CN112540934B - Method and system for ensuring quality of service when multiple delay-critical programs are jointly executed - Google Patents
Method and system for ensuring quality of service when multiple delay-critical programs are jointly executed Download PDFInfo
- Publication number
- CN112540934B CN112540934B CN202011465046.2A CN202011465046A CN112540934B CN 112540934 B CN112540934 B CN 112540934B CN 202011465046 A CN202011465046 A CN 202011465046A CN 112540934 B CN112540934 B CN 112540934B
- Authority
- CN
- China
- Prior art keywords
- program
- stage
- delay
- class
- critical
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0811—Multiuser, multiprocessor or multiprocessing cache systems with multilevel cache hierarchies
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Debugging And Monitoring (AREA)
- Memory System Of A Hierarchy Structure (AREA)
Abstract
Description
技术领域technical field
本申请涉及并行与分布计算技术领域,特别是涉及保证多个延迟关键程序共同执行时服务质量的方法及系统。The present application relates to the technical field of parallel and distributed computing, and in particular, to a method and system for ensuring quality of service when multiple delay-critical programs are jointly executed.
背景技术Background technique
本部分的陈述仅仅是提到了与本申请相关的背景技术,并不必然构成现有技术。The statements in this section merely mention the background art related to the present application and do not necessarily constitute prior art.
数据中心已经从概念走向成熟。在数据中心中,为了提高资源利用率,大量的程序在尽可能少的服务器上执行。而在一个服务器节点中,会有多个程序在一个节点上执行。多个程序共同执行的好处是可以增加服务器的利用率,而问题是会导致程序性能下降。程序性能下降程度取决于程序特征,对于某些程序,与其他程序共同执行时,性能下降不明显,而对于某些程序,与其他程序共同执行时,性能会明显下降。The data center has gone from concept to maturity. In a data center, in order to improve resource utilization, a large number of programs are executed on as few servers as possible. In a server node, multiple programs are executed on a node. The advantage of executing multiple programs together is that the utilization of the server can be increased, but the problem is that the program performance will be degraded. The degree of program performance degradation depends on the program characteristics. For some programs, the performance degradation is not obvious when executed with other programs, while for some programs, the performance drops significantly when executed with other programs.
于此同时,数据中心中运行着大量的延迟关键程序。客户将程序在数据中心执行,并对程序有一定的服务质量需求,比如程序性能不能低于单独执行时的90%。当延迟关键程序与其他程序共同执行时,很容易由于性能干扰导致严重的性能下降,从而不能满足客户的服务质量需求。这是必须要解决的问题。因此,需要一种方法,在尽可能提升系统资源利用率的基础上,还要保证延迟关键程序的服务质量。这是本申请必须要解决的问题。At the same time, a large number of latency-critical programs are running in the data center. The customer executes the program in the data center and has certain service quality requirements for the program, for example, the program performance cannot be lower than 90% of that when executed alone. When delay-critical programs are executed together with other programs, it is easy to cause serious performance degradation due to performance interference, thus failing to meet customer service quality requirements. This is a problem that must be solved. Therefore, a method is needed to ensure the quality of service of delay-critical programs on the basis of improving system resource utilization as much as possible. This is a problem that this application must solve.
发明内容SUMMARY OF THE INVENTION
为了解决现有技术的不足,本申请提供了保证多个延迟关键程序共同执行时服务质量的方法及系统;In order to solve the deficiencies of the prior art, the present application provides a method and system for ensuring the quality of service when multiple delay-critical programs are jointly executed;
第一方面,本申请提供了保证多个延迟关键程序共同执行时服务质量的方法;In the first aspect, the present application provides a method for ensuring service quality when multiple delay-critical programs are jointly executed;
保证多个延迟关键程序共同执行时服务质量的方法,包括:Methods to ensure quality of service when multiple latency-critical programs are executed together, including:
初始化硬件计数器,启动多个延迟关键程序;每个延迟关键程序均被预先设置于对应的内核中,每个内核上的延迟关键程序共享最后一级缓存空间LLC;Initialize the hardware counter and start multiple delay-critical programs; each delay-critical program is preset in the corresponding core, and the delay-critical programs on each core share the last level of cache space LLC;
将每个延迟关键程序划分为若干个程序阶段;对每个程序阶段再划分为若干个程序间隔;Divide each delay-critical program into several program stages; divide each program stage into several program intervals;
在多个延迟关键程序被共同运行的过程中,利用硬件性能计数器,对每个延迟关键程序的每个程序阶段中的程序间隔进行采样;根据采样数据计算每个程序阶段的第一、第二和第三实际性能数据;根据第一实际性能数据对相应的程序阶段的阶段类型进行分类;根据第二和第三实际性能数据对程序阶段的性能进行分类;In the process that multiple delay-critical programs are running together, the hardware performance counter is used to sample the program interval in each program stage of each delay-critical program; and third actual performance data; classify the phase type of the corresponding program stage according to the first actual performance data; classify the performance of the program stage according to the second and third actual performance data;
根据每个延迟关键程序的每个程序阶段所处的阶段类型和所处的性能类型,对每个延迟关键程序运行过程中所占用的缓存空间进行动态调整。According to the stage type and performance type of each program stage of each delay-critical program, the cache space occupied by each delay-critical program during the running process is dynamically adjusted.
第二方面,本申请提供了保证多个延迟关键程序共同执行时服务质量的系统;In the second aspect, the present application provides a system for ensuring the quality of service when multiple delay-critical programs are jointly executed;
保证多个延迟关键程序共同执行时服务质量的系统,包括:A system that guarantees quality of service when multiple latency-critical programs are executed together, including:
初始化模块,其被配置为:初始化硬件计数器,启动多个延迟关键程序;每个延迟关键程序均被预先设置于对应的内核中,每个内核上的延迟关键程序共享最后一级缓存空间LLC;an initialization module, which is configured to: initialize a hardware counter, and start a plurality of delay-critical programs; each delay-critical program is preset in a corresponding core, and the delay-critical programs on each core share the last-level cache space LLC;
阶段划分模块,其被配置为:将每个延迟关键程序划分为若干个程序阶段;对每个程序阶段再划分为若干个程序间隔;a stage division module, which is configured to: divide each delay-critical program into several program stages; further divide each program stage into several program intervals;
分类模块,其被配置为:在多个延迟关键程序被共同运行的过程中,利用硬件性能计数器,对每个延迟关键程序的每个程序阶段中的程序间隔进行采样;根据采样数据计算每个程序阶段的第一、第二和第三实际性能数据;根据第一实际性能数据对相应的程序阶段的阶段类型进行分类;根据第二和第三实际性能数据对程序阶段的性能进行分类;The classification module is configured to: sample program intervals in each program stage of each delay-critical program using hardware performance counters during a process in which a plurality of delay-critical programs are run together; calculate each delay-critical program according to the sampled data The first, second and third actual performance data of the program stage; the stage type of the corresponding program stage is classified according to the first actual performance data; the performance of the program stage is classified according to the second and third actual performance data;
动态调整模块,其被配置为:根据每个延迟关键程序的每个程序阶段所处的阶段类型和所处的性能类型,对每个延迟关键程序运行过程中所占用的缓存空间进行动态调整。The dynamic adjustment module is configured to: dynamically adjust the cache space occupied by each delay-critical program during the running process according to the stage type and performance type of each program stage of each delay-critical program.
第三方面,本申请还提供了一种电子设备,包括:一个或多个处理器、一个或多个存储器、以及一个或多个计算机程序;其中,处理器与存储器连接,上述一个或多个计算机程序被存储在存储器中,当电子设备运行时,该处理器执行该存储器存储的一个或多个计算机程序,以使电子设备执行上述第一方面所述的方法。In a third aspect, the present application also provides an electronic device, comprising: one or more processors, one or more memories, and one or more computer programs; wherein the processor is connected to the memory, and one or more of the above The computer program is stored in the memory, and when the electronic device runs, the processor executes one or more computer programs stored in the memory, so that the electronic device performs the method described in the first aspect above.
第四方面,本申请还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成第一方面所述的方法。In a fourth aspect, the present application further provides a computer-readable storage medium for storing computer instructions, and when the computer instructions are executed by a processor, the method described in the first aspect is completed.
第五方面,本申请还提供了一种计算机程序(产品),包括计算机程序,所述计算机程序当在一个或多个处理器上运行的时候用于实现前述第一方面任意一项的方法。In a fifth aspect, the present application also provides a computer program (product), including a computer program, which when run on one or more processors, is used to implement the method of any one of the foregoing first aspects.
与现有技术相比,本申请的有益效果是:Compared with the prior art, the beneficial effects of the present application are:
通过实时监测延迟关键程序的性能指标,利用CAT为不同类型的延迟关键程序动态划分LLC资源,既保证了多个延迟关键程序共同执行时的性能,又尽可能的提升了LLC资源的利用率。By monitoring the performance indicators of delay-critical programs in real time, and using CAT to dynamically divide LLC resources for different types of delay-critical programs, it not only ensures the performance of multiple delay-critical programs when they are executed together, but also improves the utilization of LLC resources as much as possible.
支持最后一级高速缓存(LLC)分配的英特尔技术可通过高速缓存分区更好地利用高速缓存。本申请可以利用这种技术,通过防止延迟关键程序污染彼此的高速缓存来保证用户的性能要求。此外,本申请可以通过给性能受益的延迟关键程序分配更多的LLC资源并且减少或停止分配给那些没有受益的延迟关键程序来更好的满足用户的性能要求。Intel technology that supports Last Level Cache (LLC) allocation enables better cache utilization through cache partitioning. The present application can take advantage of this technique to guarantee user performance requirements by preventing delay-critical programs from polluting each other's caches. In addition, the present application can better meet the user's performance requirements by allocating more LLC resources to delay-critical programs that benefit from performance and reducing or stopping the allocation to delay-critical programs that do not benefit.
本发明利用程序运行时所处阶段的性能指标对程序所占空间进行动态调整。本发明在保证程序服务质量的同时,可以尽可能的提升延迟关键程序的数量和LLC的资源利用率。The invention dynamically adjusts the space occupied by the program by using the performance index of the stage in which the program is running. The present invention can improve the quantity of delay key programs and the resource utilization rate of LLC as much as possible while ensuring the program service quality.
本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。Advantages of additional aspects of the invention will be set forth in part in the description which follows, and in part will become apparent from the description which follows, or may be learned by practice of the invention.
附图说明Description of drawings
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。The accompanying drawings that form a part of the present application are used to provide further understanding of the present application, and the schematic embodiments and descriptions of the present application are used to explain the present application and do not constitute improper limitations on the present application.
图1为第一个实施例的资源划分方法流程图;Fig. 1 is the flow chart of the resource division method of the first embodiment;
图2为第一个实施例的程序阶段性能分析流程图。FIG. 2 is a flow chart of the performance analysis of the program stage of the first embodiment.
具体实施方式Detailed ways
应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。It should be noted that the following detailed description is exemplary and intended to provide further explanation of the application. Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this application belongs.
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。It should be noted that the terminology used herein is for the purpose of describing specific embodiments only, and is not intended to limit the exemplary embodiments according to the present application. As used herein, unless the context clearly dictates otherwise, the singular is intended to include the plural as well, furthermore, it is to be understood that the terms "including" and "having" and any conjugations thereof are intended to cover the non-exclusive A process, method, system, product or device comprising, for example, a series of steps or units is not necessarily limited to those steps or units expressly listed, but may include those steps or units not expressly listed or for such processes, methods, Other steps or units inherent to the product or equipment.
在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。Embodiments of the invention and features of the embodiments may be combined with each other without conflict.
术语解释:Terminology Explanation:
延迟关键程序,是指:对尾延迟有严格要求的应用程序,尾延迟是延迟关键程序的重要性能指标。Latency-critical programs refer to applications that have strict requirements on tail latency. Tail latency is an important performance indicator for latency-critical programs.
LLC,是指:Last Level Cache,即最后一级缓存,是指通常由芯片上所有功能单元(例如CPU内核,IGP和DSP)共享的最高级缓存。LLC, refers to: Last Level Cache, the last level cache, refers to the highest level cache that is usually shared by all functional units on the chip (such as CPU cores, IGPs, and DSPs).
CAT,是指:Cache Allocation Technology,即缓存分配技术,其基本目标是基于应用程序优先级或服务等级(CLOS)启用资源分配。Intel Xeon处理器E5 v4家族(以及专注于通信的Intel Xeon处理器E5 v3家族的子集)引入了在最后一级缓存上配置和利用缓存分配技术的功能。CAT, refers to: Cache Allocation Technology, that is, cache allocation technology, the basic goal of which is to enable resource allocation based on application priority or class of service (CLOS). The Intel Xeon processor E5 v4 family (and a subset of the communications-focused Intel Xeon processor E5 v3 family) introduced the ability to configure and utilize cache allocation techniques on the last level of cache.
CLOS,是指:Class of Service,即服务等级,CLOS作为一种抽象概念可能附加了多个资源控制属性,从而减少了上下文交换时的软件开销。CLOS refers to: Class of Service, that is, service level. As an abstract concept, CLOS may have multiple resource control attributes attached, thereby reducing the software overhead during context exchange.
实施例一Example 1
本实施例提供了保证多个延迟关键程序共同执行时服务质量的方法;This embodiment provides a method for ensuring quality of service when multiple delay-critical programs are jointly executed;
保证多个延迟关键程序共同执行时服务质量的方法,包括:Methods to ensure quality of service when multiple latency-critical programs are executed together, including:
S101:初始化硬件计数器,启动多个延迟关键程序;每个延迟关键程序均被预先设置于对应的内核中,每个内核上的延迟关键程序共享最后一级缓存空间(LLC);S101: Initialize a hardware counter, and start multiple delay-critical programs; each delay-critical program is preset in a corresponding core, and the delay-critical programs on each core share the last level cache space (LLC);
S102:将每个延迟关键程序划分为若干个程序阶段;对每个程序阶段再划分为若干个程序间隔;S102: Divide each delay key program into several program stages; divide each program stage into several program intervals;
S103:在多个延迟关键程序被共同运行的过程中,利用硬件性能计数器,对每个延迟关键程序的每个程序阶段中的程序间隔进行采样;S103: in the process that multiple delay-critical programs are jointly running, use a hardware performance counter to sample the program interval in each program stage of each delay-critical program;
根据采样数据计算每个程序阶段的第一、第二和第三实际性能数据;Calculate the first, second and third actual performance data for each program stage from the sampled data;
根据第一实际性能数据对相应的程序阶段的阶段类型进行分类;classifying the phase type of the corresponding program phase according to the first actual performance data;
根据第二和第三实际性能数据对程序阶段的性能进行分类;Classifying the performance of the program phases according to the second and third actual performance data;
S104:根据每个延迟关键程序的每个程序阶段所处的阶段类型和所处的性能类型,对每个延迟关键程序运行过程中所占用的缓存空间进行动态调整。S104: Dynamically adjust the cache space occupied by each delay-critical program during the running process according to the stage type and performance type of each program stage of each delay-critical program.
应理解的,所述S101中,为保证每个延迟关键程序没有CPU时间争用,系统的初始状态将每个延迟关键程序置于不同的内核中,每个内核上的延迟关键程序共享LLC。It should be understood that in S101, in order to ensure that each delay-critical program does not have CPU time contention, the initial state of the system places each delay-critical program in a different core, and the delay-critical programs on each core share the LLC.
示例性的,所述多个延迟关键程度,是指两个及两个以上的延迟关键程序。Exemplarily, the multiple delay critical degrees refer to two or more delay critical programs.
作为一个或多个实施例,所述S101,还包括:As one or more embodiments, the S101 further includes:
假设缓存空间LLC共有N路空间,预留出M路空间作为备用空间,将剩余的N-M路空间平均分配给所有的延迟关键程序;N和M均为正整数。Assuming that the cache space LLC has a total of N-way space, M-way space is reserved as spare space, and the remaining N-M-way space is evenly distributed to all delay-critical programs; N and M are positive integers.
示例性的,利用CAT将每一个延迟关键程序划分到不同的CLOS中隔离起来,减少延迟关键程序之间的影响。Exemplarily, CAT is used to divide each delay-critical program into different CLOSs and isolate them, so as to reduce the influence among delay-critical programs.
示例性的,假设系统有N路LLC空间,预留出M路cache way空间给CLOS#1作为候补空间,将剩余N-M路空间平均分配给所有的延迟关键程序。Exemplarily, assuming that the system has N-way LLC space, M-way cache way space is reserved for CLOS#1 as a candidate space, and the remaining N-M-way space is evenly distributed to all delay-critical programs.
示例性的,假设延迟关键程序为两个,因为CAT仅支持LLC空间的连续划分,所以将LLC的空间按照地址从低到高分配。延迟关键程序1占用CLOS#0代表的空间大小,大小等于
作为一个或多个实施例,所述S102:将每个延迟关键程序划分为若干个程序阶段;具体步骤包括:As one or more embodiments, the S102: Divide each delay-critical program into several program stages; the specific steps include:
利用计数器来对指令数量进行计数,通过执行设定数量的指令数来对程序的阶段进行划分。The number of instructions is counted by a counter, and the stages of the program are divided by executing a set number of instructions.
作为一个或多个实施例,所述S102:对每个程序阶段再划分为若干个程序间隔;具体步骤包括:As one or more embodiments, the S102: subdivide each program stage into several program intervals; the specific steps include:
对条件分支指令进行计数,当执行X条条件分支指令后,触发中断;Count the conditional branch instructions, and trigger an interrupt when X conditional branch instructions are executed;
即每X条条件分支指令,作为一个程序间隔;另外一个硬件计数器负责记录下这期间执行的指令总数,X为正整数。That is, every X conditional branch instruction is regarded as a program interval; another hardware counter is responsible for recording the total number of instructions executed during this period, and X is a positive integer.
示例性的,对每个程序阶段再划分为若干个程序间隔;具体步骤还包括:Exemplarily, each program stage is further divided into several program intervals; the specific steps further include:
采用不同的采样周期,对每个程序阶段划分为若干个程序间隔。Using different sampling periods, each program stage is divided into several program intervals.
应理解的,S102中,将每个延迟关键程序划分为包含固定数量指令的程序阶段,为了更好的获取程序性能信息,本申请引入了两级阶段检测方法。It should be understood that, in S102, each delay-critical program is divided into program stages including a fixed number of instructions. In order to better obtain program performance information, the present application introduces a two-stage stage detection method.
阶段划分:程序在运行过程中,程序的性能指标(如IPC)可能会发生变化,属于同一阶段的程序片段具有类似的性能指标,而属于不同阶段的程序片段性能指标则不同,可以根据程序的性能指标,对程序划分不同的阶段。本申请使用固定的指令数以对程序的阶段进行划分,然后利用IPC指标对程序的运行时阶段进行分类,固定的指令数可为1000万、1亿、10亿。Stage division: During the running process of the program, the performance indicators (such as IPC) of the program may change. The program fragments belonging to the same stage have similar performance indicators, while the performance indicators of program fragments belonging to different stages are different. Performance indicators, which divide the program into different stages. The present application uses a fixed number of instructions to divide the stages of the program, and then uses the IPC indicator to classify the runtime stages of the program. The fixed number of instructions can be 10 million, 100 million, or 1 billion.
间隔划分。为了更详细的获取运行时程序的阶段信息,本申请采用间隔划分方法用于对程序阶段再进行细分。为了减少采样开销和信息损失,本申请采用每X条条件分支指令采样一次性能数据。本申请可以根据实际情况选择不同的采样周期,例如100M、200M。interval division. In order to obtain the phase information of the runtime program in more detail, the present application adopts an interval division method to subdivide the program phases. In order to reduce sampling overhead and information loss, the present application adopts performance data to be sampled once every X conditional branch instructions. In this application, different sampling periods can be selected according to the actual situation, such as 100M and 200M.
作为一个或多个实施例,所述S103:在多个延迟关键程序被共同运行的过程中,利用硬件性能计数器,对每个延迟关键程序的每个程序阶段的程序间隔进行采样;具体步骤包括:As one or more embodiments, the S103: in the process that multiple delay-critical programs are jointly running, use a hardware performance counter to sample the program interval of each program stage of each delay-critical program; the specific steps include: :
在多个延迟关键程序被共同运行的过程中,利用硬件性能计数器,对每个延迟关键程序的每个程序阶段的程序间隔进行采样,获取性能指标每周期指令数IPC、LLC未命中数、LLC命中数和LLC引用数。In the process that multiple delay-critical programs are running together, the hardware performance counter is used to sample the program interval of each program stage of each delay-critical program to obtain performance indicators IPC, LLC misses, LLC Hits and LLC references.
利用获取的LLC未命中数、LLC命中数和LLC引用数,计算程序间隔指标MPKILLC和HPKILLC。程序间隔的MPKILLC和HPKILLC的计算公式如下:Using the acquired LLC misses, LLC hits, and LLC citations, program gap metrics MPKI LLC and HPKI LLC are calculated. The formulas for calculating MPKI LLC and HPKI LLC for program intervals are as follows:


NumMiss指的是LLC未命中数,NumIns指的是LLC引用数,NumHit指的是LLC命中数。Num Miss refers to LLC misses, Num Ins refers to LLC citations, and Num Hit refers to LLC hits.
应理解的,利用程序阶段中所有间隔的性能指标,计算出性能指标的均值作为延迟关键程序所处阶段的性能指标,用于分析延迟关键程序的阶段行为。It should be understood that, using the performance indicators of all intervals in the program stage, the mean value of the performance indicators is calculated as the performance indicator of the stage in which the delay-critical program is located, which is used to analyze the stage behavior of the delay-critical program.
作为一个或多个实施例,所述S103:根据采样数据计算每个程序阶段的第一、第二和第三实际性能数据;具体步骤包括:As one or more embodiments, the S103: Calculate the first, second and third actual performance data of each program stage according to the sampled data; the specific steps include:
根据采样数据计算每个程序阶段的第一实际性能数据;第一实际性能数据,是指:每周期指令数IPC平均值;Calculate the first actual performance data of each program stage according to the sampled data; the first actual performance data refers to: the average IPC of the number of instructions per cycle;
根据采样数据计算每个程序阶段的第二实际性能数据;第二实际性能数据,是指:LLC上每千指令未命中指令数的均值MPKILLC;Calculate the second actual performance data of each program stage according to the sampled data; the second actual performance data refers to: the mean value MPKI LLC of the number of missed instructions per thousand instructions on the LLC ;
根据采样数据计算每个程序阶段的第三实际性能数据;第三实际性能数据,是指:LLC上每千指令命中指令数的均值HPKILLC。Calculate the third actual performance data of each program stage according to the sampled data; the third actual performance data refers to the average value of the number of hit instructions per thousand instructions on the LLC HPKI LLC .
示例性的,根据阶段中每个间隔采样的数据,计算所处阶段的IPC、MPKILLC(LLC上每千指令未命中指令数)和HPKILLC(LLC上每千指令命中指令数)的均值。IPCLLC、MPKILLC、HPKILLC的均值计算步骤如下:Exemplarily, according to the data sampled at each interval in the stage, the average value of IPC, MPKI LLC (the number of missed instructions per thousand instructions on the LLC) and HPKI LLC (the number of hit instructions per thousand instructions on the LLC) at the stage is calculated. The average calculation steps of IPC LLC , MPKI LLC and HPKI LLC are as follows:



IPCLLC1指的是第一个间隔的IPC指标,n表示一个程序阶段中的间隔数,MPKILLC1指的是第一个间隔的MPKI指标,HPKILLC1指的是第一个间隔的HPKI指标。IPC LLC1 refers to the IPC indicator for the first interval, n denotes the number of intervals in a program phase, MPKI LLC1 refers to the MPKI indicator for the first interval, and HPKI LLC1 refers to the HPKI indicator for the first interval.
作为一个或多个实施例,所述S103:根据第一实际性能数据对相应的程序阶段的阶段类型进行分类;具体步骤包括:As one or more embodiments, the S103: Classify the phase type of the corresponding program phase according to the first actual performance data; the specific steps include:
根据
A类:
B类:
C类:
其中,α是指第一设定阈值,β是指第二设定阈值。Among them, α refers to the first set threshold value, and β refers to the second set threshold value.
作为一个或多个实施例,所述S103:根据第二和第三实际性能数据对程序阶段的性能进行分类;具体步骤包括:As one or more embodiments, the S103: Classify the performance of the program stage according to the second and third actual performance data; the specific steps include:
根据

a类:
b类: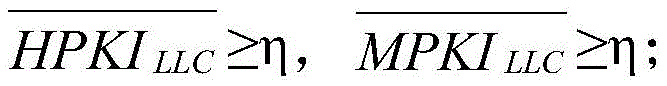
c类:
其中,η是指第三设定阈值,γ是指第四设定阈值,并且η<γ。Here, η refers to the third set threshold, γ refers to the fourth set threshold, and η<γ.
作为一个或多个实施例,所述S104:根据每个延迟关键程序的每个程序阶段所处的阶段类型和所处的性能类型,对每个延迟关键程序运行过程中所占用的缓存空间进行动态调整;具体步骤包括:As one or more embodiments, the S104: According to the stage type and the performance type of each program stage of each delay-critical program, perform the cache space occupied during the running of each delay-critical program. Dynamic adjustment; specific steps include:
判断每个延迟关键程序的每个程序阶段所处的阶段类型和所处的性能类型;Determine the stage type and performance type of each program stage of each delay-critical program;
若程序阶段类型为A类,且性能类型为a或b类,则初步判断该程序阶段需要增加缓存空间;在增加缓存空间的过程中,如果程序阶段类型不变,则立即停止增加缓存空间并减少增加的缓存空间;若阶段类型变为B或C,则保存修改;If the program stage type is class A and the performance type is class a or b, it is preliminarily judged that the program stage needs to increase the cache space; in the process of increasing the cache space, if the program stage type does not change, immediately stop increasing the cache space and Reduce the increased cache space; if the stage type becomes B or C, save the modification;
若程序阶段类型为A类,且性能类型为c类,则初步判断该程序阶段需要减少缓存空间;若减少1路缓存空间,
若程序阶段为B类,性能类型为b类,则不对该程序阶段所占缓存空间进行改变;If the program stage is class B and the performance type is class b, the cache space occupied by the program stage will not be changed;
若程序阶段为B类,性能类型为a或c类,则初步判断该程序阶段需要减少缓存空间;若减少1路缓存空间,阶段类型并未变为A类型,则继续减少缓存空间;否则,还原修改的操作;If the program stage is class B and the performance type is class a or c, it is preliminarily judged that the program stage needs to reduce the cache space; if the 1-way cache space is reduced and the stage type has not changed to type A, continue to reduce the cache space; otherwise, Revert modified operations;
若程序阶段为C类,性能类型为a类或c类,则需判断该程序阶段是否存在资源过剩的现象,若减少1路缓存空间,阶段类型并未变成A或B类型,则继续减少缓存空间;否则,还原修改的操作;If the program stage is class C, and the performance type is class a or class c, it is necessary to judge whether there is excess resources in the program stage. Cache space; otherwise, restore the modified operation;
若程序阶段为C类,性能类型为b类,则不对该程序阶段所占缓存空间进行改变;If the program stage is class C and the performance type is class b, the cache space occupied by the program stage will not be changed;
作为一个或多个实施例,所述方法还包括:As one or more embodiments, the method further includes:
获取LLC的资源使用情况进行动态管理;Obtain the resource usage of LLC for dynamic management;
若CLOS#1中有空闲空间则从CLOS#1中获取空间,若CLOS#1中的缓存空间分配完毕,则判断物理地址上相邻程序是否处于资源过剩状态;如果是则根据相邻程序的性能状况分配多余空间,若不存在资源过剩情况则继续等待空闲空间;若长时间未出现空闲空间则进行数据迁移。If there is free space in CLOS#1, the space is obtained from CLOS#1. If the cache space in CLOS#1 is allocated, it is judged whether the adjacent program on the physical address is in a state of excess resources; The performance status allocates excess space, and if there is no excess resources, it continues to wait for free space; if there is no free space for a long time, data migration is performed.
将每个程序的阶段性能数据登记在历史阶段&性能表(HPPT)。HPPT存储每个程序的阶段信息和性能信息。本申请根据正在运行的程序的阶段行为和程序运行时性能信息动态调整当前阶段所占用的缓存。The stage performance data for each program is registered in the Historical Stage & Performance Table (HPPT). HPPT stores phase information and performance information for each program. The present application dynamically adjusts the cache occupied by the current stage according to the stage behavior of the running program and the program runtime performance information.
根据延迟关键程序所处的阶段和MPKI_LLC、HPKI_LLC对延迟关键程序所占用的缓存空间进行动态调整。The cache space occupied by the delay-critical program is dynamically adjusted according to the stage of the delay-critical program and MPKI_LLC and HPKI_LLC.
图1描述资源划分方法。对于需要执行的每一个程序,利用硬件性能计数器获取程序性能信息。Figure 1 describes the resource partitioning method. For each program that needs to be executed, use hardware performance counters to obtain program performance information.
图2描述程序阶段性能分析方法。Figure 2 describes the program phase performance analysis method.
对于需要执行的每一个程序,利用


实施例二Embodiment 2
本实施例提供了保证多个延迟关键程序共同执行时服务质量的系统;This embodiment provides a system for ensuring the quality of service when multiple delay-critical programs are jointly executed;
保证多个延迟关键程序共同执行时服务质量的系统,包括:A system that guarantees quality of service when multiple latency-critical programs are executed together, including:
初始化模块,其被配置为:初始化硬件计数器,启动多个延迟关键程序;每个延迟关键程序均被预先设置于对应的内核中,每个内核上的延迟关键程序共享最后一级缓存空间LLC;an initialization module, which is configured to: initialize a hardware counter, and start a plurality of delay-critical programs; each delay-critical program is preset in a corresponding core, and the delay-critical programs on each core share the last-level cache space LLC;
阶段划分模块,其被配置为:将每个延迟关键程序划分为若干个程序阶段;对每个程序阶段再划分为若干个程序间隔;a stage division module, which is configured to: divide each delay-critical program into several program stages; further divide each program stage into several program intervals;
分类模块,其被配置为:在多个延迟关键程序被共同运行的过程中,利用硬件性能计数器,对每个延迟关键程序的每个程序阶段中的程序间隔进行采样;根据采样数据计算每个程序阶段的第一、第二和第三实际性能数据;根据第一实际性能数据对相应的程序阶段的阶段类型进行分类;根据第二和第三实际性能数据对程序阶段的性能进行分类;The classification module is configured to: sample the program interval in each program stage of each delay-critical program by using hardware performance counters in the process that a plurality of delay-critical programs are run together; calculate each delay-critical program according to the sampled data The first, second and third actual performance data of the program stage; the stage type of the corresponding program stage is classified according to the first actual performance data; the performance of the program stage is classified according to the second and third actual performance data;
动态调整模块,其被配置为:根据每个延迟关键程序的每个程序阶段所处的阶段类型和所处的性能类型,对每个延迟关键程序运行过程中所占用的缓存空间进行动态调整。The dynamic adjustment module is configured to: dynamically adjust the cache space occupied by each delay-critical program during the running process according to the stage type and performance type of each program stage of each delay-critical program.
此处需要说明的是,上述初始化模块、阶段划分模块、分类模块和动态调整模块对应于实施例一中的步骤S101至S104,上述模块与对应的步骤所实现的示例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为系统的一部分可以在诸如一组计算机可执行指令的计算机系统中执行。It should be noted here that the above initialization module, stage division module, classification module and dynamic adjustment module correspond to steps S101 to S104 in the first embodiment, and the examples and application scenarios implemented by the above modules and the corresponding steps are the same, but not the same. It is limited to the content disclosed in the first embodiment above. It should be noted that the above modules can be executed in a computer system such as a set of computer-executable instructions as part of the system.
上述实施例中对各个实施例的描述各有侧重,某个实施例中没有详述的部分可以参见其他实施例的相关描述。The description of each embodiment in the foregoing embodiments has its own emphasis. For the part that is not described in detail in a certain embodiment, reference may be made to the relevant description of other embodiments.
所提出的系统,可以通过其他的方式实现。例如以上所描述的系统实施例仅仅是示意性的,例如上述模块的划分,仅仅为一种逻辑功能划分,实际实现时,可以有另外的划分方式,例如多个模块可以结合或者可以集成到另外一个系统,或一些特征可以忽略,或不执行。The proposed system can be implemented in other ways. For example, the system embodiments described above are only illustrative. For example, the division of the above modules is only a logical function division. In actual implementation, there may be other division methods. For example, multiple modules may be combined or integrated into other A system, or some feature, can be ignored, or not implemented.
实施例三Embodiment 3
本实施例还提供了一种电子设备,包括:一个或多个处理器、一个或多个存储器、以及一个或多个计算机程序;其中,处理器与存储器连接,上述一个或多个计算机程序被存储在存储器中,当电子设备运行时,该处理器执行该存储器存储的一个或多个计算机程序,以使电子设备执行上述实施例一所述的方法。This embodiment also provides an electronic device, comprising: one or more processors, one or more memories, and one or more computer programs; wherein the processor is connected to the memory, and the one or more computer programs are Stored in the memory, when the electronic device runs, the processor executes one or more computer programs stored in the memory, so that the electronic device executes the method described in the first embodiment.
应理解,本实施例中,处理器可以是中央处理单元CPU,处理器还可以是其他通用处理器、数字信号处理器DSP、专用集成电路ASIC,现成可编程门阵列FPGA或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。It should be understood that, in this embodiment, the processor may be a central processing unit CPU, and the processor may also be other general-purpose processors, digital signal processors DSP, application-specific integrated circuits ASIC, off-the-shelf programmable gate array FPGA or other programmable logic devices , discrete gate or transistor logic devices, discrete hardware components, etc. A general purpose processor may be a microprocessor or the processor may be any conventional processor or the like.
存储器可以包括只读存储器和随机存取存储器,并向处理器提供指令和数据、存储器的一部分还可以包括非易失性随机存储器。例如,存储器还可以存储设备类型的信息。The memory may include read-only memory and random access memory and provide instructions and data to the processor, and a portion of the memory may also include non-volatile random access memory. For example, the memory may also store device type information.
在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。In the implementation process, each step of the above-mentioned method can be completed by a hardware integrated logic circuit in a processor or an instruction in the form of software.
实施例一中的方法可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器、闪存、只读存储器、可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。为避免重复,这里不再详细描述。The method in the first embodiment can be directly embodied as being executed by a hardware processor, or executed by a combination of hardware and software modules in the processor. The software modules may be located in random access memory, flash memory, read-only memory, programmable read-only memory or electrically erasable programmable memory, registers and other storage media mature in the art. The storage medium is located in the memory, and the processor reads the information in the memory, and completes the steps of the above method in combination with its hardware. To avoid repetition, detailed description is omitted here.
本领域普通技术人员可以意识到,结合本实施例描述的各示例的单元及算法步骤,能够以电子硬件或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。Those skilled in the art can realize that the units and algorithm steps of each example described in conjunction with this embodiment can be implemented by electronic hardware or a combination of computer software and electronic hardware. Whether these functions are performed in hardware or software depends on the specific application and design constraints of the technical solution. Skilled artisans may implement the described functionality using different methods for each particular application, but such implementations should not be considered beyond the scope of this application.
实施例四Embodiment 4
本实施例还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成实施例一所述的方法。This embodiment also provides a computer-readable storage medium for storing computer instructions, and when the computer instructions are executed by the processor, the method described in the first embodiment is completed.
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。The above descriptions are only preferred embodiments of the present application, and are not intended to limit the present application. For those skilled in the art, the present application may have various modifications and changes. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of this application shall be included within the protection scope of this application.
Claims (8)
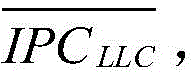
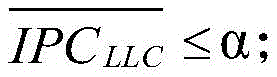

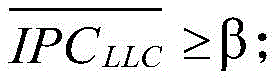
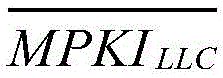



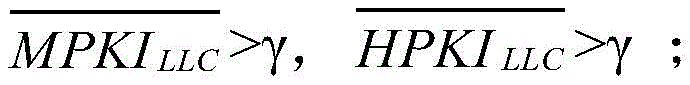




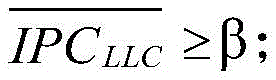

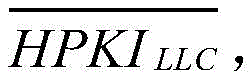



Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011465046.2A CN112540934B (en) | 2020-12-14 | 2020-12-14 | Method and system for ensuring quality of service when multiple delay-critical programs are jointly executed |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011465046.2A CN112540934B (en) | 2020-12-14 | 2020-12-14 | Method and system for ensuring quality of service when multiple delay-critical programs are jointly executed |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112540934A CN112540934A (en) | 2021-03-23 |
| CN112540934B true CN112540934B (en) | 2022-07-29 |
Family
ID=75018579
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011465046.2A Active CN112540934B (en) | 2020-12-14 | 2020-12-14 | Method and system for ensuring quality of service when multiple delay-critical programs are jointly executed |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112540934B (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113504977B (en) * | 2021-06-18 | 2024-12-13 | 山东师范大学 | Cache partitioning method and system for ensuring service quality of multiple delay-critical programs |
| CN113821324B (en) * | 2021-09-17 | 2022-08-09 | 海光信息技术股份有限公司 | Cache system, method, apparatus and computer medium for processor |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9244732B2 (en) * | 2009-08-28 | 2016-01-26 | Vmware, Inc. | Compensating threads for microarchitectural resource contentions by prioritizing scheduling and execution |
| CN101916230A (en) * | 2010-08-11 | 2010-12-15 | 中国科学技术大学苏州研究院 | Performance Optimization Method of Last Level Cache Based on Partition Awareness and Thread Awareness |
| US9401869B1 (en) * | 2012-06-04 | 2016-07-26 | Google Inc. | System and methods for sharing memory subsystem resources among datacenter applications |
| US10554505B2 (en) * | 2012-09-28 | 2020-02-04 | Intel Corporation | Managing data center resources to achieve a quality of service |
| CN103077128B (en) * | 2012-12-29 | 2015-09-23 | 华中科技大学 | Shared buffer memory method for dynamically partitioning under a kind of multi-core environment |
| CN103235764B (en) * | 2013-04-11 | 2016-01-20 | 浙江大学 | Thread aware multinuclear data pre-fetching self-regulated method |
| CN104572493A (en) * | 2013-10-23 | 2015-04-29 | 华为技术有限公司 | Memory resource optimization method and device |
| US9626295B2 (en) * | 2015-07-23 | 2017-04-18 | Qualcomm Incorporated | Systems and methods for scheduling tasks in a heterogeneous processor cluster architecture using cache demand monitoring |
| CN107463510B (en) * | 2017-08-21 | 2020-05-08 | 北京工业大学 | A high-performance heterogeneous multi-core shared cache management method |
| CN110618872B (en) * | 2019-09-25 | 2022-04-15 | 山东师范大学 | Hybrid memory dynamic scheduling method and system |
| CN111258927B (en) * | 2019-11-13 | 2022-05-03 | 北京大学 | A Sampling-Based Prediction Method for the Missing Rate Curve of the Last-Level Cache of Application Programs |
| CN112000465B (en) * | 2020-07-21 | 2023-02-03 | 山东师范大学 | Method and system for reducing performance interference of delay sensitive program in data center environment |
-
2020
- 2020-12-14 CN CN202011465046.2A patent/CN112540934B/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN112540934A (en) | 2021-03-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US6662272B2 (en) | Dynamic cache partitioning | |
| US11086792B2 (en) | Cache replacing method and apparatus, heterogeneous multi-core system and cache managing method | |
| US7899994B2 (en) | Providing quality of service (QoS) for cache architectures using priority information | |
| CN109308220B (en) | Shared resource allocation method and device | |
| JP3727887B2 (en) | Shared register file control method in multi-thread processor | |
| CN105389211B (en) | Memory allocation method and delay perception-Memory Allocation device suitable for NUMA architecture | |
| CN106708626A (en) | Low power consumption-oriented heterogeneous multi-core shared cache partitioning method | |
| US10725940B2 (en) | Reallocate memory pending queue based on stall | |
| US20170371550A1 (en) | Frame choosing during storage constraint condition | |
| CN112540934B (en) | Method and system for ensuring quality of service when multiple delay-critical programs are jointly executed | |
| KR102452660B1 (en) | System and method for store streaming detection and handling | |
| CN106294192B (en) | Memory allocation method, memory allocation device and server | |
| US8769201B2 (en) | Technique for controlling computing resources | |
| CN104461735A (en) | Method and device for distributing CPU resources in virtual scene | |
| CN112000465B (en) | Method and system for reducing performance interference of delay sensitive program in data center environment | |
| CN117667776A (en) | Memory bandwidth allocation method and device | |
| Itshak et al. | AMSQM: adaptive multiple super-page queue management | |
| CN119847609A (en) | Dynamic instruction conversion memory conflict optimization method based on memory partition | |
| US20220327063A1 (en) | Virtual memory with dynamic segmentation for multi-tenant fpgas | |
| Nikas et al. | An adaptive bloom filter cache partitioning scheme for multicore architectures | |
| JP2024016010A (en) | Memory-aware context switching | |
| Hwang et al. | Hmmsched: Hybrid main memory-aware task scheduling on multicore systems | |
| US7603522B1 (en) | Blocking aggressive neighbors in a cache subsystem | |
| CN120144063B (en) | A page storage method, virtual machine system, device, medium and product | |
| CN120892214B (en) | Memory allocation methods and electronic devices |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |