient of non-normalized cavity edge distribution at each iteration in the EPA algorithm; outputting a final estimated value of a transmission signal by the last layer of the approximate expected propagation network;
training the constructed approximate expected propagation network to obtain learnable linear correction parameters after training, and fixing the learnable linear correction parameters to obtain the trained approximate expected propagation network model.
Further, a learnable damping coefficient is introduced in each network layer to correct the mean and variance of the cavity edge distribution at each iteration in the EPA algorithm.
Further, the input parameters approximating each layer of the desired propagation network include:
Normalized matched output
A first order term coefficient for an unnormalized cavity edge distribution of a current layer;
second order term coefficients for the non-normalized cavity edge distribution before the current layer linear correction;
and, the mean and variance of the cavity edge distribution output by the previous layer;
wherein y is a real-domain received signal vector, H is a real channel matrix,
is the noise variance.
Further, the output parameters of each layer of the approximate expected propagation network include:
the coefficient of the first order term for the un-normalized cavity edge distribution of the next layer, the estimate of the transmit signal output by the current layer, and the mean and variance of the cavity edge distribution output by the current layer.
Further, the total loss function approximating the desired propagation network is a weighted average of the partial loss functions of each network layer, the partial loss functions of each network layer being set to the estimated value of the transmitted signal and the minimum mean square error of the transmitted signal at the output of each network layer.
A massive MIMO detection apparatus comprising:
a training module for constructing an approximate expected propagation network based on the deep learning network, each layer of the approximate expected propagation network corresponding to each iterative process of the EPA algorithm; introducing learnable linear correction parameters at each network layer to correct second-order coefficient of non-normalized cavity edge distribution at each iteration in the EPA algorithm; outputting a final estimated value of a transmission signal by the last layer of the approximate expected propagation network; training the constructed approximate expected propagation network to obtain learnable linear correction parameters after training, and fixing the learnable linear correction parameters to obtain the trained approximate expected propagation network model;
the acquisition module is used for acquiring a received signal vector, a channel matrix and a noise variance according to the acquired received signal, channel information and noise information;
and the estimation module is used for inputting the received signal vector, the channel matrix and the noise variance data into the trained approximate expected propagation network model to obtain an estimation value of the transmitting signal.
Further, a learnable damping coefficient is introduced in each network layer to correct the mean and variance of the cavity edge distribution at each iteration in the EPA algorithm.
Further, the input parameters approximating each layer of the desired propagation network include:
Normalized matched output
A first order term coefficient for an unnormalized cavity edge distribution of a current layer;
second order term coefficients for the non-normalized cavity edge distribution before the current layer linear correction;
and, the mean and variance of the cavity edge distribution output by the previous layer;
wherein y is a real-domain received signal vector, H is a real channel matrix,
is the noise variance.
Further, the output parameters of each layer of the approximate expected propagation network include:
the coefficient of the first order term for the un-normalized cavity edge distribution of the next layer, the estimate of the transmit signal output by the current layer, and the mean and variance of the cavity edge distribution output by the current layer.
Further, the total loss function approximating the desired propagation network is a weighted average of the partial loss functions of each network layer, the partial loss functions of each network layer being set to the estimated value of the transmitted signal and the minimum mean square error of the transmitted signal at the output of each network layer.
A computer-readable storage medium storing computer-executable instructions for performing any of the massive MIMO detection methods described above.
Compared with the prior art, the invention has the following beneficial effects:
(1) the M-MIMO detection method based on the approximate expected propagation network (EPANet) model of the invention, each layer of the approximate expected propagation network corresponds to each iteration process of the EPA algorithm; a learnable linear correction parameter is introduced into each network layer to correct a second-order coefficient of unnormalized cavity edge distribution in each iteration of an EPA algorithm, so that the coefficient is more accurate under a relevant channel, and the performance of the EPA detection method is improved;
(2) a learnable damping coefficient is introduced into each network layer to correct the mean value and variance of the unnormalized cavity edge distribution in each iteration of the EPA algorithm, so that the performance of the algorithm is further improved, and the convergence stability of the algorithm is ensured;
(3) the partial loss function of each network layer is set as the minimum mean square error of the output and the sending signal of each network layer, and the total loss function of the network layers is set as the weighted average of the loss functions of each network layer, so that the convergence performance of the algorithm is improved;
experiments prove that the performance of the method in the related channel is obviously superior to that of the prior art, the complexity is low, and better performance improvement is realized with low complexity.
Detailed Description
The present invention will be further described with reference to the accompanying drawings.
The M-MIMO system is set up as follows:
the user side is configured with Nt transmitting antennas, and the base station side is configured with NrRoot receiving antenna, wherein Nt<Nr. The M-MIMO system is simplified into the following real number domain mathematical model:
y=Hx+n (1)
wherein,
for real received signal vectors, where y
jFor the j-th dimension received signal, j is 1, 2, …, 2N
r. Since the signals in the real system are all equivalent to complex numbers, the real part and the imaginary part of the complex numbers need to be considered when converting into a real number model, so that the y vector has 2N in total
rThe components (x, H and n are similar to each other) (. C)
TIt is shown that the transpose operation,
transmitting a vector of signals for real numbers, wherein x
iFor the ith dimension, i is 1, 2, …, 2N
tH is 2N
r×2N
tA real channel matrix of dimensions is formed,
is real additive white Gaussian noise, where n
jIs a j-th dimension real number noise signal, the noise mean value is 0, and the variance is
The channel in the invention mainly considers a Kronecker related channel model, and a channel matrix under the model can be expressed as follows:
H=R1/2Hi.i.d.T1/2 (2)
wherein, R is receiving end space correlation matrix, T is sending end space correlation matrix, and its receiving end and sending end correlation usually use correlation coefficient ζ respectivelyrAnd ζtTo measure. R1/2And T1/2Can be obtained by Cholesky decomposition, Hi.i.d.Is an independent and equally distributed Rayleigh channel matrix.
Assuming that the receiving end knows the channel condition, the ith dimension sends signal x
iHas a prior probability of
Wherein,
is an indicator function indicating if signal x is transmitted
iIn the modulation constellation set Θ, the function takes a value of 1, otherwise the function takes a value of 0. The a posteriori probability of the transmitted signal vector can be expressed as:
wherein,
denotes y obedient mean as Hx and covariance matrix as
Is distributed in a multi-dimensional gaussian manner,
represents 2N
r×2N
rDimensional unit array due to
Is a non-Gaussian function, making it difficult to maximize the posterior probability, and the core idea of the EP algorithm is to transmit a signal x in the ith dimension subject to a Gaussian distribution
iApproximate prior probability distribution of
To approximate p (x)
i) Wherein, oc represents proportional to, λ
iAnd gamma
iThe coefficients of the second and first order terms of the non-normalized approximated prior probability distribution in the ith dimension, respectively, the approximated posterior probability q (x) of the transmitted signal vector can be expressed as:
setting a vector
And
diag {. is used to return a diagonal matrix. The updating formula of the mean vector mu and the covariance matrix sigma of the approximate a posteriori probability q (x) is as follows,
wherein,
is a normalized Gram matrix of the signal to be normalized,
is the normalized matching output. The (γ, a) is updated in each iteration of the EP algorithm, thereby updating the mean vector μ and covariance matrix Σ of the approximated a posteriori probabilities q (x), which become more and more accurate during the iteration.
Before the iteration starts, an initial value gamma is seti0 and λi=Es -1,EsRepresenting the average symbol energy. Calculating a cavity edge distribution (cavity marginal distribution) of the ith dimension, from an approximate posterior probability q (x) of the transmit signal xi in the ith dimensioni) Deleting the approximate prior probability distribution in the ith dimension to obtain:
wherein, V
iAnd ρ
iCoefficients of a second order term and a first order term of the ith-dimension non-normalized cavity edge distribution respectively, and then the mean value t of the ith-dimension cavity edge distribution
iSum variance
The calculation formula is as follows:
μiis q (x)i) I.e. the ith-dimension component, Σ, of μiiIs q (x)i) I.e. the (i, i) th component of the matrix sigma;
then signal x is sentiApproximate posterior probability q (x)i) Can be expressed as:
introducing a transmit signal x to a cavity edge profile of dimension i
iThe prior probability of (a) can be used to obtain a refined distribution
The EPA algorithm finds the sum from the point of view of KL divergence (Kullback-Leibler divergence) minimum
Nearest q (x)
i). Due to q (x)
i) Is a Gaussian distribution, where minimizing KL divergence is equivalent to moment matching (moment matching), i.e., the first and second moments are equal, there is
Wherein eta is
iIs a refining profile
I.e. the estimate of the ith-dimension transmitted signal xi,
for refining distribution
The average value of (a) of (b),
representing the transmitted signal x
iObey mean value of t
iVariance of
A gaussian distribution of (a). Order to
And
equation (11) can be equivalently expressed as:
ρ+γ=(V+Λ)η (13)
substituting the formula (11) and the formula (13) into the formula (5) and the formula (6), according to the related documents (x.tan, y. -l.ueng, z.zhang, x.you, and c.zhang, "low-complex MIMO detection based on adaptive amplification processing," IEEE trans.veh.technol., vol.68, No.8, pp.7260-7272, aug.2019),:
ρ=b+(-A+V)η (14)
at this point, sigma still needs to be calculated in each iterationiiThe EPA algorithm takes into account the characteristics of channel hardening in M-MIMO systems, i.e. the Gram matrix H when the number of antennas is particularly largeTH tends to a diagonal matrix, and the Gram matrix is replaced by the diagonal matrix formed by diagonal elements of the Gram matrix, so that the inversion at the moment becomes diagonal matrix inversion. Therefore, the temperature of the molten metal is controlled,
{HTH}iithe element value of the ith row and the ith column of the Gram matrix;
according to formula (12) have
It can be seen that the EPA algorithm works approximately if the Gram matrix is approximately diagonal, and the diagonal dominance of the Gram matrix in the relevant channel is no longer obvious, so the performance of the EPA deteriorates drastically.
Therefore, the scheme of the present invention is proposed to solve the problem that the performance of the existing EPA algorithm deteriorates drastically under the relevant channel.
Example 1:
as shown in fig. 1, a massive MIMO detection method includes the steps of:
step 101, constructing an approximate expected propagation network based on a deep learning network, introducing learnable linear correction parameters, and training to obtain a trained approximate expected propagation network model;
102, obtaining a received signal vector y, a channel matrix H and a noise variance according to the obtained received signal, channel information and noise information
Step 103, receiving the signal vector y, the channel matrix H and the noise variance
The data is input into a trained approximate expected propagation network model to obtain an estimated value of the transmitted signal.
Preferably, the approximate expected propagation network model training method includes:
1) constructing an approximate expected propagation network based on the deep learning network, and marking the approximate expected propagation network as EPANet, wherein each layer of the approximate expected propagation network corresponds to each iteration process of the EPA algorithm as shown in FIG. 2; introducing learnable linear correction parameters in each network layer (the network layer referred to in this disclosure represents a layer that approximates the desired propagation network) to correct second order coefficients of the unnormalized cavity edge distribution at each iteration in the EPA algorithm; the output value of the last layer of the approximate expected propagation network is used as the final estimated value of the transmitted signal;
preferably, the input parameters of each layer (i.e. the ith layer) of the approximate expected propagation network include:
normalized Gram matrix
And normalized matched output
First order coefficient for ith dimension unnormalized cavity edge distribution of ith layer
Second order coefficient for ith dimension unnormalized cavity edge distribution before linear correction for ith layer
And, the mean of the cavity edge distribution of the ith dimension of the l-1 th layer output
Sum variance
Preferably, the output parameters of each layer (i.e. the ith layer) of the approximate expected propagation network include:
coefficient of first order term for ith dimension unnormalized cavity edge distribution of layer l +1 obtained by corrected EPA algorithm
Ith dimension transmission signal x
iIs estimated value of
And cavity edge of ith dimension of ith layer outputMean value of distribution
Sum variance
2N
tAn
Estimated value vector eta of transmission signal composing output of l-th layer
(l),2N
tAn
Coefficient vector p constituting the first order term of the unnormalized cavity edge distribution for the next layer
(l+1)。
The initial values of the input parameters are calculated as follows:
setting initial values of coefficients of a second order term and a first order term for the ith dimension non-normalized approximate prior probability distribution during initialization of the EPA algorithm
And
E
srepresenting the average symbol energy. Then, according to the formulas (5) and (6), calculating to obtain a mean value vector mu of the approximate posterior probability distribution of the sending signal vector when the EPA algorithm is initialized
(0)Sum covariance matrix ∑
(0)And then, calculating coefficients of a first order term and a second order term of the ith dimension non-normalized cavity edge distribution during initialization of the EPA algorithm according to the formula (11) and the formula (12)
And V
i (0):
Wherein,
and
respectively sending the mean value and the variance of the approximate posterior probability distribution of the signal vector when the EPA algorithm is initialized; and for the first order term of the ith dimension unnormalized cavity edge distribution at the first iteration of the EPA algorithm
Each layer of the approximate expected propagation network corresponds to each iterative process of the EPA algorithm, introducing two learnable parameters α in each network layer
(l)And beta
(l)To linearly correct V at each iteration in the EPA algorithm
i (l)(i.e., the second order coefficient of the i-th dimension non-normalized cavity edge distribution at the i-th iteration, equation (16), where the superscript L represents the number of the approximate expected propagation network layer, which is also the iteration number of the EPA algorithm, and ranges from 1, 2, …, L; L is the set number of the approximate expected propagation network layers, which is the set maximum number of iterations of the EPA algorithm)
After linear correction, it is recorded as V
i (l)Then V is
i (l)The following expression is given:
wherein,
in view of V
i (l)Is q
\i(x
i) Must be greater than 0, so a ReLU activation function is added to further adjust V
i (l)Thus V
i (l)The final expression of (c) is:
where ε is a very small constant that avoids the variance becoming infinite, and takes the value of 1 × 10 in subsequent simulations-12。
By correcting the second-order term coefficient of the cavity edge distribution of which the ith dimension is not normalized during the ith iteration, the coefficient is more accurate under a relevant channel, and the performance of the EPA detection method is improved.
Calculating a cavity edge distribution q of the ith dimension of the ith layer by equations (8) and (9)
(l)\i(x
i) Mean value of
Sum variance
And substituting the average value into formula (11) to obtain the average value of the refined distribution of the first network layer
I.e. the ith dimension of the first iteration of the EPA algorithm sends signal x
i2N, will be
tAn
Component vector eta
(l)I.e. the estimated value of the transmitted signal vector at the l-th network layer; the coefficients of the first order terms of the non-normalized cavity edge distribution of the l +1 th layer are found according to equation (14):
2N
tan
Component vector rho
(l+1)A, b, ρ
(l+1)、
And
as input to the next network layer;
output value eta of Lth network layer(L)And is output as a final estimation value of the transmission signal.
Preferably, considering that the EPA iterative algorithm does not reach an optimal solution after many iterations if the convergence is too fast and easily diverges and too slow, and the iterative algorithm easily falls into a local optimal solution in the iteration process, in order to ensure the convergence stability of the algorithm and further improve the performance of the algorithm, the q is distributed to the cavity edge of the ith dimension of the ith layer
(l)\i(x
i) Mean value of
Sum variance
Introducing learnable damping coefficients
And
as will be shown below, in the following,
wherein, when l is 1,
take a value of
Take a value of
Substituting equations (19) and (20) into equation (11) to obtain the mean value of the refined distribution of the l-th network layer
I.e. the ith dimension of the first iteration of the EPA algorithm sends signal x
i2N, will be
tAn
Component vector eta
(l)I.e. the estimated value of the transmitted signal at the l-th network layer;
2) training the constructed approximate expected propagation network through training data to obtain a learnable parameter after training, and fixing the learnable parameter to obtain a trained approximate expected propagation network model;
the method specifically comprises the following steps: training the constructed approximate expected propagation network through training data to obtain a learnable parameter alpha after training(l)And beta(l)Fixing the learnable parameters to obtain a trained approximate expected propagation network model;
preferably, the approximation constructed by the training data pairs takes into account the introduction of a learnable damping coefficientTraining the expected propagation network to obtain a learnable parameter alpha after training
(l)And beta
(l)And a learnable damping coefficient
And
fixing learnable parameters and damping coefficients to obtain a trained approximate expected propagation network model;
training data and verification data are randomly generated under different channel configurations, and the method comprises the following steps: sending signal vector x, normalized Gram matrix
And normalized matched output
Preferably, the partial loss function of each network layer is set as the minimum mean square error of the estimated value of the transmission signal output by each network layer and the transmission signal (i.e. the training label), and the total loss function of the network layer is set as the weighted average of the loss functions of each network layer, so as to improve the convergence performance of the algorithm, and the total loss function of the network layer is:
wherein, wlIs the weight of the ith network layer.
The learning rate is set, batch training is used, and the minimum batch size, total training data and training iteration number are set. Selecting a specific optimizer (such as Adam) to train on a platform supporting machine learning, and optimizing parameter sets
Until a maximum number of training iterations is reached.
The order of steps 101 and 102 in this embodiment may be interchanged.
Example 2:
as shown in fig. 3, a massive MIMO detection apparatus includes:
the training module is used for training the approximate expected propagation network model, constructing the approximate expected propagation network based on the deep learning network, and each layer of the approximate expected propagation network corresponds to each iterative process of the EPA algorithm; introducing learnable linear correction parameters in each network layer to correct second-order coefficient of non-normalized cavity edge distribution at each iteration in the EPA algorithm; outputting a final estimated value of a transmission signal by the last layer of the approximate expected propagation network; training the constructed approximate expected propagation network to obtain learnable linear correction parameters after training, and fixing the learnable linear correction parameters to obtain a trained approximate expected propagation network model;
the acquisition module is used for acquiring a received signal vector, a channel matrix and a noise variance according to the acquired received signal, channel information and noise information;
and the estimation module is used for inputting the received signal vector, the channel matrix and the noise variance data into the trained approximate expected propagation network model to obtain an estimation value of the transmitting signal.
Preferably, the second order term coefficient of the unnormalized cavity edge distribution at each iteration in the corrected EPA algorithm is:
wherein,
second order term coefficients for the ith dimension unnormalized cavity edge distribution at the l iteration in the EPA algorithm before correction, { H
TH}
iiFor the value of the element in the ith row and ith column of the Gram matrix,
as a noise squarePoor, H is 2N
r×2N
tReal channel matrix of dimension, N
tFor the number of transmitting antennas, N
rFor the number of receiving antennas, α
(l)And beta
(l)The linear correction parameters which can be learnt by the l layer are all the linear correction parameters; ReLU is an activation function, and epsilon is a set constant;
the variance of the approximate a posteriori probability distribution of the transmitted signal vector at initialization of the EPA algorithm,
the coefficients of the second order term that approximate the prior probability distribution are not normalized for the ith dimension at initialization of the EPA algorithm.
Preferably, a learnable damping coefficient is introduced into each network layer to correct the mean and variance of the cavity edge distribution at each iteration in the EPA algorithm, and the formula is:
wherein,
and
mean and variance of the cavity edge distribution in the ith dimension of the ith iteration in the EPA algorithm,
and
all the damping coefficients can be learned by the introduced l-th layer, when l is 1,
has a value of
Has a value of
Preferably, the input parameters of the l-th layer of the approximate expected propagation network include:
Normalized matched output
Coefficients for first order terms of ith-dimension unnormalized cavity edge distribution for ith layer
The initial values are:
second order coefficient for ith dimension unnormalized cavity edge distribution before linear correction for ith layer
The initial values are:
and, the mean of the cavity edge distribution of the ith dimension of the l-1 th layer output
Sum variance
The initial values are:
i=1,2,…,2Nt
preferably, the output parameters of the l-th layer of the approximate expected propagation network include:
coefficient of first order term for ith dimension unnormalized cavity edge distribution of layer l +1 obtained by corrected EPA algorithm
Estimated value of ith dimension transmission signal xi
And average of the i-dimension cavity edge distribution of the l-th layer output
Sum variance
2N
tAn
Estimated value vector eta of transmission signal composing output of l-th layer
(l),2N
tAn
Coefficient vector p constituting the first order term of the unnormalized cavity edge distribution for the next layer
(l+1)。
Wherein, the superscript L represents the sequence number of the approximate expected propagation network layer, the range of L is 1, 2, …, L is the total layer number of the set approximate expected propagation network,
and
respectively the mean and variance of the approximate a posteriori probability distribution of the transmitted signal vector at initialization of the EPA algorithm,
the coefficient of the first-order term of the ith dimension non-normalized approximate prior probability distribution when the EPA algorithm is initialized; y is a real received signal vector.
Preferably, the total loss function D (η, x) approximating the desired propagation network is:
wherein, w
lIs the weight of the l network layer, x
iFor the signal to be transmitted in the i-th dimension,
sending a signal x for the ith dimension of the first iteration of the EPA algorithm
iAn estimate of (d).
Example 3:
a computer-readable storage medium storing computer-executable instructions for performing the massive MIMO detection method of any one of embodiments 1.
Example 4:
the present invention is configured as an example in such a way that a transmission signal vector x is uniformly and randomly generated from QPSK modulationThe channel matrix H is randomly generated from a correlation channel model, in which the correlation coefficient is ζt=ξr0.3 or ζt=ξrAnd (3) when the number of the transmitting antennas is 0.5, the number of the receiving antennas is 48 or 64, and the signal-to-noise ratio is randomly and uniformly selected from 0-16 dB. The learning rate was set to 0.001, batch training was used, the minimum batch size was set to 64, and the total training data size was 16000. 50 iterative training were performed by the Adam optimizer in the Pythrch platform, optimizing the parameter set { α }(l),β(l)And f, until the maximum training iteration number is reached. The simulation results were analyzed as follows:
and (3) comparing the performances of EPANet, EP, EPA and other several deep learning-based methods (including OAMPNet and DLM) under different antenna ratios and correlation coefficients:
FIG. 4 shows the correlation coefficient ζt=ζrWhen the BER (bit error rate) is plotted against the SNR (signal to noise ratio) for different numbers of transmit and receive antennas, it can be seen that EPANet has a certain improvement in performance compared to the EPA algorithm for 64 numbers of receive antennas, and is better than other machine learning-based detection methods and EP performance. In the case of 48 receiving antennas, the performance of the EPANet proposed by the present invention is significantly better than that of other detection methods. When coefficient of correlation ζt=ζrAt 0.5, as shown in fig. 5, the EPA and several other machine learning based detection methods face severe performance loss. Although the EPANet algorithm performs less than EP, it still significantly improves the performance of EPA and outperforms several other machine learning based detection methods.
A learnable damping coefficient is further introduced into the large-scale MIMO detection method, and the optimization parameter set is trained according to the experimental method
Until a maximum number of training iterations is reached. The simulation results were analyzed as follows:
and (3) comparing the performances of EPANet, EP, EPA and other several deep learning-based methods (including OAMPNet and DLM) under different antenna ratios and correlation coefficients:
FIG. 6 shows the correlation coefficient ζ
t=ζ
rThe BER (bit error rate) versus SNR (signal to noise ratio) curve for different numbers of transmit and receive antennas is 0.3, and it can be seen that the performance of EPANet is slightly improved compared with the EPA algorithm under the condition that the number of receive antennas is 64, mainly because the channel is close to the independent and identically distributed rayleigh channel under the configuration, and the performance of the EPA algorithm is close to the optimum. Nonetheless, EPANet's performance is superior to other machine learning based detection methods and superior to EP's performance. In the case of 48 receiving antennas, the performance of the EPANet proposed by the present invention is significantly better than that of other detection methods. When coefficient of correlation ζ
t=ζ
rAt 0.5, as shown in fig. 7, the EPA and several other machine learning based detection methods face severe performance loss. Although the EPANet algorithm performs less than EP, it still significantly improves the performance of EPA and outperforms several other machine learning based detection methods. At this time and in FIG. 5 only the set of optimization parameters { α }
(l),β
(l)Comparing the performances of the two groups, it can be seen that the parameter set is added
The performance is further improved and is greatly superior to the EPA algorithm and other detection methods based on machine learning.
Performance loss versus complexity for different correlation channel cases:
the EPANet network model on the abscissa in FIG. 8 is obtaining a bit error rate BER of 10
-3SNR loss compared to the EP algorithm, on the ordinate, of
For measuring the relative complexity of the algorithm, wherein
Indicating the complexity of some M-MIMO detection method,
indicating MMSThe complexity of the E detection method (minimum mean square error M-MIMO detection method), the calculation of which takes into account the floating-point number operations of exponential, multiplication, division and addition operations. The FTR represents the failure of the detection method to achieve a specified BER within the illustrated SNR. The two ends of the arrow represent the correlation coefficient xi respectively
t=ζ
r0.3 and xi
t=ζ
r0.5. EPANet Performance at ζ
t=ξ
rThe case of 0.3 is superior to EP, although ζ is superior
t=ζ
rPerformance was weaker than EP at 0.5, but EPANet complexity was only 44.36% of EP. EPANet has similar complexity to EPA, and better performance can be obtained under different channel configurations. In addition, compared with OAMPNet, the complexity of EPANet is reduced by 70%, and the performance is improved by 0.8-1.1 dB. While DLM is the lowest in complexity, it is when the channel correlation is strong, i.e.. zeta
t=ξ
rAt 0.5, its performance is severely degraded and even fails to converge. The robustness of EPANet to different channel correlations is verified by the change in SNR loss (EPANet arrow length shortest).
The above description is only of the preferred embodiments of the present invention, and it should be noted that: it will be apparent to those skilled in the art that various modifications and adaptations can be made without departing from the principles of the invention and these are intended to be within the scope of the invention.