CN112309372A - 基于语调的意图识别方法、装置、设备及存储介质 - Google Patents
基于语调的意图识别方法、装置、设备及存储介质 Download PDFInfo
- Publication number
- CN112309372A CN112309372A CN202011169292.3A CN202011169292A CN112309372A CN 112309372 A CN112309372 A CN 112309372A CN 202011169292 A CN202011169292 A CN 202011169292A CN 112309372 A CN112309372 A CN 112309372A
- Authority
- CN
- China
- Prior art keywords
- target
- voice
- intention
- data
- stream
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims abstract description 40
- 238000005070 sampling Methods 0.000 claims description 32
- 239000012634 fragment Substances 0.000 claims description 29
- 238000001514 detection method Methods 0.000 claims description 18
- 230000036651 mood Effects 0.000 claims description 15
- 238000012216 screening Methods 0.000 claims description 5
- 238000012549 training Methods 0.000 claims description 4
- 238000004590 computer program Methods 0.000 claims 1
- 238000005516 engineering process Methods 0.000 abstract description 3
- 238000013473 artificial intelligence Methods 0.000 abstract 1
- 210000003128 head Anatomy 0.000 description 13
- 239000000284 extract Substances 0.000 description 9
- 230000006870 function Effects 0.000 description 7
- 238000010586 diagram Methods 0.000 description 6
- 238000013075 data extraction Methods 0.000 description 4
- 238000004364 calculation method Methods 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 230000026676 system process Effects 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 1
- 238000013528 artificial neural network Methods 0.000 description 1
- 230000001174 ascending effect Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000008451 emotion Effects 0.000 description 1
- 230000008909 emotion recognition Effects 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 210000001061 forehead Anatomy 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/87—Detection of discrete points within a voice signal
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Machine Translation (AREA)
Abstract
本发明涉及人工智能领域,公开了一种基于语调的意图识别方法、装置、设备及存储介质,用于解决在语音智能问答的意图识别过程中不能实现识别同字不同义的功能以及提高意图识别的准确率。获取待识别语音流,所述待识别语音流至少包括音调数据和语气特征词;根据所述待识别语音流获取文本数据;基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流;根据所述目标语音流进行意图识别,得到目标意图,此外,本发明还涉及区块链技术,目标语音流可存储于区块链中。
Description
技术领域
本发明涉及语音识别领域,尤其涉及一种基于语调的意图识别方法、装置、设备及存储介质。
背景技术
随着科技的发展,智能问答系统在日常生活中发挥着越来越大的作用,根据对话的展现形式,智能问答系统可以分为在线智能问答系统和语音智能问答系统两类。目前在线智能问答系统的应用已经比较成熟,在线智能问答机器人的解决率可以达到80%以上,为企业节约大量人工成本。语音智能问答系统涉及到语音识别和情绪识别部分,由于说话人表达习惯、口音和情绪的主观性等问题,应用上没有在线智能问答系统那么成熟。
目前常见的语音智能问答系统包括呼入智能问答系统和呼出智能问答系统两种。在现有的呼出智能问答系统中,采用对语音识别转录后的文本进行处理的方式,对用户意图进行理解,然而呼出智能问答系统多类似于问卷问答形式,用户大多以“嗯”、“啊”、“额”和“哦”等单音节形式作答,同一个字不同的语气表达的意图却大相径庭,采用转录后的文本数据进行意图识别时,无法实现识别同字不同义的功能,意图识别准确率低。
发明内容
本发明的主要目的在于解决在语音智能问答中通过文本数据进行意图识别时识别准确率低的问题。
本发明第一方面提供了一种基于语调的意图识别方法,包括:获取待识别语音流,所述待识别语音流至少包括音调数据和语气特征词;根据所述待识别语音流获取文本数据;基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流;根据所述目标语音流进行意图识别,得到目标意图。
可选的,在本发明第一方面的第一种实现方式中,所述根据所述待识别语音流获取文本数据包括:对所述待识别语音流进行端点检测,得到多个语音数据片段,每个语音数据片段中包括一个语气特征词;根据所述多个语音数据片段得到文本数据。
可选的,在本发明第一方面的第二种实现方式中,所述根据所述多个语音数据片段得到文本数据包括:提取每个语音数据片段对应的声学特征,得到多个声学特征;训练所述多个声学特征,得到语言模型;将所述多个语音数据片段依次输入所述语言模型并结合预置的词典,生成文本数据。
可选的,在本发明第一方面的第三种实现方式中,所述基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流:将所述多个语音数据片段依次输入预置的语音检测模型,生成与每个语音数据片段对应的语音片段时刻戳,得到多个语音片段时刻戳;对所述文本数据进行筛选,得到筛选后的文本数据;根据正则匹配算法确定与所述筛选后的文本数据对应的目标语气特征词;基于所述目标语气特征词对应的目标语音片段在多个语音片段时刻戳中确定对应的目标语音片段时刻戳;基于目标语音片段时刻戳在待识别语音流中确定目标语音流。
可选的,在本发明第一方面的第四种实现方式中,所述根据所述目标语音流进行意图识别,得到目标意图包括:在所述音调数据中提取与所述目标语音流对应的音高曲线数据,得到目标音高曲线数据;根据所述目标音高曲线数据进行计算,得到目标音长数据;若所述目标音长数据大于音长阈值,则提取目标语音流的下一段语音流作为音长语音流,根据所述音长语音流或者与所述音长语音流对应的文本数据进行意图识别,得到目标意图;若所述目标音长数据小于或者等于所述音长阈值,则根据所述音高曲线数据计算得到目标音高曲线斜率和目标基频抖动;根据所述目标音高曲线斜率和所述目标基频抖动进行意图识别,得到目标意图。
可选的,在本发明第一方面的第五种实现方式中,所述若所述目标音长数据小于或者等于所述音长阈值,则根据所述音高曲线数据计算得到目标音高曲线斜率和目标基频抖动包括:若所述目标音长数据小于或者等于所述音长阈值,则在所述目标音高曲线数据中选取头部采样点和尾部采样点,并计算所述头部采样点和所述尾部采样点的斜率,得到目标音高曲线斜率;计算所述头部采样点和所述尾部采样点的差值,得到目标基频抖动。
可选的,在本发明第一方面的第六种实现方式中,所述根据所述目标音高曲线斜率和所述目标基频抖动进行意图识别,得到目标意图包括:当所述目标音高曲线斜率大于或者等于斜率阈值时,判断所述目标基频抖动是否大于或者等于抖动阈值;若所述目标基频抖动大于或者等于所述抖动阈值,则确定所述目标语音流的意图为疑问意图,所述疑问意图为目标意图;若所述目标基频抖动小于所述抖动阈值,则提取目标音高曲线数据对应的目标音高曲拱点,若目标音高曲拱点高于预置的肯定音高曲拱点,则确定所述目标语音流的意图为疑问意图;当所述目标音高曲线斜率小于所述斜率阈值时,判断所述目标基频抖动是否小于所述抖动阈值;若所述目标基频抖动小于所述抖动阈值,则确定所述目标语音流的意图为肯定意图,所述肯定意图为目标意图;若所述目标基频抖动大于或者等于所述抖动阈值且所述目标音高曲拱点低于或者等于所述肯定音高曲拱点,则确定所述目标语音流的意图为肯定意图。
本发明第二方面提供了一种基于语调的意图识别装置,包括:待识别语音流获取模块,用于获取待识别语音流,所述待识别语音流至少包括音调数据和语气特征词;文本获取模块,用于根据所述待识别语音流获取文本数据;特征词和语音流确定模块,用于基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流;识别模块,用于根据所述目标语音流进行意图识别,得到目标意图。
可选的,在本发明第二方面的第一种实现方式中,所述时刻戳和文本获取模块包括:检测单元,用于对所述待识别语音流进行端点检测,得到多个语音数据片段;文本数据生成单元,用于根据所述多个语音数据片段得到文本数据。
可选的,在本发明第二方面的第二种实现方式中,所述文本数据生成单元具体用于:提取每个语音数据片段对应的声学特征,得到多个声学特征;训练所述多个声学特征,得到语言模型;将所述多个语音数据片段依次输入所述语言模型并结合预置的词典,生成文本数据。
可选的,在本发明第二方面的第三种实现方式中,所述特征词和语音流确定模块具体用于:将所述多个语音数据片段依次输入预置的语音检测模型,生成与每个语音数据片段对应的语音片段时刻戳,得到多个语音片段时刻戳;对所述文本数据进行筛选,得到筛选后的文本数据;根据正则匹配算法确定与所述筛选后的文本数据对应的目标语气特征词;基于所述目标语气特征词对应的目标语音片段在多个语音片段时刻戳中确定对应的目标语音片段时刻戳;基于目标语音片段时刻戳在待识别语音流中确定目标语音流。
可选的,在本发明第二方面的第四种实现方式中,所述识别模块包括:音高曲线提取单元,用于在所述音调数据中提取与所述目标语音流对应的音高曲线数据,得到目标音高曲线数据;第一计算单元,用于根据所述目标音高曲线数据进行计算,得到目标音长数据;第一意图生成单元,若所述目标音长数据大于音长阈值,则用于提取目标语音流的下一段语音流作为音长语音流,根据所述音长语音流或者与所述音长语音流对应的文本数据进行意图识别,得到目标意图;第二计算单元,若所述目标音长数据小于或者等于所述音长阈值,则用于根据所述音高曲线数据计算得到目标音高曲线斜率和目标基频抖动;第二意图生成单元,用于根据所述目标音高曲线斜率和所述目标基频抖动进行意图识别,得到目标意图。
可选的,在本发明第二方面的第五种实现方式中,所述第二计算单元具体用于:若所述目标音长数据小于或者等于所述音长阈值,则在所述目标音高曲线数据中选取头部采样点和尾部采样点,并计算所述头部采样点和所述尾部采样点的斜率,得到目标音高曲线斜率;计算所述头部采样点和所述尾部采样点的差值,得到目标基频抖动。
可选的,在本发明第二方面的第六种实现方式中,第二意图生成单元具体用于:当所述目标音高曲线斜率大于或者等于斜率阈值时,判断所述目标基频抖动是否大于或者等于抖动阈值;若所述目标基频抖动大于或者等于所述抖动阈值,则确定所述目标语音流的意图为疑问意图,所述疑问意图为目标意图;若所述目标基频抖动小于所述抖动阈值,则提取目标音高曲线数据对应的目标音高曲拱点,若目标音高曲拱点高于预置的肯定音高曲拱点,则确定所述目标语音流的意图为疑问意图;当所述目标音高曲线斜率小于所述斜率阈值时,判断所述目标基频抖动是否小于所述抖动阈值;若所述目标基频抖动小于所述抖动阈值,则确定所述目标语音流的意图为肯定意图,所述肯定意图为目标意图;若所述目标基频抖动大于或者等于所述抖动阈值且所述目标音高曲拱点低于或者等于所述肯定音高曲拱点,则确定所述目标语音流的意图为肯定意图。
本发明第三方面提供了一种基于语调的意图识别设备,包括:存储器和至少一个处理器,所述存储器中存储有指令,所述存储器和所述至少一个处理器通过线路互连;所述至少一个处理器调用所述存储器中的所述指令,以使得所述基于语调的意图识别设备执行上述的基于语调的意图识别方法。
本发明的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述的基于语调的意图识别方法。
本发明提供的技术方案中,获取待识别语音流,所述待识别语音流至少包括音调数据和语气特征词;根据所述待识别语音流获取文本数据;基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流;根据所述目标语音流进行意图识别,得到目标意图。本发明实施例中,通过文本数据选取语气特征词,然后根据语气特征词和多个语音片段时刻戳确定对应的目标语音流,最后基于目标语音流进行意图识别,得到目标意图,通过语音流进行意图识别能够实现同字不同义的识别功能,提高了意图识别的准确率。
附图说明
图1为本发明实施例中基于语调的意图识别方法的一个实施例示意图;
图2为本发明实施例中基于语调的意图识别方法的另一个实施例示意图;
图3为本发明实施例中基于语调的意图识别装置的一个实施例示意图;
图4为本发明实施例中基于语调的意图识别装置的另一个实施例示意图;
图5为本发明实施例中基于语调的意图识别设备的一个实施例示意图。
具体实施方式
本发明实施例提供了一种基于语调的意图识别方法、装置、设备及存储介质,通过文本数据选取语气特征词,然后根据语气特征词和多个语音片段时刻戳确定对应的目标语音流,最后基于目标语音流进行意图识别,得到目标意图,通过语音流进行意图识别能够实现同字不同义的识别功能,提高了意图识别的准确率。
本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的实施例能够以除了在这里图示或描述的内容以外的顺序实施。此外,术语“包括”或“具有”及其任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
为便于理解,下面对本发明实施例的具体流程进行描述,请参阅图1,本发明实施例中基于语调的意图识别方法的一个实施例包括:
101、获取待识别语音流,待识别语音流至少包括音调数据和语气特征词;
服务器获取至少包括音调数据和语气特征词的待识别数据流。
在语音智能问答系统中,当用户接通与问答机器人的电话之后,问答机器人向用户提出问题,用户通过手持终端根据问答机器人的问题进行规范性回答,此时用户的语音信息通过手持终端输入语音智能问答系统中。当服务器向语音智能问答系统发出数据提取请求,语音智能问答系统将用户的语音信息处理为待识别语音流,服务器从语音智能问答系统中提取待识别语音流。
例如,当用户接通与问答机器人的电话之后,问答机器人向用户提出“请问您是张三先生嘛?”用户通过手机回答“嗯、啊或者不是”,假设用户回答“嗯”,通过手机将“嗯”的语音信息输入至语音智能问答系统中,服务器向语音智能问答系统发出数据提取的请求,语音智能问答系统将“嗯”的语音信息转换成语音流,并向服务器发送对应的语音流,服务器从而得到“嗯”的待识别语音流。
需要说明的是,音调数据的具体表现形式为音调曲线图,通过音调曲线图可以得到音高曲线斜率、音高曲线曲拱起点、基频抖动和有效音长。语气特征词为“嗯”或者“啊”一类的单音节词。
可以理解的是,本发明的执行主体可以为基于语调的意图识别装置,还可以是终端或者服务器,具体此处不做限定。本发明实施例以服务器为执行主体为例进行说明。
102、根据待识别语音流获取文本数据;
服务器根据待识别语音流获取文本数据。
需要说明的是,待识别语音流可以为分成多个不同的语音片段,引入端点检测算法将待识别语音流分为多个语音数据片段,然后将多个语音数据片段输入识别模型中,自动生成文本数据,文本数据用于筛选重复的语气词。
103、基于待识别语音流获取多个语音片段时刻戳,获取待识别语音流包括的语气词,得到目标语气特征词,并根据目标语气特征词和多个语音片段时刻戳确定目标语音流;
服务器根据待识别语音流获取多个用于标记待识别语音流的语音片段时刻戳,服务器对文本数据进行语气词选取,得到目标语气特征词,然后结合目标语气特征词和多个语音片段时刻戳确定目标语音流和文本数据。
需要说明的是,引入语音片段时刻戳可以对不同的语音片段进行标记,在意图识别的过程中能够通过语音片段时刻戳快速准确的找到对应的语气特征词。
例如,服务器在用户对“请问您是张三先生嘛?”的问答回答之后得到的文本数据为“嗯嗯嗯”,或者“啊啊啊”,服务器根据文本数据进行语气词的选取,得到目标语气特征词“嗯”或者目标语气特征词“啊”。然后服务器根据语气特征词“嗯”或者“啊”对应的语音片段时刻戳,在待识别数据流中确定目标语音流,需要说明的是,目标语音流也带有对应的音调数据。
104、根据目标语音流进行意图识别,得到目标意图。
服务器根据目标语音流识别用户的语气,得到目标意图。
服务器根据目标语音流对应的音调数据识别用户的语气,假设目标语音流对应的音调数据起伏较大,则对应的目标意图可能为疑问意图,假设目标语音流对应的音调数据起伏平缓,则对应的目标意图可能为肯定意图。
本发明实施例中,通过文本数据选取语气特征词,然后根据语气特征词和多个语音片段时刻戳确定对应的目标语音流,最后基于目标语音流进行意图识别,得到目标意图,通过语音流进行意图识别能够实现同字不同义的识别功能,提高了意图识别的准确率。
请参阅图2,本发明实施例中基于语调的意图识别方法的另一个实施例包括:
201、获取待识别语音流,待识别语音流至少包括音调数据和语气特征词;
服务器获取至少包括音调数据和语气特征词的待识别数据流。
在语音智能问答系统中,当用户接通与问答机器人的电话之后,问答机器人向用户提出问题,用户通过手持终端根据问答机器人的问题进行规范性回答,此时用户的语音信息通过手持终端输入语音智能问答系统中。当服务器向语音智能问答系统发出数据提取请求,语音智能问答系统将用户的语音信息处理为待识别语音流,服务器从语音智能问答系统中提取待识别语音流。
例如,当用户接通与问答机器人的电话之后,问答机器人向用户提出“请问您是张三先生嘛?”用户通过手机回答“嗯、啊或者不是”,假设用户回答“嗯”,通过手机将“嗯”的语音信息输入至语音智能问答系统中,服务器向语音智能问答系统发出数据提取的请求,语音智能问答系统将“嗯”的语音信息转换成语音流,并向服务器发送对应的语音流,服务器从而得到“嗯”的待识别语音流。
需要说明的是,音调数据的具体表现形式为音调曲线图,通过音调曲线图可以得到音高曲线斜率、音高曲线曲拱起点、基频抖动和有效音长。语气特征词为“嗯”或者“啊”一类的单音节词。
202、对待识别语音流进行端点检测,得到多个语音数据片段,每个语音数据片段中包括一个语气特征词;
服务器将待识别语音流端点检测为多个语音数据片段,每个语音数据片段中包括一个语气特征词。
端点检测也叫语音活动检测(voice activity detection,VAD),端点检测的目的是对语音区域和非语音区域进行区分。可以理解为端点检测是为了从带有噪声的语音中准确的定位出语音的开始点和结束点,去掉静音和噪声的部分,找到一段语音真正有效的内容,即包括语气特征词的内容。
服务器对待识别语音流进行端点检测,将待识别语音流中的静音和噪声部分去掉,在进行端点检测时,可以将待识别语音流输入至一个完整的声学模型,在解码的基础,通过全局信息,判别语音段(语音数据片段)和非语音段(静音段和噪声段),取出非语音端,保留语音段,从而得到多个语音数据。
203、根据多个语音数据片段得到文本数据;
服务器对多个语音数据片段进行训练,得到用于文本转换的模型,然后再将多个语音数据片段依次输入该模型中,得到文本数据。
具体的,服务器提取多个语音数据片段中每个语音数据片段对应的声学特征,得到多个声学特征,服务器再训练多个声学特征,得到语言模型,服务器将多个语音数据片段依次输入语言模型中,在语言模型中结合词典,生成文本数据。
204、基于待识别语音流获取多个语音片段时刻戳,获取待识别语音流包括的语气词,得到目标语气特征词,并根据目标语气特征词和多个语音片段时刻戳确定目标语音流;
服务器根据待识别语音流获取多个用于标记待识别语音流的语音片段时刻戳,服务器对文本数据进行语气词选取,得到目标语气特征词,然后结合目标语气特征词和多个语音片段时刻戳确定目标语音流和文本数据。
需要说明的是,引入语音片段时刻戳可以对不同的语音片段进行标记,在意图识别的过程中能够通过语音片段时刻戳快速准确的找到对应的语气特征词。
例如,服务器在用户对“请问您是张三先生嘛?”的问答回答之后得到的文本数据为“嗯嗯嗯”,或者“啊啊啊”,服务器根据文本数据进行语气词的选取,得到目标语气特征词“嗯”或者目标语气特征词“啊”。然后服务器根据语气特征词“嗯”或者“啊”对应的语音片段时刻戳,在待识别数据流中确定目标语音流,需要说明的是,目标语音流也带有对应的音调数据。
具体的,服务器将多个语音数据片段依次输入预置的语音检测模型,得到多个语音片段时刻戳,每个语音片段时刻戳对应一个语音数据片段。服务器对筛选文本数据,得到筛选后的文本数据,例如,将“嗯嗯嗯”或者“啊啊啊”的文本数据筛选为“嗯”或者“啊”的筛选后的文本数据;然后服务器根据正则匹配算法和筛选后的文本数据在多个语音数据片段中确定与筛选后的文本数据对应的语音数据片段作为目标语气特征词,例如将与筛选后的文本数据片段“嗯”对应的语音数据片段确定为目标语气特征词;最后服务器根据目标语气特征词对应的目标语音片段时刻戳在待识别语音流中确定包括音调数据的目标语音流。
需要说明的是,预置的语音检测模型为深度神经网络(deep neural networks,DNN)VAD模型,服务器将多个语音数据片段依次输入DNNVAD模型中,DNNVAD模型输出与每个语音数据片段对应的语音片段时刻戳,从而生成多个语音片段时刻戳。采用正则匹配算法只确定为单音节语气词的语音数据片段,单音节语气词包括但不限于“嗯”、“额”、“哦”和“啊”这些词。
205、根据目标语音流进行意图识别,得到目标意图。
服务器根据目标语音流识别用户的语气,得到目标意图。
服务器根据目标语音流对应的音调识别用户的语气,假设目标语音流对应的音调数据起伏较大,则对应的目标意图可能为疑问意图,假设目标语音流对应的音调数据起伏平缓,则对应的目标意图可能为肯定意图。根据目标语音流进行意图识别过程如下:
服务器基于音调数据提取与目标语音流对应的音高曲线数据,得到目标音高曲线数据;其次服务器对目标音高曲线数据进行计算,得到目标音长数据;如果目标音长数据大于音长阈值,服务器则提取目标语音流的下一段语音流作为音长语音流,然后根据音长语音流进行意图识别或者根据音长语音流对应的文本数据进行意图识别,得到目标意图;如果目标音长数据小于或者等于音长阈值,则计算音曲线数据对应的目标音高曲线斜率和目标基频抖动;最后根据目标音高曲线斜率和目标基频抖动进行意图识别,得到目标意图。
需要说明的是,目标音长数据用于判断当前语气特征词是否为标识迟疑拖音的语气词,例如,
语音智能问答系统:请问您是在北京工作吗?
情形1:用户:嗯……啊。
情形2:用户:嗯……以前在广州,现在在上海。
在以上问答中,根据“嗯”的语音数据片段,不能正确识别出用户的语气为疑问意图还是肯定意图,需要结合下一段语音数据片段或者下一段语音数据片段对应的文本数据进行语义的理解。
假设音长阈值为35,如果目标音长数据大于35,服务器则根据以下方式进行意图识别:
提取目标语音流的下一段语音流作为音长语音流,并判断音长语音流对应的语气词是否为单音节词,若是,则根据音长语音流进行识别,得到疑问意图或者肯定意图;若不是,则提取语音流对应的文本数据,采用神经语言程序学(neuro-linguisticprogramming,NLP)算法结合文本数据进行识别,得到疑问意图或者肯定意图。
如上述问答所示,情形1根据音长数据流“啊”进行识别,意图识别结果为肯定意图中的肯定“是”结果,情形2根据音长数据流“以前在广州,现在在上海”对应的文本数据进行识别,意图识别结果为肯定意图中的肯定“不是”结果。
如果目标音长数据小于等于35,服务器则根据以下方式进行意图识别:
在目标音高曲线数据中选取头部采样点和尾部采样点,分别计算头部采样点和尾部采样点的斜率和差值,得到目标音高曲线斜率和目标基频抖动。
根据人发声系统和音调语调成因分析,肯定语气词的每帧音高值比前一帧要稍微减小,呈缓慢下降趋势;而疑问语气词的每帧音高值比其前一帧要更大,呈明显上升趋势。肯定语气词的基频抖动较小,疑问语气词的基频抖动较大。因此服务器计算头部采样点和尾部采样点的斜率,得到目标音高曲线斜率,计算头部采样点和尾部采样点的差值,得到目标基频抖动,目标基频抖动可以理解为斜率的绝对值。
在一实施例中,基于目标音高曲线斜率和目标基频抖动进行意图识别的过程具体如下:
当目标音高曲线斜率大于或者等于斜率阈值时,服务器判断目标基频抖动是否大于或者等于抖动阈值;如果目标基频抖动大于或者等于抖动阈值,服务器则确定目标语音流的意图为疑问意图;如果目标基频抖动小于抖动阈值,服务器则提取目标音高曲线数据对应的目标音高曲拱点,判断目标音高曲拱点是否高于预置的肯定音高曲拱点,若目标音高曲拱点高于预置的肯定音高曲拱点,服务器则确定目标语音流的意图为疑问意图;当目标音高曲线斜率小于斜率阈值时,服务器判断目标基频抖动是否小于抖动阈值;如果目标基频抖动小于抖动阈值,服务器则确定目标语音流的意图为疑问意图;如果目标基频抖动大于或者等于抖动阈值且目标音高曲拱点低于或者等于肯定音高曲拱点,则确定目标语音流的意图为肯定意图。
例如,假设斜率阈值为0、抖动阈值为2肯定音高曲拱点150赫兹,当目标音高曲线斜率为2时,服务器判断目标基频抖动是否大于或者等于抖动阈值,如果目标基频抖动为2,则确定目标语音流的意图为疑问意图;如果目标音高曲线斜率和目标基频抖动都为1,服务器则提取目标音高曲线数据对应的目标音高曲拱点155赫兹,将目标音高曲拱点与肯定音高曲拱点进行对比,目标音高曲拱点高于肯定音高曲拱点,则确定目标语音流的意图为疑问意图,否则为肯定意图。当目标音高曲线斜率为-1且目标基频抖动为1时,服务器则确定目标语音流的意图为肯定意图,当目标音高曲线斜率为-2、目标基频抖动为2且目标音高曲拱点为145赫兹时,服务器确定目标语音流的意图为肯定意图,若目标音高曲拱点为155赫兹,服务器确定目标语音流的意图为疑问意图。
本发明实施例中,通过文本数据选取语气特征词,然后根据语气特征词和多个语音片段时刻戳确定对应的目标语音流,最后基于目标语音流进行意图识别,得到目标意图,通过语音流进行意图识别能够实现同字不同义的识别功能,提高了意图识别的准确率。
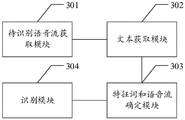
上面对本发明实施例中基于语调的意图识别方法进行了描述,下面对本发明实施例中基于语调的意图识别装置进行描述,请参阅图3,本发明实施例中基于语调的意图识别装置一个实施例包括:
待识别语音流获取模块301,用于获取待识别语音流,所述待识别语音流至少包括音调数据和语气特征词;
文本获取模块302,用于根据所述待识别语音流获取文本数据;
特征词和语音流确定模块303,用于基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流;
识别模块304,用于根据所述目标语音流进行意图识别,得到目标意图。
本发明实施例中,通过文本数据选取语气特征词,然后根据语气特征词和多个语音片段时刻戳确定对应的目标语音流,最后基于目标语音流进行意图识别,得到目标意图,通过语音流进行意图识别能够实现同字不同义的识别功能,提高了意图识别的准确率。
请参阅图4,本发明实施例中基于语调的意图识别装置的另一个实施例包括:
待识别语音流获取模块301,用于获取待识别语音流,所述待识别语音流至少包括音调数据和语气特征词;
文本获取模块302,用于根据所述待识别语音流获取文本数据;
特征词和语音流确定模块303,用于基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流;
识别模块304,用于根据所述目标语音流进行意图识别,得到目标意图。
可选的,文本获取模块302包括:
检测单元3021,用于对所述待识别语音流进行端点检测,得到多个语音数据片段;
文本数据生成单元3022,用于根据所述多个语音数据片段得到文本数据。
可选的,文本数据生成单元3023还可以具体用于:
提取每个语音数据片段对应的声学特征,得到多个声学特征;
训练所述多个声学特征,得到语言模型;
将所述多个语音数据片段依次输入所述语言模型并结合预置的词典,生成文本数据。
可选的,特征词和语音流确定模块303还可以具体用于:
将所述多个语音数据片段依次输入预置的语音检测模型,生成与每个语音数据片段对应的语音片段时刻戳,得到多个语音片段时刻戳;
对所述文本数据进行筛选,得到筛选后的文本数据;
根据正则匹配算法确定与所述筛选后的文本数据对应的目标语气特征词;
基于所述目标语气特征词对应的目标语音片段在多个语音片段时刻戳中确定对应的目标语音片段时刻戳;
基于目标语音片段时刻戳在待识别语音流中确定目标语音流。
可选的,识别模块304包括:
音高曲线提取单元3041,用于在所述音调数据中提取与所述目标语音流对应的音高曲线数据,得到目标音高曲线数据;
第一计算单元3042,用于根据所述目标音高曲线数据进行计算,得到目标音长数据;
第一意图生成单元3043,若所述目标音长数据大于音长阈值,则用于提取目标语音流的下一段语音流作为音长语音流,根据所述音长语音流或者与所述音长语音流对应的文本数据进行意图识别,得到目标意图;
第二计算单元3044,若所述目标音长数据小于或者等于所述音长阈值,则用于根据所述音高曲线数据计算得到目标音高曲线斜率和目标基频抖动;
第二意图生成单元3045,用于根据所述目标音高曲线斜率和所述目标基频抖动进行意图识别,得到目标意图。
可选的,所述第二计算单元3044还可以具体用于:
若所述目标音长数据小于或者等于所述音长阈值,则在所述目标音高曲线数据中选取头部采样点和尾部采样点,并计算所述头部采样点和所述尾部采样点的斜率,得到目标音高曲线斜率;
计算所述头部采样点和所述尾部采样点的差值,得到目标基频抖动。
可选的,第二意图生成单元3045还可以具体用于:
当所述目标音高曲线斜率大于或者等于斜率阈值时,判断所述目标基频抖动是否大于或者等于抖动阈值;
若所述目标基频抖动大于或者等于所述抖动阈值,则确定所述目标语音流的意图为疑问意图,所述疑问意图为目标意图;
若所述目标基频抖动小于所述抖动阈值,则提取目标音高曲线数据对应的目标音高曲拱点,若目标音高曲拱点高于预置的肯定音高曲拱点,则确定所述目标语音流的意图为疑问意图;
当所述目标音高曲线斜率小于所述斜率阈值时,判断所述目标基频抖动是否小于所述抖动阈值;
若所述目标基频抖动小于所述抖动阈值,则确定所述目标语音流的意图为肯定意图,所述肯定意图为目标意图;
若所述目标基频抖动大于或者等于所述抖动阈值且所述目标音高曲拱点低于或者等于所述肯定音高曲拱点,则确定所述目标语音流的意图为肯定意图。
本发明实施例中,通过文本数据选取语气特征词,然后根据语气特征词和多个语音片段时刻戳确定对应的目标语音流,最后基于目标语音流进行意图识别,得到目标意图,通过语音流进行意图识别能够实现同字不同义的识别功能,提高了意图识别的准确率。
上面图3和图4从模块化功能实体的角度对本发明实施例中的基于语调的意图识别装置进行详细描述,下面从硬件处理的角度对本发明实施例中基于语调的意图识别设备进行详细描述。
图5是本发明实施例提供的一种基于语调的意图识别设备的结构示意图,该基于语调的意图识别设备500可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(central processing units,CPU)510(例如,一个或一个以上处理器)和存储器520,一个或一个以上存储应用程序533或数据532的存储介质530(例如一个或一个以上海量存储设备)。其中,存储器520和存储介质530可以是短暂存储或持久存储。存储在存储介质530的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对基于语调的意图识别设备500中的一系列指令操作。更进一步地,处理器510可以设置为与存储介质530通信,在基于语调的意图识别设备500上执行存储介质530中的一系列指令操作。
基于语调的意图识别设备500还可以包括一个或一个以上电源540,一个或一个以上有线或无线网络接口550,一个或一个以上输入输出接口560,和/或,一个或一个以上操作系统531,例如Windows Serve,Mac OS X,Unix,Linux,FreeBSD等等。本领域技术人员可以理解,图5示出的基于语调的意图识别设备结构并不构成对基于语调的意图识别设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
进一步地,所述计算机可用存储介质可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序等;存储数据区可存储根据区块链节点的使用所创建的数据等。
本发明还提供一种计算机可读存储介质,该计算机可读存储介质可以为非易失性计算机可读存储介质,该计算机可读存储介质也可以为易失性计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在计算机上运行时,使得计算机执行所述基于语调的意图识别方法的步骤。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(read-only memory,ROM)、随机存取存储器(random access memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
本发明所指区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链(Blockchain),本质上是一个去中心化的数据库,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层等。
以上所述,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
Claims (10)
1.一种基于语调的意图识别方法,其特征在于,所述基于语调的意图识别方法包括:
获取待识别语音流,所述待识别语音流至少包括音调数据和语气特征词;
根据所述待识别语音流获取文本数据;
基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流;
根据所述目标语音流进行意图识别,得到目标意图。
2.根据权利要求1所述的基于语调的意图识别方法,其特征在于,所述根据所述待识别语音流获取文本数据包括:
对所述待识别语音流进行端点检测,得到多个语音数据片段,每个语音数据片段中包括一个语气特征词;
根据所述多个语音数据片段得到文本数据。
3.根据权利要求2所述的基于语调的意图识别方法,其特征在于,所述根据所述多个语音数据片段得到文本数据包括:
提取每个语音数据片段对应的声学特征,得到多个声学特征;
训练所述多个声学特征,得到语言模型;
将所述多个语音数据片段依次输入所述语言模型并结合预置的词典,生成文本数据。
4.根据权利要求2所述的基于语调的意图识别方法,其特征在于,所述基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流包括:
将所述多个语音数据片段依次输入预置的语音检测模型,生成与每个语音数据片段对应的语音片段时刻戳,得到多个语音片段时刻戳;
对所述文本数据进行筛选,得到筛选后的文本数据;
根据正则匹配算法确定与所述筛选后的文本数据对应的目标语气特征词;
基于所述目标语气特征词对应的目标语音片段在多个语音片段时刻戳中确定对应的目标语音片段时刻戳;
基于目标语音片段时刻戳在待识别语音流中确定目标语音流。
5.根据权利要求1-4中任意一项所述的基于语调的意图识别方法,其特征在于,所述根据所述目标语音流进行意图识别,得到目标意图包括:
在所述音调数据中提取与所述目标语音流对应的音高曲线数据,得到目标音高曲线数据;
根据所述目标音高曲线数据进行计算,得到目标音长数据;
若所述目标音长数据大于音长阈值,则提取目标语音流的下一段语音流作为音长语音流,根据所述音长语音流或者与所述音长语音流对应的文本数据进行意图识别,得到目标意图;
若所述目标音长数据小于或者等于所述音长阈值,则根据所述音高曲线数据计算得到目标音高曲线斜率和目标基频抖动;
根据所述目标音高曲线斜率和所述目标基频抖动进行意图识别,得到目标意图。
6.根据权利要求5所述的基于语调的意图识别方法,其特征在于,所述若所述目标音长数据小于或者等于所述音长阈值,则根据所述音高曲线数据计算得到目标音高曲线斜率和目标基频抖动包括:
若所述目标音长数据小于或者等于所述音长阈值,则在所述目标音高曲线数据中选取头部采样点和尾部采样点,并计算所述头部采样点和所述尾部采样点的斜率,得到目标音高曲线斜率;
计算所述头部采样点和所述尾部采样点的差值,得到目标基频抖动。
7.根据权利要求5所述的基于语调的意图识别方法,其特征在于,所述根据所述目标音高曲线斜率和所述目标基频抖动进行意图识别,得到目标意图包括:
当所述目标音高曲线斜率大于或者等于斜率阈值时,判断所述目标基频抖动是否大于或者等于抖动阈值;
若所述目标基频抖动大于或者等于所述抖动阈值,则确定所述目标语音流的意图为疑问意图,所述疑问意图为目标意图;
若所述目标基频抖动小于所述抖动阈值,则提取目标音高曲线数据对应的目标音高曲拱点,若目标音高曲拱点高于预置的肯定音高曲拱点,则确定所述目标语音流的意图为疑问意图;
当所述目标音高曲线斜率小于所述斜率阈值时,判断所述目标基频抖动是否小于所述抖动阈值;
若所述目标基频抖动小于所述抖动阈值,则确定所述目标语音流的意图为肯定意图,所述肯定意图为目标意图;
若所述目标基频抖动大于或者等于所述抖动阈值且所述目标音高曲拱点低于或者等于所述肯定音高曲拱点,则确定所述目标语音流的意图为肯定意图。
8.一种基于语调的意图识别装置,其特征在于,所述基于语调的意图识别装置包括:
待识别语音流获取模块,用于获取待识别语音流,所述待识别语音流至少包括音调数据和语气特征词;
文本获取模块,用于根据所述待识别语音流获取文本数据;
特征词和语音流确定模块,用于基于所述待识别语音流获取多个语音片段时刻戳,获取所述待识别语音流包括的语气词,得到目标语气特征词,并根据所述目标语气特征词和所述多个语音片段时刻戳确定目标语音流;
识别模块,用于根据所述目标语音流进行意图识别,得到目标意图。
9.一种基于语调的意图识别设备,其特征在于,所述基于语调的意图识别设备包括:存储器和至少一个处理器,所述存储器中存储有指令,所述存储器和所述至少一个处理器通过线路互连;
所述至少一个处理器调用所述存储器中的所述指令,以使得所述基于语调的意图识别设备执行如权利要求1-7中任意一项所述的基于语调的意图识别方法。
10.一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-7中任一项所述基于语调的意图识别方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011169292.3A CN112309372B (zh) | 2020-10-28 | 2020-10-28 | 基于语调的意图识别方法、装置、设备及存储介质 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011169292.3A CN112309372B (zh) | 2020-10-28 | 2020-10-28 | 基于语调的意图识别方法、装置、设备及存储介质 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112309372A true CN112309372A (zh) | 2021-02-02 |
| CN112309372B CN112309372B (zh) | 2024-02-23 |
Family
ID=74332169
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011169292.3A Active CN112309372B (zh) | 2020-10-28 | 2020-10-28 | 基于语调的意图识别方法、装置、设备及存储介质 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112309372B (zh) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112992151A (zh) * | 2021-03-15 | 2021-06-18 | 中国平安财产保险股份有限公司 | 语音识别方法、系统、设备和可读存储介质 |
| CN113254613A (zh) * | 2021-05-24 | 2021-08-13 | 深圳壹账通智能科技有限公司 | 对话问答方法、装置、设备及存储介质 |
| CN114547262A (zh) * | 2022-01-27 | 2022-05-27 | 联想(北京)有限公司 | 一种自然语言处理方法、装置及计算机可读介质 |
| CN114898738A (zh) * | 2022-04-27 | 2022-08-12 | 青岛海尔空调器有限总公司 | 家电设备语音交互方法、装置、家电设备及存储介质 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109671435A (zh) * | 2019-02-21 | 2019-04-23 | 三星电子(中国)研发中心 | 用于唤醒智能设备的方法和装置 |
| US20190272846A1 (en) * | 2018-03-01 | 2019-09-05 | Fu Tai Hua Industry (Shenzhen) Co., Ltd. | Smart robot and method for man-machine interaction |
| CN110930989A (zh) * | 2019-11-27 | 2020-03-27 | 深圳追一科技有限公司 | 语音意图识别方法、装置、计算机设备和存储介质 |
| WO2020085323A1 (ja) * | 2018-10-22 | 2020-04-30 | ヤマハ株式会社 | 音声処理方法、音声処理装置及び音声処理プログラム |
| CN111276148A (zh) * | 2020-01-14 | 2020-06-12 | 中国平安人寿保险股份有限公司 | 基于卷积神经网络的回访方法、系统及存储介质 |
| CN111694939A (zh) * | 2020-04-28 | 2020-09-22 | 平安科技(深圳)有限公司 | 智能调用机器人的方法、装置、设备及存储介质 |
-
2020
- 2020-10-28 CN CN202011169292.3A patent/CN112309372B/zh active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190272846A1 (en) * | 2018-03-01 | 2019-09-05 | Fu Tai Hua Industry (Shenzhen) Co., Ltd. | Smart robot and method for man-machine interaction |
| WO2020085323A1 (ja) * | 2018-10-22 | 2020-04-30 | ヤマハ株式会社 | 音声処理方法、音声処理装置及び音声処理プログラム |
| CN109671435A (zh) * | 2019-02-21 | 2019-04-23 | 三星电子(中国)研发中心 | 用于唤醒智能设备的方法和装置 |
| CN110930989A (zh) * | 2019-11-27 | 2020-03-27 | 深圳追一科技有限公司 | 语音意图识别方法、装置、计算机设备和存储介质 |
| CN111276148A (zh) * | 2020-01-14 | 2020-06-12 | 中国平安人寿保险股份有限公司 | 基于卷积神经网络的回访方法、系统及存储介质 |
| CN111694939A (zh) * | 2020-04-28 | 2020-09-22 | 平安科技(深圳)有限公司 | 智能调用机器人的方法、装置、设备及存储介质 |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112992151A (zh) * | 2021-03-15 | 2021-06-18 | 中国平安财产保险股份有限公司 | 语音识别方法、系统、设备和可读存储介质 |
| CN112992151B (zh) * | 2021-03-15 | 2023-11-07 | 中国平安财产保险股份有限公司 | 语音识别方法、系统、设备和可读存储介质 |
| CN113254613A (zh) * | 2021-05-24 | 2021-08-13 | 深圳壹账通智能科技有限公司 | 对话问答方法、装置、设备及存储介质 |
| CN114547262A (zh) * | 2022-01-27 | 2022-05-27 | 联想(北京)有限公司 | 一种自然语言处理方法、装置及计算机可读介质 |
| CN114898738A (zh) * | 2022-04-27 | 2022-08-12 | 青岛海尔空调器有限总公司 | 家电设备语音交互方法、装置、家电设备及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112309372B (zh) | 2024-02-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112309372A (zh) | 基于语调的意图识别方法、装置、设备及存储介质 | |
| CN108364632B (zh) | 一种具备情感的中文文本人声合成方法 | |
| CN109331470B (zh) | 基于语音识别的抢答游戏处理方法、装置、设备及介质 | |
| CN109920449B (zh) | 节拍分析方法、音频处理方法及装置、设备、介质 | |
| CN110853649A (zh) | 基于智能语音技术的标签提取方法、系统、设备及介质 | |
| CN107452385A (zh) | 一种基于语音的数据评价方法及装置 | |
| CN107767881B (zh) | 一种语音信息的满意度的获取方法和装置 | |
| CN110852075B (zh) | 自动添加标点符号的语音转写方法、装置及可读存储介质 | |
| KR20080086791A (ko) | 음성 기반 감정 인식 시스템 | |
| US10573311B1 (en) | Generating self-support metrics based on paralinguistic information | |
| CN112614510B (zh) | 一种音频质量评估方法及装置 | |
| US20220238118A1 (en) | Apparatus for processing an audio signal for the generation of a multimedia file with speech transcription | |
| CN111462758A (zh) | 智能会议角色分类的方法、装置、设备及存储介质 | |
| EP1280137B1 (en) | Method for speaker identification | |
| CN113920986A (zh) | 会议记录生成方法、装置、设备及存储介质 | |
| CN113535925A (zh) | 语音播报方法、装置、设备及存储介质 | |
| Płaza et al. | Call transcription methodology for contact center systems | |
| Alam et al. | Comparative study of speaker personality traits recognition in conversational and broadcast news speech. | |
| CN112712793A (zh) | 语音交互下基于预训练模型的asr纠错方法及相关设备 | |
| CN113990352A (zh) | 用户情绪识别与预测方法、装置、设备及存储介质 | |
| CN114627896A (zh) | 语音评测方法、装置、设备及存储介质 | |
| CN113436617A (zh) | 语音断句方法、装置、计算机设备及存储介质 | |
| CN110263346B (zh) | 基于小样本学习的语意分析方法、电子设备及存储介质 | |
| CN108899016B (zh) | 一种语音文本规整方法、装置、设备及可读存储介质 | |
| KR20120109763A (ko) | 신경망 컴퓨팅을 이용한 다중 음원의 음악정보 분석 장치 및 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |