CN111464442B - Method and device for routing data packet - Google Patents
Method and device for routing data packet Download PDFInfo
- Publication number
- CN111464442B CN111464442B CN201910057402.8A CN201910057402A CN111464442B CN 111464442 B CN111464442 B CN 111464442B CN 201910057402 A CN201910057402 A CN 201910057402A CN 111464442 B CN111464442 B CN 111464442B
- Authority
- CN
- China
- Prior art keywords
- node
- task type
- performance
- data packet
- nodes
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/1001—Protocols in which an application is distributed across nodes in the network for accessing one among a plurality of replicated servers
- H04L67/1004—Server selection for load balancing
- H04L67/1008—Server selection for load balancing based on parameters of servers, e.g. available memory or workload
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L45/00—Routing or path finding of packets in data switching networks
- H04L45/12—Shortest path evaluation
- H04L45/123—Evaluation of link metrics
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L45/00—Routing or path finding of packets in data switching networks
- H04L45/12—Shortest path evaluation
- H04L45/121—Shortest path evaluation by minimising delays
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L45/00—Routing or path finding of packets in data switching networks
- H04L45/70—Routing based on monitoring results
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L45/00—Routing or path finding of packets in data switching networks
- H04L45/74—Address processing for routing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L45/00—Routing or path finding of packets in data switching networks
- H04L45/74—Address processing for routing
- H04L45/745—Address table lookup; Address filtering
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/1001—Protocols in which an application is distributed across nodes in the network for accessing one among a plurality of replicated servers
- H04L67/1004—Server selection for load balancing
- H04L67/101—Server selection for load balancing based on network conditions
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/1001—Protocols in which an application is distributed across nodes in the network for accessing one among a plurality of replicated servers
- H04L67/1004—Server selection for load balancing
- H04L67/1012—Server selection for load balancing based on compliance of requirements or conditions with available server resources
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/1001—Protocols in which an application is distributed across nodes in the network for accessing one among a plurality of replicated servers
- H04L67/1004—Server selection for load balancing
- H04L67/1014—Server selection for load balancing based on the content of a request
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Computer Hardware Design (AREA)
- General Engineering & Computer Science (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Abstract
Description
技术领域technical field
本公开是关于网络通信技术领域,尤其是关于一种对数据包进行路由的方法和装置。The present disclosure relates to the technical field of network communication, in particular to a method and device for routing data packets.
背景技术Background technique
当路由节点接收到任一数据包时,路由节点可以根据当前的网络状况,确定下一跳路由节点,并将数据包转发到下一跳路由节点。其中,数据包可以携带用于指示需要从数据节点获取的目标数据的信息、携带即时通信信息或者携带用于指示需要运算节点执行目标类型的运算任务的信息(携带这种信息的数据包可称为运算任务类型的数据包)等。When the routing node receives any data packet, the routing node can determine the next-hop routing node according to the current network condition, and forward the data packet to the next-hop routing node. Among them, the data packet may carry information indicating the target data to be obtained from the data node, carrying instant messaging information, or carrying information indicating that the computing node is required to perform the computing task of the target type (the data packet carrying such information may be called data packets of the computing task type), etc.
可以执行同一类型运算任务的运算节点可以有多个,对于运算任务类型的数据包,只要将其转发至任一可以执行对应的运算任务的运算节点,该运算节点就可以执行运算任务,输出运算结果。例如,图像识别类型的数据包中携带有待识别图像,当运算节点接收到图像识别类型的数据包时,可以获取并识别待识别图像,将识别结果返回任务的发起节点。There can be multiple computing nodes that can perform the same type of computing task. For a data packet of the computing task type, as long as it is forwarded to any computing node that can perform the corresponding computing task, the computing node can perform the computing task and output the calculation result. For example, the data packet of the image recognition type carries the image to be recognized. When the computing node receives the data packet of the image recognition type, it can obtain and recognize the image to be recognized, and return the recognition result to the initiating node of the task.
在实现本公开的过程中,发明人发现至少存在以下问题:In the process of realizing the present disclosure, the inventors found at least the following problems:
在相关技术中,在对数据包进行路由的过程中,完全是根据当前的网络状况,确定如何转发数据包的。例如,可以执行运算任务A的运算节点有运算节点B和运算节点C,根据当前的网络状况,确定将运算任务A对应的数据包转发至当前的网络状况最佳的路径对应的运算节点C。然而,在实际应用中,当前的网络状况最佳的路径对应的运算节点不一定是最优的执行运算任务的节点。如果发生上述情况,会造成运算任务类型的数据包的发起节点需要等待很长时间,才能获得想要的结果。In related technologies, in the process of routing data packets, how to forward data packets is determined entirely according to current network conditions. For example, computing nodes that can execute computing task A include computing node B and computing node C. According to the current network status, it is determined to forward the data packet corresponding to computing task A to computing node C corresponding to the path with the best current network status. However, in practical applications, the calculation node corresponding to the path with the best current network condition is not necessarily the optimal node for performing calculation tasks. If the above situation occurs, the originating node of the computing task type data packet will have to wait for a long time before obtaining the desired result.
发明内容Contents of the invention
为了克服相关技术中存在的问题,本公开提供了以下技术方案:In order to overcome the problems existing in related technologies, the present disclosure provides the following technical solutions:
第一方面,提供了一种对数据包进行路由的方法,所述方法包括:In a first aspect, a method for routing data packets is provided, the method comprising:
当接收到运算任务类型的数据包时,确定所述数据包对应的第一运算任务类型;When receiving a data packet of a computing task type, determining a first computing task type corresponding to the data packet;
基于预先获取的运算任务类型、其他节点和运算性能的第一对应关系,确定所述第一运算任务类型对应的至少一个其他节点和所述至少一个其他节点对应的运算性能;Determine at least one other node corresponding to the first computing task type and computing performance corresponding to the at least one other node based on the pre-acquired first correspondence between the computing task type, other nodes, and computing performance;
基于所述至少一个其他节点对应的运算性能和本地节点分别与所述至少一个其他节点之间的链路状态,在所述至少一个其他节点中,确定目标节点;Based on the computing performance corresponding to the at least one other node and the link status between the local node and the at least one other node, in the at least one other node, determine the target node;
将所述目标节点的地址确定为所述数据包的目的地址,基于所述目的地址,对所述数据包进行转发。The address of the target node is determined as the destination address of the data packet, and the data packet is forwarded based on the destination address.
通过本公开实施例提供的方法,在对数据包进行路由的过程中,除了考虑当前的网络状况之外,还根据能够执行运算任务类型的数据包指示的运算任务的每个节点的运算性能,确定目的节点。这样,可以保证目的节点能够快速完成运算任务并将运算结果反馈给数据包的发起节点,从而缩短数据包的发起节点的等待时间。Through the method provided by the embodiments of the present disclosure, in the process of routing data packets, in addition to considering the current network conditions, it is also based on the computing performance of each node that can perform the computing task indicated by the data packet of the computing task type, Determine the destination node. In this way, it can be ensured that the destination node can quickly complete the operation task and feed back the operation result to the originating node of the data packet, thereby shortening the waiting time of the originating node of the data packet.
在一种可能的实现方式中,所述运算性能包括运算时延,所述链路状态包括数据包往返时延,所述基于所述至少一个其他节点对应的运算性能和本地节点分别与所述至少一个其他节点之间的链路状态,在所述至少一个其他节点中,确定目标节点,包括:In a possible implementation manner, the computing performance includes computing delay, and the link state includes data packet round-trip A link state between at least one other node in which a target node is determined, comprising:
对于每个其他节点,确定所述其他节点对应的运算时延和本地节点与所述其他节点之间的数据包往返时延的和值;For each other node, determine the sum of the operation delay corresponding to the other node and the round-trip delay of the data packet between the local node and the other node;
在所述至少一个其他节点中,确定最小和值对应的节点为目标节点。Among the at least one other node, it is determined that the node corresponding to the minimum sum value is the target node.
本地节点确定能够执行每种运算任务类型对应的运算任务的节点、以及每个节点执行每种运算任务类型的运算任务所需的运算时延和本地节点之间的数据包往返时延。对于每个其他节点,确定其他节点对应的运算时延和本地节点与其他节点之间的数据包往返时延的和值,在至少一个其他节点中,确定最小和值对应的节点为目标节点。The local node determines the nodes capable of performing the computing task corresponding to each computing task type, and the computing delay required by each node to execute the computing task of each computing task type and the data packet round-trip delay between the local nodes. For each other node, determine the sum of the operation delay corresponding to the other node and the round-trip delay of the data packet between the local node and the other node, and determine the node corresponding to the minimum sum value as the target node among at least one other node.
在一种可能的实现方式中,所述方法还包括:In a possible implementation, the method further includes:
当所述本地节点启动时,对于每个其他节点,向所述其他节点发送运算任务类型查询请求,接收所述其他节点返回的至少一个运算任务类型,向所述其他节点发送所述至少一个运算任务类型对应的运算性能查询请求,接收所述其他节点返回的所述至少一个运算任务类型对应的运算性能;When the local node starts, for each other node, send a computing task type query request to the other node, receive at least one computing task type returned by the other node, and send the at least one computing task type to the other node A computing performance query request corresponding to the task type, receiving the computing performance corresponding to the at least one computing task type returned by the other nodes;
基于每个其他节点分别对应的至少一个运算任务类型和所述至少一个运算任务类型对应的运算性能,建立运算任务类型、其他节点和运算性能的第一对应关系。Based on at least one computing task type corresponding to each other node and computing performance corresponding to the at least one computing task type, a first correspondence between computing task types, other nodes, and computing performance is established.
在本地节点未启动之前,本地节点中未存储有第一对应关系,第一对应关系需要在本地节点启动之后,自行建立。Before the local node is started, the first corresponding relationship is not stored in the local node, and the first corresponding relationship needs to be established after the local node is started.
在一种可能的实现方式中,所述其他节点和所述本地节点属于同一预设网络区域内,所述运算性能包括负载信息和运算时延,所述接收所述其他节点返回的所述至少一个运算任务类型对应的运算性能,包括:In a possible implementation manner, the other node and the local node belong to the same preset network area, the computing performance includes load information and computing delay, and the receiving the at least Computing performance corresponding to a computing task type, including:
接收所述其他节点返回的所述至少一个运算任务类型对应的当前的负载信息;receiving current load information corresponding to the at least one computing task type returned by the other nodes;
所述方法还包括:The method also includes:
根据预先存储的负载信息和运算时延的第二对应关系,确定所述当前的负载信息对应的运算时延,作为所述至少一个运算任务类型对应的运算时延。According to the second corresponding relationship between the pre-stored load information and the operation delay, the operation delay corresponding to the current load information is determined as the operation delay corresponding to the at least one operation task type.
可以预先在本地节点中导入并存储历史负载信息和运算时延相关数据,本地节点可以对这些历史数据进行拟合,以确定负载信息和运算时延之间的关系,进而,当确定了至少一个运算任务类型对应的当前的负载信息时,就可以确定当前的负载信息对应的运算时延。进而,就可以确定至少一个运算任务类型对应的运算时延。The historical load information and operation delay related data can be imported and stored in the local node in advance, and the local node can fit these historical data to determine the relationship between the load information and the operation delay, and then, when at least one When the current load information corresponding to the task type is calculated, the calculation delay corresponding to the current load information can be determined. Furthermore, the computing delay corresponding to at least one computing task type can be determined.
在一种可能的实现方式中,所述其他节点和所述本地节点不属于同一预设网络区域内,所述运算性能包括运算时延,所述接收所述其他节点返回的所述至少一个运算任务类型对应的运算性能,包括:In a possible implementation manner, the other node and the local node do not belong to the same preset network area, the operation performance includes operation delay, and the receiving the at least one operation returned by the other node Computing performance corresponding to the task type, including:
接收所述其他节点返回的所述至少一个运算任务类型对应的运算时延。receiving the computing delay corresponding to the at least one computing task type returned by the other node.
在一种可能的实现方式中,所述第一对应关系中还存储有运算性能的更新次数,所述方法还包括:In a possible implementation manner, the number of updates of computing performance is also stored in the first correspondence, and the method further includes:
当接收到所述其他节点中的任一其他节点发送的运算性能查询请求时,获取所述运算性能查询请求中携带的查询运算任务类型和对应的更新次数,其中,所述运算性能查询请求用于指示查询和所述本地节点属于同一预设网络区域内的其他节点的运算性能;When receiving the computing performance query request sent by any other node among the other nodes, obtain the query computing task type and the corresponding update times carried in the computing performance query request, wherein the computing performance query request uses To instruct to query the computing performance of other nodes belonging to the same predetermined network area as the local node;
在所述第一对应关系中,确定所述查询运算任务类型对应的运算性能的更新次数;In the first correspondence, determine the number of updates of the computing performance corresponding to the query computing task type;
如果确定出的更新次数大于所述运算性能查询请求中携带的更新次数,则向所述任一其他节点发送所述查询运算任务类型对应的运算性能和确定出的更新次数。If the determined update times are greater than the update times carried in the computing performance query request, send the computing performance corresponding to the query computing task type and the determined update times to any other node.
在本地节点启动时,可以初步建立第一对应关系,但是由于运算时延不是固定不变的,而是随着时间的推移根据具体情况动态变化的,因此需要对运算时延进行更新。When the local node is started, the first corresponding relationship can be initially established. However, since the operation delay is not fixed, but changes dynamically according to specific conditions as time goes by, the operation delay needs to be updated.
在一种可能的实现方式中,所述方法还包括:In a possible implementation, the method further includes:
每当接收到目的地址为和所述本地节点属于同一预设网络区域内的其他节点的目标数据包时,确定所述目标数据包对应的第二运算任务类型,并向和所述本地节点属于同一预设网络区域内的其他节点转发所述目标数据包;Whenever receiving a target data packet whose destination address is another node belonging to the same preset network area as the local node, determine the second computing task type corresponding to the target data packet, and send a message to the Other nodes in the same preset network area forward the target data packet;
当接收到和所述本地节点属于同一预设网络区域内的其他节点返回的所述目标数据包对应的运算结果时,确定转发所述目标数据包的时间点和当前时间点之间的运算时延,将所述运算时延确定为所述第二运算任务类型对应的运算性能;When the operation result corresponding to the target data packet returned by other nodes belonging to the same preset network area as the local node is received, determine the operation time between the time point of forwarding the target data packet and the current time point Delay, determining the operation delay as the operation performance corresponding to the second operation task type;
用所述第二运算任务类型对应的运算性能,替换所述第一对应关系中和所述本地节点属于同一预设网络区域内的其他节点对应的所述第二运算任务类型对应的运算性能,并对所述第一对应关系中替换后的运算性能的更新次数进行更新。using the computing performance corresponding to the second computing task type to replace the computing performance corresponding to the second computing task type corresponding to other nodes in the first correspondence that belong to the same preset network area as the local node, And update the number of updates of the replaced computing performance in the first correspondence.
第二方面,提供了一种对数据包进行路由的装置,该装置包括至少一个模块,该至少一个模块用于实现上述第一方面所提供的对数据包进行路由的方法。A second aspect provides a device for routing data packets, the device includes at least one module, and the at least one module is used to implement the method for routing data packets provided in the first aspect above.
第三方面,提供了一种节点,该节点包括处理器、存储器,处理器被配置为执行存储器中存储的指令;处理器通过执行指令来实现上述第一方面所提供的对数据包进行路由的方法。In a third aspect, a node is provided, the node includes a processor and a memory, and the processor is configured to execute instructions stored in the memory; the processor implements the routing of data packets provided in the first aspect above by executing the instructions method.
第四方面,提供了计算机可读存储介质,包括指令,当所述计算机可读存储介质在节点上运行时,使得所述节点执行上述第一方面所述的方法。In a fourth aspect, a computer-readable storage medium is provided, including an instruction, and when the computer-readable storage medium runs on a node, the node executes the method described in the above-mentioned first aspect.
第五方面,提供了一种包含指令的计算机程序产品,当所述计算机程序产品在节点上运行时,使得所述节点执行上述第一方面所述的方法。In a fifth aspect, a computer program product containing instructions is provided, and when the computer program product is run on a node, the node is made to execute the method described in the first aspect above.
本公开的实施例提供的技术方案可以包括以下有益效果:The technical solutions provided by the embodiments of the present disclosure may include the following beneficial effects:
通过本公开实施例提供的方法,在对数据包进行路由的过程中,除了考虑当前的网络状况之外,还根据能够执行运算任务类型的数据包指示的运算任务的每个节点的运算性能,确定目的节点。这样,可以保证目的节点能够快速完成运算任务并将运算结果反馈给数据包的发起节点,从而缩短数据包的发起节点的等待时间。Through the method provided by the embodiments of the present disclosure, in the process of routing data packets, in addition to considering the current network conditions, it is also based on the computing performance of each node that can perform the computing task indicated by the data packet of the computing task type, Determine the destination node. In this way, it can be ensured that the destination node can quickly complete the operation task and feed back the operation result to the originating node of the data packet, thereby shortening the waiting time of the originating node of the data packet.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。It is to be understood that both the foregoing general description and the following detailed description are exemplary and explanatory only and are not restrictive of the present disclosure.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。在附图中:The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate embodiments consistent with the disclosure and together with the description serve to explain the principles of the disclosure. In the attached picture:
图1是根据一示例性实施例示出的一种对数据包进行路由的方法的流程示意图;Fig. 1 is a schematic flowchart of a method for routing data packets according to an exemplary embodiment;
图2是根据一示例性实施例示出的一种对数据包进行路由的方法的流程示意图;Fig. 2 is a schematic flowchart of a method for routing data packets according to an exemplary embodiment;
图3是根据一示例性实施例示出的一种网络结构示意图;Fig. 3 is a schematic diagram showing a network structure according to an exemplary embodiment;
图4是根据一示例性实施例示出的一种对数据包进行路由的方法的流程示意图;Fig. 4 is a schematic flowchart of a method for routing data packets according to an exemplary embodiment;
图5是根据一示例性实施例示出的一种对数据包进行路由的方法的流程示意图;Fig. 5 is a schematic flowchart of a method for routing data packets according to an exemplary embodiment;
图6是根据一示例性实施例示出的一种对数据包进行路由的装置的结构示意图;Fig. 6 is a schematic structural diagram of a device for routing data packets according to an exemplary embodiment;
图7是根据一示例性实施例示出的一种节点的结构示意图。Fig. 7 is a schematic structural diagram of a node according to an exemplary embodiment.
通过上述附图,已示出本公开明确的实施例,后文中将有更详细的描述。这些附图和文字描述并不是为了通过任何方式限制本公开构思的范围,而是通过参考特定实施例为本领域技术人员说明本公开的概念。By means of the above-mentioned drawings, certain embodiments of the present disclosure have been shown and will be described in more detail hereinafter. These drawings and written description are not intended to limit the scope of the disclosed concept in any way, but to illustrate the disclosed concept for those skilled in the art by referring to specific embodiments.
具体实施方式Detailed ways
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。Reference will now be made in detail to the exemplary embodiments, examples of which are illustrated in the accompanying drawings. When the following description refers to the accompanying drawings, the same numerals in different drawings refer to the same or similar elements unless otherwise indicated. The implementations described in the following exemplary examples do not represent all implementations consistent with the present disclosure. Rather, they are merely examples of apparatuses and methods consistent with aspects of the present disclosure as recited in the appended claims.
本公开一示例性实施例提供了一种对数据包进行路由的方法,如图1所示,该方法的处理流程可以包括如下的步骤:An exemplary embodiment of the present disclosure provides a method for routing data packets, as shown in FIG. 1 , the processing flow of the method may include the following steps:
步骤S110,当接收到运算任务类型的数据包时,确定数据包对应的第一运算任务类型。Step S110, when a data packet of a computing task type is received, determine a first computing task type corresponding to the data packet.
在实施中,当本地节点接收到数据包时,可以确定接收到的数据包对应的任务类型,包括指示需要从数据节点获取目标数据、传输即时通信信息或者指示需要运算节点执行目标类型的运算任务(这种数据包可称为运算任务类型的数据包)等。In implementation, when the local node receives the data packet, it can determine the task type corresponding to the received data packet, including indicating that it needs to obtain target data from the data node, transmit instant messaging information, or indicate that the computing node needs to perform the computing task of the target type (This kind of data packet may be called a computing task type data packet) and so on.
当本地节点接收到运算任务类型的数据包时,可以确定数据包对应的第一运算任务类型。在实际应用中,当本地节点接收到数据包时,可以获取数据包的包头中携带的互联网协议地址(Internet Protocol Address,IP)。接着,本地节点可以确定携带的IP地址的类型,如果携带的IP地址为任一节点的IP地址,则基于任一节点的IP地址,对数据包进行转发。如果携带的IP地址对应于任一运算任务,则可以确定接收到的数据包为运算任务类型的数据包。When the local node receives a data packet of a computing task type, it may determine a first computing task type corresponding to the data packet. In practical applications, when the local node receives the data packet, it can obtain the Internet Protocol Address (Internet Protocol Address, IP) carried in the packet header of the data packet. Next, the local node can determine the type of the carried IP address, and if the carried IP address is the IP address of any node, the data packet is forwarded based on the IP address of any node. If the carried IP address corresponds to any computing task, it can be determined that the received data packet is a data packet of the computing task type.
由于运算任务可以为多种,所以需要通过运算任务类型标识对不同的运算任务进行区分,本地节点可以获取数据包的包头中携带的运算任务类型标识,确定数据包对应的第一运算任务类型。需要说明的是,在本地节点中,需要运行新的路由协议,以基于新的路由协议获取数据包的包头中携带的运算任务类型标识,并基于运算任务类型标识,对数据包进行路由处理。Since there can be many types of computing tasks, different computing tasks need to be distinguished through computing task type identifiers. The local node can obtain the computing task type identifier carried in the packet header of the data packet to determine the first computing task type corresponding to the data packet. It should be noted that in the local node, a new routing protocol needs to be run to obtain the computing task type identifier carried in the packet header of the data packet based on the new routing protocol, and based on the computing task type identifier, perform routing processing on the data packet.
步骤S120,基于预先获取的运算任务类型、其他节点和运算性能的第一对应关系,确定第一运算任务类型对应的至少一个其他节点和至少一个其他节点对应的运算性能。Step S120, based on the pre-acquired first correspondence between computing task types, other nodes and computing performance, determine at least one other node corresponding to the first computing task type and computing performance corresponding to the at least one other node.
在实施中,可以增加新的路由表项,包括运算任务类型和运算性能。可以在本地节点中预先建立运算任务类型、其他节点和运算性能的第一对应关系,基于第一对应关系,确定第一运算任务类型对应的至少一个其他节点和至少一个其他节点对应的运算性能。During implementation, new routing table items can be added, including computing task types and computing performance. A first correspondence between computing task types, other nodes, and computing performance may be pre-established in the local node, and based on the first correspondence, at least one other node corresponding to the first computing task type and computing performance corresponding to at least one other node are determined.
不同运算节点可以执行的运算任务可以为一种也可以为多种,并且不同运算节点可以执行的运算任务可以相同也可以不同。因此,首先可以确定哪些节点可以执行第一运算任务类型的运算任务,其次再在这些能够执行第一运算任务类型的运算任务的节点中,选取最优的一个节点。The computing tasks that can be performed by different computing nodes can be one type or multiple types, and the computing tasks that can be performed by different computing nodes can be the same or different. Therefore, it is first possible to determine which nodes can perform the computing task of the first computing task type, and then select the optimal node among these nodes capable of performing the computing task of the first computing task type.
例如,用户想让云端帮助识别目标图像中的所有人物,可以通过发送识别目标图像中的所有人物对应的数据包实现。当本地节点接收到识别目标图像中的所有人物对应的数据包时,可以获取数据包中的运算任务类型标识。基于运算任务类型标识,查找可以执行该运算任务类型标识对应的运算任务的节点,包括节点A、节点B和节点C。接着,可以分别确定这些节点对应的运算性能。其中,运算性能可以包括运算时延等可以体现不同节点在执行运算任务上的执行能力的参数信息。For example, if the user wants the cloud to help identify all the people in the target image, this can be achieved by sending a data packet that identifies all the people in the target image. When the local node receives the data packet for identifying all the characters in the target image, it can obtain the identification of the computing task type in the data packet. Based on the computing task type identifier, find nodes that can execute the computing task corresponding to the computing task type identifier, including node A, node B, and node C. Then, computing performances corresponding to these nodes can be determined respectively. Wherein, the computing performance may include parameter information such as computing time delay, which can reflect the execution capabilities of different nodes in executing computing tasks.
步骤S130,基于至少一个其他节点对应的运算性能和本地节点分别与至少一个其他节点之间的链路状态,在至少一个其他节点中,确定目标节点。Step S130, based on the computing performance corresponding to the at least one other node and the link status between the local node and the at least one other node, among the at least one other node, determine a target node.
在实施中,路由表项中还可以包括不同节点对应的链路状态,链路状态可以包括本地节点与其他节点之间的数据包往返时延。在实际应用中,本地节点可以确定第一运算任务类型对应的至少一个其他节点,进而确定本地节点分别与至少一个其他节点之间的链路状态。综合至少一个其他节点对应的运算性能和本地节点分别与至少一个其他节点之间的链路状态等因素,在至少一个其他节点中,确定目标节点。In an implementation, the routing table entry may also include link states corresponding to different nodes, and the link state may include round-trip delays of data packets between the local node and other nodes. In practical applications, the local node may determine at least one other node corresponding to the first computing task type, and then determine link states between the local node and the at least one other node respectively. The target node is determined in the at least one other node based on factors such as the computing performance corresponding to the at least one other node and the link status between the local node and the at least one other node.
可选地,运算性能包括运算时延,链路状态包括数据包往返时延,步骤S130可以包括:对于每个其他节点,确定其他节点对应的运算时延和本地节点与其他节点之间的数据包往返时延的和值;在至少一个其他节点中,确定最小和值对应的节点为目标节点。Optionally, the computing performance includes computing delay, and the link status includes data packet round-trip delay. Step S130 may include: for each other node, determining the computing delay corresponding to other nodes and the data between the local node and other nodes The sum value of the packet round-trip delay; among at least one other node, determine the node corresponding to the minimum sum value as the target node.
在实施中,如表1所示,可以预先建立包括运算任务类型、其他节点、运算时延、本地节点与其他节点之间的数据包往返时延的对应关系。In implementation, as shown in Table 1, correspondences including computing task types, other nodes, computing delays, and data packet round-trip delays between the local node and other nodes may be established in advance.
表1Table 1

可以基于表1,确定能够执行每种运算任务类型对应的运算任务的节点、以及每个节点执行每种运算任务类型的运算任务所需的运算时延和本地节点之间的数据包往返时延。对于每个其他节点,确定其他节点对应的运算时延和本地节点与其他节点之间的数据包往返时延的和值,在至少一个其他节点中,确定最小和值对应的节点为目标节点。Based on Table 1, it is possible to determine the nodes capable of performing the computing tasks corresponding to each computing task type, as well as the computing delay required by each node to perform computing tasks of each computing task type and the round-trip delay of data packets between local nodes . For each other node, determine the sum of the operation delay corresponding to the other node and the round-trip delay of the data packet between the local node and the other node, and determine the node corresponding to the minimum sum value as the target node among at least one other node.
如图2所示,每种运算任务类型对应的节点可以是与本地节点属于同一预设网络区域内的运算节点,也可以是与本地节点不属于同一预设网络区域内的路由节点。如果运算任务类型对应的节点是与本地节点不属于同一预设网络区域内的路由节点M,则需要将数据包转发至路由节点M,再由路由节点M将数据包转发至与路由节点M属于同一预设网络区域内的运算节点。As shown in FIG. 2 , the node corresponding to each computing task type may be a computing node belonging to the same preset network area as the local node, or a routing node not belonging to the same preset network area as the local node. If the node corresponding to the computing task type is a routing node M that does not belong to the same preset network area as the local node, the data packet needs to be forwarded to the routing node M, and then the routing node M forwards the data packet to the routing node M that belongs to the routing node M. Computing nodes in the same preset network area.
步骤S140,将目标节点的地址确定为数据包的目的地址,基于目的地址,对数据包进行转发。Step S140, determining the address of the target node as the destination address of the data packet, and forwarding the data packet based on the destination address.
在实施中,在确定目标节点后,可以查询目标节点的地址,将目标节点的地址确定为数据包的目的地址,基于目的地址,对数据包进行转发。其他路由节点在接收到以目标节点的地址为目的地址的运算任务类型的数据包时,可以只基于网络状态,对数据包进行转发,最终将数据包转发到目的节点上。In implementation, after the target node is determined, the address of the target node may be queried, the address of the target node is determined as the destination address of the data packet, and the data packet is forwarded based on the destination address. When other routing nodes receive the data packet of the computing task type with the address of the target node as the destination address, they can forward the data packet only based on the network status, and finally forward the data packet to the destination node.
目的节点在接收到以自己的地址为目的地址的运算任务类型的数据包时,可以将数据包直接转发本地的运算节点,也可以基于本公开实施例提供的方法,重新确定本地的运算节点对应的运算延时和数据包往返时延的和值是不是依然是最小的,如果不是,则重新确定目的节点。When the destination node receives a data packet of the computing task type with its own address as the destination address, it can directly forward the data packet to the local computing node, or re-determine the corresponding Whether the sum of the operation delay and the round-trip delay of the data packet is still the smallest, if not, re-determine the destination node.
数据包最终由运算节点进行处理,将处理结果返回给与运算节点属于同一预设网络区域的路由节点,再由路由节点按照原路径将处理结果返回给运算任务的发起节点。The data packet is finally processed by the computing node, and the processing result is returned to the routing node that belongs to the same preset network area as the computing node, and then the routing node returns the processing result to the initiating node of the computing task according to the original path.
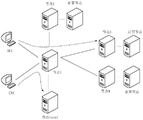
在所有路由节点启动之前,可以为这些路由节点进行区域规划以及级别规划。如图3所示,可以采用分布式与中心式相结合的方式对路由节点进行布局。路由节点之间可以存在上下级的关系,上级路由节点为下级路由节点的中心控制器,下级路由节点可以接受上级路由节点的控制,下级路由节点可以直接从上级路由节点中获取同级路由节点的节点信息,以避免下级路由节点再去挨个探测同级路由节点获取节点信息,这样可以提高获取节点信息的效率,互为同级的路由节点之间可以互相交换路由信息。Before all routing nodes are started, area planning and level planning can be performed for these routing nodes. As shown in Figure 3, routing nodes can be laid out in a distributed and central manner. There can be a superior-subordinate relationship between routing nodes. The upper-level routing node is the central controller of the lower-level routing node. The lower-level routing node can accept the control of the upper-level routing node. Node information, to avoid lower-level routing nodes from probing the same-level routing nodes one by one to obtain node information, which can improve the efficiency of obtaining node information, and routing nodes that are mutually at the same level can exchange routing information with each other.
上下级路由节点可以采用中心式的结构进行布局,同级路由节点可以采用分布式的结构进行布局。随着层级越来越高,路由节点的数量越来越少,路由节点随着层级的增加呈收敛状态,最终整个由路由节点组成的网络呈锥形状。The upper and lower routing nodes can be laid out in a central structure, and the routing nodes at the same level can be laid out in a distributed structure. As the hierarchy becomes higher and higher, the number of routing nodes decreases, and the routing nodes converge as the hierarchy increases, and finally the entire network composed of routing nodes takes on a cone shape.
上述网络中执行新的路由协议的节点,都可以作为本公开实施例提供的方法中的本地节点。在本地节点未启动之前,本地节点中未存储有第一对应关系,第一对应关系需要在本地节点启动之后,自行建立。All the nodes implementing the new routing protocol in the above network can be used as the local nodes in the method provided by the embodiments of the present disclosure. Before the local node is started, the first corresponding relationship is not stored in the local node, and the first corresponding relationship needs to be established after the local node is started.
可选地,本公开实施例提供的方法还可以包括:当本地节点启动时,对于每个其他节点,向其他节点发送运算任务类型查询请求,接收其他节点返回的至少一个运算任务类型,向其他节点发送至少一个运算任务类型对应的运算性能查询请求,接收其他节点返回的至少一个运算任务类型对应的运算性能;基于每个其他节点分别对应的至少一个运算任务类型和至少一个运算任务类型对应的运算性能,建立运算任务类型、其他节点和运算性能的第一对应关系。Optionally, the method provided by the embodiments of the present disclosure may further include: when the local node is started, for each other node, sending a computing task type query request to other nodes, receiving at least one computing task type returned by other nodes, and sending to other nodes A node sends a computing performance query request corresponding to at least one computing task type, and receives computing performance corresponding to at least one computing task type returned by other nodes; based on at least one computing task type corresponding to each other node and at least one computing task type corresponding to Computing performance, establish the first correspondence between computing task types, other nodes and computing performance.
在实施中,当本地节点启动时,本地节点的上级节点可以检测到本地节点启动,上级节点可以将本地节点的同级节点的节点信息发送至本地节点,这样本地节点可以确定同级节点。其中,同级节点包括和本地节点属于同一预设网络区域的运算节点、和本地节点不属于同一预设网络区域的路由节点,如表1中的节点A、节点B、节点C、节点D。In implementation, when the local node starts, the upper node of the local node can detect the start of the local node, and the upper node can send the node information of the peer nodes of the local node to the local node, so that the local node can determine the peer node. Among them, nodes at the same level include computing nodes that belong to the same preset network area as the local node, and routing nodes that do not belong to the same preset network area as the local node, such as node A, node B, node C, and node D in Table 1.
本地节点可以基于同级节点,建立表1,此时表1中只有其他节点,其他表项的初始值全部为0。本地节点可以向其他节点发送运算任务类型查询请求,接收其他节点返回的至少一个运算任务类型,向其他节点发送至少一个运算任务类型对应的运算性能查询请求,接收其他节点返回的至少一个运算任务类型对应的运算性能。接着,本地节点可以基于每个其他节点分别对应的至少一个运算任务类型和至少一个运算任务类型对应的运算性能,建立运算任务类型、其他节点和运算性能的第一对应关系。The local node can establish table 1 based on nodes at the same level. At this time, there are only other nodes in table 1, and the initial values of other table items are all 0. Local nodes can send computing task type query requests to other nodes, receive at least one computing task type returned by other nodes, send computing performance query requests corresponding to at least one computing task type to other nodes, and receive at least one computing task type returned by other nodes corresponding computing performance. Next, the local node may establish a first correspondence between computing task types, other nodes, and computing performance based on at least one computing task type corresponding to each other node and computing performance corresponding to the at least one computing task type.
对于和本地节点属于同一预设网络区域的运算节点,运算性能可以包括负载信息和运算时延,接收其他节点返回的至少一个运算任务类型对应的运算性能的步骤具体可以包括:接收其他节点返回的至少一个运算任务类型对应的当前的负载信息。接着,本地节点可以根据预先存储的负载信息和运算时延的第二对应关系,确定当前的负载信息对应的运算时延,作为至少一个运算任务类型对应的运算时延。For computing nodes that belong to the same preset network area as the local node, the computing performance may include load information and computing delay, and the step of receiving computing performance corresponding to at least one computing task type returned by other nodes may specifically include: receiving the computing performance returned by other nodes Current load information corresponding to at least one computing task type. Next, the local node may determine the computing latency corresponding to the current load information as the computing latency corresponding to at least one computing task type according to the second correspondence between the pre-stored load information and computing latency.
可以预先在本地节点中导入并存储历史负载信息和运算时延相关数据,本地节点可以对这些历史数据进行拟合,以确定负载信息和运算时延之间的关系,进而,当确定了至少一个运算任务类型对应的当前的负载信息时,就可以确定当前的负载信息对应的运算时延。进而,就可以确定至少一个运算任务类型对应的运算时延。The historical load information and operation delay related data can be imported and stored in the local node in advance, and the local node can fit these historical data to determine the relationship between the load information and the operation delay, and then, when at least one When the current load information corresponding to the task type is calculated, the calculation delay corresponding to the current load information can be determined. Furthermore, the computing delay corresponding to at least one computing task type can be determined.
运算时延可以简单明了的直接反应运算节点的执行某一运算任务的执行能力,虽然影响运算节点执行某一运算任务的因素有很多,但最终都可以直接反应在运算时延上。运算时延越短,证明运算节点执行某一运算任务的执行能力越强。可以影响运算节点执行某一运算任务的因素包括中央处理器(Central Processing Unit,CPU)的性能、图形处理器(Graphics Processing Unit,GPU)的性能、实时负载等。在实际应用中,有些运算任务对CPU的性能要求较高,对GPU的性能要求不高。有些运算任务对GPU的性能要求较高,对CPU的性能要求不高。例如,图像识别类型的运算任务对GPU的性能要求较高。Computational delay can simply and directly reflect the ability of a computing node to perform a certain computing task. Although there are many factors that affect a computing node's execution of a certain computing task, they can all be directly reflected in the computing delay. The shorter the computing delay, the stronger the ability of the computing node to perform a certain computing task. Factors that may affect the execution of a computing task by a computing node include performance of a central processing unit (Central Processing Unit, CPU), performance of a graphics processing unit (Graphics Processing Unit, GPU), real-time load, and the like. In practical applications, some computing tasks have higher requirements on the performance of the CPU, but not high requirements on the performance of the GPU. Some computing tasks have high performance requirements on the GPU, but not high performance requirements on the CPU. For example, computing tasks of the image recognition type have higher requirements on the performance of the GPU.
对于和本地节点不属于同一预设网络区域的路由节点,运算性能可以包括运算时延,接收其他节点返回的至少一个运算任务类型对应的运算性能的步骤可以包括:接收其他节点返回的至少一个运算任务类型对应的运算时延。For routing nodes that do not belong to the same preset network area as the local node, the computing performance may include computing delay, and the step of receiving computing performance corresponding to at least one computing task type returned by other nodes may include: receiving at least one computing returned by other nodes The computing latency corresponding to the task type.
和路由节点M属于同一预设网络区域的运算节点N,可以由路由节点M维护运算节点N的运算性能,而和路由节点M不属于同一预设网络区域的路由节点P,由于路由节点P维护着和自己属于同一预设网络区域的运算节点Q的运算性能,因此路由节点M可以直接从路由节点P中探测运算节点Q的运算性能。The computing node N that belongs to the same preset network area as the routing node M can maintain the computing performance of the computing node N by the routing node M, while the routing node P that does not belong to the same preset network area as the routing node M, because the routing node P maintains Therefore, the routing node M can directly detect the computing performance of the computing node Q from the routing node P.
对于本地节点和其他节点之间的数据包往返时延,可以按照预设的周期,通过因特网包探索器(Packet Internet Groper,PING)等交互方式,确定本地节点和其他节点之间的数据包往返时延。For the round-trip delay of data packets between the local node and other nodes, the round-trip delay of data packets between the local node and other nodes can be determined through interactive methods such as Internet packet explorer (Packet Internet Groper, PING) according to the preset period delay.
通过上述方式,在本地节点启动时,可以初步建立第一对应关系,但是由于运算时延不是固定不变的,而是随着时间的推移根据具体情况动态变化的,因此需要对运算时延进行更新。Through the above method, when the local node is started, the first corresponding relationship can be initially established. However, since the operation delay is not fixed, but changes dynamically according to the specific situation as time goes by, it is necessary to calculate the operation delay. renew.
对于和本地节点属于同一预设网络区域的运算节点,每当接收到目的地址为和本地节点属于同一预设网络区域内的其他节点的目标数据包时,确定目标数据包对应的第二运算任务类型,并向和本地节点属于同一预设网络区域内的其他节点转发目标数据包;当接收到和本地节点属于同一预设网络区域内的其他节点返回的目标数据包对应的运算结果时,确定转发目标数据包的时间点和当前时间点之间的运算时延,将运算时延确定为第二运算任务类型对应的运算性能;用第二运算任务类型对应的运算性能,替换第一对应关系中和本地节点属于同一预设网络区域内的其他节点对应的第二运算任务类型对应的运算性能,并对第一对应关系中替换后的运算性能的更新次数进行更新。For a computing node belonging to the same preset network area as the local node, whenever receiving a target data packet whose destination address is another node belonging to the same preset network area as the local node, determine the second computing task corresponding to the target data packet type, and forward the target data packet to other nodes belonging to the same preset network area as the local node; when receiving the operation result corresponding to the target data packet returned by other nodes belonging to the same preset network area as the local node, determine The computing delay between the time point of forwarding the target data packet and the current time point is determined as the computing performance corresponding to the second computing task type; the computing performance corresponding to the second computing task type is used to replace the first corresponding relationship Neutralize the computing performance corresponding to the second computing task type corresponding to other nodes in the same preset network area where the local node belongs, and update the number of updates of the computing performance after replacement in the first correspondence.
由于本地节点需要为属于同一预设网络区域的运算节点转发运算任务类型的数据包,运算节点在执行运算任务类型的数据包对应的运算任务时,可以反映当前的运算节点的状况,本地节点可以统计这些状况,并对属于同一预设网络区域的运算节点对应的运算新能进行更新。Since the local node needs to forward the data packet of the computing task type for the computing node belonging to the same preset network area, when the computing node executes the computing task corresponding to the data packet of the computing task type, it can reflect the current status of the computing node, and the local node can These conditions are counted, and the computing performance corresponding to the computing nodes belonging to the same preset network area is updated.
例如,当本地节点向属于同一预设网络区域的运算节点转发执行图像识别的数据包时,可以记录转发的时间点,当收到运算节点返回的识别结果时,可以确定返回识别结果的时间点和转发的时间点之间的运算时延,进而就可以确定当前运算节点执行图像识别的运算任务需要多长时间。第一对应关系中还存储有运算性能的更新次数,每当本地节点对属于同一预设网络区域的运算节点的运算时延进行更新时,可以将更新次数加1。更新次数的初始值可以设置为0。如表2所示,是运算任务类型、其他节点、运算时延、本地节点与其他节点之间的数据包往返时延、更新次数的对应关系。For example, when a local node forwards a data packet for performing image recognition to a computing node belonging to the same preset network area, the time point of forwarding can be recorded, and when the recognition result returned by the computing node is received, the time point of returning the recognition result can be determined The calculation delay between the forwarding time point and the forwarding time point can determine how long the current calculation node needs to perform the calculation task of image recognition. The update times of computing performance are also stored in the first correspondence, and the update times may be increased by 1 whenever the local node updates the computing delays of computing nodes belonging to the same preset network area. The initial value of the number of updates can be set to 0. As shown in Table 2, it is the corresponding relationship among computing task types, other nodes, computing delays, packet round-trip delays between the local node and other nodes, and update times.
表2Table 2

对于和本地节点不属于同一预设网络区域的路由节点,本地节点可以向路由节点发送探测包(也可称为运算性能查询请求),以获取需要更新的节点的运算性能。第一对应关系中还存储有运算性能的更新次数,本公开实施例提供的方法还可以包括:当接收到其他节点中的任一其他节点发送的运算性能查询请求时,获取运算性能查询请求中携带的查询运算任务类型和对应的更新次数,其中,运算性能查询请求用于指示查询和本地节点属于同一预设网络区域内的其他节点的运算性能;在第一对应关系中,确定查询运算任务类型对应的运算性能的更新次数;如果确定出的更新次数大于运算性能查询请求中携带的更新次数,则向任一其他节点发送查询运算任务类型对应的运算性能和确定出的更新次数。For routing nodes that do not belong to the same preset network area as the local node, the local node may send a detection packet (also called a computing performance query request) to the routing node to obtain computing performance of the node to be updated. The number of updates of computing performance is also stored in the first correspondence, and the method provided by the embodiment of the present disclosure may further include: when receiving a computing performance query request sent by any other node among other nodes, obtaining The carried query operation task type and the corresponding update times, wherein the operation performance query request is used to indicate the operation performance of other nodes belonging to the query and the local node in the same preset network area; in the first correspondence, the query operation task is determined The number of updates of the computing performance corresponding to the type; if the determined number of updates is greater than the number of updates carried in the computing performance query request, send the query computing performance corresponding to the computing task type and the determined number of updates to any other node.
如图4所示,如果当前本地节点需要对其他节点中的任一其他节点的运算新能进行更新,首先可以基于第一对应关系,确定所有与任一其他节点相关的运算任务类型标识和对应的更新次数。将与任一其他节点相关的运算任务类型标识和对应的更新次数携带在探测包中,发送至任一其他节点。As shown in Figure 4, if the current local node needs to update the computing capabilities of any other node among other nodes, it can first determine all computing task type identifiers and corresponding of updates. Carry the identification of the computing task type associated with any other node and the corresponding update times in the detection packet, and send it to any other node.
任一其他节点在接收到本地节点发送的探测包后,确定和任一其他节点属于同一预设网络区域的运算节点对应的运算任务类型对应的更新次数。如果确定出的更新次数大于探测包中携带的更新次数,则确定对应的运算任务类型对应的运算性能需要更新。任一其他节点将所有确定出的需要更新的运算任务类型对应的运算性能和任一其他节点中记录的更新次数携带在探测回包中,发送至本地节点。需要说明的是,如果任一其他节点中存在目标运算任务类型未记录在本地节点的第一对应关系中,也需要发送至本地节点,以使本地节点增加一条关于目标运算任务类型的记录。After any other node receives the detection packet sent by the local node, it determines the number of updates corresponding to the computing task type corresponding to the computing node belonging to the same preset network area as any other node. If the determined number of updates is greater than the number of updates carried in the detection packet, it is determined that the computing performance corresponding to the corresponding computing task type needs to be updated. Any other node carries all the determined computing performance corresponding to the types of computing tasks that need to be updated and the number of updates recorded in any other node in the detection return packet, and sends it to the local node. It should be noted that if any other node has a target computing task type that is not recorded in the first correspondence of the local node, it also needs to be sent to the local node, so that the local node adds a record about the target computing task type.
如表3所示,是运算任务类型、其他节点、运算时延、本地节点与其他节点之间的数据包往返时延、更新次数的对应关系。As shown in Table 3, it is the corresponding relationship among computing task types, other nodes, computing delays, packet round-trip delays between the local node and other nodes, and update times.
表3table 3


如图5所示,当用户设备(User Equipment,UE)设备如UE1发起运算任务类型1的数据包时,数据包到达节点1(本地节点),节点1作为管理节点,为数据包进行路由处理。节点1查找表3,确定能够执行运算任务类型1对应的运算任务的节点有节点local、节点2、节点3和节点4。计算每个节点的运算时延与数据包往返时延的和值,发现节点3对应的和值最小,节点1可以将数据包转发至节点3。As shown in Figure 5, when a user equipment (User Equipment, UE) device such as UE1 initiates a data packet of computing task type 1, the data packet arrives at node 1 (local node), and node 1 acts as a management node to perform routing processing for the data packet . Node 1 looks up Table 3, and determines that the nodes capable of performing the computing task corresponding to computing task type 1 include node local, node 2, node 3, and node 4. Calculate the sum of the operation delay and the data packet round-trip delay of each node, and find that the sum corresponding to node 3 is the smallest, and node 1 can forward the data packet to node 3.
当UE2发起运算任务类型2的数据包时,数据包到达节点1,节点1查找表3,确定能够执行运算任务类型2对应的运算任务的节点有节点local、节点2和节点3。计算每个节点的运算时延与数据包往返时延的和值,发现节点local对应的和值最小,节点1可以将数据包转发至节点local。When UE2 initiates a data packet of computing task type 2, the data packet arrives at node 1, node 1 looks up table 3, and determines that the nodes capable of performing computing tasks corresponding to computing task type 2 include node local, node 2, and node 3. Calculate the sum of the operation delay of each node and the round-trip delay of the data packet, and find that the sum corresponding to the node local is the smallest, and node 1 can forward the data packet to the node local.
经过一段时间之后,当UE1再次发起运算任务类型1的数据包时,数据包到达节点1,由于此时节点3带的负载较多,运算时延上升至50ms,所以本次节点2对应的和值最小,节点1可以将数据包转发至节点2。After a period of time, when UE1 initiates a data packet of computing task type 1 again, the data packet arrives at node 1. Since node 3 carries a large load at this time, the computing delay rises to 50ms, so the sum corresponding to node 2 this time If the value is the smallest, node 1 can forward the packet to node 2.
通过本公开实施例提供的方法,在对数据包进行路由的过程中,除了考虑当前的网络状况之外,还根据能够执行运算任务类型的数据包指示的运算任务的每个节点的运算性能,确定目的节点。这样,可以保证目的节点能够快速完成运算任务并将运算结果反馈给数据包的发起节点,从而缩短数据包的发起节点的等待时间。Through the method provided by the embodiments of the present disclosure, in the process of routing data packets, in addition to considering the current network conditions, it is also based on the computing performance of each node that can perform the computing task indicated by the data packet of the computing task type, Determine the destination node. In this way, it can be ensured that the destination node can quickly complete the calculation task and feed back the calculation result to the originating node of the data packet, thereby shortening the waiting time of the originating node of the data packet.
本公开又一示例性实施例提供了一种对数据包进行路由的装置,如图6所示,该装置包括:Another exemplary embodiment of the present disclosure provides an apparatus for routing data packets, as shown in FIG. 6, the apparatus includes:
确定模块610,用于当接收到运算任务类型的数据包时,确定所述数据包对应的第一运算任务类型;基于预先获取的运算任务类型、其他节点和运算性能的第一对应关系,确定所述第一运算任务类型对应的至少一个其他节点和所述至少一个其他节点对应的运算性能;基于所述至少一个其他节点对应的运算性能和本地节点分别与所述至少一个其他节点之间的链路状态,在所述至少一个其他节点中,确定目标节点,具体可以实现上述步骤S110-130中的确定功能,以及其他隐含步骤。The determining module 610 is configured to, when receiving a data packet of a computing task type, determine a first computing task type corresponding to the data packet; based on the pre-acquired first correspondence between the computing task type, other nodes, and computing performance, determine At least one other node corresponding to the first computing task type and the computing performance corresponding to the at least one other node; based on the computing performance corresponding to the at least one other node and the relationship between the local node and the at least one other node The link state, in the at least one other node, determines the target node, which can specifically implement the determination function in the above steps S110-130, and other implicit steps.
发送模块620,用于将所述目标节点的地址确定为所述数据包的目的地址,基于所述目的地址,对所述数据包进行转发,具体可以实现上述步骤S140中的发送功能,以及其他隐含步骤。The sending module 620 is configured to determine the address of the target node as the destination address of the data packet, and forward the data packet based on the destination address, which can specifically implement the sending function in the above step S140, and other implicit steps.
可选地,所述运算性能包括运算时延,所述链路状态包括数据包往返时延,所述确定模块610,用于:Optionally, the computing performance includes computing delay, the link state includes data packet round-trip delay, and the determining module 610 is configured to:
对于每个其他节点,确定所述其他节点对应的运算时延和本地节点与所述其他节点之间的数据包往返时延的和值;For each other node, determine the sum of the operation delay corresponding to the other node and the round-trip delay of the data packet between the local node and the other node;
在所述至少一个其他节点中,确定最小和值对应的节点为目标节点。Among the at least one other node, it is determined that the node corresponding to the minimum sum value is the target node.
可选地,所述装置还包括:Optionally, the device also includes:
接收模块,用于当所述本地节点启动时,对于每个其他节点,向所述其他节点发送运算任务类型查询请求,接收所述其他节点返回的至少一个运算任务类型,向所述其他节点发送所述至少一个运算任务类型对应的运算性能查询请求,接收所述其他节点返回的所述至少一个运算任务类型对应的运算性能;The receiving module is configured to, when the local node is started, for each other node, send a computing task type query request to the other node, receive at least one computing task type returned by the other node, and send to the other node The computing performance query request corresponding to the at least one computing task type, receiving the computing performance corresponding to the at least one computing task type returned by the other nodes;
建立模块,用于基于每个其他节点分别对应的至少一个运算任务类型和所述至少一个运算任务类型对应的运算性能,建立运算任务类型、其他节点和运算性能的第一对应关系。An establishment module, configured to establish a first correspondence between an operation task type, other nodes, and operation performance based on at least one operation task type corresponding to each other node and the operation performance corresponding to the at least one operation task type.
可选地,所述其他节点和所述本地节点属于同一预设网络区域内,所述运算性能包括负载信息和运算时延,所述接收模块,用于接收所述其他节点返回的所述至少一个运算任务类型对应的当前的负载信息;Optionally, the other node and the local node belong to the same preset network area, the computing performance includes load information and computing delay, and the receiving module is configured to receive the at least The current load information corresponding to a computing task type;
所述确定模块610,还用于根据预先存储的负载信息和运算时延的第二对应关系,确定所述当前的负载信息对应的运算时延,作为所述至少一个运算任务类型对应的运算时延。The determination module 610 is further configured to determine the operation delay corresponding to the current load information as the operation time corresponding to the at least one operation task type according to the second correspondence between the pre-stored load information and the operation delay. delay.
可选地,所述其他节点和所述本地节点不属于同一预设网络区域内,所述运算性能包括运算时延,所述接收模块,用于:Optionally, the other nodes and the local node do not belong to the same preset network area, the computing performance includes computing delay, and the receiving module is configured to:
接收所述其他节点返回的所述至少一个运算任务类型对应的运算时延。receiving the computing delay corresponding to the at least one computing task type returned by the other node.
可选地,所述第一对应关系中还存储有运算性能的更新次数,所述装置还包括:Optionally, the number of updates of computing performance is also stored in the first correspondence, and the device further includes:
获取模块,用于当接收到所述其他节点中的任一其他节点发送的运算性能查询请求时,获取所述运算性能查询请求中携带的查询运算任务类型和对应的更新次数,其中,所述运算性能查询请求用于指示查询和所述本地节点属于同一预设网络区域内的其他节点的运算性能;An acquisition module, configured to acquire the query operation task type and the corresponding update times carried in the operation performance query request when receiving the operation performance query request sent by any other node in the other nodes, wherein the The computing performance query request is used to instruct to query the computing performance of other nodes belonging to the same preset network area as the local node;
所述确定模块610,还用于在所述第一对应关系中,确定所述查询运算任务类型对应的运算性能的更新次数;The determining module 610 is further configured to determine, in the first correspondence, the number of updates of the computing performance corresponding to the query computing task type;
所述发送模块620,还用于当确定出的更新次数大于所述运算性能查询请求中携带的更新次数时,向所述任一其他节点发送所述查询运算任务类型对应的运算性能和确定出的更新次数。The sending module 620 is further configured to, when the determined update times are greater than the update times carried in the computing performance query request, send the computing performance corresponding to the query computing task type and the determined of updates.
可选地,所述确定模块610,还用于每当接收到目的地址为和所述本地节点属于同一预设网络区域内的其他节点的目标数据包时,确定所述目标数据包对应的第二运算任务类型,并向和所述本地节点属于同一预设网络区域内的其他节点转发所述目标数据包;当接收到和所述本地节点属于同一预设网络区域内的其他节点返回的所述目标数据包对应的运算结果时,确定转发所述目标数据包的时间点和当前时间点之间的运算时延,将所述运算时延确定为所述第二运算任务类型对应的运算性能;Optionally, the determining module 610 is further configured to determine the first node corresponding to the target data packet whenever receiving a target data packet whose destination address is another node belonging to the same preset network area as the local node. Two calculation task types, and forward the target data packet to other nodes belonging to the same preset network area as the local node; when receiving all the returned nodes in the same preset network area as the local node When calculating the operation result corresponding to the target data packet, determine the operation delay between the time point of forwarding the target data packet and the current time point, and determine the operation delay as the operation performance corresponding to the second operation task type ;
所述装置还包括:The device also includes:
更新模块,用于用所述第二运算任务类型对应的运算性能,替换所述第一对应关系中和所述本地节点属于同一预设网络区域内的其他节点对应的所述第二运算任务类型对应的运算性能,并对所述第一对应关系中替换后的运算性能的更新次数进行更新。An update module, configured to use the computing performance corresponding to the second computing task type to replace the second computing task type corresponding to other nodes in the first corresponding relationship that belong to the same preset network area as the local node corresponding computing performance, and update the number of updates of the replaced computing performance in the first correspondence.
需要说明的是,上述确定模块610和发送模块620可以由处理器实现,或者由处理器配合存储器、收发器来实现。It should be noted that the above-mentioned determining module 610 and sending module 620 may be implemented by a processor, or implemented by a processor in cooperation with a memory and a transceiver.
通过本公开实施例提供的装置,在对数据包进行路由的过程中,除了考虑当前的网络状况之外,还根据能够执行运算任务类型的数据包指示的运算任务的每个节点的运算性能,确定目的节点。这样,可以保证目的节点能够快速完成运算任务并将运算结果反馈给数据包的发起节点,从而缩短数据包的发起节点的等待时间。Through the device provided by the embodiments of the present disclosure, in the process of routing data packets, in addition to considering the current network conditions, it is also based on the computing performance of each node that can perform the computing task indicated by the data packet of the computing task type, Determine the destination node. In this way, it can be ensured that the destination node can quickly complete the operation task and feed back the operation result to the originating node of the data packet, thereby shortening the waiting time of the originating node of the data packet.
需要说明的是:上述实施例提供的对数据包进行路由的装置在对数据包进行路由时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将节点的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的对数据包进行路由的装置与对数据包进行路由的方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。It should be noted that: when the device for routing data packets provided by the above-mentioned embodiments is used for routing data packets, the division of the above-mentioned functional modules is used as an example for illustration. In practical applications, the above-mentioned functions can be allocated by Completion of different functional modules means that the internal structure of the node is divided into different functional modules to complete all or part of the functions described above. In addition, the device for routing data packets provided by the above embodiment and the method embodiment for routing data packets belong to the same idea, and the specific implementation process thereof is detailed in the method embodiment, and will not be repeated here.
节点700可以包括处理器710、存储器740和收发器730,收发器730可以与处理器710连接,如图7所示。收发器730可以包括接收器和发送器,可以用于接收或者发送消息或数据,收发器730可以是网卡。节点700还可以包括加速部件(可称为加速器),当加速部件为网络加速部件时,加速部件可以为网卡。处理器710可以是节点700的控制中心,利用各种接口和线路连接整个节点700的各个部分,如收发器730等。在本公开实施例中,处理器710可以是中央处理器(Central Processing Unit,CPU),可选的,处理器710可以包括一个或多个处理单元。处理器710还可以是数字信号处理器、专用集成电路、现场可编程门阵列或者其他可编程逻辑器件等。节点700还可以包括存储器740,存储器740可用于存储软件程序以及模块,处理器710通过读取存储在存储器的软件代码以及模块,从而执行节点700的各种功能应用以及数据处理。The node 700 may include a
本领域技术人员在考虑说明书及实践这里公开的公开后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由权利要求指出。Other embodiments of the disclosure will be readily apparent to those skilled in the art from consideration of the specification and practice of the disclosure disclosed herein. This application is intended to cover any modification, use or adaptation of the present disclosure, and these modifications, uses or adaptations follow the general principles of the present disclosure and include common knowledge or conventional technical means in the technical field not disclosed in the present disclosure . The specification and examples are to be considered exemplary only, with the true scope and spirit of the disclosure indicated by the appended claims.
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。It should be understood that the present disclosure is not limited to the precise constructions which have been described above and shown in the drawings, and various modifications and changes may be made without departing from the scope thereof. The scope of the present disclosure is limited only by the appended claims.
Claims (22)
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910057402.8A CN111464442B (en) | 2019-01-22 | 2019-01-22 | Method and device for routing data packet |
| EP24182988.6A EP4456502A3 (en) | 2019-01-22 | 2019-12-30 | Data packet routing method and apparatus |
| EP19911896.9A EP3905637B1 (en) | 2019-01-22 | 2019-12-30 | Method and device for routing data packet |
| PCT/CN2019/129881 WO2020151461A1 (en) | 2019-01-22 | 2019-12-30 | Method and device for routing data packet |
| US17/380,383 US12074796B2 (en) | 2019-01-22 | 2021-07-20 | Data packet routing method and apparatus |
| US18/780,085 US20240380695A1 (en) | 2019-01-22 | 2024-07-22 | Data packet routing method and apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910057402.8A CN111464442B (en) | 2019-01-22 | 2019-01-22 | Method and device for routing data packet |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111464442A CN111464442A (en) | 2020-07-28 |
| CN111464442B true CN111464442B (en) | 2022-11-18 |
Family
ID=71680076
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910057402.8A Active CN111464442B (en) | 2019-01-22 | 2019-01-22 | Method and device for routing data packet |
Country Status (4)
| Country | Link |
|---|---|
| US (2) | US12074796B2 (en) |
| EP (2) | EP4456502A3 (en) |
| CN (1) | CN111464442B (en) |
| WO (1) | WO2020151461A1 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111464442B (en) * | 2019-01-22 | 2022-11-18 | 华为技术有限公司 | Method and device for routing data packet |
| CN120448331B (en) * | 2025-07-14 | 2025-10-28 | 山东海量信息技术研究院 | Coherent interconnection control device, method, electronic device, product and computing system |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102136989A (en) * | 2010-01-26 | 2011-07-27 | 华为技术有限公司 | Message transmission method, system and equipment |
| CN106789661A (en) * | 2016-12-29 | 2017-05-31 | 北京邮电大学 | A kind of information forwarding method and space information network system |
| CN107634872A (en) * | 2017-08-29 | 2018-01-26 | 深圳市米联科信息技术有限公司 | A kind of method and apparatus of quick accurate measurement network link quality |
Family Cites Families (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101309201B (en) * | 2007-05-14 | 2012-05-23 | 华为技术有限公司 | Route processing method, routing processor and router |
| US8059650B2 (en) * | 2007-10-31 | 2011-11-15 | Aruba Networks, Inc. | Hardware based parallel processing cores with multiple threads and multiple pipeline stages |
| US20100223364A1 (en) * | 2009-02-27 | 2010-09-02 | Yottaa Inc | System and method for network traffic management and load balancing |
| US20130066951A1 (en) * | 2009-11-18 | 2013-03-14 | Yissum Research Development Company Of The Hebrew University Of Jerusalem | Communication system and method for managing data transfer through a communication network |
| US8797913B2 (en) * | 2010-11-12 | 2014-08-05 | Alcatel Lucent | Reduction of message and computational overhead in networks |
| CN103188152B (en) | 2011-12-31 | 2015-07-08 | 南京邮电大学 | Cognitive network quality of service (QoS) routing method based on service differentiation |
| US9847948B2 (en) * | 2012-07-09 | 2017-12-19 | Eturi Corp. | Schedule and location responsive agreement compliance controlled device throttle |
| CN104348886A (en) * | 2013-08-08 | 2015-02-11 | 联想(北京)有限公司 | Information processing method and electronic equipment |
| CN104767682B (en) * | 2014-01-08 | 2018-10-02 | 腾讯科技(深圳)有限公司 | The method and apparatus of method for routing and system and distributing routing information |
| US9477551B1 (en) * | 2014-12-01 | 2016-10-25 | Datadirect Networks, Inc. | Method and system for data migration between high performance computing architectures and file system using distributed parity group information structures with non-deterministic data addressing |
| CN105141541A (en) * | 2015-09-23 | 2015-12-09 | 浪潮(北京)电子信息产业有限公司 | Task-based dynamic load balancing scheduling method and device |
| US9935893B2 (en) * | 2016-03-28 | 2018-04-03 | The Travelers Indemnity Company | Systems and methods for dynamically allocating computing tasks to computer resources in a distributed processing environment |
| US10153964B2 (en) * | 2016-09-08 | 2018-12-11 | Citrix Systems, Inc. | Network routing using dynamic virtual paths in an overlay network |
| CN107846358B (en) * | 2016-09-19 | 2020-07-10 | 北京金山云网络技术有限公司 | Data transmission method, device and network system |
| CN107087014B (en) * | 2017-01-24 | 2020-12-15 | 无锡英威腾电梯控制技术有限公司 | A load balancing method and controller thereof |
| EP3607453B1 (en) * | 2017-04-07 | 2022-08-31 | Intel Corporation | Methods and apparatus for deep learning network execution pipeline on multi-processor platform |
| US10459958B2 (en) * | 2017-08-29 | 2019-10-29 | Bank Of America Corporation | Automated response system using smart data |
| CA3107919A1 (en) * | 2018-07-27 | 2020-01-30 | GoTenna, Inc. | Vinetm: zero-control routing using data packet inspection for wireless mesh networks |
| US20200186478A1 (en) * | 2018-12-10 | 2020-06-11 | XRSpace CO., LTD. | Dispatching Method and Edge Computing System |
| CN111464442B (en) * | 2019-01-22 | 2022-11-18 | 华为技术有限公司 | Method and device for routing data packet |
-
2019
- 2019-01-22 CN CN201910057402.8A patent/CN111464442B/en active Active
- 2019-12-30 EP EP24182988.6A patent/EP4456502A3/en active Pending
- 2019-12-30 EP EP19911896.9A patent/EP3905637B1/en active Active
- 2019-12-30 WO PCT/CN2019/129881 patent/WO2020151461A1/en not_active Ceased
-
2021
- 2021-07-20 US US17/380,383 patent/US12074796B2/en active Active
-
2024
- 2024-07-22 US US18/780,085 patent/US20240380695A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102136989A (en) * | 2010-01-26 | 2011-07-27 | 华为技术有限公司 | Message transmission method, system and equipment |
| CN106789661A (en) * | 2016-12-29 | 2017-05-31 | 北京邮电大学 | A kind of information forwarding method and space information network system |
| CN107634872A (en) * | 2017-08-29 | 2018-01-26 | 深圳市米联科信息技术有限公司 | A kind of method and apparatus of quick accurate measurement network link quality |
Also Published As
| Publication number | Publication date |
|---|---|
| US20240380695A1 (en) | 2024-11-14 |
| EP3905637A4 (en) | 2022-02-16 |
| EP4456502A3 (en) | 2025-01-01 |
| CN111464442A (en) | 2020-07-28 |
| EP4456502A2 (en) | 2024-10-30 |
| EP3905637B1 (en) | 2024-07-24 |
| US20210352014A1 (en) | 2021-11-11 |
| US12074796B2 (en) | 2024-08-27 |
| EP3905637A1 (en) | 2021-11-03 |
| WO2020151461A1 (en) | 2020-07-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3975506B1 (en) | Methods and apparatuses for transmitting messages | |
| WO2018152919A1 (en) | Path selection method and system, network acceleration node, and network acceleration system | |
| CN111327647B (en) | Method, device and electronic equipment for container to provide external services | |
| US20160112502A1 (en) | Distributed computing based on deep packet inspection by network devices along network path to computing device | |
| US20230269164A1 (en) | Method and apparatus for sending route calculation information, device, and storage medium | |
| CN112087382A (en) | Service routing method and device | |
| US20230291684A1 (en) | Packet transmission method and apparatus, device, and computer-readable storage medium | |
| US20240380695A1 (en) | Data packet routing method and apparatus | |
| CN115102896B (en) | Data broadcast method, broadcast accelerator, NOC, SOC and electronic device | |
| CN115665262A (en) | A request processing method, device, electronic device and storage medium | |
| CN110752998B (en) | ARP message processing method and related device | |
| CN118316873A (en) | Network switching method, device, electronic device, storage medium and program product | |
| CN116700985A (en) | Model deployment method, system and storage medium | |
| WO2022166607A1 (en) | Method, apparatus and system for sending packet, and storage medium | |
| US20160277280A1 (en) | Flow entry delivery method and communication system | |
| CN107332771B (en) | A method, router and routing system for ensuring routing consistency | |
| WO2024032011A1 (en) | Cdn scheduling method, cdn scheduling system, and storage medium | |
| CN113765805B (en) | Calling-based communication method, device, storage medium and equipment | |
| CN114124275B (en) | A time synchronization method, device, equipment and storage medium | |
| CN116389356A (en) | A cross-availability zone communication method, related device, and cloud network | |
| CN105991372B (en) | Link detection method and device | |
| WO2022143874A1 (en) | Method for detecting state of bgp session, apparatus and network devices | |
| CN114374649A (en) | Hybrid routing method, device and network equipment | |
| CN115002020B (en) | OSPF-based data processing method and device | |
| CN114697253A (en) | Method for determining forwarding path of service chain and communication device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |