CN113204481B - Class imbalance software defect prediction method based on data resampling - Google Patents
Class imbalance software defect prediction method based on data resampling Download PDFInfo
- Publication number
- CN113204481B CN113204481B CN202110428102.3A CN202110428102A CN113204481B CN 113204481 B CN113204481 B CN 113204481B CN 202110428102 A CN202110428102 A CN 202110428102A CN 113204481 B CN113204481 B CN 113204481B
- Authority
- CN
- China
- Prior art keywords
- minority
- data
- class data
- data set
- minority class
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/36—Prevention of errors by analysis, debugging or testing of software
- G06F11/3668—Testing of software
- G06F11/3672—Test management
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2413—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on distances to training or reference patterns
- G06F18/24147—Distances to closest patterns, e.g. nearest neighbour classification
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computer Hardware Design (AREA)
- Quality & Reliability (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
技术领域technical field
本发明属于软件缺陷预测领域,具体涉及一种基于数据重采样的类不平衡软件缺陷预测方法。The invention belongs to the field of software defect prediction, in particular to a class unbalanced software defect prediction method based on data resampling.
背景技术Background technique
随着社会的发展与科学技术的提升,互联网已经深入的融合到我们的生活中的方方面面,无论是网上购物,出门坐车,智能家居,餐厅点餐等我们日常生活中的各种活动都可以通过软件完成,软件的使用场景已经渗透在我们吃穿住行等方方面面。在软件开发的过程中,软件功能需求不断的增加,软件服务的人群数量在不断的增加,软件开发时间不断的被压缩,各种问题导致在软件开发的过程中,软件很容易出现缺陷,软件缺陷的发生会使得软件不能提供正常的功能,会造成巨大的生产和经济损失,给人们的正常生活造成巨大的影响,因此竭力避免软件缺陷的发生是重要且必要的,因此在软件开发过程中进行软件缺陷预测能够帮助开发人员尽快的发现在软件开发过程中发生的缺陷,能够及时的进行软件缺陷的代码修改,从而避免各种生产经济损失。With the development of society and the improvement of science and technology, the Internet has been deeply integrated into all aspects of our life, whether it is online shopping, going out to take a car, smart home, restaurant ordering and other various activities in our daily life can be done through The software is completed, and the usage scenarios of the software have penetrated into all aspects of our food, clothing, housing and transportation. In the process of software development, the demand for software functions continues to increase, the number of people served by software is constantly increasing, and the software development time is constantly being compressed. Various problems lead to software defects in the process of software development. The occurrence of defects will make the software unable to provide normal functions, cause huge production and economic losses, and have a huge impact on people's normal life. Therefore, it is important and necessary to try to avoid the occurrence of software defects. Therefore, in the software development process Predicting software defects can help developers find defects that occur in the software development process as soon as possible, and can timely modify the code of software defects, thereby avoiding various production economic losses.
然而在现实开发环境中,存在软件缺陷的数据是远远小于不存在软件缺陷的数据的,这时候构建的软件缺陷预测模型,更不容易发现存在软件缺陷的代码模块,然而理想的软件缺陷预测模型需要对存在缺陷的数据更敏感,能够更加精确的预测出代码模块是否存在缺陷,因此解决软件缺陷预测的类不平衡问题变得十分重要。针对上面的不足,本发明提出了一个类不平衡软件缺陷预测方法。However, in the real development environment, the data with software defects is far smaller than the data without software defects. The software defect prediction model constructed at this time is more difficult to find code modules with software defects. However, the ideal software defect prediction model The model needs to be more sensitive to defective data and can more accurately predict whether the code module has defects. Therefore, it is very important to solve the class imbalance problem of software defect prediction. In view of the above shortcomings, the present invention proposes a class-imbalanced software defect prediction method.
发明内容SUMMARY OF THE INVENTION
本发明主要目的是解决软件缺陷预测中的类不平衡问题提出一个类不平衡问题软件缺陷预测方法,普遍适用于软件缺陷预测。为了实现上述目的,本发明包括如下步骤:The main purpose of the present invention is to solve the class imbalance problem in software defect prediction and propose a software defect prediction method for class imbalance problem, which is generally applicable to software defect prediction. In order to achieve the above object, the present invention comprises the following steps:
步骤1,选取少数类数据集合中任意个少数类数据依次与少数类数据集合中每个少数类数据进行欧式距离计算,在少数类数据集合中筛选出与选取的少数类数据距离最近的少数类数据,选取少数类数据集合中任意个少数类数据依次与多数类数据集合中每个多数类数据进行欧式距离计算,在多数类数据集合中筛选出与选取的少数类数据距离最近的多数类数据,根据选取的少数类数据与少数类数据集合中每个少数类数据最近欧式距离、根据选取的少数类数据与多数类数据集合中每个少数类数据最近欧式距离计算选取的少数类数据的距离参数;在少数类数据集合中根据少数类数据的距离参数对少数类数据进行标记,并得到少数类数据的数据点类型;计算少数类数据集合中每个少数类数据的K近邻点集合,进一步在每个少数类数据的K近邻点集合划分为K近邻点多数类数据集合、K近邻点少数类数据集合,分别统计K近邻点多数类数据集合中多数类数据的数量、K 近邻点少数类数据集合中少数类数据的数量,计算少数类数据集合中每个少数类数据的新生成的少数类数据数量;Step 1: Select any minority class data in the minority class data set to perform Euclidean distance calculation with each minority class data in the minority class data set in turn, and select the minority class with the closest distance to the selected minority class data in the minority class data set. Data, select any minority class data in the minority class data set and perform Euclidean distance calculation with each majority class data in the majority class data set in turn, and filter out the majority class data in the majority class data set with the closest distance to the selected minority class data. , calculate the distance of the selected minority data according to the nearest Euclidean distance between the selected minority data and each minority data in the minority data set, and according to the nearest Euclidean distance between the selected minority data and each minority data in the majority data set parameter; mark the minority class data according to the distance parameter of the minority class data in the minority class data set, and obtain the data point type of the minority class data; calculate the K nearest neighbor point set of each minority class data in the minority class data set, and further The K-nearest neighbor point set of each minority class data is divided into the K-nearest neighbor point majority class data set and the K-nearest neighbor point minority class data set. The number of minority class data in the data set, calculate the number of newly generated minority class data for each minority class data in the minority class data set;
步骤2,分别选择第一分类器、第二分类器,对新生成的软件缺陷预测少数类数据进行置信度评价,得到训练数据集;Step 2: Select the first classifier and the second classifier respectively, and perform confidence evaluation on the newly generated software defect prediction minority data to obtain a training data set;
步骤3,运用步骤2选择的第一分类器、第二分类器以及得到的训练集S′,通过加权投票得到最终的预测结果;Step 3, use the first classifier, the second classifier and the obtained training set S' selected in step 2 to obtain the final prediction result through weighted voting;
作为优选,步骤1所述软件缺陷数据为:S={Smin,Smax};Preferably, the software defect data in step 1 is: S={S min , S max };
步骤1所述少数类数据集合为:
步骤1所述多数类数据集合为:
其中,Smin表示少数类数据集合,用Smax表示多数类数据集合,pi表示少数类数据集合中第i个少数类数据,i∈[1,N],N表示少数类数据集合中少数类数据的数量,dk表示多数类数据集合中第k个多数类数据,k∈[1,K],K表示多数类数据集合中多数类数据的数量;Among them, S min represents the minority class data set, S max represents the majority class data set, pi represents the i -th minority class data in the minority class data set, i∈[1, N], N represents the minority class data set in the minority class data set The number of class data, d k represents the kth majority class data in the majority class data set, k∈[1,K], K represents the number of majority class data in the majority class data set;
步骤1所述与选取的少数类数据距离最近的少数类数据为:
其中,
步骤1所述与选取的少数类数据距离最近的多数类数据为:
其中,
步骤1所述选取的少数类数据与少数类数据集合中每个少数类数据最近欧式距离为:
步骤1所述选取的少数类数据与多数类数据集合中每个多数类数据最近欧式距离为:
步骤1所述计算选取的少数类数据的距离参数为:The distance parameter of the selected minority data in step 1 is:

其中,∝i为少数类数据集合中第i个少数类数据的距离参数;Among them, ∝ i is the distance parameter of the i-th minority class data in the minority class data set;
步骤1所述在少数类数据集合中根据少数类数据的距离参数对少数类数据进行标记为:In step 1, the minority class data is marked in the minority class data set according to the distance parameter of the minority class data as:
若∝i<1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为安全点,flagi=1;If ∝ i < 1, the data point type in the minority class data set and the selected i-th minority class data is marked as a safe point, flag i =1;
若∝i=1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为混淆点,flagi=2;If ∝ i = 1, the data point type in the minority class data set and the selected i-th minority class data is marked as a confusion point, flag i = 2;
若∝i>1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为危险点,flagi=3;If ∝ i > 1, the data point type in the minority class data set and the selected i-th minority class data are marked as dangerous points, and flag i =3;
步骤1所述计算少数类数据集合中每个少数类数据的K近邻点集合:Calculate the K-nearest neighbor point set of each minority class data in the minority class data set described in step 1:
步骤1所述在每个少数类数据的K近邻点集合划分为K近邻点多数类数据集合、K近邻点少数类数据集合,具体为:In step 1, the K nearest neighbor point set of each minority class data is divided into K nearest neighbor point majority class data set and K nearest neighbor point minority class data set, specifically:
步骤1所述K近邻点多数类数据集合中多数类数据的数量,记为
步骤1所述K近邻点少数类数据集合中少数类数据的数量,记为
步骤1所述计算少数类数据集合中每个少数类数据的新生成的少数类数据数量,具体为:Step 1: Calculate the number of newly generated minority class data for each minority class data in the minority class data set, specifically:

其中,∝i为少数类数据集合中第i个少数类数据的距离参数,ni为少数类数据集合中第i个每个少数类数据的新生成的少数类数据数量;Among them, ∝ i is the distance parameter of the ith minority class data in the minority class data set, and n i is the number of newly generated minority class data of each i th minority class data in the minority class data set;
步骤1所述,计算新生成的软件缺陷预测数据;Described in step 1, calculate the newly generated software defect prediction data;
步骤1所述,少数类数据集合中第i个少数类数据会生成ni新少数类数据,因此将新生成的少数类数据用pnew i,j来表示,其中j∈[1,ni]As described in step 1, the i-th minority data in the minority data set will generate n i new minority data, so the newly generated minority data is represented by p new i, j , where j ∈ [1, n i ]
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据的偏离多数类的偏量,记做εi,j;The deviation of the j-th newly generated data of the i-th minority-class data in the minority-class data set described in step 1 deviates from the majority class, denoted as ε i,j ;
其中少数类数据集合中第i个少数类数据的第j个新生成数据的偏离多数类的偏量εi,j,其计算公式为:Among them, the deviation ε i,j of the jth newly generated data of the ith minority class data in the minority class data set deviates from the majority class, and its calculation formula is:

其中,

步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据偏向多数类的偏量,记做σi,j;The bias of the j-th newly generated data of the i-th minority-class data in the minority-class data set described in step 1 is biased towards the majority class, denoted as σ i,j ;
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据偏向多数类的偏量σi,j,其计算公式为:The bias σ i,j of the j-th newly generated data of the i-th minority-class data in the minority-class data set described in step 1 is biased towards the majority class, and its calculation formula is:

其中,

步骤1所述新生成的软件缺陷预测数据少数类数据,记做pnew i,j;The newly generated software defect prediction data described in step 1 is a minority class data, which is denoted as p new i,j ;
新生成的软件缺陷预测数据第i个少数类数据的第j个新生成数据计算公式为:The calculation formula of the jth newly generated data of the ith minority class data of the newly generated software defect prediction data is:
pnew i,j=pi+εi,j+σi,j p new i,j = p i +ε i,j +σ i,j
步骤1所述得到新成少数类数据集,记做Snew;Obtaining a new minority data set described in step 1, denoted as S new ;
步骤1所述少数类点pi新生成缺陷数据的个数ni,按照上面生成的少数类数据pnew的方式,得到新成少数类数据集Snew。The number n i of defect data newly generated by the minority class point p i in step 1 is obtained according to the method of the minority class data p new generated above to obtain a new minority class data set S new .
其中,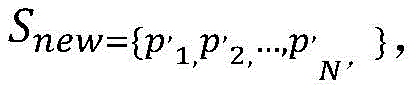

作为优选,所述步骤2具体如下:Preferably, the step 2 is as follows:
步骤2所述分别计算第一分类器的影响程度、第二分类器的影响程度;In step 2, the influence degree of the first classifier and the influence degree of the second classifier are calculated respectively;
步骤2所述利用新成少数类数据集Snew训练第一分类器H1,利用新成少数类数据集Snew,依次带入第一分类器H1,得到预测的类别Lp1,对于Snew中的第i个点p’i,其弱标记为

利用新成少数类数据集Snew训练第二分类器H2,利用新成少数类数据集Snew依次带入第二分类器H2,得到预测的类别Lp2,对于Snew中的第i个点p’i,其弱标记为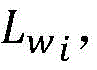

所述第一分类器的影响程度为:The degree of influence of the first classifier is:

其中,N为少数类数据集合Smin元素个数,第一分类器H1预测类别与弱标记 Lw类别相同

所述第二分类器的影响程度为:The degree of influence of the second classifier is:

其中,N为少数类数据集合Smin元素个数,第一分类器H1预测类别与弱标记 Lw类别相同

步骤2所述根据第一分类器的影响程度、第二分类器的影响程度更新少数类数据的标签更新少数类数据的标签,以构建更新后原始软件缺陷数据;In step 2, the label of the minority data is updated according to the influence degree of the first classifier and the influence degree of the second classifier, and the label of the minority data is updated to construct the updated original software defect data;
步骤2所述,计算弱标记
步骤2所述,对新少数类数据集的弱标记


步骤2所述,新成少数类数据即Snew被重新进行筛选,得到新成少数类数据 Snew′,将Snew′加入原始软件缺陷数据S得到新训练集S′;As described in step 2, the newly generated minority data, that is, S new , is re-screened to obtain newly generated minority data S new ′, and S new ′ is added to the original software defect data S to obtain a new training set S ′;
作为优选,所述步骤3具体包括下述步骤:Preferably, the step 3 specifically includes the following steps:
得到新训练数据集S′后,训练第一分类器H1和第二分类器H2,通过训练好的第一分类器H1和第二分类器H2预测数据v分别得到第一分类器预测结果L1和第二分类器L2,继续利用第一分类器的影响程度o1和第二分类器的影响程度o2,利用计算公式Lpre=L1*o1+L2*o2的值来得到预测结果;After obtaining the new training data set S', train the first classifier H 1 and the second classifier H 2 , and obtain the first classifier respectively by predicting the data v through the trained first classifier H 1 and the second classifier H 2 Predict the result L 1 and the second classifier L 2 , continue to use the influence degree o 1 of the first classifier and the influence degree o 2 of the second classifier, and use the calculation formula L pre =L 1 *o 1 +L 2 *o 2 to get the prediction result;
步骤3所述,当Lpre值大于β的时候,预测v的类别为少数类;As described in step 3, when the value of L pre is greater than β, the category of v is predicted to be a minority category;
步骤3所述,当Lpre的值小于等于β的时候,预测v的类别为多数类;As described in step 3, when the value of L pre is less than or equal to β, the category of v is predicted to be the majority category;
与现有技术相比,本发明的优点和积极效果在于:Compared with the prior art, the advantages and positive effects of the present invention are:
本发明能够良好的解决类不平衡问题。The present invention can well solve the class imbalance problem.
本文增加了对新生成少数类数据的筛选过程,去除掉偏离实际的数据,保留能够表现出少数类真实特征的数据。This paper adds a screening process for newly generated minority data, removes data that deviates from reality, and retains data that can show the true characteristics of minority classes.
本文提出了一个能解决类不平衡的软件缺陷预测方法,能够广泛的适用于各种软件缺陷数据并且解决类不平衡问题。This paper proposes a software defect prediction method that can solve the class imbalance, which can be widely applied to various software defect data and solve the class imbalance problem.
附图说明Description of drawings
图1:为本发明的类不平衡的软件缺陷预测方法图。FIG. 1 is a diagram of a software defect prediction method for class imbalance according to the present invention.
具体实施方式Detailed ways
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施对本发明做进一步描述,在此仅用本发明的适宜性实例说明来解释本发明,但并不作为本发明的限定。In order to make the purpose, technical solutions and advantages of the present invention clearer, the present invention will be further described below with reference to the accompanying drawings and specific implementations. Here, the present invention is explained only by the description of the suitability of the present invention, but is not regarded as the present invention. limit.
本发明的总实施流程图如图1所示,具体实施如下:The overall implementation flow chart of the present invention is shown in Figure 1, and the specific implementation is as follows:
步骤1,选取少数类数据集合中任意个少数类数据依次与少数类数据集合中每个少数类数据进行欧式距离计算,在少数类数据集合中筛选出与选取的少数类数据距离最近的少数类数据,选取少数类数据集合中任意个少数类数据依次与多数类数据集合中每个多数类数据进行欧式距离计算,在多数类数据集合中筛选出与选取的少数类数据距离最近的多数类数据,根据选取的少数类数据与少数类数据集合中每个少数类数据最近欧式距离、根据选取的少数类数据与多数类数据集合中每个少数类数据最近欧式距离计算选取的少数类数据的距离参数;在少数类数据集合中根据少数类数据的距离参数对少数类数据进行标记,并得到少数类数据的数据点类型;计算少数类数据集合中每个少数类数据的K近邻点集合,进一步在每个少数类数据的K近邻点集合划分为K近邻点多数类数据集合、K近邻点少数类数据集合,分别统计K近邻点多数类数据集合中多数类数据的数量、K 近邻点少数类数据集合中少数类数据的数量,计算少数类数据集合中每个少数类数据的新生成的少数类数据数量。Step 1: Select any minority class data in the minority class data set to perform Euclidean distance calculation with each minority class data in the minority class data set in turn, and select the minority class with the closest distance to the selected minority class data in the minority class data set. Data, select any minority class data in the minority class data set and perform Euclidean distance calculation with each majority class data in the majority class data set in turn, and filter out the majority class data in the majority class data set with the closest distance to the selected minority class data. , calculate the distance of the selected minority data according to the nearest Euclidean distance between the selected minority data and each minority data in the minority data set, and according to the nearest Euclidean distance between the selected minority data and each minority data in the majority data set parameter; mark the minority class data according to the distance parameter of the minority class data in the minority class data set, and obtain the data point type of the minority class data; calculate the K nearest neighbor point set of each minority class data in the minority class data set, and further The K-nearest neighbor point set of each minority class data is divided into the K-nearest neighbor point majority class data set and the K-nearest neighbor point minority class data set. The number of minority class data in the data set, calculate the number of newly generated minority class data for each minority class data in the minority class data set.
步骤1所述软件缺陷数据为:S={Smin,Smax};The software defect data in step 1 is: S={S min , S max };
步骤1所述少数类数据集合为:
步骤1所述多数类数据集合为:
其中,Smin表示少数类数据集合,用Smax表示多数类数据集合,pi表示少数类数据集合中第i个少数类数据,i∈[1,N],N表示少数类数据集合中少数类数据的数量,dk表示多数类数据集合中第k个多数类数据,k∈[1,K],K表示多数类数据集合中多数类数据的数量;Among them, S min represents the minority class data set, S max represents the majority class data set, pi represents the i -th minority class data in the minority class data set, i∈[1, N], N represents the minority class data set in the minority class data set The number of class data, d k represents the kth majority class data in the majority class data set, k∈[1,K], K represents the number of majority class data in the majority class data set;
步骤1所述与选取的少数类数据距离最近的少数类数据为:
其中,
步骤1所述与选取的少数类数据距离最近的多数类数据为:
其中,
步骤1所述选取的少数类数据与少数类数据集合中每个少数类数据最近欧式距离为:
步骤1所述选取的少数类数据与多数类数据集合中每个多数类数据最近欧式距离为:
步骤1所述计算选取的少数类数据的距离参数为:The distance parameter of the selected minority data in step 1 is:

其中,∝i为少数类数据集合中第i个少数类数据的距离参数;Among them, ∝ i is the distance parameter of the i-th minority class data in the minority class data set;
步骤1所述在少数类数据集合中根据少数类数据的距离参数对少数类数据进行标记为:In step 1, the minority class data is marked in the minority class data set according to the distance parameter of the minority class data as:
若∝i<1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为安全点,flagi=1;If ∝ i < 1, the data point type in the minority class data set and the selected i-th minority class data is marked as a safe point, flag i =1;
若∝i=1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为混淆点,flagi=2;If ∝ i = 1, the data point type in the minority class data set and the selected i-th minority class data is marked as a confusion point, flag i = 2;
若∝i>1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为危险点,flagi=3;If ∝ i > 1, the data point type in the minority class data set and the selected i-th minority class data are marked as dangerous points, and flag i =3;
步骤1所述计算少数类数据集合中每个少数类数据的K近邻点集合,实验设置K=5:In step 1, the set of K nearest neighbors of each minority class data in the minority class data set is calculated, and the experimental setting K=5:
步骤1所述在每个少数类数据的K近邻点集合划分为K近邻点多数类数据集合、K近邻点少数类数据集合,具体为:In step 1, the K nearest neighbor point set of each minority class data is divided into K nearest neighbor point majority class data set and K nearest neighbor point minority class data set, specifically:
步骤1所述K近邻点多数类数据集合中多数类数据的数量,记为
步骤1所述K近邻点少数类数据集合中少数类数据的数量,记为
步骤1所述计算少数类数据集合中每个少数类数据的新生成的少数类数据数量,具体为:Step 1: Calculate the number of newly generated minority class data for each minority class data in the minority class data set, specifically:

其中,∝i为少数类数据集合中第i个少数类数据的距离参数,ni为少数类数据集合中第i个每个少数类数据的新生成的少数类数据数量;Among them, ∝ i is the distance parameter of the ith minority class data in the minority class data set, and n i is the number of newly generated minority class data of each i th minority class data in the minority class data set;
步骤1所述,计算新生成的软件缺陷预测数据;Described in step 1, calculate the newly generated software defect prediction data;
步骤1所述,少数类数据集合中第i个少数类数据会生成ni新少数类数据,因此将新生成的少数类数据用pnew i,j来表示,其中j∈[1,ni]As described in step 1, the i-th minority data in the minority data set will generate n i new minority data, so the newly generated minority data is represented by p new i, j , where j ∈ [1, n i ]
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据的偏离多数类的偏量,记做εi,j;The deviation of the j-th newly generated data of the i-th minority-class data in the minority-class data set described in step 1 deviates from the majority class, denoted as ε i,j ;
其中少数类数据集合中第i个少数类数据的第j个新生成数据的偏离多数类的偏量εi,j,其计算公式为:Among them, the deviation ε i,j of the jth newly generated data of the ith minority class data in the minority class data set deviates from the majority class, and its calculation formula is:

其中,

步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据偏向多数类的偏量,记做σi,j;The bias of the j-th newly generated data of the i-th minority-class data in the minority-class data set described in step 1 is biased towards the majority class, denoted as σ i,j ;
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据偏向多数类的偏量σi,j,其计算公式为:The bias σ i,j of the j-th newly generated data of the i-th minority-class data in the minority-class data set described in step 1 is biased towards the majority class, and its calculation formula is:

其中,
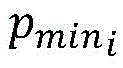
步骤1所述新生成的软件缺陷预测数据少数类数据,记做pnew i,j;The newly generated software defect prediction data described in step 1 is a minority class data, which is denoted as p new i,j ;
新生成的软件缺陷预测数据第i个少数类数据的第j个新生成数据计算公式为:The calculation formula of the jth newly generated data of the ith minority class data of the newly generated software defect prediction data is:
pnew i,j=pi+εi,j+σi,j p new i,j = p i +ε i,j +σ i,j
步骤1所述得到新成少数类数据集,记做Snew;Obtaining a new minority data set described in step 1, denoted as S new ;
步骤1所述少数类点pi新生成缺陷数据的个数ni,按照上面生成的少数类数据pnew的方式,得到新成少数类数据集Snew。The number n i of defect data newly generated by the minority class point p i in step 1 is obtained according to the method of the minority class data p new generated above to obtain a new minority class data set S new .
其中,

步骤2,分别选择第一分类器、第二分类器,对新生成的软件缺陷预测少数类数据进行置信度评价,得到训练数据集;Step 2: Select the first classifier and the second classifier respectively, and perform confidence evaluation on the newly generated software defect prediction minority data to obtain a training data set;
所述步骤2具体如下:The step 2 is as follows:
步骤2所述分别计算第一分类器的影响程度、第二分类器的影响程度;In step 2, the influence degree of the first classifier and the influence degree of the second classifier are calculated respectively;
步骤2所述利用新成少数类数据集Snew训练第一分类器H1,利用新成少数类数据集Snew,依次带入第一分类器H1,得到预测的类别Lp1,对于Snew中的第i个点p’i,其弱标记为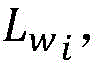

利用新成少数类数据集Snew训练第二分类器H2,利用新成少数类数据集Snew依次带入第二分类器H2,得到预测的类别Lp2,对于Snew中的第i个点p’i,其弱标记为

所述第一分类器的影响程度为:The degree of influence of the first classifier is:

其中,N为少数类数据集合Smin元素个数,第一分类器H1预测类别与弱标记 Lw类别相同

所述第二分类器的影响程度为:The degree of influence of the second classifier is:

其中,N为少数类数据集合Smin元素个数,第一分类器H1预测类别与弱标记 Lw类别相同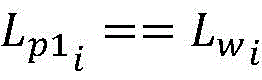

步骤2所述根据第一分类器的影响程度、第二分类器的影响程度更新少数类数据的标签更新少数类数据的标签,以构建更新后原始软件缺陷数据;In step 2, the label of the minority data is updated according to the influence degree of the first classifier and the influence degree of the second classifier, and the label of the minority data is updated to construct the updated original software defect data;
步骤2所述,计算弱标记
步骤2所述,对新少数类数据集的弱标记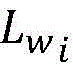


步骤2所述,新成少数类数据即Snew被重新进行筛选,得到新成少数类数据 Snew′,将Snew′加入原始软件缺陷数据S得到新训练集S′;As described in step 2, the newly generated minority data, that is, S new , is re-screened to obtain newly generated minority data S new ′, and S new ′ is added to the original software defect data S to obtain a new training set S ′;
步骤3,运用步骤2选择的第一分类器、第二分类器以及得到的训练集S′,通过加权投票得到最终的预测结果;Step 3, use the first classifier, the second classifier and the obtained training set S' selected in step 2 to obtain the final prediction result through weighted voting;
所述步骤3具体包括下述步骤:The step 3 specifically includes the following steps:
得到新训练数据集S′后,训练第一分类器H1和第二分类器H2,通过训练好的第一分类器H1和第二分类器H2预测数据v分别得到第一分类器预测结果L1和第二分类器L2,继续利用第一分类器的影响程度o1和第二分类器的影响程度o2,利用计算公式Lpre=L1*o1+L2*o2的值来得到预测结果;After obtaining the new training data set S', train the first classifier H 1 and the second classifier H 2 , and obtain the first classifier respectively by predicting the data v through the trained first classifier H 1 and the second classifier H 2 Predict the result L 1 and the second classifier L 2 , continue to use the influence degree o 1 of the first classifier and the influence degree o 2 of the second classifier, and use the calculation formula L pre =L 1 *o 1 +L 2 *o 2 to get the prediction result;
步骤3所述,当Lpre值大于β=0.5的时候,预测v的类别为少数类;As described in step 3, when the L pre value is greater than β=0.5, the category of v is predicted to be a minority category;
步骤3所述,当Lpre的值小于等于β=0.5的时候,预测v的类别为多数类。As described in step 3, when the value of L pre is less than or equal to β=0.5, the class of v is predicted to be the majority class.
本实施例将本发明的方法与现有的一些主流的SMOTE+SVM、SMOTE+决策树、 SMOTE+k近邻、SMOTE+朴素贝叶斯方法进行了比较,选取了精度、F-measure、平衡度、AUC指标比较结果。在对比的所有方法中,本发明方法的准确率最高,识别准确率已经达到了领域先进水平。This embodiment compares the method of the present invention with some existing mainstream SMOTE+SVM, SMOTE+decision tree, SMOTE+k-nearest neighbor, SMOTE+Naive Bayes methods, and selects the accuracy, F-measure, balance, AUC Metric comparison results. Among all the methods compared, the method of the present invention has the highest accuracy, and the recognition accuracy has reached the advanced level in the field.
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明所述系统及其实施方法所做的同等变化,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。The above description is only a preferred embodiment of the present invention, but the protection scope of the present invention is not limited to this. The equivalent changes made by the method and the implementation method thereof should all be included within the protection scope of the present invention. Therefore, the protection scope of the present invention should be subject to the protection scope of the claims.
Claims (2)













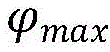


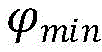




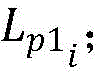












Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110428102.3A CN113204481B (en) | 2021-04-21 | 2021-04-21 | Class imbalance software defect prediction method based on data resampling |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110428102.3A CN113204481B (en) | 2021-04-21 | 2021-04-21 | Class imbalance software defect prediction method based on data resampling |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113204481A CN113204481A (en) | 2021-08-03 |
| CN113204481B true CN113204481B (en) | 2022-03-04 |
Family
ID=77027498
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110428102.3A Active CN113204481B (en) | 2021-04-21 | 2021-04-21 | Class imbalance software defect prediction method based on data resampling |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113204481B (en) |
Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105677564A (en) * | 2016-01-04 | 2016-06-15 | 中国石油大学(华东) | Adaboost software defect unbalanced data classification method based on improvement |
| CN107391452A (en) * | 2017-07-06 | 2017-11-24 | 武汉大学 | A kind of software defect estimated number method based on data lack sampling and integrated study |
| CN108563556A (en) * | 2018-01-10 | 2018-09-21 | 江苏工程职业技术学院 | Software defect prediction optimization method based on differential evolution algorithm |
| CN110471856A (en) * | 2019-08-21 | 2019-11-19 | 大连海事大学 | A kind of Software Defects Predict Methods based on data nonbalance |
| CN110533116A (en) * | 2019-09-04 | 2019-12-03 | 大连大学 | Based on the adaptive set of Euclidean distance at unbalanced data classification method |
| CN110674865A (en) * | 2019-09-20 | 2020-01-10 | 燕山大学 | Rule learning classifier integration method oriented to software defect class distribution unbalance |
| CN110942153A (en) * | 2019-11-11 | 2020-03-31 | 西北工业大学 | Data resampling method based on repeated editing nearest neighbor and clustering oversampling |
| CN111090579A (en) * | 2019-11-14 | 2020-05-01 | 北京航空航天大学 | Software Defect Prediction Method Based on Pearson Correlation Weighted Association Classification Rule |
| CN111522736A (en) * | 2020-03-26 | 2020-08-11 | 中南大学 | Software defect prediction method and device, electronic equipment and computer storage medium |
| CN111767216A (en) * | 2020-06-23 | 2020-10-13 | 江苏工程职业技术学院 | A Cross-Version Deep Defect Prediction Method That Can Alleviate the Class Overlap Problem |
| CN112465040A (en) * | 2020-12-01 | 2021-03-09 | 杭州电子科技大学 | Software defect prediction method based on class imbalance learning algorithm |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012116208A2 (en) * | 2011-02-23 | 2012-08-30 | New York University | Apparatus, method, and computer-accessible medium for explaining classifications of documents |
| CN103810101B (en) * | 2014-02-19 | 2019-02-19 | 北京理工大学 | A software defect prediction method and software defect prediction system |
| US10430315B2 (en) * | 2017-10-04 | 2019-10-01 | Blackberry Limited | Classifying warning messages generated by software developer tools |
-
2021
- 2021-04-21 CN CN202110428102.3A patent/CN113204481B/en active Active
Patent Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105677564A (en) * | 2016-01-04 | 2016-06-15 | 中国石油大学(华东) | Adaboost software defect unbalanced data classification method based on improvement |
| CN107391452A (en) * | 2017-07-06 | 2017-11-24 | 武汉大学 | A kind of software defect estimated number method based on data lack sampling and integrated study |
| CN108563556A (en) * | 2018-01-10 | 2018-09-21 | 江苏工程职业技术学院 | Software defect prediction optimization method based on differential evolution algorithm |
| CN110471856A (en) * | 2019-08-21 | 2019-11-19 | 大连海事大学 | A kind of Software Defects Predict Methods based on data nonbalance |
| CN110533116A (en) * | 2019-09-04 | 2019-12-03 | 大连大学 | Based on the adaptive set of Euclidean distance at unbalanced data classification method |
| CN110674865A (en) * | 2019-09-20 | 2020-01-10 | 燕山大学 | Rule learning classifier integration method oriented to software defect class distribution unbalance |
| CN110942153A (en) * | 2019-11-11 | 2020-03-31 | 西北工业大学 | Data resampling method based on repeated editing nearest neighbor and clustering oversampling |
| CN111090579A (en) * | 2019-11-14 | 2020-05-01 | 北京航空航天大学 | Software Defect Prediction Method Based on Pearson Correlation Weighted Association Classification Rule |
| CN111522736A (en) * | 2020-03-26 | 2020-08-11 | 中南大学 | Software defect prediction method and device, electronic equipment and computer storage medium |
| CN111767216A (en) * | 2020-06-23 | 2020-10-13 | 江苏工程职业技术学院 | A Cross-Version Deep Defect Prediction Method That Can Alleviate the Class Overlap Problem |
| CN112465040A (en) * | 2020-12-01 | 2021-03-09 | 杭州电子科技大学 | Software defect prediction method based on class imbalance learning algorithm |
Non-Patent Citations (3)
| Title |
|---|
| SMOTE: Synthetic Minority Over-sampling Technique;Nitesh V. Chawla;《Journal of Artificial Intelligence Research》;20020602;全文 * |
| 类不平衡稀疏重构度量学习软件缺陷预测;史作婷;《计算机技术与发展》;20180610;全文 * |
| 面向不平衡数据集的机器学习分类策略;徐玲玲,迟冬祥;《计算机工程与应用》;20201120;全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113204481A (en) | 2021-08-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11816149B2 (en) | Electronic device and control method thereof | |
| CN107092918B (en) | An Image Retrieval Method Based on Semantic Features and Supervised Hashing | |
| CN106682233A (en) | Method for Hash image retrieval based on deep learning and local feature fusion | |
| CN110472665A (en) | Model training method, file classification method and relevant apparatus | |
| CN110134803B (en) | A fast retrieval method for image data based on hash learning | |
| CN112148986B (en) | A crowdsourcing-based top-N service re-recommendation method and system | |
| CN116089812B (en) | Fault diagnosis method based on semi-supervised adversarial domain generalized intelligent model | |
| CN113313207A (en) | Sample unbalanced target detection method of class truth value constraint classification function | |
| CN111144466A (en) | A deep metric learning method for image sample adaptation | |
| CN114595695A (en) | A Self-training Model Construction Method for Few-Shot Intent Recognition System | |
| CN110288013A (en) | A Defect Label Recognition Method Based on Block Segmentation and Multiple Input Siamese Convolutional Neural Networks | |
| JPWO2014118978A1 (en) | Learning method, information processing apparatus, and learning program | |
| CN119027411A (en) | Integrated circuit process defect diagnosis analysis method, device and medium | |
| CN111815582A (en) | A two-dimensional code region detection method with improved background prior and foreground prior | |
| CN114611609A (en) | Graph network model node classification method, device, equipment and storage medium | |
| CN117808512A (en) | Product management methods and systems based on smart e-commerce platforms | |
| CN114884896B (en) | A mobile application traffic sensing method based on feature expansion and automatic machine learning | |
| CN113204481B (en) | Class imbalance software defect prediction method based on data resampling | |
| CN116245259A (en) | Photovoltaic power generation prediction method, device and electronic equipment based on deep feature selection | |
| CN115907926A (en) | Product recommendation method, device, electronic device, and storage medium | |
| CN114610953B (en) | Data classification method, device, equipment and storage medium | |
| CN113469251B (en) | Method for classifying unbalanced data | |
| CN115270761A (en) | A Relation Extraction Method Integrating Prototype Knowledge | |
| CN113032612B (en) | Construction method of multi-target image retrieval model, retrieval method and device | |
| CN118334170B (en) | Flow chart node recommendation method, storage medium and electronic equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |