CN111785296A - A music segmentation boundary recognition method based on repetitive melody - Google Patents
A music segmentation boundary recognition method based on repetitive melody Download PDFInfo
- Publication number
- CN111785296A CN111785296A CN202010459989.8A CN202010459989A CN111785296A CN 111785296 A CN111785296 A CN 111785296A CN 202010459989 A CN202010459989 A CN 202010459989A CN 111785296 A CN111785296 A CN 111785296A
- Authority
- CN
- China
- Prior art keywords
- frame
- music
- points
- method based
- line segment
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/031—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/031—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal
- G10H2210/061—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal for extraction of musical phrases, isolation of musically relevant segments, e.g. musical thumbnail generation, or for temporal structure analysis of a musical piece, e.g. determination of the movement sequence of a musical work
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Auxiliary Devices For Music (AREA)
Abstract
Description
技术领域technical field
本发明涉及音频信号处理技术领域,具体地说,涉及一种基于重复旋律的音乐分段边界识别方法。The present invention relates to the technical field of audio signal processing, in particular to a method for identifying boundaries of music segments based on repeated melody.
背景技术Background technique
信息常以一定结构或层级进行组织来促进传播或是理解。人类通常很善于感知这样的结构,这种行为有时甚至是无意识地进行以让我们分析和充分获取给定信息的含义。然而考虑到大数据时代下的情况,我们越来越多地需要从计算机获得信息处理上的支持。因此,自动化获取信息的结构成为当今内容处理系统的关键任务。在广泛的多媒体内容中,音乐是一个典型的例子。Information is often organized in a structure or hierarchy to facilitate dissemination or understanding. Humans are generally very good at perceiving such structures, sometimes even unconsciously, to allow us to analyze and fully grasp the meaning of a given information. However, considering the situation in the era of big data, we increasingly need to obtain information processing support from computers. Therefore, automating the structure of obtaining information becomes a critical task of today's content processing systems. Among a wide range of multimedia content, music is a typical example.
音乐分段边界识别算法研究的重要应用有播放器的作品内导航、片段和混搭自动生成、相同作品版本识别以及大规模的音乐学研究。网络与数字娱乐产品的普及和发展,使得音乐已经成为最重要的数字媒体内容之一。Important applications of music segmentation boundary recognition algorithm research include player navigation within works, automatic generation of segments and mashups, identification of versions of identical works, and large-scale musicology research. With the popularization and development of network and digital entertainment products, music has become one of the most important digital media contents.
在当下,音乐除了作为独立的娱乐产品,同时也在影视作品中以配乐的形式扮演了重要的角色。作为独立的娱乐产品,在音乐分析上音乐分段是重要的基本流程。对于某类音乐作品的分析场景下,庞大的作品数量凸显了自动音乐分段重要性。作为配乐,实际应用中比起音乐整篇出现,更多的情况是取其片段使用,自动音乐分段能够极大地提升音乐片段提取的效率。可见,音乐分段边界识别算法研究具有广阔的市场应用前景。At present, in addition to being an independent entertainment product, music also plays an important role in the form of soundtrack in film and television works. As an independent entertainment product, music segmentation is an important basic process in music analysis. In the analysis scenario of a certain type of music works, the huge number of works highlights the importance of automatic music segmentation. As a soundtrack, in practical applications, rather than the whole piece of music, the fragment is used in more cases. Automatic music segmentation can greatly improve the efficiency of music fragment extraction. It can be seen that the research of music segmentation boundary recognition algorithm has broad market application prospects.
Foote在2000年最先将自相似矩阵用于音乐分段算法研究,以用于发现音乐中的重复旋律。Bruderer等人2006年的研究指出,有一些线索与人类在音乐结构感知上高度相关,如音色改变、重复和间歇等。Paulus等人2010年的研究指出,推断音乐结构有三个原则:新奇,同质和重复。Serra等人在2014年提出的音乐分段算法综合考虑了这些原则,引入了递归图的计算方法,大大提高了分段正确率,从而提升了自动音乐分段效率,促进了音乐自动分段算法的发展。In 2000, Foote first used self-similarity matrices in music segmentation algorithms to discover repetitive melodies in music. A 2006 study by Bruderer et al. pointed out that there are cues that are highly relevant to human perception of musical structure, such as timbre changes, repetitions, and pauses. A 2010 study by Paulus et al. states that there are three principles for inferring musical structure: novelty, homogeneity, and repetition. The music segmentation algorithm proposed by Serra et al. in 2014 comprehensively considered these principles and introduced the calculation method of the recursive graph, which greatly improved the segmentation accuracy, thereby improving the efficiency of automatic music segmentation and promoting the automatic music segmentation algorithm. development of.
然而,目前应用于音乐分段的算法本身还存在诸多不足,如无监督方法的分段粒度较大,对部分音乐的短片段获取存在困难,还存在结合乐理知识程度较低、过多依赖于数学方法的问题。深度学习方法未能充分考虑分段中重复的性质,且存在对数据的依赖、模型训练成本高和难以结合乐理知识的问题。However, there are still many shortcomings in the algorithms currently applied to music segmentation. For example, the segmentation granularity of the unsupervised method is relatively large, and it is difficult to obtain short segments of some music. Problems with mathematical methods. Deep learning methods fail to fully consider the nature of repetition in segmentation, and have problems of dependence on data, high model training costs, and difficulty in integrating music theory knowledge.
发明内容SUMMARY OF THE INVENTION
本发明的目的是提供一种基于重复旋律的音乐分段边界识别方法,以提升对音乐中重复旋律的识别能力,能够在更短时长规模上对音乐进行分段。The purpose of the present invention is to provide a method for identifying the boundaries of music segments based on repetitive melody, so as to improve the ability to recognize repetitive melody in music and to segment music on a shorter time scale.
为了实现上述目的,本发明提供的基于重复旋律的音乐分段边界识别方法包括以下步骤:In order to achieve the above object, the method for identifying the boundaries of music segments based on repeated melody provided by the invention comprises the following steps:
1)对音频提取chroma特征,得到特征向量序列,共M帧;对特征向量序列首尾零填充,聚合每相邻的N帧形成新的帧向量,所有帧向量构成新的帧特征向量序列;1) extracting chroma features from the audio to obtain a sequence of feature vectors, which is a total of M frames; zero-fill the beginning and end of the sequence of eigenvectors, aggregate every adjacent N frames to form a new frame vector, and all frame vectors form a new sequence of frame eigenvectors;
2)计算帧特征序列中每个帧向量与其他帧向量的欧氏距离,得到自相似矩阵S;2) Calculate the Euclidean distance between each frame vector and other frame vectors in the frame feature sequence to obtain a self-similar matrix S;
3)基于自相似矩阵S,得到第i个帧向量最近邻帧的集合Ni,i=1,2,…,M,并依此得到自相似矩阵S的递归图R;3) Based on the self-similar matrix S, obtain the set N i of the nearest neighbor frame of the ith frame vector, i=1, 2, ..., M, and obtain the recursive graph R of the self-similar matrix S accordingly;
4)将递归图R经时间延迟处理,得到时间延迟矩阵L;4) The recursive graph R is processed by time delay to obtain a time delay matrix L;
5)对时间延迟矩阵L进行线段规整及去噪,再反时间延迟处理得到规整及去噪后的递归图R’;5) Carry out line segment regularization and denoising to the time delay matrix L, and then inverse time delay processing to obtain a recursive graph R' after regularization and denoising;
6)基于递归图R’,检测出所有的线段并进行线段聚簇,从线段最多的簇开始依次处理,得到音乐分段边界点集合B。6) Based on the recursive graph R', detect all the line segments and perform line segment clustering, and process sequentially from the cluster with the most line segments to obtain the music segment boundary point set B.
上述技术方案中,针对音乐的重复片段,分帧提取音乐的音高类概述(PitchClass Profile)特征,也称为Chroma特征,该特征将给定范围的频率组织到12个音高类中去,突出反映了音乐的旋律。In the above-mentioned technical scheme, for the repeated segments of music, the pitch class profile (PitchClass Profile) feature of the music is extracted in frames, also called the Chroma feature, which organizes the frequencies of a given range into 12 pitch classes, Highlight the melody of the music.
可选地,在一个实施例中,步骤3)中,对于集合Ni中的k个元素是所有帧向量中与第i个帧向量最相似的k个帧向量,k的取值为帧向量总数的0.01。对于递归图R中的每个点Ri,j,若i属于Nj且j属于Ni,则取Ri,j等于1,否则取Ri,j等于0,依此得到自相似矩阵S的递归图R。Optionally, in one embodiment, in step 3), for the k elements in the set N i are the k frame vectors most similar to the ith frame vector in all frame vectors, and the value of k is the frame vector 0.01 of the total. For each point R i,j in the recursive graph R, if i belongs to N j and j belongs to N i , take R i,j equal to 1, otherwise take R i,j equal to 0, and thus obtain the self-similar matrix S The recursive graph R of .
可选地,在一个实施例中,步骤4)中,令Li,j=Ri,(i+j)mod(M-1),i=1,2,…,M,j=1,2,…,M,得到递归图R的时间延迟矩阵L,即将递归图R中主对角线方向转化为水平方向。Optionally, in an embodiment, in step 4), let Li,j =R i,(i+j)mod(M-1) , i=1, 2, . . . , M, j=1, 2, ..., M, obtain the time delay matrix L of the recursive graph R, that is, convert the main diagonal direction in the recursive graph R to the horizontal direction.
可选地,在一个实施例中,步骤5)包括:Optionally, in one embodiment, step 5) includes:
5-1)对时间延迟矩阵L进行遍历,取值为1的定义为点;每找到一个点,通过广度优先搜素确定与其相连的所有点,步距小于3则认为相连;5-1) Traverse the time delay matrix L, and the value of 1 is defined as a point; every time a point is found, all points connected to it are determined by breadth-first search, and the step distance is less than 3, it is considered to be connected;
5-2)统计相连的点中每个相同纵坐标的点的数量,若点数量最多的纵坐标下点的数量大于5,则保留这些点中该纵坐标的点,其他点取值为0;否则将这些点全部取值为0;5-2) Count the number of points with the same ordinate in the connected points. If the number of points under the ordinate with the largest number of points is greater than 5, the point of the ordinate among these points is retained, and the other points are set to 0 ; otherwise, all these points are set to be 0;
5-3)令R’i,(i+j)mod(M-1)=Li,j,i=1,2,…,M,j=1,2,…,M,得到规整及去噪后的递归图R’。5-3) Let R' i,(i+j)mod(M-1) =L i,j , i=1,2,...,M,j=1,2,...,M, get the regularization and removal The noised recursive graph R'.
可选地,在一个实施例中,步骤6)中,线段聚簇包括:Optionally, in one embodiment, in step 6), the line segment clustering includes:
遍历递归图R’,设置步距为3。Traverse the recursive graph R' and set the stride to 3.
找出图中所有线段,并用{x1,x2,y1,y2}对各线段进行标准化表示,x1和x2是起止点横坐标,y1和y2是起止点的纵坐标;Find all the line segments in the figure, and use {x 1 , x 2 , y 1 , y 2 } to standardize each line segment, where x 1 and x 2 are the abscissas of the start and end points, and y 1 and y 2 are the ordinates of the start and end points. ;
取一线段,遍历其他线段,找到与该线段对应为同一段旋律的所有线段进行聚簇;判定对应为同一段旋律的依据为:x1与x2的公共长度占各自的80%以上。Take a line segment, traverse other line segments, find all the line segments corresponding to the same melody and cluster them; the basis for judging that they correspond to the same melody is: the common length of x 1 and x 2 accounts for more than 80% of each.
可选地,在一个实施例中,步骤6)中,线段聚簇后,取线段条数最多的簇,对所有x1和x2取平均值,得到

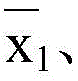
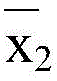
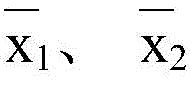
与现有技术相比,本发明的有益之处在于:Compared with the prior art, the advantages of the present invention are:
本发明利用乐理知识以及实际经验进行矩阵去噪,充分考虑了在音乐分段中噪音产生的主要原因,可以更彻底、高效地减少噪音造成的误差。而基于线段聚簇的分段点获取方法优先考虑了重复次数多的旋律片段,取平均值为分段点的方法也进一步地减少了误差,提高了泛化性能。The present invention uses music theory knowledge and practical experience to perform matrix denoising, fully considers the main reasons for noise generation in music segmentation, and can reduce errors caused by noise more thoroughly and efficiently. However, the segmentation point acquisition method based on line clustering gives priority to the melody segment with many repetitions, and the method of taking the average value as the segmentation point further reduces the error and improves the generalization performance.
附图说明Description of drawings
图1为本发明实施例中基于重复旋律的音乐分段边界识别方法的流程图;Fig. 1 is the flow chart of the music segmentation boundary identification method based on repeated melody in the embodiment of the present invention;
图2为本发明实施例中递归图R的示意图;2 is a schematic diagram of a recursive graph R in an embodiment of the present invention;
图3为本发明实施例中延迟矩阵L的示意图;3 is a schematic diagram of a delay matrix L in an embodiment of the present invention;
图4为本发明实施例中经规整去噪后的递归图R’。Fig. 4 is a recursive graph R' after regularization and denoising in an embodiment of the present invention.
具体实施方式Detailed ways
为使本发明的目的、技术方案和优点更加清楚,以下结合实施例及其附图对本发明作进一步说明。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于所描述的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described below with reference to the embodiments and the accompanying drawings. Obviously, the described embodiments are some, but not all, embodiments of the present invention. Based on the described embodiments, all other embodiments obtained by those of ordinary skill in the art without creative efforts fall within the protection scope of the present invention.
除非另外定义,本发明使用的技术术语或者科学术语应当为本发明所属领域内具有一般技能的人士所理解的通常意义。本发明中使用的“包括”或者“包含”等类似的词语意指出现该词前面的元件或者步骤涵盖出现在该词后面列举的元件或者步骤及其等同,而不排除其他元件或者步骤。Unless otherwise defined, technical or scientific terms used in the present invention should have the ordinary meaning as understood by one of ordinary skill in the art to which the present invention belongs. When used herein, "comprises" or "comprising" and similar words mean that elements or steps appearing before the word encompass the elements or steps listed after the word and their equivalents, but do not exclude other elements or steps.
实施例Example
本实施例基于重复旋律的音乐分段边界识别方法,构建基于自相似矩阵的音乐分段算法,实现音乐结构分段点自动识别。该方法可代替人工标注,用于音乐结构序列的生成,并可进一步应用于音乐分析、片段自动生成等。参见图1,其具体流程如下:This embodiment constructs a music segmentation algorithm based on a self-similar matrix based on a method for identifying the boundaries of music segments based on repeated melody, and realizes automatic identification of music structure segment points. This method can replace manual annotation for the generation of music structure sequences, and can be further applied to music analysis, automatic segment generation, etc. Referring to Figure 1, the specific process is as follows:
S100,对音频提取chroma特征,得到特征向量序列,共M帧;对特征向量序列首尾零填充,聚合每相邻的N帧形成新的帧向量,所有帧向量构成新的帧特征向量序列;S100, extract chroma features from the audio to obtain a sequence of feature vectors, totaling M frames; zero-pad the beginning and end of the sequence of feature vectors, aggregate every adjacent N frames to form a new frame vector, and all frame vectors form a new sequence of frame feature vectors;
样例音乐的特征序列为12维向量序列,长度为1344。首尾零填充得到长度为1350的长度序列,聚合每个相邻的7帧形成新的帧特征序列,得到12x7维向量序列,长度仍为1344。The feature sequence of the sample music is a 12-dimensional vector sequence with a length of 1344. The first and last zero-padding obtains a length sequence with a length of 1350, and each adjacent 7 frames are aggregated to form a new frame feature sequence, and a 12x7-dimensional vector sequence is obtained, and the length is still 1344.
S200,计算帧特征序列中每个帧向量与其他帧向量的欧氏距离,得到1344x1344的自相似矩阵S。S200 , calculating the Euclidean distance between each frame vector and other frame vectors in the frame feature sequence, to obtain a self-similar matrix S of 1344×1344.
S300,基于自相似矩阵S,得到第i帧最近邻帧的集合Ni,i=1,2,…,M,并依此得到自相似矩阵S的递归图R,参见图2;S300, based on the self-similar matrix S, obtain the set N i of the nearest neighbor frame of the ith frame, i=1, 2, ..., M, and obtain the recursive graph R of the self-similar matrix S accordingly, see Fig. 2;
集合Ni中的k个元素是所有帧中与第i帧最相似的k帧。对于递归图中的每个点Ri,j,若i属于Nj且j属于Ni,则取Ri,j等于1,否则取Ri,j等于0,得到1344x1344的递归图R。k的取值为帧总数的0.01,本实施例取13。The k elements in set Ni are the k frames most similar to the i -th frame among all frames. For each point R i,j in the recursive graph, if i belongs to N j and j belongs to N i , take Ri ,j equal to 1, otherwise take Ri ,j equal to 0, and get a recursive graph R of 1344x1344. The value of k is 0.01 of the total number of frames, which is 13 in this embodiment.
S400,将递归图R经时间延迟处理,得到时间延迟矩阵L,参见图3;S400, the recursive graph R is subjected to time delay processing to obtain a time delay matrix L, see FIG. 3;
先令Li,j=Ri,(i+j)mod(M-1),得到递归图R的时间延迟矩阵L,将递归图R中主对角线方向转化为水平方向,提升计算效率。 Let Li,j =R i,(i+j)mod(M-1) first , get the time delay matrix L of the recursive graph R, convert the main diagonal direction in the recursive graph R to the horizontal direction, and improve the computational efficiency .
S500,对时间延迟矩阵L进行线段规整及去噪,再反时间延迟处理得到规整及去噪后的递归图R’,参见图4。S500, performing line segment regularization and denoising on the time delay matrix L, and then inverse time delay processing to obtain a regularized and denoised recursive graph R', see Fig. 4 .
首先对时间延迟矩阵L进行遍历,取值为1的定义为点。每次找到一个点,通过广度优先搜素确定与其相连的所有点,步距小于3则认为相连。统计这些相连的点中每个相同纵坐标的点的数量,若点数量最多的纵坐标下点的数量大于5,则保留这些点中该纵坐标的点,其他点取值均取0。否则将这些点取值全部取0。例如某一系列点为{(1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(2,2),(3,2),(4,2)},则纵坐标为1的点最多且有6个,它们会被保留,而纵坐标为2的点将被抹去。然后,令R’i,(i+j)mod(M-1)=Li,j,得到规整及去噪后的递归图R’。First, the time delay matrix L is traversed, and the value of 1 is defined as a point. Each time a point is found, all points connected to it are determined by breadth-first search, and the step distance is less than 3, it is considered to be connected. Count the number of points with the same ordinate in each of these connected points. If the number of points on the ordinate with the largest number of points is greater than 5, keep the point of this ordinate among these points, and take 0 for other points. Otherwise, the values of these points are all 0. For example, a series of points is {(1,1),(2,1),(3,1),(4,1),(5,1),(6,1),(2,2),( 3,2). Then, let R' i,(i+j)mod(M-1) =L i,j to obtain the recursive graph R' after regularization and denoising.
S600,基于递归图R’,检测出所有的线段并进行线段聚簇,从线段最多的簇开始依次处理,得到音乐分段边界点集合B。S600, based on the recursive graph R', detect all line segments and perform line segment clustering, and process sequentially from the cluster with the most line segments to obtain a music segment boundary point set B.
首先找到递归图R’中所有的线段并标准化表示,遍历递归图R’,设置步距为3,找到所有线段。找到线段后,用{x1,x2,y1,y2}表示,x1和x2是起止点横坐标,y1和y2是起止点的纵坐标。如一段线段是{1,9,10,19},代表第10帧到第18帧与第1帧到第9帧相似。然后将所有线段中x1与x2公共部分占各自的80%以上的部分聚在同一簇,如{1,9,10,18}、{2,9,20,27}以及{2,9,31,38}。聚簇后,对x1取平均值,并将对应的y1标记,例如此处x1平均值为2,对应的3个y1会取为11、20和31。检查边界点集合B中是否存在和它们差距在20帧(与需要的分段时长相关)内的点,若不存在则将它们加入B中。这样就获得了样例音乐的分段结果。First find all the line segments in the recursive graph R' and standardize the representation, traverse the recursive graph R', set the stride to 3, and find all the line segments. After the line segment is found, it is represented by {x 1 , x 2 , y 1 , y 2 }, where x 1 and x 2 are the abscissas of the starting and ending points, and y 1 and y 2 are the ordinates of the starting and ending points. For example, a line segment is {1,9,10,19}, which means that frames 10 to 18 are similar to frames 1 to 9. Then, in all line segments, the common parts of x 1 and x 2 account for more than 80% of their respective parts, clustered in the same cluster, such as {1, 9, 10, 18}, {2, 9, 20, 27} and {2, 9} ,31,38}. After clustering, take the average value of x 1 and mark the corresponding y 1. For example, the average value of x 1 here is 2, and the corresponding 3 y 1 will be 11, 20 and 31. Check whether there are points in the boundary point set B that are within 20 frames (related to the required segmentation time) and add them to B if they do not exist. In this way, the segmentation result of the sample music is obtained.
Claims (8)


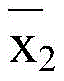

Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010459989.8A CN111785296B (en) | 2020-05-26 | 2020-05-26 | Music segmentation boundary identification method based on repeated melody |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010459989.8A CN111785296B (en) | 2020-05-26 | 2020-05-26 | Music segmentation boundary identification method based on repeated melody |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111785296A true CN111785296A (en) | 2020-10-16 |
| CN111785296B CN111785296B (en) | 2022-06-10 |
Family
ID=72753490
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010459989.8A Active CN111785296B (en) | 2020-05-26 | 2020-05-26 | Music segmentation boundary identification method based on repeated melody |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111785296B (en) |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6278972B1 (en) * | 1999-01-04 | 2001-08-21 | Qualcomm Incorporated | System and method for segmentation and recognition of speech signals |
| WO2005010865A2 (en) * | 2003-07-31 | 2005-02-03 | The Registrar, Indian Institute Of Science | Method of music information retrieval and classification using continuity information |
| US20060065106A1 (en) * | 2004-09-28 | 2006-03-30 | Pinxteren Markus V | Apparatus and method for changing a segmentation of an audio piece |
| US20070291958A1 (en) * | 2006-06-15 | 2007-12-20 | Tristan Jehan | Creating Music by Listening |
| CN103116646A (en) * | 2013-02-26 | 2013-05-22 | 浙江大学 | Cloud gene expression programming based music emotion recognition method |
| CN103854661A (en) * | 2014-03-20 | 2014-06-11 | 北京百度网讯科技有限公司 | Method and device for extracting music characteristics |
| US20140205103A1 (en) * | 2011-08-19 | 2014-07-24 | Dolby Laboratories Licensing Corporation | Measuring content coherence and measuring similarity |
| US20170148424A1 (en) * | 2015-11-23 | 2017-05-25 | Adobe Systems Incorporated | Intuitive music visualization using efficient structural segmentation |
| CN108665903A (en) * | 2018-05-11 | 2018-10-16 | 复旦大学 | An automatic detection method and system for audio signal similarity |
-
2020
- 2020-05-26 CN CN202010459989.8A patent/CN111785296B/en active Active
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6278972B1 (en) * | 1999-01-04 | 2001-08-21 | Qualcomm Incorporated | System and method for segmentation and recognition of speech signals |
| WO2005010865A2 (en) * | 2003-07-31 | 2005-02-03 | The Registrar, Indian Institute Of Science | Method of music information retrieval and classification using continuity information |
| US20060065106A1 (en) * | 2004-09-28 | 2006-03-30 | Pinxteren Markus V | Apparatus and method for changing a segmentation of an audio piece |
| US20070291958A1 (en) * | 2006-06-15 | 2007-12-20 | Tristan Jehan | Creating Music by Listening |
| US20140205103A1 (en) * | 2011-08-19 | 2014-07-24 | Dolby Laboratories Licensing Corporation | Measuring content coherence and measuring similarity |
| CN103116646A (en) * | 2013-02-26 | 2013-05-22 | 浙江大学 | Cloud gene expression programming based music emotion recognition method |
| CN103854661A (en) * | 2014-03-20 | 2014-06-11 | 北京百度网讯科技有限公司 | Method and device for extracting music characteristics |
| US20170148424A1 (en) * | 2015-11-23 | 2017-05-25 | Adobe Systems Incorporated | Intuitive music visualization using efficient structural segmentation |
| CN108665903A (en) * | 2018-05-11 | 2018-10-16 | 复旦大学 | An automatic detection method and system for audio signal similarity |
Non-Patent Citations (2)
| Title |
|---|
| 李伟等: "理解数字音乐――音乐信息检索技术综述", 《复旦学报(自然科学版)》 * |
| 肖川等: "多版本音乐识别技术研究综述", 《小型微型计算机系统》 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111785296B (en) | 2022-06-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108921130B (en) | Video key frame extraction method based on saliency region | |
| CN112417157A (en) | Emotion classification method of text attribute words based on deep learning network | |
| CN111651636A (en) | Video similar segment searching method and device | |
| CN108427925B (en) | A copy video detection method based on continuous copy frame sequence | |
| CN101398854A (en) | Video fragment searching method and system | |
| CN101655859B (en) | Method for fast removing redundancy key frames and device thereof | |
| CN108932950A (en) | It is a kind of based on the tag amplified sound scenery recognition methods merged with multifrequency spectrogram | |
| TW202217597A (en) | Image incremental clustering method, electronic equipment, computer storage medium thereof | |
| CN112100412B (en) | Image retrieval method, device, computer equipment and storage medium | |
| US8175392B2 (en) | Time segment representative feature vector generation device | |
| CN114399808B (en) | A method, system, electronic device and storage medium for estimating face age | |
| CN104715033A (en) | Step type voice frequency retrieval method | |
| CN113378946A (en) | Robust multi-label feature selection method considering feature label dependency | |
| CN115878842A (en) | Video tag determination method and device, electronic equipment and readable storage medium | |
| CN113704565B (en) | Learning type space-time index method, device and medium based on global interval error | |
| CN114357248A (en) | Video retrieval method, computer storage medium, electronic device, and computer program product | |
| CN111859057A (en) | Data feature processing method and data feature processing device | |
| WO2016110125A1 (en) | Hash method for high dimension vector, and vector quantization method and device | |
| CN111785296A (en) | A music segmentation boundary recognition method based on repetitive melody | |
| CN115879002B (en) | Training sample generation method, model training method and device | |
| CN115758191B (en) | Knowledge service entity clustering number prediction method based on deep learning | |
| CN102903104A (en) | Subtractive clustering based rapid image segmentation method | |
| CN116994043A (en) | A small sample image recognition optimization method, device, equipment and storage medium | |
| CN116248918A (en) | Video shot segmentation method and device, electronic equipment and readable medium | |
| CN114637889A (en) | Video tag identification method, apparatus, electronic device and computer readable medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |