CN113045659B - anti-CD73 humanized antibodies - Google Patents
anti-CD73 humanized antibodies Download PDFInfo
- Publication number
- CN113045659B CN113045659B CN202110292998.7A CN202110292998A CN113045659B CN 113045659 B CN113045659 B CN 113045659B CN 202110292998 A CN202110292998 A CN 202110292998A CN 113045659 B CN113045659 B CN 113045659B
- Authority
- CN
- China
- Prior art keywords
- antibody
- ser
- seq
- thr
- variable region
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 101000678236 Homo sapiens 5'-nucleotidase Proteins 0.000 claims description 97
- 102100022464 5'-nucleotidase Human genes 0.000 claims description 87
- 210000004027 cell Anatomy 0.000 claims description 56
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 49
- 239000003814 drug Substances 0.000 claims description 37
- 230000027455 binding Effects 0.000 claims description 30
- 238000009739 binding Methods 0.000 claims description 30
- 229940079593 drug Drugs 0.000 claims description 26
- 239000013598 vector Substances 0.000 claims description 21
- 238000000034 method Methods 0.000 claims description 19
- 206010028980 Neoplasm Diseases 0.000 claims description 17
- 238000002360 preparation method Methods 0.000 claims description 15
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 claims description 14
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 claims description 14
- 239000008194 pharmaceutical composition Substances 0.000 claims description 14
- 239000000427 antigen Substances 0.000 claims description 12
- 102000036639 antigens Human genes 0.000 claims description 12
- 108091007433 antigens Proteins 0.000 claims description 12
- 210000002865 immune cell Anatomy 0.000 claims description 11
- 239000000611 antibody drug conjugate Substances 0.000 claims description 10
- 229940049595 antibody-drug conjugate Drugs 0.000 claims description 10
- 239000000872 buffer Substances 0.000 claims description 9
- 238000001514 detection method Methods 0.000 claims description 9
- 201000010099 disease Diseases 0.000 claims description 9
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 9
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 9
- 239000003153 chemical reaction reagent Substances 0.000 claims description 8
- 229920001184 polypeptide Polymers 0.000 claims description 8
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 8
- 102000004190 Enzymes Human genes 0.000 claims description 7
- 108090000790 Enzymes Proteins 0.000 claims description 7
- 239000004480 active ingredient Substances 0.000 claims description 7
- 238000000338 in vitro Methods 0.000 claims description 6
- 108091033319 polynucleotide Proteins 0.000 claims description 6
- 102000040430 polynucleotide Human genes 0.000 claims description 6
- 239000002157 polynucleotide Substances 0.000 claims description 6
- 230000015572 biosynthetic process Effects 0.000 claims description 5
- 230000008878 coupling Effects 0.000 claims description 5
- 238000010168 coupling process Methods 0.000 claims description 5
- 238000005859 coupling reaction Methods 0.000 claims description 5
- 230000014509 gene expression Effects 0.000 claims description 5
- 239000003937 drug carrier Substances 0.000 claims description 4
- 238000000746 purification Methods 0.000 claims description 4
- 239000004094 surface-active agent Substances 0.000 claims description 3
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 3
- 102000004127 Cytokines Human genes 0.000 claims description 2
- 108090000695 Cytokines Proteins 0.000 claims description 2
- 238000002405 diagnostic procedure Methods 0.000 claims description 2
- 239000008223 sterile water Substances 0.000 claims description 2
- 239000003053 toxin Substances 0.000 claims description 2
- 231100000765 toxin Toxicity 0.000 claims description 2
- 102000004008 5'-Nucleotidase Human genes 0.000 abstract description 3
- 108700004024 5'-Nucleotidase Proteins 0.000 abstract description 2
- 241000282414 Homo sapiens Species 0.000 description 31
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 21
- 235000001014 amino acid Nutrition 0.000 description 19
- 150000001413 amino acids Chemical class 0.000 description 18
- 239000012634 fragment Substances 0.000 description 15
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 14
- 230000000694 effects Effects 0.000 description 14
- 241001529936 Murinae Species 0.000 description 13
- 108090000623 proteins and genes Proteins 0.000 description 13
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 12
- FIQKRDXFTANIEJ-ULQDDVLXSA-N Arg-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N FIQKRDXFTANIEJ-ULQDDVLXSA-N 0.000 description 11
- IGFJVXOATGZTHD-UHFFFAOYSA-N Arg-Phe-His Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccccc1)C(=O)NC(Cc2c[nH]cn2)C(=O)O IGFJVXOATGZTHD-UHFFFAOYSA-N 0.000 description 11
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 11
- 102000045309 human NT5E Human genes 0.000 description 10
- 238000012216 screening Methods 0.000 description 10
- 241000282693 Cercopithecidae Species 0.000 description 9
- 108020004414 DNA Proteins 0.000 description 9
- 239000007822 coupling agent Substances 0.000 description 9
- 235000018102 proteins Nutrition 0.000 description 9
- 102000004169 proteins and genes Human genes 0.000 description 9
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 8
- 108060003951 Immunoglobulin Proteins 0.000 description 8
- 241000699666 Mus <mouse, genus> Species 0.000 description 8
- BSKMOCNNLNDIMU-CDMKHQONSA-N Phe-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O BSKMOCNNLNDIMU-CDMKHQONSA-N 0.000 description 8
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 8
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 8
- 108010092854 aspartyllysine Proteins 0.000 description 8
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 8
- 108010015792 glycyllysine Proteins 0.000 description 8
- 102000018358 immunoglobulin Human genes 0.000 description 8
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 7
- AYKKKGFJXIDYLX-ACZMJKKPSA-N Asn-Gln-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O AYKKKGFJXIDYLX-ACZMJKKPSA-N 0.000 description 7
- CTQIOCMSIJATNX-WHFBIAKZSA-N Asn-Gly-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O CTQIOCMSIJATNX-WHFBIAKZSA-N 0.000 description 7
- GQRDIVQPSMPQME-ZPFDUUQYSA-N Asn-Ile-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O GQRDIVQPSMPQME-ZPFDUUQYSA-N 0.000 description 7
- SUIJFTJDTJKSRK-IHRRRGAJSA-N Asn-Pro-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SUIJFTJDTJKSRK-IHRRRGAJSA-N 0.000 description 7
- OZHXXYOHPLLLMI-CIUDSAMLSA-N Cys-Lys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OZHXXYOHPLLLMI-CIUDSAMLSA-N 0.000 description 7
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 7
- OCQUNKSFDYDXBG-QXEWZRGKSA-N Gly-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OCQUNKSFDYDXBG-QXEWZRGKSA-N 0.000 description 7
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 7
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 7
- NCSIQAFSIPHVAN-IUKAMOBKSA-N Ile-Asn-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NCSIQAFSIPHVAN-IUKAMOBKSA-N 0.000 description 7
- KUEVMUXNILMJTK-JYJNAYRXSA-N Leu-Gln-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KUEVMUXNILMJTK-JYJNAYRXSA-N 0.000 description 7
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 7
- RNYLNYTYMXACRI-VFAJRCTISA-N Leu-Thr-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O RNYLNYTYMXACRI-VFAJRCTISA-N 0.000 description 7
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 7
- RPWTZTBIFGENIA-VOAKCMCISA-N Lys-Thr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RPWTZTBIFGENIA-VOAKCMCISA-N 0.000 description 7
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 7
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 7
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 7
- 241001465754 Metazoa Species 0.000 description 7
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 7
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 7
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 7
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 7
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 7
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 7
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 7
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 7
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 7
- GRIUMVXCJDKVPI-IZPVPAKOSA-N Thr-Thr-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GRIUMVXCJDKVPI-IZPVPAKOSA-N 0.000 description 7
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 7
- HSVPZJLMPLMPOX-BPNCWPANSA-N Tyr-Arg-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O HSVPZJLMPLMPOX-BPNCWPANSA-N 0.000 description 7
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 7
- DZKFGCNKEVMXFA-JUKXBJQTSA-N Tyr-Ile-His Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O DZKFGCNKEVMXFA-JUKXBJQTSA-N 0.000 description 7
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 7
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 7
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 7
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 7
- 239000000203 mixture Substances 0.000 description 7
- 108010090894 prolylleucine Proteins 0.000 description 7
- 229940124597 therapeutic agent Drugs 0.000 description 7
- 108010003137 tyrosyltyrosine Proteins 0.000 description 7
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 6
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 6
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 6
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 6
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 6
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 6
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 6
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 6
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 6
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 6
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 6
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 6
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 6
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 6
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 6
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 6
- FLCMXEFCTLXBTL-DCAQKATOSA-N Lys-Asp-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N FLCMXEFCTLXBTL-DCAQKATOSA-N 0.000 description 6
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 6
- 108091005804 Peptidases Proteins 0.000 description 6
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 6
- 239000004365 Protease Substances 0.000 description 6
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 6
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 6
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 6
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 6
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 6
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 6
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 6
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 6
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 6
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 6
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 6
- 108010008355 arginyl-glutamine Proteins 0.000 description 6
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 6
- 230000037396 body weight Effects 0.000 description 6
- 238000006243 chemical reaction Methods 0.000 description 6
- 239000012636 effector Substances 0.000 description 6
- 125000000524 functional group Chemical group 0.000 description 6
- 108010078144 glutaminyl-glycine Proteins 0.000 description 6
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 6
- 230000003053 immunization Effects 0.000 description 6
- 238000002649 immunization Methods 0.000 description 6
- 229940072221 immunoglobulins Drugs 0.000 description 6
- 238000011534 incubation Methods 0.000 description 6
- 230000005764 inhibitory process Effects 0.000 description 6
- 150000007523 nucleic acids Chemical class 0.000 description 6
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 6
- 108010044292 tryptophyltyrosine Proteins 0.000 description 6
- 238000002965 ELISA Methods 0.000 description 5
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 5
- 239000003795 chemical substances by application Substances 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 239000013604 expression vector Substances 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- -1 halomethyl ketones Chemical class 0.000 description 5
- 108020004707 nucleic acids Proteins 0.000 description 5
- 102000039446 nucleic acids Human genes 0.000 description 5
- 210000001519 tissue Anatomy 0.000 description 5
- OACQOWPRWGNKTP-AVGNSLFASA-N Gln-Tyr-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O OACQOWPRWGNKTP-AVGNSLFASA-N 0.000 description 4
- CBWKURKPYSLMJV-SOUVJXGZSA-N Glu-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CBWKURKPYSLMJV-SOUVJXGZSA-N 0.000 description 4
- 238000001574 biopsy Methods 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000007796 conventional method Methods 0.000 description 4
- 230000002163 immunogen Effects 0.000 description 4
- 238000002823 phage display Methods 0.000 description 4
- 239000013612 plasmid Substances 0.000 description 4
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 241000880493 Leptailurus serval Species 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- 102000035195 Peptidases Human genes 0.000 description 3
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 description 3
- 210000001744 T-lymphocyte Anatomy 0.000 description 3
- 229960005305 adenosine Drugs 0.000 description 3
- 150000001540 azides Chemical class 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 125000001246 bromo group Chemical group Br* 0.000 description 3
- 125000001309 chloro group Chemical group Cl* 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 3
- 239000000562 conjugate Substances 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 238000002474 experimental method Methods 0.000 description 3
- 239000012530 fluid Substances 0.000 description 3
- 102000037865 fusion proteins Human genes 0.000 description 3
- 108020001507 fusion proteins Proteins 0.000 description 3
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 3
- 230000002401 inhibitory effect Effects 0.000 description 3
- 239000007924 injection Substances 0.000 description 3
- 238000002347 injection Methods 0.000 description 3
- 230000003834 intracellular effect Effects 0.000 description 3
- 125000002346 iodo group Chemical group I* 0.000 description 3
- 229920002477 rna polymer Polymers 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- 210000004881 tumor cell Anatomy 0.000 description 3
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 2
- FMJUDUJLTNVWCH-UHFFFAOYSA-N 2-ethoxy-3-(4-hydroxyphenyl)propanoic acid Chemical compound CCOC(C(O)=O)CC1=CC=C(O)C=C1 FMJUDUJLTNVWCH-UHFFFAOYSA-N 0.000 description 2
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- 206010009944 Colon cancer Diseases 0.000 description 2
- OHLLDUNVMPPUMD-DCAQKATOSA-N Cys-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N OHLLDUNVMPPUMD-DCAQKATOSA-N 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 2
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 2
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 2
- VUBIPAHVHMZHCM-KKUMJFAQSA-N Leu-Tyr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 VUBIPAHVHMZHCM-KKUMJFAQSA-N 0.000 description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 2
- 206010027476 Metastases Diseases 0.000 description 2
- 108010079364 N-glycylalanine Proteins 0.000 description 2
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 2
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 2
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 2
- MLQVJYMFASXBGZ-IHRRRGAJSA-N Pro-Asn-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O MLQVJYMFASXBGZ-IHRRRGAJSA-N 0.000 description 2
- HXOLCSYHGRNXJJ-IHRRRGAJSA-N Pro-Asp-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HXOLCSYHGRNXJJ-IHRRRGAJSA-N 0.000 description 2
- DEDANIDYQAPTFI-IHRRRGAJSA-N Pro-Asp-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O DEDANIDYQAPTFI-IHRRRGAJSA-N 0.000 description 2
- QGOZJLYCGRYYRW-KKUMJFAQSA-N Pro-Glu-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QGOZJLYCGRYYRW-KKUMJFAQSA-N 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 2
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 238000007792 addition Methods 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 150000001298 alcohols Chemical class 0.000 description 2
- 125000000304 alkynyl group Chemical group 0.000 description 2
- 150000001412 amines Chemical class 0.000 description 2
- 125000000539 amino acid group Chemical group 0.000 description 2
- 229940125644 antibody drug Drugs 0.000 description 2
- 108010038633 aspartylglutamate Proteins 0.000 description 2
- 108010047857 aspartylglycine Proteins 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 201000011510 cancer Diseases 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 238000012054 celltiter-glo Methods 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 208000029742 colonic neoplasm Diseases 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 239000000032 diagnostic agent Substances 0.000 description 2
- 229940039227 diagnostic agent Drugs 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 150000002148 esters Chemical class 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 239000008103 glucose Substances 0.000 description 2
- 108010049041 glutamylalanine Proteins 0.000 description 2
- 229930004094 glycosylphosphatidylinositol Natural products 0.000 description 2
- 108010050848 glycylleucine Proteins 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 238000004020 luminiscence type Methods 0.000 description 2
- 201000005202 lung cancer Diseases 0.000 description 2
- 208000020816 lung neoplasm Diseases 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 230000001404 mediated effect Effects 0.000 description 2
- 201000001441 melanoma Diseases 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 201000002528 pancreatic cancer Diseases 0.000 description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 108010077112 prolyl-proline Proteins 0.000 description 2
- 108010031719 prolyl-serine Proteins 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 210000003289 regulatory T cell Anatomy 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 239000006228 supernatant Substances 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 150000003573 thiols Chemical class 0.000 description 2
- 108010073969 valyllysine Proteins 0.000 description 2
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 1
- ALBODLTZUXKBGZ-JUUVMNCLSA-N (2s)-2-amino-3-phenylpropanoic acid;(2s)-2,6-diaminohexanoic acid Chemical compound NCCCC[C@H](N)C(O)=O.OC(=O)[C@@H](N)CC1=CC=CC=C1 ALBODLTZUXKBGZ-JUUVMNCLSA-N 0.000 description 1
- RYHBNJHYFVUHQT-UHFFFAOYSA-N 1,4-Dioxane Chemical compound C1COCCO1 RYHBNJHYFVUHQT-UHFFFAOYSA-N 0.000 description 1
- 150000003923 2,5-pyrrolediones Chemical class 0.000 description 1
- WJQDJDVDXAAXSB-UHFFFAOYSA-N 5-sulfanylidenepyrrolidin-2-one Chemical compound O=C1CCC(=S)N1 WJQDJDVDXAAXSB-UHFFFAOYSA-N 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- 208000036832 Adenocarcinoma of ovary Diseases 0.000 description 1
- 102000009346 Adenosine receptors Human genes 0.000 description 1
- 108050000203 Adenosine receptors Proteins 0.000 description 1
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 1
- FBHOPGDGELNWRH-DRZSPHRISA-N Ala-Glu-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FBHOPGDGELNWRH-DRZSPHRISA-N 0.000 description 1
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 1
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 1
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 1
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 1
- MDNAVFBZPROEHO-DCAQKATOSA-N Ala-Lys-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MDNAVFBZPROEHO-DCAQKATOSA-N 0.000 description 1
- MDNAVFBZPROEHO-UHFFFAOYSA-N Ala-Lys-Val Natural products CC(C)C(C(O)=O)NC(=O)C(NC(=O)C(C)N)CCCCN MDNAVFBZPROEHO-UHFFFAOYSA-N 0.000 description 1
- OSRZOHXQCUFIQG-FPMFFAJLSA-N Ala-Phe-Pro Chemical compound C([C@H](NC(=O)[C@@H]([NH3+])C)C(=O)N1[C@H](CCC1)C([O-])=O)C1=CC=CC=C1 OSRZOHXQCUFIQG-FPMFFAJLSA-N 0.000 description 1
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 1
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- ZJBUILVYSXQNSW-YTWAJWBKSA-N Arg-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ZJBUILVYSXQNSW-YTWAJWBKSA-N 0.000 description 1
- NVGWESORMHFISY-SRVKXCTJSA-N Asn-Asn-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NVGWESORMHFISY-SRVKXCTJSA-N 0.000 description 1
- SRUUBQBAVNQZGJ-LAEOZQHASA-N Asn-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N SRUUBQBAVNQZGJ-LAEOZQHASA-N 0.000 description 1
- COUZKSSMBFADSB-AVGNSLFASA-N Asn-Glu-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)N)N COUZKSSMBFADSB-AVGNSLFASA-N 0.000 description 1
- WQLJRNRLHWJIRW-KKUMJFAQSA-N Asn-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)O WQLJRNRLHWJIRW-KKUMJFAQSA-N 0.000 description 1
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 1
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 1
- KZYSHAMXEBPJBD-JRQIVUDYSA-N Asn-Thr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KZYSHAMXEBPJBD-JRQIVUDYSA-N 0.000 description 1
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 1
- MJIJBEYEHBKTIM-BYULHYEWSA-N Asn-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MJIJBEYEHBKTIM-BYULHYEWSA-N 0.000 description 1
- NECWUSYTYSIFNC-DLOVCJGASA-N Asp-Ala-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 NECWUSYTYSIFNC-DLOVCJGASA-N 0.000 description 1
- SVFOIXMRMLROHO-SRVKXCTJSA-N Asp-Asp-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SVFOIXMRMLROHO-SRVKXCTJSA-N 0.000 description 1
- OEUQMKNNOWJREN-AVGNSLFASA-N Asp-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N OEUQMKNNOWJREN-AVGNSLFASA-N 0.000 description 1
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 1
- OVPHVTCDVYYTHN-AVGNSLFASA-N Asp-Glu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OVPHVTCDVYYTHN-AVGNSLFASA-N 0.000 description 1
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 1
- PWAIZUBWHRHYKS-MELADBBJSA-N Asp-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)O)N)C(=O)O PWAIZUBWHRHYKS-MELADBBJSA-N 0.000 description 1
- WMLFFCRUSPNENW-ZLUOBGJFSA-N Asp-Ser-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O WMLFFCRUSPNENW-ZLUOBGJFSA-N 0.000 description 1
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 1
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 1
- KNDCWFXCFKSEBM-AVGNSLFASA-N Asp-Tyr-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O KNDCWFXCFKSEBM-AVGNSLFASA-N 0.000 description 1
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 206010005003 Bladder cancer Diseases 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- WKBOTKDWSSQWDR-UHFFFAOYSA-N Bromine atom Chemical compound [Br] WKBOTKDWSSQWDR-UHFFFAOYSA-N 0.000 description 1
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 1
- ZAMOUSCENKQFHK-UHFFFAOYSA-N Chlorine atom Chemical compound [Cl] ZAMOUSCENKQFHK-UHFFFAOYSA-N 0.000 description 1
- YMBAVNPKBWHDAW-CIUDSAMLSA-N Cys-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N YMBAVNPKBWHDAW-CIUDSAMLSA-N 0.000 description 1
- WVLZTXGTNGHPBO-SRVKXCTJSA-N Cys-Leu-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O WVLZTXGTNGHPBO-SRVKXCTJSA-N 0.000 description 1
- KSMSFCBQBQPFAD-GUBZILKMSA-N Cys-Pro-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 KSMSFCBQBQPFAD-GUBZILKMSA-N 0.000 description 1
- NDNZRWUDUMTITL-FXQIFTODSA-N Cys-Ser-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NDNZRWUDUMTITL-FXQIFTODSA-N 0.000 description 1
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 108010016626 Dipeptides Proteins 0.000 description 1
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 1
- 102000003688 G-Protein-Coupled Receptors Human genes 0.000 description 1
- 108090000045 G-Protein-Coupled Receptors Proteins 0.000 description 1
- 206010017993 Gastrointestinal neoplasms Diseases 0.000 description 1
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 1
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 1
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 1
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 1
- ZEEPYMXTJWIMSN-GUBZILKMSA-N Gln-Lys-Ser Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CO)C(O)=O)NC(=O)[C@@H](N)CCC(N)=O ZEEPYMXTJWIMSN-GUBZILKMSA-N 0.000 description 1
- OZEQPCDLCDRCGY-SOUVJXGZSA-N Gln-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)N)N)C(=O)O OZEQPCDLCDRCGY-SOUVJXGZSA-N 0.000 description 1
- XUMFMAVDHQDATI-DCAQKATOSA-N Gln-Pro-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUMFMAVDHQDATI-DCAQKATOSA-N 0.000 description 1
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 1
- KVQOVQVGVKDZNW-GUBZILKMSA-N Gln-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KVQOVQVGVKDZNW-GUBZILKMSA-N 0.000 description 1
- BETSEXMYBWCDAE-SZMVWBNQSA-N Gln-Trp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N BETSEXMYBWCDAE-SZMVWBNQSA-N 0.000 description 1
- WTJIWXMJESRHMM-XDTLVQLUSA-N Gln-Tyr-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O WTJIWXMJESRHMM-XDTLVQLUSA-N 0.000 description 1
- WPJDPEOQUIXXOY-AVGNSLFASA-N Gln-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O WPJDPEOQUIXXOY-AVGNSLFASA-N 0.000 description 1
- WIMVKDYAKRAUCG-IHRRRGAJSA-N Gln-Tyr-Glu Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O WIMVKDYAKRAUCG-IHRRRGAJSA-N 0.000 description 1
- DYFJZDDQPNIPAB-NHCYSSNCSA-N Glu-Arg-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O DYFJZDDQPNIPAB-NHCYSSNCSA-N 0.000 description 1
- GZWOBWMOMPFPCD-CIUDSAMLSA-N Glu-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N GZWOBWMOMPFPCD-CIUDSAMLSA-N 0.000 description 1
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 1
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 1
- YLJHCWNDBKKOEB-IHRRRGAJSA-N Glu-Glu-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O YLJHCWNDBKKOEB-IHRRRGAJSA-N 0.000 description 1
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 1
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 1
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 1
- BPCLDCNZBUYGOD-BPUTZDHNSA-N Glu-Trp-Glu Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 BPCLDCNZBUYGOD-BPUTZDHNSA-N 0.000 description 1
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 1
- JMQFHZWESBGPFC-WDSKDSINSA-N Gly-Gln-Asp Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JMQFHZWESBGPFC-WDSKDSINSA-N 0.000 description 1
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 1
- XVYKMNXXJXQKME-XEGUGMAKSA-N Gly-Ile-Tyr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 XVYKMNXXJXQKME-XEGUGMAKSA-N 0.000 description 1
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 1
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 1
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 1
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 1
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 1
- FYVHHKMHFPMBBG-GUBZILKMSA-N His-Gln-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FYVHHKMHFPMBBG-GUBZILKMSA-N 0.000 description 1
- HVCRQRQPIIRNLY-IUCAKERBSA-N His-Gln-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)NCC(=O)O)N HVCRQRQPIIRNLY-IUCAKERBSA-N 0.000 description 1
- TTYKEFZRLKQTHH-MELADBBJSA-N His-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O TTYKEFZRLKQTHH-MELADBBJSA-N 0.000 description 1
- TVMNTHXFRSXZGR-IHRRRGAJSA-N His-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O TVMNTHXFRSXZGR-IHRRRGAJSA-N 0.000 description 1
- PZAJPILZRFPYJJ-SRVKXCTJSA-N His-Ser-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O PZAJPILZRFPYJJ-SRVKXCTJSA-N 0.000 description 1
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 1
- 238000006736 Huisgen cycloaddition reaction Methods 0.000 description 1
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 1
- UKTUOMWSJPXODT-GUDRVLHUSA-N Ile-Asn-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N UKTUOMWSJPXODT-GUDRVLHUSA-N 0.000 description 1
- DFJJAVZIHDFOGQ-MNXVOIDGSA-N Ile-Glu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N DFJJAVZIHDFOGQ-MNXVOIDGSA-N 0.000 description 1
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 1
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 1
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 1
- JLWZLIQRYCTYBD-IHRRRGAJSA-N Leu-Lys-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JLWZLIQRYCTYBD-IHRRRGAJSA-N 0.000 description 1
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 1
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 1
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 1
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 1
- DAYQSYGBCUKVKT-VOAKCMCISA-N Leu-Thr-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O DAYQSYGBCUKVKT-VOAKCMCISA-N 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 1
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 1
- LMVOVCYVZBBWQB-SRVKXCTJSA-N Lys-Asp-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LMVOVCYVZBBWQB-SRVKXCTJSA-N 0.000 description 1
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 1
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 1
- RFQATBGBLDAKGI-VHSXEESVSA-N Lys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCCN)N)C(=O)O RFQATBGBLDAKGI-VHSXEESVSA-N 0.000 description 1
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 1
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 1
- LUTDBHBIHHREDC-IHRRRGAJSA-N Lys-Pro-Lys Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O LUTDBHBIHHREDC-IHRRRGAJSA-N 0.000 description 1
- WZVSHTFTCYOFPL-GARJFASQSA-N Lys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N)C(=O)O WZVSHTFTCYOFPL-GARJFASQSA-N 0.000 description 1
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 1
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 1
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 1
- 239000002616 MRI contrast agent Substances 0.000 description 1
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 description 1
- RKIIYGUHIQJCBW-SRVKXCTJSA-N Met-His-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O RKIIYGUHIQJCBW-SRVKXCTJSA-N 0.000 description 1
- FWAHLGXNBLWIKB-NAKRPEOUSA-N Met-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCSC FWAHLGXNBLWIKB-NAKRPEOUSA-N 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical class ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 1
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 1
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- 229910002651 NO3 Inorganic materials 0.000 description 1
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 1
- NHNBFGGVMKEFGY-UHFFFAOYSA-N Nitrate Chemical compound [O-][N+]([O-])=O NHNBFGGVMKEFGY-UHFFFAOYSA-N 0.000 description 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 1
- 206010033128 Ovarian cancer Diseases 0.000 description 1
- 206010061328 Ovarian epithelial cancer Diseases 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- JOXIIFVCSATTDH-IHPCNDPISA-N Phe-Asn-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N JOXIIFVCSATTDH-IHPCNDPISA-N 0.000 description 1
- IILUKIJNFMUBNF-IHRRRGAJSA-N Phe-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O IILUKIJNFMUBNF-IHRRRGAJSA-N 0.000 description 1
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- KPDRZQUWJKTMBP-DCAQKATOSA-N Pro-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 KPDRZQUWJKTMBP-DCAQKATOSA-N 0.000 description 1
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 1
- MHHQQZIFLWFZGR-DCAQKATOSA-N Pro-Lys-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O MHHQQZIFLWFZGR-DCAQKATOSA-N 0.000 description 1
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 1
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 1
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 1
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 229920002684 Sepharose Polymers 0.000 description 1
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 1
- HZWAHWQZPSXNCB-BPUTZDHNSA-N Ser-Arg-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HZWAHWQZPSXNCB-BPUTZDHNSA-N 0.000 description 1
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 1
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 1
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 1
- ZIFYDQAFEMIZII-GUBZILKMSA-N Ser-Leu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZIFYDQAFEMIZII-GUBZILKMSA-N 0.000 description 1
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 1
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 1
- AXOHAHIUJHCLQR-IHRRRGAJSA-N Ser-Met-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CO)N AXOHAHIUJHCLQR-IHRRRGAJSA-N 0.000 description 1
- GDUZTEQRAOXYJS-SRVKXCTJSA-N Ser-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GDUZTEQRAOXYJS-SRVKXCTJSA-N 0.000 description 1
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 1
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 1
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 1
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 1
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 208000024313 Testicular Neoplasms Diseases 0.000 description 1
- 206010057644 Testis cancer Diseases 0.000 description 1
- SXAGUVRFGJSFKC-ZEILLAHLSA-N Thr-His-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SXAGUVRFGJSFKC-ZEILLAHLSA-N 0.000 description 1
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 1
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 1
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 1
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 1
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 1
- XGFGVFMXDXALEV-XIRDDKMYSA-N Trp-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N XGFGVFMXDXALEV-XIRDDKMYSA-N 0.000 description 1
- UOXPLPBMEPLZBW-WDSOQIARSA-N Trp-Val-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 UOXPLPBMEPLZBW-WDSOQIARSA-N 0.000 description 1
- QJBWZNTWJSZUOY-UWJYBYFXSA-N Tyr-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QJBWZNTWJSZUOY-UWJYBYFXSA-N 0.000 description 1
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 1
- GFHYISDTIWZUSU-QWRGUYRKSA-N Tyr-Asn-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GFHYISDTIWZUSU-QWRGUYRKSA-N 0.000 description 1
- JJNXZIPLIXIGBX-HJPIBITLSA-N Tyr-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JJNXZIPLIXIGBX-HJPIBITLSA-N 0.000 description 1
- GZUIDWDVMWZSMI-KKUMJFAQSA-N Tyr-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GZUIDWDVMWZSMI-KKUMJFAQSA-N 0.000 description 1
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 1
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 1
- CGGVNFJRZJUVAE-BYULHYEWSA-N Val-Asp-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CGGVNFJRZJUVAE-BYULHYEWSA-N 0.000 description 1
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 1
- OACSGBOREVRSME-NHCYSSNCSA-N Val-His-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CC(N)=O)C(O)=O OACSGBOREVRSME-NHCYSSNCSA-N 0.000 description 1
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 1
- JAKHAONCJJZVHT-DCAQKATOSA-N Val-Lys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N JAKHAONCJJZVHT-DCAQKATOSA-N 0.000 description 1
- FMQGYTMERWBMSI-HJWJTTGWSA-N Val-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N FMQGYTMERWBMSI-HJWJTTGWSA-N 0.000 description 1
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 1
- KRAHMIJVUPUOTQ-DCAQKATOSA-N Val-Ser-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KRAHMIJVUPUOTQ-DCAQKATOSA-N 0.000 description 1
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 1
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 1
- UVHFONIHVHLDDQ-IFFSRLJSSA-N Val-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O UVHFONIHVHLDDQ-IFFSRLJSSA-N 0.000 description 1
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 1
- BGTDGENDNWGMDQ-KJEVXHAQSA-N Val-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N)O BGTDGENDNWGMDQ-KJEVXHAQSA-N 0.000 description 1
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 1
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 1
- 229940122803 Vinca alkaloid Drugs 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 108010087924 alanylproline Proteins 0.000 description 1
- 150000001299 aldehydes Chemical class 0.000 description 1
- HAXFWIACAGNFHA-UHFFFAOYSA-N aldrithiol Chemical class C=1C=CC=NC=1SSC1=CC=CC=N1 HAXFWIACAGNFHA-UHFFFAOYSA-N 0.000 description 1
- 125000005262 alkoxyamine group Chemical group 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 1
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 230000009830 antibody antigen interaction Effects 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- 239000008365 aqueous carrier Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 1
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 1
- 108010068265 aspartyltyrosine Proteins 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- GDTBXPJZTBHREO-UHFFFAOYSA-N bromine Substances BrBr GDTBXPJZTBHREO-UHFFFAOYSA-N 0.000 description 1
- 229910052794 bromium Inorganic materials 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 238000002659 cell therapy Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000003034 chemosensitisation Effects 0.000 description 1
- 239000006114 chemosensitizer Substances 0.000 description 1
- 229940044683 chemotherapy drug Drugs 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 239000000460 chlorine Substances 0.000 description 1
- 229960002173 citrulline Drugs 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 239000000824 cytostatic agent Substances 0.000 description 1
- 230000001085 cytostatic effect Effects 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 230000006240 deamidation Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- AFOSIXZFDONLBT-UHFFFAOYSA-N divinyl sulfone Chemical class C=CS(=O)(=O)C=C AFOSIXZFDONLBT-UHFFFAOYSA-N 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 239000000890 drug combination Substances 0.000 description 1
- 238000009510 drug design Methods 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 239000002532 enzyme inhibitor Substances 0.000 description 1
- 201000004101 esophageal cancer Diseases 0.000 description 1
- 239000004052 folic acid antagonist Substances 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 229930182480 glucuronide Natural products 0.000 description 1
- 150000008134 glucuronides Chemical class 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 1
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 1
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 1
- 108010010147 glycylglutamine Proteins 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 210000004408 hybridoma Anatomy 0.000 description 1
- 229940042795 hydrazides for tuberculosis treatment Drugs 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 238000012872 hydroxylapatite chromatography Methods 0.000 description 1
- 239000012216 imaging agent Substances 0.000 description 1
- 230000005934 immune activation Effects 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 229960001438 immunostimulant agent Drugs 0.000 description 1
- 239000003022 immunostimulating agent Substances 0.000 description 1
- 230000003308 immunostimulating effect Effects 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 229940124589 immunosuppressive drug Drugs 0.000 description 1
- 238000009169 immunotherapy Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- PNDPGZBMCMUPRI-UHFFFAOYSA-N iodine Chemical compound II PNDPGZBMCMUPRI-UHFFFAOYSA-N 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 239000012948 isocyanate Substances 0.000 description 1
- 150000002513 isocyanates Chemical class 0.000 description 1
- 150000002540 isothiocyanates Chemical class 0.000 description 1
- 125000000468 ketone group Chemical group 0.000 description 1
- 150000002576 ketones Chemical class 0.000 description 1
- 150000002605 large molecules Chemical class 0.000 description 1
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 1
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- 108010057821 leucylproline Proteins 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 230000002132 lysosomal effect Effects 0.000 description 1
- 108010003700 lysyl aspartic acid Proteins 0.000 description 1
- 108010064235 lysylglycine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 150000002730 mercury Chemical class 0.000 description 1
- 108010005942 methionylglycine Proteins 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 239000011259 mixed solution Substances 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000002808 molecular sieve Substances 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 229940126619 mouse monoclonal antibody Drugs 0.000 description 1
- 201000000050 myeloid neoplasm Diseases 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 238000013188 needle biopsy Methods 0.000 description 1
- 230000007524 negative regulation of DNA replication Effects 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 239000002773 nucleotide Substances 0.000 description 1
- 125000003729 nucleotide group Chemical group 0.000 description 1
- 208000013371 ovarian adenocarcinoma Diseases 0.000 description 1
- 201000006588 ovary adenocarcinoma Diseases 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 238000012856 packing Methods 0.000 description 1
- 125000001151 peptidyl group Chemical group 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 150000003003 phosphines Chemical class 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 238000004393 prognosis Methods 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 108010070643 prolylglutamic acid Proteins 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 108010043671 prostatic acid phosphatase Proteins 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 238000005057 refrigeration Methods 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 1
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 1
- 108010026333 seryl-proline Proteins 0.000 description 1
- 238000007086 side reaction Methods 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 229940126586 small molecule drug Drugs 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- URGAHOPLAPQHLN-UHFFFAOYSA-N sodium aluminosilicate Chemical compound [Na+].[Al+3].[O-][Si]([O-])=O.[O-][Si]([O-])=O URGAHOPLAPQHLN-UHFFFAOYSA-N 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 201000003120 testicular cancer Diseases 0.000 description 1
- 238000010257 thawing Methods 0.000 description 1
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 230000005748 tumor development Effects 0.000 description 1
- 108010079202 tyrosyl-alanyl-cysteine Proteins 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 201000005112 urinary bladder cancer Diseases 0.000 description 1
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images


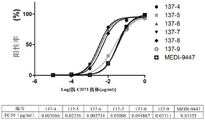




Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2896—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against molecules with a "CD"-designation, not provided for elsewhere
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/51—Complete heavy chain or Fd fragment, i.e. VH + CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/515—Complete light chain, i.e. VL + CL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Gastroenterology & Hepatology (AREA)
- Zoology (AREA)
- Toxicology (AREA)
- Cell Biology (AREA)
- Peptides Or Proteins (AREA)
Abstract
The invention provides an anti-CD73 humanized antibody. The antibody of the invention can be specifically combined with CD73 antigen, and has higher affinity and bioactivity.
Description
Technical Field
The invention relates to the field of biomedicine, in particular to an anti-CD73 humanized antibody and application thereof.
Background
CD73, cluster of differentiation 73, also called 5' -nucleotidase, is anchored to the cell membrane by GPI (glycosylphosphatidylinositol) and is structured as a dimer. CD73 plays an important role in tumor microenvironment, AMP can be converted into adenosine, adenosine is combined with a specific G protein coupled receptor, so that immune cells are abnormally infiltrated at tumor sites, the proliferation and migration of various cancers are regulated, the functions of a T cell-related immune system are mainly inhibited, and the CD73 is a marker for poor tumor prognosis.
In a number of studies in the past, it has been shown that inhibition of CD73 can prevent tumor development and metastasis. Both small molecule enzyme inhibitors of CD73 and large molecule antibodies showed anti-tumor effects. CD73 is expressed on the surface of various tumor cells, including lung cancer, melanoma, colon cancer, pancreatic cancer and other tumor cells. In addition, various immune cells are also affected by CD73, and CD73 is expressed on the surface of Tregs and participates in the inhibitory regulation of the Tregs on immune activation; secreted adenosine can bind to adenosine receptors on DC cells, thereby inhibiting DC function; high expression of CD73 on M2-type macrophages enhanced tumor metastasis.
The CD73 target has great potential in tumor treatment, and the CD73 antibody can also enhance the effects of the PD1 antibody and the CTLA4 antibody. However, no specific targeting antibody for CD73 is currently on the market. In addition, murine mabs have clinical limitations because they elicit human anti-mouse antibody responses (HAMA) when treated clinically. The antibody humanization technology can greatly reduce the immunogenicity of the murine monoclonal antibody.
Thus, in view of the role and function of CD73 in various types of related diseases, there is a need in the art to develop an anti-CD73 humanized antibody suitable for the treatment of patients.
Disclosure of Invention
The invention aims to provide an anti-CD73 humanized antibody with high affinity and high biological activity.
In a first aspect of the invention, there is provided a heavy chain variable region of an anti-CD73 antibody, said heavy chain variable region having VH-CDRs selected from the group consisting of:
(1) VH-CDR1 shown in SEQ ID NO. 3,
(2) VH-CDR2 shown in SEQ ID NO. 4, and
(3) a VH-CDR3 independently selected from the group consisting of: 21, 22, 23, 24, 25 and 26.
In another preferred embodiment, the heavy chain variable region has the amino acid sequence shown in SEQ ID No. 9.
In another preferred embodiment, the heavy chain variable region has the amino acid sequence shown in SEQ ID No. 10.
In another preferred embodiment, the heavy chain variable region has the amino acid sequence shown in SEQ ID No. 11.
In another preferred embodiment, the heavy chain variable region has the amino acid sequence shown in SEQ ID No. 12.
In another preferred embodiment, the heavy chain variable region has the amino acid sequence shown in SEQ ID No. 13.
In another preferred embodiment, the heavy chain variable region has the amino acid sequence shown in SEQ ID No. 14.
In another preferred embodiment, any one of the above amino acid sequences further comprises a derivative sequence optionally having at least one amino acid added, deleted, modified and/or substituted, and capable of retaining CD73 binding affinity.
In a second aspect of the invention, there is provided a heavy chain of an anti-CD73 antibody, said heavy chain having a heavy chain variable region as described in the first aspect of the invention.
In another preferred embodiment, the heavy chain of said antibody further comprises a heavy chain constant region.
In another preferred embodiment, the heavy chain constant region is of human, murine or rabbit origin, preferably of human origin.
In another preferred embodiment, the heavy chain constant region is a human antibody heavy chain IgG1 constant region.
In a third aspect of the invention, there is provided a light chain variable region of an anti-CD73 antibody, said light chain variable region having VL-CDRs selected from the group consisting of:
(1) VL-CDR1 shown in SEQ ID NO. 6,
(2) VL-CDR2 as shown in SEQ ID NO. 7, and
(3) a VL-CDR3 independently selected from the group consisting of: 27, 28, 29, 30, 31, 32.
In another preferred embodiment, the light chain variable region has the amino acid sequence shown in SEQ ID No. 15.
In another preferred embodiment, the light chain variable region has the amino acid sequence shown in SEQ ID No. 16.
In another preferred embodiment, the light chain variable region has the amino acid sequence shown in SEQ ID No. 17.
In another preferred embodiment, the light chain variable region has the amino acid sequence shown in SEQ ID No. 18.
In another preferred embodiment, the light chain variable region has the amino acid sequence shown in SEQ ID No. 19.
In another preferred embodiment, the light chain variable region has the amino acid sequence shown in SEQ ID No. 20.
In another preferred embodiment, any one of the above amino acid sequences further comprises a derivative sequence optionally having at least one amino acid added, deleted, modified and/or substituted, and capable of retaining CD73 binding affinity.
In a fourth aspect of the invention, there is provided a light chain of an anti-CD73 antibody, said light chain having a light chain variable region as described in the third aspect of the invention.
In another preferred embodiment, the light chain of the antibody further comprises a light chain constant region.
In another preferred embodiment, the light chain constant region is of human, murine or rabbit origin, preferably of human origin.
In another preferred embodiment, the light chain constant region is a human antibody light chain kappa constant region.
In a fifth aspect of the invention, there is provided an anti-CD73 antibody, said antibody having:
(1) a heavy chain variable region according to the first aspect of the invention; and/or
(2) A light chain variable region according to the third aspect of the invention;
alternatively, the antibody has: a heavy chain according to the second aspect of the invention; and/or a light chain according to the fourth aspect of the invention,
wherein any one of the amino acid sequences further comprises a derivative sequence which is optionally added, deleted, modified and/or substituted by at least one amino acid and can retain the binding affinity of CD 73.
In another preferred embodiment, the number of the amino acids to be added, deleted, modified and/or substituted is 1 to 5 (e.g., 1 to 3, preferably 1 to 2, and more preferably 1).
In another preferred embodiment, the antibody is a humanized antibody.
In another preferred embodiment, the antibody is selected from the group consisting of: an antibody of animal origin, a chimeric antibody, a humanized antibody, or a combination thereof.
In another preferred embodiment, the antibody is a double-chain antibody or a single-chain antibody.
In another preferred embodiment, the antibody is a monoclonal antibody.
In another preferred embodiment, the antibody comprises a monospecific, bispecific, or trispecific antibody.
In another preferred embodiment, the heavy chain variable region of the antibody further comprises a framework region of human origin, and/or the light chain variable region of the antibody further comprises a framework region of human origin.
In another preferred embodiment, the heavy chain variable region of the antibody further comprises a murine framework region, and/or the light chain variable region of the antibody further comprises a murine framework region.
In another preferred embodiment, the antibody has a heavy chain variable region according to the first aspect of the invention and a light chain variable region according to the third aspect of the invention;
wherein said heavy chain variable region comprises a VH-CDR selected from the group consisting of:
(1) VH-CDR1 shown in SEQ ID NO. 3,
(2) VH-CDR2 shown in SEQ ID NO. 4,
(3) a VH-CDR3 independently selected from the group consisting of: 21, 22, 23, 24, 25, 26; and
the light chain variable region comprises a VL-CDR selected from the group consisting of:
(1) VL-CDR1 shown in SEQ ID NO. 6,
(2) VL-CDR2 shown in SEQ ID NO. 7,
(3) a VL-CDR3 independently selected from the group consisting of: 27, 28, 29, 30, 31, 32.
In another preferred embodiment, the antibody has a heavy chain variable region according to the first aspect of the invention and a light chain variable region according to the third aspect of the invention; wherein,
wherein the heavy chain variable region comprises the following three complementarity determining regions:
VH-CDR1 shown in SEQ ID NO. 3,
VH-CDR2 shown in SEQ ID NO. 4,
a VH-CDR3 shown in SEQ ID No. 21; and
the light chain variable region comprises the following three complementarity determining regions:
VL-CDR1 shown in SEQ ID NO. 6,
VL-CDR2 shown in SEQ ID NO. 7,
VL-CDR3 shown in SEQ ID No. 27;
or
The heavy chain variable region comprises the following three complementarity determining regions:
VH-CDR1 shown in SEQ ID NO. 3,
VH-CDR2 shown in SEQ ID NO. 4,
a VH-CDR3 shown in SEQ ID No. 22; and
the light chain variable region comprises the following three complementarity determining regions:
VL-CDR1 shown in SEQ ID NO. 6,
VL-CDR2 shown in SEQ ID NO. 7,
VL-CDR3 shown in SEQ ID No. 28;
or
The heavy chain variable region comprises the following three complementarity determining regions:
VH-CDR1 shown in SEQ ID NO. 3,
VH-CDR2 shown in SEQ ID NO. 4,
VH-CDR3 shown in SEQ ID No. 23; and
the light chain variable region comprises the following three complementarity determining regions:
VL-CDR1 shown in SEQ ID NO. 6,
VL-CDR2 shown in SEQ ID NO. 7,
VL-CDR3 shown in SEQ ID No. 29;
or
The heavy chain variable region comprises the following three complementarity determining regions:
VH-CDR1 shown in SEQ ID NO. 3,
VH-CDR2 shown in SEQ ID NO. 4,
a VH-CDR3 shown in SEQ ID No. 24; and
the light chain variable region comprises the following three complementarity determining regions:
VL-CDR1 shown in SEQ ID NO. 6,
VL-CDR2 shown in SEQ ID NO. 7,
VL-CDR3 shown in SEQ ID No. 30;
or
The heavy chain variable region comprises the following three complementarity determining regions:
VH-CDR1 shown in SEQ ID NO. 3,
VH-CDR2 shown in SEQ ID NO. 4,
a VH-CDR3 shown in SEQ ID No. 25; and
the light chain variable region comprises the following three complementarity determining regions:
VL-CDR1 shown in SEQ ID NO. 6,
VL-CDR2 shown in SEQ ID NO. 7,
VL-CDR3 shown in SEQ ID No. 31;
or
The heavy chain variable region comprises the following three complementarity determining regions:
VH-CDR1 shown in SEQ ID NO. 3,
VH-CDR2 shown in SEQ ID NO. 4,
a VH-CDR3 shown in SEQ ID No. 26; and
the light chain variable region comprises the following three complementarity determining regions:
VL-CDR1 shown in SEQ ID NO. 6,
VL-CDR2 shown in SEQ ID NO. 7,
VL-CDR3 shown in SEQ ID NO. 32.
In another preferred embodiment, the antibody is a humanized antibody and the heavy chain variable region of the antibody comprises the amino acid sequence set forth in SEQ ID No. 9, 10, 11, 12, 13 or 14; and the variable region of the light chain of the antibody comprises the amino acid sequence shown in SEQ ID NO. 15, 16, 17, 18, 19 or 20.
In another preferred embodiment, the antibody is selected from the group consisting of:

in another preferred embodiment, the heavy chain variable region of the antibody has the amino acid sequence shown in SEQ ID No. 9; and the variable region of the light chain of the antibody has an amino acid sequence shown in SEQ ID NO. 15.
In another preferred embodiment, the heavy chain variable region of the antibody has the amino acid sequence shown in SEQ ID No. 10; and the variable region of the light chain of the antibody has an amino acid sequence shown in SEQ ID No. 16.
In another preferred embodiment, the heavy chain variable region of the antibody has the amino acid sequence shown in SEQ ID No. 11; and the variable region of the light chain of the antibody has an amino acid sequence shown in SEQ ID NO. 17.
In another preferred embodiment, the heavy chain variable region has the amino acid sequence shown in SEQ ID No. 12; and the light chain variable region has an amino acid sequence shown in SEQ ID NO. 18.
In another preferred embodiment, the heavy chain variable region of the antibody has the amino acid sequence shown in SEQ ID No. 13; and the variable region of the light chain of the antibody has an amino acid sequence shown in SEQ ID NO. 19.
In another preferred embodiment, the heavy chain variable region of the antibody has the amino acid sequence shown in SEQ ID No. 14; and the variable region of the light chain of the antibody has an amino acid sequence shown in SEQ ID NO. 20.
In another preferred embodiment, any one of the above amino acid sequences further comprises a derivative sequence optionally added, deleted, modified and/or substituted with at least one (e.g., 1-3, preferably 1-2, and more preferably 1) amino acid and capable of retaining the binding affinity of CD 73.
In another preferred embodiment, the amino acid sequence of the heavy chain variable region has at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% or 99% sequence homology or sequence identity with the amino acid sequence as shown in SEQ ID No. 9, 10, 11, 12, 13 or 14 of the sequence Listing.
In another preferred embodiment, the amino acid sequence of the light chain variable region has at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% or 99% sequence homology or sequence identity with the amino acid sequence as set forth in SEQ ID No. 15, 16, 17, 18, 19 or 20 of the sequence Listing.
In a sixth aspect of the present invention, there is provided a recombinant protein having:
(i) a heavy chain variable region according to the first aspect of the invention, a heavy chain according to the second aspect of the invention, a light chain variable region according to the third aspect of the invention, a light chain according to the fourth aspect of the invention, or an antibody according to the fifth aspect of the invention; and
(ii) optionally a tag sequence to facilitate expression and/or purification.
In another preferred embodiment, the tag sequence comprises a 6His tag.
In another preferred embodiment, the recombinant protein (or polypeptide) comprises a fusion protein.
In another preferred embodiment, the recombinant protein is a monomer, dimer, or multimer.
In another preferred embodiment, said recombinant protein further comprises an additional fusion element (or fusion polypeptide fragment) fused to said element (i).
In a seventh aspect of the invention, there is provided an antibody preparation comprising:
(a) a heavy chain variable region according to the first aspect of the invention, a heavy chain according to the second aspect of the invention, a light chain variable region according to the third aspect of the invention, a light chain according to the fourth aspect of the invention, or an antibody according to the fifth aspect of the invention; and
(b) a vector, said vector comprising: a buffer, sterile water, and optionally a surfactant.
In an eighth aspect of the invention, there is provided a kit comprising an antibody preparation according to the seventh aspect of the invention, and a container for holding the antibody preparation.
In a ninth aspect of the invention there is provided a CAR construct, the scFv segment of the antigen binding region of the CAR construct being a binding region that specifically binds to CD73 and having a heavy chain variable region according to the first aspect of the invention and a light chain variable region according to the third aspect of the invention.
In a tenth aspect of the invention there is provided a recombinant immune cell expressing an exogenous CAR construct according to the ninth aspect of the invention.
In another preferred embodiment, the immune cell is selected from the group consisting of: NK cells, T cells.
In another preferred embodiment, the immune cell is from a human or non-human mammal (e.g., a mouse).
In an eleventh aspect of the present invention, there is provided an antibody drug conjugate comprising:
(a) an antibody moiety selected from the group consisting of: a heavy chain variable region according to the first aspect of the invention, a heavy chain according to the second aspect of the invention, a light chain variable region according to the third aspect of the invention, a light chain according to the fourth aspect of the invention, or an antibody according to the fifth aspect of the invention, or a recombinant protein according to the sixth aspect of the invention, or a combination thereof; and
(b) a coupling moiety coupled to the antibody moiety, the coupling moiety selected from the group consisting of: a detectable label, a drug, a toxin, a cytokine, a radionuclide, an enzyme, or a combination thereof.
In a twelfth aspect of the invention there is provided the use of an active ingredient selected from the group consisting of: a heavy chain variable region according to the first aspect of the invention, a heavy chain according to the second aspect of the invention, a light chain variable region according to the third aspect of the invention, a light chain according to the fourth aspect of the invention, or an antibody according to the fifth aspect of the invention, or a recombinant protein according to the sixth aspect of the invention, a CAR construct according to the ninth aspect of the invention, an immune cell according to the tenth aspect of the invention, an antibody drug conjugate according to the eleventh aspect of the invention, or a combination thereof, wherein the active ingredient is for:
(a) preparing a detection reagent or a kit;
(b) preparing a medicament or preparation for preventing and/or treating CD73 related diseases; and/or
(c) Preparing a medicament or a preparation for preventing and/or treating cancer or tumor.
In another preferred embodiment, the cancer or tumor is selected from the group consisting of: lung cancer, melanoma, colon cancer, pancreatic cancer, bladder cancer, breast cancer, ovarian cancer, prostate cancer, testicular cancer, esophageal cancer, gastrointestinal cancer, liver cancer, lymphoma, myeloma, leukemia.
In a thirteenth aspect of the present invention, there is provided a pharmaceutical composition comprising:
(i) an active ingredient selected from the group consisting of: a heavy chain variable region according to the first aspect of the invention, a heavy chain according to the second aspect of the invention, a light chain variable region according to the third aspect of the invention, a light chain according to the fourth aspect of the invention, or an antibody according to the fifth aspect of the invention, or a recombinant protein according to the sixth aspect of the invention, a CAR construct according to the ninth aspect of the invention, an immune cell according to the tenth aspect of the invention, an antibody drug conjugate according to the eleventh aspect of the invention, or a combination thereof; and
(ii) a pharmaceutically acceptable carrier.
In another preferred embodiment, the pharmaceutical composition is a liquid preparation.
In another preferred embodiment, the pharmaceutical composition is an injection.
In another preferred embodiment, the pharmaceutical composition is used for treating tumors.
In another preferred embodiment, the tumor is a tumor highly expressing CD 73.
In a fourteenth aspect of the present invention, there is provided a polynucleotide encoding a polypeptide selected from the group consisting of:
(1) a heavy chain variable region according to the first aspect of the invention, a heavy chain according to the second aspect of the invention, a light chain variable region according to the third aspect of the invention, a light chain according to the fourth aspect of the invention, or an antibody according to the fifth aspect of the invention; or
(2) A recombinant protein according to the sixth aspect of the invention;
(3) a CAR construct according to the ninth aspect of the invention.
In a fifteenth aspect of the invention, there is provided a vector comprising a polynucleotide according to the fourteenth aspect of the invention.
In another preferred embodiment, the carrier comprises: bacterial plasmids, bacteriophages, yeast plasmids, plant cell viruses, mammalian cell viruses such as adenoviruses, retroviruses, or other vectors.
In a sixteenth aspect of the invention there is provided a genetically engineered host cell comprising a vector according to the fifteenth aspect of the invention or having integrated into its genome a polynucleotide according to the fourteenth aspect of the invention.
In a seventeenth aspect of the invention, there is provided an in vitro non-diagnostic method for detecting CD73 protein in a sample, the method comprising the steps of:
(1) contacting said sample in vitro with an antibody as described in the fifth aspect of the invention;
(2) detecting the formation of an antigen-antibody complex, wherein the formation of the complex is indicative of the presence of CD73 protein in the sample.
In another preferred embodiment, there is provided a method of treating a CD 73-associated disease, the method comprising:
administering to a subject in need thereof an antibody according to the first aspect of the invention, a drug conjugate of said antibody, or a CAR-T cell expressing said antibody, or a combination thereof.
It is to be understood that within the scope of the present invention, the above-described features of the present invention and those specifically described below (e.g., in the examples) may be combined with each other to form new or preferred embodiments. Not to be reiterated herein, but to the extent of space.
Drawings
Figure 1 shows the binding of humanized CD73 antibody to recombinant human CD73 protein.
Figure 2 shows the binding of humanized CD73 antibody to recombinant monkey CD73 protein.
FIG. 3 shows the affinity profile of CD73 antibody (humanized CD73 antibody and MEDI-9447) to SK-OV-3 cells.
FIG. 4 shows the affinity of the humanized CD73 antibody for CHOK1-cynoCD73 cells.
Figure 5 shows the inhibition of rhCD73 enzymatic activity by humanized CD73 antibody.
FIG. 6 shows the inhibition of CD73 enzyme activity on SK-OV-3 cells by humanized CD73 antibody.
FIG. 7 shows the results of humanized CD73 antibody-mediated CD73 internalization of SK-OV-3 cells.
Detailed Description
The present inventors have extensively and intensively studied and, through a large number of screenings, have unexpectedly obtained a humanized antibody of CD73 having excellent affinity. Experiments show that the CD73 antibody disclosed by the invention is specifically combined with human and monkey CD73 protein and CD73 positive cells, and has the effect of inhibiting CD73 protease activity. The antibodies of the invention may also induce tumor cell internalization of CD73, thereby treating/preventing CD 73-related diseases. The present invention has been completed based on this finding.
Term(s) for
As used herein, the terms "administration" and "treatment" refer to the application of an exogenous drug, therapeutic agent, diagnostic agent, or composition to an animal, human, subject, cell, tissue, organ, or biological fluid. "administration" and "treatment" may refer to therapeutic, pharmacokinetic, diagnostic, research, and experimental methods. The treatment of the cells comprises contacting the reagent with the cells, and contacting the reagent with a fluid, and contacting the fluid with the cells. "administering" and "treating" also mean treating in vitro and ex vivo by a reagent, a diagnostic, a binding composition, or by another cell. "treatment" when applied to a human, animal or study subject refers to therapeutic treatment, prophylactic or preventative measures, research, and diagnosis; including contact of the CD73 antibody with a human or animal, subject, cell, tissue, physiological compartment, or physiological fluid.
As used herein, the term "treatment" refers to the administration of a therapeutic agent, either internally or externally, to a patient having one or more symptoms of a disease for which the therapeutic agent is known to have a therapeutic effect, comprising any one of the CD73 antibodies of the invention and compositions thereof. Typically, the therapeutic agent is administered to the patient in an amount effective to alleviate one or more symptoms of the disease (therapeutically effective amount).
As used herein, the term "optional" or "optionally" means that the subsequently described event or circumstance may, but need not, occur. For example, "optionally comprising 1-3 antibody heavy chain variable regions" means that the antibody heavy chain variable regions of a particular sequence may, but need not, be 1, 2 or 3.
Antibodies
As used herein, the term "antibody" refers to an immunoglobulin, a tetrapeptide chain structure made up of two identical heavy chains and two identical light chains linked by interchain disulfide bonds. The constant regions of immunoglobulin heavy chains differ in their amino acid composition and arrangement, and thus, their antigenicity. Accordingly, immunoglobulins can be classified into five classes, or different classes called immunoglobulins, i.e., IgM, IgD, IgG, IgA, and IgE, and the heavy chain constant regions corresponding to the different classes of immunoglobulins are referred to as α, δ, ε, γ, and μ, respectively. IgG represents the most important class of immunoglobulins, which can be divided into 4 subclasses due to differences in chemical structure and biological function: IgG1, IgG2, IgG3, and IgG 4. Light chains are classified as kappa or lambda chains by differences in the constant regions. The subunit structures and three-dimensional configurations of different classes of immunoglobulins are well known to those skilled in the art.
The sequences of the antibody heavy and light chains, near the N-terminus, are widely varied by about 110 amino acids, being variable regions (V-regions); the remaining amino acid sequence near the C-terminus is relatively stable and is a constant region (C-region). The variable regions include 3 hypervariable regions (HVRs) and 4 FR Regions (FRs) which are relatively conserved in sequence. The amino acid sequences of the 4 FRs are relatively conserved and do not directly participate in the binding reaction. The 3 hypervariable regions determine the specificity of the antibody, also known as Complementarity Determining Regions (CDRs). Each of the Light Chain Variable Region (LCVR) and Heavy Chain Variable Region (HCVR) is composed of 3 CDR regions and 4 FR regions, which are sequentially arranged from amino terminus to carboxy terminus in the order FR1, CDR1, FR2, CDR2, FR3, CDR3, FR 4. The 3 CDR regions of the light chain, the light chain hypervariable region (LCDR), designated LCDR1, LCDR2 and LCDR 3; the 3 CDR regions of the heavy chain, the hypervariable region of the Heavy Chain (HCDR), are referred to as HCDR1, HCDR2 and HCDR 3. The CDR amino acid residues in the LCVR and HCVR regions of the antibodies or antigen-binding fragments of the invention are in number and position in accordance with known Kabat numbering convention (LCDR1-3, HCDR2-3), or in accordance with Kabat and chothia numbering convention (HCDR 1). The four FR regions in the native heavy and light chain variable regions are in a substantially β -sheet configuration, connected by three CDRs that form a connecting loop, and in some cases may form part of a β -sheet structure. The CDRs in each chain are held together tightly by the FR regions and form the antigen binding site of the antibody with the CDRs of the other chain. It is possible to determine which amino acids constitute the FR or CDR regions by comparing the amino acid sequences of antibodies of the same type. The constant regions are not directly involved in the binding of antibodies to antigens, but they exhibit different effector functions, such as participation in antibody-dependent cytotoxicity of antibodies.
The term "antigen-binding fragment," as used herein, refers to a Fab fragment, Fab 'fragment, F (ab') 2 fragment, or single Fv fragment having antigen-binding activity. Fv antibodies contain the variable regions of the antibody heavy chain, the variable regions of the light chain, but no constant regions, and have the smallest antibody fragment of the entire antigen binding site. Generally, Fv antibodies also comprise a polypeptide linker between the VH and VL domains and are capable of forming the structures required for antigen binding.
As used herein, the term "antigenic determinant" refers to a three-dimensional spatial site on an antigen that is not contiguous and is recognized by an antibody or antigen-binding fragment of the invention.
The invention includes not only intact antibodies, but also fragments of antibodies with immunological activity or fusion proteins of antibodies with other sequences. Accordingly, the invention also includes fragments, derivatives and analogs of the antibodies.
In the present invention, antibodies include murine, chimeric, humanized or fully human antibodies prepared using techniques well known to those skilled in the art. Recombinant antibodies, such as chimeric and humanized monoclonal antibodies, including human and non-human portions, can be prepared using recombinant DNA techniques well known in the art.
As used herein, the term "monoclonal antibody" refers to an antibody secreted by a clone obtained from a single cell source. Monoclonal antibodies are highly specific, being directed against a single epitope. The cell may be a eukaryotic, prokaryotic, or phage clonal cell line.
As used herein, the term "chimeric antibody" is an antibody molecule expressed by a host cell transfected with a vector by splicing a V region gene of a murine antibody to a C region gene of a human antibody into a chimeric gene. Not only retains the high specificity and affinity of the parent mouse antibody, but also ensures that the humanized Fc segment can effectively mediate the biological effect function.
The term "humanized antibody", as used herein, is a variable region engineered version of a murine antibody of the invention having CDR regions derived from (or substantially derived from) a non-human antibody (preferably a mouse monoclonal antibody), and FR and constant regions derived substantially from human antibody sequences. Because the CDR sequences are responsible for most of the antibody-antigen interactions, recombinant antibodies that mimic the properties of a particular naturally occurring antibody can be expressed by constructing an expression vector.
In the present invention, the antibody may be monospecific, bispecific, trispecific, or more multispecific.
In the present invention, the antibody of the present invention also includes conservative variants thereof, which means that at most 10, preferably at most 8, more preferably at most 5, and most preferably at most 3 amino acids are replaced by amino acids having similar or similar properties as compared with the amino acid sequence of the antibody of the present invention to form a polypeptide. These conservative variants are preferably produced by amino acid substitutions according to Table A.
Table a.
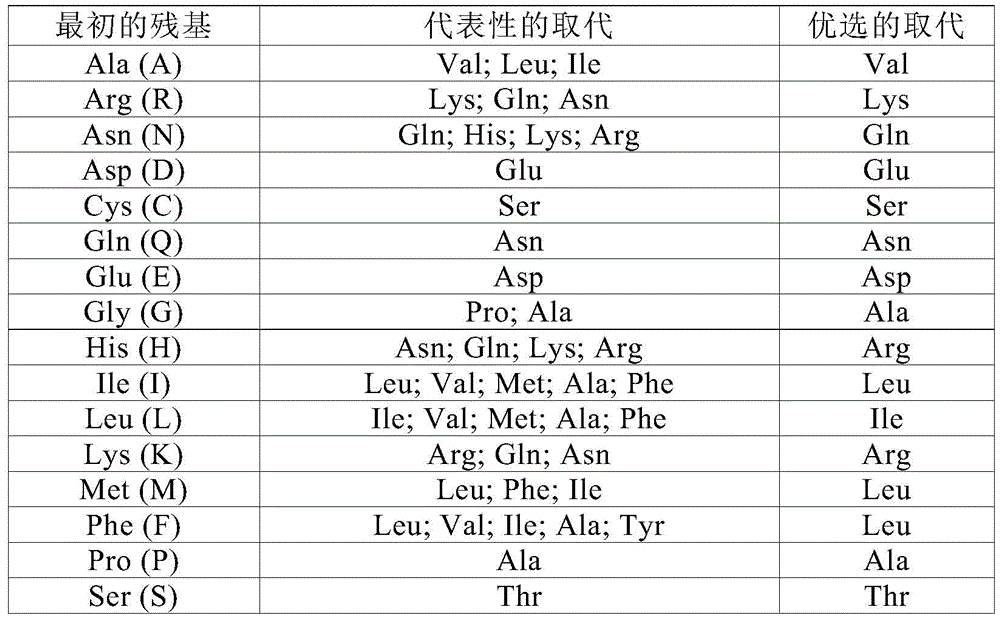

anti-CD73 antibodies
As used herein, the term "CD 73" generally refers to natural or recombinant human CD73, as well as non-human homologs of human CD 73.
The present invention provides a highly specific and high affinity antibody to CD73 comprising a heavy chain variable region (VH) amino acid sequence and a light chain comprising a light chain variable region (VL) amino acid sequence.
In the invention, a high-quality human CD73 antigen is selected to immunize a mouse, a mouse immune cell is taken to construct a phage library, a special phage display technology is adopted, a single-chain antibody (scfv) is displayed on the surface of the phage, a CD73 antigen is subjected to multiple rounds of screening to obtain an antibody sequence, the antibody sequence is constructed on a eukaryotic expression vector of an hIgG1 frame in a recombinant construction mode, and a mammal cell expresses to obtain an anti-CD73 full-length antibody (namely, a human-mouse chimeric antibody is obtained).
In a preferred embodiment of the present invention, the obtained human murine chimeric anti-CD73 full length antibody is CQ137 antibody protein. The obtained CQ137 antibody can bind to the tumor-indicated CD73 molecule and inhibit CD73 activity on human ovarian adenocarcinoma cells. Has the potential of treating various CD73 over-expression tumors.
Preferably, the CDRs of the heavy chain variable region (VH) are selected from the group consisting of:
VH-CDR1 shown in SEQ ID NO. 3,
VH-CDR2 shown in SEQ ID NO. 4, and
VH-CDR3 shown in SEQ ID NO. 5; and/or
The CDRs of the light chain variable region (VL) are selected from the group consisting of:
VL-CDR1 shown in SEQ ID NO. 6,
VL-CDR2 as shown in SEQ ID NO. 7, and
VL-CDR3 shown in SEQ ID NO. 8.
Wherein, any one of the above amino acid sequences further comprises a derivative sequence with CD73 binding affinity, which is added, deleted, modified and/or substituted with at least one (e.g., 1-5, 1-3, preferably 1-2, more preferably 1) amino acid.
In another preferred embodiment, the sequence formed by adding, deleting, modifying and/or substituting at least one amino acid sequence is preferably an amino acid sequence with homology of at least 80%, preferably at least 85%, more preferably at least 90%, and most preferably at least 95%.
The antibody of the present invention may be a double-chain or single-chain antibody, and may be selected from an animal-derived antibody, a chimeric antibody, a humanized antibody, more preferably a humanized antibody, a human-animal chimeric antibody, and still more preferably a fully humanized antibody.
The antibody derivatives of the present invention may be single chain antibodies, and/or antibody fragments, such as: fab, Fab ', (Fab')2Or other known antibody derivatives in the art, and any one or more of IgA, IgD, IgE, IgG, and IgM antibodies or antibodies of other subtypes.
Among them, the animal is preferably a mammal such as a mouse.
The antibodies of the invention may be murine, chimeric, humanized, CDR grafted and/or modified antibodies targeting human CD 73.
In a preferred embodiment of the present invention, any one or more of the above-mentioned SEQ ID No. 3, SEQ ID No. 4 and SEQ ID No. 5, or a sequence having a CD73 binding affinity thereof, which has been subjected to addition, deletion, modification and/or substitution of at least one amino acid, is located in a CDR region of a heavy chain variable region (VH).
In a preferred embodiment of the present invention, any one or more of the sequences of SEQ ID Nos. 6, 7 and 8, or a sequence having a binding affinity for CD73 wherein at least one amino acid has been added, deleted, modified and/or substituted is located in a CDR region of a light chain variable region (VL).
In a more preferred embodiment of the invention, the VH-CDR1, VH-CDR2, VH-CDR3 are each independently selected from any one or more of SEQ ID No. 3, SEQ ID No. 4 and SEQ ID No. 5, or sequences with CD73 binding affinity that have been added, deleted, modified and/or substituted with at least one amino acid; VL-CDR1, VL-CDR2 and VL-CDR3 are respectively and independently selected from any one or more sequences of SEQ ID NO. 6, SEQ ID NO. 7 and SEQ ID NO. 8, or sequences with CD73 binding affinity, wherein at least one amino acid is added, deleted, modified and/or substituted.
In the above-mentioned aspect of the present invention, the number of amino acids to be added, deleted, modified and/or substituted is preferably not more than 40%, more preferably not more than 35%, more preferably 1 to 33%, more preferably 5 to 30%, more preferably 10 to 25%, and more preferably 15 to 20% of the total number of amino acids in the original amino acid sequence.
In the present invention, the number of the amino acids to be added, deleted, modified and/or substituted is usually 1, 2, 3, 4 or 5, preferably 1 to 3, more preferably 1 to 2, and most preferably 1.
Preparation of antibodies
Any method suitable for producing monoclonal antibodies may be used to produce the CD73 antibodies of the invention. For example, an animal may be immunized with a linked or naturally occurring CD73 protein or fragment thereof. Suitable immunization methods, including adjuvants, immunostimulants, repeated booster immunizations, and one or more routes may be used.
Any suitable form of CD73 may be used as an immunogen (antigen) for the production of non-human antibodies specific for CD73, which antibodies are screened for biological activity. The immunogen may be used alone or in combination with one or more immunogenicity enhancing agents known in the art. Immunogens can be purified from natural sources or produced in genetically modified cells. The DNA encoding the immunogen may be genomic or non-genomic in origin (e.g., cDNA). DNA encoding the immunogen may be expressed using suitable genetic vectors including, but not limited to, adenoviral vectors, baculovirus vectors, plasmids and non-viral vectors.
Humanized antibodies may be selected from any class of immunoglobulins, including IgM, IgD, IgG, IgA, and IgE. Likewise, any type of light chain can be used in the compounds and methods herein. In particular, kappa, lambda chains or variants thereof are useful in the compounds and methods of the invention.
An exemplary method for preparing the CD73 antibody of the invention is described in example 1.
The sequence of the DNA molecule of the antibody or fragment thereof of the present invention can be obtained by a conventional technique, for example, by PCR amplification or genomic library screening. Alternatively, the coding sequences for the light and heavy chains may be fused together to form a single chain antibody.
Once the sequence of interest has been obtained, it can be obtained in large quantities by recombinant methods. This is usually done by cloning it into a vector, transferring it into a cell, and isolating the relevant sequence from the propagated host cell by conventional methods.
In addition, the sequence can be synthesized by artificial synthesis, especially when the fragment length is short. Generally, fragments with long sequences are obtained by first synthesizing a plurality of small fragments and then ligating them. The DNA sequence may then be introduced into various existing DNA molecules (or vectors, for example) and cells known in the art.
The term "nucleic acid molecule" refers to both DNA molecules and RNA molecules. The nucleic acid molecule may be single-stranded or double-stranded, but is preferably double-stranded DNA. A nucleic acid is "operably linked" when it is placed into a functional relationship with another nucleic acid sequence. For example, a promoter or enhancer is operably linked to a coding sequence if it affects the transcription of the coding sequence.
The term "vector" refers to a nucleic acid molecule capable of transporting another nucleic acid to which it has been linked. In one embodiment, the vector is a "plasmid," which refers to a circular double-stranded DNA loop into which additional DNA segments can be ligated.
The invention also relates to a vector comprising a suitable DNA sequence as described above and a suitable promoter or control sequence. These vectors may be used to transform an appropriate host cell so that it can express the protein.
The term "host cell" refers to a cell into which an expression vector has been introduced. The host cell may be a prokaryotic cell, such as a bacterial cell; or lower eukaryotic cells, such as yeast cells; or a higher eukaryotic cell, such as a plant or animal cell (e.g., a mammalian cell).
The steps described in the present invention for transforming a host cell with a recombinant DNA can be performed using techniques well known in the art. The obtained transformant can be cultured by a conventional method, and the transformant expresses the polypeptide encoded by the gene of the present invention. Depending on the host cell used, it is cultured in a conventional medium under suitable conditions.
Typically, the transformed host cells are cultured under conditions suitable for expression of the antibodies of the invention. The antibody of the invention is then purified by conventional immunoglobulin purification procedures, such as protein A-Sepharose, hydroxylapatite chromatography, gel electrophoresis, dialysis, ion exchange chromatography, hydrophobic chromatography, molecular sieve chromatography or affinity chromatography, using conventional separation and purification means well known to those skilled in the art.
The resulting monoclonal antibodies can be identified by conventional means. For example, the binding specificity of a monoclonal antibody can be determined by immunoprecipitation or by an in vitro binding assay, such as Radioimmunoassay (RIA) or enzyme-linked immunosorbent assay (ELISA).
Antibody-drug conjugates (ADC)
The invention also provides an antibody-conjugated drug (ADC) based on the antibody of the invention.
Typically, the antibody-conjugated drug comprises the antibody, and an effector molecule to which the antibody is conjugated, and preferably chemically conjugated. Wherein the effector molecule is preferably a therapeutically active drug. Furthermore, the effector molecule may be one or more of a toxic protein, a chemotherapeutic drug, a small molecule drug or a radionuclide.
The antibody of the invention may be conjugated to the effector molecule by a coupling agent. Examples of the coupling agent may be any one or more of a non-selective coupling agent, a coupling agent using a carboxyl group, a peptide chain, and a coupling agent using a disulfide bond. The non-selective coupling agent is a compound which enables effector molecules and antibodies to form covalent bonds, such as glutaraldehyde and the like. The coupling agent using carboxyl can be any one or more of a cis-aconitic anhydride coupling agent (such as cis-aconitic anhydride) and an acylhydrazone coupling agent (coupling site is acylhydrazone).
Certain residues on the antibody (e.g., Cys or Lys, etc.) are used to attach to a variety of functional groups, including imaging agents (e.g., chromophores and fluorophores), diagnostic agents (e.g., MRI contrast agents and radioisotopes), stabilizing agents (e.g., ethylene glycol polymers) and therapeutic agents. The antibody may be conjugated to a functional agent to form an antibody-functional agent conjugate. Functional agents (e.g., drugs, detection reagents, stabilizers) are coupled (covalently linked) to the antibody. The functional agent may be attached to the antibody directly, or indirectly through a linker.
Antibodies may be conjugated to drugs to form Antibody Drug Conjugates (ADCs). Typically, the ADC comprises a linker between the drug and the antibody. The linker may be degradable or non-degradable. Degradable linkers are typically susceptible to degradation in the intracellular environment, e.g., the linker degrades at the site of interest, thereby releasing the drug from the antibody. Suitable degradable linkers include, for example, enzymatically degradable linkers, including peptidyl-containing linkers that can be degraded by intracellular proteases (e.g., lysosomal proteases or endosomal proteases), or sugar linkers such as glucuronide-containing linkers that can be degraded by glucuronidase. The peptidyl linker may comprise, for example, a dipeptide such as valine-citrulline, phenylalanine-lysine or valine-alanine. Other suitable degradable linkers include, for example, pH sensitive linkers (e.g., linkers that hydrolyze at a pH of less than 5.5, such as hydrazone linkers) and linkers that degrade under reducing conditions (e.g., disulfide linkers). Non-degradable linkers typically release the drug under conditions in which the antibody is hydrolyzed by a protease.
Prior to attachment to the antibody, the linker has a reactive group capable of reacting with certain amino acid residues, and attachment is achieved by the reactive group. Thiol-specific reactive groups are preferred and include: for example maleimide compounds, haloamides (for example iodine, bromine or chlorine); halogenated esters (e.g., iodo, bromo, or chloro); halomethyl ketones (e.g., iodo, bromo, or chloro), benzyl halides (e.g., iodo, bromo, or chloro); vinyl sulfone, pyridyl disulfide; mercury derivatives such as 3, 6-bis- (mercuric methyl) dioxane, and the counter ion is acetate, chloride or nitrate; and polymethylene dimethyl sulfide thiolsulfonate. The linker may comprise, for example, a maleimide linked to the antibody via a thiosuccinimide.
The drug may be any cytotoxic, cytostatic, or immunosuppressive drug. In embodiments, the linker links the antibody and the drug, and the drug has a functional group that can form a bond with the linker. For example, the drug may have an amino, carboxyl, thiol, hydroxyl, or keto group that may form a bond with the linker. In the case of a drug directly attached to a linker, the drug has a reactive group prior to attachment to the antibody.
Useful classes of drugs include, for example, anti-tubulin drugs, DNA minor groove binding agents, DNA replication inhibitors, alkylating agents, antibiotics, folic acid antagonists, antimetabolites, chemosensitizers, topoisomerase inhibitors, vinca alkaloids, and the like. In the present invention, a drug-linker can be used to form an ADC in a single step. In other embodiments, bifunctional linker compounds may be used to form ADCs in a two-step or multi-step process. For example, a cysteine residue is reacted with a reactive moiety of a linker in a first step, and in a subsequent step, a functional group on the linker is reacted with a drug, thereby forming an ADC.
Generally, the functional group on the linker is selected to facilitate specific reaction with a suitable reactive group on the drug moiety. As a non-limiting example, azide-based moieties may be used to specifically react with reactive alkynyl groups on the drug moiety. The drug is covalently bound to the linker by 1, 3-dipolar cycloaddition between the azide and the alkynyl group. Other useful functional groups include, for example, ketones and aldehydes (suitable for reaction with hydrazides and alkoxyamines), phosphines (suitable for reaction with azides); isocyanates and isothiocyanates (suitable for reaction with amines and alcohols); and activated esters, such as N-hydroxysuccinimide esters (suitable for reaction with amines and alcohols). These and other attachment strategies, such as those described in bioconjugation technology, second edition (Elsevier), are well known to those skilled in the art. It will be appreciated by those skilled in the art that for selective reaction of a drug moiety and a linker, each member of a complementary pair may be used for both the linker and the drug when the reactive functional group of the complementary pair is selected.
Antibody formulations
The antibody has different stability in different preparation buffers, and is represented by the change of charge heterogeneity, degradation, polymerization and the like of antibody molecules, and the change of the quality properties is related to the physicochemical properties of the antibody, so that the preparation buffers suitable for the antibody need to be screened according to the physicochemical properties of different antibodies in the development process of antibody drugs. The currently commonly used antibody preparation buffer systems include phosphate buffer, citric acid buffer, histidine buffer, and the like, and according to the antibody properties, saline ions with different concentrations or excipients such as sorbitol, trehalose, sucrose, and the like, and a proper amount of surfactants such as tween 20 or tween 80 and the like are added to maintain the stability of the antibody.
The antibody drug combination preparation can effectively inhibit side reactions such as aggregation precipitation, hydrolysis, oxidation, deamidation and the like of the humanized antibody, and can effectively improve the stability of the product under the conditions of pressurization (high temperature, strong light irradiation, freeze thawing and the like), acceleration and long-term refrigeration.
Pharmaceutical composition
The invention also provides a composition. In a preferred embodiment, the composition is a pharmaceutical composition comprising an antibody or an active fragment thereof or a fusion protein thereof or an ADC thereof or a corresponding CAR-T cell as described above, and a pharmaceutically acceptable carrier. Generally, these materials will be formulated in a non-toxic, inert and pharmaceutically acceptable aqueous carrier medium, wherein the pH is generally from about 5 to about 8, preferably from about 6 to about 8, although the pH will vary depending on the nature of the material being formulated and the condition being treated. The formulated pharmaceutical compositions may be administered by conventional routes including, but not limited to: intratumoral, intraperitoneal, intravenous, or topical administration.
The antibody of the present invention may also be used for cell therapy by intracellular expression of a nucleotide sequence, for example, for chimeric antigen receptor T cell immunotherapy (CAR-T) and the like.
The pharmaceutical composition of the invention can be directly used for binding CD73 protein molecules, and thus can be used for preventing and treating CD73 related diseases. In addition, other therapeutic agents may also be used simultaneously.
The pharmaceutical composition of the present invention comprises a safe and effective amount (e.g., 0.001-99 wt%, preferably 0.01-90 wt%, more preferably 0.1-80 wt%) of the monoclonal antibody (or conjugate thereof) of the present invention as described above and a pharmaceutically acceptable carrier or excipient. Such vectors include (but are not limited to): saline, buffer, glucose, water, glycerol, ethanol, and combinations thereof. The pharmaceutical preparation should be compatible with the mode of administration. The pharmaceutical composition of the present invention can be prepared in the form of an injection, for example, by a conventional method using physiological saline or an aqueous solution containing glucose and other adjuvants. Pharmaceutical compositions such as injections, solutions are preferably manufactured under sterile conditions. The amount of active ingredient administered is a therapeutically effective amount, for example from about 1 microgram per kilogram of body weight to about 5 milligrams per kilogram of body weight per day. In addition, the polypeptides of the invention may also be used with other therapeutic agents.
Where a pharmaceutical composition is used, a safe and effective amount of the pharmaceutical composition is administered to the mammal, wherein the safe and effective amount is generally at least about 10 micrograms/kg body weight, and in most cases does not exceed about 50 mg/kg body weight, preferably the dose is from about 10 micrograms/kg body weight to about 20 mg/kg body weight. Of course, the particular dosage will depend upon such factors as the route of administration, the health of the patient, and the like, and is within the skill of the skilled practitioner.
Detection use and kit
The antibodies of the invention are useful in detection applications, for example, for detecting a sample, thereby providing diagnostic information.
In the present invention, the specimen (sample) used includes cells, tissue samples and biopsy specimens. The term "biopsy" as used herein shall include all kinds of biopsies known to the person skilled in the art. Thus, a biopsy as used in the present invention may comprise a tissue sample prepared, for example, by endoscopic methods or by needle or needle biopsy of an organ.
Samples for use in the present invention include fixed or preserved cell or tissue samples.
The invention also provides a kit containing the antibody (or fragment thereof) of the invention, and in a preferred embodiment of the invention, the kit further comprises a container, instructions for use, a buffer, and the like. In a preferred embodiment, the antibody of the present invention may be immobilized on a detection plate.
The main advantages of the invention include
(1) Compared with murine and chimeric antibodies, the humanized antibody has better safety;
(2) the antibody has higher affinity through competitive screening;
(3) the antibody of the invention is derived from a phage display technology, and has stronger diversity than a hybridoma technology.
The invention is further illustrated by the following examples. It should be understood that these examples are for illustrative purposes only and are not intended to limit the scope of the present invention. Experimental procedures without specifying the detailed conditions in the following examples, generally followed by conventional conditions such as Sambrook et al, molecular cloning: the conditions described in the Laboratory Manual (New York: Cold Spring Harbor Laboratory Press,1989), or according to the manufacturer's recommendations. Unless otherwise indicated, percentages and parts are by weight.
EXAMPLE 1 preparation of anti-human CD73 monoclonal antibody
This example describes mainly the sequence of anti-human CD73 single-chain antibody obtained by mouse immunization and phage display. Balb/C mice were immunized with recombinant human CD73 protein (C446, Novoprotein), after the first immunization, booster immunization was performed 14 days each, 4 times total immunization, and mouse sera were taken for antibody titer evaluation. And (4) evaluating the effective mouse, taking B cells, extracting RNA (ribonucleic acid) for reverse transcription, and constructing a phage display library. Packing the recombinant human CD73 protein according to 1-5 microgram/ml, adding the displayed phage, screening the phage library, collecting the screened phage which is not washed away, infecting host bacteria to obtain a first round of screening library, and carrying out two-round and three-round screening according to the method. After screening is completed, the screening is carried out by phase-ELISA, and the Anti-CD73 candidate sequence is obtained by sequencing the positive identification. CQ137 VH and VL are respectively constructed on eukaryotic expression vectors containing hIgG1-kappa constant regions, freestyle 293F cells are transfected, supernatants are collected after 3-7 days of culture, and CQ137 antibody protein is obtained by purifying through a protein A column.
The sequence of the CQ137 light chain variable region is shown as SEQ ID NO. 1, the sequence of the CQ137 heavy chain variable region is shown as SEQ ID NO. 2, the amino acid sequence of the hIgG1 constant region is shown as SEQ ID NO. 33, and the amino acid sequence of the kappa chain constant region is shown as SEQ ID NO. 34.
The CDRs of the CQ137 antibody are shown in Table A (defined by IMGT).
TABLE A murine anti-CD73 antibody CDR sequences

Example 2 CQ137 humanization
A series of humanized antibodies are obtained by analyzing the human framework closest to CQ137 by using structural simulation and rational design. VH and VL of humanized sequences are respectively constructed on a vector containing hIgG1 and kappa light chain constant regions, Freestyle 293F cells are transfected, supernatant is collected, and protein A column is purified to obtain the required antibody protein. The obtained CQ137 humanized antibodies are numbered 137-4, 137-5, 137-6, 137-7, 137-8, 137-9, and the VH and VL sequences thereof are shown as follows:
137-4 VH(SEQ ID NO.:9)
QVQLVQSGAEVKKPGSSVKVSCKASGYSFTGYYIHWVRQAPGQGLEWMGRINPYNGATTYNQNFKDRVTITVDKSTSTAYMELSSLRSEDTAVYYCARFHYGAVDYWGQGTLVTVSS
137-4 VL(SEQ ID NO.:15)
DIQMTQSPSSLSASVGDRVTITCKASQDINTYLTWYQQKPGKAPKTLIYRANILVDGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCLQYEEFPLTFGGGTKVEIKR
137-5 VH(SEQ ID NO.:10)
QVQLVQSGAEVKKPGSSVKVSCKASGYSFTGYYIHWVRQAPGQGLEWMGRINPYNGATTYNQNFKDRVTITVDKSTSTAYMELSSLRSEDTAVYYCARFHYGAADYWGQGTLVTVSS
137-5 VL(SEQ ID NO.:16)
DIQMTQSPSSLSASVGDRVTITCKASQDINTYLTWYQQKPGKAPKTLIYRANILVDGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCLQYNEFPLTFGGGTKVEIKR
137-6 VH(SEQ ID NO.:11)
QVQLVQSGAEVKKPGSSVKVSCKASGYSFTGYYIHWVRQAPGQGLEWMGRINPYNGATTYNQNFKDRVTITVDKSTSTAYMELSSLRSEDTAVYYCARFHYGAPEYWGQGTLVTVSS
137-6 VL(SEQ ID NO.:17)
DIQMTQSPSSLSASVGDRVTITCKASQDINTYLTWYQQKPGKAPKTLIYRANILVDGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCLQYAEFPLTFGGGTKVEIKR
137-7 VH(SEQ ID NO.:12)
QVQLVQSGAEVKKPGSSVKVSCKASGYSFTGYYIHWVRQAPGQGLEWMGRINPYNGATTYNQNFKDRVTITVDKSTSTAYMELSSLRSEDTAVYYCARFHYGAPNYWGQGTLVTVSS
137-7 VL(SEQ ID NO.:18)
DIQMTQSPSSLSASVGDRVTITCKASQDINTYLTWYQQKPGKAPKTLIYRANILVDGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCLQYDDFPLTFGGGTKVEIKR
137-8 VH(SEQ ID NO.:13)
QVQLVQSGAEVKKPGSSVKVSCKASGYSFTGYYIHWVRQAPGQGLEWMGRINPYNGATTYNQNFKDRVTITVDKSTSTAYMELSSLRSEDTAVYYCARFHYGAPDFWGQGTLVTVSS
137-8 VL(SEQ ID NO.:19)
DIQMTQSPSSLSASVGDRVTITCKASQDINTYLTWYQQKPGKAPKTLIYRANILVDGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCLQYDQFPLTFGGGTKVEIKR
137-9 VH(SEQ ID NO.:14)
QVQLVQSGAEVKKPGSSVKVSCKASGYSFTGYYIHWVRQAPGQGLEWMGRINPYNGATTYNQNFKDRVTITVDKSTSTAYMELSSLRSEDTAVYYCARFHYGAPDLWGQGTLVTVSS
137-9 VL(SEQ ID NO.:20)
DIQMTQSPSSLSASVGDRVTITCKASQDINTYLTWYQQKPGKAPKTLIYRANILVDGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCLQYDAFPLTFGGGTKVEIKR
wherein the underlining region is CDRs (defined as IMGT). Wherein, the FR region, VH-CDR1, VH-CDR2, VL-CDR1 and VL-CDR2 of the humanized antibodies 137-4, 137-5, 137-6, 137-7, 137-8 and 137-9 are the same as the corresponding sequences of the chimeric antibody CQ137, and the corresponding sequences of VH-CDR3 and VL-CDR3 of the humanized antibodies are shown in the following table:
TABLE 1 corresponding sequences of VH-CDR3, VL-CDR3 of humanized antibodies
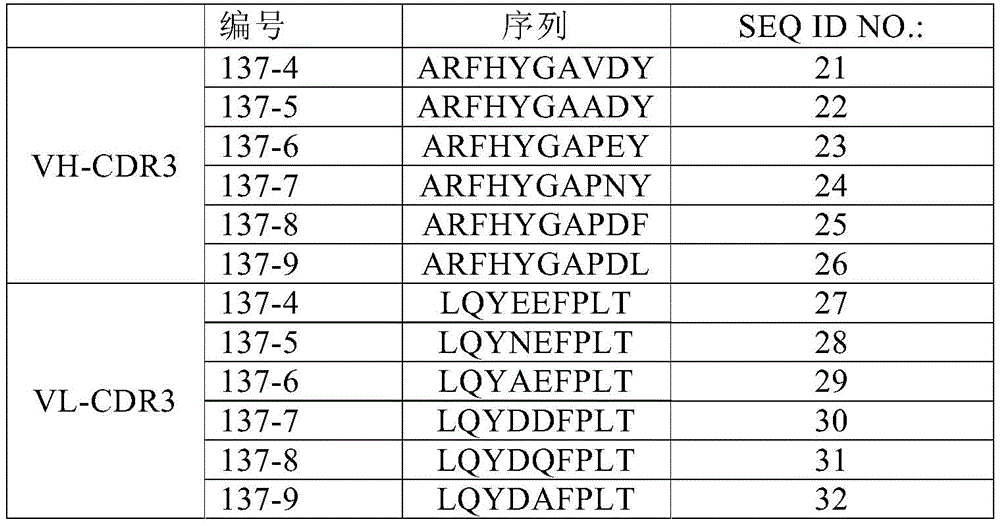
Example 3 CQ137 post-humanization affinity evaluation
This example shows the affinity of the humanized CD73 antibody to recombinant human and monkey CD73 proteins, SK-OV-3 cells positive to CD73, and CHOK1-cynoCD73 cells, respectively. In particular, the method comprises the following steps of,
(1) affinity with recombinant human CD73 protein
The recombinant human CD73 protein is coated at 3 ug/ml, and the humanized antibody is added with gradient dilution, and the binding of the antibody and the recombinant human CD73 is detected by ELISA method, the result is shown in FIG. 1, and the affinity EC50 is shown in Table 2.
Table 2: affinity results for humanized CD73 antibody and recombinant human CD73

(2) Affinity with recombinant monkey CD73 protein
The recombinant monkey CD73 protein was coated at 3. mu.g/ml, and the binding of the antibody to recombinant monkey CD73 was detected by ELISA, as shown in FIG. 2, and the affinity EC50 was shown in Table 3.
Table 3: affinity results for humanized CD73 antibody and recombinant monkey CD73

(3) Binding to human CD73 positive cells
Take 4X 105The individual cells SK-OV-3, adding gradient dilution of humanized antibody protein, after 1h incubation, using PBS washing 3 times, adding Anti-hFC-APC (from Jackson immunology), flow-on machine detection. The results are plotted as an S-curve in FIG. 3, and the affinity EC50 is shown in Table 4.
Table 4: affinity results of humanized CD73 antibody to SK-OV-3 cells

(4) Binding to monkey CD73 positive cells
Constructing monkey CD73 full length on NEO resistance-containing eukaryotic expression vector, transfecting CHO-K1 cell, screening with G418 to obtain CHOK1-cynoCD73 cell strain, and taking 4 × 105CHOK1-cynoCD73 cells were plated with Anti-hFC-APC (purchased from Jackson immunology) and assayed on a flow machine. The results are plotted as an S-curve in FIG. 4, and the affinity EC50 is shown in Table 5.
Table 5: affinity results of humanized CD73 antibody and CHOK1-cynoCD73 cell

Example 4 evaluation of enzyme Activity inhibition after humanization of CQ137
This example demonstrates that humanized 137 antibody inhibits CD73 protein and cellular enzyme activity. In particular, the method comprises the following steps of,
(1) inhibition of CD73 protease activity
CD73 protein is diluted to a working concentration of 5 mug/ml, CD73 antibody which is diluted in a gradient manner is added, incubation is carried out for 15min at 37 ℃, a mixed solution of 1mM ATP and AMP is added, incubation is carried out for 30min at 37 ℃, CellTiter-Glo detection reagent (purchased from promega) is added in an equal volume, a self-luminescence value is read by an enzyme-labeling instrument, and the activity change of rhCD73 is obtained by taking the activity of the enzyme without the addition of the antibody as 1.
The results showed that 6 humanized CD73 antibodies all inhibited the enzymatic activity of recombinant human CD 73.
(2) Inhibition of CD73 enzyme activity on human SK-OV-3 cells
Take 5X 104And adding the antibody diluted in a gradient manner into the SK-OV-3 cells, incubating at 37 ℃ for 15min, adding 1mM AMP37, incubating for 2h, adding 1mM ATP, immediately adding CellTiter-Glo detection reagent, reading a self-luminescence value by an enzyme labeling instrument, and calculating by taking the antibody not added as enzyme activity 1 to obtain a CD73 activity change graph 6 on the cells.
The results showed that 6 humanized CD73 antibodies all inhibited CD73 enzyme activity on SK-OV-3 cells.
Example 5 cell internalization mediated by humanized 137 antibody
Take 3X 105And adding 0.2 mu g of CD73 antibody into each SK-OV-3 cell, incubating at 37 ℃, incubating for 0 hour, 1 hour, 2 hours and 3 hours overnight, adding the same amount of corresponding CD73 antibody after the incubation is finished, adding Anti-hFC-APC flow antibody after the incubation is performed for 1 hour, detecting by an up-flow cytometer after the incubation and elution, and calculating the result as shown in figure 7, wherein the relative fluorescence intensity (MFI) at 0 hour is 1.
The results indicate that 6 humanized CD73 antibodies all promoted internalization of CD73 on the surface of SK-OV-3 cells.
The sequences of the invention are shown in the following table:
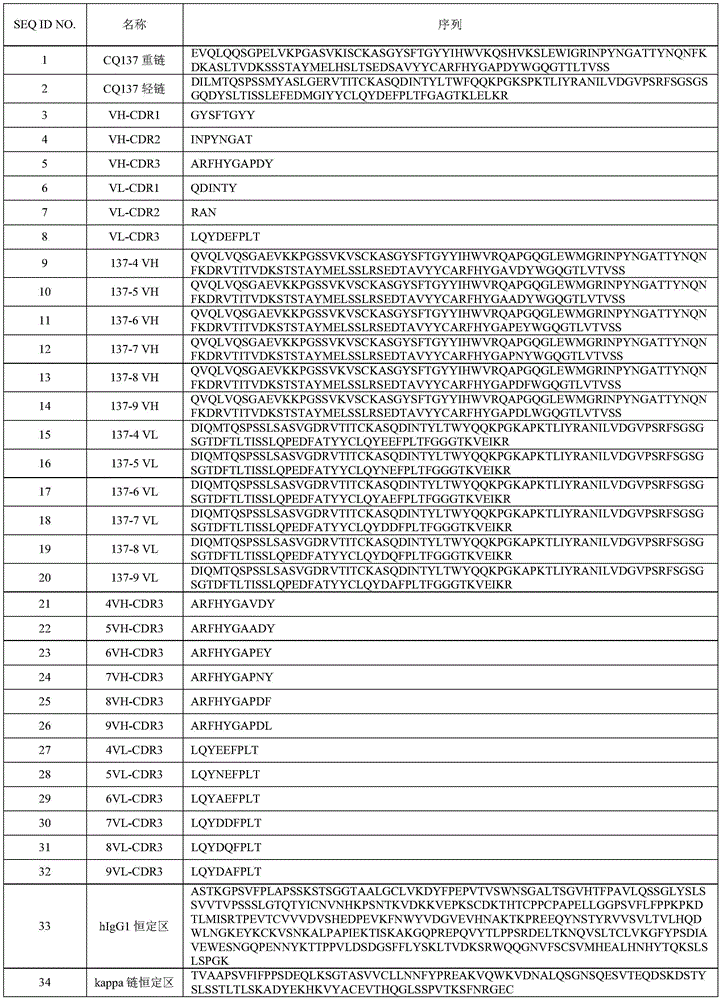
all documents referred to herein are incorporated by reference into this application as if each were individually incorporated by reference. Furthermore, it should be understood that various changes and modifications of the present invention can be made by those skilled in the art after reading the above teachings of the present invention, and these equivalents also fall within the scope of the present invention as defined by the appended claims.
Sequence listing
<110> Shanghai offshore science and technology Co., Ltd
<120> anti-CD73 humanized antibody
<130> P2021-0374
<160> 34
<170> PatentIn version 3.5
<210> 1
<211> 117
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 1
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Tyr Ile His Trp Val Lys Gln Ser His Val Lys Ser Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asn Pro Tyr Asn Gly Ala Thr Thr Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Lys Ala Ser Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu His Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Phe His Tyr Gly Ala Pro Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 2
<211> 108
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 2
Asp Ile Leu Met Thr Gln Ser Pro Ser Ser Met Tyr Ala Ser Leu Gly
1 5 10 15
Glu Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Thr Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Ile Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Ser Leu Thr Ile Ser Ser Leu Glu Phe
65 70 75 80
Glu Asp Met Gly Ile Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg
100 105
<210> 3
<211> 8
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 3
Gly Tyr Ser Phe Thr Gly Tyr Tyr
1 5
<210> 4
<211> 8
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 4
Ile Asn Pro Tyr Asn Gly Ala Thr
1 5
<210> 5
<211> 10
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 5
Ala Arg Phe His Tyr Gly Ala Pro Asp Tyr
1 5 10
<210> 6
<211> 6
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 6
Gln Asp Ile Asn Thr Tyr
1 5
<210> 7
<211> 3
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 7
Arg Ala Asn
1
<210> 8
<211> 9
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 8
Leu Gln Tyr Asp Glu Phe Pro Leu Thr
1 5
<210> 9
<211> 117
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 9
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Tyr Asn Gly Ala Thr Thr Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Arg Val Thr Ile Thr Val Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Phe His Tyr Gly Ala Val Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 10
<211> 117
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 10
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Tyr Asn Gly Ala Thr Thr Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Arg Val Thr Ile Thr Val Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Phe His Tyr Gly Ala Ala Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 11
<211> 117
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 11
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Tyr Asn Gly Ala Thr Thr Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Arg Val Thr Ile Thr Val Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Phe His Tyr Gly Ala Pro Glu Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 12
<211> 117
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 12
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Tyr Asn Gly Ala Thr Thr Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Arg Val Thr Ile Thr Val Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Phe His Tyr Gly Ala Pro Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 13
<211> 117
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 13
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Tyr Asn Gly Ala Thr Thr Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Arg Val Thr Ile Thr Val Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Phe His Tyr Gly Ala Pro Asp Phe Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 14
<211> 117
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 14
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Tyr Asn Gly Ala Thr Thr Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Arg Val Thr Ile Thr Val Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Phe His Tyr Gly Ala Pro Asp Leu Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 15
<211> 108
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 15
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Ile Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Glu Glu Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 16
<211> 108
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 16
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Ile Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Asn Glu Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 17
<211> 108
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 17
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Ile Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Ala Glu Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 18
<211> 108
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 18
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Ile Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Asp Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 19
<211> 108
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 19
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Ile Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Gln Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 20
<211> 108
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 20
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Ile Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ala Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 21
<211> 10
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 21
Ala Arg Phe His Tyr Gly Ala Val Asp Tyr
1 5 10
<210> 22
<211> 10
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 22
Ala Arg Phe His Tyr Gly Ala Ala Asp Tyr
1 5 10
<210> 23
<211> 10
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 23
Ala Arg Phe His Tyr Gly Ala Pro Glu Tyr
1 5 10
<210> 24
<211> 10
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 24
Ala Arg Phe His Tyr Gly Ala Pro Asn Tyr
1 5 10
<210> 25
<211> 10
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 25
Ala Arg Phe His Tyr Gly Ala Pro Asp Phe
1 5 10
<210> 26
<211> 10
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 26
Ala Arg Phe His Tyr Gly Ala Pro Asp Leu
1 5 10
<210> 27
<211> 9
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 27
Leu Gln Tyr Glu Glu Phe Pro Leu Thr
1 5
<210> 28
<211> 9
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 28
Leu Gln Tyr Asn Glu Phe Pro Leu Thr
1 5
<210> 29
<211> 9
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 29
Leu Gln Tyr Ala Glu Phe Pro Leu Thr
1 5
<210> 30
<211> 9
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 30
Leu Gln Tyr Asp Asp Phe Pro Leu Thr
1 5
<210> 31
<211> 9
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 31
Leu Gln Tyr Asp Gln Phe Pro Leu Thr
1 5
<210> 32
<211> 9
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 32
Leu Gln Tyr Asp Ala Phe Pro Leu Thr
1 5
<210> 33
<211> 330
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 33
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 34
<211> 106
<212> PRT
<213> Artificial Sequence (Artificial Sequence)
<400> 34
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
1 5 10 15
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
20 25 30
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
35 40 45
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
50 55 60
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
65 70 75 80
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
85 90 95
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
Claims (14)
1. An anti-CD73 antibody having a heavy chain variable region and a light chain variable region;
wherein said heavy chain variable region comprises a VH-CDR selected from the group consisting of:
(1) VH-CDR1 shown in SEQ ID NO. 3,
(2) VH-CDR2 shown in SEQ ID NO. 4,
(3) a VH-CDR3 independently selected from the group consisting of: 21, 22, 23, 24, 25, 26; and
the light chain variable region comprises a VL-CDR selected from the group consisting of:
(1) VL-CDR1 shown in SEQ ID NO. 6,
(2) VL-CDR2 shown in SEQ ID NO. 7,
(3) a VL-CDR3 independently selected from the group consisting of: 27, 28, 29, 30, 31, 32.
2. The antibody of claim 1, wherein the heavy chain variable region of the antibody has the amino acid sequence set forth in SEQ ID No. 9; and the light chain variable region of the antibody has an amino acid sequence shown in SEQ ID NO. 15.
3. The antibody of claim 1, wherein said antibody is selected from the group consisting of:
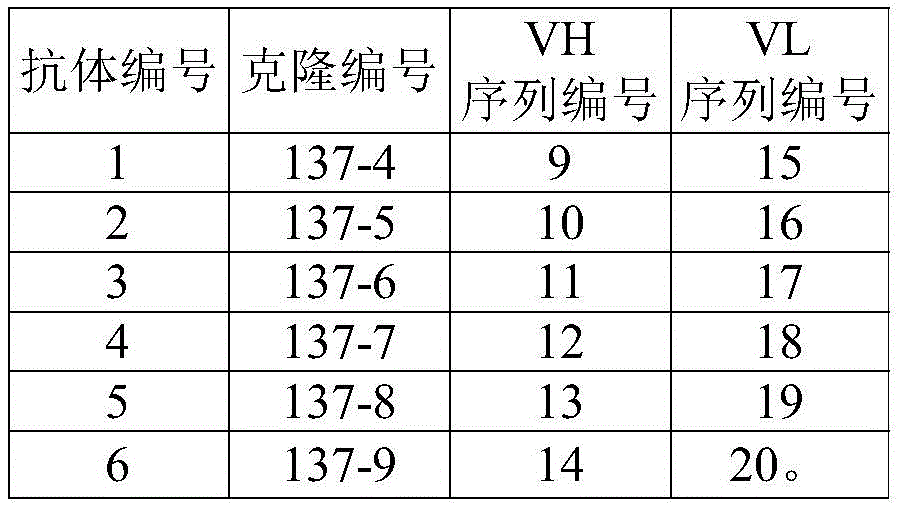
4. a recombinant protein, said recombinant protein having:
(i) the antibody of claim 1; and
(ii) optionally a tag sequence to facilitate expression and/or purification.
5. An antibody preparation, comprising:
(a) the antibody of claim 1; and
(b) a vector, said vector comprising: a buffer, sterile water, and optionally a surfactant.
6. A CAR construct, wherein the scFv segment of the antigen binding region of the CAR construct is a binding region that specifically binds to CD73, and wherein the scFv segment has a heavy chain variable region and a light chain variable region, wherein the heavy chain variable region comprises VH-CDRs selected from the group consisting of:
(1) VH-CDR1 shown in SEQ ID NO. 3,
(2) VH-CDR2 shown in SEQ ID NO. 4,
(3) a VH-CDR3 independently selected from the group consisting of: 21, 22, 23, 24, 25, 26; and
the light chain variable region comprises a VL-CDR selected from the group consisting of:
(1) VL-CDR1 shown in SEQ ID NO. 6,
(2) VL-CDR2 shown in SEQ ID NO. 7,
(3) a VL-CDR3 independently selected from the group consisting of: 27, 28, 29, 30, 31, 32.
7. A recombinant immune cell expressing an exogenous CAR construct of claim 6.
8. An antibody drug conjugate, comprising:
(a) an antibody moiety selected from the group consisting of: the antibody of claim 1, or the recombinant protein of claim 4, or a combination thereof; and
(b) a coupling moiety coupled to the antibody moiety, the coupling moiety selected from the group consisting of: a detectable label, a drug, a toxin, a cytokine, a radionuclide, an enzyme, or a combination thereof.
9. Use of an active ingredient selected from the group consisting of: the antibody of claim 1, the recombinant protein of claim 4, the CAR construct of claim 6, the immune cell of claim 7, the antibody drug conjugate of claim 8, or a combination thereof, the active ingredient for:
(a) preparing a detection reagent or a kit;
(b) preparing a medicament or preparation for preventing and/or treating CD73 related diseases; or
(c) Preparing a medicament or a preparation for preventing and/or treating the CD73 related diseases such as cancers or tumors.
10. A pharmaceutical composition, comprising:
(i) an active ingredient selected from the group consisting of: the antibody of claim 1, the recombinant protein of claim 4, the CAR construct of claim 6, the immune cell of claim 7, the antibody drug conjugate of claim 8, or a combination thereof; and
(ii) a pharmaceutically acceptable carrier.
11. A polynucleotide encoding a polypeptide selected from the group consisting of:
(1) the antibody of claim 1; or
(2) The recombinant protein of claim 4;
(3) the CAR construct of claim 6.
12. A vector comprising the polynucleotide of claim 11.
13. A genetically engineered host cell comprising the vector or genome of claim 12 having the polynucleotide of claim 11 integrated therein.
14. An in vitro non-diagnostic method for detecting CD73 protein in a sample, said method comprising the steps of:
(1) contacting the sample with the antibody of claim 1 in vitro;
(2) detecting the formation of an antigen-antibody complex, wherein the formation of the complex is indicative of the presence of CD73 protein in the sample.
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110292998.7A CN113045659B (en) | 2021-03-18 | 2021-03-18 | anti-CD73 humanized antibodies |
| PCT/CN2021/106917 WO2022179039A1 (en) | 2021-02-24 | 2021-07-16 | Anti-human cd73 antibody and use thereof |
| JP2023563043A JP7691720B2 (en) | 2021-02-24 | 2021-07-16 | Anti-human CD73 antibodies and their applications |
| US18/552,407 US20240174763A1 (en) | 2021-02-24 | 2021-07-16 | Anti-human cd73 antibody and use thereof |
| EP21927468.5A EP4299589A4 (en) | 2021-02-24 | 2021-07-16 | ANTI-HUMAN CD73 ANTIBODIES AND USE THEREOF |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110292998.7A CN113045659B (en) | 2021-03-18 | 2021-03-18 | anti-CD73 humanized antibodies |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113045659A CN113045659A (en) | 2021-06-29 |
| CN113045659B true CN113045659B (en) | 2022-03-18 |
Family
ID=76513716
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110292998.7A Active CN113045659B (en) | 2021-02-24 | 2021-03-18 | anti-CD73 humanized antibodies |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113045659B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022179039A1 (en) * | 2021-02-24 | 2022-09-01 | 苏州近岸蛋白质科技股份有限公司 | Anti-human cd73 antibody and use thereof |
| CN116903744B (en) * | 2022-08-12 | 2024-03-08 | 南京蓬勃生物科技有限公司 | anti-CD 73 antibody or antigen fragment thereof and application thereof |
| CN119744177A (en) * | 2023-07-24 | 2025-04-01 | 石药集团巨石生物制药有限公司 | Pharmaceutical composition of recombinant humanized anti-CD 73 monoclonal antibody |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| LT3218406T (en) * | 2014-11-10 | 2021-06-25 | Medimmune Limited | BINDING MOLECULARS, SPECIFIC CD73 AND THEIR USES |
| CN110240654A (en) * | 2018-03-07 | 2019-09-17 | 复旦大学 | Antibody-drug conjugates that bind to CD73 |
| EP3569618A1 (en) * | 2018-05-19 | 2019-11-20 | Boehringer Ingelheim International GmbH | Antagonizing cd73 antibody |
| CN110575548A (en) * | 2018-06-07 | 2019-12-17 | 中国科学院上海药物研究所 | Antibody-drug conjugate targeting CD73 and its preparation method and use |
| CA3118775A1 (en) * | 2018-11-12 | 2020-05-22 | Jiangsu Hengrui Medicine Co., Ltd. | Anti-cd73 antibody, antigen-binding fragment thereof and application thereof |
| CN111197058A (en) * | 2018-11-20 | 2020-05-26 | 北京百奥赛图基因生物技术有限公司 | Preparation method and application of humanized CD73 gene animal model |
| CN111434688A (en) * | 2019-01-11 | 2020-07-21 | 上海开拓者生物医药有限公司 | CD73 antibody and preparation method and application thereof |
| CN112251463B (en) * | 2020-09-30 | 2023-06-06 | 广东药康生物科技有限公司 | Construction method of CD73 humanized mouse model |
-
2021
- 2021-03-18 CN CN202110292998.7A patent/CN113045659B/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN113045659A (en) | 2021-06-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109963591B (en) | B7H3 antibody-drug conjugate and medical application thereof | |
| JP7691720B2 (en) | Anti-human CD73 antibodies and their applications | |
| CN117024591A (en) | Anti-human B7-H3 monoclonal antibodies and their applications | |
| CN112094349B (en) | Antibody targeting interleukin 36R and preparation method and application thereof | |
| EP4257605A1 (en) | Anti-tslp nanobody and use thereof | |
| KR20190140943A (en) | Anti-CD33 Antibody Formulations | |
| KR102904453B1 (en) | Antibody-drug conjugates targeting claudin 18.2 | |
| CN114763383A (en) | Monoclonal antibody targeting human BCMA and application thereof | |
| CN113045659B (en) | anti-CD73 humanized antibodies | |
| US20250197503A1 (en) | ANTI-HUMAN PD-Ll AND TLR7 DOUBLE-TARGETING NANOBODY CONJUGATE DRUG AND USE THEREOF IN RESISTING TUMOR | |
| CN112552406B (en) | Anti-human CD73 antibody | |
| WO2022151958A1 (en) | Human cd276-targeting monoclonal antibody and application thereof | |
| US20250066499A1 (en) | Antibody binding to human cd73, preparation method therefor, and use thereof | |
| CN117624366A (en) | 5T4 nanobody and its applications | |
| CN113461820B (en) | anti-CD 3 humanized antibodies | |
| CN113461821B (en) | anti-CD 3 humanized antibodies | |
| EP4397685A1 (en) | Anti-cd3 humanized antibody | |
| CN119661705B (en) | Anti-p-Tau 217 protein monoclonal antibody, preparation method and application thereof | |
| EP3904384A1 (en) | Fully humanized anti-gitr antibody and preparation method therefor | |
| CN117430708B (en) | An anti-Claudin18.2 antibody | |
| CN118324916B (en) | A monoclonal antibody against human GPRC5D and its preparation method and use | |
| CN115819581A (en) | Antibody targeting human CD47, preparation method and application | |
| CN120988123A (en) | A humanized monoclonal antibody against human NaPi2b and its application | |
| HK40034051A (en) | Antibody targeting interleukin 36r and preparation method and application thereof | |
| HK40034051B (en) | Antibody targeting interleukin 36r and preparation method and application thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |