CN112465393B - Enterprise risk early warning method based on correlation analysis FP-Tree algorithm - Google Patents
Enterprise risk early warning method based on correlation analysis FP-Tree algorithm Download PDFInfo
- Publication number
- CN112465393B CN112465393B CN202011461438.1A CN202011461438A CN112465393B CN 112465393 B CN112465393 B CN 112465393B CN 202011461438 A CN202011461438 A CN 202011461438A CN 112465393 B CN112465393 B CN 112465393B
- Authority
- CN
- China
- Prior art keywords
- risk
- enterprise
- index
- early warning
- rule
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/06—Resources, workflows, human or project management; Enterprise or organisation planning; Enterprise or organisation modelling
- G06Q10/063—Operations research, analysis or management
- G06Q10/0635—Risk analysis of enterprise or organisation activities
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/06—Resources, workflows, human or project management; Enterprise or organisation planning; Enterprise or organisation modelling
- G06Q10/063—Operations research, analysis or management
- G06Q10/0639—Performance analysis of employees; Performance analysis of enterprise or organisation operations
- G06Q10/06393—Score-carding, benchmarking or key performance indicator [KPI] analysis
Landscapes
- Business, Economics & Management (AREA)
- Human Resources & Organizations (AREA)
- Engineering & Computer Science (AREA)
- Strategic Management (AREA)
- Entrepreneurship & Innovation (AREA)
- Economics (AREA)
- Development Economics (AREA)
- Educational Administration (AREA)
- Operations Research (AREA)
- Marketing (AREA)
- Game Theory and Decision Science (AREA)
- Quality & Reliability (AREA)
- Tourism & Hospitality (AREA)
- Physics & Mathematics (AREA)
- General Business, Economics & Management (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
The invention relates to an enterprise risk early warning method based on an FP-Tree algorithm of correlation analysis. An enterprise index data set is constructed, then a mutual entropy-interval set method is used for carrying out box separation and chi-square test correlation screening indexes, and finally a correlation analysis FP-Tree algorithm is used for carrying out enterprise risk early warning. The method and the system not only can analyze the enterprise risk from single index data, but also can integrate two or more index data to mine the enterprise risk, and mine the risk existing in the enterprise more comprehensively.
Description
Technical Field
The invention belongs to the field of enterprise risk early warning, and particularly relates to an enterprise risk early warning method based on an FP-Tree algorithm of correlation analysis.
Background
The enterprise activities are comprehensive social activities integrating various aspects of economy, technology, management, organization and the like, and have uncertainty in all aspects. The enterprise risk early warning is an effective means for carrying out risk pre-control, resolving the occurrence of risks and reducing the loss caused by the risks to the minimum degree by establishing a risk assessment system. The risk analysis and management of enterprise activities are developed, the occurrence of risks is prevented and solved, the loss caused by the risks is controlled to the minimum, and the risk analysis and management method becomes one of important measures for ensuring the enterprise operation activities and creating the maximum benefits. The enterprise risk early warning index system is a scale and an important basis for measuring the financial risk condition of an enterprise. The construction of a risk early warning index system which accords with the characteristics of enterprises follows the following basic principle: (1) a comprehensive principle; (2) a scientific principle; (3) a target principle; (4) a typical principle; (5) operability principle; (6) and (4) a fairness principle.
In the prior art, enterprise risks are divided into internal risks and external risks, and the risk classification method comprises four risk comprehensive indexes: financial, technical, business, and strategic.
(1) Financial risk factor: including liquidity, financing, investment, compensation, profit, asset utilization, growth, etc.
(2) Technical risk factor: including trademarks, patents, software copyrights, works, key technologies, etc.
(3) Operating risk factors: including jurisdictions, business anomalies, administrative penalties, and the like.
(4) Strategic risk factors: including contests, business associations, development history, etc.
Currently, the following methods are mostly adopted for enterprise risk early warning: in the aspect of external environment risks, a six-force analysis model is used for reference, and the competitive environment of an enterprise is analyzed; in the aspect of internal environment risks, an index system mainly comprising financial risk factors, technical risk factors, operational risk factors and strategic risk factors is established by combining the availability of research documents and data at home and abroad, common rating methods comprise a judgment analysis method, a comprehensive judgment method, a fuzzy analysis method and the like, and finally, an early warning interval is set according to a judgment result and corresponding countermeasures are taken.
The early warning in the prior art is analyzed from single index data analysis or integral index data, and due to the current situations that the basic professional knowledge of enterprises is lack, the dimensionality of enterprise data is high, and the data volume of the enterprises is large, and the current enterprise risk early warning needs longer time in information acquisition, updating, processing and analysis, and cannot realize dynamic processing, the timeliness of the risk early warning is seriously influenced, so that the enterprise risk early warning has serious time errors to a great extent.
Disclosure of Invention
The invention aims to provide an enterprise risk early warning method based on a correlation analysis FP-Tree algorithm, which not only can analyze enterprise risks from single index data, but also can integrate two or more index data to mine enterprise risks, and mine the risks existing in the enterprises more comprehensively.
In order to achieve the purpose, the technical scheme of the invention is as follows: an enterprise risk early warning method based on an association analysis FP-Tree algorithm comprises the following steps:
step S1, according to the historical enterprise relevant behavior data, analyzing and measuring the scale and important basis of the enterprise risk condition, and designing a risk index system X ═ X1,x2,…,xi},xiA name representing an ith index of a risk index system;
step S2, according to the risk index system, big data analysis is applied to form a risk rule, namely, the value of one or more indexes is equal to a preset value or a preset interval value, the enterprise is considered to have corresponding risk, and a risk rule set B is obtained:

wherein, XkIs a subset of index system X; riskkIs composed of XkAnalyzing the corresponding risk text description obtained by inference;
step S3, acquiring enterprise related behavior data, constructing a training index data set of an enterprise risk early warning model and an enterprise index data set to be early warned, and training the training set in the training index data set: test set 4: 1;
step S4, based on the training index data set, calculating and obtaining the corresponding risk level of the enterprise through the credit dimension data of the enterprise, wherein the calculation formula is as follows:

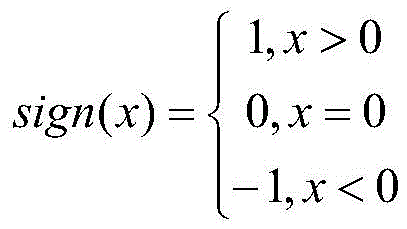
among them, creditScorenewRepresenting the normalized value of the latest credit risk score, 100. creditScorenewA base score as a risk score; creditScoreiRepresenting the credit risk score of the previous i years,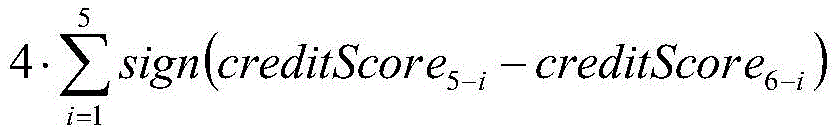 stability condition representing a credit score; the riskListCount represents the number of times of blacklisting or loss of credit in the last 5 years, and the 4. riskListCount represents the risk of blacklisting or loss of credit;
stability condition representing a credit score; the riskListCount represents the number of times of blacklisting or loss of credit in the last 5 years, and the 4. riskListCount represents the risk of blacklisting or loss of credit;
step S5, performing box separation and chi-square test on correlation screening indexes by using a mutual entropy-interval set method, performing index tokenization according to box separation results, and storing box separation rules and a remaining index list after screening;
step S6, acquiring association rule set: mining association rules of enterprise behaviors of each risk level of the enterprise by using an association analysis FP-Tree algorithm, traversing the association rules and integrating the association rules into an association rule set consisting of an index set, a risk level and a confidence coefficient, wherein the association rule set consists of elements in the form of (index set): (risk level, confidence coefficient) with the confidence coefficient being more than 0.5;
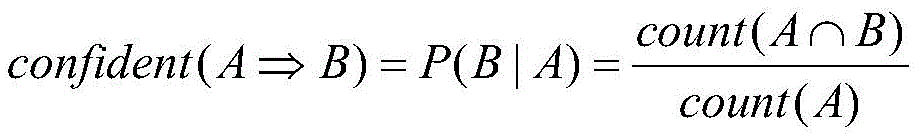
wherein, A represents a certain index set; b represents a certain risk level;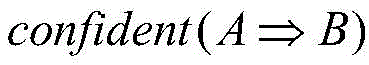 representing the confidence coefficient of the risk level B inferred by the index set A; count (A ≈ B) and count (A) respectively represent the number of samples in which the same sample exists in the element in the index set A and the risk level B at the same time, and the number of samples in which the same sample exists in the element in the index set A;
representing the confidence coefficient of the risk level B inferred by the index set A; count (A ≈ B) and count (A) respectively represent the number of samples in which the same sample exists in the element in the index set A and the risk level B at the same time, and the number of samples in which the same sample exists in the element in the index set A;
and S7, according to the association rule set obtained in the step S6 and the risk rule set obtained in the step S2, early warning is carried out on the enterprise to be early warned based on the index data set of the enterprise to be early warned, association rules of enterprise life are early warned, the enterprise risk level and possible risk points are predicted, and early warning results are output.
In an embodiment of the present invention, in step S5, the specific implementation manner of performing bin sorting and chi-square test correlation screening indexes by using the mutual entropy-interval set method is as follows:
for indexes with discrete variable attributes and continuous variables with more than 5 value types, the indexes are subjected to box separation by using a supervised mutual entropy-interval method, and the continuous variables are symbolized according to box separation results, so that the risk of model overfitting is reduced;
the mutual entropy-interval set method carries out the box dividing steps as follows:
index I to be binned includes And (3) performing box separation on the index I, wherein the initial box separation Boundary value set is Boundary { a, b }:
And (3) performing box separation on the index I, wherein the initial box separation Boundary value set is Boundary { a, b }:
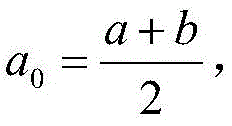
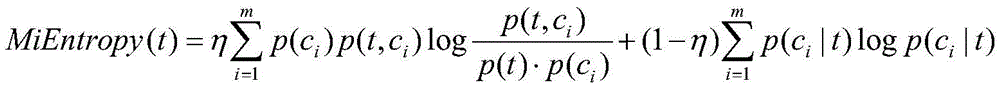
wherein t is an interval; c is a set of classes, { C ═ C1,c2,…,cmM is the number of categories; p (c)i)、p(t)、p(t,ci) Respectively in the training set ciThe number of samples of class, the number of samples of index value in interval t, the index value in interval t and belonging to ciThe ratio of the number of class samples to the total number of training set samples, p (c)iI t) index value belongs to the interval t and ciIs proportional to the number of samples of the index value in the interval t, eta is a hyper-parameter and satisfies eta ∈ [0 ],1];
Using MiEntrophpy pairs [ a, a ]0]、(a0,b]Evaluating, and turning to the step 2;
if numb (I) is more than or equal to n, the box separation is stopped
If MiEntrophy ([ a, a)0]) A is greater than or equal to throshold, and a is taken as a, b is taken as a0Jumping to the step 1;
if MiEncopy ((a)0,b]) A is not less than throshold, and a is taken as0B is equal to b and jump to step 1;
if MiEntrophy ([ a, a)0])≤MiEntropy((a0,b]) < throshold, take a as0B is b and jumps to the step 1;
if MiEncopy ((a)0,b])≤MiEntropy([a,a0]) < throshold, take a as a, b as a0Jumping to the step 1;
and 4, obtaining a box Boundary set after the box separation is finished, and sorting the box Boundary set according to the small to large sequence to obtain boundry ═ a, a1,a2,…,akB, dividing the index I into k +1 boxes according to Boundary: { [ a, a)1],(a1,a2],…,(ak,b]};
The chi-square test correlation screening indexes are specifically as follows: the relevance of index variables and enterprise risks is detected through chi-square inspection, indexes which are not beneficial to early warning are filtered, and sample space is divided according to the result of relevant analysis of chi-square inspection based on supervised sub-boxes.
In an embodiment of the present invention, the specific implementation manner of step S7 is as follows:
firstly, centralizing the enterprise index data to be early-warned in a to-be-early-warned enterprise index data set to perform the symbolization of the enterprise index data to be early-warned: the conversion of the index data is determined by the box-dividing rule of step S5, and the original index data is converted into the corresponding character identifier to obtain the converted index set of the enterprise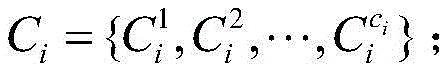 Wherein, CiThe result set is formed by the symbolization of each index value of the ith sample enterprise;
Wherein, CiThe result set is formed by the symbolization of each index value of the ith sample enterprise;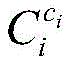 represents the ith sample enterprise ciA result value is tokenized by an index;
represents the ith sample enterprise ciA result value is tokenized by an index;
secondly, obtaining a hit association rule: traversing the association rule, if the index set of the association rule Satisfies Ci∩Rj=RjThen it indicates that the enterprise hits RjAnd (3) corresponding association rules, so that an enterprise hit risk rule index set is obtained:
Satisfies Ci∩Rj=RjThen it indicates that the enterprise hits RjAnd (3) corresponding association rules, so that an enterprise hit risk rule index set is obtained:
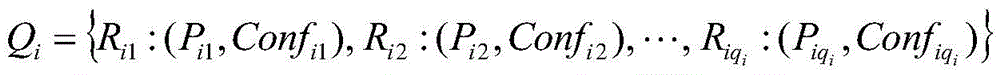
wherein,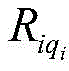 represents the qth early warning enterpriseiAn index set of risk rules for individual hits;
represents the qth early warning enterpriseiAn index set of risk rules for individual hits;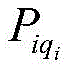 represents the qth early warning enterpriseiA risk level of the hit risk rule;
represents the qth early warning enterpriseiA risk level of the hit risk rule; represents the qth early warning enterpriseiConfidence of the risk rule for an individual hit;
represents the qth early warning enterpriseiConfidence of the risk rule for an individual hit;
then, a risk level is obtained: the risk grade is determined by the risk grade and the confidence coefficient of the hit association rule, the risk grade of the association rule is converted into a corresponding score, the confidence coefficient is used as a weight to carry out weighted average, a final risk score is obtained through calculation, and the risk grade is obtained according to the score interval of each risk grade;
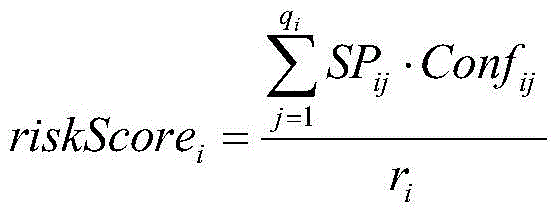
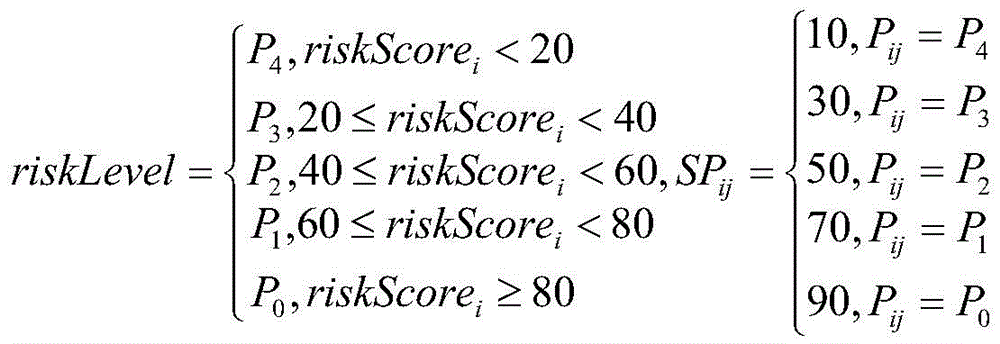
wherein, high risk is represented by P0, middle and high risk has two grades, namely P1 and P2, and the risk of P1 is greater than that of P2, low risk is represented by P3, and no risk is represented by P4; riskScoreiRepresenting a risk score of the ith early warning business; SPijA risk level score representing the risk rule of the jth hit of the ith early warning business; p isijRepresenting the risk level of the risk rule of the jth hit of the ith early warning enterprise; confijRepresenting the confidence of the risk rule of the jth hit of the ith early warning enterprise; r isiThe sum of the confidence degrees of the risk rules of the hit of the ith early warning enterprise is represented; the riskLevel is a function for mapping the risk score to the risk level;
finally, obtaining a risk description: traversing the risk rule set from step S2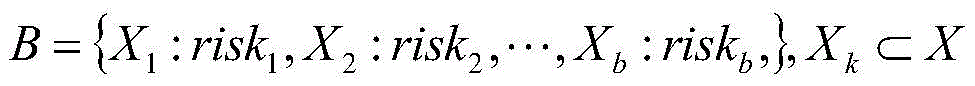 And enterprise hit risk rule index set
And enterprise hit risk rule index set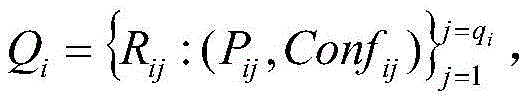 If Xk∩Rir=XkThen X exists in the enterprise probabilitykCorresponding risk point riskk(ii) a After traversing is completed, obtaining the enterprise risk point set
If Xk∩Rir=XkThen X exists in the enterprise probabilitykCorresponding risk point riskk(ii) a After traversing is completed, obtaining the enterprise risk point set And splicing the elements in the risk point set by semicolons to obtain the risk description of the elements.
And splicing the elements in the risk point set by semicolons to obtain the risk description of the elements.
Compared with the prior art, the invention has the following beneficial effects:
(1) high innovativeness. The invention relates to the specific application of an association analysis FP-Tree algorithm in the field of enterprise risk early warning analysis, fills the blank of the association analysis algorithm in the field of enterprise risk early warning analysis, performs index screening and binning by using a chi-square test principle before the FP-Tree mining association rule, improves the early warning accuracy by removing the index with weak correlation, and can more comprehensively obtain the risk of mining enterprise behaviors.
(2) And (4) timeliness. When enterprise early warning is carried out each time, the code script obtains real-time data generation indexes from the original data table, and the index screening, the binning and the association rule are correspondingly dynamically updated, so that the method can be automatically adjusted in real time according to external changes to adapt to the changes of the indexes, and time errors of enterprise risk early warning in data processing and analysis are reduced to a great extent.
(3) A low threshold. Because the enterprise risk early warning analysis method based on the correlation analysis algorithm FP-Tree is black box for the use of the end user, the end user does not need to care about the specific model construction process, only needs to store and update the required enterprise basic information and behavior information data into an enterprise information database, and the obtained early warning clues are displayed in a domain model risk clue list through a risk early warning system interface.
Drawings
FIG. 1 is a schematic diagram of the method of the present invention.
Detailed Description
The technical scheme of the invention is specifically explained below with reference to the accompanying drawings.
The invention provides an enterprise risk early warning method based on an FP-Tree algorithm of correlation analysis, which comprises the following steps:
step S1, according to the historical enterprise relevant behavior data, analyzing the scale and important basis for measuring the enterprise risk condition, and designing a risk index system X ═ X1,x2,…,xi},xiA name representing an ith index of a risk index system;
step S2, according to the risk index system, big data analysis is applied to form a risk rule, namely, the value of one or more indexes is equal to a preset value or a preset interval value, the enterprise is considered to have corresponding risk, and a risk rule set B is obtained:

wherein, XkIs a subset of the index system X; risk (r) is a chemical compoundkIs composed of XkAnalyzing the corresponding risk text description obtained by inference;
step S3, collecting enterprise related behavior data, and constructing a training index data set of an enterprise risk early warning model and an enterprise index data set to be early warned, wherein the training index data set comprises a training set: test set 4: 1;
step S4, based on the training index data set, calculating and obtaining the corresponding risk grade of the enterprise through the credit dimension data of the enterprise, wherein the calculation formula is as follows:

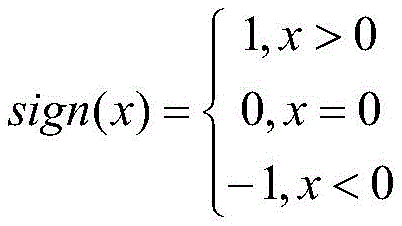
among them, creditScorenewRepresenting the normalized value of the latest credit risk score, 100. creditScorenewA base score as a risk score; creditScoreiRepresenting the credit risk score of the previous i years,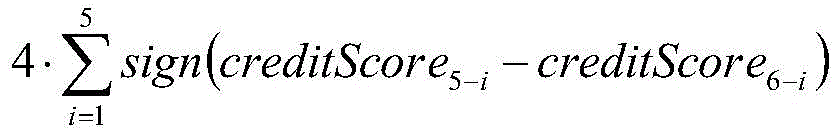 stability condition representing a credit score; the riskListCount represents the number of times of blacklisting or loss of credit in the last 5 years, and the 4. riskListCount represents the risk of blacklisting or loss of credit;
stability condition representing a credit score; the riskListCount represents the number of times of blacklisting or loss of credit in the last 5 years, and the 4. riskListCount represents the risk of blacklisting or loss of credit;
step S5, performing box separation and chi-square test on correlation screening indexes by using a mutual entropy-interval set method, performing index tokenization according to box separation results, and storing box separation rules and a remaining index list after screening;
step S6, acquiring association rule set: mining association rules of enterprise behaviors of each risk level of the enterprise by using an association analysis FP-Tree algorithm, traversing the association rules and integrating the association rules into an association rule set consisting of an index set, a risk level and a confidence coefficient, wherein the association rule set consists of elements in the form of (index set): (risk level, confidence coefficient) with the confidence coefficient being more than 0.5;

wherein, A represents a certain index set; b represents a certain risk level;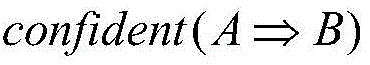 representing the confidence of the risk level B inferred by the index set A; count (A ≧ B) and count (A) respectively represent the number of samples in which the element in the index set A and the risk level B have the same sample at the same time, and the number of samples in which the element in the index set A has the same sample at the same time;
representing the confidence of the risk level B inferred by the index set A; count (A ≧ B) and count (A) respectively represent the number of samples in which the element in the index set A and the risk level B have the same sample at the same time, and the number of samples in which the element in the index set A has the same sample at the same time;
and S7, according to the association rule set obtained in the step S6 and the risk rule set obtained in the step S2, early warning is carried out on the enterprise to be early warned based on the index data set of the enterprise to be early warned, association rules of enterprise life are early warned, the enterprise risk level and possible risk points are predicted, and early warning results are output.
The following is a specific implementation of the present invention.
The invention is realized by adopting the following scheme steps:
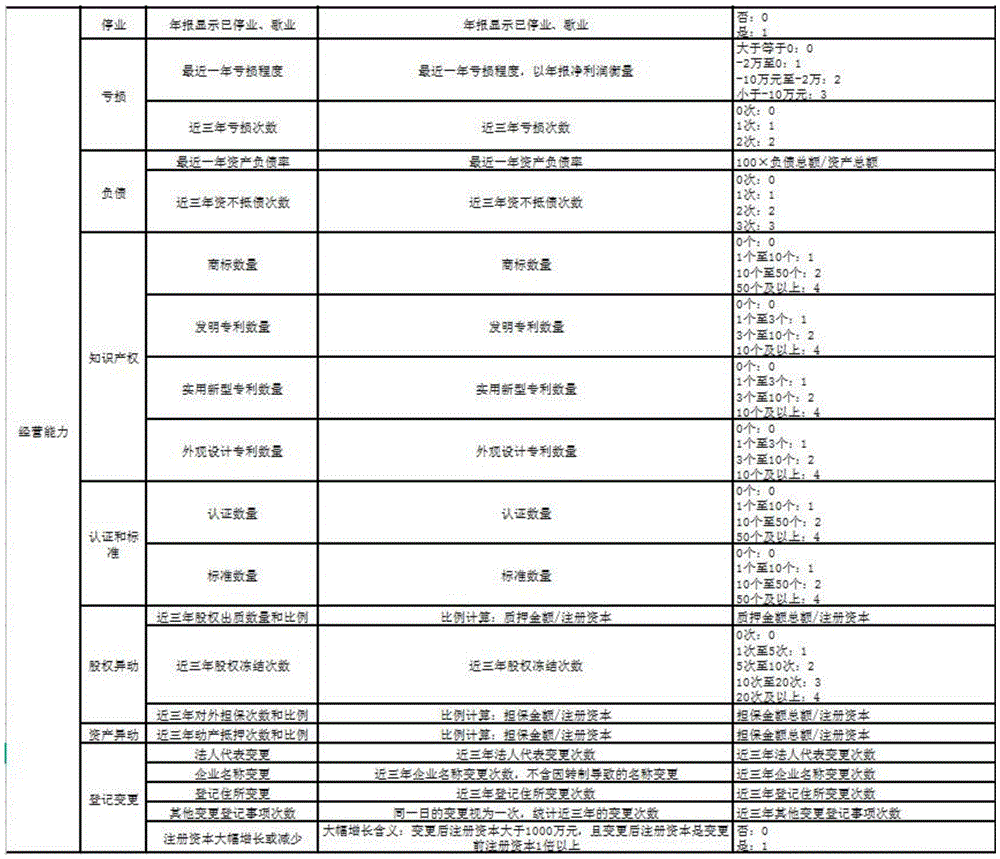
TABLE 1 Enterprise Risk indicator System
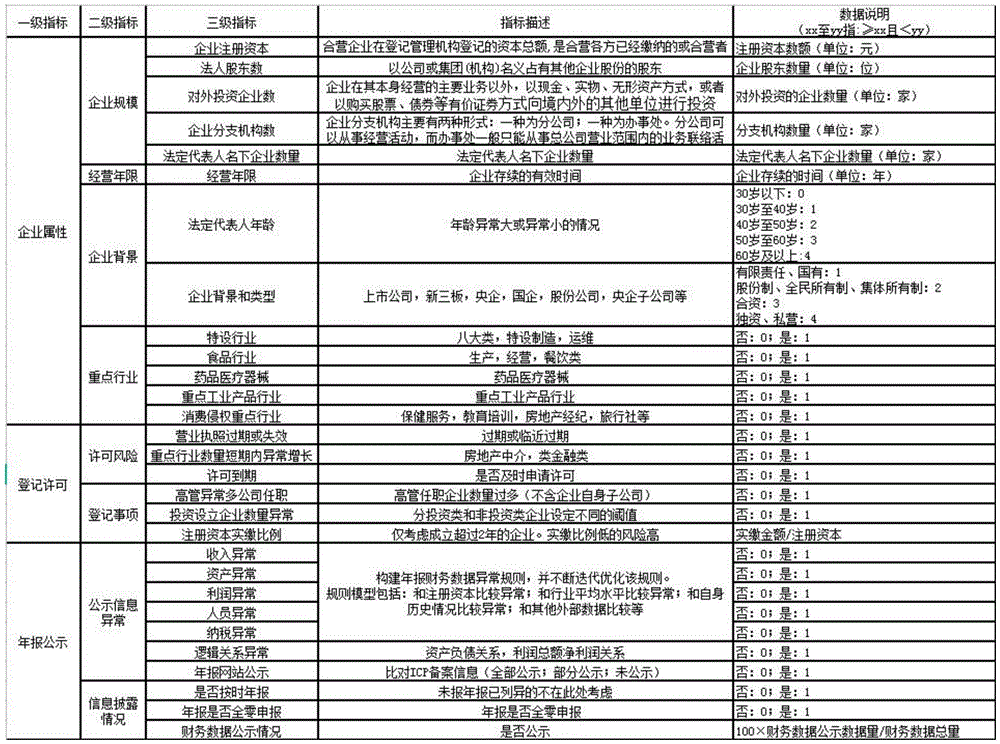
TABLE 1-CONTINUOUS 1
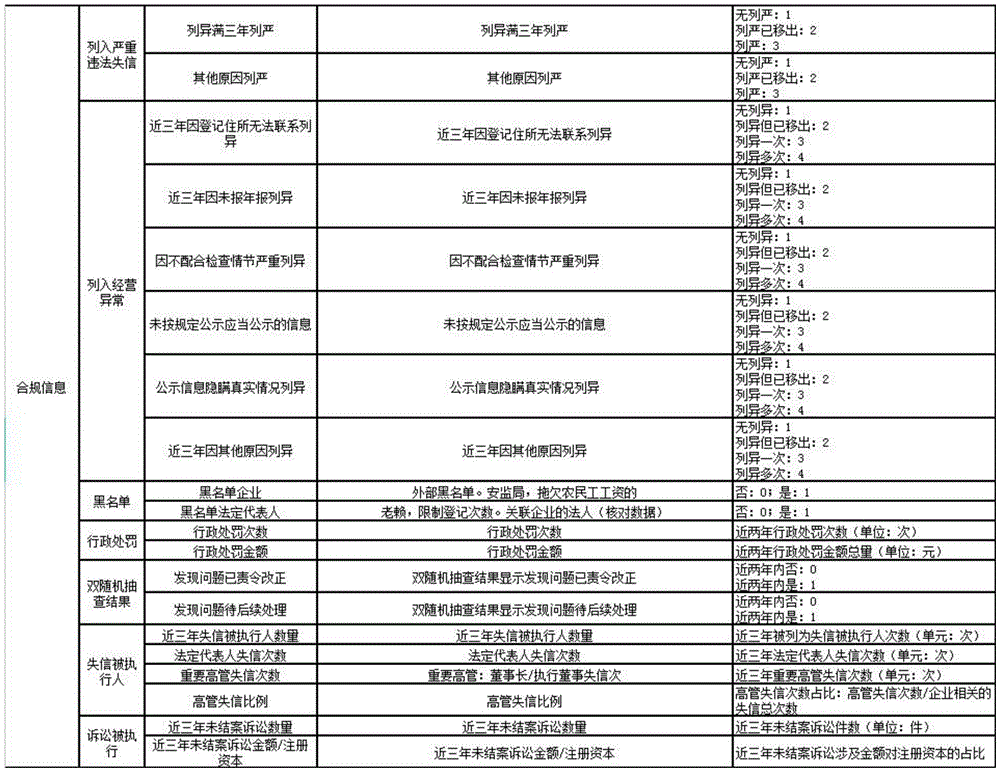
TABLE 1-CONTINUOUS 2

TABLE 1-CONTINUOUS 3
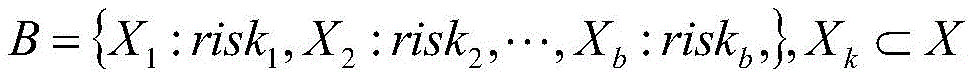
wherein,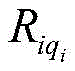 represents the qth early warning enterpriseiAn index set of risk rules for individual hits;
represents the qth early warning enterpriseiAn index set of risk rules for individual hits;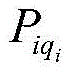 represents the qth early warning enterpriseiA risk level of the hit risk rule;
represents the qth early warning enterpriseiA risk level of the hit risk rule; represents the qth early warning enterpriseiConfidence of risk rule of individual hit;
represents the qth early warning enterpriseiConfidence of risk rule of individual hit;
Step S3, acquiring enterprise related behavior data, constructing a training index data set of an enterprise risk early warning model and an enterprise index data set to be early warned, and training the training set in the training index data set: test set 4: 1;
taking the established risk index system in table 1 as an example, the risk of ' suspected tax evasion and false deduction of enterprise exists ' can be inferred according to the three-level index income abnormity, asset abnormity, profit abnormity, personnel abnormity, tax payment abnormity and logic relation abnormity in the first-level index annual statement of enterprise, or the risk of ' suspected operation instability ' exists because the frequency of the enterprise is more than 10 times in three years according to the change of legal representative, the change of enterprise name, the change of registered residence and other change registered items, and the change of ' enterprise basic information, share right and the like is obtained by greatly increasing or reducing the registered capital, and the like.
and 4, acquiring target variables of the training samples, and calculating according to the credit dimension data design formula of the enterprise to obtain corresponding risk levels. Performing risk grade evaluation on a training data set sample by combining data such as credit scores of enterprises in the last 5 years, blacklist or credit loss times of enterprises in the last 5 years and the like, performing risk grade evaluation on the training sample enterprises according to the following formula and each risk grade score interval to serve as a target variable 'Y' of the training data set, and inputting the obtained target variable 'Y' and a training index data set into a correlation analysis algorithm for correlation rule mining;

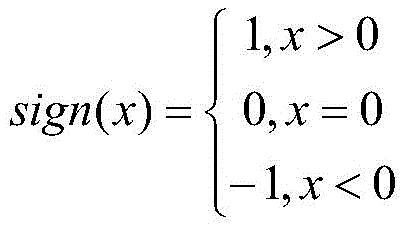
among them, creditScorenewRepresent the normalized value of the latest credit risk score, 100. creditScorenewA base score as a risk score; creditScoreiRepresenting the credit risk score of the previous i years,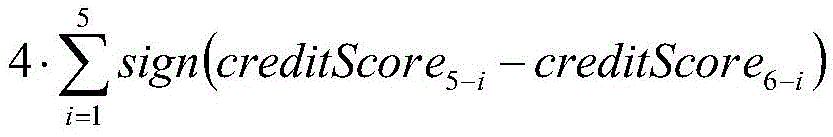 stability condition representing a credit score; the riskListCount represents the number of times of blacklisting or loss of credit in the last 5 years, and the 4. riskListCount represents the risk of blacklisting or loss of credit; table 2 is a risk score-risk level correspondence table.
stability condition representing a credit score; the riskListCount represents the number of times of blacklisting or loss of credit in the last 5 years, and the 4. riskListCount represents the risk of blacklisting or loss of credit; table 2 is a risk score-risk level correspondence table.
TABLE 2 Risk score-Risk level correspondence Table
| riskScore | (-∞,20) | [20,40) | [40,60) | [60,80) | [80,+∞) |
| Risk rating | Risk-free P4 | Low risk P3 | Middle risk P2 | Middle and high windDanger P1 | High risk P0 |
And 5, performing box separation and chi-square test by using a mutual entropy-interval set method to screen indexes (indexes which are not beneficial to the early warning model by filtering), performing index symbolization according to box separation results, and storing box separation rules and a residual index list after screening.
Further, the chi-square binning tokenization index variable in step 5 is specifically: for the index with the discrete variable attribute and the index with the value type of more than 5, a supervised cross entropy-interval set method is used for carrying out box separation on the index variables and converting the continuous variables into characters according to box separation results, so that the risk of model overfitting is reduced, for example, for the index 'enterprise registered capital (x 1)', original index data is divided into 3 boxes under chi-square box separation, and the numerical value of the index after character conversion is converted into x1_ bin0, x1_ bin1 or x1_ bin 2.
The mutual entropy-interval set method carries out the box dividing steps as follows:
index I to be binned is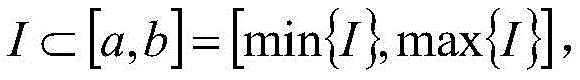 And (3) taking the initial binning Boundary value set as Boundary { a, b }, binning the index I:
And (3) taking the initial binning Boundary value set as Boundary { a, b }, binning the index I:
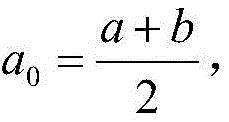
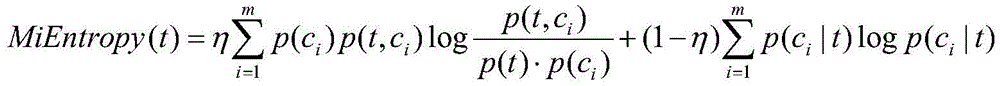
wherein t is an interval; c is a set of classes, { C ═ C1,c2,…,cmM is the number of categories; p (c)i)、p(t)、p(t,ci) Respectively in the training set ciThe number of samples of class, the number of samples of index value in interval t, the index value in interval t and belonging to ciThe ratio of the number of class samples to the total number of training set samples, p (c)iI t) index value in the interval t and belonging to ciIs proportional to the number of samples of the index value in the interval t, eta is a hyper-parameter and satisfies eta ∈ [0,1 ]]Default value is 0.5.
Using MiEntrophpy pairs [ a, a ]0]、(a0,b]Evaluating, and turning to the step 2;
if numb (I) is more than or equal to n, the box separation is stopped
If MiEntrophy ([ a, a)0]) A is greater than or equal to throshold, and a is taken as a, b is taken as a0Jumping to the step 1;
if MiEncopy ((a)0,b]) A is not less than throshold, and a is taken as0B is b and jumps to step 1
If MiEntrophy ([ a, a)0])≤MiEntropy((a0,b]) < throshold, take a as a0B is equal to b and jump to step 1;
if MiEncopy ((a)0,b])≤MiEntropy([a,a0]) < throshold, take a as a, b as a0And jumping to step 1.
And 4, obtaining a box Boundary set after the box separation is finished, and sorting the box Boundary set according to the small to large sequence to obtain boundry ═ a, a1,a2,…,akB, dividing the index I into k +1 boxes according to Boundary: { [ a, a)1],(a1,a2],…,(ak,b]}。
The chi-square test correlation screening indexes are specifically as follows: the relevance of index variables and enterprise risks are detected through chi-square detection, indexes which are not beneficial to early warning are filtered, but the result of related analysis of traditional chi-square detection depends on division of a sample space, different divisions can obtain different inference results, and the sample space is divided based on supervised binning, so that the early warning method has high detection efficiency and is stable.
And 6, acquiring an association rule set. Based on the steps, a complete enterprise training sample index set and a target variable 'Y' are obtained, association rules of enterprise behaviors of all risk levels of an enterprise in the training data are mined by using a classical association rule mining algorithm FP-Tree, the association rules are traversed and integrated into an association rule set consisting of the index set, the risk levels and confidence degrees, and the association rule set consists of elements in the form of '(index set): (risk level, confidence degree)' with the confidence degree being greater than 0.5. The association rule set mined by the enterprise by applying the FP-Tree algorithm is as follows: { (x1_ bin0, x3_ bin1, x7_ bin3, x15_ bin4): (P0,0.98), … … }.
Further, the association rule in step 6 reflects the interdependency and association between one object and other objects, and if there is an association relationship between the objects, one object can be predicted by other objects. Based on the extension of the idea, the association analysis algorithm is applied to enterprise risk early warning, and the association rules of each risk level and enterprise behaviors of the enterprise are mined by using a classical association rule mining algorithm FP-Tree.
And 7, early warning the enterprise to be early warned according to the obtained association rule and the index system risk rule combed in the step 2, early warning the association rule of enterprise hit, and predicting the enterprise risk level and possible risk points. For any enterprise to be early-warned, an early-warning result can be obtained according to the following steps:
firstly, the enterprise index data to be early-warned is converted into characters. The conversion of the index data is determined by the box-dividing rule in step 5, the original index data is converted into the corresponding character identifier, and the index set of the enterprise is obtained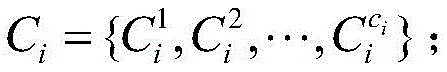
Second, a hit association rule is obtained. Traversing the association rule, and if the index set of the association rule Satisfies Ci∩Rj=RjThen it indicates that the enterprise hits RjCorresponding association rules, thus, resulting in an enterprise hit risk rule set:
Satisfies Ci∩Rj=RjThen it indicates that the enterprise hits RjCorresponding association rules, thus, resulting in an enterprise hit risk rule set:
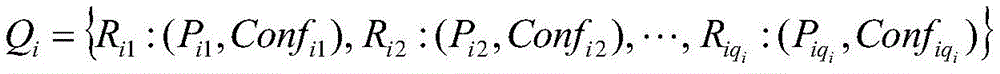
then, a risk level is obtained. And the risk grade is determined by the risk grade hitting the association rule and the confidence coefficient, the risk grade of the association rule is converted into a corresponding score, the confidence coefficient is used as a weight value to carry out weighted average, the final risk score is obtained by calculation, and the risk grade is obtained according to the score interval of each risk grade.
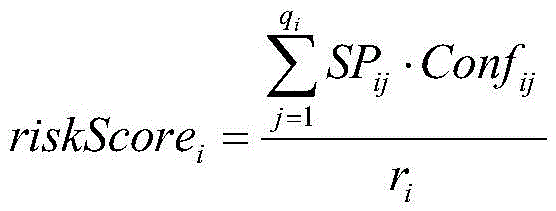

Finally, a risk description is obtained. Traversing the risk rule set obtained in step 2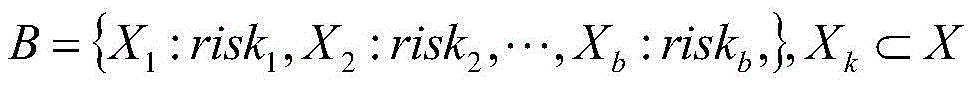 And index set of enterprise hit risk rules
And index set of enterprise hit risk rules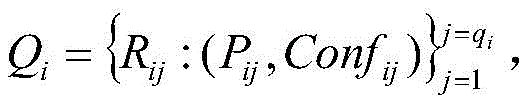 If Xk∩Rir=XkThen X exists in the enterprise probabilitykCorresponding risk point riskk. After traversing is completed, the enterprise obtains a risk point set
If Xk∩Rir=XkThen X exists in the enterprise probabilitykCorresponding risk point riskk. After traversing is completed, the enterprise obtains a risk point set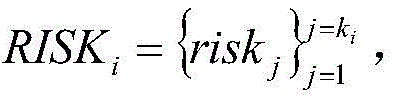 And splicing the elements in the risk point set by semicolons to obtain the risk description of the elements.
And splicing the elements in the risk point set by semicolons to obtain the risk description of the elements.
Early warning result display case: a business risk level is P0 (high risk), and the thread description is: missing annual newspaper bulletins; the enterprise registration changes frequently, and the risk of unstable operation exists; the operational finance may risk falsifying; expiration or invalidation of business license; the abnormal operation proportion of the associated enterprises is too high, and the enterprise operation risks being brought into abnormal operation; the rate of losing credit of the associated enterprises is too high, and the associated enterprises have the risk of losing credit.
The above are preferred embodiments of the present invention, and all changes made according to the technical scheme of the present invention that produce functional effects do not exceed the scope of the technical scheme of the present invention belong to the protection scope of the present invention.
Claims (2)
1. An enterprise risk early warning method based on an FP-Tree association analysis algorithm is characterized by comprising the following steps:
step S1, according to the historical related behavior data of the enterprise, analyzing and measuring a scale and an important basis of the risk condition of the enterprise, and designing a risk index system X ═ X1,X2,…,Xi},XiA name representing an ith index of a risk index system;
step S2, according to the risk index system, big data analysis is applied to form a risk rule, namely, the value of one or more indexes is equal to a preset value or a preset interval value, the enterprise is considered to have corresponding risks, and a risk rule set B is obtained:
B={X1:risk1,X2:risk2,…,Xb:riskb,},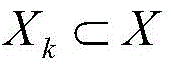
wherein, XkIs a subset of the index system X; riskkIs composed of XkAnalyzing the corresponding risk text description obtained by inference;
step S3, collecting enterprise related behavior data, and constructing a training index data set of an enterprise risk early warning model and an enterprise index data set to be early warned, wherein the training index data set comprises a training set: test set 4: 1;
step S4, based on the training index data set, calculating and obtaining the corresponding risk level of the enterprise through the credit dimension data of the enterprise, wherein the calculation formula is as follows:

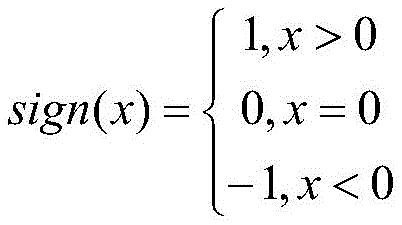
among them, creditScorenewRepresenting the normalized value of the latest credit risk score, 100. creditScorenewA base score as a risk score; creditScoreiThe first i-year credit risk score is represented,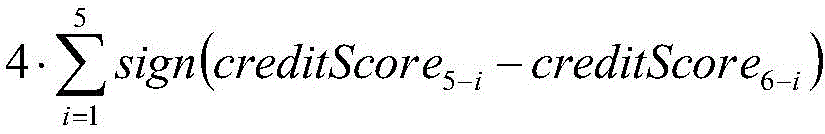 stability condition representing a credit score; the riskListCount represents the number of times of blacklisting or loss of credit in the last 5 years, and the 4. riskListCount represents the risk of blacklisting or loss of credit;
stability condition representing a credit score; the riskListCount represents the number of times of blacklisting or loss of credit in the last 5 years, and the 4. riskListCount represents the risk of blacklisting or loss of credit;
step S5, performing box separation and chi-square test on correlation screening indexes by using a mutual entropy-interval set method, performing index tokenization according to box separation results, and storing box separation rules and a remaining index list after screening;
step S6, acquiring association rule set: mining association rules of enterprise behaviors of each risk level of the enterprise by using an association analysis FP-Tree algorithm, traversing the association rules and integrating the association rules into an association rule set consisting of an index set, a risk level and a confidence coefficient, wherein the association rule set consists of elements in the forms of the index set, the risk level and the confidence coefficient, and the confidence coefficient is more than 0.5;
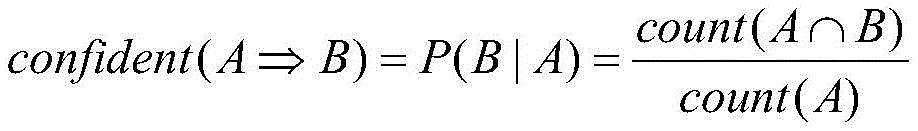
wherein, A represents one index set; b represents one of the risk levels;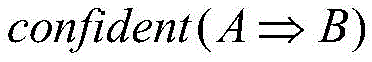 representing the confidence of the risk level B inferred by the index set A; count (A ≈ B) and count (A) respectively represent the number of samples in which the elements in the index set A and the risk level B have the same sample at the same time, and the number of samples in which the elements in the index set A have the same sample at the same time;
representing the confidence of the risk level B inferred by the index set A; count (A ≈ B) and count (A) respectively represent the number of samples in which the elements in the index set A and the risk level B have the same sample at the same time, and the number of samples in which the elements in the index set A have the same sample at the same time;
s7, according to the association rule set obtained in the step S6 and the risk rule set obtained in the step S2, early warning is conducted on the enterprise to be early warned based on the enterprise index data set to be early warned, association rules of enterprise life are early warned, enterprise risk levels and possible risk points are predicted, and early warning results are output;
in step S5, the specific implementation manner of performing binning and chi-square test on the correlation screening index by using the mutual entropy-interval set method is as follows:
for indexes with discrete variable attributes and continuous variables with more than 5 value types, the indexes are subjected to box separation by using a supervised mutual entropy-interval method, and the continuous variables are symbolized according to box separation results, so that the risk of model overfitting is reduced;
the mutual entropy-interval set method carries out the box dividing steps as follows:
step 0, presetting a threshold value threshold and a maximum box number n;
index I to be binned is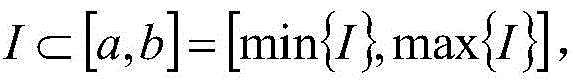 And (3) taking the initial binning Boundary value set as Boundary { a, b }, binning the index I:
And (3) taking the initial binning Boundary value set as Boundary { a, b }, binning the index I:
step 1, get Will be [ a, b ]]Divided into two intervals [ a, a0]、(a0,b]And combining mutual information and information entropy to provide a new category uncertain evaluation function MiEncopy:
Will be [ a, b ]]Divided into two intervals [ a, a0]、(a0,b]And combining mutual information and information entropy to provide a new category uncertain evaluation function MiEncopy:
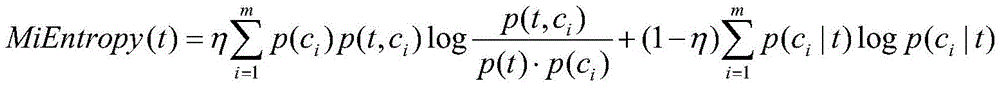
wherein t is an interval; c is a set of classes, { C ═ C1,c2,…,cmM is the number of categories; p (c)i)、p(t)、p(t,ci) Respectively, training set ciClass number of samples, index value number of samples in interval t, index value in interval t and belonging to ciThe ratio of the number of class samples to the total number of training set samples, p (c)iI t) index value in the interval t and belonging to ciIs proportional to the number of samples of the index value in the interval t, eta is a hyper-parameter and satisfies eta ∈ [0,1 ]];
Using MiEntrophpy pairs [ a, a ]0]、(a0,b]Evaluating, and turning to the step 2;
step 2, if MiEncopy ([ a, a)0]) Greater than or equal to threshold or MiEncopy ((a)0,b]) A is greater than or equal to threshold, then0Adding the mixture into Boundary, and turning to the step 3; otherwise, directly turning to the step 3;
step 3, obtaining the box number numb (I) of the index I according to Boundary:
if numb (I) is more than or equal to n, the box separation is stopped
If MiEntrophy ([ a, a)0]) A is greater than or equal to threshold, and a is taken as a, b is taken as a0Jumping to the step 1;
if MiEncopy ((a)0,b]) A is greater than or equal to threshold, and a is taken as0B is b and jumps to the step 1;
if MiEntrophy ([ a, a)0])≤MiEntropy((a0,b]) < threshold, take a ═ a0B is b and jumps to the step 1;
if MiEncopy ((a)0,b])≤MiEntropy([a,a0]) < threshold, take a ═ a, b ═ a0Jumping to the step 1;
and 4, obtaining a box Boundary set after the box separation is finished, and sequencing the box Boundary set from small to large to obtain boundry { a, a }1,a2,…,akB, dividing the index I into k +1 boxes according to Boundary: { [ a, a)1],(a1,a2],…,(ak,b]};
The chi-square test correlation screening indexes are specifically as follows: the relevance of index variables and enterprise risks is detected through chi-square inspection, indexes which are not beneficial to early warning are filtered, and sample space is divided according to the result of relevant analysis of chi-square inspection based on supervised sub-boxes.
2. The enterprise risk early warning method based on the correlation analysis FP-Tree algorithm according to claim 1, wherein the concrete implementation manner of step S7 is as follows:
firstly, centralizing the enterprise index data to be early-warned in a to-be-early-warned enterprise index data set to perform the symbolization of the enterprise index data to be early-warned: the conversion of the index data is determined by the box-dividing rule of step S5, and the original index data is converted into the corresponding character identifier to obtain the converted index set of the enterprise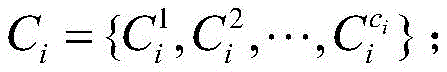
Wherein, CiPerforming the symbolization on each index value of the ith sample enterprise to obtain a result set; represents the ith sample enterprise ciA result value is tokenized by an index;
represents the ith sample enterprise ciA result value is tokenized by an index;
secondly, obtaining a hit association rule: traversing the association rule, if the index set of the association rule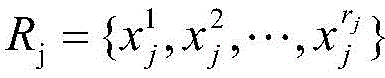 Satisfies Ci∩Rj=RjThen it indicates that the enterprise hits RjCorresponding association rule, thereby obtaining an enterprise hit risk rule index set Qi:
Satisfies Ci∩Rj=RjThen it indicates that the enterprise hits RjCorresponding association rule, thereby obtaining an enterprise hit risk rule index set Qi:
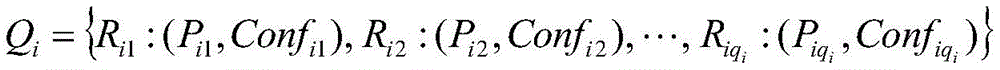
Wherein,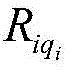 represents the qth early warning enterpriseiAn index set of risk rules for individual hits;
represents the qth early warning enterpriseiAn index set of risk rules for individual hits;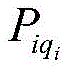 represents the qth early warning enterpriseiA risk level of the individual hit risk rule;
represents the qth early warning enterpriseiA risk level of the individual hit risk rule;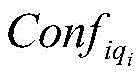 represents the qth early warning enterprise of the ithiConfidence of the risk rule for an individual hit;
represents the qth early warning enterprise of the ithiConfidence of the risk rule for an individual hit;
then, a risk level is obtained: the risk grade is determined by the risk grade and the confidence coefficient of the hit association rule, the risk grade of the association rule is converted into a corresponding score, the confidence coefficient is used as a weight to carry out weighted average, a final risk score is obtained through calculation, and the risk grade is obtained according to the score interval of each risk grade;
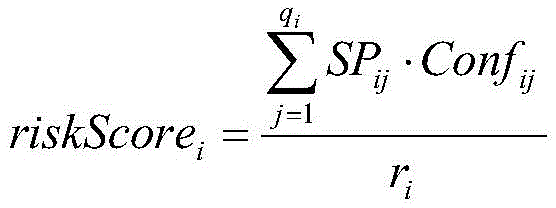
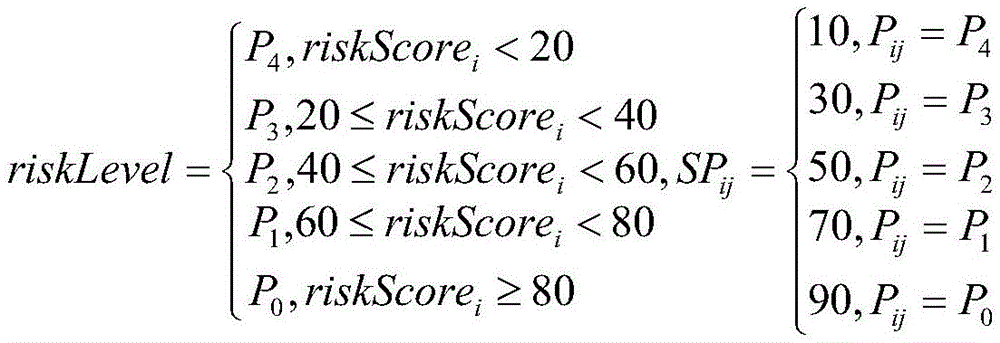
wherein, high risk is represented by P0, middle and high risk has two grades, namely P1 and P2, and the risk of P1 is greater than that of P2, low risk is represented by P3, and no risk is represented by P4; riskScoreiRepresenting a risk score for the ith early warning business; SPijA risk level score representing a risk rule of a jth hit of the ith early warning enterprise; pijRepresenting the risk level of the risk rule of the jth hit of the ith early warning enterprise; confijRepresenting the confidence of the risk rule of the jth hit of the ith early warning enterprise; r isiThe sum of the confidence degrees of the risk rules of the hit of the ith early warning enterprise is represented; the riskLevel is a function for mapping the risk score to the risk level;
finally, obtaining a risk description: the risk rule set B ═ X obtained in step S2 is traversed1:risk1,X2:risk2,…,Xb:riskb,}, And enterprise hit risk rule index set Qi={Rij:(Pij,Confij)},j=i,…,qiIf X isk∩Rij=XkThen X exists in the enterprise probabilitykCorresponding risk point riskk(ii) a After traversing, obtaining the RISK point set RISK of the enterprisei={riskj},j=1,…,kiAnd splicing the elements in the risk point set by semicolons to obtain the risk description of the elements.
And enterprise hit risk rule index set Qi={Rij:(Pij,Confij)},j=i,…,qiIf X isk∩Rij=XkThen X exists in the enterprise probabilitykCorresponding risk point riskk(ii) a After traversing, obtaining the RISK point set RISK of the enterprisei={riskj},j=1,…,kiAnd splicing the elements in the risk point set by semicolons to obtain the risk description of the elements.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011461438.1A CN112465393B (en) | 2020-12-09 | 2020-12-09 | Enterprise risk early warning method based on correlation analysis FP-Tree algorithm |
| PCT/CN2021/071403 WO2022121083A1 (en) | 2020-12-09 | 2021-01-13 | Enterprise risk early warning method based on association analysis fp-tree algorithm |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011461438.1A CN112465393B (en) | 2020-12-09 | 2020-12-09 | Enterprise risk early warning method based on correlation analysis FP-Tree algorithm |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112465393A CN112465393A (en) | 2021-03-09 |
| CN112465393B true CN112465393B (en) | 2022-07-08 |
Family
ID=74803925
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011461438.1A Active CN112465393B (en) | 2020-12-09 | 2020-12-09 | Enterprise risk early warning method based on correlation analysis FP-Tree algorithm |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN112465393B (en) |
| WO (1) | WO2022121083A1 (en) |
Families Citing this family (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113034019A (en) * | 2021-03-31 | 2021-06-25 | 建信金融科技有限责任公司 | Enterprise risk prediction method and device, computer equipment and readable storage medium |
| CN113988191B (en) * | 2021-10-29 | 2025-02-18 | 重庆富民银行股份有限公司 | A Single Dimension Strategy Automatic Mining Method |
| CN114118526B (en) * | 2021-10-29 | 2024-12-24 | 中国建设银行股份有限公司 | Enterprise risk prediction method, device, equipment and storage medium |
| CN115150194B (en) * | 2022-08-12 | 2024-11-26 | 国汽智控(北京)科技有限公司 | Method, device, equipment and storage medium for determining defense strategy |
| CN115271263B (en) * | 2022-09-27 | 2022-12-27 | 佰聆数据股份有限公司 | Power equipment defect early warning method, system and medium based on improved association rule |
| CN115576850B (en) * | 2022-11-21 | 2023-03-14 | 舟谱数据技术南京有限公司 | Data index testing method and device, electronic equipment and storage medium |
| CN116012019B (en) * | 2023-03-27 | 2023-06-06 | 北京力码科技有限公司 | Financial wind control management system based on big data analysis |
| CN116029622B (en) * | 2023-03-30 | 2023-06-30 | 中铁大桥局集团有限公司 | Plate girder bridge safety early warning method and device based on cloud evidence reasoning |
| CN116151627B (en) * | 2023-04-04 | 2023-09-01 | 支付宝(杭州)信息技术有限公司 | Business wind control method and device, storage medium and electronic equipment |
| CN116777204A (en) * | 2023-05-29 | 2023-09-19 | 深圳交易集团有限公司 | Method for realizing active supervision and early warning through configurable risk points |
| CN116644351B (en) * | 2023-06-13 | 2024-04-02 | 石家庄学院 | Data processing method and system based on artificial intelligence |
| CN116596674A (en) * | 2023-07-18 | 2023-08-15 | 山东省标准化研究院(Wto/Tbt山东咨询工作站) | Foreign trade risk assessment method based on big data analysis |
| CN117094565B (en) * | 2023-10-19 | 2024-01-12 | 赛飞特工程技术集团有限公司 | Main responsibility implementation grading evaluation system for national group enterprises |
| CN117541057B (en) * | 2023-11-23 | 2025-01-21 | 孙猛 | A method and system for early warning monitoring of enterprise operations based on data analysis |
| CN117556264B (en) * | 2024-01-11 | 2024-05-07 | 浙江同花顺智能科技有限公司 | Training method and device for evaluation model and electronic equipment |
| CN118071156B (en) * | 2024-04-17 | 2024-07-05 | 江苏金恒信息科技股份有限公司 | Enterprise risk internal control automatic early warning system and method based on big data |
| CN118428746B (en) * | 2024-07-05 | 2024-11-05 | 山东全员本安教育咨询有限公司 | A hidden danger detection system, method, device and storage medium based on double prevention mechanism |
| CN118938822A (en) * | 2024-07-22 | 2024-11-12 | 常熟理工学院 | Intelligent monitoring system and method for equipment operation status based on big data analysis |
| CN118747605B (en) * | 2024-08-02 | 2024-12-06 | 山东信发华信铝业有限公司 | A method and system for detecting risks in electrolytic aluminum production |
| CN119168371A (en) * | 2024-09-04 | 2024-12-20 | 国泰新点软件股份有限公司 | A three-dimensional situation warning method, system, device and storage medium |
| CN118798972B (en) * | 2024-09-12 | 2025-01-10 | 深圳市优讯云计算有限公司 | Marketing activity user risk early warning method apparatus, storage medium, and device |
| CN118917675B (en) * | 2024-10-11 | 2025-02-21 | 山东特联信息科技有限公司 | A multi-dimensional information evaluation method and system for enterprise safety index |
| CN119476956B (en) * | 2024-11-25 | 2025-10-03 | 复旦大学 | Label generation method and device for risk profile construction |
| CN119204699B (en) * | 2024-11-27 | 2025-02-25 | 江苏省建筑工程质量检测中心有限公司 | Method and system for dynamic adjustment of building safety alert level based on artificial intelligence drive |
| CN119886843A (en) * | 2025-03-28 | 2025-04-25 | 四川久远银海软件股份有限公司 | Automatic enterprise risk early warning method and system based on classification model |
| CN119940943A (en) * | 2025-04-08 | 2025-05-06 | 北京六一六信息技术有限公司 | A method for assessing business operation risks based on artificial intelligence analysis |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108846532A (en) * | 2018-03-21 | 2018-11-20 | 宁波工程学院 | Business risk appraisal procedure and device applied to logistics supply platform chain |
| CN109583796A (en) * | 2019-01-08 | 2019-04-05 | 河南省灵山信息科技有限公司 | A kind of data digging system and method for Logistics Park OA operation analysis |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6542894B1 (en) * | 1998-12-09 | 2003-04-01 | Unica Technologies, Inc. | Execution of multiple models using data segmentation |
| CN102012918B (en) * | 2010-11-26 | 2012-11-21 | 中金金融认证中心有限公司 | System and method for excavating and executing rule |
| US20180308158A1 (en) * | 2016-04-19 | 2018-10-25 | Dalian University Of Technology | An optimal credit rating division method based on maximizing credit similarity |
| CN105913195A (en) * | 2016-04-29 | 2016-08-31 | 浙江汇信科技有限公司 | All-industry data based enterprise's financial risk scoring method |
| CN110942171A (en) * | 2019-09-12 | 2020-03-31 | 中电科新型智慧城市研究院有限公司 | A Machine Learning-Based Risk Prediction Method for Enterprise Labor Disputes |
-
2020
- 2020-12-09 CN CN202011461438.1A patent/CN112465393B/en active Active
-
2021
- 2021-01-13 WO PCT/CN2021/071403 patent/WO2022121083A1/en not_active Ceased
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108846532A (en) * | 2018-03-21 | 2018-11-20 | 宁波工程学院 | Business risk appraisal procedure and device applied to logistics supply platform chain |
| CN109583796A (en) * | 2019-01-08 | 2019-04-05 | 河南省灵山信息科技有限公司 | A kind of data digging system and method for Logistics Park OA operation analysis |
Non-Patent Citations (3)
| Title |
|---|
| Recommendation for the Entropy Sources Used for Random Bit Generation;Elaine Barker et al;《NIST》;20120831;第15-50页 * |
| 基于BP神经网络的供应链融资中中小企业信用风险评价研究;孙凯;《中国优秀硕士学位论文全文数据库》;20160115(第1期);第11-42页 * |
| 基于云模型关联规则的企业转型战略风险预警;王德鲁 等;《中国管理科学》;20090430;第17卷(第2期);第152-158页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112465393A (en) | 2021-03-09 |
| WO2022121083A1 (en) | 2022-06-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112465393B (en) | Enterprise risk early warning method based on correlation analysis FP-Tree algorithm | |
| Moges et al. | A multidimensional analysis of data quality for credit risk management: New insights and challenges | |
| CN117764724A (en) | An intelligent credit rating report construction method and system | |
| CN118627883B (en) | Recommendation method and device for soil pollution risk enterprise investigation and classification supervision | |
| CN111583033A (en) | Association analysis method and device based on relation between listed company and stockholder | |
| CN117499103A (en) | User abnormal behavior detection method, system, device and readable storage medium | |
| CN115619090A (en) | A Model-Based and Data-Driven Safety Assessment Method | |
| CN118333732A (en) | Financial enterprise supervision method and equipment | |
| CN111738610A (en) | Public opinion data-based enterprise loss risk early warning system and method | |
| CN114282875A (en) | Process approval deterministic rules and semantic self-learning combined judgment method and device | |
| CN113642669B (en) | Feature analysis-based fraud prevention detection method, device, equipment and storage medium | |
| CN119853028B (en) | Power grid operation control method based on knowledge graph rule extraction | |
| Sueyoshi et al. | Efficiency measurement and strategic classification of Japanese banking institutions | |
| Islam et al. | Prediction of Irregular Bangladesh-EU Migration Trends Using Machine Learning Techniques | |
| De Souza et al. | Selecting and ranking leading cases in Brazilian Supreme Court decisions | |
| CN109345074B (en) | Method for identifying and evaluating public acceptability influence factors of high-level waste geological disposal | |
| Tessmer | What to learn from near misses: an inductive learning approach to credit risk assessment | |
| CN118333383A (en) | Supply chain risk management method based on quality house diagnosis | |
| CN118014372A (en) | A labor dispute prediction method, device and storage medium based on one standard and three realities | |
| CN115082262A (en) | Prediction system and prediction method | |
| CN118898514B (en) | A personal loan risk assessment method based on big data | |
| KR20040023376A (en) | Real-time quality measurement method of bibliographic database | |
| CN116307829B (en) | Method and device for evaluating influence of infectious diseases on social bearing capacity based on information entropy | |
| Sun et al. | Employment Prediction and Trend Analysis of Higher Vocational College Students Based on Data Mining Algorithm | |
| Pernisch | Mind the Change, Bridge the Gap |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |