CN112069059A - Test case generation method and system based on maximum likelihood estimation - Google Patents
Test case generation method and system based on maximum likelihood estimation Download PDFInfo
- Publication number
- CN112069059A CN112069059A CN202010811968.8A CN202010811968A CN112069059A CN 112069059 A CN112069059 A CN 112069059A CN 202010811968 A CN202010811968 A CN 202010811968A CN 112069059 A CN112069059 A CN 112069059A
- Authority
- CN
- China
- Prior art keywords
- sub
- region
- found
- test case
- regions
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/36—Prevention of errors by analysis, debugging or testing of software
- G06F11/3668—Testing of software
- G06F11/3672—Test management
- G06F11/3684—Test management for test design, e.g. generating new test cases
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/36—Prevention of errors by analysis, debugging or testing of software
- G06F11/3668—Testing of software
- G06F11/3672—Test management
- G06F11/3688—Test management for test execution, e.g. scheduling of test suites
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computer Hardware Design (AREA)
- Quality & Reliability (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Debugging And Monitoring (AREA)
Abstract
本发明公开了一种基于极大似然估计最大期望的测试用例生成方法及系统,包括将软件的输入域划分成多个子区域,并将输入域的边界区域与内部区域区别开来,将边界区域作为优先级最高的子区域;引入潜变量并结合EM算法估计内部区域中子区域里可能包含失效区域的概率,基于概率大小对内部区域中子区域进行排序;按照子区域的优先级顺序生成测试用例,直至发现软件错误;若测试用例数达到预设条件仍未发现软件错误,则继续在优先级最高的子区域生成测试用例,直至发现软件错误。本发明的方法可以很好地解决现有ART方法存在的巨大计算开销问题,并在一定程度上解决了先前ART方法的边界效应问题,同时提高了运行效率。
The invention discloses a method and system for generating a test case based on maximum likelihood estimation and maximum expectation. The area is regarded as the sub-area with the highest priority; latent variables are introduced and combined with the EM algorithm to estimate the probability that the sub-area in the inner area may contain a failure area, and the sub-areas of the inner area are sorted based on the probability; generated according to the priority order of the sub-areas Test cases until software errors are found; if the number of test cases reaches the preset condition and no software errors are found, continue to generate test cases in the sub-region with the highest priority until software errors are found. The method of the present invention can well solve the huge computational cost problem existing in the existing ART method, and to a certain extent, solves the boundary effect problem of the previous ART method, and simultaneously improves the operation efficiency.
Description
技术领域technical field
本发明涉及计算机技术领域,具体涉及一种基于极大似然估计最大期望的测试用例生成方法及系统。The invention relates to the field of computer technology, in particular to a method and system for generating a test case based on maximum likelihood estimation of maximum expectation.
背景技术Background technique
软件测试是软件开发过程中的一个重要环节,它可以通过人工或者自动化的手段来运行整个系统或部分模块,根据预期结果与实际结果是否一致来判断该软件的整体或局部功能是否满足规定的需求。当前,软件测试领域中的技术的种类十分繁多,其中最常见的软件测试技术是白盒测试、灰盒测试、黑盒测试这三大类。但是,无论测试人员选择使用哪一种测试方法,想要对软件的输入域进行完全测试是几乎不可能实现的,因此,较常见的做法是从软件输入域的一些有代表性的子集中选择测试用例来进行测试。Software testing is an important link in the software development process. It can run the entire system or some modules by manual or automated means, and judge whether the overall or partial functions of the software meet the specified requirements according to whether the expected results are consistent with the actual results. . At present, there are many types of technologies in the field of software testing, among which the most common software testing technologies are white-box testing, gray-box testing, and black-box testing. However, no matter which testing method the tester chooses to use, it is nearly impossible to fully test the input domain of the software, so it is more common to select from some representative subset of the software input domain Test cases to test.
随机测试是在输入域中随机生成实验所需要的测试用例。但由于其产生测试用例的随机性,该方法发现错误的能力并不高。Random tests are the test cases needed to randomly generate experiments in the input domain. However, due to the randomness of the test cases it generates, the ability of this method to detect errors is not high.
针对随机测试发现错误的能力较差的缺点,对随机测试进行改进,现有技术提出了 ART方法(自适应随机测试),其中经典的ART方法当属固定候选集规模的适应性随机测试方法。FSCS-ART方法(固定候选集的自适应随机测试)由于能够保证测试用例更加均匀地分布在软件输入域中,因而使发现错误的能力得到了很大提高。Aiming at the disadvantage of poor ability of random testing to find errors, the random testing is improved. The prior art proposes the ART method (adaptive random testing), among which the classic ART method is an adaptive random testing method with a fixed candidate set size. The FSCS-ART method (Adaptive Random Testing with Fixed Candidate Sets) greatly improves the ability to detect errors by ensuring that test cases are more evenly distributed in the software input domain.
但是,由于FSCS-ART方法引入了大量距离计算而导致了方法的系统计算资源开销十分巨大。而且由于FSCS-ART选择测试用例的特点,导致了其选择用来测试软件的测试用例容易堆积在软件输入域边界,从而影响检测软件错误的效果,这也就是边界效应。However, because the FSCS-ART method introduces a large number of distance calculations, the system computing resource overhead of the method is very huge. Moreover, due to the characteristics of FSCS-ART's selection of test cases, the test cases it chooses to test software tend to accumulate on the boundary of the software input domain, thereby affecting the effect of detecting software errors, which is the boundary effect.
专利申请201811501282.8提出了一种基于迭代区域均分与定位的自适应随机测试方法。Patent application 201811501282.8 proposes an adaptive random testing method based on iterative region averaging and localization.
专利申请201911030817.2提出了一种基于中心点补偿策略的自适应随机测试用例生成方法。Patent application 201911030817.2 proposes an adaptive random test case generation method based on the center point compensation strategy.
基于中心点补偿策略的自适应随机测试用例生成方法以及基于迭代区域均分与定位的自适应随机测试方法,这两个方法都对输入域进行了划分,但是对于用于测试用例生成的划分的子区域的选择都是随机的,这虽然在一定程度上减少了传统ART方法计算开销大的问题,但是对子区域的随机选择的盲目性,并不能很好地提高测试的效率。因此,本技术领域亟待提出新的具有实际应用意义的技术方案。The adaptive random test case generation method based on the center point compensation strategy and the adaptive random test method based on iterative area averaging and localization, both of which divide the input domain, but for the division used for test case generation The selection of sub-regions is random, which reduces the computational cost of the traditional ART method to a certain extent, but the blindness of the random selection of sub-regions cannot improve the test efficiency. Therefore, new technical solutions with practical application significance are urgently needed in the technical field.
发明内容SUMMARY OF THE INVENTION
本发明的目的在于针对现有技术中的方法存在的大量距离计算而导致了方法的计算开销十分巨大以及测试用例容易堆积在软件输入域边界的边界效应问题,提供了一种基于极大似然估计最大期望的测试用例生成方案。The purpose of the present invention is to provide a method based on the maximum likelihood based on the problem of boundary effect that the method in the prior art has a large number of distance calculations, resulting in a huge computational cost and easy accumulation of test cases on the boundary of the software input domain. Estimate the maximum expected test case generation scenario.
本发明技术方案提供提供一种基于极大似然估计最大期望的测试用例生成方法,包括以下步骤,The technical solution of the present invention provides a test case generation method based on maximum likelihood estimation and maximum expectation, comprising the following steps:
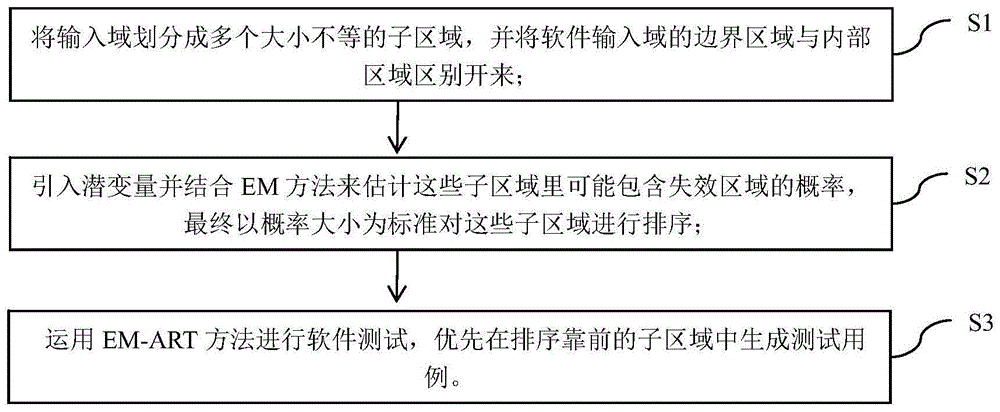
步骤S1,将软件的输入域划分成多个子区域,并将输入域的边界区域与内部区域区别开来,将边界区域作为优先级最高的子区域;In step S1, the input domain of the software is divided into multiple sub-regions, and the boundary region of the input domain is distinguished from the internal region, and the boundary region is regarded as the sub-region with the highest priority;
步骤S2,引入潜变量并结合EM算法估计内部区域中子区域里可能包含失效区域的概率,基于概率大小对内部区域中子区域进行排序;In step S2, latent variables are introduced and combined with the EM algorithm to estimate the probability that the sub-regions in the inner region may contain failure regions, and the sub-regions in the inner region are sorted based on the size of the probability;
步骤S3,按照子区域的优先级顺序生成测试用例,直至发现软件错误;若测试用例数达到预设条件仍未发现软件错误,则继续在优先级最高的子区域生成测试用例,直至发现软件错误。Step S3, generate test cases according to the priority order of the sub-areas until software errors are found; if the number of test cases reaches the preset condition and no software errors are found, continue to generate test cases in the sub-areas with the highest priority until software errors are found .
而且,步骤S1包括以下子步骤,Moreover, step S1 includes the following sub-steps,
步骤S1.1,根据输入域的失效率设置内部区域的边界长度,得到内部区域之外的边界区域,记为D1;Step S1.1, set the boundary length of the inner area according to the failure rate of the input domain, and obtain the boundary area outside the inner area, denoted as D1;
步骤S1.2,将边界区域D1的优先级排在第一位,并将内部区域划分成大小相同的两部分,记为子区域D2和D3。In step S1.2, the priority of the boundary area D1 is ranked first, and the inner area is divided into two parts of the same size, which are denoted as sub-areas D2 and D3.
而且,输入域为二维正方形时,设置内部区域的边界长度如下,Moreover, when the input domain is a two-dimensional square, set the boundary length of the inner area as follows,

其中,b为内部区域边长,a为总体的输入域边长,θ为失效率。Among them, b is the edge length of the inner region, a is the edge length of the overall input region, and θ is the failure rate.
而且,步骤S2包括以下子步骤,Moreover, step S2 includes the following sub-steps,
步骤S2.1,随机在两个内部子区域D2和D3内各产生1000个测试用例,并分别统计其中发现软件错误的测试用例的个数;Step S2.1, randomly generate 1000 test cases in each of the two internal sub-areas D2 and D3, and count the number of test cases in which software errors are found respectively;
步骤S2.2,用测试用例发现错误且落在子区域的概率替换子区域能够发现软件错误的概率;Step S2.2, replace the probability that the sub-region can find the software error with the probability that the test case finds the error and falls in the sub-region;
步骤S2.3,引入潜变量,使用EM算法对上一步的概率参数进行迭代直到参数收敛,并将达到收敛时的参数值作为其极大似然估计量;Step S2.3, introduce latent variables, use the EM algorithm to iterate the probability parameters of the previous step until the parameters converge, and use the parameter values when convergence is reached as its maximum likelihood estimator;
步骤S2.4,通过比较概率的大小,将两个内部子区域D2和D3的优先级进行排序;Step S2.4, sorting the priorities of the two internal sub-regions D2 and D3 by comparing the probabilities;
步骤S2.5,将两个内部子区域分别进一步划分成两个相同大小的两部分,设子区域D2 划分为D4与D5,D3划分为D6与D7,针对D4与D5重复上述步骤S2.1至步骤S2.4,针对D6与D7重复上述步骤S2.1至步骤S2.4;In step S2.5, the two internal sub-regions are further divided into two parts of the same size, and the sub-region D2 is divided into D4 and D5, D3 is divided into D6 and D7, and the above step S2.1 is repeated for D4 and D5. Go to step S2.4, repeat the above steps S2.1 to S2.4 for D6 and D7;
步骤S2.6,对所有划分的子区域的优先级进行排序,确定子区域D1、D4、D5、D6与D7的优先级顺序。Step S2.6, sort the priorities of all the divided sub-regions, and determine the priority order of the sub-regions D1, D4, D5, D6 and D7.
而且,步骤S3实现方式如下,Moreover, the implementation of step S3 is as follows:
1)首先从优先级最高的边界区域中不断生成测试用例,并执行测试,若发现软件错误,则停止;若未发现软件错误,且总的测试用例生成数达到了预先设置的阈值后,则在优先级第二的子区域中生成测试用例,并执行测试,若发现软件错误,则停止;若未发现软件错误,且总的测试用例生成数达到了预先设置的阈值后,则在优先级第三的子区域中生成测试用例,并执行测试,若发现软件错误,则停止;依次类推,在不断降低优先等级后,若在优先级最低的子区域仍未发现软件错误,且总的测试用例生成数达到了预先设置的阈值后,则进入步骤2);1) First, continuously generate test cases from the boundary area with the highest priority, and execute the test. If software errors are found, stop; if no software errors are found, and the total number of test cases generated reaches the preset threshold, then Generate test cases in the sub-area with the second priority, and execute the test. If software errors are found, stop; if no software errors are found, and the total number of test cases generated reaches the preset threshold, it will be executed at the priority level. Generate test cases in the third sub-area, and execute the test. If software errors are found, stop; and so on, after continuously lowering the priority level, if no software errors are found in the sub-area with the lowest priority, and the total test After the number of use cases generated reaches the preset threshold, go to step 2);
2)如果当前已经执行步骤1)一次,则返回执行步骤1),如果当前已经重复执行步骤1)两次,则改为只在优先级最高的边界区域中继续生成测试用例,并执行测试,直至发现软件错误或达到预设的测试次数上限后停止。2) If step 1) has been executed once, return to execute step 1), if step 1) has been repeatedly executed twice, instead, continue to generate test cases only in the boundary area with the highest priority, and execute the test, Stop until a software error is found or the preset upper limit of the number of tests is reached.
而且,阈值设置的优选取值为10。Also, the preferred value for the threshold setting is 10.
本发明还相应提供一种基于极大似然估计最大期望的测试用例生成系统,用于实现如上所述的一种基于极大似然估计最大期望的测试用例生成方法。The present invention also correspondingly provides a test case generation system based on maximum likelihood estimation for maximum expectation, which is used for realizing the above-mentioned method for generating test case based on maximum likelihood estimation for maximum expectation.
而且,包括以下模块,Also, the following modules are included,
第一模块,用于将软件的输入域划分成多个子区域,并将输入域的边界区域与内部区域区别开来,将边界区域作为优先级最高的子区域;The first module is used to divide the input domain of the software into a plurality of sub-regions, distinguish the boundary region of the input domain from the internal region, and use the boundary region as the sub-region with the highest priority;
第二模块,用于引入极大似然估计最大期望方式,估计内部区域中子区域里可能包含失效区域的概率,基于概率大小对内部区域中子区域进行排序;The second module is used to introduce the maximum likelihood estimation method, estimate the probability that the sub-regions in the inner region may contain failure regions, and sort the sub-regions in the inner region based on the probability;
第三模块,用于按照子区域的优先级顺序生成测试用例,直至发现软件错误;若测试用例数达到预设条件仍未发现软件错误,则继续在优先级最高的子区域生成测试用例,直至发现软件错误。The third module is used to generate test cases according to the priority order of the sub-areas until software errors are found; if the number of test cases reaches the preset condition and no software errors are found, continue to generate test cases in the sub-area with the highest priority until A software bug was found.
或者,包括处理器和存储器,存储器用于存储程序指令,处理器用于调用处理器中的存储指令执行如上所述的一种基于极大似然估计最大期望的测试用例生成方法。Or, it includes a processor and a memory, the memory is used to store program instructions, and the processor is used to call the stored instructions in the processor to execute the above-mentioned method for generating a test case based on maximum likelihood estimation and maximum expectation.
或者,包括可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序执行时,实现如上所述的一种基于极大似然估计最大期望的测试用例生成方法。Alternatively, it includes a readable storage medium on which a computer program is stored, and when the computer program is executed, implements the above-mentioned method for generating a test case based on maximum likelihood estimation and maximum expectation.
本发明公开了一种基于极大似然估计最大期望的测试用例生成方案,首先将输入域划分成多个大小不等的子区域,引入潜变量并结合EM方法来估计这些子区域里可能包含失效区域的概率,最终以概率大小为标准对这些子区域进行排序,并优先在排序靠前的子区域中生成测试用例。本发明的方法可以很好地解决了先前ART方法存在的巨大计算开销问题,并在一定程度上解决了先前ART方法的边界效应问题,同时提高了运行效率。The invention discloses a test case generation scheme based on maximum likelihood estimation and maximum expectation. First, the input domain is divided into a plurality of sub-regions of different sizes, latent variables are introduced and combined with the EM method to estimate that the sub-regions may contain The probability of failure areas is finally sorted according to the probability size, and test cases are generated in the sub-areas that are ranked first. The method of the present invention can well solve the huge computational cost problem of the previous ART method, and to a certain extent, solve the boundary effect problem of the previous ART method, and at the same time improve the operation efficiency.
附图说明Description of drawings
图1为本发明实施例提供的一种基于极大似然估计最大期望的测试用例生成方法的流程图;1 is a flowchart of a test case generation method based on maximum likelihood estimation and maximum expectation provided by an embodiment of the present invention;
图2为本发明实施例EM-ART方法第一步迭代过程展示图,其中(a)部分为D1、 D2、D3划分示意图,(b)部分为D2.1、D2.2、D3.1、D3.2虚拟划分示意图;FIG. 2 is a diagram showing the iterative process of the first step of the EM-ART method according to an embodiment of the present invention, wherein part (a) is a schematic diagram of the division of D1, D2, and D3, and part (b) is D2.1, D2.2, D3.1, D3.2 Schematic diagram of virtual division;
图3为本发明实施例EM-ART方法第二步迭代过程展示图,其中(a)部分为D4、 D5划分示意图,(b)部分为D4.1、D4.2、D5.1、D5.2虚拟划分示意图;3 is a diagram showing the iterative process of the second step of the EM-ART method according to an embodiment of the present invention, wherein part (a) is a schematic diagram of the division of D4 and D5, and part (b) is D4.1, D4.2, D5.1, and D5. 2 The schematic diagram of virtual division;
图4为本发明实施例EM-ART方法第三步迭代过程及最终划分结果展示图,其中(a)部分为D6.1、D6.2、D7.1、D7.2虚拟划分示意图;,(b)部分为D6、D7划分示意图。4 is a display diagram of the iterative process of the third step of the EM-ART method and the final division result according to the embodiment of the present invention, wherein part (a) is a schematic diagram of the virtual division of D6.1, D6.2, D7.1, and D7.2; ( Part b) is a schematic diagram of the division of D6 and D7.
具体实施方式Detailed ways
本发明提供一种基于极大似然估计最大期望的测试用例生成方法,包括:通过将输入域划分成多个大小不等的子区域,引入潜变量并结合EM方法来估计这些子区域里可能包含失效区域的概率,最终以概率大小为标准对这些子区域进行排序,并优先在排序靠前的子区域中生成测试用例,从而减少了计算开销且缓解了边界效应。为符合本技术领域习惯,现将本发明所提出基于极大似然估计最大期望的测试用例生成方法简称为 EM-ART方法。The present invention provides a test case generation method based on maximum likelihood estimation of maximum expectation, which includes: by dividing the input domain into a plurality of sub-regions of different sizes, introducing latent variables and combining EM method to estimate the possibility in these sub-regions Including the probability of failure regions, these sub-regions are finally sorted based on the probability size, and test cases are generated in the top-ranked sub-regions first, thereby reducing computational overhead and mitigating boundary effects. In order to conform to the custom in the technical field, the test case generation method based on maximum likelihood estimation and maximum expectation proposed by the present invention is now abbreviated as EM-ART method.
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。In order to make the purposes, technical solutions and advantages of the embodiments of the present invention clearer, the technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments These are some embodiments of the present invention, but not all embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
本实施例提供了一种基于极大似然估计最大期望的测试用例生成方法,请参见图1,该方法包括:This embodiment provides a method for generating a test case based on maximum likelihood estimation of maximum expectation, see FIG. 1 , and the method includes:
步骤S1:将软件的输入域划分成多个子区域,并将输入域的边界区域与内部区域区别开来,将边界区域作为优先级最高的子区域。内部区域可以分为两个或以上子区域。本发明提出,针对现有技术中ART方法存在的边界效应问题,将输入域划分成多个大小不等的子区域,并将软件输入域的边界区域与内部区域区别开来。以二维正方形输入域为例,EM-ART方法对软件输入域划分的具体思路如图2所示。Step S1: Divide the input domain of the software into a plurality of sub-regions, distinguish the boundary region of the input domain from the inner region, and take the boundary region as the sub-region with the highest priority. The inner area can be divided into two or more sub-areas. The present invention proposes to divide the input domain into a plurality of sub-regions of different sizes, and to distinguish the boundary region from the inner region of the software input domain, aiming at the problem of the boundary effect existing in the ART method in the prior art. Taking the two-dimensional square input domain as an example, the specific idea of EM-ART method to divide the software input domain is shown in Figure 2.
在一种实施方式中,步骤S1具体包括:In one embodiment, step S1 specifically includes:
步骤S1.1:根据输入域的失效率设置内部区域的边界长度。Step S1.1: Set the boundary length of the inner region according to the failure rate of the input domain.
步骤S1.2:将边界区域的优先级排在第一位,并将内部区域划分成大小相同的两部分,得到两个内部的子区域。Step S1.2: Rank the priority of the boundary area first, and divide the inner area into two parts of the same size to obtain two inner sub-areas.
总体输入域中心设置内部正方形区域,总体输入域减去中间正方形区域后的环形区域即为边界区域。具体来说,在图2中,将边界区域设为D1,并如图2中(a)部分所示,将内部区域划分成大小相同的两部分,分别设为D2和D3。也即D2与D3的合并区域就是总体输入域中心的内部正方形区域。为了使边界区域D1比较接近真正意义上的“边界”,这里还需考虑内部正方形区域的边长,根据现有技术中对输入域的失效率及失效域的几何形状的研究,这里优选将内部正方形区域的边界长度设为
具体实施时,用户可根据应用场景设置具体问题相应的θ取值,通常θ取值较小,例如为0.01、0.005、0.002、0.001、0.0005、0.0002和0.0001。During the specific implementation, the user can set the value of θ corresponding to the specific problem according to the application scenario. Usually, the value of θ is small, such as 0.01, 0.005, 0.002, 0.001, 0.0005, 0.0002, and 0.0001.
步骤S2:针对先前ART方法存在的巨大计算开销问题,引入潜变量并结合EM方法来估计内部区域中子区域里可能包含失效区域的概率,最终以概率大小为标准对内部区域中子区域进行排序(边界区域的优先级仍排在第一位,高于所有内部区域中子区域);Step S2: Aiming at the huge computational overhead problem of the previous ART method, introduce latent variables and combine the EM method to estimate the probability that the sub-regions in the inner region may contain failure regions, and finally rank the sub-regions in the inner region based on the probability size. (Boundary regions still have priority over all inner regions neutron subregions);
本发明提出,针对现有技术中ART方法存在的巨大计算开销问题,引入潜变量并结合EM算法来估计这些子区域里可能包含失效区域的概率,最终以概率大小为标准对这些子区域进行排序。The present invention proposes that, in view of the huge computational overhead problem of the ART method in the prior art, latent variables are introduced and combined with the EM algorithm to estimate the probability that these sub-regions may contain failure regions, and finally these sub-regions are sorted based on the probability size. .
为了使测试用例能够分布得更加均匀,实施例提出再将子区域D2与D3进行二等份划分,因此先基于极大似然估计最大期望确定D2与D3的优先级顺序后,再对子区域 D2与D3内的二级子区域采用同样方式进行排序。In order to distribute the test cases more evenly, the embodiment proposes to divide the sub-regions D2 and D3 into two equal parts. Therefore, the priority order of D2 and D3 is first determined based on the maximum likelihood estimation and maximum expectation, and then the sub-regions are divided into two equal parts. The secondary sub-regions within D2 and D3 are sorted in the same way.
在一种实施方式中,步骤S2具体包括:In one embodiment, step S2 specifically includes:
步骤S2.1:随机在两个内部子区域内各产生1000个测试用例,并分别统计其中发现软件错误的测试用例的个数。Step S2.1: Randomly generate 1000 test cases in each of the two internal sub-areas, and count the number of test cases in which software errors are found respectively.
具体来说,随机在D2和D3区域内各产生1000个测试用例,并分别统计其中发现软件错误的测试用例的个数,分别记为y1和y2。Specifically, 1000 test cases are randomly generated in the D2 and D3 areas, and the number of test cases in which software errors are found are counted, which are recorded as y1 and y2 respectively.
步骤S2.2:用测试用例发现错误且落在子区域的概率替换子区域能够发现软件错误的概率。Step S2.2: Replace the probability that the sub-region can find the software error with the probability that the test case finds the error and falls in the sub-region.
具体来说,假设子区域D2中能够发现软件错误的概率为β1,子区域D3中能够发现软件错误的概率为θ-β1,由于θ取值较小导致试概率迭代结果较小,实施例对两个区域能够发现错误的概率进行特殊处理,如果将研究的事件描述为测试用例发现错误且落在子区域D2或D3中,则可以用条件概率



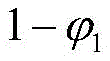
步骤S2.3:引入潜变量,使用EM方法对上一步的概率参数进行迭代直到参数收敛,并将达到收敛时的参数值作为其极大似然估计量。Step S2.3: Introduce latent variables, use the EM method to iterate the probability parameters of the previous step until the parameters converge, and use the parameter values when convergence is reached as its maximum likelihood estimator.
具体来说,如图2中(b)部分所示,假设D2和D3内部也各自存在两个子区域,其中D2可以假设分为D2.1和D2.2,假设的划分方式不限;并假设D2.1和D2.2中发现软件错误的概率分别为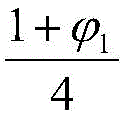
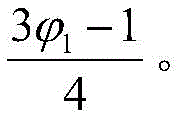


引入潜变量z1和z2后,对潜变量分别求条件期望,可以得到E步的表达式:After the latent variables z 1 and z 2 are introduced, the conditional expectation is calculated for the latent variables respectively, and the expression of step E can be obtained:

其中,in,
对上式求导并令其为零,得M步迭代公式:Taking the derivative of the above formula and setting it to zero, the M-step iterative formula is obtained:

其中,Q()指的是数学期望,i指的是迭代的次数,where Q() refers to the mathematical expectation, i refers to the number of iterations,
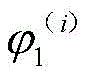

y1与y2表示D2与D3区域中发现软件错误用例数,
使用EM方法对未知参数

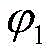



步骤S2.4:通过比较概率的大小,将两个内部子区域D2或D3的优先级进行排序。Step S2.4: Sort the priorities of the two inner sub-regions D2 or D3 by comparing the probabilities.
步骤S2.5:将两个内部子区域D2和D3分别进一步划分成两个相同大小的两部分,并重复上述步骤S2.1至步骤S2.4。Step S2.5: The two inner sub-regions D2 and D3 are further divided into two parts of the same size, and the above steps S2.1 to S2.4 are repeated.
步骤S2.6:对所有划分的子区域的优先级进行排序。Step S2.6: Sort the priorities of all divided sub-regions.
具体来说,确定了D1、D2和D3这三个子区域的优先级顺序后,如图3中(a)部分所示,再将D2区域分别按照之前相同的方式划分成两个相同的子域D4和D5。如图3 中(b)部分所示,假设D4和D5内部也各自存在两个子区域,其中D4可以假设分为D4.1 和D4.2,D5可以假设分为D5.1和D5.2,假设的划分方式不限。Specifically, after determining the priority order of the three sub-regions D1, D2 and D3, as shown in part (a) of Figure 3, the D2 region is divided into two identical sub-regions in the same way as before. D4 and D5. As shown in part (b) of Fig. 3, it is assumed that there are two sub-regions in D4 and D5, D4 can be assumed to be divided into D4.1 and D4.2, D5 can be assumed to be divided into D5.1 and D5.2, There is no limit to how the assumption is divided.
假设子区域D4中能够发现软件错误的概率为








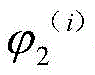

确定了D4和D5之间的优先级排序后,再对子区域D3进行与子区域D2类似的区域划分、参数迭代等处理,先将区域D3划分成了两个相等的子区域D6与D7,如图4 中(a)部分所示,假设D6和D7内部也各自存在两个子区域,其中D6可以分为D6.1和 D6.2,D7可以分为D7.1和D7.2,假设子区域D6中能够发现软件错误的概率为
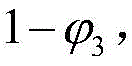
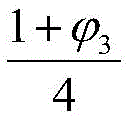



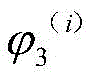
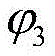


综上,如图4中(b)部分所示,经过三次参数迭代过程最终将输入域划分成了D1、D4、D5、 D6和D7这5个子区域,并对这5个子区域进行优先级排序,这就确定了之后的实验在这些子区域中产生测试用例的顺序。To sum up, as shown in part (b) of Figure 4, after three parameter iterations, the input domain is finally divided into five sub-regions D1, D4, D5, D6 and D7, and the five sub-regions are prioritized. , which determines the order in which subsequent experiments generate test cases in these subregions.
步骤S3:运用EM-ART方法进行软件测试,优先在排序靠前的子区域中生成测试用例。Step S3: Use the EM-ART method to test the software, and generate test cases in the sub-regions ranked first.
实施例中,按照子区域的优先级顺序生成测试用例,直至发现软件错误。若测试用例数达到一定程度仍未发现软件错误,则继续在优先级最高的子区域生成测试用例,直至发现软件错误。In the embodiment, the test cases are generated according to the priority order of the sub-areas until software errors are found. If the number of test cases reaches a certain level and no software errors are found, continue to generate test cases in the sub-region with the highest priority until software errors are found.
具体来说,实施例的步骤S3实现如下:Specifically, step S3 of the embodiment is implemented as follows:
1)首先从优先级最高的边界区域中不断生成测试用例,并执行测试,若发现软件错误,则停止。若未发现软件错误,且总的测试用例生成数达到了预先设置的阈值后,则在优先级第二的子区域中生成测试用例,并执行测试,若发现软件错误,则停止。若未发现软件错误,且总的测试用例生成数达到了预先设置的阈值后,则在优先级第三的子区域中生成测试用例,并执行测试,若发现软件错误,则停止。在不断降低优先等级后,若在优先级最低的子区域仍未发现软件错误,且总的测试用例生成数达到了预先设置的阈值后,则进入步骤2);1) First, continuously generate test cases from the boundary area with the highest priority, and execute the test, and stop if a software error is found. If no software errors are found, and the total number of generated test cases reaches the preset threshold, test cases are generated in the sub-area with the second priority, and the tests are executed. If software errors are found, it will stop. If no software errors are found, and the total number of test cases generated reaches the preset threshold, test cases are generated in the sub-area with the third priority, and the tests are executed. If software errors are found, it will stop. After continuously lowering the priority level, if no software error is found in the sub-region with the lowest priority, and the total number of test cases generated reaches the preset threshold, then go to step 2);
具体实施时,阈值可由本领域技术人员根据需要预先设置,实施例采用优选取值10,即按优先级顺序在每个区域依次生成10个测试用例。During specific implementation, the threshold can be preset by those skilled in the art as required. In the embodiment, a preferred value of 10 is adopted, that is, 10 test cases are sequentially generated in each area in the order of priority.
2)如果当前已经执行步骤1)一次,则返回执行步骤1),如果当前已经重复执行步骤1)两次,则改为只在优先级最高的边界区域中继续生成测试用例,并执行测试,直至发现软件错误或达到预设的测试次数上限后停止。2) If step 1) has been executed once, return to execute step 1), if step 1) has been repeatedly executed twice, instead, continue to generate test cases only in the boundary area with the highest priority, and execute the test, Stop until a software error is found or the preset upper limit of the number of tests is reached.
具体实施时,本发明技术方案提出的方法可由本领域技术人员采用计算机软件技术实现自动运行流程,实现方法的系统装置例如存储本发明技术方案相应计算机程序的计算机可读存储介质以及包括运行相应计算机程序的计算机设备,也应当在本发明的保护范围内。During specific implementation, the method proposed by the technical solution of the present invention can be realized by those skilled in the art using computer software technology to realize the automatic running process. The system device for implementing the method is, for example, a computer-readable storage medium storing a computer program corresponding to the technical solution of the present invention, and a computer that runs the corresponding computer program. The computer equipment of the program should also be within the protection scope of the present invention.
在一些可能的实施例中,提供一种基于极大似然估计最大期望的测试用例生成系统,包括以下模块,In some possible embodiments, a test case generation system based on maximum likelihood estimation of maximum expectation is provided, including the following modules,
第一模块,用于将软件的输入域划分成多个子区域,并将输入域的边界区域与内部区域区别开来,将边界区域作为优先级最高的子区域;The first module is used to divide the input domain of the software into a plurality of sub-regions, distinguish the boundary region of the input domain from the internal region, and use the boundary region as the sub-region with the highest priority;
第二模块,用于引入极大似然估计最大期望方式,估计内部区域中子区域里可能包含失效区域的概率,基于概率大小对内部区域中子区域进行排序;The second module is used to introduce the maximum likelihood estimation method, estimate the probability that the sub-regions in the inner region may contain failure regions, and sort the sub-regions in the inner region based on the probability;
第三模块,用于按照子区域的优先级顺序生成测试用例,直至发现软件错误;若测试用例数达到预设条件仍未发现软件错误,则继续在优先级最高的子区域生成测试用例,直至发现软件错误。The third module is used to generate test cases according to the priority order of the sub-areas until software errors are found; if the number of test cases reaches the preset condition and no software errors are found, continue to generate test cases in the sub-area with the highest priority until A software bug was found.
在一些可能的实施例中,提供一种基于极大似然估计最大期望的测试用例生成系统,包括处理器和存储器,存储器用于存储程序指令,处理器用于调用处理器中的存储指令执行如上所述的一种基于极大似然估计最大期望的测试用例生成方法。In some possible embodiments, a test case generation system based on maximum likelihood estimation is provided, comprising a processor and a memory, the memory is used to store program instructions, and the processor is used to call the stored instructions in the processor to execute the above A test case generation method based on maximum likelihood estimation is described.
在一些可能的实施例中,提供一种基于极大似然估计最大期望的测试用例生成系统,包括可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序执行时,实现如上所述的一种基于极大似然估计最大期望的测试用例生成方法。In some possible embodiments, a test case generation system based on maximum likelihood estimation is provided, including a readable storage medium, on which a computer program is stored, and when the computer program is executed, A test case generation method based on maximum likelihood estimation of maximum expectation as described above is realized.
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。Although the preferred embodiments of the present invention have been described, additional changes and modifications to these embodiments may occur to those skilled in the art once the basic inventive concepts are known. Therefore, the appended claims are intended to be construed to include the preferred embodiment and all changes and modifications that fall within the scope of the present invention.
显然,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明实施例的精神和范围。这样,倘若本发明实施例的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。Obviously, those skilled in the art can make various changes and modifications to the embodiments of the present invention without departing from the spirit and scope of the embodiments of the present invention. Thus, provided that these modifications and variations of the embodiments of the present invention fall within the scope of the claims of the present invention and their equivalents, the present invention is also intended to include such modifications and variations.
Claims (10)

Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010811968.8A CN112069059B (en) | 2020-08-13 | 2020-08-13 | Test case generation method and system based on maximum likelihood estimation |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010811968.8A CN112069059B (en) | 2020-08-13 | 2020-08-13 | Test case generation method and system based on maximum likelihood estimation |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112069059A true CN112069059A (en) | 2020-12-11 |
| CN112069059B CN112069059B (en) | 2022-02-15 |
Family
ID=73661583
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010811968.8A Active CN112069059B (en) | 2020-08-13 | 2020-08-13 | Test case generation method and system based on maximum likelihood estimation |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112069059B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115591742A (en) * | 2022-09-30 | 2023-01-13 | 深圳芯光智能技术有限公司(Cn) | Automatic control method and system for glue dispenser capable of identifying glue dispensing quality |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104036105A (en) * | 2013-03-08 | 2014-09-10 | 伊姆西公司 | Method and system for determining correctness of application |
| US9928040B2 (en) * | 2013-11-12 | 2018-03-27 | Microsoft Technology Licensing, Llc | Source code generation, completion, checking, correction |
| CN108845927A (en) * | 2018-05-04 | 2018-11-20 | 联动优势电子商务有限公司 | A kind of screening technique and device of test case |
| CN110377496A (en) * | 2019-04-28 | 2019-10-25 | 北京轩宇信息技术有限公司 | A kind of priorities of test cases during software regression testing based on intelligent water drop determines method |
-
2020
- 2020-08-13 CN CN202010811968.8A patent/CN112069059B/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104036105A (en) * | 2013-03-08 | 2014-09-10 | 伊姆西公司 | Method and system for determining correctness of application |
| US9928040B2 (en) * | 2013-11-12 | 2018-03-27 | Microsoft Technology Licensing, Llc | Source code generation, completion, checking, correction |
| CN108845927A (en) * | 2018-05-04 | 2018-11-20 | 联动优势电子商务有限公司 | A kind of screening technique and device of test case |
| CN110377496A (en) * | 2019-04-28 | 2019-10-25 | 北京轩宇信息技术有限公司 | A kind of priorities of test cases during software regression testing based on intelligent water drop determines method |
Non-Patent Citations (3)
| Title |
|---|
| ADEL BELOUCHRANI等: "Maximum likelihood source separation by the expectation-maximization technique: Deterministic and stochastic implementation", 《 IEEE/IEE ELECTRONIC LIBRARY》 * |
| 章晓芳等: "一种基于优先级的迭代划分测试方法", 《计算机学报》 * |
| 魏诚: "均等划分策略的适应性随机测试方法", 《科技广场》 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115591742A (en) * | 2022-09-30 | 2023-01-13 | 深圳芯光智能技术有限公司(Cn) | Automatic control method and system for glue dispenser capable of identifying glue dispensing quality |
| CN115591742B (en) * | 2022-09-30 | 2023-09-12 | 深圳芯光智能技术有限公司 | Automatic control method and system for dispensing machine for dispensing quality identification |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112069059B (en) | 2022-02-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Feige et al. | Learning and inference in the presence of corrupted inputs | |
| Livne | Coarsening by compatible relaxation | |
| CN105446885A (en) | Regression testing case priority ranking technology based on needs | |
| CN108491302B (en) | Method for detecting spark cluster node state | |
| CN110502447A (en) | A Graph-based Regression Test Case Prioritization Method | |
| Groz et al. | Skyline queries with noisy comparisons | |
| Belknap et al. | Self-tuning for SQL performance in Oracle Database 11g | |
| CN110648124A (en) | Method and apparatus for concurrently executing transactions in a blockchain | |
| CN112069059B (en) | Test case generation method and system based on maximum likelihood estimation | |
| CN115456140A (en) | A Method and Device for Determining Important Links of a Graph Neural Network Model Based on Shapley Value Interpretation | |
| Ghosh et al. | Fault-containing self-stabilizing distributed protocols | |
| Altameem | Fault tolerance techniques in grid computing systems | |
| CN112035343A (en) | Test case generation method and system based on Bayesian estimation | |
| He et al. | A bounded statistical approach for model checking of unbounded until properties | |
| US20050278669A1 (en) | Invariant checking | |
| CN106874215B (en) | Serialized storage optimization method based on Spark operator | |
| Ameloot et al. | Data partitioning for single-round multi-join evaluation in massively parallel systems | |
| CN111124694B (en) | A deadlock detection and solution method for reachable graph based on petri net | |
| CN114281691B (en) | Test case sorting method, device, computing device and storage medium | |
| US12189647B2 (en) | Adaptive distributed graph query processing for OLTP and OLAP workload | |
| Brim et al. | Assumption-based distribution of CTL model checking | |
| US11741001B2 (en) | Workload generation for optimal stress testing of big data management systems | |
| CN117493167A (en) | A global dynamic sorting method for software test case priorities considering output results | |
| CN112506565A (en) | Method, medium, and apparatus for determining importance of processor micro-architectural event | |
| CN113900789B (en) | Data processing method, device, magnetic resonance equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |