CN112131367A - Self-auditing man-machine conversation method, system and readable storage medium - Google Patents
Self-auditing man-machine conversation method, system and readable storage medium Download PDFInfo
- Publication number
- CN112131367A CN112131367A CN202011018603.6A CN202011018603A CN112131367A CN 112131367 A CN112131367 A CN 112131367A CN 202011018603 A CN202011018603 A CN 202011018603A CN 112131367 A CN112131367 A CN 112131367A
- Authority
- CN
- China
- Prior art keywords
- dialogue
- model
- reply
- self
- man
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/355—Creation or modification of classes or clusters
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/126—Character encoding
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/216—Parsing using statistical methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/049—Temporal neural networks, e.g. delay elements, oscillating neurons or pulsed inputs
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Databases & Information Systems (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Probability & Statistics with Applications (AREA)
- Machine Translation (AREA)
Abstract
本发明提供了自审核的人机对话方法、系统及可读存储介质,所述自审核的人机对话系统由输入输出模块、对话回复生成模块组成和对话自审核模块组成。用户可以输入任意对话,通过回复生成模块中的生成模型生成多个候选回复,再通过MMI评分模型计算候选回复相对于历史对话的损失,选择损失最小的作为最终回复。将生成的该回复输入对话自审核模型,先利用预训练的Bert模型提取文本特征,接着采用双向LSTM模型进行分类,判断是否属于敏感语句,若不属于敏感话语,输出该回复给用户;若判断属于敏感语句,则输出事先设置的对话模板中的回复。该发明系统可应用到任何场景进行闲聊对话。

The present invention provides a self-audit man-machine dialogue method, system and readable storage medium. The self-audit man-machine dialogue system is composed of an input and output module, a dialogue reply generation module and a dialogue self-audit module. The user can enter any dialogue, generate multiple candidate responses through the generation model in the response generation module, and then calculate the loss of the candidate responses relative to the historical dialogue through the MMI scoring model, and select the one with the smallest loss as the final response. Input the generated reply into the dialogue self-audit model, first use the pre-trained Bert model to extract text features, and then use the bidirectional LSTM model for classification to determine whether it is a sensitive sentence, if not, output the reply to the user; If it is a sensitive sentence, the reply in the dialog template set in advance is output. The inventive system can be applied to any scene for chatting.
Description
【技术领域】【Technical field】
本发明涉及人工智能处理技术领域,尤其涉及一种自审核的人机对话方法、系统及可读存储介质。The present invention relates to the technical field of artificial intelligence processing, in particular to a self-audit man-machine dialogue method, system and readable storage medium.
【背景技术】【Background technique】
近年来,随着科学技术的不断发展,对话机器人备受科学研究人员的重视,因其巨大的商业价值和潜力而被广泛应用在各个领域,出现了一系列聊天机器人产品,如微软小冰、阿里小蜜等。对话机器人的目标是对用户输入的话语可以进行任何开放领域的回复。人工智能和深度学习技术的快速发展更是极大地推动了对话系统的进步,生成像人类的回复话语已不再是幻想,逐渐允许在人类和计算机之间建立数据驱动的、开放的对话系统。In recent years, with the continuous development of science and technology, dialogue robots have attracted the attention of scientific researchers, and have been widely used in various fields because of their huge commercial value and potential. A series of chat robot products have appeared, such as Microsoft Xiaoice, Ali Xiaomi, etc. The goal of conversational bots is to make any open-domain response to user-typed utterances. The rapid development of artificial intelligence and deep learning technology has greatly promoted the progress of dialogue systems. Generating human-like replies is no longer an illusion, and gradually allows the establishment of data-driven and open dialogue systems between humans and computers.
目前市场的对话系统可分为检索式方法和生成式方法。检索式方法首先将整个上下文表示为向量,然后将该上下文向量与语料库中的候选回复的向量中进行语义匹配,选择语义最相近的进行回复。但是这种匹配方式容易丢失上下文信息,对话和回复之间的语义鸿沟仍然存在,现有算法并不能很好地克服这个问题。生成式方法主要依赖大量的语料,利用神经网络模型充分编码对话上下文信息,训练出一个更“智能”的对话机器人,回复的话语可能从未出现在语料中,更加灵活,能给用户带来更愉快的对话体验。At present, the dialogue systems in the market can be divided into retrieval methods and generative methods. The retrieval method first expresses the entire context as a vector, and then performs semantic matching between the context vector and the vector of candidate responses in the corpus, and selects the most similar semantically to reply. However, this matching method is prone to lose contextual information, and the semantic gap between dialogue and reply still exists, and existing algorithms cannot overcome this problem well. The generative method mainly relies on a large amount of corpus, uses the neural network model to fully encode the dialogue context information, and trains a more "intelligent" dialogue robot. Pleasant conversation experience.
因此,有必要研究自审核的人机对话方法、系统及可读存储介质来应对现有技术的不足,以解决或减轻上述一个或多个问题。Therefore, it is necessary to study a self-auditing human-computer dialogue method, system and readable storage medium to deal with the deficiencies of the prior art, so as to solve or alleviate one or more of the above problems.
【发明内容】[Content of the invention]
有鉴于此,本发明提供了一种自审核的人机对话方法、系统及可读存储介质,可提供多领域的自由开放式对话,就一个话题可与用户完成多轮对话,同时可对生成的回复内容进行审核,判断是否属于脏话或敏感话语,模拟人类思维模式,相当于从道德层面约束系统,避免向用户发送敏感话语而造成不好的体验,始终保持在对话场景下输出合适的、令人舒服的话语,使客户拥有愉快的聊天体验。In view of this, the present invention provides a self-audit man-machine dialogue method, system and readable storage medium, which can provide free and open dialogue in multiple fields, complete multiple rounds of dialogue with users on a topic, and can The content of the reply is reviewed to determine whether it is swearing or sensitive words, and simulate the human thinking mode, which is equivalent to restraining the system from a moral level, avoiding sending sensitive words to users and causing a bad experience, and always maintaining appropriate output in the dialogue scene. Comfortable words make customers have a pleasant chat experience.
一方面,本发明提供自审核的人机对话方法,所述自审核的人机对话方法具体包括以下步骤:On the one hand, the present invention provides a self-audit man-machine dialogue method, and the self-audit man-machine dialogue method specifically includes the following steps:
S1:对多个不同类型的语料进行收录,形成语料库;S1: Collect multiple different types of corpus to form a corpus;
S2:使用GPT2模型对语料库进行训练,将语料库中包含的每轮对话,按多轮对话产生的先后顺序进行拼接;S2: Use the GPT2 model to train the corpus, and splicing each round of dialogue contained in the corpus in the order in which multiple rounds of dialogue are generated;
S3:将输入的语言对话进行编码转换;S3: Encode the input language dialogue;
S4:通过S2和S3的结果,生成多个回复组成的候选集;S4: Generate a candidate set consisting of multiple replies through the results of S2 and S3;
S5:通过MMI模型对候选集进行评分,选择候选集中相对于对话历史损失最小的语句作为最终回复;S5: Score the candidate set through the MMI model, and select the sentence with the smallest loss relative to the dialogue history in the candidate set as the final reply;
S6:对最终回复进行特征提取和模型分类,判断最终回复是否包含敏感词,如果包含敏感词,则输出特定语句,如果不包含敏感词,则将最终回复作为输出的语言对话。S6: Perform feature extraction and model classification on the final reply, and determine whether the final reply contains sensitive words. If it contains sensitive words, output a specific sentence. If it does not contain sensitive words, use the final reply as the output language dialogue.
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述S3具体为:将输入的语言对话采用字节对编码转化成向量,表示成一段长文本x1,x2,·,xn,并且在末尾设置结束标记符。The above aspect and any possible implementation manner further provide an implementation manner, the S3 is specifically: converting the input language dialogue into a vector using byte pair encoding, and expressing it as a long text x 1 , x 2 , ·, x n , and a closing tag is set at the end.
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述S4具体包括以下步骤:The above-mentioned aspect and any possible implementation manner further provide an implementation manner, and the S4 specifically includes the following steps:
S41:将将输入的语言对话作为源句子,表示为S=x1,x2,·,xm,其中,S为源句子;S41: Taking the input language dialogue as the source sentence, expressed as S=x 1 , x 2 , ·, x m , where S is the source sentence;
S42:将语料库中回复作为目标句,表示为T=xm+1,x2,·,xn,其中,T为目标句,目标句的条件概率为:S42: Use the replies in the corpus as the target sentence, expressed as T=x m+1 , x 2 , ·, x n , where T is the target sentence, and the conditional probability of the target sentence is:

S43:通过自回归语言模型,生成多个候选句,自回归语言模型利用文本序列联合概率的密度估计建模,公式如下:S43: Generate multiple candidate sentences through the autoregressive language model. The autoregressive language model uses the density estimation of the joint probability of the text sequence to model, and the formula is as follows:
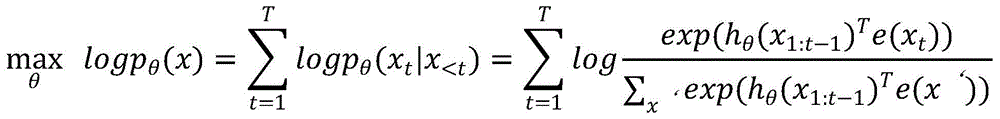
S44:通过Top-k Sampling方法选取多个生成的候选句组成多个回复组成的候选集。S44: Select a plurality of generated candidate sentences through the Top-k Sampling method to form a candidate set composed of multiple replies.
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述S5具体包括以下步骤:The above-mentioned aspect and any possible implementation manner further provide an implementation manner, and the S5 specifically includes the following steps:
S51:将候选集中的每个候选句与对话历史进行逆序拼接;S51: splicing each candidate sentence in the candidate set with the dialogue history in reverse order;
S52:以每个候选句为目标,对于每个候选句给定的回复假设H,预测源句子S,MMI模型计算公式如下:S52: Taking each candidate sentence as the target, for the given reply hypothesis H of each candidate sentence, predict the source sentence S, and the calculation formula of the MMI model is as follows:

其中,logp(H)代表惩罚项,惩罚项为对于在训练集中经常出现的回复H,其语言模型的概率会高于其他回复,减去惩罚项可使得经常出现的H的得分下降;Among them, logp(H) represents the penalty item, and the penalty item is that the probability of the language model for the frequently occurring reply H in the training set will be higher than that of other replies, and subtracting the penalty item can reduce the score of the frequently occurring H;
S53:通过MMI模型选择惩罚平淡通用的回复,计算所有候选句相对于对话历史的损失,最终选择损失最小的,作为最终回复。S53: Select and penalize plain and general replies through the MMI model, calculate the loss of all candidate sentences relative to the dialogue history, and finally select the one with the smallest loss as the final reply.
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述S6中的特征提取具体为:采用预训练的Bert模型提取最终回复的文本特征。According to the above aspect and any possible implementation manner, an implementation manner is further provided. The feature extraction in S6 is specifically: extracting text features of the final reply by using a pre-trained Bert model.
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述S6中的通过模型进行分类具体为:The above-mentioned aspect and any possible implementation manner further provide an implementation manner, and the classification by the model in the S6 is specifically:
通过双向LSTM模型,对含有敏感词的语料进行训练,通过已训练好的双向LSTM分类模型判断回复是否包含敏感词;所述双向LSTM模型如下:The bidirectional LSTM model is used to train the corpus containing sensitive words, and the trained bidirectional LSTM classification model is used to judge whether the reply contains sensitive words; the bidirectional LSTM model is as follows:
ot=σ(Wo[ht-1,xt]+bo)o t =σ(W o [h t - 1 , x t ]+b o )
ht=ot*tanh(Ct)h t =o t *tanh(C t )
其中,ht-1表示前一时刻的隐藏层状态,xt代表当前时刻的输入词,Ct代表当前时刻细胞状态。Ct的计算公式如下:Among them, h t-1 represents the hidden layer state at the previous moment, x t represents the input word at the current moment, and C t represents the cell state at the current moment. The formula for calculating Ct is as follows:
Ct=ft*ct-1+it*ct C t =f t *c t-1 +i t *c t
其中,in,
ct=tanh(Wc·[ht-1,xt])+bc c t =tanh(W c ·[h t-1 , x t ])+b c
ft=σ(Wf·[ht-1,xt]+bf)f t =σ(W f ·[h t-1 , x t ]+b f )
W为神经网络的参数,b为神经元偏置。W is the parameter of the neural network, and b is the neuron bias.
如上所述的方面和任一可能的实现方式,进一步提供一种自审核的人机对话系统,所述系统包括:The above-mentioned aspect and any possible implementation manner further provide a self-auditing human-machine dialogue system, the system comprising:
输入输出模块,用于输入和输出语言对话;Input-output modules for inputting and outputting language dialogues;
对话回复生成模块,根据输入的语言对话生成多个回复组成的候选集,并根据MMI模型进行评分,选择最终回复;The dialogue response generation module generates a candidate set composed of multiple responses according to the input language dialogue, and scores according to the MMI model, and selects the final response;
对话自审核模块,根据最终回复内容进行文本特征提取,通过双向LSTM分类模型对文本进行分类,输出机器语言。The dialogue self-audit module extracts text features according to the final reply content, classifies the text through the bidirectional LSTM classification model, and outputs machine language.
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述对话回复生成模块包括:The above aspect and any possible implementation manner further provide an implementation manner, wherein the dialogue reply generation module includes:
语料库收录单元,用于收录不同类型的语料,并形成语料库;The corpus collection unit is used to collect different types of corpus and form a corpus;
语料库训练单元,通过GPT2模型对语料库进行训练,对语料库中的包含的多轮对话,按顺序拼接每轮对话;The corpus training unit trains the corpus through the GPT2 model, and splices each round of dialogues in sequence for the multiple rounds of dialogue contained in the corpus;
编码转换单元,将输入的语言对话进行向量编码转换;The encoding conversion unit converts the input language dialogue into vector encoding;
回复语句生成单元,通过语料库训练单元和编码转换单元,生成多个回复组成的候选集;The reply sentence generation unit generates a candidate set composed of multiple replies through the corpus training unit and the encoding conversion unit;
评分回复单元,通过MMI模型对候选集进行评分,选择候选集中相对于对话历史损失最小的语句作为最终回复。The scoring and replying unit scores the candidate set through the MMI model, and selects the sentence with the smallest loss relative to the dialogue history in the candidate set as the final reply.
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述对话自审核模块包括:According to the above-mentioned aspect and any possible implementation manner, an implementation manner is further provided, wherein the dialogue self-audit module includes:
特征提取单元,对最终回复进行文本特征提取;The feature extraction unit extracts text features for the final reply;
模型分类单元,判断最终回复是否包含敏感词,如果包含敏感词,则输出特定语句,如果不包含敏感词,则将最终回复作为输出的语言对话。The model classification unit determines whether the final reply contains a sensitive word, if it contains a sensitive word, it outputs a specific sentence, and if it does not contain a sensitive word, the final reply is used as the output language dialogue.
如上所述的方面和任一可能的实现方式,进一步提供一种计算机可读存储介质,计算机可读存储介质为非易失性存储介质或非瞬态存储介质,所述计算机可读存储介质中包括人机对话方法程序,所述人机对话方法程序被处理器执行时,实现如任一项所述的一种人机对话方法的步骤。The above aspect and any possible implementation manner further provide a computer-readable storage medium, where the computer-readable storage medium is a non-volatile storage medium or a non-transitory storage medium, in which the computer-readable storage medium is A man-machine dialogue method program is included, and when the man-machine dialogue method program is executed by the processor, the steps of a man-machine dialogue method as described in any one of the above are implemented.
与现有技术相比,本发明可以获得包括以下技术效果:本发明系统可与用户实现闲聊对话,用户输入任意话语,通过对话回复生成模块中的神经网络模型可生成多个候选回复,并采用评分模型选择和对话历史更相关的回复而不只是通用的回复,使用户拥有更愉快的聊天体验。该方法较传统的生成式方法相比可以提高聊天机器人回复的准确度和相关度。同时该对话系统中的对话自审核模型可以自动过滤带有敏感词的回复,避免因为一句脏话或者带有攻击意味的话语而影响用户体验,在对话过程中始终保持良好互动存在。Compared with the prior art, the present invention can obtain the following technical effects: the system of the present invention can realize chatting with the user, the user can input any words, and the neural network model in the dialogue reply generating module can generate multiple candidate replies, and adopt The scoring model selects replies that are more relevant to the conversation history rather than just generic replies, allowing users to have a more enjoyable chat experience. Compared with traditional generative methods, this method can improve the accuracy and relevance of chatbot responses. At the same time, the dialogue self-audit model in the dialogue system can automatically filter the replies with sensitive words, avoid affecting the user experience due to a swearing or offensive words, and always maintain a good interaction in the dialogue process.
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有技术效果。Of course, any product implementing the present invention does not necessarily need to achieve all the above-mentioned technical effects at the same time.
【附图说明】【Description of drawings】
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。In order to illustrate the technical solutions of the embodiments of the present invention more clearly, the following briefly introduces the accompanying drawings used in the embodiments. Obviously, the drawings in the following description are only some embodiments of the present invention. For those of ordinary skill in the art, other drawings can also be obtained from these drawings without any creative effort.
图1是本发明一个实施例提供的自审核的人机对话方法的工作流程图;Fig. 1 is the work flow chart of the man-machine dialogue method of self-audit provided by one embodiment of the present invention;
图2是本发明一个实施例提供的自审核的人机对话系统的工作逻辑图。FIG. 2 is a working logic diagram of a self-audit man-machine dialogue system provided by an embodiment of the present invention.
【具体实施方式】【Detailed ways】
为了更好的理解本发明的技术方案,下面结合附图对本发明实施例进行详细描述。In order to better understand the technical solutions of the present invention, the embodiments of the present invention are described in detail below with reference to the accompanying drawings.
应当明确,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。It should be understood that the described embodiments are only some, but not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
在本发明实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本发明。在本发明实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。The terms used in the embodiments of the present invention are only for the purpose of describing specific embodiments, and are not intended to limit the present invention. As used in the embodiments of the present invention and the appended claims, the singular forms "a," "the," and "the" are intended to include the plural forms as well, unless the context clearly dictates otherwise.
本发明提供本发明提供一种自审核的人机对话系统,所述自审核的人机对话方法具体包括以下步骤:The present invention provides a self-audit man-machine dialogue system, and the self-audit man-machine dialogue method specifically includes the following steps:
S1:对多个不同类型的语料进行收录,形成语料库;S1: Collect multiple different types of corpus to form a corpus;
S2:使用GPT2模型对语料库进行训练,将语料库中包含的每轮对话,按多轮对话产生的先后顺序进行拼接;S2: Use the GPT2 model to train the corpus, and splicing each round of dialogue contained in the corpus in the order in which multiple rounds of dialogue are generated;
S3:将输入的语言对话进行编码转换;S3: Encode the input language dialogue;
S4:通过S2和S3的结果,生成多个回复组成的候选集;S4: Generate a candidate set consisting of multiple replies through the results of S2 and S3;
S5:通过MMI模型对候选集进行评分,选择候选集中相对于对话历史损失最小的语句作为最终回复;S5: Score the candidate set through the MMI model, and select the sentence with the smallest loss relative to the dialogue history in the candidate set as the final reply;
S6:对最终回复进行特征提取和模型分类,判断最终回复是否包含敏感词,如果包含敏感词,则输出特定语句,如果不包含敏感词,则将最终回复作为输出的语言对话。S6: Perform feature extraction and model classification on the final reply, and determine whether the final reply contains sensitive words. If it contains sensitive words, output a specific sentence. If it does not contain sensitive words, use the final reply as the output language dialogue.
所述S3具体为:将输入的语言对话采用字节对编码转化成向量,表示成一段长文本x1,x2,·,xn,并且在末尾设置结束标记符。The S3 is specifically: converting the input language dialogue into a vector using byte pair encoding, representing a long text x 1 , x 2 , ·, x n , and setting an end marker at the end.
所述S4具体包括以下步骤:The S4 specifically includes the following steps:
S41:将将输入的语言对话作为源句子,表示为S=x1,x2,·,xm,其中,S为源句子;S41: Taking the input language dialogue as the source sentence, expressed as S=x 1 , x 2 , ·, x m , where S is the source sentence;
S42:将语料库中回复作为目标句,表示为T=xm+1,x2,·,xn,其中,T为目标句,目标句的条件概率为:S42: Use the replies in the corpus as the target sentence, expressed as T=x m+1 , x 2 , ·, x n , where T is the target sentence, and the conditional probability of the target sentence is:

S43:通过自回归语言模型,生成多个候选句,自回归语言模型利用文本序列联合概率的密度估计建模,公式如下:S43: Generate multiple candidate sentences through the autoregressive language model. The autoregressive language model uses the density estimation of the joint probability of the text sequence to model, and the formula is as follows:

S44:通过Top-k Sampling方法选取多个生成的候选句组成多个回复组成的候选集。S44: Select a plurality of generated candidate sentences through the Top-k Sampling method to form a candidate set composed of multiple replies.
所述S5具体包括以下步骤:The S5 specifically includes the following steps:
S51:将候选集中的每个候选句与对话历史进行逆序拼接;S51: splicing each candidate sentence in the candidate set with the dialogue history in reverse order;
S52:以每个候选句为目标,对于每个候选句给定的回复假设H,预测源句子S,MMI模型计算公式如下:S52: Taking each candidate sentence as the target, for the given reply hypothesis H of each candidate sentence, predict the source sentence S, and the calculation formula of the MMI model is as follows:

其中,logp(H)代表惩罚项,惩罚项为对于在训练集中经常出现的回复H,其语言模型的概率会高于其他回复,减去惩罚项可使得经常出现的H的得分下降;Among them, logp(H) represents the penalty item, and the penalty item is that the probability of the language model for the frequently occurring reply H in the training set will be higher than that of other replies, and subtracting the penalty item can reduce the score of the frequently occurring H;
S53:通过MMI模型选择惩罚平淡通用的回复,计算所有候选句相对于对话历史的损失,最终选择损失最小的,作为最终回复。S53: Select and penalize plain and general replies through the MMI model, calculate the loss of all candidate sentences relative to the dialogue history, and finally select the one with the smallest loss as the final reply.
所述S6中的特征提取具体为:采用预训练的Bert模型提取最终回复的文本特征。The feature extraction in S6 is specifically: using a pre-trained Bert model to extract the text features of the final reply.
所述S6中的通过模型进行分类具体为:The classification by the model in the S6 is specifically:
通过双向LSTM模型,对含有敏感词的语料进行训练,通过已训练好的双向LSTM分类模型判断回复是否包含敏感词;所述双向LSTM模型如下:The bidirectional LSTM model is used to train the corpus containing sensitive words, and the trained bidirectional LSTM classification model is used to judge whether the reply contains sensitive words; the bidirectional LSTM model is as follows:
ot=σ(Wo[ht-1,xt]+bo)o t =σ(W o [h t - 1 , x t ]+b o )
ht=ot*tanh(Ct)h t =o t *tanh(C t )
其中,ht-1表示前一时刻的隐藏层状态,xt代表当前时刻的输入词,Ct代表当前时刻细胞状态。Ct的计算公式如下:Among them, h t-1 represents the hidden layer state at the previous moment, x t represents the input word at the current moment, and C t represents the cell state at the current moment. The formula for calculating Ct is as follows:
Ct=ft*ct-1+it*ct C t =f t *c t-1 +i t *c t
其中,in,
ct=tanh(Wc·[ht-1,xt])+bc c t =tanh(W c ·[h t-1 , x t ])+b c
ft=σ(Wf·[ht-1,xt]+bf)f t =σ(W f ·[h t-1 , x t ]+b f )
W为神经网络的参数,b为神经元偏置。W is the parameter of the neural network, and b is the neuron bias.
本发明还提供一种自审核的人机对话系统,所述系统包括:The present invention also provides a self-audit man-machine dialogue system, the system includes:
输入输出模块,用于输入和输出语言对话;Input-output modules for inputting and outputting language dialogues;
对话回复生成模块,根据输入的语言对话生成多个回复组成的候选集,并根据MMI模型进行评分,选择最终回复;The dialogue response generation module generates a candidate set composed of multiple responses according to the input language dialogue, and scores according to the MMI model, and selects the final response;
对话自审核模块,根据最终回复内容进行文本特征提取,通过双向LSTM分类模型对文本进行分类,输出机器语言。The dialogue self-audit module extracts text features according to the final reply content, classifies the text through the bidirectional LSTM classification model, and outputs machine language.
所述对话回复生成模块包括:The dialogue reply generating module includes:
语料库收录单元,用于收录不同类型的语料,并形成语料库;The corpus collection unit is used to collect different types of corpus and form a corpus;
语料库训练单元,通过GPT2模型对语料库进行训练,对语料库中的包含的多轮对话,按顺序拼接每轮对话;The corpus training unit trains the corpus through the GPT2 model, and splices each round of dialogues in sequence for the multiple rounds of dialogue contained in the corpus;
编码转换单元,将输入的语言对话进行向量编码转换;The encoding conversion unit converts the input language dialogue into vector encoding;
回复语句生成单元,通过语料库训练单元和编码转换单元,生成多个回复组成的候选集;The reply sentence generation unit generates a candidate set composed of multiple replies through the corpus training unit and the encoding conversion unit;
评分回复单元,通过MMI模型对候选集进行评分,选择候选集中相对于对话历史损失最小的语句作为最终回复。The scoring and replying unit scores the candidate set through the MMI model, and selects the sentence with the smallest loss relative to the dialogue history in the candidate set as the final reply.
所述对话自审核模块包括:The dialogue self-audit module includes:
特征提取单元,对最终回复进行文本特征提取;The feature extraction unit extracts text features for the final reply;
模型分类单元,判断最终回复是否包含敏感词,如果包含敏感词,则输出特定语句,如果不包含敏感词,则将最终回复作为输出的语言对话。The model classification unit determines whether the final reply contains a sensitive word, if it contains a sensitive word, it outputs a specific sentence, and if it does not contain a sensitive word, the final reply is used as the output language dialogue.
本发明还提供一种计算机可读存储介质,计算机可读存储介质为非易失性存储介质或非瞬态存储介质,所述计算机可读存储介质中包括人机对话方法程序,所述人机对话方法程序被处理器执行时,实现如任一项所述的一种人机对话方法的步骤。The present invention also provides a computer-readable storage medium. The computer-readable storage medium is a non-volatile storage medium or a non-transitory storage medium, and the computer-readable storage medium includes a man-machine dialogue method program. When the dialogue method program is executed by the processor, the steps of any one of the man-machine dialogue methods described above are implemented.
如图2所示,本发明提供了一种人机对话系统,由输入输出模块、对话回复生成模块组成和对话自审核模块组成。用户可以输入任意对话,通过回复生成模块中的生成模型生成多个候选回复,再通过MMI评分模型计算候选回复相对于历史对话的损失,选择损失最小的作为最终回复。将生成的该回复输入对话自审核模型,先利用预训练的Bert模型提取文本特征,接着采用双向LSTM模型进行分类,判断是否属于敏感语句,若不属于敏感话语,输出该回复给用户;若判断属于敏感语句,则输出事先设置的对话模板中的回复。该发明系统可应用到任何场景进行闲聊对话。As shown in FIG. 2 , the present invention provides a man-machine dialogue system, which is composed of an input and output module, a dialogue reply generation module, and a dialogue self-audit module. The user can enter any dialogue, generate multiple candidate responses through the generation model in the response generation module, and then calculate the loss of the candidate responses relative to the historical dialogue through the MMI scoring model, and select the one with the smallest loss as the final response. Input the generated reply into the dialogue self-audit model, first use the pre-trained Bert model to extract text features, and then use the bidirectional LSTM model for classification to determine whether it is a sensitive sentence, if not, output the reply to the user; If it is a sensitive sentence, the reply in the dialog template set in advance is output. The inventive system can be applied to any scene for chatting.
如图1所示,本发明所述方法具体内容包括以下步骤:As shown in Figure 1, the specific content of the method of the present invention includes the following steps:
S1:本发明采用包含50w个多轮对话的语料和常见的中文闲聊语料,如豆瓣语料、电视剧对白语料等组成中文语料库。S1: The present invention uses corpus containing 50w multi-round dialogues and common Chinese chat corpus, such as Douban corpus, TV drama dialogue corpus, etc. to form a Chinese corpus.
S1.1:使用GPT2模型对语料进行训练,将中文语料中的包含的多轮对话,将每轮对话按顺序拼接,例如,″[CLS]今天好点了吗?[SEP]一天比一天严重[SEP]吃药不管用,去打一针。别拖着[SEP]″。S1.1: Use the GPT2 model to train the corpus, splicing the multiple rounds of dialogue contained in the Chinese corpus, and splicing each round of dialogue in sequence, for example, "[CLS] Is it better today? [SEP] It's getting worse every day. [SEP] The medicine doesn't help, go get an injection. Don't drag [SEP]".
S2:将输入语句采用字节对编码转化成向量,表示成一段长文本x1,x2,··,xn,并且在末尾设置结束标记符。S2: Convert the input sentence into a vector using byte pair encoding, and express it as a long text x 1 , x 2 , ··, x n , and set an end marker at the end.
S3:将一轮对话的历史对话作为源句子(Source),表示为S=x1,x2,·,xm,将语料库中回复作为目标句(Target),表示为T=xm+1,x2,·,xn,此时条件概率P(T|S)被写成如下形式:S3: Take the historical dialogue of a round of dialogue as the source sentence (Source), denoted as S=x 1 , x 2 , ·, x m , and take the reply in the corpus as the target sentence (Target), denoted as T=x m+1 , x 2 , ·, x n , the conditional probability P(T|S) is written as follows:

S4:本发明模型属于自回归语言模型,即根据上文内容来预测下一个单词,天然匹配自然语言生成过程。自回归语言模型利用文本序列联合概率的密度估计建模,公式如下:S4: The model of the present invention belongs to the autoregressive language model, that is, the next word is predicted according to the above content, and the natural language generation process is naturally matched. Autoregressive language models are modeled using density estimates of joint probabilities of text sequences with the following formula:

S4.1:本发明模型继承Transformer模型的解码器(decoder),主要由12层decoder组成。单个decoder的结构由两部分组成,掩模多头自注意力机制(masked multi-headself-attention)和前馈神经网络(Feed Forward Neural Network)组成。掩模多头注意力机制是自注意力机制的进化,自注意力机制是使用点积进行相似度计算的attention,只是多除了一个(为K的维度)起到调节作用,使得内积不至于太大。多头attention(Multi-headattention)机制,对于输入的句子里面的每个词都要和该句子中的所有词进行attention计算,目的是学习句子内部的词依赖关系,捕获句子的内部结构和语义信息。而掩模自注意力在自注意力计算的时候屏蔽了来自当前计算位置右边所有单词的信息。S4.1: The model of the present invention inherits the decoder of the Transformer model, and is mainly composed of 12-layer decoders. The structure of a single decoder consists of two parts, a masked multi-head self-attention mechanism and a Feed Forward Neural Network. The mask multi-head attention mechanism is the evolution of the self-attention mechanism. The self-attention mechanism is an attention that uses the dot product for similarity calculation, but only one more (the dimension of K) is used to adjust, so that the inner product will not be too large. big. Multi-head attention (Multi-head attention) mechanism, for each word in the input sentence, the attention calculation is performed with all the words in the sentence, the purpose is to learn the word dependencies inside the sentence, and capture the internal structure and semantic information of the sentence. The mask self-attention masks the information from all words to the right of the current calculation position during the self-attention calculation.
S5:在生成部分,每次生成词(token)后,将其添加到输入序列。新的序列就会作为模型下一步的输入内容,最终得到生成的句子。在此部分,会采用Top-k Sampling方法选取生成的多个候选句组成候选回复集。S5: In the generation part, after each token is generated, it is added to the input sequence. The new sequence will be used as the input for the next step of the model, and finally the generated sentence will be obtained. In this part, the Top-k Sampling method is used to select multiple candidate sentences to form a candidate reply set.
S6:为了避免过多地生成平淡通用、无意义的回复,本发明采用互信息最大化(MMI)作为评分函数来评价候选回复集。S6: In order to avoid generating too many bland, general and meaningless replies, the present invention adopts Mutual Information Maximization (MMI) as a scoring function to evaluate the candidate reply set.
S6.1:首先将每个候选回复与对话历史进行逆序拼接,例如,″[CLS]吃药不管用,去打一针。别拖着[SEP]一天比一天严重[SEP]今天好点了吗?[SEP]″。S6.1: First, splicing each candidate reply with the dialogue history in reverse order, for example, "[CLS] taking medicine doesn't work, go for an injection. Don't drag [SEP] getting worse day by day [SEP] Today is better ? [SEP]".
S6.2:目标是对于每一条给定的回复假设H,去预测源句子S。MMI公式如下:S6.2: The goal is to predict the source sentence S for each given reply hypothesis H. The MMI formula is as follows:

其中,logp(H)代表惩罚项,这个惩罚项的意义在于,对于在训练集中经常出现的回复H,其语言模型的概率会高于其他回复,减去这个惩罚项可以使得这些经常出现的H的得分下降。通过MMI模型可以选择惩罚平淡通用的回复,计算所有候选回复相对于对话历史的损失,最终选择损失最小的,即和对话历史紧密相关的作为最终回复。Among them, logp(H) represents the penalty item. The meaning of this penalty item is that for the reply H that often appears in the training set, the probability of its language model will be higher than that of other replies. Subtracting this penalty item can make these frequently appearing H score dropped. Through the MMI model, you can choose to penalize plain and general replies, calculate the loss of all candidate replies relative to the dialog history, and finally select the one with the smallest loss, that is, the one closely related to the dialog history as the final reply.
S7:对于生成的回复送进对话自审核模块进行判断是否敏感词。该模块中的自审核模型由提取特征部分和分类模型两部分组成。S7: Send the generated reply to the dialogue self-audit module to judge whether it is a sensitive word. The self-audit model in this module consists of two parts: the extraction feature part and the classification model.
S7.1:其中,提取特征部分采用预训练的Bert模型提取文本特征。S7.1: In the feature extraction part, the pre-trained Bert model is used to extract text features.
S7.2:分类模型采用双向LSTM模型。采用标注的语料进行训练,得到训练模型。S7.2: The classification model adopts a bidirectional LSTM model. The labeled corpus is used for training, and the training model is obtained.
LSTM公式如下:The LSTM formula is as follows:
ot=σ(Wo[ht-1,xt]+bo)o t =σ(W o [h t-1 , x t ]+b o )
ht=ot*tanh(Ct)h t =o t *tanh(C t )
其中,ht-1表示前一时刻的隐藏层状态,xt代表当前时刻的输入词,Ct代表当前时刻细胞状态。Ct的计算公式如下:Among them, h t-1 represents the hidden layer state at the previous moment, x t represents the input word at the current moment, and C t represents the cell state at the current moment. The formula for calculating Ct is as follows:
Ct=ft*ct-1+it*ct C t =f t *c t-1 +i t *c t
其中,in,
ct=tanh(Wc·[ht-1,xt])+bc c t =tanh(W c ·[h t-1 , x t ])+b c
ft=σ(Wf·[ht-1,xt]+bf)f t =σ(W f ·[h t-1 , x t ]+b f )
W为神经网络的参数,b为神经元偏置。W is the parameter of the neural network, and b is the neuron bias.
S7.3:调用已训练好的分类模型判断回复是否包含敏感词。如果包含敏感词,就输出回复模板中的任意回复给用户,比如″啊~我不知道要怎么回答″、″嘿嘿嘿~″、″你说的都是对的!″、″什么鬼~哈哈哈″、″你在说什么鸭~″、″这个问题我还不知道哦,换个问题问我吧~″等;如果判断不包含敏感词,就输出上述S6.2步骤得到的回复,展示给用户。S7.3: Call the trained classification model to determine whether the reply contains sensitive words. If it contains sensitive words, it will output any reply in the reply template to the user, such as "Ah~ I don't know how to answer", "Hehehe~", "What you said is right!", "What the hell~ha Haha", "what are you talking about duck~", "I don't know this question yet, ask me another question~", etc.; if it is judged that no sensitive words are included, output the reply obtained in the above step S6.2 and show it to user.
本发明系统可与用户实现闲聊对话,用户输入任意话语,通过对话回复生成模块中的神经网络模型可生成多个候选回复,并采用评分模型选择和对话历史更相关的回复而不只是通用的回复,使用户拥有更愉快的聊天体验。该方法较传统的生成式方法相比可以提高聊天机器人回复的准确度和相关度。同时该对话系统中的对话自审核模型可以自动过滤带有敏感词的回复,避免因为一句脏话或者带有攻击意味的话语而影响用户体验,在对话过程中始终保持良好互动存在。The system of the present invention can realize chatting with the user, the user can input any words, multiple candidate replies can be generated through the neural network model in the dialog reply generation module, and the scoring model is used to select replies that are more relevant to the conversation history instead of just general replies , so that users have a more pleasant chat experience. Compared with traditional generative methods, this method can improve the accuracy and relevance of chatbot responses. At the same time, the dialogue self-audit model in the dialogue system can automatically filter the replies with sensitive words, avoid affecting the user experience due to a swearing or offensive words, and always maintain a good interaction in the dialogue process.
本发明可提供多领域的自由开放式对话,就一个话题可与用户完成多轮对话。这种没有明确任务目标的对话更加拟人化,对于客户营销、教育、心理治疗等领域都有极大的应用价值。同时本模型的设计充分考虑对话历史信息,相当于在对话过程中有着主题约束,避免与用户对话过程中出现别的话题类发言,并且捕捉用户言语风格,始终保持与用户的良好互动。The present invention can provide free and open dialogues in multiple fields, and can complete multiple rounds of dialogues with users on a topic. This kind of dialogue without a clear task goal is more anthropomorphic and has great application value for customer marketing, education, psychotherapy and other fields. At the same time, the design of this model fully considers the dialogue history information, which is equivalent to having topic constraints in the dialogue process, avoiding other topical speeches in the process of dialogue with users, capturing the user's speech style, and always maintaining good interaction with users.
本发明中的模型采用自注意力机制,相对于传统的RNN或LSTM结构,从语法和语义等多个层面学习对话中的重要信息,赋予了模型关注不同位置的能力,避免信息的过载与丢失,同时避免模型中过多的序列依赖关系,从而提高模型的并行计算能力。The model in the present invention adopts a self-attention mechanism. Compared with the traditional RNN or LSTM structure, it learns important information in the dialogue from multiple levels such as syntax and semantics, which endows the model with the ability to focus on different positions and avoids information overload and loss. , while avoiding excessive sequence dependencies in the model, thereby improving the parallel computing power of the model.
本发明系统的对话自审核模块可对生成的回复内容进行审核,判断是否属于脏话或敏感话语,模拟人类思维模式,相当于从道德层面约束系统,避免向用户发送敏感话语而造成不好的体验,始终保持在对话场景下输出合适的、令人舒服的话语,使客户拥有愉快的聊天体验。The dialogue self-audit module of the system of the present invention can audit the generated reply content, judge whether it is swear words or sensitive words, simulate the human thinking mode, which is equivalent to restraining the system from the moral level, and avoid sending sensitive words to users and causing bad experience , and always keep outputting appropriate and comfortable words in the dialogue scene, so that customers have a pleasant chat experience.
以上对本申请实施例所提供的自审核的人机对话方法、系统及可读存储介质,进行了详细介绍。以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。The self-audit man-machine dialogue method, system, and readable storage medium provided by the embodiments of the present application are described above in detail. The description of the above embodiment is only used to help understand the method of the present application and its core idea; meanwhile, for those of ordinary skill in the art, according to the idea of the present application, there will be changes in the specific embodiment and the scope of application, In conclusion, the content of this specification should not be construed as a limitation on the present application.
如在说明书及权利要求书当中使用了某些词汇来指称特定组件。本领域技术人员应可理解,硬件制造商可能会用不同名词来称呼同一个组件。本说明书及权利要求书并不以名称的差异来作为区分组件的方式,而是以组件在功能上的差异来作为区分的准则。如在通篇说明书及权利要求书当中所提及的“包含”、“包括”为一开放式用语,故应解释成“包含/包括但不限定于”。“大致”是指在可接收的误差范围内,本领域技术人员能够在一定误差范围内解决所述技术问题,基本达到所述技术效果。说明书后续描述为实施本申请的较佳实施方式,然所述描述乃以说明本申请的一般原则为目的,并非用以限定本申请的范围。本申请的保护范围当视所附权利要求书所界定者为准。As certain terms are used in the specification and claims to refer to particular components. It should be understood by those skilled in the art that hardware manufacturers may refer to the same component by different nouns. The present specification and claims do not use the difference in name as a way to distinguish components, but use the difference in function of the components as a criterion for distinguishing. As mentioned in the entire specification and claims, "comprising" and "including" are open-ended terms, so they should be interpreted as "including/including but not limited to". "Approximately" means that within an acceptable error range, those skilled in the art can solve the technical problem within a certain error range, and basically achieve the technical effect. Subsequent descriptions in the specification are preferred embodiments for implementing the present application. However, the descriptions are for the purpose of illustrating the general principles of the present application and are not intended to limit the scope of the present application. The scope of protection of this application should be determined by the appended claims.
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的商品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种商品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的商品或者系统中还存在另外的相同要素。It should also be noted that the terms "comprising", "comprising" or any other variation thereof are intended to encompass non-exclusive inclusion, such that a commodity or system comprising a list of elements includes not only those elements, but also includes not explicitly listed other elements, or elements inherent to the commodity or system. Without further limitation, an element defined by the phrase "comprising a..." does not preclude the presence of additional identical elements in the article or system that includes the element.
应当理解,本文中使用的术语“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。It should be understood that the term "and/or" used in this document is only an association relationship to describe the associated objects, indicating that there may be three kinds of relationships, for example, A and/or B, which may indicate that A exists alone, and A and B exist at the same time. B, there are three cases of B alone. In addition, the character "/" in this document generally indicates that the related objects are an "or" relationship.
上述说明示出并描述了本申请的若干优选实施例,但如前所述,应当理解本申请并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述申请构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本申请的精神和范围,则都应在本申请所附权利要求书的保护范围内。The above description shows and describes several preferred embodiments of the present application, but as mentioned above, it should be understood that the present application is not limited to the form disclosed herein, and should not be regarded as excluding other embodiments, but can be used in various various other combinations, modifications and environments, and can be modified within the scope of the concept of the application described herein, using the above teachings or skill or knowledge in the relevant field. However, modifications and changes made by those skilled in the art do not depart from the spirit and scope of the present application, and should all fall within the protection scope of the appended claims of the present application.
Claims (10)



Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011018603.6A CN112131367A (en) | 2020-09-24 | 2020-09-24 | Self-auditing man-machine conversation method, system and readable storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011018603.6A CN112131367A (en) | 2020-09-24 | 2020-09-24 | Self-auditing man-machine conversation method, system and readable storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112131367A true CN112131367A (en) | 2020-12-25 |
Family
ID=73839365
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011018603.6A Pending CN112131367A (en) | 2020-09-24 | 2020-09-24 | Self-auditing man-machine conversation method, system and readable storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112131367A (en) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112905763A (en) * | 2021-02-03 | 2021-06-04 | 深圳市人马互动科技有限公司 | Session system development method, device, computer equipment and storage medium |
| CN113220856A (en) * | 2021-05-28 | 2021-08-06 | 天津大学 | Multi-round dialogue system based on Chinese pre-training model |
| CN114706955A (en) * | 2022-04-07 | 2022-07-05 | 北京邮电大学 | Training method and device for dialogue response generation model and dialogue response generation method |
| CN114925192A (en) * | 2022-07-21 | 2022-08-19 | 北京聆心智能科技有限公司 | Man-machine collaborative dialogue method, device, equipment and storage medium |
| CN115293132A (en) * | 2022-09-30 | 2022-11-04 | 腾讯科技(深圳)有限公司 | Conversation processing method and device of virtual scene, electronic equipment and storage medium |
| CN116483974A (en) * | 2023-04-24 | 2023-07-25 | 平安科技(深圳)有限公司 | Dialogue reply screening method, device, equipment and storage medium |
| CN116710986A (en) * | 2021-02-22 | 2023-09-05 | 腾讯美国有限责任公司 | Dialogue Model Training with No-Reference Discriminators |
| CN118805166A (en) * | 2023-07-11 | 2024-10-18 | 杨子言 | A compliance detection method, device, equipment and medium for large language model data interaction |
| WO2025010882A1 (en) * | 2023-07-11 | 2025-01-16 | 杨子言 | Compliance detection method and apparatus for large language model data interaction, device, and medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108681610A (en) * | 2018-05-28 | 2018-10-19 | 山东大学 | Production takes turns more and chats dialogue method, system and computer readable storage medium |
| CN109547331A (en) * | 2018-11-22 | 2019-03-29 | 大连智讯科技有限公司 | Multi-round voice chat model construction method |
| CN110347817A (en) * | 2019-07-15 | 2019-10-18 | 网易(杭州)网络有限公司 | Intelligent response method and device, storage medium, electronic equipment |
| CN111061874A (en) * | 2019-12-10 | 2020-04-24 | 苏州思必驰信息科技有限公司 | Sensitive information detection method and device |
| CN111291172A (en) * | 2020-03-05 | 2020-06-16 | 支付宝(杭州)信息技术有限公司 | Method and device for processing text |
-
2020
- 2020-09-24 CN CN202011018603.6A patent/CN112131367A/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108681610A (en) * | 2018-05-28 | 2018-10-19 | 山东大学 | Production takes turns more and chats dialogue method, system and computer readable storage medium |
| CN109547331A (en) * | 2018-11-22 | 2019-03-29 | 大连智讯科技有限公司 | Multi-round voice chat model construction method |
| CN110347817A (en) * | 2019-07-15 | 2019-10-18 | 网易(杭州)网络有限公司 | Intelligent response method and device, storage medium, electronic equipment |
| CN111061874A (en) * | 2019-12-10 | 2020-04-24 | 苏州思必驰信息科技有限公司 | Sensitive information detection method and device |
| CN111291172A (en) * | 2020-03-05 | 2020-06-16 | 支付宝(杭州)信息技术有限公司 | Method and device for processing text |
Non-Patent Citations (9)
| Title |
|---|
| JAYLOU: "NLP 中的预训练语言模型总结", pages 1 - 20, Retrieved from the Internet <URL:https://www.infoq.cn/article/4SRM7UMVS4GdD9A90wff> * |
| ZHANG Y 等: "Dialogpt: Large-scale generative pre-training for conversational response generation", HTTPS://DOI.ORG/10.48550/ARXIV .1911. 00536, pages 1 - 10 * |
| ZHANG Y 等: "Dialogpt: Large-scale generative pre-training for conversational response generation", pages 1 - 10, Retrieved from the Internet <URL:https://doi.org/10.48550/arXiv .1911. 00536> * |
| ZHANG Y 等: "ialogpt: Large-scale generative pre-training for conversational response generation", pages 1 - 10, Retrieved from the Internet <URL:https://doi.org/10.48550/arXiv .1911. 00536> * |
| 啊黎: "李纪为论文集(1) - A Diversity-Promoting Objective Function for Neural Conversation Models 论文浅析", pages 1 - 5, Retrieved from the Internet <URL:https://zhuanlan.zhihu.com/p/35496909> * |
| 啊黎: "李纪为论文集(1) - A Diversity-Promoting Objective Function for Neural Conversation Models论文浅析", HTTPS://ZHUANLAN.ZHIHU.COM/P/35496909, pages 1 - 5 * |
| 徐畅;周志平;赵卫东;: "基于深度学习的回复类型预测聊天机器人", 计算机应用研究, no. 1, pages 223 - 224 * |
| 红雨瓢泼: "基于 GPT2 与DialoGPT 的 MMI 思想的中文闲聊模型:GPT2-chitchat", pages 1 - 9, Retrieved from the Internet <URL:https://zhuanlan.zhihu.com/p/101151633> * |
| 红雨瓢泼: "基于GPT2与DialoGPT的MMI思想的中文闲聊模型:GPT2-chitchat", HTTPS://ZHUANLAN.ZHIHU.COM/P/101151633, pages 1 - 9 * |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112905763A (en) * | 2021-02-03 | 2021-06-04 | 深圳市人马互动科技有限公司 | Session system development method, device, computer equipment and storage medium |
| CN112905763B (en) * | 2021-02-03 | 2023-10-24 | 深圳市人马互动科技有限公司 | Session system development method, device, computer equipment and storage medium |
| CN116710986A (en) * | 2021-02-22 | 2023-09-05 | 腾讯美国有限责任公司 | Dialogue Model Training with No-Reference Discriminators |
| CN113220856A (en) * | 2021-05-28 | 2021-08-06 | 天津大学 | Multi-round dialogue system based on Chinese pre-training model |
| CN114706955A (en) * | 2022-04-07 | 2022-07-05 | 北京邮电大学 | Training method and device for dialogue response generation model and dialogue response generation method |
| CN114925192A (en) * | 2022-07-21 | 2022-08-19 | 北京聆心智能科技有限公司 | Man-machine collaborative dialogue method, device, equipment and storage medium |
| CN115293132A (en) * | 2022-09-30 | 2022-11-04 | 腾讯科技(深圳)有限公司 | Conversation processing method and device of virtual scene, electronic equipment and storage medium |
| CN116483974A (en) * | 2023-04-24 | 2023-07-25 | 平安科技(深圳)有限公司 | Dialogue reply screening method, device, equipment and storage medium |
| CN118805166A (en) * | 2023-07-11 | 2024-10-18 | 杨子言 | A compliance detection method, device, equipment and medium for large language model data interaction |
| WO2025010882A1 (en) * | 2023-07-11 | 2025-01-16 | 杨子言 | Compliance detection method and apparatus for large language model data interaction, device, and medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112131367A (en) | Self-auditing man-machine conversation method, system and readable storage medium | |
| CN114722838B (en) | Conversational emotion recognition method based on common sense perception and hierarchical multi-task learning | |
| CN111488739B (en) | Implicit Discourse Recognition Method Based on Multi-Granularity Generated Image Enhanced Representation | |
| CN115329779B (en) | Multi-person dialogue emotion recognition method | |
| Su et al. | LSTM-based text emotion recognition using semantic and emotional word vectors | |
| CN111460132B (en) | Generation type conference abstract method based on graph convolution neural network | |
| CN109992780B (en) | Specific target emotion classification method based on deep neural network | |
| CN105589844B (en) | It is a kind of to be used to take turns the method for lacking semantic supplement in question answering system more | |
| CN112818107B (en) | Conversation robot for daily life and chat method thereof | |
| CN112101045B (en) | A multimodal semantic integrity recognition method, device and electronic device | |
| CN114064918A (en) | Multi-modal event knowledge graph construction method | |
| CN108829662A (en) | A kind of conversation activity recognition methods and system based on condition random field structuring attention network | |
| CN108549658B (en) | Deep learning video question-answering method and system based on attention mechanism on syntax analysis tree | |
| CN110647612A (en) | Visual conversation generation method based on double-visual attention network | |
| CN108874972A (en) | A kind of more wheel emotion dialogue methods based on deep learning | |
| CN111046157B (en) | Universal English man-machine conversation generation method and system based on balanced distribution | |
| CN112818106A (en) | Evaluation method of generating type question and answer | |
| Okur et al. | Data augmentation with paraphrase generation and entity extraction for multimodal dialogue system | |
| CN112287106A (en) | An online review sentiment classification method based on two-channel hybrid neural network | |
| CN114428850A (en) | Text retrieval matching method and system | |
| CN108595436A (en) | The generation method and system of emotion conversation content, storage medium | |
| CN112307179A (en) | Text matching method, apparatus, device and storage medium | |
| CN109271636B (en) | Training method and device for word embedding model | |
| CN113239666A (en) | Text similarity calculation method and system | |
| CN111144410A (en) | Cross-modal image semantic extraction method, system, device and medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication |
Application publication date: 20201225 |