CN112899292B - Upland cotton plant height regulation gene GhGA20ox6 and its application - Google Patents
Upland cotton plant height regulation gene GhGA20ox6 and its application Download PDFInfo
- Publication number
- CN112899292B CN112899292B CN202110162359.9A CN202110162359A CN112899292B CN 112899292 B CN112899292 B CN 112899292B CN 202110162359 A CN202110162359 A CN 202110162359A CN 112899292 B CN112899292 B CN 112899292B
- Authority
- CN
- China
- Prior art keywords
- ghga20ox6
- gene
- upland cotton
- plant height
- leu
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 244000299507 Gossypium hirsutum Species 0.000 title claims abstract description 77
- 108090000623 proteins and genes Proteins 0.000 title claims abstract description 68
- 230000033228 biological regulation Effects 0.000 title claims abstract description 10
- 235000009429 Gossypium barbadense Nutrition 0.000 claims abstract description 43
- 235000018322 upland cotton Nutrition 0.000 claims abstract description 43
- 239000002773 nucleotide Substances 0.000 claims abstract description 3
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 3
- 238000000034 method Methods 0.000 claims description 9
- 230000030279 gene silencing Effects 0.000 claims description 7
- 238000012226 gene silencing method Methods 0.000 claims description 3
- 241000196324 Embryophyta Species 0.000 abstract description 45
- 230000001105 regulatory effect Effects 0.000 abstract description 12
- 108020004414 DNA Proteins 0.000 description 28
- 230000014509 gene expression Effects 0.000 description 26
- 241000219194 Arabidopsis Species 0.000 description 19
- 230000009261 transgenic effect Effects 0.000 description 15
- 102000004169 proteins and genes Human genes 0.000 description 14
- 239000000463 material Substances 0.000 description 13
- 239000003448 gibberellin Substances 0.000 description 12
- 210000001519 tissue Anatomy 0.000 description 12
- 229930191978 Gibberellin Natural products 0.000 description 11
- IXORZMNAPKEEDV-UHFFFAOYSA-N gibberellic acid GA3 Natural products OC(=O)C1C2(C3)CC(=C)C3(O)CCC2C2(C=CC3O)C1C3(C)C(=O)O2 IXORZMNAPKEEDV-UHFFFAOYSA-N 0.000 description 11
- 239000013598 vector Substances 0.000 description 11
- 230000028604 virus induced gene silencing Effects 0.000 description 9
- 230000015572 biosynthetic process Effects 0.000 description 8
- 229920000742 Cotton Polymers 0.000 description 7
- 108090000790 Enzymes Proteins 0.000 description 7
- 150000001413 amino acids Chemical group 0.000 description 7
- 238000003786 synthesis reaction Methods 0.000 description 7
- 241000589158 Agrobacterium Species 0.000 description 6
- 102000004190 Enzymes Human genes 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 238000002474 experimental method Methods 0.000 description 6
- 230000002018 overexpression Effects 0.000 description 6
- 241000219195 Arabidopsis thaliana Species 0.000 description 5
- 241000207746 Nicotiana benthamiana Species 0.000 description 5
- 210000004027 cell Anatomy 0.000 description 5
- 210000000170 cell membrane Anatomy 0.000 description 5
- 238000011161 development Methods 0.000 description 5
- 230000012010 growth Effects 0.000 description 5
- 230000004960 subcellular localization Effects 0.000 description 5
- 239000012634 fragment Substances 0.000 description 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 3
- 241000208125 Nicotiana Species 0.000 description 3
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 3
- 240000007594 Oryza sativa Species 0.000 description 3
- 235000007164 Oryza sativa Nutrition 0.000 description 3
- 108090000417 Oxygenases Proteins 0.000 description 3
- 102000004020 Oxygenases Human genes 0.000 description 3
- 238000011529 RT qPCR Methods 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 210000001339 epidermal cell Anatomy 0.000 description 3
- 239000000835 fiber Substances 0.000 description 3
- 230000004060 metabolic process Effects 0.000 description 3
- 230000008121 plant development Effects 0.000 description 3
- 230000008635 plant growth Effects 0.000 description 3
- 239000013612 plasmid Substances 0.000 description 3
- 239000013641 positive control Substances 0.000 description 3
- 235000009566 rice Nutrition 0.000 description 3
- YHOPXCAOTRUGLV-XAMCCFCMSA-N Ala-Ala-Asp-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O YHOPXCAOTRUGLV-XAMCCFCMSA-N 0.000 description 2
- 241000620209 Escherichia coli DH5[alpha] Species 0.000 description 2
- 101001066230 Gibberella fujikuroi (strain CBS 195.34 / IMI 58289 / NRRL A-6831) Cytochrome P450 monooygenase 2 Proteins 0.000 description 2
- 240000002024 Gossypium herbaceum Species 0.000 description 2
- 235000004341 Gossypium herbaceum Nutrition 0.000 description 2
- 108090000854 Oxidoreductases Proteins 0.000 description 2
- 241000183024 Populus tremula Species 0.000 description 2
- 238000010802 RNA extraction kit Methods 0.000 description 2
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 2
- OJOBTAOGJIWAGB-UHFFFAOYSA-N acetosyringone Chemical compound COC1=CC(C(C)=O)=CC(OC)=C1O OJOBTAOGJIWAGB-UHFFFAOYSA-N 0.000 description 2
- 238000003277 amino acid sequence analysis Methods 0.000 description 2
- 238000009395 breeding Methods 0.000 description 2
- 230000001488 breeding effect Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 108091036078 conserved sequence Proteins 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 238000010195 expression analysis Methods 0.000 description 2
- 239000013604 expression vector Substances 0.000 description 2
- 238000012215 gene cloning Methods 0.000 description 2
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 2
- 108010050848 glycylleucine Proteins 0.000 description 2
- 108010087823 glycyltyrosine Proteins 0.000 description 2
- 108700004756 oxidizing) 2-oxoglutarate-oxygen oxidoreductase (20-hydroxylating gibberellin Proteins 0.000 description 2
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 2
- 239000003375 plant hormone Substances 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 238000004904 shortening Methods 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 238000011426 transformation method Methods 0.000 description 2
- 230000001052 transient effect Effects 0.000 description 2
- 230000017260 vegetative to reproductive phase transition of meristem Effects 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- RTBFRGCFXZNCOE-UHFFFAOYSA-N 1-methylsulfonylpiperidin-4-one Chemical compound CS(=O)(=O)N1CCC(=O)CC1 RTBFRGCFXZNCOE-UHFFFAOYSA-N 0.000 description 1
- HNXGGWNCFXZSAI-UHFFFAOYSA-N 2-morpholin-2-ylethanesulfonic acid Chemical compound OS(=O)(=O)CCC1CNCCO1 HNXGGWNCFXZSAI-UHFFFAOYSA-N 0.000 description 1
- KPGXRSRHYNQIFN-UHFFFAOYSA-N 2-oxoglutaric acid Chemical compound OC(=O)CCC(=O)C(O)=O KPGXRSRHYNQIFN-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- 101710197650 Actin-7 Proteins 0.000 description 1
- 241000589155 Agrobacterium tumefaciens Species 0.000 description 1
- JDIQCVUDDFENPU-ZKWXMUAHSA-N Ala-His-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CNC=N1 JDIQCVUDDFENPU-ZKWXMUAHSA-N 0.000 description 1
- PMQXMXAASGFUDX-SRVKXCTJSA-N Ala-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CCCCN PMQXMXAASGFUDX-SRVKXCTJSA-N 0.000 description 1
- IHMCQESUJVZTKW-UBHSHLNASA-N Ala-Phe-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 IHMCQESUJVZTKW-UBHSHLNASA-N 0.000 description 1
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 1
- BHFOJPDOQPWJRN-XDTLVQLUSA-N Ala-Tyr-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CCC(N)=O)C(O)=O BHFOJPDOQPWJRN-XDTLVQLUSA-N 0.000 description 1
- VHAQSYHSDKERBS-XPUUQOCRSA-N Ala-Val-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O VHAQSYHSDKERBS-XPUUQOCRSA-N 0.000 description 1
- MCYJBCKCAPERSE-FXQIFTODSA-N Arg-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N MCYJBCKCAPERSE-FXQIFTODSA-N 0.000 description 1
- OZNSCVPYWZRQPY-CIUDSAMLSA-N Arg-Asp-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OZNSCVPYWZRQPY-CIUDSAMLSA-N 0.000 description 1
- PTVGLOCPAVYPFG-CIUDSAMLSA-N Arg-Gln-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PTVGLOCPAVYPFG-CIUDSAMLSA-N 0.000 description 1
- XUGATJVGQUGQKY-ULQDDVLXSA-N Arg-Lys-Phe Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XUGATJVGQUGQKY-ULQDDVLXSA-N 0.000 description 1
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 1
- YCYXHLZRUSJITQ-SRVKXCTJSA-N Arg-Pro-Pro Chemical compound NC(=N)NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 YCYXHLZRUSJITQ-SRVKXCTJSA-N 0.000 description 1
- NMTANZXPDAHUKU-ULQDDVLXSA-N Arg-Tyr-Lys Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CC=C(O)C=C1 NMTANZXPDAHUKU-ULQDDVLXSA-N 0.000 description 1
- ACRYGQFHAQHDSF-ZLUOBGJFSA-N Asn-Asn-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ACRYGQFHAQHDSF-ZLUOBGJFSA-N 0.000 description 1
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 1
- BKDDABUWNKGZCK-XHNCKOQMSA-N Asn-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)N)N)C(=O)O BKDDABUWNKGZCK-XHNCKOQMSA-N 0.000 description 1
- WQLJRNRLHWJIRW-KKUMJFAQSA-N Asn-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)O WQLJRNRLHWJIRW-KKUMJFAQSA-N 0.000 description 1
- ZYPWIUFLYMQZBS-SRVKXCTJSA-N Asn-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N ZYPWIUFLYMQZBS-SRVKXCTJSA-N 0.000 description 1
- VWADICJNCPFKJS-ZLUOBGJFSA-N Asn-Ser-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O VWADICJNCPFKJS-ZLUOBGJFSA-N 0.000 description 1
- NPZJLGMWMDNQDD-GHCJXIJMSA-N Asn-Ser-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NPZJLGMWMDNQDD-GHCJXIJMSA-N 0.000 description 1
- LRCIOEVFVGXZKB-BZSNNMDCSA-N Asn-Tyr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LRCIOEVFVGXZKB-BZSNNMDCSA-N 0.000 description 1
- ZSJFGGSPCCHMNE-LAEOZQHASA-N Asp-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N ZSJFGGSPCCHMNE-LAEOZQHASA-N 0.000 description 1
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 1
- QNMKWNONJGKJJC-NHCYSSNCSA-N Asp-Leu-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O QNMKWNONJGKJJC-NHCYSSNCSA-N 0.000 description 1
- GWIJZUVQVDJHDI-AVGNSLFASA-N Asp-Phe-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O GWIJZUVQVDJHDI-AVGNSLFASA-N 0.000 description 1
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 1
- RVMXMLSYBTXCAV-VEVYYDQMSA-N Asp-Pro-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMXMLSYBTXCAV-VEVYYDQMSA-N 0.000 description 1
- XXAMCEGRCZQGEM-ZLUOBGJFSA-N Asp-Ser-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O XXAMCEGRCZQGEM-ZLUOBGJFSA-N 0.000 description 1
- GXHDGYOXPNQCKM-XVSYOHENSA-N Asp-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O GXHDGYOXPNQCKM-XVSYOHENSA-N 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 241000282461 Canis lupus Species 0.000 description 1
- 102100038385 Coiled-coil domain-containing protein R3HCC1L Human genes 0.000 description 1
- GEEXORWTBTUOHC-FXQIFTODSA-N Cys-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N GEEXORWTBTUOHC-FXQIFTODSA-N 0.000 description 1
- OIMUAKUQOUEPCZ-WHFBIAKZSA-N Cys-Asn-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIMUAKUQOUEPCZ-WHFBIAKZSA-N 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 108091092584 GDNA Proteins 0.000 description 1
- JFOKLAPFYCTNHW-SRVKXCTJSA-N Gln-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N JFOKLAPFYCTNHW-SRVKXCTJSA-N 0.000 description 1
- XEYMBRRKIFYQMF-GUBZILKMSA-N Gln-Asp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XEYMBRRKIFYQMF-GUBZILKMSA-N 0.000 description 1
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 1
- DQLVHRFFBQOWFL-JYJNAYRXSA-N Gln-Lys-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)O DQLVHRFFBQOWFL-JYJNAYRXSA-N 0.000 description 1
- ZGHMRONFHDVXEF-AVGNSLFASA-N Gln-Ser-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZGHMRONFHDVXEF-AVGNSLFASA-N 0.000 description 1
- JILRMFFFCHUUTJ-ACZMJKKPSA-N Gln-Ser-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O JILRMFFFCHUUTJ-ACZMJKKPSA-N 0.000 description 1
- ININBLZFFVOQIO-JHEQGTHGSA-N Gln-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O ININBLZFFVOQIO-JHEQGTHGSA-N 0.000 description 1
- WOMUDRVDJMHTCV-DCAQKATOSA-N Glu-Arg-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WOMUDRVDJMHTCV-DCAQKATOSA-N 0.000 description 1
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 1
- LGYCLOCORAEQSZ-PEFMBERDSA-N Glu-Ile-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O LGYCLOCORAEQSZ-PEFMBERDSA-N 0.000 description 1
- JZJGEKDPWVJOLD-QEWYBTABSA-N Glu-Phe-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JZJGEKDPWVJOLD-QEWYBTABSA-N 0.000 description 1
- CQGBSALYGOXQPE-HTUGSXCWSA-N Glu-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O CQGBSALYGOXQPE-HTUGSXCWSA-N 0.000 description 1
- FVGOGEGGQLNZGH-DZKIICNBSA-N Glu-Val-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FVGOGEGGQLNZGH-DZKIICNBSA-N 0.000 description 1
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 1
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 1
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 1
- FEUPVVCGQLNXNP-IRXDYDNUSA-N Gly-Phe-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FEUPVVCGQLNXNP-IRXDYDNUSA-N 0.000 description 1
- ABPRMMYHROQBLY-NKWVEPMBSA-N Gly-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)CN)C(=O)O ABPRMMYHROQBLY-NKWVEPMBSA-N 0.000 description 1
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 1
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 1
- NTXIJPDAHXSHNL-ONGXEEELSA-N His-Gly-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NTXIJPDAHXSHNL-ONGXEEELSA-N 0.000 description 1
- YEKYGQZUBCRNGH-DCAQKATOSA-N His-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CN=CN2)N)C(=O)N[C@@H](CO)C(=O)O YEKYGQZUBCRNGH-DCAQKATOSA-N 0.000 description 1
- PFOUFRJYHWZJKW-NKIYYHGXSA-N His-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O PFOUFRJYHWZJKW-NKIYYHGXSA-N 0.000 description 1
- 101000743767 Homo sapiens Coiled-coil domain-containing protein R3HCC1L Proteins 0.000 description 1
- YPQDTQJBOFOTJQ-SXTJYALSSA-N Ile-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N YPQDTQJBOFOTJQ-SXTJYALSSA-N 0.000 description 1
- UMYZBHKAVTXWIW-GMOBBJLQSA-N Ile-Asp-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UMYZBHKAVTXWIW-GMOBBJLQSA-N 0.000 description 1
- RGSOCXHDOPQREB-ZPFDUUQYSA-N Ile-Asp-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N RGSOCXHDOPQREB-ZPFDUUQYSA-N 0.000 description 1
- XLCZWMJPVGRWHJ-KQXIARHKSA-N Ile-Glu-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N XLCZWMJPVGRWHJ-KQXIARHKSA-N 0.000 description 1
- PARSHQDZROHERM-NHCYSSNCSA-N Ile-Lys-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)O)N PARSHQDZROHERM-NHCYSSNCSA-N 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- DLCXCECTCPKKCD-GUBZILKMSA-N Leu-Gln-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DLCXCECTCPKKCD-GUBZILKMSA-N 0.000 description 1
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 1
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 1
- HMDDEJADNKQTBR-BZSNNMDCSA-N Leu-His-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HMDDEJADNKQTBR-BZSNNMDCSA-N 0.000 description 1
- AUBMZAMQCOYSIC-MNXVOIDGSA-N Leu-Ile-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O AUBMZAMQCOYSIC-MNXVOIDGSA-N 0.000 description 1
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 1
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 1
- KWLWZYMNUZJKMZ-IHRRRGAJSA-N Leu-Pro-Leu Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O KWLWZYMNUZJKMZ-IHRRRGAJSA-N 0.000 description 1
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 1
- IWMJFLJQHIDZQW-KKUMJFAQSA-N Leu-Ser-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IWMJFLJQHIDZQW-KKUMJFAQSA-N 0.000 description 1
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 1
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 1
- DRCILAJNUJKAHC-SRVKXCTJSA-N Lys-Glu-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DRCILAJNUJKAHC-SRVKXCTJSA-N 0.000 description 1
- LLSUNJYOSCOOEB-GUBZILKMSA-N Lys-Glu-Asp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O LLSUNJYOSCOOEB-GUBZILKMSA-N 0.000 description 1
- WAIHHELKYSFIQN-XUXIUFHCSA-N Lys-Ile-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O WAIHHELKYSFIQN-XUXIUFHCSA-N 0.000 description 1
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 1
- QDMUMFDBUVOZOY-GUBZILKMSA-N Met-Arg-Cys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N QDMUMFDBUVOZOY-GUBZILKMSA-N 0.000 description 1
- TZLYIHDABYBOCJ-FXQIFTODSA-N Met-Asp-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O TZLYIHDABYBOCJ-FXQIFTODSA-N 0.000 description 1
- HLZORBMOISUNIV-DCAQKATOSA-N Met-Ser-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C HLZORBMOISUNIV-DCAQKATOSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 1
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 1
- 108010047562 NGR peptide Proteins 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- MPFGIYLYWUCSJG-AVGNSLFASA-N Phe-Glu-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 MPFGIYLYWUCSJG-AVGNSLFASA-N 0.000 description 1
- BSJCSHIAMSGQGN-BVSLBCMMSA-N Phe-Pro-Trp Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O BSJCSHIAMSGQGN-BVSLBCMMSA-N 0.000 description 1
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 1
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 1
- BSTPNLNKHKBONJ-HTUGSXCWSA-N Phe-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O BSTPNLNKHKBONJ-HTUGSXCWSA-N 0.000 description 1
- SZZBUDVXWZZPDH-BQBZGAKWSA-N Pro-Cys-Gly Chemical compound OC(=O)CNC(=O)[C@H](CS)NC(=O)[C@@H]1CCCN1 SZZBUDVXWZZPDH-BQBZGAKWSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- AQSMZTIEJMZQEC-DCAQKATOSA-N Pro-His-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CO)C(=O)O AQSMZTIEJMZQEC-DCAQKATOSA-N 0.000 description 1
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 1
- SXJOPONICMGFCR-DCAQKATOSA-N Pro-Ser-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O SXJOPONICMGFCR-DCAQKATOSA-N 0.000 description 1
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 1
- FYXCBXDAMPEHIQ-FHWLQOOXSA-N Pro-Trp-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CCCCN)C(=O)O FYXCBXDAMPEHIQ-FHWLQOOXSA-N 0.000 description 1
- 238000002123 RNA extraction Methods 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- DKKGAAJTDKHWOD-BIIVOSGPSA-N Ser-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)C(=O)O DKKGAAJTDKHWOD-BIIVOSGPSA-N 0.000 description 1
- DSSOYPJWSWFOLK-CIUDSAMLSA-N Ser-Cys-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O DSSOYPJWSWFOLK-CIUDSAMLSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 1
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 1
- SRKMDKACHDVPMD-SRVKXCTJSA-N Ser-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N SRKMDKACHDVPMD-SRVKXCTJSA-N 0.000 description 1
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 1
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 1
- YRNBANYVJJBGDI-VZFHVOOUSA-N Thr-Ala-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O)N)O YRNBANYVJJBGDI-VZFHVOOUSA-N 0.000 description 1
- XPNSAQMEAVSQRD-FBCQKBJTSA-N Thr-Gly-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)NCC(O)=O XPNSAQMEAVSQRD-FBCQKBJTSA-N 0.000 description 1
- ADPHPKGWVDHWML-PPCPHDFISA-N Thr-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N ADPHPKGWVDHWML-PPCPHDFISA-N 0.000 description 1
- STUAPCLEDMKXKL-LKXGYXEUSA-N Thr-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O STUAPCLEDMKXKL-LKXGYXEUSA-N 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- WNZRNOGHEONFMS-PXDAIIFMSA-N Trp-Ile-Tyr Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WNZRNOGHEONFMS-PXDAIIFMSA-N 0.000 description 1
- RNDWCRUOGGQDKN-UBHSHLNASA-N Trp-Ser-Asp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RNDWCRUOGGQDKN-UBHSHLNASA-N 0.000 description 1
- RQKMZXSRILVOQZ-GMVOTWDCSA-N Trp-Tyr-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N RQKMZXSRILVOQZ-GMVOTWDCSA-N 0.000 description 1
- VYQQQIRHIFALGE-UWJYBYFXSA-N Tyr-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VYQQQIRHIFALGE-UWJYBYFXSA-N 0.000 description 1
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 1
- CVUDMNSZAIZFAE-TUAOUCFPSA-N Val-Arg-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N CVUDMNSZAIZFAE-TUAOUCFPSA-N 0.000 description 1
- DLYOEFGPYTZVSP-AEJSXWLSSA-N Val-Cys-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N DLYOEFGPYTZVSP-AEJSXWLSSA-N 0.000 description 1
- JPPXDMBGXJBTIB-ULQDDVLXSA-N Val-His-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N JPPXDMBGXJBTIB-ULQDDVLXSA-N 0.000 description 1
- ZZGPVSZDZQRJQY-ULQDDVLXSA-N Val-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](Cc1ccccc1)C(O)=O ZZGPVSZDZQRJQY-ULQDDVLXSA-N 0.000 description 1
- MHHAWNPHDLCPLF-ULQDDVLXSA-N Val-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=CC=C1 MHHAWNPHDLCPLF-ULQDDVLXSA-N 0.000 description 1
- PQSNETRGCRUOGP-KKHAAJSZSA-N Val-Thr-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O PQSNETRGCRUOGP-KKHAAJSZSA-N 0.000 description 1
- PMKQKNBISAOSRI-XHSDSOJGSA-N Val-Tyr-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N PMKQKNBISAOSRI-XHSDSOJGSA-N 0.000 description 1
- DFQZDQPLWBSFEJ-LSJOCFKGSA-N Val-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N DFQZDQPLWBSFEJ-LSJOCFKGSA-N 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 230000009418 agronomic effect Effects 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- JFCQEDHGNNZCLN-UHFFFAOYSA-N anhydrous glutaric acid Natural products OC(=O)CCCC(O)=O JFCQEDHGNNZCLN-UHFFFAOYSA-N 0.000 description 1
- 108010001271 arginyl-glutamyl-arginine Proteins 0.000 description 1
- 108010029539 arginyl-prolyl-proline Proteins 0.000 description 1
- 108010093581 aspartyl-proline Proteins 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000003766 bioinformatics method Methods 0.000 description 1
- 238000010804 cDNA synthesis Methods 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 238000007598 dipping method Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 238000001976 enzyme digestion Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 102000034287 fluorescent proteins Human genes 0.000 description 1
- 108091006047 fluorescent proteins Proteins 0.000 description 1
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- IXORZMNAPKEEDV-OBDJNFEBSA-N gibberellin A3 Chemical compound C([C@@]1(O)C(=C)C[C@@]2(C1)[C@H]1C(O)=O)C[C@H]2[C@]2(C=C[C@@H]3O)[C@H]1[C@]3(C)C(=O)O2 IXORZMNAPKEEDV-OBDJNFEBSA-N 0.000 description 1
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 1
- 108010073628 glutamyl-valyl-phenylalanine Proteins 0.000 description 1
- 108010049041 glutamylalanine Proteins 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 1
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 1
- 108010051307 glycyl-glycyl-proline Proteins 0.000 description 1
- 108010037850 glycylvaline Proteins 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 230000013632 homeostatic process Effects 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 239000000543 intermediate Substances 0.000 description 1
- 101150044508 key gene Proteins 0.000 description 1
- 230000002015 leaf growth Effects 0.000 description 1
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- 108010057821 leucylproline Proteins 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 108010044348 lysyl-glutamyl-aspartic acid Proteins 0.000 description 1
- 108010009298 lysylglutamic acid Proteins 0.000 description 1
- 230000037353 metabolic pathway Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000009125 negative feedback regulation Effects 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 108010051242 phenylalanylserine Proteins 0.000 description 1
- 150000008442 polyphenolic compounds Chemical class 0.000 description 1
- 235000013824 polyphenols Nutrition 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000003672 processing method Methods 0.000 description 1
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 1
- 108010004914 prolylarginine Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 239000002994 raw material Substances 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 230000001743 silencing effect Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000005082 stem growth Effects 0.000 description 1
- 229930002348 tetracyclic diterpenoid Natural products 0.000 description 1
- 150000004197 tetracyclic diterpenoid derivatives Chemical class 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000012250 transgenic expression Methods 0.000 description 1
- 108010080629 tryptophan-leucine Proteins 0.000 description 1
- 108010009962 valyltyrosine Proteins 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 230000037303 wrinkles Effects 0.000 description 1
Images







Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0071—Oxidoreductases (1.) acting on paired donors with incorporation of molecular oxygen (1.14)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8201—Methods for introducing genetic material into plant cells, e.g. DNA, RNA, stable or transient incorporation, tissue culture methods adapted for transformation
- C12N15/8202—Methods for introducing genetic material into plant cells, e.g. DNA, RNA, stable or transient incorporation, tissue culture methods adapted for transformation by biological means, e.g. cell mediated or natural vector
- C12N15/8205—Agrobacterium mediated transformation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8216—Methods for controlling, regulating or enhancing expression of transgenes in plant cells
- C12N15/8218—Antisense, co-suppression, viral induced gene silencing [VIGS], post-transcriptional induced gene silencing [PTGS]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8241—Phenotypically and genetically modified plants via recombinant DNA technology
- C12N15/8261—Phenotypically and genetically modified plants via recombinant DNA technology with agronomic (input) traits, e.g. crop yield
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y114/00—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14)
- C12Y114/11—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14) with 2-oxoglutarate as one donor, and incorporation of one atom each of oxygen into both donors (1.14.11)
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Cell Biology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Virology (AREA)
- Medicinal Chemistry (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Peptides Or Proteins (AREA)
- Breeding Of Plants And Reproduction By Means Of Culturing (AREA)
Abstract
本发明公开了一种陆地棉株高调控基因GhGA20ox6及其用途,该基因具有SEQ ID NO:1所示的核苷酸序列。通过调控GhGA20ox6,能够从分子水平上调控陆地棉株高,从而对陆地棉进行改良,矮化植株,使得陆地棉有较强的抗倒伏能力,提高作物的群体光能利用率,从而提高作物的产量。
The invention discloses an upland cotton plant height regulation gene GhGA20ox6 and use thereof. The gene has the nucleotide sequence shown in SEQ ID NO: 1. By regulating GhGA20ox6, the plant height of upland cotton can be regulated at the molecular level, so as to improve the upland cotton, dwarf the plant, make the upland cotton have a strong resistance to lodging, improve the population utilization rate of light energy of the crop, and thus improve the crop's efficiency. Yield.
Description
技术领域technical field
本发明涉及基因工程技术领域,特别涉及一种陆地棉株高调控基因GhGA20ox6及其用途。The invention relates to the technical field of genetic engineering, in particular to an upland cotton plant height regulation gene GhGA20ox6 and use thereof.
背景技术Background technique
赤霉素(Gibberellin,GA),作为植物六大激素之一,是一类四环双萜类植物激素,在植物的各个生长发育阶段都发挥着重要的作用,在种子萌发、根冠的伸长、开花结果、茎的伸长、叶片生长展开等都有重要的作用。高等植物中,多种酶参与了赤霉素多步骤酶促反应的生物合成和代谢过程,这些酶基因的表达能有效地调节赤霉素的合成代谢速率。参与赤霉素合成代谢的酶有很多,GA2-氧化酶(GA2-oxidase)是植物中GA降解过程中的关键酶,GA2ox可以将植物体内具有活性的GAs以及它的前体和其中间产物分解失活,从而维持植物体内的活性GAs之间的动态平衡。GA3-氧化酶(GA3-oxidase)和GA20-氧化酶(GA20-oxidase)作为植物赤霉素合成代谢途径中的最后一步关键酶,催化GA12和GA53转变为具有活性的GA1和GA4,另外,GA3ox和GA20ox又受体内活性GAs的负反馈调节。植物赤霉素氧化酶基因家族属于2OG-Fe(Ⅱ)oxygenase亚家族,能被多基因家族编码。到目前为止,模式植物拟南芥的赤霉素合成与代谢通路研究深入透彻,其赤霉素相关基因也已被克隆鉴定。研究表明目前主要农作物的“绿色革命”都与赤霉素有着密切的关系。在植物中,赤霉素参与调解植物生长发育的优势是促进茎的伸长和植株增高,如在水稻中,通过对GA20ox相关基因的克隆与基因沉默,发现这些基因影响水稻的茎秆长度,进而导致水稻出现矮化表型,Mauriat等人研究发现,GA20ox相关基因影响山杨的茎伸长,对山杨幼苗进行GA20ox相关基因表达的增强,显示其促进幼苗体内的活性赤霉素的合成。Gibberellin (GA), as one of the six major plant hormones, is a class of tetracyclic diterpenoid plant hormones, which play an important role in all stages of plant growth and development. Growth, flowering and fruiting, stem elongation, leaf growth and unfolding have important roles. In higher plants, a variety of enzymes are involved in the biosynthesis and metabolism of gibberellin in multi-step enzymatic reactions, and the expression of these enzyme genes can effectively regulate the rate of gibberellin synthesis and metabolism. There are many enzymes involved in the synthesis and metabolism of gibberellin. GA2-oxidase (GA2-oxidase) is a key enzyme in the process of GA degradation in plants. GA2ox can decompose active GAs and its precursors and intermediates in plants. inactivated, thereby maintaining the homeostasis between active GAs in plants. GA3-oxidase (GA3-oxidase) and GA20-oxidase (GA20-oxidase), as the last key enzymes in the phyto-gibberellin synthesis pathway, catalyze the conversion of GA 12 and GA 53 into active GA 1 and GA 4 , in addition, GA3ox and GA20ox are negative feedback regulation of active GAs in the receptors. The plant gibberellin oxidase gene family belongs to the 2OG-Fe(Ⅱ)oxygenase subfamily, which can be encoded by multiple gene families. So far, the gibberellin synthesis and metabolism pathway of the model plant Arabidopsis has been thoroughly studied, and its gibberellin-related genes have also been cloned and identified. Studies have shown that the current "green revolution" of major crops is closely related to gibberellin. In plants, the advantage of gibberellin involved in regulating plant growth and development is to promote stem elongation and plant height. For example, in rice, through the cloning and gene silencing of GA20ox-related genes, it was found that these genes affect the stem length of rice, This leads to a dwarf phenotype in rice. Mauriat et al. found that GA20ox-related genes affect the stem elongation of aspen, and enhanced the expression of GA20ox-related genes in aspen seedlings, showing that it promotes the synthesis of active gibberellin in the seedlings .
棉花,作为世界上最重要的天然纤维来源,是世界上栽培最广泛的棉种之一,在许多国家仍然是一种重要的经济作物。株高是作物育种中一个重要的优良农艺性状,植株过高会产生倒伏现象,从而使作物的产量降低,植株的矮化可以有较强的抗倒伏能力,可提高作物的群体光能利用率,从而提高作物的产量。陆地棉(G.hirsutum L.,AADD)具有A、D两个亚基因组,目前,农业上基本上都是使用去势打顶来控制株高,一方面会增加劳动力,增加劳作时长。从分子水平上对陆地棉进行改良具有重要的意义。Cotton, the world's most important source of natural fiber, is one of the most widely cultivated cotton species in the world and remains an important cash crop in many countries. Plant height is an important good agronomic trait in crop breeding. Plants that are too high will cause lodging, which will reduce the yield of crops. The dwarfing plants can have strong lodging resistance and improve the utilization rate of light energy in groups of crops. , thereby increasing crop yields. Upland cotton (G.hirsutum L., AADD) has two subgenomes, A and D. At present, castration and topping are basically used in agriculture to control plant height. On the one hand, it will increase the labor force and increase the working time. It is of great significance to improve upland cotton at the molecular level.
发明内容SUMMARY OF THE INVENTION
本发明的目的在于提供一种陆地棉株高调控基因GhGA20ox6及其用途,通过调控GhGA20ox6,能够从分子水平上调控陆地棉株高,从而对陆地棉进行改良,矮化植株,使得陆地棉有较强的抗倒伏能力,提高作物的群体光能利用率,从而提高作物的产量。The purpose of the present invention is to provide a plant height regulating gene GhGA20ox6 and its application of GhGA20ox6. By regulating GhGA20ox6, the plant height of Upland cotton can be regulated at the molecular level, thereby improving the upland cotton and dwarfing the plant, so that the upland cotton has a relatively high quality. Strong anti-lodging ability, improve the utilization rate of light energy of crops, thereby increasing the yield of crops.
本发明解决其技术问题所采用的技术方案是:The technical scheme adopted by the present invention to solve its technical problems is:
一种陆地棉株高调控基因GhGA20ox6,该基因具有SEQ ID NO:1所示的核苷酸序列。An upland cotton plant height regulation gene GhGA20ox6, the gene has the nucleotide sequence shown in SEQ ID NO: 1.
发明人通过探索研究,在对陆地棉全基因组进行第一次筛选获得13个候选基因,然后再进一步探索分析,发现并确定对陆地棉株高调控的关键基因GhGA20ox6,并对其功能进行了验证。并利用发现的该功能基因从分子水平上调控陆地棉株高,从而对陆地棉种质资源进行改良。Through exploratory research, the inventor obtained 13 candidate genes in the first screening of the whole genome of Upland cotton, and then further exploration and analysis, found and determined the key gene GhGA20ox6 that regulates the plant height of Upland cotton, and verified its function. . And use the discovered functional gene to regulate the plant height of upland cotton at the molecular level, so as to improve the upland cotton germplasm resources.
一种包含权利要求1所述陆地棉株高调控基因GhGA20ox6的质粒。A plasmid comprising the upland cotton plant height regulation gene GhGA20ox6 of claim 1.
一种包含权利要求1所述陆地棉株高调控基因GhGA20ox6的植物表达载体。A plant expression vector comprising the upland cotton plant height regulation gene GhGA20ox6 according to claim 1.
一种宿主细胞,该宿主细胞包含权利要求1所述陆地棉株高调控基因GhGA20ox6。A host cell, the host cell comprising the GhGA20ox6 highly regulated gene of upland cotton as claimed in claim 1.
一种陆地棉株高调控基因GhGA20ox6编码的蛋白质,该蛋白质具有SEQ ID NO:14所示的氨基酸序列。A protein encoded by a plant height regulation gene GhGA20ox6 of Upland cotton has the amino acid sequence shown in SEQ ID NO: 14.
一种陆地棉株高调控基因GhGA20ox6的用途,用于调控陆地棉株高。The utility model relates to the use of a plant height regulating gene GhGA20ox6 of Upland cotton, which is used for regulating the plant height of Upland cotton.
一种陆地棉的矮化方法,通过对陆地棉株高调控基因GhGA20ox6进行基因沉默,从而降低陆地棉株高,实现矮化。A dwarfing method of upland cotton, which reduces the plant height of upland cotton and realizes dwarfing by gene silencing of the upland cotton plant height regulation gene GhGA20ox6.
本发明的有益效果是:通过调控GhGA20ox6,能够从分子水平上调控陆地棉株高,从而对陆地棉进行改良,矮化植株,使得陆地棉有较强的抗倒伏能力,提高作物的群体光能利用率,从而提高作物的产量。The beneficial effects of the invention are as follows: by regulating GhGA20ox6, the plant height of Upland cotton can be regulated at the molecular level, thereby improving Upland cotton, dwarfing the plant, making the Upland cotton have stronger lodging resistance, and improving the collective light energy of the crop utilization, thereby increasing crop yields.
附图说明Description of drawings
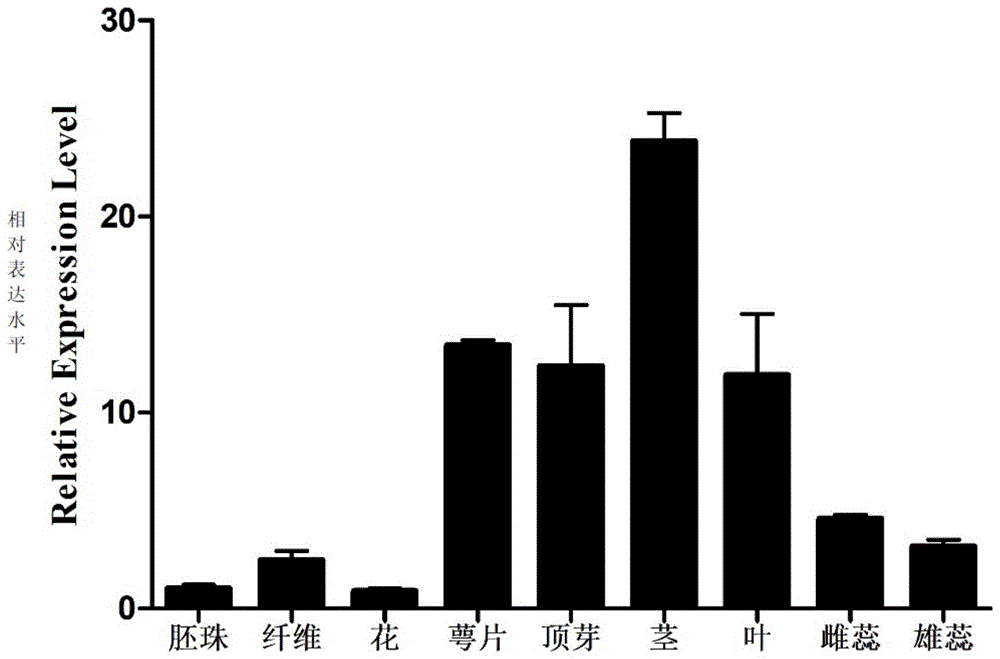
图1是GhGA20ox6基因在陆地棉不同组织中的表达水平。Figure 1 is the expression level of GhGA20ox6 gene in different tissues of Upland cotton.
图2是GhGA20ox6在本氏烟中的亚细胞定位;35S::GhGA20ox6::GFP(A~C)、35S::GFP(D~F)在本氏烟草叶细胞中的亚细胞定位。A、D:488nm激光下的表皮细胞;B、E:明场下的表皮细胞;C、F:激光和明场合并下的表皮细胞,20μm标尺。Figure 2 is the subcellular localization of GhGA20ox6 in N. benthamiana; the subcellular localization of 35S::GhGA20ox6::GFP (A-C) and 35S::GFP (D-F) in N. benthamiana leaf cells. A, D: epidermal cells under 488 nm laser; B, E: epidermal cells under bright field; C, F: epidermal cells under combined laser and bright field, 20 μm scale.
图3是阳性对照(CLCrVA::PDS)、VIGS植株(Line1、Line2和Line3)和空载体对照(CLCrVA)表型。Figure 3 is a phenotype of positive control (CLCrVA::PDS), VIGS plants (Linel, Line2 and Line3) and empty vector control (CLCrVA).
图4是VIGS阳性株与对照组的株高和节间长度;*P<0.05,**P<0.01。Figure 4 is the plant height and internode length of VIGS-positive strains and the control group; *P<0.05, **P<0.01.
图5是VIGS阳性株与对照组不同节间中GhGA20ox6的相对表达量;*P<0.05,**P<0.01。Figure 5 is the relative expression of GhGA20ox6 in different internodes between VIGS-positive strains and the control group; *P<0.05, **P<0.01.
图6是野生型拟南芥和GhGA20ox6转基因拟南芥的表型。注:A为Col-0和阳性株莲座叶表型;B、C为Col-0和阳性株株高表型。Figure 6 is a phenotype of wild-type Arabidopsis and GhGA20ox6 transgenic Arabidopsis. Note: A is the rosette leaf phenotype of Col-0 and positive plants; B and C are the plant height phenotypes of Col-0 and positive plants.
图7是转基因拟南芥中GhGA20ox6的表达水平,**P<0.01;内参基因为AtUBQ10。Figure 7 is the expression level of GhGA20ox6 in transgenic Arabidopsis, **P<0.01; the internal reference gene is AtUBQ10.
具体实施方式Detailed ways
下面通过具体实施例,对本发明的技术方案作进一步的具体说明。The technical solutions of the present invention will be further described in detail below through specific embodiments.
本发明中,若非特指,所采用的原料和设备等均可从市场购得或是本领域常用的。下述实施例中的方法,如无特别说明,均为本领域的常规方法。In the present invention, unless otherwise specified, the raw materials and equipment used can be purchased from the market or commonly used in the field. The methods in the following examples, unless otherwise specified, are conventional methods in the art.
实施例:Example:
1材料与方法1 Materials and methods
1.1实验材料与处理方式1.1 Experimental materials and processing methods
选用陆地棉(G.hirsutum L.,AADD)TM-1材料进行组织表达量的分析,种植于浙江农林大学平山基地温室(浙江省杭州市临安区),采用常规大田模式管理。Upland cotton (G.hirsutum L., AADD) TM-1 material was selected for tissue expression analysis, planted in the greenhouse of Zhejiang Agriculture and Forestry University Pingshan Base (Lin'an District, Hangzhou City, Zhejiang Province), and managed by conventional field mode.
选用本氏烟草进行基因的瞬时转化,种植于浙江农林大学学16气候室,环境条件:光照16h,黑暗8h;温度23℃;相对湿度70%~75%。N. benthamiana was selected for transient gene transformation and planted in the climate chamber of Xue 16, Zhejiang Agriculture and Forestry University. Environmental conditions: light for 16 hours, darkness for 8 hours, temperature at 23°C, and relative humidity between 70% and 75%.
选用陆地棉TM-1材料进行VIGS表型统计以及基因表达量的分析,种植于浙江农林大学学16气候室,温度条件:光照16h,黑暗8h;温度24℃;相对湿度65%~70%。Upland cotton TM-1 material was selected for VIGS phenotype statistics and gene expression analysis. It was planted in the climate chamber of Xue 16, Zhejiang Agriculture and Forestry University. The temperature conditions were: light 16h, dark 8h; temperature 24℃;
利用拟南芥(Arabidopsis thaliana)col野生型材料进行转基因过表达实验,种植于浙江农林大学学16气候室,温度条件:温度25℃;光照16h,黑暗8h;相对湿度65%~70%。Arabidopsis thaliana col wild-type material was used for transgenic overexpression experiment, which was planted in the climate chamber of Zhejiang Agriculture and Forestry University, Xue 16, temperature conditions:
以上所用材料均来自于浙江农林大学棉花育种实验室。The materials used above were all from the Cotton Breeding Laboratory of Zhejiang Agriculture and Forestry University.
1.2载体与所用试剂1.2 Carrier and reagents used
转基因表达载体pBI121、pBINGFP4以及棉花皱叶病毒载体pCLCrVA(空载体)、pCLCrVB(辅助载体)、pCLCrVA-PDS(阳性对照载体)保存于本实验室。从上海唯地生物有限公司购入大肠杆菌DH5α感受态和农杆菌(Agrobacterium tumefaciens)菌株GV3101感受态。限制性内切酶XbaI、SpeI、SacI购于TaKaRa公司(中国,大连),AscI购于NEB公司。RNA提取试剂盒、质粒提取试剂盒购自天根生化科技(北京)有限公司。基因克隆载体pMD18-T、MightyAmp高保真酶、PrimeScriptTMRT reagent Kit with gDNA Eraser反转录试剂盒、DNA片段纯化试剂盒以及荧光试剂TB
表1所用引物序列Primer sequences used in Table 1


注:下划线为酶切位点。Note: The underline is the restriction site.
1.3 RNA的提取及cDNA的合成1.3 RNA extraction and cDNA synthesis
根据RNAprep Pure多糖多酚植物总RNA提取试剂盒(DP441)说明书,提取TM-1的15DPA纤维、胚珠、花、萼片、顶芽、茎、叶、雌蕊、雄蕊这9个组织RNA,使用反转录试剂盒将这些组织RNA反转录,合成单链cDNA。According to the instructions of RNAprep Pure Polysaccharide and Polyphenol Plant Total RNA Extraction Kit (DP441), 9 tissues RNA of 15DPA fiber, ovule, flower, sepal, terminal bud, stem, leaf, pistil and stamen of TM-1 were extracted using reverse These tissue RNAs were reverse transcribed using a transcription kit to synthesize single-stranded cDNA.
1.4 GhGA20ox6基因克隆1.4 GhGA20ox6 gene cloning
利用已公布的拟南芥赤霉素20氧化酶的蛋白序列作为参照,华中农业大学发布的陆地棉全基因组数据库下载自(https://cottonfgd.org/),构建本地Blast数据库,筛选获得13个候选基因,13个候选基因分别为:GhGA20ox1(SEQ ID NO:2),GhGA20ox3(SEQ ID NO:3),GhGA20ox4(SEQ ID NO:4),GhGA20ox5(SEQ ID NO:5),GhGA20ox6(SEQ ID NO:1),GhGA20ox7(SEQ ID NO:7),GhGA20ox8(SEQ ID NO:8),GhGA20ox9(SEQ ID NO:9),GhGA20ox10(SEQ ID NO:10),GhGA20ox11(SEQ ID NO:11),GhGA20ox12(SEQ ID NO:12),GhGA20ox13(SEQ ID NO:13)。Using the published protein sequence of Arabidopsis gibberellin 20 oxidase as a reference, the upland cotton whole genome database released by Huazhong Agricultural University was downloaded from ( https://cottonfgd.org/ ), and a local Blast database was constructed. After screening, 13 13 candidate genes are: GhGA20ox1 (SEQ ID NO: 2), GhGA20ox3 (SEQ ID NO: 3), GhGA20ox4 (SEQ ID NO: 4), GhGA20ox5 (SEQ ID NO: 5), GhGA20ox6 (SEQ ID NO: 5) ID NO: 1), GhGA20ox7 (SEQ ID NO: 7), GhGA20ox8 (SEQ ID NO: 8), GhGA20ox9 (SEQ ID NO: 9), GhGA20ox10 (SEQ ID NO: 10), GhGA20ox11 (SEQ ID NO: 11) , GhGA20ox12 (SEQ ID NO: 12), GhGA20ox13 (SEQ ID NO: 13).
通过进一步探索试验,最终得到在茎中表达量较高的GhGA20ox6基因,设计特异性引物GhGA20ox6-F和GhGA20ox6-R,以TM-1材料茎组织的cDNA为模板进行GhGA20ox6的扩增,将得到的片段连接到pMD18-T载体,重组质粒转化到大肠杆菌DH5α,保存测序正确的单克隆菌液以供后续实验室用。Through further exploration experiments, the GhGA20ox6 gene with high expression in the stem was finally obtained. Specific primers GhGA20ox6-F and GhGA20ox6-R were designed, and the cDNA of the stem tissue of the TM-1 material was used as the template to amplify GhGA20ox6. The fragment was ligated into the pMD18-T vector, the recombinant plasmid was transformed into E. coli DH5α, and the correctly sequenced monoclonal bacterial solution was saved for subsequent laboratory use.
1.5GhGA20ox6的生物信息学分析Bioinformatics analysis of 1.5GhGA20ox6
将得到的GhGA20ox6蛋白质序列利用ExPASy(https://web.expasy.org/ protparam/)在线分析网站预测其理化性质,包括蛋白质的长度、等电点以及分子质量。将目的基因的氨基酸序列利用DNAMAN进行保守性的分析。利用SMART在线网站得到GhGA20ox6的保守结构域。The obtained GhGA20ox6 protein sequence was used ExPASy ( https://web.expasy.org/protparam/ ) online analysis website to predict its physicochemical properties, including protein length, isoelectric point and molecular mass. The amino acid sequence of the target gene was analyzed by DNAMAN for conservation. The conserved domain of GhGA20ox6 was obtained using the SMART online website.
1.6 GhGA20ox6空间模式表达1.6 Spatial pattern expression of GhGA20ox6
按照TB
1.7 GhGA20ox6亚细胞定位1.7 Subcellular localization of GhGA20ox6
利用GhGA20ox6-SF和GhGA20ox6-SR这对引物将目的基因片段连接到GFP荧光蛋白载体上,将构建好的过表达载体35S::GhGA20ox6::GFP利用农杆菌转化法转化农杆菌菌株GV3101。根据本氏烟草瞬时转化法,将农杆菌菌液注射到培养20天的烟草叶片中。对侵染的烟草叶片进行10小时的暗处理,培养28h后利用LSM880共聚焦显微镜下观察烟草叶片中的GFP细胞位置信号。GhGA20ox6-SF and GhGA20ox6-SR primers were used to connect the target gene fragment to the GFP fluorescent protein vector, and the constructed
1.8病毒诱导基因沉默载体(VIGS)的构建和侵染1.8 Construction and infection of virus-induced gene silencing vector (VIGS)
在育苗块上放入饱满的TM-1材料的种子,待到两片子叶完全张开。通过GhGA20ox6-VF和GhGA20ox6-VR这对酶切引物将GhGA20ox6部分基因片段与pCLCrVA病毒载体进行重组,将构建好的载体pCLCrVA-GhGA20ox6、pCLCrVA-pCLCrVB、PDS-pCLCrVB转入到农杆菌CV3101,将农杆菌菌液注射到长势一致的子叶中,进行24小时暗处理,之后放入气候室正常培养。观察记录六叶期节间之间以及总长度的变化,并取茎组织进行基因表达量的检测,验证沉默效果。Put the full seeds of TM-1 material on the seedling block and wait until the two cotyledons are fully opened. The partial gene fragment of GhGA20ox6 was recombined with the pCLCrVA viral vector through the pair of enzyme digestion primers GhGA20ox6-VF and GhGA20ox6-VR, and the constructed vectors pCLCrVA-GhGA20ox6, pCLCrVA-pCLCrVB, PDS-pCLCrVB were transferred into Agrobacterium CV3101, and the agricultural The bacillus liquid was injected into the cotyledons with the same growth potential, and dark-treated for 24 hours, and then placed in a climate chamber for normal culture. The changes of internodes and the total length of the six-leaf stage were observed and recorded, and the stem tissue was taken to detect the gene expression to verify the silencing effect.
1.9转基因拟南芥过表达1.9 Overexpression of transgenic Arabidopsis
将测序正确的pBI121-GhGA20ox6过表达载体转入到GV3101农杆菌菌株中进行扩增,利用农杆菌蘸花法转化法转化已经剪去结荚角果的col拟南芥,在气候室进行20h暗处理,收获的种子为T0代种子。将T0代种子进行继代培养,直至纯和世代。观察并记录纯合代转基因拟南芥的开花周期以及高度差异,检测转基因拟南芥中GhGA20ox6的基因表达量。The correctly sequenced pBI121-GhGA20ox6 overexpression vector was transferred into the GV3101 Agrobacterium strain for amplification, and the col Arabidopsis thaliana, which had been cut from the pods, was transformed by the Agrobacterium dipping method, and was darkened in a climate room for 20 hours. After treatment, the harvested seeds were T 0 generation seeds. The seeds of the T 0 generation were subcultured until the pure generation. The flowering cycle and height difference of homozygous transgenic Arabidopsis were observed and recorded, and the gene expression of GhGA20ox6 in transgenic Arabidopsis was detected.
2结果与分析2 Results and Analysis
2.1 GhGA20ox6基因的序列分析2.1 Sequence analysis of GhGA20ox6 gene
GhGA20ox6位于D亚组第9号染色体上,开放阅读框为1155bp,氨基酸序列长度为384个(SEQ ID NO:14),有2个内含子和3个外显子。利用ExPASy在线软件预测GhGA20ox6蛋白序列的相对分子质量为42.32kDa,等电点为6.37。DIOX_N结构域位于第63-172个氨基酸序列,2OG-Fe(Ⅱ)oxygenase结构域位于228-323个氨基酸序列。对13个候选基因对应的蛋白质进行氨基酸序列分析,结果显示GhGA20ox6在内的13个候选基因相应的蛋白都具有共同的保守蛋白质序列:与底物结合的高度保守基序LPWKET,与结合2-酮戊二酸有关的保守序列NYYPXCQKP,都具有Fe2+结合位点。GhGA20ox6 is located on chromosome 9 of subgroup D, with an open reading frame of 1155 bp, an amino acid sequence length of 384 (SEQ ID NO: 14), 2 introns and 3 exons. The relative molecular mass of the GhGA20ox6 protein sequence was predicted to be 42.32kDa and the isoelectric point was 6.37 using ExPASy online software. The DIOX_N domain is located in the 63-172nd amino acid sequence, and the 2OG-Fe(II) oxygenase domain is located in the 228-323rd amino acid sequence. The amino acid sequence analysis of the proteins corresponding to the 13 candidate genes showed that the corresponding proteins of the 13 candidate genes, including GhGA20ox6, all had a common conserved protein sequence: a highly conserved motif that binds to substrates, LPWKET, which binds to 2-keto. The conserved sequence NYYPXCQKP related to glutaric acid has an Fe 2+ binding site.
2.2 GhGA20ox6基因的空间表达模式分析2.2 Spatial expression pattern analysis of GhGA20ox6 gene
为研究GhGA20ox6的组织表达特性,利用qRT-PCR方法分析了其在TM-1陆地棉材料15DPA纤维、胚珠、花、萼片、顶芽、茎、叶、雌蕊、雄蕊这9个组织的表达量水平。结果显示:在这9个组织中,GhGA20ox6在茎中优势表达,而在胚珠与花这两个组织中的表达量较低(图1)。进一步推测GhGA20ox6在茎的生长发育过程中发挥着功能。In order to study the tissue expression characteristics of GhGA20ox6, the expression level of GhGA20ox6 in 9 tissues of TM-1 upland cotton material 15DPA fiber, ovule, flower, sepal, terminal bud, stem, leaf, pistil and stamen was analyzed by qRT-PCR. . The results showed that among these nine tissues, GhGA20ox6 was predominantly expressed in stems, while the expression levels were lower in ovules and flowers (Fig. 1). It is further speculated that GhGA20ox6 plays a role in the growth and development of stems.
2.3GhGA20ox6蛋白亚细胞定位分析2.3 Analysis of subcellular localization of GhGA20ox6 protein
将GhGA20ox6的蛋白序列在WoLF PSORT(https://wolfpsort.hgc.jp/)在线软件上进行亚细胞定位预测,结果显示定位在细胞膜。为了验证GhGA20ox6蛋白是否定位在细胞膜上,对本氏烟草的叶片细胞进行瞬时表达GhGA20ox6(图2)。结果显示,细胞膜中有明亮的绿色分布,表明细胞膜中有大量的绿色荧光信号,与预测结果相一致,说明GhGA20ox6蛋白是一个膜定位蛋白。The protein sequence of GhGA20ox6 was predicted by WoLF PSORT ( https://wolfpsort.hgc.jp/ ) online software, and the result showed that it was located in the cell membrane. In order to verify whether the GhGA20ox6 protein is localized on the cell membrane, GhGA20ox6 was transiently expressed in leaf cells of N. benthamiana (Fig. 2). The results showed that there was a bright green distribution in the cell membrane, indicating that there were a lot of green fluorescence signals in the cell membrane, which was consistent with the predicted results, indicating that the GhGA20ox6 protein was a membrane-localized protein.
2.4沉默后GhGA20ox6基因的表型观察及表达水平分析2.4 Phenotype observation and expression level analysis of GhGA20ox6 gene after silencing
阳性对照pCLCrVA-PDS的棉花植株出现白化表型,pCLCrVA-GhGA20ox6的棉花植株相对于对照组,茎的节间与对照相比出现不同程度的缩短(图3),将株高数据绘制成柱状图(图4)。结果显示经病毒诱导基因沉默的阳性株株高明显降低,第一节间长度、第三节间长度轻微的缩短,而第二节间长度、第四节间长度和第六节节间长度呈现显著的缩短,说明GhGA20ox6沉默能导致株型的矮化。测定这六节节间GhGA20ox6的表达量水平,实时荧光定量结果显示,第一节间、第三节间GhGA20ox6表达量与接种空载对照组相比无明显差异,第二节间、第四节节间、第五节间和第六节间GhGA20ox6表达量与对照组相比,有着极显著的差异(图5)。推测GhGA20ox6基因的沉默导致茎不同节间的缩短。The cotton plants of the positive control pCLCrVA-PDS showed an albino phenotype. Compared with the control group, the cotton plants of pCLCrVA-GhGA20ox6 had shortened stem internodes to varying degrees compared with the control (Fig. 3). The plant height data were plotted as a histogram (Figure 4). The results showed that the plant height of the virus-induced gene silencing of the positive strains was significantly reduced, the length of the first internode and the third internode were slightly shortened, while the length of the second, fourth and sixth internodes showed Significant shortening, indicating that GhGA20ox6 silencing can lead to dwarf plant type. The expression levels of GhGA20ox6 in the six internodes were measured, and the real-time fluorescence quantitative results showed that there was no significant difference in the expression of GhGA20ox6 in the first and third internodes compared with the inoculated empty control group. Compared with the control group, the expression levels of GhGA20ox6 in the internode, the fifth internode and the sixth internode were significantly different (Fig. 5). It is speculated that silencing of the GhGA20ox6 gene results in shortening of different internodes in the stem.
2.5 GhGA20ox6基因在拟南芥中的功能验证2.5 Functional verification of GhGA20ox6 gene in Arabidopsis
在长日照条件下,同时种植野生型和转基因拟南芥,观察生长情况(图6)。结果显示,野生型拟南芥在移苗后22天开始抽薹,平均抽薹时间为25天,转基因拟南芥在移苗18天开始抽薹,平均抽薹时间为20天,显著早于对照野生型。转基因拟南芥株系的平均株高约为31cm,显著高于对照组拟南芥的24cm,并且转基因拟南芥的莲座叶数目也显著增加(表2)。对转基因拟南芥茎进行取样,提取RNA,检测拟南芥中GhGA20ox6基因在茎中的表达情况(图7),转基因拟南芥中GhGA20ox6高调表达,符合35S启动子驱动外源基因转入的情况,说明GhGA20ox6被整合到拟南芥染色体上,说明GhGA20ox6基因促进茎的生长。Under long-day conditions, wild-type and transgenic Arabidopsis were grown simultaneously and growth was observed (Figure 6). The results showed that wild-type Arabidopsis started bolting 22 days after seedling transplant, with an average bolting time of 25 days, and transgenic Arabidopsis started bolting 18 days after transplanting, with an average bolting time of 20 days, which was significantly earlier than that of the control wild type. The average plant height of the transgenic Arabidopsis line was about 31 cm, which was significantly higher than that of the control Arabidopsis 24 cm, and the number of rosette leaves of the transgenic Arabidopsis was also significantly increased (Table 2). The stems of transgenic Arabidopsis thaliana were sampled, RNA was extracted, and the expression of GhGA20ox6 gene in Arabidopsis thaliana was detected (Figure 7). GhGA20ox6 was highly expressed in transgenic Arabidopsis thaliana, which was consistent with the 35S promoter-driven exogenous gene transfer. The results indicated that GhGA20ox6 was integrated into the Arabidopsis chromosome, indicating that the GhGA20ox6 gene promoted stem growth.
表2野生型和转基因拟南芥抽薹时间、株高及莲座叶数目统计Table 2 Statistics of bolting time, plant height and number of rosette leaves in wild-type and transgenic Arabidopsis
。.
3.讨论3 Discussion
赤霉素20氧化酶家族对植物的生长发育和环境适应方面起着重要的作用,是植物体内活性赤霉素合成的重要关键酶。The
本发明通过从TM-1陆地棉材料中克隆得到1个赤霉素氧化酶基因GhGA20ox6,经过氨基酸多重序列比对,发现GhGA20ox6蛋白序列具有与底物结合的高度保守基序LPWKET,与结合2-酮戊二酸有关的保守序列NYYPXCQKP,并且GhGA20ox6基因在TM-1不同组织中的表达量差异较显著,在茎组织中的表达量较高。认为GhGA20ox6基因参与棉花茎的生长发育,影响株高性状。In the present invention, a gibberellin oxidase gene GhGA20ox6 is obtained by cloning from TM-1 upland cotton material. After multiple amino acid sequence comparison, it is found that the GhGA20ox6 protein sequence has a highly conserved motif LPWKET that binds to the substrate, and binds 2- Ketoglutarate-related conserved sequence NYYPXCQKP, and GhGA20ox6 gene expression in different tissues of TM-1 was significantly different, and the expression level was higher in stem tissue. It is believed that GhGA20ox6 gene is involved in the growth and development of cotton stems and affects plant height traits.
目前,农业上基本上都是使用去势打顶来控制株高,一方面会增加劳动力,增加劳作时长。利用VIGS实验以及转基因过表达实验,在分子水平上通过对GhGA20ox6基因在植物体内表达量水平的研究,说明GhGA20ox6基因对植物株高性状方面起着调控的作用。At present, castration and topping are basically used in agriculture to control plant height. On the one hand, it will increase the labor force and increase the working time. Using VIGS experiment and transgene overexpression experiment, the expression level of GhGA20ox6 gene in plants was studied at the molecular level, indicating that GhGA20ox6 gene plays a regulatory role in plant height traits.
4.结论4 Conclusion
本发明通过T-A克隆方法,从陆地棉材料TM-1的茎中克隆得到GhGA20ox6基因,氨基酸序列分析GhGA20ox6基因具有2OG-Fe(Ⅱ)oxygenase以及DIOX_N结构域。GhGA20ox6基因的cDNA为1155bp,编码384个氨基酸。亚细胞定位预测以及实验结果显示都定位于细胞膜。TM-1表达水平显示,GhGA20ox6基因具有明显的组织特异性,且在茎中的表达量最高。VIGS实验结果显示,棉花中GhGA20ox6基因的沉默使棉花不同茎节相对于对照组而言,出现了不同程度的矮化表型,且GhGA20ox6基因在不同节间的表达量呈现不同程度的降低。异源过表达转基因拟南芥结果显示,转基因拟南芥跟野生型相比,莲座叶数增多,抽薹时间提前,植株高度增加明显,表明GhGA20ox6基因对株高形状具有重要作用。The present invention clones the GhGA20ox6 gene from the stem of the upland cotton material TM-1 by means of T-A cloning method. The amino acid sequence analysis of the GhGA20ox6 gene has 2OG-Fe(II)oxygenase and DIOX_N domains. The cDNA of GhGA20ox6 gene is 1155bp, encoding 384 amino acids. Subcellular localization prediction and experimental results show that it is localized to the cell membrane. The expression level of TM-1 showed that the GhGA20ox6 gene had obvious tissue specificity, and the expression level was the highest in the stem. The results of VIGS experiment showed that the silencing of GhGA20ox6 gene in cotton caused different degrees of dwarfing phenotypes in different stem nodes of cotton compared with the control group, and the expression of GhGA20ox6 gene in different nodes decreased to different degrees. The results of heterologous overexpression of transgenic Arabidopsis showed that compared with wild type, transgenic Arabidopsis had more rosette leaves, earlier bolting time, and significantly increased plant height, indicating that GhGA20ox6 gene plays an important role in plant height shape.
以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。The above-mentioned embodiment is only a preferred solution of the present invention, and does not limit the present invention in any form, and there are other variations and modifications under the premise of not exceeding the technical solution recorded in the claims.
序列表sequence listing
<110> 浙江农林大学<110> Zhejiang Agriculture and Forestry University
<120> 陆地棉株高调控基因GhGA20ox6及其用途<120> Upland cotton plant height regulation gene GhGA20ox6 and its application
<130> 2021.02<130> 2021.02
<160> 28<160> 28
<170> SIPOSequenceListing 1.0<170> SIPOSequenceListing 1.0
<210> 1<210> 1
<211> 1155<211> 1155
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 1<400> 1
atgtctctct ctgtcttaat ggattcaggt tctccaacca ttcttttaca tccatccata 60atgtctctct ctgtcttaat ggattcaggt tctccaacca ttcttttaca tccatccata 60
gaaccaagag atgagacggg tggtgtcctt tttgacccat ccaagttgca aaaccaatca 120gaaccaagag atgagacggg tggtgtcctt tttgacccat ccaagttgca aaaccaatca 120
agtttaccct cagagttcat atggccatgt ggggacttgg ttcacaccca agaagagctt 180agtttaccct cagagttcat atggccatgt ggggacttgg ttcacaccca agaagagctt 180
aacgaaccat tgatagactt gggcgggttc atcaaaggag acgaagaagc tactgcacat 240aacgaaccat tgatagactt gggcgggttc atcaaaggag acgaagaagc tactgcacat 240
gcagtgggcc ttgttaagac tgcctgttct aaacatggtt tcttccaagt tacaaaccat 300gcagtgggcc ttgttaagac tgcctgttct aaacatggtt tcttccaagt tacaaaccat 300
ggtgttgatt caaaccttat ccaagctgct taccaagaga ttgatgctgt gtttaagtta 360ggtgttgatt caaaccttat ccaagctgct taccaagaga ttgatgctgt gtttaagtta 360
ccccttaaca agaagctaag tttccaaaga aagcctggtg gtttttcagg ctattctgct 420ccccttaaca agaagctaag tttccaaaga aagcctggtg gtttttcagg ctattctgct 420
gcccatgctg accggttttc cgctaagttg ccatggaagg aaacattttc ttttggctac 480gcccatgctg accggttttc cgctaagttg ccatggaagg aaacattttc ttttggctac 480
caaggactta actccgatcc ttctgtggtt cattatttca gctctgcctt gggggaagat 540caaggactta actccgatcc ttctgtggtt cattatttca gctctgcctt gggggaagat 540
tttgagcaaa ccgggtggat ttaccaaaag tattgtgaaa agatgaggga gctgtcgcta 600tttgagcaaa ccgggtggat ttaccaaaag tattgtgaaa agatgaggga gctgtcgcta 600
ctgatattcg aactgttggc aatcagcttg gggatagatc gtttacacta cagaaaattt 660ctgatattcg aactgttggc aatcagcttg gggatagatc gtttacacta cagaaaattt 660
ttcgaagatg ggaattcaat aatgaggtgt aattactatc ccccatgcaa taattctggc 720ttcgaagatg ggaattcaat aatgaggtgt aattactatc ccccatgcaa taattctggc 720
ctcacccttg gcactggccc tcactctgat cctacttcct taacaattct tcaccaagat 780ctcacccttg gcactggccc tcactctgat cctacttcct taacaattct tcaccaagat 780
caagtgggag ggctcgaagt tttcaacaat aacaaatggt atgctgttcg acctcgacaa 840caagtgggag ggctcgaagt tttcaacaat aacaaatggt atgctgttcg acctcgacaa 840
gatgcctttg tcattaacat tggtgatact ttcatggcat tatgtaacgg aagatacaag 900gatgcctttg tcattaacat tggtgatact ttcatggcat tatgtaacgg aagatacaag 900
agttgcctgc atagagcagt ggtgaacaag gagagggaga ggagatcatt ggtatacttt 960agttgcctgc atagagcagt ggtgaacaag gagagggaga ggagatcatt ggtatacttt 960
gtgtgcccaa aagaagacaa aatagtgaga cccccacaag atctaatgtg cagatcagga 1020gtgtgcccaa aagaagacaa aatagtgaga cccccacaag atctaatgtg cagatcagga 1020
gggccaagag tgtatcctga tttcacatgg tctgatttgt tggaattcac tcaaaatcac 1080gggccaagag tgtatcctga tttcacatgg tctgatttgt tggaattcac tcaaaatcac 1080
tatagagctg acgttgctac actccaaagc ttcttccctt ggctcctttc ttctaaccct 1140tatagagctg acgttgctac actccaaagc ttcttccctt ggctcctttc ttctaaccct 1140
acttccaact tctag 1155acttccaact tctag 1155
<210> 2<210> 2
<211> 1140<211> 1140
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 2<400> 2
atggcaattg attgcgtttc caagataccc tccatgcctc atcatcctaa agatgaaaaa 60atggcaattg attgcgtttc caagataccc tccatgcctc atcatcctaa agatgaaaaa 60
agagaggagc aaaaacaact ggtttttgat gcctcggtgc ttaaatacca acccgacata 120agagaggagc aaaaacaact ggtttttgat gcctcggtgc ttaaatacca acccgacata 120
ccaaaacaat ttatatggcc cgaccacgaa aagcctaatg ttaatgcacc agaactccaa 180ccaaaacaat ttatatggcc cgaccacgaa aagcctaatg ttaatgcacc agaactccaa 180
gtgccattca ttgacctagg agggttcctt tccggtgacc ctgtttctgc aatggaagca 240gtgccattca ttgacctagg agggttcctt tccggtgacc ctgtttctgc aatggaagca 240
tcgaggctgg tcggcgaggc atgtcggcag catggtttct tccttgtggt taatcatgga 300tcgaggctgg tcggcgaggc atgtcggcag catggtttct tccttgtggt taatcatgga 300
gtggatgcaa cactggtggc tgatgctcac agttatatgg gtaacttctt tgaattgcca 360gtggatgcaa cactggtggc tgatgctcac agttatatgg gtaacttctt tgaattgcca 360
ctcaatgata agcaaagggc tcagaggaaa cttggtgagc actgtggata tgctagtagc 420ctcaatgata agcaaagggc tcagaggaaa cttggtgagc actgtggata tgctagtagc 420
ttcactggta gattctcctc caagctgcca tggaaggaaa cgctttcctt ccggtattca 480ttcactggta gattctcctc caagctgcca tggaaggaaa cgctttcctt ccggtattca 480
gctgacaaaa agtcatccaa gattgttgaa gactaccttg atggcaaatt gggagatgaa 540gctgacaaaa agtcatccaa gattgttgaa gactaccttg atggcaaatt gggagatgaa 540
ttcaagcatt tcgggagggt ttaccaagat tactgcgagg caatgagcaa gctatctcta 600ttcaagcatt tcgggagggt ttaccaagat tactgcgagg caatgagcaa gctatctcta 600
gggataatgg agctattagc cattagtctt ggcgtaggaa gatcacattt cagggaattt 660gggataatgg agctattagc cattagtctt ggcgtaggaa gatcacattt cagggaattt 660
ttcgaggaaa atgaatcaat aatgaggctg aattactacc caccatgcca aaaaccagac 720ttcgaggaaa atgaatcaat aatgaggctg aattactacc caccatgcca aaaaccagac 720
ctcactttag gaacagggcc tcattgcgat ccaacctcat taaccatcct tcaccaagac 780ctcactttag gaacagggcc tcattgcgat ccaacctcat taaccatcct tcaccaagac 780
cgagttggtg gtcttcaagt gtttgtagac aatgaatggc gttcaattag cccaaatgtc 840cgagttggtg gtcttcaagt gtttgtagac aatgaatggc gttcaattag cccaaatgtc 840
gaagcatttg tcgttaacat tggcgacacc ttcatggcac tttcaaatgg gcgatacaag 900gaagcatttg tcgttaacat tggcgacacc ttcatggcac tttcaaatgg gcgatacaag 900
agttgcttgc accgggcagt ggtgaaccgc cacatcccaa gaaaatctct ggctttcttc 960agttgcttgc accgggcagt ggtgaaccgc cacatcccaa gaaaatctct ggctttcttc 960
ctatgtccca agggtgataa agtggtagcc ccaccaacag agttggtcga cgcctataat 1020ctatgtccca agggtgataa agtggtagcc ccaccaacag agttggtcga cgcctataat 1020
cccagagtat atccagattt tacttggcct atgctgcttg aattcacaca aaagcattat 1080cccagagtat atccagattt tacttggcct atgctgcttg aattcacaca aaagcattat 1080
agagctgata tgaacacact tgaagtcttc tcaaactggg ttcaacagag aaacagctga 1140agagctgata tgaacacact tgaagtcttc tcaaactggg ttcaacagag aaacagctga 1140
<210> 3<210> 3
<211> 1257<211> 1257
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 3<400> 3
atgataccaa ataatttgat aatagcttgt aatgggagtc tattacctat atttaatgca 60atgataccaa ataatttgat aatagcttgt aatgggagtc tattacctat atttaatgca 60
actctctcac cttcttgccc tacgtccaca tacactgtct tcctaatgga ttcaacgcat 120actctctcac cttcttgccc tacgtccaca tacactgtct tcctaatgga ttcaacgcat 120
ctcctttcct ctccgcttga gattcaagat caaacactag ttgaccatca tagttcttct 180ctcctttcct ctccgcttga gattcaagat caaacactag ttgaccatca tagttcttct 180
atcggctcat cttttctcca aaaccaaacc aacgtcccca aagaatttct ttggcccaaa 240atcggctcat cttttctcca aaaccaaacc aacgtcccca aagaatttct ttggcccaaa 240
gttgatttag ttaatgctca tcaagagctg ttggagccac ttgtagatct tgaacgcttc 300gttgatttag ttaatgctca tcaagagctg ttggagccac ttgtagatct tgaacgcttc 300
tttagaggtg atgaattggc gattcaacag gctgccaagg tcattagggc tgcttgtcta 360tttagaggtg atgaattggc gattcaacag gctgccaagg tcattagggc tgcttgtcta 360
acccacggtt gctttcaagt catcaatcat ggggttgatt cccacctcat caatgctgca 420acccacggtt gctttcaagt catcaatcat ggggttgatt cccacctcat caatgctgca 420
tattatcacc tcaatcgttt cttccatttg ccacttagcc acaaattaag ggctcgaagg 480tattatcacc tcaatcgttt cttccatttg ccacttagcc acaaattaag ggctcgaagg 480
gccactactg ctggattaaa caccttgagc tattcaggtg cacattcgga tcgtttctct 540gccactactg ctggattaaa caccttgagc tattcaggtg cacattcgga tcgtttctct 540
tcgaatttgc catggaagga aactttaact ttccggttgc atgagaatcc caaggaatcc 600tcgaatttgc catggaagga aactttaact ttccggttgc atgagaatcc caaggaatcc 600
agtgtcgtag atttgttcaa atccagttta ggagatgatt ttgaagaaat gggcataaca 660agtgtcgtag atttgttcaa atccagttta ggagatgatt ttgaagaaat gggcataaca 660
tatcaaaagt actgtgaagg aatgaagagc ttagctctag cagtgatgga aatactagca 720tatcaaaagt actgtgaagg aatgaagagc ttagctctag cagtgatgga aatactagca 720
atcagcttgg gagttgatcg attgcactat aaaaattatt ttcaggacgg tgggtctata 780atcagcttgg gagttgatcg attgcactat aaaaattatt ttcaggacgg tgggtctata 780
atgcgatgta actattatcc gccatgcccc gagccaggac ttaccttcgg cactggtcct 840atgcgatgta actattatcc gccatgcccc gagccaggac ttaccttcgg cactggtcct 840
cattgtgacg ccacatcttt aacaattctc caccaagacg aagttggagg cttggaaatc 900cattgtgacg ccacatcttt aacaattctc caccaagacg aagttggagg cttggaaatc 900
tttgcaaaca acaaatggca gattgttcga cctcgtcagg atgccctagt aatcaacatc 960tttgcaaaca acaaatggca gattgttcga cctcgtcagg atgccctagt aatcaacatc 960
ggtgagacct tcacggcatt aacaaatggg agatacaaga gttgcctgca tagggcagta 1020ggtgagacct tcacggcatt aacaaatggg agatacaaga gttgcctgca tagggcagta 1020
gtaaacagcg agagggcgag aaaatcattg gtatactttg tttgcccacg agaagacaag 1080gtaaacagcg agagggcgag aaaatcattg gtatactttg tttgcccacg agaagacaag 1080
gtggtgagac ccccagagga tcttgtacaa gttgatcaac tcccaagagc ttaccctgat 1140gtggtgagac ccccagagga tcttgtacaa gttgatcaac tcccaagagc ttaccctgat 1140
ttcacatggt ccgatttcct ccatttcacc caaaactact acagagctga cgctcatact 1200ttcacatggt ccgatttcct ccatttcacc caaaactact acagagctga cgctcatact 1200
ctccatagct tcatcaaatg gctctcatct tccagcccca ttcatcacaa ccgttaa 1257ctccatagct tcatcaaatg gctctcatct tccagcccca ttcatcacaa ccgttaa 1257
<210> 4<210> 4
<211> 1140<211> 1140
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 4<400> 4
atggcaattg actgcgtctc cagcatagcc tccatgcctc accatctcaa agacgacagt 60atggcaattg actgcgtctc cagcatagcc tccatgcctc accatctcaa agacgacagt 60
aaagatgagc aaaaacaact agtttttgat gcttctgtgc ttaaatacca atcctgcata 120aaagatgagc aaaaacaact agtttttgat gcttctgtgc ttaaatacca atcctgcata 120
ccacaacaat ttatatggcc tgacgacgaa aagccttgcg ctagtgcacc agaactccaa 180ccacaacaat ttatatggcc tgacgacgaa aagccttgcg ctagtgcacc agaactccaa 180
gtaccactca ttgacattaa aggtttcctc tctggtgacc ctgttgctgc gatggaagct 240gtaccactca ttgacattaa aggtttcctc tctggtgacc ctgttgctgc gatggaagct 240
tcaaggcttg tcggcgaggc atgtcaacag catggtttct ttcttgtagt taatcatgga 300tcaaggcttg tcggcgaggc atgtcaacag catggtttct ttcttgtagt taatcatgga 300
gtcgatgcca cactcgtggc cgatgctcat aggtacatgg ataacttctt tgaattgcca 360gtcgatgcca cactcgtggc cgatgctcat aggtacatgg ataacttctt tgaattgcca 360
ctctgcgaaa agcaatgggc tcagagaaaa gttggtgagc actgtggata tgccagcagc 420ctctgcgaaa agcaatgggc tcagagaaaa gttggtgagc actgtggata tgccagcagc 420
ttcaccggca ggttctcctc caagttgcct tggaaagaaa cactttcttt tcgctactca 480ttcaccggca ggttctcctc caagttgcct tggaaagaaa cactttcttt tcgctactca 480
gctcagagaa acgcatccac gatggttgaa gactaccttg ttaataaaat gggagatgaa 540gctcagagaa acgcatccac gatggttgaa gactaccttg ttaataaaat gggagatgaa 540
ttcaggcatt tcggaagggt ataccagagc tactgcgagg ctatgagcaa gctttctcta 600ttcaggcatt tcggaagggt ataccagagc tactgcgagg ctatgagcaa gctttctcta 600
gggattatgg agcttttagc catcagtctg ggcgtaggca gagcgcattt cagggaattt 660gggattatgg agcttttagc catcagtctg ggcgtaggca gagcgcattt cagggaattt 660
tttgaggaaa atgattcaat aatgaggctg aattactatc cgctttgcca aaaaccagac 720tttgaggaaa atgattcaat aatgaggctg aattactatc cgctttgcca aaaaccagac 720
ctcactttag gaacggggcc tcattgcgat ccaacgtctt taaccatcct tcaccaagac 780ctcactttag gaacggggcc tcattgcgat ccaacgtctt taaccatcct tcaccaagac 780
cgagttggtg gtcttcaagt gtttgtagac aacgaatggc gttcaatcag cccaaatttc 840cgagttggtg gtcttcaagt gtttgtagac aacgaatggc gttcaatcag cccaaatttc 840
gaagcatttg ttgttaacat tggcgacacc ttcatggctt tatcaaatgg aagatacaaa 900gaagcatttg ttgttaacat tggcgacacc ttcatggctt tatcaaatgg aagatacaaa 900
agttgcttgc accgggcggt tgtgaacagt cacaccccaa gaaaatccct tgctttcttt 960agttgcttgc accgggcggt tgtgaacagt cacaccccaa gaaaatccct tgctttcttt 960
ttgtgcccaa agggtgataa agtggttacc ccaccaaaag agttggtgga cgcaaatagc 1020ttgtgcccaa agggtgataa agtggttacc ccaccaaaag agttggtgga cgcaaatagc 1020
cccagagtat atccagattt tacatggcct atgctgcttg aattcacaca aaagcactac 1080cccagagtat atccagattt tacatggcct atgctgcttg aattcacaca aaagcactac 1080
agagctgaca tgaatacgct tgaagtattc tcaaactggg ttcaacagag aagccgctga 1140agagctgaca tgaatacgct tgaagtattc tcaaactggg ttcaacagag aagccgctga 1140
<210> 5<210> 5
<211> 1158<211> 1158
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 5<400> 5
atggtacatt gtctgccaaa ggtttctgtc attcaagaca agccgatgct tccaccaact 60atggtacatt gtctgccaaa ggtttctgtc attcaagaca agccgatgct tccaccaact 60
gctgctgtcg caaagaataa gcatcgccct ttagctttcg atgcatcaat ccttggatct 120gctgctgtcg caaagaataa gcatcgccct ttagctttcg atgcatcaat ccttggatct 120
gagatatcct ctcagttcat atggcctgac gacgacaagc catgcctgga tgccccggaa 180gagatatcct ctcagttcat atggcctgac gacgacaagc catgcctgga tgccccggaa 180
cttgtaattc caaccattga cttgggagct ttcttgcttg gggactctct tgctgtatca 240cttgtaattc caaccattga cttgggagct ttcttgcttg gggactctct tgctgtatca 240
aaagcggcag aggcggtgaa tgaggcatgc aagaagcatg ggttttttct ggttgtaaac 300aaagcggcag aggcggtgaa tgaggcatgc aagaagcatg ggttttttct ggttgtaaac 300
catggggtgg attcagggct tatagacaaa gctcatcagt acatggaccg cttcttcagc 360catggggtgg attcagggct tatagacaaa gctcatcagt acatggaccg cttcttcagc 360
ctgcaactct ctgagaagca aaaggctaag agaaaagtag gagaaagcta tgggtatgca 420ctgcaactct ctgagaagca aaaggctaag agaaaagtag gagaaagcta tgggtatgca 420
agcagtttcg ttgggaggtt ttcctccaag ttgccatgga aagaaacact gtcttttcgg 480agcagtttcg ttgggaggtt ttcctccaag ttgccatgga aagaaacact gtcttttcgg 480
tactgtcctc acactcaaaa catcgtgcaa cactatatgg tgaattggat gggtgaagat 540tactgtcctc acactcaaaa catcgtgcaa cactatatgg tgaattggat gggtgaagat 540
tttagagatt tcgggaggct ttaccaggaa tattgtgaag ccatgaacaa ggtttcccaa 600tttagagatt tcgggaggct ttaccaggaa tattgtgaag ccatgaacaa ggtttcccaa 600
gagataatgg ggctgctagg gataagtcta ggacttgacc aagcctactt caaagacttt 660gagataatgg ggctgctagg gataagtcta ggacttgacc aagcctactt caaagacttt 660
ttcgacgaaa atgattcaat cctgagactg aatcactacc ctccatgcca aaagcctgag 720ttcgacgaaa atgattcaat cctgagactg aatcactacc ctccatgcca aaagcctgag 720
ttgactctgg ggactggtcc ccacaccgat cccacttcct tgacaatcct tcatcaggat 780ttgactctgg ggactggtcc ccacaccgat cccacttcct tgacaatcct tcatcaggat 780
caagttggag gccttcaagt gtttgcagat gaaaagtggc actccgttgc tcccatccca 840caagttggag gccttcaagt gtttgcagat gaaaagtggc actccgttgc tcccatccca 840
cgagctttcg ttgtcaacat tggcgacaca ttcatggctt tgacaaacgg tatttacaag 900cgagctttcg ttgtcaacat tggcgacaca ttcatggctt tgacaaacgg tatttacaag 900
agctgcttgc acagagcagt ggtgaatact gaaacggtga gaaaatcact tgtattcttt 960agctgcttgc acagagcagt ggtgaatact gaaacggtga gaaaatcact tgtattcttt 960
ctatgtccca agctggagag accggtgaca ccagcagctg gcctagttaa tgccgcaaat 1020ctatgtccca agctggagag accggtgaca ccagcagctg gcctagttaa tgccgcaaat 1020
tcgaggaagt acccagactt tacttgggca gcactgcttg aatttacaca gaaccattac 1080tcgaggaagt acccagactt tacttgggca gcactgcttg aatttacaca gaaccattac 1080
cgtgctgaca tgaaaaccct tgttgcattc tccaaatggg ttcaagaaca agaatcgaac 1140cgtgctgaca tgaaaaccct tgttgcattc tccaaatggg ttcaagaaca agaatcgaac 1140
aacaaattaa taccttag 1158aacaaattaa taccttag 1158
<210> 6<210> 6
<211> 1128<211> 1128
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 6<400> 6
atggttcatt gtctgccaaa ggtttctgtc attcaagaca agccgatgct tccatcaact 60atggttcatt gtctgccaaa ggtttctgtc attcaagaca agccgatgct tccatcaact 60
tctgctgtcg caaaggatga gtattggccg cctttagctt tcgatgcatc gatccttgga 120tctgctgtcg caaaggatga gtattggccg cctttagctt tcgatgcatc gatccttgga 120
tctgaatcca acataccctc tcagttcata tggcctgacg acgagaagcc atgcctggat 180tctgaatcca acataccctc tcagttcata tggcctgacg acgagaagcc atgcctggat 180
gccccagaac ttgtaattcc aaccattgac ttgggagctt tcttgcttag gtactctctt 240gccccagaac ttgtaattcc aaccattgac ttgggagctt tcttgcttag gtactctctt 240
gctgtatcaa aagcggcaga ggtggtgaat gaggcatgca agaagcatgg gttttttctg 300gctgtatcaa aagcggcaga ggtggtgaat gaggcatgca agaagcatgg gttttttctg 300
gttgtaaacc atggggtgga ttcagggctt atagacaaag ctcatcagta catggaccgc 360gttgtaaacc atggggtgga ttcagggctt atagacaaag ctcatcagta catggaccgc 360
ttcttcagcc tgcaactttc tgagaagcaa aaggctaaga gaaaagtagg agaaagctat 420ttcttcagcc tgcaactttc tgagaagcaa aaggctaaga gaaaagtagg agaaagctat 420
gggtatgcaa gcagtttcgt tgggaggttt tcctccaagt tgccatggaa agaaacactg 480gggtatgcaa gcagtttcgt tgggaggttt tcctccaagt tgccatggaa agaaacactg 480
tcttttcggt actgtcctca cactcaaaat atcgtgcaac actatatggt gaatttgatg 540tcttttcggt actgtcctca cactcaaaat atcgtgcaac actatatggt gaatttgatg 540
ggtgaagatt ttagagattt cgggttccaa gagataatgg ggctgctagg gataagtcta 600ggtgaagatt ttagagattt cgggttccaa gagataatgg ggctgctagg gataagtcta 600
ggacttgacc aagcctactt caaagacttc ttcgaagaaa atgattcaat cctgagactg 660ggacttgacc aagcctactt caaagacttc ttcgaagaaa atgattcaat cctgagactg 660
aatcactatc ccccatgcca aaagcctgag ttgactctgg gaaccggtcc ccacaccgat 720aatcactatc ccccatgcca aaagcctgag ttgactctgg gaaccggtcc ccacaccgat 720
cccacttcct tgacaatcct tcatcaggat caagtgggag gcctttcagg ttttgcagat 780cccacttcct tgacaatcct tcatcaggat caagtgggag gcctttcagg ttttgcagat 780
gaaaagtggc actccgttgc tcccatccca ggagctttcg ttgtcaacat tggcgacaca 840gaaaagtggc actccgttgc tcccatccca ggagctttcg ttgtcaacat tggcgacaca 840
ttcatggctt tgacaaacgg tatttacaag agctgcttgc acagagcagt ggtgaatact 900ttcatggctt tgacaaacgg tatttacaag agctgcttgc acagagcagt ggtgaatact 900
gaaacggtga gaaaatcact tgcattcttt ctatgtccca agctggagag accggtgaca 960gaaacggtga gaaaatcact tgcattcttt ctatgtccca agctggagag accggtgaca 960
ccagcagctg gcttagtaaa tgccgcaaat ccgaggaaat acccagactt cacttgggca 1020ccagcagctg gcttagtaaa tgccgcaaat ccgaggaaat acccagactt cacttgggca 1020
gcactgctga aatttacaca gaaccattac cgtgctgaca tgaaaaccct tgttgcattc 1080gcactgctga aatttacaca gaaccattac cgtgctgaca tgaaaaccct tgttgcattc 1080
tccaaatggg ttcaagaaca agaatcgaac aacaaattaa taccttag 1128tccaaatggg ttcaagaaca agaatcgaac aacaaattaa taccttag 1128
<210> 7<210> 7
<211> 1104<211> 1104
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 7<400> 7
atggcaattg attgcgtttc caagatatcc atgcctcatc atcctaaaga tgaaaaaaga 60atggcaattg attgcgtttc caagatatcc atgcctcatc atcctaaaga tgaaaaaaga 60
gaggagcaaa aacaactggt ttttgatgcc tcggtgctta aataccaacc cgacatacca 120gaggagcaaa aacaactggt ttttgatgcc tcggtgctta aataccaacc cgacatacca 120
aaacaattta tatggcccga caaggaaaag cctagtgtta atgcaccaga actccaagtg 180aaacaattta tatggcccga caaggaaaag cctagtgtta atgcaccaga actccaagtg 180
ccattcattg acctaggagg gttcctttcc ggtgaccctg tttctgcaat ggaagcatcg 240ccattcattg acctaggagg gttcctttcc ggtgaccctg tttctgcaat ggaagcatcg 240
aggctggtgg gcgaggcatg tcggcagcat ggtttcttcc ttgtggttaa tcatggagtg 300aggctggtgg gcgaggcatg tcggcagcat ggtttcttcc ttgtggttaa tcatggagtg 300
gatgcaacac tggtggctga tgctcacagt tatatggcaa aggctcagag gaaacttggt 360gatgcaacac tggtggctga tgctcacagt tatatggcaa aggctcagag gaaacttggt 360
gagcactgtg gatatgctag tagcttcact ggtagattct cctccaagct gccatggaag 420gagcactgtg gatatgctag tagcttcact ggtagattct cctccaagct gccatggaag 420
gaaacgcttt cctttcggta ttcagctgac aaaaactcat ccaagattgt tgaagactac 480gaaacgcttt cctttcggta ttcagctgac aaaaactcat ccaagattgt tgaagactac 480
cttgttggca aattgggaga tgaattcaag catttcggga gggtttacca agattactgc 540cttgttggca aattgggaga tgaattcaag catttcggga gggtttacca agattactgc 540
gaggcaatga gcaagctatc tctagggata atggagctat tagccattag tcttggcgta 600gaggcaatga gcaagctatc tctagggata atggagctat tagccattag tcttggcgta 600
ggaagatcac atttcaggga attttttgag gaaaatgaat caataatgag gctcaattac 660ggaagatcac atttcaggga attttttgag gaaaatgaat caataatgag gctcaattac 660
tacccaccat gccaaaaacc agacctcacc ttaggaacag ggcctcattg cgatccaacg 720tacccaccat gccaaaaacc agacctcacc ttaggaacag ggcctcattg cgatccaacg 720
tcattaacca tccttcacca agaccgagtt ggtggtcttc aagtgtttgt agacaatgaa 780tcattaacca tccttcacca agaccgagtt ggtggtcttc aagtgtttgt agacaatgaa 780
tggcgttcaa ttagcccaaa tctcgaagca tttgtcgtta acattggcga caccttcatg 840tggcgttcaa ttagcccaaa tctcgaagca tttgtcgtta acattggcga caccttcatg 840
gcactttcaa atgggcgata caagagttgc ttgcaccggg cagtggtgaa ccgccacatc 900gcactttcaa atgggcgata caagagttgc ttgcaccggg cagtggtgaa ccgccacatc 900
ccaagaaaat ctctggcttt cttcctatgt cccaagggtg ataaagtggt agccccacca 960ccaagaaaat ctctggcttt cttcctatgt cccaagggtg ataaagtggt agccccacca 960
acagagttgg tcgacgccta taatcccaga gtatatccag attttacttg gcctatgctg 1020acagagttgg tcgacgccta taatcccaga gtatatccag attttacttg gcctatgctg 1020
cttgaattca cacaaaagca ttatagagct gatatgaaca cactcgaagt cttctcaaac 1080cttgaattca cacaaaagca ttatagagct gatatgaaca cactcgaagt cttctcaaac 1080
tgggttcaac agagaaacag ctga 1104tgggttcaac agagaaacag ctga 1104
<210> 8<210> 8
<211> 1140<211> 1140
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 8<400> 8
atggcaattg attgcgtttc caagataccc tccatgcctc atcatcctaa agatgaaaaa 60atggcaattg attgcgtttc caagataccc tccatgcctc atcatcctaa agatgaaaaa 60
agagaggagc aaaaacaact ggtttttgat gcctcggtgc ttaaatacca acccgacata 120agagaggagc aaaaacaact ggtttttgat gcctcggtgc ttaaatacca acccgacata 120
ccaaaacaat ttatatggcc cgaccacgaa aagcctaatg ttaatgcacc agaactccaa 180ccaaaacaat ttatatggcc cgaccacgaa aagcctaatg ttaatgcacc agaactccaa 180
gtgccattca ttgacctagg agggttcctt tccggtgacc ctgtttctgc aatggaagca 240gtgccattca ttgacctagg agggttcctt tccggtgacc ctgtttctgc aatggaagca 240
tcgaggctgg tcggcgaggc atgtcggcag catggtttct tccttgtggt taatcatgga 300tcgaggctgg tcggcgaggc atgtcggcag catggtttct tccttgtggt taatcatgga 300
gtggatgcaa cactggtggc tgatgctcac agttatatgg gtaacttctt tgaattgcca 360gtggatgcaa cactggtggc tgatgctcac agttatatgg gtaacttctt tgaattgcca 360
ctcaatgata agcaaagggc tcagaggaaa cttggtgagc actgtggata tgctagtagc 420ctcaatgata agcaaagggc tcagaggaaa cttggtgagc actgtggata tgctagtagc 420
ttcactggta gattctcctc caagctgcca tggaaggaaa cgctttcctt ccggtattca 480ttcactggta gattctcctc caagctgcca tggaaggaaa cgctttcctt ccggtattca 480
gctgacaaaa agtcatccaa gattgttgaa gactaccttg atggcaaatt gggagatgaa 540gctgacaaaa agtcatccaa gattgttgaa gactaccttg atggcaaatt gggagatgaa 540
ttcaagcatt tcgggagggt ttaccaagat tactgcgagg caatgagcaa gctatctcta 600ttcaagcatt tcgggagggt ttaccaagat tactgcgagg caatgagcaa gctatctcta 600
gggataatgg agctattagc cattagtctt ggcgtaggaa gatcacattt cagggaattt 660gggataatgg agctattagc cattagtctt ggcgtaggaa gatcacattt cagggaattt 660
ttcgaggaaa atgaatcaat aatgaggctg aattactacc caccatgcca aaaaccagac 720ttcgaggaaa atgaatcaat aatgaggctg aattactacc caccatgcca aaaaccagac 720
ctcactttag gaacagggcc tcattgcgat ccaacctcat taaccatcct tcaccaagac 780ctcactttag gaacagggcc tcattgcgat ccaacctcat taaccatcct tcaccaagac 780
cgagttggtg gtcttcaagt gtttgtagac aatgaatggc gttcaattag cccaaatgtc 840cgagttggtg gtcttcaagt gtttgtagac aatgaatggc gttcaattag cccaaatgtc 840
gaagcatttg tcgttaacat tggcgacacc ttcatggcac tttcaaatgg gcgatacaag 900gaagcatttg tcgttaacat tggcgacacc ttcatggcac tttcaaatgg gcgatacaag 900
agttgcttgc accgggcagt ggtgaaccgc cacatcccaa gaaaatctct ggctttcttc 960agttgcttgc accgggcagt ggtgaaccgc cacatcccaa gaaaatctct ggctttcttc 960
ctatgtccca agggtgataa agtggtagcc ccaccaacag agttggtcga cgcctataat 1020ctatgtccca agggtgataa agtggtagcc ccaccaacag agttggtcga cgcctataat 1020
cccagagtat atccagattt tacttggcct atgctgcttg aattcacaca aaagcattat 1080cccagagtat atccagattt tacttggcct atgctgcttg aattcacaca aaagcattat 1080
agagctgata tgaacacact tgaagtcttc tcaaactggg ttcaacagag aaacagctga 1140agagctgata tgaacacact tgaagtcttc tcaaactggg ttcaacagag aaacagctga 1140
<210> 9<210> 9
<211> 1152<211> 1152
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 9<400> 9
atggattcaa cgcatctcct ttcctctccg cttgagattc aagatcagac actagtcgac 60atggattcaa cgcatctcct ttcctctccg cttgagattc aagatcagac actagtcgac 60
catcataatt cttctatcgg ctcatctttt ctccaaaacc aaaccaacgt ccccaaagaa 120catcataatt cttctatcgg ctcatctttt ctccaaaacc aaaccaacgt ccccaaagaa 120
tttctttggc ccaaagttga tttagttaat gctcatcaag agctgttgga gccacttgta 180tttctttggc ccaaagttga tttagttaat gctcatcaag agctgttgga gccacttgta 180
gatcttgaac gcttctttag aggtgatgaa ttggcgattc agcagtctgc caaggtcatt 240gatcttgaac gcttctttag aggtgatgaa ttggcgattc agcagtctgc caaggtcatt 240
agggctgctt gtctaaccca cggttgcttt caagtcatca atcatggggt tgattcccac 300agggctgctt gtctaaccca cggttgcttt caagtcatca atcatggggt tgattcccac 300
ctcatcaatg ctgcatatta tcacctcaat cgtttcttcc atttgccact tagccacaaa 360ctcatcaatg ctgcatatta tcacctcaat cgtttcttcc atttgccact tagccacaaa 360
ttaagggctc gaagggccac tactgctgga ttaaacacct tgaactattc aggtgcacat 420ttaagggctc gaagggccac tactgctgga ttaaacacct tgaactattc aggtgcacat 420
tcggatcgtt tctcttcgaa tttgccatgg aaggaaactt taactttccg ggtccatgag 480tcggatcgtt tctcttcgaa tttgccatgg aaggaaactt taactttccg ggtccatgag 480
aatctcaagg aatccagtgt cgtagacttg ttcaaatcca gtttaggaga tgattttgaa 540aatctcaagg aatccagtgt cgtagacttg ttcaaatcca gtttaggaga tgattttgaa 540
gaaatgggca taacatatca aaagtactgt gaaggaatga agagcttagc tctagcagtg 600gaaatgggca taacatatca aaagtactgt gaaggaatga agagcttagc tctagcagtg 600
atggaaatac tagcaatcag cttgggagtt gatcgattgc actataaaaa ttattttcag 660atggaaatac tagcaatcag cttgggagtt gatcgattgc actataaaaa ttattttcag 660
gacggtgggt ctataatgcg atgtaactat tatccgccat gccccgagcc aggacttacc 720gacggtgggt ctataatgcg atgtaactat tatccgccat gccccgagcc aggacttacc 720
ttcggcactg gtcctcattg tgacaccaca tctttaacaa ttctccacca agacgaagtt 780ttcggcactg gtcctcattg tgacaccaca tctttaacaa ttctccacca agacgaagtt 780
gggggcctgg aaatctttgc aaacaacaaa tggcagattg ttcgacctcg tcaggatgcc 840gggggcctgg aaatctttgc aaacaacaaa tggcagattg ttcgacctcg tcaggatgcc 840
ctagtaatca acatcggtga gaccttcacg gcattaacaa atgggagata caagagttgc 900ctagtaatca acatcggtga gaccttcacg gcattaacaa atgggagata caagagttgc 900
ctgcataggg cagtagtaaa cagcgagagg gcgagaaaat cattggtata ctttgtttgc 960ctgcataggg cagtagtaaa cagcgagagg gcgagaaaat cattggtata ctttgtttgc 960
ccacgagaag acaaggtggt gagaccccca gaggatcttg tacaaggtga tcaactccca 1020ccacgagaag acaaggtggt gagaccccca gaggatcttg tacaaggtga tcaactccca 1020
agagcttacc ctgatttcac atggtccgat ttcctccatt tcacccaaaa ctactacaga 1080agagcttacc ctgatttcac atggtccgat ttcctccatt tcacccaaaa ctactacaga 1080
gctgacgctc atactctcca tagcttcatc aaatggctct catcttccaa ccccattcat 1140gctgacgctc atactctcca tagcttcatc aaatggctct catcttccaa ccccattcat 1140
cacaaccgtt aa 1152cacaaccgtt aa 1152
<210> 10<210> 10
<211> 1164<211> 1164
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 10<400> 10
atggtacatt gtctgccaaa ggtttttgtc attcaagaca agccgatgct tccatcaact 60atggtacatt gtctgccaaa ggttttttgtc attcaagaca agccgatgct tccatcaact 60
gctgctgtcg caaaggatga gcatcggcct ttagctttcg atgcatcgat ccttggatct 120gctgctgtcg caaaggatga gcatcggcct ttagctttcg atgcatcgat ccttggatct 120
gaatccaaca taccctctca gttcatatgg cctgacgacg agaagccatg cctggatgcc 180gaatccaaca taccctctca gttcatatgg cctgacgacg agaagccatg cctggatgcc 180
ccggcacttg taattccaac cattgacttg ggagctttct tgcttgggga ctctcttgct 240ccggcacttg taattccaac cattgacttg ggagctttct tgcttgggga ctctcttgct 240
gtatcaaaag cggcagaggt ggtgaatgag gcatgcaaga agcatgggtt ttttctggtt 300gtatcaaaag cggcagaggt ggtgaatgag gcatgcaaga agcatgggtt ttttctggtt 300
gtaaaccatg gggtggattc agggcttata gacaaagccc atcagtacat ggaccgcttc 360gtaaaccatg gggtggattc agggcttata gacaaagccc atcagtacat ggaccgcttc 360
ttcagcctac aactctctga gaagcaaaag gctaagagaa aagtaggaga aagctatggg 420ttcagcctac aactctctga gaagcaaaag gctaagagaa aagtaggaga aagctatggg 420
tatgcaagca gtttcgttgg caggttttcc tccaagttgc catggaaaga gacactgtct 480tatgcaagca gtttcgttgg caggttttcc tccaagttgc catggaaaga gacactgtct 480
tttcggtact gtcctcacac tcaaaatatc gtgcaacact atatggtgaa ttggatgggt 540tttcggtact gtcctcacac tcaaaatatc gtgcaacact atatggtgaa ttggatgggt 540
gaagatttta gagatttcgg gaggctttac caggaatatt gtgaagccat gaacaaggtt 600gaagatttta gagatttcgg gaggctttac caggaatatt gtgaagccat gaacaaggtt 600
tcccaagaga taatggggct gctagggata agtctaggac ttgaccaagc ctacttcaaa 660tcccaagaga taatggggct gctagggata agtctaggac ttgaccaagc ctacttcaaa 660
gactttttcg aacaaaatga ttcaatcctg agactgaatc actatccccc atgccaaaag 720gactttttcg aacaaaatga ttcaatcctg agactgaatc actatccccc atgccaaaag 720
cctgagttga ctctgggaac cggtccccac accgatccca cttccttgac aatccttcat 780cctgagttga ctctgggaac cggtccccac accgatccca cttccttgac aatccttcat 780
caggatcaag ttggaggcct tcaggtgttt gcagatgaaa agtggcactc cgttgctccc 840caggatcaag ttggaggcct tcaggtgttt gcagatgaaa agtggcactc cgttgctccc 840
atcccaggag cttttgttgt caacgttggc gacacattca tggctttgac aaacggtttt 900atcccaggag cttttgttgt caacgttggc gacacattca tggctttgac aaacggtttt 900
tacaagagct gcttgcacag agcagtggtg aatactgaaa cggtgagaaa atcacttgca 960tacaagagct gcttgcacag agcagtggtg aatactgaaa cggtgagaaa atcacttgca 960
ttctttctat gtcccaagct ggagagaccg gtgacaccag cagctggctt agttactgcc 1020ttctttctat gtcccaagct ggagagaccg gtgacaccag cagctggctt agttactgcc 1020
gaaaatccga ggaaataccc agacttcact tgggcagcac tgctgaagtt cacacagaac 1080gaaaatccga ggaaataccc agacttcact tgggcagcac tgctgaagtt cacacagaac 1080
cattaccgtg ctgacatgaa aacccttgtt gcattctcca aatgggttca agaacaagaa 1140cattaccgtg ctgacatgaa aacccttgtt gcattctcca aatgggttca agaacaagaa 1140
tcgaactaca aattaatacc ttag 1164tcgaactaca aattaatacc ttag 1164
<210> 11<210> 11
<211> 1155<211> 1155
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 11<400> 11
atgtctctct ctgtcttaat ggattcaagt tctccaacca ttcttttaca tccatccata 60atgtctctct ctgtcttaat ggattcaagt tctccaacca ttcttttaca tccatccata 60
gaaccaagag atgagacggg tagtgtcctt tttgacccat ccaagttgca aaaacaatca 120gaaccaagag atgagacggg tagtgtcctt tttgacccat ccaagttgca aaaacaatca 120
agtttaccct cagagttcat atggccatgt ggggacttgg ttcacaccca agaagagctt 180agtttaccct cagagttcat atggccatgt ggggacttgg ttcacaccca agaagagctt 180
aacgagccat tgatagactt gggtgggttc atcaaaggag acgaagaagc tactgcacat 240aacgagccat tgatagactt gggtgggttc atcaaaggag acgaagaagc tactgcacat 240
gcagtcgacc ttgttaagac tgcctgttct aaacatggtt tcttccaagt tacaaaccat 300gcagtcgacc ttgttaagac tgcctgttct aaacatggtt tcttccaagt tacaaaccat 300
ggtgttgatt caaatcttat ccaagctgct taccaagaga ttgatgctgt gtttaagtta 360ggtgttgatt caaatcttat ccaagctgct taccaagaga ttgatgctgt gtttaagtta 360
ccccttaaca agaagctcgg tttccaaaga aagcctggtg gtttttcagg ctattctgct 420ccccttaaca agaagctcgg tttccaaaga aagcctggtg gtttttcagg ctattctgct 420
gcccatgctg accggttttc cgctaagttg ccatggaagg aaacattttc ttttggctac 480gcccatgctg accggttttc cgctaagttg ccatggaagg aaacattttc ttttggctac 480
caaggactta actccgatcc ttctgtggtt cattatttca gctctgcttt gggggaagat 540caaggactta actccgatcc ttctgtggtt cattatttca gctctgcttt gggggaagat 540
tttgagcaca ccgggaggat ttaccaaaag tattgtgaaa agatgaggga gctgtcgcta 600tttgagcaca ccgggaggat ttaccaaaag tattgtgaaa agatgaggga gctgtcgcta 600
gtgatcttcg aactgttggc aatcagcttg gggatagatc gtttacacta cagaaaattt 660gtgatcttcg aactgttggc aatcagcttg gggatagatc gtttacacta cagaaaattt 660
ttcgaagatg ggaattcaat aatgaggtgt aattactatc ccccatgcaa taattctggc 720ttcgaagatg ggaattcaat aatgaggtgt aattactatc ccccatgcaa taattctggc 720
ctcacccttg gcactggccc tcactctgat cctacttcct taacaattct tcaccaagat 780ctcacccttg gcactggccc tcactctgat cctacttcct taacaattct tcaccaagat 780
caagtgggag ggctcgaagt tttcatcaat aacaaatggt atgctgttcg acctcgacaa 840caagtgggag ggctcgaagt tttcatcaat aacaaatggt atgctgttcg acctcgacaa 840
gatgcctttg tcattaacat tggtgatact ttcatggcat tatgtaacgg aagatacaag 900gatgcctttg tcattaacat tggtgatact ttcatggcat tatgtaacgg aagatacaag 900
agttgcctgc atagagcagt ggtgaacaag gagagagaga ggagatcatt ggtatacttt 960agttgcctgc atagagcagt ggtgaacaag gagagagaga ggagatcatt ggtatacttt 960
gtgtgcccaa aagaagacaa aatagtgaga cccccacaag atctaatgtg cagatcagga 1020gtgtgcccaa aagaagacaa aatagtgaga cccccacaag atctaatgtg cagatcagga 1020
gggccaagag tgtatcctga tttcacatgg tctgatttgt tggacttcac tcaaaatcac 1080gggccaagag tgtatcctga tttcacatgg tctgatttgt tggacttcac tcaaaatcac 1080
tatagagctg acgttgctac actccaaagc ttctttcctt ggctcctttc ttctaaccct 1140tatagagctg acgttgctac actccaaagc ttctttcctt ggctcctttc ttctaaccct 1140
acttccaact tctag 1155acttccaact tctag 1155
<210> 12<210> 12
<211> 1083<211> 1083
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 12<400> 12
atggcaattg attgcgtttc caagataccc tccatgcctc atcatcctaa agatgaaaaa 60atggcaattg attgcgtttc caagataccc tccatgcctc atcatcctaa agatgaaaaa 60
agagaggagc aaaaacaact ggtttttgat gcctcgccta atgttaatgc accagaactc 120agagaggagc aaaaacaact ggtttttgat gcctcgccta atgttaatgc accagaactc 120
caagtgccat tcattgacct aggagggttc ctttccggtg accctgtttc tgcaatggaa 180caagtgccat tcattgacct aggagggttc ctttccggtg accctgtttc tgcaatggaa 180
gcatcgaggc tggtcggcga ggcatgtcgg cagcatggtt tcttccttgt ggttaatcat 240gcatcgaggc tggtcggcga ggcatgtcgg cagcatggtt tcttccttgt ggttaatcat 240
ggagtggatg caacactggt ggctgatgct cacagttata tgggtaactt ctttgaattg 300ggagtggatg caacactggt ggctgatgct cacagttata tgggtaactt ctttgaattg 300
ccactcaatg ataagcaaag ggctcagagg aaacttggtg agcactgtgg atatgctagt 360ccactcaatg ataagcaaag ggctcagagg aaacttggtg agcactgtgg atatgctagt 360
agcttcactg gtagattctc ctccaagctg ccatggaagg aaacgctttc cttccggtat 420agcttcactg gtagattctc ctccaagctg ccatggaagg aaacgctttc cttccggtat 420
tcagctgaca aaaagtcatc caagattgtt gaagactacc ttgatggcaa attgggagat 480tcagctgaca aaaagtcatc caagattgtt gaagactacc ttgatggcaa attgggagat 480
gaattcaagc atttcgggag ggtttaccaa gattactgcg aggcaatgag caagctatct 540gaattcaagc atttcgggag ggtttaccaa gattactgcg aggcaatgag caagctatct 540
ctagggataa tggagctatt agccattagt cttggcgtag gaagatcaca tttcagggaa 600ctagggataa tggagctatt agccattagt cttggcgtag gaagatcaca tttcagggaa 600
tttttcgagg aaaatgaatc aataatgagg ctgaattact acccaccatg ccaaaaacca 660tttttcgagg aaaatgaatc aataatgagg ctgaattact acccaccatg ccaaaaacca 660
gacctcactt taggaacagg gcctcattgc gatccaacct cattaaccat ccttcaccaa 720gacctcactt taggaacagg gcctcattgc gatccaacct cattaaccat ccttcaccaa 720
gaccgagttg gtggtcttca agtgtttgta gacaatgaat ggcgttcaat tagcccaaat 780gaccgagttg gtggtcttca agtgtttgta gacaatgaat ggcgttcaat tagcccaaat 780
gtcgaagcat ttgtcgttaa cattggcgac accttcatgg cactttcaaa tgggcgatac 840gtcgaagcat ttgtcgttaa cattggcgac accttcatgg cactttcaaa tgggcgatac 840
aagagttgct tgcaccgggc agtggtgaac cgccacatcc caagaaaatc tctggctttc 900aagagttgct tgcaccgggc agtggtgaac cgccacatcc caagaaaatc tctggctttc 900
ttcctatgtc ccaagggtga taaagtggta gccccaccaa cagagttggt cgacgcctat 960ttcctatgtc ccaagggtga taaagtggta gccccaccaa cagagttggt cgacgcctat 960
aatcccagag tatatccaga ttttacttgg cctatgctgc ttgaattcac acaaaagcat 1020aatcccagag tatatccaga ttttacttgg cctatgctgc ttgaattcac acaaaagcat 1020
tatagagctg atatgaacac acttgaagtc ttctcaaact gggttcaaca gagaaacagc 1080tatagagctg atatgaacac acttgaagtc ttctcaaact gggttcaaca gagaaacagc 1080
tga 1083tga 1083
<210> 13<210> 13
<211> 1140<211> 1140
<212> DNA<212> DNA
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 13<400> 13
atggccatcg actgcatctc caacatagcc tccatgactc accatccgaa agatgaaaaa 60atggccatcg actgcatctc caacatagcc tccatgactc accatccgaa agatgaaaaa 60
aaagatgagc agaaaaagct ggtttttgat gcctcggtgc tcaagttcga atcccagata 120aaagatgagc agaaaaagct ggtttttgat gcctcggtgc tcaagttcga atcccagata 120
ccaaaagaat ttatatggcc tgatgacgaa aagccttccg ctaatgcacc agaactccaa 180ccaaaagaat ttatatggcc tgatgacgaa aagccttccg ctaatgcacc agaactccaa 180
gtaccactca ttgacctagg aggcttcctt tctggtgacc ctgttgctac aatggaagct 240gtaccactca ttgacctagg aggcttcctt tctggtgacc ctgttgctac aatggaagct 240
tcaaggttta tcagcgaggc atgtcagcag catggtttct tccttgtagt taatcatgga 300tcaaggttta tcagcgaggc atgtcagcag catggtttct tccttgtagt taatcatgga 300
gtcgatgcaa aactcttggc tgatgcccac aagtacatgg ataacttctt tctattgcca 360gtcgatgcaa aactcttggc tgatgcccac aagtacatgg ataacttctt tctattgcca 360
cttagacaaa agcaaagggc tcaaagaaaa cttggtgagc actgtggata tgccagtagc 420cttagacaaa agcaaagggc tcaaagaaaa cttggtgagc actgtggata tgccagtagc 420
ttcactggca ggttctcgac caagctccca tggaaggaaa cactttcttt tcgctattca 480ttcactggca ggttctcgac caagctccca tggaaggaaa cactttcttt tcgctattca 480
gccgagaaca actcatccaa gatggtggaa gactaccttg ttaataaaat gggaaatgaa 540gccgagaaca actcatccaa gatggtggaa gactaccttg ttaataaaat gggaaatgaa 540
ttgaggcaac tcgggagggt ttaccaggac tactgcgagg cgatgagcaa gctttctctg 600ttgaggcaac tcgggagggt ttaccaggac tactgcgagg cgatgagcaa gctttctctg 600
gggataatgg agcttttagc cattagtctg ggcgtaggca gagcacattt ccgggagttt 660gggataatgg agcttttagc cattagtctg ggcgtaggca gagcacattt ccgggagttt 660
tttgataaaa atgattcaat aatgagacta aactactatc ccccttgtca aaaaccagac 720tttgataaaa atgattcaat aatgagacta aactactatc ccccttgtca aaaaccagac 720
ctcactttag gaacagggcc tcattgcgat ccaacgtctt taaccatcct tcaccaagac 780ctcactttag gaacagggcc tcattgcgat ccaacgtctt taaccatcct tcaccaagac 780
agagttggtg gccttcaagt gtttgtagac aacgaatggc attcaattag cccaaatttc 840agagttggtg gccttcaagt gtttgtagac aacgaatggc attcaattag cccaaatttc 840
gaagcatttg tcgttaacat tggcgacacc tttatggcac tgtcaaatgg gagatataaa 900gaagcatttg tcgttaacat tggcgacacc tttatggcac tgtcaaatgg gagatataaa 900
agttgcttgc accaagcagt ggtgaacagc cataagccaa gaaaatctct ggctttcttt 960agttgcttgc accaagcagt ggtgaacagc cataagccaa gaaaatctct ggctttcttt 960
ttgtgtccag agggggataa agtggtaacc ccaccagcag agttggtgag ccagaacagt 1020ttgtgtccag agggggataa agtggtaacc ccaccagcag agttggtgag ccagaacagt 1020
cccagagtat atccagattt tacatggcct atgctgcttg aattcacaca aaagcattac 1080cccagagtat atccagattt tacatggcct atgctgcttg aattcacaca aaagcattac 1080
agagctgaca tgaacactct tcaagaattc tcaaactggg ttcaacagag aaacagctga 1140agagctgaca tgaacactct tcaagaattc tcaaactggg ttcaacagag aaacagctga 1140
<210> 14<210> 14
<211> 384<211> 384
<212> PRT<212> PRT
<213> 陆地棉(G.hirsutum L.)<213> Upland cotton (G.hirsutum L.)
<400> 14<400> 14
Met Ser Leu Ser Val Leu Met Asp Ser Gly Ser Pro Thr Ile Leu LeuMet Ser Leu Ser Val Leu Met Asp Ser Gly Ser Pro Thr Ile Leu Leu
1 5 10 151 5 10 15
His Pro Ser Ile Glu Pro Arg Asp Glu Thr Gly Gly Val Leu Phe AspHis Pro Ser Ile Glu Pro Arg Asp Glu Thr Gly Gly Val Leu Phe Asp
20 25 30 20 25 30
Pro Ser Lys Leu Gln Asn Gln Ser Ser Leu Pro Ser Glu Phe Ile TrpPro Ser Lys Leu Gln Asn Gln Ser Ser Leu Pro Ser Glu Phe Ile Trp
35 40 45 35 40 45
Pro Cys Gly Asp Leu Val His Thr Gln Glu Glu Leu Asn Glu Pro LeuPro Cys Gly Asp Leu Val His Thr Gln Glu Glu Leu Asn Glu Pro Leu
50 55 60 50 55 60
Ile Asp Leu Gly Gly Phe Ile Lys Gly Asp Glu Glu Ala Thr Ala HisIle Asp Leu Gly Gly Phe Ile Lys Gly Asp Glu Glu Ala Thr Ala His
65 70 75 8065 70 75 80
Ala Val Gly Leu Val Lys Thr Ala Cys Ser Lys His Gly Phe Phe GlnAla Val Gly Leu Val Lys Thr Ala Cys Ser Lys His Gly Phe Phe Gln
85 90 95 85 90 95
Val Thr Asn His Gly Val Asp Ser Asn Leu Ile Gln Ala Ala Tyr GlnVal Thr Asn His Gly Val Asp Ser Asn Leu Ile Gln Ala Ala Tyr Gln
100 105 110 100 105 110
Glu Ile Asp Ala Val Phe Lys Leu Pro Leu Asn Lys Lys Leu Ser PheGlu Ile Asp Ala Val Phe Lys Leu Pro Leu Asn Lys Lys Leu Ser Phe
115 120 125 115 120 125
Gln Arg Lys Pro Gly Gly Phe Ser Gly Tyr Ser Ala Ala His Ala AspGln Arg Lys Pro Gly Gly Phe Ser Gly Tyr Ser Ala Ala His Ala Asp
130 135 140 130 135 140
Arg Phe Ser Ala Lys Leu Pro Trp Lys Glu Thr Phe Ser Phe Gly TyrArg Phe Ser Ala Lys Leu Pro Trp Lys Glu Thr Phe Ser Phe Gly Tyr
145 150 155 160145 150 155 160
Gln Gly Leu Asn Ser Asp Pro Ser Val Val His Tyr Phe Ser Ser AlaGln Gly Leu Asn Ser Asp Pro Ser Val Val His Tyr Phe Ser Ser Ala
165 170 175 165 170 175
Leu Gly Glu Asp Phe Glu Gln Thr Gly Trp Ile Tyr Gln Lys Tyr CysLeu Gly Glu Asp Phe Glu Gln Thr Gly Trp Ile Tyr Gln Lys Tyr Cys
180 185 190 180 185 190
Glu Lys Met Arg Glu Leu Ser Leu Leu Ile Phe Glu Leu Leu Ala IleGlu Lys Met Arg Glu Leu Ser Leu Leu Ile Phe Glu Leu Leu Ala Ile
195 200 205 195 200 205
Ser Leu Gly Ile Asp Arg Leu His Tyr Arg Lys Phe Phe Glu Asp GlySer Leu Gly Ile Asp Arg Leu His Tyr Arg Lys Phe Phe Glu Asp Gly
210 215 220 210 215 220
Asn Ser Ile Met Arg Cys Asn Tyr Tyr Pro Pro Cys Asn Asn Ser GlyAsn Ser Ile Met Arg Cys Asn Tyr Tyr Pro Pro Cys Asn Asn Ser Gly
225 230 235 240225 230 235 240
Leu Thr Leu Gly Thr Gly Pro His Ser Asp Pro Thr Ser Leu Thr IleLeu Thr Leu Gly Thr Gly Pro His Ser Asp Pro Thr Ser Leu Thr Ile
245 250 255 245 250 255
Leu His Gln Asp Gln Val Gly Gly Leu Glu Val Phe Asn Asn Asn LysLeu His Gln Asp Gln Val Gly Gly Leu Glu Val Phe Asn Asn Asn Lys
260 265 270 260 265 270
Trp Tyr Ala Val Arg Pro Arg Gln Asp Ala Phe Val Ile Asn Ile GlyTrp Tyr Ala Val Arg Pro Arg Gln Asp Ala Phe Val Ile Asn Ile Gly
275 280 285 275 280 285
Asp Thr Phe Met Ala Leu Cys Asn Gly Arg Tyr Lys Ser Cys Leu HisAsp Thr Phe Met Ala Leu Cys Asn Gly Arg Tyr Lys Ser Cys Leu His
290 295 300 290 295 300
Arg Ala Val Val Asn Lys Glu Arg Glu Arg Arg Ser Leu Val Tyr PheArg Ala Val Val Asn Lys Glu Arg Glu Arg Arg Ser Leu Val Tyr Phe
305 310 315 320305 310 315 320
Val Cys Pro Lys Glu Asp Lys Ile Val Arg Pro Pro Gln Asp Leu MetVal Cys Pro Lys Glu Asp Lys Ile Val Arg Pro Pro Gln Asp Leu Met
325 330 335 325 330 335
Cys Arg Ser Gly Gly Pro Arg Val Tyr Pro Asp Phe Thr Trp Ser AspCys Arg Ser Gly Gly Pro Arg Val Tyr Pro Asp Phe Thr Trp Ser Asp
340 345 350 340 345 350
Leu Leu Glu Phe Thr Gln Asn His Tyr Arg Ala Asp Val Ala Thr LeuLeu Leu Glu Phe Thr Gln Asn His Tyr Arg Ala Asp Val Ala Thr Leu
355 360 365 355 360 365
Gln Ser Phe Phe Pro Trp Leu Leu Ser Ser Asn Pro Thr Ser Asn PheGln Ser Phe Phe Pro Trp Leu Leu Ser Ser Asn Pro Thr Ser Asn Phe
370 375 380 370 375 380
<210> 15<210> 15
<211> 21<211> 21
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 15<400> 15
atgtctctct ctgtcttaat g 21atgtctctct ctgtcttaat g 21
<210> 16<210> 16
<211> 20<211> 20
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 16<400> 16
ctagaagttg gaagtagggt 20
<210> 17<210> 17
<211> 27<211> 27
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 17<400> 17
tgctctagag caatgtctct ctctgtc 27tgctctagag caatgtctct ctctgtc 27
<210> 18<210> 18
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 18<400> 18
cgagctcgct agaagttgga agt 23cgagctcgct agaagttgga agt 23
<210> 19<210> 19
<211> 30<211> 30
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 19<400> 19
cgagctcgat gtctctctct gtcttaatgg 30cgagctcgat gtctctctct gtcttaatgg 30
<210> 20<210> 20
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 20<400> 20
ggactagtga agttggaagt agg 23ggactagtga agttggaagt agg 23
<210> 21<210> 21
<211> 27<211> 27
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 21<400> 21
ggactagtgt gaacaaggag agagaga 27ggactagtgt gaacaaggag agagaga 27
<210> 22<210> 22
<211> 28<211> 28
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 22<400> 22
ttggcgcgcc aagtagggtt agaagaaa 28ttggcgcgcc aagtagggtt agaagaaa 28
<210> 23<210> 23
<211> 22<211> 22
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 23<400> 23
tgcacatgca gtcgaccttg tt 22tgcacatgca gtcgaccttg tt 22
<210> 24<210> 24
<211> 22<211> 22
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 24<400> 24
ggtcagcatg ggcagcagaa ta 22ggtcagcatg ggcagcagaa ta 22
<210> 25<210> 25
<211> 19<211> 19
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 25<400> 25
atcctccgtc ttgaccttg 19atcctccgtc ttgaccttg 19
<210> 26<210> 26
<211> 19<211> 19
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 26<400> 26
tgtccgtcag gcaactcat 19tgtccgtcag gcaactcat 19
<210> 27<210> 27
<211> 24<211> 24
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 27<400> 27
agatccagga caaggaaggt attc 24agatccagga caaggaaggt attc 24
<210> 28<210> 28
<211> 22<211> 22
<212> DNA<212> DNA
<213> 人工序列(Artificial sequence)<213> Artificial sequence
<400> 28<400> 28
cgcaggacca agtgaagagt ag 22cgcaggacca agtgaagagt ag 22
Claims (1)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110162359.9A CN112899292B (en) | 2021-02-05 | 2021-02-05 | Upland cotton plant height regulation gene GhGA20ox6 and its application |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110162359.9A CN112899292B (en) | 2021-02-05 | 2021-02-05 | Upland cotton plant height regulation gene GhGA20ox6 and its application |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112899292A CN112899292A (en) | 2021-06-04 |
| CN112899292B true CN112899292B (en) | 2022-10-25 |
Family
ID=76122981
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110162359.9A Expired - Fee Related CN112899292B (en) | 2021-02-05 | 2021-02-05 | Upland cotton plant height regulation gene GhGA20ox6 and its application |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112899292B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN119372227B (en) * | 2025-01-02 | 2025-05-13 | 浙江农林大学 | A plant height regulating gene GhSHMT10-A for upland cotton and its application |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108728420A (en) * | 2017-04-24 | 2018-11-02 | 中国科学院上海生命科学研究院 | It is a kind of regulation and control crop downgrade and its yield gene and its application |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU5346099A (en) * | 1998-08-10 | 2000-03-06 | Monsanto Company | Methods for controlling gibberellin levels |
| CN117604024A (en) * | 2016-08-17 | 2024-02-27 | 孟山都技术公司 | Methods and compositions for dwarf plants that increase harvestable yield by manipulating gibberellin metabolism |
-
2021
- 2021-02-05 CN CN202110162359.9A patent/CN112899292B/en not_active Expired - Fee Related
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108728420A (en) * | 2017-04-24 | 2018-11-02 | 中国科学院上海生命科学研究院 | It is a kind of regulation and control crop downgrade and its yield gene and its application |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112899292A (en) | 2021-06-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110872598B (en) | Cotton drought-resistant related gene GhDT1 and application thereof | |
| CN117568289B (en) | Protein for resisting soybean cyst nematode disease, encoding gene and application thereof | |
| CN107937416A (en) | Improve gene and its application of nitrogen fertilizer for paddy rice utilization ratio and yield | |
| CN104829700A (en) | Corn CCCH-type zinc finger protein, and encoding gene ZmC3H54 and application thereof | |
| CN103695438A (en) | Arabidopsis MYB family transcription factor AtMYB17 gene as well as coding sequence and application thereof | |
| CN111926024A (en) | Application of OsDNR1 gene | |
| CN118165993A (en) | A key gene NtMIXTA-like regulating the development of tobacco glandular hairs and its application | |
| CN101323853B (en) | Cloning and Application of a Transcription Factor Gene OsWOX20 Regulating Rice Root Growth and Development | |
| CN103665127A (en) | Rice tillering relevant protein, encoding gene thereof and application of rice tillering relevant protein and encoding gene thereof | |
| CN116284292B (en) | A SiTAF10 gene for improving drought resistance and salt tolerance in millet and its application | |
| CN103060285B (en) | Application of OsPP18 gene on control of rice drought resistance | |
| CN114292855B (en) | PagARR9 gene for regulating and controlling growth of xylem of poplar and application thereof | |
| CN106893731A (en) | Soybean xyloglucan transferase hydrolase gene GmXTH1 and application | |
| CN103421809A (en) | Application of OsHSF08 gene in controlling rice drought resistance | |
| CN112899292B (en) | Upland cotton plant height regulation gene GhGA20ox6 and its application | |
| CN112062823B (en) | Application of GLK7 protein and its encoding gene in plant drought resistance | |
| CN111235179B (en) | Expression and application of OsABA8ox2 promoter in root meristem, spikelets and seeds at filling stage | |
| CN101492498B (en) | Plant stress resistance-related protein and its coding gene TaERECTA and its application | |
| WO2022188286A1 (en) | Protein and biomaterial related to rice yield and application of both in improving rice yield | |
| CN119080897A (en) | AvMYB1 protein and its application in improving plant salt tolerance | |
| CN103421814B (en) | Application of DWA1 gene for controlling drought resistance of rice and leaf epidermis wax synthesis | |
| CN115948434B (en) | Application of OsPHOT1 gene in improving rice tolerance to high temperature and/or darkness | |
| CN115976049B (en) | A peanut salt-tolerant gene AhLRR-RLK265 and its application | |
| CN114958906B (en) | Genes, promoters and applications related to low potassium stress in tobacco | |
| CN118531003A (en) | Application of TaNTA-4B gene in regulation and control of wheat tillering angle |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20221025 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |