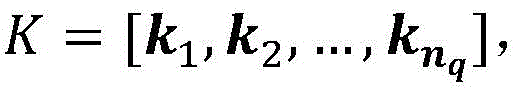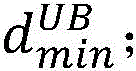Background
With the explosive growth of various types of network information in the internet technology, the World-Wide-Web (WWW) has been developed as a large distributed global information distribution site. However, the network is a double edged sword. On the one hand, a large amount of information is flushed into the Internet, a powerful support is provided for information service, and the network has become an important way for acquiring knowledge and information. On the other hand, the diversity, disorder, dispersion and pollution of network information cause interference to the acquisition of information. How to search network information efficiently and how to help network users to select needed information from massive data accurately and rapidly according to inquiry requests of the network users. Search engine technology has evolved. Depending on the vast population of commercial computers and powerful search core algorithms, users are increasingly accustomed to using search engines for information retrieval.
With the increasing sophistication of large search engine services, people are no longer satisfied with traditional document retrieval. They would prefer to directly obtain an accurate answer to the queried question rather than a set of documents that contain specified keywords. Based on this demand, intelligent question-answering tasks have become a research hotspot in industry and academia. A typical question-answering system relates to three research fields of information retrieval, information extraction and natural language processing. The main task of the system is to understand the problem through natural language processing, obtain related documents through information retrieval, generate answers through information extraction, and then return the final result to the user. According to the search field division, the question-answering system can be divided into a closed-domain question-answering system and an open-domain question-answering system, which respectively correspond to the vertical search field and the general search field. The closed domain question-and-answer task may be regarded as a simpler task because of the smaller size of data that it needs to process. Open domain question-answering systems handle almost all types of questions, including real-world, enumerated, defined, hypothetical, semantically constrained, cross-language, and the like. Therefore, how to efficiently and quickly grasp useful information from a huge data scale becomes a big problem in constructing an open-domain question-answering system. In recent years, the development of knowledge graph research work provides assistance for the research of an open-domain question-answering system.
At present, in the field of natural language processing, knowledge graphs have become an effective means for constructing a knowledge database for knowledge acquisition and reasoning, so as to answer questions posed by users. Nodes, also called entities, in the knowledge-graph are identified by uniform resource locators (Uniform Resource Locator, URIs). The nodes are connected together through directed edges with explicit semantic relations, so that a knowledge graph is formed together, and a knowledge graph sub-graph centering on a specific node forms a specific concept. Because the knowledge in the knowledge graph is usually stored in the form of triples and naturally corresponds to subjects, predicates and objects in natural language sentences, the knowledge graph can be conveniently applied to intelligent question-answering tasks.
Unlike complex question-answering systems that require multiple levels of reasoning capability, simple question-answering systems find a single-hop path in a knowledge graph to retrieve answers to questions. The problem that we refer to only a single triplet is referred to as a first order facts problem or a simple problem. In fact, these first order factual issues relating to "when", "where", "what", "which" and so on simple queries make up the major part of a general search query. In addition, with the continuous perfection of large-scale knowledge graph structures, such as CN-dbpetia, satori, google knowledge graph, etc., many complex problems can be degraded to first-order fact type problems. Simple question-and-answer tasks, which are far from being resolved, although referred to as "simple," are important both commercially and academically. How to link subjects in natural language questions to nodes in a knowledge graph and how to extract real predicates from a transformed question-method is still a research hotspot in knowledge graph question-answering tasks. The framework model of the prior knowledge graph question-answering system is as follows:
The prior knowledge graph stores knowledge in the form of triples (subject, predicate, object), which we represent as (s, p, o). Since the first order natural language question q has a unique subject s and oneOrder predicate p, so that the first order fact question-answer involves only one triplet in the knowledge graph. Specifically, the goal of the first-order knowledge-graph question-answering (Knowledge Graph Question Answering, KGQA) system is to extract subjects s from natural language questions * Sum predicate p * Then searching the knowledge graph for the s=s through the structured query language * And p=p * The triplet of conditions (s, p, o) eventually returns the answer o. The system can be modeled using a probability formula as follows:
where KG denotes a complete knowledge graph, q denotes a natural language problem, P (P, s|q) denotes a probability that a predicate P and a subject s in the knowledge graph match the problem q in the case of a known problem q, P (p|q) denotes a probability that a predicate P in the knowledge graph matches the problem q in the case of a known problem q, and P (s|p, q) denotes a probability that a subject s in the knowledge graph matches the problem q in the case of a known problem q and a determination of the predicate P. Because the scale of the knowledge graph is usually very huge, even if the model is decomposed by adopting a Bayesian formula, the calculation complexity is still very high and the model accuracy is very low, so that the KGQA system usually adopts the sub-graph C after pruning the knowledge graph to search the answer of the natural language question. The probability modeling is as follows:
Although pruning the knowledge graph can lead to the model obtaining only suboptimal solutions, the method is helpful for reducing redundant information and greatly improving the inference efficiency. Thus, the KGQA task can be broken down into three major steps: and generating a candidate pool, extracting predicates and extracting subjects.
Step one: candidate pool generation
The purpose of this step is to reduce the size of the knowledge graph that needs to be calculated. Pruning the knowledge graph KG according to the natural language problem q to obtain a knowledge graph sub-graph C associated with the problem. The method can be further divided into two sub-steps, namely a subject phrase labeling task and a knowledge graph matching task.
And (a) labeling the subject phrase. This step aims at labeling the word sequence most likely to be subject in the natural language question q, called subject related phrase g * . The formula is as follows:
g * =argmax g∈G(q) P(g|q)
where G (q) represents all possible n-gram sets for the natural language question q, n=1, |q| represents the number of words in the question q, and the n-gram of a word string refers to a continuous sub-word string of length n in the word string. P (g|q) represents the probability that an n-gram g of the question q is the subject of the question q, which models a subject related phrase labeling model for generating subject related phrases.
The specific operation is as follows:
the natural language problem can be expressed as:
q=[w 1 ,w 2 ,…,w i ,…,w |q| ]
the corresponding label forms are as follows: l= [ I (w) 1 ∈g * ),I(w 2 ∈g * ),…,I(w i ∈g * ),…,I(w |q| ∈g * )]Wherein I (·) is an indication function, g * Is a true subject; w (w) i Is a term in question q.
Since subjects are typically composed of multiple words, the label of the task should have multiple consecutive 1 s, with the remaining non-subject portions all being 0 s. And taking out the plurality of words with the longest continuous mark of 1, namely the related phrase of the subject.
Step one (b) of knowledge pattern matching
The step searches the name in the knowledge graph according to the matching strategy and the result g obtained in the step one (a) * And all the matched nodes take a subgraph formed by the nodes and first-order neighbor nodes pointed by the directed edges of the nodes as a pruned knowledge graph C. The formulation is as follows.
C={(s,p)|MF(s,g * )=1,I((s,p,o)∈KG)=1}
Wherein KG represents a complete knowledge graph; MF (s, g) * ) Is a matching function and represents a node s and a subject related phrase g in the knowledge graph * And the matching degree between the two is 1 if the function value is matched, otherwise, the function value is 0.I (·) is an indicator function, I ((s, p, o) ∈kg) =1 is used to constrain that predicates in the candidate pool must belong to a directed edge in the original knowledge graph that starts from the node where the subject is located.
The key step is to match the function MF (s, g * ) And (5) designing. The current mainstream method usually adopts strict matching, and only searches the knowledge graph entity of which the node name is completely matched with the related phrase of the subject or the n-gram. However, the situation is complicated in practical problems, such as "who is the author of the waterside? In the 'middle, for the subject's 'Shuihu', if only 'Shuihu' is transmitted in the node name and alias list corresponding to the knowledge graph but no 'Shuihu', the matched knowledge graph node cannot be found through the method. Therefore, it is necessary to improve this to increase the matching degree of the knowledge-graph.
Step two: and (3) optimizing a probability model P (p|q) on the knowledge graph subgraph C obtained in the step (I), namely extracting predicates P corresponding to the natural language problem q from the candidate predicates contained in the step (C). The task belongs to a multi-classification task, namely, candidate predicates are ordered according to the probability of matching with the problem q, and probability modeling is as follows:
wherein θ parameterizes the probabilistic model, representing weights of all parameters to be trained in the model; w (w)
pi Representing predicate p
i A corresponding weight parameter vector; v (q) is a feature representation vector of the natural language question q, n
p Representing the number of candidate predicates. The output of the model is n
p Conditional probability vector of (2)
The predicate with the highest probability is the prediction predicate. Multi-classification models typically employ a cross entropy loss function to update model parameters:
wherein,,
is a training dataset; (q, t) is training set +.>
In (3) a sample of the sample; q represents natural language question input; t represents a knowledge-graph predicate corresponding to the sample q; n is n
p Representing the number of candidate predicates, the predicate being a vector, t
i A representation vector representing an ith predicate among the candidate predicates.
Step three: subject extraction
In the step, a probability model P (s| p.q) is optimized on a knowledge graph subgraph C, namely, subject s corresponding to a problem q is extracted from candidate subjects of the C under the condition that predicates P are obtained in the step two. Because the subject extraction module is simpler, the previous node of the predicate p is needed to be searched reversely on the C, and after the subject s and the predicate p corresponding to the q are obtained, the subject s and the predicate p are directly input into the RDF (Resource Description Framework) engine for inquiry, and then the object node can be searched in the knowledge graph to be used as an answer of the problem q.
The method often has the problem that the matched answers cannot be found in the knowledge graph, and the ever-increasing material culture needs of people cannot be met, so that the link of the existing method affecting the accuracy and efficiency of the question-answering system is necessary to be improved, and the performance and accuracy of the simple question-answering system are improved.
Disclosure of Invention
The invention aims to solve the problems partially or completely, provide a candidate pool generation method and provide a more efficient and more robust knowledge graph question-answering system implementation method based on the candidate pool generation method.
The main idea of the invention is to provide a new implementation method for generating a candidate pool of a knowledge graph question-answering system, and overcome the defects of the existing method; the main content is that a non-strict N-element character string matching strategy is adopted, a subject related phrase is used as a mode to search an N-element grammar matched entity in a knowledge graph, and the N-element grammar matched entity is crossed with the strict matching, and a candidate pool is generated in an iteration mode, so that the generation efficiency of the candidate pool is improved, and meanwhile, higher accuracy can be obtained in a smaller generation scale of the candidate pool, and the performance of a knowledge graph question-answering system is improved.
The invention aims at realizing the following technical scheme:
in a first aspect, the present invention provides a candidate pool generation method, including the steps of:
Step 1, labeling related phrases of a subject on a natural language problem q to obtain related phrases g of the subject * ;
Step 2, for g * Searching matched nodes in the knowledge graph by adopting the following non-strict N-gram character string matching method to obtain a candidate subject set E:
by word string g * Searching nodes with identical node names or aliases in the knowledge graph for the keywords, and adding identifiers of the nodes into a candidate subject set E;
if E is empty, continue to find node name or alias part matches g * And adds it to candidate set E;
let n= |g if E is still empty * I-1, where I g * I represents g * The number of words in (c) and performing the following cycle: first generate g * All possible N-gram sets G N Then in g N ∈G N Searching node names or nodes with completely matched aliases for the keywords in the knowledge graph; if no matched node exists, making N=N-1 and continuing to execute the loop, otherwise, adding identifiers of all matched nodes into E and jumping out of the loop;
step 3, extracting directed edges from the elements in the E in the knowledge graph to obtain a candidate predicate set P; the nodes and directed edges of the candidate subject in the knowledge graph form a candidate pool C.
Preferably, to ensure that the subject components of the callout are continuous, the g * Obtained by the following process: firstly, collecting all n-gram continuously marked as main language components in q, wherein n is more than or equal to 1 and less than or equal to |q|, and |q| represents the number of words in a problem; then merging n-gram with only one non-labeled word, and selecting the longest n-gram after merging as the labeled phrase g of the subject * 。
In a second aspect, the present invention also provides a method for implementing a simple question-answering system based on knowledge graph matching, which includes the following steps:
step 1, generating the candidate pool C according to the method provided by the first aspect;
step 2, extracting a predicate p corresponding to the natural language question q from the candidate predicates contained in the C;
step 3, extracting subject s corresponding to the q from candidate subjects of the C according to the p;
and 4, obtaining objects by the RDF engine of the s and p input knowledge maps as answers of the q.
Preferably, the predicate p is obtained by extracting the top z predicates in the predicate extraction framework model:
wherein p (p i ) Is the candidate predicate p i T (q) is a characteristic representation of a natural language question q, n p And s (-) is a similarity calculation function used for calculating similarity scores between natural language problems and predicates, theta parameterizes the whole frame model, represents all parameter weights to be trained in the model, and z is a natural number.
Preferably, said T (q) is obtained by the following procedure:
first, the natural language question is removed from the subject related phraseWord sequences input to the embedded presentation layer to obtain an output
Wherein n is
q The length of the question sequence after the natural language question shielding subject related phrase is;
second, E is transferred into three deep neural networks DNN
Q ,DNN
K And DNN
V Then respectively obtaining three output matrixes
And->
Calculating each word representative vector Q with Q as the center of attention
i Similarity vector a between sum K
i Thereby obtaining the attention weight distribution matrix
Then by calculating V with similarity vector a
i A weighted sum vector for weights->
Obtained from the attention output matrix->
Finally, a problem feature representation matrix T is calculated according to the following formula:
said p (p) i ) Obtained by the following formula:
p=p word +W p e pred
wherein p is word Representing vectors for word levels of predicates for predicates p i After being segmented by words, the words are respectively expressed as word vectors, and the word vectors are used for initializing an embedded representation layerThen sharing feedforward neural network by weight, and obtaining by maximum pooling; wherein i is n or less p Natural number of (3); e, e pred Predicate-level representation vector for predicate, predicate p i After coding, initializing an embedded representation layer, and then outputting the embedded representation layer through a linear feedforward neural network to obtain W p e pred The network weight is W p ;
The s (-) is calculated by the following procedure:
first, using cosine similarity as a measure, a similarity vector is calculated by the following formula
m i =cos(t i ,p)
Wherein t is i The characteristic expression vector of the i-th word after the related phrase of the subject is shielded in the natural language question q, and p is the characteristic expression vector of the candidate predicate of the natural language question q;
secondly, dividing an interval where the value of the similarity vector is located into v bins by using a statistical distribution histogram, counting the number of elements falling into each bin in the similarity vector m, and obtaining a statistical distribution result c= [ c ] 1 ,c 2 ,…,c v ];
Finally, the statistical distribution is fed into a full-join layer to obtain a final similarity score s, expressed as follows:
s=tanh(w T c+b)
where w is the full link layer weight and b is the full link layer offset.
Preferably, the deep neural network is a single-layer linear feed-forward neural network.
Preferably, the similarity calculation method adopts an additive method.
Preferably, the encoding adopts the following heuristic label encoding method:
the embedded representation vector dimension k and the attenuation factor α of the tag class are set according to the inequality:
k-log 2 (n)≥2(d min -1)-log 2 (d min )
let n=n
p Calculating the minimum hamming distance upper bound
Then generating k independent samples with value range of { -1,1}, and forming candidate embedded representation vector t of label category
i Will t
i With all tags L [ j ] generated before]Performing calculation if it is satisfied->
Then t
i If the embedded representation vector is of the ith category, otherwise, continuing to sample until the condition is met, and finally obtaining tag codes t of all candidate predicates; wherein i is n or less
p J is a natural number less than i.
Preferably, the statistical distribution result c is calculated using the following gaussian radial basis function:
wherein μ represents the mean value of the gaussian distribution, σ represents the standard deviation of the gaussian distribution, and v represents the number of gaussian kernels.
Preferably, the predicate extraction framework model has a loss function of:
where q is the dataset
In the question sample, t is the predicate label corresponding to the question sample, < ->
Is a candidate predicate set generated from the problem q;
Is a candidate predicate set other than predicate label t; p (·) represents a predicate-feature representation vector; t (·) represents a problem feature representation matrix; gamma denotes a predefined Hinge Loss (Hinge Loss) margin.
The beneficial effects are that:
compared with the prior art, the invention has the following characteristics:
1. matching function MF (s, g) by using non-strict N-gram character string matching method * ) Designing to overcome the vocabulary difference between the node name of the knowledge graph and the subject phrase; the balance between the improvement of the recall rate and the reduction of the average candidate pool size is achieved, and the method is applied to a simple question-answering system, so that the possibility that the target subject node appears in the candidate pool is improved, and the candidate pool size is not greatly enlarged;
2. Subject labeling phrase g for extracting natural language problem q * When the method is used, n-gram grammar which is only separated by one non-labeling word is combined, so that continuity of labeling main word components is ensured, and the performance of a candidate pool is improved;
3. a brand new predicate extraction framework is designed, the accuracy of the predicate extraction model is improved, and the accuracy of a simple question-answering system is improved;
4. the designed predicate extraction framework based on the soft statistical distribution histogram and the self-attention mechanism improves the accuracy of predicate extraction, and the proposed heuristic label embedded coding algorithm also improves the efficiency of a simple question-answering system, and improves the accuracy with fewer resources.
Detailed Description
The invention is described in detail below with reference to the drawings and examples.
Fig. 1 shows the workflow of a knowledge graph question-answering system. Fig. 2 is a schematic diagram of a general knowledge graph question-answering system. The main purpose of the whole system is to understand the questions of the user, and then find corresponding answers from the knowledge graph and feed back the answers to the user. For example, if the user posed the question "which state the double peak is located? The knowledge graph has corresponding triples (double peaks, belonging to the region, california), and the question answering system needs to identify the subject (double peaks) and the predicate (located) in the question, and then the answer can be directly obtained by inquiring in the knowledge graph. Since the question of a question has many variations, how to accurately identify predicates from the variations is a big challenge for the question. Meanwhile, predicates in the problems are different from predicate expression forms in the knowledge graph. How to solve the expression difference is also a problem to be solved. The present invention proposes a new solution to the above problem, as further described below in connection with the examples and fig. 8, 9. Fig. 8 shows an overall schematic of an implementation method of a simple question-answering system based on knowledge-graph matching based on this example. Fig. 9 is a flowchart of an implementation method of a simple question-answering system based on knowledge-graph matching.
Examples: what instrument dose Taylor play …
Step 1, generating a candidate pool C
This step may generate the candidate pool in a conventional manner. However, in order to increase the possibility that the target subject node appears in the candidate pool, the size of the candidate pool is not greatly enlarged, for example, the candidate pool is generated by adopting the following process:
1. subject related phrase labeling
The problem can be expressed as:
q=[what,instrument,dose,Talor,play,…]
the subject of the question is then tag coded. The subject in the example problem should be Talor and the result of the encoding should be [0, 1,0, … ].
Since the example problem is relatively simple, the reality may be subject to more complex problems, as may the subject component. In this case, non-subject words may appear in the subject words at intervals, so, in order to ensure continuity of the subject, n-gram words of one non-subject word are combined, and finally, the longest n-gram word is selected as the related phrase of the subject.
2. Knowledge graph matching
The related phrase of the subject is extracted from the problem in the last step, and the subject node matched with the extracted phrase of the subject is searched in the knowledge graph according to the extracted phrase of the subject, wherein a non-strict N-element matching algorithm is adopted, and the algorithm flow is shown in fig. 3:
First, consider g * Is the most probable subject, the invention uses word string g first * Searching nodes with identical node names or aliases in the knowledge graph for the keywords, and adding identifiers of the nodes into a candidate subject set E;
if E is empty, continue to find node name or alias part matches g * And adds it to candidate set E;
if E is still empty, let N= |g in order to further increase subject recall * I-1, where I g * I represents g * The number of words in (c) and performing the following cycle: first generate g * All possible N-gram sets G N Then in g N ∈G N Searching node names or nodes with completely matched aliases for the keywords in the knowledge graph; if there are no matching nodes, let n=n-1 and continue to perform this loopOtherwise, the identifiers of all the matched nodes are added to E and the loop is jumped out.
And then searching a directed edge from the subject node, namely a corresponding predicate according to the subject node. The subject node and predicate together comprise a candidate pool. If the subject node Talor is generated, the directed edge from which it starts may be (potential_codes, structure_construction, entities_played, …).
Step 2, extracting predicates p corresponding to the natural language problem q from the candidate predicates contained in the candidate pool C generated in the previous step
The predicate can be extracted according to a traditional method, but in order to improve the accuracy of a predicate extraction model, the following brand-new predicate extraction framework model can be adopted for extraction:
wherein p (p i ) Is predicate p i T (q) is a characteristic representation of a natural language question q, n p And s (-) is a similarity calculation function used for calculating similarity scores between natural language problems and predicates, theta parameterizes the whole frame model, represents all parameter weights to be trained in the model, and z is a natural number. The probability of all candidate predicates can be given through the model, and the top-ranked predicate or top-ranked predicates can be output according to actual needs.
The predicate feature representation, the problem feature representation and the similarity calculation in the model can be expressed and calculated by adopting the existing method, such as representing predicates and sentences by using first-order logic, semantic net, word vector and the like, and calculating the similarity by using word shape similarity, word order similarity, vector similarity and the like. In order to improve accuracy and efficiency of predicate extraction, the method adopts a vector form to perform predicate, problem feature representation and similarity calculation in the following manner.
3. Representing predicates
Predicate identifiers in knowledge maps typically contain semantic information. For example, in the Freebase knowledge graph, the predicate group_member_played is composed of three parts, predicate information group_played, class information group_member to which the predicate belongs, and class domain information group to which the predicate belongs. In order to fully utilize information carried by predicates in the knowledge graph, some scholars design predicate-level and word-level predicate representation methods by means of a cyclic neural network. Wherein the predicate level represents class information of the predicate and the word level represents semantic information of the predicate.
The present example divides a representation of a predicate into two parts, predicate-level and word-level.
Because a single training sample typically contains hundreds of candidate predicates, the currently used recurrent neural network approach is computationally expensive. The invention provides a single-layer weight sharing nonlinear feedforward neural network model for extracting semantic information in knowledge spectrum predicates. The input of the method consists of a word level and a predicate level.
For predicate-level input, predicate p is sent to an embedded representation layer as a whole, and predicate level can be represented by adopting a method such as single-hot coding, but the method can cause the problem of overlong coding and reduced calculation efficiency. Thus, preferably, this step initializes the embedded representation layer with the embedded representation obtained by heuristic tag encoding, the predicate-level representation vector being symbolized as e pred 。
Heuristic tag coding:
how to find the correct predicate corresponding to the candidate predicate set P according to the problem q can be regarded as a multi-classification task, wherein the predicate P e P is a classification, and the problem q is a classification object. Typically, the multi-classification model encodes the categories using one-hot encoding, however if one-hot encoding is used, the dimension of the encoding vector is the number of categories, and the number of predicate categories in the knowledge graph is thousands or even tens of thousands, which is unacceptable in practice.
The invention is inspired by Word2Vector, if the label class uses low-dimensional embedded Vector to replace single-heat coding, the output Vector of the multi-classification model only needs to embed the representing Vector as close as possible to the real class in the measurement space and far away from other classes, and the model can successfully classify the sample. Therefore, the heuristic label coding algorithm is designed for a large multi-classification task, the output dimension of the multi-classification model is reduced, and the distance of the embedded codes of the label class in the measurement space is optimized. The heuristic algorithm provided by the invention discretizes the value range of the independent variable to approximate the original problem, namely, the element of the constraint embedded vector can only take-1 or 1.
Assume that there are n in the multi-classification task t And (3) each label category is coded into a k-dimensional embedded vector, and the optimization goal of label coding is to maximize the distance between each label category and the nearest neighbor of each label category, and the invention adopts Hamming distance to measure. The goal of the optimization is to maximize the hamming distance between each tag class and its nearest neighbor, similar to the channel coding optimization method. The optimization problem is modeled as follows:
s.t.t i,j ∈{-1,1} i=1,2,…,n t ;j=1,2,…,k
wherein the symbols are
Representing an element-wise exclusive-or operation; I.I
1 Is->
Norm, i.e. vector element summation; t is t
i,j Representing a tag embedding vector t
i Is the j-th element of (c). According to the p Luo Tejin limit, in order to encode n with a k-dimensional vector
t The minimum hamming distance of each tag must satisfy the following formula:
k-log 2 (n t )≥2(d min -1)-log 2 (d min )
wherein d min Representing the minimum hamming distance. At the same time in practice it should satisfy k.gtoreq.log 2 n t 。
Thus, given k and n
t When the above equal sign is established, the minimum hamming distance d
min Reaching the upper limit
The upper bound may be solved by dichotomy. However, there is currently no coding scheme that can reach this upper bound, so the decay factor is used herein to multiply the minimum hamming distance upper bound +.>
Obtaining a predefined minimum hamming distance α·d between label classes
min 。
In summary, for predicate-level input, this example encodes predicates in the candidate pool obtained in the previous step by:
First, determining the number n of tag categories according to the number of candidate predicates in a candidate pool
p The embedding of the tag class represents the vector dimension k, defining the attenuation factor α. In the experiment of the invention set
Then according to the inequality:
k-log 2 (n)≥2(d min -1)-log 2 (d min )
calculating the minimum hamming distance upper bound
Then generating k independent samples from Bernoulli distribution with compliance probability of 0.5 and value range of { -1,1}, and forming candidate embedded representation vector t of label category
i . Since bernoulli distribution is typically used for word random trials with only two results, it is suitable for this scenario. Of course, the generation of the k-dimensional embedded representation vector t from the Bernoulli distribution is not limited to
i Other distributions or randomly generated embedded representation vectors may be employed.
Then t is taken
i With all tags L [ j ] generated before]Performing calculation if it meets
Then t
i And if the embedded representation vector is of the ith category, otherwise, continuing to sample until the condition is met, and finally obtaining the tag codes t of all the candidate predicates.
The embedded representation layer (ebedding layer) is initialized with the vector of the last step of tag encoding (256 dimensions), and then passed through a linear feed forward neural network with a weight of W p Predicate-level representation e with 300-dimensional output pred 。
For word-level input, predicate information is firstly divided into word sequences, then word vectors pre-trained by GloVE are used for representing words, and word-level embedded representation vectors are obtained
Where m is the word sequence length. Embedding word level into a nonlinear feedforward neural network with shared matrix afferent weights and performing maximum pooling operation in a sequence direction to obtain word level semantic feature vectors:
p word =MaxPooling(tanh(W f ·E word ))
wherein W is f The parameter weight matrix to be optimized in the nonlinear feedforward neural network is shared among word sequences, and tanh (·) is the nonlinear activation function adopted.
For this example problem, word-level representation first requires word-segmentation of predicates, such as: the predicates_played in the second step can be partitioned into { instruments, played }, then these words are represented with 300-dimensional GloVe pre-trained word vectors and initialized embedded into the representation layer, which then uses 300-dimensional hidden layer output through a weight sharing feed-forward neural network in the present invention. And then the maximum pooling is carried out to obtain the word level representation p of the predicate word 。
And finally, adding the predicate-level representation and the word-level representation to obtain a predicate-feature representation vector p.
p=p word +W p e pred
Wherein W is p Is a parameter weight matrix of a linear feedforward neural network for balancing predicate-level and word-level feature extraction networksDepth. The specific process is shown in fig. 4.
4. Representing questions
This step represents the problem feature based on a self-attention mechanism. First, the natural language question sequence q= [ w ]
1 ,w
2 ,…,w
|q| ]Input to the embedded presentation layer (ebedding layer), where each word in question q is represented using a word vector pre-trained by the GloVe method, and the embedded presentation layer is initialized with this vector; where |q| represents the number of words in q. Since the semantics contained in the words constituting the entity names are not usually expressed in a conventional dictionary, special symbols are adopted in this text in order to avoid the subject's interference in the input problem<s>Masking phrases related to subject, i.e. the problem sequence of the true input model, is
Thus, the output symbol of the embedded presentation layer is denoted +.>
Wherein n is
q Is the length of the masked problem sequence.
The output E of the embedded layer is transmitted into three deep neural networks, wherein the neural network can be a single-layer bidirectional LSTM, a single-layer bidirectional GRU or a single-layer linear feedforward neural network. The invention is verified by experiments, and a single-layer linear feedforward neural network is selected. The three networks are respectively named DNN
Q ,DNN
K And DNN
V 。DNN
Q The output matrix of (a) is expressed as
DNN
K The output matrix is expressed as +.>
DNN
V The output matrix is expressed as +.>
Calculating each word representative vector Q with Q as the center of attention
i And DNN
K Similarity vector a between output matrices K
i Thereby obtaining the attention weight distribution matrix +. >
Finally, calculating V to obtain a similarity vector a
i A weighted sum vector for weights->
Obtained from the attention output matrix->
The three similarity calculation methods of the additive type, the dot product type and the generalized dot product type exist at present, and experiments show that the model is more stable by adopting the additive type, so that the additive type similarity is adopted as the attention calculation mode.
Taking the ith input word as an example, the corresponding self-attention output vector
The calculation formula is as follows:
first, q is calculated
i Similarity to all vectors in K
Then to the similarity
Normalization processing is carried out to obtain normalized similarity a
ij :/>
Finally, using normalized similarity a
ij As a weight, pairAll vectors in V are weighted and summed to obtain the self-attention vector of the ith word
Wherein w is q And w k Is the model parameter to be trained.
Furthermore, for robustness of model training, the idea of residual networks is also applied here to this model. By connecting the embedded presentation layer output cross-layer to the self-attention output matrix, the self-attention layer turns to learn the feature residual of the natural language problem, speeding up the training and alleviating the gradient vanishing problem. Thus, the output matrix of the problem-feature representation model is actually:
T is a problem feature representation matrix.
Based on the above procedure, for the example problem q, preprocessing is first performed, and the sign < s > is used to mask the subject vocabulary, which in this example should be obtained
q=[what,instrument,dose,<s>,play,…]
Q is then represented by a 300-dimensional GloVe pre-training word vector and the embedded representation layer is initialized, the output of which is E. Three bi-directional gated loop cell networks (Gate Recurrent Unit, GRU) are connected behind the embedded presentation layer, all using 300-dimensional hidden layer output. And respectively obtaining three matrix representations of Q, K and V through three neural networks. The self-attention moment array is calculated by the following formula
Then, self-attention moment array
And adding the embedded representation layer output E to obtain a problem feature representation matrix T.
The specific process is shown in fig. 5.
5. Similarity calculation
After the predicate feature representation vector p and the predicate representation matrix T are obtained through the questions and the predicate representation respectively, the similarity score s of each word in the questions and the predicate feature vector is needed to be calculated according to the predicate extraction frame model. The cosine similarity is used as a measure in the embodiment, and the cosine distance is equivalent to normalization processing of the input layer, so that the stability of the model is improved. Similarity vector
The calculation method is as follows:
m i =cos(t i ,p)
wherein t is i Is the feature representation vector of the i-th word in the natural language problem, and p is the predicate feature representation vector. Since the length of the problem is difficult to determine, the similarity vector cannot be directly fed into the neural network to calculate the final score. We note that the more words in a natural language question that are highly similar to a predicate feature vector, the more likely that predicate will represent the predicate to which the question corresponds. Therefore, the similarity calculation model needs to count the similarity distribution of all the words in m. Due to similarity vectorThe value of (2) is distributed in [ -1,1]In the interval, a simple statistical method is that the interval is uniformly divided into v sub-boxes by using a statistical distribution histogram, and the element number falling into each sub-box in a similarity vector is counted to obtain a statistical distribution result c= [ c ] 1 ,c 2 ,…,c v ]. The final similarity score s can be obtained by feeding the statistical distribution into a fully connected layer.
s=tanh(w T c+b)
Where w is the full link layer weight and b is the full link layer offset.
The statistical distribution histogram is a discrete statistical mode, so that the network becomes impossible to conduct, and the invention adopts a Gaussian radial basis function to represent the distribution condition of the similarity to solve the problem.
Firstly, calculating the distribution condition of similarity vectors on each Gaussian kernel:
Wherein μ represents the mean value of the gaussian distribution, and σ represents the standard deviation of the gaussian distribution.
Finally, s=tanh (w T c+b) calculating the final score s.
Thus, to sum up, the similarity is calculated for this example problem using the following procedure:
first, a predicate expression vector p and a term expression vector t for each of the questions are calculated using the following equation i Obtaining similarity m i :
m i =cos(t i ,p)
The similarity is then re-represented with a gaussian radial basis function. In this example implementation, 4 Gaussian kernels are used, and the initial mean and variance are taken as [ -0.66,0,0.66,1] and [0.3,0.3,0.3,0.3], respectively.
The components of each similarity vector on each gaussian kernel are calculated by the following formula, where v=4
Then, the distribution of the similarity vectors on each Gaussian kernel is input into a full-connection layer, and a final similarity score s is obtained.
s=tanh(w T c+b)
The specific process is shown in fig. 6.
6. Loss and training
First, the penalty is calculated and the predicate extraction framework model is trained using the following formula:
where q is the dataset
In question samples, t is the corresponding predicate tag, +.>
Is a candidate predicate set generated from the problem q;
Is a candidate predicate set other than predicate label t; p (·) represents a predicate-feature representation vector; t (·) represents a problem feature representation matrix; gamma denotes a predefined Hinge Loss (Hinge Loss) margin. In fact, the ordered cost function is a negative-sampling based hinge loss function, and the output vector for the constraint model is as close to the target predicate as possible in metric space, while still being far from the other candidate predicates.
At this time, the gradient of the loss function needs to be calculated
To update the training model parameter theta. The model is trained using gradient descent algorithms to update parameters:
the initial learning rate of the experiment is 0.001, the batch size is 128, the negative sampling scale is 150, the model parameter updating adopts an Adam optimization algorithm, the learning rate is updated in a self-adaptive manner, the vibration in the training process is prevented, and the loss convergence rate is improved. In this example, torch7 was used to build neural networks for deep learning frameworks
After training the predicate extraction framework model using training data, the model may be used to extract predicates based on candidate pools and questions to answer the questions.
Step 3, extracting subject s corresponding to the q from candidate subjects in the candidate pool C according to the predicates extracted in the step 2;
and 4, inputting the predicate p and the corresponding subject s into an RDF engine of the knowledge graph to obtain an object serving as an answer of the question q.
The above process is summarized as follows:
after the model is trained, if a new problem is encountered, a candidate pool is generated for the problem based on knowledge graph matching. And then, inputting Glove word vector representation of the problem and the candidate predicates and embedding label codes of the predicates into a trained neural network, calculating the similarity score between the problem and the candidate predicates through the neural network, and selecting the predicates with the highest similarity score or a plurality of predicates with the highest ranking as extraction predicates.
After the predicate is extracted, a subject node of the predicate can be selected, and finally the extracted predicate node and subject node are input RDF (Resource Description Framework) for inquiring by an engine, and then the object node can be found in the knowledge graph to be used as an answer of the question.
Evaluation index
The knowledge-graph-based question-answering system of the invention is evaluated as follows. The answer accuracy of the question-answer system is evaluated by defining recall:
P@N:
where M is the number of test set samples, y i Representing the true result of the ith sample, R i,1:N The top N of the list of candidate entities obtained. I (·) is an indication function defined as:
thus, P@N represents the average hit rate of the top N of the candidate predicates.
Data set:
data set and knowledge graph: we trained and evaluated the present invention using SimpleQuestions, which is the largest publicly available first-order simulated QA dataset, consisting of 108,442 english manual annotation questions, 75,910 for training, 10,845 for verification, and 21,687 for testing. The knowledge-graph Freebase has two subsets, namely FB5M with 5M entities (7K predicates) and FB2M with 2M entities (6K predicates).
Experimental results:
the invention designs a new candidate pool generation method and a new embedded coding mode, and designs a predicate extraction method based on a soft histogram and a self-attention mechanism. The experiment was thus performed in three parts: the method comprises the steps of (1) a candidate pool generation method effectiveness comparison experiment designed by the invention, (2) a hamming distance embedded coding algorithm effectiveness comparison experiment, and (3) a soft histogram and self-attention mechanism performance comparison experiment.
In the candidate pool generation effectiveness comparison experiment, the non-strict N-gram character string matching provided by the invention is mainly compared with the following three methods: a pure focus pruning method, a dynamic linking method and a strict local matching method.
We optimized model parameters using the training set and applied the optimal model to the test set, with experimental results shown in table 1.
Table 1 candidate pool generation task recall @ k contrast
Table 1 compares the recall @ K of candidate entities for the proposed algorithm with three comparative algorithms, recall and average size. It can be seen that the entity recall rate of the non-strict N-gram string matching algorithm is 1.5% higher than that of the purely focused pruning method due to the more careful entity matching strategy designed herein. The strict local matching method only uses the k-gram of the subject related phrase to strictly match the entity name in the knowledge graph, the k-gram of the subject related phrase is adopted to match the k-gram of the entity name in the knowledge graph, the length of k is not limited, and the experimental result also proves that the method is higher than the recall rate of 0.6 percent. The dynamic link method adopts all k-gram grammar of subject related phrases to search for matched entities, thereby greatly increasing candidate pool noise while enlarging entity recall rate. It can be seen from the table that although the recall rate is slightly lower than the dynamic linking method, the candidate pool size generated herein is much smaller than the former.
The recall rate @ K (K.epsilon. {1,5,10,20,50,100,400 }) of candidate entities of several algorithms, i.e., the percentage of test set samples containing the correct entity in the first K candidate entities. The method and the strict local matching method proposed herein both use entity node degree as entity ordering criteria, while the dynamic linking method uses the longest continuous common subsequence to calculate entity importance. From the table, the method proposed herein achieves optimal performance, proving that the proposed non-strict N-gram string matching method improves entity recall while not significantly expanding the candidate pool size.
Label embedded coding algorithm effect contrast analysis
In order to compare the effect of the label embedded coding algorithm, we performed a comparison experiment with a generic multi-classification model. Without loss of generality, the heuristic label embedding coding algorithm is applied to the predicate extraction model mentioned in the fourth step, wherein the model is a classifier based on a bidirectional cyclic neural network and is commonly used in the field of natural language processing.
As shown in fig. 7, the present experiment compares the influence of the proposed heuristic tag coding algorithm and the random initialization method on the accuracy of multi-classification tasks, and observes the influence of whether the tag embedding representation vector is updated or not on the performance. From the figure, whether the label embedding vector is updated or not, the classification accuracy of the proposed heuristic label coding algorithm is approximately 0.5% higher than that of the random initialization method on average. In addition, under the condition that the embedded vector of the label is subjected to gradient updating, the method basically achieves convergence after about 400 rounds of training on the accuracy of the test set, and the random initialization method achieves convergence only about 800 rounds, so that the superior convergence performance of the heuristic label coding algorithm is proved; in the case where the tag embedding vector is not updated, the training curve of the method herein fluctuates relatively little because the heuristic tag encoding algorithm forces the tags to be as far apart as possible in the metric space, whereas the random initialization method may cause some tags to be very close to each other in the metric space, thus becoming unreliable.
Performance contrast experiments of soft histogram and self-attention mechanism
Data set:
the data set of the experiment is used for preprocessing the SimpleQuestions data set, a special symbol < s > is used for shielding related phrases of a subject in advance, and a candidate predicate set is constructed for each natural language processing problem, so that a candidate pool generating task and a predicate extracting task are divided, and fairness of experiment comparison is guaranteed.
Table 2 accuracy contrast of predicate extraction framework components on predicate extraction tasks
The accuracy of each component of the proposed predicate extraction framework on a predicate extraction task is compared by the experiment, and the predicate extraction model based on heuristic label coding is used as a reference method for comparison.
First, experiments were performed on three modes of the problem feature representation model, with a GRU as the self-attention mechanism of the deep neural network (GRU-SA) defeating the self-attention mechanism based on LSTM and feedforward neural network FFN with an accuracy of 91.8. Although the problem feature representation based on the self-attention mechanism has only 0.1% improvement in accuracy compared to the baseline method, when it performs the predicate extraction task (GRU-sa+sffn+sh) in combination with the predicate feature representation and the similarity calculation module, the former achieves 0.3% performance benefit compared to the mode (sffn+sh) employing only the predicate feature representation and the similarity calculation module.
The predicate-feature representation model is tested on two modes, the accuracy of a single-layer weight sharing feedforward neural network mode (SFFN) defeats a reference method, and the effectiveness of the predicate-feature representation module is verified.
The similarity calculation module performs experiments on a soft statistical distribution histogram (SH) model and tests whether the mean and variance of the gaussian kernels are involved in updating the impact on model performance. As can be seen from the table data, the accuracy of the soft statistical distribution histogram mode in which the parameters are not involved in updating is 0.3% higher than that of the soft statistical distribution histogram mode in which the parameters are updated on the test set and 0.5% higher than that of the reference method, and the fact that the feature expression matrix can better retain semantic information in natural language problems compared with the feature expression vector is proved. In addition, since the soft statistical distribution histogram is located at the top layer of the predicate extraction network, the mean and variance of the gaussian kernel are greatly affected by error propagation of the loss function and gradient fluctuation of the loss function about the parameter is larger, so that the similarity calculation module parameter is difficult to converge, the output of the gaussian kernel is exponentially affected by the variance, and small fluctuation may cause huge model deviation, which is unfavorable for training of the model. Finally, the experiment combines three components of the predicate extraction framework, and performs the experiment on an optimal mode (GRU-SA+SFFN+SH, which is abbreviated as SHSA hereinafter), so that the optimal test set accuracy (93.7%) is obtained, the accuracy is 2% higher than that of a reference method, and the model superiority of the predicate extraction framework provided by the invention is verified.
In summary, the accuracy of candidate pool generation by the non-strict N-ary character string matching method provided by the invention is superior to that of a comparison experiment, and the efficiency of two components of the predicate extraction framework and the heuristic label embedded coding algorithm based on the soft statistical distribution histogram and the self-attention mechanism is also higher, so that the accuracy is superior to that of a reference experiment by fewer resources, thereby proving the effectiveness of the invention, and the invention can be applied to a first-order knowledge graph question-answering system.
For the purpose of illustrating the invention and the manner in which it is carried out, a specific embodiment is provided herein. The details are not included in the examples to limit the scope of the claims but to aid in understanding the method of the invention. Those skilled in the art will appreciate that: various modifications, changes, or substitutions of the preferred embodiment steps are possible without departing from the spirit and scope of the invention and the appended claims. Therefore, the present invention should not be limited to the preferred embodiments and the disclosure of the drawings.