CN112015911B - A Method for Retrieval of Massive Knowledge Graph - Google Patents
A Method for Retrieval of Massive Knowledge Graph Download PDFInfo
- Publication number
- CN112015911B CN112015911B CN202010857339.9A CN202010857339A CN112015911B CN 112015911 B CN112015911 B CN 112015911B CN 202010857339 A CN202010857339 A CN 202010857339A CN 112015911 B CN112015911 B CN 112015911B
- Authority
- CN
- China
- Prior art keywords
- knowledge graph
- visual data
- data matrix
- knowledge
- graph
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/367—Ontology
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/34—Browsing; Visualisation therefor
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Animal Behavior & Ethology (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
The invention discloses a massive knowledge graph retrieval method, which is used for solving the problem that the conventional knowledge graph retrieval method cannot better retrieve a knowledge graph related to a knowledge graph searched by a user to the user. The method comprises the following steps: constructing a visual data matrix of each knowledge map in a mass knowledge map set acquired in advance; calculating the association degree of the visual data matrix of the first knowledge graph and the visual data matrix of each second knowledge graph in the massive knowledge graph set according to a preset association degree algorithm; and storing the second knowledge graph corresponding to the visual data matrix with the relevance degree with the visual data matrix of the first knowledge graph as the knowledge graph with the relevance degree with the first knowledge graph. According to the method, the relevance of each knowledge graph can be accurately determined by calculating the relevance and the similarity between the knowledge graphs, so that the knowledge graph with strong relevance to the knowledge graph searched by the user can be pushed to the user, and the user experience is improved.
Description
Technical Field
The invention relates to the technical field of knowledge maps, in particular to a method for searching a mass knowledge map.
Background
Knowledge map (Knowledge Graph) is a series of different graphs which are called Knowledge domain visualization or Knowledge domain mapping map in the book intelligence world and display the relationship between the Knowledge development process and the structure. With the rapid development of theories and methods applying subjects such as mathematics, graphics, information visualization technology, information science and the like, the number of knowledge maps is also developed in a burst mode, the relevance among the knowledge maps is larger and larger, and each knowledge map is not an information isolated island any more. Therefore, how to enable a user to browse the knowledge graph related to the user in an extensible manner when searching for a certain knowledge graph enables the user to retrieve more useful information, improves the experience of the user, and becomes a hot spot of recent research. However, the matching accuracy of the current relevant knowledge graph retrieval method is low, and the user experience is poor.
Disclosure of Invention
The invention provides a massive knowledge graph retrieval method, which is used for solving the problems of low matching accuracy and poor user experience of the conventional knowledge graph retrieval method. According to the method for searching the massive knowledge maps, the relevance of each knowledge map can be accurately determined by calculating the relevance and the similarity before the knowledge map, so that the knowledge map with strong relevance with the knowledge map searched by a user can be pushed to the user, and the user experience is improved.
The invention provides a method for searching a massive knowledge map, which comprises the following steps:
constructing a visual data matrix of each knowledge map in a mass knowledge map set acquired in advance;
calculating the association degree of the visual data matrix of the first knowledge graph and the visual data matrix of each second knowledge graph in the massive knowledge graph set according to a preset association degree algorithm; the first knowledge graph is any knowledge graph in the massive knowledge graph set, and the second knowledge graph is other knowledge graphs in the massive knowledge graph set except the first knowledge graph;
storing a second knowledge graph corresponding to the visual data matrix with the relevance degree to the visual data matrix of the first knowledge graph as the knowledge graph with the relevance degree to the first knowledge graph;
receiving a retrieval request about a target knowledge-graph;
and retrieving the target knowledge graph and the knowledge graph with the association degree with the target knowledge graph, and providing a retrieval result for a user.
In one embodiment, after storing a second knowledge graph corresponding to a visualization data matrix having a degree of association with a visualization data matrix of the first knowledge graph as a knowledge graph having a degree of association with the first knowledge graph, before receiving a retrieval request regarding a target knowledge graph, the method further comprises:
calculating the similarity between the visual data matrix of the third knowledge graph and the visual data matrix of the first knowledge graph according to a preset similarity calculation method; the third knowledge graph is a knowledge graph with a degree of association with the first knowledge graph;
screening out a third knowledge graph corresponding to the visual data matrix with the similarity reaching a preset similarity threshold value with the visual data matrix of the first knowledge graph, and obtaining and storing a recommended knowledge graph set corresponding to the first knowledge graph;
the retrieving the target knowledge graph and the knowledge graph with the association degree with the target knowledge graph and providing the retrieval result to the user comprises the following steps:
and retrieving the target knowledge graph and the recommendation knowledge graph set corresponding to the target knowledge graph, and providing a retrieval result for a user.
In one embodiment, after storing a second knowledge graph corresponding to a visualization data matrix having a degree of association with a visualization data matrix of the first knowledge graph as a knowledge graph having a degree of association with the first knowledge graph, before receiving a retrieval request regarding a target knowledge graph, the method further comprises:
sorting the knowledge graphs with the relevance degrees with the first knowledge graph from high to low according to the relevance degrees of the knowledge graphs and the visual data matrix of the first knowledge graph to obtain a sorting result;
calculating the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result according to a preset similarity algorithm, wherein N is a positive integer, and the initial value of N is 1;
judging whether the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result reaches a preset similarity threshold value or not;
if the similarity between the visual data matrix of the Nth knowledge graph in the sequencing result and the visual data matrix of the first knowledge graph reaches a preset similarity threshold value, putting the knowledge graph corresponding to the visual data matrix of the Nth knowledge graph in the sequencing result into the recommended knowledge graph set corresponding to the first knowledge graph, and adding 1 to the count value of a preset counter; wherein the initial count value of the counter is 0;
judging whether the count value of the counter is equal to the preset map extension number or not;
if the count value of the counter is not equal to the preset map extension number, judging whether N is equal to M or not; the M is the number of the knowledge graphs in the sequencing result;
if N is not equal to M, after N is set to be N +1, returning to the step of executing the step of calculating the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result according to the preset similarity calculation method;
if the counting value of the counter is equal to the preset map extension number or N is equal to M, storing a recommended knowledge map set corresponding to the current first knowledge map;
if the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result does not reach a preset similarity threshold value, executing the step of judging whether N is equal to M or not;
the retrieving the target knowledge graph and the knowledge graph with the association degree with the target knowledge graph and providing the retrieval result to the user comprises the following steps:
and retrieving the target knowledge graph and the recommendation knowledge graph set corresponding to the target knowledge graph, and providing a retrieval result for a user.
In one embodiment, the preset association algorithm formula is as follows:

wherein X is the degree of association of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, pi is the circumference ratio, i and j respectively represent the row number and the column number of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, and aijData information of visual data of ith row and jth column in visual data matrix of first knowledge graph, bijThe learning rate is the data information of visual data of the ith row and the jth column in the visual data matrix of the second knowledge graph, L is an association constraint coefficient of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, e is a natural constant, alpha is a weak association weight of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, beta is expressed as a strong association weight of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, and lambda is a preset learning rate; l, e, the values of alpha, beta and lambda are all preset values.
In one embodiment, L has a value interval of [0.1,0.3], e has a value interval of 2.58, and λ has a value interval of [0,1 ].
In one embodiment, the preset similarity is calculated by the following formula:

the simY is the similarity between the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graph, the theta is expressed as the preset probability that the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graph contain the data information of the same visual data, i and j respectively express the row number, column number and S of the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graphmIs confidence coefficient, Y, of the mth data information in the visual data matrix of the first knowledge-graphmFor the confidence of the mth data information in the visualized data matrix of the third knowledge-graph, GmIs the evaluation score of the mth data information in the visual data matrix of the first knowledge graph, CmThe evaluation score of the mth data information in the visual data matrix of the third knowledge graph is shown, and omega is a useless data influence factor in the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graph; and the values of theta and omega are preset values.
In one embodiment, θ is 15%, and ω is within 0.05, 0.1.
In an embodiment, before constructing the visualized data matrix of each knowledge graph in the pre-acquired massive set of knowledge graphs, the method further includes:
acquiring a massive knowledge graph;
preprocessing each acquired knowledge graph; the pretreatment comprises the following steps: deleting repeated data and messy code data of each knowledge graph;
combining the preprocessed knowledge maps into a mass knowledge map set;
the method for constructing the visual data matrix of each knowledge graph in the pre-acquired massive knowledge graph set comprises the following steps:
analyzing each knowledge map in the massive knowledge map set to obtain visual data of each knowledge map;
taking data information of the visualized data of each knowledge graph as a matrix element, and constructing a visualized data matrix of each knowledge graph, wherein the data information of the visualized data comprises: and visualizing the keywords in the data and the connection relation of each keyword.
The invention provides a method for searching a mass knowledge graph, which comprises the steps of firstly, determining the relevance between knowledge graphs by calculating the relevance between knowledge graphs, further ensuring that when a user searches a knowledge graph, the knowledge graph with larger relevance can be recommended to the user in an extending way, expanding the searching range of the user, enabling the user to search more useful information and improving the experience of the user; furthermore, after the association degree between the knowledge graphs is calculated, the similarity between the knowledge graphs with the larger association is calculated, so that the similarity is further ensured on the basis of ensuring the association degree, the association of each knowledge graph can be more accurately determined, the accuracy of determining the association relation is improved, and the user experience is greatly improved.
Additional features and advantages of the invention will be set forth in the description which follows, and in part will be obvious from the description, or may be learned by practice of the invention. The objectives and other advantages of the invention will be realized and attained by the structure particularly pointed out in the written description and claims hereof as well as the appended drawings.
The technical solution of the present invention is further described in detail by the accompanying drawings and embodiments.
Drawings
The accompanying drawings, which are included to provide a further understanding of the invention and are incorporated in and constitute a part of this specification, illustrate embodiments of the invention and together with the description serve to explain the principles of the invention and not to limit the invention. In the drawings:
FIG. 1 is a flowchart of a first embodiment of a method for massive knowledge graph retrieval according to an embodiment of the present invention;
FIG. 2 is a flowchart of a method prior to step S101 in FIG. 1;
FIG. 3 is a flowchart of a second embodiment of a method for retrieving a mass knowledge graph according to an embodiment of the present invention;
FIG. 4 is a flowchart of a third embodiment of a method for retrieving a mass knowledge graph according to an embodiment of the present invention;
Detailed Description
The preferred embodiments of the present invention will be described in conjunction with the accompanying drawings, and it will be understood that they are described herein for the purpose of illustration and explanation and not limitation.
Fig. 1 is a flowchart of an embodiment of a method for retrieving a mass knowledge graph according to an embodiment of the present invention. As shown in fig. 1, the method comprises the following steps S101-S105:
s101: constructing a visual data matrix of each knowledge map in a mass knowledge map set acquired in advance;
in this embodiment, each mass knowledge graph is constructed into a respective visual data matrix, so that the association degree between the visual data matrices is calculated by using a preset association degree algorithm, and the association degree is the association degree between the knowledge graphs corresponding to the matrices.
As an optional manner, as shown in fig. 2, before this step S101, steps S201 to S203 may be further included:
s201: acquiring a massive knowledge graph;
in this embodiment, a massive knowledge graph, such as Baidu encyclopedia, may be obtained from some target websites.
S202: preprocessing each acquired knowledge graph; the pretreatment comprises the following steps: deleting repeated data and messy code data of each knowledge graph;
in the embodiment, the repeated data and the messy code data of each knowledge graph are deleted, so that the association degree obtained through calculation is more accurate.
S203: and combining the preprocessed knowledge maps into a mass knowledge map set.
This step S101 includes: analyzing each knowledge map in the massive knowledge map set to obtain visual data of each knowledge map; taking data information of the visualized data of each knowledge graph as a matrix element, and constructing a visualized data matrix of each knowledge graph, wherein the data information of the visualized data comprises: and visualizing the keywords in the data and the connection relation of each keyword.
S102: calculating the association degree of the visual data matrix of the first knowledge graph and the visual data matrix of each second knowledge graph in the massive knowledge graph set according to a preset association degree algorithm; the first knowledge graph is any knowledge graph in the massive knowledge graph set, and the second knowledge graph is other knowledge graphs in the massive knowledge graph set except the first knowledge graph;
in this embodiment, the preset association algorithm formula is as follows:

wherein X is the degree of association of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, pi is the circumference ratio, i and j respectively represent the row number and the column number of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, and aijData information of visual data of ith row and jth column in visual data matrix of first knowledge graph, bijThe learning rate is the data information of visual data of the ith row and the jth column in the visual data matrix of the second knowledge graph, L is an association constraint coefficient of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, e is a natural constant, alpha is a weak association weight of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, beta is expressed as a strong association weight of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, and lambda is a preset learning rate; l, e, alpha, beta and lambda values are all preset values, wherein the value range of L is [0.1,0.3]]E is 2.58, and lambda is in the range of [0,1]]λ increases with increasing data information of the visualization data.
S103: storing a second knowledge graph corresponding to the visual data matrix with the relevance degree to the visual data matrix of the first knowledge graph as the knowledge graph with the relevance degree to the first knowledge graph;
in this embodiment, as an optional manner, the step S103 includes: judging whether the association degree of the visual data matrix of the first knowledge graph and the visual data matrix of each second knowledge graph is larger than or equal to a preset association degree threshold value or not; and if the association degree of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph is larger than or equal to a preset association degree threshold value, storing the second knowledge graph as the knowledge graph with the association degree with the first knowledge graph.
S104: receiving a retrieval request about a target knowledge-graph;
s105: and retrieving the target knowledge graph and the knowledge graph with the association degree with the target knowledge graph, and providing a retrieval result for a user.
According to the method for searching the massive knowledge maps, the relevance between the knowledge maps is determined by calculating the relevance between the knowledge maps, so that a user can be ensured to be capable of extensibly browsing the knowledge map with the larger relevance when searching for a certain knowledge map, the searching range of the user is expanded, the user can search more useful information, and the experience of the user is improved.
Fig. 3 is a schematic flow chart of a second embodiment of the method for retrieving a massive knowledge map according to the present invention. Referring to fig. 3, the embodiment of the method for retrieving the massive knowledge map of the present invention includes the following steps:
s301: constructing a visual data matrix of each knowledge map in a mass knowledge map set acquired in advance;
s302: calculating the association degree of the visual data matrix of the first knowledge graph and the visual data matrix of each second knowledge graph in the massive knowledge graph set according to a preset association degree algorithm; the first knowledge graph is any knowledge graph in the massive knowledge graph set, and the second knowledge graph is other knowledge graphs in the massive knowledge graph set except the first knowledge graph;
s303: storing a second knowledge graph corresponding to the visual data matrix with the relevance degree to the visual data matrix of the first knowledge graph as the knowledge graph with the relevance degree to the first knowledge graph;
s304: calculating the similarity between the visual data matrix of the third knowledge graph and the visual data matrix of the first knowledge graph according to a preset similarity calculation method; the third knowledge graph is a knowledge graph with a degree of association with the first knowledge graph;
in this embodiment, the preset similarity calculation method includes:

the simY is the similarity between the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graph, and the theta is expressed as the preset probability that the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graph contain the data information of the same visual data, and the value is 15%; i. j represents the row number, column number, S of the visual data matrix of the first/third knowledge graph respectivelymThe confidence coefficient of the mth data information in the visual data matrix of the first knowledge graph is taken as [0,1]]The probability of the mth data information appearing in a certain region in a visual verse matrix is reduced along with the increase of the area of the region; y ismIs the confidence coefficient of the mth data information in the visual data matrix of the third knowledge graph, and the value of the mth data information is equal to SmSimilarly; gmThe evaluation score of the mth data information in the visual data matrix of the first knowledge graph is taken as [0,1]]The m-th data information occupies the data in all the data information in the first visual data matrixRatio, which increases with increasing data fraction; cmThe evaluation score of the mth data information in the visual data matrix of the third knowledge graph is the value and GmSimilarly; omega is a useless data influence factor in the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graph, and the value is [0.05, 0.1%]The value is closer to 0.1 when the amount of unnecessary data is larger, and closer to 0.05 when the amount of unnecessary data is smaller.
S305: screening out a third knowledge graph corresponding to the visual data matrix with the similarity reaching a preset similarity threshold value with the visual data matrix of the first knowledge graph, and obtaining and storing a recommended knowledge graph set corresponding to the first knowledge graph;
s306: receiving a retrieval request about a target knowledge-graph;
s307: and retrieving the target knowledge graph and the recommendation knowledge graph set corresponding to the target knowledge graph, and providing a retrieval result for a user.
According to the method for searching the massive knowledge maps, the relevance between the knowledge maps is determined by calculating the relevance between the knowledge maps, so that a user can be ensured to browse the knowledge maps with larger relevance in an extensible manner when searching for a certain knowledge map, the searching range of the user is expanded, the user can search more useful information, and the experience of the user is improved; furthermore, after the association degree between the knowledge maps is calculated, the similarity between the knowledge maps is calculated, so that the similarity is further ensured on the basis of ensuring the association degree, the association of each knowledge map can be more accurately determined, the accuracy of determining the association relation is improved, and the user experience is greatly improved.
Fig. 4 is a schematic flow chart of a third embodiment of the method for retrieving a massive knowledge map according to the present invention. Referring to fig. 4, the embodiment of the method for retrieving the massive knowledge map of the present invention includes the following steps:
s401: constructing a visual data matrix of each knowledge map in a mass knowledge map set acquired in advance;
s402: calculating the association degree of the visual data matrix of the first knowledge graph and the visual data matrix of each second knowledge graph in the massive knowledge graph set according to a preset association degree algorithm; the first knowledge graph is any knowledge graph in the massive knowledge graph set, and the second knowledge graph is other knowledge graphs in the massive knowledge graph set except the first knowledge graph;
s403: storing a second knowledge graph corresponding to the visual data matrix with the relevance degree to the visual data matrix of the first knowledge graph as the knowledge graph with the relevance degree to the first knowledge graph;
s404: sorting the knowledge graphs with the relevance degrees with the first knowledge graph from high to low according to the relevance degrees of the knowledge graphs and the visual data matrix of the first knowledge graph to obtain a sorting result;
s405: calculating the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result according to a preset similarity algorithm, wherein N is a positive integer and is initialized to 1;
s406: judging whether the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result reaches a preset similarity threshold value or not; if yes, executing step S407, otherwise, executing step S409;
s407: putting the knowledge graph corresponding to the visual data matrix of the Nth knowledge graph in the sequencing result into the recommended knowledge graph set corresponding to the first knowledge graph, and adding 1 to the count value of a preset counter; wherein the initial count value of the counter is 0;
s408: judging whether the count value of the counter is equal to the preset atlas extension number, if so, executing the step S411, otherwise, executing the step S409;
s409: judging whether N is equal to M, wherein M is the number of the knowledge maps in the sequencing result, if yes, executing a step S411, otherwise, executing a step S410;
s410: n +1, and step S405 is performed;
s411: storing a recommended knowledge map set corresponding to the current first knowledge map;
s412: receiving a retrieval request about a target knowledge-graph;
s41: 3: and retrieving the target knowledge graph and the recommendation knowledge graph set corresponding to the target knowledge graph, and providing a retrieval result for a user.
According to the method for searching the massive knowledge maps, the relevance between the knowledge maps is determined by calculating the relevance between the knowledge maps, so that a user can be ensured to browse the knowledge maps with larger relevance in an extensible manner when searching for a certain knowledge map, the searching range of the user is expanded, the user can search more useful information, and the experience of the user is improved; furthermore, according to the sequence of the relevance degrees from large to small, the similarity between the corresponding knowledge maps is sequentially calculated, the knowledge maps with the similarity reaching a certain degree are used as recommended knowledge map sets until the number of the recommended knowledge map sets reaches the preset map extension number or the relevance knowledge maps are traversed, the similarity is further ensured on the basis of ensuring the relevance degrees, the relevance of each knowledge map can be more accurately determined, the accuracy of determining the relevance relation is improved, and meanwhile, due to the fact that the energy of a user is limited, the extended knowledge maps cannot be too much, and therefore the second knowledge map with the large similarity with the first knowledge map can be selected to better meet the requirements of the user.
As will be appreciated by one skilled in the art, embodiments of the present invention may be provided as a method, system, or computer program product. Accordingly, the present invention may take the form of an entirely hardware embodiment, an entirely software embodiment or an embodiment combining software and hardware aspects. Furthermore, the present invention may take the form of a computer program product embodied on one or more computer-usable storage media (including, but not limited to, disk storage, optical storage, and the like) having computer-usable program code embodied therein.
The present invention is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the invention. It will be understood that each flow and/or block of the flow diagrams and/or block diagrams, and combinations of flows and/or blocks in the flow diagrams and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to a processor of a general purpose computer, special purpose computer, embedded processor, or other programmable data processing apparatus to produce a machine, such that the instructions, which execute via the processor of the computer or other programmable data processing apparatus, create means for implementing the functions specified in the flowchart flow or flows and/or block diagram block or blocks.
These computer program instructions may also be stored in a computer-readable memory that can direct a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory produce an article of manufacture including instruction means which implement the function specified in the flowchart flow or flows and/or block diagram block or blocks.
These computer program instructions may also be loaded onto a computer or other programmable data processing apparatus to cause a series of operational steps to be performed on the computer or other programmable apparatus to produce a computer implemented process such that the instructions which execute on the computer or other programmable apparatus provide steps for implementing the functions specified in the flowchart flow or flows and/or block diagram block or blocks.
It will be apparent to those skilled in the art that various changes and modifications may be made in the present invention without departing from the spirit and scope of the invention. Thus, if such modifications and variations of the present invention fall within the scope of the claims of the present invention and their equivalents, the present invention is also intended to include such modifications and variations.
Claims (7)
1. A method for searching massive knowledge maps is characterized by comprising the following steps:
constructing a visual data matrix of each knowledge map in a mass knowledge map set acquired in advance;
calculating the association degree of the visual data matrix of the first knowledge graph and the visual data matrix of each second knowledge graph in the massive knowledge graph set according to a preset association degree algorithm; the first knowledge graph is any knowledge graph in the massive knowledge graph set, and the second knowledge graph is other knowledge graphs in the massive knowledge graph set except the first knowledge graph;
storing a second knowledge graph corresponding to the visual data matrix with the relevance degree to the visual data matrix of the first knowledge graph as the knowledge graph with the relevance degree to the first knowledge graph;
receiving a retrieval request about a target knowledge-graph;
retrieving the target knowledge graph and the knowledge graph with the association degree with the target knowledge graph, and providing a retrieval result for a user;
wherein, after storing the second knowledge graph corresponding to the visual data matrix with the association degree with the visual data matrix of the first knowledge graph as the knowledge graph with the association degree with the first knowledge graph, before receiving the retrieval request of the target knowledge graph, the method further comprises:
sorting the knowledge graphs with the relevance degrees with the first knowledge graph from high to low according to the relevance degrees of the knowledge graphs and the visual data matrix of the first knowledge graph to obtain a sorting result;
calculating the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result according to a preset similarity algorithm, wherein N is a positive integer, and the initial value of N is 1;
judging whether the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result reaches a preset similarity threshold value or not;
if the similarity between the visual data matrix of the Nth knowledge graph in the sequencing result and the visual data matrix of the first knowledge graph reaches a preset similarity threshold value, putting the knowledge graph corresponding to the visual data matrix of the Nth knowledge graph in the sequencing result into the recommended knowledge graph set corresponding to the first knowledge graph, and adding 1 to the count value of a preset counter; wherein the initial count value of the counter is 0;
judging whether the count value of the counter is equal to the preset map extension number or not;
if the count value of the counter is not equal to the preset map extension number, judging whether N is equal to M or not; the M is the number of the knowledge graphs in the sequencing result;
if N is not equal to M, after N is set to be N +1, returning to the step of executing the step of calculating the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result according to the preset similarity calculation method;
if the counting value of the counter is equal to the preset map extension number or N is equal to M, storing a recommended knowledge map set corresponding to the current first knowledge map;
if the similarity between the visual data matrix of the Nth knowledge graph and the visual data matrix of the first knowledge graph in the sequencing result does not reach a preset similarity threshold value, executing the step of judging whether N is equal to M or not;
the retrieving the target knowledge graph and the knowledge graph with the association degree with the target knowledge graph and providing the retrieval result to the user comprises the following steps:
and retrieving the target knowledge graph and the recommendation knowledge graph set corresponding to the target knowledge graph, and providing a retrieval result for a user.
2. The method for retrieving the massive knowledge graph according to claim 1, wherein after storing a second knowledge graph corresponding to a visualized data matrix with a degree of association with a visualized data matrix of the first knowledge graph as a knowledge graph with a degree of association with the first knowledge graph, and before receiving a retrieval request regarding a target knowledge graph, the method further comprises:
calculating the similarity between the visual data matrix of the third knowledge graph and the visual data matrix of the first knowledge graph according to a preset similarity calculation method; the third knowledge graph is a knowledge graph with a degree of association with the first knowledge graph;
screening out a third knowledge graph corresponding to the visual data matrix with the similarity reaching a preset similarity threshold value with the visual data matrix of the first knowledge graph, and obtaining and storing a recommended knowledge graph set corresponding to the first knowledge graph;
the retrieving the target knowledge graph and the knowledge graph with the association degree with the target knowledge graph and providing the retrieval result to the user comprises the following steps:
and retrieving the target knowledge graph and the recommendation knowledge graph set corresponding to the target knowledge graph, and providing a retrieval result for a user.
3. The method for retrieving the massive knowledge map according to any one of claims 1-2, wherein the preset association algorithm formula is as follows:

wherein X is the degree of association of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, pi is the circumference ratio, i and j respectively represent the row number and the column number of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, and aijData information of visual data of ith row and jth column in visual data matrix of first knowledge graph, bijThe data information of visual data of ith row and jth column in the visual data matrix of the second knowledge graph is represented as L, the association constraint coefficient of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph is represented as e, alpha is a weak association weight of the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graph, and beta is represented as the visual data matrix of the first knowledge graph and the visual data matrix of the second knowledge graphThe strong correlation weight of a visual data matrix of the map is lambda, and the lambda is a preset learning rate; l, e, the values of alpha, beta and lambda are all preset values.
4. The method for retrieving the massive knowledge map as claimed in claim 3, wherein the value interval of L is [0.1,0.3], the value of e is 2.58, and the value interval of λ is [0,1 ].
5. The method for massive knowledge graph retrieval according to claim 2, wherein the algorithm formula of the preset similarity is as follows:
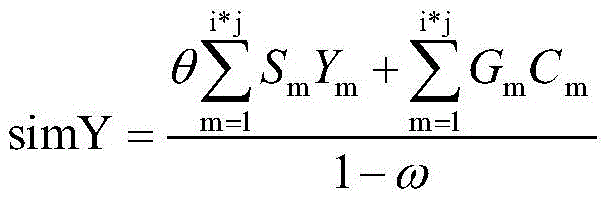
the simY is the similarity between the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graph, the theta is expressed as the preset probability that the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graph contain the data information of the same visual data, i and j respectively express the row number, column number and S of the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graphmIs confidence coefficient, Y, of the mth data information in the visual data matrix of the first knowledge-graphmFor the confidence of the mth data information in the visualized data matrix of the third knowledge-graph, GmIs the evaluation score of the mth data information in the visual data matrix of the first knowledge graph, CmThe evaluation score of the mth data information in the visual data matrix of the third knowledge graph is shown, and omega is a useless data influence factor in the visual data matrix of the first knowledge graph and the visual data matrix of the third knowledge graph; and the values of theta and omega are preset values.
6. The method for retrieving the massive knowledge map according to claim 5, wherein θ is 15%, and ω is [0.05,0.1 ].
7. The method for retrieving the massive knowledge graph according to claim 4, wherein before the constructing the visual data matrix of each knowledge graph in the pre-acquired massive knowledge graph set, the method further comprises:
acquiring a massive knowledge graph;
preprocessing each acquired knowledge graph; the pretreatment comprises the following steps: deleting repeated data and messy code data of each knowledge graph;
combining the preprocessed knowledge maps into a mass knowledge map set;
the method for constructing the visual data matrix of each knowledge graph in the pre-acquired massive knowledge graph set comprises the following steps:
analyzing each knowledge map in the massive knowledge map set to obtain visual data of each knowledge map;
taking data information of the visualized data of each knowledge graph as a matrix element, and constructing a visualized data matrix of each knowledge graph, wherein the data information of the visualized data comprises: and visualizing the keywords in the data and the connection relation of each keyword.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010857339.9A CN112015911B (en) | 2020-08-24 | 2020-08-24 | A Method for Retrieval of Massive Knowledge Graph |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010857339.9A CN112015911B (en) | 2020-08-24 | 2020-08-24 | A Method for Retrieval of Massive Knowledge Graph |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112015911A CN112015911A (en) | 2020-12-01 |
| CN112015911B true CN112015911B (en) | 2021-07-20 |
Family
ID=73505725
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010857339.9A Active CN112015911B (en) | 2020-08-24 | 2020-08-24 | A Method for Retrieval of Massive Knowledge Graph |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112015911B (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113377963B (en) | 2021-06-28 | 2023-08-11 | 中国科学院地质与地球物理研究所 | A method and device for processing well site test data based on knowledge graph |
| CN115858906A (en) * | 2022-12-26 | 2023-03-28 | 中移动信息技术有限公司 | Enterprise searching method, device, equipment, computer storage medium and program |
| CN116521656A (en) * | 2023-03-17 | 2023-08-01 | 中国船舶集团有限公司第七二四研究所 | Knowledge graph-based radar full-element data association method |
| CN118964642B (en) * | 2024-10-18 | 2025-03-21 | 山东天华通信有限公司 | An efficient retrieval method and system for structured data based on knowledge graph |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109857872A (en) * | 2019-02-18 | 2019-06-07 | 浪潮软件集团有限公司 | The information recommendation method and device of knowledge based map |
| CN111241241A (en) * | 2020-01-08 | 2020-06-05 | 平安科技(深圳)有限公司 | Case retrieval method, device and equipment based on knowledge graph and storage medium |
| CN111369318A (en) * | 2020-02-28 | 2020-07-03 | 安徽农业大学 | A recommendation method and system based on commodity knowledge graph feature learning |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109804364A (en) * | 2016-10-18 | 2019-05-24 | 浙江核新同花顺网络信息股份有限公司 | Knowledge graph construction system and method |
| US11693848B2 (en) * | 2018-08-07 | 2023-07-04 | Accenture Global Solutions Limited | Approaches for knowledge graph pruning based on sampling and information gain theory |
-
2020
- 2020-08-24 CN CN202010857339.9A patent/CN112015911B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109857872A (en) * | 2019-02-18 | 2019-06-07 | 浪潮软件集团有限公司 | The information recommendation method and device of knowledge based map |
| CN111241241A (en) * | 2020-01-08 | 2020-06-05 | 平安科技(深圳)有限公司 | Case retrieval method, device and equipment based on knowledge graph and storage medium |
| CN111369318A (en) * | 2020-02-28 | 2020-07-03 | 安徽农业大学 | A recommendation method and system based on commodity knowledge graph feature learning |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112015911A (en) | 2020-12-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112015911B (en) | A Method for Retrieval of Massive Knowledge Graph | |
| CN108804641B (en) | Text similarity calculation method, device, equipment and storage medium | |
| US8559731B2 (en) | Personalized tag ranking | |
| US8150859B2 (en) | Semantic table of contents for search results | |
| US7853599B2 (en) | Feature selection for ranking | |
| EP3937029A2 (en) | Method and apparatus for training search model, and method and apparatus for searching for target object | |
| US8880548B2 (en) | Dynamic search interaction | |
| CN109299383B (en) | Method and device for generating recommended word, electronic equipment and storage medium | |
| JP6299596B2 (en) | Query similarity evaluation system, evaluation method, and program | |
| CN103514199A (en) | Method and device for POI data processing and method and device for POI searching | |
| CN110321437B (en) | Corpus data processing method and device, electronic equipment and medium | |
| CN108959550B (en) | User interest mining method, apparatus, device and computer readable medium | |
| US20110179013A1 (en) | Search Log Online Analytic Processing | |
| Wang et al. | A distance matrix based algorithm for solving the traveling salesman problem | |
| CN113918807A (en) | Data recommendation method and device, computing equipment and computer-readable storage medium | |
| CN111079035B (en) | Domain searching and sorting method based on dynamic map link analysis | |
| CN121166876A (en) | A retrieval question answering method applied to large language models | |
| CN104750692A (en) | Information processing method, information retrieval method and corresponding device of information retrieval method | |
| CN116701567B (en) | Electronic book retrieval method and system based on artificial intelligence | |
| CN111401055A (en) | Method and apparatus for extracting context information from financial information | |
| CN106778048B (en) | Method and device for data processing | |
| CN112015914A (en) | Knowledge graph path searching method based on deep learning | |
| CN111797183B (en) | Method and device for mining road attribute of information point and electronic equipment | |
| JP6577922B2 (en) | Search apparatus, method, and program | |
| JP7631430B2 (en) | PROGRAM, TERMINAL DEVICE AND INFORMATION DISPLAY METHOD |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| PP01 | Preservation of patent right | ||
| PP01 | Preservation of patent right |
Effective date of registration: 20221020 Granted publication date: 20210720 |
|
| PD01 | Discharge of preservation of patent | ||
| PD01 | Discharge of preservation of patent |
Date of cancellation: 20241020 Granted publication date: 20210720 |