CN113038271A - Video automatic editing method, device and computer storage medium - Google Patents
Video automatic editing method, device and computer storage medium Download PDFInfo
- Publication number
- CN113038271A CN113038271A CN202110321530.6A CN202110321530A CN113038271A CN 113038271 A CN113038271 A CN 113038271A CN 202110321530 A CN202110321530 A CN 202110321530A CN 113038271 A CN113038271 A CN 113038271A
- Authority
- CN
- China
- Prior art keywords
- video
- video frame
- frame
- value
- optical flow
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/44—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs
- H04N21/44016—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs involving splicing one content stream with another content stream, e.g. for substituting a video clip
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/441—Acquiring end-user identification, e.g. using personal code sent by the remote control or by inserting a card
- H04N21/4415—Acquiring end-user identification, e.g. using personal code sent by the remote control or by inserting a card using biometric characteristics of the user, e.g. by voice recognition or fingerprint scanning
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/45—Management operations performed by the client for facilitating the reception of or the interaction with the content or administrating data related to the end-user or to the client device itself, e.g. learning user preferences for recommending movies, resolving scheduling conflicts
- H04N21/466—Learning process for intelligent management, e.g. learning user preferences for recommending movies
- H04N21/4662—Learning process for intelligent management, e.g. learning user preferences for recommending movies characterized by learning algorithms
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/47—End-user applications
- H04N21/485—End-user interface for client configuration
- H04N21/4858—End-user interface for client configuration for modifying screen layout parameters, e.g. fonts, size of the windows
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Databases & Information Systems (AREA)
- Human Computer Interaction (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Theoretical Computer Science (AREA)
- Television Signal Processing For Recording (AREA)
Abstract
本申请实施例公开了一种视频自动剪辑方法、装置及计算机存储介质,使得剪辑生成的视频能够最大化地呈现目标人物的信息以及避免呈现出其他无关人物的信息。本申请实施例包括:将计算得到的姿态信息量化值以及光流能量变化值应用于强化学习算法中对动作的回报值的计算,并将最大回报值对应的候选视频帧确定为当前视频帧的下一视频帧,将当前视频帧的下一视频帧作为新的当前视频帧,返回执行计算在当前视频帧下的动作的回报值的步骤,同时,基于目标人物在视频帧中的位置和尺寸大小确定视频画面窗口,并根据视频画面窗口提取出关于目标人物的视频画面,使得最终合成的视频最大化地呈现有关于目标人物的信息,以及避免呈现出其他无关人物的信息。

The embodiments of the present application disclose an automatic video editing method, device, and computer storage medium, so that the video generated by the editing can maximize the information of the target person and avoid the information of other irrelevant people. The embodiment of the present application includes: applying the calculated quantized value of attitude information and the change value of optical flow energy to the calculation of the reward value of the action in the reinforcement learning algorithm, and determining the candidate video frame corresponding to the maximum reward value as the current video frame. The next video frame, taking the next video frame of the current video frame as the new current video frame, returns to the step of performing the calculation of the reward value of the action under the current video frame, at the same time, based on the position and size of the target person in the video frame The size of the video picture window is determined, and the video picture about the target person is extracted according to the video picture window, so that the final synthesized video can maximize the information about the target person and avoid showing other irrelevant person information.
Description
技术领域technical field
本申请实施例涉及视频剪辑领域,具体涉及一种视频自动剪辑方法、装置及计算机存储介质。The embodiments of the present application relate to the field of video editing, and in particular, to an automatic video editing method, device, and computer storage medium.
背景技术Background technique
现有技术中,视频自动剪辑可以提高安防、教育、影视娱乐等领域中视频剪辑的工作效率。在视频被剪辑之后,视频的数据量大大减小,视频占用的存储空间减小,因此,视频自动剪辑还能缓解海量视频的存储问题,视频经过自动剪辑之后可以释放更多的存储空间。In the prior art, automatic video editing can improve the work efficiency of video editing in the fields of security, education, film and television entertainment, and the like. After the video is edited, the data volume of the video is greatly reduced, and the storage space occupied by the video is reduced. Therefore, automatic video editing can also alleviate the storage problem of massive videos. After the video is automatically edited, more storage space can be released.
现有的视频自动剪辑系统主要针对于舞会视频、音乐会视频、室外活动视频、和足球比赛视频等视频进行设计,注重于使视频内容更加丰富,使视频内容更加多样化,以增加趣味性和提高观感。但是,在一些需要在视频中着重呈现出目标人物的场景中,现有的视频自动剪辑系统并无法很好地处理,因为现有的视频自动剪辑系统注重于呈现更多的视频内容,无法聚焦在目标人物上,无法呈现出更多的有关于目标人物的信息。同时,现有的视频自动剪辑系统在剪辑的视频中呈现了与目标人物无关的其他人物的信息,也可能会造成视频中其他人物的隐私泄露问题。The existing automatic video editing system is mainly designed for videos such as dance party videos, concert videos, outdoor activity videos, and football game videos, focusing on making the video content richer and more diverse to increase interest and performance. Improve perception. However, in some scenes where the target person needs to be highlighted in the video, the existing automatic video editing system cannot handle it well, because the existing automatic video editing system focuses on presenting more video content and cannot focus On the target person, no more information about the target person can be presented. At the same time, the existing video automatic editing system presents the information of other characters unrelated to the target character in the edited video, which may also cause the privacy leakage of other characters in the video.
发明内容SUMMARY OF THE INVENTION
本申请实施例提供了一种视频自动剪辑方法、装置及计算机存储介质,使得剪辑生成的视频能够最大化地呈现目标人物的信息以及避免呈现出其他无关人物的信息。Embodiments of the present application provide an automatic video editing method, device, and computer storage medium, so that the video generated by the editing can maximize the presentation of the information of the target person and avoid the presentation of the information of other irrelevant persons.
本申请实施例第一方面提供了一种视频自动剪辑方法,所述方法包括:A first aspect of the embodiments of the present application provides an automatic video editing method, and the method includes:
计算至少一路视频中的每一视频帧的目标人物的脸部姿态信息,计算所述脸部姿态信息对应的姿态信息量化值,计算所述每一视频帧的光流能量变化值;Calculate the facial posture information of the target person of each video frame in at least one video, calculate the posture information quantization value corresponding to the facial posture information, and calculate the optical flow energy change value of each video frame;
将任一路视频中的任一视频帧作为当前视频帧;Use any video frame in any video as the current video frame;
基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在所述当前视频帧下的动作的回报值,将最大回报值对应的候选视频帧确定为所述当前视频帧的下一视频帧,将所述当前视频帧的下一视频帧作为新的当前视频帧,并返回执行所述基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在所述当前视频帧下的动作的回报值的步骤;其中,所述动作为分别从所述至少一路视频的每一路视频中选择一个候选视频帧;Based on the reinforcement learning algorithm, the reward value of the action under the current video frame is calculated according to the pose information quantization value and the optical flow energy change value of the current video frame, and the candidate video frame corresponding to the maximum reward value is determined as the current video frame. The next video frame, taking the next video frame of the current video frame as the new current video frame, and returning to execute the reinforcement learning algorithm, according to the pose information quantization value of the current video frame and the optical flow energy change value calculated at the current video frame. The step of the reward value of the action under the current video frame; wherein, the action is to select a candidate video frame from each video of the at least one video respectively;
根据当前视频帧的先后确定顺序确定视频帧序列,基于所述视频帧序列得到初始合成视频;Determine a video frame sequence according to the sequence of the current video frames, and obtain an initial composite video based on the video frame sequence;
根据所述目标人物在所述初始合成视频中的每一帧的位置和尺寸大小,确定所述初始合成视频中的每一帧的视频画面窗口的位置和尺寸大小;According to the position and size of each frame of the target character in the initial composite video, determine the position and size of the video picture window of each frame in the initial composite video;
基于所述视频画面窗口的位置和尺寸大小提取所述初始合成视频中的每一帧的视频画面,得到目标合成视频。Based on the position and size of the video picture window, a video picture of each frame in the initial composite video is extracted to obtain a target composite video.
本申请实施例第二方面提供了一种视频自动剪辑装置,所述装置包括:A second aspect of the embodiments of the present application provides an automatic video editing device, and the device includes:
计算单元,用于计算至少一路视频中的每一视频帧的目标人物的脸部姿态信息,计算所述脸部姿态信息对应的姿态信息量化值,计算所述每一视频帧的光流能量变化值;A calculation unit, used to calculate the facial posture information of the target person in each video frame in at least one video, calculate the quantized value of posture information corresponding to the facial posture information, and calculate the optical flow energy change of each video frame. value;
确定单元,用于将任一路视频中的任一视频帧作为当前视频帧;Determining unit, for taking any video frame in any video as the current video frame;
剪辑单元,用于基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在所述当前视频帧下的动作的回报值,将最大回报值对应的候选视频帧确定为所述当前视频帧的下一视频帧,将所述当前视频帧的下一视频帧作为新的当前视频帧,并返回执行所述基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在所述当前视频帧下的动作的回报值的步骤;其中,所述动作为分别从所述至少一路视频的每一路视频中选择一个候选视频帧;The editing unit is used to calculate the reward value of the action under the current video frame according to the pose information quantization value and the optical flow energy change value of the current video frame based on the reinforcement learning algorithm, and determine the candidate video frame corresponding to the maximum reward value as the selected video frame. Describe the next video frame of the current video frame, take the next video frame of the current video frame as the new current video frame, and return to execute the described based reinforcement learning algorithm, according to the attitude information quantization value and optical flow energy of the current video frame The step of calculating the reward value of the action under the current video frame by the change value; wherein, the action is to select a candidate video frame from each video of the at least one video respectively;
生成单元,用于根据当前视频帧的先后确定顺序确定视频帧序列,基于所述视频帧序列得到初始合成视频;a generating unit, configured to determine a sequence of video frames according to the sequence of the current video frames, and obtain an initial composite video based on the sequence of video frames;
所述确定单元还用于根据所述目标人物在所述初始合成视频中的每一帧的位置和尺寸大小,确定所述初始合成视频中的每一帧的视频画面窗口的位置和尺寸大小;The determining unit is further configured to determine the position and size of the video picture window of each frame in the initial composite video according to the position and size of each frame of the target character in the initial composite video;
提取单元,用于基于所述视频画面窗口的位置和尺寸大小提取所述初始合成视频中的每一帧的视频画面,得到目标合成视频。An extraction unit, configured to extract the video picture of each frame in the initial composite video based on the position and size of the video picture window to obtain a target composite video.
本申请实施例第三方面提供了一种视频自动剪辑装置,所述装置包括:A third aspect of the embodiments of the present application provides an automatic video editing device, and the device includes:
存储器,用于存储计算机程序;处理器,用于在执行所述计算机程序时实现如前述第一方面所述的视频自动剪辑方法的步骤。The memory is used to store the computer program; the processor is used to implement the steps of the automatic video editing method according to the first aspect when the computer program is executed.
本申请实施例第四方面提供了一种计算机存储介质,计算机存储介质中存储有指令,该指令在计算机上执行时,使得计算机执行前述第一方面的方法。A fourth aspect of the embodiments of the present application provides a computer storage medium, where an instruction is stored in the computer storage medium, and when the instruction is executed on a computer, the computer executes the method of the foregoing first aspect.
从以上技术方案可以看出,本申请实施例具有以下优点:As can be seen from the above technical solutions, the embodiments of the present application have the following advantages:
本实施例中,通过计算每一视频帧的目标人物的脸部姿态信息量化值以及光流能量变化值,将计算得到的姿态信息量化值以及光流能量变化值应用于强化学习算法中对动作的回报值的计算,并将最大回报值对应的候选视频帧确定为当前视频帧的下一视频帧,将当前视频帧的下一视频帧作为新的当前视频帧,返回执行计算在当前视频帧下的动作的回报值的步骤,从而使得每一次从至少一路视频中确定出的视频帧均能最大化地呈现目标人物的信息以及避免呈现出目标人物被遮挡的画面。同时,基于目标人物在视频帧中的位置和尺寸大小确定视频画面窗口,并根据视频画面窗口提取出关于目标人物的视频画面,使得最终合成的视频最大化地呈现有关于目标人物的信息,以及避免呈现出其他无关人物的信息。In this embodiment, by calculating the quantized value of the facial posture information and the optical flow energy change value of the target person in each video frame, the calculated quantized value of the posture information and the optical flow energy change value are applied to the reinforcement learning algorithm for action The calculation of the reward value of , and determine the candidate video frame corresponding to the maximum reward value as the next video frame of the current video frame, take the next video frame of the current video frame as the new current video frame, and return to perform the calculation in the current video frame. The step of the reward value of the lower action, so that each video frame determined from at least one video can maximize the information of the target person and avoid showing the screen where the target person is occluded. At the same time, a video picture window is determined based on the position and size of the target person in the video frame, and a video picture about the target person is extracted according to the video picture window, so that the final synthesized video can maximize the information about the target person, and Avoid presenting information about other irrelevant characters.
附图说明Description of drawings
图1为本申请实施例中视频自动剪辑方法一个流程示意图;1 is a schematic flowchart of a method for automatic video editing in the embodiment of the application;
图2为本申请实施例中视频自动剪辑方法另一流程示意图;2 is another schematic flowchart of the automatic video editing method in the embodiment of the application;
图3为本申请实施例中一种脸部姿态信息的示意图;3 is a schematic diagram of a facial gesture information in an embodiment of the present application;
图4为本申请实施例中视频自动剪辑装置一个结构示意图;4 is a schematic structural diagram of an automatic video editing device in an embodiment of the application;
图5为本申请实施例中视频自动剪辑装置另一结构示意图。FIG. 5 is another schematic structural diagram of an apparatus for automatic video editing according to an embodiment of the present application.
具体实施方式Detailed ways
本申请实施例提供了一种视频自动剪辑方法、装置及计算机存储介质,使得剪辑生成的视频能够最大化地呈现目标人物的信息以及避免呈现出其他无关人物的信息。Embodiments of the present application provide an automatic video editing method, device, and computer storage medium, so that the video generated by the editing can maximize the presentation of the information of the target person and avoid the presentation of the information of other irrelevant persons.
请参阅图1,本申请实施例中视频自动剪辑方法一个实施例包括:Referring to FIG. 1, an embodiment of the automatic video editing method in the embodiment of the present application includes:
101、计算至少一路视频中的每一视频帧的目标人物的脸部姿态信息,计算脸部姿态信息对应的姿态信息量化值,计算每一视频帧的光流能量变化值;101. Calculate the facial posture information of the target character of each video frame in at least one video, calculate the posture information quantization value corresponding to the facial posture information, and calculate the optical flow energy change value of each video frame;
本实施例的方法可应用于视频自动剪辑装置,该视频自动剪辑装置具体可以是终端、服务器等具备数据处理能力的计算机设备。The method of this embodiment can be applied to an automatic video editing apparatus, and the automatic video editing apparatus may specifically be a computer device with data processing capability, such as a terminal and a server.
在需要着重体现视频中的目标人物的应用场景中,本实施例将获取至少一路视频,其中每一路视频的视频画面中包括目标人物,本实施例的任务是对该至少一路视频进行自动剪辑,以使得剪辑生成的视频重点呈现出目标人物以及与目标人物交互的对象的信息,并确保其他无关人物的信息不被显示在剪辑生成的视频中,从而保护其他无关人物的隐私信息安全。In the application scenario where the target person in the video needs to be emphasized, this embodiment will acquire at least one video, wherein the video picture of each video includes the target person, and the task of this embodiment is to automatically edit the at least one video, In order to make the video generated by the clip focus on the information of the target person and objects interacting with the target person, and ensure that the information of other irrelevant people is not displayed in the video generated by the clip, so as to protect the privacy information of other irrelevant people.
在获取到至少一路视频之后,计算每一路视频的每一视频帧的目标人物的脸部姿态信息,并计算脸部姿态信息对应的姿态信息量化值。此外,本实施例还提出一种确定视频画面中目标人物被遮挡的情况,即根据光流能量变化值来确定视频画面中目标人物的遮挡情况。因此,本步骤还计算每一视频帧的光流能量变化值,通过光流能量变化值来反映目标人物的遮挡情况。After acquiring at least one video, the facial posture information of the target person in each video frame of each video is calculated, and the quantized value of posture information corresponding to the facial posture information is calculated. In addition, this embodiment also proposes a method of determining the occlusion of the target person in the video picture, that is, determining the occlusion situation of the target person in the video picture according to the change value of the optical flow energy. Therefore, in this step, the optical flow energy change value of each video frame is also calculated, and the occlusion situation of the target person is reflected by the optical flow energy change value.
102、将任一路视频中的任一视频帧作为当前视频帧;102. Use any video frame in any video as the current video frame;
本实施例采用强化学习算法来确定剪辑生成的视频中的每一帧,视频帧作为强化学习算法中的状态。用户可以指定任一路视频中的任一视频帧为当前视频帧,因此视频自动剪辑装置根据用户的指定确定当前视频帧,则当前视频帧作为强化学习算法中的一个状态,在后续的步骤中将根据当前视频帧所对应的状态确定下一状态。In this embodiment, a reinforcement learning algorithm is used to determine each frame in the video generated by the clip, and the video frame is used as a state in the reinforcement learning algorithm. The user can designate any video frame in any video as the current video frame, so the automatic video editing device determines the current video frame according to the user's designation, then the current video frame is regarded as a state in the reinforcement learning algorithm, and in the subsequent steps, the The next state is determined according to the state corresponding to the current video frame.
103、基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在当前视频帧下的动作的回报值,将最大回报值对应的候选视频帧确定为当前视频帧的下一视频帧,将当前视频帧的下一视频帧作为新的当前视频帧,并返回执行基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在当前视频帧下的动作的回报值的步骤;103. Based on the reinforcement learning algorithm, calculate the reward value of the action under the current video frame according to the pose information quantization value of the current video frame and the optical flow energy change value, and determine the candidate video frame corresponding to the maximum reward value as the next video frame of the current video frame. Video frame, take the next video frame of the current video frame as the new current video frame, and return to execute the algorithm based on reinforcement learning, according to the pose information quantization value of the current video frame and the optical flow energy change value to calculate the action under the current video frame. return value steps;
在自动剪辑过程中,本实施例依次确定剪辑生成的视频中的每一视频帧。具体的,在确定当前视频帧之后,视频自动剪辑装置基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在当前视频帧下的动作的回报值。In the automatic editing process, this embodiment sequentially determines each video frame in the video generated by the editing. Specifically, after determining the current video frame, the automatic video editing device calculates the reward value of the action under the current video frame according to the quantized value of the pose information and the optical flow energy change value of the current video frame based on the reinforcement learning algorithm.
本实施例的强化学习算法具体可以是马尔可夫决策过程。在强化学习算法中,动作的回报值越大,表明该动作越有意义,则强化学习算法中虚拟的智能体将依据最大回报值所对应的动作来优化策略,进而根据优化的策略采取下一步的动作。因此,在计算出当前视频帧下多个动作的回报值之后,将最大回报值的动作所选择出来的候选视频帧确定为当前视频帧的下一视频帧。The reinforcement learning algorithm in this embodiment may specifically be a Markov decision process. In the reinforcement learning algorithm, the larger the reward value of the action, the more meaningful the action is. The virtual agent in the reinforcement learning algorithm will optimize the strategy according to the action corresponding to the maximum reward value, and then take the next step according to the optimized strategy. Actions. Therefore, after calculating the reward values of multiple actions under the current video frame, the candidate video frame selected by the action with the largest reward value is determined as the next video frame of the current video frame.
在确定出当前视频帧的下一视频帧之后,将当前视频帧的下一视频帧作为新的当前视频帧,并返回执行基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在当前视频帧下的动作的回报值的步骤。其中,在当前视频帧下的动作是指分别从至少一路视频的每一路视频中选择一个候选视频帧。After determining the next video frame of the current video frame, take the next video frame of the current video frame as the new current video frame, and return to execute the reinforcement learning algorithm based on the quantization value of the pose information of the current video frame and the change of the optical flow energy Value Steps to compute the reward value for the action at the current video frame. The action under the current video frame refers to selecting a candidate video frame from each video of at least one video respectively.
104、根据当前视频帧的先后确定顺序确定视频帧序列,基于视频帧序列得到初始合成视频;104. Determine a video frame sequence according to the sequence of the current video frames, and obtain an initial composite video based on the video frame sequence;
通过步骤103可依次确定出每一个视频帧,并且确定出的多个视频帧具有先后的确定顺序,因此,可以根据步骤103中当前视频帧的先后确定顺序确定视频帧序列,进而基于视频帧序列得到初始合成视频。Through
105、根据目标人物在初始合成视频中的每一帧的位置和尺寸大小,确定初始合成视频中的每一帧的视频画面窗口的位置和尺寸大小;105, according to the position and size of each frame of the target character in the initial composite video, determine the position and size of the video picture window of each frame in the initial composite video;
在得到初始合成视频之后,由于本实施例的目的在于着重体现视频画面中的目标人物,因此,进一步确定初始合成视频中目标人物在每一帧画面的位置和尺寸大小,并根据目标人物在每一帧画面的位置和尺寸大小确定初始合成视频中的每一帧的视频画面窗口的位置和尺寸大小。After the initial composite video is obtained, since the purpose of this embodiment is to focus on the target person in the video picture, the position and size of the target person in each frame of the initial composite video are further determined, and according to the target person in each frame The position and size of a frame of picture determine the position and size of the video picture window of each frame in the initial composite video.
106、基于视频画面窗口的位置和尺寸大小提取初始合成视频中的每一帧的视频画面,得到目标合成视频;106. Extract the video picture of each frame in the initial composite video based on the position and size of the video picture window to obtain the target composite video;
在确定视频画面窗口的位置和尺寸大小之后,基于视频画面窗口的位置和尺寸大小提取初始合成视频中的每一帧的视频画面,从而得到目标合成视频,实现视频的自动剪辑。After determining the position and size of the video picture window, extract the video picture of each frame in the initial composite video based on the position and size of the video picture window, so as to obtain the target composite video and realize automatic video editing.
本实施例中,通过计算每一视频帧的目标人物的脸部姿态信息量化值以及光流能量变化值,将计算得到的姿态信息量化值以及光流能量变化值应用于强化学习算法中对动作的回报值的计算,并将最大回报值对应的候选视频帧确定为当前视频帧的下一视频帧,将当前视频帧的下一视频帧作为新的当前视频帧,返回执行计算在当前视频帧下的动作的回报值的步骤,从而使得每一次从至少一路视频中确定出的视频帧均能最大化地呈现目标人物的信息以及避免呈现出目标人物被遮挡的画面。同时,基于目标人物在视频帧中的位置和尺寸大小确定视频画面窗口,并根据视频画面窗口提取出关于目标人物的视频画面,使得最终合成的视频最大化地呈现有关于目标人物的信息,以及避免呈现出其他无关人物的信息。In this embodiment, by calculating the quantized value of the facial posture information and the optical flow energy change value of the target person in each video frame, the calculated quantized value of the posture information and the optical flow energy change value are applied to the reinforcement learning algorithm for action The calculation of the reward value of , and determine the candidate video frame corresponding to the maximum reward value as the next video frame of the current video frame, take the next video frame of the current video frame as the new current video frame, and return to perform the calculation in the current video frame. The step of the reward value of the lower action, so that each video frame determined from at least one video can maximize the information of the target person and avoid showing the screen where the target person is occluded. At the same time, a video picture window is determined based on the position and size of the target person in the video frame, and a video picture about the target person is extracted according to the video picture window, so that the final synthesized video can maximize the information about the target person, and Avoid presenting information about other irrelevant characters.
下面将在前述图1所示实施例的基础上,进一步详细地描述本申请实施例。请参阅图2,本申请实施例中视频自动剪辑方法另一实施例包括:Based on the foregoing embodiment shown in FIG. 1 , the embodiments of the present application will be described in further detail below. Referring to FIG. 2, another embodiment of the automatic video editing method in the embodiment of the present application includes:
201、计算至少一路视频中的每一视频帧的目标人物的脸部姿态信息,计算脸部姿态信息对应的姿态信息量化值,计算每一视频帧的光流能量变化值;201. Calculate the facial posture information of the target character of each video frame in at least one video, calculate the posture information quantization value corresponding to the facial posture information, and calculate the optical flow energy change value of each video frame;
本实施例中,可以根据人脸姿态估计算法计算每一视频帧的目标人物的脸部姿态信息。具体的,人脸姿态估计算法计算得到的脸部姿态信息可以使用旋转矩阵、旋转向量、四元数或者欧拉角来表示。由于欧拉角可读性更好,可以优选使用欧拉角来表示脸部姿态信息。如图3所示,可以根据人脸姿态估计算法计算得到目标人物的脸部姿态信息如俯仰角(pitch)的角度、偏航角(yaw)的角度以及旋转角(roll)的角度。In this embodiment, the facial posture information of the target person in each video frame can be calculated according to the facial posture estimation algorithm. Specifically, the face pose information calculated by the face pose estimation algorithm can be represented by a rotation matrix, a rotation vector, a quaternion or an Euler angle. Since Euler angles are more readable, Euler angles can preferably be used to represent facial pose information. As shown in FIG. 3 , the facial posture information of the target person, such as the pitch angle, the yaw angle and the roll angle, can be calculated according to the facial posture estimation algorithm.
为了使计算得到的脸部姿态信息与人脸的对称结构保持一致性,本实施例采用多元高斯模型来计算脸部姿态信息对应的姿态信息量化值。进一步地,为便于计算,可对计算得到的姿态信息量化值进行归一化,将归一化的姿态信息量化值用于后续的计算过程中。In order to keep the calculated facial posture information consistent with the symmetrical structure of the human face, the present embodiment adopts a multivariate Gaussian model to calculate the quantized value of posture information corresponding to the facial posture information. Further, for the convenience of calculation, the calculated quantized value of attitude information can be normalized, and the normalized quantized value of attitude information can be used in the subsequent calculation process.
具体的,本实施例计算光流能量变化值的具体方式是,计算至少一路视频中每一视频帧的光流信息以及计算与该每一视频帧属于同一路视频的其他视频帧的光流信息,根据该每一视频帧的光流信息计算该每一视频帧的光流能量,根据该其他视频帧的光流信息计算该其他视频帧的光流能量,计算该每一视频帧与该其他视频帧的光流能量差值以及该每一视频帧与该其他视频帧的间隔时间,将光流能量差值与间隔时间的商作为该每一视频帧的光流能量变化值。Specifically, the specific method of calculating the optical flow energy change value in this embodiment is to calculate the optical flow information of each video frame in at least one video and calculate the optical flow information of other video frames belonging to the same video as each video frame. , calculate the optical flow energy of each video frame according to the optical flow information of each video frame, calculate the optical flow energy of the other video frames according to the optical flow information of the other video frames, calculate the relationship between each video frame and the other video frames The optical flow energy difference value of the video frame and the interval time between each video frame and the other video frames, the quotient of the optical flow energy difference value and the interval time is taken as the optical flow energy change value of each video frame.
例如,假设视频自动剪辑装置获取到C路视频(C≥1),每一路视频包括T帧视频帧,C路视频中的某一视频帧可以表示为fc,t(c=1,…,C;t=1,…,T),则与fc,t属于同一路视频且与fc,t+1相邻的视频帧可以表示为fc,t+1。分别计算fc,t的光流信息以及fc,t+1的光流信息,根据fc,t的光流信息计算fc,t的光流能量,根据fc,t+1的光流信息计算fc,t+1的光流能量,计算fc,t的光流能量与fc,t+1的光流能量的光流能量差值以及fc,t与fc,t+1的间隔时间,再将计算得到的光流能量差值与间隔时间的商作为fc,t的光流能量变化值。For example, assuming that the automatic video editing device obtains C-channel videos (C≥1), each channel of video includes T frames of video frames, and a certain video frame in the C-channel video can be expressed as f c, t (c=1,..., C; t=1, . . . , T), then the video frame that belongs to the same channel of video as f c, t and is adjacent to f c, t+1 can be expressed as f c, t+1 . Calculate the optical flow information of f c, t and the optical flow information of f c, t+1 respectively , calculate the optical flow energy of f c, t according to the optical flow information of f c, t , according to the light of f c, t+1 The flow information calculates the optical flow energy of f c, t+1 , calculates the optical flow energy difference between the optical flow energy of f c, t and the optical flow energy of f c, t+1 , as well as f c, t and f c, t +1 interval time, and then take the quotient of the calculated optical flow energy difference and the interval time as the optical flow energy change value of f c, t .
在多元高斯模型中,当人脸的欧拉角的角度趋向于0时,脸部姿态信息对应的姿态信息量化值最大;当人脸发生偏转而产生欧拉角时,即欧拉角不等于0,此时脸部姿态信息对应的姿态信息量化值降低。欧拉角的角度导致的姿态信息量化值的变化幅度可以通过方差矩阵来控制。因此,可以设置欧拉角的方差,以此来调节欧拉角对姿态信息量化值的影响程度。In the multivariate Gaussian model, when the angle of the Euler angle of the face tends to 0, the quantized value of the posture information corresponding to the facial posture information is the largest; when the face is deflected and the Euler angle is generated, that is, the Euler angle is not equal to 0, at this time, the quantization value of the posture information corresponding to the facial posture information decreases. The variation range of the quantized value of the attitude information caused by the angle of the Euler angles can be controlled by the variance matrix. Therefore, the variance of the Euler angle can be set to adjust the degree of influence of the Euler angle on the quantized value of the attitude information.
202、将任一路视频中的任一视频帧作为当前视频帧;202. Use any video frame in any video as the current video frame;
本步骤所执行的操作与前述图1所示实施例中的步骤102所执行的操作类似,此处不再赘述。The operations performed in this step are similar to the operations performed in
203、基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在当前视频帧下的动作的回报值,将最大回报值对应的候选视频帧确定为当前视频帧的下一视频帧,将当前视频帧的下一视频帧作为新的当前视频帧,并返回执行基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在当前视频帧下的动作的回报值的步骤;203. Based on the reinforcement learning algorithm, calculate the reward value of the action under the current video frame according to the pose information quantization value of the current video frame and the optical flow energy change value, and determine the candidate video frame corresponding to the maximum reward value as the next video frame of the current video frame. Video frame, take the next video frame of the current video frame as the new current video frame, and return to execute the algorithm based on reinforcement learning, according to the pose information quantization value of the current video frame and the optical flow energy change value to calculate the action under the current video frame. return value steps;
本实施例中,在计算动作的回报值时,具体的计算方式是,确定该动作下当前视频帧到候选视频帧的转移概率,根据当前视频帧的姿态信息量化值和光流能量变化值计算在当前视频帧下的动作的初始回报值,将初始回报值与该转移概率的乘积作为该动作的回报值。In this embodiment, when calculating the reward value of an action, the specific calculation method is to determine the transition probability from the current video frame to the candidate video frame under the action, and calculate the The initial reward value of the action under the current video frame, and the product of the initial reward value and the transition probability is taken as the reward value of the action.
具体的,确定转移概率的具体方式是,当满足预设条件时,确定转移概率为1;当不满足该预设条件中的任一项时,确定转移概率为0。其中,预设条件包括:当前视频帧与候选视频帧在时间线上相邻、目标人物存在于候选视频帧的画面中、动作对应的视频索引与候选视频帧在至少一路视频中的索引一致。Specifically, the specific method of determining the transition probability is: when a preset condition is satisfied, the transition probability is determined to be 1; when any of the preset conditions is not satisfied, the transition probability is determined to be 0. The preset conditions include: the current video frame and the candidate video frame are adjacent on the timeline, the target person exists in the picture of the candidate video frame, and the video index corresponding to the action is consistent with the index of the candidate video frame in at least one video.
其中,当前视频帧与候选视频帧在时间线上相邻,是指当前视频帧与候选视频帧在视频的时间线上相邻。例如,当前视频帧为第一路视频中的第T帧视频帧,则候选视频帧可以是当前视频或者其他视频(如第二路视频、第三路视频等等)中的第T+1帧视频帧。The fact that the current video frame and the candidate video frame are adjacent on the timeline means that the current video frame and the candidate video frame are adjacent on the video timeline. For example, if the current video frame is the T-th video frame in the first channel video, the candidate video frame may be the T+1-th frame in the current video or other videos (such as the second channel video, the third channel video, etc.) video frame.
204、根据当前视频帧的先后确定顺序确定视频帧序列,基于视频帧序列得到初始合成视频;204. Determine a video frame sequence according to the sequence of the current video frames, and obtain an initial composite video based on the video frame sequence;
本步骤所执行的操作与前述图1所示实施例中的步骤104所执行的操作类似,此处不再赘述。The operations performed in this step are similar to the operations performed in
205、根据目标人物在初始合成视频中的每一帧的位置和尺寸大小,确定初始合成视频中的每一帧的视频画面窗口的位置和尺寸大小;205, according to the position and size of each frame of the target character in the initial composite video, determine the position and size of the video picture window of each frame in the initial composite video;
本实施例中,可以根据目标人物以及与目标人物交互的对象的信息确定目标人物在视频帧中的位置和大小,其中,与目标人物交互的对象的信息可以是目标人物的视线方向所关注的对象的信息。例如,目标人物的视线方向关注的是一把椅子,则确定的目标人物在视频帧中的位置和大小除了包括目标人物,还应当包括目标人物的视线方向所关注的椅子。In this embodiment, the position and size of the target character in the video frame can be determined according to the information of the target character and the object interacting with the target character, wherein the information of the object interacting with the target character can be the focus of the sight direction of the target character object information. For example, if the sight direction of the target person focuses on a chair, the determined position and size of the target person in the video frame should include not only the target person, but also the chair that the target person's sight direction focuses on.
具体的,确定视频帧中目标人物的视线方向的具体方式可以是,由于视线方向与目标人物的脸部姿态信息有关,例如人脸朝上可以确定是仰视的动作,人脸朝下可以确定是俯视的动作,因此,可以根据目标人物在初始合成视频中的每一帧的脸部姿态信息确定目标人物在初始合成视频中的每一帧的视线方向。Specifically, the specific method of determining the direction of sight of the target person in the video frame may be, since the direction of sight is related to the facial posture information of the target person, for example, it can be determined that the face up is the action of looking up, and the face down can be determined to be the action of looking up. Therefore, the gaze direction of the target person in each frame of the initial composite video can be determined according to the facial posture information of the target person in each frame of the initial composite video.
例如,朝左看和朝右看主要取决于脸部姿态信息中的偏航角(yaw),因此,可以根据偏航角来确定目标人物的视线方向。为便于后续的计算过程,可以将视线方向进行量化,例如,可以基于以下公式以数值表示视线方向:For example, looking left and right mainly depends on the yaw angle (yaw) in the facial pose information, so the direction of sight of the target person can be determined according to the yaw angle. In order to facilitate the subsequent calculation process, the line of sight direction can be quantified. For example, the line of sight direction can be represented numerically based on the following formula:
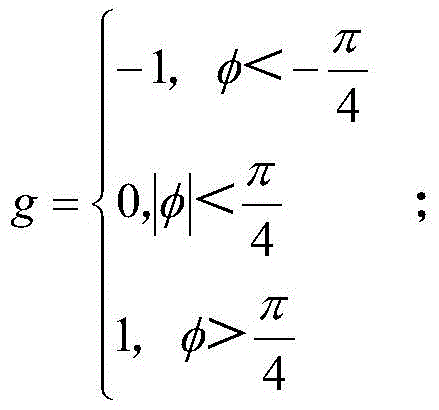
其中,g指代视线方向,φ指代偏航角。因此,根据上述公式即可确定出一定的偏航角角度对应的视线方向的取值。Among them, g refers to the line-of-sight direction, and φ refers to the yaw angle. Therefore, the value of the line-of-sight direction corresponding to a certain yaw angle can be determined according to the above formula.
在确定视线方向的取值之后,进一步根据目标人物在初始合成视频中的每一帧的视线方向确定目标人物在初始合成视频中的每一帧的位置和尺寸大小,并根据目标人物在初始合成视频中的每一帧的位置和尺寸大小,确定初始合成视频中的每一帧的视频画面窗口的位置和尺寸大小。After determining the value of the sight direction, further determine the position and size of each frame of the target person in the initial composite video according to the sight direction of the target person in each frame of the initial composite video, and determine the position and size of each frame of the target person in the initial composite video according to the target person The position and size of each frame in the video determines the position and size of the video picture window of each frame in the initial composite video.
具体的,目标人物在初始合成视频中的每一帧的位置和尺寸大小,可以表示为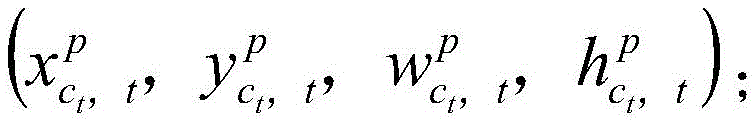






同时,初始合成视频中的每一帧的视频画面窗口的位置和尺寸大小,可以表示为






本实施例中,根据函数求解

其中,ct指代初始合成视频,t指代ct中的任一个视频帧,gt指代前文提及的视线方向的取值。Among them, ct refers to the initial composite video, t refers to any video frame in ct , and gt refers to the value of the line-of-sight direction mentioned above.
由于上述目标函数是一个凸函数,因此,可以利用凸优化算法对该目标函数进行求解,可以解得初始合成视频ct中每一帧的视频画面窗口的最优的位置和尺寸大小,即求得
因此,根据以上目标函数的表达式可以看出,在确定视频画面窗口的位置和尺寸大小时,还考虑了在目标人物的视线方向上与目标人物交互的对象的信息,将目标人物所交互的对象囊括至视频画面窗口中。Therefore, according to the expression of the above objective function, it can be seen that when determining the position and size of the video screen window, the information of the objects interacting with the target person in the direction of sight of the target person is also considered, and the interaction of the target person is taken into account. The object is included in the video frame window.
206、基于视频画面窗口的位置和尺寸大小提取初始合成视频中的每一帧的视频画面,得到目标合成视频;206. Extract the video picture of each frame in the initial composite video based on the position and size of the video picture window to obtain the target composite video;
在确定了视频画面窗口的位置和尺寸大小之后,可以基于视频画面窗口的位置和尺寸大小提取初始合成视频中的每一帧的视频画面,提取到的多帧视频画面构成目标合成视频。根据上述描述可知,由于视频画面窗口基于目标人物以及与目标人物交互的对象确定位置和尺寸大小,因此,根据视频画面窗口提取到的视频画面包括了目标人物的信息以及与目标人物交互的对象的信息,并避免了其他无关人物的信息呈现在视频画面中,一方面可以最大化地呈现出目标人物的信息,另一方面也避免呈现其他无关人物的信息,避免了隐私泄露问题。After the position and size of the video picture window are determined, the video picture of each frame in the initial composite video can be extracted based on the position and size of the video picture window, and the extracted multi-frame video pictures constitute the target composite video. According to the above description, since the position and size of the video picture window are determined based on the target person and the objects interacting with the target person, the video picture extracted according to the video picture window includes the information of the target person and the information of the objects interacting with the target person. information, and avoid the information of other irrelevant characters from being presented in the video screen, on the one hand, it can maximize the presentation of the target character’s information, and on the other hand, it also avoids the presentation of other irrelevant characters’ information, avoiding the problem of privacy leakage.
本实施例中,在视频自动剪辑上强调突出了目标人物的信息,并且避免了隐私泄露问题,使得技术方案更具有实际的应用价值,提高了方案的可实现性。In this embodiment, the information of the target person is emphasized on the automatic video editing, and the privacy leakage problem is avoided, so that the technical solution has more practical application value, and the practicability of the solution is improved.
上面对本申请实施例中的视频自动剪辑方法进行了描述,下面对本申请实施例中的视频自动剪辑装置进行描述,请参阅图4,本申请实施例中视频自动剪辑装置一个实施例包括:The automatic video editing method in the embodiment of the present application has been described above, and the automatic video editing device in the embodiment of the present application is described below. Referring to FIG. 4, an embodiment of the automatic video editing device in the embodiment of the present application includes:
计算单元401,用于计算至少一路视频中的每一视频帧的目标人物的脸部姿态信息,计算所述脸部姿态信息对应的姿态信息量化值,计算所述每一视频帧的光流能量变化值;The
确定单元402,用于将任一路视频中的任一视频帧作为当前视频帧;Determining
剪辑单元403,用于基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在所述当前视频帧下的动作的回报值,将最大回报值对应的候选视频帧确定为所述当前视频帧的下一视频帧,将所述当前视频帧的下一视频帧作为新的当前视频帧,并返回执行所述基于强化学习算法,根据当前视频帧的姿态信息量化值和光流能量变化值计算在所述当前视频帧下的动作的回报值的步骤;其中,所述动作为分别从所述至少一路视频的每一路视频中选择一个候选视频帧;The
生成单元404,用于根据当前视频帧的先后确定顺序确定视频帧序列,基于所述视频帧序列得到初始合成视频;A generating
所述确定单元402还用于根据所述目标人物在所述初始合成视频中的每一帧的位置和尺寸大小,确定所述初始合成视频中的每一帧的视频画面窗口的位置和尺寸大小;The determining
提取单元405,用于基于所述视频画面窗口的位置和尺寸大小提取所述初始合成视频中的每一帧的视频画面,得到目标合成视频。The
本实施例一种优选的实施方式中,计算单元401具体用于根据人脸姿态估计算法计算所述每一视频帧的目标人物的脸部姿态信息,所述脸部姿态信息包括俯仰角的角度、偏航角的角度以及旋转角的角度。In a preferred implementation of this embodiment, the
本实施例一种优选的实施方式中,计算单元401具体用于使用多元高斯模型计算所述脸部姿态信息对应的所述姿态信息量化值。In a preferred implementation manner of this embodiment, the calculating
本实施例一种优选的实施方式中,计算单元401具体用于计算所述每一视频帧的光流信息以及与所述每一视频帧属于同一路视频的其他视频帧的光流信息;根据所述每一视频帧的光流信息计算所述每一视频帧的光流能量,根据所述其他视频帧的光流信息计算所述其他视频帧的光流能量,计算所述每一视频帧与所述其他视频帧的光流能量差值以及所述每一视频帧与所述其他视频帧的间隔时间;将所述光流能量差值与所述间隔时间的商作为所述每一视频帧的光流能量变化值。In a preferred implementation of this embodiment, the
本实施例一种优选的实施方式中,剪辑单元403具体用于确定所述动作下所述当前视频帧到所述候选视频帧的转移概率;根据所述当前视频帧的姿态信息量化值和光流能量变化值计算在所述当前视频帧下的动作的初始回报值;将所述初始回报值与所述转移概率的乘积作为所述回报值。In a preferred implementation of this embodiment, the
本实施例一种优选的实施方式中,剪辑单元403具体用于当满足预设条件时,确定所述转移概率为1;当不满足所述预设条件中的任一项时,确定所述转移概率为0;In a preferred implementation of this embodiment, the
其中,所述预设条件包括:所述当前视频帧与所述候选视频帧在时间线上相邻、所述目标人物存在于所述候选视频帧的画面中、所述动作对应的视频索引与所述候选视频帧在所述至少一路视频中的索引一致。The preset conditions include: the current video frame and the candidate video frame are adjacent on the timeline, the target person exists in the picture of the candidate video frame, the video index corresponding to the action is the same as The indices of the candidate video frames in the at least one channel of video are consistent.
本实施例一种优选的实施方式中,确定单元402具体用于根据所述目标人物在所述初始合成视频中的每一帧的脸部姿态信息确定所述目标人物在所述初始合成视频中的每一帧的视线方向;根据所述目标人物在所述初始合成视频中的每一帧的视线方向确定所述目标人物在所述初始合成视频中的每一帧的位置和尺寸大小;根据所述目标人物在所述初始合成视频中的每一帧的位置和尺寸大小,确定所述初始合成视频中的每一帧的视频画面窗口的位置和尺寸大小。In a preferred implementation of this embodiment, the determining
本实施例中,视频自动剪辑装置中各单元所执行的操作与前述图1至图2所示实施例中描述的类似,此处不再赘述。In this embodiment, the operations performed by each unit in the apparatus for automatic video editing are similar to those described in the foregoing embodiments shown in FIG. 1 to FIG. 2 , and details are not repeated here.
本实施例中,计算单元401计算每一视频帧的目标人物的脸部姿态信息量化值以及光流能量变化值,剪辑单元403将计算得到的姿态信息量化值以及光流能量变化值应用于强化学习算法中对动作的回报值的计算,并将最大回报值对应的候选视频帧确定为当前视频帧的下一视频帧,将当前视频帧的下一视频帧作为新的当前视频帧,返回执行计算在当前视频帧下的动作的回报值的步骤,从而使得每一次从至少一路视频中确定出的视频帧均能最大化地呈现目标人物的信息以及避免呈现出目标人物被遮挡的画面。同时,确定单元402基于目标人物在视频帧中的位置和尺寸大小确定视频画面窗口,提取单元405根据视频画面窗口提取出关于目标人物的视频画面,使得最终合成的视频最大化地呈现有关于目标人物的信息,以及避免呈现出其他无关人物的信息。In this embodiment, the
下面对本申请实施例中的视频自动剪辑装置进行描述,请参阅图5,本申请实施例中视频自动剪辑装置一个实施例包括:The following describes the automatic video editing device in the embodiment of the present application. Please refer to FIG. 5 . An embodiment of the automatic video editing device in the embodiment of the present application includes:
该视频自动剪辑装置500可以包括一个或一个以上中央处理器(centralprocessing units,CPU)501和存储器505,该存储器505中存储有一个或一个以上的应用程序或数据。The automatic
其中,存储器505可以是易失性存储或持久存储。存储在存储器505的程序可以包括一个或一个以上模块,每个模块可以包括对视频自动剪辑装置中的一系列指令操作。更进一步地,中央处理器501可以设置为与存储器505通信,在视频自动剪辑装置500上执行存储器505中的一系列指令操作。Among them, the
视频自动剪辑装置500还可以包括一个或一个以上电源502,一个或一个以上有线或无线网络接口503,一个或一个以上输入输出接口504,和/或,一个或一个以上操作系统,例如Windows ServerTM,Mac OS XTM,UnixTM,LinuxTM,FreeBSDTM等。Video
该中央处理器501可以执行前述图1至图2所示实施例中视频自动剪辑装置所执行的操作,具体此处不再赘述。The
本申请实施例还提供了一种计算机存储介质,其中一个实施例包括:该计算机存储介质中存储有指令,该指令在计算机上执行时,使得该计算机执行前述图1至图2所示实施例中视频自动剪辑装置所执行的操作。An embodiment of the present application further provides a computer storage medium, wherein an embodiment includes: an instruction is stored in the computer storage medium, and when the instruction is executed on a computer, causes the computer to execute the foregoing embodiments shown in FIG. 1 to FIG. 2 . The operation performed by the automatic video editing device in .
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。Those skilled in the art can clearly understand that, for the convenience and brevity of description, the specific working process of the system, device and unit described above may refer to the corresponding process in the foregoing method embodiments, which will not be repeated here.
在本申请所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。In the several embodiments provided in this application, it should be understood that the disclosed system, apparatus and method may be implemented in other manners. For example, the apparatus embodiments described above are only illustrative. For example, the division of the units is only a logical function division. In actual implementation, there may be other division methods. For example, multiple units or components may be combined or Can be integrated into another system, or some features can be ignored, or not implemented. On the other hand, the shown or discussed mutual coupling or direct coupling or communication connection may be through some interfaces, indirect coupling or communication connection of devices or units, and may be in electrical, mechanical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and components displayed as units may or may not be physical units, that is, may be located in one place, or may be distributed to multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the solution in this embodiment.
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。In addition, each functional unit in each embodiment of the present application may be integrated into one processing unit, or each unit may exist physically alone, or two or more units may be integrated into one unit. The above-mentioned integrated units may be implemented in the form of hardware, or may be implemented in the form of software functional units.
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,read-onlymemory)、随机存取存储器(RAM,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。The integrated unit, if implemented in the form of a software functional unit and sold or used as an independent product, may be stored in a computer-readable storage medium. Based on this understanding, the technical solutions of the present application can be embodied in the form of software products in essence, or the parts that contribute to the prior art, or all or part of the technical solutions, and the computer software products are stored in a storage medium , including several instructions for causing a computer device (which may be a personal computer, a server, or a network device, etc.) to execute all or part of the steps of the methods described in the various embodiments of the present application. The aforementioned storage medium includes: U disk, removable hard disk, read-only memory (ROM, read-only memory), random access memory (RAM, random access memory), magnetic disk or optical disk and other media that can store program codes.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110321530.6A CN113038271B (en) | 2021-03-25 | 2021-03-25 | Automatic video editing method, device and computer storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110321530.6A CN113038271B (en) | 2021-03-25 | 2021-03-25 | Automatic video editing method, device and computer storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113038271A true CN113038271A (en) | 2021-06-25 |
| CN113038271B CN113038271B (en) | 2023-09-08 |
Family
ID=76473798
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110321530.6A Active CN113038271B (en) | 2021-03-25 | 2021-03-25 | Automatic video editing method, device and computer storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113038271B (en) |
Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110310237A1 (en) * | 2010-06-17 | 2011-12-22 | Institute For Information Industry | Facial Expression Recognition Systems and Methods and Computer Program Products Thereof |
| US20120093365A1 (en) * | 2010-10-15 | 2012-04-19 | Dai Nippon Printing Co., Ltd. | Conference system, monitoring system, image processing apparatus, image processing method and a non-transitory computer-readable storage medium |
| US20150318020A1 (en) * | 2014-05-02 | 2015-11-05 | FreshTake Media, Inc. | Interactive real-time video editor and recorder |
| CN106534967A (en) * | 2016-10-25 | 2017-03-22 | 司马大大(北京)智能系统有限公司 | Video editing method and device |
| CN108805080A (en) * | 2018-06-12 | 2018-11-13 | 上海交通大学 | Multi-level depth Recursive Networks group behavior recognition methods based on context |
| EP3410353A1 (en) * | 2017-06-01 | 2018-12-05 | eyecandylab Corp. | Method for estimating a timestamp in a video stream and method of augmenting a video stream with information |
| CN109618184A (en) * | 2018-12-29 | 2019-04-12 | 北京市商汤科技开发有限公司 | Method for processing video frequency and device, electronic equipment and storage medium |
| US20190222776A1 (en) * | 2018-01-18 | 2019-07-18 | GumGum, Inc. | Augmenting detected regions in image or video data |
| CN110691202A (en) * | 2019-08-28 | 2020-01-14 | 咪咕文化科技有限公司 | Video editing method, device and computer storage medium |
| CN111063011A (en) * | 2019-12-16 | 2020-04-24 | 北京蜜莱坞网络科技有限公司 | Face image processing method, device, equipment and medium |
| CN111131884A (en) * | 2020-01-19 | 2020-05-08 | 腾讯科技(深圳)有限公司 | Video clipping method, related device, equipment and storage medium |
| CN111294524A (en) * | 2020-02-24 | 2020-06-16 | 中移(杭州)信息技术有限公司 | Video editing method and device, electronic equipment and storage medium |
| CN111800644A (en) * | 2020-07-14 | 2020-10-20 | 深圳市人工智能与机器人研究院 | Video sharing and acquiring method, server, terminal equipment and medium |
| US20200380274A1 (en) * | 2019-06-03 | 2020-12-03 | Nvidia Corporation | Multi-object tracking using correlation filters in video analytics applications |
| CN112203115A (en) * | 2020-10-10 | 2021-01-08 | 腾讯科技(深圳)有限公司 | Video identification method and related device |
-
2021
- 2021-03-25 CN CN202110321530.6A patent/CN113038271B/en active Active
Patent Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110310237A1 (en) * | 2010-06-17 | 2011-12-22 | Institute For Information Industry | Facial Expression Recognition Systems and Methods and Computer Program Products Thereof |
| US20120093365A1 (en) * | 2010-10-15 | 2012-04-19 | Dai Nippon Printing Co., Ltd. | Conference system, monitoring system, image processing apparatus, image processing method and a non-transitory computer-readable storage medium |
| US20150318020A1 (en) * | 2014-05-02 | 2015-11-05 | FreshTake Media, Inc. | Interactive real-time video editor and recorder |
| CN106534967A (en) * | 2016-10-25 | 2017-03-22 | 司马大大(北京)智能系统有限公司 | Video editing method and device |
| EP3410353A1 (en) * | 2017-06-01 | 2018-12-05 | eyecandylab Corp. | Method for estimating a timestamp in a video stream and method of augmenting a video stream with information |
| US20190222776A1 (en) * | 2018-01-18 | 2019-07-18 | GumGum, Inc. | Augmenting detected regions in image or video data |
| CN108805080A (en) * | 2018-06-12 | 2018-11-13 | 上海交通大学 | Multi-level depth Recursive Networks group behavior recognition methods based on context |
| CN109618184A (en) * | 2018-12-29 | 2019-04-12 | 北京市商汤科技开发有限公司 | Method for processing video frequency and device, electronic equipment and storage medium |
| US20200380274A1 (en) * | 2019-06-03 | 2020-12-03 | Nvidia Corporation | Multi-object tracking using correlation filters in video analytics applications |
| CN110691202A (en) * | 2019-08-28 | 2020-01-14 | 咪咕文化科技有限公司 | Video editing method, device and computer storage medium |
| CN111063011A (en) * | 2019-12-16 | 2020-04-24 | 北京蜜莱坞网络科技有限公司 | Face image processing method, device, equipment and medium |
| CN111131884A (en) * | 2020-01-19 | 2020-05-08 | 腾讯科技(深圳)有限公司 | Video clipping method, related device, equipment and storage medium |
| CN111294524A (en) * | 2020-02-24 | 2020-06-16 | 中移(杭州)信息技术有限公司 | Video editing method and device, electronic equipment and storage medium |
| CN111800644A (en) * | 2020-07-14 | 2020-10-20 | 深圳市人工智能与机器人研究院 | Video sharing and acquiring method, server, terminal equipment and medium |
| CN112203115A (en) * | 2020-10-10 | 2021-01-08 | 腾讯科技(深圳)有限公司 | Video identification method and related device |
Non-Patent Citations (2)
| Title |
|---|
| 李刚等: "人脸自动识别方法综述", 《计算机应用研究》 * |
| 李刚等: "人脸自动识别方法综述", 《计算机应用研究》, no. 08, 28 August 2003 (2003-08-28) * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113038271B (en) | 2023-09-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12462394B2 (en) | Neural network for eye image segmentation and image quality estimation | |
| US11270455B2 (en) | Method and apparatus for pose processing | |
| EP3740936B1 (en) | Method and apparatus for pose processing | |
| Zhang et al. | Deep future gaze: Gaze anticipation on egocentric videos using adversarial networks | |
| US8022948B2 (en) | Image capture and buffering in a virtual world using situational measurement averages | |
| US8026913B2 (en) | Image capture and buffering in a virtual world | |
| US9075453B2 (en) | Human eye controlled computer mouse interface | |
| CN106682632B (en) | Method and device for processing face image | |
| WO2018076622A1 (en) | Image processing method and device, and terminal | |
| CN114399424B (en) | Model training methods and related equipment | |
| TW201447641A (en) | A method for enabling a screen cursor to move to a clickable object and a computer system and computer program thereof | |
| Hamid et al. | A survey of activity recognition in egocentric lifelogging datasets | |
| CN105931204B (en) | Picture restoring method and system | |
| CN113038271A (en) | Video automatic editing method, device and computer storage medium | |
| US20230245494A1 (en) | Automatic face and human subject enhancement algorithm for digital images | |
| CN114638919A (en) | Virtual image generation method, electronic device, program product and user terminal | |
| WO2019110874A1 (en) | Method and apparatus for applying video viewing behavior | |
| US11361467B2 (en) | Pose selection and animation of characters using video data and training techniques | |
| US12081722B2 (en) | Stereo image generation method and electronic apparatus using the same | |
| US20230267671A1 (en) | Apparatus and method for synchronization with virtual avatar, and system for synchronization with virtual avatar | |
| CN120390941A (en) | Mask Generation with Object and Scene Segmentation for See-Through Extended Reality (XR) | |
| KR102879262B1 (en) | Method and apparatus for tracking eye based on eye reconstruction | |
| CN115578541A (en) | Virtual object driving method, device, system, medium and product | |
| US20260038124A1 (en) | Neural network for eye image segmentation and image quality estimation | |
| US20240249421A1 (en) | Generation system and generation method for metadata for movement estimation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |